
Время на прочтение
22 мин
Количество просмотров 69K

Пост содержит перевод статьи «Error Handling in Node.js», которую подготовили сотрудники компании Joyent. Статья была опубликована 28 марта 2014 года на сайте компании. Dave Pacheco поясняет, что статья призвана устранить неурядицу среди разработчиков, касаемо лучших практик работы с ошибками в Node.js, а так же ответить на вопросы, которые часто возникают у начинающих разработчиков.
Обработка ошибок в Node.js
По мере освоения Node.js можно достаточно долго писать программы, не уделяя при этом должного внимания корректной обработке ошибок. Однако, разработка серьёзных проектов на Node.js требует осознанного подхода к этой проблеме.
У начинающих разработчиков часто возникают следующие вопросы:
- Можно ли использовать
throw, что бы вернуть ошибку из функции или следует вызывать callback-функцию передав объект ошибки в качестве аргумента? В каких случаях необходимо генерировать событие'error'у объекта класса EventEmitter? - Нужно ли производить проверку аргументов переданных функции? Что, если в функцию переданы некорректные аргументы? Нужно ли в таком случае генерировать исключение или вызывать callback-функцию, передавая ей ошибку?
- Возможно ли программно различать ошибки по типу, что бы приложение могло соответствующим образом обрабатывать ошибки согласно их типу (например, «Bad Request» или «Service Unavailable»)?
- Как функция может наиболее информативно «сообщить» программе о возникновении ошибки, чтобы та могла корректно её обработать?
- Нужно ли обрабатывать ошибки вызванные «багами» в программе?
Данная статья состоит из семи частей:
- Введение. О том, что читатель должен знать перед ознакомлением со статьей.
- Программные ошибки и ошибки программиста. Ознакомление с типами ошибок.
- Шаблоны написания функций. Основополагающие принципы написания функций, реализующих корректную работу с ошибками.
- Правила написания функций. Перечень указаний которым следует придерживаться при написании функций.
- Пример. Пример написания функции.
- Резюме. Краткое представление основных положений рассмотренных в статье.
- Приложение. Общепринятые имена полей объектов ошибок.
1. Введение
Предполагается, что читатель:
- знаком с термином «исключение» в JavaScript, Java, Python, C++, или другом подобном языке и понимает принцип работы конструкции
try/catch; - знаком с разработкой на Node.js и освоил принципы асинхронного программирования.
Читатель должен понимать, почему в представленном ниже коде не работает перехват исключений, несмотря на наличие конструкции try/catch.1
function myFunc(callback)
{
/*
* Пример некорректного перехвата исключений
*/
try {
doSomeAsyncOperation(function (err) {
if (err) {
throw (err);
}
});
} catch (ex) {
callback(ex);
}
}
Читателю следует знать, что в Node.js существует 3 основных способа, которыми функция может вернуть ошибку:
- Бросание ошибки
throw(генерирование исключения). - Вызов callback-функции с объектом ошибки в качестве первого аргумента.
- Генерирование события
'error'у объекта класса EventEmitter.
Предполагается, что читатель не знаком с доменами в Node.js.
Читатель должен понимать разницу между ошибкой и исключением в JavaScript. Ошибка — это любой объект класса Error. Ошибка может быть создана конструктором класса и возвращена из функции либо брошена с помощью инструкции ThrowStatement. Когда объект ошибки брошен, возникает исключение. Далее приведён пример бросания ошибки (генерирование исключения):2
throw new Error('произошла ошибка');
Пример, где ошибка передаётся в callback-функцию:
callback(new Error('произошла ошибка'));
Второй вариант чаще встречается в Node.js, из-за асинхронности большинства выполняемых операций. Как правило, первый вариант используется лишь при десериализации данных (например, JSON.parse), при этом брошенное исключение перехватывается с помощью конструкции try/catch. Это отличает Node.js от Java или C++ и других языков, где приходится чаще работать с исключениями.
2. Программные ошибки и ошибки программиста
Ошибки можно условно разделить на два типа:3
- Программные ошибки представляют собой конфликты, возникающие в ходе нормального функционирования программы. Они не являются «багами». Обычно, они не связаны напрямую с программой: системные ошибки (например, переполнение памяти), ошибки конфигураций (например, неверно указан адрес удалённого сервера), ошибки интернет-соединения или ошибки возникшие на удалённом сервере.
Примеры программных ошибок:- пользователь ввёл некорректные данные,
- истекло время ожидания ответа на запрос (request timeout),
- сервер ответил на запрос ошибкой с кодом 500,
- разрыв соединения,
- израсходована выделенная память.
- Ошибки программиста — это дефекты кода, приводящие к некорректной работе программы. Ошибки данного типа не могут быть правильно обработаны, так как сам факт их наличия говорит о некорректности написанного кода. Ошибки этого типа возможно устранить изменив код программы. К ошибкам программиста можно отнести:
- попытку обратиться к какому-либо полю у значения
undefined, - вызов асинхронной функции без callback-функции,
- вызов функции с некорректными аргументами.
- попытку обратиться к какому-либо полю у значения
Разработчики используют термин «ошибка» для обоих типов ошибок, несмотря на их принципиальные различия. «Файл не найден» — программная ошибка, её возникновение может означать, что программе требуется создать искомый файл. Таким образом, возникновение этой ошибки не является некорректным поведением программы. Ошибки программиста, напротив, не предполагались разработчиком. Возможно, разработчик ошибся в имени переменной или неправильно описал проверку данных, введённых пользователем. Данный тип ошибок не поддается обработке.
Возможны случаи, когда по одной и той же причине возникают как программная ошибка, так и ошибка программиста. Предположим, HTTP-сервер производит попытку считать какое-либо поле у значения undefined, что является ошибкой программиста. В результате, сервер выходит из строя. Клиент, при этом, в качестве ответа на свой запрос получает ошибку ECONNRESET, обычно описываемую Node.js как: «socket hang-up». Для клиента, это программная ошибка и корректно написанная программа-клиент соответствующим образом обработает ошибку и продолжит работу.
Отсутствие обработчика программной ошибки является ошибкой программиста. Предположим, что программа-клиент, устанавливая соединение с сервером, сталкивается с ECONNREFUSED ошибкой, в результате, объект соединения генерирует событие 'error', но для данного события не зарегистрирована ни одна функция-обработчик, по этой причине программа выходит из строя. В данном случае, ошибка соединения является программной ошибкой, однако, отсутствие обработчика для события ‘error’ объекта соединения — ошибка программиста.
Важно понимать различия между ошибками программиста и программными ошибками. Поэтому, прежде чем продолжать чтение статьи, убедитесь, что вы разобрались в этих понятиях.
Обработка программных ошибок
Обработка программных ошибок, так же как и вопросы безопасности или производительности приложения, не относится к тому типу задач, которые могут быть решены внедрением какого-либо модуля — невозможно в одном месте исходного кода решить все проблемы связанные с обработкой ошибок. Для решения задачи обработки ошибок требуется децентрализованный подход. Для всех участков программы, где возможно возникновение ошибки (обращение к файловой системе, соединение с удалённым сервером, создание дочернего процесса и т.д.) необходимо предписать соответствующие сценарии обработки для каждого возможного типа ошибки. Значит, необходимо не только выделить проблемные участки, но и понять каких типов ошибки могут в них возникнуть.
В некоторых случаях приходится передавать объект ошибки из функции, в которой она возникла, через callback-функцию на уровень выше, а из него еще выше, таким образом ошибка «всплывает» до тех пор, пока не достигнет логического уровня приложения, который ответственен за обработку данного типа ошибок. На ответственном уровне программа может принять решение: запустить ли проблемную операцию повторно, сообщить ли об ошибке пользователю или записать информацию об ошибке в лог-файл и пр. Не следует всегда полагаться на эту схему и передавать ошибки более высоким уровням иерархии, так как callback-функции на высоких уровнях ничего не знают о том, в каком контексте возникла переданная им ошибка. В результате, может возникнуть ситуация, когда на выбранном логическом уровне будет сложно описать логику обработки, соответствующую возникшей ошибке.
Выделим возможные сценарии обработки ошибок:
- Устранение ошибки. Иногда, возникшую ошибку можно устранить. Предположим, возникла ошибка ENOENT, при попытке записать информацию в лог-файл. Это может означать, что программа запущена впервые и лог-файл еще не создан. В таком случае, обработчик может устранить ошибку, создав искомый файл. Приведём более интересный пример: программе необходимо постоянно поддерживать соединение с определённым севером (например, с базой данных), но в ходе работы возник разрыв соединения. В этом случае обработчик ошибки может произвести переподключение к базе данных.
- Информирование пользователя и прекращение обработки запроса. Если нельзя решить возникшую проблему, проще всего прервать работу текущей операции, и сообщить пользователю об ошибке. Данный сценарий применим в случаях, когда известно, что причина, по которой возникла ошибка, не исчезнет с течением времени. К примеру, если ошибка возникла при попытке десериализации JSON-данных, переданных клиентом, то нет смысла повторять попытку с этими же данными.
- Повторение операции. В случае ошибок связанных с работой по сети может помочь повторный запуск операции. Предположим, программа в ответ на запрос к удалённому сервису получила в ответе ошибку 503 (Service Unavailable error), в таком случае, возможно, стоит повторить запрос спустя несколько секунд. Важно определить конечное число повторов, а так же, с какой периодичностью должны выполняться попытки. Но не следует всегда полагаться на данный сценарий. Предположим, пользователь выполнил запрос к некоторому сервису, которому для обработки запроса потребовалось обратиться к вашей программе, а ваша программа, в свою очередь, осуществляет запрос к еще одному сервису, который ответил ошибкой 503. В этом случае, лучшим решением будет не выполнять повторных попыток, а незамедлительно дать возможность обработать ошибку исходному сервису, с которым работает пользователь. Если каждый сервис, участвующий в цепочке запросов, будет производить повторные попытки, то пользователь будет ожидать ответ на свой запрос дольше чем, если бы их выполнял только исходный сервис.
- Прекращение работы программы. Если произошла непредвиденная ситуация, появление которой невозможно при нормальном функционировании программы, следует записать информацию об ошибке в соответствующий лог-файл и прекратить работу. Данный сценарий может быть использован, если ваша программа израсходовала доступную память (однако, если ваша программа получила ошибку ENOMEM от дочернего процесса, то ошибку можно обработать и не прекращать работу программы). Так же, данный сценарий можно применить если у вашей программы нет прав доступа к необходимым для работы файлам.
- Запись ошибки в лог-файл и продолжение работы. В некоторых случаях нет необходимости прекращать работу программы даже если возникшая ошибка неустранима. В пример можно привести ситуацию, когда ваша программа периодически обращается к группе удалённых сервисов через систему DNS, и один из сервисов «выпал» из DNS. В данной ситуации программа может продолжить работу с оставшимися сервисами. Но, тем не менее, необходимо записать об ошибке в лог-файл. (Для любого правила всегда есть исключения, если ошибка возникает тысячу раз в секунду, и вы не можете ничего с ней поделать, то не нужно каждый раз выполнять запись в лог, однако, стоит периодически производить логирвоание.)
Обработка ошибок программиста
Не существует правильного способа обрабатывать ошибки программиста. По определению, если возникла такая ошибка, то код программы некорректен. Устранить проблему можно лишь исправив код.
Есть программисты считающие, что в некоторых случаях можно восстанавливать программу после произошедшей ошибки таким образом, что текущая операция прерывается, но программа, тем не менее, продолжает работать и обрабатывать другие запросы. Так поступать не рекомендуется. Принимая во внимание то, что ошибка программиста вводит программу в нестабильное состояние, можете ли вы быть уверены в том, что возникшая ошибка не нарушит работу других запросов? Если запросы работают с одними и теми же сущностями (например, сервер, сокет, соединения с базой данных и т.д.), остаётся лишь надеется, что последующие запросы будут правильно обработаны.
Рассмотрим REST-сервис (реализованный, например, с помощью модуля restify). Предположим, что один из обработчиков запросов бросил исключение RefferenceError из-за того, что программист сделал опечатку в имени переменной. Если немедленно не прекратить работу сервиса, может возникнуть ряд проблем, которые бывает сложно отследить:
- Если какая-то сущность в результате опечатки оказалась равна
nullилиundefined, то последующие запросы, обратившись к ней, так же, бросят исключения и не будут обработаны. - Если функция, которая бросила исключение, работала с базой данных, может произойти утечка соединия. Каждый раз, когда подобная ошибка будет повторяться, число соединений, используя которые сервис может работать с базой данных, будет уменьшаться.
