
УДК 808.2 Б01: 10.18720/НиМ/К8К 2227-8591.39.04
Е.В. Шевчук, Ж.А. Никифорова
ПОСТРЕДАКТИРОВАНИЕ И ТИПИЧНЫЕ ОШИБКИ В АВТОМАТИЗИРОВАННОМ ПЕРЕВОДЕ НАУЧНО-ПУБЛИЦИСТИЧЕСКИХ ТЕКСТОВ
ШЕВЧУК Екатерина Владимировна — кандидат филологических наук, старший преподаватель Высшей школы сервиса и торговли, Института промышленного менеджмента, экономики и торговли; Санкт-Петербургский политехнический университет Петра Великого. ул. Политехническая, 29, Санкт-Петербург, 195251, Россия. e-mail: ekaterinashevchuk@yandex.ru
SHEVCHUK Ekaterina V. — Peter the Great St. Petersburg Polytechnic University. Politekhnicheskaya, 29, St. Petersburg, 195251, Russia. e-mail: ekaterinashevchuk@yandex.ru
НИКИФОРОВА Жанна Александровна — кандидат филологических наук, доцент Высшей школы сервиса и торговли Института промышленного менеджмента, экономики и торговли; Санкт-Петербургский политехнический университет Петра Великого.
Политехническая ул., 29, Санкт-Петербург, 195251, Россия. e-mail: nikiforovash@gmail.com
NIKIFOROVA Zhanna A. — Peter the Great St. Petersburg Polytechnic University. 29, Polytechnicheskaya, St. Petersburg, 195251, Russia. e-mail: nikiforovash@gmail.com
В статье рассматриваются вопросы типизации ошибок, с которыми переводчик сталкивается в процессе постредактирования машинного перевода. Постмашинное редактирование или постредактирование, которое обозначается в английском языке аббревиатурой PEMT (post-edited machine translation) или MTPE (machine translation post-editing), на сегодняшний день стало неотъемлемой частью переводческого процесса. Причина этому — повсеместная практика использования машинного перевода. Огромное количество российских и зарубежных переводческих компаний признает и приветствует его использование. Более того, в настоящий момент набирает популярность профессия постредактора, поскольку зачастую заказчик и сам может осуществить машинный перевод, используя сервисы компаний Google, Yandex, Microsoft, Memsource и др., но не обладает достаточной степенью владения иностранным языком для осуществления постредактирования. В данной статье предпринята попытка категоризации типичных ошибок машинного перевода, с которыми может столкнуться постредактор при работе с научно-публицистическими текстами, а также даны рекомендации по сведению подобного рода ошибок к минимуму.
МАШИННЫЙ ПЕРЕВОД; ПОСТРЕДАКТИРОВАНИЕ МАШИННОГО ПЕРЕВОДА; PEMT; НЕЙРОННЫЙ ПЕРЕВОД
Ссылка при цитировании: Шевчук Е.В., Никифорова Ж.А. Постредактирование и типичные ошибки в автоматизированном переводе научно-публицистических текстов // Вопросы методики преподавания в вузе. 2021. Т. 10. № 39. С. 46-54. Б01: 10.18720/НиМ/!88М 2227-8591.39.04
Введение. Согласно данным исследования Ричарда Уайзмена (Richard Wiseman), профессора психологии британского Университета Хертфордшира, скорость жизни за последние десятилетия растет на 1% в год [14]. Увеличение темпа скорости жизни диктует необходимость увеличивать скорость обмена информацией и, как следствие, скорость перевода текстов с одного языка на другой. Именно поэтому востребованность машинного перевода (МП) повсеместно возрастает.
Так, по данным отчета европейской переводческой отрасли за 2018 год, «более 50% переводческих компаний Европы и переводчиков-фрилансеров подтвердили, что используют МП в той или иной его форме [13], те же данные имеем и по России. Опросы показывают, что более 50 % российских … переводческих компаний уже используют его в своей практике. Порядка 20 % переводческих компаний планируют начать внедрять эту технологию в свою деятельность в ближайшее время [5].
Актуальность. Актуальность исследования обусловлена тем, что хотя нейронный перевод и совершенствуется ежегодно вопрос качества и адекватности подобного перевода не утрачивает своей остроты. Безусловно, для общего понимания смысла переведенного текста иной раз достаточно применить так называемое легкое постредактирование (light postediting). Иными словами, достаточно только слегка отшлифовать результат МП [12]. Чаще приходится прибегать к полному постредактированию (full postediting), а в этом случае ожидания от качества те же, что и при традиционном способе перевода и редактирования. Однако и этот процесс во многом можно автоматизировать, или хотя бы отчасти упростить, используя соответствующие сервисы редактирования текстов,
а кроме того, имея некий «путеводитель» по типичным ошибкам, встречающимся в текстах научно-публицистического регистра.
Методы. При проведении исследования была проанализирована актуальная отечественная и зарубежная литература по теме. Определены ключевые особенности постмашинного редактирования, его специфика и отличие от традиционного перевода с последующим редактированием и корректурой. На основе массива из 56 научно-публицистических текстов, проанализированных авторами в рамках деятельности по языковому рецензированию текстов, предпринята попытка классификации типичных ошибок, встречающихся в текстах подобного рода и регистра, а также рекомендаций по их исправлению.
Понимая, на что в первую очередь следует обратить внимание, как заказчик процедуры постмашинного редактирования, так и сам постредактор смогут существенно сэкономить время работы с редактируемым текстом.
Анализ результатов. Машинный перевод представляет собой процесс перевода письменных текстов с одного естественного языка на другой с помощью специальной компьютерной программы [2; 4]. Хотя на сегодняшний день качество машинного перевода продвинулось далеко вперед, «вопрос адекватности таких переводов до сегодняшних дней остается актуальной и требующей дальнейшего изучения проблемой» [2].
К безусловным преимуществам машинного перевода относятся:
• экономия времени,
• проста доступа к услуге,
• удобство пользования,
• относительно высокое качество перевода (современные сервисы нейронного
перевода позволяют довольно точно передать смысл переводимого текста),
• большой спектр комбинаций «язык оригинала» — «язык перевода».
Нельзя не упомянуть и о недостатках, среди которых
• необходимость редактирования текста перевода для обеспечения высокого качества,
• интерференция синтаксиса языка оригинала в язык перевода, что затрудняет понимание изложенного или вовсе препятствует этому,
• лексико-семантические и морфологические ошибки,
• орфографическая, речевая, стилистическая и т. п. ошибка автора в языке оригинала игнорируется в процессе машинного перевода (то, что легко увидит и исправит человек, машина примет как данность согласно принципу GIGO (garbage in — garbage out),
• и некоторые другие.
Уже упомянутый ранее нейронный автоматический перевод, годом появления которого считается 2016, это именно то, что предлагают пользователям сервисы компаний Google, Яндекс, Microsoft и ПРОМТ.
Основываясь на модели переводных соответствий и на результатах эмпирических исследований, А. Семенов делит все ошибки компьютерного перевода на 2 большие группы [2; 6]:
• ошибки автоматического анализа (лексические, морфологические, синтаксические, текстовые);
• ошибки автоматического синтеза (текстовые, семантические, синтаксические, морфологические, лексические).
Так, например, к ошибкам лексического анализа можно отнести появление в выходном тексте непереведенных или некорректно переведенных слов. Это может быть связано с неполнотой словаря автоматизированной системы перевода, с оши-
бочным разрешением лексической омонимии и полисемии, а равно и с человеческим фактором: наличием орфографических ошибок или опечаток во входном тексте [8].
К ошибкам морфологического анализа относятся ошибки нарушения согласования и управления, что может быть вызвано неправильной работой не только морфологического, но и синтаксического, а также семантического блоков [8]. Примером могут служить неправильно заданное падежное управление [8], неверное согласование категорий числа, лица, рода.
Ошибками синтаксического анализа следует считать неправильное или неполное определение синтаксической структуры входного предложения, что ведет к неправильному синтезу выходного предложения [8].
За процедурой автоматического анализа следует этап автоматического синтеза. Здесь, как и при автоматическом анализе, системы допускают ряд ошибок. Наиболее распространенными является нарушение порядка слов в выходном тексте, а также упущение глагола-связки в составе именного сказуемого (Nominal predicate). Что касается ошибок морфологического синтеза, то к ним можно отнести неправильное употребление форм глаголов, в том числе видовременных, если перевод осуществляется на английский язык, ошибочное согласование подлежащего и сказуемого, некорректный синтез слов, принадлежащих к различным частям речи [8].
К сожалению, авторам данной статьи не представляется возможным привести конкретные примеры ошибок анализа, по причине отсутствия оригиналов исследуемых текстов. По этой причине приведем лишь некоторые примеры ошибок синтеза:
Таблица 1
Ошибки синтеза
Ошибка: Отредактированный текст:
Морфологическая ошибка The authors believe that the concept and essence of an organization’s innovation ecosystem comes from digital transformation. The authors believe that the concept and essence of an organization’s innovation ecosystem come from digital transformation.
Синтаксическая ошибка In the Russian Federation_, the site «counterparty.no», which contains links to official and private resources that allow you to check (both for a fee and for free) various information about legal entities and individuals. The proposed in the article an integrated approach to the use of digital technologies at all stages of supply management in procurement logistics… In the Russian Federation it is the site «counterparty.no», which contains links to official and private resources that allow you to check (both for a fee and for free) various information about legal entities and individuals. The integrated approach, that is proposed in the article, is aimed at the use of digital technologies at all stages of supply management in procurement logistics.
Лексико-грамматические ошибки в таких случаях возникают, как правило, на основе неправильного выбора определенных (одного или нескольких) параметров из множества [1], а синтаксические трудности — результат языковой интерференции при переводе текста [2]. П.Н. Хроменков отмечает, что «неправильная работа системы на этапе анализа и некорректное разрешение неоднозначностей ведут … к появлению ошибок на этапе синтеза» [8].
Таким образом, как ошибки анализа, так и ошибки синтеза следует рассматривать системно, в том числе с привлечением дополнительных сведении о работе тех или иных алгоритмов перевода на каждом языке системы [8].
Тот факт, что машинный перевод используется все шире и активнее, привел к появлению новой профессии на переводческом рынке — постредактор машинного перевода. Цель постредактирования машинного перевода (postediting, PEMT) -довести выполненный машиной перевод до приемлемого качества, тем самым сэкономив время. От простого редактирования постредактирование отличается именно тем, что во втором случае перевод выполняется машиной, а далее редактуру выполняет человек, а в первом случае — как на
этапе перевода, так и на этапе редактирования задействованы люди [7]. Согласно данным отчета европейской переводческой отрасли от 2018 года, 37 % европейских переводческих компаний сообщают об увеличении доли использования РЕМТ в своей практике, а ещё 17 % заявляют, что намерены начать практиковать этот вид деятельности в ближайшее время [5; 7].
Следует отметить, что не всегда машинный перевод увеличивает скорость работы, ведь постредактирование перевода низкого качества займет больше времени, чем сам процесс перевода. Именно поэтому ассоциация TAUS (Translation Automation User Society) также выделяет цель постредактирования и задачу постредактора. Цель -сделать текст понятным реципиенту. Задача — улучшить результат МП с минимальным количеством усилий за минимальное количество времени [5]. Ключевым словом в данном случае становится «минимальное».
Еще один важный момент — уровень подготовки постредактора, зависящий и от уровня знаний испытуемого в конкретной предметной области, и от общих навыков работы с текстом, и от предыдущего опыта постредактирования, и от навыков работы с инструментами постредактирования [7; 9]. В ходе исследований были выявлены важ-
ные критерии эффективности постредактирования, к которым относятся:
1. предыдущий опыт,
2. соблюдение рекомендаций для постредактирования,
3. ориентация на качество, соответствующее цели перевода [10].
Остановимся подробнее на втором и третьем пунктах. Одной из действенных рекомендаций может стать ведение процесса постредактирования с учетом выявленной типологии ошибок. Что касается ориентации на качество, соответствующее цели перевода, стоит помнить о тех случаях, когда цель — добиться приемлемого, а не идеального качества перевода. Тем не менее, в иных случаях перевод должен соответствовать профессиональному переводу, выполненному человеком. Как раз таким случаем является перевод научно-публицистических текстов, особенно публикуемых в серьезных изданиях мирового уровня, поскольку такого рода тексты являются «имиджевым» продуктом не только для автора, но и для организации, которую он представляет.
С целью определения типологии ошибок в рамках процедуры языкового рецензирования были проанализированы 56 научно-публицистических текстов. Это
были статьи, присланные на конференцию ОБТМ-21, состоявшейся 29 и 30 сентября 2021 года в Санкт-Петербургском политехническом университете. Рабочий язык конференции — английский, так что все тексты переводились на английский язык. Мы не можем однозначно утверждать, что языком оригинала в каждом случае был русский, поскольку в числе соавторов нередко заявлены иностранные исследователи, равно как и утверждать, что статьи писались на русском языке и только потом переводились на английский, однако, в подавляющем большинстве случаев это были именно русскоговорящие коллеги и текст оригинала статьи изначально был написан на русском языке. Машинный перевод был в той или иной мере использован для перевода всех присланных трудов. Авторы признают, что машинный перевод существенно облегчает задачу, хотя бы даже и тем, что текст на английском языке не приходилось набирать на клавиатуре (что уже существенно экономит время).
Рассмотрим, какие ошибки оказались наиболее частотными. Для подсчета мы воспользовались корректорским онлайн сервисом Огашшаг1у, в основе работы которого лежит искусственный интеллект.
Таблица 2
Наиболее частотные ошибки. Артикли
Тип ошибки Кол-во
Пропущенный / избыточный артикль 136
Исходный вариант PEMT вариант
The term first appeared in 2006, in _ RenaultNissan case, as _ cost-effective, quick solution under limited resources. The term first appeared in 2006, in the RenaultNissan case, as a cost-effective, quick solution under limited resources.
The most important aspects of digitalization in _ mechanical engineering area are summarized to the categories. The most important aspects of digitization in the mechanical engineering area are summarized into categories.
Calculations of the digitalization level applied to three regions of _ Russian Federation namely _ Komi Republic, Murmansk, and Arkhangelsk Regions. Calculations of the digitalization level applied to three regions of the Russian Federation namely the Komi Republic, Murmansk, and Arkhangelsk Regions.
Таблица 2
Наиболее частотные ошибки. Артикли. Примеры
Отсутствие категории артикля в русском языке представляет собой особую сложность для носителей русского языка.
Таблица 3
Наиболее частотные ошибки. Пунктуация
Отметим, что пунктуационные правила расстановки запятых в английском языке существенно проще, чем в русском. Довольно часто в сложных предложениях запятая не нужна. Однако, есть и такие случаи, когда запятая нужна в английском варианте, при этом в русском переводе ее нет. Это касается так называемой «оксфордской» или «гарвардской» запятой, используемой в английском языке перед союзом (обычно and или or, а также nor), перед последним пунктом в списке из трёх или более элементов. Лингвисты спорят о ее обязательности, но большинство автоматизированных систем проверки орфографии и пунктуации (т. н. спеллчеркеры), рекомендуют ставить ее.
Таблица 3
Наиболее частотные ошибки. Пунктуация. Примеры
Исходный вариант PEMT вариант
Participants already know, what they’re going to work on, but did not suspect what may be the solution. Participants already know_what they’re going to work on but did not suspect what may be the solution.
Thus_it becomes possible not to overlook the information about the status of workplaces, equipment and service department operations. Thus, it becomes possible not to overlook the information about the status of workplaces, equipment, and service department operations.
Таблица 4
Наиболее частотные ошибки. Знаки кавычек
Тип ошибки Кол-во
Пунктуационные ошибки при употреблении кавычек и цитат 68
В американском и британском вариантах английского допускается использование одинарных и двойных кавычек. По две стороны океана правила немного различаются. Так, в американском английском двойные кавычки используются в первую очередь, а одинарные кавычки используются как вторые при цитировании внутри цитаты. В британском английском -наоборот. Но кавычки-«елочки» не используются ни в одном из вариантов английского.
Таблица 4
Наиболее частотные ошибки. Знаки кавычек. Примеры
Исходный вариант PEMT вариант
«What does NEETs mean and why is the concept so easily misinterpreted?» ‘What does NEETs mean and why is the concept so easily misinterpreted?’
The United States is considered the «birthplace of downshifting», respectively, it is here that the movement has developed the fastest — in 1995, 28% of the population of America considered themselves downshifters The United States is considered the ‘birthplace of downshifting’, respectively, it is here that the movement has developed the fastest — in 1995, 28% of the population of America considered themselves downshifters
In Russia, the first references to downshifting as a «depression of millionaires» began to appear in 2004, mostly in the well-known business media. In Russia, the first references to downshifting as a ‘depression of millionaires’ began to appear in 2004, mostly in the well-known business media.
Тип ошибки Кол-во
Пунктуационные ошибки при использовании запятых. 73
Что касается синтаксических ошибок, была выявлена одна довольно интересная закономерность: хотя нейронный перевод развивается стремительно, но его уровень еще недостаточен, чтобы избежать языковой интерференции. Интересно, что на общее понимание смысла это кардинальным образом не влияет, скорее, является фактором «имиджевого» уровня.
Наиболее часто мы наблюдаем случай языковой интерференции русского синтаксиса на английский язык.
Таблица 5 Языковая интерференция. Примеры
Формат журнальной статьи не позволяет подробно осветить стилистические неточности при переводе и постредактировании научно-публицистических текстов, возможно, это станет материалом для дальнейших исследований.
Выводы. Машинный перевод стал частью ежедневной практики не только профессиональных переводчиков, но и тех,
кто регулярно осуществляет коммуникацию на иностранном языке: исследователей, бизнесменов, учащихся, проходящих обучение в зарубежных вузах.
Машинный перевод позволяет существенно сэкономить время и, в целом, современные системы нейронного перевода прекрасно справляются с задачей передачи общего смысла сообщения. Однако, они еще не достигли того уровня совершенства, когда участие человека из переводческого процесса полностью исключается. Именно по этой причине сегодня набирает популярность профессия постредактора: человека, который «доводит перевод до приемлемого уровня».
Во избежание ошибок анализа и синтеза текста, для получения более качественного результата и сокращения времени, которое впоследствии будет затрачено на постредактирование, рекомендуется провести предварительную работу с исходным текстом. Убедитесь, что в исходном тексте отсутствуют опечатки, орфографические и лексико-грамматические ошибки. Удостоверьтесь, что текст логичен, трактовка слов и словосочетаний однозначна. Упростите синтаксис и пунктуацию, поскольку в языке перевода действуют иные правила. Да, сегодняшний уровень развития систем нейронного перевода нередко перестраивает синтаксис в соответствии с правилами языка перевода, но не в том случае, когда предложение перегружено придаточными конструкциями.
Осуществляя постмашинное редактирование обратите особое внимание на отсутствие артиклей и пунктуацию, поскольку именно эти ошибки являются наиболее частотными при машинном переводе русскоязычных научно-публицистических текстов на английский язык.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Языковая интерференция синтаксиса исходного языка на язык перевода не всегда ведет к искажению смысла, но может затруднить понимание, тем самым сказав-
Исходный вариант PEMT вариант
Under the potential in the context of this study, we mean the socio-economic potential that unites public relations with the process of forming and using economic benefits. In the context of this study, the potential is understood as the socioeconomic potential uniting the public relations with the process of forming and using economic benefits.
The panel indicators that we have chosen -characteristics of the socioeconomic security of the region, on the basis of which we will draw a conclusion about the level of regional economic security, are presented in Table 1. The panel indicators that we have chosen show the characteristics of the socio-economic security of the region. These are presented in Table 1 and will enable us to decide on the level of regional economic security.
The most important aspects of digitization in mechanical engineering area summarized to the categories. The most important aspects of digitization in the mechanical engineering area are summarized into categories.
шись на имидже исследователей. Научно-публицистические тексты в английском, в отличие от русского языка, не изобилуют сложными предложениями. Наоборот, для английских текстов такого рода характер-
но преобладание простых предложений. Следует принимать во внимание данный фактор при подготовке текстов к машинному переводу и в процессе последующего постредактирования.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Байтин А. Поиск и машинный перевод // Российские интернет технологии: материалы профессиональной конференции веб-разработчиков 25-26 апреля. — М., 2011. [Электронный ресурс]. https://searchengines. guru/ru/articles/9566
2. Гритчин, А.Б., Дворак Е.В. Компьютерный перевод: качество и типичные ошибки // Молодежный вестник ИрГТУ. 2020. Т. 10. № 1.С. 152-156.
3. Кочеткова Н.С., Ревина Е.В. Особенности машинного перевода // Филологические науки. Вопросы теории и практики.2017. № 6-2. C. 106-109. ISSN 1997-2911.
4. Марчук Ю. Н. Проблемы машинного перевода. М.: Наука, 1983. 201 с.
5. Нечаева Н.В., Светова С.Ю. Постредактирование машинного перевода как актуальное направление подготовки переводчиков в вузах // Вопросы методики преподавания в вузе. 2018. Т. 7. № 25. С. 64-72. DOI: 10.18720/HUM/ISSN 2227-8591.25.07
6. Семенов А. Л. Современные информационные технологии и перевод: учебное пособие.- М.: Академия, 2008. 224 с. ISBN: 978-5-7695-4459-0
7. Худяков Н.А. Постредактирование машинного перевода: теоретические аспекты // Филологический аспект. 2019. №1 (45). С. 232239. eISSN: 2412-8953
8. Хроменков П.Н. Анализ и оценка эффективности современных систем машинного
перевода : автореф. дисс….канд. филол. -10.02.21. — М., 2000. — 28 с.
9. Koby, G.S. (2001). Editor’s introduction. In Krings, H.P. Repairing Texts: Empirical Investigations of Machine Translation Post-editing Processes, Kent State University Press, pp.1-23
10. Koponen Maarit. Is machine translation post-editing worth the effort? A survey of research into post-editing and effort. — University of Helsinki. The Journal of Specialised Translation. Issue 25. January 2016. [Online] URL: http://www.jostrans. org/issue25/art_koponen.pdf
11. Temnikova Irina Cognitive Evaluation Approach for a Controlled Language Post-Editing
12. Experiment. Proceedings of the International Conference on Language Resources and Evaluation. European Language Resources Association (ELRA). — 2010. [Online] URL: https://www.research gate.net/publication/220746821_cognitive_evaluation _approach_for_a_controlled_language_post—editing_ experiment
13. PEMT [Online] URL: https://pemt.ru/pemt/].
14. 2018 Language Industry Survey — Expectations and Concerns of the European Language Industry [Online] URL: https:// ec.europa.eu/ info/ sites/info/files/2017_language_industry_survey_re port_en.pdf
15. В городах скорость жизни растет на один процент в год [Online] URL: https://lenta.ru/ news/2007/05/02/speed/].
