
- Печать
Страницы: [1] 2 Все Вниз

Тема: Ошибка шины (Прочитано 7800 раз)
0 Пользователей и 1 Гость просматривают эту тему.

Tupas

Значит, ввожу в консоли sudo apt-get install любое_имя_пакета, а в ответ получаю кучу текста такого вида:
[ 2927.929002] ata1.00: status: { DRDY ERR }Что делать?
[ 2927.942856] ata1.00: error: { UNC }
[ 2931.680190] ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0
[ 2931.694304] ata1.00: BDMA stat 0x25
[ 2931.708326] ata1.00: failed command: READ DMA
[ 2931.722101] ata1.00: cmd c8/00:08:08:a5:0c/00:00:00:00:00/e0 tag 0 dma 4096 in
[ 2931.722107] ata1.00: res 51/40:03:0c:a5:0c/00:00:00:00:00/e0 Emask 0x9 (media error)
[ 2931.777373] ata1.00: status: { DRDY ERR }
[ 2931.791188] ata1.00: error: { UNC }
[ 2931.828780] end_request: I/O error, dev sda, sector 828684
Ошибка шины
Deathrose
Что делать?
Проверьте кабели)) Проверьте жесткий диск)))
sht0rm
Заменить кабель, заменить жесткий диск.
Tupas
Ну, кабель заменить попробую. А чем можно жёсткий диск проверить?
sht0rm
666joy666
Было у меня точно так же…end-to-end error, если точней, можно посмотреть в SMART…
Решается заменой шлейфа, воткнуть шлейф в иной порт, взять иной кабель, и как апофез — сменить винт.
Pace!
Если это проблема с жёстким диском, то ведь она должна распространятся на всё, а не только на установку, так ведь?
666joy666
Если это проблема с жёстким диском, то ведь она должна распространятся на всё, а не только на установку, так ведь?
Эта ошибка не столь критична…у меня она вылазила только если я один файл пытался скопировать с одного раздела на иной, больше её не видел…
nd3
mhdd, victoria
Вы же в UBUNTU!!!
Проверить диск на битые сектора:
badblocks -v /dev/sda
MA3X
2931.791188] ata1.00: error: { UNC } — это открытым текстом сбойный сектор на харде.
невосстановимая ошибка чтения.
Винт или мучить mhdd, или менять. второе — предпочтительнее
Microsoft isn’t the answer.
Microsoft is the question, and the answer is NO.
Tupas
Нашлось 120 плохих блоков, и как их чинить?
nd3
Как чинить? badblocks -vw /dev/sda(1) это с проверкой на запись.
Внимание!!!! Вся информация будет уничтожена!
Сектора которые не пройдут тест запись-чтение, будут перенесены SMARTом в дефект лист. А по большому счету выход один — замена винчестера.
Tupas
Как чинить? badblocks -vw /dev/sda(1) это с проверкой на запись.
Внимание!!!! Вся информация будет уничтожена!
А без уничтожения никак что ли?
И это же наверное с другого диска делать надо?
nd3
Как чинить? badblocks -vw /dev/sda(1) это с проверкой на запись.
Внимание!!!! Вся информация будет уничтожена!А без уничтожения никак что ли?
И это же наверное с другого диска делать надо?
Никак, совсем. Это очевидно. 
MA3X
Я допускаю для винта не более 5-7 бб на всей поверхности, чтобы считать его еще нормальным.
Если больше — то как минимум не в рабочие машины. Временное хранение некритичных данных.
А 120 — однозначно втопка_гореть.
Microsoft isn’t the answer.
Microsoft is the question, and the answer is NO.
- Печать
Страницы: [1] 2 Все Вверх
1
1
Добрый день. Возникла проблема с VLC: плеер не стартует. Выводит сообщение «Ошибка шины» и завершается. Пробовал переустанавливать, ставить разные версии, ночнушки — все одно и тоже.
При установке, после обработки триггеров для vlc-nox, выводит сообщение
bus error
WARNING: Regenerating VLC plugin cache failed.
Please run 'vlc-cache-gen /usr/lib/vlc/plugins' manually
Пробовал этой рекомендации последовать, однако запуск vlc-cache-gen вызывает все ту же ошибку шины.
Я, к сожалению, не гуру линукса, поэтому не знаю, какую информацию ещё необходимо предоставить…
Железо:
Нетбук Packard Bell Dot SE на Intel Atom N450, 2 гига, обычный HDD, интегрированная графика.
Система Linux Mint 18 Cinnamon 64-bit
Cinnamon 3.0.7, Linux 4.4.0-21-generic.
Спасибо за любую помощь.
mmap минимальный пример POSIX 7
«Ошибка шины» происходит, когда ядро отправляет SIGBUS в процесс.
Минимальный пример, который создает его, потому что ftruncate был забыт:
#include <fcntl.h> /* O_ constants */
#include <unistd.h> /* ftruncate */
#include <sys/mman.h> /* mmap */
int main() {
int fd;
int *map;
int size = sizeof(int);
char *name = "/a";
shm_unlink(name);
fd = shm_open(name, O_RDWR | O_CREAT, (mode_t)0600);
/* THIS is the cause of the problem. */
/*ftruncate(fd, size);*/
map = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
/* This is what generates the SIGBUS. */
*map = 0;
}
Запустить с помощью:
gcc -std=c99 main.c -lrt
./a.out
Протестировано в Ubuntu 14.04.
POSIX описывает SIGBUS как:
Доступ к части undefined объекта памяти.
спецификация mmap говорит, что:
Ссылки в диапазоне адресов, начинающиеся с pa и продолжающиеся для len-байтов на целые страницы, следующие за концом объекта, должны привести к передаче сигнала SIGBUS.
И shm_open говорит, что он генерирует объекты размером 0:
Объект общей памяти имеет нулевой размер.
Итак, при *map = 0 мы касаемся конца выделенного объекта.
mmap minimal POSIX 7 example
«Bus error» happens when the kernel sends SIGBUS to a process.
