
200
Ugh… (309, 400, 403, 409, 415, 422)… a lot of answers trying to guess, argue and standardize what is the best return code for a successful HTTP request but a failed REST call.
It is wrong to mix HTTP status codes and REST status codes.
However, I saw many implementations mixing them, and many developers may not agree with me.
HTTP return codes are related to the HTTP Request itself. A REST call is done using a Hypertext Transfer Protocol request and it works at a lower level than invoked REST method itself. REST is a concept/approach, and its output is a business/logical result, while HTTP result code is a transport one.
For example, returning «404 Not found» when you call /users/ is confuse, because it may mean:
- URI is wrong (HTTP)
- No users are found (REST)
«403 Forbidden/Access Denied» may mean:
- Special permission needed. Browsers can handle it by asking the user/password. (HTTP)
- Wrong access permissions configured on the server. (HTTP)
- You need to be authenticated (REST)
And the list may continue with ‘500 Server error» (an Apache/Nginx HTTP thrown error or a business constraint error in REST) or other HTTP errors etc…
From the code, it’s hard to understand what was the failure reason, a HTTP (transport) failure or a REST (logical) failure.
If the HTTP request physically was performed successfully it should always return 200 code, regardless is the record(s) found or not. Because URI resource is found and was handled by the HTTP server. Yes, it may return an empty set. Is it possible to receive an empty web-page with 200 as HTTP result, right?
Instead of this you may return 200 HTTP code with some options:
- «error» object in JSON result if something goes wrong
- Empty JSON array/object if no record found
- A bool result/success flag in combination with previous options for a better handling.
Also, some internet providers may intercept your requests and return you a 404 HTTP code. This does not means that your data are not found, but it’s something wrong at transport level.
From Wiki:
In July 2004, the UK telecom provider BT Group deployed the Cleanfeed
content blocking system, which returns a 404 error to any request for
content identified as potentially illegal by the Internet Watch
Foundation. Other ISPs return a HTTP 403 «forbidden» error in the same
circumstances. The practice of employing fake 404 errors as a means to
conceal censorship has also been reported in Thailand and Tunisia. In
Tunisia, where censorship was severe before the 2011 revolution,
people became aware of the nature of the fake 404 errors and created
an imaginary character named «Ammar 404» who represents «the invisible
censor».
Why not simply answer with something like this?
{
"result": false,
"error": {"code": 102, "message": "Validation failed: Wrong NAME."}
}
Google always returns 200 as status code in their Geocoding API, even if the request logically fails: https://developers.google.com/maps/documentation/geocoding/intro#StatusCodes
Facebook always return 200 for successful HTTP requests, even if REST request fails: https://developers.facebook.com/docs/graph-api/using-graph-api/error-handling
It’s simple, HTTP status codes are for HTTP requests. REST API is Your, define Your status codes.
![]()
From Wikipedia, the free encyclopedia
This is a list of Hypertext Transfer Protocol (HTTP) response status codes. Status codes are issued by a server in response to a client’s request made to the server. It includes codes from IETF Request for Comments (RFCs), other specifications, and some additional codes used in some common applications of the HTTP. The first digit of the status code specifies one of five standard classes of responses. The optional message phrases shown are typical, but any human-readable alternative may be provided, or none at all.
Unless otherwise stated, the status code is part of the HTTP standard (RFC 9110).
The Internet Assigned Numbers Authority (IANA) maintains the official registry of HTTP status codes.[1]
All HTTP response status codes are separated into five classes or categories. The first digit of the status code defines the class of response, while the last two digits do not have any classifying or categorization role. There are five classes defined by the standard:
- 1xx informational response – the request was received, continuing process
- 2xx successful – the request was successfully received, understood, and accepted
- 3xx redirection – further action needs to be taken in order to complete the request
- 4xx client error – the request contains bad syntax or cannot be fulfilled
- 5xx server error – the server failed to fulfil an apparently valid request
1xx informational response
An informational response indicates that the request was received and understood. It is issued on a provisional basis while request processing continues. It alerts the client to wait for a final response. The message consists only of the status line and optional header fields, and is terminated by an empty line. As the HTTP/1.0 standard did not define any 1xx status codes, servers must not[note 1] send a 1xx response to an HTTP/1.0 compliant client except under experimental conditions.
- 100 Continue
- The server has received the request headers and the client should proceed to send the request body (in the case of a request for which a body needs to be sent; for example, a POST request). Sending a large request body to a server after a request has been rejected for inappropriate headers would be inefficient. To have a server check the request’s headers, a client must send
Expect: 100-continueas a header in its initial request and receive a100 Continuestatus code in response before sending the body. If the client receives an error code such as 403 (Forbidden) or 405 (Method Not Allowed) then it should not send the request’s body. The response417 Expectation Failedindicates that the request should be repeated without theExpectheader as it indicates that the server does not support expectations (this is the case, for example, of HTTP/1.0 servers).[2] - 101 Switching Protocols
- The requester has asked the server to switch protocols and the server has agreed to do so.
- 102 Processing (WebDAV; RFC 2518)
- A WebDAV request may contain many sub-requests involving file operations, requiring a long time to complete the request. This code indicates that the server has received and is processing the request, but no response is available yet.[3] This prevents the client from timing out and assuming the request was lost. The status code is deprecated.[4]
- 103 Early Hints (RFC 8297)
- Used to return some response headers before final HTTP message.[5]
2xx success
This class of status codes indicates the action requested by the client was received, understood, and accepted.[1]
- 200 OK
- Standard response for successful HTTP requests. The actual response will depend on the request method used. In a GET request, the response will contain an entity corresponding to the requested resource. In a POST request, the response will contain an entity describing or containing the result of the action.
- 201 Created
- The request has been fulfilled, resulting in the creation of a new resource.[6]
- 202 Accepted
- The request has been accepted for processing, but the processing has not been completed. The request might or might not be eventually acted upon, and may be disallowed when processing occurs.
- 203 Non-Authoritative Information (since HTTP/1.1)
- The server is a transforming proxy (e.g. a Web accelerator) that received a 200 OK from its origin, but is returning a modified version of the origin’s response.[7][8]
- 204 No Content
- The server successfully processed the request, and is not returning any content.
- 205 Reset Content
- The server successfully processed the request, asks that the requester reset its document view, and is not returning any content.
- 206 Partial Content
- The server is delivering only part of the resource (byte serving) due to a range header sent by the client. The range header is used by HTTP clients to enable resuming of interrupted downloads, or split a download into multiple simultaneous streams.
- 207 Multi-Status (WebDAV; RFC 4918)
- The message body that follows is by default an XML message and can contain a number of separate response codes, depending on how many sub-requests were made.[9]
- 208 Already Reported (WebDAV; RFC 5842)
- The members of a DAV binding have already been enumerated in a preceding part of the (multistatus) response, and are not being included again.
- 226 IM Used (RFC 3229)
- The server has fulfilled a request for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance.[10]
3xx redirection
This class of status code indicates the client must take additional action to complete the request. Many of these status codes are used in URL redirection.[1]
A user agent may carry out the additional action with no user interaction only if the method used in the second request is GET or HEAD. A user agent may automatically redirect a request. A user agent should detect and intervene to prevent cyclical redirects.[11]
- 300 Multiple Choices
- Indicates multiple options for the resource from which the client may choose (via agent-driven content negotiation). For example, this code could be used to present multiple video format options, to list files with different filename extensions, or to suggest word-sense disambiguation.
- 301 Moved Permanently
- This and all future requests should be directed to the given URI.
- 302 Found (Previously «Moved temporarily»)
- Tells the client to look at (browse to) another URL. The HTTP/1.0 specification (RFC 1945) required the client to perform a temporary redirect with the same method (the original describing phrase was «Moved Temporarily»),[12] but popular browsers implemented 302 redirects by changing the method to GET. Therefore, HTTP/1.1 added status codes 303 and 307 to distinguish between the two behaviours.[11]
- 303 See Other (since HTTP/1.1)
- The response to the request can be found under another URI using the GET method. When received in response to a POST (or PUT/DELETE), the client should presume that the server has received the data and should issue a new GET request to the given URI.
- 304 Not Modified
- Indicates that the resource has not been modified since the version specified by the request headers If-Modified-Since or If-None-Match. In such case, there is no need to retransmit the resource since the client still has a previously-downloaded copy.
- 305 Use Proxy (since HTTP/1.1)
- The requested resource is available only through a proxy, the address for which is provided in the response. For security reasons, many HTTP clients (such as Mozilla Firefox and Internet Explorer) do not obey this status code.
- 306 Switch Proxy
- No longer used. Originally meant «Subsequent requests should use the specified proxy.»
- 307 Temporary Redirect (since HTTP/1.1)
- In this case, the request should be repeated with another URI; however, future requests should still use the original URI. In contrast to how 302 was historically implemented, the request method is not allowed to be changed when reissuing the original request. For example, a POST request should be repeated using another POST request.
- 308 Permanent Redirect
- This and all future requests should be directed to the given URI. 308 parallel the behaviour of 301, but does not allow the HTTP method to change. So, for example, submitting a form to a permanently redirected resource may continue smoothly.
4xx client errors
This class of status code is intended for situations in which the error seems to have been caused by the client. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and whether it is a temporary or permanent condition. These status codes are applicable to any request method. User agents should display any included entity to the user.
