
TLDR;
Mysql can’t restart because it’s out of memory, check that you have an appropriate swapfile configured.
Didn’t help? If that’s not your issue, more qualified questions to continue research are:
- mysqld service stops once a day on ec2 server
- https://askubuntu.com/questions/422037/optimising-mysql-settings-mysqld-running-out-of-memory
Background
I had exactly this problem on the very first system I set up on EC2, characterised by the wordpress site hosted there going down on occasion with «Error establishing database connection».
The logs showed the same error that the OP posted. My reading of the error (timestamps removed) is:
- Out of memory error:
InnoDB: Fatal error: cannot allocate memory for the buffer pool
- InnoDB can’t start without enough memory
[ERROR] Plugin 'InnoDB' init function returned error.
[ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed.
[ERROR] Unknown/unsupported storage engine: InnoDB
[ERROR] Aborting
- mysqld is shutting down, which in this context, really means failing to restart!
[Note] /usr/sbin/mysqld: Shutdown complete
Checking /var/log/syslog and searching for mysql yields:
Out of memory: Kill process 15452 (mysqld) score 93 or sacrifice child
Killed process 15452 (mysqld) total-vm:888672kB, anon-rss:56252kB, file-rss:0kB
init: mysql main process (15452) killed by KILL signal
init: mysql main process ended, respawning
type=1400 audit(1443812767.391:30): apparmor="STATUS" operation="profile_replace" name="/usr/sbin/mysqld" pid=21984 comm="apparmor_parser"
init: mysql main process (21996) terminated with status 1
init: mysql main process ended, respawning
init: mysql post-start process (21997) terminated with status 1
<repeated>
Note: you may have to gunzip and search through archived logs if the error occurred before the logs were rotated by cron.
Solution
In my case the underlying issue was that I’d neglected to configure a swapfile.
You can check to see if you have one configured by running free -m.
total used free shared buffers cached
Mem: 604340 587364 16976 0 29260 72280
-/+ buffers/cache: 485824 118516
Swap: 0 0 0
In the example above, Swap: 0 indicates no swapfile.
Tutorials on setting one up:
- https://www.digitalocean.com/community/tutorials/how-to-add-swap-on-ubuntu-14-04
- https://help.ubuntu.com/community/SwapFaq
Note that bigger is not necessarily better! From the Ubuntu guide:
The «diminishing returns» means that if you need more swap space than twice your RAM size, you’d better add more RAM as Hard Disk Drive (HDD) access is about 10³ slower then RAM access, so something that would take 1 second, suddenly takes more then 15 minutes! And still more then a minute on a fast Solid State Drive (SSD)…
Regarding the other answers here…
The InnoDB memory heap is disabled
This isn’t really an error, just an indication that InnoDB is using the system’s internal memory allocator instead of its own. The default is yes/1, and is acceptable for production.
According to the docs, this command is deprecated, and will be removed in MySQL versions above 5.6 (and I assume MariaDB):
http://dev.mysql.com/doc/refman/5.6/en/innodb-performance-use_sys_malloc.html
Thanks to: Ruben Schade comment
[Note] Plugin 'FEDERATED' is disabled.
The message about FEDERATED disabled is not an error. It just meant that the FEDERATED engine its not ON for your mysql server. It’s not used by default. If you don’t need it, don’t care about this message.
See: https://stackoverflow.com/a/16470822/2586761
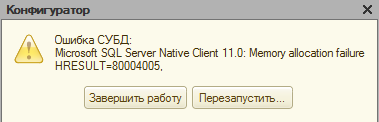
Пользуясь базами данных любой программы 1С, сотрудники предприятий и организаций часто сталкиваются с непредвиденными ситуациями. Пожалуй, одна из самых частых — когда работа программы внезапно завершается по причине того, что администратор разорвал контакт с сервером.
В данном случае Microsoft OLE DB Provider for SQL Server выдаёт такую информацию: «Неопознанная ошибка hresult 80004005». При этом главным признаком проблемы является невозможность выгрузить информацию в базу.
