
"Segmentation fault (core dumped)" is the string that Linux prints when a program exits with a SIGSEGV signal and you have core creation enabled. This means some program has crashed.
If you’re actually getting this error from running Python, this means the Python interpreter has crashed. There are only a few reasons this can happen:
-
You’re using a third-party extension module written in C, and that extension module has crashed.
-
You’re (directly or indirectly) using the built-in module
ctypes, and calling external code that crashes. -
There’s something wrong with your Python installation.
-
You’ve discovered a bug in Python that you should report.
The first is by far the most common. If your q is an instance of some object from some third-party extension module, you may want to look at the documentation.
Often, when C modules crash, it’s because you’re doing something which is invalid, or at least uncommon and untested. But whether it’s your «fault» in that sense or not — that doesn’t matter. The module should raise a Python exception that you can debug, instead of crashing. So, you should probably report a bug to whoever wrote the extension. But meanwhile, rather than waiting 6 months for the bug to be fixed and a new version to come out, you need to figure out what you did that triggered the crash, and whether there’s some different way to do what you want. Or switch to a different library.
On the other hand, since you’re reading and printing out data from somewhere else, it’s possible that your Python interpreter just read the line "Segmentation fault (core dumped)" and faithfully printed what it read. In that case, some other program upstream presumably crashed. (It’s even possible that nobody crashed—if you fetched this page from the web and printed it out, you’d get that same line, right?) In your case, based on your comment, it’s probably the Java program that crashed.
If you’re not sure which case it is (and don’t want to learn how to do process management, core-file inspection, or C-level debugging today), there’s an easy way to test: After print line add a line saying print "And I'm OK". If you see that after the Segmentation fault line, then Python didn’t crash, someone else did. If you don’t see it, then it’s probably Python that’s crashed.
Не всегда программы в Linux запускаются как положено. Иногда, в силу разных причин программа вместо нормальной работы выдает ошибку. Но нам не нужна ошибка, нам нужна программа, вернее, та функция, которую она должна выполнять. Сегодня мы поговорим об одной из самых серьезных и непонятных ошибок. Это ошибка сегментации Ubuntu. Если такая ошибка происходит только один раз, то на нее можно не обращать внимания, но если это регулярное явление нужно что-то делать.
Конечно, случается эта проблема не только в Ubuntu, а во всех Linux дистрибутивах, поэтому наша инструкция будет актуальна для них тоже. Но сосредоточимся мы в основном на Ubuntu. Рассмотрим что такое ошибка сегментирования linux, почему она возникает, а также как с этим бороться и что делать.
Что такое ошибка сегментации?
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Чтобы понять почему так происходит, давайте рассмотрим как устроена работа с памятью в Linux, я попытаюсь все упростить, но приблизительно так оно и работает.
Допустим, в вашей системе есть 6 Гигабайт оперативной памяти, каждой программе нужно выделить определенную область, куда будет записана она сама, ее данные и новые данные, которые она будет создавать. Чтобы дать возможность каждой из запущенных программ использовать все шесть гигабайт памяти был придуман механизм виртуального адресного пространства. Создается виртуальное пространство очень большого размера, а из него уже выделяется по 6 Гб для каждой программы. Если интересно, это адресное пространство можно найти в файле /proc/kcore, только не вздумайте никуда его копировать.
Выделенное адресное пространство для программы называется сегментом. Как только программа попытается записать или прочитать данные не из своего сегмента, ядро отправит ей сигнал SIGSEGV и программа завершится с нашей ошибкой. Более того, каждый сегмент поделен на секции, в некоторые из них запись невозможна, другие нельзя выполнять, если программа и тут попытается сделать что-то запрещенное, мы опять получим ошибку сегментации Ubuntu.
Почему возникает ошибка сегментации?
И зачем бы это порядочной программе лезть, куда ей не положено? Да в принципе, незачем. Это происходит из-за ошибки при написании программ или несовместимых версиях библиотек и ПО. Часто эта ошибка встречается в программах на Си или C++. В этом языке программисты могут вручную работать с памятью, а язык со своей стороны не контролирует, чтобы они это делали правильно, поэтому одно неверное обращение к памяти может обрушить программу.
Почему может возникать эта ошибка при несовместимости библиотек? По той же причине — неверному обращению к памяти. Представим, что у нас есть библиотека linux (набор функций), в которой есть функция, которая выполняет определенную задачу. Для работы нашей функции нужны данные, поэтому при вызове ей нужно передать строку. Наша старая версия библиотеки ожидает, что длина строки будет до 256 символов. Но программа была обновлена формат записи поменялся, и теперь она передает библиотеке строку размером 512 символов. Если обновить программу, но оставить старую версию библиотеки, то при передаче такой строки 256 символов запишутся нормально в подготовленное место, а вот вторые 256 перезапишут данные программы, и возможно, попытаются выйти за пределы сегмента, тогда и будет ошибка сегментирования linux.
