
This page is intended to help people collect information to troubleshoot problems with the PostgreSQL Installers supplied by EnterpriseDB.
Many problems have already been identified and fixed, so make sure you’re using the installer for the latest point-release of PostgreSQL before reporting a problem.
Because some problems can’t be fixed in the installer, but are issues with the Windows installation or how it is being used, there is also a list of frequently asked questions and frequently encountered problems with PostgreSQL on Windows. Please read the common installation errors section, or preferably the whole document. You’ll probably save some time and hassle by doing so.
If you’ve tried all that, and you’re still having problems getting PostgreSQL installed, please read on to find out how you can collect the information we need to be able to help you with installation problems.
Contents
- 1 Make sure you’re installing on a supported platform
- 2 Try again without your virus scanner or 3rd-party firewall
- 3 Read about other common installation problems
- 4 Reporting an installation error
- 4.1 Note down the basic information about your system
- 4.2 Collect the installer log file
- 4.3 Get the contents of the PostgreSQL server error log
- 4.4 Extra information Windows users need to collect
- 4.4.1 Windows: Check for messages in the Windows event log
- 4.4.2 Windows: Check what Group Policy, if any, is active on your computer
- 4.4.3 Windows: Take a copy of the environment variables set on the computer
Make sure you’re installing on a supported platform
See the installer download page and (for Windows) the Running & Installing PostgreSQL On Native Windows for platform support details.
Please do not ask the mailing list for help with installation on unsupported Windows platforms. However, one of the paid PostgreSQL consultants, or EnterpriseDB (who make the PostgreSQL installer) may be able to help you on a paid basis.
Try again without your virus scanner or 3rd-party firewall
The Windows FAQ discusses potential issues with antivirus software and 3rd-party firewalls. If you’re encountering any installation issues, please try again with your virus scanner uninstalled (not just disabled) to see if the problem goes away. If it does, please report the fact to the mailing list and to the vendor of your antivirus product.
Read about other common installation problems
Before reporting a problem, please read the windows FAQ to see if your problem is one we’ve already seen and found a workaround or fix for.
Reporting an installation error
To be able to help you with an installation problem, we will need you to collect some basic details about your computer and the problem. Please see the instructions below.
Note down the basic information about your system
Any problem report must include:
- The exact words of any error message you see when the installation fails
- The exact version of PostgreSQL you are installing
- Whether you installed a 32-bit or 64-bit release of PostgreSQL
- The operating system and version you are using, eg:
- «Windows XP Professional with Service Pack 3»
- «Mac OS X 10.4.2»
- «Fedora Core 14»
- Whether you are running a 32-bit or 64-bit version of your operating system
- How you ran the installer. Command-line arguments, what user account you ran it from, etc.
- What antivirus and/or software firewall products you have installed, if any, even if they are disabled
- Which, if any, of the troubleshooting instructions you have already tried
- Whether a previous version of PostgreSQL was installed, and if so:
- whether you uninstalled it before running the new installer
- If you uninstalled a previous version, whether you did it with the uninstaller or some other way
- Whether you removed the postgres user/service account when you uninstalled
- Additional details and platform-specific information as described below
Collect the installer log file
The installer creates a log file in the system ‘temp’ directory. This will log all manner of data about the installation, and is invaluable when troubleshooting. The log will be called install-postgresql.log if the installation completed successfully. If not, the installer may not have been able to rename it, in which case the name will be either bitrock_installer.log or bitrock_installer_xxx.log, where xxx is a number (actually the process ID of the installation attempt).
On Linux and Mac systems, the logfile will almost always be found in the /tmp/ directory.
On Windows, the easiest way to find the logfile is to click Start -> Run, enter %TEMP% in the box and then click OK (these instructions apply to Windows XP and 2003 — adjust as necessary for other versions).
Get the contents of the PostgreSQL server error log
The PostgreSQL server has its own error log. This may not exist if installation failed early on, but it can be very informative for errors that happened later in installation. You can find it in the «pg_log» folder inside the data directory you chose for PostgreSQL. If it exists, please include it in any problem reports.
Windows users must collect additional Windows-specific details to help troubleshoot installation issues:
- (On Windows Vista and Windows 7): The UAC security level
- Whether you started the installer by logging in as Administrator, started it from from your own normal user account, or ran it using the «Run As Administrator» menu option.
- Whether your computer is a part of a Windows domain. Home computers usually are not, business computers usually are.
- Whether your computer and network has any Group Policy configured. If you’re on a corporate windows domain you probably have group policy and need to ask your network administrator for details about it.
Windows: Check for messages in the Windows event log
Please check the Windows Event Viewer for messages that might be related to installation problems or service startup problems.
TODO: detail on how to collect and save events.
Windows: Check what Group Policy, if any, is active on your computer
TODO: instructions for collecting domain and local group policy.
Windows: Take a copy of the environment variables set on the computer
Open a command prompt and run «set». Then copy and paste the results into your problem report.
I’d be better to collect the «all users» environment from the system control panel, but it’s not easy to just dump this information.
Media failure is one of the crucial things that the database administrator should be aware of. Media failure is nothing but a physical problem reading or writing to files on the storage medium.
A typical example of media failure is a disk head crash, which causes the loss of all files on a disk drive. All files associated with a database are vulnerable to a disk crash, including datafiles, wal files, and control files.
This is the comprehensive post which focuses on disk failure in PostgreSQL and the ways you can retrieve the data from PostgreSQL Database after failure(other than restoring the backup).
In this post, we are going to do archaeology on the below error and will understand how to solve the error.
WARNING: page verification failed, calculated checksum 21135 but expected 3252
ERROR: invalid page in block 0 of relation base/13455/16395
During the process, you are going to learn a whole new bunch of stuff in PostgreSQL.
PostgreSQL Checksum: The definitive guide
- Chapter 1: What is a checksum?
- Chapter 2: PostgreSQL checksum: Practical implementation
- Chapter 3: How to resolve the PostgreSQL corrupted page issue?
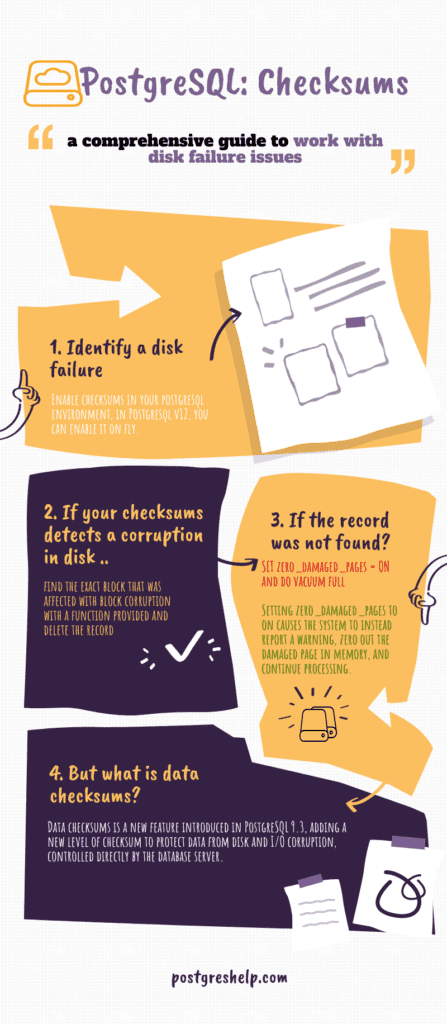
With v9.3, PostgreSQL introduced a feature known as data checksums and it has undergone many changes since then. Now we have a well-sophisticated view in PostgreSQL v12 to find the checksums called pg_checksums.
But what is a PostgreSQL checksum?
When the checksum is enabled, a small integer checksum is written to each “page” of data that Postgres stores on your hard drive. Upon reading that block, the checksum value is recomputed and compared to the stored one.
This detects data corruption, which (without checksums) could be silently lurking in your database for a long time.
