
я написал вот такую программку:
//includes
#include <iostream>
#include <chrono>
#include <string>
#include <ctime>
//namespaces
using namespace std;
using namespace chrono;
//defines
#define RETURN return 0
//main
int main() {
setlocale(LC_ALL,"ru"); //locale
const auto _BEFORE_ = high_resolution_clock::now(); //start timer (for time account)
srand(time(0));
//Create Array
int CountArrayIn_arr2D = 2;
int CountElementsIn_arr1D = 3;
int **arr2D = new int*[CountArrayIn_arr2D];
//Generate Array
for(int i = 0; i < CountArrayIn_arr2D; i++) {
for(int j = 0; j < CountElementsIn_arr1D; j++) {
arr2D[i][j] = rand() % 30 + 1;
}
}
//Print Array
for(int i = 0; i < CountArrayIn_arr2D; i++) {
for(int j = 0; j < CountElementsIn_arr1D; j++) {
cout<<"33[34m"<<arr2D[i][j]<<"33[0mt";
}
cout<<endl;
}
/*Clean memory*/
for(int i = 0; i < CountArrayIn_arr2D; i++) {
delete[] arr2D[i];
}
delete[] arr2D;
//time account
const auto _AFTER_ = high_resolution_clock::now();
const float TIME_FOR_PROGRAM = duration_cast<milliseconds>(_AFTER_-_BEFORE_).count();
cout<<"nn Programm completed in "<<TIME_FOR_PROGRAM<<"ms"<<endl;
RETURN;
}
и пишет: 
у меня 2 вопроса.
1) что значит стек сброшен на диск? на жесткий диск? удалится ли он самостоятельно? если нет то как удалить?
2) как это решить и почему это вообще произошло?
задан 29 окт 2019 в 14:44
![]()
Данил ПерелыгинДанил Перелыгин
1301 золотой знак1 серебряный знак8 бронзовых знаков
2
«Стек памяти сброшен на диск» — это [весьма-а вольный] перевод фразы «Core dumped». На диске в текущем каталоге создаётся файл с именем «core». Сам он не удалится, но он — самый обычный файл, который вы можете удалить когда захотите.
Файл core также сам по себе является кратчайшим путём к ответу на вопрос номер 2. Если ваш бинарник собран с опцией компилятора «-g», то вы можете запустить отладчик с командной строкой в виде «gdb -c core main.exe». Отладчик автоматически окажется на той строке, которая вызвала segmentation fault. О работе в gdb рекомендую почитать его документацию, она обширна и исчерпывающа.
ответ дан 29 окт 2019 в 15:03
![]()
user_587user_587
2,5311 золотой знак11 серебряных знаков20 бронзовых знаков
5
У вас явная ошибка работы с памятью. Вызов new происходит один раз, а вызов delete?
Здесь происходит выделение массива указателей на int:
int **arr2D = new int*[CountArrayIn_arr2D];
Чтобы получить двумерный массив, нужно еще в каждый указатель выделить свой блок памяти:
for (int i = 0; i < CountArrayIn_arr2D; i++)
{
arr2D[i] = new int[CountElementsIn_arr1D];
// ^^^^^^^
for (int j = 0; j < CountElementsIn_arr1D; j++)
{
// делаем что нужно
}
}
ответ дан 29 окт 2019 в 14:51
![]()
1
чел, ты забыл объявить элементы массивов в массиве)
ответ дан 29 окт 2019 в 14:55
![]()
|
Alllgator343 4 / 1 / 0 Регистрация: 20.06.2020 Сообщений: 80 |
||||
|
1 |
||||
Ошибка сегментирования (стек памяти сброшен на диск)08.08.2022, 18:58. Показов 1330. Ответов 11 Метки нет (Все метки)
Здравствуйте. Прошу помощи. При компиляции ошибок нет, двумерный массив появляется, но при выполнении блока с подсчетом локальных минимумов выдает ошибку: «Ошибка сегментирования (стек памяти сброшен на диск». Я так понимаю, что программа лезет не в свой сегмент памяти. В чем ошибка не пойму. Кликните здесь для просмотра всего текста
0 |

|
4023 / 3280 / 920 Регистрация: 25.03.2012 Сообщений: 12,266 Записей в блоге: 1 |
|
|
08.08.2022, 19:04 |
2 |
|
ну собственно твои a[i+-1][j+-1] выходят за пределы массива.
1 |
|
Folian 1704 / 1104 / 337 Регистрация: 25.01.2019 Сообщений: 2,903 |
||||
|
08.08.2022, 19:06 |
3 |
|||
|
В чем ошибка не пойму
программа лезет не в свой сегмент памяти
…
1 |

|
2341 / 1869 / 606 Регистрация: 29.06.2020 Сообщений: 7,057 |
|
|
09.08.2022, 00:55 |
4 |
|
программа лезет не в свой сегмент памяти Что бы такого не было, сделайте проверку на выход за границы массива. Вот примерчик :
1 |
|
Вездепух
10916 / 5911 / 1615 Регистрация: 18.10.2014 Сообщений: 14,859 |
|
|
09.08.2022, 02:22 |
5 |
|
Подсчитать количество локальных минимумов Как определяется «локальных минимум» для элемента, находящегося на краю массива? Может ли элемент на краю массива быть локальным минимумом?
0 |
|
4 / 1 / 0 Регистрация: 20.06.2020 Сообщений: 80 |
|
|
09.08.2022, 11:04 [ТС] |
6 |
|
Соседями элемента Аij в матрице называются элементы Аkl где формула. Элемент матрицы называется локальным минимумом, если он строго меньше всех имеющихся у него соседей. Подсчитать количество локальных минимумов. Добавлено через 56 секунд
0 |
|
SmallEvil 2341 / 1869 / 606 Регистрация: 29.06.2020 Сообщений: 7,057 |
||||
|
09.08.2022, 11:46 |
7 |
|||
|
Элемент матрицы называется локальным минимумом, если он строго меньше всех имеющихся у него соседей. Кто такие эти соседи, какие у них признаки ?
Не понимаю, объясните, пожалуйста. Я же ссылку на кота давал, там минимум правок нужно.
Добавлено через 16 минут
0 |
|
Вездепух
10916 / 5911 / 1615 Регистрация: 18.10.2014 Сообщений: 14,859 |
|
|
09.08.2022, 21:51 |
8 |
|
Соседями элемента Аij в матрице называются элементы Аkl где формула. Что значит «где формула»?
0 |
|
Alllgator343 4 / 1 / 0 Регистрация: 20.06.2020 Сообщений: 80 |
||||
|
09.08.2022, 21:59 [ТС] |
9 |
|||
|
TheCalligrapher я не знаю, так в задании указано. Видимо так копировал преподаватель. Все до чего я додумался это
Брал вот из этой темы Кликните здесь для просмотра всего текста Подсчитать количество локальных минимумов матрицы , у них вроде как все работает, у меня не хочет. Даже с подсказками целый день убил, все еще сижу, так и не понимаю, как исправить программу.
0 |
|
Вездепух
10916 / 5911 / 1615 Регистрация: 18.10.2014 Сообщений: 14,859 |
|
|
09.08.2022, 22:08 |
10 |
|
Брал вот из этой темы Что именно «брал»? Там несколько вариантов.
у них вроде как все работает Вариант вроде вашего? Нет, там он не работает. Зачем вы его оттуда взяли, если даже там указали на эту же ошибку и даже там код в итоге исправили?
0 |
|
Alllgator343 4 / 1 / 0 Регистрация: 20.06.2020 Сообщений: 80 |
||||
|
09.08.2022, 22:18 [ТС] |
11 |
|||
|
Объясните мне, пожалуйста, как этот код работает: Кликните здесь для просмотра всего текста
Зачем нужны flags, false, true? С данным кодом заработало, но он мне непонятен. Добавлено через 5 минут
0 |
|
TheCalligrapher Вездепух
10916 / 5911 / 1615 Регистрация: 18.10.2014 Сообщений: 14,859 |
||||
|
09.08.2022, 22:22 |
12 |
|||
|
Вместо того, чтобы разбираться с этими «непонятными» условиями, заведите массив на две строки и два столбца больше, чем требуется, т.е. А все остальное делайте как и раньше в центральной части матрицы
Тогда никаких дополнительных проверок будет не нужно.
1 |
- Печать
Страницы: [1] Вниз

Тема: Ошибка сегментирования (стек памяти сброшен на диск) [Решено] (Прочитано 10790 раз)
0 Пользователей и 1 Гость просматривают эту тему.

DANNNNN

Привет всем.
Есть программа. Она устанавливается из архива, который предварительно скачивается и после устанавливается.
Программа очень специфичная. Ты ей подсовываешь файл с командами, она его рассчитывает ( математического уклона программа) и выдаёт файл типа out.
И вот вчера при попытке запустить программу она выдаёт:
dan@dan-B450-AORUS-PRO:~/opt/2$ $GAUSS_EXEDIR/g16 NiFeSi2New33.inpЕстественно у меня всего один файл в папке из которой происходит запуск.
Unable to open input file "NiFeSi2New33.inp" or "NiFeSi2New33.inp".
Ошибка сегментирования (стек памяти сброшен на диск)
Что я делал. Я на создавал кучу входных файлов ( вот этот 3-ий был) и всё равно прога почему-то видит какой-то второй такой- же файл. 
Я обновлял Ubuntu, я перестановил программу поверх старой. Ничего не помогает(.
Помогите кто чем может.
« Последнее редактирование: 18 Марта 2020, 11:41:50 от zg_nico »
bezbo
Ошибка сегментирования (стек памяти сброшен на диск)
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Помогите кто чем может
вам остается только отправить отчет об ошибке разработчикам
или запустите программу отладчиком sudo gdb -q
ReNzRv
И вот вчера
До этого система обновлялась?
Автоматическое обновление системы включено в настройках?
DANNNNN
Проблема решилась(
Очень странно. Но я взял файл, который до этого запускался и немного изменил в неём параметры на те которые нужны. И всё заработало.
До этого файлы были созданы как копии того файла, который был создан на другом ПК и перенесён на этот комп через флэшку. Все копии этого файла и выдавали ошибку, не смотря на то, что некоторые из них также я переносил и на другие диски, там редактриовали переносил обратно.
Что это было- не понятно.
Короче ошибка в файле О_о.
Системе обновлялась конечно же.
P.S. До написание сюда я просидел часов 5 над проблемой.
« Последнее редактирование: 16 Ноября 2019, 10:18:29 от DANNNNN »
andytux
«Разруха в головах, а не в клозетах.»
перенесён на этот комп через флэшку. …Короче ошибка в файле
Права на файл.
- Печать
Страницы: [1] Вверх
Не всегда программы в Linux запускаются как положено. Иногда, в силу разных причин программа вместо нормальной работы выдает ошибку. Но нам не нужна ошибка, нам нужна программа, вернее, та функция, которую она должна выполнять. Сегодня мы поговорим об одной из самых серьезных и непонятных ошибок. Это ошибка сегментации Ubuntu. Если такая ошибка происходит только один раз, то на нее можно не обращать внимания, но если это регулярное явление нужно что-то делать.
Конечно, случается эта проблема не только в Ubuntu, а во всех Linux дистрибутивах, поэтому наша инструкция будет актуальна для них тоже. Но сосредоточимся мы в основном на Ubuntu. Рассмотрим что такое ошибка сегментирования linux, почему она возникает, а также как с этим бороться и что делать.
Что такое ошибка сегментации?
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Чтобы понять почему так происходит, давайте рассмотрим как устроена работа с памятью в Linux, я попытаюсь все упростить, но приблизительно так оно и работает.
Допустим, в вашей системе есть 6 Гигабайт оперативной памяти, каждой программе нужно выделить определенную область, куда будет записана она сама, ее данные и новые данные, которые она будет создавать. Чтобы дать возможность каждой из запущенных программ использовать все шесть гигабайт памяти был придуман механизм виртуального адресного пространства. Создается виртуальное пространство очень большого размера, а из него уже выделяется по 6 Гб для каждой программы. Если интересно, это адресное пространство можно найти в файле /proc/kcore, только не вздумайте никуда его копировать.
Выделенное адресное пространство для программы называется сегментом. Как только программа попытается записать или прочитать данные не из своего сегмента, ядро отправит ей сигнал SIGSEGV и программа завершится с нашей ошибкой. Более того, каждый сегмент поделен на секции, в некоторые из них запись невозможна, другие нельзя выполнять, если программа и тут попытается сделать что-то запрещенное, мы опять получим ошибку сегментации Ubuntu.
Почему возникает ошибка сегментации?
И зачем бы это порядочной программе лезть, куда ей не положено? Да в принципе, незачем. Это происходит из-за ошибки при написании программ или несовместимых версиях библиотек и ПО. Часто эта ошибка встречается в программах на Си или C++. В этом языке программисты могут вручную работать с памятью, а язык со своей стороны не контролирует, чтобы они это делали правильно, поэтому одно неверное обращение к памяти может обрушить программу.
Почему может возникать эта ошибка при несовместимости библиотек? По той же причине — неверному обращению к памяти. Представим, что у нас есть библиотека linux (набор функций), в которой есть функция, которая выполняет определенную задачу. Для работы нашей функции нужны данные, поэтому при вызове ей нужно передать строку. Наша старая версия библиотеки ожидает, что длина строки будет до 256 символов. Но программа была обновлена формат записи поменялся, и теперь она передает библиотеке строку размером 512 символов. Если обновить программу, но оставить старую версию библиотеки, то при передаче такой строки 256 символов запишутся нормально в подготовленное место, а вот вторые 256 перезапишут данные программы, и возможно, попытаются выйти за пределы сегмента, тогда и будет ошибка сегментирования linux.
Что делать если возникла ошибка сегментирования?
Если вы думаете, что это ошибка в программе, то вам остается только отправить отчет об ошибке разработчикам. Но вы все-таки еще можете попытаться что-то сделать.
Например, если падает с ошибкой сегментации неизвестная программа, то мы можем решить что это вина разработчиков, но если с такой ошибкой падает chrome или firefox при запуске возникает вопрос, может мы делаем что-то не так? Ведь это уже хорошо протестированные программы.
Первое, что нужно сделать — это обновить систему до самой последней версии, возможно, был баг и его уже исправили, а может у вас установлены старые версии библиотек и обновление решит проблему. В Ubuntu это делается так:
sudo apt update
sudo apt full-upgrade
Если это не помогло, нужно обнулить настройки программы до значений по умолчанию, возможно, удалить кэш. Настройки программ в Linux обычно содержатся в домашней папке, скрытых подкаталогах с именем программы. Также, настройки и кэш могут содержаться в каталогах ~/.config и ~/.cache. Просто удалите папки программы и попробуйте снова ее запустить. Если и это не помогло, вы можете попробовать полностью удалить программу, а потом снова ее установить, возможно, какие-нибудь зависимости были повреждены:
sudo apt remove пакет_программы
sudo apt autoremove
sudo apt install пакет_программы
Если есть возможность, попробуйте установить программу из другого источника, например, не из PPA, а более старую версию, из официальных репозиториев.
Когда вы все это выполнили, скорее всего, проблема не в вашем дистрибутиве, а в самой программе. Нужно отправлять отчет разработчикам. В Ubuntu это можно сделать с помощью программы apport-bug. Обычно Ubuntu предлагает это сделать сразу, после того как программа завершилась с ошибкой сегментирования. Если же ошибка сегментирования Ubuntu встречается не в системной программе, то вам придется самим искать разработчиков и вручную описывать что произошло.
Чтобы помочь разработчикам решить проблему, недостаточно отправить им только сообщение что вы поймали Segmentation Fault, нужно подробно описать проблему, действия, которые вы выполняли перед этим, так чтобы разработчик мог их воспроизвести. Также, желательно прикрепить к отчету последние функции, которые вызывала программа (стек вызовов функций), это может очень сильно помочь разработчикам.
Рассмотрим, как его получить. Это не так уж сложно. Сначала запустите вашу программу, затем узнайте ее PID с помощью команды:
pgrep программа
Дальше запускаем отладчик gdb:
sudo gdb -q
Подключаемся к программе:
(gdb) attach ваш_pid
После подключения программа станет на паузу, продолжаем ее выполнение командой:
(gdb) continue