- Более сложная ситуация может произойти, если в качестве базы данных используется postgres, и соединение осталось незакрытым в ходе выполнения транзакции. В этом случае, «повисшая» транзакция не даст очищать старые версии записей, которые для неё видны. Транзакция может оставаться открытой неделями. Размер, который таблица занимает в памяти, будет расти без ограничений, что приведёт к тому, что обработка последующих запросов будет замедляться.4 Конечно, данный пример достаточно специфичен и касается лишь postgres, однако, он отлично иллюстрирует, что опасно продолжать работу программы, которая пребывает в нестабильном состоянии.
- Соединение к удалённому сервису может остаться с незакрытой сессией, вследствие чего, следующий запрос может быть обработан от лица не того пользователя.
- Может остаться незакрытым сокет. По умолчанию Node.js закроет неактивный сокет через две минуты, но это поведение может быть переопределено, и если ошибка будет повторяться, то в итоге число возможных сокетов будет исчерпано. Если вы оставите конфигурации по умолчанию, отследить и исправить проблему будет тяжело, так как ошибка о неактивном сокете возникает с задержкой в две минуты.
- Может возникнуть утечка памяти, которая приведёт к её переполнению и выходу программы из строя. Или еще хуже — утечка может усложнить процесс сборки мусора, из-за чего начнет страдать производительность программы. Обнаружить причину проблемы в таком случае будет особенно затруднительно.
Учитывая вышеперечисленное, в таких ситуациях лучшим решением будет прервать работу программы. Вы можете перезапускать свою программу, после того как она была прервана — такой подход позволит автоматически восстанавливать стабильную работу вашего сервиса после возникающих ошибок.
Единственный, но существенный, недостаток этого подхода заключается в том, что будут отключены все пользователи работавшие с сервисом в момент перезапуска. Имейте ввиду следующее:
- Сбои вызванные ошибкой программиста вводят приложение в нестабильное состояние. Нужно стремиться к тому, чтобы таких ошибок не возникало, их устранение имеет наивысший приоритет.
- После перезапуска запросы могут как выполняться корректно, так и снова привести к ошибке. Может случиться так, что запросы обрабатываются некорректно, но отследить проблему сложно.
- В хорошо спроектированной системе, независимо от того вызвана ли ошибка проблемой с интернет-соединением или ошибка произошла в Node.js, программа-клиент должна уметь обрабатывать ошибки сервера (переподключаться, выполнять повторные запросы).
Если перезапуск программы происходит очень часто, то следует отлаживать код и устранять ошибки. Лучшим способом для отладки будет сохранение и анализ снимка ядра. Данный подход работает как в GNU/Linux-системах, так и в illumos-системах, и позволяет просмотреть не только последовательность функций, которые привели к ошибке, но и переданные им аргументы, а так же состояние других объектов, видимых через замыкания.
3. Шаблоны написания функций
Во-первых стоит отметить, что очень важно подробно документировать свои функции. Необходимо описывать, что возвращает функция, какие аргументы принимает и какие ошибки могут возникнуть в процессе выполнения функции. Если не определить типы возможных ошибок и не сформулировать, что они означают, то вы не сможете правильно написать обработчик.
Throw, callback или EventEmitter?
Существует три основных способа вернуть ошибку из функции:
throwвозвращает ошибку синхронно. Это значит, что исключение возникнет в том же контексте, в котором функция была вызвана. Если используется try/catch, то исключение будет поймано. В противном случае — программа выйдет из строя (если, конечно, исключение не отловит домен или обработчик события'uncaughtException'глобального объекта process, такой вариант будет рассмотрен далее).- Вызов callback-функции с объектом ошибки в качестве первого аргумента является наиболее часто используемым способом вернуть ошибку из асинхронной функции. Общепринятым шаблоном вызова callback-функции является вызов вида
callback(err, results), где только один из аргументов может принимать значения отличные отnull. - В более сложных случаях функция может генерировать событие
'error'объекта класса EventEmitter, тогда ошибка будет обработана, если зарегистрирован обработчик для события'error'. Данный вариант используется если:- производится комплексная операция, которая возвращает несколько результатов или ошибок. Примером может быть извлечение записей из базы данных. Функция возвращает объект класса EventEmitter и вызывает событие
'row'— при извлечении каждой записи,"end"— когда все записи извлечены и'error'— если возникает ошибка. - объект представляет собой сложный автомат, производящий множество асинхронных операций. В пример можно привести сокет, вызывающий события
'connect','end','timeout','drain'и'close'. При возникновении ошибки, объект будет генерировать событие'error'. Используя данный подход важно понимать, в каких ситуациях может возникать ошибка, могут ли при этом возникать и другие события и в каком порядке они возникают.
- производится комплексная операция, которая возвращает несколько результатов или ошибок. Примером может быть извлечение записей из базы данных. Функция возвращает объект класса EventEmitter и вызывает событие
Использование callback-функций и генерирование событий относятся к асинхронным способам возврата ошибок. Если производится асинхронная операция, то реализуется один из этих способов, но никогда не используются сразу оба.
Итак, когда же использовать throw, а когда использовать callback-функции или события? Это зависит от двух факторов:
- типа ошибки (ошибка программиста или программная ошибка),
- типа функции в которой возникла ошибка (асинхронная или синхронная).
Программные ошибки характерны в большей мере для асинхронных функций. Асинхронные функции принимают в качестве аргумента callback-функцию, при возникновении ошибки она вызвается с объектом ошибки в качестве аргумента. Такой подход отлично себя зарекомендовал и широко применяется. В качестве примера можно ознакомиться с Node.js модулем fs. Событийный подход так же используется, но уже в более сложных случаях.
Программные ошибки в синхронных функциях могут возникать, как правило, если функция работает с данными, введёнными пользователем (например JSON.parse). В таких функциях при возникновении ошибки бросается исключение, реже – объект ошибки возвращается оператором return.
Если в функции хотя бы одна из возможных ошибок асинхронна, то все возможные ошибки должны возвращаться из функции используя асинхронный подход. Даже если ошибка возникла в том же контексте, в котором была вызвана функция, объект ошибки следует вернуть асинхронно.
Есть важное правило: для возврата ошибок в одной и той же функции может быть реализован либо синхронный, либо асинхронный подход, но никогда и тот и другой вместе. Тогда, чтобы принимать у функции ошибку, нужно будет использовать либо callback-функцию (или функцию-обработчик события 'error'), либо конструкцию try/catch, но никогда и то и другое. В документации к функции следует указывать, какой из способов к ней применим.
Проверка входных аргументов как правило позволяет, предупредить многие ошибки, которые совершают программисты. Часто случается, что при вызове асинхронной функции, ей забывают передать callback-функцию, в результате, чтобы понять где возникает ошибка, разработчику приходится, как минимум, просмотреть стек вызванных функций. Поэтому, если функция асинхронна, то в первую очередь, важно проверять передана ли callback-функция. Если не передана, то необходимо генерировать исключение. Кроме того, в начале функции следует проверять типы переданных ей аргументов, и так же генерировать исключение, если если они некорректны.
Напомним, что ошибки программиста не являются частью нормального процесса работы программы. Они не должны отлавливаться и обрабатываться. Поэтому данные рекомендации о немедленном бросании исключений при ошибках программиста не противоречат сформулированному выше правилу о том, что одна и та же функция не должна реализовывать как синхронный так и асинхронный подход для возврата ошибок.
Рассмотренные рекомендации представлены в таблице:
| Пример функции | Тип функции | Ошибка | Тип ошибки | Как возвращать | Как обрабатывать |
fs.stat |
асинхронная | файл не найден | программная | callback | функция-обработчик |
JSON.parse |
синхронная | ошибка ввода | программная | throw |
try/catch |
fs.stat |
асинхронная | отсутствует обязательный аргумент | ошибка программиста | throw |
не обрабатывается (прекращение работы) |
В первой записи представлен наиболее часто встречаемый пример — асинхронная функция. Во второй строке – пример для синхронной функции, такой вариант встречается реже. В третей строке — ошибка программиста, желательно, чтобы подобные случаи имели место лишь в процессе разработки программы.
Ошибка ввода: ошибка программиста или программная ошибка?
Как различать ошибки программиста от программных ошибок? Вам решать, какие данные переданные функции являются корректными, а какие – нет. Если в функцию переданы аргументы не отвечающие поставленным вами требованиям, то это ошибка программиста. Если же аргументы корректны, но функция в данный момент не может с ними работать, то это программная ошибка.
Вам предстоит решать с какой строгостью производить проверку аргументов. Представим некую функцию connect, котороя принимает IP-адрес и callback-функцию в качестве аргументов. Предположим, что был произведён вызов этой функции с аргументом отличающимся по формату от IP-адреса, например: «bob». Рассмотрим что может произойти в таком случае:
- Если вы строго производите проверку, соответствует ли формат введённой строки формату IPv4 адреса, то ваша функция бросит исключение на этапе проверки аргументов. Такой сценарий является наиболее приемлимым.
- Если же вы проверяете лишь тип аргументов, то возникнет асинхронная ошибка о том, что невозможно подключиться к IP-адресу «bob».
Оба варианта удовлетворяют рассмотренным рекомендациям и вам решать насколько строго производить проверку. Функция Date.parse, например, принимает аргументы различных форматов, но на то есть причины. Всё же, для большинства функций рекомендуется строго проверять переданные аргументы. Чем более расплывчаты критерии проверки аргументов, тем более затруднительным становится процесс отладки кода. Как правило, чем строже проверка – тем лучше. И даже если в будущих версиях программы вы вдруг смягчите критерии проверки внутри какой-то функции, то вы не рискуете сломать ваш код.
Если переданное значение не удовлетворяет требованиям (например, undefined или строка имеет неверный формат), то функция должна сообщать о том, что переданное значение некорректно и прекращать работу программы. Прекращая работу программы, сообщив о некорректных аргументах, вы упрощаете процесс отладки кода себе и другим программистам.
Домены и process.on(‘uncaughtException’)
Программные ошибки всегда могут быть отловлены по определённому механизму: через try/catch, в callback-функции или обработчиком события 'error'. Домены и событие глобального объекта process 'uncaughtException' часто используются для перестраховки от непредвиденных ошибок, которые мог допустить программист. Учитывая рассмотренные выше положения, данный подход настоятельно не рекомендуется.
4. Правила написания функций
При написании функций придерживайтесь следующих правил:
- Пишите подробную документацию
Это самое важное правило. Документация к функции должна содержать информацию:- о том с какими аргументами работает функция;
- о том каких типов должны быть аргументы;
- о любых дополнительных ограничениях, которые накладываются на вид аргументов (пример: IP-адрес должен иметь корректный формат).
Если какое-то из установленных правил не выполняется, то функция должа немедленно бросать исключение.
Так же следует документировать:- какие программные ошибки могут возникнуть в ходе выполнения функции (включая имена ошибок),
- как обрабатывать возможные ошибки (отлавливать через
try/catchили использовать асинхронные подходы), - описание результата выполнения функции.
- Используйте объекты класса Error (или подклассов) для всех ошибок.
Все ваши ошибки должны быть объектами класса Error или классов, которые являются его наследниками. Используйте поляnameиmessage, полеstackтак же должно корректно работать. - Расширяйте объект ошибки полями, которые описывают подробности ошибки.
Если в функцию был передан некорректный аргумент, задайте в объекте ошибки поля propertyName и propertyValue. Для ошибок подключения к удалённому серверу расширяйте объект ошибки полем remoteIp, чтобы указать к какому адресу не удалось подключиться. При возникновении системной ошибки включайте в объект ошибки полеsyscall, поясняющее, какой системный вызов не был обработан, так же включите полеerrno, содержащее информацию о типе системной ошибки. В приложении к статье описаны рекомендуемые имена полей.Ошибка обязательно должна содержать корректные поля:
name: используется обработчиками для дифференциации ошибок по типу.message: текст описывающий возникшую проблему. Текст должен быть коротким, но достаточно ёмким, что бы можно было понять суть проблемы.stack: никогда не изменяйте объект стэка вызовов. V8 производит построение этого объекта только тогда, когда к нему производится обращение и процесс построения достаточно ресурсоёмкий, обращение к этому полю существенно снижает производительность программы.
