
Время на прочтение
16 мин
Количество просмотров 4.1K

К старту курса по Fullstack-разработке на Python делимся заключительной частью руководства по программированию сокетов, эта часть посвящена устранению неполадок и справочным сведениям.
К концу руководства вы освоите основные функции и методы модуля Python socket, научитесь применять пользовательский класс для отправки сообщений и данных между конечными точками и работать со всем этим в собственных клиент-серверных приложениях.
Устранение проблем
Что-то будет «отказываться» работать, это неизбежно. И что тогда делать? Не переживайте, это случается с каждым. Надеемся, что с помощью этого руководства, отладчика и любимой поисковой системы вы сможете продолжить работу с частью исходного кода.
Иначе вам прямая дорога в модуль socket на Python. Обязательно прочитайте всю документацию по каждой вызываемой функции или методу. А чтобы почерпнуть какие-то идеи, загляните ещё в справочный раздел.
Иногда дело не в исходном коде. Он может быть правильным, а проблема связана с другим хостом, клиентом или сервером. Или сетью. А возможно, проводится «атака посредника», в качестве которого используется роутер, брандмауэр или какое-то другое сетевое устройство.
Для решения таких проблем нужны дополнительные инструменты. Ниже приводятся инструменты и утилиты, которые могут в этом пригодиться или хотя бы подвести к решению.
ping
Отправкой запроса проверки связи по ICMP в ping проверяется, работает ли хост и подключён ли он к сети. Взаимодействие ping со стеком протоколов TCP/IP прямое, поэтому его работа не зависит от каких бы то ни было приложений, запускаемых на хосте.
Вот пример запуска ping на macOS:
$ ping -c 3 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.058 ms
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.165 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.164 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.058/0.129/0.165/0.050 ms
Статистика внизу может быть полезной, тчобы найти разрыв постоянного подключения и ответить на вопрос, теряются ли пакеты? Какова временнáя задержка? Можно посмотреть и время приёма-передачи.
Если между вами и другим хостом есть брандмауэр, запрос проверки связи в ping может быть запрещён. Политики соблюдения этого запрета реализуются администраторами брандмауэра, для которых обнаружение их хостов нежелательно. Если это ваш случай (и добавлены правила брандмауэра для взаимодействия хостов), убедитесь, что этими правилами также разрешается передача сообщений по ICMP между хостами.
ICMP — это протокол, применяемый в ping, а также протокол TCP и другие более низкоуровневые протоколы, используемые для передачи сообщений об ошибках. Причина странного поведения или медленных подключений может быть в ICMP.
ICMP-сообщения идентифицируются по типу и коду. Чтобы дать вам представление о важности их информации, приведём несколько таких сообщений:
Информацию о фрагментации и ICMP-сообщениях см. в статье об обнаружении наименьшего MTU на пути следования пакета в сети. Это пример того, чтó может быть причиной странного поведения.
netstat
В разделе «Просмотр состояния сокета» вы узнали, как можно использовать netstat для отображения информации о сокетах и их текущем состоянии. Эта утилита доступна на macOS, Linux и Windows.
В том разделе столбцы Recv-Q и Send-Q в выводе примера отсутствовали. В них показано количество байтов, которые хранятся в сетевых буферах и поставлены в очередь на передачу или приём, но по какой-то причине не считаны или не записаны в удалённом или локальном приложении.
То есть они остаются в ожидании в сетевых буферах, очередях ОС. Одна из причин — в приложении ограничено использование ресурсов ЦП либо нельзя вызвать socket.recv() или socket.send() и обработать байты. Или это проблемы с сетью, которые отражаются на передаче данных, например перегрузка сети или неисправное сетевое оборудование / кабели.
Посмотрим, сколько данных вы сможете отправить, прежде чем увидите ошибку. Попробуйте тестовый клиент с подключением к тестовому серверу и многократным вызовом socket.send(). В тестовом сервере никогда не вызывается socket.recv(), а лишь принимается подключение. Это становится причиной заполнения сетевых буферов на сервере, после чего в клиенте выдаётся ошибка.
