
Understanding workers
First, let’s briefly examine how a worker operates.
Whenever a process instance arrives at a service task, a new job is created and pushed to an internal persistent queue within Camunda Platform 8. A client application can subscribe to these jobs with the workflow engine by the task type name (which is comparable to a queue name).
If there is no worker subscribed when a job is created, the job is simply put in a queue. If multiple workers are subscribed, they are competing consumers, and jobs are distributed among them.
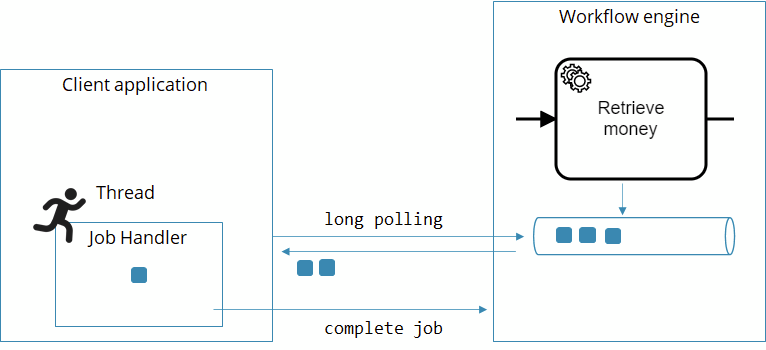
Whenever the worker has finished whatever it needs to do (like invoking the REST endpoint), it sends another call to the workflow engine, which can be one of these three:
CompleteJob: The service task went well, the process instance can move on.FailJob: The service task failed, and the workflow engine should handle this failure. There are two possibilities:remaining retries > 0: The job is retried.remaining retries <= 0: An incident is raised and the job is not retried until the incident is resolved.
ThrowError: A BPMN error is reported, which typically is handled on the BPMN level.
As the glue code in the worker is external to the workflow engine, there is no technical transaction spanning both components. Technical transactions refer to ACID (atomic, consistent, isolated, durable) properties, mostly known from relational databases.
If, for example, your application leverages those capabilities, your business logic is either successfully committed as a whole, or rolled back completely in case of any error. However, those ACID transactions cannot be applied to distributed systems (the talk lost in transaction elaborates on this). In other words, things can get out of sync if either the job handler or the workflow engine fails.
A typical example scenario is the following, where a worker calls a REST endpoint to invoke business logic:
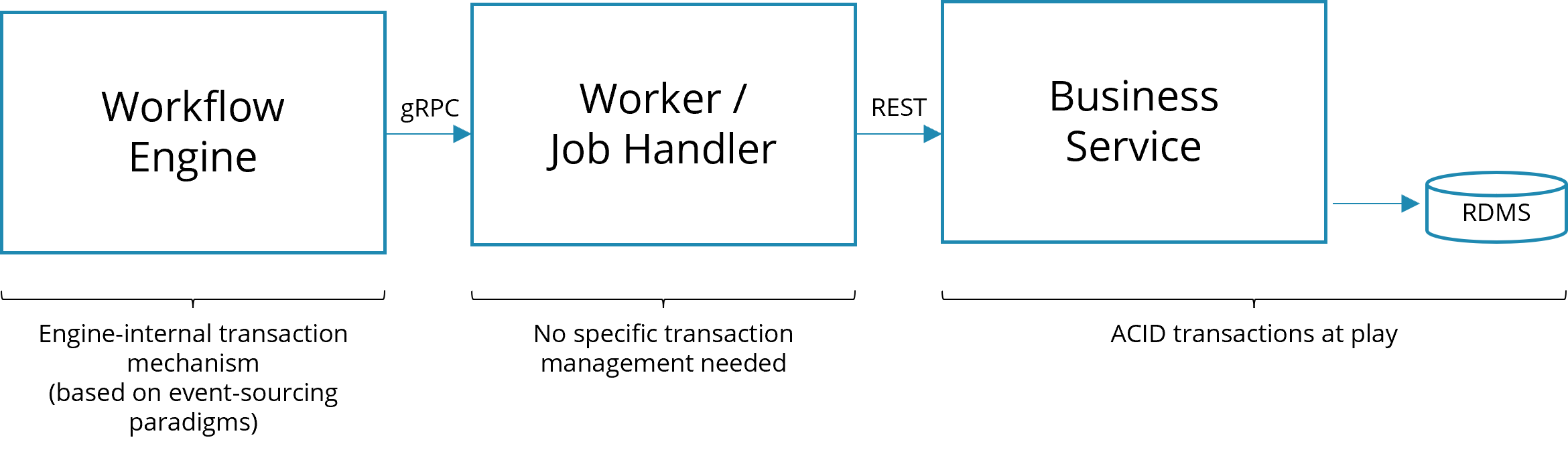
Technical ACID transaction will only be applied in the business application. The job worker mostly needs to handle exceptions on a technical level, e.g. to control retry behavior, or pass it on to the process level, where you might need to implement business transactions.
Handling exceptions on a technical level
Camunda Platform 8 only
The description of handling exceptions targets Camunda Platform 8. If you are looking for Camunda Platform 7, visit our documentation on operating Camunda Platform 7.
Leveraging retries
Using the FailJob API is pretty handy to leverage the built-in retry mechanism of Zeebe. The initial number of retries is set in the BPMN process model:
<bpmn:serviceTask id="TaskRetrieveMoney">
<bpmn:extensionElements>
<zeebe:taskDefinition retries="5" />
</bpmn:extensionElements>
</bpmn:serviceTask>
This number is typically decremented with every attempt to execute the service task. Note that you need to do that in your worker code. Example in Java:
@ZeebeWorker(type = "retrieveMoney")
public void retrieveMoney(final JobClient client, final ActivatedJob job) {
try {
// your code
} catch (Exception ex) {
jobClient.newFailCommand(job)
.retries(job.getRetries()-1) // <1>: Decrement retries
.errorMessage("Could not retrieve money due to: " + ex.getMessage()) // <2>
.send()
.exceptionally(t -> {throw new RuntimeException("Could not fail job: " + t.getMessage(), t);});
}
}
1
Decrement the retries by one.
2
Provide a meaningful error message, as this will be displayed to a human operator once an incident is created in Operate.
Example in Node.js:
zbc.createWorker("retrieveMoney", (job) => {
try {
// ...