Что делать если возникла ошибка сегментирования?
Если вы думаете, что это ошибка в программе, то вам остается только отправить отчет об ошибке разработчикам. Но вы все-таки еще можете попытаться что-то сделать.
Например, если падает с ошибкой сегментации неизвестная программа, то мы можем решить что это вина разработчиков, но если с такой ошибкой падает chrome или firefox при запуске возникает вопрос, может мы делаем что-то не так? Ведь это уже хорошо протестированные программы.
Первое, что нужно сделать — это обновить систему до самой последней версии, возможно, был баг и его уже исправили, а может у вас установлены старые версии библиотек и обновление решит проблему. В Ubuntu это делается так:
sudo apt update
sudo apt full-upgrade
Если это не помогло, нужно обнулить настройки программы до значений по умолчанию, возможно, удалить кэш. Настройки программ в Linux обычно содержатся в домашней папке, скрытых подкаталогах с именем программы. Также, настройки и кэш могут содержаться в каталогах ~/.config и ~/.cache. Просто удалите папки программы и попробуйте снова ее запустить. Если и это не помогло, вы можете попробовать полностью удалить программу, а потом снова ее установить, возможно, какие-нибудь зависимости были повреждены:
sudo apt remove пакет_программы
sudo apt autoremove
sudo apt install пакет_программы
Если есть возможность, попробуйте установить программу из другого источника, например, не из PPA, а более старую версию, из официальных репозиториев.
Когда вы все это выполнили, скорее всего, проблема не в вашем дистрибутиве, а в самой программе. Нужно отправлять отчет разработчикам. В Ubuntu это можно сделать с помощью программы apport-bug. Обычно Ubuntu предлагает это сделать сразу, после того как программа завершилась с ошибкой сегментирования. Если же ошибка сегментирования Ubuntu встречается не в системной программе, то вам придется самим искать разработчиков и вручную описывать что произошло.
Чтобы помочь разработчикам решить проблему, недостаточно отправить им только сообщение что вы поймали Segmentation Fault, нужно подробно описать проблему, действия, которые вы выполняли перед этим, так чтобы разработчик мог их воспроизвести. Также, желательно прикрепить к отчету последние функции, которые вызывала программа (стек вызовов функций), это может очень сильно помочь разработчикам.
Рассмотрим, как его получить. Это не так уж сложно. Сначала запустите вашу программу, затем узнайте ее PID с помощью команды:
pgrep программа
Дальше запускаем отладчик gdb:
sudo gdb -q
Подключаемся к программе:
(gdb) attach ваш_pid
После подключения программа станет на паузу, продолжаем ее выполнение командой:
(gdb) continue

Затем вам осталось только вызвать ошибку:
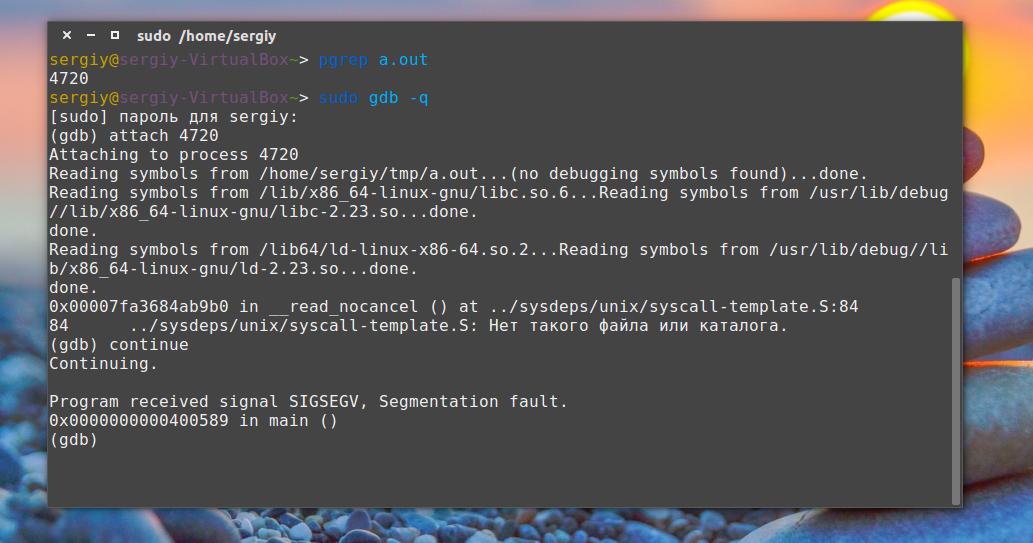
И набрать команду, которая выведет стек последних вызовов:
(gdb) backtrace
Вывод этой команды и нужно отправлять разработчикам. Чтобы отключиться от программы и выйти наберите:
(gdb) detach
(gdb) quit
Дальше остается отправить отчет и ждать исправления ошибки. Если вы не уверены, что ошибка в программе, можете поспрашивать на форумах. Когда у вас есть стек вызовов, уже можно попытаться, если не понять в чем проблема, то попытаться узнать, не сталкивался ли с подобной проблемой еще кто-то.