Сначала запустите сервер:
$ python app-server-test.py 127.0.0.1 65432
Listening on ('127.0.0.1', 65432)
Затем, чтобы увидеть ошибку, запустите клиент:
$ python app-client-test.py 127.0.0.1 65432 binary test
Error: socket.send() blocking io exception for ('127.0.0.1', 65432):
BlockingIOError(35, 'Resource temporarily unavailable')
Вот вывод netstat, когда в клиенте и на сервере продолжается выполнение. При этом в клиенте многократно выводится приведённое выше сообщение об ошибке:
$ netstat -an | grep 65432
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED
tcp4 0 0 127.0.0.1.65432 *.* LISTEN
Первая запись — это сервер (у Local Address порт 65432):
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED
Обратите внимание на 408300 в Recv-Q.
Вторая запись — это клиент (у Foreign Address порт 65432):
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED
Обратите внимание на 269868 в Send-Q.
В клиенте, конечно, пытались записать байты, но на сервере они не считывались. Это стало причиной заполнения очереди сетевого буфера как на стороне приёма на сервере, так и на стороне отправки в клиенте.
Windows
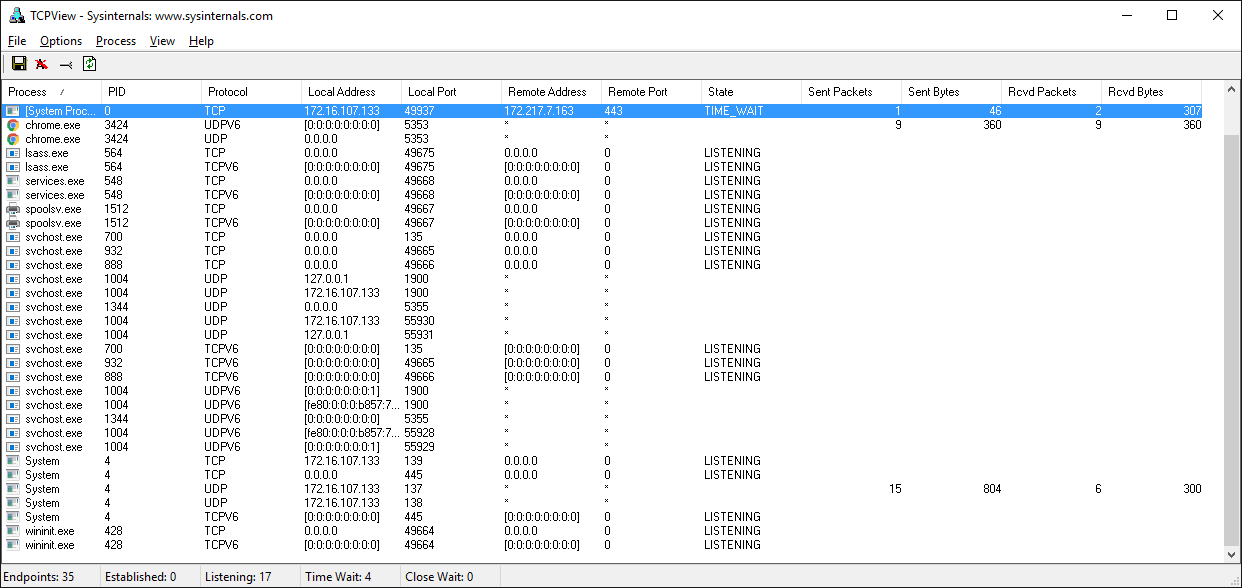
Если работаете с Windows, обязательно ознакомьтесь с набором утилит Windows Sysinternals.
Одна из них — TCPView.exe. Это графический netstat для Windows. Кроме адресов, номеров портов и состояния сокета, в ней нарастающим итогом показывается число отправленных и полученных пакетов и байтов. Как и в случае с утилитой lsof в Unix, здесь вы получаете имя и идентификатор процесса. Другие параметры отображения см. в меню.