A minimal example that produces it because ftruncate was forgotten:
#include <fcntl.h> /* O_ constants */
#include <unistd.h> /* ftruncate */
#include <sys/mman.h> /* mmap */
int main() {
int fd;
int *map;
int size = sizeof(int);
char *name = "/a";
shm_unlink(name);
fd = shm_open(name, O_RDWR | O_CREAT, (mode_t)0600);
/* THIS is the cause of the problem. */
/*ftruncate(fd, size);*/
map = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
/* This is what generates the SIGBUS. */
*map = 0;
}
Run with:
gcc -std=c99 main.c -lrt
./a.out
Tested in Ubuntu 14.04.
POSIX describes SIGBUS as:
Access to an undefined portion of a memory object.
The mmap spec says that:
References within the address range starting at pa and continuing for len bytes to whole pages following the end of an object shall result in delivery of a SIGBUS signal.
And shm_open says that it generates objects of size 0:
The shared memory object has a size of zero.
So at *map = 0 we are touching past the end of the allocated object.
Unaligned stack memory accesses in ARMv8 aarch64
This was mentioned at: What is a bus error? for SPARC, but here I will provide a more reproducible example.
All you need is a freestanding aarch64 program:
.global _start
_start:
asm_main_after_prologue:
/* misalign the stack out of 16-bit boundary */
add sp, sp, #-4
/* access the stack */
ldr w0, [sp]
/* exit syscall in case SIGBUS does not happen */
mov x0, 0
mov x8, 93
svc 0
That program then raises SIGBUS on Ubuntu 18.04 aarch64, Linux kernel 4.15.0 in a ThunderX2 server machine.
Unfortunately, I can’t reproduce it on QEMU v4.0.0 user mode, I’m not sure why.
The fault appears to be optional and controlled by the SCTLR_ELx.SA and SCTLR_EL1.SA0 fields, I have summarized the related docs a bit further here.
|
# (отредактировано 6 лет, 8 месяцев назад) |
|
|
Темы: 1 Сообщения: 20 Участник с: 30 октября 2014 |
Всем доброе время суток! Проблема такого плана. В частном доме часто плохое напряжение, и поэтому ПК работает через стабилизатор. (УПС нет) и комп часто вырубался жестко из-за этого полетело, что то в системе !!! Некоторый софт не запускается …. Вот ошибка firefox
[Child 9482] WARNING: pipe error (3): Соединение разорвано другой стороной: file /build/firefox/src/firefox-49.0.1/ipc/chromium/src/chrome/common/ipc_channel_posix.cc, line 316 |
|
vasek |
# (отредактировано 6 лет, 8 месяцев назад) |
|
Темы: 47 Сообщения: 11608 Участник с: 17 февраля 2013 |
Информации практически нет, гадать нет смысла… Ошибка шины (core dumped) — лучше погуглить по Bus error (core dumped), но вряд ли без уточнения проблемы что то можно толковое нагуглить …. а для сбора информации 1. Лучше сначала просмотреть внимательно логи — возможно есть какие то настораживающие записи перед падением … 2. Посмотри наличие коры…. $ coredumpctl list … (или в ручную — /var/lib/systemd/coredump/) — если есть в наличии, попробуй запустить в gdb …. хотя бы посмотреть, где падают …. 3. Можно попробовать потрейсить (strace) по системным вызовам … 4. Если это выскакивает у многих приложений, то это может быть связано и с аппаратными проблемами — неплохо проверить HDD и память Ошибки не исчезают с опытом — они просто умнеют |
|
vadik |
# (отредактировано 6 лет, 8 месяцев назад) |
|
Темы: 55 Сообщения: 5430 Участник с: 17 августа 2009 |
vasek, есть еще нулевой вариант — просто переустановить проблемные приложения. Только это все до лампочки. Следующий скачек напряжения может отправить в небытие и материнку, и ЖД и пр. пр. пр. Бороться в первую очередь нужно с причиной, а не с последствиями. |
|
Aivar |
# |
|
Темы: 4 Сообщения: 6897 Участник с: 17 февраля 2011 |
Жестко полетело в файловой системе. vadik, прав. |
|
ErV |
# |
|
Темы: 18 Сообщения: 121 Участник с: 03 июня 2015 |
У меня была такая ерунда когда сбоила ОЗУ, причем это проявлялось редко и по разному, но подобные ошибки были как в firefox так и в chromium. Gold Memory Test в режиме Thorough на ночь помогут вам подтвердить или исключить этот пункт. |
|
lampslave |
# |
|
Темы: 32 Сообщения: 4800 Участник с: 05 июля 2011 |
Точняк. Привезли мужика с топором в спине — а давайте ему температуру померим, может грипп у него? Купите уже УПС, не гробьте технику. |
|
vasek |
# |
|
Темы: 47 Сообщения: 11608 Участник с: 17 февраля 2013 |
lampslave, ты прав — топор нужно извлекать в первую очередь и, при необходимости, переводить в реанимцию, чтобы привести в чувство…… но рана то сама по себе никуда не исчезнет, все равно нужно лечить (после того как переведут в обычную палату) ……… если не лечить может образоваться и сепсис или что другое …….
Ошибки не исчезают с опытом — они просто умнеют |
Recently I was trying to install Mint on several nodes in my institute. At times, I could not install and got lots of ‘PCIe Bus’ errors on the screen. I have also observed a similar issue with Ubuntu 18.04.
I got stuck into it for more than a month after using many solutions and observations (solution is the same, but observation and treatment may be different), I found something which was helpful for me. I think it could be beneficial for other Ubuntu and Linux Mint users. This is why I am sharing it here.
Observations about PCIe Bus Error severity Corrected

It happened with my HP system and it seems that there is some compatibility issues with the HP hardware. The PCIe Bus Error is basically the Linux kernel reporting the hardware issue.
This error reporting turns into a nightmare because of the frequency of error messages generated by the system. I have noticed in various Linux forums that many HP user have encountered this error; probably, HP needs to improve Linux support for their hardware.
Note that this doesn’t necessarily mean you cannot use Linux on your HP system. You might be able to use Linux like everyone else. It’s just that seeing this message flashing on the screen on every boot is annoying and sometimes, it could lead to bigger troubles.
If the system keeps on reporting, it will increase the log size. If you have limited space for root, it could mean that your system will get stuck at the black screen displaying the PCIe error message and your system won’t be able to boot.
Now that you know a few things let’s see how to tackle this error.
