
Ошибка СУБД:
Продолжение сообщения может быть различным:
-
1. DATABASE не пригоден для использования
2. ERROR: type «tt7» already exists
3. ERROR: could not read block
DATABASE не пригоден для использования
Пример полного текста ошибки:
|
Ошибка при выполнении операции с информационно базой по причине: Ошибка СУБД: DATABASE не пригоден для использования |
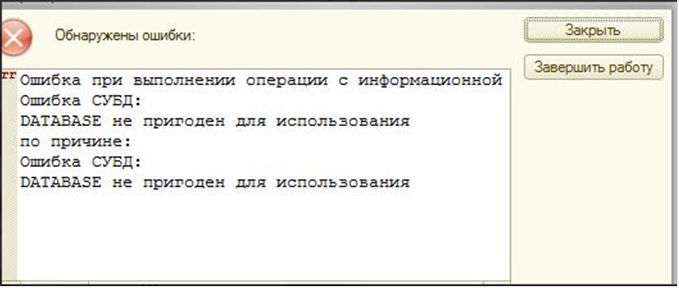
Описание ошибки:
База не запускается после установки и создания.
Решения:
Установим версию предназначенную для работы с 1С:Предприятием. Скачать такую можно с сайта 1С (при наличии купленного ИТС и открытого доступа), или приобрести у PostgresPro.
Либо проверим все ли зависимости были установлены. И установим недостающие.
ERROR: type «tt7» already exists
Пример полного текста ошибки:
|
Ошибка СУБД: ERROR: type «tt7» already exists HINT: A relation has an associated type of the same name, so you must use a name that doesn‘t conflict. |
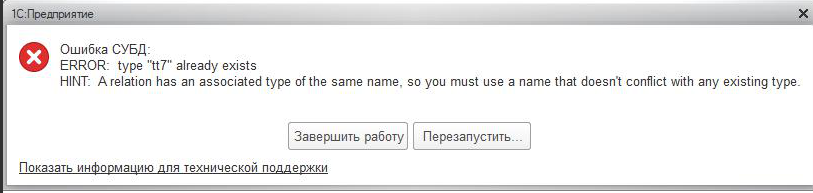
Описание:
Данная ошибка является «плавающей» и может возникать в различных местах
Решение:
Выгрузим и загрузим базу данных средствами 1С:Предприятия(через файл *.dt).
ERROR: could not read block
|
Ошибка при выполнении операции с информационно базой по причине: Ошибка СУБД: ERROR: could not read block ... in file «» Input/output error |
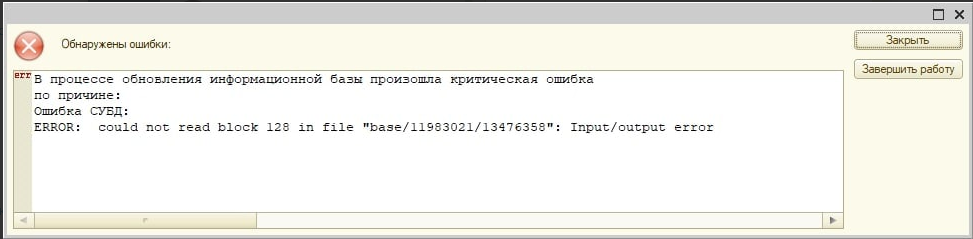
Описание ошибки:
База не запускается. Разрушились диски.
Решения:
Переносим базу на другую дисковую систему.
Разворачиваем из резервной копии.
Не удалось запустить сервер PostgreSQL
Пример полного текста ошибки:
|
Не удалось привязаться к адресу. Адрес уже используется. Возможно порт 5432 занят другим процессом postmaster? Система БД выключена.Не удалось запустить сервер. |
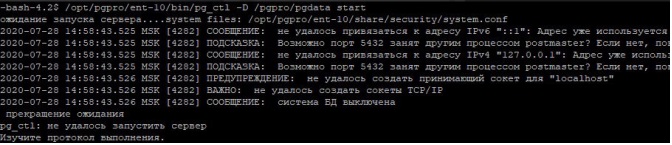
Описание:
Такая ситуация часто случается у начинающих администраторов в случае, если они хотят инициализировать сервер в каталог отличный от каталога по умолчанию. При этом сервер уже запустили из каталога по умолчанию.
