
#статьи
- 1 мар 2022
-

0
Мы собрали самые эпичные случаи ошибок в работе умных алгоритмов. И рассказали, почему они часто врут.
Иллюстрация: Альберто Блинчиков для Skillbox Media

Старший обозреватель направления «Бизнес» Skillbox Media.
Ретейл, безопасность, банки, общепит, логистика, медицина — это далеко не полный список сфер, куда успели проникнуть и где смогли закрепиться системы распознавания лиц. Технология распространяется так быстро, что пугает общественность. Например, российские правозащитники считают, что работу подобных систем следует ограничить. И страхи людей вполне обоснованны.
Предназначенные для удобства и безопасности алгоритмы иногда работают против пользователей. За последние несколько лет в России и мире прогремело несколько крупных скандалов, связанных с использованием автоматических систем биометрической идентификации. Ранее мы уже писали, как не дать соцсетям распознать своё лицо. А теперь вспомним про тех, кто пострадал от опасных ошибок таких технологий.
- Попасть в полицию на пять часов с перспективой сесть в тюрьму на восемь лет
- Неожиданно превратиться в серийного вора
- Найти повод для иска к Apple на миллиард долларов
- Лишиться работы из-за ошибки системы
- Не опознаваться как женщина из-за цвета кожи
- Почему системы ошибаются?
Россиянин Антон Леушин одним из первых испытал на себе «преимущества» новой системы распознавания лиц в московском «Ашане». В октябре 2020 года мужчина зашёл в гипермаркет за покупками, но так и не смог ничего купить — его остановили охранники. Оказалось, что система распознавания лиц определила в нём преступника, который за три недели до этого украл из «Ашана» элитный алкоголь на 78 тысяч рублей.
«На фото с камер и видео был человек среднего телосложения в чёрной кепке, чёрной кофте, синих джинсах, с обычной белой медицинской маской на лице, из-под которой была видна борода. По этим „особым“ приметам система указала на меня», — пожаловался Леушин на своей странице в Facebook* вскоре после инцидента.

Охранники вызвали полицию, и Леушина доставили в участок. По словам потерпевшего, полицейские несколько часов угрожали ему обыском в квартире. Они также говорили, что Леушину грозит до восьми лет тюрьмы, и ослабили хватку только после того, как приехал адвокат. Тогда они отпустили мужчину без составления протокола — ограничились разговором с адвокатом.
В результате Леушину всё же пришлось оплатить услуги адвоката (15 тысяч рублей). Когда инцидент получил широкий резонанс после поста в Facebook*, представители магазина извинились перед Антоном в соцсети, но причину ошибки так никто и не объяснил.
Спустя примерно год похожая история произошла в подмосковном Одинцово. Там кандидат философских наук Фёдор Ермошин получил не только неприятный опыт общения с полицией, но и побои. Трое неизвестных скрутили его на улице и затолкали в автомобиль.
Оказалось, что нападавшие работали в МВД. Система распознавания лиц в базе данных полиции определила 70-процентное сходство Ермошина с преступником, который тоже носил очки и похожую осеннюю одежду. Настоящий нарушитель закона торговал на рынке украденными ранее игровыми консолями.
«Защёлкнулись наручники, в машине меня положили на заднее сиденье лицом, двое сели сверху. Говорят: „Сейчас ты нам всё расскажешь, как украл приставки в Строгино и сбывал их на Одинцовском рынке“», — вспоминал Ермошин в разговоре с журналистами.

Недоразумение разъяснилось, когда полицейские увидели паспорт Ермошина. Однако его всё равно повезли в местный отдел полиции, где продержали несколько часов.
«„Ну извини“ — это всё, что мне сказали, когда всё выяснилось. Вернули мне паспорт, предварительно сняв отпечатки пальцев и сфотографировав меня, и выпустили», — говорит Ермошин.
После выхода из участка мужчина на всякий случай зафиксировал телесные повреждения в травмпункте. Он также написал заявление в полицию и прокуратуру, чтобы установить личности нападавших.
От ошибок, связанных с биометрической идентификацией, страдают не только россияне. В 2019 году американский студент Усман Бах подал в суд на Apple. В иске он утверждал, что система распознавания лиц в магазинах компании ложно связала его с преступником.
Незадолго до инцидента студент потерял водительское удостоверение. Он предположил, что нашедший документ злоумышленник воспользовался им, чтобы подтвердить личность при покупке в магазине. В этот момент система видеонаблюдения связала имя Баха с лицом другого человека, который позже совершил ещё несколько краж в разных городах и штатах страны. С такой версией согласился даже следователь из Нью-Йорка. Однако в других юрисдикциях Баха до сих пор обвиняют в кражах — даже несмотря на то, что у него есть алиби.
Баха арестовали в его доме в ноябре 2018 года. Однако в ордере полицейских была фотография другого человека. Подозреваемых объединял лишь чёрный цвет кожи, в остальном они были не похожи друг на друга.

В иске Бах потребовал от Apple и её подрядчика по обеспечению безопасности магазинов Security Industry Specialists миллиард долларов. Он написал, что был вынужден ответить на многочисленные ложные обвинения, которые привели к сильному стрессу и лишениям в его жизни, а также к значительному ущербу его положительной репутации, для поддержания которой он приложил много усилий.
Любопытно, что в Apple отказалась комментировать сам иск, но представители компании сказали прессе, что не используют подобных технологий в фирменных магазинах.
В октябре 2021 года ошибка системы идентификации, которую использует компания Uber в Великобритании, оставила темнокожего водителя без средств к существованию. Проработав в компании пять лет, однажды он не смог войти в свой профиль, чтобы начать развозить людей, — система просто перестала распознавать его. Водитель посчитал, что всему виной «расистское» программное обеспечение, которое некорректно работает при идентификации цветных людей.

С помощью приложения Uber пытается исключить из рядов водителей нелегалов и водителей без лицензии. Отстаивать свои права оставшийся без работы мужчина пошёл в комиссию по трудовым спорам, а его позицию поддержал Независимый профсоюз работников Великобритании (IWGB). Там заявили, что с начала пандемии как минимум 35 других водителей попали в похожую ситуацию из-за ошибок в программном обеспечении Uber. Они призвали компанию отказаться от «расистского» алгоритма и восстановить уволенных водителей.
Впрочем, подобные иски в адрес Uber были делом времени — компания использует алгоритмы для распознавания лиц от Microsoft. Ещё в 2019 году Microsoft признала, что программное обеспечение для распознавания лиц цветных людей работает хуже, чем для лиц белых. Исследования нескольких пакетов программного обеспечения для распознавания лиц показали, что частота ошибок при идентификации людей с тёмной кожей выше, чем при идентификации светлокожих.
В январе 2022 года разгорелся очередной скандал, связанный с проблемами распознавания лиц. Соцсеть Giggle, предназначенную исключительно для женщин, обвинили в дискриминации цветных женщин и в том, что оно ограничивает права транс-женщин.

Чтобы воспользоваться сервисом, нужно не только подтвердить свой номер телефона, но и сфотографироваться. ИИ анализирует лицо пользовательницы: если распознает в мужчину, зайти в приложение не получится. Проблема в том, что умные алгоритмы часто ошибались, распознавая мужчин в темнокожих женщинах и трансгендерных женщинах с мужественными чертами лица. Из-за этого разработчики приложения даже указали в описании, что у трансгендерных людей могут возникнуть проблемы при авторизации. Этими словами они лишь подлили масла в огонь.
Разработчики системы распознавания лиц из компании Kairos заявили, что идентифицируют женщину, только если уверены в результате минимум на 95%. Тем не менее даже такой точности оказалось недостаточно: незначительные ошибки привели к шквалу обвинений в адрес компании и волне негативных откликов о приложении.
Всё большее число исследований показывает, что точность алгоритмов падает, когда им приходится идентифицировать лица людей другой расы. Например, если сеть обучена на распознавание белых, количество ошибок для темнокожих будет выше.
Ещё одним вызовом для разработчиков нейросистем стало повсеместное ношение масок во время пандемии. Первыми с проблемой столкнулись владельцы iPhone, которые привыкли, что телефон разблокируется, распознавая владельца по лицу. В Сети тогда появились многочисленные инструкции, как взломать гаджет, научив его узнавать человека в маске. Это побудило Apple решать проблему масок кардинально — её исправили в анонсированном к марту 2022 года обновлении.
Сравнить человека, ровно стоящего перед камерой, с его фотографией в базе данных сегодня очень просто, поясняет руководитель отдела по машинному обучению NtechLab Андрей Беляев. Но найти человека по фотографии, на которой его плохо видно, в профиль, в маске в базе с более чем миллионом человек, — это уже вызов.

Ещё один аспект, который влияет на точность, — данные, на основе которых обучаются нейросети. Все компании пользуются практически одинаковым набором фреймворков и библиотек, на которых они разрабатывают свои системы и обучают нейросети. Однако различия всё-таки есть — в самих данных. Для обучения нейросети нужно много данных, а данные «локального» производства всегда ищутся лучше.
«Сетки, обученные китайской компанией, скорее всего, будут лучше работать на жителях Китая, чем сетки, обученные в Европе. И наоборот — европейские нейросети будут лучше работать в Европе», — поясняет Беляев в разговоре со Skillbox Media.
Тем не менее тренд по борьбе с дискриминацией укрепляется. Разработчики больше внимания уделяют тому, чтобы алгоритмы одинаково хорошо работали на представителях разных этнических групп и чтобы точность не зависела от страны, в которой находится производитель. Для этого перед выпуском алгоритма видеоаналитики на рынок разработчики проводят набор тестов для каждой отдельной этнической группы и проверяют, чтобы точность во всех случаях была одинаковой.
Затормозить этот процесс могут разве что финансовые возможности компаний, которые внедряют решения на основе Face ID. Операционный директор финтех-платформы «Фаст Ривер» Ксения Артемьева говорит, что высокоточные системы требуют и дорогостоящего оборудования. Например, распознавание 3D‑изображений более точное, чем распознавание 2D, но требует наличия мощного 3D-сканера.
«Сканеры Face ID в телефонах сейчас можно обмануть высокоточным 3D‑отпечатком лица, которое можно напечатать на принтере», — сказала Ксения Артемьева Skillbox Media.
Она также напоминает, что сегодня возможен анализ по структуре кожи и сетчатки глаз, но для этого необходимы высокоточные камеры с высоким разрешением. Существует даже анализ теплового слепка лица. Если комбинировать все доступные инструменты, это потребует больше вычислительных мощностей и сложного оборудования, но позволит снизить количество ошибок для минимума, говорит Артемьева.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook* и Instagram* на территории Российской Федерации по основаниям осуществления экстремистской деятельности».

Научитесь: Философия искусственного интеллекта
Узнать больше
Малоизвестные ошибки систем распознавания лиц. Как с ними жить и как избежать
Михайло Павлюк, 16/12/22
Компании, которые используют или собираются использовать системы распознавания лиц, знают, что системы допускают ошибки. Они могут не сопоставить известного пользователя – ложное отрицание, они могут неправильно связать разных пользователей – ложное срабатывание. Подобные интерпретации возникают из-за многих факторов, например от свойств входных фотографий или даже от демографической группы распознаваемых лиц.
-1.png?width=935&height=322&name=%D1%80%D0%B8%D1%81%20(11)-1.png)
Совместный технический комитет (ISO/IEC JTC 1) ISO (Международной организации по стандартизации) и IEC (Международной электротехнической комиссии) и, в частности, Технический подкомитет 37, который работает над новым стандартом ISO/IEC 24358, выделяют ряд технических проблем, в значительной степени влияющих на количество ошибок работы систем распознавания.
Данный стандарт будет определять свойства биометрических подсистем сбора изображений лиц следующего поколения, предназначенных для повышения пригодности фотографий для автоматического распознавания лиц, уменьшения изменчивости этих фотографий, улучшения поддержки идентификации человеческого лица и предотвращения фальсификации и незаконной модификации фотографий.

Основные проблемы систем распознавания лиц
Специалисты выделяют следующие основные проблемы.
- Большинство изображений лиц собираются с помощью камер, которые не распознают лица. Это контрастирует с ситуацией с биометрическими данными по отпечаткам пальцев и радужной оболочке глаза, когда датчики позволяют точно определить тип изображения, которое следует собрать. В итоге некоторые изображения включают два лица, возможно от кого-то на заднем плане или от рисунка футболки. Такие случаи могут подорвать узнаваемость.
- Фотографии собираются без какой-либо оценки качества, полагаясь только на фотографа.
- Оценка качества отделена от момента получения фото. Во многих случаях фотография собирается и позже отправляется на внутренний сервер, где она оценивается по качеству. Если обнаруживается низкое качество (человеческим или автоматическим способом), повторный сбор изображений лиц начинается через несколько часов или дней и с дополнительными расходами.
- Плохое предъявление. Основные причины неудачи в распознавании возникают из-за того, что субъекты не демонстрируют прямое, нейтральное выражение лица, с открытыми глазами, без очков, их лица не находятся в правильном положении.
- Доверие к повышению точности распознавания лиц. Алгоритмы распознавания лиц тщательно исследованы, а повышение точности подтверждено документально. Тем не менее нет подобных исследований в области улучшения качества изображения лица.
- Автоматизированное и ручное распознавание лиц работают с разными типами изображений. Людям нужны фото с высоким разрешением, тогда как автоматизированные алгоритмы в основном построены на стандартизированных фронтальных видах с относительно низким разрешением.
Давайте попробуем оценить, чем грозит использование систем распознавания лиц без попыток устранения вышеперечисленных проблем.
Проблема 1. Оценка рисков ошибок
На рынке биометрии по лицу давно и прочно установился негласный стандарт оценки эталонного качества в виде тестов, проводимых Национальным институтом стандартов и технологий (NIST) при Министерстве торговли США. Это самый известный и независимый тест с закрытым датасетом. Практически все крупные производители систем распознавания в нем принимают участие и по праву гордятся своими результатами в нем. Алгоритмы теста проверяются на скорость и точность работы по нескольким разным фотобазам. Эти базы условно разделены по качеству лица на фото и имеют достаточно широкий разброс ошибок, в зависимости от набора данных.
Например, ошибки FNMR (false non-match rate) одного и того же алгоритма на базе VISA Photos и WILD Photos при одном и том же FMR (false match rate) могут различаться на порядки. На какой уровень ошибок тогда ориентироваться условному банку при оценке рисков оказания услуг, связанных с распознаванием лиц?
Проблема 2. Оценка точности на собственном датасете
Хорошо иметь многомиллионные датасеты для тестов. Но как быть компании, которая владеет своим набором данных? Как оценить работу конкретного алгоритма в конкретных условиях? Как понять, какой уровень ошибок здесь и сейчас? Добавим к этому понимание того, что качество алгоритма зависит от расы и демографических групп. Ответ прост: собрать свой тестовый набор данных, провести разметку и построить ROC-кривые. Но такая работа может занять не один месяц, при этом маловероятно, что размер базы фото позволит оперировать оценкой ошибок десять в минус шестой степени.
Общие рекомендации для владельцев систем распознавания
- Ищите быстрые и многоплатформенные системы оценки качества фото. Идеально, если оценка сразу даст прогноз по уровню ошибок сравнения. Тогда часть вышеописанных проблем и задач решится автоматически. Подобных систем на рынке немного, но они есть.
- Отдавайте предпочтение производителям, которые предлагают встроенный механизм тестирования на собственных датасетах заказчика, а в идеале могут передать часть датасета для разбавления собственной базы фото. И да, вы опять будете удивлены, насколько немного таких предложений.
- Не экономьте на фронтальных компонентах получения фото. Селфи клиента, снятое одним кадром, – не лучшая идея, если вы хотите работать с качественной базой.
Ошибки распознавания лиц неизбежны, но уровень этих ошибок можно прогнозировать и оптимизировать. Хорошего вам распознавания!
Опубликовано в журнале «Системы безопасности» № 5/2022
Все статьи журнала «Системы безопасности»
доступны для скачивания в iMag >>
Фото: ixbt.com
О чем идет речь? Малоизвестные ошибки систем распознавания лиц требуют такой же проработки и учета, как и любые другие. Ложные данные – нередкое явление этой системы.
На что обратить внимание? Снизить риски поможет правильная организация сбора датасета и работы с нейросетью. Качественные фото, правильное изображение лиц и ряд других методов решают проблемы и повышают эффективность работы.
Оглавление:
- Устройство системы распознавания лиц
- Стандарты работы систем распознавания лиц
- Малоизвестные ошибки систем распознавания лиц
- Рекомендации по использованию систем распознавания лиц
Устройство системы распознавания лиц
Распознавание лиц – это возможность систем видеонаблюдения, которая позволяет в автоматическом режиме сопоставлять изображение лица человека, запечатленное на видео или фото, с сохраненными в памяти данными и определять, кто именно находится в кадре. Для работы этой функции используются нейросети. Применяются две разные нейросети. Первая – сеть-выравниватель. Она обрабатывает сохраненный кадр, определяет наличие на ней лиц одного или нескольких человек, вырезает их из кадра и сопоставляет с базой данных.
.jpg)
Алгоритм работы следующий.
- Действие № 1. Нейросеть обрезает изображения лиц, находящихся на снимке, выравнивает их и распознает глаза, нос, иные признаки. При этом могут возникать ошибки, если лица расположены вплотную друг к другу, имеют малый масштаб, повернуты в профиль относительно объектива.
- Действие № 2. Программа идентифицирует отдельные детали лица, поворачивает их в соответствии с заданным алгоритмом.
- Действие № 3. Нейросеть придает фотоизображению требуемый вид. Существуют алгоритмы, составляющие изображение более чем по семи ключевым точкам, то есть обводят овал лица. Эта функция может быть полезна при создании дипфейков.