Выводы
Теперь у вас есть приблизительный план действий, что нужно делать, когда появляется ошибка сегментирования сделан дамп памяти ubuntu. Если вы знаете другие способы решить эту проблему, напишите в комментариях!
I am implementing Kosaraju’s Strong Connected Component(SCC) graph search algorithm in Python.
The program runs great on small data set, but when I run it on a super-large graph (more than 800,000 nodes), it says «Segmentation Fault».
What might be the cause of it? Thank you!
Additional Info:
First I got this Error when running on the super-large data set:
"RuntimeError: maximum recursion depth exceeded in cmp"
Then I reset the recursion limit using
sys.setrecursionlimit(50000)
but got a ‘Segmentation fault’
Believe me it’s not a infinite loop, it runs correct on relatively smaller data. It is possible the program exhausted the resources?
![]()
asked Apr 5, 2012 at 20:28
![]()
6
This happens when a python extension (written in C) tries to access a memory beyond reach.
You can trace it in following ways.
- Add
sys.settraceat the very first line of the code. -
Use
gdbas described by Mark in this answer.. At the command promptgdb python (gdb) run /path/to/script.py ## wait for segfault ## (gdb) backtrace ## stack trace of the c code
![]()
answered Apr 5, 2012 at 20:32
![]()
Shiplu MokaddimShiplu Mokaddim
56.1k17 gold badges139 silver badges185 bronze badges
7
I understand you’ve solved your issue, but for others reading this thread, here is the answer: you have to increase the stack that your operating system allocates for the python process.
The way to do it, is operating system dependant. In linux, you can check with the command ulimit -s your current value and you can increase it with ulimit -s <new_value>
Try doubling the previous value and continue doubling if it does not work, until you find one that does or run out of memory.
answered Jul 6, 2012 at 19:19
![]()
DavideDavide
16.9k11 gold badges52 silver badges68 bronze badges
5
Segmentation fault is a generic one, there are many possible reasons for this:
- Low memory
- Faulty Ram memory
- Fetching a huge data set from the db using a query (if the size of fetched data is more than swap mem)
- wrong query / buggy code
- having long loop (multiple recursion)
![]()
Paul
5,3531 gold badge30 silver badges37 bronze badges
answered Nov 4, 2013 at 21:04
![]()
SadheeshSadheesh
8859 silver badges6 bronze badges
Updating the ulimit worked for my Kosaraju’s SCC implementation by fixing the segfault on both Python (Python segfault.. who knew!) and C++ implementations.
For my MAC, I found out the possible maximum via :
$ ulimit -s -H
65532
answered Nov 18, 2016 at 4:08
![]()
RockRock
1773 silver badges11 bronze badges
2
Google search found me this article, and I did not see the following «personal solution» discussed.
My recent annoyance with Python 3.7 on Windows Subsystem for Linux is that: on two machines with the same Pandas library, one gives me segmentation fault and the other reports warning. It was not clear which one was newer, but «re-installing» pandas solves the problem.
Command that I ran on the buggy machine.
conda install pandas
More details: I was running identical scripts (synced through Git), and both are Windows 10 machine with WSL + Anaconda. Here go the screenshots to make the case. Also, on the machine where command-line python will complain about Segmentation fault (core dumped), Jupyter lab simply restarts the kernel every single time. Worse still, no warning was given at all.

Updates a few months later: I quit hosting Jupyter servers on Windows machine. I now use WSL on Windows to fetch remote ports opened on a Linux server and run all my jobs on the remote Linux machine. I have never experienced any execution error for a good number of months 
answered Feb 10, 2019 at 18:19
![]()
llinfengllinfeng
1,3061 gold badge14 silver badges37 bronze badges
I was experiencing this segmentation fault after upgrading dlib on RPI.
I tracebacked the stack as suggested by Shiplu Mokaddim above and it settled on an OpenBLAS library.
Since OpenBLAS is also multi-threaded, using it in a muilt-threaded application will exponentially multiply threads until segmentation fault. For multi-threaded applications, set OpenBlas to single thread mode.
