
В
настоящее время начинают широко
внедряться цифровые каналы с пропускной
способностью 150,52 и 622,08 Мбит/с. Эти каналы
используются как для соединения локальных
сетей, так и непосредственно для
построения скоростных LAN. 150 Мбит/с и
могут обеспечить любые современные
телекоммуникационные услуги, кроме
телевидения высокого разрешения.
Предусмотрен стандарт и на скорость
передачи 2,48832 Гбит/c. Так как время
доставки для многих видов сетевых услуг
реального времени является крайне
важной характеристикой, АТМ находит
широкое применение при передаче данных,
в телефонии, кабельном телевидении и
других областях. Следует учитывать, что
оцифрованный видеосигнал качества VHS
требует 100 Мбит/с при отсутствии сжатия
и 1,5…6 Мбит/c – при использовании сжатия.
Файл изображения 1000х1000 пикселей при 24
битах, характеризующих цвет, занимает
3 Мбайта. ATM справится с передачей такого
кадра с учетом накладных расходов
(заголовок) за время порядка 0,2 с. При
использовании сжатия можно получить
заметно большее быстродействие. Поэтому
технология АТМ может быть использована
центрами документальной электросвязи
для оказания услуг не только передачи
данных, но и услуги видеоконференций.
Это
не значит, что доступны лишь указанные
скорости, так как интерфейсы позволяют
мультиплексировать большое число
каналов с самыми разными скоростями
обмена. Но мультиплексирование на таких
частотах представляет собой значительную
проблему. Определенные трудности
представляет то обстоятельство, что в
ATM трудно реализовать обмен без
установления соединения (аналог UTP
в Интернет). Протокол ATM является
широкополосной версией ISDN и работает
на скорости 150,52 Мбит/с с пакетом
фиксированной длины и минимальным
заголовком. Слово “асинхронный” в
названии означает, что тактовые генераторы
передатчика и приемника не синхронированы,
а сами ячейки передаются и мультиплексируются
по запросам. При мульти-плексировании
используется статистическая технология.
Асинхронная передача не предполагает
упорядочивания ячеек по каналам при
пересылке. ATM поддерживает коммутацию
каналов и пакетную коммутацию.
Каждый
пакет ATM имеет 53 байта (в англоязычной
документации пакеты ATM носят название
cell (ячейка), этот термин введен, чтобы
отличить пакеты ATM от пакетов низкоскоростных
каналов), из них 48 байт несут полезную
информацию (что для случая передачи
звука соответствует 6 мс). Для выделения
пакета из потока используются такие
же, как в ISDN, разделительные байты (0x7E).
Заголовок пакета содержит лишь 5 байт
и предназначен главным образом для
того, чтобы определить, принадлежит ли
данный пакет определенному виртуальному
каналу. Отсутствие контроля ошибок и
повторной передачи на физическом уровне
приводит к эффекту размножения ошибок.
Если происходит ошибка в поле
“идентификатора виртуального пути”
или “виртуального канала”, то коммутатор
может отправить ячейку другому получателю.
Таким образом, один получатель не получит
ячейку, а другой получит то, что ему не
предназначалось.
Виртуальный
канал в ATM формируется так же, как и в
ISDN. Формально эта процедура не является
частью ATM-протокола. Сначала здесь
формируется сигнальная схема, для этого
посылается запрос с VPI = 0 и VCI = 5. Если
процедура завершилась успешно, можно
начинать формирование виртуального
канала. При создании канала используются
шесть служебных сообщений:
-
Setup
– установление и формирование канала;
-
Call
Proceeding – осуществление запроса в процессе
исполнения;
-
Connect
– соединение выполнено;
-
Connect
ACK – подтверждение получения соединения;
-
Release
– сообщение о разъединении; -
Release
complete
– сообщение о выполненном разъединении.
Схема
обмена служебными сообщениями при
установлении и разрыве виртуального
соединения показана на рис. 3.37.

Рисунок 3.37 – Обмен сообщениями при
установлении и разрыве
виртуального соединения пользовательских
терминалов
Предполагается,
что между ЭВМ-инициализатором и
ЭВМ-адресатом находятся два ATM-переключателя
(Switch
1, 2). Каждый из узлов по пути к месту
назначения при получении запроса Setup
откликается, посылая сообщение Call
Proceeding.
Адрес места назначения указывается в
сообщении Setup. В ATM используются три вида
адресов. Первый имеет 20 байт и структуру
OSI-адреса. Первый байт указывает на вид
адреса (один из трех). Байты 2 и 3 указывают
на принадлежность стране, а байт 4 задает
формат последующей части кода адреса,
которая содержит 3 байта кода администрации
(Authority), 2 байта домена, 2 байта области и
6 байтов собственно адреса. Во втором
формате байты 2 и 3 выделены для
международных организаций, а не стран.
Остальная часть адреса имеет тот же
формат, что и в варианте 1. Третий формат
является старой формой (CCITT E.164) 15-значного
десятичного телефонного номера, как
и для ISDN.
В ATM нет специфицированного алгоритма
маршрутизации. Для выбора маршрута (от
коммутатора к коммутатору) используется
поле VCP. VCI используется лишь на последнем
шаге, когда ячейка посылается от
переключателя к ЭВМ. Такой подход
упрощает маршрутизацию отдельных
ячеек, так как при этом анализируются
12-битовые, а не 28-битовые коды. В каждом
коммутаторе (переключателе) формируются
специальные таблицы, которые решают
проблему переадресации ячеек.
Следует
обратить внимание на то, что виртуальный
канал (Circuit)
и виртуальный проход (Path) в данном
контексте не тождественны. Виртуальный
проход (маршрут) может содержать несколько
виртуальных каналов. Виртуальные каналы
всегда являются полностью дуплексными.
Сети ATM допускают создание мультикастинговых
каналов. Такой канал имеет одного
отправителя и много получателей. Первый
канал формируется обычным путем,
последующие участники сессии подключаются
позднее путем посылки сообщения Add
Party.
За простоту построения ячеек приходится
платить тем, что управляющая информация
передается в общем информационном
потоке. Высокая скорость передачи данных
требует применения аппаратно реализованных
маршрутных таблиц на каждом переключателе
пакетов. На риc. 3.38 представлен формат
заголовка пакета ATM.
|
8 7 |
|||
|
GFC |
VPI |
1 В случае сеть–сеть 2 используется 3 4 |
|
|
VPI |
VCI |
||
|
VCI |
|||
|
VCI |
PT |
RES |
CLP |
|
HEC |
5 |
Рисунок
3.38 – Формат заголовка ATM-пакета
(сетевой
интерфейс пользователя – UNI)
Заголовок
обеспечивает два механизма маршрутизации
пакетов:
-
VPI
(Virtual Path Identifier – виртуальный идентификатор
маршрута), обеспечивает соединение
точка–точка, но маршрут не является
фиксированным и задается непосредственно
перед началом пересылки с использованием
сигнальных сообщений. Слово “виртуальный”
означает, что пакеты передаются от узла
к узлу в соответствии с VPI; -
VCI
(Virtual Call Identifier – виртуальный идентификатор
запроса) запросы осуществляются в
соответствии с виртуальным
маршрутом, заданным VPI;
-
GFC
(Generic Flow Control) (4 бита, как и в описании
пакетов ISDN) – общее управление потоком; -
VPI
(Virtual Path
Identifier) (8 бит, служит для целей маршрутизации)
– идентификатор виртуального пути; -
VCI
(Virtual Call Identifier) (16 бит, служит для целей
маршрутизации) – идентификатор
виртуального канала; -
PT
(Payload Type)
(2 бита, тип данных; это поле может
занимать и зарезервированное субполе
RES); -
RES
– зарезервированный бит; -
CLP
(Cell Loss Priority – уровень приоритета при
потере пакета) указывает на то, какой
приоритет имеет пакет (cell) и будет ли
он отброшен в случае перегрузки канала; -
HEC
– (Header Error Control) (8 бит, поле контроля
ошибок).
Два
субполя – VPI
и VCI
– вместе образуют поле маршрута, которое
занимает 24 бита. Для интерфейса типа
сеть–сеть (NNI) используется ячейка с
несколько иным форматом заголовка. Там
весь первый октет выделен для VPI, а поле
GFC отсутствует. Ряд значений VCI и VPI
зафиксированы и приведены в табл. 3.17.
Таблица
3.17 –
Фиксированные значения VCI и VPI
|
VCI |
VPI |
Назначение |
|
0 |
только |
Неопределенная |
|
1 |
все |
Метауправление |
|
3 |
все |
Сетевое |
|
4 |
все |
VP-управление |
|
5 |
все |
Управление |
|
6 |
все |
Ячейка |
|
16 |
только |
UNI |
OAM – эксплуатация
и техническое обслуживание. ATM обеспечивает
любые услуги в сети, например:
-
передача
голоса на скоростях 64 кбит/с. Один
ATM-пакет соответствует 6 мс;
-
передача
музыки с использованием схемы кодирования
MUSICAM;
-
для
случая изображения передается только
переменная часть картинки, тогда ATM
идеально подходит для решения такого
рода задач.
Некоторые
значения поля PT
также зафиксированы и представлены в
табл. 3.18.
Таблица
3.18 – Заданные
значения поля PT (Payload
Type Identifier)
|
PT |
Назначение |
|
000 |
Пользовательские |
|
001 |
Пользовательские |
|
010 |
Пользовательские |
|
011 |
Пользовательские |
|
100 |
Ячейка |
|
101 |
Соединение |
|
110 |
Управление |
|
111 |
Зарезервировано |
Задачи
управления решаются менее экономно,
но, тем не менее, достаточно эффективно
(предусмотрено несколько приоритетов
для управления потоками данных). В ATM
предусмотрено несколько категорий
услуг, которые отображены в табл. 3.19.
Таблица
3.19 – Типы
категорий ATM-услуг
|
Класс |
Описание |
Пример |
|
CBR |
Постоянная |
Канал |
|
RT-VBR |
Переменная |
Видеоконференции |
|
NRT-VBR |
Переменная |
Мультимедиа |
|
ABR |
Доступная |
Просмотр |
|
UBR |
Неспецифицированная скорость |
Пересылка |
CBR
не предусматривает контроля ошибок,
управления трафиком или какой-либо
другой обработки. Класс CBR пригоден для
работы с мультимедиа реального времени.
Класс
VBR содержит в себе два подкласса –
обычный и для реального времени. ATM в
процессе доставки не вносит никакого
разброса ячеек по времени. Случаи потери
ячеек игнорируются.
Класс
ABR предназначен для работы в условиях
мгновенных вариаций трафика. Система
гарантирует некоторую пропускную
способность, но в течение короткого
времени может выдержать и большую
нагрузку. Этот класс предусматривает
наличие обратной связи между приемником
и отправителем, которая позволяет
понизить загрузку канала, если это
необходимо. Этот класс полностью отвечает
системам передачи данных с решающей
обратной связью.
Класс
UBR хорошо пригоден для посылки IP-пакетов
(нет гарантии доставки и в случае
перегрузки неизбежны потери).
ATM
использует исключительно модель с
установлением соединения (здесь нет
аналогий с UDP-протоколом). Это создает
определенные трудности для управления
трафиком с целью обеспечения требуемого
качества обслуживания (QoS). Для решения
этой задачи используется алгоритм GCRA
(Generic
Rate
Algoritm). Работа этого алгоритма
проиллюстрирована на рис. 3.39.
GCRA
имеет два параметра. Один из них
характеризует максимально допустимую
скорость передачи (PCR – Peak Cell Rate; T=1/PCR –
минимальное расстояние между ячейками),
другой – допустимую вариацию значения
скорости передачи (CDVT=L). Если клиент не
собирается посылать более 100 000 ячеек в
секунду, то Т = 10 мкс. На рис. 3.39 представлены
разные варианты следования ячеек. Если
ячейка приходит раньше чем T – τ,
она считается неподтверждаемой и может
быть отброшена. Ячейка может быть
сохранена, но при этом должен быть
установлен бит CLP = 1. Применение бита
CLP может быть разным для разных категорий
услуг (см. табл. 3.19).

Рисунок
3.39 – Иллюстрация работы алгоритма GCRA
Можно
вычислить число подтверждаемых ячеек
N, которые могут быть переданы при пиковом
потоке ячеек PCR = 1/t. Пусть время
ячейки в пути равно τ.
Тогда N = 1 + (l/(T–τ)).
Если полученное число оказалось нецелым,
оно должно быть округлено до ближайшего
меньшего целого. Трудно устранимой
проблемой для ATM
является предотвращение перегрузки на
промежуточных коммутаторах-переключателях.
Коммутаторы могут иметь 100 внешних
каналов, а загрузка может достигать 350
000 ячеек/с. Здесь можно рассматривать
две задачи: подавление долговременных
перегрузок: когда поток ячеек превосходит
имеющиеся возможности их обработки и
кратковременные пиковые загрузки. Эти
проблемы решаются различными способами:
административный контроль, резервирование
ресурсов и управление перегрузкой,
привязанное к уровню трафика.
В
низкоскоростных сетях с относительно
медленно меняющейся или постоянной
загрузкой администратор вмешивается
лишь при возникновении критической
ситуации и предпринимает меры для
понижения скорости передачи. Очень
часто такой подход не слишком эффективен,
так как за время доставки управляющих
команд приходят многие тысячи ячеек.
Кроме того, многие источники ячеек в
ATM работают с фиксированной скоростью
передачи (например, видеоконференция).
Требование понизить скорость передачи
здесь достаточно бессмысленно. По этой
причине в АТМ разумнее предотвращать
перегрузку. Но для трафика типа CBR, VBR и
UBR не существует никакого динамического
управления перегрузкой и административное
управление является единственной
возможностью. Когда ЭВМ желает установить
новый виртуальный канал, она должна
охарактеризовать ожидаемый трафик.
Сеть анализирует возможность обработки
дополнительного трафика с учетом
различных маршрутов. Если реализовать
дополнительный трафик нельзя, запрос
аннулируется. В отсутствие административного
контроля несколько пользователей, для
которых необходимы широкополосные
каналы, могут блокировать работу массы
клиентов сети, для которых достаточно
узкополосных каналов связи, например,
читающих свою почту. Резервирование
ресурсов по своей сути близко
административному контролю и выполняется
на фазе формирования виртуального
канала. Резервирование производится
вдоль всего маршрута (во всех коммутаторах)
в ходе реализации процедуры Setup.
Параметрами резервирования могут быть
пиковое значение полосы пропускания
и/или средняя загрузка.
Для
типов сервиса CBR и VBR отправитель даже
в случае перегрузки не может понизить
уровень загрузки трафика. В случае UBR
потери не играют никакой роли. Но сервис
ABR допускает регулирование трафика.
Более того, такое управление здесь
весьма эффективно. Существует несколько
механизмов реализации такого управления.
Предлагается, чтобы отправитель, желающий
послать блок данных, сначала посылал
специальную ячейку, резервирующую
требуемую полосу пропускания. После
получения подтверждения блок данных
начинает пересылаться. Преимуществом
данного способа следует считать то, что
в этом случае перегрузки вообще не
возникает. Но данное решение не
используется из-за больших задержек
(решение ATM-форума).
Другой
способ сопряжен с посылкой коммутаторами
специальных ячеек отправителю в случае
возникновения условий перегрузки. При
получении такой ячейки отправитель
должен понизить скорость передачи
вдвое. Предложены различные алгоритмы
последующего восстановления скорости
передачи. Но и эта схема отвергнута
ATM-форумом
из-за того, что сигнальные ячейки могут
быть потеряны при перегрузке. Действительно,
данный алгоритм не всегда можно признать
разумным. Например, в случае, когда
коммутатор имеет 10 каналов с трафиком
по 50 Мбит/с и один канал с потоком в 100
кбит/c, глупо требовать понижения уровня
загрузки трафика в этом канале из-за
перегрузки.
Третье
предложение использует тот факт, что
граница пакета помечается битом в
последней ячейке. Коммутатор просматривает
входящий поток и ищет конец пакета,
после чего выбрасывает все ячейки,
относящиеся к следующему пакету. Этот
пакет будет переслан позднее, а
выбрасывание M ячеек случайным образом
может вынудить повторение передачи M
пакетов, что значительно хуже. Данный
вариант подавления перегрузки был также
не принят, так как выброшенный пакет
совсем необязательно послан источником,
вызвавшим перегрузку. Но этот способ
может быть использован отдельными
производителями коммутаторов. Однако
был принят другой метод.
После каждых М
информационных ячеек каждый отправитель
посылает специальную RM-ячейку
(Resource Management). Эта
ячейка движется по тому же маршруту,
что и информационные, но RM-ячейка
обрабатывается всеми коммутаторами
вдоль пути. Когда она достигает места
назначения, ее содержимое просматривается
и корректируется, после чего ячейка
посылается назад отправителю. При этом
появляются два дополнительных механизма
управления перегрузкой. Во-первых,
RM-ячейки могут посылаться не только
первичным отправителем, но и перегруженными
коммутаторами в направлении перегрузившего
их отправителя. Во-вторых, перегруженные
коммутаторы могут устанавливать
средний PTI-бит в информационных ячейках,
движущихся от первоисточника к адресату.
Но даже выбранный метод подавления
перегрузки неидеален, так как также
уязвим из-за потерь управляющих ячеек.
Управление
перегрузкой для услуг типа ABR
базируется на том, что каждый отправитель
имеет текущую скорость передачи (ACR –
Actual Cell
Rate),
которая лежит между MCR (Minimum Cell Rate) и PCR
(Peak Cell Rate). Когда происходит перегрузка,
ACR уменьшается, но не ниже MCR. При
исчезновении перегрузки ACR
увеличивается, но не выше PCR. Каждая
RM-ячейка содержит значение загрузки,
которую намеревается реализовать
отправитель. Это значение называется
ER (Explicit Rate).
По пути к месту назначения эта величина
может быть уменьшена попутными
коммутаторами. Ни один из коммутаторов
не может увеличивать ER. Модификация ER
может производиться по пути как туда,
так и обратно. При получении RM-ячейки
отправитель может скорректировать
значение ACR, если это необходимо.
С
точки зрения построения интерфейса и
точек доступа (T, S и R), сеть ATM сходна с
ISDN. Для физического уровня предусмотрены
две скорости обмена – 155,52 и 622,08 Мбит/с.
Эти скорости соответствуют уровням
иерархии SDH STM-1 и 4STM-1.
При номинальной скорости 155,52 Мбит/с
пользователю доступна реально скорость
обмена 135 Мбит/c, это связано с издержками
на заголовки и управление. Для ATM
используются коаксиальные кабели,
скрученные пары (< 100 м для обоих
вариантов) и оптоволоконные кабели
(~ 2 км). Для канала связи рассматриваются
два кода CMI (Coded
Mark Inversion)
и импульс той же длительности. Двоичная
1 представляется в виде отрицательного
скремблера типа установка–сброс
(Set–Reset). В CMI двоичный 0 передается как
отрицательный импульс половинной длины,
за которым следует положительный, или
положительный импульс полной длины,
так, чтобы уровень менялся для
последовательно следующих единиц. Это
обеспечивает балансировку передающей
линии по постоянному напряжению, но
удваивает частоту переключения
практически вдвое. Метод скремблирования
не меняет частоту переключения, но его
эффективность зависит от передаваемой
информации. CMI предпочтительней для 155
Мбит/с. В настоящее время используются
две схемы передачи данных применительно
к ATM: базирующийся на потоке пакетов
(Cell Stream) и на SDH структурах. В первом
случае мы имеем непрерывный поток
53-байтовых пакетов, во втором – эти
пакеты уложены в STM-1 кадры. Управляющие
сообщения располагаются в заголовках
секции и пути кадра SDH. AAL (ATM Adaptation Layer)
служит для адаптации различных видов
сервиса к требованиям ATM-уровня. Каждый
вид услуг требует своего AAL-протокола.
Главной целью AAL является обеспечение
удобства при создании и исполнении
программ прикладного уровня. Для всех
AAL определены два субуровня:
-
SAR
(Segmentation And Reassemble), делит пакеты высокого
уровня, передает ATM
и наоборот (сборка сообщений из
сегментов); -
CS
(Convergent Sub-layer), зависит от вида услуг
(обработка случаев потери пакета,
компенсация задержек, мониторинга
ошибок и т. д.). Этот подуровень может,
в свою очередь, делиться на две секции:
CPCS (Сommon Part
Convergence Sublayer) – общая часть субуровня
конвергенции и SSCS (Service-Specific Convergence
Sublayer) – служебно-ориентированный
подуровень конвергенции (последний
может и отсутствовать).
AAL-протоколы
управляются значениями следующих
переменных:
-
скорость
обмена (постоянная или переменная);
-
режим
соединения (с установлением связи или
без);
-
cинхронизация
(требуется или нет синхронизация между
отправителем иполучателем).
В
настоящее время определены четыре
класса услуг, которые могут требовать
или не требовать синхронизации между
отправителем и получателем, осуществлять
обмен при постоянной или переменной
частоте передачи битов, с установлением
связи или без. Особенности этих видов
услуг для адаптивного уровня
систематизированы в табл. 3.20. Каждая из
услугимеет
свой AAL-протокол.
Таблица
3.20 –
Особенности видов услуг для адаптивного
уровня
|
Виды адаптивного |
Класс (AAL1) |
Класс (AAL2) |
Класс (AAL3/4 |
Класс D (AAL3/4 или 5) |
|
Синхронизация и |
Необходима |
Необходима |
Не |
Не |
|
Частота битов |
Постоянная |
Переменная |
Переменная |
Переменная |
|
Режим |
С |
С |
С |
Без |
Уровень адаптации
1-го уровня (AAL) выполняет для верхнего
уровня следующие услуги (передача аудио-
и видеоинформации по каналам DS-1 и DS-3;
постоянная скорость передачи):
-
синхронизацию
передатчика и приемника; -
передачу
данных с фиксированной скоростью; -
индикацию
потери и искажения данных, если эти
ошибки не устраняются на уровне
адаптации; -
передачу
от отправителя получателю информации
о структуре передаваемых данных.
Для
решения этих задач AAL первого уровня
должен устранять разброс задержек,
выявлять ячейки, доставленные не по
адресу, и потерянные ячейки, производить
сегментацию пакетов и последующее их
восстановление, выполнять мониторинг
ошибок в управляющей информации протокола
AAL-PCI (Protocol Control Information).
Характер обмена здесь строго ориентирован
на соединение. AAL-1 и использует субуровни
конвергенции и SAR. Субуровень конвергенции
обеспечивает постоянство скорости
передачи ячеек. AAL-1 конвергенции не
имеет какого-то специфического
протокольного заголовка. Этот субуровень
разбивает входные сообщения на 46- или
47-байтные блоки и передает их субуровню
SAR для пересылки.
Структура
протокольной части информационного
поля ячейки SAR-PDU
представлена на рис. 3.40. CSI позволяет
приемнику распознать уровень конвергенции.
Подуровень SAR получает значение SN
(порядковый номер) для каждого 47-байтного
блока данных от подуровня конвергенции.
Поле SNR (Sequence Number
Protection
– контрольная сумма) служит для
обнаружения и исправления ошибок в
заголовке, в качестве производящего
полинома используется G(x) = x3
+ x + 1. Один из битов SNP представляет
собой бит четности.
-
 1 октет
1 октет
CSI
SN
SNP
Протокольный
блок данных1
бит3
бита4
бита47
байт
 1 октет
1 октет
Рисунок 3.40 –
Структура PDU подуровня SAR ATM 1-го типа
(AAL1):
CSI
(Convergence Sublayer Indicator) – индикатор
подуровня
конвергенции;
SN
(Sequence Number) – номер
по
порядку;
SNP (Sequence Number Protection) – защита
номера
последовательности
Если
CSI = 1, то после поля SNP следует однобайтовое
поле “указатель”, которое используется
для определения положения начала
следующего сообщения (значения 0-92;
старший бит поля указатель зарезервирован
на будущее). Поле “данные” в этом
варианте имеет длительность 64 байта.
Для сжатой аудио- и видеоинформации
скорость передачи может варьироваться
в широких пределах. Ведь многие схемы
предусматривают периодическую отправку
полного видеокадра. При последующей
передаче транспортируются лишь отличия
последовательных кадров. Уровень
адаптации 2-го типа предоставляет
вышестоящему уровню возможность
синхронизовать передатчик и приемник,
осуществлять обмен с изменяющейся
скоростью, оповещение об ошибках и
потерях ячеек. Структура ячейки AAL 2-го
типа показана на рис. 3.41 (субуровень
SAR). Из-за переменной скорости передачи
заполнение ячеек может быть неполным.
-
Заголовок
SN
IT
Протокольный
блок данных SARLI
CRC
48
байт

 Заголовок
Заголовок
 48
48
Рисунок 3.41 –
Структура PDU подуровня SAR ATM 2-го типа
(AAL2):
IT
(Information Type)
– тип данных, cлужит
для указания начала, продолжения или
окончания сообщения; LI (Length
Indicator)
– индикатор длины, указывает число
байт в поле данных; CRC – контрольная
сумма
Поля
SN и IT имеют общую длину 1 байт, поля же
LI и CRC вместе занимают 2 байта. Поле данных
(PDU) в такой ячейке имеет длину 45 байт.
Более детальной информации о длинах
полей стандарт не оговаривает. Уровень
адаптации 3/4-го типа предназначен для
передачи данных в режиме как с установлением
соединения, так и без него. Раньше службам
С и D были выделены разные типы уровня
адаптации, позднее они были объединены.
Определены два типа обмена: “сообщение”
и “поток”. В первом случае блок
данных передается в одном интерфейсном
блоке (IDU). Сервисные блоки данных могут
иметь переменную длину. В режиме “поток”
сервисный блок данных передается через
интерфейс уровня адаптации в одном или
нескольких IDU. В этом режиме может быть
реализована услуга “внутренний
контейнер”. Здесь допускается и
прерывание передачи, частично переданный
блок теряется. AAL3/4 допускает организацию
нескольких сессий одновременно (например,
несколько удаленных Login).
Структура протокольного блока данных
подуровня SAR 3/4-го типа представлена на
рис. 3.42. Длина поля данных (PDU) составляет
44 байта. Заметим, что AAL3/4 имеет два уровня
издержек – 8 байт добавляется для каждого
сообщения и 4 избыточных байта приходятся
на каждую ячейку, это достаточно много,
особенно для коротких сообщений.
При
вычислении CRC
используется образующий полином
G(x)
= х10+
x9
+ x5
+ x4
+ x
+1.
|
|
2 октета |
||||
|
ST |
SN |
MID |
Протокольный |
LI |
CRC |
|
2 бита |
4 бита |
10 бит |
6 бит |
10 бит |
|
|
48 |
 2
2Рисунок
3.42 – Структура PDU
подуровня SAR ATM 3/4-го типа
На
рис. 3.42 представлено: ST
(Segment
Type)
– тип сегмента; начало сообщения – 10
(BOM
– Beginning
Of
Message),
продолжение – 00 (COM
– Continuation
Of
Message),
завершение сообщения – 01 (EOM
– End
Of
Message),
односегментное сообщение – 11; SN
(Sequence
Number)
– номер по порядку; MID
(Multiplexing
Identifier)
– идентификатор мультиплексирования
для протокола 4-го уровня (позволяет
мультиплексировать до 1 024 пользователей
для одного соединения), поле служит для
определения того, к какой из активных
сессий принадлежит данная ячейка; L
– длина заполнения поля данных.
Подуровень
конвергенции AAL
содержит общую часть
подуровня
CPCS (common path convergence sublayer) и
служебную
часть
подуровня
SSCS (service specific convergence sublayer). CPCS
обеспечивает негарантированную доставку
кадров любой длины в пределах 1…65535
байт. Данные пользователя передаются
непосредственно на субуровень AAL. Формат
протокольного блока данных подуровня
конвергенции AAL 3/4-го типа показан
на рис. 3.43.
|
СPI |
Btag |
BASize |
ДанныеCPCS |
PAD |
AL |
Etag |
Длина |
|
1 |
1 |
2 |
1…65 |
1 |
1 |
2 |
|
|
|
Оконечная |
||||||
|
CPCS—PDU |
 Заголовок
Заголовок
Рисунок
3.43 – Формат блока данных подуровня
конвергенцииAAL 3/4-го типа:
-
CPI
(Common
Part Indicator)
– однооктетный индикатор общей части,
используется при интерпретации
последующих полей;BTAG
(Beginning
Tag) – однооктетная метка начала, в
сочетании с ETAG определяет границы
протокольного блока данных (PDU);Basize
(Buffer
Allocation
Size)
– емкость буфера, сообщает получателю
максимальный размер буфера. Поле
занимает 2 байта;PAD
–заполнитель,
обеспечивает кратность поля данных
4 октетам;AL
(Alignment)
– выравнивание, заполняется нулями;ETAG
(End
Tag)
– метка конца (один октет);Длина
–задает
протяженность СPCS-PDU;CPCS
PDU
(Common
Part Convergence Sublayer – Protocol Data Unit) –протокольный
блок данных общей части подуровня
конвергенции
Тип
3/4 имеет существенную избыточность (4
байта из 48 на каждый SAR-PDU). По этой причине
был введен 5-й тип. Этот уровень
обеспечивает канал, ориентированный
на соединение, с переменной скоростью
обмена (VBR) в широковещательном режиме
при минимальном контроле ошибок (или
вовсе без него). IP-дейтаграммы передаются
через сети ATM через адаптационный уровень
5 (RFC-1577). Уровень AAL5 иногда называют SEAL
(Simple and Efficient Adaptation
Layer
– простой и эффективный адаптационный
уровень). AAL5 занимает в наборе протоколов
семейства ATM нишу протокола UDP
стека TCP/IP. Формат ячейки SAR-PDU 5-го типа
показан на рис. 3.44. Формат сообщения
AAL5 субуровня конвергенции показан
на рис. 3.45. Так как здесь для переноса
информации используется заголовок,
работа AAL не является независимой
от нижележащего. Однобайтовое поле,
расположенное между полями UU и “длина”,
зарезервировано для использования
уровня, что является нарушением
эталонной модели. Инкапсулироваться
в поля данных AAL5 могут блоки длиной
до 216
– 1 октетов (65 535 байт). Выполнение операций
здесь зависит от того, работает ли
система в режиме “сообщения” или
“потока”.
-
Заголовок
PT
Протокольный
блок данных SAR5
байт53
байта
 Заголовок
Заголовок
Рисунок 3.44 – Формат
ячейки SAR-PDU 5-го типа (AAL5)
-
Байтов
1
1
2
4
Поле данных
(1… 65 535)UU
Длина
CRC
Рисунок 3.45 –
Формат сообщения AAL5 субуровня конвергенции:
UU (User to User) – поле, необходимое для верхних
уровней, чтобы обеспечить мультиплексирование;
длина – двухоктетное поле длины поля
данных (PDU); CRC – четырехоктетная
контрольная сумма
На
подуровне конвергенции для передачи
протокольного блока данных ис-
пользуется
4-байтовая CRC с образующим полиномом
G(x)
= x32
+ x26
+ x23
+ x22
+ x16
+ x12
+ x11
+ x10
+ x8
+ x7
+ x5
+ x4
+ x2
+ x
+ 1,
что
обеспечивает высокую надежность доставки
блоков информации. Положение адаптационного
уровня в рамках эталонной модели показано
на рис. 3.46.
-
Сервис
ААL
Субуровень конвергенции
Субуровень сегментации и сборки АТМ
Физический уровень
Рисунок 3.46 – Положение уровней ATM в
универсальной модели
Верхние
уровни управления для ATM базируются на
рекомендациях ITU-T
I450/1 (Q.930/1). В случае использования ATM для
Интернет значение MTU по умолчанию равно
9180 (RFC-1626), так как фрагментация IP-дейтаграмм
крайне нежелательна (AAL). Работа протоколов
TCP/IP поверх ATM описана в документах
RFC-1483, -1577, -1626, -1680, -1695, -1754, -1755, -1821, -1926,
-1932. Ниже на рис. 3.47 показано, как пакеты
ATM
размещаются в кадрах STM-1 (виртуальный
контейнер VC-4).
|
|
9 |
261 |
||||||
|
3 |
Заголовок секции |
УказательAU-4 STM-1 |
||||||
|
1 |
VC-4 |
|||||||
|
Заголовок секции |
||||||||
|
АТМ-пакет |
||||||||
|
53 |
Заголовок |

Рисунок
3.47 – Размещение ATM
пакетов в STM-1 кадре
В
STM-1, для передачи ячеек выделяется полоса
пропускания
C=9×261×8/(125×10–6)
= 150,3 Мбит/c (9 рядов по 261 байту, передаваемых
каждые 125 мкс). Форматы адресов согласно
спецификации интерфейса “пользователь–сеть”
представлены на рис. 3.48. Формат ICD с
указателем международного кода отличается
от формата DCC тем, что в нем поле DCC
заменено полем международного кода
CD (International Code
Designator).
|
|
DSP |
|||||||
|
AFI |
DCC |
DFI |
AA |
RSVD |
RD |
AREA |
ESI |
SEL |
|
IDI |
HO—DSP |
 IDP
IDP
Рисунок 3.48 –
Формат DCC ATM с числовым кодом страны:
AFI
(Authority
and Format Identifier)
– идентификатор формата и привилегий;
DCC (Data Country
Code) – код данных страны (стандарт МОС
3166); DFI (DSP Format Identifier)
– идентификатор формата DSP; DSP (Domain
Specific
Part)
– часть, зависящая от домена; AA
(Administrative
Authority) – административное субполе; RSVD
(Reserved)
– резерв на будущее; RD (Routing Domain)
– область маршрутизации; AREA – идентификатор
зоны; ESI (End System
Identifier) – идентификатор оконечной
системы; SEL (Selector) – селектор; IDI (Initial
Domain
Identifier)
– идентификатор исходной области; HO
(Higher Order)
– старшая часть
Формат
адреса Е.164 NSAP, где идентификатор исходной
области является номером Е.164, представлен
на рис. 3.49. Структура номера (15 десятичных
цифр в кодировке BCD) места назначения
отображена на рис. 3.50. Важную роль в
управлении сетями АТМ играет информация
OAM (Operations And
Maintenance).
-
IDP
DSP
AFI
E.164
RSVD
RD
AREA
ESI
SEL
IDI



 IDP
IDP

Рисунок 3.49 – Формат
адреса Е.164 NSAP
-
Международный
номерЗаполнение
Код
страныНациональный
код местаназначения
Абонентский
номерНациональный
номер




Рисунок 3.50 –
Структура номеров
Здесь
осуществляется тесное взаимодействие
с потоками управления SDH
(F1…F5).
Потоки
данных F1…F5
следующие:
F1
– поток данных ОАМ уровня регенерационной
секции SDH;
F2
– поток данных ОАМ цифровой мультиплексорной
секции SDH;
F3
– поток данных ОАМ уровня пути обмена
SDH;
F4
– поток данных ОАМ виртуального пути
АТМ;
F5
– поток данных ОАМ виртуального канала
АТМ.
Код
страны (СС – Country Code)
занимает от одной до трех цифр из 15.
Маршрутизация в ATM
отличается от аналогичных процессов в
сетях с коммутацией пакетов. Сети АТМ
в основном ориентированы на соединение.
Ячейки транспортируются по уже выбранному
маршруту через коммутаторы АТМ в
соответствии со значениями
идентификаторов виртуального пути
и
виртуального
канала.
Вычисление
маршрута осуществляется на специальном
сервере. Потоки информации F4 или F5
принимаются и обрабатываются устройствами,
которые формируют виртуальные пути или
каналы. Формат информационного поля
ячейки OAM
показан на рис. 3.51. Поток информации OAM
F4 уровня виртуального пути для
идентификации потока “точка–точка”
использует идентификатор виртуального
канала VCI = 4, а для сегментных потоков –
VCI = 3.
-
48
байтТип
ОАМТип
выполняемой функцииПоле
специальных функцийРезерв
СRC
4
бита4
бита45
байт6
бит10
бит
 48
48Рисунок
3.51 – Формат ячейки OAM F4
Поток
ячеек OAM F5 уровня виртуального канала
каких-либо специальных идентификаторов
виртуальных путей не использует. В
заголовках ячеек потока OAM
F5 типа “точка–точка” в поле “типа
данных” (PT) записывается код 100, а для
сегментных потоков виртуальных каналов
– PT = 101. Значения кодов полей типа OAM и
выполняемой функции приведены в табл.
3.21.
Таблица
3.21 – Коды
полей типа ОАМ
|
Код |
Назначение |
Код |
Назначение |
|
0001 |
Обнаружение и Management) |
0000 |
Указание |
|
0001 |
Указание |
||
|
0100 |
Проверка |
||
|
1000 |
Обратная |
||
|
0010 |
Контроль рабочих характеристик |
0000 |
Прямой |
|
0001 |
Сообщение |
||
|
0010 |
Мониторинг результатов and |
||
|
1000 |
Активизация и |
0000 |
Мониторинг |
|
0001 |
Проверка |
Для
решения проблем выявления и локализации
отказов в сети АТМ используются ячейки:
AIS (Alarm Indication
Signal
– аварийный сигнал), RDI/FERF (Remote
Defect
Indication/Far
End
Reporting
Failure – указатель отказа на удаленном
конце), контроля непрерывности (Continuity
Check)
и проверки с применением обратной
связи (Loopback).
Для ячеек AIS и RDI поля “тип отказа”
имеет 8 байт (по умолчанию во все октеты
записывается 0х6А), а для указателя “места
отказа” выделено 9 байт. Полезная
часть поля данных в этих ячейках равна
45 байт, из них 28 зарезервировано на
будущее. Контроль рабочих характеристик
сети АТМ производится без нарушения
соединений и без снижения качества
обслуживания. Для запуска и остановки
процесса измерения служат ячейки типа
Activation/Deactivation.
В ячейке OAM
для этих целей в поле данных выделено
45 байт. Формат субполей поля данных
представлен на рис. 3.52.
|
|
2 бита |
8 бит |
4 бита |
4 бита |
42х8 бит |
|
Иденти-фикатор |
Направление |
Корре-ляционная |
Блок РМ Размер А-В |
Блок РМ Размер В-А |
Неиспользуемые |
 6
6Рисунок
3.52 – Формат субполей поля данных OAM
Activation/Deactivation
Субполе
“неиспользуемые октеты” заполняется
байтами 0х6А, а субполя блок РМ – кодами
0000. Значения кодов поля “идентификатор
сообщения” приведены в табл. 3.22.
Таблица
3.22 –
Коды поля “идентификатор сообщения”
|
Код |
Назначение |
|
000001 |
Активация |
|
000010 |
Подтверждение |
|
000011 |
Отвержение |
|
000101 |
Деактивация |
|
000110 |
Подтверждение |
|
000111 |
Отвержение |
В
субполе “направление действия”
заносится код 10 при направлении от А к
В и 01 – при противоположном направлении.
В поле “размер”
записывается
код 1000 при длине 1024 ячейки, 0100 – при
512, 0010 – при 256 и 0001 – при 128 ячейках.
Размеры блоков для направлений А → B
и В → A
могут быть и неравными. Мониторинг
рабочих параметров может выполняться
для А → B,
В → A
или для обоих направлений одновременно.
Формат ячеек OAM
типа “измерение рабочих характеристик”
представлен на рис. 3.53.
|
|
Мониторинг |
Сообщение |
||||
|
Порядковый мониторинга |
Общее число |
BIP-16 |
Временная |
Не Использу-ется |
Результаты |
Счет потерянных и лишних ячеек |
|
1 |
2 |
2 |
4 |
33 |
1 |
2 |

Рисунок
3.53 – Формат ячеек OAM
типа “измерение рабочих характеристик”
В
субполя BIP-16 (Bit Interleaved
Parity) и “счет потерянных ячеек” в
отсутствие прямого мониторинга по
умолчанию заносится код 0х6А, аналогичный
код записывается в субполя “число ячеек
пользователя” и “результаты анализа”
в отсутствие обратного мониторинга. В
неиспользуемое поле записываются
единицы во все биты, если не использована
временная метка. Поле “порядковый номер
мониторинга” (MSN – Monitoring
Sequence
Number)
содержит номер ячейки OAM
типа PM по модулю 256. В поле “общее число
ячеек пользователя” (TUC – Total
User
Cell)
записывается число пользовательских
ячеек, отправленных после последней
ячейки OAM типа PM.
Один
физический отказ может сгенерировать
большое число ячеек OAM. Для блокировки
такой возможности введено ограничение
на период генерации таких ячеек (не
более нескольких секунд). Операции
проверки тракта, выполняемые с помощью
ячеек OAM типа Loopback,
позволяют выявить место возникновения
неисправностей. Формат поля специальных
функций ячейки OAM типа Loopback
отображен на рис. 3.54 (см. также рис. 3.51).
|
Индикатор |
Корреля-ционная |
Идентификатор |
Идентификатор |
Не используется |
0 или 1 |
|
|
8 бит |
12 байт |
12 байт |
135 бит |
1 бит |
 8
8
Рисунок
3.54 – Формат ячейки OAM
типа Loopback
Поле
“неиспользуемое” содержит во всех
октетах по умолчанию код 0х6А. Поле
“индикатор шлейфа”
содержит 1
при посылке отправителем (остальные
семь битов равны нулю), единица заменяется
нулем в момент приема. При получении
ячейки с “индикатором шлейфа”, равным
нулю, она уничтожается. Поле “корреляционная
метка” используется отправителем для
идентификации отклика. Поле “идентификатор
места шлейфа” определяет место, откуда
ячейка должна быть послана назад. Если
поле содержит все единицы, таким местом
является адресат. Поле “идентификатор
источника” служит для распознавания
ячейки и ее уничтожения при возвращении.
Предоставление
услуг без установления соединения
соответствует уровню выше чем АТМ и
требует соединения каждого клиента с
соответствующим сервером, решающим
данную задачу. Большинство локальных
и региональных сетей АТМ реализуют
именно такой режим. Для передачи данных
без установления соединения используется
протокол доступа CLNAP (Connectionless Network
Access
Protocol),
интерфейс CLAI (Connectionless
Access
Interface)
и сетевой протокол CLNIP (Connectionless
Network
Interface
Protocol).
Размер поля данных для CLNAP не является
постоянным и составляет 9188 байт, что
подразумевает фрагментацию. Эти протоколы
работают выше подуровня конвергенции.
Соответствующая длина для CLNIP SDU равна
9236 байт. Формат блока данных CLNIP показан
на рис. 3.55. Проблему фрагментации и
инкапсуляции этих длинных пакетов в
АТМ ячейки берет на себя коммутатор
доступа.
Схема
вложения и фрагментации для пакетов
CLNAP
отображена на рис. 3.56. Из рисунка видно,
что на подуровне SAR происходит деление
пакета на части и укладка полученных
сегментов в поля данных ячеек (48 байт).
Для
использования одного и того же виртуального
канала многими протоколами служит
LLC-инкапсуляция (Logical
Link
Control).
LLC-заголовок укладывается в поле данных
перед PDU и содержит в себе информацию,
необходимую для того, чтобы корректно
обработать AAL5 CPCS-PDU. Обычно такой заголовок
имеет формат IEEE 802.2, за которым может
следовать SNAP-заголовок IEEE 802.1a.
LLC-заголовок, содержащий код 0xFE-fe-03,
говорит о том, что далее следует
маршрутизируемый PDU.

Рисунок 3.55 – Формат
структуры данных протокола CLNIP:
PI
(Protocol Identifier) – идентификатор протокола;
PADLE (Padding Length)
– длина заполнения; QoS
(Quality
of
Service)
– качество обслуживания; С (CRC Indication
Bit)
– индикатор числа битов в контрольной
сумме CRC; HEL
(Header
Extension
Length)
– длина расширения заголовка
Однооктетный код
NLPID идентифицирует сетевой протокол.
Значения кодов NLPID представлены в табл.
3.23.
Формат
PDU для маршрутизируемых данных при
использовании протоколов, не
принадлежащих ISO, представлен на
рис. 3.57 (случай IP-дейтаграммы). Пропускная
способность сети АТМ (150 Мбит/с)
позволяет передавать немного более
360 000 ячеек в секунду, что означает
для ATM-переключателя время коммутации
менее 2,7 мкс.
Реальный
переключатель может иметь от 16 до 1 024
входных линий, что может означать
коммутацию 16…1 024 ячеек каждые 2,7 мкс.
При быстродействии 622 Мбит/с новая
порция ячеек поступает каждые 700 нс.
Постоянство длины ячеек упрощает
конструкцию ключа. Все АТМ-ключи имеют
целью обеспечить коммутацию с минимальной
вероятностью потерь и исключить
возможность изменения порядка следования
ячеек. Приемлемой считается вероятность
потери ячейки не более 10–12.
Это эквивалентно для большого коммутатора
потерям 1…2 ячеек за час. Уменьшению
вероятности потерь способствует
создание буферов конвейерного типа.
Если на вход переключателя
|
Заголовок |
Поле |
|||||||
|
Уровень |
||||||||
|
AH |
CLNAP-PDU |
|||||||
|
Уровень |
Заголовок |
Поле CLNIP—PDU |
||||||
|
Подуровень |
Заголовок |
Поле |
||||||
|
|
2 |
44 |
2 |
|||||
|
Поле |
Подуровень |
Поле SAR |
||||||
|
|
5 |
|||||||
|
Поле |
Уровень |
Поле |
||||||
|
|









 53
53
Рисунок 3.56 – Схема
вложения и фрагментации для пакетов
CLNAP:
АН
(Alignment Header;
4 октета) – поле выравнивания; SAR
(Segmentation
And
Reassemble)
– сегментация и сборка; CPCS (Common Part
Convergence
Sublayer) общая часть подуровня конвергенции
длиной 216
– 4 октетов
Таблица
3.23 – Значения
кодов NLPID
|
Код |
Назначение |
|
0х00 |
Нулевой |
|
0х80 |
SNAP |
|
0х81 |
ISO |
|
0х82 |
ISO |
|
0х83 |
ISO |
|
0хСС |
Интернет |
-
LLC
0xAA-AA-03
OUT
0x00-00-00
EtherType
0x08-00
IP—PDU
Рисунок 3.57 – Формат
IP PDU при транспортировке
с использованием
AAL5 ATM
приходят
две ячейки одновременно, одна из них
обслуживается, а вторая ставится в
очередь (запоминается в буфере). Выбор
ячеек может производиться псевдослучайно
или циклически. При этом не должно
возникать предпочтений для каких-либо
каналов. Если в один цикл на вход (каналы
1, 2, 3 и 4) коммутатора пришли четыре
ячейки, предназначенные для выходных
линий J+2, J, J+2 и J+1, соответственно, то на
линии J+2 возникает конфликт. Предположим,
что будет обслужена ячейка, поступившая
по первой входной линии, а ячейка на
входной линии 3 будет поставлена в
очередь.
В
начале следующего цикла на выход попадут
три ячейки. Предположим также, что в
этот цикл на входы коммутатора (1 и 3)
придут ячейки, адресованные для линий
J+3 и J, соответственно. Ячейка, адресованная
J, будет поставлена в очередь вслед за
ячейкой, адресованной J+2. Все эти ячейки
будут переданы только на 4-ом цикле.
Таким образом, попадание в очередь на
входе ячейки блокирует передачу
последующих ячеек, даже если выходные
каналы для их передачи свободны. Чтобы
исключить блокировку такого рода, можно
организовать очередь не на входе, а на
выходе коммутатора. При этом для
коммутатора с 1 024 входами теоретически
может понадобиться 1 024 буфера на каждом
выходе. Реально число таких буферов
значительно меньше. Такая схема
АТМ-коммутатора (8×8)
показана на рис. 3.58. На рис. 3.59 показана
возможная структура АТМ-сети.
Р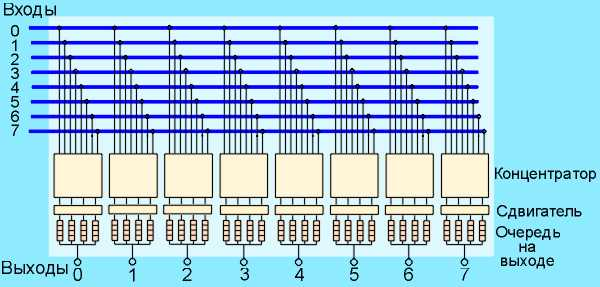 исунок
исунок
3.58 – Схема переключателя с организацией
очередей на выходе
Концентратор
выбирает N ячеек для помещения в очередь
(предполагается, что максимальная длина
очереди может быть равна N). Выходной
буфер уже заполнен, и ячейка может быть
потеряна. При построении АТМ-коммутаторов
часто используется схема сети с
многокаскадными соединениями.
В
перспективе развития сетевых технологий
в Украине до 2025 года включительно
предусматривается несколько этапов. В
будущем сети на основе технологии АТМ
можно рассматривать как сети с интеграцией
всего разнообразия служб электросвязи,
в том числе и служб документальной
электросвязи. На рис. 3.59 представлена
перспективная модель развития сетевой
технологии АТМ на основе сетей общего
пользования Украины на основе асинхронных
систем передачи информации с возможностью
оперативной коммутации. Последние
достижения в области сетевых технологий
выявили тенденцию к построению
неиерархических сетевых структур. При
этом вся сеть рассматривается как
двухуровневая, состоящая из магистральной
сети и сети доступа, чему соответствуют
сети АТМ. При таком подходе внутризоновая
и местные сети входят в сеть доступа.
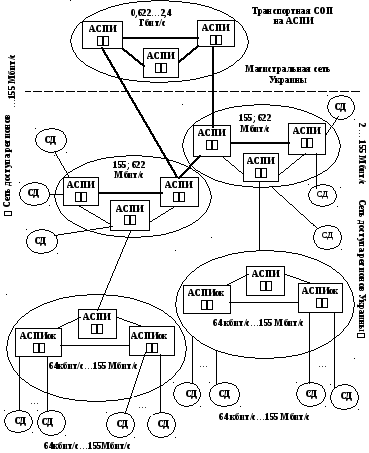
Рисунок
3.59 – Перспективная сеть внедрения АТМ
в Украине:
АСПИ,
АСПИок – узлы оперативной коммутации
АТМ; СД – сеть доступа
13.1. Протоколы сетей ATM
В настоящее время широко внедряются каналы с пропускной способностью 150,52 и 622,08 Мбит/с. Эти каналы, пригодные как для соединения локальных сетей, так и непосредственно для построения скоростных LAN, могут обеспечить любые современные телекоммуникационные услуги, кроме телевидения высокого разрешения. Предусмотрен стандарт и на скорость передачи 2,48832 Гбит/c. Так как время доставки для многих видов сетевых услуг реального времени является крайне важной характеристикой, АТМ находит широкое применение в телефонии, кабельном телевидении и других областях. Следует учитывать, что оцифрованный видеосигнал качества VHS требует 100 Мбит/с при отсутствии сжатия и 1,5-6 Мбит/c — при использовании сжатия. Кадр изображения 1000х1000 пикселей при 24 битах, характеризующих цвет, занимает 3 Мбайта. ATM справится с передачей такого кадра, с учетом накладных расходов (заголовок), за ~0,2 с. Понятно, что при использовании сжатия
можно получить заметно большее быстродействие.
Это не значит, что доступны лишь указанные скорости: интерфейсы позволяют мультиплексировать большое число каналов с самыми разными скоростями обмена. Но мультиплексирование на таких частотах представляет собой значительную проблему. Определенные трудности создает то обстоятельство, что в ATM трудно реализовать обмен без установления соединения (аналог UDP в Интернете).
Протокол ATM (Asynchronous Transfer Mode; см. также Назаров А.Н., Симонов М.В. АТМ. Технология высокоскоростных сетей. М.: ЭКО-Трендз, 1998) является широкополосной версией ISDN, работает на скорости 150,52 Мбит/с с пакетом постоянной длины и минимальным заголовком. Слово «асинхронный» в названии означает, что тактовые генераторы передатчика и приемника не синхронизованы, а сами ячейки передаются и мультиплексируются по запросам. При мультиплексировании используется статистическая технология. Асинхронная передача не предполагает упорядочивания ячеек по каналам при пересылке. ATM поддерживает аппаратную и пакетную коммутации (см. также http://book.itep.ru/4/43/atm_435.htm).
Каждый пакет ATM имеет 53 байта (в англоязычной документации пакеты ATM носят название cell (ячейка), этот термин введен, чтобы отличить пакеты ATM от пакетов низкоскоростных каналов), из них 48 байт несут полезную информацию.
Ячейка АТМ в случае транспортировки голосовых данных соответствует 6 мс звучания.
Для выделения пакета из потока используются такие же, как в ISDN, разделительные байты (0x7E). Заголовок пакета содержит лишь 5 байт и предназначен главным образом для того, чтобы определить, принадлежит ли данный пакет определенному виртуальному каналу. Отсутствие контроля ошибок и повторной передачи на физическом уровне приводит к эффекту размножения ошибок. Если происходит ошибка в поле идентификатора виртуального пути или виртуального канала, то коммутатор может отправить ячейку другому получателю. Таким образом, один получатель не получит ячейку, а другой получит то, что ему не предназначалось.
ATM -коммутаторы используют входной порт и значение поля VPI / VCI входящего пакета в качестве индекса в таблице коммутации (crossconnect), из которой они получают номер выходного порта и выходного значения VPI / VCI.
Виртуальный канал в ATM формируется так же, как и в ISDN. Формально эта процедура не является частью ATM -протокола. Сначала здесь формируется сигнальная схема, для этого посылается запрос с VPI =0 и VCI =5. Если процедура завершилась успешно, можно начинать формирование виртуального канала. При создании канала могут использоваться 6 разновидностей сообщений:
- setup — запрос формирования канала;
- call proceeding — запрос в процессе исполнения;
- connect — запрос принят;
- connect ACK — подтверждение получения запроса;
- release — сообщение о завершении;
- release complete — подтверждение получения сообщения release.
Схема обмена сообщениями при установлении (и разрыве) виртуального соединения показана на
рис.
13.14. Предполагается, что между ЭВМ-инициализатором и ЭВМ-адресатом находится два ATM -переключателя. Каждый из узлов по пути к месту назначения при получении запроса setup откликается, посылая сообщение «call proceeding». Адрес места назначения указывается в сообщении setup. В ATM используется три вида адресов. Первый адрес имеет 20 байт и структуру OSI-адреса. Первый байт указывает на вид адреса (один из трех). Байты 2 и 3 указывают на принадлежность стране, а байт 4 задает формат последующей части кода адреса, которая содержит 3 байта кода администрации (authority), 2 байта домена, 2 байта области и 6 байтов собственно адреса. Во втором формате байты 2 и 3 выделены для международных организаций, а не стран. Остальная часть адреса имеет тот же формат, что и в варианте 1.
Третий формат является старой формой (CCITT E.164) 15-цифровых десятичных телефонных номеров ISDN. В ATM не специфицировано никакого алгоритма маршрутизации. Для выбора маршрута (от коммутатора к коммутатору) используется поле VCP. VCI применяется лишь на последнем шаге, когда ячейка посылается от переключателя к ЭВМ. Такой подход упрощает маршрутизацию отдельных ячеек, так как при этом анализируется 12-, а не 28-битовые коды. В каждом коммутаторе (переключателе) формируются специальные таблицы, которые решают проблему переадресации ячеек.

Рис.
13.14.
Обмен сообщениями при установлении и разрыве виртуального соединения
Следует обратить внимание на то, что виртуальный канал (circuit) и виртуальный проход (path) в данном контексте не тождественны. Виртуальный проход (маршрут) может содержать несколько виртуальных каналов. Виртуальные каналы всегда являются полностью дуплексными.
Сети ATM допускают создание мультикастных каналов. Такой канал имеет одного отправителя и много получателей (например, в случае многоканальных телефонных или видеоконференций). Первый канал формируется обычным путем, последующие участники сессии подключаются позднее путем посылки сообщения add party.
За видимую простоту ячеек приходится платить тем, что управляющая информация передается в общем информационном потоке. Высокая скорость передачи данных требует применения аппаратно реализованных маршрутных таблиц на каждом переключателе пакетов. На
рис.
13.15 представлен формат заголовка пакета ATM. Заголовок обеспечивает два механизма маршрутизации пакетов:
- VPI (Virtual Path Identifier — виртуальный идентификатор маршрута) обеспечивает соединение «точка-точка», но маршрут не является фиксированным и задается непосредственно перед началом пересылки с использованием сигнальных сообщений. Слово «виртуальный» означает, что пакеты передаются от узла к узлу в соответствии с VPI ;
- VCI (Virtual Call Identifier — виртуальный идентификатор запроса) — запросы осуществляются в соответствии с виртуальным маршрутом, заданным VPI.
Эти два субполя вместе образуют поле маршрута, которое занимает 24 бита.
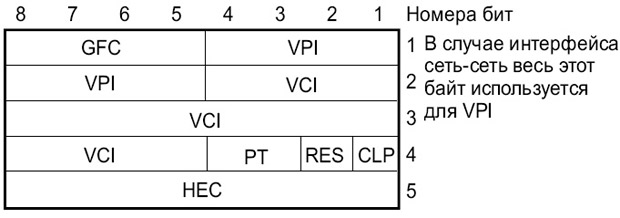
Рис.
13.15.
Формат заголовка ATM-пакета (сетевой интерфейс пользователя — UNI
Для интерфейса «сеть—сеть» ( NNI ) используется ячейка с несколько иным форматом заголовка. Там весь первый октет выделен для VPI, а поле GFC отсутствует (
таблица
13.3.1.).
| GFC | Generic Flow Control (4 бита, смотри описание пакетов ISDN ) — общее управление потоком |
|---|---|
| VPI | Virtual Path Identifier (8 бит, служит для целей маршрутизации) — идентификатор виртуального пути |
| VCI | Virtual Call Identifier (16 бит, служит для целей маршрутизации) — идентификатор виртуального канала |
| PT | Payload Type (2 бита, тип данных; это поле может занимать и зарезервированное субполе RES) |
| RES | зарезервированный бит |
| CLP | (Cell Loss Priority — уровень приоритета при потере пакета) указывает на то, какой приоритет имеет пакет (cell), и будет ли он отброшен в случае перегрузки канала |
| HEC | Header Error Control (8 бит, поле контроля ошибок – контрольная сумма) |
Ряд значений VCI и VPI имеют фиксированные значения, приведенные в таблице 13.4.
| VCI | VPI | Назначение |
|---|---|---|
| 0 | только 0 | Неопределенная ячейка |
| 1 | все | Метауправление |
| 3 | все | Сетевое управление VP-каналом |
| 4 | все | vP-управление для соединения между конечными точками |
| 5 | все | Управление доступом по схеме «точка-точка» |
| 6 | все | Ячейка управления ресурсами (для подавления перегрузки) |
| 16 | только 0 | UNI (snmp) управление сетью |
Некоторые значения поля PT зафиксированы, их значения представлены в таблице 13.5.
| PT | Назначение ячейки | Взаимодействие «пользователь-пользователь» |
|---|---|---|
| 000 | Пользовательские данные (перегрузка отсутствует) | нет |
| 001 | Пользовательские данные (перегрузка отсутствует) | нет |
| 010 | Пользовательские данные (имеет место перегрузка) | да |
| 011 | Пользовательские данные (имеет место перегрузка) | да |
| 100 | Ячейка виртуального канала oam сегментного потока f5 | |
| 101 | Соединение «точка-точка» oam сегментного потока f5 | |
| 110 | Управление ресурсами | |
| 111 | Зарезервировано |
OAM — эксплуатация и техническое обслуживание. ATM обеспечивает любые услуги в сети.
- Передача голоса на скоростях 64 Кбит/с. Один ATM -пакет соответствует 6 мс.
- Передача музыки с использованием схемы кодирования MUSICAM.
- Так как для случая изображения передается только переменная часть картинки, atm идеально подходит для решения такого рода задач.
- Задачи управления решаются менее экономно, но тем не менее достаточно эффективно (предусмотрено несколько приоритетов для управления потоками данных).
В ATM предусмотрено несколько категорий услуг (
таблица
13.6).
| Класс | Описание | Пример |
|---|---|---|
| cbr | Постоянная скорость передачи | Канал Т1 |
| rt-vbr | Переменная скорость передачи (реальное время) | Видеоконференции |
| nrt-vbr | Переменная скорость передачи (нереальное время) | Мультимедиа по электронной почте |
| abr | Доступная скорость передачи | Просмотр web-информации |
| ubr | Неспецифицированная скорость передачи | Пересылка файлов в фоновом режиме |
CBR не предусматривает контроля ошибок, управления трафиком или какой-либо другой обработки. Класс CBR пригоден для работы с мультимедиа реального времени.
Класс VBR содержит в себе два подкласса — обычный и для реального времени (см. таблицу выше). ATM в процессе доставки не вносит никакого разброса ячеек по времени. Случаи потери ячеек игнорируются.
Класс ABR предназначен для работы в условиях мгновенных вариаций трафика. Система гарантирует некоторую пропускную способность, но в течение короткого времени может выдержать и большую нагрузку. Этот класс предусматривает наличие обратной связи между приемником и отправителем, которая позволяет понизить загрузку канала, если это необходимо.
Класс UBR хорошо пригоден для посылки IP-пакетов (нет гарантии доставки и в случае перегрузки неизбежны потери).
ATM использует исключительно модель с установлением соединения (здесь нет аналогий с UDP-протоколом). Это создает определенные трудности для управления трафиком с целью обеспечения требуемого качества обслуживания (QoS). Для решения этой задачи применяется алгоритм GCRA (Generic Rate Algorithm). Работа этого алгоритма проиллюстрирована на
рис.
13.16.
GCRA имеет два параметра. Один из них характеризует максимально допустимую скорость передачи PCR (Peak Cell Rate); T=1/PCR — минимальное расстояние между ячейками), другой — допустимую вариацию значения скорости передачи ( CDVT=L ). Если клиент не собирается посылать более 100 000 ячеек в секунду, то Т = 10 мкс. На
рис.
13.16 представлены разные варианты следования ячеек. Если ячейка приходит раньше, чем T-τ, она считается неподтверждаемой и может быть отброшена. Ячейка может быть сохранена, но при этом должен быть установлен бит CLP=1. Применение бита CLP может быть разным для разных категорий услуг (см. рисунок 13.16). Данный механизм управления трафиком сходен с алгоритмом «дырявое ведро».
Можно вычислить число подтверждаемых ячеек N, которые могут быть переданы при пиковом потоке ячеек PCR=1/T. Пусть время ячейки в пути равно 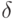 . Тогда
. Тогда 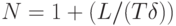 . Если полученное число оказалось нецелым, оно должно быть округлено до ближайшего меньшего целого.
. Если полученное число оказалось нецелым, оно должно быть округлено до ближайшего меньшего целого.
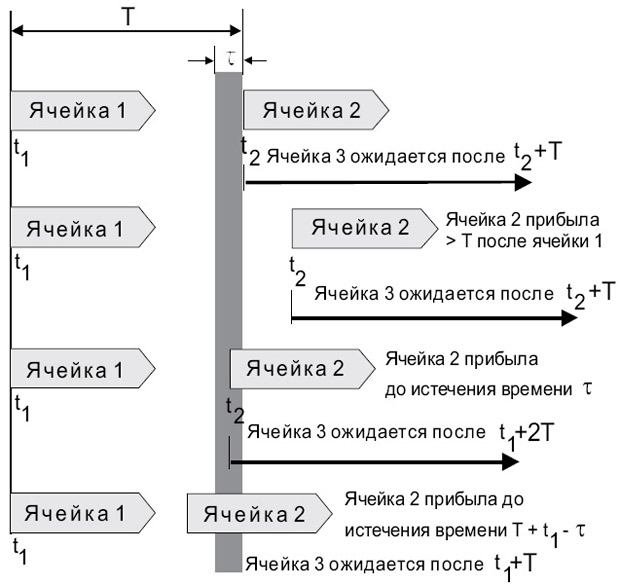
Рис.
13.16.
Иллюстрация работы алгоритма GCRA
ATM (asynchronous transfer mode — асинхронный способ передачи данных) — сетевая высокопроизводительная технология коммутации и мультиплексирования пакетов, которые представляют собой ячейки (cell) фиксированного размера в 53 байта, где первые 5 байт используются под заголовок. Является разновидностью быстрой коммутации пакетов (fast packet switching).
В отличие от синхронного способа передачи данных (STM — synchronous transfer mode), ATM лучше приспособлен для предоставления услуг передачи данных с сильно различающимся или изменяющимся битрейтом.
История
Создание
Основы технологии ATM были разработаны независимо во Франции и США в 1970-х двумя учёными: Jean-Pierre Coudreuse, который работал в исследовательской лаборатории France Telecom, и Sandy Fraser, инженер Bell Labs. Они оба хотели создать такую архитектуру, которая бы осуществляла транспортировку как данных, так и голоса на высоких скоростях, и использовала сетевые ресурсы наиболее эффективно.
Компьютерные технологии создали возможность для более быстрой обработки информации и более скоростной передачи данных между системами. В 80-х годах ХХ века операторы телефонной связи обнаружили, что неголосовой трафик более важен и начинает доминировать над голосовым. Был предложен проект ISDN, который описывал цифровую сеть с коммутацией пакетов, предоставляющую услуги телефонной связи и передачи данных. Цифровые системы передачи, сначала плезиохронные системы (PDH) на основе ИКМ, а затем синхронные системы передачи (SDH) иерархии на основе оптоволокна, позволяли обеспечить передачу данных на высокой скорости с малыми вероятностями двоичных ошибок. Но существующая технология коммутации пакетов (прежде всего, по протоколу X.25) не могла обеспечить передачу трафика в реальном масштабе времени (например, голоса), и многие сомневались, что когда-либо обеспечит. Для передачи трафика в реальном масштабе времени в общественных телефонных сетях применяли технологию коммутации каналов (КК). Эта технология идеальна для передачи голоса, но для передачи данных она неэффективна. Поэтому телекоммуникационная индустрия обратилась к ITU для разработки нового стандарта для передачи данных и голосового трафика в сетях с широкой полосой пропускания. В конце 80-х Международным телефонным и телеграфным консультативным комитетом CCITT (который затем был переименован в ITU-T) был разработан набор рекомендаций по ISDN второго поколения, так называемого B-ISDN (широкополосный ISDN), расширения ISDN. В качестве режима передачи нижнего уровня для B-ISDN был выбран ATM. В 1988 г. на собрании ITU в Женеве была выбрана длина ячейки ATM — 53 байт. Это был компромисс между специалистами США, которые предлагали длину ячейки 64 байта и специалистами Европы, предлагавшими длину ячейки 32 байта. Ни одна сторона не смогла убедительно доказать преимущество своего варианта, поэтому в итоге объём «полезной» нагрузки составил 48 байт, а для поля заголовка (служебных данных) был выбран размер 5 байт, минимальный размер, на который согласилась ITU. В 1990 г. был одобрен базовый набор рекомендаций ATM. Базовые принципы ATM положены рекомендацией I.150. Это решение было очень похоже на системы, разработанные Coudreuse и Fraser. Отсюда начинается дальнейшее развитие ATM.
Советские и российские разработки
В 1980-х — 1990-х годах исследованием и разработкой средств быстрой коммутации пакетов (БКП) для совместной передачи речи и данных занимались несколько организаций.
ЛНПО «Красная Заря»
Тему БКП и, как её разновидность, АТМ, разрабатывал отдел под руководством Г. П. Захарова в составе предприятия АООТ Научно-производственное объединение «Радуга». Ранее это предприятие было одним из подразделений ЛНПО «Красная Заря». Отдел Захарова получил как теоретические результаты, — математические модели, отчёты по проведённым отделом НИР, статьи, книги, студенческие дипломы, кандидатские и докторские диссертации по теме, — так и практические результаты:
- сначала, совместными усилиями специалистов ЛНПО «Красная Заря» и предприятия «Дальняя связь» под техническим руководством специалиста ЛНПО «Красная Заря» (НИИЭТУ) Разживина Игоря Александровича, в 1992 году был создан рабочий макет системы коммутации и приёма ячеек АТМ;
- совместно со специалистом организации «Вектор» Ю. А. Яцуновым в 1993 году разработана принципиальная схема коммутационного элемента (КЭ) для построения двоичного самомаршрутизирующего коммутационного поля (КП). В основу были положены некоторые идеи построения КЭ и КП. В самом общем плане такой КЭ описывается схемой «селектор-арбитр». Схема КЭ Яцунова-Разживина предназначалась для микросхем малой степени интеграции популярных и доступных серий, выпускавшихся тогда российской промышленностью, однако «в железе» воплощена не была сознательно, поскольку являлась только промежуточным этапом;
- затем, на основе принципиальной схемы Яцунова-Разживина был успешно реализован, также под техническим руководством Разживина И. А., КЭ в виде одной специализированной СБИС, которая была разработана специалистом московского ФГУП «НИИМА Прогресс» В. И. Лопашовым, при содействии его коллеги Халтурина В. А., и изготовлена в Москве в январе 1994 года.
Это позволяло создать коммутационное поле быстрого коммутатора пакетов, или коммутатора ячеек ATM, на одной печатной плате. Однако дальше выпуска опытной партии СБИС в количестве 10 штук, и внедрения результатов диссертационной работы Разживина И. А. в НИР «НИИМА Прогресс» и ГП НИИ «Рубин», эти работы не пошли по независящим от технических специалистов причинам.
Известны работы группы специалистов под руководством к. т. н. Георгия Ревмировича Овчинникова, предложивших свой вариант реализации аппаратных средств системы быстрой коммутации пакетов на основе самомаршрутизирующих матриц и свою математическую модель. Однако о практической реализации их предложений сведений не имеется.
Московский институт электронной техники
Было доложено описание цифрового коммутатора 16х16 на арсениде галлия, разработанного независимо от ЛНПО «Красная Заря» Московским институтом электронной техники.
1990-е годы: приход ATM на рынок
В начале 1990-х гг. технологии ATM в мире начинают уделять повышенное внимание. Корпорация Sun Microsystems ещё в 1990 г., одна из первых, объявляет о поддержке ATM. В 1991 году, с учётом, что CCITT уже не успевает своевременно предлагать рекомендации по быстроразвивающейся новой технике, создаётся ATM Forum, консорциум фирм-разработчиков и производителей техники АТМ, для координации и разработки новых практических стандартов и технических спецификаций по технологии ATM, и сайт с одноимённым названием, где все спецификации выкладывались в открытый доступ. CCITT, уже будучи ITU-T, выдаёт новые редакции своих рекомендаций, совершенствуя теоретическую базу ATM. Представители сферы IT в журналах и газетах пророчат ATM большие перспективы. В 1995 г. компания IBM объявила о своей новой стратегии в области корпоративных сетей, основанной на технологии ATM. Считалось, что ATM будет существенным подспорьем для Интернета, уничтожив нехватку ширины полосы пропускания и внеся в сети надежность. Dan Minoli, автор многих книг по компьютерным сетям, утверждал, что ATM будет внедрен в публичных сетях, и корпоративные сети будут соединены с ними таким же образом, каким в то время они использовали frame relay или X.25. Но к тому времени протокол IP уже получил широкое распространение и сложно было совершить резкий переход на ATM. Поэтому в существующих IP-сетях технологию ATM предполагалось внедрять как нижележащий протокол, то есть под IP, а не вместо IP. Для постепенного перехода традиционных сетей Ethernet и Token-Ring на оборудование ATM был разработан протокол LANE, эмулирующий пакеты данных сетей.
В 1997 г. в индустрии маршрутизаторов и коммутаторов примерно одинаковое количество компаний выстроились в ряды сторонников и противников ATM, то есть использовали или не использовали технологию ATM в производимых устройствах. Будущее этого рынка было ещё неопределенно. В 1997 г. доход от продажи оборудования и услуг ATM составил 2,4 млрд долларов США, в следующем году — 3,5 млрд, и ожидалось, что он достигнет 9,5 млрд долларов в 2001 году. Многие компании (например Ipsilon Networks) для достижения успеха использовали ATM не полностью, а в урезанном варианте. Многие сложные спецификации и протоколы верхнего уровня ATM, включая разные типы качества обслуживания, выкидывались. Оставлялась только базовая функциональность по переключению байтов с одних линий на другие.
Первый удар по ATM
И тем не менее, было также много специалистов IT, скептически относящихся к жизнеспособности технологии ATM. Как правило, защитниками ATM были представители телекоммуникационных, телефонных компаний, а противниками — представители компаний, занимавшихся компьютерными сетями и сетевым оборудованием. Steve Steinberg (в журнале Wired) посвятил целую статью скрытой войне между ними. Первым ударом по ATM были результаты исследований Bellcore о характере трафика LAN, опубликованных в 1994 г.. Эта публикация показала, что трафик в локальных сетях не подчиняется ни одной существующей модели. Трафик LAN на временной диаграмме ведёт себя как фрактал. На любом временном диапазоне от нескольких миллисекунд до нескольких часов он имеет самоповторяющийся, взрывной характер. ATM в своей работе все внеурочные пакеты должен хранить в буфере. В случае резкого увеличения трафика, коммутатор ATM просто вынужден отбрасывать невмещающиеся пакеты, а это означает ухудшение качества обслуживания. По этой причине PacBell потерпела неудачу при первой попытке использовать оборудование ATM.
Появление главного конкурента ATM — Gigabit Ethernet
В конце 90-х появляется технология Gigabit Ethernet, которая начинает конкурировать с ATM. Главными достоинствами первой является значительно более низкая стоимость, простота, лёгкость в настройке и эксплуатации. Также, переход с Ethernet или Fast Ethernet на Gigabit Ethernet можно было осуществить значительно легче и дешевле. Проблему качества обслуживания Gigabit Ethernet мог решить за счет покупки более дешевой полосы пропускания с запасом, нежели за счет умного оборудования. К окончанию 90-х гг. стало ясно, что ATM будет продолжать доминировать только в глобальных сетях. Продажи свитчей ATM для WAN продолжали расти, в то время как продажи свитчей ATM для LAN стремительно падали.
2000-е годы: поражение ATM
В 2000-е гг. рынок оборудования ATM ещё был значительным. ATM широко использовался в глобальных компьютерных сетях, в оборудовании для передачи аудио/видео потоков, как промежуточный слой между физическим и вышележащим уровнем в устройствах ADSL для каналов с пропускной способностью не более 2 Мбит/с. Но в конце десятилетия ATM начинает вытесняться новой технологией IP-VPN. Свитчи ATM стали вытесняться маршрутизаторами IP/MPLS. В 2006 Broadband Forum выпустил спецификацию TR-101 под названием «Migration to Ethernet-Based DSL
Aggregation», которая указывала как построенные на ATM агрегирующие сети могут мигрировать на построенные на Ethernet агрегирующие сети (в контексте предыдущих архитектур TR-25 и TR-59). В качестве обоснования такого перехода в спецификации сказано, что существующие DSL-архитектуры эволюционируют от сетей «низкая скорость, максимальные усилия» к инфраструктурам, способным поддерживать более высокую скорость передачи и сервисы требующие QoS, мультикаст, а также выполнять требования, которые недопустимо выполнять в системах, построенных на ATM. По прогнозу компании Uvum от 2009 г., к 2014 г. ATM и Frame Relay должны почти полностью исчезнуть, в то время как рынки Ethernet и IP-VPN будут продолжать расти с хорошим темпом. По докладу Broadband Forum за октябрь 2010 г, переход на глобальном рынке от сетей с коммутацией каналов (TDM, ATM и др.) к IP-сетям уже начался в стационарных сетях и уже затрагивает и мобильные сети. В докладе сказано, что Ethernet позволяет мобильным операторам удовлетворить растущие потребности в мобильном трафике более экономически эффективно, чем системы, основанные на TDM или ATM.
Ещё в апреле 2005 г. произошло слияние «ATM Forum» с «Frame Relay Forum» и «MPLS Forum» в общий «MFA Forum» («MPLS–Frame Relay–ATM Forum»). В 2007 г. последний был переименован в «IP/MPLS Forum». В апреле 2009 г. «IP/MPLS Forum» вошёл в состав существующего с 1994 г. консорциума «Broadband Forum» («BBF»). Спецификации ATM доступны в их исходном виде на сайте консорциума www.broadband-forum.org, но их дальнейшая разработка полностью остановлена.
Базовые принципы
Сеть ATM строится на основе соединенных друг с другом АТМ-коммутаторов. Технология реализуется как в локальных, так и в глобальных сетях. Допускается совместная передача различных видов информации, включая видео, голос.
Ячейки данных, используемые в ATM, меньше в сравнении с элементами данных, которые используются в других технологиях. Небольшой, постоянный размер ячейки, используемый в ATM, позволяет:
- Совместно передавать данные с различными классами требований к задержкам в сети, причём по каналам как с высокой, так и с низкой пропускной способностью;
- Работать с постоянными и переменными потоками данных;
- Интегрировать на одном канале любые виды информации: данные, голос, потоковое аудио- и видеовещание, телеметрия и т. п.;
- Поддерживать соединения типа точка–точка, точка–многоточка и многоточка–многоточка.
Технология ATM предполагает межсетевое взаимодействие на трёх уровнях.
Для передачи данных от отправителя к получателю в сети ATM создаются виртуальные каналы, VC (Virtual Circuit), которые бывают трёх видов:
- постоянный виртуальный канал, PVC (Permanent Virtual Circuit), который создаётся между двумя точками и существует в течение длительного времени, даже в отсутствие данных для передачи;
- коммутируемый виртуальный канал, SVC (Switched Virtual Circuit), который создаётся между двумя точками непосредственно перед передачей данных и разрывается после окончания сеанса связи.
- автоматически настраиваемый постоянный виртуальный канал, SPVC (Soft Permanent Virtual Circuit). Каналы SPVC по сути представляют собой каналы PVC, которые инициализируются по требованию в коммутаторах ATM. С точки зрения каждого участника соединения, SPVC выглядит как обычный PVC, а что касается коммутаторов ATM в инфраструктуре провайдера, то для них каналы SPVC имеют значительные отличия от PVC. Канал PVC создаётся путём статического определения конфигурации в рамках всей инфраструктуры провайдера и всегда находится в состоянии готовности. Но в канале SPVC соединение является статическим только от конечной точки (устройство DTE) до первого коммутатора ATM (устройство DCE). А на участке от устройства DCE отправителя до устройства DCE получателя в пределах инфраструктуры провайдера соединение может формироваться, разрываться и снова устанавливаться по требованию. Установленное соединение продолжает оставаться статическим до тех пор, пока нарушение работы одного из звеньев канала не вызовет прекращения функционирования этого виртуального канала в пределах инфраструктуры провайдера сети.
Для маршрутизации в пакетах используют так называемые идентификаторы пакета. Они бывают двух видов:
- VPI (virtual path identifier) — идентификатор виртуального пути (номер канала)
- VCI (virtual channel identifier) — идентификатор виртуального канала (номер соединения)
Структура ячейки
|
Формат ячейки UNI
|
Формат ячейки NNI
|
- GFC = Generic Flow Control (4 бита) — общее управление потоком;
- VPI = Virtual Path Identifier (8 бит UNI) или (12 бит NNI) — идентификатор виртуального пути;
- VCI = Virtual circuit identifier (16 бит) — идентификатор виртуального канала;
- PT = Payload Type (3 бита) — тип данных;
- CLP = Cell Loss Priority (1 бит) — уровень приоритета при потере пакета; указывает на то, какой приоритет имеет ячейка (cell), и будет ли она отброшена в случае перегрузки канала;
- HEC = Header Error Control (8 бит) — поле контроля ошибок.
- UNI = User-to-Network Interface — интерфейс пользователь-сеть. Стандарт, разработанный ATM Forum, который определяет интерфейс между конечной станцией и коммутатором в сети ATM.
- NNI = Network-to-Network Interface — интерфейс сеть-сеть. Обобщённый термин, описывающий интерфейс между двумя коммутаторами в сети.
Классы обслуживания и категории услуг
Определено пять классов трафика, отличающихся следующими качественными характеристиками:
- наличием или отсутствием пульсации трафика, то есть трафики CBR или VBR;
- требованием к синхронизации данных между передающей и принимающей сторонами;
- типом протокола, передающего свои данные через сеть ATM, — с установлением соединения или без установления соединения (только для случая передачи компьютерных данных).
CBR не предусматривает контроля ошибок, управления трафиком или какой-либо другой обработки. Класс CBR пригоден для работы с мультимедиа реального времени.
Класс VBR содержит в себе два подкласса — обычный и для реального времени (см. таблицу ниже). ATM в процессе доставки не вносит никакого разброса ячеек по времени. Случаи потери ячеек игнорируются.
Класс ABR предназначен для работы в условиях мгновенных вариаций трафика. Система гарантирует некоторую пропускную способность, но в течение короткого времени может выдержать и большую нагрузку. Этот класс предусматривает наличие обратной связи между приёмником и отправителем, которая позволяет понизить загрузку канала, если это необходимо.
Класс UBR хорошо пригоден для посылки IP-пакетов (нет гарантии доставки и в случае перегрузки неизбежны потери).
| Класс QoS | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Класс обслуживания | A | B | C | D | x |
| Тип трафика | CBR | VBR | VBR | ABR | UBR |
| Тип уровня | AAL1 | AAL2 | AAL3/4 | AAL3/4 | |
| Синхронизация | Требуется | Не требуется | |||
| Скорость передачи | Постоянная | Переменная | |||
| Режим соединения | С установлением | Без установления | |||
| Пример использования | (Е1, Т1) | Видео | Аудио | Передача данных |
У этого термина существуют и другие значения, см. ATM (значения).
ATM (англ. Asynchronous Transfer Mode — асинхронный способ передачи данных) — сетевая технология, основанная на передаче данных в виде ячеек (cell) фиксированного размера (53 байта), из которых 5 байтов используется под заголовок.
Сеть строится на основе АТМ коммутатора и АТМ маршрутизатора. Технология реализуется как в локальных, так и в глобальных сетях. Допускается совместная передача различных видов информации, включая видео, голос.
Ячейки данных, используемые в ATM, меньше в сравнении с элементами данных, которые используются в других технологиях. Небольшой, постоянный размер ячейки, используемый в ATM, позволяет:
- передавать данные по одним и тем же физическим каналам, причём как при низких, так и при высоких скоростях;
- работать с постоянными и переменными потоками данных;
- интегрировать любые виды информации: тексты, речь, изображения, видеофильмы;
- поддерживать соединения типа точка-точка, точка-многоточка, многоточка-многоточка.
Технология ATM предполагает межсетевое взаимодействие на трёх уровнях.
Для передачи данных от отправителя к получателю в сети ATM создаются виртуальные каналы, VC (англ. Virtual Circuit), которые бывают двух видов:
- постоянный виртуальный канал, PVC (Permanent Virtual Circuit), который создаётся между двумя точками и существует в течение длительного времени, даже в отсутствие данных для передачи;
- коммутируемый виртуальный канал, SVC (Switched Virtual Circuit), который создаётся между двумя точками непосредственно перед передачей данных и разрывается после окончания сеанса связи.
Для маршрутизации в пакетах используют так называемые идентификаторы пакета. Они бывают двух видов:
- VPI (англ. virtual path identificator) — идентификатор виртуального пути (номер канала)
- VCI (англ. virtual connect identificator) — идентификатор виртуального соединения (номер соединения)
Структура ячейки[править | править код]
|
Формат ячейки UNI
|
Формат ячейки NNI
|
- GFC = Generic Flow Control (4 бита) — общее управление потоком;
- VPI = Virtual Path Identifier (8 бит UNI) или (12 бит NNI) — идентификатор виртуального пути;
- VCI = Virtual channel identifier (16 бит) — идентификатор виртуального канала;
- PT = Payload Type (3 бита) — тип данных;
- CLP = Cell Loss Priority (1 бит) — уровень приоритета при потере пакета; указывает на то, какой приоритет имеет ячейка (cell), и будет ли она отброшена в случае перегрузки канала;
- HEC = Header Error Control (8 бит) — поле контроля ошибок.
- UNI = User-to-Network Interface — интерфейс пользователь-сеть. Стандарт, разработанный ATM Forum, который определяет интерфейс между конечной станцией и коммутатором в сети ATM.
- NNI = Network-to-Network Interface — интерфейс сеть-сеть. Обобщённый термин, описывающий интерфейс между двумя коммутаторами в сети.
Классы обслуживания и категории услуг[править | править код]
Определено пять классов трафика, отличающихся следующими качественными характеристиками:
- наличием или отсутствием пульсации трафика, то есть трафики CBR или VBR;
- требованием к синхронизации данных между передающей и принимающей сторонами;
- типом протокола, передающего свои данные через сеть ATM, — с установлением соединения или без установления соединения (только для случая передачи компьютерных данных).
CBR не предусматривает контроля ошибок, управления трафиком или какой-либо другой обработки. Класс CBR пригоден для работы с мультимедиа реального времени.
Класс VBR содержит в себе два подкласса — обычный и для реального времени (см. таблицу ниже). ATM в процессе доставки не вносит никакого разброса ячеек по времени. Случаи потери ячеек игнорируются.
Класс ABR предназначен для работы в условиях мгновенных вариаций трафика. Система гарантирует некоторую пропускную способность, но в течение короткого времени может выдержать и большую нагрузку. Этот класс предусматривает наличие обратной связи между приемником и отправителем, которая позволяет понизить загрузку канала, если это необходимо.
Класс UBR хорошо пригоден для посылки IP-пакетов (нет гарантии доставки и в случае перегрузки неизбежны потери).
| Класс QoS | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Класс обслуживания | A | B | C | D | x |
| Тип трафика | CBR | VBR | VBR | ABR | UBR |
| Тип уровня | AAL1 | AAL2 | AAL3/4 | AAL3/4 | |
| Синхронизация | Требуется | Не требуется | |||
| Скорость передачи | Постоянная | Переменная | |||
| Режим соединения | С установлением | Без установления | |||
| Пример использования | (Е1, Т1) | Видео | аудио | Передача данных |
Практика реализации[править | править код]
Технология ATM задумывалась и рекламировалась в прессе как универсальная замена всем имевшимся на рынке технологиям передачи данных и голоса и была призвана осуществить конвергенцию этих приложений, а так же передачи цифрового телевизионного сигнала. Подразумевалось использование ATM на всём пути передачи сигнала — от телефона к телефону (и телефоны с таким интерфейсом действительно выпускались), от компьютера к компьютеру.
Технически предполагались интерфейсы, обеспечивающие работу по этому протоколу на скоростях 100, 155 и 622Мбит/c (так же некоторыми участниками рынка был предложен вариант 25Мбит/c).
Однако, практически оказалось, что на момент начальной стандартизации этой технологии полный стек протоколов, необходимых для всех предполагавшизся ATM-приложений слишком сложен и попросту не доработан до конца. Поэтому большинство разработчиков, стремившихся поскорее выпустить свои продукты на рынок, пошло по пути выпуска продуктов с неполным или неполностью функциональным стеком, вплоть до того, что реализовывали исключительно эмуляцию Ethernet поверх ATM — так называемый режим LANE. Разумеется, ATM-продукты, поддерживавшие наверху своего стека только LANE, не обеспечивали всех разрекламированных возможностей ATM и привели к известному разочарованию потребителей.
Совокупная сложность протоколов, обеспечивающих большие функциональные возможности, оказалась сопоставима со сложностью базовых RFC, обеспечивающих работу приложений TCP/IP и частично перекрывала функциональность TCP/IP[1]. Их разработка оказалась, к тому же, подорвана конкуренцией двух архитектурных подходов — MPLS и I-PNNI (потенциально более эффективный, чем MPLS, но, впоследствии, так и не нашедший широкой поддержки на рынке), продвигавшихся двумя лидерами рынка — Cisco Systems и Bay Networks, соответственно. Менее продвинутые разработчики были вынуждены в своих планах учитывать оба эти подхода, по факту не реализуя в полной мере ни один из них.
К тому же, обнаружилось, что на скоростях свыше 622Мбит/c ATM оказался менее эффективен, чем прямая передача TCP/IP через SONET или же высокоскоростные версии Ethertnet.
Все эти обстоятельства привели к практической дезорганизации разработок ATM и тотальный захват рынка новой технологией в результате не состоялся.
В настоящее время технология ATM практически остановилась в своём развитии, её изощрённые методы приоритезации трафика оказались практически невостребованы за исключением приложений последней мили, основанных на ADSL и близких технологиях. Поскольку ADSL-сети изначально позиционировались как основа для конвергентных услуг — телефонии, передачи данных и видео (т.н. triple play), технология ATM оказалась естественным кандидатом на роль сетевого уровня в ADSL-приложениях. Практика, однако, показывает, что большинство из потенциальных возможностей ATM оказываются невостребованными даже в таких сетях.
Литература[править | править код]
- Галина Дикер-Пилдуш Сети ATM корпорации Cisco = Cisco ATM Solutions . — М.: «Вильямс», 2004. — С. 880. — ISBN 1-57870-213-5о книге
- Руководство по технологиям объединённых сетей = Internetworking Technologies Handbook . — 4. — М.: «Вильямс», 2005. — С. 1040. — ISBN 5-58705-119-2о книге
Прикладной уровень: HTTP, DHCP, IRC, SNMP, DNS, NNTP, XMPP, SIP, BitTorrent, XDR, IPP…
-
- Электронная почта: SMTP, POP3, IMAP4 • Передача файлов: FTP, TFTP, SFTP • Удалённый доступ: rlogin, Telnet, SSH
Транспортный уровень: TCP, UDP, SCTP, DCCP, RTP, RUDP…
Сетевой уровень: IPv4, IPv6, ARP, RARP, ICMP, IGMP
Канальный уровень: Ethernet, 802.11 WiFi, Token ring, FDDI, PPP, HDLC, SLIP, ATM, DTM, X.25, Frame Relay, SMDS, SDH, PDH, ISDN
Физический уровень: RS-232, EIA-422, RS-449, EIA-485…
Примечания[править | править код]
- ↑ следует отметить, что протоколы ATM не вполне соответствовали базовой модели OSI/ISO, в совокупности перекрывая уровни со второго по, местами, седьмой
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное бюджетное образовательное учреждение высшего
образования
«МОСКОВСКИЙ АВТОМОБИЛЬНО-ДОРОЖНЫЙ
ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ (МАДИ)»
ВОЛЖСКИЙ ФИЛИАЛ
Сети ЭВМ и телекоммуникации
Конспект лекций
Чебоксары
2015
Оглавление
Тема 1. Введение. ………………………………………………………………………………………. 3
Тема 2. Каналы передачи данных. …………………………………………………………….. 43
Тема 3. Локальные вычислительные сети. ………………………………………………… 67
Тема 4. Коммутация и маршрутизация. …………………………………………………… 105
Тема 5. Территориальные сети. ………………………………………………………………. 197
Тема 1. Введение.
Учебные вопросы.
Классификация вычислительных сетей.
Понятие протокола. Документы (IETF (Internet Engineering Task Force), RFC, IEEE).
Эталонная модель взаимосвязи открытых систем (OSI model.).
Пятиуровневая концептуальная модель иерархии протоколов семейства TCP/IP (RFC 791 и
RFC 1349).
5. Способы коммутации. Коммутация каналов. Коммутация пакетов Коммутирующие
матрицы.
6. Виды связи и режимы работы сетей передачи сообщений. Связь с установлением и без
установления соединения.
7. Сети одноранговые и «клиент/сервер».Понятие топологии сети.
1.
2.
3.
4.
Вопрос 1.
Классификация вычислительных сетей.
Компьютерная сеть (вычислительная сеть) — система связи компьютеров или вычислительного
оборудования (серверы, маршрутизаторы и другое оборудование). Для передачи данных могут
быть использованы различные физические явления[уточнить], как правило — различные
виды электрических сигналов, световых сигналов или электромагнитного излучения[1].
По территориальной распространенности
BAN (Body Area Network — нательная компьютерная сеть) — сеть надеваемых или
имплантированых компьютерных устройств.
PAN (Personal Area Network) — персональная сеть, предназначенная для взаимодействия
различных устройств, принадлежащих одному владельцу.
ЛВС (LAN, Local Area Network) — локальные сети, имеющие замкнутую инфраструктуру
до выхода на поставщиков услуг. Термин «LAN» может описывать и маленькую офисную
сеть, и сеть уровня большого завода, занимающего несколько сотен гектаров. Зарубежные
источники дают даже близкую оценку — около шести миль (10 км) в радиусе. Локальные
сети являются сетями закрытого типа, доступ к ним разрешён только ограниченному кругу
пользователей, для которых работа в такой сети непосредственно связана с их
профессиональной деятельностью.
CAN (Campus Area Network — кампусная сеть) — объединяет локальные сети близко
расположенных зданий.
MAN (Metropolitan Area Network) — городские сети между учреждениями в пределах
одного или нескольких городов, связывающие много локальных вычислительных сетей.
WAN (Wide Area Network) — глобальная сеть, покрывающая большие географические
регионы, включающие в себя как локальные сети, так и прочие телекоммуникационные
сети и устройства. Пример WAN — сети с коммутацией пакетов (Frame relay), через
которую могут «разговаривать» между собой различные компьютерные сети. Глобальные
сети являются открытыми и ориентированы на обслуживание любых пользователей.
Термин «корпоративная сеть» также используется в литературе для обозначения
объединения нескольких сетей, каждая из которых может быть построена на различных
технических, программных и информационных принципах.
По архитектуре
Клиент-сервер
Одноранговая сеть (децентрализованная или пиринговая сеть)
По типу сетевой топологии
Шина
Кольцо
Двойное кольцо
Звезда
Ячеистая
Решётка
Дерево
Смешанная топология
Fat Tree
По типу среды передачи
Проводные (телефонный провод, коаксиальный кабель, витая пара, волоконно-оптический
кабель)
Беспроводные (передачей информации по радиоволнам в определенном частотном
диапазоне)
По функциональному назначению
Сети хранения данных
Серверные фермы
Сети управления процессом
Сети SOHO, домовые сети
По скорости передачи
низкоскоростные (до 10 Мбит/с),
среднескоростные (до 100 Мбит/с),
высокоскоростные (свыше 100 Мбит/с);
По сетевым операционным системам
На основе Windows
На основе UNIX
На основе NetWare
На основе Cisco
По необходимости поддержания постоянного соединения
Пакетная сеть, например, Фидонет и UUCP
Онлайновая сеть, например, Интернет и GSM
2. Вопрос. Понятие протокола. Документы (IETF (Internet Engineering Task Force), RFC,
IEEE).
Протокол передачи данных — набор соглашений интерфейса логического уровня, которые
определяют обмен данными между различными программами. Эти соглашения задают
единообразный способ передачи сообщений и обработки ошибок при взаимодействии
программного обеспечения разнесённой в пространстве аппаратуры, соединённой тем или иным
интерфейсом.
Стандартизированный протокол передачи данных также позволяет разрабатывать интерфейсы
(уже на физическом уровне), не привязанные к конкретной аппаратной платформе и
производителю (например, USB, Bluetooth).
Сигнальный протокол используется для управления соединением — например, установки,
переадресации, разрыва связи. Примеры протоколов: RTSP, SIP. Для передачи данных
используются такие протоколы как RTP.
Основной организацией по стандартизации в области Интернета является IETF (www.ietf.org). Об
этом форуме я подробно писал в статье «Где рождаются стандарты Интернета»
(http://www.ripn.net/articles/ietf-intro/).
Хотя вряд ли какая-либо другая организация или форум, занимающиеся вопросами
стандартизации, могут конкурировать с IETF в области Интернета, IETF не одинок в глобальном
мире стандартов. Существует достаточно большое число других организаций, занимающихся
стандартами, область деятельности которых имеет отношение к Интернету. Некоторые из них в
прошлом довольно долго игнорировали феномен Интернета, и теперь хотят играть более
существенную роль в процессе развития Сети. В их число входят W3C (www.w3c.org), IEEE
(standards.ieee.org), ITU (www.itu.int), 3GPP (www.3gpp.org), Unicode Consortium (unicode.org).
Кратко остановимся на некоторых из них.
IETF (The Internet Engineering Task Force)
IETF не является организацией в полном смысле этого слова — у него нет ни штаб-квартиры, ни
значительного штата постоянных работников. Почти вся работа в IETF выполняется на
добровольных началах. Поэтому часто IETF называют форумом. В IETF также нет членства любой может принять участие в работе IETF, единственным требованием является доступ к
электронной почте.
IETF охватывает широкий спектр протоколов Интернета, но основным фокусом являются
протоколы уровня IP, транспортного и прикладного уровней. Соответственно и рабочие группы
объединены в так называемые предметные области: область Интернет, Транспорта и Приложений.
Вопросы маршрутизации, безопасности и эксплуатации и управления сетей также выделены в
отдельные области. Объем работ, связанных с голосовой и видео-связью в IP-сетях, SIP и IPтелефонии, а также системами мгновенного обмена сообщениями, является настолько
значительным, что соответствующие рабочие группы объединены в собственную предметную
область — в область приложений и инфраструктуры реального времени.
Результаты своей работы IETF публикует в виде так называемых RFC (Request for Comment, или
Запрос Комментариев). Не все RFC являются стандартами, часть из них носит
экспериментальный, информационный или рекомендательный характер, что отражено в статусе
документа RFC. Вопросы саморегулирования, в частности, описание собственно процесса
разработки стандартов, также документируются в RFC.
Те же RFC, которые являются стандартами IETF, проходят «многоступенчатый» процесс
обсуждений и достижения консенсуса. Работа над стандартом является коллективной и обычно
проводится в рамках рабочей группы. Этот процесс схематично приведен на рис. 1. Важную роль
в этом процессе играют так называемые «последние звонки» (Last Call, LC) — период, в течение
которого участники имеют возможность высказаться в поддержку документа или отметить
недостатки. Обычно, звонков этих два — один на уровне рабочей группы, а второй — общий
«последний звонок», в котором участвует весь IETF.
Рис. 1 Процесс стандартизации IETF
В IETF существует также понятие «зрелости» стандарта, когда по прошествии определенного
времени стандарт повышается в статусе, как правило в результате обновления на основе
накопленного опыта использования стандарта. В настоящее время в IETF существует два уровня «Proposed Standard» и «Internet Standard».
За 25 лет своего существования IETF опубликовал более 6600 RFC, являющиеся спецификациями
приложений и протоколов, на которых построен Интернет. В работе над стандартами приняло
участие более 700 различных компаний и почти 2400 авторов из более 50 стран. Хотя посещение
встреч IETF не является обязательным, три раза в год IETF собирает около 1500 участников со
всего мира. Все RFC и рабочие документы (называемые Internet Draft, или ID) свободно доступны
на сайте документов IETF -http://tools.ietf.org/html/.
Международный Союз Электросвязи, МСЭ (International Telecommunication Union, ITU)
МСЭ является учреждением ООН, работающим в соответствии с Конвенцией и Уставом,
ратифицированными Государствами-членами. В настоящее время МСЭ насчитывает в своем
составе 193 страны. Наряду с государствами, в работе МСЭ принимают участие свыше 700
организаций частного сектора и академических учреждений, хотя во многих решениях они имеют
лишь право совещательного голоса.
МСЭ охватывает широкий круг вопросов, включая распределение радиочастотного спектра и
спутниковых орбит, разработку технических стандартов, а также улучшение доступа к
информационно-коммуникационным технологиям в развивающихся регионах. В контексте
стандартизации интерес представляет Сектор стандартизации электросвязи (МСЭ-T).
Работа в МСЭ-Т организована в рамках так называемых Исследовательских Комиссий, ИК (Study
Group, SG). Каждая ИК, в состав которой может входить несколько Рабочих Групп (РГ),
координирует работу по ряду исследовательских Вопросов (Questions), касающихся
соответствующей темы, например Рабочая группа по кодированию носителей в 16-й
Исследовательской комиссии занимается всеми исследовательскими Вопросами, относящимися к
кодированию речи, аудио- и видеопотоков.
Результаты работы публикуются в виде Рекомендаций. Обычно работа над Рекомендациями
проводится не в списках рассылки, как в IETF, а в рамках очного собрания РГ или ИК. При
необходимости эксперты могут встречаться независимо от РГ или ИК в более неформальной
обстановке. Как правило, Рекомендации доступны на сайте МСЭ, хотя рабочие документы
доступны только членам Союза.
Процесс утверждения Рекомендации также существенно отличается от процесса стандартизации
IETF. Во-первых, в этом процессе участвуют Государства-Члены, имеющие право окончательного
голоса. Так называемый традиционная процедура утверждения, ТПУ (Traditional Approval Process,
TAP) имеет очень формализованную структуру и продолжительный консультационный период
(минимум 3 месяца), а утверждение стандарта проходит в рамках пленарных совещаний ИК,
проводящихся обычно два раза в год. Возражение хотя бы одного Государства-Члена достаточно
для неутверждения стандарта. Все это удлиняет и усложняет процесс принятия решений и делает
его недостаточно гибким для быстро меняющегося ландшафта информационнокоммуникационных технологий.
Существенная модернизация процесса создания стандартов путем упрощения процедур
утверждения была реализована в 2001 году. Этот процесс получил название альтернативной
процедуры утверждения (АПУ). Подавляющее большинство стандартов теперь утверждается
таким способом. Только те стандарты, которые имеют регуляторные последствия, проходят иную
процедуру и в их отношении используется ТПУ. Кроме упрощения основных процедур, связанных
с процессом утверждения, важным фактором, способствующим использованию АПУ, является
возможность доработки документов в он-лайн режиме. В подавляющем большинстве случаев
после начала процедуры утверждения оставшаяся часть процесса может быть завершения
электронным способом без необходимости в физических собраниях. Схема процесса АПУ
приведена на рисунке 2.
Рис. 2 Альтернативная процедура утверждения Рекомендации в МСЭ-Т
Многие стандарты МСЭ-Т имеют непосредственное отношение к Интернету. Примерами таких
стандартов, активно используемых в различных аспектах использования Интернета являются
кодеки для сжатия видео и аудио (H.264) и технологии канального уровня (DSL, WDM, ASON).
МСЭ-Т также работает над мета-вопросами, как Сети Последующего Поколения (Next Generation
Networks, NGN), Интернет вещей (Internet of Things, IoT), информационная безопасность.
Консорциум «Всемирной Паутины» (World Wide Web Consortium, W3C)
W3C — организация, разрабатывающая и внедряющая технологические стандарты для всемирного
вэба. Консорциум возглавляет сэр Тимоти Джон Бернерс-Ли (Tim Berners-Lee), основоположник
WWW. Консорциум был основан в 1994 году при Массачусетском Институте Технологии (MIT) и
объединил различные компании, заинтересованные в дальнейшей разработке технологий и
создании стандартов для расширения качества и возможностей WWW. Бернерс-Ли не
запатентовал свою идею, этому же принципу следует и Консорциум, чьи стандарты свободны от
патентов и роялти, обеспечивая возможность их неограниченного использования.
Стандарты W3C называются Рекомендациями (Recommendation). В соответствии с процессом
стандартизации, принятом в W3C, спецификация проходит через 4 ступени зрелости: Рабочий
проект (Working Draft), Рекомендация-кандидат (Candidate Recommendation), Предлагаемая
Рекомендация (Proposed Recommendation) и, наконец, Рекомендация W3C.
Разработка Рекомендации проходит в рамках Рабочей группы, членами которой являются
сотрудники Организаций-членов, штатные сотрудники и в некоторых случаях приглашенные
эксперты. Процесс «созревания» стандарта проходит несколько степеней согласования,
основанных на достижении консенсуса, окончательно утверждаемых директором W3C.
Работа W3C в основном ограничена вэб технологиями и включает следующие области:
Электронное Правительство (eGovernment). Многие технологии, разработанные
Консорциумом, имеют прямое отношение к этой области. Наиболее важными являются вопросы
доступности и совместимости.
Языки представления контента. Сюда входят работа над новым поколением языка HTML HTML5, поддерживающим работу с новейшими мультимедийными приложениями, а также
дальнейшее развитие XML и XHTML.
Интернационализация. Поддержка национальных языков и алфавитов является одной из
приоритетных областей работа Консорциума.
Безопасность. Сегодня, с широким применением и поддержкой активного контента, как,
например, ActiveX и Javascript, вэб браузер поистине является операционной системой, имеющей
доступ к различными элементам компьютера пользователя — данным, периферийным устройствам
и т.п. Простое просматривание вэб-страниц может явится причиной заражения компьютера
вирусом, утечки личных данных и т.п. О некоторых проблемах этого рода я писал в обзоре
«Конфиденциальность информации в Интернете» (http://www.ripn.net/articles/privacy/).
Семантический вэб. Это новая концепция и связанная с ней архитектура, целью которой является
обеспечение большей доступности вэба для компьютеров. Другими словами — вэб данных. Этот
подход открывает новые возможности в использовании паутины в задачах консолидации данных,
обнаружения и классификации информационных ресурсов, управления знаниями и т.д.
Институт инженеров по электротехнике и электронике (Institute of Electrical and Electronics
Engineers, IEEE)
IEEE — это международная некоммерческая ассоциация специалистов в области техники, мировой
лидер в области разработки стандартов. Стандарты IEEE работают в различных отраслях
промышленности, включая энергетику, здравоохранение, информационные и
телекоммуникационные технологии (ИКТ), транспорт и многие другие. В области ИКТ наиболее
значительные стандарты, имеющие отношение к Интернету, разработаны в комитете IEEE 802
LAN/MAN Standards Committee (LMSC).
Этот комитет включает более десятка активных Рабочих Групп (РГ), работающих и
сопровождающих стандарты физического и канального уровней. Наиболее известными являются
802.3 (Ethernet), 802.11 (WLAN, или Wifi) и 802.16 (Broadband Wireless Access, в частности
стандарты WiMAX).
В IEEE работа над стандартом начинается с создания так называемого запроса на авторизацию
проекта (Project Authorization Request, PAR), по существу являющимся проектом хартии будущей
РГ. PAR должен продемонстрировать, что предлагаемый стандарт имеет рыночный потенциал,
совместим с другими стандартами, решает определенную проблему, а также технически и
экономически осуществим.
В случае, если PAR утвержден (он утверждается исполкомом IEEE 802), формируется РГ. В состав
рабочей группы может войти любой желающий, основным требованием является участие в
заседаниях, которые обычно проводятся 6 раз в год (часть пленарные, часть промежуточные
заседания) и в голосовании по бюллетеням.
Следующей стадией является разработка проекта стандарта рабочей группой. Проект
окончательно согласовывается рабочей группой на основе голосования по бюллетеням, и для
перехода в следующую стадию требуется 75% голосов в поддержку и отсутствие серьезных
возражений.
После этого объявляется общее голосование, в котором может принять участие любое
заинтересованное в стандарте лицо. Необходимым условием является членство в IEEE SA
(Организации по стандартизации), но возможно также получение бюллетеня за отдельную плату.
Требованием положительного решения является возврат как минимум 75% разосланных
бюллетеней из которых 75% проголосовали в поддержку.
Если проект получает достаточную поддержку, он передается в ревизионную комиссию (RevCom)
для проверки соответствия внутренним требованиям IEEE.
Наконец, по получении положительной рекомендации ревизионной комиссии, стандарт
окончательно утверждается Советом по стандартизации IEEE большинством голосов. Этот
процесс схематично показан на рисунке 3.
Все стандарты IEEE доступны онлайн или в печатном виде, но не бесплатно. В среднем стандарт
стоит немногим более 100 долларов США.
Рис. 3 Процесс разработки и утверждения стандартов в IEEE
3. Вопрос. Эталонная модель взаимосвязи открытых систем (OSI model).
Сетевая модель OSI (англ. open systems interconnection basic reference model — базовая эталонная
модель взаимодействия открытых систем, сокр. ЭМВОС; 1978 год) — сетевая
модель стека сетевых протоколов OSI/ISO (ГОСТ Р ИСО/МЭК 7498-1-99).
В связи с затянувшейся разработкой протоколов OSI, в настоящее время основным используемым
стеком протоколов является TCP/IP, разработанный ещё до принятия модели OSI и вне связи с
ней. Он является практически самым выгодным на данный момент.
Общая характеристика модели OSI
К концу 70-х годов в мире уже существовало большое количество фирменных стеков
коммуникационных протоколов, среди которых можно назвать, например, такие популярные
стеки, как DECnet, TCP/IP и SNA. Подобное разнообразие средств межсетевого взаимодействия
вывело на первый план проблему несовместимости устройств, использующих разные протоколы.
Одним из путей разрешения этой проблемы в то время виделся всеобщий переход на единый,
общий для всех систем стек протоколов, созданный с учетом недостатков уже существующих
стеков. Такой академический подход к созданию нового стека начался с разработки модели OSI и
занял семь лет (с 1977 по 1984 год). Назначение модели OSI состоит в обобщенном представлении
средств сетевого взаимодействия. Она разрабатывалась в качестве своего рода универсального
языка сетевых специалистов, именно поэтому ее называют справочной моделью.В модели OSI
средства взаимодействия делятся на семь уровней: прикладной, представления, сеансовый,
транспортный, сетевой, канальный и физический (рис. 4.6). Каждый уровень имеет дело с
совершенно определенным аспектом взаимодействия сетевых устройств.
Приложения могут реализовывать собственные протоколы взаимодействия, используя для этих
целей многоуровневую совокупность системных средств. Именно для этого в распоряжение
программистов предоставляется прикладной программный интерфейс (Application Program
Interface, API). В соответствии с идеальной схемой модели OSI приложение может обращаться с
запросами только к самому верхнему уровню — прикладному, однако на практике многие стеки
коммуникационных протоколов предоставляют возможность программистам напрямую
обращаться к сервисам, или службам, расположенных ниже уровней. Например, некоторые СУБД
имеют встроенные средства удаленного доступа к файлам. В этом случае приложение, выполняя
доступ к удаленным ресурсам, не использует системную файловую службу; оно обходит верхние
уровни модели OSI и обращается непосредственно к ответственным за транспортировку
сообщений по сети системным средствам, которые располагаются на нижних уровнях модели OSI.
Итак, пусть приложение узла А хочет взаимодействовать с приложением узла В. Для этого
приложение А обращается с запросом к прикладному уровню, например к файловой службе. На
основании этого запроса программное обеспечение прикладного уровня формирует сообщение
стандартного формата. Но для того чтобы доставить эту информацию по назначению, предстоит
решить еще много задач, ответственность за которые несут нижележащие уровни. После
формирования сообщения прикладной уровень направляет его вниз по стеку уровню
представления. Протокол уровня представления на основании информации, полученной из
заголовка сообщения прикладного уровня, выполняет требуемые действия и добавляет к
сообщению собственную служебную информацию — заголовок уровня представления, в котором
содержатся указания для протокола уровня представления машины-адресата. Полученное в
результате сообщение передается вниз сеансовому уровню, который, в свою очередь, добавляет
свой заголовок и т. д. (Некоторые реализации протоколов помещают служебную информацию не
только в начале сообщения в виде заголовка, но и в конце в виде так называемого концевика.)
Наконец, сообщение достигает нижнего, физического, уровня, который собственно и передает его
по линиям связи машине-адресату. К этому моменту сообщение «обрастает» заголовками всех
уровней (рис. 4.7).
Физический уровень помещает сообщение на физический выходной интерфейс компьютера 1, и
оно начинает свое «путешествие» по сети (до этого момента сообщение передавалось от одного
уровню другому в пределах компьютера 1). Когда сообщение по сети поступает на входной
интерфейс компьютера 2, оно принимается его физическим уровнем и последовательно
перемещается вверх с уровня на уровень. Каждый уровень анализирует и обрабатывает заголовок
своего уровня, выполняя соответствующие функции, а затем удаляет этот заголовок и передает
сообщение вышележащему уровню. Как видно из описания, протокольные сущности одного
уровня не общаются между собой непосредственно, в этом общении всегда участвуют посредники
— средства протоколов нижележащих уровней. И только физические уровни различных узлов
взаимодействуют непосредственно.
Уровни модели OSI
Модель OSI
Уровень (layer)
Host
layers
Media
Примеры
7. Прикладной
(application)
Доступ к сетевым
службам
6. Представительск
ий (представления)
(presentation)
Представление
ишифрование данн ASCII, EBCDIC,JPEG
ых
5. Сеансовый
(session)
Управление
сеансом связи
4. Транспортный
(transport)
[
Тип данных (PDU[1]) Функции
3. Сетевой
(network)
Прямая связь
Сегменты(segment)/
между конечными
Дейтаграммы(datagra
пунктами и
m)
надежность
Пакеты(packet)
2]
RPC, PAP
TCP, UDP, SCTP
Определение
маршрута и
логическая
адресация
IPv4, IPv6, IPsec,AppleTalk
Физическая
адресация
PPP, IEEE
802.2,Ethernet,DSL,L2TP,
ARP
layers
2. Канальный (data Биты (bit)/
link)
Кадры(frame)
HTTP, FTP, SMTP
1. Физический
(physical)
Биты (bit)
Работа со средой
передачи,
сигналами и
двоичными
данными
USB, витая пара,
коаксиальный кабель,
оптический кабель
В литературе наиболее часто принято начинать описание уровней модели OSI с 7-го уровня,
называемого прикладным, на котором пользовательские приложения обращаются к сети. Модель
OSI заканчивается 1-м уровнем — физическим, на котором определены стандарты, предъявляемые
независимыми производителями к средам передачи данных:
тип передающей среды (медный кабель, оптоволокно, радиоэфир и др.),
тип модуляции сигнала,
сигнальные уровни логических дискретных состояний (нуля и единицы).
Любой протокол модели OSI должен взаимодействовать либо с протоколами своего уровня, либо с
протоколами на единицу выше и/или ниже своего уровня. Взаимодействия с протоколами своего
уровня называются горизонтальными, а с уровнями на единицу выше или ниже — вертикальными.
Любой протокол модели OSI может выполнять только функции своего уровня и не может
выполнять функций другого уровня, что не выполняется в протоколах альтернативных моделей.
Каждому уровню с некоторой долей условности соответствует свой операнд — логически
неделимый элемент данных, которым на отдельном уровне можно оперировать в рамках модели и
используемых протоколов: на физическом уровне мельчайшая единица — бит, на канальном
уровне информация объединена в кадры, на сетевом — в пакеты (датаграммы), на
транспортном — в сегменты. Любой фрагмент данных, логически объединённых для передачи —
кадр, пакет, датаграмма — считается сообщением. Именно сообщения в общем виде являются
операндами сеансового, представительского и прикладного уровней.
К базовым сетевым технологиям относятся физический и канальный уровни.
Прикладной уровень
Прикладной уровень (уровень приложений; англ. application layer) — верхний уровень модели,
обеспечивающий взаимодействие пользовательских приложений с сетью:
позволяет приложениям использовать сетевые службы:
удалённый доступ к файлам и базам данных,
пересылка электронной почты;
отвечает за передачу служебной информации;
предоставляет приложениям информацию об ошибках;
формирует запросы к уровню представления.
Протоколы прикладного
уровня: RDP, HTTP, SMTP, SNMP, POP3, FTP, XMPP, OSCAR, Modbus, SIP, TELNET и другие.
Уровень представления
Представительский уровень (уровень представления; англ. presentation layer) обеспечивает
преобразование протоколов и кодирование/декодирование данных. Запросы приложений,
полученные с прикладного уровня, на уровне представления преобразуются в формат для
передачи по сети, а полученные из сети данные преобразуются в формат приложений. На этом
уровне может осуществляться сжатие/распаковка или шифрование/дешифрование, а также
перенаправление запросов другому сетевому ресурсу, если они не могут быть обработаны
локально.
Уровень представлений обычно представляет собой промежуточный протокол для преобразования
информации из соседних уровней. Это позволяет осуществлять обмен между приложениями на
разнородных компьютерных системах прозрачным для приложений образом. Уровень
представлений обеспечивает форматирование и преобразование кода. Форматирование кода
используется для того, чтобы гарантировать приложению поступление информации для
обработки, которая имела бы для него смысл. При необходимости этот уровень может выполнять
перевод из одного формата данных в другой.
Уровень представлений имеет дело не только с форматами и представлением данных, он также
занимается структурами данных, которые используются программами. Таким образом, уровень 6
обеспечивает организацию данных при их пересылке.
Чтобы понять, как это работает, представим, что имеются две системы. Одна использует для
представления данных расширенный двоичный код обмена информацией EBCDIC, например, это
может быть мейнфрейм компании IBM, а другая — американский стандартный код обмена
информацией ASCII (его используют большинство других производителей компьютеров). Если
этим двум системам необходимо обменяться информацией, то нужен уровень представлений,
который выполнит преобразование и осуществит перевод между двумя различными форматами.
Другой функцией, выполняемой на уровне представлений, является шифрование данных, которое
применяется в тех случаях, когда необходимо защитить передаваемую информацию от доступа
несанкционированными получателями. Чтобы решить эту задачу, процессы и коды, находящиеся
на уровне представлений, должны выполнить преобразование данных. На этом уровне
существуют и другие подпрограммы, которые сжимают тексты и преобразовывают графические
изображения в битовые потоки, так что они могут передаваться по сети.
Стандарты уровня представлений также определяют способы представления графических
изображений. Для этих целей может использоваться формат PICT — формат изображений,
применяемый для передачи графики QuickDraw между программами.
Другим форматом представлений является тэгированный формат файлов изображений TIFF,
который обычно используется для растровых изображений с высоким разрешением. Следующим
стандартом уровня представлений, который может использоваться для графических изображений,
является стандарт, разработанный Объединенной экспертной группой по фотографии (Joint
Photographic Expert Group); в повседневном пользовании этот стандарт называют просто JPEG.
Существует другая группа стандартов уровня представлений, которая определяет представление
звука и кинофрагментов. Сюда входят интерфейс электронных музыкальных инструментов
(англ. Musical Instrument Digital Interface, MIDI) для цифрового представления музыки,
разработанный Экспертной группой по кинематографии стандарт MPEG, используемый для
сжатия и кодирования видеороликов на компакт-дисках, хранения в оцифрованном виде и
передачи со скоростями до 1,5 Мбит/с, и QuickTime — стандарт, описывающий звуковые и видео
элементы для программ, выполняемых на компьютерах Macintosh и PowerPC.
Протоколы уровня представления: AFP — Apple Filing Protocol, ICA — Independent Computing
Architecture, LPP — Lightweight Presentation Protocol, NCP — NetWare Core Protocol, NDR —
Network Data Representation, XDR — eXternal Data Representation, X.25 PAD — Packet
Assembler/Disassembler Protocol.
Сеансовый уровень
Сеансовый уровень (англ. session layer) модели обеспечивает поддержание сеанса связи, позволяя
приложениям взаимодействовать между собой длительное время. Уровень управляет
созданием/завершением сеанса, обменом информацией, синхронизацией задач, определением
права на передачу данных и поддержанием сеанса в периоды неактивности приложений.
Протоколы сеансового уровня: ADSP (AppleTalk Data Stream Protocol), ASP (AppleTalk Session
Protocol), H.245 (Call Control Protocol for Multimedia Communication), ISO-SP (OSI Session Layer
Protocol (X.225, ISO 8327)), iSNS (Internet Storage Name Service), L2F (Layer 2 Forwarding Protocol),
L2TP (Layer 2 Tunneling Protocol), NetBIOS (Network Basic Input Output System), PAP (Password
Authentication Protocol), PPTP (Point-to-Point Tunneling Protocol), RPC (Remote Procedure Call
Protocol), RTCP (Real-time Transport Control Protocol), SMPP (Short Message Peer-to-Peer), SCP
(Session Control Protocol), ZIP (Zone Information Protocol), SDP (Sockets Direct Protocol)..
Транспортный уровень
Транспортный уровень (англ. transport layer) модели предназначен для обеспечения надёжной
передачи данных от отправителя к получателю. При этом уровень надёжности может
варьироваться в широких пределах. Существует множество классов протоколов транспортного
уровня, начиная от протоколов, предоставляющих только основные транспортные функции
(например, функции передачи данных без подтверждения приема), и заканчивая протоколами,
которые гарантируют доставку в пункт назначения нескольких пакетов данных в надлежащей
последовательности, мультиплексируют несколько потоков данных, обеспечивают механизм
управления потоками данных и гарантируют достоверность принятых данных.
Например, UDP ограничивается контролем целостности данных в рамках одной датаграммы, и не
исключает возможности потери пакета целиком, или дублирования пакетов, нарушение порядка
получения пакетов данных; TCP обеспечивает надёжную непрерывную передачу данных,
исключающую потерю данных или нарушение порядка их поступления или дублирования, может
перераспределять данные, разбивая большие порции данных на фрагменты и наоборот склеивая
фрагменты в один пакет.
Протоколы транспортного уровня: ATP (AppleTalk Transaction Protocol), CUDP (Cyclic UDP),
DCCP (Datagram Congestion Control Protocol), FCP (Fiber Channel Protocol), IL (IL Protocol), NBF
(NetBIOS Frames protocol), NCP (NetWare Core Protocol), SCTP (Stream Control Transmission
Protocol), SPX (Sequenced Packet Exchange), SST (Structured Stream Transport), TCP (Transmission
Control Protocol), UDP (User Datagram Protocol).
Сетевой уровень
Сетевой уровень (англ. network layer) модели предназначен для определения пути передачи
данных. Отвечает за трансляцию логических адресов и имён в физические, определение
кратчайших маршрутов, коммутацию и маршрутизацию, отслеживание неполадок и «заторов» в
сети.
Протоколы сетевого уровня маршрутизируют данные от источника к получателю. Работающие на
этом уровне устройства (маршрутизаторы) условно называют устройствами третьего уровня (по
номеру уровня в модели OSI).
Протоколы сетевого уровня: IP/IPv4/IPv6 (Internet Protocol), IPX (Internetwork Packet Exchange,
протокол межсетевого обмена), X.25 (частично этот протокол реализован на уровне 2), CLNP
(сетевой протокол без организации соединений), IPsec (Internet Protocol Security). Протоколы
маршрутизации — RIP (Routing Information Protocol), OSPF (Open Shortest Path First).
Канальный уровень
Канальный уровень (англ. data link layer) предназначен для обеспечения взаимодействия сетей на
физическом уровне и контроля за ошибками, которые могут возникнуть. Полученные с
физического уровня данные, представленные в битах, он упаковывает в кадры, проверяет их на
целостность и, если нужно, исправляет ошибки (формирует повторный запрос поврежденного
кадра) и отправляет на сетевой уровень. Канальный уровень может взаимодействовать с одним
или несколькими физическими уровнями, контролируя и управляя этим взаимодействием.
Спецификация IEEE 802 разделяет этот уровень на два подуровня: MAC (англ. media access
control) регулирует доступ к разделяемой физической среде, LLC (англ. logical link control)
обеспечивает обслуживание сетевого уровня.
На этом уровне работают коммутаторы, мосты и другие устройства. Говорят, что эти устройства
используют адресацию второго уровня (по номеру уровня в модели OSI).
Протоколы канального уровня: ARCnet, ATM, Controller Area Network (CAN), Econet, IEEE
802.3 (Ethernet), Ethernet Automatic Protection Switching (EAPS), Fiber Distributed Data
Interface (FDDI), Frame Relay, High-Level Data Link Control (HDLC), IEEE 802.2 (provides LLC
functions to IEEE 802 MAC layers), Link Access Procedures, D channel (LAPD), IEEE 802.11wireless
LAN, LocalTalk, Multiprotocol Label Switching (MPLS), Point-to-Point Protocol (PPP), Point-to-Point
Protocol over Ethernet (PPPoE), Serial Line Internet Protocol (SLIP, устарел),StarLan, Token
ring, Unidirectional Link Detection (UDLD), x.25, ARP.
В программировании этот уровень представляет драйвер сетевой платы, в операционных
системах имеется программный интерфейс взаимодействия канального и сетевого уровней между
собой. Это не новый уровень, а просто реализация модели для конкретной ОС. Примеры таких
интерфейсов: ODI, NDIS, UDI.
Физический уровень
Физический уровень (англ. physical layer) — нижний уровень модели, который определяет метод
передачи данных, представленных в двоичном виде, от одного устройства (компьютера) к
другому. Составлением таких методов занимаются разные организации, в том числе: Институт
инженеров по электротехнике и электронике, Альянс электронной промышленности, Европейский
институт телекоммуникационных стандартов и другие. Осуществляют передачу электрических
или оптических сигналов в кабель или в радиоэфир и, соответственно, их приём и преобразование
в биты данных в соответствии с методами кодирования цифровых сигналов.
На этом уровне также работают концентраторы, повторители сигнала и медиаконвертеры.
Функции физического уровня реализуются на всех устройствах, подключенных к сети. Со
стороны компьютера функции физического уровня выполняются сетевым адаптером или
последовательным портом. К физическому уровню относятся физические, электрические и
механические интерфейсы между двумя системами. Физический уровень определяет такие виды
сред передачи данных как оптоволокно, витая пара, коаксиальный кабель, спутниковый канал
передач данных и т. п. Стандартными типами сетевых интерфейсов, относящимися к физическому
уровню, являются: V.35, RS-232, RS-485, RJ-11, RJ-45, разъемы AUI и BNC.
Протоколы физического уровня: IEEE 802.15 (Bluetooth), IRDA, EIA RS-232, EIA-422, EIA423, RS-449, RS-485, DSL, ISDN, SONET/SDH, 802.11 Wi-Fi, Etherloop, GSM Um radio
interface, ITU и ITU-T, TransferJet, ARINC 818, G.hn/G.9960.
Соответствие модели OSI и других моделей сетевого взаимодействия
Поскольку наиболее востребованными и практически используемыми стали протоколы (например
TCP/IP), разработанные с использованием других моделей сетевого взаимодействия, далее
необходимо описать возможное включение отдельных протоколов других моделей в различные
уровни модели OSI.
Семейство TCP/IP
Семейство TCP/IP имеет три транспортных протокола: TCP, полностью соответствующий OSI,
обеспечивающий проверку получения данных; UDP, отвечающий транспортному уровню только
наличием порта, обеспечивающий обмен датаграммами между приложениями, не гарантирующий
получения данных; и SCTP, разработанный для устранения некоторых недостатков TCP, в
который добавлены некоторые новшества. (В семействе TCP/IP есть ещё около двухсот
протоколов, самым известным из которых является служебный протокол ICMP, используемый для
внутренних нужд обеспечения работы; остальные также не являются транспортными
протоколами.
Семейство IPX/SPX
В семействе IPX/SPX порты появляются в протоколе сетевого уровня IPX, обеспечивая
обмен датаграммами между приложениями (операционная система резервирует часть сокетов для
себя). Протокол SPX, в свою очередь, дополняет IPX всеми остальными возможностями
транспортного уровня в полном соответствии с OSI.
В качестве адреса хоста ICX использует идентификатор, образованный из четырёхбайтного
номера сети (назначаемого маршрутизаторами) и MAC-адреса сетевого адаптера.
Критика
В конце 90-х годов семиуровневая модель OSI критиковалась отдельными авторами. В частности,
в книге «UNIX. Руководство системного администратора» Эви Немет (англ. Evi Nemeth) писала:
Пока комитеты ISO спорили о своих стандартах, за их спиной менялась вся концепция
организации сетей и по всему миру внедрялся протокол TCP/IP.
…
И вот, когда протоколы ISO были наконец реализованы, выявился целый ряд проблем:
эти протоколы основывались на концепциях, не имеющих в современных сетях никакого
смысла;
их спецификации были в некоторых случаях неполными;
по своим функциональным возможностям они уступали другим протоколам;
наличие многочисленных уровней сделало эти протоколы медлительными и трудными для
реализации.
…
Сейчас даже самые ярые сторонники этих протоколов признают, что OSI постепенно движется к
тому, чтобы стать маленькой сноской на страницах истории компьютеров.
— Эви Нэмет[3]
4. Вопрос. Пятиуровневая концептуальная модель иерархии протоколов семейства TCP/IP
(RFC 791 и RFC 1349).
Стек протоколов TCP/IP — набор сетевых протоколов передачи данных, используемых в сетях,
включая сеть Интернет. Название TCP/IP происходит из двух наиважнейших протоколов
семейства — Transmission Control Protocol (TCP) и Internet Protocol (IP), которые были
разработаны и описаны первыми в данном стандарте. Также изредка упоминается как модель
DOD в связи с историческим происхождением от сети ARPANET из 1970 годов (под
управлением DARPA, Министерства обороны США).
В июле 1977 Винт Серф и Боб Кан впервые продемонстрировали передачу данных с
использованием TCP по трем различным сетям. Пакет прошел по следующему маршруту: СанФранциско — Лондон — Университет Южной Калифорнии. В конце своего путешествия пакет
проделал 150 тысяч км, не потеряв ни одного бита. В 1978 году Серф, Постел и Дэни Кохэн
решили выделить в TCP две отдельные функции: TCP и протокол Интернета (Internet Protocol, IP).
TCP был ответственен за разбивку сообщения на дейтаграммы и соединение их в конечном пункте
отправки. IP отвечал за передачу (с контролем получения) отдельных дейтаграмм. Вот так родился
современный протокол Интернета. А 1 января 1983 года ARPANET перешла на новый протокол.
Этот день принято считать официальной датой рождения Интернета.
Протоколы работают друг с другом в стеке (англ. stack, стопка) — это означает, что протокол,
располагающийся на уровне выше, работает «поверх» нижнего, используя
механизмыинкапсуляции. Например, протокол TCP работает поверх протокола IP.
Стек протоколов TCP/IP включает в себя четыре уровня:
прикладной уровень (application layer),
транспортный уровень (transport layer),
сетевой уровень (Internet layer),
канальный уровень (link layer).
