
25.08.2012, 03:11. Показов 623712. Ответов 2

В первую очередь хочу сказать спасибо Charles Kludge и nonym4uk за помощь в написании этой статьи.
Итак, S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Много пользователей знает что такое S.M.A.R.T., немного меньше даже знают как его получить… Но когда встает вопрос проанализировать полученную таблицу, обычно дело стопорится. В этой статье я приведу основные значения и их расшифровку
Для любознательных
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число премещений головок, количество циклов включения-выключения);
текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 и от 0 до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое.
Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
Технология SMART позволяет осуществлять:
мониторинг параметров состояния;
сканирование поверхности;
сканирование поверхности с автоматической заменой сомнительных секторов на надёжные.
Следует заметить, что технология SMART позволяет предсказывать выход устройства из строя в результате механических неисправностей, что составляет около 60 % причин, по которым винчестеры выходят из строя.
Предсказать последствия скачка напряжения или повреждения накопителя в результате удара SMART не способна.
Следует отметить, что накопители НЕ МОГУТ сами сообщать о своём состоянии посредством технологии SMART, для этого существуют специальные программы.
Любая программа, показывающая S.M.A.R.T. для каждого атрибута имеет несколько значений, разберемся сначала с ними — ID, Value, Worst, Threshold и RAW. Итак:
ID (Number) — собственно, сам индикатор атрибута. Номера стандартны для значений атрибутов, но например,из-за кривизны перевода один и тот же атрибут может называться по-разному, проще орентироваться по ID, логично?
Value
(Current) — текущее значение атрибута в условных единицах, никому наверное неведомых . В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в уе. В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
Threshold — значение в (сюрприз!!!) уе, которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не уе, а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Теперь перейдем непосредственно к самим атрибутам.
01 (01) Raw Read Error Rate — Частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных до выдачи в интерфейс, следовательно, на пугающе огромные цифры можно реагировать спокойно.
02 (02) Throughput Performance — Общая производительность диска. Если значение атрибута уменьшается, то велика вероятность, что с диском есть проблемы.
03 (03) Spin-Up Time — Время раскрутки пакета дисков из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т. п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
04 (04) Start/Stop Count — Полное число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счётчик включения режима энергосбережения. В поле raw value хранится общее количество запусков/остановок диска.
05 (05) Reallocated Sectors Count — Число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор «переназначенным» и переносит данные в специально отведённую резервную область. Вот почему на современных жёстких дисках нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, а переназначенный сектор — remap. Чем больше значение, тем хуже состояние поверхности дисков. Поле raw value содержит общее количество переназначенных секторов. Рост значения этого атрибута может свидетельствовать об ухудшении состояния поверхности блинов диска.
06 (06) Read Channel Margin — Запас канала чтения. Назначение этого атрибута не документировано. В современных накопителях не используется.
07 (07) Seek Error Rate — Частота ошибок при позиционировании блока магнитных головок. Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
08 (08) Seek Time Performance — Средняя производительность операции позиционирования магнитными головками. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
09 (09) Power-On Hours (POH) — Число часов (минут, секунд — в зависимости от производителя), проведённых во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF — mean time between failure).
10 (0А) Spin-Up Retry Count — Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность неполадок с механической частью.
11 (0В) Recalibration Retries — Количество повторов запросов рекалибровки в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью.
12 (0С) Device Power Cycle Count — Количество полных циклов включения-выключения диска.
13 (0D) Soft Read Error Rate — Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. Все ошибки имеют
не механическую
природу и указывают лишь на неправильную размётку/взаимодействие с диском программ или операционной системы.
100(64) Erase/Program Cycles (для SSD) Общее количество циклов стирания/программирования для всей флэш-памяти за всё время ее существования. Твердотельный накопитель имеет ограничение на количество записей в него. Точные значения (ресурс) зависят от установленных микросхем флэш-памяти.
В накопителях Kingston — объём стёртого в гигабайтах.
103(67) Translation Table Rebuild (для SSD) Количество событий, когда внутренние таблицы адресов блоков были повреждены и впоследствии восстановлены. Raw-значение этого атрибута указывает фактическое количество событий.
170(AA) Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Иногда raw-значение содержит фактическое количество использованных резервных блоков.
170 атрибут связан с атрибутом 5, числом использованных резервных блоков.
171(AB) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти» — отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Значение обычно идентично атрибуту 181.
172(AC) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Идентичен атрибуту 182.
173(AD) Wear Leveller Worst Case Erase Count (для SSD) Максимальное количество операций стирания, выполняемых для одного блока флэш-памяти.
174(AE) Unexpected Power Loss (для SSD) Число неожиданных отключений питания, когда питание было потеряно до получения команды на отключение диска. На жестком диске срок службы при таких отключениях намного меньше, чем при обычном отключении. На SSD существует риск потери внутренней таблицы состояний при неожиданном завершении работы.
175(AF) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти», отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
176(B0) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
177(B1) Wear Leveling Count (для SSD)
Wear Range Delta В зависимости от производителя, максимальное количество операций стирания, выполняемых для одного блока флэш-памяти[источник не указан 269 дней] или разница между максималоьно изношенными (больше всего раз записанными) и минимально изношенными (записанными наименьшее число раз) блоками[4].
178(B2) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
179(B3) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
180(B4) Unused Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество неиспользованных резервных блоков.
181(B5) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов.
182(B6) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов.
183(B7) SATA Downshifts (для SSD) Указывает, как часто требовалось снизить скорость передачи данных SATA (с 6 Гбит/с до 3 или 1,5 Гбит/с или с 3 Гбит/с до 1,5 Гбит/с) для успешной передачи данных. Если значение атрибута уменьшается, попробуйте заменить кабель SATA.
Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1.5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута (Western Digital und Samsung).
184 (B8) End-to-End error — Назначение зависит от производителя.
У HP (часть технологии HP SMART IV) увеличивается в случае, когда после передачи данных через кэш-память чётность данных между хостом и жёстким диском не совпадает.
У Kinston это количество ошибок чтения из флэш-памяти.
185 (B9) Head Stability Стабильность головок (Western Digital).
187 (BB) Reported UNC Errors — Количество ошибок, которое накопитель сообщил хосту (интерфейсу компьютера) при любых операциях, обычно это ошибки данных на диске, которые не исправлены средствами ECC
188 (BC) Command Timeout — содержит количество операций, выполнение которых было отменено из–за превышения максимально допустимого времени ожидания отклика.Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате и т.д. Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
189 (BD) High Fly Writes — содержит количество зафиксированных случаев записи при высоте «полета» головки выше рассчитанной, скорее всего, из-за внешних воздействий, например, вибрации.
Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию
190 (BE) Airflow Temperature (WDC) — Температура воздуха внутри корпуса жёсткого диска. Для дисков Seagate рассчитывается по формуле (100 — HDA temperature). Для дисков
Western Digital
— (125 — HDA).
191 (BF) G-sense error rate — Количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который
фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухой.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно, если его не закрепить. Основное назначение датчика – прекратить операцию записи при вибрациях, чтобы избежать ошибок.
75
В сегодняшней статье:
1. Как узнать в каком состоянии мой жёсткий диск или твердотельный накопитель SSD, сколько он ещё проживёт. Как узнать состояние здоровья жёсткого диска или SSD бывшего в употреблении. Что такое S.M.A.R.T и о чём говорят его показатели: Value, Worst, Raw, Threshold?
2. Что такое бэд-блоки? Как установить — сколько сбойных секторов (бэд-блоков) на моём жёстком диске, можно ли их исправить, а самое главное, как исправить?
3. Что делать, если операционная система не загружается или зависает даже после переустановки, а жёсткий диск при работе издаёт щелчки и посторонние звуки? Почему каждый раз при загрузке Windows запускается утилита проверки диска chkdsk?
4. Как создать загрузочную флешку с программой Victoria и проверить жёсткий диск компьютера, ноутбука на бэд-блоки даже если он не загружается и так далее…
Как пользоваться одной из легендарных программ по диагностике жёстких дисков под названием Victoria!

Приветствую Вас друзья на нашем сайте remontcompa.ru! Сегодняшняя статья о программе Victoria. Скажу уверенно, данная программа самая лучшая среди утилит по диагностике и лечению жёстких дисков. Разработал сиё творение чародей первой категории Сергей Казанский.
Я очень долго и ответственно готовился к данной статье чувствуя благодарность к этой программе. Бывало Victoria спасала казалось бы уже пропавшие данные на жёстких дисках моих клиентов, друзей и знакомых (часто перед мастером НЕ стоит задача вернуть к нормальной работе неисправный жёсткий диск, а только спасти данные находящиеся на нём), а иногда возвращала к жизни и сам винчестер!
- Очень хотелось написать статью, которая помогла бы начинающим пользователям разобраться, а главное не боятся этой программы, а боятся есть чего, если пользоваться программой неосторожно, к примеру запустить бездумно сканирование в режиме Erase или ещё хуже Write , то можно удалить все данные на винте, если вы даже вовремя опомнитесь, то всё равно грохните загрузочную запись MBR и Вам не удастся в следующий раз загрузиться в операционную систему.
Друзья, невозможно всё, что я хочу рассказать и показать о программе Victoria поместить в одну статью. В результате моих стараний получилось несколько статей:
- Сегодняшняя статья. Как скачать и запустить прямо из работающей Windows программу Victoria. Что такое S.M.A.R.T. или как за пару секунд определить состояние здоровья Вашего жёсткого диска или SSD. Ещё статьи…
- Как произвести тест жёсткого диска или твердотельного накопителя SSD на наличие сбойных секторов (бэд-блоков) в программе Victoria для Windows. Как вылечить жёсткий диск.
- Как создать загрузочную флешку с программой Victoria, загрузить с неё компьютер или ноутбук (если они не загружаются нормально из-за сбойных секторов) и протестировать поверхность жёсткого диска на бэд-блоки. Как избавиться от бэд-блоков в DOS (ДОС) режиме.
- Как с помощью программы Victora произвести посекторное стирание информации с жёсткого диска и этим избавиться от сбойных секторов (бэд-блоков).
- Как обрезать на жёстком диске участок со сбойными секторами.
- Как установить точный адрес сбойного сектора в программе Victoria и исправить этот сектор.
- Как сопоставить принадлежность сбойного сектора (бэд-блока) конкретному файлу в Windows?
- Как избавить жёсткий диск ноутбука от бэд-блоков в программе Victoria
- Загрузочная флешка Live CD AOMEI PE Builder с программами для диагностики жёсткого диска: Victoria, HDDScan, CrystalDiskInfo 6.7.4, DiskMark, HDTune, DMDE
Во первых, основных версий программы Victoria две:
Первая версия позволит нам произвести диагностику и небольшой ремонт жёстких дисков прямо в работающей Windows, но хочу сказать, что диагностику винчестера с помощью этой версии произвести можно, а вот исправление сбойных секторов (ремап) часто заканчивается неудачей, да и вероятность ошибок при работе с Викторией прямо «из винды» присутствует, поэтому многие опытные пользователи и профессионалы предпочитают вторую версию программы.
Вторая версия программы Victoria будет находиться на загрузочном диске или флешке, с данного диска (флешки) мы загрузим наш стационарный компьютер или ноутбук и также проведём диагностику и если нужно лечение жёсткого диска.
Примечание: Вторая версия очень пригодится многим, так как у большинства пользователей один жёсткий диск в компьютере или тем более в ноутбуке, в этом случае можно загрузиться с диска (флешки) Виктории и работать с одним единственным винчестером.
1. Victoria на загрузочном диске очень пригодится, если из-за бэд блоков Вы не можете запустить операционную систему.
2. Если у Вас один жёсткий диск и на нём установлена операционная система и в этой же работающей операционке Вы запустите Викторию, то наверняка она откажется исправлять сбойные сектора (бэд-блоки).
Многие пользователи заметят, что зачастую хороший бэд не исправит даже Виктория, на что ответить можно так — не все бэды имеют физическую природу (разрушившийся сектор на жёстком диске), многие бэды имеют логическую природу и легко исправляются этой программой.
Примечание: все подробности о существующих бэд-блоках винчестеров, какие они бывают, логические или физические, читайте в нашей статье- Как проверить состояние жесткого диска.
Коротко лишь скажу, что физические бэды (физически разрушившийся сектор) восстановить невозможно, а логические (программные, ошибки логики сектора) восстановить можно.
Друзья, можно много говорить, но есть хорошая жизненная пословица: «Лучше один раз увидеть, чем сто раз услышать», поэтому я приведу для Вас несколько примеров работы программы Victoria.
Victoria для работы с загрузочного диска
Идём на официальный сайт программы и выбираем Victoria 3.5 Russian ISO-образ загрузочного CD-ROM.
Victoria на загрузочном диске нам тоже нужна, но работу с этой версией мы рассмотрим во вторую очередь. Если у Вас нет дисковода, тогда мы сделаем загрузочную флешку с программой Victoria.

Victoria для работы непосредственно в операционной системе Windows XP, 7, 8, 10
Также скачиваем на моём облаке версию для Windows.
Щёлкаем на скачанном архиве программы правой мышью и выбираем Извлечь файлы.

Файлы извлекаются в создавшуюся папку vcr43. Заходим в эту папку и обязательно запускаем от имени администратора исполняемый файл программы victoria43.exe.
Главное окно программы Victoria
В главном окне программы пройдёмся по всем вкладкам поверхностно, а затем подробно.
Standard
Выбираем начальную вкладку Standard. Если у Вас несколько жёстких дисков, то в правой части окна выделите левой мышью нужный Вам жёсткий диск и сразу в левой части окна отобразятся паспортные данные нашего жёсткого диска: где родился и женился, модель, прошивка, серийный номер, объём кэша и так далее. В нижней части ведётся лог наших действий.

Что такое S.M.A.R.T.
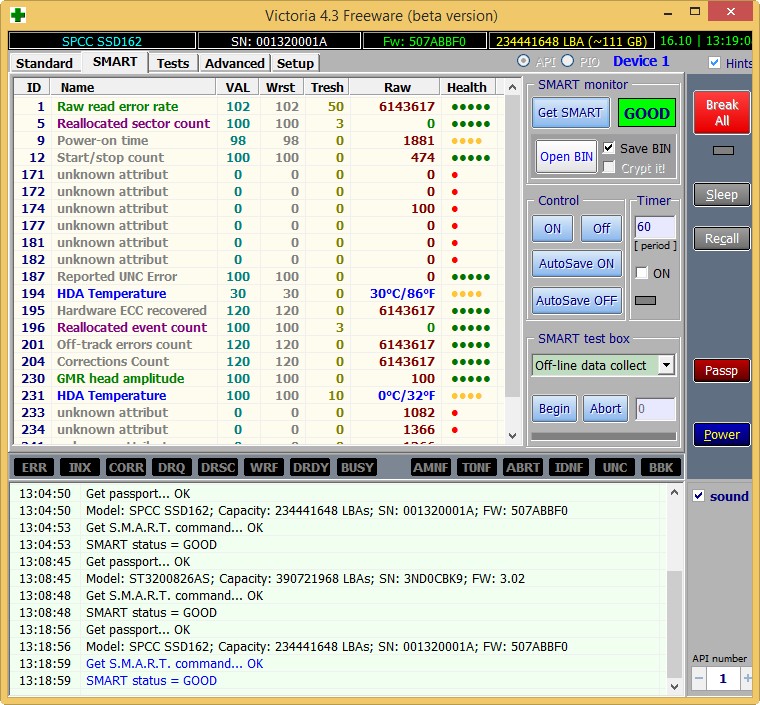
Затем выбираем в правой части окна нужный нам жёсткий диск, если у Вас их несколько и выделяем его левой мышью. Выберем к примеру жёсткий диск WDC WD5000AAKS-00A7B2(объём 500 ГБ).