- 400 Bad Request
- The server cannot or will not process the request due to an apparent client error (e.g., malformed request syntax, size too large, invalid request message framing, or deceptive request routing).
- 401 Unauthorized
- Similar to 403 Forbidden, but specifically for use when authentication is required and has failed or has not yet been provided. The response must include a WWW-Authenticate header field containing a challenge applicable to the requested resource. See Basic access authentication and Digest access authentication. 401 semantically means «unauthorised», the user does not have valid authentication credentials for the target resource.
- Some sites incorrectly issue HTTP 401 when an IP address is banned from the website (usually the website domain) and that specific address is refused permission to access a website.[citation needed]
- 402 Payment Required
- Reserved for future use. The original intention was that this code might be used as part of some form of digital cash or micropayment scheme, as proposed, for example, by GNU Taler,[14] but that has not yet happened, and this code is not widely used. Google Developers API uses this status if a particular developer has exceeded the daily limit on requests.[15] Sipgate uses this code if an account does not have sufficient funds to start a call.[16] Shopify uses this code when the store has not paid their fees and is temporarily disabled.[17] Stripe uses this code for failed payments where parameters were correct, for example blocked fraudulent payments.[18]
- 403 Forbidden
- The request contained valid data and was understood by the server, but the server is refusing action. This may be due to the user not having the necessary permissions for a resource or needing an account of some sort, or attempting a prohibited action (e.g. creating a duplicate record where only one is allowed). This code is also typically used if the request provided authentication by answering the WWW-Authenticate header field challenge, but the server did not accept that authentication. The request should not be repeated.
- 404 Not Found
- The requested resource could not be found but may be available in the future. Subsequent requests by the client are permissible.
- 405 Method Not Allowed
- A request method is not supported for the requested resource; for example, a GET request on a form that requires data to be presented via POST, or a PUT request on a read-only resource.
- 406 Not Acceptable
- The requested resource is capable of generating only content not acceptable according to the Accept headers sent in the request. See Content negotiation.
- 407 Proxy Authentication Required
- The client must first authenticate itself with the proxy.
- 408 Request Timeout
- The server timed out waiting for the request. According to HTTP specifications: «The client did not produce a request within the time that the server was prepared to wait. The client MAY repeat the request without modifications at any later time.»
- 409 Conflict
- Indicates that the request could not be processed because of conflict in the current state of the resource, such as an edit conflict between multiple simultaneous updates.
- 410 Gone
- Indicates that the resource requested was previously in use but is no longer available and will not be available again. This should be used when a resource has been intentionally removed and the resource should be purged. Upon receiving a 410 status code, the client should not request the resource in the future. Clients such as search engines should remove the resource from their indices. Most use cases do not require clients and search engines to purge the resource, and a «404 Not Found» may be used instead.
- 411 Length Required
- The request did not specify the length of its content, which is required by the requested resource.
- 412 Precondition Failed
- The server does not meet one of the preconditions that the requester put on the request header fields.
- 413 Payload Too Large
- The request is larger than the server is willing or able to process. Previously called «Request Entity Too Large» in RFC 2616.[19]
- 414 URI Too Long
- The URI provided was too long for the server to process. Often the result of too much data being encoded as a query-string of a GET request, in which case it should be converted to a POST request. Called «Request-URI Too Long» previously in RFC 2616.[20]
- 415 Unsupported Media Type
- The request entity has a media type which the server or resource does not support. For example, the client uploads an image as image/svg+xml, but the server requires that images use a different format.
- 416 Range Not Satisfiable
- The client has asked for a portion of the file (byte serving), but the server cannot supply that portion. For example, if the client asked for a part of the file that lies beyond the end of the file. Called «Requested Range Not Satisfiable» previously RFC 2616.[21]
- 417 Expectation Failed
- The server cannot meet the requirements of the Expect request-header field.[22]
- 418 I’m a teapot (RFC 2324, RFC 7168)
- This code was defined in 1998 as one of the traditional IETF April Fools’ jokes, in RFC 2324, Hyper Text Coffee Pot Control Protocol, and is not expected to be implemented by actual HTTP servers. The RFC specifies this code should be returned by teapots requested to brew coffee.[23] This HTTP status is used as an Easter egg in some websites, such as Google.com’s «I’m a teapot» easter egg.[24][25][26] Sometimes, this status code is also used as a response to a blocked request, instead of the more appropriate 403 Forbidden.[27][28]
- 421 Misdirected Request
- The request was directed at a server that is not able to produce a response (for example because of connection reuse).
- 422 Unprocessable Entity
- The request was well-formed but was unable to be followed due to semantic errors.[9]
- 423 Locked (WebDAV; RFC 4918)
- The resource that is being accessed is locked.[9]
- 424 Failed Dependency (WebDAV; RFC 4918)
- The request failed because it depended on another request and that request failed (e.g., a PROPPATCH).[9]
- 425 Too Early (RFC 8470)
- Indicates that the server is unwilling to risk processing a request that might be replayed.
- 426 Upgrade Required
- The client should switch to a different protocol such as TLS/1.3, given in the Upgrade header field.
- 428 Precondition Required (RFC 6585)
- The origin server requires the request to be conditional. Intended to prevent the ‘lost update’ problem, where a client GETs a resource’s state, modifies it, and PUTs it back to the server, when meanwhile a third party has modified the state on the server, leading to a conflict.[29]
- 429 Too Many Requests (RFC 6585)
- The user has sent too many requests in a given amount of time. Intended for use with rate-limiting schemes.[29]
- 431 Request Header Fields Too Large (RFC 6585)
- The server is unwilling to process the request because either an individual header field, or all the header fields collectively, are too large.[29]
- 451 Unavailable For Legal Reasons (RFC 7725)
- A server operator has received a legal demand to deny access to a resource or to a set of resources that includes the requested resource.[30] The code 451 was chosen as a reference to the novel Fahrenheit 451 (see the Acknowledgements in the RFC).
5xx server errors
The server failed to fulfil a request.
Response status codes beginning with the digit «5» indicate cases in which the server is aware that it has encountered an error or is otherwise incapable of performing the request. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and indicate whether it is a temporary or permanent condition. Likewise, user agents should display any included entity to the user. These response codes are applicable to any request method.
- 500 Internal Server Error
- A generic error message, given when an unexpected condition was encountered and no more specific message is suitable.
- 501 Not Implemented
- The server either does not recognize the request method, or it lacks the ability to fulfil the request. Usually this implies future availability (e.g., a new feature of a web-service API).
- 502 Bad Gateway
- The server was acting as a gateway or proxy and received an invalid response from the upstream server.
- 503 Service Unavailable
- The server cannot handle the request (because it is overloaded or down for maintenance). Generally, this is a temporary state.[31]
- 504 Gateway Timeout
- The server was acting as a gateway or proxy and did not receive a timely response from the upstream server.
- 505 HTTP Version Not Supported
- The server does not support the HTTP version used in the request.
- 506 Variant Also Negotiates (RFC 2295)
- Transparent content negotiation for the request results in a circular reference.[32]
- 507 Insufficient Storage (WebDAV; RFC 4918)
- The server is unable to store the representation needed to complete the request.[9]
- 508 Loop Detected (WebDAV; RFC 5842)
- The server detected an infinite loop while processing the request (sent instead of 208 Already Reported).
- 510 Not Extended (RFC 2774)
- Further extensions to the request are required for the server to fulfil it.[33]
- 511 Network Authentication Required (RFC 6585)
- The client needs to authenticate to gain network access. Intended for use by intercepting proxies used to control access to the network (e.g., «captive portals» used to require agreement to Terms of Service before granting full Internet access via a Wi-Fi hotspot).[29]
Unofficial codes
The following codes are not specified by any standard.
- 419 Page Expired (Laravel Framework)
- Used by the Laravel Framework when a CSRF Token is missing or expired.
- 420 Method Failure (Spring Framework)
- A deprecated response used by the Spring Framework when a method has failed.[34]
- 420 Enhance Your Calm (Twitter)
- Returned by version 1 of the Twitter Search and Trends API when the client is being rate limited; versions 1.1 and later use the 429 Too Many Requests response code instead.[35] The phrase «Enhance your calm» comes from the 1993 movie Demolition Man, and its association with this number is likely a reference to cannabis.[citation needed]
- 430 Request Header Fields Too Large (Shopify)
- Used by Shopify, instead of the 429 Too Many Requests response code, when too many URLs are requested within a certain time frame.[36]
- 450 Blocked by Windows Parental Controls (Microsoft)
- The Microsoft extension code indicated when Windows Parental Controls are turned on and are blocking access to the requested webpage.[37]
- 498 Invalid Token (Esri)
- Returned by ArcGIS for Server. Code 498 indicates an expired or otherwise invalid token.[38]
- 499 Token Required (Esri)
- Returned by ArcGIS for Server. Code 499 indicates that a token is required but was not submitted.[38]
- 509 Bandwidth Limit Exceeded (Apache Web Server/cPanel)
- The server has exceeded the bandwidth specified by the server administrator; this is often used by shared hosting providers to limit the bandwidth of customers.[39]
- 529 Site is overloaded
- Used by Qualys in the SSLLabs server testing API to signal that the site can’t process the request.[40]
- 530 Site is frozen
- Used by the Pantheon Systems web platform to indicate a site that has been frozen due to inactivity.[41]
- 598 (Informal convention) Network read timeout error
- Used by some HTTP proxies to signal a network read timeout behind the proxy to a client in front of the proxy.[42]
- 599 Network Connect Timeout Error
- An error used by some HTTP proxies to signal a network connect timeout behind the proxy to a client in front of the proxy.