Протоколы этих уровней полностью реализуют функциональные возможности модели OSI. На
стеке протоколов TCP/IP построено всё взаимодействие пользователей в IP-сетях. Стек является
независимым от физической среды передачи данных.
Уровни стека TCP/IP
Распределение протоколов по уровням модели TCP/IP
Прикладной
4 (Application
layer)
Транспортный
3
(Transport layer)
Сетевой
2
(Internet layer)
Канальный
1
(Link layer)
напр., HTTP, RTSP, FTP, DNS
напр., TCP, UDP, SCTP, DCCP
(RIP, протоколы маршрутизации, подобные OSPF, что работают поверх IP,
являются частью сетевого уровня)
Для TCP/IP это IP
(вспомогательные протоколы, вроде ICMP и IGMP, работают поверх IP, но
тоже относятся к сетевому уровню; протокол ARP является
самостоятельным вспомогательным протоколом, работающим поверх
канального уровня)
Ethernet, IEEE 802.11 Wireless Ethernet, SLIP, Token Ring, ATM и MPLS,
физическая среда и принципы кодирования информации, T1, E1
Прикладной уровень
На прикладном уровне (Application layer) работает большинство сетевых приложений.
Эти программы имеют свои собственные протоколы обмена информацией,
например, HTTP для WWW, FTP (передача файлов), SMTP (электронная почта), SSH (безопасное
соединение с удалённой машиной), DNS (преобразование символьных имён в IP-адреса) и многие
другие.
В массе своей эти протоколы работают поверх TCP или UDP и привязаны к определённому порту,
например:
HTTP на TCP-порт 80 или 8080,
FTP на TCP-порт 20 (для передачи данных) и 21 (для управляющих команд),
SSH на TCP-порт 22,
запросы DNS на порт UDP (реже TCP) 53,
обновление маршрутов по протоколу RIP на UDP-порт 520.
Эти порты определены Агентством по выделению имен и уникальных параметров протоколов
(IANA).
К этому уровню
относятся: DHCP[1], Echo, Finger, Gopher, HTTP, HTTPS, IMAP, IMAPS, IRC, NNTP, NTP, POP3, P
OPS, QOTD, RTSP, SNMP, SSH, Telnet, XDMCP.
Транспортный уровень
Протоколы транспортного уровня (Transport layer) могут решать проблему негарантированной
доставки сообщений («дошло ли сообщение до адресата?»), а также гарантировать правильную
последовательность прихода данных. В стеке TCP/IP транспортные протоколы определяют, для
какого именно приложения предназначены эти данные.
Протоколы автоматической маршрутизации, логически представленные на этом уровне
(поскольку работают поверх IP), на самом деле являются частью протоколов сетевого уровня;
например OSPF (IP идентификатор 89).
TCP (IP идентификатор 6) — «гарантированный» транспортный механизм с предварительным
установлением соединения, предоставляющий приложению надёжный поток данных, дающий
уверенность в безошибочности получаемых данных, перезапрашивающий данные в случае потери
и устраняющий дублирование данных. TCP позволяет регулировать нагрузку на сеть, а также
уменьшать время ожидания данных при передаче на большие расстояния. Более того, TCP
гарантирует, что полученные данные были отправлены точно в такой же последовательности. В
этом его главное отличие от UDP.
UDP (IP идентификатор 17) протокол передачи датаграмм без установления соединения. Также
его называют протоколом «ненадёжной» передачи, в смысле невозможности удостовериться в
доставке сообщения адресату, а также возможного перемешивания пакетов. В приложениях,
требующих гарантированной передачи данных, используется протоколTCP.
UDP обычно используется в таких приложениях, как потоковое видео и компьютерные игры, где
допускается потеря пакетов, а повторный запрос затруднён или не оправдан, либо в приложениях
вида запрос-ответ (например, запросы к DNS), где создание соединения занимает больше
ресурсов, чем повторная отправка.
И TCP, и UDP используют для определения протокола верхнего уровня число, называемое портом.
Сетевой уровень
Сетевой уровень (Internet layer) изначально разработан для передачи данных из одной (под)сети в
другую. Примерами такого протокола является X.25 и IPC в сети ARPANET.
С развитием концепции глобальной сети в уровень были внесены дополнительные возможности
по передаче из любой сети в любую сеть, независимо от протоколов нижнего уровня, а также
возможность запрашивать данные от удалённой стороны, например в
протоколе ICMP (используется для передачи диагностической информации IP-соединения)
и IGMP(используется для управления multicast-потоками).
ICMP и IGMP расположены над IP и должны попасть на следующий — транспортный — уровень,
но функционально являются протоколами сетевого уровня, и поэтому их невозможно вписать в
модель OSI.
Пакеты сетевого протокола IP могут содержать код, указывающий, какой именно протокол
следующего уровня нужно использовать, чтобы извлечь данные из пакета. Это число —
уникальный IP-номер протокола. ICMP и IGMP имеют номера, соответственно, 1 и 2.
К этому уровню относятся: DVMRP, ICMP, IGMP, MARS, PIM, RIP, RIP2, RSVP
Канальный уровень
Канальный уровень (Link layer) описывает, каким образом передаются пакеты данных через
физический уровень, включая кодирование (то есть специальные последовательности бит,
определяющих начало и конец пакета данных). Ethernet, например, в полях заголовка
пакета содержит указание того, какой машине или машинам в сети предназначен этот пакет.
Примеры протоколов канального уровня — Ethernet, IEEE 802.11 Wireless Ethernet, SLIP, Token
Ring, ATM и MPLS.
PPP не совсем вписывается в такое определение, поэтому обычно описывается в виде пары
протоколов HDLC/SDLC.
MPLS занимает промежуточное положение между канальным и сетевым уровнем и, строго говоря,
его нельзя отнести ни к одному из них.
Канальный уровень иногда разделяют на 2 подуровня — LLC и MAC.
Кроме того, канальный уровень описывает среду передачи данных (будь то коаксиальный
кабель, витая пара, оптическое волокно или радиоканал), физические характеристики такой среды
и принцип передачи данных (разделение каналов, модуляцию, амплитуду сигналов, частоту
сигналов, способ синхронизации передачи, время ожидания ответа и максимальное расстояние).
Сравнение с моделью OSI
Существуют разногласия в том, как вписать модель TCP/IP в модель OSI, поскольку уровни в этих
моделях не совпадают.
К тому же, модель OSI не использует дополнительный уровень — «Internetworking» — между
канальным и сетевым уровнями. Примером спорного протокола может быть ARP илиSTP.
Вот как традиционно протоколы TCP/IP вписываются в модель OSI:
Распределение протоколов по уровням модели OSI
TCP/IP
OSI
Прикладной
напр., HTTP, SMTP, SNMP, FTP, Telnet, SSH, SCP, SMB, NFS, R
TSP, BGP
Представлен
ия
напр., XDR, AFP, TLS, SSL
5
Сеансовый
напр., ISO 8327 / CCITT X.225, RPC, NetBIOS, PPTP, L2TP, ASP
4 Транспортн
Транспортн
напр., TCP, UDP, SCTP, SPX, ATP, DCCP, GRE
7
6
Прикладной
ый
ый
3 Сетевой
Сетевой
напр., IP, ICMP, IGMP, CLNP, OSPF, RIP, IPX, DDP, ARP
2
Канальный
напр., Ethernet, Token ring, HDLC, PPP, X.25, Frame
relay, ISDN, ATM, SPB, MPLS
Физический
напр., электрические провода, радиосвязь, волоконнооптические провода, инфракрасное излучение
Канальный
1
Обычно в стеке TCP/IP верхние 3 уровня модели OSI
(прикладной, представительский и сеансовый) объединяют в один — прикладной. Поскольку в
таком стеке не предусматривается унифицированный протокол передачи данных, функции по
определению типа данных передаются приложению.
Описание модели TCP/IP в технической литературе
В модели TCP/IP (в отличие от модели OSI) — физический уровень никак не описывается. Тем не
менее, в некоторых учебниках[2], для лучшего понимания, описывается «гибридная модель TCP/IP
— OSI» из 5 уровней, содержащая дополнительный — физический уровень.
Следующая таблица показывает различные вариации в описании модели TCP/IP. Количество
уровней варьируется от трёх до семи.
Mike
Padlipsky’s
RFC 1122,
Cisco
1982
Kurose,[3] Foro Comer,[5]Kozi Stalling Tanenbau Internet
Academ «Arpanet
uzan [4]
erok[6]
s[7]
m[8]
STD 3
y[9]
Reference
(1989)
Model»
(RFC 871)
Пять уровней
Четыре + 1
уровень
Пять
Пять
уровней уровней
«Five-layer
Internet model»
or «TCP/IP
protocol suite»
«TCP/IP
«TCP/IP 5″TCP/IP 5-layer
layer reference
model» reference
model»
model»
OSI
model
Четыре
уровня
Четыре
Три уровня
уровня
Семь
уровней
«Internet
model»
«Arpanet
«Internet
reference
model»
model»
OSI
model
Applicat
ion
Application
Application
Application
Applicat Applicatio
Applicati Application/Pr
(Прикладно
Presenta
ion
n
on
ocess
й)
tion
Session
Transport
Transport
Host-toTransport
host or
Transpor
Transport (Транспорт
Host-to-host
transpor
t
ный)
t
Transpor
t
Network
Internet
Internet Internet
Internet
(Сетевой)
Internet
work
Data link
Data link
(Network
interface)
Networ
Data link
k access
Link
Network Network
(Канальны
interface interface
й)
Physical
(Hardware)
Physical Physical
Network
Data
link
Physical
5. Вопрос. Способы коммутации. Коммутация каналов. Коммутация пакетов
Коммутирующие матрицы.
Коммутация — процесс соединения абонентов коммуникационной сети через транзитные узлы.
Коммуникационные сети должны обеспечивать связь своих абонентов между собой. Абонентами
могут выступать ЭВМ, сегменты локальных сетей, факс-аппараты или телефонные собеседники.
Как правило, в сетях общего доступа невозможно предоставить каждой паре абонентов
собственную физическую линию связи, которой они могли бы монопольно «владеть» и
использовать в любое время. Поэтому в сети всегда применяется какой-либо способ коммутации
абонентов, который обеспечивает разделение имеющихся физических каналов между несколькими
сеансами связи и между абонентами сети.
Каждый абонент соединен с коммутаторами индивидуальной линией связи, закрепленной за этим
абонентом. Линии связи, протянутые между коммутаторами, разделяются несколькими
абонентами, то есть используются совместно.
Коммутаторы
Коммутация по праву считается одной из самых популярных современных технологий.
Коммутаторы по всему фронту теснят мосты и маршрутизаторы, оставляя за последними только
организацию связи через глобальную сеть. Популярность коммутаторов обусловлена прежде всего
тем, что они позволяют за счет сегментации повысить производительность сети. Помимо
разделения сети на мелкие сегменты, коммутаторы дают возможность создавать логические сети и
легко перегруппировывать устройства в них. Иными словами, коммутаторы позволяют создавать
виртуальные сети.
В 1994 году компания IDC дала свое определение коммутатора локальных сетей: коммутатор —
это устройство, конструктивно выполненное в виде сетевого концентратора и действующее как
высокоскоростной многопортовый мост; встроенный механизм коммутации позволяет
осуществить сегментирование локальной сети, а также выделить полосу пропускания конечным
станциям в сети.
Впервые коммутаторы появились в конце 1980-х годов. Первые коммутаторы использовались для
перераспределения пропускной способности и, соответственно, повышения производительности
сети. Можно сказать, что коммутаторы первоначально применялись исключительно для
сегментации сети. В наше время произошла переориентация, и теперь в большинстве случаев
коммутаторы используются для прямого подключения к конечным станциям.
Широкое применение коммутаторов значительно повысило эффективность использования сети за
счет равномерного распределения полосы пропускания между пользователями и приложениями.
Несмотря на то, что первоначальная стоимость была довольно высока, тем не менее они были
значительно дешевле и проще в настройке и использовании, чем маршрутизаторы. Широкое
распространение коммутаторов на уровне рабочих групп можно объяснить тем, что коммутаторы
позволяют повысить отдачу от уже существующей сети. При этом для повышения
производительности всей сети не нужно менять существующую кабельную систему и
оборудование конечных пользователей.
Общий термин коммутация применяется для четырёх различных технологий:
конфигурационная коммутация,
коммутация кадров,
коммутация ячеек,
преобразование между кадрами и ячейками.
В основе конфигурационной коммутации лежит нахождение соответствия между конкретным
портом коммутатора и определенным сегментом сети. Это соответствие может программно
настраиваться при подключении или перемещении пользователей в сети.
При коммутации кадров используются кадры сетей Ethernet, Token Ring и т. д. Кадр при
поступлении в сеть обрабатывается первым коммутатором на его пути. Под термином обработка
понимается вся совокупность действий, производимых коммутатором для определения своего
выходного порта, на который необходимо направить данный кадр. После обработки он передается
далее по сети следующему коммутатору или непосредственно получателю.
В технологии АТМ также применяется коммутация, но в ней единицы коммутации носят название
ячеек. Преобразование между кадрами и ячейками позволяет станциям в сети Ethernet, Token Ring
и т. д. непосредственно взаимодействовать с устройствами АТМ. Эта технология применяется при
эмуляции локальной сети.
Коммутаторы делятся на четыре категории:
1. Простые автономные коммутаторы сетей рабочих групп позволяют некоторым сетевым
устройствам или сегментам обмениваться информацией с максимальной для данной
кабельной системы скоростью. Они могут выполнять роль мостов для связи с другими
сетевыми сегментами, но не транслируют протоколы и не обеспечивают повышенную
пропускную способность с отдельными выделенными устройствами, такими как серверы.
2. Коммутаторы рабочих групп второй категории обеспечивают высокоскоростную связь
одного или нескольких портов с сервером или базовой станцией.
3. Коммутаторы сети отдела предприятия, которые часто используются для взаимодействия
сетей рабочих групп. Они представляют более широкие возможности администрирования
и повышения производительности сети. Такие устройства поддерживают древовидную
архитектуру связей, которая используется для передачи информации по резервным
каналам и фильтрации пакетов. Физически такие коммутаторы поддерживают резервные
источники питания и позволяют оперативно менять модули.
4. Коммутаторы сети масштаба предприятия, выполняющие диспетчеризацию трафика,
определяя наиболее эффективный маршрут. Они могут поддерживать большое количество
логических соединений сети. Многие производители корпоративных коммутаторов
предлагают в составе своих изделий модули АТМ. Эти коммутаторы осуществляют
трансляцию протоколов Ethernet в протоколы АТМ.
Виды коммутации
Существует четыре принципиально различные схемы коммутации абонентов в сетях:
Коммутация каналов (КК, circuit switching) — организация составного канала через
несколько транзитных узлов из нескольких последовательно «соединённых» каналов на
время передачи сообщения (оперативная коммутация) или на более длительный срок
(постоянная/долговременная коммутация — время коммутации определяется
административно).
Коммутация сообщений (КС, message switching) — разбиение информации на сообщения,
которые передаются последовательно к ближайшему транзитному узлу, который, приняв
сообщение, запоминает его и передаёт далее сам таким же образом. Получается нечто
вроде конвейера.
Коммутация пакетов (КП, packet switching) — разбиение сообщения на «пакеты»,
которые передаются отдельно. Разница между сообщением и пакетом: размер пакета
ограничен технически, сообщения — логически. При этом, если маршрут движения
пакетов между узлами определён заранее, говорят о виртуальном канале (с установлением
соединения). Пример: коммутация IP-пакетов. Если же для каждого пакета задача
нахождения пути решается заново, говорят о датаграммном (без установления
соединения) способе пакетной коммутации.
Коммутация ячеек (КЯ, cell switching) — частный случай коммутации пакетов с
эмуляцией виртуальных каналов (см. X.25, Frame Relay, MPLS), при коммутации ячеек
пакеты всегда имеют фиксированный и относительно небольшой размер (см. Asynchronous
Trasnfer Mode).
Все виды коммутации могут использоваться в сети. Например, над КК делается КЯ, над которой
работает КП, над которой КС. Получаем SMTP поверх TCP/IP, который сидит наATM, которая
сидит на ПЦИ (PDH) / СЦИ (SDH).
Коммутация в городских телефонных сетях
Городская телефонная сеть — это совокупность линейных и станционных сооружений. Сеть,
имеющая одну АТС, называется нерайонированной. Линейные сооружения такой сети состоят
только из абонентских линий. Типовое значение ёмкости такой сети 8-10 тысяч абонентов. При
больших ёмкостях из-за резкого увеличения длины АЛ целесообразно переходить на
районированное построение сети. В этом случае территория города делится на районы, в каждом
из которых сооружается одна районная АТС (РАТС), к которой подключаются абоненты этого
района. Соединения абонентов одного района осуществляется через одну РАТС, абонентов разных
РATC — через две. РАТС связываются между собой соединительными линиями в общем случае
по принципу «каждая с каждой». Общее число пучков между РАТС равно количество РАТС/2.
При возрастании ёмкости сети число пучков СЛ, связывающих РATC между собой по принципу
«каждая с каждой», начинает резко расти, что приводит к чрезмерному возрастанию расхода
кабеля и затрат на организацию связи и Поэтому при ёмкостях сети свыше 80 тысяч абонентов
применяют дополнительный коммутационный узел. На такой сети связь между АТС разных
районов осуществляется через узлы входящего сообщения (УВС), а связь внутри своего узлового
района (УР осуществляется по принципу «каждая с каждой» или через свой УВС.
Коммутация пакетов (англ. packet switching) — способ доступа нескольких абонентов к общей
сети, при котором информация разделяется на части небольшого размера (так
называемые пакеты), которые передаются в сети независимо друг от друга. Узел-приёмник
собирает сообщение из пакетов. В таких сетях по одной физической линии связи могут
обмениваться данными много узлов.
Основные принципы
При коммутации пакетов все передаваемые пользователем данные разбиваются передающим
узлом на небольшие (до нескольких килобайт) части — пакеты (packet). Каждый пакет оснащается
заголовком, в котором указывается, как минимум, адрес узла-получателя и номер пакета. Передача
пакетов по сети происходит независимо друг от друга. Коммутаторытакой сети имеют
внутреннюю буферную память для временного хранения пакетов, что позволяет сглаживать
пульсации трафика на линиях связи между коммутаторами. Пакеты иногда
называют дейтаграммами (datagram), а режим индивидуальной коммутации пакетов —
дейтаграммным режимом.
Достоинства коммутации пакетов
1. Эффективность использования пропускной способности.
2. При перегрузе сети никого не «выбрасывает» с сообщением «сеть занята», сеть просто
снижает всем абонентам скорость передачи.
3. Абонент, использующий свой канал не полностью, фактически отдаёт пропускную
способность сети остальным.
4. Поэтому меньшие затраты.
Недостатки коммутации пакетов
1. Сложное устройство; без микропроцессорной техники пакетную сеть наладить
практически невозможно.
2. Пропускная способность расходуется на технические данные.
3. Пакет может ждать своей очереди в коммутаторе.
Сеть с коммутацией пакетов замедляет процесс взаимодействия каждой конкретной пары узлов,
поскольку их пакеты могут ожидать в коммутаторах, пока передадутся другие пакеты. Однако
общая эффективность (объем передаваемых данных в единицу времени) при коммутации пакетов
будет выше, чем при коммутации каналов. Это связано с тем, что трафик каждого отдельного
абонента носит пульсирующий характер, а пульсации разных абонентов, в соответствии с законом
больших чисел распределяются во времени, увеличивая равномерность нагрузки.
Соединение с коммутацией каналов — вид телекоммуникационной сети, в которой между
двумя узлами сети должно быть установлено соединение (канал), прежде чем они начнут обмен
информацией. Это соединение на протяжении всего сеанса обмена информацией может
использоваться только указанными двумя узлами. После завершения обмена соединение должно
быть соответствующим образом разорвано.
Примеры
Типичным примером являются ранние телефонные сети. Абонент должен попросить оператора
соединить его с другим абонентом, подключённым к тому же коммутатору или иному
коммутатору через линию связи (и другому оператору). В любом случае, конечным результатом
было физическое электрическое соединение между телефонными аппаратами абонентов в течение
всего разговора. Проводник, задействованный для подключения, не мог быть использован для
передачи других разговоров в это время, даже если абоненты на самом деле не разговаривали и на
линии была тишина.
Позже стало возможным уплотнение одной физической линии для образования в ней нескольких
каналов. Несмотря на это, один канал уплотнённой линии также мог использоваться лишь одной
парой абонентов.
Преимущества
1. Высокая стабильность параметров канала во времени.
2. Отсутствие необходимости в передаче служебной информации после установления
соединения.
3. Коммутация каналов может использоваться как в аналоговых, так и в цифровых сетях
связи, в отличие от коммутации пакетами, которая возможна только в цифровых сетях.
Недостатки
Коммутация каналов считается недостаточно эффективным способом коммутации, потому что
канальная ёмкость частично расходуется на поддержание соединений, которые установлены, но (в
настоящее время) не используются.
Альтернатива
Коммутация каналов принципиально отличается от коммутации пакетов, при которой данные,
которые передаются (например, оцифрованный звук или данные по компьютерной сети),
разделяются на отдельные пакеты, которые отдельно передаются через сеть общего пользования.
Архитектура на основе коммутационной матрицы
Параллельно с появлением архитектуры с разделяемой памятью (в середине 1990-х годов) была
разработана архитектура на основе коммутационной матрицы (Crossbar architecture). Эта
архитектура используется для построения коммутаторов различных типов.
Существует множество вариаций архитектуры этого типа. Базовая архитектура на основе
коммутационной матрицы N х Nнепосредственно соединяет N входных портов с N выходными
портами в виде матрицы. В местах пересечения проводников, соединяющих входы и выходы,
находятся коммутирующие устройства, которыми управляет специальный контроллер. В каждый
момент времени, анализируя адресную информацию, контроллер сообщает коммутирующим
устройствам, какой выход должен быть подключен к какому входу. В том случае, если два
входящих пакета от разных портов-источников будут переданы на один и тот же выходной порт,
он будет заблокирован. Существуют различные подходы к решению этой проблемы: повышение
производительности матрицы по сравнению с производительностью входных портов или
использование буферов памяти и арбитров.
Несмотря на простой дизайн, одной из фундаментальных проблем архитектуры на основе
коммутационной матрицы остается ее масштабируемость. При увеличении количества входов и
выходов усложняется схемотехника матрицы и в особенности контроллера. Поэтому для
построения многопортовых коммутационных матриц используется другой подход, который
заключается в том, что простые коммутационные матрицы связываются между собой, образуя
одну большую коммутационную матрицу.
Рис. 1.14. Архитектура на основе коммутационной матрицы
Можно выделить два типа коммутаторов на основе коммутационной матрицы:
коммутаторы на основе коммутационной матрицы с буферизацией (buffered crossbar);
коммутаторы на основе коммутационной матрицы с арбитражем (arbitrated crossbar).
Коммутаторы на основе коммутационной матрицы с буферизацией
В коммутаторах на основе коммутационной матрицы с буферизацией буферы расположены на
трех основных стадиях: на входе и выходе и непосредственно на коммутационной матрице.
Благодаря наличию очередей на трех стадиях эта архитектура позволяет избежать сложностей,
связанных с реализацией механизма централизованного арбитража. На выходе каждой из стадий
осуществляется управление очередями с помощью одного из алгоритмов диспетчеризации.
Несмотря на то, что эта архитектура является простейшей архитектурой коммутаторов, из-за
независимости стадий для нее существуют сложности с реализацией качества обслуживания (QoS)
в пределах коммутатора.
Коммутаторы на основе коммутационной матрицы с арбитражем
Эта архитектура характеризуется наличием безбуферных коммутирующих элементов и арбитра,
который управляет передачей трафика между входами и выходами матрицы. Отсутствие буферов
у коммутирующих элементов компенсируется наличием буферов входных и выходных портов.
Обычно разработчики используют один из трех методов буферизации: выходные буферы, входные
буферы, комбинированные входные и выходные буферы.
В коммутаторах с входными очередями (Input-Queued Switch) память каждого входного порта
организована в виде очереди типа FIFO (First Input First Output — «первым пришел, первым
ушел»), которая используется для буферизации пакетов перед началом процесса коммутации.
Одной из проблем этого типа коммутационной матрицы является блокировка первым в очереди
(Head-Of-Line blocking, HOL). Она возникает в том случае, когда коммутатор пытается
одновременно передать пакеты из нескольких входных очередей на один выходной порт. При
этом пакеты, находящиеся в начале этих очередей, блокируют все остальные пакеты, находящиеся
за ними. Для принятия решения о том, какой пакет и из какой очереди может получить доступ к
матрице, используется арбитр. Перед передачей пакета входные порты направляют арбитру
запросы на подключение к разделяемому ресурсу (в данном случае — пути матрицы) и получают
от него право на подключение.
Арбитр принимает решение о последовательности передачи пакетов из входных очередей на
основе алгоритма диспетчеризации (scheduling algorithm).
Рис. 1.15. Архитектура на основе коммутационной матрицы с входными очередями
Рис. 1.16. Архитектура на основе коммутационной матрицы с выходными очередями
В коммутаторах с выходными очередями (output-queued switch) пакеты буферизируются только
на выходных портах после завершения процесса коммутации. В этом случае удается избежать
проблемы, связанной с блокированием очередей HOL. Коммутаторы этой архитектуры
используют арбитр для управления временем, за которое пакеты коммутируются через матрицу.
При правильно разработанном арбитре коммутаторы с выходными очередями могут обеспечивать
качество обслуживания (QoS).
Следует отметить, что выходной буфер каждого порта требует большего объема памяти по
сравнению с входным буфером. Это позволяет избежать блокирования на выходе, когда все
входные порты пытаются подключиться к одному выходу. Еще одним важным фактором является
скорость выполнения операции «запись» коммутируемых пакетов в выходную очередь. По этим
двум причинам архитектура с выходными очередями должна быть реализована на
высокоскоростных элементах, что делает ее очень дорогостоящей.
Коммутаторы с виртуальными очередями (Virtual Output Queues, VOQ) позволяют преодолеть
проблему блокировки очередей HOL, не внося издержек по сравнению с коммутаторами с
выходными очередями. В этой архитектуре память каждого входного порта организована в
виде N (где N — количество выходных портов) логических очередей типа FIFO, по одной для
каждого выходного порта. Эти очереди используются для буферизации пакетов, поступающих на
входной порт и предназначенных для выходного портаj (j = 1,…N).
В том случае, если существует несколько виртуальных очередей, может возникнуть проблема,
связанная с одновременным доступом к коммутационной матрице и блокировкой очередей. Для
решения этой проблемы используется арбитр, который на основе алгоритма диспетчеризации
выбирает пакеты из разных очередей.
Рис. 1.17. Архитектура на основе коммутационной матрицы с виртуальными очередями
В коммутаторах с комбинированными входными и выходными очередями (Combined Input and
Output Queued, CIOQ) буферы памяти подключены как к входным, так и к выходным портам.
Память каждого из входных портов организована в виде N виртуальных выходных очередей типа
FIFO, по одной для каждого выходного порта. Каждый из N выходных портов также содержит
очередь типа FIFO, которая используется для буферизации пакетов, ожидающих передачи через
него. Система коммутации работает по принципу конвейера, каждая стадия которого называется
временным слотом (time slot). В течение временного слота 1, который называется стадией
прибытия, пакеты поступают на входные порты. Для передачи внутри коммутатора все пакеты
сегментируются на ячейки фиксированного размера. Размер такой ячейки данных определяется
производителем коммутатора. Каждая ячейка снабжается меткой с указанием размера, номера
входного порта и порта назначения и помещается в виртуальную выходную очередь
соответствующего выходного порта. Входные порты отправляют «запросы на подключение к
выходам» централизованному арбитру, а все выходные порты отправляют ему «информацию о
перегрузке» (переполнении выходных буферов).
Рис. 1.18. Архитектура на основе коммутационной матрицы с CIOQ
Во временной слот 2, который называется стадией диспетчеризации, ячейки передаются из
входных очередей в выходные. Последовательность передачи ячеек определяется
централизованным арбитром с помощью алгоритма диспетчеризации. Для того чтобы выходные
очереди быстро заполнялись пакетами из входных очередей (с целью уменьшения задержки
передачи пакетов и обеспечения QoS), алгоритм диспетчеризации должен обеспечивать
циклическое высокоскоростное сопоставление входных и выходных очередей. Это сопоставление
используется для настройки управляемых переключателей матрицы перед передачей пакетов с
входов на выходы.
Во временной слот 3, который называется стадией передачи, осуществляется сборка пакетов и их
передача с выходных портов.
6. Вопрос. Виды связи и режимы работы сетей передачи сообщений.
Передача с установлением логического соединения
Передача с установлением логического соединения
Следующий рассматриваемый нами способ продвижения пакетов основывается на знании
устройствами сети «истории» обмена данными, например, на запоминании узломотправителем
числа отправленных, а узлом-получателем — числа полученных пакетов.Такого рода информация
фиксируется в рамках логического соединения.
Процедура согласования двумя конечными узлами сети некоторых параметров процесса обмена
пакетами называется установлением логического соединения. Параметры, о которых
договариваются два взаимодействующих узла, называются параметрами логического
соединения.
Наличие логического соединения позволяет более рационально по сравнению с дейтаграммным
способом обрабатывать пакеты. Например, при потере нескольких предыдущих пакетов может
быть снижена скорость отправки последующих. Или благодаря нумерации пакетов и
отслеживанию номеров отправленных и принятых пакетов можно повысить надежность путем
отбрасывания дубликатов, упорядочивания поступивших и повторения передачи потерянных
пакетов.
Параметры соединения могут быть: постоянными, то есть не изменяющимися в течение всего
соединения (например, идентификатор соединения, способ шифрования пакета или максимальный
размер поля данных пакета), или переменными, то есть динамически отражающими текущее
состояние соединения (например, последовательные номера пере даваемых пакетов).
Когда отправитель и получатель фиксируют начало нового соединения, они, прежде всего,
«договариваются» о начальных значениях параметров процедуры обмена и только после этого
начинают передачу собственно данных.
Передача с установлением соединения более надежна, но требует больше времени для передачи
данных и вычислительных затрат от конечных узлов, что иллюстрирует рисунке ниже.
Процедура установления соединения состоит обычно из трех шагов.
1. Узел-инициатор соединения отправляет узлу-получателю служебный пакет с предложением
установить соединение.
2. Если узел-получатель согласен с этим, то он посылает в ответ другой служебный пакет,
подтверждающий установление соединения и предлагающий некоторые параметры, которые
будут использоваться в рамках данного логического соединения. Это могут быть, например,
идентификатор соединения, количество кадров, которые можно отправить без получения
подтверждения и т. п.
3. Узел-инициатор соединения может закончить процесс установления соединения отправкой
третьего служебного пакета, в котором сообщит, что предложенные параметры ему подходят.
Логическое соединение может быть рассчитано на передачу данных как в одном направлении —
от инициатора соединения, так и в обоих направлениях. После передачи некоторого законченного
набора данных, например определенного файла, узел-отправитель инициирует разрыв данного
логического соединения, посылая соответствующий служебныйкадр.
Заметим, что, в отличие от передачи дейтаграммного типа, в которой поддерживается только один
тип кадра — информационный, передаче с установлением соединения должна поддерживать как
минимум два типа кадров — информационные кадры переносят собственно пользовательские
данные, а служебные предназначаются для установления (разрыва) соединения.
После того как соединение установлено и все параметры согласованы, конечные узлы начинают
передачу собственно данных. Пакеты данных обрабатываются коммутаторами точно так же, как и
при дейтаграммной передаче: из заголовков пакетов извлекаются адреса назначения и
сравниваются с записями в таблицах коммутации, содержащих информацию о следующих шагах
по маршруту. Так же как дейтаграммы, пакеты, относящиеся к одному логическому соединению, в
некоторых случаях (например, при отказе линии связи) могут доставляться адресату по разным
маршрутам.
Однако передача с установлением соединения имеет важное отличие от дейтаграммной передачи,
поскольку в ней помимо обработки пакетов на коммутаторах имеет место дополнительная
обработка пакетов на конечных узлах. Например, если при установлении соединения была
оговорена передача данных в зашифрованном виде, то шифрование пакетов выполняется узломотправителем, а расшифровка — узлом-получателем. Аналогично, для обеспечения в рамках
логического соединения надежности всю работу по нумерации пакетов, отслеживанию номеров
доставленных и недоставленных пакетов, посылки копий и отбрасывания дубликатов берут на
себя конечные узлы.
Механизм установления логических соединений позволяет реализовывать дифференцированное
обслуживание информационных потоков. Разное обслуживание могут получить даже потоки,
относящиеся к одной и той же паре конечных узлов. Например, пара конечных узлов может
установить два параллельно работающих логических соединения, в одном из которых передавать
данные в зашифрованном виде, а в другом — открытым текстом.
Как видим, передача с установлением соединения предоставляет больше возможностей в плане
надежности и безопасности обмена данными, чем дейтаграммная передача. Однако этот способ
более медленный, так как он подразумевает дополнительные вычислительные затраты на
установление и поддержание логического соединения.
Следующий способ продвижения данных основан на частном случае логического соедине ния, в
число параметров которого входит жестко определенный для всех пакетов маршрут. То есть все
пакеты, передаваемые в рамках данного соединения, должны проходить по одному и тому же
закрепленному за этим соединением пути.
Единственный заранее проложенный фиксированный маршрут, соединяющий конечные узлы в
сети с коммутацией пакетов, называют виртуальным каналом (virtual circuit или virtual channel).
Виртуальные каналы прокладываются для устойчивых информационных потоков. С целью
выделения потока данных из общего трафика каждый пакет этого потока помечается специальным
видом признака — меткой.
Так же как в сетях с установлением логических соединений, прокладка виртуального канала
начинается с отправки из узла-источника специального пакета — запроса на установление
соединения. В запросе указываются адрес назначения и метка потока, для которого
прокладывается этот виртуальный канал. Запрос, проходя по сети, формирует новую запись в
каждом из коммутаторов, расположенных на пути от отправителя до получателя. Запись говорит о
том, каким образом коммутатор должен обслуживать пакет, имеющий заданную метку.
Образованный виртуальный канал идентифицируется той же меткой.
После прокладки виртуального канала сеть может передавать по нему соответствующий поток
данных. Во всех пакетах, которые переносят пользовательские данные, адрес назначения уже не
указывается, его роль играет метка виртуального канала. При поступлении пакета на входной
интерфейс коммутатор читает значение метки из заголовка пришедшего пакета и просматривает
свою таблицу коммутации, по которой определяет, на какой выходной порт передать пришедший
пакет.
Таблица коммутациикоммутатора S1
Адрес следущего назначения
Адрес следущего коммутатора
VC1
S2
VC2
S3
На рис. показана сеть, в которой проложены два виртуальных канала (Virtual Channel,VC),
идентифицируемых метками VC1 и VC2. Первый проходит от конечного узла с адресом М до
конечного узла с адресом N2 через промежуточные коммутаторы 51 и 52. Второй виртуальный
канал VC2 обеспечивает продвижение данных по пути M-51-53-55-M3.
В общем случае, между двумя конечными узлами может быть проложено несколько виртуальных
каналов, например еще один виртуальный канал между узлами N1 и N2 мог бы проходить через
промежуточный коммутатор 53. На рисунке показаны два пакета, несущие в своих заголовках
метки потоков VC1 и VC2, которые играют роль адресов назначения.
Таблица коммутации в сетях, использующих виртуальные каналы, отличается от таблицы
коммутации в дейтаграммных сетях. Она содержит записи только о проходящих через коммутатор
виртуальных каналах, а не обо всех возможных адресах назначения, как это имеет место в сетях с
дейтаграммным алгоритмом продвижения. Обычно в крупной сети количество проложенных через
узел виртуальных каналов существенно меньше общего количества узлов, поэтому и таблицы
коммутации в этом случае намного короче, а следовательно, анализ такой таблицы занимает у
коммутатора меньше времени. По той же причине метка короче адреса конечного узла, и
заголовок пакета в сетях с виртуальными каналами переносит по сети вместо длинного адреса
компактный идентификатор потока.
Водной и той же сетевой технологии могут быть задействованы разные способы продвижения
данных. Так, дейтаграммный протокол IP используется для передачи данных между отдельными
сетями, составляющими Интернет. В то же время обеспечением надежной доставки данных между
конечными узлами этой сети занимается протокол TCP, устанавливающий логические соединения
без фиксации маршрута. И наконец, Интернет — это пример сети, применяющей технику
виртуальных каналов, так как в состав Интернета входит немало сетей ATM и Frame Relay,
поддерживающих виртуальные каналы.
Дейтаграммная передача
Дейтаграммный способ передачи данных основан на том, что все передаваемые пакеты
продвигаются (передаются от одного узла сети другому) независимо друг от друга на основании
одних и тех же правил.
Процедура обработки пакета определяется только значениями параметров, которые он несет в
себе, и текущим состоянием сети (например, в зависимости от ее нагрузки пакет может
стоять в очереди на обслуживание большее или меньшее время). Однако никакая информация об
уже переданных пакетах сетью не хранится и в ходе обработки очередного пакета во внимание
не принимается. То есть каждый отдельный пакет рассматривается сетью как совершенно
независимая единица передачи —дейтаграмма.
Решение о продвижении пакета принимается на основе таблицы коммутации, ставящей в
соответствие адресам назначения пакетов информацию, однозначно определяющую следующий
по маршруту транзитный (или конечный) узел. В качестве такой информации могут выступать
идентификаторы интерфейсов данного коммутатора или адреса входных интерфейсов
коммутаторов, следующих по маршруту.
Таблица коммутациикоммутатора S1
Адрес назначения
Адрес следующего
коммутатора
N1
Пакет не требуется
передавать через сеть
N2
S2
N3
S3
N4
S4
N5
S5
N6
S6
На рисунке показана сеть, в которой шесть конечных узлов (М-М5) связаны семью
коммутаторами (51-57). Показаны также несколько перемещающихся по разным маршрутам
пакетов с разными адресами назначения (ЛЛ-Mi), на пути которых лежит коммутатор 51.
При поступлении каждого из этих пакетов в коммутатор 51 выполняется просмотр
соответствующей таблицы коммутации и выбор дальнейшего пути перемещения. Так пакет с
адресом N5 будет передан коммутатором 51 на интерфейс, ведущий к коммутатору 56, где в
результате подобной процедуры этот пакет будут направлен конечному узлу получателю N5.
В таблице коммутации для одного и того же адреса назначения может содержаться несколько
записей, указывающих соответственно на различные адреса следующего коммутатора. Такой
подход называется балансом нагрузки и используется для повышения производительности и
надежности сети. В примере, показанном на рисунке, пакеты, поступающие в коммутатор 51 для
узла назначения с адресом N2, в целях баланса нагрузки распределяются между двумя
следующими коммутаторами — 52 и 53, что снижает нагрузку на каждыйиз них, а значит,
сокращает очереди и ускоряет доставку.
Некоторая «размытость» путей следования пакетов с одним и тем же адресом назначения через
сеть является прямым следствием принципа независимой обработки каждого пакета, присущего
дейтаграммному методу. Пакеты, следующие по одному и тому же адресу назначения, могут
добираться до него разными путями также вследствие изменения состояния сети, например отказа
промежуточных коммутаторов.
Дейтаграммный метод работает быстро, так как никаких предварительных действий перед
отправкой данных проводить не требуется. Однако при таком методе трудно проверить факт
доставки пакета узлу назначения. Этот метод не гарантирует доставку пакета, он делает это по
мере возможности — для описания такого свойства используется термин доставка с
максимальными усилиями (best effort).
Вопрос 7. Сети одноранговые и «клиент/сервер». Понятие топологии сети.
Одноранговая, децентрализованная или пиринговая (англ. peer-to-peer, P2P — равный к
равному) сеть — это оверлейная компьютерная сеть, основанная на равноправии участников.
Часто в такой сети отсутствуют выделенные серверы, а каждый узел (peer) является как клиентом,
так и выполняет функции сервера. В отличие от архитектуры клиент-сервера, такая организация
позволяет сохранять работоспособность сети при любом количестве и любом сочетании
доступных узлов. Участниками сети являются пиры.
История
Впервые фраза «peer-to-peer» была использована в 1984 году при разработке архитектуры
Advanced Peer to Peer Networking (APPN) фирмы IBM.
Устройство одноранговой сети
В сети присутствует некоторое количество машин, при этом каждая может связаться с любой из
других. Каждая из этих машин может посылать запросы другим машинам на предоставление
каких-либо ресурсов в пределах этой сети и, таким образом, выступать в роли клиента. Будучи
сервером, каждая машина должна быть способной обрабатывать запросы от других машин в сети,
отсылать то, что было запрошено. Каждая машина также должна выполнять некоторые
вспомогательные и административные функции (например, хранить список других известных
машин-«соседей» и поддерживать его актуальность).
Любой член данной сети не гарантирует свое присутствие на постоянной основе. Он может
появляться и исчезать в любой момент времени. Но при достижении определённого критического
размера сети наступает такой момент, что в сети одновременно существует множество серверов с
одинаковыми функциями.
Пример такой сети: I2P, Gnutella2.
Приватные P2P сети
Пример сети: RetroShare
Частично децентрализованные (гибридные) сети
Помимо чистых P2P-сетей, существуют так называемые гибридные сети, в которых
существуют серверы, используемые для координации работы, поиска или предоставления
информации о существующих машинах сети и их статусе (on-line, off-line и т. д.). Гибридные сети
сочетают скорость централизованных сетей и надёжность децентрализованных благодаря
гибридным схемам с независимыми индексационными
серверами, синхронизирующими информацию между собой. При выходе из строя одного или
нескольких серверов сеть продолжает функционировать. К частично децентрализованным сетям
относятся например eDonkey, BitTorrent, Direct Connect, The Onion Router.
Пиринговая файлообменная сеть
Одна из областей применения технологии одноранговых сетей — это обмен файлами.
Пользователи файлообменной сети выкладывают какие-либо файлы в т. н. «расшаренную»
(англ. share — делиться) директорию, содержимое которой доступно для скачивания другим
пользователям. Какой-нибудь другой пользователь сети посылает запрос на поиск какого-либо
файла. Программа ищет у клиентов сети файлы, соответствующие запросу, и показывает
результат. После этого пользователь может скачать файлы у найденных источников. В
современных файлообменных сетях информация загружается сразу с нескольких источников. Ее
целостность проверяется по контрольным суммам.
Многие распространяемые в таких сетях файлы, не являющиеся свободными для распространения
с юридической точки зрения, распространяются в них без разрешения правообладателей.
Видеоиздательские и звукозаписывающие компании утверждают, что это приводит к
значительной недополученной ими прибыли. Проблем им добавляет тот факт, что пресечь
распространение файла в децентрализованной сети технически невозможно — для этого
потребуется физически отключить от сети все машины, на которых лежит этот файл, а таких
машин (см. выше) может быть очень и очень много — в зависимости от популярности файла их
число может достигать нескольких сотен тысяч. В последнее время видеоиздатели и
звукозаписывающие компании начали подавать в суд на отдельных пользователей таких сетей,
обвиняя их в незаконном распространении музыки и видео.
Такие организации, как RIAA, дискредитируют пиринговые сети, публикуя в них фальшивые
файлы (содержание которых не соответствует названию, часто носит порнографический характер).
Это привело к потере популярности сети KaZaA в пользу eDonkey, имеющей более совершенную
архитектуру.
Несмотря на то, что в феврале 2006 прекратил работу самый популярный сервер сети eD2k —
Razorback, и была прекращена разработка коммерческого клиента EDonkey2000, самасеть
ED2K продолжает функционировать, так как не завязана на конкретные серверы и существует
большое количество свободно распространяемых клиентских программ типа eMuleи mlDonkey.
Пиринговые сети распределённых вычислений
Технология пиринговых сетей (не подвергающихся квазисинхронному исчислению) применяется
также для распределённых вычислений. Они позволяют в сравнительно короткие сроки выполнять
поистине огромный объём вычислений, который даже на суперкомпьютерах потребовал бы, в
зависимости от сложности задачи, многих лет и даже столетий работы. Такая производительность
достигается благодаря тому, что некоторая глобальная задача разбивается на большое количество
блоков, которые одновременно выполняются сотнями тысяч компьютеров, принимающими
участие в проекте. Один из примеров такого использования пиринговых сетей
продемонстрировала компания Sony на игровых приставках SonyPlayStation[1].
Клиент-сервер (англ. Client-server) — вычислительная или сетевая архитектура, в которой
задания или сетевая нагрузка распределены между поставщиками услуг, называемыми серверами,
и заказчиками услуг, называемыми клиентами. Физически клиент и сервер — это программное
обеспечение. Обычно они взаимодействуют через компьютерную сеть посредством сетевых
протоколов и находятся на разных вычислительных машинах, но могут выполняться также и на
одной машине. Программы — сервера, ожидают от клиентских программ запросы и
предоставляют им свои ресурсы в виде данных (например, загрузка
файлов посредством HTTP, FTP, BitTorrent, потоковое мультимедиа или работа с базами данных)
или сервисных функций (например, работа с электронной почтой, общение посредством систем
мгновенного обмена сообщениями, просмотр web-страниц во всемирной паутине).
Преимущества
Отсутствие дублирования кода программы-сервера программами-клиентами.
Так как все вычисления выполняются на сервере, то требования к компьютерам, на
которых установлен клиент, снижаются.
Все данные хранятся на сервере, который, как правило, защищён гораздо лучше
большинства клиентов. На сервере проще организовать контроль полномочий, чтобы
разрешать доступ к данным только клиентам с соответствующими правами доступа.
Недостатки
Неработоспособность сервера может сделать неработоспособной всю вычислительную
сеть. Неработоспособным сервером следует считать сервер, производительности которого
не хватает на обслуживание всех клиентов, а также сервер, находящийся на ремонте,
профилактике и т. п.
Поддержка работы данной системы требует отдельного специалиста — системного
администратора.
Высокая стоимость оборудования.
Многоуровневая архитектура клиент-сервер
Многоуровневая архитектура клиент-сервер — разновидность архитектуры клиент-сервер, в
которой функция обработки данных вынесена на один или несколько отдельных серверов. Это
позволяет разделить функции хранения, обработки и представления данных для более
эффективного использования возможностей серверов и клиентов.
Частные случаи многоуровневой архитектуры:
Трёхуровневая архитектура
Сеть с выделенным сервером
Сеть с выделенным сервером (англ. Client/Server network) — это локальная вычислительная сеть
(LAN), в которой сетевые устройства централизованы и управляются одним или несколькими
серверами. Индивидуальные рабочие станции или клиенты (такие, как ПК) должны обращаться к
ресурсам сети через сервер(а).
Сетевая топология — это конфигурация графа, вершинам которого соответствуют конечные
узлы сети (компьютеры) и коммуникационное оборудование (маршрутизаторы), а рёбрам —
физические или информационные связи между вершинами.
Сетевая топология может быть
физической — описывает реальное расположение и связи между узлами сети.
логической — описывает хождение сигнала в рамках физической топологии.
информационной — описывает направление потоков информации, передаваемых по сети.
управления обменом — это принцип передачи права на пользование сетью.
Топологии
Полносвязная
Полносвязная топология
Сеть, в которой каждый компьютер непосредственно связан со всеми остальными. Однако этот
вариант громоздкий и неэффективный, потому что каждый компьютер в сети должен иметь
большое количество коммуникационных портов, достаточное для связи с каждым из остальных
компьютеров.
Неполносвязная
Неполносвязных топологий существует несколько. В них, в отличие от полносвязных может
применяться передача данных не напрямую между компьютерами, а через дополнительные узлы.
Шина (Bus)
Топология шина
Топология данного типа, представляет собой общий кабель (называемый шина или магистраль), к
которому подсоединены все рабочие станции. На концах кабеля находятся терминаторы, для
предотвращения отражения сигнала.
Преимущества сетей шинной топологии:
отказ одного из узлов не влияет на работу сети в целом;
сеть легко настраивать и конфигурировать;
сеть устойчива к неисправностям отдельных узлов.
Недостатки сетей шинной топологии:
разрыв кабеля может повлиять на работу всей сети;
ограниченная длина кабеля и количество рабочих станций;
трудно определить дефекты соединений.
Звезда
Топология звезда
В сети построенной по топологии типа «звезда» каждая рабочая станция подсоединяется кабелем
(витой парой) к концентратору или хабу (англ. hub). Концентратор обеспечивает параллельное
соединение ПК и, таким образом, все компьютеры, подключенные к сети, могут общаться друг с
другом.
Данные от передающей станции сети передаются через хаб по всем линиям связи всем ПК.
Информация поступает на все рабочие станции, но принимается только теми станциями, которым
она предназначается. Так как передача сигналов в топологии физическая звезда является
широковещательной, то есть сигналы от ПК распространяются одновременно во все направления,
то логическая топология данной локальной сети является логической шиной.
Данная топология применяется в локальных сетях с архитектурой 10Base-T Ethernet.
Преимущества сетей топологии звезда:
легко подключить новый ПК;
имеется возможность централизованного управления;
сеть устойчива к неисправностям отдельных ПК и к разрывам соединения отдельных ПК.
Недостатки сетей топологии звезда:
отказ хаба влияет на работу всей сети;
большой расход кабеля.
Кольцо
В сети с топологией кольцо все узлы соединены каналами связи в неразрывное кольцо
(необязательно окружность), по которому передаются данные. Выход одного ПК соединяется со
входом другого ПК. Начав движение из одной точки, данные, в конечном счете, попадают на его
начало. Данные в кольце всегда движутся в одном и том же направлении.
Топология кольцо
Принимающая рабочая станция распознает и получает только адресованное ей сообщение. В сети
с топологией типа физическое кольцо используется маркерный доступ, который предоставляет
станции право на использование кольца в определенном порядке. Логическая топология данной
сети — логическое кольцо. Данную сеть очень легко создавать и настраивать.
К основному недостатку сетей топологии кольцо является то, что повреждение линии связи в
одном месте или отказ ПК приводит к неработоспособности всей сети.
Как правило, в чистом виде топология «кольцо» не применяется из-за своей ненадёжности,
поэтому на практике применяются различные модификации кольцевой топологии.
Ячеистая топология
Получается из полносвязной топологии путём удаления некоторых связей. Допускает соединения
большого количества компьютеров и характерна для крупных сетей.
И дополнительные (производные):
Двойное кольцо
Решётка
Дерево
Fat Tree
Сеть Клоза
Снежинка
Полносвязная
Дополнительные способы являются комбинациями базовых. В общем случае такие топологии
называются смешанными или гибридными, но некоторые из них имеют собственные названия,
например «Дерево».
Смешанная топология
Сеть смешанной топологии
Смешанная топология — сетевая топология, преобладающая в крупных сетях с произвольными
связями между компьютерами. В таких сетях можно выделить отдельные произвольно связанные
фрагменты (подсети), имеющие типовую топологию, поэтому их называют сетями со смешанной
топологией.
Централизация
Топологии звезда снижает вероятность сбоя сети, подключив все периферийные узлы
(компьютеры и т. д.) к центральному узлу. Когда физическая звездная топология применяется к
логической шинной сети, такой как Ethernet, это центральный узел (обычно хаб) ретранслирует
все передачи, полученные от любого периферийного узла на все периферийные узлы в сети, в том
числе иногда инициирующего узла. Таким образом, все периферийные узлы могут
взаимодействовать со всеми остальными посредством передачи и приема только от центрального
узла. Отказ линии передачи, связывающей любой периферийный узел с центральным узлом
приведёт к тому что данный периферийный узел будет изолирован от всех остальных, а остальные
периферийные узлы затронуты не будут . Однако, недостаток заключается в том, что отказ
центрального узла приведет к отказу всех периферийных узлов.
Для снижения объема сетевого трафика, который приходит из вещания все сигналы всех узлов,
более продвинутые центральные узлы были разработаны, которые способны отслеживать
идентичностей узлов, подключенных к сети. Эти сетевые коммутаторы будут «изучать» макет
сети, «слушать» на каждом порту во время нормальной передачи данных, рассматривая пакеты
данных и записи адрес / идентификатор каждого подключенного узла и какой порт он подключен
к в справочной таблице, состоявшемся в памяти. Эта таблица поиска, то позволяет будущим
передачам, которые будут направлены только прямому назначению.
Децентрализация
В сетевой топологии существуют по крайней мере два узла с двумя или больше путями между
ними, чтобы обеспечить дополнительные пути, которые будут использоваться в случае, если один
из путей выйдет из строя. Эта децентрализация часто используется, чтобы компенсировать
недостаток выхода из строя одного пункта, используя единственное устройство в качестве
центрального узла (например, в звезде и сетях дерева). Специальный вид сети, ограничивающий
число путей между двумя узлами, называется гиперкубом. Число разветвлений в сетях делает их
более трудными к разработке и реализации, однако они являются очень удобными. В
2012 IEEE издал протокол IEEE 802-1aq (мостовое соединение по кратчайшему пути), чтобы
облегчить задачи конфигурации и обеспечить активность всех путей, что увеличивает полосу
пропускания и избыточность между всеми устройствами. В некоторой степени это подобно
линейной или кольцевой топологиям, используемых для соединения систем во многих
направлениях.
Тема 2. Каналы передачи данных.
Учебные вопросы:
1. Каналы передачи данных.
2. Количество информации. Энтропия. Коэффициент избыточности сообщения. Основные
используемые коды. Асинхронное и синхронное кодирование. Способы контроля
правильности передачи данных. Код Хемминга. Циклические коды. Коэффициент сжатия.
Алгоритмы сжатия.
Вопрос 1. Каналы передачи данных.
Линия связи (см. рисунок ниже) состоит в общем случае из физической среды, по которой
передаются электрические информационные сигналы, аппаратуры передачи данных и
промежуточной аппаратуры. Синонимом термина линия связи (line) является термин канал
связи(channel).
Рис. Состав линии связи.
Физическая среда передачи данных (medium) может представлять собой кабель, то есть набор
проводов, изоляционных и защитных оболочек и соединительных разъемов, а также земную
атмосферу или космическое пространство, через которые распространяются электромагнитные
волны.
В зависимости от среды передачи данных линии связи разделяются на следующие (см. рисунок
ниже):
проводные (воздушные);
кабельные (медные и волоконно-оптические);
радиоканалы наземной и спутниковой связи.
Рис. Типы линий связи.
Проводные (воздушные) линии связи представляют собой провода без каких-либо
изолирующих или экранирующих оплеток, проложенные между столбами и висящие в воздухе.
По таким линиям связи традиционно передаются телефонные или телеграфные сигналы, но при
отсутствии других возможностей эти линии используются и для передачи компьютерных данных.
Скоростные качества и помехозащищенность этих линий оставляют желать много лучшего.
Сегодня проводные линии связи быстро вытесняются кабельными.
Кабельные линии представляют собой достаточно сложную конструкцию. Кабель состоит из
проводников, заключенных в несколько слоев изоляции: электрической, электромагнитной,
механической, а также, возможно, климатической. Кроме того, кабель может быть оснащен
разъемами, позволяющими быстро выполнять присоединение к нему различного оборудования. В
компьютерных сетях применяются три основных типа кабеля: кабели на основе скрученных пар
медных проводов, коаксиальные кабели с медной жилой, а также волоконно-оптические кабели.
Скрученная пара проводов называется витой парой (twisted pair). Витая пара существует
в экранированном варианте (Shielded Twistedpair, STP), когда пара медных проводов
обертывается в изоляционный экран, и неэкранированном (Unshielded Twistedpair, UTP), когда
изоляционная обертка отсутствует. Скручивание проводов снижает влияние внешних помех на
полезные сигналы, передаваемые по кабелю. Коаксиальный кабель (coaxial) имеет
несимметричную конструкцию и состоит из внутренней медной жилы и оплетки, отделенной от
жилы слоем изоляции. Существует несколько типов коаксиального кабеля, отличающихся
характеристиками и областями применения — для локальных сетей, для глобальных сетей, для
кабельного телевидения и т. п. Волоконно-оптический кабель (optical fiber) состоит из тонких
(5-60 микрон) волокон, по которым распространяются световые сигналы. Это наиболее
качественный тип кабеля — он обеспечивает передачу данных с очень высокой скоростью (до 10
Гбит/с и выше) и к тому же лучше других типов передающей среды обеспечивает защиту данных
от внешних помех.
Радиоканалы наземной и спутниковой связи образуются с помощью передатчика и приемника
радиоволн. Существует большое количество различных типов радиоканалов, отличающихся как
используемым частотным диапазоном, так и дальностью канала. Диапазоны коротких, средних и
длинных волн (KB, СВ и ДВ), называемые также диапазонами амплитудной модуляции (Amplitude
Modulation, AM) по типу используемого в них метода модуляции сигнала, обеспечивают дальнюю
связь, но при невысокой скорости передачи данных. Более скоростными являются каналы,
работающие на диапазонах ультракоротких волн (УКВ), для которых характерна частотная
модуляция (Frequency Modulation, FM), а также диапазонах сверхвысоких частот (СВЧ или
microwaves). В диапазоне СВЧ (свыше 4 ГГц) сигналы уже не отражаются ионосферой Земли и
для устойчивой связи требуется наличие прямой видимости между передатчиком и приемником.
Поэтому такие частоты используют либо спутниковые каналы, либо радиорелейные каналы, где
это условие выполняется.
В компьютерных сетях сегодня применяются практически все описанные типы физических сред
передачи данных, но наиболее перспективными являются волоконно-оптические. На них сегодня
строятся как магистрали крупных территориальных сетей, так и высокоскоростные линии связи
локальных сетей. Популярной средой является также витая пара, которая характеризуется
отличным соотношением качества к стоимости, а также простотой монтажа. С помощью витой
пары обычно подключают конечных абонентов сетей на расстояниях до 100 метров от
концентратора. Спутниковые каналы и радиосвязь используются чаще всего в тех случаях, когда
кабельные связи применить нельзя — например, при прохождении канала через малонаселенную
местность или же для связи с мобильным пользователем сети, таким как шофер грузовика, врач,
совершающий обход, и т. п.
Типы характеристик и способы их определения.
К основным характеристикам линий связи относятся:
амплитудно-частотная характеристика;
полоса пропускания;
затухание;
помехоустойчивость;
перекрестные наводки на ближнем конце линии;
пропускная способность;
достоверность передачи данных;
удельная стоимость.
В первую очередь разработчика вычислительной сети интересуют пропускная
способность и достоверность передачи данных, поскольку эти характеристики прямо влияют на
производительность и надежность создаваемой сети. Пропускная способность и достоверность это характеристики как линии связи, так и способа передачи данных. Поэтому если способ
передачи (протокол) уже определен, то известны и эти характеристики. Например, пропускная
способность цифровой линии всегда известна, так как на ней определен протокол физического
уровня, который задает битовую скорость передачи данных — 64 Кбит/с, 2 Мбит/с и т. п.
Однако нельзя говорить о пропускной способности линии связи, до того как для нее определен
протокол физического уровня. Именно в таких случаях, когда только предстоит определить, какой
из множества существующих протоколов можно использовать на данной линии, очень важными
являются остальные характеристики линии, такие как полоса пропускания, перекрестные наводки,
помехоустойчивость и другие характеристики.
Для определения характеристик линии связи часто используют анализ ее реакций на некоторые
эталонные воздействия. Такой подход позволяет достаточно просто и однотипно определять
характеристики линий связи любой природы, не прибегая к сложным теоретическим
исследованиям. Чаще всего в качестве эталонных сигналов для исследования реакций линий связи
используются синусоидальные сигналы различных частот. Это связано с тем, что сигналы этого
типа часто встречаются в технике и с их помощью можно представить любую функцию времени как непрерывный процесс колебаний звука, так и прямоугольные импульсы, генерируемые
компьютером.
Амплитудно-частотная характеристика, полоса пропускания и затухание.
Степень искажения синусоидальных сигналов линиями связи оценивается с помощью таких
характеристик, как амплитудно-частотная характеристика, полоса пропускания и затухание на
определенной частоте.
Амплитудно-частотная характеристика показывает, как затухает амплитуда синусоиды на
выходе линии связи по сравнению с амплитудой на ее входе для всех возможных частот
передаваемого сигнала. Вместо амплитуды в этой характеристике часто используют также такой
параметр сигнала, как его мощность.
Рис. Амплитудно-частотная характеристика.
Знание амплитудно-частотной характеристики реальной линии позволяет определить форму
выходного сигнала практически для любого входного сигнала. Для этого необходимо найти
спектр входного сигнала, преобразовать амплитуду составляющих его гармоник в соответствии с
амплитудно-частотной характеристикой, а затем найти форму выходного сигнала, сложив
преобразованные гармоники.
Несмотря на полноту информации, предоставляемой амплитудно-частотной характеристикой о
линии связи, ее использование осложняется тем обстоятельством, что получить ее весьма трудно.
Ведь для этого нужно провести тестирование линии эталонными синусоидами по всему диапазону
частот от нуля до некоторого максимального значения, которое может встретиться во входных
сигналах. Причем менять частоту входных синусоид нужно с небольшим шагом, а значит,
количество экспериментов должно быть очень большим. Поэтому на практике вместо
амплитудно-частотной характеристики применяются другие, упрощенные характеристики полоса пропускания и затухание.
Полоса пропускания (bandwidth) — это непрерывный диапазон частот, для которого отношение
амплитуды выходного сигнала ко входному превышает некоторый заранее заданный предел,
обычно 0,5. То есть полоса пропускания определяет диапазон частот синусоидального сигнала,
при которых этот сигнал передается по линии связи без значительных искажений. Знание полосы
пропускания позволяет получить с некоторой степенью приближения тот же результат, что и
знание амплитудно-частотной характеристики. Как мы увидим ниже, ширина полосы
пропускания в наибольшей степени влияет на максимально возможную скорость передачи
информации по линии связи. Именно этот факт нашел отражение в английском эквиваленте
рассматриваемого термина (width — ширина).
Затухание (attenuation) определяется как относительное уменьшение амплитуды или мощности
сигнала при передаче по линии сигнала определенной частоты. Таким образом, затухание
представляет собой одну точку из амплитудно-частотной характеристики линии. Часто при
эксплуатации линии заранее известна основная частота передаваемого сигнала, то есть та частота,
гармоника которой имеет наибольшую амплитуду и мощность. Поэтому достаточно знать
затухание на этой частоте, чтобы приблизительно оценить искажения передаваемых по линии
сигналов. Более точные оценки возможны при знании затухания на нескольких частотах,
соответствующих нескольким основным гармоникам передаваемого сигнала.
Затухание А обычно измеряется в децибелах (дБ, decibel — dB) и вычисляется по следующей
формуле:
А = 10 log10 Рвых /Рвх,
где Рвых ~ мощность сигнала на выходе линии, Рвх — мощность сигнала на входе линии.
Так как мощность выходного сигнала кабеля без промежуточных усилителей всегда меньше, чем
мощность входного сигнала, затухание кабеля всегда является отрицательной величиной.
Например, кабель на витой паре категории 5 характеризуется затуханием не ниже -23,6 дБ для
частоты 100 МГц при длине кабеля 100 м. Частота 100 МГц выбрана потому, что кабель этой
категории предназначен для высокоскоростной передачи данных, сигналы которых имеют
значимые гармоники с частотой примерно 100 МГц. Кабель категории 3 предназначен для
низкоскоростной передачи данных, поэтому для него определяется затухание на частоте 10 МГц
(не ниже -11,5 дБ). Часто оперируют с абсолютными значениями затухания, без указания знака.
Абсолютный уровень мощности, например уровень мощности передатчика, также измеряется в
децибелах. При этом в качестве базового значения мощности сигнала, относительно которого
измеряется текущая мощность, принимается значение в 1 мВт. Таким образом, уровень мощности
р вычисляется по следующей формуле:
р = 10 log10 Р/1мВт [дБм],
где Р — мощность сигнала в милливаттах, а дБм (dBm) — это единица измерения уровня мощности
(децибел на 1 мВт).
Таким образом, амплитудно-частотная характеристика, полоса пропускания и затухание являются
универсальными характеристиками, и их знание позволяет сделать вывод о том, как через линию
связи будут передаваться сигналы любой формы.
Полоса пропускания зависит от типа линии и ее протяженности.
Рис. Полосы пропускания линий связи и популярные частотные диапазоны.
Пропускная способность линии.
Пропускная способность (throughput) линии характеризует максимально возможную скорость
передачи данных по линии связи. Пропускная способность измеряется в битах в секунду — бит/с, а
также в производных единицах, таких как килобит в секунду (Кбит/с), мегабит в секунду (Мбит/с),
гигабит в секунду (Гбит/с) и т. д.
Пропускная способность линии связи зависит не только от ее характеристик, таких как
амплитудно-частотная характеристика, но и от спектра передаваемых сигналов. Если значимые
гармоники сигнала (то есть те гармоники, амплитуды которых вносят основной вклад в
результирующий сигнал) попадают в полосу пропускания линии, то такой сигнал будет хорошо
передаваться данной линией связи и приемник сможет правильно распознать информацию,
отправленную по линии передатчиком. Если же значимые гармоники выходят за границы полосы
пропускания линии связи, то сигнал будет значительно искажаться, приемник будет ошибаться
при распознавании информации, а значит, информация не сможет передаваться с заданной
пропускной способностью.
Рис. Соответствие между полосой пропускания линии связи и спектром сигнала.
Выбор способа представления дискретной информации в виде сигналов, подаваемых на линию
связи, называется физическим или линейным кодированием. От выбранного способа
кодирования зависит спектр сигналов и, соответственно, пропускная способность линии. Таким
образом, для одного способа кодирования линия может обладать одной пропускной способностью,
а для другого — другой. Например, витая пара категории 3 может передавать данные с пропускной
способностью 10 Мбит/с при способе кодирования стандарта физического уровня l0Base-T и 33
Мбит/с при способе кодирования стандарта 100Base-T4. В примере, приведенном на рис. 2.9,
принят следующий способ кодирования — логическая 1 представлена на линии положительным
потенциалом, а логический 0 — отрицательным.
Теория информации говорит, что любое различимое и непредсказуемое изменение принимаемого
сигнала несет в себе информацию. В соответствии с этим прием синусоиды, у которой амплитуда,
фаза и частота остаются неизменными, информации не несет, так как изменение сигнала хотя и
происходит, но является хорошо предсказуемым. Аналогично, не несут в себе информации
импульсы на тактовой шине компьютера, так как их изменения также постоянны во времени. А
вот импульсы на шине данных предсказать заранее нельзя, поэтому они переносят информацию
между отдельными блоками или устройствами.
Большинство способов кодирования используют изменение какого-либо параметра
периодического сигнала — частоты, амплитуды и фазы синусоиды или же знак потенциала
последовательности импульсов. Периодический сигнал, параметры которого изменяются,
называют несущим сигналом или несущей частотой, если в качестве такого сигнала
используется синусоида.
Если сигнал изменяется так, что можно различить только два его состояния, то любое его
изменение будет соответствовать наименьшей единице информации — биту. Если же сигнал может
иметь более двух различимых состояний, то любое его изменение будет нести несколько бит
информации.
Количество изменений информационного параметра несущего периодического сигнала в секунду
измеряется в бодах (baud). Период времени между соседними изменениями информационного
сигнала называется тактом работы передатчика.
Пропускная способность линии в битах в секунду в общем случае не совпадает с числом бод. Она
может быть как выше, так и ниже числа бод, и это соотношение зависит от способа кодирования.
Если сигнал имеет более двух различимых состояний, то пропускная способность в битах в
секунду будет выше, чем число бод. Например, если информационными параметрами являются
фаза и амплитуда синусоиды, причем различаются 4 состояния фазы в 0,90,180 и 270 градусов и
два значения амплитуды сигнала, то информационный сигнал может иметь 8 различимых
состояний. В этом случае модем, работающий со скоростью 2400 бод (с тактовой частотой 2400
Гц) передает информацию со скоростью 7200 бит/с, так как при одном изменении сигнала
передается 3 бита информации.
При использовании сигналов с двумя различимыми состояниями может наблюдаться обратная
картина. Это часто происходит потому, что для надежного распознавания приемником
пользовательской информации каждый бит в последовательности кодируется с помощью
нескольких изменений информационного параметра несущего сигнала. Например, при
кодировании единичного значения бита импульсом положительной полярности, а нулевого
значения бита — импульсом отрицательной полярности физический сигнал дважды изменяет свое
состояние при передаче каждого бита. При таком кодировании пропускная способность линии в
два раза ниже, чем число бод, передаваемое по линии.
На пропускную способность линии оказывает влияние не только физическое, но и логическое
кодирование. Логическое кодирование выполняется до физического кодирования и
подразумевает замену бит исходной информации новой последовательностью бит, несущей ту же
информацию, но обладающей, кроме этого, дополнительными свойствами, например
возможностью для приемной стороны обнаруживать ошибки в принятых данных. Сопровождение
каждого байта исходной информации одним битом четности — это пример очень часто
применяемого способа логического кодирования при передаче данных с помощью модемов.
Другим примером логического кодирования может служить шифрация данных, обеспечивающая
их конфиденциальность при передаче через общественные каналы связи. При логическом
кодировании чаще всего исходная последовательность бит заменяется более длинной
последовательностью, поэтому пропускная способность канала по отношению к полезной
информации при этом уменьшается.
Помехоустойчивость и достоверность.
Помехоустойчивость линии определяет ее способность уменьшать уровень помех, создаваемых
во внешней среде, на внутренних проводниках. Помехоустойчивость линии зависит от типа
используемой физической среды, а также от экранирующих и подавляющих помехи средств самой
линии. Наименее помехоустойчивыми являются радиолинии, хорошей устойчивостью обладают
кабельные линии и отличной — волоконно-оптические линии, малочувствительные ко внешнему
электромагнитному излучению. Обычно для уменьшения помех, появляющихся из-за внешних
электромагнитных полей, проводники экранируют и/или скручивают.
Перекрестные наводки на ближнем конце (Near End Cross Talk — NEXT) определяют
помехоустойчивость кабеля к внутренним источникам помех, когда электромагнитное поле
сигнала, передаваемого выходом передатчика по одной паре проводников, наводит на другую
пару проводников сигнал помехи. Если ко второй паре будет подключен приемник, то он может
принять наведенную внутреннюю помеху за полезный сигнал. Показатель NEXT, выраженный в
децибелах, равен 10 log Рвых/Рнав, где Рвых — мощность выходного сигнала, Рнав — мощность
наведенного сигнала.
Чем меньше значение NEXT, тем лучше кабель. Так, для витой пары категории 5 показатель
NEXT должен быть меньше -27 дБ на частоте 100 МГц.
Показатель NEXT обычно используется применительно к кабелю, состоящему из нескольких
витых пар, так как в этом случае взаимные наводки одной пары на другую могут достигать
значительных величин. Для одинарного коаксиального кабеля (то есть состоящего из одной
экранированной жилы) этот показатель не имеет смысла, а для двойного коаксиального кабеля он
также не применяется вследствие высокой степени защищенности каждой жилы. Оптические
волокна также не создают сколь-нибудь заметных помех друг для друга.
В связи с тем, что в некоторых новых технологиях используется передача данных одновременно
по нескольким витым парам, в последнее время стал применяться показательPowerSUM,
являющийся модификацией показателя NEXT. Этот показатель отражает суммарную мощность
перекрестных наводок от всех передающих пар в кабеле.
Достоверность передачи данных характеризует вероятность искажения для каждого
передаваемого бита данных. Иногда этот же показатель называют интенсивностью битовых
ошибок (Bit Error Rate, BER). Величина BER для каналов связи без дополнительных средств
защиты от ошибок (например, самокорректирующихся кодов или протоколов с повторной
передачей искаженных кадров) составляет, как правило,10-4 — 10-6, в оптоволоконных линиях связи
— 10-9. Значение достоверности передачи данных, например, в 10-4говорит о том, что в среднем из
10000 бит искажается значение одного бита.
Искажения бит происходят как из-за наличия помех на линии, так и по причине искажений формы
сигнала ограниченной полосой пропускания линии. Поэтому для повышения достоверности
передаваемых данных нужно повышать степень помехозащищенности линии, снижать уровень
перекрестных наводок в кабеле, а также использовать более широкополосные линии связи.
Вопрос 2. Количество информации. Энтропия. Коэффициент избыточности сообщения.
Основные используемые коды. Асинхронное и синхронное кодирование. Способы контроля
правильности передачи данных. Код Хемминга. Циклические коды. Коэффициент сжатия.
Алгоритмы сжатия.
Подходы к определению количества информации. Формулы Хартли и Шеннона.
Американский инженер Р. Хартли в 1928 г. процесс получения информации рассматривал как
выбор одного сообщения из конечного наперёд заданного множества из N равновероятных
сообщений, а количество информации I, содержащееся в выбранном сообщении, определял как
двоичный логарифм N.
Формула Хартли: I = log2N
Допустим, нужно угадать одно число из набора чисел от единицы до ста. По формуле Хартли
можно вычислить, какое количество информации для этого требуется: I = log2100 > 6,644. Таким
образом, сообщение о верно угаданном числе содержит количество информации, приблизительно
равное 6,644 единицы информации.
Приведем другие примеры равновероятных сообщений:
1. при бросании монеты: «выпала решка», «выпал орел»;
2. на странице книги: «количество букв чётное», «количество букв нечётное».
Определим теперь, являются ли равновероятными сообщения «первой выйдет из дверей здания
женщина» и «первым выйдет из дверей здания мужчина». Однозначно ответить на этот вопрос
нельзя. Все зависит от того, о каком именно здании идет речь. Если это, например, станция метро,
то вероятность выйти из дверей первым одинакова для мужчины и женщины, а если это военная
казарма, то для мужчины эта вероятность значительно выше, чем для женщины.
Для задач такого рода американский учёный Клод Шеннон предложил в 1948 г. другую формулу
определения количества информации, учитывающую возможную неодинаковую
вероятность сообщений в наборе.
Формула Шеннона: I = — ( p1log2 p1 + p2 log2 p2 + . . . + pN log2 pN),
где pi — вероятность того, что именно i-е сообщение выделено в наборе из N сообщений.
Легко заметить, что если вероятности p1, …, pN равны, то каждая из них равна 1 / N, и формула
Шеннона превращается в формулу Хартли.
Помимо двух рассмотренных подходов к определению количества информации, существуют и
другие. Важно помнить, что любые теоретические результаты применимы лишь к
определённому кругу случаев, очерченному первоначальными допущениями.
В качестве единицы информации Клод Шеннон предложил принять один бит (англ. bit —
binary digit — двоичная цифра).
Бит в теории информации — количество информации, необходимое для различения двух
равновероятных сообщений (типа «орел»—»решка», «чет»—»нечет» и т.п.).
В вычислительной технике битом называют наименьшую «порцию» памяти компьютера,
необходимую для хранения одного из двух знаков «0» и «1», используемых для
внутримашинного представления данных и команд.
Бит — слишком мелкая единица измерения. На практике чаще применяется более крупная
единица — байт, равная восьми битам. Именно восемь битов требуется для того, чтобы
закодировать любой из 256 символов алфавита клавиатуры компьютера (256=28).
Широко используются также ещё более крупные производные единицы информации:
1 Килобайт (Кбайт) = 1024 байт = 210 байт,
1 Мегабайт (Мбайт) = 1024 Кбайт = 220 байт,
1 Гигабайт (Гбайт) = 1024 Мбайт = 230 байт.
В последнее время в связи с увеличением объёмов обрабатываемой информации входят в
употребление такие производные единицы, как:
1 Терабайт (Тбайт) = 1024 Гбайт = 240 байт,
1 Петабайт (Пбайт) = 1024 Тбайт = 250 байт.
За единицу информации можно было бы выбрать количество информации, необходимое для
различения, например, десяти равновероятных сообщений. Это будет не двоичная (бит), а
десятичная (дит) единица информации.
Обнаружение ошибок в технике связи — действие, направленное на контроль
целостности данных при записи/воспроизведении информации или при её передаче по линиям
связи.Исправление ошибок (коррекция ошибок) — процедура восстановления информации
после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления —
корректирующие коды (коды, исправляющие ошибки, коды с коррекцией
ошибок,помехоустойчивые коды).
Способы борьбы с ошибками
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают
ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих
уровнях работы с информацией (в
частности, физическом, канальном, транспортном уровнях сетевой модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
обнаружение ошибок в блоках данных и автоматический запрос повторной
передачи повреждённых блоков — этот подход применяется, в основном, на канальном и
транспортном уровнях;
обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой
подход иногда применяется в системах потокового мультимедиа, где важна задержка
передачи и нет времени на повторную передачу;
исправление ошибок (англ. forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок,
возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом
структурированную избыточную информацию (контрольное число), а при чтении (приёме) её
используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок,
которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от
первых, последние могут только установить факт наличия ошибки в переданных данных, но не
исправить её.
В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам
кодов, что и коды, исправляющие ошибки. Фактически любой код, исправляющий ошибки, может
быть также использован для обнаружения ошибок (при этом он будет способен обнаружить
большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки, делятся на блоковые, делящие
информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности,
и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть кодируемая информация делится на фрагменты длиной
бит, которые преобразуются
в кодовые слова длиной
бит. Тогда соответствующий блоковый код обычно обозначают
При этом число
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет
называется систематическим, иначе — несистематическим.
.
проверочных, такой код
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из
информационных бит сопоставляется бит кодового слова. Однако хороший код должен
удовлетворять как минимум следующим критериям:
способность исправлять как можно большее число ошибок,
как можно меньшая избыточность,
простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому
существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные
коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость
кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное
линейное подпространство (назовём его ) в -мерном линейном
пространстве, изоморфноепространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на
невырожденную матрицу , называемую порождающей матрицей.
Пусть
— ортогональное подпространство по отношению к , а
задающая базис этого подпространства. Тогда для любого вектора
— матрица,
справедливо:
Минимальное расстояние и корректирующая способность
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами
называется количество отличных бит на соответствующих позициях:
и
.
Минимальное расстояние Хемминга
является важной
характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены
коды друг от друга. Она определяет другую, не менее важную характеристику —
корректирующую способность:
.
Корректирующая способность определяет, сколько ошибок передачи кода (типа
)
можно гарантированно исправить. То есть вокруг каждого кодового слова
имеем окрестность
, которая состоит из всех возможных вариантов передачи кодового слова
с
числом ошибок (
) не более . Никакие две окрестности двух любых кодовых слов не
пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих
окрестностей) всегда больше двух их радиусов
.
Таким образом, получив искажённую кодовую комбинацию из
, декодер принимает решение,
что исходной была кодовая комбинация
, исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова
и
, расстояние Хемминга
между ними равно 3. Если было передано слово
, и канал внёс ошибку в одном бите, она может
быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову
, чем к
любому другому, и, в частности, к
. Но если каналом были внесены ошибки в двух битах (в
которых
отличалось от
), то результат ошибочной передачи
окажется ближе к
,
чем
, и декодер примет решение, что передавалось слово
.
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные
исправить одну ошибку. Код Хемминга может быть представлен в таком виде, чтосиндром
, где
— принятый вектор, будет равен номеру позиции, в которой произошла
ошибка. Это свойство позволяет сделать декодирование очень простым.
Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где
каждому значению принятого слова
соответствует наиболее вероятное переданное слово
.
Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно
небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого
вектора
вычисляется синдром
. Поскольку
, где
—
кодовое слово, а
— вектор ошибки, то
. Затем с помощью таблицы по
синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое
слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего
метода.
Линейные циклические коды
Несмотря на то, что декодирование линейных кодов значительно проще декодирования
большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно
сложен.Циклические коды, кроме более простого декодирования, обладают и другими важными
свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если
является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое
слово
представляется в виде
полинома
слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового
по модулю
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным,
то есть
могут принимать значения 0 или 1.
Порождающий (генераторный) полином
Можно показать, что все кодовые слова конкретного циклического кода кратны
определённому порождающему полиному
делителем
. Порождающий полином является
.
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В
частности:
несистематическое кодирование осуществляется путём умножения кодируемого вектора
на
:
;
систематическое кодирование осуществляется путём «дописывания» к кодируемому
слову остатка от деления
на
, то
есть
.
Коды CRC
Коды CRC (англ. cyclic redundancy check — циклическая избыточная проверка)
являются систематическими кодами, предназначенными не для исправления ошибок, а для их
обнаружения. Они используют способ систематического кодирования, изложенный выше:
«контрольная сумма» вычисляется путем деления
на
. Ввиду того, что
исправление ошибок не требуется, проверка правильности передачи может производиться точно
так же.
Таким образом, вид полинома
полиномов:
задаёт конкретный код CRC. Примеры наиболее популярных
назван
степе
ие
полином
нь
кода
CRC12
12
CRC16
16
CRC16
CCITT
CRC32
32
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их
отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не
меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния
кода есть очень сложная задача.
Математически полинома
на множители в поле Галуа.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в
блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень
распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок,
их эффективность при частых, но небольших ошибках (например, в канале сАБГШ), менее
высока.
Свёрточные коды
Свёрточный кодер (
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней
как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени
системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень
простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого
суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который
пытается восстановить переданную последовательность согласно критерию максимального
правдоподобия.
Преимущества и недостатки свёрточных кодов
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с
пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет
ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное
кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в
результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом РидаСоломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко
друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный
код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного
декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется
декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования,
при котором декодирование осуществляется в несколько проходов, каждый из которых использует
информацию от предыдущего. Это позволяет добиться большой эффективности, однако
декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPCкоды (коды Галлагера).
Сетевое кодирование
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить,
количеством избыточной информации, добавление которой требуется, а также сложностью
реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды
Пусть имеется двоичный блоковый
код с корректирующей способностью . Тогда
справедливо неравенство (называемое границей Хемминга):
Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным
кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с
большой корректирующей способностью (такие, как коды Рида — Соломона) не являются
совершенными.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения
сигнал/шум на входе демодулятора, таким образом, при постоянном уровне шума решающее
значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других
типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи
(например, телефонной) неограниченно повышать мощность сигнала не дают технические
ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении
мощность передатчика можно снизить, оставляя скорость передачи информации неизменной.
Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии
кодирования.
Применение кодов, исправляющих ошибки
Коды, исправляющие ошибки, применяются:
в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче
данных по телефонным каналам.
в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest)
основаны на технологии обнаружения ошибок. Распространены следующие методы
автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения
успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В
случае, если блок данных был принят с ошибкой, приемник передает отрицательное
подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный
метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость изза высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к
приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с
ошибочного блока (то есть передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
ATM (англ. asynchronous transfer mode — асинхронный способ передачи данных) —
сетевая высокопроизводительная технология коммутации и мультиплексирования, основанная на
передаче данных в виде ячеек (англ. cell) фиксированного размера (53 байта[1]), из которых 5
байтов используется под заголовок. В отличие от синхронного способа передачи данных (STM —
англ. synchronous transfer mode), ATM лучше приспособлен для предоставления услуг передачи
данных с сильно различающимся или изменяющимся битрейтом.
Создание
Основы технологии ATM были разработаны независимо во Франции и США в 1970-х двумя
учёными: Jean-Pierre Coudreuse[2], который работал в исследовательской лабораторииFrance
Telecom, и Sandy Fraser, инженер Bell Labs[3]. Они оба хотели создать такую архитектуру, которая
бы осуществляла транспортировку как данных, так и голоса на высоких скоростях, и использовала
сетевые ресурсы наиболее эффективно.
Компьютерные технологии создали возможность для более быстрой обработки информации и
более скоростной передачи данных между системами. В 80-х годах ХХ века операторы
телефонной связи обнаружили, что неголосовой трафик более важен и начинает доминировать над
голосовым. Был предложен проект ISDN[4], который описывал цифровую сеть с коммутацией
пакетов, предоставляющую услуги телефонной связи и передачи данных. Цифровые системы
передачи, сначала плезиохронные системы (PDH) на основе ИКМ, а затемсинхронные системы
передачи (SDH) иерархии на основе оптоволокна, позволяли обеспечить передачу данных на
высокой скорости с малыми вероятностями двоичных ошибок. Но существующая технология
коммутации пакетов (прежде всего, по протоколу X.25) не могла обеспечить передачу трафика в
реальном масштабе времени (например, голоса), и многие сомневались, что когда-либо
обеспечит[3]. Для передачи трафика в реальном масштабе времени в общественных телефонных
сетях применяли технологию коммутации каналов (КК). Эта технология идеальна для передачи
голоса, но для передачи данных она неэффективна. Поэтому телекоммуникационная индустрия
обратилась к ITU для разработки нового стандарта для передачи данных и голосового трафика в
сетях с широкой полосой пропускания[3]. В конце 80-х Международным телефонным и
телеграфным консультативным комитетом CCITT (который затем был переименован в ITU-T) был
разработан набор рекомендаций по ISDN второго поколения, так называемого BISDN (широкополосный ISDN), расширения ISDN. В качестве режима передачи нижнего уровня
для B-ISDN был выбран ATM[4]. В 1988 г. на собрании ITU в Женеве была выбрана длина ячейки
ATM — 53 байт[5]. Это был компромисс между специалистами США, которые предлагали длину
ячейки 64 байта и специалистами Европы, предлагавшими длину ячейки 32 байта. Ни одна
сторона не смогла убедительно доказать преимущество своего варианта, поэтому в итоге объём
«полезной» нагрузки составил 48 байт, а для поля заголовка (служебных данных) был выбран
размер 5 байт, минимальный размер, на который согласилась ITU. В 1990 г. был одобрен базовый
набор рекомендаций ATM[6]. Базовые принципы ATM положены рекомендацией I.150[6]. Это
решение было очень похоже на системы, разработанные Coudreuse и Fraser. Отсюда начинается
дальнейшее развитие ATM.
Советские и российские разработки
В 1980-х — 1990-х годах исследованием и разработкой средств быстрой коммутации пакетов
(БКП) для совместной передачи речи и данных занимались несколько организаций.
ЛНПО «Красная Заря»
Тему БКП и, как её разновидность, АТМ, разрабатывал отдел под руководством Г. П. Захарова в
составе предприятия АООТ НПП «Радуга». Ранее это предприятие было одним из
подразделений ЛНПО «Красная Заря». Отдел Захарова получил как теоретические результаты —
математические модели[7][8], отчёты по проведённым отделом НИР, статьи, книги, студенческие
дипломы, кандидатские и докторские диссертации по теме, так и практические результаты:
сначала, совместными усилиями специалистов ЛНПО «Красная Заря» и предприятия
«Дальняя связь» под техническим руководством специалиста ЛНПО «Красная
Заря»(НИИЭТУ) Разживина Игоря Александровича, в 1992 году был создан рабочий макет
системы коммутации и приёма ячеек АТМ[9];
совместно со специалистом организации «Вектор» Ю. А. Яцуновым в 1993
году разработана принципиальная схема коммутационного элемента (КЭ) для построения
двоичного самомаршрутизирующего коммутационного поля (КП). В основу были
положены некоторые идеи построения КЭ и КП[10][11], опубликованные специалистом из
Великобритании Питером Ньюмэном[12]. В самом общем плане такой КЭ описывается
схемой «селектор-арбитр». Схема КЭ Яцунова-Разживина предназначалась для микросхем
малой степени интеграции популярных и доступных серий[13], выпускавшихся тогда
российской промышленностью[14], однако «в железе» воплощена не была сознательно,
поскольку являлась только промежуточным этапом;
затем, на основе принципиальной схемы Яцунова-Разживина был успешно реализован,
также под техническим руководством Разживина И. А., КЭ в виде одной
специализированной СБИС, которая была разработана специалистом московского ФГУП
«НИИМА Прогресс» В. И. Лопашовым[15], при содействии его коллеги Халтурина В. А., и
изготовлена в Москве[16] в январе 1994 года.
Это позволяло создать коммутационное поле быстрого коммутатора пакетов, или коммутатора
ячеек ATM, на одной печатной плате. Однако дальше выпуска опытной партии СБИС в
количестве 10 штук, и внедрения результатов диссертационной работы Разживина И. А. в НИР
«НИИМА Прогресс» и ГП НИИ «Рубин», эти работы не пошли по независящим от технических
специалистов причинам.
Известны работы группы специалистов под руководством к. т. н. Георгия Ревмировича
Овчинникова, предложивших свой вариант реализации аппаратных средств системы быстрой
коммутации пакетов на основе самомаршрутизирующих матриц[17][18] и свою математическую
модель[19][20]. Однако о практической реализации их предложений сведений не имеется.
Московский институт электронной техники
Было доложено описание цифрового коммутатора 16х16 на арсениде галлия, разработанного
независимо от ЛНПО «Красная Заря» Московским институтом электронной техники[21].
1990-е годы: приход ATM на рынок
ATM NIC
В начале 1990-х гг. технологии ATM в мире начинают уделять повышенное внимание.
Корпорация Sun Microsystems ещё в 1990 г., одна из первых, объявляет о поддержке ATM[3]. В
1991 году, с учётом, что CCITT уже не успевает своевременно предлагать рекомендации по
быстроразвивающейся новой технике, создаётся ATM Forum[22], консорциум фирм-разработчиков
и производителей техники АТМ, для координации и разработки новых практических стандартов и
технических спецификаций по технологии ATM, и сайт с одноимённым названием, где все
спецификации выкладывались в открытый доступ. CCITT, уже будучи ITU-T, выдаёт новые
редакции своих рекомендаций, совершенствуя теоретическую базу ATM. Представители
сферы IT в журналах и газетах пророчат ATM большие перспективы. В 1995 г.
компания IBM объявила о своей новой стратегии в области корпоративных сетей, основанной на
технологии ATM[23]. Считалось, что ATM будет существенным подспорьем для Интернета,
уничтожив нехватку ширины полосы пропускания и внеся в сети надежность[24]. Dan Minoli, автор
многих книг по компьютерным сетям, утверждал, что ATM будет внедрен в публичных сетях, и
корпоративные сети будут соединены с ними таким же образом, каким в то время они
использовали frame relay или X.25[25]. Но к тому времени протокол IP уже получил широкое
распространение и сложно было совершить резкий переход на ATM. Поэтому в существующих IPсетях технологию ATM предполагалось внедрять как нижележащий протокол, то есть под IP, а не
вместо IP. Для постепенного перехода традиционных сетей Ethernet и Token-Ring на оборудование
ATM был разработан протокол LANE, эмулирующий пакеты данных сетей.
В 1997 г. в индустрии маршрутизаторов и коммутаторов примерно одинаковое количество
компаний выстроились в ряды сторонников и противников ATM, то есть использовали или не
использовали технологию ATM в производимых устройствах[3]. Будущее этого рынка было ещё
неопределенно. В 1997 г. доход от продажи оборудования и услуг ATM составил 2,4 млрд
долларов США, в следующем году — 3,5 млрд[26], и ожидалось, что он достигнет 9,5 млрд
долларов в 2001 году[27]. Многие компании (например Ipsilon Networks) для достижения успеха
использовали ATM не полностью, а в урезанном варианте. Многие сложные спецификации и
протоколы верхнего уровня ATM, включая разные типы качества обслуживания, выкидывались.
Оставлялась только базовая функциональность по переключению байтов с одних линий на другие.
Первый удар по ATM
И тем не менее, было также много специалистов IT, скептически относящихся к
жизнеспособности технологии ATM. Как правило, защитниками ATM были представители
телекоммуникационных, телефонных компаний, а противниками — представители компаний,
занимавшихся компьютерными сетями и сетевым оборудованием. Steve Steinberg (в журнале
Wired) посвятил целую статью скрытой войне между ними[24]. Первым ударом по ATM были
результаты исследований Bellcore о характере трафика LAN, опубликованных в 1994 г.[28]. Эта
публикация показала, что трафик в локальных сетях не подчиняется ни одной существующей
модели. Трафик LAN на временной диаграмме ведёт себя как фрактал. На любом временном
диапазоне от нескольких миллисекунд до нескольких часов он имеет самоповторяющийся,
взрывной характер. ATM в своей работе все внеурочные пакеты должен хранить в буфере. В
случае резкого увеличения трафика, коммутатор ATM просто вынужден отбрасывать
невмещающиеся пакеты, а это означает ухудшение качества обслуживания. По этой причине
PacBell потерпела неудачу при первой попытке использовать оборудование ATM[29].
Появление главного конкурента ATM — Gigabit Ethernet
В конце 90-х появляется технология Gigabit Ethernet, которая начинает конкурировать с ATM.
Главными достоинствами первой является значительно более низкая стоимость, простота,
лёгкость в настройке и эксплуатации. Также, переход с Ethernet или Fast Ethernet на Gigabit
Ethernet можно было осуществить значительно легче и дешевле. Проблему качества
обслуживания Gigabit Ethernet мог решить за счет покупки более дешевой полосы пропускания с
запасом, нежели за счет умного оборудования. К окончанию 90-х гг. стало ясно, что ATM будет
продолжать доминировать только в глобальных сетях[30][31]. Продажи свитчей ATM
для WAN продолжали расти, в то время как продажи свитчей ATM для LANстремительно
падали[32][33].
2000-е годы: поражение ATM
В 2000-е гг. рынок оборудования ATM ещё был значительным[34]. ATM широко использовался
в глобальных компьютерных сетях, в оборудовании для передачи аудио/видео потоков, как
промежуточный слой между физическим и вышележащим уровнем в устройствах ADSL для
каналов с пропускной способностью не более 2 Мбит/с. Но в конце десятилетия ATM начинает
вытесняться новой технологией IP-VPN[35]. Свитчи ATM стали вытесняться
маршрутизаторами IP/MPLS[36]. В 2006 Broadband Forum выпустил спецификацию TR-101 под
названием «Migration to Ethernet-Based DSL Aggregation», которая указывала как построенные на
ATM агрегирующие сети могут мигрировать на построенные на Ethernet агрегирующие сети (в
контексте предыдущих архитектур TR-25 и TR-59)[37]. В качестве обоснования такого перехода в
спецификации сказано, что существующие DSL-архитектуры эволюционируют от сетей «низкая
скорость, максимальные усилия» к инфраструктурам, способным поддерживать более высокую
скорость передачи и сервисы требующие QoS, мультикаст, а также выполнять требования,
которые недопустимо выполнять в системах, построенных на ATM. По прогнозу компании Uvum
от 2009 г., к 2014 г. ATM и Frame Relayдолжны почти полностью исчезнуть[38], в то время как
рынки Ethernet и IP-VPN будут продолжать расти с хорошим темпом. По докладу Broadband
Forum за октябрь 2010 г[39], переход на глобальном рынке от сетей с коммутацией каналов (TDM,
ATM и др.) к IP-сетям уже начался в стационарных сетях и уже затрагивает и мобильные сети. В
докладе сказано, что Ethernet позволяет мобильным операторам удовлетворить растущие
потребности в мобильном трафике более экономически эффективно, чем системы, основанные на
TDM или ATM.
Ещё в апреле 2005 г. произошло слияние «ATM Forum» с «Frame Relay Forum» и «MPLS Forum» в
общий «MFA Forum» («MPLS–Frame Relay–ATM Forum»). В 2007 г. последний был переименован
в «IP/MPLS Forum». В апреле 2009 г. «IP/MPLS Forum» вошёл в состав существующего с 1994 г.
консорциума «Broadband Forum» («BBF»). Спецификации ATM доступны в их исходном виде на
сайте консорциума www.broadband-forum.org[40], но их дальнейшая разработка полностью
остановлена.
Базовые принципы
Сеть ATM строится на основе соединенных друг с другом АТМ-коммутаторов. Технология
реализуется как в локальных, так и в глобальных сетях. Допускается совместная передача
различных видов информации, включая видео, голос.
Ячейки данных, используемые в ATM, меньше в сравнении с элементами данных, которые
используются в других технологиях. Небольшой, постоянный размер ячейки, используемый в
ATM, позволяет:
Совместно передавать данные с различными классами требований к задержкам в сети,
причём по каналам как с высокой, так и с низкой пропускной способностью;
Работать с постоянными и переменными потоками данных;
Интегрировать на одном канале любые виды информации: данные, голос, потоковое
аудио- и видеовещание, телеметрия и т. п.;
Поддерживать соединения типа точка–точка, точка–многоточка и многоточка–многоточка.
Технология ATM предполагает межсетевое взаимодействие на трёх уровнях.
Для передачи данных от отправителя к получателю в сети ATM создаются виртуальные каналы,
VC (англ. Virtual Circuit), которые бывают трёх видов:
постоянный виртуальный канал, PVC (Permanent Virtual Circuit), который создаётся между
двумя точками и существует в течение длительного времени, даже в отсутствие данных
для передачи;
коммутируемый виртуальный канал, SVC (Switched Virtual Circuit), который создаётся
между двумя точками непосредственно перед передачей данных и разрывается после
окончания сеанса связи.
автоматически настраиваемый постоянный виртуальный канал, SPVC (Soft Permanent
Virtual Circuit). Каналы SPVC по сути представляют собой каналы PVC, которые
инициализируются по требованию в коммутаторах ATM. С точки зрения каждого
участника соединения, SPVC выглядит как обычный PVC, а что касается коммутаторов
ATM в инфраструктуре провайдера, то для них каналы SPVC имеют значительные отличия
от PVC. Канал PVC создаётся путём статического определения конфигурации в рамках
всей инфраструктуры провайдера и всегда находится в состоянии готовности. Но в канале
SPVC соединение является статическим только от конечной точки (устройство DTE) до
первого коммутатора ATM (устройство DCE). А на участке от устройства DCE
отправителя до устройства DCE получателя в пределах инфраструктуры провайдера
соединение может формироваться, разрываться и снова устанавливаться по требованию.
Установленное соединение продолжает оставаться статическим до тех пор, пока
нарушение работы одного из звеньев канала не вызовет прекращения функционирования
этого виртуального канала в пределах инфраструктуры провайдера сети.
Для маршрутизации в пакетах используют так называемые идентификаторы пакета. Они бывают
двух видов:
VPI (англ. virtual path identifier) — идентификатор виртуального пути (номер канала)
VCI (англ. virtual circuit identifier) — идентификатор виртуального канала (номер
соединения)
Структура ячейки
Формат ячейки UNI
7
6
GFC
5
4
3
VPI
Формат ячейки NNI
2
1
7
VPI
6
5
4
3
2
1
VPI
VCI
VPI
VCI
VCI
VCI
VCI
PT
CLP
VCI
PT
CLP
HEC
HEC
Полезные данные ячейки (48 байт)
Полезные данные ячейки (48 байт)
GFC = Generic Flow Control (4 бита) — общее управление потоком;
VPI = Virtual Path Identifier (8 бит UNI) или (12 бит NNI) — идентификатор виртуального пути;
VCI = Virtual channel identifier (16 бит) — идентификатор виртуального канала;
PT = Payload Type (3 бита) — тип данных;
CLP = Cell Loss Priority (1 бит) — уровень приоритета при потере пакета; указывает на то, какой
приоритет имеет ячейка (cell), и будет ли она отброшена в случае перегрузки канала;
HEC = Header Error Control (8 бит) — поле контроля ошибок.
UNI = User-to-Network Interface — интерфейс пользователь-сеть. Стандарт, разработанный ATM
Forum, который определяет интерфейс между конечной станцией и коммутатором в сети ATM.
NNI = Network-to-Network Interface — интерфейс сеть-сеть. Обобщённый термин, описывающий
интерфейс между двумя коммутаторами в сети.
Классы обслуживания и категории услуг
Определено пять классов трафика, отличающихся следующими качественными характеристиками:
наличием или отсутствием пульсации трафика, то есть трафики CBR или VBR;
требованием к синхронизации данных между передающей и принимающей сторонами;
типом протокола, передающего свои данные через сеть ATM, — с установлением
соединения или без установления соединения (только для случая передачи компьютерных
данных).
CBR не предусматривает контроля ошибок, управления трафиком или какой-либо другой
обработки. Класс CBR пригоден для работы с мультимедиа реального времени.
Класс VBR содержит в себе два подкласса — обычный и для реального времени (см. таблицу
ниже). ATM в процессе доставки не вносит никакого разброса ячеек по времени. Случаи потери
ячеек игнорируются.
Класс ABR предназначен для работы в условиях мгновенных вариаций трафика. Система
гарантирует некоторую пропускную способность, но в течение короткого времени может
выдержать и большую нагрузку. Этот класс предусматривает наличие обратной связи между
приёмником и отправителем, которая позволяет понизить загрузку канала, если это необходимо.
Класс UBR хорошо пригоден для посылки IP-пакетов (нет гарантии доставки и в случае
перегрузки неизбежны потери).
Основные характеристики классов трафика ATM
Класс QoS
1
2
3
4
5
Класс обслуживания
A
B
C
D
x
Тип трафика
CBR
VBR
VBR
ABR
UBR
Тип уровня
AAL1
AAL2
AAL3/4
AAL3/4
Синхронизация
Требуется
Скорость передачи
Постоянная
Режим соединения
С установлением
Пример
использования
(Е1, Т1)
Не требуется
Переменная
Видео
Без установления
аудио
Передача данных
При передаче информации по некачественным каналам связи возможно появление искажений
передаваемой информации. Эти искажения требуют выявления и исправления. Контроль
приемника может осуществляется побайтно и пакетно.
Побайтный метод означает, что каждый передаваемый байт дополняется битом четности или
нечетности. В случае, когда количество единиц передаваемых информационным байтом четное
бит четности равен нулю, если нечетное — единице или наоборот. При использовании такого
метода вероятность не обнаружения ошибки довольно велика, такая ситуация возможна при
наличии четкого количества ошибок в информационных битах или при одновременном искажении
информационного и контрольного битов.
Пакетный метод заключается в том, что в конец каждого передаваемого пакета добавляется
контрольная сумма длиной, как правило, 8,16 или 32 бита, которая включает в себя информацию
обо всех битах пакета. Метод подсчета контрольной суммы выбирается таким образом, чтобы она
достаточно надежно выявляла ошибки и при этом ее вычисления были бы не слишком сложными.
Обычно используются контрольные суммы следующих видов:
· Суммы по модулю двух всех байтов пакета (при этом однократные ошибки обнаруживаются с
вероятностью 100%, двукратные с вероятностью 7/8). Искажение нескольких битов выявляется
при помощи такого метода достаточно плохо. Достоинство метода контрольной суммы – простота
вычисления.
· Арифметическая сумма всех байтов или слов пакета. При вычислении отбрасываются старшие
разряды для сохранения разрядности контрольной суммы (8 или 16). Однократные ошибки
обнаруживаются с вероятностью 100% двукратные с вероятностью 31/32 (в худшем случае). Такая
наихудшая ситуация наблюдается, когда в каждом из 8-ми разрядов всех байт пакета присутствует
половина логических нулей и половина логических единиц, двукратная ошибка не выявляется,
если в одном разряде один из битов переходит из нуля в единицу, а другой бит в этом же разряде
из единицы в ноль, что не меняет общей суммы. Арифметическая сумма также легко вычисляется
программным методом.
· Циклическая контрольная сумма. Применение данного метода связывают с необходимостью
повышения вероятности обнаружения ошибки. При вычислении циклической контрольной суммы
весь пакет рассматривается как двоичное число разрядности N, где N – количество бит в пакете.
Для вычисления контроля суммы это число делится по модулю двух на некоторое постоянное
число выбранное специальным образом. Частное от деления отбрасывается, а остаток
используется в качестве контроля суммы. Этот метод выявляет однократные ошибки с
вероятностью 100%, а любое другое количество ошибок с вероятностью
, где n –
количество разрядов контрольной суммы. В качестве делителя выбирается число простое (в
смысле деления по модулю двух), а его разрядность берется на единицу больше, чем требуемая
разрядность контрольной суммы.
Коды Хэмминга — наиболее известные и, вероятно, первые из самоконтролирующихся и
самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Другими словами, это алгоритм, который позволяет закодировать какое-либо информационное
сообщение определённым образом и после передачи (например по сети) определить появилась ли
какая-то ошибка в этом сообщении (к примеру из-за помех) и, при возможности, восстановить это
сообщение. Сегодня, я опишу самый простой алгоритм Хемминга, который может исправлять
лишь одну ошибку.
Также стоит отметить, что существуют более совершенные модификации данного алгоритма,
которые позволяют обнаруживать (и если возможно исправлять) большее количество ошибок.
Сразу стоит сказать, что Код Хэмминга состоит из двух частей. Первая часть кодирует исходное
сообщение, вставляя в него в определённых местах контрольные биты (вычисленные особым
образом). Вторая часть получает входящее сообщение и заново вычисляет контрольные биты (по
тому же алгоритму, что и первая часть). Если все вновь вычисленные контрольные биты
совпадают с полученными, то сообщение получено без ошибок. В противном случае, выводится
сообщение об ошибке и при возможности ошибка исправляется.
Как это работает.
Для того, чтобы понять работу данного алгоритма, рассмотрим пример.
Подготовка
Допустим, у нас есть сообщение «habr», которое необходимо передать без ошибок. Для этого
сначала нужно наше сообщение закодировать при помощи Кода Хэмминга. Нам необходимо
представить его в бинарном виде.
На этом этапе стоит определиться с, так называемой, длиной информационного слова, то есть
длиной строки из нулей и единиц, которые мы будем кодировать. Допустим, у нас длина слова
будет равна 16. Таким образом, нам необходимо разделить наше исходное сообщение («habr») на
блоки по 16 бит, которые мы будем потом кодировать отдельно друг от друга. Так как один
символ занимает в памяти 8 бит, то в одно кодируемое слово помещается ровно два ASCII
символа. Итак, мы получили две бинарные строки по 16 бит:
и
После этого процесс кодирования распараллеливается, и две части сообщения («ha» и «br»)
кодируются независимо друг от друга. Рассмотрим, как это делается на примере первой части.
Прежде всего, необходимо вставить контрольные биты. Они вставляются в строго определённых
местах — это позиции с номерами, равными степеням двойки. В нашем случае (при длине
информационного слова в 16 бит) это будут позиции 1, 2, 4, 8, 16. Соответственно, у нас
получилось 5 контрольных бит (выделены красным цветом):
Было:
Стало:
Таким образом, длина всего сообщения увеличилась на 5 бит. До вычисления самих контрольных
бит, мы присвоили им значение «0».
Вычисление контрольных бит.
Теперь необходимо вычислить значение каждого контрольного бита. Значение каждого
контрольного бита зависит от значений информационных бит (как неожиданно), но не от всех, а
только от тех, которые этот контрольных бит контролирует. Для того, чтобы понять, за какие биты
отвечает каждых контрольный бит необходимо понять очень простую закономерность:
контрольный бит с номером N контролирует все последующие N бит через каждые N бит, начиная
с позиции N. Не очень понятно, но по картинке, думаю, станет яснее:
Здесь знаком «X» обозначены те биты, которые контролирует контрольный бит, номер которого
справа. То есть, к примеру, бит номер 12 контролируется битами с номерами 4 и 8. Ясно, что
чтобы узнать какими битами контролируется бит с номером N надо просто разложить N по
степеням двойки.
Но как же вычислить значение каждого контрольного бита? Делается это очень просто: берём
каждый контрольный бит и смотрим сколько среди контролируемых им битов единиц, получаем
некоторое целое число и, если оно чётное, то ставим ноль, в противном случае ставим единицу.
Вот и всё! Можно конечно и наоборот, если число чётное, то ставим единицу, в противном случае,
ставим 0. Главное, чтобы в «кодирующей» и «декодирующей» частях алгоритм был одинаков.
(Мы будем применять первый вариант).
Высчитав контрольные биты для нашего информационного слова получаем следующее:
и для второй части:
Вот и всё! Первая часть алгоритма завершена.
Декодирование и исправление ошибок.
Теперь, допустим, мы получили закодированное первой частью алгоритма сообщение, но оно
пришло к нас с ошибкой. К примеру мы получили такое (11-ый бит передался неправильно):
Вся вторая часть алгоритма заключается в том, что необходимо заново вычислить все
контрольные биты (так же как и в первой части) и сравнить их с контрольными битами, которые
мы получили. Так, посчитав контрольные биты с неправильным 11-ым битом мы получим такую
картину:
Как мы видим, контрольные биты под номерами: 1, 2, 8 не совпадают с такими же контрольными
битами, которые мы получили. Теперь просто сложив номера позиций неправильных контрольных
бит (1 + 2 + 8 = 11) мы получаем позицию ошибочного бита. Теперь просто инвертировав его и
отбросив контрольные биты, мы получим исходное сообщение в первозданном виде! Абсолютно
аналогично поступаем со второй частью сообщения.
Заключение.
В данном примере, длина информационного сообщения именно 16 бит, потому что она наиболее
оптимальная для рассмотрения примера (не слишком длинная и не слишком короткая), но конечно
же длину можно взять любую. Только стоит учитывать, что в данной простой версии алгоритма на
одно информационное слово можно исправить только одну ошибку.
Тема 3. Локальные вычислительные сети.
Учебные вопросы:
1. Методы доступа. Множественный доступ с контролем несущей и обнаружением
конфликтов. Маркерные методы доступа.
2. Протоколы ЛВС.
3. Сети Ethernet. Структура кадра.
4. Высокоскоростные ЛВС. Сеть FDDI.
5. RadioEthemet. WiFi.
6. Аппаратные средства ЛВС. Повторители, концентраторы, мосты.
Вопрос 1. Методы доступа. Множественный доступ с контролем несущей и обнаружением
конфликтов.
Метод доступа – это способ определения того, какая из рабочих станций сможет следующей
использовать ЛВС. То, как сеть управляет доступом к каналу связи (кабелю), существенно влияет
на ее характеристики. Примерами методов доступа являются:
— множественный доступ с прослушиванием несущей и разрешением коллизий (Carrier Sense
Multiple Access with Collision Detection – CSMA/CD);
— множественный доступ с передачей полномочия (Token Passing Multiple Access – TPMA) или
метод с передачей маркера;
— множественный доступ с разделением во времени (Time Division Multiple Access – TDMA);
— множественный доступ с разделением частоты (Frequency Division Multiple Access – FDMA) или
множественный доступ с разделением длины волны (Wavelength Division Multiple Access –
WDMA).
CSMA/CD
Метод множественного доступа с прослушиванием несущей и разрешением коллизий (CSMA/CD)
устанавливает следующий порядок: если рабочая станция хочет воспользоваться сетью для
передачи данных, она сначала должна проверить состояние канала: начинать передачу станция
может, если канал свободен. В процессе передачи станция продолжает прослушивание сети для
обнаружения возможных конфликтов. Если возникает конфликт из-за того, что два узла
попытаются занять канал, то обнаружившая конфликт интерфейсная плата, выдает в сеть
специальный сигнал, и обе станции одновременно прекращают передачу. Принимающая станция
отбрасывает частично принятое сообщение, а все рабочие станции, желающие передать
сообщение, в течение некоторого, случайно выбранного промежутка времени выжидают, прежде
чем начать сообщение.
Алгоритм множественного доступа с прослушиванием несущей и разрешением коллизий
приведен на рис. 3.5.
Все сетевые интерфейсные платы запрограммированы на разные псевдослучайные промежутки
времени. Если конфликт возникнет во время повторной передачи сообщения, этот промежуток
времени будет увеличен.
Рис. 3.5. Алгоритм CSMA/CD
Стандарт типа Ethernet определяет сеть с конкуренцией, в которой несколько рабочих станций
должны конкурировать друг с другом за право доступа к сети.
TPMA
Метод с передачей маркера – это метод доступа к среде, в котором от рабочей станции к рабочей
станции передается маркер, дающий разрешение на передачу сообщения. При получении маркера
рабочая станция может передавать сообщение, присоединяя его к маркеру, который переносит это
сообщение по сети. Каждая станция между передающей станцией и принимающей видит это
сообщение, но только станция – адресат принимает его. При этом она создает новый маркер.
Маркер (token), или полномочие, – уникальная комбинация битов, позволяющая начать передачу
данных.
Алгоритм множественного доступа с передачей полномочия, или маркера, приведен на рис. 3.6.
Рис. 3.6. Алгоритм TPMA
Каждый узел принимает пакет от предыдущего, восстанавливает уровни сигналов до
номинального уровня и передает дальше. Передаваемый пакет может содержать данные или
являться маркером. Когда рабочей станции необходимо передать пакет, ее адаптер дожидается
поступления маркера, а затем преобразует его в пакет, содержащий данные, отформатированные
по протоколу соответствующего уровня, и передает результат далее по ЛВС.
Пакет распространяется по ЛВС от адаптера к адаптеру, пока не найдет своего адресата, который
установит в нем определенные биты для подтверждения того, что данные достигли адресата, и
ретранслирует его вновь в ЛВС. После чего пакет возвращается в узел из которого был отправлен.
Здесь после проверки безошибочной передачи пакета, узел освобождает ЛВС, выпуская новый
маркер.
Таким образом, в ЛВС с передачей маркера невозможны коллизии (конфликты). Метод с
передачей маркера в основном используется в кольцевой топологии.
Данный метод характеризуется следующими достоинствами:
— гарантирует определенное время доставки блоков данных в сети;
— дает возможность предоставления различных приоритетов передачи данных.
Вместе с тем он имеет существенные недостатки:
— в сети возможны потеря маркера, а также появление нескольких маркеров, при этом сеть
прекращает работу;
— включение новой рабочей станции и отключение связаны с изменением адресов всей системы.
TDMA
Множественный доступ с разделением во времени основан на распределении времени работы
канала между системами (рис. 3.7).
Доступ TDMA основан на использовании специального устройства, называемого тактовым
генератором. Этот генератор делит время канала на повторяющиеся циклы. Каждый из циклов
начинается сигналом Разграничителем. Цикл включает n пронумерованных временных
интервалов, называемых ячейками. Интервалы предоставляются для загрузки в них блоков
данных.
Рис. 3.7. Структура множественного доступа с разделением во времени
Данный способ позволяет организовать передачу данных с коммутацией пакетов и с коммутацией
каналов.
Первый (простейший) вариант использования интервалов заключается в том, что их число (n)
делается равным количеству абонентских систем, подключенных к рассматриваемому каналу.
Тогда во время цикла каждой системе предоставляется один интервал, в течение которого она
может передавать данные. При использовании рассмотренного метода доступа часто оказывается,
что в одном и том же цикле одним системам нечего передавать, а другим не хватает выделенного
времени. В результате неэффективное использование пропускной способности канала.
Второй, более сложный, но высокоэкономичный вариант заключается в том, что система получает
интервал только тогда, когда у нее возникает необходимость в передаче данных, например при
асинхронном способе передачи. Для передачи данных система может в каждом цикле получать
интервал с одним и тем же номером. В этом случае передаваемые системой блоки данных
появляются через одинаковые промежутки времени и приходят с одним и тем же временем
запаздывания. Это режим передачи данных с имитацией коммутации каналов. Способ особенно
удобен при передаче речи.
FDMA
Доступ FDMA основан на разделении полосы пропускания канала на группу полос частот (рис.
3.8), образующих логические каналы.
Широкая полоса пропускания канала делится на ряд узких полос, разделенных защитными
полосами. Размеры узких полос могут быть различными.
При использовании FDMA, именуемого также множественным доступом с разделением волны
WDMA, широкая полоса пропускания канала делится на ряд узких полос, разделенных
защитными полосами. В каждой узкой полосе создается логический канал. Размеры узких полос
могут быть различными. Передаваемые по логическим каналам сигналы накладываются на разные
несущие и поэтому в частотной области не должны пересекаться. Вместе с этим, иногда, несмотря
на наличие защитных полос, спектральные составляющие сигнала могут выходить за границы
логического канала и вызывать шум в соседнем логическом канале.
Рис. 3.8. Схема выделения логических каналов
В оптических каналах разделение частоты осуществляется направлением в каждый из них лучей
света с различными частотами. Благодаря этому пропускная способность физического канала
увеличивается в несколько раз. При осуществлении этого мультиплексирования в
один световод излучает свет большое число лазеров (на различных частотах). Через световод
излучение каждого из них проходит независимо от другого. На приемном конце разделение частот
сигналов, прошедших физический канал, осуществляется путем фильтрации выходных сигналов.
Метод доступа FDMA относительно прост, но для его реализации необходимы передатчики и
приемники, работающие на различных частотах.
Вопрос 2.
Протоколы ЛВС.
Канальный уровень (англ. Data Link layer) — второй уровень сетевой модели OSI,
предназначенный для передачи данных узлам, находящимся в том же сегменте локальной сети.
Также может использоваться для обнаружения и, возможно, исправления ошибок, возникших
на физическом уровне. Примерами протоколов, работающих на канальном уровне,
являются: Ethernet для локальных сетей (многоузловой), Point-to-Point Protocol
(PPP), HDLC и ADCCP для подключений точка-точка (двухузловой).
Канальный уровень отвечает за доставку кадров между устройствами, подключенными к одному
сетевому сегменту. Кадры канального уровня не пересекают границ сетевого сегмента. Функции
межсетевой маршрутизации и глобальной адресацииосуществляются на более высоких уровнях
модели OSI, что позволяет протоколам канального уровня сосредоточиться на локальной доставке
и адресации.
Заголовок кадра содержит аппаратные адреса отправителя и получателя, что позволяет
определить, какое устройство отправило кадр и какое устройство должно получить и обработать
его. В отличие от иерархических и маршрутизируемых адресов, аппаратные адреса
одноуровневые. Это означает, что никакая часть адреса не может указывать на принадлежность к
какой либо логической или физической группе.
Когда устройства пытаются использовать среду одновременно, возникают коллизии кадров.
Протоколы канального уровня выявляют такие случаи и обеспечивают механизмы для
уменьшения их количества или же их предотвращения.
Многие протоколы канального уровня не имеют подтверждения о приёме кадра, некоторые
протоколы даже не имеют контрольной суммы для проверкицелостности кадра. В таких случаях
протоколы более высокого уровня должны обеспечивать управление потоком данных, контроль
ошибок, подтверждение доставки и ретрансляции утерянных данных.
На этом уровне работают коммутаторы, мосты.
В программировании доступ к этому уровню предоставляет драйвер сетевой
платыВ операционных системах имеется программный интерфейс взаимодействия канального и
сетевого уровней между собой, это не новый уровень, а просто реализация модели для конкретной
ОС. Примеры таких интерфейсов: ODI, NDIS.
Длина пакета, формируемого протоколом канального уровня, ограничена сверху
посредством MTU. MTU может быть изменено. Минимальная длина кадра прописывается в
стандартах и не может быть изменена.
Подуровни канального уровня
Спецификация IEEE 802 разделяет этот уровень на 2 подуровня. MAC (Media Access Control)
регулирует доступ к разделяемой физической среде, LLC(Logical Link Control) обеспечивает
обслуживание сетевого уровня.
Функции канального уровня
1. Получение доступа к среде передачи. Обеспечение доступа — важнейшая функция
канального уровня. Она требуется всегда, за исключением случаев, когда реализована
полносвязная топология (например, два компьютера, соединенных через кроссовер, или
компьютер со свичом в полнодуплексном режиме).
2. Выделение границ кадра. Эта задача также решается всегда. Среди возможных решений
этой задачи — резервирование некоторой последовательности, обозначающей начало или
конец кадра.
3. Аппаратная адресация (или адресация канального уровня). Требуется в том случае, когда
кадр могут получить сразу несколько адресатов. В локальных сетях аппаратные адреса
(MAC-адреса) применяются всегда.
4. Обеспечение достоверности принимаемых данных. Во время передачи кадра есть
вероятность, что данные исказятся. Важно это обнаружить и не пытаться обработать кадр,
содержащий ошибку. Обычно на канальном уровне используются алгоритмы контрольных
сумм, дающие высокую гарантию обнаружения ошибок.
5. Адресация протокола верхнего уровня. В процессе декапсуляции указание формата
вложенного PDU существенно упрощает обработку информации, поэтому чаще всего
указывается протокол, находящийся в поле данных, за исключением тех случаев, когда в
поле данных может находиться один-единственный протокол.
При организации взаимодействия узлов в локальных сетях основная роль отводится протоколу
канального уровня. Однако, для того, чтобы канальный уровень мог справиться с этой задачей,
структура локальных сетей должна быть вполне определенной, так, например, наиболее
популярный протокол канального уровня — Ethernet — рассчитан на параллельное подключение всех
узлов сети к общей для них шине — отрезку коаксиального кабеля. Протокол Token Ring также
рассчитан на вполне определенную конфигурацию связей между компьютерами — соединение в
кольцо.
Подобный подход, заключающийся в использовании простых структур кабельных соединений
между компьютерами локальной сети, являлся следствием основной цели, которую ставили перед
собой разработчики первых локальных сетей во второй половине 70-х годов. Эта цель
заключалась в нахождении простого и дешевого решения для объединения нескольких десятков
компьютеров, находящихся в пределах одного здания, в вычислительную сеть. Решение должно
было быть недорогим, потому что в сеть объединялись недорогие компьютеры — появившиеся и
быстро распространившиеся тогда миникомпьютеры стоимостью в 10 000 — 20 000 долларов.
Количество их в одной организации было небольшим, поэтому предел в несколько десятков
(максимум — до сотни) компьютеров представлялся вполне достаточным для роста практически
любой локальной сети.
Для упрощения и, соответственно, удешевления аппаратных и программных решений
разработчики первых локальных сетей остановились на совместном использовании кабелей всеми
компьютерами сети в режиме разделения времени. Наиболее явным образом режим совместного
использования кабеля проявляется в сетях Ethernet, где коаксиальный кабель физически
представляет собой неделимый отрезок кабеля, общий для всех узлов сети. Но и в сетях Token
Ring и FDDI, где каждая соседняя пара компьютеров соединена, казалось бы, своими
индивидуальными отрезками кабеля, эти отрезки не могут использоваться компьютерами, которые
непосредственно к ним подключены, в произвольный момент времени. Эти отрезки образуют
кольцо, доступ к которому как к единому целому может быть получен только по вполне
определенному алгоритму, в котором участвуют все компьютеры сети. Использование кольца как
общего разделяемого ресурса упрощает алгоритмы передачи по нему кадров, так как в каждый
конкретный момент времени кольцо используется только одним компьютером.
Такой подход позволяет упростить логику работы сети. Например, отпадает необходимость
контроля переполнения узлов сети кадрами от многих станций, решивших одновременно
обменяться информацией. В глобальных сетях, где отрезки кабелей, соединяющих отдельные
узлы, не рассматриваются как общий ресурс, такая необходимость возникает, и для решения этой
проблемы в алгоритмы обмена информацией вводятся весьма сложные процедуры,
предотвращающие переполнение каналов связи и узлов сети.
Использование в локальных сетях очень простых конфигураций (общая шина и кольцо) наряду с
положительными имело и негативные стороны, из которых наиболее неприятными были
ограничения по производительности и надежности. Наличие только одного пути передачи
информации, разделяемого всеми узлами сети, в принципе ограничивало пропускную способность
сети пропускной способностью этого пути (к тому же разделенной на число компьютеров сети), а
надежность сети — надежностью этого пути. Поэтому по мере повышения популярности локальных
сетей и расширения их сфер применения все больше стали применяться специальные
коммуникационные устройства — мосты и маршрутизаторы — которые в значительной мере
снимали ограничения единственной разделяемой среды передачи данных. Базовые конфигурации
в форме общей шины и кольца превратились в элементарные структуры локальных сетей, которые
можно теперь соединять друг с другом более сложным образом, образуя параллельные основные
или резервные пути между узлами.
Тем не менее, внутри базовых структур по-прежнему работают все те же протоколы разделяемых
единственных сред передачи данных, которые были разработаны более 15 лет назад. Это связано с
тем, что хорошие скоростные и надежностные характеристики кабелей локальных сетей
удовлетворяли в течение всех этих лет пользователей небольших компьютерных сетей, которые
могли построить сеть без больших затрат только с помощью сетевых адаптеров и кабеля. К тому
же колоссальная инсталляционная база оборудования и программного обеспечения для
протоколов Ethernet и Token Ring способствовала тому, что сложился следующий подход — в
пределах небольших сегментов используются старые протоколы в их неизменном виде, а
объединение таких сегментов в общую сеть происходит с помощью дополнительного и
достаточно сложного оборудования.
В последние несколько лет наметилось движение к отказу от использования в локальных сетях
разделяемых сред передачи данных и переходу к обязательному использованию между станциями
активных коммутаторов, к которым конечные узлы присоединяются индивидуальными линиями
связи. В чистом виде такой подход предлагается в технологии ATM (Asynchronous Transfer Mode),
а смешанный подход, сочетающий разделяемые и индивидуальные среды передачи данных,
используется в технологиях, носящих традиционные названия с приставкой switching
(коммутирующий): switching Ethernet, switching Token Ring, switching FDDI.
Но, несмотря на появление новых технологий, классические протоколы локальных сетей Ethernet
и Token Ring по прогнозам специалистов будут повсеместно использоваться еще по крайней мере
лет 5 — 10, в связи с чем знание их деталей необходимо для успешного применения современной
коммуникационной аппаратуры.
Вопрос 3. Сети Ethernet. Структура кадра.
Стандарт на технологию Ethernet, описанный в документе 802.3, дает описание единственного
формата кадра МАС-уровня. Так как в кадр МАС-уровня должен вкладываться кадр уровня LLC,
описанный в документе 802.2, то по стандартам IEEE в сети Ethernet может использоваться только
единственный вариант кадра канального уровня, образованный комбинацией заголовков МАС и
LLC подуровней. Тем не менее, на практике в сетях Ethernet на канальном уровне используются
заголовки 4-х типов. Это связано с длительной историей развития технологии Ethernet до
принятия стандартов IEEE 802, когда подуровень LLC не выделялся из общего протокола и,
соответственно, заголовок LLC не применялся. Затем, после принятия стандартов IEEE и
появления двух несовместимых форматов кадров канального уровня, была сделана попытка
приведения этих форматов к некоторому общему знаменателю, что привело еще к одному
варианту кадра.
Различия в форматах кадров могут иногда приводить к несовместимости аппаратуры,
рассчитанной на работу только с одним стандартом, хотя большинство сетевых адаптеров, мостов
и маршрутизаторов умеет работать со всеми используемыми на практике форматами кадров
технологии Ethernet.
Ниже приводится описание всех четырех модификаций заголовков кадров Ethernet (причем под
заголовком кадра понимается весь набор полей, которые относятся к канальному уровню):
Кадр 802.3/LLC (или кадр Novell 802.2)
Кадр Raw 802.3 (или кадр Novell 802.3)
Кадр Ethernet DIX (или кадр Ethernet II)
Кадр Ethernet SNAP
Заголовок кадра 802.3/LLC является результатом объединения полей заголовков кадров,
определенных в стандартах 802.3 и 802.2.
Стандарт 802.3 определяет восемь полей заголовка:
Поле преамбулы состоит из семи байтов синхронизирующих данных. Каждый байт
содержит одну и ту же последовательность битов — 10101010. При манчестерском
кодировании эта комбинация представляется в физической среде периодическим
волновым сигналом. Преамбула используется для того, чтобы дать время и возможность
схемам приемопередатчиков (transceiver) прийти в устойчивый синхронизм с
принимаемыми тактовыми сигналами.
Начальный ограничитель кадра состоит из одного байта с набором битов 10101011.
Появление этой комбинации является указанием на предстоящий прием кадра.
Адрес получателя — может быть длиной 2 или 6 байтов (MAC-адрес получателя). Первый
бит адреса получателя — это признак того, является адрес индивидуальным или групповым:
если 0, то адрес указывает на определенную станцию, если 1, то это групповой адрес
нескольких (возможно всех) станций сети. При широковещательной адресации все биты
поля адреса устанавливаются в 1. Общепринятым является использование 6-байтовых
адресов.
Адрес отправителя — 2-х или 6-ти байтовое поле, содержащее адрес станции отправителя.
Первый бит — всегда имеет значение 0.
Двухбайтовое поле длины определяет длину поля данных в кадре.
Поле данных может содержать от 0 до 1500 байт. Но если длина поля меньше 46 байт, то
используется следующее поле — поле заполнения, чтобы дополнить кадр до минимально
допустимой длины.
Поле заполнения состоит из такого количества байтов заполнителей, которое обеспечивает
определенную минимальную длину поля данных (46 байт). Это обеспечивает корректную
работу механизма обнаружения коллизий. Если длина поля данных достаточна, то поле
заполнения в кадре не появляется.
Поле контрольной суммы — 4 байта, содержащие значение, которое вычисляется по
определенному алгоритму (полиному CRC-32). После получения кадра рабочая станция
выполняет собственное вычисление контрольной суммы для этого кадра, сравнивает
полученное значение со значением поля контрольной суммы и, таким образом, определяет,
не искажен ли полученный кадр.
Кадр 802.3 является кадром MAС-подуровня, в соответствии со стандартом 802.2 в его поле
данных вкладывается кадр подуровня LLC с удаленными флагами начала и конца кадра. Формат
кадра LLC был описан выше.
Результирующий кадр 802.3/LLC изображен в левой части рисунка 4. Так как кадр LLC имеет
заголовок длиной 3 байта, то максимальный размер поля данных уменьшается до 1497 байт.
Рис. 4. Форматы кадров Ethernet
Справа на этом рисунке приведен кадр, который называют кадром Raw 802.3 (то есть «грубый»
вариант 802.3) или же кадром Novell 802.3. Из рисунка видно, что это кадр MAC-подуровня
стандарта 802.3, но без вложенного кадра подуровня LLC. Компания Novell долгое время не
использовала служебные поля кадра LLC в своей операционной системе NetWare из-за отсутствия
необходимости идентифицировать тип информации, вложенной в поле данных — там всегда
находился пакет протокола IPX, долгое время бывшего единственным протоколом сетевого
уровня в ОС NetWare.