} catch (e) {
job.fail("Could not retrieve money due to: " + e.message, job.retries - 1);
}
});
Using incidents
Whenever a job fails with a retry count of 0, an incident is raised. An incident requires human intervention, typically using Operate. See incidents in the Operate docs.
Writing idempotent workers
Zeebe uses the at-least-once strategy for job handlers, which is a typical choice in distributed systems. This means that the process instance only advances in the happy case (the job was completed, the workflow engine received the complete job request and committed it). A typical failure case occurs when the worker who polled the job crashes and cannot complete the job anymore. In this case, the workflow engine gives the job to another worker after a configured timeout. This ensures that the job handler is executed at least once.
But this can mean that the handler is executed more than once! You need to consider this in your handler code, as the handler might be called more than one time. The technical term describing this is idempotency.
For example, typical strategies are described in 3 common pitfalls in microservice integration — and how to avoid them. One possibility is to ask the service provider if it has already seen the same request. A more common approach is to implement the service provider in a way that allows for duplicate calls. There are two ways of mastering this:
- Natural idempotency. Some methods can be executed as often as you want because they just flip some state. Example:
confirmCustomer(). - Business idempotency. Sometimes you have business identifiers that allow you to detect duplicate calls (e.g. by keeping a database of records that you can check). Example:
createCustomer(email).
If these approaches do not work, you will need to add a custom idempotency handling by using unique IDs or hashes. For example, you can generate a unique identifier and add it to the call. This way, a duplicate call can be easily spotted if you store that ID on the service provider side. If you leverage a workflow engine you probably can let it do the heavy lifting. Example: charge(transactionId, amount).
Whatever strategy you use, make sure that you’ve considered idempotency consciously.
Handling errors on the process level
You often encounter deviations from the «happy path» (the default scenario with a positive outcome) which shall be modeled in the process model.
Using BPMN error events
A common way to resolve these deviations is using a BPMN error event, which allows a process model to react to errors within a task. For example:
1
We decide that we want to deal with an exception in the process: in case the invoice cannot be sent automatically…
2
…we assign a task to a human user, who is now in charge of taking care of delivering the invoice.
Learn more about the usage of error events in the user guide.
Throwing and handling BPMN errors
In BPMN process definitions, we can explicitly model an end event as an error.
1
In case the item is not available, we finish the process with an error end event.
note
You can mimic a BPMN error in your glue code by using the ThrowError API. The consequences for the process are the same as if it were an explicit error end event. So, in case your ‘purchase’ activity is not a sub process, but a service task, it could throw a BPMN Error informing the process that the good is unavailable.
Example in Java:
jobClient.newThrowErrorCommand(job)
.errorCode("GOOD_UNAVAILABLE")
.errorMessage()
.send()
.exceptionally(t -> {throw new RuntimeException("Could not throw BPMN error: " + t.getMessage(), t);});
Thinking about unhandled BPMN exceptions
It is crucial to understand that according to the BPMN spec, a BPMN error is either handled via the process or terminates the process instance. It does not lead to an incident being raised. Therefore, you can and normally should always handle the BPMN error. You can, of course, also handle it in a parent process scope like in the example below:
1
The boundary error event deals with the case that the item is unavailable.
Distinguishing between exceptions and results
As an alternative to throwing a Java exception, you can also write a problematic result into a process variable and model an XOR-Gateway later in the process flow to take a different path if that problem occurs.
From a business perspective, the underlying problem then looks less like an error and more like a result of an activity, so as a rule of thumb we deal with expected results of activities by means of gateways, but model exceptional errors, which hinder us in reaching the expected result as boundary error events.
1
The task is to «check the customer’s creditworthiness», so we can reason that we expect as a result to know whether the customer is credit-worthy or not.
2
We can therefore model an exclusive gateway working on that result and decide via the subsequent process flow what to do with a customer who is not credit-worthy. Here, we just consider the order to be declined.
3
However, it could be that we cannot reach a result, because while we are trying to obtain knowledge about the customer’s creditworthiness, we discover that the ID we have is not associated with any known real person. We can’t obtain the expected result and therefore model a boundary error event. In the example, the consequence is just the same and we consider the order to be declined.
Business vs. technical errors
Note that you have two different ways of dealing with problems at your disposal now:
- Retrying. You don’t want to model the retrying, as you would have to add it to each and every service task. This will bloat the visual model and confuse business personnel. Instead, either retry or fall back to incidents as described above. This is hidden in the visual.
- Branch out separate paths, as described with the error event.
In this context, we found the terms business error and technical error can be confusing, as they emphasize the source of the error too much. This can lead to long discussions about whether a certain problem is technical or not, and if you are allowed to see technical errors in a business process model.
It’s much more important to look at how you react to certain errors. Even a technical problem can qualify for a business reaction. In the above example, upon technical problems with the invoice service you can decide to manually send the invoice (business reaction) or to retry until the invoice service becomes available again (technical reaction).
Or, for example, you could decide to continue a process in the event that a scoring service is not available, and simply give every customer a good rating instead of blocking progress. The error is clearly technical, but the reaction is a business decision.
In general, we recommend talking about business reactions, which are modeled in your process, and technical reactions, which are handled generically using retries or incidents.
Embracing business transactions and eventual consistency
Technical vs business transactions
Applications using databases can often leverage ACID (atomic, consistent, isolated, durable) capabilities of that database. This means that some business logic is either successfully committed as a whole, or rolled back completely in case of any error. It is normally referred to as «transactions».