В этой ситуации при попытке запуска видно ошибку – сервер не запускается.
А при проверке состояния видно, что сервер работает.
|
netstat –tlnp | grep 5432 |

Если проверим запущенные процессы пользователя postgres, то можно увидеть, что порт 5432 занят кластером PostgreSQL, только запущенным из каталога по умолчанию.

Решение:
Остановим работающий кластер сервера СУБД.
|
/opt/pgpro/ent—10/bin/pg_ctl —locale=ru_RU.UTF—8 —D /var/lib/pgpro/ent—10/data stop |
Инициализируем кластер из нового каталога(если он не инициализирован).
|
/opt/pgpro/ent—10/bin/initdb —locale=ru_RU.UTF—8 —D /pgpro/pgdata |
Запустим из нового каталога.
|
/opt/pgpro/ent—10/bin/pg_ctl —locale=ru_RU.UTF—8 —D /pgpro/pgdata start |
Длительный запуск 1С:Предприятия при работе с СУБД PostgreSQL
Описание:
Длительный запуск, длительный захват объектов в хранилище, длительное сохранение конфигурации 1С:Предприятия.
Решение:
Такая проблема может быть связано с настройками СУБД PostgreSQL.
Рассчитаем настройки СУБД.
Описание настроек приведено на ИТС.
Выполним настройки, для этого перейдем в терминал psql:
Через psql установим параметры командой ALTER SYSTEM SET(параметры необходимо указать для вашей СУБД):
Пример настроек:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
ALTER SYSTEM SET shared_buffers = ’96GB’; ALTER SYSTEM SET effective_cache_size = ‘288GB’; ALTER SYSTEM SET maintenance_work_mem = ’20GB’; ALTER SYSTEM SET wal_buffers = ’16MB’; ALTER SYSTEM SET default_statistics_target = 100; ALTER SYSTEM SET random_page_cost = 1.1; ALTER SYSTEM SET effective_io_concurrency = 200; ALTER SYSTEM SET work_mem = ’10GB’; ALTER SYSTEM SET max_worker_processes = 44; ALTER SYSTEM SET max_parallel_workers_per_gather = 22; ALTER SYSTEM SET temp_buffers = ‘265MB’; ALTER SYSTEM SET wal_level = ‘replica’; ALTER SYSTEM SET max_replication_slots = ‘8’; ALTER SYSTEM SET max_wal_senders = ’32’; ALTER SYSTEM SET autovaccuum = ‘on’; ALTER SYSTEM SET autovaccuum_max_workers = 16; ALTER SYSTEM SET autovacuum_naptime = ’20s’; ALTER SYSTEM SET bgwriter_delay = ’20ms’; ALTER SYSTEM SET bgwriter_lru_multiplier = 4.0; ALTER SYSTEM SET bgwriter_lru_maxpages = 400; ALTER SYSTEM SET synchronous_commit = ‘off’; ALTER SYSTEM SET checkpoint_segments = 256; ALTER SYSTEM SET checkpoint_completion_target = 0.9; ALTER SYSTEM SET min_wal_size = ‘4GB’; ALTER SYSTEM SET max_wal_size = ‘8GB’; ALTER SYSTEM SET ssl = ‘off’; ALTER SYSTEM SET max_files_per_process = 1000; ALTER SYSTEM SET standard_conforming_strings = ‘off’; ALTER SYSTEM SET escape_string_warning = ‘off’; ALTER SYSTEM SET max_locks_per_transaction = 256; ALTER SYSTEM SET max_connections = 15000; |
Из файла *xlsx загружаются в 1С иероглифы/ в файл выгружаются иероглифы.
Описание ошибки:
При загрузке данных из файла *.xlsx в 1С отображаются иероглифы. Используемая СУБД PostgreSQL/PostgresPro.