Теперь, когда необходимость идентификации протокола верхнего уровня появилась, компания
Novell стала использовать возможность инкапсуляции в кадр MAC-подуровня кадра LLC, то есть
использовать стандартные кадры 802.3/LLC. Такой кадр компания обозначает теперь в своих
операционных системах как кадр 802.2, хотя он является комбинацией заголовков 802.3 и 802.2.
Кадр стандарта Ethernet DIX, называемый также кадром Ethernet II, похож на кадр Raw 802.3 тем,
что он также не использует заголовки подуровня LLC, но отличается тем, что на месте поля длины
в нем определено поле типа протокола (поле Type). Это поле предназначено для тех же целей, что
и поля DSAP и SSAP кадра LLC — для указания типа протокола верхнего уровня, вложившего свой
пакет в поле данных этого кадра. Для кодирования типа протокола используются значения,
превышающие значение максимальной длины поля данных, равное 1500, поэтому кадры Ethernet
II и 802.3 легко различимы.
Еще одним популярным форматом кадра является кадр Ethernet SNAP (SNAP — SubNetwork Access
Protocol, протокол доступа к подсетям). Кадр Ethernet SNAP определен в стандарте 802.2H и
представляет собой расширение кадра 802.3 путем введения дополнительного поля
идентификатора организации, которое может использоваться для ограничения доступа к сети
компьютеров других организаций.
В таблице 2 приведены данные о том, какие типы кадров Ethernet обычно поддерживают
реализации популярных протоколов сетевого уровня.
Таблица 2
Тип кадра
Сетевые протоколы
Ethernet_II
IPX, IP, AppleTalk Phase I
Ethernet 802.3
IPX
Ethernet 802.2
IPX, FTAM
Ethernet_SNAP
IPX, IP, AppleTalk Phase II
Исторически первые сети технологии Ethernet были созданы на коаксиальном кабеле диаметром
0.5 дюйма. В дальнейшем были определены и другие спецификации физического уровня для
стандарта Ethernet, позволяющие использовать различные среды передачи данных в качестве
общей шины. Метод доступа CSMA/CD и все временные параметры Ethernet остаются одними и
теми же для любой спецификации физической среды.
Разновидности Ethernet
В зависимости от скорости передачи данных, и передающей среды существует несколько
вариантов технологии. Независимо от способа передачи стек сетевого протокола и программы
работают одинаково практически во всех нижеперечисленных вариантах.
В этом разделе дано краткое описание всех официально существующих разновидностей. По
некоторым причинам, в дополнение к основному стандарту многие производители рекомендуют
пользоваться другими запатентованными носителями — например, для увеличения расстояния
между точками сети используется волоконно-оптический кабель.
Большинство Ethernet-карт и других устройств имеет поддержку нескольких скоростей передачи
данных, используя автоопределение (autonegotiation) скорости и дуплексности, для достижения
наилучшего соединения между двумя устройствами. Если автоопределение не срабатывает,
скорость подстраивается под партнёра, и включается режим полудуплексной передачи. Например,
наличие в устройстве порта Ethernet 10/100 говорит о том, что через него можно работать по
технологиям 10BASE-T и 100BASE-TX, а порт Ethernet 10/100/1000 — поддерживает стандарты
10BASE-T, 100BASE-TX и 1000BASE-T.
Ранние модификации Ethernet
Xerox Ethernet — оригинальная технология, скорость 3 Мбит/с, существовала в двух
вариантах Version 1 и Version 2, формат кадра последней версии до сих пор имеет широкое
применение.
1BROAD36 — широкого распространения не получил. Один из первых стандартов,
позволяющий работать на больших расстояниях. Использовал технологию
широкополосноймодуляции, похожей на ту, что используется в кабельных модемах. В
качестве среды передачи данных использовался коаксиальный кабель.
1BASE5 — также известный, как StarLAN, стал первой модификацией Ethernetтехнологии, использующей витую пару. Работал на скорости 1 Мбит/с, но не нашёл
коммерческого применения.
10 Мбит/с Ethernet
10BASE5, IEEE 802.3 (называемый также «Толстый Ethernet») — первоначальная
разработка технологии со скоростью передачи данных 10 Мбит/с. Следуя раннему
стандарту,IEEE использует коаксиальный кабель с волновым сопротивлением 50 Ом (RG8), с максимальной длиной сегмента 500 метров.
10BASE2, IEEE 802.3a (называемый «Тонкий Ethernet») — используется кабель RG-58, с
максимальной длиной сегмента 185 метров, компьютеры присоединялись один к другому,
для подключения кабеля к сетевой карте нужен T-коннектор, а на кабеле должен
быть BNC-коннектор. Требуется наличие терминаторов на каждом конце. Многие годы
этот стандарт был основным для технологии Ethernet.
StarLAN 10 — Первая разработка, использующая витую пару для передачи данных на
скорости 10 Мбит/с. В дальнейшем эволюционировал в стандарт 10BASE-T.
Несмотря на то, что теоретически возможно подключение к одному кабелю (сегменту) витой пары
более чем двух устройств, работающих в симплексном режиме, такая схема никогда не
применяется для Ethernet, в отличие от работы с коаксиальным кабелем. Поэтому все сети на
витой паре используют топологию «звезда», в то время как сети на коаксиальном кабеле
построены на топологии «шина». Терминаторы для работы по витой паре встроены в каждое
устройство, и применять дополнительные внешние терминаторы в линии не нужно.
10BASE-T, IEEE 802.3i — для передачи данных используется 4 провода кабеля витой пары
(две скрученные пары) категории-3 или категории-5. Максимальная длина сегмента 100
метров.
FOIRL — (акроним от англ. Fiber-optic inter-repeater link). Базовый стандарт для
технологии Ethernet, использующий для передачи данных оптический кабель.
Максимальное расстояние передачи данных без повторителя — 1 км.
10BASE-F, IEEE 802.3j — Основной термин для обозначения семейства 10 Мбит/с
ethernet-стандартов, использующих оптический кабель на расстоянии до 2 километров:
10BASE-FL, 10BASE-FB и 10BASE-FP. Из перечисленного только 10BASE-FL получил
широкое распространение.
10BASE-FL (Fiber Link) — Улучшенная версия стандарта FOIRL. Улучшение коснулось
увеличения длины сегмента до 2 км.
10BASE-FB (Fiber Backbone) — Сейчас неиспользуемый стандарт, предназначался для
объединения повторителей в магистраль.
10BASE-FP (Fiber Passive) — Топология «пассивная звезда», в которой не нужны
повторители — никогда не применялся.
Быстрый Ethernet (Fast Ethernet, 100 Мбит/с)
100BASE-T — общий термин для обозначения стандартов, использующих в качестве
среды передачи данных витую пару. Длина сегмента — до 100 метров. Включает в себя
стандарты 100BASE-TX, 100BASE-T4 и 100BASE-T2.
100BASE-TX, IEEE 802.3u — развитие стандарта 10BASE-T для использования в сетях
топологии «звезда». Задействована витая пара категории 5, фактически используются
только две неэкранированные пары проводников, поддерживается дуплексная передача
данных, расстояние до 100 м.
100BASE-T4 — стандарт, использующий витую пару категории 3. Задействованы все
четыре пары проводников, передача данных идёт в полудуплексе. Практически не
используется.
100BASE-T2 — стандарт, использующий витую пару категории 3. Задействованы только
две пары проводников. Поддерживается полный дуплекс, когда сигналы распространяются
в противоположных направлениях по каждой паре. Скорость передачи в одном
направлении — 50 Мбит/с. Практически не используется.
100BASE-FX — стандарт, использующий многомодовое волокно. Максимальная длина
сегмента 400 метров в полудуплексе (для гарантированного обнаружения коллизий) или 2
километра в полном дуплексе.
100BASE-SX — стандарт, использующий многомодовое волокно. Максимальная длина
ограничена только величиной затухания в оптическом кабеле и мощностью передатчиков,
по разным материалам от 2 до 10 километров.
100BASE-FX WDM — стандарт, использующий одномодовое волокно. Максимальная
длина ограничена только величиной затухания в волоконно-оптическом кабеле и
мощностью передатчиков. Интерфейсы бывают двух видов, отличаются длиной волны
передатчика и маркируются либо цифрами (длина волны), либо одной латинской буквой
A(1310) или B(1550). В паре могут работать только парные интерфейсы: с одной стороны
передатчик на 1310 нм, а с другой — на 1550 нм.
Гигабитный Ethernet (Gigabit Ethernet, 1 Гбит/с)
1000BASE-T, IEEE 802.3ab — основной гигабитный стандарт, опубликованный в 1999
году[5], использует витую пару категории 5e. В передаче данных участвуют 4 пары, каждая
пара используется одновременно для передачи по обоим направлениям со скоростью —
250 Мбит/с. Используется метод кодирования PAM5 (5-level Phase Amplitude Modulation,
пятиуровневая фазоамплитудная модуляция)[6] с 4 линиями (4D-PAM5) и 4-х
мерной Треллис-модуляцией (TCM)[7], частота основной гармоники 62,5 МГц. Расстояние
— до 100 метров.
1000BASE-TX был создан Ассоциацией Телекоммуникационной Промышленности
(англ. Telecommunications Industry Association, TIA) и опубликован в марте 2001 года как
«Спецификация физического уровня дуплексного Ethernet 1000 Мб/с (1000BASE-TX)
симметричных кабельных систем категории 6 (ANSI/TIA/EIA-854-2001)» [8][5].
Распространения не получил из-за высокой стоимости кабелей[9], фактически устарел[10].
Стандарт разделяет принимаемые и посылаемые сигналы по парам (две пары передают
данные, каждая на 500 Мбит/с и две пары принимают), что упрощало бы конструкцию
приёмопередающих устройств. Ещё одним существенным отличием 1000BASE-TX
являлось отсутствие схемы цифровой компенсации наводок и возвратных помех, в
результате чего сложность, уровень энергопотребления и цена реализаций должны
становиться ниже, чем у стандарта 1000BASE-T. Для работы технологии требуется
кабельная система 6 категории[5]. На основе данного стандарта создано большое
количество продуктов для промышленных сетей.[источник не указан 359 дней]
1000BASE-X — общий термин для обозначения стандартов со сменными
приёмопередатчиками в форм-факторах GBIC или SFP.
1000BASE-SX, IEEE 802.3z — стандарт, использующий многомодовое волокно в первом
окне прозрачности с длиной волны, равной 850 нм. Дальность прохождения сигнала
составляет до 550 метров.
1000BASE-LX, IEEE 802.3z — стандарт, использующий одномодовое или многомодовое
оптическое волокно во втором окне прозрачности с длиной волны, равной 1310 нм.
Дальность прохождения сигнала зависит только от типа используемых
приемопередатчиков и, как правило, составляет для одномодового оптического волокна до
5 км и для многомодового оптического волокна до 550 метров.
1000BASE-CX — стандарт для коротких расстояний (до 25 метров), использующий 2-х
парный экранированную кабель (150 Ом, STP IBM Type I или лучше). Применяется
кодирование 8B/10B, сигнал передается по одной паре, принимается по другой паре
проводов; разъемы — 9-ти контактный D, HSSDC[11]. Заменён стандартом 1000BASE-T и
сейчас не используется.
1000BASE-LH (Long Haul) — стандарт, использующий одномодовое волокно. Дальность
прохождения сигнала без повторителя — до 100 километров[12].
2,5- и 5-гигабитные варианты (NBASE-T, MGBASE-T)
В 2014 появились частные инициативы NBASE-T (Cisco) и MGBASE-T (Broadcom)[13][14] по
созданию стандартов Ethernet со скоростью, промежуточной между 1 и 10 Гбит/с. Новый стандарт
должен использовать существующую кабельную инфраструктуру категории 5e на расстояниях до
100 метров, предоставляя скорости в 2,5 или, менее вероятно, 5 Гбит/с. Среди причин появления
инициатив — распространение Wi-Fi-маршрутизаторов, поддерживающих скорости более 1
гигабита (802.11ac Wave 2, 802.11ad, 802.11ax, LiFi), и невозможность использования 10 Гбит/с
стандартов Ethernet по длинным кабелям 5e и 6 категорий[15][16] Ранее группа IEEE 802 отмечала,
что гипотетический стандарт 2500BASE-T мог бы быть близок по стоимости к 1000BASE-T
решениям[17].
10-гигабитный Ethernet (10G Ethernet, 10 Гбит/с)
Новый стандарт 10-гигабитного Ethernet включает в себя семь стандартов физической среды
для LAN, MAN и WAN. В настоящее время он описывается поправкой IEEE 802.3ae и должен
войти в следующую ревизию стандарта IEEE 802.3.
10GBASE-CX4 — технология 10-гигабитного Ethernet для коротких расстояний (до
15 метров), используется медный кабель CX4 и коннекторы InfiniBand.
10GBASE-SR — технология 10-гигабитного Ethernet для коротких расстояний (до 26 или
82 метров, в зависимости от типа кабеля), используется многомодовое волокно. Он также
поддерживает расстояния до 300 метров с использованием нового многомодового волокна
(2000 МГц/км).
10GBASE-LX4 — использует уплотнение по длине волны для поддержки расстояний от
240 до 300 метров по многомодовому волокну. Также поддерживает расстояния до
10километров при использовании одномодового волокна.
10GBASE-LR и 10GBASE-ER — эти стандарты поддерживают расстояния до 10 и
40 километров соответственно.
10GBASE-SW, 10GBASE-LW и 10GBASE-EW — эти стандарты используют физический
интерфейс, совместимый по скорости и формату данных с интерфейсом OC-192 /STM64 SONET/SDH. Они подобны стандартам 10GBASE-SR, 10GBASE-LR и 10GBASEER соответственно, так как используют те же самые типы кабелей и расстояния передачи.
10GBASE-T, IEEE 802.3an-2006 — принят в июне 2006 года после 4 лет разработки.
Использует витую пару категории 6 (максимальное расстояние 55 метров)[18] и 6а
(максимальное расстояние 100 метров)[18].
10GBASE-KR — технология 10-гигабитного Ethernet для кросс-плат (backplane/midplane)
модульных коммутаторов/маршрутизаторов и серверов (Modular/Blade).
Компания Harting заявила о создании первого в мире 10-гигабитного соединителя RJ-45, не
требующего инструментов для монтажа — HARTING RJ Industrial 10G[19][20].
40-гигабитный и 100-гигабитный Ethernet
Согласно наблюдениям Группы 802.3ba[21], требования к полосе пропускания для вычислительных
задач и приложений ядра сети растут с разными скоростями, что определяет необходимость двух
соответствующих стандартов для следующих поколений Ethernet — 40 Gigabit Ethernet (или
40GbE) и 100 Gigabit Ethernet (или 100GbE). В настоящее времясерверы, высокопроизводительные
вычислительные кластеры, блейд-системы, SAN и NAS используют технологии 1GbE и 10GbE,
при этом в 2007 и 2008 гг. был отмечен значительный рост последней.
Перспективы
О Terabit Ethernet (так упрощенно называют технологию Ethernet со скоростью передачи 1 Тбит/с)
стало известно в 2008 году из заявления создателя Ethernet Боба Меткалфа на конференции
OFC[22], который предположил, что технология будет разработана к 2015 году, правда, не выразив
при этом какой-либо уверенности, ведь для этого придется решить немало проблем. Однако, по
его мнению, ключевой технологией, которая может обслужить дальнейший рост трафика, станет
одна из разработанных в предыдущем десятилетии —DWDM.
«Чтобы реализовать Ethernet 1 Тбит/с, необходимо преодолеть множество ограничений, включая
1550-нанометровые лазеры и модуляцию с частотой 15 ГГц. Для будущей сети нужны новые
схемы модуляции, а также новое оптоволокно, новые лазеры, в общем, все новое, — сказал
Меткалф. — Неясно также, какая сетевая архитектура потребуется для её поддержки. Возможно,
оптические сети будущего должны будут использовать волокно с вакуумной сердцевиной или
углеродные волокна вместо кварцевых. Операторы должны будут внедрять больше полностью
оптических устройств и оптику в свободном пространстве (безволоконную).
Вопрос 4. Высокоскоростные ЛВС. Сеть FDDI.
FDDI (англ. Fiber Distributed Data Interface — Волоконно-оптический интерфейс передачи
данных) — стандарт передачи данных в локальной сети, протянутой на расстоянии до
200километров. Стандарт основан на протоколе Token Ring. Кроме большой территории, сеть
FDDI способна поддерживать несколько тысяч пользователей.
История
Стандарт был разработан в середине 80-х годов Национальным Американским Институтом
Стандартов (ANSI). В этот период быстродействующие АРМ проектировщика уже начинали
требовать максимального напряжения возможностей существующих локальных сетей (LAN) (в
oсновном Ethernet и Token Ring). Необходимо было создать новую LAN, которая могла бы легко
поддерживать эти АРМ и их новые прикладные распределенные системы. Все большее внимание
начинает уделяться надежности, т.к. администраторы систем стали переносить критические по
назначению прикладные задачи из больших компьютеров в сети. FDDI была создана для того,
чтобы удовлетворить эти потребности. После завершения работы над FDDI, ANSI представила его
на рассмотрение в ISO. ISO разработала международный вариант FDDI, который полностью
совместим с вариантом стандарта, разработанным ANSI. Хотя реализации FDDI сегодня не столь
распространены, как Ethernet или Token Ring, FDDI приобрела значительное число своих
последователей, которое увеличивается по мере уменьшения стоимости интерфейса FDDI. FDDI
часто используется как основа технологий, а также как средство для соединения
быстродействующих компьютеров, находящихся в локальной области.
Основы технологии
Стандарт FDDI определяет 100 Мб/сек. LAN с двойным кольцом и передачей маркера, которая
использует в качестве среды передачи волоконно-оптический кабель. Он определяет физический
уровень и часть канального уровня, которая отвечает за доступ к носителю; поэтому его
взаимоотношения с эталонной моделью OSI примерно аналогичны тем, которые характеризуют
IEEE 802.3 и IЕЕЕ 802.5.
Хотя она работает на более высоких скоростях, FDDI во многом похожа на Token Ring. Oбe сети
имеют одинаковые характеристики, включая топологию (кольцевая сеть), технику доступа к
носителю (передача маркера), характеристики надежности (например, сигнализация-beaconing), и
др. За дополнительной информацией по Token Ring и связанными с ней технологиями
обращайтесь к Главе 6 «Token Ring/IEEE 802.5».
Двойное кольцо
Одной из наиболее важных характеристик FDDI является то, что она использует световод в
качестве передающей среды. Световод обеспечивает ряд преимуществ по сравнению с
традиционной медной проводкой, включая защиту данных (оптоволокно не излучает
электрические сигналы, которые можно перехватывать), надежность (оптоволокно устойчиво к
электрическим помехам) и скорость (потенциальная пропускная способность световода намного
выше, чем у медного кабеля).
При обрывах оптоволокна возможно частичное (при двух обрывах) или полное (при одном
обрыве) восстановление связности сети.
Физические соединения
FDDI устанавливает применение двойных кольцевых сетей. Трафик по этим кольцам движется в
противоположных направлениях. В физическом выражении кольцо состоит из двух или более
двухточечных соединений между смежными станциями. Одно из двух колец FDDI называется
первичным кольцом, другое-вторичным кольцом. Первичное кольцо используется для передачи
данных, в то время как вторичное кольцо обычно является дублирующим.
«Станции Класса В» или «станции, подключаемые к одному кольцу» (SAS) подсоединены к одной
кольцевой сети; «станции класса А» или «станции, подключаемые к двум кольцам» (DAS)
подсоединены к обеим кольцевым сетям. SAS подключены к первичному кольцу через
«концентратор», который обеспечивает связи для множества SAS. Koнцентратор отвечает за то,
чтобы отказ или отключение питания в любой из SAS не прерывали кольцо. Это особенно
необходимо, когда к кольцу подключен РС или аналогичные устройства, у которых питание часто
включается и выключается.
Конфигурация FDDI, включающая как DAS, так и SAS.
Типы трафика
FDDI поддерживает распределение полосы пропускания сети в масштабе реального времени, что
является идеальным для ряда различных типов прикладных задач. FDDI обеспечивает эту
поддержку путем обозначения двух типов трафика: синхронного и асинхронного. Синхронный
трафик может потреблять часть общей полосы пропускания сети FDDI, равную 100 Mb/сек;
остальную часть может потреблять асинхронный трафик. Синхронная полоса пропускания
выделяется тем станциям, которым необходима постоянная возможность передачи. Например,
наличие такой возможности помогает при передаче голоса и видеоинформации. Другие станции
используют остальную часть полосы пропускания асинхронно. Спецификация SMT для сети FDDI
определяет схему распределенных заявок на выделение полосы пропускания FDDI.
Распределение асинхронной полосы пропускания производится с использованием
восьмиуровневой схемы приоритетов. Каждой станции присваивается определенный уровень
приоритета пользования асинхронной полосой пропускания. FDDI также разрешает длительные
диалоги, когда станции могут временно использовать всю асинхронную полосу пропускания.
Механизм приоритетов FDDI может фактически блокировать станции, которые не могут
пользоваться синхронной полосой пропускания и имеют слишком низкий приоритет пользования
асинхронной полосой пропускания.
Формат блока данных
PA
SD
FC
DA
SA
PDU
FCS
ED/FS
16 бит 8 бит 8 бит 48 бит 48 бит до 4478х8 бит 32 бита 16 бит
Форматы блока данных FDDI (Представлены в таблице) аналогичны форматам Token Ring.
Preamble (PA) — Заголовок подготавливает каждую станцию для приема прибывающего блока
данных.
Start Delimitter (SD) — Ограничитель начала указывает на начало блока данных. Он содержит
сигнальные структуры, которые отличают его от остальной части блока данных.
Frame control (FC) — Поле управления блоком данных указывает на размер адресных полей, на
вид данных, содержащихся в блоке (синхронная или асинхронная информация), и на другую
управляющую информацию.
Destination address (DA), Source address (SA) — Также, как у Ethernet и Token Ring, размер адресов
равен 6 байтам. Поле адреса назначения может содержать односоставный (единственный),
многосоставный (групповой) или широковещательный (все станции) адрес, в то время как адрес
источника идентифицирует только одну станцию, отправившую блок данных.
Protocol data unit (PDU) — Информационное поле содержит либо информацию, предназначенную
для протокола высшего уровня, либо управляющую информацию.
Frame check sequence (FCS) — Также, как у Token Ring и Ethernet, поле проверочной
последовательности блока данных (FCS) заполняется величиной «проверки избыточности цикла»
(CRC), зависящей от содержания блока данных, которую вычисляет станция- источник. Станция
пункта назначения пересчитывает эту величину, чтобы определить наличие возможного
повреждения блока данных при транзите. Если повреждение имеется, то блок данных
отбрасывается.
End delimiter (ED) — Ограничитель конца содержит неинформационные символы, которые
означают конец блока данных.
Frame status (FS) — Поле состояния блока данных позволяет станции источника определять, не
появилась ли ошибка, и был ли блок данных признан и скопирован принимающей станцией.
Подключение оборудования к сети FDDI
Есть два основных способа подключения компьютеров к сети FDDI: непосредственно, а также
через мосты или маршрутизаторы к сетям других протоколов.
Непосредственное подключение.
Этот способ используется, как правило, для подключения к сети FDDI файловых, архивационных
и других серверов, средних и больших ЭВМ, то есть ключевых сетевых компонентов, являющихся
главными вычислительными центрами, предоставляющими сервис для многих пользователей и
требующих высоких скоростей ввода-вывода по сети.
Аналогично можно подключить и рабочие станции. Однако, поскольку сетевые адаптеры для
FDDI весьма дороги, этот способ применяется только в тех случаях, когда высокая скорость
обмена по сети является обязательным условием для нормальной работы приложения. Примеры
таких приложений: системы мультимедиа, передача видео и звуковой информации.
Для подключения к сети FDDI персональных компьютеров применяются специализированные
сетевые адаптеры, которые обычным образом вставляются в один из свободных слотов
компьютера. Такие адаптеры производятся фирмами: 3Com, IBM, Microdyne, Network Peripherials,
SysKonnect и др. На рынке имеются карты под все распространенные шины — ISA, EISA и Micro
Channel; есть адаптеры для подключения станций классов А или В для всех видов кабельной
системы — волоконно-оптической, экранированной и неэкранированной витых пар.
Все ведущие производители UNIX машин (DEC, Hewlett-Packard, IBM, Sun Microsystems и другие)
предусматривают интерфейсы для непосредственного подключения к сетям FDDI.
Подключение через мосты и маршрутизаторы.
Мосты (bridges) и маршрутизаторы (routers) позволяют подключить к FDDI сети других
протоколов, например, Token Ring и Ethernet. Это делает возможным экономичное подключение к
FDDI большого числа рабочих станций и другого сетевого оборудования как в новых, так и в уже
существующих ЛВС.
Конструктивно мосты ит маршрутизаторы изготавливаются в двух вариантах — в законченном
виде, не допускающем дальнейшего аппаратного наращивания или переконфигурации (так
называемые standalone-устройства), и в виде модульных концентраторов.
Примером standalone-устройств являются: Router BR фирмы Hewlett-Packard и EIFO Client/Server
Switching Hub фирмы Network Peripherals.
Модульные концентраторы применяются в сложных больших сетях в качестве центральных
сетевых устройств. Концентратор представляет собой корпус с источником питания и с
коммуникационной платой. В слоты концентратора вставляются сетевые коммуникационные
модули. Модульная конструкция концентраторов позволяет легко собрать любую конфигурацию
ЛВС, объединить кабельные системы различных типов и протоколов. Оставшиеся свободными
слоты можно использовать для дальнейшего наращивания ЛВС.
Концентраторы производятся многими фирмами: 3Com, Cabletron, Chipcom, Cisco, Gandalf, Lannet,
Proteon, SMC, SynOptics, Wellfleet и другими.
Концентратор — это центральный узел ЛВС. Его отказ может привести к остановке всей сети,
или, по крайней мере, значительной ее части. Поэтому большинство фирм, производящих
концентраторы, принимают специальные меры для повышения их отказоустойчивости. Такими
мерами являются резервирование источников питания в режиме разделения нагрузки или горячего
резервирования, а также возможность смены или доустановки модулей без отключения питания
(hot swap).
Для того чтобы снизить стоимость концентратора, все его модули запитываются от общего
источника питания. Силовые элементы источника питания являются наиболее вероятной
причиной его отказа. Поэтому резервирование источника питания существенно продлевает срок
безотказной работы. При инсталляции каждый из источников питания концентратора может быть
подключен к отдельному источнику бесперебойного питания (UPS) на случай неисправностей в
системе электроснабжения. Каждый из UPS желательно подключить к отдельным силовым
электрическим сетям от разных подстанций.
Возможность смены или доустановки модулей (часто включая и источники питания) без
отключения концентратора позволяет провести ремонт или расширение сети без прекращения
сервиса для тех пользователей, сетевые сегменты которых подключены к другим модулям
концентратора.
Самосинхронизирующиеся коды
При передаче цифровых сигналов по аналоговым линиям связи передающая и принимающая
станции должны быть синхронизированы между собой по частоте передачи бит в канале. В
противном случае неизбежны ошибки при приеме.
В случае, если приемник и передатчик расположены близко друг от друга, то для синхронизации
можно использовать отдельный канал или линию. Если же станции разнесены на большие
расстояния, то становится выгоднее встроить возможность частотной настройки в сам сигнал. Для
этого применяются самосинхронизирующиеся коды. Идея состоит в том, чтобы передаваемый
сигнал часто менял свое состояние (с 0 на 1 и наоборот) даже в случае, если передаются длинные
последовательности данных, состоящие только из одних 0 или только из одних 1.
Манчестерское кодирование — один из способов построения самосинхронизирующегося кода.
Этот код обеспечивает изменение состояния сигнала при представлении каждого бита.
Манчестерское кодирование требует удвоенной скорости передачи сигнала в бодах относительно
передаваемых данных.
Примененный в FDDI самосинхронизирующийся код 5В/4В является одной из возможных
альтернатив для манчестерского кодирования. В таблице представлен способ кодирования
четырех информационных бит пятью сигнальными битами кода 5В/4В. Коды преобразования
подобраны таким образом, чтобы обеспечить возможно более частое изменение сигнала,
независимо от вида передаваемых данных.
Вопрос 5. RadioEthernet. WiFi.
Беспроводная вычислительная сеть — вычислительная сеть без использования кабельной
проводки, полностью соответствующая стандартам для обычных проводных сетей
(например, Ethernet). В качестве носителя информации в таких сетях выступают радиоволны СВЧдиапазона.
Применение
Существует два основных направления применения беспроводных компьютерных сетей:
Работа в замкнутом объеме (офис, выставочный зал и т. п.);
Соединение удаленных локальных сетей (или удаленных сегментов локальной сети).
Для организации беспроводной сети в замкнутом пространстве применяются передатчики со
всенаправленными антеннами. Стандарт IEEE 802.11 определяет два режима работы сети — Adhoc и клиент-сервер. Режим Ad-hoc (иначе называемый «точка-точка») — это простая сеть, в
которой связь между станциями (клиентами) устанавливается напрямую, без использования
специальной точки доступа. В режиме клиент-сервер беспроводная сеть состоит, как минимум, из
одной точки доступа, подключенной к проводной сети, и некоторого набора беспроводных
клиентских станций. Поскольку в большинстве сетей необходимо обеспечить доступ к файловым
серверам, принтерам и другим устройствам, подключенным к проводной локальной сети, чаще
всего используется режим клиент-сервер. Без подключения дополнительной антенны устойчивая
связь для оборудования IEEE 802.11b достигается в среднем на следующих расстояниях: открытое
пространство — 500 м, комната, разделенная перегородками из неметаллического материала —
100 м, офис из нескольких комнат — 30 м. Следует иметь в виду, что через стены с большим
содержанием металлической арматуры (в железобетонных зданиях таковыми являются несущие
стены) радиоволны диапазона 2,4 ГГц иногда могут вообще не проходить, поэтому в комнатах,
разделенных подобной стеной, придется ставить свои точки доступа.
Для соединения удаленных локальных сетей (или удаленных сегментов локальной сети)
используется оборудование с направленными антеннами, что позволяет увеличить дальность связи
до 20 км (а при использовании специальных усилителей и большой высоте размещения антенн —
до 50 км). Причем в качестве подобного оборудования могут выступать и устройства Wi-Fi, нужно
лишь добавить к ним специальные антенны (конечно, если это допускается конструкцией).
Комплексы для объединения локальных сетей по топологии делятся на «точку-точку» и «звезду».
При топологии «точка-точка» (режим Ad-hoc в IEEE 802.11) организуется радиомост между двумя
удаленными сегментами сети. При топологии «звезда» одна из станций является центральной и
взаимодействует с другими удаленными станциями. При этом центральная станция имеет
всенаправленную антенну, а другие удаленные станции — однонаправленные антенны.
Применение всенаправленной антенны в центральной станции ограничивает дальность связи
дистанцией примерно 7 км. Поэтому, если требуется соединить между собой сегменты локальной
сети, удаленные друг от друга на расстояние более 7 км, приходится соединять их по принципу
«точка-точка». При этом организуется беспроводная сеть с кольцевой или иной, более сложной
топологией.
Мощность, излучаемая передатчиком точки доступа или же клиентской станции, работающей по
стандарту IEEE 802.11, не превышает 0,1 Вт, но многие производители беспроводных точек
доступа ограничивают мощность лишь программным путем, и достаточно просто поднять
мощность до 0,2-0,5 Вт. Для сравнения — мощность, излучаемая мобильным телефоном, на
порядок больше(в момент звонка — до 2 Вт). Поскольку, в отличие от мобильного телефона,
элементы сети расположены далеко от головы, в целом можно считать, что беспроводные
компьютерные сети более безопасны с точки зрения здоровья, чем мобильные телефоны.
Если беспроводная сеть используется для объединения сегментов локальной сети, удаленных на
большие расстояния, антенны, как правило, размещаются за пределами помещения и на большой
высоте.
Безопасность
Продукты для беспроводных сетей, соответствующие стандарту IEEE 802.11, предлагают четыре
уровня средств безопасности: физический, идентификатор набора служб (SSID — Service Set
Identifier), идентификатор управления доступом к среде (MAC ID — Media Access Control ID)
и шифрование.
Технология DSSS для передачи данных в частотном диапазоне 2,4 ГГц за последние 50 лет нашла
широкое применение в военной связи для улучшения безопасности беспроводных передач. В
рамках схемы DSSS поток требующих передачи данных «разворачивается» по каналу шириной 20
МГц в рамках диапазона ISM с помощью схемы ключей дополнительного кода (Complementary
Code Keying, CCK). Для декодирования принятых данных получатель должен установить
правильный частотный канал и использовать ту же самую схему CCK. Таким образом, технология
на базе DSSS обеспечивает первую линию обороны от нежелательного доступа к передаваемым
данным. Кроме того, DSSS представляет собой «тихий» интерфейс, так что практически все
подслушивающие устройства будут отфильтровывать его как «белый шум».
Идентификатор SSID позволяет различать отдельные беспроводные сети, которые могут
действовать в одном и том же месте или области. Он представляет собой уникальное имя сети,
включаемое в заголовок пакетов данных и управления IEEE 802.11. Беспроводные клиенты и
точки доступа используют его, чтобы проводить фильтрацию и принимать только те запросы,
которые относятся к их SSID. Таким образом, пользователь не сможет обратиться к точке доступа,
если только ему не предоставлен правильный SSID.
Возможность принятия или отклонения запроса к сети может зависеть также от значения
идентификатора MAC ID — это уникальное число, присваиваемое в процессе производства
каждой сетевой карте. Когда клиентский ПК пытается получить доступ к беспроводной сети,
точка доступа должна сначала проверить адрес MAC для клиента. Точно так же и клиентский ПК
должен знать имя точки доступа.
Механизм Wired Equivalency Privacy (WEP), определенный в стандарте IEEE 802.11, обеспечивает
еще один уровень безопасности. Он опирается на алгоритм шифрования RC4компании RSA Data
Security с 40- или 128-разрядными ключами. Несмотря на то, что использование WEP несколько
снижает пропускную способность, эта технология заслуживает более пристального внимания.
Дополнительные функции WEP затрагивают процессы сетевой аутентификации и шифрования
данных. Процесс аутентификации с разделяемым ключом для получения доступа к беспроводной
сети использует 64-разрядный ключ — 40-разрядный ключ WEP выступает как секретный, а 24разрядный вектор инициализации (Initialization Vector) — как разделяемый. Если конфигурация
точки доступа позволяет принимать только обращения с разделяемым ключом, она будет
направлять клиенту случайную строку вызова длиной 128 октетов. Клиент должен зашифровать
строку вызова и вернуть зашифрованное значение точке доступа. Далее точка доступа
расшифровывает полученную от клиента строку и сравнивает ее с исходной строкой вызова.
Наконец, право клиента на доступ к сети определяется в зависимости от того, прошел ли он
проверку шифрованием. Процесс расшифровки данных, закодированных с помощью WEP,
заключается в выполнении логической операции «исключающее ИЛИ» (XOR) над ключевым
потоком и принятой информацией. Процесс аутентификации с разделяемым ключом не допускает
передачи реального 40-разрядного ключа WEP, поэтому этот ключ практически нельзя получить
путем контроля за сетевым трафиком. Ключ WEP рекомендуется периодически менять, чтобы
гарантировать целостность системы безопасности.
Еще одно преимущество беспроводной сети связано с тем, что физические характеристики сети
делают ее локализованной. В результате дальность действия сети ограничивается лишь
определенной зоной покрытия. Для подслушивания потенциальный злоумышленник должен будет
находиться в непосредственной физической близости, а значит, привлекать к себе внимание. В
этом преимущество беспроводных сетей с точки зрения безопасности. Беспроводные сети имеют
также уникальную особенность: их можно отключить или модифицировать их параметры, если
безопасность зоны вызывает сомнения.
Несанкционированное вторжение в сеть
Для вторжения в сеть необходимо к ней подключиться. В случае проводной сети требуется
электрическое соединение, беспроводной — достаточно оказаться в зоне радиовидимости сети с
оборудованием того же типа, на котором построена сеть.
В проводных сетях основное средство защиты на физическом и MAC-уровнях —
административный контроль доступа к оборудованию, недопущение злоумышленника к
кабельной сети. В сетях, построенных на управляемых коммутаторах, доступ может
дополнительно ограничиваться по MAC-адресам сетевых устройств.
В беспроводных сетях для снижения вероятности несанкционированного доступа предусмотрен
контроль доступа по MAC-адресам устройств и тот же самый WEP. Поскольку контроль доступа
реализуется с помощью точки доступа, он возможен только при инфраструктурной топологии
сети. Механизм контроля подразумевает заблаговременное составление таблицы MAC-адресов
разрешенных пользователей в точке доступа и обеспечивает передачу только между
зарегистрированными беспроводными адаптерами. При топологии «ad-hoc» (каждый с каждым)
контроль доступа на уровне радиосети не предусмотрен.
Для проникновения в беспроводную сеть злоумышленник должен:
Иметь оборудование для беспроводных сетей, совместимое с используемым в сети
(применительно к стандартному оборудованию — соответствующей технологии
беспроводных сетей — DSSS или FHSS);
При использовании в оборудовании FHSS нестандартных последовательностей скачков
частоты узнать их;
Знать идентификатор сети, закрывающий инфраструктуру и единый для всей логической
сети (SSID);
Знать (в случае с DSSS), на какой из 14 возможных частот работает сеть, или включить
режим автосканирования;
Быть занесенным в таблицу разрешенных MAC-адресов в точке доступа при
инфраструктурной топологии сети;
Знать ключ WPA или WEP в случае, если в беспроводной сети ведется шифрованная
передача.
Решить все это практически невозможно, поэтому вероятность несанкционированного вхождения
в беспроводную сеть, в которой приняты предусмотренные стандартом меры безопасности, можно
считать очень низкой. Информация устарела. На 2010 год, принимая во внимания уязвимости
WEP, защищенной можно считать сеть, с ключом 128разрядным AES/WPA2 от 20 символов.
Radio Ethernet
Беспроводная связь, или связь по радиоканалу, сегодня используется и для построения
магистралей (радиорелейные линии), и для создания локальных сетей, и для подключения
удаленных абонентов к сетям и магистралям разного типа. Весьма динамично развивается в
последние годы стандарт беспроводной связи Radio Ethernet. Изначально он предназначался для
построения локальных беспроводных сетей, но сегодня все активнее используется для
подключения удаленных абонентов к магистралям. С его помощью решается проблема
«последней мили» (правда, в отдельных случаях эта «миля» может составлять от 100 м до 25 км).
Radio Ethernet сейчас обеспечивает пропускную способность до 54 Мбит/с и позволяет создавать
защищенные беспроводные каналы для передачи мультимедийной информации.
Данная технология соответствует стандарту 802.11, разработанному Международным институтом
инженеров по электротехнике и радиоэлектронике (IEEE) в 1997 году и описывающему
протоколы, которые позволяют организовать локальные беспроводные сети (Wireless Local Area
Network, WLAN).
Один из главных конкурентов 802.11 — стандарт HiperLAN2 (High Performance Radio LAN),
разрабатываемый при поддержке компаний Nokia и Ericsson. Следует заметить, что разработка
HiperLAN2 ведется с учетом обеспечения совместимости данного оборудования с системами,
построенными на базе 802.11а. И этот факт наглядно демонстрирует популярность средств
беспроводного доступа на основе Radio Ethernet, растущую по мере увеличения числа
пользователей ноутбуков и прочих портативных вычислительных средств.
Wi-Fi — торговая марка Wi-Fi Alliance для беспроводных сетей на базе стандарта IEEE 802.11.
Под аббревиатурой Wi-Fi (от английского словосочетания Wireless Fidelity[1], которое можно
дословно перевести как «беспроводное качество» или «беспроводная точность») в настоящее
время развивается целое семейство стандартов передачи цифровых потоков данных по
радиоканалам.
Любое оборудование, соответствующее стандарту IEEE 802.11, может быть протестировано в WiFi Alliance и получить соответствующий сертификат и право нанесения логотипа Wi-Fi.
История
Wi-Fi был создан в 1996 году в лаборатории радиоастрономии CSIRO (Commonwealth Scientific
and Industrial Research Organisation) в Канберре, Австралия [2]. Создателем беспроводного
протокола обмена данными является инженер Джон О’Салливан (John O’Sullivan).
Стандарт IEEE 802.11n был утверждён 11 сентября 2009 года. Его применение позволяет повысить
скорость передачи данных практически вчетверо по сравнению с устройствами
стандартов 802.11g (максимальная скорость которых равна 54 Мбит/с), при условии
использования в режиме 802.11n с другими устройствами 802.11n. Теоретически 802.11n способен
обеспечить скорость передачи данных до 600 Мбит/с[3]. С 2011 по 2013 разрабатывался стандарт
IEEE 802.11ac, окончательное принятие стандарта запланировано на начало 2014 года. Скорость
передачи данных при использовании 802.11ac может достигать нескольких Гбит/с. Большинство
ведущих производителей оборудования уже анонсировали устройства, поддерживающие данный
стандарт.
27 июля 2011 года Институт инженеров электротехники и электроники (IEEE) выпустил
официальную версию стандарта IEEE 802.22[4]. Системы и устройства, поддерживающие этот
стандарт, позволяют принимать данные на скорости до 22 Мбит/с в радиусе 100 км от ближайшего
передатчика.
Происхождение названия
Термин «Wi-Fi» изначально был придуман как игра слов для привлечения внимания потребителя
«намёком» на Hi-Fi (англ. High Fidelity — высокая точность). Несмотря на то, что поначалу в
некоторых пресс-релизах WECA фигурировало словосочетание «Wireless Fidelity» («беспроводная
точность»)[5], на данный момент от такой формулировки отказались, и термин «Wi-Fi» никак не
расшифровывается[6].
Принцип работы
Обычно схема Wi-Fi сети содержит не менее одной точки доступа и не менее одного клиента.
Также возможно подключение двух клиентов в режиме точка-точка (Ad-hoc), когда точка доступа
не используется, а клиенты соединяются посредством сетевых адаптеров «напрямую». Точка
доступа передаёт свой идентификатор сети (SSID) с помощью специальных сигнальных пакетов
на скорости 0,1 Мбит/с каждые 100 мс. Поэтому 0,1 Мбит/с — наименьшая скорость передачи
данных для Wi-Fi. Зная SSID сети, клиент может выяснить, возможно ли подключение к данной
точке доступа. При попадании в зону действия двух точек доступа с идентичными SSID приёмник
может выбирать между ними на основании данных об уровне сигнала. Стандарт Wi-Fi даёт
клиенту полную свободу при выборе критериев для соединения. Более подробно принцип работы
описан в официальном тексте стандарта[7].
Однако, стандарт не описывает всех аспектов построения беспроводных локальных сетей Wi-Fi.
Поэтому каждый производитель оборудования решает эту задачу по-своему, применяя те
подходы, которые он считает наилучшими с той или иной точки зрения. Поэтому возникает
необходимость классификации способов построения беспроводных локальных сетей.
По способу объединения точек доступа в единую систему можно выделить:
Автономные точки доступа (называются также самостоятельные, децентрализованные,
умные)
Точки доступа, работающие под управлением контроллера (называются также
«легковесные», централизованные)
Бесконтроллерные, но не автономные (управляемые без контроллера)
По способу организации и управления радиоканалами можно выделить беспроводные локальные
сети:
Со статическими настройками радиоканалов
С динамическими (адаптивными) настройками радиоканалов
Со «слоистой» или многослойной структурой радиоканалов
Характеристики и скорость
Преимущества Wi-Fi
Позволяет развернуть сеть без прокладки кабеля, что может уменьшить стоимость
развёртывания и/или расширения сети. Места, где нельзя проложить кабель, например, вне
помещений и в зданиях, имеющих историческую ценность, могут обслуживаться
беспроводными сетями.
Позволяет иметь доступ к сети мобильным устройствам.
Wi-Fi устройства широко распространены на рынке. Гарантируется совместимость
оборудования благодаря обязательной сертификации оборудования с логотипом Wi-Fi.
Мобильность. Вы больше не привязаны к одному месту и можете пользоваться
Интернетом в комфортной для вас обстановке.
В пределах Wi-Fi зоны в сеть Интернет могут выходить несколько пользователей с
компьютеров, ноутбуков, телефонов и т. д.
Излучение от Wi-Fi устройств в момент передачи данных на порядок (в 10 раз) меньше,
чем у сотового телефона[8].
Недостатки Wi-Fi
В диапазоне 2,4 GHz работает множество устройств, таких как устройства,
поддерживающие Bluetooth, и др, и даже микроволновые печи, что
ухудшает электромагнитную совместимость.
Производителями оборудования указывается скорость на L1 (OSI), в результате чего
создаётся иллюзия, что производитель оборудования завышает скорость, но на самом деле
в Wi-Fi весьма высоки служебные «накладные расходы». Получается, что скорость
передачи данных на L2 (OSI) в Wi-Fi сети всегда ниже заявленной скорости на L1 (OSI).
Реальная скорость зависит от доли служебного трафика, которая зависит уже от наличия
между устройствами физических преград (мебель, стены), наличия помех от других
беспроводных устройств или электронной аппаратуры, расположения устройств
относительно друг друга и т. п.[9]
Частотный диапазон и эксплуатационные ограничения в различных странах не одинаковы.
Во многих европейских странах разрешены два дополнительных канала, которые
запрещены в США; В Японии есть ещё один канал в верхней части диапазона, а другие
страны, напримерИспания, запрещают использование низкочастотных каналов. Более того,
некоторые страны, например Россия, Белоруссия и Италия, требуют регистрации всех
сетей Wi-Fi, работающих вне помещений, или требуют регистрации Wi-Fi-оператора[10].
Как было упомянуто выше — в России точки беспроводного доступа, а также адаптеры
Wi-Fi с ЭИИМ, превышающей 100 мВт (20 дБм), подлежат обязательной регистрации[11].
Стандарт шифрования WEP может быть относительно легко взломан даже при правильной
конфигурации (из-за слабой стойкости алгоритма). Новые устройства поддерживают более
совершенные протоколы шифрования данных WPA и WPA2. Принятие стандарта IEEE
802.11i (WPA2) в июне 2004 года сделало возможным применение более безопасной схемы
связи, которая доступна в новом оборудовании. Обе схемы требуют более стойкий пароль,
чем те, которые обычно назначаются пользователями. Многие организации используют
дополнительное шифрование (например VPN) для защиты от вторжения. На данный
момент основным методом взлома WPA2 является подбор пароля, поэтому рекомендуется
использовать сложные цифро-буквенные пароли для того, чтобы максимально усложнить
задачу подбора пароля.
В режиме точка-точка (Ad-hoc) стандарт предписывает лишь реализовать скорость 11
Мбит/сек (802.11b)[12]. Шифрование WPA(2) недоступно, только легковзламываемый WEP.
Беспроводные технологии в промышленности
Для использования в промышленности технологии Wi-Fi предлагаются пока ограниченным
числом поставщиков. Так Siemens Automation & Drives предлагает Wi-Fi-решения для своих
контроллеров SIMATIC в соответствии со стандартом IEEE 802.11g в свободном ISM-диапазоне
2,4 ГГц и обеспечивающим максимальную скорость передачи 54 Мбит/с. Данные технологии
применяются для управления движущимися объектами и в складской логистике, а также в тех
случаях, когда по какой-либо причине невозможно прокладывать проводные сети Ethernet.
Использование Wi-Fi устройств на предприятиях обусловлено высокой помехоустойчивостью, что
делает их применимыми на предприятиях с множеством металлических конструкций. В свою
очередь Wi-Fi приборы не создают существенных помех для узкополосных радиосигналов. В
настоящее время технология находит широкое применение на удаленном или опасном
производстве, там где нахождение оперативного персонала связано с повышенной опасностью или
вовсе затруднительно. К примеру, для задач телеметрии на нефтегазодобывающих предприятиях,
а также для контроля за перемещением персонала и транспортных средств в шахтах и рудниках,
для определения нахождения персонала в аварийных ситуациях.
Wi-Fi и телефоны сотовой связи
Некоторые считают, что Wi-Fi и подобные ему технологии со временем могут заменить сотовые
сети, такие как GSM. Препятствиями для такого развития событий в ближайшем будущем
являются отсутствие глобального роуминга, ограниченность частотного диапазона и сильно
ограниченный радиус действия Wi-Fi. Более правильным выглядит сравнение сотовых сетей с
другими стандартами беспроводных сетей, таких как UMTS, CDMA или WiMAX.
Тем не менее, Wi-Fi пригоден для использования VoIP в корпоративных сетях или в среде SOHO.
Первые образцы оборудования появились уже в начале 2000-х, однако на рынок они вышли
только в 2005 году. Тогда такие компании, как Zyxel, UT Starcomm, Samsung, Hitachi и многие
другие, представили на рынок VoIP Wi-Fi-телефоны по «разумным» ценам. В 2005 году ADSL ISP
провайдеры начали предоставлять услуги VoIP своим клиентам (например нидерландский
ISP XS4All). Когда звонки с помощью VoIP стали очень дешёвыми, а зачастую вообще
бесплатными, провайдеры, способные предоставлять услуги VoIP, получили возможность открыть
новый рынок — услуг VoIP. Телефоны GSM с интегрированной поддержкой возможностей Wi-Fi
и VoIP начали выводиться на рынок, и потенциально они могут заменить проводные телефоны.
В настоящий момент непосредственное сравнение Wi-Fi и сотовых сетей нецелесообразно.
Телефоны, использующие только Wi-Fi, имеют очень ограниченный радиус действия, поэтому
развёртывание таких сетей обходится очень дорого. Тем не менее, развёртывание таких сетей
может быть наилучшим решением для локального использования, например, в корпоративных
сетях. Однако устройства, поддерживающие несколько стандартов, могут занять значительную
долю рынка.
Стоит заметить, что при наличии в данном конкретном месте покрытия как GSM, так и Wi-Fi,
экономически намного более выгодно использовать Wi-Fi, разговаривая посредством
сервисов интернет-телефонии. Например, клиент Skype давно существует в версиях как для
смартфонов, так и для КПК.
Международные проекты
Другая бизнес-модель состоит в соединении уже имеющихся сетей в новые. Идея состоит в том,
что пользователи будут разделять свой частотный диапазон через персональные
беспроводные маршрутизаторы, комплектующиеся специальным ПО. Например FON —
испанская компания, созданная в ноябре 2005 года. Сейчас сообщество объединяет
более2 000 000 пользователей в Европе, Азии и Америке и быстро развивается. Пользователи
делятся на три категории:
linus — выделяющие бесплатный доступ в Интернет,
bills — продающие свой частотный диапазон,
aliens — использующие доступ через bills.
Таким образом, система аналогична пиринговым сервисам. Несмотря на то, что FON получает
финансовую поддержку от таких компаний, как Google и Skype, лишь со временем будет ясно,
будет ли эта идея действительно работать.
Сейчас у этого сервиса есть три основные проблемы. Первая заключается в том, что для перехода
проекта из начальной стадии в основную требуется больше внимания со стороны общественности
и СМИ. Нужно также учитывать тот факт, что предоставление доступа к вашему интернет-каналу
другим лицам может быть ограничено вашим договором синтернет-провайдером. Поэтому
интернет-провайдеры будут пытаться защитить свои интересы. Так же, скорее всего, поступят
звукозаписывающие компании, выступающие против свободного распространения MP3.
В России основное количество точек доступа сообщества FON расположено в московском
регионе.
Израильская компания WeFi создала общую сеть социальной направленности, с возможностью
поиска сетей Wi-Fi и общения между пользователями. Программа и система в целом была создана
под руководством Йосси Варди (Yossi Vardi), одного из создателей компании Mirabilis, и
протокола ICQ.
Wi-Fi в игровой индустрии
Совместим с игровыми консолями и КПК и позволяет вести сетевую игру через любую
точку доступа или в режиме точка-точка.
Все игровые консоли седьмого поколения имеют поддержку стандартов Wi-Fi IEEE
802.11g.
Некоммерческое использование Wi-Fi
Пока коммерческие сервисы пытаются использовать существующие бизнес-модели для Wi-Fi,
многие группы, сообщества, города, и частные лица строят свободные сети Wi-Fi, часто используя
общее пиринговое соглашение для того, чтобы сети могли свободно взаимодействовать друг с
другом.
Многие муниципалитеты объединяются с локальными сообществами, чтобы расширить
свободные Wi-Fi-сети. Некоторые группы строят свои Wi-Fi-сети, полностью основанные на
добровольной помощи и пожертвованиях.
Для получения более подробной информации смотрите раздел совместные беспроводные сети, где
можно также найти список свободных сетей Wi-Fi, расположенных по всему миру (см.
также Бесплатные точки доступа Wi-Fi в Москве).
Схема создания ячеистой сети (mesh-network) с использованием оборудования Wi-Fi
OLSR (en) — один из протоколов, используемых для создания свободных сетей. Некоторые сети
используют статическую маршрутизацию, другие полностью полагаются на OSPF.
В Израиле разрабатывается протокол WiPeer для создания бесплатных P2P-сетей на основе Wi-Fi.
В Wireless Leiden разработали собственное программное обеспечение для маршрутизации под
названием LVrouteD для объединения Wi-Fi-сетей, построенных на полностью беспроводной
основе. Большая часть сетей построена на основе ПО с открытым кодом, или публикуют свою
схему под открытой лицензией. (превращает любой ноутбук с установленной Mac OS X и Wi-Fiмодулем в открытый узел Wi-Fi-сети). Также следует обратить внимание на netsukuku —
Разработка всемирной бесплатной mesh-сети.
Некоторые небольшие страны и муниципалитеты уже обеспечивают свободный доступ к хотспотам Wi-Fi и доступ к Интернету через Wi-Fi по месту жительства для всех.
Например, Королевство Тонга и Эстония, которые имеют большое количество свободных хотспотов Wi-Fi по всей территории страны. В Париже OzoneParis предоставляет свободный доступ в
Интернет неограниченно всем, кто способствует развитию Pervasive Network, предоставляя крышу
своего дома для монтажа оборудования Wi-Fi. Unwire Jerusalem — это проект установки
свободных точек доступа Wi-Fi в крупных торговых центрах Иерусалима.
Многие университеты обеспечивают свободный доступ к Интернет через Wi-Fi для своих
студентов, посетителей и всех, кто находится на территории университета.
Некоторые коммерческие организации, такие как Panera Bread, предоставляют свободный доступ к
Wi-Fi постоянным клиентам. ЗаведенияMcDonald’s Corporation тоже предоставляют доступ к WiFi под брендом McInternet. Этот сервис был запущен в ресторане в Оук-Брук, Иллинойс; он также
доступен во многих ресторанах в Лондоне, Москве.
Тем не менее, есть и третья подкатегория сетей, созданных сообществами и организациями,
такими как университеты, где свободный доступ предоставляется членам сообщества, а тем, кто в
него не входит, доступ предоставляется на платной основе. Пример такого сервиса — сеть
Sparknet в Финляндии. Sparknet также поддерживает OpenSparknet — проект, в котором люди
могут делать свои собственные точки доступа частью сети Sparknet, получая от этого
определённую выгоду.
В последнее время коммерческие Wi-Fi-провайдеры строят свободные хот-споты Wi-Fi и хотзоны. Они считают, что свободный Wi-Fi-доступ привлечёт новых клиентов и инвестиции
вернутся.
Бесплатный доступ к Интернету через Wi-Fi
Независимо от исходных целей (привлечение клиентов, создание дополнительного удобства или
чистый альтруизм) во всём мире и в России, в том числе, растёт количество бесплатных хотспотов, где можно получить доступ к наиболее популярной глобальной сети (Интернет)
совершенно бесплатно. Это могут быть и крупные транспортные узлы (такие хот-спот зоны,
например, уже находятся на станциях метро в различных городах мира, таких как : Лондон,
Париж, Нью-Йорк, Токио, Сеул, Сингапур,Гонконг), где подключиться можно самостоятельно в
автоматическом режиме, и места общественного питания, где для подключения необходимо
попросить карточку доступа с паролем у персонала, и даже просто территории городского
ландшафта, являющиеся местом постоянного скопления людей.
Стандартами Wi-Fi не предусмотрено шифрование передаваемых данных в открытых сетях. Это
значит, что все данные, которые передаются по открытому беспроводному соединению, могут
быть прослушаны злоумышленниками при помощи программ-снифферов. К таким данным могут
относиться пары логин/пароль, номера банковских счетов, пластиковых карт, конфиденциальная
переписка. Поэтому, при использовании бесплатных хот-спотов не следует передавать в Интернет
подобные данные.
Первые хот- зоны в Московском метрополитене, охватывающие поезда Кольцевой линии, были
запущены совместно с оператором сотовой связи «МТС» 23 марта 2012 года. Первые месяцы
интернет работал в тестовом режиме со скоростью 7,2 Мбит/с. [13] В 2013 году московский
метрополитен провел конкурс при поддержке Правительства Москвы на установку Wi-Fi
соединения на всех станциях метрополитена.[14][15] Конкурс выиграла компания ЗАО “Максима
Телеком” и вложила в создание беспроводной сети в метрополитене 1,8 млрд. рублей. [16] Эта Wi-
Fi сеть называется MosMetro_free. Ежедневно этой сетью пользуется 1,2 млн человек. В начале
2015 года к сети Wi-Fi в метро подключилось более 55 млн. уникальных пользователей. Поезда
Московского метрополитена, в отличие от других стран мира, где точки доступа в интернет
находятся только на станциях или в туннелях, оснащены индивидуальным Wi-Fi роутером. В 2015
году Wi-Fi стал появляться не только в вагонах электропоездов, но и на эскалаторах, переходах и
в вестибюлях станций метро. [17]В 2015 году хот-зоны длительностью сессии интернет соединения в 25 минут появились на более чем 100 остановках общественного транспорта в
Москве.[18] Сеть подключения называется Mosgortrans_Free. Скорость интернет — соединения
составляет 10 Мбит/с. За 2015 год на остановках вышло в сеть более 70 тысяч уникальных
пользователей. [19] После принятия ФЗ-№97 от 5 мая 2014 года для подключения к Wi-Fi на
остановках общественного транспорта или в метрополитене нужно пройти авторизацию с
помощью SMS. На конец 2015 года было оборудовано еще 300 остановок беспроводным
интернетом.[20][21]
Wi-Fi и ПО
ОС семейства BSD (FreeBSD, NetBSD, OpenBSD) могут работать с большинством
адаптеров, начиная с 1998 года. Драйверы для чипов Atheros, Prism, Harris/Intersil и Aironet
(от соответствующих производителей Wi-Fi устройств) обычно входят в ОС BSD начиная
с версии 3. В OpenBSD 3.7, было включено больше драйверов для беспроводных чипов,
включая RealTek RTL8180L, Ralink RT25x0, Atmel AT76C50x, и Intel 2100 и
2200BG/2225BG/2915ABG. Благодаря этому частично удалось решить проблему нехватки
открытых драйверов беспроводных чипов для OpenBSD. Возможно некоторые драйверы,
реализованные для других BSD-систем, могут быть перенесены, если они ещё не были
созданы.NDISwrapper также доступен для FreeBSD.
OS X (прежнее название — Mac OS X). Адаптеры производства Apple поддерживались с
системы Mac OS 9, выпущенной в 1999 году. С 2006 года все настольные компьютеры и
ноутбуки Apple Inc. (а также появившиеся позднее телефоны iPhone, плееры iPod Touch и
планшетные компьютеры iPad) штатно оснащаются адаптерами Wi-Fi, сеть Wi-Fi в
настоящее время является основным решением Apple для передачи данных, и полностью
поддерживается OS X. Возможен режим работы адаптера компьютера в качестве точки
доступа, что позволяет при необходимости связывать компьютеры Macintosh в
беспроводные сети в отсутствии инфраструктуры. Darwin и OS X, несмотря на частичное
совпадение с BSD, имеют свою собственную, уникальную реализацию Wi-Fi.
Linux: Начиная с версии 2.6, поддержка некоторых Wi-Fi устройств появилась
непосредственно в ядре Linux. Поддержка для чипов Orinoco, Prism, Aironet, Atmel, Ralink
включена в основную ветвь ядра, чипы ADMtek и Realtek RTL8180L поддерживаются как
закрытыми драйверами производителей, так и открытыми, написанными сообществом.
Intel Calexico поддерживаются открытыми драйверами, доступными на SourceForge.net.
Atheros поддерживается через открытые проекты. Поддержка других беспроводных
устройств доступна при использовании открытого драйвера NDISwrapper, который
позволяет Linux-системам, работающим на компьютерах с архитектурой Intel x86,
«оборачивать» драйвера производителя для Microsoft Windows для прямого
использования. Известна по крайней мере одна коммерческая реализация этой
идеи. FSF создалосписок рекомендуемых адаптеров, более подробную информацию можно
найти на сайте Linux wireless.
Существует довольно большое количество Linux-based прошивок для
беспроводных роутеров, распространяемых под лицензией GNU GPL. К ним относятся так
называемая«прошивка от Олега», FreeWRT, OpenWRT, X-WRT, DD-WRT и т. д. Как
правило, они поддерживают гораздо больше функций, чем оригинальные прошивки.
Необходимые сервисы легко добавляются путём установки соответствующих пакетов.
Список поддерживаемого оборудования постоянно растёт.[22]
В ОС семейства Microsoft Windows поддержка Wi-Fi обеспечивается, в зависимости от
версии, либо посредством драйверов, качество которых зависит от поставщика, либо
средствами самой Windows.
Ранние версии Windows, такие как Windows 2000 и младше, не содержат
встроенных средств для настройки и управления, и тут ситуация зависит от
поставщика оборудования.
Microsoft Windows XP поддерживает настройку беспроводных устройств. И хотя
первоначальная версия включала довольно слабую поддержку, она значительно
улучшилась с выходом Service Pack 2, а с выходом Service Pack 3 была добавлена
поддержка WPA2.
Microsoft Windows Vista содержит улучшенную по сравнению с Windows
XP поддержку Wi-Fi.
Microsoft Windows 7 поддерживает все современные на момент её выхода
беспроводные устройства и протоколы шифрования. Помимо прочего в Windows 7
создана возможность создавать виртуальные адаптеры Wi-Fi, что теоретически
позволило бы подключаться не к одной Wi-Fi-сети, а к нескольким сразу. На
практике в Windows 7 поддерживается создание только одного виртуального
адаптера, при условии написания специальных драйверов[23]. Это может быть
полезно при использовании компьютера в локальной Wi-Fi-сети и, одновременно, в
Wi-Fi-сети подключённой к Интернет.
Юридический статус
Юридический статус Wi-Fi различен в разных странах. В США диапазон 2,5 ГГц разрешается
использовать без лицензии, при условии, что мощность не превышает определённую величину, и
такое использование не создаёт помех тем, кто имеет лицензию.
Россия
Разрешение на использование частот
В России, в соответствии с решениями Государственной комиссии по радиочастотам (ГКРЧ) от 7
мая 2007 г. № 07-20-03-001 «О выделении полос радиочастот устройствам малого радиуса
действия»[24] и от 20 декабря 2011 г. № 11-13-07-1[25], использование Wi-Fi без получения частного
разрешения на использование частот возможно для организации сети внутри зданий, закрытых
складских помещений и производственных территорий в полосах 2400—2483,5 МГц (стандарты
802.11b и 802.11g; каналы 1—13) и 5150-5350 МГц (802.11a и 802.11n; каналы 34-64). Для
легального использования внеофисной беспроводной сети Wi-Fi (например, радиоканала между
двумя соседними домами) необходимо получение разрешения на использование частот (как в
полосе 2,4 ГГц, так и 5 ГГц) на основании заключения экспертизы о возможности использования
заявленных РЭС и их электромагнитной совместимости (ЭМС) с действующими и планируемыми
для использования РЭС.
Регистрация оборудования
Радиоэлектронные средства подлежат регистрации в Роскомнадзоре в соответствии с
установленным порядком[26] . В соответствии c Постановлением Правительства Российской
Федерации от 13 октября 2011 г. № 837 «О внесении изменений в Постановление Правительства
Российской Федерации от 12 октября 2004 г. № 539»[27] не подлежат регистрации, в частности, (из
п. 13, 23, 24 приложения):
Пользовательское (оконечное) оборудование передающее, включающее в себя приемное
устройство, малого радиуса действия стандартов IEEE 802.11, IEEE 802.11.b, IEEE
802.11.g, IEEE 802.11.n (Wi-Fi), работающее в полосе радиочастот 2400—2483,5 МГц, с
допустимой мощностью излучения передатчика не более 100 мВт, в том числе встроенное
либо входящее в состав других устройств;
Пользовательское (оконечное) оборудование передающее, включающее в себя приемное
устройство, малого радиуса действия стандартов IEEE 802.11а, IEEE 802.11.n (Wi-Fi),
работающее в полосах радиочастот 5150 — 5350 МГц и 5650 — 6425 МГц, с допустимой
мощностью излучения передатчика не более 100 мВт, в том числе встроенное либо
входящее в состав других устройств;
Устройства малого радиуса действия, используемые внутри закрытых помещений, в
полосе радиочастот 5150 — 5250 МГц с максимальной эквивалентной изотропно
излучаемой мощностью передатчика не более 200 мВт;
Устройства малого радиуса действия в сетях беспроводной передачи данных внутри
закрытых помещений в полосе радиочастот 2400—2483,5 МГц с максимальной
эквивалентной изотропно излучаемой мощностью передатчика не более 100 мВт при
использовании псевдослучайной перестройки рабочей частоты.
Ответственность
За нарушение порядка использования радиоэлектронных средств предусматривается
ответственность по статьям 13.3 и 13.4 Кодекса Российской Федерации об административных
правонарушениях (КоАП РФ)[28]. Так, в июле 2006 года несколько компаний в Ростове-наДону были оштрафованы за эксплуатацию открытых сетей Wi-Fi (хот-спотов)[29]. Федеральная
служба по надзору в сфере массовых коммуникаций, связи и охраны культурного наследия издало
новое разъяснение использования и регистрации всех устройств, использующих Wi-Fi. Позднее
оказалось, что существует комментарий Россвязьохранкультуры[30], который частично опровергает
недоразумения, развитые сетевыми СМИ.
Украина
Согласно законодательству Украины использование Wi-Fi без разрешения Украинского
государственного центра радиочастот (укр. Український державний центр радіочастот)
возможно лишь в случае использования точки доступа со стандартной всенаправленной антенной
(<6 дБ, мощность сигнала ≤ 100 мВт на 2,4 ГГц и ≤ 200 мВт на 5 ГГц) для внутренних
(использование внутри помещения) потребностей организации (Решение Национальной комиссии
по регулированию связи Украины № 914 от 2007.09.06) В случае использования внешней антенны
необходимо регистрировать передатчик и получить разрешение на эксплуатацию
радиоэлектронного средства от ДП УДЦР. Кроме того, для деятельности по предоставлению
телекоммуникационных услуг с применением WiFi необходимо получить лицензию от
«НКРЗІ»[31].
Белоруссия
В Белоруссии действует специализированная Государственная комиссия по радиочастотам (ГКРЧ)
(белор. Дзяржаўная камісія па радыёчастотах (ДзКРЧ)). На основе Постановления
Министерства связи и информатизации Республики Беларусь от 26.08.2009 г. № 35 «Перечень
радиоэлектронных средств и (или) высокочастотных устройств, не подлежащих
регистрации» (рус.) оборудование Wi-Fi не требует регистрации, при условии, что их параметры
удовлетворяют следующим требованиям:
Абонентские станции широкополосного беспроводного доступа, использующие полосы
радиочастот 2400—2483,5 МГц, 2500—2700 МГц, 5150—5875 МГц и не использующие
внешние антенны (антенны, устанавливаемые вне зданий и сооружений).
Абонентские станции широкополосного беспроводного доступа сети электросвязи общего
пользования, использующие полосы радиочастот 3400—3800 МГц, 5470—5875 МГц[32].
Безопасность
В 2011 году были опубликованы результаты эксперимента по изучению влияния Wi-Fi на качество
спермы, в ходе которого было установлено снижение подвижности сперматозоидов на 20 % и
увеличение повреждений их ДНК в 2,5 раза при четырёхчасовой экспозиции эякулята около
ноутбука с включённым Wi-Fi[33] [34].
Ранее утверждалось, что Wi-Fi не наносит вред здоровью человека[35], так, один из английских
профессоров из университета Ноттингема (Nottingham University) считал достаточными
следующие меры предосторожности при работе с Wi-Fi:
Вопрос 6. Аппаратные средства ЛВС. Повторители, концентраторы, мосты.
Для организации каналов связи применяют различные способы:
1. Специализированное сетевое оборудование для организации сетей на основе медных
кабелей, чаще всего так называемой «витой пары», 8-жильного кабеля. Такие сети
являются высокоскоростными, но технология исходно предназначалась для локальных
сетей, а потому вносит ограничения на количество узлов сети, связанное со строго
регламентированным временем передачи. Скорости таких сетей могут быть 10, 100 или
1000 Мбит в секунду.
2. Сети на основе оптического кабеля. При использовании для передачи оптического кабеля
резко возрастает возможная дальность передачи, уменьшается количество помех,
снижается вероятность постороннего подключения к каналу. Но оптическое оборудование,
кабель и его монтаж сложнее и дороже аналогичного для витой пары. Оптический кабель
используют различные сетевые технологии, предусматривается его использование и в
локальных сетях — для объединения далеко отстоящих сегментов. Оптический кабель
используется и в технологиях региональных и глобальных сетей. В этом случае скорости
передачи могут достигать десятков гигабайтов, а соединение организуется в основном по
принципу «точка-точка».
3. Сети на базе существующих сетей телефонной связи. Это один из наиболее популярных
способов подключения отдельных машин к Интернету, поскольку не требует прокладки
дополнительных каналов связи. Применяются чаще других два варианта. Первый —
использование модемов для коммутируемых линий, соединяющих два узла
преобразованием цифрового сигнала в аналоговый, голосового диапазона. Требует только
наличия модемов у абонентов, но не обеспечивает надежного и скоростного соединения,
скорость не превышает 56 Кбит/с, а на специально соединенных линиях — до 512 Кбит/с.
Второй — использование незанятой полосы частот (т. е. кроме голосового диапазона) на
отрезке между точкой подключения и телефонной станцией. Такой способ позволяет
организовывать высокоскоростные соединения, не лишая возможности одновременно с
передачей данных использовать и телефон. Самая популярная технология такого рода —
ADSL (асимметричная цифровая абонентская линия) позволяет добиться скоростей до 20
Мбит/с по направлению от телефонной станции к абоненту.
4. Беспроводные сети. соединение компьютеров, получающее всё большее распространение,
особенно там, где прокладка кабелей отсутствует, затруднена или нецелесообразна.
Например, в исторических зданиях, в офисах с краткосрочной арендой и др. Такие сети
могут использовать в качестве среды передачи информации радиоволны и обеспечиваются
сетевыми радиоадаптерами с антеннами на дальность 50-200 м (тип «все-со-всеми»). Для
удалённых расстояний могут использоваться спутниковые линии связи, а с недавнего
времени – и мобильные телефонные станции.
К основным характеристикам любого канала связи относят:
Пропускную способность. Это количество информации, которое можно передать через
этот канал за единицу времени. Единицей измерения, таким образом, оказывается
количество битов в секунду. Пропускная способность каналов цифровой связи, например,
составляет от десятков тысяч до сотен миллионов килобод. Развитие цифровых каналов
приводит к революции в технике связи, открывает огромные возможности для абонентов
компьютерных сетей, обещает интегрировать в единое целое все существующие сегодня
средства связи.
Надежность канала. Под надежностью канала понимают вероятность возникновения
ошибки при передаче данных. Если возникает необходимость, ее рассчитывают как
отношение времени, когда канал не мог передавать данные, ко времени, когда он эти
данные передавал.
Максимальную длину. В зависимости от используемой технологии передачи данных,
канал связи может иметь некоторую максимальную длину. Например, в сети, построенной
по стандартам FastEthernet, максимальная длина медного кабеля между узлом и
устройством сети — 100 метров.
Стоимость. Например, оптоволокно, обладая максимальной надёжностью, имеет и
максимальную стоимость.
Резерв развития. Так у канала на основе коаксиального кабеля фактически нет
дальнейшего развития, а при использования телефонного кабеля или оптоволокна
возможности развития сети практически неограничены.
При построении локальных сетей широко применяется недорогой кабель «витая пара», т. к. при
скручивании пары проводов влияние помех на сигнал уменьшается. Еще более защищен от помех
коаксиальный кабель, который представляет собой конструкцию из внутренней медной жилы и
проводящей оплетки, отделенной от жилы изоляцией. Промышленность выпускает различные
типы коаксиального кабеля, рассчитанного на применение в ЛВС, в глобальных сетях, в
телевидении и т.д. Но наиболее совершенным в смысле скоростных характеристик и
помехозащищенности является волоконно-оптический кабель. Этот кабель состоит из множества
тонких волокон (толщиной менее 50 микрон), проводящих световые сигналы, используется в
магистральных линиях связи. Последнее время всё больше используются беспроводные сети
(технология Wi-Fi — англ. Wireless Fidelity — «беспроводная точность») — радиоканалы,
позволяющие организовать сеть без прокладки кабеля, т.е. дешевле и быстрее.
Компьютеры подключаются к линиям связи локальных сетей через сетевые адаптеры.
Сетевой адаптер (сетевая карта) — это плата расширения, обеспечивающая соединение
компьютера с линией связи.
Сетевой адаптер занимается кодированием и декодированием информации, синхронизацией
передачи сигналов по линии связи.
Если нужно организовать удаленное подключение компьютера к сети
(региональной/корпоративной или глобальной) по телефонной линии, используется
модем. Модем (сокращение от слов МОдулятор/ДЕМодулятор) — устройство, которое на стороне
передатчика обеспечивает преобразование цифрового сигнала компьютера в аналоговый сигнал, а
на стороне приемника выполняет обратное преобразование сигналов.
Существенно улучшить характеристики сети при минимальных затратах позволяют
концентраторы.
Концентратор (или повторитель, hub) — это устройство, обеспечивающее соединение
фрагментов сети в единое целое.
Концентратор имеет несколько портов, причем сигнал, пришедший на один из портов,
повторяется на всех его портах. Слово hub (англ.) в переводе — центр деятельности. Поскольку
концентратор повторяет сигналы на всех своих портах, при наращивании числа компьютеров,
обслуживаемых одним концентратором, резко падает пропускная способность сети. Избежать
этого можно, если разделить сеть на фрагменты с помощью специальных устройств коммутаторов (простые варианты этих устройств называются мостами). Однако более
эффективно, чем коммутаторы, изолируют обмен отдельных сегментов сети другие устройства,
называемые маршрутизаторами. Маршрутизаторы позволяют также связывать в единую сеть
подсети различных топологий, они выбирают рациональный маршрут следования пакета данных
из одного узла сети в другой
Типы сетевых устройств
Сетевые карты
Устройства, которые связывают конечного пользователя с сетью, называются такжеоконечными
узлами или станциями (host). Примером таких устройств является обычный персональный
компьютер или рабочая станция (мощный компьютер, выполняющий определенные функции,
требующие большой вычислительной мощности. Например, обработка видео, моделирование
физических процессов и т.д.). Для работы в сети каждый хост оснащен платой сетевого
интерфейса (Network Interface Card — NIC), также называемой сетевым адаптером. Как
правило, такие устройства могут функционировать и без компьютерной сети.
Сетевой адаптер представляет собой печатную плату, которая вставляется в слот на материнской
плате компьютера, или внешнее устройство. Каждый адаптер NIC имеет уникальный код,
называемый MAC-адресом. Этот адрес используется для организации работы этих устройств в
сети. Сетевые устройства обеспечивают транспортировку данных, которые необходимо
передавать между устройствами конечного пользователя. Они удлиняют и объединяют кабельные
соединения, преобразуют данные из одного формата в другой и управляют передачей данных.
Примерами устройств, выполняющих перечисленные функции, являются повторители,
концентраторы, мосты, коммутаторы и маршрутизаторы.
Повторители (repeater) представляют собой сетевые устройства, функционирующие на первом
(физическом) уровне эталонной модели OSI. Для того чтобы понять работу повторителя,
необходимо знать, что по мере того, как данные покидают устройство отправителя и выходят в
сеть, они преобразуются в электрические или световые импульсы, которые после этого
передаются по сетевой передающей среде. Такие импульсы называются сигналами (signals).
Когда сигналы покидают передающую станцию, они являются четкими и легко распознаваемыми.
Однако чем больше длина кабеля, тем более слабым и менее различимым становится сигнал по
мере прохождения по сетевой передающей среде. Целью использования повторителя является
регенерация и ресинхронизация сетевых сигналов на битовом уровне, что позволяет передавать их
по среде на большее расстояние. Термин повторитель (repeater) первоначально означал отдельный
порт ‘‘на входе’’ некоторого устройства и отдельный порт на его ‘‘выходе’’. В настоящее время
используются также повторители с несколькими портами. В эталонной модели OSI повторители
классифицируются как устройства первого уровня, поскольку они функционируют только на
битовом уровне и не просматривают другую содержащуюся в пакете информацию.
Концентратор — это один из видов сетевых устройств, которые можно устанавливать на уровне
доступа сети Ethernet. На концентраторах есть несколько портов для подключения узлов к
сети. Концентраторы — это простые устройства, не оборудованные необходимыми
электронными компонентами для передачи сообщений между узлами в сети. Концентратор не в
состоянии определить, какому узлу предназначено конкретное сообщение. Он просто принимает
электронные сигналы одного порта и воспроизводит (или ретранслирует) то же сообщение для
всех остальных портов.
Для отправки и получения сообщений все порты концентратора Ethernet подключаются к одному
и тому же каналу. Концентратор называется устройством с общей полосой пропускания,
поскольку все узлы в нем работают на одной полосе одного канала.
Концентраторы и повторители имеют похожие характеристики, поэтому концентраторы часто
называют многопортовыми повторителями (multiport repeater). Разница между повторителем и
концентратором состоит лишь в количестве кабелей, подсоединенных к устройству. В то время
как повторитель имеет только два порта, концентратор обычно имеет от 4 до 20 и более портов.
Свойства концентраторов
Ниже приведены наиболее важные свойства устройств данного типа:
концентраторы усиливают сигналы;
концентраторы распространяют сигналы по сети;
концентраторам не требуется фильтрация;
концентраторам не требуется определение маршрутов и коммутации пакетов;
концентраторы используются как точки объединения трафика в сети.
Функции концентраторов
Концентраторы считаются устройствами первого уровня, поскольку они всего лишь регенерируют
сигнал и повторяют его на всех своих портах (на выходных сетевых соединениях). Сетевой
адаптер узла принимает только сообщения, адресованные на правильный MAC-адрес. Узлы
игнорируют сообщения, которые адресованы не им. Только узел, которому адресовано данное
сообщение, обрабатывает его и отвечает отправителю.
Для отправки и получения сообщений все порты концентратора Ethernet подключаются к одному
и тому же каналу. Концентратор называется устройством с общей полосой пропускания,
поскольку все узлы в нем работают на одной полосе одного канала.
Через концентратор Ethernet можно одновременно отправлять только одно сообщение. Возможно,
два или более узла, подключенные к одному концентратору, попытаются одновременно отправить
сообщение. При этом происходит столкновение электронных сигналов, из которых состоит
сообщение.
Столкнувшиеся сообщения искажаются. Узлы не смогут их прочесть. Поскольку концентратор не
декодирует сообщение, он не обнаруживает, что оно искажено, и повторяет его всем портам.
Область сети, в которой узел может получить искаженное при столкновении сообщение,
называется доменом коллизий.
Внутри этого домена узел, получивший искаженное сообщение, обнаруживает, что произошла
коллизия. Каждый отправляющий узел какое-то время ждет и затем пытается снова отправить или
переправить сообщение. По мере того, как количество подключенных к концентратору узлов
растет, растет и вероятность столкновения. Чем больше столкновений, тем больше будет
повторов. При этом сеть перегружается, и скорость передачи сетевого трафика падает. Поэтому
размер домена коллизий необходимо ограничить.
————————————
Мосты
Мост (bridge) представляет собой устройство второго уровня, предназначенное для создания двух
или более сегментов локальной сети LAN, каждый из которых является отдельным коллизионным
доменом. Иными словами, мосты предназначены для более рационального использования полосы
пропускания. Целью моста является фильтрация потоков данных в LAN-сети с тем, чтобы
локализовать внутрисегментную передачу данных и вместе с тем сохранить возможность связи с
другими
частями (сегментами) LAN-сети для перенаправления туда потоков данных. Каждое сетевое
устройство имеет связанный с NIC-картой уникальный MAC-адрес. Мост
собирает информацию о том, на какой его стороне (порте) находится конкретный MAC-адрес, и
принимает решение о пересылке данных на основании соответствующего списка MAC-адресов.
Мосты осуществляют фильтрацию потоков данных на основе только MAC-адресов узлов. По этой
причине они могут быстро пересылать данные любых протоколов сетевого уровня. На решение о
пересылке не влияет тип используемого протокола сетевого уровня, вследствие этого мосты
принимают решение только о том, пересылать или не пересылать фрейм, и это решение
основывается лишь на MAC-адресе получателя. Ниже приведены наиболее важные свойства
мостов.
Свойства мостов
Мосты являются более «интеллектуальными» устройствами, чем концентраторы. «Более
интеллектуальные» в данном случае означает, что они могут анализировать входящие
фреймы и пересылать их (или отбросить) на основе адресной информации.
Мосты собирают и передают пакеты между двумя или более сегментами LAN-сети.
Мосты увеличивают количество доменов коллизий (и уменьшают их размер за счет
сегментации локальной сети), что позволяет нескольким устройствам передавать данные
одновременно, не вызывая коллизий.
Мосты поддерживают таблицы MAC-адресов.
Функции мостов
Отличительными функциями моста являются фильтрация фреймов на втором уровне и
используемый при этом способ обработки трафика. Для фильтрации или выборочной доставки
данных мост создает таблицу всех MAC-адресов, расположенных в данном сетевом сегменте и в
других известных ему сетях, и преобразует их в соответствующие номера портов. Этот процесс
подробно описан ниже.
Этап 1.
Если устройство пересылает фрейм данных впервые, мост ищет в нем MACадрес устройства отправителя и записывает его в свою таблицу адресов.
Этап 2.
Когда данные проходят по сетевой среде и поступают на порт моста, он
сравнивает содержащийся в них MAC-адрес пункта назначения с MAC-адресами,
находящимися в его адресных таблицах.
Этап 3.
Если мост обнаруживает, что MAC-адрес получателя принадлежит тому же
сетевому сегменту, в котором находится отправитель, то он не пересылает эти
данные в другие сегменты сети. Этот процесс называется фильтрацией (filtering).
За счет такой фильтрации мосты могут значительно уменьшить объем
передаваемых между сегментами данных, поскольку при этом исключается
ненужная пересылка трафика.
Этап 4.
Если мост определяет, что MAC-адрес получателя находится в сегменте,
отличном от сегмента отправителя, он направляет данные только в
соответствующий сегмент.
Этап 5.
Если MAC-адрес получателя мосту неизвестен, он рассылает данные во все
порты, за исключением того, из которого эти данные были получены. Такой
процесс называется лавинной рассылкой (flooding). Лавинная рассылка фреймов
также используется в коммутаторах.
Этап 6.
Мост строит свою таблицу адресов (зачастую ее называют мостовой таблицей
или таблицей коммутации), изучая MAC-адреса отправителей во фреймах. Если
MAC-адрес отправителя блока данных, фрейма, отсутствует в таблице моста, то
он вместе с номером интерфейса заносится в адресную таблицу. В коммутаторах,
если рассматривать (в самом простейшем приближении) коммутатор как
многопортовый мост, когда устройство обнаруживает, что MAC-адрес
отправителя, который ему известен и вместе с номером порта занесен в адресную
таблицу устройства, появляется на другом порту коммутатора, то он обновляет
свою таблицу коммутации. Коммутатор предполагает, что сетевое устройство
было физически перемещено из одного сегмента сети в другой.
Коммутаторы
Коммутаторы используют те же концепции и этапы работы, которые характерны для мостов. В
самом простом случае коммутатор можно назвать многопортовым мостом, но в некоторых
случаях такое упрощение неправомерно.
Коммутатор Ethernet используется на уровне доступа. Как и концентратор, коммутатор соединяет
несколько узлов с сетью. В отличие от концентратора, коммутатор в состоянии передать
сообщение конкретному узлу. Когда узел отправляет сообщение другому узлу через коммутатор,
тот принимает и декодирует кадры и считывает физический (MAC) адрес сообщения.
В таблице коммутатора, которая называется таблицей MAC-адресов, находится список активных
портов и MAC-адресов подключенных к ним узлов. Когда узлы обмениваются сообщениями,
коммутатор проверяет, есть ли в таблице MAC-адрес. Если да, коммутатор устанавливает между
портом источника и назначения временное соединение, которое называется канал. Этот новый
канал представляет собой назначенный канал, по которому два узла обмениваются данными.
Другие узлы, подключенные к коммутатору, работают на разных полосах пропускания канала и не
принимают сообщения, адресованные не им. Для каждого нового соединения между узлами
создается новый канал. Такие отдельные каналы позволяют устанавливать несколько соединений
одновременно без возникновения коллизий.
Поскольку коммутация осуществляется на аппаратном уровне, это происходит значительно
быстрее, чем аналогичная функция, выполняемая мостом с помощью программного обеспечения
(Следует обратить внимание, что мост считается устройством с программной, коммутатор с
аппаратной коммутацией.). Каждый порт коммутатора можно рассматривать как отдельный
микромост. При этом каждый порт коммутатора предоставляет каждой рабочей станции всю
полосу пропускания передающей среды. Такой процесс называется микросегментацией.
Микросегментация (microsegmentation) позволяет создавать частные, или выделенные
сегменты, в которых имеется только одна рабочая станция. Каждая такая станция получает
мгновенный доступ ко всей полосе пропускания, и ей не приходится конкурировать с другими
станциями за право доступа к передающей среде. В дуплексных коммутаторах не происходит
коллизий, поскольку к каждому порту коммутатора подсоединено только одно устройство.
Однако, как и мост, коммутатор пересылает широковещательные пакеты всем сегментам сети.
Поэтому в сети, использующей коммутаторы, все сегменты должны рассматриваться как один
широковещательный домен.
Некоторые коммутаторы, главным образом самые современные устройства и коммутаторы уровня
предприятия, способны выполнять операции на нескольких уровнях. Например, устройства серий
Cisco 6500 и 8500 выполняют некоторые функции третьего уровня.
Иногда к порту коммутатора подключают другое сетевое устройство, например, концентратор.
Это увеличивает количество узлов, которые можно подключить к сети. Если к порту коммутатора
подключен концентратор, MAC-адреса всех узлов, подключенных к концентратору, связываются с
одним портом. Бывает, что один узел подключенного концентратора отправляет сообщения
другому узлу того же устройства. В этом случае коммутатор принимает кадр и проверяет
местонахождение узла назначения по таблице. Если узлы источника и назначения подключены к
одному порту, коммутатор отклоняет сообщение.
Если концентратор подключен к порту коммутатора, возможны коллизии. Концентратор передает
поврежденные при столкновении сообщения всем портам. Коммутатор принимает поврежденное
сообщение, но, в отличие от концентратора, не переправляет его. В итоге у каждого порта
коммутатора создается отдельный домен коллизий. Это хорошо. Чем меньше узлов в домене
коллизий, тем менее вероятно возникновение коллизии.
Маршрутизаторы
Маршрутизаторы (router) представляют собой устройства объединенных сетей, которые
пересылают пакеты между сетями на основе адресов третьего уровня. Маршрутизаторы способны
выбирать наилучший путь в сети для передаваемых данных. Функционируя на третьем уровне,
маршрутизатор может принимать решения на основе сетевых адресов вместо использования
индивидуальных MAC-адресов второго уровня. Маршрутизаторы также способны соединять
между собой сети с различными технологиями второго уровня, такими, как Ethernet, Token Ring и
Fiber Distributed Data Interface (FDDI — распределенный интерфейс передачи данных по
волоконно»оптическим каналам). Обычно маршрутизаторы также соединяют между собой сети,
использующие технологию асинхронной передачи данных ATM (Asynchronous Transfer Mode —
ATM) и последовательные соединения. Вследствие своей способности пересылать пакеты на
основе информации третьего уровня, маршрутизаторы стали основной магистралью глобальной
сети Internet и используют протокол IP.
Маршрутизатор Cisco 1841
Функции маршрутизаторов
Задачей маршрутизатора является инспектирование входящих пакетов (а именно, данных третьего
уровня), выбор для них наилучшего пути по сети и их коммутация на соответствующий выходной
порт. В крупных сетях маршрутизаторы являются главными устройствами, регулирующими
перемещение по сети потоков данных. В принципе маршрутизаторы позволяют обмениваться
информацией любым типам компьютеров.
Как маршрутизатор определяет нужно ли пересылать данные в другую сеть? В пакете содержатся
IP-адреса источника и назначения и данные пересылаемого сообщения. Маршрутизатор считывает
сетевую часть IP-адреса назначения и с ее помощью определяет, по какой из подключенных сетей
лучше всего переслать сообщение адресату.
Если сетевая часть IP-адресов источника и назначения не совпадает, для пересылки сообщения
необходимо использовать маршрутизатор. Если узел, находящийся в сети 1.1.1.0, должен
отправить сообщение узлу в сети 5.5.5.0, оно переправляется маршрутизатору. Он получает
сообщение, распаковывает и считывает IP-адрес назначения. Затем он определяет, куда
переправить сообщение. Затем маршрутизатор снова инкапсулирует пакет в кадр и переправляет
его по назначению.
——————————————
Брандмауэры
Термин брандмауэр (firewall) используется либо по отношению к программному обеспечению,
работающему на маршрутизаторе или сервере, либо к отдельному аппаратному компоненту сети.
Брандмауэр защищает ресурсы частной сети от несанкционированного доступа пользователей из
других сетей. Работая в тесной связи с программным обеспечением маршрутизатора, брандмауэр
исследует каждый сетевой пакет, чтобы определить, следует ли направлять его получателю.
Использование брандмауэра можно сравнить с работой сотрудника, который
отвечает за то, чтобы только разрешенные данные поступали в сеть и выходили из нее.
Аппаратный брандмауэр Cisco PIX серии 535
Голосовые устройства, DSL-устройства, кабельные модемы и оптические устройства
Возникший в последнее время спрос на интеграцию голосовых и обычных данных и быструю
передачу данных от конечных пользователей в сетевую магистраль привел к появлению
следующих новых сетевых устройств:
голосовых шлюзов, используемых для обработки интегрированного голосового трафика и
обычных данных;
мультиплексоров DSLAM, используемых в главных офисах провайдеров служб для
концентрации соединений DSL»модемов от сотен индивидуальных домашних
пользователей;
терминальных систем кабельных модемов (Cable Modem Termination System — CMTS),
используемых на стороне оператора кабельной связи или в головном офисе для
концентрации соединений от многих подписчиков кабельных служб;
оптических платформ для передачи и получения данных по оптоволоконному кабелю,
обеспечивающих высокоскоростные соединения.
Беспроводные сетевые адаптеры
Каждому пользователю беспроводной сети требуется беспроводной сетевой адаптер NIC,
называемый также адаптером клиента. Эти адаптеры доступны в виде плат PCMCIA или карт
стандарта шины PCI и обеспечивают беспроводные соединения как для компактных переносных
компьютеров, так и для настольных рабочих станций. Переносные или компактные компьютеры
PC с беспроводными адаптерами NIC могут свободно перемещаться в территориальной сети,
поддерживая при этом непрерывную связь с сетью. Беспроводные адаптеры
для шин PCI (Peripheral Component Interconnect — 32-разрядная системная шина для подключения
периферийных устройств) и ISA (Industry-Standard Architecture — структура, соответствующая
промышленному стандарту) для настольных рабочих станций позволяют добавлять к локальной
сети LAN конечные станции легко, быстро и без особых материальных
затрат. При этом не требуется прокладки дополнительных кабелей. Все адаптеры имеют антенну:
карты PCMCIA обычно выпускаются со встроенной антенной, а PCI-карты комплектуются
внешней антенной. Эти антенны обеспечивают зону приема, необходимую для передачи и приема
данных.
Беспроводной сетевой адаптер
Точки беспроводного доступа
Точка доступа (Access Point — AP), называемая также базовой станцией, представляет собой
беспроводной приемопередатчик локальной сети LAN, который выполняет функции
концентратора, т.е. центральной точки отдельной беспроводной сети, или функции моста — точки
соединения проводной и беспроводной сетей. Использование нескольких точек AP позволяет
обеспечить выполнение функций роуминга (roaming), что предоставляет пользователям
беспроводного доступа свободный доступ в пределах некоторой области, поддерживая при этом
непрерывную связь с сетью.
Точка беспроводного доступа Cisco AP 541N
Беспроводные мосты
Беспроводной мост обеспечивает высокоскоростные беспроводные соединения большой
дальности в пределах видимости5 (до 25 миль) между сетями Ethernet.
В беспроводных сетях Cisco любая точка доступа может быть использована в качестве
повторителя (точки расширения).
Беспроводной мост Cisco WET200-G5 с интегрированным 5-ти портовым коммутатором
Выводы
Сегодня сложно найти устройства выполняющие только одну функцию. Все чаще производители
интегрируют в одно устройство несколько функций, которые раньше выполнялись отдельными
устройствами в сети. Поэтому деление на типы устройств становится условным. Нужно только
ясно отличать функции этих составных устройств и область их применения. Ярким примером
такой интеграции, являются маршрутизаторы со встроенными DCHP-серверами и т.д.
Тема 4. Коммутация и маршрутизация.
Учебные вопросы:
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
Функции сетевого и транспортного уровней. Транспортные и сетевые протоколы.
Назначение коммутаторов, маршрутизаторов, шлюзов.
Маршрутизация.
Алгоритмы маршрутизации Беллмана-Форда и OSPF.
Стек протоколов TCP/IP, его связь с моделью ISO/OSI.
Протокол IP. IPv4 и IPv6.
Протоколы ARPRARP.
Протокол ICMP.
Транспортные протоколы TCP и UDP.
Система доменных имен DNS.
Система имен NetBIOS. Протоколы NetBIOS/SMB.
Динамическое конфигурирование узлов DHCP.
Протоколы SPX/IPX.
Сетевые ОС. Функции и характеристики сетевых операционных систем (ОС).
Вопрос 1. Функции сетевого и транспортного уровней. Транспортные и сетевые протоколы.
Сетевой уровень (англ. Network layer) — 3-й уровень сетевой модели OSI, предназначается для
определения пути передачи данных. Отвечает за трансляциюлогических адресов и имён
в физические, определение кратчайших маршрутов, коммутацию и маршрутизацию, отслеживание
неполадок и заторов в сети. На этом уровне работает такое сетевое устройство,
как маршрутизатор.
В пределах семантики иерархического представления модели OSI Сетевой уровень отвечает на
запросы обслуживания от Транспортного уровня и направляет запросы обслуживания
на Канальный уровень.
Максимальная длина пакета сетевого уровня может быть ограничена командой ip mtu.
Классификация
Протоколы сетевого уровня маршрутизируют данные от источника к получателю и могут быть
разделены на два класса: протоколы с установкой соединения и без него.
Протоколы с установкой соединения начинают передачу данных с вызова или установки
маршрута следования пакетов от источника к получателю. После чего начинают
последовательную передачу данных и затем по окончании передачи разрывают связь.
Протоколы без установки соединения посылают данные, содержащие полную адресную
информацию в каждом пакете. Каждый пакет содержит адрес отправителя и получателя.
Далее каждое промежуточное сетевое устройство считывает адресную информацию и
принимает решение о маршрутизации данных. Письмо или пакет данных передается от
одного промежуточного устройства к другому до тех пор, пока не будет доставлено
получателю. Протоколы без установки соединения не гарантируют поступление
информации получателю в том порядке, в котором она была отправлена, так как разные
пакеты могут пройти разными маршрутами. За восстановление порядка данных при
использовании сетевых протоколов без установки соединения отвечают транспортные
протоколы.
Функции Сетевого уровня:
Для моделей с установлением соединения — установление соединения:
Сетевой уровень модели OSI может быть как с установкой соединения, так и без него. Для
сравнения — Межсетевой уровень (англ. internet) стека протоколов Модели DoD (Модель
TCP/IP) поддерживает только протокол IP, который является протоколом без установки
соединения; протоколы с установкой соединения находятся на следующих уровнях этой модели.
Присвоение адреса сетевому узлу
Каждый хост в сети должен иметь уникальный адрес, который определяет, где он находится. Этот
адрес обычно назначается из иерархической системы. В Интернете адреса известны как адреса
протокола IP.
Продвижение данных
Так как многие сети разделены на подсети и соединяются с другими сетями широковещательными
каналами, сети используют специальные хосты, которые называются шлюзами или роутерами
(маршрутизаторами) для доставления пакетов между сетями. Это также используется в интересах
мобильных приложений, когда пользователь двигается от одной базовой станции к другой, в этом
случае пакеты (сообщения) должны следовать за ним. В протоколе IPv4 такая идея описана, но
практически не применяется. IPv6 содержит более рациональное решение.
Отношение к модели TCP/IP
Модель TCP/IP описывает набор протоколов Интернета (RFC 1122). В эту модель входит уровень,
который называется Межсетевым, расположенный над Канальным уровнем. Во многих учебниках
и других вторичных источниках Межсетевой уровень часто соотносится с Сетевым уровнем
модели OSI. Однако, это вводит в заблуждение при характеристике протоколов (то есть является
ли он протоколом с установкой соединения или без), расположение этих уровней различно в двух
моделях. Межсетевой уровень TCP/IP — фактически только подмножество функциональных
возможностей Сетевого уровня. Он только описывает один тип архитектуры сети, Интернета.
Вообще, прямых или строгих сравнений между этими моделями следует избегать, так как
иерархическое представление в TCP/IP не является основным критерием сравнения и вообще, как
полагают, «вредно» (RFC 3439).
Протоколы
Open Systems Interconnection (OSI) Model
IPv4/IPv6, Internet Protocol
DVMRP, Distance Vector Multicast Routing Protocol
ICMP, Internet Control Message Protocol
IGMP, Internet Group Management Protocol
PIM-SM, Protocol Independent Multicast Sparse Mode
PIM-DM, Protocol Independent Multicast Dense Mode
IPsec, Internet Protocol Security
IPX, Internetwork Packet Exchange
RIP, Routing Information Protocol
DDP, Datagram Delivery Protocol
BGP, Border Gateway Protocol
Транспортный уровень (англ. Transport layer) — 4-й уровень сетевой модели OSI,
предназначен для доставки данных. При этом не важно, какие данные передаются, откуда и куда,
то есть, он предоставляет сам механизм передачи. Блоки данных он разделяет на фрагменты,
размер которых зависят от протокола: короткие объединяет в один, а длинные разбивает.
Протоколы этого уровня предназначены для взаимодействия типа точка-точка. Пример: TCP,
UDP, SCTP.
Существует множество классов протоколов транспортного уровня, начиная от протоколов,
предоставляющих только основные транспортные функции, например, функции передачи данных
без подтверждения приема, и заканчивая протоколами, которые гарантируют доставку в пункт
назначения нескольких пакетов данных в надлежащей последовательности, мультиплексируют
несколько потоков данных, обеспечивают механизм управления потоками данных и гарантируют
достоверность принятых данных.
Некоторые протоколы транспортного уровня, называемые протоколами без установки соединения,
не гарантируют, что данные доставляются по назначению в том порядке, в котором они были
посланы устройством-источником. Некоторые транспортные уровни справляются с этим, собирая
данные в нужной последовательности до передачи их на сеансовый уровень.
Мультиплексирование (multiplexing) данных означает, что транспортный уровень способен
одновременно обрабатывать несколько потоков данных (потоки могут поступать и от различных
приложений) между двумя системами. Механизм управления потоком данных — это механизм,
позволяющий регулировать количество данных, передаваемых от одной системы к другой.
Протоколы транспортного уровня часто имеют функцию контроля доставки данных, заставляя
принимающую данные систему отправлять подтверждения передающей стороне о приеме данных.
Вопрос 2. Назначение коммутаторов, маршрутизаторов, шлюзов.
Сетевой коммутатор (жарг. свитч от англ. switch — переключатель) — устройство,
предназначенное для соединения нескольких узловкомпьютерной сети в пределах одного или
нескольких сегментов сети. Коммутатор работает на канальном (втором) уровне модели OSI.
Коммутаторы были разработаны с использованием мостовых технологий и часто рассматриваются
как многопортовые мосты. Для соединения нескольких сетей на основе сетевого
уровня служат маршрутизаторы (3 уровень OSI).
В отличие от концентратора (1 уровень OSI), который распространяет трафик от одного
подключённого устройства ко всем остальным, коммутатор передаёт данные только
непосредственно получателю (исключение составляет широковещательный трафик всем узлам
сети и трафик для устройств, для которых неизвестен исходящий порт коммутатора). Это
повышает производительность и безопасность сети, избавляя остальные сегменты сети от
необходимости (и возможности) обрабатывать данные, которые им не предназначались.
Далее в этой статье рассматриваются исключительно коммутаторы для технологии Ethernet.
Принцип работы коммутатора
Коммутатор хранит в памяти (т.н. ассоциативной памяти) таблицу коммутации, в которой
указывается соответствие MAC-адреса узла порту коммутатора. При включении коммутатора эта
таблица пуста и он работает в режиме обучения. В этом режиме поступающие на какой-либо порт
данные передаются на все остальные порты коммутатора. При этом коммутатор
анализирует фреймы (кадры) и, определив MAC-адрес хоста-отправителя, заносит его в таблицу
на некоторое время. Впоследствии, если на один из портов коммутатора поступит кадр,
предназначенный для хоста, MAC-адрес которого уже есть в таблице, то этот кадр будет передан
только через порт, указанный в таблице. Если MAC-адрес хоста-получателя не ассоциирован с
каким-либо портом коммутатора, то кадр будет отправлен на все порты, за исключением того
порта, с которого он был получен. Со временем коммутатор строит таблицу для всех активных
MAC-адресов, в результате трафик локализуется. Стоит отметить малую латентность (задержку) и
высокую скорость пересылки на каждом порту интерфейса.
Режимы коммутации
Существует три способа коммутации. Каждый из них — это комбинация таких параметров, как
время ожидания и надёжность передачи.
1. С промежуточным хранением (Store and Forward). Коммутатор читает всю информацию в
кадре, проверяет его на отсутствие ошибок, выбирает порт коммутации и после этого
посылает в него кадр.
2. Сквозной (cut-through). Коммутатор считывает в кадре только адрес назначения и после
выполняет коммутацию. Этот режим уменьшает задержки при передаче, но в нём нет
метода обнаружения ошибок.
3. Бесфрагментный (fragment-free) или гибридный. Этот режим является модификацией
сквозного режима. Передача осуществляется после фильтрации фрагментов коллизий
(первые 64 байта кадра анализируются на наличие ошибки и при её отсутствии кадр
обрабатывается в сквозном режиме).
Задержка, связанная с «принятием коммутатором решения», добавляется к времени, которое
требуется кадру для входа на порт коммутатора и выхода с него, и вместе с ним определяет
общую задержку коммутатора.
Симметричная и асимметричная коммутация
Свойство симметрии при коммутации позволяет дать характеристику коммутатора с точки зрения
ширины полосы пропускания для каждого его порта. Симметричный коммутатор обеспечивает
коммутируемые соединения между портами с одинаковой шириной полосы пропускания,
например, когда все порты имеют ширину пропускания 10 Мб/с или 100 Мб/с.
Асимметричный коммутатор обеспечивает коммутируемые соединения между портами с
различной шириной полосы пропускания, например, в случаях комбинации портов с шириной
полосы пропускания 10 Мб/с или 100 Мб/с и 1000 Мб/с.
Асимметричная коммутация используется в случае наличия больших сетевых потоков
типа клиент-сервер, когда многочисленные пользователи обмениваются информацией с сервером
одновременно, что требует большей ширины пропускания для того порта коммутатора, к
которому подсоединён сервер, с целью предотвращения переполнения на этом порте. Для того
чтобы направить поток данных с порта 100 Мб/с на порт 10 Мб/с без опасности переполнения на
последнем, асимметричный коммутатор должен иметь буфер памяти.
Асимметричный коммутатор также необходим для обеспечения большей ширины полосы
пропускания каналов между коммутаторами, осуществляемых через вертикальные кросссоединения, или каналов между сегментами магистрали.
Буфер памяти
Для временного хранения фреймов и последующей их отправки по нужному адресу коммутатор
может использовать буферизацию. Буферизация может быть также использована в том случае,
когда порт пункта назначения занят. Буфером называется область памяти, в которой коммутатор
хранит передаваемые данные.
Буфер памяти может использовать два метода хранения и отправки фреймов: буферизация по
портам и буферизация с общей памятью. При буферизации по портам пакеты хранятся
вочередях (queue), которые связаны с отдельными входными портами. Пакет передаётся на
выходной порт только тогда, когда все фреймы, находившиеся впереди него в очереди, были
успешно переданы. При этом возможна ситуация, когда один фрейм задерживает всю очередь изза занятости порта его пункта назначения. Эта задержка может происходить даже в том случае,
когда остальные фреймы могут быть переданы на открытые порты их пунктов назначения.
При буферизации в общей памяти все фреймы хранятся в общем буфере памяти, который
используется всеми портами коммутатора. Количество памяти, отводимой порту, определяется
требуемым ему количеством. Такой метод называется динамическим распределением буферной
памяти. После этого фреймы, находившиеся в буфере, динамически распределяются выходным
портам. Это позволяет получить фрейм на одном порте и отправить его с другого порта, не
устанавливая его в очередь.
Коммутатор поддерживает карту портов, в которые требуется отправить фреймы. Очистка этой
карты происходит только после того, как фрейм успешно отправлен.
Поскольку память буфера является общей, размер фрейма ограничивается всем размером буфера,
а не долей, предназначенной для конкретного порта. Это означает, что крупные фреймы могут
быть переданы с меньшими потерями, что особенно важно при асимметричной коммутации, то
есть когда порт с шириной полосы пропускания 100 Мб/с должен отправлять пакеты на порт 10
Мб/с.
Возможности и разновидности коммутаторов
Коммутаторы подразделяются на управляемые и неуправляемые (наиболее простые).
Более сложные коммутаторы позволяют управлять коммутацией на сетевом (третьем)
уровне модели OSI. Обычно их именуют соответственно, например «Layer 3 Switch» или
сокращенно «L3 Switch». Управление коммутатором может осуществляться посредством Webинтерфейса, интерфейса командной строки (CLI), протокола SNMP, RMON и т. п.
Многие управляемые коммутаторы позволяют настраивать дополнительные
функции: VLAN, QoS, агрегирование, зеркалирование. На данный момент[когда?] многие
коммутаторы уровня доступа обладают такими расширенными возможностями, как сегментация
трафика между портами, контроль трафика на предмет штормов, обнаружение петель,
ограничение количества изучаемых mac-адресов, ограничение входящей/исходящей скорости на
портах, функции списков доступа и т.п.
Сложные коммутаторы можно объединять в одно логическое устройство — стек — с целью
увеличения числа портов. Например, можно объединить 4 коммутатора с 24 портами и получить
логический коммутатор с 90 ((4*24)-6=90) портами либо с 96 портами (если для стекирования
используются специальные порты).
Маршрутизатор (проф. жарг. раутер, рутер (от англ. router /ˈɹu:tə(ɹ)/ или /ˈɹaʊtəɹ/[1], /ˈɹaʊtɚ/)
или роутер (транслитерация английского слова)) — специализированный сетевой компьютер,
имеющий два или более сетевых интерфейсов[2] и пересылающий пакеты данных между
различными сегментами сети. Маршрутизатор может связывать разнородные сети различных
архитектур. Для принятия решений о пересылке пакетов используется информация о топологии
сети и определённые правила, заданные администратором.
Маршрутизаторы работают на более высоком «сетевом» (третьем) уровне сетевой модели OSI,
нежели коммутатор (или сетевой мост) иконцентратор (хаб), которые работают соответственно на
втором и первом уровнях модели OSI.
Принцип работы
Avaya Маршрутизатор основной (ERS-8600)
Обычно маршрутизатор использует адрес получателя, указанный в заголовке пакета, и определяет
по таблице маршрутизации путь, по которому следует передать данные. Если в таблице
маршрутизации для адреса нет описанного маршрута, пакет отбрасывается.
Существуют и другие способы определения маршрута пересылки пакетов, когда, например,
используется адрес отправителя, используемые протоколы верхних уровней и другая информация,
содержащаяся в заголовках пакетов сетевого уровня. Нередко маршрутизаторы могут
осуществлять трансляцию адресов отправителя и получателя, фильтрацию транзитного потока
данных на основе определённых правил с целью ограничения доступа,
шифрование/расшифрование передаваемых данных и т. д.
Таблица маршрутизации
Таблица маршрутизации содержит информацию, на основе которой маршрутизатор принимает
решение о дальнейшей пересылке пакетов. Таблица состоит из некоторого числа записей —
маршрутов, в каждой из которых содержится идентификатор сети получателя (состоящий из
адреса и маскисети), адрес следующего узла, которому следует передавать
пакеты, административное расстояние — степень доверия к источнику маршрута и некоторый вес
записи — метрика. Метрики записей в таблице играют роль в вычислении кратчайших маршрутов
к различным получателям. В зависимости от модели маршрутизатора и используемых протоколов
маршрутизации, в таблице может содержаться некоторая дополнительная служебная информация.
Например:
192.168.64.0/16 [110/49] via 192.168.1.2, 00:34:34, FastEthernet0/0.1
где 192.168.64.0/16 — сеть назначения,
110/- административное расстояние
/49 — метрика маршрута,
192.168.1.2 — адрес следующего маршрутизатора, которому следует
передавать пакеты для сети 192.168.64.0/16,
00:34:34 — время, в течение которого был известен этот маршрут,
FastEthernet0/0.1 — интерфейс маршрутизатора, через который можно
достичь «соседа» 192.168.1.2.
Таблица маршрутизации может составляться двумя способами:
статическая маршрутизация — когда записи в таблице вводятся и изменяются вручную.
Такой способ требует вмешательства администратора каждый раз, когда происходят
изменения в топологии сети. С другой стороны, он является наиболее стабильным и
требующим минимума аппаратных ресурсов маршрутизатора для обслуживания таблицы.
динамическая маршрутизация — когда записи в таблице обновляются автоматически
при помощи одного или нескольких протоколов маршрутизации —
RIP, OSPF, IGRP,EIGRP, IS-IS, BGP, и др. Кроме того, маршрутизатор строит таблицу
оптимальных путей к сетям назначения на основе различных критериев — количества
промежуточных узлов, пропускной способности каналов, задержки передачи данных
и т. п. Критерии вычисления оптимальных маршрутов чаще всего зависят от протокола
маршрутизации, а также задаются конфигурацией маршрутизатора. Такой способ
построения таблицы позволяет автоматически держать таблицу маршрутизации в
актуальном состоянии и вычислять оптимальные маршруты на основе текущей топологии
сети. Однако динамическая маршрутизация оказывает дополнительную нагрузку на
устройства, а высокая нестабильность сети может приводить к ситуациям, когда
маршрутизаторы не успевают синхронизировать свои таблицы, что приводит к
противоречивым сведениям о топологии сети в различных её частях и потере
передаваемых данных.
Зачастую для построения таблиц маршрутизации используют теорию графов.
Применение
Маршрутизаторы помогают уменьшить загрузку сети, благодаря её разделению на домены
коллизий или широковещательные домены, а также благодаря фильтрации пакетов. В основном их
применяют для объединения сетей разных типов, зачастую несовместимых по архитектуре и
протоколам, например для объединения локальных сетей Ethernet и WAN-соединений,
использующих протоколы xDSL, PPP, ATM, Frame relay и т. д. Нередко маршрутизатор
используется для обеспечения доступа из локальной сети в глобальную сетьИнтернет,
осуществляя функции трансляции адресов и межсетевого экрана.
В качестве маршрутизатора может выступать как специализированное (аппаратное) устройство,
так и обычный компьютер, выполняющий функции маршрутизатора. Существует несколько
пакетов программного обеспечения (на основе ядра Linux, на основе операционных систем BSD) с
помощью которого можно превратить ПК в высокопроизводительный и многофункциональный
маршрутизатор, например, Quagga, IPFW или простой в применении PF.
Устройства для дома и малого офиса
В бытовом секторе обычно используются малопортовые маршрутизаторы/роутеры,
обеспечивающие подключение домашней сети компьютеров к каналу связи провайдера интернета.
Как правило, при этом роутер обеспечивает IP-адресацию устройств локальной сети по
протоколу DHCP, а сам получает IP-адрес от внешнего провайдера. Обычно современный роутер
имеет ряд вспомогательных функций и встроенных возможностей: точка доступа Wi-Fi для
подключения мобильных устройств, файервол для защиты сети от внешних атак, резервирование
интернета от нескольких провайдеров, веб-интерфейс для упрощения настройки устройства, USBпорт для подключения принтера или дискового хранилища и другие. Бытовые маршрутизаторы
имеют различную сетевую пропускную способность, простые дешёвые модели могут
ограничивать скорость подключения интернет на высокоскоростных тарифах.
Сетевой шлюз (англ. gateway) — аппаратный маршрутизатор или программное обеспечение для
сопряжения компьютерных сетей, использующих разные протоколы (например, локальной и
глобальной).
Описание
Сетевой шлюз конвертирует протоколы одного типа физической среды в протоколы другой
физической среды (сети). Например, при соединении локального компьютера с
сетью Интернет обычно используется сетевой шлюз.
Маршрутизатор (он же — роутер) является одним из примеров аппаратных сетевых шлюзов.
Сетевые шлюзы работают на всех известных операционных системах. Основная задача сетевого
шлюза — конвертировать протоколмежду сетями. Роутер сам по себе принимает, проводит и
отправляет пакеты только среди сетей, использующих одинаковые протоколы. Сетевой шлюз
может с одной стороны принять пакет, сформатированный под один протокол (например Apple
Talk) и конвертировать в пакет другого протокола (например TCP/IP) перед отправкой в другой
сегмент сети. Сетевые шлюзы могут быть аппаратным решением, программным обеспечением или
тем и другим вместе, но обычно это программное обеспечение, установленное на роутер
или компьютер. Сетевой шлюз должен понимать все протоколы, используемые роутером. Обычно
сетевые шлюзы работают медленнее, чем сетевые мосты, коммутаторы и обычные
маршрутизаторы. Сетевой шлюз — это точка сети, которая служит выходом в другую сеть. В
сети Интернет узлом или конечной точкой может быть или сетевой шлюз, илихост. Интернетпользователи и компьютеры, которые доставляют веб-страницы пользователям — это хосты, а
узлы между различными сетями — это сетевые шлюзы. Например,сервер,
контролирующий трафик между локальной сетью компании и сетью Интернет — это сетевой
шлюз.
В крупных сетях сервер, работающий как сетевой шлюз, обычно интегрирован с проксисервером и межсетевым экраном. Сетевой шлюз часто объединен с роутером, который управляет
распределением и конвертацией пакетов в сети.
Сетевой шлюз может быть специальным аппаратным роутером или программным обеспечением,
установленным на обычный сервер или персональный компьютер. Большинство компьютерных
операционных систем использует термины, описанные выше. Компьютеры под Windows обычно
используют встроенный мастер подключения к сети, который по указанным параметрам сам
устанавливает соединение с локальной или глобальной сетью. Такие системы могут также
использовать DHCP-протокол. Dynamic Host Configuration Protocol (DHCP) — это протокол,
который обычно используется сетевым оборудованием, чтобы получить различные данные,
необходимые клиенту для работы с протоколом IP. С использованием этого протокола добавление
новых устройств и сетей становится простым и практически автоматическим.
Вопрос 3. Маршрутизация.
Маршрутизация (англ. Routing) — процесс определения маршрута следования информации в
сетях связи.
Маршруты могут задаваться административно (статические маршруты), либо вычисляться с
помощью алгоритмов маршрутизации, базируясь на информации о топологии и состоянии сети,
полученной с помощью протоколов маршрутизации (динамические маршруты).
Статическими маршрутами могут быть:
маршруты, не изменяющиеся во времени;
маршруты, изменяющиеся по расписанию;
Маршрутизация в компьютерных сетях выполняется специальными программно-аппаратными
средствами — маршрутизаторами; в простых конфигурациях может выполняться и компьютерами
общего назначения, соответственно настроенными.
Маршрутизируемые протоколы
Протокол маршрутизации может работать только с пакетами, принадлежащими к одному из
маршрутизируемых протоколов, например, IP, IPX илиXerox Network System, AppleTalk.
Маршрутизируемые протоколы определяют формат пакетов (заголовков), важнейшей
информацией из которых для маршрутизации является адрес назначения. Протоколы, не
поддерживающие маршрутизацию, могут передаваться между сетями с помощью туннелей.
Подобные возможности обычно предоставляют программные маршрутизаторы и некоторые
модели аппаратных маршрутизаторов.
Программная и аппаратная маршрутизация
Первые маршрутизаторы представляли собой специализированное ПО, обрабатывающее
приходящие IP-пакеты специфичным образом. Это ПО работало на компьютерах, у которых было
несколько сетевых интерфейсов, входящих в состав различных сетей (между которыми
осуществляется маршрутизация). В дальнейшем появились маршрутизаторы в форме
специализированных устройств. Компьютеры с маршрутизирующим ПО называютпрограммные
маршрутизаторы, оборудование — аппаратные маршрутизаторы.
В современных аппаратных маршрутизаторах для построения таблиц маршрутизации
используется специализированное ПО («прошивка»), для обработки же IP-пакетов
используетсякоммутационная матрица (или другая технология аппаратной коммутации),
расширенная фильтрами адресов в заголовке IP-пакета.
Аппаратная маршрутизация[1]
Выделяют два типа аппаратной маршрутизации: со статическими шаблонами потоков и с
динамически адаптируемыми таблицами.
Статические шаблоны потоков подразумевают разделение всех входящих в маршрутизатор IPпакетов на виртуальные потоки; каждый поток характеризуется набором признаков для
пакета такие как: IP-адресами отправителя/получателя, TCP/UDP-порт
отправителя/получателя (в случае поддержки маршрутизации на основании информации 4
уровня),порт, через который пришёл пакет. Оптимизация маршрутизации при этом строится на
идее, что все пакеты с одинаковыми признаками должны обрабатываться одинаково (по
одинаковым правилам), при этом признаки проверяются только для первого пакета в потоке (при
появлении пакета с набором признаков, не укладывающимся в существующие потоки, создаётся
новый поток), по результатам анализа этого пакета формируется статический шаблон, который и
используется для определения правил коммутации приходящих пакетов (внутри потока). Обычно
время хранения неиспользующегося шаблона ограничено (для освобождения ресурсов
маршрутизатора). Ключевым недостатком подобной схемы является инерционность по
отношению к изменению таблицы маршрутизации (в случае существующего потока изменение
правил маршрутизации пакетов не будет «замечено» до момента удаления шаблона).
Динамически адаптируемые таблицы используют правила маршрутизации «напрямую»,
используя маску и номер сети из таблицы маршрутизации для проверки пакета и определения
порта, на который нужно передать пакет. При этом изменения в таблице маршрутизации (в
результате работы, например, протоколов маршрутизации/резервирования) сразу же влияют на
обработку всех новопришедших пакетов. Динамически адаптируемые таблицы также позволяют
легко реализовывать быструю (аппаратную) проверку списков доступа.
Программная маршрутизация
Программная маршрутизация выполняется либо специализированным ПО маршрутизаторов (в
случае, когда аппаратные методы не могут быть использованы, например, в случае
организации туннелей), либо программным обеспечением на компьютере. В общем случае, любой
компьютер осуществляет маршрутизацию своих собственных исходящих пакетов (как минимум,
для разделения пакетов, отправляемых на шлюз по умолчанию и пакетов, предназначенных узлам
в локальном сегменте сети). Для маршрутизации чужих IP-пакетов, а также построения таблиц
маршрутизации используется различное ПО:
Сервис RRAS (англ. routing and remote access service) в Windows Server
Демоны routed, gated, quagga в Unix-подобных операционных системах (Linux, FreeBSD
и т. д.)
Вопрос 4. Алгоритмы маршрутизации Беллмана-Форда и OSPF.
Алгоритм Беллмана–Форда — алгоритм поиска кратчайшего пути во взвешенном графе. За
время O(|V| × |E|) алгоритм находит кратчайшие пути от одной вершины графа до всех остальных.
В отличие от алгоритма Дейкстры, алгоритм Беллмана–Форда допускает рёбра с
отрицательным весом. Предложен независимо Ричардом Беллманом и Лестером Фордом.
Алгоритм маршрутизации RIP (алгоритм Беллмана–Форда) был впервые разработан в 1969 году,
как основной для сети ARPANET.
Формулировка задачи
Дан ориентированный или неориентированный граф G со взвешенными рёбрами. Длиной пути
назовём сумму весов рёбер, входящих в этот путь. Требуется найти кратчайшие пути от
выделенной вершины s до всех вершин графа.
Заметим, что кратчайших путей может не существовать. Так, в графе, содержащем цикл с
отрицательным суммарным весом, существует сколь угодно короткий путь от одной вершины
этого цикла до другой (каждый обход цикла уменьшает длину пути). Цикл, сумма весов рёбер
которого отрицательна, называется отрицательным циклом.
Решение задачи на графе без отрицательных циклов
Решим поставленную задачу на графе, в котором заведомо нет отрицательных циклов.
Для нахождения кратчайших путей от одной вершины до всех остальных, воспользуемся
методом динамического программирования. Построим матрицу Aij, элементы которой будут
обозначать следующее: Aij — это длина кратчайшего пути из s в i, содержащего не более j рёбер.
Путь, содержащий 0 рёбер, существует только до вершины s. Таким образом, Ai0 равно 0 при i = s,
и +∞ в противном случае.
Теперь рассмотрим все пути из s в i, содержащие ровно j рёбер. Каждый такой путь есть путь
из
ребра, к которому добавлено последнее ребро. Если про пути длины
уже подсчитаны, то определить j-й столбец матрицы не составляет труда.
все данные
Так выглядит алгоритм поиска длин кратчайших путей в графе без отрицательных циклов:
for
do
for
to
do for
if
then
return
Здесь V — множество вершин графа G, E — множество его рёбер, а w — весовая функция,
заданная на ребрах графа (возвращает длину дуги, ведущей из вершины u в v), d — массив,
содержащий расстояния от вершины s до любой другой вершины.
Внешний цикл выполняется
раз, поскольку кратчайший путь не может содержать
большее число ребер, иначе он будет содержать цикл, который точно можно выкинуть.
Вместо массива d можно хранить всю матрицу A, но это требует O(V²) памяти. Зато при этом
можно вычислить и сами кратчайшие пути, а не только их длины. Для этого заведем матрицу Pij.
Если элемент Aij содержит длину кратчайшего пути из s в i, содержащего j рёбер, то Pij содержит
предыдущую вершину до i в одном из таких кратчайших путей (ведь их может быть несколько).
Теперь алгоритм Беллмана–Форда выглядит так:
for
for
to
do
for
do for
if
to
then
После выполнения этого алгоритма элементы
содержат длины кратчайших путей от s до i с
количеством ребер j, и из всех таких путей следует выбрать самый короткий. А сам кратчайший
путь до вершины i с j ребрами восстанавливается так:
while
return p
Граф с отрицательными циклами
Алгоритм Беллмана–Форда позволяет очень просто определить, существует ли в
графе G отрицательный цикл, достижимый из вершины s. Достаточно произвести внешнюю
итерацию цикла не
, a ровно |V| раз. Если при исполнении последней итерации длина
кратчайшего пути до какой-либо вершины строго уменьшилась, то в графе есть отрицательный
цикл, достижимый из s. На основе этого можно предложить следующую оптимизацию:
отслеживать изменения в графе и, как только они закончатся, сделать выход из цикла (дальнейшие
итерации будут бессмысленны).
OSPF(англ. Open Shortest Path First) — протокол динамической маршрутизации, основанный на
технологии отслеживания состояния канала (link-state technology) и использующий для
нахождения кратчайшего пути алгоритм Дейкстры.
Протокол OSPF был разработан IETF в 1988 году. Последняя версия протокола представлена
в RFC 2328. Протокол OSPF представляет собой протокол внутреннего шлюза (Interior Gateway
Protocol — IGP). Протокол OSPF распространяет информацию о доступных маршрутах
между маршрутизаторами одной автономной системы.
OSPF имеет следующие преимущества:
Высокая скорость сходимости по сравнению с дистанционно-векторными протоколами
маршрутизации;
Поддержка сетевых масок переменной длины (VLSM);
Оптимальное использование пропускной способности с построением дерева кратчайших
путей;
Терминология протокола OSPF
Интерфейс (interface) — соединение маршрутизатора и одной из подключенных к нему
сетей. При обсуждении OSPF термины интерфейс и канал (link) часто употребляются как
синонимы.
Объявление о состоянии канала (link-state advertisement, LSA) — объявление описывает
все каналы маршрутизатора, все интерфейсы и состояние каналов.
Состояние канала (link state) — состояние канала между двумя маршрутизаторами;
обновления происходят при помощи пакетов LSA.
Метрика (metric) — условный показатель «стоимости» пересылки данных по каналу;
Автономная система (autonomous system) — группа маршрутизаторов, обменивающихся
маршрутной информацией через общий протокол маршрутизации.
Зона (area) — совокупность сетей и маршрутизаторов, имеющих один и тот же
идентификатор зоны.
Соседи (neighbours) — два маршрутизатора, имеющие интерфейсы в общей сети.
Состояние смежности (adjacency) — взаимосвязь между определёнными соседними
маршрутизаторами, установленная с целью обмена информацией маршрутизации.
Hello-протокол (hello protocol) — используется для поддержания соседских отношений.
База данных соседей (neighbours database) — список всех соседей.
База данных состояния каналов (link state database, LSDB) — список всех записей о
состоянии каналов. Встречается также термин топологическая база данных (topological
database), употребляется как синоним базы данных состояния каналов.
Идентификатор маршрутизатора (router ID, RID) — уникальное 32-битовое число, которое
уникально идентифицирует маршрутизатор в пределах одной автономной системы.
Описание работы протокола
1. Маршрутизаторы обмениваются hello-пакетами через все интерфейсы, на которых
активирован OSPF. Маршрутизаторы, разделяющие общий канал передачи данных,
становятся соседями, когда они приходят к договоренности об определённых параметрах,
указанных в их hello-пакетах.
2. На следующем этапе работы протокола маршрутизаторы будут пытаться перейти в
состояние смежности со своими соседями. Переход в состояние смежности определяется
типом маршрутизаторов, обменивающихся hello-пакетами, и типом сети, по которой
передаются hello-пакеты. OSPF определяет несколько типов сетей и несколько типов
маршрутизаторов. Пара маршрутизаторов, находящихся в состоянии смежности,
синхронизирует между собой базу данных состояния каналов.
3. Каждый маршрутизатор посылает объявления о состоянии канала маршрутизаторам, с
которыми он находится в состоянии смежности.
4. Каждый маршрутизатор, получивший объявление от смежного маршрутизатора,
записывает передаваемую в нём информацию в базу данных состояния каналов
маршрутизатора и рассылает копию объявления всем другим смежным с ним
маршрутизаторам.
5. Рассылая объявления внутри одной OSPF-зоны, все маршрутизаторы строят идентичную
базу данных состояния каналов маршрутизатора.
6. Когда база данных построена, каждый маршрутизатор использует алгоритм «кратчайший
путь первым» для вычисления графа без петель, который будет описывать кратчайший
путь к каждому известному пункту назначения с собой в качестве корня. Этот граф —
дерево кратчайших путей.
7. Каждый маршрутизатор строит таблицу маршрутизации из своего дерева кратчайших
путей.
Типы сетей, поддерживаемые протоколом OSPF
Широковещательные сети со множественным доступом (Ethernet, Token Ring)
Точка-точка (T1, E1, коммутируемый доступ)
Нешироковещательные сети со множественным доступом (NBMA) (Frame relay)
Выделенный маршрутизатор (DR) и резервный выделенный маршрутизатор (BDR)
В сетях со множественным доступом отношения соседства устанавливаются между всеми
маршрутизаторами. Если бы все маршрутизаторы в состоянии соседства обменивались
топологической информацией, это привело бы к рассылке большого количество копий LSA. Если,
к примеру, количество маршрутизаторов в сети со множественным доступом равноn, то будет
установлено n(n-1)/2 отношений соседства. Каждый маршрутизатор будет рассылать n-1 LSA
своим соседям, плюс одно LSA для сети, в результате сеть сгенерирует n²LSA.
Для предотвращения проблемы рассылки копий LSA в сетях со множественным доступом
выбираются выделенный маршрутизатор (DR) и запасной выделенный маршрутизатор (BDR).
