
Is there a method in numpy for calculating the Mean Squared Error between two matrices?
I’ve tried searching but found none. Is it under a different name?
If there isn’t, how do you overcome this? Do you write it yourself or use a different lib?
![]()
asked May 27, 2013 at 13:59
![]()
4
You can use:
mse = ((A - B)**2).mean(axis=ax)
Or
mse = (np.square(A - B)).mean(axis=ax)
- with
ax=0the average is performed along the row, for each column, returning an array - with
ax=1the average is performed along the column, for each row, returning an array - with omitting the ax parameter (or setting it to
ax=None) the average is performed element-wise along the array, returning a scalar value
9
This isn’t part of numpy, but it will work with numpy.ndarray objects. A numpy.matrix can be converted to a numpy.ndarray and a numpy.ndarray can be converted to a numpy.matrix.
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(A, B)
See Scikit Learn mean_squared_error for documentation on how to control axis.
answered Apr 3, 2016 at 16:17
![]()
Even more numpy
np.square(np.subtract(A, B)).mean()
answered Nov 19, 2017 at 8:11
![]()
Mark SwardstromMark Swardstrom
17.1k5 gold badges62 silver badges69 bronze badges
1
Just for kicks
mse = (np.linalg.norm(A-B)**2)/len(A)
![]()
desertnaut
57k23 gold badges137 silver badges165 bronze badges
answered Jun 16, 2020 at 6:26
![]()
Another alternative to the accepted answer that avoids any issues with matrix multiplication:
def MSE(Y, YH):
return np.square(Y - YH).mean()
From the documents for np.square:
Return the element-wise square of the input.
![]()
desertnaut
57k23 gold badges137 silver badges165 bronze badges
answered Aug 31, 2017 at 16:04
The standard numpy methods for calculation mean squared error (variance) and its square root (standard deviation) are numpy.var() and numpy.std(), see here and here. They apply to matrices and have the same syntax as numpy.mean().
I suppose that the question and the preceding answers might have been posted before these functions became available.
answered Oct 12, 2020 at 9:58
![]()
Roger VadimRoger Vadim
3392 silver badges12 bronze badges
1
What about this to keep with the np.operation style?
mse = np.mean(np.square(A - B))
Just keep in mind that np.mean() with no axis keyword argument specified will output a scalar, just like np.sum().
answered Mar 1 at 6:37
![]()
17 авг. 2022 г.
читать 1 мин
Среднеквадратическая ошибка (MSE) — это распространенный способ измерения точности предсказания модели. Он рассчитывается как:
MSE = (1/n) * Σ(фактическое – прогноз) 2
куда:
- Σ — причудливый символ, означающий «сумма».
- n – размер выборки
- фактический – фактическое значение данных
- прогноз – прогнозируемое значение данных
Чем ниже значение MSE, тем лучше модель способна точно предсказывать значения.
Как рассчитать MSE в Python
Мы можем создать простую функцию для вычисления MSE в Python:
import numpy as np
def mse(actual, pred):
actual, pred = np.array(actual), np.array(pred)
return np.square(np.subtract(actual,pred)).mean()
Затем мы можем использовать эту функцию для вычисления MSE для двух массивов: одного, содержащего фактические значения данных, и другого, содержащего прогнозируемые значения данных.
actual = [12, 13, 14, 15, 15, 22, 27]
pred = [11, 13, 14, 14, 15, 16, 18]
mse(actual, pred)
17.0
Среднеквадратическая ошибка (MSE) для этой модели оказывается равной 17,0 .
На практике среднеквадратическая ошибка (RMSE) чаще используется для оценки точности модели. Как следует из названия, это просто квадратный корень из среднеквадратичной ошибки.