Затем вам осталось только вызвать ошибку:
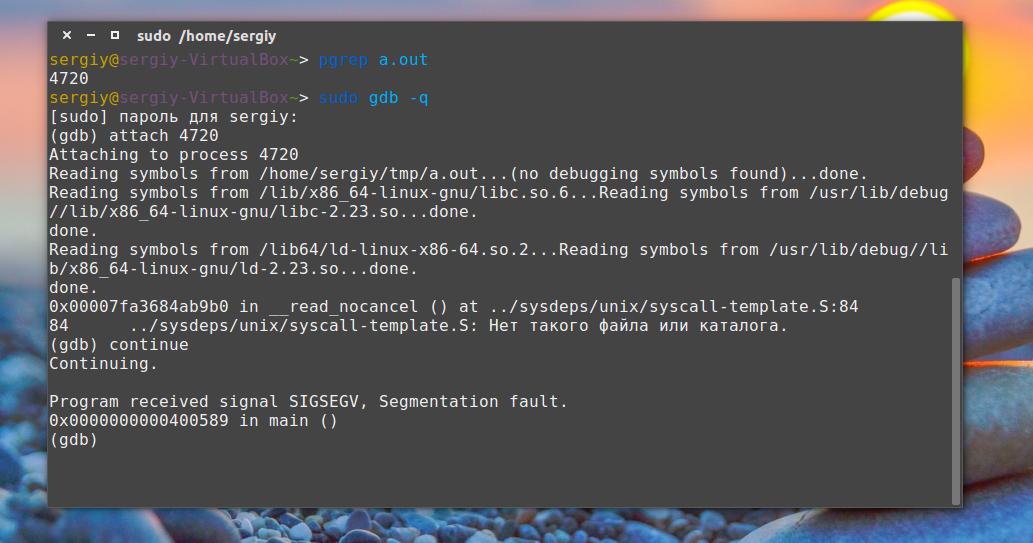
И набрать команду, которая выведет стек последних вызовов:
(gdb) backtrace
Вывод этой команды и нужно отправлять разработчикам. Чтобы отключиться от программы и выйти наберите:
(gdb) detach
(gdb) quit
Дальше остается отправить отчет и ждать исправления ошибки. Если вы не уверены, что ошибка в программе, можете поспрашивать на форумах. Когда у вас есть стек вызовов, уже можно попытаться, если не понять в чем проблема, то попытаться узнать, не сталкивался ли с подобной проблемой еще кто-то.
Выводы
Теперь у вас есть приблизительный план действий, что нужно делать, когда появляется ошибка сегментирования сделан дамп памяти ubuntu. Если вы знаете другие способы решить эту проблему, напишите в комментариях!

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Содержание
- Ошибка сегментирования Ubuntu
- Что такое ошибка сегментации?
- Почему возникает ошибка сегментации?
- Что делать если возникла ошибка сегментирования?
- Выводы
- Оцените статью:
- Об авторе
- 7 комментариев
- Ошибка сегментирования Ubuntu
- Что такое ошибка сегментации?
- Почему возникает ошибка сегментации?
- Что делать если возникла ошибка сегментирования?
- Выводы
- [проблемы из ниоткуда] ошибка сегментирования. как найти причину?
- Segmentation Fault (распределение памяти компьютера)
- Немного истории
- Совместный доступ к ресурсам
- Адресное пространство
- Виртуализация памяти
- Переадресация
- Перераспределение памяти
- Сегментация памяти
- Совместное использование сегментов
- Ограничения сегментации
- Разбиение памяти на страницы
- Буфер быстрой переадресации (TLB, Translation-lookaside Buffer)
Ошибка сегментирования Ubuntu
Не всегда программы в Linux запускаются как положено. Иногда, в силу разных причин программа вместо нормальной работы выдает ошибку. Но нам не нужна ошибка, нам нужна программа, вернее, та функция, которую она должна выполнять. Сегодня мы поговорим об одной из самых серьезных и непонятных ошибок. Это ошибка сегментации Ubuntu. Если такая ошибка происходит только один раз, то на нее можно не обращать внимания, но если это регулярное явление нужно что-то делать.
Конечно, случается эта проблема не только в Ubuntu, а во всех Linux дистрибутивах, поэтому наша инструкция будет актуальна для них тоже. Но сосредоточимся мы в основном на Ubuntu. Рассмотрим что такое ошибка сегментирования linux, почему она возникает, а также как с этим бороться и что делать.
Что такое ошибка сегментации?
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Чтобы понять почему так происходит, давайте рассмотрим как устроена работа с памятью в Linux, я попытаюсь все упростить, но приблизительно так оно и работает.
Допустим, в вашей системе есть 6 Гигабайт оперативной памяти, каждой программе нужно выделить определенную область, куда будет записана она сама, ее данные и новые данные, которые она будет создавать. Чтобы дать возможность каждой из запущенных программ использовать все шесть гигабайт памяти был придуман механизм виртуального адресного пространства. Создается виртуальное пространство очень большого размера, а из него уже выделяется по 6 Гб для каждой программы. Если интересно, это адресное пространство можно найти в файле /proc/kcore, только не вздумайте никуда его копировать.
Выделенное адресное пространство для программы называется сегментом. Как только программа попытается записать или прочитать данные не из своего сегмента, ядро отправит ей сигнал SIGSEGV и программа завершится с нашей ошибкой. Более того, каждый сегмент поделен на секции, в некоторые из них запись невозможна, другие нельзя выполнять, если программа и тут попытается сделать что-то запрещенное, мы опять получим ошибку сегментации Ubuntu.
Почему возникает ошибка сегментации?
И зачем бы это порядочной программе лезть, куда ей не положено? Да в принципе, незачем. Это происходит из-за ошибки при написании программ или несовместимых версиях библиотек и ПО. Часто эта ошибка встречается в программах на Си или C++. В этом языке программисты могут вручную работать с памятью, а язык со своей стороны не контролирует, чтобы они это делали правильно, поэтому одно неверное обращение к памяти может обрушить программу.
Что делать если возникла ошибка сегментирования?
Если вы думаете, что это ошибка в программе, то вам остается только отправить отчет об ошибке разработчикам. Но вы все-таки еще можете попытаться что-то сделать.
Например, если падает с ошибкой сегментации неизвестная программа, то мы можем решить что это вина разработчиков, но если с такой ошибкой падает chrome или firefox при запуске возникает вопрос, может мы делаем что-то не так? Ведь это уже хорошо протестированные программы.
sudo apt update
sudo apt full-upgrade
Если это не помогло, нужно обнулить настройки программы до значений по умолчанию, возможно, удалить кэш. Настройки программ в Linux обычно содержатся в домашней папке, скрытых подкаталогах с именем программы. Также, настройки и кэш могут содержаться в каталогах
/.cache. Просто удалите папки программы и попробуйте снова ее запустить. Если и это не помогло, вы можете попробовать полностью удалить программу, а потом снова ее установить, возможно, какие-нибудь зависимости были повреждены:
sudo apt remove пакет_программы
sudo apt autoremove
sudo apt install пакет_программы
Если есть возможность, попробуйте установить программу из другого источника, например, не из PPA, а более старую версию, из официальных репозиториев.
Когда вы все это выполнили, скорее всего, проблема не в вашем дистрибутиве, а в самой программе. Нужно отправлять отчет разработчикам. В Ubuntu это можно сделать с помощью программы apport-bug. Обычно Ubuntu предлагает это сделать сразу, после того как программа завершилась с ошибкой сегментирования. Если же ошибка сегментирования Ubuntu встречается не в системной программе, то вам придется самим искать разработчиков и вручную описывать что произошло.
Чтобы помочь разработчикам решить проблему, недостаточно отправить им только сообщение что вы поймали Segmentation Fault, нужно подробно описать проблему, действия, которые вы выполняли перед этим, так чтобы разработчик мог их воспроизвести. Также, желательно прикрепить к отчету последние функции, которые вызывала программа (стек вызовов функций), это может очень сильно помочь разработчикам.
Рассмотрим, как его получить. Это не так уж сложно. Сначала запустите вашу программу, затем узнайте ее PID с помощью команды:
Дальше запускаем отладчик gdb:
Подключаемся к программе:
(gdb) attach ваш_pid
После подключения программа станет на паузу, продолжаем ее выполнение командой:

Затем вам осталось только вызвать ошибку:

И набрать команду, которая выведет стек последних вызовов:
Вывод этой команды и нужно отправлять разработчикам. Чтобы отключиться от программы и выйти наберите:
(gdb) detach
(gdb) quit
Дальше остается отправить отчет и ждать исправления ошибки. Если вы не уверены, что ошибка в программе, можете поспрашивать на форумах. Когда у вас есть стек вызовов, уже можно попытаться, если не понять в чем проблема, то попытаться узнать, не сталкивался ли с подобной проблемой еще кто-то.
Выводы
Теперь у вас есть приблизительный план действий, что нужно делать, когда появляется ошибка сегментирования сделан дамп памяти ubuntu. Если вы знаете другие способы решить эту проблему, напишите в комментариях!




