
В
статистике выделяют два основных метода
исследования — сплошной и выборочный.
При проведении выборочного исследования
обязательным является соблюдение
следующих требований: репрезентативность
выборочной совокупности и достаточное
число единиц наблюдений. При выборе
единиц наблюдения возможны ошибки
смещения,
т.е. такие события, появление которых
не может быть точно предсказуемым. Эти
ошибки являются объективными и
закономерными. При определении степени
точности выборочного исследования
оценивается величина ошибки, которая
может произойти в процессе выборки
— случайная
ошибка репрезентативности (m) — является
фактической разностью между средними
или относительными величинами, полученными
при проведении выборочного исследования
и аналогичными величинами, которые были
бы получены при проведении исследования
на генеральной совокупности.
Оценка
достоверности результатов исследования
предусматривает определение:
1.
ошибки репрезентативности
2.
доверительных границ средних (или
относительных) величин в генеральной
совокупности
3.
достоверности разности средних (или
относительных) величин (по критерию t)
Расчет
ошибки репрезентативности
(mм)
средней арифметической величины
(М):

 ,
,
где σ
— среднее квадратическое отклонение; n
— численность выборки (>30).
Расчет
ошибки репрезентативности (mР)
относительной величины (Р):
 ,
,
где Р — соответствующая относительная
величина (рассчитанная, например, в %);
q
=100 — Ρ%
— величина, обратная Р; n — численность
выборки (n>30)
В
клинических и экспериментальных работах
довольно часто приходится использовать
малую
выборку, когда
число наблюдений меньше или равно 30.
При малой выборке для расчета ошибок
репрезентативности, как средних, так
и относительных величин,
число
наблюдений уменьшается на единицу,
т.е.
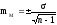 ;
;
 .
.
Величина
ошибки репрезентативности зависит от
объема выборки: чем больше число
наблюдений, тем меньше ошибка. Для оценки
достоверности выборочного показателя
принят следующий подход: показатель
(или средняя величина) должен в 3 раза
превышать свою ошибку, в этом случае он
считается достоверным.
21. Оценка достоверности разности статистических величин.
Достоверность
разности между двумя средними величинами
определяется по формуле:
 ,
,
где
М1
и М2
– две средних арифметических величины,
полученные в двух самостоятельных
независимых группах наблюдений;
m1
и m2
— их средние ошибки (выражение
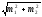 называют средней ошибкой разности двух
называют средней ошибкой разности двух
средних).
При
t ≥ 2 разность средних арифметических
может быть признана существенной и
неслучайной, то есть достоверной. Это
значит, что и в генеральной совокупности
средние величины отличаются, и что при
повторении подобных наблюдений будут
получены аналогичные различия. При t =
2 надежность также увеличивается, а риск
ошибки уменьшается. При t< 2 достоверность
разности средних величин считается
недоказанной.
23. Понятие о корреляционном анализе.
Корреляционная
связь может быть прямолинейной и
криволинейной.
Прямолинейная
связь характеризуется относительно
равномерным изменением средних значений
одного признака при равных изменениях
другого.
При
криволинейной связи – при равномерном
изменении одного признака могут
наблюдаться возрастающие и убывающие
значения другого признака.
Методы
вычисления коэффициентов корреляции:
рангов, квадратов, путем составления
корреляционной решетки.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
19.02.201618.05 Mб137patofiziologiya_sist_krovi_2010.doc
- #
- #
В
статистике выделяют два основных метода
исследования — сплошной и выборочный.
При проведении выборочного исследования
обязательным является соблюдение
следующих требований: репрезентативность
выборочной совокупности и достаточное
число единиц наблюдений. При выборе
единиц наблюдения возможны ошибки
смещения,
т.е. такие события, появление которых
не может быть точно предсказуемым. Эти
ошибки являются объективными и
закономерными. При определении степени
точности выборочного исследования
оценивается величина ошибки, которая
может произойти в процессе выборки
— случайная
ошибка репрезентативности (m)
— является
фактической разностью между средними
или относительными величинами, полученными
при проведении выборочного исследования
и аналогичными величинами, которые были
бы получены при проведении исследования
на генеральной совокупности.
Оценка
достоверности результатов исследования
предусматривает определение:
1.
ошибки репрезентативности
2.
доверительных границ средних (или
относительных) величин в генеральной
совокупности
3.
достоверности разности средних (или
относительных) величин (по критерию t)
Расчет
ошибки репрезентативности
(mм)
средней арифметической величины
(М):
![]()
![]() ,
,
где σ
— среднее квадратическое отклонение; n
— численность выборки (>30).
Расчет
ошибки репрезентативности (mР)
относительной величины (Р):
![]() ,
,
где Р — соответствующая относительная
величина (рассчитанная, например, в %);
q
=100 — Ρ%
— величина, обратная Р; n
— численность выборки (n>30)
В
клинических и экспериментальных работах
довольно часто приходится использовать
малую
выборку, когда
число наблюдений меньше или равно 30.
При малой выборке для расчета ошибок
репрезентативности, как средних, так
и относительных величин,
число
наблюдений уменьшается на единицу,
т.е.
![]() ;
;
![]() .
.
Величина
ошибки репрезентативности зависит от
объема выборки: чем больше число