Good, checksum, when enabled, detects data corruption.
How does PostgreSQL checksum work?
PostgreSQL maintains page validity primarily on the way in and out of its buffer cache.
Also read: A comprehensive guide – PostgreSQL Caching
From here we understood that the PostgreSQL page has to pass through OS Cache before it leaves or enters into shared buffers. So page validity happens before leaving the shared buffers and before entering the shared buffers.
when PostgreSQL tries to copy the page into its buffer cache then it will (if possible) detect that something is wrong, and it will not allow page to enter into shared buffers with this invalid 8k page, and error out any queries that require this page for processing with the ERROR message
ERROR: invalid page in block 0 of relation base/13455/16395
If you already have a block with invalid data at disk-level and its page version at buffer level, during the next checkpoint, while page out, it will update invalid checksum details but which is rarely possible in real-time environments.
confused, bear with me.
And finally,
If the invalid byte is part of the PostgreSQL database buffer cache, then PostgreSQL will quite happily assume nothing is wrong and attempt to process the data on the page. Results are unpredictable; Some times you will get an error and sometimes you may end up with wrong data.
How PostgreSQL Checks Page Validity?
In a typical page, if data checksums are enabled, information is stored in a 2-byte field containing flag bits after the page header.
Also Read: A comprehensive guide on PostgreSQL: page header
This is followed by three 2-byte integer fields (pd_lower, pd_upper, and pd_special). These contain byte offsets from the page start to the start of unallocated space, to the end of unallocated space, and to the start of the special space.
The checksum value typically begins with zero and every time reading that block, the checksum value is recomputed and compared to the stored one. This detects data corruption.
Checksums are not maintained for blocks while they are in the shared buffers – so if you look at a buffer in the PostgreSQL page cache with pageinspect and you see a checksum value, note that when you do page inspect on a page which is already in the buffer, you may not get the actual checksum. The checksum is calculated and stamped onto the page when the page is written out of the buffer cache into the operating system page cache.
Also read: A comprehensive guide – PostgreSQL Caching
Let’s work on the practical understanding of whatever we learned so far.
I have a table check_corruption wherein I am going to do all the garbage work.
- my table size is 8 kB.
- has 5 records.
- the version I am using is PostgreSQL v12.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) postgres=# SELECT * FROM page_header(get_raw_page(‘check_corruption’,0)); lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid ——————+—————+————+————+————+—————+—————+—————+—————— 0/17EFCA0 | 0 | 0 | 44 | 7552 | 8192 | 8192 | 4 | 0 (1 row) postgres=# dt+ check_corruption List of relations Schema | Name | Type | Owner | Size | Description ————+—————————+————+—————+——————+——————— public | check_corruption | table | postgres | 8192 bytes | (1 row) postgres=# select pg_relation_filepath(‘check_corruption’); pg_relation_filepath ——————————— base/13455/16490 (1 row) postgres=# |
First, check whether the checksum is enabled or not?
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 0
[postgres@stagdb ~]$
It is disabled.
Let me enable the page checksum in PostgreSQL v12.
Syntax: pg_checksums -D /u01/pgsql/data –enable –progress –verbose
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —enable —progress —verbose pg_checksums: checksums enabled in file «/u01/pgsql/data/global/2847» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/1260_fsm» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/4175» .. .. 23/23 MB (100%) computed Checksum operation completed Files scanned: 969 Blocks scanned: 3006 pg_checksums: syncing data directory pg_checksums: updating control file Data checksum version: 1 Checksums enabled in cluster |
Again, check the status of checksums in PostgreSQL
[postgres@stagdb ~]$
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 1
[postgres@stagdb ~]$
we can disable the checksums with –disable option
|
[postgres@stagdb ~]$ [postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —disable pg_checksums: syncing data directory pg_checksums: updating control file Checksums disabled in cluster [postgres@stagdb ~]$ |
Let’s first check the current data directory for errors, then play with data.
To check the PostgreSQL page errors, we use the following command.
pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb ~]$ pg_checksums -D /u01/pgsql/data –check
Checksum operation completed
Files scanned: 969
Blocks scanned: 3006
Bad checksums: 0
Data checksum version: 1
[postgres@stagdb ~]$
Warning!! Do not perform the below case study in your production machine.
As the table check_corruption data file is 16490, I am going to corrupt the file with the Operating system’s dd command.
dd bs=8192 count=1 seek=1 of=16490 if=16490
[postgres@stagdb 13455]$ dd bs=8192 count=1 seek=1 of=16490 if=16490
Now, log in and get the result
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
I got the result, but why?
I got the result from shared buffers. Let me restart the cluster and fetch the same.
/usr/local/pgsql/bin/pg_ctl restart -D /u01/pgsql/data
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
But again why?
As we discussed earlier, during restart my PostgreSQL has replaced error checksum with the value of shared buffer.
How can we trigger a checksum warning?
We need to get that row out of shared buffers. The quickest way to do so in this test scenario is to restart the database, then make sure we do not even look at (e.g. SELECT) the table before we make our on-disk modification. Once that is done, the checksum will fail and we will, as expected, receive a checksum error:
i.e., stop the server, corrupt the disk and start it.
- /usr/local/pgsql/bin/pg_ctl stop -D /u01/pgsql/data
- dd bs=8192 count=1 seek=1 of=16490 if=16490
- /usr/local/pgsql/bin/pg_ctl start -D /u01/pgsql/data
During the next fetch, I got below error
postgres=# select * from check_corruption;
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427
WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:06:17.434 IST [25218] ERROR: invalid page in block 1 of relation base/13455/16490
2020-02-06 19:06:17.434 IST [25218] STATEMENT: select * from check_corruption;
ERROR: invalid page in block 1 of relation base/13455/16490
Let us dig deeper into the issue and confirm that the block is corrupted
There are a couple of ways you can find the issue which includes Linux commands like
- dd
- od
- hexdump
Usind dd command : dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -1
[postgres@stagdb 13455]$ dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -2
1+0 records in
1+0 records out
8192 bytes (8.2 kB) copied, 4.5e-05 seconds, 182 MB/s
0000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d >……~…..,…<
here,
00 00 00 00 a0 fc 7e 01 the first 8 bytes indicate pd_lsn and the next two bytes
03 9a indicates checksums.
Using hexdump : hexdump -C 16490 | head -1
[postgres@stagdb 13455]$ hexdump -C 16490 | head -1
00000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d |……~…..,…|
[postgres@stagdb 13455]$
Both hexdump and dd returned same result.
Let’s understand what our PostgreSQL very own pg_checksums has to say?
command: pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb 13455]$ pg_checksums -D /u01/pgsql/data –check
pg_checksums: error: checksum verification failed in file “/u01/pgsql/data/base/13455/16490”, block 1: calculated checksum 9A04 but block contains 9A03
Checksum operation completed
Files scanned: 968
Blocks scanned: 3013
Bad checksums: 1
Data checksum version: 1
[postgres@stagdb 13455]$
here, according to pg_checksums checksum 9A03 is matching with that of hexdump’s checksum 9A03.
Converting Hex 9A03 to decimals, I got 39427
which is matching the error
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427