Ошибка должна содержать достаточно информации, чтобы обработчик мог на её основе сформировать своё сообщение об ошибке, не используя при этом поле message исходной ошибки. Возможно обработчику потребуется формировать ошибку из нескольких, чтобы выводить их в форме таблицы конечному пользователю.
- Если ошибка возвращается с низкого уровня вложенности функций, то следует оборачивать её.
В начале статьи упоминалось, что возможна ситуация, когда приходится возвращать ошибку из функции, в которой она возникла через callback-функцию на уровень выше, а затем еще выше, до тех пор пока она не достигнет логического уровня приложения, который ответственен за обработку данного типа ошибок. В таких случаях рекомендуется производить обёртку ошибки по мере её «всплытия». Обёрткой функции называется расширение исходного объекта ошибки информацией о логическом уровне через который она была передана. Модуль verror позволяет реализовать такой механизм.
Рассмотрим некую функциюfetchConfig, извлекающую настройки из удалённой базы данных. ВызовfetchConfigвыполняется при старте работы сервиса. Алгоритм работы функции описан ниже.1. Извлечение настроек 1.1 Соединение с базой данных 1.1.1 Получение адреса через систему DNS 1.1.2 Создание TCP соединения с сервером базы данных 1.1.3 Аутентификация на сервере базы данных 1.2. Выполнение запроса к базе данных 1.3. Обработка результата запроса 1.4. Настройка сервиса 2. Запуск работы сервисаПредположим, что в пункте 1.1.2 возникла ошибка. Если передавать ошибку в контекст из которого была вызвана функция
fetchConfigне оборачивая её, то сообщение об ошибке будет иметь вид:myserver: Error: connect ECONNREFUSEDПользы от такого сообщения мало.
Далее представлено сообщение о той же ошибке, но с применением обёртки:myserver: failed to start up: failed to load configuration: failed to connect to database server: failed to connect to 127.0.0.1 port 1234: connect ECONNREFUSEDЕсли не выполнять обёртку на некоторых уровнях, то можно получить более лаконичное сообщение:
myserver: failed to load configuration: connection refused from database at 127.0.0.1 port 1234.Однако, как правило, избыток информации — лучше чем дефицит.
Есть несколько нюансов о которых нужно знать, если вы решили оборачивать свои ошибки:
- Старайтесь не изменять поля начального обьекта ошибки, обработчику может потребоваться информация об исходной ошибке.
- Поле
nameошибки при обёртке можно изменять, чтобы оно больше соответствовало контексту. Однако, нет необходимости это делать, если у объекта ошибки есть иные поля, по которым обработчик может распознать её тип. - Поле
messageпри обёртке тоже может быть изменено, но не следует при этом менять message исходного объекта. Не производите никаких действий с полемstack, как уже упоминалось выше, V8 формирует объектstack, только при обращении к нему и это достаточно ресурсоёмкий процесс, который может привести к существенному снижению производительности вашей программы.
В Joyent мы используем модуль verror для обёртки ошибок, так как он имеет минималистичный синтаксис. На момент написания статьи в модуле не реализованы некоторые из рассмотренных рекомендаций, однако он будет дорабатываться.
5. Пример
Рассмотрим в качестве примера функцию, которая создаёт TCP соединение по указанному IPv4 адресу.
/*
* Функция создаёт TCP соединение по указанному IPv4 адресу. Аргументы:
*
* ip4addr строка адреса формата IPv4;
*
* tcpPort натуральное число, TCP порт;
*
* timeout натуральное число, время в миллисекундах, в течение которого
* необходимо ждать ответа от удалённого сервера;
*
* callback функция вызываемая после завершения операции,
* если операция завершилась успешно, происходит
* вызов вида callback(null, socket), где socket это
* объект класса net.Socket, если возникла ошибка,
* выполняется вызов вида callback(err).
*
* В функции могут возникнуть ошибки следующих типов:
*
* SystemError Для "connection refused", "host unreachable" и других
* ошибок, возвращаемых системным вызовом connect(2). Для
* данного типа ошибок поле errno объекта err будет содержать
* соответствующее ошибке символьное представление.
*
* TimeoutError Данный тип ошибок возникает при истечении
* времени ожидания timeout.
*
* Все возвращаемые объекты ошибок имеют поля "remoteIp" и "remotePort".
* После возникновении ошибки, сокеты, которые были открыты функцией, будут закрыты.
*/
function connect(ip4addr, tcpPort, timeout, callback)
{
assert.equal(typeof (ip4addr), 'string',
"аргумент 'ip4addr' должен быть строкового типа");
assert.ok(net.isIPv4(ip4addr),
"аргумент 'ip4addr' должен содержать IPv4 адрес");
assert.equal(typeof (tcpPort), 'number',
"аргумент 'tcpPort' должен быть числового типа");
assert.ok(!isNaN(tcpPort) && tcpPort > 0 && tcpPort < 65536,
"аргумент 'tcpPort' должен быть натуральным числом в диапазоне от 1 до 65535");
assert.equal(typeof (timeout), 'number',
"аргумент 'timeout' должен быть числового типа");
assert.ok(!isNaN(timeout) && timeout > 0,
"аргумент 'timeout' должен быть натуральным числом");
assert.equal(typeof (callback), 'function');
/* код функции */
}
Этот пример достаточно примитивен, но он иллюстрирует многие из рассмотренных рекомендаций:
- Аргументы, их типы, и предъявляемые к ним требования подробно документированы.
- Функция проверяет переданные ей аргументы и бросает исключение, если аргументы не удовлетворяют критериям.
- Документированы типы возможных ошибок, а так же поля, которые они содержат.
- Указан способ, которым функция возвращает ошибки.
- Возвращаемые ошибки имеют поля «remoteIp» и «remotePort», что позволит обработчику на основе этой информации формировать сообщение ошибки.
- Документировано состояние соединений после возникновения ошибки: «после возникновении ошибки, сокеты которые были открыты функцией, будут закрыты».
Может показаться, что в представленном примере проделано много лишней работы, однако, десять минут потраченные на опиание документации могут сэкономить несколько часов вам или другим разработчикам.
6. Резюме
- Различайте ошибки программиста и программные ошибки.
- Програмные ошибки могут и должны обрабатываться, тогда как ошибки программиста не могут быть корректно обработаны. Не следует продолжать работу программы в случае возникновения ошибок программиста, так как дальнейшее поведение программы непредсказуемо.
- Для возврата ошибок в функции может быть реализован синхронный подход (например,
throw) или асинхронный подход (callback-функция или событие), но нельзя реализовывать оба подхода в одной функции. Тогда, при использовании функции, чтобы обрабатывать возникающие в ней ошибки, нужно будет применять либо callback-функции, либо конструкцию try/catch, но никогда и то и другое. - При написании функций подробно документируйте аргументы, их типы, предъявляемые к ним требования, а так же типы возможных ошибок и то, как функция возвращает ошибки (синхронно, используя
throw, или асинхронно, используя callback-функцию или событийный подход). - Возвращаемая ошибка должна быть объектом класса Error или класса-наследника. Расширяйте объект ошибки новыми полями, чтобы включить в объект необходимую информацию об ошибке. По возможности используйте общепринятые имена полей, представленные в приложении.
7. Приложение: общепринятые имена полей ошибок
Настоятельно рекомендуется для расширения объектов ошибок использовать приведённые в таблице имена полей. Представленные имена используются в стандартных модулях Node.js, следует пользоваться ими в обработчиках ошибок, а так же при формировании сообщений об ошибках.
| Имя поля объекта ошибки | Значение поля |
localHostname |
локальное DNS-имя (например, то, по которому принимаются соединения) |
localIp |
локальный IP-адрес (например, тот, по которому принимаются соединения) |
localPort |
локальный TCP порт (например, тот, по которому принимаются соединения) |
remoteHostname |
DNS-имя удалённого сервера (например, сервера, с которым устанавливается соединение) |
remoteIp |
IP-адрес удалённого сервера (например, сервера, с которым устанавливается соединение) |
remotePort |
порт удалённого сервера (например, сервера, с которым устанавливается соединение) |
path |
путь к файлу, директории иди сокет межпроцессного взаимодействия (IPC-сокет) (например, путь к файлу, который необходимо считать) |
srcpath |
путь используемый в качестве источника (например, для копирования фала) |
dstpath |
путь назначения (например, для копирования фала) |
hostname |
DNS имя (например, то, которое используется для попытки получить IP-адрес) |
ip |
IP-адрес (например, тот, для которого производится попытка получить DNS-имя) |
propertyName |
имя свойста объекта или имя аргумента (например, в ошибке, возникшей при проверке аргументов переданных в функцию) |
propertyValue |
значение поля объекта (например, в ошибке, возникшей при проверке аргументов переданных в функцию) |
syscall |
имя невыполненного системного вызова |
errno |
символьное представление errno (например, "ENOENT") |
1 Начинающие разработчики часто допускают подобную ошибку. В данном примере try/catch и вызов функции бросающей исключение выполнятся в разных контекстах из-за асинхронности функции doSomeAsyncOperation, поэтому исключение не будет поймано.
2 В JavaScript throw может работать со значениями и других типов, но рекомендуется использовать именно объекты класса Error. Если в ThrowStatement использовать другие значения, то будет невозможно получить стэк вызовов, который привел к ошибке, что усложнит отладку кода.
3 Данные понятия возникли задолго до появления Node.js. В Java аналогом можно считать проверяемые и непроверяемые исключения. В C для работы с ошибками программиста предусмотрены утверждения.
4 Приведённый пример может показаться слишком предметным, это потому, что он не вымышлен, мы действительно сталкивались с этой проблемой, это было неприятно.
Данная статья является переводом. Ссылка на оригинал.
В статье рассмотрим:
- Объект Error
- Try…catch
- Throw
- Call stack
- Наименование функций
- Парадигму асинхронного программирования Promise
Представьте, как разрабатываете RESTful web API на Node.js.
- Пользователи отправляют запросы к серверу для получения данных.
- Вопрос времени, когда в программу придут значения, которые не ожидались.
- В таком случае, когда программа получит эти значения, пользователи будут рады видеть подробное и конкретное описание ошибки.
- В случае когда нет соответствующего обработчика ошибки, отобразится стандартное сообщение об ошибке. Таким образом, пользователь увидит сообщение об ошибке «Невозможно выполнить запрос», что не несет полезной информации о том, что произошло.
- Поэтому стоит уделять внимание обработке ошибок, чтобы наша программа стала безопасной, отказоустойчивой, высокопроизводительной и без ошибок.
Анатомия Объекта Error
Первое, с чего стоит начать изучение – это объект Error.
Разберем на примере:
throw new Error('database failed to connect');
Здесь происходят две вещи: создается объект Error и выбрасывается исключение.
Начнем с рассмотрения объекта Error, и того, как он работает. К ключевому слову throw вернемся чуть позже.
Объект Error представляет из себя реализацию функции конструктора, которая использует набор инструкций (аргументы и само тело конструктора) для создания объекта.
Тем не менее, что же такое объекты ошибок? Почему они должны быть однородными? Это важные вопросы, поэтому давайте перейдем к ним.
Первым аргументом для объекта Error является его описание.
Описание – это понятная человеку строка объекта ошибки. Также эта строка появляется в консоли, когда что-то пошло не так.
Объекты ошибок также имеют свойство name, которое рассказывает о типе ошибки. Когда создается нативный объект ошибки, то свойство name по умолчанию содержит Error. Вы также можете создать собственный тип ошибки, расширив нативный объект ошибки следующим образом:
class FancyError extends Error {
constructor(args){
super(args);
this.name = "FancyError"
}
}
console.log(new Error('A standard error'))
// { [Error: A standard error] }
console.log(new FancyError('An augmented error'))
// { [Your fancy error: An augmented error] name: 'FancyError' }
Обработка ошибок становится проще, когда у нас есть согласованность в объектах.
Ранее мы упоминали, что хотим, чтобы объекты ошибок были однородными. Это поможет обеспечить согласованность в объекте ошибки.
Теперь давайте поговорим о следующей части головоломки – throw.
Ключевое слово Throw
Создание объектов ошибок – это не конец истории, а только подготовка ошибки к отправке. Отправка ошибки заключается в том, чтобы выбросить исключение. Но что значит выбросить? И что это значит для нашей программы?
Throw делает две вещи: останавливает выполнение программы и находит зацепку, которая мешает выполнению программы.