Wireshark
Иногда нужно увидеть, что происходит при передаче по сети. Забудьте, чтó там в журнале приложения или какое значение возвращается из библиотечного вызова. Вам нужно видеть, чтó отправляется или получается в сети на самом деле. Здесь как с отладчиками: когда нужно увидеть это, они незаменимы.
Wireshark — это анализатор сетевых протоколов и приложение для захвата трафика, запускаемое на macOS, Linux, Windows и других ОС. Существует две версии: wireshark с графическим интерфейсом и текстовая tshark для терминала.
Захват трафика — это отличный способ понаблюдать за поведением приложения в сети и узнать: чтó, как часто и сколько в нём отправляется и получается. А ещё увидеть, когда клиент или сервер закрывается, когда в них прерывается подключение или прекращается отправка ответов. Эта информация может очень пригодиться при устранении проблем.
В интернете много хороших руководств и других ресурсов по основам использования Wireshark и TShark.
Вот пример захвата трафика в интерфейсе «внутренней петли» с помощью Wireshark:

А вот тот же пример с tshark:
$ tshark -i lo0 'tcp port 65432'
Capturing on 'Loopback'
1 0.000000 127.0.0.1 → 127.0.0.1 TCP 68 53942 → 65432 [SYN] Seq=0 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=0 SACK_PERM=1
2 0.000057 127.0.0.1 → 127.0.0.1 TCP 68 65432 → 53942 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=940533635 SACK_PERM=1
3 0.000068 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
4 0.000075 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Window Update] 65432 → 53942 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
5 0.000216 127.0.0.1 → 127.0.0.1 TCP 202 53942 → 65432 [PSH, ACK] Seq=1 Ack=1 Win=408288 Len=146 TSval=940533635 TSecr=940533635
6 0.000234 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=1 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
7 0.000627 127.0.0.1 → 127.0.0.1 TCP 204 65432 → 53942 [PSH, ACK] Seq=1 Ack=147 Win=408128 Len=148 TSval=940533635 TSecr=940533635
8 0.000649 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=149 Win=408128 Len=0 TSval=940533635 TSecr=940533635
9 0.000668 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [FIN, ACK] Seq=149 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
10 0.000682 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
11 0.000687 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Dup ACK 6#1] 65432 → 53942 [ACK] Seq=150 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
12 0.000848 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [FIN, ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
13 0.001004 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=150 Ack=148 Win=408128 Len=0 TSval=940533635 TSecr=940533635
^C13 packets capturedДалее приводим вам в помощь справочные материалы по программированию сокетов.
Справочный раздел
Этот раздел может использоваться в качестве справочника общего содержания с дополнительной информацией и ссылками на внешние ресурсы.
Документация Python
- Модуль socket.
- Практическое руководство по программированию сокетов.
Ошибки
Следующее взято из документации к модулю socket на Python:
«Все ошибки сопровождаются вызовом исключений. При недопустимых типах аргументов и нехватке памяти могут вызываться обычные исключения. Начиная с Python 3.3 ошибки, связанные с семантикой сокетов или адресов, сопровождаются вызовом
OSErrorили одного из его подклассов». (Источник).
Вот типичные ошибки, с которыми вы можете столкнуться при работе с сокетами:
Семейства адресов сокетов
socket.AF_INET и socket.AF_INET6 — это семейства адресов и протоколов для первого аргумента в socket.socket(). В API предполагается адрес определённого формата — в зависимости от того, создан сокет с помощью socket.AF_INET или socket.AF_INET6.
Ниже приведена выдержка из документации Python к модулю socket о значении host в кортеже адресов:
«Для IPv4-адресов вместо адреса хоста принимаются две специальные формы: пустая строка — это
INADDR_ANY, а строка'<broadcast>'— этоINADDR_BROADCAST. Такое поведение несовместимо с IPv6, так что они вам, возможно, не понадобятся, если вы намерены поддерживать IPv6 в своих программах на Python». (Источник)
Подробнее см. в документации по семействам сокетов на Python.