How to resolve the PostgreSQL corrupted page issue?
use the below function to find the exact location where the page is corrupted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE OR REPLACE FUNCTION find_bad_row(tableName TEXT) RETURNS tid as $find_bad_row$ DECLARE result tid; curs REFCURSOR; row1 RECORD; row2 RECORD; tabName TEXT; count BIGINT := 0; BEGIN SELECT reverse(split_part(reverse($1), ‘.’, 1)) INTO tabName; OPEN curs FOR EXECUTE ‘SELECT ctid FROM ‘ || tableName; count := 1; FETCH curs INTO row1; WHILE row1.ctid IS NOT NULL LOOP result = row1.ctid; count := count + 1; FETCH curs INTO row1; EXECUTE ‘SELECT (each(hstore(‘ || tabName || ‘))).* FROM ‘ || tableName || ‘ WHERE ctid = $1’ INTO row2 USING row1.ctid; IF count % 100000 = 0 THEN RAISE NOTICE ‘rows processed: %’, count; END IF; END LOOP; CLOSE curs; RETURN row1.ctid; EXCEPTION WHEN OTHERS THEN RAISE NOTICE ‘LAST CTID: %’, result; RAISE NOTICE ‘%: %’, SQLSTATE, SQLERRM; RETURN result; END $find_bad_row$ LANGUAGE plpgsql; |
Now, using the function find_bad_row(), you can find the ctid of the corrupted location.
you need hstore extension to use the function
postgres=# CREATE EXTENSION hstore;
CREATE EXTENSION
postgres=#
postgres=# select find_bad_row(‘check_corruption’);
2020-02-06 19:44:24.227 IST [25929] WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:44:24.227 IST [25929] CONTEXT: PL/pgSQL function find_bad_row(text) line 21 at FETCH
WARNING: page verification failed, calculated checksum 39428 but expected 39427
NOTICE: LAST CTID: (0,5)
NOTICE: XX001: invalid page in block 1 of relation base/13455/16490
find_bad_row
————–
(0,5)
(1 row)
Deleting that particular CTID will resolve the issue
postgres=# delete from check_corruption where ctid='(0,6)’;
DELETE 1
postgres=#
If deleting ctid has not worked for you, you have an alternative solution which is setting zero_damaged_pages parameter.
Example.,
postgres=# select * from master;
WARNING: page verification failed, calculated checksum 8770 but expected 8769
ERROR: invalid page in block 1 of relation base/13455/16770
postgres=#
I can’t access the data from table master as block is corrupted.
Solution:
postgres=# SET zero_damaged_pages = on;
SET
postgres=# vacuum full master;
|
postgres=# select * from master; WARNING: page verification failed, calculated checksum 8770 but expected 8769 WARNING: invalid page in block 1 of relation base/13455/16770; zeroing out page id | name | city ——+—————+—————— 1 | Orson | hyderabad 2 | Colin | chennai 3 | Leonard | newyork |
here, it cleared the damaged page and gave the rest of the result.
What your document has to say?
zero_damaged_pages (boolean): Detection of a damaged page header normally causes PostgreSQL to report an error, aborting the current transaction. Setting zero_damaged_pages to on causes the system to instead report a warning, zero out the damaged page in memory, and continue processing. This behavior will destroy data, namely all the rows on the damaged page. However, it does allow you to get past the error and retrieve rows from any undamaged pages that might be present in the table. It is useful for recovering data if corruption has occurred due to a hardware or software error. You should generally not set this on until you have given up hope of recovering data from the damaged pages of a table. Zeroed-out pages are not forced to disk so it is recommended to recreate the table or the index before turning this parameter off again. The default setting is off, and it can only be changed by a superuser.
There are a couple of things to be aware when using this feature though. First, using checksums has a cost in performance as it introduces extra calculations for each data page (8kB by default), so be aware of the tradeoff between data security and performance when using it.
There are many factors that influence how much slower things are when checksums are enabled, including:
- How likely things are to be read from shared_buffers, which depends on how large shared_buffers is set, and how much of your active database fits inside of it
- How fast your server is in general, and how well it (and your compiler) are able to optimize the checksum calculation
- How many data pages you have (which can be influenced by your data types)
- How often you are writing new pages (via COPY, INSERT, or UPDATE)
- How often you are reading values (via SELECT)
The more that shared buffers are used (and using them efficiently is a good general goal), the less checksumming is done, and the less the impact of checksums on database performance will be. On an average if you enable checksum the performance cost would be more than 2% and for inserts, the average difference was 6%. For selects, that jumps to 19%. Complete computation benchmark test can be found here
Bonus
You can dump the content of the file with pg_filedump before and after the test and can use diff command to analyze data corruption
- pg_filedump -if 16770 > before_corrupt.txt
- corrupt the disk block
- pg_filedump -if 16770 > before_corrupt.txt
- diff or beyond compare both the files.
Thank you for giving your valuable time to read the above information. I hope the content served your purpose in reaching out to the blog.
Suggestions for improvement of the blog are highly appreciable. Please contact us for any information/suggestions/feedback.
If you want to be updated with all our articles
please follow us on Facebook | Twitter
Please subscribe to our newsletter.
I am trying to upgrade postgres 9.5.4 to 10.1 on Ubuntu 14. The data directory for 9.5.4 is /var/lib/postgresql/data/postgresql0
The steps that I have followed
Install postgres 10.1
ubuntu@van-platform:~/build-target/launcher$sudo add-apt-repository "deb http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg main"
ubuntu@van-platform:~/build-target/launcher$wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
ubuntu@van-platform:~/build-target/launcher$ OK
ubuntu@van-platform:~/build-target/launcher$sudo apt-get update
...
ubuntu@van-platform:~/build-target/launcher$sudo apt-get install postgresql-10
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
comerr-dev krb5-multidev libgssrpc4 libkadm5clnt-mit9 libkadm5srv-mit9
libkdb5-7
Use 'apt-get autoremove' to remove them.
The following extra packages will be installed:
libpq-dev libpq5 postgresql-client-10 postgresql-client-common
postgresql-common
Suggested packages:
postgresql-doc-10 locales-all
The following NEW packages will be installed:
postgresql-10 postgresql-client-10
The following packages will be upgraded:
libpq-dev libpq5 postgresql-client-common postgresql-common
4 upgraded, 2 newly installed, 0 to remove and 14 not upgraded.
Need to get 6,595 kB of archives.
After this operation, 26.7 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg/main libpq-dev amd64 10.1-1.pgdg14.04+1 [241 kB]
Get:2 http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg/main libpq5 amd64 10.1-1.pgdg14.04+1 [157 kB]
Get:3 http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg/main postgresql-common all 188.pgdg14.04+1 [220 kB]
Get:4 http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg/main postgresql-client-common all 188.pgdg14.04+1 [81.5 kB]
Get:5 http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg/main postgresql-client-10 amd64 10.1-1.pgdg14.04+1 [1,282 kB]
Get:6 http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg/main postgresql-10 amd64 10.1-1.pgdg14.04+1 [4,613 kB]
Fetched 6,595 kB in 4s (1,473 kB/s)
Preconfiguring packages ...
(Reading database ... 102799 files and directories currently installed.)
Preparing to unpack .../libpq-dev_10.1-1.pgdg14.04+1_amd64.deb ...
Unpacking libpq-dev (10.1-1.pgdg14.04+1) over (9.5.4-1.pgdg14.04+1) ...
Preparing to unpack .../libpq5_10.1-1.pgdg14.04+1_amd64.deb ...
Unpacking libpq5:amd64 (10.1-1.pgdg14.04+1) over (9.5.4-1.pgdg14.04+1) ...
Preparing to unpack .../postgresql-common_188.pgdg14.04+1_all.deb ...
Leaving 'diversion of /usr/bin/pg_config to /usr/bin/pg_config.libpq-dev by postgresql-common'
Unpacking postgresql-common (188.pgdg14.04+1) over (175.pgdg14.04+1) ...
Preparing to unpack .../postgresql-client-common_188.pgdg14.04+1_all.deb ...
Unpacking postgresql-client-common (188.pgdg14.04+1) over (175.pgdg14.04+1) ...
Selecting previously unselected package postgresql-client-10.
Preparing to unpack .../postgresql-client-10_10.1-1.pgdg14.04+1_amd64.deb ...
Unpacking postgresql-client-10 (10.1-1.pgdg14.04+1) ...
Selecting previously unselected package postgresql-10.
Preparing to unpack .../postgresql-10_10.1-1.pgdg14.04+1_amd64.deb ...
Unpacking postgresql-10 (10.1-1.pgdg14.04+1) ...
Processing triggers for man-db (2.6.7.1-1ubuntu1) ...
Processing triggers for ureadahead (0.100.0-16) ...
Setting up libpq5:amd64 (10.1-1.pgdg14.04+1) ...
Setting up libpq-dev (10.1-1.pgdg14.04+1) ...
Setting up postgresql-client-common (188.pgdg14.04+1) ...
Installing new version of config file /etc/postgresql-common/user_clusters ...
Setting up postgresql-common (188.pgdg14.04+1) ...
Configuration file '/etc/logrotate.d/postgresql-common'
==> File on system created by you or by a script.
==> File also in package provided by package maintainer.
What would you like to do about it ? Your options are:
Y or I : install the package maintainer's version
N or O : keep your currently-installed version
D : show the differences between the versions
Z : start a shell to examine the situation
The default action is to keep your current version.
*** postgresql-common (Y/I/N/O/D/Z) [default=N] ? Y
Installing new version of config file /etc/logrotate.d/postgresql-common ...
Replacing config file /etc/postgresql-common/createcluster.conf with new version
* Starting PostgreSQL 9.5 database server [ OK ]
Setting up postgresql-client-10 (10.1-1.pgdg14.04+1) ...
Setting up postgresql-10 (10.1-1.pgdg14.04+1) ...
Creating new PostgreSQL cluster 10/main ...
/usr/lib/postgresql/10/bin/initdb -D /var/lib/postgresql/10/main --auth-local peer --auth-host md5
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /var/lib/postgresql/10/main ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting dynamic shared memory implementation ... posix
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
Success. You can now start the database server using:
/usr/lib/postgresql/10/bin/pg_ctl -D /var/lib/postgresql/10/main -l logfile start
Ver Cluster Port Status Owner Data directory Log file
10 main 5433 down postgres /var/lib/postgresql/10/main /var/log/postgresql/postgresql-10-main.log
* Starting PostgreSQL 10 database server [ OK ]
Processing triggers for libc-bin (2.19-0ubuntu6.13) ...
Create the new data directory
support@vrni-platform:~$ sudo -H -u postgres mkdir -p /var/lib/postgresql/10/data/postgresql0
Stop postgres
ubuntu@vrni-platform:~/build-target/launcher$ sudo service postgresql stop
* Stopping PostgreSQL 10 database server [ OK ]
* Stopping PostgreSQL 9.5 database server [ OK ]
Enable Checksum
support@vrni-platform:/tmp$ sudo -H -u postgres /usr/lib/postgresql/10/bin/pg_ctl -D /var/lib/postgresql/10/data/postgresql0 initdb -o '--data-checksums'
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are enabled.
fixing permissions on existing directory /var/lib/postgresql/10/data/postgresql0 ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting dynamic shared memory implementation ... posix
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
WARNING: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
/usr/lib/postgresql/10/bin/pg_ctl -D /var/lib/postgresql/10/data/postgresql0 -l logfile start
On trying to check for upgrade viability with the below command
sudo -H -u postgres /usr/lib/postgresql/10/bin/pg_upgrade
-b /usr/lib/postgresql/9.5/bin
-B /usr/lib/postgresql/10/bin
-d /var/lib/postgresql/data/postgresql0
-D /var/lib/postgresql/10/data/postgresql0
-o ' -c config_file=/etc/postgresql/9.5/main/postgresql.conf'
-O ' -c config_file=/etc/postgresql/10/main/postgresql.conf' --check
It is failing with the below error in pg_upgrade_server.log
command: "/usr/lib/postgresql/9.5/bin/pg_ctl" -w -l "pg_upgrade_server.log" -D "/var/lib/postgresql/data/postgresql0" -o "-p 50432 -b -c config_file=/etc/postgresql/9.5/main/postgresql.conf -c listen_addresses='' -c unix_socket_permissions=0700 -c unix_socket_directories='/tmp'" start >> "pg_upgrade_server.log" 2>&1
waiting for server to start....2017-11-14 15:27:31 UTC [16239-1] LOG: database system was shut down at 2017-11-14 15:16:43 UTC
2017-11-14 15:27:31 UTC [16239-2] LOG: MultiXact member wraparound protections are now enabled
2017-11-14 15:27:31 UTC [16238-1] LOG: database system is ready to accept connections
........................................................... stopped waiting
pg_ctl: could not start server
Can someone let me know what I am doing wrong and how can I get around this error?