Давайте рассмотрим эти идеи одну за другой:
- Когда JavaScript находит ключевое слово
throw, первое, что он делает – предотвращает запуск любых других функций. Остановка снижает риск возникновения любых дальнейших ошибок и облегчает отладку программ. - Когда программа остановлена, JavaScript начнет отслеживать последовательную цепочку функций, которые были вызваны для достижения оператора
catch. Такая цепочка называется стек вызовов (англ. call stack). Ближайшийcatch, который находит JavaScript, является местом, где возникает выброшенное исключение. Если операторыtry/catchне найдены, тогда возникает исключение, и процесс Node.js завершиться, что приведет к перезапуску сервера.
Бросаем исключения на примере
Мы рассмотрели теорию, а теперь давайте изучим пример:
function doAthing() {
byDoingSomethingElse();
}
function byDoingSomethingElse() {
throw new Error('Uh oh!');
}
function init() {
try {
doAthing();
} catch(e) {
console.log(e);
// [Error: Uh oh!]
}
}
init();
Здесь в функции инициализации init() предусмотрена обработка ошибок, поскольку она содержит try/catch блок.
init() вызывает функцию doAthing(), которая вызывает функцию byDoingSomethingElse(), где выбрасывается исключение. Именно в этот момент ошибки, программа останавливается и начинает отслеживать функцию, вызвавшую ошибку. Далее в функции init() и выполняет оператор catch. С помощью оператора catch мы решаем что делать: подавить ошибку или даже выдать другую ошибку (для распространения вверх).
Стек вызовов
То, что показано в приведенном выше примере – это проработанный пример стека вызовов. Как и большинство языков, JavaScript использует концепцию, известную как стек вызовов.
Но как работает стек вызовов?
Всякий раз, когда вызывается функция, она помещается в стек, а при завершении удаляется из стека. Именно от этого стека мы получили название «трассировки стека».
Трассировка стека – это список функций, которые были вызваны до момента, когда в программе произошло исключение.
Она часто выглядит так:
Error: Uh oh!
at byDoingSomethingElse (/filesystem/aProgram.js:7:11)
at doAthing (/filesystem/aProgram.js:3:5)
at init (/filesystem/aProgram.js:12:9)
at Object.<anonymous> (/filesystem/aProgram.js:19:1)
at Module._compile (internal/modules/cjs/loader.js:689:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)
at Module.load (internal/modules/cjs/loader.js:599:32)
at tryModuleLoad (internal/modules/cjs/loader.js:538:12)
at Function.Module._load (internal/modules/cjs/loader.js:530:3)
at Function.Module.runMain (internal/modules/cjs/loader.js:742:12)
На этом этапе вам может быть интересно, как стек вызовов помогает нам с обработкой ошибок Node.js. Давайте поговорим о важности стеков вызовов.
Стек вызовов предоставляет «хлебные крошки», помогая проследить путь, который привел к исключению(ошибке).
Почему у нас должны быть функции без имен? Иногда в наших программах мы хотим определить маленькие одноразовые функции, которые выполняют небольшую задачу. Мы не хотим утруждать себя задачей давать им имена, но именно эти анонимные функции могут вызвать у нас всевозможные головные боли. Анонимная функция удаляет имя функции из нашего стека вызовов, что делает наш стек вызовов значительно более сложным в использовании.
Обратите внимание, что присвоить имена функциям в JavaScript не так просто. Итак, давайте кратко рассмотрим различные способы определения функций, и рассмотрим некоторые ловушки в именовании функций.
Как называть функции
Чтобы понять, как называть функции, давайте рассмотрим несколько примеров:
// анонимная функция
const one = () => {};
// анонимная функция
const two = function () {};
// функция с явным названием
const three = function explicitFunction() {};
Вот три примера функций.
Первая – это лямбда (или стрелочная функция). Лямбда функции по своей природе анонимны. Не запутайтесь. Имя переменной one не является именем функции. Имя функции следующее за ключевым словом function необязательно. Но в этом примере мы вообще ничего не передаем, поэтому наша функция анонимна.
Примечание
Не помогает и то, что некоторые среды выполнения JavaScript, такие как V8, могут иногда угадывать имя вашей функции. Это происходит, даже если вы его не даете.
Во втором примере мы получили функциональное выражение. Это очень похоже на первый пример. Это анонимная функция, но просто объявленная с помощью ключевого слова function вместо синтаксиса жирной стрелки.
В последнем примере объявление переменной с подходящим именем explicitFunction. Это показывает, что это единственная функция, у которой соответствующее имя.
Как правило, рекомендуется указывать это имя везде, где это возможно, чтобы иметь более удобочитаемую трассировку стека.
Обработка асинхронных исключений
Мы познакомились с объектом ошибок, ключевым словом throw, стеком вызовов и наименованием функций. Итак, давайте обратим наше внимание на любопытный случай обработки асинхронных ошибок. Почему? Потому что асинхронный код ведет себя не так, как ожидаем. Асинхронное программирование необходимо каждому программисту на Node.js.
Javascript – это однопоточный язык программирования, а это значит, что Javascript запускается с использованием одного процессора. Из этого следует, что у нас есть блокирующий и неблокирующий код. Блокирующий код относится к тому, будет ли ваша программа ожидать завершения асинхронной задачи, прежде чем делать что-либо еще. В то время как неблокирующий код относится к тому, где вы регистрируете обратный вызов (callback) для выполнения после завершения задачи.
Стоит упомянуть, что есть два основных способа обработки асинхронности в JavaScript: promises (обещания или промисы) и callback (функция обратного вызова). Мы намеренно игнорируем async/wait, чтобы избежать путаницы, потому что это просто сахар поверх промисов.
В статье мы сфокусируемся на промисах. Существует консенсус в отношении того, что для приложений промисы превосходят обратные вызовы с точки зрения стиля программирования и эффективности. Поэтому в этой статье проигнорируем подход с callback-ами, и предположим, что вместо него вы выберете promises.
Примечание
Существует множество способов конвертировать код на основе callback-ов в promises. Например, вы можете использовать такую утилиту, как promisify, или обернуть свои обратные вызовы в промисы, например, так:
var request = require('request'); //http wrapped module
function requestWrapper(url, callback) {
request.get(url, function (err, response) {
if (err) {
callback(err);
} else {
callback(null, response);
}
})
}
Мы разберемся с этой ошибкой, обещаю!
Давайте взглянем на анатомию обещаний.
Промисы в JavaScript – это объект, представляющий будущее значение. Promise API позволяют нам моделировать асинхронный код так же, как и синхронный. Также стоит отметить, что обещание обычно идет в цепочке, где выполняется одно действие, затем другое и так далее.
Но что все это значит для обработки ошибок Node.js?
Промисы элегантно обрабатывают ошибки и перехватывают любые ошибки, которые им предшествовали в цепочке. С помощью одного обработчика обрабатывается множество ошибок во многих функциях.
Изучим код ниже:
function getData() {
return Promise.resolve('Do some stuff');
}
function changeDataFormat() {
// ...
}
function storeData(){
// ...
}
getData()
.then(changeDataFormat)
.then(storeData)
.catch((e) => {
// Handle the error!
})
Здесь видно, как объединить обработку ошибок для трех различных функций в один обработчик, т. е. код ведет себя так же, как если бы три функции заключались в синхронный блок try/catch.
Отлавливать или не отлавливать?
На данном этапе стоит спросить себя, повсеместно ли добавляется .catch к промисам, поскольку это опционально. Из-за проблем с сетью, аппаратного сбоя или истекшего времени ожидания в асинхронных вызовах возникает исключение. По этим причинам указывайте программе, что делать в случаях невыполнения промиса.
Запомните «Золотое правило» – каждый раз обрабатывать исключения в обещаниях.
Риски асинхронного try/catch
Мы приближаемся к концу в нашем путешествии по обработке ошибок в Node.js. Пришло время поговорить о ловушках асинхронного кода и оператора try/catch.
Вам может быть интересно, почему промис предоставляет метод catch, и почему мы не можем просто обернуть нашу реализацию промиса в try/catch. Если бы вы сделали это, то результаты были бы не такими, как вы ожидаете.
Рассмотрим на примере:
try {
throw new Error();
} catch(e) {
console.log(e); // [Error]
}
try {
setTimeout(() => {
throw new Error();
}, 0);
} catch(e) {
console.log(e); // Nothing, nada, zero, zilch, not even a sound
}
try/catch по умолчанию синхронны, что означает, что если асинхронная функция выдает ошибку в синхронном блоке try/catch, ошибка не будет брошена.
Однозначно это не то, что ожидаем.
***
Подведем итог! Необходимо использовать обработчик промисов, когда мы имеем дело с асинхронным кодом, а в случае с синхронным кодом подойдет try/catch.
Заключение
Из этой статьи мы узнали:
- как устроен объект Error;
- научились создавать свои собственные ошибки;
- как работает стек вызовов;
- практики наименования функций, для удобочитаемой трассировки стека;
- как обрабатывать асинхронные исключения.
***
Материалы по теме
- 🗄️ 4 базовых функции для работы с файлами в Node.js
- Цикл событий: как выполняется асинхронный JavaScript-код в Node.js
- Обработка миллионов строк данных потоками на Node.js

Если вы писали что-то большее, чем программы «Hello world», вы, вероятно, знакомы с концепцией ошибок в программировании. Это ошибки в вашем коде, часто называемые «bugs», которые приводят к сбою программы или неожиданному поведению. В отличие от некоторых языков, таких как Go и Rust, где вы вынуждены взаимодействовать с потенциальными ошибками на каждом этапе пути, в JavaScript и Node.js можно обойтись без согласованной стратегии обработки ошибок.
Однако это не обязательно должно быть так, потому что обработка ошибок Node.js может быть довольно простой, если вы знакомы с шаблонами, используемыми для создания, доставки и обработки потенциальных ошибок. Эта статья призвана познакомить вас с этими шаблонами, чтобы вы могли сделать свои программы более надежными, гарантируя, что вы обнаружите потенциальные ошибки и обработаете их надлежащим образом, прежде чем развертывать свое приложение в рабочей среде!
Что такое ошибки в Node.js
Ошибка в Node.js — это любой экземпляр объекта Error. Типичные примеры включают встроенные классы ошибок, таких как ReferenceError, RangeError, TypeError, URIError, EvalError, и SyntaxError. Определяемые пользователем ошибки также можно создавать путем расширения базового объекта Error, встроенного класса ошибок или другой пользовательской ошибки. При создании ошибок таким образом вы должны передать строку сообщения, описывающую ошибку. Доступ к этому сообщению можно получить через свойство объекта message. Объект Error также содержит name в свойстве stack, указав имя ошибки и точки в коде, на котором он был создан, соответственно.
const userError = new TypeError("Something happened!");
console.log(userError.name); // TypeError
console.log(userError.message); // Something happened!
console.log(userError.stack);
/*TypeError: Something happened!
at Object.<anonymous> (/home/ayo/dev/demo/main.js:2:19)
<truncated for brevity>
at node:internal/main/run_main_module:17:47 */
Получив объект Error, вы можете передать его функции или вернуть из функции. Вы также можете сделать throw, что приведет к тому, что объект Error станет исключением. Как только вы выдаете ошибку, она всплывает в стеке до тех пор, пока ее где-нибудь не поймают. Если вам не удастся еt поймать, онf станет неперехваченным исключением, которое может привести к сбою вашего приложения!
Как устранить ошибки
Подходящий способ устранения ошибок из функции JavaScript зависит от того, выполняет ли функция синхронную или асинхронную операцию. В этом разделе я подробно опишу четыре распространенных шаблона устранения ошибок из функции в приложении Node.js.
1. Исключения
Наиболее распространенный способ устранения ошибок функциями — их генерация. Когда вы выдаете ошибку, она становится исключением и должна быть перехвачена где-то в стеке с помощью блока try/catch. Если ошибка может всплывать в стеке без обнаружения, она становится uncaughtException, что приводит к преждевременному завершению работы приложения. Например, встроенный метод JSON.parse() выдает ошибку, если его строковый аргумент не является допустимым объектом JSON.
function parseJSON(data) {
return JSON.parse(data);
}
try {
const result = parseJSON('A string');
} catch (err) {
console.log(err.message); // Unexpected token A in JSON at position 0
}
Чтобы использовать этот шаблон в своих функциях, все, что вам нужно сделать, это добавить ключевое слово throw перед экземпляром ошибки. Этот шаблон сообщения об ошибках и их обработки идиоматичен для функций, выполняющих синхронные операции.
function square(num) {
if (typeof num !== 'number') {
throw new TypeError(`Expected number but got: ${typeof num}`);
}
return num * num;
}
try {
square('8');
} catch (err) {
console.log(err.message); // Expected number but got: string
}
2. Обратные вызовы с ошибкой
Из-за своей асинхронной природы Node.js широко использует функции обратного вызова для большей части обработки ошибок. Функция обратного вызова передается в качестве аргумента другой функции и выполняется, когда функция завершает свою работу. Если вы какое-то время писали код JavaScript, вы, вероятно, знаете, что шаблон обратного вызова широко используется во всем коде JavaScript.
