
Основная задача канального уровня — передача кадров (frame) по каналам связи. На этом уровне и определяется, где в потоке бит начало сообщения, где конец.

На канальном уровне проводится нахождение и корректировка ошибок для некоторых каналов с множественным доступом, где одну и ту же среду передачи данных используют несколько устройств.
Дополнительные задачи канального уровня:
- Адресация — если в канале связи (КС) есть несколько устройств, необходимо определить, к какому именно устройству адресовано передаваемое сообщение;
- Согласованный доступ к каналу. Если все гаджеты одновременно начнут передавать информацию, то данные в КС искажаются и не смогут быть приняты.
Работа с кадрами
Физический уровень предназначен для передачи потока бит по КС. А на канальном уровне необходимо передавать не отдельные биты, а целые сообщения. Задача №1 для канального уровня, выделить сообщения из потока бит, которые приходят по среде передачи данных.

Формирование кадра
Например, есть два ноутбука Хост 1 и Хост 2. И на картинке ниже есть три уровня, сетевой, канальный и физический.

Канальный уровень получает информацию от сетевого и добавляет к нему заголовок и концевик. И именно это сообщение, выделенное красным, заголовок канального уровня, пакет с сетевого уровня и концевик канального уровня и является фреймом. Такое сообщение отправляется через физический уровень по среде передачи данных и поступает на канальный уровень принимающего уровня.
Принимающее устройство читает заголовок и концевик, извлекает пакет сетевого уровня и передает вышестоящему сетевому уровню для последующей обработки.
Методы выделения кадров
Чтобы определить, где в потоке бит начинаются и заканчиваются отдельные frame, были придуманы следующие методы:
- Указание количества байт;
- Вставка байтов (byte stuffing) и битов (bit stuffing);
- Средства физического уровня.
Указатель количества байт
Наипростейший способ определить, где начинается и заканчивается кадр — добавлять длину этого кадра в начало кадра. Например, на картинке ниже показано 3 кадра выделенных разным цветом. В начале каждого кадра указано количество байт. Синим цветом — 6, желтым — 8, зеленым — 4.

Этот метод прост в реализации, но есть недостаток, искажение данных при передаче по сети. Например, при передаче первого кадра появилось искажение и вместо длины кадра шесть байт, получатель получил семь байт.

Получатель посчитает, что семь это длина кадра. Далее идет длина следующего кадра. Здесь она два байта, затем длина следующего кадра семь. Если у нас произошла хоть одна ошибка, то будет нарушена последовательность чтений. Следовательно такой метод на практике не годится к применению.
Вставка byte и bit
Чтобы определить начало и конец кадра, в начале и конце каждого кадра используют специальные последовательности байт или бит. Вставка байтов применялась в протоколах BSC компании IBM, в котором отправлялись обычные текстовые символы.
Перед передачей каждого фрейма добавлялись байты DLE STX (start of text), а после окончания передачи фрейма DLE ETX (end of text). Проблема может возникнуть в том, что в данных тоже может встретиться точно такая же последовательность.
Чтобы отличать последовательность, которая встречается в данных от управляющих символов используются Escape последовательности. В протоколе BSC это тоже последовательность символов DLE (data link escape). Если какая-то последовательность управляющих символов встречается в данных перед ними добавляются escape последовательности DLE, чтобы протокол понимал, что в реальности это данные, а не управляющие символы.
Вставка битов применяется в более современных протоколах, таких как HDLC и PPP. Здесь перед началом и концом каждого кадра добавляется последовательность бит состоящая из 01111110. Может возникнуть проблема, если в данных встречаются подряд идущие 6 или более единиц. Чтобы решить эту задачу в данные, после каждых пяти последовательно идущих 1 добавляется 0. Затем, как получатель прочитал 5 последовательно идущих 1 и встретил 0, то он, этот 0 игнорирует.
Средства физического уровня
Другой вид определения начала и конца кадра, это использование средств физического уровня и он применяется в технологии Ethernet. В первом варианте технологии ethernet использовалась преамбула — это последовательность данных, которая передается перед началом каждого кадра. Она состоит из 8 байт. Первые семь байт состоят из чередующихся 0 и 1: 10101010. Последний байт содержит чередующиеся 0 и 1, кроме двух последних бит в котором две единицы. И именно такая последовательность говорит, что начинается новый кадр.
В более старых версиях используется избыточное кодирование, позволяющее определить ошибки, но при этом не все символы являются значащими. В технологии Fast Ethernet применили эту особенность кода и используют символы, которые не применяются для представления данных в качестве сигналов о начале и конце кадра.
Перед отправкой каждого кадра передаются символы J (11000) и K (10001), а после окончания отправки кадра передается символ T (01101).
Обнаружение и исправление ошибок
Самый простой способ это обнаружить ошибку. Например, с помощью контрольной суммы или какого-либо другого алгоритма. Если у нас технология канального уровня использует обнаружение технических ошибок, то кадр в котором произошла ошибка, просто отбрасывается. Попыток восстановить данные не производится.
Более сложный механизм — это исправление ошибок. Чтобы иметь возможность исправить ошибку, нужно добавить к данным дополнительную информацию, с помощью которой мы сможем обнаружить ошибки и восстановить правильные данные. Для этого используются специальные коды исправляющие ошибки.
Другой вариант исправление ошибок при передаче данных — это повторная отправка тех кадров в которых произошла ошибка. Он используется совместно с обнаружением ошибок, когда отправитель передает данные получателю, получатель обнаруживает ошибку в данных, но вместо того чтобы исправить ошибку в передаваемых данных, отправитель передает эти данные еще раз.
Давайте рассмотрим, как реализуется повторная отправка сообщений. Предположим, что у нас есть отправитель и получатель и отправитель передал получателю некоторое сообщение. Получатель получил это сообщение проверил его на корректность убедился, что данные переданы правильно и после этого передает отправителю подтверждение о получении. Отправитель передает следующее сообщение предположим, что здесь произошла ошибка, получатель эту ошибку обнаружил или сообщение вообще не дошло до получателя, поэтому получатель не может передать подтверждение о получении этого сообщения.

Отправитель, после того как, отправил сообщение запустил таймер ожидания подтверждения. По истечению времени ожидания подтверждение не пришло, отправитель понял, что при передаче сообщения произошла проблема и нужно повторно передать то же самое сообщение.

В этот раз сообщение успешно дошло до получателя и он снова передает подтверждение. После этого отправитель может передавать следующий кадр.

Есть два варианта метода повторной отправки сообщения. Схему которую мы рассмотрели называется с остановкой и ожиданием. Отправитель передает фрейм и останавливается ожидая подтверждение. Следующий кадр передается только после того, как пришло подтверждение о получении предыдущего сообщения. Такой метод используются в технологии канального уровня Wi-Fi.
Другой вариант метода повторной отправки это скользящее окно. В этом случае отправитель передает ни одно сообщение, а сразу несколько сообщений и количество сообщений, которые можно передать не дожидаясь подтверждения называется размером окна. Здесь получатель передает подтверждение не для каждого отдельного сообщения, а для последнего полученного сообщения. Такой метод лучше работает на высокоскоростных каналах связи. Сейчас нет технологии канального уровня, которая использует этот метод, но он используется на транспортном уровне в протоколе TCP.
У нас есть несколько вариантов, что можно делать с ошибками. Можно их обнаруживать, исправлять с помощью кодов исправления ошибок, либо с помощью повторной доставки сообщений. Также мы можем исправлять и обнаруживать ошибки на канальном уровне, либо на вышестоящих уровнях.
Множественный доступ к каналам
Как это лучше делать? Практика показала, что на каналах где ошибки возникают редко, например, если данные передаются по проводам, то на канальном уровне лучше использовать простое обнаружение ошибок. А если ошибки в среде передачи данных происходят часто, например как это происходит в wifi? где используются электромагнитное излучение и много помех, то ошибки эффективнее обнаруживать и исправлять прямо на канальном уровне. Модель взаимодействия открытых систем разрабатывалась, когда на практике использовались только каналы связи “точка-точка” — это были последовательные линии связи, которые объединяли большие компьютеры.
Затем появились другие технологии канального уровня, на основе разделяемых каналов связи, когда к одной и той же среде передачи данных подключено несколько устройств. В таких каналах появились новые задачи, которые не были учтены в модели взаимодействия открытых систем, поэтому пришлось поменять эту модель и разделить канальный уровень на два подуровня.

Подуровни канального уровня
Подуровень №1 — управление логическим каналом (logical link control) LLC, а подуровень №2 — управление доступом к среде (media access control) MAC.
Подуровень LLC отвечает за передачу данных, формирование кадров, обработку ошибок и тому подобное. LLC общий уровень для различных технологий канального уровня.
Подуровень MAC используется, если технология канального уровня с разделяемым доступом. Если технология канального уровня используют соединение “точка-точка”, то подуровень MAC не нужен.
Во-первых если у нас есть несколько устройств, которые подключены к одному и тому же каналу связи, то при передаче данных мы должны явно указать, к какому устройству эти данные предназначены. Для этого используются адресация канального уровня, также необходимо обеспечить корректное, совместное использование разделяемой среды передачи данных.
Подуровень MAC особенный для разных технологий канального уровня, он зависит от того, какая среда передачи данных используется.
Услуги подуровня LLC
Мультиплексирование — передача данных через одну технологию канального уровня, нескольких типов протоколов вышестоящего уровня. Управление потоком, если в сети устройства, которые работают с разной скоростью, то более мощное устройство, может начать передавать данные очень быстро, так что более слабые устройства не успевают их принимать. В компьютерных сетях это называется “затопление” и некоторые технологии канального уровня обеспечивают защиту от затопления медленного получателя быстрым отправителем.
Множественный доступ к каналу связи
Предположим, есть какая-то общая среда передачи данных, к которой подключены несколько компьютеров и они начали передавать данные одновременно. Но так как среда передачи данных одна, то данные искажаются и не могут быть прочитаны из среды. Это называется коллизия. Подуровень MAC обеспечивает управление доступом, к разделяемой среде. В один и тот же момент времени, канал связи для передачи данных должен использовать только один отправитель. В противном случае произойдет коллизия и данные искажаются.
Методы управления доступом:
- Рандомизированный метод. Предположим, к среде подключено N устройств в этом случае для передачи данных случайным образом выбирается одно из этих устройств с вероятностью 1/N. Такой подход применяется в технологиях канального уровня изернет и вай-фай.
- Определение правил использования среды, например, в технологии Token Ring, данные может передавать только одно устройство, у которого сейчас находится токен. После того как это устройство передало данные, оно передает токен следующему устройству и следующее устройство может передавать данные. Хотя такой подход обеспечивает более эффективное использование полосы пропускания канала связи, но он требует более дорогого оборудования. Поэтому на практике получил распространение рандомизированный подход.
Раньше было очень много технологий канального уровня, каждая из которых обладала теми или иными преимуществами и недостатками. Однако сейчас в процессе развития остались только две популярные технологии это ethernet и вай-фай.
Мы рассмотрели канальный уровень, его основные задачи. Выяснили, что канальный уровень может обнаруживать и исправлять ошибки. Спасибо за прочтение статьи, надеемся она была для Вас полезной.
Data-link layer uses error control techniques to ensure that frames, i.e. bit streams of data, are transmitted from the source to the destination with a certain extent of accuracy.
Errors
When bits are transmitted over the computer network, they are subject to get corrupted due to interference and network problems. The corrupted bits leads to spurious data being received by the destination and are called errors.
Types of Errors
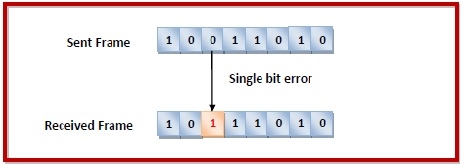
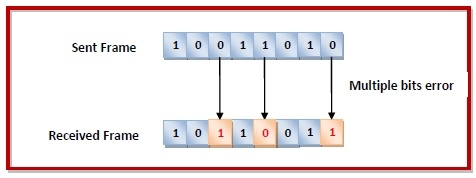
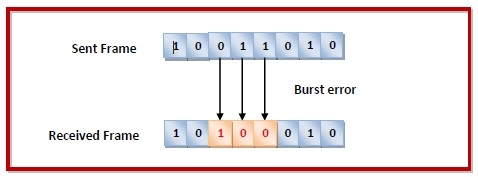
Errors can be of three types, namely single bit errors, multiple bit errors, and burst errors.
-
Single bit error − In the received frame, only one bit has been corrupted, i.e. either changed from 0 to 1 or from 1 to 0.