Иван Чувашов, DBA Okko и Southbridge, поделился жизненными кейсами с PostgreSQL, которые помогут решить ваши проблемы.
Разберем случаи из PostgreSQL: запросы в статусе idle in transaction, выключенные контрольные суммы данных, переполнение int4, убивающие базу временные файлы и загрузку CPU.
Кейс первый
Ситуация с idle in transaction – приложение открыло транзакцию, отправило изменения в базу данных, а закрыть транзакцию забыло, транзакция висит.
Как решать инженеру такие ситуации? В Интернете можно найти много статей на тему: что такое idle in transaction, с чем оно связано и даже на практике посмотреть примеры реализации этой ситуации, но не получите самую главную информацию – как решать такие проблемы?

У нас была ситуация, когда появились idle in transaction, и приложение начало тормозить – пул подключений в базе данных был забит. Они блокировали ресурсы, и нам нужно было срочно принимать какое-то решение, мы пошли самым простым путём, который напрашивается и предлагается вашему вниманию.
Первый вариант, который может быть – это выполнение команд:
select pg_cancel_backend(pid) from pg_stat_activity where state = 'idle in transactions' and datname = 'название_БД';или
select pg_terminate_backend(pid) from pg_stat_activity where state = 'idle in transactions' and datname = 'название_БД';Отличие данных функций друг от друга можно почитать тут: https://postgrespro.ru/docs/postgresql/13/functions-admin#FUNCTIONS-ADMIN-SIGNAL-TABLE.
А может ли упасть PostgreSQL?
Когда выполняете pg_terminate_backend – это не нулевая вероятность. Допустим, у вас есть процесс, который считывает данные и вы выполняете команду pg_terminate_backend, запрос подтягивает эти же данные в оперативную память PostgreSQL. Если в результате данные стали грязными, то их нельзя считывать другим процессам. Поэтому postmaster-у нужно очистить оперативную память, что он и делает, перезагружая себя.
Точечно отстреливать запросы, можно вызвать групповую команду по маске – очевидные плюсы. Но эти команды на самом деле не решают проблему с idle in transaction. Когда ситуация возникает на стороне бэкенда и мы выполнили команду, которая группой срубила запросы, то через некоторое время ситуация может повториться и тут же появятся от бэкенда запросы в статусе idle in transaction.
Другой вариант – перезагрузка сервера PostgreSQL
Какие в этом решении могут быть минусы? Конечно же, остановка сервера. К тому же часто бывает, что на одном кластере находится не одна база, а несколько или даже с десяток разных баз.
При остановке сервера PostgreSQL мы убиваем подключения к другим базам или подключения других сервисов. Все это усугубляется ситуацией, когда приложение автоматически не может переподключится к базе. Да бывает и такое! Что может привести к каскадному эффекту в перезагрузке сервисов.
Не знаю, если ли тут плюсы?
Небольшой лайхак. Чтобы быстрее перезапустить кластер, перед перезагрузкой выполните команду checkpoint.
Ещё вариант – перезагрузка бэкендов
Через pg_stat_activity определяем IP проблемного сервиса, с которого произошло подключение. Начинаем их перезагружать. В мире IT микроархитектуры этот процесс не будет являться существенной проблемой.
В нашей ситуации получилось таким образом: увидели idle in transaction – начали пачками отключать запросы. Но количество соединений с базой данных не изменялось. Тут же появлялись новые в этом же статусе. Потом мы подумали: нужно перезагружать PostgreSQL.
От этой идеи быстро отказались, потому что у нас были другие сервисы и была вероятность, того, что после перезагрузки PostgreSQL они не поднимут заново соединение с базой. Поэтому мы через pg_stat_activity нашли бэкенды, которые забивают весь пул подключений, и их перезагрузили.
Еще есть другой вариант, не рассмотренный нами выше. Если вы используете инструмент управления пулом соединений, например pgbouncer, то ситуация решилась бы довольно просто:
– установка
pgbouncerна паузу – команда pause;– перезагрузка сервера PostgreSQL;
– снятие
pgbouncerс паузы – команда resume.В другом известном инструменте управления пулом соединений Odyssey функционал, связанный с pause пока не реализован, что может ограничивать его использование в нагруженных проектах.
ЕЩЁ
В августе 2021 провели митап с Иваном по нюансам работы с PostgreSQL.
На канале Слёрм: https://youtu.be/Qx2NoGCHco8
Кейс второй
СУБД PostgreSQL работает с диском, оперативной памятью, процессором. Если выходит аппаратная часть оборудования, то идём и чиним. Но иногда бывают и скрытые проблемы, например сбой в дисковом массиве, который мы можем заметить не сразу, можем вообще не знать об этом.
Давайте воспроизведем проблему сбоя дисковой подсистемы, затем покажем её решение. У нас есть PostgreSQL – тринадцатая версия. Создадим базу и инициализируем pgbench. Она существует, чтобы нагружать сервер, снимать метрики производительности. Но нам она нужна для других целей.
Рассмотрим таблицу pgbench_branches, в ней есть три поля и одна запись.