Those ACID transactions cannot be applied to distributed systems (the talk lost in transaction elaborates on this), so if you call out to multiple services from a process, you end up with separate ACID transactions at play. The following illustrations are taken from the O’Reilly book Practical Process Automation:
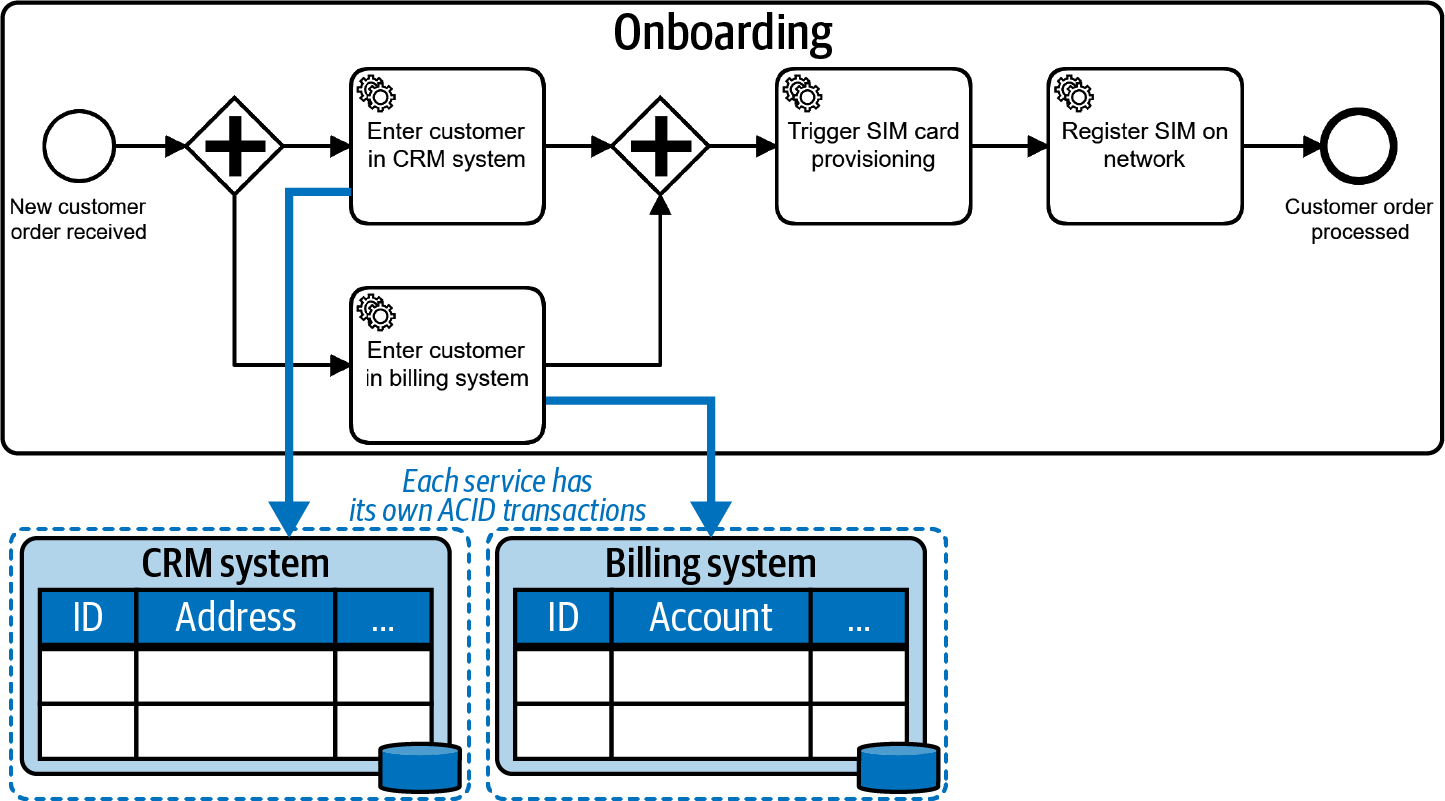
In the above example, the CRM system and the billing system have their local ACID transactions. The workflow engine itself also runs transactional. However, there cannot be a joined technical transaction.This requires a new way of dealing with consistency on the business level, which is referred to as business transaction:
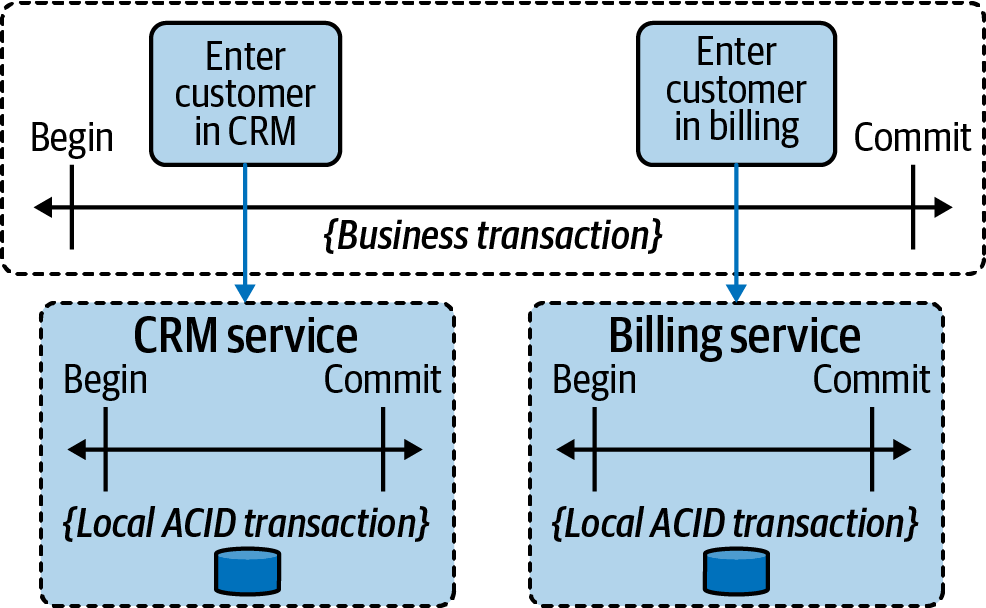
A business transaction marks a section in a process for which ‘all or nothing’ semantics (similar to a technical transaction) should apply, but from a business perspective. You might encounter inconsistent states in between (for example a new customer being present in the CRM system, but not yet in the billing system).
Eventual consistency
It is important to be aware that these temporary inconsistencies are possible. You also have to understand the failure scenarios they can cause. In the above example, you could have created a marketing campaign at a moment when a customer was already in the CRM system, but not yet in billing, so they got included in that list. Then, even if their order gets rejected and they never end up as an active customer, they might still receive an upgrade advertisement.
You need to understand the effects of this happening. Furthermore, you have to think about a strategy to resolve inconsistencies. The term eventual consistency suggests that you need to take measures to get back to a consistent state eventually. In the onboarding example, this could mean you need to deactivate the customer in the CRM system if adding them to the billing system fails. This leads to the consistent state that the customer is not visible in any system anymore.
Business strategies to handle inconsistency
There are three basic strategies if a consistency problem occurs:
- Ignore it. While it sounds strange to consider ignoring a consistency issue, it actually can be a valid strategy. It’s a question of how much business impact the inconsistency may have.