Оцените статью:
Об авторе
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
7 комментариев
Спасибо, было очень интересно почитать про отладчик.
На самом деле от этого избавится я не могу. Остаётся мне всё сваливать на свой старый компьютер с 1024 мегабайтами озу. Постоянные ошибки сегментирования когда комплимирую какую-либо программу. Чтобы скомплимировать ядро надо по миллиону раз вводить make!! Щас выкину комп и куплю новый и думаю проблема сама разрешится.
Gentoo. cmake 3.14.6. Segmentation fault.
Xeon 2620 v2 24Gb ram
Проблема сама не решается почему-то. 8-(
С ошибкой SIGSEGV или так называемой ошибкой сегментации(на самом деле это ошибки обращения с памятью) вы ничё не сможете сделать. если вы юзер, а не разработчик и она возникает в вашей проге. можете только одного не запускать эту прогу удалить её или попытаться обновить, возможно(вовсе не обязательно!) её заметили и исправили. Но вообще лицензионное соглашение по Ubuntu вас предупреждает, что вы пользуетесь системой в которой софт вовсе не обязан работать и никто за это не отвечает. вы это делаете на свой страх и риск! это краткий его перевод. А если вы купили операционку заплатили бабки и заказали техподдержку, то вы тогда уже имеете право обратиться в службу тех поддержки сообщить баг, где и как он возникает и они обязаны не просто испавить его прислав патч, но так же всем таким как вы кто заплатил. Иначе вы имеете право подать на них в суд и они обязаны компенсировать вам убытки. Но это не Ubuntu. Обратная сторона медали свободного по и бесплатных операционок. среди Линуксовых есть AIX(только платная+ техподдержка), SUSE(не путать с Open Suse) и Debian(есть free урезаный вариант и нормальный платный). Это оч серьёзная ошибка краеугольный камень всех программ и работы компа в целом. Если это ломается, то всё летит к чёрту. Конечно они стараюстся и сразу посылать вас не будут. Это их репутация! но вообще дело в програмерах. Щаз стало оч много криворуких. Вот я смотрю на их код и удивляюсь, как можно так безалаберно писать проги! Если бы вы только это видели вы бы не удивились почему всё так плохо работает. Встречаются такие кадры которые всё только портят! ну а что програмеров не хаватет, делать надо много вот и берут всех подряд. А потом начинается. Если конечно это заметили до релиза, то ладно. Но тут всё ещё зависит от тестеров. Если они хорошие то найдут баги вовремя до релиза и исправят. но у нас как бывает. Отдела тестирования нет, сэкономили.. Тестер дай бог 2-3 а то часто 1 вообще. В программе всегда много ошибок. Особенно вначале. все мы ошибаемся, особенно некоторые. Причина? Нехватка мозгов или банально невнимательность. поэтому все проги должны быть тщательнейшим образом оттестированы. только тогда она может быть допущена к релизу. А ещё заказчик подгоняет. Хорошую прогу нельзя написать в спешке. тем более большую. Такие ошибки как оч трудно найти, а если она не всегда воспроизводится, так вообще нереально, Если только случайно наткнёшься. Потому что как бывает один раз вылетела, а второй нет и пошла дальше и норм. Или пошла дальше и всё стало неправильным. с програмой начинают твориться чудеса. это всё та же ошибка с памятью, которая всё портит. Вылететь может не только ваша прога но и вся система. Но даже если она стабильно воспроизводится, то на её поиск может понадобиться дни а может и неделя две кропотливой упорной работы, носящей изнуряющий характер. искать будут всем отделом. но её тогда по крайней мере можно найти. а если нет. то вам поможет только чудо. А уж что сделают после этого с тем кто это сделал я даже не знаю! Вот такие вот они эти ошибки сегментации. Я показал то что там происходит за кадром юзера.
У меня появляется такая ошибка при попытке запуска Viber
Источник
Ошибка сегментирования Ubuntu
Не всегда программы в Linux запускаются как положено. Иногда, в силу разных причин программа вместо нормальной работы выдает ошибку. Но нам не нужна ошибка, нам нужна программа, вернее, та функция, которую она должна выполнять. Сегодня мы поговорим об одной из самых серьезных и непонятных ошибок. Это ошибка сегментации Ubuntu. Если такая ошибка происходит только один раз, то на нее можно не обращать внимания, но если это регулярное явление нужно что-то делать.
Конечно, случается эта проблема не только в Ubuntu, а во всех Linux дистрибутивах, поэтому наша инструкция будет актуальна для них тоже. Но сосредоточимся мы в основном на Ubuntu. Рассмотрим что такое ошибка сегментирования linux, почему она возникает, а также как с этим бороться и что делать.
Что такое ошибка сегментации?
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Чтобы понять почему так происходит, давайте рассмотрим как устроена работа с памятью в Linux, я попытаюсь все упростить, но приблизительно так оно и работает.
Допустим, в вашей системе есть 6 Гигабайт оперативной памяти, каждой программе нужно выделить определенную область, куда будет записана она сама, ее данные и новые данные, которые она будет создавать. Чтобы дать возможность каждой из запущенных программ использовать все шесть гигабайт памяти был придуман механизм виртуального адресного пространства. Создается виртуальное пространство очень большого размера, а из него уже выделяется по 6 Гб для каждой программы. Если интересно, это адресное пространство можно найти в файле /proc/kcore, только не вздумайте никуда его копировать.
Выделенное адресное пространство для программы называется сегментом. Как только программа попытается записать или прочитать данные не из своего сегмента, ядро отправит ей сигнал SIGSEGV и программа завершится с нашей ошибкой. Более того, каждый сегмент поделен на секции, в некоторые из них запись невозможна, другие нельзя выполнять, если программа и тут попытается сделать что-то запрещенное, мы опять получим ошибку сегментации Ubuntu.
Почему возникает ошибка сегментации?
И зачем бы это порядочной программе лезть, куда ей не положено? Да в принципе, незачем. Это происходит из-за ошибки при написании программ или несовместимых версиях библиотек и ПО. Часто эта ошибка встречается в программах на Си или C++. В этом языке программисты могут вручную работать с памятью, а язык со своей стороны не контролирует, чтобы они это делали правильно, поэтому одно неверное обращение к памяти может обрушить программу.
Что делать если возникла ошибка сегментирования?
Если вы думаете, что это ошибка в программе, то вам остается только отправить отчет об ошибке разработчикам. Но вы все-таки еще можете попытаться что-то сделать.
Например, если падает с ошибкой сегментации неизвестная программа, то мы можем решить что это вина разработчиков, но если с такой ошибкой падает chrome или firefox при запуске возникает вопрос, может мы делаем что-то не так? Ведь это уже хорошо протестированные программы.
Если это не помогло, нужно обнулить настройки программы до значений по умолчанию, возможно, удалить кэш. Настройки программ в Linux обычно содержатся в домашней папке, скрытых подкаталогах с именем программы. Также, настройки и кэш могут содержаться в каталогах
/.cache. Просто удалите папки программы и попробуйте снова ее запустить. Если и это не помогло, вы можете попробовать полностью удалить программу, а потом снова ее установить, возможно, какие-нибудь зависимости были повреждены:
Если есть возможность, попробуйте установить программу из другого источника, например, не из PPA, а более старую версию, из официальных репозиториев.
Когда вы все это выполнили, скорее всего, проблема не в вашем дистрибутиве, а в самой программе. Нужно отправлять отчет разработчикам. В Ubuntu это можно сделать с помощью программы apport-bug. Обычно Ubuntu предлагает это сделать сразу, после того как программа завершилась с ошибкой сегментирования. Если же ошибка сегментирования Ubuntu встречается не в системной программе, то вам придется самим искать разработчиков и вручную описывать что произошло.
Чтобы помочь разработчикам решить проблему, недостаточно отправить им только сообщение что вы поймали Segmentation Fault, нужно подробно описать проблему, действия, которые вы выполняли перед этим, так чтобы разработчик мог их воспроизвести. Также, желательно прикрепить к отчету последние функции, которые вызывала программа (стек вызовов функций), это может очень сильно помочь разработчикам.
Рассмотрим, как его получить. Это не так уж сложно. Сначала запустите вашу программу, затем узнайте ее PID с помощью команды:
Дальше запускаем отладчик gdb:
Подключаемся к программе:
После подключения программа станет на паузу, продолжаем ее выполнение командой:

Затем вам осталось только вызвать ошибку:

И набрать команду, которая выведет стек последних вызовов:
Вывод этой команды и нужно отправлять разработчикам. Чтобы отключиться от программы и выйти наберите:
Дальше остается отправить отчет и ждать исправления ошибки. Если вы не уверены, что ошибка в программе, можете поспрашивать на форумах. Когда у вас есть стек вызовов, уже можно попытаться, если не понять в чем проблема, то попытаться узнать, не сталкивался ли с подобной проблемой еще кто-то.
Выводы
Теперь у вас есть приблизительный план действий, что нужно делать, когда появляется ошибка сегментирования сделан дамп памяти ubuntu. Если вы знаете другие способы решить эту проблему, напишите в комментариях!
Источник
[проблемы из ниоткуда] ошибка сегментирования. как найти причину?
полагаю что дело в том что утром были найдены ошибки в файловой системе
то есть вроде бы читает файл и после этого падает. но толку.. ltrace вообще ничего не дал. похоже ошибка происходит непосредственно в коде программы ssh. ещё вчера всё работало..

1) Посмотри, нет ли записей о сегфолтах в messages.
2) Попробуй временно переименовать

ltrace ssh svn-server

Ну явно же написано, что у тебя known_hosts покоцан. Сдвинь его в сторонку и не парься.

Но таки программа не должна падать из-за проблемы в каком-то конфиге.
благодарю за толковые советы
не, я ж написал, ltrace ничего не дал:
да, кстати, вряд ли.. но я тем не менее сдвинул его.. не помогло..
можно ли как-то запустить проверку контрольных сумм всех файлов установленных пакетным менеджером?
Запустить под gdb и посмотреть почему упало.


>не, я ж написал, ltrace ничего не дал:
strace ssh svn-server
chkrootkit и rkhunter попробуй
и работал вчера ssh
ну и странно что на одном и том же месте.. скорее уж с диском проблемы..
мужик, я думаю специально для тебя нужно ввести звание Ъ^2.
Где,ж он на ровном месте? Какова вероятность, что при многочисленных попытках считать файл он всегда будет попадать на битую область?
> ну и странно что на одном и том же месте..

У меня эта штука половину портов засосала. 1111 А дело всё было в слоте памяти на материнке. И memtest86+ молчал.
libc переставь и tls и прочие либы, которыми пользуется ssh. переустановка только ssh не приведет к переустановке этих либ
Хехе. вероятная причина кроется в svn.
Сам лично сталкивался с регулярными падениями СВН составляющих в дебе. Как правило это происходило при попытке СВНа обратиться в дбасу. Но и в других ситуациях тоже, но реже.
> Хехе. вероятная причина кроется в svn.
open(«/home/andrey/.ssh/known_hosts», O_RDONLY) = 4 ★ ( 26.09.11 14:35:24 )

read() отработал нормально. Проблема где-то доальше в коде. Надо gdb.
Ага, я тоже сидел с gdb и дебажил почему svn up падает 🙂 Проблема была глубоко-глубоко 🙂 А на деле все оказалось куда проще.
Там цикл чтения по 4096. Еслибы он отработал нормально, мы бы увидели следующую итерацию (размер файла больше).
memtest’ом можно подтереться только. Инфа 100%.
Для таких вещей есть ключ для дебага. И gdb. И ещё strace.
А ещё подумай о том, что повреждение может быть в какой-то либе, которую он загружает.
Источник
Segmentation Fault (распределение памяти компьютера)

Когда я делаю ошибку в коде, то обычно это приводит к появлению сообщения “segmentation fault”, зачастую сокращённого до “segfault”. И тут же мои коллеги и руководство приходят ко мне: «Ха! У нас тут для тебя есть segfault для исправления!» — «Ну да, виноват», — обычно отвечаю я. Но многие ли из вас знают, что на самом деле означает ошибка “segmentation fault”?
Чтобы ответить на этот вопрос, нам нужно вернуться в далёкие 1960-е. Я хочу объяснить, как работает компьютер, а точнее — как в современных компьютерах осуществляется доступ к памяти. Это поможет понять, откуда же берётся это странное сообщение об ошибке.
Вся представленная ниже информация — основы компьютерной архитектуры. И без нужды я не буду сильно углубляться в эту область. Также я буду применять всем известную терминологию, так что мой пост будет понятен всем, кто не совсем на «вы» с вычислительной техникой. Если же вы захотите изучить вопрос работы с памятью подробнее, то можете обратиться к многочисленной доступной литературе. А заодно не забудьте покопаться в исходном коде ядра какой-нибудь ОС, например, Linux. Я не буду излагать здесь историю вычислительной техники, некоторые вещи не будут освещаться, а некоторые сильно упрощены.
Немного истории

