
В современном мире все уже давно поняли какой ценностью обладает информация и какой огромный потенциал заложен в развитии IT технологий. Поскольку сервера и компьютеры могут выходить из строя – автоматически возник вопрос как обеспечить безопасность данных, так как их потеря важной информации может обанкротить целые компании, а убытки могут достигать многих миллионов. В свою очередь это привело в появлению RAID массивов – технологии, которая призвана предотвратить потерю информации путем объединения нескольких накопителей в один массив. Однако, как показала практика – RAID массивы также могут ломаться.
В этой статье мы рассмотрим главные причины выхода из строя RAID массивов.

Содержание
- История развития RAID
- Что такое деградированный режим RAID?
- Причины потери данных на RAID массивах
- Выход из строя RAID контроллера
- Ошибка пересборки/сборки RAID массива
- Выход накопителя из строя
- Отсутствие разделов массива
- Поломка сервера
- Что делать при сбое RAID массива или если RAID массив не собирается после перезагрузки?
История развития RAID
В самом начале развития компьютерных технологий все внимание было направлено на том, как сделать компьютеры максимально удобными для пользователя. В те времена не существовало понятия «персональный компьютер», так как наиболее часто компьютеры использовались в военной промышленности (но там совсем другая история, так как военная индустрия обладает своими наработками по безопасности информации и т.д.) и в больших корпорациях. Но в те времена функционал компьютеров был очень небольшим и с ними по большей части работали программисты.
Даже в 1970х годах, когда Apple и Microsoft начали свою деятельность – вопрос о безопасности данных не был на первом месте. Все изменилось с появлением и развитием интернета, который начал охватывать все больше и больше стран и позволял пользователям обмениваться информацией. Стоит также отметить, что к тому времени все уже привыкли к персональным компьютерам и поняли, что они способны сильно облегчить жизнь обрабатывая огромные массивы информации. С появлением цифровых фотоаппаратов и видеокамер для личного использования всем стало ясно, что персональные компьютеры так или иначе будут практически в каждом доме. После этого начался бум цифровой индустрии, который автоматически поднял вопрос о безопасности данных. Немало этому посодействовали большие компании, которые уже в те времена обладали большими серверами для хранения данных, от которых сильно зависел уровень их эффективности. Поэтому, в 1987 году были придуманы RAID массивы. Их главным заданием было избежание потерь важной информации и поскольку технология была эффективной и предлагала на выбор несколько вариантов защиты данных, в зависимости от потребностей пользователя – она быстро приобрела распространение. Примерно так выглядит блок дисков, объединенных в RAID:

Несмотря на то, что никакой стандартизации не проводилось – следующие уровни массива RAID были приняты как стандарт:
- RAID 1 – зеркальный массив, при использовании которого каждый диск является полной копией другого;
- RAID 2 – массив дисков, в котором используется код Хемминга;
- RAID 3,4 — дисковые массивы с чередованием и выделенным диском чётности;
- RAID 5 — дисковый массив с чередованием и отсутствием выделенного диска чётности;
- RAID 0 – дисковый массив, главным заданием которого является увеличение скорости записи/чтения данных и полностью отсутствует избыточность;
Все остальные типы RAID массивов (такие как RAID 10, RAID 50 и т.д.) построены на вышеперечисленных типах RAID и так или иначе используют их концепцию.
Использование массивов RAID оказалось настолько эффективным, что на сегодняшний день практически все современные хранилища данных (сервера, NAS и т.д.) используют RAID массивы в том или ином виде.
Однако, несмотря всю надёжность такого решения стоит отметить, что вероятность потери данных все же осталась (хоть и сильно снизилась) так как даже RAID массивы иногда выходят из строя. Это может происходить по многим причинам и для того, чтобы узнать больше информации на эту тему читайте следующий пункт этой статьи.
Что такое деградированный режим RAID?
RAID массив как и обычные диски может подвергаться сбоям рода и в случае, если один из дисков выйдет из строя – весь массив перейдет в так называемый «Деградированный режим» В этом режиме данные остаются доступными и массив продолжает свою работу но с сильным снижением производительности. За переход массива в «деградированный режим» отвечает контроллер, который переводит массив в этот режим в случае обнаружение сбоев в работе любого из дисков массива или полного отсутствия одного из дисков. В случае перехода массива в деградированный режим пользователь увидит сообщение «DegradedArray event was detected on device md dev/md/1» либо «ARRAY IS DEGRADED – 1 disk is missing»

Также о переходе массива в деградированный режим может свидетельствовать символ «[U_]» при проверке состояния RAID массива в терминале. Обычно он находится возле поврежденного диска и означает, что он рассинхронизирован.

В этом случае следует немедленно заменить поврежденный диск так как в случае выхода из строя еще одного диска все данные массива будут потеряны.
Причины потери данных на RAID массивах
При использовании RAID массивов данные хранятся на таких же накопителях, что и в обычных компьютерах, которые могут ломаться и т.д. Технология RAID позволяет предотвратить потерю данных, но процесс восстановления информации может сильно затянуться, так как нередко при выходе из строя одного накопителя скорость работы всего RAID массива сильно снижается, особенно это актуально, когда речь заходит о терабайтах информации, как например на сервере. Кроме того, в некоторых случаях, чтобы заменить поврежденный носитель на новый – требуется отключение питания, что тоже не очень подходит для серверов. Поэтому лучше всего знать главные причины выхода из строя RAID массивов, чтобы иметь возможность предотвратить неприятности.
Итак, среди основных причин можно выделить следующие:
Выход из строя RAID контроллера
Контроллер RAID массива является одним из наиболее важных элементов, так как именно он отвечает за распределение данных между накопителями и позволяет работать с массивом как с единым накопителем. Если массив прекращает свою работу – наиболее часто это вызвано именно поломкой контроллера. Стоит отметить, что аппаратные контроллеры ломаются немного реже чем программные, но и стоят они на порядок дороже. Кроме того, между аппаратными контроллерами разных производителей нет совместимости. То есть, если вы приобрели контроллер от фирмы Supermicro то для восстановления работоспособности массива вам придется купить такую же модель. В противном случае вам придется создавать массив заново, что приведет к потере данных. Среди причин, из-за которых контроллер выходит и строя можно выделить такие как перепад напряжения или резкое отключение энергии. Это актуально как для аппаратных RAID контроллеров, так и для программных. Поэтому, обязательно позаботьтесь о бесперебойном источнике питания, чтобы обеспечить ваш RAID массив от возможных проблем.
Ошибка пересборки/сборки RAID массива
Во время каждой перезагрузки компьютера RAID массив пересобирается заново и от того, пройдет ли сборка нормально зависит дальнейшая работа массива. Если во время перестройки массива произойдёт перепад напряжения или другое форс-мажорное событие – массив не будет пересобран, и пользователь моет потерять данные.
Выход накопителя из строя
Все мы знаем, что главным предназначением RAID массивов является защита данных на случай выхода из строя одного или двух дисков. Обычно RAID массив без проблем справляется с этой задачей. Но иногда случаются ситуации, когда при выходе одного или нескольких дисков повреждаются данные на соседнем носителе и в такой ситуации RAID массив может оказаться полностью неработоспособным, что в свою очередь приведет к потере информации. Поэтому настоятельно рекомендуется периодически проверять состояние накопителей, из которых построен RAID массив.
Отсутствие разделов массива
Для обеспечения нормальной работы RAID массивов применяется технология чередования, главной задачей которой является распределение информации меду дисками в рамках одного логического тома. Это позволяет обеспечить высокий уровень производительности и защиты данных, однако, если механизм чередования будет повреждён – данные окажутся недоступными, даже если физически они в полной сохранности. Все дело в том, что RAID массив просто не смоет определить диски с данными и соответственно не сможет собрать массив для дальнейшей работы.
Поломка сервера
Хост компьютер, как и любой другой может поломаться или дать сбой. Это в свою очередь отобразится на RAID массиве. В 70% таких случаев данные оказываются недоступными.
Все вышеперечисленные поломки являются наиболее часто встречающимися причинами выхода из строя RAID массивов. Обычно, после таких поломок приходится использовать стороннее ПО для восстановления данных. О том, как восстановить данные на RAID массиве читайте в следующем пункте этой статьи.
Что делать при сбое RAID массива или если RAID массив не собирается после перезагрузки?
Если ваш RAID массив перестал работать после сбоя, либо не собирается после перезагрузки то для восстановления рабочего состояния без потери данных вам следует сначала извлечь данные массива, чтобы не повредить их во время восстановления работоспособности RAID. Для этого следует:
Шаг 1: Выключите питание вашего компьютера/сервера или NAS устройства и отсоедините накопители, из которых состоял RAID массив.
Шаг 2: Подсоедините эти диски в рабочему компьютеру (предварительно отключив его питание).
Шаг 3: Включите рабочий компьютер. Затем скачайте и установите програму RS RAID Retrieve следуя подсказкам мастера установки Windows.
Мы специально выбрали эту программу, так как она обладает широкими возможностями восстановления данных и интуитивно-понятным интерфейсом одновременно, а значит она отлично подходит как для неопытных пользователей, так и для профессионалов.
Шаг 4: Запустите программу RS RAID Retrieve дважды кликнув по иконке на рабочем столе. Перед вами откроется встроенный RAID конструктор.

Шаг 5: Выберите тип добавления RAID массива для сканирования. RS RAID Retrieve предлагает на выбор три варианта:
- Автоматический режим – позволяет просто указать диски, из которых состоял массив, и программа автоматически определит их порядок, тип массива и остальные параметры;
- Поиск по производителю – эту опцию следует выбрать, если вам известен производитель вашего RAID контроллера. Эта опция также автоматическая и не требует каких-либо знаний о структуре RAID массива. Наличие данных о производителе позволяют сократить время на построение массива, соответственно она быстрее предыдущей;
- Создание вручную – эту опцию стоит использовать если вы знаете какой тип RAID массива вы используете. В этом случае вы можете указать все параметры, которые вам известны, а те, которых вы не знаете – программа определит автоматически.
После того, как выберите подходящий вариант – нажмите «Далее»

Шаг 6: Выберите диски, из которых состоял RAID массив и нажмите «Далее». После этого начнется процесс обнаружения конфигураций массива. После его завершения нажмите «Готово»

Шаг 7: В окне программы выберите ваш массив, щелкните по нему правой кнопкой мыши и выберите «Сохранить диск», а затем укажите место для сохранения копии диска и снова нажмите «Сохранить»


После этого начнется копирование файлов в указанное место. Вы также можете сохранить отдельные файлы или восстановить потерянные данные, если нужно. Для этого дважды щелкните на массиве и выберите тип сканирования. RS RAID Retrieve предлагает на выбор два типа сканирования: быстрое сканирование и полное сканирование. Первый вариант стоит выбрать если вы просто хотите скопировать файлы на другой носитель, а второй вариант выберите если хотите восстановить утерянные данные.
Также на этом этапе выберите тип файловой системы вашего массива. RS RAID Retrieve поддерживает ВСЕ современные файловые системы. Теперь, когда все настроено, нажмите «Далее».

Начнётся процесс сканирования массива, по завершении которого вы увидите прежнюю структуру файлов и папок.
Шаг 8: Выберите файл, который хотите восстановить и жажды на нем щелкните. Затем выберите место, куда хотите восстановить утерянный файл. Это может быть жесткий диск, ZIP-архив, или FTP-сервер. Главное, чтобы место записи нового файлов отличалось от дисков массива. Затем нажмите «Восстановить»

Теперь, когда данные находятся в безопасности – можно приступать к восстановлению работоспособности самого массива. В первую очередь нужно найти причину проблемы и устранить ее.
RAID массив мажет не пересобираться после перезагрузки по следующим причинам:
- Ошибка в файле mdadm.conf (он находится не в том месте, или файл не существует);
- Ошибка сборки;
- Вирус или вредоносное ПО;
- Поврежденные сектора на RAID-дисках;
- Человеческая ошибка;
- Другие причины;
Первые две причины являются достаточно распространенными, поэтому на них стоит обратить особое внимание.
Если же причина или сбой были на физическом уровне – замените вышедшие из строя нужные элементы.
Если вы не хотите тратить время на исправление программных ошибок – вы можете просто создать RAID массив заново, а затем скопировать данные обратно из сохраненной копии.
Часто задаваемые вопросы
Деградированный режим значит, что один или несколько дисков массива вышли из строя, но массив еще работает. В такой ситуации настоятельно рекомендуется найти причину и заменить вышедшие из строя части.
ДА. Благодаря продвинутым алгоритмам RS RAID Retrieve без проблем перестроит ваш массив и восстановит информацию. Процесс восстановления детально расписан на нашем сайте.
Первым делом вам следует проверить состояние дисков массива, так как именно из-за выхода накопителей из строя наблюдается сильное снижение производительности.
Эта ошибка означает, что один диск не работает. Поэтому, при возникновении такой ошибки проверьте состояние массива и замените нерабочие детали, в противном случае вы можете потерять информацию
Среди главных причин выхода из строя массива RAID можно выделить такие как выход из строя RAID контроллера, выход из строя одного или нескольких дисков, поломки сервера/компьютера/NAS, отсутствие разделов массива и т.д. Более детально читайте на нашем сайте.
Привет, друзья. В прошлой статье мы с вами создали RAID 1 массив (Зеркало) — отказоустойчивый массив из двух жёстких дисков SSD. Смысл создания RAID 1 массива заключается в повышении надёжности хранения данных на компьютере. Когда два жёстких диска объединены в одно хранилище, информация на обоих дисках записывается параллельно (зеркалируется). Диски являются точными копиями друг друга, и если один из них выйдет из строя, мы получим доступ к операционной системе и нашим данным, ибо их целостность будет обеспечена работой другого диска. Также конфигурация RAID 1 повышает производительность при чтении данных, так как считывание происходит с двух дисков. В этой же статье мы рассмотрим, как восстановить массив RAID 1, если он развалится. Другими словами, мы рассмотрим, как сделать Rebuild RAID 1.

 Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
 В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
Если созданный с помощью БИОСа материнской платы RAID 1 массив развалился, неопытный пользователь может этого сразу и не понять. Мы не получим ни звукового оповещения, ни оповещения в иной форме, сигнализирующих о проблеме развала RAID 1. Возможностями аварийной сигнализации при развале массивов обладают только отдельные SAS/SATA/RAID-контроллеры, работающие через интерфейс PCI Express. За аварийную сигнализацию при проблемах с массивами отвечает специальное ПО таких контроллеров. Не имея таких контроллеров, можем использовать программы типа CrystalDiskInfo или Hard Disk Sentinel Pro, которые предупредят нас о выходе из строя одного из накопителей массива звуковым сигналом, либо электронным письмом на почту.
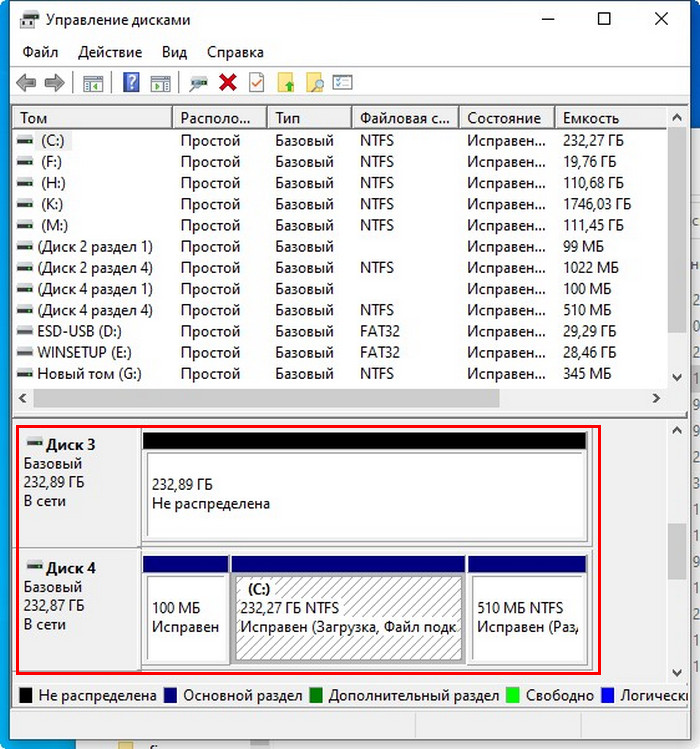
 Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
 Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
Для примера возьмём мою материнскую плату на чипсете Z490 от Intel, для которого существует специальное программное обеспечение Intel Rapid Storage Technology (Intel RST). Технология Intel Rapid Storage поддерживает SSD SATA и SSD PCIe M.2 NVMe, повышает производительность компьютеров с SSD-накопителями за счёт собственных разработок. Всесторонне обслуживает массивы RAID в конфигурациях 0, 1, 5, 10. Предоставляет пользовательский интерфейс Intel Optane Memory and Storage Management для управления системой хранения данных, в том числе дисковых массивов.

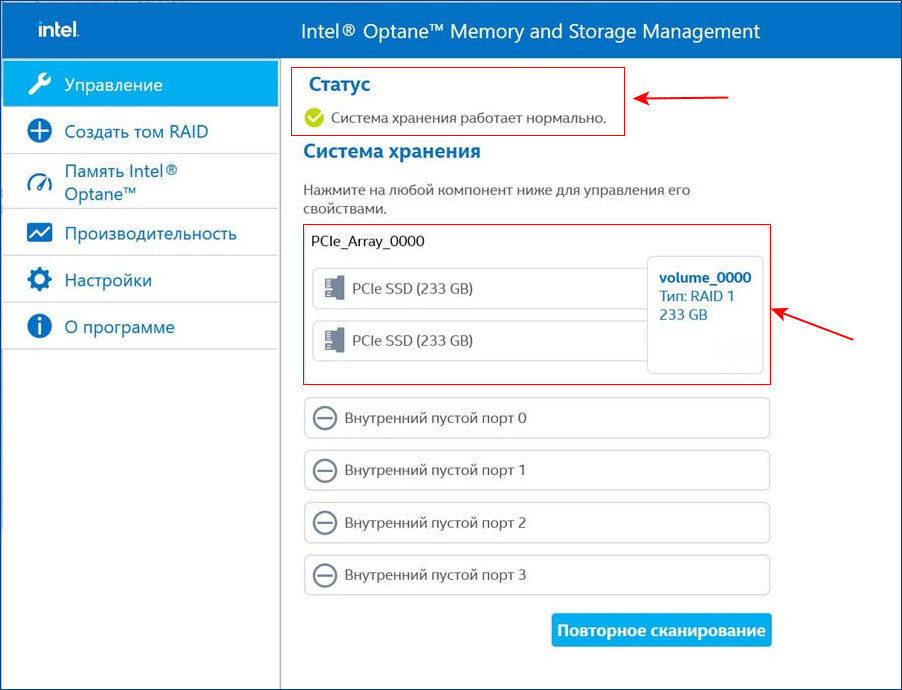
После установки Intel RST в главном окне увидим созданный нами из двух SSD M.2 NVMe Samsung 970 EVO Plus (250 Гб) RAID 1 массив, исправно функционирующий.
 Вот этот массив в управлении дисками Windows.
Вот этот массив в управлении дисками Windows.
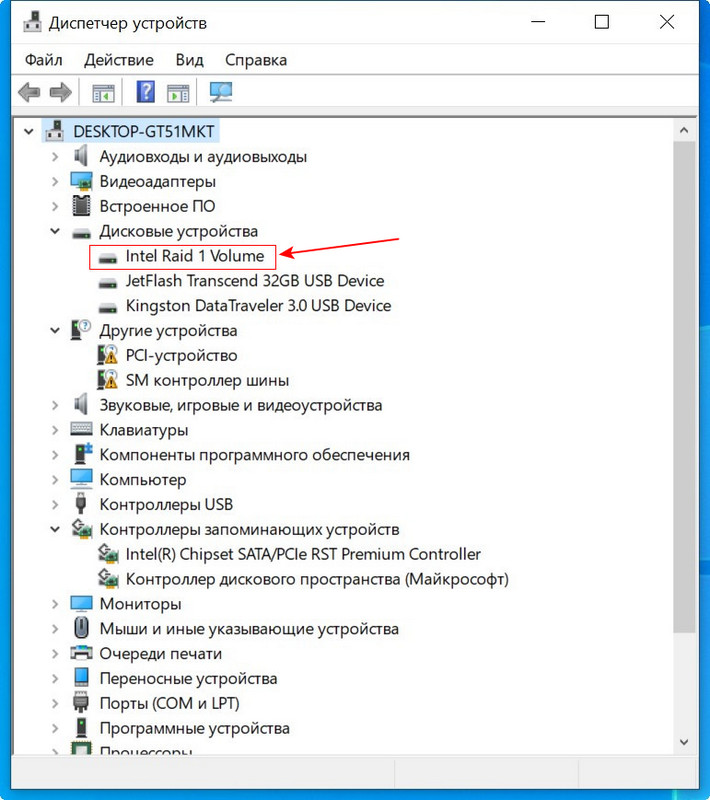
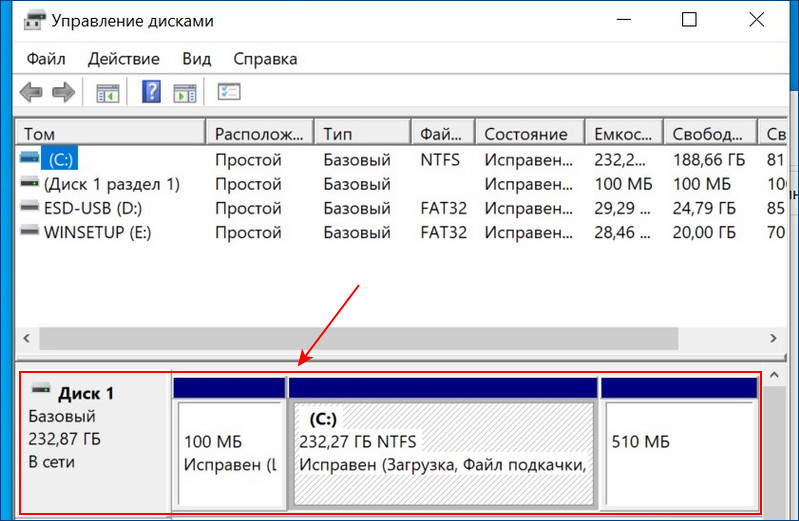 И в диспетчере устройств.
И в диспетчере устройств.
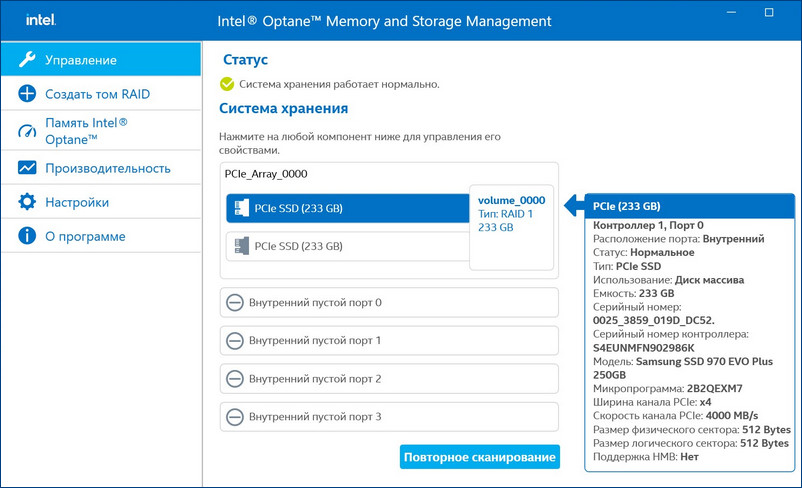
 Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
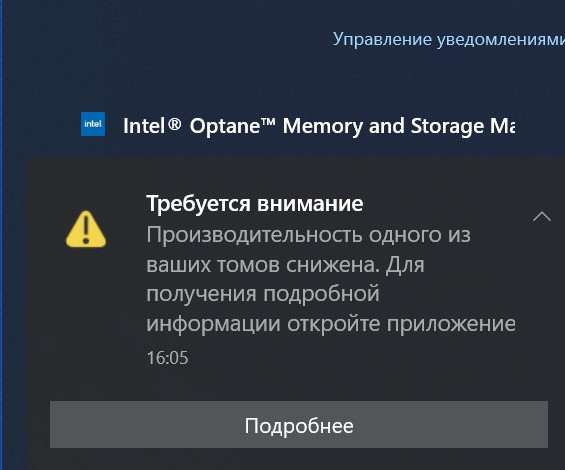
 Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
 И в главном окне программы будет значиться, что один из дисков массива неисправен.
И в главном окне программы будет значиться, что один из дисков массива неисправен.
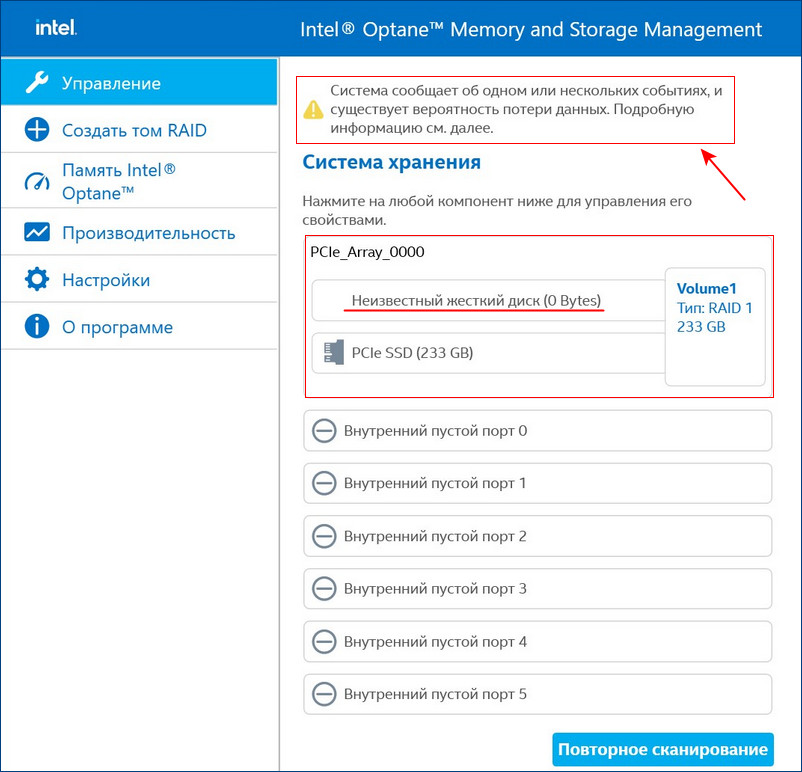 В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
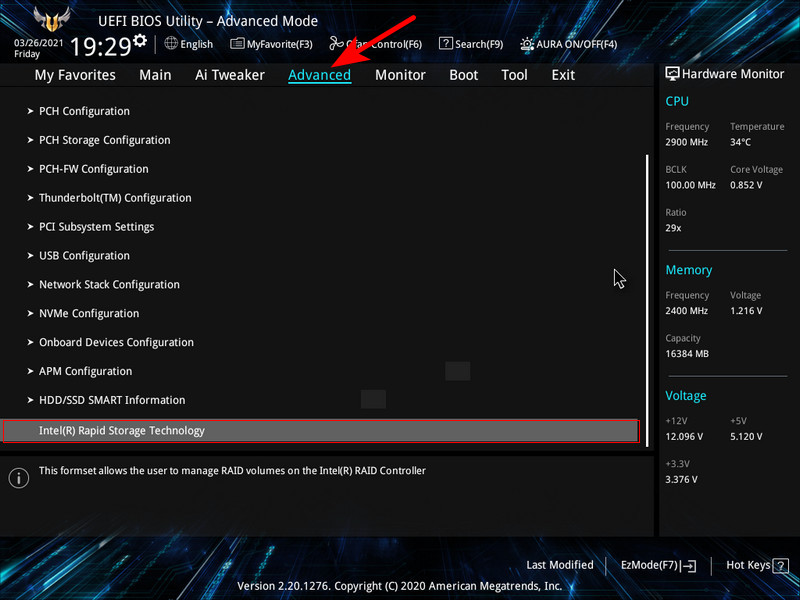
После замены неисправного диска включаем ПК и входим в БИОС. Заходим в расширенные настройки «Advanced Mode», идём во вкладку «Advanced». Переходим в пункт «Intel Rapid Storage Technology».
Видим, что наш RAID 1 массив с названием Volume 1 неработоспособен — «Volume 1 RAID 1 (mirroring), Degraded».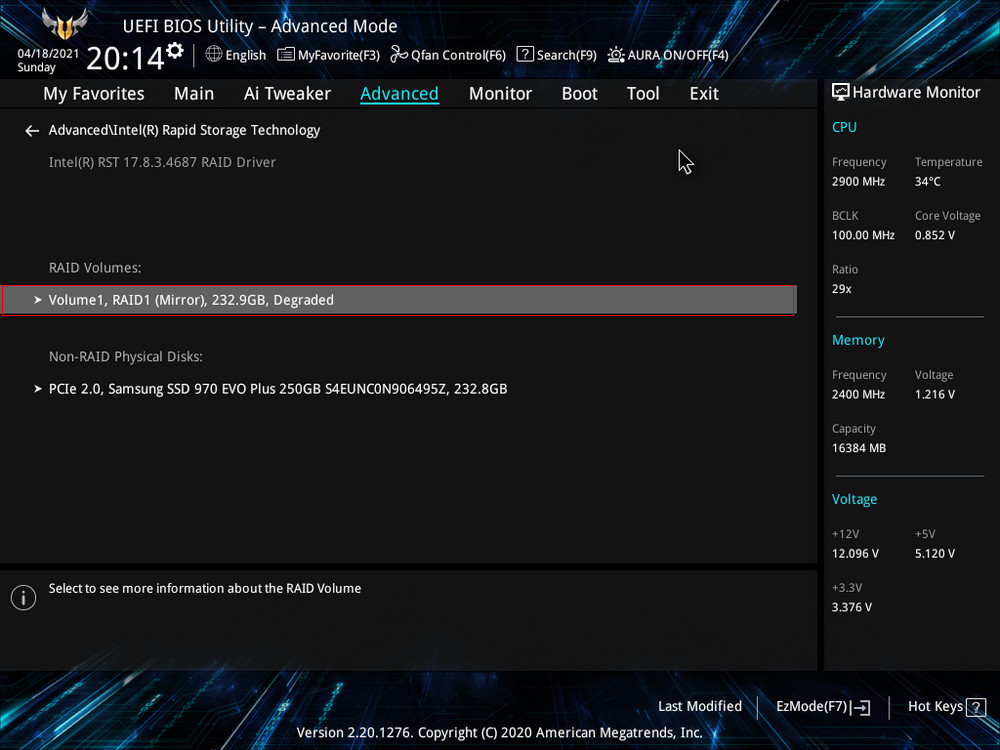 Выбираем «Rebuild» (Восстановить).
Выбираем «Rebuild» (Восстановить).
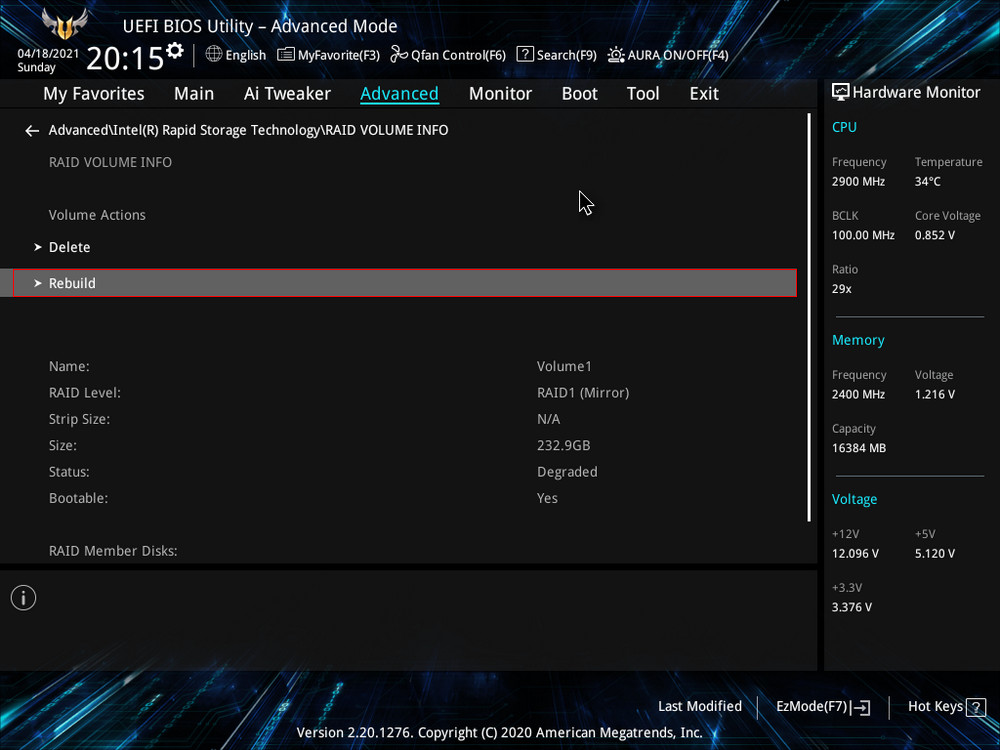 Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».
Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».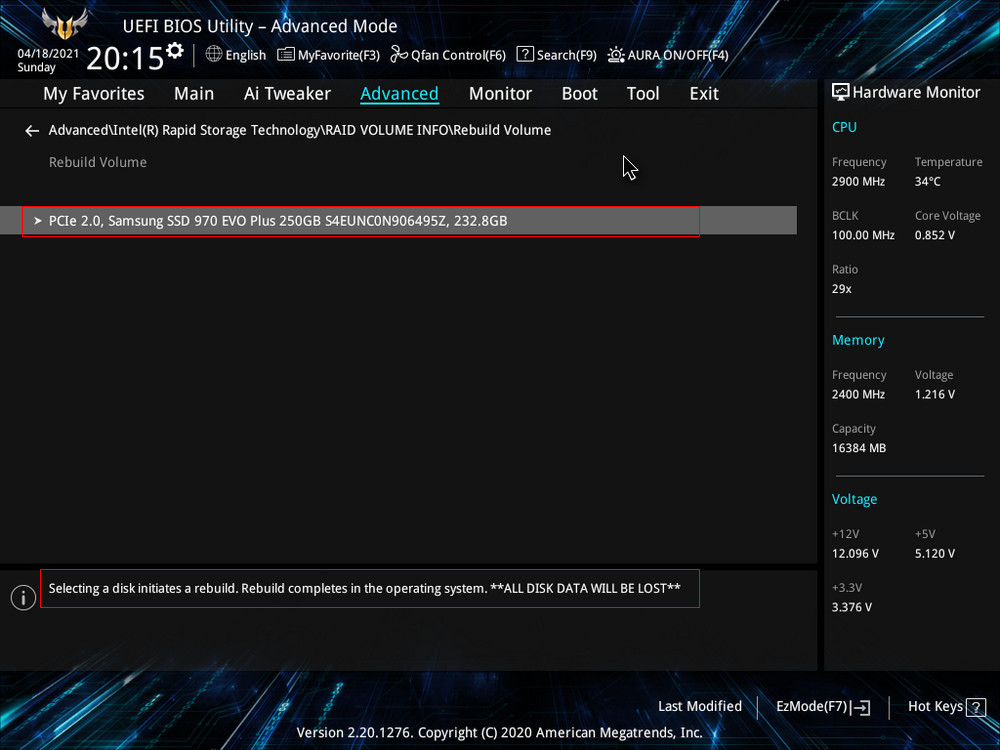 RAID 1 массив восстановлен.
RAID 1 массив восстановлен.
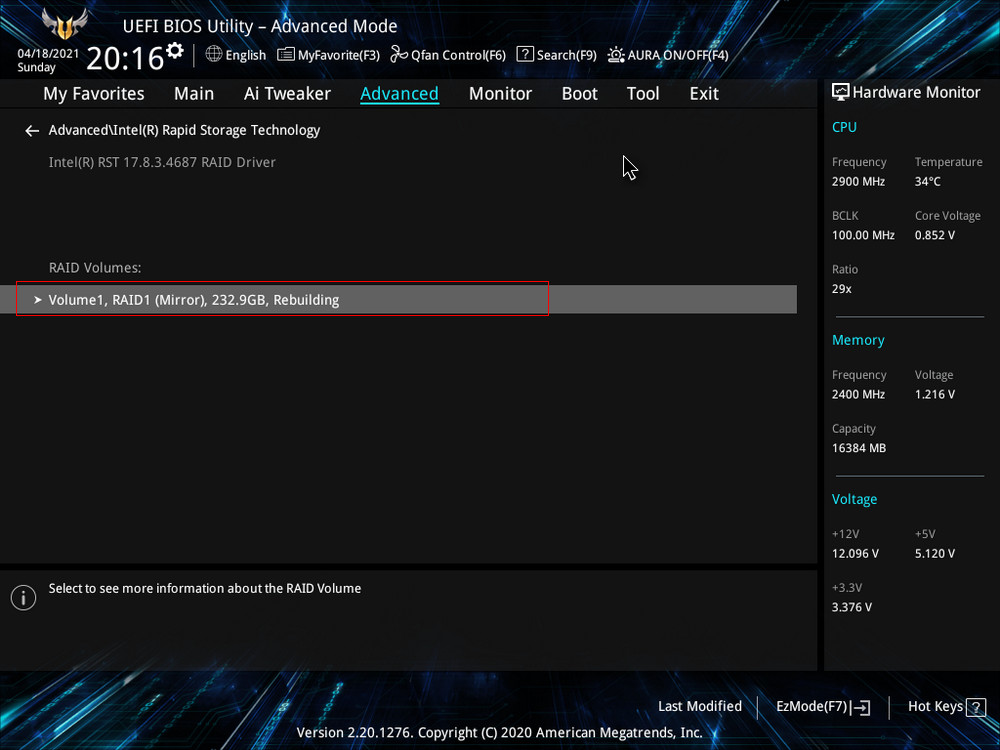 Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
После перезагрузки открываем программу Intel Optane Memory and Storage Management и видим, что всё ещё происходит перестроение массива, но операционной системой уже можно пользоваться.
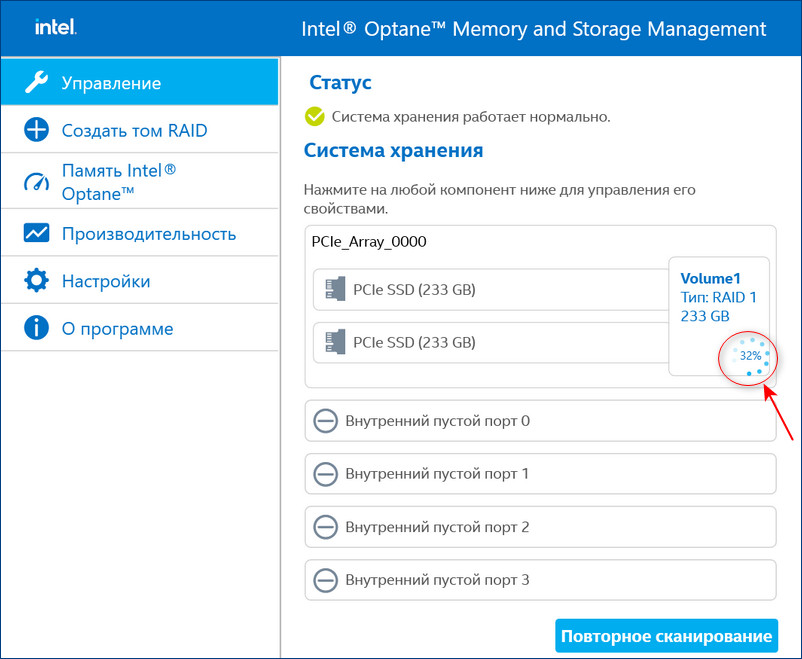
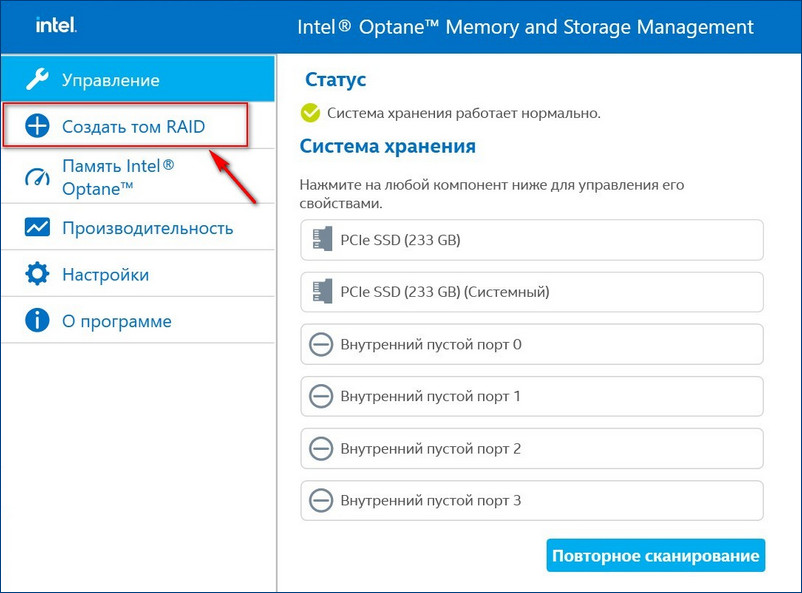
Восстановить дисковый массив можно непосредственно в программе Intel Optane Memory and Storage Management. К примеру, у нас неисправен один диск массива, и Windows 10 загружается с исправного накопителя. Выключаем компьютер, отсоединяем неисправный, а затем устанавливаем новый SSD PCIe M.2 NVMe, включаем ПК. Программа Intel Optane Memory and Storage Management определяет его как неизвестный жёсткий диск.
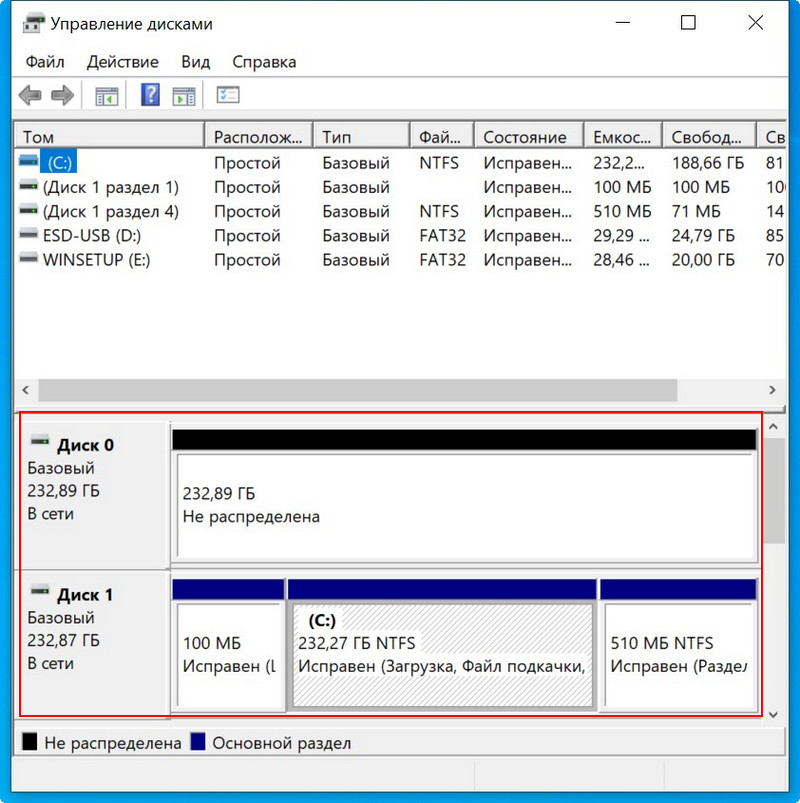 Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
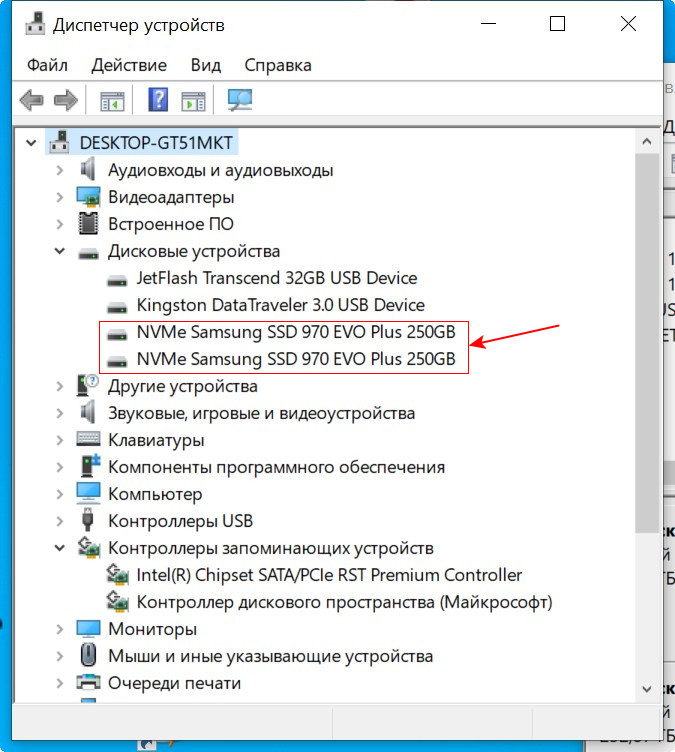 В главном окне программы жмём «Создать том RAID».
В главном окне программы жмём «Создать том RAID».
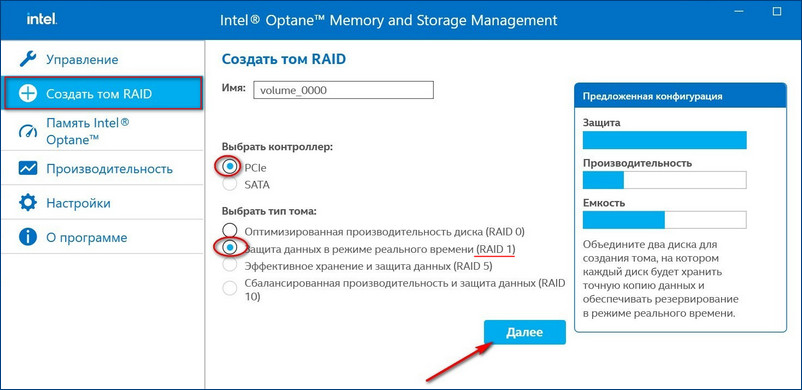
 У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
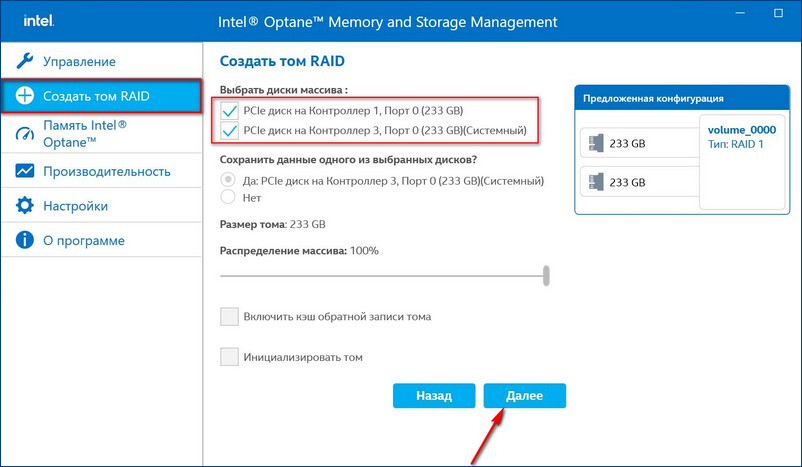
 Выбираем два наших диска SSD PCIe M.2 NVMe.
Выбираем два наших диска SSD PCIe M.2 NVMe.
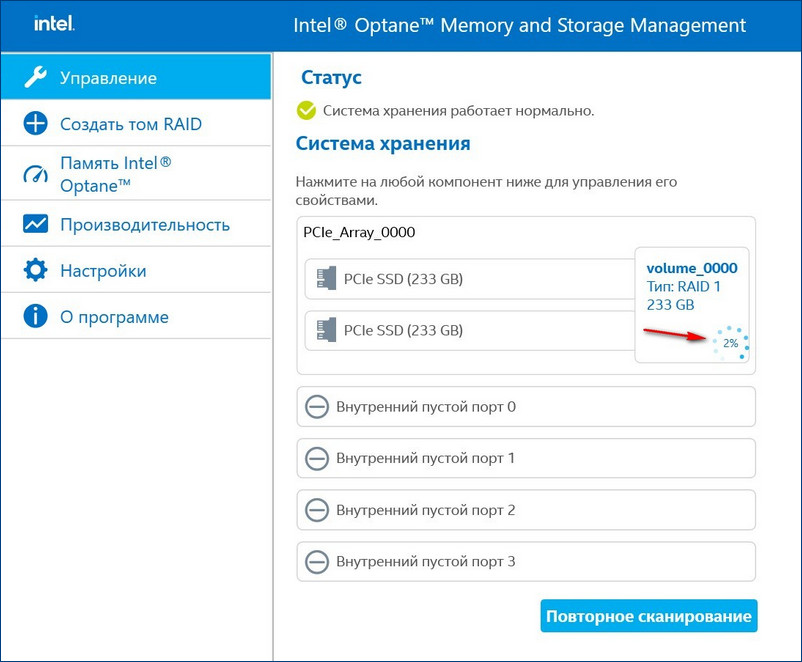
 Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID».
Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID».  Можем наблюдать процесс восстановления массива.
Можем наблюдать процесс восстановления массива.
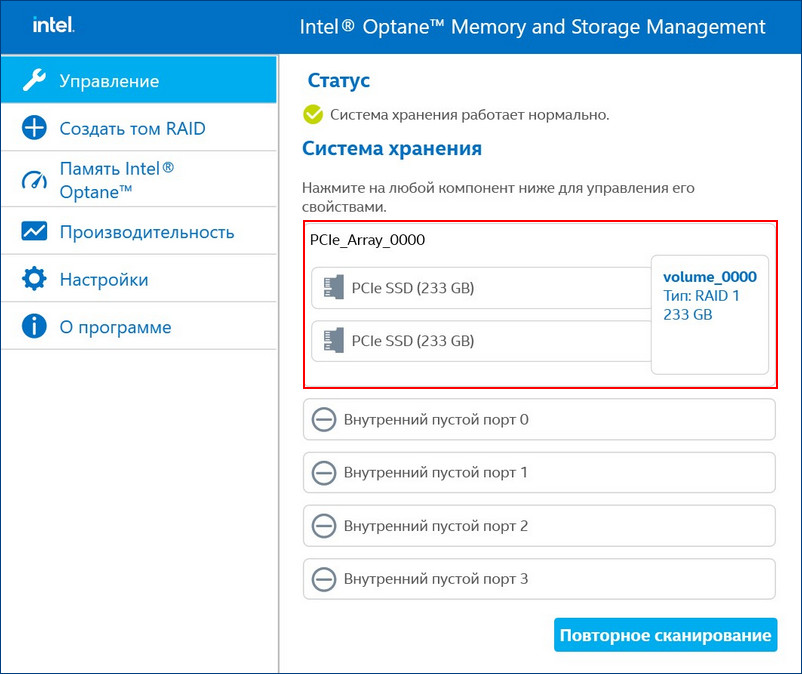
 RAID 1 массив восстановлен.
RAID 1 массив восстановлен.
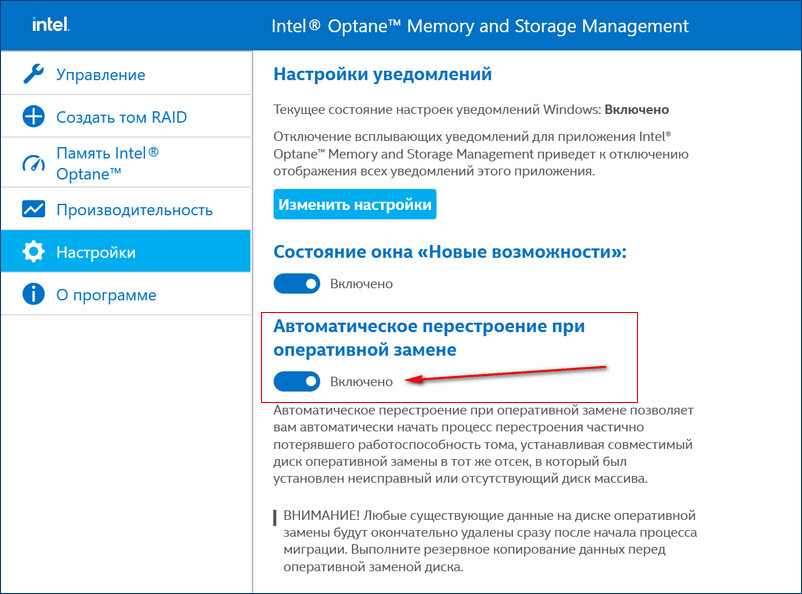
Если включить в настройках программы Intel RST «Автоматическое перестроение при оперативной замене», при замене неисправного накопителя не нужно будет ничего настраивать. Восстановление дискового массива начнётся автоматически.
Если у вас выйдут из строя сразу оба накопителя, то покупаем новые, устанавливаем в системный блок, затем создаём RAID 1 заново и разворачиваем на него резервную копию.
Что делать, если Ваш RAID вышел из строя?
Лаборатория ГОСТЛАБ имеет большой опыт в восстановлении информации со сбойных рейд-массивов. Мы оснащены по последнему слову техники, что позволяет нам заниматься даже очень тяжёлыми случаями, например, когда вышли из строя сразу несколько носителей информации.

Мы работаем со всеми конфигурациями, любыми производителями, файловыми и операционными системами и всеми типами неисправностей, будь то сбой на уровне механики, электроники или программный «глюк».
К наиболее часто встречаемым неисправностям рейд-массивов можно отнести следующие:
— нарушения в работе контроллера,
— ошибки, допущенные администратором при формировании разделов или пересборке массива,
— отказы одного или нескольких винчестеров,
— довольно распространённая ошибка со стороны пользователя — замена одного носителя на другой без проверки их совместимости,
— всевозможные проблемы электрического характера, например, скачки напряжения или перебои с питанием,
— случайные действия пользователя, такие как ошибочное форматирование разделов или удаление нужных файлов,
— последствия вирусной активности и действие других вредоносных программ,
— самые разнообразные случаи, когда смена конфигурации массива привела к потере данных о составе рейда, отсутствию доступа к той или иной информации и так далее.
Что можно предпринять при том или ином сбое RAID-массива?
Попробуем разобрать некоторые из приведённых выше ситуаций поподробнее, приведём кое-какие советы по действиям администратора.

Например, довольно часто пользователь сталкивается со случаями отказа только одного диска, когда восстановить необходимо лишь несколько отдельно взятых файлов.
Разумеется, при таком отказе восстановительные работы ограничиваются рамками одного носителя. Однако следует иметь в виду, что при конфигурации массива, в котором не предусмотрена избыточность, сбой отдельного диска может означать нарушение работоспособности всего RAID-массива.
Для таких ситуаций и конфигураций совет о резервном копировании ценных данных особенно актуален. Перед любой сменой параметров системы жизненно необходимо проводить резервное копирование с сохранением данных на альтернативный носитель. Пересборка рейд-массива существенно загружает производственные мощности Вашей системы, поэтому вероятность выхода из строя именно в такие моменты чрезвычайно высока.
Именно поэтому перед любым администрированием массива, связанным со сменой его конфигурации, необходимо резервировать ценные данные на отдельный винчестер.
Другой довольно распространённой ситуации является неисправность рейд-массива, когда сбой коснулся лишь одного элемента, но восстанавливать нужно все данные, в том числе — компоненты операционной системы.
Смена настроек конфигурации, здесь, конечно же, помочь не сможет. Однако нужно попытаться пересобрать массив из предварительно сделанных резервных копий дисков, а ещё лучше — если заранее были созданы образы этих носителей. Во многих случаях данный подход помогает, и восстановить работоспособность массива возможно.
Наконец, если вышли из строя несколько дисков, задействованных в массиве. Причинами подобного нарушения может быть целый ряд факторов, начиная от банальных скачков напряжения, заканчивая программными сбоями, когда произошёл сброс настроек конфигурации RAID-массива.
Вероятно, наиболее тяжёлые поражения системы, подразумевающие огромную трудоёмкость восстановительных работ. Поэтому всегда нужно чётко представлять себе ценность тех или иных данных, что хранятся в том или ином массиве. Осознавать последствия потерь тех или иных сведений и, соответственно, оценивать целесообразность разнообразных мер по дублированию информации, резервированию и избыточности Вашей системы.
Но всё это — меры, которые необходимо было предпринять до возникновения сбоя. Если же он произошёл, а имеющиеся возможности по восстановлению базы данных оказались недостаточными, нужно планировать реанимационные мероприятия на стороне, в профильном центре, специализирующемся на восстановлении рейд-массивов.

При выборе центра необходимо обратить внимание на репутацию, рекомендации, оснащение и квалификацию сотрудников. Конечно же, стоит попробовать снять образы дисков, перед тем как отдавать их в руки специалистов, даже если речь идёт об авторитетном центре восстановления информации. Кроме того, нельзя забывать о разнообразных неожиданностях, которые могут возникнуть в процессе, например, о банальном повреждении, полученном при транспортировке оборудования. В подобных ситуациях, вполне вероятно, резервные копии дисков станут Вашей последней надеждой на спасение данных.
Сопроводите оборудование подробным описанием проблемы с указанием действий, предпринятых всеми участниками событий. Приложите перечень важных файлов и папок, восстановление которых необходимо. В обязательном порядке промаркируйте каждый носитель с указанием возможных сбоев того или иного характера. И разумеется, тщательно упакуйте диски в тару, исключающую любое возможное повреждение в процессе транспортировки.
Ещё раз хотелось бы подчеркнуть, что если Вы не можете получить доступ к RAID-массиву с тем, чтобы произвести необходимые операции по конфигурированию, не стоит заниматься хаотичным поиском причин в интернете. Как правило, большинство советов составлено не особо сведущими в вопросе «экспертами». В то же время, специалисты лаборатории ГОСТЛАБ обладают громадным опытом по восстановлению данных с рейд-массивов любых конфигураций и при всех возможных неисправностях. Расценки на наши услуги традиционно невысоки, поэтому не стоит заниматься самодеятельностью, а лучше поручить решение проблемы грамотным специалистам.
Обращаясь в нашу лабораторию, Вы экономите своё время и нервы!
Лаборатория ГОСТЛАБ по-настоящему лидер отрасли восстановления данных. Мы занимаемся профессиональным восстановлением данных, в специально оборудованной лаборатории мы готовы взяться за восстановление любых носителей информации.
С 2001 года мы работаем на результат! Если у Вас остались вопросы, звоните по телефону 8 (495) 664-41-44 и наши специалисты грамотно ответят на все Ваши вопросы.
Поделиться:
Примеры выполненных работ
**
Популярные статьи
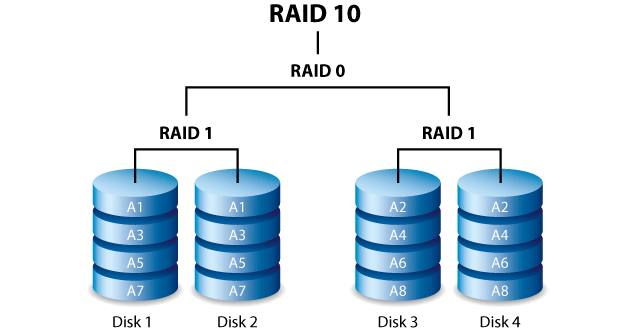
Попытка самостоятельно восстановить данные в массиве RAID 10 может привести к полной потере информации. Обычно это происходит из-за ошибочных действий системных администраторов. О каких ошибках идет речь? Об этом ниже.
Как теряется информация с массивов RAID-10
Надежность массивов RAID-10 определяется избыточностью, созданной последовательностью зеркальных дисков. Однако созданная зеркалами избыточность иногда играет злые шутки. Смотрите сами: из-за особенностей массива при выходе из строя даже половины дисков RAID-10 данные могут сохраниться. Зато при отказе всего двух из них вы можете потерять всю информацию с массива. Это происходит, если выпадают диски, составляющие зеркало.
Избыточность создает еще одну ловушку для владельцев серверов с массивом RAID-10. Вы можете не заметить выхода из строя одного диска из зеркала. Например, это происходит, если сисадмин неправильно настроил или не настроил мониторинг, или из-за некорректной работы RAID-контроллера. Проблема в том, что вы можете долго эксплуатировать сервер, не замечая проблему. При выпадении второго диска из зеркала вся информация с массива становится недоступной.

Существует еще много ситуаций, в которых теряются данные с RAID-10, среди них:
- Программный сбой RAID-контроллера.
- Поломка или некорректная замена контроллера.
- Некорректная настройка или отсутствие мониторинга.
- Аппаратная неисправность критичного количества дисков.
- Рассинхронизация массива с последующим выходом из строя актуального участника.
- Повреждения файловой системы, ошибочное удаление информации, форматирование дисков.
- Другие ошибки сисадмина. Например, удаление или изменение конфигурации (некорректное расширение массива или замена участников) или некорректные попытки восстановить данные.
При потере данных у экспертов сохраняется возможность восстановить всю или большую часть информации. Однако часто владельцы серверов совершают фатальные ошибки, которые приводят к безвозвратной утрате данных. Это происходит, когда некомпетентные пользователи пытаются самостоятельно вернуть работоспособность оборудованию.
Что делать, чтобы полностью потерять данные с массива RAID-10
Как сказано выше, нужно попробовать самостоятельно восстановить данные, не имея достаточной компетенции. При восстановлении можно ошибиться, что безусловно приведет к безвозвратной утрате доступа к информации.
Рассмотрим основные ошибки:
- Попытка восстановления данных без диагностики массива. Когда вы приходите к врачу с болью в животе, он не хватается сразу за скальпель, а расспрашивает и осматривает вас, делает анализы, чтобы понять, как вас можно лечить, а как нельзя. Такая же ситуация с восстановлением RAID-10: вы должны поставить диагноз, чтобы знать, какие процедуры будут эффективными, а какие уничтожат массив.
- Проверка дисков и исправление ошибок до анализа содержимого дисков. Эти действия могут внести изменения в информацию на дисках, что часто приводит к полной утрате данных.
- Некорректные действия с аппаратной частью: перестановка дисков, извлечение дисков до отключения машины от питания, подключение винчестера к другому оборудованию, вскрытие дисков. Такая практика часто оборачивается изменениями в конфигурации RAID-массива или физическими повреждениями носителей, после которых восстановить информацию невозможно.
- Замена контроллера или инициализация при несинхронизированном массиве и без резервной копии. В этом случае контроллер может не определить правильную конфигурацию, что приведет к потере данных.
- Попытка восстановления данных контроллером. Из-за некорректной работы микропрограммы можно разрушить массив при ребилде. Контроллер вместо записи актуальных данных на чистый диск обнуляет носитель со свежей информацией.
- Ошибочная операция с массивом. Если сисадмин вместо ребилда запускает инициализацию или синхронизацию, это приводит к повреждению или полной потере информации.
- Попытка восстановления с помощью функции make online при выходе из строя диска. Эта операция может привести к полной утрате данных сама по себе, так как процесс некорректного ребилда или инициализации может запуститься в фоновом режиме. А если после такой команды вы сами запустите инициализацию или ребилд, то наверняка получите фатальный для массива результат.
Вы можете потерять массив даже в результате безобидной операции. Например, информация может стать недоступной после простой перезагрузки системы. Поэтому при внештатных ситуациях никогда не выполняйте необдуманных действий с RAID-10.
Как видите, полностью добить массив RAID-10 несложно. Достаточно допустить ошибку при попытке восстановить информацию. Что же делать, чтобы не потерять важные данные?
Что делать, чтобы восстановить данные с массива RAID-10
Существует также безопасный метод, которым пользуются профессионалы – так называемое «софтовое восстановление RAID-массива». Его принцип заключается в работе с дисками только на чтение и использование простых, но вместе с тем гибких программных средств для правильной сборки виртуального RAID-массива.
На нашем сайте вы можете познакомиться с инструкцией по работе с массивом RAID5. В ней описаны случаи, когда можно справиться с восстановлением данных собственными силами, кроме того, в этом материале вы найдете много другой полезной информации.
Привет, %хабрачитатель%!
Несколько месяцев назад у нас возникли проблемы с одной виртуальной машиной, запущенной на сервере Dell PowerEdge R720 с ESXi 5.5. Перезагрузка этой VM длилась довольно долго и вызвала сильное падение производительности на самом хосте.
Lifecycle-лог на сервере был наполнен сообщениями вида:
PDR47
A block on Disk 0 in Backplane 1 of Integrated RAID Controller 1 was
punctured by the controller.PDR64
An unrecoverable disk media error occurred on Disk 0 in Backplane 1 of
Integrated RAID Controller 1.
Гугление привело к неутешительному выводу: рейд-массив поврежден и восстановить его невозможно. А именно — повредились данные, относящиеся к одному блоку (страйпу), сразу на нескольких дисках (double fault):
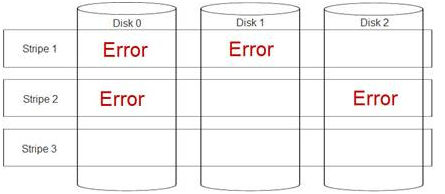
К счастью, делловские RAID-контроллеры обладают фичей продолжать работу, несмотря на неконсисентное состояние массива — puncture (https://www.dell.com/support/Article/us/en/04/438291/EN#Unique-Hyphenated-Issue-Here-2), что позволяет сохранить хотя бы ту часть данных, которая не повредились. Это, конечно, не никак отменяет необходимость последующей замены дисков и пересборки рейд-массива «с нуля».
Для предотвращения подобных ситуаций Dell рекомендует запускать проверку целостности массива не реже одного раза в месяц. Увы, но мы об этом узнали слишком поздно.
Такую проверку можно запускать как через веб-интерфейс Dell OpenManage Server Administrator (http://www.dell.com/support/contents/us/en/19/article/Product-Support/Self-support-Knowledgebase/enterprise-resource-center/Enterprise-Tools/OMSA/), так и через утилиты omconfig/omreport, входящие в OMSA. И, если бы разработчики из Dell не «забыли» включить эти утилиты в OpenManage для ESXi, то проблем с автоматизацией бы не возникло, т.к. понятно, что ручная проверка целостности массива на каждом сервере, совершенно не IT-way. Не говоря уже о том, что интерфейс OMSA очень медленный и работать с ним удовольствие еще то.
Ребята из Dell «поработали на славу» и простым способом автоматизировать проверку (например, через открытие в cURL заранее подготовленной ссылки) невозможно, т.к. веб-интерфейс генерируется динамически и постоянные ссылки в нем отсутствуют.
Что же делать?
Пришлось немного повозиться и написать утилиту проверки самому. Встречайте: Consistency Check Task Automation Tool for Dell servers with iDRAC (https://github.com/jazzl0ver/dell_raid_cc). Утилита написана с помощью фреймворка CasperJS, который позволяет автоматизировать работу как раз с подобными динамическими сайтами.
Для использования dell_raid_cc необходимо:
1. Сервер с установленным OMSA (см. ссылку выше)
2. Скачать и установить phantomjs (http://phantomjs.org/download.html)
3. Скачать и установить casperjs (http://docs.casperjs.org/en/latest/installation.html)
4. Вытащить утилиту из git:
git clone https://github.com/jazzl0ver/dell_raid_cc
5. Создать файл с параметрами доступа (например, creds.txt):
export OMSAHOST=192.168.1.191
export OMSAPORT=1311
export USERNAME=root
export PASSWORD=password
export DELLHOST=192.168.1.30
6. Загрузить его и можно запускать утилиту или ставить ее запуск в кронтаб:
source creds.txt
casperjs --ignore-ssl-errors=true --cookies-file=/tmp/dell_raid_cc_cookie.jar dell_raid_cc.js
Если все в порядке, то вывод будет примерно такой:
Found: Virtual Disk 0 [state: Ready; layout: RAID-10; size: 1,862.00GB]
CC for Virtual Disk 0 has been started
Found: Virtual Disk 1 [state: Ready; layout: RAID-1; size: 931.00GB]
CC for Virtual Disk 1 has been started
Если запустить еще раз, можно увидеть прогресс проверки, например:
Found: Virtual Disk 0 [state: Resynching; layout: RAID-6; size: 5,026.50GB]
CC for Virtual Disk 0 is still running, progress: 19% complete
Стоит сказать, что утилита не поддерживает многоконтроллерные системы (у меня просто таких нет и протестировать, соответственно, не на чем).
Надеюсь, утилита окажется полезной не только мне.
UPD. Как подсказали коллеги в комментариях, более правильно настроить запуск проверки на целостность по расписанию с помощью утилиты megacli. Например:
./MegaCli -AdpCcSched -SetStartTime 20140822 04 -aALL
Инструкции по установке на сервер с CentOS/RedHat — здесь
Настройка расписания CC — здесь
Под ESXi также легко устанавливается. Можно поставить vib напрямую, либо сделать из него bundle и поставить в качестве обновления через vCenter.
UPD. #2 Контроллеры Perc5 не поддерживают настройку расписания через MegaCli:
cd /opt/lsi/MegaCLI; ./MegaCli -AdpCcSched -Info -aALL
Adapter 0: Scheduled Chceck Consistency is not supported.
Exit Code: 0x01
Для них использование dell_raid_cc — единственный способ автоматизации.
Contents
- 1 Detecting, querying and testing
- 1.1 Detecting a drive failure
- 1.2 Querying the array status
- 1.3 Simulating a drive failure
- 1.3.1 Force-fail by hardware
- 1.3.2 Force-fail by software
- 1.4 Simulating data corruption
- 1.5 Monitoring RAID arrays
Detecting, querying and testing
This section is about life with a software RAID system, that’s
communicating with the arrays and tinkertoying them.
Note that when it comes to md devices manipulation, you should always
remember that you are working with entire filesystems. So, although
there could be some redundancy to keep your files alive, you must
proceed with caution.
Detecting a drive failure
Firstly: mdadm has an excellent ‘monitor’ mode which will send an email when a problem is detected in any array (more about that later).
Of course the standard log and stat files will record more details about a drive failure.
It’s always a must for /var/log/messages to fill screens with tons of
error messages, no matter what happened. But, when it’s about a disk
crash, huge lots of kernel errors are reported. Some nasty examples,
for the masochists,
kernel: scsi0 channel 0 : resetting for second half of retries.
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: Sending Bus Device Reset CCB #2666 to Target 0
kernel: scsi0: Bus Device Reset CCB #2666 to Target 0 Completed
kernel: scsi : aborting command due to timeout : pid 2649, scsi0, channel 0, id 0, lun 0 Write (6) 18 33 11 24 00
kernel: scsi0: Aborting CCB #2669 to Target 0
kernel: SCSI host 0 channel 0 reset (pid 2644) timed out - trying harder
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: CCB #2669 to Target 0 Aborted
kernel: scsi0: Resetting BusLogic BT-958 due to Target 0
kernel: scsi0: *** BusLogic BT-958 Initialized Successfully ***
Most often, disk failures look like these,
kernel: sidisk I/O error: dev 08:01, sector 1590410
kernel: SCSI disk error : host 0 channel 0 id 0 lun 0 return code = 28000002
or these
kernel: hde: read_intr: error=0x10 { SectorIdNotFound }, CHS=31563/14/35, sector=0
kernel: hde: read_intr: status=0x59 { DriveReady SeekComplete DataRequest Error }
And, as expected, the classic /proc/mdstat look will also reveal problems,
Personalities : [linear] [raid0] [raid1] [translucent]
read_ahead not set
md7 : active raid1 sdc9[0] sdd5[8] 32000 blocks [2/1] [U_]
Later on this section we will learn how to monitor RAID with mdadm so
we can receive alert reports about disk failures. Now it’s time to
learn more about /proc/mdstat interpretation.
Querying the array status
You can always take a look at the array status by doing cat /proc/mdstat
It won’t hurt. Take a look at the /proc/mdstat page to learn how to read the file.
Finally, remember that you can also use mdadm to check
the arrays out.
mdadm --detail /dev/mdx
These commands will show spare and failed disks loud and clear.
Simulating a drive failure
If you plan to use RAID to get fault-tolerance, you may also want to
test your setup, to see if it really works. Now, how does one
simulate a disk failure?
The short story is, that you can’t, except perhaps for putting a fire
axe thru the drive you want to «simulate» the fault on. You can never
know what will happen if a drive dies. It may electrically take the
bus it is attached to with it, rendering all drives on that bus
inaccessible. The drive may also just report a read/write fault
to the SCSI/IDE/SATA layer, which, if done properly, in turn makes the RAID layer handle this
situation gracefully. This is fortunately the way things often go.
Remember, that you must be running RAID-{1,4,5,6,10} for your array to be
able to survive a disk failure. Linear- or RAID-0 will fail
completely when a device is missing.
Force-fail by hardware
If you want to simulate a drive failure, you can just plug out the
drive. If your HW does not support disk hot-unplugging, you should do this with the power off (if you are interested in testing whether your data can survive with a disk less than the usual number, there is no point in being a hot-plug cowboy here. Take the system down, unplug the disk, and boot it up again)
Look in the syslog, and look at /proc/mdstat to see how the RAID is
doing. Did it work? Did you get an email from the mdadm monitor?
Faulty disks should appear marked with an (F) if you look at
/proc/mdstat. Also, users of mdadm should see the device state as
faulty.
When you’ve re-connected the disk again (with the power off, of
course, remember), you can add the «new» device to the RAID again,
with the mdadm —add’ command.
Force-fail by software
You can just simulate a drive failure without unplugging things.
Just running the command
mdadm --manage --set-faulty /dev/md1 /dev/sdc2
should be enough to fail the disk /dev/sdc2 of the array /dev/md1.
Now things move up and fun appears. First, you should see something
like the first line of this on your system’s log. Something like the
second line will appear if you have spare disks configured.
kernel: raid1: Disk failure on sdc2, disabling device.
kernel: md1: resyncing spare disk sdb7 to replace failed disk
Checking /proc/mdstat out will show the degraded array. If there was a
spare disk available, reconstruction should have started.
Another useful command at this point is:
mdadm --detail /dev/md1
Enjoy the view.
Now you’ve seen how it goes when a device fails. Let’s fix things up.
First, we will remove the failed disk from the array. Run the command
mdadm /dev/md1 -r /dev/sdc2
Note that mdadm cannot pull a disk out of a running array.
For obvious reasons, only faulty disks can be hot-removed from an
array (even stopping and unmounting the device won’t help — if you ever want
to remove a ‘good’ disk, you have to tell the array to put it into the
‘failed’ state as above).
Now we have a /dev/md1 which has just lost a device. This could be a
degraded RAID or perhaps a system in the middle of a reconstruction
process. We wait until recovery ends before setting things back to
normal.
So the trip ends when we send /dev/sdc2 back home.
mdadm /dev/md1 -a /dev/sdc2
As the prodigal son returns to the array, we’ll see it becoming an
active member of /dev/md1 if necessary. If not, it will be marked as
a spare disk. That’s management made easy.
Simulating data corruption
RAID (be it hardware or software), assumes that if a write to a disk
doesn’t return an error, then the write was successful. Therefore, if
your disk corrupts data without returning an error, your data will
become corrupted. This is of course very unlikely to happen, but it
is possible, and it would result in a corrupt filesystem.
RAID cannot, and is not supposed to, guard against data corruption on
the media. Therefore, it doesn’t make any sense either, to purposely
corrupt data (using dd for example) on a disk to see how the RAID
system will handle that. It is most likely (unless you corrupt the
RAID superblock) that the RAID layer will never find out about the
corruption, but your filesystem on the RAID device will be corrupted.
This is the way things are supposed to work. RAID is not a guarantee
for data integrity, it just allows you to keep your data if a disk
dies (that is, with RAID levels above or equal one, of course).
Monitoring RAID arrays
You can run mdadm as a daemon by using the follow-monitor mode. If
needed, that will make mdadm send email alerts to the system
administrator when arrays encounter errors or fail. Also, follow mode
can be used to trigger contingency commands if a disk fails, like
giving a second chance to a failed disk by removing and reinserting
it, so a non-fatal failure could be automatically solved.
Let’s see a basic example. Running
mdadm --monitor --daemonise --mail=root@localhost --delay=1800 /dev/md2
should release a mdadm daemon to monitor /dev/md2. The —daemonise switch tells mdadm to run as a deamon. The delay parameter means that polling will be done in intervals of 1800 seconds.
Finally, critical events and fatal errors should be e-mailed to the
system manager. That’s RAID monitoring made easy.
Finally, the —program or —alert parameters specify the program to be
run whenever an event is detected.
Note that, when supplying the -f switch, the mdadm daemon will never exit once it decides that there
are arrays to monitor, so it should normally be run in the background.
Remember that your are running a daemon, not a shell command.
If mdadm is ran to monitor without the -f switch, it will behave as a normal shell command and wait for you to stop it.
Using mdadm to monitor a RAID array is simple and effective. However,
there are fundamental problems with that kind of monitoring — what
happens, for example, if the mdadm daemon stops? In order to overcome
this problem, one should look towards «real» monitoring solutions.
There are a number of free software, open source, and even commercial
solutions available which can be used for Software RAID monitoring on
Linux. A search on FreshMeat should return a good number of matches.
Содержание
Эта страница целиком списана с исходной, где рассматриваются вопросы создания и обслуживания программного RAID-массива в операционной системе Linux. К сожалению, исходная страница недоступна, приходится держать копию на этом wiki.
Краткое описание mdadm
Управление программным RAID-массивом в Linux выполняется с помощью программы mdadm.
У программы mdadm есть несколько режимов работы.
Assemble(сборка)
Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
Build(построение)
Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
Create(создание)
Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
Monitor(наблюдение)
Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
Grow (расширение или уменьшение)
Расширение или уменьшение массива, включаются или удаляются новые диски.
Incremental Assembly (инкрементальная сборка)
Добавление диска в массив.
Manage (управление)
Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
Misc (разное)
Действия, которые не относятся ни к одному из перечисленных выше режимов работы.
Auto-detect (автоообнаружение)
Активация автоматически обнаруживаемых массивов в ядре Linux.
Формат вызова
mdadm [mode] [array] [options]
Режимы:
-
-A, –assemble — режим сборки
-
-B, –build — режим построения
-
-C, –create — режим создания
-
-F, –follow, –monitor — режим наблюдения
-
-G, –grow — режим расширения
-
-I, –incremental — режим инкрементальной сборки
Настройка программного RAID-массива
Рассмотрим как выполнить настройку RAID-массива 10 уровня на четырёх дисковых разделах. Мы будем использовать разделы:
/dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
В том случае если разделы иные, не забудьте использовать соответствующие имена файлов.
Создание разделов
Нужно определить на каких физических разделах будет создаваться RAID-массив. Если разделы уже есть, нужно найти свободные (fdisk -l). Если разделов ещё нет, но есть неразмеченное место, их можно создать с помощью программ fdisk или cfdisk.
Просмотреть какие есть разделы:
%# fdisk -l
Disk /dev/hda: 12.0 GB, 12072517632 bytes 255 heads, 63 sectors/track, 1467 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System /dev/hda1 * 1 13 104391 83 Linux /dev/hda2 14 144 1052257+ 83 Linux /dev/hda3 145 209 522112+ 82 Linux swap /dev/hda4 210 1467 10104885 5 Extended /dev/hda5 210 655 3582463+ 83 Linux ... ... /dev/hda15 1455 1467 104391 83 Linux
Просмотреть, какие разделы куда смонтированы, и сколько свободного места есть на них (размеры в килобайтах):
%# df -k Filesystem 1K-blocks Used Available Use% Mounted on /dev/hda2 1035692 163916 819164 17% / /dev/hda1 101086 8357 87510 9% /boot /dev/hda15 101086 4127 91740 5% /data1 ... ... ... /dev/hda7 5336664 464228 4601344 10% /var
Размонтирование
Если вы будете использовать созданные ранее разделы, обязательно размонтируйте их. RAID-массив нельзя создавать поверх разделов, на которых находятся смонтированные файловые системы.
%# umount /dev/sda1 %# umount /dev/sdb1 %# umount /dev/sdc1 %# umount /dev/sdd1
Изменение типа разделов
Желательно (но не обязательно) изменить тип разделов, которые будут входить в RAID-массив и установить его равным FD (Linux RAID autodetect). Изменить тип раздела можно с помощью fdisk.
Рассмотрим, как это делать на примере раздела /dev/hde1.
%# fdisk /dev/hde The number of cylinders for this disk is set to 8355. There is nothing wrong with that, but this is larger than 1024, and could in certain setups cause problems with: 1) software that runs at boot time (e.g., old versions of LILO) 2) booting and partitioning software from other OSs (e.g., DOS FDISK, OS/2 FDISK)
Command (m for help):
Use FDISK Help
Now use the fdisk m command to get some help:
Command (m for help): m ... ... p print the partition table q quit without saving changes s create a new empty Sun disklabel t change a partition's system id ... ... Command (m for help):
Set The ID Type To FD
Partition /dev/hde1 is the first partition on disk /dev/hde. Modify its type using the t command, and specify the partition number and type code. You also should use the L command to get a full listing of ID types in case you forget.
Command (m for help): t Partition number (1-5): 1 Hex code (type L to list codes): L
... ... ... 16 Hidden FAT16 61 SpeedStor f2 DOS secondary 17 Hidden HPFS/NTF 63 GNU HURD or Sys fd Linux raid auto 18 AST SmartSleep 64 Novell Netware fe LANstep 1b Hidden Win95 FA 65 Novell Netware ff BBT Hex code (type L to list codes): fd Changed system type of partition 1 to fd (Linux raid autodetect)
Command (m for help):
Make Sure The Change Occurred
Use the p command to get the new proposed partition table:
Command (m for help): p
Disk /dev/hde: 4311 MB, 4311982080 bytes 16 heads, 63 sectors/track, 8355 cylinders Units = cylinders of 1008 * 512 = 516096 bytes
Device Boot Start End Blocks Id System /dev/hde1 1 4088 2060320+ fd Linux raid autodetect /dev/hde2 4089 5713 819000 83 Linux /dev/hde4 6608 8355 880992 5 Extended /dev/hde5 6608 7500 450040+ 83 Linux /dev/hde6 7501 8355 430888+ 83 Linux
Command (m for help):
Save The Changes
Use the w command to permanently save the changes to disk /dev/hde:
Command (m for help): w The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy. The kernel still uses the old table. The new table will be used at the next reboot. Syncing disks.
Аналогичным образом нужно изменить тип раздела для всех остальных разделов, входящих в RAID-массив.
Создание RAID-массива
Создание RAID-массива выполняется с помощью программы mdadm (ключ –create). Мы воспользуемся опцией –level, для того чтобы создать RAID-массив 10 уровня. С помощью ключа –raid-devices укажем устройства, из которых будет собираться RAID-массив.
mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 64K
mdadm: /dev/hde1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: /dev/hdf2 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: /dev/hdg1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: size set to 48064K
Continue creating array? y
mdadm: array /dev/md0 started.
Если вы хотите сразу создать массив, где диска не хватает (degraded) просто укажите слово missing вместо имени устройства. Для RAID5 это может быть только один диск; для RAID6 — не более двух; для RAID1 — сколько угодно, но должен быть как минимум один рабочий.
Проверка правильности сборки
Убедиться, что RAID-массив проинициализирован корректно можно просмотрев файл /proc/mdstat. В этом файле отражается текущее состояние RAID-массива.
%# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
Обратите внимание на то, как называется новый RAID-массив. В нашем случае он называется /dev/md0. Мы будем обращаться к массиву по этому имени.
Создание файловой системы поверх RAID-массива
Новый RAID-раздел нужно отформатировать, т.е. создать на нём файловую систему. Сделать это можно при помощи программы из семейства mkfs. Если мы будем создавать файловую систему ext3, воспользуемся программой mkfs.ext3. :
%# mkfs.ext3 /dev/md0
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
36144 inodes, 144192 blocks
7209 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
18 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done Creating journal (4096 blocks): done Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
Имеет смысл для лучшей производительности файловой системы указывать при создании количество дисков в рейде и количество блоков файловой системы которое может поместиться в один страйп ( chunk ), это особенно важно при создании массивов уровня RAID0,RAID5,RAID6,RAID10. Для RAID1 ( mirror ) это не имеет значения так как запись идёт всегда на один device, a в других типах рейдов дата записывается последовательно на разные диски порциями соответствующими размеру stripe. Например если мы используем RAID5 из 3 дисков, с дефолтным размером страйпа в 64К и используем файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext вот так:
%# mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0
stripe-width обычно рассчитывается как stride * N ( N это дата диски в массиве — например в RAID5 — два дата диска и один parity ) Для не менее популярной файловой системы XFS надо указывать не количество блоков файловой системы соответствующих размеру stripe в массиве, а непосредственно размер самого страйпа
%# mkfs.xfs -d su=64k,sw=3 /dev/md0
Создание конфигурационного файла mdadm.conf
Система сама не запоминает какие RAID-массивы ей нужно создать и какие компоненты в них входят. Эта информация находится в файле mdadm.conf.
Строки, которые следует добавить в этот файл, можно получить при помощи команды
mdadm –detail –scan –verbose
Вот пример её использования:
%# mdadm --detail --scan --verbose ARRAY /dev/md0 level=raid5 num-devices=4 UUID=77b695c4:32e5dd46:63dd7d16:17696e09 devices=/dev/hde1,/dev/hdf2,/dev/hdg1
Если файла mdadm.conf ещё нет, можно его создать:
%# echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
%# mdadm --detail --scan --verbose | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.conf
Создание точки монтирования для RAID-массива
Поскольку мы создали новую файловую систему, вероятно, нам понадобится и новая точка монтирования. Назовём её /raid.
%# mkdir /raid
Изменение /etc/fstab
Для того чтобы файловая система, созданная на новом RAID-массиве, автоматически монтировалась при загрузке, добавим соответствующую запись в файл /etc/fstab хранящий список автоматически монтируемых при загрузке файловых систем.
/dev/md0 /raid ext3 defaults 1 2
Если мы объединяли в RAID-массив разделы, которые использовались раньше, нужно отключить их монтирование: удалить или закомментировать соответствующие строки в файле /etc/fstab. Закомментировать строку можно символом #.
#/dev/hde1 /data1 ext3 defaults 1 2 #/dev/hdf2 /data2 ext3 defaults 1 2 #/dev/hdg1 /data3 ext3 defaults 1 2
Монтирование файловой системы нового RAID-массива
Для того чтобы получить доступ к файловой системе, расположенной на новом RAID-массиве, её нужно смонтировать. Монтирование выполняется с помощью команды mount.
Если новая файловая система добавлена в файл /etc/fstab, можно смонтировать её командой mount -a (смонтируются все файловые системы, которые должны монтироваться при загрузке, но сейчас не смонтированы).
%# mount -a
Можно смонтировать только нужный нам раздел (при условии, что он указан в /etc/fstab).
%# mount /raid
Если раздел в /etc/fstab не указан, то при монтировании мы должны задавать как минимум два параметра — точку монтирования и монтируемое устройство:
%# mount /dev/md0 /raid
Проверка состояния RAID-массива
Информация о состоянии RAID-массива находится в файле /proc/mdstat.
%# raidstart /dev/md0
%# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
Если в файле информация постоянно изменяется, например, идёт пересборка массива, то постоянно изменяющийся файл удобно просматривать при помощи программы watch:
%$ watch cat /proc/mdstat
Как выполнить проверку целостности программного RAID-массива md0:
echo ‘check’ >/sys/block/md0/md/sync_action
Как посмотреть нашлись ли какие-то ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cnt
Проблема загрузки на многодисковых системах
В некоторых руководствах по mdadm после первоначальной сборки массивов рекомендуется добавлять в файл /etc/mdadm/mdadm.conf вывод команды «mdadm –detail –scan –verbose»:
ARRAY /dev/md/1 level=raid1 num-devices=2 metadata=1.2 name=linuxWork:1 UUID=147c5847:dabfe069:79d27a05:96ea160b
devices=/dev/sda1
ARRAY /dev/md/2 level=raid1 num-devices=2 metadata=1.2 name=linuxWork:2 UUID=68a95a22:de7f7cab:ee2f13a9:19db7dad
devices=/dev/sda2
, в котором жёстко прописаны имена разделов (/dev/sda1, /dev/sda2 в приведённом примере).
Если после этого обновить образ начальной загрузки (в Debian вызвать ‘update-initramfs -u’ или ‘dpkg-reconfigure mdadm’), имена разделов запишутся в файл mdadm.conf образа начальной загрузки, и вы не сможете загрузиться с массива, если конфигурация жёстких дисков изменится (нужные разделы получат другие имена). Для этого не обязательно добавлять или убирать жёсткие диски: в многодисковых системах их имена могут меняться от загрузки к загрузке.
Решение: записывать в /etc/mdadm/mdadm.conf вывод команды «mdadm –detail –scan» (без –verbose).
При этом в файле mdadm.conf будут присутствовать UUID разделов, составляющих каждый RAID-массив. При загрузке системы mdadm находит нужные разделы независимо от их символических имён по UUID.
mdadm.conf, извлечённый из образа начальной загрузки Debian:
DEVICE partitions
HOMEHOST <system>
ARRAY /dev/md/1 metadata=1.2 UUID=147c5847:dabfe069:79d27a05:96ea160b name=linuxWork:1
ARRAY /dev/md/2 metadata=1.2 UUID=68a95a22:de7f7cab:ee2f13a9:19db7dad name=linuxWork:2
Результат исследования раздела командой ‘mdadm –examine’«
/dev/sda1:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 147c5847:dabfe069:79d27a05:96ea160b
Name : linuxWork:1
Creation Time : Thu May 23 09:17:01 2013
Raid Level : raid1 Raid Devices : 2
Раздел c UUID 147c5847:dabfe069:79d27a05:96ea160b войдёт в состав массива, даже если станет /dev/sdb1 при очередной загрузке системы.
Вообще, существует 2 файла mdadm.conf, влияющих на автоматическую сборку массивов:
один при загрузке системы, записывется в образ начальной загрузки при его обновлении; другой находится в каталоге /etc/mdadm/ и влияет на автосборку массивов внутри работающей системы.
Соответственно, вы можете иметь информацию:
1) в образе начальной загрузки (ОНЗ) и в /etc/mdadm/mdadm.conf;
2) только в ОНЗ (попадает туда при его создании обновлении);
3) только в /etc/mdadm/mdadm.conf;
4) нигде.
В том месте, где есть mdadm.conf, сборка происходит по правилам; где нет — непредсказуемо.
Примечание: если вы не обновили ОНЗ после создания RAID-массивов, их конфигурация всё равно в него попадёт — при обновлении образа другой программой / при обновлении системы (но вы не будете об этом знать со всеми вытекающими).
[править] Дальнейшая работа с массивом
[править] Пометка диска как сбойного
Диск в массиве можно условно сделать сбойным, ключ –fail (-f):
%# mdadm /dev/md0 --fail /dev/hde1 %# mdadm /dev/md0 -f /dev/hde1
[править] Удаление сбойного диска
Сбойный диск можно удалить с помощью ключа –remove (-r):
%# mdadm /dev/md0 --remove /dev/hde1 %# mdadm /dev/md0 -r /dev/hde1
[править] Добавление нового диска
Добавить новый диск в массив можно с помощью ключей –add (-a) и –re-add:
%# mdadm /dev/md0 --add /dev/hde1 %# mdadm /dev/md0 -a /dev/hde1
Сборка существующего массива
Собрать существующий массив можно с помощью mdadm –assemble. Как дополнительный аргумент указывается, нужно ли выполнять сканирование устройств, и если нет, то какие устройства нужно собирать.
%# mdadm --assemble /dev/md0 /dev/hde1 /dev/hdf2 /dev/hdg1 %# mdadm --assemble --scan
Расширение массива
Расширить массив можно с помощью ключа –grow (-G). Сначала добавляется диск, а потом массив расширяется:
%# mdadm /dev/md0 --add /dev/hdh2
Проверяем, что диск (раздел) добавился:
%# mdadm --detail /dev/md0 %# cat /proc/mdstat
Если раздел действительно добавился, мы можем расширить массив:
%# mdadm -G /dev/md0 --raid-devices=4
Опция –raid-devices указывает новое количество дисков, используемое в массиве. Например, было 3 диска, а теперь расширяем до 4-х — указываем 4.
Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например добавить:
-
-backup-file=/var/backup
При необходимости можно регулировать скорость процесса расширения массива, указав нужное значение в файлах
/proc/sys/dev/raid/speed_limit_min /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
%# cat /proc/mdstat
Нужно обновить конфигурационный файл с учётом сделанных изменений:
%# mdadm --detail --scan >> /etc/mdadm/mdadm.conf %# vi /etc/mdadm/mdadm.conf
Возобновление отложенной синхронизации
Отложенная синхронизация:
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active(auto-read-only) raid1 sda1[0] sdb1[1]
78148096 blocks [2/2] [UU]
resync=PENDING
Возобновить:
echo idle > /sys/block/md0/md/sync_action
P.S.: Если вы увидели «active (auto-read-only)» в файле /proc/mdstat, то возможно вы просто ничего не записывали в этот массив. К примеру, после монтирования раздела и любых изменений в примонтированном каталоге, статус автоматически меняется:
md0 : active raid1 sdc[0] sdd[1]
Переименование массива
Для начала отмонтируйте и остановите массив:
%# umount /dev/md0 %# mdadm --stop /dev/md0
Затем необходимо пересобрать как md5 каждый из разделов sd[abcdefghijk]1
%# mdadm --assemble /dev/md5 /dev/sd[abcdefghijk]1 --update=name
или так
%# mdadm --assemble /dev/md5 /dev/sd[abcdefghijk]1 --update=super-minor
Удаление массива
Для начала отмонтируйте и остановите массив:
%# umount /dev/md0 %# mdadm -S /dev/md0
Затем необходимо затереть superblock каждого из составляющих массива:
%# mdadm --zero-superblock /dev/hde1 %# mdadm --zero-superblock /dev/hdf2
Если действие выше не помогло, то затираем так:
%# dd if=/dev/zero of=/dev/hde1 bs=512 count=1 %# dd if=/dev/zero of=/dev/hdf2 bs=512 count=1
Создание пустого массива без сихронизации данных
Не каноничный метод, применять на дисках без данных!
Смотрим информацию по массивам и выбираем жертву
%# cat /proc/mdstat
Предварительно разбираем массив
%# mdadm --stop /dev/md124
Создаём директорию для metadata файлов
%# mkdir /tmp/metadata
Снимаем дамп metadata с одного из raid дисков
%# mdadm --dump=/tmp/metadata /dev/sda1
Копируем метаданные
%# cp /tmp/metadata/sda1 /tmp/metadata/sdb1
Накатываем бекап
%# mdadm --restore=/tmp/metadata /dev/sdb1
Собираем массив
%# mdadm --create --verbose /dev/md124 --level=0 --raid-devices=2 /dev/sda /dev/sdb
Радуемся отсутствию синка и данных
%# cat /proc/mdstat
Дополнительная информация
man mdadm (англ.) man mdadm.conf (англ.) Linux Software RAID (англ.) Gentoo Install on Software RAID (англ.) HOWTO Migrate To RAID (англ.) Remote Conversion to Linux Software RAID-1 for Crazy Sysadmins HOWTO (англ.) Migrating To RAID1 Mirror on Sarge (англ.) Настройка программного RAID-1 на Debian Etch (рус.), а также обсуждение на ЛОРе Недокументированные фишки программного RAID в Linux (рус.)
Производительность программных RAID-массивов
Adventures With Linux RAID: Part 1, Part 2 (англ.) Параметры, влияющие на производительность программного RAID (рус.)
Разные заметки, имеющие отношение к RAID
BIO_RW_BARRIER - what it means for devices, filesystems, and dm/md. (англ.)
Привет, друзья. В прошлой статье мы с вами создали RAID 1 массив (Зеркало) — отказоустойчивый массив из двух жёстких дисков SSD. Смысл создания RAID 1 массива заключается в повышении надёжности хранения данных на компьютере. Когда два жёстких диска объединены в одно хранилище, информация на обоих дисках записывается параллельно (зеркалируется). Диски являются точными копиями друг друга, и если один из них выйдет из строя, мы получим доступ к операционной системе и нашим данным, ибо их целостность будет обеспечена работой другого диска. Также конфигурация RAID 1 повышает производительность при чтении данных, так как считывание происходит с двух дисков. В этой же статье мы рассмотрим, как восстановить массив RAID 1, если он развалится. Другими словами, мы рассмотрим, как сделать Rebuild RAID 1.
Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
Если созданный с помощью БИОСа материнской платы RAID 1 массив развалился, неопытный пользователь может этого сразу и не понять. Мы не получим ни звукового оповещения, ни оповещения в иной форме, сигнализирующих о проблеме развала RAID 1. Возможностями аварийной сигнализации при развале массивов обладают только отдельные SAS/SATA/RAID-контроллеры, работающие через интерфейс PCI Express. За аварийную сигнализацию при проблемах с массивами отвечает специальное ПО таких контроллеров. Не имея таких контроллеров, можем использовать программы типа CrystalDiskInfo или Hard Disk Sentinel Pro, которые предупредят нас о выходе из строя одного из накопителей массива звуковым сигналом, либо электронным письмом на почту.
Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
Для примера возьмём мою материнскую плату на чипсете Z490 от Intel, для которого существует специальное программное обеспечение Intel Rapid Storage Technology (Intel RST). Технология Intel Rapid Storage поддерживает SSD SATA и SSD PCIe M.2 NVMe, повышает производительность компьютеров с SSD-накопителями за счёт собственных разработок. Всесторонне обслуживает массивы RAID в конфигурациях 0, 1, 5, 10. Предоставляет пользовательский интерфейс Intel Optane Memory and Storage Management для управления системой хранения данных, в том числе дисковых массивов.
После установки Intel RST в главном окне увидим созданный нами из двух SSD M.2 NVMe Samsung 970 EVO Plus (250 Гб) RAID 1 массив, исправно функционирующий.
Вот этот массив в управлении дисками Windows.
И в диспетчере устройств.
Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
И в главном окне программы будет значиться, что один из дисков массива неисправен.
В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
После замены неисправного диска включаем ПК и входим в БИОС. Заходим в расширенные настройки «Advanced Mode», идём во вкладку «Advanced». Переходим в пункт «Intel Rapid Storage Technology».
Видим, что наш RAID 1 массив с названием Volume 1 неработоспособен — «Volume 1 RAID 1 (mirroring), Degraded».Выбираем «Rebuild» (Восстановить).
Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».RAID 1 массив восстановлен.
Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
После перезагрузки открываем программу Intel Optane Memory and Storage Management и видим, что всё ещё происходит перестроение массива, но операционной системой уже можно пользоваться.
Восстановить дисковый массив можно непосредственно в программе Intel Optane Memory and Storage Management. К примеру, у нас неисправен один диск массива, и Windows 10 загружается с исправного накопителя. Выключаем компьютер, отсоединяем неисправный, а затем устанавливаем новый SSD PCIe M.2 NVMe, включаем ПК. Программа Intel Optane Memory and Storage Management определяет его как неизвестный жёсткий диск.
Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
В главном окне программы жмём «Создать том RAID».
У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
Выбираем два наших диска SSD PCIe M.2 NVMe.
Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID». Можем наблюдать процесс восстановления массива.
RAID 1 массив восстановлен.
Если включить в настройках программы Intel RST «Автоматическое перестроение при оперативной замене», при замене неисправного накопителя не нужно будет ничего настраивать. Восстановление дискового массива начнётся автоматически.
Если у вас выйдут из строя сразу оба накопителя, то покупаем новые, устанавливаем в системный блок, затем создаём RAID 1 заново и разворачиваем на него резервную копию.
Управление дисковым массивом работающего на аппаратном контроллере LSI MegaRAID, мы рекомендуем производить с помощью консольного клиента MegaCLI
Установка MegaCLI:
wget http://www.lsi.com/downloads/Public/RAID%20Controllers/RAID%20Controllers%20Common%20Files/.zip
unzip 8.07.07_MegaCLI.zip
cd 8.07.07_MegaCLI/
chmod +x MegaCli
Основные команды для работы:
Получить статус и конфигурацию всех адаптеров
megacli -AdpAllInfo -aAll
Cтатус и параметры всех логических дисков
megacli -LDInfo -LAll -aAll
Статус и параметры физических устройств
megacli -PDList -a0
Статус и параметры диска в 4-м слоте
megacli -pdInfo -PhysDrv[252:4] -a0
Создание RAID6 массив MegaCLI
Давайте предположим, что у нас есть сервер с MegaRAID SAS
Получим список физических дисков:
megacli -PDlist -a0 | grep -e ‘^Enclosure Device ID:’ -e ‘^Slot Number:’
Enclosure Device ID: 29
Slot Number: 0
Enclosure Device ID: 29
Slot Number: 1
Enclosure Device ID: 29
Slot Number: 2
Enclosure Device ID: 29
Slot Number: 3
Enclosure Device ID: 29
Slot Number: 4
Enclosure Device ID: 29
Slot Number: 5
Enclosure Device ID: 29
Slot Number: 6
Enclosure Device ID: 29
Slot Number: 7
Enclosure Device ID: 29
Slot Number: 8
Enclosure Device ID: 245
Slot Number: 12
Пример конфигурирования JBOD на LSI 2208 (Supermicro X9DRH-7TF) При загрузке BIOS эти команды можно выполнить если зайти в preboot CLI по комбинации клавиш Ctrl+Y
Команды megacli и preboot CLI различаются по виду.
Например команда проверки поддержки JBOD для BIOS preboot CLI будет выглядеть так:
AdpGetProp enablejbod -aALL
А для megacli это используется как набор опций и параметров:
megacli -AdpGetProp enablejbod -aALL
Включить поддержку JBOB
megacli -AdpSetProp EnableJBOD 1 -aALL
Список доступных физических устройств:
megacli -PDList -aALL -page24
В списке надо найти значения полей Enclosure Device ID (например 252), Slot Number и Firmware state
Нужно отметить каждое из устройств которое надо сделать JBOD, как Good в поле Firmware state .
megacli -PDMakeGood -PhysDrv[252:0] -Force -a0
Или сразу много устройств:
megacli -PDMakeGood -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -Force -a0
Теперь можно создавать JBOD
megacli -PDMakeJBOD -PhysDrv[252:0] -a0
megacli -PDMakeJBOD -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -a0
Создать виртуальный диск RAID
Перед настройкой массива, возможно, потребуется удалить использованную ранее конфигурацию. Для того чтобы просто удалить логические устройства используйте CfgLdDel
megacli -CfgLdDel -Lall -aAll
Для того чтобы удалить всё (в том числе политику кэша) используйте «Очистку конфигурации»
megacli -CfgClr -aAll
Настройка RAID-0, 1 или 5. Вместо «r0» введите соответственно «r1» или «r5» (диски находятся в Enclosure 29, на портах 0 и 1, WriteBack включен, ReadCache адаптивный, Cache также включен без BBU)
megacli -CfgLdAdd -r0 [29:0,29:1] WB ADRA Cached CachedBadBBU -sz196GB -a0
Создать RAID10 Получить список дисков
megacli -PDList -aAll | egrep «Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state»
Создать массив из 6 дисков
megacli -CfgSpanAdd -r10 -Array0[252:0,252:1] -Array1[252:2,252:4] [-Array2[252:5,252:6] -a0
Показать как диски были определены в RAID-массиве:
megacli -CfgDsply -a0
Удалить массив с ID=2
MegaCli –CfgLDDel -L2 -a0
Инициализация массива Начать полную инициализацию для массива с ID=0
MegaCli -LDInit -Start -full -L0 -a0
Проверить текущий статус инициализации:
MegaCli -LDInit -ShowProg -L0 -a0
Управление CacheCade
Создать и назначить CacheCade для массива 0 (-L0) из зеркала (-r1) в режиме обратной записи (WB) на основе SSD дисков в слотах 6 и 7 (-Physdrv[252:6,252:7])
megacli -CfgCacheCadeAdd -r1 -Physdrv[252:6,252:7] WB -assign -L0 -a0
Включить
megacli -Cachecade -assign -L0 -a0
Отключить
megacli -Cachecade -remove -L0 -a0
Successfully removed VD from Cache
Просмотреть состояние:
megacli -CfgCacheCadeDsply -a0
megacli -LDInfo -LAll -a0
Замена неисправного диска
Отключить писк:
megacli -AdpSetProp -AlarmSilence -a0
Обратите внимание, что это не навсегда отключает сигнализацию, а просто выключает сигнал по текущей аварии.
Просмотреть состояние диска (подставьте нужное значение [E:S]):
megacli -pdInfo -PhysDrv [29:8] -a0
Пометить диск требующий замены как потерянный (если контроллер не сделал этого сам)
megacli -PDMarkMissing -PhysDrv [E:S] -aN
Получить параметры потерянного диска
megacli -Pdgetmissing -a0
Вы должны получить ответ подобный этому:
Adapter 0 — Missing Physical drives
No. Array Row Size Expected
0 0 4 1907200 MB
Подсветить диск который надо менять (подставьте нужное значение [E:S]):
megacli -PdLocate -start -PhysDrv [29:8] -a0
На некоторых шасси могут быть проблемы с индикацией. Это лечится такой командой:
megacli -AdpSetProp {UseDiskActivityforLocate -1} -aALL
В этом случае для маркировки диска будет использоваться лампочка активности.
Удаляем неисправный и вставляем новый диск.
Прекращаем подсветку и проверяем состояние диска:
megacli -PdLocate -stop -PhysDrv [29:8] -a0
megacli -pdInfo -PhysDrv [29:8] -a0
Может так случится, что он содержит метаданные от другого массива RAID (Foreign Configuration). Ваш контроллер не позволит использовать такой диск. Для проверки наличия Foreign Configuration
megacli -CfgForeign -Scan -aALL
Команда удаления Foreign Configuration (если вы уверены)
megacli -CfgForeign -Сlear -aALL<code>
Запускаем процесс замены
<code>megacli -PdReplaceMissing -PhysDrv [32:4] -Array0 -row4 -a0
[32:4] — это параметры диска которым вы меняете неисправный
Rebuild drive
megacli -PDRbld -Start -PhysDrv [32:4] -a0
Проверка процесса ребилда
megacli -PDRbld -ShowProg -PhysDrv [32:4] -a0
Использование smartctl
Получить список id
megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’
Получить данные смарт по диску с ID=9
smartctl /dev/sda -d megaraid,9 -a
для диска с интерфейсом sata
smartctl /dev/sda -d sat+megaraid,9 -a
пример скрипта для получения данных о всех дисках
#!/bin/sh
for arg in `megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’`
do
smartctl /dev/sda -d sat+megaraid,${arg} -l devstat
#smartctl /dev/sda -d sat+megaraid,${arg} -a
done
Для контроля состояния дисков с помощью демона smartd нужно закомментировать DEVICESCAN в /etc/smartd.conf и добавить:
/dev/sda -d sat+megaraid,0 -a -s L/../../3/02
/dev/sda -d sat+megaraid,1 -a -s L/../../3/03
/dev/sda -d sat+megaraid,2 -a -s L/../../3/04
/dev/sda -d sat+megaraid,3 -a -s L/../../3/05
Значения параметров типа /3/02 — /3/05 определяют время запуска тестов для заданного диска
Соберу в одном месте список полезных команд для mdadm.
mdadm — утилита для управления программными RAID-массивами в Linux.
С помощью mdadm можно выполнять следующие операции:
- mdadm —create, C Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
- mdadm —assemble, -A Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
- mdadm —build, -B Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
- mdadm —manage Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
- mdadm —misc Действия, которые не относятся ни к одному из других режимов работы.
- mdadm —grow, G Расширение или уменьшение массива, включаются или удаляются новые диски.
- mdadm —incremental, I Добавление диска в массив.
- mdadm —monitor, —follow, -F Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
И другие: mdadm —help.
Формат вызова:
mdadm [mode] [array] [options]
Создание массива
Для создания массива нужно использовать не смонтированные разделы. Убедитесь в этом, при необходимости демонтируйте и уберите из fstab.
Пример создания RAID5 массива из трёх дисков:
- /dev/nvme0n1
- /dev/nvme1n1
- /dev/nvme2n1
Я использую NVMe диски, у вас названия дисков будут другие.
Желательно изменить тип разделов на FD (Linux RAID autodetect). Это можно сделать с помощью fdisk (t).
Занулить суперблоки дисков:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Стереть подпись и метаданные:
wipefs --all --force /dev/nvme0n1
wipefs --all --force /dev/nvme1n1
wipefs --all --force /dev/nvme2n1С помощью ключа —create создать RAID5 массив:
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1где:
- /dev/md0 — массив, который мы создаём;
- —level 5 — уровень RAID;
- —raid-devices=3 — количество дисков, из которых собирается массив;
- /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 — диски.
Для примера RAID1 из двух дисков /dev/sdb и /dev/sdc можно создать так:
mdadm --create --verbose /dev/md2 -l 1 -n 2 /dev/sd{b,c}где:
- /dev/md2 — массив, который мы создаём;
- -l 5 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd{b,c} — диски sdb и sdc.
Состояние массива
Посмотреть инициализацию массива и текущее состояние можно с помощью команды:
cat /proc/mdstatПример 1:
root@ch01:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md127 : active raid1 nvme1n1[1] nvme0n1[0]
3750607192 blocks super 1.2 [2/2] [UU]
unused devices: <none>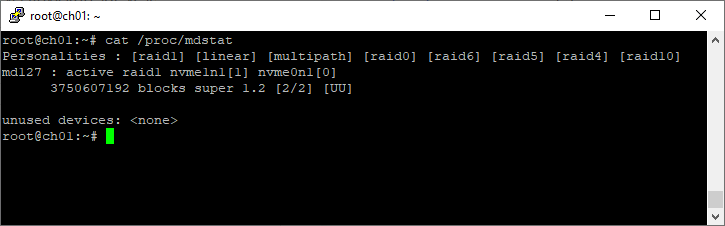
Пример 2:
[root@dbk00 ~]# cat /proc/mdstat
Personalities : [raid1] [raid0]
md10 : active raid0 sdb1[1] sda1[0]
70319335424 blocks super 1.2 512k chunks
md20 : active raid0 sdc1[0] sdd1[1]
70319335424 blocks super 1.2 512k chunks
md126 : active raid1 sde[1] sdf[0]
927881216 blocks super external:/md127/0 [2/2] [UU]
md127 : inactive sdf[1](S) sde[0](S)
10402 blocks super external:imsm
unused devices: <none>Подробный статус выбранного массива
mdadm --detail /dev/md2Пример:
root@ch01:~# mdadm --detail /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Wed May 6 16:39:32 2020
Raid Level : raid1
Array Size : 3750607192 (3576.86 GiB 3840.62 GB)
Used Dev Size : 3750607192 (3576.86 GiB 3840.62 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Fri Aug 14 17:09:47 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : VirtualDisk01
UUID : 1728ebed:ad0b0000:faad83b7:37070000
Events : 173
Number Major Minor RaidDevice State
0 259 0 0 active sync /dev/nvme0n1
1 259 1 1 active sync /dev/nvme1n1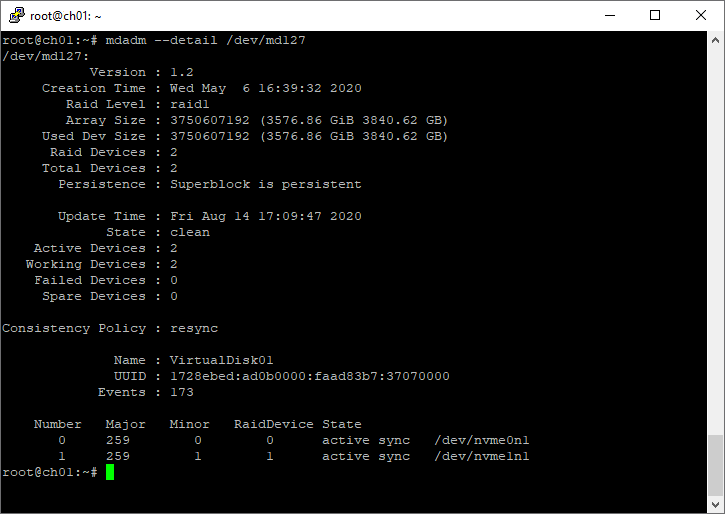
Список массивов
mdadm --detail --scan --verboseПример:
root@ch01:~# mdadm --detail --scan --verbose
ARRAY /dev/md/VirtualDisk01 level=raid1 num-devices=2 metadata=1.2 name=VirtualDisk01 UUID=1728ebed:ad0b0000:faad83b7:37070000
devices=/dev/nvme0n1,/dev/nvme1n1
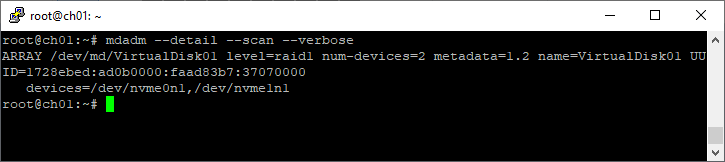
Создание файловой системы
Файловую систему в массиве можно создать с помощью mkfs, например:
mkfs.ext4 -m 0 /dev/md0Для лучшей производительности файловой системы имеет смысл указывать при её создании количество дисков в рейде и количество блоков файловой системы, которое может поместиться в один страйп (chunk), это касается массивов уровня RAID0, RAID5 ,RAID6 ,RAID10. Для RAID1 (mirror) это не имеет значения так как запись идет всегда на один device, a в других типах массивов данные записываются последовательно на разные диски порциями, соответствующими размеру stripe. Например, если мы используем RAID5 из 3 дисков с дефолтным размером страйпа в 64К и файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext3 так:
mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0stripe-width обычно рассчитывается как
stride * N
где N — это диски с данными в массиве, например, в RAID5 два диска с данными и один parity для контрольных сумм. Для файловой системы XFS нужно указывать не количество блоков файловой системы, соответствующих размеру stripe в массиве, а размер самого страйпа:
mkfs.xfs -d su=64k,sw=3 /dev/md0Создание mdadm.conf
Операционная система не запоминает какие RAID-массивы ей нужно создать и какие диски в них входят. Эта информация содержится в файле mdadm.conf.
mkdir /etc/mdadm
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.confВ интернете советуют применять команду mdadm —detail —scan —verbose, но я не рекомендую, т.к. она пишет в конфигурационный файл названия разделов, а они в некоторых случаях могут измениться, тогда RAID-массив не соберётся. А mdadm —detail —scan записывает UUID разделов, которые не изменятся.
Проверка целостности массива
echo 'check' >/sys/block/md0/md/sync_actionЕсть ли ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cntРабота с дисками
Диск в массиве можно условно сделать сбойным с помощью ключа —fail (-f):
mdadm /dev/md0 --fail /dev/nvme0n1
mdadm /dev/md0 -f /dev/nvme0n1Удалить из массива отказавший диск:
mdadm /dev/md0 --remove /dev/nvme0n1
mdadm /dev/md0 -r /dev/nvme0n1Добавить в массив заменённый диск:
mdadm /dev/md0 --add /dev/nvme0n1
mdadm /dev/md0 -a /dev/nvme0n1Сборка существующего массива
Собрать существующий массив можно с помощью mdadm —assemble:
mdadm --assemble /dev/md0 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1
mdadm --assemble --scanРасширение массива
Расширить массив можно с помощью ключа —grow (-G). Сначала добавляется диск, а потом массив расширяется:
mdadm /dev/md0 --add /dev/nvme3n1Проверяем, что диск добавился:
mdadm --detail /dev/md0
cat /proc/mdstatЕсли диск добавился, расширяем массив:
mdadm -G /dev/md0 --raid-devices=4Опция —raid-devices указывает новое количество дисков в массиве с учётом добавленного. Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например, добавить опцию:
--backup-file=/var/backup
При необходимости, можно регулировать скорость процесса расширения массива, указав нужное значение в файлах:
- /proc/sys/dev/raid/speed_limit_min
- /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
cat /proc/mdstatНужно обновить конфигурационный файл с учётом сделанных изменений:
mdadm --detail --scan >> /etc/mdadm/mdadm.confВозобновление отложенной синхронизации resync=PENDING
Если синхронизации массива отложена, состояние массива resync=PENDING, то синхронизацию можно возобновить:
echo idle > /sys/block/md0/md/sync_actionили
mdadm --readwrite /dev/md0Переименовать массив
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Собираем массив с новым именем:
mdadm --assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 --update=nameИли для старых версий:
mdadm –assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 –update=super-minorУдаление массива
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Затем необходимо затереть superblock каждого из составляющих массива:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Или с помощью dd:
dd if=/dev/zero of=/dev/nvme0n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme1n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme2n1 bs=512 count=1Содержание
- Как проверить raid массив windows
- Поиск и замена диска поврежденного диска в Raid-1
- Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
- Элементы управления окна Проверка корректности RAID
- Мониторинг raid массивов в Windows Core
- Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
- Настройка RAID
- Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
- Пару слов о дисках и мат. плате
- Пример настройки RAID 0 в BIOS
- Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Как проверить raid массив windows

Сообщения: 26925
Благодарности: 3917
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.

Сообщения: 8627
Благодарности: 2126
А посмотреть в Диспетчере Устройств?
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″> » width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 8627
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
Источник
Рассмотрим порядок действий проверки дисков выделенного сервера, с которого пришла ошибка SMART, выявления и замены неисправного диска в массиве Raid-1.

в данном примере всё с raid всё в порядке. Если бы было так: [U_], то диск sdb неисправен, если так: [_U], то sda (смотрим порядок в md-устройствах, например: md2 : active raid1 sda3[2] sdb3[3])
[X] меняем на a или b в зависимости от диска, список дисков можно посмотреть командой:
Оцениваем состояние диска по параметрам и выявляем неисправный, смотрим:

В зависимости от количества разделов выполняем соответственно для разных разделов:
Далее команда на удаление из RAID
Для проверки типа разбиения надо выполнить следующую команду:
на не замененном диске
После этого выполнить команду:
(для MBR), и
(структура разделов в этой команде копируется из /dev/sda в /dev/sdb)
(для GPT)
Источник
Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
Чтобы проверить целостность данных RAID
| * | Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID. контекстного меню |
| > | Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |

Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
Блок четности RAID корректен.
Блок четности RAID некорректен.
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.
 Элементы управления окна Проверка корректности RAID
Элементы управления окна Проверка корректности RAID
 Элементы управления окна Проверка корректности RAID
Элементы управления окна Проверка корректности RAID Номер первого сектора в ряде.
Переход к предыдущей/следующей порции данных.
Источник
Мониторинг raid массивов в Windows Core

За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:

UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Источник
Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
 Доброго дня!
Доброго дня!
Согласитесь, звучит заманчиво?! Однако, многим пользователям слово «RAID» — либо вообще ничего не говорит, либо напоминает что-то такое отдаленное и сложное (явно-недоступное для повседневных нужд на домашнем ПК/ноутбуке). На самом же деле, все проще, чем есть. 👌 (разумеется, если мы не говорим о каких-то сложных производственных задачах, которые явно не нужны на обычном ПК)
Собственно, ниже в заметке попробую на доступном языке объяснить, как можно объединить диски в эти RAID-массивы, в чем может быть их отличие, и «что с чем едят».

Настройка RAID
Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
Обратите внимание также на табличку ниже.


Разумеется, видов RAID-массивов гораздо больше (RAID 5, RAID 6, RAID 10 и др.), но все они представляют из себя разновидности вышеприведенных (и, как правило, в домашних условиях не используются).
Пару слов о дисках и мат. плате
Не все материнские платы поддерживают работу с дисковыми массивами RAID. И прежде, чем переходить к вопросу объединению дисков, необходимо уточнить этот момент.
Как это сделать : сначала с помощью спец. утилит (например, AIDA 64) нужно узнать точную модель материнской платы компьютера.
Далее найти спецификацию к вашей мат. плате на официальном сайте производителя и посмотреть вкладку «Хранение» (в моем примере ниже, мат. плата поддерживает RAID 0, RAID 1, RAID 10).

Спецификация материнской платы
Если ваша плата не поддерживает нужный вам вид RAID-массива, то у вас есть два варианта выхода из положения:

RAID-контроллер (в качестве примера)
Важная заметка : RAID-массив при форматировании логического раздела, переустановки Windows и т.д. — не разрушится. Но при замене материнской платы (при обновлении чипсета и RAID-контроллера) — есть вероятность, что вы не сможете прочитать информацию с этого RAID-массива (т.е. информация не будет недоступна. ).
Что касается дисков под RAID-массив :
Пример настройки RAID 0 в BIOS
Важно : при этом способе информация с дисков будет удалена!
Примечание : создать RAID-массив можно и из-под Windows (например, если вы хотите в целях безопасности сделать зеркальную копию своего диска).
1) И так, первым делом необходимо подключить диски к компьютеру (ноутбуку). Здесь на этом не останавливаюсь.
2) Далее нужно зайти в BIOS и установить 2 опции:
Затем нужно сохранить настройки (чаще всего это клавиша F10) и перезагрузить компьютер.


Intel Rapid Storage Technology

Create RAID Volume
5) Теперь нужно указать:
После нажатия на кнопку Create Volume — RAID-массив будет создан, им можно будет пользоваться как обычным отдельным накопителем.


Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Рассмотрю ниже пару конкретных примеров.
2) Открываете управление дисками (для этого нужно: нажать Win+R, и в появившемся окне ввести команду diskmgmt.msc).
3) Теперь действия могут несколько отличаться.
Вариант 1 : допустим вы хотите объединить два новых диска в один, чтобы у вас был большой накопитель для разного рода файлов. В этом случае просто кликните правой кнопкой мышки по одному из новых дисков и выберите создание чередующегося тома (это подразумевает RAID 0). Далее укажите какие диски объединяете, файловую систему и пр.

Создать чередующийся или зеркальный том

Вариант 2 : если же вы беспокоитесь за сохранность своих данных — то можно подключенный к системе новый диск сделать зеркальным вашему основному диску с ОС Windows, причем эта операция будет без потери данных (прим.: RAID 1).

4) После Windows начнет автоматическую синхронизацию накопителей: т.е. с выбранного вами раздела все данные будут также скопированы на новый диск.

5) В общем-то, всё, RAID 1 настроен — теперь при любых изменениях файлов на основном диске с Windows — они автоматически будут синхронизированы (перенесены) на второй диск.
6) Удалить зеркало, кстати, можно также из управления дисками : пример на скрине ниже.
Источник
Adblock
detector
| RAID 0 (распределение) | RAID 1 (зеркалирование) |
The point of RAID with redundancy is that it will keep going as long as it can, but obviously it will detect errors that put it into a degraded mode, such as a failing disk. You can show the current status of an array with mdadm --detail (abbreviated as mdadm -D):
# mdadm -D /dev/md0
<snip>
0 8 5 0 active sync /dev/sda5
1 8 23 1 active sync /dev/sdb7
Furthermore the return status of mdadm -D is nonzero if there is any problem such as a failed component (1 indicates an error that the RAID mode compensates for, and 2 indicates a complete failure).
You can also get a quick summary of all RAID device status by looking at /proc/mdstat. You can get information about a RAID device in /sys/class/block/md*/md/* as well; see Documentation/md.txt in the kernel documentation. Some /sys entries are writable as well; for example you can trigger a full check of md0 with echo check >/sys/class/block/md0/md/sync_action.
In addition to these spot checks, mdadm can notify you as soon as something bad happens. Make sure that you have MAILADDR root in /etc/mdadm.conf (some distributions (e.g. Debian) set this up automatically). Then you will receive an email notification as soon as an error (a degraded array) occurs.
Make sure that you do receive mail send to root on the local machine (some modern distributions omit this, because they consider that all email goes through external providers — but receiving local mail is necessary for any serious system administrator). Test this by sending root a mail: echo hello | mail -s test root@localhost. Usually, a proper email setup requires two things:
-
Run an MTA on your local machine. The MTA must be set up at least to allow local mail delivery. All distributions come with suitable MTAs, pick anything (but not nullmailer if you want the email to be delivered locally).
-
Redirect mail going to system accounts (at least
root) to an address that you read regularly. This can be your account on the local machine, or an external email address. With most MTAs, the address can be configured in/etc/aliases; you should have a line likeroot: djsmiley2kfor local delivery, or
root: djsmiley2k@mail-provider.example.comfor remote delivery. If you choose remote delivery, make sure that your MTA is configured for that. Depending on your MTA, you may need to run the
newaliasescommand after editing/etc/aliases.
Специалисты ГК «Интегрус» специализируются на диагностике и восстановлении данных с RAID массива любого уровня, обладая опытом работы с механическими и логическими повреждениями, спасая информацию даже в самых безнадежных случаях.

Информация – безусловная ценность, поэтому ее сохранность обеспечивается всеми доступными способами, в том числе с использованием систем хранения критически важных данных. RAID-массивы представляют собой технологию, объединяющую два или более накопителей в единую логическую систему для повышения производительности и отказоустойчивости.
Использование RAID массивов доказало свою эффективность, в результате чего они создаются на всех доступных хранилищах данных (NAS, серверах). При любой конфигурации массива он собирается из полностью идентичных носителей, соединенных контроллером.
Для бюджетных моделей чаще всего выбирается самый простой алгоритм работы, что снижает уровень безопасности и требует более частого ремонта. Использование продвинутых моделей увеличивает надежность, но не является панацеей.
Основные причины неисправности RAID
Нельзя гарантировать 100% работоспособности даже самой надежной техники. Благодаря установке различных защит, повреждение массивов происходит нечасто. В тех случаях, когда массив получил повреждение, необходимо выбрать правильную тактику поведения, чтобы восстановить RAID без потери данных.
В RAID массивах данные хранятся на стандартных дисках, таких же, как и в обычных ПК. Благодаря используемой технологии и оперативной передаче неисправных носителей в специализированную лабораторию, потеря данных случается крайне редко.
Восстановление RAID массивов остается длительным процессом, там как скорость работы заметно снижается, и может потребовать отключения питания для замены поврежденного носителя. Для серверов такое развитие событий нежелательно. Именно поэтому нужно знать причины неисправностей, чтобы избежать проблем в будущем.
Проблемы c RAID контроллером
Контроллер распределяет данные и создает из отдельных дисков единый массив. Программные контроллеры более дешевые, чаще выходят из строя. Аппаратные – надежны, но дороги, и к тому же они несовместимы с аналогичными моделями других компаний.
Для восстановления RAID дисков потребуется приобрести модель той же фирмы, какая была установлена ранее. Если этого не сделать массив придется восстанавливать заново, потеряв информацию.
Выйти из строя контроллер может из-за бросков или резкого отключения напряжения. Наличие бесперебойного источника питания помогает решить проблему, но не снимает ее до конца.
Ошибка сборки/пересборки
Каждая перезагрузка вынуждает массив пересобираться заново. Любой форс-мажор в процессе пересборки приводит к разрушению RAID. Если коробки RAID-контроллера или NAS сбоят, диск выпадает из массива, теряется конфигурация. Попытка пересоздания рейда усугубляет проблему.
Неисправность диска
Массивы защищены в случае поломки одного накопителя, но выход из строя нескольких дисков приводит к потере работоспособности и данных. Регулярная профилактика состояния винчестеров снижает риск разрушения RAID.
Проблемы логики
Чередование данных между накопителями в пределах логического тома обеспечивает нормальное функционирование массива. При удалении данных, некорректном форматировании повреждается файловая система, а массив не может собраться из-за невозможности определить диски.
Сбой сервера
Неисправность или сбой сервера в большинстве случаев приводит к необходимости восстанавливать RAID с использованием стороннего программного обеспечения.
В число других причин, влекущих необходимость восстановления RAID, входят ошибки пользователя и невнимательность системных администраторов, вредоносное ПО, использование некачественного оборудования, неполадки со SMART, внешнее воздействие, неудачный запуск утилит.
Большинство массивов умеют обнаруживать неисправность HDD, а цепная реакция, когда из-за выхода из строя одного диска вылетают другие, маловероятна (такое развитие событий опасно только для RAID 0, не имеющего избыточности). Чаще всего повреждение касается логики или программной части массива.
Как восстановить RAID массив
На процесс восстановления влияют:
- количество HDD;
- причина неисправности;
- файловая система ОС;
- уровень RAID;
- тип контроллера.
Чаще всего используют три вида массивов: RAID 1, RAID 10, RAID 5, хотя неисправность вероятна и на уровнях 2, 3, 4, 6, 0, а также их комбинациях 01, 10, 50, 05, 60, 06.
Программное восстановление
Чаще всего для восстановления данных RAID используются программные способы. Несмотря на то, что его часто рекомендуют для начинающих сисадминов, он сложен и трудоемок.
Общий алгоритм действий выглядит следующим образом:
- оценивается состояние дисков и подбираются допустимые операции;
- пригодные для анализа диски в режиме чтения подключаются в систему;
- выясняются точные параметры массива – от порядка дисков до узора контрольных сумм (чем опытнее специалист, тем больше он видит данных для анализа);
- с некорректно работающих дисков снимаются посекторные образы;
- определяются неактуальные диски, отсутствие которых не сразу повлияло на массив;
- имитируется при помощи ПО корректная работа RAID;
- создается рабочий образ с виртуального массива.
Утилита raid data (или аналогичное приложение Recovery Diskinternals) для решения простых задач, например, восстановления RAID информации с внешнего накопителя.
- подсоединить диски к ПК;
- подключить их в нужной последовательности (не более пяти);
- подключить резервный носитель, выбранный в качестве хранилища;
- запустить ОС;
- определить настройки при помощи RAID Reconstructor;
- запустить лицензионное приложение R-Studio;
- добавить участников RAID, выполнить настройки;
- при верной установке параметров появятся разделы, готовые к восстановлению.
Восстановление RAID через mdadm для ОС Linux. Утилита управляет программными массивами:
- определить наличие повреждений и диск под замену # cat /proc/mdstat (проблему листинг команды определяет как [U_];
- запросить подробную информацию о массиве # mdadm -D /dev/md0 (статус clean, degraded означает повреждение RAID);
- убрать неисправный диск # mdadm /dev/md0 —remove /dev/vdc и добавить новый # mdadm /dev/md0 —add /dev/vdd;
- восстановление запускается автоматически после замены # mdadm -D /dev/md0.
В некоторых случаях в массив при помощи утилиты можно добавить запасной диск для «горячей замены».
После некорректного отключения или перезагрузки, когда система перестает видеть массив, но определяет входящие в него диски, при помощи mdadm пересоздается RAID. Для этого потребуется:
- восстановить связь дисков;
- просканировать их;
- вписать вывод в конфигурационный файл рейда;
- смонтировать файловые системы, обозначенные в fstab;
- проверить правильность примонтированных дисков.
Несмотря на надежность NAS хранилищ, может возникнуть необходимость восстановления RAID на QNAP. В результате случайного удаления данных, сбоя системы или неисправности аппаратной части устройства критически важная информация теряется. Для ее восстановления при корректной работе хранилища файлы восстанавливаются из сетевой корзины, если такая возможность настроена заранее.
В тех случаях, когда QNAP не включается и извлечь информацию простым путем не получается, надо заменять устройство. Выполнение процедуры не гарантирует сохранности данных после настройки нового сервера, хотя шансы спасти информацию достаточно велики.
Для восстановления RAID на QNAP при выходе из строя контроллера или аппаратной части устройства, а также полоски несколько накопителей можно использовать Hetman RAID Recovery. Потребуется винчестер с объемом не меньше объема данных, хранящихся в массиве, и последовательное выполнение ряда действий:
- подключить диски с ПК с ОС Windows (при отсутствии достаточного количества портов использовать расширители или разветвители);
- запустить программу, которая просканирует диски и соберет массив;
- запустить быстрый анализ дисков (если нужные для восстановления RAID файлы не обнаружены потребуется полный анализ);
- выбрать в каталоге Multimedia файлы, подлежащие восстановлению, и путь сохранения.
Восстановить RAID на контроллере материнской платы Intel, когда требуется заменить неисправный диск, можно через Intel Rapid Storage Technology. В меню будут отображаться с серийными номерами все накопители, в том числе и нерабочий.
- Выключить ПК, отключить дефектный диск.
- Переподключить новый диск, перезапустить ПК.
- Intel RST предложит исправить массив, добавив вновь подключенный диск для восстановления.
Если выяснится, что диск из массива исключен неверно, массив получит повреждения. Для восстановления данных потребуется запустить утилиту Hetman RAID Recovery. Программное обеспечение работает для массивов всех уровней, вычитая параметры RAID и информацию о материнке, на основе которой создан.
Разработчики упрощают решение типовых проблем, но не во всех случаях программное восстановление способно помочь.
Аппаратное восстановление
Этот способ восстановления данных с жесткого диска RAID требует опыта работы с «черным ящиком», так как малейшая ошибка приводит к фатальным последствиям. В этом случае массив воссоздается «на железе», с восполнением недостающих участков за счет образов и использованием ПО для исправления разрушения логической структуры. Любые упрощения алгоритма приводят к полной потере данных.
- Уточняются параметры RAID массива – порядок винчестеров, размеры блоков, рабочие алгоритмы, узоры контрольных сумм. Исключается все ненужное, пересчитывается недостающее.
- Делаются посекторные копии для всех дисков массива.
- Массив заново создается на другом, абсолютно идентичном контроллере. Если использовать ребилд, есть все шансы потерять данные безвозвратно.
- При выборе контроллера учитывается тот факт, что некоторые модели автоматически запускают инициализацию. Это критично для данных.
- Все носители должны быть исправны – только в этом случае процесс будет успешно завершен, а данные – спасены.
- При частичном восстановлении данных применяют программные средства.
Что делать, чтобы восстановление RAID прошло успешно
Гарантированно избежать потери данных можно, регулярно создавая резервные копии. Если критически важные файлы не были сохранены заранее, не стоит заниматься самостоятельными попытками спасти информацию. Самостоятельные попытки спасения массива снижают шансы на восстановление данных с RAID.
Категорически нельзя:
- запускать утилиту chkdsk при механической неисправности диска;
- применять программы восстановления данных без предварительной диагностики проблемы;
- пересоздавать новый RAID на старых дисках;
- выполнять пересборку при разрушении файловой системы;
- вести запуск на носители после обнаружения проблемы;
- запускать автоматическую инициализацию.
Квалифицированные инженеры, обладающие опытом и знаниями по восстановлению массивов, разрабатывают индивидуальную стратегию в каждом конкретном случае. Даже при типовом повреждении требуется применение различных методик, чтобы восстановить RAID без потери данных в кратчайший срок.

Присоединяйтесь к нам, чтобы каждую неделю получать полезные и рабочие материалы для улучшения вашего бизнеса.
Кейсы и стратегии от экспертов рынка.
Время на прочтение
4 мин
Количество просмотров 6.3K
Те, кому пришлось восстанавливать данные с неисправного тома RAID, часто спрашивают, какой тип массива выбрать в дальнейшем? Однако это не совсем корректный вопрос. Тип массива, вопреки распространенному мнению, не так уж и важен. В целом, дальнейшие действия вращаются больше вокруг вашей стратегии резервного копирования данных и тактики, которая будет использована в вашем плане хранения данных.
В хранении данных стратегия резервного копирования включает в себя следующее:
-
Какие данные должны быть скопированы, а какие нет.
-
Как часто происходит резервное копирование.
-
Требуется ли управление версиями.
-
Как быстро понадобятся данные в случае поломки.
Тактика включает в себя то, как реализуется выбранная бэкап-стратегия. Например, будет ли это онлайн-бэкап или просто внешний жесткий диск? Некорректная стратегия резервного копирования, так же, как и неподходящая тактика, может «укусить» вас, если не будет выбрана осмысленно.
Стратегия резервного копирования
Выбор стратегии резервного копирования зависит от данных – их важности, объема, частоты изменения и других характеристик. Так, например, стратегия хранения семейного фотоархива фундаментально отличается от стратегии хранения постоянно изменяющихся файлов, таких как сборки приложений.
Здравый смысл может говорить нам, что бэкап нужен для всего. Но бывают случаи, когда отсутствие резервной копии вполне себе верное решение. Например, мы не копируем некоторые тома RAID, хранящие тестовый набор файлов и папок. Эти данные малоценны и могут быть воссозданы в случае необходимости.
После создания резервной копии уровень RAID совершенно не важен, потому что RAID – это не бэкап! Вместо этого главной заботой становится управление версиями, потому что RAID сразу же автоматически передает любое изменение данных, включая ошибки, на все диски в массиве. Без множества хранящихся версий ключевых данных ваш бэкап может быть поврежден и бесполезен.
Аварийная остановка
Любой системе, которая использует автоматическое копирование данных, будь то RAID или пофайловое копирование, нужен механизм аварийной остановки. Системы с этим механизмом прекращают работу или переключаются в неактивное состояние, когда происходит сбой, предотвращая дальнейшее распространение ошибок на другие системы/устройства.
Механический сбой в одном из дисков RAID, например, является случаем аварийной остановки. Как только диск перестает вращаться, он больше не может делать что-то другое. RAID-контроллер отметит, что диск оффлайн, и начнет использовать восстановление четности.
С другой стороны, сбой в памяти кэша контроллера не подразумевает аварийную остановку. Кэш предоставляет неверные данные, но контроллер не знает, что что-то не так. Неправильные данные распространяются повсюду, портя все избыточные копии. То же самое относится и к ошибке человека, поскольку система хранения данных не понимает намерений пользователя, вместо этого слепо следуя командам.
Даже если ваша система организована так, что данные копируются по расписанию на другой компьютер, который может даже находиться в другой стране, это по-прежнему RAID1 с некоторой задержкой между копиями, а не резервное копирование. Примером может послужить случай, когда не те данные сохранились в бэкапе, переписав нужные данные.
Глубина версии
Глубина версии, также известная как время хранения, – это количество времени, в течение которого хранится копия данных. Глубина версии должна быть больше, чем время между случаями реального использования данных. Например, если самое «свежее» использование файла было в 2021 году, копия, оставшаяся с того времени, должна быть в бэкапе. Если пользователю нужен доступ к этому файлу в 2022 году, а он не открывается, то с этим не будет проблем – останется резервная копия.
Распространенный сценарий ошибки заключается в том, что кнопка «Сохранить» используется для основного файла (например, шаблон документа), когда «Сохранить как» должна была использоваться для создания новой версии. Если пользователь не заметил проблему сразу же, тогда ошибка, возможно, обнаружится, когда понадобится исходный файл. Итак, повторим: глубина версии/время хранения должны быть достаточно долгими, чтобы предоставить исходную версию файла.
Очистка
Жизнь такова, что, чем дольше вы не делаете (или не проверяете) что-то, тем меньше шансов, что вы сможете сделать это в следующий раз. Системы с высоким временем безотказной работы тому пример. По мере увеличения времени безотказной работы вероятность успешного перезапуска уменьшается.
То же самое верно и для систем хранения данных. Чем дольше вы активно не работаете с данными, например, не открываете файлы и не проверяете правильность данных, тем меньше шансов, что они все еще на месте. Более того, чтобы избежать резервного копирования данных, которые уже повреждены, вы должны периодически проверять, что в бэкапе есть копия, которая все еще доступна для чтения и полезна.
Тактика
Выбор тактики обусловлен определенными требованиями для хранения данных. Обычно для домашних пользователей существуют простые решения, например, внешний жесткий диск, куда периодически копируются данные. Самая распространенная проблема в этом случае – человеческая забывчивость. Разумной альтернативой здесь могут стать онлайн-хранилища, такие как Backblaze или CrashPlan (очень удобно, но на данный момент в России не работают). Они полностью автоматизированы и часто идут со встроенным управлением версиями.
Если у вас есть подходящий план резервного копирования, вы можете безопасно использовать RAID. Если вы столкнулись со сбоем в RAID, важно выяснить, почему это произошло. Чаще всего изменение уровня RAID или переключение контроллеров не предотвращает повторение первоначальной проблемы. Самые распространенные причины сбоя в RAID – ошибка оператора (пользователя), ошибки при замене диска или ошибки при работе с программой управления RAID массивом. Уровень RAID в этих случаях имеет минимальное влияние.
Статья написана Еленой Пахомовой, одним из создателей программы для восстановления данных Volga [ссылка удалена мод.]
1. Введение
2. Небольшое отступление
3. Причины выхода RAID массивов из строя
4. Уровни RAID и принципы восстановления данных
5. Чего не стоит делать
6. Способы восстановления массивов
— программный
— аппаратный
7. Заключение
Введение
В этой статье мы рассмотрим принципы восстановление данных с RAID массивов в так называемых «простых» случаях, используя методы, которые доступны практически всем и не требуют глубоких знаний в области компьютерного «железа» и программного обеспечения. Случаи, которые можно отнести к «сложным», слишком отличаются друг от друга, и требуют индивидуального подхода, поэтому нет смысла описывать их в рамках одной статьи. Однако, можно обсудить конкретную ситуацию в предназначенном для этой цели разделе форума.
Внимание!!! Если потерянная информация критически важна, а Вы не являетесь специалистом в области восстановления данных, то настоятельно рекомендуем сразу обратиться в компанию, чьей основной областью деятельности является решение такого рода проблем.
Но если судьба данных волнует Вас меньше чем желание попробовать самостоятельно их восстановить, то эта статья для Вас.
Небольшое отступление
Рассматривая массивы, мы не можем не упомянуть о RAID контроллерах, которых сегодня великое множество, с разбросом цен от двадцати до нескольких тысяч долларов. Сравнение надёжности – вопрос сложный, но догадаться, что разница в цене «не из пальца высосана», думаю, может каждый.
Контроллеры бюджетного уровня, имеют упрощенный алгоритм работы и восстановления после сбоев, что выражается в большей вероятности потери информации. Дорогие модели заметно надёжнее, алгоритмы обработки ошибок более совершенны, но и они не безупречны.
Вопросы, касающиеся особенностей работы определённых моделей RAID контроллеров, Вы можете задать здесь.
RAID массив не является панацеей от потери информации. Практика показывает, что случаются как сбои в работе контроллера, так и сбои в работе жестких дисков, или же происходит одно вытекающее из другого. В любом случае, полностью полагаясь на надёжность массивов и не позаботившись о своевременном создании резервных копий, Вы рискуете однажды остаться без «надежно хранимой» информации.
Вероятность потери данных можно заметно уменьшить, регулярно отслеживая состояние массива и выполняя профилактические работы, но полностью свести к нулю таким образом её нельзя.
Причины выхода RAID массивов из строя
Наиболее распространённой причиной выхода из строя дисковых массивов является халатность системных администраторов, рассчитывающих на то, что «в одну воронку бомба дважды не падает». Во время работы, например RAID 5, выходит из строя один из дисков. Массив продолжает функционировать, но уже с заметным уменьшением скорости. Системный администратор, заметив сбой в работе накопителя, не очень спешит предпринимать активные действия, т.к. рассчитывает на то, что массив в таком виде еще сможет поработать некоторое время. Это порой оказывается заблуждением.
Если у Вас выходит из строя один из дисков, лучше всего немедленно произвести резервное копирование особо важных данных и потом, заменив один из накопителей, произвести ребилд массива.
Почему пришлось отметить то, что необходимо предварительно произвести бэкап? Потому что при попытке ребилда массива, иногда случается такое, что процесс «зависает». Как правило, это происходит, если в процессе чтениязаписи на одном из дисков обнаруживается бэд-блок, и контроллер не может вычитать информацию из сектора. В результате, после длительного и бесполезного ожидания, сервер перегружают. После чего выясняется, что массив полностью «развалился». Зависание в таких случаях, вероятнее всего, связано с некорректной обработкой исключительной ситуации. Как правило, описанное явление более характерно для дешевых моделей контроллеров, но встречается также и при использовании дорогого «железа».
Ещё одной распространённой причиной отказа массивов, является одновременный переход нескольких дисков в режим off-line. Как показала практика, чаще всего это происходит из-за проблем со SMART, или накопления бэд-блоков. Пока их количество не превысит определённого значения, диск работает корректно, но в один прекрасный момент массив перестает запускаться. И вроде бы все хорошо, и диск, судя по звуку, нормально стартует, и контроллером правильно определяется, но вот только непонятно, почему статус у диска off-line, массив не стартует и данные не отдает. Все из-за того, что контроллер не может считать необходимые данные с диска, либо, диагностируя SMART, определяет диск как «мертвый».
Можно привести ещё множество примеров сбоев в работе массивов, но что делать, если таки это свершилось? Информация потеряна, её необходимо восстановить.
Теория: Уровни RAID и принципы восстановления данных
Чаще всего сейчас используются массивы уровней 0, 1, 10, 5, 50. В последнее время наблюдается возрастающий интерес к шестому уровню.
Ниже приведена краткая информация о принципах работы массивов. Более подробно, об этом можно прочитать в соответствующей статье.
RAID 0 – использование чередующейся записи (страйп). Строится из двух и более накопителей. Информация записывается на все диски массива блоками определенного (8кб,16кб,32кб,64 кб, 128кб…) размера. Файлы, размер которых один блок, равномерно распределяются по двум или более дискам.
Из-за отсутствия избыточности или дублирования данных, при выходе из строя одного из дисков, восстановить информацию в полном объеме невозможно без использования данных с неисправного накопителя. Исключением будут лишь файлы, размер которых меньше размера блока. Для полноценного восстановления информации в таких случаях необходимо сначала снять данные с неисправного диска, после чего восстанавливать RAID.
В случаях, когда все диски исправны, а массив отказывается корректно работать, восстановление производится программными методами, которые описаны ниже.
RAID 1 – использование технологии зеркалирования (зеркало). Строится из двух дисков. Информация одновременно пишется на оба накопителя, каждый диск является полной копией своего собрата. В случае выхода из строя одного из дисков массив остается работоспособным.
Если происходит сбой в работе контроллера и массив перестает определяться, то восстановление данных можно выполнить, воспользовавшись советами из статьи «Простое восстановление данных». Для этого один из дисков следует подключить к компьютеру на прямую, минуя RAID контроллер. Если повезёт, после подключения Ваши данные могут оказаться доступными и без использования программ, описанных в вышеуказанной статье.
RAID 10 – это объединение уровня 0 с уровнем 1, т.е. два страйпа объединяются в зеркало. В массиве используются минимум 4 диска. Он может остаться работоспособным при выходе из строя одного из составляющих его RAID 0.
При возникновении проблемы, в первую очередь необходимо определить, с чем именно возникли неполадки – с контроллером или с дисками
Когда проблема на уровне контроллера, Вам следует определить, какие винчестеры являются парами, составляющими страйпы. Здесь важно не перепутать диски, т.к. это приведет к потерянному времени и отсутствию результата. После того, как это станет известно, берётся одна такая пара, и с неё снимается информация таким же образом, как и с самостоятельного RAID 0.
Во время эксплуатации RAID 10, случается и такое, что выходят из строя два диска. Здесь возможны следующие варианты:
1) Оба диска принадлежат к одному страйпу, контроллер корректно обрабатывает исключительную ситуацию, и массив продолжает функционировать нормально.
2) Оба диска принадлежат к одному страйпу, но массив разваливается. В этом случае просто берём исправный страйп, и программно собираем его (об этом ниже).
3) Диски принадлежат к разным страйпам, но в одном из них уцелел первый, а в другом второй накопитель. Попробуйте программно собрать из них RAID 0.
4) Вышли из строя одноимённые диски разных страйпов. Увы Один из сломанных дисков придётся отремонтировать, или каким-либо ещё образом снять с него данные. Затем программная сборка.
RAID 5 – массивы с контролем четности. Основным его достоинством является распределение блоков информации и контрольных блоков четности по всем дискам массива. Для создания такого массива требуется минимум три диска. Объём массива равен сумме объёмов составляющих его накопителей, минус один диск. Блоки контроля чётности используются для вычисления недостающей информации при выходе из строя одного из накопителей, составляющих массив. Таким образом, при утрате одного из дисков данные не теряются, и массив может продолжать работу.
Но, случается и такое, что после выхода из строя одного накопителя, контроллер неверно обрабатывает исключительную ситуацию и массив перестает корректно работать, либо полностью «падает». Подобный сбой может возникнуть также во время выполняемого после замены диска перестроения массива. Иногда в течение короткого времени после смерти первого диска, выходит из строя ещё один.
Если массив не работает, и количество неисправных дисков не более одного, то его можно собрать программно, аналогично тому, как собирается RAID 0. При выходе из строя двух накопителей, сначала потребуется восстановить работоспособность, или снять информацию на исправный диск с одного из них, и лишь затем можно заняться сборкой массива.
Практика: Чего не стоит делать
Упомянем о том, чего не стоит делать, для того, чтобы окончательно не потерять данные.
Прежде всего, не стоит создавать новый массив из старых дисков в надежде, что он запустится, и будет работать как раньше. Это может и сработать, но достаточно высока вероятность того, что контроллером будут выполнены действия, которые приведут к уже необратимой потере данных.
Запуск инициализации тоже ни к чему хорошему не приведёт, так что рекомендуется от неё отказаться, а если это не возможно, то использовать только quick init.
Чем еще можно навредить массиву? Запуском чекдиска или чего-то подобного. А вообще лучше всего помнить, что при потере информации на RAID следует отказаться от любой записи на диски. Если Вы точно не знаете, приведут ли определенные действия к утрате информации или нет, то лучше либо проконсультироваться с тем, кто это знает, либо отказаться от их выполнения.
Способы восстановления RAID
Программное восстановление RAID на примере массивов 0 и 5 уровней
Основным способом восстановления данных с RAID является программная сборка образа массива. Т.е. при помощи программных средств блоки с разных дисков выстраиваются в нужной последовательности. Порядок блоков в массиве зависит от расположения дисков на каналах и от алгоритма работы самого контроллера.
Прежде чем приступать к работе, стоит создать клоны всех дисков, дабы обезопасить себя от неверных действий. Копии можно сделать как в виде файлов, так и непосредственно на другие накопители.
Работать с копиями или оригиналами – решать Вам. Я настоятельно рекомендую использовать в работе копии, так как если на исходных носителях находятся нечитаемые или нестабильные сектора, то работа с таким дисками может значительно ухудшить их состояние или же привести к полному отказу.
Итак, приступим.
Чтобы собрать массив, необходимо знать параметры, с которыми он был создан. Это размер блока и последовательность дисков.
Если они Вам известны, то можно считать, что половина работы уже сделана, и мы сберегли кучу время для других, более приятных дел. Если нет, то придётся их подобрать.
К счастью, существуют автоматические средства поиска конфигурации и восстановления RAID, такие например, как программа RAID Reconstructor. Если задать в ней уровень массива, то она попытается найти первоначальную последовательность дисков, размер блока и предположить алгоритм записи информации на диски.
Далее опишем пошаговые действия при использовании данной утилиты.
Вот перед нами окно запущенной программы.
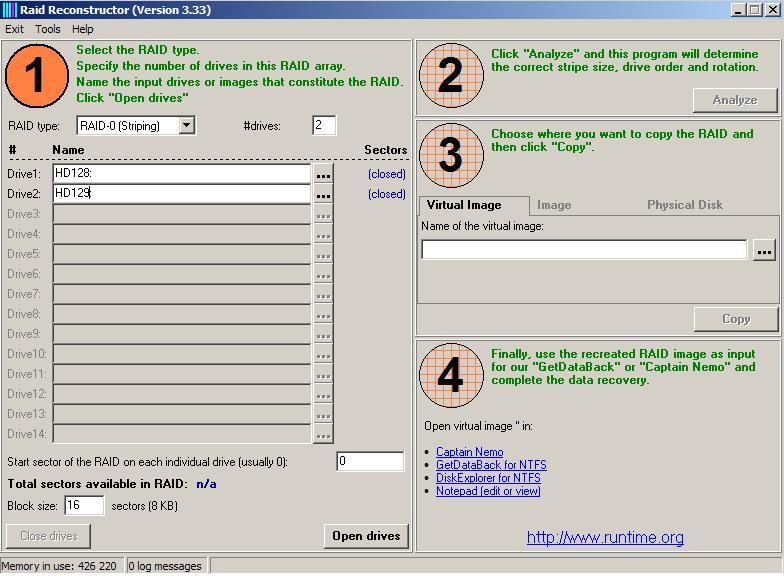
Первый шаг необходимый для начала работы – это выбор типа массива. Он осуществляется в выпадающем списке «RAID TYPE».
Задав тип массива для сборки, необходимо указать количество дисков в окошке «#drives». После того, как Вы это сделаете, ниже подсветятся белым несколько полей (их количество будет равняться количеству указанных Вами дисков). Наводим на каждое из подсвеченных окон, кликаем правой кнопкой мыши и выбираем диски, на которых находился массив. После того, как диски выбраны – переходим к пункту «Block size».
Здесь необходимо указать размер блока, если он известен, если нет, то оставляем этот пункт без изменений и смело жмем на «Open drives» и затем сразу на кнопку «Analyze».
Перед Вами появляется новое окно. В случае работы с RAID 0 такое:
Или вот такое с RAID 5:
Итак, перед нами находится окно, в котором будут задаваться параметры поиска последовательности дисков, размера блока, и, если мы собираем RAID 5, parity rotations.
Если, как было сказано выше, Вы знаете о том, на каком контроллере был создан массив, какой был использован алгоритм записи информации на диски, а также размер блока, то исключаем ненужные параметры в окошках «Block size» и «Parity rotations». Если параметры неизвестны, оставляем все как есть. Нажимаем кнопку «Next».
Начался просчет всех возможных комбинаций. По окончанию, утилита подберёт Вам наиболее верный вариант, выдав в нижней части экрана что-то типа «Recommendation: choose entry 1». Если это произошло, можно вздохнуть спокойно. Правильный алгоритм найден.
Если же нет, значит, разрушения массива достаточно серьезные, необходимо увеличить количество секторов для пробы в соответствующем поле и повторить анализ. Если и это не помогло, значит, вам поможет только специалист.
Но, продолжим. Алгоритм найден. Дальше вариантов может быть несколько. Либо переписать образ массива в файл, либо записать его на диск или массив, либо создать файл виртуального образа и продолжить его разбор в утилите Captain Nemo, Get Data Back или DiscEditor. Что выбрать – решать Вам.
Еще, как вариант, используя знания о расположении дисков, алгоритме записи и размере блока, можно восстановить RAID, используя программу под названием UFS Explorer. Руководство по использованию данного продукта можно найти в документации к нему.
Когда массив собран правильно, и файловые системы на нём не имеют логических повреждений, Вы можете получить доступ к данным стандартными способами. В частности, если образ скопирован на жесткий диск, будет достаточно подключить его к компьютеру и перезагрузить ОС (если не поддерживается горячее подключение).
Напоминаю, что изложенным выше способом можно восстановить RAID только в самых простых случаях. Описание сложных ситуаций выходит за рамки данной статьи, и подразумевает наличие специфических знаний.
Например, у Вас может не получится восстановить RAID описанным методом в случае, когда контроллер записывает в начало диска конфигурационную информацию. Не указав программе количество секторов, занятых служебными данными, можно получить неверный результат автоматического подбора конфигурации массива. Эти конфигурационные блоки являются индивидуальными для каждой модели контроллера, и точно узнать их размер можно только исследовав содержимое начальных секторов.
Аппаратное восстановление RAID
Альтернативой созданию образа может быть аппаратная сборка. Сразу оговоримся — без знания алгоритма работы контроллера, либо без наличия резервной копии абсолютно всех дисков массива, пользоваться этим «шаманским методом» категорически не рекомендуется, т.к. можно внести такие изменения на диски, в результате которых Вы уже не получите данных, даже обратившись к специалистам.
Приведённая здесь информация даётся скорее в ознакомительных целях, чем в качестве руководства к действиям.
Суть метод заключается в том, что массив пересоздается на контроллере заново, с конфигурацией, полностью аналогичной прошлой.
Внимание. Если при создании будет запущен ребилд, существует большая вероятность безвозвратной потери данных.
Некоторые модели контроллеров после создания нового массива автоматически выполняют инициализацию, что также может привести к потере данных.
Если все диски массива были исправны, то есть вероятность того, что без каких-либо дополнительных действий Вы вновь получите доступ к информации. Также не исключено, что файловая система будет частично повреждена и придется еще поработать такими утилитами как R-Studio, Get Data Back либо чем-то аналогичным.
В случаях с массивами пятого уровня, когда один из дисков неисправен, можно создать массив с заменой диска на аналогичный, исправный. Когда массив будет создан (ребилд не проводить!), после запуска операционной системы, этот диск нужно будет отключить «на горячую».
В результате, есть вероятность что Вы можете получить доступ к своим данным сразу, либо посредством использования программ для логического восстановления информации.
Заключение
В заключении ещё раз отметим – если данные очень важны, отложите эксперименты на другое время, и обратитесь к специалистам. Советуем это, зная печальный опыт многих людей.
Основное условие распространения – сохранение ссылок, содержащихся в тексте данной статьи и подписи.
Комментарии
Пожалуйста  И будет интересно чем закончилось, обязательно напишите удалось или нет.
И будет интересно чем закончилось, обязательно напишите удалось или нет.
спасибо за статью, сейчас как раз пробую востановить RAID 5, 4HDDx 320Gb
как что отпишу, действительно это очень долго, но я так понимаю просто не хватает ресурсов :-[ (жадные директора)
Валерию спасибо за консультации по телефону 
Спасибо Старался
Большое спасибо за статью. Даный материал помог мне написать реферат на тему : «Обслуживание RAID — масивов ПК» с дисциплины «Диагностика КС» (возможно отзыв позволить быстрее нагуглить эту статью нуждающимся в ней).
::) написано грамотно и доступно! Побольше таких лекций! ::)
Нет, не педагог
Наверное не педогог…А получился бы отличный…
Очень хорошая статья!!! Интересная и понеятная!
З.Ы. Вы случайно не педогог….?
Да, я сейчас планирую заняться написанием статьи о массивах. В этой статье не упоминали их т.к. доступного софта для сборки массивов уровней 1Е, 5Е пока еще нет, а статья сама именно о их восстановлении.
Толковая статья. Хорошо бы еще рассказать о массивах уровней 1Е, 5Е, 6 -они теперь часто встречаются
Описание рэйд массива и способы его восстановления
К сожалению, жесткие диски, которые являются на сегодняшний день основным хранилищем данных, не так надежны, как хотелось бы. И достаточно остро стоит проблема обезопасить свои файлы, чтобы не пришлось прибегать к восстановлению данных. Одним из путей решения этой проблемы является организация из двух и более накопителей raid массивов. Рейд массивы бывают разных конфигураций, и их создание преследует разные цели. От создания резервной копии информации, до ускорения существующей дисковой системы.
Почему может пропасть информация с RAID массива?
Основная причина, с которой мне, как инженеру по восстановлению информации приходится сталкиваться, это поломка одного или нескольких дисков рейд массива, когда перед непосредственно сборкой требуется произвести ремонт жесткого диска, вышедшего из строя. Следующая по частоте обращений с поломанным raid проблема — выход из строя рейд контроллера. Далее следуют всевозможные глюки raid контроллера, когда из рэйд массива выпадают диски (диск в raid массиве стал неактивным, получил статус degraded) и логические сбои — потеря логических томов raid или утрачена конфигурация массива. Нередко приходится сталкиваться с человеческим фактором — диски в рэйд массиве переставили местами, провели некорректную переинициализацию массива, провели неправильный ребилд рэйда.
В особо сложных случаях приходится сталкиваться с ситуациями, когда рейд массив был некорректно собран, и после такой пересборки были запущены проверочные утилиты Windows — чекдиск и им подобные.
Рассмотрим основные типы рэйд массивов:
Raid 0
Raid 0 описание
Рэйд 0 или рейд страйп (raid stripe) состоит в простейшем случае из двух дисков, блоки которых чередуются следующим образом: первые 64 килобайта на первом диске с 0-го сектора, второй блок в 64 килобайта на втором диске с 0-го сектора, третий блок опять на первом диске сразу по окончании первого, четвертый на втором диске по окончании второго блока и так далее. Размер блоков может варьироваться. За счет подобной организации массива достигается повышенная пропускная способность, по сравнению с одиночным диском, и как следствие повышается общая производительность дисковой подсистемы.

Raid 0 описание
Минимально необходимое количество дисков для создания raid0 массива — 2. При выходе из строя одного жесткого диска рэйд массив перестает функционировать, как говорится, рейд рассыпался и нужно восстановить информацию.
Восстановление raid 0
Как восстановить данные с raid0 массива? Очень просто. Определяем порядок и очередность дисков, размер блока, после чего с помощью программного обеспечения, которое может реализовывать виртуальный рэйд массив, указав все характеристики raid 0 массива, производим виртуальную сборку рэйд 0. По окончании этого процесса данные с raid 0 можно копировать на внешнее хранилище информации.
Raid 1
Raid 1 описание
Рэйд 1 или рейд зеркало, зеркальный raid массив, mirrored raid. В названии содержится его суть. Все диски массива имеют зеркальную копию содержимого raid array. Подобный raid массив имеет повышенную отказоустойчивость, и может функционировать до тех пор, пока хоть один из дисков рэйд массива продолжает работать.

Raid 1 описание
Минимально необходимое количество дисков для создания raid1 массива — 2, но в ряде случаев, в частности когда нужно программно восстановить LVM, собирается массив из одного диска с изначальным статусом degraded.
Восстановление raid 1
Не смотря на кажущуюся простоту — для того, чтобы восстановить данные с рэйд1 достаточно казалось бы восстановить информацию с любого из накопителей, на деле инженер сталкивается с необходимостью восстановления данных с наиболее актуального диска в массиве, т.к. изначально сложно сказать, какой именно диск в raid 1 массиве вышел из строя раньше и соответственно содержит устаревшие версии данных, а какой позже, и соответственно актуальность этого диска выше. В худшем случае приходится организовывать доступ к пользовательским данным на всех дисках для восстановления информации с неисправного raid 1 массива.
Raid 1e
Raid 1e описание
В raid 1E реализована функция сквозной записи блоков данных (stripe) когда каждый следующий блок записывается на следующий жесткий диск, кроме того на него же дублируется блок данных с предыдущего диска. Такая схема позволяет использовать нечетное количество дисков в рейде. При отказе одного диска в системе, потери данных не происходит. Ремонт raid 1e массива требуется при отказе более одного диска.
Raid 5
Raid 5 описание
По сути, RAID 5, пятый рэйд это тот же страйп, дополненный блоками контрольных сумм. Минимальное количество дисков для организации рейд массива пятого уровня — три HDD. Raid 5 подразделяется на forward (форвард), backward (бэквард), forward dynamic (форвард динамик) и backward dynamic (бэквард динамик). Отличия между этими типами raid 5 в очередности блоков контрольной суммы и их ротации. Отдельно стоит упомянуть про особенности восстановления raid 5 с серверов HP восстановление raid 5 hewlett Packard) где средствами контроллера организован так называемый delay, задержка, после которой собственно и начинается ротация блоков.

Raid 5 backward описание

Raid 5 forward описание

Raid 5 forward dynamic описание

Raid 5 backward dynamic описание
Минимально необходимое количество дисков для создания raid5 массива — 3. Рэйд 5 способен функционировать при выходе из строя одного диска в массиве. В этом случае замедляется скорость работы системы в целом. Появляются задержки особенно заметные при работе с базами данных. При выходе из строя двух дисков и более, raid 5 перестает работать и требуется восстановление данных.
Восстановление raid 5
Для восстановления данных с raid 5 массива требуется создание клонов по возможности всех дисков массива и сборка рейда виртуально. Порядок тот же, что и в случаях с восстановлением данных на raid 0, а именно: определение порядка дисков, размера блока и на финальных стадиях восстановления данных с рэйд 5 массива определение актуальной сборки в тех случаях, когда в массиве сперва вышел из строя один диск, какое-то время сервер работал в критическом режиме, и только потом на raid 5 отказало два диска или более.
Raid 5e
Raid 5e описание
Массив RAID 5e (RAID 5 enhanced) является усовершенствованной версией RAID5, с повышенной производительностью и сохранностью данных. Кроме резервирования места для контрольных сумм, также резервируется место для горячей замены (hot-spare). Причем, запись производится на каждый из жестких дисков и резервированное место так же есть на каждом из hdd. Таким образом , возрастает скорость работы raid-массива и каждый из жестких дисков используется равномерно. Для построения Raid 5E потребуется как минимум 4 жестких диска. Отличительная особенность массива этого уровня в том, что резервная область hot spare расположена в логическом конце физических дисков.

Raid 5-e backward описание
Восстановление raid 5e
По сравнению с обычной пятеркой рейд 5е собирается несколько сложнее, так как приходится учитывать наличие hot spare пространства. Если из массива не выпадали в процессе диски, не шел процесс самовосстановления raid массива средствами контроллера, то сборка 5e рэйд массива ни чем не отличается от обычной пятерки. Если же хот спейр пространство было использовано (или началось использоваться) то приходится этот нюанс учитывать. Но в целом базовый подход такой же — определение очередности накопителей, определения размера блока, типа ротации блоков четности и определение актуальности жестких дисков в массиве.
Raid 5ee
Raid 5ee описание
RAID 5EE отличается от RAID 5E только логической структурой расположения данных. Если в RAID 5E резервное место выделяется общим куском в конце массива, то в RAID 5EE это место делится на блоки которые ротируются с блоками контрольной суммы и блоками данных. При перестройке(rebuild) массива, такая схема расположения блоков ускоряет процесс восстановления работоспособности. Рэйд 5 ее так же весьма напоминает по своему строению raid 6 где вместо одного из блоков четности используется hot-spare блок.

Raid 5-ee backward описание
Восстановление raid 5ee
Особенности восстановления информации с такого, прямо скажем нечасто встречающегося рейд массива, каким является raid 5ee заключаются в сложности его идентификации. Если массив вышел из строя по причине поломки рэйд контроллера идентификация достаточно проста, наличие регулярно повторяющихся пустых блоков ожидаемого размера говорит само за себя. Если же в процессе работы рэйд массива вышел из строя один жесткий диск и его заменили другим, начался процесс переинициализации массива (ребилд рэйда) который закончился с ошибкой, или raid контроллер перевел массив в аварийный режим, то ранее пустые блоки могут содержать данные, рассчитанные контроллером по контрольным суммам.
Raid 6
Raid 6 описание
Дальнейшее логическое развитие пятого рэйда — raid 6, который от пятого отличается наличием двух блоков контрольных сумм, и соответственно в состоянии пережить выход из строя двух дисков в массиве. Типы ротации блоков контрольных сумм те же — forward, backward и их dynamic вариации. При выходе из строя трех дисков и больше в рэйд 6 массиве сервер перестает функционировать и требуется восстановление информации. Точно так же различают рэйд форвард, рэйд бэквард и их динамик вариации.

Raid 6 backward описание

Raid 6 forward описание
Минимально необходимое количество дисков для создания raid6 массива — 4.
Восстановление raid 6
И опять методология сходна с восстановлением информации на raid 5, проблема осложняется только тем, что из коммерческого программного обеспечения мало кто может похвастаться поддержкой восстановления данных с raid 6. Но в целом порядок тот же — определение очередности, размера блоков и выяснение степени актуальности. Кроме того, нужно отметить что на raid 6 массивах чаще чем на 5-х и уж тем более чаще чем на страйпах или рейд-зеркалах встречаются такие вещи, как слайсы, десятки виртуальных машин, малораспространенные файловые *NIX системы и прочие прелести.
Рекомендую к прочтению дополнительные материалы: восстановление raid 6 и raid 6 wide pace proNAS OS
Raid 10
Raid 10 описание
Raid 10 представляет из себя комбинацию рейдов первого и нулевого уровней. В raid 10 используется 4 (или более) жестких диска, которые попарно зеркалированы друг на друга(RAID 1), а пары объединены в RAID 0. Поломка диска внутри пары, не приводит к потере данных, однако при выходе из строя пары, данные теряются и требуется процедура восстановления.

Raid 10 описание
Минимально необходимое количество дисков для создания raid10 массива — 4.
Восстановление raid 10
Восстановление данных с рэйд массива raid 10 вышедшего из строя по причине аппаратного сбоя (поломки нескольких жестких дисков в рэйд массиве) приходится делать не часто. Гораздо чаще приносят на восстановление raid10 массивы на которых потеряны данные вследствие сбоя контроллера или неквалифицированных действий персонала (системных администраторов). Ввиду недостаточно эффективного использования дискового пространства подобные рэйд-массивы используют в крупных коммерческих организациях и как правило подобные задачи осложнены использованием слайсов, когда идет поступенчатое представление физические жесткие диски — логические — физические — логические. Когда аппаратно собранный неразмеченный еще рейд-массив средствами raid контроллера делится на слайсы, которые опять таки представляются как физические накопители, из которых в свою очередь собирается другой raid массив, возможно с другой конфигурацией, например рэйд5 или рэйд0.
Raid JBOD
JBOD Raid описание
JBOD (Just a bundle of disks), то есть связка жестких дисков, рейд массивом строго говоря не является. Однако несколько дисков могут быть объединены в один логический раздел с помощью операционной системы, либо аппаратно, с помощью рэйд контроллера, поддерживающего функцию построения jbod массива. Файлы обычно записываются последовательно до конца диска, далее запись продолжается на следующий указанный hdd. Подобная организация данных не требует специального оборудования, как я сказал выше, и может быть реализована на программном уровне средствами ОС или стороннего ПО. Однако при поломке одного из дисков файловая система разрушается и требуется операция восстановления данных jbod массива.

JBOD массив описание
Минимально необходимое количество томов (дисков) для создания jbod — 2.
Восстановление JBOD
В случае выхода из строя дискового jbod массива необходимо определиться с порядком дисков, это не сложно сделать, если в джибод-массиве всего два накопителя, и задача становится сложнее, если дисков три или более. В этом случае нужно провести анализ таблиц размещения файлов, определиться с адресацией начала файла или директории и проведя необходимые вычисления достаточно легко определить очередность дисков в массиве. Так же нужно отметить, что в ряде случаев, когда один или несколько дисков jbod массива вышли из строя и не подлежат восстановлению, информацию с поврежденного jbod все же можно достать, пусть и частично.
Raid 50
Raid 50 описание
Raid 50 является комбинацией между двумя рэйд-массивами пятого уровня, объединенными между собой в страйп, или raid 0. Минимальное количество дисков для построения рэйд 50 массива — шесть штук.

Raid 50 описание
На иллюстрации показан частный случай организации такого массива. Нужно иметь ввиду, что на ряде контроллеров идет каскадное представление дисков по цепочке физический-логический-физический. То есть шесть физических жестких дисков объединяются в два логических массива (диска) raid-5, далее они представляются как два физических диска соответствующего размера и уже эти диски объединяются между собой в страйп, со своим размером блока и очередностью и восстановление raid может быть в такой ситуации весьма нетривиальной задачей. Полученный логический диск собранный по технологии рейд 50, уже средствами ОС воспринимается как физический, и размечается и форматируется.
В качестве иллюстрации возможных нагромождений представим что этот «физический» диск raid-50 делится средствами ОС на два логических, из которых собирается JBOD или raid-0 уже средствами ОС. Инженер осуществляющий восстановление данных raid и получивший шесть дисков которые состояли в подобном массиве может потратить массу времени на построение таблиц соответствия блоков и дисков.
Восстановление Raid-50
Как и в случаях с рэйд массивами 6-го уровня, на raid-50 достаточно часто встречаются надстройки в виде слайсов, крутятся десятки виртуальных машин, *nix файловые системы, VMFS и прочие радости бытия. Восстановление информации с raid50 является достаточно сложной задачей. Для начала нужно попытаться получить максимально полную информацию о предполагаемой конфигурации, количестве и размере разделов и т.п. Далее, определившись с конфигурацией, целесообразно идти по пути сборки, которой оперировал raid контроллер. То есть сначала собираются все рэйд-5 массивы входившие в состав raid50, выгружаются в отдельные образы и уже они объединяются в виртуальный страйп.
Какой raid массив
лучше использовать на практике?
Рекомендации по выбору рэйд массива и эксплуатации рэйд массивов
Для того, чтобы ответить на вопрос, какой же рэйд массив лучше использовать на практике, нужно определиться с задачами, которые стоят перед конторой или системным администратором. В общем случае таких задач две, повышение скорости дисковой подсистемы и повышение надежности хранения информации. Редко какая то из этих двух целей доминирует, как правило, используется комбинированный подход со смещением приоритетов в сторону быстродействия или сохранности данных. Немаловажную роль в принятии решения играет и финансовая составляющая, которую можно условно представить как цена за гигабайт дискового пространства. Очевидно, что у страйпа и JBOD она будет ниже всего, т.к. потерь нет, дисковое пространство всех жестких дисков в массиве суммируется, а например на зеркальном рэйде стоимость доступного гигабайта будет больше всего.
Комбинированные решения, они же наиболее популярные, это массивы Raid level 5. Эти массивы являются абсолютными лидерами по использованию, соответственно и обращаются с проблемами в рйэд 5 массивах чаще.
Наиболее критичные данные целесообразно держать на рэйд 1 или рэйд 10, либо на рэйд 5 с обязательной продуманной политикой создания резервных копий на внешние диски, не входящие в состав массива. Страйпы целесообразно использовать для выделенного дискового пространства в файлах подкачки на графических станциях, известно, что тот же Photoshop очень любит свопы туда сюда прокачивать и при работе с большими изображениями это может серьезно сказаться на быстродействии системы.
JBOD как правило используют, чтобы достичь объема единого диска, недоступного в качестве физического. То есть если вам требуется диск на 10 терабайт для выгрузки части образа при восстановлении raid 10 на 24-х двух терабайтниках (а это еще не самый сложный массив с которым приходилось сталкиваться), то создание JBOD массива это самый удобный и правильный в этой ситуации подход к решению задачи.
Если вы столкнулись с потерей данных на рэйд массиве, вы можете получить бесплатную online или телефонную консультацию и рекомендации к дальнейшим действиям от специалиста по восстановлению данных.