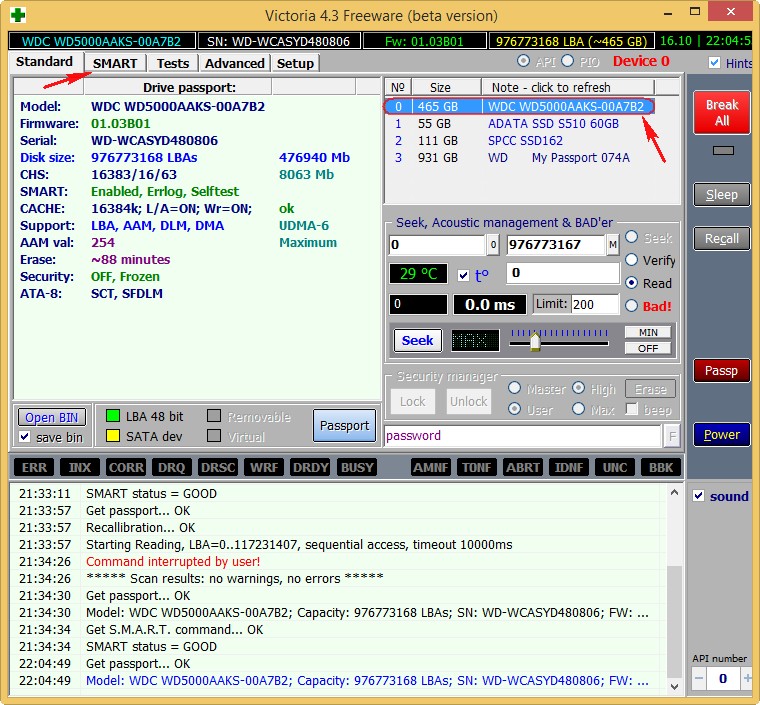
Переходим на вкладку SMART, жмем кнопку Get SMART, справа от кнопки засветится сообщение GOOD и откроется S.M.A.R.T. выбранного нами жёсткого диска.
S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology) — разработанная в 1995 году крупнейшими производители жёстких дисков усовершенствованная технология самоконтроля, анализа и отчётности винчестера.
Другими словами друзья, если посмотреть это окно, то можно узнать в каком состоянии Ваш жёсткий диск.
Обратите внимания программа Victoria подсветила красным (тревога!) цифру 8 на значении Raw, самого важного для здоровья жёсткого диска атрибута
5 Reallocated Sector Count — (remap), обозначающий число переназначенных секторов.
Примечание: значение атрибута Raw очень важно, читаем почему.
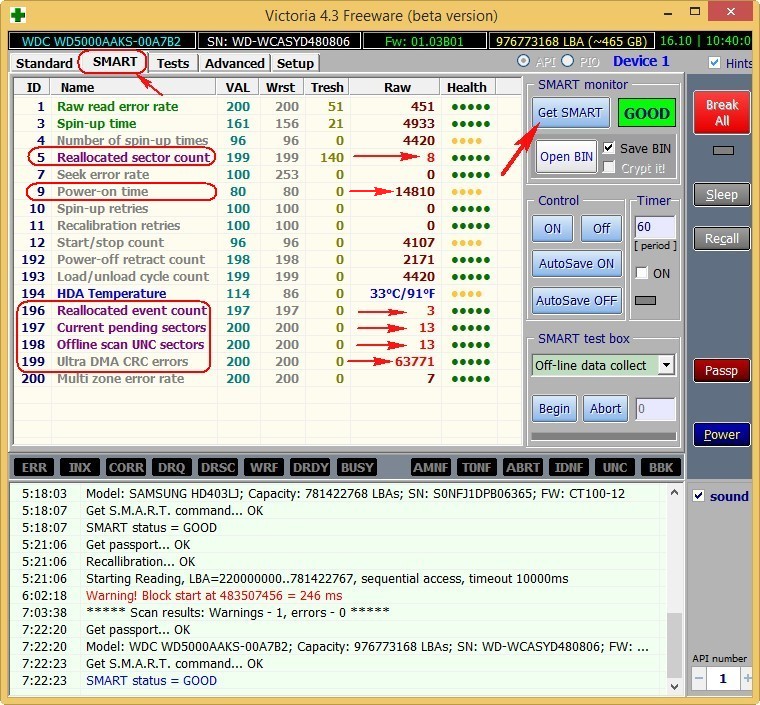
Простыми словами, если микропрограмма, встроенная в жёсткий диск, обнаружит сбойный сектор (бэд-блок), то она переназначит этот сектор сектором с резервной дорожки (процесс называется remapping). Но резервных секторов на жёстком диске не бесконечное число и программа нас предупреждает, что скоро бэд-блоки переназначать будет нечем, а это чревато потерей данных и нам надо готовиться менять жёсткий диск на новый. Забегая вперёд, скажу, что в следующей статье мы попробуем подлечить этот жёсткий диск.
9 Power-On time — общее количество отработанных жёстким диском часов 14810, не подсвечено красным, но хочу сказать, что приближение к цифре 20000 наработки в большинстве случаев связано с болезнями и нестабильной работой жёсткого диска.
Также подсвечены атрибуты:
196 Reallocation Event Count — 3. Количество операций переназначения бэд-блоков секторами с резервных дорожек (ремаппинг), учитываются как успешные, так и неуспешные операции.
197 Current Pending Sector — 13. Показатель количества нестабильных секторов реальных претендентов в бэд-блоки. Данные сектора микропрограмма жёсткого диска планирует в будущем заменить секторами из резервной области (remap), но всё же есть надежда, что в дальнейшем какой-то из этих секторов прочитается хорошо и будет исключён из списка претендентов.
198 Offline scan UNC sectors — 13. Количество реально существующих на жёстком диске не переназначенных бэдов (возможно исправимых имеющих логическую структуру — подробности далее в статье).
199 UltraDMA CRC Errors — 63771. Ошибки, возникающие при передаче информации по внешнему интерфейсу, причина — возможно перекрученный и некачественный SATA шлейф и его нужно заменить или расшатанный разъём SATA на материнской плате или на самом жёстком диске. А может сам винчестер интерфейса SATA 6 Гбит/с подключен в разъём на материнской плате SATA 3 Гбит/с, надо переподключить.
Атрибуты S.M.A.R.T и их значения. Очень важно знать!
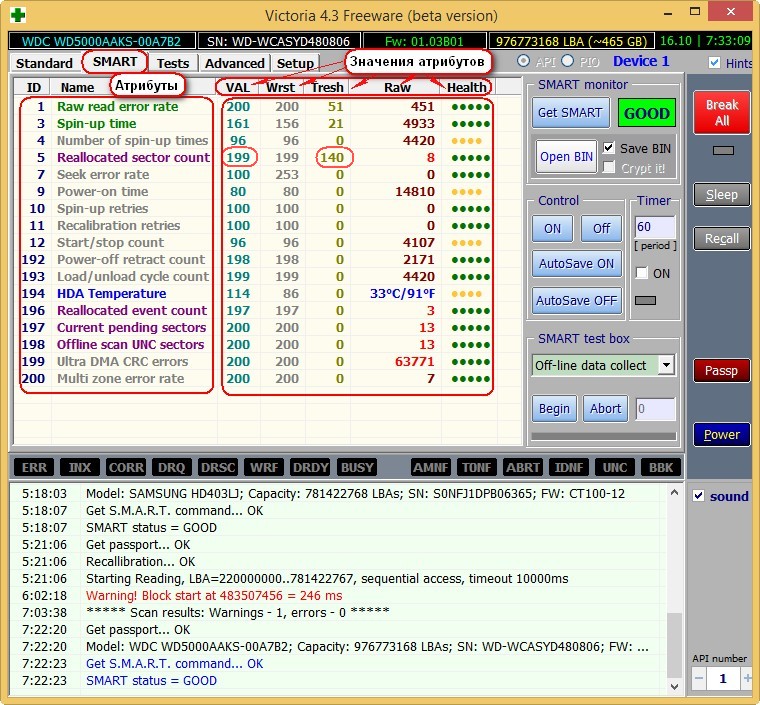
Значения атрибутов
Val—текущее значение атрибута, оно должно быть высоким (до 255), если значение Val равно критическому Tresh или даже менее его, то это соответствует неудовлетворительной оценке параметра. К примеру в нашем случае на жёстком диске WDC WD5000AAKS-00A7B2 (500 ГБ, 7200 RPM, SATA-II) атрибут Reallocated Sector Count имеет значение Val—199, а атрибут Tresh (порог) имеет значение 140, это плохо, но значение Val—199 ещё не равно значению Tresh (порог) 140 и у нас есть время скопировать данные с этого диска и отправить его на пенсию.
Wrst—самый низкий показатель атрибута Val за всё время работы винчестера.
Tresh—пороговое значения атрибута, данное значение должно быть намного ниже значения Val (текущее значение).
Raw—«сырое значение», которое будет пересчитано в значение Value, чем меньше это значение, тем лучше. Важный показатель для оценки атрибута, представляет реальное число, исходя из которого формируется значение Value, но как именно происходит процесс формирования значения Value — это фирменный секрет каждого производителя жёсткого диска!
Расшифровка S.M.A.R.T.
Давайте разберёмся во всех атрибутах S.M.A.R.T, но хочу сказать, что чаще всего на «плохих» жёстких дисках неудовлетворительным будет именно этот атрибут Reallocated Sector Count (Переназначенные сектора). Это уже повод насторожиться и провести тест поверхности жёсткого диска или SSD (как это сделать узнаем далее в статье).
Друзья, для моментальной оценки здоровья жёсткого диска S.M.A.R.T я использую ещё одну простую программу на русском языке CrystalDiskInfo, обязательно скачайте и установите её себе. В ней все атрибуты указаны на русском языке!
http://crystalmark.info/download/index-e.html
Выберите Shizuku Edition (exe).
В данном окне язык программы можете выбрать русский.
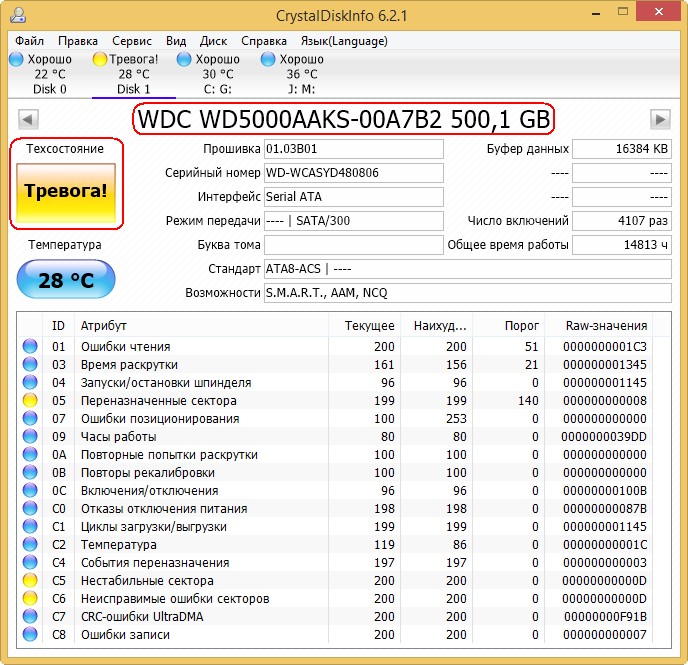
Как видите, CrystalDiskInfo прямо указывает нам (подтверждая опасения «Виктории»), на жёстком диске WDC WD5000AAKS-00A7B2 (объём 500 ГБ) нехорошие значения атрибутов отвечающих за Переназначенные сектора, Нестабильные сектора, Неисправимые ошибки секторов, подсвечивая их жёлтым цветом и указывает на тех. состояние жёсткого диска одним словом «Тревога»
Как выглядит S.M.A.R.T неисправного жёсткого диска
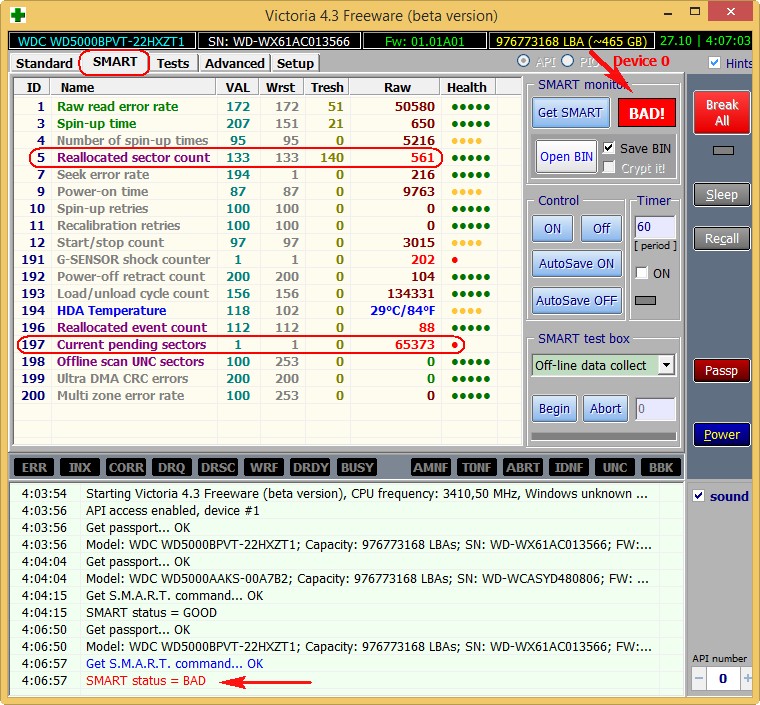
А вот S.M.A.R.T неисправного жёсткого диска WDC WD500BPVT ноутбука, который мне принесли на ремонт.


Victoria из Windows. Обратите внимание на атрибут:
5 Reallocated Sector Count (переназначенные сектора), он имеет значение Val—133, а атрибут Tresh (порог) имеет значение 140, это неудовлетворительно, так как значение Val—133 не должно быть меньше предельного значения Tresh (порог) 140, то есть количество сбойных секторов будет расти, а переназначать их уже нечем, запасные сектора на резервных дорожках уже закончились.
197 Current Pending Sector — показатель количества нестабильных секторов реальных претендентов в бэд-блоки зашкалил все возможные пределы.
И самое главное, самооценка SMART status=BAD (непригоден).
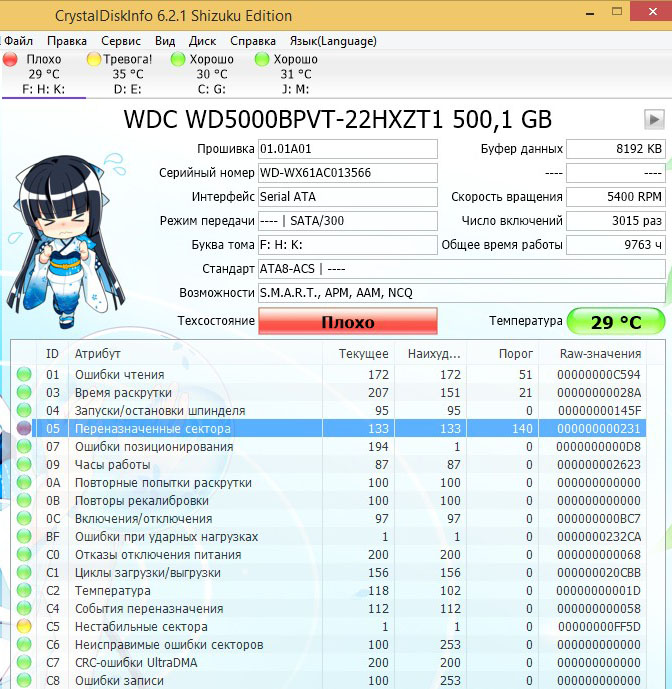
Программа CrystalDiskInfo (ссылка на скачивание чуть выше). Видим тоже самое, атрибут Переназначенные сектора (Reallocated Sector Count) имеет значение Val (текущее)—133, а атрибут Tresh (порог) имеет значение 140, программа оценила оценку тех состояния жёсткого диска как Плохо.
этот ноутбук ужасно тормозит, данные c него невозможно скопировать, Windows невозможно переустановить, периодически винчестер пропадает из БИОС, то есть такой жёсткий диск подлежит замене без раздумий, даже наша Victoria не сможет полностью вылечить подобный винт, так как здоровые сектора на резервных дорожках закончились и сбойные сектора переназначать уже нечем, а копирование данных с него будет настоящим приключением на неделю (обязательно напишу про это статью).
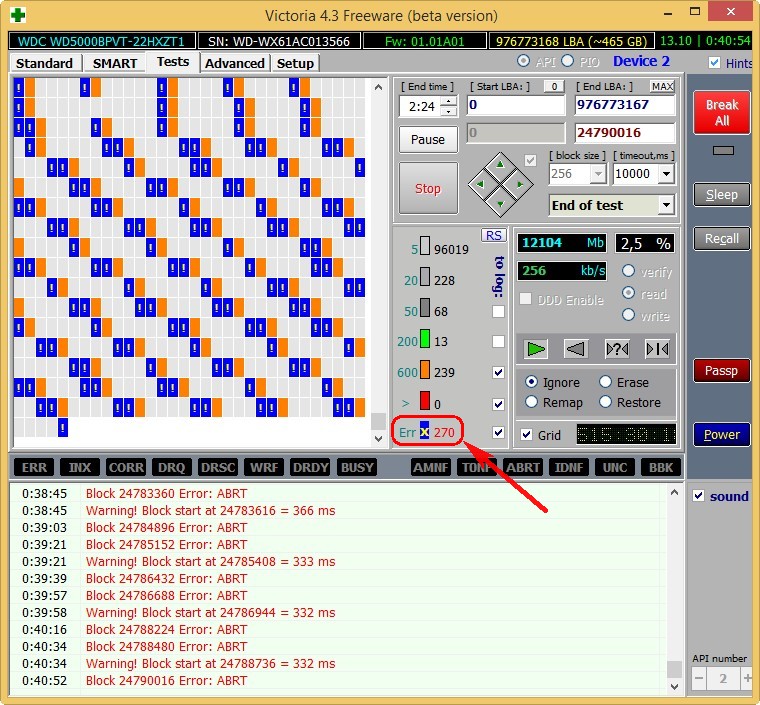
Забегая вперёд скажу, что тест этого винта в программе Victoria показал наличие 500 неисправимых сбойных секторов (бэд-блоков).
ДОС — версия программы Виктория.

Примечание: Чтобы Вам упростить жизнь, некоторые программы диагностики жёстких дисков сопоставляют каждый атрибут, хороший он или плохой, цвету значка.
Зелёный—атрибут жёсткого диска соответствует нормальному.
Жёлтый—говорит о небольшом расхождении с эталоном и на этом винте важные данные лучше не хранить, если у Вас на таком жёстком диске находится Windows, перенесите её на SSD.
Красный—говорит о значительном расхождении с эталоном и жёсткий диск нужно было менять уже вчера.
S.M.A.R.T этого же жёсткого диска WDC WD500BPVT в программе HDDScan
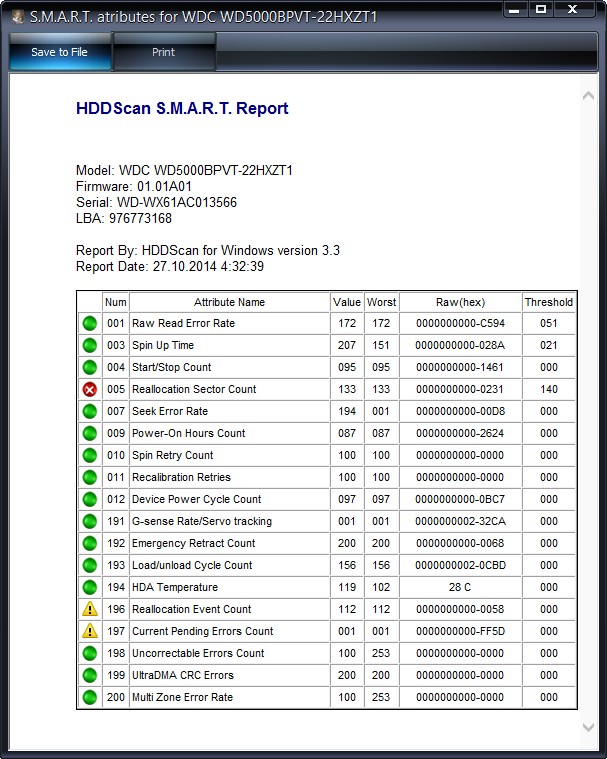
Атрибуты
001 Raw Read Error Rate—частота ошибок при чтении информации с диска
002 Spinup Time—время раскрутки дисков до рабочего состояния
003 Start/Stop Count—общее количество стартов/остановок шпинделя.
005 Reallocated Sector Count — (remap) говорит о числе переназначенных секторов. Если микропрограмма встроенная в жёсткий диск обнаружит сбойный сектор (бэд-блок), то она переназначит этот сектор сектором с резервной дорожки (процесс называется remapping). Но резервных секторов на жёстком диске не бесконечное число и программа нас предупреждает, что скоро бэд-блоки переназначать будет нечем, а это чревато потерей данных и нам надо готовиться менять жёсткий диск на новый
007 Seek Error Rate—частота ошибок при позиционировании блока головок, постоянно растущее значение, говорит о перегреве винчестера и неустойчивом положении в корзине, к примеру плохо закреплён.
009 Power-on Hours Count—число часов, проведённых во включенном состоянии.
010 Spin Retry Count—число повторных раскруток диска до рабочей скорости при неудачной первой.
012 Device Power Cycle Count—Число полных циклов включения-выключения дисков
187 Reported Uncorrectable Error—Ошибки, которые не не смогла восстановить микропрограмма винчестера, используя свои методы устранения ошибки аппаратными средствами, последствия перегрева и вибрации.
189 High Fly Writes—записывающая головка находилась над поверхностью выше, чем нужно, а значит магнитное поле было недостаточным для надежной записи носителя. Причина– вибрация (удар).
Для ноутбуков данная цифра немного выше.
190 Важные параметры касающиеся температуры. Важно, что бы температура не поднималась выше 45 градусов.
194 HDA Temperature—температура механической части жёсткого диска
195 Hardware ECC Recovered—число ошибок, которые были исправлены самим винчестером.
196 Reallocation Event Count — Количество операций переназначения бэд-блоков секторами с резервных дорожек (ремаппинг), учитываются как успешные, так и неуспешные операции.
197 Current Pending Errors Count — неисправимые ошибки секторов, тоже важный параметр, число секторов, считывание которых затруднено и сильно отличается от считывания нормального сектора. То есть, эти секторы контроллер жёсткого диска не смог прочитать с первого раза, обычно к данным секторам принадлежат софт-бэды, ещё называют программные или логические бэд-блоки (ошибка логики сектора) — при записи в сектор пользовательской информации, так же записывается служебная информация, а именно контрольная сумма сектора ECC (Error Correction Code-код коррекции ошибок), она позволяет восстанавливать данные, если они были прочитаны с ошибкой, но иногда данный код не записывается, а значит сумма пользовательских данных в секторе не совпадает с контрольной суммой ECC. К примеру так происходит при внезапном отключении компьютера из-за сбоев с электричеством, из-за этого информация в сектор жёсткого диска была записана, а контрольная сумма нет.
- Логические бэд-блоки нельзя исправить простым форматированием, так как при форматировании контроллер жёсткого диска попытается в первую очередь прочитать информацию из сбойного сектора, если ему это не удастся (в большинстве случаев), то значит не произойдёт никакой перезаписи и бэд-блок останется бэд-блоком. Исправить положение можно в программе Victoria, она принудительно впишет в сектор информацию (вылечит сектор), затем прочитает её, сравнит контрольную сумму ECC и бэд-блок станет нормальным сектором. Более подробно про все виды бэд-блоков в нашей статье Как проверить жёсткий диск.
198 Offline scan UNC sectors — Количество реально существующих на жёстком диске непереназначенных бэдов (возможно исправимых имеющих логическую структуру — подробности далее в статье).
198 Uncorrectable Errors Count—число нескорректированных ошибок при обращении к сектору, указывает на дефекты поверхности.
Reported Uncorrectable Errors — показывает число неисправленных сбойных секторов.
199 UltraDMA CRC Errors—число ошибок, возникающих при передаче информации по внешнему интерфейсу, причина- перекрученный и некачественный SATA шлейф, возможно его нужно поменять.
200 Write Error Rate—частота ошибок, происходящих при записи на винчестер, по данному показателю обычно судят о качестве поверхности накопителя и его механической части.
202 Data Address Mark Errors—расшифровки нигде не встречал, буквально Ошибка данных адресного маркера, означать может то, что знает один лишь производитель данного винчестера.
Как быстро проверить жёсткий диск или SSD на пригодность к работе?
Друзья, Вы меня часто спрашиваете: «Как быстро проверить жёсткий диск или SSD на пригодность к работе?»
Ответ: «Используйте программы: Victoria, CrystalDiskInfo, HDDScan, они сразу покажут Вам S.M.A.R.T любого жёсткого диска.
Как выглядит S.M.A.R.T абсолютно нового жёсткого диска
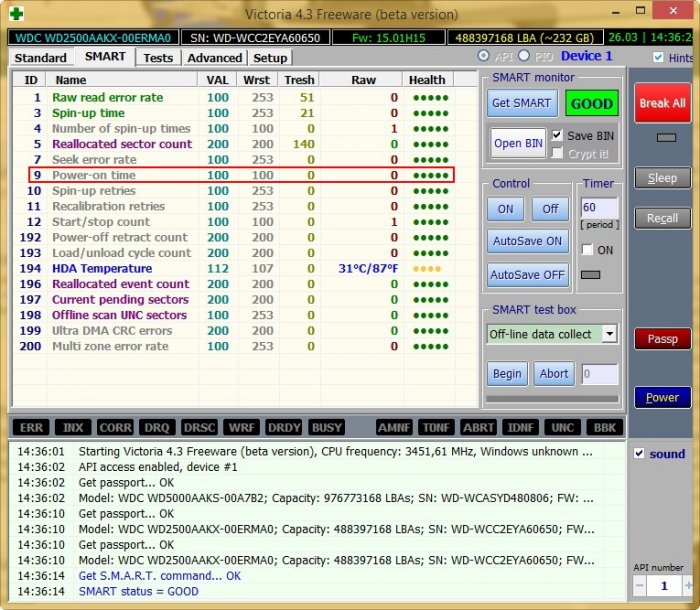
Во первых, смотрите как выглядит S.M.A.R.T абсолютно нового жёсткого диска WDC WD2500AAKX-00ERMA0

Как видим, все показатели накопителя в отличном состоянии и отработал он ноль часов (параметр 9 Power-On Time)
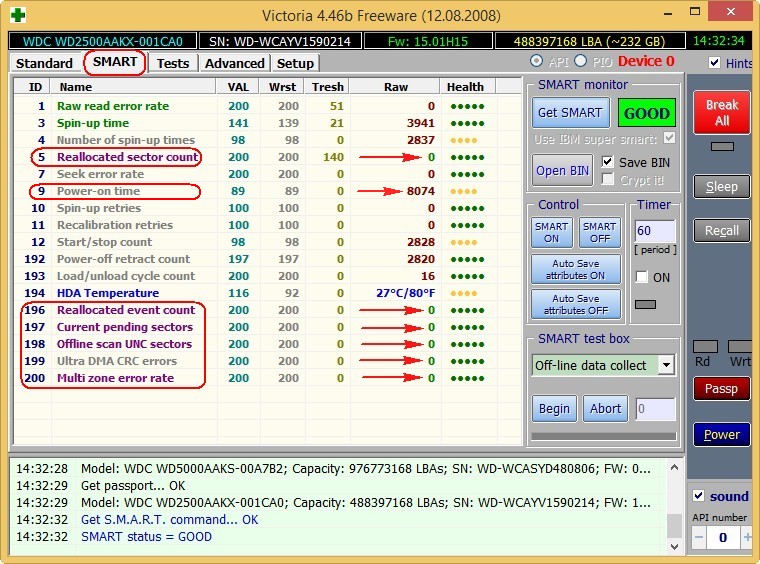
Теперь берём почти новый жёсткий диск WDC WD2500AAKX-001CA0 и смотрим S.M.A.R.T, как видим, винчестер практически в идеальном состоянии, хотя и отработал уже 8000 часов (параметр 9 Power-On Time)

Victoria
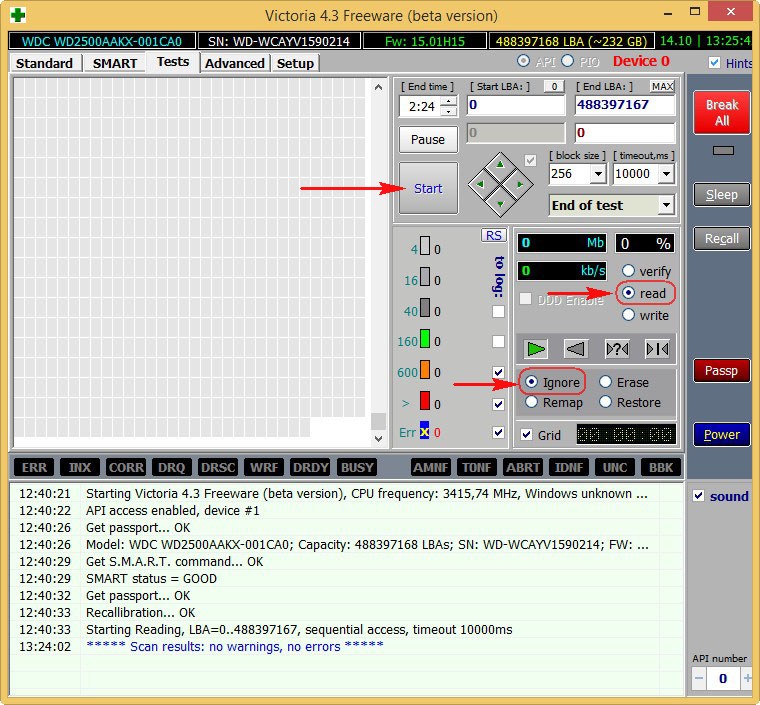
Тест поверхности жёсткого диска!
В правой части окна программы отметьте пункт Ignor и пункт read и нажмите Start. Этим Вы запустите простой тест поверхности жёсткого диска без исправления ошибок. Данный тест не принесёт никаких отрицательных и положительных воздействий на жёсткий диск, но зато по окончании теста Вы будете знать в каком состоянии находится Ваш винчестер..
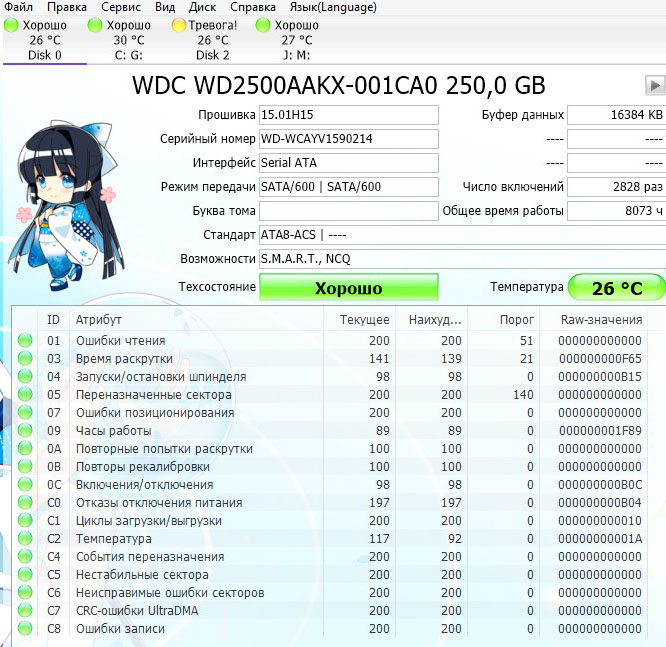
Результаты теста отличные. Ни одного блока с задержкой более 30 мc!