То есть на ОС приходилась, скажем, четверть всей доступной памяти, а остальной объём отдавался под пользовательские задачи. В то время роль ОС заключалась в простом управлении оборудованием с помощью прерываний ЦПУ. Так что операционке нужна была память для себя, для копирования данных с устройств и для работы с ними (режим PIO). Для вывода данных на экран нужно было использовать часть основной памяти, ведь видеоподсистема либо не имела своей оперативки, либо обладала считанными килобайтами. А уже сама программа выполнялась в области памяти, идущей сразу после ОС, и решала свои задачи.
Совместный доступ к ресурсам
Из-за непомерной стоимости мало кто мог позволить себе приобрести сразу несколько компьютеров, чтобы обрабатывать одновременно несколько задач. Поэтому люди начали искать способы совместного доступа к вычислительным ресурсам одного компьютера. Так наступила эра многозадачности. Обратите внимание, что в те времена ещё никто не помышлял о многопроцессорных компьютерах. Так как же можно заставить компьютер с одним ЦПУ выполнять несколько разных задач?
Решением стало использование планировщика задач (scheduling): пока один процесс прерывался, ожидая завершения операций ввода/вывода, ЦПУ мог выполнять другой процесс. Я не буду здесь больше касаться планировщика задач, это слишком обширная тема, не имеющая отношения к памяти.
Если компьютер способен поочерёдно выполнять несколько задач, то распределение памяти будет выглядеть примерно так:
Задачи А и В хранятся в памяти, поскольку копировать их на диск и обратно слишком затратно. И по мере того, как процессор выполняет ту или иную задачу, он обращается к памяти за соответствующими данными. Но тут возникает проблема.
Когда один программист будет писать код для выполнения задачи В, он должен знать границы выделяемых сегментов памяти. Допустим, задача В занимает в памяти отрезок от 10 до 12 Кб, тогда каждый адрес памяти должен быть жёстко закодирован в пределах этих границ. Но если компьютер будет выполнять сразу три задачи, то память будет поделена на большее количество сегментов, и значит сегмент для задачи В может оказаться сдвинут. Тогда код программы придётся переписывать, чтобы она могла оперировать меньшим объёмом памяти, а также изменить все указатели.
Здесь всплывает и иная проблема: что если задача В обратится к сегменту памяти, выделенному для задачи А? Такое легко может произойти, ведь при работе с указателями памяти достаточно сделать маленькую ошибку, и программа будет обращаться к совершенно другому адресу, нарушив целостность данных другого процесса. При этом задача А может работать с очень важными с точки зрения безопасности данными. Нет никакого способа помешать В вторгнуться в область памяти А. Наконец, вследствие ошибки программиста задача В может перезаписать область памяти ОС (в данном случае от 0 до 4 Кб).
Адресное пространство
Чтобы можно было спокойно выполнять несколько задач, хранящихся в памяти, нам нужна помощь от ОС и оборудования. В частности, адресное пространство. Это некая абстракция памяти, выделяемая ОС для какого-то процесса. На сегодняшний день это фундаментальная концепция, которая используется везде. По крайней мере, во ВСЕХ компьютерах гражданского назначения принят именно этот подход, а у военных могут быть свои секреты. Персоналки, смартфоны, телевизоры, игровые приставки, умные часы, банкоматы — ткните в любой аппарат, и окажется, что распределение памяти в нём осуществляется по принципу «код-стек-куча» (code-stack-heap).
Адресное пространство содержит всё, что нужно для выполнения процесса:
Виртуализация памяти
Допустим, задача А получила в своё распоряжение всю доступную пользовательскую память. И тут возникает задача В. Как быть? Решение было найдено в виртуализации.
Напомню одну из предыдущих иллюстраций, когда в памяти одновременно находятся А и В:
Допустим, А пытается получить доступ к памяти в собственном адресном пространстве, например по индексу 11 Кб. Возможно даже, что это будет её собственный стек. В этом случае ОС нужно придумать, как не подгружать индекс 1500, поскольку по факту он может указывать на область задачи В.
На самом деле, адресное пространство, которое каждая программа считает своей памятью, является памятью виртуальной. Фальшивкой. И в области памяти задачи А индекс 11 Кб будет фальшивым адресом. То есть — адресом виртуальной памяти.
Каждая программа, выполняющаяся на компьютере, работает с фальшивой (виртуальной) памятью. С помощью некоторых чипов ОС обманывает процесс, когда он обращается к какой-либо области памяти. Благодаря виртуализации ни один процесс не может получить доступ к памяти, которая ему не принадлежит: задача А не влезет в память задачи В или самой ОС. При этом на пользовательском уровне всё абсолютно прозрачно, благодаря обширному и сложному коду ядра ОС.
Таким образом, каждое обращение к памяти регулируется операционной системой. И это должно осуществляться очень эффективно, чтобы не слишком замедлять работу различных выполняющихся программ. Эффективность обеспечивается с помощью аппаратных средств, преимущественно — ЦПУ и некоторых компонентов вроде MMU. Последний появился в виде отдельного чипа в начале 1970-х, а сегодня MMU встраиваются непосредственно в процессор и в обязательном порядке используются операционными системами.
Вот небольшая программка на С, демонстрирующая работу с адресами памяти:
На моей машине LP64 X86_64 она показывает такой результат:
Code is at 0x40054c
Stack is at 0x7ffe60a1465c
Heap is at 0x1ecf010
Как я и описывал, сначала идёт кодовый сегмент, затем куча, а затем стек. Но все эти три адреса фальшивые. В физической памяти по адресу 0x7ffe60a1465c вовсе не хранится целочисленная переменная со значением 3. Никогда не забывайте, что все пользовательские программы манипулируют виртуальными адресами, и только на уровне ядра или аппаратных драйверов допускается использование адресов физической памяти.
Переадресация
Переадресация (транслирование, перевод, преобразование адресов) — это термин, обозначающий процесс сопоставления виртуального адреса физическому. Занимается этим модуль MMU. Для каждого выполняющегося процесса операционка должна помнить соответствия всех виртуальных адресов физическим. И это довольно непростая задача. По сути, ОС приходится управлять памятью каждого пользовательского процесса при каждом обращении. Тем самым она превращает кошмарную реальность физической памяти в полезную, мощную и лёгкую в использовании абстракцию.
Давайте рассмотрим подробнее.
Итак, это виртуальное адресное пространство:
А это его физический образ:
Физический адрес = виртуальный адрес + base
Если получившийся физический адрес (6 Кб) выбивается из границ выделенной области (4—20 Кб), это означает, что процесс пытается обратиться к памяти, которая ему не принадлежит. Тогда ЦПУ генерирует исключение и сообщает об этом ОС, которая обрабатывает данное исключение. В этом случае система обычно сигнализирует процессу о нарушении: SIGSEGV, Segmentation Fault. Этот сигнал по умолчанию прерывает выполнение процесса (это можно настраивать).
Перераспределение памяти
Если задача А исключена из очереди на выполнение, то это даже лучше. Это означает, что планировщик попросили выполнить другую задачу (допустим, В). Пока выполняется В, операционка может перераспределить всё физическое пространство задачи А. Во время выполнения пользовательского процесса ОС зачастую теряет управление процессором. Но когда процесс делает системный вызов, процессор снова возвращается под контроль ОС. До этого системного вызова операционка может что угодно делать с памятью, в том числе и целиком перераспределять адресное пространство процесса в другой физический раздел.
В нашем примере это осуществляется достаточно просто: ОС перемещает 16-килобайтную область в другое свободное место подходящего размера и просто обновляет значения переменных base и bounds для задачи А. Когда процессор возвращается к её выполнению, процесс переадресации всё ещё работает, но физическое адресное пространство уже изменилось.
С точки зрения задачи А ничего не меняется, её собственное адресное пространство по-прежнему расположено в диапазоне 0-16 Кб. При этом ОС и MMU полностью контролируют каждое обращение задачи к памяти. То есть программист манипулирует виртуальной областью 0-16 Кб, а MMU берёт на себя сопоставление с физическими адресами.
После перераспределения образ памяти будет выглядеть так:
Программисту теперь не нужно заботиться о том, с какими адресами памяти будет работать его программа, не нужно переживать о конфликтах. ОС в связке с MMU снимают с него все эти заботы.
Сегментация памяти
В предыдущих главах мы рассмотрели вопросы переадресации и перераспределения памяти. Однако у нашей модели работы с памятью есть ряд недостатков:
Для решения некоторых из этих проблем давайте рассмотрим более сложную систему организации памяти — сегментацию. Смысл её прост: принцип “base and bounds” распространяется на все три сегмента памяти — кучу, кодовый сегмент и стек, причём для каждого процесса, вместо того чтобы рассматривать образ памяти как единую уникальную сущность.
В результате мы больше не теряем память между стеком и кучей:
Допустим, у кучи задачи А параметр base равен 126 Кб, а bounds — 2 Кб. Пусть задача А обращается к виртуальному адресу 3 Кб (в куче). Тогда физический адрес определяется как 3 – 2 Кб (начало кучи) = 1 Кб + 126 Кб (сдвиг) = 127 Кб. Это меньше 128, а значит ошибки обращения не будет.
Совместное использование сегментов
Сегментирование физической памяти не только не позволяет виртуальной памяти отъедать физическую, но также даёт возможность совместного использования физических сегментов с помощью виртуальных адресных пространств разных процессов.
Если дважды запустить задачу А, то кодовый сегмент у них будет один и тот же: в обеих задачах выполняются одинаковые машинные инструкции. В то же время у каждой задачи будут свои стек и куча, поскольку они оперируют разными наборами данных.
При этом оба процесса не подозревают, что делят с кем-то свою память. Такой подход стал возможен благодаря внедрению битов защиты сегмента (segment protection bits).
Поскольку сам код нельзя модифицировать, то все кодовые сегменты создаются с флагами RX. Это значит, что процесс может загружать эту область памяти для последующего выполнения, но в неё никто не может записывать. Другие два сегмента — куча и стек — имеют флаги RW, то есть процесс может считывать и записывать в эти свои два сегмента, однако код из них выполнять нельзя. Это сделано для обеспечения безопасности, чтобы злоумышленник не мог повредить кучу или стек, внедрив в них свой код для получения root-прав. Так было не всегда, и для высокой эффективности этого решения требуется аппаратная поддержка. В процессорах Intel это называется “NX bit”.
Флаги могут быть изменены в процессе выполнения программы, для этого используется mprotect().
Под Linux все эти сегменты памяти можно посмотреть с помощью утилит /proc//maps или /usr/bin/pmap.
Здесь есть все необходимые подробности относительно распределения памяти. Адреса виртуальные, отображаются разрешения для каждой области памяти. Каждый совместно используемый объект (.so) размещён в адресном пространстве в виде нескольких частей (обычно код и данные). Кодовые сегменты являются исполняемыми и совместно используются в физической памяти всеми процессами, которые разместили подобный совместно используемый объект в своём адресном пространстве.
Shared Objects — это одно из крупнейших преимуществ Unix- и Linux-систем, обеспечивающее экономию памяти.
Также с помощью системного вызова mmap() можно создавать совместно используемую область, которая преобразуется в совместно используемый физический сегмент. Тогда у каждой области появится индекс s, означающий shared.
Ограничения сегментации
Итак, сегментация позволила решить проблему неиспользуемой виртуальной памяти. Если она не используется, то и не размещается в физической памяти благодаря использованию сегментов, соответствующих именно объёму используемой памяти.
Но это не совсем верно.
Допустим, процесс запросил у кучи 16 Кб. Скорее всего, ОС создаст в физической памяти сегмент соответствующего размера. Если пользователь потом освободит из них 2 Кб, тогда ОС придётся уменьшить размер сегмента до 14 Кб. Но вдруг потом программист запросит у кучи ещё 30 Кб? Тогда предыдущий сегмент нужно увеличить более чем в два раза, а возможно ли это будет сделать? Может быть, его уже окружают другие сегменты, не позволяющие ему увеличиться. Тогда ОС придётся искать свободное место на 30 Кб и перераспределять сегмент.
Главный недостаток сегментов заключается в том, что из-за них физическая память сильно фрагментируется, поскольку сегменты увеличиваются и уменьшаются по мере того, как пользовательские процессы запрашивают и освобождают память. А ОС приходится поддерживать список свободных участков и управлять ими.
Фрагментация может привести к тому, что какой-нибудь процесс запросит такой объём памяти, который будет больше любого из свободных участков. И в этом случае ОС придётся отказать процессу в выделении памяти, даже если суммарный объём свободных областей будет существенно больше.
ОС может попытаться разместить данные компактнее, объединяя все свободные области в один большой чанк, который в дальнейшем можно использовать для нужд новых процессов и перераспределения.
Но подобные алгоритмы оптимизации сильно нагружают процессор, а ведь его мощности нужны для выполнения пользовательских процессов. Если ОС начинает реорганизовывать физическую память, то система становится недоступной.
Так что сегментация памяти влечёт за собой немало проблем, связанных с управлением памятью и многозадачностью. Нужно как-то улучшить возможности сегментации и исправить недостатки. Это достигается с помощью ещё одного подхода — страниц виртуальной памяти.
Разбиение памяти на страницы
Как было сказано выше, главный недостаток сегментации заключается в том, что сегменты очень часто меняют свой размер, и это приводит к фрагментации памяти, из-за чего может возникнуть ситуация, когда ОС не выделит для процессов нужные области памяти. Эта проблема решается с помощью страниц: каждое размещение, которое ядро делает в физической памяти, имеет фиксированный размер. То есть страницы — это области физической памяти фиксированного размера, ничего более. Это сильно облегчает задачу управления свободным объёмом и избавляет от фрагментации.
Давайте рассмотрим пример: виртуальное адресное пространство объёмом 16 Кб разбито на страницы.
Мы не говорим здесь о куче, стеке или кодовом сегменте. Просто делим память на куски по 4 Кб. Затем то же самое делаем с физической памятью:
ОС хранит таблицу страниц процесса (process page table), в которой представлены взаимосвязи между страницей виртуальной памяти процесса и страницей физической памяти (страничный кадр, page frame).
Теперь мы избавились от проблемы поиска свободного места: страничный кадр либо используется, либо нет (unused). И ядру не в пример легче найти достаточное количество страниц, чтобы выполнить запрос процесса на выделение памяти.
Страница — это мельчайшая и неделимая единица памяти, которой может оперировать ОС.
У каждого процесса есть своя таблица страниц, в которой представлена переадресация. Здесь уже используются не значения границ области, а номер виртуальной страницы (VPN, virtual page number) и сдвиг (offset).
Пример: размер виртуального пространства 16 Кб, следовательно, нам нужно 14 бит для описания адресов (2 14 = 16 Кб). Размер страницы 4 Кб, значит нам нужно 4 Кб (16/4), чтобы выбрать нужную страницу:
Когда процесс хочет использовать, например, адрес 9438 (вне границ 16 384), то он запрашивает в двоичном коде 10.0100.1101.1110:
Это 1246-й байт в виртуальной странице номер 2 («0100.1101.1110»-й байт в «10»-й странице). Теперь ОС достаточно просто обратиться к таблице страниц процесса, чтобы найти эту страницу номер 2. В нашем примере она соответствует восьмитысячному байту физической памяти. Следовательно, виртуальный адрес 9438 соответствует физическому адресу 9442 (8000 + сдвиг 1246).
Как уже было сказано, каждый процесс обладает лишь одной таблицей страниц, поскольку у каждого процесса собственная переадресация, как и у сегментов. Но где же именно хранятся все эти таблицы? Наверное, в физической памяти, где же ещё им быть?
Если сами таблицы страниц хранятся в памяти, то для получения VPN надо обращаться к памяти. Тогда количество обращений к ней удваивается: сначала мы извлекаем из памяти номер нужной страницы, а затем обращаемся к самим данным, хранящимся в этой странице. И если скорость доступа к памяти невелика, то ситуация выглядит довольно грустно.
Буфер быстрой переадресации (TLB, Translation-lookaside Buffer)
Использование страниц в качестве основного инструмента поддержки виртуальной памяти может привести к сильному снижению производительности. Разбиение адресного пространства на небольшие куски (страницы) требует хранения большого количества данных о размещении страниц. А раз эти данные хранятся в памяти, то при каждом обращении процесса к памяти осуществляется ещё одно, дополнительное обращение.
Для поддержания производительности снова используется помощь оборудования. Как и при сегментации, мы аппаратными методами помогаем ядру эффективно осуществлять переадресацию. Для этого используется TLB, входящий в состав MMU, и представляющий собой простой кэш для некоторых VPN-переадресаций. TLB позволяет ОС не обращаться к памяти лишний раз, чтобы получить физический адрес из виртуального.
Аппаратный MMU инициируется при каждом обращении к памяти, извлекает из виртуального адреса VPN и запрашивает у TLB, хранится ли в нём переадресация с этого VPN. Если да, то его роль выполнена. Если нет, то MMU находит нужную таблицу страниц процесса, и если она ссылается на валидный адрес, то обновляет данные в TLB, чтобы тот предоставлял их при следующем обращении.
Как вы понимаете, если в кэше отсутствует нужная переадресация, то это замедляет обращение к памяти. Можно предположить, что чем больше размер страниц, тем больше вероятность, что в TLB окажутся нужные данные. Но тогда мы будем тратить больше памяти на каждую страницу. Так что здесь нужен какой-то компромисс. Современные ядра умеют использовать страницы разных размеров. Например, Linux способен оперировать «огромными» страницами по 2 Мб вместо традиционных 4 Кб.
Также рекомендуется хранить данные компактно, в смежных адресах памяти. Если вы раскидаете их по всей памяти, то куда чаще в TLB не будет обнаруживаться нужной переадресации, либо он будет постоянно переполняться. Это называется эффективностью пространственной локальности (spacial locality efficiency): данные, которые расположены в памяти сразу за вашими, могут размещаться в той же физической странице, и тогда благодаря TLB вы получите выигрыш в производительности.
Кроме того, TLB в каждой записи хранит так называемые ASID (Address Space Identifier, идентификатор адресного пространства). Это нечто вроде PID, идентификатора процесса. Каждый процесс, поставленный в очередь на выполнение, имеет собственный ASID, и TLB может управлять обращением любого процесса к памяти, без риска ошибочных обращений со стороны других процессов.
Повторимся снова: если пользовательский процесс пытается обратиться к неправильному адресу, тот наверняка будет отсутствовать в TLB. Следовательно, будет запущена процедура поиска в таблице страниц процесса. В ней хранится переадресация, но с неправильным набором битов. В х86-системах переадресации имеют размер 4 Кб, то есть битов в них немало. А значит есть вероятность найти правильный бит, равно как и другие вещи, наподобие бита изменения («грязного бита», dirty bit), битов защиты (protection bit), бита обращения (reference bit) и т.д. И если запись помечена как неправильная, то ОС по умолчанию выдаст SIGSEGV, что приведёт к ошибке “segmentation fault”, даже если о сегментах уже и речи не идёт.
На самом деле разбиение памяти на страницы в современных ОС устроено куда сложнее, чем я расписал. В частности, используются многоуровневые записи в таблицах страниц, многостраничные размеры, вытеснение страниц (page eviction), также известное как «обмен» (ядро скидывает страницы из памяти на диск и обратно, что повышает эффективность использования основной памяти и создаёт у процессов иллюзию её неограниченности).
Источник
Содержание
- Ошибка сегментирования Ubuntu
- Что такое ошибка сегментации?
- Почему возникает ошибка сегментации?
