
Корректурные (корректорские) знаки (значки)
- Category: Наш справочник
-
Hits: 61428
Эта статья посвящена корректорским знакам. Если быть точным то знаки должны называться корректурные, но 95 % пользователей ищут в интернете эти значки именно под название корректорские и только 5% – корректурные, отсюда и название статьи. Но для общего кругозора верное название этих значков — корректурные знаки ГОСТ 7.62-90.
Когда делать корректуру?
Не зависимо от того что вы делаете — издаете книгу, печатаете брошюру, издаете газету или журнал – первую корректуру необходимо делать до передачи материала в верстку. Если материалы в рукописном или в печатном виде, но на бумаге то, прежде всего, переведите материалы в электронный вид в любой текстовый формат. О том как «правильно» набирать текст вы узнаете в статье Правила набора текста. После работы редактора (если такая предполагается) и после внесения всех авторских правок этот материал передают корректору для первой корректорской вычитки. Наше агентство, как правило, согласовывает с автором все внесенные исправления корректора и уже после материалы передаются в верстку.
Для чего же нужны корректорские знаки, если все изменения вносятся корректором в электронный вариант. Дело в том, что есть еще одна корректорская правка – правка сверстанного материала и его правка проходит с листа (распечатки сверстанного материала). Мы рекомендуем это делать уже после утверждения автором верстки и перед передачей материала в типографию.
Сколько должно быть корректур?
Минимум две, первая до передачи материала в верстку и вторая перед передачей в типографию. Большее количество корректуры может понадобиться при внесении изменений большой части текста автором в процессе верстки, что крайне не желательно – поэтому старайтесь менять текст до верстки. Задачи первой корректуры — правка всех орфографических ошибок, задачи второй корректуры- выявить пропущенные ошибки и правка технических ошибок верстки (отдельная статья с которой мы рекомендуем ознакомиться всем).
Для чего нужны корректорские знаки?
Прежде всего, если корректор использует общепринятые знаки, то у верстальщика не возникнет дополнительных вопросов и работа внесения исправлений будет ускорена. Но очень часто возникают ситуации, когда не хватает общепринятых корректорских знаков или их можно трактовать двусмысленно, в этом случае мы рекомендует отходить от правил и вносить все пояснения на полях как можно подробней. Всегда надо помнить, что корректуру делают, прежде всего, для исправления ошибок, а не для создания новых «ребусов».
Как делать корректуру?
Самое главное, что бы все исправления корректора были четко видны и разборчивы.
Если вы правите черный текст, то всегда используйте красную ручку — наиболее яркую и заметную. Если используете карандаш или темную ручку, то выбирайте их тонкими и яркими. Не зависимо, какой корректорский знак вы ставите, рекомендует ставить галочку на полях напротив внесенного исправления (скажу сразу, это против правил), это сильно упрощает процесс внесения правки в электронный вариант и снизит вероятность пропуска внесенных исправлений.
Не мельчите. Если возникла задача помещения нового текста или корректорские знаки перестановки начинают пересекаться и только путают – перечеркните этот текст, поставьте цифру в кружочке и на полях или отдельном листочке под этой цифрой напишите нужный текст.
Корректорские знаки замены букв

Наверное, самые распространенный и частый вид правки. Знак должен перечеркнуть неверный символ, далее знак дублируют на полях с нужной буквой. Если в одной строке встречаются несколько замен, то ставят разные знаки. Чтобы не возникало путаницы – знаков придумали много, но все они однотипные.
Корректорские знаки замены слов или целых строк

Главное отличие в том, что знак перечеркивает полностью неверное слово или строку. Самая распространенная ошибка, это когда корректор начинает мельчить на полях при исправлении большого куска текста. Выносите знак на самое большое поле и там пишите правку, а от знака зачеркнутого текста лучше отведите стрелку в знак с правкой — может быть это не правильно, но точно ясно.
Корректорские знаки замены текста
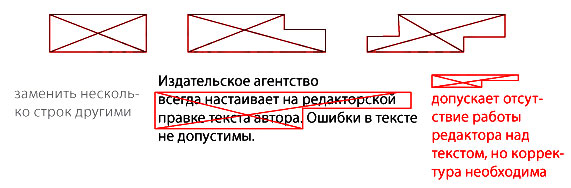
Мне кажется с этим знаком все понятно.
Корректорский знак вставки

Все знаки имеют формы галочки — отличительная черта знака вставки. Знак ставят в промежуток, куда нужно поместить вставку. Ошибки – не забывайте указывать знаки препинания во вставках.
Корректорский знак удаления буквы слова или целого предложения

Так как этот знак сильно похож на знак замены, то надо четко рисовать волну — отличающую знаки удаления.
Корректорский знак перестановки