Найдем, где находится физически эта таблица на диске:
psql -p5432 -d test -c "select pg_relation_filepath('pgbench_branches')"

Остановим кластер PostgreSQL. Откроем файл base/16839/16853 и допишем любой текст в середине файла. Сохраним его.
Можно воспользоваться просто командой:sed -i 's/@/@123@/' ~/13/main/base/16839/16853

Запустим PostgreSQL. Попробуем прочитать данные из таблицы.

В таблице также одна запись, но теперь в ней просто пустые строки.
Мы знаем, что файл у нас поврежден, но при этом PostgreSQL об этом не знает, и это достаточно серьезная проблема, с которой можно встретится в PostgreSQL.
Как проблему можно решить? Если мы посмотрим: включена ли у нас контрольная сумма страниц данных в кластере, то мы увидим, что off. Когда PostgreSQL обращается к данным, он рассчитывает контрольную сумму данных страницы, сравнивая её с сохраненной в заголовке страницы, и если она не соответствует, то он выдаёт ошибку.

Насколько это просаживает перформанс? Есть статистика, что – от одного до трёх процентов, но при этом вы точно знаете, что данные у вас повреждены или не повреждены. Это стоит того, чтобы включать контрольную сумму данных у себя. В девелоперской базе неважно. В препроде на ваше усмотрение. А в продовской обязательно должно быть включено.
В двенадцатой версии появилась хорошая утилита pg_checksums. Если раньше до двенадцатой версии вам приходилось создавать новый кластер уже с включенной контрольной суммой данных и в него переносить данные, то с двенадцатой версии можно выключить текущий сервер PostgreSQL и запустить эту утилиту, и она просмотрит все страницы и запишет в заголовках контрольные суммы данных.
Спросите про прострой? Она настолько производительна, что будет упираться в ваш диск. Когда мы переводили кластер полтора-терабайтный во включенную контрольную сумму данных, у нас это заняло сорок минут.

Проделаем ту же процедуру с повреждением данных, что и ранее.
И теперь если прочитаем данные из таблицы pgbench_branches увидим, что у нас появилась ошибка о несовпадении контрольных сумм.

Но если мы всё-таки хотим извлечь эти данные, то есть флаг ignore_checksum_failure. Когда мы его включаем, у нас выдаётся предупреждение, что контрольная сумма данных не совпадает, но запрос исполняется.

Часто приложения используют только оперативные данные. PostgreSQL не обращается к старым страницам данных. И если в них есть повреждения, то мы можем узнать об этом слишком поздно, когда в резервных копиях тоже будут содержаться они.
Для проверки каталога данных можно воспользоваться командой
checkdbв утилите pg_probackup. Хотя данная утилита создана для создания/восстановления резервных копий, в ней есть дополнительный инструмент проверки рабочего каталога базы данных и целостности индексов.
Пример из жизни. Запросы шли в базу и некоторые их них повисали. На сутки, двое, трое. Потом пул запросов стало большим и они начал забирать всю оперативную память. Приходил omm killer и убивал PostgreSQL.
Контрольные суммы страниц не были включены на том кластере. Мы не предполагали, что данные повреждены (любые проверки утверждали, что каталог данных и индексы не содержит повреждений) и думали, что у нас сложный запрос, который пытается вытащить много данных, висит и занимает всю оперативную память (что являлось фантастическим предположением).
Предполагали три варианта:
-
что-то с картой видимостью,
-
что-то с индексами на этой таблице,
-
что-то с данными в самой таблице.
Решили удалить индексы и посмотреть, что будет – как только мы это сделали у нас приложение перестало работать. Это был фейл – приложение не работало три часа. Но нам стало сразу ясно, где проблема. Индексы ссылали на данные, которых нет в БД (страница данных нулевого размера).
Как вышли из ситуации? Создали новую пустую таблицу и по блокам перетаскивали данные со старой таблицы в новую. Потом били блоки на меньшего размера и так до тех пор пока не выявили семнадцать битых строк, для которых были ссылки в других таблицах, но в целевой отсутствовали.
ЕЩЁ. Под спойлером о курсе по PostgreSQL от Ивана.
23–25 сентября 2021 года Иван проводит второй поток обучения продвинутого курса по PostgreSQL.
Посмотреть программу: https://slurm.club/3ko7ts1.
Кейс третий
Кейс разбит на три ситуации и они о предотвращении проблем, а не исправлении.