В этом руководстве применяются сокеты IPv4. Если в вашей сети поддерживается IPv6, попробуйте по возможности протестировать и использовать эту версию. Это легко делается с функцией socket.getaddrinfo(). Её аргументы host и port преобразуются в последовательность из пяти кортежей со всеми аргументами, необходимыми для создания сокета, подключённого к этому сервису. В socket.getaddrinfo() принимаются и интерпретируются переданные IPv6-адреса и имена хостов, которые разрешаются не только в IPv4, но и в IPv6-адреса.
В следующем примере возвращается информация об адресе для TCP-подключения к example.org в порте 80:
>>> socket.getaddrinfo("example.org", 80, proto=socket.IPPROTO_TCP)
[(<AddressFamily.AF_INET6: 10>, <SocketType.SOCK_STREAM: 1>,
6, '', ('2606:2800:220:1:248:1893:25c8:1946', 80, 0, 0)),
(<AddressFamily.AF_INET: 2>, <SocketType.SOCK_STREAM: 1>,
6, '', ('93.184.216.34', 80))]
На вашем компьютере результаты могут отличаться, если IPv6 не включена. Возвращаемые выше значения можно передавать в socket.socket() и socket.connect(). В документации Python к модулю socket, в разделе с примерами, содержится пример клиента и сервера.
Использование имён хостов
Кстати, этот раздел примени́м в основном к использованию имён хостов с .bind() и .connect() или .connect_ex(), когда задействуется интерфейс «внутренней петли» (localhost). Но примени́м он и в любой момент, когда вы используете имя хоста и ожидается его разрешение в определённый адрес. Причём имя хоста имеет особое значение для приложения, что отражается на его поведении или делаемых в нём допущениях. Это отличается от типичного сценария, когда в клиенте имя хоста используется для подключения к серверу, разрешённому при помощи DNS, например www.example.com.
Следующее взято из документации к модулю socket на Python:
«Если использовать имя хоста в хостовой части адреса сокета IPv4/v6, в программе может проявиться недетерминированное поведение, поскольку в Python используется первый адрес, возвращаемый из DNS-разрешения. Адрес сокета будет разрешён в фактический адрес IPv4/v6 по-разному в зависимости от результатов из DNS-разрешения и/или конфигурации хоста. Для детерминированного поведения используйте в хостовой части числовой адрес». (Источник).
Стандартным именем localhost предусматривается его разрешение в 127.0.0.1 или ::1, интерфейс «внутренней петли». В вашей системе наверняка так и будет. А может, и нет. Это зависит от того, как она сконфигурирована для разрешения имён. Как и во всём, что связано с ИТ, всегда имеются исключения, и нет никаких гарантий, что при использовании имени localhost произойдёт подключение к интерфейсу «внутренней петли».
Например, на Linux см. файл конфигурации man nsswitch.conf диспетчера службы имён. На macOS и Linux стóит ещё заглянуть в файл /etc/hosts. На Windows см. C:WindowsSystem32driversetchosts. В файле hosts имеется статическая таблица сопоставления имён и адресов в простом текстовом формате. DNS — это совершенно иная часть пазла.
Примечательно, что с июня 2018 года существует черновой вариант RFC Let ‘localhost’ be localhost («Пусть ‘localhost’ будет localhost»), где обсуждаются соглашения, допущения и вопросы безопасности, связанные с применением имени localhost.
Важно понимать: когда в приложении используются имена хостов, в качестве адресов может возвращаться буквально всё что угодно. Не делайте допущений относительно имени, если в приложении важна безопасность. Представляет это повод для беспокойства или нет — зависит от приложения и окружения.
Даже если в приложении важность безопасности неочевидна, соответствующие рекомендации всё равно применяются. Если в приложении имеется доступ к сети, оно должно сопровождаться и быть защищено. То есть это как минимум:
- Регулярные обновления системного ПО и исправления уязвимостей, в том числе на Python. Обязательно также проверяйте и обновляйте любые сторонние библиотеки.
- Чтобы подключаться только к доверенным системам, по возможности используйте выделенный брандмауэр или межсетевой экран узлов.