Мы можем определить аналогичную функцию для вычисления RMSE:
import numpy as np
def rmse(actual, pred):
actual, pred = np.array(actual), np.array(pred)
return np.sqrt(np.square(np.subtract(actual,pred)).mean())
Затем мы можем использовать эту функцию для вычисления RMSE для двух массивов: одного, содержащего фактические значения данных, и другого, содержащего прогнозируемые значения данных.
actual = [12, 13, 14, 15, 15, 22, 27]
pred = [11, 13, 14, 14, 15, 16, 18]
rmse(actual, pred)
4.1231
Среднеквадратическая ошибка (RMSE) для этой модели оказывается равной 4,1231 .
Дополнительные ресурсы
Калькулятор среднеквадратичной ошибки (MSE)
Как рассчитать среднеквадратичную ошибку (MSE) в Excel
The mean squared error is a common way to measure the prediction accuracy of a model. In this tutorial, you’ll learn how to calculate the mean squared error in Python. You’ll start off by learning what the mean squared error represents. Then you’ll learn how to do this using Scikit-Learn (sklean), Numpy, as well as from scratch.
What is the Mean Squared Error
The mean squared error measures the average of the squares of the errors. What this means, is that it returns the average of the sums of the square of each difference between the estimated value and the true value.
The MSE is always positive, though it can be 0 if the predictions are completely accurate. It incorporates the variance of the estimator (how widely spread the estimates are) and its bias (how different the estimated values are from their true values).
The formula looks like below:

Now that you have an understanding of how to calculate the MSE, let’s take a look at how it can be calculated using Python.
Interpreting the Mean Squared Error
The mean squared error is always 0 or positive. When a MSE is larger, this is an indication that the linear regression model doesn’t accurately predict the model.
An important piece to note is that the MSE is sensitive to outliers. This is because it calculates the average of every data point’s error. Because of this, a larger error on outliers will amplify the MSE.
There is no “target” value for the MSE. The MSE can, however, be a good indicator of how well a model fits your data. It can also give you an indicator of choosing one model over another.
Loading a Sample Pandas DataFrame
Let’s start off by loading a sample Pandas DataFrame. If you want to follow along with this tutorial line-by-line, simply copy the code below and paste it into your favorite code editor.
# Importing a sample Pandas DataFrame
import pandas as pd
df = pd.DataFrame.from_dict({
'x': [1,2,3,4,5,6,7,8,9,10],
'y': [1,2,2,4,4,5,6,7,9,10]})
print(df.head())
# x y
# 0 1 1
# 1 2 2
# 2 3 2
# 3 4 4
# 4 5 4You can see that the editor has loaded a DataFrame containing values for variables x and y. We can plot this data out, including the line of best fit using Seaborn’s .regplot() function:
# Plotting a line of best fit
import seaborn as sns
import matplotlib.pyplot as plt
sns.regplot(data=df, x='x', y='y', ci=None)
plt.ylim(bottom=0)
plt.xlim(left=0)
plt.show()This returns the following visualization:
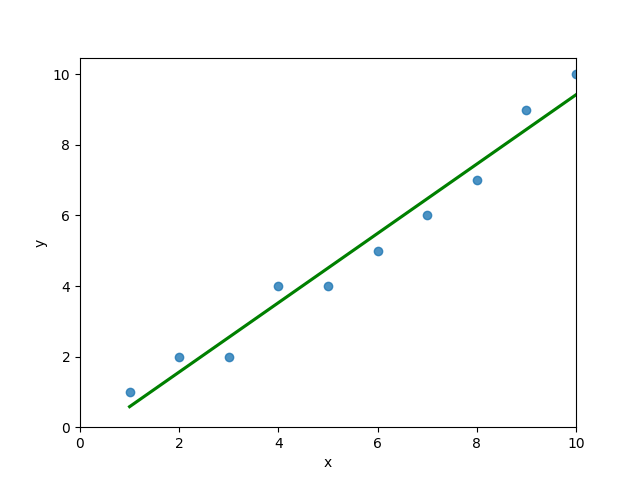
The mean squared error calculates the average of the sum of the squared differences between a data point and the line of best fit. By virtue of this, the lower a mean sqared error, the more better the line represents the relationship.
