
Формирование выборки
Характерными
особенностями количественных исследований
является четко определенный формат
собираемых данных и источники их
получения, а обработка собранных данных
осуществляется с помощью упорядоченных
процедур, в основном количественных по
своей природе. Результаты количественных
исследований дают ответы на вопросы:
Кто?, Что?, Где?, Когда?, Сколько?
Если
исследование охватывает весь изучаемый
массив, оно будет сплошным,
т.
е. в таком исследовании каждый элемент
генеральной совокупности служит единицей
сбора информации. В тех случаях, когда
объект исследования насчитывает более
500 человек, единственно правильным
признается применение выборочного
метода.
§ 1. Формирование выборки исследования
Совокупность
всех возможных социальных объектов,
которые подлежат изучению в пределах
программы исследования, называется
генеральной
совокупностью.
Выборочная
совокупность (выборка)
— часть
объектов генеральной совокупности,
отобранная с помощью специальных приемов
для получения информации о всей
совокупности. Репрезентативность
— свойство
выборочной совокупности воспроизводить
параметры и значимые элементы структуры
генеральной совокупности.
Преимущества
выборочного исследования по отношению
к сплошному
состоят
в том, что оно:
-
позволяет
сократить затраты на сбор и обработку
информации; -
позволяет
добиться большей оперативности; -
имеет
более широкую область применения; -
в
ряде случаев позволяет получить более
достоверные сведения.
Процесс
выборки основан на двух моментах:
во-первых,
на взаимосвязи и
взаимообусловленности
качественных характеристик и признаков
социальных объектов; во-вторых,
на правомерности выводов о целом на
основании изучения его части при условии,
что по своей структуре эта часть является
микромоделью целого.
Единицы
отбора
—
элемент или набор элементов, предназначенный
для отбора на определенной ступени
выборки.
Единицы
анализа
—
элементы выборочной совокупности
(респонденты), подлежащие изучению.
Переменная
—
множество отдельных значений характеристик
элементов совокупности. Параметр
—
суммарное описание переменной в
генеральной совокупности. Статистика
—
суммарное описание переменной в
выборочной совокупности.
Основная
цель выборочного метода
— выбор элементов из совокупности таким
образом, чтобы распределение этих
элементов в выборке повторяло их
распределение в совокупности. Достижению
этой цели служит вероятностная выборка.
Модель
вероятностной (случайной) выборки
связана с понятием статистической
вероятности,
изучаемой
в социальных науках (вероятность
некоторого ожидаемого события есть
отношение числа ожидаемых событий к
числу всех возможных).
Случайная
выборка носит наиболее распространенный
характер.
Самый легкий путь получения случайной
выборки — присвоить каждому элементу
свой номер, а затем с помощью компьютера
рассчитать случайные числа, из которых
и берется выборка (например, каждый
десятый номер в каждой случайной цепи).
Можно выбирать из генеральной совокупности
по какому-то принципу (каждая тысячная
фамилия из списка абонентов телефонной
сети, каждый третий дом на определенной
улице, студенты, родившиеся в сентябре,
и т. д.)
Преимущества
случайной выборки:
-
объективность
и точность отбора респондентов; -
не
требуется детальное знание изучаемой
совокупности; -
использование
методов математической вероятности.
Недостатки
случайной выборки:
-
сложность
процедуры отбора; -
затратность
ресурсов.
На
практике часто применяется метод
гнездовой выборки.
Он
предполагает отбор в качестве единиц
анализа не отдельных людей, а групп
(семьи, студенческие группы, бригады и
т. д.), с последующим сплошным опросом в
отобранных группах. Гнездовая выборка
будет репрезентативна в том случае,
если состав групп в максимальной степени
близок по основным демографическим
признакам респондентов.
В
некоторых случаях невозможно использование
вероятностных схем отбора, описанных
выше. Тогда используется целенаправленная
выборка,
к
которой неприменимы правила теории
вероятности. Она осуществляется с
помощью следующих
методов:
стихийной
выборки,
метода
квот и метода основного массива.
В
случае
стихийной
выборки
невозможно
предопределить структуру массива
респондентов и соответственно трудно
определить репрезентативность. Существует
несколько разновидностей
стихийного отбора:
так
называемый отбор «первого встречного».
Встречается в практике обследований,
проводимых средствами массовой
информации. Исследователь проводит
опрос лиц, которые встретились ему в
месте опроса (например, на улице);
отбор
«себе подобных».
Исследователь подбирает для опроса или
наблюдения респондентов из своего
окружения (знакомые, коллеги);
отбор
«желающих участвовать».
Примером может служить почтовый опрос
читателей газеты или журнала. При таких
опросах решение о включении в выборку
принимает сам респондент.
Метод
квотной выборки
— распространенный способ отбора
респондентов при массовых опросах
общественного мнения. Его используют
в том случае, если до начала исследования
имеются статистические данные о
контрольных признаках элементов
генеральной совокупности. Все данные
о том или ином контрольном признаке
выступают в качестве квоты. Респонденты
отбираются целенаправленно, с соблюдением
параметров квот.
Число характеристик, данные о которых
выбираются в качестве квот, как правило,
не превышает четырех.
Главная
задача для интервьюера
заключается
в том, чтобы создать условия, близкие к
случайному отбору, с равными шансами
для каждого элемента генеральной
совокупности попасть в выборку.
Метод
квот позволяет существенно сократить
время и средства,
затрачиваемые на опросы. К преимуществам
квотной выборки относятся также
оперативность и малая трудоемкость.
Недостатки
квотной выборки:
-
требуется
детальное знание изучаемой совокупности; -
субъективизм
интервьюера при отборе респондентов; -
ограниченное
время посещения респондентов; -
уклонение
респондентов от опроса;1 -
не
позволяет использовать методы
математической вероятности.
Метод
основного массива
применяется в разведывательных
исследованиях
для
уточнения какого-нибудь контрольного
вопроса. В таких случаях опрашивается
50-60% потенциальных респондентов.
Все
рассмотренные методы представляют
собой пример одноступенчатой выборки.
Многоступенчатые
выборки
осуществляются
в несколько ступеней: на
первой ступени
обычно реализуется гнездовая выборка,
а потом
проводится случайный отбор респондентов
в гнездах.
Многоступенчатая
выборка используется в крупномасштабных
исследованиях, когда в генеральной
совокупности насчитываются тысячи и
миллионы единиц, размещенных на
значительной территории. При построении
многоступенчатой выборки используются
несколько способов отбора элементов
выборочной совокупности.
Районированный
отбор (типический)
производится
на основе распределения заданного числа
отбираемых единиц измерения, т. е. объема
выборки, между так называемыми районами,
типами — группами элементов генеральной
совокупности, выделяемыми в соответствии
со значениями изучаемого в исследовании
заданного «базового признака». Выделяемые
таким образом слои будут внутренне
однородными, но отличными друг от друга
и взятые вместе исчерпывать всю
совокупность.
В
крупномасштабных многоступенчатых
выборках требования к точности оценок
смещаются на второй план,
уступая место вопросам снижения стоимости
исследования благодаря выбору минимально
допустимого числа единиц опроса.
Объем
выборки определяется аналитическими
задачами исследования,
ее
репрезентативность
— целевой
установкой программы.
Объем
выборки влияет на ошибки репрезентации:
чем больше величина выборки, тем меньше
возможная ошибка. Для
увеличения точности в два раза необходимо
увеличить выборку в четыре раза.
Ошибка
репрезентации
—
это различие между характеристиками
генеральной и выборочной совокупности.
Количество респондентов, включенных в
выборочную совокупность, должно
составлять 10% от генеральной совокупности,
но не превышать 2000—2500 человек (если
величина генеральной совокупности 5000
человек и более).
Для
пробных опросов достаточна выборочная
совокупность объемом 100-250 человек. При
массовых опросах, если величина
генеральной совокупности составляет
менее 5000 человек, достаточный объем
выборочной совокупности, гарантирующий
достоверные результаты исследования,
составляет 500 человек.
Оценка
надежности результатов выборочного
обследования проводится следующим
образом:
-
ошибка
выборки до 3% — повышенная надежность; -
ошибка
выборки 3-10% — обыкновенная; -
ошибка
выборки от 10 до 20% — приближенная; -
ошибка
выборки от 20 до 40% — ориентировочная; -
более
40% — прикидочная надежность.
В
аналитических и экспериментальных
исследованиях проблема репрезентативности
выборки является второстепенной в
сравнении с необходимостью обеспечить
качественное представительство изучаемых
объектов.
Качество
выборки зависит:
а) от
меры однородности социальных объектов
по наиболее существенным характеристикам
(чем более они однородны, тем меньшая
численность может обеспечить статистически
достоверные выводы);
б) от
степени дробности группировок анализа,
планируемых по задачам исследования;
в) от
целесообразного уровня надежности
выводов из предпринимаемого исследования.
Традиционно
выделяют следующие виды ошибок:
-
случайные
отклонения выборочных значений
параметров; -
систематические
ошибки (ошибки смещения); -
погрешности
вычислений.
Погрешности
вычислений
возникают
при математико-статистической обработке
результатов измерений. О погрешности
вычислений необходимо помнить при
оценке точности и надежности выборочных
данных и при интерпретации результатов.
Случайные
ошибки
бывают
следствием большого числа разнообразных
факторов, и учесть действие каждого из
них невозможно. Ошибка выборки считается
случайной, а выборочная совокупность
репрезентативной, если отклонение не
превышает в среднем 5%.
Наиболее
опасный вид ошибок — систематические
ошибки
(или
ошибки смещения). Такие ошибки являются
результатом действий в одном направлении
определенной группы причин, которую
возможно выявить.
Источники
систематических ошибок:
а) неверные
статистические данные о параметрах
контрольных признаков генеральной
совокупности;
б) ошибочная
модель выборки;
в) неправильное
формирование выборочной совокупности;
г) несовершенство
инструментария и ошибки в организации
сбора данных;
д) неправильная
интерпретация результатов первичных
измерений и неправильная последующая
обработка и анализ информации.
На
правильность результатов исследования
в наибольшей степени влияют
ошибки смещения, вызванные неправильной
реализацией модели выборки, несовершенством
инструментария и организации сбора
данных. Систематические ошибки могут
появиться на любом этапе исследования.
