
«Тестировать нельзя диагностировать» – куда бы вы поставили запятую в данном предложении? Надеемся, что после прочтения данного материала вы без проблем можете чётко дать ответ на этот вопрос. Многие пользователи когда-либо сталкивались с потерей данных по той или иной причине, будь то программная или аппаратная проблема самого накопителя или же нестандартное физическое воздействие на него, если вы понимаете, о чём мы. Но именно о физических повреждениях сегодня речь и не пойдёт. Поговорим мы как раз о том, что от наших рук не зависит. Стоит ли тестировать SSD каждый день/неделю/месяц или это пустая трата его ресурса? А чем их вообще тестировать? Получая определённые результаты, вы правильно их понимаете? И как можно просто и быстро убедиться, что диск в порядке или ваши данные под угрозой?

Тестирование или диагностика? Программ много, но суть одна
На первый взгляд диагностика и подразумевает тестирование, если думать глобально. Но в случае с накопителями, будь то HDD или SSD, всё немного иначе. Под тестированием рядовой пользователь подразумевает проверку его характеристик и сопоставление полученных показателей с заявленными. А под диагностикой – изучение S.M.A.R.T., о котором мы сегодня тоже поговорим, но немного позже. На фотографию попал и классический HDD, что, на самом деле, не случайность…
Так уж получилось, что именно подсистема хранения данных в настольных системах является одним из самых уязвимых мест, так как срок службы накопителей чаще всего меньше, чем у остальных компонентов ПК, моноблока или ноутбука. Если ранее это было связано с механической составляющей (в жёстких дисках вращаются пластины, двигаются головки) и некоторые проблемы можно было определить, не запуская каких-либо программ, то сейчас всё стало немного сложнее – никакого хруста внутри SSD нет и быть не может. Что же делать владельцам твердотельных накопителей?
Программ для тестирования SSD развелось великое множество. Какие-то стали популярными и постоянно обновляются, часть из них давно забыта, а некоторые настолько хороши, что разработчики не обновляют их годами – смысла просто нет. В особо тяжёлых случаях можно прогонять полное тестирование по международной методике Solid State Storage (SSS) Performance Test Specification (PTS), но в крайности мы бросаться не будем. Сразу же ещё отметим, что некоторые производители заявляют одни скорости работы, а по факту скорости могут быть заметно ниже: если накопитель новый и исправный, то перед нами решение с SLC-кешированием, где максимальная скорость работы доступна только первые несколько гигабайт (или десятков гигабайт, если объём диска более 900 ГБ), а затем скорость падает. Это совершенно нормальная ситуация. Как понять объём кеша и убедиться, что проблема на самом деле не проблема? Взять файл, к примеру, объёмом 50 ГБ и скопировать его на подопытный накопитель с заведомо более быстрого носителя. Скорость будет высокая, потом снизится и останется равномерной до самого конца в рамках 50-150 МБ/с, в зависимости от модели SSD. Если же тестовый файл копируется неравномерно (к примеру, возникают паузы с падением скорости до 0 МБ/с), тогда стоит задуматься о дополнительном тестировании и изучении состояния SSD при помощи фирменного программного обеспечения от производителя.
Яркий пример корректной работы SSD с технологией SLC-кеширования представлен на скриншоте:
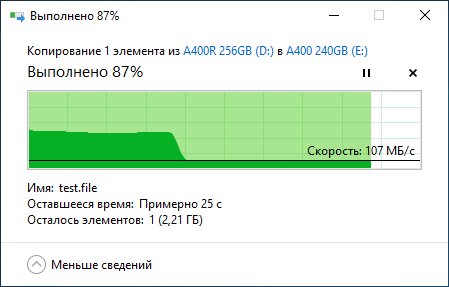
Те пользователи, которые используют Windows 10, могут узнать о возникших проблемах без лишних действий – как только операционная система видит негативные изменения в S.M.A.R.T., она предупреждает об этом с рекомендацией сделать резервные копии данных. Но вернёмся немного назад, а именно к так называемым бенчмаркам. AS SSD Benchmark, CrystalDiskMark, Anvils Storage Utilities, ATTO Disk Benchmark, TxBench и, в конце концов, Iometer – знакомые названия, не правда ли? Нельзя отрицать, что каждый из вас с какой-либо периодичностью запускает эти самые бенчмарки, чтобы проверить скорость работы установленного SSD. Если накопитель жив и здоров, то мы видим, так сказать, красивые результаты, которые радуют глаз и обеспечивают спокойствие души за денежные средства в кошельке. А что за цифры мы видим? Чаще всего замеряют четыре показателя – последовательные чтение и запись, операции 4K (КБ) блоками, многопоточные операции 4K блоками и время отклика накопителя. Важны все вышеперечисленные показатели. Да, каждый из них может быть совершенно разным для разных накопителей. К примеру, для накопителей №1 и №2 заявлены одинаковые скорости последовательного чтения и записи, но скорости работы с блоками 4K у них могут отличаться на порядок – всё зависит от памяти, контроллера и прошивки. Поэтому сравнивать результаты разных моделей попросту нельзя. Для корректного сравнения допускается использовать только полностью идентичные накопители. Ещё есть такой показатель, как IOPS, но он зависит от иных вышеперечисленных показателей, поэтому отдельно говорить об этом не стоит. Иногда в бенчмарках встречаются показатели случайных чтения/записи, но считать их основными, на наш взгляд, смысла нет.
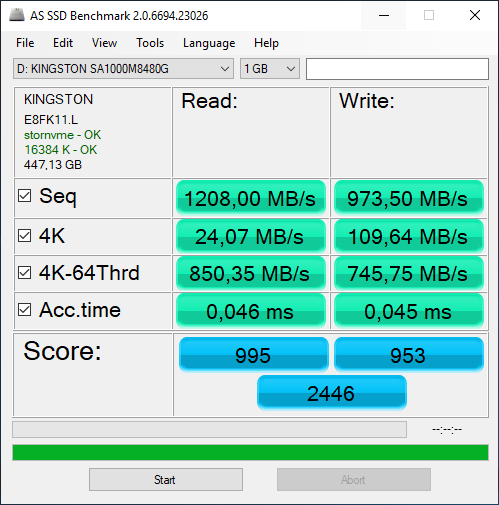
И, как легко догадаться, результаты каждая программа может демонстрировать разные данные – всё зависит от тех параметров тестирования, которые устанавливает разработчик. В некоторых случаях их можно менять, получая разные результаты. Но если тестировать «в лоб», то цифры могут сильно отличаться. Вот ещё один пример теста, где при настройках «по умолчанию» мы видим заметно отличимые результаты последовательных чтения и записи. Но внимание также стоит обратить на скорости работы с 4K блоками – вот тут уже все программы показывают примерно одинаковый результат. Собственно, именно этот тест и является одним из ключевых.