We can calculate this line of best using Scikit-Learn. You can learn about this in this in-depth tutorial on linear regression in sklearn. The code below predicts values for each x value using the linear model:
# Calculating prediction y values in sklearn
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(df[['x']], df['y'])
y_2 = model.predict(df[['x']])
df['y_predicted'] = y_2
print(df.head())
# Returns:
# x y y_predicted
# 0 1 1 0.581818
# 1 2 2 1.563636
# 2 3 2 2.545455
# 3 4 4 3.527273
# 4 5 4 4.509091Calculating the Mean Squared Error with Scikit-Learn
The simplest way to calculate a mean squared error is to use Scikit-Learn (sklearn). The metrics module comes with a function, mean_squared_error() which allows you to pass in true and predicted values.
Let’s see how to calculate the MSE with sklearn:
# Calculating the MSE with sklearn
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(df['y'], df['y_predicted'])
print(mse)
# Returns: 0.24727272727272714This approach works very well when you’re already importing Scikit-Learn. That said, the function works easily on a Pandas DataFrame, as shown above.
In the next section, you’ll learn how to calculate the MSE with Numpy using a custom function.
Calculating the Mean Squared Error from Scratch using Numpy
Numpy itself doesn’t come with a function to calculate the mean squared error, but you can easily define a custom function to do this. We can make use of the subtract() function to subtract arrays element-wise.
# Definiting a custom function to calculate the MSE
import numpy as np
def mse(actual, predicted):
actual = np.array(actual)
predicted = np.array(predicted)
differences = np.subtract(actual, predicted)
squared_differences = np.square(differences)
return squared_differences.mean()
print(mse(df['y'], df['y_predicted']))
# Returns: 0.24727272727272714The code above is a bit verbose, but it shows how the function operates. We can cut down the code significantly, as shown below:
# A shorter version of the code above
import numpy as np
def mse(actual, predicted):
return np.square(np.subtract(np.array(actual), np.array(predicted))).mean()
print(mse(df['y'], df['y_predicted']))
# Returns: 0.24727272727272714Conclusion
In this tutorial, you learned what the mean squared error is and how it can be calculated using Python. First, you learned how to use Scikit-Learn’s mean_squared_error() function and then you built a custom function using Numpy.
The MSE is an important metric to use in evaluating the performance of your machine learning models. While Scikit-Learn abstracts the way in which the metric is calculated, understanding how it can be implemented from scratch can be a helpful tool.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Pandas Variance: Calculating Variance of a Pandas Dataframe Column
- Calculate the Pearson Correlation Coefficient in Python
- How to Calculate a Z-Score in Python (4 Ways)
- Official Documentation from Scikit-Learn
Время на прочтение
4 мин
Количество просмотров 3.6K

Функции потерь Python являются важной частью моделей машинного обучения. Эти функции показывают, насколько сильно предсказанный моделью результат отличается от фактического.
Существует несколько способов вычислить эту разницу. В этом материале мы рассмотрим некоторые из наиболее распространенных функций потерь.
Ниже будут рассмотрены следующие четыре функции потерь.
-
Среднеквадратическая ошибка
-
Среднеквадратическая ошибка
-
Средняя абсолютная ошибка
-
Кросс-энтропийные потери
Из этих четырех функций потерь первые три применяются к модели классификации.