Handling PCIe Bus Error messages if you can boot in to your Linux system
If you see the PCIe Bus Error message on the screen while booting but can still log in, you could do a workaround for this annoyance.
You can do little on the hardware compatibility front. I mean you (most probably) cannot go ahead and start coding drivers for your hardware or fix the existing drivers code. If your system works fine, your main concern should be that too much of error reporting doesn’t eat up the disk space.
In that regard, you can change the Linux kernel parameter and ask it to stop reporting the PCIe errors. To do that, you need to edit the grub configuration.
Basically, you just have to use a text editor to edit the file.
First thing first, make a backup of your grub config file so that you can revert in case you are not sure of things you changed. Open a terminal and use the following command:
cp /etc/default/grub ~/grub.backNow open the file with Gedit for editing:
sudo gedit /etc/default/grubLook for the line that has GRUB_CMDLINE_LINUX_DEFAULT=”quiet splash”
Add pci=noaer in this line. AER stands for Advanced Error Reporting and ‘noaer’ asks the kernel not to use/log Advanced Error Reporting. The changed line should look like this:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=noaer"Once you have saved the file, you should update the grub using this command:
sudo update-grubRestart Ubuntu and you shouldn’t see the ‘PCIe Bus Error severity Corrected messages’ anymore.
If this doesn’t fix the issue, you can try changing other kernel parameters.
Further troubleshooting: Disable MSI
Now you are resorting to hit and trial. You may try disabling MSI. Though Linux kernel supports MSI for several years now, a wrong implementation of MSI from some hardware manufacturer may lead to the PCIe errors.
The drill is practically the same as you saw in the previous section. You edit the grub configuration and make the GRUB_CMDLINE_LINUX_DEFAULT line look like this:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=nomsi"Update grub and reboot the system:
sudo update-grubEven further troubleshooting: Disable mmconf
I know it’s getting repetitive but if you are still facing the issue, it could be worth to give this a last try. This time, disable the mmconf parameter in Linux kernel.
mmconf means ‘memory mapped config’ and if you have an old computer, a buggy BIOS may lead to this issue.
The steps remain the same. Just change the line GRUB_CMDLINE_LINUX_DEFAULT in your grub config to make it look like:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=nommconf"Can’t boot! How to edit grub config now?
In some cases, if you are not even able to boot at all, perhaps your root is out of space. An idea here would be to delete old log files and see if you could boot now and if yes, change the grub config.
On reboot, if you are stuck with logs on the screen and do a hard boot (use power button to turn it off and on again). When you power on, choose to go into recovery mode from the grub screen. It should be under Advanced options.
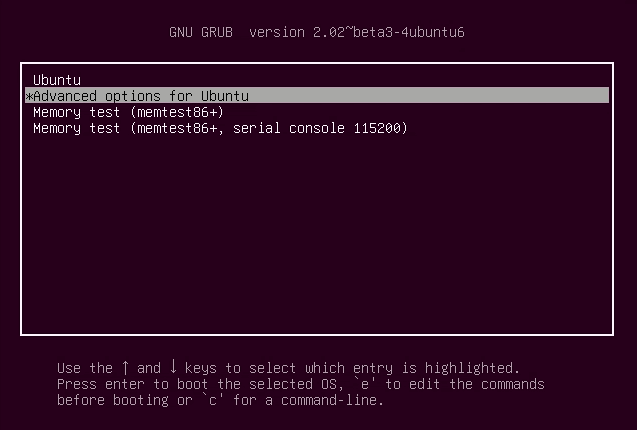
If your system doesn’t show the grub screen, press and hold shift key at boot. In some systems, pressing the Esc key brings the grub screen.
In the advanced option->recovery mode:
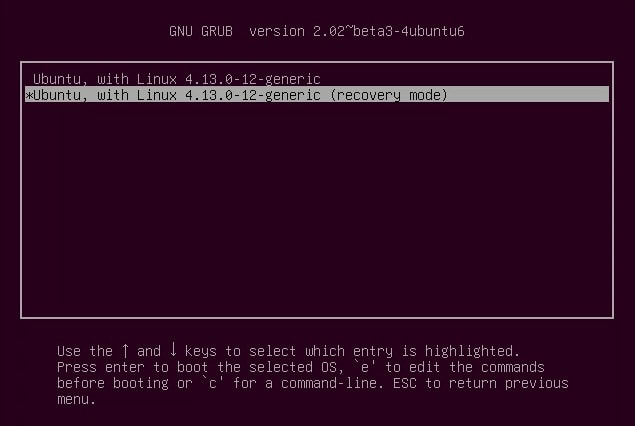
Drop into root shell:
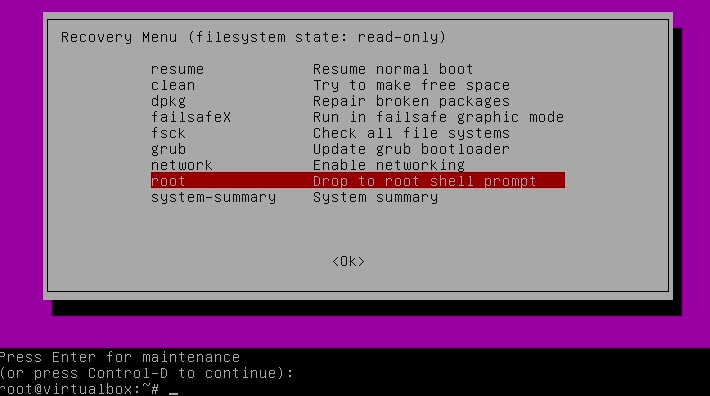
If you use the ls command to find large files, you’ll see that sys.log and kern.log take huge space:
ls -s -S /var/logYou can empty the log files in Linux command line this way:
$ > syslog
$ > kern.logOnce that is done, reboot your system. You should be able to log in. You should quickly change the grub parameters as discussed above. Adding pci=noaer should help you in this case.
I know it’s more of a workaround than a solution. But this is something that troubled me for long and helped me get around the error. Otherwise, I had to reinstall the system.
I just wanted to share what worked for me with the community here. I hope it helps you as well.
✍🏻
This article is written by Arun Shrimali. Arun is IT Head at Resonance Institute in India and he tries to implement Open Source Software across his organization. The article has been edited by Abhishek Prakash.