У нас есть три таблички: заказы, продукты и таблица, которая связывает многие ко многим. В какой-то момент времени бизнес решил, что нужно сравнивать значения в одно регистре, обратите внимание на тип у колонки id в таблице orders. Можно со стороны приложения переводить все данные к нижнему или верхнему регистру и делать сравнение в запросе. Но можно воспользоваться встроенным типом данных citext. Рассмотрим, как разработчики решили переходить на новый тип данных.
Первая команда у нас создаст эксклюзивную блокировку, которая дропнет constraint. Достаточно быстрая операция. Вторая – по изменению типа, он относится к одному виду типов, поэтому быстрее заменится, проблем с этим не будет. Далее меняем тип на связные таблицах и пытаемся создать constraint.
Что у нас получается – эксклюзивная блокировка на две таблицы product orders и orders, чтобы данные не изменялись. И это будет выполняться в одном потоке. Когда у нас 100-200 записей, то проблем нет – это доли секунды. Если записей стало больше, миллионы, тогда эти внешний ключ будет накатываться очень долго.
Разработчики выкатывают релиз, и у нас останавливается сервис. Моя была ошибка, что пропустил этот pull request. Разобрались, срубили запрос. Ночью мы остановили сервис бэкенда, накатили sql-скрипты.
Какие еще есть варианты решения? Можно воспользоваться конструкцией:ADD CONSTRAINT ... NOT VALID
VALIDATE CONSTRAINT
В этом случае будут наложены более легкие блокировки.
Вариант 2, более специфичный, но рабочий. С десятой версии Postgres появилась логическая репликация
product_orders в product_orders_replic, в которой уже есть внешний ключproduct_orders_product_id_fkey. Когда мы скопировали все данные, мы взяли и поменяли таблички: product_orders -> product_orders_tmp, product_orders_replic -> product_orders. Это можно делать всё в одной транзакции, и будет достаточно быстро.
Ситуация номер два, из жизни

Представим, что есть таблички folders и folder_files. Мы хотим пробежаться по всем подпапкам и вытаскивать файлы, которые там есть. Когда у нас десятки-сотни тысяч записей, то проблем нет. Но когда появляются десятки миллионов записей, то тут нужно искать другие способы раскрутки дерева.
Но у нас был простой рекурсивный цикл. Что произошло? По каким-то причинам оптимизатор решил не использовать индекс, а делать полное сканирование таблицы folders. На каждом шаге создавать временные файлы большого размера на диске. Что привело к остановке базы данных из-за отсутствия места.


Было выбрано решение – разделить запрос на два:
-
отдельно рекурсивное cte, ограничив его по уровню вложенности;
-
отдельно маппинг результата cte с данными.
Тут можно предложить много способов оптимизации. Например, если дерево не меняется, то использовать не рекурсию, а вложенные интервалы. Но я не видел такой практической реализации.
Ситуация три – немного о другом

Производительность базы данных сильно снизилась, что привело к деградации приложения. Анализ мониторинга железа не показывал явных проблем с производительность.
Загрузка CPU доходит до полтинника. Проблемы наблюдаются достаточно давно. Нагрузка 50% – это не критично. Нагрузка по диску каких-то 400 ops.

Смотрим логи, а там постоянно такие записи.

Вставка 62 секунды. Копаем дальше, смотрим различные метрики. И видим, что в таблице items отсутствуют первичный ключ. При вставке данных в таблицу history из-за внешнего ключа проверялось наличие записи в таблице items. Починили.
Проблему не решило. Копаем дальше, смотрим представление pg_statio_all_tables и раскрываем всю суть.

Запрос select * from pg_statio_all_tables показывает кто генерит большую нагрузку на диск. Первая строчка history_text_default. В дефолтовую секцию ничего не должно писаться, но именно она создает нагрузку на диск. А количество чтений с диска на три порядка больше, чем в позиции на втором месте. Дефолтовая секция, большое количество чтений с диска – и мы понимаем, что перестало работать секционирование таблицы history_text.
Мы использовали расширение pg_partman, пересобрали табличку history_text. По ссылке можно найти, как мы это сделали: https://github.com/Doctorbal/zabbix-postgres-partitioning#zabbiz-history-and-trends-tables.
Как только мы устранили проблему, деградация системы прекратилась и приложение заработало.
Надеемся, что кейсы были полезны. Под спойлером о курсе по PostgreSQL от Ивана.
А вот, что ждёт инженеров, которые пройдут продвинутый курс Ивана по PostgreSQL:
— Научитесь оценивать состояние кластера в критический момент, принимать быстрые и эффективные решения по обеспечению работоспособности кластера.
— Узнаете, как внедрить новое оптимальное архитектурное решение в своей команде, а также сможете лидировать этот процесс.— сэкономите компании время и деньги путем оптимизации процессов администрирования.
— Поймете, как действовать в случае критических ситуаций с базой данных PostgreSQL и будете знать, где и с помощью какого алгоритма искать проблему.
Это всё тоже написано на странице курса, а ещё там есть программа и немного о формате обучения: https://slurm.club/3ko7ts1.
- What’s New?
- Forum
- New Posts
- FAQ
- Calendar
- Advanced Search

- Forum
- Foreign Language Support
- Русский форум
- Ошибка при установке PostgreSQL

Thread: Ошибка при установке PostgreSQL
-
09-22-2011, 06:33 AM
#1
Junior Member
Здравствуйте, уже замучился с установкой ХМ из-за того, что не устанавливается PostgreSQL. Пробовал уже на 2-х компьютерах все безрезультатно. В конце установки говорит, что возникла ошибка. Пробовал и обычный установщик и комбо. Не могу понять в чем дело? Очень надо!
-
09-22-2011, 07:07 AM
#2
Junior Member
При загрузке ХМ пишет о следующей ошибке. The following error occurred when trying to open the database. Failed to establish a connection to 127.0.0.1
ФРэймворк устанвлен
-
09-26-2011, 10:44 AM
#3
Holdem Manager Support
Если операционная система Вин7 (или Виста), следует иметь в виду все это:
1) Имя компьютера должно быть на английском и «в одно слово» (без пробелов) — после изменения требуется перезагрузка2) Имя пользователя Виндовс — аналогично. Если это не так, следует создать нового пользователя с английским именем, дать ему права администратора и перегрузить компьютер под него. Затем установить Postgres и ХМ, после чего снова перегрузить комп — обратно под старого пользователя, а этого можно будет удалить — его миссия завершена.
3) Служба «Вторичный вход в систему» должна быть установлена на «Автостарт». Панель управления — администрирование — Службы.
4) Контроль учетных записей UAC надо выключить. ( How to Disable and Turn Off UAC in Windows 7 � My Digital Life )
5) При установке Postgres и ХМ рекомендуется выключить антивирус и файерволл. Или совсем их деинсталлировать на это время.
6) Все установки обязательно запускать «от администратора» (по правому клику на файл) — невзирая на то, что у пользователя Виндовс права администратора, как правило, имеются. И желательно запускать установки первым делом после перезагрузки компа.
7) Если есть необходимость устанавливать Postgres не в папку по умолчанию (см следующий пункт), или использовать неумолчальную папку для базы данных — следует скачать отдельный установщик Download PostgreSQL | EnterpriseDB (при выборе версии 9.0 над брать тот, что соответствует разрядности Виндовс на компе).
Если Виндовс не на английском — устанавливать Postgres надо именно не в умолчальную папку. Требуется создат в корне диска (например) папку и ставить программу в нее.
9) Устанавливать Postgres и ХМ надо отдельно, по очереди. От админа. and HM separarelly, one after one. Когда ХМ после первого запуска сообщит, что отстуствует база данных — просто создать ее через DBControlpanel.exe
10) После каждой неудачной попытки установки Postgres ее следует не только деинсталлировать через Панель управления, но и удалить из системы пользователя по имени «postgres»:
«Пуск», «Выполнить», набрать с клавиатуры «cmd» и по правому клику запустить командную строку от админа
В черном окне набрать без ошибок следующую команду (и нажать Enter):
net user postgres /del
Должно появиться сообщение, что команда выполнена успешно. Для проверки набрать
net user
(без параметров) — получим список пользователей, в котором не должно быть пользователя postgres
11) Кстати, все клиенты покер-румов также должны запускаться «от админа»