1. Среднеквадратическая ошибка (MSE)
Среднеквадратичная ошибка (MSE) рассчитывается как среднее значение квадратов разностей между прогнозируемыми и фактически наблюдаемыми значениями. Математически это можно выразить следующим образом:
Реализация MSE на языке Python выглядит следующим образом:
import numpy as np # импортируем библиотеку numpy
def mean_squared_error(act, pred): # функция
diff = pred - act # находим разницу между прогнозируемыми и наблюдаемыми значениями
differences_squared = diff ** 2 # возводим в квадрат (чтобы избавиться от отрицательных значений)
mean_diff = differences_squared.mean() # находим среднее значение
return mean_diff
act = np.array([1.1,2,1.7]) # создаем список актуальных значений
pred = np.array([1,1.7,1.5]) # список прогнозируемых значений
print(mean_squared_error(act,pred))
Выход :
0.04666666666666667Вы также можете использовать mean_squared_error из sklearn для расчета MSE. Вот как работает функция:
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred)
Выход :
0.04666666666666667
2. Корень среднеквадратической ошибки (RMSE)
Итак, ранее, для того, чтобы найти действительную ошибку среди между прогнозируемыми и фактически наблюдаемыми значениями (там могли быть положительные и отрицательные значения), мы возводили их в квадрат (для того чтобы отрицательные значения участвовали в расчетах в полной мере). Это была среднеквадратичная ошибка (MSE).
Корень среднеквадратической ошибки (RMSE) мы используем для того чтобы избавиться от квадратной степени, в которую мы ранее возвели действительную ошибку среди между прогнозируемыми и фактически наблюдаемыми значениями. Математически мы можем представить это следующим образом:
Реализация Python для RMSE выглядит следующим образом:
import numpy as np
def root_mean_squared_error(act, pred):
diff = pred - act # находим разницу между прогнозируемыми и наблюдаемыми значениями
differences_squared = diff ** 2 # возводим в квадрат
mean_diff = differences_squared.mean() # находим среднее значение
rmse_val = np.sqrt(mean_diff) # извлекаем квадратный корень
return rmse_val
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(root_mean_squared_error(act,pred))
Выход :
0.21602468994692867
Вы также можете использовать mean_squared_error из sklearn для расчета RMSE. Давайте посмотрим, как реализовать RMSE, используя ту же функцию:
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred, squared = False) #Если установлено значение False, функция возвращает значение RMSE.
Выход :
0.21602468994692867
Если для параметра squared установлено значение True, функция возвращает значение MSE. Если установлено значение False, функция возвращает значение RMSE.
3. Средняя абсолютная ошибка (MAE)
Средняя абсолютная ошибка (MAE) рассчитывается как среднее значение абсолютной разницы между прогнозами и фактическими наблюдениями. Математически мы можем представить это следующим образом:
Реализация Python для MAE выглядит следующим образом:
import numpy as np
def mean_absolute_error(act, pred): #
diff = pred - act # находим разницу между прогнозируемыми и наблюдаемыми значениями
abs_diff = np.absolute(diff) # находим абсолютную разность между прогнозами и фактическими наблюдениями.
mean_diff = abs_diff.mean() # находим среднее значение
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act,pred)
Выход :
0.20000000000000004
Вы также можете использовать mean_absolute_error из sklearn для расчета MAE.
from sklearn.metrics import mean_absolute_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act, pred)
Выход :
0.20000000000000004
4. Функция потерь перекрестной энтропии в Python
Функция потерь перекрестной энтропии также известна как отрицательная логарифмическая вероятность. Это чаще всего используется для задач классификации. Проблема классификации — это проблема, в которой вы классифицируете пример как принадлежащий к одному из более чем двух классов.
Давайте посмотрим, как вычислить ошибку в случае проблемы бинарной классификации.
Давайте рассмотрим проблему классификации, когда модель пытается провести классификацию между собакой и кошкой.
Код Python для поиска ошибки приведен ниже.
from sklearn.metrics import log_loss
log_loss(["Dog", "Cat", "Cat", "Dog"],[[.1, .9], [.9, .1], [.8, .2], [.35, .65]])
Выход :
0.21616187468057912
Мы используем метод log_loss из sklearn.
Первый аргумент в вызове функции — это список правильных меток классов для каждого входа. Второй аргумент — это список вероятностей, предсказанных моделью.
Вероятности представлены в следующем формате:
[P(dog), P(cat)]
Заключение
Это руководство было посвящено функциям потерь в Python. Мы рассмотрели различные функции потерь как для задач регрессии, так и для задач классификации. Надеюсь, вам понравился материал, ведь все было достаточно легко и понятно!