In python virtual environment, tell OpenBLAS to only use a single thread by editing:
$ workon <myenv>
$ nano .virtualenv/<myenv>/bin/postactivate
and add:
export OPENBLAS_NUM_THREADS=1
export OPENBLAS_MAIN_FREE=1
After reboot I was able to run all my image recognition apps on rpi3b which were previously crashing it.
reference:
https://github.com/ageitgey/face_recognition/issues/294
answered Mar 22, 2019 at 12:42
![]()
Looks like you are out of stack memory. You may want to increase it as Davide stated. To do it in python code, you would need to run your «main()» using threading:
def main():
pass # write your code here
sys.setrecursionlimit(2097152) # adjust numbers
threading.stack_size(134217728) # for your needs
main_thread = threading.Thread(target=main)
main_thread.start()
main_thread.join()
Source: c1729’s post on codeforces. Runing it with PyPy is a bit trickier.
answered Apr 12, 2020 at 21:02
![]()
Rustam A.Rustam A.
8098 silver badges15 bronze badges
I’d run into the same error. I learnt from another SO answer that you need to set the recursion limit through sys and resource modules.
answered Nov 12, 2021 at 2:30
![]()
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
import csv from xlsxwriter import Workbook as excel from math import ceil from datetime import datetime as dt from random import randint as rnd import os #from os import nice as proc_load #load = min(100, int(20 * int(input('Proc%: ')) / 100)) #proc_load(load) #raise DocumentTooLarge( #pymongo.errors.DocumentTooLarge: BSON document too large (49304358 bytes) - the connected server supports BSON document sizes up to 16793598 bytes. file_type = 'excel' #input('csv / excel') file_name = 'report' max_rows = int(input('Max rows(50000)')) or 50000 rows = int(input('Rows(100000)')) or 100000 ff = './{}-{}/{}'.format("111", "reports", "Task_test") True if os.path.exists('./reports/') else os.makedirs('./reports/') data = {} data['Columns'] = [1,2,3,4,5,6,7,8] data['Data'] = [521538, '2022-09-11', '00:12:01', 31, 5, 8243.0, 82.43, 8325.43] * rows start = dt.now() if file_type == 'csv': # pythonworld.ru/moduli/modul-csv.htm with open(f"{file_name}.csv", 'w', newline='', encoding='utf-8') as file: w = csv.writer(file, delimiter=',', quoting=csv.QUOTE_MINIMAL) #w.writerow(data['Columns']) for d in data['Data']: w.writerow(d) elif file_type == 'excel': lencolumns = lambda s: 0 if s == None else len(str(s)) parts = ceil(len(data['Data']) / max_rows) gendata = (d for d in data['Data']) for part in range(1, parts + 1): with excel("./reports/{}{}.xlsx".format(file_name, f'-{part}' if parts > 1 else '')) as file: file.set_properties({ 'title': f'{file_name}', 'subject': 'dates', 'keywords': 'Sample, Example, Properties', 'category': 'Example spreadsheets', 'comments': f'Part: {part} / {parts}', 'author': 'Reports Builder', 'company': 'FinComp', 'manager':'Data analyst', }) #file.set_custom_property('Checked by', 'Andrey') #file.read_only_recommended() sheet = file.add_worksheet() first_row = 0 ## if 0: ## sheet.merge_range(0, 0, 0, len(data['Columns']) - 1 if 0 else 25, data['Heading']) ## row_format = file.add_format({'align': 'left', 'valign': 'vcenter', 'indent': 1, 'bold': True, 'fg_color': '#6A5ACD', 'font_size': 20}) # 'border': 1 ## sheet.set_row(0, None, row_format) ## first_row = 1 ## lens = map(lencolumns, data['Columns']) sheet.write_row(first_row, 0, data['Columns']) row_format = file.add_format({'align': 'center', 'valign': 'vcenter', 'border': 0, 'bold': True, 'fg_color': '#696969', 'font_size': 14}) sheet.set_row(first_row, None, row_format) first_row +=1 row_format = file.add_format({'border': 0, 'valign': 'vcenter', 'fg_color': '#D3D3D3'}) for r in range(first_row, first_row + max_rows): try: d = next(gendata) sheet.write_row(r, 0, d) sheet.set_row(r, None, None if r % 2 else row_format) row = list(map(lencolumns, d)) lens = map(max, zip(lens, row)) except: pass for i, w in enumerate(lens): sheet.set_column(i, i, w + 1) print(part, parts, list(lens)) print(dt.now() - start) |
Уведомления
- Начало
- » Python для новичков
- » ошибка сегментирования на 64-разр.
#1 Ноя. 4, 2011 09:23:05
ошибка сегментирования на 64-разр.
Почему режеться указатель при передачи в сишный модуль? Это баг Питона или неправильное кодирование? Как можно устранить?
На более маленьких массивах все ok. Т.ж. на 32-битных системах работает без проблем.