наблюдений, тем меньше ошибка. Для оценки
достоверности выборочного показателя
принят следующий подход: показатель
(или средняя величина) должен в 3 раза
превышать свою ошибку, в этом случае он
считается достоверным.
83. Определение доверительных границ средних и относительных величин.
Знание
величины ошибки недостаточно для того,
чтобы быть уверенным в результатах
выборочного исследования, так как
конкретная ошибка выборочного
исследования может быть значительно
больше (или меньше) величины средней
ошибки репрезентативности. Для
определения точности, с которой
исследователь желает получить результат,
в статистике используется такое понятие,
как вероятность безошибочного
прогноза, которая является характеристикой
надежности результатов выборочных
медико-биологических статистических
исследований. Обычно, при проведении
медико-биологических статистических
исследований используют вероятность
безошибочного прогноза 95% или 99%. В
наиболее ответственных случаях, когда
необходимо сделать особенно важные
выводы в теоретическом или практическом
отношении, используют вероятность
безошибочного прогноза 99,7%
Определенной
степени вероятности безошибочного
прогноза соответствует определенная
величина предельной
ошибки случайной выборки (Δ
— дельта),
которая определяется по формуле:
Δ=t
* m
, где t
— доверительный коэффициент, который
при большой выборке при вероятности
безошибочного прогноза 95% равен 2,6;
при вероятности безошибочного
прогноза 99% — 3,0; при вероятности
безошибочного прогноза 99,7% — 3,3, а при
малой выборке определяется по специальной
таблице значений t
Стьюдента.
Используя
предельную ошибку выборки (Δ),
можно определить доверительные
границы,
в которых с определенной вероятностью
безошибочного прогноза заключено
действительное значение статистической
величины,
характеризующей
всю генеральную совокупность (средней
или относительной).
Для
определения доверительных границ
используются следующие формулы:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
ДЕПАРТАМЕНТ ОБРАЗОВАНИЯ И НАУКИ ГОРОДА МОСКВЫ
Государственное бюджетное профессиональное образовательное учреждение города Москвы
«ЮРИДИЧЕСКИЙ КОЛЛЕДЖ»
(ГБПОУ Юридический колледж)
ПЛАН-КОНСПЕКТ учебного занятия
по ОП.11 Статистика
учебной дисциплине/междисциплинарному курсу
для обучающихся 2 курса
специальность 40.02.01 Право и организация социального обеспечения
(набор 2016 г.)
(углубленная подготовка)
дата проведения занятия по расписанию
Тема 3.1. Выборочное наблюдение
Занятие 15. ПЗ №8 Определение ошибки репрезентативности.
Определение объема выборочной совокупности
Цель занятия: отработать практические навыки по определению доверительных пределов и исчислению ошибок выборки
Задачи занятия:
Обучающая: Обеспечить усвоение обучающимися материала о понятиях: ошибки репрезентативности, выборка, выборочная совокупность;
Воспитательная: воспитывать навыки самостоятельной работы, чувство ответственности за порученный участок работы, дисциплину умственного труда, уверенность в своих силах, стремление к достижению результата;
Развивающая: создавать условия для развития самостоятельности мышления, способности высказывания собственной точки зрения, систематизировать необходимую информацию, анализировать, сравнивать и обобщать информацию, развивать монологическую речь.
Основная литература:
Глава 11. Выборочное наблюдение. (211-220) Статистика: учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО
Дополнительная литература:
Савюк Л.К. Правовая статистика: Учебник. — М.: Юрист, 2016
Интернет-ресурсы:
- Информационно-издательский центр «Статистика России» http://www.statbook.ru
- Электронный фонд правовой и технической документации http://docs.cntd.ru
- Информационно правовой портал http://www.garant.ru/
Междисциплинарные связи: Право социальное обеспечение
Внутридисциплинарные связи: Тема 2.1. Сводка и группировка статистических данных
1. Актуализация знаний по ранее пройденному материалу учебного курса
(ответить на вопросы (тестовые задания) и провести самооценку усвоенного материала)
Таблица 1.
|
Вопрос (тестовое задание) |
Ответ |
|
|
|
|
|
|
|
|
|
2. Изучаемые вопросы занятия
|
1. Определение ошибки репрезентативности. |
|
2. Определение объема выборочной совокупности. |
Вопрос 1. Определение ошибки репрезентативности
В статистике выделяют два основных метода исследования – сплошной и выборочный. При проведении выборочного исследования обязательным является соблюдение следующих требований: репрезентативность выборочной совокупности и достаточное число единиц наблюдений. При выборе единиц наблюдения возможны Ошибки смещения, т. е. такие события, появление которых не может быть точно предсказуемым. Эти ошибки являются объективными и закономерными. При определении степени точности выборочного исследования оценивается величина ошибки, которая может произойти в процессе выборки – Случайная ошибка репрезентативности (M) – Является фактической разностью между средними или относительными величинами, полученными при проведении выборочного исследования и аналогичными величинами, которые были бы получены при проведении исследования на генеральной совокупности.
Оценка достоверности результатов исследования предусматривает определение:
1. ошибки репрезентативности
2. доверительных границ средних (или относительных) величин в генеральной совокупности
3. достоверности разности средних (или относительных) величин (по критерию t)
Расчет ошибки репрезентативности (mм) средней арифметической величины (М):

