
Ошибки и исключения в триггерах
Ошибки и исключения в триггерах
Если база достаточно сложная (лучше сказать, достаточно реальная), то вам никак не избежать появления ошибок. Более того, ошибки типа «конфликт с другими пользователями» являются повседневным и нормальным явлением в многопользовательской среде. Как InterBase обрабатывает ошибки в триггерах? Ведь ситуация может быть достаточно нетривиальная — например, вставка записи в главную таблицу запускает хранимую процедуру, которая вставляет записи в подчиненные таблицы, причем при вставке в подчиненные таблицы срабатывают триггеры на вставку, которые получают новые значения генераторов и подставляют их в нужные поля. Можно представить не один подобный уровень вложенности. Что произойдет, когда где-то в «дальних» ветках этого дерева событий возникнет ошибка?
При возникновении ошибок на любом этапе — в триггере, в вызываемых им ХП или в неявно активизируемых других триггерах — InterBase сообщит об ошибке и откатит изменения в таблицах, проведенные в рамках инициировавшего эту цепочку оператора. Оператор — это предложение INSERT/UPDATE/DELETE или SELECT, а также EXECUTE PROCEDURE.
Таких операторов может быть в транзакции несколько. Отменяется все действия только в рамках оператора, вызвавшего ошибку. Клиентское приложение может отследить возникновение ошибки и подтвердить транзакцию. Другими словами, ошибка в триггере не обязательно требует отката транзакции. Клиентское приложение может обработать ошибку, полученную при выполнении оператора и, например, выполнить вместо этих изменений какие-то другие, если такова логика предметной области, или изменить логику выполнения дальнейших изменений в этой транзакции и подтвердить реально выполненные в транзакции изменения
Теперь, когда мы знаем, что делает InterBase при возникновении ошибки в триггере, неплохо бы понять, что можем сделать мы, чтобы обработать ошибочную ситуацию. Если мы будем верить в то, что все наши триггеры и ХП не имеют ошибок и конфликтов между действиями пользователей быть не может, то можем вообще не обрабатывать ошибки на уровне базы данных. Если же ошибка возникнет, InterBase пошлет нашему клиентскому приложению сообщение об ошибке, которое мы вольны обработать или нет, — в любом случае InterBase уже выполнил свою миссию — откатил ошибочное действие в триггере. Однако есть и другой путь.
Мы можем воспользоваться обработкой ошибочных ситуаций непосредственно в теле триггера (или хранимой процедуры) с помощью конструкции WHEN…DO. Использование этой конструкции аналогично применению ее в хранимых процедурах, и подробнее об использовании WHEN…DO см. главу «Расширенные возможности языка хранимых процедур InterBase» (ч. 1).
Точно так же как и в хранимых процедурах, в триггерах можно возбуждать собственные исключения. Так как триггер фактически представляет собой разновидность исполнимой хранимой процедуры, то возбуждение в нем исключения прервет работу триггера и приведет к отмене всех действий, совершенных в триггере, — явных и неявных.
Читайте также
Ошибки и исключения
Ошибки и исключения
Под ошибками понимаются исключительные ситуации, которые время от времени могут возникать в известных местах программы. Так, обнаружение ошибок, возникающих во время выполнения системных вызовов, и немедленный вывод сообщений о них должны
Исключения
Исключения
СОМ имеет специфическую поддержку выбрасывания (throwing) исключительных ситуаций из реализации методов. Поскольку в языке C++ не существует двоичного стандарта для исключений, СОМ предлагает явные API-функции для выбрасывания и перехвата объектов СОМ-исключений://
Внутренние исключения
Внутренние исключения
Вы можете догадываться, что вполне возможно генерировать исключения и во время обработки другого исключения. Например, предположим, что вы обрабатываете CarIsDeadException в рамках конкретного блока catch и в процессе обработки пытаетесь записать след стека
11.1. Возбуждение исключения
11.1. Возбуждение исключения
Исключение – это аномальное поведение во время выполнения, которое программа может обнаружить, например: деление на 0, выход за границы массива или истощение свободной памяти. Такие исключения нарушают нормальный ход работы программы, и на них
11.3.1. Объекты-исключения
11.3.1. Объекты-исключения
Объявлением исключения в catch-обработчикемогут быть объявления типа или объекта. В какихслучаях это следует делать? Тогда, когда необходимополучить значение или как-то манипулировать объектом,созданным в выражении throw. Если классы исключений
19.2. Исключения и наследование
19.2. Исключения и наследование
Обработка исключений – это стандартное языковое средство для реакции на аномальное поведение программы во время выполнения. C++ поддерживает единообразный синтаксис и стиль обработки исключений, а также способы тонкой настройки этого
Исключения
Исключения
Обработчики исключений могут быть написаны, чтобы «съесть» ошибку, обрабатывая ее разными способами. Например, в итеративной подпрограмме входная строка, вызывающая исключение, необязательно должна приводить к остановке всего процесса. Обработка исключения
Тип исключения
Тип исключения
Если вызывается исключение, для которого отсутствует обработчик и не определен универсальный обработчик исключений всех типов, тогда вызывается функция terminate из стандартной библиотеки. Она вызывает функцию abort, завершающую работу программы.Вы можете
Исключения
Исключения
Вооружившись понятием отказа, можно теперь определить понятие «исключение». Программа приводит к отказу из-за возникновения некоторых специфических событий (арифметического переполнения, нарушения спецификаций), прерывающих ее выполнение. Такие события и
Исключения разработчика
Исключения разработчика
Все исключения, изучаемые до сих пор, были результатом событий внешних по отношению к ПО (сигналы операционной системы) или принудительных следствий его работы (нарушение утверждений). В некоторых приложениях полезно, чтобы исключения возникали
Дисциплинированные исключения
Дисциплинированные исключения
Исключения, как они были введены, дают способ справиться с аномалиями, возникающими в процессе выполнения: нарушениями утверждений, сигналами аппаратуры, попытками получить доступ к void ссылкам.Исследуемый нами подход основан на метафоре
Время на прочтение
17 мин
Количество просмотров 168K
Традиционно статья написана тезисно. Более подробное содержание можно найти в приложенном внизу статьи видео с записью лекции про триггеры Oracle.
- Общие сведения о триггерах Oracle
- DML triggers
- Псевдозаписи
- Instead of dml triggers
- Instead of triggers on Nested Table Columns of Views.
- Составные DML триггера (compound DML triggers)
- Структура составного триггера
- Основные правила определения DML триггеров
- Ограничения DML триггеров
- Ошибка мутирования таблицы ORA-04091
- Системные триггеры (System triggers)
- Триггеры уровня схемы (schema triggers)
- Триггеры уровня базы данных (database triggers)
- Instead of create triggers
- Атрибуты системных триггеров
- События срабатывания системных триггеров
- Компиляция триггеров
- Исключения в триггерах
- Порядок выполнения триггеров
- Включение/отключение триггеров
- Права для операций с триггерами
- Словари данных с информацией о триггерах
Общие сведения о триггерах
Триггер – это именованный pl/sql блок, который хранится в базе данных.
- Нельзя самому вызвать триггер, он всегда срабатывает только на определенное событие автоматически(если он enable)
- Не стоит создавать рекурсивные триггера. Т.е., например, триггер after update, в котором выполняется update той же таблицы. В этом случае триггер будет срабатывать рекурсивно до тех пор, пока не закончится память.
Классификация триггеров:
- DML trigger (на таблицу или представление)
- System trigger (на схему или базу данных)
- Conditional trigger (те, которые имеют условие when)
- Instead of trigger (dml триггер на представление или system триггер на команду create)
Зачем использовать триггеры:
- Для автоматической генерации значений виртуального поля
- Для логгирования
- Для сбора статистики
- Для изменения данных в таблицах, если в dml операции участвует представление
- Для предотвращения dml операций в какие-то определенные часы
- Для реализации сложных ограничений целостности данных, которые невозможно осуществить через описательные ограничения, установленные при создании таблиц
- Для организации всевозможных видов аудита
- Для оповещения других модулей о том, что делать в случае изменения информации в БД
- Для реализации бизнес логики
- Для организации каскадных воздействий на таблицы БД
- Для отклика на системные события в БД или схеме

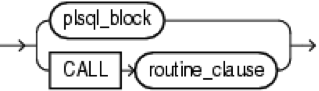
где plsql_trigger_source, это такая конструкция:
Конструкции simple_dml_trigger, instead_of_dml_trigger, compound_dml_trigger и system_trigger будут приведены в соответствующих разделах статьи.
DML triggers
- DML триггеры создаются для таблиц или представлений, срабатывают при вставке, обновлении или удалении записей.
- Триггер может быть создан в другой схеме, отличной от той, где определена таблицы. В таком случае текущей схемой при выполнении триггера считается схема самого триггера.
- При операции MERGE срабатывают триггеры на изменение, вставку или удаление записей в зависимости от операции со строкой.
- Триггер – часть транзакции, ошибка в триггере откатывает операцию, изменения таблиц в триггере становятся частью транзакции.
- Если откатывается транзакция, изменения триггера тоже откатываются.
- В триггерах запрещены операторы DDL и управления транзакциями (исключения – автономные транзакции).
Конструкция simple_dml_trigger:
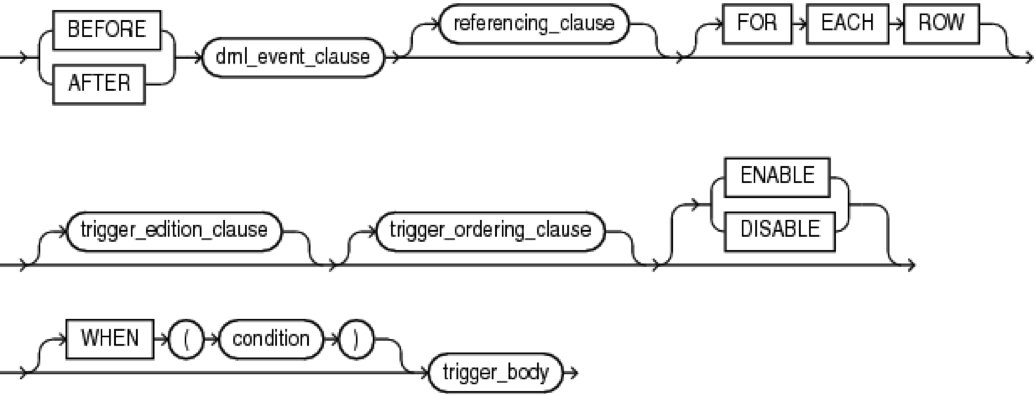
Где, dml_event_clause:
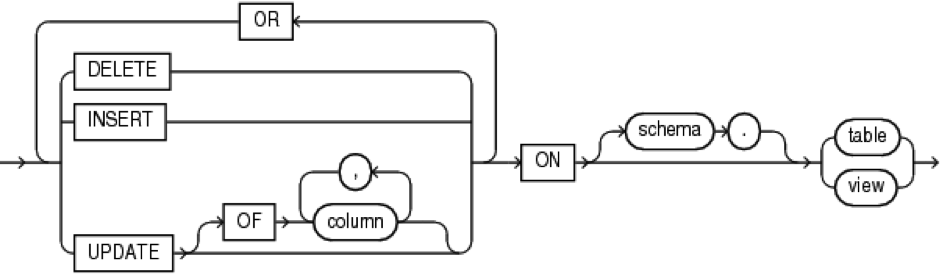
referencing_clause:

trigger_edition_clause:
trigger_body:
По привязанному объекту делятся на:
- На таблице
- На представлении (instead of trigger)
По событиям запуска:
- Вставка записей (insert)
- Обновление записей (update)
- Удаление записей (delete)
По области действия:
- Уровень всей команды (statement level triggers)
- Уровень записи (row level triggers)
- Составные триггеры (compound triggers)
По времени срабатывания:
- Перед выполнением операции (before)
- После выполнения операции (after)
Crossedition triggers — служат для межредакционного взаимодействия, например для переноса и трансформации данных из полей, отсутствующих в новой редакции, в другие поля.
Условные предикаты для определения операции, на которую сработал триггер:
| Предикат | Описание |
|---|---|
| Inserting | True, если триггер сработал на операцию Insert |
| Updating | True, если триггер сработал на операцию Update |
| Updating(‘colum’) | True, если триггер сработал на операцию Update, которая затрагивает определенное поле |
| Deleting | True, если триггер сработал на операцию Delete |
Эти предикаты могут использоваться везде, где можно использовать Boolean выражения.
Пример
CREATE OR REPLACE TRIGGER t
BEFORE
INSERT OR
UPDATE OF salary, department_id OR
DELETE
ON employees
BEGIN
CASE
WHEN INSERTING THEN
DBMS_OUTPUT.PUT_LINE('Inserting');
WHEN UPDATING('salary') THEN
DBMS_OUTPUT.PUT_LINE('Updating salary');
WHEN UPDATING('department_id') THEN
DBMS_OUTPUT.PUT_LINE('Updating department ID');
WHEN DELETING THEN
DBMS_OUTPUT.PUT_LINE('Deleting');
END CASE;
END;
Псевдозаписи
Существуют псевдозаписи, позволяющие обратиться к полям изменяемой записи и получить значения полей до изменения и значения полей после изменения. Это записи old и new. С помощью конструкции Referencing можно изменить их имена. Структура этих записей tablename%rowtype. Эти записи есть только у триггеров row level или у compound триггеров (с секциями уровня записи).
| Операция срабатывания триггера | OLD.column | NEW.column |
|---|---|---|
| Insert | Null | Новое значение |
| Update | Старое значение | Новое значение |
| Delete | Старое значение | Null |
Restrictions:
- С псевдозаписями запрещены операции уровня всей записи ( :new = null;)
- Нельзя изменять значения полей записи old
- Если триггер срабатывает на delete, нельзя изменить значения полей записи new
- В триггере after нельзя изменить значения полей записи new
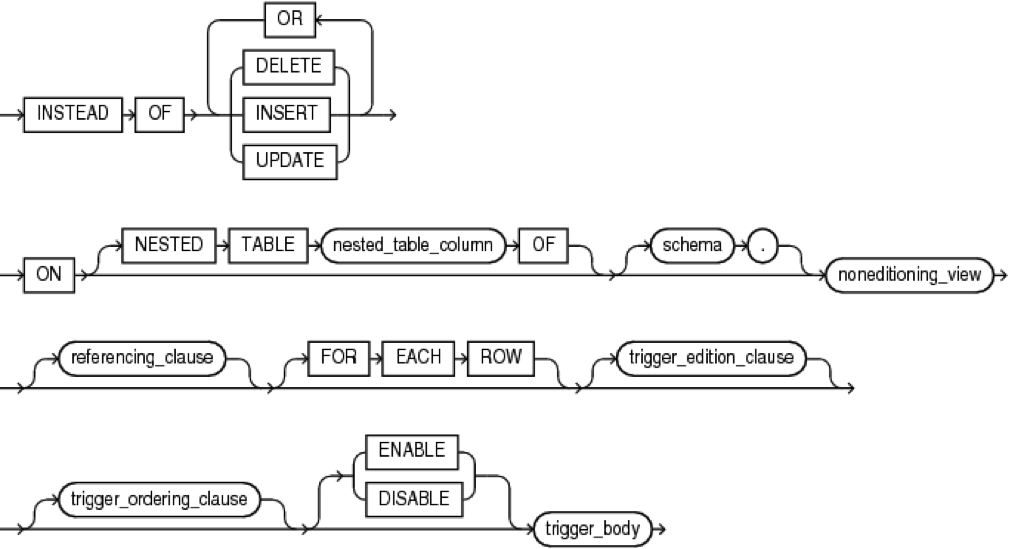
Instead of dml triggers
- Создаются для представлений (view) и служат для замещения DML операций своим функционалом.
- Позволяют производить операции вставки/обновления или удаления для необновляемых представлений.
Конструкция instead_of_dml_trigger:
- Это всегда триггер уровня записи (row level)
- Имеет доступ к псевдозаписям old и new, но не может изменять их
- Заменяет собой dml операцию с представлением (view)
Пример
CREATE OR REPLACE VIEW order_info AS
SELECT c.customer_id, c.cust_last_name, c.cust_first_name,
o.order_id, o.order_date, o.order_status
FROM customers c, orders o
WHERE c.customer_id = o.customer_id;
CREATE OR REPLACE TRIGGER order_info_insert
INSTEAD OF INSERT ON order_info
DECLARE
duplicate_info EXCEPTION;
PRAGMA EXCEPTION_INIT (duplicate_info, -00001);
BEGIN
INSERT INTO customers
(customer_id, cust_last_name, cust_first_name)
VALUES (
:new.customer_id,
:new.cust_last_name,
:new.cust_first_name);
INSERT INTO orders (order_id, order_date, customer_id)
VALUES (
:new.order_id,
:new.order_date,
:new.customer_id);
EXCEPTION
WHEN duplicate_info THEN
RAISE_APPLICATION_ERROR (
num=> -20107,
msg=> 'Duplicate customer or order ID');
END order_info_insert;
Instead of triggers on Nested Table Columns of Views
Можно создать триггер для вложенной в представлении таблицы. В таком триггере также присутствует дополнительная псевдозапись – parent, которая ссылается на всю запись представления (стандартные псевдозаписи old и new ссылаются только на записи вложенной таблицы)
Пример такого триггера
-- Create type of nested table element:
CREATE OR REPLACE TYPE nte
AUTHID DEFINER IS
OBJECT (
emp_id NUMBER(6),
lastname VARCHAR2(25),
job VARCHAR2(10),
sal NUMBER(8,2)
);
/
-- Created type of nested table:
CREATE OR REPLACE TYPE emp_list_ IS
TABLE OF nte;
/
-- Create view:
CREATE OR REPLACE VIEW dept_view AS
SELECT d.department_id,
d.department_name,
CAST (MULTISET (SELECT e.employee_id, e.last_name, e.job_id, e.salary
FROM employees e
WHERE e.department_id = d.department_id
)
AS emp_list_
) emplist
FROM departments d;
-- Create trigger:
CREATE OR REPLACE TRIGGER dept_emplist_tr
INSTEAD OF INSERT ON NESTED TABLE emplist OF dept_view
REFERENCING NEW AS Employee
PARENT AS Department
FOR EACH ROW
BEGIN
-- Insert on nested table translates to insert on base table:
INSERT INTO employees (
employee_id,
last_name,
email,
hire_date,
job_id,
salary,
department_id
)
VALUES (
:Employee.emp_id, -- employee_id
:Employee.lastname, -- last_name
:Employee.lastname || '@company.com', -- email
SYSDATE, -- hire_date
:Employee.job, -- job_id
:Employee.sal, -- salary
:Department.department_id -- department_id
);
END;
Запускает триггер оператор insert
INSERT INTO TABLE (
SELECT d.emplist
FROM dept_view d
WHERE department_id = 10
)
VALUES (1001, 'Glenn', 'AC_MGR', 10000);
Составные DML триггера (compound DML triggers)
Появившиеся в версии 11G эти триггера включают в одном блоке обработку всех видов DML триггеров.
Конструкция compound_dml_trigger:
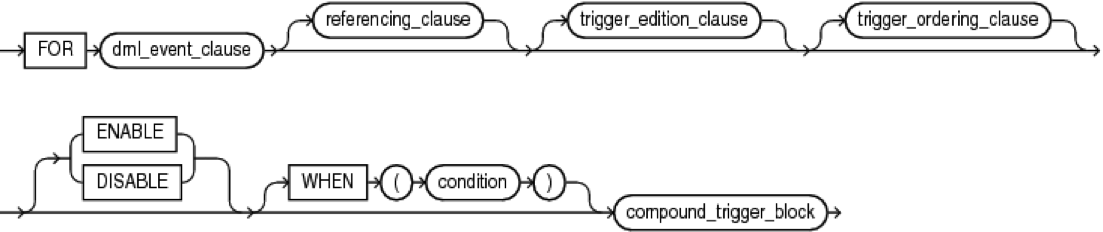
Где, compound_trigger_block:

timing_point_section:

timing_point:
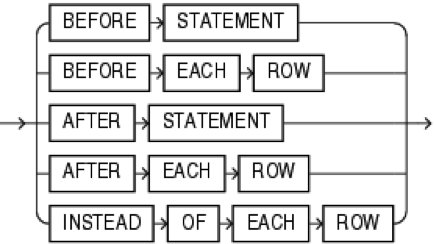
tps_body:

- Срабатывают такие триггера при разных событиях и в разные моменты времени (на уровне оператора или строки, при вставке/обновлении/удалении, до или после события).
- Не могут быть автономными транзакциями.
В основном используются, чтобы:
- Собирать в коллекцию строки для вставки в другую таблицу, чтобы периодически вставлять их пачкой
- Избежать ошибки мутирующей таблицы (mutating-table error)
Структура составного триггера
Может содержать переменные, которые живут на всем протяжении выполнения оператора, вызвавшего срабатывание триггера.
Такой триггер содержит следующие секции:
- Before statement
- After statement
- Before each row
- After each row
В этих триггерах нет секции инициализации, но для этих целей можно использовать секцию before statement.
Если в триггере нет ни before statement секции, ни after statement секции, и оператор не затрагивает ни одну запись, такой триггер не срабатывает.
Restrictions:
- Нельзя обращаться к псевдозаписям old, new или parent в секциях уровня выражения (before statement и after statement)
- Изменять значения полей псевдозаписи new можно только в секции before each row
- Исключения, сгенерированные в одной секции, нельзя обрабатывать в другой секции
- Если используется оператор goto, он должен указывать на код в той же секции
Пример
create or replace trigger tr_table_test_compound
for update or delete or insert on table_test
compound trigger
v_count pls_integer := 0;
before statement is
begin
dbms_output.put_line ( 'before statement' );
end before statement;
before each row is
begin
dbms_output.put_line ( 'before insert' );
end before each row;
after each row is
begin
dbms_output.put_line ( 'after insert' );
v_count := v_count + 1;
end after each row;
after statement is
begin
dbms_output.put_line ( 'after statement' );
end after statement;
end tr_table_test_compound;
Основные правила определения DML триггеров
- Update of – позволяет указать список изменяемых полей для запуска триггера
- Все условия в заголовке и When … проверяются без запуска триггера на стадии выполнения SQL
- В операторе When можно использовать только встроенные функции
- Можно делать несколько триггеров одного вида, порядок выполнения не определен по умолчанию, но его можно задать с помощью конструкции FOLLOWS TRIGGER_FIRST
- Ограничения уникальности проверяются при изменении записи, то есть после выполнения триггеров before
- Секция объявления переменных определяется словом DECLARE
- Основной блок триггера подчиняется тем же правилам, что и обычные PL/SQL блоки
Ограничения DML триггеров
- нельзя выполнять DDL statements (только в автономной транзакции)
- нельзя запускать подпрограммы с операторами контроля транзакций
- не имеет доступа к SERIALLY_REUSABLE пакетов
- размер не может превышать 32К
- нельзя декларировать переменные типа LONG и LONG RAW
Ошибка мутирования таблицы ORA-04091
Если в триггере уровня строки попытаться получить или изменить данные в целевой таблицы, то Oracle не позволит это сделать и выкинет ошибку ORA-04091 Таблица TABLE_TEST изменяется, триггер/функция может не заметить это.
Для обхода данной проблемы используются следующие приемы:
- использовать триггеры уровня операции
- автономная транзакция в триггере
- использовать сторонние структуры (коллекции уровня пакета)
- использовать COMPOUND TRIGGER
- изменение самого алгоритма с выносом функционала из триггера
Системные триггеры (System triggers)
Конструкция system_trigger:
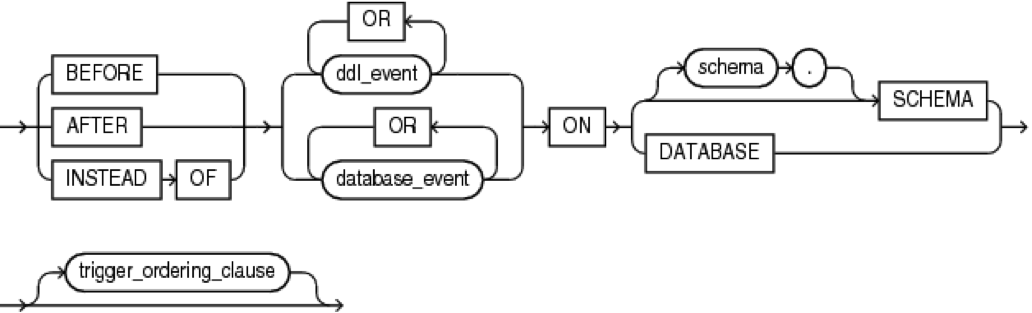
Такие триггеры относятся или к схеме, или ко всей базе данных.
Есть несколько вариантов, в какой момент времени срабатывает системный триггер:
- До того, как будет выполнена операция (на которую срабатывает триггер)
- После того, как будет выполнена операция (на которую срабатывает триггер)
- Вместо выполнения оператора Create
Триггеры уровня схемы (schema triggers)
- Срабатывает всегда, когда пользователь-владелец схемы запускает событие (выполняет операцию), на которую должен срабатывать триггер.
- В случае, если любой другой пользователь запускает процедуру/функцию, которая вызывается с правами создателя, и в этой процедуре/функции выполняется операция, на которую создан системный триггер – этот триггер сработает.
Пример триггера
CREATE OR REPLACE TRIGGER drop_trigger
BEFORE DROP ON hr.SCHEMA
BEGIN
RAISE_APPLICATION_ERROR (
num => -20000,
msg => 'Cannot drop object');
END;
Триггеры уровня базы данных (database triggers)
- Такой триггер срабатывает когда любой пользователь БД выполняет команду, на которую создан триггер.
Пример триггера
CREATE OR REPLACE TRIGGER check_user
AFTER LOGON ON DATABASE
BEGIN
check_user;
EXCEPTION
WHEN OTHERS THEN
RAISE_APPLICATION_ERROR
(-20000, 'Unexpected error: '|| DBMS_Utility.Format_Error_Stack);
END;
Instead of create triggers
- Это триггер уровня схемы, который срабатывает на команду create и заменяет собой эту команду (т.е. вместо выполнения команды create выполняется тело триггера).
Пример триггера
CREATE OR REPLACE TRIGGER t
INSTEAD OF CREATE ON SCHEMA
BEGIN
EXECUTE IMMEDIATE 'CREATE TABLE T (n NUMBER, m NUMBER)';
END;
Атрибуты системных триггеров
| Атрибут | Возвращаемое значение и тип |
|---|---|
| ora_client_ip_address | Varchar2 ip-адрес клиента Пример: |
| ora_database_name | Varchar2(50) имя базы данных Пример: |
| ora_des_encrypted_password | Varchar2 зашифрованный по стандарту DES пароль пользователя, который создается или изменяется Пример: |
| ora_dict_obj_name | Varchar2(30) имя объекта, над которым совершается операция DDL Пример: |
| ora_dict_obj_name_list ( name_list OUT ora_name_list_t ) |
Pls_integer количество изменненых командой объектов Name_list – список измененных командой объектов Пример: |
| ora_dict_obj_owner | Varchar2(30) владелец объекта, над которым совершается операция DDL Пример: |
| ora_dict_obj_owner_list ( owner_list OUT ora_name_list_t ) |
Pls_integer количество владельцев измененных командой объектов Owner_list – список владельцев изменных командой объектов Пример: |
| ora_dict_obj_type | Varchar2(20) тип объекта, над которым совершается операция ddl Пример: |
| ora_grantee ( user_list OUT ora_name_list_t ) |
Pls_integer количество пользователей, участвующих в операции grant User_list – список этих пользователей Пример: |
| ora_instance_num | Number номер инстанса Пример: |
| ora_is_alter_column ( column_name IN VARCHAR2 ) |
Boolean True, если указанное поле было изменено операцией alter. Иначе false Пример: |
| ora_is_creating_nested_table | Boolean true, если текущее событие – это создание nested table. Иначе false Пример: |
| ora_is_drop_column ( column_name IN VARCHAR2 ) |
Boolean true, если указанное поле удалено. Иначе false Пример: |
| ora_is_servererror ( error_number IN VARCHAR2 ) |
Boolean true, если сгенерированно исключение с номером error_number. Иначе false Пример: |
| ora_login_user | Varchar2(30) имя текущего пользователя Пример: |
| ora_partition_pos | Pls_integer в instead of trigger для create table позиция в тексте sql команды, где может быть вставлена конструкция partition Пример: |
| ora_privilege_list ( privilege_list OUT ora_name_list_t ) |
Pls_integer количество привилегий, участвующее в операции grant или revoke Privilege_list – список этих привилегий Пример: |
| ora_revokee ( user_list OUT ora_name_list_t ) |
Pls_integer количество пользователей, участвующих в операции revoke User_list – список этих пользователей Пример: |
| ora_server_error ( position IN PLS_INTEGER ) |
Number код ошибки в указанной позиции error stack, где 1 – это вершина стека Пример: |
| ora_server_error_depth | Pls_integer количество сообщений об ошибка в error stack Пример: |
| ora_server_error_msg ( position IN PLS_INTEGER ) |
Varchar2 сообщение об ошибке в указанном месте error stack Пример: |
| ora_server_error_num_params ( position IN PLS_INTEGER ) |
Pls_integer количество замещенных строк (с помощью формата %s) в указанной позиции error stack Пример: |
| ora_server_error_param ( position IN PLS_INTEGER, param IN PLS_INTEGER ) |
Varchar2 замещенный текст в сообщении об ошибке в указанной позиции error stack (возвращается param по счету замещенный текст) Пример: |
| ora_sql_txt ( sql_text OUT ora_name_list_t ) |
Pls_integer количество элементов в pl/sql коллекции sql_text. Сам параметр sql_text возвращает текст команды, на которую сработал триггер Пример: |
| ora_sysevent | Varchar2(20) название команды, на которую срабатывает триггер Пример: |
| ora_with_grant_option | Boolean true, если привилегии выдаются with grant option. Иначе false. Пример: |
| ora_space_error_info ( error_number OUT NUMBER, error_type OUT VARCHAR2, object_owner OUT VARCHAR2, table_space_name OUT VARCHAR2, object_name OUT VARCHAR2, sub_object_name OUT VARCHAR2 ) |
Boolean true, если ошибка возникает из-за нехватки места. В выходных параметрах информация об объекте. Пример: |
События срабатывания системных триггеров
| Событие | Описание | Доступные атрибуты |
|---|---|---|
| AFTER STARTUP | При запуске БД. Бывает только уровня БД. При ошибке пишет в системный лог. | ora_sysevent ora_login_user ora_instance_num ora_database_name |
| BEFORE SHUTDOWN | Перед тем, как сервер начнет процесс останова. Бывает только уровня БД. При ошибке пишет в системный лог. | ora_sysevent ora_login_user ora_instance_num ora_database_name |
| AFTER DB_ROLE_CHANGE | При запуске БД в первый раз после смены ролей from standby to primary or from primary to standby. используется только в конфигурации Data Guard,, бывает только уровня БД. |
ora_sysevent ora_login_user ora_instance_num ora_database_name |
| AFTER SERVERERROR | Если случается любая ошибка (если с условием, то срабатывает только на ошибку, указанную в условии). При ошибке в теле триггера не вызывает себя рекурсивно. | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_server_error ora_is_servererror ora_space_error_info |
| BEFORE ALTER
AFTER ALTER |
Если объект изменяется командой alter | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_type ora_dict_obj_name ora_dict_obj_owner ora_des_encrypted_password (for ALTER USER events) ora_is_alter_column (for ALTER TABLE events) ora_is_drop_column (for ALTER TABLE events) |
| BEFORE DROP
AFTER DROP |
При удалении объекта | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_type ora_dict_obj_name ora_dict_obj_owner |
| BEFORE ANALYZE
AFTER ANALYZE |
При срабатывании команды analyze | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner |
| BEFORE ASSOCIATE STATISTICS
AFTER ASSOCIATE STATISTICS |
При выполнении команды associate statistics | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner ora_dict_obj_name_list ora_dict_obj_owner_list |
| BEFORE AUDIT
AFTER AUDIT BEFORE NOAUDIT AFTER NOAUDIT |
При выполнении команды audit или noaudit | ora_sysevent ora_login_user ora_instance_num ora_database_name |
| BEFORE COMMENT
AFTER COMMENT |
При добавлении комментария к объекту | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner |
| BEFORE CREATE
AFTER CREATE |
При создании объекта | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_type ora_dict_obj_name ora_dict_obj_owner ora_is_creating_nested_table (for CREATE TABLE events) |
| BEFORE DDL
AFTER DDL |
Срабатывает на большинство команд DDL, кроме: alter database, create control file, create database. | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner |
| BEFORE DISASSOCIATE STATISTICS
AFTER DISASSOCIATE STATISTICS |
При выполнении команды disassociate statistics | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner ora_dict_obj_name_list ora_dict_obj_owner_list |
| BEFORE GRANT
AFTER GRANT |
При выполнении команды grant | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner ora_grantee ora_with_grant_option ora_privilege_list |
| BEFORE LOGOFF | Срабатывает перед дисконнеком пользователя, бывает уровня схемы или БД | ora_sysevent ora_login_user ora_instance_num ora_database_name |
| AFTER LOGON | Срабатывает после того, как пользователь успешно установил соединение с БД. При ошибке запрещает пользователю вход. Не действует на SYS. | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_client_ip_address |
| BEFORE RENAME
AFTER RENAME |
При выполнении команды rename | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_owner ora_dict_obj_type |
| BEFORE REVOKE
AFTER REVOKE |
При выполнении команды revoke | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner ora_revokee ora_privilege_list |
| AFTER SUSPEND | Срабатывает в случае, если sql команда приостанавливается по причине серверной ошибки (нехватки памяти). При этом триггер должен изменить условия таким образом, чтобы выполнение команды было возобновлено) |
ora_sysevent ora_login_user ora_instance_num ora_database_name ora_server_error ora_is_servererror ora_space_error_info |
| BEFORE TRUNCATE
AFTER TRUNCATE |
При выполнении команды truncate | ora_sysevent ora_login_user ora_instance_num ora_database_name ora_dict_obj_name ora_dict_obj_type ora_dict_obj_owner |
Компиляция триггеров
Если во время выполнения команды create trigger произошла ошибка, триггер все равно будет создан, но будет в невалидном состоянии. При этом все попытки выполнить операцию(на которую должен срабатывать триггер) над объектом, на котором висит такой триггер, будут завершаться ошибкой. Это не относится к случаям, когда:
- Триггер создан в состоянии disabled (или переведен в такое состояние)
- Событие триггера after startup on database
- Событие триггера after logon on database или after logon on schema и происходит попытка залогиниться под пользователем System
Чтобы перекомпилировать триггер, используйте команду alter trigger.
Исключения в триггерах
В случае, если в триггере возникает исключение, вся операция откатывается (включая любые изменения, сделанные внутри триггера). Исключения из этого:
- Если событие триггера after startup on database или before shutdown on database
- Если событие триггера after logon on database и пользователь имеет привилегию administer database trigger
- Если событие триггера after logon on schema и пользователь или является владельцем схемы, или имеет привилегию alter any trigger
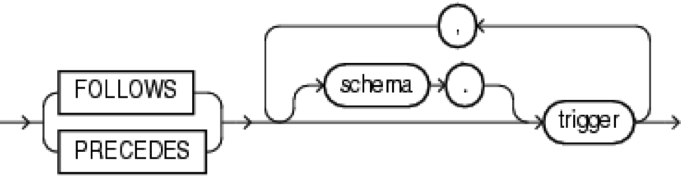
Порядок выполнения триггеров
Конструкция trigger_ordering_clause:
- Сначала выполняются все before statement триггера
- Потом все before each row триггера
- После все after each row триггера
- И в конце все after statement триггера
Чтобы задать явно порядок выполнения триггеров, срабатывающих в одинаковый момент времени (потому что по умолчанию такой порядок не определен), используйте конструкции follows и precedes.
Включение/отключение триггеров
Это может понадобиться, например, для загрузки большого объема информации в таблицу.
Выполнить включение/отключение триггера можно с помощью команды:
ALTER TRIGGER [schema.]trigger_name { ENABLE | DISABLE };
Чтобы включить/отключить сразу все триггеры на таблице:
ALTER TABLE table_name { ENABLE | DISABLE } ALL TRIGGERS;
Для изменения триггера можно или воспользоваться командой Create or replace trigger, или сначала удалить триггер drop trigger, а потом создать заново create trigger.
Операция alter trigger позволяет только включить/отключить триггер, скомпилировать его или переименовать.
Компиляция триггера:
alter trigger TRIGGER_NAME compile;
Права для операций с триггерами
Для работы с триггерами даже в своей схеме необходима привилегия create trigger, она дает права на создание, изменение и удаление.
grant create trigger to USER;
Для работы с триггерами во всех других схемах необходима привилегия * any trigger. Обратите внимание, что права даются отдельно на создание, изменение и удаление.
grant create any trigger to USER;
grant alter any trigger to USER;
grant drop any trigger to USER;
Для работы с системными триггерами уровня DATABASE необходима привилегия ADMINISTER DATABASE TRIGGER.
grant ADMINISTER DATABASE TRIGGER to USER;
Словари данных с информацией о триггерах:
- dba_triggers – информация о триггерах
- dba_source — код тела триггера
- dba_objects – валидность триггера
Видео-запись лекции, по материалам которой и была написана эта статья:
Множество других видео по темам Oracle можно найти на этом канале: www.youtube.com/c/MoscowDevelopmentTeam
Другие статьи по Oracle
Все о коллекциях в Oracle
Дизайн полей таблицы
Директивы компилятора
Триггер
В FoxPro существует некоторая путаница с этим термином (впрочем, как и с большинством других терминов), вызванная не столько неясностью самого термина, сколько особенностью его использования.
Триггер — это выражение, значение которого вычисляется при наступлении определенного события. Это выражение должно вернуть обязательно логическое значение .T. или .F.
Но все дело в том, что в качестве одного из аргументов этого выражения может стоять некоторая функция (или несколько функций). Вот эти-то функции, вызываемые из выражения триггера, также называют «триггер».
Как правило, когда речь идет о триггере, то подразумевают именно функцию — триггер, а не выражение — триггер.
Вычисление выражения триггера происходит при наступлении одного из следующих событий: добавлении записи, удалении записи, модификации записи. Соответственно различают 3 вида триггеров: триггер на вставку, триггер на удаление и триггер на модификацию.
Если выражение триггера вернет .T., то сделанные модификации принимаются и записываются в базу данных. Если же выражение триггера вернет .F., то сделанные модификации отвергаются и генерится ошибка с кодом 1539 (ошибка триггера). Уточнить, какой именно вид триггера вызвал ошибку, можно используя функцию AERROR().
Триггер — это «вратарь» или последний этап проверки корректности введенных данных. После него уже идет собственно модификация данных без каких-либо еще проверок. Причем триггер не обращает внимания на всякие «ложные» попытки модификации данных, а реагирует только на окончательную (физическую) модификацию данных. Имеется в виду, что триггер не сработает при модификации буфера таблицы, но выполнит проверку в момент сброса буфера.
О некоторых особенностях поведения триггеров в FoxPro Вы можете почитать в описании к команде CREATE TRIGGER. Замечу, что в этой команде речь идет именно о выражении, но никак не о функции триггера.
Особенности использования функций — триггеров
Функции триггеров хранятся в хранимых процедурах, поскольку это действия, которые связаны напрямую с данными и не должны зависеть от приложения.
При использовании функций триггеров следует учитывать некоторые особенности их использования в FoxPro. В дальнейшем, используя термин «триггер», я буду подразумевать именно функцию — триггер.
- Триггер всегда анализирует изменения сделанные только в одной записи таблицы. Иначе говоря, даже если вы использовали некоторую групповую команду вставки или модификации (например, APPEND FROM), тем не менее, модификация будет производиться по одной записи за раз чтобы дать возможность триггерам выполнить свои проверки.
- Внутри тела триггера (внутри выражения или первой функции) произойдет автоматический переход в ту рабочую область и на ту запись, которые и вызвали срабатывание тела триггера. Однако если Вы используете в качестве выражения триггера несколько функций триггера (например, «Func1().AND.Func2()»), то во второй функции такого автоматического перехода уже не произойдет. Поэтому при завершении функции триггера необходимо особо проконтролировать возврат в ту рабочую область, в которой началось выполнение функции триггера.
- По завершении вычисления выражения триггера Вы вернетесь в ту рабочую область, в которой была дана команда, вызвавшая срабатывание триггера.
- Внутри тела триггера запрещено перемещать указатель записи в той рабочей области, которая вызвала срабатывание триггера. Этот запрет можно обойти, открыв ту же самую таблицу еще раз в другой рабочей области (USE MyTab IN 0 AGAIN ALIAS MyTab2)
- Запрещен рекурсивный вызов триггера в пределах одной и той же таблицы. Т.е. если сработал, например, триггер на удаление, то Вы никаким способом не сможете внутри триггера на удаление удалить какие-либо еще записи из этой же таблицы (удалить «ветку» в древовидной структуре через триггер не получится). Хотя допустимо удалить записи из другой таблицы.
- В принципе, функция триггера может вернуть абсолютно любое значение. Важно только чтобы выражение триггера возвращало именно логическое значение. Ну, например, если в качестве выражения триггера используется что-то вроде: «Func1() > Func2()», то главное, чтобы эти 2 функции возвращали значения, которые можно сравнить между собой, а какого именно типа уже не важно.
- Следует помнить, что если внутри тела триггера произойдет ошибка, то выражение триггера автоматически вернет .F. и будет сообщение об ошибке 1539 (ошибка триггера), но никак не о той ошибке, которая произошла внутри тела триггера. Поэтому внутри тела триггера следует предусмотреть собственный обработчик ошибок, записывающий причину возможной ошибки в какой-либо объект. Например, внутри тела триггеров автоматически создающихся FoxPro (Referential Integrity) для этой цели создается глобальный массив gaErrors[n,12]. Т.е. из 12 столбцов, а количество строк зависит от количества ошибок.
- Если Вы модифицируете данные в режиме буферизации, а сброс изменений в исходные таблицы осуществляется исключительно командой TABLEUPDATE(), то в случае возникновении ошибки триггера никакого сообщения об ошибке не появится. Просто команда TableUpdate() вернет .F. Чтобы уточнить причину отказа в сбросе буфера следует использовать функцию AERROR(). Примерно так:
IF TableUpdate(.T.,.T.)=.F. LOCAL laError(1) =AERROR(laError) DO CASE CASE laError[1,1]=1539 * Триггер вернул .F. уточняю какой именно триггер DO CASE CASE laError[1,5] =1 * Ошибка триггера Insert CASE laError[1,5] =2 * Ошибка триггера Update CASE laError[1,5] =3 * Ошибка триггера Delete ENDCASE ENDCASE ENDIF
- Внутри тела триггера значения полей текущей записи содержат данные после модификации. Чтобы получить значения тех же полей до модификации следует использовать функцию OldVal(). Следует иметь в виду, что если это триггер на вставку и создается действительно новая запись (а не восстановление ранее удаленной по RECALL), то OldVal() вернет значение NULL, даже если данное поле и не может принимать значение NULL. Опираясь на эту особенность, можно внутри тела триггера определить из какого именно типа триггера данная функция была вызвана примерно следующим способом:
DO CASE CASE Deleted() * вызов из триггера на удаление CASE NVL(OldVal("Deleted()"),.T.) * вызов из триггера на вставку OTHERWISE * вызов из триггера на модификацию ENDCASE
Такой анализ позволяет в некоторых случаях писать универсальный триггер (функцию — триггер) вне зависимости от того из какого типа триггера он был вызван без ввода дополнительных параметров.
Кроме того, триггер UPDATE срабатывает при модификации любого поля таблицы. Если же тригер предназначен для контроля изменения только определенного поля таблицы, то разумно в самое начало триггера вставить проверку на факт изменения проверяемого поля:
IF MyField=OldVal("MyField") * Значение поля MyField не изменилось, нет смысла запускать триггер RETURN .T. ENDIF
Referential Integrity
В простых случаях FoxPro может самостоятельно создать как выражение, так и функцию триггера. Для этой цели и служит пункт главного меню «DataBase», подпункт «Edit Referential Integrity».
«Ссылочная целостность» предназначена для автоматической генерации выражения и функции триггера для пары связанных таблиц. Иначе говоря, она следит за тем, чтобы значение внешнего ключа дочерней таблицы всегда соответствовало значению ключевого поля родительской таблицы. Никакие другие поля в данном случае значения не имеют.
Для указания построителю, какое поле считать ключевым, а какое внешним ключом, необходимо установить между двумя таблицами «постоянную связь». Далее вы выбираете один из 3 возможных типов отношений между этими двумя таблицами (для триггера на вставку только 2 варианта). Ну, какие именно варианты есть достаточно понятно.
| Update | Cascade | При изменении значения ключевого поля родительской таблицы изменить значение внешнего ключа во всех соответствующих записях подчиненной таблицы. |
| Restrict | Запрет на модификацию ключевого поля родительской таблицы, если существует хотя бы одна соответствующая ей запись в подчиненной таблице | |
| Ignore | Не настраивать никаких отношений между таблицами. Модификация в одной таблице никак не влияет на модификацию в другой | |
| Delete | Cascade | При удалении записи в родительской таблицы удалить все соответствующие записи подчиненной таблицы. |
| Restrict | Запрет на удаление записи в родительской таблице, если существует хотя бы одна соответствующая ей не удаленная запись в подчиненной таблице | |
| Ignore | Не настраивать никаких отношений между таблицами. Модификация в одной таблице никак не влияет на модификацию в другой | |
| Insert | Cascade | Не существует, поскольку данный тип взаимоотношений между двумя таблицами не имеет физического смысла |
| Restrict | Запрет на создание новой записи в подчиненной таблице, если в родительской таблице не существует записи с указанным значением ключевого поля. | |
| Ignore | Не настраивать никаких отношений между таблицами. Модификация в одной таблице никак не влияет на модификацию в другой |
Подчеркну еще раз, что данные правила относятся исключительно к содержимому ключевого поля родительской таблицы и внешнего ключа дочерней.
После того, как Вы выберите типы взаимоотношений между таблицами, произойдет следующее:
- в хранимых процедурах базы данных будут созданы функции, обеспечивающие указанный тип взаимоотношений выбранных таблиц
- в свойствах таблиц будут добавлены в выражения триггеров вызов соответствующих функций
В принципе, по окончании создания триггеров «Referential Integrity» постоянную связь, послужившую основой для создания данной ссылочной целостности можно удалить. Это уже никак не скажется на факте существования созданных триггеров. Однако я не советовал бы этого делать по той причине, что в случае внесения изменений в «Referential Integrity» (пусть даже по отношению к другим таблицам) генератор «затрет» ранее созданные триггера.
Генератор «Referential Integrity» несколько прямолинеен. Он действует по принципу: удалить все — создать заново. Поэтому, если постоянная связь была удалена, то триггера функции, созданные на ее основе, при очередной модификации «Referential Integrity» будут удалены, хотя останутся триггера выражения в свойствах таблицы. А это вызовет сообщение об ошибке при попытке вызвать несуществующие функции.
Как правило, функции триггеров, созданных «Referential Integrity» получают имена вроде __RI_UPDATE_MyTab. Если теперь открыть хранимые процедуры на модификацию и посмотреть содержимое созданных функций, то первой реакцией будет немедленно это закрыть. Очень уж громоздко и неприглядно это все выглядит.
Если же преодолеть первый испуг и попытаться разобраться в этих «играх нечеловеческого разума», то общая логика достаточно проста:
- Если вызов триггера произошел в результате действий пользователя, а не как результат модификации данных в другом триггере (это отслеживается по значению системной переменной _triggerlevel), то делаются некоторые предварительные настройки
- Делаются некоторые настройки среды окружения
- Функция триггера обязательно окружается транзакцией на случай групповых (Cascade) модификаций данных.
- Настраивается свой обработчик ошибок (RIError). Ошибки, возникшие внутри тела триггера, попадут в глобальный массив gaErrors[n,12]. Количество строк определяется количеством ошибок. Запоминать ошибки необходимо потому, что в случае возникновения ошибки в теле триггера выражение триггера вернет .F. и будет ошибка 1539, но никак не та, что привела к прерыванию триггера. Кроме того, массив gaErrors позволяет записать причину отказа в принятии данных изменений (т.е. если произошла логическая ошибка, для контроля которой данный триггер и был создан). В этом случае значение gaErros[1,1] = -1.
- Связанная таблица (в которой надо сделать проверки или изменения) открывается еще раз в новой рабочей области (RIOpen). Причем организована специальная проверка, чтобы не открывать одну и ту же таблицу несколько раз. Причина повторного открытия в том, что внутри тела триггера недопустимо перемещать указатель записи в той рабочей области, которая вызвала срабатывание триггера.
- Выполняются нужные проверки или действия. Причем каскадное удаление или обновление реализуются через функции общие для всех триггеров (RIDelete, RIUpdate)
- Функция RIReUse «освобождает» повторно открытую таблицу. Т.е. устанавливает признак того, что данная копия таблицы уже не используется и ее можно использовать в другом триггере. Это сделано, чтобы повторно не открывать одну и ту же таблицу несколько раз внутри одной иерархии цепочки триггеров.
- По окончании триггера среда возвращается в то состояние, в котором она была на момент начала выполнения триггера, закрывается транзакция, и закрываются все открытые внутри триггера таблицы (RIEnd)
Вот собственно и все, что делается в этих триггерах. Несколько громоздко и избыточно, но ничего особого сложного.
Однако даже в такой относительно простой вещи есть некоторые «подводные камни».
- Настройка Referential Integrity связана с модификацией контейнера базы данных, поэтому требует единоличного (Exclusive) доступа к базе данных
- При выполнении модификации базы данных под ногами не должен болтаться всякий мусор оставшийся от предыдущих модификаций. Т.е. непосредственно перед настройкой Referential Integrity необходимо выполнить очистку базы данных
Если одно из этих условий не будет выполнено, то при вызове пункта главного меню «DataBase», подпункт «Edit Referential Integrity» Вы получите предупреждение. Это будет либо напоминание о том, что база данных не открыта в режиме Exclusive и изменения сохранены не будут (хотя состояние Referential Integrity посмотреть можно), либо настойчивое предложение выполнить очистку базы данных (в этом случае даже посмотреть Referential Integrity не удастся).
Еще одна тонкость при использовании «Referential Integrity» заключается в том, что в случае модификации «Referential Integrity» FoxPro ищет, что именно надо заменить в выражении триггерра, опираясь именно на стандартные имена функций. При этом все то, что отличается от имен по умолчанию остается неизменным.
Например, если до настройки «Referential Integrity» Вы уже написали в выражении триггера какую-либо свою функцию (MyFunc()), то Referential Integrity не удалит эту функцию, но добавит к ней свою. В результате выражение триггера примет примерно такой вид: «__RI_UPDATE_MyTab().AND.(MyFunc())»
Стоит ли использовать Referential Integrity? А почему бы и нет. Следует только помнить о том, что триггера созданные при помощи Referential Integrity касаются только и исключительно поддержания ссылочной целостности между парой таблиц. Причем не всех возможных видов ссылочной целостности, а только определенных ее видов. Т.е. в больших проектах этих триггеров недостаточно. Придется дописывать еще что-то свое.
Только не надо модифицировать те функции, которые были созданы автоматически при настройке Referential Integrity (несмотря на то, что очень хочется). Иначе при очередной модификации базы данных Вы можете с удивлением обнаружить, что триггеры не работают, как положено, поскольку все внесенные Вами изменения куда-то пропали.
Когда и для чего использовать триггер
О чем собственно речь? А речь о том, в каких случаях следует использовать именно триггер, а не что-нибудь другое.
Основная задача триггера — это, прежде всего проверка допустимости уже сделанных изменений. Внесение изменений в теле триггера допустимо, но тут есть ряд ограничений.
Если Вы читали эту статью с самого начала, то уже знаете, что триггер не контролирует изменения данных в буфере. Т.е. процесс формирования данных триггер не интересует. Он работает уже с предполагаемым результатом.
Таким образом, при использовании триггера предполагается, что Вы уже полностью сформировали данные (по крайней мере, в таблице, вызвавшей срабатывание триггера) и хотите убедиться, что данные изменения допустимы, либо внести изменения в другие таблицы, опираясь на данные изменения.
Например, если у Вас стоит задача создания журнала изменений (кто, когда и что именно изменил в базе данных), то нет смысла делать запись в журнал при редактировании буфера. Может пользователь и вообще не примет эти изменения. Но уж если пользователь захотел эти изменения записать, то вот тут-то и надо сделать запись в журнал. А в этот момент как раз и срабатывают триггера.
Более спорный момент — это контроль уникальности данных. Достаточно подробно это описано в главе Индексы, раздел Контроль уникальности данных при помощи индекса.
А вот для чего триггер точно не стоит использовать, так это для модификации той записи, изменение в которой и вызвало срабатывание триггера. Даже если опустить тот момент, что в FoxPro это просто невозможно, то все равно для этой цели лучше использовать Rule уровня записи.
Правила (Rule)
В FoxPro существует некоторая путаница с этим термином (впрочем, как и с большинством других терминов), вызванная не столько неясностью самого термина, сколько особенностью его использования.
Правило — это выражение, значение которого вычисляется при наступлении определенного события. Это выражение должно вернуть обязательно логическое значение .T. или .F.
Но все дело в том, что в качестве одного из аргументов этого выражения может стоять некоторая функция (или несколько функций). Вот эти-то функции, вызываемые из выражения правила, также называют «правило».
Как правило, в большинстве случаев подразумевают именно функцию — правило.
В FoxPro различают 2 вида правил:
- Правило на поле текущей записи таблицы
- Правило на запись таблицы
Вычисление значения выражения — правила для поля текущей записи таблицы происходит в случае модификации соответствующего поля.
Вычисление значения выражения — правила для записи таблицы происходит в случае модификации любого поля записи.
Точнее, вычисление происходит при завершении модификации. Но момент завершения модификации зависит от самого способа модификации.
Например, если Вы редактируете данные в Grid (Browse-окне), то правило для поля сработает при переходе на другое поле или запись или при попытке перейти на другой объект. А правило на запись сработает при попытке перехода на другую запись или на другой объект.
Если используется объект формы (не Grid, например, TextBox или EditBox) для редактирования содержимого поля, на которое наложено правило, то при попытке выйти из этого объекта после его редактирования сначала срабатывает правило для соответствующего поля, затем все события объекта-формы (Valid, LostFocus) и затем правило уровня записи таблицы (если есть). Т.е. выполнение правила на запись выполняется при завершении модификации одного поля, даже если Вы и не делаете попытку перейти на другую запись.
Таким образом, при редактировании поля через объект формы Вы никак не сможете перехватить выполнение правила событиями формы. Правило для поля будет выполнено в первую очередь. Конечно, если было редактирование.
В случае же использования для модификации какой-либо команды (например, REPLACE) правила срабатывают сразу же на этой команде. При этом порядок срабатывания правил для полей определяется порядком следования полей в соответствующей команде, либо, если порядок следования полей не указан явно (например, APPEND BLANK), в порядке их физического расположения в таблице.
Разумеется, правило на запись срабатывает только после обработки правил на поля текущей записи, если все они вернули .T. Более того, если одно из правил для поля вернуло .F., то выполнение команды модификации немедленно прерывается и не предпринимается даже попытки выполнить модификацию остальных полей.
Правила вычисляются при любой модификации данных любым способом. Т.е. они работают и в буферизированных данных. Поэтому, если правило вернет .F., то немедленно будет отображено сообщение об ошибке 1582 (отказ в правиле — поля) или 1583 (отказ в правиле — записи). Вы можете написать собственное сообщение об ошибке в предусмотренном для этого окне Message в конструкторе таблиц. Это сообщение будет отображаться только в том случае, если соответствующее правило вернет .F.
Если же Вы будете обрабатывать ошибку правила программно, используя функцию AERROR(), то при ошибках правила — поля текущей записи пятый столбец полученного массива будет содержать порядковый номер поля, в котором произошла ошибка вычисления правила.
При программном добавлении правила через команду CREATE TABLE или ALTER TABLE подразумевается именно выражение — правило, но никак не функция. Для добавления правила в этих командах используется ключевое слово CHECK.
Особенности использования правил (Rule)
Функции правил следует хранить в хранимых процедурах, поскольку это действия, которые связаны напрямую с данными и не должны зависеть от приложения.
При использовании функций правил следует учитывать некоторые особенности их использования в FoxPro. В дальнейшем, используя термин «правило», я буду подразумевать именно функцию — правило.
- Правила всегда анализирует изменения сделанные только в одной записи таблицы. Иначе говоря, даже если вы использовали некоторую групповую команду вставки или модификации (например, APPEND FROM), тем не менее, модификация будет производиться по одной записи за раз чтобы дать возможность правилам выполнить свои проверки.
- Внутри тела правила (внутри выражения или первой функции) произойдет автоматический переход в ту рабочую область и на ту запись, которые и вызвали срабатывание тела правила. Однако если Вы используете в качестве выражения правила несколько функций правила (например, «Func1().AND.Func2()»), то во второй функции такого автоматического перехода уже не произойдет. Поэтому при завершении функции правила необходимо особо проконтролировать возврат в ту рабочую область, в которой началось выполнение функции правила.
- По завершении вычисления выражения правила Вы вернетесь в ту рабочую область, в которой была дана команда, вызвавшая срабатывание правила.
- Внутри тела правила запрещено перемещать указатель записи в той рабочей области, которая вызвала срабатывание правила. Этот запрет можно обойти, открыв ту же самую таблицу еще раз в другой рабочей области (USE MyTab IN 0 AGAIN ALIAS MyTab2)
- Внутри правила допустимо модифицировать поля той же записи, в которой Вы сейчас и выполняете проверку правил. Но я не рекомендовал бы делать это в правилах для поля, поскольку в этом случае велик риск «зацикливания». Ведь модификация поля тут же вызовет срабатывание правила для этого поля, а если внутри него опять выполняется его же модификация, то Вы можете получить бесконечное срабатывание правила на поле.
- При модификации полей записи в правиле на запись повторное срабатывание правила на запись НЕ происходит. Т.е. даже если внутри тела правила для записи Вы модифицируете поле, которое имеет свое правило, то зацикливания не произойдет. Просто будет выполнено еще раз правило для измененного поля. Поэтому, если Вам необходимо внутри правила выполнить модификацию каких-то полей этой же записи, то их следует выполнить в правиле на запись
- Сообщение об ошибке правила будет отображено немедленно, как только выражение правила вернет .F. При этом все прочие правила в той же записи выполнены уже не будут.
- При удалении записи правила не срабатывают. Однако они срабатывают при создании новой записи или восстановлении ранее удаленной (RECALL)
- Внутри тела правила значения полей текущей записи содержат данные после модификации. Чтобы получить значения тех же полей до модификации следует использовать функцию OldVal() даже если таблица не была буферезирована. Следует иметь в виду, что если создается действительно новая запись (а не восстановление ранее удаленной по RECALL), то OldVal() вернет значение NULL, даже если данное поле и не может принимать значение NULL. Таким образом, можно выполнить проверку на факт реального изменения значения поля:
IF MyField=OldVal("MyField") * Значение поля MyField не изменилось, нет выполнять проверку RETURN .T. ENDIF
Когда и для чего использовать правило
О чем собственно речь? А речь о том, в каких случаях следует использовать именно правило, а не что-нибудь другое.
Основная задача правила — это, прежде всего проверка допустимости изменений именно в процессе их внесения. Внесение изменений в теле правила допустимо, но тут есть ряд ограничений.
Если Вы читали эту статью с самого начала, то уже знаете, что правило контролирует изменения данных даже в буфере. Т.е. правило следит за процессом формирования данных. В отличие от триггера, который контролирует именно результат.
Таким образом, при использовании правила предполагается, что процесс формирования данных еще не завершен. Фактически правило определяет, какие именно данные можно ввести в данное поле, а какие — нет.
Например, Вы можете написать правило для вычисления контрольной суммы ИНН (Идентификационный Номер Налогоплательщика). Если пользователь ошибся при вводе ИНН, то правило на данное поле тут же ему сообщит, что введено некорректное значение и не даст выйти из поля пока не будет введено корректное значение (и закрыть форму не даст!). Другой вопрос, насколько оправдан такой жесткий контроль. Но это уже зависит от логики Вашей программы.
Можно, конечно, в случае некорректного ввода ввести корректное значение, но тут есть опасность «зацикливания». Бесконечного вызова правила на изменяемое поле. Поэтому лучше этого не делать.
Пожалуй, наиболее удобным, является использование правил для фиксации времени изменений. Т.е. если в Вашей таблице введено специальное поле, например, LastModify типа DateTime, то Вы можете создать правило на запись, в котором и сделать присвоение:
REPLACE LastModify WITH DateTime()
Т.е. при любой модификации записи (кроме удаления) в поле LastModify будет записано дата и время этой модификации. А если добавить еще и поле, содержащее логин пользователя, то Вы получите информацию о том, кто и когда последний раз изменил данную запись. Разумеется, дата и время будут взяты с клиентской машины, где произошло изменение.
Крайне нежелательно изнутри тела правила ссылаться вовне базы данных. Если такая необходимость все-таки существует, то следует всерьез задуматься о необходимости реализации логики именно через правила. Возможно, разумнее вынести нужную проверку на уровень приложения, а не базы данных.
Также неразумно внутри тела правила делать ожидание реакции пользователя. Правило должно выполняться без каких-либо дополнительных действий со стороны пользователя. Опять же, если необходима реакция со стороны пользователя, то желательно вынести данную процедуру на уровень приложения
Значение по умолчанию (Default)
В FoxPro существует некоторая путаница с этим термином (впрочем, как и с большинством других терминов), вызванная не столько неясностью самого термина, сколько особенностью его использования.
Значение по умолчанию — это выражение, значение которого вычисляется при наступлении определенного события. Это выражение должно вернуть значение того типа данных, что и тип данных поля для которого это значение и указывается. Впрочем, иногда это правило сознательно нарушают. Но об этом чуть ниже.
Однако в качестве одного из аргументов этого выражения может стоять некоторая функция (или несколько функций). Вот эти-то функции, вызываемые из выражения значения по умолчанию, также называют «значение по умолчанию».
Вычисление значения по умолчанию происходит только в момент создания новой записи, если значение соответствующего поля не указано явно.
Этот момент требует пояснения, поскольку именно с ним связано большинство недоразумений
Если запись уже существует, то, разумеется, ни о каких значениях по умолчанию не может быть и речи, поскольку данные уже введены во все без исключения поля текущей записи. FoxPro просто не умеет по-другому, поскольку выделяет физическое место на диске под все поля записи сразу в момент ее создания. Ну, пожалуй, кроме полей типа Memo и General, но это отдельный разговор, да и то, выделение места все равно происходит.
Значит, значения по умолчанию вычисляются только в момент создания новой записи, причем обязательно до того, как новая запись будет создана физически.
Однако если Вы в команде создания новой записи явно укажете значение поля, для которого есть значение по умолчанию, то в этом случае вычисление значения по умолчанию не произойдет. Будет использовано то значение, которое указано явно в команде создания новой записи.
Ну, например, для поля MyField таблицы MyTab Вы написали некоторое выражение по умолчанию. Если для создания новой записи Вы используете команду вида:
INSERT INTO MyTab (MyField) VALUES ("Новое значение")
То в новой записи в качестве значения поля MyField будет указано именно «Новое значение», а не то выражение, которое Вы указали как значение по умолчанию.
С другой стороны, если для создания новой записи Вы используете команду APPEN BLANK или ту же команду INSERT-SQL, но, не указав в списке полей поле MyField, то в этом случае, поскольку FoxPro явно не указали, какое именно значение следует присвоить полю MyField, будет использовано значение по умолчанию.
Более того, следует иметь в виду, что значение по умолчанию будет использовано и при создании новой записи в буферизированных таблицах.
Вычисление правила для поля таблицы произойдет после формирования значения по умолчанию. Что, в общем-то, и логично: чтобы проверить правильность введенного значения это значение сначала необходимо сформировать.
Особенности использования значения по умолчанию
Функции значений по умолчанию следует хранить в хранимых процедурах, поскольку это действия, которые связаны напрямую с данными и не должны зависеть от приложения.
При использовании функций значений по умолчанию следует учитывать некоторые особенности их использования в FoxPro. В дальнейшем, используя термин «значение по умолчанию», я буду подразумевать именно функцию — значения по умолчанию.
- Значение по умолчанию всегда формирует значение только в одной записи таблицы. Иначе говоря, даже если вы использовали некоторую групповую команду вставки (например, APPEND FROM), тем не менее, вставка будет производиться по одной записи за раз чтобы дать возможность вычислить значение по умолчанию для каждой вставляемой записи.
- Внутри тела значения по умолчанию (внутри выражения или первой функции) произойдет автоматический переход в ту рабочую область и на ту запись, которые и вызвали срабатывание тела значения по умолчанию. Однако если Вы используете в качестве выражения значения по умолчанию несколько функций (например, «Func1()+Func2()»), то во второй функции такого автоматического перехода уже не произойдет. Поэтому при завершении функции значения по умолчанию необходимо особо проконтролировать возврат в ту рабочую область, в которой началось выполнение функции.
- По завершении вычисления выражения значения по умолчанию Вы вернетесь в ту рабочую область, в которой была дана команда, вызвавшая срабатывание этого выражения.
- Внутри тела функции значения по умолчанию запрещено перемещать указатель записи в той рабочей области, которая вызвала срабатывание функции. Этот запрет можно обойти, открыв ту же самую таблицу еще раз в другой рабочей области (USE MyTab IN 0 AGAIN ALIAS MyTab2)
- Внутри тела функции значения по умолчанию не имеет смысла ссылаться на поля создаваемой записи той же таблицы, поскольку в общем случае не известно какие значения эти поля будут иметь в момент формирования значения по умолчанию отдельного поля. Т.е. сами поля уже будут существовать, но вот будут ли они содержать какое-либо значимое значение или же все еще будут оставаться пустыми заранее предсказать невозможно.
- Если в результате расчета функция значения по умолчанию вернет значение, которое не может быть использовано в качестве значения данного поля, то Вы получите сообщение об ошибке, и новая запись создана не будет. Иногда это свойство используют сознательно, чтобы прервать создание новой записи в определенных ситуациях.
- Если в качестве значения по умолчанию в реквизитах поля таблицы ничего не указано, то FoxPro использует в качестве значений по умолчанию пустые значения (для строк — пробелы, для чисел — ноль и т.п.), но ни в коем случае не значение NULL. Если Вы хотите использовать значение NULL, как значение по умолчанию, то его следует прописать явно как значение по умолчанию. Не забыв, разумеется, указать признак допустимости использования значения NULL для данного поля.
Когда и для чего использовать значение по умолчанию
О чем собственно речь? А речь о том, в каких случаях следует использовать именно значение по умолчанию, а не что-нибудь другое.
Основная задача значения по умолчанию — это сформировать некоторое значение автоматически, когда в случае отсутствия явного указания значения Вас не устраивает пустое значение поля.
Ну, например, генерация нового значения суррогатного ключа. Как правило, это всегда относительно сложная функция (конечно, если Вы не используете поле типа Integer (AutoIncrement), появившееся в 8 версии FoxPro). Эту функцию записывают в хранимых процедурах, а в свойствах таблицу указывают в качестве значения по умолчанию имя этой функции.
Кстати, использование функции для генерации нового значения суррогатного ключа удобно еще тем, что ее вызов можно добавить в значение по умолчанию ключевого поля Local View (кнопка Properties на закладке Fields в дезайнере Local View). В этом случае новое значение ключевого поля будет создаваться сразу при создании новой записи в Local View, а при сбросе изменений в исходную таблицу в качестве значения ключевого поля будет использовано значение, вычисленное в Local View.
Если в процессе вычисления нового значения суррогатного ключа произошла ошибка или по каким-то причинам новое значение сформировать нельзя, то надо как-то сообщить внешнему приложению, что сформировать новое значение суррогатного ключа не удалось.
Самым простым решением в данном случае является присвоение значения NULL при том условии, что данное поле не имеет признака допустимости использования значения NULL. Т.е. сформировать значение, которое заведомо будет отвергнуто в качестве допустимого значения. Это и будет сигналом внешнему приложению, что при создании нового значения суррогатного ключа произошла какая-то ошибка.
А вот для чего не следует использовать значение по умолчанию, так это для формирования внешнего ключа, т.е. ссылки на родительскую таблицу. Проблема в том, что в этом случае Вам придется опираться на текущее положение указателя записи в родительской таблице. А это не всегда соответствует нужной записи родительской таблице. Поэтому переложите контроль ссылочной целостности на триггеры, которые, в общем-то, для этого и предназначены. А значение внешнего ключа всегда присваивайте явно в самом приложении при создании новых записей подчиненной таблицы.
Дизайн полей таблицы
В этом разделе я опишу те свойства полей таблицы, о которых либо вообще не упомянул в других разделах, либо упомянул буквально парой слов. Дело в том, что эти свойства предназначены не столько для контроля корректности ввода данных и целостности базы данных, сколько для удобства построения пользовательского интерфейса. Речь идет о следующих свойствах полей таблицы:
- Format
- Input Mask
- Caption
- Display library
- Display class
Главное, что следует понять об этих свойствах — это то, что данные свойства предлагают соответствующие настройки по умолчанию при отображении данных полей в пользовательском приложении. Однако они могут быть перекрыты соответствующими настройками в самом приложении.
Например, если Вы укажете для какого-либо поля значение свойства Format=»T» (отсечение ведущих пробелов), то это отнюдь не значит, что Вы в принципе не сможете ввести в данное поле значение, имеющее ведущие пробелы.
Да, ведущие пробелы будут отсечены, если Вы будете редактировать данное поле в Browse-окне или же использовать прямые команды модификации данных (REPLACE, INSERT-SQL и т.п.)
Однако если Вы будете редактировать данное поле через объект формы (TextBox, Grid), то настройки свойства FORMAT используемых объектов перекроют настройки Format поля таблицы.
Таким образом, эти настройки определяют некоторые реквизиты полей таблицы, если явно не указаны другие значения для этих же реквизитов
В общем-то, назначение каждого из этих реквизитов ясно уже из их названия, но все-таки вкратце опишу их назначение:
Format — определяет формат ввода и вывода данных. Принимаемые значения можно посмотреть в описании к Format property
Input Mask — определяет способ ввода и вывода данных. Принимаемые значения можно посмотреть в описании к InputMask property
По большому счету и Format, и Input Mask предназначены для одного и того же. Просто Format действует на итоговое введенное значение (т.е. значение надо сначала ввести и только потом оно будет модифицировано в соответствии с настройками Format), а Input Mask на процесс ввода
Caption — название поля. Это будет либо заголовок поля в Browse-окне, либо Header.Caption в Grid (если Вы создадите Grid путем «перетаскивания» таблицы из DataEnvironment формы), либо Label.Caption слева от поля (если Вы создадите TextBox путем «перетаскивания» поля из DataEnvironment формы).
Лично мне эта настройка только мешает. Поскольку в процессе отладки я достаточно часто открываю таблицы в Browse-окне для уточнения тех или иных действий. И если вместо имени поля я вижу значение Caption, то приходится прилагать дополнительные усилия, чтобы уточнить о каком именно поле идет речь. Впрочем, это дело личных предпочтений и способов отладки приложения.
Display class — в каком классе следует отобразить содержимое данного поля
Display library — из какой библиотеки классов следует взять класс, указанный в свойстве Display class. Если он не указан, то предполагается базовая библиотека классов.
Вообще-то, какая именно реакция будет при «перетаскивании» полей из DataEnvironment формы определяется в настройках FoxPro: пункт главного меню Tools, подпункт Options, закладка Field Mapping
На этой закладке представлен список классов, которые будут использованы по умолчанию для отображения содержимого тех или иных типов данных, а под этим списком — набор переключателей, определяющих, что именно будет перенесено в объекты формы при «перетаскивании» поля из DataEnvironment
Как видите можно отключить копирование настроек Format, Input Mask, Caption при «перетаскивании» поля из DataEnvironment. Т.е. фактически отменить действие этих настроек в объектах формы.
Надо ли использовать эти настройки? А почему бы и нет! Надо только помнить, что в отличие от всех прочих настроек полей таблиц изменения в этих настройках не приведут к изменению соответствующих настроек в ранее созданных объектах формы. Поэтому после их модификации придется пройтись по всем ранее созданным классам, формам и отчетам для приведения ранее сделанных настроек в соответствие с новыми.
Директивы компилятора
Директивы компилятора — это те команды, которые начинаются с символа «#». Наиболее известные из них это:
Однако есть и другие аналогичные команды.
Из-за недопонимания того, что собственно делают эти команды, возникает масса недоразумений. Самое главное, что следует понять об этих командах, это то, что они не работают в уже готовом (откомпилированном) приложении. Их цель — это указание компилятору, что именно надо подставить в данном месте именно в процессе компиляции. Собственно, поэтому они и называются «директивы компилятора»
Рассмотрим простейший код:
#DEFINE MY_CONST 1
?MY_CONST
Что собственно делает этот код. И самое главное, когда он это делает. А происходит следующее:
- На этапе компиляции фрагмента приложения, как только компилятор встречает директиву #DEFINE, он запоминает, что вместо слова MY_CONST необходимо подставить число 1
- Если при дальнейшей компиляции компилятор встречает слово MY_CONST, он вместо него подставляет число 1 и продолжает компиляцию.
Т.е. фактически происходит замена слова MY_CONST на цифру 1, начиная с директивы #DEFINE и «ниже».
А «ниже» — это где?
Если речь идет о файле PRG, то тут все ясно: «ниже» — это до конца файла. И именно файла, а не процедуры. Т.е. если файл PRG содержит несколько процедур, то действие директивы #DEFINE будет распространяться на все строки файла PRG физически расположенные «ниже» нее вне зависимости от любых других команд (исключая другую директиву #UNDEFINE).
Но если речь идет о форме, и команда #DEFINE была дана в одном из методов формы, то предсказать на какие еще события и методы она подействует заранее невозможно. Поэтому, если необходимо, чтобы директива #DEFINE подействовала на все без исключения события и методы формы (или класса), эти директивы собирают в один общий файл, называемый «файл заголовка» или «заголовочный файл». И далее подключают этот заголовочный файл через специальный пункт меню Form (или Class), подпункт Include File.
Заголовочный файл — это обычный текстовый файл, имеющий расширение из одной буквы «h»
Следует иметь в виду, что директива компилятора действует только и исключительно в пределах одного объекта проекта. Чаще всего, под объектом проекта понимается конкретный файл. Хотя в отношении библиотеки классов, под объектом проекта следует понимать отдельный класс этой библиотеки классов.
Это значит, что если Вы подключили заголовочный файл в каком-либо классе, то указанные там директивы будут действовать только в данном классе, а вот на объекты, созданные на основе данного класса они уже распространяться не будут! Поскольку это уже другие объекты проекта.
Из этого следует довольно неудобный вывод. Если Вы хотите, чтобы директивы компилятора, указанные в одном заголовочном файле действовали во всех объектах Вашего проекта, то его необходимо будет подключать во всех объектах. Т.е. невозможно будет сделать подключение в каком-нибудь стартовом модуле, с тем, чтобы он распространился на весь проект. Не получится.
В принципе, до некоторой степени эту рутинную работу по подключению заголовочного файла можно автоматизировать. Для этой цели служит системная переменная _INCLUDE или (что, то же самое) настройка через пункт системного меню Tools, подпункт Options, закладка File Locations, строка «Default Include File»
Т.е. если Вы дадите команду
_INCLUDE="C:MyDirMyHeadFile.h"
Или укажите этот файл в опциях, то при создании новых формы и классов указанный файл автоматически будет подключаться к этим формам и классам. Но эта настройка никак не повлияет на ранее созданные формы и классы. Более того, воспользовавшись пунктом меню Form (или Class), подпункт Include File Вы можете заменить подставленный заголовочный файл на другой или вовсе его удалить.
В этом пункте меню можно указать только один заголовочный файл. Поэтому, если Вам надо указать несколько заголовочных файлов, то придется создать еще один файл, который и объединит в себе несколько других. Его содержание будет примерно следующим:
#INCLUDE C:MyDirMyHeadFile1.h #INCLUDE C:MyDirMyHeadFile2.h #INCLUDE C:MyDirMyHeadFile3.h
Проблема заключается в том, что на этапе компиляции факт отсутствия заголовочного файла не вызовет сообщения об ошибке, поскольку все слова, которые следовало бы заменить будут восприняты компилятором как переменные памяти. Ошибка возникнет только на этапе исполнения готового приложения.
Обращаю внимание еще раз. Директивы компилятора действуют только в момент компиляции. В готовом приложении они не работают. Это значит, что нет необходимости поставлять заголовочный файл клиенту или включать этот файл внутрь приложения. Все что можно взять из этого файла проект возьмет в момент компиляции.
Разумеется, если Вы собираетесь компилировать какие-то фрагменты кода «на лету» в готовом приложении, то тогда заголовочный файл может пригодиться.
Но если директивы компилятора так неудобно использовать, то почему же их вообще продолжают использовать?
У меня нет достаточно убедительного ответа на этот вопрос. Поэтому ограничусь тем, что директивы компилятора — это еще один инструмент, который дает Вам FoxPro. А использовать его или нет, решайте сами.
 Триггеры PL/SQL уровня команд
Триггеры PL/SQL уровня команд DML (или просто триггеры DML) активизируются после вставки, обновления или удаления строк конкретной таблицы (рис. 1). Это самый распространенный тип триггеров, особенно часто применяемый разработчиками. Остальные триггеры используются преимущественно администраторами базы данных Oracle. В Oracle появилась возможность объединения нескольких триггеров DML в один составной триггер.
Прежде чем браться за написание триггера, необходимо ответить на следующие вопросы:
- Как триггер PL/SQL будет запускаться — по одному разу для каждой команды SQL или для каждой модифицируемой ею строки?
- Когда именно должен вызываться создаваемый триггер — до или после выполнения операции над строками?
- Для каких операций должен срабатывать триггер — вставки, обновления, удаления или их определенной комбинации?

Рис. 1. Схема срабатывания триггеров DML
Основные концепции триггеров
Прежде чем переходить к синтаксису и примерам использования триггеров DML, следует познакомиться с их концепциями и терминологией.
- Триггер BEFORE. Вызывается до внесения каких-либо изменений (например,
BEFORE INSERT). - Триггер AFTER. Выполняется для отдельной команды
SQL, которая может обрабатывать одну или более записей базы данных (например,AFTERUPDATE). - Триггер уровня команды. Выполняется для команды
SQLв целом (которая может обрабатывать одну или несколько строк базы данных). - Триггер уровня записи. Выполняется для отдельной записи, обрабатываемой командой SQL. Если, предположим, таблица books содержит 1000 строк, то следующая команда UPDATE модифицирует все эти строки:
UPDATE books SET title = UPPER (title);И если для таблицы определен триггер уровня записи, он будет выполнен 1000 раз.
- Псевдозапись NEW. Структура данных с именем
NEWтак же выглядит и обладает (почти) такими же свойствами, как записьPL/SQL. Эта псевдозапись доступна только внутри триггеров обновления и вставки; она содержит значения модифицированной записи после внесения изменений. - Псевдозапись OLD. Структура данных с именем
OLDтак же выглядит и обладает (почти) такими же свойствами, как записьPL/SQL. Эта псевдозапись доступна только внутри триггеров обновления и вставки; она содержит значения модифицированной записи до внесения изменений. - Секция WHEN. Часть триггера
DML, определяющая условия выполнения кода триггера (и позволяющая избежать лишних операций).
Примеры сценариев с использованием триггеров DML
На сайте github размещены примеры сценариев, демонстрирующих работу описанных в предыдущем разделе типов триггеров.

Триггеры в транзакциях
По умолчанию триггеры DML участвуют в транзакциях, из которых они запущены. Это означает, что:
- если триггер инициирует исключение, будет выполнен откат соответствующей части транзакции;
- если триггер сам выполнит команду
DML(например, вставит запись в таблицу- журнал), она станет частью главной транзакции; - в триггере
DMLнельзя выполнять командыCOMMITиROLLBACK.
Если триггер
DMLопределен как автономная транзакция PL/SQL, то все командыDML, выполняемые внутри триггера, будут сохраняться или отменяться (командойCOMMITилиROLLBACK) независимо от основной транзакции.
В следующем разделе описан синтаксис объявления триггера DML и приведен пример, в котором использованы многие компоненты и параметры триггеров этого типа.
Создание триггера DML
Команда создания (или замены) триггера DML имеет следующий синтаксис:
1 CREATE [OR REPLACE] TRIGGER имя_триггера
2 {BEFORE | AFTER}
3 {INSERT | DELETE | UPDATE | UPDATE OF список_столбцов } ON имя_таблицы
4 [FOR EACH ROW]
5 [WHEN (...)]
6 [DECLARE ... ]
7 BEGIN
8 ...исполняемые команды...
9 [EXCEPTION ... ]
10 END [имя_триггера];
Описание всех перечисленных элементов приведено в таблице.
| Строки | Описание |
| 1 | Создание триггера с заданным именем. Секция OR REPLACE не обязательна. Если триггерсуществует, а секция REPLACE отсутствует, попытка создания триггера приведет к ошибке ORA-4081. Вообще говоря, триггер и таблица могут иметь одинаковые имена (а также триггер и процедура), но мы рекомендуем использовать схемы выбора имен, предотвращающиеподобные совпадения с неизбежной путаницей |
| 2 | Задание условий запуска триггера: до (BEFORE) или после (AFTER) выполнения командылибо обработки строки |
| 3 | Определение команды DML, с которой связывается триггер: INSERT, UPDATE или DELETE.Обратите внимание: триггер, связанный с командой UPDATE, может быть задан для всей строки или только для списка столбцов, разделенных запятыми. Столбцы можно объединять оператором OR и задавать в любом порядке. Кроме того, в строке 3 определяется таблица, с которой связывается данный триггер. Помните, что каждый триггер DML должен быть связан с одной таблицей |
| 4 | Если задана секция FOR EACH ROW, триггер будет запускаться для каждой обрабатываемойкомандой строки. Но если эта секция отсутствует, по умолчанию триггер будет запускаться только по одному разу для каждой команды (то есть будет создан триггер уровня команды) |
| 5 | Необязательная секция WHEN, позволяющая задать логику для предотвращения в лишнихвыполнений триггера |
| 6 | Необязательный раздел объявлений для анонимного блока, составляющего код триггера. Если объявлять локальные переменные не требуется, это ключевое слово может отсутствовать. Никогда не объявляйте псевдозаписи NEW и OLD — они создаются автоматически |
| 7,8 | Исполняемый раздел триггера. Он является обязательным и должен содержать как минимум одну команду |
| 9 | Необязательный раздел исключений. В нем перехватываются и обрабатываются исключения, инициируемые только в исполняемом разделе |
| 10 | Обязательная команда END. Для наглядности в нее можно включить имя триггера |
Рассмотрим пару примеров триггеров DML.
- Первый триггер выполняет несколько проверок при добавлении или изменении строки в таблице сотрудников. В нем содержимое полей псевдозаписи
NEWпередается отдельным программам проверки:
TRIGGER validate_employee_changes
AFTER INSERT OR UPDATE
ON employees
FOR EACH ROW
BEGIN
check_date (:NEW.hire_date);
check_email (:NEW.email);
END;
- Следующий триггер, запускаемый перед вставкой данных, проверяет изменения, производимые в таблице ceo_compensation. Для сохранения новой строки таблицы аудита вне главной транзакции в нем используется технология автономных транзакций:
TRIGGER bef_ins_ceo_comp
BEFORE INSERT
ON ceo_compensation
FOR EACH ROW
DECLARE
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
INSERT INTO ceo_comp_history
VALUES (:NEW.name,
:OLD.compensation, :NEW.compensation,
'AFTER INSERT', SYSDATE);
COMMIT;
END;
Предложение WHEN
Предложение WHEN предназначено для уточнения условий, при которых должен выполняться код триггера. В приведенном далее примере с его помощью мы указываем, что основной код триггера должен быть реализован только при изменении значения столбца salary:
TRIGGER check_raise
AFTER UPDATE OF salary
ON employees
FOR EACH ROW
WHEN ((OLD.salary != NEW.salary) OR
(OLD.salary IS NULL AND NEW.salary IS NOT NULL) OR
(OLD.salary IS NOT NULL AND NEW.salary IS NULL))
BEGIN
Иными словами, если при обновлении записи пользователь по какой-то причине оставит salary текущее значение, триггер активизируется, но его основной код выполняться не будет. Проверяя это условие в предложении WHEN, можно избежать затрат, связанных с запуском соответствующего кода PL/SQL.
В файле genwhen.sp на сайте github представлена процедура для генерирования секции WHEN, которая проверяет, что новое значение действительно отличается от старого.
В большинстве случаев секция WHEN содержит ссылки на поля псевдозаписей NEW и OLD. В эту секцию разрешается также помещать вызовы встроенных функций, что и делается в следующем примере, где с помощью функции SYSDATE ограничивается время вставки новых записей:
TRIGGER valid_when_clause
BEFORE INSERT ON frame
FOR EACH ROW
WHEN ( TO_CHAR(SYSDATE,'HH24') BETWEEN 9 AND 17 )
При использовании WHEN следует соблюдать ряд правил:
- Все логические выражения всегда должны заключаться в круглые скобки. Эти скобки не обязательны в команде
IF, но необходимы в секцииWHENтриггера. - Перед идентификаторами
OLDиNEWне должно стоять двоеточие (:). В секцииWHENследует использовать только встроенные функции. - Пользовательские функции и функции, определенные во встроенных пакетах (таких, как
DBMS_UTILITY), в нем вызывать нельзя. Чтобы вызвать такую функцию, переместите соответствующую логику в начало исполняемого раздела триггера.
Предложение WHEN может использоваться только в триггерах уровня записи. Поместив его в триггер уровня команды, вы получите сообщение об ошибке компиляции (ORA-04077).
Работа с псевдозаписями NEW и OLD
При запуске триггера уровня записи ядро PL/SQL создает и заполняет две структуры данных, имеющие много общего с записями. Речь идет о псевдозаписях NEW и OLD (префикс «псевдо» указывает на то, что они не обладают всеми свойствами записей PL/SQL). В псевдозаписи OLD хранятся исходные значения обрабатываемой триггером записи, а в псевдозаписи NEW — новые. Их структура идентична структуре записи, объявленной с атрибутом %ROWTYPE и создаваемой на основе таблицы, с которой связан триггер. Несколько правил, которые следует принимать во внимание при работе с псевдозаписями NEW и OLD:
- Для триггеров, связанных с командой
INSERT, структура OLD не содержит данных, поскольку старого набора значений у операции вставки нет. - Для триггеров, связанных с командой
UPDATE, заполняются обе структуры,OLDиNEW. СтруктураOLDсодержит исходные значения записи до обновления, аNEW— значения, которые будут содержаться в строке после обновления. - Для триггеров, связанных с командой
DELETE, заполняется только структураOLD, а структураNEWостается пустой, поскольку запись удаляется. - Псевдозаписи
NEWиOLDтакже содержат столбец ROWID, который в обеих псевдозаписях всегда заполняется одинаковыми значениями. - Значения полей записи
OLDизменять нельзя; попытка приведет к ошибкеORA- 04085. Значения полей структурыNEWмодифицировать можно. - Структуры
NEWиOLDнельзя передавать в качестве параметров процедурам или функциям, вызываемым из триггера. Разрешается передавать лишь их отдельные поля. В сценарииgentrigrec.spсодержится программа, которая генерирует код копирования данныхNEWиOLDв записи, передаваемые в параметрах. - В ссылках на структуры
NEWиOLDв анонимном блоке триггера перед соответствующими ключевыми словами необходимо ставить двоеточие:
IF :NEW.salary > 10000 THEN...- Над структурами NEW и OLD нельзя выполнять операции уровня записи. Например, следующая команда вызовет ошибку компиляции триггера:
BEGIN :new := NULL; END;С помощью секции REFERENCING в триггере можно менять имена псевдозаписей данных; это помогает писать самодокументированный код, ориентированный на конкретное приложение. Пример:
/* Файл в Сети: full_old_and_new.sql */
TRIGGER audit_update
AFTER UPDATE
ON frame
REFERENCING OLD AS prior_to_cheat NEW AS after_cheat
FOR EACH ROW
BEGIN
INSERT INTO frame_audit
(bowler_id,
game_id,
old_score,
new_score,
change_date,
operation)
VALUES(:after_cheat.bowler_id,
:after_cheat.game_id,
:prior_to_cheat.score,
:after_cheat.score,
SYSDATE,
'UPDATE');
END;
Запустите файл сценария full_old_and_new.sql и проанализируйте поведение псевдозаписей NEW и OLD.
Идентификация команды DML в триггере
Oracle предоставляет набор функций (также называемых операционными директивами) для идентификации команды DML, вызвавшей запуск триггера:
INSERTING— возвращаетTRUE, если триггер запущен в ответ на вставку записи в таблицу, с которой он связан, иFALSEв противном случае.-
UPDATING— возвращаетTRUE, если триггер запущен в ответ на обновление записи в таблице, с которой он связан, иFALSEв противном случае. DELETING— возвращаетTRUE, если триггер запущен в ответ на удаление записи из таблицы, с которой он связан, иFALSEв противном случае.
Пользуясь этими директивами, можно создать один триггер, который объединяет действия для нескольких операций. Пример:
/* Файл в Сети: one_trigger_does_it_all.sql */
TRIGGER three_for_the_price_of_one
BEFORE DELETE OR INSERT OR UPDATE ON account_transaction
FOR EACH ROW
BEGIN
-- Сохранение информации о пользователе, вставившем новую строку
IF INSERTING
THEN
:NEW.created_by := USER;
:NEW.created_date := SYSDATE;
-- Сохранение информации об удалении с помощью специальной программы
ELSIF DELETING
THEN
audit_deletion(USER,SYSDATE);
-- Сохранение информации о пользователе, который последним обновлял строку
ELSIF UPDATING
THEN
:NEW.UPDATED_BY := USER;
:NEW.UPDATED_DATE := SYSDATE;
END IF;
END;
Функция UPDATING имеет перегруженную версию, которой в качестве аргумента передается имя конкретного столбца. Перегрузка функций является удобным способом изоляции операций обновления отдельных столбцов.
/* Файл в Сети: overloaded_update.sql */
TRIGGER validate_update
BEFORE UPDATE ON account_transaction
FOR EACH ROW
BEGIN
IF UPDATING ('ACCOUNT_NO')
THEN
errpkg.raise('Account number cannot be updated');
END IF;
END;
В спецификации имени столбца игнорируется регистр символов. Имя столбца до запуска триггера не анализируется, и если в таблице, связанной с триггером, заданного столбца не оказывается, функция просто возвращает FALSE.
Операционные директивы можно вызывать из любого кода PL/SQL, а не только из триггеров. Однако значение TRUE они возвращают лишь при использовании в триггерах DML или вызываемых из них программах.
Пример триггера DML
Одной из идеальных областей для применения триггеров является аудит изменений. Допустим, Памела, хозяйка боулинга, стала получать жалобы на посетителей, которые жульничают со своими результатами. Памела недавно написала приложение для ведения счета в игре и теперь хочет усовершенствовать его, чтобы выявить нечестных игроков.
В приложении Памелы центральное место занимает таблица frame, в которой записывается результат конкретного фрейма конкретной партии конкретного игрока:
/* Файл в Сети: bowlerama_tables.sql */
TABLE frame
(bowler_id NUMBER,
game_id NUMBER,
frame_number NUMBER,
strike VARCHAR2(1) DEFAULT 'N',
spare VARCHAR2(1) DEFAULT 'N',
score NUMBER,
CONSTRAINT frame_pk
PRIMARY KEY (bowler_id, game_id, frame_number))
Памела дополняет таблицу frame версией, в которой сохраняются все значения «до» и «после», чтобы она могла сравнить их и выявить несоответствия:
TABLE frame_audit
(bowler_id NUMBER,
game_id NUMBER,
frame_number NUMBER,
old_strike VARCHAR2(1),
new_strike VARCHAR2(1),
old_spare VARCHAR2(1),
new_spare VARCHAR2(1),
old_score NUMBER,
new_score NUMBER,
change_date DATE,
operation VARCHAR2(6))Для каждого изменения в таблице frame Памела хочет отслеживать состояние строки до и после изменения. Она создает простой триггер:
/* Файл в Сети: bowlerama_full_audit.sql */
1 TRIGGER audit_frames
2 AFTER INSERT OR UPDATE OR DELETE ON frame
3 FOR EACH ROW
4 BEGIN
5 IF INSERTING THEN
6 INSERT INTO frame_audit(bowler_id,game_id,frame_number,
7 new_strike,new_spare,new_score,
8 change_date,operation)
9 VALUES(:NEW.bowler_id,:NEW.game_id,:NEW.frame_number,
10 :NEW.strike,:NEW.spare,:NEW.score,
11 SYSDATE,'INSERT');
12
13 ELSIF UPDATING THEN
14 INSERT INTO frame_audit(bowler_id,game_id,frame_number,
15 old_strike,new_strike,
16 old_spare,new_spare,
17 old_score,new_score,
18 change_date,operation)
19 VALUES(:NEW.bowler_id,:NEW.game_id,:NEW.frame_number,
20 :OLD.strike,:NEW.strike,
21 :OLD.spare,:NEW.spare,
22 :OLD.score,:NEW.score,
23 SYSDATE,'UPDATE');
24
25 ELSIF DELETING THEN
26 INSERT INTO frame_audit(bowler_id,game_id,frame_number,
27 old_strike,old_spare,old_score,
28 change_date,operation)
29 VALUES(:OLD.bowler_id,:OLD.game_id,:OLD.frame_number,
30 :OLD.strike,:OLD.spare,:OLD.score,
31 SYSDATE,'DELETE');
32 END IF;
33 END audit_frames;В секции INSERTING (строки 6-11) для заполнения строки аудита используется псевдозапись NEW. Для UPDATING (строки 14-23) используется сочетание информации NEW и OLD. Для DELETING (строки 26-31) доступна только информация OLD. Памела создает триггер и ждет результатов.
Конечно, она не распространяется о своей новой системе. Салли — амбициозный, но не очень искусный игрок — понятия не имеет, что ее действия могут отслеживаться. Салли решает, что в этом году она должна стать чемпионом, и она не остановится ни перед чем. У нее есть доступ к SQI*Plus, и она знает, что ее идентификатор игрока равен 1. Салли располагает достаточной информацией, чтобы полностью обойти графический интерфейс, подключиться к SQL*Plus и пустить в ход свое беспринципное «волшебство». Салли сходу выписывает себе страйк в первом фрейме:
SQL> INSERT INTO frame
2 (BOWLER_ID,GAME_ID,FRAME_NUMBER,STRIKE)
3 VALUES(1,1,1,'Y');
1 row created.Но затем она решает умерить аппетит и понижает результат первого фрейма, чтобы вызвать меньше подозрений:
SQL> UPDATE frame
2 SET strike = 'N',
3 spare = 'Y'
4 WHERE bowler_id = 1
5 AND game_id = 1
6 AND frame_number = 1;
1 row updated.Но что это? Салли слышит шум в коридоре. Она теряет самообладание и пытается замести следы:
SQL> DELETE frame
2 WHERE bowler_id = 1
3 AND game_id = 1
4 AND frame_number = 1;
1 row deleted.
SQL> COMMIT;
Commit complete.Она даже убеждается в том, что ее исправления были удалены:
SQL> SELECT * FROM frame;
no rows selectedВытирая пот со лба, Салли завершает сеанс, но рассчитывает вернуться и реализовать свои планы.
Бдительная Памела подключается к базе данных и моментально обнаруживает, что пыталась сделать Салли. Для этого она выдает запрос к таблице аудита (кстати, Памела также может настроить ежечасный запуск задания через DBMS_JOB для автоматизации этой части аудита):
SELECT bowler_id, game_id, frame_number
, old_strike, new_strike
, old_spare, new_spare
, change_date, operation
FROM frame_auditРезультат:
| BOWLER_ID | GAME_ID | FRAME_NUMBER | O | N | O | N | CHANGE_DA | OPERAT |
| 1 | 1 | 1 | Y | N | 12-SEP-00 | INSERT | ||
| 1 | 1 | 1 | Y | N | N | Y | 12-SEP-00 | UPDATE |
| 1 | 1 | 1 | N | N | 12-SEP-00 | DELETE |
Салли поймана с поличным! Из записей аудита прекрасно видно, что она пыталась сделать, хотя в таблице frame никаких следов не осталось. Все три команды — исходная вставка записи, понижение результата и последующее удаление записи — были перехвачены триггером DMI.
Применение секции WHEN
После того как система аудита успешно проработала несколько месяцев, Памела принимает меры для дальнейшего устранения потенциальных проблем. Она просматривает интерфейсную часть своего приложения и обнаруживает, что изменяться могут только поля strike, spare и score. Следовательно, триггер может быть и более конкретным:
TRIGGER audit_update
AFTER UPDATE OF strike, spare, score
ON frame
REFERENCING OLD AS prior_to_cheat NEW AS after_cheat
FOR EACH ROW
BEGIN
INSERT INTO frame_audit (...)
VALUES (...);
END;
Проходит несколько недель. Памеле не нравится ситуация, потому что новые записи создаются даже тогда, когда значения задаются равными сами себе. Обновления вроде следующего создают бесполезные записи аудита, которые показывают лишь отсутствие изменений:
SQL> UPDATE FRAME
2 SET strike = strike;
1 row updated.
SQL> SELECT old_strike,
2 new_strike,
3 old_spare,
4 new_spare,
5 old_score,
6 new_score
7 FROM frame_audit;
O N O N OLD SCORE NEW SCORE
- - - - --------- ---------
Y Y N N
Триггер нужно дополнительно уточнить, чтобы он срабатывал только при фактическом изменении значений. Для этого используется секция WHEN:
/* Файл в Сети: final_audit.sql */
TRIGGER audit_update
AFTER UPDATE OF STRIKE, SPARE, SCORE ON FRAME
REFERENCING OLD AS prior_to_cheat NEW AS after_cheat
FOR EACH ROW
WHEN ( prior_to_cheat.strike != after_cheat.strike OR
prior_to_cheat.spare != after_cheat.spare OR
prior_to_cheat.score != after_cheat.score )
BEGIN
INSERT INTO FRAME_AUDIT ( ... )
VALUES ( ... );
END;
Теперь данные будут появляться в таблице аудита только в том случае, если данные действительно изменились, а Памеле будет проще выявить возможных мошенников. Небольшая завершающая проверка триггера:
SQL> UPDATE frame
2 SET strike = strike;
1 row updated.
SQL> SELECT old_strike,
2 new_strike,
3 old_spare,
4 new_spare,
5 old_score,
6 new_score
7 FROM frame_audit;
no rows selected
Использование псевдозаписей для уточнения триггеров
Памела реализовала в системе приемлемый уровень аудита; теперь ей хотелось бы сделать систему более удобной для пользователя. Самая очевидная идея — сделать так, чтобы система сама увеличивала счет во фреймах, заканчивающихся страйком или спэром, на 10. Это позволяет счетчику отслеживать счет только за последующие броски, а счет за страйк будет начисляться автоматически:
/* Файл в Сети: set_score.sql */
TRIGGER set_score
BEFORE INSERT ON frame
FOR EACH ROW
WHEN ( NEW.score IS NOT NULL )
BEGIN
IF :NEW.strike = 'Y' OR :NEW.spare = 'Y'
THEN
:NEW.score := :NEW.score + 10;
END IF;
END;
Помните, что значения полей в записях NEW могут изменяться только в BEFORE— триггерах строк.
Будучи человеком пунктуальным, Памела решает добавить проверку счета в ее набор триггеров:
/* File on Сети: validate_score.sql */
TRIGGER validate_score
AFTER INSERT OR UPDATE
ON frame
FOR EACH ROW
BEGIN
IF :NEW.strike = 'Y' AND :NEW.score < 10
THEN
RAISE_APPLICATION_ERROR (
-20001,
'ERROR: Score For Strike Must Be >= 10'
);
ELSIF :NEW.spare = 'Y' AND :NEW.score < 10
THEN
RAISE_APPLICATION_ERROR (
-20001,
'ERROR: Score For Spare Must Be >= 10'
);
ELSIF :NEW.strike = 'Y' AND :NEW.spare = 'Y'
THEN
RAISE_APPLICATION_ERROR (
-20001,
'ERROR: Cannot Enter Spare And Strike'
);
END IF;
END;
Теперь любая попытка ввести строку, нарушающую это условие, будет отклонена:
SQL> INSERT INTO frame VALUES(1,1J1J'Y'JNULLJ5);
2 INSERT INTO frame *
ERROR at line 1:
ORA-20001: ERROR: Score For Strike Must >= 10
Однотипные триггеры
Oracle позволяет связать с таблицей базы данных несколько триггеров одного типа. Рассмотрим такую возможность на примере, связанном с игрой в гольф. Следующий триггер уровня строки вызывается при вставке в таблицу новой записи и добавляет в нее комментарий, текст которого определяется соотношением текущего счета с номинальным значением 72:
/* Файл в Сети: golf_commentary.sql */
TRIGGER golf_commentary
BEFORE INSERT
ON golf_scores
FOR EACH ROW
DECLARE
c_par_score CONSTANT PLS_INTEGER := 72;
BEGIN
:new.commentary :=
CASE
WHEN :new.score < c_par_score THEN 'Under'
WHEN :new.score = c_par_score THEN NULL
ELSE 'Over' || ' Par'
END;
END;
Эти же действия можно выполнить и с помощью трех отдельных триггеров уровня строки типа BEFORE INSERT с взаимоисключающими условиями, задаваемыми в секциях WHEN:
TRIGGER golf_commentary_under_par
BEFORE INSERT ON golf_scores
FOR EACH ROW
WHEN (NEW.score < 72)
BEGIN
:NEW.commentary := 'Under Par';
END;
TRIGGER golf_commentary_par
BEFORE INSERT ON golf_scores
FOR EACH ROW
WHEN (NEW.score = 72)
BEGIN
:NEW.commentary := 'Par';
END;
TRIGGER golf_commentary_over_par
BEFORE INSERT ON golf_scores
FOR EACH ROW
WHEN (NEW.score > 72)
BEGIN
:NEW.commentary := 'Over Par';
END;
Обе реализации абсолютно допустимы, и каждая обладает своими достоинствами и недостатками. Решение с одним триггером проще в сопровождении, поскольку весь код сосредоточен в одном месте, а решение с несколькими триггерами сокращает время синтаксического анализа и выполнения при необходимости более сложной обработки.
Очередность вызова триггеров
До выхода Oraclellg порядок срабатывания нескольких триггеров DML был непредсказуемым. В рассмотренном примере он несущественен, но как показывает следующий пример, в других ситуациях могут возникнуть проблемы. Какой результат будет получен для последнего запроса?
/* Файл в Сети: multiple_trigger_seq.sql */
TABLE incremented_values
(value_inserted NUMBER,
value_incremented NUMBER);
TRIGGER increment_by_one
BEFORE INSERT ON incremented_values
FOR EACH ROW
BEGIN
:NEW.value_incremented := :NEW.value_incremented + 1;
END;
TRIGGER increment_by_two
BEFORE INSERT ON incremented_values
FOR EACH ROW
BEGIN
IF :NEW.value_incremented > 1 THEN
:NEW.value_incremented := :NEW.value_incremented + 2;
END IF;
END;
INSERT INTO incremented_values
VALUES(1,1);
SELECT *
FROM incremented_values;
SELECT *
FROM incremented_values;
Есть какие-нибудь предположения? Для моей базы данных результаты получились такими:
SQL> SELECT *
2 FROM incremented_values;
VALUE INSERTED VALUE INCREMENTED
-------------- -----------------
1 2
Это означает, что первым сработал триггер increment_by_two, который не выполнил никаких действий, потому что значение столбца value_incremented не превышало 1; затем сработал триггер increment_by_one, увеличивший значение столбца value_incremented на 1. А вы тоже получите такой результат? Вовсе не обязательно. Будет ли этот результат всегда одним и тем же? Опять-таки, ничего нельзя гарантировать. До выхода Oracle11g в документации Oracle было явно указано, что порядок запуска однотипных триггеров, связанных с одной таблицей, не определен и произволен, поэтому задать его явно невозможно. На этот счет существуют разные теории, среди которых наиболее популярны две: триггеры запускаются в порядке, обратном порядку их создания или же в соответствии с идентификаторами их объектов, но полагаться на такие предположения не стоит. Начиная с Oracle11g гарантированный порядок срабатывания триггеров может определяться при помощи условия FOLLOWS, как показано в следующем примере:
TRIGGER increment_by_two
BEFORE INSERT ON incremented_values
FOR EACH ROW
FOLLOWS increment_by_one
BEGIN
IF :new.value_incremented > 1 THEN
:new.value_incremented := :new.value_incremented + 2;
END IF;
END;
Теперь этот триггер заведомо будет активизирован раньше триггера increment_by_one. Тем самым гарантируется и результат вставки:
SQL> INSERT INTO incremented_values
2 VALUES(1,1);
1 row created.
SQL> SELECT *
2 FROM incremented_values;
VALUE INSERTED VALUE INCREMENTED
-------------- -----------------
1 4
Триггер increment_by_one увеличил вставленное значение до 2, а триггер increment_by_two увеличил его до 4. Такое поведение гарантировано, потому что оно определяется на уровне самого триггера — нет необходимости полагаться на догадки и предположения. Связи последовательности триггеров можно просмотреть в представлении зависимостей словаря данных Oracle:
SQL> SELECT referenced_name,
2 referenced_type,
3 dependency_type
4 FROM user_dependencies
5 WHERE name = 'INCREMENT_BY_TWO'
6 AND referenced_type = 'TRIGGER';
REFERENCED NAME REFERENCED TYPE DEPE
---------------- --------------- ----
INCREMENT_BY_ONE TRIGGER REF
Несмотря на поведение, описанное выше для Oracle Database 11g, при попытке откомпилировать триггер, следующий за неопределенным триггером, выводится сообщение об ошибке:
Trigger "SCOTT"."BLIND_FOLLOWER" referenced in FOLLOWS or PRECEDES clause may not
existОшибки при изменении таблицы
Изменяющиеся объекты трудно анализировать и оценивать. Поэтому когда триггер уровня строки пытается прочитать или изменить данные в таблице, находящейся в состоянии изменения (с помощью команды INSERT, UPDATE или DELETE), происходит ошибка с кодом ORA-4091.
В частности, эта ошибка встречается тогда, когда триггер уровня строк пытается выполнить чтение или запись в таблицу, для которой сработал триггер. Предположим, для таблицы сотрудников требуется задать ограничение на значения в столбцах, которое заключается в том, что при повышении оклада сотрудника его новое значение не должно превышать следующее значение по отделу более чем на 20%.
Казалось бы, для проверки этого условия можно использовать следующий триггер:
TRIGGER brake_on_raises
BEFORE UPDATE OF salary ON employee
FOR EACH ROW
DECLARE
l_curr_max NUMBER;
BEGIN
SELECT MAX (salary) INTO l_curr_max
FROM employee;
IF l_curr_max * 1.20 < :NEW.salary
THEN
errpkg.RAISE (
employee_rules.en_salary_increase_too_large,
:NEW.employee_id,
:NEW.salary
);
END IF;
END;
Однако при попытке удвоить, скажем, оклад программиста PL/SQL, Oracle выдаст сообщение об ошибке:
ORA-04091: table SCOTT.EMPLOYEE is mutating, trigger/function may not see itТем не менее некоторые приемы помогут предотвратить выдачу этого сообщения об ошибке:
- В общем случае триггер уровня строки не может считывать или записывать данные таблицы, с которой он связан. Но подобное ограничение относится только к триггерам уровня строки. Триггеры уровня команд могут и считывать, и записывать данные своей таблицы, что дает возможность произвести необходимые действия.
- Если триггер выполняется как автономная транзакция (директива
PRAGMA AUTONOMOUS TRANSACTIONи выполнениеCOMMITв теле триггера), тогда в нем можно запрашивать содержимое таблицы. Однако модификация такой таблицы все равно будет запрещена.
С каждым выпуском Oracle проблема ошибок изменения таблицы становится все менее актуальной, поэтому мы не станем приводить полное описание. На сайте github размещен демонстрационный сценарий mutation_zone.sql. Кроме того, в файле mutating_template.sql представлен пакет, который может послужить шаблоном для создания вашей собственной реализации перевода логики уровня записей на уровень команд.
Составные триггеры
По мере создания триггеров, содержащих все больший объем бизнес-логики, становится трудно следить за тем, какие триггеры связаны с теми или иными правилами и как триггеры взаимодействуют друг с другом. В предыдущем разделе было показано, как три типа команд DML (вставка, обновление, удаление) объединяются в одном триггере, но разве не удобно было бы разместить триггеры строк и команд вместе в одном объекте кода? В Oracle Database 11g появилась возможность использования составных триггеров для решения этой задачи. Следующий простой пример демонстрирует этот синтаксис:
/* Файл в Сети: compound_trigger.sql */
1 TRIGGER compounder
2 FOR UPDATE OR INSERT OR DELETE ON incremented_values
3 COMPOUND TRIGGER
4
5 v_global_var NUMBER := 1;
6
7 BEFORE STATEMENT IS
8 BEGIN
9 DBMS_OUTPUT.PUT_LINE('Compound:BEFORE S:' || v_global_var);
10 v_global_var := v_global_var + 1;
11 END BEFORE STATEMENT;
12
13 BEFORE EACH ROW IS
14 BEGIN
15 DBMS_OUTPUT.PUT_LINE('Compound:BEFORE R:' || v_global_var);
16 v_global_var := v_global_var + 1;
17 END BEFORE EACH ROW;
18
19 AFTER EACH ROW IS
20 BEGIN
21 DBMS_OUTPUT.PUT_LINE('Compound:AFTER R:' || v_global_var);
22 v_global_var := v_global_var + 1;
23 END AFTER EACH ROW;
24
25 AFTER STATEMENT IS
26 BEGIN
27 DBMS_OUTPUT.PUT_LINE('Compound:AFTER S:' || v_global_var);
28 v_global_var := v_global_var + 1;
29 END AFTER STATEMENT;
30
31 END;
Сходство с пакетами
Составные триггеры похожи на пакеты PL/SQL, не правда ли? Весь сопутствующий код и логика находятся в одном месте, что упрощает его отладку и изменение. Рассмотрим синтаксис более подробно.
Самое очевидное изменение — конструкция COMPOUND TRIGGER, сообщающая Oracle, что триггер содержит несколько триггеров, которые должны срабатывать вместе. Следующее (и пожалуй, самое долгожданное) изменение встречается в строке 5: глобальная переменная! Наконец-то глобальные переменные могут определяться вместе с кодом, который с ними работает, — специальные пакеты для них больше не нужны:
PACKAGE BODY yet_another_global_package AS
v_global_var NUMBER := 1;
PROCEDURE reset_global_var IS
...
END;
В остальном синтаксис составных триггеров очень похож на синтаксис автономных триггеров, но не так гибок:
-
BEFORE STATEMENT— код этого раздела выполняется до командыDML, как и в случае с автономным триггеромBEFORE. -
BEFORE EACH ROW— код этого раздела выполняется перед обработкой каждой строки командойDML. -
AFTER EACH ROW— код этого раздела выполняется после обработки каждой строки командойDML. -
AFTER STATEMENT— код этого раздела выполняется после командыDML, как и в случае с автономным триггеромAFTER.
Правила автономных триггеров также применимы и к составным триггерам — например, значения записей (OLD и NEW) не могут изменяться в триггерах уровня команд.
Различия с пакетами
Итак, составные триггеры похожи на пакеты PL/SQL, но означает ли это, что они так же работают? Нет — они работают лучше! Рассмотрим следующий пример:
SQL> BEGIN
2 insert into incremented_values values(1,1);
3 insert into incremented_values values(2,2);
4 END;
5 /
Compound:BEFORE S:1
Compound:BEFORE R:2
Compound:AFTER R:3
Compound:AFTER S:4
Compound:BEFORE S:1
Compound:BEFORE R:2
Compound:AFTER R:3
Compound:AFTER S:4
PL/SQL procedure successfully completed.
Обратите внимание: при выполнении второй команды для глобальной переменной снова выводится 1. Это связано с тем, что область действия составного триггера ограничивается командой DML, которая его инициирует. После завершения этой команды составной триггер и его значения, хранящиеся в памяти, перестают существовать. Это обстоятельство упрощает логику.
Дополнительным преимуществом ограниченной области действия является упрощенная обработка ошибок. Чтобы продемонстрировать это обстоятельство, я определяю в таблице первичный ключ для последующего нарушения:
SQL> ALTER TABLE incremented_values
2 add constraint a_pk
3 primary key ( value_inserted );
Теперь вставим одну запись:
SQL> INSERT INTO incremented_values values(1,1);
Compound:BEFORE S:1
Compound:BEFORE R:2
Compound:AFTER R:3
Compound:AFTER S:4
1 row created.
Пока без сюрпризов. Но следующая команда INSERT выдает ошибку из-за нарушения нового первичного ключа:
SQL> INSERT INTO incremented_values values(1,1);
Compound:BEFORE S:1
Compound:BEFORE R:2
insert into incremented_values values(1,1)
*
ERROR at line 1:
ORA-00001: unique constraint (SCOTT.A_PK) violated
Следующая команда INSERT также снова выдает ошибку первичного ключа. Но в этом как раз ничего примечательного нет — примечательно то, что глобальная переменная была снова инициализирована значением 1 без написания дополнительного кода. Команда DML завершилась, составной триггер вышел из области действия, и со следующей командой все начинается заново:
SQL> INSERT INTO incremented_values values(1,1);
Compound:BEFORE S:1
Compound:BEFORE R:2
insert into incremented_values values(1,1)
*
ERROR at line 1:
ORA-00001: unique constraint (DRH.A_PK) violated
Теперь мне не нужно включать дополнительную обработку ошибок или пакеты только для сброса значений при возникновении исключения.
FOLLOWS с составными триггерами
Составные триггеры также могут использоваться с синтаксисом FOLLOWS:
TRIGGER follows_compounder
BEFORE INSERT ON incremented_values
FOR EACH ROW
FOLLOWS compounder
BEGIN
DBMS_OUTPUT.PUT_LINE('Following Trigger');
END;
Результат:
SQL> INSERT INTO incremented_values
2 values(8,8);
Compound:BEFORE S:1
Compound:BEFORE R:2
Following Trigger
Compound:AFTER R:3
Compound:AFTER S:4
1 row created.
Конкретные триггеры, находящиеся внутри составного триггера, не могут определяться как срабатывающие после каких-либо автономных или составных триггеров.
Если автономный триггер определяется как следующий за составным триггером, который не содержит триггер, срабатывающий по той же команде или строке, секция FOLLOWS просто игнорируется.
Вас заинтересует / Intresting for you:
Table of Contents
- Introduction
- Problem Definition
- Solution
- Conclusion
- See Also
- Other Languages
Introduction
The goal of this article is to provide a simple and easy to use error handling mechanism within triggers context. This article is completely compatible with SQL Server
2012 and 2014.
Problem Definition
Triggers are strange objects that have their own rules!
- The first rule says that triggers are part of the invoking transaction (the transaction that fired them). Yes, this is True and it means that at the beginning of the trigger, both values of @@trancount
and xact_state() are «1». So, if we use COMMIT or ROLLBACK inside the trigger, their values will change to «0» just after executing these statements. - The second strange rule is that if the transaction ended in the trigger, the database raises an abortion error. An example of this rule is executing COMMIT or ROLLBACK within the trigger.
Next code shows these rules:
-- create test table
IF OBJECT_ID('dbo.Test',
'U') IS
NOT NULL
DROP
TABLE
dbo.Test ;
GO
CREATE
TABLE
dbo.Test
( Id
INT
IDENTITY PRIMARY
KEY,
NAME
NVARCHAR(128)
) ;
GO
-- create test trigger
CREATE
TRIGGER
dbo.TriggerForTest
ON
dbo.Test
AFTER
INSERT
AS
BEGIN
SET
NOCOUNT ON;
-- declare variables
DECLARE
@trancount CHAR(1) ,
@XACT_STATE
CHAR(1) ;
-- fetch and print values at the beginning of the trigger
SET
@trancount = @@TRANCOUNT ;
SET
@XACT_STATE = XACT_STATE() ;
PRINT
'------------------------------------------------------------------------'
;
PRINT
'When trigger starts @@trancount value is ('
+ @trancount + ' ).';
PRINT
'When trigger starts XACT_STATE() return value is ('
+ @XACT_STATE + ' ).';
PRINT
'------------------------------------------------------------------------'
;
-- ending the transaction inside the trigger
COMMIT
TRAN ;
-- fetch and print values again
SET
@trancount = @@TRANCOUNT ;
SET
@XACT_STATE = XACT_STATE() ;
PRINT
'After executing COMMIT statement, @@trancount value is ('
+ @trancount + ' ).';
PRINT
'After executing COMMIT statement, XACT_STATE() return value is ('
+ @XACT_STATE + ' ).';
PRINT
'------------------------------------------------------------------------'
;
END
;
GO
-- test time!
INSERT
dbo.Test ( Name
)
VALUES
( N'somthing'
) ;
Figure 1

So, what is the Error Handling mechanism within Triggers?
Solution
There can be two types of solution
Classic Solution
This solution uses the second rule to rollback trigger and raise an error. The following code shows this mechanism:
-- create test table
IF OBJECT_ID('dbo.Test',
'U') IS
NOT NULL
DROP
TABLE
dbo.Test ;
GO
CREATE
TABLE
dbo.Test
( Id
INT
IDENTITY PRIMARY
KEY,
NAME
NVARCHAR(128)
) ;
GO
-- create test trigger
CREATE
TRIGGER
dbo.TriggerForTest
ON
dbo.Test
AFTER
INSERT
AS
BEGIN
SET
NOCOUNT ON;
IF 1 = 1
BEGIN
-- rollback and end the transaction inside the trigger
ROLLBACK
TRAN ;
-- raise an error
RAISERROR (
'Error Message!', 16, 1) ;
END
END
;
GO
-- test time!
INSERT
dbo.Test ( Name
)
VALUES
( N'somthing'
) ;
Figure 2

Pitfall
This solution works fine until the RAISERROR is the last statement in trigger. If we have some statements after RAISERROR,
they will execute as shown in next code:
-- create test table
IF OBJECT_ID('dbo.Test',
'U') IS
NOT NULL
DROP
TABLE
dbo.Test ;
GO
CREATE
TABLE
dbo.Test
( Id
INT
IDENTITY PRIMARY
KEY,
NAME
NVARCHAR(128)
) ;
GO
-- create test trigger
CREATE
TRIGGER
dbo.TriggerForTest
ON
dbo.Test
AFTER
INSERT
AS
BEGIN
SET
NOCOUNT ON;
IF 1 = 1
BEGIN
-- rollback and end the transaction inside the trigger
ROLLBACK
TRAN ;
-- raise an error
RAISERROR (
'Error Message!', 16, 1) ;
END
INSERT
dbo.Test ( Name
)
VALUES
( N'extra'
) ;
END
;
GO
-- test time!
INSERT
dbo.Test ( Name
)
VALUES
( N'somthing'
) ;
GO
SELECT
*
FROM
dbo.Test
Figure 3

Modern Solution
This solution is applicable to SQL Server 2012 and above versions. THROW statement enhances the error handling in triggers. It rollback the statements and throw an error message. Next code shows this mechanism:
-- create test table
IF OBJECT_ID('dbo.Test',
'U') IS
NOT NULL
DROP
TABLE
dbo.Test ;
GO
CREATE
TABLE
dbo.Test
( Id
INT
IDENTITY PRIMARY
KEY,
NAME
NVARCHAR(128)
) ;
GO
-- create test trigger
CREATE
TRIGGER
dbo.TriggerForTest
ON
dbo.Test
AFTER
INSERT
AS
BEGIN
SET
NOCOUNT ON;
IF 1 = 1
-- just throw!
THROW 60000,
'Error Message!', 1 ;
END
;
GO
-- test time!
INSERT
dbo.Test ( Name
)
VALUES
( N'somthing'
) ;
GO
SELECT
*
FROM
dbo.Test ;
Figure 4

Conclusion
As I explained in
former article, introducing the THROW statement was a revolutionary movement in SQL Server 2012 Error Handling. This article proves it again, this time with triggers.
See Also
- Structured Error Handling Mechanism in SQL Server 2012
- T-SQL: Error Handling for CHECK Constraints
- Transact-SQL Portal
- SQL Server 2012
- Structured Error Handling Mechanism in SQL Server 2012