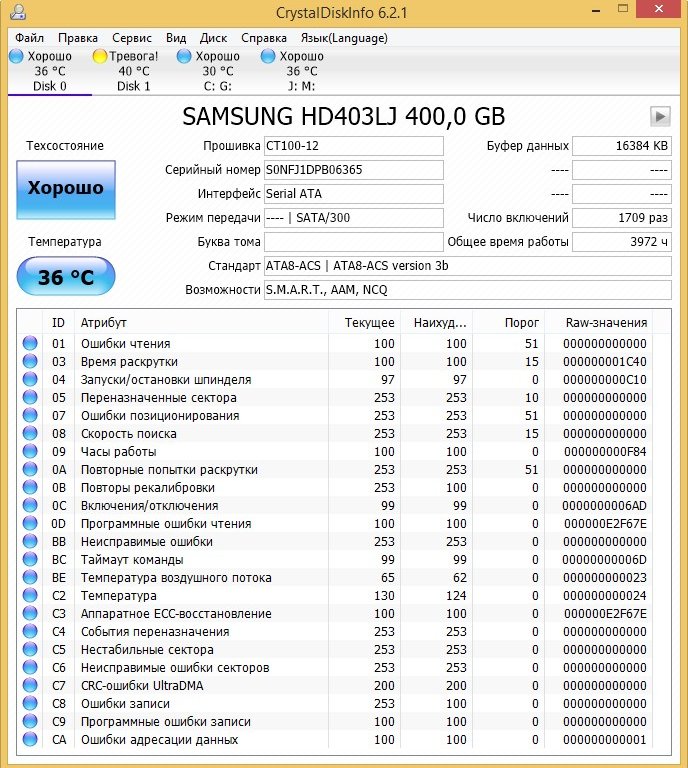
CrystalDiskInfo
HDDScan

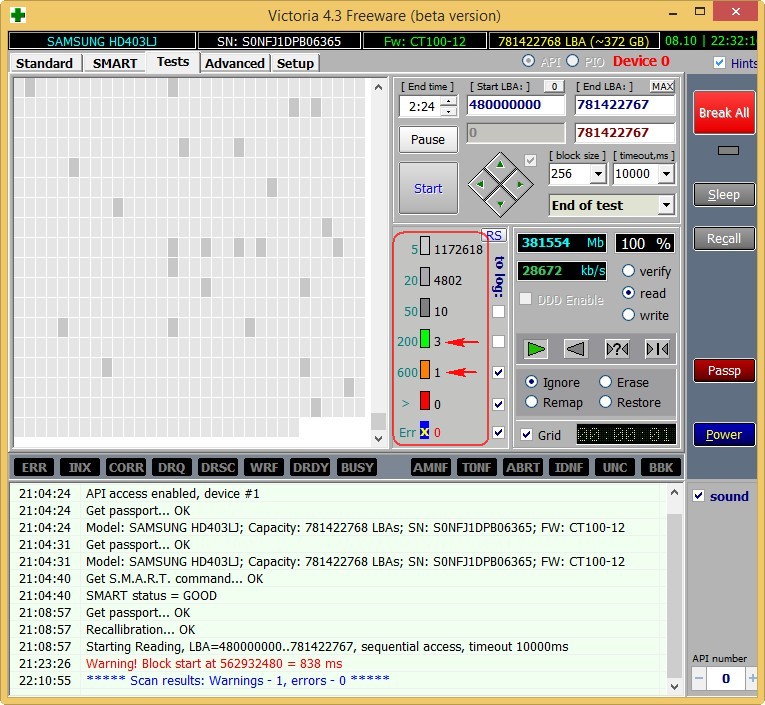
Жёсткий диск SAMSUNG HD403LJ (372 ГБ) из недавней статьи Как перенести Windows 7, 8, 8,1 на SSD с помощью программы Acronis True Image.
На нём были бэд-блоки и мне пришлось переносить с него Windows 8 на SSD, после успешного переноса, хозяин (мой одноклассник) подарил мне этот винт и Victoria вскоре вернула его к жизни после «записи по всей поляне» (алгоритм Write). Прежний хозяин забирать вылеченный винчестер отказался.

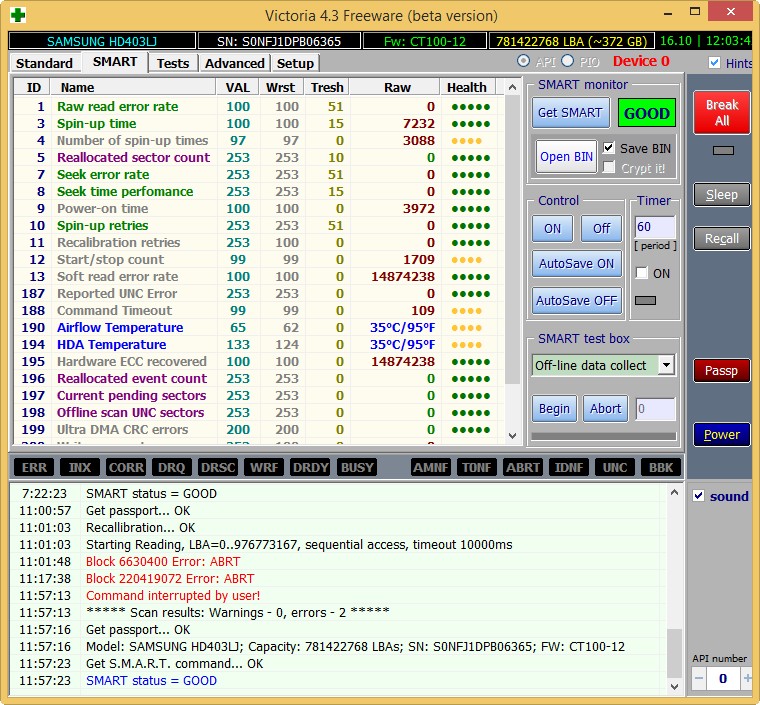
Результаты теста чуть хуже. 3 блока с задержкой более 200 мс и 1 блок с задержкой 600 мс (возможно кандидат в бэды).

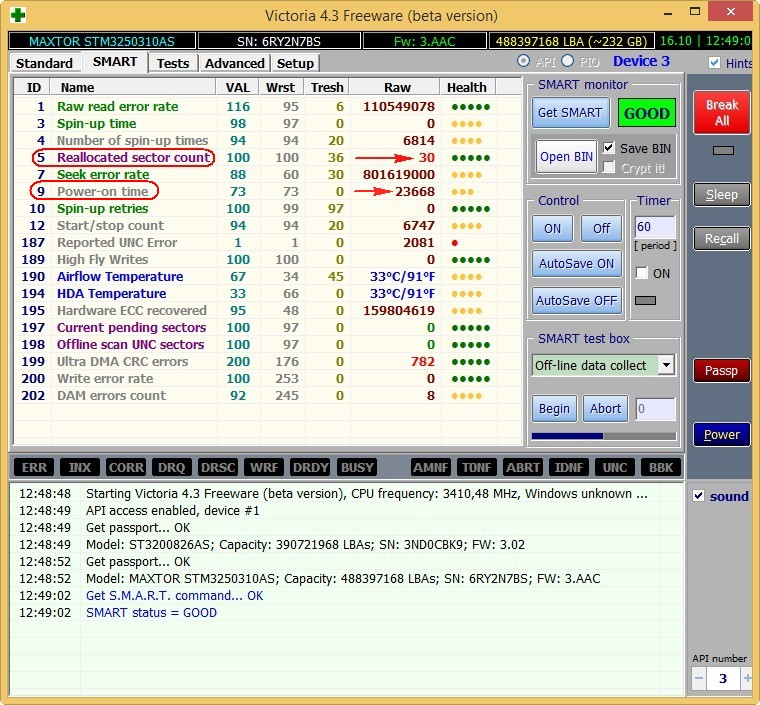
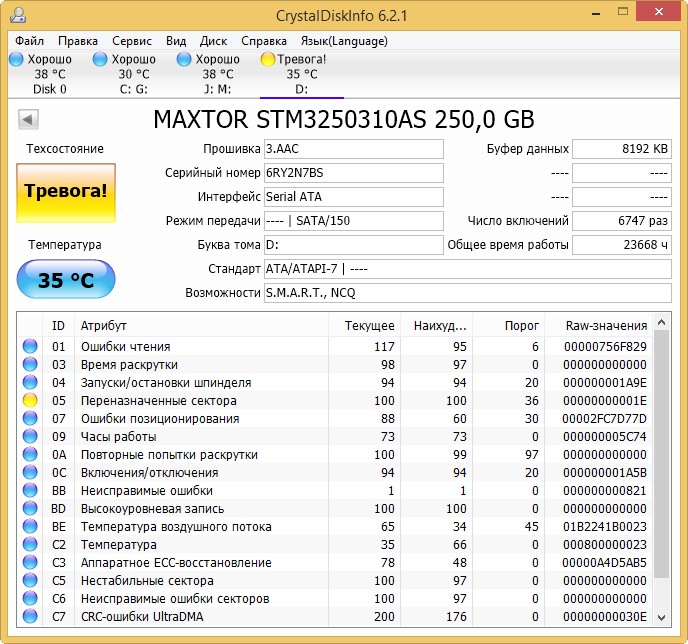
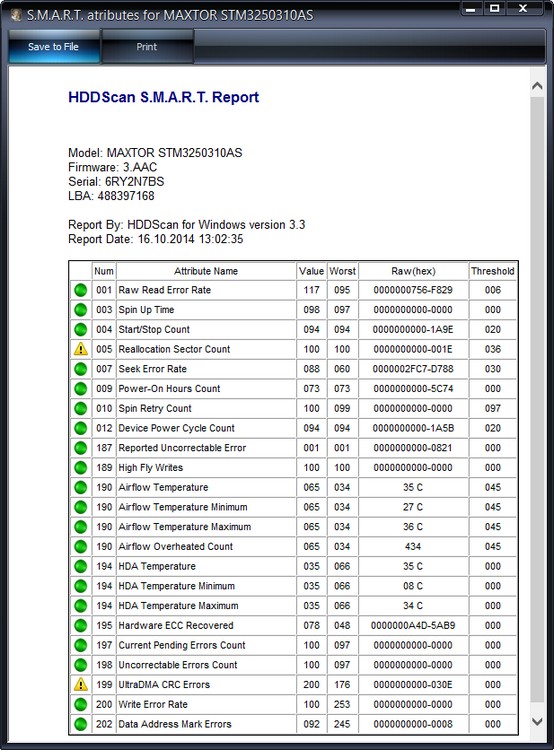
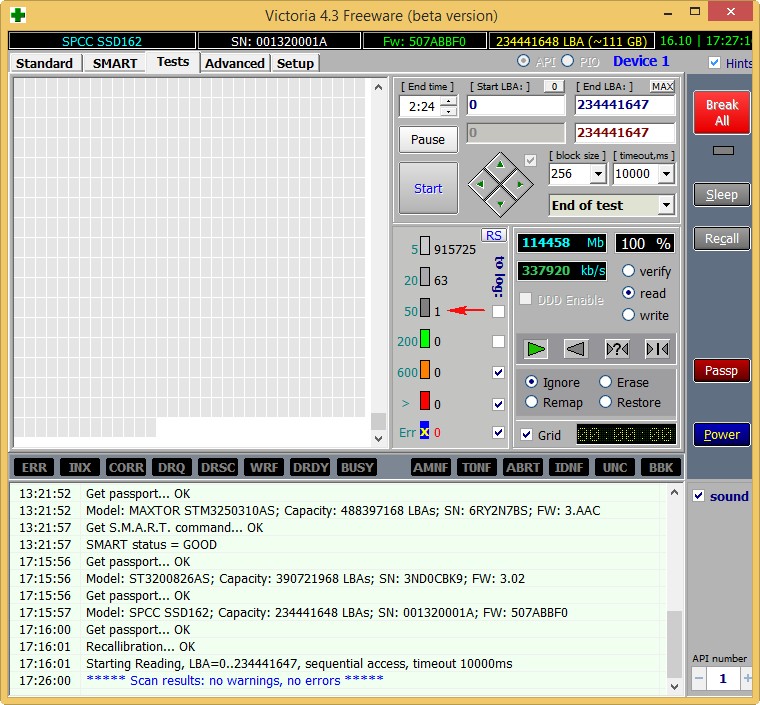
Не вполне исправный жёсткий диск MAXTOR STM3250310AS (250 ГБ, 7200 RPM, SATA-II) ему 8 лет (ветеран) и он всё ещё работает, правда я его берегу, храню на нём только файлы неважных данных.

Хоть явных бэдов на нём и нет, видим, что атрибут 5 Reallocated Sector Count — (remap), обозначающий число переназначенных секторов критический и скоро бэды переназначать будет нечем.
9 Power-On time — общее количество отработанных жёстким диском часов 23668, это очень много, обычно проблемы у жёстких дисков начинаются после 20000 часов отработки.
Также неважнецкий атрибут 199 UltraDMA CRC Errors — 63771,ошибки, возникающие при передаче информации по внешнему интерфейсу, причина — некачественный шлейф SATA шлейф и его нужно заменить (не всегда дело в этом).
Результаты теста ещё хуже. 71 блок с задержкой более 200 мс и 1 блок с задержкой 600 мс (возможно кандидат в бэды).
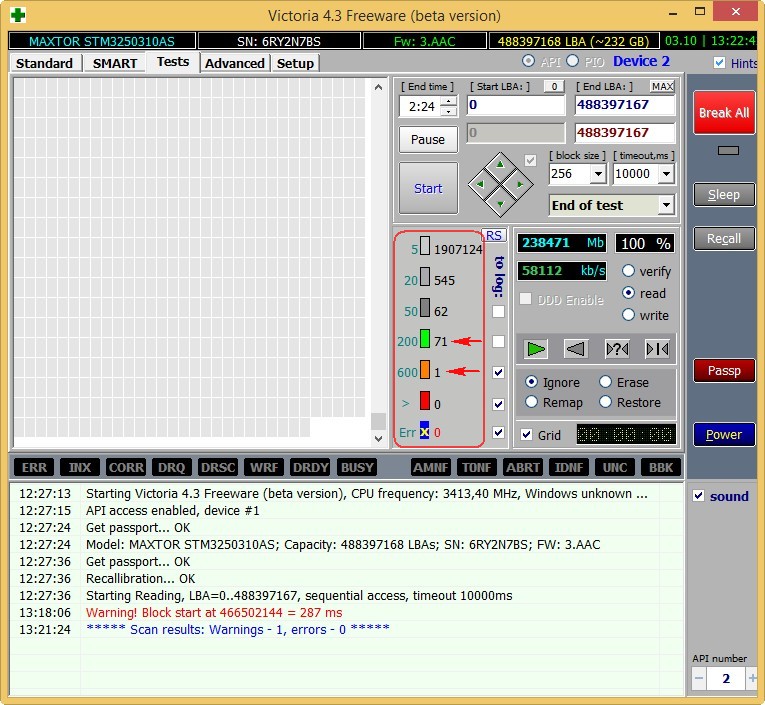
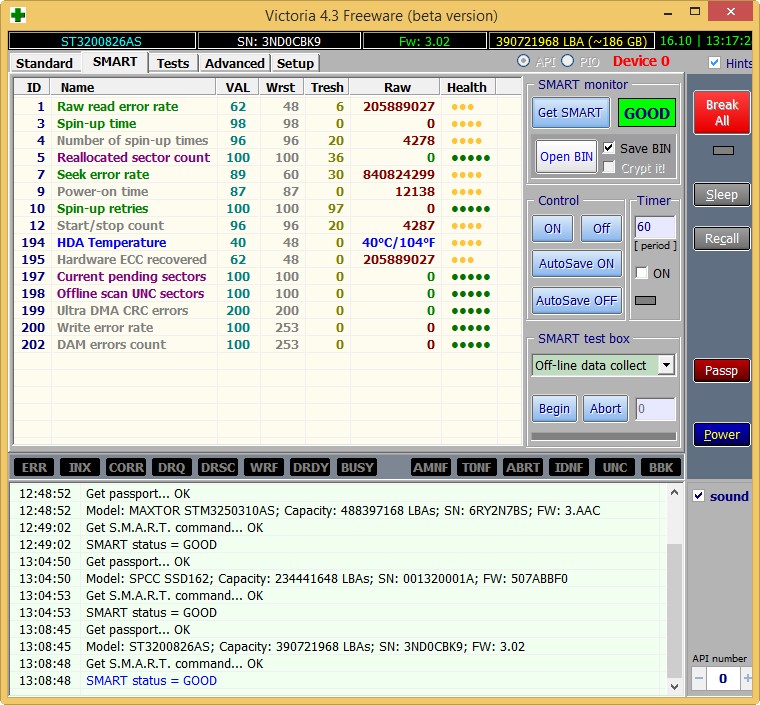
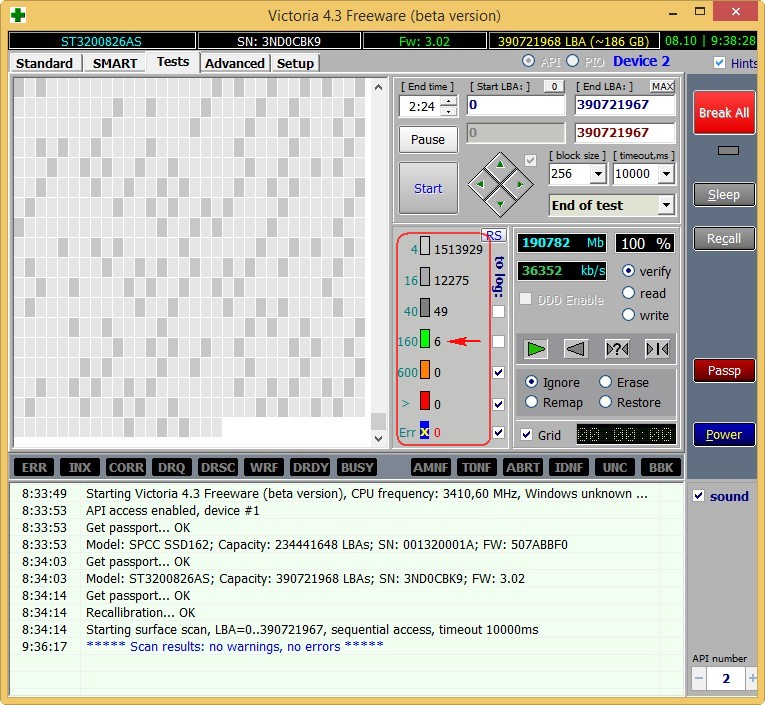
Жёсткий диск ST3200826AS (200 ГБ, 7200 RPM, SATA). Винту около трёх лет и полёт пока нормальный.