- Apologize. This is an extension of the strategy to ignore. You don’t try to prevent inconsistencies, but you do make sure that you apologize when their effects come to light.
- Resolve it. Tackle the problem head-on and actively resolve the inconsistency. This could be done by different means, such as the reconciliation jobs mentioned earlier, but this practice focuses on how BPMN can help by looking into the Saga pattern.
Selecting the right strategy is a clear business decision, as none of them are right or wrong, but simply more or less well suited to the situation at hand. You should always think about the cost/value ratio.
The Saga pattern and BPMN compensation
The Saga pattern describes long-running transactions in distributed systems. The main idea is simple: when you can’t roll back tasks, you undo them. (The name Saga refers back to a paper written in the 1980s about long-lived transactions in databases.)
Camunda supports this through BPMN compensation events, which can link tasks with their undo tasks.
1
Assume the customer was already added to the CRM system…
2
…when an error occurred…
3
…the process triggers the compensation to happen. This will roll back the business transaction.
4
All compensating activities of successfully completed tasks will be executed, in this case also this one.
5
As a result, the customer will be deactivated, as the API of the CRM system might not allow to simply delete it.
Now that we can Orchestrate RPA Bots let’s have a look at how to react to a failing RPA bot or — generally speaking — how to handle the result of a bot as a BPMN error. Please note that the features presented here only work with a Camunda Platform 7.15 or later.
Scenarios
As mentioned already, we can generally react to the result of an RPA bot execution by throwing a BPMN error. There are two main use cases for this:
- Business Error: In case an RPA bot completes as expected, its output parameters might indicate that – from a business perspective – the execution should be treated as an exceptional case.
- Technical Error: An RPA bot fails with a specific error message and stack trace, indicating a technical error that should be treated as an exceptional business case that can be handled in a structured way in the process model.
Configuration
To be able to properly react to failures of RPA bots, we recommend enabling the following properties in your Camunda engine instance (e.g. an instance of Camunda Run):
skipOutputMappingOnCanceledActivities: Enabling this flag will ensure that output mappings created for your service tasks will not be evaluated if the task is canceled. Since the failure of an RPA bot will cancel the service task through the RPA Bridge, this will ensure that your service tasks will be properly handled even if the RPA bot does not deliver expected output parameters on failure.enableExceptionsAfterUnhandledBpmnError: Enabling this flag will lead to an exception after throwing uncaught BPMN errors from your service task. We will get to how to throw such an error in a minute. In general, we recommend catching all BPMN Errors that can be thrown in a process. Enabling this flag will lead to processes not ending unexpectedly but rather failing with exceptions that can be observed in system logs – this can come in handy while developing the process.
Throwing BPMN Errors
To throw BPMN errors from your service tasks, add an error definition to your template in the Catalog in Cawemo.

Edit the template under BPMN Errors as follows:
- Name: human-readable name for your error
- Code: this value is used to match the thrown error to an Error Catch event
- Message: add further details if applicable
- Throw Expression for Business Error
- You can access Output Parameters from the bot, like
${outputParameter.startsWith("something")}or${outputParameter > 3000} - You can refer to the Output Parameters as they are named in the Output Parameter section.
- You can access Output Parameters from the bot, like
- Throw Expression for Technical Error
- You can access the error details from the service task instance, like
${externalTask.getErrorDetails() != null}or${externalTask.getErrorDetails().contains("Application not available")} - Don’t rely on Output Parameters to be available in such cases, as those might not be returned on failure by the bot.
- You can access the error details from the service task instance, like
The first Throw Expression that matches will be applied. Any following expressions will not be evaluated.
Please remember, before the template can be used in the Camunda Modeler, it needs to be published once by clicking the “Publish” button in the upper right corner.
After publishing the template, you can synchronize it in the Camunda Modeler and update the template there at your service task.
You can now adjust the error definition details if necessary.
Catching BPMN Errors
To handle the BPMN error that we just defined, we need to create a Boundary Error Event at the service task. This boundary event can now reference the error definition we created with the template to properly catch it.
Alternatively to catching the error directly at the service task itself, you can also catch it with
- a boundary error event on a surrounding subprocess
- an event subprocess with an error start event
- a parent process that calls this process via a Call Activity
Catching the error concludes the handling of business errors for this guide.
| title | weight | menu | ||||||
|---|---|---|---|---|---|---|---|---|
|
Error Handling |
280 |
|
Error Handling Strategies
There are a couple of basic strategies to handle errors and exceptions within processes. The decision which strategy to use depends on:
- Technical vs. Business Errors: Does the error have some business meaning and causes an alternative process flow (like «item not on stock») or is it a technical malfunction (like «network currently down»)?
- Explicit error handling or generic approach: For some situations you want to explicitly model what should happen in case of an error (typically for business errors). For a lot of situations you don’t want to do that but have some generic mechanism which applies for errors, simplifying your process models (typical for technical errors, imagine you would have to model network outage on every task were it might possibly occur? You wouldn’t be able to recognize your business process any more).
In the context of the process engine, errors are normally raised as Java exceptions which you have to handle. Let’s have a look at how to handle them.
Transaction Rollbacks
The standard handling strategy is that exceptions are thrown to the client, meaning that the current transaction is rolled back. This means that the process state is rolled back to the last wait state. This behavior is described in detail in the [Transactions in Processes]({{< ref «/user-guide/process-engine/transactions-in-processes.md» >}}) section of the [User Guide]({{< ref «/user-guide/_index.md» >}}). Error handling is delegated to the client by the engine.
Let’s show this in a concrete example: the user gets an error dialog on the frontend stating that the stock management software is currently not reachable due to network errors. To perform a retry, the user might have to click the same button again. Even if this is often not desired it is still a simple strategy applicable in a lot of situations.
Async and Failed Jobs
If you don’t want the exception being shown to the user, one option is to make service calls, which might cause an error, async (as described in [Transactions in Processes]({{< ref «/user-guide/process-engine/transactions-in-processes.md» >}})). In that case the exception is stored in the process engine database and the [Job]({{< ref «/user-guide/process-engine/the-job-executor.md» >}}) in the background is marked as failed (to be more precise, the exception is stored and some retry counter is decremented).
In the example above this means that the user will not see an error but an «everything successful» dialog. The exception is stored on the job. Now either a clever retry strategy will automatically re-trigger the job later on (when the network is available again) or an operator needs to have a look at the error and trigger an additional retry. This is shown later in more detail.