Internet Information Services
Microsoft’s Internet Information Services (IIS) web server expands the 4xx error space to signal errors with the client’s request.
- 440 Login Time-out
- The client’s session has expired and must log in again.[43]
- 449 Retry With
- The server cannot honour the request because the user has not provided the required information.[44]
- 451 Redirect
- Used in Exchange ActiveSync when either a more efficient server is available or the server cannot access the users’ mailbox.[45] The client is expected to re-run the HTTP AutoDiscover operation to find a more appropriate server.[46]
IIS sometimes uses additional decimal sub-codes for more specific information,[47] however these sub-codes only appear in the response payload and in documentation, not in the place of an actual HTTP status code.
nginx
The nginx web server software expands the 4xx error space to signal issues with the client’s request.[48][49]
- 444 No Response
- Used internally[50] to instruct the server to return no information to the client and close the connection immediately.
- 494 Request header too large
- Client sent too large request or too long header line.
- 495 SSL Certificate Error
- An expansion of the 400 Bad Request response code, used when the client has provided an invalid client certificate.
- 496 SSL Certificate Required
- An expansion of the 400 Bad Request response code, used when a client certificate is required but not provided.
- 497 HTTP Request Sent to HTTPS Port
- An expansion of the 400 Bad Request response code, used when the client has made a HTTP request to a port listening for HTTPS requests.
- 499 Client Closed Request
- Used when the client has closed the request before the server could send a response.
Cloudflare
Cloudflare’s reverse proxy service expands the 5xx series of errors space to signal issues with the origin server.[51]
- 520 Web Server Returned an Unknown Error
- The origin server returned an empty, unknown, or unexpected response to Cloudflare.[52]
- 521 Web Server Is Down
- The origin server refused connections from Cloudflare. Security solutions at the origin may be blocking legitimate connections from certain Cloudflare IP addresses.
- 522 Connection Timed Out
- Cloudflare timed out contacting the origin server.
- 523 Origin Is Unreachable
- Cloudflare could not reach the origin server; for example, if the DNS records for the origin server are incorrect or missing.
- 524 A Timeout Occurred
- Cloudflare was able to complete a TCP connection to the origin server, but did not receive a timely HTTP response.
- 525 SSL Handshake Failed
- Cloudflare could not negotiate a SSL/TLS handshake with the origin server.
- 526 Invalid SSL Certificate
- Cloudflare could not validate the SSL certificate on the origin web server. Also used by Cloud Foundry’s gorouter.
- 527 Railgun Error
- Error 527 indicates an interrupted connection between Cloudflare and the origin server’s Railgun server.[53]
- 530
- Error 530 is returned along with a 1xxx error.[54]
AWS Elastic Load Balancer
Amazon’s Elastic Load Balancing adds a few custom return codes
- 460
- Client closed the connection with the load balancer before the idle timeout period elapsed. Typically when client timeout is sooner than the Elastic Load Balancer’s timeout.[55]
- 463
- The load balancer received an X-Forwarded-For request header with more than 30 IP addresses.[55]
- 464
- Incompatible protocol versions between Client and Origin server.[55]
- 561 Unauthorized
- An error around authentication returned by a server registered with a load balancer. You configured a listener rule to authenticate users, but the identity provider (IdP) returned an error code when authenticating the user.[55]
Caching warning codes (obsoleted)
The following caching related warning codes were specified under RFC 7234. Unlike the other status codes above, these were not sent as the response status in the HTTP protocol, but as part of the «Warning» HTTP header.[56][57]
Since this «Warning» header is often neither sent by servers nor acknowledged by clients, this header and its codes were obsoleted by the HTTP Working Group in 2022 with RFC 9111.[58]
- 110 Response is Stale
- The response provided by a cache is stale (the content’s age exceeds a maximum age set by a Cache-Control header or heuristically chosen lifetime).
- 111 Revalidation Failed
- The cache was unable to validate the response, due to an inability to reach the origin server.
- 112 Disconnected Operation
- The cache is intentionally disconnected from the rest of the network.
- 113 Heuristic Expiration
- The cache heuristically chose a freshness lifetime greater than 24 hours and the response’s age is greater than 24 hours.
- 199 Miscellaneous Warning
- Arbitrary, non-specific warning. The warning text may be logged or presented to the user.
- 214 Transformation Applied
- Added by a proxy if it applies any transformation to the representation, such as changing the content encoding, media type or the like.
- 299 Miscellaneous Persistent Warning
- Same as 199, but indicating a persistent warning.
See also
- Custom error pages
- List of FTP server return codes
- List of HTTP header fields
- List of SMTP server return codes
- Common Log Format
Explanatory notes
- ^ Emphasised words and phrases such as must and should represent interpretation guidelines as given by RFC 2119
References
- ^ a b c «Hypertext Transfer Protocol (HTTP) Status Code Registry». Iana.org. Archived from the original on December 11, 2011. Retrieved January 8, 2015.
- ^ Fielding, Roy T. «RFC 9110: HTTP Semantics and Content, Section 10.1.1 «Expect»«.
- ^ Goland, Yaronn; Whitehead, Jim; Faizi, Asad; Carter, Steve R.; Jensen, Del (February 1999). HTTP Extensions for Distributed Authoring – WEBDAV. IETF. doi:10.17487/RFC2518. RFC 2518. Retrieved October 24, 2009.
- ^ «102 Processing — HTTP MDN». 102 status code is deprecated
- ^ Oku, Kazuho (December 2017). An HTTP Status Code for Indicating Hints. IETF. doi:10.17487/RFC8297. RFC 8297. Retrieved December 20, 2017.
- ^ Stewart, Mark; djna. «Create request with POST, which response codes 200 or 201 and content». Stack Overflow. Archived from the original on October 11, 2016. Retrieved October 16, 2015.
- ^ «RFC 9110: HTTP Semantics and Content, Section 15.3.4».
- ^ «RFC 9110: HTTP Semantics and Content, Section 7.7».
- ^ a b c d e Dusseault, Lisa, ed. (June 2007). HTTP Extensions for Web Distributed Authoring and Versioning (WebDAV). IETF. doi:10.17487/RFC4918. RFC 4918. Retrieved October 24, 2009.
- ^ Delta encoding in HTTP. IETF. January 2002. doi:10.17487/RFC3229. RFC 3229. Retrieved February 25, 2011.
- ^ a b «RFC 9110: HTTP Semantics and Content, Section 15.4 «Redirection 3xx»«.
- ^ Berners-Lee, Tim; Fielding, Roy T.; Nielsen, Henrik Frystyk (May 1996). Hypertext Transfer Protocol – HTTP/1.0. IETF. doi:10.17487/RFC1945. RFC 1945. Retrieved October 24, 2009.
- ^ «The GNU Taler tutorial for PHP Web shop developers 0.4.0». docs.taler.net. Archived from the original on November 8, 2017. Retrieved October 29, 2017.
- ^ «Google API Standard Error Responses». 2016. Archived from the original on May 25, 2017. Retrieved June 21, 2017.
- ^ «Sipgate API Documentation». Archived from the original on July 10, 2018. Retrieved July 10, 2018.
- ^ «Shopify Documentation». Archived from the original on July 25, 2018. Retrieved July 25, 2018.
- ^ «Stripe API Reference – Errors». stripe.com. Retrieved October 28, 2019.
- ^ «RFC2616 on status 413». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ «RFC2616 on status 414». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ «RFC2616 on status 416». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ TheDeadLike. «HTTP/1.1 Status Codes 400 and 417, cannot choose which». serverFault. Archived from the original on October 10, 2015. Retrieved October 16, 2015.
- ^ Larry Masinter (April 1, 1998). Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0). doi:10.17487/RFC2324. RFC 2324.
Any attempt to brew coffee with a teapot should result in the error code «418 I’m a teapot». The resulting entity body MAY be short and stout.
- ^ I’m a teapot
- ^ Barry Schwartz (August 26, 2014). «New Google Easter Egg For SEO Geeks: Server Status 418, I’m A Teapot». Search Engine Land. Archived from the original on November 15, 2015. Retrieved November 4, 2015.
- ^ «Google’s Teapot». Retrieved October 23, 2017.[dead link]
- ^ «Enable extra web security on a website». DreamHost. Retrieved December 18, 2022.
- ^ «I Went to a Russian Website and All I Got Was This Lousy Teapot». PCMag. Retrieved December 18, 2022.
- ^ a b c d Nottingham, M.; Fielding, R. (April 2012). «RFC 6585 – Additional HTTP Status Codes». Request for Comments. Internet Engineering Task Force. Archived from the original on May 4, 2012. Retrieved May 1, 2012.
- ^ Bray, T. (February 2016). «An HTTP Status Code to Report Legal Obstacles». ietf.org. Archived from the original on March 4, 2016. Retrieved March 7, 2015.
- ^ alex. «What is the correct HTTP status code to send when a site is down for maintenance?». Stack Overflow. Archived from the original on October 11, 2016. Retrieved October 16, 2015.