Результаты теста. 6 блоков с задержкой более 200 мс.
Новый твердотельный накопитель SSD SPCC SSD162

Тест
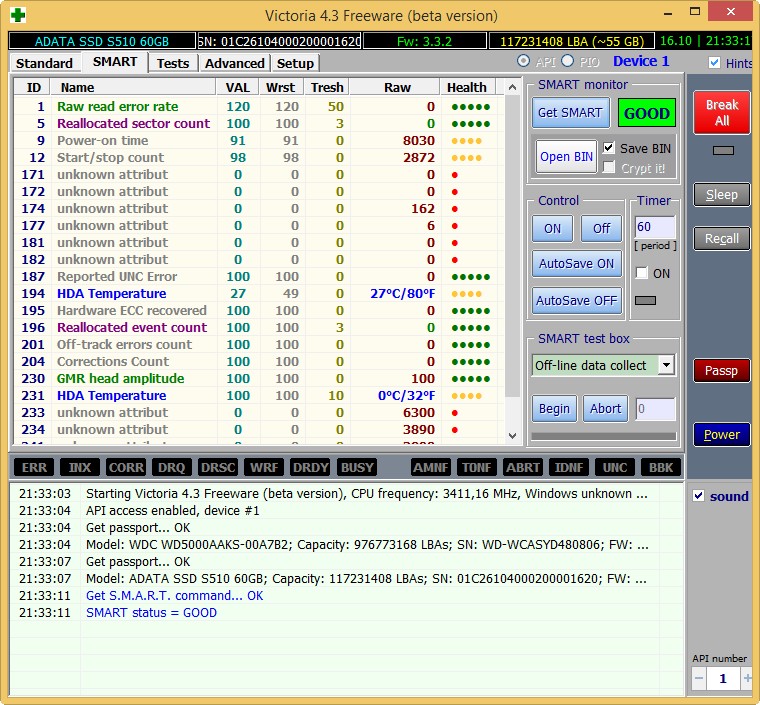
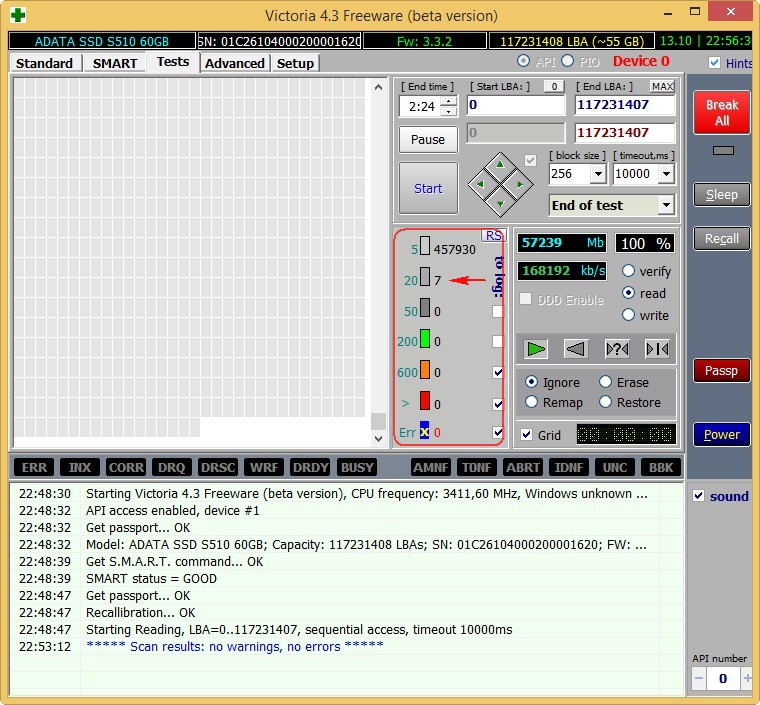
Под конец статьи проверим мой самый старый твердотельный накопитель SSD — ADATA S510 60GB (60 ГБ, SATA-III)
Ему уже третий год, но работает он отменно, жалко что объём всего 60 ГБ, но когда я его покупал больше и не было, а стоил он около двухсот баксов.

Методы защиты серверов от космического излучения
Время на прочтение
6 мин
Количество просмотров 4.3K

В прошлой статье мы подробно разобрали проблему «флипбитов» — непредсказуемого изменения битов в компьютерной памяти из-за проникновения высокоэнергетических частиц в чувствительные области компьютерных микросхем. В научной литературе и компьютерной документации данный феномен известен как «одиночные сбои» (single event upset, SEU).
Раньше считалось, что проблема характерна только для авионики и космонавтики. Но эксперименты доказали, что SEU неминуемо происходят даже на уровне океана (то есть под защитой атмосферы) в компьютерных системах с модулями оперативной памяти (RAM). Можно рассчитать вероятность такого повреждения: примерно 1 битфлип на 256 МБ оперативной памяти в месяц (см. также статистику аппаратных сбоев в одном миллионе пользовательских ПК).
Как мы уже говорили, столкновение космических частиц с атомами в земной атмосфере порождает каскад из нейтронов и протонов, которые, в свою очередь, взаимодействуют с земной электроникой.
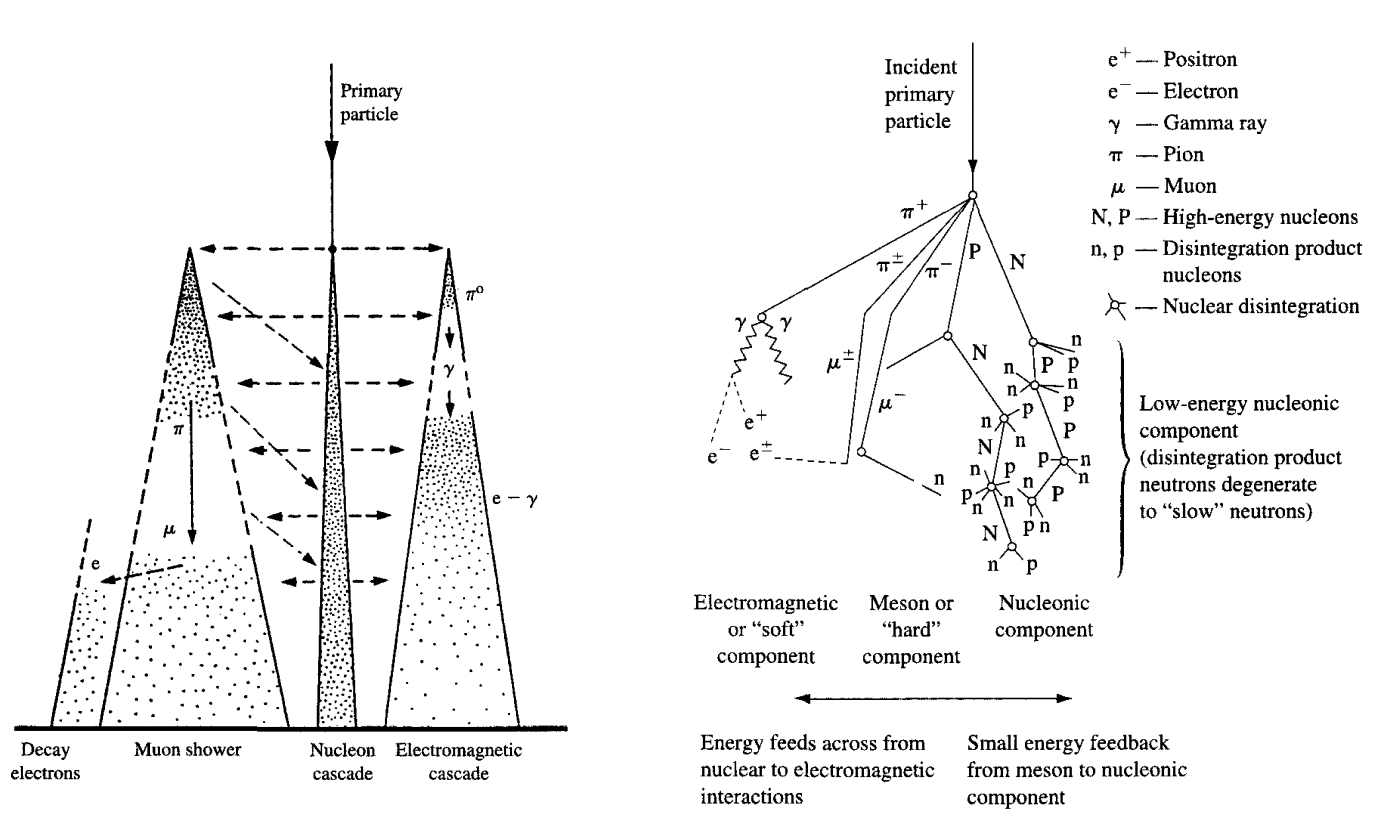
Ещё одна причина SEU — альфа-частицы от радиоактивных примесей в корпусировке микросхем или присутствие иных источников излучения. В любом случае внешнее излучение — основной источник битфлипов в кремниевых чипах.
Если от альфа-излучения несложно защититься путём экранирования, то защита от нейтронов представляет более трудную задачу, потому что эффективных абсорбентов до сих пор не найдено. По некоторым расчётам, для полного экранирования от нейтронов толщина бетонной стены должна составлять примерно 6 м.
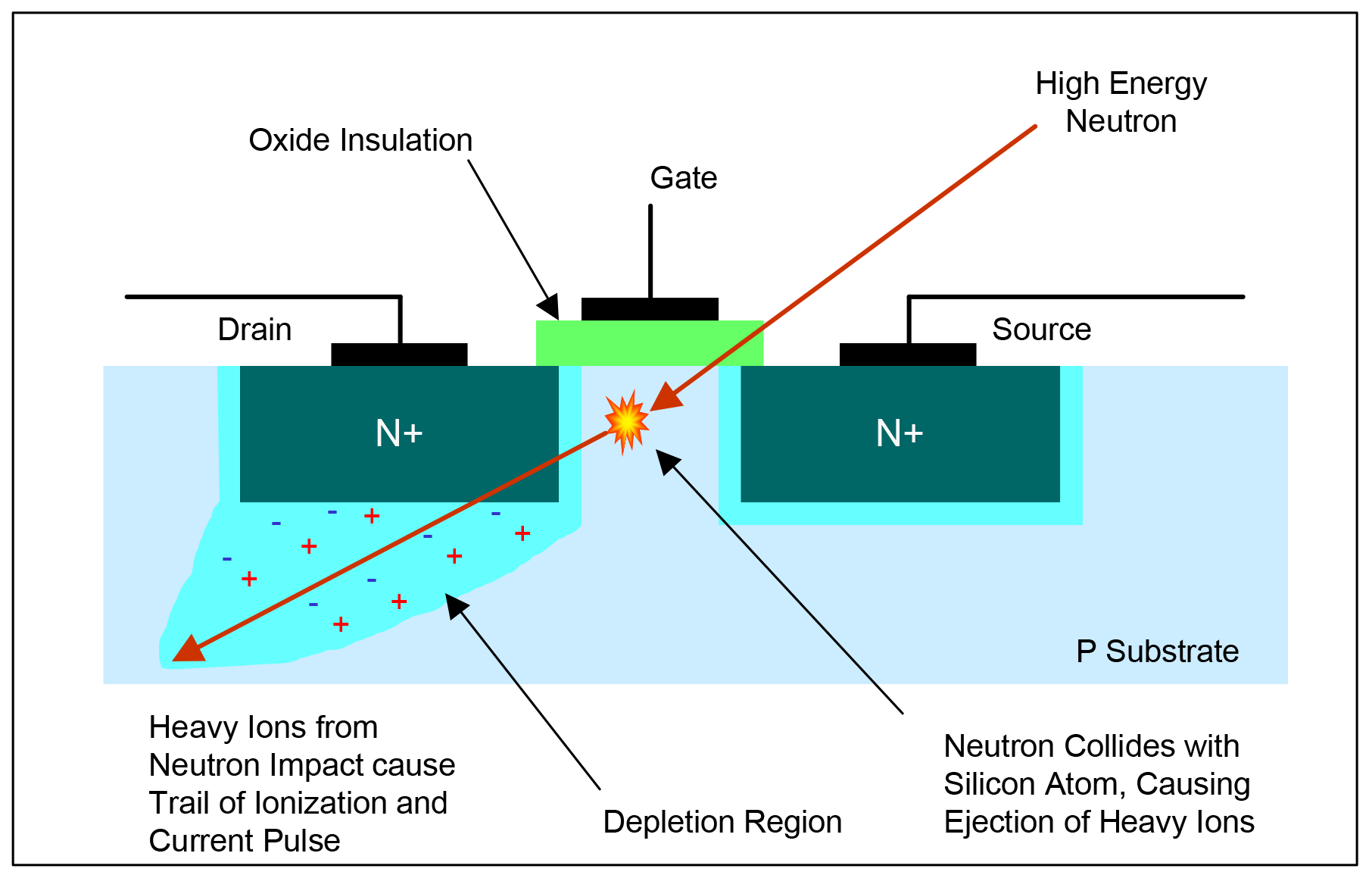
Эффект попадания нейтрона в интегральную схему, источник: Neutron and alpha particle single event upset (SEU) failures in SRAM technologies, технический отчёт, Actel Corporation, 2006
Исправление битфлипов
Самый очевидный способ борьбы с SEU — контроль ошибок.
В теории информации контроль ошибок — это методы, позволяющие надёжно передавать цифровые данные по ненадёжным каналам. В частности, одним из таких методов является корректирующий код или помехоустойчивый код (ECC, error correction code). Первый ECC изобретён математиком Ричардом Хэммингом в 1950 году.
Корректирующий код Хэмминга включает несколько бит, которые добавляются к исходному блоку. Существует огромное количество вариантов кодов Хэмминга, в зависимости от размера исходного блока и кодового слова.
Получение кодового слова выглядит следующим образом:

На вход декодера поступает семь бит, которые могут быть искажены в процессе передачи. Классический (7,4)-код Хэмминга обеспечивает исправление всех однобитных ошибок и обнаружение двухбитных (без исправления).
Для компьютерных систем больше подходит код с восьмибитными словами. При этом на практике размер добавочного кода в восьмибитных словах можно сократить до трёх бит.
В теории информации существует понятие расстояние Хэмминга (кодовое расстояние) — число позиций, по которым отличаются два слова. В качестве офтопика, по очень похожему принципу работает исправление ошибок в ДНК (такие ошибки случаются при делении клеток). Двойная спираль нужна для резервирования данных, но, начиная с некоторого расстояния Хэмминга, её образование становится невозможным. Коды коррекции и резервирование данных в программах живых организмов изучают биоинформатика и геномика.
 Корректирующие коды давно используются в разных схемах кодирования. Например, в СССР на русский язык переводили учебник Питерсона и Уэлдона «Коды, исправляющие ошибки» (1976), а также учебник Блейхута «Теория и практика кодов, контролирующих ошибки» (1986).
Корректирующие коды давно используются в разных схемах кодирования. Например, в СССР на русский язык переводили учебник Питерсона и Уэлдона «Коды, исправляющие ошибки» (1976), а также учебник Блейхута «Теория и практика кодов, контролирующих ошибки» (1986).
Но в свете новых исследований SEU корректирующие коды решили снова реализовать в модулях компьютерной памяти. Почему «снова»? Потому что изначально бит чётности был реализован практически во всех персональных компьютерах, в том числе в оригинальных IBM PC начала 90-х. Но потом эту практику прекратили.
Сегодня коррекцию ошибок в памяти выполняют контроллеры памяти. Дополнительно — некоторые модули памяти оснащаются встроенной поддержкой ECC, независимо от контроллера. В данном случае контроль ошибок реализован с помощью одной дополнительной (избыточной) микросхемы памяти на каждые восемь рабочих микросхем.

Сейчас ECC DRAM часто встречается в серверах, но редкий гость в настольных компьютерах или других вычислительных устройствах. Этот печальный факт огорчает даже Линуса Торвальдса, то есть речь не о маркетинговом хайпе, а о реально важной технической фиче с точки зрения надёжности систем.
Вообще, память с поддержкой ECC (включая флэш) может использовать одну из нескольких реализаций корректирующего кода:
- Самый простой код Хэмминга используется в чипах флэш-памяти SLC NAND.