Node.js использует в большинстве своих асинхронных методов соглашение об обратном вызове «сначала ошибка», чтобы убедиться, что ошибки проверяются должным образом до того, как будут использованы результаты операции. Эта функция обратного вызова обычно является последним аргументом функции, инициирующей асинхронную операцию, и вызывается один раз при возникновении ошибки или при получении результата операции. Ее подпись показана ниже:
function (err, result) {}
Первый аргумент зарезервирован для объекта ошибки. Если в ходе асинхронной операции возникает ошибка, она будет доступна через аргумент err и result будет иметь значение undefined. Однако, если ошибки не возникнет err будет null или undefined и result будет содержать ожидаемый результат операции. Этот шаблон можно продемонстрировать, прочитав содержимое файла с помощью встроенного метода fs.readFile():
const fs = require('fs');
fs.readFile('/path/to/file.txt', (err, result) => {
if (err) {
console.error(err);
return;
}
// Log the file contents if no error
console.log(result);
});
Как вы можете видеть метод readFile() ожидает функцию обратного вызова в качестве своего последнего аргумента, который придерживается описанной ранее сигнатуры функции «сначала ошибка». В этом сценарии аргумент result содержит содержимое прочитанного файла, если не возникает ошибки. В противном случае undefined и аргумент err заполняется объектом ошибки, содержащим информацию о проблеме (например, файл не найден или недостаточные разрешения).
Как правило, методы, которые используют этот шаблон обратного вызова для доставки ошибок, не могут знать, насколько важна ошибка, которую они производят, для вашего приложения. Это может быть серьезным или тривиальным. Вместо того, чтобы принимать решение самостоятельно, ошибка отправляется вам для обработки. Важно контролировать поток содержимого функции обратного вызова, всегда проверяя наличие ошибки перед попыткой доступа к результату операции. Игнорировать ошибки небезопасно, и вы не должны доверять содержимому result перед проверкой ошибок.
Если вы хотите использовать этот шаблон обратного вызова с первой ошибкой в своих собственных асинхронных функциях, все, что вам нужно сделать, это принять функцию в качестве последнего аргумента и вызвать ее, как показано ниже:
function square(num, callback) {
if (typeof callback !== 'function') {
throw new TypeError(`Callback must be a function. Got: ${typeof callback}`);
}
// simulate async operation
setTimeout(() => {
if (typeof num !== 'number') {
// if an error occurs, it is passed as the first argument to the callback
callback(new TypeError(`Expected number but got: ${typeof num}`));
return;
}
const result = num * num;
// callback is invoked after the operation completes with the result
callback(null, result);
}, 100);
}
Любому вызывающему объекту этой функции square потребуется передать функцию обратного вызова, чтобы получить доступ к ее результату или ошибке. Обратите внимание, что во время выполнения возникает исключение, если аргумент обратного вызова не является функцией.
square('8', (err, result) => {
if (err) {
console.error(err)
return
}
console.log(result);
});
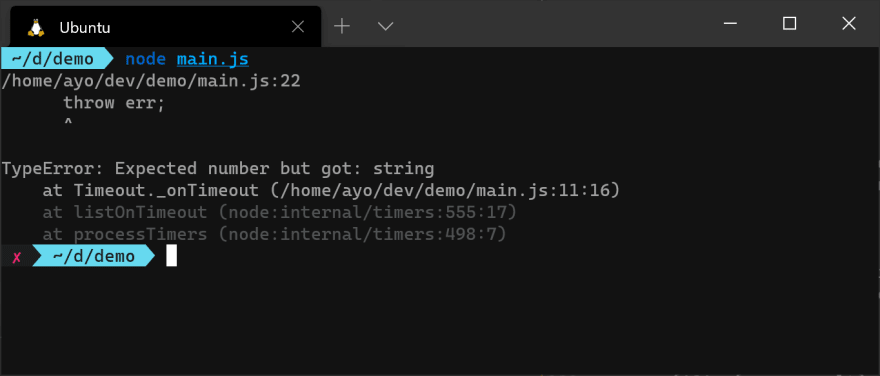
Вам не нужно напрямую обрабатывать ошибку в функции обратного вызова. Вы можете распространить его вверх по стеку, передав его другому обратному вызову, но не генерируйте исключение из функции, потому что оно не будет перехвачено, даже если вы окружите код блоком try/catch. Асинхронное исключение невозможно перехватить, поскольку окружающий блок try/catch завершается до выполнения обратного вызова. Таким образом, исключение будет распространяться на вершину стека, вызывая сбой приложения, если для него не зарегистрирован обработчик process.on('uncaughtException'), который будет обсуждаться позже.
try {
square('8', (err, result) => {
if (err) {
throw err; // not recommended
}
console.log(result);
});
} catch (err) {
// This won't work
console.error("Caught error: ", err);
}
3. Отказ от промисов
Промисы — это современный способ выполнения асинхронных операций в Node.js, и в настоящее время они обычно предпочтительнее обратных вызовов, потому что этот подход имеет лучший поток, который соответствует тому, как мы анализируем программы, особенно с шаблоном async/await. Любой API-интерфейс Node.js, который использует обратные вызовы для асинхронной обработки ошибок, может быть преобразован в промисы с помощью встроенного метода util.promisify(). Например, вот как можно использовать метод fs.ReadFile() для использования промисов:
const fs = require('fs');
const util = require('util');
const readFile = util.promisify(fs.readFile);
Переменная ReadFile — это обещанная версия fs.ReadFile(), в которой отклонения промисов используются для сообщения об ошибках. Эти ошибки могут быть обнаружены с помощью метода цепочки catch, как показано ниже:
readFile('/path/to/file.txt')
.then((result) => console.log(result))
.catch((err) => console.error(err));
Вы также можете использовать обещанные API в функции async, такой как показанна ниже. Это преобладающий способ использования обещаний в современном JavaScript, потому что код читается как синхронный код, а для обработки ошибок можно использовать знакомый механизм try/catch. Важно использовать await перед асинхронным методом, чтобы промис был выполнен (выполнен или отклонен) до того, как функция возобновит свое выполнение. Если промис отклоняется, выражение await выдает отклоненное значение, которое впоследствии перехватывается в окружающем блоке catch
(async function callReadFile() {
try {
const result = await readFile('/path/to/file.txt');
console.log(result);
} catch (err) {
console.error(err);
}
})();
Вы можете использовать промисы в своих асинхронных функциях, возвращая промис из функции и помещая код функции в обратный вызов промиса. Если есть ошибка, reject с объектом Error. В противном случае resolve промис с результатом, чтобы оно было доступно в цепочке метода .then или непосредственно в качестве значения функции async при использовании async/await.
function square(num) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (typeof num !== 'number') {
reject(new TypeError(`Expected number but got: ${typeof num}`));
}
const result = num * num;
resolve(result);
}, 100);
});
}
square('8')
.then((result) => console.log(result))
.catch((err) => console.error(err));
4. Генераторы событий
Другой шаблон, который можно использовать при работе с длительными асинхронными операциями, которые могут привести к множеству ошибок или результатов, заключается в возврате EventEmitter из функции и создании события как в случае успеха, так и в случае неудачи. Пример этого кода показан ниже:
const { EventEmitter } = require('events');
function emitCount() {
const emitter = new EventEmitter();
let count = 0;
// Async operation
const interval = setInterval(() => {
count++;
if (count % 4 == 0) {
emitter.emit(
'error',
new Error(`Something went wrong on count: ${count}`)
);
return;
}
emitter.emit('success', count);
if (count === 10) {
clearInterval(interval);
emitter.emit('end');
}
}, 1000);
return emitter;
}
Функция emitCount() возвращает новый источник событий, который сообщает как об успехе, так и о сбое в асинхронной операции. Функция увеличивает переменную count и генерирует событие success каждую секунду, а также событие error, если count делится на 4. Когда count достигает 10, генерируется событие end. Этот шаблон позволяет выполнять потоковую передачу результатов по мере их поступления, а не ждать завершения всей операции.
Вот как вы можете обрабатывать и реагировать на каждое из событий, исходящих от функции emitCount():
const counter = emitCount();
counter.on('success', (count) => {
console.log(`Count is: ${count}`);
});
counter.on('error', (err) => {
console.error(err.message);
});
counter.on('end', () => {
console.info('Counter has ended');
});
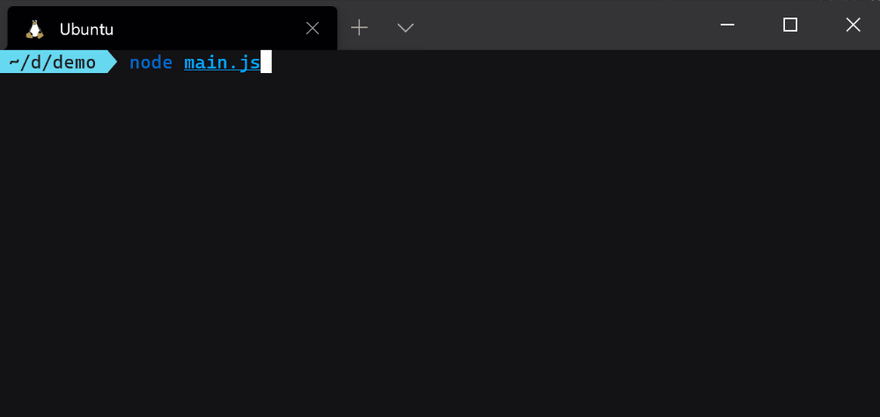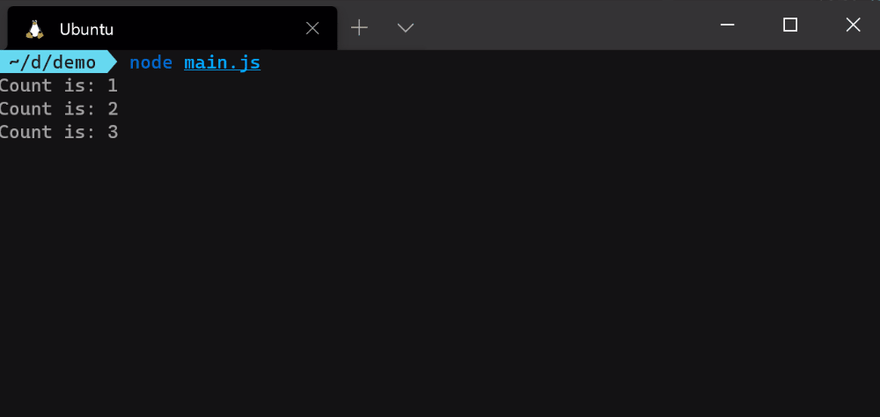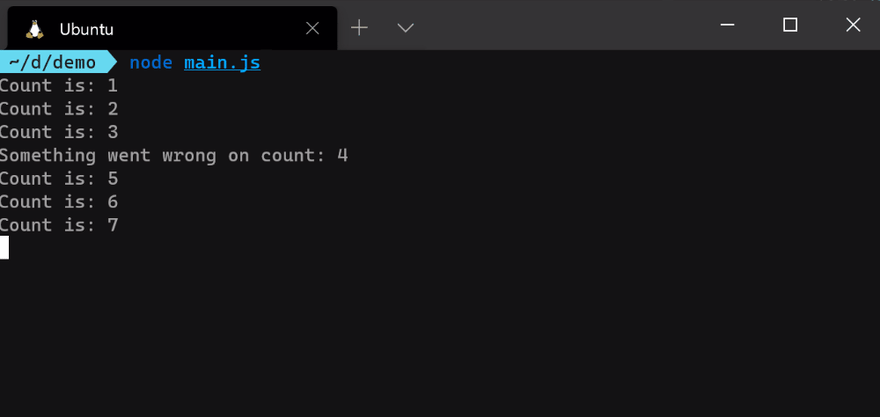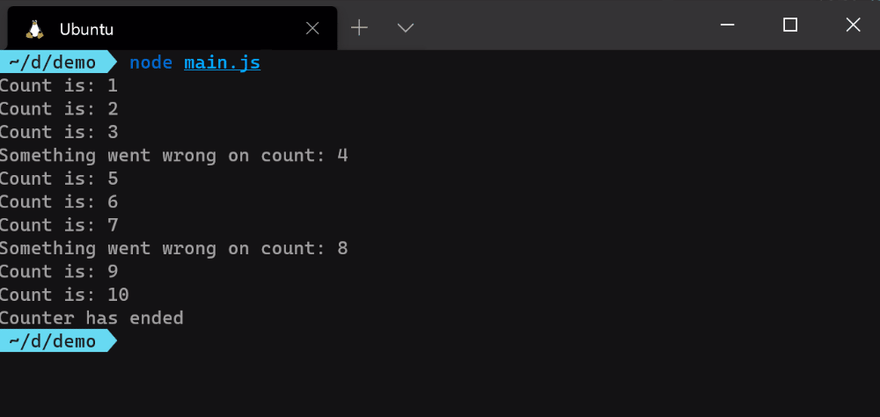
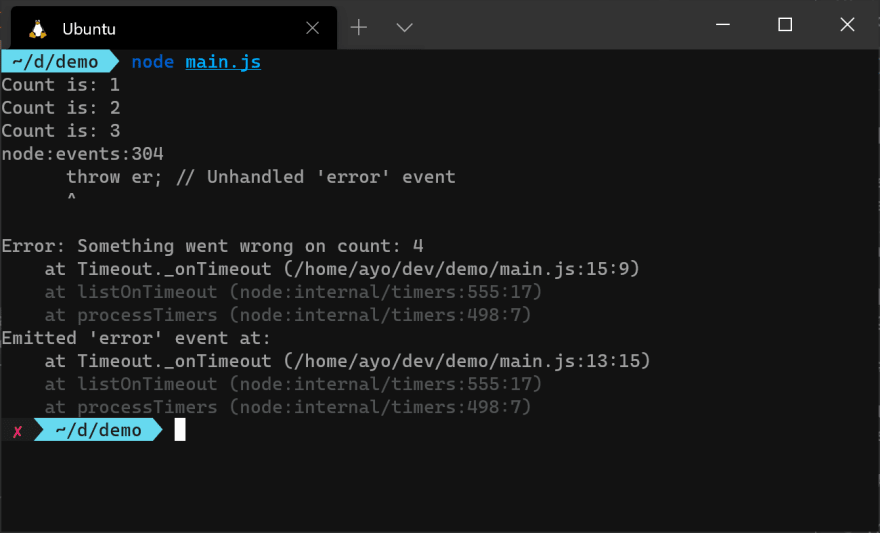
Как вы можете видеть на изображении выше, функция обратного вызова для каждого обработчика событий выполняется независимо, как только событие генерируется. Событие error является особым случаем в Node.js, потому что, если для него нет обработчика, процесс Node.js завершится сбоем. Вы можете закомментировать обработчик событий error выше и запустить программу, чтобы посмотреть, что произойдет.