Следует отметить, что ошибки, содержащие именно код 80004005, встречаются постоянно. У них есть особая классификация, которую при желании можно найти в соответствующей литературе.
Для начала нужно провести проверку конфигурации. Там может содержаться мусор (иными, словами, информация, которая является некорректной). Необходимо проверить конфигурацию с помощью соответствующей команды. Вы увидите флажок, предназначенный для того, чтобы проверить её логическую целостность. Если имеются проблемы, пользователь будет уведомлен об этом с помощью сообщения.
Данные, являющиеся неверными, система удалит в автоматическом режиме, но для этого нужно дать ей доступ, чтобы она изменила главный объект. К примеру, если вы работаете в облачном хранилище, его надо просто захватить.
Поддержка конфигурации требует её проверки и у поставщиков. С этой целью:
- нужно сохранить данные о конфигурации поставщиков. Для этого используйте CF-файл;
- теперь необходимо провести загрузку файла в обновлённую базу;
- выполните операцию, которая описана в п.1.
При получении сообщения об исправлении ошибки имейте в виду то, что конфигурация, имеющаяся у поставщика, содержала неправильные данные. Если такое произошло, снимите свою конфигурацию с поддержки и установите её снова. При этом её надо объединить с новой (от поставщика).
Сейчас уже любой релиз, который выпускает 1С, не имеет таких сложностей.
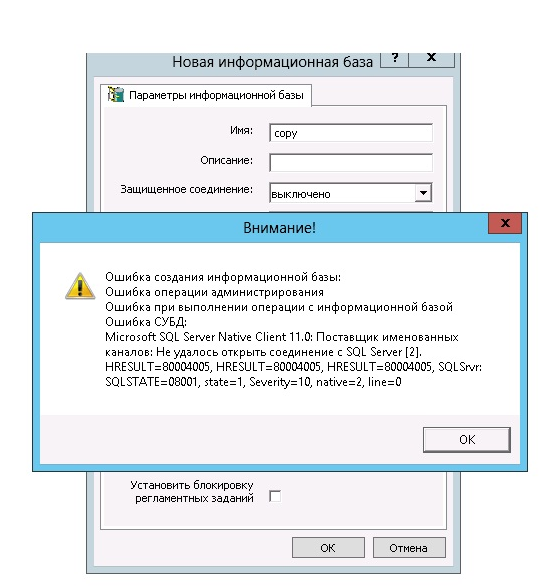
Сопутствующая проблема и методы её решения
С ситуацией, описанной ранее, тесно связана ещё одна, происходящая параллельно. Выглядит она так: 10007066.
Суть проблемы: когда используется СУБД MS SQL SERVER, во время записи объекта из базы с несколькими колонками (например, «Значения» и «Хранилища»), часто случается другой тип ошибки.
Выглядит она таким образом:
Ошибка СУБД:Microsoft OLE DB Provider for SQL Server: String data length mismatchHRESULT=80004005.
Когда происходит ошибка 1с hresult clr 80004005, программа завершает свою работу в аварийном режиме.
Если вы ознакомитесь во время загрузки программы со специальным журналом (речь идёт о технологическом журнале), там есть табличка, содержащая информацию об этих хранилищах.
С помощью средств MS SQL Server Query Analizer нужно найти в табличке несколько колонок image и сделать для каждой следующий запрос
select top 10 DATALENGTH(_Fld4044 from _InfoReg4038 order by DATALENGTH(_Fld4044) desc
При этом, со стороны стандартных проверок, проводимых платформой (chdbfl), поступит информация о том, что база полностью в порядке.
Ошибка выделения памяти hresult 80004005 (на английском это out of memory for query result 1с) может происходить вследствие различных причин, имеющей общую черту. Для системы 1С это, прежде всего, недостаток оперативной памяти. Если говорить точнее, речь идёт о некорректном применении возможностей памяти, поэтому для решения задачи лучше использовать несколько косвенных алгоритмов.