-
Multiple bits error − In the received frame, more than one bits are corrupted.

-
Burst error − In the received frame, more than one consecutive bits are corrupted.

Error Control
Error control can be done in two ways
-
Error detection − Error detection involves checking whether any error has occurred or not. The number of error bits and the type of error does not matter.
-
Error correction − Error correction involves ascertaining the exact number of bits that has been corrupted and the location of the corrupted bits.
For both error detection and error correction, the sender needs to send some additional bits along with the data bits. The receiver performs necessary checks based upon the additional redundant bits. If it finds that the data is free from errors, it removes the redundant bits before passing the message to the upper layers.
Error Detection Techniques
There are three main techniques for detecting errors in frames: Parity Check, Checksum and Cyclic Redundancy Check (CRC).
Parity Check
The parity check is done by adding an extra bit, called parity bit to the data to make a number of 1s either even in case of even parity or odd in case of odd parity.
While creating a frame, the sender counts the number of 1s in it and adds the parity bit in the following way
-
In case of even parity: If a number of 1s is even then parity bit value is 0. If the number of 1s is odd then parity bit value is 1.
-
In case of odd parity: If a number of 1s is odd then parity bit value is 0. If a number of 1s is even then parity bit value is 1.
On receiving a frame, the receiver counts the number of 1s in it. In case of even parity check, if the count of 1s is even, the frame is accepted, otherwise, it is rejected. A similar rule is adopted for odd parity check.
The parity check is suitable for single bit error detection only.
Checksum
In this error detection scheme, the following procedure is applied
-
Data is divided into fixed sized frames or segments.
-
The sender adds the segments using 1’s complement arithmetic to get the sum. It then complements the sum to get the checksum and sends it along with the data frames.
-
The receiver adds the incoming segments along with the checksum using 1’s complement arithmetic to get the sum and then complements it.
-
If the result is zero, the received frames are accepted; otherwise, they are discarded.
Cyclic Redundancy Check (CRC)
Cyclic Redundancy Check (CRC) involves binary division of the data bits being sent by a predetermined divisor agreed upon by the communicating system. The divisor is generated using polynomials.
-
Here, the sender performs binary division of the data segment by the divisor. It then appends the remainder called CRC bits to the end of the data segment. This makes the resulting data unit exactly divisible by the divisor.
-
The receiver divides the incoming data unit by the divisor. If there is no remainder, the data unit is assumed to be correct and is accepted. Otherwise, it is understood that the data is corrupted and is therefore rejected.
Error Correction Techniques
Error correction techniques find out the exact number of bits that have been corrupted and as well as their locations. There are two principle ways
-
Backward Error Correction (Retransmission) − If the receiver detects an error in the incoming frame, it requests the sender to retransmit the frame. It is a relatively simple technique. But it can be efficiently used only where retransmitting is not expensive as in fiber optics and the time for retransmission is low relative to the requirements of the application.
-
Forward Error Correction − If the receiver detects some error in the incoming frame, it executes error-correcting code that generates the actual frame. This saves bandwidth required for retransmission. It is inevitable in real-time systems. However, if there are too many errors, the frames need to be retransmitted.
The four main error correction codes are
- Hamming Codes
- Binary Convolution Code
- Reed – Solomon Code
- Low-Density Parity-Check Code
Обнаружение и коррекция ошибок
Канальный
уровень должен обнаруживать ошибки
передачи данных, связанные с искажением
бит в принятом кадре данных или с потерей
кадра, и по возможности их корректировать.
Большая
часть протоколов канального уровня
выполняет только первую задачу —
обнаружение ошибок, считая, что
корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную
информацию, должны протоколы верхних
уровней. Так работают такие популярные
протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют
протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают
задачу восстановления искаженных или
потерянных кадров.
Очевидно,
что протоколы должны работать наиболее
эффективно в типичных условиях работы
сети. Поэтому для сетей, в которых
искажения и потери кадров являются
очень редкими событиями, разрабатываются
протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения
ошибок. Действительно, наличие процедур
восстановления данных потребовало бы
от конечных узлов дополнительных
вычислительных затрат, которые в условиях
надежной работы сети являлись бы
избыточными.
Напротив,
если в сети искажения и потери случаются
часто, то желательно уже на канальном
уровне использовать протокол с коррекцией
ошибок, а не оставлять эту работу
протоколам верхних уровней. Протоколы
верхних уровней, например транспортного
или прикладного, работая с большими
тайм-аутами, восстановят потерянные
данные с большой задержкой. В глобальных
сетях первых поколений, например сетях
Х.25, которые работали через ненадежные
каналы связи, протоколы канального
уровня всегда выполняли процедуры
восстановления потерянных и искаженных
кадров.
Поэтому
нельзя считать, что один протокол лучше
другого потому, что он восстанавливает
ошибочные кадры, а другой протокол —
нет. Каждый протокол должен работать в
тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все
методы обнаружения ошибок основаны на
передаче в составе кадра данных служебной
избыточной информации, по которой можно
судить с некоторой степенью вероятности
о достоверности принятых данных. Эту
служебную информацию принято называть
контрольной
суммой
(или последовательностью
контроля кадра — Frame Check Sequence, FCS).
Контрольная сумма вычисляется как
функция от основной информации, причем
необязательно только путем суммирования.
Принимающая сторона повторно вычисляет
контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с
контрольной суммой, вычисленной
передающей стороной, делает вывод о
том, что данные были переданы через сеть
корректно. Существует несколько
распространенных алгоритмов вычисления
контрольной суммы, отличающихся
вычислительной сложностью и способностью
обнаруживать ошибки в данных.
Контроль
по паритету
представляет собой наиболее простой
метод контроля данных. В то же время это
наименее мощный алгоритм контроля, так
как с его помощью можно обнаружить
только одиночные ошибки в проверяемых
данных. Метод заключается в суммировании
по модулю 2 всех бит контролируемой
информации. Например, для данных 100101011
результатом контрольного суммирования
будет значение 1. Результат суммирования
также представляет собой один бит
данных, который пересылается вместе с
контролируемой информацией. При искажении
при пересылке любого одного бита исходных
данных (или контрольного разряда)
результат суммирования будет отличаться
от принятого контрольного разряда, что
говорит об ошибке. Однако двойная ошибка,
например 110101010, будет неверно принята
за корректные данные. Поэтому контроль
по паритету применяется к небольшим
порциям данных, как правило, к каждому
байту, что дает коэффициент избыточности
для этого метода 1/8. Метод редко применяется
в вычислительных сетях из-за его большой
избыточности и невысоких диагностических
способностей.
Вертикальный
и горизонтальный контроль по паритету
представляет собой модификацию описанного
выше метода. Его отличие состоит в том,
что исходные данные рассматриваются в
виде матрицы, строки которой составляют
байты данных. Контрольный разряд
подсчитывается отдельно для каждой
строки и для каждого столбца матрицы.
Этот метод обнаруживает большую часть
двойных ошибок, однако обладает еще
большей избыточностью. На практике
сейчас также почти не применяется.
Циклический
избыточный контроль (Cyclic Redundancy Check, CRC)
является в настоящее время наиболее
популярным методом контроля в
вычислительных сетях (и не только в
сетях, например, этот метод широко
применяется при записи данных на диски
и дискеты). Метод основан на рассмотрении
исходных данных в виде одного
многоразрядного двоичного числа.
Например, кадр стандарта Ethernet, состоящий
из 1024 байт, будет рассматриваться как
одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается
остаток от деления этого числа на
известный делитель R. Обычно в качестве
делителя выбирается семнадцати- или
тридцати трехразрядное число, чтобы
остаток от деления имел длину 16 разрядов
(2 байт) или 32 разряда (4 байт). При получении
кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при
этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю,
то делается вывод об отсутствии ошибок
в полученном кадре, в противном случае
кадр считается искаженным.
Этот
метод обладает более высокой вычислительной
сложностью, но его диагностические
возможности гораздо выше, чем у методов
контроля по паритету. Метод CRC обнаруживает
все одиночные ошибки, двойные ошибки и
ошибки в нечетном числе бит. Метод
обладает также невысокой степенью
избыточности. Например, для кадра
Ethernet размером в 1024 байт контрольная
информация длиной в 4 байт составляет
только 0,4 %.
(Существует
несколько модифицированная процедура
вычисления остатка, приводящая к
получению в случае отсутствия ошибок
известного ненулевого остатка, что
является более надежным показателем
корректности.)
Соседние файлы в папке РИС гр.446зс 2015
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Канальный уровень должен обнаруживать ошибки передачи данных, связанные с
искажением бит в принятом кадре данных или с потерей кадра, и по возможности их
корректировать.
Большая часть протоколов канального уровня выполняет только первую задачу —
обнаружение ошибок, считая, что корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную информацию, должны протоколы верхних
уровней. Так работают такие популярные протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают задачу восстановления искаженных
или потерянных кадров.
Очевидно, что протоколы должны работать наиболее эффективно в типичных
условиях работы сети. Поэтому для сетей, в которых искажения и потери кадров являются
очень редкими событиями, разрабатываются протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения ошибок. Действительно, наличие процедур
восстановления данных потребовало бы от конечных узлов дополнительных
вычислительных затрат, которые в условиях надежной работы сети являлись бы
избыточными.
Напротив, если в сети искажения и потери случаются часто, то желательно уже
на канальном уровне использовать протокол с коррекцией ошибок, а не оставлять
эту работу протоколам верхних уровней. Протоколы верхних уровней, например
транспортного или прикладного, работая с большими тайм-аутами, восстановят
потерянные данные с большой задержкой. В глобальных сетях первых поколений,
например сетях Х.25, которые работали через ненадежные каналы связи, протоколы
канального уровня всегда выполняли процедуры восстановления потерянных и
искаженных кадров.
Поэтому нельзя считать, что один протокол лучше другого потому, что он
восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен
работать в тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все методы обнаружения ошибок основаны на передаче в составе кадра данных
служебной избыточной информации, по которой можно судить с некоторой степенью
вероятности о достоверности принятых данных. Эту служебную информацию принято
называть контрольной суммой или (последовательностью
контроля кадра — Frame Check Sequence, FCS). Контрольная сумма вычисляется
как функция от основной информации, причем необязательно только путем суммирования.
Принимающая сторона повторно вычисляет контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей
стороной, делает вывод о том, что данные были переданы через сеть корректно.
Существует несколько распространенных алгоритмов вычисления контрольной
суммы, отличающихся вычислительной сложностью и способностью обнаруживать
ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же
время это наименее мощный алгоритм контроля, так как с его помощью можно
обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в
суммировании по модулю 2 всех бит контролируемой информации. Например, для
данных 100101011 результатом контрольного суммирования будет значение 1.
Результат суммирования также представляет собой один бит данных, который
пересылается вместе с контролируемой информацией. При искажении при пересылке
любого одного бита исходных данных (или контрольного разряда) результат суммирования
будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные
данные. Поэтому контроль по паритету применяется к небольшим порциям данных,
как правило, к каждому байту, что дает коэффициент избыточности для этого
метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой
избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию
описанного выше метода. Его отличие состоит в том, что исходные данные
рассматриваются в виде матрицы, строки которой составляют байты данных.
Контрольный разряд подсчитывается отдельно для каждой строки и для каждого
столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако
обладает еще большей избыточностью. На практике сейчас также почти не
применяется.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в настоящее время наиболее
популярным методом контроля в вычислительных сетях (и не только в сетях,
например, этот метод широко применяется при записи данных на диски и дискеты).
Метод основан на рассмотрении исходных данных в виде одного многоразрядного
двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт,
будет рассматриваться как одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается остаток от деления этого числа на
известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати
трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт)
или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю1 (1 Существуетнесколько
модифицированная процедура вычисления остатка, приводящая к получению в случае
отсутствия ошибок известного ненулевого остатка, что является более надежным
показателем корректности.), то делается вывод об отсутствии ошибок в полученном
кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его
диагностические возможности гораздо выше, чем у методов контроля по паритету.
Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном
числе бит. Метод обладает также невысокой степенью избыточности. Например, для
кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт
составляет только 0,4 %.
Методы восстановления искаженных и потерянных кадров
Методы коррекции ошибок в вычислительных сетях основаны на повторной
передаче кадра данных в том случае, если кадр теряется и не доходит до адресата
или приемник обнаружил в нем искажение информации. Чтобы убедиться в
необходимости повторной передачи данных, отправитель нумерует отправляемые
кадры и для каждого кадра ожидает от приемника так называемой положительной
квитанции — служебного кадра, извещающего о том, что исходный кадр был
получен и данные в нем оказались корректными. Время этого ожидания ограничено —
при отправке каждого кадра передатчик запускает таймер, и, если по его
истечении положительная квитанция на получена, кадр считается утерянным.
Приемник в случае получения кадра с искаженными данными может отправить отрицательную
квитанцию — явное указание на то, что данный кадр нужно передать
повторно.
Существуют два подхода к организации процесса обмена квитанциями: с
простоями и с организацией «окна».
Метод с простоями (Idle Source) требует, чтобы источник, пославший кадр, ожидал получения квитанции
(положительной или отрицательной) от приемника и только после этого посылал
следующий кадр (или повторял искаженный). Если же квитанция не приходит в
течение тайм-аута, то кадр (или квитанция) считается утерянным и его передача
повторяется. На рис. 2.24, а видно, что в этом случае производительность обмена
данными существенно снижается, — хотя передатчик и мог бы послать следующий
кадр сразу же после отправки предыдущего, он обязан ждать прихода квитанции.
Снижение производительности этого метода коррекции особенно заметно на
низкоскоростных каналах связи, то есть в территориальных сетях.

