
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Определения
Пусть дана выборка  из неизвестного совместного распределения , и поставлена бинарная задача проверки статистических гипотез:
из неизвестного совместного распределения , и поставлена бинарная задача проверки статистических гипотез:
где — нулевая гипотеза, а — альтернативная гипотеза. Предположим, что задан статистический критерий
,
сопоставляющий каждой реализации выборки одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
-
Распределение
выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть . -
Распределение
выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть . -
Распределение
выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть . -
Распределение
выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно. 1)2)
| Верная гипотеза | |||
|---|---|---|---|
|
|
|
||
|
Результат
применения критерия |
|
верно принята |
неверно принята
(Ошибка второго рода) |
|
|
неверно отвергнута
(Ошибка первого рода) |
верно отвергнута |
О смысле ошибок первого и второго рода
Из определения выше видно, что ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы и , то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследуемый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня. Слово «положительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают положительный результат (т.е. показывают наличие заболевания у пациента), когда на самом деле пациент этим заболеванием не страдает. Такой результат называется ложноположительным.
В других областях обычно используют словосочетания со схожим смыслом, например, «ложное срабатывание», «ложная тревога» и т.п. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Слово «отрицательный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают отрицательный результат (т.е. показывают отсутствие заболевания у пациента), когда на самом деле пациент страдает этим заболеванием. Такой результат называется ложноотрицательным.
В других областях обычно используют словосочетания со схожим смыслом, например, «пропуск события», и т.п. В информационных технологиях часто используют английский термин false negative без перевода.
Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок.
Вероятности ошибок (уровень значимости и мощность)
Вероятность ошибки первого рода при проверке статистических гипотез называют уровнем значимости и обычно обозначают греческой буквой (отсюда название -errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой (отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле . Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объема, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования
Радиолокация
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «ложная тревога» и «пропуск цели» являются одним из основных элементов как теории, так и практики построения радиолокационных станций. Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютеры
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
-
когда авторизованные пользователи классифицируются как нарушители (ошибки первого рода)
-
когда нарушители классифицируются как авторизованные пользователи (ошибки второго рода)
Фильтрация спама
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «антиспам»-алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда антиспам-система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности антиспам-алгоритма.
Пока не удалось создать антиспамовую систему без корреляции между вероятностью ошибок первого и второго рода. Вероятность пропустить спам у современных систем колеблется в пределах от 1% до 30%. Вероятность ошибочно отвергнуть валидное сообщение — от 0,001 % до 3 %. Выбор системы и её настроек зависит от условий конкретного получателя: для одних получателей риск потерять 1% хорошей почты оценивается как незначительный, для других же потеря даже 0,1% является недопустимой.
Вредоносное программное обеспечение
Понятие ошибки первого рода также используется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с антитроянскими и антишпионскими программами.
Поиск в компьютерных базах данных
При поиске в базе данных к ошибкам первого рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек.
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т.п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т.д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т.п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.3)
Массовая медицинская диагностика (скрининг)
В медицинской практике есть существенное различие между скринингом и тестированием:
-
Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
-
Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые, в основном, применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.4))
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15%, это самый высокий показатель в мире.5) Самый низкий уровень наблюдается в Нидерландах, 1%.6)
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70%, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.7)
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т.д.), которое имеет обычное объяснение. 
См. также
5.6. Вероятность ошибки р
Если следовать подразделению статистики на описательную и аналитическую, то задача аналитической статистики — предоставить методы, с помощью которых можно было бы объективно выяснить,
например, является ли наблюдаемая разница в средних значениях или взаимосвязь (корреляция) выборок случайной или нет.
Например, если сравниваются два средних значения выборок, то можно сформулировать две предварительных гипотезы:
-
Гипотеза 0 (нулевая): Наблюдаемые различия между средними значениями выборок находятся в пределах случайных отклонений.
-
Гипотеза 1 (альтернативная): Наблюдаемые различия между средними значениями нельзя объяснить случайными отклонениями.
В аналитической статистике разработаны методы вычисления так называемых тестовых (контрольных) величин, которые рассчитываются по определенным формулам на основе данных,
содержащихся в выборках или полученных из них характеристик. Эти тестовые величины соответствуют определенным теоретическим распределениям
(t-pacnpeлелению, F-распределению, распределению X2 и т.д.), которые позволяют вычислить так называемую вероятность ошибки. Это вероятность равна проценту ошибки,
которую можно допустить отвергнув нулевую гипотезу и приняв альтернативную.
Вероятность определяется в математике, как величина, находящаяся в диапазоне от 0 до 1. В практической статистике она также часто выражаются в процентах. Обычно вероятность обозначаются буквой р:
0 < р < 1
Вероятности ошибки, при которой допустимо отвергнуть нулевую гипотезу и принять альтернативную гипотезу, зависит от каждого конкретного случая.
В значительной степени эта вероятность определяется характером исследуемой ситуации. Чем больше требуемая вероятность, с которой надо избежать ошибочного решения,
тем более узкими выбираются границы вероятности ошибки, при которой отвергается нулевая гипотеза, так называемый доверительный интервал вероятности.
Обычно в исследованиях используют 5% вероятность ошибки.
Существует общепринятая терминология, которая относится к доверительным интервалам вероятности:
- Высказывания, имеющие вероятность ошибки р <= 0,05 — называются значимыми.