Необходимо сделать рестарт (перезапуск) сервера. Таким образом памяти, которая доступна для работы, временно станет больше. Также есть возможность воспользоваться сервером в 64 разряда, содержащем приложения.
Исходя из опыта, ошибка СУБД hresult 80004005 чаще определяется двумя факторами:
- данные хранятся в хранилище значений (реквизите);
- в таблице конфигураций содержатся двоичные данные объёмом более 120 мегабайт.
Когда советы от сотрудников 1С не приносят результата (ошибка 1с hresult 80004005 остаётся), попробуйте воспользоваться другой пошаговой инструкцией:
Наши постоянные клиенты по 1С:









- используйте все базы, включив у них все фоновые задачи;
- в 8.1.11. должен появиться переключатель о запрете на фоновые задачи (во время создания базы);
- сделайте перезапуск сервера.
Имеет смысл проверки работоспособности. Тем не менее вследствие утечек памяти проблема может возникнуть снова — после перезапуска. В этом случае целесообразно:
- воспользоваться инструментами sql и сделать бэкап;
- снять базу с поддержки;
- выгрузить cf.
Во время любых действий следует копировать файлы в резерв, так как в любой момент может возникнуть необходимость возвращения к исходному статусу информации. Далее надо убрать в менеджменте консоли (config) запись «более 120 мегабайт» и провести загрузку конфигурации (не объединять, а загрузить).
Есть ещё один способ, с помощью которого неопознанная ошибка субд hresult 80004005 может быть исправлена. Нужно открыть конфигуратор и снять конфигурацию, не сохраняя её. Далее, сохранив, нужно поместить её в отдельный файл без сохранения её изменённого вида.
Выполните в SQL операцию, предназначенную для конкретной базы:
DELETE FROM dbo.Config WHERE DataSize > 125829120
После выполнения этой команды проведите загрузку сохранённой конфигурации.
Что касается радикальных шагов, используемых в особо трудных ситуациях, иногда помогает такая схема:
- удалите таблицу config из базы данных, воспользовавшись менеджментом консоли DROP TABLE [dbo].[Config];
- проведите загрузку конфигурации (не «объединить»,а именно «загрузить»).
После проведения проверки проблема должна уйти.
- Стоимость работ специалистов IT Rush — 2000 руб./час
- Абонемент от 50 часов в месяц – 1900 руб./час
- Абонемент от 100 часов в месяц – 1800 руб./час
Нам доверяют:
Содержание
- 1 Ошибка mysql: «Fatal error: cannot allocate memory…»
- 1.1 Как это происходит:
- 2 Что же тут делать чтобы избежать падений?
- 3 Как проверить наличие swap и создать его
- 3.1 Создаем свопфайл
- 4 Меняем параметры ядра Linux, политику распределения памяти
- 5 Оптимизация параметров mysql
Одна из распостраненных задач, которые доводится решать в системном администрировании — это обеспечение стабильной работы сервера баз данных. Чаще всего в этой роли выступает Mysql. Есть и другие, postgresql тоже отличный сервер, хотя он используется обычно для не коробочных проектов, для индивидуальных разработок. Например, для приложений на python часто применяется. Но большинство популярных коробочных CMS, таких как WordPress, DLE, Joomla, работают в связке с базой данных Mysql. Поэтому я хочу рассмотреть решение проблем Mysql, возникающих у многих вебмастеров.
К примеру, частая проблема — это «Ошибка подключения к базе данных». Так например ругается wordpress, когда не может установить связь с БД. Чаще всего это случается когда Mysql просто выключается. Такое может происходить например при нехватке ресурсов, допустим на серверах минимальных тарифов и конфигураций, даже под небольшой нагрузкой.
Выглядит это примерно следующим образом.