 , где σ – среднее квадратическое отклонение; n – численность выборки (>30).
, где σ – среднее квадратическое отклонение; n – численность выборки (>30).
Расчет ошибки репрезентативности (mР) относительной величины (Р):
 , где Р – соответствующая относительная величина (рассчитанная, например, в %);
, где Р – соответствующая относительная величина (рассчитанная, например, в %);
Q =100 – Ρ% – величина, обратная Р; n – численность выборки (n>30)
В клинических и экспериментальных работах довольно часто приходится использовать Малую выборку, Когда число наблюдений меньше или равно 30. При малой выборке для расчета ошибок репрезентативности, как средних, так и относительных величин, Число наблюдений уменьшается на единицу, т. е.
 ;
;  .
.
Величина ошибки репрезентативности зависит от объема выборки: чем больше число наблюдений, тем меньше ошибка. Для оценки достоверности выборочного показателя принят следующий подход: показатель (или средняя величина) должен в 3 раза превышать свою ошибку, в этом случае он считается достоверным.
Знание величины ошибки недостаточно для того, чтобы быть уверенным в результатах выборочного исследования, так как конкретная ошибка выборочного исследования может быть значительно больше (или меньше) величины средней ошибки репрезентативности. Для определения точности, с которой исследователь желает получить результат, в статистике используется такое понятие, как вероятность безошибочного прогноза, которая является характеристикой надежности результатов выборочных медико-биологических статистических исследований. Обычно, при проведении медико-биологических статистических исследований используют вероятность безошибочного прогноза 95% или 99%. В наиболее ответственных случаях, когда необходимо сделать особенно важные выводы в теоретическом или практическом отношении, используют вероятность безошибочного прогноза 99,7%
Определенной степени вероятности безошибочного прогноза соответствует определенная величина Предельной ошибки случайной выборки (Δ – дельта), которая определяется по формуле:
Δ=t * m, где t – доверительный коэффициент, который при большой выборке при вероятности безошибочного прогноза 95% равен 2,6; при вероятности безошибочного прогноза 99% – 3,0; при вероятности безошибочного прогноза 99,7% – 3,3, а при малой выборке определяется по специальной таблице значений t Стьюдента.
Используя предельную ошибку выборки (Δ), можно определить Доверительные границы, в которых с определенной вероятностью безошибочного прогноза заключено действительное значение статистической величины, Характеризующей всю генеральную совокупность (средней или относительной).
Для определения доверительных границ используются следующие формулы:
- для средних величин:
 ,где Мген – доверительные границы средней величины в генеральной совокупности;
,где Мген – доверительные границы средней величины в генеральной совокупности;
Мвыб – средняя величина, Полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент, значение которого определяется степенью вероятности безошибочного прогноза, с которой исследователь желает получить результат; mM – ошибка репрезентативности средней величины.
2) для относительных величин:
 , где Рген – доверительные границы относительной величины в генеральной совокупности; Рвыб – относительная величина, полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент; mP – ошибка репрезентативности относительной величины.
, где Рген – доверительные границы относительной величины в генеральной совокупности; Рвыб – относительная величина, полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент; mP – ошибка репрезентативности относительной величины.