- Что делать если возникла ошибка сегментирования?
- Выводы
- Оцените статью:
- Об авторе
- 7 комментариев
- Ошибка сегментирования Ubuntu
- Что такое ошибка сегментации?
- Почему возникает ошибка сегментации?
- Что делать если возникла ошибка сегментирования?
- Выводы
- [проблемы из ниоткуда] ошибка сегментирования. как найти причину?
- Segmentation Fault (распределение памяти компьютера)
- Немного истории
- Совместный доступ к ресурсам
- Адресное пространство
- Виртуализация памяти
- Переадресация
- Перераспределение памяти
- Сегментация памяти
- Совместное использование сегментов
- Ограничения сегментации
- Разбиение памяти на страницы
- Буфер быстрой переадресации (TLB, Translation-lookaside Buffer)
Ошибка сегментирования Ubuntu
Не всегда программы в Linux запускаются как положено. Иногда, в силу разных причин программа вместо нормальной работы выдает ошибку. Но нам не нужна ошибка, нам нужна программа, вернее, та функция, которую она должна выполнять. Сегодня мы поговорим об одной из самых серьезных и непонятных ошибок. Это ошибка сегментации Ubuntu. Если такая ошибка происходит только один раз, то на нее можно не обращать внимания, но если это регулярное явление нужно что-то делать.
Конечно, случается эта проблема не только в Ubuntu, а во всех Linux дистрибутивах, поэтому наша инструкция будет актуальна для них тоже. Но сосредоточимся мы в основном на Ubuntu. Рассмотрим что такое ошибка сегментирования linux, почему она возникает, а также как с этим бороться и что делать.
Что такое ошибка сегментации?
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Чтобы понять почему так происходит, давайте рассмотрим как устроена работа с памятью в Linux, я попытаюсь все упростить, но приблизительно так оно и работает.
Допустим, в вашей системе есть 6 Гигабайт оперативной памяти, каждой программе нужно выделить определенную область, куда будет записана она сама, ее данные и новые данные, которые она будет создавать. Чтобы дать возможность каждой из запущенных программ использовать все шесть гигабайт памяти был придуман механизм виртуального адресного пространства. Создается виртуальное пространство очень большого размера, а из него уже выделяется по 6 Гб для каждой программы. Если интересно, это адресное пространство можно найти в файле /proc/kcore, только не вздумайте никуда его копировать.
Выделенное адресное пространство для программы называется сегментом. Как только программа попытается записать или прочитать данные не из своего сегмента, ядро отправит ей сигнал SIGSEGV и программа завершится с нашей ошибкой. Более того, каждый сегмент поделен на секции, в некоторые из них запись невозможна, другие нельзя выполнять, если программа и тут попытается сделать что-то запрещенное, мы опять получим ошибку сегментации Ubuntu.
Почему возникает ошибка сегментации?
И зачем бы это порядочной программе лезть, куда ей не положено? Да в принципе, незачем. Это происходит из-за ошибки при написании программ или несовместимых версиях библиотек и ПО. Часто эта ошибка встречается в программах на Си или C++. В этом языке программисты могут вручную работать с памятью, а язык со своей стороны не контролирует, чтобы они это делали правильно, поэтому одно неверное обращение к памяти может обрушить программу.
Что делать если возникла ошибка сегментирования?
Если вы думаете, что это ошибка в программе, то вам остается только отправить отчет об ошибке разработчикам. Но вы все-таки еще можете попытаться что-то сделать.
Например, если падает с ошибкой сегментации неизвестная программа, то мы можем решить что это вина разработчиков, но если с такой ошибкой падает chrome или firefox при запуске возникает вопрос, может мы делаем что-то не так? Ведь это уже хорошо протестированные программы.
sudo apt update
sudo apt full-upgrade
Если это не помогло, нужно обнулить настройки программы до значений по умолчанию, возможно, удалить кэш. Настройки программ в Linux обычно содержатся в домашней папке, скрытых подкаталогах с именем программы. Также, настройки и кэш могут содержаться в каталогах
/.cache. Просто удалите папки программы и попробуйте снова ее запустить. Если и это не помогло, вы можете попробовать полностью удалить программу, а потом снова ее установить, возможно, какие-нибудь зависимости были повреждены:
sudo apt remove пакет_программы
sudo apt autoremove
sudo apt install пакет_программы
Если есть возможность, попробуйте установить программу из другого источника, например, не из PPA, а более старую версию, из официальных репозиториев.
Когда вы все это выполнили, скорее всего, проблема не в вашем дистрибутиве, а в самой программе. Нужно отправлять отчет разработчикам. В Ubuntu это можно сделать с помощью программы apport-bug. Обычно Ubuntu предлагает это сделать сразу, после того как программа завершилась с ошибкой сегментирования. Если же ошибка сегментирования Ubuntu встречается не в системной программе, то вам придется самим искать разработчиков и вручную описывать что произошло.
Чтобы помочь разработчикам решить проблему, недостаточно отправить им только сообщение что вы поймали Segmentation Fault, нужно подробно описать проблему, действия, которые вы выполняли перед этим, так чтобы разработчик мог их воспроизвести. Также, желательно прикрепить к отчету последние функции, которые вызывала программа (стек вызовов функций), это может очень сильно помочь разработчикам.
Рассмотрим, как его получить. Это не так уж сложно. Сначала запустите вашу программу, затем узнайте ее PID с помощью команды:
Дальше запускаем отладчик gdb:
Подключаемся к программе:
(gdb) attach ваш_pid
После подключения программа станет на паузу, продолжаем ее выполнение командой:
Затем вам осталось только вызвать ошибку:
И набрать команду, которая выведет стек последних вызовов:
Вывод этой команды и нужно отправлять разработчикам. Чтобы отключиться от программы и выйти наберите:
(gdb) detach
(gdb) quit
Дальше остается отправить отчет и ждать исправления ошибки. Если вы не уверены, что ошибка в программе, можете поспрашивать на форумах. Когда у вас есть стек вызовов, уже можно попытаться, если не понять в чем проблема, то попытаться узнать, не сталкивался ли с подобной проблемой еще кто-то.
Выводы
Теперь у вас есть приблизительный план действий, что нужно делать, когда появляется ошибка сегментирования сделан дамп памяти ubuntu. Если вы знаете другие способы решить эту проблему, напишите в комментариях!
Оцените статью:
Об авторе
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
7 комментариев
Спасибо, было очень интересно почитать про отладчик.
На самом деле от этого избавится я не могу. Остаётся мне всё сваливать на свой старый компьютер с 1024 мегабайтами озу. Постоянные ошибки сегментирования когда комплимирую какую-либо программу. Чтобы скомплимировать ядро надо по миллиону раз вводить make!! Щас выкину комп и куплю новый и думаю проблема сама разрешится.
Gentoo. cmake 3.14.6. Segmentation fault.
Xeon 2620 v2 24Gb ram
Проблема сама не решается почему-то. 8-(
С ошибкой SIGSEGV или так называемой ошибкой сегментации(на самом деле это ошибки обращения с памятью) вы ничё не сможете сделать. если вы юзер, а не разработчик и она возникает в вашей проге. можете только одного не запускать эту прогу удалить её или попытаться обновить, возможно(вовсе не обязательно!) её заметили и исправили. Но вообще лицензионное соглашение по Ubuntu вас предупреждает, что вы пользуетесь системой в которой софт вовсе не обязан работать и никто за это не отвечает. вы это делаете на свой страх и риск! это краткий его перевод. А если вы купили операционку заплатили бабки и заказали техподдержку, то вы тогда уже имеете право обратиться в службу тех поддержки сообщить баг, где и как он возникает и они обязаны не просто испавить его прислав патч, но так же всем таким как вы кто заплатил. Иначе вы имеете право подать на них в суд и они обязаны компенсировать вам убытки. Но это не Ubuntu. Обратная сторона медали свободного по и бесплатных операционок. среди Линуксовых есть AIX(только платная+ техподдержка), SUSE(не путать с Open Suse) и Debian(есть free урезаный вариант и нормальный платный). Это оч серьёзная ошибка краеугольный камень всех программ и работы компа в целом. Если это ломается, то всё летит к чёрту. Конечно они стараюстся и сразу посылать вас не будут. Это их репутация! но вообще дело в програмерах. Щаз стало оч много криворуких. Вот я смотрю на их код и удивляюсь, как можно так безалаберно писать проги! Если бы вы только это видели вы бы не удивились почему всё так плохо работает. Встречаются такие кадры которые всё только портят! ну а что програмеров не хаватет, делать надо много вот и берут всех подряд. А потом начинается. Если конечно это заметили до релиза, то ладно. Но тут всё ещё зависит от тестеров. Если они хорошие то найдут баги вовремя до релиза и исправят. но у нас как бывает. Отдела тестирования нет, сэкономили.. Тестер дай бог 2-3 а то часто 1 вообще. В программе всегда много ошибок. Особенно вначале. все мы ошибаемся, особенно некоторые. Причина? Нехватка мозгов или банально невнимательность. поэтому все проги должны быть тщательнейшим образом оттестированы. только тогда она может быть допущена к релизу. А ещё заказчик подгоняет. Хорошую прогу нельзя написать в спешке. тем более большую. Такие ошибки как оч трудно найти, а если она не всегда воспроизводится, так вообще нереально, Если только случайно наткнёшься. Потому что как бывает один раз вылетела, а второй нет и пошла дальше и норм. Или пошла дальше и всё стало неправильным. с програмой начинают твориться чудеса. это всё та же ошибка с памятью, которая всё портит. Вылететь может не только ваша прога но и вся система. Но даже если она стабильно воспроизводится, то на её поиск может понадобиться дни а может и неделя две кропотливой упорной работы, носящей изнуряющий характер. искать будут всем отделом. но её тогда по крайней мере можно найти. а если нет. то вам поможет только чудо. А уж что сделают после этого с тем кто это сделал я даже не знаю! Вот такие вот они эти ошибки сегментации. Я показал то что там происходит за кадром юзера.
У меня появляется такая ошибка при попытке запуска Viber
Источник
Ошибка сегментирования Ubuntu
Не всегда программы в Linux запускаются как положено. Иногда, в силу разных причин программа вместо нормальной работы выдает ошибку. Но нам не нужна ошибка, нам нужна программа, вернее, та функция, которую она должна выполнять. Сегодня мы поговорим об одной из самых серьезных и непонятных ошибок. Это ошибка сегментации Ubuntu. Если такая ошибка происходит только один раз, то на нее можно не обращать внимания, но если это регулярное явление нужно что-то делать.
Конечно, случается эта проблема не только в Ubuntu, а во всех Linux дистрибутивах, поэтому наша инструкция будет актуальна для них тоже. Но сосредоточимся мы в основном на Ubuntu. Рассмотрим что такое ошибка сегментирования linux, почему она возникает, а также как с этим бороться и что делать.
Что такое ошибка сегментации?
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Чтобы понять почему так происходит, давайте рассмотрим как устроена работа с памятью в Linux, я попытаюсь все упростить, но приблизительно так оно и работает.
Допустим, в вашей системе есть 6 Гигабайт оперативной памяти, каждой программе нужно выделить определенную область, куда будет записана она сама, ее данные и новые данные, которые она будет создавать. Чтобы дать возможность каждой из запущенных программ использовать все шесть гигабайт памяти был придуман механизм виртуального адресного пространства. Создается виртуальное пространство очень большого размера, а из него уже выделяется по 6 Гб для каждой программы. Если интересно, это адресное пространство можно найти в файле /proc/kcore, только не вздумайте никуда его копировать.
Выделенное адресное пространство для программы называется сегментом. Как только программа попытается записать или прочитать данные не из своего сегмента, ядро отправит ей сигнал SIGSEGV и программа завершится с нашей ошибкой. Более того, каждый сегмент поделен на секции, в некоторые из них запись невозможна, другие нельзя выполнять, если программа и тут попытается сделать что-то запрещенное, мы опять получим ошибку сегментации Ubuntu.
Почему возникает ошибка сегментации?
И зачем бы это порядочной программе лезть, куда ей не положено? Да в принципе, незачем. Это происходит из-за ошибки при написании программ или несовместимых версиях библиотек и ПО. Часто эта ошибка встречается в программах на Си или C++. В этом языке программисты могут вручную работать с памятью, а язык со своей стороны не контролирует, чтобы они это делали правильно, поэтому одно неверное обращение к памяти может обрушить программу.
Что делать если возникла ошибка сегментирования?
Если вы думаете, что это ошибка в программе, то вам остается только отправить отчет об ошибке разработчикам. Но вы все-таки еще можете попытаться что-то сделать.
Например, если падает с ошибкой сегментации неизвестная программа, то мы можем решить что это вина разработчиков, но если с такой ошибкой падает chrome или firefox при запуске возникает вопрос, может мы делаем что-то не так? Ведь это уже хорошо протестированные программы.
Если это не помогло, нужно обнулить настройки программы до значений по умолчанию, возможно, удалить кэш. Настройки программ в Linux обычно содержатся в домашней папке, скрытых подкаталогах с именем программы. Также, настройки и кэш могут содержаться в каталогах
/.cache. Просто удалите папки программы и попробуйте снова ее запустить. Если и это не помогло, вы можете попробовать полностью удалить программу, а потом снова ее установить, возможно, какие-нибудь зависимости были повреждены:
Если есть возможность, попробуйте установить программу из другого источника, например, не из PPA, а более старую версию, из официальных репозиториев.
Когда вы все это выполнили, скорее всего, проблема не в вашем дистрибутиве, а в самой программе. Нужно отправлять отчет разработчикам. В Ubuntu это можно сделать с помощью программы apport-bug. Обычно Ubuntu предлагает это сделать сразу, после того как программа завершилась с ошибкой сегментирования. Если же ошибка сегментирования Ubuntu встречается не в системной программе, то вам придется самим искать разработчиков и вручную описывать что произошло.
Чтобы помочь разработчикам решить проблему, недостаточно отправить им только сообщение что вы поймали Segmentation Fault, нужно подробно описать проблему, действия, которые вы выполняли перед этим, так чтобы разработчик мог их воспроизвести. Также, желательно прикрепить к отчету последние функции, которые вызывала программа (стек вызовов функций), это может очень сильно помочь разработчикам.
Рассмотрим, как его получить. Это не так уж сложно. Сначала запустите вашу программу, затем узнайте ее PID с помощью команды:
Дальше запускаем отладчик gdb:
Подключаемся к программе:
После подключения программа станет на паузу, продолжаем ее выполнение командой:
Затем вам осталось только вызвать ошибку:
И набрать команду, которая выведет стек последних вызовов:
Вывод этой команды и нужно отправлять разработчикам. Чтобы отключиться от программы и выйти наберите:
Дальше остается отправить отчет и ждать исправления ошибки. Если вы не уверены, что ошибка в программе, можете поспрашивать на форумах. Когда у вас есть стек вызовов, уже можно попытаться, если не понять в чем проблема, то попытаться узнать, не сталкивался ли с подобной проблемой еще кто-то.
Выводы
Теперь у вас есть приблизительный план действий, что нужно делать, когда появляется ошибка сегментирования сделан дамп памяти ubuntu. Если вы знаете другие способы решить эту проблему, напишите в комментариях!
Источник
[проблемы из ниоткуда] ошибка сегментирования. как найти причину?
полагаю что дело в том что утром были найдены ошибки в файловой системе
то есть вроде бы читает файл и после этого падает. но толку.. ltrace вообще ничего не дал. похоже ошибка происходит непосредственно в коде программы ssh. ещё вчера всё работало..
1) Посмотри, нет ли записей о сегфолтах в messages.
2) Попробуй временно переименовать
ltrace ssh svn-server
Ну явно же написано, что у тебя known_hosts покоцан. Сдвинь его в сторонку и не парься.
Но таки программа не должна падать из-за проблемы в каком-то конфиге.
благодарю за толковые советы
не, я ж написал, ltrace ничего не дал:
да, кстати, вряд ли.. но я тем не менее сдвинул его.. не помогло..
можно ли как-то запустить проверку контрольных сумм всех файлов установленных пакетным менеджером?
Запустить под gdb и посмотреть почему упало.
>не, я ж написал, ltrace ничего не дал:
strace ssh svn-server
chkrootkit и rkhunter попробуй
и работал вчера ssh
ну и странно что на одном и том же месте.. скорее уж с диском проблемы..
мужик, я думаю специально для тебя нужно ввести звание Ъ^2.
Где,ж он на ровном месте? Какова вероятность, что при многочисленных попытках считать файл он всегда будет попадать на битую область?
> ну и странно что на одном и том же месте..
У меня эта штука половину портов засосала. 1111 А дело всё было в слоте памяти на материнке. И memtest86+ молчал.
libc переставь и tls и прочие либы, которыми пользуется ssh. переустановка только ssh не приведет к переустановке этих либ
Хехе. вероятная причина кроется в svn.
Сам лично сталкивался с регулярными падениями СВН составляющих в дебе. Как правило это происходило при попытке СВНа обратиться в дбасу. Но и в других ситуациях тоже, но реже.
> Хехе. вероятная причина кроется в svn.
open(«/home/andrey/.ssh/known_hosts», O_RDONLY) = 4 ★ ( 26.09.11 14:35:24 )
read() отработал нормально. Проблема где-то доальше в коде. Надо gdb.
Ага, я тоже сидел с gdb и дебажил почему svn up падает 🙂 Проблема была глубоко-глубоко 🙂 А на деле все оказалось куда проще.
Там цикл чтения по 4096. Еслибы он отработал нормально, мы бы увидели следующую итерацию (размер файла больше).
memtest’ом можно подтереться только. Инфа 100%.
Для таких вещей есть ключ для дебага. И gdb. И ещё strace.
А ещё подумай о том, что повреждение может быть в какой-то либе, которую он загружает.
Источник
Segmentation Fault (распределение памяти компьютера)
Когда я делаю ошибку в коде, то обычно это приводит к появлению сообщения “segmentation fault”, зачастую сокращённого до “segfault”. И тут же мои коллеги и руководство приходят ко мне: «Ха! У нас тут для тебя есть segfault для исправления!» — «Ну да, виноват», — обычно отвечаю я. Но многие ли из вас знают, что на самом деле означает ошибка “segmentation fault”?
Чтобы ответить на этот вопрос, нам нужно вернуться в далёкие 1960-е. Я хочу объяснить, как работает компьютер, а точнее — как в современных компьютерах осуществляется доступ к памяти. Это поможет понять, откуда же берётся это странное сообщение об ошибке.
Вся представленная ниже информация — основы компьютерной архитектуры. И без нужды я не буду сильно углубляться в эту область. Также я буду применять всем известную терминологию, так что мой пост будет понятен всем, кто не совсем на «вы» с вычислительной техникой. Если же вы захотите изучить вопрос работы с памятью подробнее, то можете обратиться к многочисленной доступной литературе. А заодно не забудьте покопаться в исходном коде ядра какой-нибудь ОС, например, Linux. Я не буду излагать здесь историю вычислительной техники, некоторые вещи не будут освещаться, а некоторые сильно упрощены.
Немного истории
То есть на ОС приходилась, скажем, четверть всей доступной памяти, а остальной объём отдавался под пользовательские задачи. В то время роль ОС заключалась в простом управлении оборудованием с помощью прерываний ЦПУ. Так что операционке нужна была память для себя, для копирования данных с устройств и для работы с ними (режим PIO). Для вывода данных на экран нужно было использовать часть основной памяти, ведь видеоподсистема либо не имела своей оперативки, либо обладала считанными килобайтами. А уже сама программа выполнялась в области памяти, идущей сразу после ОС, и решала свои задачи.
Совместный доступ к ресурсам
Из-за непомерной стоимости мало кто мог позволить себе приобрести сразу несколько компьютеров, чтобы обрабатывать одновременно несколько задач. Поэтому люди начали искать способы совместного доступа к вычислительным ресурсам одного компьютера. Так наступила эра многозадачности. Обратите внимание, что в те времена ещё никто не помышлял о многопроцессорных компьютерах. Так как же можно заставить компьютер с одним ЦПУ выполнять несколько разных задач?