Хранение кода Хэмминга в чипе NAND, источник - В более современных и менее надёжных чипах MLC NAND используются более сложные коды для детектирования и исправления многобитных ошибок: например, коды Бозе — Чёдхури — Хокуингхема (BCH, они же БЧХ-коды) или коды Рида — Соломона, как во многих технологиях типа CD, DVD, QR-кодов и др. В то же время память NOR Flash обычно не использует никакой коррекции ошибок.
- В модулях оперативной памяти DRAM обычно используются коды SECDED (single error correction, double error detection). Как понятно из названия, они позволяют обнаружить и исправить однобитные ошибки и обнаружить двухбитные, как и классический код Хэмминга.
Интересно, что тут присутствует некоторый компромисс. Дело в том, что если декодеру не требуется исправлять ошибки, то он может надёжно обнаруживать даже трёхбитные ошибки. Но если он занимается исправлением, то некоторые тройные ошибки будут приняты за одинарные и «исправлены» на неверное значение.
Для исправления двухбитных ошибок можно применять одновременно несколько кодов SECDED или схему DEC-TED с оверхедом минимум 13% вместо 7%.
Table 1: ECC storage array overheads
В микросхемах оперативной памяти особенно популярен (72,64)-код Хэмминга — усечённый вариант (127,120)-кода. Как видно из количества битов, он занимает столько же места, сколько и (9,8)-код чётности.
Проблема лишь в том, что далеко не вся оперативная память в компьютере поддерживает корректирующие коды (ECC). Да, такие модули памяти часто используются в серверах, но в любом ЦОД найдётся множество других устройств с оперативной памятью без ECC: сетевые устройства, GPU, чипсеты материнских плат, кэши процессоров и т. д.
В любом случае стандартный ECC исправляет только однобитные ошибки, что не всегда позволяет предотвратить сбой. Для большей гарантии желательно перемешивать данные, а также использовать ECC в сочетании с физической защитой сервера, которая минимизирует облучение космическими частицами.
Среднее количество ошибок
Битфлипы в микросхемах памяти приводят к ошибкам четырёх типов:
- незаметная ошибка, которая допускается системой;
- исправляемые ошибки, которые обнаруживаются и успешно исправляются;
- обнаруженные неисправимые ошибки (DUE);
- тихое повреждение данных (SDC), т.е. необнаруженная ошибка, которая повредила данные.
Очевидно, самые опасные ошибки — это DUE и SDC. Ошибки DUE приводят к сбоям, а SDC — к потере данных.
По оценке ITRS (International Technology Roadmap for Semiconductors), для типичного сервера рекомендуется ориентироваться на такие показатели надёжности:
1 FIT (Failure In Time) = 1 сбой в 10^9 часов
Соответственно, система проектируется исходя из требуемой надёжности.
Согласно исследованиям, количество флипбитов в обычной оперативной памяти SRAM легко достигает 1000 FIT на 1 Мбит, что значительно превышает допустимые показатели.
Физическая защита серверов
В современных серверах для защиты от SEU используются традиционные методы контроля ошибок, включая коды ECC и EDEC, биты чётности и резервирование, в том числе RAID.
В качестве дополнительного метода защиты можно оценить расположение микросхем относительно земной поверхности. Например, такой метод предлагают авторы научной статьи Soft Error Considerations for Computer Web Servers (doi: 10.1109/SSST.2010.5442820), инженеры из компании Juniper Networks и Обернского университета (США). Статья опубликована в сборнике 42nd South Eastern Symposium on System Theory в далёком 2010 году.
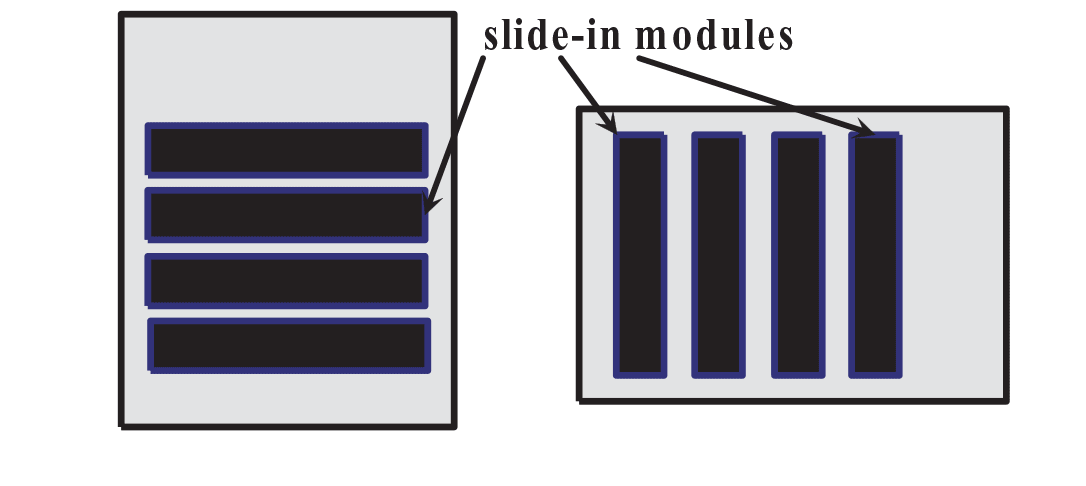
Горизонтальный и вертикальный дизайн серверных модулей
Предполагается, что вертикальное размещение модулей памяти DIMM значительно снижает количество сбоев по сравнению с горизонтальным расположением, поскольку уменьшает площадь поверхности.
Учёные предлагают самостоятельно замерить количество ошибок в памяти при разном расположении оперативной памяти относительно горизонта — и выбрать наиболее оптимальный вариант. В процессе эксперимента нужно учитывать, что количество сбоев в RAM зависит от солнечной активности, времени суток, высоты над уровнем моря и других факторов.
Есть опасение, что по мере дальнейшего увеличения плотности DRAM, уменьшения размеров компонентов и снижения рабочих напряжений чипы будут чаще подвергаться битфлипам. Это логично, поскольку тогда частицы меньшей энергии смогут изменить состояние ячейки памяти. С другой стороны, меньшие ячейки уменьшают мишень, а переход на новые технологии вроде КНИ (кремний на изоляторе) может сделать ячейки менее восприимчивыми к SEU. Так что опасения могут быть необоснованны.
В любом случае дублирование систем для избыточной надёжности никогда не помешает.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
В сегодняшней статье:
1. Как узнать в каком состоянии мой жёсткий диск или твердотельный накопитель SSD, сколько он ещё проживёт. Как узнать состояние здоровья жёсткого диска или SSD бывшего в употреблении. Что такое S.M.A.R.T и о чём говорят его показатели: Value, Worst, Raw, Threshold?
2. Что такое бэд-блоки? Как установить — сколько сбойных секторов (бэд-блоков) на моём жёстком диске, можно ли их исправить, а самое главное, как исправить?
3. Что делать, если операционная система не загружается или зависает даже после переустановки, а жёсткий диск при работе издаёт щелчки и посторонние звуки? Почему каждый раз при загрузке Windows запускается утилита проверки диска chkdsk?
4. Как создать загрузочную флешку с программой Victoria и проверить жёсткий диск компьютера, ноутбука на бэд-блоки даже если он не загружается и так далее…
Как пользоваться одной из легендарных программ по диагностике жёстких дисков под названием Victoria!
Приветствую Вас друзья на нашем сайте remontcompa.ru! Сегодняшняя статья о программе Victoria. Скажу уверенно, данная программа самая лучшая среди утилит по диагностике и лечению жёстких дисков. Разработал сиё творение чародей первой категории Сергей Казанский.
Я очень долго и ответственно готовился к данной статье чувствуя благодарность к этой программе. Бывало Victoria спасала казалось бы уже пропавшие данные на жёстких дисках моих клиентов, друзей и знакомых (часто перед мастером НЕ стоит задача вернуть к нормальной работе неисправный жёсткий диск, а только спасти данные находящиеся на нём), а иногда возвращала к жизни и сам винчестер!
- Очень хотелось написать статью, которая помогла бы начинающим пользователям разобраться, а главное не боятся этой программы, а боятся есть чего, если пользоваться программой неосторожно, к примеру запустить бездумно сканирование в режиме Erase или ещё хуже Write , то можно удалить все данные на винте, если вы даже вовремя опомнитесь, то всё равно грохните загрузочную запись MBR и Вам не удастся в следующий раз загрузиться в операционную систему.
Друзья, невозможно всё, что я хочу рассказать и показать о программе Victoria поместить в одну статью. В результате моих стараний получилось несколько статей:
- Сегодняшняя статья. Как скачать и запустить прямо из работающей Windows программу Victoria. Что такое S.M.A.R.T. или как за пару секунд определить состояние здоровья Вашего жёсткого диска или SSD. Ещё статьи…
- Как произвести тест жёсткого диска или твердотельного накопителя SSD на наличие сбойных секторов (бэд-блоков) в программе Victoria для Windows. Как вылечить жёсткий диск.
- Как создать загрузочную флешку с программой Victoria, загрузить с неё компьютер или ноутбук (если они не загружаются нормально из-за сбойных секторов) и протестировать поверхность жёсткого диска на бэд-блоки. Как избавиться от бэд-блоков в DOS (ДОС) режиме.
- Как с помощью программы Victora произвести посекторное стирание информации с жёсткого диска и этим избавиться от сбойных секторов (бэд-блоков).
- Как обрезать на жёстком диске участок со сбойными секторами.
- Как установить точный адрес сбойного сектора в программе Victoria и исправить этот сектор.
- Как сопоставить принадлежность сбойного сектора (бэд-блока) конкретному файлу в Windows?
- Как избавить жёсткий диск ноутбука от бэд-блоков в программе Victoria
- Загрузочная флешка Live CD AOMEI PE Builder с программами для диагностики жёсткого диска: Victoria, HDDScan, CrystalDiskInfo 6.7.4, DiskMark, HDTune, DMDE
Во первых, основных версий программы Victoria две:
Первая версия позволит нам произвести диагностику и небольшой ремонт жёстких дисков прямо в работающей Windows, но хочу сказать, что диагностику винчестера с помощью этой версии произвести можно, а вот исправление сбойных секторов (ремап) часто заканчивается неудачей, да и вероятность ошибок при работе с Викторией прямо «из винды» присутствует, поэтому многие опытные пользователи и профессионалы предпочитают вторую версию программы.
Вторая версия программы Victoria будет находиться на загрузочном диске или флешке, с данного диска (флешки) мы загрузим наш стационарный компьютер или ноутбук и также проведём диагностику и если нужно лечение жёсткого диска.
Примечание: Вторая версия очень пригодится многим, так как у большинства пользователей один жёсткий диск в компьютере или тем более в ноутбуке, в этом случае можно загрузиться с диска (флешки) Виктории и работать с одним единственным винчестером.
1. Victoria на загрузочном диске очень пригодится, если из-за бэд блоков Вы не можете запустить операционную систему.
2. Если у Вас один жёсткий диск и на нём установлена операционная система и в этой же работающей операционке Вы запустите Викторию, то наверняка она откажется исправлять сбойные сектора (бэд-блоки).
Многие пользователи заметят, что зачастую хороший бэд не исправит даже Виктория, на что ответить можно так — не все бэды имеют физическую природу (разрушившийся сектор на жёстком диске), многие бэды имеют логическую природу и легко исправляются этой программой.
Примечание: все подробности о существующих бэд-блоках винчестеров, какие они бывают, логические или физические, читайте в нашей статье- Как проверить состояние жесткого диска.
Коротко лишь скажу, что физические бэды (физически разрушившийся сектор) восстановить невозможно, а логические (программные, ошибки логики сектора) восстановить можно.
Друзья, можно много говорить, но есть хорошая жизненная пословица: «Лучше один раз увидеть, чем сто раз услышать», поэтому я приведу для Вас несколько примеров работы программы Victoria.
Victoria для работы с загрузочного диска
Идём на официальный сайт программы и выбираем Victoria 3.5 Russian ISO-образ загрузочного CD-ROM.
Victoria на загрузочном диске нам тоже нужна, но работу с этой версией мы рассмотрим во вторую очередь. Если у Вас нет дисковода, тогда мы сделаем загрузочную флешку с программой Victoria.
Victoria для работы непосредственно в операционной системе Windows XP, 7, 8, 10
Также скачиваем на моём облаке версию для Windows.
Щёлкаем на скачанном архиве программы правой мышью и выбираем Извлечь файлы.
Файлы извлекаются в создавшуюся папку vcr43. Заходим в эту папку и обязательно запускаем от имени администратора исполняемый файл программы victoria43.exe.
Главное окно программы Victoria
В главном окне программы пройдёмся по всем вкладкам поверхностно, а затем подробно.
Standard
Выбираем начальную вкладку Standard. Если у Вас несколько жёстких дисков, то в правой части окна выделите левой мышью нужный Вам жёсткий диск и сразу в левой части окна отобразятся паспортные данные нашего жёсткого диска: где родился и женился, модель, прошивка, серийный номер, объём кэша и так далее. В нижней части ведётся лог наших действий.
Что такое S.M.A.R.T.
Затем выбираем в правой части окна нужный нам жёсткий диск, если у Вас их несколько и выделяем его левой мышью. Выберем к примеру жёсткий диск WDC WD5000AAKS-00A7B2(объём 500 ГБ).
Переходим на вкладку SMART, жмем кнопку Get SMART, справа от кнопки засветится сообщение GOOD и откроется S.M.A.R.T. выбранного нами жёсткого диска.
S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology) — разработанная в 1995 году крупнейшими производители жёстких дисков усовершенствованная технология самоконтроля, анализа и отчётности винчестера.
Другими словами друзья, если посмотреть это окно, то можно узнать в каком состоянии Ваш жёсткий диск.
Обратите внимания программа Victoria подсветила красным (тревога!) цифру 8 на значении Raw, самого важного для здоровья жёсткого диска атрибута
5 Reallocated Sector Count — (remap), обозначающий число переназначенных секторов.
Примечание: значение атрибута Raw очень важно, читаем почему.
Простыми словами, если микропрограмма, встроенная в жёсткий диск, обнаружит сбойный сектор (бэд-блок), то она переназначит этот сектор сектором с резервной дорожки (процесс называется remapping). Но резервных секторов на жёстком диске не бесконечное число и программа нас предупреждает, что скоро бэд-блоки переназначать будет нечем, а это чревато потерей данных и нам надо готовиться менять жёсткий диск на новый. Забегая вперёд, скажу, что в следующей статье мы попробуем подлечить этот жёсткий диск.
9 Power-On time — общее количество отработанных жёстким диском часов 14810, не подсвечено красным, но хочу сказать, что приближение к цифре 20000 наработки в большинстве случаев связано с болезнями и нестабильной работой жёсткого диска.
Также подсвечены атрибуты:
196 Reallocation Event Count — 3. Количество операций переназначения бэд-блоков секторами с резервных дорожек (ремаппинг), учитываются как успешные, так и неуспешные операции.
197 Current Pending Sector — 13. Показатель количества нестабильных секторов реальных претендентов в бэд-блоки. Данные сектора микропрограмма жёсткого диска планирует в будущем заменить секторами из резервной области (remap), но всё же есть надежда, что в дальнейшем какой-то из этих секторов прочитается хорошо и будет исключён из списка претендентов.
198 Offline scan UNC sectors — 13. Количество реально существующих на жёстком диске не переназначенных бэдов (возможно исправимых имеющих логическую структуру — подробности далее в статье).
199 UltraDMA CRC Errors — 63771. Ошибки, возникающие при передаче информации по внешнему интерфейсу, причина — возможно перекрученный и некачественный SATA шлейф и его нужно заменить или расшатанный разъём SATA на материнской плате или на самом жёстком диске. А может сам винчестер интерфейса SATA 6 Гбит/с подключен в разъём на материнской плате SATA 3 Гбит/с, надо переподключить.
Атрибуты S.M.A.R.T и их значения. Очень важно знать!
Значения атрибутов
Val—текущее значение атрибута, оно должно быть высоким (до 255), если значение Val равно критическому Tresh или даже менее его, то это соответствует неудовлетворительной оценке параметра. К примеру в нашем случае на жёстком диске WDC WD5000AAKS-00A7B2 (500 ГБ, 7200 RPM, SATA-II) атрибут Reallocated Sector Count имеет значение Val—199, а атрибут Tresh (порог) имеет значение 140, это плохо, но значение Val—199 ещё не равно значению Tresh (порог) 140 и у нас есть время скопировать данные с этого диска и отправить его на пенсию.
Wrst—самый низкий показатель атрибута Val за всё время работы винчестера.
Tresh—пороговое значения атрибута, данное значение должно быть намного ниже значения Val (текущее значение).
Raw—«сырое значение», которое будет пересчитано в значение Value, чем меньше это значение, тем лучше. Важный показатель для оценки атрибута, представляет реальное число, исходя из которого формируется значение Value, но как именно происходит процесс формирования значения Value — это фирменный секрет каждого производителя жёсткого диска!
Расшифровка S.M.A.R.T.
Давайте разберёмся во всех атрибутах S.M.A.R.T, но хочу сказать, что чаще всего на «плохих» жёстких дисках неудовлетворительным будет именно этот атрибут Reallocated Sector Count (Переназначенные сектора). Это уже повод насторожиться и провести тест поверхности жёсткого диска или SSD (как это сделать узнаем далее в статье).
Друзья, для моментальной оценки здоровья жёсткого диска S.M.A.R.T я использую ещё одну простую программу на русском языке CrystalDiskInfo, обязательно скачайте и установите её себе. В ней все атрибуты указаны на русском языке!
http://crystalmark.info/download/index-e.html
Выберите Shizuku Edition (exe).
В данном окне язык программы можете выбрать русский.
Как видите, CrystalDiskInfo прямо указывает нам (подтверждая опасения «Виктории»), на жёстком диске WDC WD5000AAKS-00A7B2 (объём 500 ГБ) нехорошие значения атрибутов отвечающих за Переназначенные сектора, Нестабильные сектора, Неисправимые ошибки секторов, подсвечивая их жёлтым цветом и указывает на тех. состояние жёсткого диска одним словом «Тревога»
Как выглядит S.M.A.R.T неисправного жёсткого диска
А вот S.M.A.R.T неисправного жёсткого диска WDC WD500BPVT ноутбука, который мне принесли на ремонт.
Victoria из Windows. Обратите внимание на атрибут:
5 Reallocated Sector Count (переназначенные сектора), он имеет значение Val—133, а атрибут Tresh (порог) имеет значение 140, это неудовлетворительно, так как значение Val—133 не должно быть меньше предельного значения Tresh (порог) 140, то есть количество сбойных секторов будет расти, а переназначать их уже нечем, запасные сектора на резервных дорожках уже закончились.
197 Current Pending Sector — показатель количества нестабильных секторов реальных претендентов в бэд-блоки зашкалил все возможные пределы.
И самое главное, самооценка SMART status=BAD (непригоден).
Программа CrystalDiskInfo (ссылка на скачивание чуть выше). Видим тоже самое, атрибут Переназначенные сектора (Reallocated Sector Count) имеет значение Val (текущее)—133, а атрибут Tresh (порог) имеет значение 140, программа оценила оценку тех состояния жёсткого диска как Плохо.
этот ноутбук ужасно тормозит, данные c него невозможно скопировать, Windows невозможно переустановить, периодически винчестер пропадает из БИОС, то есть такой жёсткий диск подлежит замене без раздумий, даже наша Victoria не сможет полностью вылечить подобный винт, так как здоровые сектора на резервных дорожках закончились и сбойные сектора переназначать уже нечем, а копирование данных с него будет настоящим приключением на неделю (обязательно напишу про это статью).
Забегая вперёд скажу, что тест этого винта в программе Victoria показал наличие 500 неисправимых сбойных секторов (бэд-блоков).
ДОС — версия программы Виктория.
Примечание: Чтобы Вам упростить жизнь, некоторые программы диагностики жёстких дисков сопоставляют каждый атрибут, хороший он или плохой, цвету значка.
Зелёный—атрибут жёсткого диска соответствует нормальному.
Жёлтый—говорит о небольшом расхождении с эталоном и на этом винте важные данные лучше не хранить, если у Вас на таком жёстком диске находится Windows, перенесите её на SSD.
Красный—говорит о значительном расхождении с эталоном и жёсткий диск нужно было менять уже вчера.
S.M.A.R.T этого же жёсткого диска WDC WD500BPVT в программе HDDScan
Атрибуты
001 Raw Read Error Rate—частота ошибок при чтении информации с диска
002 Spinup Time—время раскрутки дисков до рабочего состояния
003 Start/Stop Count—общее количество стартов/остановок шпинделя.
005 Reallocated Sector Count — (remap) говорит о числе переназначенных секторов. Если микропрограмма встроенная в жёсткий диск обнаружит сбойный сектор (бэд-блок), то она переназначит этот сектор сектором с резервной дорожки (процесс называется remapping). Но резервных секторов на жёстком диске не бесконечное число и программа нас предупреждает, что скоро бэд-блоки переназначать будет нечем, а это чревато потерей данных и нам надо готовиться менять жёсткий диск на новый
007 Seek Error Rate—частота ошибок при позиционировании блока головок, постоянно растущее значение, говорит о перегреве винчестера и неустойчивом положении в корзине, к примеру плохо закреплён.
009 Power-on Hours Count—число часов, проведённых во включенном состоянии.
010 Spin Retry Count—число повторных раскруток диска до рабочей скорости при неудачной первой.
012 Device Power Cycle Count—Число полных циклов включения-выключения дисков
187 Reported Uncorrectable Error—Ошибки, которые не не смогла восстановить микропрограмма винчестера, используя свои методы устранения ошибки аппаратными средствами, последствия перегрева и вибрации.
189 High Fly Writes—записывающая головка находилась над поверхностью выше, чем нужно, а значит магнитное поле было недостаточным для надежной записи носителя. Причина– вибрация (удар).
Для ноутбуков данная цифра немного выше.
190 Важные параметры касающиеся температуры. Важно, что бы температура не поднималась выше 45 градусов.
194 HDA Temperature—температура механической части жёсткого диска
195 Hardware ECC Recovered—число ошибок, которые были исправлены самим винчестером.
196 Reallocation Event Count — Количество операций переназначения бэд-блоков секторами с резервных дорожек (ремаппинг), учитываются как успешные, так и неуспешные операции.
197 Current Pending Errors Count — неисправимые ошибки секторов, тоже важный параметр, число секторов, считывание которых затруднено и сильно отличается от считывания нормального сектора. То есть, эти секторы контроллер жёсткого диска не смог прочитать с первого раза, обычно к данным секторам принадлежат софт-бэды, ещё называют программные или логические бэд-блоки (ошибка логики сектора) — при записи в сектор пользовательской информации, так же записывается служебная информация, а именно контрольная сумма сектора ECC (Error Correction Code-код коррекции ошибок), она позволяет восстанавливать данные, если они были прочитаны с ошибкой, но иногда данный код не записывается, а значит сумма пользовательских данных в секторе не совпадает с контрольной суммой ECC. К примеру так происходит при внезапном отключении компьютера из-за сбоев с электричеством, из-за этого информация в сектор жёсткого диска была записана, а контрольная сумма нет.
- Логические бэд-блоки нельзя исправить простым форматированием, так как при форматировании контроллер жёсткого диска попытается в первую очередь прочитать информацию из сбойного сектора, если ему это не удастся (в большинстве случаев), то значит не произойдёт никакой перезаписи и бэд-блок останется бэд-блоком. Исправить положение можно в программе Victoria, она принудительно впишет в сектор информацию (вылечит сектор), затем прочитает её, сравнит контрольную сумму ECC и бэд-блок станет нормальным сектором. Более подробно про все виды бэд-блоков в нашей статье Как проверить жёсткий диск.
198 Offline scan UNC sectors — Количество реально существующих на жёстком диске непереназначенных бэдов (возможно исправимых имеющих логическую структуру — подробности далее в статье).
198 Uncorrectable Errors Count—число нескорректированных ошибок при обращении к сектору, указывает на дефекты поверхности.
Reported Uncorrectable Errors — показывает число неисправленных сбойных секторов.
199 UltraDMA CRC Errors—число ошибок, возникающих при передаче информации по внешнему интерфейсу, причина- перекрученный и некачественный SATA шлейф, возможно его нужно поменять.
200 Write Error Rate—частота ошибок, происходящих при записи на винчестер, по данному показателю обычно судят о качестве поверхности накопителя и его механической части.
202 Data Address Mark Errors—расшифровки нигде не встречал, буквально Ошибка данных адресного маркера, означать может то, что знает один лишь производитель данного винчестера.
Как быстро проверить жёсткий диск или SSD на пригодность к работе?
Друзья, Вы меня часто спрашиваете: «Как быстро проверить жёсткий диск или SSD на пригодность к работе?»
Ответ: «Используйте программы: Victoria, CrystalDiskInfo, HDDScan, они сразу покажут Вам S.M.A.R.T любого жёсткого диска.
Как выглядит S.M.A.R.T абсолютно нового жёсткого диска
Во первых, смотрите как выглядит S.M.A.R.T абсолютно нового жёсткого диска WDC WD2500AAKX-00ERMA0
Как видим, все показатели накопителя в отличном состоянии и отработал он ноль часов (параметр 9 Power-On Time)
Теперь берём почти новый жёсткий диск WDC WD2500AAKX-001CA0 и смотрим S.M.A.R.T, как видим, винчестер практически в идеальном состоянии, хотя и отработал уже 8000 часов (параметр 9 Power-On Time)
Victoria
Тест поверхности жёсткого диска!
В правой части окна программы отметьте пункт Ignor и пункт read и нажмите Start. Этим Вы запустите простой тест поверхности жёсткого диска без исправления ошибок. Данный тест не принесёт никаких отрицательных и положительных воздействий на жёсткий диск, но зато по окончании теста Вы будете знать в каком состоянии находится Ваш винчестер..
Результаты теста отличные. Ни одного блока с задержкой более 30 мc!
CrystalDiskInfo
HDDScan
Жёсткий диск SAMSUNG HD403LJ (372 ГБ) из недавней статьи Как перенести Windows 7, 8, 8,1 на SSD с помощью программы Acronis True Image.
На нём были бэд-блоки и мне пришлось переносить с него Windows 8 на SSD, после успешного переноса, хозяин (мой одноклассник) подарил мне этот винт и Victoria вскоре вернула его к жизни после «записи по всей поляне» (алгоритм Write). Прежний хозяин забирать вылеченный винчестер отказался.
Результаты теста чуть хуже. 3 блока с задержкой более 200 мс и 1 блок с задержкой 600 мс (возможно кандидат в бэды).
Не вполне исправный жёсткий диск MAXTOR STM3250310AS (250 ГБ, 7200 RPM, SATA-II) ему 8 лет (ветеран) и он всё ещё работает, правда я его берегу, храню на нём только файлы неважных данных.
Хоть явных бэдов на нём и нет, видим, что атрибут 5 Reallocated Sector Count — (remap), обозначающий число переназначенных секторов критический и скоро бэды переназначать будет нечем.
9 Power-On time — общее количество отработанных жёстким диском часов 23668, это очень много, обычно проблемы у жёстких дисков начинаются после 20000 часов отработки.
Также неважнецкий атрибут 199 UltraDMA CRC Errors — 63771,ошибки, возникающие при передаче информации по внешнему интерфейсу, причина — некачественный шлейф SATA шлейф и его нужно заменить (не всегда дело в этом).
Результаты теста ещё хуже. 71 блок с задержкой более 200 мс и 1 блок с задержкой 600 мс (возможно кандидат в бэды).
Жёсткий диск ST3200826AS (200 ГБ, 7200 RPM, SATA). Винту около трёх лет и полёт пока нормальный.
Результаты теста. 6 блоков с задержкой более 200 мс.
Новый твердотельный накопитель SSD SPCC SSD162
Тест
Под конец статьи проверим мой самый старый твердотельный накопитель SSD — ADATA S510 60GB (60 ГБ, SATA-III)
Ему уже третий год, но работает он отменно, жалко что объём всего 60 ГБ, но когда я его покупал больше и не было, а стоил он около двухсот баксов.
25.08.2012, 03:11. Показов 584825. Ответов 2