- Какие DNS-серверы сконфигурированы? Вы доверяете им и их администраторам?
- Убедитесь, что данные запроса максимально очищены и проверены, прежде чем вызывать другой код, в котором они обрабатываются. Используйте для этого фаззинг-тесты и запускайте их регулярно.
Независимо от того, используете вы имена хостов или нет, если в приложении нужна поддержка безопасных подключений через шифрование и аутентификацию, то вам, вероятно, стóит попробовать TLS. Но это — тема отдельной статьи и в настоящем руководстве не рассматривается. Чтобы начать с ним работу, см. документацию по модулю ssl на Python. Это тот же протокол, который применяется в браузерах для безопасного подключения к сайтам.
Интерфейсы, IP-адреса, разрешения имён… Переменных много. Что же делать? Если у вас нет процесса рассмотрения сетевых приложений, используйте эти рекомендации:
Для клиентов или серверов, если нужно аутентифицировать хост, к которому подключаетесь, стóит попробовать TLS.
Блокирующие вызовы
Блокирующий вызов — это функция или метод сокета, на которых работа приложения временно приостанавливается. Например, .accept(), .connect(), .send() и .recv() блокируются, то есть немедленного возвращения в них не происходит. Прежде чем от блокирующих вызовов возвращается значение, они находятся в ожидании завершения системных (ввод-вывод). Поэтому источник вызова блокируется до их завершения, или истечения тайм-аута, или возникновения другой ошибки.
Чтобы в блокирующих вызовах сокетов происходило немедленное возвращение значений, такие вызовы можно настроить на неблокируемый режим. При этом, чтобы обрабатывать готовую операцию сокета, нужно как минимум провести рефакторинг или перепроектирование приложения.
Поскольку в вызове значения возвращаются немедленно, данные могут быть не готовы. Вызываемая сторона находится в сети в ожидании — ей не хватило времени завершить свою работу. В этом случае текущий статус — это errno-значение socket.EWOULDBLOCK. Неблокируемый режим поддерживается с помощью .setblocking().
По умолчанию сокеты всегда создаются в блокируемом режиме. Описание трёх режимов см. в примечаниях по тайм-аутам сокетов.
Закрытие подключений
В TCP примечательно то, что в клиенте или на сервере совершенно допустимо закрывать свою сторону подключения, пока другая остаётся открытой. Это называется «полуоткрытым» подключением. Желательно оно или нет — решается в приложении. Вообще говоря, нежелательно. В этом состоянии со стороны, чей конец подключения закрыт, данные больше отправляться не смогут. Они будут только приниматься.
Этот подход рекомендуется не как обязательный, но в HTTP в качестве примера используется заголовок с именем Connection для стандартизации того, как в приложениях должны закрываться или сохраняться открытыми подключения. Подробнее см. в разделе 6.3 RFC 7230 о протоколе передачи гипертекста (HTTP/1.1), синтаксисе и маршрутизации сообщений.
При разработке и написании приложения и его протокола прикладного уровня рекомендуется заранее продумать закрытие подключений. Иногда это просто и очевидно, а иногда могут потребоваться создание прототипов и предварительное тестирование. Всё зависит от приложения и от того, как обрабатывается цикл сообщений с ожидаемыми данными. Просто убедитесь, что сокеты всегда своевременно закрываются после завершения работы.
Порядок следования байтов
Подробнее о том, как порядок байтов хранится в памяти разных ЦП, см. в соответствующей статье «Википедии». При интерпретации отдельных байтов это не проблема. Но при обработке нескольких байтов, считываемых и обрабатываемых как одно значение, например 4-байтовое целое число, порядок байтов нужно изменить на противоположный, если взаимодействовать с компьютером, на котором другой порядок следования байтов.
Порядок байтов важен и для текстовых строк, представленных в виде многобайтовых последовательностей, таких как «Юникод». Если только вы не используете всегда true, строгий ASCII и не контролируете реализацию клиента и сервера, вам наверняка лучше использовать «Юникод» с кодировкой вроде UTF-8 или той, которой поддерживается маркер последовательности байтов.