Ошибка mysql: «Fatal error: cannot allocate memory…»
В логах mysql звучит оно чаще всего именно так. Обычно что-то вроде
InnoDB: Fatal error: cannot allocate memory for the buffer pool
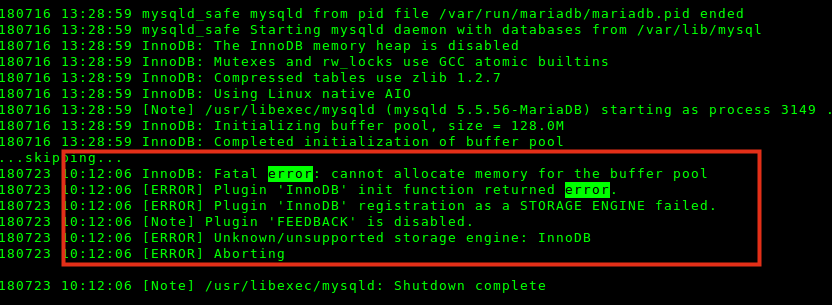
При этом всём, сервер не будет показывать явную нехватку памяти. Именно это и заводит обычно разбирающихся с проблемой в тупик. Чаще всего это бывает, когда на сервере 1-2 гб памяти.
Происходит при этом интересная вещь. Mysql аккуратно убивается ядром системы. Для того, чтобы системе хватило памяти на саму себя и другие процессы. Обычно это конечно неоправданно, ибо на сервере нет других столь же ресурсоёмких процессов, как mysql или mariadb. Не всегда причина в этом, но это наиболее частая, типичная картина при регулярных падениях базы данных сайта.
Убедиться в том можно посмотрев в системный лог /var/log/messages либо /var/log/syslog — в зависимости от семейства OS. Там будут сообщения о том, что сработал OOMKiller и выключил mysql.
Как это происходит:
Чаще всего, с mysql за потребление памяти конкурирует Apache. Скажем, на сервере 1 гб памяти. Из них, скажем, в норме mysql использует 200, апач 100 и ядро OS и вся остальная система 100. В сумме 400 мегабайт занято, всё хорошо, система работает стабильно. Тут начинается час пик, на сайт идёт трафик. Апач начинает есть 200 мб памяти, mysql 500, а ОС все так же 100. В сумме — 800. А у нас на сервере 1 gb, всё хорошо, проблем быть не должно. Но по-умолчанию политика 50%. Ядро видит, что mysql взяло 500, не дожидается что пока оно съест ещё больше, и убивает его. А иначе вероятна ситуация, что процесс съест память, и система умрёт сама. Для защиты от этого и предназначен сей механизм.
Отсюда и возникают проблемы с базой данных. Обычно вебмастера «лечат» это обычной перезагрузкой сервера. Что и логично — всё перезагрузили, память переспределилась, потребление меньше — система работает. Но буквально через считанные минуты под нагрузкой всё может повториться. Те кто продвинутей, понимают, что дёргать весь сервер смысла нет. Можно перезапускать процессы.
Начинающие сисадмины могут «лечить» это костылем куда нибудь в cron, типа перезапуск mysql каждые 10 минут. В принципе вариант. Но довольно опасный. Ибо можно, и часто так и бывает, убить данные в базах таким способом. У вас через какое-то время просто перестанет корректно подниматься база, посыпятся таблицы, и т.д.
Что же тут делать чтобы избежать падений?
Логичный вариант — добавить оперативной памяти на сервер. Но многие скажут — да как же, у нас и так всего 800 из одного гб используется, какой смысл добавлять ещё? И будут правы.
Можно не добавлять. Особенно если сайты у вас не такие уж и посещаемые, вы уверены, что нагрузка там не такая уж большая и вашего 1 gb должно хватать. И действительно, это лечится. Многие уже догадались, что нужно лишь изменить политику распределения памяти в ядре.
Дело в том, что в ядре Linux есть параметры, отвечающие за выделение памяти процессам. По-умолчанию задана политика, когда на процесс не может быть выделено более 50% доступной машине памяти. И есть там такая штука, которая прибивает процессы, требующие большего объема памяти, чем указано в этой политике. Называется она OOMKiller. OOM = Out Of Memory — классическая аббревиатура, обозначающая нехватку памяти. А в логах ещё обычно пишут «cannot allocate memory».