- Высказывания с вероятностью ошибки р <= 0,01 — очень значимыми,
- А высказывания с вероятностью ошибки р <= 0,001 — максимально значимыми.
В литературе такие ситуации иногда обозначают одной, двумя или тремя звездочками.
| Вероятность ошибки | Значимость | Обозначение |
| р > 0.05 | Не значимая | ns |
| р <= 0.05 | Значимая | * |
| р <= 0.01 | Очень значимая | ** |
| р <= 0.001 | Максимально значимая | *** |
В SPSS вероятность ошибки р имеет различные обозначения; звездочки для указания степени значимости применяются лишь в немногих случаях. Обычно в SPSS значение р обозначается Sig. (Significant).
Времена, когда не было компьютеров, пригодных для статистического анализа, давали практикам по крайней мере одно преимущество. Так как все вычисления надо было выполнять вручную,
статистик должен был сначала тщательно обдумать, какие вопросы можно решить с помощью того или иного теста. Кроме того, особое значение придавалось точной формулировке нулевой гипотезы.
Но с помощью компьютера и такой мощной программы, как SPSS, очень легко можно провести множество тестов за очень короткое время. К примеру, если в таблицу сопряженности свести 50 переменных
с другими 20 переменными и выполнить тест X2, то получится 1000 результатов проверки значимости или 1000 значений р. Некритический подбор значимых величин может
дать бессмысленный результат, так как уже при граничном уровне значимости р = 0,05 в пяти процентах наблюдений, то есть в 50 возможных наблюдениях, можно ожидать значимые результаты.
Этим ошибкам первого рода (когда нулевая гипотеза отвергается, хотя она верна) следует уделять достаточно внимания. Ошибкой второго рода называется ситуация,
когда нулевая гипотеза принимается, хотя она ложна. Вероятность допустить ошибку первого рода равна вероятности ошибки р. Вероятность ошибки второго рода тем меньше, чем больше вероятность ошибки р.
Ошибки, встроенные в систему: их роль в статистике
Время на прочтение
6 мин
Количество просмотров 13K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):
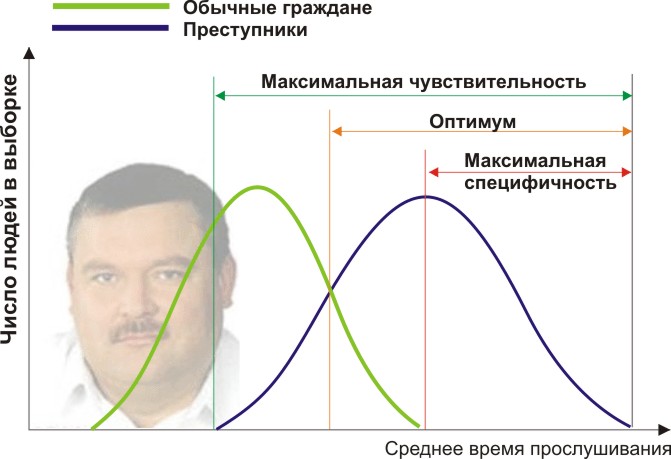
Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:

Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):

А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
Маркетинг – та сфера, где больше всего любят работать с большими данными (англ. big data), однако излюбленный инструмент маркетологов – A/B-тестирование – предполагает использование малых данных (англ. small data). При этом какие бы цифры ни были получены по итогам теста, все сводится к анализу статистической выборки и определению статистической значимости результатов эксперимента. Неотъемлемой частью данного исследования является P-значение, о котором мы хотим рассказать в этой статье.
Что такое P-значение
P-value или p-значение – одна из ключевых величин, используемых в статистике при тестировании гипотез. Она показывает вероятность получения наблюдаемых результатов при условии, что нулевая гипотеза верна, или вероятность ошибки в случае отклонения нулевой гипотезы.
Этот термин первым упомянул в своих работах К. А. Браунли в 1960 году. Он описал p-уровень значимости как показатель, который находится в обратной зависимости от истинности результатов. Чем выше р-value, тем ниже степень доверия в выборке зависимости между переменными.
Другими словами, в статистике p-значение – это наименьшее значение уровня значимости, при котором полученная проверочная статистика ведет к отказу от основной (нулевой) гипотезы.
Значение p-уровня чаще всего соответствует статистической значимости, равной 0,05. Если значение р меньше 0,05, нулевую гипотезу отклоняют. При этом чем меньше это значение, тем лучше, т. к. растет предполагаемая значимость альтернативной гипотезы и «сила» отвержения нулевой.
Часто p-значение понимают неправильно. Например, если значение р = 0,05, можно сказать о том, что существует 5% вероятности, что результат получен случайно и не соответствует действительности.

Кратко о главном
- Р-значение показывает вероятность того, что наблюдаемая разница в результатах могла быть случайной.
- Значение p применяется как альтернатива выбранным уровням достоверности для тестирования идей или в дополнение к ним.
- Со снижением p-значения повышается статистическая значимость разницы, полученной в ходе исследования.
Статистическая значимость
Эксперимент начинается с формулирования нулевой гипотезы. Она показывает, что два исследуемых явления никаким образом не связаны друг с другом.
Эксперимент проводится с целью выявить или показать какое-либо влияние или тип взаимодействия рассматриваемых явлений. Если в итоге анализа подтверждается нулевая гипотеза, значит, тест провалился.