В первую очередь хочу сказать спасибо Charles Kludge и nonym4uk за помощь в написании этой статьи.
Итак, S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Много пользователей знает что такое S.M.A.R.T., немного меньше даже знают как его получить… Но когда встает вопрос проанализировать полученную таблицу, обычно дело стопорится. В этой статье я приведу основные значения и их расшифровку
Для любознательных
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число премещений головок, количество циклов включения-выключения);
текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 и от 0 до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое.
Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
Технология SMART позволяет осуществлять:
мониторинг параметров состояния;
сканирование поверхности;
сканирование поверхности с автоматической заменой сомнительных секторов на надёжные.
Следует заметить, что технология SMART позволяет предсказывать выход устройства из строя в результате механических неисправностей, что составляет около 60 % причин, по которым винчестеры выходят из строя.
Предсказать последствия скачка напряжения или повреждения накопителя в результате удара SMART не способна.
Следует отметить, что накопители НЕ МОГУТ сами сообщать о своём состоянии посредством технологии SMART, для этого существуют специальные программы.
Любая программа, показывающая S.M.A.R.T. для каждого атрибута имеет несколько значений, разберемся сначала с ними — ID, Value, Worst, Threshold и RAW. Итак:
ID (Number) — собственно, сам индикатор атрибута. Номера стандартны для значений атрибутов, но например,из-за кривизны перевода один и тот же атрибут может называться по-разному, проще орентироваться по ID, логично?
Value
(Current) — текущее значение атрибута в условных единицах, никому наверное неведомых . В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в уе. В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
Threshold — значение в (сюрприз!!!) уе, которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не уе, а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Теперь перейдем непосредственно к самим атрибутам.
01 (01) Raw Read Error Rate — Частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных до выдачи в интерфейс, следовательно, на пугающе огромные цифры можно реагировать спокойно.
02 (02) Throughput Performance — Общая производительность диска. Если значение атрибута уменьшается, то велика вероятность, что с диском есть проблемы.
03 (03) Spin-Up Time — Время раскрутки пакета дисков из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т. п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
04 (04) Start/Stop Count — Полное число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счётчик включения режима энергосбережения. В поле raw value хранится общее количество запусков/остановок диска.
05 (05) Reallocated Sectors Count — Число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор «переназначенным» и переносит данные в специально отведённую резервную область. Вот почему на современных жёстких дисках нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, а переназначенный сектор — remap. Чем больше значение, тем хуже состояние поверхности дисков. Поле raw value содержит общее количество переназначенных секторов. Рост значения этого атрибута может свидетельствовать об ухудшении состояния поверхности блинов диска.
06 (06) Read Channel Margin — Запас канала чтения. Назначение этого атрибута не документировано. В современных накопителях не используется.
07 (07) Seek Error Rate — Частота ошибок при позиционировании блока магнитных головок. Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
08 (08) Seek Time Performance — Средняя производительность операции позиционирования магнитными головками. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
09 (09) Power-On Hours (POH) — Число часов (минут, секунд — в зависимости от производителя), проведённых во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF — mean time between failure).
10 (0А) Spin-Up Retry Count — Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность неполадок с механической частью.
11 (0В) Recalibration Retries — Количество повторов запросов рекалибровки в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью.
12 (0С) Device Power Cycle Count — Количество полных циклов включения-выключения диска.
13 (0D) Soft Read Error Rate — Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. Все ошибки имеют
не механическую
природу и указывают лишь на неправильную размётку/взаимодействие с диском программ или операционной системы.
100(64) Erase/Program Cycles (для SSD) Общее количество циклов стирания/программирования для всей флэш-памяти за всё время ее существования. Твердотельный накопитель имеет ограничение на количество записей в него. Точные значения (ресурс) зависят от установленных микросхем флэш-памяти.
В накопителях Kingston — объём стёртого в гигабайтах.
103(67) Translation Table Rebuild (для SSD) Количество событий, когда внутренние таблицы адресов блоков были повреждены и впоследствии восстановлены. Raw-значение этого атрибута указывает фактическое количество событий.
170(AA) Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Иногда raw-значение содержит фактическое количество использованных резервных блоков.
170 атрибут связан с атрибутом 5, числом использованных резервных блоков.
171(AB) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти» — отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Значение обычно идентично атрибуту 181.
172(AC) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Идентичен атрибуту 182.
173(AD) Wear Leveller Worst Case Erase Count (для SSD) Максимальное количество операций стирания, выполняемых для одного блока флэш-памяти.
174(AE) Unexpected Power Loss (для SSD) Число неожиданных отключений питания, когда питание было потеряно до получения команды на отключение диска. На жестком диске срок службы при таких отключениях намного меньше, чем при обычном отключении. На SSD существует риск потери внутренней таблицы состояний при неожиданном завершении работы.
175(AF) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти», отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
176(B0) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
177(B1) Wear Leveling Count (для SSD)
Wear Range Delta В зависимости от производителя, максимальное количество операций стирания, выполняемых для одного блока флэш-памяти[источник не указан 269 дней] или разница между максималоьно изношенными (больше всего раз записанными) и минимально изношенными (записанными наименьшее число раз) блоками[4].
178(B2) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
179(B3) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
180(B4) Unused Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество неиспользованных резервных блоков.
181(B5) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов.
182(B6) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов.
183(B7) SATA Downshifts (для SSD) Указывает, как часто требовалось снизить скорость передачи данных SATA (с 6 Гбит/с до 3 или 1,5 Гбит/с или с 3 Гбит/с до 1,5 Гбит/с) для успешной передачи данных. Если значение атрибута уменьшается, попробуйте заменить кабель SATA.
Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1.5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута (Western Digital und Samsung).
184 (B8) End-to-End error — Назначение зависит от производителя.
У HP (часть технологии HP SMART IV) увеличивается в случае, когда после передачи данных через кэш-память чётность данных между хостом и жёстким диском не совпадает.
У Kinston это количество ошибок чтения из флэш-памяти.
185 (B9) Head Stability Стабильность головок (Western Digital).
187 (BB) Reported UNC Errors — Количество ошибок, которое накопитель сообщил хосту (интерфейсу компьютера) при любых операциях, обычно это ошибки данных на диске, которые не исправлены средствами ECC
188 (BC) Command Timeout — содержит количество операций, выполнение которых было отменено из–за превышения максимально допустимого времени ожидания отклика.Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате и т.д. Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
189 (BD) High Fly Writes — содержит количество зафиксированных случаев записи при высоте «полета» головки выше рассчитанной, скорее всего, из-за внешних воздействий, например, вибрации.
Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию
190 (BE) Airflow Temperature (WDC) — Температура воздуха внутри корпуса жёсткого диска. Для дисков Seagate рассчитывается по формуле (100 — HDA temperature). Для дисков
Western Digital
— (125 — HDA).
191 (BF) G-sense error rate — Количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который
фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухой.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно, если его не закрепить. Основное назначение датчика – прекратить операцию записи при вибрациях, чтобы избежать ошибок.
75

Восстановить жесткий диск, используя специальные программы. Они позволяют протестировать винчестер, а также исправить незначительные неисправности. Зачастую, этого вполне достаточно для продолжения плодотворной работы. Из статьи вы узнаете об одной из них под названием Victoria.
Проверка жесткого диска программой Victoria полностью бесплатна. Также программа обладает множеством функций и рассчитана не только на профессионалов, но также и на неопытных пользователей. Итак, сейчас вы узнаете, как проверить жесткий диск программой Victoria.
Технология S.M.A.R.T.
Все современные накопители на жестких магнитных дисках поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков.
В процессе совершенствования оборудования накопителей, возможности технологии также дорабатывались, и после стандарта SMART появился SMART II, затем — SMART III, который, очевидно, тоже не станет последним.
Жесткий диск в процессе своего функционирования постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне. Данные атрибутов могут быть считаны специальным программным обеспечением.
Атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется накопителями разных моделей. Некоторые атрибуты могут быть определены конкретным производителем оборудования, и поддерживаться только отдельными моделями накопителей.
Атрибуты состоят из нескольких полей, каждое из которых имеет определенный смысл. Обычно, программы считывания S.M.A.R.T. выдают расшифровку атрибутов в виде:
- Attribute — имя атрибута
- ID — идентификатор атрибута
- Value — текущее значение атрибута
- Threshold — минимальное пороговое значения атрибута
- Worst — самое низкое значение атрибута за все время работы накопителя
- Raw — абсолютное значение атрибута
- Type (необязательно) — тип атрибута — характеризует производительность (PR — Performance-related), характеризует сбои (ER — Error rate), счетчик событий (EC — Events count), определено производителем или не используется (SP — Self-preserve);
Для анализа состояния накопителя, пожалуй, самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, до достижения которого, производитель гарантирует его работоспособность — поле Threshold. Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять. Перечень атрибутов и их значения жестко не стандартизированы и определяются изготовителем накопителя, но наиболее важные из них интерпретируются одинаково. Например, атрибут с идентификатором 5 (Reallocated sector count) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, и для устройств производства компании Seagate, и для Western Digital, Samsung, Maxtor.
Жесткий диск не имеет возможности, по собственной инициативе, передать данные SMART потребителю. Их считывание выполняется специальным программным обеспечением.
В настройках большинства современных BIOS материнских плат имеется пункт позволяющий запретить или разрешить считывание и анализ атрибутов SMART в процессе выполнения тестов оборудования перед выполнением начальной загрузки системы. Включение опции позволяет подпрограмме тестирования оборудования BIOS считать значения критических атрибутов и, при превышении порога, предупредить об этом пользователя. Как правило, без особой детализации:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Выполнение подпрограммы BIOS приостанавливается, чтобы привлечь внимание:
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить критическое состояние накопителя (при включении данной опции) средствами Базовой Системы Ввода-Вывода (BIOS).
Анализ данных S.M.A.R.T. жесткого диска
Для получения данных SMART в среде операционной системы могут использоваться специальные программы, в частности, практически все утилиты для тестирования оборудования жестких дисков.
Одной из самых популярных программ для тестирования жестких дисков является Victoria Сергея Казанского.
На сайте автора найдете последнюю версию программы, а также массу полезной информации, в том числе и подробное описание работы с Victoria.
Программа Victoria имеет две разновидности — для работы в среде DOS и, для работы в среде Windows. DOS-версия может напрямую работать с контроллером жесткого диска и обладает значительно большими возможностями по сравнению с версией для Windows.
Назначение, основные возможности и порядок использования программы найдете на сайте автора
Программа проста в использовании и позволяет оценить техническое состояние накопителя, выполнить его тестирование и некоторые настройки — уровня шума, производительности, физического объема. Режимы тестирования поверхности накопителя позволяют принудительно избавиться от сбойных секторов с помощью режима Remap нескольких видов. Вызов меню тестирования выполняется по нажатию клавиши F4 (SCAN). Пользователь имеет возможность задать.
область тестирования
Start LBA :0 — начало области (по умолчанию — 0)
End LBA :14680064 — конец области (по умолчанию — номер последнего блока диска)
Режим тестирования
Линейное чтение — последовательное чтение от начального блока до конечного
Случайное чтение — номер считываемого блока формируется случайным образом.
BUTTERFLY чтение — выполняется чтение блоков, начиная от граничных номеров (начала и конца), к центру области тестирования.
Изменение режима выполняется по нажатию клавиши «пробел»
Режим обработки ошибок
Этот пункт позволяет выполнить скрытие дефектных блоков, с использованием переназначения (ремап) из резервной области. Выбор режима выполняется клавишей «пробел». Выбранный метод работы с дефектами отображается в правом верхнем углу экрана, под часами, а также в нижней строке в момент запуска теста. Изменить режим можно в и в процессе выполнения сканирования.
Ignore Bad Blocks — программа не будет выполнять никаких действий при обнаружении ошибки.
BB = RESTORE DATA — программа попытается восстановить данные из поврежденных секторов.
BB = Classic REMAP — выполняется запись в поврежденный сектор для вызова процедуры переназначения.
BB = Advanced REMAP — улучшенный алгоритм скрытия сбойных блоков. Используется, когда не помогает классический ремап. Программа выполняет специальную последовательность операций с целью формирования признака кандидата на ремап (атрибут 197) у сбойного блока. Затем выполняется 10-кратная запись, обрабатываемая микропрограммой накопителя как обычная обработка кандидата на ремап — если есть ошибка, выполняется переназначение, если нет ошибки — блок считается нормальным и удаляется из кандидатов на ремап. Данный режим позволяет выполнить скрытие сбойных блоков без потери пользовательских данных. Конечно, только в случаях, когда накопитель технически исправен и есть свободное место в резервной области для переназначения.
BB = Fujitsu Remap — выполнение специфических алгоритмов, основанных на недокументированных возможностях некоторых моделей накопителей Fujitsu
BB = Erase 256 sect — при обнаружении сбойного сектора выполняется перезаписывание блока из 256 секторов. Пользовательские данные не сохраняются.

В процессе работы с программой можно вызвать контекстную справку клавишей F1
Расшифровка кодов ошибок в Victoria:
BBK (Bad Block Detected) — Найден бэд-блок.
UNCR (Uncorrectable Error) — Неисправимая ошибка. Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных (софтовый Bad Block), так и неисправностью HDD;
IDNF (ID Not Found) — Не найден идентификатор сектора. Обычно говорит о разрушении микрокода или формата низкого (физического уровня) HDD . У исправных HDD такая ошибка выдается при попытке обратиться к несуществующему адресу физического сектора;
ABRT (Aborted Command) — HDD отверг команду в результате неисправности, или команда не поддерживается данным HDD (пароль, устаревшая или слишком новая модель и т.д.)
T0NF (Track 0 Not Found) — не найдена нулевая дорожку, невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
AMNF (Address Mark Not Found) — адресный маркер не найден, невозможно прочитать сектор, обычно в результате неисправности тракта чтения или дефекта поверхности.
Версия Victoria For Windows обладает более скромными возможностями по настройке накопителя и выбору режимов тестирования, и на данный момент не имеет поддержки русского языка , однако ей проще пользоваться и имеющихся возможностей вполне достаточно для считывания таблицы SMART и оценки технического состояния накопителя.
Программа не требует установки, просто скачайте ее по ссылке на странице загрузки сайта автора.
Программа должна выполняться под учетной записью с павами администратора. В среде Windows 7 / 8 необходимо использовать контекстное меню «Запуск от имени администратора».
Для анализа состояния SMART-атрибутов выбираем режим работы через программный интерфейс Windows — включаем кнопку API в правой верхней части основного окна. Затем выбираем накопитель для проверки — нажимаем на кнопку Standard в основном меню программы и подсвечиваем мышкой нужный диск в окне со списком. В информационном окне будет отображен паспорт накопителя — модель, версию аппаратной прошивки, серийный номер, размер и т.п. Для получения данных SMART выбираем пункт меню SMART и жмем кнопку «Get SMART». Результат будет отображен в информационном окне программы.

Краткое описание атрибутов
- 001 ( 1 ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще могут не поддерживать данный атрибут.
- 003 ( 3 ) Spin Up Time — Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости.
- 004 ( 4 ) Start/Stop Count — Количество циклов запуск/останов шпинделя.
- 005 ( 5 ) Reallocated Sector Count — Количество переназначенных секторов. Современные накопители имеют довольно большую (тысячи секторов) резервную область поверхности накопителя для использования ее в случае ухудшения характеристик секторов из основной зоны. Если накопитель обнаруживает проблемы с записью/считыванием какого — либо сектора, то он автоматически перемещает его данные в резервную область, а данный сектор помечается как «переназначенный». Часто этот процесс называют «remapping», или «automatic defect reassignment», он выполняется микропрограммой накопителя и для пользователя (операционной системы) невидим. Поле raw value содержит общее количество переназначенных секторов. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительную операцию установки головок на дорожки резервной области, обычно расположенной в конце диска.
- 007 ( 7 ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Накопитель контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. Для данного накопителя причиной большого числа ошибок явился перегрев.
- 008 ( 8 ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 ( 9 ) Power-On Hours — Количество часов во включенном состоянии. Достижение предельного значения этого атрибута означает выработку накопителем заданной производителем наработки на отказ (MTBF — Mean Time Between Failures).
- 010 ( 0A ) Spin Retry Count — Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения для данного устройства ( например 5400 , 7200, 10000 об/мин.) за определенное время. В случае неудачи — увеличивается счетчик повторов и повторяется попытка старта.
- 011 ( 0B ) Recalibration Retries — количество попыток рекалибровки, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 ( 0C ) Device Power Cycle Count — Количество циклов включения/выключения диска.
- 184 ( B8 ) End-to-End error — Данный атрибут — часть технологии HP SMART IV — означает, что после передачи данных через буферную память чётность данных между контроллером компьютера и жестким диском не совпадает.
- 187 ( BB ) Reported Uncorrectable Error — Характеризует количество ошибок, которые не были исправлены микропрограммой накопителя.
- 188 ( BC ) Command Timeout Количество прерванных операций в связи с отсутствием ответа от накопителя. Обычно это значение атрибута должно быть равно нулю, и, если значение гораздо выше нуля, то, возможными причинами могут быть проблемы с питанием или окислением контактов интерфейсного кабеля.
- 189 ( BD ) High Fly Writes — Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 ( BE ) Airflow Temperature — температура окружающей среды блока магнитных головок. Для различных моделей HDD данный атрибут отсутствует и используются атрибуты 194 или 231.
- 191 (BF ) Mechanical Shock — количество механических ударов. Вместо данного атрибута может использоваться атрибут 221.
- 192 ( C0 ) Power-off retract count — количество циклов выключений или аварийных отказов (включений/выключений питания накопителя).
- 193 ( C1 ) Load/Unload Cycle — количество циклов перемещения блока магнитных головок в зону парковки.
- 194 ( C2 ) HDA Temperature — температура самого накопителя (HDA — Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило — нижняя ). Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), Raw value — текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 ( CD ) Thermal asperity rate (TAR) фиксирующий количество опасных перепадов температуры. В некоторых моделях накопителей вместо атрибута 194 может использоваться атрибут 231.
- 195 ( C3 ) Hardware ECC recovered — характеризует количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 ( C4 ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле Raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле Raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 ( C6 ) Uncorrectable Sector Count — Счетчик некорректируемых ошибок. Это ошибки, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Может быть вызвано неисправностью отдельных элементов или отсутствием свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 ( C7 ) UltraDMA CRC Error Count — Счетчик ошибок, возникших при передаче данных в режиме UltraDMA . Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, нестабильным питанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 ( C8 ) Write Error Rate ( Multi-Zone Error Rate ) — Характеризует наличие ошибок при записи данных. Может быть вызвано ухудшением состояния поверхности, головок или характеристик тракта записи данных. Чем ниже значение Value, тем опаснее использовать такой накопитель.
- 201 ( C9 ) Soft Read Error Rate — количество некорректируемых ошибок чтения, обнаруженных программным обеспечением.
- 202 ( CA ) Data Address Mark Errors — количество некорректируемых ошибок при чтении собственного адреса сектора.
- 203 ( CB ) Run Out Cancel — количество ошибок, зафиксированных при выполнении коррекции данных.
- 204 ( CC ) Soft ECC Correction — количество ошибок, исправленных внутренней микропрограммой накопителя.
- 205 ( CD ) Thermal Asperity Rate — общее количество проблем, вызванных повышенной температурой.
- 206 ( CE ) Flying Height — высота полета головок над поверхностью диска.
- 207 ( CF ) Spin High Current — ток, необходимый для раскручивания двигателя.
- 208 ( D0 ) Spin Buzz — количество повторных попыток запуска двигателя из-за пониженного тока.
- 209 ( D1 ) Offline Seek Performance — производительность, определенная при выполнении внутренних тестов накопителя.
- 210 ( D2 ) Vibration During Write — вибрации, зафиксированные при выполнении операций записи.
- 211 ( D3 ) Shock During Write — удары, зафиксированные при выполнении операций записи.
- 220 ( DC ) Disk Shift — смещение блока дисков относительно вертикальной оси шпинделя. В основном возникает из-за сильного удара или падения накопителя и как правило, является сигналом для его замены.
- 221 ( DD ) G-Sense Error Rate— количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков — большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 222 ( DE ) Loaded Hours — количество часов, отработанных накопителем.
- 223 ( DF ) Load/Unload Retry Count — количество операций ввода/вывода головок в зону данных.
- 226 ( E0 ) Load-in Time — общее время нахождения головок в зоне данных.
- 228 ( E4 ) Power-Off Retract Cycle — Количество автоматических парковок магнитных головок при пропадании питания.
- 230 ( E6 ) GMR Head Amplitude — Амплитуда перемещения головок между операциями.
- 231 ( E7 ) Hard Disk Temperature — температура, зафиксированная внутренними датчиками накопителя.
Современные накопители поддерживают не только формирование атрибутов S.M.A.R.T, но и ведут дополнительные журналы статистики, а также поддерживают протокол SCT (SMART Command Transport), обеспечивающий считывание данных журналов. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG. В журналах отображается информация о выполнении встроенных тестов S.M.A.R.T ( self-test ), статистика ошибок, номера сбойных блоков LBA и т.п.
Ремап (Remap) и проверка поверхности жесткого диска
Удивительно, как долго могут существовать ошибочные представления о жестких дисках и их правильной эксплуатации. В частности, даже неплохие специалисты в области компьютерной техники, бывает, рекомендуют выполнять в среде ОС Windows полное форматирование поверхности вместо быстрого, или даже низкоуровневое форматирование. Что касается последнего, свою лепту в путаницу с форматированием вносят и некоторые производители программного обеспечения, выпускающие программы для «низкоуровневого форматирования», которые ничего не форматируют. Низкоуровневое форматирование (Low Level Format) — это разметка поверхности диска специальной служебной информацией, в соответствии с геометрией накопителя, выполняемой специальной командой посылаемой накопителю. В стандарте ST506/412, который предшествовал современному стандарту ATA (AT attachment) имелась команда 50h (Format Track), при выполнении которой производилась разметка дорожки адресными маркерами, в соответствии с геометрией диска, т.е. в соответствии с номером цилиндра, номером головки и количеством секторов на дорожке. В дальнейшем, при записи данных, эта часть информации никогда не изменялась. При выполнении команды записи данных в сектор, накопитель никогда и ничего не записывает в ту область дорожки, которая является служебной и была создана при низкоуровневом форматировании дорожек поверхности специально для этого предназначенной командой 50h.
В современных накопителях стандарта ATA команды низкоуровневого форматирования вообще отсутствуют, а рекламируемые некоторыми производителями программы для выполнения данной операции являются простыми «стиралками» данных, выполняющими запись в область данных секторов. Нет, и не может быть, никаких программ для выполнения настоящего низкоуровневого форматирования в среде любой операционной системы. Любое подобное «низкоуровневое» форматирование — это высокоуровневое форматирование логической структуры пользовательских данных.
Что же касается полного форматирования в среде Windows, то по сравнению с быстрым, сразу создающим пустое оглавление, оно просто добавляет проверку поверхности диска перед тем, как выполнить то же самое, что делает быстрое форматирование. Что также не имеет смысла, поскольку проверка и отбраковка нестабильных секторов выполняется средствами аппаратной реализации технологии S.M.A.R.T накопителя, которая с данной задачей справляется гораздо эффективнее автоматически и в непрерывном режиме. Полное форматирование имело смысл на старых дисках, которые не могли выполнять замену нестабильных секторов на сектора из резервной зоны, и такие сектора сразу становились дефектными блоками ( Bad Block ), которые исключались из файловой структуры при форматировании с проверкой поверхности. Существует также утверждение, что при полном форматировании выполняется стирание всей поверхности диска. Это тоже не соответствует действительности, что легко проверяется любыми программами мониторинга обращений к диску , например, утилитой Disk Monitor из пакета Sysinternals Suite. Программа показывает, что при полном форматировании выполняется чтение поверхности, и небольшое количество операций записи, выполняемой после проверки поверхности при формировании пустого оглавления, в самом конце работы. И даже из того факта, что существую программы для восстановления данных после форматирования ( любого, в том числе и полного ) вполне логично следует вывод – никакого стирания данных не происходит.
При записи жесткий диск не проверяет, что и как было записано в область данных сектора, кроме случаев, когда предварительная диагностика, которой накопитель занимается все «свободное время», не пометила в соответствующих журналах эти сектора, как проблемные, или кандидаты на переназначение, что отражается в атрибуте 197 SMART (Current Pending Sectors).
Кандидат — это сектор (или группа секторов), который не был считан за стандартное время и с установленным числом повторов. В режиме простоя, запустится программа самотестирования, которая попытается считать данные с применением дополнительных режимов. Если сектор будет успешно считан — программа самодиагностики попытается записать данные обратно, и если запись выполнится успешно, то из кандидатов такой сектор удалится. Если же записанная на то же место информация не будет нормально считываться, то выполнится переназначение сектора (Remap), данные запишутся в сектор из специально для этого предназначенной резервной области (spare area). В дальнейшем, всегда вместо этого сбойного сектора будут считываться данные из резервной области. А сектор-кандидат на переназначение, не исправленный программой самотестирования, увеличит значение атрибута 198 (Offline Scan UNC Sectors). Убрать такой «бед» можно только перезаписью. Но если резервная область закончилась, то все последующие кандидаты на переназначение превратятся в реальные «плохие секторы» (Bad Blocks). В этом случае программы полного форматирования и проверки поверхности могут исключить сбойный сектор из логической структуры диска, однако, использовать накопитель с закончившейся резервной областью — это очень рискованная идея, которая обязательно закончится потерей данных. Использовать такой диск можно разве что для опасных экспериментов, хранения некритичных данных, или выбросить его на помойку.
При возникновении плохих блоков (Bad Block) нередко возникает необходимость проверки принадлежности сбойного участка конкретному файлу. Для этих целей можно воспользоваться консольной утилитой NFI.EXE (NTFS File Sector Information Utility) из состава пакета Support Tools от Microsoft. Скачать 10кб
Формат командной строки
nfi.exe Диск Номер логического сектора
Подсказку по использованию NFI.EXE можно получить по команде nfi.exe /?
Букву логического диска можно задавать без двоеточия. Номер логического сектора — это номер сектора относительно начала логического диска. Обратите внимание на тот факт, что программы сканирования работают со всей поверхностью физического диска и используют нумерацию секторов, не привязанную к его логической структуре. А номер сектора, задаваемый в качестве параметра утилиты NFI.EXE — это номер сектора логического диска (раздела), и он отличается величиной смещения начального сектора раздела от начала диска. Значение номеров начальных секторов логических дисков можно получить нажав кнопку View part data вкладки «Advanced» программы Victoria For Windows.
nfi.exe C: 655234 — выдать имя файла, которому принадлежит сектор 655234
nfi.exe C: 0xBF5E34 — то же самое, но номер сектора задан в шестнадцатеричной системе счисления
В результате выполнения команды будет выдано сообщение
***Logical sector 12541492 (0xbf5e34) on drive C is in file number 49502.
WINDOWS system32 D3DCompiler_38.dll
Т.е. интересующий нас сбойный сектор принадлежит файлу D3DCompiler_38.dll в каталоге Windowssystem32. В случае, когда сбойные блоки принадлежат системным файлам Windows, возможно появление синих экранов смерти или зависаний системы с перезагрузкой. В большинстве случаев, информация о наличии сбоев дисковой подсистемы, будет отображаться в системном журнале Windows.
Для выполнения тестирования поверхности накопителя с принудительным переназначением (ремапом) сбойных секторов можно воспользоваться программами тестирования HDD, алгоритм работы которых специально разработан таким образом, чтобы «заставить» внутреннюю микропрограмму накопителя выполнить переназначение нестабильного участка.
Так, например, подобные алгоритмы будут использоваться, в упоминаемой выше программе Victoria, если выбран режим тестирования поверхности с выполнением операций восстановления или переназначения (Classic Remap, Advanced Remap :). Изначально режим выполнения теста установлен в Ignore Bad Blocks