Выделенный маршрутизатор (designated router, DR) — управляет процессом рассылки LSA в
сети. Каждый маршрутизатор сети устанавливает отношения смежности с DR. Информация об
изменениях в сети отправляется маршрутизатором, обнаружившим это изменение, на выделенный
маршрутизатор, а тот, в свою очередь, отвечает за то, чтобы эта информация была отправлена
остальным маршрутизаторам сегмента множественного доступа.
Недостатком в схеме работы с DR маршрутизатором является то, что при выходе его из строя
должен быть выбран новый DR. Новые отношения соседства должны быть сформированы и, пока
базы данных маршрутизаторов не синхронизируются с базой данных нового DR, сеть будет
недоступна для пересылки пакетов. Для устранения этого недостатка выбирается BDR.
Резервный выделенный маршрутизатор (backup designated router, BDR). Каждый
маршрутизатор сети устанавливает отношения соседства не только с DR, но и BDR. DR и BDR
также устанавливают отношения соседства и между собой. При выходе из строя DR, BDR
становится DR и выполняет все его функции. Так как маршрутизаторы сети установили
отношения соседства с BDR, время недоступности сети минимизируется.
Маршрутизатор, выбранный DR или BDR в одной присоединённой к нему сети множественного
доступа, может не быть DR (BDR) в другой присоединённой сети множественного доступа. Роль
DR (BDR) является свойством интерфейса, а не свойством всего маршрутизатора. Иными словами,
в каждом сегменте множественного доступа (например, коммутационном сегменте Ethernet), в
котором общаются два или более OSPF-маршрутизатора, процесс выбора и распределение ролей
DR/BDR происходит независимо от других сегментов множественного доступа.
Таймеры протокола
HelloInterval — Интервал времени в секундах по истечении которого маршрутизатор
отправляет следующий hello-пакет с интерфейса. Для широковещательных сетей и сетей
точка-точка значение по умолчанию, как правило, 10 секунд. Для нешироковещательных
сетей со множественным доступом значение по умолчанию 30 секунд.
RouterDeadInterval — Интервал времени в секундах по истечении которого сосед будет
считаться «мертвым». Этот интервал должен быть кратным значению HelloInterval. Как
правило, RouterDeadInterval равен 4 интервалам отправки hello-пакетов, то есть 40 секунд.
Wait Timer — Интервал времени в секундах по истечении которого маршрутизатор
выберет DR в сети. Его значение равно значению интервала RouterDeadInterval.
RxmtInterval — Интервал времени в секундах по истечении которого маршрутизатор
повторно отправит пакет на который не получил подтверждения о получении (например,
Database Description пакет или Link State Request пакеты). Этот интервал называется также
Retransmit interval. Значение интервала 5 секунд.
Типы маршрутизаторов
Внутренний маршрутизатор (internal router) — маршрутизатор, все интерфейсы которого
принадлежат одной зоне. У таких маршрутизаторов только одна база данных состояния каналов.
Пограничный маршрутизатор (area border router, ABR) — соединяет одну или больше зон с
магистральной зоной и выполняет функции шлюза для межзонального трафика. У пограничного
маршрутизатора всегда хотя бы один интерфейс принадлежит магистральной зоне. Для каждой
присоединенной зоны маршрутизатор поддерживает отдельную базу данных состояния каналов.
Магистральный маршрутизатор (backbone router) — маршрутизатор у которого всегда хотя бы
один интерфейс принадлежит магистральной зоне. Определение похоже на пограничный
маршрутизатор, однако магистральный маршрутизатор не всегда является пограничным.
Внутренний маршрутизатор, интерфейсы которого принадлежат нулевой зоне, также является
магистральным.
Пограничный маршрутизатор автономной системы (AS boundary router, ASBR) —
обменивается информацией с маршрутизаторами принадлежащими другим автономным системам.
Пограничный маршрутизатор автономной системы может находиться в любом месте автономной
системы и быть внутренним, пограничным или магистральным маршрутизатором.
Типы объявлений о состоянии канала (LSA)
Type 1 LSA — Router LSA — объявление о состоянии каналов маршрутизатора. Эти LSA
распространяются всеми маршрутизаторами. В LSA содержится описание всех каналов
маршрутизатора и стоимость (cost) каждого канала. Распространяются только в пределах одной
зоны.
Type 2 LSA — Network LSA — объявление о состоянии каналов сети. Распространяется DR в
сетях со множественным доступом. В LSA содержится описание всех маршрутизаторов
присоединенных к сети, включая DR. Распространяются только в пределах одной зоны.
Type 3 LSA — Network Summary LSA — суммарное объявление о состоянии каналов сети.
Объявление распространяется пограничными маршрутизаторами. Объявление описывает только
маршруты к сетям вне зоны и не описывает маршруты внутри автономной системы. Пограничный
маршрутизатор отправляет отдельное объявление для каждой известной ему сети.
Когда маршрутизатор получает Network Summary LSA от пограничного маршрутизатора он не
запускает алгоритм вычисления кратчайшего пути. Маршрутизатор просто добавляет к стоимости
маршрута указанного в LSA стоимость маршрута к пограничному маршрутизатору. Затем
маршрут к сети через пограничный маршрутизатор помещается в таблицу маршрутизации.
Type 4 LSA — ASBR Summary LSA — суммарное объявление о состоянии каналов пограничного
маршрутизатора автономной системы. Объявление распространяется пограничными
маршрутизаторами. ASBR Summary LSA отличается от Network Summary LSA тем, что
распространяется информация не о сети, а о пограничном маршрутизаторе автономной системы.
Type 5 LSA — AS External LSA — объявление о состоянии внешних каналов автономной
системы. Объявление распространяется пограничным маршрутизатором автономной системы в
пределах всей автономной системы. Объявление описывает маршруты, внешние для автономной
системы OSPF, или маршруты по умолчанию (default route), внешние для автономной системы
OSPF.
Type 6 LSA — Multicast OSPF LSA — специализированный LSA, который используют
мультикаст OSPF приложения (Not implemented by CISCO).
Type 7 LSA — AS External LSA for NSSA — объявления о состоянии внешних каналов
автономной системы в NSSA зоне. Это объявление может передаваться только в NSSA зоне. На
границе зоны пограничный маршрутизатор преобразует type 7 LSA в type 5 LSA.
Type 8 LSA — Link LSA — анонсирует link-local адрес и префикс(ы) маршрутизатора всем
маршрутизаторам разделяющим канал (link). Отправляется только если на канале присутствует
более чем один маршрутизатор. Распространяются только в пределах канала (link).
Type 9 LSA — Intra-Area-Prefix LSA ставит в соответствие: список префиксов IPv6 и
маршрутизатор, указывая на Router LSA, список префиксов IPv6 и транзитную сеть, указывая на
Network LSA. Распространяются только в пределах одной зоны.
Типы зон
При разделении автономной системы на зоны маршрутизаторам, принадлежащим к одной зоне, не
известна информация о детальной топологии других зон.
Разделение на зоны позволяет:
Снизить нагрузку на ЦП маршрутизаторов за счёт уменьшения количества перерасчётов
по алгоритму OSPF
Уменьшить размер таблиц маршрутизации
Уменьшить количество пакетов обновлений состояния канала
Каждой зоне присваивается идентификатор зоны (area ID). Идентификатор может быть указан в
десятичном формате или в формате записи IP-адреса. Однако идентификаторы зон не являются IPадресами и могут совпадать с любым назначенным IP-адресом.
Существует несколько типов зон:
Магистральная зона (backbone area)
Магистральная зона (известная также как нулевая зона или зона 0.0.0.0) формирует ядро сети
OSPF. Все остальные зоны соединены с ней, и межзональная маршрутизация происходит через
маршрутизатор соединенный с магистральной зоной. Магистральная зона ответственна за
распространение маршрутизирующей информации между немагистральными зонами.
Магистральная зона должна быть смежной с другими зонами, но она не обязательно должна быть
физически смежной; соединение с магистральной зоной может быть установлено и с помощью
виртуальных каналов.
Стандартная зона (standard area)
Обычная зона, которая создается по умолчанию. Эта зона принимает обновления каналов,
суммарные маршруты и внешние маршруты.
Тупиковая зона (stub area)
Тупиковая зона не принимает информацию о внешних маршрутах для автономной системы, но
принимает маршруты из других зон. Если маршрутизаторам из тупиковой зоны необходимо
передавать информацию за границу автономной системы, то они используют маршрут по
умолчанию. В тупиковой зоне не может находиться ASBR.
Totally stubby area
Totally stubby area не принимает информацию о внешних маршрутах для автономной системы и
маршруты из других зон. Если маршрутизаторам необходимо передавать информацию за пределы
зоны, то они используют маршрут по умолчанию. Cisco-proprietary тип зоны.
Not-so-stubby area (NSSA)
Зона NSSA определяет дополнительный тип LSA — LSA type 7. В NSSA зоне может находиться
ASBR.
Формат OSPF-пакетов
OSPF-пакет инкапсулируется непосредственно в поле данных IP-пакета. Значение поля «протокол
верхнего уровня» в заголовке IP-дейтаграммы для OSPF равно 89.
Заголовок пакета
Окте
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9
т
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
0—3
Version
Type
4—7
Router ID
Packet length
8—11 Area ID
12—
15
Checksum
Authentication type
16—
19
Authentication
20—
23
Version — номер версии протокола OSPF, текущая версия OSPF для сетей IPv4 — 2;
Type — тип OSPF-пакета;
Packet length — длина пакета, включая заголовок;
Router ID — идентификатор маршрутизатора, уникальное 32-битное число,
идентифицирующее маршрутизатор в пределах автономной системы;
Area ID — 32-битный идентификатор зоны;
Checksum — поле контрольной суммы, подсчитывается для всего пакета, включая
заголовок;
Authentication type — тип используемой схемы аутентификации, возможные значения:
0 — аутентификация не используется
1 — аутентификация открытым текстом
2 — MD5-аутентификация
Authentication — поле данных аутентификации.
Hello-пакет
Hello-пакет предназначен для установления и поддержания отношений с соседями. Пакет
периодически посылается на все интерфейсы маршрутизатора.
Окте
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9
т
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
0—3
Version
4—7
Router ID
Type = 1
Packet length
8—11 Area ID
12—
15
Checksum
Authentication type
16—
19
Authentication
20—
23
24—
27
Network mask
28—
31
Hello interval
32—
35
Router dead interval
36—
39
Designated router
40—
43
Backup designated router
44—
47
Neighbor ID
…
…
Options
Router priority
Network mask — сетевая маска интерфейса, через который отправляется hello-пакет;
Hello interval — интервал задающий частоту рассылки приветственных сообщений для
обнаружения соседей в автономной системе, для LAN значение по умолчанию равно 10
секундам;
Options — 8-битное поле опций, описывает возможности маршрутизатора;
Router priority — приоритет маршрутизатора, 8-битное число, символизирующее
приоритет маршрутизатора при выборе DR (англ. Designated router) и BDR (англ. Backup
designated router);
Router dead interval — период времени, в течение которого маршрутизатор ожидает ответа
соседей;
Designated router (DR) — IP-адрес DR;
Backup designated router (BDR) — IP-адрес BDR;
Neighbor ID — идентификатор соседа. Список составляется из идентификаторов соседей,
от которых маршрутизатор получил hello-пакеты в течение времени, заданного в поле
router dead interval;
Database Description
Пакет Database Description описывает содержание базы данных состояния канала. Обмен пакетами
производится при установлении состояния смежности.
Окте
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3
0 1 2 3 4 5 6 7 8 9
31
т
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0
0—3
Version
4—7
Router ID
Type = 2
Packet length
8—11 Area ID
12—
15
Checksum
Authentication type
16—
19
Authentication
20—
23
24—
27
Interface MTU
28—
31
DD sequence number
Options
0 0 0 0 0 I
M
M
S
LSA headers
Interface MTU — размер в байтах наибольшей IP дейтаграммы, которая может быть
послана через данный интерфейс без фрагментации;
I-бит — устанавливается для первого пакета в последовательности;
M-бит — указывает наличие последующих дополнительных пакетов;
MS-бит — устанавливается для ведущего, сбрасывается для ведомого;
DD sequence number — в начальном пакете устанавливается на уникальное значение, при
передаче каждого последующего пакета увеличивается на единицу, пока не будет передана
вся база данных;
LSA headers — массив заголовков базы данных состояния каналов.
Link State Request
Пакет Link State Request предназначен для запроса части базы данных соседнего маршрутизатора.
Окте
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9
т
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
0—3
Version
4—7
Router ID
Type = 3
Packet length
8—11 Area ID
12—
15
Checksum
Authentication type
16—
19
Authentication
20—
23
24—
27
LS Type
28—
31
Link State ID
32—
35
Advertising Router
…
…
LS Type — тип объявления о состоянии канала;
Link State ID — идентификатор домена маршрутизации;
Advertising Router — идентификатор маршрутизатора, создавшего объявление о состоянии
канала.
Link State Update
Пакет Link State Update предназначен для рассылки объявлений о состоянии канала. Пакет
посылается по групповому адресу на один транзитный участок.
Окте
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9
т
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
0—3
Version
4—7
Router ID
Type = 4
Packet length
8—11 Area ID
12—
15
Checksum
16—
Authentication
Authentication type
19
20—
23
24—
27
Number of LSA
LSA
Number of LSA — количество объявлений в пакете.
Link State Acknowledgment
Подтверждает получение пакета Link State Update.
Окте
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9
т
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
0—3
Version
4—7
Router ID
Type = 5
Packet length
8—11 Area ID
12—
15
Checksum
16—
19
Authentication
20—
23
LSA headers
Версии протокола OSPF
OSPF версия 1
OSPF версия 2
поддерживает версию протокола IPv4
OSPF версия 3
поддерживает версию протокола IPv6
Критика
Authentication type
Считается, что благодаря использованию алгоритма Дейкстры специфического критерия качества
распределения входного потока информации, он абсолютно не защищает IP-сеть от перегрузок,
что требует реализации дополнительных методов по снижению вероятности перегрузки.
Например, предлагается использовать в критерии распределения остаточнуюпропускную
способность канала.[1]
В то же время, к положительным качествам протокола можно отнести относительную простоту
практической реализации алгоритма.
Вопрос 5. Стек протоколов TCP/IP, его связь с моделью ISO/OSI.
Transmission Control Protocol/Internet Protocol (TCP/IP) — это промышленный стандарт стека
протоколов, разработанный для глобальных сетей.
Стандарты TCP/IP опубликованы в серии документов, названных Request for Comment (RFC).
Документы RFC описывают внутреннюю работу сети Internet. Некоторые RFC описывают сетевые
сервисы или протоколы и их реализацию, в то время как другие обобщают условия применения.
Стандарты TCP/IP всегда публикуются в виде документов RFC, но не все RFC определяют
стандарты.
Стек был разработан по инициативе Министерства обороны США (Department of Defence, DoD)
более 20 лет назад для связи экспериментальной сети ARPAnet с другими сателлитными сетями
как набор общих протоколов для разнородной вычислительной среды. Сеть ARPA поддерживала
разработчиков и исследователей в военных областях. В сети ARPA связь между двумя
компьютерами осуществлялась с использованием протокола Internet Protocol (IP), который и по
сей день является одним из основных в стеке TCP/IP и фигурирует в названии стека.
Большой вклад в развитие стека TCP/IP внес университет Беркли, реализовав протоколы стека в
своей версии ОС UNIX. Широкое распространение ОС UNIX привело и к широкому
распространению протокола IP и других протоколов стека. На этом же стеке работает всемирная
информационная сеть Internet, чье подразделение Internet Engineering Task Force (IETF) вносит
основной вклад в совершенствование стандартов стека, публикуемых в форме спецификаций RFC.
Если в настоящее время стек TCP/IP распространен в основном в сетях с ОС UNIX, то реализация
его в последних версиях сетевых операционных систем для персональных компьютеров (Windows
NT 3.5, NetWare 4.1, Windows 95) является хорошей предпосылкой для быстрого роста числа
установок стека TCP/IP.
Итак, лидирующая роль стека TCP/IP объясняется следующими его свойствами:
Это наиболее завершенный стандартный и в то же время популярный стек сетевых
протоколов, имеющий многолетнюю историю.
Почти все большие сети передают основную часть своего трафика с помощью протокола
TCP/IP.
Это метод получения доступа к сети Internet.
Этот стек служит основой для создания intranet- корпоративной сети, использующей
транспортные услуги Internet и гипертекстовую технологию WWW, разработанную в
Internet.
Все современные операционные системы поддерживают стек TCP/IP.
Это гибкая технология для соединения разнородных систем как на уровне транспортных
подсистем, так и на уровне прикладных сервисов.
Это устойчивая масштабируемая межплатформенная среда для приложений клиент-сервер.
Структура стека TCP/IP. Краткая характеристика протоколов
Так как стек TCP/IP был разработан до появления модели взаимодействия открытых систем
ISO/OSI, то, хотя он также имеет многоуровневую структуру, соответствие уровней стека TCP/IP
уровням модели OSI достаточно условно.
Структура протоколов TCP/IP приведена на рисунке 2.1. Протоколы TCP/IP делятся на 4 уровня.
Рис. 2.1. Стек TCP/IP
Самый нижний (уровень IV) соответствует физическому и канальному уровням модели OSI. Этот
уровень в протоколах TCP/IP не регламентируется, но поддерживает все популярные стандарты
физического и канального уровня: для локальных сетей это Ethernet, Token Ring, FDDI, Fast
Ethernet, 100VG-AnyLAN, для глобальных сетей — протоколы соединений «точка-точка» SLIP и
PPP, протоколы территориальных сетей с коммутацией пакетов X.25, frame relay. Разработана
также специальная спецификация, определяющая использование технологии ATM в качестве
транспорта канального уровня. Обычно при появлении новой технологии локальных или
глобальных сетей она быстро включается в стек TCP/IP за счет разработки соответствующего
RFC, определяющего метод инкапсуляции пакетов IP в ее кадры.
Следующий уровень (уровень III) — это уровень межсетевого взаимодействия, который занимается
передачей пакетов с использованием различных транспортных технологий локальных сетей,
территориальных сетей, линий специальной связи и т. п.
В качестве основного протокола сетевого уровня (в терминах модели OSI) в стеке используется
протоколIP, который изначально проектировался как протокол передачи пакетов в составных
сетях, состоящих из большого количества локальных сетей, объединенных как локальными, так и
глобальными связями. Поэтому протокол IP хорошо работает в сетях со сложной топологией,
рационально используя наличие в них подсистем и экономно расходуя пропускную способность
низкоскоростных линий связи. Протокол IP является дейтаграммным протоколом, то есть он не
гарантирует доставку пакетов до узла назначения, но старается это сделать.
К уровню межсетевого взаимодействия относятся и все протоколы, связанные с составлением и
модификацией таблиц маршрутизации, такие как протоколы сбора маршрутной
информации RIP(Routing Internet Protocol) и OSPF (Open Shortest Path First), а также протокол
межсетевых управляющих сообщений ICMP (Internet Control Message Protocol). Последний
протокол предназначен для обмена информацией об ошибках между маршрутизаторами сети и
узлом — источником пакета. С помощью специальных пакетов ICMP сообщается о невозможности
доставки пакета, о превышении времени жизни или продолжительности сборки пакета из
фрагментов, об аномальных величинах параметров, об изменении маршрута пересылки и типа
обслуживания, о состоянии системы и т.п.
Следующий уровень (уровень II) называется основным. На этом уровне функционируют протокол
управления передачей TCP (Transmission Control Protocol) и протокол дейтаграмм
пользователя UDP(User Datagram Protocol). Протокол TCP обеспечивает надежную передачу
сообщений между удаленными прикладными процессами за счет образования виртуальных
соединений. Протокол UDP обеспечивает передачу прикладных пакетов дейтаграммным
способом, как и IP, и выполняет только функции связующего звена между сетевым протоколом и
многочисленными прикладными процессами.
Верхний уровень (уровень I) называется прикладным. За долгие годы использования в сетях
различных стран и организаций стек TCP/IP накопил большое количество протоколов и сервисов
прикладного уровня. К ним относятся такие широко используемые протоколы, как протокол
копирования файлов FTP, протокол эмуляции терминала telnet, почтовый протокол SMTP,
используемый в электронной почте сети Internet, гипертекстовые сервисы доступа к удаленной
информации, такие как WWW и многие другие. Остановимся несколько подробнее на некоторых
из них.
Протокол пересылки файлов FTP (File Transfer Protocol) реализует удаленный доступ к файлу. Для
того, чтобы обеспечить надежную передачу, FTP использует в качестве транспорта протокол с
установлением соединений — TCP. Кроме пересылки файлов протокол FTP предлагает и другие
услуги. Так, пользователю предоставляется возможность интерактивной работы с удаленной
машиной, например, он может распечатать содержимое ее каталогов. Наконец, FTP выполняет
аутентификацию пользователей. Прежде, чем получить доступ к файлу, в соответствии с
протоколом пользователи должны сообщить свое имя и пароль. Для доступа к публичным
каталогам FTP-архивов Internet парольная аутентификация не требуется, и ее обходят за счет
использования для такого доступа предопределенного имени пользователя Anonymous.
В стеке TCP/IP протокол FTP предлагает наиболее широкий набор услуг для работы с файлами,
однако он является и самым сложным для программирования. Приложения, которым не требуются
все возможности FTP, могут использовать другой, более экономичный протокол — простейший
протокол пересылки файлов TFTP (Trivial File Transfer Protocol). Этот протокол реализует только
передачу файлов, причем в качестве транспорта используется более простой, чем TCP, протокол
без установления соединения — UDP.
Протокол telnet обеспечивает передачу потока байтов между процессами, а также между
процессом и терминалом. Наиболее часто этот протокол используется для эмуляции терминала
удаленного компьютера. При использовании сервиса telnet пользователь фактически управляет
удаленным компьютером так же, как и локальный пользователь, поэтому такой вид доступа
требует хорошей защиты. Поэтому серверы telnet всегда используют как минимум
аутентификацию по паролю, а иногда и более мощные средства защиты, например, систему
Kerberos.
Протокол SNMP (Simple Network Management Protocol) используется для организации сетевого
управления. Изначально протокол SNMP был разработан для удаленного контроля и управления
маршрутизаторами Internet, которые традиционно часто называют также шлюзами. С ростом
популярности протокол SNMP стали применять и для управления любым коммуникационным
оборудованием — концентраторами, мостами, сетевыми адаптерами и т.д. и т.п. Проблема
управления в протоколе SNMP разделяется на две задачи.
Первая задача связана с передачей информации. Протоколы передачи управляющей информации
определяют процедуру взаимодействия SNMP-агента, работающего в управляемом оборудовании,
и SNMP-монитора, работающего на компьютере администратора, который часто называют также
консолью управления. Протоколы передачи определяют форматы сообщений, которыми
обмениваются агенты и монитор.
Вторая задача связана с контролируемыми переменными, характеризующими состояние
управляемого устройства. Стандарты регламентируют, какие данные должны сохраняться и
накапливаться в устройствах, имена этих данных и синтаксис этих имен. В стандарте SNMP
определена спецификация информационной базы данных управления сетью. Эта спецификация,
известная как база данных MIB (Management Information Base), определяет те элементы данных,
которые управляемое устройство должно сохранять, и допустимые операции над ними.
Соответствие уровней каждого стека уровням модели OSI.Основные протоколы каждого
стека, их распределение по уровням.
Cтек TCP/IP
Стек протоколов TCP/IP — набор сетевых протоколов, на которых базируется интернет. Обычно в
стеке TCP/IP верхние 3 уровня (прикладной, представительный и сеансовый) модели OSI
объединяют в один — прикладной. Поскольку в таком стеке не предусматривается
унифицированный протокол передачи данных, функции по определению типа данных передаются
приложению.
Уровни стека TCP/IP
1. Физический уровень описывает среду передачи данных (будь то кабель,
оптоволокно или радиоканал), физические характеристики такой среды и принцип
передачи данных.
2. Канальный уровень описывает каким образом передаются пакеты данных через
физический уровень, включая кодирование (т.е. специальные последовательности
битов, определяющих начало и конец пакета данных).
3. Сетевой уровень изначально разработан для передачи данных из одной (под)сети в
другую. Примерами такого протокола является X.25 и IPC в сети ARPANET.С
развитием концепции глобальной сети в уровень были внесены дополнительные
возможности по передаче из любой сети в любую сеть, независимо от протоколов
нижнего уровня, а также возможность запрашивать данные от удалённой стороны,
4. Протоколы транспортного уровня могут решать проблему негарантированной
доставки сообщений («дошло ли сообщение до адресата?»), а также гарантировать
правильную последовательность прихода данных.
5. На прикладном уровне работает большинство сетевых приложений.Эти программы
имеют свои собственные протоколы обмена информацией, например, HTTP для
WWW, FTP (передача файлов), SMTP (электронная почта), SSH (безопасное
соединение с удалённой машиной), DNS (преобразование символьных имён в IPадреса) и многие другие.
Существуют разногласия в том, как вписать модель TCP/IP в модель OSI, поскольку уровни в этих
моделях не совпадают.
Упрощенно интерпретацию стека TCP/IP можно представить так:
ISO/OSI
TCP/IP
7 Прикладной
HTTP, FTP, Telnet,SMTP, DNS (RIP,
работающий поверх UDP, и BGP,
работающий поверх TCP, являются
частью сетевого уровня), LDAP
6
Представительный
Прикладной
5 Сеансовый
4 Транспортный
TCP, UDP, RTP, SCTP, DCCP
(протоколы маршрутизации, подобные
OSPF, что работают поверх IP,
являются частью сетевого уровня)
Транспортный
3 Сетевой
IP (вспомогательные протоколы, вроде
ICMP и IGMP работают поверх IP, но
являются частью сетевого уровня; ARP
не работает поверх IP)
Сетевой
Ethernet, Token ring, и подобные
Физический
2 Канальный
1 Физический
Вопрос. 6. Протокол IP. IPv4 и IPv6.
Основу транспортных средств стека протоколов TCP/IP составляет протокол межсетевого
взаимодействия — Internet Protocol (IP). К основным функциям протокола IP относятся:
перенос между сетями различных типов адресной информации в унифицированной форме,
сборка и разборка пакетов при передаче их между сетями с различным максимальным
значением длины пакета.
Формат пакета IP
Пакет IP состоит из заголовка и поля данных. Заголовок пакета имеет следующие поля:
Поле Номер версии (VERS) указывает версию протокола IP. Сейчас повсеместно
используется версия 4 и готовится переход на версию 6, называемую также IPng (IP next
generation).
Поле Длина заголовка (HLEN) пакета IP занимает 4 бита и указывает значение длины
заголовка, измеренное в 32-битовых словах. Обычно заголовок имеет длину в 20 байт (пять
32-битовых слов), но при увеличении объема служебной информации эта длина может
быть увеличена за счет использования дополнительных байт в поле Резерв (IP OPTIONS).
Поле Тип сервиса (SERVICE TYPE) занимает 1 байт и задает приоритетность пакета и вид
критерия выбора маршрута. Первые три бита этого поля образуют подполе приоритета
пакета (PRECEDENCE). Приоритет может иметь значения от 0 (нормальный пакет) до 7
(пакет управляющей информации). Маршрутизаторы и компьютеры могут принимать во
внимание приоритет пакета и обрабатывать более важные пакеты в первую очередь. Поле
Тип сервиса содержит также три бита, определяющие критерий выбора маршрута.
Установленный бит D (delay) говорит о том, что маршрут должен выбираться для
минимизации задержки доставки данного пакета, бит T — для максимизации пропускной
способности, а бит R — для максимизации надежности доставки.
Поле Общая длина (TOTAL LENGTH) занимает 2 байта и указывает общую длину пакета с
учетом заголовка и поля данных.
Поле Идентификатор пакета (IDENTIFICATION) занимает 2 байта и используется для
распознавания пакетов, образовавшихся путем фрагментации исходного пакета. Все
фрагменты должны иметь одинаковое значение этого поля.
Поле Флаги (FLAGS) занимает 3 бита, оно указывает на возможность фрагментации пакета
(установленный бит Do not Fragment — DF — запрещает маршрутизатору фрагментировать
данный пакет), а также на то, является ли данный пакет промежуточным или последним
фрагментом исходного пакета (установленный бит More Fragments — MF — говорит о том
пакет переносит промежуточный фрагмент).
Поле Смещение фрагмента (FRAGMENT OFFSET) занимает 13 бит, оно используется для
указания в байтах смещения поля данных этого пакета от начала общего поля данных
исходного пакета, подвергнутого фрагментации. Используется при сборке/разборке
фрагментов пакетов при передачах их между сетями с различными величинами
максимальной длины пакета.
Поле Время жизни (TIME TO LIVE) занимает 1 байт и указывает предельный срок, в
течение которого пакет может перемещаться по сети. Время жизни данного пакета
измеряется в секундах и задается источником передачи средствами протокола IP. На
шлюзах и в других узлах сети по истечении каждой секунды из текущего времени жизни
вычитается единица; единица вычитается также при каждой транзитной передаче (даже
если не прошла секунда). При истечении времени жизни пакет аннулируется.
Идентификатор Протокола верхнего уровня (PROTOCOL) занимает 1 байт и указывает,
какому протоколу верхнего уровня принадлежит пакет (например, это могут быть
протоколы TCP, UDP или RIP).
Контрольная сумма (HEADER CHECKSUM) занимает 2 байта, она рассчитывается по
всему заголовку.
Поля Адрес источника (SOURCE IP ADDRESS) и Адрес назначения (DESTINATION IP
ADDRESS) имеют одинаковую длину — 32 бита, и одинаковую структуру.
Поле Резерв (IP OPTIONS) является необязательным и используется обычно только при
отладке сети. Это поле состоит из нескольких подполей, каждое из которых может быть
одного из восьми предопределенных типов. В этих подполях можно указывать точный
маршрут прохождения маршрутизаторов, регистрировать проходимые пакетом
маршрутизаторы, помещать данные системы безопасности, а также временные отметки.
Так как число подполей может быть произвольным, то в конце поля Резерв должно быть
добавлено несколько байт для выравнивания заголовка пакета по 32-битной границе.
Максимальная длина поля данных пакета ограничена разрядностью поля, определяющего эту
величину, и составляет 65535 байтов, однако при передаче по сетям различного типа длина пакета
выбирается с учетом максимальной длины пакета протокола нижнего уровня, несущего IP-пакеты.
Если это кадры Ethernet, то выбираются пакеты с максимальной длиной в 1500 байтов,
умещающиеся в поле данных кадра Ethernet.
Управление фрагментацией
Протоколы транспортного уровня (протоколы TCP или UDP), пользующиеся сетевым уровнем для
отправки пакетов, считают, что максимальный размер поля данных IP-пакета равен 65535, и
поэтому могут передать ему сообщение такой длины для транспортировки через интерсеть. В
функции уровня IP входит разбиение слишком длинного для конкретного типа составляющей сети
сообщения на более короткие пакеты с созданием соответствующих служебных полей, нужных
для последующей сборки фрагментов в исходное сообщение.
В большинстве типов локальных и глобальных сетей определяется такое понятие как
максимальный размер поля данных кадра или пакета, в которые должен инкапсулировать свой
пакет протокол IP. Эту величину обычно называют максимальной единицей транспортировки Maximum Transfer Unit, MTU. Сети Ethernet имеют значение MTU, равное 1500 байт, сети FDDI 4096 байт, а сети Х.25 чаще всего работают с MTU в 128 байт.
Работа протокола IP по фрагментации пакетов в хостах и маршрутизаторах иллюстрируется
рисунком 4.1.
Пусть компьютер 1 связан с сетью, имеющей значение MTU в 4096 байтов, например, с сетью
FDDI. При поступлении на IP-уровень компьютера 1 сообщения от транспортного уровня
размером в 5600 байтов, протокол IP делит его на два IP-пакета, устанавливая в первом пакете
признак фрагментации и присваивая пакету уникальный идентификатор, например, 486. В первом
пакете величина поля смещения равна 0, а во втором — 2800. Признак фрагментации во втором
пакете равен нулю, что показывает, что это последний фрагмент пакета. Общая величина IPпакета составляет 2800+20 (размер заголовка IP), то есть 2820 байтов, что умещается в поле
данных кадра FDDI.
Рис. 4.1. Фрагментация IP-пакетов при передаче между сетями с разными
максимальными размерами пакетов. К1 и Ф1 канальный и физический уровень сети 1,
К2 и Ф2 канальный и физический уровень сети 2
Далее компьютер 1 передает эти пакеты на канальный уровень К1, а затем и на физический
уровень Ф1, который отправляет их маршрутизатору, связанному с данной сетью.
Маршрутизатор видит по сетевому адресу, что прибывшие два пакета нужно передать в сеть 2,
которая имеет меньшее значение MTU, равное 1500. Вероятно, это сеть Ethernet. Маршрутизатор
извлекает фрагмент транспортного сообщения из каждого пакета FDDI и делит его еще пополам,
чтобы каждая часть уместилась в поле данных кадра Ethernet. Затем он формирует новые пакеты
IP, каждый из которых имеет длину 1400 + 20 = 1420 байтов, что меньше 1500 байтов, поэтому
они нормально помещаются в поле данных кадров Ethernet.
В результате в компьютер 2 по сети Ethernet приходит четыре IP-пакета с общим
идентификатором 486, что позволяет протоколу IP, работающему в компьютере 2, правильно
собрать исходное сообщение. Если пакеты пришли не в том порядке, в котором были посланы, то
смещение укажет правильный порядок их объединения.
Отметим, что IP-маршрутизаторы не собирают фрагменты пакетов в более крупные пакеты, даже
если на пути встречается сеть, допускающая такое укрупнение. Это связано с тем, что отдельные
фрагменты сообщения могут перемещаться по интерсети по различным маршрутам, поэтому нет
гарантии, что все фрагменты проходят через какой-либо промежуточный маршрутизатор на их
пути.
При приходе первого фрагмента пакета узел назначения запускает таймер, который определяет
максимально допустимое время ожидания прихода остальных фрагментов этого пакета. Если
таймер истекает раньше прибытия последнего фрагмента, то все полученные к этому моменту
фрагменты пакета отбрасываются, а в узел, пославший исходный пакет, направляется сообщение
об ошибке с помощью протокола ICMP.
Маршрутизация с помощью IP-адресов
Рассмотрим теперь принципы, на основании которых в сетях IP происходит выбор маршрута
передачи пакета между сетями.
Сначала необходимо обратить внимание на тот факт, что не только маршрутизаторы, но и
конечные узлы — компьютеры — должны принимать участие в выборе маршрута. Пример,
приведенный на рисунке 4.2, демонстрирует эту необходимость. Здесь в локальной сети имеется
несколько маршрутизаторов, и компьютер должен выбирать, какому из них следует отправить
пакет.
Рис. 4.2. Выбор маршрутизатора конечным узлом
Длина маршрута может существенно измениться в зависимости от того, какой маршрутизатор
выберет компьютер для передачи своего пакета на сервер, расположенный, например, в Германии,
если маршрутизатор 1 соединен выделенной линией с маршрутизатором в Копенгагене, а
маршрутизатор 2 имеет спутниковый канал, соединяющий его с Токио.
В стеке TCP/IP маршрутизаторы и конечные узлы принимают решения о том, кому передавать
пакет для его успешной доставки узлу назначения, на основании так называемых таблиц
маршрутизации (routing tables).
Следующая таблица представляет собой типичный пример таблицы маршрутов, использующей IPадреса сетей:
Адрес сети
назначения
Адрес следующего маршрутизатора
Номер выходного
портаРасстояние до
сети назначения
56.0.0.0
198.21.17.7
120
56.0.0.0
213.34.12.4.
2130
116.0.0.0
213.34.12.4
21450
129.13.0.0
198.21.17.6
150
198.21.17.0
—
20
213. 34.12.0
—
10
default
198.21.17.7
1-
В этой таблице в столбце «Адрес сети назначения» указываются адреса всех сетей, которым
данный маршрутизатор может передавать пакеты. В стеке TCP/IP принят так
называемый одношаговый подход к оптимизации маршрута продвижения пакета (next-hop routing)
— каждый маршрутизатор и конечный узел принимает участие в выборе только одного шага
передачи пакета. Поэтому в каждой строке таблицы маршрутизации указывается не весь маршрут
в виде последовательности IP-адресов маршрутизаторов, через которые должен пройти пакет, а
только один IP-адрес — адрес следующего маршрутизатора, которому нужно передать пакет.
Вместе с пакетом следующему маршрутизатору передается ответственность за выбор следующего
шага маршрутизации. Одношаговый подход к маршрутизации означает распределенное решение
задачи выбора маршрута. Это снимает ограничение на максимальное количество транзитных
маршрутизаторов на пути пакета.
(Альтернативой одношаговому подходу является указание в пакете всей последовательности
маршрутизаторов, которые пакет должен пройти на своем пути. Такой подход называется
маршрутизацией от источника — Source Routing. В этом случае выбор маршрута производится
конечным узлом или первым маршрутизатором на пути пакета, а все остальные маршрутизаторы
только отрабатывают выбранный маршрут, осуществляя коммутацию пакетов, то есть передачу их
с одного порта на другой. Алгоритм Source Routing применяется в сетях IP только для отладки,
когда маршрут задается в поле Резерв (IP OPTIONS) пакета.)
В случае, если в таблице маршрутов имеется более одной строки, соответствующей одному и тому
же адресу сети назначения, то при принятии решения о передаче пакета используется та строка, в
которой указано наименьшее значение в поле «Расстояние до сети назначения».
При этом под расстоянием понимается любая метрика, используемая в соответствии с заданным в
сетевом пакете классом сервиса. Это может быть количество транзитных маршрутизаторов в
данном маршруте (количество хопов от hop — прыжок), время прохождения пакета по линиям
связи, надежность линий связи, или другая величина, отражающая качество данного маршрута по
отношению к конкретному классу сервиса. Если маршрутизатор поддерживает несколько классов
сервиса пакетов, то таблица маршрутов составляется и применяется отдельно для каждого вида
сервиса (критерия выбора маршрута).
Для отправки пакета следующему маршрутизатору требуется знание его локального адреса, но в
стеке TCP/IP в таблицах маршрутизации принято использование только IP-адресов для сохранения
их универсального формата, не зависящего от типа сетей, входящих в интерсеть. Для нахождения
локального адреса по известному IP-адресу необходимо воспользоваться протоколом ARP.
Конечный узел, как и маршрутизатор, имеет в своем распоряжении таблицу маршрутов
унифицированного формата и на основании ее данных принимает решение, какому
маршрутизатору нужно передавать пакет для сети N. Решение о том, что этот пакет нужно вообще
маршрутизировать, компьютер принимает в том случае, когда он видит, что адрес сети назначения
пакета отличается от адреса его собственной сети (каждому компьютеру при конфигурировании
администратор присваивает его IP-адрес или несколько IP-адресов, если компьютер одновременно
подключен к нескольким сетям). Когда компьютер выбрал следующий маршрутизатор, то он
просматривают кэш-таблицу адресов своего протокола ARP и, может быть, находит там
соответствие IP-адреса следующего маршрутизатора его MAC-адресу. Если же нет, то по
локальной сети передается широковещательный ARP-запрос и локальный адрес извлекается из
ARP-ответа.
После этого компьютер формирует кадр протокола, используемого на выбранном порту,
например, кадр Ethernet, в который помещает МАС-адрес маршрутизатора. Маршрутизатор
принимает кадр Ethernet, извлекает из него пакет IP и просматривает свою таблицу
маршрутизации для нахождения следующего маршрутизатора. При этом он выполняет те же
действия, что и конечный узел.
Одношаговая маршрутизация обладает еще одним преимуществом — она позволяет сократить
объем таблиц маршрутизации в конечных узлах и маршрутизаторах за счет использования в
качестве номера сети назначения так называемого маршрута по умолчанию — default, который
обычно занимает в таблице маршрутизации последнюю строку. Если в таблице маршрутизации
есть такая запись, то все пакеты с номерами сетей, которые отсутствуют в таблице
маршрутизации, передаются маршрутизатору, указанному в строке default. Поэтому
маршрутизаторы часто хранят в своих таблицах ограниченную информацию о сетях интерсети,
пересылая пакеты для остальных сетей в порт и маршрутизатор, используемые по умолчанию.
Подразумевается, что маршрутизатор, используемый по умолчанию, передаст пакет на
магистральную сеть, а маршрутизаторы, подключенные к магистрали, имеют полную
информацию о составе интерсети.
Особенно часто приемом маршрутизации по умолчанию пользуются конечные узлы. Хотя они
также в общем случае имеют в своем распоряжении таблицу маршрутизации, ее объем обычно
незначителен, так как маршрутизация для компьютера — не основное занятие. Главная роль в
маршрутизации пакетов в концепции протокола IP отводится, естественно, маршрутизаторам,
которые должны обладать гораздо более полными таблицами маршрутизации, чем конечные узлы.
Конечный узел часто вообще работает без таблицы маршрутизации, имея только сведения об IPадресе маршрутизатора по умолчанию. При наличии одного маршрутизатора в локальной сети
этот вариант — единственно возможный для всех конечных узлов. Но даже при наличии
нескольких маршрутизаторов в локальной сети, когда проблема их выбора стоит перед конечным
узлом, задание маршрута по умолчанию часто используется в компьютерах для сокращения
объема их маршрутной таблицы.
Другим способом разгрузки компьютера от необходимости ведения больших таблиц
маршрутизации является получение от маршрутизатора сведений о рациональном маршруте для
какой-нибудь конкретной сети с помощью протокола ICMP.
Кроме маршрута default, в таблице маршрутизации могут встретиться два типа специальных
записей — запись о специфичном для узла маршруте и запись об адресах сетей, непосредственно
подключенных к портам маршрутизатора.
Специфичный для узла маршрут содержит вместо номера сети полный IP-адрес, то есть адрес,
имеющий ненулевую информацию не только в поле номера сети, но и в поле номера узла.
Предполагается, что для такого конечного узла маршрут должен выбираться не так, как для всех
остальных узлов сети, к которой он относится. В случае, когда в таблице есть разные записи о
продвижении пакетов для всей сети N и ее отдельного узла, имеющего адрес N,D, при
поступлении пакета, адресованного узлу N,D, маршрутизатор отдаст предпочтение записи для
N,D.
Записи в таблице маршрутизации, относящиеся к сетям, непосредственно подключенным к
маршрутизатору, в поле «Расстояние до сети назначения» содержат нули.
Еще одним отличием работы маршрутизатора и конечного узла при выборе маршрута является
способ построения таблицы маршрутизации. Если маршрутизаторы обычно автоматически
создают таблицы маршрутизации, обмениваясь служебной информацией, то для конечных узлов
таблицы маршрутизации создаются, как правило, вручную администраторами, и хранятся в виде
постоянных файлов на дисках.
Существуют различные алгоритмы построения таблиц для одношаговой маршрутизации. Их
можно разделить на три класса:
алгоритмы фиксированной маршрутизации,
алгоритмы простой маршрутизации,
алгоритмы адаптивной маршрутизации.
Независимо от алгоритма, используемого для построения таблицы маршрутизации, результат их
работы имеет единый формат. За счет этого в одной и той же сети различные узлы могут строить
таблицы маршрутизации по своим алгоритмам, а затем обмениваться между собой недостающими
данными, так как форматы этих таблиц фиксированы. Поэтому маршрутизатор, работающий по
алгоритму адаптивной маршрутизации, может снабдить конечный узел, применяющий алгоритм
фиксированной маршрутизации, сведениями о пути к сети, о которой конечный узел ничего не
знает.
Фиксированная маршрутизация
Этот алгоритм применяется в сетях с простой топологией связей и основан на ручном составлении
таблицы маршрутизации администратором сети. Алгоритм часто эффективно работает также для
магистралей крупных сетей, так как сама магистраль может иметь простую структуру с
очевидными наилучшими путями следования пакетов в подсети, присоединенные к магистрали.
Различают одномаршрутные таблицы, в которых для каждого адресата задан один путь, и
многомаршрутные таблицы, определяющие несколько альтернативных путей для каждого
адресата. При использовании многомаршрутных таблиц должно быть задано правило выбора
одного из них. Чаще всего один путь является основным, а остальные — резервными.
Простая маршрутизация
Алгоритмы простой маршрутизации подразделяются на три подкласса:
Случайная маршрутизация — пакеты передаются в любом, случайном направлении, кроме
исходного.
Лавинная маршрутизация — пакеты передаются во всех направлениях, кроме исходного
(применяется в мостах для пакетов с неизвестным адресом доставки).
Маршрутизация по предыдущему опыту — таблицы маршрутов составляются на основании
данных, содержащихся в проходящих через маршрутизатор пакетах. Именно так работают
прозрачные мосты, собирая сведения об адресах узлов, входящих в сегменты сети. Такой
способ маршрутизации обладает медленной адаптируемостью к изменениям топологии
сети.
Адаптивная маршрутизация
Это основной вид алгоритмов маршрутизации, применяющихся маршрутизаторами в
современных сетях со сложной топологией. Адаптивная маршрутизация основана на том, что
маршрутизаторы периодически обмениваются специальной топологической информацией об
имеющихся в интерсети сетях, а также о связях между маршрутизаторами. Обычно учитывается
не только топология связей, но и их пропускная способность и состояние.
Адаптивные протоколы позволяют всем маршрутизаторам собирать информацию о топологии
связей в сети, оперативно отрабатывая все изменения конфигурации связей. Эти протоколы имеют
распределенный характер, который выражается в том, что в сети отсутствуют какие-либо
выделенные маршрутизаторы, которые бы собирали и обобщали топологическую информацию:
эта работа распределена между всеми маршрутизаторами.
Пример взаимодействия узлов с использованием протокола IP
Рассмотрим на примере интерсети, приведенной на рисунке 4.3, каким образом происходит
взаимодействие компьютеров через маршрутизаторы и доставка пакетов компьютеру назначения.
Рис. 4.3. Пример взаимодействия компьютеров через интерсеть
Пусть в приведенном примере пользователь компьютера cit.dol.ru, находящийся в сети Ethernet с
IP-адресом 194.87.23.0 (адрес класса С), хочет взаимодействовать по протоколу FTP с
компьютером s1.msk.su, принадлежащем сети Ethernet с IP-адресом 142.06.0.0 (адрес класса В).
Компьютер cit.dol.ru имеет IP-адрес 194.87.23.1.17, а компьютер s1.msk.su — IP-адрес 142.06.13.14.
1. Пользователь компьютера cit.dol.ru знает символьное имя компьютера s1.msk.su, но не знает его
IP-адреса, поэтому он набирает команду
> ftp s1.msk.su
для организации ftp-сеанса.
В компьютере cit.dol.ru должны быть заданы некоторые параметры для стека TCP/IP, чтобы он мог
выполнить поставленную перед ним задачу.
В число этих параметров должны входить собственный IP-адрес, IP-адрес DNS-сервера и IP-адрес
маршрутизатора по умолчанию. Так как к сети Ethernet, к которой относится компьютер cit.dol.ru,
подключен только один маршрутизатор, то таблица маршрутизации конечным узлам этой сети не
нужна, достаточно знать IP-адрес маршрутизатора по умолчанию. В данном примере он равен
194.87.23.1.
Так как пользователь в команде ftp не задал IP-адрес узла, с которым он хочет взаимодействовать,
то стек TCP/IP должен определить его самостоятельно. Он может сделать запрос к серверу DNS по
имеющемуся у него IP-адресу, но обычно каждый компьютер сначала просматривает свою
собственную таблицу соответствия символьных имен и IP-адресов. Такая таблица хранится чаще
всего в виде текстового файла простой структуры — каждая его строка содержит запись об одном
символьном имени и его IP-адресе. В ОС Unix такой файл традиционно носит имя HOSTS.
2. Будем считать, что компьютер cit.dol.ru имеет файл HOSTS, а в нем есть строка
142.06.13.14 s1.msk.su.
Поэтому разрешение имени выполняется локально, так что протокол IP может теперь
формировать IP-пакеты с адресом назначения 142.06.13.14 для взаимодействия с компьютером
s1.msk.su.
3. Протокол IP компьютера cit.dol.ru проверяет, нужно ли маршрутизировать пакеты для адреса
142.06.13.14. Так как адрес сети назначения равен 142.06.0.0, а адрес сети, к которой принадлежит
компьютер, равен 194.87.23.0, то маршрутизация необходима.
4. Компьютер cit.dol.ru начинает формировать кадр Ethernet для отправки IP-пакета
маршрутизатору по умолчанию с IP-адресом 194.87.23.1. Для этого ему нужен МАС-адрес порта
маршрутизатора, подключенного к его сети. Этот адрес скорее всего уже находится в кэш-таблице
протокола ARP компьютера, если он хотя бы раз за последнее включение обменивался данными с
компьютерами других сетей. Пусть этот адрес в нашем примере был найден именно в кэш-памяти.
Обозначим его МАС11, в соответствии с номером маршрутизатора и его порта.
5. В результате компьютер cit.dol.ru отправляет по локальной сети кадр Ethernet, имеющий
следующие поля:
DA (Ethernet)
…
МАС11
DESTINATION IP
……
142.06.13.14
6. Кадр принимается портом 1 маршрутизатора 1 в соответствии с протоколом Ethernet, так как
МАС-узел этого порта распознает свой адрес МАС11. Протокол Ethernet извлекает из этого кадра
IP-пакет и передает его программному обеспечению маршрутизатора, реализующему протокол IP.
Протокол IP извлекает из пакета адрес назначения и просматривает записи своей таблицы
маршрутизации. Пусть маршрутизатор 1 имеет в своей таблице маршрутизации запись
142.06.0.0 135.12.0.11 2 1,
которая говорит о том, что пакеты для сети 142.06. 0.0 нужно передавать маршрутизатору
135.12.0.11, подключенному к той же сети, что и порт 2 маршрутизатора 1.
7. Маршрутизатор 1 просматривает параметры порта 2 и находит, что он подключен к сети FDDI.
Так как сеть FDDI имеет значение максимального транспортируемого блока MTU больше, чем
сеть Ethernet, то фрагментация поля данных IP-пакета не требуется. Поэтому маршрутизатор 1
формирует кадр формата FDDI, в котором указывает MAC-адрес порта маршрутизатора 2,
который он находит в своей кэш-таблице протокола ARP:
DA (FDDI)
МАС21
…
DESTINATION IP
142.06.13.14
……
8. Аналогично действует маршрутизатор 2, формируя кадр Ethernet для передачи пакета
маршрутизатору 3 по сети Ethernet c IP-адресом 203.21.4.0:
DA (Ethernet)
…
МАС32
DESTINATION IP
……
142.06.13.14
9. Наконец, после того, как пакет поступил в маршрутизатор сети назначения — маршрутизатор 3,
появляется возможность передачи этого пакета компьютеру назначения. Маршрутизатор 3 видит,
что пакет нужно передать в сеть 142.06.0.0, которая непосредственно подключена к его первому
порту. Поэтому он посылает ARP-запрос по сети Ethernet c IP-адресом компьютера s1.msk.su
(считаем, что этой информации в его кэше нет), получает ответ, содержащий адрес MACs1, и
формирует кадр Ethernet, доставляющий IP-пакет по локальной сети адресату.
DA (Ethernet)
…
МАСs1
DESTINATION IP
……
142.06.13.14
Структуризация сетей IP с помощью масок
Часто администраторы сетей испытывают неудобства, из-за того, что количество централизовано
выделенных им номеров сетей недостаточно для того, чтобы структурировать сеть надлежащим
образом, например, разместить все слабо взаимодействующие компьютеры по разным сетям.
В такой ситуации возможны два пути. Первый из них связан с получением от NIC
дополнительных номеров сетей. Второй способ, употребляющийся более часто, связан с
использованием так называемыхмасок, которые позволяют разделять одну сеть на несколько
сетей.
Маска — это число, двоичная запись которого содержит единицы в тех разрядах, которые должны
интерпретироваться как номер сети.
Например, для стандартных классов сетей маски имеют следующие значения:
255.0.0.0 — маска для сети класса А,
255.255.0.0 — маска для сети класса В,
255.255.255.0 — маска для сети класса С.
В масках, которые использует администратор для увеличения числа сетей, количество единиц в
последовательности, определяющей границу номера сети, не обязательно должно быть кратным 8,
чтобы повторять деление адреса на байты.
Пусть, например, маска имеет значение 255.255.192.0 (11111111 11111111 11000000 00000000). И
пусть сеть имеет номер 129.44.0.0 (10000001 00101100 00000000 00000000), из которого видно, что
она относится к классу В. После наложения маски на этот адрес число разрядов,
интерпретируемых как номер сети, увеличилось с 16 до 18, то есть администратор получил
возможность использовать вместо одного, централизованно заданного ему номера сети, четыре:
129.44.0.0 (10000001 00101100 00000000 00000000)
129.44.64.0 (10000001 00101100 01000000 00000000)
129.44.128.0 (10000001 00101100 10000000 00000000)
129.44.192.0 (10000001 00101100 11000000 00000000)
Например, IP-адрес 129.44.141.15 (10000001 00101100 10001101 00001111), который по
стандартам IP задает номер сети 129.44.0.0 и номер узла 0.0.141.15, теперь, при использовании
маски, будет интерпретироваться как пара:
129.44.128.0 — номер сети, 0.0. 13.15 — номер узла.
Таким образом, установив новое значение маски, можно заставить маршрутизатор по-другому
интерпретировать IP-адрес. При этом два дополнительных последних бита номера сети часто
интерпретируются как номера подсетей.
Еще один пример. Пусть некоторая сеть относится к классу В и имеет адрес 128.10.0.0 (рисунок
4.4). Этот адрес используется маршрутизатором, соединяющим сеть с остальной частью
интерсети. И пусть среди всех станций сети есть станции, слабо взаимодействующие между собой.
Их желательно было бы изолировать в разных сетях. Для этого сеть можно разделить на две сети,
подключив их к соответствующим портам маршрутизатора, и задать для этих портов в качестве
маски, например, число 255.255.255.0, то есть организовать внутри исходной сети с
централизовано заданным номером две подсети класса C (можно было бы выбрать и другой
размер для поля адреса подсети). Извне сеть по-прежнему будет выглядеть, как единая сеть класса
В, а на местном уровне это будут две отдельные сети класса С. Приходящий общий трафик будет
разделяться местным маршрутизатором между подсетями.
Рис. 4.4. Пример использования масок для структурирования сети
Необходимо заметить, что, если принимается решение об использовании механизма масок, то
соответствующим образом должны быть сконфигурированы и маршрутизаторы, и компьютеры
сети.
IPv6 (англ. Internet Protocol version 6) — новая версия протокола IP, призванная решить проблемы,
с которыми столкнулась предыдущая версия (IPv4) при её использовании в Интернете, за счёт
использования длины адреса 128 бит вместо 32. Протокол был разработан IETF.
В настоящее время протокол IPv6 уже используется в нескольких тысячах сетей по всему миру
(более 14000 сетей на осень 2013), но пока ещё не получил столь широкого распространения в
Интернете, как IPv4. На конец 2012 года доля IPv6 в сетевом трафике составляла около 1 %[1]. К
концу 2013 года ожидался рост до 3 %[2]. В России коммерческое использование операторами
связи невелико (не более 1 % трафика). DNS-серверы многих российских регистраторов доменов и
провайдеров хостинга используют IPv6.
После того, как адресное пространство в IPv4 закончится, два стека протоколов — IPv6 и IPv4 —
будут использоваться параллельно (англ. dual stack), с постепенным увеличением доли трафика
IPv6, по сравнению с IPv4. Такая ситуация станет возможной из-за наличия огромного количества
устройств, в том числе устаревших, не поддерживающих IPv6 и требующих специального
преобразования для работы с устройствами, использующими только IPv6.
История создания
В конце 1980-х стала очевидна необходимость разработки способов сохранения адресного
пространства Интернета. В начале 1990-х, несмотря на внедрение бесклассовой адресации, стало
ясно, что этого недостаточно для предотвращения исчерпания адресов и необходимы дальнейшие
изменения инфраструктуры Интернета. К началу 1992 года появилось несколько предложений, и к
концу 1992 года IETF объявила конкурс для рабочих групп на создание интернет-протокола
следующего поколения (англ. IP Next Generation — IPng). 25 июля 1994 года IETF утвердила
модель IPng, с образованием нескольких рабочих групп IPng. К 1996 году была выпущена
серия RFC, определяющих Интернет протокол версии 6, начиная с RFC 1883.
IETF назначила новому протоколу версию 6, так как версия 5 была ранее
назначена экспериментальному протоколу, предназначенному для передачи видео и аудио.
Исчерпание IPv4 адресов
Оценки времени полного исчерпания IPv4 адресов различались в 2000-х. Так, в 2003 году
директор APNIC Пол Уилсон (англ. Paul Wilson) заявил, что, основываясь на темпах
развёртывания сети Интернет того времени, свободного адресного пространства хватит на одно—
два десятилетия. В сентябре 2005 года Cisco Systems предположила, что пула доступных адресов
хватит на 4—5 лет.
3 февраля 2011 агентство IANA распределило последние 5 блоков /8 IPv4 региональным интернетрегистраторам. На этот момент ожидалось, что общий запас свободных блоков адресов у
региональных интернет-регистраторов (RIR) закончится в течение срока от полугода (APNIC) до
пяти лет (AfriNIC)[3].
По состоянию на сентябрь 2015 года об исчерпании общего запаса свободных блоков IPv4 адресов
и ограничениях на выдачу новых диапазонов адресов объявили все региональные регистраторы,
кроме AfriNIC; ARIN объявил о полном исчерпании свободных IPv4 адресов, а для остальных
регистраторов этот момент прогнозируется начиная с 2017 года. Выделение IPv4 адресов в
Европе, Азии и Латинской Америке (регистраторы APNIC, RIPE NCC и LACNIC) продолжается
блоками /22 (по 1024 адреса)[4][5]
Тестирование протокола
8 июня 2011 года состоялся Международный день IPv6 — мероприятие по тестированию
готовности мирового интернет-сообщества к переходу с IPv4 на IPv6, в рамках которого
участвующие в акции компании добавили к своим сайтам IPv6-записи на один день. Тестирование
прошло успешно, накопленные данные будут проанализированы и учтены при последующем
внедрении протокола и для составления рекомендаций.
Внедрение протокола
Перевод на IPv6 начал осуществляться внутри Google с 2008 года. Тестирование IPv6 признано
успешным[6]. 6 июня 2012 года состоялся Всемирный запуск IPv6[7]. Интернет-провайдеры
включат IPv6 как минимум для 1 % своих пользователей (уже подписались AT&T, Comcast, Free
Telecom, Internode, KDDI, Time Warner Cable, XS4ALL). Производители сетевого оборудования
активируют IPv6 в качестве настроек по умолчанию в маршрутизаторах (Cisco, D-Link). Вебкомпании включат IPv6 на своих основных сайтах (Google, Facebook, Microsoft Bing, Yahoo), а
некоторые переводят на IPv6 также корпоративные сети. В спецификации стандарта мобильных
сетей LTE указана обязательная поддержка протокола IPv6.
Сравнение с IPv4
Иногда утверждается, что новый протокол может обеспечить до 5·1028 адресов на каждого жителя
Земли. Такое большое адресное пространство было введено ради иерархичности адресов (это
упрощает маршрутизацию). Тем не менее, увеличенное пространство адресов
сделает NAT необязательным. Классическое применение IPv6 (по сети /64 на абонента;
используется только unicast-адресация) обеспечит возможность использования более 300 млн IPадресов на каждого жителя Земли.
Из IPv6 убраны функции, усложняющие работу маршрутизаторов:
Маршрутизаторы больше не должны фрагментировать пакет, вместо этого пакет
отбрасывается с ICMP-уведомлением о превышении MTU. Передающая сторона в IPv6,
таким образом, обречена на использование технологии Path MTU discovery. Для лучшей
работы протоколов, требовательных к потерям, минимальный MTU поднят до 1280 байт.
Фрагментация поддерживается как опция (информация о фрагментации пакетов вынесена
из основного заголовка в расширенные) и возможна только по инициативе передающей
стороны.
Из IP-заголовка исключена контрольная сумма. С учётом того, что канальные (Ethernet) и
транспортные (TCP и UDP) протоколы имеют свои контрольные суммы, еще одна
контрольная сумма на уровне IP воспринимается как излишняя. Кроме того, модификация
поля hop limit (или TTL в IPv4) на каждом маршрутизаторе в IPv4 приводила к
необходимости её постоянного перерасчёта.
Несмотря на огромный размер адреса IPv6, благодаря этим улучшениям заголовок пакета
удлинился всего лишь вдвое: с 20 до 40 байт.
Улучшения IPv6 по сравнению с IPv4:
В сверхскоростных сетях возможна поддержка огромных пакетов (джамбограмм) — до 4
гигабайт;
Time to Live переименовано в Hop Limit;
Появились метки потоков и классы трафика;
Появилось многоадресное вещание.
Автоконфигурация (Stateless address autoconfiguration — SLAAC)
При инициализации сетевого интерфейса ему назначается локальный IPv6-адрес, состоящий из
префикса fe80::/10 и идентификатора интерфейса, размещённого в младшей части адреса. В
качестве идентификатора интерфейса часто используется 64-битный расширенный уникальный
идентификатор EUI-64, часто ассоциируемый с MAC-адресом. Локальный адрес действителен
только в пределах сетевого сегмента канального уровня и используется, в основном, для обмена
информационными ICMPv6 пакетами.
Для настройки других адресов узел может запросить информацию о настройках сети у
маршрутизаторов, отправив ICMPv6 сообщение «Router Solicitation» на групповой адрес
маршрутизаторов. Маршрутизаторы, получившие это сообщение, отвечают ICMPv6 сообщением
«Router Advertisement», в котором может содержаться информация о сетевом префиксе,
адресе шлюза, адресах рекурсивных DNS серверов[8], MTU и множестве других параметров.
Объединяя сетевой префикс и идентификатор интерфейса, узел получает новый адрес. Для защиты
персональных данных идентификатор интерфейса может быть заменён на псевдослучайное число.
Для большего административного контроля может быть использован DHCPv6, позволяющий
администратору маршрутизатора назначать узлу конкретный адрес.
Для провайдеров может использоваться функция делегирования префиксов клиенту, что позволяет
клиенту просто переходить от провайдера к провайдеру, без изменения каких-либо настроек.
Метки потоков
Введение в протоколе IPv6 поля «Метка потока» позволяет значительно упростить процедуру
маршрутизации однородного потока пакетов. Поток — это последовательность пакетов,
посылаемых отправителем определённому адресату. При этом предполагается, что все пакеты
данного потока должны быть подвергнуты определённой обработке. Характер данной обработки
задаётся дополнительными заголовками.
Допускается существование нескольких потоков между отправителем и получателем. Метка
потока присваивается узлом-отправителем путём генерации псевдослучайного 20-битного числа.
Все пакеты одного потока должны иметь одинаковые заголовки,
обрабатываемые маршрутизатором.
При получении первого пакета с меткой потока маршрутизатор анализирует дополнительные
заголовки, выполняет предписанные этими заголовками функции и запоминает результаты
обработки (адрес следующего узла, опции заголовка переходов, перемещение адресов в заголовке
маршрутизации и т. д.) в локальном кэше. Ключом для такой записи является комбинация адреса
источника и метки потока. Последующие пакеты с той же комбинацией адреса источника и метки
потока обрабатываются с учётом информации кэша без детального анализа всех полей заголовка.
Время жизни записи в кэше составляет не более 6 секунд, даже если пакеты этого потока
продолжают поступать. При обнулении записи в кэше и получении следующего пакета потока
пакет обрабатывается в обычном режиме, и для него происходит новое формирование записи в
кэше. Следует отметить, что указанное время жизни потока может быть явно определено узлом
отправителем с помощью протокола управления или опций заголовка переходов и может
превышать 6 секунд.
Обеспечение безопасности в протоколе IPv6 осуществляется с использованием протокола IPSec,
поддержка которого является обязательной для данной версии протокола.
QoS
Приоритет пакетов маршрутизаторы определяют на основе первых шести бит поля Traffic Class.
Первые три бита определяют класс трафика, оставшиеся биты определяют приоритет удаления.
Чем больше значение приоритета, тем выше приоритет пакета.
Разработчики IPv6 рекомендуют использовать для определённых категорий приложений
следующие коды класса трафика:
Класс трафика Назначение
Нехарактеризованный трафик
1
Заполняющий трафик (сетевые новости)
2
Несущественный информационный трафик (электронная почта)
3
Резерв
4
Существенный трафик (FTP, HTTP, NFS)
5
Резерв
6
Интерактивный трафик (Telnet, X-terminal, SSH)
7
Управляющий трафик (Маршрутная информация, SNMP)
Механизмы безопасности
В отличие от SSL и TLS, протокол IPSec позволит шифровать любые данные (в том числе UDP)
без необходимости какой-либо поддержки со стороны прикладного ПО.
Основы адресации IPv6
Существуют различные типы адресов IPv6: одноадресные (Unicast), групповые (Anycast) и
многоадресные (Multicast).
Адреса типа Unicast хорошо всем известны. Пакет, посланный на такой адрес, достигает в
точности интерфейса, который этому адресу соответствует.
Адреса типа Anycast синтаксически неотличимы от адресов Unicast, но они адресуют группу
интерфейсов. Пакет, направленный такому адресу, попадёт в ближайший (согласно метрике
маршрутизатора) интерфейс. Адреса Anycast могут использоваться только маршрутизаторами.
Адреса типа Multicast идентифицируют группу интерфейсов. Пакет, посланный на такой адрес,
достигнет всех интерфейсов, привязанных к группе многоадресного вещания.
Широковещательные адреса IPv4 (обычно xxx.xxx.xxx.255) выражаются адресами многоадресного
вещания IPv6.
Адреса разделяются двоеточиями (напр. fe80:0:0:0:200:f8ff: fe21:67cf). Большое количество
нулевых групп может быть пропущено с помощью двойного двоеточия (fe80::200:f8ff: fe21:67cf).
Такой пропуск должен быть единственным в адресе.
Типы Unicast адресов
Глобальные
Соответствуют публичным IPv4 адресам. Могут находиться в любом не занятом диапазоне. В
настоящее время региональные интернет-регистраторы распределяют блок адресов 2000::/3 (с
2000:: по 3FFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF).
Link-Local
Соответствуют автосконфигурированным с помощью протокола APIPA IPv4 адресам. Начинаются
с FE80.
Используется:
1. В качестве исходного адреса для Router Solicitation(RS) и Router Advertisement(RA)
сообщений, для обнаружения маршрутизаторов
2. Для обнаружения соседей (эквивалент ARP для IPv4)
3. Как next-hop адрес для маршрутов
Unique-Local
RFC 4193, соответствуют внутренним IP адресам, которыми в версии IPv4 являлись 10.0.0.0/8,
172.16.0.0/12 и 192.168.0.0/16. Начинаются с цифр FC00 и FD00.
Типы Multicast адресов
Адреса мультикаст бывают двух типов:
Назначенные (Assigned multicast) — специальные адреса, назначение которых
предопределено. Это зарезервированные для определённых групп устройств
мультикастовые адреса. Отправляемый на такой адрес пакет будет получен всеми
устройствами, входящими в группу.
Запрошенные (Solicited multicast) — остальные адреса, которые устройства могут
использовать для прикладных задач. Адрес этого типа автоматически появляется, когда на
некотором интерфейсе появляется юникастовый адрес. Адрес формируется из сети
FF02:0:0:0:0:1:FF00::/104, оставшиеся 24 бита — такие же как у настроенного
юникастового адреса.
Формат пакета
Пакеты состоят из управляющей информации, необходимой для доставки пакета адресату, и
полезных данных, которые требуется переслать. Управляющая информация делится на
содержащуюся в основном фиксированном заголовке, и содержащуюся в одном из
необязательных дополнительных заголовков. Полезные данные, как правило, это дейтаграмма или
фрагмент протокола более высокого транспортного уровня, но могут быть и данные сетевого
уровня (например ICMPv6), или же канального уровня (например OSPF).
IPv6-пакеты обычно передаются с помощью протоколов канального уровня, таких как Ethernet,
который инкапсулирует каждый пакет в кадр. Но IPv6-пакет может быть передан с
помощью туннельного протокола более высокого уровня, например в 6to4 или Teredo.
Нотация
Адреса IPv6 отображаются как восемь четырёхзначных шестнадцатеричных чисел (то есть групп
по четыре символа), разделённых двоеточием. Пример адреса:
2001:0db8:11a3:09d7:1f34:8a2e:07a0:765d
Если одна или более групп подряд равны 0000, то они могут быть опущены и заменены на
двойное двоеточие (::). Например, 2001:0db8:0000:0000:0000:0000:ae21:ad12 может быть сокращён
до 2001:db8::ae21:ad12, или 0000:0000:0000:0000:0000:0000:ae21:ad12 может быть сокращён
до ::ae21:ad12. Сокращению не могут быть подвергнуты 2 разделённые нулевые группы из-за
возникновения неоднозначности.
При использовании IPv6-адреса в URL необходимо заключать адрес в квадратные скобки:
http://[2001:0db8:11a3:09d7:1f34:8a2e:07a0:765d]/
Если необходимо указать порт, то он пишется после скобок:
http://[2001:0db8:11a3:09d7:1f34:8a2e:07a0:765d]:8080/
Зарезервированные адреса IPv6
IPv6 адрес
Длина
префикса
(биты)
Описание
Заметки
::
128
—
см. 0.0.0.0 в IPv4
::1
128
loopback адрес
см. 127.0.0.1 в IPv4
Нижние 32 бита это адрес IPv4. Также
называется IPv4 совместимым IPv6 адресом.
Устарел и больше не используется.
::xx.xx.xx.xx 96
встроенный IPv4
::ffff:
xx.xx.xx.xx
96
Адрес IPv4,
Нижние 32 бита — это адрес IPv4 для хостов, не
отображенный на IPv6 поддерживающих IPv6.
2001:db8::
32
Документирование
Зарезервирован для примеров в документации
в RFC 3849
fe80:: —
febf::
10
link-local
Аналог 169.254.0.0/16 в IPv4
fec0:: — feff:: 10
site-local
Помечен как устаревший в RFC 3879 (Аналог
внутренних сетей 10.0.0.0; 172.16.0.0; 192.168.0.0)
Пришёл на смену Site-Local RFC 4193
fc00::
7
Unique Local Unicast
ff00::
8
multicast
Вопрос 7. Протоколы ARPRARP.
ARP (англ. Address Resolution Protocol — протокол определения адреса) — протокол в
компьютерных сетях, предназначенный для определения MAC-адреса по известному IP-адресу.
Рассмотрим суть функционирования ARP на простом примере. Компьютер А (IP-адрес 10.0.0.1) и
компьютер Б (IP-адрес 10.22.22.2) соединены сетью Ethernet. Компьютер А желает переслать пакет
данных на компьютер Б, IP-адрес компьютера Б ему известен. Однако сеть Ethernet, которой они
соединены, не работает с IP-адресами. Поэтому компьютеру А для осуществления передачи через
Ethernet требуется узнать адрес компьютера Б в сети Ethernet (MAC-адрес в терминах Ethernet).
Для этой задачи и используется протокол ARP. По этому протоколу компьютер А отправляет
широковещательный запрос, адресованный всем компьютерам в одном с ним широковещательном
домене. Суть запроса: «компьютер с IP-адресом 10.22.22.2, сообщите свой MAC-адрес компьютеру
с IP-адресом 10.0.0.1». Сеть Ethernet доставляет этот запрос всем устройствам в том же сегменте
Ethernet, в том числе и компьютеру Б. Компьютер Б отвечает компьютеру А на запрос и сообщает
свой MAC-адрес (напр. 00:ea:d1:11:f1:11) Теперь, получив MAC-адрескомпьютера Б, компьютер А
может передавать ему любые данные через сеть Ethernet.
Наибольшее распространение ARP получил благодаря повсеместности сетей IP, построенных
поверх Ethernet, поскольку практически в 100 % случаев при таком сочетании используется ARP.
В семействе протоколов IPv6 ARP не существует, его функции возложены наICMPv6.
Описание протокола было опубликовано в ноябре 1982 года в RFC 826. ARP был
спроектирован для случая передачи IP-пакетов через сегмент Ethernet. При этом общий
принцип, предложенный для ARP, может, и был использован и для сетей других типов.
Существуют следующие типы сообщений ARP: запрос ARP (ARP request) и ответ ARP (ARP
reply). Система-отправитель при помощи запроса ARP запрашивает физический адрес
системы-получателя. Ответ (физический адрес узла-получателя) приходит в виде ответа ARP.
Перед тем как передать пакет сетевого уровня через сегмент Ethernet, сетевой стек проверяет
кэш ARP, чтобы выяснить, не зарегистрирована ли в нём уже нужная информация об узлеполучателе. Если такой записи в кэше ARP нет, то выполняется широковещательный запрос
ARP. Этот запрос для устройств в сети имеет следующий смысл: «Кто-нибудь знает
физический адрес устройства, обладающего следующим IP-адресом?» Когда получатель с
этим IP-адресом примет этот пакет, то должен будет ответить: «Да, это мой IP-адрес. Мой
физический адрес следующий: …» После этого отправитель обновит свой кэш ARP и будет
способен передать информацию получателю. Ниже приведён пример запроса и ответа
ARP. <см. внизу страницы>
Записи в кэше ARP могут быть статическими и динамическими. Пример, данный выше,
описывает динамическую запись кэша. Можно также создавать статические записи в таблице
ARP. Это можно сделать при помощи команды:
arp -s
В системах семейства Windows до NT 6.0 записи в таблице ARP, созданные динамически,
остаются в кэше в течение 2-х минут. Если в течение этих двух минут произошла повторная
передача данных по этому адресу, то время хранения записи в кэше продлевается ещё на 2
минуты. Эта процедура может повторяться до тех пор, пока запись в кэше просуществует до
10 минут. После этого запись будет удалена из кэша, и будет отправлен повторный запрос
ARP[1]. Сейчас же время хранения записей в ARP таблице и метод хранения выбирается
программно, и при желании его можно изменить.
Вариации ARP-протокола
ARP изначально был разработан не только для IP протокола, но в настоящее время в основном
используется для сопоставления IP- и MAC-адресов.
ARP также можно использовать для разрешения MAC-адресов для различных адресов
протоколов 3-го уровня (Layer 3 protocols addresses). ARP был адаптирован также для
разрешения других видов адресов 2-го уровня (Layer 2 addresses); например, ATMARP
используется для разрешения ATM NSAP адресов в Classical IP over ATM протоколе.
Inverse ARP
Inverse Address Resolution Protocol, Inverse ARP или InARP — протокол для получения
адресов сетевого уровня (например IP адресов) других рабочих станций по их адресам
канального уровня (например, DLCI в Frame Relay сетях). В основном используется во Frame
Relay и ATM сетях.
Сравнение ARP и InARP
ARP переводит адреса сетевого уровня в адреса канального уровня, в то же время InARP
можно рассматривать как его инверсию. InARP реализовано как расширение ARP. Форматы
пакетов этих протоколов одни и те же, различаются лишь коды операций и заполняемые поля.
Reverse ARP (RARP), как и InARP, переводит адреса канального уровня в адреса сетевого
уровня. Но RARP используется для получения логических адресов самих станций
отправителей, в то время как в InARP-протоколе отправитель знает свои адреса и запрашивает
логический адрес другой станции. От RARP отказались в пользу BOOTP, который был в свою
очередь заменён DHCP.
Принцип работы
1. Узел, которому нужно выполнить отображение IP-адреса на локальный адрес[2], формирует
ARP запрос, вкладывает его в кадр протокола канального уровня, указывая в нем
известный IP-адрес, и рассылает запрос широковещательно.
2. Все узлы локальной сети получают ARP запрос и сравнивают указанный там IP-адрес с
собственным.
3. В случае их совпадения узел формирует ARP-ответ, в котором указывает свой IP-адрес и
свой локальный адрес и отправляет его уже направленно, так как в ARP запросе
отправитель указывает свой локальный адрес.
Преобразование адресов выполняется путем поиска в таблице. Эта таблица, называемая ARPтаблицей, хранится в памяти и содержит строки для каждого узла сети. В двух столбцах
содержатся IP- и Ethernet-адреса. Если требуется преобразовать IP-адрес в Ethernet-адрес, то
ищется запись с соответствующим IP-адресом. Ниже приведен пример упрощенной ARPтаблицы.
———————————————|
223.1.2.1
08:00:39:00:2F:C3 |
|
223.1.2.3
08:00:5A:21:A7:22 |
|
223.1.2.4
08:00:10:99:AC:54 |
———————————————Структура пакета
Ниже проиллюстрирована структура пакета, используемого в запросах и ответах ARP. В
сетях Ethernet в этих пакетах используется EtherType 0x0806, и рассылаются
широковещательно MAC-адрес — FF:FF:FF:FF:FF:FF. Отметим, что в структуре пакета,
показанной ниже в качестве SHA, SPA, THA, & TPA условно используются 32-битные слова
— реальная длина определяется физическим устройством и протоколом.
+
Bits 0 — 7
8 — 15
Hardware type (HTYPE)
32
Hardware length (HLEN)
64
Sender hardware address (SHA)
?
Sender protocol address (SPA)
?
Target hardware address (THA)
?
Target protocol address (TPA)
16 — 31
Protocol type (PTYPE)
Protocol length (PLEN)
Operation (OPER)
Hardware type (HTYPE)
Каждый канальный протокол передачи данных имеет свой номер, который хранится в этом
поле. Например, Ethernet имеет номер 0x0001.
Protocol type (PTYPE)
Код сетевого протокола. Например, для IPv4 будет записано 0x0800.
Hardware length (HLEN)
Длина физического адреса в байтах. Адреса Ethernet имеют длину 6 байт.
Protocol length (PLEN)
Длина логического адреса в байтах. IPv4 адреса имеют длину 4 байта.
Operation
Код операции отправителя: 0001 в случае запроса и 0002 в случае ответа.
Sender hardware address (SHA)
Физический адрес отправителя.
Sender protocol address (SPA)
Логический адрес отправителя.
Target hardware address (THA)
Физический адрес получателя. Поле пусто при запросе.
Target protocol address (TPA)
Логический адрес получателя.
Пример запроса
Если хост с IPv4 адресом 10.10.10.123 и MAC адресом 00:09:58:D8:11:22 хочет послать пакет
другому хосту с адресом 10.10.10.140, но не знает его MAC адрес, то он должен послать ARP
запрос для разрешения адреса.
Пакет, изображённый ниже, изображает широковещательный запрос. Если хост с IP
10.10.10.140 присутствует в сети и доступен, то он получает этот запрос ARP и возвращает
ответ.
+
Bits 0 — 7
8 — 15
16 — 31
Hardware type = 0x0001
32
Hardware length = 6
64
SHA (first 32 bits) = 0x000958D8
96
SHA (last 16 bits) = 0x1122
SPA (first 16 bits) = 0x0A0A
128
SPA (last 16 bits) = 0x0A7B
THA (first 16 bits) = 0xFFFF
160
THA (last 32 bits) = 0xFFFFFFFF
192
TPA = 0x0A0A0A8C
Protocol type = 0x0800
Protocol length = 4
Operation = 1
Пример ответа
В ситуации, описанной выше, если узел с адресом 10.10.10.140 имеет MAC адрес
00:09:58:D8:33:AA, то он отправит в ответ пакет, проиллюстрированный ниже. Заметим, что
блоки адресов отправителя и получателя теперь поменяли значения (отправитель ответа
теперь получатель запроса; получатель ответа — отправитель запроса). Кроме того, в ответе
есть MAC-адрес узла 10.10.10.140 в поле физического адреса отправителя (SHA).
Любой узел в той же сети, что и отправитель с получателем, тоже получит запрос (так как он
широковещательный) и таким образом добавит в свой кэш информацию об отправителе. Ответ
ARP направлен только источнику запроса ARP, поэтому ответ ARP не доступен другим узлам
в сети.
+
Bits 0 — 7
Hardware type = 0x0001
32
Hardware length = 6
64
SHA (first 32 bits) = 0x000958D8
96
SHA (last 16 bits) = 0x33AA
SPA (first 16 bits) = 0x0A0A
128
SPA (last 16 bits) = 0x0A8C
THA (first 16 bits) = 0x0009
160
THA (last 32 bits) = 0x58D81122
192
TPA = 0x0A0A0A7B
8 — 15
16 — 31
Protocol type = 0x0800
Protocol length = 4
Operation = 2
Замечание: Длина полей SHA, SPA, THA, TPA зависит от параметров Hardware length и
Protocol length соответственно
ARP кэш
Эффективность функционирования ARP во многом зависит от ARP кэша (ARP cache), который
присутствует на каждом хосте. В кэше содержатся IP адреса и соответствующие им
аппаратные адреса.
Время жизни записи в кэше оставлено на усмотрение разработчика. По умолчанию может
составлять от десятков секунд (например, 20 секунд) до четырёх часов (Cisco IOS).[3]
ARP Обнаружение Конфликтов Адресов (Address Conflict Detection)
Протокол ARP может использоваться для обнаружения конфликтов IP-адресов в локальной
сети. RFC 5227 определяет формат запроса ‘ARP Probe’ с полем SPA состоящим из всех нулей
(ip-адрес 0.0.0.0). Перед использованием IP-адреса хост может проверить что данный IP-адрес
не используется другим хостом сегмента локальной сети.
ARP Оповещение
ARP-оповещение (ARP Announcement) — это пакет (обычно ARP запрос [4]), содержащий
корректную SHA и SPA хоста-отправителя, с TPA, равной SPA. Это не разрешающий запрос, а
запрос на обновление ARP-кэша других хостов, получающих пакет.
Большинство операционных систем посылают такой пакет при включении хоста в сеть, что
позволяет предотвратить ряд проблем. Например, при смене сетевой карты (когда необходимо
обновить связь между IP- и MAC-адресами), такой запрос исправит записи в ARP-кэше других
хостов в сети.
ARP-оповещения также используются для ‘защиты’ IP-адресов в RFC 3927 (Zeroconf)
протоколе.
ARP-запросы могут решать и другие задачи. Так, при загрузке сетевого обеспечения ЭВМ
такой запрос может выяснить, не присвоен ли идентичный IP-адрес какому-то еще объекту в
сети.
В рамках протокола ARP возможны самообращенные запросы (gratuitous ARP). При таком
запросе инициатор формирует пакет, где в качестве IP-адреса используется его собственный
адрес. Это бывает нужно, когда осуществляется стартовая конфигурация сетевого интерфейса.
В таком запросе IP-адреса отправителя и получателя совпадают.
Самообращенный запрос позволяет ЭВМ решить две проблемы. Во-первых, определить, нет
ли в сети объекта, имеющего тот же IР-адрес. Если на такой запрос придет отклик, то ЭВМ
выдаст на консоль сообщение Duplicate IP address sent from Ethernet address <…>. Во-вторых, в
случае смены сетевой карты производится корректировка записи в АRP-таблицах ЭВМ,
которые содержали старый МАС-адрес инициатора. Машина, получающая ARP-запрос c
адресом, который содержится в ее таблице, должна обновить эту запись.
Вторая особенность такого запроса позволяет резервному файловому серверу заменить
основной, послав самообращенный запрос со своим МАС-адресом, но с IP-адресом
вышедшего из строя сервера. Этот запрос вызовет перенаправление кадров, адресованных
основному серверу, на резервный. Клиенты сервера при этом могут и не знать о выходе
основного сервера из строя. При этом возможны и неудачи, если программные реализации в
ЭВМ не в полной мере следуют регламентациям протокола ARP.
RARP (англ. Reverse Address Resolution Protocol — Обратный протокол преобразования
адресов) — протокол сетевого уровня модели OSI, выполняет обратное отображение адресов,
то есть преобразует физический адрес в IP-адрес.
Протокол применяется во время загрузки узла (например компьютера), когда он посылает
групповое сообщение-запрос со своим физическим адресом. Сервер принимает это сообщение
и просматривает свои таблицы (либо перенаправляет запрос куда-либо ещё) в поисках
соответствующего физическому, IP-адреса. После обнаружения найденный адрес отсылается
обратно на запросивший его узел. Другие станции также могут «слышать» этот диалог и
локально сохранить эту информацию в своих ARP-таблицах.
RARP позволяет разделять IP-адреса между не часто используемыми хост-узлами. После
использования каким-либо узлом IP-адреса он может быть освобождён и выдан другому узлу.
RARP является дополнением к ARP, и описан в RFC 903.
RARP отличается от «обратного» ARP (Inverse Address Resolution Protocol, или InARP),
описанного в RFC 2390, который предназначен для получения IP-адреса, соответствующего
MAC-адресу другого узла. InARP является дополнением к протоколу разрешения адресов и
используется для обратного поиска. RARP является скорее аналогом DHCP/BOOTP.
Вопрос 7. Протокол ICMP.
ICMP (англ. Internet Control Message Protocol — протокол межсетевых управляющих
сообщений[1]) — сетевой протокол, входящий встек протоколов TCP/IP. В основном ICMP
используется для передачи сообщений об ошибках и других исключительных ситуациях,
возникших при передаче данных, например, запрашиваемая услуга недоступна, или хост,
или маршрутизатор не отвечают. Также на ICMP возлагаются некоторые сервисные функции.
Технические подробности
Протокол ICMP описал в RFC 792 от 1981 года Jon Postel (с дополнениями в RFC 950) и
является стандартом Интернета (входит в стандарт STD 5 вместе с IP). Хотя формально ICMP
использует IP (ICMP-пакеты инкапсулируются в IP пакеты), он является неотъемлемой
частью IP и обязателен при реализации стека TCP/IP. Текущая версия ICMP для IPv4называется
ICMPv4. В IPv6 существует аналогичный протокол ICMPv6.
ICMP-сообщение строится из IP-пакетов, сгенерировавших ICMP-ответ. IP инкапсулирует
соответствующее ICMP-сообщение с новым заголовком IP (чтобы отправить ICMP-сообщение
обратно отправителю) и передает полученные пакеты дальше.
Например, каждая машина (такая, как маршрутизатор), которая перенаправляет IP-пакеты,
уменьшает Time to live (TTL) поля заголовка IP на единицу, если TTL достигает 0, ICMPсообщение о превышении TTL отправляется на источник пакета.
ICMP основан на протоколе IP. Каждое ICMP-сообщение инкапсулируется непосредственно в
пределах одного IP-пакета, и, таким образом, как и UDP и в отличие от TCP, ICMP является т. н.
«ненадежным» (не контролирующим доставку и её правильность). В отличие от UDP, где
реализация надёжности возложена на ПО прикладного уровня, ICMP (в силу специфики
применения) обычно не нуждается в реализации надёжной доставки. Его цели отличны от целей
транспортных протоколов, таких как TCP и UDP: он, как правило, не используется для передачи и
приёма данных между конечными системами. ICMP не используется непосредственно в
приложениях пользователей сети (исключение составляют инструменты Ping и Traceroute). Тот же
Ping, например, служит обычно как раз для проверки потерь IP-пакетов на маршруте.
Использование ICMP-сообщений
ICMP-сообщения (тип 12) генерируются при нахождении ошибок в заголовке IP-пакета (за
исключением самих ICMP-пакетов, дабы не привести к бесконечно растущему потоку ICMPсообщений об ICMP-сообщениях).
ICMP-сообщения (тип 3) генерируются маршрутизатором при отсутствии маршрута к адресату.
Утилита Ping, служащая для проверки возможности доставки IP-пакетов, использует ICMPсообщения с типом 8 (эхо-запрос) и 0 (эхо-ответ).
Утилита Traceroute, отображающая путь следования IP-пакетов, использует ICMP-сообщения с
типом 11.
ICMP-сообщения с типом 5 используются маршрутизаторами для обновления записей в таблице
маршрутизации отправителя.
ICMP-сообщения с типом 4 используются получателем (или маршрутизатором) для управления
скоростью отправки сообщений отправителем.
Формат пакета ICMP
Окте
т
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9
(байт
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
)
[0—3] Тип
…
Код
Контрольная сумма
Данные (формат зависит от значений полей «Код» и «Тип»)
Типы пакетов ICMP
Тип Код Сообщение
Данные (длина, бит)
Идентификатор (16)
Эхо-ответ
Номер последовательности
(16)
Данные (переменная)
Зарезервировано
1, 2
Адресат недоступен
Сеть недостижима
1
Узел недостижим
2
Протокол недостижим
3
Порт недостижим
4
Необходима фрагментация,
но установлен флаг её
запрета (DF)
5
Неверный маршрут от
источника
6
Сеть назначения неизвестна
7
Узел назначения неизвестен
8
Узел источник изолирован
Не используется (32)
9
Сеть административно
запрещена
Заголовок IP, Начало исходной дейтаграммы (64)
10
Узел административно
запрещён
11
Сеть недоступна для ToS
12
Узел недоступен для ToS
13
Коммуникации
административно запрещены
14
Нарушение порядка
предпочтения узлов
15
Активно отсечение порядка
предпочтения
Сдерживание источника
(отключение источника при
переполнении очереди)
3
4
Перенаправление
Перенаправление пакетов в
сеть
1
Перенаправление пакетов к
узлу
2
Перенаправление для
каждого типа обслуживания
(ToS)
3
Перенаправление пакета к
узлу для каждого типа
обслуживания
Альтернативный адрес узла
Адрес маршрутизатора (32)
5
6
Заголовок IP, Начало исходной дейтаграммы (64)
Зарезервировано
7
Идентификатор (16)
8
Эхо-запрос
Номер последовательности
(16)
Данные (переменная)
Количество
адресов (8)
Размер
Срок действия (16)
элемента (8)
Адрес[1] (32)
9
Объявление маршрутизатора
Предпочтительность[1] (32)
…
Адрес[N] (32)
Предпочтительность[N] (32)
10
Запрос маршрутизатора
Не используется (32)
Время жизни дейтаграммы
истекло
11
1
12
Время жизни пакета (TTL)
истекло при
транспортировке
Не используется (32)
Заголовок IP, Начало исходной дейтаграммы (64)
Время жизни пакета истекло
при сборке фрагментов
Неверный параметр (проблема с параметрами дейтаграммы: ошибка в IP-заголовке или
отсутствует необходимая опция)
Указатель говорит об
ошибке
Указатель
(8)
Не используется (24)
Заголовок IP, Начало исходной дейтаграммы (64)
13
1
Отсутствует требуемая
опция
2
Некорректная длина
Запрос метки времени
Не используется (32)
Заголовок IP, Начало исходной дейтаграммы (64)
Идентификатор (16)
Номер последовательности
(16)
Начальное время (32)
14
Ответ с меткой времени
Время приёма (32)
Время отправки (32)
15
Информационный запрос
16
Информационный ответ
17
Запрос адресной маски
18
Отклик на запрос адресной
маски
19
Зарезервировано (для
обеспечения безопасности)
20—
29
Зарезервировано (для
экспериментов на
устойчивость к ошибкам)
Трассировка маршрута
Идентификатор (16)
Номер последовательности
(16)
Идентификатор (16)
Номер последовательности
(16)
Маска (32)
Идентификатор (16)
Исходящий пакет успешно
отправлен
Количество хопов
Количество хопов исходящего
возвращающегося
пакета (16)
пакета (16)
1
Путь для исходящего пакета
не найден, пакет уничтожен
Скорость линии связи (32)
30
MTU линии связи (32)
31
Не используется (16)
Ошибка преобразования
датаграммы
Указатель (32)
Неизвестная или
неуказанная ошибка
1
Невозможно конвертировать
опцию
2
Неизвестная обязательная
опция
3
Неподдерживаемая
обязательная опция
4
Неподдерживаемый
транспортный протокол
5
Превышена полная длина
6
Превышена длина заголовка
IP
7
Номер транспортного
протокола больше 255
8
Номер порта вне
допустимого диапазона
9
Превышена длина заголовка
транспортного протокола
10
Переход через границу 32
бит и установлен бит ACK
11
Неизвестная обязательная
опция транспортного
протокола
32
Перенаправление для
мобильного узла
33
IPv6 Where-Are-You (где вы
находитесь)
34
IPv6 I-Am-Here (я здесь)
35
Запрос перенаправления для
мобильного узла
36
Отклик на запрос
перенаправления для
мобильного узла
37
Запрос доменного имени
Заголовок IP и транспортного протокола исходной
дейтаграммы
38
Ответ на запрос доменного
имени
39
Обнаружение алгоритма
безопасности SKIP (SKIP
algorithm discovery ICMP
message)
Photuris
Зарезервировано
1
Неизвестный индекс
параметров безопасности
2
Параметры безопасности
верны, но произошла
ошибка аутентификации
3
Параметры безопасности
верны, но произошёл сбой
при расшифровке
4
Требуется проверка
подлинности
5
Требуется авторизация
40
41—
252
253254
255
Зарезервировано
Зарезервировано для
экспериментов по RFC 3692
Зарезервировано
Правила генерации ICMP-пакетов
1. При потере ICMP-пакета никогда не генерируется новый.
2. ICMP-пакеты никогда не генерируются в ответ на IP-пакеты с широковещательным или
групповым адресом, чтобы не вызывать перегрузку в сети (так называемый
«широковещательный шторм»).
3. При повреждении фрагментированного IP-пакета ICMP-сообщение отправляется только
после получения первого повреждённого фрагмента, поскольку отправитель всё равно
повторит передачу всего IP-пакета целиком.
Вопрос 9. Транспортные протоколы TCP и UDP.
TCP (англ. transmission control protocol — протокол управления передачей) — один из
основных протоколов передачи данныхинтернета, предназначенный для управления передачей
данных. Сети и подсети, в которых совместно используются протоколы TCP иIP называются
сетями TCP/IP.
В стеке протоколов IP TCP выполняет функции протокола транспортного уровня модели OSI.
Механизм TCP предоставляет поток данных с предварительной установкой соединения,
осуществляет повторный запрос данных в случае потери данных и устраняет дублирование при
получении двух копий одного пакета, гарантируя тем самым, в отличие от UDP, целостность
передаваемых данных и уведомление отправителя о результатах передачи.
Реализации TCP обычно встроены в ядра ОС. Существуют реализации TCP, работающие
в пространстве пользователя.
Когда осуществляется передача от компьютера к компьютеру через Интернет, TCP работает на
верхнем уровне между двумя конечными системами, например, браузером и веб-сервером. TCP
осуществляет надежную передачу потока байтов от одной программы на некотором компьютере к
другой программе на другом компьютере (например, программы для электронной почты, для
обмена файлами). TCP контролирует длину сообщения, скорость обмена сообщениями, сетевой
трафик
Заголовок сегмента TCP
Структура заголовка
Бит
0—3
4—9
10 — 15
16 — 31
Порт источника
32
Порядковый номер
64
Номер подтверждения
96
Длина
Зарезервировано Флаги
заголовка
Размер Окна
128
Контрольная сумма
Указатель важности
160
Опции (необязательное, но используется практически всегда)
Порт назначения
160/192+ Данные
Порт источника, Порт назначения
Эти 16-битные поля содержат номера портов — числа, которые определяются по специальному
списку.
Порт источника идентифицирует приложение клиента, с которого отправлены пакеты. Ответные
данные передаются клиенту на основании этого номера.
Порт назначения идентифицирует порт, на который отправлен пакет.
Порядковый номер
Порядковый номер выполняет две задачи:
1. Если установлен флаг SYN, то это изначальный порядковый номер — ISN (Initial Sequence
Number), и первый байт данных, которые будут переданы в следующем пакете, будет
иметь номер, равный ISN + 1.
2. В противном случае, если SYN не установлен, первый байт данных, передаваемый в
данном пакете, имеет этот порядковый номер
Поскольку поток TCP в общем случае может быть длиннее, чем число различных состояний этого
поля, то все операции с порядковым номером должны выполняться по модулю 2^32. Это
накладывает практическое ограничение на использование TCP. Если скорость передачи
коммуникационной системы такова, чтобы в течение MSL (максимального времени жизни
сегмента) произошло переполнение порядкового номера, то в сети может появиться два сегмента с
одинаковым номером, относящихся к разным частям потока, и приёмник получит некорректные
данные.
Номер подтверждения
Если установлен флаг ACK, то это поле содержит порядковый номер, ожидаемый получателем в
следующий раз. Помечает этот сегмент как подтверждение получения.
Длина заголовка (смещение данных)
Это поле определяет размер заголовка пакета TCP в 4-байтных (4-октетных) словах.
Минимальный размер составляет 5 слов, а максимальный — 15, что составляет 20 и 60 байт
соответственно. Смещение считается от начала заголовка TCP.
Зарезервировано
Зарезервировано (6 бит) для будущего использования и должно устанавливаться в ноль. Из них
два (5-й и 6-й) уже определены:
CWR (Congestion Window Reduced) — Поле «Окно перегрузки уменьшено» — флаг
установлен отправителем, чтобы указать, что получен пакет с установленным флагом ECE
(RFC 3168)
ECE (ECN-Echo) — Поле «Эхо ECN» — указывает, что данный узел способен на ECN
(явное уведомление перегрузки) и для указания отправителю о перегрузках в сети (RFC
3168)
Флаги (управляющие биты)
Это поле содержит 6 битовых флагов:
URG — поле «Указатель важности» задействовано (англ. Urgent pointer field is
significant)
ACK — поле «Номер подтверждения» задействовано (англ. Acknowledgement field is
significant)
PSH — (англ. Push function) инструктирует получателя протолкнуть данные,
накопившиеся в приемном буфере, в приложение пользователя
RST — оборвать соединения, сбросить буфер (очистка буфера) (англ. Reset the connection)
SYN — синхронизация номеров последовательности (англ. Synchronize sequence numbers)
FIN (англ. final, бит) — флаг, будучи установлен, указывает на завершение соединения
(англ. FIN bit used for connection termination).
Размер окна
В этом поле содержится число, определяющее в байтах размер данных, которые отправитель
может отправить без получения подтверждения.
Контрольная сумма
Поле контрольной суммы — это 16-битное дополнение к сумме всех 16-битных слов
заголовка(включая псевдозаголовок) и данных. Если сегмент, по которому вычисляется
контрольная сумма, имеет длину не кратную 16-ти битам, то длина сегмента увеличивается до
кратной 16-ти, за счет дополнения к нему справа нулевых битов заполнения. Биты заполнения (0)
не передаются в сообщении и служат только для расчёта контрольной суммы. При расчёте
контрольной суммы значение самого поля контрольной суммы принимается равным 0.
Указатель важности
16-битовое значение положительного смещения от порядкового номера в данном сегменте. Это
поле указывает порядковый номер октета, которым заканчиваются важные (urgent) данные. Поле
принимается во внимание только для пакетов с установленным флагом URG.
Опции
Могут применяться в некоторых случаях для расширения протокола. Иногда используются для
тестирования. На данный момент в опции практически всегда включают 2 байта NOP (в данном
случае 0x01) и 10 байт, задающих timestamps. Вычислить длину поля опции можно через значение
поля смещения.
Механизм действия протокола
В отличие от традиционной альтернативы — UDP, который может сразу же начать передачу
пакетов, TCP устанавливает соединения, которые должны быть созданы перед передачей данных.
TCP соединение можно разделить на 3 стадии:
Установка соединения
Передача данных
Завершение соединения
Состояния сеанса TCP
Упрощённая диаграмма состояний TCP. Более подробно в TCP EFSM diagram (на английском
языке)
Состояния сеанса TCP
CLOSED
Начальное состояние узла. Фактически фиктивное
LISTEN
Сервер ожидает запросов установления соединения от клиента
SYN-SENT
Клиент отправил запрос серверу на установление соединения и ожидает ответа
SYNRECEIVED
Сервер получил запрос на соединение, отправил ответный запрос и ожидает
подтверждения
ESTABLISHED Соединение установлено, идёт передача данных
FIN-WAIT-1
Одна из сторон (назовём её узел-1) завершает соединение, отправив сегмент с
флагом FIN
CLOSE-WAIT
Другая сторона (узел-2) переходит в это состояние, отправив, в свою очередь
сегмент ACK и продолжает одностороннюю передачу
FIN-WAIT-2
Узел-1 получает ACK, продолжает чтение и ждёт получения сегмента с флагом
FIN
LAST-ACK
Узел-2 заканчивает передачу и отправляет сегмент с флагом FIN
TIME-WAIT
Узел-1 получил сегмент с флагом FIN, отправил сегмент с флагом ACK и ждёт
2*MSL секунд, перед окончательным закрытием соединения
CLOSING
Обе стороны инициировали закрытие соединения одновременно: после отправки
сегмента с флагом FIN узел-1 также получает сегмент FIN, отправляет ACK и
находится в ожидании сегмента ACK (подтверждения на свой запрос о
разъединении)
Установка соединения
Процесс начала сеанса TCP (также называемый «рукопожатие» (англ. handshake)), состоит из трёх
шагов.
1. Клиент, который намеревается установить соединение, посылает серверу сегмент с номером
последовательности и флагом SYN.
Сервер получает сегмент, запоминает номер последовательности и пытается создать сокет
(буферы и управляющие структуры памяти) для обслуживания нового клиента.
В случае успеха сервер посылает клиенту сегмент с номером последовательности и
флагами SYN и ACK, и переходит в состояние SYN-RECEIVED.
В случае неудачи сервер посылает клиенту сегмент с флагом RST.
2. Если клиент получает сегмент с флагом SYN, то он запоминает номер последовательности и
посылает сегмент с флагом ACK.
Если он одновременно получает и флаг ACK (что обычно и происходит), то он переходит в
состояние ESTABLISHED.
Если клиент получает сегмент с флагом RST, то он прекращает попытки соединиться.
Если клиент не получает ответа в течение 10 секунд, то он повторяет процесс соединения
заново.
3. Если сервер в состоянии SYN-RECEIVED получает сегмент с флагом ACK, то он переходит в
состояние ESTABLISHED.
В противном случае после тайм-аута он закрывает сокет и переходит в состояние
CLOSED.
Процесс называется «трёхэтапным согласованием» (англ. three way handshake), так как несмотря
на то что возможен процесс установления соединения с использованием четырёх сегментов (SYN
в сторону сервера, ACK в сторону клиента, SYN в сторону клиента, ACK в сторону сервера), на
практике для экономии времени используется три сегмента.
Пример базового 3-этапного согласования:
TCP A
1. CLOSED
2. SYN-SENT
TCP B
LISTEN
—>
—> SYN-RECEIVED
3. ESTABLISHED <— <— SYN-RECEIVED
4. ESTABLISHED —>
—> ESTABLISHED
5. ESTABLISHED <—
<— ESTABLISHED
В строке 2 TCP A начинает передачу сегмента SYN, говорящего об использовании номеров
последовательности, начиная со 100. В строке 3 TCP B передает SYN и подтверждение для
принятого SYN в адрес TCP A. Надо отметить, что поле подтверждения показывает ожидание TCP
B приема номера последовательности 101, подтверждающего SYN с номером 100.
В строке 4 TCP A отвечает пустым сегментом с подтверждением ACK для сегмента SYN от TCP
B; в строке 5 TCP B передает некоторые данные. Отметим, что номер подтверждения сегмента в
строке 5 (ACK=101) совпадает с номером последовательности в строке 4 (SEQ=101), поскольку
ACK не занимает пространства номеров последовательности (если это сделать, придется
подтверждать подтверждения — ACK для ACK).
Существуют экспериментальные расширения протокола TCP, сокращающие количество пакетов
при установлении соединения, например TCP Fast Open. Ранее также существовало
расширение T/TCP. Для прозрачного шифрования данных предлагается использовать
расширение tcpcrypt.
Передача данных
При обмене данными приемник использует номер последовательности, содержащийся в
получаемых сегментах, для восстановления их исходного порядка. Приемник уведомляет
передающую сторону о номере последовательности, до которой он успешно получил данные,
включая его в поле «номер подтверждения». Все получаемые данные, относящиеся к промежутку
подтвержденных последовательностей, игнорируются. Если полученный сегмент содержит номер
последовательности больший, чем ожидаемый, то данные из сегмента буферизируются, но номер
подтвержденной последовательности не изменяется. Если впоследствии будет принят сегмент,
относящийся к ожидаемому номеру последовательности, то порядок данных будет автоматически
восстановлен исходя из номеров последовательностей в сегментах.
Для того, чтобы передающая сторона не отправляла данные интенсивнее, чем их может
обработать приемник, TCP содержит средства управления потоком. Для этого используется поле
«окно». В сегментах, направляемых от приемника передающей стороне, в поле «окно»
указывается текущий размер приемного буфера. Передающая сторона сохраняет размер окна и
отправляет данных не более, чем указал приемник. Если приемник указал нулевой размер окна, то
передача данных в направлении этого узла не происходит, пока приемник не сообщит о большем
размере окна.
В некоторых случаях передающее приложение может явно затребовать протолкнуть данные до
некоторой последовательности принимающему приложению, не буферизируя их. Для этого
используется флаг PSH. Если в полученном сегменте обнаруживается флаг PSH, то реализация
TCP отдает все буферизированные на текущий момент данные принимающему приложению.
«Проталкивание» используется, например, в интерактивных приложениях. В сетевых терминалах
нет смысла ожидать ввода пользователя после того, как он закончил набирать команду. Поэтому
последний сегмент, содержащий команду, обязан содержать флаг PSH, чтобы приложение на
принимающей стороне смогло начать её выполнение.
Завершение соединения
Завершение соединения можно рассмотреть в три этапа:
1. Посылка серверу от клиента флага FIN на завершение соединения.
2. Сервер посылает клиенту флаги ответа ACK , FIN, что соединение закрыто.
3. После получения этих флагов клиент закрывает соединение и в подтверждение отправляет
серверу ACK , что соединение закрыто.
Известные проблемы
Максимальный размер сегмента
TCP требует явного указания максимального размера сегмента (MSS) в случае, если виртуальное
соединение осуществляется через сегмент сети, где максимальный размер блока (MTU) менее, чем
стандартный MTU Ethernet (1500 байт).
В протоколах туннелирования, таких как GRE, IPIP, а также PPPoE MTU туннель меньше, чем
стандартный, поэтому сегмент TCP максимального размера имеет длину пакета больше, чем MTU.
Это приводит к фрагментации и уменьшению скорости передачи полезных данных. Если на
каком-либо узле фрагментация запрещена, то со стороны пользователя это выглядит как
«зависание» соединений. При этом «зависание» может происходить в произвольные моменты
времени, а именно тогда, когда отправитель использовал сегменты длиннее допустимого размера.
Для решения этой проблемы на маршрутизаторах применяются правила Firewall-а, добавляющие
параметр MSS во все пакеты, инициирующие соединения, чтобы отправитель использовал
сегменты допустимого размера.
MSS может также управляться параметрами операционной системы.
Обнаружение ошибок при передаче данных
Хотя протокол осуществляет проверку контрольной суммы по каждому сегменту, используемый
алгоритм считается слабым [1]. Так, в 2008 году ошибка в передаче одного бита, не обнаруженная
сетевыми средствами, привела к остановке серверов системы Amazon Web Services [2].
В общем случае распределенным сетевым приложениям рекомендуется использовать
дополнительные программные средства для гарантирования целостности передаваемой
информации[3].
Атаки на протокол
Недостатки протокола проявляются в успешных теоретических и практических атаках, при
которых злоумышленник может получить доступ к передаваемым данным, выдать себя за другую
сторону или привести систему в нерабочее состояние.
Реализация
Псевдозаголовок
TCP-заголовок не содержит информации об адресе отправителя и получателя, поэтому даже при
совпадении порта получателя нельзя с точностью сказать, что сообщение пришло в нужное место.
Поскольку назначением протокола TCP является надёжная доставка сообщений, то этот момент
имеет принципиальное значение. Эту задачу можно было решить разными способами. Самый
очевидный — добавить информацию об адресе назначения в заголовок TCP, однако это, вопервых, приводит к дублированию информации, что снижает долю полезной информации
переносимой TCP-сегментом, а во-вторых, нарушает принцип инкапсуляции модели OSI. Поэтому
разработчики протокола пошли другим путём и использовали дополнительный псевдозаголовок:
TCP-псевдозаголовок IPv4
Бит
ы
0 1 2 3 4 5 6 7 8 9
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
0-31
IP-адрес отправителя (Source address)
32-63 IP-адрес получателя (Destination address)
64-95 0 0 0 0 0 0 0 0 Протокол (Protocol)
Длина TCP-сегмента (TCP length)
TCP-псевдозаголовок IPv6
Бит
ы
0 1 2 3 4 5 6 7 8 9
0-96
IP-адрес отправителя (Source address)
128224
IP-адрес получателя (Destination address)
256
Длина TCP-сегмента (TCP length)
288
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
Протокол верхнего
уровня (Next header)
Протокол (Protocol)/Протокол верхнего уровня (Next header) — содержит в себе значение 6
(00000110 в двоичном виде, 0x6 — в шестнадцатеричном) — идентификатор TCPпротокола.
Длина TCP-сегмента (TCP length) — содержит в себе длину TCP-сегмента в байтах (TCPзаголовок + данные; длина псевдозаголовка не учитывается).
Псевдозаголовок не включается в TCP-сегмент. Он используется для расчета контрольной суммы
перед отправлением сообщения и при его получении (получатель составляет свой
псевдозаголовок, используя адрес хоста, с которого пришло сообщение, и собственный адрес, а
затем считает контрольную сумму).
Освобождение от расчёта контрольной суммы
Многие реализации стека TCP/IP предоставляют возможности использования аппаратной
поддержки для автоматического расчёта контрольной суммы в сетевом адаптере до передачи в
сеть или после приёма из сети для верификации. Это может освобождать операционную систему
от использования ценных тактов процессора при вычислении контрольной суммы.
Эта функция может приводить к тому, что анализаторы трафика, перехватывающие исходящие
пакеты до их передачи в сетевой адаптер и не знающие о делегировании расчёта контрольной
суммы сетевому адаптеру, могут сообщать об ошибке контрольной суммы в исходящих пакетах.
UDP (англ. User Datagram Protocol — протокол пользовательских датаграмм) — один из
ключевых элементов TCP/IP, набора сетевых протоколов для Интернета. С UDP компьютерные
приложения могут посылать сообщения (в данном случае называемыедатаграммами) другим
хостам по IP-сети без необходимости предварительного сообщения для установки специальных
каналов передачи или путей данных. Протокол был разработан Дэвидом П. Ридом в 1980 году и
официально определён в RFC 768.
UDP использует простую модель передачи, без неявных «рукопожатий» для обеспечения
надёжности, упорядочивания или целостности данных. Таким образом, UDP предоставляет
ненадёжный сервис, и датаграммы могут прийти не по порядку, дублироваться или вовсе
исчезнуть без следа. UDP подразумевает, что проверка ошибок и исправление либо не нужны,
либо должны исполняться в приложении. Чувствительные ко времени приложения часто
используют UDP, так как предпочтительнее сбросить пакеты, чем ждать задержавшиеся пакеты,
что может оказаться невозможным в системах реального времени. При необходимости
исправления ошибок на сетевом уровне интерфейса приложение может
задействовать TCP или SCTP, разработанные для этой цели.
Природа UDP как протокола без сохранения состояния также полезна для серверов, отвечающих
на небольшие запросы от огромного числа клиентов, например DNS и потоковые мультимедийные
приложения вроде IPTV, Voice over IP, протоколы туннелирования IP и многие онлайн-игры.
Служебные порты
UDP-приложения используют датаграммные сокеты для установки соединения между хостами.
Приложение связывает сокет с его конечной точкой передачи данных, которая является
комбинацией IP-адреса и порта службы. Порт — это программная структура, определяемая
номером порта — 16-битным целочисленным значением (то есть от 0 до 65535). Порт 0
зарезервирован, хотя и является допустимым значением порта источника в случае, если процессотправитель не ожидает ответных сообщений.
IANA разбила номера портов на три группы.
Порты с номерами от 0 до 1023 используются для обычных, хорошо известных служб.
В Unix-подобных операционных системах для использования таких портов необходимо
разрешение суперпользователя.
Порты с номерами от 1024 до 49151 предназначены для зарегистрированных IANA служб.
Порты с 49152 по 65535 могут быть использованы для любых целей, поскольку
официально не разработаны для какой-то определённой службы. Они также используются
какдинамические (временные) порты, которые запущенное на хосте программное
обеспечение может случайным образом выбрать для самоопределения. По сути, они
используются как временные порты в основном клиентами при связи с серверами.
Структура пакета
UDP — минимальный ориентированный на обработку сообщений протокол транспортного
уровня, задокументированный в RFC 768.
UDP не предоставляет никаких гарантий доставки сообщения для вышестоящего протокола и не
сохраняет состояния отправленных сообщений. По этой причине UDP иногда называют Unreliable
Datagram Protocol (англ. — Ненадёжный протокол датаграмм).
UDP обеспечивает многоканальную передачу (с помощью номеров портов) и проверку
целостности (с помощью контрольных сумм) заголовка и существенных данных. Надёжная
передача в случае необходимости должна реализовываться пользовательским приложением.
Биты 0 — 15
0-31
16 — 31
Порт отправителя (Source port) Порт получателя (Destination port)
32-63 Длина датаграммы (Length)
Контрольная сумма (Checksum)
64-… Данные (Data)
Заголовок UDP состоит из четырёх полей, каждое по 2 байта (16 бит). Два из них необязательны к
использованию в IPv4 (розовые ячейки в таблице), в то время как в IPv6 необязателен только порт
отправителя.
Порт отправителя
В этом поле указывается номер порта отправителя. Предполагается, что это значение задаёт порт,
на который при необходимости будет посылаться ответ. В противном же случае, значение должно
быть равным 0. Если хостом-источником является клиент, то номер порта будет, скорее всего,
динамическим. Если источником является сервер, то его порт будет одним из «хорошо
известных».
Порт получателя
Это поле обязательно и содержит порт получателя. Аналогично порту отправителя, если хостомполучателем является клиент, то номер порта динамический, если получатель — сервер, то это
будет «хорошо известный» порт.
Длина посылки
Поле, задающее длину всей датаграммы (заголовка и данных) в байтах. Минимальная длина равна
длине заголовка — 8 байт. Теоретически, максимальный размер поля — 65535 байт для UDPдатаграммы (8 байт на заголовок и 65527 на данные). Фактический предел для длины данных при
использовании IPv4 — 65507 (помимо 8 байт на UDP-заголовок требуется ещё 20 на IP-заголовок).
На практике также следует учитывать, что если длина IPv4 пакета с UDP будет
превышать MTU (для Ethernet по умолчанию 1500 байт), то отправка такого пакета может вызвать
его фрагментацию, что может привести к тому, что он вообще не сможет быть доставлен, если
промежуточные маршрутизаторы или конечный хост не будут поддерживать фрагментированные
IP пакеты. Также в RFC791 указывается минимальная длина IP пакета 576 байт, которую должны
поддерживать все участники, и рекомендуется отправлять IP пакеты большего размера только в
том случае если вы уверены, что принимающая сторона может принять пакеты такого размера.
Следовательно, чтобы избежать фрагментации UDP пакетов (и возможной их потери), размер
данных в UDP не должен превышать: MTU — (Max IP Header Size) — (UDP Header Size) = 1500 —
60 — 8 = 1432 байт. Для того чтобы быть уверенным, что пакет будет принят любым хостом,
размер данных в UDP не должен превышать: (минимальная длина IP пакета) — (Max IP Header
Size) — (UDP Header Size) = 576 — 60 — 8 = 508 байт.
В Jumbogram’мах IPv6 пакеты UDP могут иметь больший размер. Максимальное значение
составляет 4 294 967 295 байт (232 — 1), из которых 8 байт соответствуют заголовку, а остальные 4
294 967 287 байт — данным.
Следует заметить, что большинство современных сетевых устройств отправляют и принимают
пакеты IPv4 длиной до 10000 байт без их разделения на отдельные пакеты. Неофициально такие
пакеты называют «Jumbo-пакетами», хотя понятие Jumbo официально относится к IPv6. Тем не
менее, «Jumbo-пакеты» поддерживают не все устройства и перед организацией связи с помощью
UDP/IP IPv4 посылок с длиной превышающей 1500 байт нужно проверять возможность такой
связи опытным путём на конкретном оборудовании[1].
Контрольная сумма
Поле контрольной суммы используется для проверки заголовка и данных на ошибки. Если сумма
не сгенерирована передатчиком, то поле заполняется нулями. Поле не является обязательным для
IPv4.
Расчёт контрольной суммы
Метод для вычисления контрольной суммы определён в RFC 1071[2].
Перед расчётом контрольной суммы, если длина UDP-сообщения в байтах нечётна, то UDPсообщение дополняется в конце нулевым байтом (псевдозаголовок и добавочный нулевой байт не
отправляются вместе с сообщением, они используются только при расчёте контрольной суммы).
Поле контрольной суммы в UDP-заголовке во время расчёта контрольной суммы принимается
нулевым.
Для расчёта контрольной суммы псевдозаголовок и UDP-сообщение разбивается на двухбайтные
слова. Затем рассчитывается сумма всех слов в арифметике обратного кода (т. е. кода, в котором
отрицательное число получается из положительного инверсией всех разрядов числа и существует
два нуля: 0х0000 (обозначается +0) и 0xffff(обозначается -0)). Результат записывается в
соответствующее поле в UDP-заголовке.
Значение контрольной суммы, равное 0х0000 (+0 в обратном коде), зарезервировано и означает,
что для посылки контрольная сумма не вычислялась. В случае, если контрольная сумма
вычислялась и получилась равной 0х0000, то в поле контрольной суммы заносят значение 0xffff(-0
в обратном коде).
При получении сообщения получатель считает контрольную сумму заново (уже учитывая поле
контрольной суммы), и, если в результате получится -0 (то есть 0xffff), то контрольная сумма
считается сошедшейся. Если сумма не сходится (данные были повреждены при передаче, либо
контрольная сумма неверно посчитана на передающей стороне), то решение о дальнейших
действиях принимает принимающая сторона. Как правило, в большинстве современных
устройств, работающих с UDP/IP-пакетами имеются настройки, позволяющие либо игнорировать
такие пакеты, либо пропускать их на дальнейшую обработку, невзирая на неправильность
контрольной суммы.
Пример расчёта контрольной суммы
Для примера рассчитаем контрольную сумму нескольких 16-битных слов: 0x398a, 0xf802, 0x14b2,
0xc281.
Для этого можно сначала сложить попарно числа, рассматривая их как 16-разрядные беззнаковые
числа с последующим приведением к дополнительному коду путём прибавления единицы к
результату, если при сложении произошёл перенос в старший (17-й) разряд (т. е. де-факто, этой
операцией мы переводим отрицательное число из дополнительного вобратный код). Или, что
равноценно, можно считать, что перенос прибавляется к младшему разряду числа.
0x398a + 0xf802 = 0x1318c → 0x318d (перенос в старший разряд)
0x318d + 0x14b2 = 0x0463f → 0x463f (число положительное)
0x463f + 0xc281 = 0x108c0 → 0x08c1
В конце выполняется инверсия всех битов получившегося числа
0x08c1 = 0000 1000 1100 0001 → 1111 0111 0011 1110 = 0xf73e или, иначе — 0xffff − 0x08c1 =
0xf73e. Это и есть искомая контрольная сумма.
В документе RFC 1071[2] приведены и другие способы расчёта контрольной суммы, в частности, с
использованием 32х-разрядной арифметики.
Псевдозаголовки
Псевдозаголовок для IPv4
Если UDP работает над IPv4, контрольная сумма вычисляется при помощи псевдозаголовка,
который содержит некоторую информацию из заголовка IPv4. Псевдозаголовок не является
настоящим IPv4-заголовком, используемым для отправления IP-пакета. В таблице приведён
псевдозаголовок, используемый только для вычисления контрольной суммы.
Биты 0 — 7
8 — 15
Адрес источника
16 — 23
24 — 31
32
Адрес получателя
64
Нули
96
Порт источника
Порт получателя
128
Длина
Контрольная сумма
Протокол Длина UDP
160+ Данные
Адреса источника и получателя берутся из IPv4-заголовка. Значения поля «Протокол» для UDP
равно 17 (0x11). Поле «Длина UDP» соответствует длине заголовка и данных.
Вычисление контрольной суммы для IPv4 необязательно, если она не используется, то значение
равно 0.
Псевдозаголовок для IPv6
При работе UDP над IPv6 контрольная сумма обязательна. Метод для её вычисления был
опубликован в RFC 2460:
При вычислении контрольной суммы опять используется псевдозаголовок, имитирующий
реальный IPv6-заголовок:
Биты 0 — 7
8 — 15
16 — 23
24 — 31
32
Адрес источника
64
96
128
160
Адрес получателя
192
224
256
Длина UDP
288
Нули
320
Порт источника
Порт получателя
352
Длина
Контрольная сумма
384+
Данные
Следующий заголовок
Адрес источника такой же, как и в IPv6-заголовке. Адрес получателя — финальный получатель;
если в IPv6-пакете не содержится заголовка маршрутизации (Routing), то это будет адрес
получателя из IPv6-заголовка, в противном случае, на начальном узле, это будет адрес последнего
элемента заголовка маршрутизации, а на узле-получателе — адрес получателя из IPv6-заголовка.
Значение «Следующий заголовок» равно значению протокола — 17 для UDP. Длина UDP —
длина UDP-заголовка и данных.
Надёжность и решения проблемы перегрузок
Из-за недостатка надёжности приложения UDP должны быть готовы к некоторым потерям,
ошибкам и дублированиям. Некоторые из них (например, TFTP) могут при необходимости
добавить элементарные механизмы обеспечения надёжности на прикладном уровне.
Но чаще такие механизмы не используются UDP-приложениями и даже мешают им. Потоковые
медиа, многопользовательские игры в реальном времени и VoIP — примеры приложений, часто
использующих протокол UDP. В этих конкретных приложениях потеря пакетов обычно не
является большой проблемой. Если приложению необходим высокий уровень надёжности, то
можно использовать другой протокол (TCP) или воспользоваться методами помехоустойчивого
кодирования (en:Erasure code).
Более серьёзной потенциальной проблемой является то, что в отличие от TCP, основанные на UDP
приложения не обязательно имеют хорошие механизмы контроля и избегания перегрузок.
Чувствительные к перегрузкам UDP-приложения, которые потребляют значительную часть
доступной пропускной способности, могут поставить под угрозу стабильность в Интернете.
Сетевые механизмы были предназначены для того, чтобы свести к минимуму возможные эффекты
от перегрузок при неконтролируемых, высокоскоростных нагрузках. Такие сетевые элементы, как
маршрутизаторы, использующие пакетные очереди и техники сброса, часто являются
единственным доступным инструментом для замедления избыточного UDP-трафика. DCCP (англ.
Datagram Congestion Control Protocol — протокол контроля за перегрузками датаграмм) разработан
как частичное решение этой потенциальной проблемы с помощью добавления конечному хосту
механизмов для отслеживания перегрузок для высокоскоростных UDP-потоков вроде потоковых
медиа.
Приложения
Многочисленные ключевые Интернет-приложения используют UDP, в их числе — DNS (где
запросы должны быть быстрыми и состоять только из одного запроса, за которым следует один
пакет ответа), Простой Протокол Управления Сетями (SNMP), Протокол Маршрутной
Информации (RIP), Протокол Динамической Конфигурации Узла (DHCP).
Голосовой и видеотрафик обычно передается с помощью UDP. Протоколы потокового видео в
реальном времени и аудио разработаны для обработки случайных потерь пакетов так, что качество
лишь незначительно уменьшается вместо больших задержек при повторной передаче потерянных
пакетов. Поскольку и TCP, и UDP работают с одной и той же сетью, многие компании замечают,
что недавнее увеличение UDP-трафика из-за этих приложений реального времени мешает
производительности TCP-приложений вроде систем баз данныхили бухгалтерского учёта. Так как
и бизнес-приложения, и приложения в реальном времени важны для компаний, развитие качества
решений проблемы некоторыми рассматривается в качестве важнейшего приоритета.
Сравнение UDP и TCP
TCP — ориентированный на соединение протокол, что означает необходимость «рукопожатия»
для установки соединения между двумя хостами. Как только соединение установлено,
пользователи могут отправлять данные в обоих направлениях.
Надёжность — TCP управляет подтверждением, повторной передачей и тайм-аутом
сообщений. Производятся многочисленные попытки доставить сообщение. Если оно
потеряется на пути, сервер вновь запросит потерянную часть. В TCP нет ни пропавших
данных, ни (в случае многочисленных тайм-аутов) разорванных соединений.
Упорядоченность — если два сообщения последовательно отправлены, первое сообщение
достигнет приложения-получателя первым. Если участки данных прибывают в неверном
порядке, TCP отправляет неупорядоченные данные в буфер до тех пор, пока все данные не
могут быть упорядочены и переданы приложению.
Тяжеловесность — TCP необходимо три пакета для установки сокет-соединения перед
тем, как отправить данные. TCP следит за надёжностью и перегрузками.
Потоковость — данные читаются как поток байтов, не передается никаких особых
обозначений для границ сообщения или сегментов.
UDP — более простой, основанный на сообщениях протокол без установления соединения.
Протоколы такого типа не устанавливают выделенного соединения между двумя хостами. Связь
достигается путём передачи информации в одном направлении от источника к получателю без
проверки готовности или состояния получателя. В приложениях для голосовой связи через
интернет-протокол (Voice over IP, TCP/IP) UDP имеет преимущество над TCP, в котором любое
«рукопожатие» помешало бы хорошей голосовой связи. В VoIP считается, что конечные
пользователи в реальном времени предоставят любое необходимое подтверждение о получении
сообщения.
Ненадёжный — когда сообщение посылается, неизвестно, достигнет ли оно своего
назначения — оно может потеряться по пути. Нет таких понятий, как подтверждение,
повторная передача, тайм-аут.
Неупорядоченность — если два сообщения отправлены одному получателю, то порядок их
достижения цели не может быть предугадан.
Легковесность — никакого упорядочивания сообщений, никакого отслеживания
соединений и т. д. Это небольшой транспортный уровень, разработанный на IP.
Датаграммы — пакеты посылаются по отдельности и проверяются на целостность только
если они прибыли. Пакеты имеют определенные границы, которые соблюдаются после
получения, то есть операция чтения на сокете-получателе выдаст сообщение таким, каким
оно было изначально послано.
Нет контроля перегрузок — UDP сам по себе не избегает перегрузок. Для приложений с
большой пропускной способностью возможно вызвать коллапс перегрузок, если только
они не реализуют меры контроля на прикладном уровне.
Вопрос 10. Система доменных имен DNS.
DNS (англ. Domain Name System — система доменных имён) — компьютерная распределённая
система для получения информации одоменах. Чаще всего используется для получения IPадреса по имени хоста (компьютера или устройства), получения информации о маршрутизации
почты, обслуживающих узлах для протоколов в домене (SRV-запись).
Распределённая база данных DNS поддерживается с помощью иерархии DNS-серверов,
взаимодействующих по определённомупротоколу.
Основой DNS является представление об иерархической структуре доменного имени и зонах.
Каждый сервер, отвечающий за имя, может делегировать ответственность за дальнейшую
часть домена другому серверу (с административной точки зрения — другой организации или
человеку), что позволяет возложить ответственность за актуальность информации на серверы
различных организаций (людей), отвечающих только за «свою» часть доменного имени.
Начиная с 2010 года в систему DNS внедряются средства проверки целостности передаваемых
данных, называемые DNS Security Extensions (DNSSEC). Передаваемые данные не шифруются,
но их достоверность проверяется криптографическими способами. Внедряемый
стандарт DANE обеспечивает передачу средствами DNS достоверной криптографической
информации (сертификатов), используемых для установления безопасных и защищённых
соединений транспортного и прикладного уровней.
Ключевые характеристики DNS
DNS обладает следующими характеристиками:
Распределённость администрирования. Ответственность за разные части иерархической
структуры несут разные люди или организации.
Распределённость хранения информации. Каждый узел сети в обязательном порядке
должен хранить только те данные, которые входят в его зону ответственности, и
(возможно) адреса корневых DNS-серверов.
Кеширование информации. Узел может хранить некоторое количество данных не из своей
зоны ответственности для уменьшения нагрузки на сеть.
Иерархическая структура, в которой все узлы объединены в дерево, и каждый узел может
или самостоятельно определять работу нижестоящих узлов, или делегировать(передавать)
их другим узлам.
Резервирование. За хранение и обслуживание своих узлов (зон) отвечают (обычно)
несколько серверов, разделённые как физически, так и логически, что обеспечивает
сохранность данных и продолжение работы даже в случае сбоя одного из узлов.
DNS важна для работы Интернета, так как для соединения с узлом необходима информация о
его IP-адресе, а для людей проще запоминать буквенные (обычно осмысленные) адреса, чем
последовательность цифр IP-адреса. В некоторых случаях это позволяет использовать
виртуальные серверы, например, HTTP-серверы, различая их по имени запроса.
Первоначально преобразование между доменными и IP-адресами производилось с
использованием специального текстового файла hosts, который составлялся централизованно и
автоматически рассылался на каждую из машин в своей локальной сети. С ростом Сети
возникла необходимость в эффективном, автоматизированном механизме, которым и стала
DNS.
DNS была разработана Полом Мокапетрисом в 1983 году; оригинальное описание механизмов
работы содержится в RFC 882 и RFC 883. В 1987 публикация RFC 1034 и RFC 1035изменила
спецификацию DNS и отменила RFC 882, RFC 883 и RFC 973 как устаревшие.