- ^ Holtman, Koen; Mutz, Andrew H. (March 1998). Transparent Content Negotiation in HTTP. IETF. doi:10.17487/RFC2295. RFC 2295. Retrieved October 24, 2009.
- ^ Nielsen, Henrik Frystyk; Leach, Paul; Lawrence, Scott (February 2000). An HTTP Extension Framework. IETF. doi:10.17487/RFC2774. RFC 2774. Retrieved October 24, 2009.
- ^ «Enum HttpStatus». Spring Framework. org.springframework.http. Archived from the original on October 25, 2015. Retrieved October 16, 2015.
- ^ «Twitter Error Codes & Responses». Twitter. 2014. Archived from the original on September 27, 2017. Retrieved January 20, 2014.
- ^ «HTTP Status Codes and SEO: what you need to know». ContentKing. Retrieved August 9, 2019.
- ^ «Screenshot of error page». Archived from the original (bmp) on May 11, 2013. Retrieved October 11, 2009.
- ^ a b «Using token-based authentication». ArcGIS Server SOAP SDK. Archived from the original on September 26, 2014. Retrieved September 8, 2014.
- ^ «HTTP Error Codes and Quick Fixes». Docs.cpanel.net. Archived from the original on November 23, 2015. Retrieved October 15, 2015.
- ^ «SSL Labs API v3 Documentation». github.com.
- ^ «Platform Considerations | Pantheon Docs». pantheon.io. Archived from the original on January 6, 2017. Retrieved January 5, 2017.
- ^ «HTTP status codes — ascii-code.com». www.ascii-code.com. Archived from the original on January 7, 2017. Retrieved December 23, 2016.
- ^
«Error message when you try to log on to Exchange 2007 by using Outlook Web Access: «440 Login Time-out»«. Microsoft. 2010. Retrieved November 13, 2013. - ^ «2.2.6 449 Retry With Status Code». Microsoft. 2009. Archived from the original on October 5, 2009. Retrieved October 26, 2009.
- ^ «MS-ASCMD, Section 3.1.5.2.2». Msdn.microsoft.com. Archived from the original on March 26, 2015. Retrieved January 8, 2015.
- ^ «Ms-oxdisco». Msdn.microsoft.com. Archived from the original on July 31, 2014. Retrieved January 8, 2015.
- ^ «The HTTP status codes in IIS 7.0». Microsoft. July 14, 2009. Archived from the original on April 9, 2009. Retrieved April 1, 2009.
- ^ «ngx_http_request.h». nginx 1.9.5 source code. nginx inc. Archived from the original on September 19, 2017. Retrieved January 9, 2016.
- ^ «ngx_http_special_response.c». nginx 1.9.5 source code. nginx inc. Archived from the original on May 8, 2018. Retrieved January 9, 2016.
- ^ «return» directive Archived March 1, 2018, at the Wayback Machine (http_rewrite module) documentation.
- ^ «Troubleshooting: Error Pages». Cloudflare. Archived from the original on March 4, 2016. Retrieved January 9, 2016.
- ^ «Error 520: web server returns an unknown error». Cloudflare.
- ^ «527 Error: Railgun Listener to origin error». Cloudflare. Archived from the original on October 13, 2016. Retrieved October 12, 2016.
- ^ «Error 530». Cloudflare. Retrieved November 1, 2019.
- ^ a b c d «Troubleshoot Your Application Load Balancers – Elastic Load Balancing». docs.aws.amazon.com. Retrieved May 17, 2023.
- ^ «Hypertext Transfer Protocol (HTTP/1.1): Caching». datatracker.ietf.org. Retrieved September 25, 2021.
- ^ «Warning — HTTP | MDN». developer.mozilla.org. Retrieved August 15, 2021.
 Some text was copied from this source, which is available under a Creative Commons Attribution-ShareAlike 2.5 Generic (CC BY-SA 2.5) license.
Some text was copied from this source, which is available under a Creative Commons Attribution-ShareAlike 2.5 Generic (CC BY-SA 2.5) license.
- ^ «RFC 9111: HTTP Caching, Section 5.5 «Warning»«. June 2022.
External links
- «RFC 9110: HTTP Semantics and Content, Section 15 «Status Codes»«.
- Hypertext Transfer Protocol (HTTP) Status Code Registry at the Internet Assigned Numbers Authority
- MDN status code reference at mozilla.org
Справочник ошибок и ответов API
При выполнении некорректного запроса к системе наше API может вернуть код ошибки, в случае же верного запроса, API вернёт ответ. Вы, конечно, уже обрабатывали ответ сервера в ходе отладки своих виджетов или написании скриптов, взаимодействующих с нашей системой. Для Вашего удобства, мы решили систематизировать все возможные ответы и ошибки, отдаваемые нашей системой и разместить их на отдельной странице. Надеемся это облегчит и ускорит интеграцию Ваших проектов с amoCRM.
Ошибки при валидации данных
Если переданные данные не совпадают с теми, что доступны для сущности, запрос вернет HTTP-код 400 Bad Request и массив с параметрами, которые не подошли под условия.
Пример ошибки валидации данных
{
"validation-errors": [
{
"request_id": "0",
"errors": [
{
"code": "NotSupportedChoice",
"path": "custom_fields_values.0.field_id",
"detail": "The value you selected is not a valid choice."
}
]
}
],
"title": "Bad Request",
"type": "https://httpstatus.es/400",
"status": 400,
"detail": "Request validation failed"
}
Ответы при авторизации
Подробнее об авторизации читайте здесь
| Код | HTTP код | Описание |
|---|---|---|
| 110 | 401 Unauthorized | Общая ошибка авторизации. Неправильный логин или пароль. |
| 111 | 401 Unauthorized | Возникает после нескольких неудачных попыток авторизации. В этом случае нужно авторизоваться в аккаунте через браузер, введя код капчи. |
| 112 | 401 Unauthorized | Возникает, когда пользователь выключен в настройках аккаунта “Пользователи и права” или не состоит в аккаунте. |
| 113 | 403 Forbidden | Доступ к данному аккаунту запрещён с Вашего IP адреса. Возникает, когда в настройках безопасности аккаунта включена фильтрация доступа к API по “белому списку IP адресов”. |
| 101 | 401 Unauthorized | Возникает в случае запроса к несуществующему аккаунту (субдомену). |
Ответы при работе с контактами
Подробнее о работе с контактами читайте здесь
| Код | Описание |
|---|---|
| 202 | Добавление контактов: нет прав |
| 203 | Добавление контактов: системная ошибка при работе с дополнительными полями |
| 205 | Добавление контактов: контакт не создан |
| 212 | Обновление контактов: контакт не обновлён |
| 219 | Список контактов: ошибка поиска, повторите запрос позднее |
| 330 | Добавление/Обновление контактов: количество привязанных сделок слишком большое |
Ответы при работе со сделками
Подробнее о работе со сделками читайте здесь
| Код | Описание |
|---|---|
| 330 | Добавление/Обновление сделок: количество привязанных контактов слишком большое |
Ответы при работе с событиями
Подробнее о работе с событиями читайте здесь
| Код | Описание |
|---|---|
| 244 | Добавление событий: недостаточно прав для добавления события |
| 225 | Обновление событий: события не найдены |
Ответы при работе с задачами
Подробнее о работе с задачами читайте здесь
| Код | Описание |
|---|---|
| 231 | Обновление задач: задачи не найдены |
| 233 | Добавление событий: по данному ID элемента не найдены некоторые контакты |
| 234 | Добавление событий: по данному ID элемента не найдены некоторые сделки |
| 235 | Добавление задач: не указан тип элемента |
| 236 | Добавление задач: по данному ID элемента не найдены некоторые контакты |
| 237 | Добавление задач: по данному ID элемента не найдены некоторые сделки |
| 244 | Добавление сделок: нет прав. |
Ответы при работе со списками
Подробнее о работе со списками читайте здесь
| Код | Описание |
|---|---|
| 244 | Добавление/Обновление/Удаление каталогов: нет прав. |
| 281 | Каталог не удален: внутренняя ошибка |
| 282 | Каталог не найден в аккаунте. |
Ответы при работе с элементами каталога
Подробнее о работе с элементами каталога читайте здесь
| Код | Описание |
|---|---|
| 203 | Добавление/Обновление элементов каталога: системная ошибка при работе с дополнительными полями |
| 204 | Добавление/Обновление элементов каталога: дополнительное поле не найдено |
| 244 | Добавление/Обновление/Удаление элементов каталога: нет прав. |
| 280 | Добавление элементов каталога: элемент создан. |
| 282 | Элемент не найден в аккаунте. |
Ответы при работе с покупателями
Подробнее о работе с покупателями читайте здесь
| Код | Описание |
|---|---|
| 288 | Недостаточно прав. Доступ запрещен. |
| 402 | Необходимо оплатить функционал |
| 425 | Функционал недоступен |
| 426 | Функционал выключен |
Другие ответы
Ошибки и ответы, не относящиеся к какому-либо конкретному разделу
| Код | Описание | Примечание |
|---|---|---|
| 400 | Неверная структура массива передаваемых данных, либо не верные идентификаторы кастомных полей | |
| 422 | Входящие данные не мог быть обработаны. | |
| 405 | Запрашиваемый HTTP-метод не поддерживается | |
| 402 | Подписка закончилась | Вместе с этим ответом отдаётся HTTP код №402 “Payment Required” |
| 403 | Аккаунт заблокирован, за неоднократное превышение количества запросов в секунду | Вместе с этим ответом отдаётся HTTP код №403 |
| 429 | Превышено допустимое количество запросов в секунду | Вместе с этим ответом отдаётся HTTP код №429 |
| 2002 | По вашему запросу ничего не найдено | Вместе с этим ответом отдаётся HTTP код №204 “No Content” |
HTTP status codes are like short notes from a server that get tacked onto a web page. They’re not actually part of the site’s content. Instead, they’re messages from the server letting you know how things went when it received the request to view a certain page.