Рис. 2.24. Методы восстановления искаженных и
потерянных кадров
Второй метод называется методом «скользящего окна» (sliding
window). В этом методе для повышения коэффициента использования линии
источнику разрешается передать некоторое количество кадров в непрерывном
режиме, то есть в максимально возможном для источника темпе, без получения на
эти кадры положительных ответных квитанций. (Далее, где это не искажает
существо рассматриваемого вопроса, положительные квитанции для краткости будут
называться просто «квитанциями».) Количество кадров, которые разрешается
передавать таким образом, называется размером окна. Рисунок 2.24, б
иллюстрирует данный метод для окна размером в W кадров.
В начальный момент, когда еще не послано ни одного кадра, окно определяет
диапазон кадров с номерами от 1 до W включительно. Источник начинает передавать
кадры и получать в ответ квитанции. Для простоты предположим, что квитанции
поступают в той же последовательности, что и кадры, которым они соответствуют.
В момент t1 при получении первой квитанции К1 окно сдвигается
на одну позицию, определяя новый диапазон от 2 до (W+1).
Процессы отправки кадров и получения квитанций идут достаточно независимо
друг от друга. Рассмотрим произвольный момент времени tn, когда источник
получил квитанцию на кадр с номером n. Окно сдвинулось вправо и определило
диапазон разрешенных к передаче кадров от (n+1) до (W+n). Все множество кадров,
выходящих из источника, можно разделить на перечисленные ниже группы (рис.
2.24, б).
- Кадры с номерами от 1 доп. уже были отправлены и квитанции на них
получены, то есть они находятся за пределами окна слева. - Кадры, начиная с номера (п+1) и кончая номером
(W+n), находятся в пределах окна и
потому могут быть отправлены не дожидаясь прихода какой-либо квитанции.
Этот диапазон может быть разделен еще на два поддиапазона: - кадры с номерами от (n+1) до
т, которые уже отправлены, но квитанции на них еще не получены; - кадры с номерами от m до
(W+n), которые пока не отправлены, хотя запрета на это нет. - Все кадры с номерами, большими или равными
(W+n+1), находятся за пределами окна
справа и поэтому пока не могут быть отправлены.
Перемещение окна вдоль последовательности номеров кадров показано на рис.
2.24, в. Здесь t0 — исходный момент, t1 и tn —
моменты прихода квитанций на первый и n-й кадр соответственно. Каждый раз,
когда приходит квитанция, окно сдвигается влево, но его размер при этом не
меняется и остается равным W. Заметим, что хотя в данном примере размер окна в
процессе передачи остается постоянным, в реальных протоколах (например, TCP)
можно встретить варианты данного алгоритма с изменяющимся размером окна.
Итак, при отправке кадра с номером n источнику разрешается передать еще W-1
кадров до получения квитанции на кадр n, так что в сеть последним уйдет кадр с
номером (W+n-1). Если же за это время квитанция на кадр n так и не пришла, то
процесс передачи приостанавливается, и по истечении некоторого тайм-аута кадр n
(или квитанция на него) считается утерянным, и он передается снова.
Если же поток квитанций поступает более-менее регулярно, в пределах допуска
в W кадров, то скорость обмена достигает максимально возможной величины для
данного канала и принятого протокола.
Метод скользящего окна более сложен в реализации, чем метод с простоями,
так как передатчик должен хранить в буфере все кадры, на которые пока не
получены положительные квитанции. Кроме того, требуется отслеживать несколько
параметров алгоритма: размер окна W, номер кадра, на который получена
квитанция, номер кадра, который еще можно передать до получения новой
квитанции.
Приемник может не посылать квитанции на каждый принятый корректный кадр.
Если несколько кадров пришли почти одновременно, то приемник может послать
квитанцию только на последний кадр. При этом подразумевается, что все
предыдущие кадры также дошли благополучно.
Некоторые методы используют отрицательные квитанции. Отрицательные
квитанции бывают двух типов — групповые и избирательные. Групповая квитанция
содержит номер кадра, начиная с которого нужно повторить передачу всех кадров,
отправленных передатчиком в сеть. Избирательная отрицательная квитанция требует
повторной передачи только одного кадра.
Метод скользящего окна реализован во многих протоколах: LLC2, LAP-B, X.25,
TCP, Novell NCP Burst Mode.
Метод с простоями является частным случаем метода скользящего окна, когда
размер окна равен единице.
Метод скользящего окна имеет два параметра, которые могут заметно влиять на
эффективность передачи данных между передатчиком и приемником, — размер окна и
величина тайм-аута ожидания квитанции. В надежных сетях, когда кадры искажаются
и теряются редко, для повышения скорости обмена данными размер окна нужно
увеличивать, так как при этом передатчик будет посылать кадры с меньшими
паузами. В ненадежных сетях размер окна следует уменьшать, так как при частых
потерях и искажениях кадров резко возрастает объем вторично передаваемых через
сеть кадров, а значит, пропускная способность сети будет расходоваться во
многом вхолостую — полезная пропускная способность сети будет падать.
Выбор тайм-аута зависит не от надежности сети, а от задержек передачи
кадров сетью.
Во многих реализациях метода скользящего окна величина окна и тайм-аут
выбираются адаптивно, в зависимости от текущего состояния сети.
В предыдущей лекции мы выяснили, что на
физическом уровне происходит
непосредственно передача битов по
проводам. Однако реальная линия связи
состоит не только из кабеля, но еще
включает дополнительное оборудование:
маршрутизаторы, коммутаторы и т.п. Это
оборудование помогает управлять
передачей информации в сети определенной
топологии от компьютера к компьютеру.
Задачей качественного, быстрого и
надежного установления соединения
компьютеров с помощью такого рода
оборудования и занимается канальный
уровень.
Рассматривая
модель OSI, мы выяснили, что канальный
уровень оперирует кадрамиданных,
поскольку работает с компьютерами,
которые не обмениваются информацией
по битно. Кадры образуются определенным
набором бит данных. Они содержат в себе,
как минимум, адрес получателя, и
отправляются узлом-источником для
передачи по кабелю методами физического
уровня, затем оборудование сети, в
зависимости от ее топологии, распознает
— кому эти кадры предназначены, и
отправляет их по кабелю к узлу-приемнику.
Таким образом, канальный уровень — это
по сути логика установки соединений в
сети. С одной стороны он привязан к
физическому уровню, то есть к типам
используемых линий связи и методам
передач физического уровня. Но с другой
стороны он связан с сетевым уровнем,
который уже управляет передачей
информации между локальными сетями.
На
канальном уровне для каждой топологии
сети имеются свои правила работы —
протоколы. Если на физическом уровне
не решаются вопросы какой компьютер и
когда может использовать кабель линии
связи, то на канальном уровне важно
обеспечить качественную доставку кадра
от узла к узлу. Именно на канальном
уровне происходит «борьба за кабель»,за доставку информации к нужному узлу
сети, он занимается проблемами
взаимодействия станций друг с другом,
обеспечением гарантии доставки кадра
информации к станции в любой из
используемой топологии сети.
В этой
лекции мы поговорим в общем плане о
форматах кадров, рассмотрим способы
передачи данных на канальном уровне,
методы управления обменом информации
в сети с определенной топологией и т.д.
6.1. Структура типичного кадра компьютерной
сети.
Информация
в локальных сетях предается отдельными
порциями, называемыми в различных
источниках кадрами, пакетами илиблоками. Использование кадров
связано с тем, что в сети одновременно
может происходить несколько сеансов
связи, т.е. в течении одного и того
интервала времени могут идти два или
больше процессов передачи данных между
абонентами. Кадры (пакеты) собственно
и позволяют разделить во времени сеть
между передающими абонентами и уравнять
в правах доступа всех абонентов и
обеспечить для всех абонентов интегральную
скорость передачи информации. Длина
кадра зависит от типа сети и составляет
от 10 байт – до 10 Кбайт. Важно делить
информацию на кадры и для контроля
правильности передачи информации. Кадры
имеют преимущества пред побайтовой
(8бит) или пословной (16 бит и 32 бита)
передачей, т.к. при этом уменьшается
количество служебной информации и
увеличивается полезная загрузка сети.
Структура
кадра определяется аппаратурными
особенностями данной сети, выбранной
топологией и типом среды передачи
информации, а также существенно зависит
от используемого протокола (порядка
обмена информацией).
Типичный
кадр содержит в себе следующие основные
поля:
-
стартовая
комбинацияили преамбула — обеспечивает
настройку аппаратуры адаптера на прием
и обработку кадров, может отсутствовать
или сводится к одному стартовому биту; -
сетевой
адрес(идентификатор) принимающего
абонента — индивидуальный или групповой
номер, присвоенный принимающему абоненту
в сети, позволяющему приемнику распознать
кадр, адресованный ему лично, группе,
или всем абонентам сети; -
сетевой
адрес(идентификатор) предающего
абонента — индивидуальный или групповой
номер, присвоенный передающему абоненту,
информирует принимающего абонента,
откуда пришел данный кадр, включение
в кадр этого идентификатора необходимо,
если приемнику могут попеременно
приходить кадры от разных передатчиков; -
служебная
информация— указывает на тип кадра,
его номер, размер, формат, маршрут
доставки и т.д.; -
данные— собственно предаваемая информация.
Существуют управляющие кадры (сетевые
команды – начало и конец связи,
подтверждение приема кадра и т.д.), в
которых это поле отсутствует и
информационные – поле данных имеется; -
контрольная
суммакадра — числовой код, формируемый
передатчиком по определенным правилам
и содержащий в свернутом виде информацию
обо всем кадре, используется для проверки
правильности передачи кадра на приемном
конце. Приемник повторяя вычисления
сделанные передатчиком сравнивает
результат с контрольной суммой и делает
вывод о правильности или ошибочности
передачи кадра. -
стоповая
комбинация— информирует принимающего
абонента об окончании кадра, обеспечивает
выход аппаратуры из состояния приема.
Поле может отсутствовать, если
используется самосинхронизирующийся
код, позволяющий детектировать факт
передачи кадра.