Итак, за это отвечают два параметра:
vm.overcommit_ratio = 50
vm.overcommit_memory = 0
Именно такие значения они имеют по-умолчанию. Нам же нужно их изменить следующим образом:
vm.overcommit_ratio = 90
vm.overcommit_memory = 2
Я не буду вдаваться в подробности и объяснения по второму параметру. Кому нужна эта информация может ознакомиться здесь.
Переопределять эти параметры нужно в файле /etc/sysctl.conf. Но прежде, нужно сделать ещё одну важную вещь, без которой вы можете сильно навредить системе. Перед тем как назначить такие значения ядру, необходимо убедиться в том, что на вашем сервере есть swap. То есть файл или раздел подкачки. И если нет, то нужно его создать. Он необходим для распределения памяти согласно заданным параметрам ядра.
Как проверить наличие swap и создать его
Для этого нужно лишь взглянуть на менеджер процессов в вашей системе. Обычно это top:
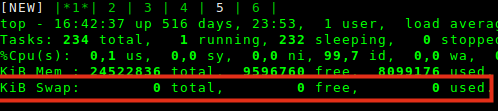
На скрине отмечена информация о свопе. А точнее, о его отсутствии.
Но я сам люблю и всем рекомендую пользоваться htop (поставьте его командой yum install -y htop )
В нем это гораздо наглядней и понятней:

Как видите, нижняя строка — Swp — 0. Это значит, что в системе свопа нет. Скорей всего ваш случай. Только у вас строка Mem над ней будет выглядеть иначе, поскольку у вас скорей всего будет меньше памяти. А если говорить конкретно об этом сервере, откуда я сделал скрин — то для него отсутствие свопа не проблема, ибо на нём памяти более чем достаточно и её нехватки не предвидится ( Кстати, такой мощный сервер с 24 гб памяти и 6 ядрами, 600 GB SSD стоит всего 15 евро в месяц )
Если же своп у вас уже есть, то выглядеть это будет примерно вот так:

Создаем свопфайл
Вообще, на большинстве серверов обычно своп создается по умолчанию, при установке системы. Под него выделяется отдельный раздел диска. Но поскольку вебмастера чаще имеют дело с VPS, то если он не был создан хостером при создании VPS, возможности создать его отдельным разделом уже нет. Или это довольно сложно и не нужно. Удобно и достаточно создать swap-файл.
Делается это следующим образом:
dd if=/dev/zero of=/swapfile bs=1M count=1024
Эта команда создаст файл по адресу /swapfile объемом в 1 гб . Если же вы хотите создать подкачку большего объема, соответственно вам нужно в параметре count указать большее значение — например 2048 для создания свопа в 2 gb.
По завершении команда выдаст отчет о том что сколько-то данных было записано и с какой скоростью.
Теперь нужно этот файл инициализировать и подключить в качестве свопа.
chmod 0600 /swapfile
mkswap /swapfile
Теперь нужно прописать его в таблицу файловых систем, чтобы после перезагрузки сервера он подключался автоматически.
Для этого добавим строку в файл /etc/fstab такого содержания:
/swapfile swap swap defaults 0 0
В приниципе после перезагрузки у нас своп теперь появится. Но чтобы подключить его в первый раз сразу и без перезагрузки мы можем дать такую команду:
swapon -a
Эта команда перечитает файл /etc/fstab и подключит наш новый своп. Теперь можем снова смотреть в htop, и увидим что он появился.
Меняем параметры ядра Linux, политику распределения памяти
Для этого открываем файл /etc/sysctl.conf и дописываем строки
vm.overcommit_ratio = 90
vm.overcommit_memory = 2
Если вы этого ещё не сделали.