I have a new HP Pavilion Gaming Notebook and a new installation of Ubuntu 16.04. When I press Ctrl + Alt + F1 I go start seeing the errors shown in the following image and it doesn’t allow me to interact with the console:

I also see these errors for a while everytime I boot. I need to do Ctrl + Alt + F1 to access a non graphical terminal to install some Nvidia drivers. What’s going on?
What’s causing the problem seems to be:
00:1c.5 PCI bridge [0604]: Intel Corporation Sunrise Point-H PCI Express Root Port #6 [8086:a115] (rev f1)
jpiabrantes@joao:~$ lspci -nn
00:00.0 Host bridge [0600]: Intel Corporation Sky Lake Host Bridge/DRAM Registers [8086:1910] (rev 07)
00:01.0 PCI bridge [0604]: Intel Corporation Sky Lake PCIe Controller (x16) [8086:1901] (rev 07)
00:02.0 VGA compatible controller [0300]: Intel Corporation Skylake Integrated Graphics [8086:191b] (rev 06)
00:04.0 Signal processing controller [1180]: Intel Corporation Skylake Processor Thermal Subsystem [8086:1903] (rev 07)
00:14.0 USB controller [0c03]: Intel Corporation Sunrise Point-H USB 3.0 xHCI Controller [8086:a12f] (rev 31)
00:14.2 Signal processing controller [1180]: Intel Corporation Sunrise Point-H Thermal subsystem [8086:a131] (rev 31)
00:16.0 Communication controller [0780]: Intel Corporation Sunrise Point-H CSME HECI #1 [8086:a13a] (rev 31)
00:17.0 SATA controller [0106]: Intel Corporation Sunrise Point-H SATA Controller [AHCI mode] [8086:a103] (rev 31)
00:1c.0 PCI bridge [0604]: Intel Corporation Sunrise Point-H PCI Express Root Port #5 [8086:a114] (rev f1)
00:1c.5 PCI bridge [0604]: Intel Corporation Sunrise Point-H PCI Express Root Port #6 [8086:a115] (rev f1)
00:1c.6 PCI bridge [0604]: Intel Corporation Sunrise Point-H PCI Express Root Port #7 [8086:a116] (rev f1)
00:1f.0 ISA bridge [0601]: Intel Corporation Sunrise Point-H LPC Controller [8086:a14e] (rev 31)
00:1f.2 Memory controller [0580]: Intel Corporation Sunrise Point-H PMC [8086:a121] (rev 31)
00:1f.3 Audio device [0403]: Intel Corporation Sunrise Point-H HD Audio [8086:a170] (rev 31)
00:1f.4 SMBus [0c05]: Intel Corporation Sunrise Point-H SMBus [8086:a123] (rev 31)
01:00.0 3D controller [0302]: NVIDIA Corporation GM107M [GeForce GTX 950M] [10de:139a] (rev a2)
07:00.0 Unassigned class [ff00]: Realtek Semiconductor Co., Ltd. RTS522A PCI Express Card Reader [10ec:522a] (rev 01)
08:00.0 Network controller [0280]: Realtek Semiconductor Co., Ltd. RTL8723BE PCIe Wireless Network Adapter [10ec:b723]
09:00.0 Ethernet controller [0200]: Realtek Semiconductor Co., Ltd. RTL8101/2/6E PCI Express Fast/Gigabit Ethernet controller [10ec:8136] (rev 0a)
asked May 13, 2016 at 16:15
![]()
João AbrantesJoão Abrantes
7631 gold badge6 silver badges10 bronze badges
5
Try this,
Use this link ( about the adding paramter to kernel here) to understand about adding kernel boot paramter temporarily and making it permanent.
Then,
Add the parameter , pci=nomsi
And reboot.
If the problem is solved then make the change permanent.
If does not work then try,
pci=noaer
same way and make it permanent if this works.
(*Reason for appearance is related to the recent Intel Skylake architecture CPUs and Realtek rtl8723be wireless adaptor.
The ubuntu team knows about it. Read more here Bug_track_ubuntu_PCIe bus error )
![]()
answered May 13, 2016 at 16:33
![]()
ankit7540ankit7540
4,1351 gold badge25 silver badges41 bronze badges
8
Here already answers are provided which also helped me a lot. I use text mode of ubuntu 16.04 and so
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=nomsi"
didn’t helped me. Here what I changed was — (in /etc/default/grub)
GRUB_DISTRIBUTOR=`lsb_release -i -s 2> /dev/null || echo Debian`
#GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=nomsi"
GRUB_CMDLINE_LINUX="text pci=nomsi"
# Uncomment to enable BadRAM filtering, modify to suit your needs
# This works with Linux (no patch required) and with any kernel that obtains
# the memory map information from GRUB (GNU Mach, kernel of FreeBSD ...)
#GRUB_BADRAM="0x01234567,0xfefefefe,0x89abcdef,0xefefefef"
# Uncomment to disable graphical terminal (grub-pc only)
GRUB_TERMINAL=console
# The resolution used on graphical terminal
# note that you can use only modes which your graphic card supports via VBE
# you can see them in real GRUB with the command `vbeinfo'
#GRUB_GFXMODE=640x480
which solved my error(NOTE — I used only pci=nomsi, and in case it don’t work other option is pci=noaer), that may help solve anyone facing the same error.
answered Jun 17, 2017 at 6:42
![]()
2
I always have the same issue when reinstall Ubuntu 18.04.4 with ASUS X555UQ Laptop.
Answers above helped me a lot about adding which parameter to /etc/default/grub/ but I can’t reach terminal (also tty), because after installing OS via live usb, it gives a blank screen(or mentioned issue) instead of login screen.
Then I thought that I have to get to the GRUB menu at boot-time so, according to this link how to get to the GRUB menu at boot-time, pressing esc while booting did not cause the GRUB menu to appear. It shows please select boot device section for me. Then I pressed Enter to boot again and while booting, pressed esc again. Finally it reached to the GRUB menu and I pressed e to edit the commands(this page starts with set params 'Ubuntu'). Then I added pci=nomsi to end of the line starting with linux and pressed F10 to boot.
After this operation, I was able to reach login screen and terminal. Then I followed the @Ujjal Kumar Das’s answer above and updated my /etc/default/grub/ file permanently.