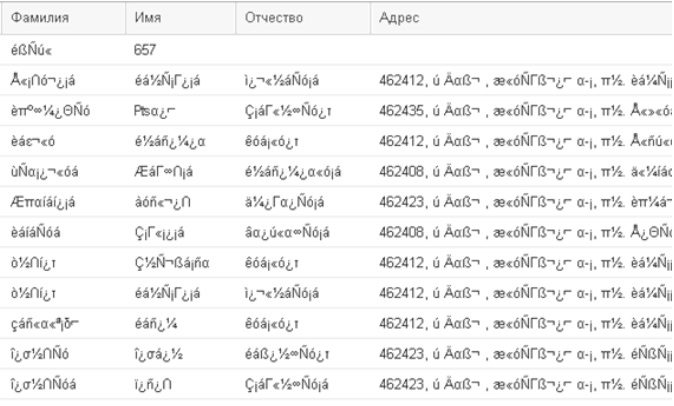
Также возможна проблема с кодировкой в выгружаемом файле из 1С:
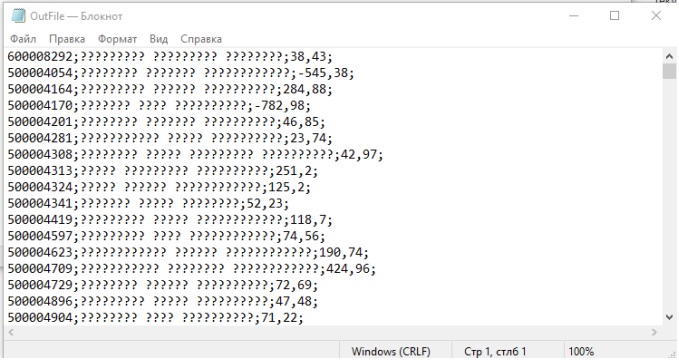
Решение:
На сервере СУБД проверим и выполним настройку локали.
1. Проверим наличие локали:
2. Проверим переменную:
Корректное значение результатов выполнения команд 2, 3:
3. Если результат не соответствует, выполним:
|
export LANG=«ru_RU.UTF-8» |
4. Выполним:
|
localectl set—locale LANG=ru_RU.utf8 |
5. Выполним перезапуск серверов СУБД
22.03.12 — 06:39
Добрый день.
Случилась беда с базой
Конф: v8 УТ 10.3.6.8
база на PostgreSQL 8.4.3-3.1C
При тестировании и исправлении вылетает ошибка
Ошибка СУБД
Error: Could not read block 26637 of relation base/50468/3305609: invalid argument
В конфигураторе останавливается на надписи:
Проверка логической целостности. Регистры накопления. Продажи. — 15%
Дамп базы не делается ни средствами 1с ни PostgreSQL.
База работает. Сбоев нет.
Кто сталкивался? Что делать?
1 — 22.03.12 — 06:44
прогони копию базы, её же штатной проверкой, в папке 1cv82/../bin/chdbfl.exe
как вариант попробуй
2 — 22.03.12 — 06:50
Не уследил в какой момент перестали создаваться копии. И уже все затерлись ((..Есть совсем старые но там нет ошибок.
3 — 22.03.12 — 07:09
(2) а новую копию создать нельзя??
4 — 22.03.12 — 07:15
В том то и дело, не могу сделать резервную копию вылетает с ошибкой. Думаю связано как раз что то с этим блоком.
5 — 22.03.12 — 07:16
Ну пробуй через XML в чистую базу выгрузить, возможно частями
6 — 22.03.12 — 07:21
Хотелось бы конечно выгрузить базу штатными средствами и потом уже сменить PostgreSQL или дело не в нем ведь?
7 — 22.03.12 — 07:34
(6) я просто не знаю, в SQL вообще не скопировать базу как в файловых??? там ведь есть путь к базе?
8 — 22.03.12 — 07:34
Поди БД файловая 
9 — 22.03.12 — 07:36
можно вообще очистить этот регистр в субд, только потом востанавливать тяжело будет.