These kinds of messages are returned every time your browser interacts with a server, even if you don’t see them. If you’re a website owner or developer, understanding HTTP status codes is critical. When they do show up, HTTP status codes are an invaluable tool for diagnosing and fixing website configuration errors.
This article introduces several server status and error codes, and explains what they reveal about what’s happening on the server behind the scenes.
Let’s dive in!
Prefer to watch the video version?
What Are HTTP Status Codes?
Every time you click on a link or type in a URL and press Enter, your browser sends a request to the webserver for the site you’re trying to access. The server receives and processes the request, and then sends back the relevant resources along with an HTTP header.
HTTP status codes are delivered to your browser in the HTTP header. While status codes are returned every single time your browser requests a web page or resource, most of the time you don’t see them.
It’s usually only when something goes wrong that you might see one displayed in your browser. This is the server’s way of saying: “Something isn’t right. Here’s a code that explains what went wrong.”

If you want to see the status codes that your browser doesn’t normally show you, there are many different tools that make it easy. Browser extensions are available for developer-friendly platforms such as Chrome and Firefox, and there are many web-based header fetching tools like Web Sniffer.
To see HTTP status codes with one of these tools, look for the line appearing near the top of the report that says “Status: HTTP/1.1”. This will be followed by the status code that was returned by the server.
Understanding HTTP Status Code Classes
HTTP status codes are divided into 5 “classes”. These are groupings of responses that have similar or related meanings. Knowing what they are can help you quickly determine the general substance of a status code before you go about looking up its specific meaning.
The five classes include:
- 100s: Informational codes indicating that the request initiated by the browser is continuing.
- 200s: Success codes returned when browser request was received, understood, and processed by the server.
- 300s: Redirection codes returned when a new resource has been substituted for the requested resource.
- 400s: Client error codes indicating that there was a problem with the request.
- 500s: Server error codes indicating that the request was accepted, but that an error on the server prevented the fulfillment of the request.
Within each of these classes, a variety of server codes exist and may be returned by the server. Each individual code has a specific and unique meaning, which we’ll cover in the more comprehensive list below.
Why HTTP Status Codes and Errors Matter for Search Engine Optimization (SEO)
Search engine bots see HTTP status codes while they’re crawling your site. In some cases, these messages can influence if and how your pages get indexed, as well as how search engines perceive the health of your site.
Generally speaking, 100- and 200-level HTTP status codes won’t have much impact on your SEO. They signal that everything is working as it should on your site, and enable search engine bots to continue on their way. However, they aren’t going to boost your rankings either.
For the most part, it’s the higher-level codes that matter for SEO. 400- and 500-level responses can prevent bots from crawling and indexing your pages. Too many of these errors can also indicate that your site isn’t of high quality, possibly lowering your rankings.
300-level codes have a bit more complicated relationship with SEO. The main thing you need to know to understand their impact is the difference between permanent and temporary redirects, which we’ll cover in more detail in the relevant section below.
In a nutshell, however, permanent redirects share link equity from backlinks, but temporary ones do not. In other words, when you use temporary redirects for pages that have moved, you lose the SEO advantage of all the link building you’ve done.
Checking for HTTP Status Codes in Google Search Console
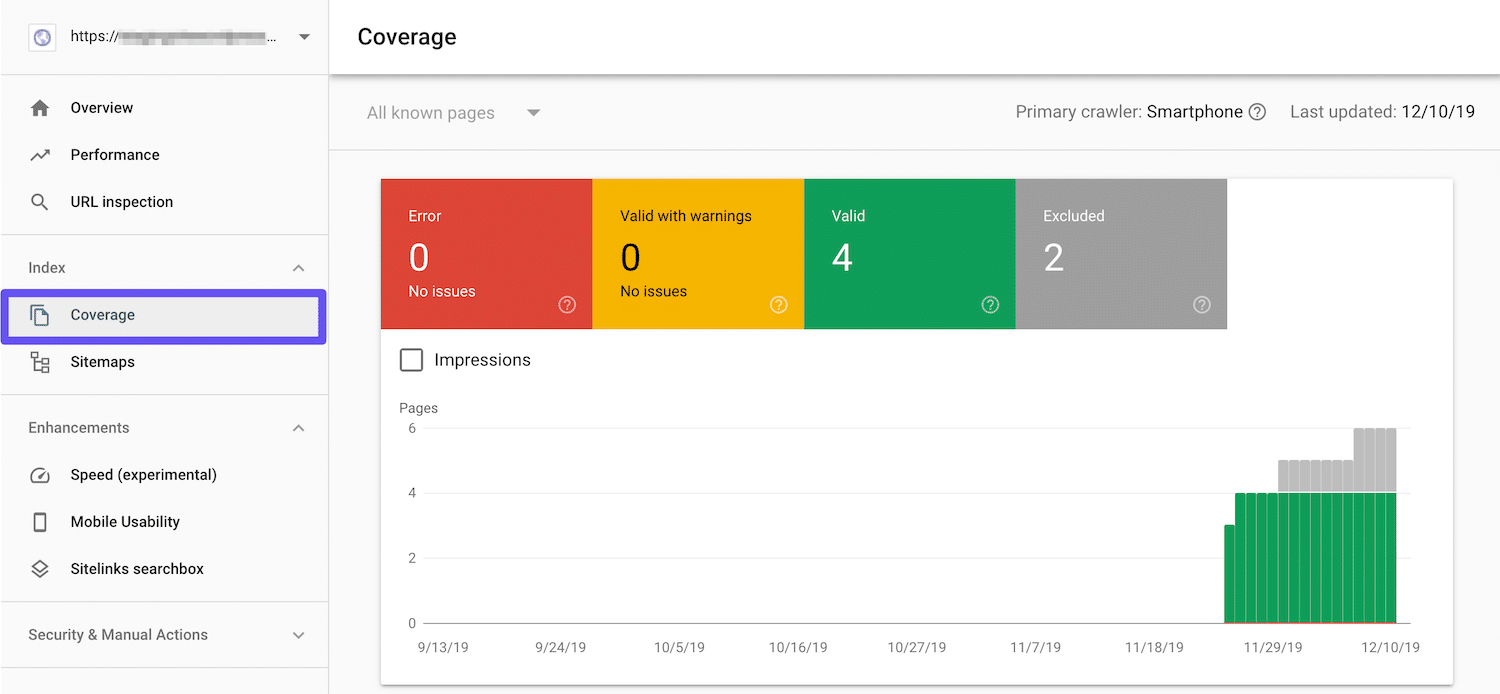
One way to monitor how Google perceives the HTTP status codes on your site is to use Google Search Console. You can view 300-, 400-, and 500-level status codes in the Coverage report:
This area of your dashboard shows four types of content on your site:
- Pages that return errors.
- Valid pages that have warnings.
- Resources that are valid.
- Content excluded from the index.