 Если Виндовс не на английском — устанавливать Postgres надо именно не в умолчальную папку. Требуется создат в корне диска (например) папку и ставить программу в нее.
Если Виндовс не на английском — устанавливать Postgres надо именно не в умолчальную папку. Требуется создат в корне диска (например) папку и ставить программу в нее. Similar Threads
-
Replies: 2
Last Post: 08-08-2011, 09:11 AM
-
Replies: 9
Last Post: 06-21-2011, 03:32 AM
-
Replies: 1
Last Post: 05-22-2011, 10:49 AM
-
Replies: 1
Last Post: 02-19-2011, 04:36 PM
-
Replies: 2
Last Post: 02-01-2011, 06:00 AM
Posting Permissions

- You may not post new threads
- You may not post replies
- You may not post attachments
- You may not edit your posts
- BB code is On
- Smilies are On
- [IMG] code is On
- [VIDEO] code is On
- HTML code is Off
Forum Rules
Media failure is one of the crucial things that the database administrator should be aware of. Media failure is nothing but a physical problem reading or writing to files on the storage medium.
A typical example of media failure is a disk head crash, which causes the loss of all files on a disk drive. All files associated with a database are vulnerable to a disk crash, including datafiles, wal files, and control files.
This is the comprehensive post which focuses on disk failure in PostgreSQL and the ways you can retrieve the data from PostgreSQL Database after failure(other than restoring the backup).
In this post, we are going to do archaeology on the below error and will understand how to solve the error.
WARNING: page verification failed, calculated checksum 21135 but expected 3252
ERROR: invalid page in block 0 of relation base/13455/16395
During the process, you are going to learn a whole new bunch of stuff in PostgreSQL.
PostgreSQL Checksum: The definitive guide
- Chapter 1: What is a checksum?
- Chapter 2: PostgreSQL checksum: Practical implementation
- Chapter 3: How to resolve the PostgreSQL corrupted page issue?
With v9.3, PostgreSQL introduced a feature known as data checksums and it has undergone many changes since then. Now we have a well-sophisticated view in PostgreSQL v12 to find the checksums called pg_checksums.
But what is a PostgreSQL checksum?
When the checksum is enabled, a small integer checksum is written to each “page” of data that Postgres stores on your hard drive. Upon reading that block, the checksum value is recomputed and compared to the stored one.
This detects data corruption, which (without checksums) could be silently lurking in your database for a long time.
Good, checksum, when enabled, detects data corruption.
How does PostgreSQL checksum work?
PostgreSQL maintains page validity primarily on the way in and out of its buffer cache.
Also read: A comprehensive guide – PostgreSQL Caching
From here we understood that the PostgreSQL page has to pass through OS Cache before it leaves or enters into shared buffers. So page validity happens before leaving the shared buffers and before entering the shared buffers.
when PostgreSQL tries to copy the page into its buffer cache then it will (if possible) detect that something is wrong, and it will not allow page to enter into shared buffers with this invalid 8k page, and error out any queries that require this page for processing with the ERROR message
ERROR: invalid page in block 0 of relation base/13455/16395
If you already have a block with invalid data at disk-level and its page version at buffer level, during the next checkpoint, while page out, it will update invalid checksum details but which is rarely possible in real-time environments.
confused, bear with me.
And finally,
If the invalid byte is part of the PostgreSQL database buffer cache, then PostgreSQL will quite happily assume nothing is wrong and attempt to process the data on the page. Results are unpredictable; Some times you will get an error and sometimes you may end up with wrong data.
How PostgreSQL Checks Page Validity?
In a typical page, if data checksums are enabled, information is stored in a 2-byte field containing flag bits after the page header.
Also Read: A comprehensive guide on PostgreSQL: page header
This is followed by three 2-byte integer fields (pd_lower, pd_upper, and pd_special). These contain byte offsets from the page start to the start of unallocated space, to the end of unallocated space, and to the start of the special space.
The checksum value typically begins with zero and every time reading that block, the checksum value is recomputed and compared to the stored one. This detects data corruption.
Checksums are not maintained for blocks while they are in the shared buffers – so if you look at a buffer in the PostgreSQL page cache with pageinspect and you see a checksum value, note that when you do page inspect on a page which is already in the buffer, you may not get the actual checksum. The checksum is calculated and stamped onto the page when the page is written out of the buffer cache into the operating system page cache.
Also read: A comprehensive guide – PostgreSQL Caching
Let’s work on the practical understanding of whatever we learned so far.
I have a table check_corruption wherein I am going to do all the garbage work.
- my table size is 8 kB.
- has 5 records.
- the version I am using is PostgreSQL v12.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) postgres=# SELECT * FROM page_header(get_raw_page(‘check_corruption’,0)); lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid ——————+—————+————+————+————+—————+—————+—————+—————— 0/17EFCA0 | 0 | 0 | 44 | 7552 | 8192 | 8192 | 4 | 0 (1 row) postgres=# dt+ check_corruption List of relations Schema | Name | Type | Owner | Size | Description ————+—————————+————+—————+——————+——————— public | check_corruption | table | postgres | 8192 bytes | (1 row) postgres=# select pg_relation_filepath(‘check_corruption’); pg_relation_filepath ——————————— base/13455/16490 (1 row) postgres=# |
First, check whether the checksum is enabled or not?
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 0
[postgres@stagdb ~]$
It is disabled.
Let me enable the page checksum in PostgreSQL v12.
Syntax: pg_checksums -D /u01/pgsql/data –enable –progress –verbose
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —enable —progress —verbose pg_checksums: checksums enabled in file «/u01/pgsql/data/global/2847» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/1260_fsm» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/4175» .. .. 23/23 MB (100%) computed Checksum operation completed Files scanned: 969 Blocks scanned: 3006 pg_checksums: syncing data directory pg_checksums: updating control file Data checksum version: 1 Checksums enabled in cluster |
Again, check the status of checksums in PostgreSQL
[postgres@stagdb ~]$
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 1
[postgres@stagdb ~]$
we can disable the checksums with –disable option
|
[postgres@stagdb ~]$ [postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —disable pg_checksums: syncing data directory pg_checksums: updating control file Checksums disabled in cluster [postgres@stagdb ~]$ |
Let’s first check the current data directory for errors, then play with data.
To check the PostgreSQL page errors, we use the following command.
pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb ~]$ pg_checksums -D /u01/pgsql/data –check
Checksum operation completed
Files scanned: 969
Blocks scanned: 3006
Bad checksums: 0
Data checksum version: 1
[postgres@stagdb ~]$
Warning!! Do not perform the below case study in your production machine.
As the table check_corruption data file is 16490, I am going to corrupt the file with the Operating system’s dd command.
dd bs=8192 count=1 seek=1 of=16490 if=16490
[postgres@stagdb 13455]$ dd bs=8192 count=1 seek=1 of=16490 if=16490
Now, log in and get the result
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
I got the result, but why?
I got the result from shared buffers. Let me restart the cluster and fetch the same.
/usr/local/pgsql/bin/pg_ctl restart -D /u01/pgsql/data
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
But again why?