судя по ошибке у тебя сама посгрей посыпалась
10 — 22.03.12 — 07:37
Я ведь написал БД на PostgreSQL, Резервная копия не делается ни средствами 1с ни средствами Postgre
11 — 22.03.12 — 07:37
(8) Написано же, «база на PostgreSQL 8.4.3-3.1C «
12 — 22.03.12 — 07:40
(9) Отчеты строятся по любым периодам, ошибок не бывает..или это не связано?
13 — 22.03.12 — 07:40
А по теме, «Продажи» — регистр оборотный, перепроведением восстановится. Так что грохнуть таблицу регистра, загрузить конфигурацию, реструктуризацию запустить, потом перепровести.
14 — 22.03.12 — 07:43
(13) Опасно конечно заниматься этим без резервной копии..может есть ещё варианты?
15 — 22.03.12 — 07:48
(14) а копию сделать кто мешает?
останавливаешь службу и копируешь файлы
16 — 22.03.12 — 07:50
(14) Образ винчестера сделай.
17 — 22.03.12 — 07:50
(14)А постгри потом стартанет если заменить базу на старую?
18 — 22.03.12 — 07:51
(16)
19 — 22.03.12 — 07:56
(17) Без танцев с бубном точно нет, но зато файлы останутся…
«Продажи» — первый поломатый регистр, на котором спотыкается ТиИ. Их может быть 100500…
20 — 22.03.12 — 08:01
(19) Плохо дело чувствую
21 — 22.03.12 — 08:05
Кстати, идея. Недавно делал РБД с этого узла и она создалась без сбоев. Там конечно обрезанный узел но нужно попробовать на полном плане. А с файловой уже проще.
22 — 22.03.12 — 08:16
сделай так:
1. создай новую пустую базу с этой конфигурацией
2. экспортом гони таблицы из поломатой в новую
3. составляешь список таблиц которые не удалось копирнуть
4. принимаешь решение чего дальше
способ безопасный, геморный, но понятный
23 — 22.03.12 — 08:20
(22) +1 за такой подход
24 — 22.03.12 — 08:27
(22) Спасибо попробую.
Один вопрос Экспорт — это ты имеешь ввиду средство 1с или Postgre? Ни разу не сталкивался.
25 — 22.03.12 — 08:31
(24) средстави СУБД, я с пости не работал, я только со скулем, зато так например востанавливал базу 7.7 примерно 60 гигов после краха винта и скульного рековера, там черти что было
26 — 22.03.12 — 08:39
(25) Понял Спасибо. Буду пробовать. Отпишусь.
27 — 22.03.12 — 08:42
Беда случилась уже давно когда Выбирали СУБД на учёбу забыли денег выделить ..)
28 — 22.03.12 — 08:55
))
29 — 23.03.12 — 07:26
Нашел таблицу которая дает ошибку.
accumreg7721
ERROR: could not read block 26637 of relation base/50468/3305609: Invalid argument
Кто знает что за таблица?
30 — 23.03.12 — 08:03
(29) регист…
теперь тупо в новой базе сделай ТиИс и потом полное перепроведение, и все будет рабочее.
31 — 23.03.12 — 08:03
(29) ERROR: could not read block 26637 of relation base/50468/3305609: Invalid argument
судя по последним словам, может это по больничным листам?)))))))
32 — 23.03.12 — 08:08
(30) хотя лучше не перепроведение, а что-то более правильное, на сколько я понял у тебя один регист «продажы» крякнул, подумай как его заполнить без перепроведения
33 — 23.03.12 — 08:10
(29) Объясни что такое ТиИс?
И как в новой? — я не могу её залить в новую базу.
(30) Да конечно лучше как то заполнить )
34 — 23.03.12 — 08:14
(33) Тестирование и Исправление.
35 — 23.03.12 — 08:17
Тоесть перенести все таблицы в новую базу кроме этой и уже например средствами 1с её заполнить..? дошло
36 — 23.03.12 — 08:27
А можно как то посмотреть что это за блок такой 26637?