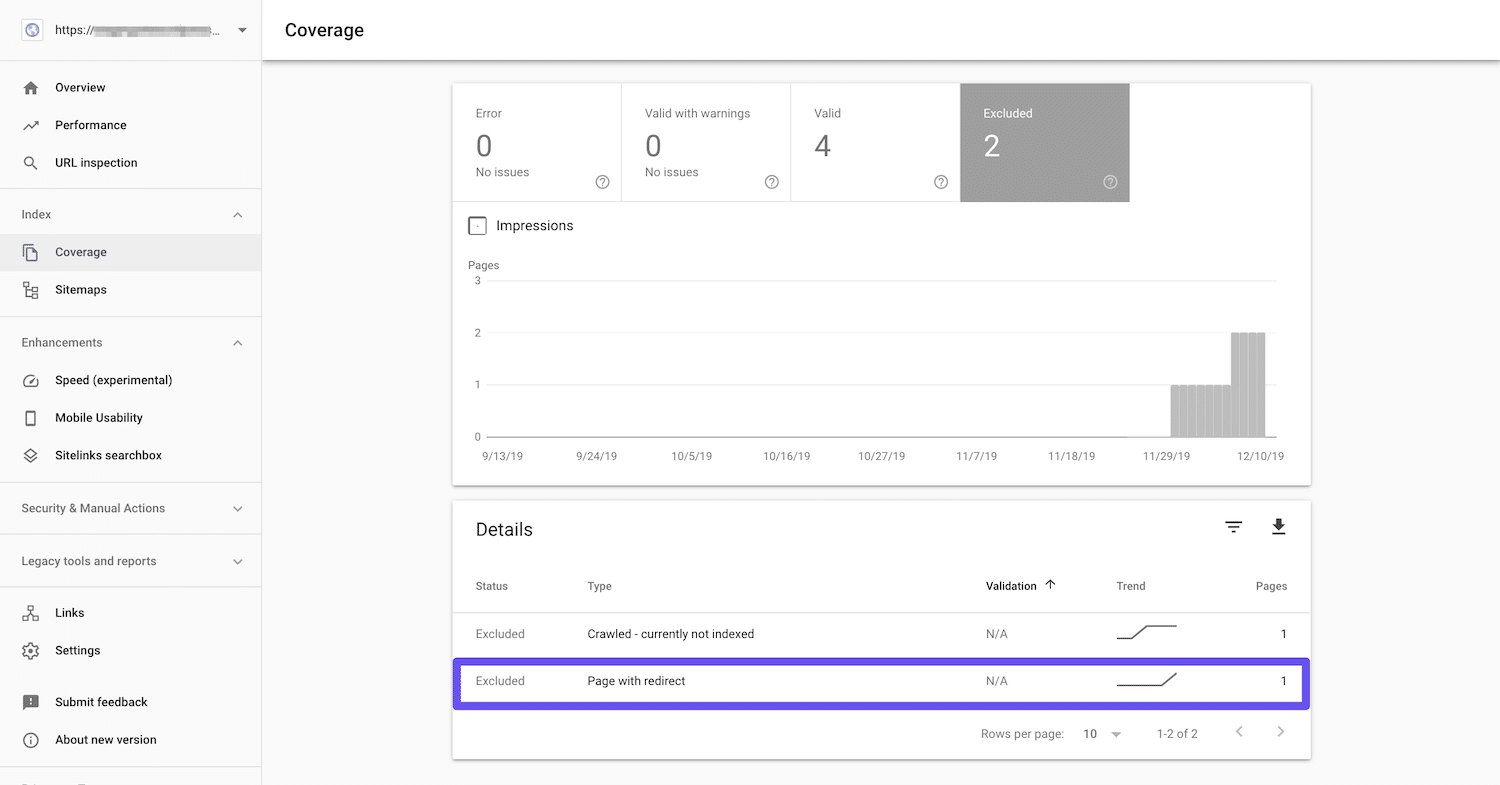
You may find pages with 300-, 400-, and 500-level HTTP status codes under the Excluded, Error, or Valid with warnings sections, depending on the type of code. For instance, 301 redirects may be listed under Excluded as Page with redirect:
400- and 500-level status codes will likely turn up under Error.
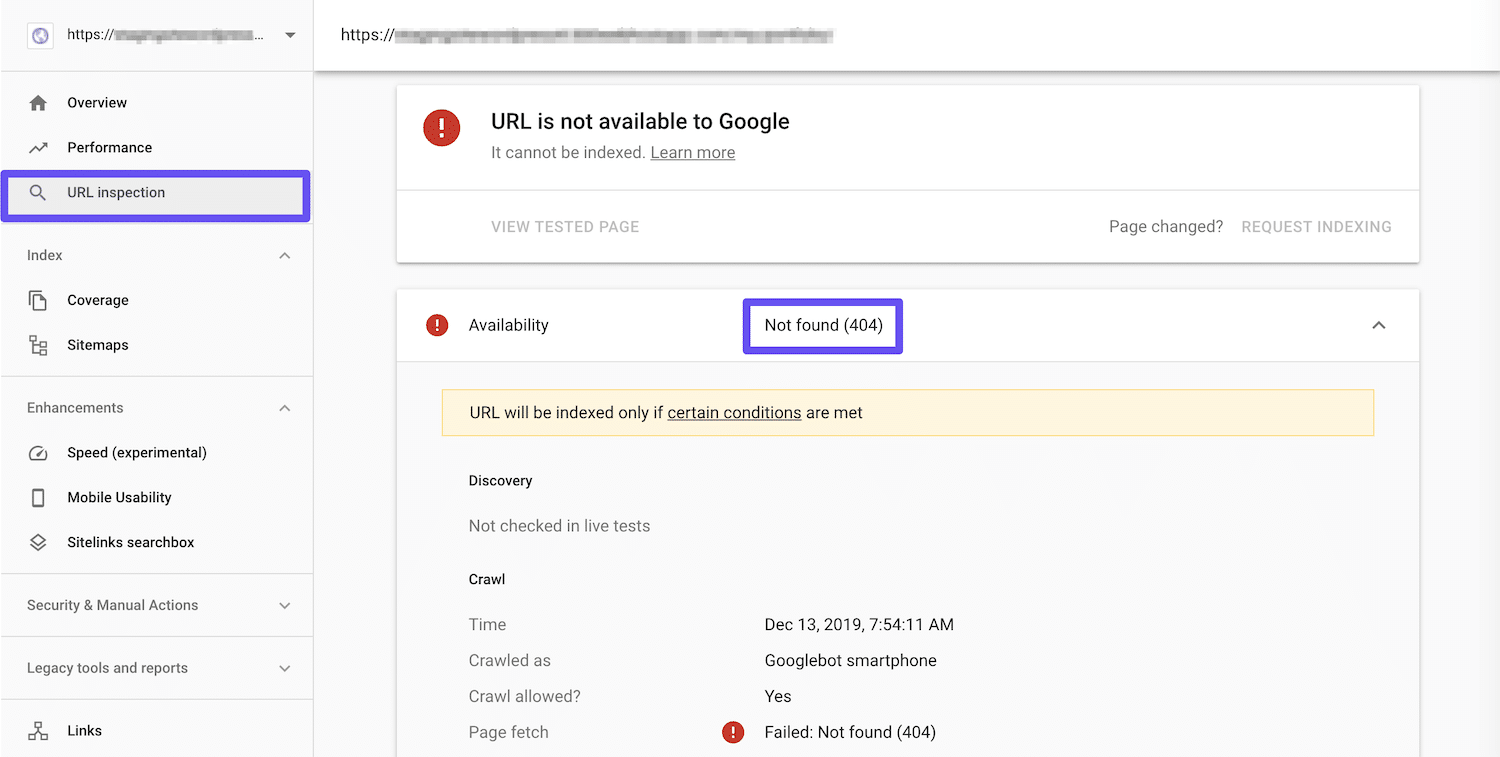
Another way to view HTTP status codes is by using the URL Inspection tool. If Google is unable to index a specific page due to an error, you’ll see that here:
For more tips on using Google Search Console, check out our comprehensive guide to the platform.
A Complete Guide and List of HTTP Status Codes
While there are over 40 different server status codes, you’ll likely encounter fewer than a dozen on a regular basis. Below, we’ve covered the more common ones, as well as a few of the more obscure codes you may still run across.
100 Status Codes
A 100-level status code tells you that the request you’ve made to the server is still in progress for some reason. This isn’t necessarily a problem, it’s just extra information to let you know what’s going on.
- 100: “Continue.” This means that the server in question has received your browser’s request headers, and is now ready for the request body to be sent as well. This makes the request process more efficient since it prevents the browser from sending a body request even though the headers have been rejected.
- 101: “Switching protocols.” Your browser has asked the server to change protocols, and the server has complied.
- 103: “Early hints.” This returns some response headers before the rest of the server’s response is ready.
200 Status Codes
This is the best kind of HTTP status code to receive. A 200-level response means that everything is working exactly as it should.
- 200: “Everything is OK.” This is the code that is delivered when a web page or resource acts exactly the way it’s expected to.
- 201: “Created.” The server has fulfilled the browser’s request, and as a result, has created a new resource.
- 202: “Accepted.” The server has accepted your browser’s request but is still processing it. The request ultimately may or may not result in a completed response.
- 203: “Non-Authoritative Information.” This status code may appear when a proxy is in use. It means that the proxy server received a 200 “Everything is OK” status code from the origin server, but has modified the response before passing it on to your browser.
- 204: “No Content.” This code means that the server has successfully processed the request, but is not going to return any content.
- 205: “Reset Content.” Like a 204 code, this means that how server has processed the request but is not going to return any content. However, it also requires that your browser resets the document view.
- 206: “Partial Content.” You may see this status code if your HTTP client (also known as your browser) uses ‘range headers’. This enables your browser to resume paused downloads, as well as to split a download into multiple streams. A 206 code is sent when a range header causes the server to send only part of the requested resource.
300 Status Codes
Redirection is the process used to communicate that a resource has been moved to a new location. There are several HTTP status codes that accompany redirections, in order to provide visitors with information about where to find the content they’re looking for.
- 300: “Multiple Choices.” Sometimes, there may be multiple possible resources the server can respond with to fulfill your browser’s request. A 300 status code means that your browser now needs to choose between them. This may occur when there are multiple file type extensions available, or if the server is experiencing word sense disambiguation.
- 301: “The requested resource has been moved permanently.” This code is delivered when a web page or resource has been permanently replaced with a different resource. It is used for permanent URL redirection.
- 302: “The requested resource has moved, but was found.” This code is used to indicate that the requested resource was found, just not at the location where it was expected. It is used for temporary URL redirection.
- 303: “See Other.” Understanding a 303 status code requires that you know the difference between the four primary HTTP request methods. Essentially, a 303 code tells your browser that it found the resource your browser requested via POST, PUT, or DELETE. However, to retrieve it using GET, you need to make the appropriate request to a different URL than the one you previously used.