Кстати, для тех, кто хотел бы пойти дальше в изучении функций потерь, мы предлагаем разобрать одну вот такую — это очень интересная функция потерь Triplet Loss в Python (функцию тройных потерь), которую для вас любезно подготовил автор.
Mean squared error (MSE) of an estimator measures the average of the squared errors, it means averages squared difference between the actual and estimated value.
MSE is almost positive because MSE of an estimator does not account for information that could produce more accurate estimate.
In statistical modelling, MSE is defined as the difference between actual values and predicted values by the model and used to determine prediction accuracy of a model.
In this tutorial, we will discuss about how to calculate mean squared error (MSE) in python.
Mean Squared Error Formula
The mean squared error (MSE) formula is defined as follows:
Where,
n = sample data points
y – actual sizey^ – predictive values
MSE is the means of squares of the errors ( yi – yi^)2.
We will be using numpy library to generate actual and predication values.
As there is no in built function available in python to calculate mean squared error (MSE), we will write simple function for calculation as per mean squared error formula.
pip install numpy
If you don’t have numpy package installed on your system, use below command in command prompt
pip install numpy
Lets understand with examples about how to calculate mean squared error (MSE) in python with given below python code
import numpy as np
def mse(actual,prediction):
return np.square(np.subtract(actual,prediction)).mean()
#define Actual and Prediction data array
actual = np.array([10,11,12,12,14,18,20])
pred = np.array([9,10,13,14,17,16,18])
#Calculate MSE
result = mse(actual,pred)
#print the result
print("Mean squared error (MSE) :", result)
In the above example, we have created actual and prediction array with the help of numpy package array function.
We have written simple function mse() as per mean squared error formula which takes two parameters actual and prediction data array. It calculates mean of the squares of (actual – prediction) using numpy packages square and mean function.
Above code returns mean squared error (MSE) value for given actual and prediction model is 3.42857
Lets check out Mean squared Error (MSE) calculation with few other examples
Info Tip: How to calculate SMAPE in Python!
Example 1 – Mean Squared Error Calculation
Lets assume we have actual and forecast dataset as below
actual = [4,7,3,9,12,8,14,10,12,12]
prediction = [5,7,3,8,10,8,12,11,11,13]
Calculate MSE for given model.
Here, again we will be using numpy package to create actual and prediction array and simple mse() function for mean squared error calculation in python code as below
import numpy as np
def mse(actual,pred):
return np.square(np.subtract(actual,pred)).mean()
#define Actual and Prediction data array
actual = np.array([4,7,3,9,12,8,14,10,12,12])
pred = np.array([5,7,3,8,10,8,12,11,11,13])
#Calculate MSE
result = mse(actual,pred)
#print the result
print("Mean squared error (MSE) :", result)
Above code returns mean squared error (MSE) for given actual and prediction dataset is 1.3
Info Tip: How to calculate rolling correlation in Python!
Example 2 – Mean Squared Error Calculation
Lets take another example with below actual and prediction data values
actual = [-2,-1,1,4]
prediction = [-3,-1,2,3]
Calcualte MSE for above model.
Using below python code, lets calculate MSE
import numpy as np
def mse(actual,pred):
return np.square(np.subtract(actual,pred)).mean()
#define Actual and Prediction data array
actual = np.array([-2,-1,1,4])
pred = np.array([-3,-1,2,3])
#Calculate MSE
result = mse(actual,pred)
#print the result
print("Mean squared error (MSE) :", result)
Above code returns mean squared error (MSE) for given actual and prediction dataset is 0.75. It means it has less squared error and hence this model predicts more accuracy.
Info Tip: How to calculate z score in Python!
Conclusion
I hope, you may find how to calculate MSE in python tutorial with step by step illustration of examples educational and helpful.
Mean squared error (MSE) measures the prediction accuracy of model. Minimizing MSE is key criterion in selecting estimators.