Чтобы правильно интерпретировать результаты, рассчитывают показатель статистической значимости.
Статистическая значимость – это критерий, с помощью которого можно определить, необходимо ли отвергнуть или принять ту или иную гипотезу.
Перед началом тестирования следует установить порог значимости (альфа). Если значение р меньше альфа, можно говорить о том, что наш результат является статистически значимым. Это говорит о том, что наблюдаемое явление действительно имело место, и нулевую гипотезу нужно отклонить.
Порог значимости альфа устанавливается обычно на уровне 0,05 или 0,01. Выбор значения определяется поставленной задачей.
Порог значимости равен 0,05, а p-значение – 0,02. Т. к. установленное значение альфа больше p-уровня, делаем вывод, что это статистически значимый результат.
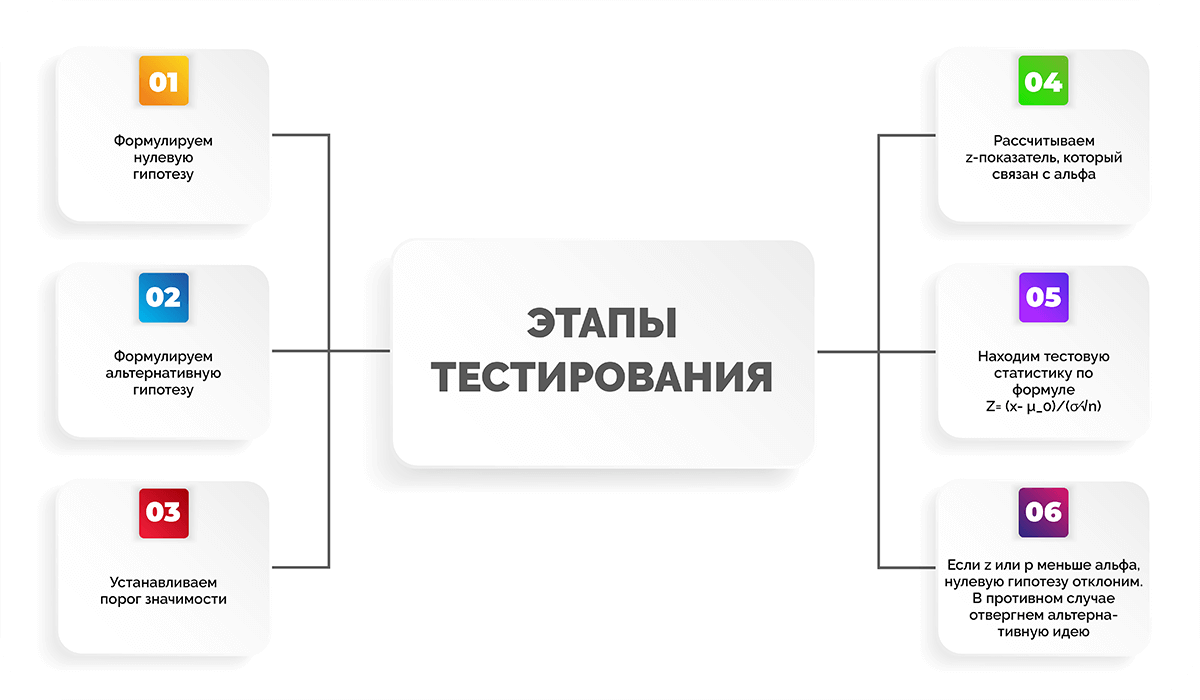
Все тестирование можно разделить на несколько этапов:
- Формулируем нулевую гипотезу.
- Формулируем альтернативную гипотезу.
- Устанавливаем порог значимости.
- Рассчитываем z-показатель, который связан с альфа.
- Находим тестовую статистику по формуле .
- Если z-показатель или p-значение меньше уровня альфа, нулевую гипотезу отклоним. В противном случае отвергнем альтернативную идею.
 .
.Если идет речь о явлениях, которые управляются случайными процессами, обычно это приводит к нормальному распределению значений. В этом случае нулевую гипотезу представляют в виде кривой Гаусса, которая отражает распределение ожидаемых наблюдений. Это распределение актуально в случае, если одна переменная в эксперименте не зависит от другой.