Но, как мы заметили, только одним из ключевых. Да и ещё кое-что надо держать в уме – состояние накопителя. Если вы принесли диск из магазина и протестировали его в одном из перечисленных выше бенчмарков, практически всегда вы получите заявленные характеристики. Но если повторить тестирование через некоторое время, когда диск будет частично или почти полностью заполнен или же был заполнен, но вы самым обычным способом удалили некоторое количество данных, то результаты могут разительно отличаться. Это связано как раз с принципом работы твердотельных накопителей с данными, когда они не удаляются сразу, а только помечаются на удаление. В таком случае перед записью новых данных (тех же тестовых файлов из бенчмарков), сначала производится удаление старых данных. Более подробно мы рассказывали об этом в предыдущем материале.
На самом деле в зависимости от сценариев работы, параметры нужно подбирать самим. Одно дело – домашние или офисные системы, где используется Windows/Linux/MacOS, а совсем другое – серверные, предназначенные для выполнения определённых задач. К примеру, в серверах, работающих с базами данных, могут быть установлены NVMe-накопители, прекрасно переваривающие глубину очереди хоть 256 и для которых таковая 32 или 64 – детский лепет. Конечно, применение классических бенчмарков, перечисленных выше, в данном случае – пустая трата времени. В крупных компаниях используют самописные сценарии тестирования, например, на основе утилиты fio. Те, кому не требуется воспроизведение определённых задач, могут воспользоваться международной методикой SNIA, в которой описаны все проводимые тесты и предложены псевдоскрипты. Да, над ними потребуется немного поработать, но можно получить полностью автоматизированное тестирование, по результатам которого можно понять поведение накопителя – выявить его сильные и слабые места, посмотреть, как он ведёт себя при длительных нагрузках и получить представление о производительности при работе с разными блоками данных.
В любом случае надо сказать, что у каждого производителя тестовый софт свой. Чаще всего название, версия и параметры выбранного им бенчмарка дописываются в спецификации мелким шрифтом где-нибудь внизу. Конечно, результаты примерно сопоставимы, но различия в результатах, безусловно, могут быть. Из этого следует, как бы грустно это ни звучало, что пользователю надо быть внимательным при тестировании: если результат не совпадает с заявленным, то, возможно, просто установлены другие параметры тестирования, от которых зависит очень многое.
Теория – хорошо, но давайте вернёмся к реальному положению дел. Как мы уже говорили, важно найти данные о параметрах тестирования производителем именно того накопителя, который вы приобрели. Думаете это всё? Нет, не всё. Многое зависит и от аппаратной платформы – тестового стенда, на котором проводится тестирование. Конечно, эти данные также могут быть указаны в спецификации на конкретный SSD, но так бывает не всегда. Что от этого зависит? К примеру, перед покупкой SSD, вы прочитали несколько обзоров. В каждом из них авторы использовали одинаковые стандартные бенчмарки, которые продемонстрировали разные результаты. Кому верить? Если материнские платы и программное обеспечение (включая операционную систему) были одинаковы – вопрос справедливый, придётся искать дополнительный независимый источник информации. А вот если платы или ОС отличаются – различия в результатах можно считать в порядке вещей. Другой драйвер, другая операционная система, другая материнская плата, а также разная температура накопителей во время тестирования – всё это влияет на конечные результаты. Именно по этой причине получить те цифры, которые вы видите на сайтах производителей или в обзорах, практически невозможно. И именно по этой причине нет смысла беспокоиться за различия ваших результатов и результатов других пользователей. Например, на материнской плате иногда реализовывают сторонние SATA-контроллеры (чтобы увеличить количество соответствующих портов), а они чаще всего обладают худшими скоростями. Причём разница может составлять до 25-35%! Иными словами, для воспроизведения заявленных результатов потребуется чётко соблюдать все аспекты методики тестирования. Поэтому, если полученные вами скоростные показатели не соответствуют заявленным, нести покупку обратно в магазин в тот же день не стоит. Если, конечно, это не совсем критичная ситуация с минимальным быстродействием и провалами при чтении или записи данных. Кроме того, скорости большинства твердотельных накопителей меняются в худшую скорость с течением времени, останавливаясь на определённой отметке, которая называется стационарная производительность. Так вот вопрос: а надо ли в итоге постоянно тестировать SSD? Хотя не совсем правильно. Вот так лучше: а есть ли смысл постоянно тестировать SSD?
Регулярное тестирование или наблюдение за поведением?
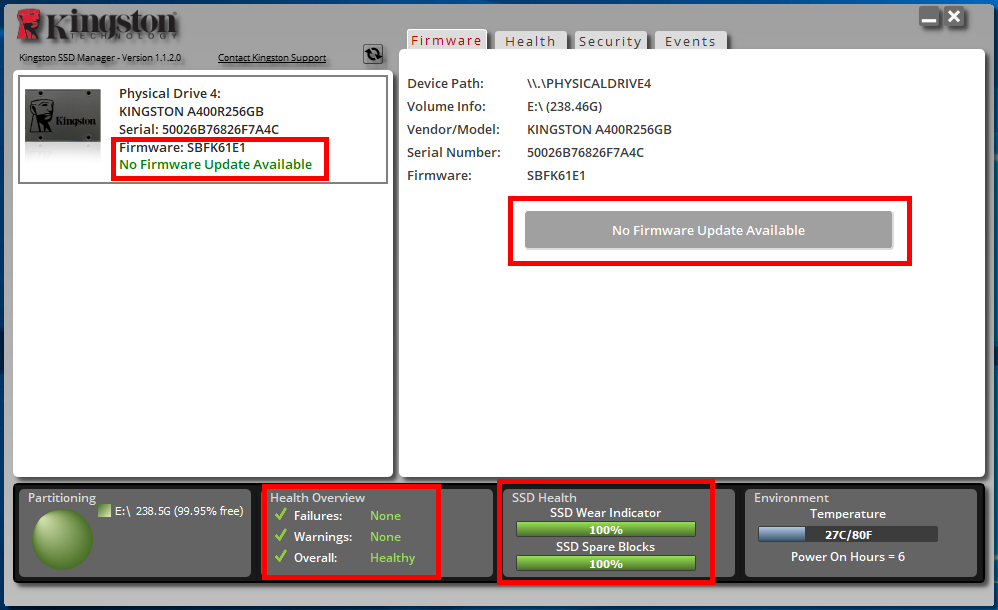
Так надо ли, приходя с работы домой, приниматься прогонять в очередной раз бенчмарк? Вот это, как раз, делать и не рекомендуется. Как ни крути, но любая из существующих программ данного типа пишет данные на накопитель. Какая-то больше, какая-то меньше, но пишет. Да, по сравнению с ресурсом SSD записываемый объём достаточно мал, но он есть. Да и функции TRIM/Deallocate потребуется время на обработку удалённых данных. В общем, регулярно или от нечего делать запускать тесты никакого смысла нет. Но вот если в повседневной работе вы начинаете замечать подтормаживания системы или тяжёлого программного обеспечения, установленного на SSD, а также зависания, BSOD’ы, ошибки записи и чтения файлов, тогда уже следует озадачиться выявлением причины возникающей проблемы. Не исключено, что проблема может быть на стороне других комплектующих, но проверить накопитель – проще всего. Для этого потребуется фирменное программное обеспечение от производителя SSD. Для наших накопителей – Kingston SSD Manager. Но перво-наперво делайте резервные копии важных данных, а уже потом занимайтесь диагностикой и тестированием. Для начала смотрим в область SSD Health. В ней есть два показателя в процентах. Первый – так называемый износ накопителя, второй – использование резервной области памяти. Чем ниже значение, тем больше беспокойства с вашей стороны должно быть. Конечно, если значения уменьшаются на 1-2-3% в год при очень интенсивном использовании накопителя, то это нормальная ситуация. Другое дело, если без особых нагрузок значения снижаются необычно быстро. Рядом есть ещё одна область – Health Overview. В ней кратко сообщается о том, были ли зафиксированы ошибки разного рода, и указано общее состояние накопителя. Также проверяем наличие новой прошивки. Точнее программа сама это делает. Если таковая есть, а диск ведёт себя странно (есть ошибки, снижается уровень «здоровья» и вообще исключены другие комплектующие), то можем смело устанавливать.
Если же производитель вашего SSD не позаботился о поддержке в виде фирменного софта, то можно использовать универсальный, к примеру – CrystalDiskInfo. Нет, у Intel есть своё программное обеспечение, на скриншоте ниже – просто пример  На что обратить внимание? На процент состояния здоровья (хотя бы примерно, но ситуация будет понятна), на общее время работы, число включений и объёмы записанных и считанных данных. Не всегда эти значения будут отображены, а часть атрибутов в списке будут видны как Vendor Specific. Об этом чуть позже.
На что обратить внимание? На процент состояния здоровья (хотя бы примерно, но ситуация будет понятна), на общее время работы, число включений и объёмы записанных и считанных данных. Не всегда эти значения будут отображены, а часть атрибутов в списке будут видны как Vendor Specific. Об этом чуть позже.

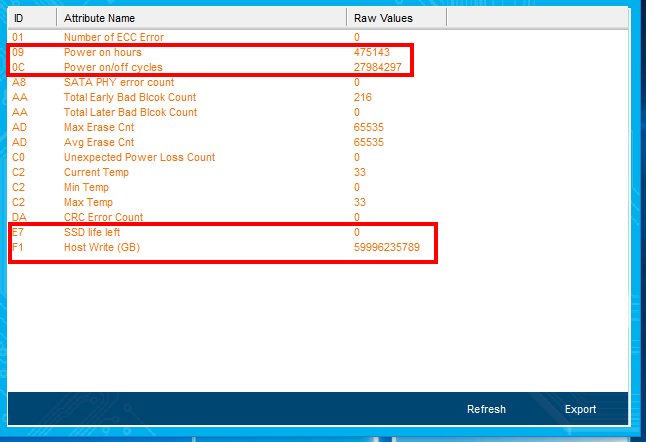
А вот яркий пример уже вышедшего из строя накопителя, который работал относительно недолго, но потом начал работать «через раз». При включении система его не видела, а после перезагрузки всё было нормально. И такая ситуация повторялась в случайном порядке. Главное при таком поведении накопителя – сразу же сделать бэкап важных данных, о чём, правда, мы сказали совсем недавно. Но повторять это не устанем. Число включений и время работы – совершенно недостижимые. Почти 20 тысяч суток работы. Или около 54 лет…