Решением стало использование планировщика задач (scheduling): пока один процесс прерывался, ожидая завершения операций ввода/вывода, ЦПУ мог выполнять другой процесс. Я не буду здесь больше касаться планировщика задач, это слишком обширная тема, не имеющая отношения к памяти.
Если компьютер способен поочерёдно выполнять несколько задач, то распределение памяти будет выглядеть примерно так:
Задачи А и В хранятся в памяти, поскольку копировать их на диск и обратно слишком затратно. И по мере того, как процессор выполняет ту или иную задачу, он обращается к памяти за соответствующими данными. Но тут возникает проблема.
Когда один программист будет писать код для выполнения задачи В, он должен знать границы выделяемых сегментов памяти. Допустим, задача В занимает в памяти отрезок от 10 до 12 Кб, тогда каждый адрес памяти должен быть жёстко закодирован в пределах этих границ. Но если компьютер будет выполнять сразу три задачи, то память будет поделена на большее количество сегментов, и значит сегмент для задачи В может оказаться сдвинут. Тогда код программы придётся переписывать, чтобы она могла оперировать меньшим объёмом памяти, а также изменить все указатели.
Здесь всплывает и иная проблема: что если задача В обратится к сегменту памяти, выделенному для задачи А? Такое легко может произойти, ведь при работе с указателями памяти достаточно сделать маленькую ошибку, и программа будет обращаться к совершенно другому адресу, нарушив целостность данных другого процесса. При этом задача А может работать с очень важными с точки зрения безопасности данными. Нет никакого способа помешать В вторгнуться в область памяти А. Наконец, вследствие ошибки программиста задача В может перезаписать область памяти ОС (в данном случае от 0 до 4 Кб).
Адресное пространство
Чтобы можно было спокойно выполнять несколько задач, хранящихся в памяти, нам нужна помощь от ОС и оборудования. В частности, адресное пространство. Это некая абстракция памяти, выделяемая ОС для какого-то процесса. На сегодняшний день это фундаментальная концепция, которая используется везде. По крайней мере, во ВСЕХ компьютерах гражданского назначения принят именно этот подход, а у военных могут быть свои секреты. Персоналки, смартфоны, телевизоры, игровые приставки, умные часы, банкоматы — ткните в любой аппарат, и окажется, что распределение памяти в нём осуществляется по принципу «код-стек-куча» (code-stack-heap).
Адресное пространство содержит всё, что нужно для выполнения процесса:
Виртуализация памяти
Допустим, задача А получила в своё распоряжение всю доступную пользовательскую память. И тут возникает задача В. Как быть? Решение было найдено в виртуализации.
Напомню одну из предыдущих иллюстраций, когда в памяти одновременно находятся А и В:
Допустим, А пытается получить доступ к памяти в собственном адресном пространстве, например по индексу 11 Кб. Возможно даже, что это будет её собственный стек. В этом случае ОС нужно придумать, как не подгружать индекс 1500, поскольку по факту он может указывать на область задачи В.
На самом деле, адресное пространство, которое каждая программа считает своей памятью, является памятью виртуальной. Фальшивкой. И в области памяти задачи А индекс 11 Кб будет фальшивым адресом. То есть — адресом виртуальной памяти.
Каждая программа, выполняющаяся на компьютере, работает с фальшивой (виртуальной) памятью. С помощью некоторых чипов ОС обманывает процесс, когда он обращается к какой-либо области памяти. Благодаря виртуализации ни один процесс не может получить доступ к памяти, которая ему не принадлежит: задача А не влезет в память задачи В или самой ОС. При этом на пользовательском уровне всё абсолютно прозрачно, благодаря обширному и сложному коду ядра ОС.
Таким образом, каждое обращение к памяти регулируется операционной системой. И это должно осуществляться очень эффективно, чтобы не слишком замедлять работу различных выполняющихся программ. Эффективность обеспечивается с помощью аппаратных средств, преимущественно — ЦПУ и некоторых компонентов вроде MMU. Последний появился в виде отдельного чипа в начале 1970-х, а сегодня MMU встраиваются непосредственно в процессор и в обязательном порядке используются операционными системами.
Вот небольшая программка на С, демонстрирующая работу с адресами памяти:
На моей машине LP64 X86_64 она показывает такой результат:
Code is at 0x40054c
Stack is at 0x7ffe60a1465c
Heap is at 0x1ecf010
Как я и описывал, сначала идёт кодовый сегмент, затем куча, а затем стек. Но все эти три адреса фальшивые. В физической памяти по адресу 0x7ffe60a1465c вовсе не хранится целочисленная переменная со значением 3. Никогда не забывайте, что все пользовательские программы манипулируют виртуальными адресами, и только на уровне ядра или аппаратных драйверов допускается использование адресов физической памяти.
Переадресация
Переадресация (транслирование, перевод, преобразование адресов) — это термин, обозначающий процесс сопоставления виртуального адреса физическому. Занимается этим модуль MMU. Для каждого выполняющегося процесса операционка должна помнить соответствия всех виртуальных адресов физическим. И это довольно непростая задача. По сути, ОС приходится управлять памятью каждого пользовательского процесса при каждом обращении. Тем самым она превращает кошмарную реальность физической памяти в полезную, мощную и лёгкую в использовании абстракцию.
Давайте рассмотрим подробнее.
Итак, это виртуальное адресное пространство:
А это его физический образ:
Физический адрес = виртуальный адрес + base
Если получившийся физический адрес (6 Кб) выбивается из границ выделенной области (4—20 Кб), это означает, что процесс пытается обратиться к памяти, которая ему не принадлежит. Тогда ЦПУ генерирует исключение и сообщает об этом ОС, которая обрабатывает данное исключение. В этом случае система обычно сигнализирует процессу о нарушении: SIGSEGV, Segmentation Fault. Этот сигнал по умолчанию прерывает выполнение процесса (это можно настраивать).
Перераспределение памяти
Если задача А исключена из очереди на выполнение, то это даже лучше. Это означает, что планировщик попросили выполнить другую задачу (допустим, В). Пока выполняется В, операционка может перераспределить всё физическое пространство задачи А. Во время выполнения пользовательского процесса ОС зачастую теряет управление процессором. Но когда процесс делает системный вызов, процессор снова возвращается под контроль ОС. До этого системного вызова операционка может что угодно делать с памятью, в том числе и целиком перераспределять адресное пространство процесса в другой физический раздел.
В нашем примере это осуществляется достаточно просто: ОС перемещает 16-килобайтную область в другое свободное место подходящего размера и просто обновляет значения переменных base и bounds для задачи А. Когда процессор возвращается к её выполнению, процесс переадресации всё ещё работает, но физическое адресное пространство уже изменилось.
С точки зрения задачи А ничего не меняется, её собственное адресное пространство по-прежнему расположено в диапазоне 0-16 Кб. При этом ОС и MMU полностью контролируют каждое обращение задачи к памяти. То есть программист манипулирует виртуальной областью 0-16 Кб, а MMU берёт на себя сопоставление с физическими адресами.
После перераспределения образ памяти будет выглядеть так:
Программисту теперь не нужно заботиться о том, с какими адресами памяти будет работать его программа, не нужно переживать о конфликтах. ОС в связке с MMU снимают с него все эти заботы.
Сегментация памяти
В предыдущих главах мы рассмотрели вопросы переадресации и перераспределения памяти. Однако у нашей модели работы с памятью есть ряд недостатков:
Для решения некоторых из этих проблем давайте рассмотрим более сложную систему организации памяти — сегментацию. Смысл её прост: принцип “base and bounds” распространяется на все три сегмента памяти — кучу, кодовый сегмент и стек, причём для каждого процесса, вместо того чтобы рассматривать образ памяти как единую уникальную сущность.
В результате мы больше не теряем память между стеком и кучей:
Допустим, у кучи задачи А параметр base равен 126 Кб, а bounds — 2 Кб. Пусть задача А обращается к виртуальному адресу 3 Кб (в куче). Тогда физический адрес определяется как 3 – 2 Кб (начало кучи) = 1 Кб + 126 Кб (сдвиг) = 127 Кб. Это меньше 128, а значит ошибки обращения не будет.
Совместное использование сегментов
Сегментирование физической памяти не только не позволяет виртуальной памяти отъедать физическую, но также даёт возможность совместного использования физических сегментов с помощью виртуальных адресных пространств разных процессов.
Если дважды запустить задачу А, то кодовый сегмент у них будет один и тот же: в обеих задачах выполняются одинаковые машинные инструкции. В то же время у каждой задачи будут свои стек и куча, поскольку они оперируют разными наборами данных.
При этом оба процесса не подозревают, что делят с кем-то свою память. Такой подход стал возможен благодаря внедрению битов защиты сегмента (segment protection bits).
Поскольку сам код нельзя модифицировать, то все кодовые сегменты создаются с флагами RX. Это значит, что процесс может загружать эту область памяти для последующего выполнения, но в неё никто не может записывать. Другие два сегмента — куча и стек — имеют флаги RW, то есть процесс может считывать и записывать в эти свои два сегмента, однако код из них выполнять нельзя. Это сделано для обеспечения безопасности, чтобы злоумышленник не мог повредить кучу или стек, внедрив в них свой код для получения root-прав. Так было не всегда, и для высокой эффективности этого решения требуется аппаратная поддержка. В процессорах Intel это называется “NX bit”.
Флаги могут быть изменены в процессе выполнения программы, для этого используется mprotect().
Под Linux все эти сегменты памяти можно посмотреть с помощью утилит /proc//maps или /usr/bin/pmap.
Здесь есть все необходимые подробности относительно распределения памяти. Адреса виртуальные, отображаются разрешения для каждой области памяти. Каждый совместно используемый объект (.so) размещён в адресном пространстве в виде нескольких частей (обычно код и данные). Кодовые сегменты являются исполняемыми и совместно используются в физической памяти всеми процессами, которые разместили подобный совместно используемый объект в своём адресном пространстве.
Shared Objects — это одно из крупнейших преимуществ Unix- и Linux-систем, обеспечивающее экономию памяти.
Также с помощью системного вызова mmap() можно создавать совместно используемую область, которая преобразуется в совместно используемый физический сегмент. Тогда у каждой области появится индекс s, означающий shared.
Ограничения сегментации
Итак, сегментация позволила решить проблему неиспользуемой виртуальной памяти. Если она не используется, то и не размещается в физической памяти благодаря использованию сегментов, соответствующих именно объёму используемой памяти.
Но это не совсем верно.
Допустим, процесс запросил у кучи 16 Кб. Скорее всего, ОС создаст в физической памяти сегмент соответствующего размера. Если пользователь потом освободит из них 2 Кб, тогда ОС придётся уменьшить размер сегмента до 14 Кб. Но вдруг потом программист запросит у кучи ещё 30 Кб? Тогда предыдущий сегмент нужно увеличить более чем в два раза, а возможно ли это будет сделать? Может быть, его уже окружают другие сегменты, не позволяющие ему увеличиться. Тогда ОС придётся искать свободное место на 30 Кб и перераспределять сегмент.
Главный недостаток сегментов заключается в том, что из-за них физическая память сильно фрагментируется, поскольку сегменты увеличиваются и уменьшаются по мере того, как пользовательские процессы запрашивают и освобождают память. А ОС приходится поддерживать список свободных участков и управлять ими.
Фрагментация может привести к тому, что какой-нибудь процесс запросит такой объём памяти, который будет больше любого из свободных участков. И в этом случае ОС придётся отказать процессу в выделении памяти, даже если суммарный объём свободных областей будет существенно больше.
ОС может попытаться разместить данные компактнее, объединяя все свободные области в один большой чанк, который в дальнейшем можно использовать для нужд новых процессов и перераспределения.
Но подобные алгоритмы оптимизации сильно нагружают процессор, а ведь его мощности нужны для выполнения пользовательских процессов. Если ОС начинает реорганизовывать физическую память, то система становится недоступной.
Так что сегментация памяти влечёт за собой немало проблем, связанных с управлением памятью и многозадачностью. Нужно как-то улучшить возможности сегментации и исправить недостатки. Это достигается с помощью ещё одного подхода — страниц виртуальной памяти.
Разбиение памяти на страницы
Как было сказано выше, главный недостаток сегментации заключается в том, что сегменты очень часто меняют свой размер, и это приводит к фрагментации памяти, из-за чего может возникнуть ситуация, когда ОС не выделит для процессов нужные области памяти. Эта проблема решается с помощью страниц: каждое размещение, которое ядро делает в физической памяти, имеет фиксированный размер. То есть страницы — это области физической памяти фиксированного размера, ничего более. Это сильно облегчает задачу управления свободным объёмом и избавляет от фрагментации.
Давайте рассмотрим пример: виртуальное адресное пространство объёмом 16 Кб разбито на страницы.
Мы не говорим здесь о куче, стеке или кодовом сегменте. Просто делим память на куски по 4 Кб. Затем то же самое делаем с физической памятью:
ОС хранит таблицу страниц процесса (process page table), в которой представлены взаимосвязи между страницей виртуальной памяти процесса и страницей физической памяти (страничный кадр, page frame).
Теперь мы избавились от проблемы поиска свободного места: страничный кадр либо используется, либо нет (unused). И ядру не в пример легче найти достаточное количество страниц, чтобы выполнить запрос процесса на выделение памяти.
Страница — это мельчайшая и неделимая единица памяти, которой может оперировать ОС.
У каждого процесса есть своя таблица страниц, в которой представлена переадресация. Здесь уже используются не значения границ области, а номер виртуальной страницы (VPN, virtual page number) и сдвиг (offset).
Пример: размер виртуального пространства 16 Кб, следовательно, нам нужно 14 бит для описания адресов (2 14 = 16 Кб). Размер страницы 4 Кб, значит нам нужно 4 Кб (16/4), чтобы выбрать нужную страницу:
Когда процесс хочет использовать, например, адрес 9438 (вне границ 16 384), то он запрашивает в двоичном коде 10.0100.1101.1110:
Это 1246-й байт в виртуальной странице номер 2 («0100.1101.1110»-й байт в «10»-й странице). Теперь ОС достаточно просто обратиться к таблице страниц процесса, чтобы найти эту страницу номер 2. В нашем примере она соответствует восьмитысячному байту физической памяти. Следовательно, виртуальный адрес 9438 соответствует физическому адресу 9442 (8000 + сдвиг 1246).
Как уже было сказано, каждый процесс обладает лишь одной таблицей страниц, поскольку у каждого процесса собственная переадресация, как и у сегментов. Но где же именно хранятся все эти таблицы? Наверное, в физической памяти, где же ещё им быть?
Если сами таблицы страниц хранятся в памяти, то для получения VPN надо обращаться к памяти. Тогда количество обращений к ней удваивается: сначала мы извлекаем из памяти номер нужной страницы, а затем обращаемся к самим данным, хранящимся в этой странице. И если скорость доступа к памяти невелика, то ситуация выглядит довольно грустно.
Буфер быстрой переадресации (TLB, Translation-lookaside Buffer)
Использование страниц в качестве основного инструмента поддержки виртуальной памяти может привести к сильному снижению производительности. Разбиение адресного пространства на небольшие куски (страницы) требует хранения большого количества данных о размещении страниц. А раз эти данные хранятся в памяти, то при каждом обращении процесса к памяти осуществляется ещё одно, дополнительное обращение.
Для поддержания производительности снова используется помощь оборудования. Как и при сегментации, мы аппаратными методами помогаем ядру эффективно осуществлять переадресацию. Для этого используется TLB, входящий в состав MMU, и представляющий собой простой кэш для некоторых VPN-переадресаций. TLB позволяет ОС не обращаться к памяти лишний раз, чтобы получить физический адрес из виртуального.
Аппаратный MMU инициируется при каждом обращении к памяти, извлекает из виртуального адреса VPN и запрашивает у TLB, хранится ли в нём переадресация с этого VPN. Если да, то его роль выполнена. Если нет, то MMU находит нужную таблицу страниц процесса, и если она ссылается на валидный адрес, то обновляет данные в TLB, чтобы тот предоставлял их при следующем обращении.
Как вы понимаете, если в кэше отсутствует нужная переадресация, то это замедляет обращение к памяти. Можно предположить, что чем больше размер страниц, тем больше вероятность, что в TLB окажутся нужные данные. Но тогда мы будем тратить больше памяти на каждую страницу. Так что здесь нужен какой-то компромисс. Современные ядра умеют использовать страницы разных размеров. Например, Linux способен оперировать «огромными» страницами по 2 Мб вместо традиционных 4 Кб.
Также рекомендуется хранить данные компактно, в смежных адресах памяти. Если вы раскидаете их по всей памяти, то куда чаще в TLB не будет обнаруживаться нужной переадресации, либо он будет постоянно переполняться. Это называется эффективностью пространственной локальности (spacial locality efficiency): данные, которые расположены в памяти сразу за вашими, могут размещаться в той же физической странице, и тогда благодаря TLB вы получите выигрыш в производительности.
Кроме того, TLB в каждой записи хранит так называемые ASID (Address Space Identifier, идентификатор адресного пространства). Это нечто вроде PID, идентификатора процесса. Каждый процесс, поставленный в очередь на выполнение, имеет собственный ASID, и TLB может управлять обращением любого процесса к памяти, без риска ошибочных обращений со стороны других процессов.
Повторимся снова: если пользовательский процесс пытается обратиться к неправильному адресу, тот наверняка будет отсутствовать в TLB. Следовательно, будет запущена процедура поиска в таблице страниц процесса. В ней хранится переадресация, но с неправильным набором битов. В х86-системах переадресации имеют размер 4 Кб, то есть битов в них немало. А значит есть вероятность найти правильный бит, равно как и другие вещи, наподобие бита изменения («грязного бита», dirty bit), битов защиты (protection bit), бита обращения (reference bit) и т.д. И если запись помечена как неправильная, то ОС по умолчанию выдаст SIGSEGV, что приведёт к ошибке “segmentation fault”, даже если о сегментах уже и речи не идёт.
На самом деле разбиение памяти на страницы в современных ОС устроено куда сложнее, чем я расписал. В частности, используются многоуровневые записи в таблицах страниц, многостраничные размеры, вытеснение страниц (page eviction), также известное как «обмен» (ядро скидывает страницы из памяти на диск и обратно, что повышает эффективность использования основной памяти и создаёт у процессов иллюзию её неограниченности).
Источник
Ошибка в этом фрагменте кода. Никак не могу понять, в чем дело
Сама программа должна возвращать двоичную последовательность длины n
#include <iostream>
#include <vector>
using namespace std;
void func(int a, vector<int>& v1){
if(a == v1.size()){
for(int i = 0; i < v1.size(); ++i){
cout << v1[i];
}
cout << endl;
return;
}
for(int i = 0; i < v1.size(); ++i){
v1[a] = i;
func(i + 1, v1);
}
}
int main(){
int n;
cin >> n;
vector<int> v;
for(int i = 0; i < n; ++i){
v.push_back(0);
}
for(int i = 0; i < n; ++i){
cout << v[i];
}
func(1, v);
return 0;
}-
Вопрос заданболее года назад
-
932 просмотра
Пригласить эксперта
Ваша программа бесконечно уходит в рекурсию, у нее кончаетсся память и она падает. func(1, v) в цикле при i=0 вызовет func(1,v1), которая опять же вызовет func(1,v1), которая опять же… И так пока программе не поплохеет.
-
Показать ещё
Загружается…
06 июн. 2023, в 10:33
5000 руб./за проект
06 июн. 2023, в 10:25
200000 руб./за проект
06 июн. 2023, в 10:23
190000 руб./за проект
Минуточку внимания
|
# (отредактировано 5 лет, 2 месяца назад) |
|
|
Темы: 37 Сообщения: 298 Участник с: 20 сентября 2015 |
Здравствуйте. Не запускается VLC, вот что говорит терминал. Полная переустановка с зачищением хвостов, установка микрокода, запуск без интерфейса не помогают. |

|
Morisson |
# |
|
Темы: 18 Сообщения: 1414 Участник с: 11 января 2017 |
Раньше QT4 требовался. Теперь, если не ошибаюсь, qt5-base. Для морды лица ему надо. |

|
ZeniaM |
# |
|
Темы: 37 Сообщения: 298 Участник с: 20 сентября 2015 |
Это было раньше :(, всё это перепробовал, подозреваю что он с кем-то конфликтует, но вот с кем и как выяснить. |
|
alexandr05 |
# |
|
Темы: 16 Сообщения: 108 Участник с: 16 октября 2011 |
Попробуйте на вновь созданном пользователе. Года два назад, у меня была похожая ситуация. После чистки кэша в домашней папке всё заработало. |
|
ZeniaM |
# |
|
Темы: 37 Сообщения: 298 Участник с: 20 сентября 2015 |
Не помогает. Та-же ошибка. |
|
vs220 |
# |
|
Темы: 22 Сообщения: 8111 Участник с: 16 августа 2009 |
или Посмотреть на чем падает |
|
ZeniaM |
# |
|
Темы: 37 Сообщения: 298 Участник с: 20 сентября 2015 |
Это вывод на /usr/bin/cvlc: А <strace /usr/bin/cvlc>, вывод очень большой получается. Пробую записать вывод в файл (strace /usr/bin/cvlc > vlclog.txt) не записывает. |
|
vs220 |
# (отредактировано 5 лет, 2 месяца назад) |
|
Темы: 22 Сообщения: 8111 Участник с: 16 августа 2009 |
Так весь не надо последние строк 50 посмотреть на каком вызове падает. P.S.
Например |
|
RusWolf |
# |
|
Темы: 11 Сообщения: 2466 Участник с: 16 июля 2016 |