Необходимо стремиться к тому, чтобы по
возможности исключить ситуации,
способствующие возникновению ошибок,
критически анализировать полученные
результаты, природу расхождений
выборочных и генеральных совокупностей.
При
конструировании модели выборки
целесообразно консультироваться со
специалистами по математической
статистике.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет

Любая научная работа (особенно в психологии, медицине) предполагает проведение некоего эксперимента для сбора доказательств и оценки реальной ситуации. Притом чем больше факторов учитывает автор, тем точнее результаты исследования и возможности их использования в дальнейшем.
В любом эксперименте важно определить оптимальный объем выборки, который бы позволили получить достоверный результат. В этой статье Вы узнаете, какое число испытуемых считается достаточным, и как грамотно подобрать объем выборки для собственного исследования.
Влияет ли объем выборки на результаты исследования?
Результаты исследования зависят от множества факторов: объем и достоверность первоначальных данных, цель (достижимая и реалистичная или не поддающаяся измерению и достижению), качество материалов (достоверные, актуальные и пр.) и т.д. Если научное изыскание предполагает проведение практических мероприятий, то одним из важнейших моментов являются определение объема выборки.

Объем выборки представляет собой число испытуемых, которое будет принимать участие в эксперименте и подлежать оценке. Количество респондентов, их действия напрямую отражаются на результатах исследования. Если в эксперименте будет участвовать малая часть испытуемых, то не всегда будет возможно получить репрезентативные результаты.
Большое число участников же в значительной степени усложняет ход исследования, но позволяет получить более точные результаты при условии, если исследователь внимательно следит за ходом событий и учитывает все факторы, погрешности и отклонения и пр.
Таким образом, объем выборки влияет не только на точность измерений, но и качество исследования.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!

Больше – лучше, или наоборот?
Казалось бы, чем больше число испытуемых, тем точнее результаты. На самом деле, здесь палка о двух концах.
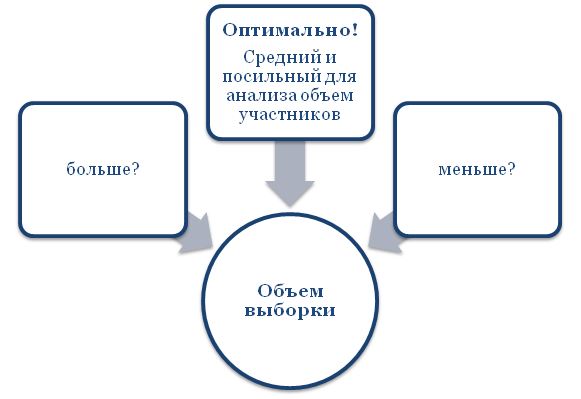
С одной стороны, большое число испытуемых позволяет получить более точные результаты исследования, определить динамику или тенденции развития событий. В то же время внушительное количество респондентов требует более пристального внимания со стороны автора: моментальное фиксирование результатов, контроль за каждым индивидом, оценка всех действий и достижений/итогов и пр. Сможет ли автор в одиночку уследить за 100-200 и более испытуемыми.
Во-вторых, большой объем выборки провоцирует рождение более высоких затрат на организацию и проведение эксперимента: привлечение сторонних экспертов для контроля за ходом исследования, подготовка дополнительных материалов для испытуемых (анкеты или опросники, задания, создание специальных условий (например, для проживания и пр.)) и т.д.
Небольшой объем выборки – самый оптимальный в плане затратности, но он дает менее точные результаты. Если в эксперименте принимает участие всего 2-4 человека, то это не значит, что выборка будет репрезентативной. В данной ситуации автор оценит лишь частный случай, но не данные генеральной совокупности.
Поэтому чтобы результаты исследования были пригодными для более широкой аудитории, важно, чтобы выборка оказалась репрезентативной, а для этого необходимо подобрать оптимальное число испытуемых.
Какой объем выборки считается оптимальным?
Объем выборки зависит не только от вида исследования, но и его масштабов. Например, в социологических опросах принято проводить соответствующие мероприятия (например, задать вопросы всем подряд или конкретной группе) с целью определения общественного мнения. Как правило, в таких проектах принимает участие свыше 1000 человек.

В психологических и медицинских экспериментах и исследованиях количество испытуемых гораздо меньше, так как обработка данных здесь может занять более длительное время, а информация обладает таким свойством как актуальность, которая может быть утрачена из-за медлительности. Оптимальным числом для таких научных изысканий считается 10-30 человек, притом все испытуемые подлежат строгой классификации по конкретному признаку.
Оптимальный объем выборки – это то количество изучаемых объектов и явлений, которое позволяет получить достоверный и максимально точный (приближенный) результат с минимальными погрешностями, который можно «репрезентовать» на более широкий круг лиц. В случае нерепрезентативности выборки исследователь получит «частный эксперимент» с субъективной оценкой происходящего.
Как определить оптимальный объем выборки для научного исследования?
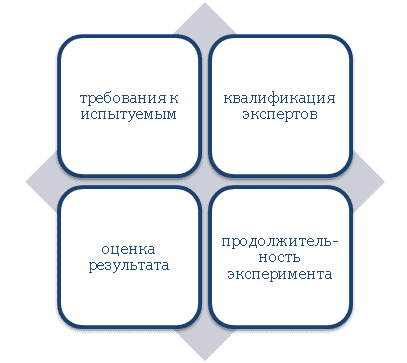
Каждый исследователь самостоятельно определяет, какой объем выборки для него оптимальный. Данный параметр зависит от ряда условий:
- Сколько авторов и компетентных ученых принимает участие в организации и проведении научного изыскания?
- За сколькими испытуемыми автор сможет следить самостоятельно?
- Какое количество объектов посильно для каждого «контролера»?
- Возможность оперативной фиксации получаемых результатов?
- Объем факторов, которые должны быть учтены в ходе испытания?
- Шкала для оценки полученных итогов?
- Наличие определенных знаний навыков, образования или опыта работы в конкретной области для проведения научного изыскания?
- Методы исследования?
- Требования к испытуемым?
- Продолжительность исследования?
- Точность результатов, допустимые погрешности и пр.?
Оптимальный объем выборки предполагает подбор стольких испытуемых, за которыми посильно проследить и оценить их результаты без лишних затрат времени, материальных и иных ресурсов с учетом располагаемых сил.
Если исследование предполагает оценку конкретной ситуации в определенной отрасли, то достаточно подобрать 10-30 участников, соответствующих конкретных условиям и требованиям.
Если же научное изыскание носит глобальный масштаб, то необходимо подобрать опытную и сильную команду, грамотно распределить обязанности, а затем, исходя из общих возможностей команды, определить объем выборки: до 100 участников, от 101 до 500, более 500 и пр.
В идеале на каждого «контролера» должно приходиться не более 10-20 испытуемых, чтобы качество получаемых данных было высоким, а жизнь контролера проходила не только в стенах «лаборатории». Поэтому объему выборки необходимо уделять особое внимание, так как именно этот критерий позволяет получить более качественные результаты научных и иных изысканий.
Вопрос 1. Метод вероятностной выборки, предусматривающий расчет шага (интервала) отбора выборки
- Ответ: Метод систематической (механической) выборки
Вопрос 2. Основное преимущество панельного метода исследования, состоит в …
- Ответ: возможности регулярного изучения поведения потребителей
Вопрос 3. Тип вопроса в анкете, предусматривающий возможность выбора нескольких вариантов ответов
- Ответ: Альтернативный
Вопрос 4. Цель пилотажа анкет
- Ответ: Определение реакции респондентов на содержание анкеты
Вопрос 5. Такое требование к маркетинговой информации как актуальность подразумевает …
- Ответ: представление реальных сведений в нужный момент времени
Вопрос 6. В анкете нужны вопросы-фильтры для того, чтобы …
- Ответ: проконтролировать правильность ответов респондентов
Вопрос 7. Вид маркетинговых исследований, к которому относятся исследования деятельности посредников, называется …
- Ответ: изучение каналов распределения
Вопрос 8. Под контуром выборки в маркетинговых исследованиях подразумевается …
- Ответ: список всех единиц генеральной совокупности
Вопрос 9. Анализ, в основе которого лежит использование статистических процедур (например, проверка гипотез) с целью обобщения полученных результатов на всю совокупность, называется …
- Ответ: выводным анализом
Вопрос 10. Система, которая в ответ на вопрос типа: «что если?» дает немедленные ответы, используемые при принятии маркетинговых решений
- Ответ: Маркетинговая информационная система (МИС)
Вопрос 11. Такой критерий оценки отчета о маркетинговом исследовании, как ясность предполагает …
- Ответ: внятность и четкость фразеологии отчета
Вопрос 12. Перед внедрением нового товара на рынок проводят его рыночные испытания. Если исследователи предлагают специально отобранной группе потребителей посетить «виртуальный магазин» (с использованием программного продукта «Simul-Shop») и сделать покупки с целью проверки реакции на новые товары, то используется …
- Ответ: процедура моделируемого пробного маркетинга
Вопрос 13. Метод сбора информации, предусматривающий групповую дискуссию, которая направляется модератором
- Ответ: Фокус-группа
Вопрос 14. Вид тестирования эффективности рекламы, используемый в случае, если группе потребителей (читателям определенного журнала, зрителям определенного телевизионного канала и т.п.) задают следующий вопрос: «Какую из реклам они помнят, и какие ее части могут воспроизвести/пересказать?»
- Ответ: Тест на узнавание
Вопрос 15. Документ, в котором сформулированы основные требования к содержанию стандартного отчета о маркетинговом исследовании
- Ответ: Международный кодекс ЕSОМАR и МТП по практике маркетинговых и социальных исследований
Вопрос 16. Результаты обследования фокус-групп можно считать репрезентативными.