This strategy is pretty powerful and applied often in real-life projects, however, it still hides the error in the BPMN diagram, so for business errors which you want to be visible in the process diagram, it would be better to use [Error Events]({{< relref «#bpmn-2-0-error-event» >}}).
Catch Exception and use Data Based XOR-Gateway
If you call Java Code which can throw an exception, you can catch the exception within the Java Delegate, CDI Bean or whatsoever. Maybe it is already sufficient to log some information and go on, meaning that you ignore the error. More often you write the result into a process variable and model an XOR-Gateway later in the process flow to take a different path if that error occurs.
In that case you model the error handling explicitly in the process model but you make it look like a normal result and not like an error. From a business perspective it is not an error but a result, so the decision should not be made lightly. A rule of thumb is that results can be handled this way, exceptional errors should not. However, the BPMN perspective does not always have to match the technical implementation.
Example:
{{< img src=»../img/error-result-xor.png» title=»Error Result XOR» >}}
We trigger a «check data completeness» task. The Java Service might throw a «DataIncompleteException». However, if we check for completeness, incomplete data is not an exception, but an expected result, so we prefer to use an XOR-Gateway in the process flow which evaluates a process variable, e.g., «#{dataComplete==false}».
BPMN 2.0 Error Event
The BPMN 2.0 error event gives you the possibility to explicitly model errors, tackling the use case of business errors. The most prominent example is the «intermediate catching error event», which can be attached to the boundary of an activity. Defining a boundary error event makes most sense on an embedded subprocess, a call activity or a Service Task. An error will cause the alternative process flow to be triggered:
{{< img src=»../img/bpmn.boundary.error.event.png» title=»Error Boundary Event» >}}
See the [Error Events]({{< ref «/reference/bpmn20/events/error-events.md» >}}) section of the [BPMN 2.0 Implementation Reference]({{< ref «/reference/bpmn20/_index.md» >}}) and the [Throwing Errors from Delegation Code]({{< ref «/user-guide/process-engine/delegation-code.md#throw-bpmn-errors-from-delegation-code» >}}) section of the [User Guide]({{< ref «/user-guide/_index.md» >}}) for more information.
BPMN 2.0 Compensation and Business Transactions
BPMN 2.0 transactions and compensations allow you to model business transaction boundaries (however, not in a technical ACID manner) and make sure already executed actions are compensated during a rollback. Compensation means to make the effect of the action invisible, e.g. book in goods if you have previously booked out the goods. See the [BPMN Compensation event]({{< ref «/reference/bpmn20/events/cancel-and-compensation-events.md» >}}) and the [BPMN Transaction Subprocess]({{< ref «/reference/bpmn20/subprocesses/transaction-subprocess.md» >}}) sections of the [BPMN 2.0 Implementation Reference]({{< ref «/reference/bpmn20/_index.md» >}}) for details.
Monitoring and Recovery Strategies
In case the error occurred, different recovery strategies can be applied.
Let the User Retry
As mentioned above, the simplest error handling strategy is to throw the exception to the client, meaning that the user has to retry the action himself. How he does that is up to the user, normally reloading the page or clicking again.
Retry Failed Jobs
If you use Jobs (async), you can leverage Cockpit as monitoring tool to handle failed jobs, in this case no end user sees the exception. Then you normally see failures in cockpit when the retries are depleted (see the [Failed Jobs]({{< ref «/user-guide/process-engine/the-job-executor.md#failed-jobs» >}}) section of the [Web Applications]({{< ref «/webapps/cockpit/_index.md» >}}) for more information).
See the [Failed Jobs in Cockpit]({{< ref «/webapps/cockpit/bpmn/failed-jobs.md» >}}) section of the [Web Applications]({{< ref «/webapps/cockpit/_index.md» >}}) for more details.
If you don’t want to use Cockpit, you can also find the failed jobs via the API yourself:
List<Job> failedJobs = processEngine.getManagementService().createJobQuery().withException().list(); for (Job failedJob : failedJobs) { processEngine.getManagementService().setJobRetries(failedJob.getId(), 1); }
Explicit Modeling
Of course you can always explicitly model a retry mechanism as pointed out in Where is the retry in BPMN 2.0:
{{< img src=»../img/retry.png» title=»Retry Mechanism» >}}
We would recommend to limit it to cases where you want to see it in the process diagram for a good reason. We prefer asynchronous continuation, as it doesn’t bloat your process diagram and basically can do the same thing with even less runtime overhead, as «walking» through the modeled loop involves additional action, e.g., writing an audit log.
User Tasks for Operations
We often see something like this in projects:
{{< img src=»../img/error-handling-user-task.png» title=»User Task Error Handling» >}}
Actually this is a valid approach in which you assign errors to an operator as User Tasks and model what options he has to solve the problem. However, this is a strange mixture: We want to handle a technical error we but add it to our business process model. Where do we stop? Do we have to model it on every Service Task now?
Having a failed jobs list instead of using the «normal» task list feels like a more natural approach for this situation, which is why we normally recommend the other possibility and do not consider this to be best practice.
Exception codes
Sometimes an API call doesn’t succeed because a problem occurs. The Java programming model uses exceptions
to handle these situations. Exceptions that occur on the process engine’s application level are
of the type {{< javadocref page="org/camunda/bpm/engine/ProcessEngineException.html" text="ProcessEngineException" >}}.
Here are two examples of everyday situations in which the engine throws a ProcessEngineException:
- You cannot start a process instance since the variable’s value is too long.
- Two users in parallel complete the same task.
You can read the exception message to understand the reason for a ProcessEngineException. However,
sometimes the message of the top-level exception is too generic. In these situations, the cause might
contain a more insightful exception message. Traversing through exception causes might be tedious.
Also, causes are unavailable when an error occurs on the REST API level.
While reading the error message might help users to understand the root cause of the problem,
evaluating exception messages in an automated way is not a good idea since:
- The message might change with newer versions.
- Relying on fragments of the message can be error-prone.
This is why we introduced static exception codes your business logic can rely on to determine specific
problems and react accordingly.
You can access error codes via Java as well as [REST API]({{< ref «/reference/rest/overview/_index.md#exception-codes» >}}).
Built-in codes
We identified common situations in which the engine throws an exception and assigned a built-in
error code to the exception. You can look up the built-in codes in the Categories, ranges, and codes section.