Дополнительные возможности
поддержка динамических обновлений
защита данных (DNSSEC) и транзакций (TSIG)
поддержка различных типов информации
Терминология и принципы работы
Ключевыми понятиями DNS являются:
Домен (англ. domain — область) — узел в дереве имён, вместе со всеми подчинёнными
ему узлами (если таковые имеются), то есть именованная ветвь или поддерево в дереве
имен. Структура доменного имени отражает порядок следования узлов в иерархии;
доменное имя читается справа налево от младших доменов к доменам высшего уровня (в
порядке повышения значимости): вверху находится корневой домен (не имеющий
идентификатора), ниже идут домены первого уровня (доменные зоны), затем — домены
второго уровня, третьего и т. д. (например, для адреса ru.wikipedia.org. домен первого
уровня — org, второго wikipedia, третьего ru). На практике точку перед корневым доменом
часто опускают («ru.wikipedia.org» вместо «ru.wikipedia.org.»), но она бывает важна в
случаях разделения между относительными доменами и FQDN (англ. Fully Qualifed
Domain Name, полностью определённое имя домена).
Поддомен (англ. subdomain) — подчинённый домен (например, wikipedia.org — поддомен
домена org, а ru.wikipedia.org — домена wikipedia.org). Теоретически такое деление может
достигать глубины 127 уровней, а каждая метка может содержать до 63 символов, пока
общая длина вместе с точками не достигнет 254 символов. Но на практикерегистраторы
доменных имён используют более строгие ограничения. Например, если у вас есть домен
вида mydomain.ru, вы можете создать для него различные поддомены
вида mysite1.mydomain.ru, mysite2.mydomain.ru и т. д.
Ресурсная запись — единица хранения и передачи информации в DNS. Каждая ресурсная
запись имеет имя (то есть привязана к определенному Доменному имени, узлу в дереве
имен), тип и поле данных, формат и содержание которого зависит от типа.
Зона — часть дерева доменных имен (включая ресурсные записи), размещаемая как
единое целое на некотором сервере доменных имен (DNS-сервере, см. ниже), а чаще —
одновременно на нескольких серверах (см. ниже). Целью выделения части дерева в
отдельную зону является передача ответственности (см. ниже) за
соответствующий домендругому лицу или организации. Это
называется делегированием (см. ниже). Как связная часть дерева, зона внутри тоже
представляет собой дерево. Если рассматривать пространство имен DNS как структуру из
зон, а не отдельных узлов/имен, тоже получается дерево; оправданно говорить о
родительских и дочерних зонах, о старших и подчиненных. На практике большинство зон
0-го и 1-го уровня (‘.’, ru, com, …) состоят из единственного узла, которому
непосредственно подчиняются дочерние зоны. В больших корпоративных доменах (2-го и
более уровней) иногда встречается образование дополнительных подчиненных уровней без
выделения их в дочерние зоны.
Делегирование — операция передачи ответственности за часть дерева доменных имен
другому лицу или организации. За счет делегирования в DNS обеспечивается
распределенность администрирования и хранения. Технически делегирование выражается
в выделении этой части дерева в отдельную зону, и размещении этой зоны на DNSсервере (см. ниже), управляемой этим лицом или организацией. При этом в родительскую
зону включаются «склеивающие» ресурсные записи (NS и А), содержащие указатели
на DNS-сервера дочерней зоны, а вся остальная информация, относящаяся к дочерней
зоне, хранится уже на DNS-серверах дочерней зоны.
DNS-сервер — специализированное ПО для обслуживания DNS, а также компьютер, на
котором это ПО выполняется. DNS-сервер может быть ответственным за некоторые зоны
и/или может перенаправлять запросы вышестоящим серверам.
DNS-клиент — специализированная библиотека (или программа) для работы с DNS. В
ряде случаев DNS-сервер выступает в роли DNS-клиента.
Авторитетность (англ. authoritative) — признак размещения зоны на DNS-сервере.
Ответы DNS-сервера могут быть двух типов: авторитетные (когда сервер заявляет, что
сам отвечает за зону) и неавторитетные (англ. Non-authoritative), когда сервер
обрабатывает запрос, и возвращает ответ других серверов. В некоторых случаях вместо
передачи запроса дальше DNS-сервер может вернуть уже известное ему (по запросам
ранее) значение (режим кеширования).
DNS-запрос (англ. DNS query) — запрос от клиента (или сервера) серверу. Запрос может
быть рекурсивным или нерекурсивным (см. Рекурсия).
Система DNS содержит иерархию DNS-серверов, соответствующую иерархии зон.
Каждая зона поддерживается как минимум одним авторитетным сервером
DNS (отангл. authoritative — авторитетный), на котором расположена информация о домене.
Имя и IP-адрес не тождественны — один IP-адрес может иметь множество имён, что позволяет
поддерживать на одном компьютере множество веб-сайтов (это называетсявиртуальный
хостинг). Обратное тоже справедливо — одному имени может быть сопоставлено множество
IP-адресов: это позволяет создавать балансировку нагрузки.
Для повышения устойчивости системы используется множество серверов, содержащих
идентичную информацию, а в протоколе есть средства, позволяющие поддерживать
синхронность информации, расположенной на разных серверах. Существует 13 корневых
серверов, их адреса практически не изменяются.[1]
Протокол DNS использует для работы TCP- или UDP-порт 53 для ответов на запросы.
Традиционно запросы и ответы отправляются в виде одной UDP-датаграммы. TCP
используется, когда размер данных ответа превышает 512 байт, и для AXFR-запросов.
Рекурсия
Термином Рекурсия в DNS обозначают алгоритм поведения DNS-сервера, при котором
сервер выполняет от имени клиента полный поиск нужной информации во всей системе DNS,
при необходимости обращаясь к другим DNS-серверам.
DNS-запрос может быть рекурсивным — требующим полного поиска, —
и нерекурсивным (или итеративным) — не требующим полного поиска.
Аналогично — DNS-сервер может быть рекурсивным (умеющим выполнять полный поиск)
и нерекурсивным (не умеющим выполнять полный поиск). Некоторые программы DNSсерверов, например, BIND, можно сконфигурировать так, чтобы запросы одних клиентов
выполнялись рекурсивно, а запросы других — нерекурсивно.
При ответе на нерекурсивный запрос, а также при неумении или запрете
выполнять рекурсивные запросы, DNS-сервер либо возвращает данные о зоне, за которую
он ответственен, либо возвращает ошибку. Настройки нерекурсивного сервера, когда при
ответе выдаются адреса серверов, которые обладают большим объёмом информации о
запрошенной зоне, чем отвечающий сервер (чаще всего — адреса корневых серверов),
являются некорректными, и такой сервер может быть использован для организации DoS-атак.
В случае рекурсивного запроса DNS-сервер опрашивает серверы (в порядке убывания уровня
зон в имени), пока не найдёт ответ или не обнаружит, что домен не существует (на практике
поиск начинается с наиболее близких к искомому DNS-серверов, если информация о них есть
в кэше и не устарела, сервер может не запрашивать другие DNS-серверы).
Рассмотрим на примере работу всей системы.
Предположим, мы набрали в браузере адрес ru.wikipedia.org. Браузер спрашивает у сервера
DNS: «какой IP-адрес у ru.wikipedia.org»? Однако сервер DNS может ничего не знать не только
о запрошенном имени, но и даже обо всём домене wikipedia.org. В этом случае сервер
обращается к корневому серверу — например, 198.41.0.4. Этот сервер сообщает — «У меня нет
информации о данном адресе, но я знаю, что 204.74.112.1 является ответственным за зону org.»
Тогда сервер DNS направляет свой запрос к 204.74.112.1, но тот отвечает «У меня нет
информации о данном сервере, но я знаю, что 207.142.131.234 является ответственным за
зону wikipedia.org.» Наконец, тот же запрос отправляется к третьему DNS-серверу и получает
ответ — IP-адрес, который и передаётся клиенту — браузеру.
В данном случае при разрешении имени, то есть в процессе поиска IP по имени:
браузер отправил известному ему DNS-серверу рекурсивный запрос — в ответ на такой тип
запроса сервер обязан вернуть «готовый результат», то есть IP-адрес, либо пустой ответ и
код ошибки NXDOMAIN;
DNS-сервер, получивший запрос от браузера, последовательно
отправлял нерекурсивные запросы, на которые получал от других DNS-серверов ответы,
пока не получил ответ от сервера, ответственного за запрошенную зону;
остальные упоминавшиеся DNS-серверы обрабатывали запросы нерекурсивно (и, скорее
всего, не стали бы обрабатывать запросы рекурсивно, даже если бы такое требование
стояло в запросе).
Иногда допускается, чтобы запрошенный сервер передавал рекурсивный запрос
«вышестоящему» DNS-серверу и дожидался готового ответа.
При рекурсивной обработке запросов все ответы проходят через DNS-сервер, и он получает
возможность кэшировать их. Повторный запрос на те же имена обычно не идет
дальшекэша сервера, обращения к другим серверам не происходит вообще. Допустимое время
хранения ответов в кэше приходит вместе с ответами (поле TTL ресурсной записи).
Рекурсивные запросы требуют больше ресурсов от сервера (и создают больше трафика), так
что обычно принимаются от «известных» владельцу сервера узлов (например, провайдер
предоставляет возможность делать рекурсивные запросы только своим клиентам, в
корпоративной сети рекурсивные запросы принимаются только из локального сегмента).
Нерекурсивные запросы обычно принимаются ото всех узлов сети (и содержательный ответ
даётся только на запросы о зоне, которая размещена на узле, на DNS-запрос о других зонах
обычно возвращаются адреса других серверов).
Обратный DNS-запрос
DNS используется в первую очередь для преобразования символьных имён в IP-адреса, но он
также может выполнять обратный процесс. Для этого используются уже имеющиеся средства
DNS. Дело в том, что с записью DNS могут быть сопоставлены различные данные, в том числе
и какое-либо символьное имя. Существует специальный домен in-addr.arpa, записи в котором
используются для преобразования IP-адресов в символьные имена. Например, для получения
DNS-имени для адреса 11.22.33.44 можно запросить у DNS-сервера запись 44.33.22.11.inaddr.arpa, и тот вернёт соответствующее символьное имя. Обратный порядок записи частей IPадреса объясняется тем, что в IP-адресах старшие биты расположены в начале, а в символьных
DNS-именах старшие (находящиеся ближе к корню) части расположены в конце.
Записи DNS
Записи DNS, или Ресурсные записи (англ. Resource Records, RR) — единицы хранения и
передачи информации в DNS. Каждая ресурсная запись состоит из следующих полей:
имя (NAME) — доменное имя, к которому привязана или которому «принадлежит» данная
ресурсная запись,
TTL (Time To Live) — допустимое время хранения данной ресурсной записи в
кэше неответственного DNS-сервера,
тип (TYPE) ресурсной записи — определяет формат и назначение данной ресурсной
записи,
класс (CLASS) ресурсной записи; теоретически считается, что DNS может
использоваться не только с TCP/IP, но и с другими типами сетей, код в
поле класс определяет тип сети[2],
длина поля данных (RDLEN),
поле данных (RDATA), формат и содержание которого зависит от типа записи.
Наиболее важные типы DNS-записей:
Запись A (address record) или запись адреса связывает имя хоста с адресом протокола
IPv4. Например, запрос A-записи на имя referrals.icann.org вернёт его IPv4-адрес —
192.0.34.164.
Запись AAAA (IPv6 address record) связывает имя хоста с адресом протокола IPv6.
Например, запрос AAAA-записи на имя K.ROOT-SERVERS.NET вернёт его IPv6-адрес —
2001:7fd::1.
Запись CNAME (canonical name record) или каноническая запись имени (псевдоним)
используется для перенаправления на другое имя.
Запись MX (mail exchange) или почтовый обменник указывает сервер(ы) обмена
почтой для данного домена.
Запись NS (name server) указывает на DNS-сервер для данного домена.
Запись PTR (point to reverse) или запись указателя связывает IP-адрес хоста с его
каноническим именем. Запрос в домене in-addr.arpa на IP-адрес хоста в reverse-форме
вернёт имя (FQDN) данного хоста (см. Обратный DNS-запрос). Например (на момент
написания), для IP-адреса 192.0.34.164 запрос записи PTR 164.34.0.192.in-addr.arpa вернёт
его каноническое имя referrals.icann.org. В целях уменьшения объёма нежелательной
корреспонденции (спама) многие серверы-получатели электронной почты могут проверять
наличие PTR-записи для хоста, с которого происходит отправка. В этом случае PTR-запись
для IP-адреса должна соответствовать имени отправляющего почтового сервера, которым
он представляется в процессе SMTP-сессии.
Запись SOA (Start of Authority) или начальная запись зоны указывает, на каком сервере
хранится эталонная информация о данном домене, содержит контактную информацию
лица, ответственного за данную зону, тайминги (параметры времени) кеширования зонной
информации и взаимодействия DNS-серверов.
SRV-запись (server selection) указывает на серверы для сервисов, используется, в
частности, для Jabber и Active Directory.
Зарезервированные доменные имена
Документ RFC 2606 (Reserved Top Level DNS Names — Зарезервированные имена доменов
верхнего уровня) определяет названия доменов, которые следует использовать в качестве
примеров (например, в документации), а также для тестирования.
Кроме example.com, example.org и example.net, в эту группу также входят test, invalid и др.
Интернациональные доменные имена
Доменное имя может состоять только из ограниченного набора ASCII-символов, позволяя
набрать адрес домена независимо от языка пользователя. ICANN утвердил основанную
наPunycode систему IDNA, преобразующую любую строку в кодировке Unicode в допустимый
DNS набор символов.
Программное обеспечение DNS
Серверы имен:
BIND (Berkeley Internet Name Domain) [1]
djbdns (Daniel J. Bernstein’s DNS) [2]
MaraDNS [3]
NSD (Name Server Daemon) [4]
PowerDNS [5]
OpenDNS [6]
Microsoft DNS Server (в серверных версиях операционных систем Windows NT)
MyDNS [7]
Вопрос 11. Система имен NetBIOS. Протоколы NetBIOS/SMB.
NetBIOS (Network Basic Input/Output System) — протокол для работы в локальных сетях на
персональных ЭВМ типа IBM/PC, разработан в виде интерфейса, который не зависит от фирмыпроизводителя. Был разработан фирмой Sytek Corporation по заказу IBM в 1983 году. Он включает
в себя интерфейс сеансового уровня (англ. NetBIOS interface), в качестветранспортных
протоколов использует TCP и UDP.
Особенностью NetBIOS является возможность его работы поверх разных протоколов, самыми
распространёнными/известными из которых являются NetBEUI, IPX и стек протоколовTCP/IP;
причём если старые версии Windows ориентировались на более лёгкие в реализации и менее
ресурсоёмкие NetBEUI и IPX, то современные Windows ориентируются наTCP/IP. При
использовании NetBEUI и IPX NetBIOS сам обеспечивает надёжность доставки данных
(функциональность SPX не использовалась), а при использовании TCP/IPнадёжность доставки
обеспечивает TCP, за что удостоился отдельного имени «NBT».
Интерфейс NetBIOS представляет собой стандартный интерфейс разработки приложений (API)
для обеспечения сетевых операций ввода-вывода и управления низлежащим транспортным
протоколом. Приложения, использующие NetBIOS API интерфейс, могут работать только при
наличии протокола, допускающего использование такого интерфейса.
NetBIOS также определяет протокол, функционирующий на сеансовом/транспортном уровнях
модели OSI. Этот протокол используется протоколами нижележащих уровней, такими как NBFP
(NetBEUI) и NetBT для выполнения сетевых запросов ввода-вывода и операций, описанных в
стандартном интерфейсном наборе команд NetBIOS. То есть NetBIOS сам не поддерживает
выполнение файловых операций. Эта функция возлагается на протоколы нижележащих уровней, а
сам NetBIOS обеспечивает только связь с этими протоколами и NetBIOS API интерфейс.
Пакет NETBIOS создан для использования группой ЭВМ. Поддерживает как режим сессий
(работа через соединение), так и режим дейтограмм (без установления соединения). 16-и
символьные имена объектов в NETBIOS распределяются динамически. NETBIOS имеет
собственную DNS, которая может взаимодействовать с интернетовской. Имя объекта при работе с
NETBIOS не может начинаться с символа *.
Приложения могут через NETBIOS найти нужные им ресурсы, установить связь и послать или
получить информацию. NETBIOS использует для службы имен порт — 137, для службы
дейтограмм — порт 138, а для сессий — порт 139. Любая сессия начинается с NETBIOS-запроса,
задания IP-адреса и определения TCP-порта удаленного объекта, далее следует обмен NETBIOS-
сообщениями, после чего сессия закрывается. Сессия осуществляет обмен информацией между
двумя NETBIOS-приложениями. Длина сообщения лежит в пределах от 0 до 131071 байт.
Допустимо одновременное осуществление нескольких сессий между двумя объектами. При
организации IP-транспорта через NETBIOS IP-дейтограмма вкладывается в NETBIOS-пакет.
Информационный обмен происходит в этом случае без установления связи между объектами.
Имена NETBIOS должны содержать в себе IP-адреса. Так часть NETBIOS-адреса может иметь
вид, IP.**.**.**.**, где IP указывает на тип операции (IP через Netbios), а **.**.**.** — IP-адрес.
Система NETBIOS имеет собственную систему команд (call, listen, hang up, send, receive, session
status, reset, cancel, adapter status, unlink, remote program load) и примитивов для работы с
дейтограммами (send datagram, send broadcast datagram, receive datagram, receive broadcast
datagram). Все оконечные узлы NETBIOS делятся на три типа:
широковещательные («b») узлы;
узлы точка-точка («p»);
узлы смешанного типа («m»).
IP-адрес может ассоциироваться с одним из указанных типов. B-узлы устанавливают связь со
своим партнером посредством широковещательных запросов. P- и M-узлы для этой цели
используют netbios сервер имен (NBNS) и сервер распределения дейтограмм (NBDD).
NetBIOS обеспечивает:
регистрацию и проверку сетевых имен;
установление и разрыв соединений;
связь с гарантированной доставкой информации;
связь с негарантированной доставкой информации;
поддержку управления и мониторинга драйвера и сетевой карты.
Стек NetBIOS/SMB
Стек NetBIOS/SMB является совместной разработкой компаний IBM и Microsof (рис. 1). На
физическом и канальном уровнях этого стека также задействованы уже получившие
распространение протоколы, такие как Ethernet, Token Ring, FDDI, а на верхних уровнях —
специфические протоколы NetBEUI и SMB.
Протокол Network Basic Input/Output System (NetBIOS) появился в 1984 году как сетевое
расширение стандартных функций базовой системы ввода-вывода (BIOS) IBM PC для сетевой
программы PC Network фирмы IBM. В дальнейшем этот протокол был заменен так называемым
протоколом расширенного пользовательского интерфейса NetBEUI (NetBIOS Extended User
Interface). Для совместимости приложений в качестве интерфейса к протоколу NetBEUI был
сохранен интерфейс NetBIOS. NetBEUI разрабатывался как эффективный протокол,
потребляющий немного ресурсов и предназначенный для сетей, насчитывающих не более 200
рабочих станций. Этот протокол содержит много полезных сетевых функций, которые можно
отнести к транспортному и сеансовому уровням модели 0SI, однако с его помощью невозможна
маршрутизация пакетов. Это ограничивает при-менение протокола NetBEUI локальными сетями,
не разделенными на подсети, и делает невозможным его использование в составных сетях.
Протокол Server Message Block (SMB) поддерживает функции сеансового уровня, уровня
представления и прикладного уровня. На основе SMB реализуется файловая служба, а также
службы печати и передачи сообщений между приложениями.
Вопрос 12. Динамическое конфигурирование узлов DHCP.
DHCP (англ. Dynamic Host Configuration Protocol — протокол динамической настройки узла) —
сетевой протокол, позволяющий компьютерам автоматически получать IP-адрес и другие
параметры, необходимые для работы в сети TCP/IP. Данный протокол работает по модели
«клиент-сервер». Для автоматической конфигурации компьютер-клиент на этапе конфигурации
сетевого устройства обращается к так называемому серверу DHCP и получает от него нужные
параметры. Сетевой администратор может задать диапазон адресов, распределяемых сервером
среди компьютеров. Это позволяет избежать ручной настройки компьютеров сети и уменьшает
количество ошибок. Протокол DHCP используется в большинстве сетей TCP/IP.
DHCP является расширением протокола BOOTP, использовавшегося ранее для
обеспечения бездисковых рабочих станций IP-адресами при их загрузке. DHCP
сохраняет обратную совместимость с BOOTP.
История
Стандарт протокола DHCP был принят в октябре 1993 года. Действующая версия протокола
(март 1997 года) описана в RFC 2131. Новая версия DHCP, предназначенная для использования в
среде IPv6, носит название DHCPv6 и определена в RFC 3315 (июль 2003 года).
Распределение IP-адресов
Протокол DHCP предоставляет три способа распределения IP-адресов:
Ручное распределение. При этом способе сетевой администратор сопоставляет
аппаратному адресу (для Ethernet сетей это MAC-адрес) каждого клиентского компьютера
определённый IP-адрес. Фактически, данный способ распределения адресов отличается от
ручной настройки каждого компьютера лишь тем, что сведения об адресах хранятся
централизованно (на сервере DHCP), и потому их проще изменять при необходимости.
Автоматическое распределение. При данном способе каждому компьютеру на постоянное
использование выделяется произвольный свободный IP-адрес из определённого
администратором диапазона.
Динамическое распределение. Этот способ аналогичен автоматическому распределению, за
исключением того, что адрес выдаётся компьютеру не на постоянное пользование, а на
определённый срок. Это называется арендой адреса. По истечении срока аренды IP-адрес
вновь считается свободным, и клиент обязан запросить новый (он, впрочем, может
оказаться тем же самым). Кроме того, клиент сам может отказаться от полученного адреса.
Некоторые реализации службы DHCP способны автоматически обновлять записи DNS,
соответствующие клиентским компьютерам, при выделении им новых адресов. Это производится
при помощи протокола обновления DNS, описанного в RFC 2136.
Опции DHCP
Помимо IP-адреса, DHCP также может сообщать клиенту дополнительные параметры,
необходимые для нормальной работы в сети. Эти параметры называются опциями DHCP. Список
стандартных опций можно найти в RFC 2132.
Опции – строки переменной длины, состоящие из октетов. Первый октет — код опции, второй октет
– количество следующих октетов, остальные октеты зависят от кода опции.
Например, опция “DHCP Message Type” при отправке сообщения “Offer” будет выглядеть так :
0x35,0x01,0x02, где 0x35 – код опции “DHCP Message Type” , 0x01 – означает, что далее идет
только один октет, 0x02 – значение “Offer”.
Некоторыми из наиболее часто используемых опций являются:
IP-адрес маршрутизатора по умолчанию;
маска подсети;
адреса серверов DNS;
имя домена DNS.
Некоторые поставщики программного обеспечения могут определять собственные
дополнительные опции DHCP.
В следующих таблицах перечислены доступные DHCP опции, как указано в RFC2132:
RFC1497 расширения поставщиков программного обеспечения.
Код
Название
Длина
Примечание
Используется для дополнения других опций, чтобы они
выравнивались по границе слова.
Pad
0 октетов
Должн быть отправлен после опции “router” (опция 3),
если оба включены.
1
Subnet Mask
4 октета
2
Time Offset
4 октета
3
4
Router
Time Server
кратное 4
октетам
кратное 4
октетам
Доступные маршрутизаторы должны быть перечислены в
порядке предпочтения.
Доступные серверы для синхронизации должны быть
перечислены в порядке предпочтения.
Доступные IEN 116 – имена серверов, должны быть
перечислены в порядке предпочтения.
5
Name Server
кратное 4
октетам
6
Domain Name
Server
кратное 4
октетам
Доступные DNS-сервера должны быть перечислены в
порядке предпочтения.
7
Log Server
кратное 4
октетам
Доступные Log–сервера должны быть перечислены в
порядке предпочтения.
8
Cookie Server
кратное 4
октетам
9
LPR Server
кратное 4
октетам
10
Impress Server
кратное 4
октетам
11
Resource Location
Server
кратное 4
октетам
Код
Название
Длина
Примечание
12
Host Name
минимум 1
октет
Длина загрузочного образа в 4-килобайтных блоках.
Boot File Size
2 октета
14
Merit Dump File
минимум 1
октет
15
Domain Name
минимум 1
октет
16
Swap Server
4 октета
17
Root Path
минимум 1
октет
18
Extensions Path
минимум 1
октет
255
End
0 октетов
13
Путь до места хранения аварийных дампов.
Используется для обозначения конца поля.
Параметры IP-уровня клиента.
Код
Название
Длина
19
IP Forwarding Enable/Disable
1 октет
20
Non-Local Source Routing Enable/Disable 1 октет
21
Policy Filter
Кратное 8 октетам
22
Maximum Datagram Reassembly Size
2 октета
23
Default IP Time-to-live
1 октет
24
Path MTU Aging Timeout
4 октета
25
Path MTU Plateau Table
Кратное 2 октетам
Параметры интерфейса Ip-уровня.
Код
Название
Длина
26
Interface MTU
2
Примечание
Примечание
Код
Название
Длина
27
All Subnets are Local
1
28
Broadcast Address
4
29
Perform Mask Discovery
1
30
Mask Supplier
1
31
Perform Router Discovery 1
32
Router Solicitation Address 4
33
Static Route
Примечание
Кратно 8 октетам
Параметры интерфейса уровня связи.
Код
Название
Длина
34
Trailer Encapsulation Option 1
35
ARP Cache Timeout
4
36
Ethernet Encapsulation
1
Примечание
TCP –параметры.
Код
Название
Длина
37
TCP Default TTL
1
38
TCP Keepalive Interval 4
39
TCP Keepalive Garbage 1
Примечание
Параметры сервисов и приложений.
Код
Название
Длина
40
Network Information Service Domain
минимум 1 октет
41
Network Information Servers
кратное 4 октетам
42
Network Time Protocol Servers
кратное 4 октетам
43
Vendor Specific Information
минимум 1 октет
44
NetBIOS over TCP/IP Name Server
кратное 4 октетам
45
NetBIOS over TCP/IP Datagram Distribution Server кратное 4 октетам
46
NetBIOS over TCP/IP Node Type
1
Примечание
Код
Название
Длина
47
NetBIOS over TCP/IP Scope
минимум 1 октет
48
X Window System Font Server
кратное 4 октетам
49
X Window System Display Manager
кратное 4 октетам
64
Network Information Service+ Domain
минимум 1 октет
65
Network Information Service+ Servers
кратное 4 октетам
68
Mobile IP Home Agent
кратное 4 октетам
69
Simple Mail Transport Protocol (SMTP) Server
кратное 4 октетам
70
Post Office Protocol (POP3) Server
кратное 4 октетам
71
Network News Transport Protocol (NNTP) Server
кратное 4 октетам
72
Default World Wide Web (WWW) Server
кратное 4 октетам
73
Default Finger Server
кратное 4 октетам
74
Default Internet Relay Chat (IRC) Server
кратное 4 октетам
75
StreetTalk Server
кратное 4 октетам
76
StreetTalk Directory Assistance (STDA) Server
кратное 4 октетам
DHCP – расширения.
Код
Название
Длина
50
Requested IP address
4
51
IP address Lease Time
4
52
Option Overload
1
53
DHCP Message Type
1
54
Server Identifier
4
55
Parameter Request List
минимум 1 октет
56
Message
минимум 1 октет
57
Maximum DHCP Message Size 2
58
Renewal (T1) Time Value
4
Примечание
Примечание
Код
Название
Длина
59
Rebinding (T2) Time Value
4
60
Vendor class identifier
минимум 1 октет
61
Client-identifier
минимум 2 октета
66
TFTP server name
минимум 1 октет
67
Bootfile name
минимум 1 октет
Примечание
Идентификация поставщика.
Опция существует, чтобы определить поставщика и функциональность клиента DHCP.
Информация представляется строкой переменной длины, состоящей из символов или октетов,
которые имеют значение, указанное поставщиком клиента DHCP. Один из методов позволяет
DHCP клиенту оповещать сервер о том, что он использует определенный тип низкоуровневого
обеспечения или прошивки для заполнения опции Vendor Class Identifier(VCI)(опция 60). Этот
метод позволяет различать запросы клиентских машин и процессов. Значение опции VCI дает
DHCP-серверу подсказку о любой необходимой дополнительной информации, которую
необходимо отправить клиенту в ответ.
Устройство протокола
Протокол DHCP является клиент-серверным, то есть в его работе участвуют клиент DHCP
и сервер DHCP. Передача данных производится при помощи протокола UDP. По умолчанию
запросы от клиента делаются на 67 порт к серверу, сервер в свою очередь отвечает на порт 68 к
клиенту, выдавая адрес IP и другую необходимую информацию, такую, как сетевую маску,
маршрутизатор и серверы DNS.
Структура сообщений DHCP
Все сообщения протокола DHCP разбиваются на поля, каждое из которых содержит
определённую информацию. Все поля, кроме последнего (поля опций DHCP), имеют
фиксированную длину.
Поле
Описание
op
Тип сообщения. Например может принимать значения: BOOTREQUEST (1, запрос от клиента к серв
htype
Тип аппаратного адреса. Допустимые значения этого поля определены в RFC1700 «Assigned Numbe
значение 1.
hlen
Длина аппаратного адреса в байтах. Для MAC-адреса Ethernet — 6.
hops
Количество промежуточных маршрутизаторов (так называемых агентов ретрансляции DHCP), чере
xid
Уникальный идентификатор транзакции, генерируемый клиентом в начале процесса получения адре
secs
Время в секундах с момента начала процесса получения адреса. Может не использоваться (в этом сл
flags
Поле для флагов — специальных параметров протокола DHCP.
ciaddr
IP-адрес клиента. Заполняется только в том случае, если клиент уже имеет собственный IP-адрес и с
процедуру обновления адреса по истечении срока аренды).
yiaddr Новый IP-адрес клиента, предложенный сервером.
siaddr IP-адрес сервера. Возвращается в предложении DHCP (см. ниже).
giaddr IP-адрес агента ретрансляции, если таковой участвовал в процессе доставки сообщения DHCP до сер
chaddr Аппаратный адрес (обычно MAC-адрес) клиента.
sname Необязательное имя сервера в виде нуль-терминированной строки.
Необязательное имя файла на сервере, используемое бездисковыми рабочими станциями при удалён
строки.
file
Поле опций DHCP. Здесь указываются различные дополнительные параметры конфигурации. В нача
options 99 («волшебные числа»), позволяющие серверу определить наличие этого поля. Поле имеет перемен
сообщение длиной в 576 байт (в этом сообщении поле options имеет длину 340 байт).
Пример процесса получения адреса
Рассмотрим пример процесса получения IP-адреса клиентом от сервера DHCP. Предположим,
клиент ещё не имеет собственного IP-адреса, но ему известен его предыдущий адрес —
192.168.1.100. Процесс состоит из четырёх этапов.
Обнаружение DHCP
Вначале клиент выполняет широковещательный запрос по всей физической сети с целью
обнаружить доступные DHCP-серверы. Он отправляет сообщение типа DHCPDISCOVER, при
этом в качестве IP-адреса источника указывается 0.0.0.0 (так как компьютер ещё не имеет
собственного IP-адреса), а в качестве адреса назначения — широковещательный
адрес255.255.255.255.
Клиент заполняет несколько полей сообщения начальными значениями:
В поле xid помещается уникальный идентификатор транзакции, который позволяет
отличать данный процесс получения IP-адреса от других, протекающих в то же время.
В поле chaddr помещается аппаратный адрес (MAC-адрес) клиента.
В поле опций указывается последний известный клиенту IP-адрес. В данном примере это
192.168.1.100. Это необязательно и может быть проигнорировано сервером.
Сообщение DHCPDISCOVER может быть распространено за пределы локальной физической сети
при помощи специально настроенных агентов ретрансляции DHCP, перенаправляющих
поступающие от клиентов сообщения DHCP серверам в других подсетях.
Не всегда процесс получения IP адреса начинается с DHCPDISCOVER. В случае, если клиент
ранее уже получал IP адрес и срок его аренды ещё не прошёл — клиент может пропустить стадию
DHCPDISCOVER, начав с запроса DHCPREQUEST отправляемого с идентификатором сервера,
который выдал адрес в прошлый раз. В случае же отсутствия ответа от DHCP сервера, выдавшего
настройки в прошлый раз, клиент отправляет DHCPDISCOVER. Тем самым клиент начинает
процесс получения с начала, обращаясь уже ко всем DHCP серверам в сегменте сети.
Предложение DHCP
Получив сообщение от клиента, сервер определяет требуемую конфигурацию клиента в
соответствии с указанными сетевым администратором настройками. В данном случае DHCPсервер согласен с запрошенным клиентом адресом 192.168.1.100. Сервер отправляет ему ответ
(DHCPOFFER), в котором предлагает конфигурацию. Предлагаемый клиенту IP-адрес
указывается в поле yiaddr. Прочие параметры (такие, как адреса маршрутизаторов и DNSсерверов) указываются в виде опций в соответствующем поле.
Это сообщение DHCP-сервер отправляет хосту, пославшему DHCPDISCOVER, на его MAC, при
определенных обстоятельствах сообщение может распространяться как широковещательная
рассылка. Клиент может получить несколько различных предложений DHCP от разных серверов;
из них он должен выбрать то, которое его «устраивает».
Запрос DHCP
Выбрав одну из конфигураций, предложенных DHCP-серверами, клиент отправляет запрос DHCP
(DHCPREQUEST). Он рассылается широковещательно; при этом к опциям, указанным клиентом
в сообщении DHCPDISCOVER, добавляется специальная опция — идентификатор сервера —
указывающая адрес DHCP-сервера, выбранного клиентом (в данном случае — 192.168.1.1).
Подтверждение DHCP
Наконец, сервер подтверждает запрос и направляет это подтверждение (DHCPACK) клиенту.
После этого клиент должен настроить свой сетевой интерфейс, используя предоставленные опции.
Вид сообщений
Ниже приведены значения каждого поля для каждого из отправляемых в процессе сообщений
DHCP.
Обнаружение DHCP
DHCPDISCOVER
Предложение DHCP
DHCPOFFER
Запрос DHCP
DHCPREQUEST
UDP Src=0.0.0.0
Dest=255.255.255.255
UDP Src=192.168.1.1
Dest=255.255.255.255
UDP Src=0.0.0.0
Dest=255.255.255.255
OP
HTY HLE HO
PE
N
PS
0x0
0x01
1
0x06 0x00
OP
HTY
PE
0x0
0x01
2
HLE HO
N
PS
OP
HTY HLE HO
PE
N
PS
0x06 0x00
0x0
0x01
1
XID
XID
XID
0x3903F326
0x3903F326
0x3903F326
0x06 0x00
Подтверждение
DHCP
DHCPACK
UDP Src=192.168.1.1
Dest=255.255.255.255
OP
HTY
PE
0x0
0x01
2
HLE HO
N
PS
0x06 0x00
XID
0x3903F326
SECS
FLAGS
SECS
FLAGS
SECS
FLAGS
0x0000
0x0000
0x0000
0x0000
0x0000
0x0000
CIADDR
CIADDR
CIADDR
0xC0A80164
0x00000000
0xC0A80164
YIADDR
YIADDR
YIADDR
0x00000000
0xC0A80164
0x00000000
SIADDR
SIADDR
SIADDR
0x00000000
0xC0A80101
0x00000000
GIADDR
GIADDR
GIADDR
SECS
FLAGS
0x0000
0x0000
CIADDR
0x00000000
YIADDR
0xC0A80164
SIADDR
0x00000000
GIADDR
0x00000000
0x00000000
0x00000000
0x00000000
CHADDR
CHADDR
CHADDR
CHADDR
0x0000001d6057ed80
0x0000001d6057ed80
0x0000001d6057ed80
0x0000001d6057ed80
SNAME
SNAME
SNAME
SNAME
(пустое поле)
(пустое поле)
(пустое поле)
(пустое поле)
FILE
FILE
FILE
FILE
(пустое поле)
(пустое поле)
(пустое поле)
(пустое поле)
OPTIONS
OPTIONS
OPTIONS
OPTIONS
Опция DHCP 53:
обнаружение DHCP
Опция DHCP 53:
предложение DHCP
Опция DHCP 53:
запрос DHCP
Опция DHCP 53:
подтверждение DHCP
Опция DHCP 50:
запрос адреса
192.168.1.100
Опция DHCP 1: маска
подсети 255.255.255.0
Опция DHCP 50:
запрос адреса
192.168.1.100
Опция DHCP 1: маска
подсети 255.255.255.0
Опция DHCP
3: маршрутизатор 192.
168.1.1
Опция DHCP 51: срок
аренды IP-адреса — 1
день
Опция DHCP 54:
DHCP-сервер
192.168.1.1
Опция DHCP 54:
DHCP-сервер
192.168.1.1
Опция DHCP
3: маршрутизатор 192.
168.1.1
Опция DHCP 51: срок
аренды IP-адреса — 1
день
Опция DHCP 54:
DHCP-сервер
192.168.1.1
Прочие сообщения DHCP
Помимо сообщений, необходимых для первоначального получения IP-адреса клиентом, DHCP
предусматривает несколько дополнительных сообщений для выполнения иных задач.
Отказ DHCP
Если после получения подтверждения (DHCPACK) от сервера клиент обнаруживает, что
указанный сервером адрес уже используется в сети, он рассылает широковещательное сообщение
отказа DHCP (DHCPDECLINE), после чего процедура получения IP-адреса повторяется.
Использование IP-адреса другим клиентом можно обнаружить, выполнив запросARP.
Сообщение отмены DHCP (DHCPNAK). При получении такого сообщения соответствующий
клиент должен повторить процедуру получения адреса.
Освобождение DHCP
Клиент может явным образом прекратить аренду IP-адреса. Для этого он отправляет сообщение
освобождения DHCP (DHCPRELEASE) тому серверу, который предоставил ему адрес в аренду. В
отличие от других сообщений DHCP, DHCPRELEASE не рассылается широковещательно.
Информация DHCP
Сообщение информации DHCP (DHCPINFORM) предназначено для определения
дополнительных параметров TCP/IP (например, адреса маршрутизатора по умолчанию, DNS-
серверов и т. п.) теми клиентами, которым не нужен динамический IP-адрес (то есть адрес
которых настроен вручную). Серверы отвечают на такой запрос сообщением подтверждения
(DHCPACK) без выделения IP-адреса.
Реализации
Компания Microsoft впервые включила сервер DHCP в поставку серверной версии Windows NT
3.5, выпущенной в 1994 году. Начиная с Windows 2000 Server реализация DHCP-сервера от
Microsoft позволяет динамически обновлять записи DNS, что используется в Active Directory.
Internet Systems Consortium выпустил первую версию ISC DHCP Server (для Unix-подобных
систем) 6 декабря 1997 года. 22 июня 1999 года вышла версия 2.0, более точно соответствующая
стандарту.
Компания Cisco включила сервер DHCP в Cisco IOS 12.0 в феврале 1999 года. Sun добавила
DHCP-сервер в Solaris 8 в июле 2001 года.
В настоящее время существуют реализации сервера DHCP для ОС Windows в виде отдельных
программ, в том числе открытых[2], позволяющих выполнять роль сервера DHCP компьютерам
под управлением не серверных версий данной ОС.
Вопрос 13. Протоколы SPX/IPX.
Стек протоколов IPX/SPX (от англ. internetwork packet exchange/sequenced packet exchange —
межсетевой обмен пакетами/последовательный обмен пакетами) — стек протоколов,
используемый в сетях Novell NetWare. Протокол IPX работает на сетевом уровне модели OSI,
обеспечивает доставку пакетов (аналог IP из стека TCP/IP). Протокол SPX работает
натранспортном и сеансовом уровнях, обеспечивает поддержание сеанса связи и гарантированную
доставку данных (аналог TCP).
История и применение
Стек протоколов IPX/SPX реализован сетевой операционной системы NetWare, поставляемой
компанией «Novell» с 1983 года, и считается развитием стека протоколов Xerox Network
Systems компании «Xerox». IPX/SPX считался оптимальным для применения в локальных
вычислительных сетях, в то время как TCP/IP предполагался более эффективным дляглобальных
сетей.
К концу 1990-х TCP/IP, являвшийся стандартным стеком интернета, фактически вытеснил
IPX/SPX и из локальных вычислительных сред. Стек IPX/SPX никогда не имел применения в
глобальных сетях.
В настоящее время протокол не является обязательным к использованию в сетях Netware (начиная
с версий 4.x) и поддерживается не только ей.
Реализации
По состоянию на 2011 год многие операционные системы всё ещё поддерживают IPX/SPX, но
поддержка продолжает сокращаться.
DOS
Изначально клиент стека протоколов IPX/SPX был разработан компанией «Novell» для ОС DOS и
широко применялся как в корпоративных сетях, так и для сетевых игр. Клиент был выполнен в
виде резидентной программы. Первые реализации требовали создания исполняемого файла под
каждую сетевую карту, но в дальнейшем процедура настройки была упрощена, и стало
возможным использовать готовые исполняемые модули.
Windows
Ввиду широкого распространения протоколов IPX/SPX в 1990-х годах, компания «Microsoft»
реализовала их под свою ОС Windows, начиная с Windows for Workgroups и Windows NT, под
названием «NWLink». Тем не менее, они по умолчанию использовались только как транспорт
для SMB/NetBIOS, а для связи с серверами NetWare требовалось установка отдельного клиента
«NCP». В Windows 95 был включен базовый клиент, но по умолчанию он не устанавливался.
«NWLink» включался в состав ОС Windows до Windows 2003 включительно и был исключён из
поставки в Windows Vista. Клиент, разработанный «Novell», использует свою реализацию
протокола, хотя некоторые версии позволяли использовать «NWLink» (с предупрежденим о
возможной несовместимости).
UNIX
Для ОС UNIX существовали различные реализации, разработанные как самой «Novell», так и
сторонними авторами. Novell UnixWare имела родную поддержку IPX/SPX, хотя и требовала
дополнительных программ для поддержки общего доступа к файлам и принтерам.
Также существуют реализации для Linux[1] и FreeBSD. OpenBSD отказалась от поддержки
IPX/SPX в версии 4.2[2].
Компания «Sun Microsystems» реализовала стек IPX/SPX для своей ОС Solaris.
Сетевая ОС Novell Open Enterprise Server (основанная на ОС Linux) не поддерживает IPX/SPX.
Другие
В течение нескольких лет «Novell» поставляла клиент для ОС OS/2, похожий по структуре на
клиент ОС DOS. Также она поставляла клиент для ОС Mac OS Classic (только для «классических»
версий, от 7.6 до 9.x) под названием «MacIPX».
ОС IOS компании «Cisco Systems» предоставляет сервисы маршрутизации IPX (в настоящее время
только в редакции «Enterprise Base»).
Протоколы маршрутизации
Для IPX/SPX доступны следующие протоколы:
RIP;
EIGRP (разработан компанией «Cisco Systems»);
NLSP (Netware Link Services Protocol) — адаптированная для IPX версия сетевого
протокола IS-IS[3].
Вопрос 14. Сетевые ОС. Функции и характеристики сетевых операционных систем (ОС).
Сетевая операционная система составляет основу любой вычислительной сети. Каждый
компьютер в сети в значительной степени автономен, поэтому под сетевой операционной
системой в широком смысле понимается совокупность операционных систем отдельных
компьютеров, взаимодействующих с целью обмена сообщениями и разделения ресурсов по
единым правилам — протоколам. В узком смысле сетевая ОС — это операционная система
отдельного компьютера, обеспечивающая ему возможность работать в сети.
Рис. 1.1. Структура сетевой ОС
В сетевой операционной системе отдельной машины можно выделить несколько частей (рисунок
1.1):
Средства управления локальными ресурсами компьютера: функции распределения
оперативной памяти между процессами, планирования и диспетчеризации процессов,
управления процессорами в мультипроцессорных машинах, управления периферийными
устройствами и другие функции управления ресурсами локальных ОС.
Средства предоставления собственных ресурсов и услуг в общее пользование — серверная
часть ОС (сервер). Эти средства обеспечивают, например, блокировку файлов и записей,
что необходимо для их совместного использования; ведение справочников имен сетевых
ресурсов; обработку запросов удаленного доступа к собственной файловой системе и базе
данных; управление очередями запросов удаленных пользователей к своим периферийным
устройствам.
Средства запроса доступа к удаленным ресурсам и услугам и их использования клиентская часть ОС (редиректор). Эта часть выполняет распознавание и перенаправление
в сеть запросов к удаленным ресурсам от приложений и пользователей, при этом запрос
поступает от приложения в локальной форме, а передается в сеть в другой форме,
соответствующей требованиям сервера. Клиентская часть также осуществляет прием
ответов от серверов и преобразование их в локальный формат, так что для приложения
выполнение локальных и удаленных запросов неразличимо.
Коммуникационные средства ОС, с помощью которых происходит обмен сообщениями в
сети. Эта часть обеспечивает адресацию и буферизацию сообщений, выбор маршрута
передачи сообщения по сети, надежность передачи и т.п., то есть является средством
транспортировки сообщений.
В зависимости от функций, возлагаемых на конкретный компьютер, в его операционной системе
может отсутствовать либо клиентская, либо серверная части.
На рисунке 1.2 показано взаимодействие сетевых компонентов. Здесь компьютер 1 выполняет
роль «чистого» клиента, а компьютер 2 — роль «чистого» сервера, соответственно на первой машине
отсутствует серверная часть, а на второй — клиентская. На рисунке отдельно показан компонент
клиентской части — редиректор. Именно редиректор перехватывает все запросы, поступающие от
приложений, и анализирует их. Если выдан запрос к ресурсу данного компьютера, то он
переадресовывается соответствующей подсистеме локальной ОС, если же это запрос к
удаленному ресурсу, то он переправляется в сеть. При этом клиентская часть преобразует запрос
из локальной формы в сетевой формат и передает его транспортной подсистеме, которая отвечает
за доставку сообщений указанному серверу. Серверная часть операционной системы компьютера
2 принимает запрос, преобразует его и передает для выполнения своей локальной ОС. После того,
как результат получен, сервер обращается к транспортной подсистеме и направляет ответ клиенту,
выдавшему запрос. Клиентская часть преобразует результат в соответствующий формат и
адресует его тому приложению, которое выдало запрос.
Рис. 1.2. взаимодействие компонентов операционной системы при взаимодействии компьютеров
На практике сложилось несколько подходов к построению сетевых операционных систем
(рисунок 1.3).
Рис. 1.3. Варианты построения сетевых ОС
Первые сетевые ОС представляли собой совокупность существующей локальной ОС и
надстроенной над ней сетевой оболочки. При этом в локальную ОС встраивался минимум сетевых
функций, необходимых для работы сетевой оболочки, которая выполняла основные сетевые
функции. Примером такого подхода является использование на каждой машине сети
операционной системы MS DOS (у которой начиная с ее третьей версии появились такие
встроенные функции, как блокировка файлов и записей, необходимые для совместного доступа к
файлам). Принцип построения сетевых ОС в виде сетевой оболочки над локальной ОС
используется и в современных ОС, таких, например, как LANtastic или Personal Ware.
Однако более эффективным представляется путь разработки операционных систем, изначально
предназначенных для работы в сети. Сетевые функции у ОС такого типа глубоко встроены в
основные модули системы, что обеспечивает их логическую стройность, простоту эксплуатации и
модификации, а также высокую производительность. Примером такой ОС является система
Windows NT фирмы Microsoft, которая за счет встроенности сетевых средств обеспечивает более
высокие показатели производительности и защищенности информации по сравнению с сетевой
ОС LAN Manager той же фирмы (совместная разработка с IBM), являющейся надстройкой над
локальной операционной системой OS/2.
Одноранговые сетевые ОС и ОС с выделенными серверами
В зависимости от того, как распределены функции между компьютерами сети, сетевые
операционные системы, а следовательно, и сети делятся на два класса: одноранговые и
двухранговые (рисунок 1.4). Последние чаще называют сетями с выделенными серверами.
(а)
(б)
Рис. 1.4. (а) — Одноранговая сеть, (б) — Двухранговая сеть
Если компьютер предоставляет свои ресурсы другим пользователям сети, то он играет роль
сервера. При этом компьютер, обращающийся к ресурсам другой машины, является клиентом. Как
уже было сказано, компьютер, работающий в сети, может выполнять функции либо клиента, либо
сервера, либо совмещать обе эти функции.
Если выполнение каких-либо серверных функций является основным назначением компьютера
(например, предоставление файлов в общее пользование всем остальным пользователям сети или
организация совместного использования факса, или предоставление всем пользователям сети
возможности запуска на данном компьютере своих приложений), то такой компьютер называется
выделенным сервером. В зависимости от того, какой ресурс сервера является разделяемым, он
называется файл-сервером, факс-сервером, принт-сервером, сервером приложений и т.д.
Очевидно, что на выделенных серверах желательно устанавливать ОС, специально
оптимизированные для выполнения тех или иных серверных функций. Поэтому в сетях с
выделенными серверами чаще всего используются сетевые операционные системы, в состав
которых входит нескольких вариантов ОС, отличающихся возможностями серверных частей.
Например, сетевая ОС Novell NetWare имеет серверный вариант, оптимизированный для работы в
качестве файл-сервера, а также варианты оболочек для рабочих станций с различными
локальными ОС, причем эти оболочки выполняют исключительно функции клиента. Другим
примером ОС, ориентированной на построение сети с выделенным сервером, является
операционная система Windows NT. В отличие от NetWare, оба варианта данной сетевой ОС Windows NT Server (для выделенного сервера) и Windows NT Workstation (для рабочей станции) могут поддерживать функции и клиента и сервера. Но серверный вариант Windows NT имеет
больше возможностей для предоставления ресурсов своего компьютера другим пользователям
сети, так как может выполнять более широкий набор функций, поддерживает большее количество
одновременных соединений с клиентами, реализует централизованное управление сетью, имеет
более развитые средства защиты.
Выделенный сервер не принято использовать в качестве компьютера для выполнения текущих
задач, не связанных с его основным назначением, так как это может уменьшить
производительность его работы как сервера. В связи с такими соображениями в ОС Novell
NetWare на серверной части возможность выполнения обычных прикладных программ вообще не
предусмотрена, то есть сервер не содержит клиентской части, а на рабочих станциях отсутствуют
серверные компоненты. Однако в других сетевых ОС функционирование на выделенном сервере
клиентской части вполне возможно. Например, под управлением Windows NT Server могут
запускаться обычные программы локального пользователя, которые могут потребовать
выполнения клиентских функций ОС при появлении запросов к ресурсам других компьютеров
сети. При этом рабочие станции, на которых установлена ОС Windows NT Workstation, могут
выполнять функции невыделенного сервера.
Важно понять, что несмотря на то, что в сети с выделенным сервером все компьютеры в общем
случае могут выполнять одновременно роли и сервера, и клиента, эта сеть функционально не
симметрична: аппаратно и программно в ней реализованы два типа компьютеров — одни, в
большей степени ориентированные на выполнение серверных функций и работающие под
управлением специализированных серверных ОС, а другие — в основном выполняющие
клиентские функции и работающие под управлением соответствующего этому назначению
варианта ОС. Функциональная несимметричность, как правило, вызывает и несимметричность
аппаратуры — для выделенных серверов используются более мощные компьютеры с большими
объемами оперативной и внешней памяти. Таким образом, функциональная несимметричность в
сетях с выделенным сервером сопровождается несимметричностью операционных систем
(специализация ОС) и аппаратной несимметричностью (специализация компьютеров).
В одноранговых сетях все компьютеры равны в правах доступа к ресурсам друг друга. Каждый
пользователь может по своему желанию объявить какой-либо ресурс своего компьютера
разделяемым, после чего другие пользователи могут его эксплуатировать. В таких сетях на всех
компьютерах устанавливается одна и та же ОС, которая предоставляет всем компьютерам в
сети потенциально равные возможности. Одноранговые сети могут быть построены, например, на
базе ОС LANtastic, Personal Ware, Windows for Workgroup, Windows NT Workstation.
В одноранговых сетях также может возникнуть функциональная несимметричность: одни
пользователи не желают разделять свои ресурсы с другими, и в таком случае их компьютеры
выполняют роль клиента, за другими компьютерами администратор закрепил только функции по
организации совместного использования ресурсов, а значит они являются серверами, в третьем
случае, когда локальный пользователь не возражает против использования его ресурсов и сам не
исключает возможности обращения к другим компьютерам, ОС, устанавливаемая на его
компьютере, должна включать и серверную, и клиентскую части. В отличие от сетей с
выделенными серверами, в одноранговых сетях отсутствует специализация ОС в зависимости от
преобладающей функциональной направленности — клиента или сервера. Все вариации
реализуются средствами конфигурирования одного и того же варианта ОС.
Одноранговые сети проще в организации и эксплуатации, однако они применяются в основном
для объединения небольших групп пользователей, не предъявляющих больших требований к
объемам хранимой информации, ее защищенности от несанкционированного доступа и к скорости
доступа. При повышенных требованиях к этим характеристикам более подходящими являются
двухранговые сети, где сервер лучше решает задачу обслуживания пользователей своими
ресурсами, так как его аппаратура и сетевая операционная система специально спроектированы
для этой цели.
ОС для рабочих групп и ОС для сетей масштаба предприятия
Сетевые операционные системы имеют разные свойства в зависимости от того, предназначены
они для сетей масштаба рабочей группы (отдела), для сетей масштаба кампуса или для сетей
масштаба предприятия.
Сети отделов — используются небольшой группой сотрудников, решающих общие задачи.
Главной целью сети отдела является разделение локальных ресурсов, таких как
приложения, данные, лазерные принтеры и модемы. Сети отделов обычно не разделяются
на подсети.
Сети кампусов — соединяют несколько сетей отделов внутри отдельного здания или внутри
одной территории предприятия. Эти сети являются все еще локальными сетями, хотя и
могут покрывать территорию в несколько квадратных километров. Сервисы такой сети
включают взаимодействие между сетями отделов, доступ к базам данных предприятия,
доступ к факс-серверам, высокоскоростным модемам и высокоскоростным принтерам.
Сети предприятия (корпоративные сети) — объединяют все компьютеры всех территорий
отдельного предприятия. Они могут покрывать город, регион или даже континент. В таких
сетях пользователям предоставляется доступ к информации и приложениям, находящимся
в других рабочих группах, других отделах, подразделениях и штаб-квартирах корпорации.
Главной задачей операционной системы, используемой в сети масштаба отдела, является
организация разделения ресурсов, таких как приложения, данные, лазерные принтеры и,
возможно, низкоскоростные модемы. Обычно сети отделов имеют один или два файловых сервера
и не более чем 30 пользователей. Задачи управления на уровне отдела относительно просты. В
задачи администратора входит добавление новых пользователей, устранение простых отказов,
инсталляция новых узлов и установка новых версий программного обеспечения. Операционные
системы сетей отделов хорошо отработаны и разнообразны, также, как и сами сети отделов, уже
давно применяющиеся и достаточно отлаженные. Такая сеть обычно использует одну или
максимум две сетевые ОС. Чаще всего это сеть с выделенным сервером NetWare 3.x или Windows
NT, или же одноранговая сеть, например сеть Windows for Workgroups.
Пользователи и администраторы сетей отделов вскоре осознают, что они могут улучшить
эффективность своей работы путем получения доступа к информации других отделов своего
предприятия. Если сотрудник, занимающийся продажами, может получить доступ к
характеристикам конкретного продукта и включить их в презентацию, то эта информация будет
более свежей и будет оказывать большее влияние на покупателей. Если отдел маркетинга может
получить доступ к характеристикам продукта, который еще только разрабатывается инженерным
отделом, то он может быстро подготовить маркетинговые материалы сразу же после окончания
разработки.
Итак, следующим шагом в эволюции сетей является объединение локальных сетей нескольких
отделов в единую сеть здания или группы зданий. Такие сети называют сетями кампусов. Сети
кампусов могут простираться на несколько километров, но при этом глобальные соединения не
требуются.
Операционная система, работающая в сети кампуса, должна обеспечивать для сотрудников одних
отделов доступ к некоторым файлам и ресурсам сетей других отделов. Услуги, предоставляемые
ОС сетей кампусов, не ограничиваются простым разделением файлов и принтеров, а часто
предоставляют доступ и к серверам других типов, например, к факс-серверам и к серверам
высокоскоростных модемов. Важным сервисом, предоставляемым операционными системами
данного класса, является доступ к корпоративным базам данных, независимо от того,
располагаются ли они на серверах баз данных или на миникомпьютерах.
Именно на уровне сети кампуса начинаются проблемы интеграции. В общем случае, отделы уже
выбрали для себя типы компьютеров, сетевого оборудования и сетевых операционных систем.
Например, инженерный отдел может использовать операционную систему UNIX и сетевое
оборудование Ethernet, отдел продаж может использовать операционные среды DOS/Novell и
оборудование Token Ring. Очень часто сеть кампуса соединяет разнородные компьютерные
системы, в то время как сети отделов используют однотипные компьютеры.
Корпоративная сеть соединяет сети всех подразделений предприятия, в общем случае
находящихся на значительных расстояниях. Корпоративные сети используют глобальные связи
(WAN links) для соединения локальных сетей или отдельных компьютеров.
Пользователям корпоративных сетей требуются все те приложения и услуги, которые имеются в
сетях отделов и кампусов, плюс некоторые дополнительные приложения и услуги, например,
доступ к приложениям мейнфреймов и миникомпьютеров и к глобальным связям. Когда ОС
разрабатывается для локальной сети или рабочей группы, то ее главной обязанностью является
разделение файлов и других сетевых ресурсов (обычно принтеров) между локально
подключенными пользователями. Такой подход не применим для уровня предприятия. Наряду с
базовыми сервисами, связанными с разделением файлов и принтеров, сетевая ОС, которая
разрабатывается для корпораций, должна поддерживать более широкий набор сервисов, в который
обычно входят почтовая служба, средства коллективной работы, поддержка удаленных
пользователей, факс-сервис, обработка голосовых сообщений, организация видеоконференций и
др.
Кроме того, многие существующие методы и подходы к решению традиционных задач сетей
меньших масштабов для корпоративной сети оказались непригодными. На первый план вышли
такие задачи и проблемы, которые в сетях рабочих групп, отделов и даже кампусов либо имели
второстепенное значение, либо вообще не проявлялись. Например, простейшая для небольшой
сети задача ведения учетной информации о пользователях выросла в сложную проблему для сети
масштаба предприятия. А использование глобальных связей требует от корпоративных ОС
поддержки протоколов, хорошо работающих на низкоскоростных линиях, и отказа от некоторых
традиционно используемых протоколов (например, тех, которые активно используют
широковещательные сообщения). Особое значение приобрели задачи преодоления гетерогенности
— в сети появились многочисленные шлюзы, обеспечивающие согласованную работу различных
ОС и сетевых системных приложений.
К признакам корпоративных ОС могут быть отнесены также следующие особенности.
Поддержка приложений. В корпоративных сетях выполняются сложные приложения, требующие
для выполнения большой вычислительной мощности. Такие приложения разделяются на
несколько частей, например, на одном компьютере выполняется часть приложения, связанная с
выполнением запросов к базе данных, на другом — запросов к файловому сервису, а на клиентских
машинах — часть, реализующая логику обработки данных приложения и организующая интерфейс
с пользователем. Вычислительная часть общих для корпорации программных систем может быть
слишком объемной и неподъемной для рабочих станций клиентов, поэтому приложения будут
выполняться более эффективно, если их наиболее сложные в вычислительном отношении части
перенести на специально предназначенный для этого мощный компьютер — сервер приложений.
Сервер приложений должен базироваться на мощной аппаратной платформе
(мультипроцессорные системы, часто на базе RISC-процессоров, специализированные кластерные
архитектуры). ОС сервера приложений должна обеспечивать высокую производительность
вычислений, а значит поддерживать многонитевую обработку, вытесняющую многозадачность,
мультипроцессирование, виртуальную память и наиболее популярные прикладные среды (UNIX,
Windows, MS-DOS, OS/2). В этом отношении сетевую ОС NetWare трудно отнести к
корпоративным продуктам, так как в ней отсутствуют почти все требования, предъявляемые к
серверу приложений. В то же время хорошая поддержка универсальных приложений в Windows
NT собственно и позволяет ей претендовать на место в мире корпоративных продуктов.
Справочная служба. Корпоративная ОС должна обладать способностью хранить информацию обо
всех пользователях и ресурсах таким образом, чтобы обеспечивалось управление ею из одной
центральной точки. Подобно большой организации, корпоративная сеть нуждается в
централизованном хранении как можно более полной справочной информации о самой себе
(начиная с данных о пользователях, серверах, рабочих станциях и кончая данными о кабельной
системе). Естественно организовать эту информацию в виде базы данных. Данные из этой базы
могут быть востребованы многими сетевыми системными приложениями, в первую очередь
системами управления и администрирования. Кроме этого, такая база полезна при организации
электронной почты, систем коллективной работы, службы безопасности, службы инвентаризации
программного и аппаратного обеспечения сети, да и для практически любого крупного бизнесприложения.
База данных, хранящая справочную информацию, предоставляет все то же многообразие
возможностей и порождает все то же множество проблем, что и любая другая крупная база
данных. Она позволяет осуществлять различные операции поиска, сортировки, модификации и
т.п., что очень сильно облегчает жизнь как администраторам, так и пользователям. Но за эти
удобства приходится расплачиваться решением проблем распределенности, репликации и
синхронизации.
В идеале сетевая справочная информация должна быть реализована в виде единой базы данных, а
не представлять собой набор баз данных, специализирующихся на хранении информации того или
иного вида, как это часто бывает в реальных операционных системах. Например, в Windows NT
имеется по крайней мере пять различных типов справочных баз данных. Главный справочник
домена (NT Domain Directory Service) хранит информацию о пользователях, которая используется
при организации их логического входа в сеть. Данные о тех же пользователях могут содержаться и
в другом справочнике, используемом электронной почтой Microsoft Mail. Еще три базы данных
поддерживают разрешение низкоуровневых адресов: WINS — устанавливает соответствие Netbiosимен IP-адресам, справочник DNS — сервер имен домена — оказывается полезным при подключении
NT-сети к Internet, и наконец, справочник протокола DHCP используется для автоматического
назначения IP-адресов компьютерам сети. Ближе к идеалу находятся справочные службы,
поставляемые фирмой Banyan (продукт Streettalk III) и фирмой Novell (NetWare Directory Services),
предлагающие единый справочник для всех сетевых приложений. Наличие единой справочной
службы для сетевой операционной системы — один из важнейших признаков ее корпоративности.
Безопасность. Особую важность для ОС корпоративной сети приобретают вопросы безопасности
данных. С одной стороны, в крупномасштабной сети объективно существует больше
возможностей для несанкционированного доступа — из-за децентрализации данных и большой
распределенности «законных» точек доступа, из-за большого числа пользователей,
благонадежность которых трудно установить, а также из-за большого числа возможных точек
несанкционированного подключения к сети. С другой стороны, корпоративные бизнесприложения работают с данными, которые имеют жизненно важное значение для успешной
работы корпорации в целом. И для защиты таких данных в корпоративных сетях наряду с
различными аппаратными средствами используется весь спектр средств защиты, предоставляемый
операционной системой: избирательные или мандатные права доступа, сложные процедуры
аутентификации пользователей, программная шифрация.
Тема 5. Территориальные сети.
Учебные вопросы:
1. Сети Intranet, Internet. Extranet. Определения, сходства и различия.
2. Сервисы территориальных сетей.
3. Протоколы теледоступа.
4. Электронная почта.
5. Файловый обмен.
6. Видеоконференции.
7. Информационная система WWW.
8. Реализация сетевых протоколов и служб в OS Unix и Windows.
9. Информационная безопасность в сетях. Подходы к обеспечению информационной
безопасности.
10. Виртуальные частные сети VPN. VPN- соединение.
11. Сети Х.25 и Frame Relay.
12. Сети ATM.
13. Протоколы туннелирования. Режим туннелирования.
14. Шифрование данных с использованием IPSec.
15. Шифрование на уровне соединения SSL. Использование средств шифрования на уровне
приложений.
16. Фильтрация трафика маршрутизаторами и межсетевыми экранами.
17. Рекомендации по проектированию корпоративных вычислительных сетей.
Вопрос 1. Сети Intranet, Internet. Extranet. Определения, сходства и различия.
Интернет ( Internet ), или всемирная информационная сеть, был разработан в США
первоначально для решения военных задач, а затем стал использоваться для коммерческих целей,
в результате чего образовался глобальный виртуальный мир всемирной информации и связи,
объединяющий потоками информации и банки данных всего мира. «Всемирная паутина» является
высшей ступенью в развитии технологий международных информационных сетей и в настоящее
время занимает лидирующие позиции в мировой информационной среде
Интернет строится на базе гипертекстового представления информации, т.е. в виде текста,
содержащего ссылки на другие информационные блоки. Такая система позволяет отображать
графику, включать мультимедийные (звуковые и видео) вставки.
«Всемирная паутина» позволяет манипулировать информацией, находящейся в миллионах
компьютеров, разбросанных по всему миру и объединенных данной информационной сетью Она
позволяет получать международную маркетинговую информацию, вести электронную торговлю,
осуществлять рекламу и связи с общественностью, разрабатывать новые продукты, привлекая
огромное число пользователей Интернета
Экстранет ( Extranet ) — это вертикальные сети, объединяющие компании-контрагенты
(компании-производители и фирмы оптовой торговли, компании-производители и субподрядчики,
поставщики сырья и материалов и т.д.), входящие в межфирменные объединения с вертикальными
производственными и сбытовыми связями, и комплексные сети,имеющие межотраслевой
характер, которые создаются совместно компаниями-контрагентами из различных отраслей
экономики и обеспечивают главным образом обмен информацией о получении и выполнении
заказов, оплату счетов, общение между посетителями сети в режиме реального времени. Сети
Экстранет обеспечивают также связь компании с ее потребителями. Наряду с Интернетом они
имеют большое значение для организации электронной торговли.
Экстранет позволяет партнерам компании получить доступ к определенной части ее внутренней
сети. В Экстранете содержится различная информация специального, а не чисто ознакомительного
характера, которая не открыта для широкого доступа. Поэтому для подключения к ней требуются
регистрация и особый пароль — протокол, Экстранет не только активизирует и повышает
эффективность сложившихся деловых связей компании, но и позволяет привлекать новых
партнеров по бизнесу и новых клиентов, предоставляя им возможность пользоваться
определенной частью своей информации.
Данная сеть создается на базе Интернет-протоколов и WWW, которые тщательно защищены от
проникновения извне. При создании экстрасети компания может использовать свою интрасеть, а
также автоматизировать всю цепочку движения товара сырье — готовая продукция — сбытовые
организации — потребитель, включая его заказ, оплату и доставку Подключение к сети возможно
только при регистрации.
Экстрасеть может быть создана на базе информационной сети данной фирмы (Интранет) или быть
вынесенной за ее пределы с тем, чтобы отдельная организация создавала и управляла ею.
Последний вариант позволяет обеспечить более стойкую защиту информации компании от
проникновений со стороны и не отвлекать компанию от ее основной деятельности.
Интранет ( Intranet ) — объединение удаленных локальных сетей в рамках одной компании или
одной группы компаний посредством механизма удаленного доступа. Обычно это горизонтальные
сети внутри группы компаний, предназначенные для сбора и накопления статистической
информации по производству и сбыту для всех компаний — членов группы, а также для
обработки информации по общей схеме и единым критериям. Они строго защищены от
проникновения извне.
Интрасети позволяют использовать возможности Web для размещения и распространения
информации в пределах компании или единой группы компаний Интранет не имеет подключений
извне и защищена от проникновения посторонних лиц и организаций. Защита внутренних сетей
обеспечивается за счет так называемых протоколов, т е наборов кодов или сигналов, с помощью
которых компьютеры устанавливают друг с другом связь и передают информацию. В Интернете
— это TCP/IP, в локальных сетях — сетевые протоколы. Интранет дешевле специализированных локальных баз данных и сетей Около половины
американских компаний используют во внутрикорпоративном управлении и международном
маркетинге систему Интранет. Эти сети надежны и просты в управлении и эксплуатации. С
помощью Интранета сотрудники входящих в нее компаний имеют возможность совместно
использовать информацию различного вида, заходить в разрешенные базы данных компании, быть
в курсе основных внутрикорпоративных событий, подключиться к любой составляющей
Интранета и получить любую заложенную в эту сеть информацию.
Это касается информации о товаре, его продажах и продвижении, ценовой линии. Кроме того, сеть
позволяет быстро и эффективно общаться между собой по интересующим вопросам различным
подразделениям, будучи уверенными в том, что данная информация недоступна внешним лицам и
организациям. Такая информационная система позволяет сотрудникам компании быстро и
эффективно войти в курс основных тенденций и данных относительно деятельности компании,
получать требуемые документы, оперативно и гибко реагировать на происходящие изменения,
повышает степень самостоятельности в принятии решений и тем самым повышает
производительность труда в компании или в группе объединенных компаний, в том числе и за
счет замены бумажных аналогов.
Специалисты по маркетингу ведут базы данных по товарам, клиентам, конкурентам, рынкам и т.д.
Они организуют группы новостей и интерактивные беседы (чаты) по маркетинговой тематике,
касающейся деятельности подразделений компании в масштабах всего земного шара, Сеть
Интранет позволяет повышать координированность их действий при реализации международных
маркетинговых программ и стратегий.
Оборудование и обслуживание сети Интранет оказывается дешевле, чем Интернет» и обмен
данными в них происходит быстрее, чем в Интернете. Обычно в рамках внутренней сети в
компании могут проводиться видео- и телеконференции и дискуссионные «клубы» в письменной
форме, когда авторы высказываемых предложении или критических замечаний могут быть
неизвестны. Особенно это важно при изучении мнений сотрудников филиалов и дочерних
компаний, разбросанных по всему миру.
Если ранее существовало значительное различие принципов построения и функционирования
сетей Интернет и Интранет, то в настоящий период происходит сглаживание различий и
технологии «всемирной паутины» активно проникают в системы внутрифирменной сети:
электронная почта, группы новостей, передача файлов и т.д.
Вопрос 2. Сервисы территориальных сетей.
На рисунке 1.13 приведен типичный пример внутренней структуры глобальной сети передачи
данных. Сеть строится на основе некоммутируемых каналов связи, которые соединяются между
собой коммутаторами S глобальной сети. Приведенная структура характерна как для
магистральных сетей типа АТМ или frame relay, так и для сетей, используемых для удаленного
доступа — аналоговых телефонных сетей, сетей ISDN или первичных цифровых сетей PDH/SDH.
Все эти сети можно разделить на три класса по способу коммутации, применяемому в
коммутаторах S:
Первичные сети с постоянной коммутацией каналов. В сетях этого типа абоненты сети
не могут инициировать коммутацию соединений между собой — каналы между абонентами
коммутируются на постоянной основе оператором сети. Говорят, что такие сети
предоставляют сервис выделенных (dedicated или leased) каналов, так как для пользователя
коммутаторы сети «не видны» и сеть представляется каналом «точка — точка». Эти сети
делятся на два подкласса — аналоговые и цифровые, в зависимости от типа техники
мультиплексирования и коммутации каналов.Аналоговые сети используют
мультиплексирование с частотным разделением каналов — технику FDM (Frequency
Division Multiplexing), а цифровые — мультиплексирование с временным разделением
каналов — технику TDM (Time Division Multiplexing). В свою очередь цифровые первичные
сети подразделяются на сети, использующие аппаратуру и протоколы технологии PDH со
скоростями каналов от 64 Кб/с до 45 Мб/с, и сети, построенные на основе аппаратуры и
протоколов технологии SONET/SDH со скоростями каналов от 51 Мб/c до 2.4 Гб/с.
Частным случаем первичной сети является канал «точка — точка», образованный кабелем
без промежуточной аппаратуры мультиплексирования и коммутации. Такой канал иногда
называют ненагруженным, подчеркивая факт отсутствия коммутаторов.
Сети с коммутацией каналов. К сетям этого типа относятся телефонные сети,
позволяющие абонентам сети динамически инициировать установление соединений друг с
другом. Телефонные сети делятся на аналоговые, использующие технику
мультиплексирования FDM, и цифровые, основанные на технике мультиплексирования
TDM. Наиболее распространенным типом цифровых телефонных сетей являются сети
ISDN.
Сети с коммутацией пакетов. Это сети, в которых коммутаторы оперируют с пакетами
пользовательских данных. К сетям этого типа относятся все сети, разработанные
специально для передачи компьютерного трафика — Х.25, frame relay, TCP/IP, ATM
(последний тип предназначен в равной степени как для передачи компьютерных данных,
так и для передачи голоса и любых других видов мультимедийного трафика).
Вопрос 3. Электронная почта.
Электронная почта (англ. email, e-mail, от англ. electronic mail) — технология и предоставляемые
ею услуги по пересылке и получению электронных сообщений (называемых «письма» или
«электронные письма») по распределённой (в том числе глобальной) компьютерной сети.
Электронная почта по составу элементов и принципу работы практически повторяет систему
обычной (бумажной) почты, заимствуя как термины (почта, письмо, конверт, вложение, ящик,
доставка и другие), так и характерные особенности — простоту использования, задержки передачи
сообщений, достаточную надёжность и в то же время отсутствие гарантии доставки.
Достоинствами электронной почты являются: легко воспринимаемые и запоминаемые человеком
адреса вида имя_пользователя@имя_домена(например, [email protected]); возможность
передачи как простого текста, так и форматированного, а также произвольных файлов;
независимость серверов (в общем случае они обращаются друг к другу непосредственно);
достаточно высокая надёжность доставки сообщения; простота использования человеком и
программами.
Недостатки электронной почты: наличие такого явления, как спам (массовые рекламные
и вирусные рассылки); возможные задержки доставки сообщения (до нескольких суток);
ограничения на размер одного сообщения и на общий размер сообщений в почтовом ящике
(персональные для пользователей).
В настоящее время любой начинающий пользователь может завести свой бесплатный
электронный почтовый ящик, достаточно зарегистрироваться на одном из интернет-порталов.
Названия
Если в Европе, Америке и др. регионах при написании используются только два варианта —
«email» и, реже, «e-mail» (с марта 2011 года англоязычным СМИ рекомендуется писать
сокращение от «электронная почта» как «email», а не «e-mail»[1]), то в русском языке присутствует
значительная вариативность. Наиболее часто в кириллических текстах также используется «email», то есть написание латиницей без транслитерации (визуальное восприятие других форм
написания хуже). Но можно встретить и другие написания:
электронная почта, эл. почта, элп, почта
интернет-почта[2]
имейл, мейл (транскрипция с английского).[3]
е-мейл, емейл, емайл (различные варианты транслитерации)
мыло или мел (в просторечии, от английского «мейл»)
электронка (в просторечии, сокращение от «электронная почта»)
Правильное написание пока не зафиксировано в словарях. Справочное
бюро Грамота.ру указывает, что Е. Ваулина в словаре «Мой компьютер» предлагает писать eмайл и е-мэйл, но замечает, что такое написание не соответствует литературной норме, в то же
время, в другом ответе советуют писать e-mail латиницей.[3][4]
Де-факто в официальных русскоязычных документах:
в тексте (в смысле «способ связи») употребляют выражение «электронная почта»;
в списке контактов используют префикс «e-mail» (E-mail: [email protected]).
История
Появление электронной почты можно отнести к 1965 году, когда сотрудники Массачусетского
технологического института (MIT) Ноэль Моррис и Том Ван Влек написали программуMail
для операционной системы CTSS (Compatible Time-Sharing System), установленную на
компьютере IBM 7090/7094.
Текстовый интерфейс программы mail
Общее развитие электронной почты шло через развитие локального взаимодействия
пользователей на многопользовательских системах. Пользователи могли, используя программу
mail (или её эквивалент), пересылать друг другу сообщения в пределах
одногомейнфрейма (большого компьютера). Следующий шаг был в возможности переслать
сообщение пользователю на другой машине — для этого использовалось указание имени машины
и имени пользователя на машине. Адрес мог записываться в виде foo!joe (пользователь joe на
компьютере foo). Третий шаг для становления электронной почты произошёл в момент появления
передачи писем через третий компьютер. В случае использования UUCP-адрес пользователя
включал в себя маршрут до пользователя через несколько промежуточных машин
(например, gate1!gate2!foo!joe — письмо для joe через машину gate1, gate2 на машину foo).
Недостатком такой адресации было то, что отправителю (или администратору машины, на
которой работал отправитель) необходимо было знать точный путь до машины адресата.
После появления распределённой глобальной системы имён DNS, для указания адреса стали
использоваться доменные имена —[email protected] — пользователь user на машине
example.com. Одновременно с этим происходило переосмысление понятия «на машине»: для
почты стали использоваться выделенные серверы, на которые не имели доступ обычные
пользователи (только администраторы), а пользователи работали на своих машинах, при этом
почта приходила не на рабочие машины пользователей, а на почтовый сервер, откуда
пользователи забирали свою почту по различным сетевым протоколам (среди распространённых
на настоящий момент — POP3, IMAP, MAPI, веб-интерфейсы). Одновременно с появлением DNS
была продумана система резервирования маршрутов доставки почты, а доменное имя в почтовом
адресе перестало быть именем конкретного компьютера и стало просто фрагментом почтового
адреса. За обслуживание домена могут отвечать многие серверы (возможно, физически
размещённые на разных континентах и в разных организациях), а пользователи из одного домена
могут не иметь между собой ничего общего (особенно подобное характерно для пользователей
бесплатных серверов электронной почты).
Кроме того, существовали и другие системы электронной почты (некоторые из них существуют и
сейчас), как то: Netmail в сети Фидонет, X.400 в сетях X.25[уточнить]. Доступ к ним из сети Интернет
и обратно осуществляется через почтовый шлюз. Для маршрутизации почты в сетях X.25 в DNS
предусмотрена специальная ресурсная запись c соответствующим названием X25 (код 19).
Хронология
1996 год, 4 июля (день Независимости США) — начало коммерческого функционирования
почтового сервиса Hotmail. Дата старта сервиса символизировала освобождение
отинтернет-провайдеров.
1997 год, 8 марта — компания Yahoo! приобретает портал RocketMail — один из первых
бесплатных почтовых сервисов. Появление сервиса Yahoo! Mail.
1998 год, 15 октября — заработала бесплатная электронная почта от Mail.Ru.
2000 год, 26 июня — запущена Яндекс.Почта — бесплатный почтовый сервис от
компании Яндекс.
2004 год, 1 апреля — запущен бесплатный почтовый сервис Gmail от компании Google.
MxA-классификация
Взаимоотношения между MTA, MDA и MUA при передаче электронной почты
В терминологии электронной почты выделяются следующие компоненты:
MTA (англ. Mail Transfer Agent — агент пересылки почты) — отвечает за отправку почты;
чаще всего это почтовый сервер, но, в принципе, возможна реализация с отправкой почты
через smart host.
MDA (англ. Mail Delivery Agent — агент доставки почты) — отвечает за доставку почты
конечному пользователю.
MUA (англ. Mail user agent — почтовый агент пользователя; в русской нотации закрепился
термин почтовый клиент) — программа, обеспечивающая пользовательский интерфейс,
отображающая полученные письма и предоставляющая возможность отвечать, создавать,
перенаправлять письма.
MRA англ. Mail retrieve agent — почтовый сервер, забирающий почту с другого сервера по
протоколам, предназначенным для MDA.[5]
В случае использования веб-интерфейса MDA и MUA могут совпадать. В случае использования
выделенных серверов для хранения почты пользователей всё взаимодействие пользователя с
сервером может происходить по протоколам, не укладывающимся в эту схему.
Почтовые сервера обычно выполняют роль MTA и MDA. Некоторые почтовые сервера
(программы) выполняют роль как MTA, так и MDA, некоторые подразумевают разделение на два
независимых сервера: сервер-MTA и сервер-MDA (при этом, если для доступа к ящику
используются различные протоколы — например, POP3 и IMAP, — то MDA в свою очередь
может быть реализован либо как единое приложение, либо как набор приложений, каждое из
которых отвечает за отдельный протокол).
Современная архитектура (SMTP)
Простейший случай пересылки почты
Общепринятым в мире протоколом обмена электронной почтой является SMTP (англ. Simple mail
transfer protocol — простой протокол передачи почты). В общепринятой реализации он
использует DNS для определения правил пересылки почты (хотя в частных системах,
вроде Microsoft Exchange, SMTP может действовать исходя из информации из других источников).
В различных доменах настроены свои, независимые друг от друга, почтовые системы. У каждого
почтового домена может быть несколько пользователей. (Однако, фактически, может быть так,
что одна организация или персона владеет многими доменами, которые обслуживаются
(физически) одной почтовой системой). Почта передаётся между узлами с использованием
программ пересылки почты (англ. Mail transfer agent, MTA; такими, как,
например, sendmail, exim4, postfix, Microsoft Exchange Server, Lotus Domino и т. д.). Поведение
систем при связи друг с другом строго стандартизировано, для этого используется протокол SMTP
(и соблюдение этого стандарта, наравне с всеобщей поддержкой DNS всеми участниками,
является основой для возможности связи «всех со всеми» без предварительных договорённостей).
Взаимодействие почтовой системы и пользователей, в общем случае, никак не регламентируется и
может быть произвольным, хотя существуют как открытые, так и закрытые (завязанные на ПО
конкретных производителей) протоколы взаимодействия между пользователями и почтовой
системой. Программа, работающая в почтовой системе и обслуживающая пользователей,
называется MDA (англ. mail delivery agent, агент доставки почты). В некоторых почтовых
системах MDA и MTA могут быть объединены в одну программу, в других системах могут быть
разнесены в виде разных программ или вообще выполняться на различных серверах. Программа, с
помощью которой пользователь осуществляет доступ, называется MUA (англ. mail user agent). В
случае использования веб-интерфейса для работы с почтой, ее роль выполняет приложение вебинтерфейса, запускаемое на сервере.
Внутри заданной почтовой системы (обычно находящейся в рамках одной организации) может
быть множество почтовых серверов, выполняющих как пересылку почты внутри организации, так
и другие, связанные с электронной почтой задачи: фильтрацию спама, проверку вложений
антивирусом, обеспечение автоответа, архивация входящей/исходящей почты, обеспечение
доступа пользователям различными методами (от POP3 до ActiveSync). Взаимодействие между
серверами в рамках одной почтовой системы может быть как подчинено общим правилам
(использование DNS и правил маршрутизации почты с помощью протокола SMTP), так и
следовать собственным правилам компании (используемого программного обеспечения).
Релеи
DNS позволяет указать в качестве принимающего сервера (MX-запись) любой узел интернета, не
обязательно являющийся частью доменной зоны домена получателя. Это может использоваться
для настройки релеинга (пересылки) почты через третьи серверы. Сторонний сервер (например,
более надёжный, чем серверы пользователя) принимает почту для домена пользователя и
пересылает его на почтовые серверы пользователя как только появляется возможность.
Исторически контроля за тем, «кому пересылать» почту, не было (или этому не придавали
должного значения) и серверы без подобного контроля передавали почту на любые домены. Такие
серверы называются открытыми релеями (в настоящее время новые открытые релеи появляются в
основном из-за ошибок в конфигурировании).
Для своих пользователей серверы почтовой системы являются релеями (пользователи отправляют
почту не на серверы почтовой системы адресата, а на «свой» почтовый сервер, который передаёт
письма далее). Во многих сетях провайдеров возможность отправлять письма по
протоколу SMTP за пределы сети закрыта (из-за использования этой
возможноститроянами, вирусами). В этом случае провайдер предоставляет свой SMTP-сервер,
через который и направляется вся почта за пределы сети. Открытым релеем при этом считается
такой релей, который не проверяет, является ли пользователь «своим» (проверка может
осуществляться как на основании сетевого адреса компьютера пользователя, так и на основании
идентификации пользователя паролем/сертификатом).
Маршрутизация почты
Почтовый сервер, получив почту (из локального источника или от другого сервера) проверяет,
существуют ли специфичные правила для обработки почты (правила могут основываться на имени
пользователя, на домене в адресе, содержимом письма и т. д.), если специфичных правил не
обнаружено, то проверяется, является ли почтовый доменлокальным для сервера (то есть является
ли сервер конечным получателем письма). Если является, то письмо принимается в обработку.
Если же домен письма не является локальным, то применяется процедура маршрутизации почты
(являющаяся основой для передачи писем между различными серверами в Интернете).
При маршрутизации используется только доменная часть адреса получателя (то есть часть,
находящаяся после символа @). Для домена получателя ищутся все MX-записи. Они сортируются
в порядке убывания приоритета. Если адрес почтового сервера совпадает с одним из узлов,
указанных в MX-записях, то все записи с приоритетом меньшим приоритета узла в MX-записи (а
также MX-запись самого узла) отбрасываются, а доставка осуществляется на первый отвечающий
узел (узлы пробуются в порядке убывания приоритета). Это сделано на случай, если почтовый
сервер отправителя является релеем почтового сервера получателя. Если MX-запись для домена не
найдена, то делается попытка доставить почту по A-записи, соответствующей домену. Если же
записи о домене нет, то формируется сообщение о невозможности доставки (Bounce message). Это
сообщение формируется с MAIL FROM:<> (RFC 5321), в поле «To» указывается отправитель
исходного письма, в поле в поле «From» — E-Mail вида MAILER-DAEMON@имя сервера. Под
именем сервера понимается имя хоста в Интернет, который сгенерировал уведомление. MAIL
FROM:<> позволяет защитить почтовые сервера от бесконечного хождения сообщений об ошибке
между серверами — если сервер обнаруживает, что не может доставить письмо с пустым
обратным адресом, то он уничтожает его. Сообщение о невозможности доставки, так же, может
формироваться через некоторое время. Это происходит в случае, если обнаруженная проблема
определяется, как временная, но истекает время нахождения сообщения в очереди (RFC 5321,
раздел 4.5.4.1. Sending Strategy).
Если сеть имеет различные DNS-серверы (например, внешние — в Интернете, и локальные — в
собственных пределах), то возможна ситуация, когда «внутренние» DNS-серверы в качестве
наиболее приоритетного получателя указывают на недоступный в Интернете сервер, куда и
перенаправляется почта с релея, указанного как узел-получатель для Интернета. Подобное
разделение позволяет осуществлять маршрутизацию почты по общим правилам между серверами,
не имеющими выхода в Интернет.
Протоколы получения почты
После попадания почты на конечный сервер, он осуществляет временное или постоянное
хранение принятой почты. Существует две различные модели работы с почтой:
концепцияпочтового хранилища (ящика) и почтового терминала.
POP3
В концепции почтового хранилища почта на сервере хранится временно, в ограниченном объёме
(аналогично почтовому ящику для бумажной почты), а пользователь периодически обращается к
ящику и «забирает» письма (то есть почтовый клиент скачивает копию письма к себе и удаляет
оригинал из почтового ящика). На основании этой концепции действует протокол POP3.
IMAP
Концепция почтового терминала подразумевает, что вся корреспонденция, связанная с почтовым
ящиком (включая копии отправленных писем), хранится на сервере, а пользователь обращается к
хранилищу (иногда его по традиции также называют «почтовым ящиком») для просмотра
корреспонденции (как новой, так и архива) и написания новых писем (включая ответы на другие
письма). На этом принципе действует протокол IMAP и большинство веб-интерфейсов бесплатных
почтовых служб. Подобное хранение почтовой переписки требует значительно больших
мощностей от почтовых серверов, в результате, во многих случаях происходит разделение между
почтовыми серверами, пересылающими почту, и серверами хранения писем.
Различия
Основываясь на работе протоколов можно разделить их по двум основным критериям:
Производительность сервера — в данном случае, IMAP более требователен к ресурсам
нежели POP3, так как вся работа по обработке почты (такая как поиск) ложится на плечи
сервера, POP3 только передает почту клиенту;
Пропускной способности канала — тут IMAP в выигрыше; POP3 передает тела всех писем
целиком, тогда как IMAP — только заголовки писем, а остальное — по запросу.
В определённых условиях сервер хранения писем может быть настроен на поведение, подобное
клиенту: такой сервер обращается к почтовому серверу по протоколу POP3 и забирает почту себе.
Подобные решения используются обычно в малых организациях, в которых нет инфраструктуры
для развёртывания полноценных почтовых серверов; в этом случае используется локальный
сервер для хранения почты и почтовый сервер провайдера, предоставляющий услугу получения
почты по POP3 (например, с помощью fetchmail). Основным недостатком подобного решения
является задержка в доставке (так как забирающее почту ПО обращается на сервера с некоторой
задержкой) — например, POP3 connector из Exchange 2003 Server в составе Windows SBS не
позволяет через интерфейс конфигурирования выставить интервал менее 15 минут.[6]
Структура письма
При передаче по протоколу SMTP Электронное письмо состоит из следующих частей:
Данные SMTP-конверта, полученные сервером. Часть этих данных может отсутствовать в
самом сообщении. Так, например, в RCPT TO (envelope to) содержится список получателей
письма, при этом в самом письме получатель может быть не указан. Эта информация
передаётся за пределы сервера только в рамках протокола SMTP, и смена протокола при
доставке почты (например, на узле-получателе в ходе внутренней маршрутизации) может
приводить к потере этой информации. В большинстве случаев эта информация недоступна
конечному получателю, который использует не-SMTP протоколы (POP3, IMAP) для
доступа к почтовому ящику. Для возможности контролировать работоспособность
системы эта информация обычно сохраняется в журналах почтовых серверов.
Самого сообщения (в терминологии протокола SMTP — ‘DATA’), которое, в свою очередь,
состоит из следующих частей, разделённых пустой строкой:
Заголовков (англ. headers) письма. В заголовке указывается служебная информация
и пометки почтовых серверов, через которые прошло письмо, пометки о
приоритете, указание на адрес и имя отправителя и получателя письма, тема
письма и другая информация.
Тела письма. В теле письма находится, собственно, сообщение письма.
Данные SMTP-конверта
Данные SMTP-конверта содержат в себе следующую информацию:
Параметр HELO/EHLO — содержит имя отправляющего узла (не имя отправителя, а имя
сервера или компьютера пользователя, который обратился к серверу).
Параметр MAIL FROM — содержит адрес отправителя. Адрес может быть произвольным
(в том числе с несуществующих доменов), однако, это значение используется для
формирования уведомлений об ошибках доставки сообщений (а, отнюдь, не значение из
поля From заголовка сообщения). В силу этого, неправильное значение не позволит Вам
узнать судьбу Вашего отправления. Этот адрес, так же, может проверяться при первичной
проверке на спам[7]. При отправке сообщения, обычный почтовый клиент формируетMAIL
FROM из содержимого поля From.
Параметр RCPT TO — наиболее важное поле для доставки почты, содержит электронный
адрес одного или нескольких получателей. В SMTP-конверте может быть несколько таких
полей. При отправке сообщения, обычный почтовый клиент формирует список для RCPT
TO из содержимого полей сообщения To, Cc и Bcc.
Заголовки письма
Заголовки письма описываются стандартами RFC:
RFC 2076 — Common Internet Message Headers (общепринятые стандарты заголовков
сообщений), включает в себя информацию из других RFC: RFC 822, RFC 1036, RFC
1123,RFC 1327, RFC 1496, RFC 1521, RFC 1766, RFC 1806, RFC 1864, RFC 1911).
RFC 4021 — Registration of Mail and MIME Header Fields (регистрация почты и поля
заголовков MIME).
Заголовки отделяются от тела письма пустой строкой. Заголовки используются для
журналирования прохождения письма и служебных пометок (иногда их называют кладжами). В
Microsoft Outlook эти заголовки называются «Заголовки Интернет». В заголовках обычно
указываются: почтовые серверы, через которые прошло письмо (каждый почтовый сервер
добавляет информацию о том, от кого он получил это письмо), информацию о том, похоже ли это
письмо на спам, информацию о проверке антивирусами, уровень срочности письма (может
меняться почтовыми серверами). Также в заголовке обычно пишется программа, с помощью
которой было создано письмо. Поскольку заголовки являются служебной информацией, то чаще
всего почтовые клиенты скрывают их от пользователя при обычном чтении писем, но также
предоставляют возможность увидеть эти заголовки, если возникает потребность в более
детальном анализе письма. В случае, если письмо из формата SMTP конвертируется в другой
формат (например, в Microsoft Exchange 2007 письма конвертируются в MAPI), то заголовки
сохраняются отдельно, для возможности диагностики.
Заголовки обычно добавляются снизу вверх (то есть каждый раз, когда к сообщению нужно
добавить заголовок, он дописывается первой строкой, перед всеми предыдущими).
Помимо служебной информации, заголовки письма также хранят и показываемую пользователю
информацию, это обычно отправитель письма, получатель, тема и дата отправки.
Заголовки сообщения могут содержать только 7-битные символы[8]. При необходимости
использовать национальные символы в каких-то полях, требуется использование кодировок. Как
правило, это Base64 или Quoted-Printable.
Часто используемые заголовки
Return-Path: (RFC 821, RFC 1123) — адрес возврата в случае неудачи, когда невозможно
доставить письмо по адресу назначения. Может отличаться от MAIL FROM и
заголовковFrom:, Sender: или Reply-To:, но обычно совпадает с MAIL FROM.
Received: (RFC 822, RFC 1123) — данные о прохождении письма через каждый
конкретный почтовый сервер (MTA). При прохождении через несколько почтовых
серверов (обычная ситуация), новые заголовки дописываются над предыдущими, в
конечном итоге, журнал перемещения будет записан в обратном порядке (от ближайшего к
получателю узла к самому дальнему).
MIME-Version: (RFC 1521) — версия MIME, с которым это сообщение создано. Зачастую
этот заголовок создаётся раньше всех остальных, поэтому он обычно самый первый (то
есть последний в списке).
From: (RFC 822, RFC 1123, RFC 1036) — имя и адрес отправителя (именно в этом
заголовке появляется текстовое поле с именем отправителя). Может не совпадать с returnpathи даже не совпадать с заголовком SMTP MAIL FROM:.
Sender: (RFC 822, RFC 1123) — Отправитель письма. Добавлено для возможности указать,
что письмо от чьего-то имени (from) отправлено другой персоной (например, секретарём
от имени начальника). Некоторые почтовые клиенты показывают сообщение при наличии
sender и from как «сообщение от ‘sender’ от имени ‘from’». Sender является
информационным заголовком (и также может отличаться от заголовка SMTP MAIL
FROM).
To: (RFC 822, RFC 1123) — имя и адрес получателя. Может содержаться несколько раз
(если письмо адресовано нескольким получателям). На основании этого поля формируется
содержимое поля SMTP RCPT TO.
Сc: (RFC 822, RFC 1123) — (от англ. carbon copy) содержит имена и адреса вторичных
получателей письма, к которым направляется копия. Участвует в формировании поля
SMTP RCPT TO, как и поле «To».
Bcc: (RFC 822, RFC 1123) — (от англ. blind carbon copy) содержит имена и адреса
получателей письма, чьи адреса не следует показывать другим получателям. Участвует в
формировании поля SMTP RCPT TO, как поля «To» и «Cc», но отсутствует в отправляемом
сообщении.
Reply-To: (RFC 822, RFC 1036) — имя и адрес, куда следует адресовать ответы на это
письмо. Если, например, письмо рассылается роботом, то в качестве Reply-To будет указан
адрес почтового ящика, готового принять ответ на письмо.
Message-ID: (RFC 822, RFC 1036) — уникальный идентификатор сообщения. Состоит из
адреса узла-отправителя и номера (уникального в пределах узла). Алгоритм генерации
уникального номера зависит от сервера/клиента. Выглядит примерно
так: [email protected]. Вместе с
другими идентификаторами используется для поиска прохождения конкретного
сообщения по журналам почтовой системы (почтовые системы фиксируют прохождение
письма по его Message-ID) и для указания на письмо из других писем (используется для
группировки и построения цепочек писем). Обычно создаётся почтовым клиентом (MUA)
в момент составления письма.
In-Reply-To: (RFC 822) — указывает на Message-ID, для которого это письмо является
ответом (с помощью этого почтовые клиенты могут легко выстраивать цепочку
переписки — каждый новый ответ содержит Message-ID для предыдущего сообщения).
Subject: (RFC 822, RFC 1036) — тема письма.
Date: (RFC 822, RFC 1123, RFC 1036) — дата отправки письма.
Content-Type: (RFC 1049, RFC 1123, RFC 1521, RFC 1766) — тип содержимого письма
(HTML, RTF, Plain text) и кодировка, в которой создано письмо (см. ниже про кодировки).
Return-Receipt-To: (RFC 2076) — E-Mail, куда почтовый сервер получателя должен
отправить уведомление о доставке. В RFC 2076 упоминается в разделе «Not Internet
standard», в силу этого может не поддерживаться серверами.
Disposition-Notification-To: (RFC 3798) — E-Mail, куда почтовый клиент получателя
должен отправить уведомление о доставке, если это разрешит пользователь (посредством
настроек и т.п.).
Помимо стандартных, почтовые клиенты, серверы и роботы обработки почты могут добавлять
свои собственные заголовки, начинающиеся с «X-» (например, X-Mailer, X-MyServer-NoteOK или X-Spamassasin-Level).
Тело письма
Тело письма отделяется от заголовка пустой строкой. В не-smtp стандартах формат письма зависит
от стандарта системы (например, MAPI), но перед «выходом» письма за пределы MAPIсовместимой системы (например, перед пересылкой через Интернет) обычно приводится к SMTPсовместимому виду (иначе маршрутизация письма была бы невозможной, так как стандартом
передачи почты в Интернете является SMTP).
В теле сообщения допускаются только печатные символы. Потому для целей передачи бинарной
информации (картинок, исполняемых файлов и т.п.) применяются кодировки, приводящие данные
с 7-битному виду — Base64 или UUE. Кроме того, в самом начале существования E-Mail
ограничение было более жёстким — некоторые почтовые системы поддерживали только 7-битные
сообщения. С целью работы с такими системами обычный текст, при наличии национальных
символов, так же, может кодироваться в 7-битный вид. Для этого
используются Base64 или Quoted-Printable. Однако, почтовые системы, которые могут работать
только с 7-битными сообщениями сейчас, вряд ли существуют.
Цепочки писем
Благодаря наличию в письме уникального идентификатора, а также тому, что подавляющее
большинство почтовых клиентов при ответе на письмо копируют его идентификатор в поле InReply-To («в ответ на»), появляется возможность достоверной группировки писем
по цепочке (англ. thread). В разных почтовых клиентах это реализовано по разному, например,
Microsoft Outlook позволяет найти все связанные с заданным письма; веб-интерфейс GMail
группирует сообщения на основании данных о цепочке в единый объект. Некоторые почтовые
клиенты (например, mutt) позволяют структурировать цепочки (образующиеся обычно в почтовых
рассылках, когда в беседе участвует много подписчиков) в форме дерева (вопрос породил
несколько ответов, на каждый из которых дали комментарий — это сформировало несколько
ветвей дерева). Также такие клиенты обычно умеют принудительно резать цепочки при смене
темы сообщения (считая, что смена темы сообщения означает новое обсуждение, хотя, быть
может, и вызванное предыдущей беседой).
Шифрование почты
Для шифрования почты в настоящий момент широко применяются два
стандарта: S/MIME (использующий инфраструктуру открытых ключей) и Open
PGP (использующий сертификаты со схемой доверия, группирующегося вокруг пользователя).
Ранее также существовали стандарты MOSS и PEM, но, из-за несовместимости друг с другом и
неудобства использования, они не прижились.
Стандарты S/MIME и Open PGP позволяют обеспечить три вида защиты: защиту от изменения,
неотзывную подпись и конфиденциальность (шифрование). Дополнительно, S/MIME третьей
версии позволяет использовать защищённое квитирование (при котором квитанция о получении
письма может быть сгенерирована успешно только в том случае, когда письмо дошло до
получателя в неизменном виде).
Оба стандарта используют симметричные криптоалгоритмы для шифрования тела письма, а
симметричный ключ шифруют с использованием открытого ключа получателя. Если письмо
адресуется группе лиц, то симметричный ключ шифруется по-очереди каждым из открытых
ключей получателей (и иногда, для удобства, открытым ключом отправителя, чтобы он имел
возможность прочитать отправленное им письмо).
Коммерческое использование
В настоящий момент существуют следующие модели коммерческого применения почтовых
систем:
Домашние и корпоративные почтовые системы — функционируют на собственном или
арендованном оборудовании владельца почтовой системы (обычно он же является и
владельцем домена, в котором работает почтовый сервер).
Услуга приёма/отправки электронной почты осуществляется сторонней организацией.
Организация (персона) владеет доменом и самостоятельно хранит архив переписки.
Услуги приёма/отправки и хранения почты осуществляет сторонняя организация на своих
мощностях. Заказчик получает доступ к системе исполнителя для отправки писем и для
доступа к архиву писем. Почтовый домен при этом находится в собственности заказчика.
Приём, отправка, хранение писем осуществляет исполнитель, почтовый домен
принадлежит исполнителю. Большинство подобных сервисов бесплатны и работают за
счёт показа рекламы пользователю или являются бесплатным дополнением к другим
сервисам исполнителя (подробнее, см.: Бесплатные почтовые сервисы).
Почтовые рассылки
Почтовая система позволяет организовать сложные системы, основанные на пересылке почты от
одного ко многим абонентам, это:
Почтовые рассылки — письмо от одного адреса с одинаковым (или меняющимся по
шаблону) содержимым, рассылаемое подписчикам рассылки. Технически может быть
организовано как отправка множества писем (используется при шаблонных письмах) или
как отправка письма с множеством получателей (в полях TO, CC, BCC). Для управления
крупными почтовыми рассылками (более 10-50 абонентов) используются
специализированные программы (например, mailman). Правильно организованная
почтовая рассылка должна контролировать возврат писем (сообщения о невозможности
доставить письмо) с исключением недоступных адресатов из списка рассылки, позволять
подписчикам отписываться от рассылок. Нежелательные почтовые рассылки
называются спамом и существенно осложняют функционирование почтовых систем.
Группы переписки — специализированный тип почтовой рассылки, в которой письмо
на адрес группы (обычный почтовый адрес, обработкой почты которого занимается
специализированная программа) рассылается всем участникам группы. Является аналогом
новостных конференций, эхоконференций. Правильно настроенная почтовая рассылка
должна контролировать циклы (два робота рассылок, подписанные друг на друга способны
создать бесконечный цикл пересылки писем), ограничивать список участников рассылки,
имеющих право на помещение сообщения, выполнять прочие требования к почтовой
рассылке.
Для управления почтовыми рассылками используются менеджеры почтовых рассылок. Помимо
ведения списка адресов и выполнения отсылки заданного сообщения они обеспечивают
фильтрацию писем, возможности премодерации писем перед помещением в рассылку, ведение
архивов, управление подпиской/отпиской, рассылку дайджестов (краткого содержимого) вместо
всего объёма рассылки.
Примеры программ управления рассылками:
mailman
Sympa
Majordomo
Спам
Спам — разновидность почтовой рассылки с целью рекламы (часто нежелательной) того или
иного товара или услуги, аналог бумажной рекламы, бесплатно распространяемой по почтовым
ящикам жилых домов.
По мере роста популярности электронной почты, она (наравне с новостными группами usenet),
начала использоваться для рассылки незапрошенных рекламных сообщений, аналогично тому, как
раскидываются рекламные брошюры в обычные почтовые ящики. Однако, в отличие от
существенной стоимости бумажной рассылки, отправка значительного количества (миллионов и
миллиардов) сообщений практически ничего не стоит отправителю. Это привело к
непропорциональному росту количества и размера рекламных рассылок (по некоторым данным[9],
спам в настоящее время составляет 70-90 % от всех почтовых сообщений, то есть превысил объём
полезной почтовой нагрузки в 2-10 раз).
Для рассылки спама в настоящий момент активно используются все возможные технические
ухищрения: открытые релеи, ремейлеры, прокси-серверы, бесплатные серверы электронной почты
(допускающие автоматизацию отправки почты), ботнеты, поддельные сообщения о
невозможности доставки.
По мере ужесточения запрета на размещение рекламы, сообщения разделились на легитимные
рассылки (на которые обычно подписывается пользователь и от которых он может отказаться в
любой момент) и нелегитимные (собственно и называемые спамом). Для борьбы со спамом были
разработаны различные механизмы (чёрные списки отправителей, серые списки, требующие
повторного обращения почтового сервера для отправки, контекстные фильтры). Одним из
последствий внедрения средств борьбы со спамом стала вероятность «ошибочно положительного»
решения относительно спама, то есть часть писем, не являющихся спамом, стала помечаться как
спам. В случае агрессивной антиспам-политики (уничтожение писем, кажущихся спамом, в
автоматическом режиме без уведомления отправителя/получателя) это приводит к
труднообнаруживаемым проблемам с прохождением почты.
Законодательное регулирование в России
Федеральный закон № 152-ФЗ «О персональных данных».
Вопрос 5. Файловый обмен.
FTP (англ. File Transfer Protocol — протокол передачи файлов) — стандартный протокол,
предназначенный для передачи файлов по TCP-сетям (например, Интернет). Использует 21-й
порт. FTP часто используется для загрузки сетевых страниц и других документов с частного
устройства разработки на открытые сервера хостинга.
Протокол построен на архитектуре «клиент-сервер» и использует разные сетевые соединения для
передачи команд и данных между клиентом и сервером. Пользователи FTP могут пройти
аутентификацию, передавая логин и пароль открытым текстом, или же, если это разрешено на
сервере, они могут подключиться анонимно. Можно использовать протокол SSH для безопасной
передачи, скрывающей (шифрующей) логин и пароль, а также шифрующей содержимое.
Первые клиентские FTP-приложения были интерактивными инструментами командной строки,
реализующими стандартные команды и синтаксис. Графические пользовательские интерфейсы с
тех пор были разработаны для многих используемых по сей день операционных систем. Среди
этих интерфейсов как программы общего веб-дизайна вроде Microsoft Expression Web, так и
специализированные FTP-клиенты (например, FileZilla).
FTP является одним из старейших прикладных протоколов, появившимся задолго до HTTP, и даже
до TCP/IP, в 1971 году. В первое время он работал поверх протокола NCP[1]. Он и сегодня широко
используется для распространения ПО и доступа к удалённым
Отличие от HTTP
Свойство
FTP
HTTP
Основан на сессиях работы
Да
Нет
Встроена аутентификация пользователей
Да
Нет
В основном предусмотрен для передачи
Больших двоичных
файлов
Небольших текстовых
файлов
Модель соединения
Двойное
подключение
Одиночное
подключение
В основном приспособлен для приёма/передачи
Приёма и передачи
Приёма
Поддерживает текстовый и двоичный режимы
передачи
Да
Нет
Поддерживает указание типов передаваемых
данных (MIME заголовки)
Нет
Да
Поддерживает операции над файловой системой
(mkdir, rm, rename, и т. д.)
Да
Нет
Достаточно яркая особенность протокола FTP в том, что он использует множественное (как
минимум — двойное) подключение. При этом один канал является управляющим, через который
поступают команды серверу и возвращаются его ответы (обычно через TCP-порт 21), а через
остальные происходит собственно передача данных, по одному каналу на каждую передачу.
Поэтому в рамках одной сессии по протоколу FTP можно передавать одновременно несколько
файлов, причём в обоих направлениях. Для каждого канала данных открывается свой TCP порт,
номер которого выбирается либо сервером, либо клиентом, в зависимости от режима передачи[2].
Протокол FTP имеет двоичный режим передачи, что сокращает накладные расходы трафика и
уменьшает время обмена данными при передаче больших файлов. Протокол же HTTP обязательно
требует кодирования двоичной информации в текстовую форму, например при помощи
алгоритма Base64.
Начиная работу через протокол FTP, клиент входит в сессию, и все операции проводятся в рамках
этой сессии (проще говоря, сервер помнит текущее состояние). Протокол HTTP ничего не
«помнит» — его задача — отдать данные и забыть, поэтому запоминание состояния при
использовании HTTP осуществляется внешними по отношению к протоколу методами[2].
FTP работает на прикладном уровне модели OSI и используется для передачи файлов с
помощью TCP/IP. Для этого должен быть запущен FTP-сервер, ожидающий входящих
запросов. Компьютер-клиент может связаться с сервером по порту 21. Это соединение (поток
управления) остаётся открытым на время сессии. Второе соединение (поток данных), может быть
открыт как сервером из порта 20 к порту соответствующего клиента (активный режим), или же
клиентом из любого порта к порту соответствующего сервера (пассивный режим), что необходимо
для передачи файла данных. Поток управления используется для работы с сессией — например,
обмен между клиентом и сервером командами и паролями с помощью telnet-подобного протокола.
Например, «RETR имя файла» передаст указанный файл от сервера клиенту. Вследствие этой
двухпортовой структуры, FTP считается внешнеполосным протоколом, в отличие от
внутриполосного HTTP.
Соединение и передача данных
Протокол определен в RFC 959. Сервер отвечает по потоку управления трёхзначными ASCIIкодами состояния с необязательным текстовым сообщением. Например, «200» (или «200 ОК»)
означает, что последняя команда была успешно выполнена. Цифры представляют код ответа, а
текст — разъяснение или запрос. Текущая передача по потоку данных может быть прервана с
помощью прерывающего сообщения, посылаемого по потоку управления.
FTP может работать в активном или пассивном режиме, от выбора которого зависит способ
установки соединения. В активном режиме клиент создаёт управляющее TCP-соединение с
сервером и отправляет серверу свой IP-адрес и произвольный номер клиентского порта, после чего
ждёт, пока сервер запустит TCP-соединение с этим адресом и номером порта. В случае, если
клиент находится за брандмауэром и не может принять входящее TCP-соединение, может быть
использован пассивный режим. В этом режиме клиент использует поток управления, чтобы
послать серверу команду PASV, и затем получает от сервера его IP-адрес и номер порта, которые
затем используются клиентом для открытия потока данных с произвольного клиентского порта к
полученному адресу и порту. Оба режима были обновлены в сентябре 1998 г. для поддержки IPv6.
В это время были проведены дальнейшие изменения пассивного режима, обновившие его до
расширенного пассивного режима.
При передаче данных по сети могут быть использованы четыре представления данных:
ASCII — используется для текста. Данные, если необходимо, до передачи конвертируются
из символьного представления на хосте-отправителе в «восьмибитный ASCII», и (опять
же, если необходимо) в символьное представление принимающего хоста. В частности,
изменяются символы перевода строки (CR /chr(13)/, LF /chr(10)/ в Windows на LF /chr(10)/
в Unix/Linux. Как следствие, этот режим не подходит для файлов, содержащих не только
обычный текст.
Режим изображения (обычно именуемый бинарным) — устройство-отправитель посылает
каждый файл байт за байтом, а получатель сохраняет поток байтов при получении.
Поддержка данного режима была рекомендована для всех реализаций FTP.
EBCDIC — используется для передачи обычного текста между хостами в кодировке
EBCDIC. В остальном, этот режим аналогичен ASCII-режиму.
Локальный режим — позволяет двум компьютерам с идентичными установками посылать
данные в собственном формате без конвертации в ASCII.
Для текстовых файлов предоставлены различные форматы управления и настройки структуры
записи. Эти особенности были разработаны для работы с файлами, содержащими Telnetили ASAформатирование.
Передача данных может осуществляться в любом из трёх режимов:
Поточный режим — данные посылаются в виде непрерывного потока, освобождая FTP от
выполнения какой бы то ни было обработки. Вместо этого, вся обработка
выполняетсяTCP. Индикатор конца файла не нужен, за исключением разделения данных
на записи.
Блочный режим — FTP разбивает данные на несколько блоков (блок заголовка,
количество байт, поле данных) и затем передаёт их TCP.
Режим сжатия — данные сжимаются единым алгоритмом (обычно, кодированием длин
серий).
Аутентификация
FTP-аутентификация использует схему имя пользователя/пароль для предоставления доступа. Имя
пользователя посылается серверу командой USER, а пароль — командой PASS. Если
предоставленная клиентом информация принята сервером, то сервер отправит клиенту
приглашение и начинается сессия. Пользователи могут, если сервер поддерживает эту
особенность, войти в систему без предоставления учётных данных, но сервер может предоставить
только ограниченный доступ для таких сессий.
Анонимный FTP
Хост, обеспечивающий FTP-сервис, может предоставить анонимный доступ к FTP. Пользователи
обычно входят в систему как «anonymous» (может быть регистрозависимым на некоторых FTPсерверах) в качестве имени пользователя. Хотя обычно пользователей просят прислать адрес
их электронной почты вместо пароля, никакой проверки фактически не производится. Многие
FTP-хосты, предоставляющие обновления программного обеспечения, поддерживают анонимный
доступ.
NAT-PT
Специально для работы FTP-протокола через межсетевые экраны было сделано расширение NAT,
называемое NAT-PT (rfc2766), позволяющее транслировать входящие соединения от сервера к
клиенту через NAT. В процессе такого соединения NAT подменяет передаваемые данные от
клиента, указывая серверу истинный адрес и порт, с которым сможет соединиться сервер, а потом
транслирует соединение от сервера от этого адреса клиенту на его адрес. Несмотря на все меры и
нововведения, принятые для поддержки FTP-протокола, на практике функция NAT-PT обычно
отключается во всех роутерах и маршрутизаторах с целью обеспечения дополнительной
безопасности от вирусных угроз.
NAT и обход брандмауэров
FTP обычно передает данные при наличии соединения сервера с клиентом, после того как клиент
отправил команду PORT. Это создает проблему как для NAT, так и для брандмауэров, которые не
разрешают соединения из интернета к внутренним хостам. Для NAT дополнительной проблемой
является то, что представление IP-адресов и номера порта в команде PORT относится к IP-адресу
и порту внутреннего хоста, вместо публичного IP-адреса и NAT-порта. Существует два подхода к
этой проблеме. Первый заключается в том, что FTP-клиент и FTP-сервер используют команду
PASV, которая вызывает соединение для передачи данных, установленное от клиента к серверу.
Второй подход — изменение для NAT значений команды PORT с помощью шлюза на прикладном
уровне.
Поддержка веб-браузерами
Большая часть обычных веб-браузеров может извлекать файлы, расположенные на FTP-серверах,
хотя они могут не поддерживать расширения протоколов вроде FTPS. Когда указан FTP-адрес, а
не HTTP-адрес, доступный контент на удалённом сервере представляется аналогично остальному
веб-контенту. Полностью функциональный FTP-клиент может быть запущен в Firefox как
расширение FireFTP.
Синтаксис
Синтаксис FTP URL описан в RFC1738, в форме:
ftp://[<пользователь>[:<пароль>]@]<хост>[:<порт>]/<путь> (параметры в квадратных скобках
необязательны). Например:
ftp://public.ftp-servers.example.com/mydirectory/myfile.txt
или:
ftp://user001:[email protected]/mydirectory/myfile.txt
Более детально об указании имени пользователя и пароля написано в документации браузеров. По
умолчанию, большинство веб-браузеров используют пассивный (PASV) режим, который лучше
обходит брандмауэры конечного пользователя.
Безопасность
FTP не разрабатывался как защищённый (особенно по нынешним меркам) протокол и имеет
многочисленные уязвимости в защите. В мае 1999 авторы RFC 2577 свели уязвимости в
следующий список проблем:
Скрытые атаки (bounce attacks)
Спуф-атаки (spoof attacks)
Атаки методом грубой силы (brute force attacks)
Перехват пакетов, сниффинг (packet capture, sniffing)
Защита имени пользователя
Захват портов (port stealing)
FTP не может зашифровать свой трафик, все передачи — открытый текст, поэтому имена
пользователей, пароли, команды и данные могут быть прочитаны кем угодно,
способнымперехватить пакет по сети. Эта проблема характерна для многих спецификаций
Интернет-протокола (в их числе SMTP, Telnet, POP, IMAP), разработанных до создания таких
механизмов шифрования, как TLS и SSL. Обычное решение этой проблемы — использовать
«безопасные», TLS-защищённые версии уязвимых протоколов (FTPS для FTP, TelnetS для Telnet
и т. д.) или же другой, более защищённый протокол, вроде SFTP/SCP, предоставляемого с
большинством реализаций протокола Secure Shell.
Безопасный FTP
Существует несколько методов безопасной передачи файлов, в одно или другое время называемых
«Безопасным FTP».
FTPS
Явный FTPS — расширение стандарта FTP, позволяющее клиентам требовать того, чтобы FTPсессия была зашифрована. Это реализуется отправкой команды «AUTH TLS». Сервер обладает
возможностью позволить или отклонить соединения, которые не запрашивают TLS. Это
расширение протокола определено в спецификации RFC 4217. Неявный FTPS — устаревший
стандарт для FTP, требующий использования SSL- или TLS-соединения. Этот стандарт должен
был использовать отличные от обычного FTP порты.
SFTP
SFTP, или «SSH File Transfer Protocol», не связан с FTP, за исключением того, что он тоже
передаёт файлы и имеет аналогичный набор команд для пользователей. SFTP, или безопасный
FTP, — это программа, использующая SSH (Secure Shell) для передачи файлов. В отличие от
стандартного FTP он шифрует и команды, и данные, предохраняя пароли и конфиденциальную
информацию от открытой передачи через сеть. По функциональности SFTP похож на FTP, но так
как он использует другой протокол, клиенты стандартного FTP не могут связаться с SFTPсервером и наоборот.
FTP через SSH (не SFTP)
FTP через SSH (не SFTP) относится к практике туннелирования обычной FTP-сессии через SSHсоединение. Поскольку FTP использует несколько TCP-соединений, туннелирование через SSH
особенно затруднительно. Когда много SSH-клиентов пытаются установить туннель для канала
управления (изначальное «клиент-сервер» соединение по порту 21), защищён будет только этот
канал; при передаче данных программное обеспечение FTP на любом конце установит новые TCPсоединения (каналы данных), которые обойдут SSH-соединение и, таким образом,
лишатся целостной защиты.
Иначе, для клиентского программного обеспечения SSH необходимо иметь определённые знания
о FTP для отслеживания и перезаписи сообщений потока управления FTP и автономного открытия
новых перенаправлений для потока данных FTP. Программные пакеты, поддерживающие этот
режим:
Tectia ConnectSecure (Win/Linux/Unix) из пакета SSH Communications Security
Tectia Server for IBM z/OS из пакета SSH Communications Security
FONC (под лицензией GPL)
Co:Z FTPSSH Proxy
FTP через SSH иногда относят к безопасным FTP; но не стоит путать его с другими методами,
такими как SSL/TLS (FTPS). Другие методы передачи файлов с помощью SSH и не связанные с
FTP — SFTP и SCP; в каждом из них и учётные и файловые данные всегда защищены протоколом
SSH.
История
Первая реализация протокола (1971 г.) предусматривала обмен между клиентом и сервером
сообщениями, состоящими из заголовка (72 бит) и данных переменной длины. Заголовок
сообщения включал в себя запрос к FTP-серверу или ответ от него, тип и длину передаваемых
данных. В качестве данных передавались параметры запроса (например, путь и имя файла),
информация от сервера (например, список файлов в каталоге) и сами файлы. Таким образом,
команды и данные передавались по одному и тому же каналу.
В 1972 г. протокол был полностью изменён, и принял вид, близкий к современному. Команды с
параметрами от клиента и ответы сервера передаются по TELNET-соединению (канал
управления), для передачи данных создаётся отдельное соединение (канал данных).
В последующих редакциях была добавлена возможность работы в пассивном режиме, передачи
файлов между FTP-серверами, введены команды получения информации, смены текущего
каталога, создания и удаления каталогов, сохранения файлов под уникальным именем. Некоторое
время существовали команды для передачи электронной почты через FTP, однако впоследствии
они были исключены из протокола.
В 1980 г. FTP-протокол стал использовать TCP. Последняя редакция протокола была выпущена в
1985 г. В 1997 г. появилось дополнение к протоколу, позволяющее шифровать и подписывать
информацию в канале управления и канале данных. В 1999 г. выпущено дополнение, посвящённое
интернационализации протокола, которое рекомендует использовать кодировку UTF-8 для команд
и ответов сервера и определяет новую команду LANG, устанавливающую язык ответов.
Основные команды
ABOR — Прервать передачу файла
CDUP — Сменить директорию на вышестоящую.
CWD — Сменить директорию.
DELE — Удалить файл (DELE filename).
EPSV — Войти в расширенный пассивный режим. Применяется вместо PASV.
HELP — Выводит список команд, принимаемых сервером.
LIST — Возвращает список файлов директории. Список передаётся через соединение
данных.
MDTM — Возвращает время модификации файла.
MKD — Создать директорию.
NLST — Возвращает список файлов директории в более кратком формате, чем LIST.
Список передаётся через соединение данных.
NOOP — Пустая операция.
PASS — Пароль.
PASV — Войти в пассивный режим. Сервер вернёт адрес и порт, к которому нужно
подключиться, чтобы забрать данные. Передача начнётся при введении следующих
команд: RETR, LIST и т. д.
PORT — Войти в активный режим. Например PORT 12,34,45,56,78,89. В отличие от
пассивного режима для передачи данных сервер сам подключается к клиенту.
PWD — Возвращает текущую директорию.
QUIT — Отключиться.
REIN — Реинициализировать подключение.
RETR — Скачать файл. Перед RETR должна быть команда PASV или PORT.
RMD — Удалить директорию.
RNFR и RNTO — Переименовать файл. RNFR — что переименовывать, RNTO — во что.
SIZE — Возвращает размер файла.
STOR — Закачать файл. Перед STOR должна быть команда PASV или PORT.
SYST — Возвращает тип системы (UNIX, WIN, …).
TYPE — Установить тип передачи файла (бинарный, текстовый).
USER — Имя пользователя для входа на сервер.
Коды ответов FTP
Ниже представлено краткое описание кодов ответа, которые могут быть возвращены FTPсервером. Эти коды были стандартизированы IETF в RFC 959. Как было сказано ранее, код
ответа — трёхзначное число. Первая цифра отвечает за один из трёх исходов: успех, отказ или
указание на ошибку либо неполный ответ.
2xx — Успешный ответ
4xx/5xx — Команда не может быть выполнена
1xx/3xx — Ошибка или неполный ответ
Вторая цифра определяет тип ошибки:
x0z — Синтаксическая.
x1z — Информация. Соответствует информационному сообщению.
x2z — Соединения. Сообщение относится к управляющему соединению либо к
соединению данных.
x3z — Соответствует сообщениям об аутентификации пользователя и его правах.
x4z — Не определено.
x5z — Файловая система. Соответствует сообщению о состоянии файловой системы.
Третья цифра окончательно специфицирует ошибку.
Пример
220 FTP server ready.
USER ftp //Анонимус
230 Login successful.
PASV
227 Entering Passive Mode (192,168,254,253,233,92)//Клиент должен открыть соединение на
переданный IP
LIST
150 Here comes the directory listing. //Сервер передает список файлов в директории
226 Directory send OK.
CWD incoming
250 Directory successfully changed.
PASV
227 Entering Passive Mode (192,168,254,253,207,56)
STOR gyuyfotry.avi
150 Ok to send data. //Клиент передает содержимое файла
226 File receive OK.
QUIT
221 Goodbye.
Аргумент 192,168,254,253,207,56 означает, что соединение к серверу ожидается на узле с IPадресом 192.168.254.253 на порту 207 << 8 + 56 = 53048 (где << — операция побитового сдвига,
207 записывается в младший разряд, а потом сдвигается в старший, чтобы в младший записать 56
или 207*256+56=53048).
На многих FTP-серверах существует каталог (под названием incoming, upload и т. п.), открытый на
запись и предназначенный для закачки файлов на сервер. Это позволяет пользователям наполнять
сервера свежими данными.
FXP
FXP (англ. File eXchange Protocol — протокол обмена файлами) — способ передачи файлов
между двумя FTP-серверами напрямую, не закачивая их на свой компьютер. При FXP-сессии
клиент открывает два FTP-соединения к двум разным серверам, запрашивая файл на первом
сервере, указывая в команде PORT IP-адрес второго сервера.
Несомненным преимуществом поддержки стандарта FXP является то, что на конечных
пользователей, желающих скопировать файлы с одного FTP-сервера на другой, уже не действует
ограничение пропускной способности их собственного интернет-соединения. Нет необходимости
скачивать себе файл, чтобы потом загрузить его на другой FTP-сервер. Таким образом, время
передачи файлов будет зависеть только от скорости соединения между двумя удаленными FTPсерверами, которая в большинстве случаев заведомо больше «пользовательской».
FXP стал использоваться злоумышленниками для атак на другие серверы: в команде PORT
указывается IP-адрес и порт атакуемого сервиса на компьютере жертвы, и командами RETR/STOR
производится обращение на этот порт от лица FTP-сервера, а не атакующей машины, что
позволяло устраивать масштабные DDoS-атаки с использованием сразу многих FTP-серверов,
либо обходить систему безопасности компьютера жертвы, если он полагается только на проверку
IP клиента и используемый для атаки FTP-сервер находится в доверенной сети или на шлюзе. В
результате сейчас практически все серверы проверяют соответствие IP-адреса, указанного в
команде PORT, IP-адресу FTP-клиента и по умолчанию запрещают использование там IP-адресов
третьих сторон. Таким образом, использование FXP невозможно при работе с публичными FTPсерверами.
Вопрос 6. Видеоконференции.
Видеоконференция (от англ. videoconference) — область информационной технологии,
обеспечивающая одновременно двустороннюю передачу, обработку, преобразование и
представление интерактивной информации на расстоянии в режиме реального времени с
помощью аппаратно-программных средств вычислительной техники.
Взаимодействие в режиме видеоконференций также называют сеансом видео-конференц-связи.
Видео-конференц-связь[1] (ВКС) — это телекоммуникационная технология
интерактивного взаимодействия двух и более удаленных абонентов, при которой между ними
возможен обмен аудио- и видеоинформацией в реальном времени, с учётом
передачи управляющих данных.
Цели внедрения видео-конференц-связи
Видеоконференция применяется как средство оперативного принятия решения в той или иной
ситуации; при чрезвычайных ситуациях; для сокращения командировочных расходов в
территориально распределенных организациях; повышения эффективности; проведения судебных
процессов с дистанционным участием осужденных[2], а также как один из элементов
технологий телемедицины и дистанционного обучения.
Во многих государственных и коммерческих организациях видеоконференция приносит большие
результаты и максимальную эффективность, а именно:
снижает время на переезды и связанные с ними расходы;
ускоряет процессы принятия решений в чрезвычайных ситуациях[3];
сокращает время рассмотрения дел в судах общей юрисдикции[4];
увеличивает производительность труда[5];
решает кадровые вопросы и социально-экономические ситуации[6][7];
дает возможность принимать более обоснованные решения за счёт привлечения при
необходимости дополнительных экспертов[8];
быстро и эффективно распределяет ресурсы[9], и так далее.
Для общения в режиме видеоконференции абонент должен иметь терминальное устройство
(кодек) видео-конференц-связи, видеотелефон или иное средство вычислительной техники. Как
правило, в комплекс устройств для видео-конференц-связи входит:
центральное устройство — кодек с видеокамерой и микрофоном, обеспечивающего
кодирование/декодирование аудио- и видео- информации, захват и отображение контента;
устройство отображения информации и воспроизведения звука.
В качестве кодека может использоваться персональный компьютер с программным обеспечением
для видеоконференций.
Большую роль в видеоконференции играют каналы связи, то есть транспортная сеть передачи
данных. Для подключения к каналам связи используются сетевые протоколы IP илиISDN.
Существует два режима работы ВКС, которые позволяют проводить двусторонние (режим «точкаточка») и многосторонние (режим «многоточка») видеоконференции.
Как правило, видео-конференц-связь в режиме «точка-точка» удовлетворяет потребности только
на начальном этапе внедрения технологии, и довольно скоро возникает необходимость
одновременного взаимодействия между несколькими абонентами. Такой режим работы
называется «многоточечный» или многоточечной видео-конференц-связью. Для реализации
данного режима требуется наличие активации многоточечной лицензии в кодеке при условии,
если устройство поддерживает данную функцию, либо специального
видеосервера MCU (англ. Multipoint Control Unit), или программно-аппаратной системы
управления.
Задачи внедрения видео-конференц-связи
Для внедрения видео-конференц-связи руководителю (лицу, принимающему решения)
организации необходимо определить главную цель применения[10]: проведение совещаний, подбор
персонала, оперативность при принятии решений, осуществление контроля, дистанционное
обучение, консультация врачей, проведение судебных заседаний, допрос свидетелей и так далее.
При этом необходимо учитывать основные правила видео-конференц-связи:
гарантированная высокоскоростная услуга связи или выделенные каналы связи только для
сеансов видеоконференций;
стабильное и надёжное электропитание телекоммуникационного оборудования и видеоконференц-связи;
оптимальные шумо- и эхо- поглощающие особенности помещения, в котором будет
установлено оборудование видео-конференц-связи;
правильное расположение оборудования видео-конференц-связи по отношению к
световому фону помещения;
корректная настройка телекоммуникационного оборудования и видео-конференц-связи
по обслуживанию качества услуги связи с приоритизацией передачи данных;
компетентный обслуживающий технический персонал;
техническое сопровождение и подписка на обновление оборудования через
сертифицированного производителем поставщика;
Основные категории и классы видео-конференц-связи
Учитывая функции и цели применения, оборудование видео-конференц-связи систематизируется
на категории и классы[11].