- Ответ: Нет
Вопрос 17. Основное отличие рекомендаций, данных в отчете, от заключений
- Ответ: В том, что они интерпретируют полученную информацию с точки зрения того, что она может означать для дальнейшего развития бизнеса
Вопрос 18. Вид маркетинговых исследований, к которому относятся исследования отношения к марке товара, называется …
- Ответ: изучение потребителей
Вопрос 19. Основное условие осуществления вероятностной выборки – наличие …
- Ответ: полного списка всех элементов генеральной совокупности
Вопрос 20. Вид маркетинговых исследований, к которому относятся мотивационные исследования
- Ответ: Изучение потребителей
Вопрос 21. Виды маркетинговой информации по источнику ее получения
- Ответ: первичная и вторичная
Вопрос 22. Ошибка, допущенная при формулировке следующего вопроса анкеты: «Какое количество банок майонеза Вы приобрели за последние полгода? – меньше 20 банок – около 20 банок – больше 20 банок»
- Ответ: Превышение возможностей памяти респондента
Вопрос 23. Использование таких статистических мер, как средняя величина (средняя), мода, среднее квадратическое отклонение, размах вариации лежит в основе …
- Ответ: дескриптивного анализа
Вопрос 24. Под гипотезой маркетингового исследования подразумевается …
- Ответ: вероятностное суждение о возможных путях решения поставленных проблем
Вопрос 25. Совокупность процедур, методов, персонала, оборудования, предназначенных для регулярного сбора, анализа, распределения достоверной информации для подготовки и принятия маркетинговых решений
- Ответ: Маркетинговая информационная система (МИС)
Вопрос 26. Алгоритм, с помощью которого осуществляется измерение в том случае, если исследователь стремиться отобразить изучаемые явления количественно
- Ответ: шкала измерения
Вопрос 27. Суть метода логико-смыслового моделирования проблем исследования заключается в …
- Ответ: формировании каталога проблем, их структуризации и ранжировании по степени приоритетности
Вопрос 28. Возможно использование индивидуальных экспертных оценок.
- Ответ: Да
Вопрос 29. В основной части типового отчета о маркетинговом исследовании содержится(атся) …
- Ответ: описание методологии исследования, его основные результаты и ограничения
Вопрос 30. Результаты … исследований можно переносить на группы большего размера.
- Ответ: количественных
Вопрос 31. Последовательность этапов процесса маркетинговых исследований
- Ответ: 1-определение проблемы
- Ответ: 2-отбор источников информации
- Ответ: 3-сбор информации
- Ответ: 4-обработка и анализ информации
- Ответ: 5-представление выводов и рекомендаций
Вопрос 32. Простая табуляция полученных в результате исследования данных подразумевает подсчет количества событий, которые попадают в …
- Ответ: каждую категорию анализа, когда категории базируются на одной переменной
Вопрос 33. Ошибка, допущенная при формулировке следующего вопроса анкеты: «Часто ли Ваше внимание привлекает реклама моющих средств?» – в газетах – по радио – по телевидению»
- Ответ: Несоответствие между смыслом вопроса и характером предлагаемых ответов
Вопрос 34. Более емкое понятие
- Ответ: Маркетинговое исследование
Вопрос 35. Ошибка, допущенная при формулировке следующего вопроса анкеты: «На самом ли деле реклама заставляет Вас покупать тот или иной товар?»
- Ответ: Подталкивание респондента к нужному ответу
Вопрос 36. Объем выборки влияет на ее репрезентативность.
- Ответ: Нет
Вопрос 37. Вид маркетинговых исследований, к которому относятся мотивационные исследования, называется …
- Ответ: изучение потребителей
Вопрос 38. Проекционные методы относятся к … исследованиям.
- Ответ: качественным
Вопрос 39. Если Вы стремитесь к высокому проценту возврата ответов, хотите сэкономить средства на проведение исследования, и у Вас ограничено время. Влияние исследователя на респондента Вас не беспокоит. Вы предпочтете …
- Ответ: опрос по телефону
Вопрос 40. В маркетинговых исследованиях под ошибкой выборки подразумеваются отклонения (различия) между данными …
- Ответ: полученными от выборки и истинными данным
Вопрос 41. Статистический способ моделирования зависимости результативного признака от факторного признака/признаков – это … анализ.
- Ответ: регрессионный
Вопрос 42. Тип исследований, который помогает выдвинуть возможные гипотезы исследования, это …исследования.
- Ответ: качественные
Вопрос 43. Тип вопроса, не содержащий никаких подсказок и дающий возможность респонденту выразить свое мнение
- Ответ: Открытый
Вопрос 44. Точность измерений по отношению к тому, что существует в реальности, – это … измерения.
- Ответ: достоверность
Вопрос 45. Информация, извлекаемая из публикаций в специализированной печати, относится к … информации.
- Ответ: вторичной
Вопрос 46. Максимальный размер рынка при наибольшей активности маркетинговых усилий всех компаний, входящих в отраслевой сектор, при определенном состоянии окружающей маркетинговой среды – это …
- Ответ: рыночный потенциал
Вопрос 47. Под таким принципом проведения маркетингового исследования, как объективность подразумевается …
- Ответ: учет возможных погрешностей при измерении того или иного явления
Вопрос 48. Тип вопроса, который следует использовать в том случае, если от респондента требуется выразить критическое отношение к себе
- Ответ: Косвенный
Вопрос 49. Свойства выборки, которые позволяют ей выступать моделью (представителем) генеральной совокупности с точки зрения ее характеристик, которые изучаются при проведении исследования, – это … выборки.
- Ответ: репрезентативность
Вопрос 50. Число случаев появления каждого значения измеренной характеристики (признака) в каждом выбранном диапазоне ее значений, можно определить с помощью …
- Ответ: распределения частот
Вопрос 51. Техника шкалирования, использованная при формулировке следующего вопроса анкеты: «Согласны ли Вы с утверждением, что крупные фирмы обычно выпускают товары лучшего качества, чем мелкие?» – совсем не согласен – не согласен – частично согласен – согласен – полностью согласен
- Ответ: шкала Лайкерта
Вопрос 52. Экспертный опрос, проводимый в несколько туров с целью последовательного уточнения оценок экспертов без непосредственного контакта между ними
- Ответ: Метод Дельфи
Вопрос 53. Тип вопроса в анкете, предусматривающий наличие набора всех возможных вариантов ответов
- Ответ: Закрытый
Вопрос 54. Присвоение численной оценки объектам, которые обладают некоторыми качественными характеристиками
- Ответ: измерение
Вопрос 55. Параллельное использование нескольких методов формирования выборки, основанное на поэтапном отборе ее объектов, – это … выборка.
- Ответ: многоступенчатая
Вопрос 56. Основное преимущество опроса состоит в …
- Ответ: возможности табулирования полученных данных и проведения статистического анализа результатов
Вопрос 57. Если тестируемой группе потребителей предлагают набор альтернативных рекламных роликов и просят дать их оценку по вербальной шкале с точки зрения привлекательности, убедительности и поведенческой ценности, то используется …
- Ответ: прямая оценка
Вопрос 58. Когда исследователь использует случайную выборку, основанную на информации о числовых характеристиках генеральной совокупности, то …
- Ответ: наиболее корректный подход к определению объема выборки основан на расчете доверительных интервалов и среднего квадратического отклонения
Вопрос 59. Чем больше различий внутри генеральной совокупности, тем больше величина возможной ошибки выборки.
- Ответ: Да
Вопрос 60. Взаимосвязанный набор систем данных, инструментов и методик, поддерживаемый программным обеспечением, с помощью которого фирма собирает и интерпретирует информацию для принятия маркетинговых действий, называется
- Ответ: Система собственных маркетинговых исследований
Вопрос 61. Упорядоченный и постоянно обновляемый массив данных о потенциальных потребителях и клиентах фирмы
- Ответ: Маркетинговая база данных (БДМ)
Вопрос 62. Необходимость в проведении маркетингового исследования возникает, когда …
- Ответ: обнаруживается, что комплекс маркетинга не соответствует условиям рынка
Вопрос 63. Основные функции анкет заключаются в …
- Ответ: возможности обратиться к определенной совокупности респондентов и систематизировать данные, извлекаемых их ответов
Вопрос 64. Предпочтительный метод сбора данных в том случае, если результат исследования складывается под влиянием нескольких переменных
- Ответ: Эксперимент
Вопрос 65. Статистический показатель, характеризующий степень несхожести респондентов или их ответов
- Ответ: Размах вариации
Вопрос 66. Цель поискового исследования заключается в …
- Ответ: сборе предварительной информации, предназначенной для более точного определения проблемы
Вопрос 67. Основная цель маркетинговых исследований
- Ответ: Создать информационно-аналитическую базу для принятия маркетинговых решений
Вопрос 68. Фирмы, специализирующиеся на продаже стандартизированной маркетинговой информации относятся к фирмам, специализирующимся на …
- Ответ: сборе синдикативной (подходящей сразу для нескольких заказчиков) информации
Вопрос 69. Метод сбора данных, предусматривающий использование ассоциативных тестов
- Ответ: Проекционный
Вопрос 70. Структурные части анкеты
- Ответ: Введение, основная часть, реквизитная часть
Вопрос 71. Существует единый типовой образец плана маркетингового исследования.
- Ответ: Нет
Вопрос 72. Существует единый типовой образец МИС.
- Ответ: Нет
Вопрос 73. Быстро определить удельный вес той доли совокупности, которая находиться выше или ниже некоторой заданной величины значения переменной можно с помощью …
- Ответ: кумулятивного (накопленного) распределения частот
Вопрос 74. Показатель, обладающий большей степенью информативности для исследователя – это …
- Ответ: средняя величина
Вопрос 75. Ключевая характеристика вероятностной (случайной) выборки заключается в том, что …
- Ответ: все единицы выборки имеют известную вероятность (шанс) попасть в выборку
Вопрос 76. Юридические и физические лица, обладающие нужными фирме сведениями и занимающиеся определенной рыночной деятельностью – это … информации.
- Ответ: носитель
Вопрос 77. Анализ степени согласия или несогласия потребителей с набором утверждений подобного рода: – Мне нравится пробовать новые и разнообразные вещи. – Я всегда стараюсь одеваться согласно тенденциям моды. – Если мои дети больны, я бросаю все, чтобы заняться ими. – Политика – это дело мужчин, а не женщин. – Загрязнение окружающей среды – крупнейшая проблема нашей эпохи. – Мы часто принимаем гостей.
- Ответ: лежит в основе исследования стиля жизни и социально-культурной сегментации потребителей
Вопрос 78. Ключевая характеристика дескриптивного исследования
- Ответ: Описание тех или иных аспектов реальной маркетинговой ситуации
Вопрос 79. Возможно ли использование индивидуальных экспертных оценок.