$ cat test.py
#!/usr/bin/python
import ctypes
import numpy
from sys import path
path.append('./../')
from module.matrix import *
A = myones(200,200)
print A$ cat ../module/libmatrix.c
void ones_matrix(
const int n,
const int m,
double* mtx)
{
for(int i=0; i<n; ++i)
for(int j=0; j<m; ++j)
*(mtx++)=(i+j)/2.;
}$ gcc -std=gnu99 -fpic -shared -g -pg libmatrix.c -o libmatrix.so
$ cat ../module/matrix.py
#!/usr/bin/python
from numpy import ctypeslib, ndarray, zeros
from ctypes import c_double, byref, cdll
from os import path
from sys import platform
path = path.dirname(path.realpath(__file__))
if 'linux' in platform:
mod_matrix_maker=cdll.LoadLibrary("%s/libmatrix.so" % path)def myones(n,m):
A=ndarray((n,m),dtype='d')
mod_matrix_maker.ones_matrix(n,m,A.reshape(-1,1).ctypes.data)
return A
$ gdb -arg python ./test.py
GNU gdb (Ubuntu/Linaro 7.3-0ubuntu2) 7.3-2011.08
Copyright (C) 2011 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
For bug reporting instructions, please see:
<http://bugs.launchpad.net/gdb-linaro/>...
Reading symbols from /usr/bin/python...(no debugging symbols found)...done.
(gdb) start
Temporary breakpoint 1 at 0x41aa40
Starting program: /usr/bin/python ./test.py
[Thread debugging using libthread_db enabled]Temporary breakpoint 1, 0x000000000041aa40 in main ()
(gdb) next
Single stepping until exit from function main,
which has no line number information.
0x00000000004ee1e0 in Py_Main ()
(gdb) next
Single stepping until exit from function Py_Main,
which has no line number information.Program received signal SIGSEGV, Segmentation fault.
0x00007ffff34bd5e2 in ones_matrix (n=200, m=200, mtx=0xf346e010) at libmatrix.c:11
11 *(mtx++)=(i+j)/2.;
$ pmap -d 7419
7419: /usr/bin/python ./test.py
Address Kbytes Mode Offset Device Mapping
0000000000400000 2252 r-x-- 0000000000000000 0fd:00000 python2.7
0000000000832000 4 r---- 0000000000232000 0fd:00000 python2.7
0000000000833000 420 rw--- 0000000000233000 0fd:00000 python2.7
000000000089c000 5184 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff346e000 316 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff34bd000 4 r-x-- 0000000000000000 0fd:00002 libmatrix.so
00007ffff34be000 2044 ----- 0000000000001000 0fd:00002 libmatrix.so
00007ffff36bd000 4 r---- 0000000000000000 0fd:00002 libmatrix.so
00007ffff36be000 4 rw--- 0000000000001000 0fd:00002 libmatrix.so
00007ffff36bf000 292 r-x-- 0000000000000000 0fd:00000 mtrand.so
00007ffff3708000 2048 ----- 0000000000049000 0fd:00000 mtrand.so
00007ffff3908000 4 r---- 0000000000049000 0fd:00000 mtrand.so
00007ffff3909000 112 rw--- 000000000004a000 0fd:00000 mtrand.so
00007ffff3925000 4 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff3926000 36 r-x-- 0000000000000000 0fd:00000 fftpack_lite.so
00007ffff392f000 2044 ----- 0000000000009000 0fd:00000 fftpack_lite.so
00007ffff3b2e000 4 r---- 0000000000008000 0fd:00000 fftpack_lite.so
00007ffff3b2f000 4 rw--- 0000000000009000 0fd:00000 fftpack_lite.so
00007ffff3b30000 212 r-x-- 0000000000000000 0fd:00000 libquadmath.so.0.0.0
00007ffff3b65000 2044 ----- 0000000000035000 0fd:00000 libquadmath.so.0.0.0
00007ffff3d64000 4 r---- 0000000000034000 0fd:00000 libquadmath.so.0.0.0
00007ffff3d65000 4 rw--- 0000000000035000 0fd:00000 libquadmath.so.0.0.0
00007ffff3d66000 84 r-x-- 0000000000000000 0fd:00000 libgcc_s.so.1
00007ffff3d7b000 2044 ----- 0000000000015000 0fd:00000 libgcc_s.so.1
00007ffff3f7a000 4 r---- 0000000000014000 0fd:00000 libgcc_s.so.1
00007ffff3f7b000 4 rw--- 0000000000015000 0fd:00000 libgcc_s.so.1
00007ffff3f7c000 1104 r-x-- 0000000000000000 0fd:00000 libgfortran.so.3.0.0