Если же сделали ранее, то ваши параметры ещё не применились, поскольку нам нужно было создать своп сначала, чтобы не повесить систему. Дело в том, что здесь как и с файлом fstab — настройки будут подхватываться только при перезагрузке. Но дабы опять таки без оной обойтись, мы можем просто сказать:
sysctl -p
Эта команда перечитает файл sysctl.conf и принудительно задаст наши параметры из него, о чём и отрапортует после выполнения.
На этом всё. Теперь ни mysql, ни любой другой процесс не будет убиваться ядром при большем потреблении памяти. Своп мы создали в качестве страховки, он как бы дополняет и продолжает основную память системы, является используемым резервом.
Однако не всегда всего вышеописанного может быть достаточно для стабильной работы mysql. Часто есть необходимость также изменить параметры самого mysql. Ибо в его конфигурации также есть много параметров, отвечающих за использование памяти. Это всевозможные кэши, пулы и буферы.
Но это история для другой статьи. Впрочем, в подробностях уже писал об оптимизации параметров mysql в своем большом руководстве по оптимизации серверов.
Ну а мне за сим остаётся только пожелать вашим серверам, базам данных и сайтам стабильной и быстрой работы. А также без лишней скромности напомнить, что в случае проблем с mysql или mariadb, (или даже postgresql чего доброго) вы всегда можете обращаться по контактам к автору сего опуса.
Как раз для полноты, оператор SQL Chinjoo, вероятно, будет примерно таким:
mySqlQueries.insertChatUser = «вставить в значения ChatUsers (UserName, Password, FirstName, LastName, sex) (?,?,?,?,?);»;
Это называется параметризованной вставкой, где каждый знак вопроса представляет один из его параметров. В этом простом примере порядок параметров в коллекции параметров в коде должен соответствовать порядку имен столбцов в инструкции SQL.
Хотя он менее элегантный, чем использование функции, исправление для его нулевой проблемы будет выглядеть примерно так для одного из его параметров:
OdbcParameter LastName = новый OdbcParameter ( «@LastName», u.LastName);
заменяется на
//если значение «null» возвращает DBNull, иначе просто значение
OdbcParameter LastName = новый OdbcParameter ( «@LastName»,
(u.LastName == null)? System.DBNull.Value: (объект) u.LastName);
По крайней мере, в моем коде (который немного отличается) требуется внутренний объект cast to type, поскольку в противном случае компилятор не уверен, какой тип должен возвращать оператор?:
Надеюсь, это поможет любому, кто относительно новичок в параметризации и т.д.
Никакой критики в отношении Чинджо не подразумевалось вообще — его публикация помогла мне! Просто подумал, что я поделюсь для менее опытных. Я ни в коем случае не эксперт, поэтому возьмите все, что я говорю, с солью.
Предисловие
Недавно я столкнулся с проблемой в сети. Экземпляр MySQL сообщил об ошибке Ошибка в munmap (): не удается выделить память, что привело к аварийному завершению процесса.
Введение
MySQL использует jemalloc для выделения памяти. Причина ошибки в том, что количество VMA в процессе MySQL превышает верхний предел операционной системы.
Вот несколько предисловий
Область виртуальной памяти VMA
Процессы Linux управляются vma, и каждый процесс имеет связанный список vma, поддерживаемый в структуре, где каждый узел vma соответствует непрерывной памяти процесса. Под непрерывностью здесь понимается непрерывность в пространстве процесса, не обязательно непрерывность в физическом пространстве. Если процесс применяется к памяти, ядро добавит в процесс узел vma
/proc/pid/maps
/ proc / pid / maps записывает использование виртуальной памяти процессом
Например, карты процесса b.out следующие: каждая строка представляет собой VMA (некоторые повторяющиеся строки удалены.