Рис. 6.1. Структура пакета
1,2,3,4 —
образуют начальное управляющее поле,
5 — поле данных, 6,7- конечное управляющее
поле.
-
Передача
кадров на канальном уровне
При
передаче кадров данных на канальном
уровне используются как дейтаграммные
процедуры, работающие без становления
соединения(connectionless), так и процедурыс предварительным установлением
логического соединения (connection-oriented).
При дейтаграммной передаче кадр
посылается в сеть «без предупреждения»,
и никакой ответственности за его утерю
протокол не несет. Предполагается, что
сеть всегда готова принять кадр от
конечного узла. Дейтаграммный метод
работает быстро, так как никаких
предварительных действий перед отправкой
данных не выполняется. Однако при таком
методе трудно организовать в рамках
протокола отслеживание факта доставки
кадра узлу назначения. Этот метод не
гарантирует доставку пакета.
Передача с установлением соединения
более надежна, но требует больше времени
для передачи данных и вычислительных
затрат от конечных узлов. В этом случае
узлу-получателю отправляется служебный
кадр специального формата с предложением
установить соединение. Если узел-получатель
согласен с этим, то он посылает в ответ
другой служебный кадр, подтверждающий
установление соединения и предлагающий
для данного логического соединения
некоторые параметры, например идентификатор
соединения,максимальное значение
поля данных кадров, которые будут
использоваться в рамках данного
соединения, и т. п. Узел-инициатор
соединения может завершить процесс
установления соединения отправкой
третьего служебного кадра, в котором
сообщит, что предложенные параметры
ему подходят. На этом логическое
соединение считается установленным, и
в его рамках можно передавать информационные
кадры с пользовательскими данными.

Рис 6.2 Пример обмена кадрами при сеансе
связи
После
передачи некоторого законченного набора
данных, например определенного файла,
узел инициирует разрыв данного логического
соединения, посылая соответствующий
служебный кадр.
Заметим,
что, в отличие от протоколов дейтаграммного
типа, которые поддерживают только один
тип кадра — информационный, протоколы,
работающие по процедуре с установлением
соединения, должны поддерживать несколько
типов кадров — служебные, для установления
(и разрыва) соединения, и информационные,
переносящие собственно пользовательские
данные.
В общем
случае логическое соединение обеспечивает
передачу данных как в одном направлении
— от инициатора соединения, так и в обоих
направлениях.
6.3.Методы гарантии
доставки кадров информации
При
установке соединения не маловажным
вопросом становится обеспечение гарантии
доставки кадра и обнаружение ошибок.
Рассмотрим
общие подходы решению проблемы гарантии
доставки кадров. Для того, чтобы
гарантировать доставку всех кадров,
надо обеспечить такой режим установки
соединения, при котором можно было бы
в любой момент времени повторить
отосланный ранее кадр, в случае обнаружения
его потери или искажения. Чтобы убедиться
в необходимости повторной передачи
данных, отправитель нумерует отправляемые
кадры и для каждого кадра ожидает от
приемника так называемой положительной
квитанции— служебного кадра, извещающего
о том, что исходный кадр был получен и
данные в нем оказались корректными.
Время этого ожидания ограничено — при
отправке каждого кадра передатчик
запускает таймер, и, если по его истечении
положительная квитанция не получена,
кадр считается утерянным.
Приемник
в случае получения кадра с искаженными
данными может отправить отрицательную
квитанцию — явное указание на то, что
данный кадр нужно передать повторно.
В итоге,
путем обмена такого рода квитанциями,
можно определить есть ли утечки информации
в сети, и не просто определить, а обеспечить
ее повторную передачу в случае каких-либо
сбоев. Таким образом, канальный уровень
обеспечивает гарантированную доставку
кадров.
Организацией процесса обмена квитанциями
занимается метод скользящего окна.
Перед тем как рассмотреть этот, сначала
познакомится с частным случаем этого
метода, который называетсяметод с
простоями.
Метод с простоями (Idle Source)требует,
чтобы источник, пославший кадр, ожидал
получения квитанции (положительной или
отрицательной) от приемника и только
после этого посылал следующий кадр (или
повторял искаженный). Если же квитанция
не приходит в течение тайм-аута, то кадр
(или квитанция) считается утерянным и
его передача повторяется.
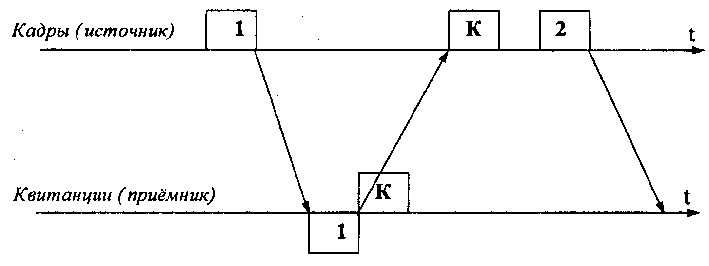
Рис.
6.3 Обмен кадрами и квитанциями при методе
с простоями
На
рисунке видно, что в этом случае
производительность обмена данными
существенно снижается, — хотя передатчик
и мог бы послать следующий кадр сразу
же после отправки предыдущего, он обязан
ждать прихода квитанции. Иногда
использование такого метода может
привести к тому, что, что время ожидания
квитанции будет существенно превышать
время посылки сообщения. Снижение
производительности этого метода
коррекции особенно заметно на
низкоскоростных каналах связи
Метод скользящего окна (sliding window)
работает гораздо эффективней. Для
повышения коэффициента использования
линии источнику разрешается передать
некоторое количество кадров в непрерывном
режиме, то есть в максимально возможном
для источника темпе, без получения на
эти кадры положительных ответных
квитанций. (Далее, где это не искажает
существо рассматриваемого вопроса,
положительные квитанции для краткости
будут называться просто квитанциями.)
Количество кадров, которые разрешается
передавать в непрерывном режиме,
называется размером окна.

Рис.
6.4 Обмен кадрами квитанциями при методе
скользящего окна
На
рис.6.4. показан метод скользящего окна
для окна размером в W кадров. В начальный
момент, когда еще не послано ни одного
кадра, окно определяет диапазон кадров
с номерами от 1 до W включительно. Источник
начинает передавать кадры и получать
в ответ квитанции. Для простоты
предположим, что квитанции поступают
в той же последовательности, что и кадры,
которым они соответствуют. В определенный
момент t1 при получении первой квитанции
окно сдвигается на одну позицию, определяя
новый диапазон от 2 до (W+1). Процессы
отправки кадров и получения квитанций
идут достаточно независимо друг от
друга. Если допустим, что в произвольный
момент времени tn источник получил
квитанцию на кадр с номером n. Окно
сдвинулось вправо и определило диапазон
разрешенных к передаче кадров от (n+1) до
(W+n). Все множество кадров, выходящих из
источника, можно разделить на перечисленные
ниже группы:
1. Кадры
с номерами от 1 до n — уже были отправлены
и квитанции на них получены, то есть они
находятся за пределами окна слева.
2. Кадры,
начиная с номера (n+1) и кончая номером
(W+n) , находятся в пределах окна и потому
могут быть отправлены не дожидаясь
прихода какой-либо квитанции. Этот
диапазон может быть разделен еще на два
поддиапазона:
кадры с номерами от (n+1) до m, которые уже
отправлены, но квитанции на них еще не
получены;
кадры с номерами от m до (W+n) , которые
пока не отправлены, хотя запрета на это
нет.
3.Все
кадры с номерами, большими или равными
(W+n+1) , находятся за пределами окна справа
и поэтому пока не могут быть отправлены.
Каждый
раз, когда приходит квитанция, окно
сдвигается влево, но его размер при этом
не меняется и остается равным W. Заметим,
что хотя в данном примере размер окна
в процессе передачи остается постоянным,
в реальных протоколах можно встретить
варианты данного алгоритма с изменяющимся
размером окна.
Итак,
при отправке кадра с номером n источнику
разрешается передать еще W-1 кадров до
получения квитанции на кадр n, так что
в сеть последним уйдет кадр с номером
(W+n-1) .
Если
же за это время квитанция на кадр n так
и не пришла, то процесс передачи
приостанавливается, и по истечении
некоторого тайм-аута кадр n (или квитанция
на него) считается утерянным, и он
передается снова.
Если
же поток квитанций поступает более-менее
регулярно, в пределах допуска в W кадров,
то скорость обмена достигает максимально
возможной величины для данного канала
и принятого протокола.
Метод скользящего окна более сложен в
реализации, чем метод с простоями, так
как передатчик должен хранить в буфере
все кадры, на которые пока не получены
положительные квитанции. Кроме того,
требуется отслеживать несколько
параметров алгоритма: размер окна W,
номер кадра, на который получена
квитанция, номер кадра, который еще
можно передать до получения новой
квитанции.
Приемник
может не посылать квитанции на каждый
принятый корректный кадр. Если несколько
кадров пришли почти одновременно, то
приемник может послать квитанцию только
на последний кадр. При этом подразумевается,
что все предыдущие кадры также дошли
благополучно.
Некоторые
методы используют отрицательные
квитанции. Отрицательные квитанции
бывают двух типов — групповые и
избирательные. Групповая квитанция
содержит номер кадра, начиная с которого
нужно повторить передачу всех кадров,
отправленных передатчиком в сеть.
Избирательная отрицательная квитанция
требует повторной передачи только
одного кадра.
Метод скользящего окна имеет два
параметра, которые могут заметно влиять
на эффективность передачи данных между
передатчиком и приемником, — размер окна
и величина тайм-аута ожидания квитанции.
В
надежных сетях, когда кадры искажаются
и теряются редко, для повышения скорости
обмена данными размер окна нужно
увеличивать, так как при этом передатчик
будет посылать кадры с меньшими паузами.
В ненадежных сетях размер окна следует
уменьшать, так как при частых потерях
и искажениях кадров резко возрастает
объем вторично передаваемых через сеть
кадров, а значит, пропускная способность
сети будет расходоваться во многом
вхолостую — полезная пропускная
способность сети будет падать.
Выбор
тайм-аута зависит не от надежности сети,
а от задержек передачи кадров сетью. Во
многих реализациях метода скользящего
окна величина окна и тайм-аут выбираются
адаптивно, в зависимости от текущего
состояния сети.
6.4. Методы обнаружения ошибок на
канальному уровне.
После
того, как мы выяснили, какими средствами
располагает канальный уровень для
коррекции ошибок при передаче, очевидно,
нам нужно познакомится и с его методами
их обнаружения.
Канальный уровень должен обнаруживать
ошибки передачи данных, связанные с
искажением бит в принятом кадре данных
или с потерей кадра, и по возможности
их корректировать.
Большая
часть протоколов канального уровня
выполняет только первую задачу —
обнаружение ошибок, считая, что
корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную
информацию, должны протоколы верхних
уровней.
Однако
существуют протоколы канального уровня,
которые самостоятельно решают задачу
восстановления искаженных или потерянных
кадров.
Очевидно,
что протоколы должны работать наиболее
эффективно в типичных условиях работы
сети. Поэтому для сетей, в которых
искажения и потери кадров являются
очень редкими событиями, разрабатываются
протоколы, в которых не предусматриваются
процедуры устранения ошибок. Действительно,
наличие процедур восстановления данных
потребовало бы от конечных узлов
дополнительных вычислительных затрат,
которые в условиях надежной работы сети
являлись бы избыточными.
Напротив,
если в сети искажения и потери случаются
часто, то желательно уже на канальном
уровне использовать протокол с коррекцией
ошибок, а не оставлять эту работу
протоколам верхних уровней. Протоколы
верхних уровней, например транспортного
или прикладного, работая с большими
тайм-аутами, восстановят потерянные
данные с большой задержкой.
Поэтому
нельзя считать, что один протокол лучше
другого потому, что он восстанавливает
ошибочные кадры, а другой протокол —
нет. Каждый протокол должен работать в
тех условиях, для которых он разработан.
Все методы обнаружения ошибок на
канальном уровне основаны на передаче
в составе кадра данных служебной
избыточной информации, по которой можно
судить с некоторой степенью вероятности
о достоверности принятых данных. Эту
служебную информацию принято называть
контрольной суммой или (последовательностью
контроля кадра — Frame Check Sequence, FCS).
Контрольная сумма вычисляется как
функция от основной информации, причем
необязательно только путем суммирования.
Принимающая сторона повторно вычисляет
контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с
контрольной суммой, вычисленной
передающей стороной, делает вывод о
том, что данные были переданы через сеть
корректно.
Существует
несколько распространенных алгоритмов
вычисления контрольной суммы, отличающихся
вычислительной сложностью и способностью
обнаруживать ошибки в данных.
Контроль по паритету . Этот метод
представляет собой наиболее простой
метод контроля данных и наименее мощный
алгоритм контроля, так как с его помощью
можно обнаружить только одиночные
ошибки в проверяемых данных. Метод
заключается в суммировании по модулю
2 всех бит контролируемой информации.
Например, для данных 100101011 результатом
контрольного суммирования будет значение
1.
Результат
суммирования также представляет собой
один бит данных, который пересылается
вместе с контролируемой информацией.
При искажении при пересылке любого
одного бита исходных данных (или
контрольного разряда) результат
суммирования будет отличаться от
принятого контрольного разряда, что
говорит об ошибке.
Однако
двойная ошибка, например 110101010, будет
неверно принята за корректные данные.
Поэтому контроль по паритету применяется
к небольшим порциям данных, как правило,
к каждому байту, что дает коэффициент
избыточности для этого метода 1/8. Метод
редко применяется в вычислительных
сетях из-за его большой избыточности и
невысоких диагностических способностей.
Вертикальный и горизонтальный контроль
по паритетупредставляет собой
модификацию описанного выше метода.
Его отличие состоит в том, что исходные
данные рассматриваются в виде матрицы,
строки которой составляют байты данных.
Контрольный разряд подсчитывается
отдельно для каждой строки и для каждого
столбца матрицы.