00007ffff4090000 2044 ----- 0000000000114000 0fd:00000 libgfortran.so.3.0.0
00007ffff428f000 4 r---- 0000000000113000 0fd:00000 libgfortran.so.3.0.0
00007ffff4290000 8 rw--- 0000000000114000 0fd:00000 libgfortran.so.3.0.0
00007ffff4292000 9108 r-x-- 0000000000000000 0fd:00000 liblapack.so.3gf.0
00007ffff4b77000 2044 ----- 00000000008e5000 0fd:00000 liblapack.so.3gf.0
00007ffff4d76000 4 r---- 00000000008e4000 0fd:00000 liblapack.so.3gf.0
00007ffff4d77000 16 rw--- 00000000008e5000 0fd:00000 liblapack.so.3gf.0
00007ffff4d7b000 1076 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff4e88000 20 r-x-- 0000000000000000 0fd:00000 lapack_lite.so
00007ffff4e8d000 2048 ----- 0000000000005000 0fd:00000 lapack_lite.so
00007ffff508d000 4 r---- 0000000000005000 0fd:00000 lapack_lite.so
00007ffff508e000 4 rw--- 0000000000006000 0fd:00000 lapack_lite.so
00007ffff508f000 16 r-x-- 0000000000000000 0fd:00000 _compiled_base.so
00007ffff5093000 2044 ----- 0000000000004000 0fd:00000 _compiled_base.so
00007ffff5292000 4 r---- 0000000000003000 0fd:00000 _compiled_base.so
00007ffff5293000 4 rw--- 0000000000004000 0fd:00000 _compiled_base.so
00007ffff5294000 772 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff5355000 12 r-x-- 0000000000000000 0fd:00000 _heapq.so
00007ffff5358000 2044 ----- 0000000000003000 0fd:00000 _heapq.so
00007ffff5557000 4 r---- 0000000000002000 0fd:00000 _heapq.so
00007ffff5558000 8 rw--- 0000000000003000 0fd:00000 _heapq.so
00007ffff555a000 260 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff559b000 152 r-x-- 0000000000000000 0fd:00000 scalarmath.so
00007ffff55c1000 2044 ----- 0000000000026000 0fd:00000 scalarmath.so
00007ffff57c0000 4 r---- 0000000000025000 0fd:00000 scalarmath.so
00007ffff57c1000 8 rw--- 0000000000026000 0fd:00000 scalarmath.so
00007ffff57c3000 612 r-x-- 0000000000000000 0fd:00000 libblas.so.3gf.0
00007ffff585c000 2044 ----- 0000000000099000 0fd:00000 libblas.so.3gf.0
00007ffff5a5b000 4 r---- 0000000000098000 0fd:00000 libblas.so.3gf.0
00007ffff5a5c000 4 rw--- 0000000000099000 0fd:00000 libblas.so.3gf.0
00007ffff5a5d000 20 r-x-- 0000000000000000 0fd:00000 _dotblas.so
00007ffff5a62000 2044 ----- 0000000000005000 0fd:00000 _dotblas.so
00007ffff5c61000 4 r---- 0000000000004000 0fd:00000 _dotblas.so
00007ffff5c62000 4 rw--- 0000000000005000 0fd:00000 _dotblas.so
00007ffff5c63000 84 r-x-- 0000000000000000 0fd:00000 _sort.so
00007ffff5c78000 2044 ----- 0000000000015000 0fd:00000 _sort.so
00007ffff5e77000 4 r---- 0000000000014000 0fd:00000 _sort.so
00007ffff5e78000 4 rw--- 0000000000015000 0fd:00000 _sort.so
00007ffff5e79000 304 r-x-- 0000000000000000 0fd:00000 umath.so
00007ffff5ec5000 2044 ----- 000000000004c000 0fd:00000 umath.so
00007ffff60c4000 4 r---- 000000000004b000 0fd:00000 umath.so
00007ffff60c5000 16 rw--- 000000000004c000 0fd:00000 umath.so
00007ffff60c9000 8 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff60cb000 536 r-x-- 0000000000000000 0fd:00000 multiarray.so
00007ffff6151000 2044 ----- 0000000000086000 0fd:00000 multiarray.so
00007ffff6350000 4 r---- 0000000000085000 0fd:00000 multiarray.so
00007ffff6351000 44 rw--- 0000000000086000 0fd:00000 multiarray.so
00007ffff635c000 8 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff635e000 124 r-x-- 0000000000000000 0fd:00000 _ctypes.so
00007ffff637d000 2048 ----- 000000000001f000 0fd:00000 _ctypes.so
00007ffff657d000 4 r---- 000000000001f000 0fd:00000 _ctypes.so
00007ffff657e000 16 rw--- 0000000000020000 0fd:00000 _ctypes.so
00007ffff6582000 4 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff6583000 4072 r---- 0000000000000000 0fd:00000 locale-archive