Порог вероятности
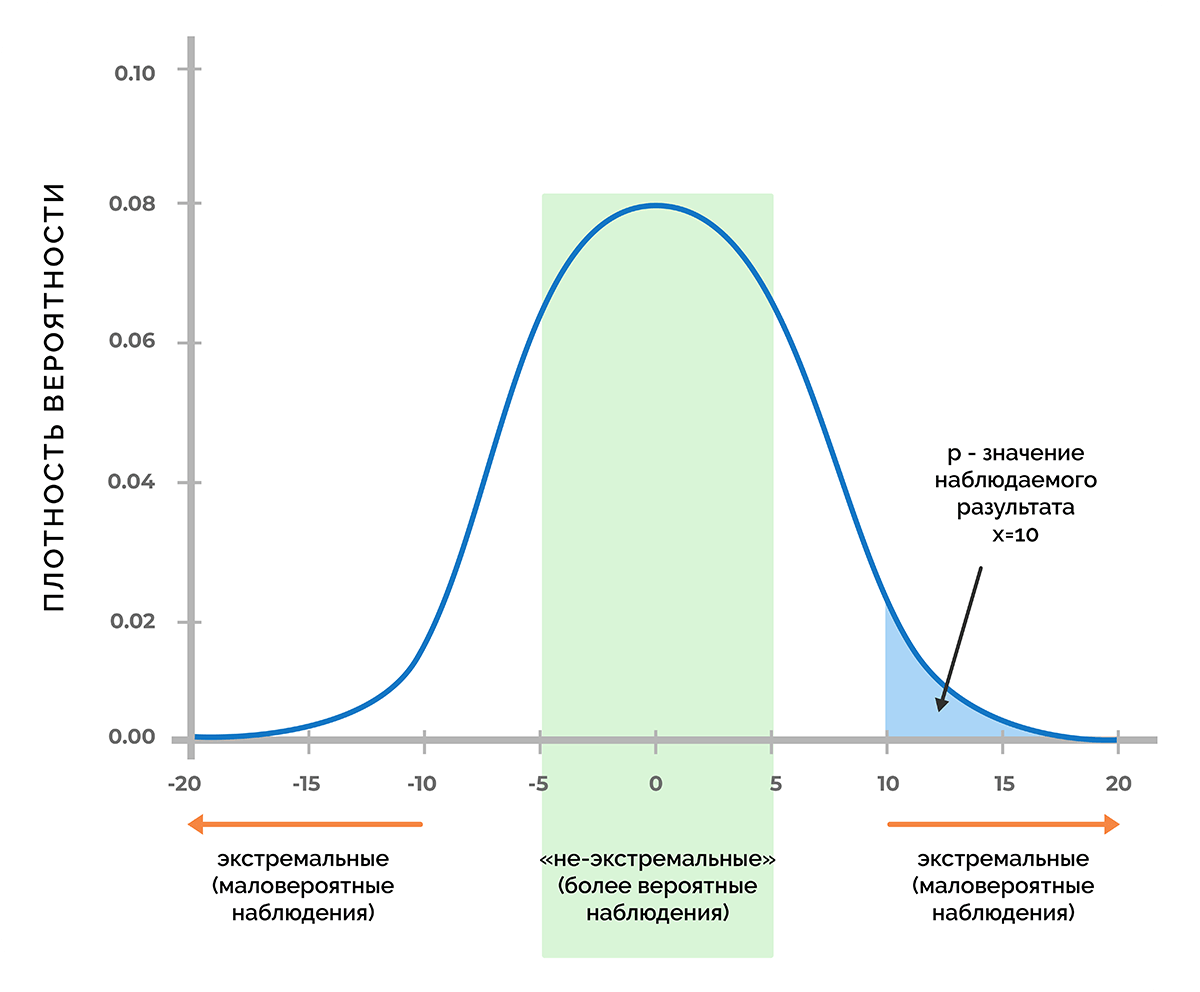
В основе статистической значимости лежит вероятность получения определенного результата при верности нулевой гипотезы. Чтобы разобрать смысл этого определения, предположим, что в процессе тестирования получили некое число х. Это может быть любая метрика, например, прибыль от продаж, величина конверсии, количество довольных покупателей и т. д.
Используя функцию плотности вероятности, которая связана с нулевой гипотезой, можно выяснить, удастся ли получить число х (или любое другое значение, которое маловероятнее, чем х) с вероятностью менее 5% (p < 0,05) или менее 1% (p < 0,01), или другого порога, при котором p меньше заданного уровня значимости.
Таким образом, p-критерий отражает вероятность получения результата, который равен или является более экстремальным, чем фактически наблюдаемый результат, в случае отсутствия взаимосвязи между исследуемыми переменными.
Доверительные уровни
Доверительный уровень значимости выбирается перед запуском статистического эксперимента. Чаще всего используются значения 90%, 95% или 99%.
Ниже в таблице приводим критические p-значения, а также z-оценки для разных доверительных уровней.
|
Доверительный уровень |
Стандартное отклонение (z-оценка) |
Вероятность (p-уровень) |
|
90% |
< -1,65 или > +1,65 |
< 0,10 |
|
95% |
< -1,96 или > +1,96 |
< 0,05 |
|
99% |
< -2,58 или > +2,58 |
< 0,01 |
Значения, которые находятся в пределах области нормального распределения z-оценки (стандартного отклонения), представляют ожидаемый результат.
Проверка статистических гипотез
Проверка гипотезы – это статистическое исследование, которое проводится, чтобы подтвердить или опровергнуть какую-либо гипотезу (простую или сложную).
Можно предположить, что посадочная страница с красной кнопкой CTA даст больше конверсий, чем текущая версия лендинга с синей. Проверить это можно путем тестирования, в котором будут участвовать нулевая и альтернативная гипотезы.

Нулевая гипотеза – первоначальное условие, при котором нет никакой разницы между текущей и новой версиями лендинга в плане конверсии
Альтернативная гипотеза – подразумевает, что изменение цвета кнопки на странице является причиной роста конверсии.
В статистике применяется рандомизация и нормализация нулевой гипотезы.
Рандомизация нулевой гипотезы – пространственная модель данных, которую мы наблюдаем, является одним из многих вариантов пространственных организаций данных. При этом все другие варианты не будут заметно отличаться от наблюдаемых.
Нормализация нулевой гипотезы подразумевает, что наблюдаемые значения являются одним из многих случайных вариантов выборок. При этом ни пространственное расположение данных, ни их значения не установлены.
