
I needed to parse a site, but i got an error 403 Forbidden.
Here is a code:
url = 'http://worldagnetwork.com/'
result = requests.get(url)
print(result.content.decode())
Its output:
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
Please, say what the problem is.
![]()
asked Jul 20, 2016 at 19:36
![]()
Толкачёв ИванТолкачёв Иван
1,6993 gold badges10 silver badges13 bronze badges
2
It seems the page rejects GET requests that do not identify a User-Agent. I visited the page with a browser (Chrome) and copied the User-Agent header of the GET request (look in the Network tab of the developer tools):
import requests
url = 'http://worldagnetwork.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
result = requests.get(url, headers=headers)
print(result.content.decode())
# <!doctype html>
# <!--[if lt IE 7 ]><html class="no-js ie ie6" lang="en"> <![endif]-->
# <!--[if IE 7 ]><html class="no-js ie ie7" lang="en"> <![endif]-->
# <!--[if IE 8 ]><html class="no-js ie ie8" lang="en"> <![endif]-->
# <!--[if (gte IE 9)|!(IE)]><!--><html class="no-js" lang="en"> <!--<![endif]-->
# ...
answered Jul 20, 2016 at 19:48
![]()
2
Just add to Alberto’s answer:
If you still get a 403 Forbidden after adding a user-agent, you may need to add more headers, such as referer:
headers = {
'User-Agent': '...',
'referer': 'https://...'
}
The headers can be found in the Network > Headers > Request Headers of the Developer Tools. (Press F12 to toggle it.)
answered Jul 9, 2019 at 5:44
![]()
5
If You are the server’s owner/admin, and the accepted solution didn’t work for You, then try disabling CSRF protection (link to an SO answer).
I am using Spring (Java), so the setup requires You to make a SecurityConfig.java file containing:
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure (HttpSecurity http) throws Exception {
http.csrf().disable();
}
// ...
}
answered May 26, 2018 at 11:31
![]()
AleksandarAleksandar
3,4081 gold badge37 silver badges42 bronze badges
I’m using the Requests library in Python. In the browser, my URL loads okay. In Python, it throws a 403.
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>403 Forbidden</title>
</head><body>
<h1>Forbidden</h1>
<p>You don't have permission to access /admin/license.php on this server.</p>
<p>Additionally, a 404 Not Found error was encountered while trying to use an ErrorDocument to handle the request.</p>
</body></html>
This is my own site, and I don’t have any robot protection on it that I know of. I made the PHP file that I’m loading and it’s just a simple database query. In the root of the site, I have a WordPress site with default settings. However, I’m not sure if that’s relevant.
My code:
import requests
url = "myprivateurl.com"
r = requests.get(url)
print r.text
Does anyone have any guesses why it’s throwing a 403 by Python and not by browser?
Thanks so much.
Собственно, проблема следующая:
Postman отрабатывает отлично и возвращает ожидаемый результат
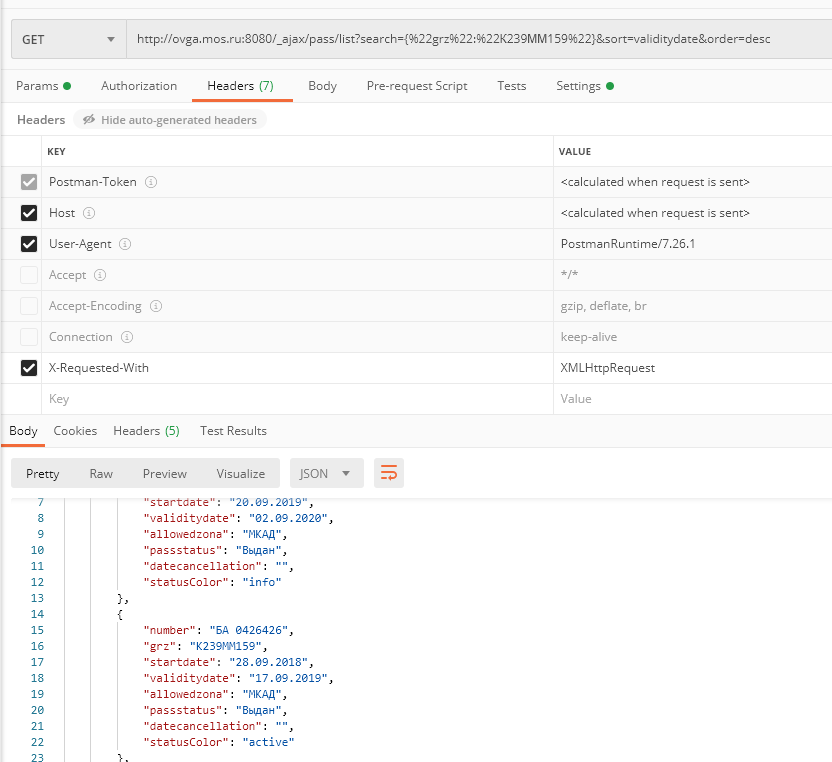
А python на аналогичный запрос выдает 403 код. Хотя вроде как заголовки одинаковые. Что ему, собаке, не хватает?
import requests
from pprint import pprint
url = 'http://ovga.mos.ru:8080/_ajax/pass/list?search={%22grz%22:%22К239ММ159%22}&sort=validitydate&order=desc'
headers = {"X-Requested-With": "XMLHttpRequest",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/54.0.2840.99 Safari/537.36',
}
response = requests.get(url, headers)
pprint(response)
<Response [403]>-
Вопрос заданболее двух лет назад
-
2546 просмотров
Ты не все заголовки передал. Postman по-умолчанию генерирует некоторые заголовки самостоятельно, вот так подключается нормально:
headers = {
'Host': 'ovga.mos.ru',
'User-Agent': 'Magic User-Agent v999.26 Windows PRO 11',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'X-Requested-With': 'XMLHttpRequest'
}
url = 'http://ovga.mos.ru:8080/_ajax/pass/list?search={"grz":"К239ММ159"}&sort=validitydate&order=desc'
response = requests.get(url, headers=headers)<Response [200]>
Пригласить эксперта
-
Показать ещё
Загружается…
05 июн. 2023, в 15:13
2000 руб./в час
05 июн. 2023, в 15:03
150000 руб./за проект
05 июн. 2023, в 15:02
7000 руб./за проект
Минуточку внимания
|
olm18 0 / 0 / 0 Регистрация: 15.12.2016 Сообщений: 3 |
||||
|
1 |
||||
|
18.03.2019, 22:28. Показов 19527. Ответов 3 Метки 403, get запрос, requests (Все метки)
Делаю запрос. Статус запроса 403. Через браузер запрос выполнить получается. Везде пишут, что в такой ситуации надо указать User-Agent. Я указал, но никакого результата. Пробовал добавлять различные параметры в headers, но та же ошибка 403. Подскажите, что я делаю не так?
Миниатюры
0 |

|
5407 / 3831 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
18.03.2019, 22:49 |
2 |
|
Сайту нужна кука — поэтому используйте сессию. В requests сессия есть.
0 |
|
olm18 0 / 0 / 0 Регистрация: 15.12.2016 Сообщений: 3 |
||||||||
|
19.03.2019, 00:24 [ТС] |
3 |
|||||||
|
Делаю так. В результате всё равно ошибка 403
Добавлено через 59 минут
0 |
|
Garry Galler
5407 / 3831 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
||||
|
19.03.2019, 00:33 |
4 |
|||
|
Решение
Очень странно, но этот параметр из кук (несмотря на предварительный запрос) почему-то в сессионных куках отсутствует, и поэтому без него ничего не работает.
0 |
 Сообщение было отмечено olm18 как решение
Сообщение было отмечено olm18 как решение
Python:
import requests
cookies = {
'_ALGOLIA': 'xxx',
'wtstp_sid': 'xxx',
'wtstp_eid': 'xxx',
'_dy_c_exps': '',
'_dy_c_att_exps': '',
'_dycnst': 'xxx',
'_dyid': 'xxx',
'.Nop.Customer': 'xxx',
'dy_fs_page': 'www.computeruniverse.net%2Fen%2Fc%2Flaptops-tablet-pcs-pcs%2Flaptops-notebooks',
'_dy_geo': 'KZ',
'_dy_df_geo': 'Kazakhstan',
'_dy_toffset': '0',
'_dyid_server': 'xxx',
'_dycst': 'xxx.',
'__cf_bm': 'xxx',
'cu-edge-hints': xxx',
'_dy_soct': 'xxx',
}
headers = {
'authority': 'www.computeruniverse.net',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'max-age=0',
'if-modified-since': 'Sat, 17 Dec 2022 03:23:59 GMT',
'sec-ch-ua': '"Opera";v="93", "Not/A)Brand";v="8", "Chromium";v="107"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 OPR/93.0.0.0',
}
params = {
'lang': '1',
'cachecountry': 'KZ',
}
response = requests.get('https://webapi.computeruniverse.net/api/catalog/topmenu/', params=params, cookies=cookies, headers=headers)
print(response.status_code)Содержание
- [Fixed] urllib.error.httperror: http error 403: forbidden
- What is a 403 error?
- Why urllib.error.httperror: http error 403: forbidden occurs?
- Why do sites use security that sends 403 responses?
- Resolving urllib.error.httperror: http error 403: forbidden?
- Method 1: using user-agent
- Method 2: using Session object
- Catching urllib.error.httperror
- HOWTO Fetch Internet Resources Using The urllib Package¶
- Introduction¶
- Fetching URLs¶
- Data¶
- Headers¶
- Handling Exceptions¶
- URLError¶
- HTTPError¶
- Error Codes¶
- Wrapping it Up¶
- Number 1В¶
- Number 2В¶
- info and geturl¶
- Openers and Handlers¶
- Basic Authentication¶
- Proxies¶
- Sockets and Layers¶
- Footnotes¶
[Fixed] urllib.error.httperror: http error 403: forbidden
The urllib module can be used to make an HTTP request from a site, unlike the requests library, which is a built-in library. This reduces dependencies. In the following article, we will discuss why urllib.error.httperror: http error 403: forbidden occurs and how to resolve it.
What is a 403 error?
The 403 error pops up when a user tries to access a forbidden page or, in other words, the page they aren’t supposed to access. 403 is the HTTP status code that the webserver uses to denote the kind of problem that has occurred on the user or the server end . For instance, 200 is the status code for – ‘everything has worked as expected, no errors’. You can go through the other HTTP status code from here.
Why urllib.error.httperror: http error 403: forbidden occurs?
ModSecurity is a module that protects websites from foreign attacks. It checks whether the requests are being made from a user or from an automated bot. It blocks requests from known spider/bot agents who are trying to scrape the site. Since the urllib library uses something like python urllib/3.3.0 hence, it is easily detected as non-human and therefore gets blocked by mod security.
ModSecurity blocks the request and returns an HTTP error 403: forbidden error if the request was made without a valid user agent. A user-agent is a header that permits a specific string which in turn allows network protocol peers to identify the following:
- The Operating System, for instance, Windows, Linux, or macOS.
- Websserver’s browser
Moreover, the browser sends the user agent to each and every website that you get connected to. The user-Agent field is included in the HTTP header when the browser gets connected to a website. The header field data differs for each browser.
Why do sites use security that sends 403 responses?
According to a survey, more than 50% of internet traffic comes from automated sources. Automated sources can be scrapers or bots. Therefore it gets necessary to prevent these attacks. Moreover, scrapers tend to send multiple requests, and sites have some rate limits. The rate limit dictates how many requests a user can make. If the user(here scraper) exceeds it, it gets some kind of error, for instance, urllib.error.httperror: http error 403: forbidden.
Resolving urllib.error.httperror: http error 403: forbidden?
This error is caused due to mod security detecting the scraping bot of the urllib and blocking it. Therefore, in order to resolve it, we have to include user-agent/s in our scraper. This will ensure that we can safely scrape the website without getting blocked and running across an error. Let’s take a look at two ways to avoid urllib.error.httperror: http error 403: forbidden.
Method 1: using user-agent
- In the code above, we have added a new parameter called headers which has a user-agent Mozilla/5.0. Details about the user’s device, OS, and browser are given by the webserver by the user-agent string. This prevents the bot from being blocked by the site.
- For instance, the user agent string gives information to the server that you are using Brace browser and Linux OS on your computer. Thereafter, the server accordingly sends the information.
 Using the user-agent, the error gets resolved.
Using the user-agent, the error gets resolved.
Method 2: using Session object
There are times when even using user-agent won’t prevent the urllib.error.httperror: http error 403: forbidden. Then we can use the Session object of the request module. For instance:
The site could be using cookies as a defense mechanism against scraping. It’s possible the site is setting and requesting cookies to be echoed back as a defense against scraping, which might be against its policy.
The Session object is compatible with cookies.
 Using Session object to resolve urllib.error
Using Session object to resolve urllib.error
Catching urllib.error.httperror
urllib.error.httperror can be caught using the try-except method. Try-except block can capture any exception, which can be hard to debug. For instance, it can capture exceptions like SystemExit and KeyboardInterupt. Let’s see how can we do this, for instance:
You can try the following steps in order to resolve the 403 error in the browser try refreshing the page, rechecking the URL, clearing the browser cookies, check your user credentials.
Scrapers often don’t use headers while requesting information. This results in their detection by the mod security. Hence, scraping modules often get 403 errors.
Источник
HOWTO Fetch Internet Resources Using The urllib Package¶
There is a French translation of an earlier revision of this HOWTO, available at urllib2 — Le Manuel manquant.
Introduction¶
You may also find useful the following article on fetching web resources with Python:
A tutorial on Basic Authentication, with examples in Python.
urllib.request is a Python module for fetching URLs (Uniform Resource Locators). It offers a very simple interface, in the form of the urlopen function. This is capable of fetching URLs using a variety of different protocols. It also offers a slightly more complex interface for handling common situations — like basic authentication, cookies, proxies and so on. These are provided by objects called handlers and openers.
urllib.request supports fetching URLs for many “URL schemes” (identified by the string before the «:» in URL — for example «ftp» is the URL scheme of «ftp://python.org/» ) using their associated network protocols (e.g. FTP, HTTP). This tutorial focuses on the most common case, HTTP.
For straightforward situations urlopen is very easy to use. But as soon as you encounter errors or non-trivial cases when opening HTTP URLs, you will need some understanding of the HyperText Transfer Protocol. The most comprehensive and authoritative reference to HTTP is RFC 2616. This is a technical document and not intended to be easy to read. This HOWTO aims to illustrate using urllib, with enough detail about HTTP to help you through. It is not intended to replace the urllib.request docs, but is supplementary to them.
Fetching URLs¶
The simplest way to use urllib.request is as follows:
If you wish to retrieve a resource via URL and store it in a temporary location, you can do so via the shutil.copyfileobj() and tempfile.NamedTemporaryFile() functions:
Many uses of urllib will be that simple (note that instead of an вЂhttp:’ URL we could have used a URL starting with вЂftp:’, вЂfile:’, etc.). However, it’s the purpose of this tutorial to explain the more complicated cases, concentrating on HTTP.
HTTP is based on requests and responses — the client makes requests and servers send responses. urllib.request mirrors this with a Request object which represents the HTTP request you are making. In its simplest form you create a Request object that specifies the URL you want to fetch. Calling urlopen with this Request object returns a response object for the URL requested. This response is a file-like object, which means you can for example call .read() on the response:
Note that urllib.request makes use of the same Request interface to handle all URL schemes. For example, you can make an FTP request like so:
In the case of HTTP, there are two extra things that Request objects allow you to do: First, you can pass data to be sent to the server. Second, you can pass extra information (“metadata”) about the data or about the request itself, to the server — this information is sent as HTTP “headers”. Let’s look at each of these in turn.
Data¶
Sometimes you want to send data to a URL (often the URL will refer to a CGI (Common Gateway Interface) script or other web application). With HTTP, this is often done using what’s known as a POST request. This is often what your browser does when you submit a HTML form that you filled in on the web. Not all POSTs have to come from forms: you can use a POST to transmit arbitrary data to your own application. In the common case of HTML forms, the data needs to be encoded in a standard way, and then passed to the Request object as the data argument. The encoding is done using a function from the urllib.parse library.
Note that other encodings are sometimes required (e.g. for file upload from HTML forms — see HTML Specification, Form Submission for more details).
If you do not pass the data argument, urllib uses a GET request. One way in which GET and POST requests differ is that POST requests often have “side-effects”: they change the state of the system in some way (for example by placing an order with the website for a hundredweight of tinned spam to be delivered to your door). Though the HTTP standard makes it clear that POSTs are intended to always cause side-effects, and GET requests never to cause side-effects, nothing prevents a GET request from having side-effects, nor a POST requests from having no side-effects. Data can also be passed in an HTTP GET request by encoding it in the URL itself.
This is done as follows:
Notice that the full URL is created by adding a ? to the URL, followed by the encoded values.
We’ll discuss here one particular HTTP header, to illustrate how to add headers to your HTTP request.
Some websites 1 dislike being browsed by programs, or send different versions to different browsers 2. By default urllib identifies itself as Python-urllib/x.y (where x and y are the major and minor version numbers of the Python release, e.g. Python-urllib/2.5 ), which may confuse the site, or just plain not work. The way a browser identifies itself is through the User-Agent header 3. When you create a Request object you can pass a dictionary of headers in. The following example makes the same request as above, but identifies itself as a version of Internet Explorer 4.
The response also has two useful methods. See the section on info and geturl which comes after we have a look at what happens when things go wrong.
Handling Exceptions¶
urlopen raises URLError when it cannot handle a response (though as usual with Python APIs, built-in exceptions such as ValueError , TypeError etc. may also be raised).
HTTPError is the subclass of URLError raised in the specific case of HTTP URLs.
The exception classes are exported from the urllib.error module.
URLError¶
Often, URLError is raised because there is no network connection (no route to the specified server), or the specified server doesn’t exist. In this case, the exception raised will have a вЂreason’ attribute, which is a tuple containing an error code and a text error message.
HTTPError¶
Every HTTP response from the server contains a numeric “status code”. Sometimes the status code indicates that the server is unable to fulfil the request. The default handlers will handle some of these responses for you (for example, if the response is a “redirection” that requests the client fetch the document from a different URL, urllib will handle that for you). For those it can’t handle, urlopen will raise an HTTPError . Typical errors include вЂ404’ (page not found), вЂ403’ (request forbidden), and вЂ401’ (authentication required).
See section 10 of RFC 2616 for a reference on all the HTTP error codes.
The HTTPError instance raised will have an integer вЂcode’ attribute, which corresponds to the error sent by the server.
Error Codes¶
Because the default handlers handle redirects (codes in the 300 range), and codes in the 100–299 range indicate success, you will usually only see error codes in the 400–599 range.
http.server.BaseHTTPRequestHandler.responses is a useful dictionary of response codes in that shows all the response codes used by RFC 2616. The dictionary is reproduced here for convenience
When an error is raised the server responds by returning an HTTP error code and an error page. You can use the HTTPError instance as a response on the page returned. This means that as well as the code attribute, it also has read, geturl, and info, methods as returned by the urllib.response module:
Wrapping it Up¶
So if you want to be prepared for HTTPError or URLError there are two basic approaches. I prefer the second approach.
Number 1В¶
The except HTTPError must come first, otherwise except URLError will also catch an HTTPError .
Number 2В¶
info and geturl¶
The response returned by urlopen (or the HTTPError instance) has two useful methods info() and geturl() and is defined in the module urllib.response ..
geturl — this returns the real URL of the page fetched. This is useful because urlopen (or the opener object used) may have followed a redirect. The URL of the page fetched may not be the same as the URL requested.
info — this returns a dictionary-like object that describes the page fetched, particularly the headers sent by the server. It is currently an http.client.HTTPMessage instance.
Typical headers include вЂContent-length’, вЂContent-type’, and so on. See the Quick Reference to HTTP Headers for a useful listing of HTTP headers with brief explanations of their meaning and use.
Openers and Handlers¶
When you fetch a URL you use an opener (an instance of the perhaps confusingly named urllib.request.OpenerDirector ). Normally we have been using the default opener — via urlopen — but you can create custom openers. Openers use handlers. All the “heavy lifting” is done by the handlers. Each handler knows how to open URLs for a particular URL scheme (http, ftp, etc.), or how to handle an aspect of URL opening, for example HTTP redirections or HTTP cookies.
You will want to create openers if you want to fetch URLs with specific handlers installed, for example to get an opener that handles cookies, or to get an opener that does not handle redirections.
To create an opener, instantiate an OpenerDirector , and then call .add_handler(some_handler_instance) repeatedly.
Alternatively, you can use build_opener , which is a convenience function for creating opener objects with a single function call. build_opener adds several handlers by default, but provides a quick way to add more and/or override the default handlers.
Other sorts of handlers you might want to can handle proxies, authentication, and other common but slightly specialised situations.
install_opener can be used to make an opener object the (global) default opener. This means that calls to urlopen will use the opener you have installed.
Opener objects have an open method, which can be called directly to fetch urls in the same way as the urlopen function: there’s no need to call install_opener , except as a convenience.
Basic Authentication¶
To illustrate creating and installing a handler we will use the HTTPBasicAuthHandler . For a more detailed discussion of this subject – including an explanation of how Basic Authentication works — see the Basic Authentication Tutorial.
When authentication is required, the server sends a header (as well as the 401 error code) requesting authentication. This specifies the authentication scheme and a вЂrealm’. The header looks like: WWW-Authenticate: SCHEME realm=»REALM» .
The client should then retry the request with the appropriate name and password for the realm included as a header in the request. This is вЂbasic authentication’. In order to simplify this process we can create an instance of HTTPBasicAuthHandler and an opener to use this handler.
The HTTPBasicAuthHandler uses an object called a password manager to handle the mapping of URLs and realms to passwords and usernames. If you know what the realm is (from the authentication header sent by the server), then you can use a HTTPPasswordMgr . Frequently one doesn’t care what the realm is. In that case, it is convenient to use HTTPPasswordMgrWithDefaultRealm . This allows you to specify a default username and password for a URL. This will be supplied in the absence of you providing an alternative combination for a specific realm. We indicate this by providing None as the realm argument to the add_password method.
The top-level URL is the first URL that requires authentication. URLs “deeper” than the URL you pass to .add_password() will also match.
In the above example we only supplied our HTTPBasicAuthHandler to build_opener . By default openers have the handlers for normal situations – ProxyHandler (if a proxy setting such as an http_proxy environment variable is set), UnknownHandler , HTTPHandler , HTTPDefaultErrorHandler , HTTPRedirectHandler , FTPHandler , FileHandler , DataHandler , HTTPErrorProcessor .
top_level_url is in fact either a full URL (including the вЂhttp:’ scheme component and the hostname and optionally the port number) e.g. «http://example.com/» or an “authority” (i.e. the hostname, optionally including the port number) e.g. «example.com» or «example.com:8080» (the latter example includes a port number). The authority, if present, must NOT contain the “userinfo” component — for example «joe:password@example.com» is not correct.
Proxies¶
urllib will auto-detect your proxy settings and use those. This is through the ProxyHandler , which is part of the normal handler chain when a proxy setting is detected. Normally that’s a good thing, but there are occasions when it may not be helpful 5. One way to do this is to setup our own ProxyHandler , with no proxies defined. This is done using similar steps to setting up a Basic Authentication handler:
Currently urllib.request does not support fetching of https locations through a proxy. However, this can be enabled by extending urllib.request as shown in the recipe 6.
HTTP_PROXY will be ignored if a variable REQUEST_METHOD is set; see the documentation on getproxies() .
Sockets and Layers¶
The Python support for fetching resources from the web is layered. urllib uses the http.client library, which in turn uses the socket library.
As of Python 2.3 you can specify how long a socket should wait for a response before timing out. This can be useful in applications which have to fetch web pages. By default the socket module has no timeout and can hang. Currently, the socket timeout is not exposed at the http.client or urllib.request levels. However, you can set the default timeout globally for all sockets using
This document was reviewed and revised by John Lee.
Google for example.
Browser sniffing is a very bad practice for website design — building sites using web standards is much more sensible. Unfortunately a lot of sites still send different versions to different browsers.
The user agent for MSIE 6 is вЂMozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)’
For details of more HTTP request headers, see Quick Reference to HTTP Headers.
In my case I have to use a proxy to access the internet at work. If you attempt to fetch localhost URLs through this proxy it blocks them. IE is set to use the proxy, which urllib picks up on. In order to test scripts with a localhost server, I have to prevent urllib from using the proxy.
urllib opener for SSL proxy (CONNECT method): ASPN Cookbook Recipe.
Источник
- the
urllibModule in Python - Check
robots.txtto PreventurllibHTTP Error 403 Forbidden Message - Adding Cookie to the Request Headers to Solve
urllibHTTP Error 403 Forbidden Message - Use Session Object to Solve
urllibHTTP Error 403 Forbidden Message

Today’s article explains how to deal with an error message (exception), urllib.error.HTTPError: HTTP Error 403: Forbidden, produced by the error class on behalf of the request classes when it faces a forbidden resource.
the urllib Module in Python
The urllib Python module handles URLs for python via different protocols. It is famous for web scrapers who want to obtain data from a particular website.
The urllib contains classes, methods, and functions that perform certain operations such as reading, parsing URLs, and robots.txt. There are four classes, request, error, parse, and robotparser.
Check robots.txt to Prevent urllib HTTP Error 403 Forbidden Message
When using the urllib module to interact with clients or servers via the request class, we might experience specific errors. One of those errors is the HTTP 403 error.
We get urllib.error.HTTPError: HTTP Error 403: Forbidden error message in urllib package while reading a URL. The HTTP 403, the Forbidden Error, is an HTTP status code that indicates that the client or server forbids access to a requested resource.
Therefore, when we see this kind of error message, urllib.error.HTTPError: HTTP Error 403: Forbidden, the server understands the request but decides not to process or authorize the request that we sent.
To understand why the website we are accessing is not processing our request, we need to check an important file, robots.txt. Before web scraping or interacting with a website, it is often advised to review this file to know what to expect and not face any further troubles.
To check it on any website, we can follow the format below.
https://<website.com>/robots.txt
For example, check YouTube, Amazon, and Google robots.txt files.
https://www.youtube.com/robots.txt
https://www.amazon.com/robots.txt
https://www.google.com/robots.txt
Checking YouTube robots.txt gives the following result.
# robots.txt file for YouTube
# Created in the distant future (the year 2000) after
# the robotic uprising of the mid-'90s wiped out all humans.
User-agent: Mediapartners-Google*
Disallow:
User-agent: *
Disallow: /channel/*/community
Disallow: /comment
Disallow: /get_video
Disallow: /get_video_info
Disallow: /get_midroll_info
Disallow: /live_chat
Disallow: /login
Disallow: /results
Disallow: /signup
Disallow: /t/terms
Disallow: /timedtext_video
Disallow: /user/*/community
Disallow: /verify_age
Disallow: /watch_ajax
Disallow: /watch_fragments_ajax
Disallow: /watch_popup
Disallow: /watch_queue_ajax
Sitemap: https://www.youtube.com/sitemaps/sitemap.xml
Sitemap: https://www.youtube.com/product/sitemap.xml
We can notice a lot of Disallow tags there. This Disallow tag shows the website’s area, which is not accessible. Therefore, any request to those areas will not be processed and is forbidden.
In other robots.txt files, we might see an Allow tag. For example, http://youtube.com/comment is forbidden to any external request, even with the urllib module.
Let’s write code to scrape data from a website that returns an HTTP 403 error when accessed.
Example Code:
import urllib.request
import re
webpage = urllib.request.urlopen('https://www.cmegroup.com/markets/products.html?redirect=/trading/products/#cleared=Options&sortField=oi').read()
findrows = re.compile('<tr class="- banding(?:On|Off)>(.*?)</tr>')
findlink = re.compile('<a href =">(.*)</a>')
row_array = re.findall(findrows, webpage)
links = re.findall(findlink, webpage)
print(len(row_array))
Output:
Traceback (most recent call last):
File "c:UsersakinlDocumentsPythonindex.py", line 7, in <module>
webpage = urllib.request.urlopen('https://www.cmegroup.com/markets/products.html?redirect=/trading/products/#cleared=Options&sortField=oi').read()
File "C:Python310liburllibrequest.py", line 216, in urlopen
return opener.open(url, data, timeout)
File "C:Python310liburllibrequest.py", line 525, in open
response = meth(req, response)
File "C:Python310liburllibrequest.py", line 634, in http_response
response = self.parent.error(
File "C:Python310liburllibrequest.py", line 563, in error
return self._call_chain(*args)
File "C:Python310liburllibrequest.py", line 496, in _call_chain
result = func(*args)
File "C:Python310liburllibrequest.py", line 643, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
The reason is that we are forbidden from accessing the website. However, if we check the robots.txt file, we will notice that https://www.cmegroup.com/markets/ is not with a Disallow tag. However, if we go down the robots.txt file for the website we wanted to scrape, we will find the below.
User-agent: Python-urllib/1.17
Disallow: /
The above text means that the user agent named Python-urllib is not allowed to crawl any URL within the site. That means using the Python urllib module is not allowed to crawl the site.
Therefore, check or parse the robots.txt to know what resources we have access to. we can parse robots.txt file using the robotparser class. These can prevent our code from experiencing an urllib.error.HTTPError: HTTP Error 403: Forbidden error message.
Passing a valid user agent as a header parameter will quickly fix the problem. The website may use cookies as an anti-scraping measure.
The website may set and ask for cookies to be echoed back to prevent scraping, which is maybe against its policy.
from urllib.request import Request, urlopen
def get_page_content(url, head):
req = Request(url, headers=head)
return urlopen(req)
url = 'https://example.com'
head = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive',
'refere': 'https://example.com',
'cookie': """your cookie value ( you can get that from your web page) """
}
data = get_page_content(url, head).read()
print(data)
Output:
<!doctype html>n<html>n<head>n <title>Example Domain</title>nn <meta
'
'
'
<p><a href="https://www.iana.org/domains/example">More information...</a></p>n</div>n</body>n</html>n'
Passing a valid user agent as a header parameter will quickly fix the problem.
Use Session Object to Solve urllib HTTP Error 403 Forbidden Message
Sometimes, even using a user agent won’t stop this error from occurring. The Session object of the requests module can then be used.
from random import seed
import requests
url = "https://stackoverflow.com/search?q=html+error+403"
session_obj = requests.Session()
response = session_obj.get(url, headers={"User-Agent": "Mozilla/5.0"})
print(response.status_code)
Output:
The above article finds the cause of the urllib.error.HTTPError: HTTP Error 403: Forbidden and the solution to handle it. mod_security basically causes this error as different web pages use different security mechanisms to differentiate between human and automated computers (bots).
Summary
TL;DR: requests raises a 403 while requesting an authenticated Github API route, which otherwise succeeds while using curl/another python library like httpx
Was initially discovered in the ‘ghexport’ project; I did a reasonable amount of debugging and created this repo before submitting this issue to PyGithub, but thats a lot to look through, just leaving it here as context.
It’s been hard to reproduce, the creator of ghexport (where this was initially discovered) didn’t have the same issue, so I’m unsure of the exact reason
Expected Result
requests succeeds for the authenticated request
Actual Result
Request fails, with:
{'message': 'Must have push access to repository', 'documentation_url': 'https://docs.github.com/rest/reference/repos#get-repository-clones'}
failed
Traceback (most recent call last):
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 47, in <module>
main()
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 44, in main
make_request(requests.get, url, headers)
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 31, in make_request
resp.raise_for_status()
File "/home/sean/.local/lib/python3.9/site-packages/requests/models.py", line 941, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
Reproduction Steps
Apologies if this is a bit too specific, but otherwise requests works great on my system and I can’t find any other way to reproduce this — Is a bit long as it requires an auth token
Go here and create a token with scopes like:

I’ve compared this to httpx, where it doesn’t fail:
#!/usr/bin/env python3 from typing import Callable, Any import requests import httpx # extract status/status_code from the requests/httpx item def extract_status(obj: Any) -> int: if hasattr(obj, "status"): return obj.status if hasattr(obj, "status_code"): return obj.status_code raise TypeError("unsupported request object") def make_request(using_verb: Callable[..., Any], url: str, headers: Any) -> None: print("using", using_verb.__module__, using_verb.__qualname__, url) resp = using_verb(url, headers=headers) status = extract_status(resp) print(str(resp.json())) if status == 200: print("succeeded") else: print("failed") resp.raise_for_status() def main(): # see https://github.com/seanbreckenridge/pygithub_requests_error for token scopes auth_token = "put your auth token here" headers = { "Authorization": "token {}".format(auth_token), "User-Agent": "requests_error", "Accept": "application/vnd.github.v3+json", } # replace this with a URL you have access to url = "https://api.github.com/repos/seanbreckenridge/albums/traffic/clones" make_request(httpx.get, url, headers) make_request(requests.get, url, headers) if __name__ == "__main__": main()
That outputs:
using httpx get https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
{'count': 15, 'uniques': 10, 'clones': [{'timestamp': '2021-04-12T00:00:00Z', 'count': 1, 'uniques': 1}, {'timestamp': '2021-04-14T00:00:00Z', 'count': 1, 'uniques': 1}, {'timestamp': '2021-04-17T00:00:00Z', 'count': 1, 'uniques': 1}, {'timestamp': '2021-04-18T00:00:00Z', 'count': 2, 'uniques': 2}, {'timestamp': '2021-04-23T00:00:00Z', 'count': 9, 'uniques': 5}, {'timestamp': '2021-04-25T00:00:00Z', 'count': 1, 'uniques': 1}]}
succeeded
using requests.api get https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
{'message': 'Must have push access to repository', 'documentation_url': 'https://docs.github.com/rest/reference/repos#get-repository-clones'}
failed
Traceback (most recent call last):
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 48, in <module>
main()
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 45, in main
make_request(requests.get, url, headers)
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 32, in make_request
resp.raise_for_status()
File "/home/sean/.local/lib/python3.9/site-packages/requests/models.py", line 943, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
Another thing that may be useful as context is the pdb trace I did here, which was me stepping into where the request was made in PyGithub, and making all the requests manually using the computed url/headers. Fails when I use requests.get but httpx.get works fine:
> /home/sean/.local/lib/python3.8/site-packages/github/Requester.py(484)__requestEncode()
-> self.NEW_DEBUG_FRAME(requestHeaders)
(Pdb) n
> /home/sean/.local/lib/python3.8/site-packages/github/Requester.py(486)__requestEncode()
-> status, responseHeaders, output = self.__requestRaw(
(Pdb) w
/home/sean/Repos/ghexport/export.py(109)<module>()
-> main()
/home/sean/Repos/ghexport/export.py(84)main()
-> j = get_json(**params)
/home/sean/Repos/ghexport/export.py(74)get_json()
-> return Exporter(**params).export_json()
/home/sean/Repos/ghexport/export.py(60)export_json()
-> repo._requester.requestJsonAndCheck('GET', repo.url + '/traffic/' + f)
/home/sean/.local/lib/python3.8/site-packages/github/Requester.py(318)requestJsonAndCheck()
-> *self.requestJson(
/home/sean/.local/lib/python3.8/site-packages/github/Requester.py(410)requestJson()
-> return self.__requestEncode(cnx, verb, url, parameters, headers, input, encode)
> /home/sean/.local/lib/python3.8/site-packages/github/Requester.py(486)__requestEncode()
-> status, responseHeaders, output = self.__requestRaw(
(Pdb) url
'/repos/seanbreckenridge/advent-of-code-2019/traffic/views'
(Pdb) requestHeaders
{'Authorization': 'token <MY TOKEN HERE>', 'User-Agent': 'PyGithub/Python'}
(Pdb) import requests
(Pdb) requests.get("https://api.github.com" + url, headers=requestHeaders).json()
{'message': 'Must have push access to repository', 'documentation_url': 'https://docs.github.com/rest/reference/repos#get-page-views'}
(Pdb) httpx.get("https://api.github.com" + url, headers=requestHeaders).json()
{'count': 0, 'uniques': 0, 'views': []}
(Pdb) httpx succeeded??
System Information
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "3.4.7"
},
"idna": {
"version": "2.10"
},
"implementation": {
"name": "CPython",
"version": "3.9.3"
},
"platform": {
"release": "5.11.16-arch1-1",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "101010bf",
"version": "20.0.1"
},
"requests": {
"version": "2.25.1"
},
"system_ssl": {
"version": "101010bf"
},
"urllib3": {
"version": "1.25.9"
},
"using_pyopenssl": true
}
$ pip freeze | grep -E 'requests|httpx'
httpx==0.16.1
requests==2.25.1
- the
urllibModule in Python - Check
robots.txtto PreventurllibHTTP Error 403 Forbidden Message - Adding Cookie to the Request Headers to Solve
urllibHTTP Error 403 Forbidden Message - Use Session Object to Solve
urllibHTTP Error 403 Forbidden Message

Today’s article explains how to deal with an error message (exception), urllib.error.HTTPError: HTTP Error 403: Forbidden, produced by the error class on behalf of the request classes when it faces a forbidden resource.
the urllib Module in Python
The urllib Python module handles URLs for python via different protocols. It is famous for web scrapers who want to obtain data from a particular website.
The urllib contains classes, methods, and functions that perform certain operations such as reading, parsing URLs, and robots.txt. There are four classes, request, error, parse, and robotparser.
Check robots.txt to Prevent urllib HTTP Error 403 Forbidden Message
When using the urllib module to interact with clients or servers via the request class, we might experience specific errors. One of those errors is the HTTP 403 error.
We get urllib.error.HTTPError: HTTP Error 403: Forbidden error message in urllib package while reading a URL. The HTTP 403, the Forbidden Error, is an HTTP status code that indicates that the client or server forbids access to a requested resource.
Therefore, when we see this kind of error message, urllib.error.HTTPError: HTTP Error 403: Forbidden, the server understands the request but decides not to process or authorize the request that we sent.
To understand why the website we are accessing is not processing our request, we need to check an important file, robots.txt. Before web scraping or interacting with a website, it is often advised to review this file to know what to expect and not face any further troubles.
To check it on any website, we can follow the format below.
https://<website.com>/robots.txt
For example, check YouTube, Amazon, and Google robots.txt files.
https://www.youtube.com/robots.txt
https://www.amazon.com/robots.txt
https://www.google.com/robots.txt
Checking YouTube robots.txt gives the following result.
# robots.txt file for YouTube
# Created in the distant future (the year 2000) after
# the robotic uprising of the mid-'90s wiped out all humans.
User-agent: Mediapartners-Google*
Disallow:
User-agent: *
Disallow: /channel/*/community
Disallow: /comment
Disallow: /get_video
Disallow: /get_video_info
Disallow: /get_midroll_info
Disallow: /live_chat
Disallow: /login
Disallow: /results
Disallow: /signup
Disallow: /t/terms
Disallow: /timedtext_video
Disallow: /user/*/community
Disallow: /verify_age
Disallow: /watch_ajax
Disallow: /watch_fragments_ajax
Disallow: /watch_popup
Disallow: /watch_queue_ajax
Sitemap: https://www.youtube.com/sitemaps/sitemap.xml
Sitemap: https://www.youtube.com/product/sitemap.xml
We can notice a lot of Disallow tags there. This Disallow tag shows the website’s area, which is not accessible. Therefore, any request to those areas will not be processed and is forbidden.
In other robots.txt files, we might see an Allow tag. For example, http://youtube.com/comment is forbidden to any external request, even with the urllib module.
Let’s write code to scrape data from a website that returns an HTTP 403 error when accessed.
Example Code:
import urllib.request
import re
webpage = urllib.request.urlopen('https://www.cmegroup.com/markets/products.html?redirect=/trading/products/#cleared=Options&sortField=oi').read()
findrows = re.compile('<tr class="- banding(?:On|Off)>(.*?)</tr>')
findlink = re.compile('<a href =">(.*)</a>')
row_array = re.findall(findrows, webpage)
links = re.findall(findlink, webpage)
print(len(row_array))
Output:
Traceback (most recent call last):
File "c:UsersakinlDocumentsPythonindex.py", line 7, in <module>
webpage = urllib.request.urlopen('https://www.cmegroup.com/markets/products.html?redirect=/trading/products/#cleared=Options&sortField=oi').read()
File "C:Python310liburllibrequest.py", line 216, in urlopen
return opener.open(url, data, timeout)
File "C:Python310liburllibrequest.py", line 525, in open
response = meth(req, response)
File "C:Python310liburllibrequest.py", line 634, in http_response
response = self.parent.error(
File "C:Python310liburllibrequest.py", line 563, in error
return self._call_chain(*args)
File "C:Python310liburllibrequest.py", line 496, in _call_chain
result = func(*args)
File "C:Python310liburllibrequest.py", line 643, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
The reason is that we are forbidden from accessing the website. However, if we check the robots.txt file, we will notice that https://www.cmegroup.com/markets/ is not with a Disallow tag. However, if we go down the robots.txt file for the website we wanted to scrape, we will find the below.
User-agent: Python-urllib/1.17
Disallow: /
The above text means that the user agent named Python-urllib is not allowed to crawl any URL within the site. That means using the Python urllib module is not allowed to crawl the site.
Therefore, check or parse the robots.txt to know what resources we have access to. we can parse robots.txt file using the robotparser class. These can prevent our code from experiencing an urllib.error.HTTPError: HTTP Error 403: Forbidden error message.
Passing a valid user agent as a header parameter will quickly fix the problem. The website may use cookies as an anti-scraping measure.
The website may set and ask for cookies to be echoed back to prevent scraping, which is maybe against its policy.
from urllib.request import Request, urlopen
def get_page_content(url, head):
req = Request(url, headers=head)
return urlopen(req)
url = 'https://example.com'
head = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive',
'refere': 'https://example.com',
'cookie': """your cookie value ( you can get that from your web page) """
}
data = get_page_content(url, head).read()
print(data)
Output:
<!doctype html>n<html>n<head>n <title>Example Domain</title>nn <meta
'
'
'
<p><a href="https://www.iana.org/domains/example">More information...</a></p>n</div>n</body>n</html>n'
Passing a valid user agent as a header parameter will quickly fix the problem.
Use Session Object to Solve urllib HTTP Error 403 Forbidden Message
Sometimes, even using a user agent won’t stop this error from occurring. The Session object of the requests module can then be used.
from random import seed
import requests
url = "https://stackoverflow.com/search?q=html+error+403"
session_obj = requests.Session()
response = session_obj.get(url, headers={"User-Agent": "Mozilla/5.0"})
print(response.status_code)
Output:
The above article finds the cause of the urllib.error.HTTPError: HTTP Error 403: Forbidden and the solution to handle it. mod_security basically causes this error as different web pages use different security mechanisms to differentiate between human and automated computers (bots).