Рис.
6.5 Метод вертикального и горизонтального
контроля по паритету
Этот
метод обнаруживает большую часть двойных
ошибок, однако обладает еще большей
избыточностью. На практике сейчас также
почти не применяется.
Циклический избыточный контроль
(Cyclic Redundancy Check, CRC) Этот метод является
в настоящее время наиболее популярным
методом контроля в вычислительных сетях
(и не только в сетях, например, этот метод
широко применяется при записи данных
на диски и дискеты). Метод основан на
рассмотрении исходных данных в виде
одного многоразрядного двоичного числа.
Например, кадр, состоящий из 1024 байт,
будет рассматриваться как одно число,
состоящее из 8192 бит. В качестве контрольной
информации рассматривается остаток от
деления этого числа на известный делитель
R. Обычно в качестве делителя выбирается
семнадцати- или тридцати трехразрядное
число, чтобы остаток от деления имел
длину 16 разрядов (2 байт) — CRC16, или 32
разряда (4 байт) — CRC32.
При
получении кадра данных снова вычисляется
остаток от деления на тот же делитель
R, но при этом к данным кадра добавляется
и содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю,
то делается вывод об отсутствии ошибок
в полученном кадре, в противном случае
кадр считается искаженным. Этот метод
обладает более высокой вычислительной
сложностью, но его диагностические
возможности гораздо выше, чем у методов
контроля по паритету. Метод CRC обнаруживает
все одиночные ошибки, двойные ошибки и
ошибки в нечетном числе бит. Метод
обладает также невысокой степенью
избыточности. Например, для кадра
размером в 1024 байт контрольная информация
длиной в 4 байт составляет только 0,4 %.
-
Адресация
пакетов.
Каждый
абонент (узел) локальной сети должен
иметь свой уникальный адрес (идентификатор,
МАС-адрес), чтобы ему можно было адресовать
пакеты.
Существуют
две основные системы присвоения адресам
абонентам:
1.При установке сети каждому абоненту
присваивается аппаратно (с помощью
переключателей на плате адаптера) или
программно. При этом количество разрядов
адреса определяется как 2n>Nmax,
где n — количество разрядов адреса;Nmax– максимально возможное число абонентов
сети (Например, n=8, еслиNmax=255,
один адрес используется для адресации
пакетов всем абонентам сети –
широковещательной передачи). Реализован
вArcnet.Достоинства:
простота и малый объем служебной
информации в пакете, а также простота
аппаратуры адаптера, распознающей адрес
пакета. Недостаток: трудоемкость задания
адресов и возможность ошибки (например,
двум абонентам сети может быть присвоен
один и тот же адрес).
2. Разработан международной организацией
IEEE, используется в
большинстве сетей. Уникальный сетевой
адрес присваивается каждому адаптеру
сети еще на этапе его изготовления. Был
выбран 48-битный формат адреса, что
соответствует примерно 280триллионам различных адресов. Чтобы
распределить возможные диапазоны
адресов между многочисленными
изготовителями сетевых адаптеров, была
предложена следующая структура адреса,
которая представлена на рис 6.6

Рис. 6.6.Структура 48-битного
стандартного адреса
Младшие 24разряда кода
адреса называютсяOUA(OrganizationallyUniqueAddress) —
организационно уникальный адрес.
Именно их присваивает производитель
сетевого адаптера. Всего возможно
свыше 1б миллионов
комбинаций.
Следующие 22разряда кода
называютсяOUI(OrganizationallyUniqueIdentifier)
— организационно уникальный
идентификатор.IEEEприсваивает один или несколько
OUIкаждому производителю сетевых
адаптеров. Это позволяет исключить
совпадения адресов адаптеров от разных
производителей. Всего возможно свыше
4миллионов разных OUI.Вместе OUAи OUIназываютсяUAA(UniversallyAdministeredAddress)
—универсально управляемый
адресили IEEE-адрес.
Два старших разряда адреса являются
управляющими и определяют тип адреса,
способ интерпретации остальных
46 разрядов.
Старший бит I/G
(Individual/Group)определяет, индивидуальный это адрес
или групповой. Если он установлен в
0,то мы имеем дело с индивидуальным
адресом, если установлен в
1,то с групповым (многопунктовым
или функциональным) адресом. Пакеты
с групповым адресом получают все
имеющие его сетевые адаптеры, причём
групповой адрес определяется всеми
46младшими разрядами.
Второй управляющий бит U/L
(Universal/Local)называется флажком универсального/местного
управления и определяет, как был присвоен
адрес данному сетевому адаптеру. Обычно
он установлен в 0.Установка
бита U/Lв 1означает, что адрес задан не производителем
сетевого адаптера, а организацией,
использующей данную сеть. Это довольно
редкая ситуация.
Для широковещательной передачи
используется специально выделенный
сетевой адрес, все 48битов
которого установлены в единицу. Его
принимают все абоненты сети независимо
от их индивидуальных и групповых
адресов.
Данной
системы адресов придерживаются, например,
такие популярные сети, как Ethernet,FastEthernet,Token-Ring,FDDI,
100VG-AnyLAN.
Ее
недостатки — высокая сложность аппаратуры
сетевых адаптеров, а также большая
доля служебной информации в передаваемом
пакете (адрес источника и адрес приемника
требуют уже 96 (48+48)битов
пакета, или 12байт).
Во многих сетевых адаптерах предусмотрен
так называемый циркулярный режим. В
этом режиме адаптер принимает все
пакеты, приходящие к нему, независимо
от значения поля адреса приемника. Этот
режим используется, например, для
проведения диагностики сети, измерения
ее производительности, контроля за
ошибками передачи. В этом случае один
компьютер принимает и контролирует все
пакеты, проходящие по сети, но сам ничего
не передает. В этом же режиме работают
сетевые адаптеры мостов и коммутаторы,
которые должны обрабатывать перед
ретрансляцией все приходящие к ним
пакеты.
6.6
Методы управления обменом.
6.6.1 Классификация методов управления
обменом.
Сеть всегда объединяет несколько
абонентов, каждый из которых имеет право
передавать свои пакеты. Но по одному
кабелю не может одновременно
передаваться два пакета, иначе возможен
конфликт (коллизия), что приведет к
искажению и потере обоих пакетов. Следует
установить очередность доступа к сети
(захвата сети) всеми абонентами, желающими
передавать.
Поэтому
в любой сети применяется тот или иной
метод управления обменом (он же метод
доступа, он же метод арбитража), разрешающий
или предотвращающий конфликты между
абонентами. От эффективности выбранного
метода зависит очень многое: скорость
обмена информацией между компьютерами,
нагрузочная способность сети, время
реакции сети на внешние события и т.д.
Метод
управления -это один из
важнейших параметров сети. Тип метода
управления обменом во многом определяется
особенностями топологии сети.
Методы управления обменом делятся на
две группы:
—
Централизованные методы, при
которых все управление сосредоточенно
в одном месте — центре. Недостатки таких
методов:неустойчивость
к отказам центра, малая гибкость
управления. Достоинство -отсутствие конфликтов.
—
Децентрализованные методы, при
которых отсутствует центр управления.
Достоинства таких методов: высокая
устойчивость к отказам и большая
гибкость, а недостатки — возможны
конфликты, которые надо разрешать.
Децентрализованные
методы делятся на:
—
Детерминированные методы,
которые определяют четкие правила
чередования захвата сети абонентами.
Абоненты имеют различные приоритеты.
При этом конфликты полностью исключены
(или маловероятны), но некоторые
абоненты могут дожидаться своей очереди
слишком долго. К детерминированным
методам относится, например, маркерный
доступ, при котором право передачи
передается по эстафете от абонента к
абоненту.
Случайные
методы, которые определяют случайное
чередование передающих абонентов. В
этом случае имеется возможность
конфликтов, но предлагаются способы
их разрешения. Случайные методы
работают хуже, чем детерминированные,
при больших информационных потоках в
сети (при большом графике сети) и не
гарантируют абоненту величину времени
доступа (это интервал между возникновением
желания передавать и получением
возможности передать свой пакет).
Пример случайного метода -стандартный методCSMA/CD(Carrier-SenseMultipleAccesswithCollisionDetection)МНДК/ОК(множественный доступ с контролем
несущей и обнаружением коллизий
(столкновений)).
Рассмотрим
три наиболее типичных метода управления
обменом, характерных для трех основных
топологий.
6.6.2 Управление обменом в сети типа
«звезда».
Речь
идет только об активной истинной звезде.
Чаще всего центральный абонент может
производить обмен только с одним
периферийных абонентов. Поэтому в любой
момент времени нужно выделить только
одного абонента ведущего передачу.
Здесь возможны два решения:
-
Активный
центр. Ц посылает запросы (управляющие
пакеты) по очереди всем АП. АП, который
хочет передавать (первый из опрошенных)
посылает ответ и сразу же начинает
передавать. После окончания сеанса Ц
продолжает опрос по кругу. АП имеют
географические приоритеты: максимальный
приоритет у того, кто ближе к последнему
абоненту, закончившему обмен. Ц передает
без всякой очереди. -
Пассивный
центр. Ц не опрашивает, а слушает всех
АП по очереди (т.е. принимает пакеты
только от одного из них.) АП посылают
запросы и ждут ответа. Когда центр
принимает запрос, он отвечает запросившему
АП (разрешает ему передачу).
Управление
обменом централизованное.