Категории видео-конференц-связи
Персональные системы
Персональные системы обеспечивают возможность индивидуального видеообщения пользователя
в режиме реального времени, не покидая своего рабочего места. Конструктивно индивидуальные
системы обычно выполняются в виде настольных терминалов либо в виде программных решений.
Групповые системы
Групповые системы предназначены для проведения групповых сеансов видео-конференц-связи в
переговорных (совещательных) комнатах. Групповая система способна превратить помещение
любого размера в видео-конференц-студию для проведения интерактивных совещаний. К
групповым системам относятся приставки видео-конференц-связи (set-top) стандартного
разрешения и с поддержкой высокой чёткости (High Definition). К этой же категории относятся и
системы класса TelePresence[12] (телеприсутствие), которые предоставляют собой комплекс
средств, обеспечивающий максимальный эффект присутствия удалённых собеседников в одной
комнате.
Отраслевые системы
Отраслевые системы — это системы, которые применяются непосредственно в определенной
отрасли. Например, в медицинской отрасли очень часто применяют системы для проведения
операций (телемедицина), в судебной системе — для проведения дистанционных кассационных и
надзорных судебных процессов, в нефтегазовой, энергетической, строительной области для
оперативности представления информации.
Мобильные системы
Мобильные системы[13] — это компактные переносные системы видео-конференц-связи для
использования в удалённых районах и экстремальных условиях. Мобильные системы позволяют
за короткое время организовать сеанс видео-конференц-связи в нестандартных условиях. Данные
системы обычно используются государственными органами, принимающими оперативные
решения (военные, спасатели, врачи, службы экстренного реагирования). Типичный пример
использования мобильных систем — организация ситуационного центра.
Инфраструктура сети видео-конференц-связи
К инфраструктуре сети видео-конференц-связи относится совокупность аппаратно-программных
средств администрирования/управления с использованием различного оконечного оборудования и
программного обеспечения — сервера многоточечной видео-конференц-связи (Multipoint Control
Unit), интеграция с Унифицированные коммуникации, системы управления видеоконференциями
(учёт, управления конфигурацией, безопасностью, производительностью и ошибками узлов,
линий и оконечного оборудования видео-конференц-связи), системы распределения нагрузки
распределенных серверов, шлюзы для прохождения трафика через межсетевые экраны, шлюзы с
мобильными сетями и абонентами H.320.
Классы видео-конференц-связи
Категории подразделяются на классы, которые включают в себя пять различных классов.
Программное решение
Программные решения (англ. Software solution) устанавливаются на персональный компьютер,
ноутбук или мобильное устройство. В качестве периферии для захвата и воспроизведения видео и
звука могут использоваться, как встроенные в устройство камера, микрофон или динамик, так и
внешние устройства, такие как веб-камера, головная гарнитура или спикерфон.
Платные решения, в отличие от бесплатных, обычно обеспечивают более широкие
функциональные возможности при проведении конференций (например, поддерживается большое
число участников) и совместимость с аппаратными решениями видео-конференц-связи различных
производителей (благодаря использованию открытых стандартов SIP и H.323).
Программные решения, как и аппаратные, имеют отдельные клиентскую часть (аналог
аппаратного терминала) и серверную (аналог MCU). Серверная часть, как и клиентская, работает
на ПК. Серверные части программных решений не осуществляют перекодирование видеопотоков,
а только перенаправляют их на клиентские приложения, что значительно снижает системные
требования к аппаратной части ПК, используемых в роли сервера и удешевляет решение в целом.
Построение «картинки» из нескольких видеоокон во время групповых видеоконференций, а также
кодирование и декодирование данных в программных решениях осуществляется только на
клиентской стороне. Использование технологии SVC на серверной части программных решений
позволяет в реальном времени изменять качество потоков для каждого из участников, не создавая
вычислительную нагрузку на сервер.
Преимущества программных решений:
возможность обновлений без необходимости замены аппаратной части;
не требуют капитальных вложений в инфраструктуру;
нет необходимости в дополнительном оборудовании для реализации доп. возможностей
(запись, совместная работа и т. п.);
приспособлены для работы на нестабильных каналах связи, таких как интернет;
поставляются в виде лицензий.
Общие ограничения программных решений:
предназначены в основном для индивидуального использования (практически невозможно
применять для проведения групповых сеансов видео-конференц-связи, например, в
переговорных комнатах);
высокая нагрузка на центральный процессор ПК.
Видеоконференции стандартного качества
Видеоконференции стандартного качества (англ. Standard Definition) подразумевают поддержку
четырёх стандартных видеоразрешений: SQCIF (128×96), QCIF (176×144), CIF(352х288) и 4CIF
(704×576) на скоростях передачи данных от 64 Кбит/с до 768 Кбит/с.
Разрешения SQCIF и QCIF изначально были введены для медленных каналов связи (от 64 Кбит/с)
и в настоящее время практически не используются. Разрешение CIF поддерживается на скоростях
от 256 Кбит/с. Самое высокое стандартное разрешение 4CIF доступно на скоростях от 384 Кбит/с.
Минимальные значения скоростей передачи данных для того или иного разрешения могут
варьироваться в зависимости от производителя оборудования.
Видеоконференции высокой чёткости
Класс высокой четкости (англ. High Definition или англ. HD) появился в связи с выпуском на
рынок систем ВКС с более высоким разрешением, чем 4CIF, то есть разрешение HD (1280х720),
которое требует в несколько раз больше пикселей для построения изображения по сравнению со
стандартной видео-конференц-связью, и, соответственно, для её передачи необходима более
высокая скорость.
Появлению видеоконференции высокой чёткости способствовало несколько факторов:
в западных странах начался массовый переход на цифровое телевидение, в результате
которого мониторы, фотоаппараты, камеры стали поддерживать технологии высокой
четкости;
в дополнение к H.323 был ратифицирован стандарт сжатия видео H.264, обеспечивающий
более эффективный алгоритм сжатия громоздких файлов для передачи видео по сети, в
том числе беспроводной;
одновременно с этим на рынок было выпущено новое поколение высокопроизводительных
специализированных процессоров для обработки видео.
Термин «High Definition» никаким стандартом не определяется. Он появился как маркетинговое
понятие, подразумевающее передачу видеоизображения с разрешением выше 4CIF и его
сопровождение более качественным звуком. Качество изображения уровня HD может быть
получено при ширине канала от 512 Кбит/с[14][15] и выше. При отсутствии необходимой полосы
пропускания системы видео-конференц-связи, работающие с разрешением HD, обычно
адаптируются под существующий канал связи, уменьшая, соответственно, качество
видеоизображения. То есть, если полосы пропускания недостаточно для поддержки качества HD,
то система видео-конференц-связи не откажется работать, а автоматически снизит разрешение
изображения. Такая функция уже реализована на базе видеодвижков
компаний: Skype, Google, Microsoft, TrueConf и других.
Телеприсутствие
Телеприсутствие (англ. TelePresence) — технология проведения сеансов видео-конференц-связи с
использованием нескольких кодеков (аппаратных вычислительных блоков терминала
видеоконферецсвязи), обеспечивающая максимально возможный эффект присутствия за счёт
специальным образом установленных экранов, мебели, отделки помещения и т. п.
Отличия от оборудования видео-конференц-связи высокой чёткости:
эффект общения собеседников в одной комнате;
позиция и размер собеседников;
линия взгляда — «глаза в глаза»;
инструменты для совместной работы;
естественное акустическое окружение;
освещение;
отделка помещения.
Ситуационные и диспетчерские центры
Ситуационные/диспетчерские центры (англ. Situation and Control Centers) или комнаты
предназначены для лиц, принимающих решения и могут быть использованы в различных областях
деятельности. В общем случае ситуационный центр состоит из ситуационной комнаты,
оснащенной всеми коммуникациями, включая средства видеоконференцсвязи или
телеприсутствия и диспетчерского центра, осуществляющего сбор, анализ и подготовку
информации для передачи в ситуационную комнату для принятия решения. Также диспетчерская
ситуационной комнаты обеспечивает связь ситуационной комнаты с внешним миром.
Ситуационные и диспетчерские центры предоставляют возможность:
экспресс-анализа текущего положения[16];
моделирования сценариев возможных событий[17];
экспертной оценки принимаемых решений и их оптимизации;
выбора наиболее эффективного управленческого воздействия на ту или иную ситуацию и
так далее.
Организация каналов связи
Основную роль в видеоконференции играют каналы связи между абонентами. Рассмотрим
несколько методов организации каналов связи для видеоконференций.
В сети Интернет
Самый простой и дешёвый метод организации видео-конференц-связи — через Интернет. Однако
качество сеанса связи в данном случае может быть низким, так как интернет не является
гарантированным каналом передачи аудио- и видеоданных. К этому добавляется
проблема безопасности видеоконференции, то есть она может стать «общественным достоянием».
Для организации видео-конференц-связи через Интернет требуется иметь статические IP-адреса и
каналы связи с пропускной способностью не менее 384 кБит/с в обе стороны (для исходящего и
входящего трафика).
Немного сложнее настраивается связь по протоколу инкапсуляции видовой
маршрутизации GRE (англ. Generic Routing Encapsulation). Протокол принадлежит к сетевому
уровню. Он может инкапсулировать другие протоколы, а затем осуществлять маршрутизацию
всего набора до места назначения. В данном случае обеспечивается минимальная защита
видеотрафика в сети интернет, что позволяет предотвратить основное число «неопытных»
вторжений в информационное облако видео-конференц-связи. Тот же принцип, хоть и намного
более высокого уровня безопасности, заложен и в протоколе IPsec.
По протоколу ISDN
Аббревиатура ISDN (англ. Integrated Services Digital Network) расшифровывается как цифровая
сеть с интеграцией услуг. Цифровые сети с интегральными услугами относятся к сетям, в которых
основным режимом связи является режим коммутации каналов, а данные обрабатываются в
цифровой форме. Данная услуга не очень распространена в России. Один из самых крупных
реализованных проектов развития сети ISDN является сеть ОАО «Ростелеком», которая
объединяет более 500 городов в РФ и СНГ.
ISDN имеет ряд преимуществ по сравнению с традиционными аналоговыми сетями, однако, по
сравнению с новыми телекоммуникационными технологиями передачи данных, имеет ряд
критичных недостатков:
тяжело отследить, на каком участке произошел сбой связи;
низкая оперативность восстановления каналов связи;
небольшая распространенность на территории РФ;
всего несколько операторов связи поддерживают данную технологию;
сравнительно высокая стоимость применения услуги связи при межрегиональном
соединении.
По технологии IP VPN MPLS
Услуга связи по технологии IP VPN MPLS в настоящее время является одной из самых надежных
и дешевых для организации видеоконференций. Этому способствует:
VPN (англ. Virtual Private Network) — виртуальная частная сеть, то есть обобщённое
название технологий, позволяющих обеспечить одно или несколько сетевых защищенных
соединений (логическую сеть) поверх другой сети.
MPLS (англ. Multiprotocol Label Switching) — мультипротокольная коммутация по меткам,
то есть механизм передачи данных, который эмулирует различные свойства сетей с
коммутацией каналов поверх сетей с коммутацией пакетов.
Технология IP VPN MPLS по степени защищенности используемой среды относится к
доверительной зоне. Она используется в случаях, когда передающую среду можно считать
надёжной и необходимо решить лишь задачу создания виртуальной подсети в рамках большей
сети.
Протоколы организации видео-конференц-связи
Стандартные протоколы передачи данных призваны сделать видеоконференции столь же
распространенными, как телефонная и факсимильная связь. Благодаря протоколам системы
поддержки видеоконференций разных производителей могут без проблем устанавливать связь
между собой, как связываются между собой другие телекоммуникационные устройства. Но
прежде, чем начать повествовать про специализированные протоколы видеоконференции, кратко
дадим определение протокола.
Протокол для видеоконференции — это набор соглашений, который определяет обмен данными
между различным программным обеспечением. Протоколы задают способы передачи данных и
обработки ошибок в сети, а также позволяют разрабатывать стандарты, не привязанные к
конкретной аппаратной платформе.
В 1990 году был одобрен первый международный стандарт в области технологий
видеоконференций — спецификация H.320 для поддержки видеоконференций по ISDN.
ЗатемITU одобрил ещё целую серию рекомендаций, относящихся к видеоконференциям.
Эта серия рекомендаций, часто называемая H.32x, помимо H.320, включает в себя
стандарты H.321-H.324, которые предназначены для различных типов сетей передачи
данных.
Во второй половине 90-х годов интенсивное развитие получили IP сети и Интернет. Они
превратились в экономичную среду передачи данных и стали практически повсеместными.
Однако, в отличие от ISDN, IP сети были плохо приспособлены для передачи аудио- и
видеопотоков. Стремление использовать сложившуюся структуру IP-сетей привело к
появлению в 1996 году стандарта H.323 — видеотелефоны и терминальное оборудование
для локальных сетей с негарантированным качеством обслуживания (англ. Visual
Telephone Systems and Terminal Equipment for Local Area Networks which Provide a NonGuaranteed Quality of Service).
В 1998 году была одобрена вторая версия этого стандарта H.323 v.2 — Мультимедийные
системы связи для сетей с коммутаций пакетов (англ. Packet-based multimedia
communication systems).
В сентябре 1999 года была одобрена третья версия рекомендаций.
17 ноября 2001 года была одобрена четвёртая версия стандарта H.323. Сейчас H.323 —
один из важнейших стандартов из этой серии. H.323 — это рекомендации ITU-T для
мультимедийных приложений в вычислительных сетях, не обеспечивающих
гарантированное качество обслуживания (QoS). Такие сети включают в себя сети пакетной
коммутации IP и IPX на базе Ethernet, Fast Ethernet и Token Ring.
Основные стандарты видео-конференц-связи (Коммуникационные протоколы)
Стандарт мультимедийных приложений H.323 С целью проведения аудио- и видеоконференций по
телекоммуникационным сетям ITU-T разработала серию рекомендаций H.32x. Эта серия включает
в себя ряд стандартов по обеспечению проведения видеоконференций.
1. H.320 — по сетям ISDN;
2. H.321 — по сетям Ш-ЦСИО и ATM;
3. H.322 — по сетям с коммутацией пакетов с гарантированной пропускной способностью;
4. H.323 — по сетям с коммутацией пакетов с негарантированной пропускной способностью;
5. H.324 — по телефонным сетям общего пользования;
6. H.324/C — по сетям мобильной связи;
7. H.239 — поддержка двух потоков от разных источников, изображение участника и данных
(вторая камера или презентация) выводятся на два разных дисплея или в режиме PIP на один
дисплей.
8. H.460.17/.18/.19 — поддержка прохождения аудио- и видеотрафика видео-конференц-связи
через NAT и Firewall
Рекомендации ITU-T, входящие в стандарт H.323, определяют порядок функционирования
абонентских терминалов в сетях передачи данных с разделяемым ресурсом, в основном не
гарантирующих качества обслуживания.
Рекомендации H.323 предусматривают:
управление полосой пропускания;
возможность взаимодействия сетей;
платформенную независимость;
поддержку многоточечных конференций;
поддержку многоадресной передачи;
стандарты для кодеков;
поддержку групповой адресации.
Управление полосой пропускания — передача аудио- и видеоинформации, например, в
видеоконференциях, весьма интенсивно нагружает каналы связи, и, если не следить за ростом этой
нагрузки, работоспособность критически важных сетевых сервисов может быть нарушена.
Поэтому рекомендации H.323 предусматривают управление полосой пропускания. Можно
ограничить как число одновременных соединений, так и суммарную полосу пропускания для всех
приложений H.323. Эти ограничения помогают сохранить необходимые ресурсы для работы
других сетевых приложений. Каждый терминал H.323 может управлять своей полосой
пропускания в конкретной сессии конференции.
Стандарты сжатия видеоизображения
Основные видеостандарты:
1. Стандарт H.261 — разработан организацией по стандартам телекоммуникаций ITU. На практике
первый кадр в стандарте H.261 всегда представляет собой изображение стандартаJPEG,
компрессированное с потерями и с высокой степенью сжатия.
2. Стандарт H.263 — это стандарт сжатия видео, предназначенный для передачи видео по каналам
с довольно низкой пропускной способностью (обычно ниже 128 кбит/с). Применяется в
программном обеспечении для видеоконференций.
3. Стандарт H.264 — это новый расширенный кодек, также известный как AVC и MPEG-4, часть
10.
4. Стандарт H.264 High Profile — это самый производительный профайл H.264 с алгоритмом
сжатия видео Context Adaptive Binary Arithmetic Coding (CABAC), впервые внедрен на
оборудовании Polycom, позволяет устраивать HD-видеоконференции на канале от 512 Kbps
Для видеоконференций на сегодняшний день чаще всего используется стандарт H.263 и H.264.
Стандарты сжатия звука
Некоторые стандарты компрессии аудиосигнала основаны на технологии оцифровки звука,
называемой импульсно-кодовой модуляцией или ИКМ.
Основные аудиостандарты:
1. Opus — современный открытый стандарт, позволяющий кодировать аудиосигнал в любом
требуемом качестве.
2. G.711 — устаревающий, но всё ещё широко применяемый стандарт логарифмического
кодирования аудио (аудиокомпандирования).
3. G.722 — широкополосный (более качественный, в сравнении с G.711) голосовой кодек
стандарта ITU-T со скоростью 32-64 Кбит/сек.
G.722.1 (1999 г.) — стандарт аудиосжатия G.722.1 Annex C базируется на
стандарте Polycom Siren 14.
G.722.2 (2002 г.) — более используемый вариант кодека, также известный как Adaptive
Multi Rate — WideBand (AMR-WB) «Адаптивный, с Переменной Скоростью —
Широкополосный».
4. G.726 — кодек предназначен для передачи звука с минимальной задержкой и описывает
передачу голоса полосой в 16, 24, 32, и 40 Кбит/сек.
5. G.729 — популярный в России узкополосный речевой кодек с рекордным битрейтом 8 Кбит/с,
применяется для эффективного цифрового представления узкополосной телефонной речи (сигнала
телефонного качества).
Для всех типов кодеков справедливо правило: чем меньше плотность цифрового потока, тем
больше восстановленный сигнал отличается от оригинала. Однако восстановленный сигнал
гибридных кодеков обладает вполне высокими характеристиками, восстанавливается тембр
речевого сигнала, его динамические характеристики, другими словами, его «узнаваемость» и
«распознаваемость».
Системы видеоконференций базируются на достижениях технологий средств телекоммуникаций и
мультимедиа. Изображение и звук с помощью средств вычислительной техники передаются по
каналам связи локальных и глобальных вычислительных сетей. Ограничивающими факторами для
таких систем будет гарантированная пропускная способность канала связи и алгоритмы
компрессии/декомпрессии цифрового изображения и звука.
Системы управления видео-конференц-связью
Существует общемировое правило — чем больше сеть, тем сложнее сетью становится управлять.
Для обеспечения надежности, повышения эффективности, отказоустойчивости и безопасности
сетей видеоконференции используются технологии, получившие название «системы управления
сетями».
В понятие «системы управления сетями видеоконференций» должны входить[18]
Обработка и анализ ошибок — обеспечение необходимыми инструментами для
обнаружения сбоев и отказов сетевых и терминальных устройств, определения их причин
и принятия действий по восстановлению работоспособности.
Управление конфигурацией — отслеживание и настройка конфигурации сетевого
аппаратно-программного обеспечения.
Учёт — измерение использования и доступности сетевых ресурсов.
Управление производительностью — измерение производительности сети, сбор и анализ
статистической информации о поведении сети для её поддержания на приемлемом уровне
как для оперативного управления сетью, так и для планирования её развития.
Управление безопасностью — контроль доступа к оборудованию и сетевым ресурсам с
ведением журналов доступа для обнаружения, предотвращения и пресечения
несанкционированного доступа.
Вопрос 7. Информационная система WWW
Всемирная паутина (англ. World Wide Web) — распределённая система, предоставляющая доступ
к связанным между собой документам, расположенным на различных компьютерах,
подключённых к Интернету. Для обозначения Всемирной паутины также используют
слово веб (англ. web «паутина») и аббревиатуру WWW.
Всемирную паутину образуют сотни миллионов веб-серверов. Большинство ресурсов Всемирной
паутины основаны на технологии гипертекста. Гипертекстовые документы, размещаемые во
Всемирной паутине, называются веб-страницами. Несколько веб-страниц, объединённых общей
темой, дизайном, а также связанных между собой ссылками и обычно находящихся на одном и
том же веб-сервере, называются веб-сайтом. Для загрузки и просмотра веб-страниц используются
специальные программы — браузеры (англ. browser).
Всемирная паутина вызвала настоящую революцию в информационных технологиях и взрыв в
развитии Интернета. В повседневной речи, говоря об Интернете, часто имеют в виду именно
Всемирную паутину. Однако важно понимать, что это не одно и то же.
Структура и принципы Всемирной паутины
Всемирная паутина вокруг Википедии
Всемирную паутину образуют миллионы веб-серверов сети Интернет, расположенных по всему
миру. Веб-сервер — этокомпьютерная программа, запускаемая на подключённом к
сети компьютере и использующая протокол HTTP для передачи данных. В простейшем виде такая
программа получает по сети HTTP-запрос на определённый ресурс, находит соответствующий
файл на локальном жёстком диске и отправляет его по сети запросившему компьютеру. Более
сложные веб-серверы способны в ответ на HTTP-запрос динамически генерировать документы с
помощью шаблонов и сценариев.
Для просмотра информации, полученной от веб-сервера, на клиентском компьютере применяется
специальная программа — веб-браузер. Основная функция веб-браузера —
отображение гипертекста. Всемирная паутина неразрывно связана с понятиями гипертекста
и гиперссылки. Большая часть информации в Вебе представляет собой именно гипертекст.
Для создания, хранения и отображения гипертекста во Всемирной паутине традиционно
используется язык HTML (англ. HyperText Markup Language «язык разметки гипертекста»). Работа
по созданию (разметке) гипертекстовых документов называется вёрсткой, она делается вебмастером либо отдельным специалистом по разметке — верстальщиком. После HTML-разметки
получившийся документ сохраняется в файл, и такие HTML-файлы являются основным типом
ресурсов Всемирной паутины. После того, как HTML-файл становится доступен веб-серверу, его
начинают называть «веб-страницей». Набор веб-страниц образует веб-сайт.
Гипертекст веб-страниц содержит гиперссылки. Гиперссылки помогают пользователям
Всемирной паутины легко перемещаться между ресурсами (файлами) вне зависимости от того,
находятся ресурсы на локальном компьютере или на удалённом сервере. Для определения
местонахождения ресурсов во Всемирной паутине используются единообразные локаторы
ресурсов URL (англ. Uniform Resource Locator). Например, полный URL главной страницы
русского раздела Википедии выглядит так: http://ru.wikipedia.org/wiki/Заглавная_страница.
Подобные URL-локаторы сочетают в себе технологию идентификации URI (англ. Uniform
Resource Identifier «единообразный идентификатор ресурса») и системудоменных
имён DNS (англ. Domain Name System). Доменное имя (в данном случае ru.wikipedia.org) в составе
URL обозначает компьютер (точнее — один из его сетевых интерфейсов), который исполняет код
нужного веб-сервера. URL текущей страницы обычно можно увидеть в адресной строке браузера,
хотя многие современные браузеры предпочитают по умолчанию показывать лишь доменное имя
текущего сайта.
Технологии Всемирной паутины
Для улучшения визуального восприятия веба стала широко применяться технология CSS, которая
позволяет задавать единые стили оформления для множества веб-страниц. Ещё одно
нововведение, на которое стоит обратить внимание, — система обозначения
ресурсов URN (англ. Uniform Resource Name).
Популярная концепция развития Всемирной паутины — создание семантической паутины.
Семантическая паутина — это надстройка над существующей Всемирной паутиной, которая
призвана сделать размещённую в сети информацию более понятной для компьютеров.
Семантическая паутина — это концепция сети, в которой каждый ресурс на человеческом языке
был бы снабжён описанием, понятным компьютеру. Семантическая паутина открывает доступ к
чётко структурированной информации для любых приложений, независимо от платформы и
независимо от языков программирования. Программы смогут сами находить нужные ресурсы,
обрабатывать информацию, классифицировать данные, выявлять логические связи, делать выводы
и даже принимать решения на основе этих выводов. При широком распространении и грамотном
внедрении семантическая паутина может вызвать революцию в Интернете. Для создания
понятного компьютеру описания ресурса, в семантической паутине используется
формат RDF (англ. Resource Description Framework), который основан на синтаксисе XML и
использует идентификаторы URI для обозначения ресурсов. Новинки в этой области —
это RDFS (англ. RDF Schema) и SPARQL(англ. Protocol And RDF Query Language) (произносится
как «спаркл»), новый язык запросов для быстрого доступа к данным RDF.
История Всемирной паутины
Так выглядит самый первый веб-сервер, разработанный Тимом Бернерсом-Ли
Изобретателями всемирной паутины считаются Тим Бернерс-Ли и, в меньшей степени, Роберт
Кайо. Тим Бернерс-Ли является автором технологий HTTP, URI/URL и HTML. В 1980 году он
работал в Европейском совете по ядерным исследованиям (фр. conseil européen pour la recherche
nucléaire, CERN) консультантом по программному обеспечению. Именно там,
в Женеве (Швейцария), он для собственных нужд написал программу «Энквайр» (англ. Enquire,
можно вольно перевести как «Дознаватель»), которая использовала случайные ассоциации для
хранения данных и заложила концептуальную основу для Всемирной паутины.
Развитие информационных технологий
В 1989 году, работая в CERN над внутренней сетью организации, Тим Бернерс-Ли предложил
глобальный гипертекстовый проект, теперь известный как «Всемирная паутина». Проект
подразумевал публикацию гипертекстовых документов, связанных между собой гиперссылками,
что облегчило бы поиск и консолидацию информации для учёных CERN. Для осуществления
проекта Тимом Бернерсом-Ли (совместно с его помощниками) были изобретены
идентификаторы URI, протокол HTTP и язык HTML. Это технологии, без которых уже нельзя себе
представить современный Интернет. В период с 1991 по 1993 год Бернерс-Ли усовершенствовал
технические спецификации этих стандартов и опубликовал их. Но, всё же, официально годом
рождения Всемирной паутины нужно считать 1989 год.
В рамках проекта Бернерс-Ли написал первый в мире веб-сервер, называвшийся «httpd», и первый
в мире гипертекстовый веб-браузер, называвшийся «WorldWideWeb». Этот браузер был
одновременно и WYSIWYG-редактором (сокр. от англ. what you see is what you get — что видишь,
то и получишь), его разработка была начата в октябре 1990 года, а закончена в декабре того же
года. Программа работала в среде NeXTStep и начала распространяться по Интернету летом 1991
года.
Майк Сендал (Mike Sendall) покупает в это время компьютер «NeXT cube» для того, чтобы понять,
в чём состоят особенности его архитектуры, и отдает его затем Тиму [Бернерс-Ли]. Благодаря
совершенству программной системы «NeXT cube» Тим написал прототип, иллюстрирующий
основные положения проекта, за несколько месяцев. Это был впечатляющий результат: прототип
предлагал пользователям, кроме прочего, такие развитые возможности, как WYSIWYG
browsing/authoring!… В течение одной из сессий совместных обсуждений проекта в кафетерии
ЦЕРНа мы с Тимом попытались подобрать «цепляющее» название (catching name) для
создаваемой системы. Единственное, на чём я настаивал, это чтобы название не было в очередной
раз извлечено все из той же греческой мифологии. Тим предложил «world wide web». Все в этом
названии мне сразу очень понравилось, только трудно произносится по-французски.
— Robert Cailliau, 2 ноября 1995[1]
Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа 1991 года на первом вебсервере доступном по адресуhttp://info.cern.ch/, (здесь архивная копия). Ресурс определял понятие
«Всемирной паутины», содержал инструкции по установке веб-сервера, использования браузера
и т. п. Этот сайт также являлся первым в мире интернет-каталогом, потому что позже Тим
Бернерс-Ли разместил и поддерживал там список ссылок на другие сайты.
Первая фотография во Всемирной паутине — группа Les Horribles Cernettes
На первой фотографии, появившейся во Всемирной паутине, была изображена пародийная филкгруппа Les Horribles Cernettes[2]. Тим Бернес-Ли попросил у лидера группы отсканированные
фотографии после музыкального фестиваля «CERN hardronic festival».
И всё же теоретические основы веба были заложены гораздо раньше Бернерса-Ли. Ещё в 1945
году Ваннавер Буш разработал концепциюMemex — вспомогательных механических средств
«расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои
книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое
выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и
дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование
текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации.
Следующим значительным шагом на пути ко Всемирной паутине было
создание гипертекста (термин введён Тедом Нельсоном в 1965 году).
С 1994 года основную работу по развитию Всемирной паутины взял на себя консорциум
Всемирной паутины (англ. world wide web consortium, три буквы «W» и «C», W3C), основанный и
до сих пор возглавляемый Тимом Бернерсом-Ли. Данный консорциум — организация,
разрабатывающая и внедряющая технологические стандарты для Интернета и Всемирной
паутины. Миссия W3C: «Полностью раскрыть потенциал Всемирной паутины путём создания
протоколов и принципов, гарантирующих долгосрочное развитие Сети». Две другие важнейшие
задачи консорциума — обеспечить полную «интернационализацию Сети» и сделать Сеть
доступной для людей с ограниченными возможностями.
W3C разрабатывает для Интернета единые принципы и стандарты (называемые
«рекомендациями», англ. W3C recommendations), которые затем внедряются производителями
программ и оборудования. Таким образом достигается совместимость между программными
продуктами и аппаратурой различных компаний, что делает Всемирную сеть более совершенной,
универсальной и удобной. Все рекомендации консорциума Всемирной паутины открыты, то есть
не защищены патентами и могут внедряться любым человеком без всяких финансовых отчислений
консорциуму.
Перспективы развития Всемирной паутины
В настоящее время наметились два направления в развитии Всемирной паутины: семантическая
паутина и социальная паутина.
Семантическая паутина предполагает улучшение связности и релевантности информации
во Всемирной паутине через введение новых форматов метаданных.
Социальная паутина полагается на пользователей, выполняющих упорядочивание
имеющейся в сети информации.
В рамках второго направления наработки, являющиеся частью семантической паутины, активно
используются в качестве инструментов (RSS и другие форматы веб-каналы, OPML,микроформаты
XHTML). Частично семантизированные участки дерева категорий «Википедии» помогают
пользователям осознанно перемещаться в информационном пространстве, однако, очень мягкие
требования к подкатегориям не дают основания надеяться на расширение таких участков. В связи
с этим интерес могут представлять попытки составления атласов Знания.
Существует также популярное понятие Web 2.0, обобщающее сразу несколько направлений
развития Всемирной паутины.
Способы активного отображения информации во Всемирной паутине
Представленная в сети информация может быть доступна:
только для чтения («пассивно»);
для чтения и добавления/изменения («активно»).
К способам активного отображения информации во Всемирной паутине относятся:
гостевые книги (англ. guestbook);
форумы (англ. forum);
чаты (англ. chat);
блоги (англ. blog);
wiki-проекты;
социальные сети (англ. social networking service);
системы управления контентом (англ. content management system, англ. CMS).
Следует отметить, что это деление весьма условно. Так, скажем, блог или гостевую книгу можно
рассматривать как частный случай форума, который, в свою очередь, является частным случаем
системы управления контентом. Обычно разница проявляется в назначении, подходе и
позиционировании того или иного продукта.
Отчасти информация с сайтов может также быть доступна через речь. В Индии уже
началось[3] тестирование системы, делающей текстовое содержимое страниц доступным даже для
людей, не умеющих читать и писать.
«World wide web» иногда иронично называют «Wild wild web» («дикий, дикий web») — по
аналогии с названием одноименного фильма «Wild wild west» (Дикий, дикий Запад, 1999,США)[4].
Безопасность
Для киберпреступников Всемирная паутина стала ключевым способом
распространения вредоносного программного обеспечения. Кроме того, под понятие сетевой
преступности подпадают кража личных данных, мошенничество, шпионаж и незаконный сбор
сведений о тех или иных субъектах или объектах[5]. Веб-уязвимости, по некоторым данным, в
настоящее время превосходят по количеству любые традиционные проявления
проблем компьютерной безопасности; по оценкам Google, примерно одна из десяти страниц во
Всемирной паутине может содержать вредоносный код[6][7][8]. По данным компании Sophos,
британского производителя антивирусных решений, большинство кибератак в веб-пространстве
совершается со стороны легитимных ресурсов, размещённых по преимуществу
в США, Китае и России[9]. Наиболее распространённым видом подобных нападений, по сведениям
от той же компании, является SQL-инъекция — злонамеренный ввод прямых запросов к базе
данных в текстовые поля на страницах ресурса, что при недостаточном уровне защищённости
может привести к раскрытию содержимого БД[10]. Другой распространённой угрозой,
использующей возможности HTML и уникальных идентификаторов ресурсов, для сайтов
Всемирной паутины является межсайтовое выполнение сценариев (XSS), которое стало
возможным с введением технологии JavaScript и набрало обороты в связи с развитием Web
2.0 и Ajax — новые стандарты веб-дизайна поощряли использование
интерактивных сценариев[11][12][13]. По оценкам 2008 года, до 70 % всех веб-сайтов в мире были
уязвимы для XSS-атак против их пользователей[14].
Предлагаемые решения соответствующих проблем существенно варьируются вплоть до полного
противоречия друг другу. Крупные поставщики защитных решений вроде McAfeeразрабатывают
продукты для оценки информационных систем на предмет их соответствия определённым
требованиям, другие игроки рынка (например, Finjan) рекомендуют проводить активное
исследование программного кода и вообще всего содержимого в режиме реального времени, вне
зависимости от источника данных[15][5]. Есть также мнения, согласно которым предприятия
должны воспринимать безопасность как удачную возможность для развития бизнеса, а не как
источник расходов; для этого на смену сотням компаний, обеспечивающих защиту
информации сегодня, должна прийти немногочисленная группа организаций, которая приводила
бы в исполнение инфраструктурную политику постоянного и повсеместного управления
цифровыми правами[16][17].
Конфиденциальность
Каждый раз, когда пользовательский компьютер запрашивает у сервера веб-страницу, сервер
определяет и, как правило, протоколирует IP-адрес, с которого поступил запрос. Аналогичным
образом большинство обозревателей Интернета записывают сведения о посещённых страницах,
которые затем можно просмотреть в журнале браузера, а такжекэшируют загруженное
содержимое для возможного повторного использования. Если при взаимодействии с сервером не
используется зашифрованное HTTPS-соединение, запросы и ответы на них передаются
через Интернет открытым текстом и могут быть считаны, записаны и просмотрены на
промежуточных узлах сети.
Когда веб-страница запрашивает, а пользователь предоставляет определённый объём личных
сведений, таких, к примеру, как имя и фамилия либо реальный или электронный адрес, поток
данных может быть деанонимизирован и ассоциирован с конкретным человеком. Если веб-сайт
использует файлы cookie, поддерживает аутентификацию пользователя или другие технологии
отслеживания активности посетителей, то между предыдущими и последующими визитами также
может быть установлена взаимосвязь. Таким образом, работающая во Всемирной паутине
организация имеет возможность создавать и пополнять профиль конкретного клиента,
пользующегося её сайтом (или сайтами). Такой профиль может включать, к примеру, информацию
о предпочитаемом отдыхе и развлечениях, потребительских интересах, роде занятий и
других демографических показателях. Такие профили представляют существенный интерес
для маркетологов, сотрудников рекламных агентств и других специалистов подобного рода. В
зависимости от условий обслуживания конкретных сервисов и местных законов такие профили
могут продаваться или передаваться третьим сторонам без ведома пользователя.
Раскрытию сведений способствуют также социальные сети, предлагающие участникам
самостоятельно изложить определённый объём личных данных о себе. Неосторожное обращение с
возможностями таких ресурсов может приводить к попаданию в открытый доступ сведений,
которые пользователь предпочел бы скрыть; помимо прочего, такая информация может
становиться предметом внимания хулиганов или, более того, киберпреступников. Современные
социальные сети предоставляют своим участникам довольно широкий спектр настроек
конфиденциальности профиля, однако эти настройки могут быть излишне сложны — в
особенности для неопытных пользователей[18].
Распространение
В период с 2005 по 2010 год количество веб-пользователей удвоилось и достигло отметки двух
миллиардов[19]. Согласно ранним исследованиям 1998 и 1999 годов, большинство существующих
веб-сайтов не индексировались корректно поисковыми системами, а сама веб-сеть оказалась
крупнее, чем ожидалось[20][21]. По данным на 2001 год было создано уже более 550 миллионов веб-
документов, большинство из которых однако находились в пределах невидимой сети[22]. По
данным на 2002 год было создано более 2 миллиардов веб-страниц[23], 56,4 % всего интернетсодержимого было на английском языке, после него шёл немецкий (7.7 %), французский (5.6 %)
и японский (4.9 %). Согласно исследованиям, проводимым в конце января 2005 года на 75 разных
языках было определено более 11,5 миллиардов веб-страниц, которые были индексированы в
открытой сети[24]. А по данным на март 2009 года, количество страниц увеличилось до 25.21
миллиардов[25]. 25 июля 2008 года инженеры программного обеспечения Google Джессе Альперт и
Ниссан Хайай объявили, что поисковик Google Search засёк более миллиарда уникальных URLссылок[26].
Памятник
В 2011 году в Санкт-Петербурге планировали установить памятник Всемирной паутине.
Композиция должна была представлять собой уличную скамейку в виде аббревиатуры
WWW с бесплатным доступом в Сеть[27].
Вопрос 8. Реализация сетевых протоколов и служб в OS Unix и Windows.
Современные вычислительные системы невозможно представить без наличия сетей. Технологии
взаимодействия между информационными системами развиваются с 70-х годов, не намного
опередив развитие UNIX. Операционная система UNIX почти с самого рождения интегрировала в
себя технологии локальных сетей, на её основе затем была построена сеть Internet,
распространившаяся ныне по всему миру.
Сеть в UNIX
Презентация 5-01: введение в сети
Введение в сети
Организация взаимодействия между устройствами и программами в сети является сложной
задачей. Сеть объединяет разное оборудование, различные операционные системы и программы –
это было бы невозможно без принятия общепринятых правил, стандартов.
В области компьютерных сетей существует множество международных и промышленных
стандартов, среди которых следует особенно выделить международный стандарт OSI и набор
стандартов IETF (Internet Engineering Task Force). Семиуровневая модель OSI
Презентация 5-02: взаимодействие открытых систем
В модели OSI, называемой также моделью взаимодействия открытых систем (Open Systems
Interconnection – OSI) и разработанной Международной Организацией по Стандартам (International
Organization for Standardization – ISO), средства сетевого взаимодействия делятся на семь уровней,
для которых определены стандартные названия и функции (см. Рисунок 4.1, «Уровни ISO OSI»).
Рисунок 4.1. Уровни ISO OSI Уровни ISO OSI
Каждый уровень предоставляет интерфейс к вышележащему уровню, скрывая детали реализации.
При построении транспортной подсистемы какого-либо приложения наибольший интерес
представляют функции физического, канального и сетевого уровней, тесно связанные с
используемым в данной сети оборудованием: сетевыми адаптерами, концентраторами, мостами,
коммутаторами, маршрутизаторами. Функции прикладного и сеансового уровней, а также уровня
представления реализуются операционными системами и системными приложениями конечных
узлов. Транспортный уровень выступает посредником между этими двумя группами протоколов.
Удалённые процессы при обмене информацией взаимодействуют только с самым верхним
уровнем, но данные при продвижения по сети проходят через все уровни на одной машине и затем
в обратном порядке на другой машине.
Рассмотрим подробнее назначения каждого из уровней: Физический уровень
Физический уровень выполняет передачу битов по физическим каналам, таким, как витая пара,
оптоволоконный кабель или радиоволны. На этом уровне определяются характеристики
физических сред передачи данных и параметров электрических сигналов. Канальный уровень
Канальный уровень обеспечивает передачу кадра данных между любыми узлами в сетях с типовой
топологией либо между двумя соседними узлами в сетях с произвольной топологией, отвечает за
установление соединения и корректность доставки данных по физическим каналам. В протоколах
канального уровня заложена определенная структура связей между компьютерами и способы их
адресации. Адреса, используемые на канальном уровне в локальных сетях, часто называют МАСадресами (Media Access Control, управление доступом к среде). Часть канального уровня требует
аппаратной реализации, в операционной системе он, как правило, представлен драйвером сетевой
карты. Сетевой уровень
Сетевой уровень в первую очередь должен предоставлять средства для решения следующих задач:
доставки пакетов в сети с произвольной топологией;
структуризации сети путем надежной локализации трафика;
согласования различных протоколов канального уровня.
Сетевой уровень позволяет передавать данные между любыми, произвольно связанными узлами
сети (при этом не берёт на себя никаких обязательств по надежности передачи данных). Это
достигается благодаря наличию адресации – каждый узел в сети имеет свой уникальный
идентификатор.
Реализация протокола сетевого уровня подразумевает наличие в сети специального устройства –
маршрутизатора. Маршрутизаторы объединяют отдельные сети в общую составную сеть. К
каждому маршрутизатору могут быть присоединены несколько сетей (по крайней мере две).
Транспортный уровень
Транспортный уровень обеспечивает передачу данных между любыми узлами сети с требуемым
уровнем надежности. Для этого на транспортном уровне имеются средства установления
соединения, нумерации, буферизации и упорядочивания пакетов. Сеансовый уровень
Сеансовый уровень предоставляет средства управления диалогом, позволяющие фиксировать,
какая из взаимодействующих сторон является активной в настоящий момент, а также
предоставляет средства синхронизации в рамках процедуры обмена сообщениями. Уровень
представления
В отличии от нижележащих уровней, которые имеют дело с надежной и эффективной передачей
битов от отправителя к получателю, уровень представления имеет дело с внешним
представлением данных. На этом уровне могут выполняться различные виды преобразования
данных, такие как компрессия и декомпрессия, шифровка и дешифровка данных. Прикладной
уровень
Прикладной уровень – это в сущности набор разнообразных сетевых сервисов, предоставляемых
конечным пользователям и приложениям. Примерами таких сервисов являются, например,
электронная почта, передача файлов, подключение удаленных терминалов к компьютеру по сети.
Существует несколько групп протоколов (называемые также «стеки протоколов»), которые
частично или полностью соответствуют уровням эталонной модели OSI. Для нас наибольший
интерес представляет набор протоколов TCP/IP. Протоколы Internet: TCP/IP
Презентация 5-03: протоколы Internet: TCP/IP
Протоколы TCP/IP (Transmission Control Protocol / Internet Protocol) были разработаны по заказу
Министерства обороны США 30 лет назад для связи экспериментальной сети ARPAnet и
представляет собой набор общих протоколов для разнородной вычислительной среды. Большой
вклад в развитие стека TCP/IP внёс университет Беркли, реализовав этот протокол для
операционнной системы UNIX. Популярность UNIX и удачные идеи, заложенные в TCP/IP,
привели к образованию и бурному развитию международной сети Internet. Все протоколы
семейства TCP/IP и связанные с ними проходят стандартизацию в организации IETF через выпуск
так называемых RFC (Request For Comment) документов.
Протоколы, входящие в TCP/IP частично соответствуют модели OSI (см. Рисунок 4.2,
«Соответствие стека TCP/IP модели OSI»). Стек TCP/IP поддерживает на нижнем уровне все
популярные стандарты физического и канального уровней: для локальных сетей – Ethernet, Token
Ring, FDDI, для глобальных – PPP, ISDN. Основными протоколами стека, давшими ему название,
являются протоколы IP и TCP, относящиеся соответственно к сетевому и транспортному уровню.
IP обеспечивает продвижение пакета по сети, TCP гарантирует надёжность его доставки.
За долгие годы использования стек TCP/IP обзавёлся множеством протоколов прикладного
уровня: FTP, SMTP, HTTP и т.п..
Рисунок 4.2. Соответствие стека TCP/IP модели OSI Соответствие стека TCP/IP модели OSI
Поскольку стек TCP/IP изначально создавался для глобальной сети, он имеет много особеностей,
дающих ему преимущество перед другими протоколами, когда речь заходит о глобальных связях.
Это способности фрагментации пакетов, гибкая система адресации, простота широковещательных
запросов.
Сегодня набор протоколов TCP/IP самый распространённый протокол вычислительных сетей, к
тому же он является наиболее «оригинальным» для UNIX-систем. Рассмотрим, как производится
администрирование этих протоколов в UNIX.
Сетевой интерфейс в UNIX
Презентация 5-04: сетевой интерфейс в UNIX
Основной сетевой подсистемы UNIX является сетевой интерфейс. Сетевой интерфейс – это
абстракция, используемая для представления связи канального уровня сети с протоколом TCP/IP в
UNIX.
Каждый сетевой интерфейс в системе имеет уникальное имя, сотстоящее из типа устройства и
номера (0 или больше для однотипных устройств). Под типами устройств в различных UNIXсистемах может пониматься вид протокола канального уровня (Ethenet – eth) или название
драйвера устройства (Realtek – rl).
Интерфейс имеет набор параметров, большинство которых относятся к сетевому уровню (IPадрес, маска сети и т.п.). Важным параметром сетевого интерфейса является аппаратный адрес (В
Ethernet аппаратный адрес называется MAC-адрес и состоит из шести байтов, которые принято
записывать в шестнадцатеричной системе исчисления и разделять двоеточиями).
Узнать параметры интерфейса можно с помощью команды ifconfig, указав в качестве аргумента
его имя:
Пример 4.1. Пример выполнения команды ifconfig
desktop ~ # ifconfig eth0
eth0
Link encap:Ethernet HWaddr 00:0D:60:8D:42:AA
inet addr:192.168.1.5 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:6160 errors:0 dropped:0 overruns:0 frame:0
TX packets:5327 errors:0 dropped:0 overruns:0 carrier:0
collisions:1006 txqueuelen:1000
RX bytes:3500059 (3.3 Mb) TX bytes:2901625 (2.7 Mb)
Base address:0x8000 Memory:c0220000-c0240000
desktop ~ # ifconfig lo
lo
Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:188 errors:0 dropped:0 overruns:0 frame:0
TX packets:188 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:14636 (14.2 Kb) TX bytes:14636 (14.2 Kb)
Создание сетевого интерфейса производится в момент загрузки драйвера сетевой карты или
создания логического соединения (например, в PPP). Настройка сетевых параметров, связанных с
интерфейсом производится той же командой ifconfig, о чем будет сказано далее.
Для диагностики трафика на канальном уровне применяется специальные программы. Самыми
распространёнными в UNIX являются tcpdump и ethereal. При «прослушивании» канала, эти
программы взаимодействуют с заданным сетевым интерфейсом.
Конфигурация IP-сетей
Сетевой адрес
Презентация 5-05: сетевой адрес
В IP-сетях каждому сетевому интерфейсу присваивается некоторый единственный на всю
глобальную сеть адрес, который не зависит от среды передачи данных и всегда имеет один и тот
же формат.
Адрес, определяемый протоколом IP, состоит из четырех байтов, записываемых традиционно в
десятичной системе счисления и разделяемых точкой. Адрес сетевого интерфейса eth0 из примера
– 192.168.1.5.
Второй сетевой интерфейс из примера, lo, – так называемая заглушка (loopback), которая
используется для организации сетевых взаимодействий компьютера с самим собой: любой
посланный в заглушку пакет немедленно обрабатывается как принятый оттуда. Заглушка обычно
имеет адрес 127.0.0.1.
Для установления связи между интерфейсом и IP-адресом необходимо выполнить команду:
desktop ~ # ifconfig eth0 192.168.1.1 up
Маршрутизация
Презентация 5-06: маршрутизация
Маска подсети позволяет определить все узлы, находящиеся в той же локальной сети. Пакеты к
ним будут доставляться напрямую через канальный уровень.
Более сложный вопрос встает, если IP-адрес компьютера-адресата не входит в локальную сеть
компьютера-отправителя. Ведь и в этом случае пакет необходимо отослать какому-то абоненту
локальной сети, с тем, чтобы тот перенаправил его дальше. Этот абонент, маршрутизатор,
подключен к нескольким сетям, и ему вменяется в обязанность пересылать пакеты между ними по
определенным правилам. В самом простом случае таких сетей две: «внутренняя», к которой
подключены компьютеры, и «внешняя», соединяющая маршрутизатор со всей глобальной сетью.
Таблицу, управляющую маршрутизацией пакетов, можно просмотреть с помощью команды netstat
-r или route (обе команды имеют ключ -n, заставляющий их использовать в выдаче IP-адреса, а не
имена компьютеров):
Пример 4.2. Пример выполнения команды route
desktop ~ # route -n
Kernel IP routing table
Destination
Gateway
192.168.1.0
0.0.0.0
127.0.0.0
0.0.0.0
0.0.0.0
192.168.1.1
Genmask
Flags Metric Ref
255.255.255.0 U
255.0.0.0
0.0.0.0
U
UG
Use Iface
0 eth0
0 lo
0 eth0
Компьютер или аппаратное устройство, осуществляющее маршрутизацию между локальной сетью
и Internet обычно называется шлюзом.
Задавать параметры маршрутизации можно с помощью той же команды route. Служебный
протокол ICMP
Презентация 5-07: протокол ICMP
Есть такие протоколы уровня IP, действие которых этим уровнем и ограничивается. Например,
служебный протокол ICMP (Internet Control Message Protocol), предназначенный для передачи
служебных сообщений.
Примером применения ICMP является утилита ping, которая позволяет проверить
работоспособность узлов в сети. Другое применение ICMP – сообщать отправителю, почему его
пакет невозможно доставить адресату, или передавать информацию об изменении маршрута, о
возможности фрагментации и т. п.
Протоколом ICMP пользуется утилита traceroute, позволяющая приблизительно определять
маршрут следования пакета:
Пример 4.3. Пример выполнения команды traceroute
desktop ~ # traceroute ya.ru
traceroute to ya.ru (213.180.204.8), 64 hops max, 40 byte packets
1 195.91.230.65 (195.91.230.65) 0.890 ms 1.907 ms 0.809 ms
2 cs7206.rinet.ru (195.54.192.28) 0.895 ms 0.769 ms 0.605 ms
3 ix2-m9.yandex.net (193.232.244.93) 1.855 ms 1.519 ms 2.95 ms
4 c3-vlan4.yandex.net (213.180.210.146) 3.412 ms 2.698 ms 2.654 ms
5 ya.ru (213.180.204.8) 2.336 ms 2.612 ms 3.482 ms
Утилита traceroute показывает список абонентов, через которых проходит пакет по пути к
адресату, и потраченное на это время. Однако список этот приблизительный. Строго говоря,
неизвестно, каким маршрутом шла очередная группа пакетов, потому что с тех пор, как
посылалась предыдущая группа, какой-нибудь из промежуточных маршрутизаторов мог
передумать и послать новые пакеты другим путем. Информация о соединениях
Презентация 5-08: сетевые соединения
Транспортных протоколов в TCP/IP два – это TCP (Transmission Control Protocol, протокол
управления соединением) и UDP (User Datagram Protocol). UDP устроен просто. Пользовательские
данные помещаются в единственный транспортный пакет-датаграмму, которой приписываются
обычные для транспортного уровня данные: адреса и порты отправителя и получателя, после чего
пакет уходит в сеть искать адресата. Проверять, был ли адресат способен этот пакет принять,
дошел ли пакет до него и не испортился ли по дороге, предоставляется следующему –
прикладному – уровню.
В UNIX существует прозрачный механизм именования сетевых протоколов. Согласно стандартам
Internet для большинства приложений существуют стандартные порты, на которых
соответствующие приложения должны принимать соединения. В файле /etc/services можно
увидеть список соответствия имён протоколов номерам портов. Благодаря этому файлу, в UNIX
можно во всех утилитах вместо номера порта писать имя соответвтвующего протокола.
Другое дело – TCP. Этот протокол очень заботится о том, чтобы передаваемые данные дошли до
адресата в целости и сохранности. Для этого предпринимаются следующие действия:
установление соеднинения;
обработка подтверждения корректной доставки;
отслеживание состояния абонентов.
Для просмотра всех существующих в настоящий момент сетевых соединений можно
воспользоваться командой netstat:
Пример 4.4. Пример выполнения команды netstat
desktop ~ # netstat -an
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address
Foreign Address
State
tcp
0 0.0.0.0:32769
0.0.0.0:*
LISTEN
tcp
0 0.0.0.0:32770
0.0.0.0:*
LISTEN
tcp
0 0.0.0.0:111
0.0.0.0:*
LISTEN
tcp
0 0.0.0.0:22
0.0.0.0:*
LISTEN
tcp
0 192.168.11.5:34949
83.149.196.70:5223
ESTABLISHED
tcp
0 192.168.11.5:39833
213.248.55.180:5223
ESTABLISHED
tcp
0 192.168.11.5:59577
192.168.11.1:22
udp
0 0.0.0.0:32768
0.0.0.0:*
udp
0 0.0.0.0:32769
0.0.0.0:*
udp
0 0.0.0.0:111
0.0.0.0:*
TIME_WAIT
Настройка сети при загрузке системы
Для того, чтобы каждый раз при загрузке не задавать сетевые параметры, существует возможность
задать настройки сети в конфигурационных файлах операционной системы. В этом случае при
старте системы будет произведена процедура настройки интерфейса, маршрутизации и т.п..
Такие файлы конфигурации являются специфичными для отдельно взятых версий UNIX. Примеры
будут рассмотрены на практическом занятии.
Сервисы Internet
Служба доменных имён
Презентация 5-09: служба доменных имён
В предыдущих примерах использовался ключ -n многих сетевых утилит, чтобы избежать
путаницы между IP-адресами и доменными именами компьютеров. С другой стороны, доменные
имена – несколько слов (часто осмысленных), запоминать гораздо удобнее, чем адреса (четыре
числа).
Когда-то имена всех компьютеров в сети, соответствующие IP-адресам, хранились в файле
/etc/hosts. Пока абоненты Internet были наперечет, поддерживать правильность его содержимого не
составляло труда. Как только сеть начала расширяться, неувязок стало больше. Трудность была не
только в том, что содержимое hosts быстро менялось, но и в том, что за соответствие имен адресам
в различных сетях отвечали разные люди и разные организации. Появилась необходимость
структурировать глобальную сеть не только топологически (с помощью IP и сетевых масок), но и
административно, с указанием, за какие группы адресов кто отвечает.
Проще всего было структурировать сами имена компьютеров. Вся сеть была поделена на домены
– зоны ответственности отдельных государств («us», «uk», «ru», «it» и т. п.) или независимые зоны
ответственности («com», «org», «net», «edu» и т. п.). Для каждого из таких доменов первого уровня
должно присутствовать подразделение, выдающее всем абонентам имена, заканчивающиеся на
«.домен» Подразделение обязано организовать и поддерживать службу, заменяющую файл hosts:
любой желающий имеет право узнать, какой IP-адрес соответствует имени компьютера в этом
домене или какому доменному имени соответствует определенный IP-адрес.
Такая служба называется DNS (Domain Name Service, служба доменных имен). Она имеет
иерархическую структуру. Если за какую-то группу абонентов домена отвечают не хозяева
домена, а кто-то другой, ему выделяется поддомен (или домен второго уровня), и он сам
распоряжается именами вида «имя_компьютера.поддомен.домен». Таким образом, получается
нечто вроде распределенной сетевой базы данных, хранящей короткие записи о соответствии
доменных имен IP-адресам.
В самом простом случае для того, чтобы сказать системе, какой сервер доменных имён
использовать, необходимо изменить файл /etc/resolv.conf. В более сложных системах можно
установить и настроить собственный сервер доменных имён.
Для проверки работы системы DNS используются утилиты dig и host.
Удалённый терминал
Презентация 5-10: удалённый терминал
Концепция терминала, описанная в главе «Терминал», может быть расширена на сеть.
Действительно, было бы удобно получить доступ к удалённой машине и работать с ней как за
обычными монитором и клавиатурой. Отпадает необходимость иметь аппаратный терминал к
каждому хосту, можно зайти терминалом на один хост, затем удаленным терминалом по сети на
любой другой хост. В современных условиях повсеместности сети Internet, удалённые терминалы
становятся основным рабочим инструментом администратора системы.
В сетях TCP/IP существует несколько приложений, позволяющих осуществить терминальный
заход. Рассмотрим два из них: telnet и ssh. Оба построены по единому клиент-серверному
принципу.
Telnet – стандартное приложение, которое присутствует практически в каждой реализации TCP/IP.
Оно может быть использовано для связи между хостами, работающими под управлением
различных операционных систем. Telnet использует согласование опций клиента и сервера, чтобы
определить, какие характеристики присутствуют с той и с другой стороны.
Клиент telnet взаимодействует и с пользователем, находящимся за терминалом, и с протоколами
TCP/IP. Обычно, все что пользователь вводит с клавиатуры отправляется по TCP соединению, а
все что приходит по соединению попадает на терминал.
Сервер telnet обычно взаимодействует с так называемыми псевдотерминальными устройствами в
UNIX системах. Это делает его похожим на командный интерпритатор (shell), который
запускается на сервере, или на любую программу, которая запускается из командной оболочки,
так как именно они общаются с терминальными устройствами. Некоторые приложения, например,
полноэкранные редакторы, считают, что они общаются с терминальным устройством.
Клиент telnet имеет еще одно полезное преминение. С его помощью можно тестировать
стандартные сетевые протоколы – если в качестве порта назначения назначить порт
соответствующего приложения. Telnet отправляет текстовые строки, разделённые знаками
переноса строки, что делает его совместимым со многими протоколами Internel (SMTP, HTTP и
т.п.).
Программа telnet обладает значительным недостатком – вся информация в ней (в том числе
аутентификация пользователей) производится открытым текстом. В современных условиях
глобальной сети это уже небезопасно. Решением этой проблемы является программа ssh, которая,
будучи аналогичной по функциональности программе telnet, устанавливает защищённое
соединение и предоставляет удалённый терминал с шифрацией всего промежуточного трафика.
В настоящее время для удалённого администрирования серверами в Internet применяется
исключительно команда ssh.
Прокси-серверы
Прокси-сервер – специальная служба, расположенная между локальной сетью и Internet, которая
обеспечивает доступ в Internet по протоколам HTTP, FTP и т.п. всем локальным компьютерам.
Такой сервер может поддерживать аутентификацию пользователей, учёт и фильтрацию трафика.
Недостатком такой схемы является то, что клиент в локальной сети должен явным образом
устанавливать соединение с прокси-сервером для запроса к удаленному хосту в Internet.
Межсетевой экран
Презентация 5-11: межсетевой экран iptables
В UNIX существует мощный механизм анализа сетевых и транспортных пакетов, позволяющий
избавляться от нежелательной сетевой активности, манипулировать потоками данных и даже
преобразовывать служебную информацию в них. Обычно такие средства носят название firewall
(«fire wall» – противопожарная стена, брандмауэр), общепринятый русский термин – межсетевой
экран.
В различных версиях UNIX функциональность и управление межсетевым экраном может
значительно отличаться. В данных лекциях будет рассматриваться приложение iptables, которое
используется для организации межсетевого экрана в Linux. Концепции iptables
Суть iptables в следующем. Обработка сетевого пакета системой представляется как его
конвейерная обработка. Пакет нужно получить из сетевого интерфейса или от системного
процесса, затем следует выяснить предполагаемый маршрут этого пакета, после чего отослать его
через сетевой интерфейс либо отдать какому-нибудь процессу, если пакет предназначался нашему
компьютеру. Налицо три конвейера обработки пакетов: «получить – маршрутизировать –
отослать» (действие маршрутизатора), «получить – маршрутизировать – отдать» (действие при
получении пакета процессом) и «взять – маршрутизировать – отослать» (действие при отсылке
пакета процессом).
Между каждыми из этих действий системы помещается модуль межсетевого экрана, именуемый
цепочкой. Цепочка обрабатывает пакет, исследуя, изменяя и даже, возможно, уничтожая его. Если
пакет уцелел, она передает его дальше по конвейеру. В этой стройной схеме есть два исключения.
Во-первых, ядро Linux дает доступ к исходящему пакету только после принятия решения о его
маршрутизации, поэтому связка «взять – маршрутизировать» остается необработанной, а цепочка,
обрабатывающая исходящие пакеты (она называется OUTPUT) вставляется после маршрутизации.
Во-вторых, ограничения на «чужие» пакеты, исходящие не от нас и не для нас предназначенные,
существенно отличаются от ограничений на пакеты «свои», поэтому после маршрутизации
транзитные пакеты обрабатываются еще одной цепочкой (она называется FORWARD). Цепочка,
обслуживающая связку «получить – маршрутизировать», называется PREROUTING, цепочка,
обслуживающая связку «маршрутизировать – отдать» – INPUT, а цепочка, стоящая
непосредственно перед отсылкой пакета – POSTROUTING (см. Рисунок 4.3, «Обработка пакета в
iptables»).
Рисунок 4.3. Обработка пакета в iptables Обработка пакета в iptables
Если пакет не имеет свойств, требуемых первым правилом, к нему применяется второе, если
второе также не подходит – третье, и так вплоть до последнего, правила по умолчанию, которое
применяется к любому пакету. Если свойства пакета удовлетворяют правилу, над ним
совершается действие. Действие DROP уничтожает пакет, а действие ACCEPT немедленно
выпускает его из таблицы, после чего пакет движется дальше по конвейеру. Некоторые действия,
например LOG, никак не влияют на судьбу пакета, после их выполнения он остается в таблице: к
нему применяется следующее правило, и т. д. до ACCEPT или DROP.
Одной из важных функций сетевого экрана является подмена адресов и модификация сетевых
пакетов. NAT (Network Address Translation – подмена сетевых адресов) – это механизм,
позволяющий организовать передачу пакетов между сетями, не имеющими сведений о сетевых
адресах друг друга. Этот процесс, чем-то схожий с маршрутизацией, позволяет организовывать
шлюзы локальных сетей в Internet, распределять внешние соединения на отдельные машины
внутри сети и т.п..
Следует помнить, что чем больше транспортных соединений отслеживается межсетевым экранам,
тем больше требуется оперативной памяти ядру Linux и тем медленнее работает процедура
сопоставления проходящих пакетов таблице. Впрочем, мощность современных компьютеров
позволяет без каких-либо затруднений обслуживать преобразование адресов для сети с
пропускной способностью 100Мбит/с и даже выше.
Таким образом, администратору возможны несколько функций воздействия на пакеты:
фильтрация, подмена адресов, изменение других параметров пакетов. Пример организации
межсетевого экрана будет рассмотрен на практическом занятии.
Резюме
Презентация 5-12: резюме
Сеть состоит из различных аппаратно-программных узлов, для объединения которых
используются стандартные протоколы. Эталонной моделью взаимодействия таких систем является
семиуровневая модель OSI.
Протокол TCP/IP частично реализует уровни OSI. Основные протоколы IP (сетевого уровня) и
TCP (транспортного уровня) позволили объединить разрозненные локальные сети в глобальную
сеть Internet.
В UNIX основной сетевого взаимодействия является интерфейс, который находится между
канальным и сетевым уровнем. Конфигурация TCP/IP включает в себя настройку интерфейса,
маршрутизации и сервисов Internet, в первую очередь сервера доменных имен.
Для удаленного управления компьютерами используется программа telnet и её современный
защищённый аналог – ssh.
Важным элементом сетевой инфраструктуры является межсетевой экран, который позволяет
ограничить сетевой трафик и изменить его свойства. На лекции был рассмотрен межсетевой экран
Linux – iptables.
Ключевые термины:OSI, физический уровень, канальный уровень, МАС-адрес, сетевой уровень,
маршрутизатор, транспортный уровень, сеансовый уровень, уровень представления, прикладной
уровень, сетевой интерфейс, IP-адрес, шлюз, служба доменных имен, удалённый терминал,
прокси-сервер, межсетевой экран, цепочка, NAT
Особенности реализации стека TCP/IP в ОС Windows NT
Так как большинство операционных систем поддерживают протоколы TCP/IP, они могут
использовать этот стек протоколов как средство взаимодействия. Используя TCP/IP, Windows NT
может общаться со многими операционными системами, включая
хосты сети Internet;
системы Apple Macintosh;
системы на базе Unix;
мэйнфреймы IBM;
компьютеры сетей DEC Pathworks;
принтеры с сетевыми адаптерами, непосредственно подключенные к сети.
9.1.1. Обзор стека TCP/IP
Transmission Control Protocol/Internet Protocol (TCP/IP) — это промышленный стандарт стека
протоколов, разработанный для глобальных сетей.
Стандарты TCP/IP опубликованы в серии документов, названных Request for Comment (RFC).
Документы RFC описывают внутреннюю работу сети Internet. Некоторые RFC описывают сетевые
сервисы или протоколы и их реализацию, в то время как другие обобщают условия применения.
Стандарты TCP/IP всегда публикуются в виде документов RFC, но не все RFC определяют
стандарты.
Реализация стека TCP/IP в ОС Windows NT дает следующие преимущества:
Это стандартный корпоративный сетевой протокол, который представляет собой наиболее
завершенный и популярный сетевой протокол. Все современные операционные системы
поддерживают TCP/IP, а почти все большие сети передают основную часть своего трафика
с помощью протокола TCP/IP.
Это метод получения доступа к сети Internet.
Это технология для соединения разнородных систем. Стек предоставляет многие
стандартные средства взаимодействия для доступа и передачи данных между
разнородными системами, включая протокол передачи файлов FTP и протокол эмуляции
терминала Telnet. Некоторые из этих стандартных средств включены в состав Windows
NT.
Это устойчивая масштабируемая межплатформенная среда для приложений клиентсервер.
Microsoft TCP/IP предлагает интерфейс Windows Sockets, который представляет собой
очень удобное средство для разработки приложений клиент-сервер. Эти приложения могут
работать на стеках других производителей с интерфейсом Windows Sockets. Приложения
для Windows Sockets могут также использоваться другими сетевыми протоколами такими
как Microsoft NWLink или NetBIOS.
Стек TCP/IP в среде Windows NT содержит:
Базовые протоколы — TCP, IP, UDP, ARP, ICMP.
Прикладные программные интерфейсы — Windows NT Sockets для сетевого
программирования, RPC — для взаимодействия между компьютерами, NetBIOS для
использования логических имен и сессий в сети, сетевую версию DDE для разделения
информации, встроенной в документы, по сети.
Сервисы прикладного уровня, включая Finger, FTP, RCP, REXEC, RSH, Telnet, TFTP. Эти
сервисы позволяют пользователям Windows NT Server использовать ресурсы компьютеров
с ОС, разработанными отличными от Microsoft компаниями, например, Unix.
Диагностические средства TCP/IP, включающие ARP, HOSTNAME, IPCONFIG,
NBTSTAT, NETSTAT, PING, ROUTE. Эти утилиты используются для обнаружения и
устранения сетевых проблем при работе со стеком TCP/IP.
SNMP — агент протокола TCP/IP. Эта компонента позволяет управлять компьютером
Windows NT по сети, используя такие средства, как Sun Net Manager или HP Open View.
9.1.2. Утилиты и сервисы TCP/IP в Windows NT
Windows NT Server включает дополнительные утилиты и сервисы TCP/IP:
DHCP — обеспечивает автоматическое конфигурирование параметров стека TCP/IP в средах
Windows NT Server, Windows NT Workstation, Windows for Workgroups и сетевых клиентов
производства компании Microsoft.
WINS — динамически регистрирует имена компьютеров и поддерживает их соответствие
IP-адресам.
LPDSVC — обеспечивает доступ к принтерам работающим в среде Unix.
Функция наблюдения для сервера FTP позволяет регистрировать все FTP-операции.
Кроме того, к Windows NT Server добавлен ряд дополнительных простых TCP/IP-протоколов, к
которым относятся:
ECHO — возвращает любые получаемые данные назад источнику.
DISCARD — отбрасывает любые получаемые данные.
CHARGER — это генератор символов, который отправляет данные, не обращая внимания на
получаемые данные. Хотя эти данные могут быть любыми, рекомендуется использовать
некоторые образцы.
QUOTE — отсылает короткую цитату дня. Эта цитата может извлекаться из
пользовательского файла цитат или из файла цитат, который поставляется вместе с данным
сервисом.
DAYTIME — отсылает текущее значение даты и времени в виде символьной строки, без
учета получаемых данных.
В качестве основного протокола сетевого уровня (в терминах модели OSI) в стеке используется
протокол IP, который изначально проектировался как протокол передачи пакетов в составных
сетях, состоящих из большого количества локальных сетей, объединенных как локальными, так и
глобальными связями. Поэтому стек TCP/IP хорошо работает в сетях со сложной топологией,
рационально используя наличие в них подсистем и экономно расходуя пропускную способность
низкоскоростных глобальных линий связи.
Основные функции протокола IP — маршрутизация пакетов, а также сборка и разборка пакетов.
Последняя функция необходима в том случае, когда пакеты формируются в одной сети и
передаются через другую сеть, максимальная длина пакета в которой меньше. Протокол IP
является датаграммным протоколом.
К этому же уровню относится и протокол межсетевых управляющих сообщений ICMP (Internet
Control Message Protocol). Этот протокол предназначен для обмена информацией об ошибках
между маршрутизатором или шлюзом, системой-источником и системой-приемником, то есть для
организации обратной связи. С помощью специальных пакетов ICMP сообщается о
невозможности доставки пакета, превышении времени жизни или продолжительности сборки
пакета из фрагментов, об аномальных величинах параметров, об изменении маршрута пересылки и
типа обслуживания, запросы-ответы о состоянии системы и т.п.
На более высоком уровне функционируют протокол управления передачей TCP (Transmission
Control Protocol) и протокол дейтаграмм пользователя UDP (User Datagram Protocol). Протокол
TCP обеспечивает устойчивое виртуальное соединение между удаленными прикладными
процессами. Протокол UDP обеспечивает передачу прикладных пакетов датаграммным методом,
то есть без установления виртуального соединения, и поэтому требует меньших накладных
расходов, чем TCP.
Самый верхний уровень стека TCP/IP называется прикладным. За долгие годы использования в
сетях различных стран и организаций стек TCP/IP накопил большое количество протоколов и
сервисов прикладного уровня. К ним относятся такие широко используемые протоколы, как
протокол пересылки файлов FTP, протокол эмуляции терминала telnet, почтовый протокол SMTP,
используемый в электронной почте сети Internet, гипертекстовые сервисы доступа к удаленной
информации, такие как WWW и многие другие.
Рис. 9.1. Стек протоколов Microsoft TCP/IP
Протокол SNMP (Simple Network Management Protocol) используется для организации сетевого
управления. Модель управления в семействе TCP/IP разделяет проблему управления на две части.
Первая часть связана с передачей информации. Протоколы передачи управляющей информации
определяют, как программа-клиент, работающая на хосте администратора, взаимодействует с
сервером. Они определяют формат и смысл сообщений, которыми обмениваются клиенты и
серверы, а также форматы имен и адресов. Вторая часть связана с контролируемыми данными.
Стандарты регламентируют, какие данные должны сохраняться и накапливаться в серверах, имена
этих данных и синтаксис этих имен. В стандарте SNMP определена спецификация
информационной базы данных управления сетью. Эта спецификация, известная как база
данных MIB (Management Information Base), определяет те элементы данных, которые хост или
шлюз должен сохранять, и допустимые операции над ними.
Протокол управления сетью SNMP определяет правила взаимодействия между программойклиентом системы управления сетью, с которой работает администратор, и программой-сервером,
собирающей информацию.
Протокол пересылки файлов FTP (File Transfer Protocol) реализует удаленный доступ к файлу. Он
может использоваться приложениями и пользователями для передачи файлов по сети. Для того,
чтобы обеспечить надежную передачу, FTP использует в качестве транспорта протокол с
установлением соединений — TCP. Однако, кроме пересылки файлов, протокол FTP предлагает и
другие услуги. Так, пользователю предоставляется возможность интерактивной работы с
удаленной машиной, например, он может распечатать содержимое ее каталогов. Кроме того, FTP
позволяет пользователю указывать тип и формат запоминаемых данных. Наконец, FTP выполняет
аутентификацию пользователей. Прежде, чем передать требуемый файл, в соответствии с
протоколом пользователи должны сообщить свое имя и пароль.
Хотя FTP является наиболее общим протоколом передачи файлов в стеке TCP/IP, он является и
самым сложным для программирования. Приложения, которым не требуются все возможности
FTP, могут использовать другой, более экономичный протокол — простейший протокол пересылки
файлов TFTP (Trivial File Transfer Protocol). Этот протокол реализует только передачу файлов,
причем в качестве транспорта используется более простой, чем TCP, протокол без установления
соединения — UDP.
Протокол telnet обеспечивает передачу потока байтов между процессами, а также между
процессом и терминалом. Наиболее часто этот протокол используется для эмуляции терминала
удаленной ЭВМ. Для обеспечения такой передачи в протоколе telnet терминалам предоставляется
широкий спектр средств обслуживания.
Протоколы канального, сетевого и транспортного уровней реализуются в Windows NT, как и в
большинстве других сетевых операционных систем, в виде драйверов. Протоколы прикладного
уровня стека TCP/IP реализованы в Windows NT в виде утилит, которые работают в режиме
командной строки (кроме утилиты telnet). Некоторые вспомогательные утилиты реализуют
протоколы или некоторые функции протоколов нижних уровней, таких как ICMP или ARP.
Имеются также утилиты, не реализующие коммуникационные протоколы, а отображающие
информацию о конфигурации стека TCP/IP или сессии TCP/IP.
Утилиты TCP/IP
PING — проверяет конфигурацию и тестирует соединения.
FTP — обеспечивает двунаправленную передачу файлов между компьютерами Windows NT
и хостами TCP/IP с использованием протокола UDP.
Telnet — обеспечивает эмуляцию терминала.
Remote Copy Protocol (RCP) — копирует файлы между компьютером Windows NT и Unixхостом.
Remote Shell (RSH) — запускает команды на удаленном Unix-хосте.
Remote Execution (REXEC) — запускает процесс на удаленном компьютере.
Finger — получает системную информацию от удаленного компьютера, который
поддерживает сервис Finger.
ARP — показывает содержимое локального кэша, в котором хранится информация о
соответствии IP-адресов МАС-адресам.
IPCONFIG — отображает текущую конфигурацию стека TCP/IP.
NBTSTAT — показывает список имен компьютеров протокола NetBIOS, которые
отображены на IP-адреса.
NETSTAT — показывает информацию о сессии TCP/IP.
ROUTE — отображает или модифицирует таблицу маршрутизации.
HOSTNAME — возвращает имя компьютера, на котором выполняется эта команда.
9.2. Инсталляция и конфигурирование стека TCP/IP
Для использования стека TCP/IP в среде Windows NT Server необходимо сконфигурировать три
параметра :
IP-адрес (IP-address) — 32-битовый логический адрес, который идентифицирует TCP/IP-хост
маска подсети (subnet mask) — используется для выделения части IP-адреса,
соответствующей номеру сети. Когда хост хочет взаимодействовать с другим хостом, то
маска подсети используется для того, чтобы определить, принадлежит ли другой хост
данной сети или удаленной.
маршрутизатор по умолчанию (default gateway) — для взаимодействия с хостом,
принадлежащим другой сети, необходимо указать IP-адрес маршрутизатора, с помощью
которого можно достичь указанной сети. Если конкретный маршрут к указанной сети не
известен, то используется маршрутизатор по умолчанию. Если маршрутизатор по
умолчанию не задан, то взаимодействие ограничивается только локальной сетью.
Пользователь может добавить статические маршруты с помощью утилиты route, чтобы
определить маршрут к конкретной системе. Статические маршруты всегда имеют
приоритет перед маршрутами по умолчанию. Для надежности можно определить
несколько маршрутизаторов по умолчанию.
Ручное конфигурирование этих параметров необходимо только в том случае, если для этих целей
не используется сервер DHCP, описанный в разделе
Тестирование стека TCP/IP с помощью утилиты Ping
Ping (Packet Internet Gropper) — это диагностическое средство, используемое для тестирования
конфигурации сети TCP/IP и диагностики ошибок соединения. Ping использует сообщения echo
request и echo reply протокола ICMP, для того чтобы определить, доступен ли хост с определенным
адресом и работоспособен ли он. Если Ping завершается успешно, то он выдает следующее
сообщение:
Reply from IP_address
Для проверки корректности конфигурации вашего компьютера и тестирования соединения с
маршрутизатором необходимо выполнить следующие действия.
1. Выполните команду Ping с адресом обратной связи для того, чтобы проверить, что стек
TCP/IP установлен правильно:
2. ping 127.0.0.1
3. Выполните команду Ping с IP-адресом вашего компьютера для проверки возможного
дублирования IP-адресов:
4. ping IP-адрес вашего компьютера
5. Выполните команду Ping с IP-адресом маршрутизатора по умолчанию:
6. ping IP-адрес маршрутизатора по умолчанию
7. Выполните команду Ping с IP-адресом удаленного хоста, чтобы проверить, что вы можете
осуществлять взаимодействие через маршрутизатор:
8. ping IP-адрес вашего хоста
9.3. Использование службы DHCP для автоматической конфигурации сети
Назначение IP-адресов представляет для администратора утомительную процедуру. Ситуация
усложняется еще тем, что многие пользователи не обладают достаточными знаниями для того,
чтобы конфигурировать свои компьютеры для работы в интерсети и должны поэтому полагаться
на администраторов. Протокол Dynamic Host Configuration Protocol (DHCP) был разработан для
того, чтобы освободить администратора от этих проблем. DHCP обеспечивает надежный и
простой способ конфигурации сети TCP/IP, гарантируя отсутствие конфликтов адресов за счет
централизованного управления их распределением. DHCP динамически распределяет IP-адреса
для компьютеров. Администратор управляет процессом назначения адресов с помощью параметра
«продолжительности аренды» (lease duration), которая определяет, как долго компьютер может
использовать назначенный IP-адрес, перед тем как снова запросить его от сервера DHCP в аренду.
Примером работы протокола DHCP может служить ситуация, когда компьютер, являющийся
клиентом DHCP, удаляется из подсети. При этом назначенный ему IP-адрес автоматически
освобождается. Когда компьютер подключается к другой подсети, то ему автоматически
назначается новый адрес. Ни пользователь, ни сетевой администратор не вмешиваются в этот
процесс. Это свойство очень важно для мобильных пользователей.
Протокол DHCP использует модель клиент-сервер (рисунок 9.2). Во время старта системы
(состояние «инициализация») компьютер-клиент DHCP посылает сообщение discover
(исследовать), которое широковещательно распространяется по локальной сети и передается всем
DHCP-серверам частной интерсети. Каждый DHCP-сервер, получивший это сообщение, отвечает
на него сообщением offer (предложение), содержащее IP-адрес и конфигурационную информацию.
Рис. 9.2. Клиенты сервиса DHCP
Компьютер-клиент DHCP переходит в состояние «выбор» и собирает конфигурационные
предложения от DHCP-серверов. Затем он выбирает одно из этих предложений, переходит в
состояние «запрос» и отправляет сообщение request (запрос) тому DHCP-серверу, чье предложение
было выбрано.
Выбранный DHCP-сервер посылает сообщение DHCP-acknowledgment (подтверждение), которое
содержит IP-адрес, который уже был послан ранее на стадии исследования, а также параметр
аренды для этого адреса. Кроме того, DHCP-сервер посылает параметры сетевой конфигурации.
После того, как клиент получит это подтверждение, он переходит в состояние «связь», находясь в
котором он может принимать участие в работе сети TCP/IP. Компьютеры-клиенты, которые имеют
локальные диски, сохраняют полученный адрес для использования при последующих стартах
системы. При приближении момента истечения срока аренды адреса компьютер пытается
обновить параметры аренды у DHCP-сервера, а если этот IP-адрес не может быть выделен снова,
то ему возвращается другой IP-адрес.
Серверы DHCP управляются централизованно с помощью утилиты DHCP Manager.
Для того, чтобы клиентский компьютер получал параметры стека от сервера DHCP, необходимо в
параметрах стека TCP/IP отметить опцию «Obtain an IP address from DHCP server».
После перезагрузки компьютер получит IP-адрес от сервера DHCP.
9.4. Многопротокольная маршрутизация
Многопротокольная маршрутизация в Windows NT Server реализуется маршрутизатором MPR.
Этот маршрутизатор выполняет динамическую маршрутизацию по протоколам IP и IPX с
использованием протокола обмена маршрутной информацией RIP.
Маршрутизатор MPR включен в состав дистрибутива систем Windows NT Server и Windows NT
Workstation 4.0.
На сервере www.microsoft.com находится также более мощный вариант маршрутизатора
SteelHead, который наряду с RIP поддерживает также и OSPF.
9.5. Использование служб имен DNS и WINS в сетях Windows NT
9.5.1. Способы разрешения имен в сетях Windows
Конфигурирование стека TCP/IP в среде Windows NT связано с назначением IP-адреса и имени
компьютера, которые уникально идентифицируют каждый компьютер в сети. Для сети TCP/IP и
сети Internet используется составное имя компьютера — это глобально известное системное имя
плюс имя домена DNS. (В локальной сети Microsoft имя компьютера — это имя в стиле протокола
NetBIOS, которое было определено во время инсталляции Windows NT.)
Для идентификации друг друга компьютеры используют IP-адреса, но пользователи обычно
предпочитают работать с именами компьютеров. Следовательно, в сети TCP/IP должен быть
предусмотрен механизм для установления соответствия между именами и IP-адресами. Для того,
чтобы обеспечить уникальность как имени, так и адреса, компьютер Windows NT, использующий
TCP/IP, регистрирует свое имя и IP-адрес во время старта системы. Компьютер Windows NT
может использовать один или несколько из следующих методов для того, чтобы обеспечить
корректное разрешение имен в интерсетях TCP/IP.
Windows Internet Name Service (WINS)
Компьютеры Windows NT могут использовать сервис WINS, если в сети имеется один или
несколько серверов WINS, которые содержат динамическую базу данных, отображающую имена
компьютеров на IP-адреса. WINS может использоваться в сочетании с широковещательным
разрешением имен для интерсети, в которой другие методы разрешения имен не работают. Как
описывается в следующем разделе, WINS — режим работы NetBIOS поверх TCP/IP, определенный
в RFC 1001/1002 как режим p-node.
Широковещательное разрешение имен
Компьютеры Windows NT могут также использовать широковещательное разрешение имен,
которое представляет собой режим работы NetBIOS поверх TCP/IP, определенный в RFC
1001/1002 как режим b-node. Этот метод основан на том, что компьютер посылает
широковещательные сообщения IP-уровня для регистрации своего имени в сети. Каждый
компьютер этой широковещательной области следит за тем, чтобы регистрируемое имя не
дублировалось. Все они также отвечают на запросы о собственных именах.
Разрешение имен с помощью DNS
В Windows NT 4.0 реализован клиент службы DNS (Domain Name System). Служба DNS
обеспечивает способ просмотра отображения имен при подключения компьютеров к посторонним
(не Windows NT) хостам, в которых работают DNS-серверы. Эта служба предназначена для тех
случаев, когда подключение осуществляется путем использования NetBIOS поверх TCP/IP или для
приложений, использующих интерфейс Windows Sockets, таких как FTP. DNS — это
распределенная база данных, разработанная для решения задач направления трафика, которые
возникли во время быстрого роста сети Internet в начале 80-х годов.
Файл LMHOSTS, в котором задается соответствие имен протокола NetBIOS и IP-адресов,
или использование файла HOSTS, в котором задается соответствие DNS-имен и IPадресов.
Файл HOSTS используется приложениями, работающим с интерфейсом Windows Sockets, а файл
LMHOSTS используется приложениями, работающими с интерфейсом NetBIOS поверх TCP/IP.
Файл LMHOSTS используется обычно для разрешения имен в сетях небольшого масштаба, где
служба WINS не установлена.
9.5.2. Разрешение имен в протоколе NetBIOS поверх TCP/IP
NetBIOS поверх TCP/IP — это сетевой сервис сессионного уровня, который выполняет отображение
имен в IP-адреса.
Режимы работы NetBIOS поверх TCP/IP определяют способ идентификации сетевых ресурсов и
доступа к ним. Имеется два аспекта функционирования этого механизма: регистрация- фиксация
уникального имени для каждого компьютера сети и разрешение — получение адреса по имени.
В протоколе NetBIOS поверх TCP/IP используются следующие режимы:
b-node, при котором для разрешения имен используются широковещательные сообщения;
p-node, при котором для разрешения имен используется взаимодействие типа точка-точка с
сервером имен WINS, который представляет собой улучшенный вариант сервера NetBIOS
Name Server (NBNS);
m-node, при котором сначала используется режим b-node, а затем p-node, если
широковещательный запрос не смог разрешить имя;
h-node, при котором сначала используется режим p-node, а затем b-node, если сервер имен
недоступен или в его базе данных отсутствует запрашиваемое имя.
В сети Windows NT пользователям сервиса DHCP тип режима разрешения имени назначается
сервером DHCP. Если в сети имеются серверы WINS, то протокол NetBIOS поверх TCP/IP
разрешает имена путем взаимодействия с сервером WINS. Когда серверы WINS отсутствуют,
протокол NetBIOS поверх TCP/IP использует для разрешения имен широковещательный режим b-
node. Протокол NetBIOS поверх TCP/IP в среде Windows NT может также использовать файлы
LMHOSTS и службу DNS для разрешения имен в зависимости от того, как сконфигурирован стек
TCP/IP на конкретном компьютере. В Windows NT 3.5 модуль NETBT.SYS обеспечивает работу
протокола NetBIOS поверх TCP/IP, при этом поддерживаются все перечисленные выше режимы.
Сервер DHCP в Windows NT Server позволяет гибко управлять назначением IP-адресов,
комбинируя для одной и той же подсети диапазоны динамически и статически выделяемых
адресов. Сервер RAS также может быть клиентом сервиса DHCP, получая от него IP-адреса для
удаленных компьютеров.
Кроме IP-адреса сервер DHCP может также передать своему клиенту и другую информацию,
необходимую для корректной работы стека TCP/IP:
IP-адрес серверов WINS
IP-адрес серверов DNS
IP-адрес маршрутизатора по умолчанию
имя домена DNS, которое нужно добавлять к плоскому имени компьютера
Для того, чтобы запросы и ответы протокола DHCP нормально циркулировали между серверами и
клиентами DHCP, разделенными маршрутизаторами, эти маршрутизаторы должны поддерживать
спецификацию RFC 1542. Программный маршрутизатор MPR, работающий в составе стека TCP/IP
Windows NT Server, поддерживает спецификацию RFC 1542 (DHCP/BOOTP relay agent).
9.5.3. Служба имен WINS
WINS представляет собой распределенную базу данных, предназначенную для регистрации и
динамического отображения имен компьютеров в IP-адреса в маршрутизируемой сетевой среде.
Служба WINS уменьшает интенсивность локальных широковещательных сообщений, связанных с
разрешением имен, и позволяет пользователям легко обнаруживать нужный компьютер в
удаленных сетях. Кроме того, когда служба DHCP динамически изменяет адрес компьютера, то
эти изменения автоматически переносятся в базу данных WINS. Ни пользователь, ни сетевой
администратор не принимают никакого участия в этом процессе.
Служба WINS состоит из двух компонент: сервера WINS, который обрабатывает запросы о
именах и регистрирует их, и клиентской части, которая посылает запросы на разрешение имен
(рисунок 9.3).
Сетевые клиенты Windows (Windows NT или Windows for Workgroups) могут использовать службу
WINS непосредственно. Компьютеры, не поддерживающие службу WINS, но использующие
широковещательный режим b-node, могут получать доступ к службе WINS через посредников.
Эти посредники представляют собой поддерживающие службу WINS компьютеры, которые
воспринимают широковещательные запросы на разрешение имен, а затем отвечают на имена,
которые не принадлежат локальной подсети или принадлежат компьютерам, поддерживающим
только режим p-node.
Рис. 9.3. Взаимодействие клиента и сервера WINS
В сети Windows NT пользователи могут осуществлять прозрачный просмотр сети через
маршрутизаторы. Для того, чтобы обеспечить просмотр в отсутствие серверов WINS, сетевой
администратор должен сделать так, чтобы первичный домен имел Windows NT Server или
Windows NT Workstation с обеих сторон маршрутизатора, которые бы действовали как главные
просмоторщики (Master browsers). В этих компьютерах необходимо правильно сконфигурировать
файлы LMHOSTS, в которых должны быть записи о просмоторщике в других подсетях.
При наличии серверов WINS такая стратегия не является необходимой, так как серверы WINS и
компьютерыпосредники обеспечивают прозрачность, необходимую для просмотра ресурсов через
маршрутизаторы (когда домен включает маршрутизаторы).
На рисунке 9.4 изображена небольшая интерсеть, состоящая из трех локальных сетей,
соединенных двумя маршрутизаторами.
Две из этих подсетей содержат серверы WINS, которые могут использоваться клиентами обеих
подсетей. Поддерживающие службу WINS компьютеры, включая посредников, непосредственно
обращаются к серверу WINS, а компьютеры, использующие широковещательный сервис,
обращаются к серверу WINS через посредников. Посредники только передают пакеты с запросами
имен и проверяют, что регистрируемое имя не дублируется в базе данных WINS. Однако,
посредники не регистрируют компьютеры типа b-node в базе данных WINS.
Рис. 9.4. Клиенты сервиса WINS
Компьютер-посредник взаимодействует с сервером WINS для разрешения имен (а не
поддерживает собственную базу данных), а затем кэширует имена на определенное время.
Посредник действует как промежуточный элемент, взаимодействуя либо с сервером WINS, либо
поставляя отображение имя — IP-адрес из своего кэша. Рисунок 9.4 иллюстрирует
взаимоотношения между сервером WINS и клиентами, основанные на использовании
компьютеров-посредников для клиентов, не поддерживающих службу WINS.
Как показано на рисунке, компьютер ClientA устанавливает соответствие символьных имен IPадресам, для этого он сначала запрашивает серверы WINS, а если эта попытка оказывается
неудачной, то он использует широковещательные запросы. Компьютер ClientB, который не
поддерживает службу WINS, может использовать для разрешения имен только
широковещательные запросы. Когда компьютер ClientC получает такой запрос, то он передает его
в соответствующей форме серверу WINS, а затем возвращает полученный адрес компьютеру
ClientB.
При разрешении имен в сложных сетях возникают дополнительные проблемы. Например, если
интерсеть состоит из двух подсетей, причем все компьютеры, относящиеся к домену А,
присоединены к подсети 1, все компьютеры домена В — присоединены к подсети 2, а компьютеры
домена С присоединены частично к одной, частично к другой подсети. В этом случае при
отсутствии службы WINS компьютеры домена А могут просматривать подсеть 1, компьютеры
домена В могут просматривать подсеть 2, а компьютеры домена С могут просматривать обе
подсети до тех пор, пока имеется первичный контроллер домена для домена С. При наличии
службы WINS компьютеры всех доменов могут просматривать все подсети, если их серверы
WINS разделяют свои базы данных.
Если клиентский компьютер Windows NT поддерживает протокол DHCP и администратор
установил сервер WINS, как часть этого протокола, то компьютер автоматически
конфигурируется с базой данных WINS. Если компьютер не поддерживает DHCP, то адреса для
службы WINS нужно задавать посредством диалогового окна «TCP/IP Configuration». Если вы
хотите, чтобы компьютер работал как посредник протокола WINS, то нужно установить опцию
enable WINS Proxy Agent в окне диалога «Advanced Microsoft TCP/IP Configuration».
Если в интерсети имеются серверы WINS, то при разрешении имен используется два основных
метода, в зависимости от того, поддерживается или нет протокол WINS на каждом отдельном
компьютере. Независимо от того, какой метод разрешения используется, этот процесс прозрачен
для пользователя после конфигурирования системы.
Протокол WINS не поддерживается. Компьютер регистрирует свое имя путем
широковещательной рассылки пакетов name registration request (запрос регистрации имени) по
локальной подсети с помощью дейтаграмм протокола UDP. Для того, чтобы найти адрес
конкретного компьютера, компьютер, не поддерживающий протокол WINS, широковещательно
распространяет пакеты name query request (запрос разрешения имени) по локальной подсети, эти
пакеты не передаются через IP-маршрутизаторы. Если на этот запрос не приходит ответ, то
используются данные из файла LMHOSTS. Описанный процесс происходит независимо от того,
является ли данный компьютер сервером или рабочей станцией.
Протокол WINS поддерживается. В этом случае компьютер выполняет следующие действия:
1. Во время конфигурации стека TCP/IP имя компьютера регистрируется в сервере WINS, а
IP-адрес сервера WINS хранится локально, так что сервер WINS может быть найден в
интерсети. База данных WINS реплицируется между всеми серверами WINS интерсети.
2. Запросы разрешения имени посылаются сначала на сервер WINS, включая запросы от
удаленных клиентов, которые в этом случае маршрутизируются через IP-маршрутизатор.
Эти запросы представляют собой направленные дейтаграммы UDP. Если имя содержится в
базе данных WINS, то в ответ возвращается IP-адрес.
3. Если имя не найдено в базе данных WINS, а клиентский компьютер сконфигурирован как
h-node, то он использует широковещательные пакеты name query request тем же способом,
что и компьютер, не поддерживающий службу WINS.
4. Наконец, если все предыдущие методы не привели к успеху, просматривается файл
LMHOSTS.
Сервис WINS интегрируется со службой DHCP. Если компьютер одновременно является клиентом
DHCP и WINS, то при получении IP-адреса от сервера DHCP соответствие имени компьютера его
новому IP-адресу автоматически регистрируется в сервере WINS.
9.5.4. Служба DNS
DNS (Domain Name System) — это распределенная база данных, поддерживающая иерархическую
систему имен для идентификации хостов в сети Internet. Спецификация DNS определяется
стандартами RFC 1034 и 1035. Хотя служба DNS на первый взгляд может показаться похожей на
службу WINS, между ними есть существенное различие. DNS требует статической конфигурации
для отображения имени компьютера в IP-адрес, а WINS работает в динамическом режиме и
требует гораздо меньше административных усилий.
База данных DNS имеет структуру дерева, называемого доменным пространством имен, в котором
каждый домен (узел дерева) имеет имя и может содержать поддомены. Имя домена
идентифицирует его положение в этой базе данных по отношению к родительскому домену,
причем точки в имени отделяют части, соответствующие узлам домена.
Корень базы данных DNS управляется центром Internet Network Information Center. Домены
верхнего уровня назначаются для каждой страны, а также на организационной основе. Имена этих
доменов должны следовать международному стандарту ISO 3166. Для обозначения стран
используются трехбуквенные и двухбуквенные аббревиатуры, а для различных типов организаций
используются следующие аббревиатуры:
com — коммерческие организации (например, microsoft.com);
edu — образовательные (например, mit.edu);
gov — правительственные организации (например, nsf.gov);
org — некоммерческие организации (например, fidonet.org);
net — организации, поддерживающие части сети Internet (например, nsf.net).
Каждый домен DNS администрируется отдельной организацией, которая обычно разбивает свой
домен на поддомены и передает функции администрирования этих поддоменов другим
организациям. Каждый домен имеет уникальное имя, а каждый из поддоменов имеет уникальное
имя внутри своего домена. Имя домена может содержать до 63 символов. Каждый хост в сети
Internet однозначно определяется своимполным доменным именем (fully qualified domain name,
FQDN), которое включает имена всех доменов по направлению от хоста к корню. Пример полного
имени DNS:
citint.dol.ru.
Служба DNS использует модель клиент-сервер, в соответствии с которой серверы DNS хранят
часть распределенной базы данных DNS и предоставляют эту информацию клиентам (resolver’s),
которые обращаются по сети с запросами о разрешении имен к серверам DNS. Серверы имен DNS
— это программы, которые хранят информацию о частях доменного пространства, называемых
зонами. Начиная с версии 4.0 Windows NT Server включает сервер DNS, который полностью
соответствует спецификациям Internet. В Windows NT Server 4.0 сервер DNS интегрирован с WINS
и снабжен графической утилитой администрирования.
Windows NT Workstation включает клиентскую часть DNS, которая используется приложениями
через интерфейсы NetBIOS поверх TCP/IP или Windows Sockets.
Если локальный сервер имен не хранит адрес запрашиваемого имени, то он возвращает клиенту
имена и адреса других серверов имен, которые могут знать эту информацию. Затем клиент
опрашивает эти серверы имен, пока не найдет нужные отображения. Этот процесс ускоряется изза того, что серверы имен постоянно кэшируют информацию, предоставляемую по запросам. Все
программное обеспечение клиента DNS инсталлируется одновременно со стеком Microsoft TCP/IP
и активизируется опцией в окне диалога конфигурации DNS. Приложения, использующие
интерфейс Windows Sockets на компьютерах Windows NT Server 3.5, Windows NT Workstation 3.5
или Windows for Workgroups 3.11 с установленным стеком TCP/IP-32, могут пользоваться для
разрешения имен либо службой DNS, либо сервисами протокола Net-BIOS поверх TCP/IP.
9.5.5. Интеграция WINS и DNS
Domain Name System (DNS) служит для разрешения IP-адреса по имени хоста и в традиционной
реализации требует указывать статическое соответствие между именем хоста и его адресом.
Структура зоны DNS обновляется всякий раз при добавлении нового хоста или перемещении его в
другую подсеть. Так как DNS не динамичен, кто-то должен вручную делать изменения в базе DNS
для отражения в ней происшедших перемен. Это сильно осложняет жизнь администраторов,
особенно управляющих зонами с часто выполняемыми модификациями.
Стандарта на динамический вариант DNS, который мог бы принимать изменения в соответствии
между именами и IP-адресами, пока нет — в настоящее время IETF его разрабатывает.
В Windows NT Server 4.0 реализовано временное решение об интеграции трех служб — DHCP,
WINS и DNS. Так как WINS динамически отслеживает изменения, которые выполняет DHCP, то
решено было несколько модифицировать службу DNS. Сервер DNS в Windows NT Server 4.0
может использовать для поиска имен, которые он не нашел в своей собственной базе данных,
серверы WINS. Для этого у сервера DNS имеется опция «Use WINS Resolution», с помощью
которой указываются IP-адреса серверов WINS, имеющихся в сети.
Для того, чтобы тройка DHCP-WINS-DNS работала корректно, необходимо использовать имена
NetBIOS, которыми именуются компьютеры Windows NT и Windows 95, в качестве младшей
компоненты составного имени DNS. Сервер DNS должен быть сконфигурирован так, чтобы он
самостоятельно выполнял разрешение только старшей части имени, а за разрешением младшей
обращался к серверу WINS.
Вопрос 9. Информационная безопасность в сетях.
Способы обеспечения информационной безопасности
Существует два подхода к проблеме обеспечения безопасности компьютерных систем и сетей
(КС): «фрагментарный» и комплексный.
«Фрагментарный» подход направлен на противодействие четко определенным угрозам в
заданных условиях. В качестве примеров реализации такого подхода можно указать отдельные
средства управления доступом, автономные средства шифрования, специализированные
антивирусные программы и т. п.
Достоинством такого подхода является высокая избирательность к конкретной угрозе.
Существенный недостаток — отсутствие единой защищенной среды обработки информации.
Фрагментарные меры защиты информации обеспечивают защиту конкретных объектов КС только
от конкретной угрозы. Даже небольшое видоизменение угрозы ведет к потере эффективности
защиты.
Комплексный подход ориентирован на создание защищенной среды обработки информации в КС,
объединяющей в единый комплекс разнородные меры противодействия угрозам. Организация
защищенной среды обработки информации позволяет гарантировать определенный уровень
безопасности КС, что является несомненным достоинством комплексного подхода. К недостаткам
этого подхода относятся: ограничения на свободу действий пользователей КС, чувствительность к
ошибкам установки и настройки средств защиты, сложность управления.
Комплексный подход применяют для защиты КС крупных организаций или небольших КС,
выполняющих ответственные задачи или обрабатывающих особо важную информацию.
Нарушение безопасности информации в КС крупных организаций может нанести огромный
материальный ущерб как самим организациям, так и их клиентам. Поэтому такие организации
вынуждены уделять особое внимание гарантиям безопасности и реализовы-вать комплексную
защиту. Комплексного подхода придерживаются большинство государственных и крупных
коммерческих предприятий и учреждений. Этот подход нашел свое отражение в различных
стандартах.
Комплексный подход к проблеме обеспечения безопасности основан на разработанной для
конкретной КС политике безопасности. Политика безопасности регламентирует эффективную
работу средств защиты КС. Она охватывает все особенности процесса обработки информации,
определяя поведение системы в различных ситуациях. Надежная система безопасности сети не
может быть создана без эффективной политики сетевой безопасности. Политики безопасности
подробно рассматриваются в гл. 3.
Для защиты интересов субъектов информационных отношений необходимо сочетать меры
следующих уровней:
• законодательного (стандарты, законы, нормативные акты и т. п.);
• административно-организационного (действия общего характера, предпринимаемые
руководством организации, и конкретные меры безопасности, имеющие дело с людьми);
• программно-технического (конкретные технические меры). Меры законодательного уровня
очень важны для обеспечения
информационной безопасности. К этому уровню относится комплекс мер, направленных на
создание и поддержание в обществе негативного (в том числе карательного) отношения к
нарушениям и нарушителям информационной безопасности.
Информационная безопасность — это новая область деятельности, здесь важно не только
запрещать и наказывать, но и учить, разъяснять, помогать. Общество должно осознать важность
данной проблематики, понять основные пути решения соответствующих проблем. Государство
может сделать это оптимальным образом. Здесь не нужно больших материальных затрат,
требуются интеллектуальные вложения.
Меры административно-организационного уровня. Администрация организации должна сознавать
необходимость поддержания режима безопасности и выделять на эти цели соответствующие
ресурсы. Основой мер защиты административно-организационного уровня является политика
безопасности (см. гл. 3) и комплекс организационных мер.
К комплексу организационных мер относятся меры безопасности, реализуемые людьми.
Выделяют следующие группы организационных мер:
• управление персоналом;
• физическая защита;
• поддержание работоспособности;
• реагирование на нарушения режима безопасности;
• планирование восстановительных работ.
Для каждой группы в каждой организации должен существовать набор регламентов,
определяющих действия персонала.
Меры и средства программно-технического уровня. Для поддержания режима информационной
безопасности особенно важны меры программно-технического уровня, поскольку основная угроза
компьютерным системам исходит от них самих: сбои оборудования, ошибки программного
обеспечения, промахи пользователей и администраторов и т. п. В рамках современных
информационных систем должны быть доступны следующие механизмы безопасности:
• идентификация и проверка подлинности пользователей;
• управление доступом;
• протоколирование и аудит;
• криптография;
• экранирование;
• обеспечение высокой доступности.
Необходимость применения стандартов. Информационные системы (ИС) компаний почти всегда
построены на основе программных и аппаратных продуктов различных производителей. Пока нет
ни одной компании-разработчика, которая предоставила бы потребителю полный перечень
средств (от аппаратных до программных) для построения современной ИС. Чтобы обеспечить в
разнородной ИС надежную защиту информации требуются специалисты высокой квалификации,
которые должны отвечать за безопасность каждого компонента ИС: правильно их настраивать,
постоянно отслеживать происходящие изменения, контролировать работу пользователей.
Очевидно, что чем разнороднее ИС, тем сложнее обеспечить ее безопасность. Изобилие в
корпоративных сетях и системах устройств защиты, межсетевых экранов (МЭ), шлюзов и VPN, а
также растущий спрос на доступ к корпоративным данным со стороны сотрудников, партнеров и
заказчиков приводят к созданию сложной среды защиты, трудной для управления, а иногда и
несовместимой.
Интероперабельность продуктов защиты является неотъемлемым требованием для КИС. Для
большинства гетерогенных сред важно обеспечить согласованное взаимодействие с продуктами
других производителей. Принятое организацией решение безопасности должно гарантировать
защиту на всех платформах в рамках этой организации. Поэтому вполне очевидна потребность в
применении единого набора стандартов как поставщиками средств защиты, так и компаниями —
системными интеграторами и организациями, выступающими в качестве заказчиков систем
безопасности для своих корпоративных сетей и систем.
Стандарты образуют понятийный базис, на котором строятся все работы по обеспечению
информационной безопасности, и определяют критерии, которым должно следовать управление
безопасностью. Стандарты являются необходимой основой, обеспечивающей совместимость
продуктов разных производителей, что чрезвычайно важно при создании систем сетевой
безопасности в гетерогенных средах.
Комплексный подход к решению проблемы обеспечения безопасности, рациональное сочетании
законодательных, административно-организационных и программно-технических мер и
обязательное следование промышленным, национальным и международным стандартам — это тот
фундамент, на котором строится вся система защиты корпоративных сетей.
Пути решения проблем защиты информации в сетях
Для поиска решений проблем информационной безопасности при работе в сети Интернет был
создан независимый консорциум ISTF (Internet Security Task Force) — общественная организация,
состоящая из представителей и экспертов компаний-поставщиков средств информационной
безопасности, электронных бизнесов и провайдеров Internet-инфраструктуры. Цель консорциума
— разработка технических, организационных и операционных руководств по безопасности работы
в Internet.
Консорциум ISTF выделил 12 областей информационной безопасности, на которых в первую
очередь должны сконцентрировать свое внимание создатели электронного бизнеса, чтобы
обеспечить его работоспособность. Этот список, в частности, включает:
• аутентификацию (механизм объективного подтверждения идентифицирующей информации);
• право на частную, персональную информацию (обеспечение конфиденциальности информации);
• определение событий безопасности (Security Events);
• защиту корпоративного периметра;
• определение атак;
• контроль за потенциально опасным содержимым;
• контроль доступа;
• администрирование;
• реакцию на события (Incident Response). Рекомендации ISTF предназначены для существующих
или вновь образуемых компаний электронной коммерции и электронного бизнеса.
Их реализация означает, что защита информации в системе электронного бизнеса должна быть
комплексной.
Для комплексной зашиты от угроз и гарантии экономически выгодного и безопасного
использования коммуникационных ресурсов для электронного бизнеса необходимо:
• проанализировать угрозы безопасности для системы электронного бизнеса;
• разработать политику информационной безопасности;
• защитить внешние каналы передачи информации, обеспечив конфиденциальность, целостность и
подлинность передаваемой по ним информации;
• гарантировать возможность безопасного доступа к открытым ресурсам внешних сетей и Internet,
а также общения с пользователями этих сетей;
• защитить отдельные наиболее коммерчески значимые ИС независимо от используемых ими
каналов передачи данных;
• предоставить персоналу защищенный удаленный доступ к информационным ресурсам
корпоративной сети;
• обеспечить надежное централизованное управление средствами сетевой защиты.
Согласно рекомендациям ISTF, первым и важнейшим этапом разработки системы
информационной безопасности электронного бизнеса являются механизмы управления доступом к
сетям общего пользования и доступом из них, а также механизмы безопасных коммуникаций,
реализуемые МЭ и продуктами защищенных виртуальных сетей VPN.
Сопровождая их средствами интеграции и управления всей ключевой информацией системы
защиты (PKI — инфраструктура открытых ключей), можно получить целостную, централизованно
управляемую систему информационной безопасности.
Следующий этап включает интегрируемые в общую структуру средства контроля доступа
пользователей в систему вместе с системой однократного входа и авторизации (Single Sign On).
Антивирусная защита, средства аудита и обнаружения атак, по существу, завершают создание
интегрированной целостной системы безопасности, если речь не идет о работе с
конфиденциальными данными. В этом случае требуются средства криптографической защиты
данных и электронно-цифровой подписи.
Для реализации основных функциональных компонентов системы безопасности для электронного
бизнеса применяются различные методы и средства защиты информации:
• защищенные коммуникационные протоколы;
• средства криптографии;
• механизмы аутентификации и авторизации;
• средства контроля доступа к рабочим местам сети и из сетей общего пользования;
• антивирусные комплексы;
• программы обнаружения атак и аудита;
• средства централизованного управления контролем доступа пользователей, а также безопасного
обмена пакетами данных и сообщениями любых приложений по открытым IP-сетям.
Применение комплекса средств защиты на всех уровнях корпоративной системы позволяет
построить эффективную и надежную систему обеспечения информационной безопасности.
Вопрос 10. Виртуальные частные сети VPN.
VPN (англ. Virtual Private Network — виртуальная частная сеть[1]) — обобщённое название
технологий, позволяющих обеспечить одно или несколько сетевых соединений (логическую сеть)
поверх другой сети (например, Интернет). Несмотря на то, что коммуникации осуществляются по
сетям с меньшим или неизвестным уровнем доверия (например, по публичным сетям), уровень
доверия к построенной логической сети не зависит от уровня доверия к базовым сетям благодаря
использованию средств криптографии (шифрования, аутентификации, инфраструктуры открытых
ключей, средств для защиты от повторов и изменений, передаваемых по логической сети
сообщений).
В зависимости от применяемых протоколов и назначения, VPN может обеспечивать соединения
трёх видов: узел-узел,узел-сеть и сеть-сеть.
Уровни реализации
Обычно VPN развёртывают на уровнях не выше сетевого, так как применение криптографии на
этих уровнях позволяет использовать в неизменном виде транспортные протоколы (такие
как TCP, UDP).
Пользователи Microsoft Windows обозначают термином VPN одну из реализаций виртуальной
сети — PPTP, причём используемую зачастую не для создания частных сетей.
Чаще всего для создания виртуальной сети используется инкапсуляция протокола PPP в какойнибудь другой протокол — IP (такой способ использует реализация PPTP — Point-to-Point
Tunneling Protocol) или Ethernet (PPPoE) (хотя и они имеют различия). Технология VPN в
последнее время используется не только для создания собственно частных сетей, но и
некоторыми провайдерами «последней мили» на постсоветском пространстве для предоставления
выхода в Интернет.
При должном уровне реализации и использовании специального программного обеспечения сеть
VPN может обеспечить высокий уровень шифрования передаваемой информации. При
правильной настройке всех компонентов технология VPN обеспечивает анонимность в Сети.
Структура VPN
VPN состоит из двух частей: «внутренняя» (подконтрольная) сеть, которых может быть несколько,
и «внешняя» сеть, по которой проходит инкапсулированное соединение (обычно
используется Интернет). Возможно также подключение к виртуальной сети
отдельного компьютера. Подключение удалённого пользователя к VPN производится посредством
сервера доступа, который подключён как к внутренней, так и к внешней (общедоступной) сети.
При подключении удалённого пользователя (либо при установке соединения с другой
защищённой сетью) сервер доступа требует прохождения процесса идентификации, а затем
процесса аутентификации. После успешного прохождения обоих процессов удалённый
пользователь (удаленная сеть) наделяется полномочиями для работы в сети, то есть происходит
процесс авторизации.
Классификация VPN
Классификация VPN
Классифицировать VPN решения можно по нескольким основным параметрам:
По степени защищённости используемой среды
Защищённые
Наиболее распространённый вариант виртуальных частных сетей. С его помощью возможно
создать надежную и защищённую сеть на основе ненадёжной сети, как правило, Интернета.
Примером защищённых VPN являются: IPSec, OpenVPN и PPTP.
Доверительные
Используются в случаях, когда передающую среду можно считать надёжной и необходимо решить
лишь задачу создания виртуальной подсети в рамках большей сети. Проблемы безопасности
становятся неактуальными. Примерами подобных VPN решений являются: Multi-protocol label
switching (MPLS) иL2TP (Layer 2 Tunnelling Protocol) (точнее будет сказать, что эти протоколы
перекладывают задачу обеспечения безопасности на другие, например L2TP, как правило,
используется в паре с IPSec).
По способу реализации
В виде специального программно-аппаратного обеспечения
Реализация VPN сети осуществляется при помощи специального комплекса программноаппаратных средств. Такая реализация обеспечивает высокую производительность и, как правило,
высокую степень защищённости.
В виде программного решения
Используют персональный компьютер со специальным программным обеспечением,
обеспечивающим функциональность VPN.
Интегрированное решение
Функциональность VPN обеспечивает комплекс, решающий также задачи фильтрации сетевого
трафика, организации сетевого экрана и обеспечения качества обслуживания.
По назначению
Intranet VPN
Используют для объединения в единую защищённую сеть нескольких распределённых филиалов
одной организации, обменивающихся данными по открытым каналам связи.
Remote Access VPN
Используют для создания защищённого канала между сегментом корпоративной сети
(центральным офисом или филиалом) и одиночным пользователем, который, работая дома,
подключается к корпоративным ресурсам с домашнего компьютера,
корпоративного ноутбука, смартфона или c компьютера общественного пользования.
Extranet VPN
Используют для сетей, к которым подключаются «внешние» пользователи (например, заказчики
или клиенты). Уровень доверия к ним намного ниже, чем к сотрудникам компании, поэтому
требуется обеспечение специальных «рубежей» защиты, предотвращающих или ограничивающих
доступ последних к особо ценной, конфиденциальной информации.
Internet VPN
Используется для предоставления доступа к интернету провайдерами, обычно если по одному
физическому каналу подключаются несколько пользователей. Протокол PPPoE стал стандартом
в ADSL-подключениях.
PPTP/L2TP без шифрования были широко распространены в середине-конце 2000-х годов
в домовых сетях: в те времена внутрисетевой трафик не оплачивался, а внешний стоил дорого. Это
давало возможность контролировать расходы: когда VPN-соединение выключено, пользователь
ничего не платит. В настоящее время (2015) средняя цена на проводной доступ к Интернету
существенно снизилась, а трафик, как правило, является безлимитным. В итоге решения на базе
туннельных протоколов становятся избыточными для данной отрасли, зачастую даже
обременительными для клиентских устройств маршрутизации SOHO-класса, которые в последнее
время получили широкое распространение.
Client/Server VPN
Он обеспечивает защиту передаваемых данных между двумя узлами (не сетями) корпоративной
сети. Особенность данного варианта в том, что VPN строится между узлами, находящимися, как
правило, в одном сегменте сети, например, между рабочей станцией и сервером. Такая
необходимость очень часто возникает в тех случаях, когда в одной физической сети необходимо
создать несколько логических сетей. Например, когда надо разделить трафик между финансовым
департаментом и отделом кадров, обращающихся к серверам, находящимся в одном физическом
сегменте. Этот вариант похож на технологию VLAN, но вместо разделения трафика используется
его шифрование.
По типу протокола
Существуют реализации виртуальных частных сетей под TCP/IP, IPX и AppleTalk. Но на
сегодняшний день наблюдается тенденция к всеобщему переходу на протокол TCP/IP, и
абсолютное большинство VPN решений поддерживает именно его. Адресация в нём чаще всего
выбирается в соответствии со стандартом RFC5735, из диапазона Приватных сетей TCP/IP.
По уровню сетевого протокола
По уровню сетевого протокола на основе сопоставления с уровнями эталонной сетевой модели
ISO/OSI.
Примеры VPN
IPSec (IP security) — часто используется поверх IPv4.
PPTP (point-to-point tunneling protocol) — разрабатывался совместными усилиями
нескольких компаний, включая Microsoft.
PPPoE (PPP (Point-to-Point Protocol) over Ethernet)
L2TP (Layer 2 Tunnelling Protocol) — используется в продуктах компаний Microsoft
и Cisco.
L2TPv3 (Layer 2 Tunnelling Protocol version 3).
OpenVPN SSL VPN с открытым исходным кодом, поддерживает режимы PPP, bridge, pointto-point, multi-client server
freelan SSL P2P VPN с открытым исходным кодом
Hamachi — программа для создания одноранговой VPN-сети.
NeoRouter — zeroconfig, прямое соединение компьютеров за NAT, можно выбрать свой
сервер.
Многие крупные провайдеры предлагают свои услуги по организации VPN-сетей для бизнесклиентов.
Вопрос 11. Сети Х.25 и Frame Relay.
X.25 — стандарт канального уровня сетевой модели OSI. Предназначался для
организации WAN на основе телефонных сетей с линиями с достаточно высокой частотой
ошибок, поэтому содержит развитые механизмы коррекции ошибок. Ориентирован на работу с
установлением соединений. Исторически является предшественником протокола Frame Relay.
X.25 обеспечивает множество независимых виртуальных каналов (Permanent Virtual Circuits, PVC
и Switched Virtual Circuits, SVC) в одной линии связи, идентифицируемых в X.25-сети по
идентификаторам подключения к соединению идентификаторы логического канала (Logical
Channel Identifier, LCI) или номера логического канала (Logical Channel Number, LCN).
Благодаря надёжности протокола и его работе поверх телефонных сетей общего пользования X.25
широко использовался как в корпоративных сетях, так и во всемирных специализированных сетях
предоставления услуг, таких как SWIFT (банковская платёжная система, прекратили
использование в 2005 году) и SITA (фр. Société Internationale de Télécommunications
Aéronautiques — система информационного обслуживания воздушного транспорта), однако в
настоящее время X.25 вытесняется другими технологиями канального уровня (Frame
Relay, ISDN, ATM) и протоколом IP, оставаясь, однако, достаточно распространённым в странах и
территориях с неразвитой телекоммуникационной инфраструктурой.
MTU для X.25 равно 576 байт. Также это число считается минимальным размером дейтаграммы,
которую должен уметь принять и обработать любой хост в интернете.[1]
История и стандартизация
Разработан Study Group VII Международного союза электросвязи (ITU) в качестве пакетного
протокола передачи данных в телефонных сетях принят в 1976 г. и стал основой всемирной
системы PSPDN (англ. Packet-Switched Public Data Networks), то есть WAN. Существенные
дополнения к протоколу были приняты в 1984 г., в настоящее время действует стандарт ISO 8208
протокола X.25, стандартизовано также и применение X.25 в локальных сетях (стандарт ISO
8881).
По мере распространения IP-сетей IETF стандартизовал ряд RFC, описывающих работу и
взаимодействие X.25 и TCP/IP:
RFC 887 A Standard for the Transmission of IP Datagrams Over Public Data Networks
RFC 1086 ISO-TP0 bridge between TCP and X.25
RFC 1090 SMTP on X.25
RFC 1356 Multiprotocol Interconnect on X.25 and ISDN in the Packet Mode
RFC 1381 SNMP MIB Extension for X.25 LAPB
RFC 1381 SNMP MIB Extension for the X.25 Packet Layer
RFC 1461 SNMP MIB extension for Multiprotocol Interconnect over X.25
RFC 1598 PPP in X.25
RFC 1613 Cisco Systems X.25 over TCP (XOT)
Архитектура
.——.
| HOST |
.———.
.——.
.——.
.——.
|—. |
| Терминал|——| DTE |=====| DCE |____________| DCE |=====|PAD| |
| USER
| ^ | PAD |
`———‘ | `——‘
|
`——‘
`——‘
:
:
:
«NATIVE»
|—‘ |
`——‘
:
:—- Пакетная сеть —-:
PROTOCOL
Режимы и типы пакетов X.25
1. Режим установления соединения (Call setup mode) используется при установлении
соединения SVC между DTE-устройствами. В этом режиме на уровне PLP используется
схема адресации X.121 для установления виртуального соединения. Режим установления
соединения работает на уровне виртуальных каналов, то есть в пределах одного
физическогоDTE-устройства одни SVC могут быть в состоянии установления соединения,
а другие — в режиме передачи данных или разрыва соединения. Режим установления
соединения используется только в случае установления SVC, но не PVC.
2. Режим передачи данных (Data transfer mode) используется при передаче данных по
виртуальному каналу. При этом X.25 PLP ответственен за сегментацию данных в пакеты и
сборку пакетов, управление передачей данных и коррекцию ошибок. Режим передачи
данных работает на уровне виртуальных каналов и используется в случае как SVC, так и
PVC.
3. Режим ожидания (Idle mode) характеризуется отсутствием передачи данных при
установленном виртуальном канале. Работает на уровне виртуальных каналов и
используется только в случае установления SVC, но не PVC.
4. Режим разрыва соединения (Call clearing mode) используется при разрыве соединения SVC
между DTE-устройствами. Работает на уровне виртуальных каналов и используется только
в случае разрыва SVC, но не PVC.
5. Режим перезапуска (Restarting mode) используется для переустановки соединений между
DTE-устройством и локально работающих с ним DCE-устройствами. В отличие от других
режимов, выполняется в пределах одного физического DTE-устройства, что
сопровождается разрывом всех виртуальных каналов, установленных с этим DTE.
Типы пакетов X.25
Packet Type
DCE
DTE
Установление и разрыв
Incoming Call
соединений
Данные и прерывания
Flow Control and Reset
Restart
DTE
DCE
Service VC PVC
CALL REQ Запрос
соединения
X
Call Connected
CALL ACC Вызов принят
X
Clear Indication
CLR REQ Запрос разрыва
X
Clear Confirmation
CLR CNF Подтверждение
разрыва
X
Data
Data Пакет данных
X
X
Interrupt
INT REQ Запрос
прерывания
X
X
Interrupt Confirmation
INT CNF Подтверждение
прерывания
X
X
Reciever Ready
RR Приемник готов
X
X
Reciever Not Ready
RNR Приемник не готов
X
X
REJ Отказ
X
X
Reset Indication
RES REQ Запрос сброса
X
X
Reset Confirmation
RES CNF Подтверждение
сброса
X
X
Restart Indication
RSTR REQ Запрос
перезапуска
X
X
Restart Confirmation
RSTR CNF Подтверждение
перезапуска
X
X
Diagnostic
DIAG Диагностика
X
X
Registration
REG CNF Подтверждение REG REQ Запрос
регистрации
регистрации
X
X
Frame relay (англ. «ретрансляция кадров», FR) — протокол канального уровня сетевой модели
OSI. Служба коммутации пакетов Frame Relay в настоящее время широко распространена во всём
мире. Максимальная скорость, допускаемая протоколом FR — 34,368 мегабит/сек (каналы E3).
Коммутация: точка-точка.
Frame Relay был создан в начале 1990-х в качестве замены протоколу X.25 для быстрых надёжных
каналов связи, технология FR архитектурно основывалась на X.25 и во многом сходна с этим
протоколом, однако в отличие от X.25, рассчитанного на линии с достаточно высокой частотой
ошибок, FR изначально ориентировался на физические линии с низкой частотой ошибок, и
поэтому большая часть механизмов коррекции ошибок X.25 в состав стандарта FR не вошла. В
разработке спецификации принимали участие многие организации; многочисленные поставщики
поддерживают каждую из существующих реализаций, производя соответствующее аппаратное и
программное обеспечение.
Frame relay обеспечивает множество независимых виртуальных каналов (Virtual Circuits, VC) в
одной линии связи, идентифицируемых в FR-сети по идентификаторам подключения к
соединению (DLCI). Вместо средств управления потоком включает функции извещения о
перегрузках в сети. Возможно назначение минимальной гарантированной скорости (CIR) для
каждого виртуального канала.
В основном применяется при построении территориально распределённых корпоративных сетей, а
также в составе решений, связанных с обеспечением гарантированной пропускной способности
канала передачи данных (VoIP, видеоконференции и т. п.).
Формат кадра
Флаг (1 Byte) Адрес (2-4 Byte) Данные (переменный размер) FCS (2 Byte) Флаг (1 Byte)
Каждый кадр начинается и замыкается «флагом» — последовательностью «01111110». Для
предотвращения случайной имитации последовательности «флаг» внутри кадра при его
передаче проверяется всё его содержание между двумя флагами и после каждой
последовательности, состоящей из пяти идущих подряд бит «1», вставляется бит «0». Эта
процедура (bit stuffing) обязательна при формировании любого кадра FR, при приёме эти
биты «0» отбрасываются.
FCS (Frame Check Sequence) — проверочная последовательность кадра служит для
обнаружения ошибок и формируется аналогично циклическому коду HDLC.
Поле данных имеет минимальную длину в 1 октет, максимальную по стандарту Frame
Relay Forum — 1600 октетов, однако в реализациях некоторых производителей FRоборудования допускается превышение максимального размера (до 4096 октетов).
Поле Адрес кадра Frame Relay, кроме собственно адресной информации, содержит также и
дополнительные поля управления потоком данных и уведомлений о перегрузке канала и
имеет следующую структуру:
DLCI (6
Bit)
C/R (1
Bit)
EA (1
Bit)
DLCI (4
Bit)
FECN (1
Bit)
BECN (1
Bit)
DE (1
Bit)
EA (1
Bit)
Наименования и значения полей:
Имя
поля
Назначение
DLCI
Data Link Connection Identifier — идентификатор виртуального канала (PVC),
мультиплексируемого в физический канал. DLCI имеют только локальное значение и не
обеспечивают внутрисетевой адресации.
C/R
Command / Response — признак «команда-ответ», по аналогии с протоколом HDLC.
EA
Address Field Extension Bit — бит расширения адреса. DLCI содержится в 10 битах,
входящих в два октета заголовка, однако возможно расширение заголовка на целое число
дополнительных октетов с целью указания адреса, состоящего более чем из 10 бит. EA
устанавливается в конце каждого октета заголовка; если он имеет значение «1», то это
означает, что данный октет в заголовке последний.
FECN
Forward Explicit Congestion Notification — извещение о перегрузке канала в прямом
направлении.
BECN
Backward Explicit Congestion Notification — извещение о перегрузке канала в обратном
направлении.
DE
Discard Eligibility Indicator — индикатор разрешения сброса кадра при перегрузке канала.
Выставляется в «1» для данных, подлежащих передаче в негарантированной полосе (EIR)
и указывает на то, что данный кадр может быть уничтожен в первую очередь.
Виртуальные каналы
Для передачи данных от отправителя к получателю в сети Frame Relay создаются виртуальные
каналы, VC (англ. Virtual Circuit), которые бывают двух видов:
постоянный виртуальный канал, PVC (Permanent Virtual Circuit), который создаётся между
двумя точками и существует в течение длительного времени, даже в отсутствие данных
для передачи;
коммутируемый виртуальный канал, SVC (Switched Virtual Circuit), который создаётся
между двумя точками непосредственно перед передачей данных и разрывается после
окончания сеанса связи
CIR и EIR
CIR (англ. Committed Information Rate) — гарантированная полоса пропускания виртуального
канала PVC в сетях FR.
В первоначальном наборе стандартов (ANSI T1S1) CIR как отдельный параметр отсутствует, но
для отдельного виртуального канала были определены параметры B(c) (bits committed, Committed
Burst Size), B(e) (bits excess) и T(c) (Committed Rate Measurement Interval). B(c) при этом
определяется как количество бит, гарантированно передаваемых за время T(c) даже при
перегрузке сети, B(e) — максимальное количество бит, которые могут быть переданы за время
T(c) при недогрузке сети, то есть без гарантии доставки: заголовки пакетов, отправляемые после
превышения B(c) метятся битом DE (discard eligible, аналогичен CLP в ATM) и в случае
возникновения в сети перегрузки уничтожаются на коммутаторах перегруженного участка.
Таким образом, для виртуального канала могут быть определены две полосы пропускания:
CIR=B(c)/T(c) — гарантированная полоса пропускания;
EIR=B(e)/T(c) — максимальная негарантированная полоса пропускания (добавляется
возможный дополнительный объем трафика).
Возможна настройка и работа FR-каналов со значением CIR, равным нулю.
В ANSI T1S1 значение T(c) не было определено, так как значения T(c), B(c) и B(e) являются
связанными параметрами, зависящими от скоростей физических интерфейсов, агрегированных
полос пропускания виртуальных каналов, размеров буферов FR-коммутатора и других
параметров, зависящих от реализации и настроек коммутатора.
Однако CIR и EIR оказались удобными показателями для описания параметров каналов при
заключении соглашений между операторами FR-сетей и потребителями их услуг, более того, во
многих случаях T(c) может динамически пересчитываться в зависимости от характера трафика,
поэтому в RFC 3133 (Terminology for Frame Relay Benchmarking) CIR является первичным
параметром и T(c) определяется как временной интервал, необходимый для поддержания CIR, то
есть T(c)=B(c)/CIR, выступая в качестве аналога TCP Sliding Window.
В сетевых технологиях при множественном доступе к разделяемому каналу с двухуровневой
приоритезацией (некоторые беспроводные и спутниковые сети и т. д.) также используют термин
CIR для приоритезируемой клиентской полосы пропускания, при этом CIR является одним из
целевых параметров конфигурации шейперов (shapers) — подсистем сглаживания трафика с
буферизацией (RFC 2963, A Rate Adaptive Shaper for Differentiated Services), в этом случае вместо
EIR используется комбинация параметров MIR (Maximum Information Rate) и PIR (Peak
Information Rate).
Вопрос 12. Сети ATM.
ATM (англ. asynchronous transfer mode — асинхронный способ передачи данных) —
сетевая высокопроизводительная технология коммутации и мультиплексирования, основанная на
передаче данных в виде ячеек (англ. cell) фиксированного размера (53 байта[1]), из которых 5
байтов используется под заголовок. В отличие от синхронного способа передачи данных (STM —
англ. synchronous transfer mode), ATM лучше приспособлен для предоставления услуг передачи
данных с сильно различающимся или изменяющимся битрейтом.
История
Создание
Основы технологии ATM были разработаны независимо во Франции и США в 1970-х двумя
учёными: Jean-Pierre Coudreuse[2], который работал в исследовательской лабораторииFrance
Telecom, и Sandy Fraser, инженер Bell Labs[3]. Они оба хотели создать такую архитектуру, которая
бы осуществляла транспортировку как данных, так и голоса на высоких скоростях, и использовала
сетевые ресурсы наиболее эффективно.