Custom codes
Sometimes you may want to assign codes to specific errors Camunda hasn’t covered so far.
You can either define custom codes from delegation code or by registering your custom ExceptionCodeProvider.
Delegation code
Learn more on how to assign a custom error code to an exception in the documentation about [Delegation Code]({{< ref «/user-guide/process-engine/delegation-code.md#exception-codes» >}}).
Configuration
You can configure the exception error codes feature in your [process engine configuration]({{< ref «/reference/deployment-descriptors/tags/process-engine.md#exception-codes» >}}):
- To disable the exception codes feature entirely, set the flag
disableExceptionCode
in your process engine configuration totrue. - To disable the built-in exception code provider, set the flag
disableBuiltinExceptionCodeProvider
in your process engine configuration totrue. Disabling the built-in exception code
provider allows overriding the reserved code range with your custom exception codes.
Register a Custom Code Provider
With the help of a [ProcessEnginePlugin]({{< ref «/user-guide/process-engine/process-engine-plugins.md» >}}) you can register a custom {{< javadocref page="org/camunda/bpm/engine/impl/errorcode/ExceptionCodeProvider.html" text="ExceptionCodeProvider" >}}:
engineConfig.setCustomExceptionCodeProvider(new ExceptionCodeProvider() { @Override public Integer provideCode(ProcessEngineException processEngineException) { // Put your business logic here to determine the // error code in case a process engine exception was thrown. return 22_222; } @Override public Integer provideCode(SQLException sqlException) { // Put your business logic here to determine the // error code in case a sql exception was thrown. return 33_333; } });
{{< note title=»Heads-up!» class=»info» >}}
If your custom error code violates the reserved code range, it will be overridden with 0 unless you disable the built-in code provider.
{{< /note >}}
Categories, ranges, and codes
In the table below, you will find an overview of all categories, ranges, and codes:
| Category | Range | Code | Description | Safe to retry |
|---|---|---|---|---|
| Fallback | 0 | All errors with no code assigned. | ||
| Engine | [1, 9999] | 1 | OptimisticLockingException/CrdbTransactionRetryException |
X |
| Persistence | [10000, 19999] | 10,000 | Deadlock situation occurred. | X |
| 10,001 | A foreign key constraint was violated. | |||
| 10,002 | The column size is too small. | |||
| Custom | [20000, 39999] | E.g., 22,222 | E.g., custom JavaDelegate validation error. |
Reserved code range
The codes <= 19,999 and >= 40,000 are reserved for built-in codes. If you disable the built-in code provider,
you can also use the reserved code range for your custom codes.
In this tutorial, we are going to learn about how to handle exceptions in Camunda. For this
Create a Spring Boot project with the embedded Camunda Engine using this link. Use version 7.15.0.
Other Requirements
- Spring Boot 2.4.3
- Camunda 7.15.0
- Eclipse or any other IDE
- Maven
Handle Exceptions in Camunda
Import the Maven project into Eclipse and add the required dependencies.
- Create service task in Camunda modeler and add error catch event to that service task.
- Whenever an exception occurred in the service task, an error catch event will catch the exception and throws that service task into the respective journey flow.
- If you did not give any error catch event it will be created as an incident in the cockpit and the token will be rolled back to the start event.
Use Camunda modeler to save the below XML content with the .bpmn extension to get the process model, which is having an error catch event.
<?xml version="1.0" encoding="UTF-8"?>
<bpmn:definitions xmlns:bpmn="http://www.omg.org/spec/BPMN/20100524/MODEL" xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI" xmlns:dc="http://www.omg.org/spec/DD/20100524/DC" xmlns:camunda="http://camunda.org/schema/1.0/bpmn" xmlns:di="http://www.omg.org/spec/DD/20100524/DI" id="Definitions_12zbd5u" targetNamespace="http://bpmn.io/schema/bpmn" exporter="Camunda Modeler" exporterVersion="4.5.0">
<bpmn:collaboration id="Collaboration_1vtn4s6">
<bpmn:participant id="Participant_18yien5" name="Error Handling" processRef="Process_1jtu8ae" />
</bpmn:collaboration>
<bpmn:process id="Process_1jtu8ae" isExecutable="true">
<bpmn:startEvent id="StartEvent_1">
<bpmn:outgoing>Flow_0vs3b46</bpmn:outgoing>
</bpmn:startEvent>
<bpmn:endEvent id="Event_08wul9s">
<bpmn:incoming>Flow_0kby2yc</bpmn:incoming>
</bpmn:endEvent>
<bpmn:sequenceFlow id="Flow_0vs3b46" sourceRef="StartEvent_1" targetRef="Activity_0snk7cd" />
<bpmn:sequenceFlow id="Flow_0kby2yc" sourceRef="Activity_0snk7cd" targetRef="Event_08wul9s" />
<bpmn:serviceTask id="Activity_0snk7cd" name="Service Task" camunda:delegateExpression="${ServiceTaskDelegate}">
<bpmn:incoming>Flow_0vs3b46</bpmn:incoming>
<bpmn:outgoing>Flow_0kby2yc</bpmn:outgoing>
</bpmn:serviceTask>
<bpmn:sequenceFlow id="Flow_0qbi7m4" sourceRef="Event_01bk0vq" targetRef="Event_0my2aab" />
<bpmn:boundaryEvent id="Event_01bk0vq" attachedToRef="Activity_0snk7cd">
<bpmn:outgoing>Flow_0qbi7m4</bpmn:outgoing>
<bpmn:errorEventDefinition id="ErrorEventDefinition_1eepl13" errorRef="Error_00fdfpv" camunda:errorCodeVariable="code_variable" />
</bpmn:boundaryEvent>
<bpmn:endEvent id="Event_0my2aab">
<bpmn:incoming>Flow_0qbi7m4</bpmn:incoming>
<bpmn:errorEventDefinition id="ErrorEventDefinition_1hkclb7" errorRef="Error_00fdfpv" />
</bpmn:endEvent>
</bpmn:process>
<bpmn:error id="Error_00fdfpv" name="BPMN_ERROR" errorCode="error_code" />
<bpmndi:BPMNDiagram id="BPMNDiagram_1">
<bpmndi:BPMNPlane id="BPMNPlane_1" bpmnElement="Collaboration_1vtn4s6">
<bpmndi:BPMNShape id="Participant_18yien5_di" bpmnElement="Participant_18yien5" isHorizontal="true">
<dc:Bounds x="129" y="52" width="600" height="316" />
</bpmndi:BPMNShape>
<bpmndi:BPMNEdge id="Flow_0qbi7m4_di" bpmnElement="Flow_0qbi7m4">
<di:waypoint x="390" y="228" />
<di:waypoint x="390" y="290" />
<di:waypoint x="462" y="290" />
</bpmndi:BPMNEdge>
<bpmndi:BPMNEdge id="Flow_0kby2yc_di" bpmnElement="Flow_0kby2yc">
<di:waypoint x="440" y="170" />
<di:waypoint x="512" y="170" />
</bpmndi:BPMNEdge>
<bpmndi:BPMNEdge id="Flow_0vs3b46_di" bpmnElement="Flow_0vs3b46">
<di:waypoint x="278" y="170" />
<di:waypoint x="340" y="170" />
</bpmndi:BPMNEdge>
<bpmndi:BPMNShape id="_BPMNShape_StartEvent_2" bpmnElement="StartEvent_1">
<dc:Bounds x="242" y="152" width="36" height="36" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape id="Event_08wul9s_di" bpmnElement="Event_08wul9s">
<dc:Bounds x="512" y="152" width="36" height="36" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape id="Activity_0h53qgw_di" bpmnElement="Activity_0snk7cd">
<dc:Bounds x="340" y="130" width="100" height="80" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape id="Event_1vjkbhx_di" bpmnElement="Event_0my2aab">
<dc:Bounds x="462" y="272" width="36" height="36" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape id="Event_18eo0oc_di" bpmnElement="Event_01bk0vq">
<dc:Bounds x="372" y="192" width="36" height="36" />
</bpmndi:BPMNShape>
</bpmndi:BPMNPlane>
</bpmndi:BPMNDiagram>
</bpmn:definitions>
After copy-pasting the above XML file in the Camunda modeler you can see the below diagram.