Но и это ещё не всё – взгляните на значения из фирменного ПО производителя! Невероятные значения, верно? Вот в таких случаях может помочь обновление прошивки до актуальной версии. Если таковой нет, то лучше обращаться к производителю в рамках гарантийного обслуживания. А если новая прошивка есть, то после обновления не закидывать на диск важные данные, а поработать с ним осторожно и посмотреть на предмет стабильности. Возможно, проблема будет решена, но возможно – нет.
Добавить можно ещё вот что. Некоторые пользователи по привычке или незнанию используют давно знакомый им софт, которым производят мониторинг состояния классических жёстких дисков (HDD). Так делать настоятельно не рекомендуется, так как алгоритмы работы HDD и SSD разительно отличаются, как и набор команд контроллеров. Особенно это касается NVMe SSD. Некоторые программы (например, Victoria) получили поддержку SSD, но их всё равно продолжают дорабатывать (а доработают ли?) в плане корректности демонстрации информации о подключённых носителях. К примеру, прошло лишь около месяца с того момента, как показания SMART для SSD Kingston обрели хоть какой-то правильный вид, да и то не до конца. Всё это касается не только вышеупомянутой программы, но и многих других. Именно поэтому, чтобы избежать неправильной интерпретации данных, стоит пользоваться только тем софтом, в котором есть уверенность, – фирменные утилиты от производителей или же крупные и часто обновляемые проекты.
Присмотр за каждой ячейкой – смело. Глупо, но смело
Некоторые производители реализуют в своём программном обеспечении возможность проверки адресов каждого логического блока (LBA) на предмет наличия ошибок при чтении. В ходе такого тестирования всё свободное пространство накопителя используется для записи произвольных данных и обратного их считывания для проверки целостности. Такое сканирование может занять не один час (зависит от объёма накопителя и свободного пространства на нём, а также его скоростных показателей). Такой тест позволяет выявить сбойные ячейки. Но без нюансов не обходится. Во-первых, по-хорошему, SSD должен быть пуст, чтобы проверить максимум памяти. Отсюда вытекает ещё одна проблема: надо делать бэкапы и заливать их обратно, что отнимает ресурс накопителя. Во-вторых, ещё больше ресурса памяти тратится на само выполнение теста. Не говоря уже о затрачиваемом времени. А что в итоге мы узнаем по результатам тестирования? Варианта, как вы понимаете, два – или будут битые ячейки, или нет. В первом случае мы впустую тратим ресурс и время, а во втором – впустую тратим ресурс и время. Да-да, это так и звучит. Сбойные ячейки и без такого тестирования дадут о себе знать, когда придёт время. Так что смысла в проверки каждого LBA нет никакого.
А можно несколько подробнее о S.M.A.R.T.?
Все когда-то видели набор определённых названий (атрибутов) и их значений, выведенных списком в соответствующем разделе или прямо в главном окне программы, как это видно на скриншоте выше. Но что они означают и как их понять? Немного вернёмся в прошлое, чтобы понять что к чему. По идее, каждый производитель вносит в продукцию что-то своё, чтобы этой уникальностью привлечь потенциального покупателя. Но вот со S.M.A.R.T. вышло несколько иначе.
В зависимости от производителя и модели накопителя набор параметров может меняться, поэтому универсальные программы могут не знать тех или иных значений, помечая их как Vendor Specific. Многие производители предоставляют в открытом доступе документацию для понимания атрибутов своих накопителей – SMART Attribute. Её можно найти на сайте производителя.
Именно поэтому и рекомендуется использовать именно фирменный софт, который в курсе всех тонкостей совместимых моделей накопителей. Кроме того, настоятельно рекомендуется использовать английский интерфейс, чтобы получить достоверную информацию о состоянии накопителя. Зачастую перевод на русский не совсем верен, что может привести в замешательство. Да и сама документация, о которой мы сказали выше, чаще всего предоставляется именно на английском.
Сейчас мы рассмотрим основные атрибуты на примере накопителя Kingston UV500. Кому интересно – читаем, кому нет – жмём PageDown пару раз и читаем заключение. Но, надеемся, вам всё же интересно – информация полезная, как ни крути. Построение текста может выглядеть необычно, но так для всех будет удобнее – не потребуется вводить лишние слова-переменные, а также именно оригинальные слова будет проще найти в отчёте о вашем накопителе.
(ID 1) Read Error Rate – содержит частоту возникновения ошибок при чтении.
(ID 5) Reallocated Sector Count – количество переназначенных секторов. Является, по сути, главным атрибутом. Если SSD в процессе работы находит сбойный сектор, то он может посчитать его невосполнимо повреждённым. В этом случае диск использует вместо него сектор из резервной области. Новый сектор получает логический номер LBA старого, после чего при обращении к сектору с этим номером запрос будет перенаправляться в тот, что находится в резервной области. Если ошибка единичная – это не проблема. Но если такие сектора будут появляться регулярно, то проблему можно считать критической.
(ID 9) Power On Hours – время работы накопителя в часах, включая режим простоя и всяческих режимов энергосбережения.
(ID 12) Power Cycle Count – количество циклов включения и отключения накопителя, включая резкие обесточивания (некорректное завершение работы).
(ID 170) Used Reserved Block Count – количество использованных резервных блоков для замещения повреждённых.
(ID 171) Program Fail Count – подсчёт сбоев записи в память.
(ID 172) Erase Fail Count – подсчёт сбоев очистки ячеек памяти.
(ID 174) Unexpected Power Off Count – количество некорректных завершений работы (сбоев питания) без очистки кеша и метаданных.
(ID 175) Program Fail Count Worst Die – подсчёт ошибок сбоев записи в наихудшей микросхеме памяти.
(ID 176) Erase Fail Count Worst Die – подсчёт ошибок сбоев очистки ячеек наихудшей микросхемы памяти.
(ID 178) Used Reserved Block Count worst Die – количество использованных резервных блоков для замещения повреждённых в наихудшей микросхеме памяти.
(ID 180) Unused Reserved Block Count (SSD Total) – количество (или процент, в зависимости от типа отображения) ещё доступных резервных блоков памяти.
(ID 187) Reported Uncorrectable Errors – количество неисправленных ошибок.
(ID 194) Temperature – температура накопителя.
(ID 195) On-the-Fly ECC Uncorrectable Error Count – общее количество исправляемых и неисправляемых ошибок.
(ID 196) Reallocation Event Count – количество операций переназначения.
(ID 197) Pending Sector Count – количество секторов, требующих переназначения.
(ID 199) UDMA CRC Error Count – счётчик ошибок, возникающих при передаче данных через SATA интерфейс.
(ID 201) Uncorrectable Read Error Rate – количество неисправленных ошибок для текущего периода работы накопителя.
(ID 204) Soft ECC Correction Rate – количество исправленных ошибок для текущего периода работы накопителя.
(ID 231) SSD Life Left – индикация оставшегося срока службы накопителя на основе количества циклов записи/стирания информации.
(ID 241) GB Written from Interface – объём данных в ГБ, записанных на накопитель.
(ID 242) GB Read from Interface – объём данных в ГБ, считанных с накопителя.
(ID 250) Total Number of NAND Read Retries – количество выполненных попыток чтения с накопителя.
Пожалуй, на этом закончим список. Конечно, для других моделей атрибутов может быть больше или меньше, но их значения в рамках производителя будут идентичны. А расшифровать значения достаточно просто и обычному пользователю, тут всё логично: увеличение количества ошибок – хуже диску, снижение резервных секторов – тоже плохо. По температуре – всё и так ясно. Каждый из вас сможет добавить что-то своё – это ожидаемо, так как полный список атрибутов очень велик, а мы перечислили лишь основные.
Паранойя или трезвый взгляд на сохранность данных?
Как показывает практика, тестирование нужно лишь для подтверждения заявленных скоростных характеристик. В остальном – это пустая трата ресурса накопителя и вашего времени. Никакой практической пользы в этом нет, если только морально успокаивать себя после вложения определённой суммы денег в SSD. Если есть проблемы, они дадут о себе знать. Если вы хотите следить за состоянием своей покупки, то просто открывайте фирменное программное обеспечение и смотрите на показатели, о которых мы сегодня рассказали и которые наглядно показали на скриншотах. Это будет самым быстрым и самым правильным способом диагностики. И ещё добавим пару слов про ресурс. Сегодня мы говорили, что тестирование накопителей тратит их ресурс. С одной стороны – это так. Но если немного подумать, то пара-тройка, а то и десяток записанных гигабайт – не так уж много. Для примера возьмём бюджетный Kingston A400R ёмкостью 256 ГБ. Его значение TBW равно 80 ТБ (81920 ГБ), а срок гарантии – 1 год. То есть, чтобы полностью выработать ресурс накопителя за этот год, надо ежедневно записывать на него 224 ГБ данных. Как это сделать в офисных ПК или ноутбуках? Фактически – никак. Даже если вы будете записывать порядка 25 ГБ данных в день, то ресурс выработается лишь практически через 9 лет. А ведь у накопителей серии A1000 ресурс составляет от 150 до 600 ТБ, что заметно больше! С учётом 5-летней гарантии, на флагман ёмкостью 960 ГБ надо в день записывать свыше 330 ГБ, что маловероятно, даже если вы заядлый игрок и любите новые игры, которые без проблем занимают под сотню гигабайт. В общем, к чему всё это? Да к тому, что убить ресурс накопителя – достаточно сложная задача. Куда важнее следить за наличием ошибок, что не требует использования привычных бенчмарков. Пользуйтесь фирменным программным обеспечением – и всё будет под контролем. Для накопителей Kingston и HyperX разработан SSD Manager, обладающий всем необходимым для рядового пользователя функционалом. Хотя, вряд ли ваш Kingston или HyperX выйдет из строя… На этом – всё, успехов во всём и долгих лет жизни вашим накопителям!
P.S. В случае возникновения проблем с SSD подорожник всё-таки не поможет 

Для получения дополнительной информации о продуктах Kingston обращайтесь на сайт компании.
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.

Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Такое же исправление ошибок также помогает исправить битовые ошибки из-за носить на Память сами клетки , Истощение может вызвать «застревание» битов в том или ином состоянии (известное как «жесткая» ошибка или жесткая ошибка) и может увеличить частоту «мягких» ошибок.
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
If ECC может быть используемый чтобы исправить эти «жесткие» ошибки, а «мягкие» ошибки не увеличиваются, срок службы всего блока значительно удлиняется, что значительно превышает сопротивление, указанное производителем.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.

Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .

Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.
Оглавление
- Вступление
- Коррекция ошибок
- Финансовая сторона
- Тестовый стенд
- Методика тестирования
- Результаты тестирования
- Тест памяти
- 3DMark
- 7Zip
- Cinebench
- CrystalMark
- Fritz
- LinX
- wPrime
- AIDA64 Extreme
- Заключение
Вступление
На сегодняшний день на просторах Рунета можно встретить открытые темы на форумах с вопросами – стоит ли брать рабочую станцию с ECC-памятью или можно обойтись обычной? В данных ветках можно прочесть множество противоречивых утверждений, и часть из них говорит о том, что коррекция ошибок сильно замедляет память, а следовательно и ЦП. Но мало кто это проверял на деле на современных процессорах.
Сегодня мы разберемся в этом вопросе и сравним производительность серверного процессора с обоими типами памяти. Но для начала небольшой экскурс.
Коррекция ошибок
Для чего необходима коррекция? И почему в работе памяти возникают ошибки? Перед ответом на эти вопросы следует разделить ошибки на два типа:
- Аппаратные ошибки;
- Случайные ошибки.
Причиной появления аппаратных ошибок является дефектная микросхема DRAM, а случайные ошибки возникают под воздействием излучения, альфа-частиц, элементарных частиц и прочего. Соответственно, первые в принципе неисправимы – если чип дефектный, то поможет только его замена; а вот вторые могут быть исправлены.
Почему же так необходима коррекция ошибок в рабочих станциях и серверах? Однобитовая ошибка в 64-битном слове меняет содержимое ячейки памяти, а в конечном итоге на жесткий диск может быть записано другое число, другие данные, при этом компьютер не зафиксирует эту подмену. А изменение бита в оперативной памяти может вызвать сбой программы, что для рабочей станции и сервера недопустимо.
рекомендации
3060 дешевле 30тр в Ситилинке
3070 Gigabyte Gaming за 50 тр с началом
<b>13900K</b> в Регарде по СТАРОМУ курсу 62
3070 Gainward Phantom дешевле 50 тр
10 видов <b>4070 Ti</b> в Ситилинке — все до 100 тр
13700K дешевле 40 тр в Регарде
MSI 3050 за 25 тр в Ситилинке
13600K дешевле 30 тр в Регарде
4080 почти за 100тр — дешевле чем по курсу 60
12900K за 40тр с началом в Ситилинке
RTX 4090 за 140 тр в Регарде
Компьютеры от 10 тр в Ситилинке
3060 Ti Gigabyte дешевле 40 тр в Регарде
3070 дешевле 50 тр в Ситилинке
-7% на 4080 Gigabyte Gaming
Для обнаружения изменения битов памяти можно использовать метод подсчета контрольной суммы, но он позволяет лишь обнаруживать ошибки без их исправления.
В свое время было предложено много различных способов решения данной проблемы, но на сегодняшний день наибольшее распространение получил метод коррекции ошибок или ECC (Error-Correcting Code). Данный метод позволяет автоматически исправлять однобитовые ошибки в 64-битном слове – SEC (Single Error Correction) и детектировать двухбитовые – DED (Double Error Detection).
Физическая реализация ECC заключается в размещении дополнительной микросхемы памяти на модуле ОЗУ – соответственно, при одностороннем дизайне модуля памяти вместо восьми чипов располагается девять, а при двустороннем вместо шестнадцати – восемнадцать. Таким образом, ширина модуля становится не 64 бита, а 72 бита.
Метод коррекции ошибок работает следующим образом: при записи 64 бит данных в ячейку памяти происходит подсчет контрольной суммы, составляющей 8 бит. Когда процессор обращается к этим данным и производит считывание, проводится повторный подсчет контрольной суммы и сравнение с исходной. Если суммы не совпадают – произошла ошибка. Если она однобитовая, то неправильный бит исправляется автоматически, если двухбитовая – детектируется и сообщается ОС.
Финансовая сторона
Прежде чем приступить к тестированию, необходимо затронуть финансовый вопрос.
Стоимость обычного модуля памяти DDR3-1600 с напряжением 1.35 В и объемом 8 Гбайт составляет около 3600 рублей, а с коррекцией ошибок – 4800 рублей. На первый взгляд ECC-память выходит на 30-35% дороже, что, в целом, не позволяет их сравнивать в силу существенно большей стоимости последней. Но почему же тогда такой вопрос возникает при сборке рабочей станции? Все просто – необходимо смотреть на данный вопрос шире, а именно – смотреть на общую стоимость рабочей станции.
Ценник однопроцессорной станции на базе четырехъядерного восьмипоточного Xeon (настольные процессоры серий i5 и i7 не поддерживают ECC-память) с 32 Гбайтами памяти, материнской платы с чипсетом C222/С224/С226 (десктопные наборы логики Z87/Z97 и другие также не поддерживают память с коррекцией ошибок) будет превышать 70 000 рублей (при условии, что устанавливаются серверные SSD с повышенным ресурсом). А если включить в эту стоимость и дискретную видеокарту, и прочие сопутствующие компоненты, например, ИБП, то ценник из пятизначного превратится в шестиизначный, перевалив планку в 100 000 рублей.
Покупка 32 Гбайт памяти с коррекцией ошибок потребует дополнительных 4-6 тысяч рублей, что по отношению к общей стоимости рабочей станции не превышает 5%, то есть не является критичным. Также переход от десктопного к серверному железу предоставит и другие преимущества, например: интегрированные графические карты P4600 в процессорах Intel Xeon E3-1200 третьего поколения получили оптимизированные драйверы, которые должны повышать производительность в профессиональных приложениях, например, в CAD; поддержка технологии Intel VT-d, которая позволяет пробрасывать устройства в виртуальную среду, например, видеокарты; прочие серверные технологии – Intel AMT или IPMI, WatchDog и другие, которые также могут оказаться полезными.
Таким образом, хоть и сама ECC-память стоит заметно дороже обычной, в общей стоимости рабочей станции данная статья затрат является несущественной, и переплата не превышает 5%.
Тестовый стенд
Для данного обзора использовалась следующая конфигурация:
- Материнская плата: Supermicro X10SAE (Intel C226, LGA 1150);
- Процессор: Xeon E3-1245V3 (Turbo Boost – off, EIST – off, HT – on);
- Оперативная память:
- 2x Kingston DDR3-1600 ECC 8 Гбайт (KVR16LE11/8 CL11, 1.35 В);
- 2x Kingston DDR3-1600 8 Гбайт (KVR16LN11/8 CL11, 1.35 В);
- ОС: Windows 8.1 Pro 64-bit.
Методика тестирования
В рамках тестирования были произведены замеры производительности как при одноканальном режиме работы ИКП, так и при двухканальном. Суммарный объем ОЗУ составил 8 (один модуль) и 16 Гбайт (два модуля) соответственно.
Программное обеспечение:
- 3DMark 2006 1.2;
- 7Zip 9.20;
- AIDA64 Extreme 5.20.3400;
- Cinebench R15;
- CrystalMark 2004R3;
- Fritz 4.20;
- LinX 0.6.5;
- wPrime 2.10.
Результаты тестирования
Тест памяти
Перед тем, как приступить к тестированию, проведем замер пропускной способности памяти и латентности.

При изучении результатов можно заключить, что производительность ECC- и non-ECC- памяти находится на одном и том же уровне в рамках погрешности.

Если в предыдущем тесте от замера к замеру выигрывал то один, то другой тип памяти, то при замере латентности ECC-память постоянно показывает большие задержки. Но разница несущественна – всего лишь 1 нс.
Таким образом, замер ПС и латентности памяти не показал особых различий между ECC- и non-ECC-памятью. Посмотрим, повторится ли это в последующих тестах.
3DMark
Тестовый пакет 3DMark содержит подтесты как для процессора, так и для графической карты. Здесь и кроется самое интересное – давно известно, что встроенному видеоядру не хватает существующей ПСП в 25.6 Гбайт/с, поэтому именно в графических подтестах можно выявить негативное влияние коррекции ошибок, если оно вообще есть,…

… но разницы нет – что ECC, что non-ECC. Ни процессор, ни интегрированное ядро никак не реагируют на замену обычной памяти на DDR с коррекцией ошибок – результаты одинаковы в рамках погрешности. Среднеарифметическая разница составила 0.02% в пользу ECC-памяти для одноканального режима и 1.6% для двухканального режима.
При этом нельзя сказать, что встроенная видеокарта P4600 не зависит от скорости ОЗУ – при одноканальном доступе общий результат почти на 30% ниже, чем при двухканальном. Другими словами, скорость ОЗУ критична для графического ядра, но сами по себе «ECC-версии» не влияют ни на скорость ОЗУ, ни на видеокарту.
7Zip
Архиваторы, как известно, чувствительны к памяти, поэтому, возможно, здесь получится зафиксировать влияние типа памяти на производительность.

Ситуация с архивацией неоднозначная: с одной стороны – в одноканальном режиме (как при распаковке, так и при сжатии) ECC-память уверенно оказывается медленнее на 2%; с другой – в двухканальном режиме при сжатии ECC-память уверенно быстрее, а при распаковке – медленнее, а среднее арифметическое – быстрее на 0.65%.
Скорее всего, причина в следующем – пропускной способности памяти при одноканальном доступе процессору явно недостаточно, и поэтому чуть большая латентность ECC-памяти сказывается на производительности; а при двухканальном доступе ПСП полностью покрывает нужды CPU и поэтому чуть большая латентность памяти с коррекцией ошибок не сказывается на производительности. В любом случае зафиксировать существенного влияния на скорость архивации не получилось.
Cinebench
Тестовый пакет Cinebench содержит подтест как процессора, так и видеокарты.