Компьютерные технологии создали возможность для более быстрой обработки информации и
более скоростной передачи данных между системами. В 80-х годах ХХ века операторы
телефонной связи обнаружили, что неголосовой трафик более важен и начинает доминировать над
голосовым. Был предложен проект ISDN[4], который описывал цифровую сеть с коммутацией
пакетов, предоставляющую услуги телефонной связи и передачи данных. Цифровые системы
передачи, сначала плезиохронные системы (PDH) на основе ИКМ, а затемсинхронные системы
передачи (SDH) иерархии на основе оптоволокна, позволяли обеспечить передачу данных на
высокой скорости с малыми вероятностями двоичных ошибок. Но существующая технология
коммутации пакетов (прежде всего, по протоколу X.25) не могла обеспечить передачу трафика в
реальном масштабе времени (например, голоса), и многие сомневались, что когда-либо
обеспечит[3]. Для передачи трафика в реальном масштабе времени в общественных телефонных
сетях применяли технологию коммутации каналов (КК). Эта технология идеальна для передачи
голоса, но для передачи данных она неэффективна. Поэтому телекоммуникационная индустрия
обратилась к ITU для разработки нового стандарта для передачи данных и голосового трафика в
сетях с широкой полосой пропускания[3]. В конце 80-х Международным телефонным и
телеграфным консультативным комитетом CCITT (который затем был переименован в ITU-T) был
разработан набор рекомендаций по ISDN второго поколения, так называемого BISDN (широкополосный ISDN), расширения ISDN. В качестве режима передачи нижнего уровня
для B-ISDN был выбран ATM[4]. В 1988 г. на собрании ITU в Женеве была выбрана длина ячейки
ATM — 53 байт[5]. Это был компромисс между специалистами США, которые предлагали длину
ячейки 64 байта и специалистами Европы, предлагавшими длину ячейки 32 байта. Ни одна
сторона не смогла убедительно доказать преимущество своего варианта, поэтому в итоге объём
«полезной» нагрузки составил 48 байт, а для поля заголовка (служебных данных) был выбран
размер 5 байт, минимальный размер, на который согласилась ITU. В 1990 г. был одобрен базовый
набор рекомендаций ATM[6]. Базовые принципы ATM положены рекомендацией I.150[6]. Это
решение было очень похоже на системы, разработанные Coudreuse и Fraser. Отсюда начинается
дальнейшее развитие ATM.
Советские и российские разработки
В 1980-х — 1990-х годах исследованием и разработкой средств быстрой коммутации пакетов
(БКП) для совместной передачи речи и данных занимались несколько организаций.
ЛНПО «Красная Заря»
Тему БКП и, как её разновидность, АТМ, разрабатывал отдел под руководством Г. П. Захарова в
составе предприятия АООТ НПП «Радуга». Ранее это предприятие было одним из
подразделений ЛНПО «Красная Заря». Отдел Захарова получил как теоретические результаты —
математические модели[7][8], отчёты по проведённым отделом НИР, статьи, книги, студенческие
дипломы, кандидатские и докторские диссертации по теме, так и практические результаты:
сначала, совместными усилиями специалистов ЛНПО «Красная Заря» и предприятия
«Дальняя связь» под техническим руководством специалиста ЛНПО «Красная
Заря»(НИИЭТУ) Разживина Игоря Александровича, в 1992 году был создан рабочий макет
системы коммутации и приёма ячеек АТМ[9];
совместно со специалистом организации «Вектор» Ю. А. Яцуновым в 1993
году разработана принципиальная схема коммутационного элемента (КЭ) для построения
двоичного самомаршрутизирующего коммутационного поля (КП). В основу были
положены некоторые идеи построения КЭ и КП[10][11], опубликованные специалистом из
Великобритании Питером Ньюмэном[12]. В самом общем плане такой КЭ описывается
схемой «селектор-арбитр». Схема КЭ Яцунова-Разживина предназначалась для микросхем
малой степени интеграции популярных и доступных серий[13], выпускавшихся тогда
российской промышленностью[14], однако «в железе» воплощена не была сознательно,
поскольку являлась только промежуточным этапом;
затем, на основе принципиальной схемы Яцунова-Разживина был успешно реализован,
также под техническим руководством Разживина И. А., КЭ в виде одной
специализированной СБИС, которая была разработана специалистом московского ФГУП
«НИИМА Прогресс» В. И. Лопашовым[15], при содействии его коллеги Халтурина В. А., и
изготовлена в Москве[16] в январе 1994 года.
Это позволяло создать коммутационное поле быстрого коммутатора пакетов, или коммутатора
ячеек ATM, на одной печатной плате. Однако дальше выпуска опытной партии СБИС в
количестве 10 штук, и внедрения результатов диссертационной работы Разживина И. А. в НИР
«НИИМА Прогресс» и ГП НИИ «Рубин», эти работы не пошли по независящим от технических
специалистов причинам.
Известны работы группы специалистов под руководством к. т. н. Георгия Ревмировича
Овчинникова, предложивших свой вариант реализации аппаратных средств системы быстрой
коммутации пакетов на основе самомаршрутизирующих матриц[17][18] и свою математическую
модель[19][20]. Однако о практической реализации их предложений сведений не имеется.
Московский институт электронной техники
Было доложено описание цифрового коммутатора 16х16 на арсениде галлия, разработанного
независимо от ЛНПО «Красная Заря» Московским институтом электронной техники[21].
1990-е годы: приход ATM на рынок
В начале 1990-х гг. технологии ATM в мире начинают уделять повышенное внимание.
Корпорация Sun Microsystems ещё в 1990 г., одна из первых, объявляет о поддержке ATM[3]. В
1991 году, с учётом, что CCITT уже не успевает своевременно предлагать рекомендации по
быстроразвивающейся новой технике, создаётся ATM Forum[22], консорциум фирм-разработчиков
и производителей техники АТМ, для координации и разработки новых практических стандартов и
технических спецификаций по технологии ATM, и сайт с одноимённым названием, где все
спецификации выкладывались в открытый доступ. CCITT, уже будучи ITU-T, выдаёт новые
редакции своих рекомендаций, совершенствуя теоретическую базу ATM. Представители
сферы IT в журналах и газетах пророчат ATM большие перспективы. В 1995 г.
компания IBM объявила о своей новой стратегии в области корпоративных сетей, основанной на
технологии ATM[23]. Считалось, что ATM будет существенным подспорьем для Интернета,
уничтожив нехватку ширины полосы пропускания и внеся в сети надежность[24]. Dan Minoli, автор
многих книг по компьютерным сетям, утверждал, что ATM будет внедрен в публичных сетях, и
корпоративные сети будут соединены с ними таким же образом, каким в то время они
использовали frame relay или X.25[25]. Но к тому времени протокол IP уже получил широкое
распространение и сложно было совершить резкий переход на ATM. Поэтому в существующих IPсетях технологию ATM предполагалось внедрять как нижележащий протокол, то есть под IP, а не
вместо IP. Для постепенного перехода традиционных сетей Ethernet и Token-Ring на оборудование
ATM был разработан протокол LANE, эмулирующий пакеты данных сетей.
В 1997 г. в индустрии маршрутизаторов и коммутаторов примерно одинаковое количество
компаний выстроились в ряды сторонников и противников ATM, то есть использовали или не
использовали технологию ATM в производимых устройствах[3]. Будущее этого рынка было ещё
неопределенно. В 1997 г. доход от продажи оборудования и услуг ATM составил 2,4 млрд
долларов США, в следующем году — 3,5 млрд[26], и ожидалось, что он достигнет 9,5 млрд
долларов в 2001 году[27]. Многие компании (например Ipsilon Networks) для достижения успеха
использовали ATM не полностью, а в урезанном варианте. Многие сложные спецификации и
протоколы верхнего уровня ATM, включая разные типы качества обслуживания, выкидывались.
Оставлялась только базовая функциональность по переключению байтов с одних линий на другие.
Первый удар по ATM
И тем не менее, было также много специалистов IT, скептически относящихся к
жизнеспособности технологии ATM. Как правило, защитниками ATM были представители
телекоммуникационных, телефонных компаний, а противниками — представители компаний,
занимавшихся компьютерными сетями и сетевым оборудованием. Steve Steinberg (в журнале
Wired) посвятил целую статью скрытой войне между ними[24]. Первым ударом по ATM были
результаты исследований Bellcore о характере трафика LAN, опубликованных в 1994 г.[28]. Эта
публикация показала, что трафик в локальных сетях не подчиняется ни одной существующей
модели. Трафик LAN на временной диаграмме ведёт себя как фрактал. На любом временном
диапазоне от нескольких миллисекунд до нескольких часов он имеет самоповторяющийся,
взрывной характер. ATM в своей работе все внеурочные пакеты должен хранить в буфере. В
случае резкого увеличения трафика, коммутатор ATM просто вынужден отбрасывать
невмещающиеся пакеты, а это означает ухудшение качества обслуживания. По этой причине
PacBell потерпела неудачу при первой попытке использовать оборудование ATM[29].
Появление главного конкурента ATM — Gigabit Ethernet
В конце 90-х появляется технология Gigabit Ethernet, которая начинает конкурировать с ATM.
Главными достоинствами первой является значительно более низкая стоимость, простота,
лёгкость в настройке и эксплуатации. Также, переход с Ethernet или Fast Ethernet на Gigabit
Ethernet можно было осуществить значительно легче и дешевле. Проблему качества
обслуживания Gigabit Ethernet мог решить за счет покупки более дешевой полосы пропускания с
запасом, нежели за счет умного оборудования. К окончанию 90-х гг. стало ясно, что ATM будет
продолжать доминировать только в глобальных сетях[30][31]. Продажи свитчей ATM
для WAN продолжали расти, в то время как продажи свитчей ATM для LANстремительно
падали[32][33].
2000-е годы: поражение ATM
В 2000-е гг. рынок оборудования ATM ещё был значительным[34]. ATM широко использовался
в глобальных компьютерных сетях, в оборудовании для передачи аудио/видео потоков, как
промежуточный слой между физическим и вышележащим уровнем в устройствах ADSL для
каналов с пропускной способностью не более 2 Мбит/с. Но в конце десятилетия ATM начинает
вытесняться новой технологией IP-VPN[35]. Свитчи ATM стали вытесняться
маршрутизаторами IP/MPLS[36]. В 2006 Broadband Forum выпустил спецификацию TR-101 под
названием «Migration to Ethernet-Based DSL Aggregation», которая указывала как построенные на
ATM агрегирующие сети могут мигрировать на построенные на Ethernet агрегирующие сети (в
контексте предыдущих архитектур TR-25 и TR-59)[37]. В качестве обоснования такого перехода в
спецификации сказано, что существующие DSL-архитектуры эволюционируют от сетей «низкая
скорость, максимальные усилия» к инфраструктурам, способным поддерживать более высокую
скорость передачи и сервисы требующие QoS, мультикаст, а также выполнять требования,
которые недопустимо выполнять в системах, построенных на ATM. По прогнозу компании Uvum
от 2009 г., к 2014 г. ATM и Frame Relayдолжны почти полностью исчезнуть[38], в то время как
рынки Ethernet и IP-VPN будут продолжать расти с хорошим темпом. По докладу Broadband
Forum за октябрь 2010 г[39], переход на глобальном рынке от сетей с коммутацией каналов (TDM,
ATM и др.) к IP-сетям уже начался в стационарных сетях и уже затрагивает и мобильные сети. В
докладе сказано, что Ethernet позволяет мобильным операторам удовлетворить растущие
потребности в мобильном трафике более экономически эффективно, чем системы, основанные на
TDM или ATM.
Ещё в апреле 2005 г. произошло слияние «ATM Forum» с «Frame Relay Forum» и «MPLS Forum» в
общий «MFA Forum» («MPLS–Frame Relay–ATM Forum»). В 2007 г. последний был переименован
в «IP/MPLS Forum». В апреле 2009 г. «IP/MPLS Forum» вошёл в состав существующего с 1994 г.
консорциума «Broadband Forum» («BBF»). Спецификации ATM доступны в их исходном виде на
сайте консорциума www.broadband-forum.org[40], но их дальнейшая разработка полностью
остановлена.
Базовые принципы
Сеть ATM строится на основе соединенных друг с другом АТМ-коммутаторов. Технология
реализуется как в локальных, так и в глобальных сетях. Допускается совместная передача
различных видов информации, включая видео, голос.
Ячейки данных, используемые в ATM, меньше в сравнении с элементами данных, которые
используются в других технологиях. Небольшой, постоянный размер ячейки, используемый в
ATM, позволяет:
Совместно передавать данные с различными классами требований к задержкам в сети,
причём по каналам как с высокой, так и с низкой пропускной способностью;
Работать с постоянными и переменными потоками данных;
Интегрировать на одном канале любые виды информации: данные, голос, потоковое
аудио- и видеовещание, телеметрия и т. п.;
Поддерживать соединения типа точка–точка, точка–многоточка и многоточка–многоточка.
Технология ATM предполагает межсетевое взаимодействие на трёх уровнях.
Для передачи данных от отправителя к получателю в сети ATM создаются виртуальные каналы,
VC (англ. Virtual Circuit), которые бывают трёх видов:
постоянный виртуальный канал, PVC (Permanent Virtual Circuit), который создаётся между
двумя точками и существует в течение длительного времени, даже в отсутствие данных
для передачи;
коммутируемый виртуальный канал, SVC (Switched Virtual Circuit), который создаётся
между двумя точками непосредственно перед передачей данных и разрывается после
окончания сеанса связи.
автоматически настраиваемый постоянный виртуальный канал, SPVC (Soft Permanent
Virtual Circuit). Каналы SPVC по сути представляют собой каналы PVC, которые
инициализируются по требованию в коммутаторах ATM. С точки зрения каждого
участника соединения, SPVC выглядит как обычный PVC, а что касается коммутаторов
ATM в инфраструктуре провайдера, то для них каналы SPVC имеют значительные отличия
от PVC. Канал PVC создаётся путём статического определения конфигурации в рамках
всей инфраструктуры провайдера и всегда находится в состоянии готовности. Но в канале
SPVC соединение является статическим только от конечной точки (устройство DTE) до
первого коммутатора ATM (устройство DCE). А на участке от устройства DCE
отправителя до устройства DCE получателя в пределах инфраструктуры провайдера
соединение может формироваться, разрываться и снова устанавливаться по требованию.
Установленное соединение продолжает оставаться статическим до тех пор, пока
нарушение работы одного из звеньев канала не вызовет прекращения функционирования
этого виртуального канала в пределах инфраструктуры провайдера сети.
Для маршрутизации в пакетах используют так называемые идентификаторы пакета. Они бывают
двух видов:
VPI (англ. virtual path identifier) — идентификатор виртуального пути (номер канала)
VCI (англ. virtual circuit identifier) — идентификатор виртуального канала (номер
соединения)
Структура ячейки
Формат ячейки UNI
7
6
5
4
3
Формат ячейки NNI
2
1
7
GFC
VPI
VPI
VPI
VCI
VPI
VCI
VCI
6
5
4
3
2
1
VCI
VCI
PT
CLP
VCI
PT
CLP
HEC
HEC
Полезные данные ячейки (48 байт)
Полезные данные ячейки (48 байт)
GFC = Generic Flow Control (4 бита) — общее управление потоком;
VPI = Virtual Path Identifier (8 бит UNI) или (12 бит NNI) — идентификатор виртуального пути;
VCI = Virtual channel identifier (16 бит) — идентификатор виртуального канала;
PT = Payload Type (3 бита) — тип данных;
CLP = Cell Loss Priority (1 бит) — уровень приоритета при потере пакета; указывает на то, какой
приоритет имеет ячейка (cell), и будет ли она отброшена в случае перегрузки канала;
HEC = Header Error Control (8 бит) — поле контроля ошибок.
UNI = User-to-Network Interface — интерфейс пользователь-сеть. Стандарт, разработанный ATM
Forum, который определяет интерфейс между конечной станцией и коммутатором в сети ATM.
NNI = Network-to-Network Interface — интерфейс сеть-сеть. Обобщённый термин, описывающий
интерфейс между двумя коммутаторами в сети.
Классы обслуживания и категории услуг
Определено пять классов трафика, отличающихся следующими качественными характеристиками:
наличием или отсутствием пульсации трафика, то есть трафики CBR или VBR;
требованием к синхронизации данных между передающей и принимающей сторонами;
типом протокола, передающего свои данные через сеть ATM, — с установлением
соединения или без установления соединения (только для случая передачи компьютерных
данных).
CBR не предусматривает контроля ошибок, управления трафиком или какой-либо другой
обработки. Класс CBR пригоден для работы с мультимедиа реального времени.
Класс VBR содержит в себе два подкласса — обычный и для реального времени (см. таблицу
ниже). ATM в процессе доставки не вносит никакого разброса ячеек по времени. Случаи потери
ячеек игнорируются.
Класс ABR предназначен для работы в условиях мгновенных вариаций трафика. Система
гарантирует некоторую пропускную способность, но в течение короткого времени может
выдержать и большую нагрузку. Этот класс предусматривает наличие обратной связи между
приёмником и отправителем, которая позволяет понизить загрузку канала, если это необходимо.
Класс UBR хорошо пригоден для посылки IP-пакетов (нет гарантии доставки и в случае
перегрузки неизбежны потери).
Основные характеристики классов трафика ATM
Класс QoS
1
2
3
4
5
Класс обслуживания
A
B
C
D
x
Тип трафика
CBR
VBR
VBR
ABR
UBR
Тип уровня
AAL1
AAL2
AAL3/4
AAL3/4
Синхронизация
Требуется
Скорость передачи
Постоянная
Режим соединения
С установлением
Пример
(Е1, Т1)
Не требуется
Переменная
Видео
Без установления
аудио
Передача данных
использования
Вопрос 13. Протоколы туннелирования. Режим туннелирования.
Туннелирование (от англ. tunnelling — «прокладка туннеля») в компьютерных сетях — процесс,
в ходе которого создается защищенное логическое соединение между двумя конечными точками
посредством инкапсуляции различных протоколов. Туннелирование представляет собой метод
построения сетей, при котором один сетевой протоколинкапсулируется в другой. От обычных
многоуровневых сетевых моделей (таких как OSI или TCP/IP) туннелирование отличается тем, что
инкапсулируемый протокол относится к тому же или более низкому уровню, чем используемый в
качестве тоннеля.
Суть туннелирования состоит в том, чтобы «упаковать» передаваемую порцию данных, вместе со
служебными полями, в новый «конверт» для обеспечения конфиденциальности и целостности
всей передаваемой порции, включая служебные поля. Туннелирование может применяться на
сетевом и на прикладном уровнях. Комбинация туннелирования и шифрования позволяет
реализовать закрытые виртуальные частные сети (VPN). Туннелирование обычно применяется для
согласования транспортных протоколов либо для создания защищённого соединения
между узлами сети.
Типы протоколов
В процессе инкапсуляции (туннелирования) принимают участие следующие типы протоколов:
1. транспортируемый протокол;
2. несущий протокол;
3. протокол инкапсуляции.
Протокол транзитной сети является несущим, а протокол объединяемых сетей —
транспортируемым. Пакеты транспортируемого протокола помещаются в поле данных
пакетовнесущего протокола с помощью протокола инкапсуляции. Пакеты-«пассажиры» не
обрабатываются при транспортировке по транзитной сети никаким образом. Инкапсуляцию
выполняет пограничное устройство (маршрутизатор или шлюз), которое находится на границе
между исходной и транзитной сетями. Извлечение пакетов транспортируемогопротокола из
несущих пакетов выполняет второе пограничное устройство, расположенное на границе между
транзитной сетью и сетью назначения. Пограничные устройства указывают в несущих пакетах
свои адреса, а не адреса узлов в сети назначения.
Согласование транспортных протоколов
Туннель может быть использован, когда две сети с одной транспортной технологией необходимо
соединить через сеть, использующую другую транспортную технологию. При этом
пограничные маршрутизаторы, которые подключают объединяемые сети к транзитной,
упаковывают пакеты транспортного протокола объединяемых сетей в пакеты транспортного
протокола транзитной сети. Второй пограничный маршрутизатор выполняет обратную операцию.
Обычно туннелирование приводит к более простым и быстрым решениям по сравнению с
трансляцией, так как решает более частную задачу, не обеспечивая взаимодействия с узлами
транзитной сети.
Основные компоненты туннеля
Основными компонентами туннеля являются:
инициатор туннеля;
маршрутизируемая сеть;
туннельный коммутатор;
один или несколько туннельных терминаторов.
Инициатор туннеля встраивает (инкапсулирует) пакеты в новый пакет, содержащий наряду с
исходными данными новый заголовок с информацией об отправителе и получателе. Несмотря на
то, что все передаваемые по туннелю пакеты являются пакетами IP, инкапсулируемые пакеты
могут принадлежать к протоколу любого типа, включая пакеты немаршрутизируемых протоколов.
Маршрут между инициатором и терминатором туннеля определяет обычная маршрутизируемая
сеть IP, которая может быть и сетью, отличной отInternet. Терминатор туннеля выполняет процесс,
который является обратным инкапсуляции — он удаляет новые заголовки и направляет каждый
исходный пакет в локальный стекпротоколов или адресату в локальной сети. Инкапсуляция сама
по себе никак не влияет на защищенность пакетов сообщений, передаваемых по туннелю VPN. Но
инкапсуляция даёт возможность полной криптографической защиты инкапсулируемых пакетов.
Конфиденциальность инкапсулируемых пакетов обеспечивается путем их криптографического
закрытия, т. е. зашифровывания, а целостность и подлинность — путем формирования цифровой
подписи. Так как существует множество методов криптозащиты данных, необходимо чтобы
инициатор и терминатор туннеля использовали одни и те же методы и могли согласовывать друг с
другом эту информацию. Более того, для возможности расшифровывания данных и проверки
цифровой подписи при приеме инициатор и терминатор туннеля должны поддерживать функции
безопасного обмена ключами. Чтобы туннели VPN создавались только между уполномоченными
пользователями, конечные стороны взаимодействия требуется аутентифицировать.
Вопрос 14. Шифрование данных с использованием IPSec.
IPSec (сокращение от IP Security) — определенный IETF стандарт достоверной/конфиденциальной
передачи данных по сетям IP. Чаще всего IPSec используется для создания VPN (Virtual Private
Network).
IPSec является неотъемлемой частью IPv6 — Интернет-протокола следующего поколения, и
расширением существующие версии Интернет-протокола IPv4. IPSec определён в RFC с 2401 по
2412.
Практически все механизмы сетевой безопасности могут быть реализованы на третьем уровне
эталонной модели ISO/OSI в соответствии с рисунком 1.1. Кроме того, IP-уровень можно считать
оптимальным для размещения защитных средств, поскольку при этом достигается удачный
компромисс между защищенностью, эффективностью функционирования и прозрачностью для
приложений.
Рисунок 1.1 — Модель OSI/ISO
Стандартизованными механизмами IP-безопасности могут (и должны) пользоваться протоколы
более высоких уровней и, в частности, управляющие протоколы, протоколы конфигурирования и
маршрутизации.
Средства безопасности для IP описываются семейством спецификаций IPSec, разработанных
рабочей группой IP Security.
Протоколы IPSec обеспечивают управление доступом, целостность вне соединения,
аутентификацию источника данных, защиту от воспроизведения, конфиденциальность и
частичную защиту от анализа трафика.
Основополагающими понятиями IPSec являются:
— аутентификационный заголовок (АН);
— безопасное сокрытие данных (ESP);
— режимы работы: туннельный и транспортный;
— контексты (ассоциации) безопасности (SA);
— управление ключами (IKE);
Содержание
2. ОСНОВНЫЕ СОСТАВЛЯЮЩИЕ АРХИТЕКТУРЫ И ИХ ОСОБЕННОСТИ
Архитектура средств безопасности для IP-уровня специфицирована в документе Security
Architecture for the Internet Protocol. Ее основные составляющие представлены в соответствии с
рисунком 2.1. Это, прежде всего протоколы обеспечения аутентичности (протокол
аутентифицирующего заголовка — Authentication Header, AH) и конфиденциальности (протокол
инкапсулирующей защиты содержимого — Encapsulating Security payload, ESP), а также механизмы
управления криптографическими ключами. На более низком архитектурном уровне располагаются
конкретные алгоритмы шифрования, контроля целостности и аутентичности. Наконец, роль
фундамента выполняет так называемый домен интерпретации (Domain of Interpretation, DOI),
являющийся, по сути, базой данных, хранящей сведения об алгоритмах, их параметрах,
протокольных идентификаторах.
Рисунок 2.1 — Основные элементы архитектуры средств безопасности IP-уровня
Деление на уровни важно для всех аспектов информационных технологий. Там же, где участвует
еще и криптография, важность возрастает вдвойне, поскольку приходится считаться не только с
чисто техническими факторами, но и с особенностями законодательства различных стран, с
ограничениями на экспорт и/или импорт криптосредств.
IPSec поддерживает две формы целостности: целостность соединения и частичную целостность
последовательности. Целостность соединения является сервисом безопасности, который
определяет модификацию конкретной IP датаграммы, безотносительно последовательности
датаграмм в потоке трафика. Частичная целостность последовательности является anti-reply
сервисом, с помощью которого определяется получение дубликатов IP датаграм.
Эти сервисы как раз и реализуются с использованием двух протоколов обеспечения безопасного
трафика, Authentication Header (AH) и Encapsulating Security Payload (ESP), и с помощью процедур
и протоколов управления криптографическим ключом. Множество применяемых IPSec
протоколов и метод их использования определяются требованиями безопасности.
Когда данные механизмы установлены корректно, они не мешают пользователям, хостам и другим
компонентам Internet, которые не применяют данные механизмы безопасности для защиты своего
трафика. Протоколы обеспечения аутентичности и конфиденциальности в IPSec не зависят от
конкретных криптографических алгоритмов. (Более того, само деление на аутентичность и
конфиденциальность предоставляет и разработчикам, и пользователям дополнительную степень
свободы в ситуации, когда к криптографическим относят только шифровальные средства.) В
каждой стране могут применяться свои алгоритмы, соответствующие национальным стандартам,
но для этого, как минимум, нужно позаботиться об их регистрации в домене интерпретации. Это
означает возможность выбора различного набора алгоритмов без воздействия на другие части
реализации. Например, различные группы пользователей могут выбрать при необходимости
различные наборы алгоритмов.
Определен стандартный набор алгоритмов по умолчанию для обеспечения интероперабельности.
Использование этих алгоритмов совместно с защитой трафика на основе IPSec и протоколами
управления ключа позволяет обеспечить высокую степень криптографической безопасности.
Алгоритмическая независимость протоколов имеет и оборотную сторону, состоящую в
необходимости предварительного согласования набора применяемых алгоритмов и их параметров,
поддерживаемых общающимися сторонами. Иными словами, стороны должны выработать общий
контекст безопасности (Security Association, SA) и затем использовать такие его элементы, как
алгоритмы и их ключи. SA подробно рассматривается далее. За формирование контекстов
безопасности в IPSec отвечает особое семейство протоколов ISAKMP, которое рассматривается
также в отдельном разделе.
Безопасность, обеспечиваемая IPSec, зависит от многих факторов операционного окружения, в
котором IPSec выполняется. Например, от безопасности ОС, источника случайных чисел, плохих
протоколов управления системой.
Содержание
3. РАЗМЕЩЕНИЕ И ФУНКЦИОНИРОВАНИЕ IPSEC
IPSec выполняется на хосте или шлюзе безопасности, обеспечивая защиту IP- трафика. Термин
<шлюз безопасности> используется для обозначения промежуточной системы, которая реализует
IPSec-протоколы. Защита основана на требованиях, определенных в Базе Данных Политики
Безопасности (Security Policy Database- SPD), определяемой и поддерживаемой системным
администратором. Пакеты обрабатываются одним из трех способов на основании соответствия
информации заголовка IP или транспортного уровня записям в SPD. Каждый пакет либо
отбрасывается сервисом безопасности IPSec, либо пропускается без изменения, либо
обрабатывается сервисом IPSec на основе применения определенной политики.
IPSec обеспечивает сервисы безопасности на IP-уровне, выбирая нужные протоколы безопасности,
определяя алгоритмы, используемые сервисами, и предоставляя все криптографические ключи
требуемым сервисам. IPSec может использоваться для защиты одного или нескольких <путей>
между парой хостов, между парой шлюзов безопасности или между шлюзом безопасности и
хостом.
IPSec использует два протокола для обеспечения безопасности трафика — Authentication Header
(AH) и Encapsulating Security Payload (ESP). Хотя бы один из этих сервисов должен быть
задействован при использовании ESP.
Эти протоколы могут применяться как по отдельности так и в комбинации с друг другом для
обеспечения необходимого набора сервисов безопасности в IPv4 и IPv6. Каждый протокол
поддерживает два режима использования: режим транспорта и режим туннелирования. В
транспортном режиме протоколы обеспечивают защиту главным образом для протоколов более
высокого уровня; в режиме туннелирования протоколы применяются для скрытия IP-заголовков
исходных пакетов. Разница между двумя режимами рассматривается дальше.
IPSec позволяет системному администратору управлять детализацией, с которой предоставляется
сервис безопасности. Например, можно создать единственный зашифрованный туннель между
двумя безопасными шлюзами, или для каждого ТСР соединения может быть создан
зашифрованный туннель между парой хостов. IPSec позволяет указывать следующие параметры:
а) какие сервисы используются, и в какой комбинации;
б) необходимый уровень детализации применяемой защиты;
в) алгоритмы, используемые для обеспечения безопасности на основе криптографии;
Существует несколько способов реализации IPSec на хосте или в соединении с роутером или
firewall (для создания безопасного шлюза). Несколько общих примеров:
а) интеграция IPSec в конкретную реализацию IP, что требует доступа к исходному коду IP и
применимо как к хостам, так и к шлюзам безопасности;
б) bump-in-the-stack (BITS) реализации, где IPSec действует <внизу> существующей реализации
стека протоколов IP, между обычным IP и локальными сетевыми драйверами; доступа к
исходному коду стека IP в данном контексте не требуется, что делает такой подход пригодным для
встраивания в существующие системы, и реализации на хостах;
в) использование внешнего криптопроцессора (обычно в военных и в некоторых коммерческих
системах), как правило, это является Bump-in-the-stack (BITS) реализацией, используется как на
хостах, так и на шлюзах, обычно BITS-устройства являются IP-адресуемыми;
Транспортный режим работы.
В этом варианте механизмы безопасности применяются только для протоколов, начиная с
транспортного (TCP) уровня и выше, оставляя данные самого сетевого уровня (заголовок IP) без
дополнительной защиты. Места размещения дополнительной информации, вставляемой
протоколами в пакет, представлены в соответствии с рисунком 3.1.
Рисунок 3.1 — Транспортный режим
Туннельный режим работы.
Этот режим интересен тем, что обеспечивает защиту также и данных сетевого уровня путем
добавления нового IP-заголовка. После определения ассоциаций безопасности (например, между
двумя шлюзами) истинные адреса хостов отправления и назначения (и другие служебные поля)
полностью защищаются от модификаций для АН или вообще скрываются для ESP, а в новый
заголовок выставляются адреса и другие данные для шлюзов (отправления/получения). В
соответствии с рисунком 3.2 видны преимущества и недостатки обоих протоколов. ESP
обеспечивает сокрытие данных, но не полную аутентификацию всего пакета. АН полностью
аутентифицирует, но не скрывает данные. В этом причина того, что для обеспечения высокого
уровня безопасности, применение протоколов совмещается.
Рисунок 3.2 — Туннельный режим
Содержание
4. КОНТЕКСТЫ (АССОЦИАЦИИ) БЕЗОПАСНОСТИ И УПРАВЛЕНИЕ КЛЮЧАМИ
Формирование контекстов безопасности в IPSec разделено на две фазы. Сначала создается
управляющий контекст, назначение которого — предоставить доверенный канал, т. е.
аутентифицированный, защищенный канал для выработки (в рамках второй фазы) протокольных
контекстов и, в частности, для формирования криптографических ключей, используемых
протоколами AH и ESP.
В принципе, для функционирования механизмов IPSec необходимы только протокольные
контексты; управляющий играет вспомогательную роль. Более того, явное выделение двух фаз
утяжеляет и усложняет формирование ключей, если рассматривать последнее как однократное
действие. Тем не менее, из архитектурных соображений управляющие контексты не только могут,
но и должны существовать, поскольку обслуживают все протокольные уровни стека TCP/IP,
концентрируя в одном месте необходимую функциональность. Первая фаза начинается в
ситуации, когда взаимодействующие стороны не имеют общих секретов (общих ключей) и не
уверены в аутентичности друг друга. Если с самого начала не создать доверенный канал, то для
выполнения каждого управляющего действия с ключами (их модификация, выдача
диагностических сообщений и т.п.) в каждом протоколе (AH, ESP, TLS и т.д.) этот канал придется
формировать заново.
Общие вопросы формирования контекстов безопасности и управления ключами освещаются в
спецификации «Контексты безопасности и управление ключами в Internet» (Internet Security
Association and Key Management Protocol, ISAKMP). Здесь вводятся две фазы выработки
протокольных ключей, определяются виды управляющих информационных обменов и
используемые форматы заголовков и данных. Иными словами строится протокольно-независимый
каркас.
Существует несколько способов формирования управляющего контекста. Они различаются двумя
показателями:
— используемым механизмом выработки общего секретного ключа;
— степенью защиты идентификаторов общающихся сторон;
В простейшем случае секретные ключи задаются заранее (ручной метод распределения ключей).
Для небольших сетей такой подход вполне работоспособен, но он не является масштабируемым.
Последнее свойство может быть обеспечено при автоматической выработке и распределении
секретных ключей в рамках протоколов, основанных на алгоритме Диффи-Хелмана. Пример тому
— «Протокол для обмена ключами в Internet » (The Internet Key Exchange, IKE).
При формировании управляющего контекста идентификаторы общающихся сторон (например, IPадреса) могут передаваться в открытом виде или шифроваться. Поскольку ISAKMP
предусматривает функционирование в режиме клиент/сервер (т. е. ISAKMP-сервер может
формировать контекст для клиента), сокрытие идентификаторов в определенной степени
повышает защищенность от пассивного прослушивания сети.
Последовательность передаваемых сообщений, позволяющих сформировать управляющий
контекст и обеспечивающих защиту идентификаторов, выглядит в соответствии с рисунком 4.1.
Рисунок 4.1 — Формирование управляющего контекста
В первом сообщении (1) инициатор направляет предложения по набору защитных алгоритмов и
конкретных механизмов их реализации. Предложения упорядочиваются по степени
предпочтительности (для инициатора). В ответном сообщении (2) партнер информирует о
сделанном выборе — какие алгоритмы и механизмы его устраивают. Для каждого класса защитных
средств (генерация ключей, аутентификация, шифрование) выбирается только один элемент.
В сообщениях (3) и (4) инициатор и партнер отправляют свои части ключевого материала,
необходимые для выработки общего секретного ключа (опускаются детали, специфичные для
алгоритма Диффи-Хелмана). Одноразовые номера (nonce) представляют собой псевдослучайные
величины, служащие для защиты от воспроизведения сообщений.
Посредством сообщений (5) и (6) происходит обмен идентификационной информацией,
подписанной (с целью аутентификации) секретным ключом отправителя и зашифрованной
выработанным на предыдущих шагах общим секретным ключом. Для аутентификации
предполагается использование сертификатов открытых ключей. В число подписываемых данных
входят одноразовые номера.
В представленном виде протокол формирования управляющего контекста защищает от атак,
производимых нелегальным посредником, а также от нелегального перехвата соединений. Для
защиты от атак на доступность, для которых характерно прежде всего навязывание интенсивных
вычислений, присущих криптографии с открытым ключом, применяются так называемые
идентифицирующие цепочки (cookies). Эти цепочки, формируемые инициатором и его партнером
с использованием текущего времени (для защиты от воспроизведения), на самом деле
присутствуют во всех ISAKMP-сообщениях и в совокупности идентифицируют управляющий
контекст (в первом сообщении, по понятным причинам, фигурирует только цепочка инициатора).
Согласно спецификациям, заголовок ISAKMP-сообщения имеет вид в соответствии с рисунком
4.2. Если злоумышленник пытается «завалить» кого-либо запросами на создание управляющего
контекста, подделывая при этом свой IP-адрес, то в сообщении (3) он не сможет предъявить
идентифицирующую цепочку партнера, поэтому до выработки общего секретного ключа и, тем
более, электронной подписи и полномасштабной проверки аутентичности дело попросту не
дойдет.
Рисунок 4.2 — Формат заголовка ISAKMP-сообщения
Управляющие контексты являются двунаправленными в том смысле, что любая из общающихся
сторон может инициировать с их помощью выработку новых протокольных контекстов или иные
действия. Для передачи ISAKMP-сообщений используется любой протокол, однако в качестве
стандартного принят UDP с номером порта 500.
Содержание
5. ПРОТОКОЛЬНЫЕ КОНТЕКСТЫ (АССОЦИАЦИИ) И ПОЛИТИКА БЕЗОПАСНОСТИ
Системы, реализующие IPSec, должны поддерживать две базы данных:
— базу данных политики безопасности (Security Policy Database, SPD);
— базу данных протокольных контекстов безопасности (Security Association Database, SAD);
Все IP-пакеты (входящие и исходящие) сопоставляются с упорядоченным набором правил
политики безопасности. При сопоставлении используется фигурирующий в каждом правиле
селектор — совокупность анализируемых полей сетевого уровня и более высоких протокольных
уровней. Первое подходящее правило определяет дальнейшую судьбу пакета:
— пакет может быть ликвидирован;
— пакет может быть обработан без участия средств IPSec;
— пакет должен быть обработан средствами IPSec с учетом набора протокольных контекстов,
ассоциированных с правилом;
Таким образом, системы, реализующие IPSec, функционируют как межсетевые экраны, фильтруя
и преобразуя потоки данных на основе предварительно заданной политики безопасности.
Далее рассматриваются контексты и политика безопасности, а также порядок обработки сетевых
пакетов.
Протокольный контекст безопасности в IPSec — это однонаправленное «соединение» (от источника
к получателю), предоставляющее обслуживаемым потокам данных набор защитных сервисов в
рамках какого-то одного протокола (AH или ESP). В случае симметричного взаимодействия
партнерам придется организовать два контекста (по одному в каждом направлении). Если
используются и AH, и ESP, потребуется четыре контекста.
Элементы базы данных протокольных контекстов содержат следующие поля (в каждом
конкретном случае некоторые значения полей будут пустыми):
— используемый в протоколе AH алгоритм аутентификации, его ключи и т.п.;
— используемый в протоколе ESP алгоритм шифрования, его ключи, начальный вектор и т.п.;
— используемый в протоколе ESP алгоритм аутентификации, его ключи и т.п.;
— время жизни контекста;
— режим работы IPSec: транспортный или туннельный;
— максимальный размер пакетов;
— группа полей (счетчик, окно, флаги) для защиты от воспроизведения пакетов;
Пользователями протокольных контекстов, как правило, являются прикладные процессы. Вообще
говоря, между двумя узлами сети может существовать произвольное число протокольных
контекстов, так как число приложений в узлах произвольно. В качестве пользователей
управляющих контекстов обычно выступают узлы сети (поскольку в этих контекстах желательно
сосредоточить общую функциональность, необходимую сервисам безопасности всех
протокольных уровней эталонной модели для управления криптографическими ключами).
Управляющие контексты — двусторонние, т. е. любой из партнеров может инициировать новый
ключевой обмен. Пара узлов может одновременно поддерживать несколько активных
управляющих контекстов, если имеются приложения с существенно разными
криптографическими требованиями. Например, допустима выработка части ключей на основе
предварительно распределенного материала, в то время как другая часть порождается по
алгоритму Диффи-Хелмана.
Протокольный контекст для IPSec идентифицируется целевым IP-адресом, протоколом (AH или
ESP), а также дополнительной величиной — индексом параметров безопасности (Security Parameter
Index, SPI). Последняя величина необходима, поскольку могут существовать несколько контекстов
с одинаковыми IP-адресами и протоколами. Далее показано, как используются индексы SPI при
обработке входящих пакетов.
IPSec обязывает поддерживать ручное и автоматическое управление контекстами безопасности и
криптографическими ключами. В первом случае все системы заранее снабжаются ключевым
материалом и иными данными, необходимыми для защищенного взаимодействия с другими
системами. Во втором — материал и данные вырабатываются динамически, на основе
определенного протокола — IKE, поддержка которого обязательна.
Протокольный контекст создается на базе управляющего с использованием ключевого материала
и средств аутентификации и шифрования последнего. В простейшем случае, когда протокольные
ключи генерируются на основе существующих, последовательность передаваемых сообщений
выглядит в соответствии с рисунком 5.1.
Рисунок 5.1 — Формирование протокольного контекста
Когда вырабатывался управляющий контекст, для него было создано три вида ключей:
— SKEYID_d — ключевой материал, используемый для генерации протокольных ключей;
— SKEYID_a — ключевой материал для аутентификации;
— SKEYID_e — ключевой материал для шифрования;
Все перечисленные виды ключей задействованы в обмене. Ключом SKEYID_e шифруются
сообщения. Ключ SKEYID_a служит аргументом хэш-функций и тем самым аутентифицирует
сообщения. Наконец, протокольные ключи — результат применения псевдослучайной (хэш)
функции к SKEYID_d с дополнительными параметрами, в число которых входят одноразовые
номера инициатора и партнера. В результате создание протокольного контекста оказывается
аутентифицированным, защищенным от несанкционированного ознакомления, от
воспроизведения сообщений и от перехвата соединения.
Сообщения (1) и (2) могут нести дополнительную нагрузку, например, данные для выработки
«совсем новых» секретных ключей или идентификаторы клиентов, от имени которых ISAKMPсерверы формируют протокольный контекст. В соответствии с протоколом IKE, за один обмен
(состоящий из трех показанных сообщений) формируется два однонаправленных контекста — по
одному в каждом направлении. Получатель контекста задает для него индекс параметров
безопасности (SPI), помогающий находить контекст для обработки принимаемых пакетов IPSec.
Протокольные контексты играют вспомогательную роль, будучи лишь средством проведения в
жизнь политики безопасности; она должна быть задана для каждого сетевого интерфейса с
задействованными средствами IPSec и для каждого направления потоков данных
(входящие/исходящие). Согласно спецификациям IPSec, политика рассчитывается на
бесконтекстную (независимую) обработку IP-пакетов, в духе современных фильтрующих
маршрутизаторов. Разумеется, должны существовать средства администрирования базы данных
SPD, так же, как и средства администрирования базы правил межсетевого экрана, однако этот
аспект не входит в число стандартизуемых.
С внешней точки зрения, база данных политики безопасности (SPD) представляет собой
упорядоченный набор правил. Каждое правило задается как пара:
— совокупность селекторов;
— совокупность протокольных контекстов безопасности;
Селекторы служат для отбора пакетов, контексты задают требуемую обработку. Если правило
ссылается на несуществующий контекст, оно должно содержать достаточную информацию для
его (контекста) динамического создания. В этом случае требуется поддержка автоматического
управления контекстами и ключами. В принципе, функционирование системы может начинаться с
задания базы SPD при пустой базе контекстов (SAD); последняя будет наполняться по мере
необходимости.
Дифференцированность политики безопасности определяется селекторами, употребленными в
правилах. Например, пара взаимодействующих хостов может использовать единственный набор
контекстов, если в селекторах фигурируют только IP-адреса; с другой стороны, набор может быть
своим для каждого приложения, если анализируются номера TCP- и UDP-портов. Аналогично, два
защитных шлюза способны организовать единый туннель для всех обслуживаемых хостов или же
расщепить его (путем организации разных контекстов) по парам хостов или даже приложений.
Все реализации IPSec должны поддерживать селекцию следующих элементов:
— исходный и целевой IP-адреса (адреса могут быть индивидуальными и групповыми, в правилах
допускаются диапазоны адресов и метасимволы «любой»;
— имя пользователя или узла в формате DNS или X.500;
— транспортный протокол;
— номера исходного и целевого портов (здесь также могут использоваться диапазоны и
метасимволы);
Обработка исходящего и входящего трафика, не является симметричной. Для исходящих пакетов
просматривается база SPD, находится подходящее правило, извлекаются ассоциированные с ним
протокольные контексты и применяются соответствующие механизмы безопасности. Во
входящих пакетах для каждого защитного протокола уже проставлено значение SPI, однозначно
определяющее контекст. Просмотр базы SPD в таком случае не требуется; можно считать, что
политика безопасности учитывалась при формировании соответствующего контекста.
(Практически это означает, что ISAKMP-пакеты нуждаются в особой трактовке, а правила с
соответствующими селекторами должны быть включены в SPD.)
Отмеченная асимметрия отражает определенную незавершенность архитектуры IPSec. В более
раннем документе RFC 1825 понятия базы данных политики безопасности и селекторов
отсутствовали. В новой редакции сделано полшага вперед — специфицирован просмотр базы SPD
как обязательный для каждого исходящего пакета, но не изменена обработка входящих пакетов.
Извлечение контекста по индексу SPI эффективнее, чем просмотр набора правил, но при таком
подходе, затрудняется оперативное изменение политики безопасности. Что касается
эффективности просмотра правил, то ее можно повысить методами кэширования, широко
используемыми при реализации IP.
Содержание
6. АУТЕНТИФИКАЦИОННЫЙ ЗАГОЛОВОК (AH)
Аутентификационный заголовок (англ. authentication header) AH предназначен для обеспечения
аутентификации отправителя, контроля целостности данных и опционально для предотвращения
повторной посылки (англ. replay) пакета — при условии, что принимающая сторона настроена
производить проверку последовательного номера пакета. Поля IP-пакета, которые изменяются в
пути следования, не подлежат контролю целостности. AH защищает данные протоколов более
высоких уровней и те поля IP-заголовков, которые не меняются на маршруте доставки или
меняются предсказуемым образом (число «непредсказуемых» полей невелико — это prio. (Traffic
Class), Flow Label и Hop Limit. Предсказуемо меняется целевой адрес при наличии
дополнительного заголовка исходящей маршрутизации.).
Формат заголовка AH показан в соответствии с рисунком 6.1.
Рисунок 6.1 — Формат заголовка AH
— поле «Следующий заголовок» (Next header) идентифицирует тип следующих значимых данных за
аутентификационным заголовком; значения поля берутся из предопределенного множества
установленных IANA (Internet Assigned Numbers Authority) номеров;
— поле «Длина значимих данных» (Payload length) определяет длину самого АН в 32-битовых
словах минус 2 слова, поскольку для заголовков, расширяемых для IPv6, установлено требование
сокращения длины заголовка на 64 бита;
— зарезервированное поле должно быть нулевым;
— поле «Индекс параметров безопасности» (Security Parameters Index — SPI) — это значение, которое в
совокупности с адресом назначения и самим протоколом (в данном случае АН) однозначно
определяет ассоциацию безопасности (Security Association — SA) для данной датаграммы в виде 32битного номера; номера с 1 по 255 зарезервированы IANA; SPI, равный нулю, означает, что SA не
установлена; ассоциация безопасности — это набор параметров (версия алгоритмов шифрования и
аутентификации, схема обмена ключами и т. п.), определяющих, каким образом будет
обеспечиваться защита данных;
— поле «Последовательный номер» (Sequence number) — зто монотонно возрастающий от 0 (при
установлении SA) номер пакета. Он используется для возможности контроля получателем
ситуации повторной пересылки пакетов;
— поле «Данные аутентификации» (Authentication data) содержат значение контроля целостности
(Integrity check value — ICV), рассчитанное по всем данным, которые не изменяются в пути
следования пакета или предсказуемы на момент достижения им получателя. Значение ICV
рассчитывается в зависимости от алгоритма, определенного в SA, например код аутентификации
сообщения (Message Authentication Code — МАС) с ключом симметричного или асимметричного
алгоритма или хэшфункции;
Содержание
7. БЕЗОПАСНОЕ СОКРЫТИЕ СУЩЕСТВЕННЫХ ДАННЫХ
Протокол инкапсулирующей защиты содержимого (Encapsulating Security payload, ESP)
предоставляет три вида сервисов безопасности:
— обеспечение конфиденциальности (шифрование содержимого IP-пакетов, а также частичная
защита от анализа трафика путем применения туннельного режима);
— обеспечение целостности IP-пакетов и аутентификации источника данных;
— обеспечение защиты от воспроизведения IP-пакетов;
Функциональность ESP шире, чем у AH (добавляется шифрование); ESP не обязательно
предоставляет все сервисы, но либо конфиденциальность, либо аутентификация должны быть
задействованы. Формат заголовка ESP выглядит в соответствии с рисунком 7.1. Это не столько
заголовок, сколько обертка (инкапсулирующая оболочка) для зашифрованного содержимого.
Например, ссылку на следующий заголовок нельзя выносить в начало, в незашифрованную часть,
так как она лишится конфиденциальности.
Рисунок 7.1 — Формат заголовка ESP
Поля «Индекс параметров безопасности (SPI)», «Порядковый номер» и «Аутентификационные
данные» (последнее присутствует только при включенной аутентификации) имеют тот же смысл,
что и для AH. ESP аутентифицирует лишь зашифрованную часть пакета (плюс два первых поля
заголовка).
Применение протокола ESP к исходящим пакетам можно представлять себе следующим образом.
Пусть остаток пакета та его часть, которая помещается после предполагаемого места вставки
заголовка ESP. При этом не важно, какой режим используется — транспортный или туннельный.
Шаги протокола таковы:
— остаток пакета копируется в буфер;
— к остатку приписываются дополняющие байты, их число и номер (тип) первого заголовка
остатка, с тем чтобы номер был прижат к границе 32-битного слова, а размер буфера удовлетворял
требованиям алгоритма шифрования;
— текущее содержимое буфера шифруется;
— в начало буфера приписываются поля «Индекс параметров безопасности (SPI)» и «Порядковый
номер» с соответствующими значениями;
— пополненное содержимое буфера аутентифицируется, в его конец помещается поле
«Аутентификационные данные»;
— в новый пакет переписываются начальные заголовки старого пакета и конечное содержимое
буфера;
Если в ESP включены и шифрование, и аутентификация, то аутентифицируется зашифрованный
пакет. Для входящих пакетов действия выполняются в обратном порядке, т. е. сначала
производится аутентификация. Это позволяет не тратить ресурсы на расшифровку поддельных
пакетов, что в какой-то степени защищает от атак на доступность.
Содержание
8. ПРОТОКОЛ ОБМЕНА КЛЮЧАМИ — IKE
8.1 Общие сведения
Поскольку основным механизмом обеспечения безопасности данных протокола являются
криптографические методы, участники защищенного соединения должны наладить обмен
соответствующими криптографическими ключами. Обеспечить настройку процесса такого обмена
можно вручную и автоматически. Первый способ допустим для небольшого количества
достаточно статичных систем, а в общем случае это производится автоматически.
Для автоматического обмена ключами по умолчанию используется Протокол управления ключами
в Интернете (Internet Key Management Protocol — IKMP), иначе называемый Обмен ключами в
Интернете (Internet Key Exchange — IKE). Дополнительно или альтернативно могут быть
применены другие протоколы, такие как Kerberos или SKIP.
IKE совмещает в себе три основных направления (отдельных протокола):
— ISAKMP (Internet Security Association and Key Management Protocol) — протокол ассоциаций
безопасности и управления ключами в интернете; это общее описание (framework) для
обеспечения аутентификации и обмена ключей без указания конкретных прикладных алгоритмов;
— Oakley (Oakley key determination protocol) — протокол определения ключей Окли; он описывает
последовательности обмена ключами — моды (mode) и описывает предоставляемые ими функции;
— SKEMI (Secure Key Exchange Mechanism for Internet) — механизм безопасного обмена ключами в
Интернете; он описывает многофункциональные технологии, предоставляющие анонимность,
неотрекаемость (аппелируемость) и быстрое обновление ключей;
IKE содержит две фазы согласования ключей. В первой фазе происходит создание защищенного
канала, во второй — согласование и обмен ключами, установление SA. Первая фаза использует
один из двух режимов: основной (англ. Main Mode) или агрессивный (англ. Aggressive Mode).
Различие между ними в уровне защищенности и скорости работы. Основной режим, более
медленный, защищает всю информацию, передаваемую между узлами. Агрессивный режим для
ускорения работы оставляет ряд параметров открытыми и уязвимыми для прослушивания, его
рекомендуется использовать только в случае, когда критическим вопросом является скорость
работы. Во второй фазе используется быстрый режим (англ. Quick Mode), названный так потому,
что не производит аутентификации узлов, считая, что это было сделано в первой фазе. Эта фаза
обеспечивает обмен ключами, с помощью которых происходит шифрование данных.
Определим следующие нотации для дальнейшего использования:
HDR — это заголовок ISAKMP, который определяет тип обмена. Запись HDR* означает, что
содержимое зашифровано.
SA — это содержимое переговоров SA с одним или более Proposals. Инициатор может предоставить
несколько Proposals для переговоров; получатель должен выбрать только одну.
_b — это тело содержимого
. Например, SA_b есть все тело содержимого SA (минус общий
заголовок ISAKMP), т.е. DOI, Situation, все Proposals и все Transforms, представленные
Инициатором.
CKY-I и CKY-R есть cookie Инициатора и cookie Получателя, соответственно, из ISAKMPзаголовка.
g^xi и g^xr — это открытые значения Диффи-Хеллмана Инициатора и Получателя соответственно.
КЕ — это содержимое обмена ключа, т.е. открытая информация, которой обмениваются в
алгоритме Диффи-Хеллмана. Специального шифрования, используемого для содержимого КЕ, не
существует.
Nx — это содержимое nonce; x может быть i или r для ISAKMP Инициатора и Получателя
соответственно.
IDx — есть содержимое идентификации для <х>. Х может быть или для ISAKMP Инициатора и
Получателя соответственно во время Фазы 1 переговоров; или или для Инициатора и Получателя
соответственно во время Фазы 2.
SIG — это содержимое подписи. Подписываемые данные зависят от обмена.
СERT — это содержимое сертификата.
HASH — это содержимое хэша, которое определяется методом аутентификации.
prf (key, msg) — это псевдослучайная функция, часто хэш-функция, основанная на ключе,
используемая для создания детерминированного выхода, который можно рассматривать как
псевдослучайный. Prf используется как для получения ключа, так и для аутентификации (т.е. как
МАС с ключом).
SKEYID есть строка, полученная из секрета и известная только участникам обмена.
SKEYID_e есть материал ключа, используемый ISAKMP для обеспечения конфиденциальности
сообщений.
SKEYID_а есть материал ключа, используемый ISAKMP для аутентификации своих сообщений.
SKEYID_d есть материал ключа, используемый для получения ключей для не-ISAKMP
безопасных ассоциаций.
y определяет, что х зашифровано ключом y.
=> указывает на направление взаимодействия от Инициатора к Получателю (запрос).
? указывает на направление взаимодействия от Получателя к Инициатору (ответ).
| обозначает конкатенацию информации.
[x] обозначает, что х не является обязательным.
Шифрование сообщения (когда указана * после ISAKMP заголовка) должно начинаться сразу
после ISAKMP-заголовка. При защищенном взаимодействии все содержимые после ISAKMP
заголовка должны шифроваться. Ключи шифрования создаются из SKEYID_e тем способом,
который определен для каждого алгоритма.
8.2 Введение
IKE представляет различные обмены как режимы, которые выполняются в одной из двух фаз.
В течение Фазы 1 участники устанавливают безопасный аутентифицированный канал, по
которому они будут взаимодействовать. Это называется ISAKMP SA. Для фазы 1 определено два
режима: Main Mode и Aggressive Mode.
Фаза 2 определяется тогда, когда уже установлены ISAKMP SA. определен для второй фазы
обмена.
реально ни с Фазой 1, ни с Фазой 2 не связан. Он следует за Фазой 1, но служит для установления
новой группы, которая может использоваться при будущих переговорах.
ISAKMP SA является двунаправленной. Это означает, что установив однажды, каждый участник
может инициировать Quick Mode, Informational и New Group Mode-обмены. ISAKMP SA
идентифицируется cookie Инициатора, которые следуют за cookie Получателя — роли каждого
участника в Фазе 1 обмена определяют, какие cookie являются cookie Инициатора.
Последовательность cookie, установленная в Фазе 1 обмена, продолжает идентификацию ISAKMP
SA, независимо от направления обменов Quick Mode, Informational или New Group. Другими
словами, cookie при изменении направления ISAKMP SA не должны меняться местами.
В результате использования фаз ISAKMP может выполнять обмен ключа достаточно быстро.
Кроме того, может требоваться единственная фаза 2 переговоров для создания нескольких SAs.
Main Mode для Фазы 1 обеспечивает защиту идентификации. Когда нет необходимости в защите
идентификации, может использоваться Aggressive Mode для уменьшения числа взаимных передач.
Также следует заметить, что при аутентификации шифрованием с открытым ключом в Aggressive
Mode также обеспечивается защита идентификации.
Следующие атрибуты используются в IKE и о них договариваются участники ISAKMP SA. (Эти
атрибуты принадлежат только ISAKMP SA, а не каким-то другим Безопасным Ассоциациям, для
которых ISAKMP может вести переговоры от имени других сервисов.)
— алгоритм шифрования;
— хэш-алгоритм;
— метод аутентификации;
— информация о группе для алгоритма Диффи-Хеллмана;
Все эти атрибуты обязательны, и о них должны вестись переговоры. Кроме того, возможны
дополнительные переговоры о псевдослучайной функции (). Если prf в переговорах не участвует,
то версия HMAC хэш-алгоритма, о котором договорились, используется в качестве
псевдослучайной функции.
Группа Диффи-Хеллмана задается по номеру или путем определения всех атрибутов группы.
Атрибуты группы не должны зависеть от значений группы, определенной в предыдущем случае.
8.3 Обмены
Существует два основных режима, используемых для установления аутентифицированного
обмена ключа: Main Mode и Aggressive Mode. Каждый из них создает аутентифицированный
ключевой материал из обмена Диффи-Хеллмана. Обязательно должен быть реализован Main
Mode. Кроме того, Quick Mode должен быть реализован в качестве механизма для создания нового
материала ключа и переговоров не-ISAKMP SA (т.е. AH SA и ESP SA). В дополнение к этому New
Group Mode может быть реализован в качестве механизма определения частных групп для
обменов Диффи-Хеллмана.
Содержимое SA должно предшествовать всем другим содержимым в Фазе 1 обмена. Кроме этого
не существует никаких других требований ни к содержимым ISAKMP в любом сообщении, ни к
их упорядоченности.
Открытое значение Диффи-Хеллмана передается в содержимом КЕ в Фазе 1, оно может
передаваться в Фазе 2 обмена, если требуется PFS. Длина открытого значения Диффи-Хеллмана
определяется во время переговоров.
Длина содержимого nonce колеблется между 8 и 256 байтами.
Main Mode является реализацией обмена с защищенной идентификацией: в первых двух
сообщениях договариваются о политике; в следующих двух сообщениях обмениваются
открытыми значениями Диффи-Хеллмана и вспомогательными данными (т.е. nonces),
необходимыми для обмена; последние два сообщения аутентифицируют обмен Диффи-Хеллмана.
Метод аутентификации является частью переговоров начального ISAKMP-обмена, влияющий на
композицию содержимых, но не на их цель.
В первых двух сообщениях Aggressive Mode договариваются о политике, обмениваются
открытыми значениями Диффи-Хеллмана и вспомогательными данными, необходимыми для
обмена, а также идентификациями. Второе сообщение аутентифицирует получателя. Третье
сообщение аутентифицирует инициатора. Заключительное сообщение может не посылаться по
ISAKMP SA, позволяя каждому участнику откладывать в случае необходимости вычисление
экспоненты до завершения переговоров.
Во время переговоров инициатор представляет получателю предложения о потенциальных
безопасных ассоциациях. Получатель не должен модифицировать атрибуты любого предложения.
Если инициатор обмена замечает, что значения атрибутов были изменены или атрибуты были
добавлены или уничтожены из предложенного метода, ответ должен быть отброшен.
Допускаются четыре различных метода аутентификации как для Main Mode, так и для Aggressive
Mode — цифровая подпись, две формы аутентификации шифрованием открытым ключом и
предварительно распределенным секретом. Значение SKEYID вычисляется отдельно для каждого
метода аутентификации.
Для подписей:
SKEYID = prf (Ni_b | Nr_b, g^xy)
Для шифрования открытым ключом:
SKEYID = prf ( HASH (Ni_b | Nr_b), CKY-I | CKY-R)
Для предварительно распределенного секрета:
SKEYID = prf (pre-shared-key, Ni_b | Nr_b)
Результатом как Main Mode, так и Aggressive Mode являются три группы аутентифицированного
материала ключа:
SKEYID_d = prf (SKEYID, g^xy | CKY-I | CKY-R | 0)
SKEYID_a = prf (SKEYID, SKEYID_d | g^xy | CKY-I | CKY-R | 1)
SKEYID_e = prf (SKEYID, SKEYID_a | g^xy | CKY-I | CKY-R | 2)
и согласованная политика по защите дальнейших коммуникаций. Значения 0, 1 и 2 представлены в
одном октете. Ключ, используемый для шифрования, получается из SKEYID_e с помощью
специфицированного алгоритма.
Для аутентификации обмена инициатора протокола создается HASH_I и для получателя создается
HASH_R, где
HASH_I = prf (SKEYID, g^xi | g^xr | CKY-I | CKY-R | SAi_b | IDii_b)
HASH_R = prf (SKEYID, g^xr | g^xi | CKY-R | CKY-I | SAi_b | IDir_b)
При аутентификации с помощью цифровых подписей HASH_I и HASH_R подписаны и
верифицированы; при аутентификации либо шифрованием открытым ключом, либо pre-shared
ключами HASH_I и HASH_R непосредственно аутентифицируют обмен. Все содержимое ID
(включая тип ID, порт и протокол, но исключая общий заголовок) хэшировано как в HASH_I, так
и в HASH_R.
Метод аутентификации, о котором договорились, влияет на содержимое и использование
сообщений для Фазы 1 режимов, но не на их цели. При использовании для аутентификации
открытых ключей обмен Фазы 1 может быть завершен либо использованием подписей, либо
использованием шифрования открытым ключом (если алгоритм поддерживает это). Далее
следуют обмены Фазы 1 с различными опциями аутентификации.
8.4 IKE Фаза 1 с аутентификацией с помощью подписей
При использовании подписей вспомогательной информацией, которой обмениваются при второй
круговой передаче, являются nonces; обмен аутентифицируется путем подписывания хэша. Main
Mode с аутентификацией с помощью подписи выполняется в соответствии с рисунком 8.1.
Рисунок 8.1 — Main Mode с аутентификацией с помощью подписи
Aggressive Mode с аутентификацией с помощью подписи выполняется в соответствии с рисунком
8.2.
Рисунок 8.2 — Aggressive Mode с аутентификацией с помощью подписи
В обоих режимах подписанные данные, SIG_I или SIG_R, являются результатом алгоритма
цифровой подписи, примененным к HASH_I или HASH_R соответственно.
В общем случае подпись выполняется поверх HASH_I и HASH_R, при этом используется prf или
версия НМАС для хэш-функции (если участники не договорились о prf).
Могут быть дополнительно переданы один или более сертификатов.
8.5 Фаза 1 аутентификации шифрованием открытым ключом
При использовании шифрования открытым ключом для аутентификации обмена применяются
зашифрованные nonces. Каждый участник имеет возможность восстановить хэш (доказывая, что
другой участник дешифровал nonce), аутентифицируя обмен.
Для того чтобы выполнить шифрование открытым ключом, инициатор должен уже иметь
открытый ключ получателя. В случае, когда получатель имеет несколько открытых ключей,
инициатор использует хэш сертификата, передаваемой как часть третьего сообщения. При таком
способе получатель может определить, какой закрытый ключ использовать для дешифрования
зашифрованного содержимого и защищенной идентификации.
В дополнение к nonce идентификации участников (IDii и IDir) также зашифрованы открытым
ключом другого участника. Если методом аутентификации является шифрование открытым
ключом, то содержимые nonce и идентификации должны быть зашифрованы открытым ключом
другого участника. Шифруется только тело содержимого, заголовки содержимого не шифруются.
При использовании для аутентификации шифрования Main Mode выполняется в соответствии с
рисунком 8.3.
Рисунок 8.3 — Аутентификация шифрования Main Mode
Aggressive Mode выполняется в соответствии с рисунком 8.4.
Где HASH (1) есть хэш сертификата, который инициатор использовал для шифрования nonce и
идентификации.
Использование шифрования для аутентификации обеспечивает невозможность отказа от обмена.
В отличие от других методов аутентификации, аутентификация шифрованием открытым ключом
допускает защиту идентификации в Aggressive Mode.
Рисунок 8.4 — Аутентификация шифрования Aggressive Mode
8.6 Фаза 1 аутентификации с Revised Mode шифрования открытым ключом
Аутентификация шифрованием открытым ключом имеет важное преимущество по сравнению с
аутентификацией с использованием подписей. Ценой являются 4 операции открытого ключа — две
операции шифрования открытым ключом и две операции дешифрования закрытым ключом.
Данный метод аутентификации сохраняет преимущества аутентификации с использованием
шифрования с открытым ключом, но делает это с использованием половины операций открытого
ключа.
В данном режиме nonce все еще зашифрован с использованием открытого ключа
противоположной стороны, однако идентификация противоположной стороны (и сертификат,
если он послан) шифруется с использованием алгоритма симметричного шифрования, о котором
договорились (из содержимого SA) с ключом, полученным из nonce. Это решение добавляет
минимальную сложность, и на каждой стороне используется две операции открытого ключа.
Дополнительно содержимое Key Exchange также зашифровано с использованием того же самого
ключа. Это обеспечивает дополнительную защиту против криптоанализа обмена ДиффиХеллмана.
Как и в методе аутентификации шифрованием открытым ключом содержимое HASH может быть
послано для идентификации сертификата, если получатель имеет несколько сертификатов. Если
содержимое HASH послано, оно должно быть первым содержимым сообщения второго обмена, и
за ним должен следовать зашифрованный nonce. Если содержимое HASH не послано, первым
содержимым сообщения второго обмена должен быть зашифрованный nonce. Дополнительно
инициатор может послать содержимое с сертификатом для указания получателю использованного
открытого ключа.
При использовании для аутентификации пересмотренного режима шифрования Main Mode
определяется в соответствии с рисунком 8.5.
Рисунок 8.5 — Аутентификация пересмотренного режима шифрования Main Mode
Aggressive Mode, аутентифицируемый с помощью пересмотренного метода шифрования,
определяется в соответствии с рисунком 8.6.
Рисунок 8.6 — Аутентификация пересмотренного режима шифрования Aggressive Mode
Где HASH (1) была определена выше. Ke_i и Ke_r являются ключами для алгоритма
симметричного шифрования, о котором участники договорились при обмене содержимом SA.
Шифруется только тело содержимых (как в операциях с открытым ключом, так и симметричного
шифрования), общие заголовки содержимого не шифруются.
Симметричные ключи шифрования получаются из дешифрованных nonces следующим образом.
Прежде всего вычисляются значения Ne_i и Ne_r:
Ne_i = prf (Ni_b, CKY-I)
Ne_r = prf (Nr_b, CKY-R)
Если длина выхода prf, о которой договорились, больше или равна длине ключа, необходимой для
шифрования, Ke_i и Ke_r получаются из старших битов Ne_i и Ne_r, соответственно. Если
требуемая длина Ke_i и Ke_r превышает длину выхода prf, необходимое количество битов
получается после повторным применением prf и конкатенацией результата необходимое число
раз. Например, если алгоритм шифрования требует 320 битов ключа и выход prf дает только 128
бит, в качестве Ke_i берутся старшие биты K, где
K = K1 | K2 | K3
K1 = prf (Ne_i, 0)
K2 = prf (Ne_i, K1)
K3 = prf (Ne_i, K2)
Для краткости показано получение только Ke_i; Ke_r получается аналогично. Значение 0 при
вычислении K1 является одним октетом. Заметим, что Ne_i, Ne_r, Ke_i и Ke_r после
использования должны быть сброшены.
Существуют требования только на размещение дополнительного содержимого HASH и
обязательного содержимого nonce, более никаких содержимых не требуется. Все содержимые — в
любом порядке — следующие за зашифрованным nonce, должны быть зашифрованы с ключом Ke_i
или Ke_r в зависимости от направления.
8.7 Фаза 1 аутентификации с Pre-Shared ключом
Ключ, полученный некоторым внешним механизмом, может также использоваться для
аутентификации обмена.
Когда выполняется pre-shared аутентификация, Main Mode определяется в соответствии с
рисунком 8.7.
Рисунок 8.7 — Определение Main Mode при выполнении pre-shared аутентификации
Aggressive режим с pre-shared ключом описывается в соответствии с рисунком 8.8.
При использовании аутентификации с pre-shared ключом с Main Mode ключ может только
идентифицироваться по IP-адресу противоположной стороны, так как HASH_I должен быть
вычислен до того, как инициатор обработает IDir. Aggressive Mode охватывает более широкий
диапазон идентификаторов используемого pre-shared секрета. Дополнительно Aggressive Mode
позволяет двум участникам поддерживать несколько различных pre-shared ключей и
идентификаций для отдельного обмена.
Рисунок 8.8 — Определение Aggressive Mode при выполнении pre-shared аутентификации
8.8 Фаза 2 — Quick Mode
Quick Mode сам по себе законченным обменом не является (это означает, что он связан с фазой 1
обмена), он используется как часть процесса переговоров SA (фаза 2) для получения материала
ключа и обсуждений разделяемой политики для не-ISAKMP SAs. Информация, которой
обмениваются в Quick Mode, должна быть защищена ISAKMP SA, т.е. все содержимые за
исключением заголовка ISAKMP должны быть зашифрованы. В Quick Mode содержимое HASH
должно непосредственно следовать за заголовком ISAKMP и содержимое SA должно
непосредственно следовать за HASH. Данный HASH аутентифицирует сообщение и обеспечивает
доказательство существования.
Quick Mode проводит переговоры об SA и обменивается nonces, которые обеспечивают защиту от
повторов. Nonces используются для создания нового материала ключа и предотвращения replay-
атак, создающих ложные SA. Можно произвести обмен дополнительным содержимым KE, чтобы
допустить дополнительный обмен экспонентами Диффи-Хеллмана при Quick Mode.
Базовый Quick Mode (без содержимого KE) обновляет материал ключа, полученный из
экспоненты в Фазе 1. Это не обеспечивает PFS. При использовании дополнительного содержимого
KE вычисляется дополнительная экспонента и тем самым обеспечивается PFS для материала
ключа.
Все предложения, сделанные в течение Quick Mode, являются логически взаимосвязанными и
должны быть согласованы. Например, если послано содержимое KE, атрибут, описывающий
группу Диффи-Хеллмана, должен быть включен в каждый Transform каждой Proposal каждой SA,
о которой ведутся переговоры. Аналогично, если используются идентификации клиента, они
должны применяться к каждой SA, о которой ведутся переговоры.
Quick Mode определяется в соответствии с рисунком 8.9.
Рисунок 8.9 — Определение Quick Mode
Где:
HASH (1) есть prf поверх сообщения id (M-ID) из ISAKMP заголовка, присоединенного ко всему
сообщению;
HASH (2) идентичен HASH (1) за исключением nonce инициатора — Ni, минус заголовок
содержимого, который добавляется после M-ID, но перед завершенным сообщением. Добавление
nonce в HASH (2) сделано для доказательства существования;
HASH (3) — для доказательства существования — является prf поверх нулевого значения,
представленного одним октетом, за которым следует конкатенация id сообщения и два nonces инициатора и получателя — минус заголовок содержимого. Другими словами, хэши предыдущего
обмена есть:
HASH (1) = prf (SKEYID_a, M-ID | SA | Ni [ | KE ] [ | IDci | IDcr ])
HASH (2) = prf (SKEYID_a, M-ID | Ni_b | SA | Nr [ | KE ] [ | IDci | IDcr ])
HASH (3) = prf (SKEYID_a, 0 | M-ID | Ni_b | Nr_b)
За исключением содержимых HASH, SA и необязательных ID, не существует содержимых, для
которых определены ограничения упорядоченности в Quick Mode. HASH (1) и HASH (2) могут
отличаться от приведенных выше, если порядок содержимых в сообщении отличается от
приведенного выше или если в сообщение включены дополнительные содержимые.
Если PFS не является необходимой и обмен содержимым KE не выполняется, то новый материал
ключа определяется как
KEYMAT = prf (SKEYID_d, protocol | SPI | Ni_b | Nr_b)
Если PFS требуется и участники обмениваются содержимым KE, то новый материал ключа
определяется как
KEYMAT = prf (SKEYID_d, g (qm) ^xy | protocol | SPI | Ni_b | Nr_b)
Где g (qm) ^xy является разделяемым секретом из одноразового обмена Диффи-Хеллмана для
данного Quick Mode.
В любом случае protocol и SPI берутся из ISAKMP Proposal Payload, содержащим Transform, о
котором договариваются.
Единственным результатом переговоров SA являются две безопасные ассоциации — одна входящая
и одна выходящая. Различные SPIs для каждой SA (один выбирается инициатором, другой
получателем) гарантируют различные ключи для каждого направления. SPI, выбираемые
получателем, используются для получения KEYMAT для данной SA.
В ситуации, когда количество требуемого материала ключа больше, чем предлагается prf,
KEYMAT расширяется конкатенацией результатов до тех пор, пока не будет получено
необходимое количество материала ключа. Другими словами
KEYMAT = K1 | K2 | K3 | _
Где
K1 = prf (SKEYID_d, [g (qm) ^xy | ] protocol | SPI | Ni_b | Nr_b)
K2 = prf (SKEYID_d, K1 | [g (qm) ^xy | ] protocol | SPI | Ni_b | Nr_b)
K3 = prf (SKEYID_d, K2 | [g (qm) ^xy | ] protocol | SPI | Ni_b | Nr_b)
Данный материал ключа (с PFS или без, полученный непосредственно или с помощью
конкатенации) должен использоваться в SA, о которой ведутся переговоры. Это определяет
ключи, которые получаются из материала ключа.
Используя Quick Mode, за один обмен можно договориться о нескольких SAs и ключах в
соответствии с рисунком 8.10.
Рисунок 8.10 — Определение SAs и ключей при использовании Quick Mode
8.9 New Group Mode
New Group Mode не должен использоваться до установления ISAKMP SA. Описание новой группы
должно следовать только за фазой 1 переговоров. (Однако это не фаза 2 обмена).
Где HASH (1) является выходом prf с использованием SKEYID_a в качестве ключа, и message-ID
из заголовка ISAKMP, присоединенного ко всему SA proposal, как телу, так и заголовку; HASH (2)
есть выход prf с использованием SKEYID_a в качестве ключа, и message-ID из заголовка ISAKMP,
присоединенного к ответу. Другими словами, хэшами для обменов являются:
HASH (1) = prf (SKEYID_a, M-id | SA)
HASH (2) = prf (SKEYID_a, M-id | SA)
Proposal определяется характеристиками группы. Описания группы для частных групп должны
быть больше или равны 215. Если группа не принимается, получатель должен ответить
сообщением с содержимым Notify, и тип сообщения установить в ATTRIBUTE-NOT-SUPPORTED
(13).
Реализации ISAKMP могут требовать частных групп для устанавливаемых SA.
О группах можно непосредственно договариваться в SA Proposal в Main Mode. Чтобы это сделать,
компоненты — MODP группы, тип, простое и генератор; тип для EC2N группы, несократимый
полином, генератор группы One, генератор группы Two, группа эллиптической кривой А, группа
эллиптической кривой В и порядок группы — передаются в качестве атрибутов SA.
8.10 Информационные обмены ISAKMP
Данный протокол, когда это возможно, защищает информационные обмены ISAKMP. После того
как безопасная ассоциация ISAKMP установлена (и SKEYID_e и SKEYID_a созданы)
информационные обмены ISAKMP при использовании данного протокола представляют собой
следующее:
Где N/D есть либо ISAKMP Notify Payload, либо ISAKMP Delete Payload и HASH (1) есть выход
prf с использованием SKEYID_a в качестве ключа, и M-ID, уникальный для данного обмена,
присоединяется в качестве данных ко всему информационному содержимому (либо Notify, либо
Delete). Другими словами, хэшем для предыдущего обмена является:
HASH (1) = prf (SKEYID_a, M-ID | N/D)
ID сообщения в заголовке ISAKMP — и используемые в prf вычисления — являются уникальными
для данного обмена и не должны повторять ID сообщения для другой фазы 2 обмена, во время
которой был создан данный информационный обмен.
Если безопасная ассоциация ISAKMP ко времени информационного обмена еще не установлена,
обмен выполняется в явном виде без сопутствующего HASH содержимого в соответствии с
рисунком 8.11.
Рисунок 8.11 — Информационные обмены ISAKMP
8.11 Проблемы безопасности Internet Key Exchange (IKE)
Сила ключа, полученная из обмена Диффи-Хеллмана, использующего определенную группу,
зависит от силы самой группы, используемой длины экспоненты и энтропии, обеспечиваемой
используемым генератором случайных чисел. Группа Диффи-Хеллмана по умолчанию (номер
один) при использовании сильного генератора случайных чисел и экспоненты не менее 160 бит
является достаточной при использовании для DES. Группы со второй по четвертую обеспечивают
большую безопасность. Реализации должны помнить об этой общей оценке при определении
политики и обсуждаемых параметрах безопасности.
Это не является ограничением на сами группы Диффи-Хеллмана. Ничто не препятствует IKE
использовать более сильные группы и ничто не ослабляет силу этих групп. Расширяемый каркас
IKE поддерживает определение многих групп; использование групп эллиптических кривых
увеличивает силу при использовании меньших чисел.
В ситуациях, когда определенные группы не обеспечивают необходимую силу, можно
использовать New Group Mode для обмена группой Диффи-Хеллмана, которая обеспечит ее.
Предполагается, что экспоненты Диффи-Хеллмана для данного обмена после использования
удаляются из памяти. В частности, эти экспоненты не должны получаться из долго живущих
секретов, подобных seed для псевдослучайного генератора.
Хотя сообщения последней круговой передачи в Main Mode (и не обязательно последнее
сообщение Aggressive Mode) являются зашифрованными, они не являются
аутентифицированными. Активная атака замены для зашифрованного текста может привести к
разрушению содержимого. Если такая атака имела место для обязательных содержимых, это будет
определено и приведет к падении аутентификации, но если это произошло для дополнительных
содержимых (например, для содержимых уведомления, измененных в последнем сообщении Main
Mode обмена), это может быть не определено.
Содержание
9. РАСШИРЕННЫЙ ОБЗОР БЕЗОПАСНЫХ АССОЦИАЦИЙ (КОНТЕКСТОВ)
9.1 Основные определения
Понятие «безопасные ассоциации» (Security Association — SA) является фундаментальным в IPSec.
SA есть симплексное (однонаправленное) логическое соединение, создаваемое для обеспечения
безопасности. Весь трафик, передаваемый по SA, некоторым образом обрабатывается в целях
обеспечения безопасности. И AH, и ESP используют в своей работе SAs. Одной из основных
функций IKE является установление SA. Далее приводятся различные аспекты управления SA,
определим требуемые характеристики управления политикой SA, обработку трафика и технологии
управления SA.
SA есть совокупность параметров соединения, которые дают возможность сервисам обеспечивать
безопасный трафик. SA определяет использование AH или ESP. Если к потоку трафика
применяются оба протокола, AH и ESP, то создаются две SAs. При двунаправленном соединении
между двумя хостами или между двумя шлюзами безопасности требуется два SA (по одному на
каждое направление).
SA однозначно определяется тройкой, состоящей из Security Parameter Index (SPI), IP Destination
Address (адресом назначения) и идентификатора протокола безопасности (AH или ESP). В
принципе адрес назначения может быть единственным адресом, широковещательным (broadcast)
адресом или групповым (multicast) адресом. Однако механизм управления SA в настоящее время
определяется только для единственной SA. Следовательно, SAs будут описаны в контексте pointto-point соединения, даже если концепция также применяется в случае point-to-multipoint.
Определены два режима SA: режим транспорта и режим туннелирования. Транспортный режим
SA обеспечивает безопасную связь между двумя хостами. В IPv4 заголовок протокола
безопасности транспортного режима появляется сразу после IP заголовка и всех опций и перед
любыми протоколами более высокого уровня (ТСР или UDP). В случае ESP транспортный режим
SA обеспечивает сервисы безопасности только для протоколов более высокого уровня, но не для
IP-заголовка. В случае AH защита также распространяется на отдельные части IP-заголовка.
Другим режимом SA является режим туннелирования. Если хотя бы одним из концов соединения
является шлюз безопасности, то SA обязательно должна выполняться в туннелирующем режиме.
SA между двумя шлюзами безопасности всегда находится в туннелирующем режиме, так же, как и
SA между хостом и шлюзом безопасности. Заметим, что когда трафик предназначен для шлюза
безопасности, например, в случае SNMP-команд, шлюз безопасности рассматривается как хост, и
допустим транспортный режим. Два хоста могут при желании так же устанавливать
туннелирующий режим.
B туннелирующем режиме SA существует «внешний» IP-заголовок, который определяет пункт
назначения IPSec, и «внутренний» IP-заголовок, который определяет конечный пункт назначения
для пакета. Заголовок протокола безопасности расположен после внешнего IP-заголовка и перед
внутренним IP-заголовком. Если AH используется в туннелирующем режиме, части внешнего IP
заголовка являются защищенными, как и весь туннелируемый IP-пакет, т.е. все внутренние
заголовки защищены, как и все протоколы более высокого уровня. Если применяется ESP, зашита
обеспечивается только для туннелируемого пакета, а не для внешнего IP-заголовка.
9.2 Функциональность
Набор реализуемых SA сервисов безопасности зависит от выбранного протокола безопасности,
режима SA, конечных точек SA и выбора дополнительных сервисов в протоколе. Например, AH
обеспечивает аутентификацию исходных данных и целостность соединения для IP датаграм (в
дальнейшем будем называть это «аутентификацией»). «Точность» сервиса аутентификации
является функцией от степени детализованности SA, для которой используется AH.
AH также предоставляет анти-replay сервис (целостность отдельной последовательности) для
получателя, помогая предотвратить атаки отказа в сервисе. AH применяется, когда не требуется
конфиденциальность. AH также обеспечивает аутентификацию отдельных частей IP-заголовка, за
исключением изменяющихся частей IP-заголовка.
ESP обеспечивает конфиденциальность трафика. Сила сервиса конфиденциальности зависит от
используемого алгоритма шифрования. ESP также может дополнительно обеспечивать
аутентификацию. Область аутентификации, обеспечиваемая ESP, является более узкой по
сравнению с AH, т.е. IP-заголовок (заголовки), <внешние> по отношению к ESP заголовку, не
защищены. Если аутентификация нужна только протоколам более высокого уровня, то
аутентификация ESP является подходящей альтернативой, причем более эффективной, чем
использование AH, инкапсулирующего ESP. Если для ESP SA используется аутентификация,
получатель также может выбрать усиление использованием анти-replay сервиса с теми же самыми
возможностями, что и AH анти-replay сервис. Хотя и конфиденциальность, и аутентификация
являются необязательными, оба сервиса не могут быть опущены. По крайней мере, один из них
должен присутствовать.
Использование туннелирующего режима позволяет зашифровывать внутренние IP-заголовки,
скрывая отправителя и получателя. Следует заметить, что сильно детализированные SAs обычно
являются более уязвимыми для анализа трафика, чем слабо детализированные.
9.3 Комбинации SA
Иногда политика безопасности может требовать комбинации сервисов для конкретного потока
трафика. В таких случаях необходимо установить несколько SAs для реализации принятой
политики безопасности. Термин «узел безопасных ассоциаций» или «узел SA» применяется к
последовательности SA, через которые должен проходить трафик для обеспечения требуемой
политики безопасности. Заметим, что SAs, которые образуют узел, могут заканчиваться в
различных точках.
Безопасные aссоциации могут комбинироваться в узлы двумя способами: транспортное соседство,
в соответствии с рисунком 9.1, и повторное туннелирование:
а) транспортное соседство означает применение более одного протокола для одной и той же IPдатаграммы без использования туннелирования; данный подход при комбинировании AH и ESP
допускает только один уровень комбинации; дальнейшие вложенные поля не добавляют
преимущества (в случае использования одинаково сильных алгоритмов для каждого протокола);
Рисунок 9.1 — Транспортное соседство SAs
б) повторное туннелирование означает применение нескольких протоколов, выполняющих
туннелирование;
Существует три основных варианта повторного туннелирования:
а) оба конца SAs являются одинаковыми, в соответствии с рисунком 9.2 — внутренний и внешний
туннели могут быть каждый AH или ESP, хотя маловероятно, что протоколы будут одинаковые,
например, AH внутри AH или ESP внутри ESP;
Рисунок 9.2 — Повторное туннелирование SAs — оба конца одинаковы
б) один конец нескольких SAs является одним и тем же, в соответствии с рисунком 9.3 внутренний и внешний туннели могут оба быть AH или ESP;
Рисунок 9.3 — Повторное туннелирование SAs — один конец общий
в) ни один из концов нескольких SAs не является одним и тем же, в соответствии с рисунком 9.4 каждый внутренний и внешний туннели могут быть AH или ESP;
Рисунок 9.4 — Повторное туннелирование SAs — оба конца разные
Эти два подхода также могут комбинироваться, например, узел SA может быть сконструирован из
одного SA туннелирующего режима и одного или двух SAs транспортного режима, применяемых
последовательно.
9.4 Базы данных безопасной ассоциации
Многие детали, связанные с обработкой IP-трафика в реализации IPSec не являются предметом
стандартизации. Некоторые внешние аспекты обработки должны быть стандартизованы для
обеспечения интероперабельности IPSec.
Существуют две БД: БД Политики Безопасности (SPD) и БД Безопасной Ассоциации (SAD).
Первая описывает политики, которые определяют характер обработки всего IP трафика. Вторая
БД содержит параметры, которые связаны с каждой активной безопасной ассоциацией. Определим
также понятие Селектора как множества значений полей IP протокола и протокола более высокого
уровня, которые используются БД Политики Безопасности для отображения трафика на SA.
Каждый сетевой интерфейс, для которого необходима обработка IPSec, требует определения баз
данных для входящего и исходящего трафика.
9.4.1 База данных политики безопасности (SPD)
В конечном счете, SA используется для осуществления политики безопасности в окружении IPSec.
Таким образом, существенным элементом выполнения SA является лежащая в основе База
Данных Политики Безопасности (SPD), которая определяет, какие сервисы обрабатывают IP
датаграммы и каким образом. Форма БД и ее интерфейс находятся вне области стандартизации.
Тем не менее определим основные возможности управления, которые должны быть представлены,
чтобы системный администратор мог управлять применением IPSec к трафику, передаваемому
или получаемому хостом или проходящему через шлюз безопасности.
SPD должна рассматриваться при обработке всего трафика (входящего и исходящего), включая не
— IPSec-трафик. Для того чтобы это поддерживать, SPD требует различных записей для входящего
и выходящего трафика. Можно считать, что это отдельные SPDs (входящая и выходящая). Кроме
того, отдельная SPD должна существовать для каждого IPSec-интерфейса.
SPD должна распознавать трафик, который разрешен защитой IPSec, и трафик, которому
разрешено проходить IPSec без обработки. Для любой выходящей или входящей датаграммы
существует три возможных способа обработки: отбросить датаграмму, обойти IPSec или
применить IPSec. Первый вариант означает, что трафик не разрешен для хоста, не может
пересекать шлюз безопасности или не может быть доставлен на уровень приложения. Второй
вариант означает, что трафику разрешено проходить без дополнительной IPSec-защиты. Третий
вариант означает, что к трафику применяется IPSec защита и для такого трафика SPD должна
специфицировать применяемые сервисы безопасности, применяемые протоколы, используемые
алгоритмы и т.д.
Каждая реализация IPSec должна иметь программный интерфейс, который позволяет системному
администратору управлять SPD. SPD должна определять, какие действия должны быть выполнены
в том или ином случае. Таким образом, программный интерфейс должен позволять
специфицировать обработку, применяемую к любому пакету, входящему или выходящему из
системы. Интерфейс управления для SPD должен допускать создание последовательности
записей, и должна поддерживаться упорядоченность этих записей. Возможно использование
символа <*> в различных полях.
Определим стандартный набор элементов SPD, который должны поддерживать все реализации
IPSec.
SPD содержит упорядоченный список записей политики. Каждая запись политики является
ключом для одного или более селекторов, которые определяют множество IP трафика,
соответствующего данной записи политики. Это определяет детализированность политики и
создаваемых SAs. Каждая запись включает индикатор, показывающий, что трафик,
соответствующий данной политике, должен быть пропущен, отброшен или обработан IPSec. Если
применяется обработка IPSec, запись содержит описание SA (или узла SA), список применяемых
протоколов, режимов и алгоритмов, включая любые дополнительные требования. Например,
запись может указывать, что трафик защищается ESP в транспортном режиме, используя 3DESCBC с явным IV, и вложен в AH в туннелирующем режиме с помощью НМАС/SHA-1.
Записи SPD должны быть упорядочены, и SPD должна всегда просматриваться в одном и том же
порядке. Это требование является необходимым, чтобы воздействие на обрабатываемый трафик
записей SPD было детерминированным.
Так как политика безопасности может требовать, чтобы более одной SA применялось к трафику в
определенной последовательности, запись политики в SPD должна эту последовательность
определять.
SA (или узел SA) может быть хорошо структурирована или грубоструктурирована в зависимости
от селекторов, используемых для определения трафика, обрабатываемого SA. Например, весь
трафик между двумя хостами может быть направлен через единственную SA, и может быть
определен лишь один набор сервисов безопасности. В другом случае трафик между парой хостов
может направляться через несколько SAs, в зависимости от используемых приложений, с
различными сервисами безопасности, предоставляемыми различными SAs. Аналогично, весь
трафик между парой шлюзов безопасности может быть направлен через единственную SA, или
для каждой взаимодействующей пары хостов может быть определена своя SA.
9.4.2 База данных Безопасной Ассоциации (SAD)
В IPSec существует База Данных Безопасных Ассоциаций, в которой каждая запись определяет
параметры, связанные с конкретной SA. Соответственно, каждая SA имеет запись в SAD. Для
выходящей обработки записи ссылаются на записи в SPD. Для входящей обработки каждая запись
в SAD индексируется IP адресом назначения, типом протокола IPSec и SPI. Рассмотрим
минимально необходимые элементы данных, требуемые для поддержки SA в реализации IPSec.
Для входящей обработки следующие поля пакета используются для поиска SA в SAD:
а) IP адрес назначения внешнего заголовка: IPv4- или IPv6-адрес назначения.
б) Протокол IPSec: AH или ESP, используемый в качестве индекса SA в данной БД. Определяет
протокол IPSec, применяемый к трафику для данной SA.
в) SPI: 32-битное значение, применяемое для идентификации различных SA, заканчивающихся
одним и тем же адресом назначения и использующих один и тот же IPSec-протокол.
Следующие поля SAD используются для IPSec-обработки:
а) Sequence Number Counter: 32-битное значение, используемое для создания поля Sequence
Number в AH или ESP заголовках (используется только для исходящего трафика).
б) Sequence Number Overflow: флаг, указывающий, было ли переполнение Sequence Number
Counter, должен вызывать событие аудита и предотвращать передачу дополнительных пакетов по
данной SA (используется только для исходящего трафика).
в) Anti-Replay Window: 32-битный счетчик или битовая карта (или некий эквивалент),
используемые для проверки, является ли входящий AH- или ESP-пакет повтором. (Используется
только для входящего трафика. Замечание: если anti-reply сервис не используется получателем,
например, в случае ручных ключей SA, когда anti-reply window не используется.).
д) Алгоритм аутентификации для AH, ключи и т.д.
е) Алгоритм шифрования для ESP, ключи, режим, IV и т.д.
ж) Алгоритм аутентификации для ESP, ключи и т.д. Если сервис аутентификации не выбран,
данное поле будет нулевым.
и) Время жизни данной SA: интервал времени, после которого SA должна быть заменена новой
SA (и новым SPI) или завершение SA, а также определения того, какое из этих действий должно
выполняться. Это может быть выражено в виде времени или количества байтов, или и того, и
другого одновременно. Реализации должны поддерживать оба типа времени жизни и
одновременное применение обоих типов. Если используется время и если IKE задействует
сертификаты Х.509 для установления SA, то время жизни SA должно входить в допустимый
интервал для сертификатов. В этом смысле как инициатор, так и получатель ответственны за
установление корректного времени жизни SA.
Должно быть два типа времени жизни: soft — время жизни, по истечении которого выдается
предупреждение начать действия по замене SA, и hard — время жизни, по истечении которого
текущая SA завершается.
Режим IPSec-протокола: туннель или транспорт. Определяет применяемый режим AH или ESP к
трафику для данной SA.
9.5 Примеры комбинаций SA
Приведем четыре примера комбинаций SA, которые должны поддерживаться IPSec-хостами и
шлюзами безопасности. Дополнительные комбинации AH и/или ESP в туннелирующем и/или
транспортном режимах могут поддерживаться по усмотрению разработчиков. Реализации должны
иметь возможность создавать и обрабатывать эти четыре комбинации. Введем следующие
обозначения в соответствии с рисунком 9.5.
=
одна или более SA (AH или ESP, транспорт или туннель);
соединение (или административная граница);
Нх
хост х;
SGx
шлюз безопасности х;
Х*
Х поддерживает IPsec.
Рисунок 9.5 — Условные обозначения
Замечание: рассматриваемые ниже безопасные ассоциации могут быть как AH, так и ESP. Режим
(туннель или транспорт) определяется характером конечных точек. Для host-to-host SAs-режим
может быть как транспортным, так и туннелирующим.
В данном случае как транспортный, так и туннелирующей режим могут быть хостами в
соответствии с рисунками 9.6 и 9.7. Заголовки в пакете между Н1 и Н2 должны выглядеть в
соответствии с таблицей 1.
Рисунок 9.6 — Вариант 1. Обеспечение end-to-end безопасности между двумя хостами через Internet
(или intranet)
Таблица 1. Последовательность заголовков при соединении Host-Host
Transport
Tunnel
1. [IP1] [AH] [upper]
1. [IP2] [AH] [IP1] [upper]
2. [IP1] [ESP] [upper]
2. [IP2] [ESP] [IP1] [upper]
3. [IP1] [AH] [ESP] [upper]
Рисунок 9.7 — Вариант 1. Обеспечение end-to-end безопасности между двумя хостами через Internet
(или Intranet)
Во втором варианте требуется только туннелирующий режим в соответствии с рисунком 9.8. При
этом заголовки в пакете между SG1 и SG2 должны выглядеть в соответствии с таблицей 2.
Рисунок 9.8 — Вариант 2. Создание простых виртуальных частных сетей
Таблица 2. Последовательность заголовков при соединении SG-SG
Tunnel
1. [IP2] [AH] [IP1] [upper]
2. [IP2] [ESP] [IP1] [upper]
Рисунок 1.11 — Варианты 3 и 4
Вариант 3. Комбинация вариантов 1 и 2 путем добавления end-to-end безопасности между хостами
отправителя и получателя. Для хостов или шлюзов безопасности не вводится новых требований,
кроме требования, чтобы шлюз безопасности был сконфигурирован для прохождения IPSecтрафика (включая ISAKMP трафик) для хостов позади него.
Вариант 4. Рассматривается случай, когда удаленный хост (Н1) использует Internet для
достижения firewall’a организации ( SG2) и затем получает доступ к некоторому серверу или
другой машине (Н2). Удаленный хост может быть мобильным хостом (Н1), подсоединяющимся по
dial up к локальному РРР-серверу (на диаграмме это не показано) по Internet и затем проходящему
по Internet к firewall организации (SG2) и т.д.
Между Н1 и SG2 возможен только туннелирующий режим. Вариант для SA между Н1 и SG2
может быть быть один из тех, что представлены в варианте 2. Альтернатива для SA между Н1 и
Н2 должна быть одной из тех, что представлены в варианте 1.
В данном варианте отправитель должен применять транспортный заголовок перед
туннелирующим заголовком. Следовательно, интерфейс управления в реализациях IPSec должен
поддерживать конфигурацию SPD и SAD, гарантирующую данную упорядоченность заголовка
IPSec.
Поддержка дополнительных комбинаций AH и ESP не является обязательной. Дополнительные
комбинации могут неблагоприятно сказываться на интероперабельности.
9.6 SA и Управление Ключом
IPSec поддерживает как ручные, так и автоматически созданные SA и соответствующее
управление криптографическими ключами. Протоколы AH и ESP практически не зависят от
используемых технологий управления ключом, хотя эти технологии могут некоторым образом
влиять на сервисы безопасности, предоставляемые протоколами. Например, дополнительные antireplay сервисы требуют автоматического управления SA. Более того, детализированность
используемого распределения ключа определяет детализированность предоставляемой
аутентификации.
Простейшей формой управления является ручное управление, при котором администратор
вручную конфигурирует каждую систему материалом ключа и данными управления безопасной
ассоциацией. Ручные технологии применяются в маленьких, статичных окружениях, и они не
масштабируются. Например, компания может создать VPN, используя IPSec на хостах. Если
количество хостов мало, и если все хосты расположены в пределах одного административного
домена, то возможно применение ручных технологий управления. В данном случае хост должен
выборочно защищать трафик и от других хостов в организации, используя вручную
сконфигурированные ключи, допуская незащищенный трафик для других получателей. Данные
технологии можно задействовать и в том случае, когда только выборочные коммуникации должны
быть безопасны. Аналогичный аргумент может быть применен для использования IPSec в
организации с небольшим числом хостов и/или шлюзов.
Широкое использование IPSec требует стандартного для Internet, масштабируемого,
автоматического протокола управления SA. Такая поддержка необходима для использования antireplay возможностей AH и ESP и для возможности создания SAs.
Протоколом автоматического управления ключом по умолчанию является IKE, но могут быть
реализованы и другие протоколы автоматического управления ключом.
Использование IPSec навязывает высокую вычислительную стоимость на хостах и шлюзах
безопасности, которые реализуют эти протоколы. Эта цена связана с памятью, необходимой для
структур данных IPSec, вычисление значений проверки целостности, шифрование и
дешифрование, а также дополнительное управление пакетом. Использование протоколов
управления SA/ ключом, особенно тех, которые реализуют криптографию с открытым ключом,
также добавляет соответствующую вычислительную стоимость в использование IPSec.
Использование IPSec также увеличивает стоимость компонентов, осуществляющих пересылку и
роутинг в инфраструктуре Internet, но не реализующих IPSec. Это происходит из-за возрастания
размера пакета в результате добавления заголовков AH и/или ESP, AH- и ESP-туннелирования
(который добавляет второй IP-заголовок) и возрастании трафика, связанного с протоколами
управления ключом. Ожидается, что в большинстве примеров это возрастание не будет сильно
влиять на инфраструктуру Internet.
Содержание
10. INTERNET SECURITY ASSOCIATION AND KEY MANAGEMENT PROTOCOL
(ISAKMP)
ISAKMP определяет общие процедуры и форматы пакетов для ведения переговоров об
установлении, изменении и удалении SA. SAs содержат всю информацию, необходимую для
выполнения различных сетевых сервисов безопасности. ISAKMP определяет содержимое обменов
для создания ключей и аутентификации участников. Эти форматы обеспечивают
взаимосогласованную основу для передаваемого ключа и аутентификационных данных, которая
не зависит от технологии создания ключа, алгоритма шифрования и механизма аутентификации.
Существует много различных протоколов обмена ключом с различными свойствами безопасности.
Тем не менее, требуется общий каркас для форматов атрибутов SA, для переговоров о
модификации и удалении SA. Таким общим форматом и является ISAKMP.
Атрибуты SA, необходимые для протоколов AH и ESP, как минимум, должны включать механизм
аутентификации, криптографический алгоритм, режим алгоритма, длину ключа и
инициализационный вектор (IV). Установление SA является частью протокола управления
ключом.
ISAKMP обеспечивает полную безопасность последующих обменов (Perfect Forward Secrecy PFS) — это означает, что при компрометации одного ключа возможен только доступ к данным,
защищенным одним этим ключом. При PFS ключ, используемый для защиты передаваемых
данных, не должен использоваться для получения любых дополнительных ключей, и если ключ,
используемый для защиты передаваемых данных, был получен из некоторого другого ключевого
материала, то этот ключевой материал не должен больше использоваться для получения других
ключей.
ISAKMP обеспечивает аутентифицированный обмен ключа. ISAKMP не определяет конкретный
алгоритм обмена ключа. Тем не менее, как правило, вместе с ISAKMP используется протокол IKE.
Защита от DoS-атак является одной из наиболее трудных задач. Для этой цели в ISAKMP
используются «Cookie» или знак анти-препятствия (anti-clogging token — ACT), которые
предназначены для защиты вычислительных ресурсов от подобной атаки без расходования
собственных ресурсов на ее обнаружение. Абсолютная защита от отказа в сервисе невозможна, но
такой знак анти-препятствия предоставляет технологию для того, чтобы сделать защиту более
надежной.
Следует заметить, что в обменах, показанных далее, механизм анти-препятствия должен
использоваться вместе с механизмом сбора мусора; атакующий может завалить сервер, используя
пакеты с поддельными IP- адресами. Подобные технологии управления памятью должны быть
внедрены в протоколы, использующие ISAKMP.
ISAKMP предотвращает создание соединения с атакующим, объединяя аутентификацию, обмен
ключа и создание SA. Это объединение не позволяет злоумышленнику дождаться завершения
аутентификации и затем осуществить имперсонизацию в одну из аутентифицированных
сущностей.
Атаки man-in-the-middle включают перехват, вставку, уничтожение и модификацию сообщений,
отправку сообщений назад отправителю, повтор старых сообщений и перенаправление
сообщений. ISAKMP предупреждает все эти типы атак. Объединение сообщений ISAKMP
защищает от возможности встроить сообщения в обмены протокола. Протокол ISAKMP позволяет
хосту обнаружить уничтоженные сообщения. Требование наличия нового cookie с новой отметкой
времени для каждого нового установления SA предотвращает атаки, которые включают повтор
старых сообщений. Требование ISAKMP сильной аутентификации предотвращает установление
SA с кем-то, кроме заданного участника. Сообщения можно перенаправить к другому получателю
или модифицировать, но это будет обнаружено, и SA установлена не будет.
10.1 Основные концепции и терминология
Протокол безопасности: протокол безопасности состоит из записи в конкретной точке стека
сетевых протоколов, выполняющей сервис безопасности для сетевого соединения. Например,
IPSec ESP и IPSec AH являются двумя различными протоколами безопасности. Протокол
безопасности может выполнять более одного сервиса, например, обеспечивая целостность и
конфиденциальность в одном модуле.
Набор защиты: набор защиты является списком сервисов безопасности, которые могут быть
применены к различным протоколам безопасности. Например, набор защиты может состоять из
DES шифрования для ESP и MD5 с ключом для AH.
Безопасная ассоциация (SA): безопасная ассоциация определяет протокол безопасности и
конкретный набор параметров сервисов и механизмов, необходимых для защиты трафика. Эти
параметры могут включать идентификаторы алгоритмов, режимы, криптографические ключи и
т.д. SA ссылается на связанный с ней протокол безопасности (например, , ).
ISAKMP SA: SA используется ISAKMP для обеспечения защиты собственного трафика.
Domain of Interpretation (DOI) определяет форматы содержимого, типы обменов и соглашения по
именованию информации, относящейся к безопасности, такой как политики безопасности или
криптографические алгоритмы и режимы. Идентификатор DOI используется для интерпретации
содержимого ISAKMP. DOI определяет:
а) : набор информации, которая будет использоваться для определения требуемых сервисов
безопасности;
б) Набор политик безопасности, которые могут и должны поддерживаться;
в) Синтаксис для описания предлагаемых сервисов безопасности;
д) Схема именования относящейся к безопасности информации, включая алгоритмы шифрования,
алгоритмы обмена ключа, атрибуты политики безопасности и сертификационные центры;
е) Специфицированные форматы для различного содержания;
ж) Дополнительные типы обмена, если потребуется;
Situation: ситуация содержит всю относящуюся к безопасности информацию, которую система
считает нужным рассматривать, принимая решение о том, какие необходимы сервисы
безопасности для защиты сессии, начавшей переговоры. Ситуация может включать адреса,
классификации безопасности, режимы операций (нормальный или аварийный) и т.д.
Proposal: proposal — это список, упорядоченный по уменьшению предпочтений, наборов защиты,
которые система будет применять для защиты трафика в данной ситуации.
Payload: ISAKMP определяет несколько типов содержимого, которые используются при передаче
информации, такой как данные SA или данные обмена ключа, в форматах, определенных DOI.
Содержимое состоит из общего заголовка и строки октетов, которые ISAKMP не различает.
ISAKMP использует DOI-определяемую функциональность для создания и интерпретации
данного содержимого. В одном сообщении ISAKMP может быть послано несколько содержимых .
Далее будут определены детали типов полезной информации.
Exchange Type: тип обмена определяет число сообщений в ISAKMP- обмене и типы содержимого
в каждом из этих сообщений. Считается, что каждый тип обмена предоставляет конкретный набор
сервисов безопасности, таких как анонимность участников, свойство PFS для ключевого
материала, аутентификация участников и т.д., далее определяется множество типов ISAKMPобмена по умолчанию. При необходимости могут быть добавлены другие типы для поддержки
дополнительных обменов ключа.
10.2 Фазы переговоров
ISAKMP предполагает две фазы переговоров. Во время первой фазы две сущности (ISAKMPсерверы) договариваются о том, как защищать дальнейший трафик переговоров, устанавливая
ISAKMP SA. Эта ISAKMP SA затем используется для защиты переговоров о требуемой SA.
Вторая фаза переговоров используется для установления SA для других протоколов безопасности.
Эта вторая фаза может применяться для установления нескольких безопасных ассоциаций.
Хотя подход, основанный на двух фазах, является достаточно дорогостоящим для большинства
простых сценариев, существует несколько причин, чтобы он оказывался в большинстве случаев
предпочтительным.
Во-первых, ISAKMP серверы могут уменьшить время установления первой фазы до нескольких
секунд. Это позволяет устанавливать несколько SAs между двумя участниками за одно и то же
время с начала соединения.
Во-вторых, сервисы безопасности, которые ведут переговоры во время первой фазы,
предоставляют свойства безопасности для второй фазы. Например, после первой фазы
переговоров шифрование, предоставляемое ISAKMP SA, может обеспечивать защиту
идентификации, потенциально допуская возможность применения более простых обменов во
второй фазе. С другой стороны, если канал, устанавливаемый в течение первой фазы, адекватно не
защищает идентификации, вторая фаза должна вести переговоры, учитывая это.
Для каждой фазы переговоров могут применяться различные сервисы безопасности. Например,
разные участники осуществляют аутентификацию в течение каждой фазы переговоров. На первой
фазе участниками, осуществляющими аутентификацию, могут быть ISAKMP серверы или хосты,
в то время как на второй фазе аутентификация осуществляется на уровне пользователей или
прикладных программ.
10.3 Идентификация безопасных соединений
Хотя при установлении безопасных каналов между системами ISAKMP не может предполагать
существования сервисов безопасности, должна обеспечиваться некоторая степень защиты.
Следовательно, SA ISAKMP отличается от остальных типов SA, и ее идентификация отличается
от идентификации других типов SA. ISAKMP использует два поля cookie в заголовке ISAKMP для
идентификации ISAKMP SAs. Message ID в ISAKMP Header и поле SPI в Proposal payload
используются при установлении SA для идентификации SA других протоколов безопасности.
В приведенной ниже таблице 3 показано наличие или отсутствие определенных полей при
установлении SA. Следующие поля необходимы для различных операций, связанных с
установлением SA: cookies в заголовке ISAKMP, поле Message ID в заголовке ISAKMP, поле SPI в
Proposal payload. в столбце означает, что значение должно присутствовать. в столбце означает, что
значение в операции не применяется.
Таблица 3. Поля при установлении SA
Операция
IRMessage
Cookie Cookie ID
SPI
1. Начало
ISAKMP SA
переговоров
X
2. Ответ ISAKMP
X
SA переговоров
X
3. Инициализация
других SA
X
переговоров
X
X
X
4. Ответ других
переговоров SA
X
X
X
X
5. Другое (КЕ, ID
X
и т.д.)
X
X/0
NA
6. Протокол
безопасности
(ESP, AH)
NA
NA
X
NA
Первая строка таблицы свидетельствует о том, что инициатор включает поле Initiator Cookie в
ISAKMP Header.
Вторая строка таблицы свидетельствует о том, что отвечающий включает поля Initiator и
Responder Cookie в ISAKMP Header. Взаимодействующие стороны ISAKMP могут обмениваться
дополнительными сообщениями в зависимости от типа обмена ISAKMP, используемого в первой
фазе переговоров. После завершения первой фазы обмена Initiator и Responder cookies включаются
в ISAKMP Header всех обменов между участниками ISAKMP.
В течение первой фазы переговоров cookies инициатора и получателя определяют ISAKMP SA.
Следовательно, поле SPI в Proposal payload избыточно и может быть установлено в 0 или может
содержать cookie передаваемых сущностей.
Третья строчка таблицы свидетельствует о том, что инициатор связывает Message ID с Protocols,
содержащимися в SA Proposal. Это Message ID и SPI(s) инициатора связываются с каждым
протоколом в Proposal и посылаются получателю. SPI(s) будут использоваться в протоколах
безопасности сразу после завершения второй фазы переговоров.
В четвертой строке таблицы получатель включает тот же самый Message ID, и SPI(s) получателя
связываются с каждым протоколом в принимаемом Proposal. Эта информация возвращается
инициатору.
Пятая строка таблицы свидетельствует о том, что инициатор и получатель используют поле
Message ID в ISAKMP Header для отслеживания выполнения протокола переговоров. Это
применяется на второй фазе обмена, и значение должно быть 0 для первой фазы обмена, потому
что комбинированные cookies определяют ISAKMP SA. Поле SPI в Proposal payload не
применяется, потому что Proposal payload используется только на протяжении обмена
сообщениями переговоров SA (шаги 3 и 4).
В шестой строке таблицы фаза 2 переговоров завершается.
При установлении SA должно создаваться SPI. ISAKMP предполагает применение SPIs различных
размеров. Это достигается путем использования поля SPI Size в Proposal payload при установлении
SA.
При начальном установлении SA одна из сторон выступает в роли инициатора, а другая — в роли
получателя. После того как SA установлена, как инициатор, так и получатель могут начать вторую
фазу переговоров с противоположной сущностью. Таким образом, ISAKMP SAs по своей природе
являются двунаправленными.
Далее описывается понятие: Создание Token анти-препятствия (cookie).
Детали создания cookie зависят от реализации, но в целом должны выполняться следующие
основные требования:
а) Cookie должны зависеть только от данных участников; это не позволит злоумышленнику
получить cookie, используя реальный IP-адрес и UDP-порт, и затем используя его для того, чтобы
засыпать жертву запросами на вычисления по алгоритму Диффи-Хеллмана со случайных IPадресов или портов;
б) Не должно быть такого, чтобы выходящая сущность создавала те же самые cookie, что и
получающая сущность. Это подразумевает, что выходящая сущность должна использовать
локальную секретную информацию при создании cookie. Возможности вычислить эту секретную
информацию из конкретного cookie существовать не должно;
в) Функция создания cookie должна быть быстрой, чтобы предотвратить атаки, направленные на
использование ресурсов ЦП;
Кэрн (Karn) предложил метод создания cookie, основанный на выполнении быстрого хэша
(например, MD5) над IP-адресами источника и получателя, портов UDP-источника и получателя и
локально созданного секретного случайного значения. ISAKMP требует, чтобы cookie были
уникальными для каждой устанавливаемой SA для того, чтобы предотвратить replay-атаки и,
следовательно, в хэшируемую информацию должны добавляться значения даты и времени.
Созданные cookie помещаются в заголовок ISAKMP инициатора и получателя. Эти поля имеют
длину 8 октетов, таким образом, создаваемые cookie должны быть длиной 8 октетов.
10.5 Содержимые ISAKMP
Содержимые ISAKMP обеспечивают возможность конструировать ISAKMP-сообщения из
модульно построенных блоков. Наличие и последовательность содержимых в ISAKMP
определяется полем Exchange Type, размещаемым в заголовке ISAKMP. Типы содержимых
ISAKMP приводятся далее. Описания сообщений и обменов показаны, используя сетевой порядок
представления октетов.
10.5.1 Формат заголовка ISAKMP
Сообщение ISAKMP имеет фиксированный формат заголовка, показанный в соответствии с
рисунком 10.1, за которым следует переменное число определенных содержимых. Фиксированный
заголовок проще разбирать, что делает ПО более легким для реализации. Фиксированный
заголовок содержит информацию, необходимую протоколу для поддержки состояния, обработки
содержимого и, возможно, предотвращения DoS-атак и replay-атак.
Поля заголовка ISAKMP определяются следующим образом:
Рисунок 10.1 — Формат заголовка ISAKMP
а) Initiator Cookie (8 октетов) — cookie участника, который инициировал установление SA,
уведомление SA или уничтожение SA;
б) Responder Cookie (8 октетов) — cookie участника, который является получателем запроса
установления SA, уведомления SA или уничтожения SA;
в) Next Payload (1 октет) — определяет тип первого содержимого в сообщении; формат обработки
каждого содержимого определяется далее;
д) Major Version (4 бита) — определяет старший номер версии используемого протокола ISAKMP;
е) Minor Version (4 бита) — определяет младший номер версии используемого протокола ISAKMP;
ж) Exchange Type (1 октет) — определяет тип используемого обмена; это определяет сообщение и
упорядоченность полезной информации в ISAKMP-обменах;
и) Flags (1 октет) — определяет конкретные опции, которые установлены для ISAKMP-обмена;
флаги, перечисленные ниже, определяются в поле Flags, начиная с крайнего левого бита, т.е. бит
Encription является нулевым битом поля Flags, бит Commit является первым битом поля Flags и
бит Authentication Only является вторым битом поля Flags; оставшиеся биты поля Flags при
передаче должны быть установлены в 0;
— E (encryption bit) — если установлен, то все содержимые, следующие после заголовка, шифруются,
используя алгоритм шифрования, определенный в ISAKMP SA; ISAKMP SA Identifier является
комбинацией cookie инициатора и получателя; рекомендуется, чтобы шифрование соединения
между участниками начинало выполняться как можно быстрее; для всех ISAKMP-обменов
шифрование должно начинаться после того как оба участника обменяются содержимыми Key
Exchange; если данный бит не установлен, то содержимые не шифруются;
— C (commit bit) — данный бит используется для сигнала синхронизации обмена ключа; он
позволяет гарантировать, что зашифрованный материал не будет получен до завершения
установления SA; Commit Bit может быть установлен в любое время любым из участников
установления SA и может использоваться в обеих фазах установления ISAKMP SA; тем не менее,
значение должно быть сброшено после Фазы 1 переговоров; если установлено (1), сущность,
которая не установила Commit Bit, должна ждать Information Exchange, содержащий Notify payload
от сущности, которая установила Commit Bit; получение и обработка Informational Exchange
говорит о том, что установление SA прошло успешно, и обе сущности могут теперь продолжать
взаимодействие по зашифрованному каналу; дополнительно к синхронизации обмена ключа
Commit Bit может использоваться для защиты от падения соединения по ненадежным сетям и
предохранять от необходимости многочисленных повторных восстановлений;
— A (authentication only bit) — данный бит используется с Informational Exchange с Notify payload и
позволяет передавать информацию с контролем целостности, но без шифрования (т.е. <аварийный
режим>); если бит Authentication Only установлен, ко всему содержимому Notify Informational
Exchange применяются только сервисы аутентификации, и содержимое не шифруется;
к) Message ID (4 октета) — уникальный идентификатор сообщения, используется для
идентификации состояния протокола в Фазе 2 переговоров; данное значение создается случайным
образом инициатором в Фазе 2 переговоров;
л) Length (4 октета) — длина всего сообщения (заголовок + содержимое) в октетах; шифрование
может увеличить размер ISAKMP-сообщения;
Таблица 4 — Типы содержимого
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
10.5.2 Общий заголовок содержимого
Каждое содержимое ISAKMP, определяемое далее, начинается с общего заголовка, показанного в
соответствии с рисунком 10.2, который обеспечивает возможность <связывания> содержимых и
позволяет явно определять границы содержимого.
Поля общего заголовка содержимого определяются следующим образом:
Рисунок 10.2 — Общий заголовок содержимого
а) Next Payload (1 октет) — идентификатор типа содержимого следующего содержимого в
сообщении; если текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина текущего содержимого, включая общий заголовок;
10.5.3 Атрибуты данных
Существует несколько случаев в ISAKMP, когда должны быть представлены атрибуты данных.
Примером могут служить атрибуты SA, содержащиеся в Transform payload. Эти атрибуты данных
не являются самостоятельным содержимым ISAKMP, а представляют собой часть некоторого
содержимого. Формат атрибутов данных обеспечивает гибкость представления различных типов
информации. В содержимом может существовать много атрибутов данных. Длина атрибутов
данных или равна 4 октетам, или определяется полем Attribute Length. Это определяется битом
формата атрибута, описанным ниже.
Поля атрибутов данных определяются следующим образом в соответствии с рисунком 10.3:
Рисунок 10.3 — Атрибуты данных
а) Attribute Type (2 октета) — уникальный идентификатор каждого типа атрибута;
бит Attribute Format (AF) указывает, будут ли атрибуты данных определяться форматом
Type/Length/Value (TLV) или короткой формой формата Type/Value (TV); если бит AF = 0, то
атрибуты данных имеют форму TLV; если бит AF = 1, то атрибуты данных имеют форму TV;
б) Attribute Length (2 октета) — длина значения атрибута в октетах; при AF = 1 значение атрибута
имеет только 2 октета, и поле длины атрибута не представлено;
в) Attribute Value (переменной длины) — значение атрибута, связанное с Attribute Type; если бит AF
= 0, то это поле имеет переменную длину, определяемую полем Attribute Length; если бит AF = 1,
то Attribute Value имеет длину 2 октета;
10.5.4 Содержимое SA
Содержимое SA используется при переговорах об атрибутах безопасности и для определения
Situation, при котором переговоры имеют место. Формат полезной информации SA в соответствии
с рисунком 10.4:
Рисунок 10.4 — Содержимое SA
а) Next Payload (1 октет) — идентификатор типа содержимого Next payload в сообщении; если
текущее содержимое является последним в сообщении, то это поле будет 0; данное поле не
должно содержать значений для Proposal или Transform payloads, т.к. они являются частью
содержимого SA; например, это поле должно содержать значение <10> (Nonce payload) в первом
сообщении Base Exchange, и значение <0> в первом сообщении Identity Protect Exchange;
б) Payload Length (2 октета) — длина в октетах всего содержимого SA, включая SA payload, все
Proposal payloads и все Transform payloads, связанные с создаваемой SA;
в) Domain of Interpretation (4 октета) — определяет DOI, которым определяются данные переговоры;
DOI является 32-битным беззнаковым целым; значение 0 DOI в течение Фазы 1 обмена определяет
Generic ISAKMP SA, который может использоваться любым протоколом в течение Фазы 2 обмена;
значение 1 DOI связано с IPSec DOI; все другие значения DOI зарезервированы IANA для
дальнейшего использования; IANA обычно не связывает значение DOI без некоторой открытой
спецификации, такой как RFC;
д) Situation (переменной длины) — поле, определяемое DOI, которое идентифицирует ситуацию,
при которой ведутся переговоры; Situation используется для того, чтобы определить политику и
соответствующие атрибуты безопасности, при которых ведутся переговоры;
10.5.5 Содержимое Proposal
Proposal Payload содержит информацию, используемую в течение переговоров SA. Proposal
состоит из механизмов безопасности, или преобразований, используемых для обеспечения
безопасности информационного канала. Формат Proposal Payload в соответствии с рисунком 10.5.
Рисунок 10.5 — Формат Proposal Payload
Поля Proposal Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; это поле
должно содержать только значения <2> или <0>; если существуют дополнительные Proposal
payload, то это поле должно быть 2; если текущий Proposal payload является последним в SA
proposal, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах всего Proposal payload, включая общий заголовок
содержимого, Proposal payload и все Transform payloads, связанные с данным proposal;
в) Proposal # (1 октет) — определяет номер Proposal для текущего содержимого;
д) Protocol-Id (1 октет) — определяет идентификатор протокола для текущих переговоров;
примерами являются IPSEC ESP, IPSEC AH;
е) SPI Size (1 октет) — длина SPI в октетах как определено Protocol-Id; в случае ISAKMP пара cookie
Инициатора и Получателя из заголовка ISAKMP является идентификацией ISAKMP,
следовательно, SPI Size не имеет значения и может быть от нуля до 16;
ж) # of Transforms (1 октет) — определяет количество преобразований для Proposal; каждое из них
содержится в Transform payload;
и) SPI (переменной длины) — SPI получающей сущности;
Тип содержимого для Proposal Payload равен 2.
10.5.6 Содержимое Transform
Transform Payload содержит информацию, используемую SA при переговорах. Transform Payload
состоит из конкретных механизмов безопасности, или преобразований, которые используются для
обеспечения безопасности информационного канала. Transform Payload также содержит атрибуты
SA, связанные с конкретным преобразованием. Эти атрибуты SA определяются DOI. Формат
Transform Payload в соответствии с рисунком 10.6.
Рисунок 10.6 — Формат Transform Payload
Поля Transform Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; это поле
должно содержать только значения <3> или <0>; если есть дополнительные Transform Payloads в
Proposal, то данное поле должно быть равно 3; если текущая Transform Payload является последней
в proposal, то данное поле должно быть равно 0;
б) Payload Length (2 октета) — длина в октетах текущей полезной информации, включая общий
заголовок, значения Transform и все атрибуты SA;
в) Transform # (1 октет) — определяет количество преобразований для текущего содержимого; если
для конкретного протокола существует более одного преобразования, то каждая Transform рayload
имеет уникальный номер преобразования;
д) Transform-Id (1 октет) — определяет идентификатор преобразования для протокола в текущей
Proposal; эти преобразования зависят от протокола, для которого ведутся переговоры;
е) SA Attributes (переменной длины) — данное поле содержит атрибуты SA как они определены для
данного преобразования в поле Transform-Id; атрибуты SA должны представляться с
использованием формата Data Attributes;
Тип полезной информации для Transform Payload есть 3.
10.5.7 Содержимое Key Exchange
Key Exchange Payload поддерживает различные технологии обмена ключами. Примерами обмена
ключами являются Oakley, Diffie-Hellman, расширенный обмен ключами Diffie-Hellman,
описанный в Х9.42, и обмен ключами на основе RSA, используемый в PGP. Формат Key Exchange
рayload в соответствии с рисунком 10.7.
Рисунок 10.7 — Формат Key Exchange Payload
Поля Key Exchange Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним в сообщении, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Key Exchange Data (переменной длины) — данные, необходимые для создания ключа сессии;
Тип полезной информации для Key Exchange Payload есть 4.v
10.5.8 Содержимое Identification
Identification Payload содержит данные, используемые при обмене идентификационной
информацией.
Рисунок 10.8 — Формат Identification Payload
Поля Identification Payload определяются следующим образом в соответствии с рисунком 10.8:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущая полезная информация является последней, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) ID Type (1 октет) — спецификация типа используемой идентификации;
д) DOI Specific ID Data (3 октета) — содержит данные идентификации; если не используется, то
данное поле должно устанавливаться в 0;
е) Identification Data (переменной длины) — содержит идентификационную информацию; формат
определяется полем ID Type;
Тип полезной информации для Identification Payload есть 5.
10.5.9 Содержимое Certificate
Certificate Payload обеспечивает способ передачи сертификатов или другой информации,
относящейся к сертификатам, с помощью ISAKMP и может появляться в любом сообщении
ISAKMP. Формат Certificate Payload в соответствии с рисунком 10.9.
Рисунок 10.9 — Формат Certificate Payload
Поля Certificate Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущая полезная информация является последней, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Certificate Encoding (1 октет) — данное поле определяет тип сертификата или информации,
относящейся к сертификату, содержащейся в поле Certificate Data;
д) Certificate Data (переменной длины) — конкретное представление данных сертификата; тип
сертификата определяется полем Certificate Encoding;
Тип содержимого для Certificate Payload есть 6.
10.5.10 Содержимое Certificate Request
Certificate Request Payload обеспечивает значение для запроса сертификатов с помощью ISAKMP и
может появиться в любом сообщении. Certificate Request рayload должен приниматься в любой
точке обмена. Получатель Certificate Request рayload должен послать свой сертификат. Если
требуется несколько сертификатов, то должны передаваться несколько Certificate Request рayloads.
Формат Certificate Request Payload в соответствии с рисунком 10.10.
Рисунок 10.10 — Формат Сertificate Request Payload
Поля Certificate Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Certificate Type (1 октет) — содержит тип запрашиваемого сертификата;
д) Certificate Authority (переменной длины) — содержит обозначение принимаемых
сертификационных центров для запрашиваемых сертификатов; например, для сертификата Х.509
оно должно содержать значение DN CA, принимаемого отправителем; это должно помочь
получателю определить, какую цепочку сертификатов необходимо послать в ответ на данный
запрос; если требуемый сертификационный центр не указан, данное поле включаться не должно;
Тип содержимого для Certificate Request Payload есть 7.
10.5.11 Содержимое HASH
Hash Payload содержит данные, создаваемые хэш-функцией (определенной во время обмена при
установлении SA), для некоторой части сообщения и/или состояния ISAKMP. Данное содержимое
может использоваться для проверки целостности данных в ISAKMP-сообщении или для
аутентификации сущностей, ведущих переговоры. Формат Hash Payload в соответствии с
рисунком 10.11.
Рисунок 10.11 — Формат HASH Payload
Поля Hash Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Hash Data (переменной длины) — данные, которые являются результатом применения хэшфункции к ISAKMP-сообщению и/или состоянию;
10.5.12 Содержимое Signature
Signature Payload содержит данные, созданные функцией цифровой подписи (выбранной при
обмене во время установления SA) для определенной части сообщения и/или ISAKMP-состояния.
Данное содержимое используется для проверки целостности данных в ISAKMP-сообщении, и
может быть использовано для сервисов невозможности отказа. Формат Signature Payload в
соответствии с рисунком 10.12.
Рисунок 10.12 — Формат Signature Payload
Поля Signature Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Signature Data (переменной длины) — данные, которые являются результатом применения
функции цифровой подписи для ISAKMP сообщения;
Тип содержимого для Signature Payload есть 9.
10.5.13 Содержимое Nonce
Nonce Payload содержит случайные данные, используемые для гарантии своевременности обмена
и отсутствия replay-атак. Формат Nonce Payload в соответствии с рисунком 10.13. Если nonces
используются в конкретном обмене ключа, то применение Nonce рayload определяется обменом
ключа. Nonces могут передаваться как часть данных обмена ключа или как отдельное содержимое.
Это, однако, определяется обменом ключа, а не ISAKMP.
Рисунок 10.13 — Формат Nonce Payload
Поля Nonce Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Nonce Data (переменной длины) — содержит случайные данные, созданные передающей
сущностью;
Тип содержимого для Nonce Payload есть 10.
10.5.14 Содержимое Notification
Notification Payload может содержать как определяемые ISAKMP, так и определяемые DOI данные
и использоваться при передаче информационных данных, таких как ошибочные условия. Можно
послать несколько Notification Payload в одном сообщении ISAKMP. Формат Notification Payload в
соответствии с рисунком 10.14.
Рисунок 10.14 — Формат Notification Data
Notification, которые возникают на Фазе 1 переговоров, идентифицируются парой cookie
Инициатора и Получателя в заголовке ISAKMP. Идентификатором протокола в данном случае
является ISAKMP, и значение SPI есть 0, потому что пара cookie в заголовке ISAKMP
идентифицирует ISAKMP SA. Если notification имеет место перед завершением обмена ключевой
информацией, то она не будет защищена.
Notification, которые возникают во время Фазы 2 переговоров, определяются парой cookie
Инициатора и Получателя в заголовке ISAKMP, и Message ID и SPI связаны с текущими
переговорами.
Поля Notification Data определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Domain of Interpretation (4 октета) — идентификация DOI, с помощью которой данное
уведомление имело место;
д) Protocol-Id (1 октет) — определяет идентификатор протокола для текущего уведомления;
примерами являются ISAKMP, ESP, AH;
е) SPI Size (1 октет) — длина SPI в октетах как определено в Protocol-Id; в случае ISAKMP пара
cookie Инициатора и Получателя из заголовка ISAKMP есть ISAKMP SPI, следовательно, SPI Size
не имеет отношения к делу и, следовательно, может быть от 0 до 16; если SPI Size — не 0,
содержимое поля SPI должно игнорироваться;
ж) Notify Message Type (2 октета) — определяет тип сообщения уведомления; дополнительный
текст размещается в поле Notification Data;
и) SPI (переменной длины) — Security Parameter Index. SPI получающей сущности; длина этого поля
определяется полем SPI Size;
к) Notification Data (переменной длины) — информация или данные об ошибке, передаваемые в
дополнение к Notify Message Type;
Тип содержимого для Notification Payload есть 11.