- Ответ: Да
Вопрос 80. Метод экспертного опроса, направленный на получение большого количества идей, высказанных в ходе свободной дискуссии
- Ответ: Метод мозгового штурма
Вопрос 81. Под таким принципом проведения маркетингового исследования, как достоверность подразумевается …
- Ответ: получение адекватных данных за счет обеспечения научных принципов их сбора и проведения
Вопрос 82. Если Вы стремитесь к высокому проценту возврата ответов, у Вас достаточно средств, ограничено время, а влияние исследователя на респондента Вас не беспокоит, то Вы предпочтете …
- Ответ: личное интервью
Вопрос 83. Единодушие большинства экспертов является критерием достоверности данных ими оценок тех или иных явлений или прогнозов их развития в будущем.
- Ответ: Не всегда
Вопрос 84. Средняя характеристика из высказанных группой компетентных специалистов мнений о каком-либо явлении или процессе, при условии, что удалось достичь согласованности их взглядов, называется …
- Ответ: Экспертная оценка
Вопрос 85. Школа неформального подхода к проведению маркетингового исследования подразумевает …
- Ответ: использование качественных оценок, отказ от использования математического аппарата
Вопрос 86. Отличие качественных исследований от количественных исследований состоит в том, что они направлены на …
- Ответ: объяснение наблюдаемых явлений и помогают выдвинуть гипотезы исследования
Вопрос 87. Аналитический процесс, включающий определение проблемы, сбор, обработку и анализ информации, а также выработку рекомендаций по решению проблемы
- Ответ: Маркетинговые исследования
Вопрос 88. На первом этапе экспертного опроса, проводимого методом Дельфи, осуществляется …
- Ответ: анонимное заполнение экспертами заранее разработанных анкет
Вопрос 89. Экспертный опрос, проводимый в несколько туров с целью последовательного уточнения оценок экспертов без непосредственного контакта между ними, называется …
- Ответ: Метод Дельфи
Вопрос 90. Фундаментальный критерий, по которому оцениваются все отчеты об исследованиях
- Ответ: обеспечение связи (эффективной коммуникации) исследователя с заказчиком исследования
Вопрос 91. Исследования, проводимые с помощью омнибусных панелей это … исследования.
- Ответ: мультиспонсируемые
Вопрос 92. Заранее подготовленный бланк с перечнем вопросов, на которые должен ответить респондент
- Ответ: анкета
Вопрос 93. Вид маркетинговых исследований, к которому относятся исследования деятельности посредников
- Ответ: Изучение каналов распределения
Вопрос 94. Представляя отчет заказчику – менеджеру специализированного спортивного магазина, исследователь заявил следующее: «Были проанализированы данные по признанной удовлетворительной выборке, объемом 15 магазинов. Результаты показали, что 95% доверительный интервал для среднегодового объема продаж в генеральной совокупности спортивных магазинов составляет 1000000 + 150000 млн. руб.» Правильно ли исследователь сформулировал данный вывод с точки зрения возможности его понимания слушателями?
- Ответ: Вывод сформулирован правильно, но большей части аудитории он будет непонятен
Вопрос 95. Более емкое понятие, это …
- Ответ: Маркетинговое исследование
Вопрос 96. Величина признака, появляющаяся наиболее часто по сравнению с другими величинами данного признака, называется …
- Ответ: модой
Вопрос 97. Статистическая модель, выражающая в математической форме динамические закономерности развития изучаемого явления или процесса
- Ответ: Трендовая модель
Вопрос 98. Упорядоченная совокупность источников информации и процедур их получения, используемая для воссоздания текущей картины, происходящих в рыночной среде перемен – это система …
- Ответ: сбора внешней информации (маркетинговой разведки)
Вопрос 99. Основное преимущество наблюдения, как метода сбора данных заключается в …
- Ответ: отсутствии влияния на изучаемые явления со стороны исследователя
Вопрос 100. Основной недостаток экспериментов заключается в …
- Ответ: высокой стоимости и длительности проведения
Вопрос 101. Источники внешней вторичной информации
- Ответ: официальные отчеты фирм, специальные издания, Интернет, данные государственной статистики
Вопрос 102. Аналитический процесс, включающий определение проблемы, сбор, обработку и анализ информации, а также выработку рекомендаций по решению проблемы, называется …
- Ответ: маркетинговые исследования
Вопрос 103. Цель казуального исследования заключается в …
- Ответ: обосновании гипотез, определяющих содержание выявленных причинно-следственных связей
Вопрос 104. Ключевая характеристика метода экспертных оценок – он основан …
- Ответ: на использовании интуиции, опыта и воображения людей
Вопрос 105. Метод выборки, предусматривающий отбор единиц выборки (респондентов), способных дать наиболее точные сведения
- Ответ: выборка по усмотрению
Вопрос 106. Методы сбора первичных данных, используемые при проведении маркетингового исследования
- Ответ: Наблюдение, эксперимент, опрос
Вопрос 107. Основные преимущества синдикативной маркетинговой информации
- Ответ: Долевая стоимость
- Ответ: Высокое качество
Вопрос 108. При изучении перспектив и факторов успеха нового товара проводятся разнообразные исследования. Если группе потенциальных потребителей предлагают описание нового товара и просят ответить на следующие вопросы теста: – Ясен ли Вам замысел товара: насколько легко он воспринимается? – Видите ли Вы у этого товара достоинства по сравнению с товарами-конкурентами? – Верите ли Вы в реальность этих достоинств? – Предпочтете ли Вы этот товар товарам-конкурентам? – Отвечает ли этот товар Вашим реальным потребностям? – Готовы ли Вы купить этот товар? то при этом осуществляется:
- Ответ: Проверка концепции товара
Вопрос 109. Основное отличие вторичной маркетинговой информации от первичной заключается в том, что она …
- Ответ: собрана ранее, для других целей
Вопрос 110. Метод экспертного опроса, направленный на получение большого количества идей, высказанных в ходе свободной дискуссии, называется …
- Ответ: Метод мозгового штурма
Вопрос 111. Магазинные тесты, направленные на тестирование альтернативных концепций упаковки товара относятся к … экспериментам.
- Ответ: полевым
Вопрос 112. Ключевая характеристика метода экспертных оценок
- Ответ: Он основан на использовании интуиции, опыта и воображения людей
Вопрос 113. Тип наблюдения, предусматривающий использование заранее разработанной схемы и стандартного листа наблюдений
- Ответ: Структурированное
Вопрос 114. Совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
- Ответ: Генеральная совокупность
Вопрос 115. Вид маркетинговых исследований, к которому относятся исследования отношения к марке товара
- Ответ: Изучение потребителей
Вопрос 116. Объем выборки влияет на ее ошибку.
- Ответ: Да
Вопрос 117. Цели исследования с помощью фокус-групп
- Ответ: Выдвижение гипотез исследования, изучение мотивов покупки товаров, реакции на новые товары, отношения к рекламе
Вопрос 118. Маркетинговая информационная система (МИС) компании позволяет получать информацию, …
- Ответ: на основе которой можно принимать управленческие решения
Вопрос 119. Блок Маркетинговой Информационной Системы, в котором содержатся данные о заказах, продажах, ценах, товарных запасах предприятия
- Ответ: данных, полученных в результате собственных маркетинговых исследований
Вопрос 120. Методы, относящиеся к методам обработки маркетинговой информации
- Ответ: определения средних величин
- Ответ: регрессионный
- Ответ: корреляционный анализ
Вопрос 121. Предсказательный анализ направлен на
- Ответ: прогнозирование развития событий в будущем (например, путем анализа временных рядов)
Вопрос 122. Элемент Маркетинговой Информационной Системы, для которого используются такие источники информации, как торговый персонал фирмы, конкуренты, дистрибьюторы, розничные торговцы – это система …
- Ответ: сбора внешней информации (маркетинговой разведки)
Вопрос 123. Данные, полученные по заказу конкретных фирм и недоступные для широкой публики – это … информация.
- Ответ: синдикативная
Вопрос 124. Основные преимущества вторичной маркетинговой информации
- Ответ: экономия времени и денег
Вопрос 125. Пробный маркетинг относится к …
- Ответ: эксперименту
Вопрос 126. Рассмотрите следующую последовательность: 68, 45, 72, 50, 56, 50, 45, 45, 50, 56, 45, 68, 45, 68, 45, 72, 45. Какое из следующих утверждений является верным
- Ответ: Мода равна 45
Вопрос 127. Выявление смысловых единиц текста, количество которых характеризует общую направленность анализируемого документа, называется …
- Ответ: контент-анализ
Вопрос 128. Классификация панелей по характеру изучаемых единиц
- Ответ: Потребительские, торговые, промышленные
Вопрос 129. Фирмы, специализирующиеся на продаже стандартизированной маркетинговой информации относятся к фирмам, …
- Ответ: специализирующимся на сборе синдикативной (подходящей сразу для нескольких заказчиков) информации
Вопрос 130. Методы сбора данных, используемые при проведении количественных исследований
- Ответ: Фокус-группы, наблюдения, эксперименты
Вопрос 131. Средняя характеристика из высказанных группой компетентных специалистов мнений о каком-либо явлении или процессе, при условии, что удалось достичь согласованности их взглядов
- Ответ: Экспертная оценка
Вопрос 132. Тип шкалы измерений, использованный при формулировке следующего вопроса анкеты: «Какой безалкогольный напиток из приведенного списка Вам нравится больше всего? – Coca-cola – Pepsi – Sprite – Seven Up
- Ответ: номинальная
Вопрос 133. Статистический показатель, характеризующий значение признака, занимающего срединное место в упорядоченном ряду значений данного признака
- Ответ: Медиана
Вопрос 134. Такое требование к маркетинговой информации как релевантность подразумевает …
- Ответ: соответствие информации целям и задачам исследования
Вопрос 135. Метод выборки, используемый в том случае, если генеральная совокупность разделяется на страты, а затем для каждой из них производится расчет простой случайной выборки – метод …
- Ответ: стратифицированной выборки
Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!
Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:
где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).
Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:
Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)
где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.
Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).
Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.
Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.
При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
1. Совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
Выборка
Генеральная совокупность
Панель
Простая совокупность
2. Свойства выборки, которые позволяют ей выступать моделью (представителем) генеральной совокупности с точки зрения ее характеристик, которые изучаются при проведении исследования, – это … выборки.