REFERENCES
1. Bajtin A. Poisk i mashinnyj perevod // Rossijskie internet tehnologii: materialy professional’noj konferencii veb-razrabotchikov 25-26 apr. 2011. Moskva, [Jelektronnyj resurs]. https://sear chengines.guru/ru/articles/9566
2. Gritchin A.B., Dvorak E.V. Computer Translation: Quality and Common Mistakes. Young Researchers’ Journal of ISTU. 2020. Vol.10. No 1. P. 152-156
3. Kochetkova N.S., Revina E.V. Osobennosti mashinnogo perevoda // Filologicheskie nauki. Voprosy teorii i praktiki. 2017. No 6-2(72). P. 106109. ISSN 1997-2911.
4. Marchuk Ju.N. Problemy mashinnogo perevoda. M.: Nauka, 1983. 201 s.
5. Nechaeva N.V., Svetova S.Y. Post-Editing Machine Translation as a New Activity for Teaching Translation at Universities. Teaching Methodology in
Higher Education. 2018. Vol. 7. No 25. P. 64-72. DOI: 10.18720/HUM/ISSN 2227-8591.25.07
6. Semenov A.L. Sovremennye informacionnye tehnologii i perevod: uchebnoe posobie. — M.: Akademija, 2008. 224 a ISBN: 978-5-7695-4459-0
7. Khudiakov N. A. Machine translation post-editing: theoretical aspect. Filologicheskij aspekt. 2019. No 1 (45). P. 232-239. elSSN: 2412-8953
8. Hromenkov P.N. Analiz i ocenka jeffektivnosti sovremennyh sistem mashinnogo perevoda : avtoref. diss….kand. filol. — 10.02.21. — M., 2000. — 28 s.
9. Koby, G.S.(2001) Editor’s introduction. In Krings, H.P. Repairing Texts: Empirical Investigations of Machine Translation Post-editing Processes, Kent State University Press, pp: 1-23
10. Koponen Maarit. Is machine translation post-editing worth the effort? A survey of research into post-editing and effort. — University of Helsinki. The Journal of Specialised Translation. Issue 25.
January 2016. [Online] URL: http://www.jostrans. org/issue25/art_koponen.pdf
11. Temnikova Irina. Cognitive Evaluation Approach for a Controlled Language Post-Editing Experiment. Proceedings of the International Conference on Language Resources and Evaluation. European Language Resources Association (ELRA). — 2010. [Online] URL: https://www.re searchgate .net/publication/220746821_cognitive_eva luation_approach_for_a_controlled_language_post—editing_expe riment
12. PEMT [Online] URL: https://pemt.ru/pemt/].
13. 2018 Language Industry Survey -Expectations and Concerns of the European Language Industry [Online] URL: https://ec.eu ropa.eu/info/sites/info/files/2017_language_indust ry_survey_report_en.pdf
14. V gorodah skorost’ zhizni rastet na odin procent v god [Online] URL: https://lenta.ru/news /2007/05/02/speed/].
Shevchuk Ekaterina V., Nikiforova Zhanna A. Post-editing and typical mistakes in the computer-aided translation of academic, scientific, and journalistic texts. The article deals with typical errors in editing a computer-aided translation (CAT). Post-machine editing or post-editing (PEMT — post-edited machine translation or MTPE — machine translation post-editing) has now become an integral part of the translation process. The reason for this is the widespread practice of using computer-aided translation. A great deal of Russian and foreign translation companies recognize and welcome the use of CAT. Moreover, the job of post-editor is now gaining popularity, since the customer himself can often carry out computer-aided translation using the services of Google, Yandex, Microsoft, Memsource, etc., but does not have a sufficient degree of knowledge of a foreign language to perform post-editing. We have tried to categorize typical machine translation errors that a post-editor may encounter when working with academic, scientific, and journalistic texts, and provide recommendations for minimizing the number of such errors.
COMPUTER-AIDED TRANSLATION; CAT; POST-EDITED MACHINE TRANSLATION; PEMT; NEURAL MACHINE TRANSLATION; NMT-GENERATED TRANSLATION
Статья поступила в редакцию 03.11.2021; одобрена после рецензирования 12.12.2021 принята к публикации 28.12.2021.
The article was submitted 03.11.2021; approved after reviewing 12.12.2021; accepted for publication 28.12.2021
Citation: Shevchuk E.V. Nikiforova Zh.A. Post-editing and typical mistakes in the computer-aided translation of academic, scientific, and journalistic texts. Teaching Methodology in Higher Education. 2021. Vol. 10. No 39. P. 46-54. DOI: 10.18720/HUM/ISSN 2227-8591.39.04
© Санкт-Петербургский политехнический университет Петра Великого, 2021
-
Описание ошибок в машинном переводе
Применение
машинного перевода без настройки на
тематику (или с намеренно неверной
настройкой) служит предметом многочисленных
бродящих по Интернету шуток.
Зачастую
программы машинного перевода понимаются
как какое-то уникальное средство, которое
способно вытеснить живых, мыслящих
переводчиков. Некоторые пользователи
полагают, что, если с помощью компьютера
сегодня можно добыть любые сведения из
многочисленных информационных источников,
от него можно ожидать соответствующей
компетентности также в вопросах
качественной трансформации этих сведений
в любой возможный языковой формат.
Однако
ни для кого не секрет, что такое
преставление крайне ошибочное. Знающие
специалисты, равно как и производители
подобных программ, понимают, что в
действительности ситуация выглядит
иначе. Конечно, рекламируя свои программные
продукты, производители честно признаются,
что качество машинного перевода далеко
от идеального и что получение адекватного
перевода возможно только при вмешательстве
человека, однако не всегда раскрывается
тот факт, что человек, которому предстоит
обработать такой перевод, должен быть
квалифицированным переводчиком и ему
придется потратить массу времени на
придание машинному тексту качества,
достойного профессионального перевода.
И
как бы ни пытались производители
приукрасить достоинства своей продукции,
пользователи многочисленных
онлайн-переводчиков всегда имеют
возможность убедиться в том, что
виртуальные «толмачи» не всегда способны
достойно справляться с поставленными
перед ними задачами. Доказательством
этому служат многочисленные шутки,
переходящие с сайта на сайт и высмеивающие
недостаточную компетентность
онлайн-переводчиков в вопросах
качественного перевода. К числу любимых
развлечений скептически настроенных
пользователей онлайн-переводчиков
относится перевод коротких предложений
или текстов песен в различных направлениях
и сравнение полученного результата с
исходным вариантом. К избитым примерам
относится перевод предложения «Мама
мыла раму» на английский язык, который
звучит как “Mum washed the frame”. Если затем
снова перевести полученное предложение
на русский язык, то разные переводчики
выдают свои результаты: «мама вымыла
структуру» (перевод Translate.ru – компания
PROMT) или «мама помыла рамку» (вариант
Babelfish.yahoo.com). Всем известен также пример
с переводом предложения “My
cat has given birth to four kittens, two yellow, one white and one
black”,
выполненным онлайн-переводчиком компании
PROMT, которое в русскоязычном исполнении
звучит как «Моя
кошка родила четырех котят, два желтых
цвета, одно белое и одного афроамериканца».
Нужно отметить, что разработчики
поработали над усовершенствованием
своего продукта, так как раньше данное
предложение начиналось с абсурдного
«Мой кот родил…», однако радует, что
данный переводчик компетентен в вопросе
политкорректности. К числу подобных
примеров относятся также переводы
различных песен и литературных
произведений, доставляющие немало
веселья экспериментаторам.
Сотрудники
многих фирм на каждом шагу встречаются
с многочисленными примерами абсурдных
переводов, выполненных посредством
онлайн-переводчиков. Зарубежные клиенты,
желающие сделать запрос на перевод, или
коллеги, предлагающие свое сотрудничество
в сфере переводов, часто прибегают к
помощи онлайн-переводчиков, столкнувшись
с необходимостью перевода электронных
сообщений на русский язык.
Например,
однажды сотрудники одной из фирм получили
электронное сообщение следующего
содержания:
Привет
Уважаемые! Пожалуйста, как вы! Надеюсь,
ты штраф и в отличном состоянии health.
I пошел через ваш профиль сегодня на
www.multitran.ru
и я прочитал его и принял в ней интереса,
пожалуйста, если вы не возражаете, я
хотел, чтобы вы напишите мне по этому
ID (***@yahoo.com)
надеются услышать от вас в ближайшее
время, и я буду Жду ваших почту, потому
что я что-то очень важно, чтобы рассказать
вам. Много любви Грейс.
Автор
сообщения сопроводил данное обращение
исходным текстом на английском языке:
Hi
Dear! Please how are you! hope you are fine and in perfect condition
of health. I went through your profile today at www.multitran.ru and
i read it and took interest in it, please if you don’t mind i will
like you to write me on this ID (***@yahoo.com
) hope to hear from you soon, and I will be waiting for your
mail because i have something VERY important to tell you. Lots
of love Grace.
Не
нужно долго гадать, чтобы понять, что
сообщение на русском языке является
результатом работы онлайн-переводчика.
Кстати, путем несложного эксперимента
было установлено, что автором данного
перевода был онлайн-переводчик Google. Это
сообщение является ярким подтверждением
тому, что данный онлайн-переводчик не
особо преуспел в своем деле и вряд ли
может бросить достойный вызов
профессиональному переводчику. Не
вдаваясь в глубокий анализ, можно
отметить, что основным недостатком
онлайн-переводчика является незнание
грамматических правил (в основном это
касается согласования частей речи и
членов предложений), а также неумение
распознавать и корректно переводить
некоторые лексические единицы,
употребленные в рамках заданного
контекста, и устойчивые выражения, в
результате чего, вместо «надеюсь, у Вас
все хорошо», переводчик выдал нелепое
и искажающее смысл предложения выражение
«надеюсь, ты штраф» (слово «fine» было
употреблено в значении «штраф»). Истинная
причина получения таких низкосортных
переводов кроется в том, что программы
машинного перевода не способны учитывать
экстралингвистические факторы. Именно
поэтому многие переводчики дословно
переводят те или иные термины и, кроме
того, не всегда отличают имена собственные
от знаменательных слов.
Ярким
примером этому может послужить перевод
статьи, посвященной Лоре Буш, супруге
бывшего президента Америки, выполненный
с помощью программы-переводчика. Ее
полное имя зазвучало на французском
языке как «le buisson de Laura», то есть «кустарник
Лоры». Программа не распознала фамилию
«Bush» как имя собственное и дословно
перевела ее на французский как «кустарник».
Но вся нелепость этой ситуации заключается
в том, что на французском сленге слово
«buisson» имеет сексуальную коннотацию.
Данные
примеры свидетельствуют о том, что
научить самый современный компьютер
языковой логике значительно сложнее,
чем математическим алгоритмам и логике
статистического анализа. Чтобы создать
в той или иной степени связный машинный
текст, программа может лишь использовать
ограниченный набор определенных
лингвистических алгоритмов, заложенных
в ее базу. Сначала система подвергает
анализу структурные элементы исходного
предложения, затем изменяет его в
соответствии правилами языка и выдает
конечный вариант. Однако как бы ни
пытались производители программ
машинного перевода усовершенствовать
свои разработки, еще ни одна технология
не выдерживала сравнения с теми
алгоритмами перевода и многочисленными
трансформациями, которым учат живых
переводчиков в школах и вузах. Безусловно,
для получения связного текста программу
можно снабдить богатой словарной базой,
включающей устойчивые выражения, а
также подключить специализированные
словари, чтобы переводчик смог перевести
тематические тексты. Но, как показывает
реальный опыт работы с онлайн-переводчиками,
это лишь малая часть того, что необходимо
для обеспечения приемлемого качества.
Основной проблемой таких переводчиков,
равно как и других систем машинного
перевода, является отсутствие фоновых
знаний. Компьютер знает только языковые
соответствия, а ведь переводчику очень
часто приходится выходить за рамки
формального текста и обращаться не к
языковым знаниям, а к экстралингвистическим
факторам, включающим знания о реальном
мире, культуре, истории, технике.
Профессиональные переводчики, особенно
технические, – это очень образованные
люди, и все их знания непосредственно
задействованы в процессе перевода.
Только в таком случае может быть
гарантировано действительно первоклассное
качество переводов. Поэтому если
разработчики сервисов онлайн-перевода
стремятся к предоставлению адекватных,
качественных переводов, они должны
снабдить своих машинных переводчиков
такими же фоновыми знаниями и, главное,
научить их правильно обращаться с
заложенным багажом знаний. Проще говоря,
программа должна понять, что возникла
какая-то проблема, для решения которой
необходимо прибегнуть к дополнительным
знаниям, и правильно сформулировать
запрос к имеющейся базе. Показательным
примером служит перевод на западноевропейские
языки предложений, в которых упоминаются
известные правители или их дети. В таких
предложениях артикль, категория которого
характерна для языков данной языковой
семьи, должен ставиться в зависимости
от общего количества детей. Например,
при переводе выражения «сын царя Федора»
артикль необходимо выбирать в зависимости
от того, сколько сыновей было у царя
Федора.
В
качестве аналогичного примера можно
привести перевод надписи на постаменте
памятника, открытого во Франции в честь
Анны Ярославны, дочери князя Киевского
Ярослава Мудрого. Перевод надписи на
французском языке звучал как «Anne de
Kiev la reine de la France», и все бы ничего, если
бы не лишний артикль. В случае с Францией
«la France» звучит как «единая
Франция», что не искажает смысл. Что
же касается дочери князя, «la reine»
означает, что она единственная за всю
историю королева Франции. Переводчик,
знакомый со всеми нюансами французской
грамматики, не допустил бы такую нелепую
ошибку, а вот для электронного переводчика
– это довольно типичная ошибка.
Чаще
всего подобные шутки связаны с тем, что
программа не распознаёт контекст фразы
и переводит термины дословно, к тому же
не отличая собственных имён от обычных
слов. Тот же переводчик ПРОМТ превращает
«bra-ket
notation» в «примечание Кети лифчика»,
«Lie
algebra» — в «алгебру Лжи», «eccentricity
vector» — в «вектор оригинальности»,
«Shawnee
Smith» в «индеец племени шони Смит» и
т. п. Переводчик
Google, наоборот, слово «rice»
часто принимал за фамилию госсекретаря
США.
А
теперь рассмотрим примеры машинного
перевода отрывков из художественных и
научных текстов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- Языкознание
- Прикладная и математическая лингвистика
автореферат диссертации по филологии, специальность ВАК РФ 10.02.21
диссертация на тему: Анализ и оценка эффективности современных систем машинного перевода
-
Год:
2000 -
Автор научной работы:
Хроменков, Павел Николаевич -
Ученая cтепень:
кандидата филологических наук -
Место защиты диссертации:
Москва -
Код cпециальности ВАК:
10.02.21
450 руб.

Полный текст автореферата диссертации по теме «Анализ и оценка эффективности современных систем машинного перевода»
МОСКОВСКИЙ ПЕДАГОГИЧЕСКИЙ УНИВЕРСИТЕТ
на правах рукописи
РГБ ОД
ХРОМЕНКОВ 2 О НОЯ ?ПП0
Павел Николаевич
АНАЛИЗ И ОЦЕНКА ЭФФЕКТИВНОСТИ СОВРЕМЕННЫХ СИСТЕМ МАШИННОГО ПЕРЕВОДА
Специальность 10.02.21 — «Структурная, прикладная и математическая лингвистика»
Автореферат
диссертации на соискание учёной степени кандидата филологических наук
МОСКВА — 2000
Диссертация выполнена на кафедре теоретической и прикладной лингвистики Московского педагогического университета.
Научный руководитель: академик МАИ,
доктор филологических наук, профессор Ю.Н.Марчук
Официальные оппоненты: доктор филологических наук,
профессор А.Л. Семенов, кандидат филологических наук, доцент Веселов П.В.
Ведущая организация: Отдел прикладного языкознания
Института языкознания РАН
17-
Защита состоится: ‘ июля 2000г. в 11 часов на заседании диссертационного совета Д. 113.11.05 в Московском педагогическом университете по адресу: 107042 Москва, Переведеновский пер., 5/7.
С диссертацией можпо ознакомится в библиотеке Московского педагогического университета по адресу: 107005, Москва, ул. Радио, д. 10а.
Автореферат диссертации разослав Йюоня 2000г.
Ученый секретарь диссертационного еовега доктор филологических наук,-профессор ——Г.Т. Хухуии
Даппая работа посвящена анализу и типологическому описанию современных систем машинного перевода.
Мы живем в мире информационных технологий, которые прочно вош;и в нашу жизнь. С каждым годом увеличивается число пользователей Интернета -Всемирной паутины, которая претендует ш роль единого информационнохо пространства в планетарном маенггабе. Единственной преградой, которая незримо присутствует во всей Сети, является языковой барьер. Эта ггробле»ма, общая как для реального, так и для «виртуального» мира сети Интернет, до настоящего момента так и не нашла своего кардинального решения. Попытки внедрения универсального языка типа Эсперанто или какого-либо другого языка не привели к их массовому использованию, и единственным способом преодоления языкового несоответствия является перевод, известный еще с древнейших времен, когда этим делом занимались толмачи.
Но нынешний век, где информация изменяется 24 часа в сутки, применяются электронные средства связи, диктует свои условия. В такой ситуации классический подход к осуществлению перевода не всегда оправдывает себя, т.к. требует больших капиталовложений и временных затрат. В некоторых случаях более целесообразным представляется использование машинного игог автоматического перевода и систем машинного перевода (СМП). Развитие таких систем позволит оперативно осуществлять перевод информации и обрабатывать большие массивы документов в предельно сжатые сроки, т.е. удовлетворять основному требованию сегодняшней жизни: оперативной обработке огромных массивов информации при мшшматьяых затратах.
Выбор данной темы исследования обусловлен в первую очередь ее новизной, недостаточной степенью исследованности и актуальпостью рассматриваемых задач. Проблема эффективности машинного перевода является одним из ключевых факторов, определяющих перспективность развития данной области науки. В настоящее время не существует единой системы оценки эффективности работы существующих СМП. В данной работе предпринимается попытка проведения сравнительного анализа современных коммерческих СМП. В исследовании участвовали системы, осуществляклцие перевод с русского языка на английский и обратно и системы перевода с английского языка на немецкий и обратно.
Целью настоящей работы является сопоставительное исследование эффективности современных СМП. В основу качественного показателя результатов перевода и эффективности систем были положены не только лингвистические, но и экстралингвистические критерий оценки СМП.
Для достижения поставленной цели потребоватось разрешение следующих
задач:
— выявление современных СМП, нашедших сюе промышленное и коммерческое применение и являющихся уже не исследовательскими прототипами, а реально действующими системами, обладающими свойствами готового продукта;
— типологическое описание современных СМП и выявление доминирующего типа СМП;
— выделение основных критериев оценки эффективности машинного перевода (МП);
— проведение сравнительного исследования результатов переводов, выполненных современными СМП;
— анализ и типология ошибок при работе с СМП;
— апробация методов оценки на действующих системах МП и оценка их эффективности.
Теоретический аспект данной работы заключается в лингвистической разработке методов оценки. Системы рассматриваются, изучаются и оцениваются по принципу «черного ящика», который подразумевает отсутствие полной информации об алгоритмах работы системы, и на входном этапе мы априорно не знаем, с какой системой работаем. В результате исследования лингвистической компоненты систем МП создается теоретическое обоснование для определения типа системы и ее лингвистического обеспечения. Теоретическая значимость данного исследования заключается в возможности определения, дальнейшего моделирования и совершенствования лшн-Биотической составляющей не только в СМП, но и в целом в системах искусственного интеллекта (ИИ), неотъемлемой частью которых собственно и является МП. В рамках исследования предлагается расширить типологию переводных соответствий, предложенную Марчуком Ю.Н. (Марчук, 1983).
Практические исследования направлены на подтверждение правильности выработанных критериев и методов оценки СМЛ, возможности их использования в качестве тестового массива не только для рассматриваемых в данной работе СМП, но и в делом для оценки эффективности существующих СМП, которые работают с указанными языковыми парами. Практическая ценность данной работы заключается в том, что потенциальный пользователь СМП при выборе программы машинного перевода может воспользоваться приводимыми в данной работе тестами для проведения первичной оценки СМП.
Материалом исследования стали более 300 текстов на русском, английском и немедком языках. Источником языкового материала послужила сеть Интернет, наиболее динамично реагирующая па языковые преобразования современности.
Методами исследования послужили принцип «черного ящика», привлечение тестовых групп конечных пользователей, типологическое, лингвистическое и экстралингвисгическое сопоставительное описание.
На защиту выносятся следующие положения:
1. Доминирующим типом современных СМП являются СМП трансферного типа, получившие достаточно широкое промышленное и коммерческое распространение. Таким образом, системы трансферного типа представляют собой единственный класс СМП, который может быть подвержен сравнительно-сопоставительному исследованию с целью выявления эффективности современных систем МП.
2. Функционирование, развитие и совершенствование систем машинного перевода в настоящее время происходит в сети Интернет, которая является источником материалов не только для тестирования систем, но и служит рабочим пространством для такого рода систем в планетарном масштабе. Дальнейшая эксплуатация и разработка новейших СМП будет осуществляться посредством Интернета.
3. При типологическом исследовании ошибок при работе систем МП следует придерживаться комплексного подхода, базирующегося на учете этапов функционирования системы. Следует выделять ошибки автоматического анализа и синтеза, которые в свою очередь подразделяются на более конкретные подклассы, отражающие работу алгоритмического аппарата системы.
4. Подавляющее большинство современных СМП основано на принципе переводных соответствий. В результате типологического исследования модели ■ переводных соответствий возникла необходимость создания расширенной классификации переводных соответствий. Предложенная типология переводных соответствий на основе лингвистического обеспечения СМП позволяет более широко рассматривать проблему ошибок при работе систем МП и может быть использована при создании новых систем, основанных на применении принципа параллельных текстов.
5. Практическая классификация современных СМП, основанная на учете экстралингвиетпческих факторов и качества переводов, выполненных данными системами, позволяет составить впечатление об эффективности и функциональных возможностях каждой системы. Указанная 1-радация СМП представляет практическую ценность при выборе конкретной системы МП.
СТРУКТУРА РАБОТЫ
Диссертация состоит из введения, трех глав, заключения, списка использованной литературы и одного приложения. Приложение содержит образцы параллельных переводов текста в различных СМП.
СОДЕРЖАНИЕ ИССЛЕДОВАНИЯ
Во введении обоснован выбор темы, ее актуальность, научная новизна, дели, задачи, теоретическая и практическая ценность диссертационно!« исследования. Сформулированы методы исследования и положения, выносимые на защиту.
Первая глава посвящена описанию современного состояния машинного перевода и типологической классификации существующих коммерческих систем МП.
За последнее десятилетие значительно возрос интерес к разрабопсс и использованию СМП. Такое положение вещей связано в первую очередь с бурным ростом и развитием вычислительной техники и постепенной интеграцией всемирного информационного пространства в единую сеть, прототипом которой
является Интернет. Уже более года на таком крупном и известном поисковом узле как AltaVista используется машинный лерепод в режиме реальною времени. На данном сервере, получившем название Babelfish, существуют различные возможности бесплатного перепода:
— можно перевести первые 250 слов любого документа, имеющегося у потенциального посетителя сайга;
— можно перевести любую страничку, задав в соответствующем окне ее адрес;
— а можно перевести и результаты поиска, полученные даяиой поисковой системой.