Доверительные границы показывают, в каких пределах может колебаться размер выборочного показателя в зависимости от причин случайного характера.
При малом числе наблюдений (n<30), для вычисления доверительных границ значение коэффициента t находят по специальной таблице Стьюдента. Значения t расположены в таблице на пересечении с избранной вероятностью безошибочного прогноза и строки, Указывающей на имеющееся число степеней свободы (n), Которое равно n-1.
на определение ошибок репрезентативности (m) и доверительных границ средней величины генеральной совокупности (Мген) при числе наблюдений больше 30
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было установлено, что средняя частота пульса у 36 обследованных водителей сельскохозяйственных машин через 1 ч работы составила 80 ударов в 1 минуту; σ = ± 6 ударов в минуту.
Задание: определить ошибку репрезентативности (mM) и доверительные границы средней величины генеральной совокупности (Мген).
Решение.
- Вычисление средней ошибки средней арифметической (ошибки репрезентативности) (m): m = σ / √n = 6 / √36 = ±1 удар в минуту
- Вычисление доверительных границ средней величины генеральной совокупности (Мген). Для этого необходимо:
- а) задать степень вероятности безошибочного прогноза (Р = 95 %);
- б) определить величину критерия t. При заданной степени вероятности (Р=95%) и числе наблюдений меньше 30 величина критерия t, определяемого по таблице, равна 2 (t = 2). Тогда Мген = Мвыб ± tm = 80 ± 2×1 = 80 ± 2 удара в минуту.
Вывод. Установлено с вероятностью безошибочного прогноза Р = 95%, что средняя частота пульса в генеральной совокупности, т.е. у всех водителей сельскохозяйственных машин, через 1 ч работы в аналогичных условиях будет находиться в пределах от 78 до 82 ударов в минуту, т.е. средняя частота пульса менее 78 и более 82 ударов в минуту возможна не более, чем у 5% случаев генеральной совокупности.
на определение ошибок репрезентативности (m) и доверительных границ относительного показателя генеральной совокупности (Рген)
Условие задачи: при медицинском осмотре 164 детей 3 летнего возраста, проживающих в одном из районов городе Н., в 18% случаев обнаружено нарушение осанки функционального характера.
Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя генеральной совокупности (Рген).
Решение.
- Вычисление ошибки репрезентативности относительного показателя: m = √P x q / n = √18 x (100 — 18) / 164 = ± 3%
- Вычисление доверительных границ средней величины генеральной совокупности (Рген) производится следующим образом:
- необходимо задать степень вероятности безошибочного прогноза (Р=95%);
- при заданной степени вероятности и числе наблюдений больше 30, величина критерия t равна 2 (t = 2). Тогда Рген = Рвыб± tm = 18% ± 2 х 3 = 18% ± 6%.
Вывод. Установлено с вероятностью безошибочного прогноза Р=95%, что частота нарушения осанки функционального характера у детей 3 летнего возраста, проживающих в городе Н., будет находиться в пределах от 12 до 24% случаев.
на оценку достоверности разности средних величин
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было установлено, что средняя частота пульса у водителей сельскохозяйственных машин через 1 ч после начала работы составила 80 ударов в минуту; m = ± 1 удар в мин. Средняя частота пульса у этой же группы водителей до начала работы равнялась 75 ударам в минуту; m = ± 1 удар в минуту.
Задание: оценить достоверность различий средних значений пульса у водителей сельскохозяйственных машин до и после 1 ч работы.
Решение.