Maybe this method works for the users who have the same laptop model like me. I like using Ubuntu, but this issue is so annoying every time.
answered Mar 29, 2020 at 21:50
![]()
|
# (отредактировано 6 лет, 3 месяца назад) |
|
|
Темы: 1 Сообщения: 20 Участник с: 30 октября 2014 |
Всем доброе время суток! Проблема такого плана. В частном доме часто плохое напряжение, и поэтому ПК работает через стабилизатор. (УПС нет) и комп часто вырубался жестко из-за этого полетело, что то в системе !!! Некоторый софт не запускается …. Вот ошибка firefox
[Child 9482] WARNING: pipe error (3): Соединение разорвано другой стороной: file /build/firefox/src/firefox-49.0.1/ipc/chromium/src/chrome/common/ipc_channel_posix.cc, line 316 |
|
vasek |
# (отредактировано 6 лет, 3 месяца назад) |
|
Темы: 47 Сообщения: 11417 Участник с: 17 февраля 2013 |
Информации практически нет, гадать нет смысла… Ошибка шины (core dumped) — лучше погуглить по Bus error (core dumped), но вряд ли без уточнения проблемы что то можно толковое нагуглить …. а для сбора информации 1. Лучше сначала просмотреть внимательно логи — возможно есть какие то настораживающие записи перед падением … 2. Посмотри наличие коры…. $ coredumpctl list … (или в ручную — /var/lib/systemd/coredump/) — если есть в наличии, попробуй запустить в gdb …. хотя бы посмотреть, где падают …. 3. Можно попробовать потрейсить (strace) по системным вызовам … 4. Если это выскакивает у многих приложений, то это может быть связано и с аппаратными проблемами — неплохо проверить HDD и память Ошибки не исчезают с опытом — они просто умнеют |
|
vadik |
# (отредактировано 6 лет, 3 месяца назад) |
|
Темы: 55 Сообщения: 5410 Участник с: 17 августа 2009 |
vasek, есть еще нулевой вариант — просто переустановить проблемные приложения. Только это все до лампочки. Следующий скачек напряжения может отправить в небытие и материнку, и ЖД и пр. пр. пр. Бороться в первую очередь нужно с причиной, а не с последствиями. |
|
Aivar |
# |
|
Темы: 4 Сообщения: 6897 Участник с: 17 февраля 2011 |
Жестко полетело в файловой системе. vadik, прав. |
|
ErV |
# |
|
Темы: 18 Сообщения: 121 Участник с: 03 июня 2015 |
У меня была такая ерунда когда сбоила ОЗУ, причем это проявлялось редко и по разному, но подобные ошибки были как в firefox так и в chromium. Gold Memory Test в режиме Thorough на ночь помогут вам подтвердить или исключить этот пункт. |
|
lampslave |
# |
|
Темы: 32 Сообщения: 4800 Участник с: 05 июля 2011 |
Точняк. Привезли мужика с топором в спине — а давайте ему температуру померим, может грипп у него? Купите уже УПС, не гробьте технику. |
|
vasek |
# |
|
Темы: 47 Сообщения: 11417 Участник с: 17 февраля 2013 |
lampslave, ты прав — топор нужно извлекать в первую очередь и, при необходимости, переводить в реанимцию, чтобы привести в чувство…… но рана то сама по себе никуда не исчезнет, все равно нужно лечить (после того как переведут в обычную палату) ……… если не лечить может образоваться и сепсис или что другое …….
Ошибки не исчезают с опытом — они просто умнеют |
mmap минимальный пример POSIX 7
«Ошибка шины» происходит, когда ядро отправляет SIGBUS в процесс.
Минимальный пример, который создает его, потому что ftruncate был забыт:
#include <fcntl.h> /* O_ constants */
#include <unistd.h> /* ftruncate */
#include <sys/mman.h> /* mmap */
int main() {
int fd;
int *map;
int size = sizeof(int);
char *name = "/a";
shm_unlink(name);
fd = shm_open(name, O_RDWR | O_CREAT, (mode_t)0600);
/* THIS is the cause of the problem. */
/*ftruncate(fd, size);*/
map = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
/* This is what generates the SIGBUS. */
*map = 0;
}
Запустить с помощью:
gcc -std=c99 main.c -lrt
./a.out
Протестировано в Ubuntu 14.04.
POSIX описывает SIGBUS как:
Доступ к части undefined объекта памяти.
спецификация mmap говорит, что:
Ссылки в диапазоне адресов, начинающиеся с pa и продолжающиеся для len-байтов на целые страницы, следующие за концом объекта, должны привести к передаче сигнала SIGBUS.
И shm_open говорит, что он генерирует объекты размером 0:
Объект общей памяти имеет нулевой размер.
Итак, при *map = 0 мы касаемся конца выделенного объекта.

Спокойно работал, вдруг, всё стало доступно только для чтения, браузер не смог открывать страницы, ничего не компилируется, не запускается, терминал тоже глючит. Потом мне во включенном терминале написало:
Код
KeyboardInterrupt
Traceback (most recent call last):
File "/usr/lib/command-not-found", line 1, in <module>
KeyboardInterrupt
KeyboardInterrupt
^C
На любые существующие команды — «Ошибка шины», на несуществующие вообще ничего не пишет (даже то, что команда отсутствует)
Сейчас всё нормально загружается, но, по-моему, только в оперативку. Диск стал доступен только для чтения. В чём дело?
Ещё несколько команд проделал:
Код
root@vladiator:~# cd gaming #нормально root@vladiator:~/gaming# ls #нормально vlacer root@vladiator:~/gaming# cd vlacer #нормально root@vladiator:~/gaming/vlacer# ./jojee #ненормально bash: ./jojee: Нет такого файла или каталога root@vladiator:~/gaming/vlacer# ls #Ненормально Ошибка шины
В общем, я не знаю, какая информация нужна, спрашивайте её, если надо. Могу сказать лишь то, что у меня огромные проблемы.
Недавно открывал системник и закрыл его. Возможно, что-то там слетело (тем более, у меня в последнее время часто кабель для соединения диска с материнкой отваливается), но проверил соединение — вроде норм.