37 — 23.03.12 — 08:28
(36) никак, это к 1с не имеет отношение, это номер страницы в файле субд
38 — 23.03.12 — 08:30
а вообще если такая ошибка появилась — это ОЧЕНЬ серьезный звонок админу, вариантов масса, от начала рассыпания дисков, до серьезных проблемм с софтом.
нет никакой гарантии что на этом сервере сабж не повторится но уже в КРУПНЫХ МАСШТАБАХ
39 — 23.03.12 — 10:23
Спасибо за помощь vde69
40 — 23.03.12 — 10:58
В Postgre подобные ошибки случаются с завидным постоянством, и, что самое плохое, — нет штатных утилит по лечению тип DBCC в MSSQL, поэтому главное правило — регулярные архивы.
Схема лечения такой ошибки следующая.
В pgadmin нужно запустить переиндексацию с перебором всех таблиц, например, подобным скриптом:
CREATE OR REPLACE FUNCTION _Reindex_Base(
schema_name in name,
result out bigint
)
LANGUAGE plpgsql as $BODY$
DECLARE table_name name;
BEGIN
FOR table_name IN (
SELECT t.table_name
FROM information_schema.tables t
WHERE t.table_schema = schema_name
AND t.table_type = ‘BASE TABLE’
— AND t.table_name > ‘_reference84’
ORDER BY t.table_name
) LOOP
raise info ‘reindex %s’, table_name;
EXECUTE ‘REINDEX TABLE ‘
||quote_ident(schema_name)||’.’||quote_ident(table_name);
END LOOP;
RETURN;
END;
$BODY$;
SELECT result
FROM _Reindex_Base(‘public’);
Нормальные таблицы будут переиндексироваться, на битых будет спотыкаться.
Битые таблицы потом нужно идентифицировать, каким объектам базы они соответствуют — благо обработок по представлению структуре базы везде валяется немеряно.
Далее битые таблицы придется удалить и пересоздать — проще всего автогенерируемым CREATE скриптом в том же pgadmin.
После этого восстанавливать данные, исходя из важности потерянных таблиц и имеющихся архивов. Служебные данные, типа итогов регистров — переформировать; движения регистров — можно восстанавливать, можно заново получить перепроведением. Справочники, документы, перечисления, независимые регистры сведений — только восстанавливать из бэкапов — либо тянуть в виде таблиц Postgre, либо разворачиать архивные базы полностью и выгружать-загружать средствами 1С.
41 — 23.03.12 — 11:01
(40) вот по этому я и сижу на скуле а пости извени это пРости какое-то
42 — 23.03.12 — 11:48
(40) Спасибо большое, сейчас пробую.
43 — 23.03.12 — 11:52
не гонялся бы ты поп за дешевизной…
44 — 23.03.12 — 12:49
Да уже тоже сижу думаю об этом..)
45 — 23.03.12 — 13:39
Бесплатность линуксов нивелируется стоимостью поддержки.
46 — 23.03.12 — 14:03
Это всего лишь стоимость несделанного вовремя бэкапа(ОС, СУБД и все остальное, практически, не имеет значения). Ключевая фраза в (3) — «Не уследил…»
ansh15
47 — 23.03.12 — 14:05
Извините, в (2)
We have some serious issues with our PostgreSQL-Server (Version 8.4). Our webapplication uses jdbc to connect to the PostgreSQL Server. Suddenly our webapplication cant connect to the PostgreSQL Server. We get the PSQLException: Broken Pipe. Cause of this, i tried to connect via pg_admin. This works, but i’m getting errors like this:
ERROR: could not read block 32570 of relation base/16390/2663: read
only 0 of 8192 bytes
I tried to make a dump to backup the data and this doesnt work too:
(Look on the edit at the bottom of the side)
pg_dump: SQL command failed
pg_dump: Error message from server: ERROR: could not read block 32570 of relation
base/16390/2663: read only 0 of
8192 bytespg_dump: The command was: LOCK TABLE
public.results_233_top100_disease_state_karyotype IN ACCESS SHARE MODE
I tried to get some information with
SELECT oid, relname FROM pg_class WHERE oid=2663
The result was this:
2663 ; «pg_class_relname_nsp_index»
During my effort of collecting some information, i read, that recreating that specific index could help. So reindexed it with the following command:
REINDEX INDEX pg_class_relname_nsp_index
This didnt helped at all, and now i’m pretty helpless. Has somebody an idea what i can do ? Another point is, that we do weekly backups. Is it possible to overwrite the data folder: /var/lib/postgresql/8.4./main with our data from the backup?