устойчивость
достоверность
надежность
репрезентативность
3. Метод вероятностной выборки, предусматривающий расчет шага (интервала) отбора выборки
Метод жребия
Метод построения таблиц случайных чисел
Метод систематической (механической) выборки
Гнездовая выборка
4. Объем выборки влияет на ее репрезентативность.
Да
Нет
5. Чем больше различий внутри генеральной совокупности, тем больше величина возможной ошибки выборки.
Да
Нет
6. Объем выборки влияет на ее ошибку.
Да
Нет
7. Параллельное использование нескольких методов формирования выборки, основанное на поэтапном отборе ее объектов, – это … выборка.
пропорциональная
стратифицированная
квотированная
многоступенчатая
8. Основное условие осуществления вероятностной выборки – наличие …
полного списка всех элементов генеральной совокупности
согласия респондентов на участие в опросе
списка участников опроса
9. Под контуром выборки в маркетинговых исследованиях подразумевается …
список всех единиц генеральной совокупности
совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
определенная часть генеральной совокупности, которая призвана отражать все ее базовые характеристики
10. В маркетинговых исследованиях под ошибкой выборки подразумеваются отклонения (различия) между данными …
полученными от выборки и истинными данным
существующего и предыдущего исследования
вероятностной и невероятностной выборки
11. Метод выборки, предусматривающий отбор единиц выборки (респондентов), способных дать наиболее точные сведения
выборка по доступности
метод снежного кома
квотированная выборка
выборка по усмотрению
12. Когда исследователь использует случайную выборку, основанную на информации о числовых характеристиках генеральной совокупности, то …
наиболее корректный подход к определению объема выборки основан на расчете доверительных интервалов и среднего квадратического отклонения
невозможно точно рассчитать ошибку выборки и указать уровень ее надежности
13. Метод выборки, используемый в том случае, если генеральная совокупность разделяется на страты, а затем для каждой из них производится расчет простой случайной выборки – метод …
зональной выборки
многоступенчатой выборки
стратифицированной выборки
типичных представителей
14. Ключевая характеристика вероятностной (случайной) выборки заключается в том, что …
принцип отбора единиц выборки отличен от случайного
все единицы выборки имеют известную вероятность (шанс) попасть в выборку
невозможно рассчитать ошибку выборки
Запуск рекламной кампании в маркетинге предполагает А/В-тестирование, однако не каждый проведенный тест будет показательным, а его результаты – значимыми для статистики. Одна из распространенных ошибок при проведении исследований – неправильное определение нормального размера выборки. Как следствие – запуск рекламы, которая не даст результатов, и зря потраченные деньги.
Что такое объем выборки
Объем выборки – это количество людей из общего числа целевой аудитории (ЦА) продукта или бренда, участвовавших в исследовании, или количество заполненных анкет, которые были учтены при подсчете результатов.
![]()
![]()

Термин «выборка» говорит о том, что из всей совокупности участников опроса проводится оценка лишь части ответов.
В зависимости от параметров проекта, которые были указаны изначально, выборка может быть разной. Например, при случайной выборке респонденты выбираются из целевой совокупности случайным образом.
Зачем необходимо рассчитывать
Объем выборки определяют перед запуском количественных исследований в маркетинге (например, контент-анализа), чтобы узнать, какое число представителей ЦА должно поучаствовать в тестировании, и получить достоверные результаты. Если данных о объеме выборки нет, это может стать причиной того, что исследователь получит некорректные результаты.
Для качественных исследований объем выборки не определяют. Также он неактуален, если речь идет о проведении пилотных, т. е. предварительных исследований.
Основные понятия определения
В определении размера выборки участвуют различные параметры:
- генеральная совокупность;
- выборочная совокупность;
- достоверность измерений;
- репрезентативность выборки;
- нулевая и альтернативная гипотезы;
- доверительная вероятность;
- уровень значимости;
- мощность;
- клинически важный размер эффекта;
- односторонний / двусторонний тест значимости;
- доверительный интервал;
- погрешность измерения;
- процент ответов.
Разберем, что означают основные из них.
Генеральная совокупность
Генеральной совокупностью называется общее количество объектов наблюдения, которые обладают определенными общими признаками (возраст, пол, оборот, численность, доход и пр.) и о которых будут сделаны заявления после обработки результатов исследования.
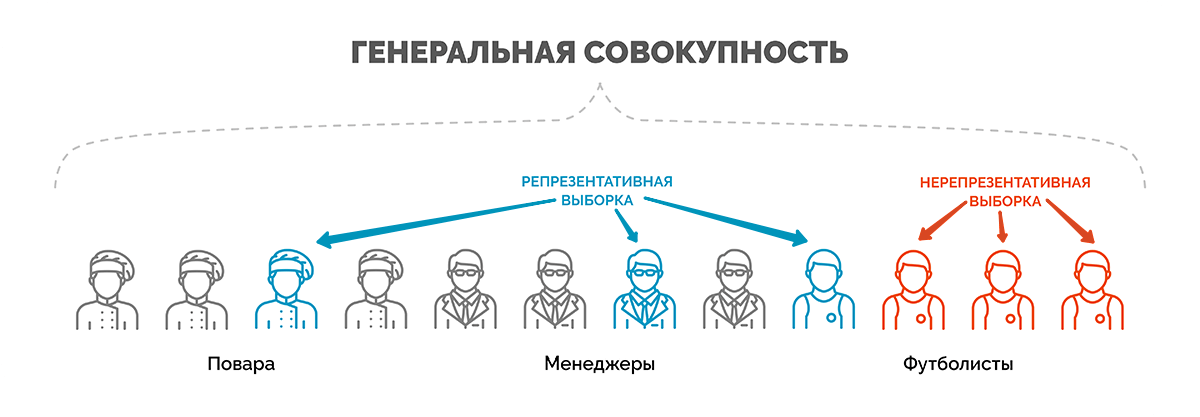
Объектами наблюдения могут быть люди, предприятия, домохозяйства, населенные пункты, отдельные малые социальные группы и т. д.
Если известно, что результаты опроса касаются всех жителей Москвы, то генеральная совокупность будет равна общей численности населения города, т. е. 13 млн человек (по данным 2021 года).
Оценивать свойства генеральный совокупностей, основываясь на выборочных методах, позволяет кривая нормального распределения.
Выборочная совокупность
Выборка или выборочная совокупность – это некоторая часть объектов из числа генеральной совокупности, отобранная для участия в исследовании с целью оценить распределение мнений и сделать итоговое заключение, которое будет распространяться на всю генеральную совокупность.
Характеристики выборочной совокупности должны корректно отражать параметры генеральной совокупности, т. е. обладать свойством репрезентативности. Только в данном случае заключение, сделанное исходя из результатов анализа выборки, будет с одинаковой вероятностью распространяться на представителей всей генеральной совокупности.
Выборка, состоящая из работников московских предприятий, не будет репрезентировать население города трудоспособного возраста и особенно все население столицы, т. к. не включает неработающих людей, женщин в декрете, удаленных сотрудников и т. д. Даже если мы будем увеличивать количество опрошенных работников столичных компаний, выборка все равно не сможет отразить характеристики генеральной совокупности, т. е. всего трудоспособного населения Москвы.
Погрешность измерений
Допустимая погрешность измерений – это процент возможной ошибки или отклонения результатов исследования, т. е. то значение, на которое истинный показатель может откланяться от значения, полученного в результате исследования.
Чем меньше погрешность, тем больше должна быть выборка.
Результаты опроса показали, что 60% опрощенных предпочитают делать покупки в сетевых магазинах. Предел погрешности 5% говорит о том, что в генеральной совокупности доля сторонников сетевых точек продаж может увеличиться или уменьшиться на 5% относительно уровня полученных 60%. Т. е. фактическое значение будет лежать в пределах значений от 55 до 65%.
Достоверность измерений
Уровень достоверности (надежности) измерений – это вероятность того, что полученные в результате исследования истинные результаты выбранного параметра генеральной совокупности находятся в пределах ее доверительного интервала (в примере выше это интервал 55-65%). Простыми словами, это степень уверенности в репрезентативности результатов.
Чем меньше доверительный интервал и выше заданный уровень достоверности, тем больше должна быть выборочная совокупность.
Если взять приведенный выше в статье пример с погрешностью в 5%, вы можете быть уверены в следующем: вероятность того факта, что от 55 до 65% людей предпочитают совершать покупки в сетевых магазинах, составляет не менее 95%.
Репрезентативность выборки
Под репрезентативностью понимают степень соответствия характеристик выборочной совокупности характеристикам генеральной совокупности, которые можно экстраполировать на всю популяцию.
- выборка, состоящая на 100% из автомобилистов Санкт-Петербурга, не репрезентирует всех жителей Санкт-Петербурга;
- выборка, состоящая только из российских фирм B2B с количеством сотрудников до 200 человек, не репрезентирует все компании страны, работающих в этом сегменте.
Исследование должно быть репрезентативным, если стоит задача по результатам количественного исследования сформировать представление о популяции в целом и правильно оценить ее. Если же исследование качественное или люди опрашиваются ради сбора мнений, предложений, идей, в этом случае репрезентативная выборка практически не играет роли.
