
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
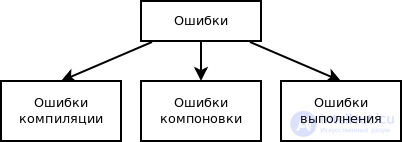
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
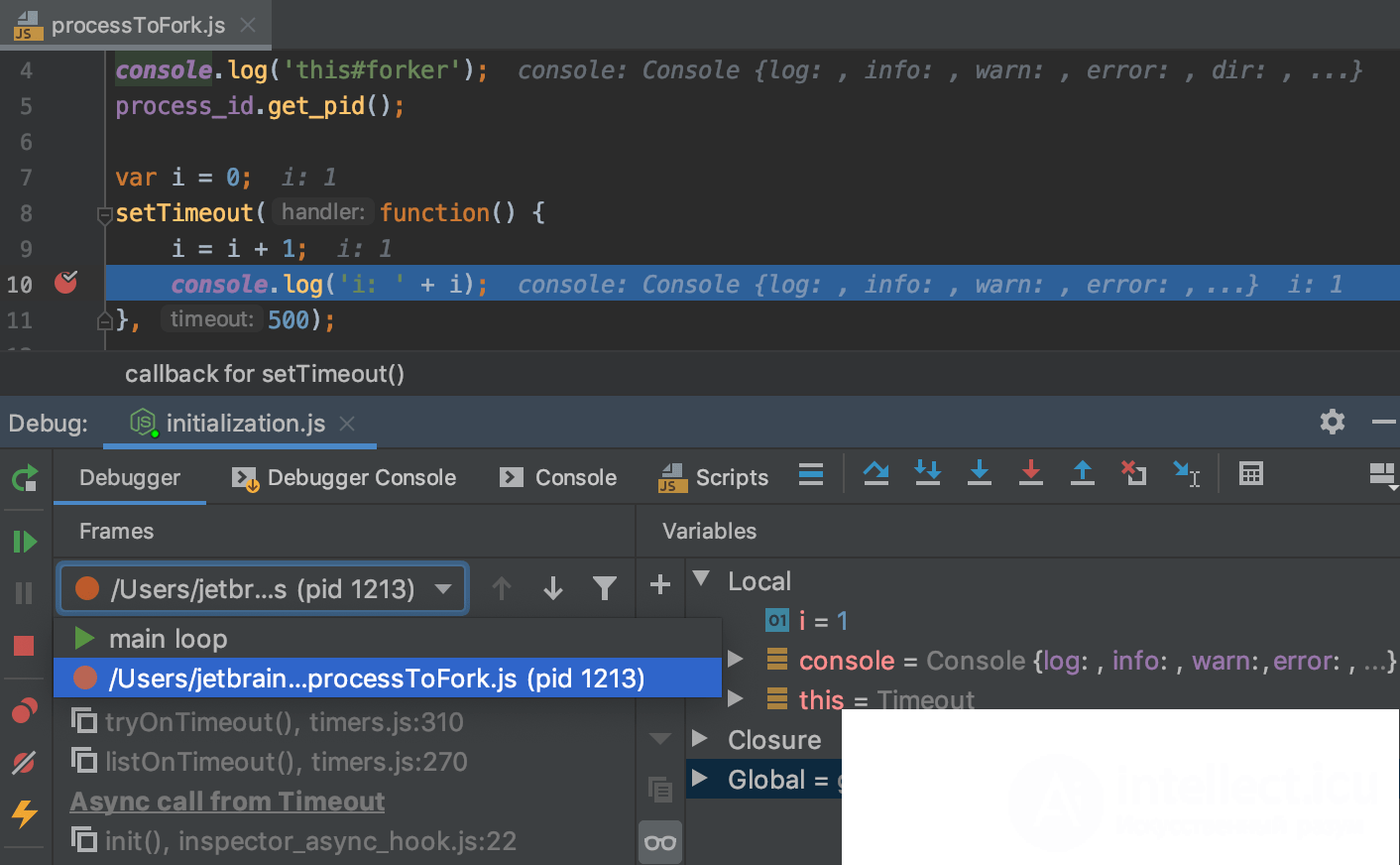 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
Классификация ошибок по этапу обработки программы
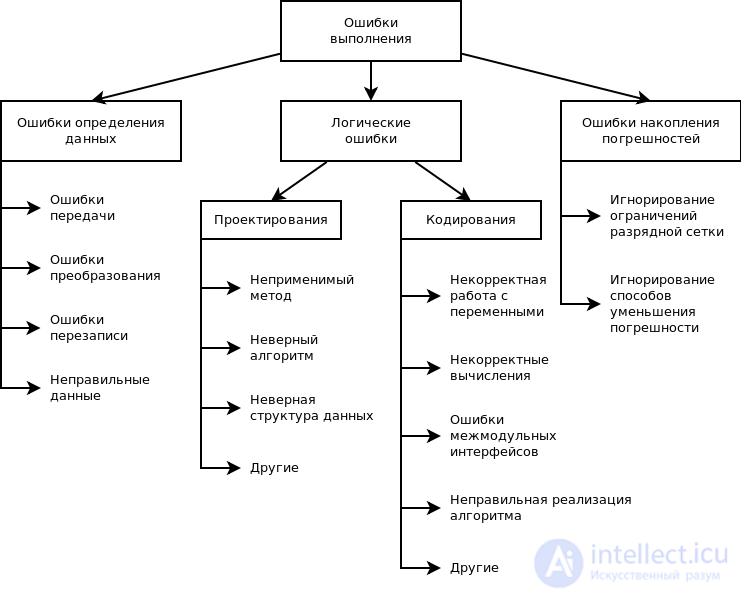
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:

Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.

Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Отладка — это локализация и устранение
ошибок. Отладка является следствием
успешного тестирования. Это значит, что
если тестовый вариант обнаруживает
ошибку, то процесс отладки уничтожает
ее.
Итак, процессу отладки предшествует
выполнение тестового варианта. Его
результаты оцениваются, регистрируется
несоответствие между ожидаемым и
реальным результатами. Несоответствие
является симптомом скрытой причины.
Процесс отладки пытается сопоставить
симптом с причиной, вследствие чего
приводит к исправлению ошибки. Возможны
два исхода процесса отладки:
1) причина найдена, исправлена, уничтожена;
2) причина не найдена.
Во втором случае отладчик может
предполагать причину. Для проверки этой
причины он просит разработать
дополнительный тестовый вариант, который
поможет проверить предположение. Таким
образом, запускается итерационный
процесс коррекции ошибки.
Возможные разные способы проявления
ошибок:
1) программа завершается нормально, но
выдает неверные результаты;
2) программа зависает;
3) программа завершается по прерыванию;
4) программа завершается, выдает ожидаемые
результаты, но хранимые данные испорчены
(это самый неприятный вариант).
Характер проявления ошибок также может
меняться. Симптом ошибки может быть:
-
постоянным;
-
мерцающим;
-
пороговым (проявляется при превышении
некоторого порога в обработке — 200
самолетов на экране отслеживаются, а
201-й — нет);
-
отложенным (проявляется только после
исправления маскирующих ошибок).
В ходе отладки мы встречаем ошибки в
широком диапазоне: от мелких неприятностей
до катастроф. Следствием увеличения
ошибок является усиление давления на
отладчика — «найди ошибки быстрее!!!».
Часто из-за этого давления разработчик
устраняет одну ошибку и вносит две новые
ошибки.
Английский термин debugging
(отладка) дословно
переводится как «ловля блох», который
отражает специфику процесса — погоню
за объектами отладки, «блохами».
Рассмотрим, как может быть организован
этот процесс «ловли блох» [3], [64].
Различают две группы методов отладки:
-
аналитические;
-
экспериментальные.
Аналитические методы базируются на
анализе выходных данных для тестовых
прогонов. Экспериментальные методы
базируются на использовании вспомогательных
средств отладки (отладочные печати,
трассировки), позволяющих уточнить
характер поведения программы при тех
или иных исходных данных.
Общая стратегия отладки — обратное
прохождение от замеченного симптома
ошибки к исходной аномалии (месту в
программе, где ошибка совершена).
В простейшем случае место проявления
симптома и ошибочный фрагмент совпадают.
Но чаще всего они далеко отстоят друг
от друга.
Цель отладки
— найти оператор программы, при исполнении
которого правильные аргументы приводят
к неправильным результатам. Если место
проявления симптома
ошибки не является искомой аномалией,
то один из аргументов оператора должен
быть неверным. Поэтому надо перейти к
исследованию предыдущего оператора,
выработавшего этот неверный аргумент.
В итоге пошаговое обратное прослеживание
приводит к искомому ошибочному месту.
В разных методах прослеживание
организуется по-разному. В аналитических
методах — на основе логических заключений
о поведении программы. Цель — шаг за
шагом уменьшать область программы,
подозреваемую в наличии ошибки. Здесь
определяется корреляция между значениями
выходных данных и особенностями
поведения.
Основное преимущество
аналитических методов отладки состоит
в том, что исходная программа остается
без изменений.
В экспериментальных методах для
прослеживания выполняется:
-
Выдача значений переменных в указанных
точках. -
Трассировка переменных (выдача их
значений при каждом изменении). -
Трассировка потоков управления (имен
вызываемых процедур, меток, на которые
передается управление, номеров операторов
перехода).
Преимущество экспериментальных
методов отладки состоит
в том, что основная рутинная работа по
анализу процесса вычислений перекладывается
на компьютер. Многие трансляторы имеют
встроенные средства отладки для получения
информации о ходе выполнения программы.
Недостаток экспериментальных
методов отладки — в
программу вносятся изменения, при
исключении которых могут появиться
ошибки. Впрочем, некоторые системы
программирования создают специальный
отладочный экземпляр программы, а в
основной экземпляр не вмешиваются.
Темы
3.4.-3.6. Тестирование. Типы и методы
тестирования. Ручное и автоматизированное
тестирование. Инструментальные средства.
В целом
разработчики различают дефекты
программного обеспечения и сбои. В
случае сбоя программа ведет себя не
так, как ожидает пользователь. Дефект
— это ошибка/неточность, которая может
быть (а может и не быть) следствием сбоя.