Благодаря значению p можно увидеть, насколько нулевая гипотеза правдоподобна с учетом данных выборки. Таким образом, если нулевая гипотеза подтвердится, p-значение будет свидетельствовать об отсутствии увеличения конверсии вследствие изменения цвета кнопки.
Подход p-value к проверке гипотез
Значение р может использоваться для выявления доказательства для отклонения нулевой (первоначальной) гипотезы в ходе эксперимента.
Мы уже упоминали выше о том, что уровень значимости обозначается до начала исследования, чтобы определить, насколько малое значение p нужно получить для опровержения нулевой гипотезы. Однако в разных случаях разные люди могут использовать разные уровни значимости, поэтому при интерпретации итогов двух разных тестирований другими людьми могут возникать трудности. Решить эту проблему помогает p-value.
Рассмотрим пример, в котором в компании провели исследование, в ходе него сравнили доходность двух активов. Тест и анализ проводили два специалиста, которые брали за основу одни и те же самые исходные данные, но использовали разные уровни значимости. Есть вероятность, что эти люди сделают противоположные выводы о различии активов. Предположим, что один специалист для отклонения нулевой гипотезы взял уровень достоверности 90%, а другой – 95%. При этом среднее значение p наблюдаемой разницы между результатами равнялось 0,08, что отвечает уровню достоверности 92%. В таком случае первый специалист выявит значимое различие между двумя доходами, а второй статистически значимой разницы не обнаружит.
Чтобы избежать подобной ситуации, можно сообщить значение p-value эксперимента и дать возможность независимым наблюдателям самостоятельно оценивать статистическую значимость итоговых данных. Данный подход к проверке утверждений стали называть «подход p-value».
Как рассчитать P-value
Чаще всего p-значения определяют с помощью таблиц p-value или специализированного статистического ПО. Также помогает в этом калькулятор на тематических сайтах. Подобные расчеты основываются на известном или предполагаемом распределении вероятностей определенной статистики. Определение среднего значения р зависит от отклонения между выбранным эталонным и тестовым значением. При этом учитывается нормальное распределение вероятностей статистики.
Что касается ручного математического расчета значения р, существуют разные способы, которые рассмотрим далее в статье.
Как рассчитать p-значение, используя тестовую статистику
Распределение тестовой статистики происходит с предполагаемым условием, что верна нулевая гипотеза. Чтобы выразить вероятность того, что статистика эксперимента будет такой же экстремальной, как значение x для выборки, используется кумулятивная функция распределения.
Левосторонний эксперимент:
P-value = cdf (x)
Правосторонний эксперимент:
P-value = 1 – cdf (x)
Двусторонний эксперимент:
P-value = 2 × мин {{cdf (x), 1 – cdf (x)}}
Ручной расчет значения p затрудняют распространенные распределения вероятностей, которыми характеризуется проверка гипотез. Для расчета примерных показателей cdf удобнее использовать статистическую таблицу или ПК.
Пошаговый алгоритм расчета p-значения
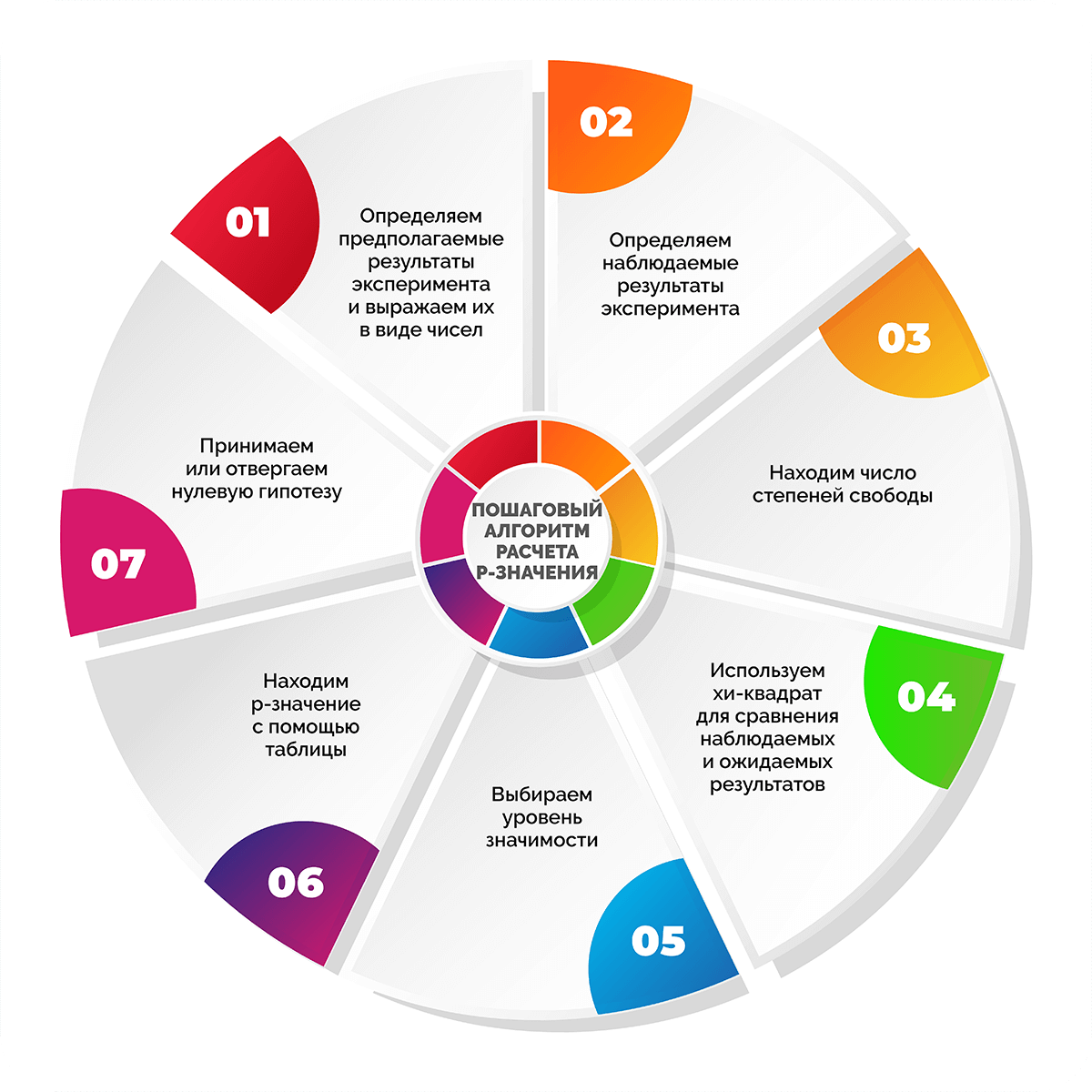
Шаг 1. Определяем предполагаемые результаты эксперимента и выражаем их в виде чисел