EDIT: I fixed the problem with reindexing the table that had the error. Now i’m getting another error:
pg_dump: SQL command failed
pg_dump: Error message from server: ERROR: invalid page header in block 1047 of relation base/16390/16398
pg_dump: The command was: COPY public.data_1 (sampleid, feature, value) TO stdout;
I have a service running and inserting data (a lot of data). Sometime, and this is only about few weeks, I receive this error:
ERROR: XX001: could not read block 2354 of relation 1663/17633/17925: read only 0 of 8192 bytes.
This error is from the Npgsql connector of PostGresql:
Exception trace: at Npgsql.NpgsqlConnector.CheckErrors()
at Npgsql.NpgsqlConnector.CheckErrorsAndNotifications()
at Npgsql.NpgsqlCommand.ExecuteCommand()
at Npgsql.NpgsqlCommand.ExecuteNonQuery()
If I do the query that create that error inside PGAdmin, I have this error too. Anyone have an idea of why this Insert query that has nothing special has this error? This table has a primary key but not Foreign Key and I have verified manually, this table doesn’t contain the primary key.
How can I solve that error?
Ans:
I had to deal with corrupted Postgres database cluster. At the end, we couldn’t able to recover some of the data but managed to recover most part of it. Having experience working with dozens of database systems, I’m pleasantly surprised to experience resiliency of Postgres database.
Kudos to Postgres Development team for building the most resilience database in the world
Here is my Postgres database recovery story
Disclaimer:
I'm posting the steps carried out during the recovery process for information purpose only. This post doesn't provide any guarantee that it will work for your use-case and/or environment.
Note: The actual database name has been replaced with “dbname” and actual table names with “tablename”.
One of the Postgres DB cluster database experienced disk level corruption thus we were hitting this error:
ERROR: 58030:could not read block 36 in file "base/14241237/15856837";input/output error
ERROR: 58030:could not read block 37 in file "base/14241237/15856837";input/output error
(OR)
postgres=# c dbname
FATAL: could not read block 0 in file "base/16389/11930": Input/output error
Uh oh?? Really bad, isn’t it? Fortunately, it wasn’t mission critical system so we managed to take extended outage and work on partial recovery process because we didn’t want to loose all the data!!
Once we received the complaint, we immediately backed up corrupted database and created recovery cluster to bring up on different server so we can go through recovery efforts!!
Trial 1:
As many of you know, the first option is to bring up recovery database cluster with zero_damaged_pages=on . You can set the value in Postgres config file and try to reindex system catalog:
reindexdb -p 5433 --system dbname
reindexdb: could not connect to database dbname: FATAL: index "pg_index_indexrelid_index" contains unexpected zero page at block 0
HINT: Please REINDEX it.
Doh! Still, we could still not be able to connect to database !!
Trial 2:
If you aren’t aware, you should note down that there is a way to ignore indexes at system level. We started up recovery cluster with ignore_system_indexes=true setting:
pg_ctl -D /data -o '-c ignore_system_indexes=true'
restarted
dbname=# c dbname
Yay! I could able to connect to DB now!
Trial 3:
Let’s try to reindex the database…
dbname=# reindex database "dbname";
NOTICE: table "pg_catalog.pg_class" was reindexed
2016-08-22 15:53:14.179 PDT rhost=[local] app=psql:user=postgres:db=dbname:ERROR: could not create unique index "pg_statistic_relid_att_inh_index"
2016-08-22 15:53:14.179 PDT rhost=[local] app=psql:user=postgres:db=dbname:DETAIL: Key (starelid, staattnum, stainherit)=(2608, 5, f) is duplicated.
2016-08-22 15:53:14.179 PDT rhost=[local] app=psql:user=postgres:db=dbname:STATEMENT: reindex database "dbname";
ERROR: could not create unique index "pg_statistic_relid_att_inh_index"
DETAIL: Key (starelid, staattnum, stainherit)=(2608, 5, f) is duplicated.
As the table is corrupted with duplicate entries, let’s find out and fix them.
dbname=# select starelid, staattnum, stainherit from pg_catalog.pg_statistic where starelid=2608 order by 2;
starelid | staattnum | stainherit
----------+-----------+------------
2608 | 1 | f
2608 | 2 | f
2608 | 3 | f
2608 | 4 | f
2608 | 5 | f
2608 | 5 | f
2608 | 6 | f
2608 | 7 | f
(8 rows)
Let’s remove one of the entry based on XMIN :
dbname=# delete from pg_catalog.pg_statistic where starelid=2608 and staattnum=5 and xmin=1228447;
DELETE 1
Trial 4:
Restart REINDEX but it failed again!!
2016-08-22 16:01:29.698 PDT rhost=[local] app=psql:user=postgres:db=dbname:ERROR: 1 constraint record(s) missing for rel tablename
2016-08-22 16:01:29.698 PDT rhost=[local] app=psql:user=postgres:db=dbname:STATEMENT: reindex database "dbname";
ERROR: 1 constraint record(s) missing for rel tablename
Trial 5:
Let’s try to vacuum analzye the table
dbname=# vacuum analyze tablename;
2016-08-22 16:04:01.282 PDT rhost=[local] app=psql:user=postgres:db=dbname: 1 constraint record(s) missing for rel tablename
2016-08-22 16:04:01.282 PDT rhost=[local] app=psql:user=postgres:db=dbname:STATEMENT: vacuum analyze tablename;
ERROR: 1 constraint record(s) missing for rel tablename
hrm…it’s still complaining about constraint
Trial 6:
let’s disable constraint check….
dbname=# update pg_class set relchecks=0 where relname='tablename';
UPDATE 1
The above update fixed the the constraint error
Trial 7:
Let’s reindex the database again!
dbname =# reindex database "dbname";
Yay, Reindex is successful.
Once the reindex is successfully completed, we restarted recovery cluster without zero_damaged_page and ignore_system_indices settings.
Partial tables recovery through pg_dump process:
As the database is corrupted, it makes sense to kick off the pg_dump on the database … we kicked off the pg_dump but it was still showing some of the sequences with errors!!
/usr/lib/postgresql/9.4/bin/pg_dump dbname -p 5433 -Fc >recovery_dbname.dmp
2016-08-22 16:22:09.517 PDT rhost=[local] app=pg_dump:user=postgres:db=dbname:ERROR: invalid page in block 0 of relation base/16389/2825248
2016-08-22 16:22:09.517 PDT rhost=[local] app=pg_dump:user=postgres:db=dbname:STATEMENT: SELECT sequence_name, start_value, increment_by, CASE WHEN increment_by > 0 AND max_value = 9223372036854775807 THEN NULL WHEN increment_by < 0 AND max_value = -1 THEN NULL ELSE max_value END AS max_value, CASE WHEN increment_by > 0 AND min_value = 1 THEN NULL WHEN increment_by < 0 AND min_value = -9223372036854775807 THEN NULL ELSE min_value END AS min_value, cache_value, is_cycled FROM XX_id_seq
pg_dump: [archiver (db)] query failed: ERROR: invalid page in block 0 of relation base/16389/2825248
pg_dump: [archiver (db)] query was: SELECT sequence_name, start_value, increment_by, CASE WHEN increment_by > 0 AND max_value = 9223372036854775807 THEN NULL WHEN increment_by < 0 AND max_value = -1 THEN NULL ELSE max_value END AS max_value, CASE WHEN increment_by > 0 AND min_value = 1 THEN NULL WHEN increment_by < 0 AND min_value = -9223372036854775807 THEN NULL ELSE min_value END AS min_value, cache_value, is_cycled FROM XX_id_seq
We had issue recovering a couple of tables but we managed to recover the most of the tables in the database