Общепринятая
практика состоит в том, что после
завершения продукта и до передачи его
заказчику независимой группой
тестировщиков проводится тестирование
ПО. Эта практика часто выражается в виде
отдельной фазы тестирования (в общем
цикле разработки ПО), которая часто
используется для компенсирования
задержек, возникающих на предыдущих
стадиях разработки. Другая практика
состоит в том, что тестирование начинается
вместе с началом проекта и продолжается
параллельно созданию продукта до
завершения проекта. Второй путь обычно
требует больших трудозатрат, но качество
тестирования при этом будет выше.
Уровни
тестирования:
• модульное
тестирование. Тестируется минимально
возможный для тестирования компонент,
например отдельный класс или функция;
• интеграционное
тестирование. Проверяется, есть ли
какие-либо проблемы в интерфейсах и
взаимодействии между интегрируемыми
компонентами, например, не передается
информация, передается некорректная
информация;
• системное
тестирование. Тестируется интегрированная
система на ее соответствие исходным
требованиям:
— альфа-тестирование
— имитация реальной работы с системой
штатными разработчиками либо реальная
работа с системой потенциальными
пользователями/заказчиком на стороне
разработчика. Часто альфа-тестирование
применяется для законченного продукта
в качестве внутреннего приемочного
тестирования. Иногда альфа-тестирование
выполняется под отладчиком или с
использованием окружения, которое
помогает быстро выявлять найденные
ошибки. Обнаруженные ошибки могут быть
переданы тестировщикам для дополнительного
исследования в окружении, подобном
тому, в котором будет использоваться
ПО;
— бета-тестирование
— в некоторых случаях выполняется
распространение версии с ограничениями
(по функциональности или времени работы)
для некоторой группы лиц с тем, чтобы
убедиться, что продукт содержит достаточно
мало ошибок. Иногда бета-тестирование
выполняется для того, чтобы получить
обратную связь о продукте от его будущих
пользователей.
Термины
и определения
Выполнение
программы с целью обнаружения ошибок
называется тестированием.
Виды
ошибок и способы их обнаружения приведены
в табл. 5.1.
Таблица
5.1. Виды программных ошибок и способы
их обнаружения
|
Виды |
Способы |
|
Синтаксические |
Статический |
|
Ошибки
а)
б) в) |
Динамический
аппаратурой
run-time операционной |
|
Программа |
Целенаправленное |
|
Спецификация |
Испытания, |
Эффективность
контроля 1-го вида зависит и от языка, и
от компилятора. Контроль 2-го вида
осуществляется с помощью исключений —
Exceptions и весьма полезен для проверки
правдоподобности промежуточных
результатов.
Тест —
это набор контрольных входных данных
совместно с ожидаемыми результатами.
В число входных данных время зависимых
программ входят события и временные
параметры.
Ключевой
вопрос — полнота тестирования: какое
количество каких тестов гарантирует,
возможно, более полную проверку программы?
Исчерпывающая
проверка на всем множестве входных
данных недостижима. Пример: программа,
вычисляющая функцию двух переменных:
Y=f(X, Z). Если X, Y, Z — real, то полное число
тестов (232)2 = 264« 1031
Если на
каждый тест тратить 1 мс, то 264 мс = 800 млн
лет. Следовательно:
• в любой
нетривиальной программе на любой стадии
ее готовности содержатся необнаруженные
ошибки;
• тестирование
— технико-экономическая проблема,
основанная на компромиссе время —
полнота. Поэтому нужно стремиться к
возможно меньшему количеству хороших
тестов с желательными свойствами.
Детективность:
тест должен с большой вероятностью
обнаруживать возможные ошибки
Покрывающая
способность:
один тест должен выявлять как можно
больше ошибок.
Воспроизводимость:
ошибка должна выявляться независимо
от изменяющихся условий (например, от
временных соотношений) — это труднодостижимо
для времязависимых программ, результаты
которых часто невоспроизводимы.
Только
на основании выбранного критерия можно
определить тот момент времени, когда
конечное множество тестов окажется
достаточным для проверки программы с
некоторой полнотой (степень полноты,
впрочем, определяется экспериментально).
Используется два вида критериев (табл.
5.2):
• функциональные
тесты составляются исходя из спецификации
программы;
• структурные
тесты составляются исходя из текста
программы.
На рис.
5.1, а видно отличие тестирования команд
(достаточен один тест) от С1 (необходимы
два теста как минимум). Рисунок 5.1, б
иллюстрирует различие С1 (достаточно
двух тестов, покрывающих пути 1, 4 или 2,
3) от С2 (необходимо четыре теста для всех
четырех путей). С2 недостижим в реальных
програм мах из-за их цикличности, поэтому
ограничиваются тремя путями для каждого
цикла: 0, 1 и N повторений цикла.
Таблица
5.2. Виды критериев и их функциональность
|
Вид |
Функциональность |
|
Функциональные |
|
|
Тестирование |
Содержать |
|
Тестирование |
|
|
Тестирование |
Каждая |
|
Структурные |
|
|
Тестирование |
Каждая |
|
Критерий |
Каждая |
|
Критерий |
Каждый |
Рис. 5.1.
Траектории вычислений при структурном
тестировании
Остаются
проблемы назначения классов входных/выходных
данных для функционального тестирования
и проектирования тестов для структурного
тестирования. Классы, как правило,
назначаются исходя из семантики решаемой
задачи [6].