Вывод. Значение критерия t = 3,5 соответствует вероятности безошибочного прогноза Р > 99,7%, следовательно можно утверждать, что различия в средних значениях пульса у водителей сельскохозяйственных машин до и после 1 ч работы не случайно, а достоверно, существенно, т.е. обусловлено влиянием воздействия шума и низкочастотной вибрации.
на оценку достоверности разности относительных показателей
Условие задачи: при медицинском осмотре детей 3 летнего возраста в 18% (m = ± 3%) случаях обнаружено нарушение осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 4-летнего возраста составила 24% (m = ± 2,64%).
Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп.
Решение.

Вывод. Значение критерия t=1,5 соответствует вероятности безошибочного прогноза Р<95%. Следовательно, различие в частоте нарушений осанки среди детей, сравниваемых возрастных групп случайно, недостоверно, несущественно, т.е. не обусловлено влиянием возраста детей.
|
Источники информации по 1 вопросу |
Автор и наименование |
Страницы (форма доступа для Интернет-ресурсов) |
|
Основная литература |
Глава 11. Выборочное наблюдение. Статистика: учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО |
стр. 211-220 |
|
Интернет ресурсы |
|
http://www.statbook.ru |
|
http://docs.cntd.ru |
|
|
http://www.garant.ru/ |
Контрольное задание по Вопросу 1
- Записать в тетрадь конспект (1-2 стр.)
Вопрос 2. Определение объема выборочной совокупности
Социологические исследования редко бывают сплошными, как, например, перепись населения. Обычно сплошное исследование проводится при небольшой генеральной совокупности.
Чаще всего исследования носят выборочный характер, при котором наиболее важным основанием является возможность распространения полученных результатов и выводов на всю генеральную совокупность. В таком случае сплошное исследование нецелесообразно. Обеспечение этой нецелесообразности — вопрос о репрезентативности выборки, т.е. достаточной количественной и качественной представительности генеральной совокупности в выборке.
Условиями соблюдения репрезентативности выборки являются:
1) равная возможность каждого члена генеральной совокупности попасть в выборку;
2) отбор необходимо проводить независимо от изучаемого признака (иначе в выборку могут попасть, например, только спортсмены);
3) отбор по возможности должен производиться из однородных совокупностей;
4) величина выборки должна быть достаточно большой.
Далее возникает вопрос: как определить достаточный объем выборки? Для этого необходимо иметь характеристики генеральной совокупности по важнейшим (с точки зрения исследования) признакам. К ним, например, можно отнести сведения о количестве желающих заниматься физической культурой и спортом, о числе занимающихся и т.д. Но, как правило, такие характеристики (или многие из них) не известны. Пилотажные исследования как раз и направлены на их выявление.
Приведем пример определения объема выборочной совокупности. В ходе подготовки к проведению конкретно-социологического исследования на основании теоретических посылок были выделены характеристики и признаки, подлежащие изучению. Например, желание заниматься физической культурой, спортом, величина потребности, участие в видах деятельности и др.
На основании результатов изучения этих признаков в пробном исследовании (30 и более респондентов) определяется объем выборки.
Предположим, что в пробном исследовании опрошено 147 студентов 4-х курсов в четырех вузах Республики Беларусь.
Для желания заниматься физической культурой получены следующие распределения:
1.«Нет, не хочу» — 5 человек;
2.«Скорее не хочу, чем хочу» — 3 человека;
3.«Безразлично» — 11 человек;
4.«Скорее хочу, чем не хочу» — 34 человека;
5.«Да, хочу» — 72 человека.
Для расчета объема выборки используются формулы:

t — 1,96 — распределение Стьюдента для вероятности 0,95 или 95% (т.е., если требуемая вероятность соответствия характеристик выборки и характеристик генеральной совокупности 95%, всегда = 1,96. Их соответствие на 95% — общепринятое требование в социологических исследованиях.
Для нашего распределения:

При условии, что выборка в пробном исследовании представляла бы собой модель генеральной совокупности, величина выборочной совокупности для изучения желания заниматься физической культурой должна быть не меньше 147 человек. Тогда с вероятностью 95% можно утверждать, что генеральное среднее лежит в пределах 4,39+0,155.
Поскольку модель выборки в пробном исследовании во вузам не представляет собой модели генеральной совокупности (опрос был в четырех вузах из 30), то увеличиваем полученное n (30/4) в 7,5 раза. Тогда необходимый объем выборки — 1102 респондента.
Качественная представительность полученной выборки оценивается сравнением существенных характеристик (либо связанных с существенными) генеральной совокупности и выборки. Для студенчества, например, такими характеристиками являются: соотношение по полу, охват учебными занятиями по физическому воспитанию, соотношение форм занятий и др.
Когда информация о признаках элементов генеральной совокупности отсутствует, исключается возможность определения объема выборочной совокупности при помощи формул. В этом случае можно опереться на многолетний опыт социологов — практиков, свидетельствующий о том, что для пробных опросов достаточна выборка объемом 100-250 человек. При массовых опросах, если величина генеральной совокупности 5000 человек, достаточный объем выборочной совокупности — не менее 500 человек, если же величина генеральной совокупности 5000 человек и более, то — 10% ее состава (но не более 2000-2500 человек). Это характеризует достаточно достоверные результаты исследования.
ПРИМЕР 1
При проверке импортирования груза на таможне методом случайной выборки было обработано 200 изделий. В результате был установлен средний вес изделия 30г., при СКО=4г с вероятностью 0,997. Определите пределы в которых находится средний вес изделий генеральной совокупности.
Решение.
В данном примере – случайный повторный отбор.
n=200
 =30г
=30г
 =4г — СКО
=4г — СКО
p=0,997, тогда t=3
Формула средней ошибки для случайного повторного отбора:

 =0,84 г
=0,84 г
 г
г
Определяем величину средней ошибки.

Ответ: пределы в которых находится средний вес изделий: г
г
ПРИМЕР 2
В городе проживает 250тыс. семей. Для определения среднего числа детей в семье была организована 2%-я бесповторная выборка семей. По ее результатам было получено следующее распространение семей по числу детей:
P=0,954. Найти пределы в которых будет находится среднее число детей в генеральной совокупности.
|
Число детей в семье, xi |
0 |
1 |
2 |
3 |
4 |
5 |
|
Кол-во детей в семье |
1000 |
2000 |
1200 |
400 |
200 |
200 |
Решение
2%-я выборка означает: n=250000*0,02= 5000 семей было исследовано.
Т.к. выборка бесповторная, используем следующую формулу для определения средней величины ошибки:

Найдем среднее число детей в выборочной совокупности:
 ребенка
ребенка
Определим дисперсию

 ребенка – средняя величина ошибки
ребенка – средняя величина ошибки
Т.к p = 0,954, то t = 2
 ребенка
ребенка
 ребенка
ребенка
Вывод: из-за слишком малой величины ошибки, среднее число детей в генеральной совокупности можно принять за 1,5 ребенка.
|
Источники информации по 2 вопросу |
Автор и наименование |
Страницы (форма доступа для Интернет-ресурсов) |
|
Основная литература |
Глава 11. Выборочное наблюдение. Статистика: учебник / И.В. Гладун. – 3-е издание, стер. – М.: КНОРУС, 2019. – 232 с. – СПО |
стр. 211-220 |
|
Интернет ресурсы |
|
http://www.statbook.ru |
|
http://docs.cntd.ru |
|
|
http://www.garant.ru/ |
Контрольное задание по Вопросу 2
- Записать в тетрадь конспект (1-2 стр.)
3. Подведение итогов учебного занятия
(ответить на вопросы (тестовые задания) и провести самооценку усвоенного материала)
Таблица 2.
|
Наименование изученного вопроса учебного занятия |
Контрольное задание по изученному вопросу |
Ответ |
|
Определение ошибки репрезентативности. |
ЗАДАНИЕ 1 Условие задачи: при медицинском осмотре 126 детей 6 летнего возраста, проживающих в одном из районов городе А., в 12% случаев обнаружено нарушение осанки функционального характера. Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя генеральной совокупности (Рген). |
|
|
Определение ошибки репрезентативности. |
ЗАДАНИЕ 2. Условие задачи: при медицинском осмотре детей 6 летнего возраста в 15% (m = ± 3%) случаях обнаружено нарушение осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 7-летнего возраста составила 24% (m = ± 2,64%). Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп. |
|
|
Определение объема выборочной совокупности |
ЗАДАНИЕ 3. В городе проживает 300 тыс. семей. Для определения среднего числа детей в семье была организована 2%-я бесповторная выборка семей. По ее результатам было получено следующее распространение семей по числу детей: P=0,954. Найти пределы в которых будет находится среднее число детей в генеральной совокупности |
|
|
Определение объема выборочной совокупности |
Сформулируйте понятие генеральной совокупности |
|
|
Определение объема выборочной совокупности |
Перечислите способы отбора единиц для выборочного наблюдения |
- Домашнее задание на следующее занятие
- Выучить основные понятия. Глава 11. Выборочное наблюдение. Статистика: учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО (стр. 211-220)
- Выполнить задание 11.1. в тетради (стр. 224) учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО
Преподаватель Ю.В. Древаль
|
СОГЛАСОВАНО Протокол заседания ЦК дисциплин профессионального цикла специальности «Право и организация социального обеспечения» ГБПОУ Юридический колледж от ____________ 2017 г. № ___ |

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет