
В
практике большое распространение
получил так называемый допусковый
контроль,
суть которого состоит в определении
путем измерения или испытания значения
контролируемого параметра объекта и
сравнение полученного результата с
заданными граничными допустимыми
значениями. Частным случаем допускового
контроля является поверка средств
измерений, в процессе которой исследуется
попадание погрешностей средства
измерений в допустимые пределы. По
расположению зоны контролируемого
состояния различают допусковый контроль
состояний:
• ниже
допускаемого значения Х
< Хдн;
• выше
допускаемого значения Х
> Хдв;
• между
верхним и нижним допускаемыми значениями
Хдн< Х
< Хдв.
Результатом
контроля является не число, а одно из
взаимоисключающих утверждений:
• «контролируемая
характеристика (параметр) находится в
пределах допускаемых значений»,
результат контроля
— «годен»;
• «контролируемая
характеристика (параметр) находится за
пределами допускаемых значений»,
результат контроля
—»не
годен » или «брак».
Для
определенности примем, что решение
«годен» должно приниматься, если
выполняется условие Хдн
Х
Xвд,
где
X, Хдн, Xдв
— истинное значение и допускаемые
верхнее и нижнее значения контролируемого
параметра. На самом же деле с допускаемыми
значениями Хд и Хд сравнивается не
истинное значение Х (поскольку оно
неизвестно), а его оценка Хо, полученная
в результате измерений. Значение Х
отличается от Х на величину погрешности
измерения: Хо
= Хо+ А.
Решение «годен» при проведении
контроля принимается в случае выполнения
неравенства ХднХоХдв.
Отсюда следует, что при допусковом
контроле возможны четыре исхода.
-
Принято
решение «годен», когда значение
контролируемого параметра находится
в допускаемых пределах, т.е. имели место
события ХднХХдв
, ХднХоХдв.
Если известны плотности вероятностей
законов распределения f(X)
контролируемого параметра Х и погрешности
его измерения f(А),
то при взаимной независимости тих
законов и заданных допустимых верхнем
и нижнем значениях параметра вероятность
события «годен» .

2.
Принято решение «брак», когда
значение контролируемого параметра
находится вне пределов допускаемых
значений, т.е. имели место события Х
< Хдн или
Х >
Хдв и Хо< Хдн или Хо> Хдв. При оговоренных
допущениях вероятность события «негоден»
или «брак»

-
Принято
решение «брак», когда истинное
значение контролируемого параметра
лежит в пределах допускаемых значений,
т.е. Хо<Хдн или Хо>Хдв и Хдн
Х Хдв
и забракован исправный объект. В этом
случае принято говорить, что имеет
место ошибка
I рода. Ее
вероятность
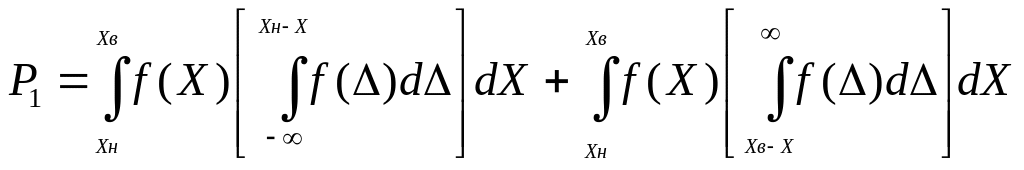
4.
Принято решение «годен», когда
истинное значение контролируемого
параметра лежит вне пределов допускаемых
значений, т.е. имели место события Х
< Хдн или
Х>Хдв и ХднХо<Хдв
и неисправный объект признан годным. В
этом случае говорят, что произошла
ошибка
II рода,
вероятность которой

Очевидно,
что ошибки I
и
II родов
имеют разное значение для изготовителей
и потребителей (заказчиков) контролируемой
продукции
[26]. Ошибки
I рода ведут
к прямым потерям изготовителя, так как
ошибочное признание негодным в
действительности годного изделия
приводит к дополнительным затратам на
исследование, доработку и регулировку
изделия. Ошибки
II рода
непосредственно сказываются на
потребителе, который получает
некачественное изделие. При нормальной
организации отношений между потребителем
и производителем брак, обнаруженный
первым из них, приводит к рекламациям
и ущербу для изготовителя.
Рассмотренные
вероятности Рг, Рнг, Р1, и Р2 при массовом
контроле партии изделий характеризуют
средние доли годных, негодных,
неправильно забракованных и неправильно
пропущенных изделий среди всей
контролируемой их совокупности. Очевидно,
что Рг+Ргн+Р1+Р2=
1.
Достоверность
результатов допускового контроля
описывается различными показателями,
среди которых наибольшее распространение
получили вероятности ошибок
I (Р1
) и
II (Р2
) родов
и риски изготовителя и заказчика
(потребителя):
![]()
![]()
![]()
Одна
из важнейших задач планирования контроля
— выбор
оптимальной точности измерения
контролируемых параметров. При завышении
допускаемых погрешностей измерения
уменьшается стоимость средств измерений,
но увеличиваются вероятности ошибок
при контроле, что в конечном итоге
приводит к потерям. При занижении
допускаемых погрешностей стоимость
средств измерений возрастает,
вероятность ошибок контроля уменьшается,
увеличивает себестоимости выпускаемой
продукции. Очевидно, что существует
некоторая оптимальная точность,
соответствующая минимуму суммы потерь
от брака и стоимости контроля.
Приведенные
формулы позволяют осуществить
целенаправленный поиск таких значений
погрешности измерения, которые бы при
заданных верхнем и нижнем значениях
контролируемого параметра обеспечили
бы допускаемые значения вероятностей
ошибок
I и
II родов
(Р1д и Р2д
) или
соответствующих рисков. Этот поиск
производится путем численного или
графического интегрирования. Следовательно,
для рационального выбора точностных
характеристик средств измерений,
используемых при проведении контроля,
каждом конкретном случае должны быть
заданы допускаемые значения Р1д и Р2д.
3.7.
Метод импульсной рефлектометрии для
контроля протяженных объектов.
Метод
импульсной рефлектометрии, называемый
также методом
отраженных импульсов
или локационным
методом, базируется на распространении
импульсных сигналов в двух- и многопроводных
системах.
Сущность
метода импульсной рефлектометрии
заключается в следующих операциях:
-
Зондировании
трубопроводной системы импульсами
напряжения. -
Приеме импульсов,
отраженных от места повреждения и
неоднородностей волнового сопротивления. -
Выделении отражений
от места повреждений на фоне помех
(случайных и отражений от неоднородностей
трубопроводов). -
Определении
расстояния до повреждения по временной
задержке отраженного импульса
относительно зондирующего.
Упрощенная
структурная схема измерений с помощью
импульсного рефлектометра приведена
на рисунке 3.
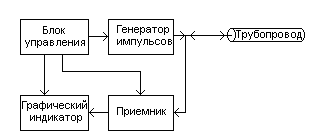
Рис.3. Упрощенная
структурная схема измерений.
С
генератора импульсов зондирующие
импульсы подаются в трубопровод.
Отраженные импульсы поступают с
трубопровода в приемник, в котором
производятся необходимые преобразования
над ними. С выхода приемника преобразованные
сигналы поступают на графический
индикатор. Все блоки импульсного
рефлектометра функционируют по сигналам
блока управления. На графическом
индикаторе рефлектометра воспроизводится
рефлектограмма трубопровода — реакция
трубопровода на зондирующий импульс.
Образование
рефлектограммы трубопровода легко
проследить по диаграмме, приведенной
на рисунке 4. Здесь осью ординат является
ось расстояния, а осью абсцисс — ось
времени.
В левой
части рисунка показан трубопровод из
двух секций с согласующим устройством
и коротким замыканием, а в нижней части
— рефлектограмма этого трубопровода.
Анализируя рефлектограмму трубопровода,
оператор получает информацию о наличии
или отсутствии в ней повреждений и
неоднородностей.

Рис.4. Пример
рефлектограммы с двумя неоднородностями
в трубопроводе.
Например, по
приведенной рефлектограмме можно
сделать несколько выводов:
-
На рефлектограмме,
кроме зондирующего импульса, есть
только два отражения: отражение от
согласующего устройства и отражение
от короткого замыкания. Это свидетельствует
о хорошей однородности трубопровода
от начала до согласующего устройства
и от согласующего устройства до короткого
замыкания. -
Выходное
сопротивление рефлектометра согласовано
с волновым сопротивлением трубопровода,
так как переотраженные сигналы, которые
при отсутствии согласования располагаются
на двойном расстоянии, отсутствуют. -
Повреждение имеет
вид короткого замыкания, так как
отраженный от него сигнал изменил
полярность. -
Короткое замыкание
полное, так как после отражения от него
других отражений нет. -
Линия имеет большое
затухание, так как амплитуда отражения
от короткого замыкания много меньше,
чем амплитуда зондирующего сигнала.
Если
выходное сопротивление рефлектометра
не согласовано с волновым сопротивлением
трубопровода, то в моменты времени 2*
tм,
4* tм
и т.д. будут наблюдаться переотраженные
сигналы от согласующего устройства,
убывающие по амплитуде, а в моменты
времени 2*
tх,
4*tх
и т.д. — переотражения от места короткого
замыкания.
Основную
сложность и трудоемкость при методе
отраженных импульсов представляет
выделение отражения от места повреждения
на фоне помех.
Важное
значение для метода импульсной
рефлектометрии имеет отношение между
напряжением и током введенной в систему
электромагнитной волны, которое одинаково
в любой точке трубопровода. Это
соотношение:
Z
= U/I
имеет размерность
сопротивления и называется волновым
сопротивлением трубопровода.
При использовании метода импульсной
рефлектометрии в трубопроводную систему
контроля посылают зондирующий импульс
и измеряют интервал tх — время двойного
пробега этого импульса до места
повреждения (неоднородности волнового
сопротивления). Расстояние до места
повреждения рассчитывают по выражению:
Lx
= tx*V/2
,
где
V
— скорость распространения импульса в
трубопровода.
Отношение
амплитуды отраженного импульса Uо к
амплитуде зондирующего импульса Uз
обозначают коэффициентом отражения p:
p
= Uo/Uз = (Z1
— Z)
/ (Z1
+ Z),
где:
Z
— волновое сопротивление трубопровода
до места повреждения (неоднородности),
Z1
— волновое сопротивление трубопровода
в месте повреждения (неоднородности).
Отраженный
сигнал появляется в тех местах
трубопровода, где волновое сопротивление
отклоняется от своего среднего значения:
согласующие устройства, изгибах
трубопроводов, в месте обрыва, короткого
замыкания и т.д.
Если
выходное сопротивление импульсного
рефлектометра отличается от волнового
сопротивления измеряемого трубопровода,
то в месте подключения рефлектометра
к трубопровода возникают переотражения.
Переотражения
— это отражения от входного сопротивления
рефлектометра отраженных сигналов,
которые пришли к месту подключения
рефлектометра из трубопровода.
В
зависимости от соотношения входного
сопротивления рефлектометра и волнового
сопротивления трубопровода изменяется
полярность и амплитуда переотражений,
которая может оказаться соизмеримой с
амплитудой отражений. Поэтому перед
измерением рефлектометром обязательно
нужно выполнить операцию согласования
выходного сопротивления рефлектометра
с волновым сопротивлением трубопровода.
Примеры
рефлектограммы трубопровода с
переотражением без согласования
выходного сопротивления с трубопроводом
и с согласованием приведены на рис. 5 и
6:
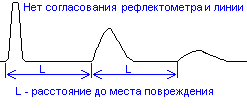
Рис.5. Рефлектограмма
трубопровода в отсутствие согласования.
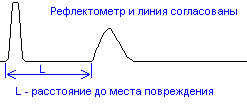
Рис.6. Рефлектограмма
трубопровода при согласовании.
При
распространении вдоль трубопровода
импульсный сигнал затухает. Затухание
трубопровода определяется ее геометрической
конструкцией и выбором материалов для
проводников и изоляции и является
частотно-зависимым. Следствием
частотной зависимости является изменение
зондирующих импульсов при их распространении
по трубопроводу: изменяется не только
амплитуда, но и форма импульса —
длительности фронта и среза импульса
увеличиваются («расплывание”
импульса). Чем длиннее трубопроводная
система, тем больше “расплывание” и
меньше амплитуда импульса. Это затрудняет
точное определение расстояния до
повреждения.
Примеры
рефлектограмм трубопроводов без
затухания и с затуханием показаны на
рисунке 7.


Рис.7. Влияние
затухания трубопровода на вид
рефлектограммы в отсутствие согласования.
Для
более точного измерения необходимо
правильно, в соответствии с длиной и
частотной характеристикой затухания
трубопровода, выбирать параметры
зондирующего импульса в рефлектометре.
Критерием правильного выбора является
минимальное «расплывание» и
максимальная амплитуда отраженного
сигнала.
Если при подключенном
трубопроводе на рефлектограмме
наблюдается только зондирующий импульс,
а отраженные сигналы отсутствуют, то
это свидетельствует о точном согласовании
выходного сопротивления рефлектометра
с волновым сопротивлением трубопровода,
отсутствии повреждений и наличии на
конце трубопровода нагрузки равной
волновому сопротивлению трубопровода
(Рис.8).

Рис.8. Рефлектограмма
при идеальном согласовании.
Вид
отраженного сигнала зависит от характера
повреждения или неоднородности. Например,
при обрыве отраженный импульс имеет ту
же полярность, что и зондирующий, а при
коротком замыкании отраженный импульс
меняет полярность (Рис.9).

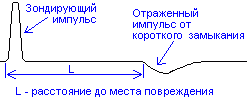
Рис.9. Рефлектограммы
при обрыве и коротком замыкании.
В
идеальном случае, когда отражение от
повреждения полное и затухание
отсутствует, амплитуда отраженного
сигнала равна амплитуде зондирующего
импульса.
Рассмотрим два
случая эквивалентных схем повреждений,
которые наиболее часто встречаются на
практике: шунтирующая
утечка
и продольное
сопротивление.
Пусть
место повреждения трубопровода
представляет собой
шунтирующую утечку
Rш:
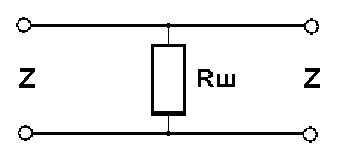
С изменением
сопротивления утечки от нуля (соответствует
короткому замыканию) до бесконечности
(соответствует исправности трубопровода),
при положительном зондирующем импульсе
отраженный импульс имеет отрицательную
полярность и изменяется по амплитуде
от максимального значения до нулевого,
в соответствии с выражением:
p=
(Z1
— Z)
/ (Z1
+ Z)
= — Z
/ (Z+2*Rш),
где:
Rш
— сопротивление шунтирующей утечки,
Z1
— волновое сопротивление трубопровода
в месте повреждения, определяется
выражением:
Z1
= (Z*R
ш) / (Z
+ Rш)
Так,
например, при коротком замыкании (Rш=0)
получаем:
p
= -1
В
этом случае сигнал отражается полностью
с изменением полярности.
При отсутствии
шунтирующей нагрузки (Rш=![]()
)
имеем:
p
= 0
Сигнал
не отражается вообще.
При
изменении Rш
от 0 до
амплитуда отраженного сигнала уменьшается
от максимального значения до нулевого,
сохраняя отрицательную полярность (см.
рисунок).
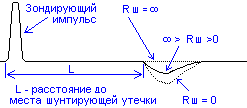
Рис.10. Рефлектограмма
при наличии шунта.
Если
эквивалентная схема места повреждения
трубопровода имеет вид включения
продольного сопротивления (например,
нарушение спайки), то с изменением
величины продольного сопротивления
отраженный импульс изменяется по
амплитуде, оставаясь той же полярности
что и зондирующий импульс.
Выражение для коэффициента отражения
при наличии включения продольного
сопротивления
будет иметь вид:
p
= (Z1
— Z)
/ (Z1
+ Z)
= 1 / (1+2*Z/Rп),
где:
Rп
— продольное сопротивление,
Z1
— волновое сопротивление трубопровода
в месте включения продольного повреждения,
определяемое выражением:
Z1
= Rп + Z
В
случае обрыва жилы (Rп=
)
получаем
коэффициент отражения:
р = 1.
Это
означает, что сигнал отражается полностью
без изменения полярности.
При нулевом
значении продольного сопротивления
(Rп=0)
имеем:
р = 0
С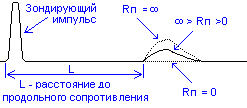
игнал
не отражается вообще.
При
изменении Rп
от
до
0 отраженный сигнал уменьшается по
амплитуде от максимального значения
до нулевого, без изменения полярности.
Рис.11. Рефлектограмма
— влияние продольного сопротивления.
Разрешающая
способность —
это минимальное расстояние между двумя
неоднородностями волнового сопротивления
при котором отраженные от них сигналы
еще наблюдаются как отдельные сигналы.
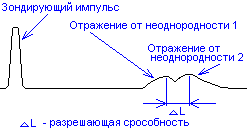
Рис.12. Рефлектограмма
— отражение от двух близких неоднородностей.
На рисунке 11
отраженные от двух неоднородностей
импульсы еще наблюдаются раздельно.
Зондирующие импульсы
распространяются в кабельных линиях
по определенным волновым каналам.
Импульсный
сигнал распространяется в трубопроводе
с определенной скоростью, которая
зависит от типа диэлектрика и определяется
выражением:
![]()
где
с
— скорость света,
g
— коэффициент укорочения электромагнитной
волны в трубопровода,
ε
— диэлектрическая проницаемость материала
изоляции трубопровода.
Коэффициент
укорочения
показывает, во сколько раз скорость
распространения импульса в трубопроводе
меньше скорости распространения в
воздухе.
В любом рефлектометре
перед измерением расстояния нужно
установить коэффициент укорочения.
Точность измерения расстояния до места
повреждения зависит от правильной
установки коэффициента укорочения.
По соотношению величин
отражения от повреждения и напряжения
помех все отражения можно разделить на
простые
и сложные.
Простое
повреждение — это такое повреждение
кабельной трубопровода, при котором
амплитуда отражения от места повреждения
больше амплитуды помех.
Сложное
повреждение — это такое повреждение,
для которого амплитуда отражения от
места повреждения меньше или равна
амплитуде помех.
По
источникам возникновения помехи бывают
асинхронные
(аддитивные)
и синхронные.
Асинхронные
помехи
не связаны с зондирующим сигналом и
неоднородностями кабельной трубопровода
и вызваны наводками от соседних кабельных
трубопроводов, от оборудования, транспорта
и различной аппаратуры.
Пример рефлектограммы трубопровода с
асинхронными помехами показан на рисунке
13.
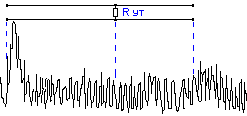
Рис.13. Рефлектограмма
трубопровода с асинхронными помехами.
На рефлектограмме
асинхронные помехи полностью закрывают
отражение от повреждения. Это отражение
невозможно рассмотреть на фоне помех.
Эффективными
методами отстройки от асинхронных помех
являются аналоговая
фильтрация
и цифровое
накопление сигнала.
Сущность цифрового
накопления
заключается в том, что одну и туже
рефлектограмму считывают несколько
раз и вычисляют среднее значение. В
связи с тем, что асинхронные помехи
носят случайный характер, после цифрового
накопления их уровень значительно
снижается.
Пример
предыдущей рефлектограммы трубопровода,
«очищенной» в результате цифрового
накопления рефлектометром, приведен
на рисунке.

Рис.14. Рефлектограмма
с асинхронными помехами после цифровой
очистки.
На
этой рефлектограмме можно легко выделить
сигнал, отраженный от места утечки.
Синхронные
помехи связаны с зондирующим сигналом
и являются отражениями зондирующего
сигнала от неоднородностей волнового
сопротивления трубопровода (отражения
от согласующих устройств, неоднородностей
трубопроводов технологического характера
и др.).
В принципе трубопроводы
не предназначены для передачи коротких
импульсных сигналов, используемых при
методе импульсной рефлектометрии.
Поэтому этим системам контроля
трубопроводов присуще большое количество
синхронных помех. Пример рефлектограммы
трубопровода с синхронными помехами
показан на рисунке.
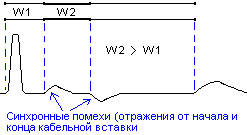
Рис.11. Рефлектограмма
трубопровода с синхронными помехами.
Синхронные
помехи можно существенно уменьшить
посредством сравнения
или
дифференциального
анализа.
При сравнении
накладывают
рефлектограммы двух трубопроводов
(неповрежденного и поврежденного),
проложенных по одной трассе.
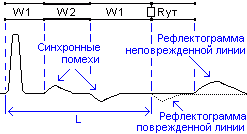
Наложение
двух рефлектограмм позволяет быстро
обнаружить начальную точку их различия,
по которой и определяют расстояние L до
повреждения.
При
дифференциальном
анализе рефлектограммы поврежденного
и неповрежденного трубопроводов
вычитают, как показано на рисунке ниже
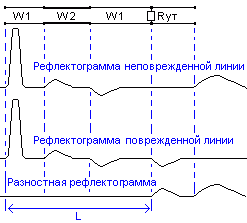
Из
рисунка видно, что при вычитании все
синхронные помехи компенсируются. По
разностной рефлектограмме легко
обнаружить отражение от места повреждения
и определить расстояние L
до него.
При
измерении качества трубопровода методом
импульсной рефлектометрии асинхронные
и синхронные помехи присутствуют на
рефлектограмме одновременно.
Асинхронные
помехи (кроме помех импульсного
характера), как правило, имеют одинаковые
величины, независимо от того, с какого
конца кабельной трубопровода ведется
измерение рефлектометром.
Синхронные
помехи при измерении с разных концов
кабеля имеют различную величину, в
зависимости от многих факторов: длины
кабельной трубопровода, затухания
импульсных сигналов, удаленности места
повреждения и мест неоднородностей
волнового сопротивления трубопровода,
точности согласования выходного
сопротивления импульсного рефлектометра
с волновым сопротивлением трубопровода
и других факторов. Поэтому отраженный
сигнал от одной и той же неоднородности
может иметь различные величины при
измерении с разных концов трубопровода.
Если
хотя бы предположительно известно, к
какому концу кабельной трубопровода
ближе может быть расположено место
повреждения, то для измерений нужно
выбирать именно этот конец кабельной
трубопровода. В других случаях желательно
проводить измерения последовательно
с двух концов трубопровода.
Следует учитывать, что даже такие
повреждения как «короткое замыкание»
и «обрыв», дающие максимальные
отражения зондирующего сигнала, не
всегда можно легко обнаружить на фоне
помех. Например, при большом затухании
и больших неоднородностях волнового
сопротивления трубопровода амплитуда
отражения от удаленного повреждений
типа “короткое замыкание” или “обрыв”
зачастую бывает меньше, чем отражения
от близко расположенных неоднородностей
волнового сопротивления. Поэтому такие
повреждения являются сложным для
обнаружения.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибки, встроенные в систему: их роль в статистике
Время на прочтение
6 мин
Количество просмотров 13K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):
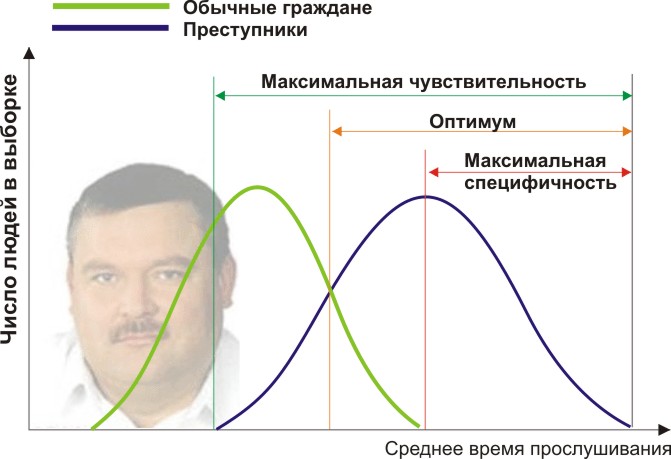
Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:

Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):

А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
Проблема множественного тестирования гипотез
Ваш исследовательский вопрос может быть таким, что вам интересно оценить воздействия разных типов тритмента, то есть у вас есть несколько экспериментальных групп и одна контрольная. При такой постановке мы хотим проверить не одну, а сразу много статистических гипотез о различии в группах. При проверке любой гипотезы существует вероятность совершить ошибку первого рода (отклонить нулевую гипотезу, если она верна = обнаружить эффект, которого нет). Особенность множественного тестирования гипотез состоит в том, что чем больше гипотез мы проверяем на одних и тех же данных, тем больше будет вероятность допустить как минимум одну ошибку первого рода – эффект множественных сравнений (multiple comparisons/testing).
Источниками множественного тестирования могут быть:
-
Несколько типов воздействия (Multiple treatment arms)
-
Гетерогенное воздействие (Heterogeneous treatment effects)
-
Несколько способов оценки (Multiple estimators)
-
Несколько зависимых переменных (Multiple outcomes), эффект на которые мы хотим оценить
Рассмотрим это на примере. Предположим, что у нас есть 3 группы (A, B и С), в которых мы хотим сравнить среднее значение переменной интереса. Как и ранее, мы будем использовать t-тест Стьюдента. Если мы получили достаточно большое значение t-статистики такое, что p-value < 0.05, то мы отклоняем нулевую гипотезу и заключаем, что группы статистически различаются по переменной интереса. Отсечка p-value < 0.05 значит, что вероятность ошибочного вывода о различии между групповыми средними не превышает 0.05. Это будет работать именно так, когда у нас всего две группы, но в случае множественного тестирования вероятность будет больше 5%.
Выполняя тест Стьюдента, исследователь проверяет нулевую гипотезу об отсутствии разницы между двумя группами. Сравнивая группы A и В, он может ошибиться с вероятностью 5%, В и С – 5%, А и С – тоже 5%. Соответственно, вероятность ошибиться хотя бы в одном из этих трех сравнений составит:
(P = 1 — left(1-alpha right)^n = 1 — 0.95^3 approx 0.14 > 0.05) – такая ошибка называется family-wise error rate
Если бы групп было бы 5:
(P = 1 — left(1-alpha right)^n = 1 — 0.95^{10} approx 0.4 > 0.05)
К счастью, существует несколько методов, позволяющих преодолеть эту сложность:
-
Корректировка p-value (p-value adjustments)
-
Планирование эксперимента и фиксирование его условий (pre-analysis plans)
-
Повтороное проведение эксперимента (replication)
В рамках курса мы будем обсуждать первый способ борьбы с ошибками, возникающими при множественном тестировании гипотез.
Предположим, что мы проверяем (n) гипотез. Для каждой гипотезы мы будем проводить тест Стьюдента. Результаты наших тестов можно обобщить следующим образом:
| Число принятых нулевых гипотез ((p-value > alpha) Rightarrow hat{tau}=0) | Число отвергнутых нулевых гипотез ((p-value < alpha) Rightarrow hat{tau}neq 0) | Всего гипотез | |
|---|---|---|---|
| Число верных нулевых гипотез (hat{tau}=0) | Число безошибочно принятых нулевых гипотез (TN, true negatives) | Число ошибочно отвергнутых нулевых гипотез (FP, false positives) – ошибка первого рода | (m_0) – Число верных нулевых гипотез (true null hypotheses) |
| Число неверных нулевых гипотез (hat{tau}neq 0) | Число ошибочно принятых нулевых гипотез (FN, false negatives) – ошибка второго рода) | Число безошибочно отвергнутых нулевых гипотез (TP, true positives) | (m-m_0) – Число истинных альтернативных гипотез (true alternative hypotheses) |
| Всего гипотез | (m-R) – Общее число принятых гипотез | (R) – Общее число отвергнутых гипотез | (m) – всего гипотез |
В теории всего существует (m_0) верных нулевых гипотез. В результате наших тестов мы ошибочно отвергаем (FP) гипотез и верно принимаем остальные (TN) гипотез. Также существует (m−m_0) альтернативных гипотез, из которых (TP) гипотез безошибочно отвергаются, а (FN) гипотез – ошибочно принимаются. Важно, что общие количества отвергнутых и принятых гипотез ((R) и (m-R)), а следовательно, и суммарное число гипотез (n) нам известны, тогда как остальные величины ((m_0), (TN), (FP), (FN) и (TP)) мы не наблюдаем.
Групповая вероятность ошибки первого рода (family-wise error rate)
При одновременной проверке семейства статистических гипотез мы хотим, чтобы количество наших ошибок ((FP) и (FN)) было минимальным. Традиционно исследователи пытаются минимизировать величину ошибочно отвергнутых гипотез (FP). Это вполне логично, поскольку ложно отвергнутая нулевая гипотеза грозит нам ложноположительным найденным эффектом, которого реально может не быть.
Если (FP geq 1), мы совершаем как минимум одну ошибку первого рода. Вероятность допущения такой ошибки при множественной проверке гипотез называют групповой вероятностью ошибки (familywise error rate, FWER или experiment-wise error rate). По определению, (FWER = P(FP geq 1)) – вероятность ошибочно отклонить хотя бы одну нулевую гипотезу во всех тестах. Соответственно, когда мы говорим, что хотим контролировать групповую вероятность ошибки на определенном уровне значимости (alpha), мы подразумеваем, что должно выполняться неравенство (FWER leq alpha).
Ниже мы обсудим методы, которые позволяют это делать.
Коррекция Бонферрони
Вернемся к нашему примеру, когда мы сравнили 3 группы A, B и C с помощью t-теста. Предположим, что мы получили следующие Р-значения: 0.001, 0.01 и 0.04.
Как было сказано выше, мы хотим, чтобы групповая вероятность ошибки была не больше уровня значимости (FWER leq alpha). Согласно методу Бонферрони, мы должны сравнить каждое из полученных p-значений не с (alpha), а с (frac{alpha}{n}), где (n) – число проверяемых гипотез. Деление исходного уровня значимости (alpha) на (n) – это и есть поправка Бонферрони. В рассматриваемом примере каждое из полученных p-значений необходимо было бы сравнить с (frac{alpha}{n}), например, с (frac{0.01}{3}approx 0.017).