Как правило, на начало исследования уже есть видение того, какие числа можно считать приемлемыми. Выводы могут быть основаны на опыте проведения предыдущих экспериментов, наборах достоверных данных или общих сведеньях из научной литературы и других источников.
Опыт работы с лендингами показывает, что посадочные страницы с CTA-кнопкой на первом экране приводят примерно вдвое больше покупателей, чем версии без таких кнопок. Необходимо определить, действительно ли наличие кнопки влияет на посетителей сайта. Для этого будем анализировать конверсии в покупку. Если взять условные 300 конверсий, то предполагается, что 200 из них произойдут благодаря лендингам с CTA-кнопкой, а 100 – сайтам без кнопки при условии, что пользователи требовательны к наличию кнопок.
Шаг 2. Определяем наблюдаемые результаты эксперимента
Теперь нужно провести тест и получить реальные, т. е. наблюдаемые значения, которые таже будут выражаться в числовом формате. Если в экспериментальных условиях реальные цифры не совпадут с ожидаемыми, то будет два варианта – или это обусловлено действиями в ходе эксперимента, или получилось случайно. В данном случае цель определения p-value – понять, действительно ли наблюдаемые значения отличаются от ожидаемых настолько, что нулевая гипотеза не будет опровергнута.
Предположим, что мы выбрали 300 случайных конверсий с наших сайтов, на которых либо была кнопка на первом экране, либо ее не было. Определили, что 220 конверсий произошли благодаря лендингам с кнопкой и 80 – без нее. Результаты отличаются от ожидаемых, которые составляли 200 и 100 соответственно. Теперь предстоит узнать, действительно ли к изменению в значениях привел наш тест (добавление кнопки на первый экран) или это случайное отклонение. Определить это поможет p-значение.
Шаг 3. Находим число степеней свободы
Число степеней свободы показывает, насколько может измениться эксперимент. При этом степень изменяемости зависит от количества исследуемых категорий.
Число степеней свободы = n – 1, где n – количество анализируемых переменных или категорий.
В нашем эксперименте 2 условия и, соответственно, две категории результатов: для лендингов без кнопки на первом экране и для лендингов с ней.
Число степеней свободы = 2 – 1 = 1.
Если бы в эксперименте мы сравнивали посадочные станицы с CTA-кнопкой, без кнопки и с pop-up окном, то получили бы 2 степени свободы и т. д.
Шаг 4. Используем хи-квадрат для сравнения наблюдаемых и ожидаемых результатов
Хи-квадрат (х2) – числовое отражение разницы между наблюдаемыми (фактическими) и ожидаемыми значениями тестирования.

где:
о – наблюдаемое значение;
е – ожидаемое значение.
Подставляем наши цифры в уравнение и учитываем, что  нужно подсчитать дважды – для двух видов лендинга.
нужно подсчитать дважды – для двух видов лендинга.
х2 = ((220 – 200)2/200) + ((80 – 100)2/100) = ((20)2/200)) + ((-20)2/100) = (400/200) + (400/100) = 2 + 4 = 6.
Шаг 5. Выбираем уровень значимости
Уровень значимости отражает степень уверенности в полученных результатах. Если статистическая значимость низкая, это говорит о низкой вероятности случайного получения экспериментальных результатов.
Для большинства тестов достаточно статистической значимости, равной 0,05 или 5%. При этом будет вероятность 95%, что исследователь получил значимый результат вследствие проведенных мероприятий, а не случайно.
В нашем случае примем статистическую значимость, равную 0,05.