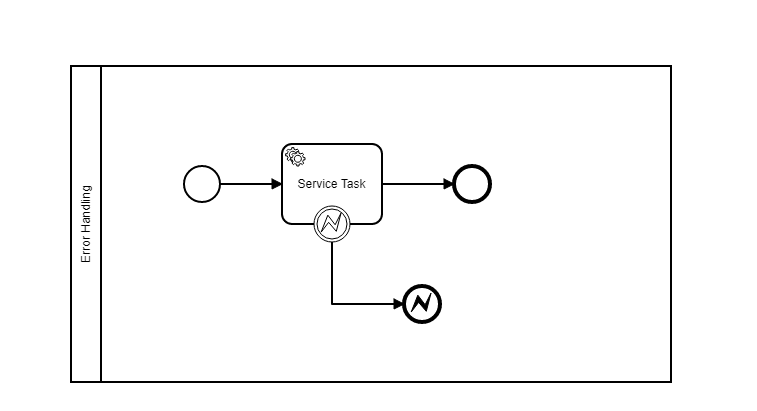
Add the below snippet to the exception handling
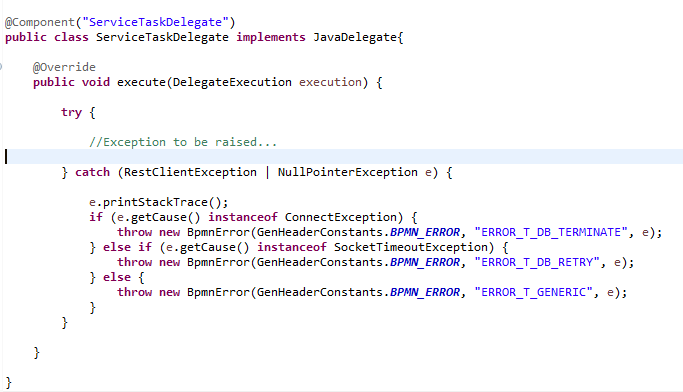
Run the application using the main class file and observe the output where the exception is caught by the error catch event and passed through the error throws event.
Opinions expressed by DZone contributors are their own.
The External Task pattern turns the push mechanism of service tasks into a pull principle. When running a process with Camunda platform, one or more separate applications fetch External Tasks via the Rest API of the process engine, execute them, and return some results. In a previous article, we have already discussed potential advantages and disadvantages of using External Tasks, and we have shown how to use Camunda’s official Java client. In this article, we discuss the error behavior of External Tasks, how you can simplify it by externalizing common behavior, and finally provide a Spring Boot Starter.
A German version of this blog post can be found here.
Errors? Errors do not occur! (The Happy Path)
Ideally, errors never occur during the execution of software so one does not need to even think about error handling at all. However, no matter how much a developer hopes for it: error handling should never be excluded from software architecture. That is why it is important to prepare for any possible error, thrown by the application itself or caused by invalid user-inputs perhaps unreliable surrounding systems. Especially the latter is hard to influence by any developer. The keyword is «resilience».
We use the following example process to ellaborate our intentions: A clerk composes an e-mail, specifies the address, and finally the e-mail is being sent by the service task «Send E-mail».
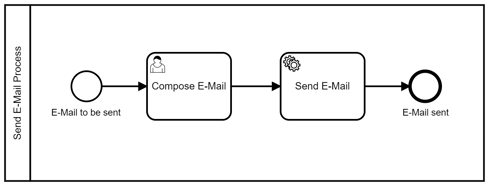
External-Task-Worker
The associated External Task Worker in this scenario could be implemented as follows. It would obtain the recipient’s address and the e-mail content from the process context, which was previously created in a user task. Finally, a mail service sends the data and after that the task is completed: taskService.complete(task). This implementation is valid and works — at least as long as no errors occur.
Note
Our examples are implemented based on the official Java client from Camunda. If you use a custom implementation, similar considerations are necessary, but the implementation may vary. Since version 7.15, Camunda als provides a Spring Boot Starter besides their Java client for External Tasks. With this starter, the previously required configuration becomes obsolete, and External Task Workers can be controlled through an application.yaml and the annotation @ExternalTaskSubscription. More information is available in the Camunda-Blog. In our code samples we also use this approach.
What could go wrong?