00007ffff697d000 1620 r-x-- 0000000000000000 0fd:00000 libc-2.13.so
00007ffff6b12000 2044 ----- 0000000000195000 0fd:00000 libc-2.13.so
00007ffff6d11000 16 r---- 0000000000194000 0fd:00000 libc-2.13.so
00007ffff6d15000 4 rw--- 0000000000198000 0fd:00000 libc-2.13.so
00007ffff6d16000 24 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff6d1c000 524 r-x-- 0000000000000000 0fd:00000 libm-2.13.so
00007ffff6d9f000 2044 ----- 0000000000083000 0fd:00000 libm-2.13.so
00007ffff6f9e000 4 r---- 0000000000082000 0fd:00000 libm-2.13.so
00007ffff6f9f000 4 rw--- 0000000000083000 0fd:00000 libm-2.13.so
00007ffff6fa0000 92 r-x-- 0000000000000000 0fd:00000 libz.so.1.2.3.4
00007ffff6fb7000 2044 ----- 0000000000017000 0fd:00000 libz.so.1.2.3.4
00007ffff71b6000 4 r---- 0000000000016000 0fd:00000 libz.so.1.2.3.4
00007ffff71b7000 4 rw--- 0000000000017000 0fd:00000 libz.so.1.2.3.4
00007ffff71b8000 1568 r-x-- 0000000000000000 0fd:00000 libcrypto.so.1.0.0
00007ffff7340000 2048 ----- 0000000000188000 0fd:00000 libcrypto.so.1.0.0
00007ffff7540000 100 r---- 0000000000188000 0fd:00000 libcrypto.so.1.0.0
00007ffff7559000 40 rw--- 00000000001a1000 0fd:00000 libcrypto.so.1.0.0
00007ffff7563000 16 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff7567000 296 r-x-- 0000000000000000 0fd:00000 libssl.so.1.0.0
00007ffff75b1000 2044 ----- 000000000004a000 0fd:00000 libssl.so.1.0.0
00007ffff77b0000 12 r---- 0000000000049000 0fd:00000 libssl.so.1.0.0
00007ffff77b3000 20 rw--- 000000000004c000 0fd:00000 libssl.so.1.0.0
00007ffff77b8000 8 r-x-- 0000000000000000 0fd:00000 libutil-2.13.so
00007ffff77ba000 2044 ----- 0000000000002000 0fd:00000 libutil-2.13.so
00007ffff79b9000 4 r---- 0000000000001000 0fd:00000 libutil-2.13.so
00007ffff79ba000 4 rw--- 0000000000002000 0fd:00000 libutil-2.13.so
00007ffff79bb000 8 r-x-- 0000000000000000 0fd:00000 libdl-2.13.so
00007ffff79bd000 2048 ----- 0000000000002000 0fd:00000 libdl-2.13.so
00007ffff7bbd000 4 r---- 0000000000002000 0fd:00000 libdl-2.13.so
00007ffff7bbe000 4 rw--- 0000000000003000 0fd:00000 libdl-2.13.so
00007ffff7bbf000 96 r-x-- 0000000000000000 0fd:00000 libpthread-2.13.so
00007ffff7bd7000 2044 ----- 0000000000018000 0fd:00000 libpthread-2.13.so
00007ffff7dd6000 4 r---- 0000000000017000 0fd:00000 libpthread-2.13.so
00007ffff7dd7000 4 rw--- 0000000000018000 0fd:00000 libpthread-2.13.so
00007ffff7dd8000 16 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff7ddc000 132 r-x-- 0000000000000000 0fd:00000 ld-2.13.so
00007ffff7e1c000 260 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff7e5d000 4 rwx-- 0000000000000000 000:00000 [ anon ]
00007ffff7e5e000 780 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff7f53000 540 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff7ff9000 8 rw--- 0000000000000000 000:00000 [ anon ]
00007ffff7ffb000 4 r-x-- 0000000000000000 000:00000 [ anon ]
00007ffff7ffc000 4 r---- 0000000000020000 0fd:00000 ld-2.13.so
00007ffff7ffd000 8 rw--- 0000000000021000 0fd:00000 ld-2.13.so
00007ffffffcc000 204 rw--- 0000000000000000 000:00000 [ stack ]
ffffffffff600000 4 r-x-- 0000000000000000 000:00000 [ anon ]
mapped: 85000K writeable/private: 10260K shared: 0K
Офлайн
- Пожаловаться
#2 Ноя. 4, 2011 12:37:32
ошибка сегментирования на 64-разр.
потому что нужно учитывать strides — массив не обязан быть непрерывным в памяти. А лучше смотреть на .ctypes и не трогать .reshape.
Офлайн
- Пожаловаться
#3 Ноя. 4, 2011 15:27:14
ошибка сегментирования на 64-разр.
Андрей Светлов
потому что нужно учитывать strides — массив не обязан быть непрерывным в памяти. А лучше смотреть на .ctypes и не трогать .reshape.
Можно поподробнее ?