С 1994 года в службе CompuServe проводится эксперимент по внедрению и использованию СМП п онлайновых форумах. В настоящее время функция машинного перевода внедрена на б форумах. Компания Globalink. организовала в сети Интернет онлайновую службу машинного перевода, получившую название Comprende и являющуюся реачьной коммерческой системой, осуществляющей перевод с использованием СМП.
Российские ресурсы сети Интернет в области онлайнового перевода не сто ль обширны и разнообразны, что определяется в первую очередь ограниченным числом фирм, профессионально занимающихся созданием СМП. Перевод в режиме реального времени мозкпо полутать на сайте признанного лидера в области создания российских СМП, фирмы «ПРОМТ, Translate.ru. Перевод осуществляется с русского языка на английский, немецкий, французский и обратно, а также с английского на французский и обратно, с английскою на испанский, с немецкого на английский и с немецкого языка на французский и обратно. На сайте фирмы «Арсен&ть», занимающейся разработкой СМП, также имеется возможность осуществления онлайнового перевода. Однако в отличие от сервера фирмы «ПРОМТ», перевод осуществляется только с английског о языка на русский и обратно.
В последнее время в комплект поставок современных СМП все чаще и чаще входят программные продукты, обеспечивающие возможность перевода вебстраниц, электронной почты и онлайновых конференций.
Среди зарубежных фирм-производителей СМП, следует отметить компании SYSTRAN и Globalink. В комплект поставки SYSTRAN PRO 2.0 входит программа для перевода в Сета (WcbTrans), которая поддерживает все использующиеся в CMII рабочие языки, также существует возможность подключения модулей перевода к
почтовой программе Eudora и Интернет-браузеру Netscape Navigator. Компания Globalink- также разработала программу перевода в Интернете под названием Web Translator и создала модули перевода для программы Eudora. Фирма «ПРОМТ’ разработала Интернет-переводчик, подучивший название PROMT Internet. Он переводит с английского, немецкого, французского языков на русский и обратно. Компания «Арсеналь» также выпустила Интернет-переводчик под названием «Сократ интернег», представляющий собой браузер на основе Internet Explorer 4.0, который переводит с английского, немецкого, французского языков и обратно.
Системы машинного перевода занимают немаловажное место среди лингвистических процессоров, относясь в большей степей! к классу текстовых процессоров. Ках отмечал Пиотровский Р.Г., к лингвистическим процессорам относят автоматизированные системы обработки текстовой и речевой информации. К классу текстовых процессоров, согласно классификации, предложенной Златоустовой JI.B., Королевы« Э.И, Марчуком Ю.Н. и другими авторами, кроме СМП также относятся (ГрязнухинаТ.А., Зубов A.B., Нелюбин Л.Л., Smith P.D.):
— автоматизированные информационные системы (АИС) и системы управления базами данных (СУБД);
— автоматические словари;
— системы автоматического проектирования (САПР);
— системы машинного перевода (СМП);
— редакционвд-издательские системы;
— системы автоматической компрессии текстов;
— системы автоматической адаптации текстов;
— автоматизированные обучающие системы;
— экспертные системы;
— системы шифровки и дешифровки текстов;
— системы автоматической атрибуции текстов.
Системы машинного перевода, являясь лишь частью перечисленных выше лингвистических процессоров, тем не менее, юрагот важную роль в развитии лингвистических автоматов. Б настоящее время наибольшее развитие получит! СМП, относящиеся к классу текстовых процессоров. Несмотря на это, ведутся активные работы в области создания СМП устной речи на иностранный язык. Такие
исследования проводились в British Telecom, SLT, ATR, при создании системы Verbmobil, в университете Каряеги Меллона в рамках проектов SNAP и Janus. Таким образом, можно говорить о непосредственной снязи СМП с другими текстовыми (в частности с автоматизированными информационными системами (АИС) и автоматизированными переводными словарями) и речевыми процессорами. Особого внимания заслуживает уже состоявшийся коммерческий проект, который осуществила компания Linguatec. Суть этого проекта заключается в слиянии СМП Personal Translator и системы распознавания речи Via Voice компании IBM для преобразования речи в текст, дальнейшего его перевода и обратного преобразования в речь, что является, по сути, переводом.
Современные СМП, согласно классификации, предложенной А.Д. Бакуловым, H.H. Леонтьевой, Э.И. Королевым н другими исследователями, подразделяются на следующие типы (Капанадзе О.Г., Кулагина О.С., Bátori I., Ilutchins W.J., Meli S., Schmitz В., Trujillo А.):
— СМП прямого rana;
— Трансферные СМП;
— СМП семантического типа.
Подавляющее большинство современных коммерческих СМП относится к системам трансферного типа. Кроме этого, мм полагаем, что, учитывая степень современного теоретическою обоснования СМП, совершенно уместно говорить об одном доминирующем типе СМП, а именно о системах трансферного типа и их модификациях (системы, основанные на использовании примеров и параллельных текстов, Example-Based Machine Translation (ЕВМТ) и т.д.).
Системы прямого типа в настоящее время практически не используются, став достоянием истории развития СМП. Системы, основанные на использовании баз знаний и языка-посредника, на сегодняшний день все же являются системами будущего, находясь на этапе лабораторных исследований и являясь, по сути, экспериментальными системами.
Следует также проводить классификацию СМП по степени их разработанности. В соответствии с делением, предложенным H.H. Леонтьевой, З.М. Шаляпиной и Э.И. Королевым, мы подразделяем СМП на следующие типы:
— исследовательские прототипы (изложен принцип действия системы безотносительно к условиям ее функционирования);
— экспериментальные системы (системы, прошедшие проверку на экспериментальных тестовых массивах);
— промышленные системы, работающие с реальными текстами, имеющие определенные помехоустойчивые, качественные и скоростные характеристики и прошедшие тестовые испытания,
— коммерческие системы — системы, обладающие всеми свойствами промышленных систем, предназначенные для коммерческой продажи и представляющие собой законченный самодостаточный продукт, имеющий свойства товара.
Подавляющее большинство рассматриваемых; в данном исследовании систем МП относится к коммерческим системам.
В 1952 году при поддержке фонда Рокфеллера в Массачусетсом технологическом институте (MIT) прошла первая конференция, посвященная проблемам машинного перевода. Результатом этой конференции стало создание в Джорджтаунском университете исследовательской группы под руководством Леона Досгерта, которая занялась подготовкой первого эксперимента по машинному переводу. Публичная демонстрация МП состоялась 7 января 1954 года в Нью-Йорке, в здании вычислительного центра IBM и получила впоследствии название Джорджтаунского эксперимента. Исследования в области МП в СССР начались вскоре после проведения Джордасгаунского эксперимента в начале 1954 года. В это время начали работу 3 основные группы; две в Москве и одна в Ленинграде. В 1955 году в Институте точной механики и вычислительной техники АН СССР проходит первый эксперимент по осуществлению МП в СССР. В рамках эксперимента на компьютере БЭСМ Академии наук СССР был осуществлен перевод с английского языка на русский текстов по прикладной математике. Объем словаря составлял уже 2300 слов. В 1956 году в Москве была создана Лаборатория машинного перевода под руководством Ю.А. Моторина. К 1957 году группа Моторина обработала почти 5 млн, словоупотреблений, на основе которых были созданы частотные словари, покрывающие до 98,5% английского текста газетной тематики. В 1959 году Лаборатория машинного перевода продемонстрировала СМИ, способную
переводить любые английские тексты общественно-политической тематики. Система могла работать на любом типе ЭВМ, что обеспечивало ее мобильность. Несмотря на то, что данная СМП нуждалась в доработке, ее можно с полным правом отнести к первым промыпшешиым СМП.
Особенностью систем МП прямого типа является перевод достаточно низкого качества, используемый в основной в качестве чернового варианта. К системам прямого перевода относятся ранние версии таких прохрамм как SYSTRAN, LOGOS,
SPANAM, TRANSOFT, АМПАР-АНРЛП-СБРИНТ, СИЛОД, GERENG-GERRUS и др.
С середины 60-х годов начинается бурное развитие синтаксической теории. Для систем МП данного типа характерен развернутый синтаксический анализ и синтез, причем анализ осуществляется в категориях входного языка, а синтез в категориях выходного языка. Для того чтобы преобразовать результаты анализа в категории, используемые для синтаксического синтеза, требуется трансфер. Следует отметить, что современные трансфсрные СМП, согласно концепции переводных соответствий, предложенной Марчуком Ю.Н., все же целесообразно отнести к системам машинного перевода траясфсриого типа, основанным на переводных соответствиях.
Переводные соответствия подразделяются на:
— эквивалентные (эквиваленты, появившиеся в силу языкового тождества);
— вариантные (контекстуально-зависимые эквиваленты);
— трансформационные (требуют различных преобразований для правильной передачи смысла).
В 1984 году М. Нагао предложил принцип перевода с помощью примеров или параллельных текстов (Example-Based Machine Translation (ЕВМТ)), который во многом перекликается с концепцией переводных соответствий, выдвинутой Ю.Н. Марчуком. Принцип действия систем МП, основанных на использовании параллельных текстов, заключается в создании архива переводов, где храгоггея уже переведенные предложения, как на исходном, так и на выходном языках. Кроме этого структура предложений, которые носят наиболее общий характер, представляется в виде эталона (как во входном, так и в выходном предчожениях), по аналогии с которым строятся реальные предложения.
В последнее время стали также создаваться СМП, использующие комбинированные принципы перевода (mulii-engine machine translation, МЕМТ). В таких системах наряду с СМП травсферного типа существует архив переводов, принцип действия которого описан выше. Среди современных коммерческих СМП к этому классу относятся СМП Langenscheidt T1 Plus 3.0 и Power Translator Plus.
Оценивая состояние современных СМП трансферного типа, следует отметить доминирующую роль модели «текст-текст», предложенной Марчуком Ю.Н. и являющейся продолжением его концепции переводных соответствий.
В 80-х годах появились СМП, основанные на знаниях (КВМТ). Основным отличием данных систем от других программ машинного перевода является наличие компоненты, включающей экстралингвистические знания. К этому классу относятся системы семантического типа, иснользурщие , модель. ‘¡смысд<->текст»,
Ъ cz^^roua-bui симтф Olfr- Г Г if/
. пазраоотаннуку) А.К. Жолковским, И.А. Мельчушм. Существует достаточное ‘PlJUsuM^ КЛлЩшга^^Яи» . , h £ / crfi. rt 7 -i^ïT,
‘ количество исследовательских прототипов данного класса: ASCOF, ATLAS 11, DLT,
CONTRAST, HICATS/JE, КВМТ-89, LUTE, PIVOT, PLAIN, ROSETTA, SEMSYN,
TRANSLATOR. Данное направление, возможно, получит свое широкое
распространение лшшь после прорыва в области создания систем ИИ, когда станут
возможными формализация и представление в системе экстралингвистческих
знаний.
Следует отметить основные тенденции развития, наметившиеся в последнее
время:
— распространение номенклатуры СМП — увеличение числа рабочих языков и тематики систем;
— переход к разработке речевых СМП, связь с текстовыми СМП и другими речевыми и текстовыми ЛП в интегральных системах;
— сокращение сроков разработки СМП, распространение промышленных и коммерческих систем МП трансферного типа;
— важность этапов совершенствования и оценки эффективности СМП;
— массовое внедрение СМП в сети Интернет и дальнейшее распространение систем во Всемирной паутине.
Вторая глава посвящена типологическому описанию ошибок при работе МП и построению расширенной модели переводных соответствий.
Проблемой оценки эффективности СМП занимаются на протяжении длительного времени. Несмотря на все многообразие предлагаемых методик, в настоящий момент нет единой общепринятой методики оценки эффективности СМП.
Кроме практического подхода к оценке переводов, выполненных с помощью систем МП, существуют и: теоретические аспекты данной деятельности. Ванников Ю.В. предлагает оценивать перевод, учитывая различные типы адекватности перевода: семантико-стилистическуго, функциональную и дезидеративную. Соотнесенность перевода с оригиналом также может быть выявлена на основе их преобразований в базиспые структуры и последующего сравнения с учетом некоторого числа допустимых расхождений. Такие трансформации в глубинно-синтетические структуры предлагаются Мартемьяновым Ю.С., а Шаляпина З.М. преобразует их в глубинно-семантические структуры. А. И. Новиков предлагает сравнивать тексты оригинала и перевода на основе декотатной структуры предложений. Королев Э.И., придерживаясь традиционного подхода к оценке качества перевода, предлагает считать основными критериями эффективности перевода понятность и адекватность. Кулагина О.С. в своей работе отмечает, что для репрезентативности оценки эффективности СМП необходимо проводить их тестирование на представительных массивах информации. Проблемой понятности и адекватности перевода, выполненного СМП, занимались не только отечественные ученые, цо и их зарубежные коллега. Одним из первых результатов оценки эффективности СМП можно считать знаменитый доклад ALP АС.
Приведем пятибалльную шкалу оценки перевода, предложенную Nagao:
1. Смысл предложения понятен и не возникает никаких вопросов. Грамматика, словоупотребление и стиль соответствуют общей структуре текста и не требуют постредактирования.
2. Смысл предложения понятен, но возникают большие проблемы с грамматикой, словоупотреблением и стилем.
3. Общий смысл предложения понятен, но смысл некоторых его частей вызывает сомнение из-за неправильного грамматического строя,
словоупотребления и стилистических ошибок. Требуется обращение к оригиналу.
4. В предложении имеется большое количество грамматических, словоупотребителышх и стилистических ошибок. Смысл предложения с трудом можно понять после внимательного изучения.
5. Смысл предложения непонятен.
Критерий адекватности, наряду с критерием понятности, являются одними из важнейших элементов оценки качества перевода. Для исследования большинства коммерческих СМП независимыми экспертами применяется принцип «черного ящика», когда предположение о внутренней структуре системы МП и ее типе делается на основании выполненных ею переводов. В противовес принципу «черного ящика» используется принцип прозрачности системы, иначе именуемый «glass box». Этот принцип применяется при оценке эффективности системы ее создателями и разработчиками. Также широкое применение нашел принцип использования тестовых массивов текста. Для этой цели используются как реальные тексты, гак и искусственно созданные для проверки правильности перевода того шш иного языкового явления. Так Маргарет Кинг и Фалкедал предлагают комбинированное использование тестовых и реальных массивов текста для того, чтобы проверить функционирование системы не только в заранее заданных для нее условиях, но и в непредсказуемой обстановке реального текста, смоделировать которую практически невозможно.
При проведении оценки эффективности СМП немаловажную роль играет цель такого исследования а его непосредственные участники. Согласно градации, принятой М. Кинг, Труджилло, Хатчинсом, Сомерсом и другими исследователями, выделяются следующие группы:
Исследователи Спонсоры исследований Разработчики Покупатели Переводчики
Конечные пользователи переводов
Системы МЛ кроме лингвистической компоненты состоят также из программного обеспечения. D связи с этим в рамках проекта EAGLES/TEMAA были разработаны и созданы специальные стандарты (ISO 9126 и ISO 14000). Для этого были специально выявлены шесть основных характеристик качества программного обеспечения: функциональность, надежность, практичность, эффективность, открытость и портативность. Данные критерии применимы также ко всем остальным типам программного обеспечения.
Несмотря иа многообразие рассмотренных теоретических и практических подходов к решению данной проблемы, их объединяет одна общая тенденция: какой бы ни была методика оценки качества переводов, она так или иначе исследует, классифицирует и пытается устранить ошибки, допущенпые в процессе перевода.
Для оценки рассматриваемых нами систем применяется принцип «черного ящика», теоретически обоснованный моделью нсреводиых соответствий. Модель переводных соответствий состоит из двух компонентов: предметного и динамического. Следует сразу отметить, что динамический компонент не будет рассматриваться в рамках данной работы ввиду невозможности исследования лингвистического обеспечения и алгоритмов рассматривасмых систем. Предметный компонент также состоит из двух элементов: предметного и переводного. В состав предметного элемента входят лексика, грамматика и семантика. Перечисленные составляющие во взаимодействии образуют текст. Переводной компонент состоит из типов переводных соответствий, с учетом которых будет строиться типология ошибок при работе МП. Нами рассматриваются 3 основных типа переводных соответствий: эквивалентные, вариантные и трансформационные.
Развивая модель переводных соотвегствий, предложенную Марчуком Ю.Н., Киселев A.II. предлагает уточнить типологию переводных соответствий, сообразно условиям функционирования СМП СПРИНТ. Согласно уточненной типологии, выделяются следующие типы переводных соответствий: на уровне отдельных слов:
— однозначные (табличные);
— многозначные (схемные); на уровне словосочетаний:
— табличные;
— схемные.
на уровне грамматических конструкций (схемные); на уровне грамматических категорий (схемные).
Под табличными понимаются независимые от контекста соответствия, которые задаются в системе в виде жестко взаимосвязанных таблиц. Схемными считаются такие соответствия, выбор которых, несмотря на конечную заданиость всех возможных вариантов, зависит от контекста.
Основываясь на модели переводных соответствий и результатах эмпирических исследований современных коммерческих СМП, проведенных по принципу «черного ящика», нами были выявлены следующие типы ошибок, характерных для МП:
— ошибки автоматического анализа:
— лексического анализа
— морфологического анализа
— синтаксического анализа
— текстового анализа;
— ошибки автоматического синтеза:
— текстового
— семантического
— синтаксического
— морфологического
— лексического.
Ошибки лексического анализа наиболее гранспарентны при оценке качества МП. К таким ошибкам относится появление в выходном тексте непереведенных или неправильно переведенных слов, причинами которого являются как неполнота автоматического словаря, так и наличие орфографических ошибок во входном тексте и неправильное разрешение лексической омонимии и полисемии: Publishable translation / publishable трансляции, Types of translation / типы трансляции, Natural-language translation enigine / двигатель трансляции естественного языка / перевода естественного языка, развитие Интернета / Entwicklung Интернета, darüber
hinaus ! out of darüber, ohne deren Layouts zu verändern / without layouts to verändern, mit eingeschränktem Funktionsumfang J with United Funktionsumfang.
Приведенные выше примеры отражают наиболее общие ошибки лексического анализа, вызванные неполнотой словаря и неправильным разрешением омонимии и полисемии. Словарные ошибки, относящиеся к разряду лексикографических, moot быть достаточно легко исправлены путем дополнения словарей и создания при необходимости алгоритмов разрешения омонимии и полисемии. В настоящее время проблема многозначности решается в основном путем создания узкоспециализированных словарей, позволяющих пользователю наиболее точно задать контекст переводимого текста.
К ошибкам, вызванным конкретной работой автоматического анализа, относятся ошибки нарушения согласования и управления. Такие ошибки, как отмечает Рябцева Н.К., могут быть вызваны неправильной работой не только морфологического, но и синтаксического, а также семантического блоков. Примером таких ошибок может служить неправильно заданное падежное управление (например: to help companies expand i помочь компаниям расширять; finds useful — находит … полезный), предполагав управление (например, send invoices to а different address — посылать счета различному адресу / послать счет фактуру в другой адрес), неправильное согласование числа (company officials say-иредставители компании говорит).
К ошибкам собственно морфологического анализа относится неправильное определение грамматических планов. Проиллюстрируем данное явление на конкретных примерах: доставка заказанных товаров ¡delivery of booking goods, Gut ist die Kompatibilität / Tocap является совместимостью, ist gedacht / is imaginarily.
К ошибкам синтаксического анализа относится неправильное или неполное определение синтаксической структуры входного ¿федложения, которое в свою очередь ведет к неправильному синтезу выходного предложения: Der virtuelle Uebersetzer im Word … der sich erweitern läßt J The virtual translator … which is extend can, My newsletter is read in France … / Мое информационное письмо читать в Франция.
Среди ошибок, вызванных текстовым анализом, самыми распространенными являются неправильное распознавание антецедентов местоимений, анафорических
отношений и эллиптичных структур. К сожалению, данная проблема до настоящего момента не нашла своего кардинального решения, так как распознавание и понимание данных структур человеком основывается на использовании понятийно-категориального аппарата и широком рассмотрении контекста. Приведем примеры таких ошибок: … I received letter from a French company … I put it through the translator / … Я получил символ от Французской кампании … Я помещал это через переводчика … / Я устанавливаю этому через переводчика / Ich führte sie durch …
. По завершении автоматического анализа и необходимых трансферных. преобразований наступает этап автоматического синтеза. При такого рода преобразованиях, равно как и при автоматическом анализе, системы допускают целый ряд ошибок на уровне текстового, синтаксического, морфологического и лексического синтеза.
Ошибки текстового синтеза заключаются в неправильном синтезе связочных конструкций, антецедентов и т.д. Приведем примеры ошибок при текстовом синтезе: The explosion of interest in machine translation is not about productivity … It’s about trying to do the types of translations… / Взрыв интереса (процента) в машинном переводе не относительно производительности… Это — относительно попытки делать типы трансляций…
В процессе синтаксического синтеза наиболее распространенной ошибкой является неправильный порядок слов в выходном тексте: Siemens habe sich ehrgeizige Ziele gesetzt und werde nicht auf Etappenzielen stehen bleiben. / Siemens садился ehrgeizige цели и не будет относиться (не стоять) на цепях этапа остаются. The current Web site allows users to … / Der aktuelle Netzstandort Benutzern erlaubt…
К ошибкам морфологического синтеза относятся: неправильное употребление форм глаголов, неверное согласование составного сказуемого, некорректный синтез слов, принадлежащих к различным частям речи: Августовский кризис не привел к значительному снижению трафика / august crisis not has bringed about significant reduction of traffic …, I got the idea /Я получать идея.
К ошибкам лексического синтеза мы относим не только собственно лексические ошибки, но и ошибки управления. Такая классификация рассматривается нами уместной в связи с тем, что функции сипьноуправлязощих предлогов в подавляющем большинстве случаев включаются в информационную
ячейку слова в АС (автоматическом словаре). Приведем некоторые примеры: бизнесмены / businessmans, российский пользователи / russia users, пользователи Интернета / users Internonthal, machine translation / Maschirte-Uebersetzung.
Ошибки, допущенные на этапе лексического анализа, оказывают влияние на морфологический, синтаксический и текстовый этапы анализа и ммут повлечь за собой появление новых ошибок на указанных этапах. Неправильная работа системы на этапе анализа и некорректное разрешение неоднозначностей ведут в свою очередь к появлению ошибок на этапе синтеза. Исходя из этого, мы полагаем, что ошибки, возникающие в результате работы СМП, необходимо рассматривать системно, с учетом не только имеющейся па выходе информации, но и с привлечением дополнительных сведении о работе тех или иных алгоритмов перевода на каждом языке системы.