Важно явно определить кодировку, применяемую в протоколе прикладного уровня. Это можно сделать, установив в качестве обязательной для всего текста UTF-8 или использовав заголовок content-encoding, в котором эта кодировка указана. Так приложение избавляется от необходимости определять кодировку, которую по возможности следует избегать.
Это становится проблематичным, когда имеются данные, которые хранятся в файлах или базе данных, и недоступны метаданные, в которых указана их кодировка. Когда данные передаются на другую конечную точку, в ней придётся попробовать определить кодировку. Идеи для обсуждения см. в статье «Википедии» о «Юникоде», в которой упоминается о RFC 3629: UTF-8, формат преобразования ISO 10646:
«Однако в RFC 3629 (стандарт UTF-8) рекомендуется запрещать маркер последовательности байтов в протоколах с UTF-8, но обсуждаются случаи, когда это бывает невозможно. Кроме того, под большим ограничением на возможные шаблоны в UTF-8 (например, не может быть одиночных байтов с установленным старшим битом) подразумевается, что должна быть возможность отличать UTF-8 от других кодировок символов без применения маркера последовательности байтов». (Источник).
А вывод из этого такой: всегда сохранять кодировку, используемую для обрабатываемых в приложении данных, если она может меняться. То есть пытаться каким-то образом сохранять кодировку в виде метаданных, если это не всегда UTF-8 или какая-то другая кодировка с маркером последовательности байтов. Затем можно отправить её в заголовке вместе с данными, чтобы сообщить получателю, что это такое.
В TCP/IP применяется обратный порядок байтов, который называется сетевым. Сетевой порядок используется для представления целых чисел на нижних уровнях стека протоколов, таких как IP-адреса и номера портов. В модуль socket на Python включены функции, в которых целые числа преобразуются в порядок байтов сети и хоста и обратно:
Кроме того, чтобы с помощью строк формата упаковывать и распаковывать двоичные данные, можно использовать модуль struct:
import struct
network_byteorder_int = struct.pack('>H', 256)
python_int = struct.unpack('>H', network_byteorder_int)[0]
Заключение
В этом руководстве рассмотрено много вопросов! Сети и сокеты — это большие темы. Если они вам в новинку, пусть вас не смущают все эти термины и сокращения.
Чтобы понять, как здесь всё сочетается, нужно ознакомиться с кучей подробностей. Но в Python начинаешь лучше понимать целое, осваивая отдельные части и проводя с ними больше времени. Теперь вы можете задействовать свой пользовательский класс и, опираясь на него, проще и быстрее создавать собственные приложения с сокетами.
Ознакомиться с примерами можно по ссылке ниже:
исходный код из руководства для примеров в этом руководстве.
Поздравляем с тем, что добрались до конца! Вы уже готовы применять сокеты в собственных приложениях. Желаю вам успехов в разработке сокетов.
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом. Новогодняя акция — скидки до 50% по промокоду HABR:

- Профессия Fullstack-разработчик на Python (16 месяцев)
- Профессия Data Scientist (24 месяца)
I’m running socket.io on node.js and the socket.io client on an Apache website. If I don’t start the node.js server and load the client page, the error event is triggered with an empty error message, which results in the following console output:
GET http://example.com:1337/socket.io/1/?t=1359731838906 socket.io.js:1659
Socket.handshake socket.io.js:1659
Socket.connect socket.io.js:1699
Socket socket.io.js:1551
io.connect socket.io.js:94
(anonymous function) general.js:7
(anonymous function)
What can I do to stop this error being written to the console?
![]()
leonheess
14.9k14 gold badges72 silver badges109 bronze badges
asked Feb 1, 2013 at 15:28
![]()
1
You can not «catch» these errors in the sense that they are not appearing in the console but you can still act upon them by listening for 'connect_error', 'connect_failed' and 'disconnect' of the socket and then either handling them directly or redirecting them to a custom function like handleErrors():
const socket = io.connect(url, { reconnection: false })
socket.on('update', data => console.log(data))
socket.on('connect_error', err => handleErrors(err))
socket.on('connect_failed', err => handleErrors(err))
socket.on('disconnect', err => handleErrors(err))
answered Aug 18, 2019 at 21:00
![]()
leonheessleonheess
14.9k14 gold badges72 silver badges109 bronze badges
The only way to hide that error is by never calling io.connect in the first place – which of course would mean your app’s socket functions wouldn’t work even if the server is up.
It’s important to understand that the error message you’re seeing is neither something placed there by socket.io itself (via console.error()) nor is it an uncaught JS Exception.
The error message is placed in your console by the browser’s XHR object itself. It’s telling you that a XHR request has failed (since your server isn’t running). The stack trace is telling you what code initiated the XHR request; it isn’t a trace of an actual Exception.
Since socket.io must make a request to the server, there’s no way it (or you) could prevent that error message from appearing in the console if the server isn’t responding.
answered Feb 1, 2013 at 17:18
![]()
josh3736josh3736
138k33 gold badges215 silver badges263 bronze badges
1
До сих пор мы работали на локальных серверах, что почти никогда не даст нам ошибок, связанных с соединениями, тайм-аутами и т. Д. Однако в реальных производственных средах обработка таких ошибок имеет первостепенное значение. Поэтому сейчас мы обсудим, как мы можем обрабатывать ошибки подключения на стороне клиента.
Клиентский API предоставляет нам следующие встроенные события –
-
Connect – когда клиент успешно подключается.
-
Подключение – когда клиент находится в процессе подключения.
-
Отключить – когда клиент отключен.
-
Connect_failed – при сбое соединения с сервером.
-
Ошибка – сообщение об ошибке отправлено с сервера.
-
Сообщение – когда сервер отправляет сообщение, используя функцию отправки .
-
Переподключение – когда переподключение к серверу прошло успешно.
-
Переподключение – когда клиент находится в процессе подключения.
-
Reconnect_failed – когда попытка переподключения не удалась.
Connect – когда клиент успешно подключается.
Подключение – когда клиент находится в процессе подключения.
Отключить – когда клиент отключен.
Connect_failed – при сбое соединения с сервером.
Ошибка – сообщение об ошибке отправлено с сервера.
Сообщение – когда сервер отправляет сообщение, используя функцию отправки .
Переподключение – когда переподключение к серверу прошло успешно.
Переподключение – когда клиент находится в процессе подключения.
Reconnect_failed – когда попытка переподключения не удалась.
Для обработки ошибок мы можем обрабатывать эти события, используя объект out-socket, который мы создали на нашем клиенте.
Например, если у нас не удается установить соединение, мы можем использовать следующий код для повторного подключения к серверу.
We have worked on local servers until now, which will almost never give us errors related to connections, timeouts, etc. However, in real life production environments, handling such errors are of utmost importance. Therefore, we will now discuss how we can handle connection errors on the client side.
The client API provides us with following built in events −
-
Connect − When the client successfully connects.
-
Connecting − When the client is in the process of connecting.
-
Disconnect − When the client is disconnected.
-
Connect_failed − When the connection to the server fails.
-
Error − An error event is sent from the server.
-
Message − When the server sends a message using the send function.
-
Reconnect − When reconnection to the server is successful.
-
Reconnecting − When the client is in the process of connecting.
-
Reconnect_failed − When the reconnection attempt fails.
To handle errors, we can handle these events using the out-socket object that we created on our client.
For example – If we have a connection that fails, we can use the following code to connect to the server again −
socket.on('connect_failed', function() {
document.write("Sorry, there seems to be an issue with the connection!");
})
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Although C does not provide direct support to error handling (or exception handling), there are ways through which error handling can be done in C. A programmer has to prevent errors at the first place and test return values from the functions.
A lot of C function calls return a -1 or NULL in case of an error, so quick test on these return values are easily done with for instance an ‘if statement’. For example, In Socket Programming, the returned value of the functions like socket(), listen() etc. are checked to see if there is an error or not.
Example: Error handling in Socket Programming
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0)
{
perror("socket failed");
exit(EXIT_FAILURE);
}
Different methods of Error handling in C
- Global Variable errno: When a function is called in C, a variable named as errno is automatically assigned a code (value) which can be used to identify the type of error that has been encountered. Its a global variable indicating the error occurred during any function call and defined in the header file errno.h.
Different codes (values) for errno mean different types of errors. Below is a list of few different errno values and its corresponding meaning:errno value Error 1 /* Operation not permitted */ 2 /* No such file or directory */ 3 /* No such process */ 4 /* Interrupted system call */ 5 /* I/O error */ 6 /* No such device or address */ 7 /* Argument list too long */ 8 /* Exec format error */ 9 /* Bad file number */ 10 /* No child processes */ 11 /* Try again */ 12 /* Out of memory */ 13 /* Permission denied */
#include <stdio.h>#include <errno.h>intmain(){FILE* fp;fp =fopen("GeeksForGeeks.txt","r");printf(" Value of errno: %dn ",errno);return0;}Output:
Value of errno: 2
Note: Here the errno is set to 2 which means – No such file or directory. On online IDE it may give errorno 13, which says permission denied.
- perror() and strerror(): The errno value got above indicate the types of error encountered.
If it is required to show the error description, then there are two functions that can be used to display a text message that is associated with errorno. The functions are:- perror: It displays the string you pass to it, followed by a colon, a space, and then the textual representation of the current errno value.
Syntax:void perror (const char *str) str: is a string containing a custom message to be printed before the error message itself.
- strerror(): returns a pointer to the textual representation of the current errno value.
Syntax:char *strerror (int errnum) errnum: is the error number (errno).
#include <stdio.h>#include <errno.h>#include <string.h>intmain (){FILE*fp;fp =fopen(" GeeksForGeeks.txt ","r");printf("Value of errno: %dn ",errno);printf("The error message is : %sn",strerror(errno));perror("Message from perror");return0;}Output:
On Personal desktop:Value of errno: 2 The error message is : No such file or directory Message from perror: No such file or directory
On online IDE:
Value of errno: 13 The error message is : Permission denied
Note: The function perror() displays a string passed to it, followed by a colon and the textual message of the current errno value.
- perror: It displays the string you pass to it, followed by a colon, a space, and then the textual representation of the current errno value.
- Exit Status: The C standard specifies two constants: EXIT_SUCCESS and EXIT_FAILURE, that may be passed to exit() to indicate successful or unsuccessful termination, respectively. These are macros defined in stdlib.h.
#include <stdio.h>#include <errno.h>#include <string.h>#include <stdlib.h>intmain (){FILE* fp;fp =fopen("filedoesnotexist.txt","rb");if(fp == NULL){printf("Value of errno: %dn",errno);printf("Error opening the file: %sn",strerror(errno));perror("Error printed by perror");exit(EXIT_FAILURE);printf("I will not be printedn");}else{fclose(fp);exit(EXIT_SUCCESS);printf("I will not be printedn");}return0;}Output:
Value of errno: 2 Error opening the file: No such file or directory Error printed by perror: No such file or directory
- Divide by Zero Errors: A common pitfall made by C programmers is not checking if a divisor is zero before a division command. Division by zero leads to undefined behavior, there is no C language construct that can do anything about it. Your best bet is to not divide by zero in the first place, by checking the denominator.
#include<stdio.h>#include <stdlib.h>voidfunction(int);intmain(){intx = 0;function(x);return0;}voidfunction(intx){floatfx;if(x==0){printf("Division by Zero is not allowed");fprintf(stderr,"Division by zero! Exiting...n");exit(EXIT_FAILURE);}else{fx = 10 / x;printf("f(x) is: %.5f", fx);}}Output:
Division by Zero is not allowed
This article is contributed by MAZHAR IMAM KHAN. If you like GeeksforGeeks and would like to contribute, you can also write an article using contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Last Updated :
02 Jun, 2017
Like Article
Save Article