Расширение объекта ошибки
Использование встроенных классов ошибок или универсального экземпляра объекта Error обычно недостаточно точно для сообщения всех различных типов ошибок. Поэтому необходимо создавать пользовательские классы ошибок, чтобы лучше отражать типы ошибок, которые могут возникнуть в вашем приложении. Например, у вас может быть класс ValidationError для ошибок, возникающих при проверке пользовательского ввода, DatabaseError для операций с базой данных, класс TimeoutError для операций, для которых истекают назначенные им тайм-ауты, и так далее.
Пользовательские классы ошибок, расширяющие объект ошибки, сохранят основные свойства ошибки, такие как message, name, и stack, но они также могут иметь собственные свойства. Например ValidationError можно улучшить, добавив значимые свойства, такие как часть ввода, вызвавшую ошибку. По сути, вы должны включить достаточно информации, чтобы обработчик ошибок правильно обработал ошибку или создал свои собственные сообщения об ошибках.
Вот как расширить встроенный объект Error в Node.js:
class ApplicationError extends Error {
constructor(message) {
super(message);
// name is set to the name of the class
this.name = this.constructor.name;
}
}
class ValidationError extends ApplicationError {
constructor(message, cause) {
super(message);
this.cause = cause
}
}
Приведенный выше класс ApplicationError является общей ошибкой для приложения, а класс ValidationError представляет любую ошибку, возникающую при проверке пользовательского ввода. Он наследуется от класса ApplicationError и дополняет его свойством cause, чтобы указать ввод, вызвавший ошибку. Вы можете использовать пользовательские ошибки в своем коде так же, как и с обычной ошибкой. Например, вы можете throw:
function validateInput(input) {
if (!input) {
throw new ValidationError('Only truthy inputs allowed', input);
}
return input;
}
try {
validateInput(userJson);
} catch (err) {
if (err instanceof ValidationError) {
console.error(`Validation error: ${err.message}, caused by: ${err.cause}`);
return;
}
console.error(`Other error: ${err.message}`);
}
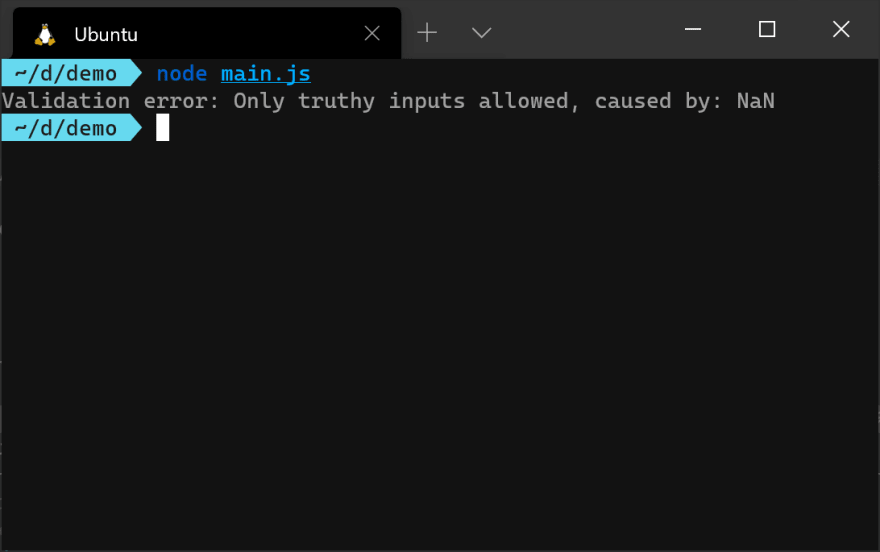
Ключевое слово instanceof следует использовать для проверки определенного типа ошибок, как показано выше. Не используйте имя ошибки для проверки типа, как в err.name === 'ValidationError', потому что это не сработает, если ошибка получена из подкласса ValidationError.
Типы ошибок
Полезно различать разные типы ошибок, которые могут возникнуть в приложении Node.js. Как правило, ошибки можно разделить на две основные категории: ошибки программиста и операционные проблемы. Плохие или неверные аргументы функции — это пример проблем первого типа, тогда как временные сбои при работе с внешними API относятся ко второй категории.
1. Операционные ошибки
Операционные ошибки — это в основном ожидаемые ошибки, которые могут возникнуть в процессе выполнения приложения. Это не обязательно ошибки, но внешние обстоятельства, которые могут нарушить ход выполнения программы. В таких случаях все последствия ошибки можно понять и соответствующим образом обработать. Некоторые примеры операционных ошибок в Node.js включают следующее:
- Запрос API завершается ошибкой по какой-либо причине (например, сервер не работает или превышен лимит скорости).
- Соединение с базой данных потеряно, возможно, из-за неисправного сетевого соединения.
- ОС не может выполнить ваш запрос на открытие файла или запись в него.
- Пользователь отправляет на сервер неверный ввод, например неверный номер телефона или адрес электронной почты.
Эти ситуации не возникают из-за ошибок в коде приложения, но с ними нужно правильно обращаться. В противном случае они могут вызвать более серьезные проблемы.
2. Ошибки программиста
Ошибки программиста — это ошибки в логике или синтаксисе программы, которые можно исправить только путем изменения исходного кода. Эти типы ошибок не могут быть обработаны, потому что по определению они являются ошибками в программе. Вот некоторые примеры ошибок программиста:
- Синтаксические ошибки, такие как невозможность закрыть фигурную скобку.
- Ошибки типа, когда вы пытаетесь сделать что-то недопустимое, например, выполнять операции с операндами несовпадающих типов.
- Неверные параметры при вызове функции.
- Ссылочные ошибки при неправильном написании имени переменной, функции или свойства.
- Попытка доступа к местоположению за концом массива.
- Не удалось обработать операционную ошибку.
Оперативная обработка ошибок
Операционные ошибки в основном предсказуемы, поэтому их необходимо предвидеть и учитывать в процессе разработки. По сути, обработка этих типов ошибок включает в себя рассмотрение того, может ли операция завершиться неудачно, почему она может завершиться неудачно и что должно произойти, если это произойдет. Рассмотрим несколько стратегий обработки операционных ошибок в Node.js.
1. Сообщите об ошибке вверх по стеку
Во многих случаях подходящим действием является остановка потока выполнения программы, очистка всех незавершенных процессов и сообщение об ошибке вверх по стеку, чтобы ее можно было обработать соответствующим образом. Часто это правильный способ устранения ошибки, когда функция, в которой она возникла, находится ниже по стеку и не имеет достаточно информации для непосредственной обработки ошибки. Сообщить об ошибке можно с помощью любого из методов доставки ошибок, описанных ранее в этой статье.
2. Повторите операцию
Сетевые запросы к внешним службам иногда могут завершаться ошибкой, даже если запрос полностью действителен. Это может быть связано с временным сбоем, который может возникнуть при сбое сети или перегрузке сервера. Такие проблемы обычно непродолжительны, поэтому вместо того, чтобы немедленно сообщать об ошибке, вы можете повторить запрос несколько раз, пока он не будет успешным или пока не будет достигнуто максимальное количество повторных попыток. Первое соображение заключается в том, чтобы определить, уместно ли повторить запрос. Например, если исходный код состояния HTTP-ответа — 500, 503 или 429, может оказаться целесообразным повторить запрос после небольшой задержки.
Вы можете проверить, присутствует ли в ответе HTTP-заголовок Retry-After. В этом заголовке указывается точное время ожидания перед выполнением последующего запроса. Если заголовок Retry-After не существует, вам необходимо отложить последующий запрос и постепенно увеличивать задержку для каждой последующей повторной попытки. Это известно как экспоненциальная стратегия отсрочки. Вам также необходимо определить максимальный интервал задержки и количество повторных попыток запроса, прежде чем отказаться от него. В этот момент вы должны сообщить вызывающему абоненту, что целевая служба недоступна.
3. Отправить ошибку клиенту
Имея дело с внешним вводом от пользователей, следует исходить из того, что ввод неверен по умолчанию. Поэтому первое, что нужно сделать перед запуском каких-либо процессов, — это проверить ввод и незамедлительно сообщить пользователю о любых ошибках, чтобы его можно было исправить и повторно отправить. При доставке ошибок клиента не забудьте включить всю информацию, необходимую клиенту для создания сообщения об ошибке, понятного пользователю.
4. Прервать программу
В случае неисправимых системных ошибок единственным разумным действием является регистрация ошибки и немедленное завершение программы. Возможно, вы даже не сможете корректно завершить работу сервера, если исключение невозможно восстановить на уровне JavaScript. В этот момент от системного администратора может потребоваться изучить проблему и исправить ее, прежде чем программа сможет снова запуститься.
Предотвращение ошибок программиста
Из-за своей природы ошибки программиста не могут быть обработаны; это ошибки в программе, возникающие из-за неработающего кода или логики, которые впоследствии необходимо исправлять. Однако есть несколько вещей, которые вы можете сделать, чтобы значительно снизить частоту их появления в вашем приложении.
1. Примите TypeScript
TypeScript — является строго типизированным надмножеством JavaScript. Его основная цель разработки — статическая идентификация конструкций, которые могут быть ошибочными, без каких-либо штрафов во время выполнения. Приняв TypeScript в свой проект (с максимально строгими параметрами компилятора), вы сможете устранить целый класс ошибок программиста во время компиляции. Например, после проведения постфактум-анализа ошибок было подсчитано, что 38% ошибок в кодовой базе Airbnb можно было предотвратить с помощью TypeScript.