Рис. 6.7.Централизованный
метод управления обменом в сетяхтопологией «звезда»
Преимущества:
-
невозможность
конфликтов между абонентами. -
гарантированное
время доступа, т.е. время между возникешим
желанием передать до момента предачи.
Недостатки:
-
низкая
устойчивость к отказам (если Ц выходит
из строя) -
недостаточная
гибкость (Ц всегда работает по жестко
заданному алгоритму) -
низкая
скорость управления (если работает
только один ему приходится ждать пока
опросят всех).
6.6.3.Управление обменом в сети типа
«шина».
Тоже
возможны два решения:
Централизованное
и децентрализованное
Централизованное
управление, как и в звезде (физически
шина, но логически звезда). Ц посылает
всем АП запросы, выясняя, кто хочет
предать, разрешая ему передачу. После
окончания передачи АП посылает сообщение,
что он закончил и Ц начинает опрос снова.
Единственное отличие от звезды, что Ц
не перекачивает информацию от одного
АП к другому, а только управляет обменом.

Однако
гораздо чаще в шине используется
децентрализованное случайное
управление— при этом все абоненты
имеют равный доступ к сети, т.к. аппаратные
средства всех АП одинаковы, и они имеют
одинаковые права доступа к сети. Решение
о том, когда можно передавать свой пакет,
принимается каждым абонентом исходя
из анализа состояния сети. Возникает
конкуренция за захват сети и, следовательно,
возможны искажения передаваемых сигналов
из-за наложения пакетов.
Существует
множество алгоритмов доступа или
сценариев доступа. Рассмотрим некоторые:
Децентрализованный кодовый приоритетный
арбитраж. Его смысл состоит в
распознавании столкновений двух или
более пакетов в начале передачи и
прекращения в случае столкновения
передачи всеми абонентами кроме одного.
Т.е. нужно определить, занята или свободна
сеть, для этого передаваемые пакеты
снабжаются начальной (кодовой) информацией.
Идет жесткая привязка к коду передачи
информации.
Децентрализованный временной
приоритетный арбитраж. Основная идея
данного метода состоит в том, чтобы
свести вероятность столкновений к
пренебрежимо малой величине. Предлагается
следующий алгоритм. Сначала все абоненты
следят за состоянием сети. Если она
свободна, то передача начинается сразу
же после возникновения заявки на нее.
Если сеть занята, то сразу же после ее
освобождения все абоненты отсчитывают
свой собственный уникальный временной
интервал, пропорциональный коду сетевого
адреса данного абонента. Таким образом
абонент 0 начинает передачу сразу,
абонент с 1-м адресом через времяt со вторым через время 2tи т.д. Если к концу временного интервала
сеть все еще остается свободной, то
абонент начинает передачу. В противном
случае ждет освобождения сети.
При большой загрузке сети абонентам с
малыми приорететами приходится долго
ждать. Приоритет определяетмя исходя
из времени задаржки начала передачи
минимальное время — максимальный
приоритет. О гарантированном времени
доступа к сети для всех абонентов и
говорить не приходится. Этот метод
полностью не исключает столкновений
(заявки на передачу при свободной сети
могут возникнуть одновременно).
Третий метод можно считать развитием
второго и он получил название множественный
доступ с контролем несущей и обнаружением
коллизий (столкновений).(МНДК/ОК
CSMA/CD Carrier-Sense Multiple Access/Collision Detection). Один
из самых популярных, используемый в
сетяхEthernet,FastEthernet. Относится к
децентрализованным случайным (точнее
квазислучайным) методам. Подробнее о
названии метода. В сети работавшей с
1970 года на Гавайских островах, использовался
Радиоканал и установленный на спутнике
ретранслятор – отсюда слово «несущая»
в названии метода. В этой сети был
реализован множественный доступ с
контролем несущей без обнаружения
коллизий. В сетяхEthernet,FastEthernetв
качестве несущей частоты выступает
синхросигнал «подмешиваемый» в
передаваемые данные.
Идея
метода состоит в том , чтобы уравнять в
правах всех абонентов, т.е. чтобы не было
фиксированных приоритетов, и абоненты
не могли надолго заблокировать обмен.
Для этого время задержки вычисляется
каждым абонентом самостоятельно.
Информация передается абонентами
кадрами или пакетами (для МНДК/ОК понятия
кадр и пакет не различаются). Алгоритм
МНДК/ОК можно представить следующим
образом:
-
Абонент
желающий передавать следит за состоянием
сети (контроль несущей частоты Мачестер
2). Если сеть свободна, то передача
начинается после того, как прошло время,
составляющее межкадровый интервал —
промежуток времени между передаваемыми
пакетами (блок 1, 2). -
После
освобождения сети абонент сразу же
начинает передавать и одновременно
после передачи каждого бита контролирует
состояние сети (обнаружение коллизий),
если столкновений не обнаруживается,
то передача доводится до окончания
пакета. В этом случае считается, что
передача прошла успешно. -
Если
после передачи какого либо бита
столкновение обнаружено, то передача
пакета прекращается. Абонент усиливает
коллизию передавая 32-битный сигнал
ПРОБКА. Увеличивает значение счетчика
попыток. Максимальное число попыток
не более 16. Если счетчик переполнился,
то считается, сто сеть сильно перегружена,
в ней сильно много коллизий, ситуация
аварийная и обрабатывается на более
высоких уровнях протоколов обмена. -
После прекращения неудачной передачи
абонент вычислчет время задержки по
некоторой формуле, где присутствует
генератор случайных чисел. Выдерживает
выбранный промежуток времени и повторяет
попытку(п. 1) -
Если
в момент возникновения заявки на
передачу сеть занята, то абонент ждет
освобождения сети.
При
любом случайном методе управления
обменом возникает вопрос о том, какой
должна быть минимальная длительность
пакета, чтобы коллизию обнаружили все
начавшие предавать абоненты. Минимально
допустима длительность пакета в сети
должна составлять Dmin=2L/V,
гдеL– полная длина
сети;V- скорость
распространения сигнала в используемом
кабеле. Это время называют двойным или
круговым временем задержки сигнала в
пути илиPVD(PathDelayValue).Этот временной интервал можно рассматривать
как универсальную меру одновременности
любых событий в сети.

Рис. 6
8 Расчет минимальной длительности пакета
Например,
абонент 1закончил свою
передачу, а абоненты 2и
3захотели передавать во время
передачи абонента 1.После
освобождения сети абонент 3узнает об этом событии и начинает свою
передачу через временной интервал
прохождения сигнала по всей длине сети,
то есть через времяL/V,
а абонент2 начнет передавать сразу после
освобождения сети. Пакет от абонента
3дойдет до абонента 2еще через временной интервал
L/Vпосле начала передачи абонентом
3(обратный путь сигнала). К этому
моменту передача пакета абонентом
2ни в коем случае не должна еще
закончиться, иначе абонент
2так и не узнает столкновении
пакетов (о коллизии).
Отдельно стоит остановиться на том, как
сетевые адаптеры распознают коллизию,
то есть столкновение пакетов. Ведь
простое сравнение передаваемой
абонентом информации с той, которая
реально присутствует в сети, возможно
только в случае самого простого кода
NRZ, используемого
довольно редко. При применении кода
Манчестер-2, который обычно подразумевается
в случае метода управления обменомCSMA/CD,
требуется принципиально другой
подход.
Сигнал
в коде Манчестер-2 всегда имеет постоянную
составляющую, равную половине размаха
сигнала (если один из двух уровней
сигнала нулевой). Однако в случае
столкновения двух и более пакетов
(коллизии) это правило выполняться не
будет. Постоянная составляющая
суммарного сигнала в сети будет
обязательно больше или меньше половины
размаха (рис. 6.9).Ведь
пакеты всегда отличаются друг от друга
и к тому же сдвинуты друг относительно
друга во времени. Именно по выходу уровня
постоянной составляющей за установленные
пределы и определяет каждый сетевой
адаптер наличие коллизии в сети.
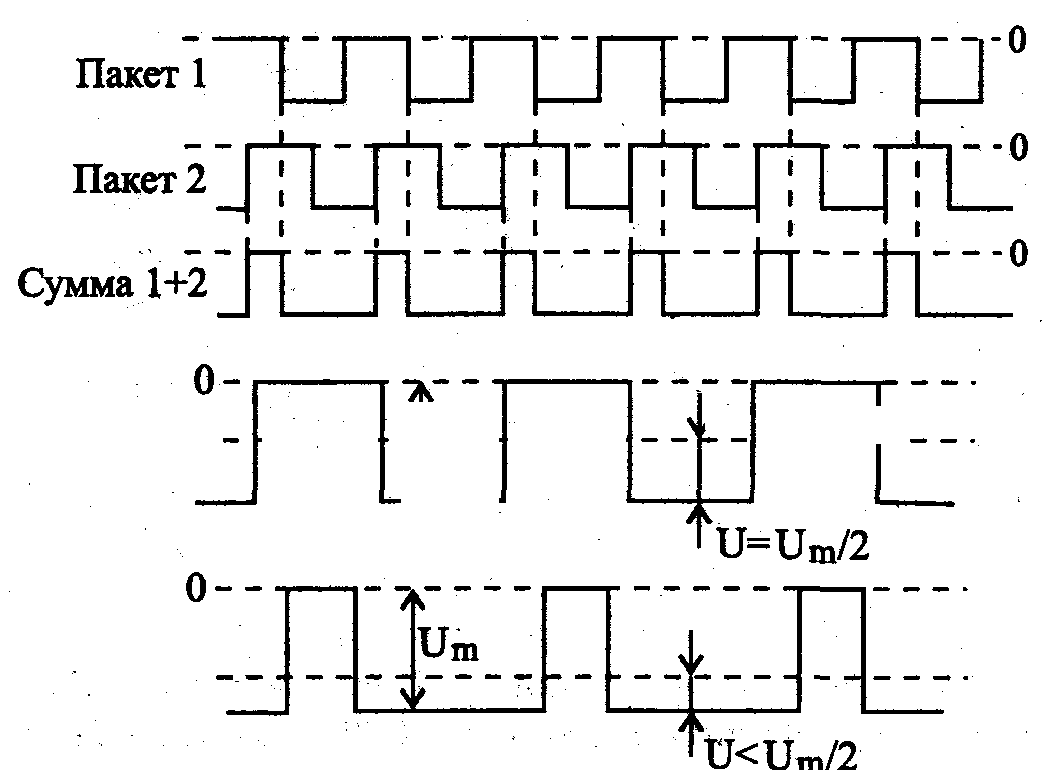
Рис
6.9 Определение факта коллизии при
использовании кода Манчестер-2
6.6.4Управление обменом в сети типа
«кольцо».
Кольцевая
топология имеет свои особенности при
выборе управления обменом. Важным
фактором является то, что любой пакет,
посланный по кольцу последовательно
пройдя всех абонентов, через некоторое
время возвратится в ту же точку — топология
замкнутая. Здесь нет одновременного
распространения сигнала в обе стороны
как по шине. Отметим, что сети типа кольцо
бывают однонаправленными и двунаправленными.
Мы будем рассматривать только
однонаправленные, как более распространенные.
Наиболее
популярными методами управления обменом
в сетях типа кольцо считаются маркерные
(эстафетные) методы, которые используют
небольшой специальный управляющий
пакет – маркер.
Маркерный
метод управления относится, как и
методы опроса (централизованые), к
детерминированным. В отличие от
рассмотренных случайных детерминированные
методы принципиально исключают любые
конфликты в сети, т.к. в них предусмотрен
механизм временного распределения сети
между абонентами. При случайных методах
АП могут начать передачу в любой момент
времени поэтому там конфликты неизбежны.