Нажатие пробела изменяет режим обработки сбоев. При выполнении такого вида тестирования накопителя, пользовательские данные остаются в сохранности.
Добавлю, что режим Advanced Remap, хотя и является наиболее эффективным, на практике может приводить к «зависанию» микропрограммы на некоторых моделях HDD, выйти из которого можно только с использованием принудительного сброса (режим Reset, клавиша F3). После чего можно продолжить тестирование. Если в режиме Advanced Remap таймауты происходят слишком часто, имеет смысл перейти к использованию классического ремапа.
Для программы Victoria For Windows переназначение сбойных секторов включается установками режима выполнения теста в правой части основного окна. По умолчанию установлен режим Ignore — ничего не делать при обнаружении сбоя, а нужно установить режим Remap

Страницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться
RSS
Сообщений [ 22 ] Просмотров: 27 562
1 22.07.2013 03:22:37 (9 лет 6 месяцев назад)

- m84
- Участник
- Автор темы
- Неактивен
- Откуда: Барнаул
- Стаж: 15 лет 2 месяца
- Сообщений: 486
- Репутация : [ 16 | 0 ]
Тема: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
Не первый раз наблюдаю картину, когда абсолютно новые компы, без разгона, укомплектованные материнкой ASUS и винтом Seagate, показывают неуклонный рост параметра SMART «Hardware ECC Recovered».
В принципе можно не обращать внимания на это — все отлично работает, но… не дает покоя мысль: раз значение параметра растет, значит, винт получает ошибки по каналу передачи данных, что может привести к проблемам вплоть до потери данных.
Кто-нибудь сталкивался с этим? Что делали в подобных случаях?
P.S.: шлейфы менялись — проблема остается. Бывает, что винт на любых материнках так себя ведет; бывает, что материка с любыми винтами Seagate (у Samsung и Hitachi такого параметра SMART нет, с другими — не проверял) — тут, собственно, ясно, что проблема либо в матери, либо в винте (хотя до конца все же неясно).
Решение вроде бы очевидно — либо взять другую материнку, либо винт, либо то и другое. Но как объяснить клиенту, ПОЧЕМУ это нужно сделать?
И является ли подобная «проблема» поводом для замены винта или материнки? Но даже если магазин пойдет навстречу и обменяет товар, может получиться, что проблема останется… Как быть?
2 Ответ от John409 22.07.2013 03:36:59 (9 лет 6 месяцев назад)

- John409
- Участник
- Неактивен

- Стаж: 13 лет 4 месяца
- Сообщений: 7 069
- Репутация : [ 50 | 1 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
это ты сон тут так успел записать? ![]()
3 Ответ от m84 22.07.2013 04:15:04 (9 лет 6 месяцев назад)
- m84
- Участник
- Автор темы
- Неактивен
- Откуда: Барнаул
- Стаж: 15 лет 2 месяца
- Сообщений: 486
- Репутация : [ 16 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
Плюсанул за чувство юмора ![]()
4 Ответ от KT_ 22.07.2013 07:59:26 (9 лет 6 месяцев назад)

- KT_
- Участник
- Неактивен

- Стаж: 15 лет 1 месяц
- Сообщений: 8 803
- Репутация : [ 216 | 1 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
John409 пишет:
это ты сон тут так успел записать?
![]()
![]()
![]()
8-(92З)-1б1-552I
*
5 Ответ от Athlon82 22.07.2013 08:04:22 (9 лет 6 месяцев назад)
- Athlon82
- МАСТЕРю
- Неактивен
- Откуда: Павловский тракт, 293
- Стаж: 15 лет 2 месяца
- Сообщений: 45 485
- Репутация : [ 1340 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84, макс, забей, все норм
====================================================
Ремонт и чистка ПК, ноут/нетбуков, телефонов, планшетов
99% всех ошибок компьютера сидит на расстоянии пол-метра от монитора.
6 Ответ от alex1 22.07.2013 08:27:45 (9 лет 6 месяцев назад)
- alex1
- Участник
- Неактивен
- Стаж: 13 лет 6 месяцев
- Сообщений: 5 801
- Репутация : [ 198 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
ТС, забей. В инете эту тему обсосали уже до дыр давным давно. Почитай педивикию для успокоения. Там, правда, только для 1-го параметра написано, но всё верно и для твоего.
Отредактировано alex1 (22.07.2013 08:30:44, 9 лет 6 месяцев назад)
96О-9сорак1-48-осемнацать
7 Ответ от m84 22.07.2013 11:33:52 (9 лет 6 месяцев назад)
- m84
- Участник
- Автор темы
- Неактивен
- Откуда: Барнаул
- Стаж: 15 лет 2 месяца
- Сообщений: 486
- Репутация : [ 16 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
(с) http://www.ixbt.com/storage/hdd-smart-testing.shtml
Читал я это. Но все равно напрягает. В некоторых случаях постоянный рост значений 01, 07 и 195 связан не с винтом, а с материнкой. Так, например, купил б/у винт Seagate с нулевым значением параметра 195 (Hardware ECC Recovered), подключил — и понеслось… Вот что думать в таких случаях, когда на одних материнках растет значение, а на других нет? Спрашивал в СЦ, говорят, что может возникать из-за некачественной пайки южника…
Забить-то можно. Но правильно ли это?
Отредактировано m84 (22.07.2013 11:37:18, 9 лет 6 месяцев назад)
8 Ответ от mixall 22.07.2013 11:37:35 (9 лет 6 месяцев назад)
- mixall
- Участник
- Неактивен
- Стаж: 12 лет 11 месяцев
- Сообщений: 3 378
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84 пишет:
Спрашивал в СЦ, говорят, что может возникать из-за некачественной пайки южника
больше в этот СЦ не ходите
m84 пишет:
Забить-то можно, но всегда ли нужно?
в данном случае необходимо, от материнки это не зависит, а диск пусть мотает циферки, если ему нравится
У меня уже давно другой номер телефона.
9 Ответ от bis 22.07.2013 11:41:26 (9 лет 6 месяцев назад)
- bis
- Участник
- Неактивен
- Откуда: Барнаул — столица мира
- Стаж: 10 лет 5 месяцев
- Сообщений: 30 082
- Репутация : [ 762 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
Да это проблема Сигейтов, хреновые винты стали они делать ![]() Возьми WD’шку и посмотри
Возьми WD’шку и посмотри ![]()
Отредактировано bis (22.07.2013 11:41:53, 9 лет 6 месяцев назад)
90% проблем решаются сами собой, 10% не решаются в принципе
PS Телефон всегда в кармане, проще позвонить чем написать
Резина Micheline 245/70 R16 комплект
10 Ответ от CrashX 22.07.2013 11:42:02 (9 лет 6 месяцев назад)

- CrashX
- ===РИДДИК^2===
- Неактивен

- Стаж: 12 лет 8 месяцев
- Сообщений: 16 956
- Репутация : [ 446 | 3 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
я сегейты не покупаю очень давно и рад этому очень
я за WD Blue
11 Ответ от bis 22.07.2013 11:42:24 (9 лет 6 месяцев назад)
- bis
- Участник
- Неактивен
- Откуда: Барнаул — столица мира
- Стаж: 10 лет 5 месяцев
- Сообщений: 30 082
- Репутация : [ 762 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
CrashX пишет:
я сегейты не покупаю очень давно и рад этому очень
я за WD Blue
+100
90% проблем решаются сами собой, 10% не решаются в принципе
PS Телефон всегда в кармане, проще позвонить чем написать
Резина Micheline 245/70 R16 комплект
12 Ответ от alex1 22.07.2013 12:26:45 (9 лет 6 месяцев назад)
- alex1
- Участник
- Неактивен
- Стаж: 13 лет 6 месяцев
- Сообщений: 5 801
- Репутация : [ 198 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84 пишет:
Спрашивал в СЦ, говорят, что может возникать из-за некачественной пайки южника…
![]()
![]()
m84 пишет:
Забить-то можно. Но правильно ли это?
Да. Википедию читали?
195 0xC3 Hardware ECC Recovered N/A (Vendor specific raw value.) The raw value has different structure for different vendors and is often not meaningful as a decimal number.
Перевести на русский надо?
96О-9сорак1-48-осемнацать
13 Ответ от m84 22.07.2013 14:39:10 (9 лет 6 месяцев назад)
- m84
- Участник
- Автор темы
- Неактивен
- Откуда: Барнаул
- Стаж: 15 лет 2 месяца
- Сообщений: 486
- Репутация : [ 16 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
alex1 пишет:
Да. Википедию читали?
195 0xC3 Hardware ECC Recovered N/A (Vendor specific raw value.) The raw value has different structure for different vendors and is often not meaningful as a decimal number.
Перевести на русский надо?
читал. Даже процитировал выше фрагмент статьи, ссылка на которую была в вики (русский вариант). Переводить не нужно — на базовом уровне владею английским. Обидно только, что либо сигейты испортились, либо производители материнок, т.к. раньше такого не было.
CrashX пишет:
я сегейты не покупаю очень давно и рад этому очень
я за WD Blue
я тоже не фанат сигейтов, отчасти из-за подобных «сюрпризов», но не только. Я за тошибу, хитачи, wd.
14 Ответ от alex1 22.07.2013 15:39:39 (9 лет 6 месяцев назад)
- alex1
- Участник
- Неактивен
- Стаж: 13 лет 6 месяцев
- Сообщений: 5 801
- Репутация : [ 198 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84 пишет:
Обидно только, что либо сигейты испортились, либо производители материнок, т.к. раньше такого не было.
Да неужели? Fujitsu в начале 2000-х не помните (а ведь были одни из самых надёжных по механике)? IBM 40Gb тоже? Про матери вообще молчу… Или вы из тех, у кого «раньше небо было голубее и трава зеленее и …»?
96О-9сорак1-48-осемнацать
15 Ответ от m84 22.07.2013 15:59:52 (9 лет 6 месяцев назад)
- m84
- Участник
- Автор темы
- Неактивен
- Откуда: Барнаул
- Стаж: 15 лет 2 месяца
- Сообщений: 486
- Репутация : [ 16 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
Я из тех, кто сравнивает сигейты трехгодовалой давности с новыми (в одинаковом ценовом сегменте) и наблюдает неприятную тенденцию ухудшения качества. И раньше (на моей памяти) такого не было, чтобы новые материнки с новыми винтами сыпали в SMART кучу ошибок.
16 Ответ от Dim76 22.07.2013 16:00:58 (9 лет 6 месяцев назад)
- Dim76
- Профиль закрыт / 24.10.2020
- Неактивен
- Стаж: 11 лет 11 месяцев
- Сообщений: 21 620
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84, ты не заходи в программы где смарт показывает — и всё будет хорошо ![]()
17 Ответ от bis 22.07.2013 21:12:00 (9 лет 6 месяцев назад)
- bis
- Участник
- Неактивен
- Откуда: Барнаул — столица мира
- Стаж: 10 лет 5 месяцев
- Сообщений: 30 082
- Репутация : [ 762 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84 пишет:
Я из тех, кто сравнивает сигейты трехгодовалой давности с новыми (в одинаковом ценовом сегменте) и наблюдает неприятную тенденцию ухудшения качества. И раньше (на моей памяти) такого не было, чтобы новые материнки с новыми винтами сыпали в SMART кучу ошибок.
Начиная с линейки 7200.11 у них ни одного хорошего винта еще не было, все с косяками
90% проблем решаются сами собой, 10% не решаются в принципе
PS Телефон всегда в кармане, проще позвонить чем написать
Резина Micheline 245/70 R16 комплект
18 Ответ от Slayer 22.07.2013 21:16:35 (9 лет 6 месяцев назад)

- Slayer
- Местный
- Неактивен

- Стаж: 14 лет 9 месяцев
- Сообщений: 5 337
- Репутация : [ 119 | 1 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
CrashX пишет:
я сегейты не покупаю очень давно и рад этому очень
я за WD Blue
+1… Только WD доверяю… Blue в простых компах, черные в подороже. Зеленые под торренты
***
19 Ответ от alex1 23.07.2013 14:47:48 (9 лет 6 месяцев назад)
- alex1
- Участник
- Неактивен
- Стаж: 13 лет 6 месяцев
- Сообщений: 5 801
- Репутация : [ 198 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84 пишет:
такого не было, чтобы новые материнки с новыми винтами сыпали в SMART кучу ошибок.
Это весьма специфические ошибки. Ошибки позиционирования как и ошибки чтения (которые исправлены коррекцией), при современных техпроцессах неизбежны в любых винтах. Ну выводят сигейты их в смарт, другие не выводят. Думаете их нет в других винтах, WD или Hitachi?
96О-9сорак1-48-осемнацать
20 Ответ от m84 24.07.2013 12:31:14 (9 лет 6 месяцев назад)
- m84
- Участник
- Автор темы
- Неактивен
- Откуда: Барнаул
- Стаж: 15 лет 2 месяца
- Сообщений: 486
- Репутация : [ 16 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
alex1 пишет:
Думаете их нет в других винтах, WD или Hitachi?
но ведь раньше и у сигейтов таких ошибок не было — вот я про что.
21 Ответ от alex1 24.07.2013 12:37:43 (9 лет 6 месяцев назад)
- alex1
- Участник
- Неактивен
- Стаж: 13 лет 6 месяцев
- Сообщений: 5 801
- Репутация : [ 198 | 0 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
m84 пишет:
но ведь раньше и у сигейтов таких ошибок не было — вот я про что.
раньше и небо было голубее и трава зеленее и … ![]()
раньше — это когда? 10 лет назад?
ну другие технологии тогда были, всё другое было. и что?
96О-9сорак1-48-осемнацать
22 Ответ от steals 25.07.2013 16:16:05 (9 лет 6 месяцев назад)
- steals
- Трудно всё время оставаться человеком-люди мешают
- Неактивен
- Откуда: Барнапаль
- Стаж: 11 лет 3 месяца
- Сообщений: 4 425
- Репутация : [ 101 | 4 ]
Re: Рост значения S.M.A.R.T. ‘Hardware ECC Recovered’
Был у меня винт Maxtor не помню модели но оч тонкий на 250 гб ! Мля че сним только не делали включенном состоянии били!!!Об стену летал фиг не одного бэда вика не разу даже оранжевого сектора не показала! Может и до сих пор жив!!! ![]()
Отредактировано steals (25.07.2013 16:16:50, 9 лет 6 месяцев назад)
![]()


-Ремонт оборудования TROTEC KONICA MINOLTA EPSON
Просматривают тему: 1 гость, 0 пользователей
Страницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться
«ECC recovered» means that there were bit errors that could be corrected during read. That is not great, because there were media errors, but to a certain extent these are to be expected, which is why the ECC mechanism exists in the first place.
«Uncorrectable ECC» means that enough bit errors existed in a sector that ECC could only tell that some bits were wrong, but could no longer tell which (because if you know which are wrong, you flip them and get the right answer). That is an error that is reported to the host, and means data was lost.
If the host has another copy of the data (e.g. because the disk is part of a RAID array), then the sector is rewritten, possibly stored somewhere else (you’d see that in the «reallocated sector count») and the error shouldn’t reoccur. If there is no other copy, then the error remains on the media, and every further attempt to read the data again reports the sector as unreadable and increments the «uncorrectable» error counter.
So it is difficult to tell whether this is a single error in a place that is used a lot, or a lot of errors in different places, and without a rewrite of the offending sectors, these won’t go away.
I’d run a «long» offline selftest in the SMART utility, followed by chkdsk with a bad sector scan (so chkdsk /r followed by the drive letter), that should make the file system avoid the unreadable sectors, and tell you which files were damaged. This will keep the remapped count at zero, because the sectors will never be rewritten, and the space (a few kilobytes) is lost, but that’s the best you can do in a single-disk setup.
The best way (in my opinion) to run chkdsk is as a scheduled task on startup. If that is the system partition, it should suggest that automatically. This will take a while as it will read the entire disk once.
In the long run, this disk probably has some issues, so make sure you keep backups. I have a lot of disks, and only one has similar numbers, so this is certainly not normal.