Что влияет на результаты
Результаты тестирования могут изменяться под влиянием ряда факторов:
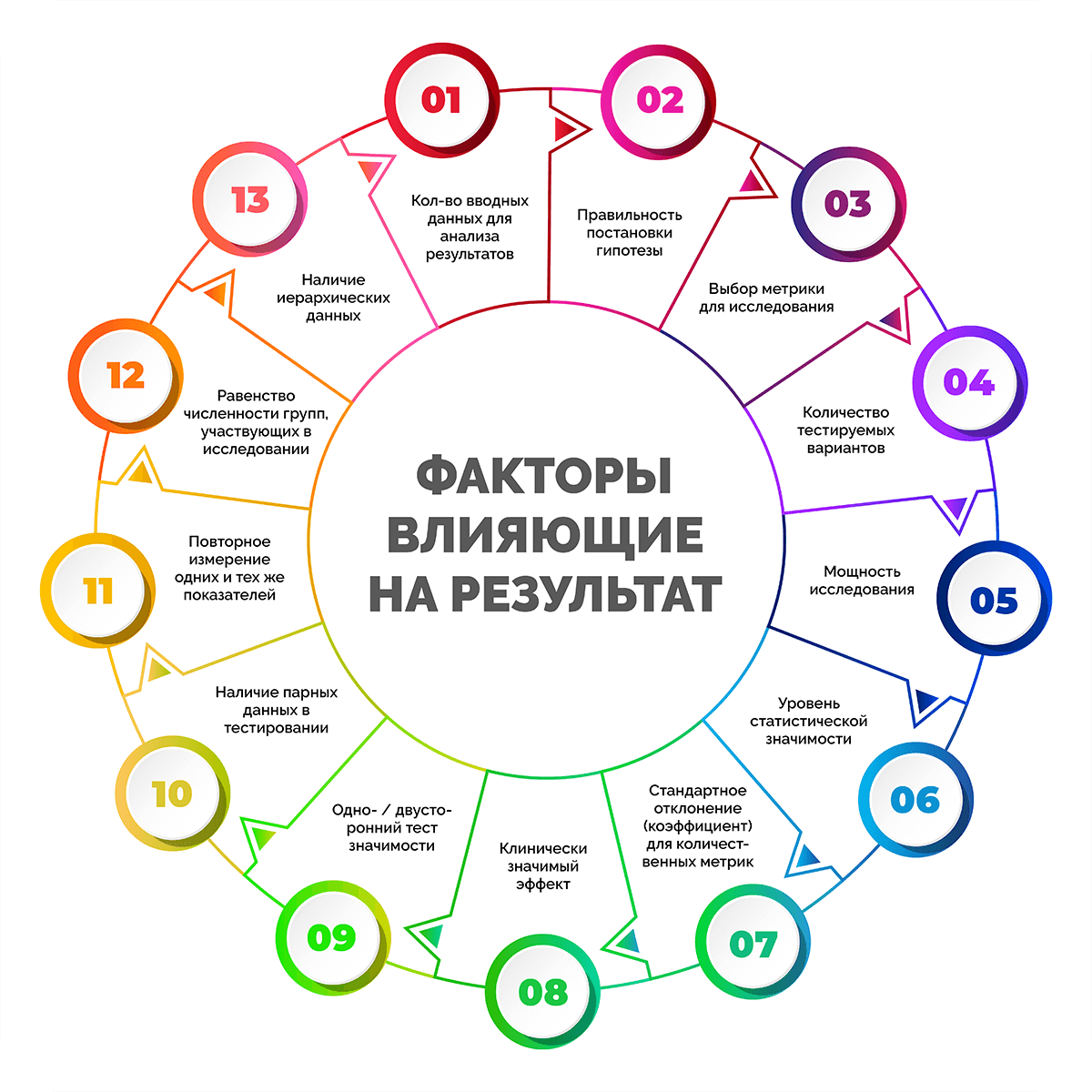
- количество вводных данных для анализа результатов;
- правильность постановки гипотезы;
- выбор той или иной метрики (показателя, переменных) для исследования;
- количество тестируемых вариантов;
- мощность исследования;
- уровень статистической значимости;
- стандартное отклонение (коэффициент) для количественных метрик;
- клинически значимый эффект;
- одно- / двусторонний тест значимости;
- наличие парных данных в тестировании;
- повторное измерение одних и тех же показателей;
- равенство численности групп, участвующих в исследовании;
- наличие иерархических данных.
Также расчет размера выборки может давать разные результаты, если анализ является:
- рандомизированным и контролируемым;
- рандомизированным и кластерным;
- нерандомизированным экспериментом вмешательства;
- исследованием эквивалентности;
- исследованием распространенности;
- обсервационным;
- изучением специфичности и чувствительности теста.
Нерандомизированные тестирования взаимосвязей или различий предполагают задействования в маркетинговых исследованиях выборки гораздо большего размера, чтобы при анализе было не сложно учесть влияние третьих факторов.
Типы выборок
Различают два типа выборок: вероятностные и невероятностные или детерминированные. Каждая группа включает в себя виды. Разберем, какие из них входят в каждый тип.
Вероятностные выборки:
- Случайная или простой случайный отбор – предполагает полный список элементов (отбираются при помощи таблицы случайных чисел), равную вероятность доступности всех из них и однородную генеральную совокупность;
- Механическая или систематическая – выступает в качестве разновидности случайной выборки, при этом упорядочивание происходит по тому или иному признаку, причем первый элемент отбирается случайно, затем с шагом n отбирается каждый последующий элемент;
- Стратифицированная или районированная – выборка используется при неоднородной генеральной совокупности, которая разделяется на страты (группы), в каждой из которых выполняется случайный отбор пропорционально их доле в генеральной совокупности;
- Серийная или кластерная, или гнездовая – единицами отбора выступают целые группы (гнезда или кластеры), которые могут попасть в выборку случайным образом, а все объекты внутри них подлежат сплошному исследованию.
Невероятностные (детерминированные) выборки:
- Квотная выборка – формируется несколько групп объектов, в каждой из которых зачастую пропорционально доле в генеральной совокупности задается определенное число объектов, которые нужно исследовать;
- Метод снежного кома – для формирования выборки каждый участник опроса предоставляет контакты своих знакомых; применяется для исследования труднодоступных групп респондентов;
- Стихийная выборка или выборка «первого встречного» – ее состав и размер заранее неизвестен и зависит от активности людей, опрос проводится среди самых доступных респондентов (интернет-опросы, опросы в журналах и газетах, анкеты на самозаполнение и т. д.);
- Выборка типичных случаев – для исследования отбираются отдельные представители генеральной совокупности, которым присуще среднее значение исследуемого признака.
Отбор в детерминированных выборках происходит не случайно, а по субъективным критериям: типичности, доступности, равного представительства каждой стороны и пр.
Расчет объема выборки
Расчет объема выборки – своего рода компромисс между требуемой мощностью исследования и возможностью реализовать его на практике с учетом имеющихся ресурсов и фокус-группы. При этом выбор метода расчета во многом определяется знаниями о параметрах и характеристиках изучаемых параметров.
Определить объем выборки можно двумя способами: по таблицам и с помощью формулы. Разберем эти методы.
По таблицам
Когда никаких данных о предстоящем исследовании нет, а сам эксперимент является инновационным, никто ранее ничего подобного не проводил и не предлагал решения, для определения объема выборки лучше выбрать табличный метод.
Ниже представлены различные методики. Выбор той или иной из них определяется имеющимися исходными данными или пожеланиями исследователя.
Таблица А. Определение объема выборки по методике К. А. Отдельновой
|
Уровень значимости |
Уровень точности |
||
|
Ориентировочное знакомство |
Исследование средней точности |
Исследование высокой точности |
|
|
0,01 |
100 |
225 |
900 |
|
0,05 |
44 |
100 |
400 |
Объем выборки указан в абсолютных значениях.
Таблица Б. Методика определения размера выборки В. И. Паниотто
|
Размер генеральной совокупности |
500 |
1000 |
2000 |
3000 |
4000 |
5000 |
10000 |
100000 |
∞ |
|
Объем выборки |
222 |
286 |
333 |
350 |
360 |
370 |
385 |
398 |
400 |
Данные указаны в единицах.
Таблица В. Методика N. Fox для определения объема выборки
|
Процент допускаемой ошибки |
Объем выборки в единицах |
|
10 |
88 |
|
5 |
350 |
|
3 |
971 |
|
2 |
2188 |
|
1 |
8750 |
Таблица Г. Определение размера согласно способу K. Mitra, S. Das, M. Mandal
|
Величина различий между основной и контрольной группами |
Уровень значимости |
Мощность |
Объем выборки |
|
0,2 |
0,5 |
80 |
586 |
|
0,2 |
0,1 |
80 |
773 |
|
0,2 |
0,5 |
90 |
746 |
|
0,4 |
0,5 |
80 |
146 |
|
0,4 |
0,1 |
80 |
193 |
|
0,4 |
0,5 |
90 |
186 |
|
0,6 |
0,5 |
80 |
65 |
|
0,6 |
0,1 |
80 |
86 |
|
0,6 |
0,5 |
90 |
83 |
По формулам
Объем выборки, достаточный для проведения новых исследований, определяется следующими параметрами:
- изменчивость признака;
- уровень доверия;
- размер эффекта.
Объем выборки всегда зависит от предполагаемой строгости эксперимента и изменчивости исследуемого признака.
Формула для оценки среднего значения размера выборки:
n = (z × σ / H)2, где:
n – размер выборки;
z – доверительный уровень (при р = 0,05 z = 1,96);
σ – стандартное отклонение;
Н – допустимая ошибка в натуральных величинах.
Формула для оценки доли выборки:

Где:
n – размер выборки;
z – доверительный уровень (при р = 0,05 z = 1,96);
p – доля признака (наибольшее значение достигается при р = 0,5);
H – допустимая ошибка в процентах.
Еще одна формула расчета объема выборки (чаще всего калькулятор размера выборки использует именно ее):

Где:
n – размер выборки;
z – нормированное отклонение;
p – вариация для выборки;
q = 1 – р;
е – допустимая ошибка.
Нормированное отклонение (z) определяется по таблице, зная основные значения доверительной вероятности (α).
|
α, % |
60 |
70 |
80 |
85 |
90 |
95 |
97 |
99 |
99,7 |
|
z |
0,84 |
1,03 |
1,29 |
1,44 |
1,65 |
1,96 |
2,18 |
2,58 |
3,0 |
Последняя формула расчета имеет особенности.
- Начинать считать размер выборки следует с проведения качественного анализа генеральной совокупности, чтобы выяснить степень схожести и близости исследуемых единиц совокупности относительно их географических, демографических, социальных и других характеристик.
- Рекомендуется предварительно выполнить пилотное исследование с целью определения приблизительного значения р.
- Если максимальная вариация р = 50%, то и значение q = 50%, что является наиболее худшим вариантом.
Пример расчета размера выборки
Маркетолог проводит исследование с целью определить, нужны ли компании визитки. Для этого промоутеру предстоит опросить потенциальных клиентов и задавать только один вопрос: «Вы пользуетесь визитками?». На что человек должен будет ответить «Да» или «Нет».
