
Каждый раз, когда мы кликаем на какую-то ссылку или на наш сайт заходят поисковые роботы, происходит один из диалогов примерно такого содержания:
— Привет, сервер! Я поисковый робот. Могу я просканировать эту страницу?
— Привет! Конечно, заходи.
— А если вот эту страницу?
— А вот здесь пока ведутся ремонтные работы, приходи позже.
Язык ответов HTTP понимают и браузеры, и поисковые роботы, и SEO-специалисты, которым он нужен при работе с сайтом.
Если вы до сих пор путаете 301 с 302, и не знаете, зачем нужен 410 ответ — вам просто необходимо разобраться в кодах ответов HTTP, которые встречаются чаще всего. О них я и расскажу в этой статье. А еще мы узнаем, какую роль они отыграют в SEO и как не допустить ошибок в их использовании.
Какие ответы серверов существуют?
Начнем с того, что все коды ответов (состояния) серверов делятся на 5 классов, каждый из которых несет определенный смысл:
- 1XX. Эти информационные коды говорят о том, что запрос был понят, принят сервером и уже обрабатывается. Такие временные ответы обычно не отображаются на экране пользователей, но служат внутренними кодами для браузеров.
- 2XX. Обозначают успешную обработку полученного запроса. Они используются браузерами для подтверждения того, что запрос был принят, обработан и отражают его текущий статус.
- 3XX. Это коды перенаправления. Говорят о том, что серверу нужно выполнить дополнительные действия — например, перейти по редиректу на новый адрес.
- 4XX. Говорят об ошибке на стороне пользователя. Чаще всего появляются, если время ожидания браузера истекло или запрос был введен неправильно.
- 5XX. Говорят об ошибке сервера. Это значит, что вы запрашиваете специфический ресурс и он найден, но сервер не может дать вам к нему доступ. В конечном счете, запрос не может быть обработан.
Не все ответы сервера можно увидеть прямо на экране, большинство так и остаются внутренними кодами для браузеров и поисковых роботов. Чтобы быстро узнать статус любой страницы, откройте инструменты разработчика в браузере Chrome (нажмите F12). Перейдите на вкладку Network, обновите страницу и получите список статусов каждого элемента, включая саму страницу:

Именно в этих трех цифрах в колонке Status зашифрованы данные о состоянии страницы: можно ли ее сканировать, находится ли она по этому адресу, загружается ли все ее содержимое и т. д.
Какие же коды ответов сервера встречаются чаще всего? И что они значат для оптимизации сайта? Давайте внимательно рассмотрим самые полезные для SEO ответы и способы их обработки.
Ответы серверов, которые встречаются чаще всего
На самом деле существует более 70 различных кодов состояния сервера, но, скорее всего, вы никогда не столкнетесь с большей половиной из них. Однако знать самые распространенные коды состояния HTTP очень важно, потому что ответы сервера напрямую влияют на индексацию вашего сайта, краулинговый бюджет и продвижение ресурса в поисковых системах.
301 Moved Permanently
Говорит о том, что URL был навсегда перенесен на новое место. Браузеры самостоятельно переходят по 301 переадресации — никакого действия от пользователя не требуется.

301 код ответа обычно используют при переводе сайта с HTTP на HTTPS, склейке зеркал (страниц с www и без www), настройке слеша в конце URL, а также при переносе части сайта или всех страниц на новый домен. Этот редирект идеально подходит, если вы хотите передать ссылочный вес старой страницы на новую и сохранить результаты SEO-продвижения.
Совет: Старайтесь не перенаправлять пользователей с удаленного URL на главную страницу сайта. Например, в вашем интернет-магазине есть карточка с неактуальным товаром, но с неплохой ссылочной массой. Вы хотите сохранить этот вес и ставите 301 редирект на главную. Здесь и кроется ошибка! Такой редирект воспринимается Google как 404 Soft, а это означает, что поисковик не будет передавать сигналы со старого URL на новый. В такой ситуации всегда перенаправляйте страницу на максимально похожую (или 404, если аналогичная страница отсутствует).
Кроме того, избегайте цепочек редиректов с двумя и больше переадресациями, так как они создают дополнительную нагрузку на сервер и даже могут помешать пользователям перейти на ваш сайт как небезопасный. Google не индексирует дальше 4-го редиректа, и после каждого теряется вес, поэтому лучше ставьте прямые редиректы (вместо 1 -> 2 -> 3, сразу 1 -> 3).

Через несколько лет можете смело удалять 301, чтобы уменьшить нагрузку на сервер.
302 Found / Moved Temporarily
В отличие от постоянного 301 редиректа, этот — временный. Он говорит о том, что страница найдена, но пока размещена по другому адресу.
Обычно его путали с 301, а после того, как Google объявил, что все 3хx редиректы передают ссылочный вес, — ситуация усугубилась. По факту, его нужно ставить, если вы точно уверены, что будете использовать старый URL снова. Как раз об этом вы и сообщаете поисковику с помощью 302 сигнала, а он в ответ оставляет весь ссылочный вес за старой страницей.

Если вы будете использовать 302 редирект на постоянной основе, Google в конечном итоге воспримет его как 301 со всеми вытекающими последствиями. Также проверьте, нет ли на вашем сайте 302 редиректов, которые на самом деле должны быть 301 — такая ошибка встречается очень часто.
304 Not Modified
Сервер отдает 304 Not Modified ответ, когда страница остается неизменной со времени последнего посещения.
Все браузеры хранят в своем кэше данные заголовка Last-Modified. В свою очередь, это позволяет им точно знать, когда страница была в последний раз изменена. И когда поисковые роботы заходят на страницу и видят, что значение заголовка совпадает с уже сохраненным в кэше, сервер возвращает 304 ответ.

Этот код можно использовать для ускорения индексации сайта. Ведь получив такой ответ, поисковый робот не будет загружать страницу, а значит, успеет проиндексировать больше других страниц.
Лучший ответ сервера для оптимизатора ― 200 ОК. Он означает, что запрос успешно обработан. Но 304 несет ту же нагрузку. Как правило, на новые страницы и первое посещение должен выдаваться ответ 200, на все последующие, если не произошло изменений — 304.
403 Forbidden
Этот код ответа говорит о том, что пользователю запрещен доступ к странице.

403 ошибка может появиться, если пользователь вошел на сайт, но у него нет разрешения для доступа к закрытой внутренней сети. Например, если я попытаюсь зайти в кабинет админа SE Ranking по прямому URL, используя пароль и логин личного аккаунта, на экране будет 403 ошибка «Нет доступа». Также 403 ошибка возникает, если индексный файл для главной указан неправильно. Он обязательно должен иметь название index и расширение: *.shtml, *.html, *.htm, *.phtml или *.php.
Кроме того, когда вы переносите сайт на HTTPS, то 403 ответ появится, когда DNS-кэш ещё не успел обновиться, а вы уже что-то от него хотите. Лучше подождите, или, если это вопрос жизни и смерти, обновите кэш принудительно.
Совет: страницы с 403 кодом ответа в конечном итоге будут удалены из индекса, поэтому Google рекомендует использовать 404 ответ вместо 403.
404 Not Found
Самая «любимая» ошибка в SEO. Говорит о том, что сервер ничего не нашел по указанному адресу, хотя соединение между сервером и клиентом прошло успешно.

Не стоит переживать, если вы увидите много 404 страниц в своей Google Search Console. Поисковик просто сообщает вам, какие страницы удалены, а вам уже решать, нужно ли их проверять. Но что стоит точно сделать — убрать все ссылки на удаленные страницы, чтобы не путать посетителей при навигации по вашему сайту.
Обычно мы видим этот код ошибки, когда вводим неправильный URL в браузер и, как следствие, пытаемся получить доступ к несуществующей странице. Или, например, владелец сайта удалил страницу без редиректа URL по новому адресу. Как результат — 404 ошибка. Чтобы решить проблему, посетителю нужно перепроверить написание URL или попробовать найти информацию на сайте самостоятельно через поиск, а владельцу ресурса ― исправить «битые» ссылки на рабочие.
404 страница не индексируется и не передает вес. Поэтому некоторые оптимизаторы грешат «мягкой 404», выдавая стандартную страницу с ответом 200 вместо 404. Но это считается плохой практикой, потому что 200 код говорит Google, что по этому URL есть реальная страница. В конечном счете, страница оказывается в индексе, и поисковик продолжает свои попытки сканировать несуществующие URL-адреса вместо сканирования ваших реальных страниц.
Как настроить 404 страницу для своего сайта
Если раньше после перехода на несуществующую страницу пользователь видел перед собой только цифру 404, то сейчас — просто море креатива. Но не стоит забывать, что он пришел с конкретным запросом и ваша задача — дать решение, а не развлечь его. Поэтому не забудьте оптимизировать 404 страницу — добавьте навигацию своего сайта или контактную форму, особенно если на 404 страницы идет трафик.

Если ваша CMS (система управления контентом) не создала 404 страницу, вы можете создать ее самостоятельно.
С помощью htaccess
Самый простой способ настроить страницу с 404 ошибкой — добавить сообщение об ошибке, например ErrorDocument 404 “<H1> Not Found </ H1>” в сам файл .htaccess.
В результате у вас должно получиться что-то вроде этого:

Через PHP
Вы можете использовать функцию заголовка и менять контент 404 страницы в зависимости от разных сценариев (например, юзер сделал ошибку в URL самостоятельно или уже перешел по «битой» ссылке с какого-то ресурса).
Детальнее — в этой инструкции.
Через WordPress
У вас есть несколько вариантов:
- Отредактируйте существующую страницу 404, которая уже есть в вашей теме.
- Добавьте свою 404 страницу, если ваша тема ее не предлагает по умолчанию.
- Используйте плагин для 404 страницы.
Подробности можно узнать здесь.
410 Gone
Этот ответ говорит о том, что страница или документ не доступны по указанному адресу и новый адрес неизвестен.
Более того, инструмент проверки URL в Google Search Console обозначает 410 ответы как 404, что приводит к еще большему количеству 404 ошибок, обнаруженных в консоли.

410 ответ чаще всего встречается на страницах с низким трастом, без ссылок или тех, что удалены безвозвратно. Например, с товаром, которого больше не будет в продаже.
Поскольку Google все-таки относится к 404 и 410 ошибкам по-разному, нужно использовать 410 код только тогда, когда вы точно знаете, что страница удалена и больше не вернется. Такой ответ по умолчанию кэшируется, поисковый робот больше не заходит на страницу, а она в свою очередь удаляется из индекса.