- 304: “The requested resource has not been modified since the last time you accessed it.” This code tells the browser that the resources stored in the browser cache haven’t changed. It’s used to speed up web page delivery by reusing previously-downloaded resources.
- 307: “Temporary Redirect.” This status code has replaced 302 “Found” as the appropriate action when a resource has been temporarily moved to a different URL. Unlike the 302 status code, it does not allow the HTTP method to change.
- 308: “Permanent Redirect.” The 308 status code is the successor to the 301 “Moved Permanently” code. It does not allow the HTTP method to change and indicates that the requested resource is now permanently located at a new URL.
400 Status Codes
At the 400 level, HTTP status codes start to become problematic. These are error codes specifying that there’s a fault with your browser and/or request.
- 400: “Bad Request.” The server can’t return a response due to an error on the client’s end. See our guide for resolving this error.
- 401: “Unauthorized” or “Authorization Required.” This is returned by the server when the target resource lacks valid authentication credentials. You might see this if you’ve set up basic HTTP authentication using htpasswd.
- 402: “Payment Required.” Originally, this code was created for use as part of a digital cash system. However, that plan never followed through. Instead, it’s used by a variety of platforms to indicate that a request cannot be fulfilled, usually due to a lack of required funds. Common instances include:
- You’ve reached your daily request limit to the Google Developers API.
- You haven’t paid your Shopify fees and your store has been temporarily deactivated.
- Your payment via Stripe has failed, or Stripe is trying to prevent a fraudulent payment.
- 403: “Access to that resource is forbidden.” This code is returned when a user attempts to access something that they don’t have permission to view. For example, trying to reach password-protected content without logging in might produce a 403 error.
- 404: “The requested resource was not found.” This is the most common error message of them all. This code means that the requested resource does not exist, and the server does not know if it ever existed.
- 405: “Method not allowed.” This is generated when the hosting server (origin server) supports the method received, but the target resource doesn’t.
- 406: “Not acceptable response.” The requested resource is capable of generating only content that is not acceptable according to the accept headers sent in the request.
- 407: “Proxy Authentication Required.” A proxy server is in use and requires your browser to authenticate itself before continuing.
- 408: “The server timed out waiting for the rest of the request from the browser.” This code is generated when a server times out while waiting for the complete request from the browser. In other words, the server didn’t get the full request that was sent by the browser. One possible cause could be net congestion resulting in the loss of data packets between the browser and the server.
- 409: “Conflict.” A 409 status code means that the server couldn’t process your browser’s request because there’s a conflict with the relevant resource. This sometimes occurs due to multiple simultaneous edits.
- 410: “The requested resource is gone and won’t be coming back.” This is similar to a 404 “Not Found” code, except a 410 indicates that the condition is expected and permanent.
- 411: “Length Required.” This means that the requested resource requires that the client specify a certain length and that it did not.
- 412: “Precondition Failed.” Your browser included certain conditions in its request headers, and the server did not meet those specifications.
- 413: “Payload Too Large” or “Request Entity Too Large.” Your request is larger than the server is willing or able to process.
- 414: “URI Too Long.” This is usually the result of a GET request that has been encoded as a query string that is too large for the server to process.
- 415: “Unsupported Media Type.” The request includes a media type that the server or resource doesn’t support.
- 416: “Range Not Satisfiable.” Your request was for a portion of a resource that the server is unable to return.
- 417: “Expectation Failed.” The server is unable to meet the requirements specified in the request’s expect header field.
- 418: “I’m a teapot.” This code is returned by teapots that receive requests to brew coffee. It’s also an April Fool’s Joke from 1998.

- 422: “Unprocessable Entity.” The client request contains semantic errors, and the server can’t process it.
- 425: “Too Early.” This code is sent when the server is unwilling to process a request because it may be replayed.
- 426: “Upgrade Required.” Due to the contents of the request’s upgrade header field, the client should switch to a different protocol.
- 428: “Precondition Required.” The server requires conditions to be specified before processing the request.
- 429: “Too many requests.” This is generated by the server when the user has sent too many requests in a given amount of time (rate-limiting). This can sometimes occur due to bots or scripts attempting to access your site. In this case, you might want to try changing your WordPress login URL. You can also check out our guide to fixing a 429 “Too Many Requests” error.
- 431: “Request Header Fields Too Large.” The server can’t process the request because the header fields are too large. This may indicate a problem with a single header field, or all of them collectively.
- 451: “Unavailable for Legal Reasons.” The operator of the server has received a demand to prohibit access to the resource you’ve requested (or a set of resources including the one you’ve requested). Fun fact: This code is a reference to Ray Bradbury’s novel Fahrenheit 451.
- 499: “Client closed request.” This is returned by NGINX when the client closes the request while Nginx is still processing it.
500 Status Codes
500-level status codes are also considered errors. However, they denote that the problem is on the server’s end. This can make them more difficult to resolve.
- 500: “There was an error on the server and the request could not be completed.” This is generic code that simply means “internal server error”. Something went wrong on the server and the requested resource was not delivered. This code is typically generated by third-party plugins, faulty PHP, or even the connection to the database breaking. Check out our tutorials on how to fix the error establishing a database connection and other ways to resolve a 500 internal server error.
- 501: “Not Implemented.” This error indicates that the server does not support the functionality required to fulfill the request. This is almost always a problem on the web server itself, and usually must be resolved by the host. Check out our recommendations on how to resolve a 501 not implemented error.
- 502: “Bad Gateway.” This error code typically means that one server has received an invalid response from another, such as when a proxy server is in use. Other times a query or request will take too long, and so it is canceled or killed by the server and the connection to the database breaks. For more details, see our in-depth tutorial on how to fix the 502 Bad Gateway error.
- 503: “The server is unavailable to handle this request right now.” The request cannot be completed at this point in time. This code may be returned by an overloaded server that is unable to handle additional requests. We have a full guide on how to fix the 503 Service Unavailable Error.
- 504: “The server, acting as a gateway, timed out waiting for another server to respond.” This is the code returned when there are two servers involved in processing a request, and the first server times out waiting for the second server to respond. You can read more about how to fix 504 errors in our dedicated guide.
- 505: “HTTP Version Not Supported.” The server doesn’t support the HTTP version the client used to make the request.
- 508: “Resource Limit Is Reached” limits on resources set by your web host have been reached. Check out our tutorial on how to resolve “508 Resource Limit Is Reached” error.
- 509: “Bandwidth Limit Exceeded” means your website is using more bandwidth than your hosting provider allows.
- 511: “Network Authentication Required.” This status code is sent when the network you’re trying to use requires some form of authentication before sending your request to the server. For instance, you may need to agree to the Terms and Conditions of a public Wi-Fi hotspot.
- 521: “Web server is down.” Error 521 is a Cloudflare-specific error message. It means that your web browser was able to successfully connect to Cloudflare, but Cloudflare was not able to connect to the origin web server.
- 525: “SSL Handshake Failed“. Error 525 means that the SSL handshake between a domain using Cloudflare and the origin web server failed. If you are experiencing issues there are five methods you can try to easily fix error 525.
Where to Learn More About HTTP Status Codes
In addition to the HTTP status codes we’ve covered in this list, there are some more obscure ones you may want to learn about. There are several resources you can consult to read up on these rarer codes, including:
- This comprehensive list of HTTP status codes from Wikipedia.
- Status code definitions from the Internet Engineering Task Force (IETF).
- RFC 7231.
Knowing these status codes may help you resolve some unique issues while maintaining your own website, or even when you encounter them on other sites.
They might seem intimidating at first, but HTTP status codes are important to understand what’s happening on your site. Here’s a thorough list of those you should get familiar with! 📟🌐Click to Tweet
Summary
While they may seem confusing or intimidating on the surface, HTTP status codes are actually very informative. By learning some of the common ones, you can troubleshoot problems on your site more quickly.
In this post, we’ve defined 40+ HTTP status codes that you may encounter. From the milder 100- and 200-level codes to the trickier 400- and 500-level errors, making sense of these messages is crucial for maintaining your website and making sure it’s accessible to users.
Время на прочтение
6 мин
Количество просмотров 15K
Почти все разработчики так или иначе постоянно работают с api по http, клиентские разработчики работают с api backend своего сайта или приложения, а бэкендеры «дергают» бэкенды других сервисов, как внутренних, так и внешних. И мне кажется, одна из самых главных вещей в хорошем API это формат передачи ошибок. Ведь если это сделано плохо/неудобно, то разработчик, использующий это API, скорее всего не обработает ошибки, а клиенты будут пользоваться молчаливо ломающимся продуктом.
За 7 лет я как поддерживал множество legacy API, так и разрабатывал c нуля. И я поработал, наверное, с большинством стратегий по возвращению ошибок, но каждая из них создавала дискомфорт в той или иной мере. В последнее время я нащупал оптимальный вариант, о котором и хочу рассказать, но с начала расскажу о двух наиболее популярных вариантах.
№1: HTTP статусы
Если почитать апологетов REST, то для кодов ошибок надо использовать HTTP статусы, а текст ошибки отдавать в теле или в специальном заголовке. Например:
Success:
HTTP 200 GET /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 404 GET /v1/user/1
Body: 'Не найден пользователь'Если у вас примитивная бизнес-логика или API из 5 url, то в принципе это нормальный подход. Однако как-только бизнес-логика станет сложнее, то начнется ряд проблем.