Рассмотрим
пример. Найти минимальный набор тестов
для программы нахождения вещественных
корней квадратного уравнения ах2 + Ъх +
с — 0.
Решение
представлено в табл. 5.3.
Таблица
5.3. Поиск численного решения минимального
набора тестов
|
Номер |
а |
b |
с |
Ожидаемый |
Что |
|
1 |
2 |
-5 |
2 |
X1 |
Случай |
|
2 |
3 |
2 |
5 |
Сообщение |
Случай |
|
3 |
3 |
-12 |
0 |
x1 |
Нулевой |
|
4 |
0 |
0 |
10 |
Сообщение |
Неразрешимое |
|
5 |
0 |
0 |
0 |
Сообщение |
Неразрешимое |
|
6 |
0 |
5 |
17 |
Сообщение |
Неквадратное |
|
7 |
9 |
0 |
0 |
X1 |
(деление Корень |
Таким
образом, для этой программы предлагается
минимальный набор функциональных
тестов, исходя из 7 классов выходных
данных.
Тестирование
«белого ящика» и «черного ящика»
В
терминологии профессионалов тестирования
(программного и некоторого аппаратного
обеспечения) фразы тестирование «белого
ящика» и тестирование «черного ящика»
относятся к тому, имеет ли разработчик
тестов доступ к исходному коду тестируемого
ПО, или же тестирование выполняется
через пользовательский интерфейс либо
прикладной программный интерфейс,
предоставленный тестируемым модулем.
При
тестировании «белого ящика» (англ.
white-box testing, также говорят — прозрачного
ящика) разработчик теста имеет доступ
к исходному коду и может писать код,
который связан с библиотеками тестируемого
ПО. Это типично для юнит-тестирования
(англ. unit testing), при котором тестируются
только отдельные части системы. Оно
обеспечивает то, что компоненты
конструкции работоспособны и устойчивы
до определенной степени.
При
тестировании «черного ящика» (англ.
black-box testing) тестировщик имеет доступ к
ПО только через те же интерфейсы, что и
заказчик или пользователь, либо через
внешние интерфейсы, позволяющие другому
компьютеру либо другому процессу
подключиться к системе для тестирования.
Например, тестирующий модуль может
виртуально нажимать клавиши или кнопки
мыши в тестируемой программе с помощью
механизма взаимодействия процессов с
уверенностью в том, что эти события
вызывают тот же отклик, что и реальные
нажатия клавиш и кнопок мыши.
Если
альфа- и бета-тестирование относятся к
стадиям до выпуска продукта (а также,
неявно, к объему тестирующего сообщества
и ограничениям на методы тестирования),
тестирование «белого ящика» и «черного
ящика» имеет отношение к способам,
которыми тестировщик достигает цели.
Бета-тестирование
в целом ограничено техникой «черного
ящика» (хотя постоянная часть тестировщиков
обычно продолжает тестирование «белого
ящика» параллельно бета-тестированию).
Таким образом, термин бета-тестирование
может указывать на состояние программы
(ближе к выпуску, чем альфа) или может
указывать на некоторую группу тестировщиков
и процесс, выполняемый этой группой.
Итак, тестировщик может продолжать
работу по тестированию «белого ящика»,
хотя ПО уже «в бете» (стадия), но в этом
случае он не является частью
бета-тестирования (группы/процесса).
Порядок
разработки тестов
По внешней
спецификации разрабатываются тесты
[3]:
• для
каждого класса входных данных;
• для
граничных и особых значений входных
данных.
Контролируется,
все ли классы выходных данных при этом
проверяются, и добавляются при
необходимости нужные тесты.
Разрабатываются
тесты для тех функций, которые не
проверяются в п. 1.
По тексту
программы проверяется, все ли условные
переходы выполнены в каждом направлении
(С1). При необходимости добавляются новые
тесты.
Аналогично
проверяется, проходятся ли пути для
каждого цикла: без выполнения тела, с
однократным и максимальным числом
повторений.
Готовятся
тесты, проверяющие исключительные
ситуации, недопустимые входные данные,
аварийные ситуации. Функциональное
тестирование дополняется здесь
структурным. Классы входных/выходных
данных должны быть определены в плане
тестирования уже во внешней спецификации.
Согласно
статистике 1-й и 2-й пункты обеспечивают
степень охвата С1 в среднем 40—50 %. Проверка
по С1 (пункт 3) обычно выявляет 90 % всех
ошибок, найденных при тестировании.
(Все программное обеспечение ВВС США
принимается с проверкой по С1.)
Систематическое
тестирование предполагает также ведение
журнала отладки (Bug Book), в котором
фиксируется ошибка (описание, дата
обнаружения, автор модуля) и в дальнейшем
— исправление (дата, автор).
Приведем
так называемые аксиомы тестирования.
1. Тест
должен быть направлен на обнаружение
ошибки, а не на подтверждение правильности
программы.
2. Автор
теста — не автор программы.
3. Тесты
разрабатываются одновременно или до
разработки программы.
4. Необходимо
предсказывать ожидаемые результаты
теста до его выполнения и анализировать
причины расхождения результатов.
5. Предыдущее
тестирование необходимо повторять
после каждого внесения исправлений в
программу.
6. Следует
повторять полное тестирование после
внесения изменений в программу или
после переноса ее в другую среду.
7. В те
программы, в которых обнаружено много
ошибок, необходимо дополнить первоначальный
набор тестов [6].
Автоматизация
тестирования
А.
Автоматизация прогона тестов актуальна
для 5-й и 6-й аксиом Майерса. Пишутся
командные файлы для запуска программы
с каждым тестом из набора и сравнением
реального результата с ожидаемым.
Существуют специальные средства
(например система MIL-S для PL/1 фирмы IBM).
Разрабатывается стандарт ШЕЕ скриптового
языка для описания тестовых наборов
[3].
Б. Средства
автоматизации подготовки тестов и
анализа их результатов.
1. Генераторы
случайных тестов в заданных областях
входных данных.
2. Отладчики
(для локализации ошибок).
3. Анализаторы
динамики (profilers). Обычно входят в состав
отладчиков; применяются для проверки
соответствия тестовых наборов структурным
критериям тестирования.
4. Средства
автоматической генерации структурных
тестов методом «символического
выполнения» Кинга.
Модульное
тестирование
Модульное
тестирование — это тестирование
программы на уровне отдельно взятых
модулей, функций или классов. Цель
модульного тестирования заключается
в выявлении локализованных в модуле
ошибок в реализации алгоритмов, а также
в определении степени готовности системы
к переходу на следующий уровень разработки
и тестирования. Модульное тестирование
проводится по принципу «белого ящика»,
т. е. основывается на знании внутренней
структуры программы и часто включает
те или иные методы анализа покрытия
кода.
Модульное
тестирование обычно подразумевает
создание вокруг каждого модуля
определенной среды, включающей заглушки
для всех интерфейсов тестируемого
модуля. Некоторые из них могут
использоваться для подачи входных
значений, другие — для анализа результатов,
присутствие третьих может быть
продиктовано требованиями, накладываемыми
компилятором и сборщиком.
На уровне
модульного тестирования проще всего
обнаружить дефекты, связанные с
алгоритмическими ошибками и ошибками
кодирования алгоритмов, типа работы с
условиями и счетчиками циклов, а также
с использованием локальных переменных
и ресурсов. Ошибки, связанные с неверной
трактовкой данных, некорректной
реализацией интерфейсов, совместимостью,
производительностью и т. п., обычно
пропускаются на уровне модульного
тестирования и выявляются на более
поздних стадиях тестирования.
Именно
эффективность обнаружения тех или иных
типов дефектов должна определять
стратегию модульного тестирования, т.
е. расстановку акцентов при определении
набора входных значений. У организации,
занимающейся разработкой программного
обеспечения, как правило, имеется
историческая база данных (Repository)
разработок, хранящая конкретные сведения
о разработке предыдущих проектов: о
версиях и сборках кода (build), зафиксированных
в процессе разработки продукта, о
принятых решениях, допущенных просчетах,
ошибках, успехах и т. п. Проведя анализ
характеристик прежних проектов, подобных
заказанному разработчику, можно
предохранить новую разработку от старых
ошибок, например, определив типы дефектов,
поиск которых наиболее эффективен на
различных этапах тестирования.
В данном
случае анализируется этап модульного
тестирования. Если анализ не дал нужной
информации, например, в случае проектов,
в которых соответствующие данные не
собирались, то основным правилом
становится поиск локальных дефектов,
у которых код, ресурсы и информация,
вовлеченные в дефект, характерны именно
для данного модуля. В этом случае на
модульном уровне ошибки, связанные,
например, с неверным порядком или
форматом параметров модуля, могут быть
пропущены, поскольку они вовлекают
информацию, затрагивающую другие модули
(а именно, спецификацию интерфейса), в
то время как ошибки в алгоритме обработки
параметров довольно легко обнаруживаются.
Являясь
по способу исполнения структурным
тестированием или тестированием «белого
ящика», модульное тестирование
характеризуется степенью, в которой
тесты выполняют или покрывают логику
программы (исходный текст). Тесты,
связанные со структурным тестированием,
строятся по следующим принципам:
• на
основе анализа потока управления. В
этом случае элементы, которые должны
быть покрыты при прохождении тестов,
определяются на основе структурных
критериев тестирования СО, CI, C2. К ним
относятся вершины, дуги, пути управляющего
графа программы (УГП), условия, комбинации
условий и т. п.
• на
основе анализа потока данных, когда
элементы, которые должны быть покрыты,
определяются на основе потока данных,
т. е. информационного графа программы.
Тестирование
на основе потока управления.
Особенности использования структурных
критериев тестирования СО, CI, С2 были
рассмотрены в разд. 5.2. К ним следует
добавить критерий покрытия условий,
заключающийся в покрытии всех логических
(булевых) условий в программе. Критерии
покрытия решений (ветвей — С1) и условий
не заменяют друг друга, поэтому на
практике используется комбинированный
критерий покрытия условий/решений,
совмещающий требования по покрытию и
решений, и условий.
К популярным
критериям относится критерий покрытия
функций программы, согласно которому
каждая функция программы должна быть
вызвана хотя бы 1 раз, и критерий покрытия
вызовов, согласно которому каждый вызов
каждой функции в программе должен быть
осуществлен хотя бы 1 раз. Критерий
покрытия вызовов известен также как
критерий покрытия пар вызовов (call pair
coverage).
Тестирование
на основе потока данных.
Этот вид тестирования направлен на
выявление ссылок на неинициализированные
переменные и избыточные присваивания
(аномалий потока данных). Как основа для
стратегии тестирования поток данных
впервые был описан в [14]. Предложенная
там стратегия требовала тестирования
всех взаимосвязей, включающих в себя
ссылку (использование) и определение
переменной, на которую
указывает
ссылка (т. е. требуется покрытие дут
информационного графа программы).
Недостаток стратегии в том, что она не
включает критерий С1 и не гарантирует
покрытия решений.
Стратегия
требуемых пар
[15] также тестирует упомянутые взаимосвязи.
Использование переменной в предикате
дублируется в соответствии с числом
выходов решения, и каждая из таких
требуемых взаимосвязей должна быть
протестирована. К популярным критериям
принадлежит критерий СР, заключающийся
в покрытии всех таких пар дуг v и w, что
из дуги v достижима дуга w, поскольку
именно на дуге может произойти потеря
значения переменной, которая в дальнейшем
уже не должна использоваться. Для
покрытия еще одного популярного критерия
Cdu достаточно тестировать пары (вершина,
дуга), поскольку определение переменной
происходит в вершине УГП, а ее использование
— на дугах, исходящих из решений, или в
вычислительных вершинах.
Методы
проектирования тестовых путей для
достижения заданной степени тестированности
в структурном тестировании.
Процесс
построения набора тестов при структурном
тестировании принято делить на три
фазы:
• конструирование
УГП;
• выбор
тестовых путей;
• генерация
тестов, соответствующих тестовым путям.
Первая
фаза соответствует статическому анализу
программы, задача которого состоит в
получении графа программы и зависящего
от него и от критерия тестирования
множества элементов, которые необходимо
покрыть тестами.
На третьей
фазе по известным путям тестирования
осуществляется поиск подходящих тестов,
реализующих прохождение этих путей.
Вторая
фаза обеспечивает выбор тестовых путей.
Выделяют три подхода к построению
тестовых путей:
• статические
методы;
• динамические
методы;
• методы
реализуемых путей.
Статические
методы.
Самое простое и легко реализуемое
решение — построение каждого пути
посредством постепенного его удлинения
за счет добавления дуг, пока не будет
достигнута выходная вершина управляющего
графа программы. Эта идея может быть
усилена в так называемых адаптивных
методах, которые каждый раз добавляют
только один тестовый путь (входной
тест), используя предыдущие пути (тесты)
как руководство для выбора последующих
путей в соответствии с некоторой
стратегией. Чаще всего адаптивные
стратегии применяются по отношению к
критерию С1. Основной недостаток
статических методов заключается в том,
что не учитывается возможная
нереализуемость
построенных путей тестирования.
Динамические
методы.
Такие методы предполагают построение
полной системы тестов, удовлетворяющих
заданному
критерию,
путем одновременного решения задачи
построения покрывающего множества
путей и тестовых данных. При этом можно
автоматически учитывать реализуемость
или нереализуемость ранее рассмотренных
путей или их частей. Основной идеей
динамических методов является
подсоединение к начальным реализуемым
отрезкам путей дальнейших их частей
так, чтобы:
1) не терять
при этом реализуемости вновь полученных
путей;
2) покрыть
требуемые элементы структуры программы.
Методы
реализуемых путей.
Данная методика [16] заключается в
выделении из множества путей подмножества
всех реализуемых путей. После этого
покрывающее множество путей строится
из полученного подмножества реализуемых
путей.
Достоинство
статических методов состоит в сравнительно
небольшом количестве необходимых
ресурсов как при использовании, так и
при разработке. Однако их реализация
может содержать непредсказуемый процент
брака (нереализуемых путей).
Кроме
того, в этих системах переход от
покрывающего множества путей к полной
системе тестов пользователь должен
осуществить вручную, а эта работа
достаточно трудоемкая. Динамические
методы требуют значительно больших
ресурсов как при разработке, так и при
эксплуатации, однако увеличение затрат
происходит в основном за счет разработки
и эксплуатации аппарата определения
реализуемости пути (символический
интерпретатор, решатель неравенств).
Достоинство этих методов заключается
в том, что их продукция имеет некоторый
качественный уровень — реализуемость
путей. Методы реализуемых путей дают
самый лучший результат [33].
Интеграционное
тестирование
Интеграционное
тестирование — это тестирование части
системы, состоящей из двух и более
модулей. Основная задача интеграционного
тестирования — поиск дефектов, связанных
с ошибками в реализации и интерпретации
интерфейсного взаимодействия между
модулями.
С
технологической точки зрения интеграционное
тестирование является количественным
развитием модульного, поскольку так
же, как и модульное тестирование,
оперирует интерфейсами модулей и
подсистем и требует создания тестового
окружения, включая заглушки (Stub) на месте
отсутствующих модулей.