- (p-value_1=0.001 < alpha_{adjusted}=0.017) – гипотеза отклонена
- (p-value_2=0.01 < alpha_{adjusted}=0.017) – гипотеза отклонена
- (p-value_3=0.04 > alpha_{adjusted}=0.017) – гипотеза принята
Вместо деления уровня значимости на число гипотез, мы могли бы умножить каждое p-значение на это число и получить точно такие же выводы (эта эквивалентная процедура реалирована в R):
- (p-value_{1,adjusted} = 0.001 cdot 3 = 0.003 < alpha = 0.05) – гипотеза отклонена
- (p-value_{2,adjusted} = 0.01 cdot 3 = 0.03 < alpha = 0.05) – гипотеза отклонена
- (p-value_{3,adjusted} = 0.04 cdot 3 = 0.12 > alpha = 0.05) – гипотеза принята
Иногда при домножении p-значений результат может получиться больше единицы. Из теории вероятностей мы знаем, что вероятность не может быть больше одного, поэтому в таких случаях p-значение принимают равным за единицу.
Различные виды коррекций p-значений представлены в функции p.adjust(), выбрать тип коррекции можно с помощью аргумента method. В этой функции используется домножение исходных p-значений на количество тестируемых гипотез, а не корректировка уровня значимости.
Проверим наши рассчеты:
p.adjust(c(0.001, 0.01, 0.04), method = "bonferroni")Можно на выходе сразу получить выводы относительно гипотез при (alpha = 5%):
alpha <- 0.05
p.adjust(c(0.001, 0.01, 0.04), method = "bonferroni") < alpha # отклоняем H_0 (есть эффект)? Важно помнить об уязвимости коррекции Бонферрони – с ростом числа гипотез мощность метода уменьшается. Чем больше гипотез мы хотим проверить, тем сложнее нам будет их отвергать (даже если они реально должны быть отвергнуты). Например, для 5 групп (10 гипотез), применение поправки Бонферрони привело бы к снижению исходного уровня значимости до 0.01/10 = 0.001. Соответственно, для отклонения гипотез, соответствующие p-значения должны быть меньше 0.001, а это довольно жесткая отсечка. Из этого делаем вывод, что при большом числе гипотез коррекцию Бонферрони лучше не использовать.
Низходящая процедура Хольма (Хольма-Бонферрони)
Метод Хольма позволяет побороть недостатки метода Бонферрони. Он устроен следующим образом:
- Сначала p-значения сортируются по возрастанию (displaystyle{p-value_1 leq p-value_2 leq … leq p-value_n}).
- Затем проверяется условие для первого из p-значений: (displaystyle{p-value_1 geq frac{alpha}{n-i+1}=frac{alpha}{n}}), если условие выполнено, то все нулевые гипотезы принимаются, и процедура останавливается, иначе первая из гипотез отвергается, и начинается следующий шаг.
- На следующем шаге проверяется условие (displaystyle{p-value_2 geq frac{alpha}{n-i+1}=frac{alpha}{n-1}}), если условние выполнено, то все гипотезы, начиная со второй, принимаются, иначе первые две гипотезы отклоняются и начинается следующий шаг.
- На последнем шаге проверяется условие вида (displaystyle{p-value_n geq frac{alpha}{n-n+1}}), если оно выполнено, то последняя гипотеза принимается, если нет – отклоняется, на этом процедура заканчивается.
Метод Хольма называют нисходящей (step-down) процедурой. Он начинается с наименьшего p-значения в упорядоченном ряду и последовательно “спускается” вниз к более высоким значениям. На каждом шаге соответствующее значение (p-value_i) сравнивается со скорректированным уровнем значимости (displaystyle{alpha_{adjusted}=frac{alpha}{n+i-1}}). Аналогично коррекции Бонферрони можно вместо корректировки уровня значимости корректировать p-значения (displaystyle{p-value_{i,adjusted}=p-value_{i}cdot(n-i+1)}) (эта эквивалентная процедура реалирована в R). Возвращаясь к нашему примеру:
- (p-value_{1,adjusted} = 0.001 cdot (3-1+1) = 0.003 < alpha = 0.01) – гипотеза отклонена
- (p-value_{2,adjusted} = 0.01 cdot (3-2+1) = 0.02 > alpha = 0.01) – гипотеза принята
- (p-value_{3,adjusted} = 0.04 cdot (3-3+1) = 0.04 > alpha = 0.01) – гипотеза принята
А теперь проверим себя с помощью R:
p.adjust(c(0.001, 0.01, 0.04), method = "holm")И результаты проверки гипотез при (alpha =5%):
alpha <- 0.05
p.adjust(c(0.001, 0.01, 0.04), method = "holm") < alpha # отклоняем H_0 (есть эффект)? Средняя доля ложных отклонений (false discovery rate)
Рассмотренные выше FWER методы обеспечивают контроль над групповой вероятностью ошибки первого рода. Как мы выяснили, эти методы чересчур жестко работают, когда нужно одновременно проверить слишком много гипотез (падает статистическая мощность).Под “недостаточной мощностью” понимается сохранение многих нулевых гипотез, которые потенциально могут представлять исследовательский интерес и которые, соответственно, следовало бы отклонить. Недостаточная мощность традиционных процедур множественной проверки гипотез привела к разработке новых методов, например, метода Бенджамини-Хохберга.
Для преодоления недостаточной мощности FWER методов был предложен новый подход к проблеме множественных проверок статистических гипотез. Суть подхода заключается в том, что вместо контроля над групповой вероятностью ошибки первого рода выполняется контроль над ожидаемой долей ложных отклонений (false discovery rate, FDR) среди всех отклоненных гипотез.
В терминах таблицы выше эта ожидаемая доля может быть записана следующим образом: (displaystyle{FDR=left(frac{FP}{R}right)}) (считают, что если (R=0), то и (FDR=0)). Часто можно встретить запись через мат. ожидание (displaystyle{FDR=mathbb{E}left(frac{FP}{R}right)}). FDR – ожидаемая доля ложных отклоненийсреди всех отклоненных гипотез.
В отличие от уровня значимости (alpha), каких-либо общепринятых значений FDR не существует. Многие исследователи по аналогии контролируют FDR на уровне 5%. Интерпретация порогового значения FDR очень проста: например, если в ходе анализа данных отклонено 1000 гипотез, то при q=0.10 ожидаемая доля ложно отклоненных гипотез не превысит 100.
Восходящая процедура Бенджамини — Хохберга
В статье (Benjamini, Hochberg, 1995) описание процедуры контроля над FDR выглядит так:
- Сначала p-значения сортируются по возрастанию (displaystyle{p-value_1 leq p-value_2 leq … leq p-value_n}).
- Находят максимальное значение (k) среди всех индексов (i=1,…,n), для которого (p-value_i leq frac{i}{n}q) выполняется неравенство
- Отклоняют все гипотезы (H_i) с индексами (i=1,…,k)
Эквивалентная процедура, реалированая в R отличается тем, что вместо нахождения максимального индекса (k), исходные p-значения корректируются следующим образом: (q_i=frac{p_in}{i}).
В качестве примера рассмотрим следующий ряд из 15 упорядоченных по возрастанию p-значений (из оригинальной статьи Benjamini and Hochberg 1995):
p.adjust(c(0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000), method = "BH") [1] 0.00150000 0.00300000 0.00950000 0.03562500 0.06030000 0.06385714
[7] 0.06385714 0.06450000 0.07650000 0.48600000 0.58118182 0.71487500
[13] 0.75323077 0.81321429 1.00000000И результаты проверки гипотез при (alpha =5 %):
alpha <- 0.05
p.adjust(c(0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000), method = "BH") < alpha # отклоняем H_0 (есть эффект)? [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[13] FALSE FALSE FALSEИнтерпретация этих Р-значений с поправкой (в большинстве литературных источников их называют q-значениями) такова:
- Допустим, что мы хотим контролировать долю ложно отклоненных гипотез на уровне FDR = 0.05
- Все гипотезы, q-значения которых (q-value leq 0.05), отклоняются
- Среди всех этих отклоненных гипотез доля отклоненных по ошибке не превышает 5%
Коррекция Р-значений по методу Беньямини-Хохберга работает особенно хорошо в ситуациях, когда необходимо принять общее решение по какому-либо вопросу при наличии информации (=проверенных гипотез) по многим параметрам.
Следует помнить, что описанный здесь метод контроля над ожидаемой долей ложных отклонений предполагает, что все тесты, при помощи которых получают p-значения, независимы. На практике в большинстве случаев это условие выполняться не будет.
Восходящая процедура Бенджамини-Йекутили
Для преодоления ограничения независимости тестов при проверке гипотез в работе (Benjamini and Yekutieli 2001) был предложен усовершенствованный метод, учитывающий наличие корреляции между проверяемыми гипотезами.
Процедура Бенджамини-Йекутили очень похожа на процедуру Бенджамини-Хохберга. Основное отличие заключается во введении поправочной константы (displaystyle{c_n=sum limits_{i=1}^{n}frac{1}{i}}), далее аналогично:
- Сначала p-значения сортируются по возрастанию (displaystyle{p-value_1 leq p-value_2 leq … leq p-value_n}).
- Находят максимальное значение (k) среди всех индексов (i=1,…,n), для которого (p-value_i leq frac{i}{n} frac{q}{c_n}) выполняется неравенство
- Отклоняют все гипотезы (H_i) с индексами (i=1,…,k)
В R реализуется эквивалентная процедура:
Эквивалентная процедура, реалированая в R отличается тем, что вместо нахождения максимального индекса (k), исходные p-значения корректируются следующим образом: (displaystyle{q_i=frac{p_icdot ncdot c_n}{i}}).
p.adjust(c(0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000), method = "BY") [1] 0.004977343 0.009954687 0.031523175 0.118211908 0.200089208 0.211892623
[7] 0.211892623 0.214025770 0.253844518 1.000000000 1.000000000 1.000000000
[13] 1.000000000 1.000000000 1.000000000И результаты проверки гипотез при (alpha = 5%):
alpha <- 0.05
p.adjust(c(0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000), method = "BY") < alpha # отклоняем H_0 (есть эффект)? [1] TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[13] FALSE FALSE FALSEОбобщающий алгоритм для разных процедур

Источник – мне не очень нравится сам текст, но схема хорошая.
Симуляция и сравнение результатов работы разных коррекций p-value
Сравним как работают разные методы:
alpha <- 0.05
n <- 50
set.seed(123)
x <- rnorm(n, mean = c(rep(0, n/2), rep(3, n/2))) # генерим вектор t статистик
pval <- round(2*pnorm(sort(-abs(x))), 3) # переводим статистики в p-value
default_bool <- pval < alpha # вектор с исходными выводами о принятии гипотез без коррекции
bonferroni_pval <- p.adjust(pval, method = "bonferroni")
bonferroni_bool <- p.adjust(pval, method = "bonferroni") < alpha # отклоняем H_0 (есть эффект)?
holm_pval <- p.adjust(pval, method = "holm")
holm_bool <- p.adjust(pval, method = "holm") < alpha # отклоняем H_0 (есть эффект)?
bh_pval <- p.adjust(pval, method = "BH")
bh_bool <- p.adjust(pval, method = "BH") < alpha # отклоняем H_0 (есть эффект)?
by_pval <- p.adjust(pval, method = "BY")
by_bool <- p.adjust(pval, method = "BY") < alpha # отклоняем H_0 (есть эффект)?
methods <- cbind(default_bool, bonferroni_bool, holm_bool, bh_bool, by_bool) # склеиваем столбики с выводами о принятии гипотез для разных корректировок; если бы вдруг хотели склеить строчки, то есть аналогичная функция rbind()
colnames(methods) <- c('Без коррекции', 'Бонферрони', 'Хольм', 'Бенджамини-Хохберг', 'Бенджамини-Йекутили') # добавляем шапку таблицы
rownames(methods) <- c(1:n) # добавляем номера строчкам
methods Без коррекции Бонферрони Хольм Бенджамини-Хохберг Бенджамини-Йекутили
1 TRUE TRUE TRUE TRUE TRUE
2 TRUE TRUE TRUE TRUE TRUE
3 TRUE TRUE TRUE TRUE TRUE
4 TRUE TRUE TRUE TRUE TRUE
5 TRUE TRUE TRUE TRUE TRUE
6 TRUE TRUE TRUE TRUE TRUE
7 TRUE TRUE TRUE TRUE TRUE
8 TRUE TRUE TRUE TRUE TRUE
9 TRUE TRUE TRUE TRUE TRUE
10 TRUE TRUE TRUE TRUE TRUE
11 TRUE FALSE TRUE TRUE TRUE
12 TRUE FALSE FALSE TRUE TRUE
13 TRUE FALSE FALSE TRUE FALSE
14 TRUE FALSE FALSE TRUE FALSE
15 TRUE FALSE FALSE TRUE FALSE
16 TRUE FALSE FALSE TRUE FALSE
17 TRUE FALSE FALSE TRUE FALSE
18 TRUE FALSE FALSE TRUE FALSE
19 TRUE FALSE FALSE TRUE FALSE
20 TRUE FALSE FALSE TRUE FALSE
21 TRUE FALSE FALSE FALSE FALSE
22 TRUE FALSE FALSE FALSE FALSE
23 FALSE FALSE FALSE FALSE FALSE
24 FALSE FALSE FALSE FALSE FALSE
25 FALSE FALSE FALSE FALSE FALSE
26 FALSE FALSE FALSE FALSE FALSE
27 FALSE FALSE FALSE FALSE FALSE
28 FALSE FALSE FALSE FALSE FALSE
29 FALSE FALSE FALSE FALSE FALSE
30 FALSE FALSE FALSE FALSE FALSE
31 FALSE FALSE FALSE FALSE FALSE
32 FALSE FALSE FALSE FALSE FALSE
33 FALSE FALSE FALSE FALSE FALSE
34 FALSE FALSE FALSE FALSE FALSE
35 FALSE FALSE FALSE FALSE FALSE
36 FALSE FALSE FALSE FALSE FALSE
37 FALSE FALSE FALSE FALSE FALSE
38 FALSE FALSE FALSE FALSE FALSE
39 FALSE FALSE FALSE FALSE FALSE
40 FALSE FALSE FALSE FALSE FALSE
41 FALSE FALSE FALSE FALSE FALSE
42 FALSE FALSE FALSE FALSE FALSE
43 FALSE FALSE FALSE FALSE FALSE
44 FALSE FALSE FALSE FALSE FALSE
45 FALSE FALSE FALSE FALSE FALSE
46 FALSE FALSE FALSE FALSE FALSE
47 FALSE FALSE FALSE FALSE FALSE
48 FALSE FALSE FALSE FALSE FALSE
49 FALSE FALSE FALSE FALSE FALSE
50 FALSE FALSE FALSE FALSE FALSEplot(pval, bonferroni_pval, col = "orange", type="p", pch=1)
lines(pval, holm_pval, col="green", type="p", pch=1)
lines(pval, bh_pval, col="blue", type="p", pch=1)
lines(pval, by_pval, col="violet", type="p", pch=1)
abline(h=alpha, col="red")
abline(v=alpha, col="red")
legend(x=0.6, y=0.5, # координаты верхнего левого угла легенды
legend=c('Бонферрони', 'Хольм', 'Бенджамини-Хохберг', 'Бенджамини-Йекутили', 'Уровень значимости'), # категории легенды
col=c("orange", "green", "blue", "violet", "red"), # цвета категорий
bty = "n", # чтобы не было рамочки вокруг легенды
pch=1) # форма маркера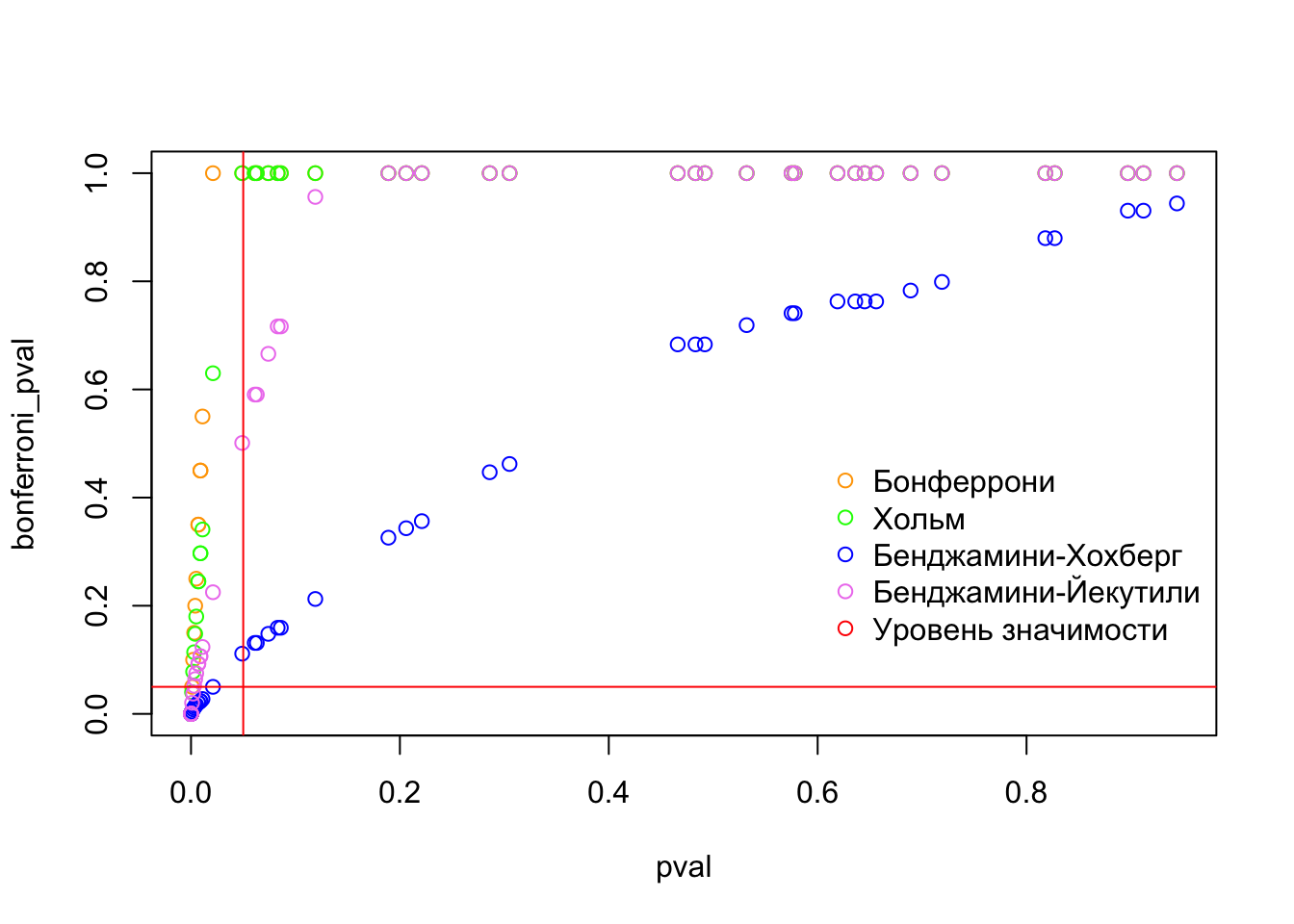
8 июля 2021 г.
При проверке гипотез нулевая гипотеза — это гипотеза по умолчанию, которая утверждает, что между переменными нет статистической значимости. Исследователь проверяет нулевую гипотезу, чтобы увидеть, достаточно ли статистической значимости, чтобы опровергнуть ее, и это иногда приводит к ошибке типа 1 или типа 2. Если вы занимаетесь проверкой гипотез как частью своей работы, важно понимать, как ошибки типа 1 и типа 2 могут повлиять на ваши результаты.
В этой статье мы объясним, что такое ошибки типа 1 и типа 2, рассмотрим, как они могут возникнуть, обсудим их важность в исследованиях и приведем примеры, которые помогут вам понять эти концепции.
Ошибки типа 1 и типа 2 относятся к неправильным определениям нулевой гипотезы, но они различаются тем, что исследователь считает верным или ложным в отношении гипотезы. Ошибка 1-го типа, также называемая ложноположительной, возникает, когда исследователь отвергает нулевую гипотезу, которая является истинной, и решает, что существует статистически значимое различие, которого не существует. Ошибка типа 2 является обратной ошибкой типа 1. Также известная как ложный отрицательный результат, она возникает, когда исследователь не отвергает нулевую гипотезу, когда альтернативная гипотеза верна.
Например, в судебном деле нулевая гипотеза будет заключаться в том, что обвиняемый невиновен, пока его вина не будет доказана, а альтернативная гипотеза будет состоять в том, что он виновен. Есть четыре возможных исхода в отношении истинного характера дела:
-
Истинно отрицательный: признан невиновным в суде и невиновен на самом деле.
-
Ложное срабатывание: признан виновным в суде, но на самом деле невиновен.
-
Ложноотрицательный: признан невиновным в суде, но на самом деле виновен.
-
Истинно положительный: признан виновным в суде и фактически виновен
В приведенном выше примере второй и третий результаты являются ошибками типа 1 и типа 2 соответственно. В случае ложного срабатывания присяжные ошибочно отвергают нулевую гипотезу, утверждающую, что подсудимый невиновен. В случае ложноотрицательного результата они ошибочно не отвергают нулевую гипотезу.
Почему возникают ошибки первого рода?
Есть два фактора, которые обычно способствуют возникновению ошибок 1-го рода:
Шанс
Проверка гипотез никогда не бывает стопроцентной, поэтому всегда есть возможность сделать неверные выводы на основе имеющихся данных. Как правило, данные поступают из выборочной совокупности, относительно небольшой выборки лиц, предназначенных для обозначения более широкой демографической группы. Иногда данные, генерируемые выборочными совокупностями, искажают выводы, которые не обязательно отражают интересы всего населения. Это переменная, которую исследователи не могут контролировать, но они могут помочь смягчить ее, выбрав более крупные выборки.
Злоупотребление служебным положением
Иногда ошибки 1-го рода возникают из-за неправильной исследовательской практики. Например, исследователи могут неосознанно исказить результаты теста, завершив его слишком рано. Им может показаться, что у них достаточно данных, хотя стандартная практика рекомендует продолжить тест. В качестве альтернативы они могут сделать вывод, несмотря на то, что им не удалось достичь соответствующего уровня статистической значимости. Исследователи могут избежать выводов типа 1, связанных с злоупотреблением служебным положением, если будут следовать протоколам исследований и обеспечивать надежность своей практики.
Почему возникают ошибки второго рода?
Основным фактором, способствующим возникновению ошибок 2-го рода, является размер выборки. Чем больше размер выборки, тем больше вероятность обнаружения различий в статистическом тесте. Например, если вы хотите проверить, относятся ли студенты колледжа положительно или отрицательно к определенному продукту, группа из трех человек может выразить только два к одному разнообразию или вообще ничего не сказать. Для сравнения, выборка из 1000 человек с большей вероятностью вызовет широкий спектр мнений и, таким образом, более точно отразит большую часть населения.
Какова важность ошибок типа 1 по сравнению с ошибками типа 2?
Ошибки типа 1 и типа 2 являются значительными из-за последствий, которые они имеют в реальных приложениях. Ошибки типа 1 обычно приводят к ненужному использованию ресурсов без какой-либо выгоды. Например, если исследователь-медик совершает ошибку 1-го рода в отношении эффективности нового лечения, он может подтвердить ошибочность исследований и методов, что может привести к созданию лекарства, не приносящего облегчения.
Ошибки 2-го типа важны тем, что могут помешать выделению ресурсов и выполнению необходимых действий. Например, при скрининге пациента на наличие заболевания ложноотрицательный результат может свидетельствовать о том, что пациент здоров, хотя на самом деле он нуждается в медицинском вмешательстве.
Примеры ошибок типа 1 и типа 2
Рассмотрим эти примеры ошибок типа 1 и типа 2, чтобы помочь вам понять, что они из себя представляют:
Пример ошибки 1 рода
Медицинский исследователь проверяет эффективность домашнего средства от головной боли. Нулевая гипотеза состоит в том, что домашнее средство не влияет на головную боль, в то время как альтернативная гипотеза состоит в том, что оно лечит головную боль. Исследователь набирает выборку из 20 пациентов с хроническими головными болями и назначает лекарство половине из них в течение одного месяца. Половина, не получающая лекарство, продолжает страдать от хронических головных болей, в то время как у шести человек из оставшейся половины головные боли прекратились.
На основании вышеизложенного исследователь отвергает нулевую гипотезу. Однако, учитывая небольшое количество тех, кто испытал облегчение, могут возникнуть сомнения относительно того, было ли это лекарство или посторонний фактор, который улучшил состояние шести участников. Если эти шесть участников использовали другие средства от головной боли вместе с тестируемым средством, вполне вероятно, что исследователь совершил ошибку 1-го типа.
Пример ошибки 2 рода
Интернет-магазин хочет знать, могут ли изменения дизайна его веб-сайта помочь увеличить продажи. Нулевая гипотеза состоит в том, что изменения дизайна не влияют на продажи, а альтернативная гипотеза говорит об обратном. Продавец проводит A/B-тестирование, в ходе которого сравниваются две версии сайта, существующая версия и обновленная версия. Три дня мониторят продажи на основе существующей версии. Затем в течение следующих трех дней они представляют новую версию и смотрят, как она повлияет на продажи. По истечении шести дней они не видят значительных изменений в показателях продаж.
Однако возможно, что увеличение периодов наблюдения для каждой версии сайта привело бы к статистически значимой разнице. Если бы розничный продавец отслеживал продажи в течение одного месяца каждый и заметил увеличение продаж во втором месяце, он совершил бы ошибку второго рода, ошибочно приняв нулевую гипотезу.
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Содержание
- 1 Определения
- 2 О смысле ошибок первого и второго рода
- 3 Вероятности ошибок (уровень значимости и мощность)
- 4 Примеры использования
- 4.1 Радиолокация
- 4.2 Компьютеры
- 4.2.1 Компьютерная безопасность
- 4.2.2 Фильтрация спама
- 4.2.3 Вредоносное программное обеспечение
- 4.2.4 Поиск в компьютерных базах данных
- 4.2.5 Оптическое распознавание текстов (OCR)
- 4.2.6 Досмотр пассажиров и багажа
- 4.2.7 Биометрия
- 4.3 Массовая медицинская диагностика (скрининг)
- 4.4 Медицинское тестирование
- 4.5 Исследования сверхъестественных явлений
- 5 См. также
- 6 Примечания
Определения[править | править исходный текст]
Пусть дана выборка  из неизвестного совместного распределения
из неизвестного совместного распределения  , и поставлена бинарная задача проверки статистических гипотез:
, и поставлена бинарная задача проверки статистических гипотез:

где  — нулевая гипотеза, а
— нулевая гипотеза, а  — альтернативная гипотеза. Предположим, что задан статистический критерий
— альтернативная гипотеза. Предположим, что задан статистический критерий
 ,
,
 ,
,сопоставляющий каждой реализации выборки  одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
 соответствует гипотезе
соответствует гипотезе  .
. .
.Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно. [1][2]
| Верная гипотеза | |||
|---|---|---|---|
| |
|
||
| Результат применения критерия |
|
верно принята |
неверно принята (Ошибка второго рода) |
| |
неверно отвергнута (Ошибка первого рода) |
верно отвергнута |
О смысле ошибок первого и второго рода[править | править исходный текст]
Как видно из вышеприведённого определения, ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы и , то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследуемый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня. Слово «положительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают положительный результат (т.е. показывают наличие заболевания у пациента), когда на самом деле пациент этим заболеванием не страдает. Такой результат называется ложноположительным.
В других областях обычно используют словосочетания со схожим смыслом, например, «ложное срабатывание», «ложная тревога» и т.п. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Слово «отрицательный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают отрицательный результат (т.е. показывают отсутствие заболевания у пациента), когда на самом деле пациент страдает этим заболеванием. Такой результат называется ложноотрицательным.
В других областях обычно используют словосочетания со схожим смыслом, например, «пропуск события», и т.п. В информационных технологиях часто используют английский термин false negative без перевода.
Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок.
Вероятности ошибок (уровень значимости и мощность)[править | править исходный текст]
Вероятность ошибки первого рода при проверке статистических гипотез называют уровнем значимости и обычно обозначают греческой буквой  (отсюда название -errors).
(отсюда название -errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой  (отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле
(отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле  . Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
. Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объема, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования[править | править исходный текст]
Радиолокация[править | править исходный текст]
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «пропуск цели» и «ложная тревога» являются одним из основных элементов как теории, так и практики построения радиолокационных станций. Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютеры[править | править исходный текст]
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность[править | править исходный текст]
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
- когда авторизованные пользователи классифицируются как нарушители (ошибки первого рода)
- когда нарушители классифицируются как авторизованные пользователи (ошибки второго рода)
Фильтрация спама[править | править исходный текст]
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «антиспам»-алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда антиспам-система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности антиспам-алгоритма.
Пока не удалось создать антиспамовую систему без корреляции между вероятностью ошибок первого и второго рода. Вероятность пропустить спам у современных систем колеблется в пределах от 1% до 30%. Вероятность ошибочно отвергнуть валидное сообщение — от 0,001 % до 3 %. Выбор системы и её настроек зависит от условий конкретного получателя: для одних получателей риск потерять 1% хорошей почты оценивается как незначительный, для других же потеря даже 0,1% является недопустимой.
Вредоносное программное обеспечение[править | править исходный текст]
Понятие ошибки первого рода также используется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с антитроянскими и антишпионскими программами.
Поиск в компьютерных базах данных[править | править исходный текст]
При поиске в базе данных к ошибкам второго рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)[править | править исходный текст]
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек, которые используемый алгоритм расценил как «a».
Досмотр пассажиров и багажа[править | править исходный текст]
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т.п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия[править | править исходный текст]
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т.д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т.п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.[3]
Массовая медицинская диагностика (скрининг)[править | править исходный текст]
В медицинской практике есть существенное различие между скринингом и тестированием:
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые, в основном, применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.[4]
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15%, это самый высокий показатель в мире.[5] Самый низкий уровень наблюдается в Нидерландах, 1%.[6]
Медицинское тестирование[править | править исходный текст]
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70%, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.[7]
Исследования сверхъестественных явлений[править | править исходный текст]
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т.д.), которое имеет обычное объяснение.[8]
См. также[править | править исходный текст]
- Статистическая значимость
- Атака второго рода
- Случаи ложного срабатывания систем предупреждения о ракетном нападении
- Receiver_operating_characteristic
Примечания[править | править исходный текст]
- ↑ ГОСТ Р 50779.10-2000. «Статистические методы. Вероятность и основы статистики. Термины и определения.». Стр. 26
- ↑ Valerie J. Easton, John H. McColl. Statistics Glossary: Hypothesis Testing.
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. [1])
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90-95% женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (высокий порог снижает статистическую эффективность теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи Теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS) (недоступная ссылка с 13-05-2013 (398 дней)) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research) (недоступная ссылка с 13-05-2013 (398 дней) — история).