СМ-
свободный маркер; ЗМ- занятый
маркер;ПМ-занятый маркер с подтверрждением;
ПД – пакет данных
Рис.
Маркерный метод управления обменом
Идея
метода состоит в том, что по кольцу
запускается специальный пакет, называемый
маркером, который отмечает время
возможного начала пакета. Маркер ходит
по кольцу, синхронизируя работу абонентов
сети.
Алгоритм
управления предполагает следующую
последовательность действий:
-
А1,
желающий передать ждет свободный маркер
(пакет, помеченный как свободный).
Получив его А1 помечает его как занятый,
добавляя к нему свой пакет и отправляет
полученный блок следующему по кольцу
абоненту. -
Каждый
абонент кольца (А1,А2,А3) получив блок
маркер+пакет проверяет ему ли адресован
пакет и если пакет не его отправляют
дальше по кольцу. -
Абонент,
распознавший пакет (пусть это будет
А3) принимает пакет и устанавливает в
маркере бит подтверждение и отправляет
посылку маркер + пакет дальше. -
Передававший
абонент (А1) получает обратно свою
посылку освобождает маркер и снова
посылает маркер в сеть.
Приоритет
в данном случае географический, т.е.
право передачи переходит к следующему
за передававшим по кольцу. Здесь нет
выделенного центра, однако один и АП
или спец. устройство должен следить за
тем, чтобы маркер не потерялся. Надежность
в этом случае снижается. Однако основным
преимуществом является гарантированное
время доступа. Следует отметить, что
метод маркерного доступа используется
не только в кольце IBMTokenRing, но и в шинеArcnet-BUS,
и в звездеArcnet-STAR.
В этих случаях используется логическое
кольцо.
Метод
кольцевых сегментов — слотов. Примером
сети, использующий этот метод может
служитьCambridgeRing.
Основное отличие этого метода от
маркерного состоит в том, что нескольким
абонентам разрешена передача одновременно
и в любой момент. Вместо одного маркера
в сети используются несколько так
называемых слотов (от 2 до 8), которые
выполняют туже функцию, что и маркер.
Эти слоты идут довольно часто, временной
интервал между ними невелик и поэтому
информации между ними может уместиться
немного обычно от 8 до 32 байт. При этом
каждый слот может находится в свободном
или занятом состоянии. Алгоритм включает
в себя следующие этапы:
-
АП,
желающий передавать разбивает информацию
на слоты -
затем
ждет прихода свободного слота и загружает
в него часть своей информации, ждет
прихода следующего свободного и
загружает следующую часть и т.д. В каждом
слоте существует бит — свободен или
занят слот, поле сетевого адреса
приемника и передатчика и бит признака
конца информации. -
АП,
которому адресована информация выбирает
слоты, содержащие адресованную ему
информацию и устанавливает бит
подтверждения и так продолжается до
последнего адресованного ему слота. -
Передающий
АП получает свои слоты обратно по кольцу
и освобождает их — помечает как свободные.
Преимущество
данного метода перед маркерным состоит
в том, что сеть занимается несколькими
абонентами. Время доступа гарантированное
и в наихудшем случае случае оно составит
время передачи пакета помноженное на
число абонентов в сети.
Основное
преимущество данных методов перед
CSMA/CDсостоит
в гарантированности времени доступа,
величина которого составляет
![]() , гдеN- число абонентов в
, гдеN- число абонентов в
сети;
![]() — время доступа абонент;
— время доступа абонент;
![]() — время прохождения пакета по кольцу.
— время прохождения пакета по кольцу.
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Способы борьбы с ошибками
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется в основном на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически, любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть кодируемая информация делится на фрагменты длиной 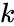 бит, которые преобразуются в кодовые слова длиной
бит, которые преобразуются в кодовые слова длиной 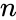 бит. Тогда соответствующий блоковый код обычно обозначают
бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число 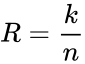 называется скоростью кода.
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет 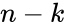 проверочных, такой код называется систематическим, иначе несистематическим.
проверочных, такой код называется систематическим, иначе несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако, хороший код должен удовлетворять, как минимум, следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство (назовём его 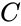 ) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу 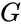 , называемую порождающей матрицей.
, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к , а
— ортогональное подпространство по отношению к , а 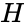 — матрица, задающая базис этого подпространства. Тогда для любого вектора
— матрица, задающая базис этого подпространства. Тогда для любого вектора  справедливо:
справедливо:

Минимальное расстояние и корректирующая способность
-
Основная статья: Расстояние Хемминга
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами  и
и  называется количество отличных бит на соответствующих позициях,
называется количество отличных бит на соответствующих позициях,  , что равно числу «единиц» в векторе
, что равно числу «единиц» в векторе  .
.
Минимальное расстояние Хемминга  является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
 , округляем «вниз», так чтобы .
, округляем «вниз», так чтобы .
 , округляем «вниз», так чтобы
, округляем «вниз», так чтобы  .
.Корректирующая способность определяет, сколько ошибок передачи кода (типа  ) можно гарантированно исправить. То есть вокруг каждого кода
) можно гарантированно исправить. То есть вокруг каждого кода  имеем
имеем  -окрестность
-окрестность  , которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов
, которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом получив искажённый код из декодер принимает решение, что был исходный код , исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова и  , расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
, расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
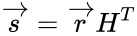 , где
, где 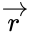 — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
— принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова  соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром  . Поскольку
. Поскольку  , где
, где  — кодовое слово, а
— кодовое слово, а  — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды
Несмотря на то, что декодирование линейных кодов уже значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово  представляется в виде полинома
представляется в виде полинома  . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на  по модулю
по модулю  .
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть  могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному 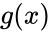 . Порождающий полином является делителем .
. Порождающий полином является делителем .
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC
Коды CRC (cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путем деления 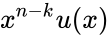 на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| название кода | степень | полином |
|---|---|---|
| CRC-12 | 12 | 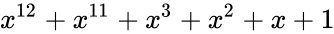
|
| CRC-16 | 16 | 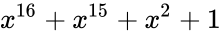
|
| CRC-CCITT | 16 | 
|
| CRC-32 | 32 | 
|
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Математически полинома на множители в поле Галуа.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды
Файл:ECC NASA standard coder.png
Свёрточный кодер ( )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако, декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды
-
Основная статья: Граница Хэмминга
Пусть имеется двоичный блоковый  код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):
код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть, передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также
- Цифровая связь
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. М.: Мир, 1986.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. М.: Техносфера, 2005. — ISBN 5-94836-035-0
Ссылки
Имеется викиучебник по теме:
Обнаружение и исправление ошибок
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006.
Эта страница использует содержимое раздела Википедии на русском языке. Оригинальная статья находится по адресу: Обнаружение и исправление ошибок. Список первоначальных авторов статьи можно посмотреть в истории правок. Эта статья так же, как и статья, размещённая в Википедии, доступна на условиях CC-BY-SA .
Канальный
уровень (Data Link layer)
Проблемы
передачи по каналу.
Сервис,
предоставляемый сетевому уровню
Разбиение на
кадры
Контроль
ошибок.
Управление
потоком.
Доступ к
среде передачи данных
Проблема
предоставления канала
Статическое
предоставление канала
Динамическое
предоставление канала
Протоколы
множественного доступа
Протоколы
множественного доступа с обнаружением несущей
Бесконфликтные
протоколы
Протоколы
с ограниченным числом конфликтов
Протоколы
с множественным доступом и разделением частот
Этот уровень предназначен для обеспечения взаимодействия сетей на физическом
уровне и контроля за ошибками, которые могут возникнуть. Полученные с
физического уровня данные он упаковывает в кадры данных, проверяет на
целостность, если нужно исправляет ошибки и отправляет на сетевой уровень.
Канальный уровень может взаимодействовать с одним или несколькими физическими
уровнями, контролируя и управляя этим взаимодействием. Спецификация IEEE 802
разделяет этот уровень на 2 подуровня — MAC (Media Access Control) регулирует
доступ к разделяемой физической среде, LLC (Logical Link Control) обеспечивает
обслуживание сетевого уровня. На этом уровне работают коммутаторы, мосты.
Проблемы передачи по каналу.
Сервис, предоставляемый сетевому уровню
Основной задачей канального уровня обеспечить сервис сетевому уровню.
Назначение этого сервиса — помочь передать данные процесса на сетевом уровне
одной машины процессу на сетевой уровень другой машины.
Канальный уровень может создаваться для различного сервиса,
который может варьироваться от системы к системе. Однако, есть три общие вида
сервиса:
- Сервис без уведомления и без соединения.
- Сервис с уведомлением и без соединения.
- Сервис с уведомлением и с соединением.
Не желательно на сетевом уровне заниматься пропажей кадров. Это задача
канального уровня обеспечить надежный канал. Это особенно важно при
беспроводной среде передачи.
Разбиение на кадры
Сервис, создаваемый канальным уровнем для сетевого, опирается на сервис,
создаваемый физическим уровнем. На физическом уровне протекают потоки битов.
Посланное количество битов не обязательно равно принятому, значение посланного
бита так же не обязательно равно принятому. Все это требует специальных усилий
на канальном уровне по обнаружению и исправлению ошибок.
Типовой подход к решению этой проблемы — разбиение потока битов на кадры,
подсчет контрольной суммы для каждого кадра при посылке данных. При приеме
контрольная сумма вычисляется для каждого кадра заново и сравнивается с той что
храниться в кадре. Если они различаются, то это признак ошибки передачи.
Канальный уровень должен принять меры к исправлению ошибки, например, сбросить
плохой кадр, послать сообщение об ошибке тому кто прислал этот кадр.
Так как временные методы ненадежны, то применяются другие. Здесь мы
рассмотрим четыре основных:
- счетчик символов
- вставка специальных стартовых и конечных символов
- вставка стартовых и концевых битов
- нарушение кодировки на физическом уровне
На практике используют, как правило, комбинацию этих
методов. Например, счетчик символов с одним из выше перечисленных. Тогда если
число символов в кадре совпадает с кодировкой границы кадра, кадр считается
переданным правильно.
Контроль ошибок.
Таймеры и нумерация кадров — это основные средства на
канальном уровне, обеспечивающие доставку каждого кадра до сетевого уровня в
единственном экземпляре
Обнаружение и исправление ошибок
В разных средах характер ошибок разный. Ошибки
могут быть одиночные, а могут возникать группами, сразу по несколько.
Для надежной передачи кодов было предложено два основных метода. Первый —
внести избыточность в форме дополнительных битов в передаваемый блок данных
так, чтобы, анализируя полученный блок, можно было бы указать где возникли
искажения. Это, так называемые, коды с исправлением ошибок. Второй —
внести избыточность, но лишь настолько, чтобы, анализируя полученные данные,
можно было сказать есть в переданном блоке ошибки или нет. Это, так называемые,
коды с обнаружением ошибок.
Коды с исправлением ошибок— Код хемминга(может
исправлять только единичные ошибки. Однако, есть прием, который позволяет
распространить идеи Хемминга на случай групповых ошибок)
Коды обнаруживающие ошибки- CRC код(Cyclic Redundancy
Code)
(CRC-16 и CRC-CCITT ловят одиночные, двойные ошибки,
групповые ошибки длины не более 16 и нечетное число изолированных ошибок с
вероятностью 99,997%.)
Управление потоком.
Это управление предполагает
обратную связь между отправителем и получателем, которая позволяет им
урегулировать такие ситуации. Есть много схем управления потоком, но все они в
основе своей используют следующий сценарий. Прежде чем отправитель начнет
передачу он спрашивает у получателя сколько кадров тот может принять.
Получатель сообщает ему определенное число кадров. Отправитель после того как
передаст это число кадров, должен приостановить передачу и спросить получателя
опять получателя опять как много кадров тот может принять и т.д.
Доступ к среде передачи
данных
В средах с множественным доступом ключевым является вопрос: как определить
кому из запросивших отдать канал? Протоколы для определения кто захватит канал
в случае конкуренции относятся к подуровню канального уровня, который
называется МАС — Medium Access Control.
Проблема предоставления канала
Основной вопрос — как распределять единственный канал между
многими конкурирующими пользователями.
Статическое предоставление канала
Как мы уже рассматривали ранее есть два основных подхода к
мультиплексированию нескольких конкурирующих пользователей на одном канале — частотное
разделение (FDM-Frequency Division Multiplexing).Частотное
разделение хорошо работает в условиях, когда число пользователей фиксировано и каждый
порождает плотную загрузку канала. Тогда каждому из них выделяется своя полоса
частот, которую он использует независимо от других. Однако, когда число
пользователей велико или величина переменная, или когда трафик очень не
регулярный,у FDM появляются проблемы.
Те же самые рассуждения можно применить к временному разделению (TDM—Time Division Multiplexing). Таким образом, ни один из известных
статических методов не позволяет эффективно распределять нагрузку.
Динамическое предоставление канала
Протоколы множественного доступа
Чистая ALOHA
Идея чистой ALOHA проста — любой пользователь пытается передать сообщение.
Благодаря тому, что в вещательной среде он всегда имеет обратную связь, то он
видит возникновение конфликта при передаче. Эта обратная связь в среде LAN
происходит практически мгновенно, в системах спутниковой связи задержка составляет
около 270 mсек.
Обнаружив конфликт, пользователь ожидает некоторый случайный отрезок времени
после чего повторяет попытку. Ожидание должно быть случайным, иначе конкуренты
будут повторять попытки в одно и то же время, что приведет к блокировке. Системы
подобного типа, где пользователи конкурируют за получение общего канала,
называются системами с состязаниями.
Неважно когда произошел конфликт когда первый бит одного кадра наложился на
последний бит другого кадра или как-то иначе, оба кадра считаются испорченными
и должны быть переданы повторно. Контрольная суммам не позволяет различать
разные случаи наложения.
Какова эффективность системы ALOHA? Какая часть кадров избежала коллизий?
Рассмотрим следующую модель. Есть неограниченное число пользователей,
работающих на компьютерах. Все что они могут делать это — либо набирать текст,
либо ждать пока набранный текст передается. Когда пользователь заканчивает
набирать очередную строку, он останавливается и ждет ответа от системы. Система
пытается передать эту строку. Когда она сделает это успешно, пользователь видит
отклик и может продолжать работу.
Назовем временем кадра — время необходимое на передачу кадра стандартной
фиксированной длины. Предполагаем, что пользователей не ограниченное число и
они порождаю кадры по закону Пуассона со средним ![]() кадров за время кадра. Поскольку
кадров за время кадра. Поскольку
при ![]() очередь
очередь
на передачу будет только расти и все кадры будут страдать от коллизий, то мы
будем предполагать, ![]() .
.
Также будем предполагать что вероятность k попыток послать как новые, так и
ранее не прошедшие кадры за время кадра распределена по закону Пуассона со
средним ![]() попыток.
попыток.
Понятно, что ![]() .
.
При слабой загрузке (![]() приближенно равно нулю) будет не много
приближенно равно нулю) будет не много
передач, а следовательно и коллизий — G приближенно равно ![]() . При высокой загрузке
. При высокой загрузке ![]() . При любой
. При любой
нагрузке пропускная способность это — число кадров, которые надо передать,
умноженное на вероятность успешной передачи. Если обозначить ![]() — вероятность успешной
— вероятность успешной
передачи, то ![]() .
.
Рассмотрим внимательно сколько времени надо отправителю, чтобы обнаружить
коллизию. Пусть он начал передачу в момент времени ![]() и пусть требуется время
и пусть требуется время ![]() , чтобы кадр
, чтобы кадр
достиг самой отдаленной станции. Тогда если в тот момент, когда кадр почти
достиг этой отдаленной станции она начнет передачу ( ведь в системе ALOHA
станция сначала передает, а потом слушает), то отправитель узнает об этом
только через ![]() .
.
Вероятность появления k кадров на передачу при распределении Пуассона равна
![]()
поэтому вероятность, что появится 0 кадров равна ![]() . За двойное время кадра среднее
. За двойное время кадра среднее
число кадров будет ![]() , отсюда
, отсюда
![]() ,
,
а так как![]() ,
,
то
![]() .
.
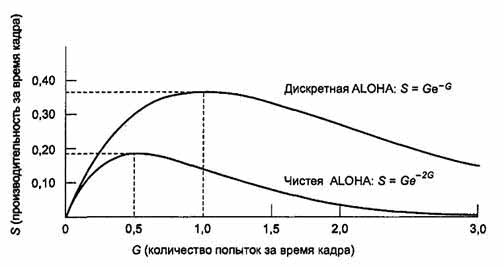
Рис.3.1 Зависимость производительности канала от
предлагаемого трафика для систем ALOHA
Зависимость между нагрузкой и пропускной способность показана на Рис.3.1. максимальная
пропускная способность достигается при ![]() при
при ![]() , что составляет примерно 18%. Результат не
, что составляет примерно 18%. Результат не
очень вдохновляющий.
Слотированная ALOHA.
В 1972 году Робертс предложил модификацию чистой ALOHA. Все время разделяют на
слоты — один кадр на слот. Ясно, что это требует синхронизации. Одна станция
должна испускать сигнал начала очередного слота. Поскольку передачу теперь
можно начинать не в любой момент, а только по специальному сигналу, то время на
обнаружение коллизии сокращается в двое. Отсюда
![]() .
.
Как видно из рис. 1 максимум пропускной способности слотированной ALOHA
наступает при ![]() ,
,
где ![]() , т.е.
, т.е.
около 0,37, что в двое больше чем у чистой ALOHA.
Рассмотрим как ![]() влияет на пропускную способность подсчитаем
влияет на пропускную способность подсчитаем
вероятность успешной передачи за ![]() попыток. Так как
попыток. Так как ![]() вероятность отсутствия коллизии при
вероятность отсутствия коллизии при
передаче, то вероятность что кадр будет передан ровно за ![]() попыток, равна
попыток, равна
![]()
Среднее ожидаемое число повторных передач будет ![]()
Эта экспоненциальная зависимость показывает, что с ростом ![]() резко возрастает число
резко возрастает число
повторных попыток, а следовательно и общая пропускная способность канала.
Протоколы множественного доступа с обнаружением несущей
В локальных сетях есть возможность определить, что делают другие станции и
только после этого решать, что делать.
Протоколы, которые реализую именно эту идею — определить есть ли передача и
действовать соответствующе, называются протоколами с обнаружением несущей
CSMA (Carrier Sense Multiply Access).
Настойчивые и не настойчивые CSMA.
Согласно протоколу, который мы сейчас рассмотрим, станция прежде чем что-либо
передавать определяет состояние канала. Если канал занят, то она ждет. Как
только канал освободился она пытается начать передачу. Если при этом произошла
коллизия, она ожидает случайный интервал времени и все начинает с начала. Этот
протокол называется CSMA настойчивым протоколом первого уровня или 1-настойчивым
CSMA протоколом, потому что он начинает передачу с вероятностью 1 как
только обнаруживает, что канал свободен.
Другой вариант CSMA — не настойчивый CSMA протокол. Основное отличие
его от предыдущего в том, что готовая к передаче станция не опрашивает
постоянно канал, в ожидании когда он освободиться, а делает это через случайные
отрезки времени. Это несколько увеличивает задержку при передаче, но общая
эффективность возрастает.
И ,наконец, CSMA настойчивый протокол уровня р. Он
применяется к слотированным каналам. Когда станция готова к передаче она
опрашивает канал, если он свободен, то она с вероятностью р передает свой кадр
и с вероятностью q=1-p ждет следующего слота. Так она действует пока не
передаст кадр. Если произошла коллизия вовремя передачи, она ожидает случайный
интервал времени и опрашивает канал опять. Если при опросе канала он оказался
занят, станция ждет начала следующего слота и весь алгоритм повторяется.
На рисунке показана пропускная способность в зависимости от нагрузки.
CSMA с обнаружением коллизий
Настойчивые и ненастойчивые CSMA протоколы несомненно есть улучшение ALOHA,
т.к. они начинают передачу только проверив состояние канала. Другим улучшением,
которое можно сделать, — станции должны уметь определять коллизии как можно
раньше, а не по окончании отправки кадра. Это экономит время и пропускную
способность канала. Такой протокол, известный как CSMA/CD — Carrier Sense
Multiply Access with Collision Detection , широко используется в локальных
сетях.
Бесконфликтные протоколы
Bit-Map протокол
Идея этого метода показана на рисунке:
Выделяется специальный период состязаний, где количество слотов равно числу
станций. Каждая станция, имеющая кадр для передачи , проставляет 1 в свой слот.
В результате, в конце состязаний все станции знают кто будет передавать и в
каком порядке. Передача происходит в том же порядке, в каком пронумерованы
слоты. Раз станции знают кто будет передавать и в каком порядке конфликтов не
будет. Если станция опоздала с заявкой на передачу, то она должна ждать
следующего периода состязаний, который начнется по окончании передач,
заявленных на предыдущем периоде состязаний. Такие протоколы, когда заявки на
передачу откладываются и могут быть сделаны лишь в определенные периоды времени
называются протоколами с резервированием.
Адресный счетчик
В этом методе каждая станция, желающая передать выставляет свой адрес бит за
битом, начиная со старшего разряда. Эти разряды подвергаются логическому
сложению. Если станция выставила на очередном шаге 0, а результат логического
сложения — 1, то она должна ждать и в текущих состязаниях участия не принимает.
Этот метод проиллюстрирован на рисунке левее. Эффективность этого метода d/(d +
log2N)
Протоколы с ограниченным числом конфликтов
Существую протоколы, объединяющие в себе свойства 2 предыдущих групп. Эти
протоколы называются протоколы с ограниченным числом конфликтов.
Общая производительность системы может быть улучшена если разным станциям
будет сопоставлена разная вероятность.
График этой функции показан на рисунке левее. При небольшом
числе станций шансы передать кадр достаточно велики, но с ростом числа станций
они резко падают. Единственным способом увеличить шансы на передачу сократить
состязания. Для этого в протоколах с ограниченным числом конфликтов все станции
разбиваются на непересекающиеся группы. За слот с номером 0 состязаются только
станции из группы 0. Если передавать нечего или была коллизия, то члены группы
1 начинают состязания за слот 1 и т.д. Основную сложность составляет
распределение станций по группам.
Адаптивный древовидный протокол.
На рисунке показано как эта процедура протокола применяется к станциями.
Станции — листья. За слот 0 борются все станции. Если какая-то победила —
хорошо. Если нет, то за слот 1 борются только станции поддерева с корнем в
вершине 2. Если какая-то победила, то следующий слот резервируется для станций
поддерева 3. Если был конфликт, то за следующий слот борются станции поддерева
4 и т.д.
Протоколы с множественным доступом и разделением
частот
рассмотрим работу протоколов множественного доступа для оптоволоконных
систем. Они построены на идее разделения частот. Вся полоса разделяется на
каналы по два на станцию. Они узкий — управляющий канал, второй широкий для
передачи данных. Каждый канал разбит на слоты. Все слоты синхронизируются от
единых часов. Отмечается только 0 слот, чтобы можно было определить начало
каждого цикла.