В таком случае размер выборки будет рассчитываться так. Принимаем, что уровень доверительности равен 95% (стандартное значение). При этом нормированное отклонение z составит 1,96. После предварительного анализа предположим, что 80% представителей генеральной совокупности дадут положительный ответ, а значит, р = 0,8. Соответственно, q = 1 – 0,8 = 0,2. Вероятность допустимой ошибки примем за 10%, т. е. e = 0,1. Теперь можно выполнить расчет.

Округлив значение, получаем размер выборки n = 62 человека. Соответственно, в опросе с заданными параметрами нужно задействовать 62 человека из числа целевой аудитории компании.
Подходы к определению размера выборки
Выделяют несколько подходов, которые позволяют установить объем выборки для проведения статистического исследования.
- Арбитражный подход. Объем выборки составляет определенный процент от генеральной совокупности. Например, 10% от общего количество потребителей.
- Традиционный подход. Выборка составляется на основе определенных норм, которые были выработаны в процессе проведенных ранее исследований. Подход игнорирует обстоятельства и условия, строгая логика отсутствует.
- Затратный подход. Объем выборки определяется в зависимости от стоимости сбора информации и возможных затрат на материалы для проведения исследования.
- Подход на основе использования доверительных интервалов. Размер выборки в этом случае рассчитывается по формуле, что обеспечивает высокую точность результата:
n = (p × q) / s2, где:
n – размер выборки;
p – вероятность того, что нужное событие наступит, %;
q = 100% – p;
s – стандартное отклонение, которое соответствует доверительному уровню.
Ошибки выборки
Объем выборки при массовом исследовании определяется двумя факторами:
- Точностью полученных данных или статистической погрешностью.
- Размером и количеством подгрупп, на которые будет разбита выборка при проведении анализа.
При любом исследовании, которое предполагает выборочный опрос респондентов из генеральной совокупности, может присутствовать погрешность данных или ошибка выборки. Выделяют два ее типа:
- случайная – обусловлена действием статистических законов, поэтому очень легко рассчитывается по формулам теории вероятности и математической статистики;
- систематическая – является следствием неточностей при проектировании выборки, определить ее степень смещения, направление и размер практически невозможно.
При расчете размера выборки важно так собрать данные, чтобы вероятность систематической ошибки в результате работы была минимальной.
Расчет случайной ошибки выборки зависит от объема последней, а также от степени однородности данных (дисперсии). Принцип такой: чем меньше дисперсия, тем меньше ошибка. Для расчета чаще всего используют онлайн калькуляторы.
Также выделяют:
- Ошибки первого рода – альфа-ошибка, при которой делается вывод о достоверности гипотезы, которая на самом деле неверна. Величина выбирается произвольно в диапазоне от 0 до 1, чаще всего это значение 0,05 или 0,01.
- Ошибки второго рода – бета-ошибка, при которой тот факт, что гипотеза неверна, остается не выявленным. Значение, как правило, устанавливается на уровне 0,2.
Расчет доверительного интервала
Для расчета доверительного интервала применяются достаточно простые формулы, выбор которых зависит от доли выборки в составе генеральной совокупности.
Если выборка значительно меньше генеральной совокупности:

Если выборка и генеральная совокупность сопоставимы:

В обеих формулах:
Δ – предельная ошибка выборки в процентах;
z – нормированное отклонение или z-фактор;
p – доля респондентов с наличием признака, который исследуется;
q – доля респондентов без исследуемого признака;
n – размер выборки;
N – объем генеральной совокупности (сколько всего респондентов).
Доверительный интервал удобно рассчитывать с помощью онлайн-калькулятора, который использует те же формулы, что мы привели выше. Просто введите необходимые переменные, и система рассчитает результат.
Расчет статистической значимости
Определить этот показатель проще всего с помощью онлайн-сервиса. Калькулятор позволяет проверить, существует ли статистически значимая разница между долями признака, которые были получены из независимых выборок.

Рассчитывать статистическую значимость можно только в том случае, если произведения (n × p) и (n × (1 – р)) превышают значение 5. При этом n – объем выборки, р – доля признака.
Часто задаваемые вопросы
Обычно размер выборки и ее статистическая значимость прямо пропорциональны, т. е. с ростом выборки получение случайных результатов сводится к минимуму. Важность статистической значимости зависит от определенной ситуации. Вот некоторые из них.
|
Ситуация |
Важность статистической значимости |
|
Опросы сотрудников |
Важна, т. к. повышает всесторонность выводов по итогам опроса. |
|
Опросы клиентов об уровне их удовлетворенности |
Не имеет значения, т. к. важен каждый ответ независимо от того, положительный он или отрицательный. |
|
Исследование рынка |
Имеет решающее значение, т. к. помогает сделать вывод о целевом рынке. |
|
Опросы об образовании |
Важна, если нужно использовать результаты исследования при внесении изменений в учебном заведении. |
|
Здравоохранение |
Помогает выявлять серьезные проблемы, делать выводы в исследованиях. Если же опрос проводится ради оценки удовлетворенности пациентов, то не имеет значения. |
|
Опросы для развлечения |
Не важна. |
Заданный размер выборки нужен для получения оценок с желаемым уровнем точности, если речь идет об исследовании распространенности в популяции конкретной характеристики.
- Мало просмотров.
- Узкая тематика.
- Низкий бюджет.
- Высокий бюджет.
Чтобы правильно рассчитать размер выборки и провести показательное исследование с учетом выдвинутых требований:
- наберитесь терпения и дождитесь, пока соберется требуемое количество респондентов;
- будьте последовательны и показывайте рекламу только ЦА в определенное время;
- устанавливайте высокий уровень достоверности при расчете выборки.
При определении объема выборки основную роль играет переменная исхода конкретного исследования. Если в расчет добавляются дополнительные важные переменные, то размер выборки должен позволять адекватно проанализировать их.
Это такое количество объектов исследования, которое позволит получить максимально точный и достоверный результат с предельно небольшой погрешностью. При этом его можно репрезентовать на более широкую аудиторию, в т. ч. по отношению к генеральной совокупности.
Заключение
Объем выборки – важный показатель, без которого невозможно провести адекватное исследование и сделать объективные выводы. Он отражает количество представителей целевой аудитории, которое будет принимать непосредственное участие в эксперименте, и требуется во всех случаях, когда стоит задача сделать определенные заключения по результатам опроса.
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter
Формирование выборки
Характерными
особенностями количественных исследований
является четко определенный формат
собираемых данных и источники их
получения, а обработка собранных данных
осуществляется с помощью упорядоченных
процедур, в основном количественных по
своей природе. Результаты количественных
исследований дают ответы на вопросы:
Кто?, Что?, Где?, Когда?, Сколько?
Если
исследование охватывает весь изучаемый
массив, оно будет сплошным,
т.
е. в таком исследовании каждый элемент
генеральной совокупности служит единицей
сбора информации. В тех случаях, когда
объект исследования насчитывает более
500 человек, единственно правильным
признается применение выборочного
метода.
§ 1. Формирование выборки исследования
Совокупность
всех возможных социальных объектов,
которые подлежат изучению в пределах
программы исследования, называется
генеральной
совокупностью.
Выборочная
совокупность (выборка)
— часть
объектов генеральной совокупности,
отобранная с помощью специальных приемов
для получения информации о всей
совокупности. Репрезентативность
— свойство
выборочной совокупности воспроизводить
параметры и значимые элементы структуры
генеральной совокупности.
Преимущества
выборочного исследования по отношению
к сплошному
состоят
в том, что оно:
-
позволяет
сократить затраты на сбор и обработку
информации; -
позволяет
добиться большей оперативности; -
имеет
более широкую область применения; -
в
ряде случаев позволяет получить более
достоверные сведения.
Процесс
выборки основан на двух моментах:
во-первых,
на взаимосвязи и
взаимообусловленности
качественных характеристик и признаков
социальных объектов; во-вторых,
на правомерности выводов о целом на
основании изучения его части при условии,
что по своей структуре эта часть является
микромоделью целого.
Единицы
отбора
—
элемент или набор элементов, предназначенный
для отбора на определенной ступени
выборки.
Единицы
анализа
—
элементы выборочной совокупности
(респонденты), подлежащие изучению.
Переменная
—
множество отдельных значений характеристик
элементов совокупности. Параметр
—
суммарное описание переменной в
генеральной совокупности. Статистика
—
суммарное описание переменной в
выборочной совокупности.
Основная
цель выборочного метода
— выбор элементов из совокупности таким
образом, чтобы распределение этих
элементов в выборке повторяло их
распределение в совокупности. Достижению
этой цели служит вероятностная выборка.
Модель
вероятностной (случайной) выборки
связана с понятием статистической
вероятности,
изучаемой
в социальных науках (вероятность
некоторого ожидаемого события есть
отношение числа ожидаемых событий к
числу всех возможных).
Случайная
выборка носит наиболее распространенный
характер.
Самый легкий путь получения случайной
выборки — присвоить каждому элементу
свой номер, а затем с помощью компьютера
рассчитать случайные числа, из которых
и берется выборка (например, каждый
десятый номер в каждой случайной цепи).
Можно выбирать из генеральной совокупности
по какому-то принципу (каждая тысячная
фамилия из списка абонентов телефонной
сети, каждый третий дом на определенной
улице, студенты, родившиеся в сентябре,
и т. д.)
Преимущества
случайной выборки:
-
объективность
и точность отбора респондентов; -
не
требуется детальное знание изучаемой
совокупности; -
использование
методов математической вероятности.
Недостатки
случайной выборки:
-
сложность
процедуры отбора; -
затратность
ресурсов.
На
практике часто применяется метод
гнездовой выборки.
Он
предполагает отбор в качестве единиц
анализа не отдельных людей, а групп
(семьи, студенческие группы, бригады и
т. д.), с последующим сплошным опросом в
отобранных группах. Гнездовая выборка
будет репрезентативна в том случае,
если состав групп в максимальной степени
близок по основным демографическим
признакам респондентов.
В
некоторых случаях невозможно использование
вероятностных схем отбора, описанных
выше. Тогда используется целенаправленная
выборка,
к
которой неприменимы правила теории
вероятности. Она осуществляется с
помощью следующих
методов:
стихийной
выборки,
метода
квот и метода основного массива.
В
случае
стихийной
выборки
невозможно
предопределить структуру массива
респондентов и соответственно трудно
определить репрезентативность. Существует
несколько разновидностей
стихийного отбора:
так
называемый отбор «первого встречного».