Перестановка может быть: букв, слов или строк. В случае перестановки в слове, мы рекомендуем на полях продублировать знак и написать рядом верное слово.
Корректорские знаки, определяющие очередность слов или предложений в тексте
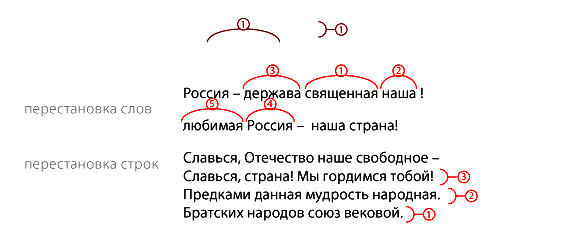
Используют если перестановок много или слова стоят не подряд.
Корректорские знаки переноса слов или части текста с одной страницы на другую

Корректорские знаки работы с пробелами

Часто встречающийся тип правки. Обязательно дублируйте его на полях в виде знака либо виде галочек-внимания – этот знак корректорской правки пропустить легче всего.
И самый главный знак корректорской правки – знак отмены правки

Самый главный знак, потому что больше всего вносит путаницы.
Корректорские знаки выравнивания
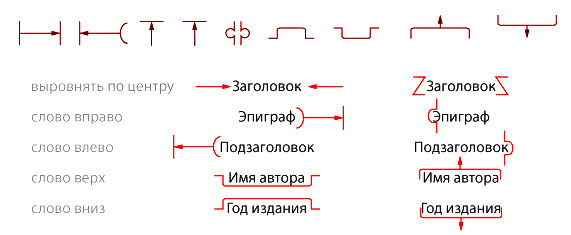
Эти знаки обозначают выравнивание текста на странице.
Корректорские знаки «верхнего и нижнего регистра»

Знаки показывают расположение буквы относительно базовой лини набора текста. Если галочки две — символ поднимают еще выше.
Корректорский знак «абзаца»

Знак ставиться в пробел, где должен быть абзац, либо объединяет текст набираемый в подбор.
Вот и все основные знаки.
Есть еще знаки определяющие начертание (жирное, курсивное, заглавные, в разрядку и т.д.), но мы специально не приводим их. Мы рекомендуем в таких случаях сделать пометку на полях в виде слов, если правка часто встречается то, на первой странице нарисуйте знак и присвойте ему вид правки, что бы человек вносящий правку знал, что этот знак означает.
Иногда нужно вставить в текст символ, который отсутствует на клавиатурной раскладке. В разных операционных системах приходится для этого открывать какие-то приложения и оттуда копировать нужные символы, что порой очень неудобно.
Поэтому я решил создать такую таблицу символов, рассортированных по тематическим группам.
Нужно понимать, что если вы хотите скопировать отсюда символ и вставить в свой текст, то ваш текст должен быть в кодировке Unicode (UTF). Если же вы набираете текст в документе с другой однобайтной кодировкой (например Windows-1251, она же CP1251), то вы вставить подобные символы туда не сможете.
Однобайтные кодировки не поддерживают подобные символы.
Вообще, самые универсальные способы вставки символов, которых нет на клавиатуре – это по их Unicode-номеру, но тут многое зависит от операционной системы и приложения.. Если в меню приложения нет опции для вставки специального символа из визуальной таблицы символов, то можно, зная Unicode-номер ввести символ вручную.
Для операционных систем Windows:
1-й способ: набрать шестнадцатеричный код символа, затем одновременно клавиши «Alt» и «X».
2-й способ: удерживая клавишу «Alt», на цифровой клавиатуре (NUM-паде) набрать десятичный Unicode-номер символа.
Для операционных систем типа Linux (Ubuntu):
Одновременно набрать «Ctrl» «Shift» «U», затем шестнадцатеричный Unicode-номер символа и нажать «Enter»
Знак ударения (ставится после ударной буквы):
Для того чтобы скопировать этот специфический знак, нужно его либо выделить мышью, либо щелкнуть мышью за ним, затем, удерживая клавишу Shift, один раз нажать стрелку ←, затем, как обычно ctrl-c.
́
В некоторых шрифтах (например Verdana) на разных операционных системах этот знак ударения может отображаться некорректно, не копироваться.
UTF-8 код этого символа в десятичной системе: 769, в шестнадцатеричной: 0301.
Соответственно HTML-коды: ́ ́
Ещё знак ударения можно вставить методом ввода его Unicode номера. В шестнадцатеричной записи его код 0301, в десятеричной, соответственно 769 (256*3 + 0 + 1 = 769).
Знаки тире:
Длинное тире —
Среднее тире –
Цифровое тире ‒
Горизонтальная линия ―
Математические дроби:
⅟ ½ ⅓ ¼ ⅕ ⅙ ⅐ ⅛ ⅑ ⅒ ⅔ ¾ ⅖ ⅗ ⅘ ⅚ ⅜ ⅝ ⅞
Математические символы:
∫ ∬ ∭ ∮ ∯ ∰ ∱ ∲ ∳
∃ ∄ ∅ ∆ ∇ ∈ ∉ ∊ ∋ ∌ ∍ ∎ ∏ ∐ ∑ − ∓ ∔ ∕ ∖ ∗ ∘ ∙ √ ∛ ∜ ∝ ∟ ∠ ∡ ∢ ∣ ∤ ∥ ∦ ∧ ∨ ∩ ∪ ∴ ∵ ∶ ∷ ∸ ∹ ∺ ∻ ∼ ∽ ∾ ∿ ≀ ≁ ≂ ≃ ≄ ≅ ≆ ≇ ≈ ≉ ≊ ≋ ≌ ≍ ≎ ≏ ≐ ≑ ≒ ≓ ≔ ≕ ≖ ≗ ≘ ≙ ≚ ≛ ≜ ≝ ≞ ≟ ≠ ≡ ≢ ≣ ≤ ≥ ≦ ≧ ≨ ≩ ≪ ≫ ≬ ≭ ≮ ≯ ≰ ≱ ≲ ≳ ≴ ≵ ≶ ≷ ≸ ≹ ≺ ≻ ≼ ≽ ≾ ≿ ⊀ ⊁ ⊂ ⊃ ⊄ ⊅ ⊆ ⊇ ⊈ ⊉ ⊊ ⊋ ⊌ ⊍ ⊎ ⊏ ⊐ ⊑ ⊒ ⊓ ⊔ ⊕ ⊖ ⊗ ⊘ ⊙ ⊚ ⊛ ⊜ ⊝ ⊞ ⊟ ⊠ ⊡ ⊢ ⊣ ⊤ ⊥ ⊦ ⊧ ⊨ ⊩ ⊪ ⊫ ⊬ ⊭ ⊮ ⊯ ⊰ ⊱ ⊲ ⊳ ⊴ ⊵ ⊶ ⊷ ⊸ ⊹ ⊺ ⊻ ⊼ ⊽ ⊾ ⊿ ⋀ ⋁ ⋂ ⋃ ⋄ ⋅ ⋆ ⋇ ⋈ ⋉ ⋊ ⋋ ⋌ ⋍ ⋎ ⋏ ⋐ ⋑ ⋒ ⋓ ⋔ ⋕ ⋖ ⋗ ⋘ ⋙ ⋚ ⋛ ⋜ ⋝ ⋞ ⋟ ⋠ ⋡ ⋢ ⋣ ⋤ ⋥ ⋦ ⋧ ⋨ ⋩ ⋪ ⋫ ⋬ ⋭ ⋮ ⋯ ⋰ ⋱ ⋲ ⋳ ⋴ ⋵ ⋶ ⋷ ⋸ ⋹ ⋺ ⋻ ⋼ ⋽ ⋾ ⋿ ✕ ✖ ✚
Символ (знак) промилле:
‰
Римские цифры:
Ⅰ Ⅱ Ⅲ Ⅳ Ⅴ Ⅵ Ⅶ Ⅷ Ⅸ Ⅹ Ⅺ Ⅻ
ⅰ ⅱ ⅲ ⅳ ⅴ ⅵ ⅶ ⅷ ⅸ ⅹ ⅺ ⅻ
Цифры в кружочках:
⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ➊ ➋ ➌ ➍ ➎ ➏ ➐ ➑ ➒ ➓
⓪ ➀ ➁ ➂ ➃ ➄ ➅ ➆ ➇ ➈ ➉ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳
❶ ❷ ❸ ❹ ❺ ❻ ❼ ❽ ❾ ❿ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴
Латинские буквы в кружочках:
ⒶⒷⒸⒹⒺⒻⒼⒽⒾⒿⓀⓁⓂⓃⓄⓅⓆⓇⓈⓉⓊⓋⓌⓍⓎⓏ
ⓐⓑⓒⓓⓔⓕⓖⓗⓘⓙⓚⓛⓜⓝⓞⓟⓠⓡⓢⓣⓤⓥⓦⓧⓨⓩ
Знаки валют:
$ € ¥ £ ƒ ₣ ¢ ¤ ฿ ₠ ₡ ₢ ₤
Круги и окружности:
∅ ❂ ○ ◎ ● ◯ ◕ ◔ ◐ ◑ ◒ ◓ ⊗ ⊙ ◍ ◖◗ ◉ ⊚ ʘ ⊕ ⊖ ⊘ ⊚ ⊛ ⊜ ⊝
Стрелочки:
↪ ↩ ← ↑ → ↓ ↔ ↕ ↖ ↗ ↘ ↙ ↚ ↛ ↜ ↝ ↞ ↟ ↠ ↡ ↢ ↣ ↤ ↦ ↥ ↧ ↨ ↫ ↬ ↭ ↮ ↯ ↰ ↱ ↲ ↴ ↳ ↵ ↶ ↷ ↸ ↹ ↺ ↻ ⟲ ⟳ ↼ ↽ ↾ ↿ ⇀ ⇁ ⇂ ⇃ ⇄ ⇅ ⇆ ⇇ ⇈ ⇉ ⇊ ⇋ ⇌ ⇍ ⇏ ⇎ ⇑ ⇓ ⇐ ⇒ ⇔ ⇕ ⇖ ⇗ ⇘ ⇙ ⇳ ⇚ ⇛ ⇜ ⇝ ⇞ ⇟ ⇠ ⇡ ⇢ ⇣ ⇤ ⇥ ⇦ ⇨ ⇩ ⇪ ⇧ ⇫ ⇬ ⇭ ⇮ ⇯ ⇰ ⇱ ⇲ ⇴ ⇵ ⇶ ⇷ ⇸ ⇹ ⇺ ⇻ ⇼ ⇽ ⇾ ⇿ ⟰ ⟱ ⟴ ⟵ ⟶ ⟷ ⟸ ⟹ ⟽ ⟾ ⟺ ⟻ ⟼ ⟿ ⤀ ⤁ ⤅ ⤂ ⤃ ⤄ ⤆ ⤇ ⤈ ⤉ ⤊ ⤋ ⤌ ⤍ ⤎ ⤏ ⤐ ⤑ ⤒ ⤓ ⤔ ⤕ ⤖ ⤗ ⤘ ⤙ ⤚ ⤛ ⤜ ⤝ ⤞ ⤟ ⤠ ⤡ ⤢ ⤣ ⤤ ⤥ ⤦ ⤧ ⤨ ⤩ ⤪ ⤭ ⤮ ⤯ ⤰ ⤱ ⤲ ⤳ ⤻ ⤸ ⤾ ⤿ ⤺ ⤼ ⤽ ⤴ ⤵ ⤶ ⤷ ⤹ ⥀ ⥁ ⥂ ⥃ ⥄ ⥅ ⥆ ⥇ ⥈ ⥉ ⥒ ⥓ ⥔ ⥕ ⥖ ⥗ ⥘ ⥙ ⥚ ⥛ ⥜ ⥝ ⥞ ⥟ ⥠ ⥡ ⥢ ⥣ ⥤ ⥥ ⥦ ⥧ ⥨ ⥩ ⥪ ⥫ ⥬ ⥭ ⥮ ⥯ ⥰ ⥱ ⥲ ⥳ ⥴ ⥵ ⥶ ⥷ ⥸ ⥹ ⥺ ⥻ ➔ ➘ ➙ ➚ ➛ ➜ ➝ ➞ ➟ ➠ ➡ ➢ ➣ ➤ ➥ ➦ ➧ ➨ ➩ ➪ ➫ ➬ ➭ ➮ ➯ ➱ ➲ ➳ ➴ ➵ ➶ ➷ ➸ ➹ ➺ ➻ ➼ ➽ ➾ ⬀ ⬁ ⬂ ⬃ ⬄ ⬅ ⬆ ⬇ ⬈ ⬉ ⬊ ⬋ ⬌ ⬍ ⏎ ▲ ▼ ◀ ▶ ⬎ ⬏ ⬐ ⬑ ☇ ☈ ⍃ ⍄ ⍇ ⍈ ⍐ ⍗ ⍌ ⍓ ⍍ ⍔ ⍏ ⍖ ⍅ ⍆
Заглавные и строчные буквы греческого алфавита:
ΑΒΓΔΕΖΗΘΚΛΜΝΞΟΠΡΣΤΥΦΧΨΩ
αβγδεζηθικλμνξοπρστυφχψω
Перевернутые буквы (латинский и русский алфавиты):
zʎxʍʌnʇsɹbdouɯlʞɾıɥƃɟǝpɔqɐ
ʁєqqıqmmҺцхфʎɯɔduонwvʞиεжǝ6ɹʚgɐ
Смайлики:
㋛ ソ ッ ヅ ツ ゾ シ ジ ッ ツ シ ン 〴 ت ☺ ☻ ☹
Значки знаков зодиака:
♈ ♉ ♊ ♋ ♌ ♍ ♎ ♏ ♐ ♑ ♒ ♓
Снежинки:
✽ ✾ ✿ ✥ ❀ ❁ ❃ ❄ ❅ ❆ ❇ ❈ ❉ ❊ ✢ ✣ ✤ ❋ ٭ ✱ ✲ ✳ ✴ ✶ ✷ ✸ ✹ ✺ ✻ ✼ ⁂
Звездочки:
✪★☆✫✬✭✮✯✰⋆✧✩✵✦
Шахматные фигуры:
♔♕♖♗♘♙♚♛♜♝♞♟
Рука, указательный палец:
☚☛☜☝☞☟✌
Значки сообщений, почты:
✉ ✍ ✎ ✏ ✐ ✑ ✒
Карточные масти символами (червы, трефы, бубны, пики):
♡ ♢ ♣ ♤ ♥ ♦ ♧
Нотные знаки:
♪ ♫ ♩ ♬ ♭ ♮ ♯ ° ø
Ножницы:
✁ ✂ ✃ ✄
Телефоны:
✆ ☎ ☏
Галочки (значок найк):
☑ ✓ ✔
Trademark, Copyright, Registered:
™ © ®
Сердечки:
♡ ღ ❥ ❤ ♥ ❣ ❢ ❦ ❧
Кресты, крестики:
☩ ☨ ☦ ✙ ✚ ✛ ✜ ✝ ✞ ✠ † ┿
Крестики (закрыть, удалить):
☒ ☓ ✕ ✖ ✗ ✘ ✇ ☣
Треугольники:
▲◣◢ ◥▼△▽ ⊿◤◥ △ ▴ ▵ ▶ ▷ ▸ ▹ ► ▻ ▼ ▽ ▾ ▿ ◀ ◁ ◂ ◃ ◄ ◅ ◬ ◭ ◮
Квадраты и блоки:
❏ ❐ ❑ ❒ ▀ ▄ □ ■ ◙ ▢ ▣ ◘ ◧ ◨ ◩ ◪ ◫ ▤ ▥ ▦ ▧ ▨ ▩ ▱ ▰ ▪ ▫ ▬ ▭ ▮ ▯ ◊ ◈ ☰ ☲ ☱ ☴ ☵ ☶ ☳ ☷ ░ ▒ ▓ ▌█▉▇▆▅▄▃▂
Буквенные символы:
А — Ꭿ 凡 Ꮨ ∀ ₳ Ǻ ǻ α ά Ά ẫ Ắ ắ Ằ ằ ẳ Ẵ ẵ Ä ª ä Å À Á Â å ã â à á Ã ᗩ ᵰ
B — ℬ Ᏸ β ฿ ß Ђ ᗷ ᗸ ᗹ ᗽ ᗾ ᗿ Ɓ ƀ ხ 方 ␢ Ꮄ
C — ☾ ℭ ℂ Ç ¢ ç Č ċ Ċ ĉ ς Ĉ ć Ć č Ḉ ḉ ⊂ Ꮸ ₡ ¢
D — ᗫ Ɗ Ď ď Đ đ ð ∂ ₫ ȡ
E — ℯ ໂ ६ £ Ē ℮ ē Ė ė Ę ě Ě ę Έ ê ξ Ê È € É ∑ Ế Ề Ể Ễ é è ع Є є έ ε
F — ℱ ₣ ƒ ∮ Ḟ ḟ ჶ ᶂ φ
G — Ꮹ Ꮆ ℊ Ǥ ǥ Ĝ ĝ Ğ ğ Ġ ġ Ģ ģ פ ᶃ ₲
H — ℍ ℋ ℎ ℌ ℏ ዙ Ꮵ Ĥ Ħ ħ Ή ♅ 廾 Ћ ђ Ḩ Һ ḩ♄
I — ℐ ℑ ί ι Ï Ί Î ì Ì í Í î ϊ ΐ Ĩ ĩ Ī ī Ĭ ĭ İ į Į Ꭵ
J — ჟ Ĵ ĵ ᶖ ɉ
K — ₭ Ꮶ Ќ k ќ ķ Ķ Ҝ ҝ ﻸ ᶄ
L — ℒ ℓ Ŀ ŀ £ Ĺ ĺ Ļ ļ λ ₤ Ł ł ľ Ľ Ḽ ḽ ȴ Ꮭ £ Ꮑ
M — ℳ ʍ ᶆ Ḿ ḿ ♍ ᗰ ᙢ 爪 ♏ ₥
N — ℕ η ñ ח Ñ ή ŋ Ŋ Ń ń Ņ ņ Ň ň ʼn ȵ ℵ ₦
O — ℴ ტ ٥ Ό ó ό σ ǿ Ǿ Θ ò Ó Ò Ô ô Ö ö Õ õ ờ ớ ọ Ọ ợ Ợ ø Ø Ό Ở Ờ Ớ Ổ ổ Ợ Ō ō
P — ℙ ℘ þ Þ ρ Ꭾ Ꮅ 尸 Ҏ ҏ ᶈ ₱ ☧ ᖘ ק ァ
Q — ℚ q Q ᶐ Ǭ ǭ ჹ
R — ℝ ℜ ℛ ℟ ჩ ᖇ ř Ř ŗ Ŗ ŕ Ŕ ᶉ Ꮢ 尺
S — Ꮥ Ṧ ṧ ȿ ى § Ś ś š Š ş Ş ŝ Ŝ ₰ ∫ $ ֆ
T — ₸ † T t τ ΐ Ţ ţ Ť ť ŧ Ŧ ィ 干 Ṫ ṫ ナ Ꮏ Ꮖ テ ₮
U — ∪ ᙀ Ũ ⋒ Ủ Ừ Ử Ữ Ự ύ ϋ Ù ú Ú ΰ ù Û û Ü ử ữ ự Џ ü ừ Ũ ũ Ū ū Ŭ ŭ ų Ų ű Ű ů Ů
V — ✔ ✓ ∨ √ Ꮙ Ṽ ṽ ᶌ / ℣ ʋ
W — ₩ ẃ Ẃ ẁ Ẁ ẅ ώ ω ŵ Ŵ Ꮤ Ꮃ ฬ ᗯ ᙡ Ẅ ѡ ಎ ಭ Ꮚ Ꮗ ผ ฝ พ ฟ
X — χ × ✗ ✘ ᙭ ჯ Ẍ ẍ ᶍ ⏆
Y — ɣ Ꭹ Ꮍ Ẏ ẏ ϒ ɤ ¥ り
Z — ℤ ℨ ჳ 乙 Ẑ ẑ ɀ Ꮓ
Кстати, в Unicode (Utf) существуют всякие управляющие (непечатные) символы типа вертикальной табуляции, сдвига каретки назад, надстрочных и подстрочных модификаторов и т. п. Что дает иногда поле для творчества хакерам и просто креативщикам. Например, если хотите написать текст в таком виде (это называется Zalgo текст),
.")
- Залго-текст (Zalgo text example).
- zalgo-text.gif (12.09 Кб) Просмотров: 1847910
.")
можете воспользоваться одним из сервисов. На мой взгляд наиболее удачный сервис — этот. Хотя я на своём форуме такое, наверное, не позволял бы такое вставлять..
Но этот Zalgo текст на разных операционных системах и даже в разных браузерах по-разному будет отображаться.
Последний раз редактировалось Александр 16 фев 2020, 19:13, всего редактировалось 12 раз(а).
Здравствуйте, уважаемые читатели, почитатели и прочие хорошие люди!
Случалось ли Вам получать и читать письма на “фиг каком пойми языке” или заходить на какой-нибудь интернет-ресурс и вместо привычных букв видеть сплошные кракозябры? Если да, тогда эта заметка для Вас, ибо в ней мы поговорим о кодировке страниц, её форматах, почему оная возникает и как впредь избежать непонятных иероглифов.

Итак, сегодня нас ждет не легкая софтовая статья, а суровая техническая, так что приготовьтесь: будем немного ударяться в суровые реалии.
Поехали.
-
Что такое кодировка текста и с чем ее едят?
-
Виды кодировок текста
-
Решаем проблемы с кодировкой или как убрать кракозябры?
-
Послесловие
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).

Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая — со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста (HTML), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа” проекта [Sonikelf’s Project’s], но не глазами обычного пользователя, а «глазами» поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome) и видим следующую картину (см. изображение):

Перед нами машинный вариант sonikelf.ru, вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML-виде. Обратите внимание на строку с надписью UTF-8, это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст.
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “Charset”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“Codepage”) – 1 байтовая (8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:
Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
к содержанию ↑
Виды кодировок текста
А их, в общем-то, хватает.
- ASCII
Одной из самых “древних” считается американская кодировочная таблица (ASCII, читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
- Кириллица
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256. Заточена под русскоязычную аудиторию.
- Кодировки семейства MS Windows: Windows 1250-1258.
8-битные кодировки, появились как следствие разработки самой популярной операционной системы, Windows. Номера с 1250 по 1258 указывают на язык, под который они заточены, например, 1250 – для языков центральной Европы; 1251 – кириллический алфавит.
- Код обмена информацией 8 бит – КОИ8
KOI8-R, KOI8-U, KOI-7 – стандарт для русской кириллицы в юникс-подобных операционных системах.
- Юникод (Unicode)
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “U+xxxx” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format): UTF-8, 16, 32.
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС, которые использовали 8-битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “Вид-Кодировка-Выбрать список” и ознакомиться со всевозможными их вариантами (см. изображение).

Думаю возник резонный вопрос: “Какого лешего столько кодировок?”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта «Заметки Сис.Админа» с этим, как Вы заметили всё в порядке :).
Все эти кодировки – рабочие варианты, созданные разработчиками “под себя” и решение своих задач. Когда же их количество перевалило за все разумные пределы, а в поисковиках стали плодиться запросы типа: “Как убрать кракозябры в браузере?” — разработчики стали ломать голову над приведением всей этой каши к единому стандарту, чтобы, так сказать, всем было хорошо. И кодировка Unicode, в общем-то, это “хорошо” и сделала. Теперь если такие проблемы и возникают, то они носят локальный характер, и не знают как их исправить только совсем непросвещенные пользователи (впрочем, часто беда с кодировкой и отображением сайтов появляется из-за того, что веб-мастер указал на стороне сервера некорректный формат, и приходится переключать кодировку в браузере).
Ну вот, собственно, пока вся «базово необходимая» теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
к содержанию ↑
Решаем проблемы с кодировкой или как убрать кракозябры?
Итак, наша статья была бы неполной, если бы мы не затронули пользовательско-бытовые вопросы. Давайте их и рассмотрим и начнем с того, как (с помощью чего) можно посмотреть кодировку?
В любой операционной системе имеется таблица символов, ее не нужно докачивать, устанавливать – это данность свыше, которая располагается по адресу: “Пуск-программы-стандартные-служебные-таблица символов”. Это таблица векторных форм всех установленных в Вашей операционной системе шрифтов.

Выбрав “дополнительные параметры” (набор Unicode) и соответствующий тип начертания шрифта, Вы увидите полный набор символов, в него входящих. Кликнув по любому символу, Вы увидите его код в формате UTF-16, состоящий из 4-х шестнадцатеричных цифр (см. изображение).
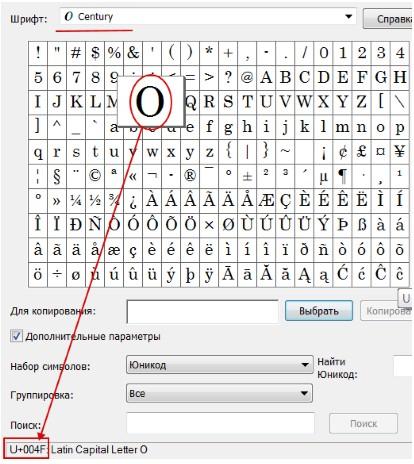
Теперь пара слов о том, как убрать кракозябры. Они могут возникать в двух случаях:
- Со стороны пользователя — при чтении информации в интернет (например, при заходе на сайт);
- Или, как говорилось чуть выше, со стороны веб-мастера (например, при создании/редактировании текстовых файлов с поддержкой синтаксиса языков программирования в программе Notepad++ или из-за указания неправильной кодировки в коде сайта).
Рассмотрим оба варианта.
№1. Иероглифы со стороны пользователя.
Допустим, Вы запустили ОС и в каком-то из приложений у Вас отображаются пресловутые каракули. Чтобы это исправить, идем по адресу: “Пуск — Панель управления — Язык и региональные стандарты — Изменение языка” и выбираем из списка, «Россия«.

Также проверьте во всех вкладках, чтобы локализация была “Россия/русский” – это так называемая системная локаль.
Если Вы открыли сайт и вдруг поняли, что почитать информацию Вам не дают иероглифы, тогда стоит поменять кодировку средствами браузера (“Вид — Кодировка”). На какую? Тут все зависит от вида этих кракозябр. Ориентируйтесь на следующую шпаргалку (см. изображение).

№2. Иероглифы со стороны веб-мастера.
Очень часто начинающие разработчики сайтов не придают большого значения кодировке создаваемого документа, в результате чего потом и сталкиваются с вышеозначенной проблемой. Вот несколько простых базовых советов для веб-мастеров, чтобы исправить беду.
Чтобы такого не происходило, заходим в редактор Notepad++ и выбираем в меню пункт “Кодировки”. Именно он поможет преобразовать имеющийся документ. Спрашивается, какой? Чаще всего (если сайт на WordPress или Joomla), то “Преобразовать в UTF-8 без BOM” (см. изображение).

Сделав такое преобразование, Вы увидите изменения в строке статуса программы.

Также во избежание кракозябр необходимо принудительно прописать информацию о кодировке в шапке сайта. Тем самым Вы укажите браузеру на то, что сайт стоит считывать именно в прописанной кодировке. Начинающему веб-мастеру необходимо понимать, что чехарда с кодировкой чаще всего возникает из-за несоответствия настроек сервера настройкам сайта, т.е. на сервере в базе данных прописана одна кодировка, а сайт отдает страницы в браузер в совершенной другой.
Для этого необходимо прописать “внаглую” (в шапку сайта, т.е, как частенько, в файл header.php) между тегами <head> </head> следующую строчку:
<meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″>
Прописав такую строчку, Вы заставите браузер правильно интерпретировать кодировку, и иероглифы пропадут.
Также может потребоваться корректировка вывода данных из БД (MySQL). Делается сие так:
mysql_query(‘SET NAMES utf8’ );
myqsl_query(‘SET CHARACTER SET utf8’ );
mysql_query(‘SET COLLATION_CONNECTION=»utf8_general_ci'» ‘);
Как вариант, можно еще сделать ход конём и прописать в файл .htaccess такие вот строчки:
# BEGIN UTF8
AddDefaultCharset utf-8
AddCharset utf-8 *
<IfModule mod_charset.c>
CharsetSourceEnc utf-8
CharsetDefault utf-8
</IfModule>
# END UTF8
Все вышеприведенные методы (или некоторые из них), скорее всего, помогут Вам и Вашим будущим посетителям избавиться от ненавистных иероглифов и проблем с кодировкой. К сожалению, более подробно мы здесь инструкцию по веб-мастерским штукам рассматривать не будем, думаю, что они обязательно разберутся в подробностях при желании (как-никак у нас несколько другая тематика сайта).
Ну, вот и практическая часть статьи закончена, осталось подвести небольшие итоги.
к содержанию ↑
Послесловие
Сегодня мы познакомились с таким понятием, как кодировка текста. Уверен, теперь при возникновении каракулей на мониторе компьютера Вы не спасуете, а вспомните все приведенные здесь методы и решите вопрос в свою пользу!
На сим все, спасибо за внимание и до новых встреч.
P.S. Комментарии, как и всегда, ждут Ваших горячих дискуссий и вопросов, так что отписываем.
P.P.S: За существование данной статьи спасибо члену команды 25 КАДР
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
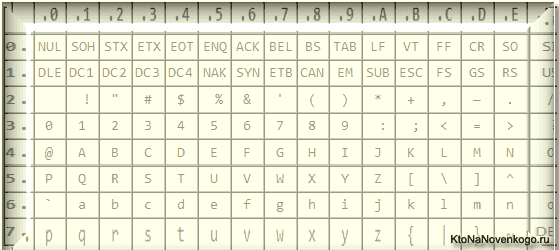
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
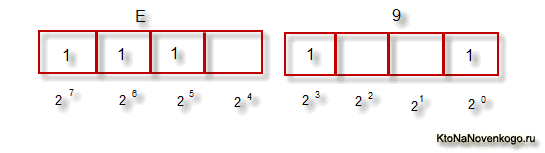
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
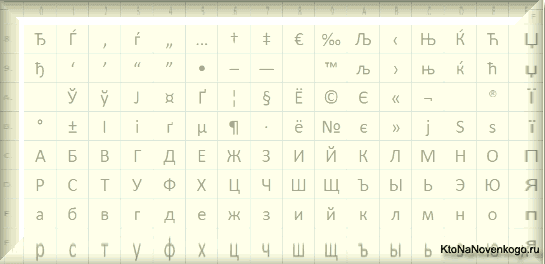
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
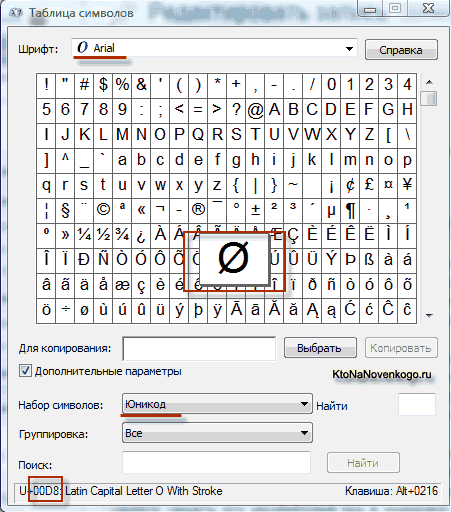
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
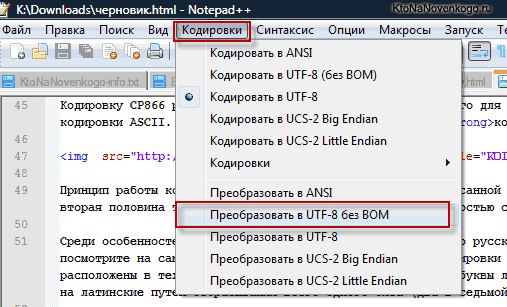
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Ç
ü
é
â
ä
à
å
ç
ê
ë
è
ï
î
ì
Ä
Å
É
æ
Æ
ô
ö
ò
û
ù
ÿ
Ö
Ü
¢
£
¥
₧
ƒ
á
í
ó
ú
ñ
Ñ
ª
º
¿
⌐
¬
½
¼
¡
«
»
░
▒
▓
│
┤
╡
╢
╖
╕
╣
║
╗
╝
╜
╛
┐
└
┴
┬
├
─
┼
╞
╟
╚
╔
╩
╦
╠
═
╬
╧
╨
╤
╥
╙
╘
╒
╓
╫
╪
┘
┌
█
▄
▌
▐
▀
α
ß
Γ
π
Σ
σ
µ
Τ
Φ
Θ
Ω
δ
∞
φ
ε
∩
≡
±
≥
≤
⌠
⌡
÷
≈
°
∙
·
√
ⁿ
²
■
€
‚
ƒ
„
…
†
‡
ˆ
‰
Š
‹
Œ
Ž
‘
’
“
”
•
–
—
˜

š
›
œ
ž
Ÿ
¡
¢
£
¤
¥
¦
§
¨

ª
«
¬

¯
°
±
²
³
´
µ
¶
·
¸
¹
º
»
¼
½
¾
¿
À
Á
Â
Ã
Ä
Å
Æ
Ç
È
É
Ê
Ë
Ì
Í
Î
Ï
Ð
Ñ
Ò
Ó
Ô
Õ
Ö
×
Ø
Ù
Ú
Û
Ü
Ý
Þ
ß
à
á
â
ã
ä
å
æ
ç
è
é
ê
ë
ì
í
î
ï
ð
ñ
ò
ó
ô
õ
ö
÷
ø
ù
ú
û
ü
ý
þ
ÿ