|

|
vs220 |
# |
|
Темы: 22 Сообщения: 8111 Участник с: 16 августа 2009 |
И чем это поможет? |
~/.mozilla/firefox/ID.default/places.sqlite поместить в новый профиль.
Вот же блин, прочитал то же самое на сайте мозиллы. Включил поиск Ctrl + F в Dolphin и ничего не нашло. Нафиг нужен такой поиск, если он в скрытых папках не ищет. Спасибо за путь, на сайте мозиллы он как раз не указан… Скопировал файлик places.sqlite.
Еще старые копии ~/.mozilla/firefox/ID.default/bookmarkbackups
Я так понял с places.sqlite проще? Его просто копируешь и все само работает, а файлы «*.jsonlz4» не только копировать надо, но и восстанавливать через браузер, больше действий. Т.е. главное хранилище это именно places.sqlite — туда все запишется?
А вот эти бэкапы в виде jsonlz4-файлов — их кто создает? Автоматически? Я чето просто логики не уловил. Сам не экспортировал (через браузер) никогда, а судя по датам jsonlz4-файлов, то как-то хаотично бэкапится. Может по дате последних изменений/добавлений в меню закладок создает очередной jsonlz4-файл?
Но лучше сохранить всю папку ~/.mozilla.
Так и сделал, это еще проще. Спасибо за советы!
Теперь видимо буду переустанавливать браузер. Надеюсь запустится…
Жаль нельзя как в стиме, нажал кнопочку «Fix» и файлы программ сверились с эталоном на сервере, и если битый где или нехватает, то докачался. Было бы прикольно! Интересно, почему такой штуки еще не сделали в линуксе.
anonymous
(08.11.19 00:56:34 MSK)
- Показать ответы
- Ссылка
я написал вот такую программку:
//includes
#include <iostream>
#include <chrono>
#include <string>
#include <ctime>
//namespaces
using namespace std;
using namespace chrono;
//defines
#define RETURN return 0
//main
int main() {
setlocale(LC_ALL,"ru"); //locale
const auto _BEFORE_ = high_resolution_clock::now(); //start timer (for time account)
srand(time(0));
//Create Array
int CountArrayIn_arr2D = 2;
int CountElementsIn_arr1D = 3;
int **arr2D = new int*[CountArrayIn_arr2D];
//Generate Array
for(int i = 0; i < CountArrayIn_arr2D; i++) {
for(int j = 0; j < CountElementsIn_arr1D; j++) {
arr2D[i][j] = rand() % 30 + 1;
}
}
//Print Array
for(int i = 0; i < CountArrayIn_arr2D; i++) {
for(int j = 0; j < CountElementsIn_arr1D; j++) {
cout<<"33[34m"<<arr2D[i][j]<<"33[0mt";
}
cout<<endl;
}
/*Clean memory*/
for(int i = 0; i < CountArrayIn_arr2D; i++) {
delete[] arr2D[i];
}
delete[] arr2D;
//time account
const auto _AFTER_ = high_resolution_clock::now();
const float TIME_FOR_PROGRAM = duration_cast<milliseconds>(_AFTER_-_BEFORE_).count();
cout<<"nn Programm completed in "<<TIME_FOR_PROGRAM<<"ms"<<endl;
RETURN;
}
и пишет:
у меня 2 вопроса.
1) что значит стек сброшен на диск? на жесткий диск? удалится ли он самостоятельно? если нет то как удалить?
2) как это решить и почему это вообще произошло?
Ответы (3 шт):
У вас явная ошибка работы с памятью. Вызов new происходит один раз, а вызов delete?
Здесь происходит выделение массива указателей на int:
int **arr2D = new int*[CountArrayIn_arr2D];
Чтобы получить двумерный массив, нужно еще в каждый указатель выделить свой блок памяти:
for (int i = 0; i < CountArrayIn_arr2D; i++)
{
arr2D[i] = new int[CountElementsIn_arr1D];
// ^^^^^^^
for (int j = 0; j < CountElementsIn_arr1D; j++)
{
// делаем что нужно
}
}
→ Ссылка
Автор решения: Alexander Prokoshev
«Стек памяти сброшен на диск» — это [весьма-а вольный] перевод фразы «Core dumped». На диске в текущем каталоге создаётся файл с именем «core». Сам он не удалится, но он — самый обычный файл, который вы можете удалить когда захотите.
Файл core также сам по себе является кратчайшим путём к ответу на вопрос номер 2. Если ваш бинарник собран с опцией компилятора «-g», то вы можете запустить отладчик с командной строкой в виде «gdb -c core main.exe». Отладчик автоматически окажется на той строке, которая вызвала segmentation fault. О работе в gdb рекомендую почитать его документацию, она обширна и исчерпывающа.
→ Ссылка