Но ни первый, ни вторая никак не отреагировали на ECC-память.
Зато налицо явная зависимость видеокарты от ПСП – при одноканальном доступе результат в OpenGL оказался на 25% ниже, чем при двухканальном. Вспоминая результаты 3DMark и смотря на нынешние, можно заключить, что производительность интегрированной видеокарты хоть и зависит от ПСП, но ECC-память не оказывает на нее негативного влияния.
Ошибки при хранении
информации в памяти неизбежны. Они
обычно классифицируются как отказы и
нерегулярные ошибки (сбои). Если нормально
функционирующая микросхема вследствие,
например, физического повреждения
начинает работать неправильно, то все
происходящее и называется постоянным
отказом. Чтобы устранить этот тип отказа,
обычно требуется заменить некоторую
часть аппаратных средств памяти, например
неисправную микросхему SIMM или DIMM.
Другой, более
коварный тип отказа
нерегулярная ошибка (сбой). Это непостоянный
отказ, который не происходит при
повторении условий функционирования
или через регулярные интервалы.
Приблизительно
20 лет назад сотрудники Intel
установили, что причиной сбоев являются
альфа-частицы. Поскольку альфа-частицы
не могут проникнуть даже через тонкий
лист бумаги, выяснилось, что их источником
служит вещество, используемое в
полупроводниках. При исследовании были
обнаружены частицы тория и урана в
пластмассовых и керамических корпусах
микросхем, применявшихся в те годы.
Изменив технологический процесс,
производители памяти избавились от
этих примесей.
В настоящее время
производители памяти почти полностью
устранили источники альфа-частиц. И
многие стали думать, что проверка
четности не нужна вовсе. Например, сбои
в памяти емкостью 16 Мбайт из-за альфа-частиц
случаются в среднем только один раз за
16 лет! Однако сбои памяти происходят
значительно чаще.
Сегодня самая
главная причина нерегулярных ошибок
космические лучи. Поскольку они имеют
очень большую проникающую способность,
от них практически нельзя защититься
с помощью экранирования.
К сожалению,
производители персональных компьютеров
не признали это причиной погрешностей
памяти; случайную природу сбоя намного
легче оправдать разрядом электростатического
электричества, большими выбросами
мощности или неустойчивой работой
программного обеспечения (например,
использованием новой версии операционной
системы или большой прикладной программы).
Хотя космические
лучи и радиация являются причиной
большинства программных ошибок памяти,
существуют и другие факторы.
-
Скачки в
энергопотреблении или шум на линии.
Причиной может быть неисправный блок
питания или настенная розетка. -
Использование
неверного типа или параметра быстродействия
памяти. Тип
памяти должен поддерживаться конкретным
набором микросхем и обладать определенной
этим набором скоростью доступа. -
Радиочастотная
интерференция.
Связана с расположением радиопередатчиков
рядом с компьютером, что иногда приводит
к генерированию паразитных электрических
сигналов в монтажных соединениях и
схемах компьютера. Беспроводные сети,
мыши и клавиатуры увеличивают риск
появления радиочастотной интерференции. -
Статические
разряды.
Вызывают моментальные скачки в
энергоснабжении, что может повлиять
на целостность данных. -
Ошибки
синхронизации. Не
поступившие своевременно данные могут
стать причиной появления программных
ошибок. Зачастую причина заключается
в неверных параметрах BIOS,
оперативной памяти, быстродействие
которой ниже, чем требуется системой,
«разогнанных» процессорах и прочих
ситемных компонентах.
Большинство
системных проблем не приводят к
прекращению работы микросхем памяти,
однако могут повлиять на хранимые
данные.
Игнорирование
сбоев, конечно, не лучший способ борьбы
с ними. К сожалению, именно этот способ
сегодня выбрали многие производители
компьютеров. Лучше было бы увеличить
отказоустойчивость систем. Для этого
необходимы механизмы обнаружения и,
возможно, исправления ошибок в памяти
персонального компьютера. В основном
для повышения отказоустойчивости в
современных компьютерах применяются
следующие методы:
-
контроль четности;
-
коды коррекции
ошибок (ECC).
Соседние файлы в папке Сватов лабы
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Контроль четности и коды коррекции ошибок (ECC).
Ошибки при хранении информации в памяти неизбежны. Они обычно классифицируются как отказы и нерегулярные ошибки (сбои). Если нормально функционирующая микросхема вследствие, например, физического повреждения начинает работать неправильно, то все происходящее и называется постоянным отказом. Чтобы устранить этот тип отказа, обычно требуется заменить некоторую часть аппаратных средств памяти, например неисправную микросхему памяти.
Другой, более коварный тип отказа — нерегулярная ошибка (сбой). Это непостоянный отказ, который не происходит при повторении условий функционирования или через регулярные интервалы.
Приблизительно 20 лет назад сотрудники Intel установили, что причиной сбоев являются альфа-частицы. Поскольку альфа-частицы не могут проникнуть даже через тонкий лист бумаги, выяснилось, что их источником служит вещество, используемое в полупроводниках. При исследовании были обнаружены частицы тория и урана в пластмассовых и керамических корпусах микросхем, применявшихся в те годы. Изменив технологический процесс, производители памяти избавились от этих примесей.
В настоящее время производители памяти почти полностью устранили источники альфачастиц. И многие стали думать, что проверка четности не нужна вовсе. Например, сбои в памяти емкостью 16 Мбайт из-за альфа-частиц случаются в среднем только один раз за 16 лет! Однако сбои памяти происходят значительно чаще.
Сегодня самая главная причина нерегулярных ошибок — космические лучи. Поскольку они имеют очень большую проникающую способность, от них практически нельзя защититься с помощью экранирования.
Эксперимент, проверяющий степень влияния космических лучей на появление ошибок в работе микросхем, показал, что соотношение “сигнал–ошибка” (signal-to-error ratio — SER) для некоторых модулей DRAM составило 5950 единиц интенсивности отказов (failure units — FU) на миллиард часов наработки для каждой микросхемы. Измерения проводились в условиях, приближенных к реальной жизни, с учетом длительности в несколько миллионов машиночасов. В среднестатистическом компьютере это означало бы появление программной ошибки памяти примерно каждые шесть месяцев. В серверных системах или мощных рабочих станциях с большим объемом установленной оперативной памяти подобная статистика указывает на одну ошибку (или даже более) в работе памяти каждый месяц! Когда тестовая система с теми же модулями DIMM была размещена в надежном убежище на глубине более 15 метров каменной породы, что полностью устраняет влияние космических лучей, программные ошибки в работе памяти вообще не были зафиксированы. Эксперимент продемонстрировал не только опасность влияния космических лучей, но и доказал, насколько эффективно устранять влияние альфалучей и радиоактивных примесей в оболочках модулей памяти.
К сожалению, производители ПК не признали это причиной погрешностей памяти; случайную природу сбоя намного легче оправдать разрядом электростатического электричества, большими выбросами мощности или неустойчивой работой программного обеспечения (например, использованием новой версии операционной системы или большой прикладной программы). Исследования показали, что для систем ECC доля программных ошибок в 30 раз больше, чем аппаратных. Это неудивительно, учитывая вредное влияние космических лучей. Количество ошибок зависит от числа установленных модулей памяти и их объема. Программные ошибки могут случаться и раз в месяц, и несколько раз в неделю, и даже чаще!
Хотя космические лучи и радиация являются причиной большинства программных ошибок памяти, существуют и другие факторы:
1. Скачки в энергопотреблении или шум на линии. Причиной может быть неисправный блок питания или настенная розетка.
2. Использование неверного типа или параметра быстродействия памяти. Тип памяти
должен поддерживаться конкретным набором микросхем и обладать определенной
этим набором скоростью доступа.
3. Электромагнитные помехи. Возникают при расположении радиопередатчиков рядом с
компьютером, что иногда приводит к генерированию паразитных электрических сигна-
лов в монтажных соединениях и схемах компьютера. Имейте в виду, что беспроводные
сети, мыши и клавиатуры увеличивают риск появления электромагнитных помех.
4. Статические разряды. Вызывают моментальные скачки в энергоснабжении, что может
повлиять на целостность данных.
5. Ошибки синхронизации. Не поступившие своевременно данные могут стать причиной
появления программных ошибок. Зачастую причина заключается в неверных парамет-
рах BIOS, оперативной памяти, быстродействие которой ниже, чем требуется систе-
мой, “разогнанных” процессорах и прочих системных компонентах.
Большинство описанных проблем не приводят к прекращению работы микросхем памяти (хотя некачественное энергоснабжение или статическое электричество могут физически повредить микросхемы), однако могут повлиять на хранимые данные.
Игнорирование сбоев, конечно, не лучший способ борьбы с ними. К сожалению, именно этот способ сегодня выбрали многие производители компьютеров. Лучше было бы повысить отказоустойчивость систем. Для этого необходимы механизмы определения и, возможно, исправления ошибок в памяти ПК. В основном для повышения отказоустойчивости в современных компьютерах применяются следующие методы:
— контроль четности;
— коды коррекции ошибок (ECC).
Системы без контроля четности вообще не обеспечивают отказоустойчивости данных. Единственная причина, по которой они используются, — их минимальная базовая стоимость. При этом, в отличие от других технологий (ECC и контроль четности), не требуется дополнительная оперативная память.
Байт данных с контролем четности включает в себя 9, а не 8 бит, поэтому стоимость памяти с контролем четности выше примерно на 12,5%. Кроме того, контроллеры памяти, не требующие логических мостов для подсчета данных четности или ECC, обладают упрощенной внутренней архитектурой. Портативные системы, для которых вопрос минимального энергопотребления особенно важен, выигрывают от уменьшенного энергопотребления памяти благодаря использованию меньшего количества микросхем DRAM. И наконец, шина данных памяти без контроля четности имеет меньшую разрядность, что выражается в сокращении количества буферов данных. Статистическая вероятность возникновения ошибок памяти в современных настольных компьютерах составляет примерно одну ошибку в несколько месяцев. При этом количество ошибок зависит от объема и типа используемой памяти. Подобный уровень ошибок может быть приемлемым для обычных компьютеров, не используемых для работы с важными приложениями. В этом случае цена играет основную роль, а дополнительная стоимость модулей памяти с поддержкой контроля четности и кода ECC себя не оправдывает.
Применение не отказоустойчивых к ошибкам компьютеров рискованно и предполагает отсутствие ошибок памяти при эксплуатации систем. При этом также учитывается, что совокупная стоимость потерь, вызванная ошибками в работе памяти, будет меньше, чем затраты на приобретение дополнительных аппаратных устройств для определения таковых ошибок.
Тем не менее ошибки памяти вполне могут стать причиной серьезных проблем: например, представьте себе указание неверного значения суммы в банковском чеке. Ошибки в работе оперативной памяти серверных систем зачастую приводят к “зависанию” последних и отключению всех клиентских компьютеров, соединенных с серверами по локальной сети. Наконец, отследить причину возникновения проблем в компьютерах, не поддерживающих контроль четности или код ECC, крайне сложно. Последние технологии по крайней мере однозначно укажут на оперативную память как на источник проблемы, тем самым экономя время и усилия системных администраторов.
Контроль четности
Это один из стандартов, введенных IBM, в соответствии с которым информация в банках памяти хранится фрагментами по девять битов, причем восемь из них (составляющих один байт) предназначены собственно для данных, а девятый является битом четности (parity). Использование девятого бита позволяет схемам управления памятью на аппаратном уровне контролировать целостность каждого байта данных. Если обнаруживается ошибка, работа компьютера останавливается и на экран выводится сообщение о неисправности.
Технология контроля четности не позволяет исправлять системные ошибки, однако дает возможность их обнаружить пользователю компьютера, что имеет следующие преимущества:
— контроль четности оберегает от последствий проведения неверных вычислений на базе некорректных данных;
— контроль четности точно указывает на источник возникновения ошибок, помогая разобраться с проблемой и улучшая степень эксплутационной надежности компьютера.
Для реализации поддержки памяти с контролем четности или без него не требуется особых усилий. В частности, внедрить поддержку контроля четности для системной платы не составит никакого труда. Основная стоимость внедрения относится к цене самих модулей памяти с контролем четности. Если покупатели нуждаются в контроле четности для работы с определенными приложениями, поставщики компьютеров могут без проблем предложить соответствующие системы.
Компания Intel и прочие производители наборов микросхем системной логики внедрили поддержку контроля четности и кода ECC в большинстве своих продуктов (особенно в наборах микросхем, ориентированных на рынок высокопроизводительных серверов). В то же время наборы микросхем низшей ценовой категории, как правило, не поддерживают эти технологии. Пользователям, требовательным к надежности выполняемых приложений, следует обращать особое внимание на поддержку контроля четности и ECC.
Код коррекции ошибок
Коды коррекции ошибок (Error Correcting Code — ECC) позволяют не только обнаружить ошибку, но и исправить ее в одном разряде. Поэтому компьютер, в котором используются подобные коды, в случае ошибки в одном разряде может работать без прерывания, причем данные не будут искажены. Коды коррекции ошибок в большинстве ПК позволяют только обнаруживать, но не исправлять ошибки в двух разрядах. Но приблизительно 98% сбоев памяти вызвано именно ошибкой в одном разряде, т.е. она успешно исправляется с помощью данного типа кодов. Данный тип ECC получил название SEC)DED (single-bit error-correction double-bit error detection — одноразрядная коррекция, двухразрядное обнаружение ошибок). В кодах коррекции ошибок этого типа для каждых 32 бит требуется дополнительно семь контрольных разрядов при 4-байтовой и восемь — при 8-байтовой организации (64-разрядные процессоры Athlon/Pentium). Реализация кода коррекции ошибок при 4-байтовой организации, очевидно, дороже реализации проверки нечетности или четности, но при 8-байтовой организации стоимость реализации кода коррекции ошибок не превышает стоимости реализации проверки четности.
Для использования кодов коррекции ошибок необходим контроллер памяти, вычисляющий контрольные разряды при операции записи в память. При чтении из памяти такой контроллер сравнивает прочитанные и вычисленные значения контрольных разрядов и при необходимости исправляет испорченный бит (или биты). Стоимость дополнительных логических схем для реализации кода коррекции ошибок в контроллере памяти не очень высока, но это может значительно снизить быстродействие памяти при операциях записи. Это происходит потому, что при операциях записи и чтения необходимо ждать, когда завершится вычисление контрольных разрядов. При записи части слова вначале следует прочитать полное слово, затем перезаписать изменяемые байты и только после этого — новые вычисленные контрольные разряды.
В большинстве случаев сбой памяти происходит в одном разряде, и потому такие ошибки успешно исправляются кодом коррекции ошибок. Использование отказоустойчивой памяти обеспечивает высокую надежность компьютера. Память с кодом ECC предназначена для серверов, рабочих станций или приложений, для которых последствия потенциальных ошибок памяти менее желательны, чем дополнительные затраты на приобретение добавочных модулей памяти и вычислительные затраты на коррекцию ошибок. Если данные имеют особое значение и компьютеры применяются для решения важных задач, без памяти ECC не обойтись. По сути, ни один уважающий себя системный инженер не будет использовать сервер, даже самый неприхотливый, без памяти ECC.
Пользователи имеют выбор между системами без контроля четности, с контролем четности и с ECC, т.е. между желательным уровнем отказоустойчивости компьютера и степенью ценности используемых данных.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, an error correction code, sometimes error correcting code, (ECC) is used for controlling errors in data over unreliable or noisy communication channels.[1][2] The central idea is the sender encodes the message with redundant information in the form of an ECC. The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without retransmission. The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[2]
ECC contrasts with error detection in that errors that are encountered can be corrected, not simply detected. The advantage is that a system using ECC does not require a reverse channel to request retransmission of data when an error occurs. The downside is that there is a fixed overhead that is added to the message, thereby requiring a higher forward-channel bandwidth. ECC is therefore applied in situations where retransmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. Long-latency connections also benefit; in the case of a satellite orbiting around Uranus, retransmission due to errors can create a delay of five hours. ECC information is usually added to mass storage devices to enable recovery of corrupted data, is widely used in modems, and is used on systems where the primary memory is ECC memory.
ECC processing in a receiver may be applied to a digital bitstream or in the demodulation of a digitally modulated carrier. For the latter, ECC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many ECC encoders/decoders can also generate a bit-error rate (BER) signal, which can be used as feedback to fine-tune the analog receiving electronics.
The maximum fractions of errors or of missing bits that can be corrected are determined by the design of the ECC code, so different error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced ECC systems as of 2016[3] come very close to the theoretical maximum.
Forward error correction[edit]
In telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[4][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels. The central idea is that the sender encodes the message in a redundant way, most often by using an ECC.
The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without re-transmission. FEC gives the receiver the ability to correct errors without needing a reverse channel to request re-transmission of data, but at the cost of a fixed, higher forward channel bandwidth. FEC is therefore applied in situations where re-transmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. FEC information is usually added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, is widely used in modems, is used on systems where the primary memory is ECC memory and in broadcast situations, where the receiver does not have capabilities to request re-transmission or doing so would induce significant latency. For example, in the case of a satellite orbiting Uranus, a re-transmission because of decoding errors would create a delay of at least 5 hours.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC coders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon answers the question of how much bandwidth is left for data communication while using the most efficient code that turns the decoding error probability to zero. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. His proof is not constructive, and hence gives no insight of how to build a capacity achieving code. However, after years of research, some advanced FEC systems like polar code[3] achieve the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
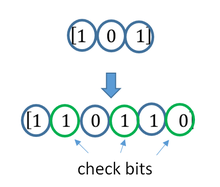
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[5]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[6][7] NOR Flash typically does not use any error correction.[6]
Classical block codes are usually decoded using hard-decision algorithms,[8] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[9]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[10] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[11] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[12]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[13] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[14] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[15] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[16]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[14][17] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[18]
- a contention-free quadratic permutation polynomial (QPP).[19] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[20]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[21]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[22] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[23] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[24]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[25]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most
 bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ a b c Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
Skip to content
Как исправить Soft ECC Correction (0xCC)?