Таким образом, в результате наших исследований мы пришли к выводу о целесообразности рассмотрения переводных соответствий иа лексическом, морфологическом и синтаксическом уровнях. Основой предложенного деления соответствий послужил!’ результаты типологического исследования ошибок при работе СМП. Поэтому мы выделили следующие типы переводных соответствий: по программному обеспечению: табличные схемные
по лингвистическому обеспечению:
эквивалентные соответствия лексического типа; эквивалентные соответствия морфологического типа; эквивалентные соответствия синтаксического тина; вариантные соответствия лексического типа; вариантные соответствия морфологического типа; варианпше соответствия синтаксического типа; трансформационные соответствия лексического типа; трансформационные соответствия морфологического типа; трансформационные соответствия синтаксического типа; трансформационные соответствия текстового типа.
Рассмотрим переводные соответствия лексического типа с точки зрения оцешш качества работы современных. СМП и выявления ошибок перевода. Эквивалентные соответствия лексического типа представляют собой диалектическое противоречие, являясь, с одной стороны, наиболее простыми элементами для перевода, а, с другой стороны, составляя едва ли не самый обширный класс переводческих ошибок. Ввиду однозначного соответствия лексических единил входного и выходного языка их перевод осуществляется по установленной схеме, а именно путем внесения в автоматический словарь значений соответствующих единиц.
Вариантные соответствия лексического типа также составляют один из наиболее крупных классов лексических ошибок при МП. В отличие от эквивалентных соответствий, вариантные соответствия лексического типа и ошибки, вызванные их неправильным переводом, не могут быть столь оперативно устранены. Разрешение многозначности в процессе МП решается не только словарными, но и алгоритмическими методами. Тем не менее, данная проблема не имеет однозначного решения, и пополнение словарей пользователем может вызвать некорректную работу системы на других массивах текстов. Приведем примеры таких ошибок: Web Site / Selmnetz-Aufstellungsort ! участок ткани / Spinnwebe / Gewebe-Gelande, I received a letter /Я получил символ, newsletter / Mitteilungsblatt.
Трансформационные соответствия лексического типа — наиболее сложный вид соответствий для перевода посредством СМП, который в большинстве случаев переводится некорректно, так как требует коренного преобразования структуры словосочетания.
Рассмотрим функционирование переводных соответствий на морфологическом уровне. Под эквивалентными соответствиями морфологического типа мы предлагаем рассматривать такие соответствия морфологического уровня, которые остаются пеизметшми и образуют переводное единство в рамках взятого текста. В приводимом ниже примере, глагол «sein», который в исходном предложении находится в прошедшем времени и множественном числе, переводится на русский язык глаголом «быть», который также представлен во множественном числе и прошедшем времени: Die Uebersetzungen waren bei schwierigen Texten holprig / Переводы были при трудных текстах holprig. Суть данных соответствий
заключается в том, что сходные структуры, вне зависимости от контекста и прочих факторов будут иметь одинаковый перевод на уровне морфологических характеристик. Мы полагаем, что закономерности такого рода должны найти свое отражение при функционировании ЕВМТ-систем (Example-Based Machine Translation systems), позволяя осуществлять корректный перевод по аналогии с образцом, имеющимся в архиве системы.
К вариантным соответствиям морфологического типа относятся конструкции, при переводе которых существует несколько взаимоприемлемых в условиях машинного перевода вариантов отображения морфологических характеристик. Причем оба варианта считаются приемлемыми для СМП с последующим выбором доминирующего варианта на уровне постредактирования человеком: шляпа моего отца/ der Hut von meinem Vater, der Hut meines Vaters, оперение птицы /das Gefieder von dein Vogel; das Gefieder des Vogels.
Трансформационные соответствия морфологического типа встречаются довольно редко, если их рассматривать в чистом виде, как они описаны у Марчука Ю.Н., где они функционируют в основном на синтаксическом уровне.
Минимальной единицей переводных соответствий синтаксического типа является предложение. Целесообразно также отмечать эквивалентные, вариантные и трансформационные соответствия и на уровне предложений. Под эквивалентными соответствиями синтаксического типа мы предлагаем рассматривать такие предложения, структура которых на входном языке полностью соответствует структуре предложений на выходном языке: Sie läuft unter Windows 95/98 und MT4.0 sowie mit eingeschränktem Funktionsumfang auch unter Window,i3. Ix. / It runs under Window 95/98 and MT 4.0 as well as with reduced function range also under Windows 3Jx.
Трансформационные соответствия синтаксического типа подразумевают полное перестроение структуры выходного предложения rio сравнению со структурой входного предложения. Приведем для иллюстрации пример, заимствованный у Комиссарова: If the funeral had been yesterday, I could not recollect it better. Правильно это предложение переводится на русский язык следующим образом: «Я помню эти похороны так, как будто они были вчера». А вот как его перевели системы МП: Если похороны были вчера, я ne мог бы
вспоминать их лучше. Wenn das Begräbnis gestern gewesen war, könnte ich sich nicht besser erinnern. Результаты перевода свидетельствуют о том, что данные структуры, в которых необходима трансформация, не всегда правильно переводятся СМП, требуя редакторской правки.
В результате типологического исследования ошибок машинного перевода стало возможным уточнение модели переводных соответствий с вычленением новых типов соответствий, характерных дня функционирования современных СМП. Расншрецкая классификация позволяет определять соответствия и, соответственно, исправлять ошибки на всех языковых уровнях, используемых в современных системах.
Третья глава посвящена описанию действующих коммерческих систем и оценке их эффективности. Объектом исследования стали следующие СМП: PROMT 98, SYSTRAN PRO 2.0, СПРИНТ-5, Сократ 2.0, Langenscheidt T1 Standard 3.0, Personal Translator Plus 2.0, I’fnver Translator Deluxe и опНпс-переводчики (wvwv.translate.ru, Сократ онлайн).
Системы машинного перевода, рассматриваемые в нашем исследовании, тестируются по принципу «черного ящика» в соответствии с типологией ошибок, изложенной во второй главе. Каждая система оценивается по пятибальной шкале:
5 — отличный перевод (смысл нонятен, требует минимального постредактирования)
4 — хороший перевод (общий смысл понятен, требуется постредактирование)
3 — удовлетворительный перевод (общий смысл в большинстве случаев понятен, на требуется постредактирование с обращением к оригиналу)
2 — неудовлетворительный перевод (общий смысл б» обращения к оригиналу понять сложно, необходим большой объем постредактирования)
1 — неприемлемый перевод (смысл понять невозможно, обьем постредактирования сопоставим с выполнением перевода еще раз)
Оценка понятности и адекватности перевода исходному тексту осуществлялась не только самими исследователям!, к этому анализу привлекались также участники контрольных групп, в состав которых входили студенты лингвистического отделения Московского педагогического университета (МПУ). Помимо лингвистических факторов, которые легли в основу оценочной шкалы для рассматриваемых СМП, анализироватись также и экстралингвистические факторы. В результате исследования были получены следующие результаты, свидегельстауюшие об эффективности рассматриваемых систем:
Группа СМП, поддерживающая русский язык: Англо-русское направление перевода
1. CMII PROMT 98: перевод подавляющего большинства текстов удовлетворительный (3 — в скобках представляется бал по предложенной ранее оценочной шкале), встречаются тексты, которые могли бы быть отнесены к разряду хороших переводов (4). Постредактирование требуется во всех случаях. Занимает первое место среди систем, осуществляющих перевод с английского языка на русский. В процессе перевода требуется пополнение пользовательского словаря. В некоторых случаях сложно понять выходной текст без обращения к оригиналу, и ои не всегда адекватен оригиналу. По сервисным возможностям и количеству специализированных словарей данная СМП является бесспорным лидером. PROMT 98 считается самой дорогой программой среди СМП российских разработчиков.
2. СПРИНТ-5 характеризуется удовлетворительным переводом текстов (3). Выходные тексты требуют обязательного постредактирования. Система занимает второе место среди российских СМП по качеству перевода. СМП СПРИНТ-5 требует дальнейшей отладки и изменения некоторых алгоритмов перевода. Сервисные функции системы и ее цепа исследованию не подвергались, так как на настоящий момент данная СМП не является конкурентоспособной по данным показателям.
3. Сократ 2.0: данная CM1I осуществляет перевод удовлетворительного качества (3), требующий значительного постредактирования. Некоторые отрезки выходного текста невозможно понять без обращения к оригиналу. Требуется пополнение словарей и расширение их номенклатуры, которая уступает рассмотренным выше системам. Сервисные функции системы крайне отраничены. Данная СМП занимает третье место среди остальных программ Mil по качеству перевода и сервисным функциям. Соотношение цепа/качество является сбалансированным.
Русско-английское направление перевода
PROMT 98: система показала хорошее качество перевода (4) с необходимым постредактированием. Количество незнакомых слов было незначительным. Рассматриваемая СМП занимает первое место среди систем МП с русского языка на английский. Сочетание сервисных функций и количества словарей является оптимальным. Соотношение цена/качество является несколько непропорциональным с явным завышением в сторону стоимости системы.
1. SYSTRAN PRO 2.0: система выполняет переводы хорошего качества (4), требующие дальнейшего постредактирования. Требуется некоторое пополнение словарей системы. По качеству перевода и сервисным функциями СМП SYSTRAN PRO 2.0 занимает второе место. Учитывая, что русский язык не является основным языковым направлением, разрабатываемым в системе SYSTRAN, такие результаты тестирования свидетельствуют о высоком уровне всей системы. По сервисным характеристикам СМП SYSTRAN PRO 2.0 уступает СМП PROMT 98, однако количество специализированных словарей достаточно велико. Соотношение цена/качество полностью соответствует предоставляемым программой переводам и по этому показателю CMII SYSTRAN PRO 2.0 опережает СМП PROMT 98, предоставляя качественные переводы при более низких капиталовложениях. Основным достоинством системы является го, что все специализированные словари (а их насчитывается 22) поставляются в комплекте с программой и входят в ее базовую стоимость.
2. Сократ 2.0 показала удовлетворительное качество перевода (3), требующего значительного постредактирования. В протестированных текстах были обнаружены грубые ошибки анализа, и синтеза, которые свидетельствуют о
несовершенстве или ошибках в алгоритмах системы. Появление таких ошибок в различных версиях системы свидетельствует об их закономерности. Система нуждается в некоторой доработке и устранении выявленных ошибок. Сервисные функции практически полностью отсутствуют. Соотношение цена/качество является реальным.
2. Группа СМП, осуществляющая перевод с английского языка па немецкий и с немецкого на английский
1. SYSTRAN PRO 2.0 занимает лидирующее положение среди рассматриваемых СМП, показывая хорошие результата перевода (4) в целом. В отдельных случаях система продемонстрировала отличный перевод (5), практически не требующий постредактирования. Однако в подавляющем большинстве случаев все-таки требуется определенная обработка выходного текста с изменением структуры предложения и добавлением новой лексики, особенно при работе с англонемецкой языковой парой. По сервисным функциям и количеству специализированных словарей CMII SYSTRAN PRO 2.0 также занимает ведущие позиции, однако, не всегда является бесспорным лидером. Соотношение цена/качество оправданно, несмотря на более высокую, по сравнению с остальными системами, стоимость.
2. Personal Translator Plus: система показала удовлетворительное качество перевода (3), требующее значительного постредактирования с обращением к оригиналу в некоторых случаях. Общий смысл переведенных текстов ясен без обращения к оригиналу, однако требуется изменение структуры предложения и добавление новой лексики. Такого рода преобразования имеют место преимущественно при переводе с английского языка на немецкий. СМП Personal Translator Plus предоставляет расширенные сервисные функции, позволяя осуществлять перевод с помощью архива уже переведенных предложений. Соотношение цена/качество является приемлемым при переводе, продемонстрированным системой.
3. Power Translator Deluxe: система показата удовлетворительные результаты (3), заняв третье место среда тестируемых СМП. Выходной текст требует несколько большего по сравнению с рассмотренными выше системами объема
постредактирования. Во многих случаях требуется пополнение словаря новой лексикой и изменение структуры выходных предложений на немецком языке. СМП Power Translator Deluxe обладает хорошими сервисными функциями, однако, отсутствие специализированных словарей сказывается на разрешении многозначности и качестве перевода в делом. 4. Langenscheidt T1 Standard 3.0 выполняет переводы удовлетворительного качества (3). Однако объем постредактирования, добавления повой лексики и ошибки алгоритмического характера при переводе существительных на немецкий язык позволяет поставить систему только на четвертое место в ряду протестированных СМП. Система МП Langenscheidt T1 Standard 3.0 предоставляет стандартные сервисные возможности и предлагает большое количество специализированных словарей. Достоинством данной системы является возможность тематического деления добавляемой лексики. Такая функция имеется только у данной программы и не представлена больше ни в одной из рассматриваемых нами систем. Соотношение цепа/качество является оправданным, при повышении качества переводов данное соотношение станет оптимальным.
Бесспорным лидером среди российских оп1ше-переводчиков является сайг www.translate.ru фирмы «ПРОМТ». Для работы сайта используется модифицированный модуль перевода, несколько отличный от используемого в базовых системах. Качество перевода, выполненного данным опИпе-переьодчиком, сопоставимо и не уступает качеству работы базовых систем. На сайте имеется возможность подключения некоторого числа специализированных словарей, что является несомненным преимуществом по сравнению с остальными рассматриваемыми online-переводчиками (Сократ-онлайп, AltaVista), где такая опция отсутствует.
В заключении изложены общие выводы проведенного исследования.
СМП гармонично сочетаются с другими текстовыми и речевыми процессорами, образуя самодостаточный конгломерат, который может быть использован в системах искусственного интеллекта (ИИ) и прочих информационных системах. Современные СМП активно используются и интегрируются в сеть Интернет. Дальнейшее развитие СМП будет происходить с помощью Всемирной паутины.
СМГ1 трансферного типа являются единственными программами МП, голучившими свое промышленное и коммерческое распространение, и занимают [омипируюгцее положение. В основу функционирования современных сметем тина 1ВМТ, МЕМТ и других положен принцип переводных соответствий на основе юдели «текст-текст». СМП семантического типа находятся на этапе геследовательских прототипов и не в состоянии конкурировать на рынке с истемами трансферного типа.
Несмотря на многообразие методик оценки эффективности систем МП, в [астоящее время превалируют эмпирические методы тестирования СМП. 1аибольшее распространение получили статистические методы, принцип «черного гщика», учет семантической полноты и точности, а также принцип понятности и декватности. Широко попользуется метод привлечения конечных пользователей да оценки выходного текста. В исследовании применяется принцип «черного |щика» с последующей классификацией ошибок, допущенных системой в процессе 1еревода, привлечением оценки, полученной в тестовых группах и окончательным ранжированием СМП по пятибальной оценочной шкале.
Предложена новая, более развернутая классификация переводных »ответствий по лингвистическому обеспечению, отвечающая задачам описания анализа и синтеза современных СМП. Данная классификация позволяет описывать зее языковые уровни и служит прекрасным инструментарием для создания и разработки систем МП, основанных на использовании примеров (ЕВМТ).
Типологическое исследование ошибок машинного перевода целесообразно проводить не на основе грамматических явлений, а с учетом этапов работы системы.
Проблема оценки современных СМП должна решаться комплексно с учетом не только лингвистических, но и экстралингвистических факторов функционирования программы. Данная методика позволяет оценивать рассматриваемые систсмы не только с точки зрения лингвистических факторов, но и с учетом экспертного заключения от тестовых групп и привлечением экстралипгвистических факторов. Предложенная градация систем МП по эффективности их работы позволяет потенциальному пользователю более четко ориентироваться в возможностях систем и необходимых затратах па их содержание.
Результаты нашего исследования могут быть использованы при принятии решения о приобретении той или иной СМП.
Итоги работы обсуждались на научной конференции «Коммуникативные стратегии на пороге XXI века» (Москва, МГУ, январь 1999 года), на конференции «Теория н практика речевых исследований (АРСО-99)» (Москва, МГУ, сентябрь 1999 года) и были представлены в виде тезисов на Десятую сессию Российского акустического общества (Москва, Акустический институт им. акад. H.H. Андреева, май 2000 года). Основное содержание диссергациояного исследования отражено в следующих публикациях:
1. Хроменков П.Н. Виртуальный мир: миф или реальность. Вестник Московского педагогического университета, Вып. 2, Москва, 1998. — Стр. 50-55.
2. Хроменков ГШ. Системы машинного перевода в сети Интернет. Проблемы филологии, лингводидактики и межкультурной коммуникации. Москва, 1999. — Стр. 121 — 141.
3. Хроменков П.Н. Совремешюе состояние и перспективы развития систем машинного перевода (СМП). Материаш конференции «Теория и практика речевых исследований (АРСО-99)», Москва, 1999. — Стр. 56 — 57.
4. Хроменков П.Н. К вопросу об анализе ошибок в современных системах автоматического перевода. Сборник трудов X сессии Российског о акустического общества, Т.2, Российская академия естественных наук, М., 2000. — Стр. 336 -338.
5. Хроменков П.Н. СМП PROMT 98 и СМИ SYSTRAN PRO 2.0: общие черты и различия. В печати.
Оглавление научной работы автор диссертации — кандидата филологических наук Хроменков, Павел Николаевич
Введение з
Глава 1 Современное состояние разработки систем машинного перевода
1.1 Роль и место СМП среди других лингвистических процессоров
1.2 Типология современных систем МП
1.3 Системы прямого перевода
1.4 Трансферные СМП
1.5 СМП семантического типа
1.6 Выводы к главе
Глава 2 Современная методология оценки эффективности систем машинного перевода
2.1 Современные методы оценки СМП
2.2 Типология ошибок при работе МП
2.3 Выводы к главе
Глава 3 Оценка эффективности основных действующих систем машинного перевода
3.1 Краткая характеристика систем МП: PROMT 98, Systran Pro 2.0, СПРИНТ-5, Сократ 2.0, Langenscheidt Т1 Standard 3.0, Personal Translator Plus 2.0, Power Translator Deluxe
3.2 Оценка эффективности современных СМП: PROMT 98, Systran Pro 2.0, СПРИНТ-5, Сократ 2.0, Langenscheidt T1 Standard 3.0, Personal Translator Plus 2.0, Power Translator Deluxe
3.3 Выводы к главе.
Введение диссертации2000 год, автореферат по филологии, Хроменков, Павел Николаевич
Мы живем в мире информационных технологий, которые прочно вошли в нашу жизнь. На работе и дома мы пользуемся современными средствами связи; компьютер превратился в неотъемлемый элемент нашей жизни не только на рабочем месте, но и в обыденной жизни. Бурное развитие новых информационных технологий свидетельствует о всевозрастающей роли вычислительной техники в мировом информационном пространстве, о постепенной дигитализа-ции все новых и новых отраслей нашей жизни. С каждым годом увеличивается число пользователей Интернета — Всемирной паутины, которая претендует на роль единого информационного пространства в планетарном масштабе. Несмотря на противоречивость нашего мира, наличие вооруженных конфликтов и разногласий между странами, Сеть становится «виртуальной реальностью» особого типа, позволяющей осуществлять такую интеграцию между народами, которая в реальной жизни остается все еще несбыточной мечтой. Сеть Интернет — это мир без границ, где в течение нескольких секунд можно оказаться на другой части земного шара. Единственной преградой, которая незримо присутствует во всей Сети, является языковой барьер. Эта проблема, общая как для реального, так и для «виртуального» мира сети Интернет, до настоящего момента так и не нашла своего кардинального решения. Попытки внедрения универсального языка типа Эсперанто или какого-либо другого языка не привели к их массовому использованию, и единственным способом преодоления языкового несоответствия является перевод, известный еще с древнейших времен, когда этим делом занимались толмачи.
Но нынешний век, где информация изменяется 24 часа в сутки и применяются электронные средства связи, диктует свои условия. В такой ситуации классический подход к осуществлению перевода не всегда оправдывает себя, т.к. требует больших капиталовложений и временных затрат. По сравнению с прошлыми веками объем информации, предназначенной для перевода, значительно увеличился. В некоторых случаях более целесообразным представляется использование машинного или автоматического перевода и систем машинного перевода (СМП). Развитие таких систем позволит оперативно осуществлять перевод информации и обрабатывать большие массивы документов в предельно сжатые сроки, т.е. удовлетворять основному требованию сегодняшней жизни: оперативной обработке огромных массивов информации при минимальных затратах.
Выбор данной темы исследования обусловлен в первую очередь ее новизной, недостаточной степенью исследованности и актуальностью рассматриваемых задач. Проблема эффективности машинного перевода является одним из ключевых факторов, определяющих перспективность развития данной области науки. В настоящее время не существует единой системы оценки эффективности работы существующих СМП. В данной работе предпринимается попытка проведения сравнительного анализа эффективности современных коммерческих СМП. В исследовании участвовали системы, осуществляющие перевод с русского языка на английский и обратно, и системы перевода с английского языка на немецкий и обратно. Для определения степени влияния языковой интерференции на качество перевода в эксперимент были включены англонемецкая и немецко-английская языковые пары.
Целью настоящей работы является сопоставительное исследование эффективности современных СМП. В основу качественного показателя результатов перевода и эффективности систем были положены не только лингвистические, но и экстралингвистические критерии оценки СМП.
Для достижения поставленной цели потребовалось разрешение следующих задач: выявление современных СМП, нашедших свое промышленное и коммерческое применение и являющихся уже не исследовательскими прототипами, а реально действующими системами, обладающими свойствами готового продукта; типологическое описание современных СМП и выявление доминирующего типа СМП; выделение основных критериев оценки эффективности машинного перевода (МП); проведение сравнительного исследования результатов переводов, выполненных современными СМП; анализ и типология ошибок при работе с СМП; апробация методов оценки на действующих системах МП и оценка их эффективности.
Теоретический аспект данной работы заключается в лингвистической разработке методов оценки. Системы рассматриваются, изучаются и оцениваются по принципу «черного ящика», который подразумевает отсутствие полной информации об алгоритмах работы системы, и на входном этапе мы априорно не знаем, с какой системой работаем. В результате исследования лингвистической компоненты систем МП создается теоретическое обоснование для определения типа системы и ее лингвистического обеспечения. Теоретическая значимость данного исследования заключается в возможности определения, дальнейшего моделирования и совершенствования лингвистической составляющей не только в СМП, но и в целом в системах искусственного интеллекта (ИИ), неотъемлемой частью которых собственно и является МП. В рамках исследования предлагается расширить типологию переводных соответствий, предложенную МарчукомЮ.Н. (Марчук, 1983).
Практические исследования направлены на подтверждение правильности выработанных критериев и методов оценки СМП, возможности их использования в качестве тестового массива не только для рассматриваемых в данной работе СМП, но и в целом для оценки эффективности существующих СМП, которые работают с указанными языковыми парами. Практическая ценность данной работы заключается в том, что потенциальный пользователь СМП при выборе программы машинного перевода может воспользоваться приводимыми в данной работе тестами для проведения первичной оценки СМП. На основе результатов такого теста можно будет принять окончательное решение о целесообразности применения СМП в тех или иных отраслях промышленности и получить начальное представление о качестве машинного перевода и имеющихся на сегодняшний день недостатках в этой области. Такие предварительные исследования, основанные на материалах, приводимых в данной работе, позволят сэкономить капиталовложения, избежать последующих финансовых потерь и разочарований вследствие завышенных требований к СМП.