As we discussed earlier, during restart my PostgreSQL has replaced error checksum with the value of shared buffer.
How can we trigger a checksum warning?
We need to get that row out of shared buffers. The quickest way to do so in this test scenario is to restart the database, then make sure we do not even look at (e.g. SELECT) the table before we make our on-disk modification. Once that is done, the checksum will fail and we will, as expected, receive a checksum error:
i.e., stop the server, corrupt the disk and start it.
- /usr/local/pgsql/bin/pg_ctl stop -D /u01/pgsql/data
- dd bs=8192 count=1 seek=1 of=16490 if=16490
- /usr/local/pgsql/bin/pg_ctl start -D /u01/pgsql/data
During the next fetch, I got below error
postgres=# select * from check_corruption;
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427
WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:06:17.434 IST [25218] ERROR: invalid page in block 1 of relation base/13455/16490
2020-02-06 19:06:17.434 IST [25218] STATEMENT: select * from check_corruption;
ERROR: invalid page in block 1 of relation base/13455/16490
Let us dig deeper into the issue and confirm that the block is corrupted
There are a couple of ways you can find the issue which includes Linux commands like
- dd
- od
- hexdump
Usind dd command : dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -1
[postgres@stagdb 13455]$ dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -2
1+0 records in
1+0 records out
8192 bytes (8.2 kB) copied, 4.5e-05 seconds, 182 MB/s
0000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d >……~…..,…<
here,
00 00 00 00 a0 fc 7e 01 the first 8 bytes indicate pd_lsn and the next two bytes
03 9a indicates checksums.
Using hexdump : hexdump -C 16490 | head -1
[postgres@stagdb 13455]$ hexdump -C 16490 | head -1
00000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d |……~…..,…|
[postgres@stagdb 13455]$
Both hexdump and dd returned same result.
Let’s understand what our PostgreSQL very own pg_checksums has to say?
command: pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb 13455]$ pg_checksums -D /u01/pgsql/data –check
pg_checksums: error: checksum verification failed in file “/u01/pgsql/data/base/13455/16490”, block 1: calculated checksum 9A04 but block contains 9A03
Checksum operation completed
Files scanned: 968
Blocks scanned: 3013
Bad checksums: 1
Data checksum version: 1
[postgres@stagdb 13455]$
here, according to pg_checksums checksum 9A03 is matching with that of hexdump’s checksum 9A03.
Converting Hex 9A03 to decimals, I got 39427
which is matching the error
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427
How to resolve the PostgreSQL corrupted page issue?
use the below function to find the exact location where the page is corrupted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE OR REPLACE FUNCTION find_bad_row(tableName TEXT) RETURNS tid as $find_bad_row$ DECLARE result tid; curs REFCURSOR; row1 RECORD; row2 RECORD; tabName TEXT; count BIGINT := 0; BEGIN SELECT reverse(split_part(reverse($1), ‘.’, 1)) INTO tabName; OPEN curs FOR EXECUTE ‘SELECT ctid FROM ‘ || tableName; count := 1; FETCH curs INTO row1; WHILE row1.ctid IS NOT NULL LOOP result = row1.ctid; count := count + 1; FETCH curs INTO row1; EXECUTE ‘SELECT (each(hstore(‘ || tabName || ‘))).* FROM ‘ || tableName || ‘ WHERE ctid = $1’ INTO row2 USING row1.ctid; IF count % 100000 = 0 THEN RAISE NOTICE ‘rows processed: %’, count; END IF; END LOOP; CLOSE curs; RETURN row1.ctid; EXCEPTION WHEN OTHERS THEN RAISE NOTICE ‘LAST CTID: %’, result; RAISE NOTICE ‘%: %’, SQLSTATE, SQLERRM; RETURN result; END $find_bad_row$ LANGUAGE plpgsql; |
Now, using the function find_bad_row(), you can find the ctid of the corrupted location.
you need hstore extension to use the function
postgres=# CREATE EXTENSION hstore;
CREATE EXTENSION
postgres=#
postgres=# select find_bad_row(‘check_corruption’);
2020-02-06 19:44:24.227 IST [25929] WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:44:24.227 IST [25929] CONTEXT: PL/pgSQL function find_bad_row(text) line 21 at FETCH
WARNING: page verification failed, calculated checksum 39428 but expected 39427
NOTICE: LAST CTID: (0,5)
NOTICE: XX001: invalid page in block 1 of relation base/13455/16490
find_bad_row
————–
(0,5)
(1 row)
Deleting that particular CTID will resolve the issue
postgres=# delete from check_corruption where ctid='(0,6)’;
DELETE 1
postgres=#
If deleting ctid has not worked for you, you have an alternative solution which is setting zero_damaged_pages parameter.
Example.,
postgres=# select * from master;
WARNING: page verification failed, calculated checksum 8770 but expected 8769
ERROR: invalid page in block 1 of relation base/13455/16770
postgres=#
I can’t access the data from table master as block is corrupted.
Solution:
postgres=# SET zero_damaged_pages = on;
SET
postgres=# vacuum full master;
|
postgres=# select * from master; WARNING: page verification failed, calculated checksum 8770 but expected 8769 WARNING: invalid page in block 1 of relation base/13455/16770; zeroing out page id | name | city ——+—————+—————— 1 | Orson | hyderabad 2 | Colin | chennai 3 | Leonard | newyork |
here, it cleared the damaged page and gave the rest of the result.
What your document has to say?
zero_damaged_pages (boolean): Detection of a damaged page header normally causes PostgreSQL to report an error, aborting the current transaction. Setting zero_damaged_pages to on causes the system to instead report a warning, zero out the damaged page in memory, and continue processing. This behavior will destroy data, namely all the rows on the damaged page. However, it does allow you to get past the error and retrieve rows from any undamaged pages that might be present in the table. It is useful for recovering data if corruption has occurred due to a hardware or software error. You should generally not set this on until you have given up hope of recovering data from the damaged pages of a table. Zeroed-out pages are not forced to disk so it is recommended to recreate the table or the index before turning this parameter off again. The default setting is off, and it can only be changed by a superuser.
There are a couple of things to be aware when using this feature though. First, using checksums has a cost in performance as it introduces extra calculations for each data page (8kB by default), so be aware of the tradeoff between data security and performance when using it.
There are many factors that influence how much slower things are when checksums are enabled, including:
- How likely things are to be read from shared_buffers, which depends on how large shared_buffers is set, and how much of your active database fits inside of it
- How fast your server is in general, and how well it (and your compiler) are able to optimize the checksum calculation
- How many data pages you have (which can be influenced by your data types)
- How often you are writing new pages (via COPY, INSERT, or UPDATE)
- How often you are reading values (via SELECT)
The more that shared buffers are used (and using them efficiently is a good general goal), the less checksumming is done, and the less the impact of checksums on database performance will be. On an average if you enable checksum the performance cost would be more than 2% and for inserts, the average difference was 6%. For selects, that jumps to 19%. Complete computation benchmark test can be found here
Bonus
You can dump the content of the file with pg_filedump before and after the test and can use diff command to analyze data corruption
- pg_filedump -if 16770 > before_corrupt.txt
- corrupt the disk block
- pg_filedump -if 16770 > before_corrupt.txt
- diff or beyond compare both the files.
Thank you for giving your valuable time to read the above information. I hope the content served your purpose in reaching out to the blog.
Suggestions for improvement of the blog are highly appreciable. Please contact us for any information/suggestions/feedback.
If you want to be updated with all our articles
please follow us on Facebook | Twitter
Please subscribe to our newsletter.