00400000-00401000 r-xp 00000000 fd:01 1574192 /u01/b.out
00602000-00701000 rw-p 00000000 00:00 0 [heap]
7ffff71f8000-7ffff73b0000 r-xp 00000000 fd:01 1049989 /usr/lib64/libc-2.17.so
7ffff75b6000-7ffff75bb000 rw-p 00000000 00:00 0
7ffff75bb000-7ffff75d0000 r-xp 00000000 fd:01 1052643 /usr/lib64/libgcc_s-4.8.5-20150702.so.1
7ffff77d1000-7ffff78d2000 r-xp 00000000 fd:01 1049997 /usr/lib64/libm-2.17.so
fff7ad3000 rw-p 00101000 fd:01 1049997 /usr/lib64/libm-2.17.so
7ffff7ad3000-7ffff7bbc000 r-xp 00000000 fd:01 1050280 /usr/lib64/libstdc++.so.6.0.19
dc6000 rw-p 000f1000 fd:01 1050280 /usr/lib64/libstdc++.so.6.0.19
7ffff7dc6000-7ffff7ddb000 rw-p 00000000 00:00 0
7ffff7ddb000-7ffff7dfc000 r-xp 00000000 fd:01 1049982 /usr/lib64/ld-2.17.so
7ffff7fce000-7ffff7ff4000 rw-p 00000000 00:00 0
7ffff7ff9000-7ffff7ffa000 rw-p 00000000 00:00 0
7ffff7ffa000-7ffff7ffc000 r-xp 00000000 00:00 0 [vdso]
7ffff7ffc000-7ffff7ffd000 r--p 00021000 fd:01 1049982 /usr/lib64/ld-2.17.so
7ffff7ffd000-7ffff7ffe000 rw-p 00022000 fd:01 1049982 /usr/lib64/ld-2.17.so
7ffff7ffe000-7ffff7fff000 rw-p 00000000 00:00 0
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
- Первый столбец, например 00400000-00401000.
Начальный и конечный адреса виртуального пространства - Второй столбец, например rw-p
Разрешения VMA, первые три rwx обозначают доступный для чтения, записи и исполняемый файл соответственно, «-» означает отсутствие такого разрешения; четвертый p / s обозначает частный / общий сегмент. - Третий столбец, например 00021000
Смещение начального адреса виртуальной памяти в файле, анонимно сопоставленное с 0 - Четвертый столбец, например fd: 01
Устройство, которому принадлежит файл сопоставления, хорошее, а анонимное сопоставление — 0 - Пятая колонка, например 1049982
Номер узла файла сопоставления, анонимное сопоставление — 0 - Шестой столбец, например /u01/b.out /usr/lib64/libstdc++.so.6.0.19 [stack]
Имя файла сопоставления, [куча] означает куча, [стек] означает стек.
vm.max_map_count
max_map_count — максимальное количество VMA, которое может иметь память процесса
Когда процесс достигает верхнего предела VMA, но может освободить только небольшой объем памяти для использования другими процессами ядра, операционная система выдаст ошибку нехватки памяти.
Ошибка в munmap (): невозможно выделить память, вызывает эту ошибку
Повторение проблемы
Операционная система vm.max_map_count = 65530
Выполните следующий код, вы можете воспроизвести ошибку, из-за которой munmap не может выделить память.
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#define VM_MAX_MAP_COUNT (65530)
#define VM_SIZE (4096)
#define VM_CNT (VM_MAX_MAP_COUNT * 2)
static void* vma[VM_CNT];
int main(void)
{
int i;
for (i = 0; i < VM_CNT; i++)
{
vma[i] = mmap(0, VM_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0 );
}
for (i = 0; i < VM_CNT; i++)
{
if (munmap(vma[i], VM_SIZE) != 0)
printf("mumap() ERROR");
}
}
Сначала используйте mmap для выделения 65530 * 2 пространств виртуальной памяти
Поскольку он выделяется постоянно, операционная система будет объединена в одну VMA. Как видно на рисунке ниже, в файле / proc / pid / maps есть еще одна VMA.