Материалом исследования послужили более 300 текстов на русском, английском и немецком языках. Источником языкового материала послужила сеть Интернет, наиболее динамично реагирующая на языковые преобразования современности.
Методами исследования послужили принцип «черного ящика», метод тестовых групп конечных пользователей, типологическое, лингвистическое и экстралингвистическое сопоставительное описание.
На защиту выносятся следующие положения: 1. Доминирующим типом современных СМП являются СМП трансферного типа, получившие достаточно широкое промышленное и коммерческое распространение. Таким образом, системы трансферного типа представляют собой единственный класс СМП, который может быть подвержен сравнительно-сопоставительному исследованию с целью выявления эффективности сож JTTT временных систем МП.
2. Функционирование, развитие и совершенствование систем машинного перевода в настоящее время происходит в сети Интернет, которая является источником материалов не только для тестирования систем, но и служит рабочим пространством для такого рода систем в планетарном масштабе. Дальнейшая эксплуатация и разработка новейших СМП будет осуществляться посредством Интернета.
3. При типологическом исследовании ошибок при работе систем МП следует придерживаться комплексного подхода, базирующегося на учете этапов функционирования системы. Следует выделять ошибки автоматического анализа и синтеза, которые в свою очередь подразделяются на более конкретные подклассы, отражающие работу алгоритмического аппарата системы.
4. Подавляющее большинство современных СМП основано на принципе переводных соответствий. В результате типологического исследования модели переводных соответствий возникла необходимость создания расширенной классификации переводных соответствий. Предложенная типология переводных соответствий на основе лингвистического обеспечения СМП позволяет более широко рассматривать проблему ошибок при работе систем МП и может быть использована при создании новых систем, основанных на применении принципа параллельных текстов.
5. Практическая классификация современных СМП, основанная на учете экстралингвистических факторов и качества переводов, выполненных данными системами, позволяет составить впечатление об эффективности и функциональных возможностях каждой системы. Указанная градация СМП представляет практическую ценность при выборе конкретной системы МП.
Результаты работы обсуждались на научной конференции «Коммуникативные стратегии на пороге XXI века» (Москва, МГУ, январь 1999 года), на конференции «Теория и практика речевых исследований (АРСО-99)» (Москва, МГУ, сентябрь 1999 года) и были представлены в виде тезисов на Десятую сессию Российского акустического общества (Москва, Акустический институт им. акад. Н.Н. Андреева, май 2000 года). Основное содержание диссертационного исследования отражено в 5 публикациях.
Заключение научной работыдиссертация на тему «Анализ и оценка эффективности современных систем машинного перевода»
3.3 Выводы к главе
В результате исследования эффективности современных СМП были выявлены системы, показавшие наилучшие результаты в ходе проведенного тестирования. Следует отметить, что за исключением некоторых систем практически все рассмотренные СМП показывают одинаковый базовый уровень перевода и обладают основными сервисными функциями.
Проведенное нами исследование и деление отражают эффективность лингвистического обеспечения и качество перевода для каждой отдельной программы. В результате исследования было выявлено, что все без исключения системы нуждаются в настройке на предметную область, в которой они будут использоваться. Без проведения такой отладки трудно говорить об успешном использовании СМП. Результаты данного исследования представляют практическую ценность при выборе той или иной СМП, т.к. системы, занявшие первые места в нашей классификации, обладают хорошим качеством перевода и значительными сервисными возможностями.
Тестирование СМП с английским и немецким языками показало, что перевод, вследствие близости данных языков, выполняется с меньшим числом ошибок, нежели в случае с русским языком. Однако такие явления, которые присущи только одному языку из рассматриваемой пары (например, рамочная конструкция в немецком языке), переводятся не всегда корректно и требуют вмешательства редактора. На основании полученных результатов можно сделать вывод, что языковая интерференция способствует повышению качества перевода и сокращает количество ошибок, т.к. все преобразования происходят на уровне эквивалентных и вариантных соответствий. Проведенный анализ результатов перевода позволяет также выдвинуть гипотезу об универсальном характере переводческих трудностей при работе систем МП. Гипотеза требует дальнейшей проверки и развития.
Данные исследования, полученные эмпирическим путем, позволяют сделать вывод, что лучшей СМП, осуществляющей перевод с русского и на русский язык, является СМП PROMT 98. Среди зарубежных систем, работающих с английским и немецким языками, следует выделить СМП SYSTRAN PRO 2.0, которая показала наилучшие результаты перевода. Указанные системы являются лидерами не только среди традиционных СМП, но и в области таких новых информационных технологий, как Интернет, предоставляя услуги бесплатного перевода в режиме реального времени. Мы полагаем, что сфера информационных технологий станет играть ключевую роль в развитии СМП.
Заключение
В результате типологического и сравнительно-сопоставительного исследования современных СМП по принципу «черного ящика» и на основе случайной выборки текстов можно сделать следующие выводы.
СМП гармонично сочетаются с другими текстовыми и речевыми процессорами, образуя самодостаточный конгломерат, который может быть использован в системах искусственного интеллекта (ИИ) и прочих информационных системах. Современные СМП активно используются и интегрируются в сеть Интернет. Дальнейшее развитие СМП будет происходить с помощью Всемирной паутины, неотъемлемой частью которой станут современные системы машинного перевода, работающие в режиме реального времени. Наблюдается тенденция к увеличению номенклатуры рабочих языков и созданию систем, работающих с редкими языками,
СМП трансферного типа являются единственными программами МП, получившими свое промышленное и коммерческое распространение, и занимают доминирующее положение. В основу функционирования современных систем типа ЕВМТ, МЕМТ и других положен принцип переводных соответствий на основе модели «текст-текст». СМП семантического типа находятся на этапе исследовательских прототипов и не в состоянии конкурировать на рынке с системами трансферного типа. Несмотря на попытки создания новой универсальной теории представления и формализации экстралингвистических знаний, данная проблема по-прежнему не решена.
Несмотря на многообразие методик оценки эффективности систем МП, в настоящее время превалируют эмпирические методы тестирования СМП. Наибольшее распространение получили статистические методы, принцип «черного ящика», учет семантической полноты и точности, а также принцип понятности и адекватности. Широко используется метод привлечения конечных пользователей для оценки выходного текста. Отсутствие единого стандарта оценки современных систем МП свидетельствует о недостаточной исследованности данной отрасли науки и наличии неразрешенных проблем и разногласий между исследователями. В нашем исследовании применяется принцип «черного ящика» с последующей классификацией ошибок, допущенных системой в процессе перевода, привлечением оценки, полученной в тестовых группах, и окончательным ранжированием СМП по пятибалльной оценочной шкале.
В результате исследования была выявлена необходимость расширенной трактовки модели переводных соответствий. Имеющаяся типология переводных соответствий не охватывает всего спектра межъязыковых отношений. Таким образом, была предложена новая, более развернутая классификация переводных соответствий по лингвистическому обеспечению, отвечающая задачам описания анализа и синтеза современных СМП. Данная классификация позволяет описывать все языковые уровни и служит прекрасным инструментарием для создания и разработки систем МП, основанных на использовании примеров (ЕВМТ).
Типологическое исследование ошибок машинного перевода целесообразно проводить не на основе грамматических явлений, а с учетом этапов работы системы. В этой связи нам представляется уместным выделять ошибки автоматического анализа и синтеза, которые в свою очередь делятся на ряд классов, соответствующих конкретным этапам работы алгоритмов системы. Основываясь на результатах исследования, мы считаем целесообразным применение системного подхода к проблеме оценки качества современных систем МП. Причины возникновения переводческих ошибок настолько взаимосвязаны, что исправление одной ошибки без учета общей ситуации может привести к снижению эффективности системы в целом.
Проблема оценки современных СМП должна решаться комплексно с учетом не только лингвистических, но и экстралингвистических факторов функционирования программы. Данная методика позволяет оценивать рассматриваемые системы не только с точки зрения лингвистических факторов, но и с учетом экспертного заключения от тестовых групп и привлечением экстралингвистических факторов. Предложенная градация систем МП по эффективности их работы позволяет потенциальному пользователю более четко ориентироваться в возможностях систем и необходимых затратах на их содержание. Результаты нашего исследования могут быть использованы при принятии решения о приобретении той или иной СМП.
Рассмотренный в данной работе круг проблем не является исчерпывающим и требует продолжения исследований в данной области. Отдельного развернутого исследования требует проблема типологии переводных соответствий. На основе переводных соответствий нового типа, описанных в данной работе, возможно построение универсальной системы оценки эффективности СМП, которая, возможно, будет находиться в корреляционной зависимости с предложенным тезисом об универсальном характере переводческих трудностей при работе СМП. Предложенная гипотеза требует отдельного изучения и проверки, т.к. в рамках данной работы была осуществлена лишь постановка проблемы и определены основные направления исследования.
Список научной литературыХроменков, Павел Николаевич, диссертация по теме «Прикладная и математическая лингвистика»
1. Андреев Н. Д. Основные направления работы экспериментальной лаборатории машинного перевода. В кн.: Hutchins W.J. Machine Translation: Past, Present, Future — New York, 1986. — 382 p.
2. Апресян Ю.Д. Идеи и методы современной структурной лингвистики. М.: Просвещение., 1966. — 302 с.
3. Бакулов А.Д., Леонтьева Н.Н., Шаляпина З.М. Отечественные системы машинного перевода. В кн.: ИИ-90: Искусственный интеллект/ Справочник/ Книга 1. Системы общения и экспертные системы. М.: Радио и связь. -1990. Стр. 248-261.
4. Боброва В .Я. Системы машинного перевода. Итоги науки и техники. Сер. Информатика. М.: ВИНИТИ. -1990. — Т.14. — Стр. 149-178.
5. Ванников Ю.В. Виды адекватности и типология перевода.— В кн.: Совершенствование перевода научно-технической литературы и документов: Тез. докл. всесоюзн. конф. М. — 1982.
6. Ванников Ю.В. Понятие адекватности текста и типы адекватности перевода.— В кн.: Уровни текста и методы его лингвистического анализа. М., 1982а.
7. Вардуль И.Ф. Об изучении семантического аспекта языка. Вопросы языкознания № 6/73. — Стр. 9-21.
8. Вольф М. Европа «проспала» интернет-торговлю? PCWeek/RE, 2 сентября 1998 г.
9. Грязнухина Т.А., Дарчук Н.П., Клименко Н.Ф. и др. Использование ЭВМ в лингвистических исследованиях. Киев: Наукова Думка. — 1990. — 266 с.
10. Искусственный интеллект/ Справочник/ Книга 1. Системы общения и экспертные системы. М.: Радио и связь. — 1990. — 458 с.
11. Капанадзе О.Г. Современные зарубежные системы машинного перевода. -М.: ВЦП.- 1989.- 102 с.
12. Каничев М. Встреча компьютерных толмачей. Мир ПК, №8 1998. — Стр. 100-102.
13. Ким Т. В 2005 году население Интернета перевалит за полмиллиарда. ZDNet UK, 18 декабря 1998 г.
14. Киселев А.Н. Элементы теории и практики переводных соответствий // НТИ / ВИНИТИ. Сер. 2, Информ. процессы и системы. М., 1993. — N 8. — Стр. 1621.
15. Комиссаров В.Н. Слово о переводе. М.: ИНО, 1973. — Стр. 237.23 .Королев Э.И. Промышленные системы машинного перевода — М.: ВЦП, 1991. — 100 с.
16. Котов Р.Г., Марчук Ю.Н., Нелюбин JI.JI. Машинный перевод в начале 80-х годов// ВЯ. 1983. — N1. — Стр. 31-38.
17. Кулагина О.С. Исследования по машинному переводу. М.: Наука. — 1979. -320 с.
18. Кулагина О.С. Машинный перевод: современное состояние // Семиотика и информатика. М., 1989. — Вып. 29. — Стр. 5-33.
19. Кулагина О.С. О семантическом анализе на основе предпочтений. Препринт Института прикладной математики АН СССР. Москва №3/90. — Стр. 1-20.
20. Кюннап Э. Автоматическое распознавание речи. Таллинн: Ин-т кибернетики АН Эстонии — 1989. — 108 с.
21. Леонтьева Н.Н. База знаний и автоматический перевод (проект многоязычной информационно-справочной системы)// Междунар. семин. по машин, переводу «ЭВМ И ПЕРЕВОД 89″/ Тбилиси, 27.11.-02.12. 1989 г./ Тезисы докладов. М.- 1989. —Стр. 178-181.
22. Леонтьева Н.Н., Шаляпина З.М. Современное состояние машинного перевода. В кн.: ИИ-90: Искусственный интеллект/ Справочник/ Книга 1. Системы общения и экспертные системы. М.: Радио и связь. 1990. — Стр.216.248.
23. ЛЭС: Лингвистический энциклопедический словарь. — М.: Советская энциклопедия, 1990. — 685 с.
24. Мартемьянов Ю. С. Эквивалентность в порождающей грамматике.— В кн.: Теория перевода и научные основы подготовки переводчиков: Тез. всесоюзн. конф. М., 1975. —Ч. II.
25. Марчук Ю.Н, Об автоматизации составления схем перевода многозначных слов. Научно-техническая информация, ВИНИТИ АН СССР, № 9, 1964. — Стр. 35-38.
26. Марчук Ю.Н., Моторин Ю.А. Основные принципы автоматизации перевода с английского языка на русский. Вопросы радиоэлектроники, серия ЭВТ, вып. 7, 1970. —Стр. 11-19.
27. Марчук Ю.Н. Синтактико-семантический анализ в системе машинного перевода АМПАР. В кн.: Международный семинар по машинному переводу (под ред. Марчука Ю.Н.). Тезисы докладов, М.: ВЦП, 1979. — Стр. 8-9.
28. Марчук Ю.Н. Проблемы машинного перевода. М.: Наука. — 1983. — 201 с.
29. Марчук Ю.Н. Методы моделирования перевода. — М,: Наука. 1985. — 233с.
30. Марчук Ю.Н. Математические методы в языкознании/ Обзор материалов конференции COLING-88. М.: ИНИОН. — 1990. — 46 с.
31. Марчук Ю.Н. Проблемы компьютерной лингвистики; Модель «текст-текст» и переводные соответствия в теории машинного перевода. Сборник научных статей. Минск 1997. — Стр. 21-29
32. Марчук Ю.Н. Основы компьютерной лингвистики. М.; Народный учитель. -2000. — 227 с.41 .Международный семинар по машинному переводу (под ред. Марчука Ю.Н.). Тезисы докладов, М.: ВЦП, 1979. — 196 с.
33. Мельчук И.А. Опыт теории лингвистических моделей «СМЫСЛ-ТЕКСТ». -М.: Наука. 1974.-314 с.
34. Мельчук И.А. Русский язык в модели «смысл-текст». Москва-Вена-Школа «Языки русской культуры», 1995. — 682 с.
35. Митин В. ПРОМТ владеет французским на 30% лучше, чем конкуренты. PC Week: 12 ноября 1999 г.
36. Молдокулова Н.В., Трунин-Донской В.Н. Лингво-акустические проблемы создания системы распознавания слитной речи на ЗВМ. Фрунзе: Илим. -1989.- 136 с.
37. Моторин Ю.А., Марчук Ю.Н. Реализация автоматического перевода на современных серийных ЭВМ общего назначения. Вопросы радиоэлектроники, серия ЭВТ, вып. 7, 1970.— Стр. 20-29.
38. Моуд Д. Машинный перевод: новое поколение технологий. Новые продукты помогают переводить основной смысл содержания глобальных интрасетей. PC Week.
39. МСМП-89: ЭВМ и перевод/ Международный семинар по машинному переводу/ Тбилиси, 27.11.-02,12. 1989 г./ Тезисы докладов. М.: ВЦП. — 1989. — Стр. 348.
40. Нелюбин Л.Л. Перевод и прикладная лингвистика. М.: Высшая школа., 1983. —207 с.
41. Методическое пособие). М.; Всесоюзный центр переводов, 1991. — 152 с.
42. Нелюбин Jl.JI., Хухуни Г.Т. История и теория зарубежного перевода. Учебник, М.: МПУ, Издательство Сигнал, 1999. — 144 с.
43. Нелюбин Л.Л., Хухуни Г.Т. История и теория перевода в России. Учебник, М.: МПУ, Издательство Сигнал, 1999а. — 151 с.
44. Новиков А. И. Применение денотатной структуры текста для перевода научно-технической литературы.— В кн.: Психолингвистические аспекты грамматики. М. — 1979.
45. Перминов С. Купля-продажа в сети Интернет. «Московская правда» №11 (23584) от 20 января 1999 г.
46. Пиотровский Р.Г. Машинный перевод в группе «Статистика речи»: результаты и перспективы. В кн.: Международный семинар по машинному переводу (под ред. Марчука Ю.Н.). Тезисы докладов, М.: ВЦП, 1979. — Стр. 5-7.
47. Пиотровский Р.Г. На путях создания интеллектуальных систем обработки текста/о лингвистическом автомате/ ЭВМ и перевод. М.: ВЦП, 1991.
48. Попов Э.В. Экспертные системы. Решение неформализованных задач в диалоге с ЭВМ. М.: Наука, 1987. — 288 с.
49. Потапова Р.К. Речевое управление роботом. М.: Радио и связь. — 1989 — 248 с.
50. Потапова Р.К. Тайны современного кентавра. М.: Радио и связь. 1992 -248с.
51. Потапова Р.К. Речь: коммуникация, информация, кибернетика. — М.: Радио и связь, 1996. —1500 с.
52. Рецкер Я.И. О закономерных соответствиях при переводе на родной язык. Теория и методика учебного перевода. М.: 1950.
53. Рябцева Н.К. Информационные процессы и машинный перевод: Лингвист, аспект / Отв. ред. Котов Р.Г.; АН СССР. Ин-т языкознания. М.: Наука, 1986.- 167 с.
54. Рябцева Н.К. Текст как объект содержательного анализа и проблемы формализации перевода // Текст и перевод. М., 1988. — Стр. 101-113.
55. Суханова М. Кто лучше переводит. Мир ПК, № 1/97.
56. Суханова М. Страна Советов. Мир ПК, № 6/98. — Стр. 95.
57. Федоров А.В. Основы общей теории перевода. -М.: Высшая школа, 1983.
58. Хауорт Р. Веб-устройства заговорили. ZDNet, 28 мая 2000 г.
59. Шаляпина З.М. К проблеме построения формальной модели процесса перевода. — В кн.: Теория перевода и научные основы подготовки переводчиков: Тез. докл. всесоюзн. конф. М., 1975. Ч. II.
60. Alshawi H. The Core Language Engine. MIT Press, Cambridge, MA, 1992.
61. Alshawi H., Carter D. Training and Scaling Preference Functions for Disambiguation. Computational Linguistics. 20(4), 1994. —pp. 635-648.
62. Arnold D., Balkan L., Humphreys R.L., Meijer S., Sadler L. Machine Translation: An Introductory Guide. Oxford: NCC and Oxford Blackwell, 1994.
63. Barnett M. E-commerce standard should enable «one-click» shopping. June 15, The Industry Standard, 1999.
64. Batori I., Weber H.J. Neue Ansatze in Maschineller Sprachubersetzung:
65. Wissensprasentation und Textbezug, Niemeyer, Tubingen, 1986.
66. Batori I. Paradigmen der Maschinellen Sprachubersetzung, In Baton I., Weber H.J. Neue Ansatze in Maschineller Sprachubersetzung: Wissensprasentation und Textbezug. Niemeyer, Tubingen, 1986, pp. 3-27.
67. Boitet K. Twelve Problems for Machine Translation // International Conference on Current Issues in Computational Linguistics University Sains Malaysia, Penang, Malaysia, 1991 Proceedings, pp. 45-47.
68. Borchers D., Huskes R. Web-TV undNetPC, c’t 8/97. — S. 14-15.
69. Bowman L.M. Open your eyes, get some cash, ZDNN, 03. 09. 1998.
70. BroersmaM. Israel set to double its Net population. ZDNetNews, 06. 07. 1998.
71. Brown R. Example-Based Machine Translation in the Pangloss System. In Proceedings of the 16th International Conference on Computational Linguistics (COLING’96), 1996.
72. Bub Т., Wahlster W., Waibel A. Verbmobil: The Combination of Deep and Shallow Processing for Spontaneous Speech Translation. In Proceedings of ICASSP-97, Munich, Germany, 1997.
73. Buschbeck-Wolf B. Resolution on Demand. Verbmobil Report 196, IMS, Universitat Stuttgart, Germany, 1997.
74. Buschbeck-Wolf В., Dorna M. Quality and Robustness in MT — A Balancing Act, in Lecture Notes in Artificial Intelligence 1529, Berlin, Heidelberg, New York: Springer-Verlag, 1998: pp. 62-72.
75. BYTE: BYTE, 1993, January, —pp. 153-186.
76. Collins В., Cunningham P. Adaptation-guided retrieval: Approaching EBMT with caution. In Proceedings of TMI-97, Santa Fe, New Mexico, 1997, pp. 119-126.
77. Das Stillworterbuch der deutschen Sprache, Bd.2 Duden, Mannheim Leipzig -Wien — Zurich: Dudenverlag, 1988, 864 p.
78. Dorna M. The ADT-Package for the Verbmobil Interface Term. Verbmobil Report 104, IMS, Universitat Stuttgart, Germany, 1996.
79. Dorr В.J. Machine Translation: A View from the Lexicon. Cambridge, MA, MIT, 1993,432р.91 .Dorr B.J. Machine Translation divergences. A formal description and proposed solution. Computational linguistics 20(4), 1994, pp. 597-633.
80. EAGLES Evaluation Group Workshop Evaluation in Natural Language Engineering: Standards and Sharing. Brussels, November 26th and 27th, 1997.
81. EAGLES and Current Evaluation Practices, Workshop ETI, University of Geneva, September 8-9,1998.
82. EAI: Encyclopedia of Artificial Intelligence. — New York: A Wiley Interscience Publication, 1990, 1200 p.
83. ELL: Encyclopedia of Language and Linguistics. — Oxford — New York — Seoul — Tokyo: 1994, 5644 p.
84. Engler T. Der Vermobil-Forschungsprototyp Report, Maschinelle Ubersetzung, DFKI, Kiinstliche Intelligent BMBF, c’t 7/97, S. 108.
85. Fourchin A.J., Harland G., Barry W. et al, eds. Speech Input and Output Assessment: Multilingual Methods and Standards. Chichester, England: Ellis Horwood. — 1989, 290 p.
86. Frederking R., Nirenburg S. Three Heads are Better than One. In Proceedings of ANLP’94, Stuttgart, Germany, 1994.
87. Frederking R. et al. Integrating Translations from Multiple Sources with the Pangloss Mark III Machine Translation System. In Proceedings of the First Conference for Machine Translation in Americas (AMTA), Columbia, Maryland, October 1994.