Шаг 6. Находим p-значение с помощью таблицы
Для облегчения расчетов статисты применяют специализированные таблицы. Они довольно простые и позволяют легко найти значение р, зная число степеней свободы и хи-значение. Слева по вертикали располагаются значения числа степеней свободы. Вверху по горизонтали находятся p-значения. По данным таблицы сначала находят нужное число степеней свободы, затем в соответствующем ему ряду выбирают первое значение, которое превышает расчетное значение хи-квадрата. Число в верхней горизонтальной строке будет соответствовать p-значению. При этом нужное значение р находится в диапазоне чисел между найденным и следующим за ним слева.
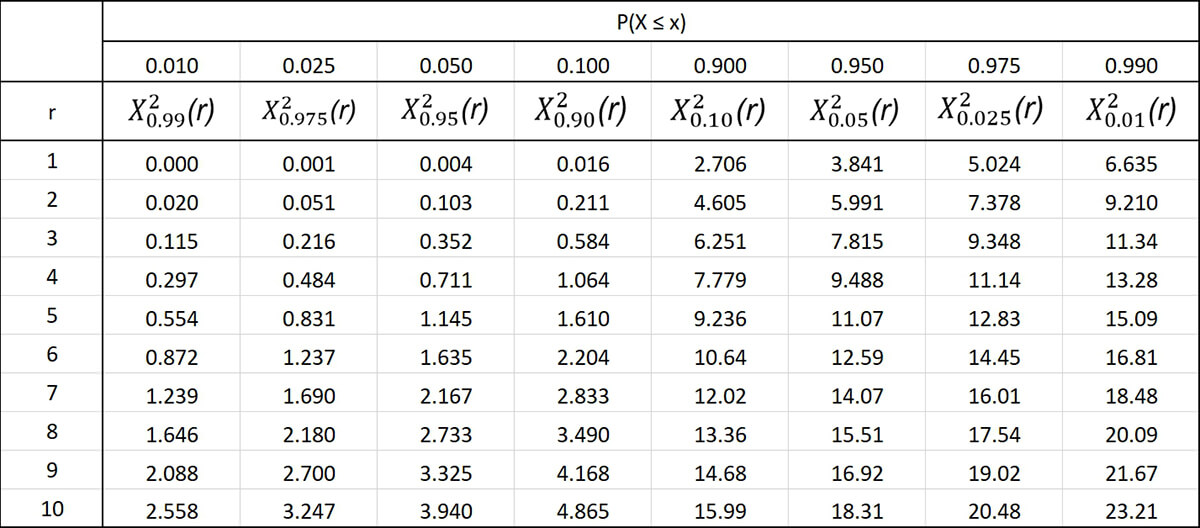
В нашем примере всего одна степень свободы, а хи-квадрат равен 6. Поэтому в таблице выбираем первую строку и движемся по ней слева направо до тех пор, пока не увидим первое значение больше 6 – это число 6,635. Оно соответствует p-значению 0,01, а значит, наше p-значение находится в диапазоне между 0,01 и 0,025.
Шаг 7. Принимаем или отвергаем нулевую гипотезу
Если найденное приблизительное значение p меньше уровня значимости, можно заключить, что вероятна связь между экспериментальными переменными и полученными результатами. В противном случае нельзя утверждать с уверенностью, связаны ли результаты с манипуляцией переменными или стали случайностью.
В нашем эксперименте диапазон значений р 0,01-0,025 определенно меньше установленной статистической значимости 0,05, что позволяет отклонить нулевую гипотезу. А значит, можно сделать вывод, что посадочные страницы с CTA-кнопкой на 1-м экране конвертируют лучше, чем аналогичные версии без такой кнопки. Вероятность того, что рост конверсий на лендингах с кнопкой является случайностью, составляет не больше 1-2,5%.
Как интерпретировать P-значение
P-уровень тесно связан с уровнем статистической значимости. Последний таже определяет исход эксперимента.
- Если p-значение меньше уровня значимости, то нулевую гипотезу можно смело отклонить и считать истинной альтернативную гипотезу.
- Если p-значение больше уровня значимости, это означает, что в ходе эксперимента выявили недостаточно оснований для отклонения нулевой гипотезы.
Отвержение нулевой гипотезы говорит о том, что в процессе исследования была обнаружена закономерная связь между тестируемыми переменными.
P-значение – это…
- вероятность того, что в ходе исследования наблюдения были случайными. То есть, если p = 0,05, есть 5% вероятности того, что наблюдаемое явление случайно и 95% вероятности того, что результат является следствием созданных условий;
- вероятность того, что будет сделан неверный вывод о взаимосвязи переменных. Если р = 0,05, то на каждые 100 экспериментов, где наблюдалась взаимосвязь, 95 их них действительно была, а 5 – нет.
Что нужно помнить о P-значениях
- «Неожиданность» определяет тот, кто проводит эксперимент. Подводит итоги теста по факту тот, кто его проводит. Чем выше значение р, тем чаще вы будете получать неожиданные результаты.
- Применение p-значения имеет довольно извилистую логику. Чтобы оценить аргументы в пользу отклонения нулевой гипотезы, необходимо изначально считать, что она верна. Именно это является причиной путаницы.
- По значению p невозможно оценить вероятность того, что один исследуемый вариант лучше другого. Также по этому показателю нельзя понять, какая вероятность того, что предпочтение одного варианта другому ошибочно. На самом деле, p-значение показывает лишь вероятность того, что при верности нулевой гипотезы удастся вычислить результат, отличный от нуля.