Что делать с «0xCC Soft ECC Correction»?
При загрузке компьютера или ноутбука возникает S.M.A.R.T. ошибка «0xCC Soft ECC Correction»?
Что означает «0xCC»: Soft ECC Correction? Допустимые значения атрибута «Soft ECC Correction» отличаются для различных производителей жестких дисков WD (Western Digital), Samsung, Seagate, HGST (Hitachi), Toshiba.
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Программа для восстановления данных
Прекратите использование сбойного HDD
Получение от системы сообщения о диагностике ошибки не означает, что диск уже вышел из строя. Но в случае наличия S.M.A.R.T. ошибки,
нужно понимать, что диск уже в процессе выхода из строя. Полный отказ может наступить как в течении нескольких минут,
так и через месяц или год. Но в любом случае, это означает, что вы больше не можете доверить свои данные такому диску.
Необходимо побеспокоится о сохранности ваших данных, создать резервную копию или перенести файлы на другой носитель информации.
Одновременно с сохранностью ваших данных, необходимо предпринять действия по замене жесткого диска.
Жесткий диск, на котором были определены S.M.A.R.T. ошибки нельзя использовать – даже если он полностью не выйдет из строя он может частично повредить ваши данные.
Конечно же, жесткий диск может выйти из строя и без предупреждений S.M.A.R.T. Но данная технология даёт вам преимущество предупреждая о скором выходе диска из строя.
Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно
создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным.
В таком случае можно использовать программу для восстановления данных жесткого диска — Hetman Partition Recovery.
Для этого:
- Загрузите программу, установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов. Нажав кнопку «Далее», программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить».
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой «0xCC Soft ECC Correction».
Программа для восстановления данных
Просканируйте диск на наличие «битых» секторов

Запустите проверку всех разделов жесткого диска и попробуйте исправить найденные ошибки.
Для этого, откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с SMART ошибкой.
Выберите Свойства / Сервис / Проверить в разделе Проверка диска на наличия ошибок.
[скриншот]
В результате сканирования обнаруженные на диске ошибки могут быть исправлены.
Снизьте температуру диска

Иногда, причиной возникновения «S M A R T» ошибки может быть превышение максимально допустимой температуры работы диска.
Такая ошибка может быть устранена путём улучшения вентиляции компьютера.
Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась
до нормального уровня, то SMART ошибка может больше не возникнуть.
Произведите дефрагментацию жесткого диска
Откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с ошибкой «
0xCC
Soft ECC Correction». Выберите Свойства / Сервис / Оптимизировать в разделе Оптимизация и дефрагментация диска. Выберите диск, который необходимо оптимизировать и кликните Оптимизировать.

Примечание. В Windows 10 дефрагментацию и оптимизацию диска можно настроить таким образом, что она будет осуществляться автоматически.
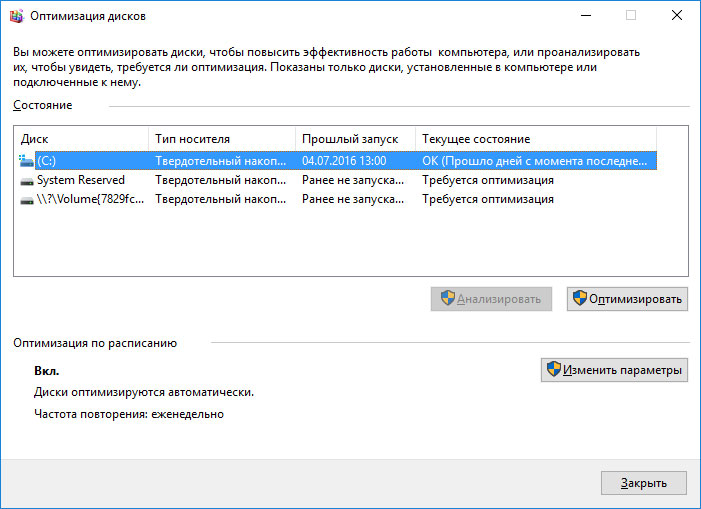
Ошибка «Soft ECC Correction» для SSD диска

Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того,
что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска.
Например, «209 Remaining Drive Life», «231 SSD life left» и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек,
и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Сбросьте ошибку
SMART ошибки можно легко сбросить в BIOS (или UEFI). Но разработчики всех операционных систем категорически не рекомендуют этого делать.
Если же для вас не имеют ценности данные на жестком диске, то вывод SMART ошибок можно отключить.
Для этого необходимо сделать следующее:
- Перезагрузите компьютер, и с помощью нажатия указанной на загрузочном экране комбинации клавиш (у разных производителей они разные, обычно «F2» или «Del») перейдите в BIOS (или UEFI).
- Перейдите в: Аdvanced > SMART settings > SMART self test. Установите значение Disabled.
Примечание: место отключения функции указано ориентировочно, так как в зависимости от версии BIOS или UEFI,
место расположения такой настройки может незначительно отличаться.
Приобретите новый жесткий диск
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман.
Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения
часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска,
можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства.
Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
Как выбрать новый накопитель?
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени.
То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
- Тип диска: HDD, SSD или SSHD. Каждому типу присущи свои плюсы и минусы, которые не имеют решающего значения для одних пользователей и очень важны для других. Основные из них — это скорость чтения и записи информации, объём и устойчивость к многократной перезаписи.
- Размер. Два основных форм-фактора дисков: 3,5 дюймов и 2,5 дюймов. Размер диска определяется в соответствии с установочным местом конкретного компьютера или ноутбука.
- Интерфейс. Основные интерфейсы жестких дисков: SATA, IDE, ATAPI, ATA, SCSI, Внешний диск (USB, FireWire и.т.д.).
-
Технические характеристики и производительность:
- Вместимость;
- Скорость чтения и записи;
- Размер буфера памяти или cache;
- Время отклика;
- Отказоустойчивость.
- S.M.A.R.T. Наличие в диске данной технологи поможет определить возможные ошибки его работы и вовремя предупредить утерю данных.
- Комплектация. К данному пункту можно отнести возможное наличие кабелей интерфейса или питания, а также гарантии и сервиса.
Актуально для:
WD HDD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (ударостойкие)
- 25H (ударостойкие)
- 25C (простые)
- 25A (с узором)
- 35T (настольные)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- Express 2.5
- V3700 2.5
- Server
- Near Line 2.5
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
- d2
A-Data HDD
- DashDrive
- HV
- Durable)
- HD
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (портативные)
- Save (настольные)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- M.2
- ProII
- Portable
- Panther
GOODRAM SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
Patriot SSD
- Flare (MLC)
- Scorch (MLC, M.2)
- Spark (TLC)
- Blast/P (TLC)
- Burst (3D TLC)
- Viper (TLC, M.2)
Samsung SSD
- PRO (3D MLC)
- EVO
- QVO (3D QLC)
- Portable (внешние)
- DCT (серверные)
- PM (серверные)
Seagate SSD
- Nytro
- Maxtor
- FireCuda
- BarraCuda
- Expansion
- IronWolf
A-Data SSD
- Premier (MLC/TLC)
- Ultimate (3D NAND)
- XPG
- SC (внешние)
- SE (внешние)
- Durable
WD SSD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Transcend SSD
- SSDXXX
- PATA
- MTSXXX
- MSAXXX
- ESDXXX
Contents
- Stop Using The Faulty HDD
- Restore The Deleted Data From The Disk
- Scan The Disk For Bad Sectors
- Reduce The Disk Temperature
- Run Hard Disk Defragmentation
- «0xCC» In an SSD
- How Can You Reset «0xCC Soft ECC Correction»?
-
Buy a New Hard Disk
- Is It Worth Repairing an HDD?
- How to choose a new HDD?
- Article Suitable for:
Read more how to fix «0xCC Soft ECC Correction» in Windows 11, Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Stop Using The Faulty HDD
If you receive a system message about an error diagnosed, it doesn’t mean the disk is out of order already. However, in case of a S.M.A.R.T. error, you should realize the disk is on the way to its breakdown. It can fail completely anytime – both within several minutes or in a month or even in a year. Anyway, it does mean you cannot trust to keep your data there.
You should take some care about the safety of your data, make a backup copy or transfer files to another media. Along with these actions meant to save your data, you should also replace your hard disk. The disk where S.M.A.R.T. errors were found cannot be used – even if it doesn’t break down completely, it can still damage your data partially.
Of course, a hard disk can fail even without showing any S.M.A.R.T. messages, but this technology gives you a certain advantage of warning you about the coming breakdown problem.
Restore The Deleted Data From The Disk
If there is a SMART error, restoring data from the disk is not always necessary. In case of an error, it is recommended to create a backup copy of important information immediately, because now the disk can fail completely at any time. However, there are errors that make data copying impossible. In this case, you can use special hard disk data recovery software — Hetman Partition Recovery.
The tool recovers data from any devices, regardless of the cause of data loss.

To do it:
-
Download the program, install and launch it.
-
By default, you will be suggested to use File Recovery Wizard. After clicking Next the program will suggest you to choose a disk to recover files from.
-
Double-click on the faulty disk and choose the type of analysis. Select Full analysis and wait for the scanning process to finish.
-
After the scanning process is over you will be shown files for recovery. Select the necessary files and click Recover.
-
Select one of the suggested ways to save files. Do not save the recovered files to the disk having an error «0xCC Soft ECC Correction».
Scan The Disk For Bad Sectors
Start scanning all partitions of the disk and try correcting any mistakes that are found.
To do it, open This PC and right-click on the disk with a SMART error.
Select Properties / Tools / Check in the tab Error checking.

Errors found on the disk as a result of scanning can be corrected.
Go to view

How to Check Your Hard Disk for Errors and Fix Them in Windows 10
Reduce The Disk Temperature
Sometimes a SMART error can be caused by exceeding the maximum temperature of the disk. This problem can be eliminated by improving the case ventilation. First of all, make sure that your computer has sufficient ventilation and that all coolers are in proper working order.
If you found and eliminated the ventilation problem, which helped to bring the disk temperature back to normal, this SMART error can never appear again.
Go to view
How to Check the Processor (CPU), Video Card (GPU) or Hard Disk (HDD) Temperature
Run Hard Disk Defragmentation
Open This PC and right-click on the disk having an error «0xCC Soft ECC Correction». Select Properties / Tools / Optimize in the tab Optimize and defragment drive.
Go to view
How to Defragment Your PC’s Hard Drive on Windows 10

Select the disk you need to optimize and click Optimize.
Note. In Windows 10 disk defragmentation and optimization can be adjusted to take place automatically.
«Soft ECC Correction» In an SSD
Even if you have no problems with an SSD performance, its operability is reducing slowly because SSD memory cells have a limited number of overwrite cycles. The wear resistance function minimizes this effect but never takes it away completely.
SSD disks have their specific SMART attributes which send signals about the state of disk memory cells. For example, «209 Remaining Drive Life,» «231 SSD life left» etc. Such errors may occur when memory cell operability is reduced, and it means the information kept there can be damaged or lost.
In case of failure, SSD cells cannot be recovered or replaced.
Go to view
SSD Diagnostics: Programs to Find and Fix SSD Errors
How Can You Reset «0xCC Soft ECC Correction»?
SMART errors can be easily reset in BIOS (or UEFI) but all OS developers strongly discourage users from this step. Yet if the data on the hard disk is of little importance for you, displaying SMART errors can be disabled.
Here is the procedure to follow:
-
Restart the computer, and use combinations of keys shown on the loading screen (they depend on a specific manufacturer, usually «F2» or «Del») to go to BIOS (or UEFI).
-
Go to Аdvanced > SMART settings > SMART self test. Set the value as Disabled.
Note: The place where you disable the function is given approximately, because its specific location depends on the version of BIOS or UEFI and can differ slightly.
Buy a New Hard Disk
Is It Worth Repairing an HDD?
It is important to realize that any of the ways to eliminate a SMART error is self-deception. It is impossible to completely remove the cause of the error, as it often involves physical wear of the hard disk mechanism.
To replace the hard disk components which operate incorrectly you can go to a service center or a special laboratory dealing with hard disks.
However, the cost of work will be higher than the price of a new device, so it is justified only when you need to restore data from a disk which is no longer operable.
How to choose a new HDD?
If you encounter a hard disk SMART error, then buying a new HDD is only a matter of time. The disk type you need depends on how you work on the computer and the purposes you use your computer for.
Here are some points to consider when buying a new hard disk:
-
Disk type: HDD, SSD или SSHD. Each type has its advantages and disadvantages which may be unimportant for one user and crucial for another. These are read and write speed, capacity and tolerance to multiple overwriting.
-
Size. There are two main form factors for hard disks, 3.5 inch and 2.5 inch. The size of disks is determined in accordance to the slot in a particular computer or laptop.
-
Interface. The main interfaces of hard disks are as follows:
-
SATA;
-
IDE, ATAPI, ATA;
-
SCSI;
-
External Disk (USB, FireWire etc).
-
-
Technical characteristics and performance:
-
Capacity;
-
Read and write speed;
-
Memory cache size;
-
Response time;
-
Fail safety.
-
-
S.M.A.R.T. Availability of this technology in the disk will help determining possible mistakes in its work and prevent loss of data before it is too late.
-
Package. This item can include interface or power cables as well as warranty and service options.
Article Suitable for:
WD HDD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (wstrząsoodporny)
- 25H (wstrząsoodporny)
- 25C (proste)
- 25A (wzorzec)
- 35T (pulpitowe)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- Express 2.5
- V3700 2.5
- Server
- Near Line 2.5
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
- d2
A-Data HDD
- DashDrive
- HV
- Durable)
- HD
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (przenośny)
- Save (pulpitowe)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- M.2
- ProII
- Portable
- Panther
Crucial SSD
- BX
- MX
GOODRAM SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
WD HDD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (ударостойкие)
- 25H (ударостойкие)
- 25C (простые)
- 25A (с узором)
- 35T (настольные)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- Express 2.5
- V3700 2.5
- Server
- Near Line 2.5
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
- d2
A-Data HDD
- DashDrive
- HV
- Durable)
- HD
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (портативные)
- Save (настольные)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- M.2
- ProII
- Portable
- Panther
Crucial SSD
- BX
- MX
GOODRAM SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
Patriot SSD
- Flare (MLC)
- Scorch (MLC, M.2)
- Spark (TLC)
- Blast/P (TLC)
- Burst (3D TLC)
- Viper (TLC, M.2)
Samsung SSD
- PRO (3D MLC)
- EVO
- QVO (3D QLC)
- Portable (внешние)
- DCT (серверные)
- PM (серверные)
Seagate SSD
- Nytro
- Maxtor
- FireCuda
- BarraCuda
- Expansion
- IronWolf
A-Data SSD
- Premier (MLC/TLC)
- Ultimate (3D NAND)
- XPG
- SC (внешние)
- SE (внешние)
- Durable
WD SSD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Transcend SSD
- SSDXXX
- PATA
- MTSXXX
- MSAXXX
- ESDXXX