Добавлено через 1 минуту
Код
root@vladiator:~/gaming/vlacer# badblocks -v /dev/sda bash: /sbin/badblocks: Ошибка ввода/вывода
Добавлено через 3 минуты
Если бы диск полностью отрубился, то gnome-panel бы вылетел и появилось сообщение с кучей квадратов (как при отключении диска и rm -rf)
Добавлено через 5 минут
Сделал перезапуск, всё нормально, но хотелось бы узнать, из-за чего это было. Возможно, соединение действительно ненадолго пропало, но могло ли это привести к таким последствиям?
- Печать
Страницы: [1] 2 Все Вниз
Тема: Ошибка шины (Прочитано 7629 раз)
0 Пользователей и 1 Гость просматривают эту тему.
Tupas
Значит, ввожу в консоли sudo apt-get install любое_имя_пакета, а в ответ получаю кучу текста такого вида:
[ 2927.929002] ata1.00: status: { DRDY ERR }Что делать?
[ 2927.942856] ata1.00: error: { UNC }
[ 2931.680190] ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0
[ 2931.694304] ata1.00: BDMA stat 0x25
[ 2931.708326] ata1.00: failed command: READ DMA
[ 2931.722101] ata1.00: cmd c8/00:08:08:a5:0c/00:00:00:00:00/e0 tag 0 dma 4096 in
[ 2931.722107] ata1.00: res 51/40:03:0c:a5:0c/00:00:00:00:00/e0 Emask 0x9 (media error)
[ 2931.777373] ata1.00: status: { DRDY ERR }
[ 2931.791188] ata1.00: error: { UNC }
[ 2931.828780] end_request: I/O error, dev sda, sector 828684
Ошибка шины
Deathrose
Что делать?
Проверьте кабели)) Проверьте жесткий диск)))
sht0rm
Заменить кабель, заменить жесткий диск.
Tupas
Ну, кабель заменить попробую. А чем можно жёсткий диск проверить?
sht0rm
666joy666
Было у меня точно так же…end-to-end error, если точней, можно посмотреть в SMART…
Решается заменой шлейфа, воткнуть шлейф в иной порт, взять иной кабель, и как апофез — сменить винт.
Pace!
Если это проблема с жёстким диском, то ведь она должна распространятся на всё, а не только на установку, так ведь?
666joy666
Если это проблема с жёстким диском, то ведь она должна распространятся на всё, а не только на установку, так ведь?
Эта ошибка не столь критична…у меня она вылазила только если я один файл пытался скопировать с одного раздела на иной, больше её не видел…
nd3
mhdd, victoria
Вы же в UBUNTU!!!
Проверить диск на битые сектора:
badblocks -v /dev/sda
MA3X
2931.791188] ata1.00: error: { UNC } — это открытым текстом сбойный сектор на харде.
невосстановимая ошибка чтения.
Винт или мучить mhdd, или менять. второе — предпочтительнее
Microsoft isn’t the answer.
Microsoft is the question, and the answer is NO.
Tupas
Нашлось 120 плохих блоков, и как их чинить?
nd3
Как чинить? badblocks -vw /dev/sda(1) это с проверкой на запись.
Внимание!!!! Вся информация будет уничтожена!
Сектора которые не пройдут тест запись-чтение, будут перенесены SMARTом в дефект лист. А по большому счету выход один — замена винчестера.
Tupas
Как чинить? badblocks -vw /dev/sda(1) это с проверкой на запись.
Внимание!!!! Вся информация будет уничтожена!
А без уничтожения никак что ли?
И это же наверное с другого диска делать надо?
nd3
Как чинить? badblocks -vw /dev/sda(1) это с проверкой на запись.
Внимание!!!! Вся информация будет уничтожена!А без уничтожения никак что ли?
И это же наверное с другого диска делать надо?
Никак, совсем. Это очевидно.
MA3X
Я допускаю для винта не более 5-7 бб на всей поверхности, чтобы считать его еще нормальным.
Если больше — то как минимум не в рабочие машины. Временное хранение некритичных данных.
А 120 — однозначно втопка_гореть.
Microsoft isn’t the answer.
Microsoft is the question, and the answer is NO.
- Печать
Страницы: [1] 2 Все Вверх
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 17:22, 21 мая 2019.
Ошибка на шине (bus error)- это ошибка, которая была вызвана аппаратным обеспечением, уведомляющим операционную систему о том , что процесс пытается получить доступ к памяти, которую процессор не может физически адресовать из-за того, что у адресной шины недопустимый адрес, а следовательно, и имя. В современном использовании на большинстве архитектур они встречаются гораздо реже , чем ошибки сегментации, которые возникают в основном из-за нарушений доступа к памяти: проблем с логическим адресом или разрешениями.
На платформах, совместимых с портативным интерфейсом операционной системы( POSIX), ошибки шины обычно приводят к тому, что сигнал SIGBUS, который сигнализирует об ошибке шины, при обращении к физической памяти, передается процессу, который вызвал ошибку. SIGBUS также может быть вызван любой общей неисправностью устройства, которую обнаруживает компьютер, хотя ошибка шины редко означает, что компьютерное оборудование физически сломано, в основном это вызвано ошибкой в программном обеспечении.
Содержание
- 1 Причины возникновения
- 1.1 Недействующий адрес
- 1.2 Несогласованный доступ
- 1.3 Ошибка страницы
- 1.4 Несуществующий сегмент(x86)
- 2 Источники
Причины возникновения
Существует 4 основных причины возникновения данной ошибки.
Рассмотрим каждую из них.
Недействующий адрес
Программное обеспечение указывает процессору на чтение или запись определенного адреса физической памяти . Соответственно, центральный процессор устанавливает этот физический адрес на своей адресной шине и запрашивает все другое оборудование, подключенное к нему, чтобы ответить с результатами, если они отвечают за этот конкретный адрес. Если никакое другое оборудование не отвечает, центральный процессор вызывает исключение, указывающее, что запрошенный физический адрес не распознан всей компьютерной системой. Состоит отметить, что это касается только физических адресов памяти. Попытка доступа к неопределенному адресу виртуальной памяти обычно считается ошибкой сегментации, а не ошибкой шины, хотя если блок управления памятью (MMU) является отдельным, процессор не может определить разницу.