In the previous example, no error handling is considered at all. This could lead to the service task being completed, although the e-mail has never been sent. This would happen if the mail service reacted inappropriately to errors and the complete-method were called mistakenly. However, it could also lead to the task never being completed. And in this case, the e-mail might be sent several times, namely if any error occurs after sending the mail but before the task is completed. The External Task would be released by the process engine after the configured locking time, some External Task Worker executes it again, but might run into the same error again: an infinite loop — at least until the error is detected and fixed. Referring to conventional Java Delegates: Implementing some error behavior explicitly might be a good idea as well, but it is not mandatory, because in the worst case the process engine creates an incident by default, which is displayed in the cockpit.
Implement error behavior
Handling technical errors might look as follows: The entire business logic resides within a try block. Errors of the mail service are caught and handled in the catch block. The handleFailure() method requires values for the remaining number of retries and the waiting time until the next retry as well as an error cause. In contrast to a Java Delegate, when implementing an External Task Worker you have to take care of these issues yourself — it is not sufficient to configure some retry behavior in the process model. As soon as there are no retries left an incident is created at the corresponding process step. The remaining retries can be obtained from the task object using getRetries() (Attention: This value can be null). Based on this, a fixed, ascending error behavior is implemented in our next example, which is repeated up to five times, each delayed by one additional minute.
Recipient unknown
Besides technical errors, business errors might occur, e.g. if the data is incorrect. Such business errors will not be fixed even by multiple retries, because the data always stays the same. In this case, the retry behavior can be skipped completely, and the External Task Worker might end with a BPMN error. In our example, we extend the process model to include a user task if the recipient cannot be found.
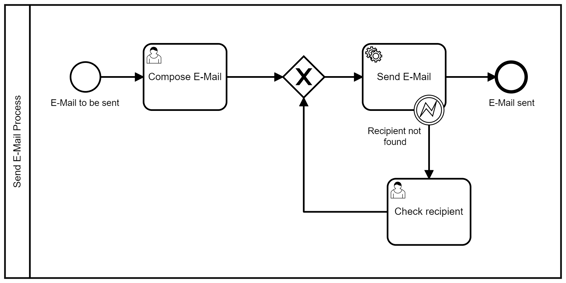
Business errors
The different error behavior in the case of an invalid e-mail address is implemented by an additional catch block: As soon as the mail service throws a RecipientNotFoundException, the logic to determine the next retry is skipped, and the External Task is completed using the handleBpmnError() method. Neither the number of remaining retries nor a time-delay is necassary. Instead, an error code and a message as well as optional variables can be returned. Caution: BPMN errors must be handled in the process model, like the error boundary event in our example. If a BPMN error is thrown which is not mapped in the model, a process instance terminates without any further notification.
Configure error behavior
Using conventional Java Delegates, process architects and developers are used to speficy the retry behavior as part of the process model itself. As soon as a service task is marked as «Asynchronous Before», the text field for «Retry Time Cycle» appears which can be used to specify when and how often the execution of a task should be retried, if the execution of the task fails. Using the ISO-8601 standard, a possible value looks like «R3/PT5M», which means three retries each after five minutes. Also possible: «PT5M,PT30M,PT1H» — First retry after five minutes, a second retry after 30 minutes if necessary, and finally another retry after one hour.
This feature can also be emulated for External Tasks by using the extension-properties of a task element. The retry behavior must be specified using a defined name, so it can be obtained at runtime by calling getExtensionProperties(). Depending on whether it is a custom notation or the official ISO-8601 standard, an according logic must be provided that calculates the subsequent retry.
Note
Values for extension-properties being available at runtime must be enabled for each worker that should use this feature. Either within the application.yaml (available in the Spring Boot Starter) or in the original worker configuration of the Spring Boot application.
camunda.bpm.client: base-url: http://localhost:8080/engine-rest subscriptions: send-mail: include-extension-properties: true
Automate retry behavior (Retry-Aspect)
We used the previously described approach to generalize the desired behavior in a separate Spring Boot Starter. This way, the retry behavior does not have to be added to each External Task Worker individually as sort of boilerplate code, but it is added automatically by simply adding a dependency to the project itself.
More information about this project is available on GitHub: https://github.com/viadee/external-task-retry-aspect
<dependency> <groupId>de.viadee.bpm.camunda</groupId> <artifactId>external-task-retry-aspect-spring-boot-starter</artifactId> <version>${version.retry-aspect}</version></dependency>
External-Task-Retry-Aspect
By using our Spring Boot Starter, all failures during an External Task execution leads at least to some sort of error behavior, even without any other measure implemented. By default this is three retry attempts each after five minutes each. Both, the default behavior as well as the retry behavior per task, are configurable of course.
Furthermore, business errors can be simply created by throwing an ExternalTaskBusinessError, which corresponds to the call of the handleBpmnError() method from above. Additionally, it is possible to entirely skip the error behavior to create an incident immediately by using an InstantIncidentException. Both features are optional, so that a developer might focus on the business logic exclusively without implementing any try-catch blocks. The default error behavior will still be present, because in any case a rudimentary treatment takes place in the background, so endless loops are avoided for sure. Nonetheless, errors can still be handled explicitly if the default behavior is insufficient.
Conclusion
The External Task pattern still offers great potential in different categories. We have already highlighted this in our previous article. A decoupling between process engine and execution through External Tasks is a future-proof concept and is becoming more and more popular. This is also indicated by the new Spring Boot Starter for External Task clients provided by Camunda since version 7.15. However, developers have to be aware of the differences compared to the classic variant with Java Delegates: Previously, in the worst case, things such as forgetting atry-catch block could leads to unnecessary retries and potentially an incident visible in the cockpit. But using External Tasks, lacking or faulty error handling might lead to endless loops or worse. The External-Task-Retry-Aspect represents a workaround for this drawback, adds basic error handling capabilites to an External Task Workers and can be added simply in a Spring Boot Starter manner.
Code samples on GitHub: https://github.com/viadee/bpmnExternalTaskWorkerExample
External-Task-Retry-Aspect: https://github.com/viadee/external-task-retry-aspect
Update 15. September 2022: Please also read our new blogpost about Camunda External Task Workers and Quarkus.
PROCESS MANAGEMENT DIRECTLY WITHIN Confluence
Do you know our viadee BPMN Modeler? It is a lightweight extension for the Enterprise Wiki System Atlassian Confluence. With the BPMN Modeler it is possible to carry out methodically profound process management directly within Confluence. The numerous and valuable advantages of this approach resulted from the extensive project experience of our BPM experts and were the motivation for the development of the plug-in.
Visit our BPMN Modeler page or go directly to the Atlassian Marketplace.
Back to blog overview