Основная
разница между модульным и интеграционным
тестированием состоит в целях, т. е. в
типах обнаруживаемых дефектов, которые,
в свою очередь, определяют стратегию
выбора входных данных и методов анализа.
В частности, на уровне интеграционного
тестирования часто применяются методы,
связанные с покрытием интерфейсов,
например, вызовов функций или методов,
или анализ использования интерфейсных
объектов, таких как глобальные ресурсы,
средства коммуникаций, предоставляемых
операционной системой.
На рис.
5.2 приведена структура комплекса программ
К, состоящего из оттестированных на
этапе модульного тестирования модулей
М1, М2, М11, М12, М21, М22. Задача, решаемая
методом интеграционного тестирования,
— тестирование межмодульных связей,
реализующихся при исполнении программного
обеспечения комплекса К. Интеграционное
тестирование использует модель «белого
ящика» на модульном уровне. Поскольку
тестировщику текст программы известен
с детальностью до вызова всех модулей,
входящих в тестируемый комплекс,
применение структурных критериев на
данном этапе возможно и оправданно.
Рис. 5.2.
Пример структуры комплекса программ
Интеграционное
тестирование применяется на этапе
сборки модульно оттестированных модулей
в единый комплекс.
Известны
два метода сборки модулей:
• монолитный,
характеризующийся одновременным
объединением всех модулей в тестируемый
комплекс;
• инкрементальный,
характеризующийся пошаговым (помодульным)
наращиванием комплекса программ с
пошаговым тестированием собираемого
комплекса. В инкрементальном методе
выделяют две стратегии добавления
модулей:
— «сверху
вниз» и соответствующее ему восходящее
тестирование;
— «снизу
вверх» и соответственно нисходящее
тестирование.
Особенности
монолитного тестирования заключаются
в следующем: для замены не разработанных
к моменту тестирования модулей, кроме
самого верхнего (К на рис. 5.2), необходимо
дополнительно разрабатывать драйверы
(test driver) и/или заглушки (stub) [9], замещающие
отсутствующие на момент сеанса
тестирования модули нижних уровней.
Сравнение
монолитного и интегрального подходов
дает следующие результаты.
Монолитное
тестирование требует больших трудозатрат,
связанных с дополнительной разработкой
драйверов и заглушек и со сложностью
идентификации ошибок, проявляющихся в
пространстве собранного кода.
Пошаговое
тестирование связано с меньшей
трудоемкостью идентификации ошибок за
счет постепенного наращивания объема
тестируемого кода и соответственно
локализации добавленной области
тестируемого кода.
Монолитное
тестирование предоставляет большие
возможности распараллеливания работ,
особенно на начальной фазе тестирования.
Особенности
нисходящего тестирования заключаются
в следующем: организация среды для
исполняемой очередности вызовов
оттестированными модулями тестируемых
модулей, постоянная разработка и
использование заглушек, организация
приоритетного тестирования модулей,
содержащих операции обмена с окружением,
или модулей, критичных для тестируемого
алгоритма.
Например,
порядок тестирования комплекса К (см.
рис. 5.2) при нисходящем тестировании
может быть таким, как показано в примере
5.3, где тестовый набор, разработанный
для модуля Mi, обозначен как XYi = (X, Y)i.
1) К ->
XYK
2) М1 ->
XY1
3)MM->XYM
4)
М2
-> XY2
5)
М22
-> XY22
6)
M21
-> XY21
7) M12 ->
XY12
Пример
5.1. Возможный порядок тестов при нисходящем
тестировании (html, txt).
Недостатки
нисходящего тестирования:
• проблема
разработки достаточно «интеллектуальных»
заглушек, т. е. заглушек, способных к
использованию при моделировании
различных режимов работы комплекса,
необходимых для тестирования;
• сложность
организации и разработки среды для
реализации исполнения модулей в нужной
последовательности;
• параллельная
разработка модулей верхних и нижних
уровней приводит к не всегда эффективной
реализации модулей из-за подстройки
(специализации) еще не тестированных
модулей нижних уровней к уже оттестированным
модулям верхних уровней.
Особенности
восходящего тестирования в организации
порядка сборки и перехода к тестированию
модулей, соответствующему порядку их
реализации.
Например,
порядок тестирования комплекса К (см.
рис. 5.2) при восходящем тестировании
может быть следующим (см. пример 5.4).
1)М11->ХУ11
2) M12 ->
XY12
3) М1 ->
XY1
4)
М21
-> XY21
5)
M2(M21, Stub(M22)) -> XY2
6)
К(М1,
M2(M2I, Stub(M22)) -> XYK
7) М22 ->
XY22
 М2 ->
М2 ->
XY2
9) К ->
XYK
Пример
5.2. Возможный порядок тестов при восходящем
тестировании.
Недостатки
восходящего тестирования:
• запаздывание
проверки концептуальных особенностей
тестируемого комплекса;
• необходимость
в разработке и использовании драйверов
[33].
Системное
тестирование
Системное
тестирование качественно отличается
от интеграционного и модульного уровней.
Системное тестирование рассматривает
тестируемую систему в целом и оперирует
на уровне пользовательских интерфейсов,
в отличие от последних фаз интеграционного
тестирования, которое оперирует на
уровне интерфейсов модулей. Различны
и цели этих уровней тестирования. На
уровне системы часто сложно и малоэффективно
анализировать прохождение тестовых
траекторий внутри программы или
отслеживать правильность работы
конкретных функций.