Http статусы предназначались для описания ошибок при передаче данных, а про логику вашего приложения никто не думал. Статусов явно не хватает для описания всего разнообразия ошибок в вашем проекте, да они и не были для этого предназначены. И тут начинается натягивание «совы на глобус»: все начинают спорить, какой статус ошибки дать в том или ином случае. Пример: Есть API для task manager. Какой статус надо вернуть в случае, если пользователь хочет взять задачу, а ее уже взял в работу другой пользователь? Ссылка на http статусы. И таких проблемных примеров можно придумать много.
REST скорее концепция, чем формат общения из чего следует неоднозначность использования статусов. Разработчики используют статусы как им заблагорассудится. Например, некоторые API при отсутствии сущности возвращают 404 и текст ошибки, а некоторые 200 и пустое тело.
Бэкенд разработчику в проекте непросто выбрать статус для ошибки, а клиентскому разработчику неочевидно какой статус предназначен для того или иного типа ошибок бизнес-логики. По-хорошему в проекте придется держать enum для того, чтобы описать какие ошибки относятся к тому или иному статусу.
Когда бизнес-логика приложения усложняется, начинают делать как-то так:
HTTP 400 PUT /v1/task/1 { status: 'doing' }
Body: { error_code: '12', error_message: 'Задача уже взята другим исполнителем' }
Из-за ограниченности http статусов разработчики начинают вводить “свои” коды ошибок для каждого статуса и передавать их в теле ответа. Другими словами, пользователю API приходится писать нечто подобное:
if (status === 200) {
// Success
} else if (status === 500) {
// some code
} else if (status === 400) {
if (body.error_code === 1) {
// some code
} else if (body.error_code === 2) {
// some code
} else {
// some code
}
} else if (status === 404) {
// some code
} else {
// some code
}Из-за этого ветвление клиентского кода начинает стремительно расти: множество http статусов и множество кодов в самом сообщении. Для каждого ошибочного http статуса необходимо проверить наличие кодов ошибок в теле сообщения. От комбинаторного взрыва начинает конкретно пухнуть башка! А значит обработку ошибок скорее всего сведут к сообщению типа “Произошла ошибка” или к молчаливому некорректному поведению.
Многие системы мониторинга сервисов привязываются к http статусам, но это не помогает в мониторинге, если статусы используются для описания ошибок бизнес логики. Например, у нас резкий всплеск ошибок 429 на графике. Это началась DDOS атака, или кто-то из разработчиков выбрал неудачный статус?
Итог: Начать с таким подходом легко и просто и для простого API это вполне подойдет. Но если логика стала сложнее, то использование статусов для описания того, что не укладывается в заданные рамки протокола http приводит к неоднозначности использования и последующим костылям для работы с ошибками. Или что еще хуже к формализму, что ведет к неприятному пользовательскому опыту.
№2: На все 200
Есть другой подход, даже более старый, чем REST, а именно: на все ошибки связанные с бизнес-логикой возвращать 200, а уже в теле ответа есть информация об ошибке. Например:
Вариант 1:
Success:
HTTP 200 GET /v1/user/1
Body: { ok: true, data: { name: 'Вася' } }
Error:
HTTP 200 GET /v1/user/1
Body: { ok: false, error: { code: 1, msg: 'Не найден пользователь' } }Вариант 2:
Success:
HTTP 200 GET /v1/user/1
Body: { data: { name: 'Вася' }, error: null }
Error:
HTTP 200 GET /v1/user/1
Body: { data: null, error: { code: 1, msg: 'Не найден пользователь' } }
На самом деле формат зависит от вас или от выбранной библиотеки для реализации коммуникации, например JSON-API.
Звучит здорово, мы теперь отвязались от http статусов и можем спокойно ввести свои коды ошибок. У нас больше нет проблемы “впихнуть невпихуемое”. Выбор нового типа ошибки не вызывает споров, а сводится просто к введению нового числового номера (например, последовательно) или строковой константы. Например:
module.exports = {
NOT_FOUND: 1,
VALIDATION: 2,
// ….
}
module.exports = {
NOT_FOUND: ‘NOT_AUTHORIZED’,
VALIDATION: ‘VALIDATION’,
// ….
}
Клиентские разработчики просто основываясь на кодах ошибок могут создать классы/типы ошибок и притом не бояться, что сервер вернет один и тот же код для разных типов ошибок (из-за бедности http статусов).
Обработка ошибок становится менее ветвящейся, множество http статусов превратились в два: 200 и все остальные (ошибки транспорта).
if (status === 200) {
if (body.error) {
var error = body.error;
if (error.code === 1) {
// some code
} else if (error.code === 2) {
// some code
} else {
// some code
}
} else {
// Success
}
} else {
// transport erros
}
В некоторых случаях, если есть библиотека десериализации данных, она может взять часть работы на себя. Писать SDK вокруг такого подхода проще нежели вокруг той или иной имплементации REST, ведь реализация зависит от того, как это видел автор. Кроме того, теперь никто не вызовет случайное срабатывание alert в мониторинге из-за того, что выбрал неудачный код ошибки.
Но неудобства тоже есть:
-
Избыточность полей при передаче данных, т.е. нужно всегда передавать 2 поля: для данных и для ошибки. Это усложняет чтение логов и написание документации.
-
При использовании средств отладки (Chrome DevTools) или других подобных инструментов вы не сможете быстро найти ошибочные запросы бизнес логики, придется обязательно заглянуть в тело ответа (ведь всегда 200)
-
Мониторинг теперь точно будет срабатывать только на ошибки транспорта, а не бизнес-логики, но для мониторинга логики надо будет дописывать парсинг тела сообщения.
В некоторых случаях данный подход вырождается в RPC, то есть по сути вообще отказываются от использования url и шлют все на один url методом POST, а в теле сообщения передают все параметры. Мне кажется это не правильным, ведь url это прекрасный именованный namespace, зачем от этого отказываться, не понятно?! Кроме того, RPC создает проблемы:
-
нельзя кэшировать по http GET запросы, так как замешали чтение и запись в один метод POST
-
нельзя делать повторы для неудавшихся GET запросов (на backend) на реверс-прокси (например, nginx) по указанной выше причине
-
имеются проблемы с документированием – swagger и ApiDoc не подходят, а удобных аналогов я не нашел
Итог: Для сложной бизнес-логики с большим количеством типов ошибок такой подход лучше, чем расплывчатый REST, не зря в проектах c “разухабистой” бизнес-логикой часто именно такой подход и используют.
№3: Смешанный
Возьмем лучшее от двух миров. Мы выберем один http статус, например, 400 или 422 для всех ошибок бизнес-логики, а в теле ответа будем указывать код ошибки или строковую константу. Например:
Success:
HTTP 200 /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 400 /v1/user/1
Body: { error: { code: 1, msg: 'Не найден пользователь' } }Коды:
-
200 – успех
-
400 – ошибка бизнес логики
-
остальное ошибки в транспорте
Тело ответа для удачного запроса у нас имеет произвольную структуру, а вот для ошибки есть четкая схема. Мы избавляемся от избыточности данных (поле ошибки/данных) благодаря использованию http статуса в сравнении со вторым вариантом. Клиентский код упрощается в плане обработки ошибки (в сравнении с первым вариантом). Также мы снижаем его вложенность за счет использования отдельного http статуса для ошибок бизнес логики (в сравнении со вторым вариантом).
if (status === 200) {
// Success
} else if (status === 400) {
if (body.error.code === 1) {
// some code
} else if (body.error.code === 2) {
// some code
} else {
// some code
}
} else {
// transport erros
}
Мы можем расширять объект ошибки для детализации проблемы, если хотим. С мониторингом все как во втором варианте, дописывать парсинг придется, но и риска “стрельбы” некорректными alert нету. Для документирования можем спокойно использовать Swagger и ApiDoc. При этом сохраняется удобство использования инструментов разработчика, таких как Chrome DevTools, Postman, Talend API.
Итог: Использую данный подход уже в нескольких проектах, где множество типов ошибок и все крайне довольны, как клиентские разработчики, так и бэкендеры. Внедрение новой ошибки не вызывает споров, проблем и противоречий. Данный подход объединяет преимущества первого и второго варианта, при этом код более читабельный и структурированный.
Самое главное какой бы формат ошибок вы бы не выбрали лучше обговорить его заранее и следовать ему. Если эту вещь пустить на “самотек”, то очень скоро обработка ошибок в проекте станет невыносимо сложной для всех.
P.S. Иногда ошибки любят передавать массивом
{ error: [{ code: 1, msg: 'Не найден пользователь' }] }Но это актуально в основном в двух случаях:
-
Когда наш API выступает в роли сервиса без фронтенда (нет сайта/приложения). Например, сервис платежей.
-
Когда в API есть url для загрузки какого-нибудь длинного отчета в котором может быть ошибка в каждой строке/колонке. И тогда для пользователя удобнее, чтобы ошибки в приложении сразу показывались все, а не по одной.
В противном случае нет особого смысла закладываться сразу на массив ошибок, потому что базовая валидация данных должна происходить на клиенте, зато код упрощается как на сервере, так и на клиенте. А user-experience хакеров, лезущих напрямую в наше API, не должен нас волновать?HTTP