10.5.15 Содержимое Delete
Delete Payload содержит идентификатор SA которую отправитель удаляет из своей БД SA и
которая, следовательно, более не доступна. Формат Delete Payload в соответствии с рисунком
10.15. Возможна посылка нескольких SPIs в Delete Payload, однако каждый SPI должен быть
предназначен для того же самого протокола.
Рисунок 10.15 — Формат Delete Payload
Удаление, которое относится к ISAKMP SA, содержит Protocol-Id для ISAKMP, и SPIs есть cookies
отправителя и получателя из заголовка ISAKMP. Удаление, которое имеет дело с Protocol SA,
такими как ESP или АН, будет содержать Protocol-Id протокола (т.е. ESP, AH), и SPI есть SPI(s)
посылающей сущности.
Поля Delete Payload определены следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Domain of Interpretation (4 октета) — идентификация DOI, с помощью которой данное
уведомление было сделано;
д) Protocol-Id (1 октет) — ISAKMP может устанавливать безопасные ассоциации для различных
протоколов, включая ISAKMP и IPSec;
е) SPI Size (1 октет) — длина SPI в октетах определяется Protocol-Id; в случае ISAKMP ISAKMP SPI
является пара cookie Инициатора и Получателя; в этом случае SPI Size есть 16 октетов для
каждого удаляемого SPI;
ж) # of SPIs (2 октета) — количество SPIs, содержащихся в Delete payload; размер каждого SPI
определяется полем SPI Size;
и) Securiry Parameter Index(es) (переменной длины) — идентификаторы, определяющие удаляемые
безопасные ассоциации;
Тип содержимого для Delete Payload есть 12.
10.5.16 Содержимое Vendor ID
Vendor ID Payload содержит константу, определяющую разработчика. Данная константа
используется разработчиком для собственной идентификации и удаленной сущностью для
распознавания разработчика. Данный механизм позволяет разработчику экспериментировать с
новыми возможностями, сохраняя обратную совместимость.Формат Vendor ID Payload в
соответствии с рисунком 10.16.
Рисунок 10.16 — Формат Vendor ID Payload
Поля Vendor ID Payload определяются следующим образом:
а) Next Payload (1 октет) — идентификатор типа следующего содержимого в сообщении; если
текущее содержимое является последним, то данное поле должно быть 0;
б) Payload Length (2 октета) — длина в октетах текущего содержимого, включая общий заголовок;
в) Vendor ID (переменной длины) — хэш строки разработчика плюс версия;
Тип содержимого Vendor ID есть 13.
Вопрос 15. Шифрование на уровне соединения SSL.
SSL (англ. secure sockets layer — уровень защищённых сокетов) — криптографический протокол,
который подразумевает более безопасную связь. Он использует асимметричную криптографию
для аутентификации ключей обмена, симметричное шифрование для сохранения
конфиденциальности, коды аутентификации сообщений для целостности сообщений. Протокол
широко использовался для обмена мгновенными сообщениями и передачи голоса
через IP (англ. Voice over IP — VoIP) в таких приложениях, как электронная почта, Интернет-факс
и др. В настоящее время известно, что протокол не является безопасным[1]. SSL должен быть
исключен из работы в пользу TLS (см. CVE-2014-3566).
SSL изначально разработан компанией Netscape Communications для добавления
протокола HTTPS в свой веб-браузер Netscape Navigator. Впоследствии на основании протокола
SSL 3.0 был разработан и принят стандарт RFC, получивший имя TLS.
Содержание
[показать]
Описание
Протокол SSL обеспечивает защищенный обмен данных за счет двух следующих элементов:
Аутентификация
Шифрование
SSL использует асимметричную криптографию для аутентификации ключей обмена,
симметричный шифр для сохранения конфиденциальности, коды аутентификации сообщений для
целостности сообщений.
Протокол SSL предоставляет «безопасный канал», который имеет три основных свойства:
1. Канал является частным. Шифрование используется для всех сообщений после простого
диалога, который служит для определения секретного ключа.
2. Канал аутентифицирован. Серверная сторона диалога всегда аутентифицируется, а
клиентская делает это опционно.
3. Канал надежен. Транспортировка сообщений включает в себя проверку целостности.
Преимуществом SSL является то, что он независим от прикладного протокола. Протоколы
приложений (HTTP, FTP, TELNET и т.д.) могут работать поверх протокола SSL совершенно
прозрачно, т.е. SSL может согласовывать алгоритм шифрования и ключ сессии, а также
аутентифицировать сервер до того, как приложение примет или передаст первый байт сообщения.
История и развитие
SSL 1.0, 2.0 и 3.0
Протокол SSL был изначально разработан компанией Netscape Communications. Версия 1.0
никогда не была обнародована. Версии 2.0 была выпущена в феврале 1995 года, но содержала
много недостатков по безопасности, которые привели к разработке SSL версии 3.0[2]. SSL версии
3.0, выпущенный в 1996 году, послужил основой для создания протоколаTLS 1.0, стандарт
протокола Internet Engineering Task Force (IETF), который впервые был определен в RFC 2246 в
январе 1999 года. Visa, Master Card, American Express и многие другие организации имеют
лицензию на использование протокола SSL для коммерческих целей в сети Интернет. Тем самым
SSL расширяемо в соответствии с проектом о поддержке прямой и обратной совместимости и
переговорам между соединениями в одноранговой сети.
TLS 1.0
TLS 1.0 впервые был определен в RFC 2246 в январе 1999 года в качестве обновления версии SSL
3.0. Как указано в RFC, «различия между этим протоколом и SSL 3.0 не критичны, но они
значительны для появления несовместимости при взаимодействии TLS 1.0 и SSL 3.0». TLS 1.0
действительно включает средства, с помощью которых реализация подключения TLS к SSL 3.0
ослабит безопасность.
TLS 1.1
TLS 1.1 презентовали в RFC 4346 в апреле 2006 года[3]. Это было обновление TLS версии 1.0.
Значительные изменения в этой версии включают в себя:
добавлена защита от атак, использующих режим сцепления блоков шифротекста (Cipher
Block Chaining);
неявный Вектор инициализации (IV) был заменен на явный IV;
было проведено изменение в обработке ошибок;
введена поддержка IANA регистрации параметров.
TLS 1.2
TLS 1.2 был анонсирован в RFC 5246 в августе 2008 года. Он основан на ранее предложенной
версии TLS 1.1.
Принцип работы
SSL использует среду с несколькими слоями, что обеспечивает безопасность обмена
информацией. Конфиденциальность общения присутствует за счет того, что безопасное
соединение открыто только целевым пользователям.
Многослойная среда
Протокол SSL размещается между двумя протоколами: протоколом, который использует
программа-клиент (HTTP, FTP, LDAP, TELNET etc) и транспортным протоколом TCP/IP. SSL
защищает данные, выступая в роли фильтра для обеих сторон и передает их далее на
транспортный уровень. Работу протокола можно разделить на два уровня:
1. Слой протокола подтверждения подключения (Handshake Protocol Layer)
2. Слой протокола записи
Первый слой, в свою очередь, состоит из трех подпротоколов:
1. Протокол подтверждения подключения (Handshake Protocol)
2. Протокол изменения параметров шифра (Cipher Spec Protocol)
3. Предупредительный протокол (Alert Protocol)
Протокол подтверждения подключения используется для согласования данных сессии между
клиентом и сервером. К данным сессии относятся:
Идентификационный номер сессии
Сертификаты обеих сторон
Параметры алгоритма шифрования
Алгоритм сжатия информации
«Общий секрет» применен для создания ключей; открытый ключ
Протокол изменения параметров шифра используется для изменения данных ключа
(keyingmaterial) — информации, которая используется для создания ключей шифрования. Протокол
состоит всего из одного сообщения, в котором сервер говорит, что отправитель хочет изменить
набор ключей.
Предупредительный протокол содержит сообщение, которое показывает сторонам изменение
статуса или сообщает о возможной ошибке. Обычно предупреждение отсылается тогда, когда
подключение закрыто и получено неправильное сообщение, сообщение невозможно
расшифровать или пользователь отменяет операцию.
Протокол подтверждения подключения производит цепочку обмена данными, что в свою
очередь начинает аутентификацию сторон и согласовывает шифрование, хэширование и сжатие.
Следующий этап — аутентификация участников, которая осуществляется также протоколом
подтверждения подключения.
Цифровые сертификаты
Протокол SSL использует сертификаты для проверки соединения. Сертификаты расположены на
безопасном сервере и используются для шифрования данных и идентификации Web-сайта.
Способы получения SSL-сертификата:
1. Использовать сертификат, выданный CA
2. Использовать самоподписанный сертификат
3. Использовать «пустой» сертификат
Самоподписанный сертификат — сертификат, созданный самим пользователем — в этом случае
издатель сертификата совпадает с владельцем сертификата. «Пустой» сертификат — сертификат,
содержащий фиктивную информацию, используемую в качестве временной для настройки SSL и
проверки его функциональности в данной среде.
Механизмы образования ключа для текущей сессии в SSL/TLS
Существует 4 основных алгоритма для образования ключей: RSA, Fixed Diffie-Hellman,
Ephemenral Diffie-Hellman, Anonymous Diffie-Hellman
RSA
При «утере» приватного ключа RSA криптоаналитик, получивший его, получает возможность
расшифровать все записанные прошлые сообщения и будущие сообщения. Реализация обмена
ключей в RSA является односторонней: вся необходимая информация для образования
симметричного ключа, который создается на этапе рукопожатия, пересылается на сервер и
шифруется публичным ключом сервера. Раскрытие приватного ключа дает возможность узнать
симметричный ключ данной сессии.
Diffie-Hellman
Механизм Fixed Diffie-Hellman использует постоянный публичный ключ, который прописан в
сертификате сервера. Это также означает, что при каждом новом соединении клиент
предоставляет свою часть ключа. После обмена ключами образуется новый симметричный ключ
для обмена информацией для текущей сессии. При раскрытии приватного ключа сервера
криптоаналитик может расшифровать ранее записанные сообщения, а также все будущие
сообщения. Это становится возможным из-за самого механизма. Так как криптоаналитик знает
частный ключ сервера, он сможет узнать симметричный ключ каждой сессии, и даже тот факт, что
механизм образования ключа является двусторонним, не поможет.
Механизм Anonymous Diffie-Hellman не предоставляет гарантий секретности, ибо данные
передаются незашифрованными.
Единственный вариант, при котором гарантируется безопасность прошлых и будущих сообщений
—Ephemeral Diffie-Hellman. Разница по сравнению с ранее рассмотренными методами
заключается в том, что при каждом новом соединении сервером и клиентом создается
одноразовый ключ. Таким образом, даже если криптоаналитику достанется текущий частный
ключ, он сможет расшифровать только текущую сессию, но не предыдущие или будущие сессии.
Особенности шифрования
Существует два основных способа шифрования данных: симметричный ключ (общий секретный
ключ) и асимметричный ключ (открытый ключ).
SSL использует как асимметричную, так и симметричную криптографию.
Суть асимметричного шифрования заключается в том, что используется пара ключей. Один из
них используется в качестве открытого (как правило, он публикуется в самом сертификате
владельца), второй ключ называется секретным — он держится в тайне и никогда никому не
открывается. Оба ключа работают в паре: один используется для запуска противоположных
функций другого ключа. Если открытый ключ используется для того, чтобы зашифровать данные,
то расшифровать их можно только секретным ключом и наоборот. Такая взаимосвязь позволяет
делать две важные вещи.
1. Любой пользователь может получить открытый ключ по назначению и использовать его
для шифрования данных, расшифровать которые может только пользователь, владеющий
секретным ключом.
2. Если заголовок шифрует данные, используя свой секретный ключ, каждый может
расшифровать данные, используя соответствующий открытый ключ. Именно это является
основой для цифровых подписей.
RSA — самый распространенный алгоритм шифрования с использованием асимметричных ключей.
При шифровании симметричным ключом используется один и тот же ключ для шифрованных
данных. Если стороны хотят обменяться зашифрованными сообщениями в безопасном режиме, то
у обеих сторон должны быть одинаковые симметричные ключи. Такой тип шифрования
используется для большого объема данных. Обычно используются алгоритмы DES, 3DES, RC2, RC4 и AES.
Протокол SSL использует шифрование с открытым ключом для аутентификации клиент-сервер и
наоборот, а также для определения ключа сессии, который, в свою очередь, используется более
быстрыми алгоритмами симметричной криптографии для шифрования большого объема данных.
Хеширование
Хеш-значение является идентификатором сообщения, его размер меньше размера оригинального
сообщения. Самыми известными хеш-алгоритмами являются MD5 (Message Digest 5), который
создает 128-битное хеш-значение, SHA-1 (Standard Hash Algorithm), создающий 160-битное хешзначение, SHA-2 и SHA-3. Результат работы алгоритма хеширования — значение, которое
используется для проверки целостности передачи данных.
Уровень записи
Протокол на уровне слоя записи получает зашифрованные данные от программы-клиента и
передает их на транспортный слой. Протокол записи берет данные, разбивает их на блоки и
выполняет шифрование (расшифровывание) данных. При этом активно используется информация,
которая была согласована во время подтверждения данных.
Протокол SSL позволяет использовать шифрование симметричным ключом, используя
либо блочные, либо потоковые шифры. Обычно на практике применяются блочные шифры.
Принцип работы блочного шифра заключается в отображении блока открытого текста в такой же
блок шифрованного текста. Этот шифр можно представить в виде таблицы, содержащей 2128 строк,
каждая строка содержит блок открытого текста M и соответствующий ему блок шифрованного
текста C. Подобная таблица существует для каждого ключа.
Шифрование можно обозначить в виде функции
C = E(Key, M), где M — исходные данные, Key — ключ шифрования, С — зашифрованные данные.
Как правило, блоки имеют небольшой размер (обычно 16 байт), поэтому возникает вопрос: как
зашифровать длинное сообщение?
Первый режим для подобного шифрования называется ECB (Electronic Codebook) или режим
простой замены. Его суть состоит в том, что мы разбиваем исходное сообщение на блоки (по те же
16 байт) и шифруем каждый блок отдельно. Однако, данный режим применяет редко из-за
проблемы сохранения статистических особенностей исходного текста: 2 одинаковых блока
открытого текста после шифрования превратятся в два одинаковых блока зашифрованного текста.
Для решения этой проблемы был разработан второй режим — CBC (Cipher-block chaining). В этом
случае каждый новый блок шифротекста XOR’ится с предыдущим результатом шифрования.
Первый блок XOR’ится c некоторым вектором инициализации (Initialization Vector, IV). Однако
вся вышеизложенная теория разработана для одного большого объекта, в то время как SSL,
являясь криптографическим протоколом, должен шифровать серию пакетов. В такой ситуации
существует два способа применения CBC:
1. Обрабатывать каждое сообщение как отдельный объект, генерируя для него каждый раз
новый вектор инициализации
2. Обрабатывать все сообщения как один большой объект, сохраняя режим CBC между ними.
В таком случае в качестве вектора инициализации для сообщения n будет использоваться
последний блок шифрования предыдущего сообщения (n-1)
Применение
При проектировании приложений SSL реализуется поверх любого другого протокола
транспортного уровня, таких как HTTP, FTP, SMTP, NNTP и XMPP. Исторически SSL был
использован в первую очередь с надёжными транспортными протоколами, такими
как Transmission Control Protocol (TCP). Тем не менее, он также был реализован с датаграммными
транспортными протоколами, такими как User Datagram Protocol (UDP) и Datagram Control
Protocol (DCCP), использование которого было стандартизировано, что привело к появлению
термина Datagram Transport Layer Security (DTLS).
Вебсайты
Частое использование протокола SSL привело к формированию протокола HTTPS (Hypertext
Transfer Protocol Secure), поддерживающего шифрование. Данные, которые передаются по
протоколу HTTPS, «упаковываются» в криптографический протокол SSL или TLS, тем самым
обеспечивая защиту этих данных. Такой способ защиты широко используется в мире Веб для
приложений, в которых важна безопасность соединения, например в платёжных системах. В
отличие от HTTP, для HTTPS по умолчанию используется TCP-порт 443.
Сайт поддержки протокола
Версия протокола Безопасность Поддержка сайтами
SSL 2.0
Нет
28.4 %
SSL 3.0
Нет
99.8 %
TLS 1.0
Может быть
99.4 %
TLS 1.1
10.4 %
Да
TLS 1.2
12.7 %
Браузеры
По состоянию на 2013 г. все основные веб-браузеры, поддерживающие SSL/TLS:
Браузеры, поддерживающие SSL/TLS
TLS
1.0
Браузер
Платформы
Chrome 0-21
Android, iOS, Linux, Mac OS X, Windows (XP, Vista, 7,
Да
8)[a][b]
TLS
1.1
TLS
1.2
Нет
Нет
Chrome 29текущая
Android, iOS, Linux, Mac OS X, Windows (XP, Vista, 7,
Да[4]
8,10)[a][b]
Firefox 2
Linux, Mac OS X, Windows (XP, Vista, 7, 8)[c][b]
IE 6
Да[4]
Да[5]
Да[6]
Нет[7]
Нет[8]
Windows (XP)[d]
Да
Нет
Нет
IE 7-8
Windows (XP, Vista)[d]
Да
Нет
Нет
IE 8-9
Windows 7[d]
Да
Да
Да
IE 9
Windows Vista[d]
Да
Нет
Нет
IE 10
Windows (7, 8)[d]
Да
Да
Да
Opera 5-7
Linux, Mac OS X, Windows
Да[9]
Нет
Нет
Opera 8-9
Linux, Mac OS X, Windows
Да
Да[10]
Нет
Да
Да
Да
Opera 10-текущая Linux, Mac OS X, Windows[e]
Safari 4
Mac OS X, Windows (XP, Vista, 7), iOS 4.0[f]
Да
Нет
Нет
Safari 5
Mac OS X, Windows (XP, Vista, 7)[f]
Да
Нет
Нет
Safari 5-текущая
iOS 5.0-[g]
Да
Да
Да
Уточнения:
В OS X используется TLS, предоставляемый Network Security Services (NSS). По
состоянию на март 2013 года NSS 3.14.3 поддерживает TLS 1.0 и 1.1, но не версию 1.2.
Firefox 31.2 поддерживает TLS 1.0, 1.1 и 1.2, поддержка SSL 3.0 по умолчанию отключена.
IE использует реализацию TLS от операционной системы Microsoft Windows,
предоставляемый SChannel. TLS 1.1 и 1.2 по умолчанию отключены[11][12].
Opera 10 имеет поддержку TLS 1.2. Предыдущие версии поддерживали TLS 1.0 и 1.1[13].
TLS 1.1 и 1.2 по умолчанию отключены (за исключением версии 9[14]).
Safari использует реализацию операционной системы Mac OS X, Windows (XP, Vista,
7)[15][16]. Safari 5 является последней версией, доступной для Windows.
Mobile Safari и программное обеспечение сторонних производителей с использованием
библиотечных систем UIWebView поддерживают TLS 1.2, как и iOS 5.0[17][18][19].
Использование и реализация
Изначально виртуальные частные сети (VPN) на основе SSL разрабатывались как дополнительная
и альтернативная технология удалённого доступа на основе IPsec VPN. Однако, такие факторы,
как достаточная надёжность и дешевизна, сделали эту технологию привлекательной для
организации VPN. Также SSL получил широкое применение в электронной почте. Наиболее
распространённая реализация SSL — криптографический пакет с открытым исходным
кодом OpenSSL, основанный на SSLeay, написанной Эриком Янгом. Последняя версия OpenSSL
поддерживает SSLv3. Пакет предназначен для создания и управления различного
рода сертификатами. Также в его состав входит библиотека для поддержки SSL различными
программами. Библиотека используется, например, модулем SSL в распространенном HTTPсервере Apache.
Спецификация протокола записей SSL
Формат заголовка записей SSL
Все данные в SSL пересылаются в виде записей или рекордов — объектов, которые состоят из
заголовка и некоторого количества данных. Каждый заголовок рекорда содержит 2 или 3 байта
кода длины. Если старший бит в первом байте кода длины рекорда равен 1, тогда рекорд не имеет
заполнителя и полная длина заголовка равна 2 байтам, в противном случае рекорд содержит
заполнитель, и полная длина заголовка равна 3 байтам. В случае длинного (3 байта) заголовка
второй по старшинству бит первого байта имеет специальное значение. Если он равен 0 — рекорд
является информационным, если он равен 1 — рекорд является security escape. Код длины рекорда
не включает в себя число байт заголовка. Для 2-байтового заголовка его длина вычисляется так:
RECORD-LENGTH = ((byte[0] & 0x7F) <<  | byte[1];
| byte[1];
Здесь byte[0] — первый полученный байт, а byte[1] — второй полученный байт.
Для 3-байтового заголовка длина рекорда вычисляется следующим образом:
RECORD-LENGTH = ((byte[0] & 0x3F) <<8) | byte[1];
IS-ESCAPE = (byte[0] & 0x40) !=0;
PADDING = byte[2];
Значение PADDING специфицирует число байтов добавленных отправителем к исходному
рекорду. Данные заполнителя используются для того, чтобы сделать длину рекорда кратной
размеру блока шифра. Отправитель добавляет PADDING после имеющихся данных, а затем
шифрует все это, т. к. длина этого массива кратна размеру блока используемого шифра. Поскольку
известен объем передаваемых данных, заголовок сообщения может быть сформирован с учетом
объема PADDING. Получатель сообщения дешифрует все поле данных и получает исходную
информацию, затем вычисляет истинное значение RECORD-LENGTH, при этом PADDING из
поля “данные” удаляется.
Формат информационных записей SSL
Часть данных рекорда SSL состоит из 3х компонентов:
1. MAC-DATA[MAC-SIZE]
2. ACTUAL-DATA[N]
3. PADDING-DATA[PADDING]
MAC-DATA — код аутентификации сообщения
MAC-SIZE — функция используемого алгоритма вычисления хеш-суммы
ACTUAL-DATA — реально переданные данные или поле данных сообщения
PADDING-DATA — данные PADDING (при блочном шифровании)
MAC-DATA = HASH[ SECRET, ACTUAL-DATA, PADDING-DATA, SEQUENCE-NUMBER ]
Здесь SECRET передается хеш-функции первым, затем следует ACTUAL-DATA и PADDINGDATA, за которыми передается SEQUENCE-NUMBER — порядковый номер.
Значение SECRET зависит от того, кто именно посылает сообщение. Если это делает клиент,
то SECRET равен CLIENT-WRITE-KEY. Если же клиент получает сообщение,
SECRET равен CLIENT-READ-KEY.
Порядковый номер представляет собой 32-битовый код, который передается хеш-функции в виде
4 байт, используя сетевой порядок передачи “от старшего к младшему”. Порядковый номер счетчик для сервера или клиента. Для каждого направления передачи используется пара счетчиков
— для отправителя и для получателя; каждый раз, когда отправляется сообщение, счетчик
увеличивает свое значение на 1.
Получатель сообщения использует ожидаемое значение порядкового номера для
передачи MAC (тип хеш-функции определяется параметром CIPHER-CHOICE). Вычисленное
значение MAC-DATA должно совпадать с переданным значением. Если сравнение не прошло,
сообщение считается поврежденным, что приводит к возникновению ошибки, которая вызывает
закрытие соединения.
Окончательная проверка соответствия выполняется, когда используется блочный шифр. Объем
данных в сообщении (RECORD-LENGTH) должен быть кратен размеру блока шифра. Если
данное условие не выполнено, сообщение считается поврежденным, что приводит к разрыву
соединения.
Для 2х-байтового заголовка максимальная длина сообщения равно 32767 байтов, для 3х-байтового
16383 байтов. Сообщения протокола диалога SSL должны соответствовать одиночным рекордам
протокола SSL, а сообщения прикладного протокола могут занимать несколько рекордов SSL.
Протокол диалога SSL
Протокол диалога SSL содержит 2 основные фазы.
Фаза 1
Первая фаза используется для установления конфиденциального канала коммуникаций.
Эта фаза инициализирует соединение, когда оба партнера обмениваются сообщениями “hello”.
Клиент посылает сообщение CLIENT-HELLO. Сервер получает это сообщение, обрабатывает его
и посылает в ответ сообщение SERVER-HELLO.
В этот момент и сервер и клиент имеют достаточно информации, чтобы знать, нужен ли
новый master key. Если ключ не нужен, сервер и клиент переходят в фазу 2.
Когда возникает необходимость создания нового master key, сообщение сервера SERVERHELLO уже содержит достаточно данных для того, чтобы клиент мог сгенерироватьmaster key. В
эти данные входят подписанный сертификат сервера, список базовых шифров и идентификатор
соединения (случайное число, сгенерированное сервером, которое используется на протяжении
всей сессии). После генерации клиентом master key он посылает серверу сообщение CLIENTMASTER-KEY или же сообщение об ошибке, когда клиент и сервер не могут согласовать
базовый шифр.
После определения master key сервер посылает клиенту сообщение SERVER-VERIFY, что
аутентифицирует сервер.
Фаза 2
Фаза 2 называется фазой аутентификации. Т. к. сервер уже аутентифицирован на первой фазе, то
на второй фазе осуществляется аутентификация клиента. Сервер отправляет запрос клиенту и,
если у клиента есть необходимая информация, он присылает позитивный отклик, если же нет, то
сообщение об ошибке. Когда один партнер выполнил аутентификацию другого партнера, он
посылает сообщение finished. В случае клиента сообщение CLIENT-FINISHED содержит
зашифрованную форму идентификатора CONNECTION-ID, которую должен верифицировать
сервер. Если верификация была неудачной, сервер посылает сообщение ERROR.
Когда один из партнеров послал сообщение finished он должен принимать сообщения до тех пор,
пока не получит сообщение finished от другого партнера, и только когда оба партнера послали и
получили сообщения finished протокол диалога SSL закончит свою работу. С этого момента
начинает работу прикладной протокол.
Типовой протокол обмена сообщениями
Ниже представлено несколько вариантов обмена сообщениями в рамках протокола диалога SSL.
Клиент — C , сервер — S. “{smth}key” означает что “smth” зашифровано с помощью ключа.
При отсутствии идентификатора сессии
Client-hello
C ® S: challenge, cipher_specs
Server-hello
S ® C: connection-id,server_certificate,cipher_specs
Client-master-key C ® S: {master_key}server_public_key
Client-finish
C ® S: {connection-id}client_write_key
Server-verify
S ® C: {challenge}server_write_key
Server-finish
S ® C: {new_session_id}server_write_key
Идентификатор сессии найден клиентом и сервером
Client-hello C ® S: challenge, session_id, cipher_specs
Server-hello S ® C: connection-id, session_id_hit
Client-finish C ® S: {connection-id}client_write_key
Server-verify S ® C: {challenge}server_write_key
Server-finish S ® C: {session_id}server_write_key
Использован идентификатор сессии и аутентификация клиента
Client-hello
C ® S: challenge, session_id, cipher_specs
Server-hello
S ® C: connection-id, session_id_hit
Client-finish
C ® S: {connection-id}client_write_key
Server-verify
S ® C: {challenge}server_write_key
Request-certificate S ® C: {auth_type ,challenge’}server_write_key
Client-certificate
C ® S: {cert_type,client_cert, response_data}client_write_key
Server-finish
S ® C: {new_session_id}server_write_key
Аутентификация и обмен ключами
SSL поддерживает 3 типа аутентификации:
аутентификация обеих сторон (клиент — сервер),
аутентификация сервера с неаутентифицированным клиентом,
полная анонимность.
Если сервер аутентифицирован, то его сообщение о сертификации должно обеспечить верную
сертификационную цепочку, ведущую к приемлемому центру сертификации. Проще говоря,
аутентифицированный сервер должен предоставить допустимый сертификат клиенту. Каждая
сторона отвечает за проверку того, что сертификат другой стороны еще не истек и не был отменен.
Всякий раз, когда сервер аутентифицируется, канал устойчив (безопасен) к попытке перехвата
данных между веб-сервером и браузером, но полностью анонимная сессия по своей сути уязвима к
такой атаке. Анонимный сервер не может аутентифицировать клиента. Главная цель процесса
обмена ключами — это создание секрета клиента (pre_master_secret), известного только клиенту и
серверу. Секрет (pre_master_secret) используется для создания общего секрета (master_secret).
Общий секрет необходим для того, чтобы создать сообщение для проверки сертификата, ключей
шифрования, секрета MAC (message authentication code) и сообщения «finished». Отсылая
сообщение «finished», стороны указывают, что они знают верный секрет (pre_master_secret).
Анонимный обмен ключами
Полностью анонимная сессия может быть установлена при использовании
алгоритма RSA или Диффи-Хеллмана для создания ключей обмена. В случае
использования RSA клиент шифрует секрет (pre_master_secret) с помощью открытого ключа
несертифицированного сервера. Открытый ключ клиент узнает из сообщения обмена ключами от
сервера. Результат посылается в сообщении обмена ключами от клиента. Поскольку перехватчик
не знает закрытого ключа сервера, то ему будет невозможно расшифровать секрет
(pre_master_secret). При использовании алгоритма Диффи-Хеллмана открытые параметры сервера
содержатся в сообщении обмена ключами от сервера, и клиенту посылают в сообщении обмена
ключами. Перехватчик, который не знает приватных значений, не сможет найти секрет
(pre_master_secret).
Аутентификация и обмен ключами при использовании RSA
В этом случае обмен ключами и аутентификация сервера может быть скомбинирована. Открытый
ключ также может содержаться в сертификате сервера или может быть использован временный
ключ RSA, который посылается в сообщении обмена ключами от сервера. Когда используется
временный ключ RSA, сообщения обмена подписываются server’s RSA или сертификат DSS (???).
Сигнатура содержит текущее значение сообщения Client_Hello.random, таким образом, старые
сигнатуры и старые временные ключи не могут повторяться. Сервер может использовать
временный ключ RSA только однажды для создания сессии. После проверки сертификата сервера
клиент шифрует секрет (pre_master_secret) при помощи открытого ключа сервера. После
успешного декодирования секрета (pre_master_secret) создается сообщение «finished», тем самым
сервер демонстрирует, что он знает частный ключ, соответствующий сертификату сервера.
Когда RSA используется для обмена ключами, для аутентификации клиента используется
сообщение проверки сертификата клиента. Клиент подписывается значением, вычисленным из
master_secret и всех предшествующих сообщений протокола рукопожатия. Эти сообщения
рукопожатия содержат сертификат сервера, который ставит в соответствие сигнатуре сервера
сообщение Server_Hello.random, которому ставит в соответствие сигнатуру текущему сообщению
рукопожатия (???).
Аутентификация и обмен ключами при использовании Diffie-Hellman
В этом случае сервер может также поддерживать содержащий конкретные параметры алгоритм
Диффи-Хеллмана или может использовать сообщения обмена ключами от сервера для посылки
набора временных параметров, подписанных сертификатами DSS или RSA. Временные параметры
хэшируются с сообщением hello.random перед подписанием для того, чтобы злоумышленник не
смог совершить повтор старых параметров. В любом случае клиент может проверить сертификат
или сигнатуру для уверенности, что параметры принадлежат серверу.
Если клиент имеет сертификат, содержащий параметры алгоритма Diffie-Hellman, то сертификат
также содержит информацию, требующуюся для того, чтобы завершить обмен ключами. В этом
случае клиент и сервер должны будут сгенерировать одинаковые Diffie-Hellman результаты
(pre_master_secret) каждый раз, когда они устанавливают соединение. Для того, чтобы
предотвратить хранение секрета (pre_master_secret) в памяти компьютера на время дольше, чем
необходимо, секрет должен быть переведен в общий секрет (master_secret) настолько быстро,
насколько это возможно. Параметры клиента должны быть совместимы с теми, которые
поддерживает сервер для того, чтобы работал обмен ключами.
Протокол записи
Протокол записи (Record Layer) — это уровневый протокол. На каждом уровне сообщения
включают поля для длины, описания и проверки. Протокол записи принимает сообщения, которые
нужно передать, фрагментирует данные в управляемые блоки, разумно сжимает данные, применяя
MAC (message authentication code), шифрует и передаёт результат. Полученные данные он
расшифровывает, проверяет, распаковывает, собирает и доставляет к более верхним уровням
клиента.
Существует четыре протокола записи:
1. Протокол рукопожатия (handshake protocol);
2. Протокол тревоги (alert protocol);
3. Протокол изменения шифра (the change cipher spec protocol);
4. Протокол приложения (application data protocol);
Если SSL реализация получает тип записи, который ей неизвестен, то эта запись просто
игнорируется. Любой протокол, созданный для использования совместно с SSL, должен быть
хорошо продуман, так как будет иметь дело с атаками на него. Заметим, что из-за типа и длины
записи, протокол не защищен шифрованием. Внимание следует уделить тому, чтобы
минимизировать трафик.
Протокол рукопожатия
SSL клиент и сервер договариваются об установлении связи с помощью процедуры рукопожатия.
Во время рукопожатия клиент и сервер договариваются о различных параметрах, которые будут
использованы, чтобы обеспечить безопасность соединения:
1. Клиент посылает серверу номер версии SSL клиента, поддерживаемые алгоритмы
шифрования и сжатия, специфичные данные для сеанса и другую информацию, которая
нужна серверу, чтобы общаться с клиентом, используя SSL.
2. Сервер посылает клиенту номер версии SSL сервера, алгоритм сжатия и шифрования
(выбранные из посланных ранее клиентом), специфичные данные для сеанса и другую
информацию, которая нужна серверу, чтобы общаться с клиентом по протоколу SSL.
Сервер также посылает свой сертификат, который требует проверки подлинности клиента.
После идентификации сервер запрашивает сертификат клиента.
3. Клиент использует информацию, переданную сервером для проверки подлинности. Если
сервер не может быть проверен, пользователь получает предупреждение о проблеме и о
том, что шифрование и аутентификация соединения не может быть установлена. Если
сервер успешно прошел проверку, то клиент переходит к следующему шагу.
4. Используя все данные, полученные до сих пор от процедуры рукопожатие, клиент (в
сотрудничестве с сервером) создает предварительный секрет сессии, в зависимости от
используемого шифра от сервера, шифрует его с помощью открытого ключа сервера
(полученного из сертификата сервера, отправленного на 2-м шаге), а затем отправляет его
на сервер.
5. Если сервер запросил аутентификацию клиента (необязательный шаг рукопожатия),
клиент также подписывает еще один кусок данных, который является уникальным для
этого рукопожатия и известным как для клиента, так и сервера. В этом случае, клиент
отправляет все подписанные данные и собственный сертификат клиента на сервер вместе с
предварительно зашифрованным секретом.
6. Сервер пытается аутентифицировать клиента. Если клиент не может пройти проверку
подлинности, сеанс заканчивается. Если клиент может быть успешно аутентифицирован,
сервер использует свой закрытый ключ для расшифровки предварительного секрета, а
затем выполняет ряд шагов (которые клиент также выполняет), чтобы создать главный
секрет.
7. И клиент, и сервер используют секрет для генерации ключей сеансов, которые являются
симметричными ключами, использующиеся для шифрования и расшифрования
информации, которой обмениваются во время SSL сессии. Происходит проверка
целостности (то есть, для обнаружения любых изменений в данных между временем когда
он был послан, и временем его получения на SSL-соединении).
8. Клиент посылает сообщение серверу, информируя его, что будущие сообщения от клиента
будут зашифрованы с помощью ключа сеанса. Затем он отправляет отдельное,
зашифрованное сообщение о том, что часть рукопожатие закончена.
9. И в заключение, сервер посылает сообщение клиенту, информируя его, что будущие
сообщения от сервера будут зашифрованы с помощью ключа сеанса. Затем он отправляет
отдельное, зашифрованное сообщение о том, что часть рукопожатие закончена.
На этом рукопожатие завершается, и начинается защищенное соединение, которое
зашифровывается и расшифровывается с помощью ключевых данных. Если любое из
перечисленных выше действий не удается, то рукопожатие SSL не удалось, и соединение не
создается.
Протокол изменения параметров шифрования
Протокол изменения параметров шифрования существует для сигнализации перехода в режим
шифрования. Протокол содержит единственное сообщение, которое зашифровано и сжато при
текущем установленном соединении. Сообщение состоит только из одного бита со значением 1.
struct {
enum { change_cipher_spec(1), (255) } type;
} ChangeCipherSpec;
Сообщение изменения шифра посылается клиентом и сервером для извещения принимающей
стороны, что последующие записи будут защищены в соответствии с новым договоренным
CipherSpec и ключами. Принятие этого сообщения заставляет получателя отдать приказ уровню
записи незамедлительно копировать состояние отложенного чтения в состояние текущего чтения.
Сразу после послания этого сообщения, тот кто послал должен отдать приказ уровню записи
перевести режим отложенной записи в режим текущей записи. Сообщение изменения шифра
посылается во время рукопожатия, после того как параметры защиты были переданы, но перед тем
как будет послано сообщение «finished».
Протокол тревоги
Один из типов проверки, поддерживаемых в протоколе SSL записи, — это протокол тревоги.
Сообщение тревоги передаёт трудности, возникшие в сообщении, и описание тревоги. Сообщение
тревоги с критическим уровнем незамедлительно прерывает соединение. В этом случае другие
соединения, соответствующие сессии, могут быть продолжены, но идентификатор сессии должен
быть признан недействительным. Как и другие сообщения, сообщение тревоги зашифровано и
сжато, как только указано текущее состояние соединения.
Протокол приложения
Сообщение приложения данных работает на уровне записи. Он фрагментируется, сжимается и
шифруется на основе текущего состояния соединения. Сообщения считаются прозрачными для
уровня записи.
Безопасность
SSL 2.0
Существует ряд атак, которые могут быть предприняты против протокола SSL. Однако SSL
устойчив к этим атакам при условии, что пользователь использует только доверенные сервера для
обработки информации. SSL 2.0 уязвима в некоторых ситуациях[20]:
1. Идентичные криптографические ключи используются для аутентификации и шифрования
сообщений;
2. SSL 2.0 имеет слабую MAC конструкцию, которая использует MD5 хэш-функцию с
секретом префикса, что делает его уязвимым для атак;
3. SSL 2.0 не имеет никакой защиты для протокола рукопожатия, то есть атаки типа
злоумышленник посередине (man-in-the-middle) могут остаться незамеченными;
4. SSL 2.0 использует TCP закрытое соединенние, чтобы указать конец данных. Это означает,
что возможна следующая атака: злоумышленник просто подделывает TCP FIN, оставив
получателя без сообщения о конце передачи данных (в SSL 3.0 эту ошибку исправили);
5. SSL 2.0 предполагает наличие единой службы поддержки и фиксированного домена, что
идет вразрез со стандартной функцией виртуального хостинга на веб-серверах.
SSL 2.0 по умолчанию отключена в браузерах начиная с Internet Explorer 7[21], Mozilla
Firefox 2[22], Opera 9.5[23] и Safari.
SSL 3.0
14 октября 2014 года была выявлена уязвимость CVE-2014-3566, названная POODLE (Padding
Oracle On Downgraded Legacy Encryption). Данная уязвимость позволяет злоумышленнику
осуществить атаку Man-in-the-Middle на соединение, зашифрованное с помощью SSL 3.0.
Уязвимость POODLE — это уязвимость протокола, а не какой-либо его реализации,
соответственно, ей подвержены все соединения зашифрованные SSL v3.
В SSL 3.0 есть и иные слабые моменты. К примеру, половина мастер-ключа (master key), которая
устанавливается, полностью зависит от хэш-функции MD5, которая не является устойчивой к
коллизиям и, следовательно, не считается безопасной[24].
Виды возможных атак
Атака по словарю
Такой тип атак производится, когда атакующий имеет представление о том, какого типа
сообщения посылаются.
Криптоаналитик может сформировать базу данных, где ключами являются зашифрованные строки
открытого текста. По созданной базе данных можно определить ключ сессии, соответствующий
определенному блоку данных.
Вообще для SSL такие атаки возможны. Но SSL пытается противостоять этим атакам, используя
большие ключи сессии — клиент генерирует ключ, который длиннее, чем допускается экспортными
ограничениями, часть которого посылается серверу открытым текстом, а остальная часть
объединяется с секретной частью, чтобы получить достаточно длинный ключ (например, 128 бит,
как этого требует RC4). Способ блокирования атак открытого текста заключается в том, чтобы
сделать объем необходимого текста неприемлемо большим. Каждый бит, добавляемый к длине
ключа сессии, увеличивает размер словаря в 2 раза. Использование ключа сессии длиной 128 бит
делает размер словаря далеко за пределами современных технических возможностей (решение
потребует такого количества атомов, которого нет во всей вселенной). Другой способ, с помощью
которого SSL может противостоять данной атаке, заключается в использовании максимально
возможных длин ключей (в случае не экспортного варианта). Следствием этого является то, что
самым простым и дешевым способом атаки становится лобовая атака ключа, но для 128-битного
ключа стоимость его раскрытия можно считать бесконечной.
Атака отражением
Злоумышленник записывает коммуникационную сессию между сервером и клиентом. Позднее он
пытается установить соединение с сервером, воспроизводя записанные сообщения клиента. Но
SSL отбивает эту атаку при помощи особого уникального идентификатора соединения (ИС).
Конечно, теоретически третья сторона не в силах предсказать ИС, потому что он основан на
наборе случайных событий. Однако, злоумышленник с большими ресурсами может записать
большое количество сессий и попытаться подобрать «верную» сессию, основываясь на коде nonce,
который послал сервер в сообщение Server_Hello. Но коды nonce SSL имеют, по меньшей мере,
длину 128 бит, а значит, злоумышленнику необходимо записать 264 кодов nonce, чтобы получить
вероятность угадывания 50 %. Но 264 достаточно большое число, что делает эти атаки
бессмысленными.
Атака протокола рукопожатия
Злоумышленник может попытаться повлиять на обмен рукопожатиями для того, чтобы стороны
выбрали разные алгоритмы шифрования, а не те, что они выбирают обычно. Из-за того, что
многие реализации поддерживают экспортированное шифрование, а некоторые даже 0шифрование или MAC-алгоритм, эти атаки представляют большой интерес.
Для такой атаки злоумышленнику необходимо быстро подменить одно или более сообщений
рукопожатия. Если это происходит, то клиент и сервер вычислят различные значения хэшей
сообщения рукопожатия. В результате чего стороны не примут друг от друга сообщения
«finished». Без знания секрета злоумышленник не сможет исправить сообщение «finished»,
поэтому атака может быть обнаружена.
Взлом SSL-соединений внутри ЦОД
Наиболее известный инцидент по массовому взлому информации, защищенной протоколами SSL,
был произведен агентами ФБР с помощью систем Carnivore и NarusInsight, что привело к
судебному процессу от лица правозащитной организации Electronic Frontier Foundation против
AT&T, который установил данные комплексы для взлома криптографически защищенной
информации.
Несмотря на высокий общественный резонанс в США данного дела и расследование на уровне
конституционного комитета Палаты представителей, технологически взлом протокола SSL
агентами ФБР не производился. Carnivore и NarusInsight были установлены в самом ЦОД, где
находились сервера, ведущие SSL-соединенения с удаленными клиентами. NarusInsight полностью
восстановил зашифрованную информацию путем прослушивания не SSL-соединения, а
внутреннего траффика между серверами приложений внутри самого ЦОД, уже после того как
данные, поступившие по SSL, были расшифрованы самим сервером, принявшим их от внешних
пользователей.
Тем не менее, указанный инцидент показал, что SSL не может являться надёжным средством
криптозащиты данных серверов в Интернете, так как спецслужбы могут установить системы
прослушивания, такие как NarusInsight или СОРМ-2, в ЦОД. Любой вид криптографии,
подразумевающий, что ключи от шифров находятся у сервера-получателя в ЦОД,
взламываются снифферами спецслужб в автоматическом режиме за счет внедрения их в самого
получателя. Далее данные полностью реконструируются по процедурам, которые на данный
момент регулируются и законодательными актами, такими как «Патриотический акт». Причем
указанные законодательные акты запрещают вплоть до судебного преследования владельцев ЦОД
удаление снифферов спецслужб из внутренней части серверов-получателей. С учетом наличия
данных систем, протокол SSL может защищать только соединение двух пользователей в
Интернете, но не SSL-соединение с внешним Web-сайтом.
BEAST атака
23 сентября 2011 года тайские исследователи Дуонг и Джулиано Риццо, используя Java апплет,
продемонстрировали «доказательство концепции» под названием Beast («Browser Exploit Against
SSL/TLS»), указывающей уязвимость в TLS 1.0[25][26]. Ранее эту уязвимость, которая
первоначально была обнаружена Phillip Rogaway[27] в 2002 году, практически никто не мог
продемонстрировать. Уязвимость TLS 1.1 была зафиксирована в 2006 году.
Атака строится на нескольких допущениях, но, как оказалось, их вполне реально реализовать. Вопервых, криптоаналитик должен иметь возможность сниффать трафик, передаваемый браузером.
Во-вторых, необходимо как-то заставить пользователя передавать данные по тому же самому
безопасному каналу связи. Пусть между компьютерами Боба (B) и Алисы (А) установлено
безопасное соединение. Предположим, что i-ый блок попавшего к нам сообщения содержит
секретную информацию (например, пароль).
Ci = E( Key, Mi xor Ci-1), где Ci -зашифрованный блок, Mi — секретный текст
Предположим что пароль А — P. Мы можем проверить правильность нашего предположения:
Итак, мы смогли перехватить вектор инициализации, который используется для шифрования
первого блока следующего сообщения, но это же есть последний блок предыдущего сообщения( в
зашифрованном виде) — IV. Также мы перехватили Ci-1.При помощи этих данных мы формируем
сообщение так, чтобы первый блок стал равен следующему:
M1 = Ci-1 xor IV xor P
Если криптоаналитик сможет передать сообщение по тому же защищенному каналу, то первый
блок нового сообщения примет вид:
C1 = E(Key, M1 xor IV) = E(Key, (Ci-1 xor IV xor P) xor P) xor IV) = E(Key, (Ci-1 xor P)) = Ci
Получается, если P = M, то первый зашифрованный блок нового сообщения С1 будет равен ранее
перехваченному Сi.
На практике возникает проблема: блок М — 16 байтов в длину, даже если мы знаем все байты
кроме двух нам потребуется 215 попыток чтобы угадать оставшееся. А если мы не знаем ничего?
Отсюда вывод что данная практика может сработать в том случае, если криптоаналитик имеет
ограниченное количество предположений относительно значения М, а точнее большую часть
содержимого данного блока. Следующее допущение: криптоаналитик может контролировать
расположение данных в блоке, например знать что пароль — n символов в длину. Зная это,
криптоаналитик располагает пароль таким образом чтобы в первый блок попал только 1 символ, а
оставшиеся (n-1) в следующий — т. е. в первых 15 байтах лежат заведомо известные данные. А для
угадывания 1 символа злоумышленнику потребуется в худшем 256 попыток.
На самом деле, об уязвимости знали гораздо раньше, просто разработчики утилиты — первые, кому
удалось реализовать все условия для данной атаки. А именно:
1. Криптоаналитик имеет возможность прослушивать сетевые соединение, инициированные
браузером атакуемого компьютера
2. У криптоаналитика есть возможность внедрить агент в браузер жертвы
3. Агент имеет возможность отправлять произвольные HTTPS-запросы
Вот список различных технологий и браузерных плагинов, которые могут выполнить внедрение
агента в браузер жертвы: Javascript XMLHttpRequest API, HTML5 WebSocket API, Flash
URLRequest API, Java Applet URLConnection API, и Silverlight WebClient API.
RC4 атака
В 2013 году в Сингапуре прошла конференция, на которой профессор Дэн Бернстейн представил
новую технику для взлома протоколов SSL/TLS, если в таковых используется шифр RC4, который
в 2011 году был предложен как средство защиты от BEAST. Уязвимость обнаруженная в RC4
связана с недостаточной случайностью потока битов, которым скремблируется сообщение.
Прогнав через него одно и то же сообщение много раз было выявлено достаточное количество
повторяющихся паттернов для восстановления исходного текста. Для атаки придется прогнать
через шифр гигантский объем данных. В представленной реализации взлом занимал до 32 часов,
однако не исключалась возможность оптимизации процесса. Но данная атака трудно реализуема
на практике. Создатели утверждают, что для восстановления 80 байт из 256 необходимо
256 шифротекстов.
Раскрытие шифров
Как известно, SSL зависит от различных криптографических параметров. Шифрование с
открытым ключом RSA необходимо для пересылки ключей и аутентификации сервера/клиента.
Однако в качестве шифра используются различные криптографические алгоритмы. Таким
образом, если осуществить успешную атаку на эти алгоритмы, то SSL не может уже считаться
безопасным. Атака на определенные коммуникационные сессии производится записью сессии, и
потом, в течение долгого времени подбирается ключ сессии или ключ RSA.
Атака «злоумышленник посередине»
Также известна как MitM (Man-in-the-Middle) атака. Предполагает участие трех сторон: сервера,
клиента и злоумышленника, находящегося между ними. В данной ситуации злоумышленник
может перехватывать все сообщения, которые следуют в обоих направлениях, и подменять их.
Злоумышленник представляется сервером для клиента и клиентом для сервера. В случае обмена
ключами по алгоритму Диффи-Хелмана данная атака является эффективной, так как целостность
принимаемой информации и ее источник проверить невозможно. Однако такая атака невозможна
при использовании протокола SSL[28], так как для проверки подлинности источника (обычно
сервера) используются сертификаты, заверенные центром сертификации[29].
Атака будет успешной, если:
Сервер не имеет подписанного сертификата.
Клиент не проверяет сертификат сервера.
Пользователь игнорирует сообщение об отсутствии подписи сертификата центром
сертификации или сообщение о несовпадении сертификата с кэшированным[30].
Данный вид атаки можно встретить в крупных организациях, использующих межсетевой
экран Forefront TMG компании Microsoft или прокси-сервер Blue Coat Proxy SG. В данном случае
«злоумышленник» находится на границе сети организации и производит подмену оригинального
сертификата своим. Данная атака становится возможной благодаря возможности указать в
качестве доверенного центра сертификации сам прокси-сервер (либо как корневого, либо как
дочернего по отношению к корпоративному корневому). Обычно подобная процедура внедрения
проходит прозрачно для пользователя за счет работы корпоративных пользователей в среде Active
Directory. Данное средство может использоваться как для контроля за передаваемой информацией,
так и в целях похищения личных данных, передаваемых с помощью защищенного соединения
HTTPS.
Наиболее спорным становится вопрос информированности пользователя о возможности перехвата
данных, так как в случае подмены корневого сертификата никаких сообщений безопасности
выводиться не будет и пользователь будет ожидать конфиденциальности передаваемых данных.
Кроме того, при использовании Forefront TMG в качестве SSL-прокси возникает возможность
проведения второй MitM-атаки на стороне интернета, так как оригинальный сертификат не будет
передан пользователю, а Forefront TMG может быть настроен на прием и последующую подмену
самоподписанных или отозванных сертификатов. Для защиты от подобной атаки необходимо
полностью запретить работу с веб-серверами, чьи сертификаты содержат какие-либо ошибки, что
безусловно приведет к невозможности работы по протоколу HTTPS со множеством сайтов.
Blue Coat Proxy SG от второй MitM-атаки защищен: система позволяет настроить политику таким
образом, что в случае недоверенного сертификата веб-сервера система также выпускает
сертификат, подписанный не доверенной цепочкой, а временной самоподписанной.
THC-SSL-DOS
24 октября 2011 года организация The Hacker’s Choice (THC) выпустила утилиту THC-SSL-DOS,
которую можно использовать для проведения DoS-атак на SSL серверы. Данная утилита
использует уязвимость в функции повторного подтверждения SSL — SSL Renegotiation, которая
изначально была предназначена для обеспечения большей безопасности SSL. Повторное
подтверждение позволяет серверу создавать новый секретный ключ поверх уже имеющегося SSLсоединения. Эта функция по умолчанию включена в большинство серверов. Установка
безопасного соединения, а также выполнение повторного подтверждения SSL, требуют в
несколько раз больше ресурсов на стороне сервера, чем на стороне клиента, т. е. если клиент
отправляет множество запросов на повторное подтверждение SSL, это истощает системные
ресурсы сервера.
Согласно одному из участников THC, для успешного проведения атаки нужен ноутбук с
установленной утилитой и доступ в интернет. Программа была опубликована в свободном
доступе, потому что ее аналог появился в сети уже несколько месяцев тому назад. Также, по
утверждениям разработчиков, атака может быть произведена даже в том случае, если сервер не
поддерживает функцию повторного подтверждения, хотя для этого придется модифицировать
метод атаки. В этом случае устанавливается множество TCP-соединений для нового рукопожатия
SSL, но для эффективной атаки необходимо больше ботов.
В качестве защиты некоторые разработчики ПО рекомендуют устанавливать особые правила для
разрыва соединения с клиентом, который выполняет операцию повторного подтверждения больше
установленного количества раз в секунду.
SSLstrip
В 2009 году на конференции Black Hat в Вашингтоне Мокси Марлинспайк — независимый хакер продемонстрировал новую утилиту SSLstrip, при помощи которой можно достать важную
информацию, заставив пользователей поверить, что они находятся на защищенной странице, хотя
на самом деле это не так. Этого можно достичь конвертируя страницы, обычно защищенные
протоколом SSL в их незащищенные аналоги, причем обманывается как сервер, так и клиент.
Утилита работает потому, что многие сайты использующие защиту SSL имеют незащищенную
главную страницу. Они шифруют только те разделы, где передается важная информация. И когда
пользователь кликает по странице авторизации утилита подменяет ответ сайта меняя https на http.
В SSLstrip используются следующие приемы: во-первых, в локальной сети разворачивается
прокси-сервер, имеющий действительный сертификат — отсюда в адресной строке пользователь
продолжает видеть https, во вторых используется техника для создания длинных URL содержащих
в адресной строке фальшивые ‘/‘ — это нужно, чтобы избежать преобразования символов
браузерами. Для доказательства работы системы Мокси запустил SSLstrip на сервере,
обслуживающем сеть Tor и за 24 часа выловил 254 пароля пользователей Yahoo, Gmail,
Ticketmaster, PayPal и Linkedln.
Обработка ошибок в протоколе SSL
В протоколе SSL обработка ошибок очень проста. Когда ошибка обнаружена, тот, кто её
обнаружил, посылает об этом сообщение своему партнёру. Неустранимые ошибки требуют от
сервера и клиента разрыва соединения[31]. Протокол SSL определяет следующие ошибки:
1. Unsupported_Certificate_Type_Error: такая ошибка возникает, когда клиент/сервер
получает тип сертификата, который не поддерживается. Ошибка устранима (только для
аутентификации клиента).
2. No_Cipher_Error: ошибка возникает, когда сервер не может найти размер ключа или
шифр, который поддерживается также и клиентом. Ошибка неустранима.
3. Bad_Certificate_Error: такая ошибка возникает, когда сертификат считается
принимающей стороной плохим. Это означает, что или некорректна подпись сертификата,
или его значение некорректно. Ошибка устранима (только для аутентификации клиента).
4. No_Certificate_Error: если послано сообщение Request_Certificate, то эта ошибка может
быть прислана по причине того, что клиент не имеет сертификата. Ошибка устранима.
Алгоритмы, использующиеся в SSL
Для обмена ключами и проверки их подлинности применяются: RSA, DiffieHellman, ECDH, SRP, PSK[32].
Для аутентификации: RSA, DSA, ECDSA[33].
Для симметричного шифрования: RC2, RC4, IDEA, DES, Triple DES или AES, Camellia.
Для хеш-функций: SHA, MD5, MD4 и MD2.
Вопрос 16. Фильтрация трафика маршрутизаторами и межсетевыми экранами.
лобальная сеть Интернет создавалась как открытая система, предназначенная для свободного
обмена информации. В силу открытости своей идеологии Интернет предоставляет
злоумышленникам значительно большие возможности по проникновению в информационные
системы. Через Интернет нарушитель может:
вторгнуться во внутреннюю сеть предприятия и получить несанкционированный доступ к
конфиденциальной информации;
незаконно скопировать важную и ценную для предприятия информацию;
получить пароли, адреса серверов, а подчас и их содержимое;
войти в информационную систему предприятия под именем зарегистрированного
пользователя и т.д.
Посредством получения злоумышленником информации может быть серьезно подорвана
конкурентоспособность предприятия и доверие его клиентов.
Ряд задач по отражению наиболее вероятных угроз для внутренних сетей способны решать
межсетевые экраны. Межсетевой экран — это система межсетевой защиты, позволяющая
разделить каждую сеть на две и более части и реализовать набор правил, определяющих условия
прохождения пакетов с данными через границу из одной части общей сети в другую. Как правило,
эта граница проводится между корпоративной (локальной) сетью предприятия и глобальной сетью
Интернет, хотя ее можно провести и внутри корпоративной сети предприятия. Использование
межсетевых экранов позволяет организовать внутреннюю политику безопасности сети
предприятия, разделив всю сеть на сегменты. Это позволяет сформулировать основные принципы
архитектуры безопасности корпоративной сети:
1. Введение N категорий секретности и создание соответственно N выделенных сетевых
сегментов пользователей. При этом каждый пользователь внутри сетевого сегмента имеет
одинаковый уровень секретности (допущен к информации одного уровня секретности).
Данный случай можно сравнить с секретным заводом, где все сотрудники в соответствии
со своим уровнем доступа имеют доступ только к определенным этажам. Эта структура
объясняется тем, что ни в коем случае нельзя смешивать потоки информации разных
уровней секретности. Не менее очевидным объяснением подобного разделения всех
пользователей на N, изолированных сегментов является легкость осуществления атаки
внутри одного сегмента сети.
2. Выделение в отдельный сегмент всех внутренних серверов компании. Эта мера также
позволяет изолировать потоки информации между пользователями, имеющими различные
уровни доступа.
3. Выделение в отдельный сегмент всех серверов компании, к которым будет предоставлен
доступ из Интернета (создание демилитаризованной зоны для внешних ресурсов).
4. Создание выделенного сегмента административного управления.
5. Создание выделенного сегмента управления безопасностью.
Межсетевой экран пропускает через себя весь трафик, принимая относительно каждого
проходящего пакета решение: дать ему возможность пройти или нет. Для того чтобы межсетевой
экран мог осуществить эту операцию, ему необходимо определить набор правил фильтрации.
Решение о том, фильтровать ли с помощью межсетевого экрана конкретные протоколы и адреса,
зависит от принятой в защищаемой сети политики безопасности. Межсетевой экран представляет
собой набор компонентов, настраиваемых для реализации выбранной политики безопасности.
Политика сетевой безопасности каждой организации должна включать две составляющие:
1. Политика доступа к сетевым сервисам.
2. Политика реализации межсетевых экранов.
Политика доступа к сетевым сервисам должна быть уточнением общей политики организации в
отношении защиты информационных ресурсов в организации. Для того чтобы межсетевой экран
успешно защищал ресурсы организации, политика доступа пользователей к сетевым сервисам
должна быть реалистичной. Таковой считается политика, при которой найден гармоничный
баланс между защитой сети организации от известных рисков и необходимостью доступа
пользователей к сетевым сервисам. В соответствии с принятой политикой доступа к сетевым
сервисам определяется список сервисов Интернета, к которым пользователи должны иметь
ограниченный доступ. Задаются также ограничения на методы доступа, необходимые для того,
чтобы пользователи не могли обращаться к запрещенным сервисам Интернета обходными путями.
Межсетевой экран может реализовать ряд политик доступа к сервисам. Но обычно политика
доступа к сетевым сервисам основана на одном из следующих принципов:
1. Запретить доступ из Интернета во внутреннюю сеть и разрешить доступ из внутренней
сети в Интернет.
2. Разрешить ограниченный доступ во внутреннюю сеть из Интернета, обеспечивая работу
только отдельных авторизованных систем, например информационных и почтовых
серверов.
В соответствии с политикой реализации межсетевых экранов определяются правила доступа к
ресурсам внутренней сети. Прежде всего необходимо установить, насколько «доверительной» или
«подозрительной» должна быть система защиты. Иными словами, правила доступа к внутренним
ресурсам должны базироваться на одном из следующих принципов:
1. Запрещать все, что не разрешено в явной форме.
2. Разрешать все, что не запрещено в явной форме.
Эффективность защиты внутренней сети с помощью межсетевых экранов зависит не только от
выбранной политики доступа к сетевым сервисам и ресурсам внутренней сети, но и от
рациональности выбора и использования основных компонентов межсетевого экрана.
Функциональные требования к межсетевым экранам охватывают следующие сферы:
фильтрация на сетевом уровне;
фильтрация на прикладном уровне;
настройка правил фильтрации и администрирование;
средства сетевой аутентификации;
внедрение журналов и учет.
Классификация межсетевых экранов
настоящее время не существует единой и общепризнанной классификации межсетевых
экранов. Выделим следующие классы межсетевых экранов:
1. Фильтрующие маршрутизаторы.
2. Шлюзы сеансового уровня.
3. Шлюзы уровня приложений.
Эти категории можно рассматривать как базовые компоненты реальных межсетевых экранов.
Лишь немногие межсетевые экраны включают лишь одну из перечисленных категорий. Тем не
менее эти компоненты отражают ключевые возможности, отличающие межсетевые экраны друг от
друга.
Фильтрующие маршрутизаторы
Фильтрующий маршрутизатор представляет собой маршрутизатор или работающую на сервере
программу, сконфигурированные таким образом, чтобы фильтровать входящие и исходящие
пакеты. Фильтрация пакетов осуществляется на основе информации, содержащейся в TCP- и IPзаголовках пакетов.
Фильтрующий маршрутизатор обычно может фильтровать IP-пакеты на основе группы
следующих полей заголовка пакета:
IP-адрес отправителя;
IP-адрес получателя;
порт отправителя;
порт получателя.
Некоторые маршрутизаторы проверяют, с какого сетевого интерфейса маршрутизатора пришел
пакет, и затем используют эту информацию как дополнительный критерий фильтрации.
Фильтрация может быть реализована различными способами для блокирования соединений с
определенными компьютерами или портами. Например, можно блокировать соединения, идущие
от конкретных адресов тех компьютеров и сетей, которые считаются враждебными или
ненадежными.
Правила фильтрации пакетов формулируются сложно, к тому же обычно не существует средств
для проверки их корректности, кроме медленного ручного тестирования. При этом в отсутствие
фильтрующего маршрутизатора средств протоколирования (если правила фильтрации пакетов всетаки позволят опасным пакетам пройти через маршрутизатор) такие пакеты не смогут быть
выявлены до обнаружения последствий проникновения. Даже если администратору сети удастся
создать эффективные правила фильтрации, их возможности останутся ограниченными. Например,
администратор задает правило, в соответствии с которым маршрутизатор будет отбраковывать все
пакеты с неизвестным адресом отправителя. Однако в данном случае хакер для проникновения
внутрь защищенной сети может осуществить атаку, которую называют подменой адреса. В таких
условиях фильтрующий маршрутизатор не сумеет отличить поддельный пакет от настоящего и
пропустит его.
К положительным качествам фильтрующих маршрутизаторов можно отнести следующие:
сравнительно невысокая стоимость;
гибкость в определении правил фильтрации;
небольшая задержка при прохождении пакетов.
Недостатки фильтрующих маршрутизаторов:
внутренняя сеть видна (маршрутизируется) из сети Интернет;
правила фильтрации пакетов трудны в описании и требуют очень хороших знаний
технологий TCP и UDP;
при нарушении работоспособности межсетевого экрана с фильтрацией пакетов все
компьютеры за ним становятся полностью незащищенными либо недоступными;
отсутствует аутентификация на пользовательском уровне.
Шлюзы сеансового уровня
Данный класс маршрутизаторов представляет собой транслятор TCP-соединения. Шлюз
принимает запрос авторизованного клиента на конкретные услуги и после проверки допустимости
запрошенного сеанса устанавливает соединение с местом назначения (внешним хостом). После
этого шлюз копирует пакеты в обоих направлениях, не осуществляя их фильтрации. Как правило,
пункт назначения задается заранее, в то время как источников может быть много. Используя
различные порты, можно создавать разнообразные конфигурации соединений. Данный тип шлюза
позволяет создать транслятор TCP-соединения для любого определенного пользователем сервиса,
базирующегося на ТСР, осуществлять контроль доступа к этому сервису и сбор статистики по его
использованию.
Шлюз следит за подтверждением (квитированием) связи между авторизованным клиентом и
внешним хостом, определяя, является ли запрашиваемый сеанс связи допустимым. Чтобы выявить
допустимость запроса на сеанс связи, шлюз выполняет следующую процедуру. Когда
авторизованный клиент запрашивает некоторый сервис, шлюз принимает этот запрос, проверяя,
удовлетворяет ли данный клиент базовым критериям фильтрации. Затем, действуя от имени
клиента, шлюз устанавливает соединение с внешним хостом и следит за выполнением процедуры
квитирования связи по протоколу ТСР. Эта процедура состоит из обмена ТСР-пакетами, которые
помечаются флагами SYN (синхронизировать) и АСК (подтвердить).
Первый пакет сеанса ТСР, помеченный флагом SYN и содержащий произвольное число, например
500, является запросом клиента на открытие сеанса. Внешний хост, получивший этот пакет,
посылает в ответ другой, помеченный флагом АСК и содержащий число на единицу большее, чем
в принятом пакете (в нашем случае 501), подтверждая тем самым прием пакета SYN от клиента.
Далее осуществляется обратная процедура: хост посылает клиенту пакет SYN с исходным числом,
например 700, а клиент подтверждает его получение передачей пакета АСК, содержащего число
701. На этом процесс квитирования связи завершается.
Шлюз сеансового уровня признает завершенное соединение допустимым только в том случае,
если при выполнении процедуры квитирования связи флаги SYN и АСК, а также числа,
содержащиеся в ТСР-пакетах, оказываются логически связанными между собой.
После того как шлюз определил, что доверенный клиент и внешний хост являются
авторизованными участниками сеанса ТСР, и проверил его допустимость, он устанавливает
соединение. Начиная с этого момента шлюз копирует и перенаправляет пакеты туда и обратно, не
проводя никакой фильтрации. Он поддерживает таблицу установленных соединений, пропуская
данные, которые относятся к одному из сеансов связи, зафиксированных в данной таблице. Когда
сеанс завершается, шлюз удаляет соответствующий элемент из таблицы и разрывает сеть,
использовавшуюся в текущем сеансе.
Недостатком шлюзов сеансового уровня является отсутствие проверки содержимого
передаваемых пакетов, что дает возможность нарушителю проникнуть через такой шлюз.
Шлюзы уровня приложений
С целью защиты ряда уязвимых мест, присущих фильтрующим маршрутизаторам, межсетевые
экраны должны использовать прикладные программы для фильтрации соединений с такими
сервисами, как Telnet и FTP. Подобное приложение называется proxy-службой, а хост, на котором
работает proxy-служба, — шлюзом уровня приложений. Такой шлюз исключает прямое
взаимодействие между авторизованным клиентом и внешним хостом. Шлюз фильтрует все
входящие и исходящие пакеты на прикладном уровне.
Обнаружив сетевой сеанс, шлюз приложений останавливает его и вызывает уполномоченное
приложение для оказания завершаемой услуги. Для достижения более высокого уровня
безопасности и гибкости шлюзы уровня приложений и фильтрующие маршрутизаторы могут быть
объединены в межсетевом экране.
Шлюзы прикладного уровня позволяют обеспечить надежную защиту, поскольку взаимодействие
с внешним миром реализуется через небольшое число уполномоченных приложений, полностью
контролирующих весь входящий и исходящий трафик. Следует отметить, что шлюзы уровня
приложений требуют отдельного приложения для каждого сетевого сервиса.
По сравнению с работающими в обычном режиме, при котором прикладной трафик пропускается
непосредственно к внутренним хостам, шлюзы прикладного уровня имеют ряд преимуществ:
невидимость структуры защищаемой сети из глобальной сети Интернет. Имена
внутренних систем можно не сообщать внешним системам через DNS, поскольку шлюз
прикладного уровня может быть единственным хостом, имя которого будет известно
внешним системам;
надежная аутентификация и регистрация. Прикладной трафик может быть
аутентифицирован, прежде чем он достигнет внутренних хостов, и зарегистрирован более
эффективно, чем с помощью стандартной регистрации;
приемлемое соотношение цены и эффективности. Дополнительные программные или
аппаратные средства аутентификации или регистрации нужно устанавливать только на
шлюзе прикладного уровня;
простые правила фильтрации. Правила на фильтрующем маршрутизаторе оказываются
менее сложными, чем на маршрутизаторе, который самостоятельно фильтрует прикладной
трафик и отправляет его большому числу внутренних систем. Маршрутизатор должен
пропускать прикладной трафик, предназначенный только для шлюза прикладного уровня,
и блокировать весь остальной;
возможность организации большого числа проверок. Защита на уровне приложений
позволяет осуществлять большое количество дополнительных проверок, что снижает
вероятность взлома с использованием «дыр» в программном обеспечении.
Недостатками шлюзов уровня приложений являются:
относительно низкая производительность по сравнению с фильтрующими
маршрутизаторами. В частности, при использовании клиент-серверных протоколов, таких
как Telnet, требуется двухшаговая процедура для входных и выходных соединений;
более высокая стоимость по сравнению с фильтрующими маршрутизаторами.
Одним из важных элементов концепции межсетевых экранов является аутентификация (проверка
подлинности пользователя), то есть пользователь получает право воспользоваться тем или иным
сервисом только после того, как будет установлено, что он действительно тот, за кого себя выдает.
При этом считается, что сервис для данного пользователя разрешен (процесс определения, какие
сервисы разрешены конкретному пользователю, называется авторизацией).
При получении запроса на использование сервиса от имени какого-либо пользователя межсетевой
экран проверяет, какой способ аутентификации определен для данного субъекта, и передает
управление серверу аутентификации. После получения положительного ответа от сервера
аутентификации межсетевой экран осуществляет запрашиваемое пользователем соединение. Как
правило, большинство коммерческих межсетевых экранов поддерживает несколько различных
схем аутентификации, предоставляя администратору сетевой безопасности возможность сделать
выбор наиболее приемлемой в сложившихся условиях схемы.
Основные способы развертывания межсетевых экранов в корпоративных сетях
ри подключении корпоративной или локальной сети к глобальным сетям администратор
сетевой безопасности должен решать следующие задачи:
защита корпоративной или локальной сети от несанкционированного удаленного доступа
со стороны глобальной сети;
скрытие информации о структуре сети и ее компонентов от пользователей глобальной
сети;
разграничение доступа в защищаемую сеть из глобальной и из защищаемой сети в
глобальную.
Необходимость работы с удаленными пользователями требует установления жестких ограничений
доступа к информационным ресурсам защищаемой сети. При этом в организации часто возникает
потребность иметь в составе корпоративной сети несколько сегментов с разными уровнями
защищенности:
свободно доступные сегменты;
сегменты с ограниченным доступом;
закрытые сегменты.
Для защиты корпоративной или локальной сети применяются следующие основные схемы
организации межсетевых экранов:
1. Межсетевой экран, представленный как фильтрующий маршрутизатор.
2. Межсетевой экран на основе двухпортового шлюза.
3. Межсетевой экран на основе экранированного шлюза.
4. Межсетевой экран с экранированной подсетью.
Межсетевой экран, представленный как фильтрующий маршрутизатор
Межсетевой экран, основанный на фильтрации пакетов, является самым распространенным и
наиболее простым в реализации, представляя собой фильтрующий маршрутизатор,
расположенный между защищаемой сетью и Интернетом.
Фильтрующий маршрутизатор сконфигурирован для блокирования или фильтрации входящих и
исходящих пакетов на основе анализа их адресов и портов.
Компьютеры, находящиеся в защищаемой сети, имеют прямой доступ в Интернет, в то время как
большая часть доступа к ним из Интернета блокируется. В принципе, фильтрующий
маршрутизатор может реализовать любую из политик безопасности, описанных ранее. Однако
если маршрутизатор не фильтрует пакеты по порту источника и номеру входного и выходного
порта, то реализация политики «запрещено все, что не разрешено» в явной форме может быть
затруднена.
Межсетевые экраны, основанные на фильтрации пакетов, имеют те же недостатки, что и
фильтрующие маршрутизаторы.
Межсетевой экран на основе двухпортового шлюза
Межсетевой экран на базе двухпортового прикладного шлюза представляет собой хост с двумя
сетевыми интерфейсами. При передаче информации между этими интерфейсами и осуществляется
основная фильтрация. Для обеспечения дополнительной защиты между прикладным шлюзом и
Интернетом размещают фильтрующий маршрутизатор. В результате между прикладным шлюзом
и маршрутизатором образуется внутренняя экранированная подсеть. Ее можно использовать для
размещения доступного извне информационного сервера. Размещение информационного сервера
увеличивает безопасность сети, поскольку даже при проникновении на него злоумышленник не
сможет получить доступ к системам сети через шлюз с двумя интерфейсами.
В отличие от схемы межсетевого экрана с фильтрующим маршрутизатором, прикладной шлюз
полностью блокирует трафик IP между Интернетом и защищаемой сетью. Только
уполномоченные приложения, расположенные на прикладном шлюзе, могут предоставлять услуги
и доступ пользователям.
Данный вариант межсетевого экрана реализует политику безопасности, основанную на принципе
«запрещено все, что не разрешено в явной форме»; при этом пользователю доступны только те
службы, для которых определены соответствующие полномочия. Такой подход обеспечивает
высокий уровень безопасности, поскольку маршруты к защищенной подсети известны лишь
межсетевому экрану и скрыты от внешних систем.
Рассматриваемая схема организации межсетевого экрана относительно проста и достаточно
эффективна. Поскольку межсетевой экран использует хост, то на нем могут быть установлены
программы для усиленной аутентификации пользователей. Межсетевой экран может также
протоколировать доступ, попытки зондирования и атак системы, что позволяет выявить действия
злоумышленников.
Межсетевой экран на основе экранированного шлюза
Межсетевой экран на основе экранированного шлюза обладает большей гибкостью по сравнению
с межсетевым экраном, построенным на основе шлюза с двумя интерфейсами, однако эта гибкость
достигается ценой некоторого уменьшения безопасности. Межсетевой экран состоит из
фильтрующего маршрутизатора и прикладного шлюза, размещаемого со стороны внутренней
сети. Прикладной шлюз реализуется на хосте и имеет только один сетевой интерфейс.
В данной схеме первичная безопасность обеспечивается фильтрующим маршрутизатором,
который фильтрует или блокирует потенциально опасные протоколы, чтобы они не достигли
прикладного шлюза и внутренних систем. Пакетная фильтрация в фильтрующем маршрутизаторе
может быть реализована одним из следующих способов:
внутренним хостам позволяется открывать соединения с хостами в сети Интернет для
определенных сервисов (доступ к ним разрешается среде пакетной фильтрации);
запрещаются все соединения от внутренних хостов (им надлежит использовать
уполномоченные приложения на прикладном шлюзе).
В подобной конфигурации межсетевой экран может использовать комбинацию двух политик,
соотношение между которыми зависит от конкретной политики безопасности, принятой во
внутренней сети. В частности, пакетная фильтрация на фильтрующем маршрутизаторе может
быть организована таким образом, чтобы прикладной шлюз, используя свои уполномоченные
приложения, обеспечивал для систем защищаемой сети сервисы типа Telnet, FTP, SMTP.
Основной недостаток схемы межсетевого экрана с экранированным шлюзом заключается в том,
что если атакующий нарушитель сумеет проникнуть в хост, перед ним окажутся незащищенными
системы внутренней сети. Другой недостаток связан с возможной компрометацией
маршрутизатора. Если маршрутизатор окажется скомпрометированным, внутренняя сеть станет
доступна атакующему нарушителю.
Межсетевой экран с экранированной подсетью
Межсетевой экран, состоящий из экранированной подсети, представляет собой развитие схемы
межсетевого экрана на основе экранированного шлюза. Для создания экранированной подсети
используются два экранирующих маршрутизатора. Внешний маршрутизатор располагается между
Интернетом и экранируемой подсетью, а внутренний — между экранируемой подсетью и
защищаемой внутренней сетью. В экранируемую подсеть входит прикладной шлюз, а также могут
включаться информационные серверы и другие системы, требующие контролируемого доступа.
Эта схема межсетевого экрана обеспечивает высокий уровень безопасности благодаря
организации экранированной подсети, которая еще лучше изолирует внутреннюю защищаемую
сеть от Интернета.
Внешний маршрутизатор защищает от вторжений из Интернета как экранированную подсеть, так
и внутреннюю сеть. Внешний маршрутизатор запрещает доступ из Глобальной сети к системам
внутренней сети и блокирует весь трафик к Интернету, идущий от систем, которые не должны
являться инициаторами соединений.
Этот маршрутизатор может быть использован также для блокирования других уязвимых
протоколов, которые не должны передаваться к хост-компьютерам внутренней сети или от них.
Внутренний маршрутизатор защищает внутреннюю сеть от несанкционированного доступа как из
Интернета, так и внутри экранированной подсети. Кроме того, он осуществляет большую часть
пакетной фильтрации, а также управляет трафиком к системам внутренней сети и от них.
Межсетевой экран с экранированной подсетью хорошо подходит для защиты сетей с большими
объемами трафика или с высокими скоростями обмена.
К его недостаткам можно отнести то, что пара фильтрующих маршрутизаторов нуждается в
большом внимании для обеспечения необходимого уровня безопасности, поскольку из-за ошибок
в их конфигурировании могут возникнуть провалы в системе безопасности всей сети. Кроме того,
существует принципиальная возможность доступа в обход прикладного шлюза.
Недостатки применения межсетевых экранов
ежсетевые экраны используются при организации защищенных виртуальных частных сетей.
Несколько локальных сетей, подключенных к глобальной, объединяются в одну защищенную
виртуальную частную сеть. Передача данных между этими локальными сетями является
невидимой для пользователей, а конфиденциальность и целостность передаваемой информации
должны обеспечиваться при помощи средств шифрования, использования цифровых подписей и
т.п. При передаче данных может шифроваться не только содержимое пакета, но и некоторые поля
заголовка.
Межсетевой экран не в состоянии решить все проблемы безопасности корпоративной сети.
Помимо описанных выше достоинств межсетевых экранов имеется ряд ограничений в их
использовании, а также существуют угрозы безопасности, от которых межсетевые экраны не
могут защитить. Отметим наиболее существенные ограничения в применении межсетевых
экранов:
большое количество остающихся уязвимых мест. Межсетевые экраны не защищают от
черных входов (люков) в сети. Например, если можно осуществить неограниченный
доступ по модему в сеть, защищенную межсетевым экраном, атакующие могут
эффективно обойти межсетевой экран;
неудовлетворительная защита от атак сотрудников компании. Межсетевые экраны обычно
не обеспечивают защиты от внутренних угроз;
ограничение в доступе к нужным сервисам. Самый очевидный недостаток межсетевого
экрана заключается в том, что он может блокировать ряд сервисов, которые применяют
пользователи, — Telnet, FTP и др. Для решения подобных проблем требуется проведение
хорошо продуманной политики безопасности, в которой будет соблюдаться баланс между
требованиями безопасности и потребностями пользователей;
концентрация средств обеспечения безопасности в одном месте. Это позволяет легко
осуществлять администрирование работы межсетевого экрана;
ограничение пропускной способности.
Организация комплексной защиты корпоративной сети
ля защиты информационных ресурсов и обеспечения оптимальной работы распределенных
корпоративных информационных систем необходимо применение комплексной системы
информационной безопасности, которая позволит эффективно использовать достоинства
межсетевых экранов и компенсировать их недостатки с помощью других средств безопасности.
Полнофункциональная защита корпоративной сети должна обеспечить:
безопасное взаимодействие пользователей и информационных ресурсов, расположенных в
экстранет- и интранет-сетях, с внешними сетями, например с Интернетом;
технологически единый комплекс мер защиты для распределенных и сегментированных
локальных сетей подразделений предприятия;
наличие иерархической системы защиты, предоставляющей адекватные средства
обеспечения безопасности для различных по степени закрытости сегментов корпоративной
сети.
Характер современной обработки данных в корпоративных системах Интернет/интранет требует
наличия у межсетевых экранов следующих основных качеств:
мобильность и масштабируемость относительно различных аппаратно-программных
платформ;
возможность интеграции с аппаратно-программными средствами других производителей;
простота установки, конфигурирования и эксплуатации;
управление в соответствии с централизованной политикой безопасности.
В зависимости от масштабов организации и принятой на предприятии политики безопасности
могут применяться различные межсетевые экраны. Для небольших предприятий, использующих
до десятка узлов, подойдут межсетевые экраны с удобным графическим интерфейсом,
допускающие локальное конфигурирование без применения централизованного управления. Для
крупных предприятий предпочтительнее системы с консолями и менеджерами управления,
которые обеспечивают оперативное управление локальными межсетевыми экранами, поддержку
виртуальных частных сетей.
Увеличение потоков информации, передаваемых по Интернету компаниями и частными
пользователями, а также потребность в организации удаленного доступа к корпоративным сетям
являются причинами постоянного совершенствования технологий подключения корпоративных
сетей к Интернету.
Следует отметить, что в настоящее время ни одна из технологий подключения, обладая высокими
характеристиками по производительности, в стандартной конфигурации не может обеспечить
полнофункциональной защиты корпоративной сети. Решение данной задачи становится
возможным только при использовании технологии межсетевых экранов, организующей
безопасное взаимодействие с внешней средой.
Рассмотрим более подробно технологии межсетевого экранирования.
Защита корпоративной сети от несанкционированного доступа из Интернет
При подключении сети предприятия к Интернету можно защитить корпоративную сеть от
несанкционированного доступа с помощью одного из следующих решений:
аппаратно-программный или программный межсетевой экран;
маршрутизатор со встроенным пакетным фильтром;
специализированный маршрутизатор, реализующий механизм защиты на основе списков
доступа;
операционная система семейства UNIX или, реже, MS Windows, усиленная специальными
утилитами, реализующими пакетную фильтрацию.
Защита корпоративной сети на основе межсетевого экрана позволяет получить высокую степень
безопасности и реализовать следующие возможности:
семантическая фильтрация циркулирующих потоков данных;
фильтрация на основе сетевых адресов отправителя и получателя;
фильтрация запросов на транспортном уровне на установление виртуальных соединений;
фильтрация запросов на прикладном уровне к прикладным сервисам;
локальная сигнализация попыток нарушения правил фильтрации;
запрет доступа неизвестного субъекта или субъекта, подлинность которого при
аутентификации не подтвердилась;
обеспечение безопасности от точки до точки: межсетевой экран, авторизация маршрута и
маршрутизатора, туннель для маршрута и криптозащита данных и др.
Следует отметить, что межсетевые экраны позволяют организовать комплексную защиту
корпоративной сети от несанкционированного доступа, основанную как на традиционной
синтаксической (IP-пакетной) фильтрации контролируемых потоков данных, осуществляемой
большинством ОС семейства Windows и UNIX, так и на семантической (контентной), доступной
только коммерческим специальным решениям.
В настоящее время все выпускаемые межсетевые экраны можно классифицировать по следующим
основным признакам:
по исполнению:
o
— аппаратно-программный,
o
— программный;
по функционированию на уровнях модели OSI:
o
— шлюз экспертного уровня,
o
— экранирующий шлюз (прикладной шлюз),
o
— экранирующий транспорт (шлюз сеансового уровня),
o
— экранирующий маршрутизатор (пакетный фильтр);
по используемой технологии:
o
— контроль состояния протокола,
o
— на основе модулей-посредников (proxy);
по схеме подключения:
o
— схема единой защиты сети,
o
— схема с защищаемым закрытым и не защищаемым открытым сегментами сети,
o
— схема с раздельной защитой закрытого и открытого сегментов сети.
Довольно распространенная на сегодня защита корпоративной сети на основе маршрутизатора со
списком доступа основывается на использовании специализированных маршрутизаторов. Данная
схема обладает высокой эффективностью и достаточной степенью безопасности. В качестве
такого решения получили широкое распространение маршрутизаторы компании Cisco серий
12000, 7600. Для подключения сети предприятия к Интернету можно также использовать
предшествующие серии маршрутизаторов этой фирмы.
Защита корпоративной сети на основе операционных систем, усиленных функциями пакетной
фильтрации, построена на том, что системное программное обеспечение выполняет функции
маршрутизации, фильтрации, сервисного обслуживания и др. По уровню надежности,
безопасности и производительности наиболее предпочтительны решения на основе UNIXподобной операционной системы.
Организация внутренней политики безопасности корпоративной сети
В современных условиях более 50% различных атак и попыток доступа к информации
осуществляется изнутри локальных сетей. Корпоративную сеть можно считать действительно
защищенной от несанкционированного доступа только при наличии в ней как средств защиты
точек входа со стороны Интернета, так и решений, обеспечивающих безопасность отдельных
компьютеров, корпоративных серверов и фрагментов локальной сети предприятия. Безопасность
отдельных компьютеров, корпоративных серверов и фрагментов локальной сети наилучшим
образом обеспечивают решения на основе распределенных или персональных межсетевых
экранов.
Внутренние корпоративные серверы компании, как правило, представляют собой приложения под
управлением операционной системы Windows NT/2000, NetWare или, реже, семейства UNIX. По
этой причине корпоративные серверы становятся потенциально уязвимыми к различного рода
атакам.
Простейший способ защиты серверов — установка между серверами и Интернетом межсетевого
экрана, например Firewall-1 компании Checkpoint. При правильной конфигурации большинство
межсетевых экранов может защитить внутренние серверы от внешних злоумышленников, а
некоторые выявляют и предотвращают атаки типа «отказ в обслуживании». Тем не менее этот
подход не лишен некоторых недостатков. Когда корпоративные серверы защищены однимединственным межсетевым экраном, все правила контроля доступа и данные оказываются
сосредоточенными в одном месте. Таким образом, межсетевой экран становится узким местом и
по мере нарастания нагрузки значительно теряет в производительности.
Альтернатива предыдущей схеме — приобретение дополнительных серверов и установка
межсетевого экрана Firewall-1 компании Checkpoint или Cisco PIX компании Cisco перед каждым
сервером. В результате того, что межсетевой экран становится выделенным ресурсом сервера,
решается проблема узкого места и уменьшается влияние отказа отдельного межсетевого экрана на
общее состояние сети. Однако и данный подход нельзя назвать идеальным, поскольку резко
увеличиваются затраты компании на приобретение оборудования. К тому же возрастают
трудозатраты на администрирование и обслуживание сети.
Наиболее удачным решением проблемы защиты корпоративных серверов представляется
размещение средств безопасности на одной платформе с сервером, который они будут защищать.
Эта задача выполняется путем использования распределенных или персональных межсетевых
экранов, например CyberwallPLUS компании Network-1 Security Solution. Данные решения
существенно дополняют функциональные возможности традиционных (периметровых)
межсетевых экранов и могут использоваться для защиты как внутренних, так и Интернетсерверов.
В отличие от традиционных межсетевых экранов, представляющих собой, как правило, локальные
«контрольные точки» контроля доступа к критическим информационным ресурсам корпорации,
распределенные межсетевые экраны являются дополнительным программным обеспечением,
которое надежно защищает корпоративные серверы, например Интернет-сервер.
Сравним традиционный и распределенный межсетевые экраны по нескольким показателям.
Эффективность. Традиционный межсетевой экран часто располагается по периметру, обеспечивая
лишь один слой защиты. Персональный межсетевой экран функционирует на уровне ядра
операционной системы и надежно защищает корпоративные серверы, проверяя все входящие и
исходящие пакеты.
Простота установки. Традиционный межсетевой экран должен устанавливаться как часть
конфигурации корпоративной сети. Распределенный межсетевой экран представляет собой
программное обеспечение, которое устанавливается и удаляется в считанные минуты.
Управление. Традиционный межсетевой экран управляется сетевым администратором.
Распределенный межсетевой экран может управляться либо сетевым администратором, либо
пользователем локальной сети.
Производительность. Традиционный межсетевой экран является устройством обеспечения
межсетевого обмена с фиксированным ограничением производительности по пакетам в секунду и
не подходит для растущих серверных парков, соединенных друг с другом коммутированными
местными сетями. Распределенный межсетевой экран позволяет наращивать серверные парки без
ущерба принятой политике безопасности.
Стоимость. Традиционные межсетевые экраны, как правило, являются системами с
фиксированными функциями и достаточно высокой стоимостью. Распределенные межсетевые
экраны представляют собой программное обеспечение, стоимость которого, как правило,
составляет от 20 до 10% от стоимости традиционных экранов. К примеру, распределенный
межсетевой экран CyberwallPLUS компании Network-1 Security Solution стоит 6 тыс. долл., в то
время как цена межсетевого экрана Cisco PIX 535 компании Cisco составляет порядка 50 тыс.
долл.
Распределенные межсетевые экраны сочетают в себе средства контроля сетевого доступа со
встроенными средствами выявления несанкционированного доступа и работают в режиме ядра,
проверяя каждый пакет информации по мере его поступления из сети. Такие виды деятельности,
как попытки взлома и несанкционированного доступа, блокируются этим экраном до перехода на
уровень приложений сервера.
К основным преимуществам распределенных межсетевых экранов относятся:
обеспечение безопасности входящего и исходящего трафика;
обеспечение масштабируемой архитектуры путем распространения защиты с помощью
межсетевого экрана на многочисленные серверы;
устранение традиционного межсетевого экрана как единственного места сбоев;
обеспечение недорогого, простого в реализации и управлении решения безопасности.
Таким образом, межсетевые экраны CyberwallPLUS обеспечивают дополнительный уровень
защиты платформ под управлением операционной системы Windows NT/2000, на которых
установлены корпоративные приложения, например Интернет-сервер. Кроме того, межсетевой
экран CyberwallPLUS может предотвратить применение известных типов атак для вторжений на
критичные серверы компании и сообщить администратору безопасности о подозрительной
деятельности в сети.
Итак, межсетевой экран:
защищает передаваемую информацию независимо от средств и среды передачи данных
(спутниковые каналы, оптические линии связи, телефонные соединения, радиорелейные
линии);
выполняет защиту любых приложений, не требуя их изменений;
прозрачен для конечных пользователей;
позволяет реализовать масштабируемые системы защиты с возможностью дальнейшего их
наращивания и усложнения по мере роста организаций и совершенствования требований
политики безопасности;
защищает отдельные сетевые информационные системы и приложения независимо от
топологии сетей, которые они используют;
защищает информационную систему предприятия от атак из внешней среды;
защищает информацию от перехвата и изменения не только на внешних открытых
соединениях, но и во внутренних сетях корпорации;
может быть легко переконфигурирован по мере развития корпоративной политики
информационной безопасности, добавления ресурсов, обновления технологий, роста сети
корпорации.
Реализации межсетевых экранов
настоящее время большое количество как иностранных, так и отечественных компаний
предлагают различные аппаратно-программные и программные реализации межсетевых экранов.
Ниже приводится краткое описание некоторых выпускаемых сегодня продуктов ведущих
иностранных производителей.
Компания NetScreen Technologies предлагает широкий спектр продуктов, начиная от устройств,
обеспечивающих доступ отдельных пользователей к корпоративной сети предприятия по
защищенному каналу, и заканчивая моделями, предназначенными для внедрения в структуры
больших предприятий и создания систем безопасности с высокой пропускной способностью.
Каждый продукт серии NetScreen представляет собой комбинацию межсетевого экрана и
устройства VPN (virtual private network).
Серия продуктов NetScreen-5 позволяет создавать межсетевой экран с пропускной способностью
70 Мбит/с для модели NetScreen-5XT и 20 Мбит/с для модели NetScreen-5XP, а также VPN с
пропускной способностью 20 и 13 Мбит/с соответственно. В отличие от NetScreen-5XP,
поддерживающей до пяти портов 10Base-T, модель NetScreen-5XT обеспечивает пять интерфейсов
Fast Ethernet.
Оба продукта способны поддерживать до 2 тыс. туннелей VPN и до 2 тыс. одновременных
соединений TCP. Они комплектуются операционной системой NetScreen ScreenOS 4.0, которая
используется для настройки физических и виртуальных интерфейсов в соответствии с
требованиями безопасности.
Продукты серии NetScreen-5 идеальным образом подходят для установки между домашним
компьютером пользователя и Web или для обеспечения защищенного доступа к локальной сети
предприятия.
Для внедрения на мелких и средних предприятиях компанией NetScreen Technologies разработаны
продукты серий NetScreen-25, -50, -100, -200. Они позволяют создавать межсетевые экраны с
пропускной способностью от 100 до 550 Мбит/с. К тому же данные при шифровании по протоколу
Triple DES со 168-битным ключом передаются между узлами по туннелю виртуальной частной
сети на скоростях от 20 до 200 Мбит/с. Эти серии продуктов поддерживают от четырех до восьми
портов Fast Ethernet.
Семейство устройств NetScreen-500, NetScreen-1000 и NetScreen-5000 отличается исключительной
пропускной способностью, поэтому является наилучшим решением для внедрения на крупных
предприятиях. Модель NetScreen-500 обеспечивает пропускную способность почти 750 Мбит/с, а
также VPN со скоростью 240 Мбит/с.
Модель NetScreen-5200 позволяет реализовать межсетевой экран с пропускной способностью 4
Гбит/с и VPN с 2 Гбит/с. Она поддерживает до восьми портов Gigabit Ethernet или два порта
Gigabit Ethernet и 24 Fast Ethernet. Модель NetScreen-5400 обеспечивает скорость в 12 Гбит/с для
межсетевого экрана и 6 Гбит/с для VPN. Она поддерживает до 78 портов Gigabit Ethernet и Fast
Ethernet.
Оба продукта способны поддерживать до 25 тыс. туннелей VPN и до миллиона одновременных
соединений TCP. Они комплектуются операционной системой NetScreen ScreenOS 3.1. Кроме
того, продукты компании NetScreen Technologies поддерживают протокол RADIUS (Remote
Authentication Dial-In User Service — служба дистанционной аутентификации пользователей по
коммутируемым линиям) и имеют собственную базу данных для аутентификации пользователей,
подающих запрос на удаленный доступ.
Компания WatchGuard Technologies предлагает модели, предназначенные для внедрения как на
мелких и средних, так и на крупных предприятиях. Для использования на предприятиях малого и
среднего бизнеса предлагаются продукты серии Firebox III (4500, 2500, 1000, и 700). Модели
Firebox 4500 и 2500 представляют собой аппаратные межсетевые экраны под управлением ОС
Linux с защищенным ядром. Пропускная способность межсетевых экранов составляет 197 Мбит/с
в режиме пакетной фильтрации и 60 Мбит/с — в режиме посредника (прозрачный proxy) на
прикладном уровне. Каждый межсетевой экран имеет три сетевых интерфейса 10/100 Мбит/с Fast
Ethernet.
Оба межсетевых экрана могут поддерживать до 3 тыс. туннелей VPN, но модель FireBox 4500
позволяет достичь более высоких по сравнению с FireBox 2500 скоростей шифрования
информации по алгоритму TripleDES — 100 и 55 Мбит/с соответственно.
Для небольших и средних предприятий и удаленных офисов компания выпускает продукты
Firebox SOHO 6, Firebox SOHO 6/tc и Firebox 700.
Firebox 700 способен обслуживать одновременно до 250 пользователей. Это межсетевой экран,
поддерживающий как пакетную фильтрацию, так и фильтры — посредники приложений.
Специалисты WatchGuard оценивают производительность Firebox 700 в 131 Мбит/с в режиме
пакетной фильтрации и в 43 Мбит/с в режиме посредника. Firebox 700 позволяет создавать
виртуальную частную сеть с 150 туннелями одновременно и выполнять шифрование TripleDES со
скоростью 5 Мбит/с.
Firebox SOHO 6 поддерживает функционирование пакетных фильтров с пропускной способностью
75 Мбит/с. Он также поддерживает виртуальную частную сеть с пятью туннелями и пропускной
способностью 20 Мбит/с (модификация SOHO/tc) при использовании шифрования TripleDES.
Для обеспечения высокоскоростной пропускной способности крупных информационных
компаний разработана модель Firebox Vclass, позволяющая получить пропускную способность до
600 Мбит/с. Продукт способен поддерживать до 20 тыс. туннелей VPN. В режиме шифрования
достигается скорость 300 Мбит/с.
Компания Cisco Systems предлагает серию межсетевых экранов Cisco PIX Firewall,
обеспечивающих высокий уровень безопасности, производительности и надежности. Модельный
ряд межсетевых экранов представлен следующими продуктами: PIX 506E, 515E, 525 и 535.
Межсетевые экраны Cisco PIX 506E и 515Е являются модернизациями моделей Cisco PIX 506 и
515 соответственно. Данные модели предназначены для использования в корпоративных сетях
небольших компаний, а также для обеспечения безопасности удаленных клиентов корпоративных
сетей предприятий. Модель 506Е имеет производительность 20 Мбит/с, а 515Е — 188 Мбит/с.
Шифрование потока данных может осуществляться как с использованием алгоритма DES с 56битным ключом, так и TripleDES с 168-битным ключом. Пропускная способность Cisco PIX 506E
при шифровании DES — 20 Мбит/с, TripleDES — 16 Мбит/с. Скорость шифрования для модели
515Е на алгоритме TripleDES равна 63 Мбит/с. Модель 515Е поддерживает до 2 тыс. туннелей
VPN.
Для использования на предприятиях среднего и крупного масштаба компания Cisco выпускает
модели 525 и 535. Пропускная способность модели 525 составляет 370 Мбит/с. Данная модель
может одновременно обслуживать до 280 тыс. сеансов. Модель Cisco PIX 535 имеет
производительность 1 Гбит/с и поддерживает VPN с пропускной способностью 100 Мбит/с. Кроме
того, эта модель поддерживает до 2 тыс. туннелей VPN и до 500 тыс. одновременных соединений
TCP.
В качестве метода защиты в межсетевых экранах компании Cisco используются разновидность
алгоритма контекстной проверки Adaptive Security Algorithm (ASA) и внутренняя операционная
система PIX OS, позволяющие обеспечить высокую надежность и безопасность со стороны
возможных Интернет-атак.
Компанией eSoft, Inc. в ноябре 2002 года представлена новая серия продуктов InstaGate xSP,
которая пришла на смену более ранним моделям InstaGate EX2 и InstaGate PRO. Под маркой
InstaGate xSP компанией eSoft выпускаются InstaGate xSP Branch Office для небольших и
распределенных офисов и InstaGate xSP Business для средних и больших офисов. Продукты серии
xSP поставляются с пакетом приложений SoftPak, что позволяет пользователям быстро и легко
создавать надежную систему безопасности всего периметра корпоративной сети. Серия продуктов
xSP полностью совместима с существующими моделями InstaGate и позволяет создавать
виртуальные частные сети на базе IPSec и PPTP. InstaGate xSP Branch Office поддерживает до 10
пользователей и 10 туннелей VPN, а InstaGate xSP Business до 100 пользователей и 100 туннелей
VPN. Продукты этой серии отличаются относительно невысокой стоимостью.
Компания 3Com предлагает на рынок два типа межсетевых экранов: SuperStack 3,
предназначенные для штаб-квартир корпораций и крупных офисов, а также для клиентов,
которым требуется высокопроизводительный доступ к виртуальной частной сети, и OfficeConnect
— для небольших офисов с числом сотрудников менее ста, домашних офисов и работающих на
дому специалистов.
По оценкам производителей, SuperStack 3 поддерживает неограниченное число пользователей
корпоративной сети и обеспечивает до 1000 туннелей VPN. Пропускная способность данной
модели при шифровании алгоритмом TripleDES составляет 45 Мбит/с.
Модельный ряд OfficeConnect представлен моделями OfficeConnect Internet Firewall 25 и
OfficeConnect Internet Firewall DMZ. Модель OfficeConnect Internet Firewall DMZ, используя порт
DMZ, позволяет обеспечить безопасный внешний доступ к ресурсам сети. OfficeConnect Internet
Firewall DMZ поддерживает до 100 пользователей, а OfficeConnect Internet Firewall 25 — 25
пользователей. Совместно с межсетевыми экранами OfficeConnect Internet Firewall DMZ и
OfficeConnect Internet Firewall 25 используется фильтр Web-сайтов OfficeConnect Web Site Filter,
обеспечивающий фильтрацию доступа к нежелательным Web-сайтам. Все межсетевые экраны
компании 3Com имеют сертификат ICSA. Семейство межсетевых экранов компании 3Com
сочетает исключительную простоту в использовании с гибкостью выбора решений. Межсетевые
экраны компании 3Com легко устанавливаются и обеспечивают чрезвычайно высокий уровень
защиты. Установка в режиме plug-and-play исключает сложные и длительные процедуры
настройки и администрирования без ущерба для строгости, полноты и детальности стратегии
безопасности.
Таким образом, применение межсетевых экранов является ключевым элементом в построении
высокопроизводительных, безопасных и надежных информационно-аналитических систем и
систем автоматизации предприятий, финансовых систем, распределенных баз данных, систем
удаленного доступа работников к внутренним ресурсам корпоративных сетей, сегментов
корпоративной сети и корпоративной сети в целом.
Вопрос 17. Рекомендации по проектированию корпоративных вычислительных сетей.
При проектировании корпоративной сети полезно ее представление в виде многослойной
пирамиды. Хотя слои этой пирамиды связаны и оказывают непосредственное влияние друг на
друга, обычно каждый слой проектируется достаточно автономно, специалистами и фирмами
соответствующего профиля.
В зависимости от направления движения по этой пирамиде: сверху вниз — от бизнес-приложений к
аппаратной платформе, или снизу вверх — от аппаратуры к приложениям, или от середины — от
конкретной СУБД, — все фирмы, работающие в области сетевой интеграции, можно условно
разделить на три группы:
1. Фирмы-производители или дистрибьюторы аппаратуры, выступающие в роли
интеграторов. У этих интеграторов пирамида опирается на очень узкое основание из одной
платформы от одного-двух производителей. Минусы и некоторые плюсы в работе такого
интегратора достаточно очевидны.
2. Фирмы, ориентирующиеся на одну из СУБД, например, только на Oracle или Informix. В
этом случае узким местом пирамиды является середина: при попытке использовать
несколько аппаратных платформ и широкий спектр прикладного программного
обеспечения, ограничения диктуются используемой СУБД.
3. Наконец, третья группа — независимые интеграторы, которые могут предлагать любые
решения на каждом из уровней пирамиды и которых нельзя уличить в особой
привязанности к определенной платформе, сетевым конфигурациям или приложениям. У
таких интеграторов единственным критерием выбора каждого конкретного решения в
идеале является требование достижения максимального эффекта в рамках заданных
ресурсов. В таком случае есть возможность гибко строить любые конфигурации, что
позволяет достаточно просто решать проблемы, связанные с тем, что заказчик уже
использует, например, какую-либо СУБД и не хочет переучивать свой персонал для
работы с другой базой данных.
При этом, при проектировании какого-либо слоя характеристики других слоев, оказывающих
влияние на принятие проектных решений, берутся в виде исходных данных, чаще всего в весьма
обобщенном виде. Например, при проектировании приложений учитываются скорости, которые
может обеспечить сегодняшнее коммуникационное оборудование вполне определенного
диапазона стоимости — того диапазона, который имеется в распоряжении предприятия. И
наоборот, разработчики транспортной системы ориентируются на усредненные данные о трафике,
который могут создать имеющиеся на предприятии приложения и те приложения, которые
намечено ввести в действие в ближайшие год-два.
10.1.1. Этапы проектирования
Следует оговориться, что рассматриваемые в этом разделе вопросы методологии проектирования
часто не вполне соответствуют существующей сейчас практике реализации проектов фирмамиинтеграторами. Нельзя однозначно сказать, насколько это хорошо или плохо, но одновременно с
произошедшими за последние пять лет изменениями отношений собственности и глубокой
организационной перестройкой предприятий была утеряна и культура выполнения проектных
работ, включавшая в себя следование строго регламентированному перечню этапов, непременное
сопровождение каждого этапа стандартной документацией, ведение протоколов рабочих
совещаний и всевозможных видов актов «приемно-сдаточных испытаний «.
Сейчас каждый сетевой интегратор выполняет проекты согласно своим собственным
представлениям о рациональной организации труда, и методика проектирования каждой фирмы
является неким «ноу-хау». Тем не менее, с учетом более богатого (но, может быть, не всегда нам
подходящего) западного опыта можно сформулировать некоторые типовые этапы выполнения
сетевых проектов:
Анализ требований. На этом этапе формулируются основные деловые цели предприятия, для
которого разрабатывается проект, например, сокращение производственного цикла, более
оперативный прием заказов или повышение производительности труда за счет более
эффективного взаимодействия сотрудников, то есть те цели предприятия, которые в настоящий
момент, при существующих средствах и технологиях не вполне достигаются. Осуществляется
поиск аналогичных систем, анализируются их сильные и слабые стороны, определяется
возможность использования удачного опыта для проектируемой системы.
Разработка бизнес-модели. Бизнес-модель можно по-другому назвать функциональной моделью
производства, она описывает деловые процедуры, последовательность и взаимозависимость всех
выполняемых на предприятии работ. При этом внимание концентрируется не на компьютерной
системе, а на деловой практике.
Разработка технической модели. Техническая модель описывает в достаточно общих терминах,
какое компьютерное оборудование нужно использовать, чтобы достичь целей, определенных в
бизнес-модели. Для построения технической модели необходимо провести инвентаризацию всего
имеющегося оборудования, определить требования к новой системе (при этом требования должны
быть сформулированы не с технической точки зрения, а с позиций руководителей и конечных
пользователей сети), на основании этого определить, что из существующего оборудования может
быть использовано в новой системе. Далее необходимо определить полный функциональный
набор необходимых аппаратных средств без конкретизации марок и моделей оборудования.
После того, как выбрана техническая модель, описывающая сеть в общих терминах, создается так
называемая физическая модель, которая является подробным описанием конкретных продуктов,
их количества, технических параметров и способов взаимодействия.
Установка и наладка системы. Данный этап подразумевает координирование поставок от
субподрядчиков, управление конфигурированием, инсталляцию и наладку оборудования,
обучение персонала.
Тестирование системы. На этом этапе должны проводиться приемочные испытания, оговоренные
в контракте с интегратором.
Сопровождение и эксплуатация системы. Этот этап не имеет четко определенных временных
границ, а представляет собой непрерывный процесс.
Для каждого из упомянутых этапов и даже для отдельных более мелких задач может быть
разработанотехническое задание. Постановка задачи зависит от того, какую часть работы решено
отдать внешнему интегратору, а какую часть — выполнить своими силами. Этот этап тесно связан с
этапами выбора интегратора и заключения с ним контракта.
10.1.2. Роль системных интеграторов
Задачи системного интегратора могут меняться в зависимости от условий контракта, в наиболее
же общей форме в его обязанности входят следующие:
Принятие и обоснование решений на всех этапах разработки сети, начиная от анализа
требований к системе и кончая сопровождением и эксплуатацией системы. Эти решения
должны обеспечивать подбор и взаимоувязку всех разнородных компонентов
корпоративной сети, исходя из конечных потребностей пользователя, то есть наиболее
рационально отвечать деловым целям организации-заказчика. Интегратор должен
стремиться к вовлечению заказчика в процесс принятия проектных решений для
уменьшения вероятности создания системы, не отвечающей целям заказчика, которые
могут не вполне четко формулироваться на начальных этапах разработки.
Управление действиями, направленными на решение конечной задачи. При наличии
нескольких субподрядчиков генеральный подрядчик должен обеспечивать их
взаимодействие и взаимопонимание. Обычно интеграторы специализируются на
проектировании какого-либо одного слоя вычислительной системы, например, слоя
сетеобразующего коммуникационного оборудования или же слоя баз данных и т.д.
Поэтому для разработки общего проекта корпоративной сети заказчик может либо сам
заключать отдельные контракты на раздельное проектирование каждого слоя, либо
заключить контракт с генеральным подрядчиком, который в свою очередь, нанимает
субподрядчиков на выполнение отдельных проектов. В первом случае заказчик берет на
себя роль координатора работ и, в конечном счете, ответственность за успех системы, а во
втором это делает интегратор.
Координация работы всех поставщиков оборудования и программного обеспечения.
Обеспечение выполнения работ в указанные сроки и в пределах установленной сметы
расходов. Чем сложнее замысел и крупнее система, тем больше вероятность несоблюдения
сроков или сметы.
10.2. Этапы проектирования корпоративных сетей
10.2.1. Анализ требований
Нельзя построить хорошую корпоративную сеть без ясного понимания деловых целей
предприятия и без четкого плана достижения этих целей. Первый шаг, заключающийся в
определении проблем предприятия и, следовательно, целей проекта называется анализом
требований.
Анализ требований к сети поможет оценить деловую значимость информационно-технологических решений, определить главные цели и выбрать приоритеты для отдельных частей
компьютерной системы, которую вы хотите улучшить или расширить. Четкое определение
требований к функциям сети поможет избежать реализации не нужных свойств сети, что
сэкономит средства вашего предприятия. Тщательный анализ требований к сети является основой
для написания хорошего технического задания, на базе которого системные интеграторы смогут
разработать проект сети. Наконец, ясное понимание целей поможет сформулировать критерии
качества для оценки и тестирования реализованной сети.
Для большинства администраторов локальных сетей, особенно масштаба отдела, анализ
требований к сети является чем-то экзотическим. Очень часто такой администратор покупает
сетевое оборудование, операционные системы и приложения в ближайшем компьютерном
магазине. В лучшем случае он консультируется с дистрибьютором или дилером. Очевидно, что
администратор сети отдела скорее всего не захочет заниматься анализом требований, так как он
покупает простую сеть для отдела, а не для предприятия в целом. Такой произвольный выбор
вполне допустим для масштаба отдела, так как эта сеть не оказывает значительного влияния на
работу предприятия. Если эта сеть откажет, то это повлияет только на пользователей одного
отдела. Кроме того, в связи с тем, что цена такой сети сравнительно невелика, не очень велики и
потери в случае ошибки.
Работы по проектированию и установке корпоративной сети лучше всего поручить сотрудникам
отдела автоматизации, а не администраторам сетей групп и отделов. Хорошо, если сотрудники
этого отдела имели дело с мейнфреймами; в этом случае у них есть опыт тщательного
информационного анализа системы, планирования и установки ответственных приложений для
больших машин. Вместе с тем совершенно необходим и опыт работы с сетями, для которых (в
отличие от централизованных систем на базе мейнфреймов) характерно большее разнообразие
оборудования, программного обеспечения и протоколов, а также разнообразие поставщиков.
Для выполнения анализа требований к корпоративной сети необходимо:
оценить текущее состояние локальных сетей и парка компьютеров на предприятии, что
поможет выявить, какие проблемы требуют решения;
определить цели и выгоды от корпоративной сети, что поможет вам правильно
спроектировать сеть;
обосновать перед руководством предприятия необходимость покупок;
написать эффективное техническое задание;
определить критерии для оценки качества сети.
Различные компании выполняют анализ требований к сети различными способами с различной
степенью детализации в соответствии с традициями предприятия и его технической политикой.
Документ, описывающий требования к сети, может быть объемом от 10 до 150 страниц.
Некоторые предприятия выполняют такой анализ сами. Другие предприятия прибегают к помощи
консультантов или системных интеграторов. Это делается в тех случаях, когда персонал отдела
автоматизации не имеет достаточного опыта в проектировании и установке сетей. Кроме того,
использование независимых консультантов или системных интеграторов в силу их объективности
поможет взглянуть по-новому на проблемы и на их решения.
10.2.2. Построение функциональной модели производства
Сеть предприятия предназначена для того, чтобы выполнять производственные функции, поэтому
следует оценить ее роль в производственной структуре предприятия. Для успешного построения
корпоративной сети нужно построить функциональную модель (или, по-другому, бизнес-модель),
из которой потом получить техническую и физическую модели сети. Большинство крупных
системных интеграторов придерживаются такой стратегии.
Архитектура приложений и вычислительной системы играет ключевую роль в деловой
архитектуре предприятия. Бизнес предприятия базируется на архитектуре управления данными, на
приложениях и архитектуре сети. Успешный анализ требований и успешное построение
корпоративной сети требуют от технического специалиста умения думать как бизнесмен. Общей
ошибкой некоторых руководителей проектов является мышление только в технических и
технологических терминах.
Перед тем, как начать оценивать требования к корпоративной сети, нужно получить общее
представление о том, что происходит в каждом отделе. Именно бизнес-модель описывает, как
делаются дела на предприятии. В ней обычно не упоминается компьютерная система, она скорее
концентрируется на деловой практике и последовательности работ. Сначала постройте модель, в
которой отражается последовательность работ всего предприятия, а затем постройте модель для
последовательности работ в каждом отделе. Детально опишите, как выполняются работы, кто
выполняет эти работы и каковы взаимосвязи между рабочими группами и отделами.
Для разработки бизнес-модели необходимо собрать бригаду, состоящую из руководителей
отделов, ведущих специалистов и сотрудников отдела автоматизации. Обратите внимание на
следующие моменты:
необходимо назначить руководителя работы;
нужно опросить руководителей отделов и конечных пользователей корпоративной сети,
чтобы определить их функции и выяснить, как их компьютерные системы помогают им в
работе;
необходимо выяснить, как работа переходит из одного отдела в другой, и каким образом
информация и задачи передаются от одного сотрудника к другому;
необходимо узнать, в чем заключаются зависимости — кто утверждает какой-либо этап
работы и в какой последовательности должны завершаться этапы;
нужно понять, какие узкие места имеются у системы — слишком большое время ответа или
же неэффективная обработка данных.
10.2.2.1. Работа с руководящим составом
Опросите руководителей подразделений и пользователей для того, чтобы определить, что они
хотят получить от корпоративной сети. Их ответы будут лежать в диапазоне от «Я хочу в точности
то, что имею сегодня» до прогрессивных идей на переднем плане науки и техники таких, как
полностью автоматизированное производство и электронный документооборот. Действительно ли
руководители хотят уменьшить количество денег, затрачиваемых на экспресс-доставку и обмен
сообщениями за счет улучшения коммуникаций? Действительно ли они хотят взаимодействовать
электронным способом с покупателями и поставщиками?
На этой ранней стадии проекта есть время для воображения и мозговых атак. Спросите
руководителей, какие сервисы они хотели бы иметь, если бы цена не имела никакого значения.
Расспросите руководителей и пользователей о существующей компьютерной системе. Не
слишком ли она много простаивает из-за отказов? Не слишком ли она медленная? К каким
источникам информации они обычно обращаются? Затем попросите руководителей отделов
упорядочить свои требования в порядке их приоритетности. Этот список поможет вам определить
этапы развертывания сети.
На этом этапе руководители подразделений предприятия должны оценить эффективность своих
ручных и компьютеризованных операций. Автоматизация неэффективных деловых процедур
приводит к неэффективным компьютерным системам. Действительно ли руководители готовы
изменить процедуры своей деятельности или же эти изменения чересчур нарушат их деловую
практику?
После того, как вы уяснили функции подразделений, вы должны объяснить их руководителям, как
корпоративная сеть может кардинально изменить и улучшить их работу. Необходимо потратить
большое количество времени, чтобы объяснить, как сеть может изменить ведение дел на
предприятии.
При этом необходимо пользоваться терминами, понятными руководителям. Общей ошибкой
является употребление технических терминов, а не производственных. Руководителей не волнуют
преимущества 100 Мбитной сети FDDI по сравнению с 16 Мбитной сетью TokenRing. Им нет дела
до разницы между обнаружением коллизий и передачей токена. Однако их беспокоит, сможет ли
сеть помочь им производить больше телевизоров, продавать больше автомобилей, уменьшить
страховые запасы сырья. Объясните, что руководители отделов и менеджеры теперь смогут
уменьшить время ожидания потенциальных заказчиков за телефоном. А, например, руководителю
издательской фирмы необходимо объяснить, что, имея сеть, сотрудники могут не только
передавать текст, но также и звуки, и изображение. Информация будет передаваться как единое
целое, а не как разрозненный набор чисел, слов, картинок. Использование конкретных
содержательных примеров поможет деловым людям понять, какое влияние сеть окажет на
организацию работ и на производительность.
Построение бизнес-модели предприятия — не простая задача. Это объясняется дефицитом
технических специалистов, понимающих производственные проблемы, и наоборот, отсутствием
понимания технических аспектов у многих управленцев. Технические специалисты и
управленческие работники должны взаимно обучаться для того, чтобы построить эффективную и
полезную корпоративную сеть.
Построение бизнес-модели поможет также получить поддержку руководства предприятия, так как
покажет, что разработчики сети понимают и производственные моменты предприятия, а не только
технические. Общая стратегия заключается в том, чтобы найти руководителя или менеджера,
который увидит выгоду для себя от внедрения корпоративной сети. Этот человек потом будет
выступать как ваш «спонсор» перед высшим руководством.
10.2.2.2. Работа с пользователями сети
Корпоративная сеть строится для удовлетворения производственных потребностей. Конечные
пользователи будут работать с ней каждый день, поэтому обязательно нужно сделать, чтобы им
было удобно работать с сетью. К сожалению, о конечных пользователях часто забывают во время
планирования, проектирования и установки корпоративной сети. И когда сеть полностью
установлена, пользователи начинают говорить «Она не работает» или «Она всегда отказывает».
Они говорят, что печать теперь занимает больше времени, чем раньше, и что сеть им не нравится
вообще. Вместо того, чтобы использовать сеть как инструмент, они смотрят на нее как на помеху.
Одним из главных условий успешной работы является общение. Как правило, сотрудники отдела
автоматизации слишком мало разговаривают не только друг с другом, но и с конечными
пользователями. Конечные пользователи часто больше других знают о компьютерных системах, и
именно они создают наибольшую нагрузку на компьютеры. Так как они работают с сетью каждый
день, то часто обладают наилучшим пониманием того, как взаимосвязаны деловые функции и
компьютерные системы. Обязанностью сотрудников отдела автоматизированных
информационных систем является выбор такого оборудования, которое наилучшим образом
удовлетворяет потребностям конечного пользователя, а не просто самой новой, самой быстрой
продукции.
Необходимо назначить по крайней мере одного конечного пользователя, ответственного за связь
между пользователями и отделом автоматизации, чтобы пользователи были уверены, что их
интересы кто-то представляет. Этот «связной» должен периодически встречаться с другими
пользователями, оповещать их о ходе разработки и служить постоянной обратной связью.
Недовольство пользователей иногда основывается на неверных, часто завышенных, ожиданиях.
Необходимо дать пользователям реалистичную картину того, что сеть может делать. Необходимо
объяснить, какое ожидается среднее время простоев из-за отказов. (Во время анализа требований
необходимо выяснить, какое время простоев пользователи считают допустимым.) Нужно честно
рассказать пользователям об этапности установки сети. Часто сотрудники отдела
автоматизированных информационных систем не говорят о том, что, например, при установки
первой очереди корпоративной сети связь с компьютерами VAX и не планировалась, и что она
вступит в строй только через год. Пользователи, не предупрежденные об этом, будут очень
разочарованы.
Необходимо иметь ввиду, что на предприятии имеется две группы сотрудников, которые будут
работать с корпоративной сетью: сотрудники отдела автоматизации, которые будут поддерживать
сеть и управлять ею, и конечные пользователи, которые будут использовать ее как инструмент.
Цели и потребности этих двух групп часто противоположны. В то время, как конечные
пользователи заинтересованы в расширении функций и сервисов сети, сотрудники отдела
автоматизации больше озабочены простотой эксплуатации и поддержания надежной работы сети.
И те, и другие требуют обучения, хотя и по разным причинам, и по разным программам.
Конечных пользователей надо обучать, чтобы работа в корпоративной сети не показалась им
странной и неудобной, сотрудников отдела автоматизации необходимо обучать обслуживанию
новой современной техники, чтобы они не боялись потерять в будущем работу и не противились
внедрению корпоративной сети.
Нужно иметь ввиду, что большинство людей не любит перемен. Они привыкли к используемым
программам и компьютерам, многие не хотят отказываться от твердо укоренившихся в памяти
приемов. При разработке взаимодействия пользователя с будущей системой будет полезно
промоделировать существующее взаимодействие при условии, что оно будет иметь смысл в новом
окружении. Необходимо также помнить, что нельзя уменьшать существующие функциональные
возможности системы — их можно только наращивать.
10.2.3. Построение технической модели
После разработки бизнес-модели предприятия и определения того, какие процедуры требуют
изменения или улучшения, необходимо построить техническую модель сети. Техническая модель
описывает в достаточно общих терминах, какое компьютерное оборудование нужно использовать,
чтобы достичь целей, определенных в бизнес-модели. Чтобы построить техническую модель,
нужно проанализировать существующее оборудование, определить системные требования,
оценить сегодняшнее и завтрашнее состояния техники.
10.2.3.1. Инвентаризация существующего оборудования и приложений
Не многие предприятия могут себе позволить роскошь построения корпоративной сети с нуля.
Большинство же вместо этого строят свои компьютерные системы с использованием имеющегося
оборудования, которое уже эксплуатируется какое-то время. Необходимо оценить, какое
существующее оборудование продолжает иметь стратегическое значение для предприятия, а какое
может быть безболезненно списано. Однако сначала необходимо все же определить, что же вы
имеете.
Для каждого отдела и офиса необходимо провести инвентаризацию существующего
компьютерного оборудования и выяснить, какое действительно используется. Например,
действительно ли еще используются 286-е IBMPC-совместимые персональные компьютеры,
сколько их? Сколько имеется других компьютеров? Выполняются ли какие-либо приложения
мейнфреймом IBM 370? Какие используются типы сетевого оборудования и протоколов, а также
сетевых операционных систем: SNA, IPX/SPX, TCP/IP, NetWare, WindowsforWorkgroups, Unix,
WindowsNT и т.п. Где это оборудование находится, и в каком оно состоянии? Есть ли
экономический смысл продолжать эксплуатировать эту технику или же более эффективно перейти
на новую технику? Например, если в программное обеспечение мейнфрейма вложено
значительное количество денег, и система работает без проблем, то, очевидно, нет смысла ее
заменять. В этом случае корпоративная сеть должна уметь взаимодействовать и с этим
мейнфреймом.
После того, как проведена ревизия оборудования, необходимо проделать то же самое с
приложениями. Необходимо выяснить:
Какие приложения используются в каждом офисе и отделе, сколько людей пользуются
каждым приложением, и трафик какой интенсивности они создают?
Могут ли эти приложения быть использованы в корпоративной сети?
Где хранятся эти приложения и каким образом пользователи смогут получать к ним доступ
в новой операционной среде?
Существуют ли более эффективные приложения аналогичного назначения и захотят ли
сотрудники перейти на них?
Инвентаризация — очень скучная процедура, но тем не менее ее нужно осуществить, чтобы точно
знать, чем вы располагаете и что нужно приобрести. Для такой большой системы, как
корпоративная сеть, очень важно, чтобы каждый элемент, будь то кабель или плата памяти, был
промаркирован и учтен. Процесс инвентаризации можно и нужно автоматизировать. Существуют
программы, которые могут автоматически исследовать состав аппаратного и программного
обеспечения уже работающих в сети компьютеров.
В общем случае такие программы могут выяснить тип CPU, имеющуюся память, тип диска и
свободное пространство на нем, имеющиеся дополнительные контроллеры — такие как сетевые
адаптеры, факс-модемы и т.п. Для программного обеспечения можно узнать наименование и
версию приложений, версии операционной системы, установленные сетевые драйверы.
Программы-исследователи создают базу данных подобной информации, которая может
использоваться для справок или при устранении неисправностей. Администратор может
периодически запускать исследовательскую программу и получать недельную, месячную или
квартальную справку о текущем состоянии сетевых ресурсов.
10.2.3.2. Определение системных требований
После инвентаризации существующей вычислительной системы необходимо определить
требования к новой системе. Для определения технических параметров сети рассматривайте
системные требования не с технической точки зрения, а с позиций руководителей, менеджеров и
конечных пользователей.
Для выяснения системных требований необходимо ответить на следующие вопросы:
Что нужно соединять? Требуется ли сотрудникам какого-либо подразделения общаться с
небольшим (большим) количеством людей в пределах небольшой территории или же им
нужно общаться с небольшим (большим) количеством людей в пределах географически
обширной области? Объем и распределение трафика поможет определить требуемую
мощность компьютеров, а также типы и скорости коммуникационного оборудования и
сервисов.
Что из существующего аппаратного и программного обеспечения будет использоваться в
новой системе? Какие системы нужно оставить в разрабатываемой корпоративной сети?
Нужно ли эти системы соединять в сеть? Будут ли существующие системы нормально
работать в новой сети? Существуют ли какие-либо стандарты предприятия, существуют ли
преобладающие приложения? Какое оборудование и приложения нужно добавить, чтобы
достигнуть поставленных производственных целей?
Какие объемы информации будут передаваться по сети? Объем передаваемой информации
определяет требуемую пропускную способность сети. По корпоративной сети будет
передаваться больше или меньше информации? Определите это подсчетом количества
пользователей сети, среднего количества выполняемых транзакций в день каждым из
пользователей и среднего объема транзакции. Такой подсчет поможет определить
технологию доступа к среде передачи данных (Ethernet, FDDI, …) и требования к
глобальным сервисам.
Какое время реакции сети является приемлемым? Будут ли пользователи ждать одну
секунду, полсекунды или две секунды? Такие измерения помогут определить требования к
скорости оборудования, приложений и коммуникационных связей.
В течение какого времени сеть существенно необходима для работы предприятия? Нужна
ли сеть 24 часа в день и 7 дней в неделю или же только в течение 8 часов в день и 5 дней в
неделю? Нужно ли увеличить сегодняшние параметры использования сети?
Какие требования предъявляются к среднему времени устранения неисправностей? Как
отражаются операции по обслуживанию и ремонту сети на эффективности ведения дел
предприятием? Потеряет ли предприятие 5 миллионов долларов или же 100 тысяч
долларов, если сеть будет неисправна в течение одного часа? Каков будет ущерб от
простоя сети в течение двух часов?
Каков планируемый рост системы? Каков текущий коэффициент использования сети и как
он может измениться в течение ближайших 6 месяцев, одного года, двух лет? Даже если
вы тщательно спланировали сеть, но не учли возможности ее роста и развития, то
системные требования придется изменить и увеличить. Рост сети нужно планировать
заранее, а не просто реагировать на фактический рост ее нагрузки.
10.2.3.3. Разработка технической модели
После того, как системные требования определены, можно описать техническую модель
корпоративной сети. На этом этапе нужно определить, каким образом предполагается
удовлетворить производственные требования с технической точки зрения. Большинство
проектировщиков сетей хорошо знакомы с методами разработки технической модели.
Прежде всего подвергните анализу существующую систему. Что нужно из нее сохранить, а что
отбросить? Будут ли согласовываться различное сетевое оборудование, операционные системы и
приложения, используемые сегодня?
После этого оцените доступную технологию. Что на сегодня является технической вершиной?
Хотите ли вы использовать самую передовую технику и технологию? Нужна ли вам на самом деле
самая передовая техника? Например, если вы строите сеть для отдела закупок, то технология
FastEthernet очевидно будет излишней, даже если в отделе обрабатывается большое число
документов. В то же время в инженерном отделе технология FastEthernet будет более
целесообразна, так как там имеют дело с большими файлами. Можно также рассмотреть
целесообразность сети Ethernet с отдельными сегментами для каждого пользователя. Построение
хорошей сети означает постоянное сопоставление ваших желаний и потребностей предприятия.
Нужно использовать только такие технические решения, которые необходимы.
Тщательно обдумайте выбор между передовой технологией и технологией, проверенной
временем. Например, Ethernet и TokenRing являются проверенными технологиями, а ATM сравнительно новой. Не многие проектировщики хорошо с ней знакомы, а капиталовложения
необходимо сделать значительные.
Далее нужно оценить, какое семейство технических средств удовлетворяет производственным
потребностям. Например, нужны ли вашей сети мосты и маршрутизаторы? (Это зависит от
интенсивности трафика, количества сегментов, распределения сегментов и уровня квалификации
администраторов.) Будете ли вы использовать смешанную топологию или топологию звезды? (Это
зависит от структуры и организации вашего предприятия.) Какие коммуникационные связи и с
какими скоростями нужны для вашей сети? (Это зависит от того, что будет передаваться по сети, в
том числе от того, хотите ли вы комбинировать передачу голоса и данных.) Для принятия
подобных решений вы должны узнать сравнительные характеристики различных технологий и
технических средств, а также тщательно проанализировать интенсивность и типы передаваемых
по сети данных.
Проектировщик также должен обеспечить нужный набор функций и требуемое время доступности
сети. Например, если сеть должна быть доступна по ночам и в выходные дни, в ответственных
файл-серверах нужно предусмотреть избыточные диски и источники бесперебойного питания.
Необходимо решить, достаточно ли применение способа зеркального отображения дисков или
требуется использовать дисковый массив. Какой запас аккумуляторов нужен для источников
бесперебойного питания?
Далее нужно выяснить, какие технологии и технические средства станут доступными в
ближайшее время, а также каковы долгосрочные перспективы этих новшеств. Оцените, сможет ли
проектируемая сеть принять завтрашние технологические новинки.
Искусство проектировщика заключается в оценке имеющихся на сегодня решений, предвидении
того, что станет доступным завтра, и объединении этих решений в элегантную и эффективную
сеть. Например, сегодня неэкранированная витая пара категории 5 устраивает практически все
протоколы локальных сетей, в том числе и АТМ на 155 Мб/с. Поэтому можно сделать несложный
вывод о том, что внутри зданий на вашем предприятии лучше использовать витую пару, а не
коаксиальный кабель.