Несогласованный доступ
В основном центральные процессоры (CPU) являются байт-адресуемыми, где каждый уникальный адрес памяти ссылается на 8-битный байт . Большинство из них могут получить доступ к отдельным байтам из каждого адреса памяти, но они, как правило, не могут получить доступ к более крупным блокам (16 бит, 32 бит, 64 бит и т. д.) без «выравнивания» структуры данных этих блоков к определенной границе.
К примеру, если многобайтовый доступ должен быть 16-битным, адреса (заданные в байтах) в 0, 2, 4, 6 и так далее будут считаться выровненными и, следовательно, доступными, в то время как адреса 1, 3, 5 и так далее будут считаться не выровненными. Аналогично, если многобайтовый доступ должен быть 32-разрядным, адреса 0, 4, 8, 12 и так далее будут считаться выровненными и, следовательно, доступными, а все промежуточные адреса будут считаться не выровненными. Попытка получить доступ к блоку размером больше байта по не выровненному адресу может привести к ошибке шины.
Некоторые системы могут быть смешанные в зависимости от используемой архитектуры. Например, для аппаратного обеспечения, основанного на мэйнфрейме IBM System/360 , включая IBM System z, Fujitsu B8000, RCA Spectra и UNIVAC Series 90 , инструкции должны находиться на 16-разрядной границе, то есть адреса выполнения должны начинаться с четного байта. Попытка ветвления на нечетный адрес приводит к исключению спецификации. Данные, однако, могут быть извлечены из любого адреса в памяти, и могут быть размером от одного байта или больше, в зависимости от инструкции.
Процессоры, как правило, получают доступ к данным на всей ширине своей шины данных в любое время.
Система связи , которая передает данные между компонентами внутри компьютера или между компьютерами.Шина это система связи , которая передает данные между компонентами внутри компьютера или между компьютерами. Чтобы обратиться к байтам, они обращаются к памяти на всей ширине своей шины данных, затем маскируют и сдвигают для обращения к отдельному байту. Системы терпят этот неэффективный алгоритм, так как он является неотъемлемой особенностью большинства программ, особенно обработки строк. В отличие от байтов, большие блоки могут охватывать два выровненных адреса и, таким образом, требуют более одной выборки на шине данных. Процессоры могут поддерживать эту функцию, но эта функциональность редко требуется непосредственно в машинном коде уровень, таким образом, проектировщики центрального процессора обычно избегают его реализации и вместо этого выдают ошибки шины для не выровненного доступа к памяти.
Ошибка страницы
Такие ОС как,FreeBSD, Linux и Solaris могут сигнализировать об ошибке шины, когда страницы виртуальной памяти не могут быть выгружены, например, потому, что она исчезла (например, доступ к файлу с отображением памяти или выполнение двоичного образа, который был усечен во время работы программы), или потому, что только что созданный файл с отображением памяти не может быть физически выделен, потому что диск заполнен.
Несуществующий сегмент(x86)
На x86(емейство архитектур наборов команд,основанных на микропроцессоре Intel 8086 ) существует старый механизм управления памятью, известный как сегментация. Если приложение загружает регистр сегмента с селектором несуществующего сегмента , генерируется исключение. Некоторые ОС использовали это для подкачки, но под Linux это генерирует SIGBUS.
Источники
- https://stackoverflow.com/questions/212466/what-is-a-bus-error
- https://www.geeksforgeeks.org/segmentation-fault-sigsegv-vs-bus-error-sigbus/
- https://studfiles.net/preview/307512/page:15/
Что такое ошибка шины?
Что означает сообщение об ошибке шины и чем оно отличается от сегфоута?
Ответы:
В настоящее время ошибки шины встречаются редко на x86 и возникают, когда ваш процессор не может даже попытаться получить доступ к памяти, как правило:
- использование инструкции процессора с адресом, который не удовлетворяет его требованиям выравнивания.
Ошибки сегментации возникают при доступе к памяти, которая не принадлежит вашему процессу, они очень распространены и обычно являются результатом:
- используя указатель на то, что было освобождено.
- используя неинициализированный, следовательно, фиктивный указатель.
- используя нулевой указатель.
- переполнение буфера.
PS: если быть более точным, это не манипулирование самим указателем, который вызовет проблемы, это доступ к памяти, на которую он указывает (разыменование).
Segfault обращается к памяти, к которой у вас нет доступа. Это только для чтения, у вас нет разрешения и т.д …
Ошибка шины пытается получить доступ к памяти, которая не может быть там. Вы использовали адрес, который не имеет смысла для системы, или неправильный адрес для этой операции.
mmap минимальный пример POSIX 7
«Ошибка шины» возникает, когда ядро отправляет SIGBUSпроцесс.
Минимальный пример, который производит это, потому что ftruncateбыл забыт:
#include <fcntl.h> /* O_ constants */
#include <unistd.h> /* ftruncate */
#include <sys/mman.h> /* mmap */
int main() {
int fd;
int *map;
int size = sizeof(int);
char *name = "/a";
shm_unlink(name);
fd = shm_open(name, O_RDWR | O_CREAT, (mode_t)0600);
/* THIS is the cause of the problem. */
/*ftruncate(fd, size);*/
map = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
/* This is what generates the SIGBUS. */
*map = 0;
}
Бежать с:
gcc -std=c99 main.c -lrt
./a.out
Протестировано в Ubuntu 14.04.
POSIX описывает SIGBUS как:
Доступ к неопределенной части объекта памяти.
Спецификация mmap говорит, что:
Ссылки в пределах диапазона адресов, начинающиеся с pa и продолжающиеся для длинных байтов до целых страниц после конца объекта, должны привести к доставке сигнала SIGBUS.
И shm_open говорит, что генерирует объекты размером 0:
Объект общей памяти имеет нулевой размер.
Таким образом, *map = 0мы касаемся конца выделенного объекта.
Нераспределенный доступ к памяти стека в ARMv8 aarch64
Это было упомянуто в: Что такое ошибка шины? для SPARC, но здесь я приведу более воспроизводимый пример.
Все, что вам нужно, это отдельная программа aarch64:
.global _start
_start:
asm_main_after_prologue:
/* misalign the stack out of 16-bit boundary */
add sp, sp, #-4
/* access the stack */
ldr w0, [sp]
/* exit syscall in case SIGBUS does not happen */
mov x0, 0
mov x8, 93
svc 0
Затем эта программа вызывает SIGBUS на Ubuntu 18.04 aarch64, ядре Linux 4.15.0 на сервере ThunderX2 .