Совет: подумайте дважды, прежде чем удалять страницу навсегда. Если вы сомневаетесь, лучше поставить редирект на похожую страницу и получить хотя бы часть текущего трафика. Если же удаления страницы не избежать, обязательно проверьте ссылки, которые на нее ведут — как только страница будет удалена, магия ссылок закончится тоже.
503 Service Unavailable
Этот статус говорит поисковым роботам и пользователям, что в данный момент страница недоступна и, следовательно, сервер не может обработать входящий запрос.

В большинстве случаев 503 появляется, если сервер перегружен, например, превышено ограничение на число входящих запросов или сервер проходит техническое обслуживание.
Могут быть ещё такие причины:
- DDOS-атака на сайт.
- Использование большого количества скриптов и других элементов с внешних ресурсов: виджеты, картинки.
- Запросы к базе данных и извлечение оттуда информации занимают слишком много времени.
- Чрезмерное количество обращений к сайту от поисковиков, пользователей или сервисов по парсингу сайта.
Совет: в идеале в сообщении с 503 ошибкой обязательно нужно указать, что пользователю нужно вернуться на сайт через Х времени. К сожалению, так очень редко делают — обычно просят попытать удачу позже.
И последнее, но не менее важное: код состояния 503 не позволяет поисковым системам индексировать сайт. Кроме того, он сообщает, что сайт плохо обслуживается, потому что пользователи не могут попасть, куда хотели. Поэтому важно, чтобы неполадки были устранены как можно быстрее — иначе это скажется на позициях сайта.
Как настроить 503 страницу для своего сайта через PHP
Вот как выглядит код состояния 503 в PHP:
<?php
header("HTTP/1.1 503 Service Temporarily Unavailable");
header("Status: 503 Service Temporarily Unavailable");
header("Retry-After: 3600");
?>
Больше подробностей можно почитать в этой инструкции.
Как проверить коды состояния всех страниц на сайте
Чтобы быть в курсе всего, что происходит на вашем сайте, нужно мониторить коды состояния всех ваших страниц. Конечно, для этого можно использовать расширение Live HTTP Headers для Chrome или отчет «Покрытие» в Google Search Console, но лучше, если вы проанализируете ответы до того, как до них доберутся поисковые роботы.
Если вы хотите быстро проверить коды состояния всех страниц вашего сайта одним кликом, обязательно попробуйте наш инструмент «Аудит сайта».
Инструмент не просто проверит все страницы на вашем сайте и проанализирует ключевые параметры оптимизации, но и выполнит SEO-аудит всего ресурса по важным техническим параметрам, найдет ошибки и даже подскажет методы их решения.

Все статусы страниц вы увидите в основном отчете, в котором проанализированы технические параметры, страницы, мета-теги, ссылки и контент.
Кстати, вы можете воспользоваться бесплатной пробной версией, чтобы протестировать все основные функции аудита.
Если же вас интересуют только коды состояния всех страниц, просто перейдите на вкладку «Сканированные страницы». Все данные можно экспортировать в формате XLS для подробного изучения:
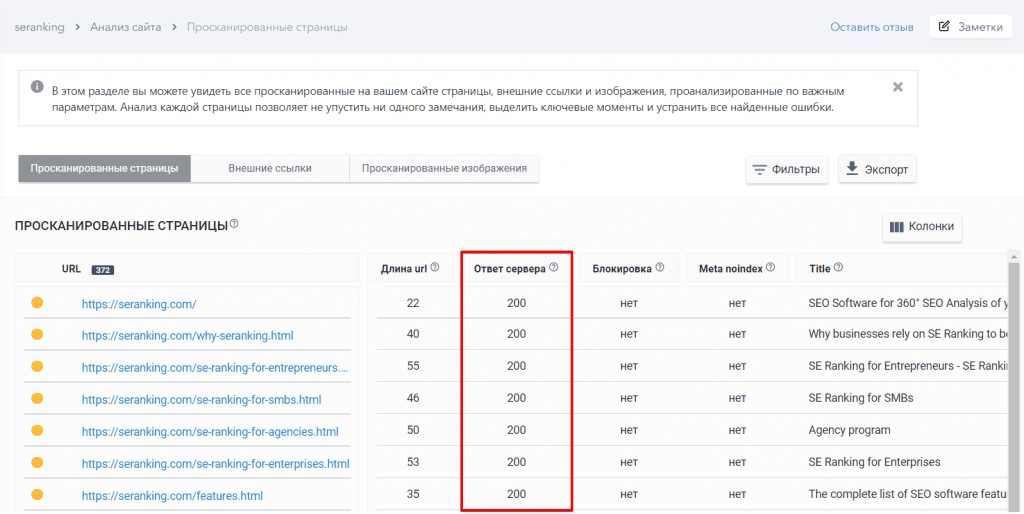
Безусловно, найти ошибки в кодах ответов это только полдела. Решать проблемы, связанные с ошибками сервера, вам все равно придется самостоятельно, но сам поиск ошибок у вас теперь будет занимать считанные минуты. Оптимизировав коды состояния своих страниц, не забудьте отправить их на повторную индексацию.
Чтобы сдать этот экзамен на отлично, мы подготовили для вас шпаргалку по правилам HTTP-знаков с лучшими SEO-советами. Теперь какой бы знак не встретился у вас на пути, вы будете знать, что делать.

Юлия — контент-маркетолог c 10-летним опытом работы в журналистике, копирайтинге, рекламе и PR.
Своим опытом и знаниями она делится, создавая полезные статьи про SEO и диджитал-маркетинг для блога SE Ranking и популярных медиа.
Когда Юлия не пишет статьи, она осваивает новые асаны, путешествует и помогает волонтерской организации YWCA.
Уровень сложности
Простой
Время на прочтение
9 мин
Количество просмотров 15K
Привет! Меня зовут Ивасюта Алексей, я техлид команды Bricks в Авито в кластере Architecture. Я решил написать цикл статей об истории и развитии HTTP, рассмотреть каждую из его версий и проблемы, которые они решали и решают сейчас.
Весь современный веб построен на протоколе HTTP. Каждый сайт использует его для общения клиента с сервером. Между собой сервера тоже часто общаются по этому протоколу. На данный момент существует четыре его версии и все они до сих пор используются. Поэтому статьи будут полезны инженерам любых уровней и специализаций, и помогут систематизировать знания об этой важной технологии.

Что такое HTTP
HTTP — это гипертекстовый протокол передачи данных прикладного уровня в сетевой модели OSI. Его представил миру Тим Бернерс-Ли в марте 1991 года. Главная особенность HTTP — представление всех данных в нём в виде простого текста. Через HTTP разные узлы в сети общаются между собой. Модель клиент-серверного взаимодействия классическая: клиент посылает запрос серверу, сервер обрабатывает запрос и возвращает ответ клиенту. Полученный ответ клиент обрабатывает и решает: прекратить взаимодействие или продолжить отправлять запросы.
Ещё одна особенность: протокол не сохраняет состояние между запросами. Каждый запрос от клиента для сервера — отдельная транзакция. Когда поступают два соседних запроса, сервер не понимает, от одного и того же клиента они поступили, или от разных. Такой подход значительно упрощает построение архитектуры веб-серверов.
Как правило, передача данных по HTTP осуществляется через открытое TCP/IP-соединение1. Серверное программное обеспечение по умолчанию обычно использует TCP-порт 80 для работы веб-сервера, а порт 443 — для HTTPS-соединений.
HTTPS (HTTP Secure) — это надстройка над протоколом HTTP, которая поддерживает шифрование посредством криптографических протоколов SSL и TLS. Они шифруют отправляемые данные на клиенте и дешифруют их на сервере. Это защищает данные от чтения злоумышленниками, даже если им удастся их перехватить.
HTTP/0.9
В 1991 году была опубликована первая версия протокола с названием HTTP/0.9. Эта реализация была проста, как топор. От интернет-ресурса того времени требовалось только загружать запрашиваемую HTML-страницу и HTTP/0.9 справлялся с этой задачей. Обычный запрос к серверу выглядел так:
GET /http-spec.htmlВ протоколе был определен единственный метод GET и и указывался путь к ресурсу. Так пользователи получали страничку. После этого открытое соединение сразу закрывалось.
HTTP/1.0
Годы шли и интернет менялся. Стало понятно, что нужно не только получать странички от сервера, но и отправлять ему данные. В 1996 году вышла версия протокола 1.0.
Что изменилось:
-
В запросе теперь надо было указывать версию протокола. Так сервер мог понимать, как обрабатывать полученные данные.
-
В ответе от сервера появился статус завершения обработки запроса.
-
К запросу и ответу добавился новый блок с заголовками.
-
Добавили поддержку новых методов:
-
HEAD запрашивает ресурс так же, как и метод GET, но без тела ответа. Так можно получить только заголовки, без самого ресурса.
-
POST добавляет сущность к определённому ресурсу. Часто вызывает изменение состояния или побочные эффекты на сервере. Например, так можно отправить запрос на добавление нового поста в блог.
Структура запроса
Простой пример запроса:
GET /path HTTP/1.0
Content-Type: text/html; charset=utf-8
Content-Length: 4
X-Custom-Header: value
testВ первой строчке указаны метод запроса — GET, путь к ресурсу — /path и версия протокола — HTTP/1.0.
Далее идёт блок заголовков. Заголовки — это пары ключ: значение, каждая из которых записывается с новой строки и разделяется двоеточием. Они передают дополнительные данные и настройки от клиента к серверу и обратно.
HTTP — это текстовый протокол, поэтому и все данные передаются в виде текста. Заголовки можно отделить друг от друга только переносом строки. Нельзя использовать запятые, точку с запятой, или другие разделители. Всё, что идет после имени заголовка с двоеточием и до переноса строки, будет считаться значением заголовка2.
В примере серверу передали три заголовка:
-
Content-Type— стандартный заголовок. Показывает, в каком формате будут передаваться данные в теле запроса или ответа. -
Content-Length— сообщает длину контента в теле запроса в байтах. -
X-Custom-Header— пользовательские заголовки, начинающиеся сX-с произвольными именем. Через них реализуется специфическая логика обработки для конкретного сервера. Если веб-сервер не поддерживает такие заголовки, то он проигнорирует их.
После блока заголовков идёт тело запроса, в котором передается текст test.
А так может выглядеть ответ от сервера:
HTTP/1.1 200 OK
Date: Thu, 29 Jul 2021 19:20:01 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 2
Connection: close
Server: gunicorn/19.9.0
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
OKВ первой строке — версия протокола и статус ответа, например, 200 ОК. Далее идут заголовки ответа. После блока заголовков — тело ответа, в котором записан текст OK.
Статусы ответов
Клиенту зачастую недостаточно просто отправить запрос на сервер. Во многих случаях надо дождаться ответа и понять, как сервер обработал запрос. Для этого были придуманы статусы ответов. Это трёхзначные числовые коды с небольшими текстовыми обозначениями. Их можно увидеть в терминале или браузере. Сами коды делятся на 5 классов:
-
Информационные ответы: коды 100–199
-
Успешные ответы: коды 200–299
-
Редиректы: коды 300–399
-
Клиентские ошибки: коды 400–499
-
Серверные ошибки: коды 500–599
Мы рассмотрим основные коды, которые чаще всего встречаются в реальных задачах. С остальными более подробно можно ознакомиться в реестре кодов состояния HTTP.
Информационные ответы
100 Continue — промежуточный ответ. Он указывает, что запрос успешно принят. Клиент может продолжать присылать запросы или проигнорировать этот ответ, если запрос был завершён.
Примечание
Этот код ответа доступен с версии HTTP/1.1.
101 Switching Protocol присылается в ответ на запрос, в котором есть заголовок Upgrade. Это означает, что сервер переключился на протокол, который был указан в заголовке. Такая методика используется, например, для переключения на протокол Websocket.
102 Processing — запрос получен сервером, но его обработка ещё не завершена.
Успешные ответы
200 OK — запрос принят и корректно обработан веб-сервером.
201 Created — запрос корректно обработан и в результате был создан новый ресурс. Обычно он присылается в ответ на POST запрос.
Редиректы
301 Moved Permanently — запрашиваемый ресурс на постоянной основе переехал на новый адрес. Тогда новый путь к ресурсу указывается сервером в заголовке Location ответа.
Примечание
Клиент может изменить метод последующего запроса с POST на GET.
302 Found — указывает, что целевой ресурс временно доступен по другому URl. Адрес перенаправления может быть изменен в любое время, а клиент должен продолжать использовать действующий URI для будущих запросов. Тогда временный путь к ресурсу указывается сервером в заголовке Location ответа.
Примечание
Клиент может изменить метод последующего запроса с POST на GET.
307 Temporary Redirect — имеет то же значение, что и код 302, за исключением того, что клиент не может менять метод последующего запроса.
308 Permanent Redirect — имеет то же значение, что и код 301, за исключением того, что клиент не может менять метод последующего запроса.
Клиентские ошибки
400 Bad Request — запрос от клиента к веб-серверу составлен некорректно. Обычно это происходит, если клиент не передаёт необходимые заголовки или параметры.
401 Unauthorized — получение запрашиваемого ресурса доступно только аутентифицированным пользователям.
403 Forbidden — у клиента не хватает прав для получения запрашиваемого ресурса. Например, когда обычный пользователь сайта пытается получить доступ к панели администратора.
404 Not Found — сервер не смог найти запрашиваемый ресурс.
405 Method Not Allowed — сервер знает о существовании HTTP-метода, который был указан в запросе, но не поддерживает его. В таком случае сервер должен вернуть список поддерживаемых методов в заголовке Allow ответа.
Серверные ошибки
500 Internal Server Error — на сервере произошла непредвиденная ошибка.
501 Not Implemented — метод запроса не поддерживается сервером и не может быть обработан.
502 Bad Gateway — сервер, действуя как шлюз или прокси, получил недопустимый ответ от входящего сервера, к которому он обращался при попытке выполнить запрос.
503 Service Unavailable — сервер не готов обработать запрос (например, из-за технического обслуживания или перегрузки). Обратите внимание, что вместе с этим ответом должна быть отправлена удобная страница с объяснением проблемы. Этот ответ следует использовать для временных условий, а HTTP-заголовок Retry-After по возможности должен содержать расчётное время до восстановления службы.
504 Gateway Timeout — этот ответ об ошибке выдается, когда сервер действует как шлюз и не может получить ответ за отведенное время.
505 HTTP Version Not Supported — версия HTTP, используемая в запросе, не поддерживается сервером.
В HTTP из всего диапазона кодов используется совсем немного. Те коды, которые не используются для задания определенной логики в спецификации, являются неназначенными и могут использоваться веб-серверами для определения своей специфической логики. Это значит, что вы можете, например, придать коду 513 значение «Произошла ошибка обработки видео», или любое другое. Неназначенные коды вы можете посмотреть в реестре кодов состояния HTTP.3
Тело запроса и ответа
Тело запроса опционально и всегда отделяется от заголовков пустой строкой. А как понять, где оно заканчивается? Всё кажется очевидным: где кончается строка, там и заканчивается тело. Однако, два символа переноса строки в HTTP означают конец запроса и отправляют его на сервер. Как быть, если мы хотим передать в теле текст, в котором есть несколько абзацев с разрывами в две строки?
POST /path HTTP/1.1
Host: localhost
Первая строка
Вторая строка после разрываПо логике работы HTTP соединение отправится сразу после второй пустой строки и сервер получит в качестве данных только строку Первая строка. Описанную проблему решает специальный заголовок Content-Length. Он указывает на длину контента в байтах. Обычно клиенты (например, браузеры) автоматически считают длину передаваемых данных и добавляют к запросу заголовок с этим значением. Когда сервер получит запрос, он будет ожидать в качестве контента ровно столько байт, сколько указано в заголовке.
Однако, этого недостаточно для того, чтобы передать данные на сервер. Поведение зависит от реализации сервера, но для большинства из них необходимо также передать заголовок Content-Type. Он указывает на тип передаваемых данных. В качестве значения для этого заголовка используют MIME-типы.4
MIME (Multipurpose Internet Mail Extensions, многоцелевые расширения интернет-почты) — стандарт, который является частью протокола HTTP. Задача MIME — идентифицировать тип содержимого документа по его заголовку. К примеру, текстовый файл имеет тип text/plain, а HTML-файл — text/html.
Для передачи данных в формате обычного текста надо указать заголовок Content-Type: text/plain, а для JSON — Content-Type: application/json.
Можно ли передать тело с GET-запросом?
Популярный вопрос на некоторых собеседованиях: «Можно ли передать тело с GET-запросом?». Правильный ответ — да. Тело запроса не зависит от метода. В стандарте не описана возможность принимать тело запроса у GET-метода, но это и не запрещено. Технически вы можете отправить данные в теле, но скорее всего веб-сервер будет их игнорировать.
Представим, что на абстрактном сайте есть форма аутентификации пользователя, в которой есть всего два поля: email и пароль.
Если пользователь ввёл данные и нажал на кнопку «Войти», то данные из полей формы должны попасть на сервер. Самым простым и распространенным форматом передачи таких данных будет MIME application/x-www-form-urlencoded. В нем все поля передаются в одной строке в формате ключ=значение и разделяются знаком &.
Запрос на отправку данных будет выглядеть так:
POST /login HTTP/1.0
Host: example.com
Content-Type: application/x-www-form-urlencoded; charset=utf-8
Content-Length: 26
login=user&password=qwertyТут есть небольшая особенность. Как понять, где заканчивается ключ и начинается его значение, если в пароле будет присутствовать знак «=» ?
POST /login HTTP/1.0
Host: example.com
Content-Type: application/x-www-form-urlencoded; charset=utf-8
Content-Length: 26
login=user&password=123=45В этом случае сервер не сможет понять, как разбить строку на параметры и их значения. На самом деле значения кодируются при помощи механизма url encoding.5 При использовании этого механизма знак «=» будет преобразован в код %3D .
Тогда наш запрос приобретёт такой вид:
POST /login HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded; charset=utf-8
Content-Length: 28
login=user&password=123%3D45Query string
Данные на сервер можно передавать через тело запроса и через так называемую строку запроса Query String. Это параметры формата ключ=значение, которые располагаются в пути к ресурсу:
GET /files?key=value&key2=value2 HTTP/1.0При этом параметры можно передавать прямо от корня домена:
GET /?key=value&key2=value2 HTTP/1.0Query String имеет такой же формат, как и тело запроса с MIME application/x-www-form-urlencoded, только первая пара значений отделяется от адреса вопросительным знаком.
Некоторые инженеры ошибочно полагают, что Query String являются параметрами GET-запроса и даже называют их GET-параметрами, но на самом деле это не так. Как и тело запроса, Query String не имеет привязки к HTTP-методам и может передаваться с любым типом запросов.
Обычно параметры Query String используются в GET-запросах, чтобы конкретизировать получаемый ресурс. Например, можно получить на сервере список файлов, имена которых будут начинаться с переданного значения.
GET-запросы по своей идеологии должны быть идемпотентными. Это значит, что множественный вызов метода с одними и теми же параметрами должен приводить к одному и тому же результату. Например, поисковые боты перемещаются по сайту только по ссылкам и делают только GET-запросы, потому что исходя из семантики они не смогут таким образом изменить данные на сайте и повлиять на его работу.
На этом я закончу говорить про версию протокола 1.0, структуру ответов и запросов. В следующей статье я расскажу, что такое Cookies, для чего нужен CORS и как это всё работает. А пока напоследок оставлю полезные ссылки, которые упомянул в тексте:
-
Основы TCP/IP
-
Заголовки HTTP
-
Реестр кодов состояния HTTP
-
MIME типы
-
Алгоритм кодирования URL encoding
Следующая статья: Ультимативный гайд по HTTP. Cookies и CORS
![]()
From Wikipedia, the free encyclopedia
This is a list of Hypertext Transfer Protocol (HTTP) response status codes. Status codes are issued by a server in response to a client’s request made to the server. It includes codes from IETF Request for Comments (RFCs), other specifications, and some additional codes used in some common applications of the HTTP. The first digit of the status code specifies one of five standard classes of responses. The optional message phrases shown are typical, but any human-readable alternative may be provided, or none at all.
Unless otherwise stated, the status code is part of the HTTP standard (RFC 9110).
The Internet Assigned Numbers Authority (IANA) maintains the official registry of HTTP status codes.[1]
All HTTP response status codes are separated into five classes or categories. The first digit of the status code defines the class of response, while the last two digits do not have any classifying or categorization role. There are five classes defined by the standard:
- 1xx informational response – the request was received, continuing process
- 2xx successful – the request was successfully received, understood, and accepted
- 3xx redirection – further action needs to be taken in order to complete the request
- 4xx client error – the request contains bad syntax or cannot be fulfilled
- 5xx server error – the server failed to fulfil an apparently valid request
1xx informational response
An informational response indicates that the request was received and understood. It is issued on a provisional basis while request processing continues. It alerts the client to wait for a final response. The message consists only of the status line and optional header fields, and is terminated by an empty line. As the HTTP/1.0 standard did not define any 1xx status codes, servers must not[note 1] send a 1xx response to an HTTP/1.0 compliant client except under experimental conditions.
- 100 Continue
- The server has received the request headers and the client should proceed to send the request body (in the case of a request for which a body needs to be sent; for example, a POST request). Sending a large request body to a server after a request has been rejected for inappropriate headers would be inefficient. To have a server check the request’s headers, a client must send
Expect: 100-continueas a header in its initial request and receive a100 Continuestatus code in response before sending the body. If the client receives an error code such as 403 (Forbidden) or 405 (Method Not Allowed) then it should not send the request’s body. The response417 Expectation Failedindicates that the request should be repeated without theExpectheader as it indicates that the server does not support expectations (this is the case, for example, of HTTP/1.0 servers).[2] - 101 Switching Protocols
- The requester has asked the server to switch protocols and the server has agreed to do so.
- 102 Processing (WebDAV; RFC 2518)
- A WebDAV request may contain many sub-requests involving file operations, requiring a long time to complete the request. This code indicates that the server has received and is processing the request, but no response is available yet.[3] This prevents the client from timing out and assuming the request was lost. The status code is deprecated.[4]
- 103 Early Hints (RFC 8297)
- Used to return some response headers before final HTTP message.[5]
2xx success
This class of status codes indicates the action requested by the client was received, understood, and accepted.[1]
- 200 OK
- Standard response for successful HTTP requests. The actual response will depend on the request method used. In a GET request, the response will contain an entity corresponding to the requested resource. In a POST request, the response will contain an entity describing or containing the result of the action.
- 201 Created
- The request has been fulfilled, resulting in the creation of a new resource.[6]
- 202 Accepted
- The request has been accepted for processing, but the processing has not been completed. The request might or might not be eventually acted upon, and may be disallowed when processing occurs.
- 203 Non-Authoritative Information (since HTTP/1.1)
- The server is a transforming proxy (e.g. a Web accelerator) that received a 200 OK from its origin, but is returning a modified version of the origin’s response.[7][8]
- 204 No Content
- The server successfully processed the request, and is not returning any content.
- 205 Reset Content
- The server successfully processed the request, asks that the requester reset its document view, and is not returning any content.
- 206 Partial Content
- The server is delivering only part of the resource (byte serving) due to a range header sent by the client. The range header is used by HTTP clients to enable resuming of interrupted downloads, or split a download into multiple simultaneous streams.
- 207 Multi-Status (WebDAV; RFC 4918)
- The message body that follows is by default an XML message and can contain a number of separate response codes, depending on how many sub-requests were made.[9]
- 208 Already Reported (WebDAV; RFC 5842)
- The members of a DAV binding have already been enumerated in a preceding part of the (multistatus) response, and are not being included again.
- 226 IM Used (RFC 3229)
- The server has fulfilled a request for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance.[10]
3xx redirection
This class of status code indicates the client must take additional action to complete the request. Many of these status codes are used in URL redirection.[1]
A user agent may carry out the additional action with no user interaction only if the method used in the second request is GET or HEAD. A user agent may automatically redirect a request. A user agent should detect and intervene to prevent cyclical redirects.[11]
- 300 Multiple Choices
- Indicates multiple options for the resource from which the client may choose (via agent-driven content negotiation). For example, this code could be used to present multiple video format options, to list files with different filename extensions, or to suggest word-sense disambiguation.
- 301 Moved Permanently
- This and all future requests should be directed to the given URI.
- 302 Found (Previously «Moved temporarily»)
- Tells the client to look at (browse to) another URL. The HTTP/1.0 specification (RFC 1945) required the client to perform a temporary redirect with the same method (the original describing phrase was «Moved Temporarily»),[12] but popular browsers implemented 302 redirects by changing the method to GET. Therefore, HTTP/1.1 added status codes 303 and 307 to distinguish between the two behaviours.[11]
- 303 See Other (since HTTP/1.1)
- The response to the request can be found under another URI using the GET method. When received in response to a POST (or PUT/DELETE), the client should presume that the server has received the data and should issue a new GET request to the given URI.
- 304 Not Modified
- Indicates that the resource has not been modified since the version specified by the request headers If-Modified-Since or If-None-Match. In such case, there is no need to retransmit the resource since the client still has a previously-downloaded copy.
- 305 Use Proxy (since HTTP/1.1)
- The requested resource is available only through a proxy, the address for which is provided in the response. For security reasons, many HTTP clients (such as Mozilla Firefox and Internet Explorer) do not obey this status code.
- 306 Switch Proxy
- No longer used. Originally meant «Subsequent requests should use the specified proxy.»
- 307 Temporary Redirect (since HTTP/1.1)
- In this case, the request should be repeated with another URI; however, future requests should still use the original URI. In contrast to how 302 was historically implemented, the request method is not allowed to be changed when reissuing the original request. For example, a POST request should be repeated using another POST request.
- 308 Permanent Redirect
- This and all future requests should be directed to the given URI. 308 parallel the behaviour of 301, but does not allow the HTTP method to change. So, for example, submitting a form to a permanently redirected resource may continue smoothly.
4xx client errors
This class of status code is intended for situations in which the error seems to have been caused by the client. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and whether it is a temporary or permanent condition. These status codes are applicable to any request method. User agents should display any included entity to the user.
- 400 Bad Request
- The server cannot or will not process the request due to an apparent client error (e.g., malformed request syntax, size too large, invalid request message framing, or deceptive request routing).
- 401 Unauthorized
- Similar to 403 Forbidden, but specifically for use when authentication is required and has failed or has not yet been provided. The response must include a WWW-Authenticate header field containing a challenge applicable to the requested resource. See Basic access authentication and Digest access authentication. 401 semantically means «unauthorised», the user does not have valid authentication credentials for the target resource.
- Some sites incorrectly issue HTTP 401 when an IP address is banned from the website (usually the website domain) and that specific address is refused permission to access a website.[citation needed]
- 402 Payment Required
- Reserved for future use. The original intention was that this code might be used as part of some form of digital cash or micropayment scheme, as proposed, for example, by GNU Taler,[14] but that has not yet happened, and this code is not widely used. Google Developers API uses this status if a particular developer has exceeded the daily limit on requests.[15] Sipgate uses this code if an account does not have sufficient funds to start a call.[16] Shopify uses this code when the store has not paid their fees and is temporarily disabled.[17] Stripe uses this code for failed payments where parameters were correct, for example blocked fraudulent payments.[18]
- 403 Forbidden
- The request contained valid data and was understood by the server, but the server is refusing action. This may be due to the user not having the necessary permissions for a resource or needing an account of some sort, or attempting a prohibited action (e.g. creating a duplicate record where only one is allowed). This code is also typically used if the request provided authentication by answering the WWW-Authenticate header field challenge, but the server did not accept that authentication. The request should not be repeated.
- 404 Not Found
- The requested resource could not be found but may be available in the future. Subsequent requests by the client are permissible.
- 405 Method Not Allowed
- A request method is not supported for the requested resource; for example, a GET request on a form that requires data to be presented via POST, or a PUT request on a read-only resource.
- 406 Not Acceptable
- The requested resource is capable of generating only content not acceptable according to the Accept headers sent in the request. See Content negotiation.
- 407 Proxy Authentication Required
- The client must first authenticate itself with the proxy.
- 408 Request Timeout
- The server timed out waiting for the request. According to HTTP specifications: «The client did not produce a request within the time that the server was prepared to wait. The client MAY repeat the request without modifications at any later time.»
- 409 Conflict
- Indicates that the request could not be processed because of conflict in the current state of the resource, such as an edit conflict between multiple simultaneous updates.
- 410 Gone
- Indicates that the resource requested was previously in use but is no longer available and will not be available again. This should be used when a resource has been intentionally removed and the resource should be purged. Upon receiving a 410 status code, the client should not request the resource in the future. Clients such as search engines should remove the resource from their indices. Most use cases do not require clients and search engines to purge the resource, and a «404 Not Found» may be used instead.
- 411 Length Required
- The request did not specify the length of its content, which is required by the requested resource.
- 412 Precondition Failed
- The server does not meet one of the preconditions that the requester put on the request header fields.
- 413 Payload Too Large
- The request is larger than the server is willing or able to process. Previously called «Request Entity Too Large» in RFC 2616.[19]
- 414 URI Too Long
- The URI provided was too long for the server to process. Often the result of too much data being encoded as a query-string of a GET request, in which case it should be converted to a POST request. Called «Request-URI Too Long» previously in RFC 2616.[20]
- 415 Unsupported Media Type
- The request entity has a media type which the server or resource does not support. For example, the client uploads an image as image/svg+xml, but the server requires that images use a different format.
- 416 Range Not Satisfiable
- The client has asked for a portion of the file (byte serving), but the server cannot supply that portion. For example, if the client asked for a part of the file that lies beyond the end of the file. Called «Requested Range Not Satisfiable» previously RFC 2616.[21]
- 417 Expectation Failed
- The server cannot meet the requirements of the Expect request-header field.[22]
- 418 I’m a teapot (RFC 2324, RFC 7168)
- This code was defined in 1998 as one of the traditional IETF April Fools’ jokes, in RFC 2324, Hyper Text Coffee Pot Control Protocol, and is not expected to be implemented by actual HTTP servers. The RFC specifies this code should be returned by teapots requested to brew coffee.[23] This HTTP status is used as an Easter egg in some websites, such as Google.com’s «I’m a teapot» easter egg.[24][25][26] Sometimes, this status code is also used as a response to a blocked request, instead of the more appropriate 403 Forbidden.[27][28]
- 421 Misdirected Request
- The request was directed at a server that is not able to produce a response (for example because of connection reuse).
- 422 Unprocessable Entity
- The request was well-formed but was unable to be followed due to semantic errors.[9]
- 423 Locked (WebDAV; RFC 4918)
- The resource that is being accessed is locked.[9]
- 424 Failed Dependency (WebDAV; RFC 4918)
- The request failed because it depended on another request and that request failed (e.g., a PROPPATCH).[9]
- 425 Too Early (RFC 8470)
- Indicates that the server is unwilling to risk processing a request that might be replayed.
- 426 Upgrade Required
- The client should switch to a different protocol such as TLS/1.3, given in the Upgrade header field.
- 428 Precondition Required (RFC 6585)
- The origin server requires the request to be conditional. Intended to prevent the ‘lost update’ problem, where a client GETs a resource’s state, modifies it, and PUTs it back to the server, when meanwhile a third party has modified the state on the server, leading to a conflict.[29]
- 429 Too Many Requests (RFC 6585)
- The user has sent too many requests in a given amount of time. Intended for use with rate-limiting schemes.[29]
- 431 Request Header Fields Too Large (RFC 6585)
- The server is unwilling to process the request because either an individual header field, or all the header fields collectively, are too large.[29]
- 451 Unavailable For Legal Reasons (RFC 7725)
- A server operator has received a legal demand to deny access to a resource or to a set of resources that includes the requested resource.[30] The code 451 was chosen as a reference to the novel Fahrenheit 451 (see the Acknowledgements in the RFC).
5xx server errors
The server failed to fulfil a request.
Response status codes beginning with the digit «5» indicate cases in which the server is aware that it has encountered an error or is otherwise incapable of performing the request. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and indicate whether it is a temporary or permanent condition. Likewise, user agents should display any included entity to the user. These response codes are applicable to any request method.
- 500 Internal Server Error
- A generic error message, given when an unexpected condition was encountered and no more specific message is suitable.
- 501 Not Implemented
- The server either does not recognize the request method, or it lacks the ability to fulfil the request. Usually this implies future availability (e.g., a new feature of a web-service API).
- 502 Bad Gateway
- The server was acting as a gateway or proxy and received an invalid response from the upstream server.
- 503 Service Unavailable
- The server cannot handle the request (because it is overloaded or down for maintenance). Generally, this is a temporary state.[31]
- 504 Gateway Timeout
- The server was acting as a gateway or proxy and did not receive a timely response from the upstream server.
- 505 HTTP Version Not Supported
- The server does not support the HTTP version used in the request.
- 506 Variant Also Negotiates (RFC 2295)
- Transparent content negotiation for the request results in a circular reference.[32]
- 507 Insufficient Storage (WebDAV; RFC 4918)
- The server is unable to store the representation needed to complete the request.[9]
- 508 Loop Detected (WebDAV; RFC 5842)
- The server detected an infinite loop while processing the request (sent instead of 208 Already Reported).
- 510 Not Extended (RFC 2774)
- Further extensions to the request are required for the server to fulfil it.[33]
- 511 Network Authentication Required (RFC 6585)
- The client needs to authenticate to gain network access. Intended for use by intercepting proxies used to control access to the network (e.g., «captive portals» used to require agreement to Terms of Service before granting full Internet access via a Wi-Fi hotspot).[29]
Unofficial codes
The following codes are not specified by any standard.
- 419 Page Expired (Laravel Framework)
- Used by the Laravel Framework when a CSRF Token is missing or expired.
- 420 Method Failure (Spring Framework)
- A deprecated response used by the Spring Framework when a method has failed.[34]
- 420 Enhance Your Calm (Twitter)
- Returned by version 1 of the Twitter Search and Trends API when the client is being rate limited; versions 1.1 and later use the 429 Too Many Requests response code instead.[35] The phrase «Enhance your calm» comes from the 1993 movie Demolition Man, and its association with this number is likely a reference to cannabis.[citation needed]
- 430 Request Header Fields Too Large (Shopify)
- Used by Shopify, instead of the 429 Too Many Requests response code, when too many URLs are requested within a certain time frame.[36]
- 450 Blocked by Windows Parental Controls (Microsoft)
- The Microsoft extension code indicated when Windows Parental Controls are turned on and are blocking access to the requested webpage.[37]
- 498 Invalid Token (Esri)
- Returned by ArcGIS for Server. Code 498 indicates an expired or otherwise invalid token.[38]
- 499 Token Required (Esri)
- Returned by ArcGIS for Server. Code 499 indicates that a token is required but was not submitted.[38]
- 509 Bandwidth Limit Exceeded (Apache Web Server/cPanel)
- The server has exceeded the bandwidth specified by the server administrator; this is often used by shared hosting providers to limit the bandwidth of customers.[39]
- 529 Site is overloaded
- Used by Qualys in the SSLLabs server testing API to signal that the site can’t process the request.[40]
- 530 Site is frozen
- Used by the Pantheon Systems web platform to indicate a site that has been frozen due to inactivity.[41]
- 598 (Informal convention) Network read timeout error
- Used by some HTTP proxies to signal a network read timeout behind the proxy to a client in front of the proxy.[42]
- 599 Network Connect Timeout Error
- An error used by some HTTP proxies to signal a network connect timeout behind the proxy to a client in front of the proxy.
Internet Information Services
Microsoft’s Internet Information Services (IIS) web server expands the 4xx error space to signal errors with the client’s request.
- 440 Login Time-out
- The client’s session has expired and must log in again.[43]
- 449 Retry With
- The server cannot honour the request because the user has not provided the required information.[44]
- 451 Redirect
- Used in Exchange ActiveSync when either a more efficient server is available or the server cannot access the users’ mailbox.[45] The client is expected to re-run the HTTP AutoDiscover operation to find a more appropriate server.[46]
IIS sometimes uses additional decimal sub-codes for more specific information,[47] however these sub-codes only appear in the response payload and in documentation, not in the place of an actual HTTP status code.
nginx
The nginx web server software expands the 4xx error space to signal issues with the client’s request.[48][49]
- 444 No Response
- Used internally[50] to instruct the server to return no information to the client and close the connection immediately.
- 494 Request header too large
- Client sent too large request or too long header line.
- 495 SSL Certificate Error
- An expansion of the 400 Bad Request response code, used when the client has provided an invalid client certificate.
- 496 SSL Certificate Required
- An expansion of the 400 Bad Request response code, used when a client certificate is required but not provided.
- 497 HTTP Request Sent to HTTPS Port
- An expansion of the 400 Bad Request response code, used when the client has made a HTTP request to a port listening for HTTPS requests.
- 499 Client Closed Request
- Used when the client has closed the request before the server could send a response.
Cloudflare
Cloudflare’s reverse proxy service expands the 5xx series of errors space to signal issues with the origin server.[51]
- 520 Web Server Returned an Unknown Error
- The origin server returned an empty, unknown, or unexpected response to Cloudflare.[52]
- 521 Web Server Is Down
- The origin server refused connections from Cloudflare. Security solutions at the origin may be blocking legitimate connections from certain Cloudflare IP addresses.
- 522 Connection Timed Out
- Cloudflare timed out contacting the origin server.
- 523 Origin Is Unreachable
- Cloudflare could not reach the origin server; for example, if the DNS records for the origin server are incorrect or missing.
- 524 A Timeout Occurred
- Cloudflare was able to complete a TCP connection to the origin server, but did not receive a timely HTTP response.
- 525 SSL Handshake Failed
- Cloudflare could not negotiate a SSL/TLS handshake with the origin server.
- 526 Invalid SSL Certificate
- Cloudflare could not validate the SSL certificate on the origin web server. Also used by Cloud Foundry’s gorouter.
- 527 Railgun Error
- Error 527 indicates an interrupted connection between Cloudflare and the origin server’s Railgun server.[53]
- 530
- Error 530 is returned along with a 1xxx error.[54]
AWS Elastic Load Balancer
Amazon’s Elastic Load Balancing adds a few custom return codes
- 460
- Client closed the connection with the load balancer before the idle timeout period elapsed. Typically when client timeout is sooner than the Elastic Load Balancer’s timeout.[55]
- 463
- The load balancer received an X-Forwarded-For request header with more than 30 IP addresses.[55]
- 464
- Incompatible protocol versions between Client and Origin server.[55]
- 561 Unauthorized
- An error around authentication returned by a server registered with a load balancer. You configured a listener rule to authenticate users, but the identity provider (IdP) returned an error code when authenticating the user.[55]
Caching warning codes (obsoleted)
The following caching related warning codes were specified under RFC 7234. Unlike the other status codes above, these were not sent as the response status in the HTTP protocol, but as part of the «Warning» HTTP header.[56][57]
Since this «Warning» header is often neither sent by servers nor acknowledged by clients, this header and its codes were obsoleted by the HTTP Working Group in 2022 with RFC 9111.[58]
- 110 Response is Stale
- The response provided by a cache is stale (the content’s age exceeds a maximum age set by a Cache-Control header or heuristically chosen lifetime).
- 111 Revalidation Failed
- The cache was unable to validate the response, due to an inability to reach the origin server.
- 112 Disconnected Operation
- The cache is intentionally disconnected from the rest of the network.
- 113 Heuristic Expiration
- The cache heuristically chose a freshness lifetime greater than 24 hours and the response’s age is greater than 24 hours.
- 199 Miscellaneous Warning
- Arbitrary, non-specific warning. The warning text may be logged or presented to the user.
- 214 Transformation Applied
- Added by a proxy if it applies any transformation to the representation, such as changing the content encoding, media type or the like.
- 299 Miscellaneous Persistent Warning
- Same as 199, but indicating a persistent warning.
See also
- Custom error pages
- List of FTP server return codes
- List of HTTP header fields
- List of SMTP server return codes
- Common Log Format
Explanatory notes
- ^ Emphasised words and phrases such as must and should represent interpretation guidelines as given by RFC 2119
References
- ^ a b c «Hypertext Transfer Protocol (HTTP) Status Code Registry». Iana.org. Archived from the original on December 11, 2011. Retrieved January 8, 2015.
- ^ Fielding, Roy T. «RFC 9110: HTTP Semantics and Content, Section 10.1.1 «Expect»«.
- ^ Goland, Yaronn; Whitehead, Jim; Faizi, Asad; Carter, Steve R.; Jensen, Del (February 1999). HTTP Extensions for Distributed Authoring – WEBDAV. IETF. doi:10.17487/RFC2518. RFC 2518. Retrieved October 24, 2009.
- ^ «102 Processing — HTTP MDN». 102 status code is deprecated
- ^ Oku, Kazuho (December 2017). An HTTP Status Code for Indicating Hints. IETF. doi:10.17487/RFC8297. RFC 8297. Retrieved December 20, 2017.
- ^ Stewart, Mark; djna. «Create request with POST, which response codes 200 or 201 and content». Stack Overflow. Archived from the original on October 11, 2016. Retrieved October 16, 2015.
- ^ «RFC 9110: HTTP Semantics and Content, Section 15.3.4».
- ^ «RFC 9110: HTTP Semantics and Content, Section 7.7».
- ^ a b c d e Dusseault, Lisa, ed. (June 2007). HTTP Extensions for Web Distributed Authoring and Versioning (WebDAV). IETF. doi:10.17487/RFC4918. RFC 4918. Retrieved October 24, 2009.
- ^ Delta encoding in HTTP. IETF. January 2002. doi:10.17487/RFC3229. RFC 3229. Retrieved February 25, 2011.
- ^ a b «RFC 9110: HTTP Semantics and Content, Section 15.4 «Redirection 3xx»«.
- ^ Berners-Lee, Tim; Fielding, Roy T.; Nielsen, Henrik Frystyk (May 1996). Hypertext Transfer Protocol – HTTP/1.0. IETF. doi:10.17487/RFC1945. RFC 1945. Retrieved October 24, 2009.
- ^ «The GNU Taler tutorial for PHP Web shop developers 0.4.0». docs.taler.net. Archived from the original on November 8, 2017. Retrieved October 29, 2017.
- ^ «Google API Standard Error Responses». 2016. Archived from the original on May 25, 2017. Retrieved June 21, 2017.
- ^ «Sipgate API Documentation». Archived from the original on July 10, 2018. Retrieved July 10, 2018.
- ^ «Shopify Documentation». Archived from the original on July 25, 2018. Retrieved July 25, 2018.
- ^ «Stripe API Reference – Errors». stripe.com. Retrieved October 28, 2019.
- ^ «RFC2616 on status 413». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ «RFC2616 on status 414». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ «RFC2616 on status 416». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ TheDeadLike. «HTTP/1.1 Status Codes 400 and 417, cannot choose which». serverFault. Archived from the original on October 10, 2015. Retrieved October 16, 2015.
- ^ Larry Masinter (April 1, 1998). Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0). doi:10.17487/RFC2324. RFC 2324.
Any attempt to brew coffee with a teapot should result in the error code «418 I’m a teapot». The resulting entity body MAY be short and stout.
- ^ I’m a teapot
- ^ Barry Schwartz (August 26, 2014). «New Google Easter Egg For SEO Geeks: Server Status 418, I’m A Teapot». Search Engine Land. Archived from the original on November 15, 2015. Retrieved November 4, 2015.
- ^ «Google’s Teapot». Retrieved October 23, 2017.[dead link]
- ^ «Enable extra web security on a website». DreamHost. Retrieved December 18, 2022.
- ^ «I Went to a Russian Website and All I Got Was This Lousy Teapot». PCMag. Retrieved December 18, 2022.
- ^ a b c d Nottingham, M.; Fielding, R. (April 2012). «RFC 6585 – Additional HTTP Status Codes». Request for Comments. Internet Engineering Task Force. Archived from the original on May 4, 2012. Retrieved May 1, 2012.
- ^ Bray, T. (February 2016). «An HTTP Status Code to Report Legal Obstacles». ietf.org. Archived from the original on March 4, 2016. Retrieved March 7, 2015.
- ^ alex. «What is the correct HTTP status code to send when a site is down for maintenance?». Stack Overflow. Archived from the original on October 11, 2016. Retrieved October 16, 2015.
- ^ Holtman, Koen; Mutz, Andrew H. (March 1998). Transparent Content Negotiation in HTTP. IETF. doi:10.17487/RFC2295. RFC 2295. Retrieved October 24, 2009.
- ^ Nielsen, Henrik Frystyk; Leach, Paul; Lawrence, Scott (February 2000). An HTTP Extension Framework. IETF. doi:10.17487/RFC2774. RFC 2774. Retrieved October 24, 2009.
- ^ «Enum HttpStatus». Spring Framework. org.springframework.http. Archived from the original on October 25, 2015. Retrieved October 16, 2015.
- ^ «Twitter Error Codes & Responses». Twitter. 2014. Archived from the original on September 27, 2017. Retrieved January 20, 2014.
- ^ «HTTP Status Codes and SEO: what you need to know». ContentKing. Retrieved August 9, 2019.
- ^ «Screenshot of error page». Archived from the original (bmp) on May 11, 2013. Retrieved October 11, 2009.
- ^ a b «Using token-based authentication». ArcGIS Server SOAP SDK. Archived from the original on September 26, 2014. Retrieved September 8, 2014.
- ^ «HTTP Error Codes and Quick Fixes». Docs.cpanel.net. Archived from the original on November 23, 2015. Retrieved October 15, 2015.
- ^ «SSL Labs API v3 Documentation». github.com.
- ^ «Platform Considerations | Pantheon Docs». pantheon.io. Archived from the original on January 6, 2017. Retrieved January 5, 2017.
- ^ «HTTP status codes — ascii-code.com». www.ascii-code.com. Archived from the original on January 7, 2017. Retrieved December 23, 2016.
- ^
«Error message when you try to log on to Exchange 2007 by using Outlook Web Access: «440 Login Time-out»«. Microsoft. 2010. Retrieved November 13, 2013. - ^ «2.2.6 449 Retry With Status Code». Microsoft. 2009. Archived from the original on October 5, 2009. Retrieved October 26, 2009.
- ^ «MS-ASCMD, Section 3.1.5.2.2». Msdn.microsoft.com. Archived from the original on March 26, 2015. Retrieved January 8, 2015.
- ^ «Ms-oxdisco». Msdn.microsoft.com. Archived from the original on July 31, 2014. Retrieved January 8, 2015.
- ^ «The HTTP status codes in IIS 7.0». Microsoft. July 14, 2009. Archived from the original on April 9, 2009. Retrieved April 1, 2009.
- ^ «ngx_http_request.h». nginx 1.9.5 source code. nginx inc. Archived from the original on September 19, 2017. Retrieved January 9, 2016.
- ^ «ngx_http_special_response.c». nginx 1.9.5 source code. nginx inc. Archived from the original on May 8, 2018. Retrieved January 9, 2016.
- ^ «return» directive Archived March 1, 2018, at the Wayback Machine (http_rewrite module) documentation.
- ^ «Troubleshooting: Error Pages». Cloudflare. Archived from the original on March 4, 2016. Retrieved January 9, 2016.
- ^ «Error 520: web server returns an unknown error». Cloudflare.
- ^ «527 Error: Railgun Listener to origin error». Cloudflare. Archived from the original on October 13, 2016. Retrieved October 12, 2016.
- ^ «Error 530». Cloudflare. Retrieved November 1, 2019.
- ^ a b c d «Troubleshoot Your Application Load Balancers – Elastic Load Balancing». docs.aws.amazon.com. Retrieved May 17, 2023.
- ^ «Hypertext Transfer Protocol (HTTP/1.1): Caching». datatracker.ietf.org. Retrieved September 25, 2021.
- ^ «Warning — HTTP | MDN». developer.mozilla.org. Retrieved August 15, 2021.
 Some text was copied from this source, which is available under a Creative Commons Attribution-ShareAlike 2.5 Generic (CC BY-SA 2.5) license.
Some text was copied from this source, which is available under a Creative Commons Attribution-ShareAlike 2.5 Generic (CC BY-SA 2.5) license.
- ^ «RFC 9111: HTTP Caching, Section 5.5 «Warning»«. June 2022.
External links
- «RFC 9110: HTTP Semantics and Content, Section 15 «Status Codes»«.
- Hypertext Transfer Protocol (HTTP) Status Code Registry at the Internet Assigned Numbers Authority
- MDN status code reference at mozilla.org
Обычные посетители сайта обращают внимание в первую очередь на качественный контент, а поисковые краулеры – на ответы сервера.
Сегодня научимся проверять код как одной страницы, так и всех сразу, а также разберем все коды ответа и узнаем, что именно они означают.
Немного теории
Определить доступность веб-страницы поможет анализ кода состояния HTTP. Технически он представляет из себя стандартный запрос. Он отправляется, когда мы переходим по определенной ссылке на сайте или просто вводим ее в поисковой строке браузера. При обработке запроса сервер самостоятельно формирует и отдает трехзначный цифровой код.
Благодаря коду ответа понять реакцию сайта на запрос может не только поисковый краулер, но и обычный пользователь. Здесь нет ничего сложного даже для начинающих вебмастеров.
Сперва определимся с терминами.
- Клиент – компьютер, смартфон или другое мобильное устройство, которое имеет подключение к интернету.
- Сервер – определенный компьютер, который хранит все данные сайта (включая страницы и системные файлы). Именно на сервере «живет» сайт.
Выделяют пять классов ответов. Идентифицировать класс можно по первой цифре.
- 5** – техническая ошибка на стороне сервера. Точная причина указывается сразу после кода. Иногда пятисотая говорит о внутренних сбоях, реже – о превышении статической нагрузки на сервер.
- 4** – сбой на стороне юзера.
- 3** – обнаружен редирект на другой адрес (не ошибка).
- 2** – запрос обработан успешно (не ошибка).
- 1** – служебный класс кодов, который чаще всего относится к информационным сообщениям (не ошибка).
Логика кодов, таким образом, весьма проста:

Продвинем ваш бизнес
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Подробнее

Что значат коды состояния HTTP
Причины / решения / пояснения ошибок, я буду давать только для самых часто встречающихся кодов. Для всех остальных – только краткое описание.
Двухсотые – успешные запросы
200 – успешный запрос данных. Код не является ошибкой.
201 – завершена успешная транзакция. Код говорит о том, что сформирован новый ресурс (или документ).
202 – запрос принят, но еще не завершен. Необходимо дождаться окончания обработки.
203 – данные получены не из первоисточника (возвращаемые данные идут не от исходного сервера, а от какого-то другого) и могут быть устаревшими.
204 – запрос был обработан правильно, но отсутствует содержимое. Есть заголовок ответа, но содержимое для него отсутствует. Обновлять и актуализировать содержимое не нужно.
205 – клиенту необходимо осуществить сброс содержимого. Саму страницу обновлять не требуется.
206 – ошибка частичного содержимого. Если клиент хочет выполнить загрузку данных в несколько потоков, а сервер выполняет только часть GET-запроса, будет возникать 206-ая ошибка.
GET-запрос предназначен для получения данных, в то время как POST-запрос нужен для отправки данных.
Код также может быть отправлен с сервера, когда клиент запросил диапазон (например, условно: «Дайте мне первые 2 МБ видеоданных»). Происходит возврат только частичного контента, соответствующего Range-заголовку (данный заголовок дает понять серверу, какую именно часть страницы от него требуют, и какую ему нужно вернуть).
Если страница отдает этот код, следует обратить внимание на выполнение кэширования и на исходящий запрос.
207 – выполнено несколько операций. Найти их можно в XML, в строке MultiStatus.
226 – обработан IM-заголовок. Содержимое будет возвращено для получения информации об ответе вместе с ранее обозначенными параметрами.
Трехсотые – запросы на редирект
300 – не удалось идентифицировать точный URL. Такой ответ возникает, когда существует множественный выбор, и краулер не знает, к какой именно странице относится ресурс.
301 – документ был навсегда перемещен на новый URL. Так должны отвечать все веб-страницы, которые удалены или являются зеркалами, дублями. Со временем все указанные страницы будут склеены с целевой веб-страницей (присоединены к ней) автоматически. Если возникает такая ошибка, нужно настроить 301-ое перенаправление с устаревшего URL на актуальный (если речь идет о веб-странице, которая уже ранжировалась, но ее URL изменился). В таком случае все позитивные метрики, включая вес URL, будут сохранены.
302 – документ был временно перемещен на новый URL. Это абсолютно корректный ответ сервера, который актуален для веб-страниц с распродажами или сезонными акциями, распространяющимися на какой-либо товар. Код указывает, что данный URI будет учитываться клиентом в последующих запросах. Другими словами, страница была найдена, но перенесена. Такие документы из индекса не удаляются. Если адрес был изменен навсегда, вместо 302-го, лучше использовать 303-ий или 307-ой ответ.
303 – нужно направить пользователя на иной URL. 303-ый код можно получить исключительно GET-запросом. В идеале, этот код нужно отдавать, когда требуется редиректнуть посетителя на близкорелевантую, но не идентичную странице.
304 – документ не модифицировался. Этот код не является стандартным редиректом. Он помогает краулерам определять страницы, которые не изменились с последнего визита.
Если на вашем сайте немного страниц (до 1 000), использовать код 304 нет смысла. Если вас напрягает этот редирект, то в заголовке нужно поправить параметр Last-Modified (последняя дата изменения) – он не должен быть старше, чем заголовок If-Modified-Since (если изменялся спустя заданное количество времени).
305 – доступ к этому документу возможен исключительно через прокси.
307 – документ был временно перемещен на иной URL. Идеальный вариант, если требуется временно редиректнуть посетителя, но оставить техническую возможность отправки POST-запросов.
Четырехсотые – сбои на стороне клиента
400 – ошибка синтаксиса. Сервер не может идентифицировать запрос, так как была допущена опечатка в синтаксисе. Проверьте корректность отправляемого запроса.
401 – отсутствует аутентификация. Код отдается, когда для доступа требуется пароль или регистрация.
403 – отсутствует доступ к документу. Возникает, когда пользователь хочет открыть системные файлы (robots, htaccess). Либо вы сделали опечатку при вводе URL и пытаетесь воспользоваться веб-страницей, которая не предназначена для обычного пользователя, либо вам нужно: пройти авторизацию для доступа к системным файлам.
404 – отсутствует соответствующий ресурс по введенному URL. Разберитесь, по каким причинам была удалена / перемещена страница. Возможно, вы допустили ошибку и удалили ее случайно. Если так – просто восстановите ее.
Задумайтесь над созданием красивой, кастомизированной 404-ой. Например, такой:

405 – некорректный метод (указывается в запросной строке клиента) для выбранного документа. Метод запроса определяет точное действие, которое должно быть выполнено для указанного ресурса.
406 – некорректный / неподдерживаемый краулером формат запроса. Код отдается, когда сервер не способен возвратить ответ, релевантный листу допустимых значений. Самый распространенный случай – поисковый робот не поддерживает кодировку документа или его язык. Убедитесь, что в теле сообщения содержится лист доступных ресурсов. Подробное описание ошибка на сайте веб-разработчиков Mozilla.
407 – отсутствует регистрация прокси или авторизация файервола.
408 – таймаут запроса. Соединение разорвано, так как полный запрос не был передан. Другими словами, запрос занял слишком много времени, а сервер не готов был ждать. На каждом сайте существует свое время таймаута. Проверьте наличие интернета и просто обновите страницу. Подробное объяснение этой ошибки на сайте веб-разработчиков Mozilla.
409 – несовместимость двух запросов. Запрос невозможно выполнить при текущем состоянии сервера. Самый распространенный случай – операции c PUT-запросом. Например, когда нужно скачать файл, возраст которого превышает возраст уже существующего, расположенного на сервере.
410 – ресурс более не существует по указанному URL. Если страница удаляется целенаправленно, лучше делать так, чтобы она отдавала именно 410-ый. Краулер обойдет такую страницу, получит этот код и больше никогда на нее не вернется, так как поймет, что она удалена навсегда. Если речь о веб-странице, которая была удалена временно, гораздо эффективнее использовать 404-ый ответ. Если страница удалена намерено и навсегда, но в SERP имела хорошие места и приносила трафик, лучше сделать редирект на максимально релевантную существующую страницу.
411 – сервер сам отклоняет отправляемый запрос, так как не находит значение Content-Length. Этот ответ характерен как для обычных POST-запросов, так и для PUT-запросов (подразумевают замену существующих представлений документа на данные, которые содержатся в самом запросе).
412 –не были до конца выполнены условные поля HTTP-заголовка, например, If-Match. 412-ый код появляется в случаях, когда доступ к целевому документу отклоняется. Нужно проверить соблюдение и корректность HTTP-заголовков выполняемого запроса.
413 – у каждого сервера есть свой собственный максимальный размер запроса, определяемый не самим HTTP-протоколом (у него ограничения по длине запроса просто напросто отсутствуют), а ограничениями со стороны браузеров. Браузеры поддерживают запросы от 2 до 8 килобайт. Вышеуказанный код отдается, когда сервер не понимает запрос из-за слишком большого размера.
414 – возникает, когда отправляется чрезвычайно длинный URL. Запросы, содержащие излишне длинные URL, не могут правильно интерпретироваться сервером. Самые частые случаи появления этого ответа – попытка передать удлиненные параметры (излишне большое количество данных через GET- запрос).
415 – некорректный медиаформат. Текущий тип данных не может быть интерпретирован сервером.
416 – некорректное значение Range (диапазон). Ответ возникает в случаях, когда в самом HTTP-заголовке прописывается некорректный байтовый диапазон. 416-ый отдается в случаях, когда сервер не может взаимодействовать с запрашиваемыми диапазонами. Причина – отсутствие диапазона в необходимом документе или опечатка в синтаксисе.Сервер просто не имеет возможности работать с запрашиваемыми диапазонами. Проверьте синтаксис значения Range – он должен обязательно соблюдаться. Скорее всего, документ просто не имеет запрашиваемых диапазонов. Обновите страницу.
417 – указанное значение Expect не может быть удовлетворено (речь о заголовке запроса). Прокси некорректно идентифицировал содержимое поля «Expect: 100-Continue». Устранить эту ошибку самостоятельно не удастся. Если вы используете прокси Squid, обратитесь в поддержку. Вам нужно активировать ignore_expect_100. Другой вариант разрешите BS_PingHost обращаться к интернет-сети без участия прокси.
422 – существует определенная логическая ошибка. Какая именно, данный код не указывает. Копайте в сторону ошибок в семантике документа.
423 – используемый ресурс был заблокирован для выбранного HTTP—метода. Перезагрузите роутер и компьютер. Используйте только статистический IP.
424 – зависимый ресурс был блокирован по соображением безопасности. Данный код отдается, если в запросе присутствуют признаки несанкционированного доступа к файлам CMS.
426 – некорректные значения полей Upgrade и Conection. Этот ответ возникает, когда серверу требуется обновление до SSL-протокола, но клиент не имеет его поддержки.
429 – слишком много запросов. Ошибка отдается, когда один пользователь проявляет чрезмерно большую активность за короткий временной интервал. Проверьте плагины используемой CMS. В идеале, отключите их все и включайте по очереди, пока не доберетесь до источника проблемы.
451 – доступ к серверу заблокирован по решению судебных органов. Можно плодить бесконечные дубли или вообще создать новый домен, но рано или поздно страницу с идентичным содержимым все равно заблокируют. Временное решение – разместить проблемное содержимое на другом домене. Провайдеры могут подстраховаться и блокировать не только отдельные страницы, но и сайты целиком. Не нарушать закон – единственное, что можно посоветовать в этом случае.
Пятисотые – серверные сбои
500 – серверу не удается полностью обработать запрос. Такой код отдается, когда существует непредвиденное условие, мешающее выполнению запроса. Чаще всего внутренняя ошибка сервера может появляться при серверных сбоях. Проверяйте, корректно ли указаны директивы в системных файлах (особенно htaccess), нет ли ошибки прав доступа к файлам. Обратите внимание на ошибки внутри скриптов и их медленную работу.
Проверяйте конфликты плагинов и дополнений. Нередко 500-ая возникает, когда в настройках административной панели хостинга указана одна версия PHP, а на самом сайте используется другая. Последнее также создает высокую статическую нагрузку на хостинг. Если вам было бы узнать о пятисотой подробнее, пишите в комментариях, и я напишу развернутый материал на эту тему.
501 – не выполнено. Этот код отдается, когда сам сервер не может идентифицировать метод запроса. Сами вы эту ошибку не исправите. Устранить ее может только сервер.
502 – шлюзовый сбой. Возникает при получении некорректного ответа от сервера, находящегося по иерархии выше. Актуально исключительно для прокси и шлюзовых конфигураций.
503 – данный ответ возникает в случаях, когда существуют технические неполадки, не позволяющие интерпретировать введенный запрос. Скорее всего, ваш сервер просто на обслуживании или сильно перегружен. Уменьшите число перманентных запросов к базам данных. Убедитесь, что на сервере нет профилактических или других работ, ограничивающих его пропускную способность. Не используйте VPN.
504 – отсутствует ответ. Этот код отдается в одной ситуации – если сервер не может получит ответ за необходимый период времени. Отклика нет и возникает таймаут. Как и 501-ый ответ, 504-ый исправить самостоятельно не получится. Здесь дело в прокси, часто – в веб-сервере. Первым делом просто обновите веб-страницу. Если не помогло, нужно почистить DNS-кэш. Для этого используем сочетание горячих клавиш Windows+R и вводим команду cmd (Control+пробел). В открывшемся окне указываем команду ipconfig / flushdns и подтверждаем ее нажатием Enter.
Также полезно посмотреть, как страница ведет себя различных мобильных устройствах и в разных браузерах. Проверьте дебаг. Если сайт на WP, то проверить дебан проще всего. Достаточно добавить этот код в wp-config.php:

Теперь все сбои будут фиксировать в файле debug.log (находится в папке wp-сontents). Если вы используете другую CMS, найдите к ней мануал и посмотрите, как активировать в ней журнал ошибок.
Также 504-ая отдает, когда на сайте существуют проблемы, связанные с задействованием CDN или кастомизированных серверов DNS. Отключите CDN на своем сайте.
Иногда 504-ый код пропадает, если просто подождать несколько часов. Часто 504-ая появляется на сайтах, которые используют CloudFlare.
505 – отсутствует поддержка текущей версии HTTP-протокола.
507 – не хватает места на жестком диске для выполнения запроса.
510 – не найдено расширение, желающее задействовать клиент.
Массово проверяем ответ веб-страницы
Самый простой способ проверить ответ веб-страницы – воспользоваться готовыми сервисами. Наиболее популярны:
- mainspy;
- 2ip;
- cy-pr;
- wwhois;
- 4seo.
Возьмем для примера mainspy. Тут проверить код ответа проще всего:

Таким образом, для проверки кода просто открываем страницу и вводим необходимые URL. Кликаем «Проверить». Будет выведен отчет. Напротив каждого проверяемого URL будет отображаться код ответа сервера:

Кроме перечисленных сервисов есть также замечательный плагин для Google Chrome – HTTP Header Spy. Он позволяет проверять код ответа сервера как одной, так и нескольких страниц сразу:

Послесловие
Коды ответа HTTP – это универсальный язык, который понимают не только краулеры Google / «Яндекса», но и люди. 5 классов кодов позволят с первого взгляда определить, где именно существует ошибка при выполнении HTTP запроса и куда копать для ее устранения.
Если ваш код ответа не указан в этом мануале, значит речь идет о кастомизированном сервере. Чтобы правильно истолковать ответ такого сервера и перевести его на человеческий язык, придется обратится к его разработчику.
Оптимизируйте свои подборки
Сохраняйте и классифицируйте контент в соответствии со своими настройками.
На этой странице описывается, как коды статуса HTTP, а также ошибки сети и DNS отражаются на позиции вашего контента в Google Поиске. Мы поговорим о 20 наиболее распространенных кодах статуса, которые обнаруживает на веб-страницах робот Googlebot, а также о самых частых ошибках сети и DNS. Такие редко встречающиеся коды, как 418 (I'm a teapot), в этой статье не рассматриваются. Все перечисленные на этой странице проблемы приводят к появлению ошибки или предупреждения в отчете об индексировании страниц, доступном в Search Console.
Коды статуса HTTP
Когда сервер, на котором размещен сайт, получает запрос клиента (например, браузера или поискового робота), в ответ он отправляет код статуса HTTP. Каждый такой код имеет свое значение, но многие из них предполагают, что запрос будет обрабатываться одинаково. Например, о переадресации могут сигнализировать несколько разных кодов.
Сообщения об ошибке, генерируемые в Search Console, относятся к кодам статуса в диапазоне 4xx–5xx, а также к неудачной переадресации (3xx). Если в ответе сервера указан код статуса 2xx, полученный контент может быть проиндексирован.
В таблице ниже приведены коды статуса HTTP, с которыми чаще всего сталкивается робот Googlebot, и пояснения о том, как обрабатывается каждый такой код.
| Коды статуса HTTP | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Роботы Google проверяют, можно ли проиндексировать контент. Если контент не загружается, например появляется пустая страница или сообщение об ошибке, в Search Console будет зарегистрирована ошибка
|
|||||||||||
|
Робот Googlebot выполняет до 10 переходов в цепочке переадресаций. Если за это время поисковый робот не получает контент, в отчете об индексировании страниц этого сайта в Search Console будет указана ошибка переадресации. Количество переходов робота Googlebot зависит от агента пользователя, например у роботов Googlebot Smartphone и Googlebot Image оно будет отличаться.
Googlebot выполняет пять переходов в цепочке переадресаций согласно спецификации RFC 1945. Затем он прерывает операцию и интерпретирует ситуацию как ошибку Наши роботы игнорируют любой контент, получаемый с URL переадресации. При индексировании используется контент, размещенный по конечному целевому URL.
|
|||||||||||
|
Роботы Google не индексируют URL с кодом статуса
Роботы Googlebot игнорируют любой контент, получаемый с URL, которые возвращают код статуса
|
|||||||||||
|
В случае ошибок сервера Если файл robots.txt выдает ошибку сервера более 30 дней, будут выполняться правила, указанные в последней кешированной копии этого файла. Если такой копии нет, роботы Google будут действовать без ограничений.
Роботы Googlebot игнорируют любой контент, получаемый с URL, которые возвращают код статуса
|
Ошибки soft 404
Ошибкой soft 404 называется ситуация, когда посетитель веб-страницы видит сообщение о том, что ее не существует, при этом браузер получает ответ с кодом статуса 200 (success). Этот код означает «Успешно». В некоторых случаях открывается страница, на которой нет основного или вообще никакого контента.
Такие страницы создаются веб-сервером, где размещен сайт, системой управления контентом или браузером пользователя. Причины могут быть разными. Пример:
- Отсутствие файла SSI
- Ошибка при обращении к базе данных
- Пустая внутренняя страница результатов поиска
- Незагруженный или отсутствующий по другой причине файл JavaScript
Мы не рекомендуем возвращать код статуса 200 (success), а затем выводить сообщение об ошибке или указывать на наличие ошибки на странице. Пользователи могут подумать, что попали на действующую страницу, но после этого увидят сообщение об ошибке. Подобные страницы исключаются из Google Поиска.
Если алгоритмы Google по контенту страницы определяют, что она содержит сообщение об ошибке, то в отчете об индексировании страниц этого сайта в Search Console будет указана ложная ошибка soft 404.
Порядок исправления ошибок soft 404
Есть разные способы устранения ошибок soft 404 в зависимости от состояния сайта
и от желаемого результата:
- Страница и ее контент больше не доступны
- Страница или ее контент были перенесены
- Страница и ее контент по-прежнему существуют
Подумайте, какое решение будет оптимальным для ваших пользователей.
Страница и ее контент больше не доступны
Если страница удалена и для нее нет замены на вашем сайте с аналогичным контентом, нужно отправлять ответ с кодом статуса 404 (not found) или 410 (gone). Эти коды статуса сообщают поисковым системам, что страницы не существует, а контент не нужно индексировать.
Если у вас есть доступ к файлам конфигурации вашего сервера, страницы с сообщениями об ошибках можно сделать полезными для пользователей. Например, на такой странице 404 вы можете разместить функции, призванные помогать посетителям в поиске нужной информации, или полезный контент, который удержит их на вашем ресурсе. Вот несколько советов по созданию полезной страницы 404:
- Пользователям должно быть понятно, что запрашиваемая страница недоступна. Подготовьте сообщение, которое не вызовет отторжения.
-
Страница
404должна быть выполнена в том же стиле (включая элементы навигации), что и основной сайт. - Разместите на странице ссылки на самые популярные статьи или записи блога, а также на главную страницу.
- Дайте пользователям возможность сообщать о неработающих ссылках.
Полезные страницы 404 создаются исключительно для удобства пользователей. Поисковые системы игнорируют такие страницы, поэтому рекомендуем возвращать для этих страниц код статуса HTTP 404, чтобы они не индексировались.
Страница или ее контент перемещены
Если страница перенесена или у нее есть замена, отправляйте ответ с кодом 301 (permanent redirect), чтобы перенаправлять пользователей. Посетителям сайта это не помешает, а поисковые системы узнают новое расположение страницы. Чтобы узнать, правильный ли код ответа отправляется при открытии страницы, используйте инструмент проверки URL.
Страница и ее контент по-прежнему существуют
Если нормально работающая страница вызвала ошибку soft 404, вероятно, она не была корректно загружена роботом Googlebot, во время отрисовки не были доступны важные ресурсы или показывалось заметное сообщение об ошибке. Проанализируйте отрисованный контент и код ответа HTTP с помощью инструмента проверки URL. Если на обработанной странице нет или очень мало контента или он вызывает ошибку, ошибка soft 404 может быть обусловлена тем, что страница содержит ресурсы (например, изображения, скрипты и прочие нетекстовые элементы), которые не удается загрузить.
Возможные причины проблем с загрузкой – блокировка доступа в файле robots.txt, слишком большое количество ресурсов или слишком большой их размер, а также любые ошибки сервера.
Ошибки сети и DNS
Ошибки сети и DNS отрицательно влияют на показ URL в результатах поиска Google.
Робот Googlebot интерпретирует тайм-ауты сети, факты сброса подключения и ошибки DNS так же, как и ошибки серверов 5xx. В случае сетевых ошибок сканирование начинает постепенно замедляться, поскольку сетевая ошибка означает, что сервер может не справиться с нагрузкой. Так как роботы Googlebot не смогли получить доступ к серверу, на котором размещен сайт, значит, им не удалось извлечь контент. В результате Google не может проиндексировать ранее просканированные URL, а недоступные нашим роботам URL, которые уже были проиндексированы, будут удалены из индекса Google в течение нескольких дней. Search Console может создавать сообщения о каждой возникающей ошибке.
Ошибки отладки сети
Эти ошибки возникают до того, как Google начинает сканирование URL, или во время этого процесса.
Поскольку они зачастую уже присутствуют до того, как сервер возвращает ответ, то из-за отсутствия кода статуса диагностика этих ошибок может вызывать трудности. Чтобы отладить ошибки тайм-аута и сброса подключения, выполните следующие действия:
- Проверьте настройки брандмауэра и записи в журнале. У вас может быть задано слишком общее правило блокировки. Нужно, чтобы ни одно правило брандмауэра не блокировало IP-адреса робота Googlebot.
- Проанализируйте сетевой трафик с помощью таких инструментов как tcpdump и Wireshark. Они помогут вам найти в пакетах TCP аномалии, относящиеся к определенному сетевому компоненту или модулю сервера.
- Если вы не можете найти ничего подозрительного, обратитесь к своему хостинг-провайдеру.
Ошибка может относиться к любому серверному компоненту, который обрабатывает сетевой трафик. Возможно, что перегруженные интерфейсы сети не могут передавать пакеты, что приводит к тайм-аутам (невозможности установить подключение) и сбросу подключений (отправляется пакет RST, поскольку порт был закрыт по ошибке).
Устранение ошибок DNS
Ошибки DNS чаще всего вызваны неправильной конфигурацией, но могут также возникать из-за правил брандмауэра, которые блокируют DNS-запросы робота Googlebot. Чтобы устранить ошибки DNS, выполните следующие действия:
-
Проверьте правила брандмауэра. Нужно, чтобы ни одно правило не блокировало IP-адреса Google и чтобы были разрешены запросы как по протоколу
UDP, так и по протоколуTCP. -
Проверьте записи DNS. Убедитесь, что записи
AиCNAMEведут на правильные IP-адреса и имена хостов. Пример:dig +nocmd example.com a +noall +answer
dig +nocmd www.example.com cname +noall +answer
-
Убедитесь, что все ваши DNS-серверы указывают на правильные IP-адреса вашего сайта. Пример:
dig +nocmd example.com ns +noall +answerexample.com. 86400 IN NS a.iana-servers.net. example.com. 86400 IN NS b.iana-servers.net.dig +nocmd @a.iana-servers.net example.com +noall +answerexample.com. 86400 IN A 93.184.216.34dig +nocmd @b.iana-servers.net example.com +noall +answer... - Если вы внесли изменения в конфигурацию DNS в течение последних 72 часов, на их применение во всей сети DNS может потребоваться некоторое время. Чтобы ускорить внедрение новых настроек, вы можете очистить общедоступный кеш DNS.
- Если вы используете собственный DNS-сервер, убедитесь, что он исправен и не перегружен.
Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons «С указанием авторства 4.0», а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2023-02-20 UTC.