удаление reshape не изменяет ситуации:
def myones(n,m):
A=ndarray((n,m),dtype='d')
mod_matrix_maker.ones_matrix(n,m,A.ctypes.data)
return A
Офлайн
- Пожаловаться
#4 Ноя. 4, 2011 16:03:11
ошибка сегментирования на 64-разр.
Stride: The distance (in bytes) between the two consecutive elements along an axis. Numpy expresses strides in bytes because the distance between elements is not necessarily a multiple of the element size.
Или нужно еще подробней?
Офлайн
- Пожаловаться
#5 Ноя. 4, 2011 21:45:09
ошибка сегментирования на 64-разр.
Андрей Светлов
Stride: The distance (in bytes) between the two consecutive elements along an axis. Numpy expresses strides in bytes because the distance between elements is not necessarily a multiple of the element size.
Или нужно еще подробней?
ошибка сегментирования даже для вот такого кода возникает (при записи в самую первую позицию не нужно же учитывать stride):
void ones_matrix(.
const int n,.
const int m,.
double* mtx).
{
*mtx = 1.0;
}
Офлайн
- Пожаловаться
#7 Ноя. 5, 2011 21:44:46
ошибка сегментирования на 64-разр.
к сожалению со strides не прошло, при этом на 32-битных и 64-битных системах strides одинаковые значения имеет, ну и соответственно опять при трассировке указатель на первый элемент mtx обрезан на 64-битной.
$ cat libmatrix.c
#include<math.h>
#include<stdio.h>void ones_matrix( const int n0, const int n1, const int s0, const int s1, double* mtx )
{
int byte_offset;
for(int i=0; i<n0; ++i)
for(int j=0; j<n1; ++j)
{
printf("i=%i j=%i n0=%i n1=%i s0=%i s1=%in",i,j,n0,n1,s0,s1);
byte_offset = s0*i + s1*j;
mtx[byte_offset] = (i+j)/2.;
}
}$ cat matrix.py
#!/usr/bin/python
from numpy import ctypeslib, ndarray, zeros
from ctypes import c_double, byref, cdll
from os import path
from sys import platform
path = path.dirname(path.realpath(__file__))
if 'linux' in platform:
mod_matrix_maker=cdll.LoadLibrary("%s/libmatrix.so" % path)def myones(n,m):
A=ndarray((n,m),dtype='d')
s0=A.strides[0]
s1=A.strides[1]
print "A.shape", A.shape
print "A.strides", A.strides
mod_matrix_maker.ones_matrix(n,m,s0,s1,A.ctypes.data)
return A$ ../test/test.py
A.shape (400, 400)
A.strides (3200, 8)
i=0 j=0 n0=400 n1=400 s0=3200 s1=8
Ошибка сегментирования
Офлайн
- Пожаловаться
#8 Ноя. 5, 2011 22:00:48
ошибка сегментирования на 64-разр.
Андрей Светлов
http://docs.python.org/py3k/library/ctypes.html?highlight=argtypes#ctypes._FuncPtr.argtypes
По умолчанию ctypes аргументы считает как int, насколько помню
Для amd64
sizeof(int) == 4
sizeof(long) == 8
sizeoof(void*) == 8
дошло !
mod_matrix_maker.ones_matrix(n,m,s0,s1, A.ctypes.data_as(POINTER(c_long)))
спасибо!
P.S. strides все таки нужно учитывать ?
здесь вопрос в чем, если писать так
$ cat libmatrix.c
#include<math.h>
#include<stdio.h>void ones_matrix( const int n0, const int n1, const int s0, const int s1, double* mtx )
{
int byte_offset;
int size_double = sizeof(double);
for(int i=0; i<n0; ++i)
for(int j=0; j<n1; ++j)
{
printf("i=%i j=%i n0=%i n1=%i s0=%i s1=%in",i,j,n0,n1,s0,s1);
byte_offset = s0*i + s1*j;
mtx[byte_offset/size_double] = (i+j)/2.;
}
}
то какая разница в таком смещении: здесь тоже смещение на sizeof(double):
или Питон может свое смещение устанавливать, например не 8 байт, а как-то неплотно, например 10 байт для каждого элемента?
или имеется ввиду что для массива n0xn1 мы может получить strides не с двумя измерениями , а с многими , как бы учитывающие хранение его не в непрерывной памяти. а в разрывной ?
или всетаки массив строго в непрерывной памяти хранится ?
Отредактировано (Ноя. 5, 2011 22:21:52)
Офлайн
- Пожаловаться
#9 Ноя. 7, 2011 14:40:29
ошибка сегментирования на 64-разр.
Нет гарантии, что без strides будет всегда и везде работать. Для оптимального выравнивания бывает полезно вставить пустые байты в конце строки, например. И т.д.
Офлайн
- Пожаловаться
- Начало
- » Python для новичков
- » ошибка сегментирования на 64-разр.