Два других существующих VMA были изменены

Дополнительный VMA 7fffd73fc000-7ffff71f8000 имеет всего 130566 VM_SIZE
7ffff7fef000-7ffff7ff4000 (0x5000) -> 7ffff7dfc000-7ffff7ff5000 (0x1f9000) еще 500 VM_SIZE
7ffff7ff9000-7ffff7ffa000 -> 7ffff7ff5000-7ffff7ffa000 Начальный адрес сдвигается вперед на 0x4000, еще 4 VM_SIZE
130566 + 500 + 4 = 131070 = 65536 * 2 — это точно размер запрошенной в программе памяти
Затем используйте munmap, чтобы выпускать VM_SIZE через каждые другие VM_SIZE, чтобы сделать исходное непрерывное пространство виртуальной памяти прерывистым. Это сформирует 65536 VMA, плюс несколько VMA, которые изначально существовали, что превышает VMA, установленную операционной системой. Верхний предел 65530
При фактическом выполнении, когда количество VMA достигает 65530, при повторном выполнении munmap будет сообщено об ошибке.
jemalloc и glibc malloc
MySQL использует jemalloc для выделения памяти, а jemalloc использует mmap () / munmap () для выделения и освобождения памяти по умолчанию. Было подтверждено, что jemalloc вызовет исключение, которое не может выделить память, когда max_map_count мало.
Используйте тот же сценарий, чтобы проверить, имеет ли glibc malloc такая же проблема. Когда glibc malloc выделяет память выше 128 КБ, по умолчанию используется mmap, а по умолчанию используется sbrk, когда память меньше 128 КБ, поэтому здесь мы меняем VM_SIZE на 129 КБ
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#define VM_MAX_MAP_COUNT (65530)
#define VM_SIZE (129 * 1024)
#define VM_CNT (VM_MAX_MAP_COUNT * 2)
static void* vma[VM_CNT];
int main(void)
{
int i;
for (i = 0; i < VM_CNT; i++)
{
vma[i] = malloc(VM_SIZE);
}
for (i = 0; i < VM_CNT; i++)
{
free(vma[i])
}
}

Как видно из рисунка выше, помимо подачи заявки на новую VMA, пространство кучи также увеличилось.
Добавлен VMA 7ffde73e7000-7ffff71f8000, всего 67044 VM_SIZE
7ffff7fef000-7ffff7ff4000 -> 7ffff7e00000-7ffff7ff4000 всего 15 VM_SIZE
[heap] 00602000-00701000 -> 00602000-20467e000 65531 VM_SIZE всего
Много ''
Здесь выделено 1530 VM_SIZE, которое должно контролироваться внутренним механизмом glibc, поэтому дальнейшее изучение не требуется.
Дело в том, чтобы подать заявку на 65531 VM_SIZE [heap] space, на эту часть пространства претендует sbrk ()
### mmap () и sbrk ()
Когда malloc применяется для менее 128 КБ памяти, используйте sbrk () для выделения, если больше 128 КБ, используйте mmap () по умолчанию
В то же время mmap () выделяет память до 65536 раз, после ее превышения используйте sbrk () для выделения
mmap () находит свободное выделение адреса в виртуальном адресном пространстве, выделенная память может быть освобождена по желанию
sbrk () подталкивает вверх указатель _edata, который указывает на наивысший адрес сегмента данных, и опускает _edata при его освобождении; очевидно, что sbrk () не может освободить память по своему желанию. При освобождении части памяти должна быть освобождена вся память выше, чем его адрес Взаимодействие с другими людьми
Как показано на рисунке, изначально _edata находится внизу кучи, когда выделяется A, _edata помещается ниже A, а когда выделяется B / C, _edata помещается ниже B / C.
Когда C освобожден, _edata будет помещен ниже B, но до того, как B будет освобожден, A может быть помечен только как неиспользуемый для следующего выделения и не может быть перемещен. _Edata
<p style="text-align:center">
</p>
Очевидно, что при освобождении памяти, запрошенной sbrk (), количество VMA не увеличится, поэтому glibc malloc не приведет к тому, что количество VMA превысит max_map_count и не вызовет вышеуказанные проблемы.
###подводить итоги
Причина проблемы очевидна, количество VMA превышает max_map_count, увеличение max_map_count может решить эту проблему просто и грубо.