- Значимость p-значения при подведении итогов сплит-тестов – тема неутихающих споров в научном сообществе. Большинство маркетологов остаются приверженцами классической проверки на статистическую значимость и отстаивают ее как «золотой стандарт». При этом специалисты по статистике приводят аргументы в пользу других методов проверки, что провоцирует жаркие дебаты.
- Всегда можно получить существенное (высшее) значение p. Есть типичная ошибка, которая зависит с одной стороны от объема выборки, с другой – от изменений генеральной совокупности данных. Если во втором случае повлиять на изменения никак нельзя, то собирать и накапливать данные ничто не мешает. Но есть ли польза от такого количества сведений? Сам факт того, что у полученного параметра высокое p-значение, практического значения не имеет.
- Не стоит волноваться раньше времени. В первую очередь нужно собрать данные, которые помогут сформировать рабочую идею. Всегда трудно делать выбор между вариантами, которые почти не отличаются друг от друга. Если выделить предпочтительный вариант проблематично из-за похожих результатов, можно просто выбрать один из них и не беспокоиться о том, правильный ли это выбор.
- P-значение не повод прекращать тест. Для получения достоверных результатов, которые позволят интерпретировать p-значение, необходимо вычислить размер выборки, затем провести эксперимент. В процессе тестирования предстоит выбрать время, когда пора его закончить. При этом оно не должно быть связано с достижением статистической значимости или высокого показателя p-значения. Главное – получить реальные результаты в конце теста, например, обеспечить рост прибыли, оптимизировать конверсию и т. д.
Примеры интерпретации P-значений
На нескольких примерах рассмотрим, как правильно интерпретировать p-значения при проверке разных идей.
По мнению интернет-провайдера, 90% пользователей довольны качеством предоставляемых услуг. Чтобы это проверить, была собрана простая выборка, куда вошли 500 случайных абонентов. 85% дали утвердительный ответ на вопрос об удовлетворенности услугами провайдера. По данным выборки удалось вычислить p-значение, равное 0,018.
Если выдвинуть гипотезу о том, что 90% пользователей действительно довольны обслуживанием провайдера, получим реальную наблюдаемую разницу или более экстремальную разницу, которая составит 1,8% потребителей услуг вследствие ошибки случайной выборки.
Ресторан вводит услугу доставки еды и утверждает, что время доставки составляет около 30 минут или меньше. Однако есть мнение, что реальный срок доставки превышает заявленное время. Для проверки этих вариантов были отобраны случайные заказы еды с доставкой и проведены расчеты. По результатам выяснили, что среднее время доставки составляет 40 минут (больше на 10 минут, чем заявляет ресторан), а p-значение равно 0,03.
Результаты показывают, что в случае, когда нулевая гипотеза верна, т. е. доставка еды занимает 30 минут или меньше, есть вероятность 3%, что среднее время доставки будет как минимум на 10 минут больше из-за эффекта случайности.
Отдел маркетинга разрабатывает новый скрипт продаж для менеджеров. Предполагается, что с его помощью компания будет продавать минимум на 30% больше, чем со старым скриптом. Чтобы это проверить, собирается простая случайная выборка из 100 контактов с клиентами по новому скрипту и 100 – по старому. В результате эксперимента новый скрипт привел 60 покупателей, а старый – 45. Вычислили среднее значение p, равное 0,011.
Если взять за основу мнение, что новый скрипт приводит столько же клиентов, сколько и старый, или меньше, будет получена крайняя разница в 1,1% тестирований вследствие случайной ошибки выборки.
Часто задаваемые вопросы
P-значение – вероятность того, что исследуемая статистика удовлетворит конкретным условиям. Поскольку вероятности отрицательными не бывают, отрицательного значения p тоже быть не может.
Если p-значение высокое, это свидетельствует о том, что статистика эксперимента для другой выборки будет иметь столь же экстремальное значение, как и в тестируемой выборке. При высоком p-значении отвергнуть нулевую гипотезу нельзя.
Если получено низкое p-значение, это значит, что вероятность получить такое же критическое значение, как и наблюдаемое в текущей выборке, в тестовой статистике для другой выборки окажется очень низкой. При низком p-значении нулевую гипотезу отвергают и принимают альтернативную.
Некоторые считают, что p-значения показывают вероятность совершить ошибку при отклонении истинной нулевой гипотезы (ошибка первого типа) – это заблуждение. P-значения не свидетельствуют о частоте вероятных ошибок по двум причинам:
- При расчете p-значения в основе утверждение, что верна нулевая гипотеза, а разница в итоговых данных обусловлена случайностью. То есть величина p-значения не отражает вероятность того, что ноль будет ложным или истинным, т. к. с учетом изначального предположения он полностью верен.
- Несмотря на то, что при низком p-значении при условии истинности нулевого значения выборочные данные маловероятны, p-значение все еще не может четко показать, какой из вариантов имеет большую вероятность стать истиной: когда нуль действительно является ложным или когда нуль является верным, но выборка нечеткая.
Заключение
Несмотря на то, что при интерпретации результатов исследований часто допускают ошибки, неправильно используя статистическую значимость, она продолжает оставаться важным методом в экспериментах. P-значение или p-value является одной из обязательных составляющих при оценке результатов тестирования. Именно этот показатель дает возможность понять, с какой вероятностью полученные итоги удовлетворяют определенным значениям.

Олег Вершинин
Специалист по продукту
Все статьи автора
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter