
В данном разделе описаны способы проверки XML-файла по XSD-схеме. Сделать это можно разными способами, существует много программ для этих целей. По XSD-схеме, например, проверяет программа Tester, но она только показывает ошибки и не дает их исправить. Для большего удобства лучше использовать специализированные редакторы такие, как XMLPad или MS Visual Studio.
MS Visual Studio является спецаилизированным инструментом для программистов, обладающим огромным функционалом. Работа с XML и автоматическая проверка по XSD – лишь одна из множества функций среды разработки. MS Visual Studio 15 можно скачать бесплатно с официального сайта: https://www.visualstudio.com/ru-ru/products/visual-studio-community-vs.
XMLPad — многофункциональный специализированный XML редактор. XMLPad обладает богатым функционалом, поддерживает XPath, возможность удалять целые блоки тегов, смену кодировок, проверку валидности и т.д. XMLPad доступен для бесплатного использования на сайте: http://xmlpad-mobile.com.
Совет
XMLPad уступает по удобству и возможностям MS Visual Studio, но если вы не являетесь программистом и у вас не установлена MS Visual Studio, лучше воспользоваться XMLPad.
Примечание
Перед проверкой файлов необходимо предварительно скачать файлы XSD-схем. Скачать XSD-схемы можно с официальных сайтов контролирующих органов. В качестве примера взята декларация по НДС, скачать XSD-схему для нее можно с сайта Справочник налоговой и бухгалтерской отчетности.
Проверка по XSD-схеме в XMLPad¶
- Откройте XML-файл, который требуется проверить в XMLPad File > Open.

- Чтобы проверить файл по заданной XSD-схеме, его надо с ней ассоциировать. Перейдите в меню XML > Assign Schema/DTD.

- Выберите W3C Schema и нажмите Browse, затем выберите XSD-схему для проверки.


- После того, как XSD-схема ассоциирована, нажмите
F7или XML > Validate, чтобы проверить файл. В нижней части окна будут выведены ошибки, нажав на которые можно подсветить строку, в которой они находятся.

Совет
Для удобства отображения можно включить переносы строк Edit > Word Wrap.
Проверка по XSD-схеме в MS Visual Studio¶
- Откройте XML-файл, который требуется проверить в MS Visual Studio Файл > Открыть > Файл.

- Чтобы проверить файл по заданной XSD-схеме, его надо с ней ассоциировать. Перейдите в меню XML-код > Схемы….

- Нажмите Добавить и выберите файл XSD-схемы.

Проверка на соответсвие XSD-схеме будет осуществляться автоматически на лету. Внизу в окне Списка ошибок будет отображаться список ошибок. При нажатии на ошибку, она будет подсвечена в редакторе.
Совет
Добавить окно Списка ошибок можно через Вид > Списка ошибок.
I need to validate a XML file against a schema. The XML file is being generated in code and before I save it I need to validate it to be correct.
I have stripped the problem down to its barest elements but am having an issue.
XML:
<?xml version="1.0" encoding="utf-16"?>
<MRIDSupportingData xmlns="urn:GenericLabData">
<MRIDNumber>MRIDDemo</MRIDNumber>
<CrewMemberIdentifier>1234</CrewMemberIdentifier>
<PrescribedTestDate>1/1/2005</PrescribedTestDate>
</MRIDSupportingData>
Schema:
<?xml version="1.0" encoding="utf-16"?>
<xs:schema xmlns="urn:GenericLabData" targetNamespace="urn:GenericLabData"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="MRIDSupportingData">
<xs:complexType>
<xs:sequence>
<xs:element name="MRIDNumber" type="xs:string" />
<xs:element minOccurs="1" name="CrewMemberIdentifier" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
ValidationCode: (This code is from a simple app I wrote to test the validation logic. The XML and XSD files are stored on disk and are being read from there. In the actual app, the XML file would be in memory already as an XmlDocument object and the XSD would be read from an internal webserver.)
private void Validate()
{
XmlReaderSettings settings = new XmlReaderSettings();
settings.ValidationType = ValidationType.Schema;
//settings.ValidationFlags |= XmlSchemaValidationFlags.ProcessInlineSchema;
//settings.ValidationFlags |= XmlSchemaValidationFlags.ProcessSchemaLocation;
//settings.ValidationFlags |= XmlSchemaValidationFlags.ReportValidationWarnings;
settings.ValidationEventHandler += new ValidationEventHandler(OnValidate);
XmlSchemaSet schemas = new XmlSchemaSet();
settings.Schemas = schemas;
try
{
schemas.Add(null, schemaPathTextBox.Text);
using (XmlReader reader = XmlReader.Create(xmlDocumentPathTextBox.Text, settings))
{
validateText.AppendLine("Validating...");
while (reader.Read()) ;
validateText.AppendLine("Finished Validating");
textBox1.Text = validateText.ToString();
}
}
catch (Exception ex)
{
textBox1.Text = ex.ToString();
}
}
StringBuilder validateText = new StringBuilder();
private void OnValidate(object sender, ValidationEventArgs e)
{
switch (e.Severity)
{
case XmlSeverityType.Error:
validateText.AppendLine(string.Format("Error: {0}", e.Message));
break;
case XmlSeverityType.Warning:
validateText.AppendLine(string.Format("Warning {0}", e.Message));
break;
}
}
When running the above code with the XML and XSD files defined above I get this output:
Validating…
Error: The element ‘MRIDSupportingData’ in namespace ‘urn:GenericLabData’ has invalid child element ‘MRIDNumber’ in namespace ‘urn:GenericLabData’. List of possible elements expected: ‘MRIDNumber’.
Finished Validating
What am I missing? As far as I can tell, MRIDNumber is MRIDNumber so why the error?
The actual XML file is much larger as well as the XSD, but it fails at the very beginning, so I have reduced the problem to almost nothing.
Any assistance on this would be great.
Thank you,
Keith
BTW, These files do work:
XML:
<?xml version='1.0'?>
<bookstore xmlns="urn:bookstore-schema">
<book genre="novel">
<title>The Confidence Man</title>
<author>
<first-name>Herman</first-name>
<last-name>Melville</last-name>
</author>
<price>11.99</price>
</book>
</bookstore>
Schema:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns="urn:bookstore-schema"
elementFormDefault="qualified"
targetNamespace="urn:bookstore-schema">
<xsd:element name="bookstore">
<xsd:complexType>
<xsd:sequence >
<xsd:element name="book" maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence >
<xsd:element name="title" type="xsd:string"/>
<xsd:element name="author">
<xsd:complexType>
<xsd:sequence >
<xsd:element name="first-name" type="xsd:string"/>
<xsd:element name="last-name" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="price" type="xsd:decimal"/>
</xsd:sequence>
<xsd:attribute name="genre" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
I have an XML form with an element 0, which is well-formed but not valid.
When I try to validate it XMLSpy I get a following error:
Nothing is allowed inside empty element ‘hidden’.
Below is my schema:
<xs:element name="hidden">
<xs:complexType>
<xs:attribute name="datatype" type="xs:string" use="optional"/>
<xs:attribute name="alias" type="xs:string" use="optional"/>
<xs:attribute name="source" type="xs:string" use="optional"/>
<xs:attribute name="name" type="xs:string" use="required"/>
<xs:attribute name="lookup" type="xs:string" use="optional"/>
</xs:complexType>
</xs:element>
What do I need to add to the above schema to fix this error? Thanx ml
![]()
Luc Touraille
79.5k15 gold badges90 silver badges137 bronze badges
asked Jan 15, 2009 at 12:50
![]()
2
Your «hidden» element is defined as being empty since you don’t have anything in the schema explicitly allowing child elements. I’m assuming you’re wanting something like
<hidden *[attributes]*>
<some_other_element/>
</hidden>
But according to http://www.w3schools.com/Schema/schema_complex_empty.asp you have implicitly defined «hidden» to be empty. You need to define which elements can appear inside «hidden». There are many ways to do this and I suggest starting by reading http://www.w3schools.com/Schema/schema_complex.asp.
answered Jan 15, 2009 at 13:03
![]()
WelbogWelbog
59k9 gold badges110 silver badges123 bronze badges
1
As welbog noted, you defined a complex empty element. Assuming you want only text within the hidden tag, you could write a schema along theses lines :
<xs:element name="hidden">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:integer">
<xs:attribute name="datatype" type="xs:string" use="optional"/>
<xs:attribute name="alias" type="xs:string" use="optional"/>
<xs:attribute name="source" type="xs:string" use="optional"/>
<xs:attribute name="name" type="xs:string" use="required"/>
<xs:attribute name="lookup" type="xs:string" use="optional"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
This way, you can have a piece of XML like this one:
<hidden datatype="foo" name="bar">0</hidden>
What is going on here is that I defined «hidden» to be an extension of xs:integer (by the way, you can make it extends any type you want), which means that «hidden» elements are like integers element, but with additional constraints, or in this case with additional attributes.
answered Jan 15, 2009 at 14:19
![]()
Luc TourailleLuc Touraille
79.5k15 gold badges90 silver badges137 bronze badges
1
Время на прочтение
8 мин
Количество просмотров 30K
XSD — это язык описания структуры XML документа. Его также называют XML Schema. При использовании XML Schema XML-парсер может проверить не только правильность синтаксиса XML документа, но также его структуру, модель содержания и типы данных. Многие так или иначе сталкивались с процедурой полной валидации, обеспечивающей соответствие документа заданной схеме или сообщающей о возможных ошибках. В данной статье речь пойдет о частичной валидации, кроме вышеописанного, позволяющей конструировать валидные документы «на лету». Мы разберемся, какие возможности может предоставить такой подход и способы его реализации.
Основная цель
Зачем вообще может понадобиться конструировать документ, обладающий заданными свойствами, и какими свойствами мы можем управлять? На первый вопрос ответ практически очевиден; большинство документов не являются просто текстом, а наделены некоторой семантикой. XML решает вопрос синтаксического представления, а схема – частично решает вопрос семантического значения. Благодаря соответствию документа схеме, можно выполнять над ним набор предопределенных действий, допустимых для целого класса валидных документов, будь то представление в другом формате, экспорт значимой части информации для конкретной задачи, импорт новой информации с учетом глобальных ограничений. Наиболее часто применяемый механизм в таком случае – это XSLT преобразование, смысл которого можно проиллюстрировать следующей диаграммой:
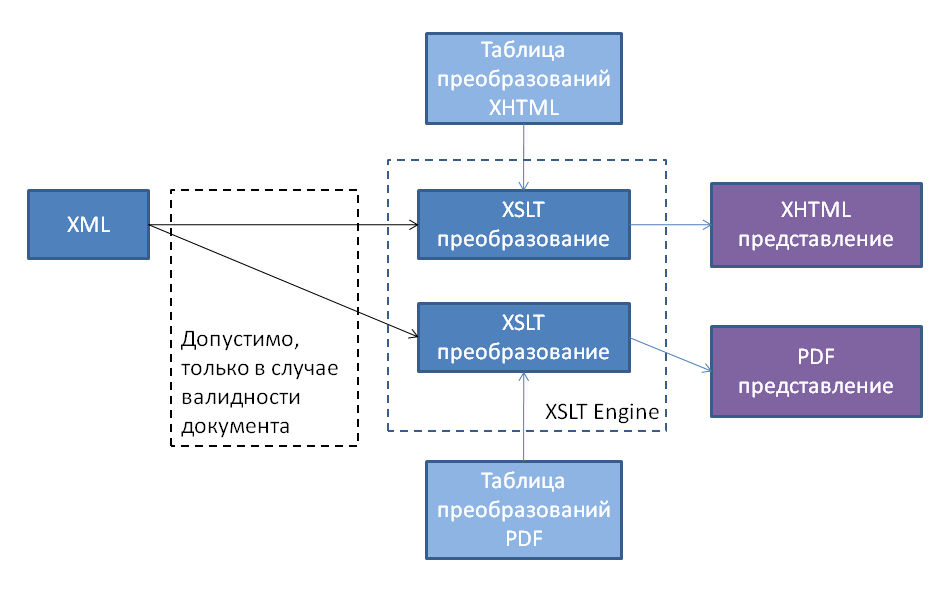
На второй вопрос полностью ответит спецификация схемы, а мы остановимся лишь на самых важных пунктах, которые дают представление о возможностях схем. Итак, схема позволяет:
- Строго контролировать типизацию данных узлов и атрибутов;
- Определять порядок следования узлов, следить за наличием обязательных узлов и атрибутов;
- Требовать уникальность элементов в заданном контексте;
- Создавать вариантные узлы, требующие наличия одних атрибутов или других, в зависимости от контекста;
- Требовать выполнения определенного предиката на группе узлов или атрибутов.
В качестве простого примера можно привести оглавление статьи – схемой можно задать семантику данных «название – страница», проконтролировать, что страницы идут по возрастанию, что нет одинаковых названий, что предопределенный элемент «Введение» идет до «Списка литературы» и обязателен, если есть элемент «Заключение». Наиболее сложным и мощным примером являются XML-базы данных, где и типизация и валидность данных определяются исключительно схемами.
Часто возникает желание модифицировать документ, уже отвечающий выбранной схеме, таким образом, чтобы он не потерял валидность. Здесь речь идет и о автоматических модификациях, например добавление веб-агентами (агрегаторами) информации в документ или модифицирующие запросы в XML-базу данных, так и о ручной модификации, скажем, в визуальном XML-редакторе. Операция полной валидации для больших документов может занимать существенное время, десятки секунд и более, что в целом препятствует использованию подхода «атомарное изменение – проверка – отказ/разрешение». А для визуальных редакторов хотелось бы еще больше – иметь возможность не только проверить атомарное действие, а предложить все допустимые по схеме варианты модификации конкретного узла. Однако, хорошие XML-редакторы умеют это делать, и мы попробуем разобраться каким образом у них это получается.
Необходимая информация о XML схеме
W3C XML схема является развитием идеи XML DTD (Document Type Definition). Оба стандарта описывают схему документа посредством набора объявлений (объектов-параметров, элементов и атрибутов), которые описывают его класс (или тип) с точки зрения синтаксических ограничений этого документа. DTD рассматривает набор регулярных выражений над атомарными термами или элементами словаря типов. Каждый тип строится на основе других типов, атомарных термов и операций альтернативы “|”, конкатенации “,” и операторов “?”, “+”, “*”, означающих опциональность, наличие одного-или-более или нуля-или-более элементов. XML схема отличается от XML DTD синтаксисом, и расширяет функционал DTD в трех направлениях:
- Шаблоны (any, anyType, anyAttribute), позволяющие использовать любой элемент, соответствующий заданному пространству имен;
- Группы подстановки, определяющие набор типов, который может быть использован вместо конкретного описания типа;
- Количество повторений, определяющее для каждого элемента минимальное и максимально допустимое количество его вхождений в тип (обобщение операторов Клини: «*», «+»).
Алгоритмически валидация по схеме является более сложной задачей, чем соответствующая задача для DTD [1], но более поздний стандарт описания XML схем дополнен правилом существенно облегчающим валидацию.
Правило Unique Particle Attribution (однозначность определения частиц) требует, чтобы каждый элемент документа однозначно соответствовал ровно одной частице xsd:element или xsd:any в модели содержимого родительского элемента [2].
Вообще говоря, правило Unique Particle Attribution (UPA) не является жестким требованием к структуре XML схем, а только крайне желательной рекомендацией и часть используемых схем ему не соответствует. Рассмотрим простейший пример, иллюстрирующий нарушение правила однозначности определения частиц.
Определим схему следующим образом:
<xsd:element name="root">
<xsd:complexType>
<xsd:choice>
<xsd:element name="e1"/>
<xsd:any namespace="##any"/>
</xsd:choice>
</xsd:complexType>
</xsd:element>
Тогда XML документ, состоящий из одного элемента , доказывает нарушение правила однозначности; элемент может быть сопоставлен и ветке xsd:elment и xsd:any одновременно.
К счастью, большая часть готовых схем следуют правилу UPA. Дальнейшие рассуждения будут верны только в случае соответствия схемы правилу UPA, но в целом небольшими модификациями рассуждения можно добиться корректности и на не совместимых с UPA-схемах, за счет потери скорости.
Построение валидатора
Для начала определим элементарные изменения структуры, которые мы и будем проверять на корректность:
- ADD: создание подэлемента с типом x на позиции n;
- REMOVE: удаление подэлемента, стоящего на позиции n;
- MOVE: перенос элемента с позиции n на позицию m (хоть перенос и сводится к выполнению удаления и добавления элементов, но промежуточное состояние может нарушать валидность документа).
Теперь опишем модель содержимого сложного типа схемы:
- Частица:
• MinOccurs – минимальное число повторений терма (если 0, то терм становится опциональным);
• MaxOccurs – максимальное число повторений терма (допустима бесконечность – inf).
• Терм: описание элемента, шаблон, последовательность или выбор; - Описание элемента (typedef):
• Локальное имя;
• Имя пространства имен (может быть опущено, тогда элемент считается допустимым в любом пространстве имен);
• Группа подстановки – множество всех элементов, принимаемых в выражениях содержащих typedef; - Шаблон (any):
• Имя пространства имен, допустимого для элемента подстановки (может отсутствовать); - Последовательность (sequence):
• Последовательное перечисление допустимых частиц; - Выбор (choice):
• Множество допустимых частиц.
Можно переходить непосредственно к алгоритму валидации. Первое необходимое действие – построение соответствия «тип схемы» -> «автомат, который умеет проверять потомков элемента этого типа на валидность». Задача сводится к двум рекурсивным действиям:
1. Построение недетерминированного конечного автомата (NFA) с заданным конечным состоянием S по заданной частице:
a. Установим начальное состояние n на S;
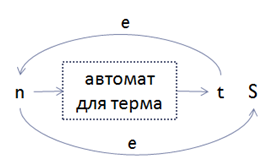
b. Если MaxOccurs частицы равен бесконечности (inf):
• Добавим новое промежуточное состояние t; получаемое из преобразования терма в NFA (случай 2); добавим эпсилон-ребра из t в n и из n в S:
c. Если MaxOccurs частицы – число m:
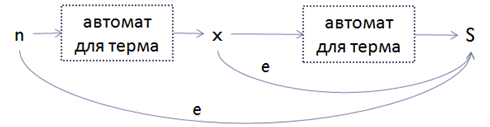
• Строим цепочку из (MaxOccurs-MinOccurs) преобразований терма, начиная из конечного состояния S, добавляя эпсилон-ребро из промежуточного состояния на каждом шаге в конечное состояние S;
Например, для MaxOccurs=4 и MinOccurs=2 получаем следующий автомат:
d. Достраиваем minOccurs копий преобразования терма от нового начального состояния n, до начального состояния, полученного на предыдущих шагах.
2. Построение недетерминированного конечного автомата с заданным принимающим состоянием S по заданному терму:
a. Если терм – шаблон (any):
• Создаем новое состояние b, и соединяем его с S ребром, помеченным типом терма, возвращаем b;
b. Если терм – описание элемента:
• Создаем новое состояние b, затем для каждого элемента группы подстановки создаем ребро из b в S, помеченное типом элемента и возвращаем b;
c. Если терм – выбор (choice):
• Создаем новое состояние b, для каждого элемента выбора создаем автомат (случай 1) и соединяем его эпсилон-ребрами с состоянием b и состоянием S. Возвращаем b;
d. Если терм – последовательность (sequence):
• Для каждого элемента выбора создаем автомат (случай 1) и соединяем полученные автоматы в обратном порядке, начиная с состояния S, и возвращаем первое состояние в цепочке;
Затем применим алгоритм Томпсона к полученным NFA [3], для построения детерминированных автоматов. Алгоритм Томпсона можно применить в тех же случаях, что и алгоритм построения детерминированного автомата Ахо и Ульмана, основанный на сворачивании одинаково помеченных не-эпсилон ребер [4]. Однако в ряде случаев по исходному автомату (созданному на шагах 1–2) алгоритм Ахо и Ульмана не сможет построить детерминированный автомат.
Это происходит когда существуют два исходящих ребра из одной вершины, такие что:
- Их метки являются описаниями типов с одинаковыми локальными именами и названиями пространства имен;
- Их метки – это названия шаблонов, с перекрывающимся областями;
- Метка одного ребра – шаблон, другого – описание типа, оба лежат в одном пространстве имен, и описание типа входит в область шаблона.
Нетрудно показать, что каждый случай отвечает нарушению ограничения UPA (третий случай уже был рассмотрен в примере схемы нарушающей правило однозначности определения частиц). Таким образом, эти пункты не помешают корректности решения, и на выходе алгоритма мы всегда получим детерминированный конечный автомат, валидирующий содержание элементов соответствующего типа.
Применим предложенный алгоритм к каждому типу схемы и получим соответствие тип -> автомат, который умеет проверять потомков элемента этого типа.
Осталось решить последнюю задачу – выбор нужного конечного автомата при валидации операции над заданным элементом дерева. С этим нам поможет структура привязки типов валидации (PSVI, Post-Schema-Validation Infoset), порождаемая почти любым (например, MSXML или libxml) полным валидатором. Для любого элемента дерева она указывает на соответствующий ему тип в описании схемы – в точности тот, по которому мы порождали нужный автомат.

В нашем случае реализация структуры PSVI представляется ссылкой на тип схемы для каждого элемента дерева.
Операции MOVE и REMOVE не меняют тип операнда (поэтому не требуют изменения структуры PSVI), а операция ADD вместе с добавлением элемента x, потребует добавления в структуру PSVI типа x. Таким образом, вместе с изменением структуры мы меняем и информационное множество привязки типов валидации, решая задачу частичной валидации и поддерживая дерево PSVI без вызова внешнего валидатора.
Сравнение результатов
Вообще говоря, непосредственного сравнения не будет – ведь мы описали надстройку, решающую частную задачу (операции ADD/REMOVE/MOVE) в частном случае (соответствие UPA), но хочется показать что в этом случае она дает существенный прирост скорости, относительно попытки использовать полную валидацию. В качестве эталонного валидатора, генерирующего PSVI был выбран MSXML6, поэтому и сравнивать будем с его временем работы.
| Количество элементов структуры | Уровни вложенности | Количество типов схемы | Среднее время валидации MSXML6 | Среднее время валидации с использованием описанной надстройки |
| 32 | 4 | 16 | 10 ms | <1 ms |
| 32 | 4 | 40 | 16 ms | <1 ms |
| 120000 | 4 | 16 | 51 ms | <2 ms |
| 120000 | 4 | 40 | 62 ms | <2 ms |
| 120000 | 32 | 16 | 2300 ms | <5 ms |
| 120000 | 32 | 40 | 2600 ms | <6 ms |
Таким образом, мы получили вполне допустимое среднее время ожидания проверки, позволяющее реализовать механизм Drag’n’Drop «на лету» в визуальном редакторе, и обеспечивающее хорошее количество запросов в секунду для возможной XML-базы данных.
Ссылки
[1] XML Schema Validator. Thompson, Henry S. and R. Tobin, W3C and University of Edinburgh, 2003.
[2] XML Schema Part 1: Structures. Henry S. Thompson, David Beech, Murray Maloney, Noah Mendelsohn, editors. W3C Recommendation, 2001.
[3] Regular Expression Matching Can Be Simple And Fast. Russ Cox, 2007.
[4] Принципы построения компиляторов. А. Ахо. Д. Ульман. М.: Мир, 1977.
|
|
|
|



Валидация XSD схемы
, ошибки при валидации XSD схемы
- Подписаться на тему
- Сообщить другу
- Скачать/распечатать тему
|
|
|
|
Подскажите пожалуйста как решить проблему с валидацие XSD. Использую программу XMLSpear, во время валидации получаю ошибки 1. src-resolve.4.2: Error resolving component ‘TypeOrganization’. It was detected that ‘TypeOrganization’ is in namespace ‘moreq-ua.xsd’, but components from this namespace are not referenceable from schema document ‘file:///D:/Work/tmp/moreq-ua.xsd’. If this is the incorrect namespace, perhaps the prefix of ‘TypeOrganization’ needs to be changed. If this is the correct namespace, then an appropriate ‘import’ tag should be added to ‘file:///D:/Work/tmp/moreq-ua.xsd’. 2. src-resolve: Cannot resolve the name ‘TypeDocType’ to a(n) ‘simpleType definition’ component. 3. src-resolve: Cannot resolve the name ‘TypeCollection’ to a(n) ‘simpleType definition’ component. 4. src-resolve: Cannot resolve the name ‘TypeDocType’ to a(n) ‘simpleType definition’ component. 5. src-resolve: Cannot resolve the name ‘TypeCollection’ to a(n) ‘simpleType definition’ component. 6. s4s-att-invalid-value: Invalid attribute value for ‘base’ in element ‘extension’. Recorded reason: UndeclaredPrefix: Cannot resolve ‘define:TypeHeader_Base’ as a QName: the prefix ‘define’ is not declared. 7. s4s-att-must-appear: Attribute ‘base’ must appear in element ‘extension’. в XSD не силен, по этому прошу помощи. В итоге мне надо будет получить XML по этой схеме… |

|
mitok |
|
|
аттач к предыдущему посту. сори, забыл прикрепить. в аттаче собственно сама схема… |
 moreq_ua.zip (2,07 Кбайт, скачиваний: 245)
moreq_ua.zip (2,07 Кбайт, скачиваний: 245)|
ss |
|
|
Senior Member
Рейтинг (т): 41 |
<xs:schema xmlns=»moreq-ua.xsd» xmlns:xs=»http://www.w3.org/2001/XMLSchema» id=»moreq-ua.xsd» targetNamespace=»moreq-ua.xsd»> Добавлено 05.09.11, 13:52
сам создам его для тебя, о повелитель» |




|
mitok |
|
|
Цитата ss @ 05.09.11, 13:47
<xs:schema xmlns=»moreq-ua.xsd» xmlns:xs=»http://www.w3.org/2001/XMLSchema» id=»moreq-ua.xsd» targetNamespace=»moreq-ua.xsd»> Добавлено 05.09.11, 13:52
сам создам его для тебя, о повелитель»
Спасибо большое 1. [443:61]: s4s-att-invalid-value: Invalid attribute value for ‘base’ in element ‘extension’. Recorded reason: UndeclaredPrefix: Cannot resolve ‘define:TypeHeader_Base’ as a QName: the prefix ‘define’ is not declared. 2. [443:61]: s4s-att-must-appear: Attribute ‘base’ must appear in element ‘extension’. Сейчас скачаю XMLSpy, может он подскажет решение |
 осталось еще две ошибки
осталось еще две ошибки|
ss |
|
|
Senior Member
Рейтинг (т): 41 |
Решение он не подскажет. Я подскажу: найди схему, в которой определён TypeHeader_Base, и заимпорть её + xmlns:define=»<нэймспейс из той схемы>». |
|
mitok |
|
|
Цитата ss @ 05.09.11, 14:22 Решение он не подскажет. Я подскажу: найди схему, в которой определён TypeHeader_Base, и заимпорть её + xmlns:define=»<нэймспейс из той схемы>». а я поубирал define в куске кода, где оно ругалось и ошибки пропали, потом сгенерировал XML. я не знаю правильно или нет. а зачем там define надо, в остальных местах в complexType нигде не юзается define… <xs:element name=»Header»> |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
- Предыдущая тема
- XML, XSL, XSLT
- Следующая тема
![]()
![]()
[ Script execution time: 0,0254 ] [ 17 queries used ] [ Generated: 6.06.23, 07:37 GMT ]