Основная
задача системного тестирования —
выявления дефектов, связанных с работой
системы в целом, таких как неверное
использование ресурсов системы,
непредусмотренные комбинации данных
пользовательского уровня, несовместимость
с окружением, непредусмотренные сценарии
использования, отсутствующая или
неверная функциональность, неудобство
в применении и т. п.
Системное
тестирование производится над проектом
в целом с помощью метода «черного ящика».
Структура программы не имеет никакого
значения, для проверки доступны только
входы и выходы, видимые пользователю.
Тестированию подлежат коды и
пользовательская документация.
Категории
тестов системного тестирования:
1. Полнота
решения функциональных задач.
2. Стрессовое
тестирование — на предельных объемах
нагрузки входного потока.
3.
Корректность использования ресурсов
(утечка памяти, возврат ресурсов).
4. Оценка
производительности.
5.
Эффективность защиты от искажения
данных и некорректных действий.
6. Проверка
инсталляции и конфигурации на разных
платформах.
7.
Корректность документации.
Поскольку
системное тестирование проводится на
пользовательских интерфейсах, создается
иллюзия того, что построение специальной
системы автоматизации тестирования не
всегда необходимо. Однако объемы данных
на этом уровне таковы, что обычно более
эффективным подходом является полная
или частичная автоматизация тестирования,
что приводит к созданию тестовой системы,
гораздо более сложной, чем система
тестирования, применяемая на уровне
тестирования модулей или их комбинаций.
![]()
Ответ на вопрос в сканворде (кроссворде) «Этап разработки компьютерной программы, на котором обнаруживают, локализуют и устраняют ошибки», 7 букв (первая — о, последняя — а):
отладка
(ОТЛАДКА) 👍 1 👎 0
Другие определения (вопросы) к слову «отладка» (26)
- Действие по глаголу отлаживать
- Настройка механизма
- Регулировка
- Доводка механизма, настройка
- Настройка чего-либо, устранение ошибок в программе
- Настройка четкости работы механизма
- Регулировка прибора
- Поиск ошибок в программе
- Доводка механизма до нужной кондиции
- Наладка, приведение в рабочее состояние, регулировка
- Настройка промышленного оборудов
- Регулировка оборудования
- Регулировка механизма
- Заключительная часть ремонта оборудования
- Процесс настройки системы
- Настройка и доводка оборудования
- Обслуживание станков и оборудования
- Этап устранения ошибок в программе
- Доведение оборудования до рабочего состояния
- Настройка системы
- Регулировка, наладка
- То же, что настройка
- «Ловля жуков» в программе
- Настройка промышленного оборудования
- Устранение ошибок в компьютерной программе
- Окончательная регулировка
- (при разработке компьютерной программы) этап, на котором обнаруживают, локализуют и устраняют ошибки
Определение 1
ОТЛА́ДКА,
-и, ж. Спец.
Действие по значению глагола отладить—отлаживать.
Отладка оружия. Отладка механизмов.
Определение 2
ОТЛА́ДИТЬ,
—ла́жу, —ла́дишь; причастие страдательное прошедшего времени отла́женный, —жен, -а, -о; совершенный вид, переходный глагол
(несовершенный вид отлаживать). Специальное Отрегулировать работу какого-либо механизма, приготовить механизм к действию.
Отладить спуск у капкана. ◆ Я хорошо отладил и смазал свой максим, и он работал довольно исправно. Дегтярев, Моя жизнь.
Отладка программы
Отла́дка — этап разработки компьютерной программы, на котором обнаруживают, локализуют и устраняют ошибки. Чтобы понять, где возникла ошибка, приходится:
- узнавать текущие значения переменных;
- выяснять, по какому пути выполнялась программа.
Существуют две взаимодополняющие технологии отладки:
- Использование отладчиков — программ, которые включают в себя пользовательский интерфейс для пошагового выполнения программы: оператор за оператором, функция за функцией, с остановками на некоторых строках исходного кода или при достижении определённого условия.
- Вывод текущего состояния программы с помощью расположенных в критических точках программы операторов вывода — на экран, принтер, громкоговоритель или в файл. Вывод отладочных сведений в файл называется журналированием.
Показать дальше
Наверх ↑
Словарь синонимов | Ассоциации | Словарь антонимов | Толковый словарь | Фонетический разбор слова онлайн | Составить слова из заданных букв
Что искали другие
- Ученый прогнозист
- Врач, который видит пациентов насквозь
- Дикий предок домашнего карпа
- Шапка кавалериста
- Вулканическая горная порода
Случайное
- И плохая работа, и побочный заработок
- Воздействие, прилагаемое к рычагу
- Карающий … правосудия
- Собака с милицейским уклоном
- Китайский финик
- Поиск занял 0.029 сек. Вспомните, как часто вы ищете ответы? Добавьте sinonim.org в закладки, чтобы быстро искать их, а также синонимы, антонимы, ассоциации и предложения.
Пишите, мы рады комментариям
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
Классификация ошибок по этапу обработки программы
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
Вау!! 😲 Ты еще не читал? Это зря!
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.