88. Furuse O., Iida H. Constituent boundary parsing for example-based machine translation. In Proceedings of COLING’94, Kyoto, 1994, pp. 105-111.
89. Gerwen R.P. Automatic Text-to-Speech Conversion for Spanish. -Nijmegen -1991, 115 p.
90. Goodman K., Nirenburg S. The KBMT Project: A Case Study in Knowledge-Based Machine Translation. San Mateo, CA, Morgan Kaufmann, 1991.
91. Hakkani D.Z., Tur G., Oflazer K., Mitamura Т., Nyberg E.H. An English-to-Turkish Interlingual MT System. In Lecture Notes in Artificial Intelligence 1529, Berlin, Heidelberg, New York: Springer -Verlag, 1998, p. 83
92. Harper K. Soviet research in machine translation, 1961. In: Hutchins W.J. Machine Translation: Past, Present, Future — New York, 1986, 382 p.
93. Hauenschild C., Heizmann S. Machine Translation and translation theory. Berlin; New York; Mounton de Gruyter, 1997,263 p.
94. Heizmann S. SCS-Studie: Maschinelle Ubersetzung SCS Informationstechnik
95. Hovy E., Gerber L. MT at the paragraph level: Improving English Synthesis in SYSTRAN. In Proceedings of TMI-97, Santa Fe, 1997, pp. 47-54.113 .Hutchins W.J. Machine Translation: Past, Present, Future — New York, 1986, 382 p.
96. Hutchins W.J. Recent Developments in Machine Translation. A Review of the Last Five Years. New Directions in Machine Translation/ Conference Proceedings. Budapest. — 1988, pp. 7-62.
97. Hutchins W.J. Out of the Shadows. A Retrospect of Machine Translation in the Eighties// ЭВМ и перевод. M.: ВЦП. — 1991.
98. Jordan P.W., Dorr B.J., Benoit J.W. A first-pass approach for evaluating machine translation systems. Machine Translation 8(1), Special Issue on Evaluation, 1993, pp. 49-58.
99. Kasper W., Bos J., Schiehlen M., Thielen C. Definition of Abstract Semantic Classes. Verbmobil Technical Report 61, DFKI GmbH, Saarbrucken, Germany and Universitat des Saarlandes, Saarbrucken, Germany and IMS, Universitat Stuttgart, Germany, 1997.
100. Kay M., Gawron M., Norvig P. Verbmobil: A Translation System for Face-to-Face Dialog. Number 33 in Lecture Notes, Standford, CA: CSLI, 1994.
101. King M., Falkedal К. Using test suites in evaluation of machine translation systems. In Proceedings of the 13th COLING’90, Helsinki, Finland, 1990, pp. 211-216.
102. King M. Evaluation of MT systems Panel discussion. In Proceedings of MT Summit III, Washington, DC, 1991, pp. 141-146.
103. King M., Evaluating natural language processing systems. Communications of the ACM 39(1), 1996, pp. 73-79.
104. King M. Evaluating translation. In Machine Translation and translation theory / ed. By Christa Hauenschild, Susanne Heizmann -Berlin; New York; Mounton de Gruyter, 1997, pp. 251-263.
105. Klostermeier J. Preparations for ‘Internet Strike’ in Germany running full steam ahead. ZDNet Germany, ZDNN, 29.09.1998.
106. Knowles A. Compaq readies fingerprint ID security for PCs. PC Week Online, 07.07.1998.
107. Kogure K., Kume M., Iida H. Illocutionary Act Based Translation of Dialogue. In Proceedings of the TMI-90, Austin, 1990.
108. Kroner H.J., Schwinn J. Fallbasierte Ubersetzung. DFKI GmbH, Kaiserslautern, Germany, Undocumented Software, 1997.
109. Kulagina O.S., Martynova A.I., Nikolaeva T.M. Mechanical translation at the Academy of Sciences of the USSR. 1961. In: Hutchins W.J. Machine Translation: Past, Present, Future — New York, 1986, 382 p.
110. Kulagina O.S. History and present state of machine translation. Cybernetics 6, pp. 937-944., 1976. In: Hutchins W.J. Machine Translation: Past, Present, Future — New York, 1986,382 р.
111. Laurie G., Yang J. SYSTRAN MT Dictionary Development. Machine Translation: Past, Present and Future: Proceedings of the Machine Translation Summit VI, 1997, pp. 211 -218.
112. Lawson V. A Translator’s Map of Machine Translation// ЭВМ и перевод. M.: ВЦП. — 1991.
113. Leckebusch J. Sprachwandler Ubersetzungshilfen Englisch-Deutsch Priifstand, Maschinelle Ubersetzung, Tl, Systran, Personal Translator, PT, Web-Translator, Easy Translator, c’t 8/97, S. 258.
114. Lehrberger J., Bourbeau L. Machine Translation linguistic characteristics of MT systems and general methodology of evaluation. Studies in French and general Linguistics. Amsterdam, John Benjamins, 1988, 240 p.
115. Levin В., Pinker S. Lexical and conceptual Semantics. Cognition Special Issues. Cambridge, MA, Blackwell, 1992.
116. Levitt J.R. KANT Mapper Specification. Carnegie Mellon University, Center for Machine Translation, 1993.
117. Loritz D. Voice Recognition Technology for Machine Translation// ЭВМ и перевод. M.: ВЦП. — 1991.
118. Luckhardt H.D. SUSY: capabilities and range of application. Multilingua 1(4), 1982, pp. 213-219.
119. Maas H.D. Das Saarbriicker Uebersetzungssystem SUSY. Sprache und Datenverarbeitung 2(1), 1978, pp. 43-61.
120. Maas H. D. SUSY I und SUSY II: verschiedene Analysestrategien in der Machinellen Uebersetzung. Sprache und Datenverarbeitung 5(1/2), 1981, pp. 915.
121. Madden J. Study: IT spending by small business reached $ 138B in ’97 PC Week Online, 1997.
122. Maier E. et al. Dialogue Processing in Spoken Language Systems, Volume 1236 of Lecture Notes in Artificial Intelligence, Berlin: Springer-Verlag, 1996.
123. Maxwell D., Schubert K., Witkan T. New Directions in Machine Translation. Number 4 in Distributed Language Translation. Dordrecht, The Netherlands, Foris, 1988,318 р.
124. Mayfield L., Gavalda M., Seo Y.H., Suhm В., Ward W., Waibel A. Parsing Real Input in Janus: A Concept Based Approach. In Proceedings of TMI-95,1995.
125. McTait K., Trujillo A. A language neutral sparse-data algorithm for extracting translation patterns. In Proceedings of TMI-99, Chester, UK, 1999.
126. Meli S. Informationsmarkt der Maschinellen Ubersetzung: Linguistischer Hintergrund, Typologie, Systeme, Ubersetzungshilfen, Projekte und Ubersetzungsdienste// Terminologie et Traduction. 1989. — N3., pp. 63-107.
127. Minnis S. Constructive machine translation evaluation. Machine Translation, 8, 1993, pp. 67-75.
128. Morimoto Т., Suzuki M., Takeazawa Т., Kikui G., Nagata M., Tomokiyo M. A Spoken Language Translation System: SLTRANS2E. In Actes du quinzieme colloque international en linguistque informatique, COLING’92, Nantes, 1992, pp. 1048-1052.
129. MT Summit-87: Machine Translation Summit. Hakone — 1989, 215 p.
130. Nagao M. A Framework for a mechanical translation between Japanese and English by analog principle. In Elithorn A. and Manerji R. (eds): Artificial and Human Intelligence. B.V. NATO Elsevier Publishers, 1984.
131. Nagao M., Tsujii J., Nakamura J. The Japanese government project for machinetranslation, 1988, pp. 141-186.
132. Niccolai J. AltaVista Offers Slicker Translations. June 15, 2000, IDG News Service.
133. Nirenburg S., ed. Machine Translation: Theoretical and Methodological Issues. -Cambridge, Mass. 1987, 350 p.
134. Nirenburg S., Carbonell J., Tomita M., Goodman K. Machine Translation: A Knowledge based Approach. San Mateo, CA, Morgan Kaufmann, 1992.
135. Nyberg E.H., Mitamura T. The KANT System; Fast, Accurate, High-Quality Translation in Practical Domains. In Proceedings of COLING’92, Nantes, France, July 1992.
136. Nyberg E.H., Mitamura Т., Carbonell J.G. Evaluation Metrics for Knowledge-Based Machine Translation. In Proceedings of COLING’94, 1994.158.0nyshkevich В., Nirenburg S. A lexicon for knowledge-based MT. Machine Translation 10(1/2), 1995, pp. 5-57.
137. Piggot I.M, Systemes operationnels en traduction automatique//Terminologie et Traduction. 1989. — N3., — pp. 47-53.
138. Pulman S.G. A Computational Theory of Context Dependence. In Proceedings of the Tilburg Workshop on Computational Semantics, 1994.
139. Rayner M., Bouillon P. Hybrid Transfer in an English-French Spoken Language Translator. In Proceedings of IA’95, Montpellier, 1995.
140. Reithinger N., Klesen M. Dialogue Act Classification Using Language Models. In Proceedings of EuroSpeech-97, Rhodes, Greece, 1997, pp. 2235-2238.
141. Sato S., Nagao M. Towards memory based translation. In Proceedings of COLING’90, Helsinki, Finland, 1990.
142. Sato S. MBT2: a method for combining fragments of examples in example-based translation. Artificial Intelligence 75(1), 1995, pp. 31-49.
143. Seminerio M. Survey says 21 percent of U.S. adults are online. ZDNN, 1998.
144. Schauble P., Sheridan P. Cross-Language Information Retrieval (CLIR) Track Overview. In Proceedings of the Sixth Text Retrieval Conference (TREC6). 1998.
145. Schubert K. The architecture of DLT-Interlingual or double direct. In Maxwell D., Schubert K., Witkan T. New Directions in Machine Translation. Number 4 in Distributed Language Translation. Dordrecht, The Netherlands, Foris, 1988, pp. 131-144.
146. Schmitz B. Pragmatikbasiertes Maschinelles Dolmetschen. Heidelberg: Groos, 1998, 159 p.
147. Seewald U. Markttibersicht: Kommerzielle Systeme und Werkzeuge Antibabylonisch (Systran), iX 12/95, S. 88.
148. Sinaiko H.W., Klare G.R. Further experiments in language translation: readability of computer translations. ITL (Review of Institute of Applied Linguistics, Louvain) 15, 1972, pp. 1-29.
149. Slocum J. Machine Translation Systems. Studies in Natural Language Processing. Cambridge, UK: Cambridge University Press, 1988.
150. Smith P.D. An Introduction to Text Processing. Cambridge, MA: The MIT Press. — 1990. — 300 p.
151. Sparck J.K., Galliers J.R. Evaluating Natural Language Processing Systems: An Analysis and Review, Berlin, Springer, 1995.
152. Stone MX. Web embraces language translation. ZDNN, 21.07.1998
153. Sumita E., Iida H., Experiments and prospects of example-based machine translation. In Proceedings of the 29th Annual Conference of the ACL, Berkley, CA, 1991.
154. TEMAAD16 Final Report, October 1997.
155. Thompson H. Linguistic Corpora for the Language Industry: A European Community Public Utility// Terminologie et Traduction. 1989. — N3., — pp. 55-61.181 .Toma P. SYSTRAN as a Multilingual MT System// OLB. 1977. — Vol. 1 „ -pp.569-581.
156. Trujillo A. Translation engines: Techniques for Machine Translation, Springer, 1999, 303 p.
157. Tucker A.B., Nirenburg S. Machine Translation: a contemporary view. Annual Review of Information Science and Technology 19, 1984, pp. 129-160.
158. Vasconcellous M. Machine translation at the Pan American Health Organisation. British Computer Society, Natural Language Translation Specialist Group Newsletter 14, 1984, pp. 17-34.
159. Viegas E., Mahesh K., Nirenburg S. Semantics in Action. In P. Saint-Dizier (Ed.), Forms in Natural Language and in Lexical Knowledge Bases, Kluwer Academic Press, 1999.
160. Waibel A. Interactive Translation of Conversation Speech. Computer, 29(7), 1997, pp. 41-48.
161. Watanabe H. A method for distinguishing exceptional and general examples in example-based transfer systems. In Proceedings of the 15th International Conference on Computational Linguistics COLING’94, Kyoto, 1994, pp. 39-44.
162. Whitelock P., Kilby K. Linguistic and Computational Techniques in Machine Translation Systems. Design, London, UCL Press, 1995.
-
Описание ошибок в машинном переводе
Применение
машинного перевода без настройки на
тематику (или с намеренно неверной
настройкой) служит предметом многочисленных
бродящих по Интернету шуток.
Зачастую
программы машинного перевода понимаются
как какое-то уникальное средство, которое
способно вытеснить живых, мыслящих
переводчиков. Некоторые пользователи
полагают, что, если с помощью компьютера
сегодня можно добыть любые сведения из
многочисленных информационных источников,
от него можно ожидать соответствующей
компетентности также в вопросах
качественной трансформации этих сведений
в любой возможный языковой формат.
Однако
ни для кого не секрет, что такое
преставление крайне ошибочное. Знающие
специалисты, равно как и производители
подобных программ, понимают, что в
действительности ситуация выглядит
иначе. Конечно, рекламируя свои программные
продукты, производители честно признаются,
что качество машинного перевода далеко
от идеального и что получение адекватного
перевода возможно только при вмешательстве
человека, однако не всегда раскрывается
тот факт, что человек, которому предстоит
обработать такой перевод, должен быть
квалифицированным переводчиком и ему
придется потратить массу времени на
придание машинному тексту качества,
достойного профессионального перевода.
И
как бы ни пытались производители
приукрасить достоинства своей продукции,
пользователи многочисленных
онлайн-переводчиков всегда имеют
возможность убедиться в том, что
виртуальные «толмачи» не всегда способны
достойно справляться с поставленными
перед ними задачами. Доказательством
этому служат многочисленные шутки,
переходящие с сайта на сайт и высмеивающие
недостаточную компетентность
онлайн-переводчиков в вопросах
качественного перевода. К числу любимых
развлечений скептически настроенных
пользователей онлайн-переводчиков
относится перевод коротких предложений
или текстов песен в различных направлениях
и сравнение полученного результата с
исходным вариантом. К избитым примерам
относится перевод предложения «Мама
мыла раму» на английский язык, который
звучит как “Mum washed the frame”. Если затем
снова перевести полученное предложение
на русский язык, то разные переводчики
выдают свои результаты: «мама вымыла
структуру» (перевод Translate.ru – компания
PROMT) или «мама помыла рамку» (вариант
Babelfish.yahoo.com). Всем известен также пример
с переводом предложения “My
cat has given birth to four kittens, two yellow, one white and one
black”,
выполненным онлайн-переводчиком компании
PROMT, которое в русскоязычном исполнении
звучит как «Моя
кошка родила четырех котят, два желтых
цвета, одно белое и одного афроамериканца».
Нужно отметить, что разработчики
поработали над усовершенствованием
своего продукта, так как раньше данное
предложение начиналось с абсурдного
«Мой кот родил…», однако радует, что
данный переводчик компетентен в вопросе
политкорректности. К числу подобных
примеров относятся также переводы
различных песен и литературных
произведений, доставляющие немало
веселья экспериментаторам.
Сотрудники
многих фирм на каждом шагу встречаются
с многочисленными примерами абсурдных
переводов, выполненных посредством
онлайн-переводчиков. Зарубежные клиенты,
желающие сделать запрос на перевод, или
коллеги, предлагающие свое сотрудничество
в сфере переводов, часто прибегают к
помощи онлайн-переводчиков, столкнувшись
с необходимостью перевода электронных
сообщений на русский язык.
Например,
однажды сотрудники одной из фирм получили
электронное сообщение следующего
содержания:
Привет
Уважаемые! Пожалуйста, как вы! Надеюсь,
ты штраф и в отличном состоянии health.
I пошел через ваш профиль сегодня на
www.multitran.ru
и я прочитал его и принял в ней интереса,
пожалуйста, если вы не возражаете, я
хотел, чтобы вы напишите мне по этому
ID (***@yahoo.com)
надеются услышать от вас в ближайшее
время, и я буду Жду ваших почту, потому
что я что-то очень важно, чтобы рассказать
вам. Много любви Грейс.
Автор
сообщения сопроводил данное обращение
исходным текстом на английском языке:
Hi
Dear! Please how are you! hope you are fine and in perfect condition
of health. I went through your profile today at www.multitran.ru and
i read it and took interest in it, please if you don’t mind i will
like you to write me on this ID (***@yahoo.com
) hope to hear from you soon, and I will be waiting for your
mail because i have something VERY important to tell you. Lots
of love Grace.
Не
нужно долго гадать, чтобы понять, что
сообщение на русском языке является
результатом работы онлайн-переводчика.
Кстати, путем несложного эксперимента
было установлено, что автором данного
перевода был онлайн-переводчик Google. Это
сообщение является ярким подтверждением
тому, что данный онлайн-переводчик не
особо преуспел в своем деле и вряд ли
может бросить достойный вызов
профессиональному переводчику. Не
вдаваясь в глубокий анализ, можно
отметить, что основным недостатком
онлайн-переводчика является незнание
грамматических правил (в основном это
касается согласования частей речи и
членов предложений), а также неумение
распознавать и корректно переводить
некоторые лексические единицы,
употребленные в рамках заданного
контекста, и устойчивые выражения, в
результате чего, вместо «надеюсь, у Вас
все хорошо», переводчик выдал нелепое
и искажающее смысл предложения выражение
«надеюсь, ты штраф» (слово «fine» было
употреблено в значении «штраф»). Истинная
причина получения таких низкосортных
переводов кроется в том, что программы
машинного перевода не способны учитывать
экстралингвистические факторы. Именно
поэтому многие переводчики дословно
переводят те или иные термины и, кроме
того, не всегда отличают имена собственные
от знаменательных слов.
Ярким
примером этому может послужить перевод
статьи, посвященной Лоре Буш, супруге
бывшего президента Америки, выполненный
с помощью программы-переводчика. Ее
полное имя зазвучало на французском
языке как «le buisson de Laura», то есть «кустарник
Лоры». Программа не распознала фамилию
«Bush» как имя собственное и дословно
перевела ее на французский как «кустарник».
Но вся нелепость этой ситуации заключается
в том, что на французском сленге слово
«buisson» имеет сексуальную коннотацию.
Данные
примеры свидетельствуют о том, что
научить самый современный компьютер
языковой логике значительно сложнее,
чем математическим алгоритмам и логике
статистического анализа. Чтобы создать
в той или иной степени связный машинный
текст, программа может лишь использовать
ограниченный набор определенных
лингвистических алгоритмов, заложенных
в ее базу. Сначала система подвергает
анализу структурные элементы исходного
предложения, затем изменяет его в
соответствии правилами языка и выдает
конечный вариант. Однако как бы ни
пытались производители программ
машинного перевода усовершенствовать
свои разработки, еще ни одна технология
не выдерживала сравнения с теми
алгоритмами перевода и многочисленными
трансформациями, которым учат живых
переводчиков в школах и вузах. Безусловно,
для получения связного текста программу
можно снабдить богатой словарной базой,
включающей устойчивые выражения, а
также подключить специализированные
словари, чтобы переводчик смог перевести
тематические тексты. Но, как показывает
реальный опыт работы с онлайн-переводчиками,
это лишь малая часть того, что необходимо
для обеспечения приемлемого качества.
Основной проблемой таких переводчиков,
равно как и других систем машинного
перевода, является отсутствие фоновых
знаний. Компьютер знает только языковые
соответствия, а ведь переводчику очень
часто приходится выходить за рамки
формального текста и обращаться не к
языковым знаниям, а к экстралингвистическим
факторам, включающим знания о реальном
мире, культуре, истории, технике.
Профессиональные переводчики, особенно
технические, – это очень образованные
люди, и все их знания непосредственно
задействованы в процессе перевода.
Только в таком случае может быть
гарантировано действительно первоклассное
качество переводов. Поэтому если
разработчики сервисов онлайн-перевода
стремятся к предоставлению адекватных,
качественных переводов, они должны
снабдить своих машинных переводчиков
такими же фоновыми знаниями и, главное,
научить их правильно обращаться с
заложенным багажом знаний. Проще говоря,
программа должна понять, что возникла
какая-то проблема, для решения которой
необходимо прибегнуть к дополнительным
знаниям, и правильно сформулировать
запрос к имеющейся базе. Показательным
примером служит перевод на западноевропейские
языки предложений, в которых упоминаются
известные правители или их дети. В таких
предложениях артикль, категория которого
характерна для языков данной языковой
семьи, должен ставиться в зависимости
от общего количества детей. Например,
при переводе выражения «сын царя Федора»
артикль необходимо выбирать в зависимости
от того, сколько сыновей было у царя
Федора.
В
качестве аналогичного примера можно
привести перевод надписи на постаменте
памятника, открытого во Франции в честь
Анны Ярославны, дочери князя Киевского
Ярослава Мудрого. Перевод надписи на
французском языке звучал как «Anne de
Kiev la reine de la France», и все бы ничего, если
бы не лишний артикль. В случае с Францией
«la France» звучит как «единая
Франция», что не искажает смысл. Что
же касается дочери князя, «la reine»
означает, что она единственная за всю
историю королева Франции. Переводчик,
знакомый со всеми нюансами французской
грамматики, не допустил бы такую нелепую
ошибку, а вот для электронного переводчика
– это довольно типичная ошибка.
Чаще
всего подобные шутки связаны с тем, что
программа не распознаёт контекст фразы
и переводит термины дословно, к тому же
не отличая собственных имён от обычных
слов. Тот же переводчик ПРОМТ превращает
«bra-ket
notation» в «примечание Кети лифчика»,
«Lie
algebra» — в «алгебру Лжи», «eccentricity
vector» — в «вектор оригинальности»,
«Shawnee
Smith» в «индеец племени шони Смит» и
т. п. Переводчик
Google, наоборот, слово «rice»
часто принимал за фамилию госсекретаря
США.
А
теперь рассмотрим примеры машинного
перевода отрывков из художественных и
научных текстов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Hisamova Venera Nafikovna, Sitdikova Farida Bizyanovna, Usmanov Timur Ravilevich MACHINE TRANSLATION ERRORS (ON THE BASIS OF ANALYSIS …
philological sciences -linguistics
УДК 81’32
DOI: 10.26140/bgz3-2019-0802-0079
«ПЕРЕДНЯЯ ЧАСТЬ ПРАВОГО ТЕЛЕНКА», ИЛИ ОШИБКИ МАШИННОГО ПЕРЕВОДА (НА ОСНОВЕ АНАЛИЗА АВТОМАТИЧЕСКИХ СУБТИТРОВ)
© 2019
Ситдикова Фарида Бизяновна, кандидат филологических наук, доцент
Хисамова Венера Нафиковна, доктор филологических наук, профессор Усманов Тимур Равилевич, кандидат педагогических наук, доцент Казанский федеральный университет (420008, Россия, Казань ул. Кремлевская, 18, e-mail: farida7777@yandex.ru)
Аннотация. Статья посвящена анализу ошибок, сделанных машинным переводчиком Google Translate при переводе с английского на русский. Проблема качества машинного перевода является крайне актуальной в настоящее время в связи с возрастающей интенсивностью интернет-коммуникаций. В статье рассматриваются как достоинства, так и недостатки машинного перевода. Решение поставленной задачи — оценка качества машинного перевода — проводилось на материале автоматических субтитров, переведенных машинным переводчиком. На основании большого количества языковых примеров проведен анализ наиболее характерных ошибок переводчика Google Translate. Ошибки были поделены на несколько типов. Лексико-семантические ошибки включали в себя следующие: 1) неспособность выбрать нужное по контексту значение; 2) перевод семантических конструкций; 3) перевод имен собственных; 4) перевод аббревиатур. Рассматривались также морфологические, синтаксические и стилистические ошибки. Собрана статистика по количеству ошибок каждого типа. Делается вывод по количеству ошибок каждого типа. На основании проведенного опроса делается вывод о возможности использовать машинный перевод субтитров в практических целях в качестве сигнальной версии перевода субтитров. Материалом для исследования послужили автоматические субтитры, переведенные на русский язык Google Translate, которые сравнивались с английским оригиналом. Статья может представлять интерес для исследователей, интересующихся проблемами и перспективами машинного перевода.
Ключевые слова: компьютерная лингвистика, машинный перевод (МП), MT, машинный переводчик, автоматический перевод, автоматический переводчик, статистический МП, SMT, нейронный МП, NMT, система машинного перевода (СМП), постредактирование, ошибки машинного перевода
MACHINE TRANSLATION ERRORS (ON THE BASIS OF ANALYSIS OF AUTOMATIC SUBTITLES)
© 2019
Hisamova Venera Nafikovna, Doctor of Philology, professor Sitdikova Farida Bizyanovna, Candidate of Philological Sciences, Associate Professor Usmanov Timur Ravilevich, Candidate of Pedagigics, Associate Professor Kazan Federal University (420008, Russia, Kazan, Kremlevskaya St., 18, e-mail: farida7777@yandex.ru)
Abstract. The article describes typical errors made by Google Translate in the process of translation from English into Russian. Quality of machine translation is an acute problem due to increasing intensity of Internet communication. The article discusses both advantages and disadvantages of machine translation. The work objective was to evaluate the quality of machine translation. Subtitles generated automatically served as a study material. We used a large number of language examples to perform analysis of the most characteristic mistakes made by Google Translate. The errors were divided into several types. The lexico-semantic errors included: 1) choosing a wrong contextual meaning; 2) incorrect translation of semantic constructions; 3) incorrect translation of proper names; 4) incorrect translation of bbreviations. Morphological, syntactic and stylistic mistakes were also considered. We performed statistical analysis of each type of the detected errors. Based on the obtained data, it was shown that it is possible to use automatically generated subtitles for practical purposes as a signal version of the subtitle translation. The article may be of interest to researchers studying the problems and prospects of machine translation.
Keywords: computational linguistics, machine translation (MT), MT, machine translator, automatic translation, automatic translator, statistical MP, SMT, neural MT, NMT, machine translation system (SMP), post-editing, machine translation errors
В статье исследуется проблема качества машинного перевода на основе анализа автоматических субтитров. Для начала уточним, что машинный перевод (МП, MT, Machine Translation) — это перевод текстов с одного естественного языка на другой специальной компьютерной программой. Такое же название носит направление научных исследований, связанных с построением подобных систем [1].
Актуальность статьи связана с возрастающей интенсивностью интернет-коммуникаций, соответственно возникает проблема быстрого и качественного, по возможности дешевого перевода. В настоящее время все больше людей в связи с растущими объемами информации используют системы машинного перевода. Поэтому значение автоматизированных систем перевода постоянно повышается [2]. К сожалению, на сегодняшний день переводы, сделанные машинными переводчиками, остаются несовершенными. В связи с этим исследование проблем машинного перевода представляется актуальным в целях повышения качества таких переводов [3].
Целью нашего исследования было рассмотреть возможность применения машинных переводчиков без участия переводчика-человека в практической сфере, а именно, для перевода автоматических субтитров. Для достижения данной цели были поставлены следующие задачи:
1) рассмотреть понятие МП и кратко описать различные системы МП;
2) раскрыть достоинства и недостатки МП;
3) сделать выборку переведенных предложений, содержащих ошибки того или иного рода;
4) проанализировать ошибки, провести классификацию и разбить их на группы;
5) сделать выводы относительно качества МП и возможностей практического применения.
Для начала отметим, что существуют различные типы систем машинного перевода:
1) основанные на правилах грамматики;
2) использующие в своей работе статистический анализ;
филологические науки —
языкознание
Ситдикова Фарида Бизяновна, Хисамова Венера Нафиковна, Усманов Тимур Равилевич MACHINE TRANSLATION ERRORS (ON THE BASIS OF ANALYSIS …
3) системы гибридного типа;
4) основанные на нейронных сетях и характеризующиеся способностью к обучению [4, 5].
Первый подход является традиционным и используется большинством разработчиков систем машинного перевода (например, ПРОМТ в России (год создания 1991), SYSTRAN во Франции, Linguatec в Германии и т.д.). Ко второму типу относятся такие сервисы, как Яндекс. Переводчик (2009), Переводчик Google (2003), а также новый сервис от ABBYY [6].
Особенностью статистического МП является то, что системы такого рода в своей работе используют статистический анализ. В систему загружается корпус текстов на двух языках, после этого система выдает анализ статистики языковых соответствий и различных синтаксических конструкций в двух языках. Преимущество системы в том, что она является самообучаемой, т.е. при выборе нужного варианта перевода она исходит из полученной ранее статистики. Чем больше объем словаря для языковой пары и чем выше его качество, тем лучше результаты данного виде перевода. К наиболее значительным недостаткам систем SMT можно отнести наличие многочисленных лексических и грамматических ошибок и нестабильность перевода [7].
За последние годы произошел ряд технологических прорывов и существенный рост вычислительной мощности компьютеров, благодаря чему интенсивное развитие получила технология машинного обучения. Эта концепция нашла применение и в области машинного перевода. Так, в 2016 года сразу несколько крупных компаний объявили о создании новейших технологий MT, основанных на нейронных сетях (англ. Neural MT (NMT)).
Нейронный машинный перевод (Neural Machine Translation, NMT) — это вид МП, в котором используется искусственная нейронная сеть. Этот способ принципиально отличается от использованных ранее методов [8]. Модели NMT способны обучаться во время работы и со временем их перевод становится более эффективным.
В сентябре 2016 года компания Google представила систему нейронного машинного перевода (Google Neural Machine Translation system, GNMT) [9]. Как утверждают разработчики, она превосходит по качеству все предыдущие технологии в этой области. Применение GNMT сокращает количество ошибок в машинном переводе на 55-85% [10]. В 2016 г. движок перевода был включен в обе стороны для девяти языков: английского, французского, немецкого, испанского, португальского, китайского, японского, корейского и турецкого. В марте 2017 г. были добавлены ещё три языка: русский, хинди и вьетнамский [11]. Преимуществом нейронной сети является сам подход к обработке текста. Большинство переводчиков обрабатывают каждое слово по отдельности, а нейросеть переводит фразы и предложения целиком, с учетом контекста. Это дает надежду на то, что уже в ближайшие годы мы можем ожидать улучшения качества машинного перевода.
В 2017 г. компания Yandex запустила нейросетевой перевод, главным достоинством которого была заявлена гибридность. СМП Yandex переводит предложение сразу двумя методами — статистическим и нейросетевым, а потом с помощью алгоритма CatBoost, в основе которого лежит машинное обучение, находит наиболее подходящий вариант [12].
У существующих онлайн-переводчиков есть ряд достоинств, которые нужно признать и которые способствуют повышению их популярности у пользователей Интернета:
1) бесплатный перевод;
2) доступность в любое время дня и ночи, был бы интернет;
3) скорость перевода — практически сразу после ввода;
4) большое количество языковых пар (например, раз-
работчики Гугла сообщили, что их система в настоящее время способна понимать 90% человечества [13]);
5) простой и понятный интерфейс;
6) отметим также такой важный фактор, как конфиденциальность информации;
7) наконец, онлайн переводчики могут встраиваться в различные сервисы, например, переводить страницы на сайтах [14].
С другой стороны, несмотря на то, что ежегодно вкладываются миллиарды долларов в развитие систем машинного перевода, на сегодняшний день нет машинного переводчика, который давал бы перевод, сравнимый с результатом работы переводчика-человека. В связи с этим представляет интерес анализ наиболее характерных ошибок, допускаемых машинными переводчиками, а также их классификация и сбор статистических данных.
Анализ ошибок машинного перевода проводился рядом авторов. В частности, Переходько И.В., Мячин Д.А. [15] предприняли попытку анализа текстов переводов Интернет-сайтов, выполненных с помощью систем компьютерного перевода, на основе лингвостилистического анализа и на основе автоматической обработки текстов с использованием метрики METEOR по методу N-грамм. Авторы делают вывод о том, что наибольшее количество ошибок в машинных переводах связано с переводом семантических конструкций.
Ряд авторов [16, 17], ставят целью использовать автоматическую оценку качества МП и анализ качества перевода научно-технического текста с помощью различных метрик. При этом сами авторы отмечают, что важным недостатком автоматических метрик является то, что они не могут предоставить оценку качества МП на уровне смысла.
Наше исследование по оценке качества машинного перевода представляло анализ переводов, выполненных машинным переводчиком Google Translate. Методическая новизна заключалась в материале исследования, которым послужили автоматические субтитры, сделанные этой СМП. Анализ автоматических субтитров проводился при просмотре детективного сериала «Парочка следователей» («Partners for Justice») [18], который переводился с английского на русский с использованием английских субтитров. Задолго до «человеческого» перевода выкладывались автоматические субтитры. Для этой цели использовался скрипт Translate Shell, доступный по адресу: https://github.com/soimort/ translate-shell. Субтитры в формате SRT скачивались либо с https://avistaz.to/, либо с https://subscene.com/. В результате появлялся текст, который вполне давал возможность понять большую часть содержания, за исключением некоторых моментов, на которых мы остановимся далее.
Несколько слов о том, как собирались и анализировались примеры. Просматривались серии с автоматическими субтитрами и методом сплошной выборки отбирались предложения, не соответствующие языковым нормам или не позволяющие вывести смысл.
После этого просматривалась соответствующая серия с английскими субтитрами и сравнивалась с машинным переводом, сделанным Google Translate. Другими словами, использовались метод сплошной выборки, сравнительно-сопоставительный метод и лексико-се-мантический анализ.
Google Translate — бесспорно одна из самых лучших СМП на сегодняшний день. При создании текста перевода она использует примеры из миллионов документов, чтобы выбрать правильный вариант. Тем не менее, в отличие от переводчика-человека, система может допускать ряд ошибок, которые мы разбили на следующие группы:
I. Лексико-семантические ошибки. Это, на наш взгляд, самые существенные ошибки, которые часто препятствуют пониманию смысла высказывания. Среди
Hisamova Venera Nafikovna, Sitdikova Farida Bizyanovna, Usmanov Timur Ravilevich MACHINE TRANSLATION ERRORS (ON THE BASIS OF ANALYSIS …
philological sciences -linguistics
них важнейшей ошибкой является 1) неспособность выбрать нужное по контексту значение лексической единицы — то, с чем без труда справляется переводчик-человек. Возьмем пример, использованный в заголовке. Машинный перевод приведен во втором столбце, верный перевод — в третьем.
The front of right calf, multiple skin abrasions. Передняя часть правого теленка, множественные царапины на коже. Передняя часть правой голени, множественные царапины на коже (ер.25, 0:12).
Контекстом являлись слова паталогоанатома, делающего вскрытие. Понятно, что имелась в виду передняя часть правой голени. Приведем еще один пример:
Darn it, this jerk! Оберните это, этот рывок! Черт побери, этот придурок! (ep. 29, 11:30).
Этот и другие многочисленные случаи говорят о том, что машинным переводчиком выбираются значения слова без учета контекста. Среди лексических ошибок можно также выделить 2) перевод словосочетаний с переносным значением (назовем их семантическими конструкциями), которые переводились дословно. Например:
If this becomes one more cold case, we’ll all have to retire. Если это станет еще одним холодным случаем, мы все должны уйти в отставку. Если это станет еще одним нераскрытым случаем, мы все должны уйти в отставку ^.29, 07:59).
Переносное значение выделенного словосочетания — нераскрытое дело, «глухарь». При таком переводе смысл предложения может быть не понят зрителем. Еще один пример:
The murderer’s gone out of the grid for 30 years. Убийца ушел с сетки в течение 30 лет. Убийца затаился на 30 лет. (ep. 3, 0: 22).
Ошибки такого рода свидетельствуют о том, что машинные переводчики на сегодняшний день не справляются с переводом семантических конструкций и выдают калькированный перевод, который приводит к нелепым результатам, далеким от настоящего смысла. Приведем третий пример:
You are normally this straightforward once you have set your mind on something. Ты обычно такой прямолинейный, после того, как вы установили свой ум на что-то. Вы обычно идете напролом, если что-то задумали. ^. 10, 31: 50).
Where’s So Hi? (женское имя)
Где такХи?
Где Со Хи? (ep. 22, 23:02).
I am such a bad boss. I owe Sang An so much.
Я паршивый начальник. Я должна спеть так много.
Я неблагодарный начальник. Я так многим обязан Сан Ан. (ep. 22, 27:12).
Справедливости ради надо отметить, что Гугл с годами все же улучшает качество перевода имен собственных. Вспоминается случай, когда несколько лет назад при переводе с русского на английский сочетания улица Горького выдавался перевод Bitter street, то есть имя собственное воспринималось как нарицательное bitter — горький. Но если сейчас ввести это словосочетание в переводчик Гугл, то на выходе получим верный перевод: Gorky Street. Огромная работа, проводимая разработчиками этой СПМ, позволяет надеяться на то, что в перспективе можно ожидать более качественных результатов автоматического перевода.
Наконец, следует сказать несколько слов о 5) переводе аббревиатур. Нам встретился только один подобный пример, но автоматический переводчик оставил его без перевода, в исходном виде. Возможно, это связано с тем, что это латинское выражение (modus operandi):
Она была
She was murdered Она была убита с убита тем же
with the same MO. той же МО. способом^. 23,
3:09).
2. Морфологические ошибки, связанные с переводом частей речи и их употреблением, т.е. ошибки в переводе рода, числа, склонения, падежа существительных, видо-временных форм глагола т.д. Приведем несколько примеров ошибок этого типа.
Are you kidding me? Вы меня издеваетесь? Вы надо мной издеваетесь? ^. 23, 10:12).
You can’t do an autopsy on my Dad. Вы не можете сделать вскрытие моей папе. Вы не можете сделать вскрытие моему папе. ^.24, 15:48).
Didn’t Dad go to hospital regularly? Разве папа не пошел в больницу регулярно? Разве папа не ходил в больницу регулярно? ^.24, 7:56).
Объясняя причины калькированного перевода, некоторые исследователи считают, что система МП на основе переводных соответствий не всегда может справиться с одной из принципиальных задач перевода, а именно, перехода от конструкции исходного языка к конструкции выходного языка, поэтому в тексте перевода появляются конструкции, характерные языку оригинала, но не языку перевода [19].
Таким образом, мы можем наблюдать, как при МП могут нарушаться языковые нормы того языка, на который осуществляется перевод.
Отдельным случаем лексико-семантических ошибок является 3) перевод имен собственных. Часто система переводит имена собственные (особенно короткие, в данном случае корейские) как нарицательные слова, например:
В первом случае использован неверный падеж, во втором ошибка в переводе рода существительного, в третьем примере неверный вид глагола. Но хотя перевод данных предложений не соответствует нормам русского языка, эти ошибки не являются такими серьезными, как ошибки первого типа, т.к. не препятствуют извлечению смысла.
3. Стилистические и синтаксические ошибки.
Стилистические ошибки включают нарушение сочетаемости слов, тавтология, лексическая недостаточность, частые повторы слов, смешение стилей и т.д. Сюда также относятся нарушение порядка слов в предложении, нарушение согласования с главным словом, пропуск или неверное употребление предлога, синтаксическая неоднозначность, отсутствие смысловой законченности предложения. Так же, как и морфологические, эти ошибки вполне позволяют извлечь смысл фразы или высказывания. Приведем несколько примеров:
Интересен случай, когда имя переведено с английского как глагол прошедшего времени, потому что по написанию совпадало с ним:
Thanks to your care-taking, I think I healed quickly. Благодаря вашей заботе, я быстро зажила. Благодаря вашей заботе, у меня всё быстро зажило. ^.7, 6:55).
The fridge and cabinets are bare. Холодильник и шкафы голые. Холодильник и шкафы пустые.(ер.23. 27:54).
You are to take this position after me. Вы должны забрать этот пост за мной. Ты должен занять это место после меня22, 19:34).
Подводя итоги, следует отметить, что наиболее существенными для понимания и самыми многочисленны-
филологические науки -языкознание
Ситдикова Фарида Бизяновна, Хисамова Венера Нафиковна, Усманов Тимур Равилевич MACHINE TRANSLATION ERRORS (ON THE BASIS OF ANALYSIS …
ми были лексико-семантические ошибки (около 53%). Морфологические ошибки не мешали пониманию текста, но также были довольно многочисленными (28%). Оставшуюся часть (19%) составляли стилистические и синтаксические ошибки. Наши результаты хорошо кор-релируются с выводами других исследователей, например [15], [20].
Далее был организован опрос пользователей группы в ВК, смотревших данный сериал. Было опрошено 57 пользователей с целью выяснить, насколько часто при просмотре сериала с автоматическими субтитрами им приходилось пересматривать серии с «человеческим» переводом. Полученные результаты описываются в выводах.
Выводы.
1. За последние десятилетия разработок области машинного перевода качество перевода улучшилось, и машинные переводчики вполне способны выстраивать разумные фразы. Уже сейчас системы МП оказывают большую помощь, делая для переводчиков черновую работу и оставляя человеку лишь постредактирование.
2. Наше исследование продемонстрировало, что сегодняшний день МП, хотя и является несовершенным, но вполне успешно может использоваться в практических целях. Примером того служит автоматический перевод субтитров, выполненный Google Translate, который, как показала практика, с успехом можно использовать как сигнальную версию, дающую представление о содержании текста (в данном случае содержании сериала). В 89,5% случаев (51 зрителей из 57) просмотра серий с автоматическими субтитрами не потребовался просмотр серий с переводом.
Возможно, такой высокий процент объясняется тем, что перевод субтитров — это не перевод текста в чистом виде. При просмотре фильма зритель получает также визуальную информацию и при понимании руководствуется не только текстом, но и контекстом и ситуацией.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
3. В отличие от переводчика-человека машинный переводчик Google Translate при переводе допускает ошибки, которые мы разбили на несколько групп.
Общее количество ошибок 200 100%
1) лексико-семантические 106 53
2) морфологические 56 28
3) стилистические и синтаксические 38 19
4. Говоря о статистических результатах, следует отметить, что наиболее существенными для понимания и самыми многочисленными были лексико-семантиче-ские ошибки (около 53%).
5. К досадным ошибкам приводил калькированный перевод семантических конструкций, к которым относятся фразеологические обороты, образные выражения, метафоры, фразовые глаголы английского языка и т.д. В объяснении причин такого явления мы согласны с исследователями, утверждающими, что система МП на основе переводных соответствий не может совершить переход от конструкции исходного языка к конструкции выходного языка [18], поэтому в тексте перевода появляются конструкции, характерные языку оригинала, на языке перевода звучащие нелепо.
6. Морфологические ошибки не мешали пониманию текста, но также были довольно многочисленными (примерно 28%).
7. Стилистические и синтаксические ошибки составляли оставшуюся часть (19%).
8. Пока сложно сделать прогноз, насколько может улучшиться качество машинного перевода в ближайшие десятилетия. Но даже если системы МП не смогут достичь того же уровня, что «человеческий перевод», тем не менее сложно представить будущее без машинных переводчиков, т.к. их помощь человеку сложно переоценить.
СПИСОК ЛИТЕРАТУРЫ:
1. Воронович В.В. Машинный перевод. Конспект лекций для студентов 5-го курса специальности «Современные иностранные языки». Минск, 2013 — 39 с.
2. Евдокимов А.С. Искусство машинного перевода //Hard’N’Soft.
— 2005. -№ 7. — С. 86-91.
3. Марчук Ю.Н. Компьютерная лингвистика : учеб. пособие /Ю. Н. Марчук. -М. : АСТ : Восток-Запад, 2007. — 317 с.
4. Ситдикова Ф.Б. Эволюция машинного перевода./Янбекова Г.Б., Галимзянова З.В., Ситдикова Ф.Б. // Научные революции: Сущность и роль в развитии науки и техники: Сборник статей по итогам Международной научно-практической конференции (Оренбург, 30 апреля 2018 г.). — Стерлитамак: АМИ, 2018. С. 53-58.
5. О термине «машинный перевод». [Электронный ресурс] URL: http://ru.wikipedia.org/wiki/Машинный_перевод (дата обращения: 9.04.2019).
6. Андреева А.Д., Меньшиков И.Л., Мокрушин А.А. Обзор систем машинного перевода //Молодой ученый. — 2013. — №12. — С. 64-66.
— [Электронный ресурс] URL https://moluch.ru/archive/59/8581/ (дата обращения: 9.04.2019).
7. Леонтьева Н.Н. Автоматическое понимание текстов. Системы, модели, ресурсы. — Москва: ACADEMIA, 2006. 7. Google Translate начал использовать нейроперевод. [Электронный ресурс] URL: https://www.armadaboard.com/topic59199.html (дата обращения: 9.04.2019).
8. Нейронный машинный перевод. Вводный курс. [Электронный ресурс]URL:http://datareview.info/article/neyronnyiy-mashinnyiy-perevod-s-primeneniem-gpu-vvodnyiy-kurs-chast-1/ (дата обращения: 9.04.2019).
9. Google Translate подключил русский язык к переводу с глубинным обучением. [Электронный ресурс]. URL: https://habr.com/post/370243/ (дата обращения: 9.04.2019).
10. Краткая история машинного перевода. [Электронный ресурс]. URL: http://linguisticus.com/ru/TranslationTheory/OpenFolder/ ISTORIJA_MASHINNOGO_PEREVODA (дата обращения: 9.04.2019).
11. Нейронный машинный перевод Google [Электронный ресурс]. URL: https://habr.com/ru/post/414343/ (дата обращения: 9.04.2019).
12. Яндекс запустил гибридную систему перевода. [Электронный ресурс]URL: https://yandex.ru/blog/company/kak-pobedit-mornikov-yandeks-zapustil-gibridnuyu-sistemu-perevoda (дата обращения: 9.04.2019).
13. Нейросеть Google Translate составила единую базу смыслов человеческих слов. [Электронный ресурс]URL: https://habr.com/ru/ post/369913/(дата обращения: 9.04.2019).
14. Анализ машинного перевода и сравнение онлайн-переводчиков
— новая жизнь старого проекта. [Электронный ресурс]. URL: http:// news.flarus.ru/?topic=632 (дата обращения: 9.04.2019).
15. Переходько И.В., Мячин Д.А. Оценка качества компьютерного перевода. -Вестник Оренбургского государственного университета.
— 2017. — № 2. — С. 92-96.
16. Улиткин И.А. Автоматическая оценка качества перевода научно-технического текста. [Электронный ресурс]. URL: https:// vestnik-mgou.ru/Articles/Doc/10973 (дата обращения: 9.04.2019).
17. Кедрова Г.Е., Потемкин С.Г. Автоматическая оценка качества машинного перевода на основе семантической метрики // Вiсник Луганського нащонального педагогiчногоунiверситету iменi Т. Шевченка. — № 15(95). — С. 35-41.
18. Парочка следователей | Partners for Justice. [Электронный ресурс]. URL: http://doramatv.ru/partners_forjustice (дата обращения: 9.04.2019).
19. Томин В.В. О проблемах машинного перевода научно-технического текста в информационном поле кросс-культурного взаимодействия. [Электронный ресурс]. URL: http://vestnik.osu.ru/2015_1/5.pdf (дата обращения: 9.04.2019).
20. Кочеткова Н. С., Ревина Е.В. Особенности машинного перевода // Филологические науки. Вопросы теории и практики Тамбов: Грамота, 2017. — № 6(72): в 3-х ч. Ч. 2. C. 106-109. ISSN 1997-2911
Статья поступила в редакцию 23.03.2019 Статья принята к публикации 27.05.2019
Библиографическое описание:
Красильникова, В. Г. Анализ качества машинного перевода системами Google Translate и Яндекс.Переводчик (на материале отрывка из научно-популярного издания по медицине) / В. Г. Красильникова, А. Д. Сафронова. — Текст : непосредственный // Молодой ученый. — 2021. — № 23 (365). — С. 492-494. — URL: https://moluch.ru/archive/365/81991/ (дата обращения: 31.01.2023).
В рамках данного исследования был проведён анализ ошибочно переведённых фрагментов машинного перевода на материале отрывка из научно-популярного издания о деменции.Мы выделили массив ошибок, допущенных системами Google Translate и Яндекс.Переводчик, и классифицировали их по трём группам ошибок, связанных с денотативным и жанрово-стилистическим содержанием оригинала, а также с оформлением текста на языке перевода, и постарались объяснить причины их возникновения.
Ключевые слова:
машинный перевод, переводческие ошибки, постредактирование, научно-популярная литература, медицинский дискурс.
Книгоиздание является одним из процессов, подлежащих возможной автоматизации в будущем. На сегодняшний день количество книг, переведённых системами машинного перевода и отредактированных далее человеком слишком мало, чтобы делать выводы об эффективности машинных переводчиков в этой области, однако и разработчики, и представители книжного рынка, и постредакторы машинного перевода позитивно относятся к тому, чтобы делегировать часть переводческих задач автоматизированным системам, тем самым осуществить переквалификацию действующих переводчиков [1, 3, 4, 5, 6].
Мы проанализировали ошибки, допущенные двумя популярными системами машинного перевода. Ошибками в переводе считаются неоправданные переводческие трансформации, нарушение логики изложения на языке перевода и несоблюдение узуса и норм переводящего языка. Для данной работы в качестве основы была выбрана классификация ошибок по Д. М. Бузаджи и соавт. [2]. В ней выделяется четыре крупные группы переводческих ошибок, но поскольку в исследуемом материале не была представлена группа, связанная с нарушениями передачи авторской оценки, было принято решение не учитывать её при демонстрации полученных результатов. Несмотря на тот факт, что в научно-популярной литературе оценочная лексика встречается гораздо чаще, чем в специализированных текстах [2, с. 60], конкретно в анализируемом отрывке изложение материала близится к объективному с нейтральным уровнем экспрессии. Авторы не говорят о себе и не выражают свою позицию по тому или иному вопросу, лишь популяризуют знание. Таким образом, мы ограничились тремя группами переводческих ошибок, а именно:
1) нарушения при передаче денотативного содержания текста;
2) нарушения при передаче стилистических характеристик оригинала;
3) нарушения нормы и узуса ПЯ.
Материалом исследования послужил отрывок из англоязычной научно-популярной книги о деменции [7]: разделы, описывающие деменцию как заболевание, её симптомы и четыре основных вида. Перевод осуществлялся системами Google Translate и Яндекс.Переводчик, которые различаются в своём подходе к данному процессу. Первая система использует нейронный машинный перевод, изредка обращаясь к статистическому подходу; вторая переводит по гибридному типу, выбирая один из вариантов статистического или нейронного перевода для каждого исходного сегмента. Обе системы постоянно обучаются за счёт пополнения учебных корпусов (как правило, это web-тексты) и активного участия пользовательского сообщества в развитии данных систем. Переведённый машинными переводчиками текст подлежал сравнению с опубликованным на русском языке переводом данного произведения [8]. Для удобства сравнения анализируемый текст был разбит на смысловые единства согласно опубликованному переводу. Каждый такой блок, содержащий заголовок, абзац или группу абзацев помещался в поле для исходного текста в интерфейсе машинных переводчиков. Выведенный в поле с переводом текст подлежал дальнейшему количественно-качественному анализу содержащихся в нём ошибок. Текст машинного перевода нами не редактировался.
Всего в переводе от Google Translate было зафиксировано 405 случаев переводческих ошибок (100 %), из которых наибольшую частотность имеет такой вид ошибок, как неточная передача информации: 139 случаев (34.3 %). Далее следуют нарушения при передаче жанрово-стилистических особенностей текста оригинала: 82 случая (20.2 %). Третье место по частотности разделяют калькирование и нарушения узуса ПЯ: по 40 случаев каждого вида (9.9 %). Общее число случаев переводческих ошибок в рамках исследованного материала от Яндекс.Переводчика составило 439 единиц (100 %). Распределение ошибок по частотности аналогично тому, что было у зарубежной системы машинного перевода. Неточная передача информации представлена наиболее часто: 143 случая (32.6 %). Вторыми по частотности являются нарушения при передаче жанрово-стилистических особенностей текста оригинала: 91 случай (20.7 %). Далее следует калькирование: 56 случаев (12.8 %).
Табличное отображение ошибок по видам внутри групп для каждой системы машинного перевода выглядит следующим образом:
Таблица 1
Частотность ошибок, допущенных системами машинного перевода
Google
Translate
и
Яндекс.Переводчик
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.1 |
опущение информации |
17 |
4.2 % |
12 |
2.7 % |
|
1.2 |
добавление информации |
10 |
2.5 % |
3 |
0.7 % |
|
1.3 |
замена информации |
23 |
5.7 % |
30 |
6.8 % |
|
1.4 |
неточная передача информации |
139 |
34.3 % |
143 |
32.6 % |
|
|
|
|
|
|
|
|
2.1. |
нарушения при передаче жанрово-стилистических особенностей текста оригинала |
82 |
20.2 % |
91 |
20.7 % |
|
2.2. |
калькирование |
40 |
9.9 % |
56 |
12.8 % |
|
2.3. |
нарушения узуса ПЯ |
40 |
9.9 % |
39 |
8.9 % |
|
|
|
|
|
|
|
|
3.1. |
ошибки в орфографии и пунктуации |
2 |
0.5 % |
4 |
0.9 % |
|
3.2. |
ошибки при передаче имен собственных при наличии или отсутствии традиционного варианта |
3 |
0.7 % |
4 |
0.9 % |
|
3.3. |
нарушения стилистических норм ПЯ |
37 |
9.1 % |
29 |
6.6 % |
|
3.4. |
ошибки при передаче некоторых цифровых данных |
3 |
0.7 % |
2 |
0.5 % |
|
3.5. |
нарушения требований к оформлению данного типа текстов |
9 |
2.2 % |
26 |
5.9 % |
|
|
|
|
|
|
|
Так как Яндекс.Переводчик обучается на корпусах русских текстов, ожидалось, что перевод от данной системы будет содержать меньшее количество ошибок, однако обе системы выдают переводы одинакового уровня качества, которые безусловно нуждаются в постредактуре. По результатам исследования, 89–92 % текста, генерируемого машинными переводчиками, содержало переводческие ошибки.
Чаще всего допускались ошибки по типу неточной передачи информации из оригинального текста, для избегания которых необходимо владеть таким приёмом переводческих трансформаций как модуляция. Именно распознавание тонких смысловых оттенков значений и логическое развитие оригинальной мысли на переводящем языке недоступно для нейросетей на настоящем этапе их развития. Кроме того, векторное представление слов для текстов научно-популярного медицинского дискурса у нейросетей развито недостаточно, поэтому наблюдаются проблемы с актуальным членением предложения в тексте переводов, что тоже относится к неточной передаче информации. Ошибки дискурсивного характера могут быть связаны с тем, что машинные переводчики, в отличие от реальных, не работают с коммуникативной целью исходного текста. В связи с этим в тексте перевода не соблюдается единая терминология, происходит неуместный переход от научной лексики к разговорно-бытовой, термины претерпевают генерализацию или же идентификация терминов вовсе не осуществляется, и машинный переводчик переходит на лексическое или синтаксическое калькирование. Аналогичные переводческие ошибки наблюдались в терминосодержащих словосочетаниях. Наконец, третья группа ошибок представляла собой нарушения нормы и узуса переводящего языка, но не с точки зрения смыслов, авторских сем, а графического и стилистического оформления текстов на русском языке. Данные переводческие ошибки возникали несистематично, спонтанно. Они обусловлены «шумами», «мусором» в учебных корпусах текстов. Так, в тексте перевода наблюдались лишние пробелы и символы, изменение регистра и нарушения стилистических норм. Такой вид ошибок, как сбои в передаче цифровых данных, в нашем случае объясняется отсутствием в базе корпусов системы синонимов и эквивалентов мер времени, которые, как известно, различаются в англоязычной и русскоязычной культурах.
Системы машинного перевода постепенно набирают популярность среди профессиональных переводчиков благодаря тому, что они способны в значительной степени упростить процесс перевода. Владение навыком работы в таких системах и постредактирования найденных ошибок определяет востребованность современного переводчика и его конкурентоспособность. Это одна из новейших задач в переводческой индустрии. Стоит отметить, что абсолютная замена реальных переводчиков компьютерными программами перевода не предвидится, по крайней мере, в ближайшем будущем. Несмотря на то, что переводчик теперь склонен выбирать и редактировать наиболее оптимальный из предложенных его «коллегой» вариантов, условием качественного машинного перевода остаётся человеческая экспертиза и авторство перевода, в любом случае, принадлежит людям.
Литература:
- Бенюмов, К. «Как думаете, какой запрос самый распространенный?» Глава Google Translate Барак Туровски — о том, как сервис переходит на нейросети [Интервью] / К. Бенюмов — Текст: электронный // Meduza. — 07.03.2017. — URL: https://meduza.io/feature/2017/03/07/kak-dumaete-kakoy-zapros-samyy-rasprostranennyy (дата обращения: 20.03.2021).
- Бузаджи, Д. М. Новый взгляд на классификацию переводческих ошибок / Д. М. Бузаджи, В. В. Гусев, В. К. Ланчиков, Д. В. Псурцев. — Москва: Всероссийский центр переводов, 2009. — 121 c. — Текст: непосредственный.
- Воронович, В. В. Машинный перевод / В. В. Воронович. — Текст: непосредственный // Конспект лекций для студентов 5-го курса специальности «Современные иностранные языки». — Минск: Белорусский государственный университет, 2013.
- Сандалов, Ф. Редакторские тяготы — часть вторая: переводы / Ф. Сандалов. — Текст: электронный // Facebook: [сайт]. — URL: https://www.facebook.com/from.depot/posts/10224120155289932 (дата обращения: 20.03.2021).
- Тарарак, Е. Машина vs Человек. Отберет ли искусственный интеллект хлеб у переводчиков? [Интервью] / Е. Тарарак. — Текст: электронный // Новая газета: [сайт]. — URL: https://novayagazeta.ru/articles/2020/12/13/88357-mashina-vs-chelovek (дата обращения: 20.03.2021).
- Zaretskaya, A. Integration of Machine Translation in CAT Tools: State of the Art, Evaluation and User Attitudes / A. Zaretskaya, P. G. Corpas, M. Seghiri. — Текст: непосредственный // SKASE Journal of Translation and Interpretation. — 2015. — № 8. — С. 76–88.
- Warner, J. A Pocket Guide to Understanding Alzheimer’s Disease and Other Dementias / J. Warner, N. Graham. — Second Edition. — London : Jessica Kingsley Publishers, 2018. — 160 c.
- Грэм, Н. Поговорим о болезни Альцгеймера. Карманный справочник для ухаживающих за близким с деменцией / Н. Грэм, Дж Уорнер. — Москва : Олимп-Бизнес, 2018. — 121 c. — (Как жить (Олимп-Бизнес)
Основные термины (генерируются автоматически): машинный перевод, ошибка, неточная передача информации, переводчик, система, жанрово-стилистическая особенность текста оригинала, нарушение, нарушение нормы, переводящий язык, передача.
На сегодняшний день существует два наиболее распространённых языка описания аппаратуры: Verilog/SystemVerilog и VHDL. Сами языки описания аппаратуры являются достаточно универсальными средствами, но всегда ли это так? И от чего может зависеть «не универсальность» языка описания аппаратуры?
Идея написания данной статьи возникла при синтезе одного проекта в разных средах разработки, в результате чего были получены отличные друг от друга результаты. Так как исходный модуль является достаточно объёмным, то для демонстрации полученных результатов был написан тестовый модуль меньшего объёма, но синтез которого вызывал те же предупреждения/ошибки. В качестве тестового модуля был использован 4-х битный регистр с асинхронным сбросом, а в качестве сред разработки были выбраны Libero SoC 18.1, Quartus Prime 17.1, Vivado 2017.4.1.
Сначала представлен вариант описания такого модуля на языке Verilog, текст которого воспринимается выбранными средами разработки верно:
module test1
(
input clk,
input arst,
input [3:0] data,
output reg [3:0] q
);
always @( posedge clk or negedge arst ) begin
if ( ~ arst ) begin
q <= 4'h0 ;
end
else begin
q <= data ;
end
end
endmodule
В результате осуществления синтеза данного модуля были получены следующие схемы:
- Libero SoC v11.8
test1 Libero SoC

- Quartus Prime 17.1
test1 Quartus Prime
- Vivado 2017.4.1
test1 Vivado


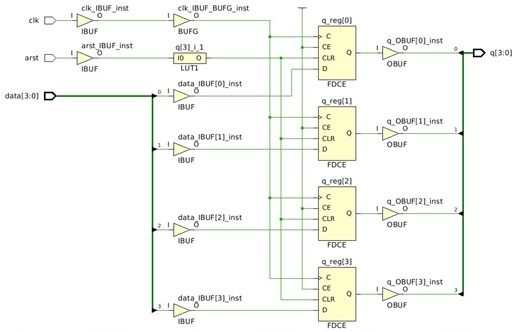
На всех синтезируемых схемах для test1 были использованы D-триггеры либо с инверсным входом сброса (Quartus Prime), либо с добавлением инвертора (VERIFIC_INV в случае Libero SoC и LUT1 в случае Vivado).
Будет ли отличаться синтезируемая схема, если изменить проверку состояния асинхронного сброса? Для этого необходимо изменить текст модуля test1 на описание модуля test2:
module test2
(
input clk,
input arst,
input [3:0] data,
output reg [3:0] q
);
always @(posedge clk or negedge arst) begin
if (arst) begin
q<=data;
end
else begin
q<=4'h0;
end
end
endmoduleМожно предположить, что синтез модуля test2 не должен отличаться от синтеза модуля test1, так как логики описания обоих модулей не противоречат друг другу. Однако, синтез модуля test2 привёл к следующим результатам:
- Libero SoC v11.8
Синтез схемы осуществился, однако в сообщениях появилось следующее предупреждение «Edge and condition mismatch (CG136)». Данное предупреждение означает несоответствие списка чувствительности и проверки условия сброса. Однако, синтезируемая схема не отличается от модуля test1.test2 Libero SoC
- Quartus Prime 17.1
Синтез схемы не осуществился с ошибкой:
«Error (10200): Verilog HDL Conditional Statement error at test2.v(10): cannot match operand(s) in the condition to the corresponding edges in the enclosing event control of the always construct». Текст ошибки схож с предупреждением, выданным Libero SoC.
- Vivado 2017.4.1
Синтез схемы осуществился с предупреждением:
«[Synth 8-5788] Register q_reg in module test is has both Set and reset with same priority. This may cause simulation mismatches. Consider rewriting code [«/home/vlasovdv0111/project_1/project_1.srcs/sources_1/new/test2.v»:10]». Также, как и в средах Libero SoC и Quartus Prime было выдано схожее предупреждение. Кроме этого в предупреждении было сказано о возможном несоответствии итогов моделирования и работы в «железе», вследствие этого предложено переписать код модуля.
test2 Vivado
После описания модулей test1 и test2 появилась идея проверить, что будет, если выполнить синтез следующего кода:
module test3
(
input clk,
input arst,
input [3:0] data,
output reg [3:0] q
);
always @(posedge clk or negedge arst) begin
if (arst) begin
q<=4'h0;
end
else begin
q<=data;
end
end
endmoduleОписание такого регистра не является логичным, так как сброс триггеров в данном случае происходит, когда линия сброса в неактивном состоянии.
Результаты синтеза оказались следующие:
- Libero SoC v11.8
Синтез схемы не осуществился с ошибкой: «Logic for q[3:0] does not match a standard flip-flop (CL123)», тем самым отказавшись производить синтез схемы, сославшись на отсутствие необходимого для синтеза типа триггеров.
- Quartus Prime 17.1
Синтез схемы не осуществился со следующей ошибкой: «Error (10200): Verilog HDL Conditional Statement error at test3.v(9): cannot match operand(s) in the condition to the corresponding edges in the enclosing event control of the always construct». Текст данной ошибки не отличается от текста ошибки для модуля test2.
- Vivado 2017.4.1
Синтез схемы осуществился без ошибок:
test3 Vivado
Однако, что будет если описать модуль, в котором список чувствительности не противоречит проверке условия сброса, но при этом сброс триггеров происходит в момент неактивного состоянии линии сброса, как и в случае описания модуля test3. Описание такого модуля test4 следующее:
module test4
(
input clk,
input arst,
input [3:0] data,
output reg [3:0] q
);
always @( posedge clk or negedge arst ) begin
if ( ~ arst ) begin
q <= data ;
end
else begin
q <= 4'h0 ;
end
end
endmoduleПри синтезе были получены следующие результаты:
- Libero SoC v11.8
Синтез схемы осуществился с предупреждением:
«Found signal identified as System clock which controls 4 sequential elements including q_1[3]. Using this clock, which has no specified timing constraint, can adversely impact design performance. (MT532)».
test4 Libero SoC
- Quartus Prime 17.1
В результате синтеза схемы были получены предупреждения:
«Warning (13004): Presettable and clearable registers converted to equivalent circuits with latches. Registers power-up to an undefined state, and DEVCLRn places the registers in an undefined state.
Warning (13310): Register "q[0]~reg0" is converted into an equivalent circuit using register "q[0]~reg0_emulated" and latch "q[0]~1"
Warning (13310): Register "q[1]~reg0" is converted into an equivalent circuit using register "q[1]~reg0_emulated" and latch "q[1]~1"
Warning (13310): Register "q[2]~reg0" is converted into an equivalent circuit using register "q[2]~reg0_emulated" and latch "q[2]~1"
Warning (13310): Register "q[3]~reg0" is converted into an equivalent circuit using register "q[3]~reg0_emulated" and latch "q[3]~1"»
Все вышеописанные предупреждения соответствуют тому, что вместо триггеров были использованы защёлки.test4 Quartus Prime
- Vivado 2017.4.1
Синтез схемы осуществился с одним предупреждением:
«[Synth 8-5788] Register q_reg in module test is has both Set and reset with same priority. This may cause simulation mismatches. Consider rewriting code [«/home/vlasovdv0111/project_1/project_1.srcs/sources_1/new/test.v»:11]». Текст данной ошибки полностью повторяет текст ошибки для модуля test2.
test4 Vivado

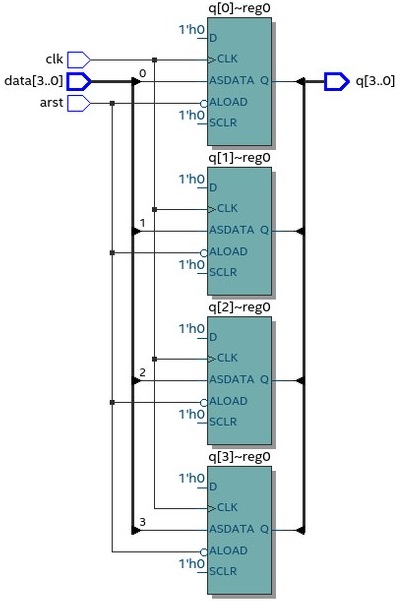
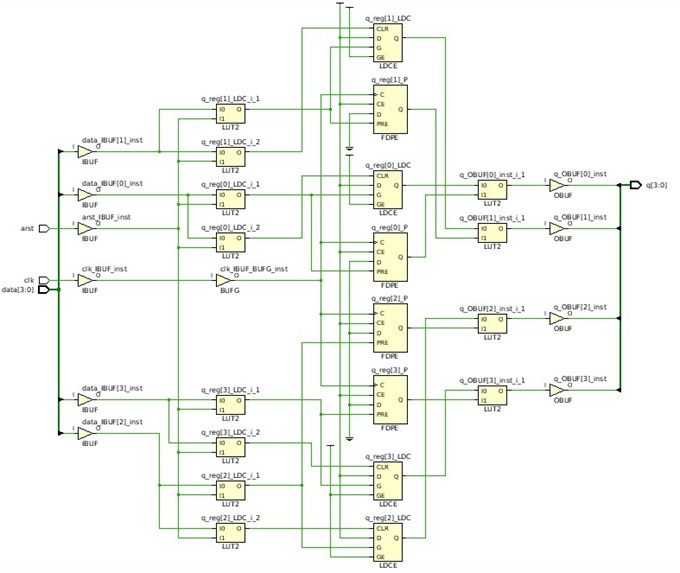
Из всех описанных экспериментов можно сделать следующие выводы:
- язык Verilog является универсальным языком описания аппаратуры, ограничениями которого являются возможности самих сред разработки;
- для правильного описания аппаратуры необходимо знать синтаксис языка, а также анализировать списки предупреждений и ошибок, возникающих на каждом этапе построения проекта.