Когда вы переносите весь свой проект на TypeScript, такие ошибки, как « undefined is not a function», синтаксические ошибки или ошибки ссылок, больше не должны существовать в вашей кодовой базе. К счастью, это не так страшно, как кажется. Миграция всего вашего приложения Node.js на TypeScript может выполняться поэтапно, чтобы вы могли сразу же начать пожинать плоды в важнейших частях кодовой базы. Вы также можете использовать такой инструмент, как ts-migrate, если вы собираетесь выполнить миграцию за один раз.
2. Определите поведение для неверных параметров
Многие ошибки программиста возникают из-за передачи неправильных параметров. Это может быть связано не только с очевидными ошибками, такими как передача строки вместо числа, но и с тонкими ошибками, например, когда аргумент функции имеет правильный тип, но выходит за пределы того, что может обработать функция. Когда программа запущена и функция вызывается таким образом, она может незаметно завершиться ошибкой и выдать неправильное значение, например NaN. Когда сбой в конце концов заметен (обычно после прохождения через несколько других функций), может быть трудно определить его причины.
Вы можете справиться с неправильными параметрами, определив их поведение, выдав ошибку или вернув специальное значение, такое как null, undefined, или -1, когда проблема может быть решена локально. Первый — это подход, используемый JSON.parse(), который генерирует исключение SyntaxError, если строка для синтаксического анализа не является допустимой JSON, тогда как метод string.indexOf() является примером последнего. Что бы вы ни выбрали, обязательно задокументируйте, как функция обрабатывает ошибки, чтобы вызывающая сторона знала, чего ожидать.
3. Автоматизированное тестирование
Сам по себе язык JavaScript мало помогает вам найти ошибки в логике вашей программы, поэтому вам нужно запустить программу, чтобы определить, работает ли она должным образом. Наличие набора автоматизированных тестов повышает вероятность того, что вы обнаружите и исправите различные ошибки программиста, особенно логические. Они также помогают выяснить, как функция работает с нетипичными значениями. Использование среды тестирования, такой как Jest или Mocha, — хороший способ начать модульное тестирование приложений Node.js.
Неперехваченные исключения и необработанные отказы от промисов
Неперехваченные исключения и необработанные отклонения промисов вызваны ошибками программиста, возникающими из-за невозможности перехватить сгенерированное исключение и отклонение промисов соответственно. Событие uncaughtException возникает, когда исключение, созданное где-либо в приложении, не перехвачено до того, как оно достигнет цикла событий. Если обнаружено неперехваченное исключение, приложение немедленно выйдет из строя, но вы можете добавить обработчик этого события, чтобы переопределить это поведение. Действительно, многие люди используют это как крайний способ поглотить ошибку, чтобы приложение могло продолжать работать, как будто ничего не произошло:
// unsafe
process.on('uncaughtException', (err) => {
console.error(err);
});
Однако это неправильное использование этого события, поскольку наличие необработанного исключения указывает на то, что приложение находится в неопределенном состоянии. Таким образом, попытка нормального возобновления работы без восстановления после ошибки считается небезопасной и может привести к дальнейшим проблемам, таким как утечка памяти и зависание сокетов. Надлежащее использование обработчика uncaughtException заключается в очистке всех выделенных ресурсов, закрытии соединений и регистрации ошибки для последующей оценки перед выходом из процесса.
// better
process.on('uncaughtException', (err) => {
Honeybadger.notify(error); // log the error in a permanent storage
// attempt a gracefully shutdown
server.close(() => {
process.exit(1); // then exit
});
// If a graceful shutdown is not achieved after 1 second,
// shut down the process completely
setTimeout(() => {
process.abort(); // exit immediately and generate a core dump file
}, 1000).unref()
});
Точно так же событие unhandledRejection генерируется, когда отклоненное обещание не обрабатывается блоком catch. В отличие от uncaughtException, эти события не вызывают немедленного сбоя приложения. Однако необработанные отказы от промисов устарели и могут немедленно прервать процесс в будущем выпуске Node.js. Вы можете отслеживать необработанные отказы обещаний через обработчик событий unhandledRejection, как показано ниже:
process.on('unhandledRejection', (reason, promise) => {
Honeybadger.notify({
message: 'Unhandled promise rejection',
params: {
promise,
reason,
},
});
server.close(() => {
process.exit(1);
});
setTimeout(() => {
process.abort();
}, 1000).unref()
});
Вы всегда должны запускать свои серверы с помощью диспетчера процессов, который автоматически перезапустит их в случае сбоя. Распространенным является PM2, но у вас также есть systemd или upstart в Linux, и пользователи Docker могут использовать его политику перезапуска. Как только это будет сделано, надежный сервис будет восстановлен почти мгновенно, и вы по-прежнему будете иметь сведения о неперехваченном исключении, чтобы его можно было быстро исследовать и исправить. Вы можете пойти дальше, запустив более одного процесса и используя балансировщик нагрузки для распределения входящих запросов. Это поможет предотвратить простои в случае временной потери одного из экземпляров.
Централизованная отчетность об ошибках
Ни одна стратегия обработки ошибок не будет полной без надежной стратегии ведения журнала для вашего работающего приложения. Когда происходит сбой, важно выяснить, почему он произошел, записав как можно больше информации о проблеме. Централизация этих журналов позволяет легко получить полную информацию о вашем приложении. Вы сможете сортировать и фильтровать свои ошибки, просматривать основные проблемы и подписываться на оповещения, чтобы получать уведомления о новых ошибках.
Honeybadger предоставляет все необходимое для отслеживания ошибок, возникающих в вашем рабочем приложении. Выполните следующие шаги, чтобы интегрировать его в свое приложение Node.js:
1. Установите пакет
Используйте npm для установки пакета:
$ npm install @honeybadger-io/js --save
2. Импортируйте библиотеку
Импортируйте библиотеку и настройте ее с помощью своего ключа API, чтобы начать сообщать об ошибках:
const Honeybadger = require('@honeybadger-io/js');
Honeybadger.configure({
apiKey: '[ YOUR API KEY HERE ]'
});
3. Сообщите об ошибках
Вы можете сообщить об ошибке, вызвав метод notify(), как показано в следующем примере:
try {
// ...error producing code
} catch(error) {
Honeybadger.notify(error);
}
Для получения дополнительной информации о том, как Honeybadger интегрируется с веб-фреймворками Node.js, см. полную документацию или ознакомьтесь с образцом приложения Node.js/Express на GitHub.
Резюме
Класс (или подкласс) Error всегда должен быть использован для связи ошибок в коде. Технически, вы можете throw что угодно в JavaScript, а не только объекты Error, но это не рекомендуется, так как это значительно снижает полезность ошибки и делает обработку ошибок подверженной ошибкам. Последовательно используя объекты Error, вы можете надежно рассчитывать на доступ error.message или error.stack в местах, где ошибки обрабатываются или регистрируются. Вы даже можете дополнить класс ошибок другими полезными свойствами, относящимися к контексту, в котором произошла ошибка.
Операционные ошибки неизбежны и должны учитываться в любой корректной программе. В большинстве случаев следует использовать стратегию исправимых ошибок, чтобы программа могла продолжать работать без сбоев. Однако, если ошибка достаточно серьезная, может быть целесообразно завершить программу и перезапустить ее. Попробуйте завершить работу корректно, если возникнут такие ситуации, чтобы программа могла снова запуститься в чистом состоянии.
Ошибки программиста нельзя обработать или исправить, но их можно смягчить с помощью набора автоматизированных тестов и инструментов статической типизации. При написании функции определите поведение для неверных параметров и действуйте соответствующим образом после их обнаружения. Разрешите сбой программы при обнаружении uncaughtException или unhandledRejection. Не пытайтесь исправить такие ошибки!
Используйте службу мониторинга ошибок, например Honeybadger, для сбора и анализа ваших ошибок. Это может помочь вам значительно повысить скорость отладки и разрешения проблем.
Вывод
Правильная обработка ошибок является непреложным требованием, если вы хотите писать хорошее и надежное программное обеспечение. Используя методы, описанные в этой статье, вы будете на правильном пути к этому.
Спасибо за чтение и удачного кодирования!
Following is a summarization and curation from many different sources on this topic including code example and quotes from selected blog posts. The complete list of best practices can be found here
Best practices of Node.JS error handling
Number1: Use promises for async error handling
TL;DR: Handling async errors in callback style is probably the fastest way to hell (a.k.a the pyramid of doom). The best gift you can give to your code is using instead a reputable promise library which provides much compact and familiar code syntax like try-catch
Otherwise: Node.JS callback style, function(err, response), is a promising way to un-maintainable code due to the mix of error handling with casual code, excessive nesting and awkward coding patterns
Code example — good
doWork()
.then(doWork)
.then(doError)
.then(doWork)
.catch(errorHandler)
.then(verify);
code example anti pattern – callback style error handling
getData(someParameter, function(err, result){
if(err != null)
//do something like calling the given callback function and pass the error
getMoreData(a, function(err, result){
if(err != null)
//do something like calling the given callback function and pass the error
getMoreData(b, function(c){
getMoreData(d, function(e){
...
});
});
});
});
});
Blog quote: «We have a problem with promises»
(From the blog pouchdb, ranked 11 for the keywords «Node Promises»)
«…And in fact, callbacks do something even more sinister: they deprive us of the stack, which is something we usually take for granted in programming languages. Writing code without a stack is a lot like driving a car without a brake pedal: you don’t realize how badly you need it, until you reach for it and it’s not there. The whole point of promises is to give us back the language fundamentals we lost when we went async: return, throw, and the stack. But you have to know how to use promises correctly in order to take advantage of them.«
Number2: Use only the built-in Error object
TL;DR: It pretty common to see code that throws errors as string or as a custom type – this complicates the error handling logic and the interoperability between modules. Whether you reject a promise, throw exception or emit error – using Node.JS built-in Error object increases uniformity and prevents loss of error information
Otherwise: When executing some module, being uncertain which type of errors come in return – makes it much harder to reason about the coming exception and handle it. Even worth, using custom types to describe errors might lead to loss of critical error information like the stack trace!
Code example — doing it right
//throwing an Error from typical function, whether sync or async
if(!productToAdd)
throw new Error("How can I add new product when no value provided?");
//'throwing' an Error from EventEmitter
const myEmitter = new MyEmitter();
myEmitter.emit('error', new Error('whoops!'));
//'throwing' an Error from a Promise
return new promise(function (resolve, reject) {
DAL.getProduct(productToAdd.id).then((existingProduct) =>{
if(existingProduct != null)
return reject(new Error("Why fooling us and trying to add an existing product?"));
code example anti pattern
//throwing a String lacks any stack trace information and other important properties
if(!productToAdd)
throw ("How can I add new product when no value provided?");
Blog quote: «A string is not an error»
(From the blog devthought, ranked 6 for the keywords “Node.JS error object”)
«…passing a string instead of an error results in reduced interoperability between modules. It breaks contracts with APIs that might be performing instanceof Error checks, or that want to know more about the error. Error objects, as we’ll see, have very interesting properties in modern JavaScript engines besides holding the message passed to the constructor..»
Number3: Distinguish operational vs programmer errors
TL;DR: Operations errors (e.g. API received an invalid input) refer to known cases where the error impact is fully understood and can be handled thoughtfully. On the other hand, programmer error (e.g. trying to read undefined variable) refers to unknown code failures that dictate to gracefully restart the application
Otherwise: You may always restart the application when an error appear, but why letting ~5000 online users down because of a minor and predicted error (operational error)? the opposite is also not ideal – keeping the application up when unknown issue (programmer error) occurred might lead unpredicted behavior. Differentiating the two allows acting tactfully and applying a balanced approach based on the given context
Code example — doing it right
//throwing an Error from typical function, whether sync or async
if(!productToAdd)
throw new Error("How can I add new product when no value provided?");
//'throwing' an Error from EventEmitter
const myEmitter = new MyEmitter();
myEmitter.emit('error', new Error('whoops!'));
//'throwing' an Error from a Promise
return new promise(function (resolve, reject) {
DAL.getProduct(productToAdd.id).then((existingProduct) =>{
if(existingProduct != null)
return reject(new Error("Why fooling us and trying to add an existing product?"));
code example — marking an error as operational (trusted)
//marking an error object as operational
var myError = new Error("How can I add new product when no value provided?");
myError.isOperational = true;
//or if you're using some centralized error factory (see other examples at the bullet "Use only the built-in Error object")
function appError(commonType, description, isOperational) {
Error.call(this);
Error.captureStackTrace(this);
this.commonType = commonType;
this.description = description;
this.isOperational = isOperational;
};
throw new appError(errorManagement.commonErrors.InvalidInput, "Describe here what happened", true);
//error handling code within middleware
process.on('uncaughtException', function(error) {
if(!error.isOperational)
process.exit(1);
});
Blog Quote: «Otherwise you risk the state»
(From the blog debugable, ranked 3 for the keywords «Node.JS uncaught exception»)
«…By the very nature of how throw works in JavaScript, there is almost never any way to safely “pick up where you left off”, without leaking references, or creating some other sort of undefined brittle state. The safest way to respond to a thrown error is to shut down the process. Of course, in a normal web server, you might have many connections open, and it is not reasonable to abruptly shut those down because an error was triggered by someone else. The better approach is to send an error response to the request that triggered the error, while letting the others finish in their normal time, and stop listening for new requests in that worker»
Number4: Handle errors centrally, through but not within middleware
TL;DR: Error handling logic such as mail to admin and logging should be encapsulated in a dedicated and centralized object that all end-points (e.g. Express middleware, cron jobs, unit-testing) call when an error comes in.