Встречается в практике обследований,
проводимых средствами массовой
информации. Исследователь проводит
опрос лиц, которые встретились ему в
месте опроса (например, на улице);
отбор
«себе подобных».
Исследователь подбирает для опроса или
наблюдения респондентов из своего
окружения (знакомые, коллеги);
отбор
«желающих участвовать».
Примером может служить почтовый опрос
читателей газеты или журнала. При таких
опросах решение о включении в выборку
принимает сам респондент.
Метод
квотной выборки
— распространенный способ отбора
респондентов при массовых опросах
общественного мнения. Его используют
в том случае, если до начала исследования
имеются статистические данные о
контрольных признаках элементов
генеральной совокупности. Все данные
о том или ином контрольном признаке
выступают в качестве квоты. Респонденты
отбираются целенаправленно, с соблюдением
параметров квот.
Число характеристик, данные о которых
выбираются в качестве квот, как правило,
не превышает четырех.
Главная
задача для интервьюера
заключается
в том, чтобы создать условия, близкие к
случайному отбору, с равными шансами
для каждого элемента генеральной
совокупности попасть в выборку.
Метод
квот позволяет существенно сократить
время и средства,
затрачиваемые на опросы. К преимуществам
квотной выборки относятся также
оперативность и малая трудоемкость.
Недостатки
квотной выборки:
-
требуется
детальное знание изучаемой совокупности; -
субъективизм
интервьюера при отборе респондентов; -
ограниченное
время посещения респондентов; -
уклонение
респондентов от опроса;1 -
не
позволяет использовать методы
математической вероятности.
Метод
основного массива
применяется в разведывательных
исследованиях
для
уточнения какого-нибудь контрольного
вопроса. В таких случаях опрашивается
50-60% потенциальных респондентов.
Все
рассмотренные методы представляют
собой пример одноступенчатой выборки.
Многоступенчатые
выборки
осуществляются
в несколько ступеней: на
первой ступени
обычно реализуется гнездовая выборка,
а потом
проводится случайный отбор респондентов
в гнездах.
Многоступенчатая
выборка используется в крупномасштабных
исследованиях, когда в генеральной
совокупности насчитываются тысячи и
миллионы единиц, размещенных на
значительной территории. При построении
многоступенчатой выборки используются
несколько способов отбора элементов
выборочной совокупности.
Районированный
отбор (типический)
производится
на основе распределения заданного числа
отбираемых единиц измерения, т. е. объема
выборки, между так называемыми районами,
типами — группами элементов генеральной
совокупности, выделяемыми в соответствии
со значениями изучаемого в исследовании
заданного «базового признака». Выделяемые
таким образом слои будут внутренне
однородными, но отличными друг от друга
и взятые вместе исчерпывать всю
совокупность.
В
крупномасштабных многоступенчатых
выборках требования к точности оценок
смещаются на второй план,
уступая место вопросам снижения стоимости
исследования благодаря выбору минимально
допустимого числа единиц опроса.
Объем
выборки определяется аналитическими
задачами исследования,
ее
репрезентативность
— целевой
установкой программы.
Объем
выборки влияет на ошибки репрезентации:
чем больше величина выборки, тем меньше
возможная ошибка. Для
увеличения точности в два раза необходимо
увеличить выборку в четыре раза.
Ошибка
репрезентации
—
это различие между характеристиками
генеральной и выборочной совокупности.
Количество респондентов, включенных в
выборочную совокупность, должно
составлять 10% от генеральной совокупности,
но не превышать 2000—2500 человек (если
величина генеральной совокупности 5000
человек и более).
Для
пробных опросов достаточна выборочная
совокупность объемом 100-250 человек. При
массовых опросах, если величина
генеральной совокупности составляет
менее 5000 человек, достаточный объем
выборочной совокупности, гарантирующий
достоверные результаты исследования,
составляет 500 человек.
Оценка
надежности результатов выборочного
обследования проводится следующим
образом:
-
ошибка
выборки до 3% — повышенная надежность; -
ошибка
выборки 3-10% — обыкновенная; -
ошибка
выборки от 10 до 20% — приближенная; -
ошибка
выборки от 20 до 40% — ориентировочная; -
более
40% — прикидочная надежность.
В
аналитических и экспериментальных
исследованиях проблема репрезентативности
выборки является второстепенной в
сравнении с необходимостью обеспечить
качественное представительство изучаемых
объектов.
Качество
выборки зависит:
а) от
меры однородности социальных объектов
по наиболее существенным характеристикам
(чем более они однородны, тем меньшая
численность может обеспечить статистически
достоверные выводы);
б) от
степени дробности группировок анализа,
планируемых по задачам исследования;
в) от
целесообразного уровня надежности
выводов из предпринимаемого исследования.
Традиционно
выделяют следующие виды ошибок:
-
случайные
отклонения выборочных значений
параметров; -
систематические
ошибки (ошибки смещения); -
погрешности
вычислений.
Погрешности
вычислений
возникают
при математико-статистической обработке
результатов измерений. О погрешности
вычислений необходимо помнить при
оценке точности и надежности выборочных
данных и при интерпретации результатов.
Случайные
ошибки
бывают
следствием большого числа разнообразных
факторов, и учесть действие каждого из
них невозможно. Ошибка выборки считается
случайной, а выборочная совокупность
репрезентативной, если отклонение не
превышает в среднем 5%.
Наиболее
опасный вид ошибок — систематические
ошибки
(или
ошибки смещения). Такие ошибки являются
результатом действий в одном направлении
определенной группы причин, которую
возможно выявить.
Источники
систематических ошибок:
а) неверные
статистические данные о параметрах
контрольных признаков генеральной
совокупности;
б) ошибочная
модель выборки;
в) неправильное
формирование выборочной совокупности;
г) несовершенство
инструментария и ошибки в организации
сбора данных;
д) неправильная
интерпретация результатов первичных
измерений и неправильная последующая
обработка и анализ информации.
На
правильность результатов исследования
в наибольшей степени влияют
ошибки смещения, вызванные неправильной
реализацией модели выборки, несовершенством
инструментария и организации сбора
данных. Систематические ошибки могут
появиться на любом этапе исследования.
Необходимо стремиться к тому, чтобы по
возможности исключить ситуации,
способствующие возникновению ошибок,
критически анализировать полученные
результаты, природу расхождений
выборочных и генеральных совокупностей.
При
конструировании модели выборки
целесообразно консультироваться со
специалистами по математической
статистике.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
UCHEES.RU — помощь студентам и школьникам
Объем выборки влияет на ее ошибку.
В 16:41 поступил вопрос в раздел Методология маркетинговых исследований в регионе, который вызвал затруднения у обучающегося.
Вопрос вызвавший трудности
Объем выборки влияет на ее ошибку.
Ответ подготовленный экспертами Учись.Ru
Для того чтобы дать полноценный ответ, был привлечен специалист, который хорошо разбирается требуемой тематике «Методология маркетинговых исследований в регионе». Ваш вопрос звучал следующим образом: Объем выборки влияет на ее ошибку.
После проведенного совещания с другими специалистами нашего сервиса, мы склонны полагать, что правильный ответ на заданный вами вопрос будет звучать следующим образом:
- Ответ: Да
НЕСКОЛЬКО СЛОВ ОБ АВТОРЕ ЭТОГО ОТВЕТА:

Работы, которые я готовлю для студентов, преподаватели всегда оценивают на отлично. Я занимаюсь написанием студенческих работ уже более 4-х лет. За это время, мне еще ни разу не возвращали выполненную работу на доработку! Если вы желаете заказать у меня помощь оставьте заявку на этом сайте. Ознакомиться с отзывами моих клиентов можно на этой странице.
Полякова Ярослава Алексеевна — автор студенческих работ, заработанная сумма за прошлый месяц 63 922 рублей. Её работа началась с того, что она просто откликнулась на эту вакансию
ПОМОГАЕМ УЧИТЬСЯ НА ОТЛИЧНО!
Выполняем ученические работы любой сложности на заказ. Гарантируем низкие цены и высокое качество.
![]()
Деятельность компании в цифрах:
Зачтено оказывает услуги помощи студентам с 1999 года. За все время деятельности мы выполнили более 400 тысяч работ. Написанные нами работы все были успешно защищены и сданы. К настоящему моменту наши офисы работают в 40 городах.
РАЗДЕЛЫ САЙТА
Ответы на вопросы — в этот раздел попадают вопросы, которые задают нам посетители нашего сайта. Рубрику ведут эксперты различных научных отраслей.
Полезные статьи — раздел наполняется студенческой информацией, которая может помочь в сдаче экзаменов и сессий, а так же при написании различных учебных работ.
Красивые высказывания — цитаты, афоризмы, статусы для социальных сетей. Мы собрали полный сборник высказываний всех народов мира и отсортировали его по соответствующим рубрикам. Вы можете свободно поделиться любой цитатой с нашего сайта в социальных сетях без предварительного уведомления администрации.
ЗАДАТЬ ВОПРОС
НОВЫЕ ОТВЕТЫ
- Абадзехская стоянка, Даховская пещера. ..
- По закону сохранения заряда каждый шарик после соприкасl..
- 2)прогудел первый мохнатый шмель 3) Зазвенела Прогудел 4) ..
- В мілкій траві ворушаться сліди веселих, сполоханих доще
..
ПОХОЖИЕ ВОПРОСЫ
- Ключевая характеристика метода экспертных оценок
- Тип наблюдения, предусматривающий использование заранее разработанной схемы и стандартного листа наблюдений
- Совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
- Вид маркетинговых исследований, к которому относятся исследования отношения к марке товара
Площадка Учись.Ru разработана специально для студентов и школьников. Здесь можно найти ответы на вопросы по гуманитарным, техническим, естественным, общественным, прикладным и прочим наукам. Если же ответ не удается найти, то можно задать свой вопрос экспертам. С нами сотрудничают преподаватели школ, колледжей, университетов, которые с радостью помогут вам. Помощь студентам и школьникам оказывается круглосуточно. С Учись.Ru обучение станет в несколько раз проще, так как здесь можно не только получить ответ на свой вопрос, но расширить свои знания изучая ответы экспертов по различным направлениям науки.
2020 — 2023 — UCHEES.RU
14 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе