
Когда я только начинал изучать тему разработки сайтов, кракозябры были одной из моих постоянных проблем. Создал HTML-страницу — в браузере кракозябры, установил денвер и попробовал создать сайт на PHP — снова вместо букв кракозябры. Скачал иностранную тему, подключился к базе данных — та же проблема.
На своих сайтах я обычно использую UTF-8 (это такая кодировка текста, она ещё называется юникод), соответственно она будет присутствовать во всех примерах в этой статье.
1. UTF-8 без BOM
Начнём с самой простой проблемы. Вы создали какой-то HTML-файл, открыли его в браузере и получили:
")
Проблема актуальна в основном для пользователей Windows, на маке я с таким ни разу не сталкивался.
Решение проблемы зависит в основном от того, каким редактором вы пользуетесь. Для пользователей Windows я рекомендую бесплатный офигительный Notepad++.
Значит, открываем файл в Notepad++ и переходим в Кодировки > Преобразовать в UTF-8 без BOM. Вопрос — почему без BOM? Потому что с BOM у вас будут постоянно вставляться пустые символы (на самом деле они не пустые, у них тоже есть своя функция, но нам она в данном случае не нужна) куда не надо, а для PHP это уже критично.

2. Мета тег charset
Если вы сделали то, что я описывал в предыдущем шаге и ваша проблема не разрешилась, тогда самое время испробовать второй метод устранения кракозябров.
Всё, что нам требуется, это вставить следующий код между тегами <head> сайта. Прежде всего проверьте, возможно этот метатег у вас уже присутствует. Если да, то посмотрите какое у него стоит значение параметра charset.
В темах WordPress обычно этот тег уже имеется по умолчанию и выглядит следующим образом:
<meta charset="<?php bloginfo('charset'); ?>" />
3. .htaccess
Если русские буквы до сих пор отображаются кракозябрами, тогда открываем ваш .htaccess, который лежит в корне сайта и вставляем туда с новой строки это:
4. Заголовки сервера через header()
Ещё один способ определения кодировки. На этот раз через PHP. На WordPress никогда не приходилось им пользоваться.
header('Content-Type: text/html; charset=utf-8');
Важно! Этот код должен вставляться до того, как будет что-либо выведено на странице сайта, иначе — ошибка.
5. Проблемы с последним символом при обрезке строки
На многих сайтах встречаются блоки с популярными записями, последними комментариями, отзывами и так далее. Обычно в таких обзорных блоках выводится часть записи/комментария/отзыва и кнопка «читать далее». Так вот, для того, чтобы вывести первые несколько предложений или первые несколько слов текста, используется функция PHP substr(). Конечно же в основном я имею ввиду англоязычные темы, которых так много в интернете. Даже если у этих тем есть локализация — то есть вроде бы она на русском — переведена админка, переведён практически весь сайт, но при этом мы встречаем такие вот косяки:
")
Как решить эту проблему?
Легко — всё что нам нужно, это найти функцию substr() в коде и поменять её на mb_substr().
Если после этого у вас полезут ошибки на сайт, то скорее всего multibyte-функции не поддерживаются вашим хостингом, первое, что вам следует сделать, это написать в супорт и спросить, нельзя ли их подключить на ваш аккаунт. Если нет, меняем хостинг, например на тот, которым пользуюсь я.
6. MySQL
У меня не раз бывало такое, что я подключался к MySQL, вытаскивал какие-нибудь данные, и при их выводе на сайте, текст отображался кракозябрами.
Такое может произойти, если кодировка вашего сайта не совпадает с кодировкой базы данных, к которой вы подключаетесь. В WordPress обычно таких проблем не бывает.
Для того, чтобы исправить это, после подключения к БД, делаем следующее:
mysql_query("SET NAMES 'UTF8'");
Если ни один из вышеперечисленных методов вам не помог, оставляйте комментарий и попробуем вместе разобраться.

Миша
Впервые познакомился с WordPress в 2009 году. Организатор и спикер на конференциях WordCamp. Преподаватель в школе Нетология.
Пишите, если нужна помощь с сайтом или разработка с нуля.
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ!…
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
- Используется устаревший браузер.
- В браузере / программе установлена одна кодировка, на сайте – другая. В таком случае нужно поменять кодировку в программе.
- В БД и других файлах сайта указаны несовпадающие кодировки. В этом случае нужно выбрать одну кодировку для всего сайта.

Как поменять кодировку в браузере
Проблему с кодировкой на стороне браузера исправить легко.
Internet Explorer
- Открываем проблемную веб-страницу.
- Вызываем контекстное меню, кликнув правой кнопкой мыши по любому месту на странице.
- Выбираем «Кодировка».
- Кликаем Unicode (UTF-8).
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
- Открываем магазин Chrome.
- Кликаем «Расширения» в левой части экрана.
- Указываем слово «кодировка».
- Устанавливаем любое подходящее расширение.
Safari
- Выбираем пункт «Вид».
- Кликаем по разделу «Кодировка текста».
- Выбраем вариант Unicode (UTF-8).
Firefox
- Выбираем пункт «Вид».
- Кликаем по раздел «Кодировка текста».
- Нужно выбрать вариант Unicode (UTF-8).
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
UTF-8 может закодировать любой unicode-символ. Пожалуй, именно это достоинство позволило кодировке стать одной из самых популярных в мире.
Windows-1251 известна в меньшей степени, но Windows-1251 и не отличается такой универсальностью и распространенностью как UTF-8. Проблемы с кодировкой могут встречаться на всех сайтах, даже на отлаженных площадках, которые работают в течение многих лет. Чтобы предотвратить проблемы с «кракозябрами» на своем сайте в будущем, необходимо с самого начала выбирать единую кодировку. Как вы уже догадались, лучший кандидат на эту роль – UTF-8.
Как узнать, какая кодировка используется на моем сайте
Узнать, какая кодировка используется на всем сайте или на конкретной странице, можно за несколько секунд. Для этого нужно просмотреть исходник HTML-страницы. Чтобы увидеть его, используем одновременное нажатие горячих клавиш Сtrl + U (на «Маке» активируем шорткатом Option/Alt + Command + U). Появится такое окно:

Теперь используем сочетание горячих клавиш Ctrl + F (Command + F) – откроется окно поиска. Вводим в поисковую строку атрибут charset (он же character set, кодировка документа). После этого атрибута мы увидим знак равенства. За ним и будет указана кодировка страницы.

Если атрибут charset не задан, его придется задать. Предварительно нужно проверить сайт при помощи сторонних сервисов. Один из них – Browserstack. Платформа платная, но, чтобы проверить кодировку, платить необязательно. Достаточно открыть сайт и выбрать пункт Get started free, создать аккаунт (можно просто залогиниться при помощи «Google-аккаунта»). После авторизации появится такое окно:

Выбираем интересующую нас операционную систему / устройство и вводим сайт, который нужно протестировать:

Если с кодировкой на сайте что-то не так, все ошибки будут представлены в результатах теста.
Для проверки и определения ошибок кодировки можно использовать не только Browserstack. Альтернатива – бесплатный сервис Validator. Он позволит идентифицировать кодировку сразу по нескольким данным, включая заголовки. Пример ошибки кодировки в результатах анализа Validator:

Также неплохие возможности для проверки технических ошибок сайта дает pr-cy.ru. Не забудьте выбрать пункт «Аудит страниц»:

Хорошие инструменты для проверки кодировки предоставляют сервисы NetPeak и SeoFrog. Последний удобен еще тем, что позволяет проверить кодировку сразу по всем страницам сайта, а не только по одной.
Кодировка и оптимизация
Даже если кодировка на сайте не совсем обычная или отличается на разных страницах, Google и «Яндекс» все равно проиндексируют такой сайт, но при условии, что контент уникален и не переспамлен ключами. Одна из самых неприятных ошибок здесь – несовместимость кодировки веб-ресурса с той, которая используется на сервере. Даже в таком случае Google, например, способен корректно идентифицировать ошибку. Сайт будет в выдаче, если соответствующие условия были соблюдены.
Ошибки кодировки сами по себе не влияют на оптимизацию сайта прямым образом. Они сказываются на отказах и времени, проведенном на сайте, а также на иных поведенческих показателях аудитории.
Если на вашем сайте возникают ошибки кодировки, и контент отображается некорректно, то посетитель ни при каких обстоятельствах не будет тратить свое время, пытаясь настроить правильную кодировку и, тем более, пытаться ее преобразовать в читаемую. Большинство посетителей просто не знают, как это сделать, но даже если знают, не будут тратить время и точно уйдут к конкурентам на тот сайт, где содержимое изначально отображается корректно.
Устранить проблемы кодировки сложно: мало поменять ее на одной или нескольких страницах. Обычно приходится исправлять ее также в мете (одноименных тегах), БД MySQL, файле htaccess и других системных файлах сайта.
Как исправить ошибки кодировки на своем сайте
Инструкция предназначена только для опытных пользователей и не является призывом к действию. Код и настройки я привожу исключительно в качестве примера. Если вы решитесь вносить изменения в БД и системные файлы, особенно в root, обязательно сделайте резервную копию всех данных сайта!
Документы / HTML-файлы
Если возникают проблемы с документами, необходимо удостовериться в том, что они имеют одинаковую кодировку, и в том, что она вообще задана. Для этого открываем HTML-файл при помощи любого редактора, который позволяет работать с кодом. Например, через Notepad++. Открываем проблемный документ и выполняем следующую последовательность действий:

Htaccess
«Кракозябра» может появляться даже в тех случаях, когда ошибки в документах уже исправлены. В таком случае нужно проверить файл htaccess. Открываем его при помощи редактора кода, затем, используя одновременное сочетание горячих клавиш Ctrl + F, открываем окно «Поиск по странице» и вводим уже знакомый нам атрибут Charset. Если атрибут найден, его необходимо исправить на тот, который является стандартным для вашего сайта. Если его нет вообще, добавляем атрибут AddDefaultCharset UTF-8 в любом месте в самом начале документа.
Теги типа meta
Именно мета-тег используется для установки требуемой кодировки. Кроме этого, в нем прописываются и другие мета-теги, которые задействованы для хранения информации, используемой браузерами. Прописываются теги типа meta в head-разделе. Выглядит следующим образом:
<!DOCTYPE HTML>
<html>
<head>
<title>Тег META</title>
<meta charset="utf-8">
</head>
<body>
<p>...</p>
</body>
</html>
Этот код приводится в качестве примера. Не исключено появление ошибок.
Базы данных
Если «кракозябры» при открытии страниц так и не исчезают, придется проверять MySQL. Нас интересуют значения, прописанные в таблицах баз данных. Чтобы устранить эту проблему, необходимо подключиться к серверу через mysql root. Для этого выполняем следующие шаги:

Так мы приведем кодировку БД к единому стандарту UTF-8.
Онлайн-декодеры
Онлайн-декодеры и другие инструменты с аналогичным функционалом позволяют преобразовать «кракозябру» в читаемый текст. Foxtools – приятный и удобный декодер, который работает в автоматическом режиме. У Foxtools вообще много полезных инструментов:

2cyr – еще более функциональный инструмент, который не только преобразует «кракозябры» в читаемый текст, но и выводит множество возможных вариантов. Бывает и такое, что все варианты «расшифровки» являются некорректными:

Итоги
Чтобы вовремя идентифицировать проблемы с кодировкой на своем сайте, используйте перечисленные выше инструменты. Не забывайте и об онлайн-декодерах: они эффективно расшифровывают нечитаемый текст в случаях, когда необходимо быстро преобразовать «кракозябру». Помните, что иероглифы на сайте недопустимы, и устранять такие ошибки нужно как можно скорее. В противном случае ухудшатся поведенческие факторы, и сайт может навсегда выпасть из поисковой выдачи.
Проблемы с кодировкой на сайте

Одной из самых частых проблем, с которой сталкивается начинающий Web-мастер (да и не только начинающие), это проблемы с кодировкой на сайте. Даже у меня постоянно появляется при создании сайтов «абракадабра«. Но, благо, я прекрасно знаю, как эту проблему решить, поэтому всё привожу в порядок в течение нескольких секунд. И в этой статье я постараюсь научить Вас также быстро решать проблемы, связанные с кодировкой на сайте.
Первое, что стоит отметить, это то, что все проблемы с появлением «абракадабры» связаны с несовпадением кодировки документа и кодировки, выставляемой браузером. Допустим, документ в windows-1251, а браузер почему-то выставляет UTF-8. А уже источником такого несовпадения могут быть следующие причины.
Первая причина
Неправильно прописан мета-тег content-type. Будьте внимательны, в нём всегда должна находиться та кодировка, в котором написан Ваш документ.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
Вторая причина
Вроде бы, мета-тег прописан так, как Вы хотите, и браузер выставляет именно то, что Вы хотите, но почему-то всё равно с кодировкой проблемы. Здесь, почти наверняка, виновато то, что сам документ имеет отличную кодировку. Если Вы работаете в Notepad++, то внизу справа есть название кодировки текущего документа (например, ANSI). Если Вы ставите в мета-теге UTF-8, а сам документ написан в ANSI, то сделайте преобразование в UTF-8 (через меню «Кодировки» и пункт «Преобразовать в UTF-8 без BOM«).
Третья причина
Мета-тег написан правильно, кодировка документа верная, но браузер почему-то настойчиво выбирает другую кодировку. Это уже связано с настройками сервера. Способ решения данной проблемы можно прочитать здесь: как задать кодировку в htaccess.
Четвёртая причина
И, наконец, последняя популярная причина — это проблема с кодировкой в базе данных. Во-первых, убедитесь, что все Ваши таблицы и поля написаны в одной кодировке, которая совпадает с кодировкой остального сайта. Если это не помогло, то сразу после подключения в скрипте выполните следующий запрос:
SET NAMES 'utf8'
Вместо «utf8» может стоять другая кодировка. После этого все данные из базы должны выходить в правильной кодировке.
В данной статье я, надеюсь, разобрал, как минимум, 90% проблем, связанных с появлением «абракадабры» на сайте. Теперь Вы должны расправляться с такой популярной и простой проблемой, как неправильная кодировка, в два счёта.
-

Создано 21.05.2012 13:43:04
-
Михаил Русаков

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
- Кнопка:
Она выглядит вот так:
- Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):

Как кодировка влияет на отображение сайта, чем отличается UTF-8 от Windows 1251 и где указать кодировку.
В статье:
-
Зачем нужна кодировка
-
Виды кодировок
-
Как определить кодировку на сайте
-
Если кодировка не отображается
-
Где указать кодировку сайта
Разбираем, на что влияет кодировка, нужно ли указывать ее самостоятельно, и почему могут появиться так называемые «кракозябры» на сайте.
Зачем нужна кодировка
Кодировка (Charset) — способ отображения кода на экране, соответствие набора символов набору числовых значений. О ней сообщает строка Content-Type и сервер в header запросе.
Несовпадение кодировок сервера и страницы будет причиной появления ошибок. Если они не совпадают, информация декодируется некорректно, так что контент на сайте будет отображаться в виде набора бессвязных букв, иероглифов и символов, в народе называемых «кракозябрами». Такой текст прочитать невозможно, так что пользователь просто уйдет с сайта и найдет другой ресурс. Или останется, если ему не очень важно содержание:

Google рекомендует всегда указывать сведения о кодировке, чтобы текст точно корректно отображался в браузере пользователя.
Кодировка влияет на SEO?
Разберемся, как кодировка на сайте влияет на индексацию в Яндекс и Google.
Яндекс четко заявляет:
«Тип используемой на сайте кодировки не влияет на индексирование сайта. Если ваш сервер не передает в заголовке кодировку, робот Яндекса также определит ее самостоятельно».
Позиция Google такая же. Поисковики не рассматривают Charset как фактор ранжирования или сигнал для индексирования, тем не менее, она косвенно влияет на трафик и позиции.
Если кодировка сервера не совпадает с той, что указана на сайте, пользователи увидят нечитабельные символы вместо контента. На таком сайте сложно что-либо понять, так что скорее всего пользователи сбегут, а на сайте будут расти отказы.

Поэтому она важна для SEO, хоть и влияет на него косвенно через поведенческие. Пользователи должны видеть читабельный текст на человеческом языке, чтобы работать с сайтом.
Виды кодировок
Существует довольно много видов, но сейчас распространены два:
UTF-8
Unicode Transformation Format — универсальный стандарт кодирования, который работает с символами почти всех языков мира. Символы могут занимать от 1 до 4 байт, такое кодирование позволяет создавать мультиязычные сайты.
Есть несколько вариантов — UTF-8, 16, 32, но чаще используют восьмибитное.
Windows-1251
Этот вид занимает второе место по популярности после UTF-8. Windows-1251 — кодирование для кириллицы, созданное на базе кодировок, использовавшихся в русификаторах операционной системы Windows. В ней есть все символы, которые используются в русской типографике, кроме значка ударения. Символы занимают 1 байт.
Выбор кодировки остается на усмотрение веб-мастера, но UTF-8 используют намного чаще — ее поддерживают все популярные браузеры и распознают поисковики, а еще ее удобнее использовать для сайтов на разных языках.
Определить кодировку страницы своего или чужого сайта можно через исходный код страницы. Откройте страницу сайта, выберите «Просмотр кода страницы» (сочетание горячих клавиш Ctrl+U» в Google Chrome) и найдите упоминание «charset» внутри тега head.
На странице сайта используется кодировка UTF-8:

Узнать вид кодирования можно с помощью «Анализа сайта». Сервис проверяет в том числе и техническую сторону ресурса: анализирует серверную информацию, определяет кодировку, проверяет редиректы и другие пункты.

С помощью этого же сервиса можно проверить корректность указанного кодирования. Аудит внутренних страниц «Анализа сайта» проверяет кодировку сервера и сравнивает ее с той, которая указана на внутренней странице. Найденные ошибки Анализ покажет в результатах проверки, и вы сразу узнаете, где нужно исправить.


Проверить кодировку еще можно через сервис Validator.w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.

Если валидатор не обнаружит Charset, он покажет ошибку:

Но валидатор работает не точно: он проверяет только синтаксис разметки, поэтому может не показать ошибку, даже если кодирование указано неправильно.
Если кодировка не отображается
Если вы зашли на чужой сайт с абракадаброй, а вам все равно очень интересно почитать контент, то в Справке Google объясняют, как исправить кодирование текста через браузер.
О проблеме возникновения абракадабры на вашем сайте будут сигнализировать метрики поведения: вырастут отказы, уменьшится глубина просмотров. Но скорее всего вы и раньше заметите, что что-то пошло не так.
Главное правило — для всех файлов, скриптов, баз данных сайта и сервера должна быть указана одна кодировка. Ошибка может возникнуть, если вы случайно указали на сайте разные виды кодировки.
Яндекс советует использовать одинаковую кодировку для страниц и кириллических адресов структуры. К примеру, если робот встретит ссылку href=»/корзина» на странице с кодировкой UTF-8, он сохранит ее в этом же UTF-8, так что страница должна быть доступна по адресу «/%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0».
Где указать кодировку сайта
Если проблема возникла на вашем сайте, способ исправления зависит от вида сайта. Для одностраничника достаточно указать кодировку в мета-теге страницы, а для большого сайта есть разные варианты:
- кодировка в мета-теге;
- кодировка в .htaccess;
- кодировка документа;
- кодировка в базе данных MySQL.
Кодировка в мета-теге
Добавьте указание кодировки в head файла шаблона сайта.
При создании документа HTML укажите тег meta в начале в блоке head. Некоторые браузеры могут не распознать указание кодировки, если оно будет ниже.
Мета-тег может выглядеть так:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">или так:
<meta charset="utf-8">В HTML5 они эквивалентны.

В темах WordPress обычно тег «charset» с кодировкой указан по умолчанию, но лучше проверить.
Кодировка в файле httpd.conf
Инструкции для сервера находятся в файле httpd.conf, обычно его можно найти на пути «/usr/local/apache/conf/».
Если вам нужно сменить кодировку Windows-1251 на UTF-8, замените строчку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Осторожнее: если вы измените в файле кодировку по умолчанию, то она изменится для всех проектов на этом сервере.
Убедитесь, что сервер не передает HTTP-заголовки с конфликтующими кодировками.
Кодировка в .htaccess
Добавьте кодировку в файл .htaccess:
- Откройте панель управления хостингом.
- Перейдите в корневую папку сайта.
- В файле .htaccess добавьте в самое начало код:
- для указания кодировки UTF-8 — AddDefaultCharset UTF-8;
- для указания кодировки Windows-1251 — AddDefaultCharset WINDOWS-1251.
- Перейдите на сайт и очистите кэш браузера.
Кодировка документа
Готовые файлы HTML важно сохранять в нужной кодировке сайта. Узнать текущую кодировку файла можно через Notepad++: откройте файл и зайдите в «Encoding». Меняется она там же: чтобы сменить кодировку на UTF-8, выберите «Convert to UTF-8 without BOOM». Нужно выбрать «без BOOM», чтобы не было пустых символов.
Кодировка Базы данных
Выбирайте нужную кодировку сразу при создании базы данных. Распространенный вариант — «UTF-8 general ci».
Где менять кодировку у БД:
- Кликните по названию нужной базы в утилите управления БД phpMyAdmin и откройте ее.
- Кликните на раздел «Операции»:
- Введите нужную кодировку для базы данных MySQL:
- Перейдите на сайт и очистите кэш.


С новой БД проще, но если вы меняете кодировку у существующей базы, то у созданных таблиц и колонок заданы свои кодировки, которые тоже нужно поменять.
Для всех таблиц, колонок, файлов, сервера и вообще всего, что связано с сайтом, должна быть одна кодировка.
Проблема может не решиться, если все дело в кодировке подключения к базе данных. Что делать:
- Подключитесь к серверу с правами mysql root пользователя:
mysql -u root -p - Выберите нужную базу:
USE имя_базы; - Выполните запрос:
SET NAMES ‘utf8’;
Если вы хотите указать Windows-1251, то пишите не «utf-8», а «cp1251» — обозначение для кодировки Windows-1251 у MySQL.
Чтобы установить UTF-8 по умолчанию, откройте на сервере my.cnf и добавьте следующее:
В области [client]:
default-character-set=utf8
В области [mysql]:
default-character-set=utf8
В области [mysqld]:
collation-server = utf8_unicode_ci
init-connect='SET NAMES utf8'
character-set-server = utf8Вы когда-нибудь сталкивались с проблемами кодировки на сайте?
Как исправить некорректную кодировку текста
Значения классификации Google в файле с расширением .txt в браузере могут отображаться неверно. Чтобы это исправить, нужно поменять настройки кодировки.
Найдите свой браузер в списке ниже и следуйте указаниям.
Chrome
В браузере Chrome нельзя поменять настройки кодировки, однако можно попробовать установить для этого расширение.
- Откройте Интернет-магазине Chrome.
- Выберите Расширения в меню слева.
- Введите запрос, например «кодировка текста».
- Выберите подходящее расширение.
Подробнее о том, как устанавливать расширения и управлять ими…
Firefox
- Откройте меню «Вид» в верхней части браузера.
- Нажмите «Кодировка текста».
- Выберите Unicode (UTF-8) в раскрывающемся меню.
Safari
- Откройте меню «Вид» в верхней части браузера.
- Нажмите «Кодировка текста».
- Выберите Unicode (UTF-8) в раскрывающемся меню.
Internet Explorer
- Откройте страницу с некорректной кодировкой.
- Нажмите правой кнопкой на экран.
- Наведите указатель мыши на пункт «Кодировка».
- В раскрывшемся меню выберите Unicode (UTF-8).
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Что делать если на сайте проблема с кодировкой и отображаются непонятные символы? Все предельно просто. Кодировка задается всего в трех местах, и чтобы решить проблему вам нужно эти три места проверить и убедиться, что кодировка везде совпадает.
Заголовки ответа сервера
Это практически всегда наиболее значимый для браузеров параметр. Когда вы открываете какую то страницу у себя в браузере, то самое первое что браузер получает в ответ от сервера это «заголовки». Один из этих заголовков может указывать на кодировку, обратите внимание на строку «Content-Type: text/html; charset=utf-8». Чтобы проверить какую кодировку выставляет ваш сервер, нужно воспользоваться средствами разработчика в браузере (ctrl + shift + I в Опере, Хроме). Подробнее на скриншоте:
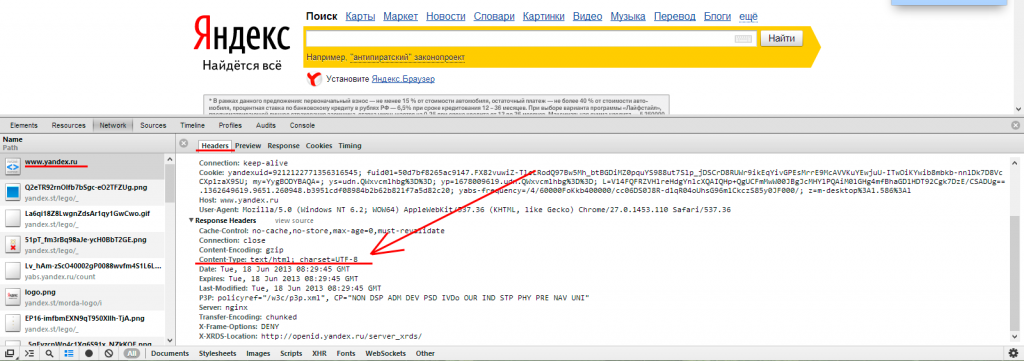
Кодировка в заголовках ответа сервера Яндекса (кликабельно)
Этот заголовок может отсутствовать. Ничего страшного, проверяйте дальше если не нашли нужный заголовок.
Кодировка в meta-тэге
Второе место которое вам необходимо проверить это кодировка в исходном html-коде страницы. Откройте проблемную страницу в браузере, кликните правой кнопкой мыши в любом месте страницы и выберите пункт «Просмотр исходного кода страницы» или похожий. В исходном коде страницы сделайте поиск по слову «meta». Вы найдете один из этих вариантов:
- Если страница сверстана в html4, xhtml
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> - Если страница сверстана в HTML5
<meta charset="UTF-8">
На скриншоте показан один из этих вариантов:
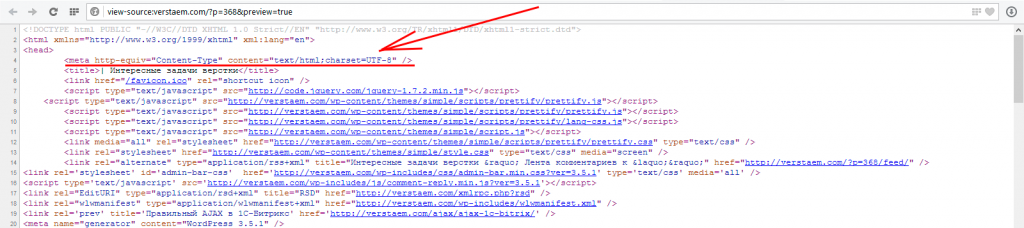
Кодировка в мета тэге (кликабельно)
Мета-тэг может отсутствовать на странице. В этом опять таки ничего страшного нет. Проверьте заголовки сервера и кодировку текста.
Кодировка самого текста
И последнее место которое вам нужно проверить — это кодировка самого текста. Если проблемный текст хранится в файлах (например как в битриксе, статические страницы), то нужно проверить кодировку тех файлов в которых хранится текст. Для проверки нужно скачать файл и открыть его например в notepad++, там есть отдельный пункт меню «Кодировки», где сразу все видно:
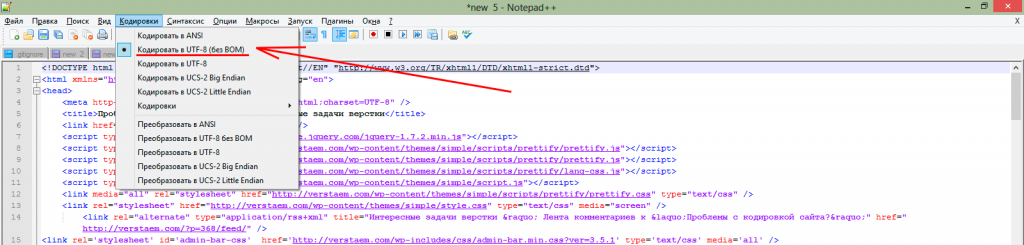
Кодировка файла (кликабельно)
Как правило кодировка у всех файлов сайта совпадает. То есть вообще все файлы сайта практически всегда хранятся в одинаковой кодировке. Можете скачать несколько файлов наугад, например файлы темы и какие то служебные скрипты, а потом сверьте в них кодировку.
Текст который выводится на страницу может хранится в базе данных, а не в файле. В базе данных содержимое страниц хранится у многих CMS, например у wordpress и drupal. Если текст хранится в БД, то вам нужно будет посмотреть содержимое таблиц, это можно сделать с помощью phpmyadmin. Вот так выглядит список таблиц в отдельной базе данных, там есть отдельный столбец с кодировками:
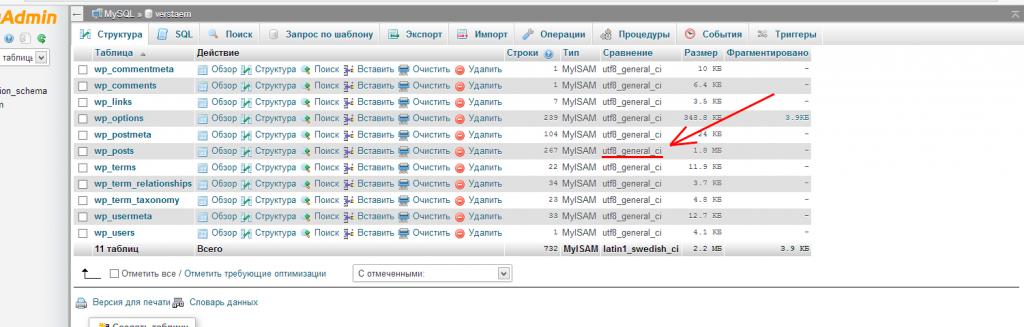
Список таблиц в БД (кликабельно)
Сам текст внутри таблицы должен нормально читаться, как на скриншоте:
Содержимое отдельной таблицы (кликабельно)
Если вы в notepad++ при открытии файла или в БД видите кракозябры, то значит файл был сохранен в неправильной кодировке и возможно даже несколько раз подряд. В этом случае довольно сложно будет разобраться какая была кодировка у текста изначально. Для определения изначальной кодировки текста после череды сохранений воспользуйтесь бесплатным инструментом от студии Артемия Лебедева, декодером. Вот ссылка на декодер:
http://www.artlebedev.ru/tools/decoder/
Туда нужно скопировать сами кракозябры и нажать кнопку «Расшифрвать». Есть неплохой шанс, что вам удастся узнать изначальную кодировку текста.
Кодировка должна совпадать!
Обращаю ваше внимание еще раз. Во всех трех местах кодировка должна быть одинаковая. И в заголовках ответа сервера, и в мета-тэге и сам текст должны храниться в одинаковой кодировке. Кроме того, совсем не обязательно, чтобы кодировка была указана везде. Иногда бывает так, что кодировка в ответах сервера не отдается, ничего страшного нет, проверяйте другие места. Мета-тэг тоже не всегда присутствует на странице. Только у текста всегда есть кодировка. Не бывает текста без кодировки.
В общем то и все. После проверки всех трех мест вы поймете где именно проблема, и можно уже ее решать.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
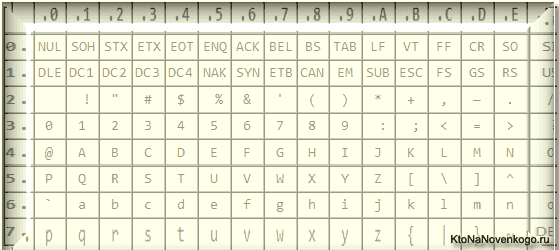
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
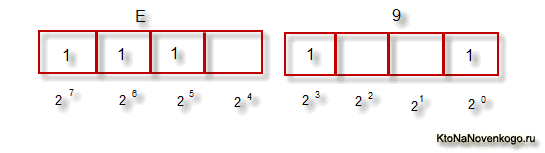
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
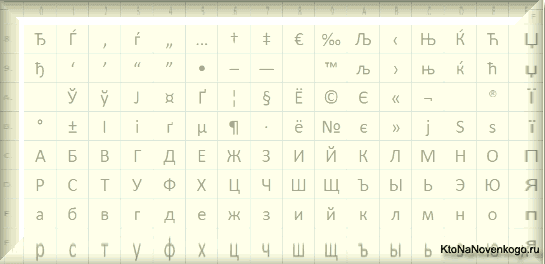
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
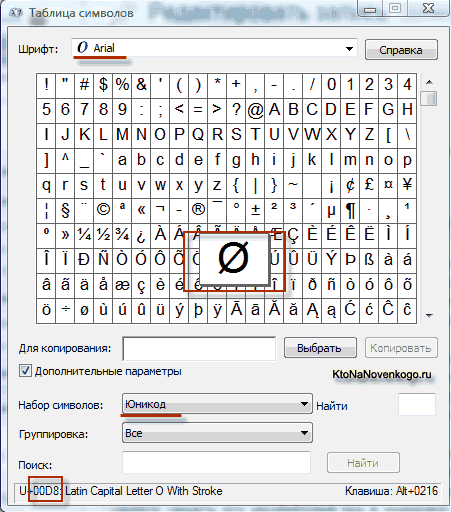
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
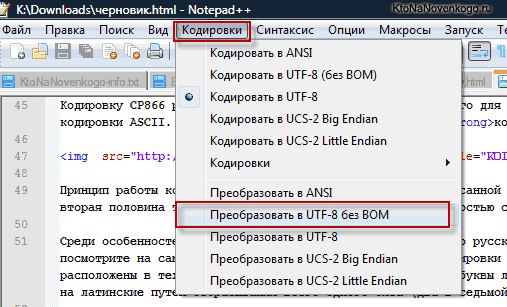
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
![]()
Кодировки, кракозябры и подарки // Владимир Тычинский
Кракозя́бры (крякозя́бры) — бессмысленный с точки зрения читателя набор символов, чаще всего получаемый на компьютере в результате неправильного перекодирования осмысленного текста.
Чаще всего кракозябры образуются на выводе программ по причине неправильно настроенной кодировки символов, а также из-за использования неподходящего шрифта. Проблема может быть связана и непосредственно с браузером: например, в Google Chrome русская кодировка CP-866 отсутствует, а многие старые браузеры не умели читать в UTF-16.
Термин[править]
Жаргонизм «кракозябры» не имеет на сегодняшний день устоявшейся формы, существует множество вариаций произношения и написания этого слова: части крако-, кроко-, кряко-; -зябры, -зябли и другие могут встречаться в разных сочетаниях. Кроме того, данное явление может быть обозначено и другими словами, например:
- абракадабра
- бнопня
- зюки
- мусор
- иероглифы
- стриказяблик
Название «бнопня» (или, более точно, «бНОПНЯ») напрямую происходит от явления неправильной настройки кодировок в почтовых программах. Так выглядит слово «Вопрос», преобразованное из кодировки CP1251 в KOI8-R. По слову «бНОПНЯ» опытные пользователи сразу определяли новичков, задававших вопрос по настройке кодировки.
Этимология[править]
Происхождение слова неизвестно.
В народной этимологии приводится аналогия с детскими каракулями (гибрид крокодила и зебры), а также производное от английского глагола «to crack» — ломать, крушить.
Возможная связь: В польском детском научно-популярном журнале «Горизонты техники для детей», русскоязычная версия которого продавалась в СССР (№ 12 за 1979 год), был опубликован фантастический рассказ «КАИС» Гали и Лены Марьиных, 11 и 13 лет. В рассказе фигурирует форма инопланетной жизни «стреказябли».
В единственном числе «кракозябра» — вообще любой компьютерный символ, для которого в русском языке нет общеизвестного звука (а то и названия), например, значок @.
В других языках[править]
По-японски явление, аналогичное кракозябрам, называется модзибакэ (яп. 文字化け «искажённые символы»), а по-китайски — луаньма (кит. 乱码 «мешанина из знаков»). Болгары называют этот эффект маймуница («обезьянья азбука»), сербы — ђубре («мусор»), немцы — Buchstabensalat («салат из букв») и Krähenfüße («вороньи лапки»), поляки — krzaki («знаки китайского письма; помехи видные в телевизоре, когда нет сигнала», буквально «кусты»), в иврите джибриш(Шаблон:Hebrew).
История[править]

Кракозябры на бандероли, написанные от руки и исправленные почтовым служащим перед доставкой
В 1980-е и 1990-е пользователи компьютеров и с 1990 г. — пользователи русскоязычной части интернета вынуждены были мириться с существованием нескольких конкурирующих кодировок кириллицы: основная — ГОСТ, альтернативная — DOS 866 (Unix KOI8-R, Windows CP-1251, ISO 8859-5), MacCyrillic. В результате неправильной конфигурации серверов и недостаточной совместимости тексты очень часто было невозможно прочесть. Получая сообщения по электронной почте или зайдя на веб-сайт, неопытные пользователи могли наткнуться на странные необычные символы вместо букв кириллицы.
Несмотря на всё более широкое распространение Юникода, феномен кракозябр иногда встречается и сегодня. Есть возможность получить неадекватные символы при использовании неправильных шрифтов при печати на принтере или фотонаборном автомате, неверно настроенной локали программы (когда вместо кодовой страницы CP1251 используется CP1252).
При использовании UTF-8 всё равно остаётся риск получить кракозябры при выводе текста по HTTP: если кодировка нигде не указана, RFC 2616 даёт значение по умолчанию — ISO-8859-1[1].
Примеры[править]
Для примера использована панграмма (без кавычек): «Широкая электрификация южных губерний даст мощный толчок подъёму сельского хозяйства.».
| Исходная кодировка | При декодировании воспринято как | Результат |
|---|---|---|
| При воспроизведении применяется та же кодировка, что и при создании текста. | Широкая электрификация южных губерний даст мощный толчок подъёму сельского хозяйства. | |
| Windows-1251 | Windows-1252 или ISO 8859-1[2] |
Øèðîêàÿ ýëåêòðèôèêàöèÿ þæíûõ ãóáåðíèé äàñò ìîùíûé òîë÷îê ïîäú¸ìó ñåëüñêîãî õîçÿéñòâà. |
| KOI8-R | ьХПНЙЮЪ ЩКЕЙРПХТХЙЮЖХЪ ЧФМШУ ЦСАЕПМХИ ДЮЯР ЛНЫМШИ РНКВНЙ ОНДЗ╦ЛС ЯЕКЭЯЙНЦН УНГЪИЯРБЮ. | |
| ISO 8859-5 | иш№юърџ §ыхъђ№шєшърішџ ўцэћѕ уѓсх№эшщ фрёђ ьюљэћщ ђюыїюъ яюфњИьѓ ёхыќёъюую ѕючџщёђтр. | |
| CP 866 | ╪шЁюър ¤ыхъЄЁшЇшърЎш ■цэ√ї уєсхЁэшщ фрёЄ ью∙э√щ Єюыўюъ яюф·╕ьє ёхы№ёъюую їюч щёЄтр. | |
| KOI8-R | Windows-1252 или ISO 8859-1[2] |
ûÉÒÏËÁÑ ÜÌÅËÔÒÉÆÉËÁÃÉÑ ÀÖÎÙÈ ÇÕÂÅÒÎÉÊ ÄÁÓÔ ÍÏÝÎÙÊ ÔÏÌÞÏË ÐÏÄߣÍÕ ÓÅÌØÓËÏÇÏ ÈÏÚÑÊÓÔ×Á. |
| Windows-1251 | ыЙТПЛБС ЬМЕЛФТЙЖЙЛБГЙС АЦОЩИ ЗХВЕТОЙК ДБУФ НПЭОЩК ФПМЮПЛ РПДЯЈНХ УЕМШУЛПЗП ИПЪСКУФЧБ. | |
| ISO 8859-5 | ћЩвЯЫСб мЬХЫдвЩЦЩЫСУЩб РжЮйШ ЧеТХвЮЩЪ ФСгд ЭЯнЮйЪ дЯЬоЯЫ аЯФпЃЭе гХЬигЫЯЧЯ ШЯкбЪгдзС. | |
| CP 866 | √╔╥╧╦┴╤ ▄╠┼╦╘╥╔╞╔╦┴├╔╤ └╓╬┘╚ ╟╒┬┼╥╬╔╩ ─┴╙╘ ═╧▌╬┘╩ ╘╧╠▐╧╦ ╨╧─▀г═╒ ╙┼╠╪╙╦╧╟╧ ╚╧┌╤╩╙╘╫┴. | |
| 7 бит | {IROKAQ LEKTRIFIKACIQ @VNYH GUBERNIJ DAST MO]NYJ TOL^OK POD_#MU SELXSKOGO HOZQJSTWA. | |
| ISO 8859-5 | Windows-1252 или ISO 8859-1[2] |
ÈØàÞÚÐï íÛÕÚâàØäØÚÐæØï îÖÝëå ÓãÑÕàÝØÙ ÔÐáâ ÜÞéÝëÙ âÞÛçÞÚ ßÞÔêñÜã áÕÛìáÚÞÓÞ åÞ×ïÙáâÒÐ. |
| Windows-1251 | ИШаЮЪРп нЫХЪваШдШЪРжШп оЦЭле УгСХаЭШЩ ФРбв ЬЮйЭлЩ вЮЫзЮЪ ЯЮФксЬг бХЫмбЪЮУЮ еЮЧпЩбвТР. | |
| KOI8-R | хьЮчзпО МшузБЮьДьзпФьО НжщКЕ сЦяуЮщьы тпАБ эчИщКы БчшГчз ъчтЙЯэЦ АушЛАзчсч ЕчвОыАБрп. | |
| CP 866 | ╚╪р▐┌╨я э█╒┌тр╪ф╪┌╨ц╪я ю╓▌ых ╙у╤╒р▌╪┘ ╘╨ст ▄▐щ▌ы┘ т▐█ч▐┌ ▀▐╘ъё▄у с╒█ьс┌▐╙▐ х▐╫я┘ст╥╨. | |
| CP 866 | Windows-1252[2] | ˜¨à®ª ï í«¥ªâà¨ä¨ª æ¨ï î¦ëå £ã¡¥à¨© ¤ áâ ¬®éë© â®«ç®ª ¯®¤êñ¬ã ᥫì᪮£® 宧ï©á⢠. |
| Windows-1251 | �Ёа®Є п н«ҐЄваЁдЁЄ жЁп о¦ле ЈгЎҐаЁ© ¤ бв ¬®йл© в®«з®Є Ї®¤кс¬г ᥫмбЄ®Ј® 宧п©бвў . | |
| KOI8-R | ≤╗Ю╝╙═О М╚╔╙БЮ╗Д╗╙═Ф╗О Н╕╜КЕ ёЦ║╔Ю╜╗╘ ╓═АБ ╛╝И╜К╘ Б╝╚Г╝╙ ╞╝╓ЙЯ╛Ц А╔╚ЛА╙╝ё╝ Е╝╖О╘АБ╒═. | |
| ISO 8859-5 | �ЈрЎЊ я эЋЅЊтрЈфЈЊ цЈя юІых ЃуЁЅрЈЉ Є ст ЌЎщыЉ тЎЋчЎЊ ЏЎЄъёЌу сЅЋьсЊЎЃЎ хЎЇяЉстЂ . | |
| CP 437 | ÿ¿α«¬á∩ φ½Ñ¬Γα¿Σ¿¬áµ¿∩ δσ úπíÑα¡¿⌐ ñáßΓ ¼«Θ¡δ⌐ Γ«½τ«¬ »«ñΩ±¼π ßѽ∞߬«ú« σ«º∩⌐ßΓóá. | |
| UTF-8[3] | Windows-1252[2] | Ð¨Ð¸Ñ€Ð¾ÐºÐ°Ñ ÑÐ»ÐµÐºÑ‚Ñ€Ð¸Ñ„Ð¸ÐºÐ°Ñ†Ð¸Ñ ÑŽÐ¶Ð½Ñ‹Ñ… губерний даÑÑ‚ мощный толчок подъёму ÑельÑкого хозÑйÑтва. |
| Windows-1251 | Широкая электрификация южных губерний даст мощный толчок подъёму сельского хозяйства. | |
| KOI8-R | п╗п╦я─п╬п╨п╟я▐ я█п╩п╣п╨я┌я─п╦я└п╦п╨п╟я├п╦я▐ я▌п╤п╫я▀я┘ пЁя┐п╠п╣я─п╫п╦п╧ п╢п╟я│я┌ п╪п╬я┴п╫я▀п╧ я┌п╬п╩я┤п╬п╨ п©п╬п╢я┼я▒п╪я┐ я│п╣п╩я▄я│п╨п╬пЁп╬ я┘п╬п╥я▐п╧я│я┌п╡п╟. | |
| ISO 8859-5 | аЈаИб�аОаКаАб� б�аЛаЕаКб�б�аИб�аИаКаАб�аИб� б�аЖаНб�б� аГб�аБаЕб�аНаИаЙ аДаАб�б� аМаОб�аНб�аЙ б�аОаЛб�аОаК аПаОаДб�б�аМб� б�аЕаЛб�б�аКаОаГаО б�аОаЗб�аЙб�б�аВаА. | |
| CP 866 | ╨и╨╕╤А╨╛╨║╨░╤П ╤Н╨╗╨╡╨║╤В╤А╨╕╤Д╨╕╨║╨░╤Ж╨╕╤П ╤О╨╢╨╜╤Л╤Е ╨│╤Г╨▒╨╡╤А╨╜╨╕╨╣ ╨┤╨░╤Б╤В ╨╝╨╛╤Й╨╜╤Л╨╣ ╤В╨╛╨╗╤З╨╛╨║ ╨┐╨╛╨┤╤К╤С╨╝╤Г ╤Б╨╡╨╗╤М╤Б╨║╨╛╨│╨╛ ╤Е╨╛╨╖╤П╨╣╤Б╤В╨▓╨░. | |
| UTF-16 | CP 866 | (♦8♦@♦>♦:♦0♦O♦ M♦;♦5♦:♦B♦@♦8♦D♦8♦:♦0♦F♦8♦O♦ N♦6♦=♦K♦E♦ 3♦C♦1♦5♦@♦=♦8♦9♦ 4♦0♦A♦B♦ <♦>♦I♦=♦K♦9♦ B♦>♦;♦G♦>♦:♦ ?♦>♦4♦J♦Q♦<♦C♦ A♦5♦;♦L♦A♦:♦>♦3♦>♦ E♦>♦7♦O♦9♦A♦B♦2♦0♦. |
Перекодировка[править]
Для восстановления текста (и для перекодировки) в POSIX-совместимых системах можно использовать утилиту iconv, например:
<syntaxhighlight lang=»bash»>
iconv -c -f cp1251 -t cp1252 source.txt > target.txt
</syntaxhighlight>
Если возможности применить iconv нет, следует открыть текстовый файл с неизвестной кодировкой с помощью любого популярного браузера, в котором доступно ручное указание кодировки (обычно: Вид — кодировка — … в верхнем меню, либо в контекстном меню). Позже, когда методом перебора удастся получить читаемый текст, его можно скопировать в текстовой редактор и сохранить в нужной кодировке. Также существует множество утилит, позволяющих ручное (с выбором пары кодировок) или автоматическое (вплоть до нескольких уровней глубины) перекодирование текста, например, для Windows: TotalRecode или «Штирлиц».
Перекодировка с целью восстановления исходного текста не всегда возможна. Например, уже при двукратной перекодировке, произошедшей, к примеру, при передаче сообщения через несколько неверно настроенных почтовых серверов, может произойти необратимая потеря информации, так как определённые различные символы исходного текста при определённых условиях могут замениться на другие, но одинаковые неправильные символы, и восстановить такое сообщение невозможно, даже если знать, какие перекодировки и в каком порядке были произведены.
Другие искажения, связанные с перекодировкой[править]
Нередко бывает, что перекодировка осуществляется в правильном направлении, но сам перекодировщик работает не совсем корректно. Например, некоторые программы-перекодировщики преобразуют только базовые русские буквы, а все остальные символы оставляют на месте. В итоге при перекодировке KOI8-R → Windows-1251 буква ё превращается в Ј (сербская буква), значок градуса (°) превращается в њ и т. д. (такие тексты в изобилии встречаются в Интернете, достаточно поискать слова «всЈ» или «њС»).
Другой вариант искажений связан с тем, что в целевой кодировке могут отсутствовать символы, имеющиеся в исходной кодировке. В этом случае отсутствующие символы могут просто выбрасываться, заменяться на символ-заменитель (часто знак вопроса — ?, иногда �) или же заменяться на похожие символы из ASCII (например, знак минуса (U+2212, −) может заменяться на простой дефис (U+002D, -), буква š может заменяться на s и т. д. В случае простого текста такие потери информации неизбежны, однако, если преобразованию подвергается файл HTML или XML, то корректным преобразованием будет замена отсутствующих в целевой кодировке символов на соответствующие мнемоники HTML: например, знак минуса должен заменяться на − или − буква š должна заменяться на š или š и т. д.
В культуре[править]
В 1997 г. московское издательство «АРГО-РИСК» выпустило сборник рассказов «Проблемы с кодировкой» (составитель Д. Кузьмин), в котором «все тексты напечатаны не поддающимимся прочтению наборами букв или иных знаков, возникающими обыкновенно при конвертировании текста из одной компьютерной программы в другую как следствие некорректной перекодировки»; в книгу вошли рассказы Николая Байтова, Вячеслава Курицына, Владимира Тучкова, Игоря Жукова, Максима Скворцова и Данилы Давыдова[4]. По мнению Д. Суховей, таким «акционным» жестом издатели, вероятно, стремились привлечь внимание к новым эффектам, возникающими в результате „компьютеризации“ литературы[5].
См. также[править]
- Буква зю
Источники[править]
- ↑ RFC 2616 — Hypertext Transfer Protocol — HTTP/1.1
- ↑ 2,0 2,1 2,2 2,3 2,4 Кодовая таблица ISO 8859-1 отличается лишь отсутствием ряда изображённых символов. В системе Microsoft Windows вместо кодовой страницы ISO 8859-1 применяется её расширение Windows-1252.
- ↑
Варианты декодирования в UTF-8 не приводятся, так как бо́льшая часть русского текста, записанного в 8-битной кодовой странице, будет сочтена ошибочной (не имеющей представления). - ↑ Коротко о новых книгах. 1997 // «Литературная жизнь Москвы»
- ↑ Д. Суховей. Круги компьютерного рая // «Новое литературное обозрение», № 62, 2003.
Ссылки[править]
- Почтовый декодер Студии Артемия Лебедева
| Кодировки символов | ||
|---|---|---|
| Основы | Алфавит • текст • набор символов • конверсия | |
| Исторические кодировки | Докомп.: | семафорная (Макарова) • Морзе • Бодо • МТК-2 |
| Комп.: | 6-битная • УПП • RADIX-50 • EBCDIC ( ДКОИ-8 ) • КОИ-7 • ISO 646 | |
| современное 8-битное представление |
символы | ASCII ( управляющие • печатные ) |
| 8-битные код.стр. | ISO 8859 • кириллица (КОИ-8 • ГОСТ 19768-87 • MacCyrillic) | |
| Windows | 1250 • 1251 (кир.) • 1252 • 1253 • 1254 • 1255 • 1256 • 1257 • 1258 • WGL4 | |
| IBM & DOS | 437 • 850 • 852 • 855 • 866 «альт.» • МИК • НИИ ЭВМ | |
| Многобайтные | Традиционные | DBCS ( GB 2312 ) • HTML |
| Unicode | UTF • список символов (кириллица • латиница) | |
| Связанные темы | интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • кракозябры • транслит • нестандартные шрифты |
Время на прочтение
9 мин
Количество просмотров 58K
Зачем эта статья?
Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с «простым текстом» (взять даже наши горячо любимые вставки на французском из «Война и мир») или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру «ó», поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Обратите внимание на следующий запрос:

Запрос содержит символ с модифицирующим акутом, однако во втором результате мы можем заметить, что выделено найденное слово из запроса, только вот оно не содержит вышеупомянутый символ, просто букву «о».
Конечно, уже есть много готовых инструментов, которые довольно неплохо справляются с обработкой текстов и могут делать разные крутые вещи, но я не об этом хочу вам поведать. Я не буду рассказывать про nltk, стемминг, лемматизацию и т.п. Я хочу опуститься на несколько ступенек ниже и обсудить некоторые тонкости кодировок, байтов, их обработки.
Откуда взялась статья?
Одним из важных составляющих в области ИИ является обработка текстов на естественном языке. В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
Важная ремарка: я не являюсь специалистом в области обработки текстов. Изложенный материал является результатом исключительно любительского изучения.
Проблема чтения файлов
Допустим, у нас есть файл с текстом. Нам нужно этот текст прочитать. Казалось бы, пиши себе такой вот скрипт для чтения из файла да и радуйся:
with open("some_text.txt", "r") as file:
content = file.read()
print(content)В файле содержится вот такое вот изречение:
pitónчто переводится с испанского как питон. Однако консоль OC Windows 10 покажет нам немного другой результат:
C:myhabrTextsInPython> python .script1.py
pitónСейчас мы разберёмся, что именно пошло не так и по какой причине.
Кодировка
Думаю, это не будет сюрпризом, если я скажу, что любой символ, который заносится в память компьютера, хранится в виде числа, а не в виде литерала. Это число определяется как идентификатор или кодовая позиция символа. Кодировка определяет, какое именно число будет ассоциировано с символом.
Предположим, у нас есть некоторый файл с неизвестным содержимым, и нам нужно его прочитать, однако мы не знаем, какая у файла кодировка. Попробуем декодировать содержимое файла.
with open("simple_text.txt", "r") as file:
text = file.read()
print(text)Посмотрим на результат:
C:myhabrTextsInPython> python .script2.py
ÿþ<♦8♦@♦Очень интересно, ничего непонятно. По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него). Попробуем перебрать несколько кодировок и найти подходящую.
codecs = ["cp1252", "cp437", "utf-16be", "utf-16"]
for codec in codecs:
with open("simple_text.txt", "r", encoding=codec) as file:
text = file.read()
print(codec.rjust(12), "|", text)Результат:
C:myhabrTextsInPython> python .script3.py
cp1252 | ÿþ<8@
cp437 | ■<8@
utf-16be | 㰄㠄䀄
utf-16 | мирРазные кодировки расшифровывают байты из файла по-разному, то есть разным кодовым позициям могут соотвествовать разные символы. Пример примитивный, несложно догадаться, что истинная кодировка файла — это utf-16.
Важный поинт: при записи и чтении из файлов следует указывать конкретную кодировку, это позволит избежать путаницы в дальнейшем.
Ошибки, связанные с кодировками
При возникновении ошибки, связанной с кодировками, интерпретатор выдаст одно из следующих исключений:
-
UnicodeError. Это общее исключение для ошибок кодировки. -
UnicodeDecodeError. Данное исключение возбуждается, если встречается кодовая позиция, которая отсутствует в кодировке. -
UnicodeEncodeError. А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
Попытка выполнения вот такого кода (в файле всё ещё содержится испанский питон):
with open("some_text.txt", "r", encoding="ascii") as file:
file.read()даст нам следующий результат:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)Кодировка ASCII не поддерживает никакой алфавит, кроме английского. Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов encode и decode — параметр errors. Он может принимать следующие значения:
Для обеих функций:
|
Обозначение |
Суть |
|
|
Значение по умолчанию. Несоотвествующие кодировке символы возбуждают исключения |
|
|
Несоответсвующие символы пропускаются без возбуждения исключений. |
Только для метода encode:
|
Обозначение |
Суть |
|---|---|
|
|
Несоотвествующие символы заменяются на символ |
|
|
Несоответствующие символы заменяются на соответсвующие значения XML. |
|
|
Несоответствующие символы заменяются на определённые последовательности с обратным слэшем. |
|
|
Несоответствующие символы заменяются на имена этих символов, которые берутся из базы данных Unicode. |
Также отдельно выделены значения surrogatepass и surrogateescape.
Приведём пример использования таких обработчиков:
>>> text = "pitón"
>>> text.encode("ascii", errors="ignore")
b'pitn'
>>> text.encode("ascii", errors="replace")
b'pit?n'
>>> text.encode("ascii", errors="xmlcharrefreplace")
b'pitón'
>>> text.encode("ascii", errors="backslashreplace")
b'pit\xf3n'
>>> text.encode("ascii", errors="namereplace")
b'pit\N{LATIN SMALL LETTER O WITH ACUTE}n'Важный поинт: если в текстах могут встретиться неожиданные для кодировки символы, во избежание возбуждения исключений можно использовать обработчики.
Cворачивание регистра
Сворачивание регистра — это попытка унифицировать текст любого представления к канонической форме. Например, приведение всего текста в нижний регистр. Также над текстом производятся некоторые преобразования (например, немецкая «эсцет» — «ß» — преобразуется в «ss»). В Python 3.3 появился метод str.casefold(), который как раз выполняет сворачивание регистра. Если текст содержит только символы кодировки latin1, результат применения этого метода будет аналогичен методу str.lower().
И по классике приведём пример:
>>> text = "Die größte Stadt der Welt liegt in China"
>>> text.casefold()
'die grösste stadt der welt liegt in china'В результате применённый метод не только привёл весь текст к нижнему регистру, но и преобразовал специфический немецкий символ.
Важный поинт: привести текст можно не только методом str.lower(), но и методом str.casefold(), который может выполнить дополнительные преобразования текста.
Нормализация
Нормализация — это полноценное приведение текста к единому представлению.
Чтобы обозначить важность нормализации, приведём простой пример:
letter1 = "µ"
letter2 = "μ"Внешне два этих символа выглядят абсолютно одинаково. Однако если мы попытаемся вывести имена этих символов, как их видит интерпретатор Python’a, результат нас порядком удивит.
В Python есть отличный встроенный модуль, который содержит данные о символах Unicode, их имена, являются ли они цифрамии и т.п. (методы по типу str.isdigit() берут информацию из этих данных). Воспользуемся данным модулем, чтобы вывести имена символов, исходя из информации, которая содержится в базе данных Unicode.
import unicodedata
letter1 = "µ"
letter2 = "μ"
print(unicodedata.name(letter1))
print(unicodedata.name(letter2))Результат выполнения данного кода:
C:myhabrTextsInPython> python .script7.py
MICRO SIGN
GREEK SMALL LETTER MUИтак, интерпретатор Python’a видит эти символы как два разных, но в стандарте Unicode они имеют одинаковое отображение.Такие символы называют каноническими эквивалентами. Приложения будут считать два этих символа одинаковыми, но не интерпретатор.
Посмотрим на ещё один пример:
>>> s1 = 'café'
>>> s2 = 'cafeu0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> len(s1), len(s2)
(4, 5)
Данные символы также будут являться каноническими эквивалентами. Из примера мы видим, что символ «é» в стандарте Unicodeможет быть представлен двумя способами, которые к тому же имеют разную длину. Символ «é» может быть представлен одним или двумя байтами.
Решением таких конфликтов занимается нормализация. Она реализована в Python в функции unicodedata.normalize.Первым аргумент является так называемая форма нормализации — нормализации строк Unicode, которые позволяют определить, эквивалентны ли какие-либо две строки Unicode друг другу. Всего предлагается четыре формы:
|
Форма |
Описание |
|---|---|
|
Normalization Form D (NFD) |
Canonical Decomposition |
|
Normalization Form C (NFC) |
Canonical Decomposition, следующая за Canonical Composition |
|
Normalization Form KD (NFKD) |
Compatibility Decomposition |
|
Normalization Form KC (NFKC) |
Compatibility Decomposition, следующая за Canonical Composition |
Разберём каждую форму немного подробнее.
-
NFC
При указании данной формы нормализации происходит каноническая композиция (как, собственно, и гласит название) кодовых позиций с целью получения самой короткой эквивалентной строки.
>>> unicodedata.normalize("NFC", s1), unicodedata.normalize("NFC", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFC", s1)), len(unicodedata.normalize("NFC", s2))
(4, 4)
>>> unicodedata.normalize("NFC", s1) == unicodedata.normalize("NFC", s2)
True
>>> len(unicodedata.normalize("NFC", s1)) == len(unicodedata.normalize("NFC", s2))
TrueИтак, нормализация обеих строк внешне их не изменила, однако длина строки s2 стала равной 4 (т.е. на один байт меньше). Была произведена композиция байтов eu0301, которые являлись отображением «é». Данная последовательность была заменена на минимальное представление символа, т.е. теперь представление этого символа для интерпретатора выглядит как в строке s1. Как результат, мы видим, что длина нормализованных строк стала равной, и сами строки также стали равны.
-
NFD
С этой формой ситуация аналогичная, только происходит декомпозиция байтов, т.е. разложение символа на несколько байт.
>>> unicodedata.normalize("NFD", s1), unicodedata.normalize("NFD", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFD", s1)), len(unicodedata.normalize("NFD", s2))
(5, 5)
>>> unicodedata.normalize("NFD", s1) == unicodedata.normalize("NFD", s2)
True
>>> len(unicodedata.normalize("NFD", s1)) == len(unicodedata.normalize("NFD", s2))
TrueЗдесь мы видим, что длина строки s1 увеличилась на один байт. Думаю, уже несложно догадаться, почему.
На данном этапе настал момент ввести понятие символа совместимости. Символы совместимости (compatibility characters) были введены в Unicode ради совместимости с другими стандартами, в частности, стандарты, которые предшествовали Unicode. Это означает, что некоторые символы могут встречаться в стандарте несколько раз. Мы уже могли наблюдать это явление в начале этого раздела на примере с символом «мю». Он считается символом совместимости.
-
NFKC и NFKD
При данных формах нормализации символы совместимости заменяются на его более предпочтительное представление, что также называется совместимой декомпозицией. Однако при данных формах нормализации может быть потеряно форматирование.
Немного модифицируем наш пример из начала раздела. Выведем кодовые позиции символов до и после нормализации:
import unicodedata
letter1 = "µ"
letter2 = "μ"
print("Before normalizing:", ord(letter1), ord(letter2))
letter1 = unicodedata.normalize("NFKC", letter1)
letter2 = unicodedata.normalize("NFKC", letter2)
print("After normalizing:", ord(letter1), ord(letter2))И результат выполнения кода:
Before normalizing: 181 956
After normalizing: 956 956Итак, мы видим, что первый символ (который являлся знаком «микро») был заменён на греческую «мю», т.е. более предпочтительное представление символа. Таким образом, если необходимо, например, провести частотный анализ текста, формы нормализации, которые затрагивают символы совместимости, могут помочь с этим, приводя символы совместимости к единому представлению.
Важный поинт: нормализация может очень помочь для поиска валидных документов или индексирования текста. Если вы занимаетесь разработкой таких систем, не стоит сбрасывать алгоритмы нормализации со счетов.
Дополнительные материалы: что использовалось в статье и что почитать по теме
«Fluent Python», Лучано Ромальо
В этой книге целая глава посвящена изучению строк, байтов и Unicode (Глава 4. Тексты и байты). Она есть на русском и английском языках, но в русском переводе допущено немало ошибок, так что открывайте русский вариант на свой страх и риск. Материал статьи в большей степени опирается на данную книгу. Некоторые примеры также взяты оттуда.
Документация для Unicode на официальном сайте Python
Куда ж без неё, родимой. Там тоже можно найти немало полезной информации, если вам понадобится работать с текстами и делать больше, чем просто считывание из файла. Хотя в некоторых случаях и на этом можно споткнуться.
Unicode® Standard Annex
Это части стандарта Unicode, которые выложены в открытый доступ в виде отдельных статей. Почитать их можно вот здесь.
Когда я только начинал изучать тему разработки сайтов, кракозябры были одной из моих постоянных проблем. Создал HTML-страницу — в браузере кракозябры, установил денвер и попробовал создать сайт на PHP — снова вместо букв кракозябры. Скачал иностранную тему, подключился к базе данных — та же проблема.
На своих сайтах я обычно использую UTF-8 (это такая кодировка текста, она ещё называется юникод), соответственно она будет присутствовать во всех примерах в этой статье.
1. UTF-8 без BOM
Начнём с самой простой проблемы. Вы создали какой-то HTML-файл, открыли его в браузере и получили:
Проблема актуальна в основном для пользователей Windows, на маке я с таким ни разу не сталкивался.
Решение проблемы зависит в основном от того, каким редактором вы пользуетесь. Для пользователей Windows я рекомендую бесплатный офигительный Notepad++.
Значит, открываем файл в Notepad++ и переходим в Кодировки > Преобразовать в UTF-8 без BOM. Вопрос — почему без BOM? Потому что с BOM у вас будут постоянно вставляться пустые символы (на самом деле они не пустые, у них тоже есть своя функция, но нам она в данном случае не нужна) куда не надо, а для PHP это уже критично.
2. Мета тег charset
Если вы сделали то, что я описывал в предыдущем шаге и ваша проблема не разрешилась, тогда самое время испробовать второй метод устранения кракозябров.
Всё, что нам требуется, это вставить следующий код между тегами <head> сайта. Прежде всего проверьте, возможно этот метатег у вас уже присутствует. Если да, то посмотрите какое у него стоит значение параметра charset.
В темах WordPress обычно этот тег уже имеется по умолчанию и выглядит следующим образом:
<meta charset="<?php bloginfo('charset'); ?>" />
3. .htaccess
Если русские буквы до сих пор отображаются кракозябрами, тогда открываем ваш .htaccess, который лежит в корне сайта и вставляем туда с новой строки это:
4. Заголовки сервера через header()
Ещё один способ определения кодировки. На этот раз через PHP. На WordPress никогда не приходилось им пользоваться.
header('Content-Type: text/html; charset=utf-8');
Важно! Этот код должен вставляться до того, как будет что-либо выведено на странице сайта, иначе — ошибка.
5. Проблемы с последним символом при обрезке строки
На многих сайтах встречаются блоки с популярными записями, последними комментариями, отзывами и так далее. Обычно в таких обзорных блоках выводится часть записи/комментария/отзыва и кнопка «читать далее». Так вот, для того, чтобы вывести первые несколько предложений или первые несколько слов текста, используется функция PHP substr(). Конечно же в основном я имею ввиду англоязычные темы, которых так много в интернете. Даже если у этих тем есть локализация — то есть вроде бы она на русском — переведена админка, переведён практически весь сайт, но при этом мы встречаем такие вот косяки:
Как решить эту проблему?
Легко — всё что нам нужно, это найти функцию substr() в коде и поменять её на mb_substr().
Если после этого у вас полезут ошибки на сайт, то скорее всего multibyte-функции не поддерживаются вашим хостингом, первое, что вам следует сделать, это написать в супорт и спросить, нельзя ли их подключить на ваш аккаунт. Если нет, меняем хостинг, например на тот, которым пользуюсь я.
6. MySQL
У меня не раз бывало такое, что я подключался к MySQL, вытаскивал какие-нибудь данные, и при их выводе на сайте, текст отображался кракозябрами.
Такое может произойти, если кодировка вашего сайта не совпадает с кодировкой базы данных, к которой вы подключаетесь. В WordPress обычно таких проблем не бывает.
Для того, чтобы исправить это, после подключения к БД, делаем следующее:
mysql_query("SET NAMES 'UTF8'");
Если ни один из вышеперечисленных методов вам не помог, оставляйте комментарий и попробуем вместе разобраться.
Миша
Впервые познакомился с WordPress в 2009 году. Организатор и спикер на конференциях WordCamp. Преподаватель в школе Нетология.
Пишите, если нужна помощь с сайтом или разработка с нуля.