ECC DIMM обычно имеют девять микросхем памяти с каждой стороны, на одну больше, чем обычно в модулях DIMM без ECC (некоторые модули могут иметь 5 или 18).[1]
Память кода с исправлением ошибок (Память ECC) является разновидностью компьютерное хранилище данных который может обнаруживать и исправлять n-битные повреждение данных что происходит в памяти. Память ECC используется в большинстве компьютеров, где повреждение данных недопустимо ни при каких обстоятельствах, например, в приложениях промышленного управления, критически важных базах данных или кэше инфраструктурной памяти.
Как правило, память ECC поддерживает систему памяти, невосприимчивую к однобитовым ошибкам: данные, считываемые из каждой слово всегда совпадает с записанными в него данными, даже если один из фактически сохраненных битов перешел в неправильное состояние. Большая часть памяти без ECC не может обнаруживать ошибки, хотя некоторая память без ECC с поддержкой четности позволяет обнаруживать, но не исправлять.
Описание
ECC защищает от необнаруженного повреждения данных памяти и используется в компьютерах, где такое повреждение недопустимо, например, в некоторых научных и финансовых вычислительных приложениях, или в файловые серверы. ECC также снижает количество сбоев, которые особенно недопустимы в многопользовательских серверных приложениях и системах максимальной доступности.
Электрические или магнитные помехи внутри компьютерной системы могут вызвать одиночный разряд динамическая память с произвольным доступом (DRAM) для самопроизвольного перехода в противоположное состояние. Первоначально считалось, что это произошло в основном из-за альфа-частицы испускается загрязнителями в упаковочном материале для чипов, но исследования показали, что большинство одноразовых мягкие ошибки в микросхемах DRAM возникают в результате фоновое излучение, в основном нейтроны от космический луч вторичные, которые могут изменять содержимое одного или нескольких ячейки памяти или вмешиваться в схемы, используемые для чтения или записи в них.[2] Следовательно, частота ошибок быстро увеличивается с увеличением высоты; например, по сравнению с уровнем моря скорость нейтронный поток в 3,5 раза выше на 1,5 км и в 300 раз выше на 10–12 км (крейсерская высота коммерческих самолетов).[3] В результате системы, работающие на больших высотах, требуют особого обеспечения надежности.
Например, космический корабль Кассини – Гюйгенс, выпущенный в 1997 году, содержал два идентичных бортовых самописца, каждый с 2,5 гигабитами памяти в виде массивов коммерческих микросхем DRAM. Благодаря встроенному EDAC функциональность, инженерная телеметрия космического корабля сообщала о количестве (исправляемых) ошибок типа один бит на слово и (не исправляемых) ошибок двойного бит на слово. В течение первых 2,5 лет полета космический аппарат сообщал о почти постоянной частоте однобитовых ошибок около 280 ошибок в день. Однако 6 ноября 1997 г., в течение первого месяца полета, количество ошибок увеличилось более чем в четыре раза за этот день. Это было приписано событие солнечной частицы что было обнаружено спутником GOES 9.[4]
Были некоторые опасения, что по мере дальнейшего увеличения плотности DRAM и, следовательно, уменьшения размеров компонентов на микросхемах, в то время как рабочие напряжения продолжают падать, микросхемы DRAM будут подвергаться воздействию такого излучения чаще, поскольку частицы с более низкой энергией смогут для изменения состояния ячейки памяти.[3] С другой стороны, меньшие ячейки создают меньшие цели и переходят к таким технологиям, как ТАК ЧТО Я может сделать отдельные клетки менее восприимчивыми и, таким образом, противодействовать или даже обратить вспять эту тенденцию. Недавние исследования[5] показывают, что единичные сбои из-за космического излучения резко сокращаются с изменением геометрии технологического процесса, и предыдущие опасения по поводу увеличения количества ошибок в битовых ячейках необоснованны.
Исследование
Работа, опубликованная в период с 2007 по 2009 год, показала сильно различающийся уровень ошибок с разницей более чем на 7 порядков величины, начиная от 10−10 ошибка / бит · ч (примерно одна битовая ошибка в час на гигабайт памяти) до 10−17 ошибка / бит · ч (примерно одна битовая ошибка на миллениум на гигабайт памяти).[5][6][7] Масштабное исследование, основанное на Google очень большое количество серверов было представлено на конференции SIGMETRICS / Performance ’09.[6] Фактический коэффициент ошибок был на несколько порядков выше, чем в предыдущих мелкомасштабных или лабораторных исследованиях, с 25000 (2,5 × 10−11 ошибка / бит · ч) и 70 000 (7,0 × 10−11 ошибка / бит · ч, или 1 битовая ошибка на гигабайт ОЗУ за 1,8 часа) ошибок на миллиард часов устройства на мегабит. Ежегодно более 8% модулей памяти DIMM подвергались ошибкам.
Последствия ошибки памяти зависят от системы. В системах без ECC ошибка может привести либо к сбою, либо к повреждению данных; на крупных производственных объектах ошибки памяти являются одной из наиболее частых аппаратных причин сбоев оборудования.[6] Ошибки памяти могут вызвать уязвимости системы безопасности.[6] Ошибка памяти не может иметь последствий, если она немного изменяет бит, который не вызывает наблюдаемых сбоев и не влияет на данные, используемые в расчетах или сохраняемые. Имитационное исследование 2010 года показало, что для веб-браузера только небольшая часть ошибок памяти вызвала повреждение данных, хотя, поскольку многие ошибки памяти являются прерывистыми и коррелированными, влияние ошибок памяти было больше, чем можно было бы ожидать от независимых программных ошибок.[8]
Некоторые тесты показывают, что изоляция DRAM Ячейки памяти можно обойти с помощью непреднамеренных побочных эффектов специально созданного доступа к соседним ячейкам. Таким образом, доступ к данным, хранящимся в DRAM, приводит к тому, что ячейки памяти теряют свои заряды и электрически взаимодействуют в результате высокой плотности ячеек в современной памяти, изменяя содержимое соседних строк памяти, которые фактически не были адресованы в исходном доступе к памяти. Этот эффект известен как гребной молот, и он также использовался в некоторых повышение привилегий компьютерная безопасность подвиги.[9][10]
Пример однобитовой ошибки, которая будет проигнорирована системой без проверки ошибок, остановит машину с проверкой четности или будет незаметно исправлена ECC: один бит застревает на 1 из-за неисправного чипа, или становится 1 из-за фона или космического излучения; загружается электронная таблица, хранящая числа в формате ASCII, и символ «8» (десятичное значение 56 в кодировке ASCII) сохраняется в байте, который содержит застрявший бит в его самой нижней битовой позиции; затем в электронную таблицу вносятся изменения, и она сохраняется. В результате «8» (0011 1000 двоичный) молча превратился в «9» (0011 1001).
Решения
Было разработано несколько подходов для борьбы с нежелательными переворотами битов, в том числе программирование с учетом иммунитета, Четность RAM память и ECC объем памяти.
Эту проблему можно смягчить, используя модули DRAM, которые включают в себя дополнительные биты памяти, и контроллеры памяти, которые используют эти биты. Эти дополнительные биты используются для записи паритет или использовать код исправления ошибок (ECC). Четность позволяет обнаруживать все однобитовые ошибки (фактически, любое нечетное количество ошибочных битов). Наиболее распространенный код исправления ошибок, a исправление одиночной ошибки и обнаружение двойной ошибки (ОТДЕЛЬНО) Код Хэмминга, позволяет исправлять однобитовые ошибки и (в обычной конфигурации с дополнительным битом четности) обнаруживать двухбитовые ошибки. Чипкилл ECC — более эффективная версия, которая также исправляет несколько битовых ошибок, включая потерю всего чипа памяти.
Реализации
Сеймур Крей классно сказал «паритет для фермеров «когда его спросили, почему он оставил это вне CDC 6600.[11] Позже, он включил паритет в CDC 7600, что заставило ученых мужей заметить, что «очевидно, что многие фермеры покупают компьютеры». Оригинал IBM PC и все ПК до начала 1990-х годов использовали проверку четности.[12] Более поздние по большей части этого не сделали. Многие современные микропроцессорные контроллеры памяти поддерживают ECC, но многие материнские платы, в частности платы, использующие младшие наборы микросхем, не поддерживают.[нужна цитата ]
Контроллер памяти с поддержкой ECC может обнаруживать и исправлять ошибки одного бита на 64-битный «слово «(единица автобус передачи), и обнаруживать (но не исправлять) ошибки двух битов на 64-битное слово. В BIOS на некоторых компьютерах при использовании с операционными системами, такими как некоторые версии Linux, macOS, и Windows,[нужна цитата ] позволяет подсчитывать обнаруженные и исправленные ошибки памяти, в частности, чтобы помочь выявить неисправные модули памяти до того, как проблема станет катастрофической.
Некоторые микросхемы DRAM включают «внутренние» схемы коррекции ошибок на кристалле, которые позволяют системам с контроллерами памяти без ECC по-прежнему получать большинство преимуществ памяти ECC.[13][14] В некоторых системах подобный эффект может быть достигнут при использовании Память EOS модули.
Обнаружение и исправление ошибок (EDAC) зависит от ожидаемого типа возникающих ошибок. Неявно предполагается, что сбой каждого бита в слове памяти независим, что приводит к маловероятности двух одновременных ошибок. Раньше так было, когда микросхемы памяти имели ширину в один бит, что было типично для первой половины 1980-х годов; более поздние разработки переместили много битов в один и тот же чип. Этот недостаток устраняется различными технологиями, в том числе IBM с Чипкилл, Sun Microsystems ‘ Расширенный ECC, Hewlett Packard с Chipspare, и Intel с Коррекция данных одного устройства (SDDC).
DRAM память может обеспечить повышенную защиту от мягкие ошибки полагаясь на коды исправления ошибок. Такие исправляющая память, известный как ECC или EDAC-защищенный память, особенно желательна для приложений с высокой отказоустойчивостью, таких как серверы, а также для приложений дальнего космоса из-за увеличения радиация. Некоторые системы также «скраб «память» путем периодического чтения всех адресов и обратной записи исправленных версий, если это необходимо для удаления программных ошибок.
Чередование позволяет распределить эффект одного космического луча, потенциально нарушая несколько физически соседних битов в нескольких словах, связывая соседние биты с разными словами. Пока одно событие расстроено (SEU) не превышает пороговое значение ошибки (например, единственная ошибка) в любом конкретном слове между доступами, это может быть исправлено (например, с помощью однобитового кода исправления ошибок), и эффективно безошибочная система памяти может быть поддерживается.[15]
Контроллеры памяти с исправлением ошибок традиционно используют Коды Хэмминга, хотя некоторые используют тройное модульное резервирование (ПМР). Последнее предпочтительнее, потому что его оборудование быстрее, чем у схемы исправления ошибок Хэмминга.[15] В космических спутниковых системах часто используется TMR,[16][17][18] хотя спутниковая RAM обычно использует исправление ошибок Хэмминга.[19]
Многие ранние реализации корректируемых ошибок памяти ECC маскируют, действуя «так, как будто» ошибки никогда не возникали, и сообщают только о неисправимых ошибках. Современные реализации регистрируют как исправимые ошибки (CE), так и неисправимые ошибки (UE). Некоторые люди заблаговременно заменяют модули памяти, которые демонстрируют высокий уровень ошибок, чтобы снизить вероятность возникновения неисправимых ошибок.[20]
Многие системы памяти ECC используют «внешнюю» схему EDAC между процессором и памятью. Некоторые системы с памятью ECC используют как внутренние, так и внешние системы EDAC; внешняя система EDAC должна быть разработана таким образом, чтобы исправлять определенные ошибки, которые внутренняя система EDAC не может исправить.[13] Современные настольные и серверные ЦП интегрируют схему EDAC в ЦП,[21] еще до перехода на контроллеры памяти, интегрированные в ЦП, которые связаны с NUMA архитектура. Интеграция с ЦП обеспечивает систему EDAC без штрафных санкций во время безошибочной работы.
С 2009 года наиболее распространенные коды исправления ошибок используют коды Хэмминга или Сяо, которые обеспечивают исправление однобитовых ошибок и обнаружение двухбитовых ошибок (SEC-DED). Для защиты памяти были предложены другие коды с коррекцией ошибок — коды с двухбитовой коррекцией ошибок и трехбитовые коды с обнаружением ошибок (DEC-TED), коды с исправлением ошибок с одним полубайтом и коды обнаружения ошибок с двумя полубайтами (SNC-DND), Исправление ошибок Рида – Соломона коды и т. д. Однако на практике многобитовая коррекция обычно осуществляется путем чередования нескольких кодов SEC-DED.[22][23]
Ранние исследования пытались минимизировать накладные расходы на площадь и задержку в схемах ECC. Хэмминг впервые продемонстрировал, что коды SEC-DED возможны с одной конкретной проверочной матрицей. Сяо показал, что альтернативная матрица со столбцами с нечетным весом обеспечивает возможность SEC-DED с меньшей площадью аппаратного обеспечения и более короткой задержкой, чем традиционные коды Хэмминга SEC-DED. В более поздних исследованиях также делается попытка минимизировать мощность в дополнение к минимизации площади и задержки.[24][25][26]
Кеш
Многие процессоры используют коды исправления ошибок в кэш на кристалле, включая Intel Itanium и Xeon[27] процессоры AMD Athlon, Opteron, все Дзен —[28] и Дзен + -на основании[29] процессоры (EPYC, EPYC встроенный, Райзен и Райзен Threadripper ) и DEC Alpha 21264.[22][30]
По состоянию на 2006 г., EDC / ECC и ECC / ECC — два наиболее распространенных метода защиты от ошибок кэша, используемые в коммерческих микропроцессорах. Метод EDC / ECC использует код обнаружения ошибок (EDC) в кэше уровня 1. При обнаружении ошибки данные восстанавливаются из кэша уровня 2, защищенного с помощью ECC. В методе ECC / ECC используется кэш уровня 1 с защитой ECC и кэш уровня 2 с защитой ECC.[31] ЦП, которые всегда используют технологию EDC / ECC сквозная запись все ХРАНИЛИЩА в кэш уровня 2, так что при обнаружении ошибки во время чтения из кеша данных уровня 1 копия этих данных может быть восстановлена из кеша уровня 2.
Зарегистрированная память
Зарегистрированная или буферизованная память — это не то же самое, что ECC; технологии выполняют разные функции. Обычно память, используемая на серверах, регистрируется, чтобы позволить использовать многие модули памяти без электрических проблем, и ECC для целостности данных. Память, используемая в настольных компьютерах, не предназначена для экономии. Однако доступна небуферизованная (незарегистрированная) память ECC,[32] а некоторые несерверные материнские платы поддерживают функции ECC таких модулей при использовании с ЦП, поддерживающим ECC.[33] Зарегистрированная память не работает надежно на материнских платах без схемы буферизации, и наоборот.
Преимущества и недостатки
В конечном итоге существует компромисс между защитой от необычной потери данных и более высокой стоимостью.
Память ECC обычно имеет более высокую цену по сравнению с памятью без ECC из-за дополнительного оборудования, необходимого для производства модулей памяти ECC, а также из-за меньших объемов производства памяти ECC и связанного с ней системного оборудования. Материнские платы, чипсеты и процессоры, поддерживающие ECC, также могут быть более дорогими.
Поддержка ECC варьируется от производителей материнских плат, поэтому память ECC может просто не распознаваться материнской платой, несовместимой с ECC. Наиболее материнские платы а процессоры для менее важных приложений не предназначены для поддержки ECC, поэтому их цены могут быть ниже. Некоторые платы и процессоры с поддержкой ECC могут поддерживать небуферизованную (незарегистрированную) ECC, но также будут работать с памятью без ECC; микропрограмма системы включает функцию ECC, если установлена память ECC.
ECC может снизить производительность памяти примерно на 2–3 процента в некоторых системах, в зависимости от приложения и реализации, из-за дополнительного времени, необходимого контроллерам памяти ECC для выполнения проверки ошибок.[34] Однако современные системы интегрируют тестирование ECC в ЦП, не создавая дополнительной задержки при доступе к памяти, пока не обнаруживаются ошибки.[21][35][36]
Память с поддержкой ECC может способствовать дополнительному потреблению энергии из-за схемы исправления ошибок.
использованная литература
- ^ Вернер Фишер. «RAM раскрыта». admin-magazine.com. Получено 20 октября, 2014.
- ^ Расстройство одиночного мероприятия на уровне земли, Юджин Норманд, член IEEE, Boeing Defense & Space Group, Сиэтл, Вашингтон, 98124-2499
- ^ а б «Обзор методов моделирования и повышения надежности вычислительных систем «, IEEE TPDS, 2015 г.
- ^ Гэри М. Свифт и Стивен М. Гертин. «Наблюдения в полете множественных сбоев в DRAM». Лаборатория реактивного движения
- ^ а б Боруки, «Сравнение ускоренных коэффициентов мягких ошибок DRAM, измеренных на уровне компонентов и систем», 46-й ежегодный международный симпозиум по физике надежности, Феникс, 2008 г., стр. 482–487
- ^ а б c d Шредер, Бьянка; Пинейро, Эдуардо; Вебер, Вольф-Дитрих (2009). Ошибки DRAM в дикой природе: крупномасштабное полевое исследование (PDF). СИГМЕТРИКА / Производительность. ACM. ISBN 978-1-60558-511-6. Сложить резюме – ZDNet.
- ^ «Измерение программных ошибок памяти в производственных системах». Архивировано из оригинал на 2017-02-14. Получено 2011-06-27.
- ^ Ли, Хуанг; Шен, Чу (2010). ««Реалистичная оценка аппаратных ошибок памяти и уязвимости программного обеспечения «. Ежегодная техническая конференция Usenix 2010» (PDF).
- ^ Юнгу Ким; Росс Дейли; Джереми Ким; Крис Фоллин; Джи Хе Ли; Донхёк Ли; Крис Вилкерсон; Конрад Лай; Онур Мутлу (24.06.2014). «Перемещение битов в памяти без доступа к ним: экспериментальное исследование ошибок нарушения памяти DRAM» (PDF). ece.cmu.edu. IEEE. Получено 2015-03-10.
- ^ Дэн Гудин (10 марта 2015 г.). «Передовой хакерский метод дает статус суперпользователя, используя слабые места DRAM». Ars Technica. Получено 2015-03-10.
- ^ «CDC 6600». Microsoft Research. Получено 2011-11-23.
- ^ «Проверка четности». Pcguide.com. 2001-04-17. Получено 2011-11-23.
- ^ а б А. Х. Джонстон.«Эффекты космической радиации в сложных воспоминаниях о вспышках» В архиве 2016-03-04 в Wayback Machine.NASA Программа электронных компонентов и упаковки (NEPP). 2001 г.
- ^ «ECC DRAM — интеллектуальная память». Intelligentmemory.com. Получено 2014-12-23.
- ^ а б «Использование StrongArm SA-1110 в бортовом компьютере наноспутника». Космический центр Цинхуа, Университет Цинхуа, Пекин. Архивировано из оригинал на 2011-10-02. Получено 2009-02-16.
- ^ «Инженеры Actel используют трехмодульное резервирование в новой ПЛИС Rad-Hard». Военная и аэрокосмическая электроника. Архивировано из оригинал на 2012-07-14. Получено 2009-02-16.
- ^ «Упрочнение SEU программируемых вентильных матриц (FPGA) для космических приложений и определения характеристик устройств». Klabs.org. 2010-02-03. Архивировано из оригинал на 2011-11-25. Получено 2011-11-23.
- ^ «ПЛИС в космосе». Techfocusmedia.net. Получено 2011-11-23.[постоянная мертвая ссылка ]
- ^ «Технологии коммерческой микроэлектроники для применения в радиационной среде спутников». Radhome.gsfc.nasa.gov. Получено 2011-11-23.
- ^ Дуг Томпсон, Мауро Карвалью Чехаб.«EDAC — обнаружение и исправление ошибок» В архиве 2009-09-05 на Wayback Machine.2005 — 2009. «Цель модуля ядра ‘edac’ — обнаруживать и сообщать об ошибках, которые происходят в компьютерной системе, работающей под Linux».
- ^ а б «Руководство по программному обеспечению / BIOS системного контроллера AMD-762 ™, стр. 179» (PDF).
- ^ а б До Хён Юн; Мэттан Эрез. «Memory Mapped ECC: недорогая защита от ошибок для кэшей последнего уровня». 2009. с. 3
- ^ Даниэле Росси; Никола Тимончини; Майкл Спика; Сесилия Метра.«Анализ кода с исправлением ошибок для обеспечения высокой надежности и производительности кэш-памяти» В архиве 2015-02-03 в Wayback Machine.
- ^ Шалини Гош; Сугато Басу; и Нур А. Туба. «Выбор кодов исправления ошибок для минимизации мощности в схемах проверки памяти» В архиве 2015-02-03 в Wayback Machine. п. 2 и стр. 4.
- ^ Крис Вилкерсон; Алаа Р. Аламельдин; Зешан Чишти; Вэй Ву; Динеш Сомасекхар; Ши-лен Лу. «Снижение мощности кэш-памяти с помощью недорогих многобитовых кодов с исправлением ошибок». Дои: 10.1145/1816038.1815973.
- ^ M. Y. Hsiao. «Класс оптимальных кодов SEC-DED для столбца с минимальным нечетным весом». 1970.
- ^ Корпорация Intel.«Семейство процессоров Intel Xeon E7: надежность, доступность и удобство обслуживания».2011.p. 12.
- ^ «Микроархитектура AMD Zen — Иерархия памяти». WikiChip. Получено 15 октября 2018.
- ^ «Микроархитектура AMD Zen + — Иерархия памяти». WikiChip. Получено 15 октября 2018.
- ^ Чану Ким; Никос Хардавеллас; Кен Май; Бабак Фальсафи; Джеймс С. Хоу.«Многобитовые кэши, устойчивые к ошибкам, использующие двумерное кодирование ошибок».2007.стр. 2.
- ^ Натан Н. Сэдлер и Дэниел Дж. Сорин.«Выбор схемы защиты от ошибок для кэша данных L1 микропроцессора».2006.p. 1.
- ^ «Типичный модуль ОЗУ без буферизации ECC: Crucial CT25672BA1067».
- ^ Спецификация системной платы для настольных ПК, которая поддерживает небуферизованную оперативную память как с ECC, так и без ECC с совместимыми процессорами
- ^ «Обсуждение ECC на pcguide». Pcguide.com. 2001-04-17. Получено 2011-11-23.
- ^ Тест платформы AMD-762 / Athlon с ECC и без него В архиве 2013-06-15 на Wayback Machine
- ^ «ECCploit: память ECC все-таки уязвима для атак Rowhammer». Группа системной и сетевой безопасности в VU Amsterdam. Получено 2018-11-22.
внешние ссылки
- SoftECC: система проверки целостности программной памяти
- Настраиваемая программная библиотека обнаружения и исправления ошибок DRAM для HPC
- Обнаружение и исправление скрытых искажений данных для крупномасштабных высокопроизводительных вычислений
- Однобитовые ошибки: взгляд поставщика модуля памяти на причину, влияние и обнаружение
- Руководство по настройке памяти для процессоров Intel Xeon E3 — 1200 семейства продуктов