Otherwise: Not handling errors within a single place will lead to code duplication and probably to errors that are handled improperly
Code example — a typical error flow
//DAL layer, we don't handle errors here
DB.addDocument(newCustomer, (error, result) => {
if (error)
throw new Error("Great error explanation comes here", other useful parameters)
});
//API route code, we catch both sync and async errors and forward to the middleware
try {
customerService.addNew(req.body).then(function (result) {
res.status(200).json(result);
}).catch((error) => {
next(error)
});
}
catch (error) {
next(error);
}
//Error handling middleware, we delegate the handling to the centrzlied error handler
app.use(function (err, req, res, next) {
errorHandler.handleError(err).then((isOperationalError) => {
if (!isOperationalError)
next(err);
});
});
Blog quote: «Sometimes lower levels can’t do anything useful except propagate the error to their caller»
(From the blog Joyent, ranked 1 for the keywords “Node.JS error handling”)
«…You may end up handling the same error at several levels of the stack. This happens when lower levels can’t do anything useful except propagate the error to their caller, which propagates the error to its caller, and so on. Often, only the top-level caller knows what the appropriate response is, whether that’s to retry the operation, report an error to the user, or something else. But that doesn’t mean you should try to report all errors to a single top-level callback, because that callback itself can’t know in what context the error occurred»
Number5: Document API errors using Swagger
TL;DR: Let your API callers know which errors might come in return so they can handle these thoughtfully without crashing. This is usually done with REST API documentation frameworks like Swagger
Otherwise: An API client might decide to crash and restart only because he received back an error he couldn’t understand. Note: the caller of your API might be you (very typical in a microservices environment)
Blog quote: «You have to tell your callers what errors can happen»
(From the blog Joyent, ranked 1 for the keywords “Node.JS logging”)
…We’ve talked about how to handle errors, but when you’re writing a new function, how do you deliver errors to the code that called your function? …If you don’t know what errors can happen or don’t know what they mean, then your program cannot be correct except by accident. So if you’re writing a new function, you have to tell your callers what errors can happen and what they mea
Number6: Shut the process gracefully when a stranger comes to town
TL;DR: When an unknown error occurs (a developer error, see best practice number #3)- there is uncertainty about the application healthiness. A common practice suggests restarting the process carefully using a ‘restarter’ tool like Forever and PM2
Otherwise: When an unfamiliar exception is caught, some object might be in a faulty state (e.g an event emitter which is used globally and not firing events anymore due to some internal failure) and all future requests might fail or behave crazily
Code example — deciding whether to crash
//deciding whether to crash when an uncaught exception arrives
//Assuming developers mark known operational errors with error.isOperational=true, read best practice #3
process.on('uncaughtException', function(error) {
errorManagement.handler.handleError(error);
if(!errorManagement.handler.isTrustedError(error))
process.exit(1)
});
//centralized error handler encapsulates error-handling related logic
function errorHandler(){
this.handleError = function (error) {
return logger.logError(err).then(sendMailToAdminIfCritical).then(saveInOpsQueueIfCritical).then(determineIfOperationalError);
}
this.isTrustedError = function(error)
{
return error.isOperational;
}
Blog quote: «There are three schools of thoughts on error handling»
(From the blog jsrecipes)
…There are primarily three schools of thoughts on error handling: 1. Let the application crash and restart it. 2. Handle all possible errors and never crash. 3. Balanced approach between the two
Number7: Use a mature logger to increase errors visibility
TL;DR: A set of mature logging tools like Winston, Bunyan or Log4J, will speed-up error discovery and understanding. So forget about console.log.
Otherwise: Skimming through console.logs or manually through messy text file without querying tools or a decent log viewer might keep you busy at work until late
Code example — Winston logger in action
//your centralized logger object
var logger = new winston.Logger({
level: 'info',
transports: [
new (winston.transports.Console)(),
new (winston.transports.File)({ filename: 'somefile.log' })
]
});
//custom code somewhere using the logger
logger.log('info', 'Test Log Message with some parameter %s', 'some parameter', { anything: 'This is metadata' });
Blog quote: «Lets identify a few requirements (for a logger):»
(From the blog strongblog)
…Lets identify a few requirements (for a logger):
1. Time stamp each log line. This one is pretty self explanatory – you should be able to tell when each log entry occured.
2. Logging format should be easily digestible by humans as well as machines.
3. Allows for multiple configurable destination streams. For example, you might be writing trace logs to one file but when an error is encountered, write to the same file, then into error file and send an email at the same time…
Number8: Discover errors and downtime using APM products
TL;DR: Monitoring and performance products (a.k.a APM) proactively gauge your codebase or API so they can auto-magically highlight errors, crashes and slow parts that you were missing
Otherwise: You might spend great effort on measuring API performance and downtimes, probably you’ll never be aware which are your slowest code parts under real world scenario and how these affects the UX
Blog quote: «APM products segments»
(From the blog Yoni Goldberg)
«…APM products constitutes 3 major segments:1. Website or API monitoring – external services that constantly monitor uptime and performance via HTTP requests. Can be setup in few minutes. Following are few selected contenders: Pingdom, Uptime Robot, and New Relic
2. Code instrumentation – products family which require to embed an agent within the application to benefit feature slow code detection, exceptions statistics, performance monitoring and many more. Following are few selected contenders: New Relic, App Dynamics
3. Operational intelligence dashboard – these line of products are focused on facilitating the ops team with metrics and curated content that helps to easily stay on top of application performance. This is usually involves aggregating multiple sources of information (application logs, DB logs, servers log, etc) and upfront dashboard design work. Following are few selected contenders: Datadog, Splunk»
The above is a shortened version — see here more best practices and examples
Debugging errors is the hardest part of programming. Errors can appear in your code in a variety of ways, whether as syntax errors, errors in logic, or the most dreaded of all, runtime errors. Runtime errors occur whenever something unexpected occurs in your application, and they often lead to catastrophic issues that can crash your program.
Like many languages, Node.js provides a mechanism to anticipate errors before they occur. When an error occurs in your code, it turns into an object called an exception. Properly handling these exceptions allows you to recover gracefully from unforeseen issues, resulting in a much better user experience.
In this post, we’ll take a look at what causes these errors in Node.js, and how to recover from them.
What can cause an error exception in Node.js?
Runtime errors can occur in a variety of ways. One example includes referencing an undefined variable, or passing the wrong type to an argument.
Other common Node.js errors include:
- EvalError: errors that occur within the global function
eval - RangeError: these errors occur when you attempt to access a variable outside its range, such as trying to get the fifth element of an array with only three items
- ReferenceError: these errors arise when you attempt to use a variable that doesn’t exist
- SyntaxError: these errors come from invalid code
- TypeError: this occurs when you attempt to use a variable that is not a valid type
- URIError: this error occurs whenever
encodeURIordecodeURIare given invalid parameters
In most cases, these exceptions occur outside of your control. For example, if you run the following line of code:
null.toString()You should expect to receive the following error:
Uncaught TypeError: Cannot read property 'someMethod' of nullNode.js Throw Exception
However, you can also throw an error yourself:
throw new Error('Throw makes it go boom!')Why would you want to do this? Well, consider the case where you know an error can occur. For example, suppose you have a calculator app written in Node.js, and you want to throw an error if the denominator in the division function is a zero:
function divide(numerator, denominator) {
if (denominator == 0) {
throw new Error('divide by zero!')
}
else {
return numerator / denominator;
}
}Why would you want to do this? Well, admittedly, catching a generic Error is not very helpful. But you can create a custom error subclass:
class DivideByZeroError extends Error {
constructor(message) {
super(message);
this.name = "DivideByZeroError";
}
}This allows you to set up a more appropriate error in the code:
function divide(numerator, denominator) {
if (denominator == 0) {
throw new DivideByZeroError('divide by zero!')
}
else {
return numerator / denominator;
}
}If you take this concept further, you could throw errors for any kind of issue. Compare the following ways of handling errors:
let user = JSON.parse(json);
if (!user.age || user.age < 0) {
throw new InvalidAgeError("No field: age");
}
if (!user.name) {
throw new MissingNameError("No field: name");
}
if (!user.address) {
throw new Error("Required");
}By throwing your own exception, your immediate benefit will be a more legible code base, as in the case of age and name above. But your error classes will also show up in your logs and data analytics pipelines, which can help you narrow down specifically what problems may be occurring. When trying to track down an error, it can be hard to rationalize what Error is supposed to mean, as opposed to InvalidAge or MissingName.
Regardless, catching errors like this is essential in Node.js. Because Node runs in an asynchronous environment, an event that occurs sometimes doesn’t have an immediate effect. In our example above, we tried to rely on user.address in a situation where it doesn’t exist, however, the program will crash, but not when we might expect it to! On the other hand, try/catch operates synchronously; as soon as an error is thrown, the program halts, allowing you to recover without unintended side effects.
How do you protect your application against exceptions?
If you know where an error can occur, your next likely step would be to prevent this error from taking down your application or upsetting your user. To prevent this, Node.js has a special syntax called the try-catch block.
As its name suggests, a try-catch block lets you run a piece of code, and if an error is thrown, halts the program and lets you recover. Let’s take a look at how that might work in practice with our earlier toString() example. Suppose you have a function like this:
function showString(var) {
return var.toString();
}Now, we can’t guarantee that toString() will work on var. Maybe it’s null, or maybe this function is called on some dynamic user input we can’t control. Since we know we have the potential to run into a TypeError here, we can use a try-catch block to anticipate this error and do something else:
function showString(var) {
try {
return var.toString()
} catch (TypeError) {
// report error message to the user
return "Error! String not given";
}
}If there is no error, then the code in the catch block is never executed. Keep in mind that the error provided to the catch statement must match the error you expect, or else that code won’t run. Unfortunately, this can prevent your code from catching errors, and try-catch not working.
If you think an error might occur, but you aren’t sure what its type would be, and you want to ensure that you catch any potential errors, you can just protect against the base Error class:
try {
someFunction();
}
catch (Error) {
// do something else
}Since all errors extend this base Error class, it will catch any thrown errors.
Another neat addition is the ability to add a finally statement to these lines. For example:
try {
openDatabase();
updateDatabase(x, y);
}
catch (Error) {
return "Error! Database could not be updated.";
}
finally {
// always a good idea to close a database connection when you're done
closeDatabase();
}finally will always execute at the end of the try-catch block, regardless of whether or not the catch statement catches an error. It can clean up any remaining state, such as closing an open database connection. At least one catch or a finally must be present in a try block.
Wrapping Up
Exceptions and try-catch blocks aren’t unique to Node. For a more high-level overview, you can check out their documentation on the subject.
We’ve talked a lot about exceptions in this article. It’s important to keep in mind that errors can still occur in alarming volume, despite your best efforts to prevent them. Mistaken code can always make it to production, and rather than foist availability issues onto your users, a platform like Rollbar can help you fix unforeseen issues before they become problems. With its real-time Node error monitoring, AI-assisted workflows, and root cause analysis, Rollbar can protect your app by predicting problems before they affect your users.
Track, Analyze and Manage Errors With Rollbar

Managing errors and exceptions in your code is challenging. It can make deploying production code an unnerving experience. Being able to track, analyze, and manage errors in real-time can help you to proceed with more confidence. Rollbar automates error monitoring and triaging, making fixing errors easier than ever. Try it today.