К сожалению, я не могу воспроизвести его в пользовательском режиме QEMU v4.0.0, я не уверен почему.
Неисправность , как представляется, по желанию и контролируются SCTLR_ELx.SAи SCTLR_EL1.SA0полями, я обобщил связанные документы немного дальше здесь .
Я полагаю, что ядро вызывает SIGBUS, когда приложение демонстрирует смещение данных на шине данных. Я думаю, что, поскольку большинство [?] Современных компиляторов для большинства процессоров дополняют / выравнивают данные для программистов, проблемы выравнивания в прошлом (по крайней мере) смягчаются, и, следовательно, в наши дни SIGBUS не видят слишком часто (AFAIK).
От: Здесь
Вы также можете получить SIGBUS, если по какой-то причине невозможно вставить кодовую страницу.
Один классический случай ошибки шины возникает в некоторых архитектурах, таких как SPARC (по крайней мере, некоторые SPARC, возможно, это было изменено), когда вы делаете неправильный доступ. Например:
unsigned char data[6];
(unsigned int *) (data + 2) = 0xdeadf00d;Этот фрагмент кода пытается записать 32-разрядное целочисленное значение 0xdeadf00dв адрес, который (скорее всего) не выровнен должным образом, и сгенерирует ошибку шины на архитектурах, которые «разборчивы» в этом отношении. Intel x86, кстати, не такая архитектура, она позволила бы доступ (хотя и выполнял его медленнее).
Конкретный пример ошибки шины, с которой я только что столкнулся при программировании C на OS X:
#include <string.h>
#include <stdio.h>
int main(void)
{
char buffer[120];
fgets(buffer, sizeof buffer, stdin);
strcat("foo", buffer);
return 0;
}В случае, если вы не помните, документы strcatдобавляют второй аргумент к первому, изменяя первый аргумент (переверните аргументы, и все работает нормально). В Linux это дает ошибку сегментации (как и ожидалось), но в OS X это дает ошибку шины. Зачем? Я действительно не знаю.
Это зависит от вашей ОС, процессора, компилятора и, возможно, других факторов.
В общем, это означает, что шина ЦП не смогла выполнить команду или столкнулась с конфликтом, но это может означать целый ряд вещей, зависящих от среды и выполняемого кода.
-Адам
Обычно это означает неприсоединенный доступ.
Попытка получить доступ к памяти, которая физически отсутствует, также приведет к ошибке шины, но вы не увидите этого, если используете процессор с MMU и операционную систему, которая не глючит, потому что у вас не будет никаких -существующая память сопоставлена с адресным пространством вашего процесса.
Я получал ошибку шины, когда корневой каталог был на 100%.
Причиной ошибки шины в Mac OS X было то, что я попытался выделить около 1 МБ в стеке. Это хорошо работало в одном потоке, но при использовании openMP это приводит к ошибке шины, потому что Mac OS X имеет очень ограниченный размер стека для неосновных потоков .
Я согласен со всеми ответами выше. Вот мои 2 цента относительно ошибки шины:
Ошибка BUS не должна возникать из инструкций в коде программы. Это может произойти, когда вы запускаете двоичный файл и во время выполнения двоичный файл изменяется (перезаписывается сборкой или удаляется и т. Д.).
Проверка, так ли это:
Простой способ проверить, является ли это причиной, — запустить запущенные экземпляры одного и того же двоичного файла и запустить сборку. Оба запущенных экземпляра вылетят с SIGBUSошибкой вскоре после завершения сборки и заменят двоичный файл (тот, который в данный момент запущен обоими экземплярами)
Основная причина:
это происходит потому, что ОС меняет страницы памяти, и в некоторых случаях двоичный файл может загружаться не полностью в память, и эти сбои происходят, когда ОС пытается извлечь следующую страницу из того же двоичного файла, но двоичный файл изменился с момента последнего прочитай это.
Чтобы добавить к ответу blxtd выше, также возникают ошибки шины, когда ваш процесс не может попытаться получить доступ к памяти определенной «переменной» .
for (j = 0; i < n; j++) {
for (i =0; i < m; i++) {
a[n+1][j] += a[i][j];
}
}Заметили « непреднамеренное » использование переменной «i» в первом «цикле for»? Вот что в этом случае вызывает ошибку шины.
Я только что обнаружил, что на процессоре ARMv7 вы можете написать некоторый код, который выдает ошибку сегментации в неоптимизированном состоянии, но при компиляции с -O2 выдает ошибку шины (оптимизируйте больше).
Я использую кросс-компилятор GCC ARM gnueabihf из Ubuntu 64 бит.
Типичное переполнение буфера, которое приводит к ошибке шины,
{
char buf[255];
sprintf(buf,"%s:%sn", ifname, message);
}Здесь, если размер строки в двойных кавычках («») больше размера буфера, это дает ошибку шины.
Модератор: Модераторы разделов
-

simulacrum`
- Сообщения: 70
- ОС: openSUSE 11.1

Re: Kdevelop вываливается выдавая «ошибку шины»
Сообщение
simulacrum` » 17.12.2007 02:32
simulacrum@simulacrum:~/Install> gdb kdevdesigner
GNU gdb 6.6.50.20070726-cvs
Copyright © 2007 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type «show copying» to see the conditions.
There is absolutely no warranty for GDB. Type «show warranty» for details.
This GDB was configured as «i586-suse-linux»…
(no debugging symbols found)
Using host libthread_db library «/lib/libthread_db.so.1».
(gdb) r
Starting program: /opt/kde3/bin/kdevdesigner
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
[Thread debugging using libthread_db enabled]
[New Thread 0xb69ce8e0 (LWP 29672)]
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
—Type <return> to continue, or q <return> to quit—
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
(no debugging symbols found)
—Type <return> to continue, or q <return> to quit—r
(no debugging symbols found)
(no debugging symbols found)
Program received signal SIGBUS, Bus error.
[Switching to Thread 0xb69ce8e0 (LWP 29672)]
0xb7f9554d in ?? () from /lib/ld-linux.so.2