Вторая используемая нейросеть – это сеть-распознаватель. Она работает с изображением, предварительно подготовленным предыдущим алгоритмом. После обработки эта программа формирует вектор лица, представляющий собой набор чисел фиксированной длины. В разных программах векторы свои, обычно они выражаются определенной степенью двойки, например 512. Если в базе данных сохранены изображения с похожими векторами, то они выдаются пользователю в результатах совпадения.
.jpg)
Для примера используем фото Владимира Машкова и два фото Сергея Безрукова, которые пропустим через нейросеть. По каждому из них будет составлен вектор. Если сравнить расстояние между векторами Машкова и Безрукова и между двумя Безруковыми, то в первом случае разница будет значительная, поскольку используются фото двух разных людей. Во втором случае расстояние будет минимально, так как обработаны два фото одного человека.
Чтобы научить нейросеть распознавать лица, требуются миллионы фотографий. Изначально в систему вводятся данные, кому принадлежит то или иное изображение. В процессе обучения нейросеть обретает способность генерировать все более точные результаты. После тестирования на миллионах изображений сеть может определять даже те лица, которых изначально не было в базе.
Программа FaceID, используемая в смартфонах, работает по иному алгоритму. Она использует ряд ключевых инфракрасных точек лица, которые проецируются через камеру. Созданная таким образом трехмерная модель сопоставляется с той, что сохранна в памяти устройства.
Стандарты работы систем распознавания лиц
Совместный технический комитет (ISO/IEC JTC 1) Международной организации по стандартизации и Международная электротехническая комиссия, разрабатывающая усовершенствованный стандарт ISO/IEC 24358, отмечают отдельные ошибки, которые могут влиять на точность автоматического распознавания лиц.

10 шагов, которые помогут
выбрать добросовестного подрядчика
Поможет сохранить
бюджет и уложиться в сроки проекта
Уже скачали 11 507

Новый стандарт ляжет в основу биометрических программ следующего поколения и позволит повысить качество распознавания лиц, минимизировать вносимые программой изменения в исходные фото, поможет исключить подделку и неправомерное изменение изображений.
Малоизвестные ошибки систем распознавания лиц
Эксперты обращают внимание на следующие малоизвестные ошибки систем распознавания лиц.
- Основная масса изображений лиц формируются с помощью видеокамер, которые сами не выполняют функцию распознавания. В этом их уязвимость по сравнению, например, с дактилоскопической идентификацией, позволяющей точно определить тип изображения, которое необходимо собрать. Если лица двух людей расположены непосредственно рядом друг с другом или лицо изображено на одежде человека, попавшего в объектив, то ошибки идентификации могут быть достаточно серьезными.
- Важно, чтобы эталонное изображение, которое загружается в базу, было корректным: без эмоций, мимики, хорошо равномерно освещено, без грима, очков и т. п. Чем дальше от «идеала» эталон, тем ниже вероятность распознавания.
- Определение качества и пригодности для идентификации выполняется отдельно от момента съемки. Обычно изображение собирается и передается программе, выполняющей непосредственное распознавание. При недостаточном качестве изображений получение новых происходит по прошествии некоторого периода и влечет дополнительные издержки.
- Важно , чтобы камера сформировала изображение максимально приближенное к эталону. Помимо очков, маски и пр., играет важную роль выбор правильного расположения камеры, т. к. в том числе и ракурс влияет на точность распознавания.
- Доверие к уровню точности распознавания. Технологии идентификации лиц изучены достаточно подробно, их эффективность подтверждена экспериментальным путем. Однако аналогичных исследований в части улучшения качества исходных изображений не проводилось.
- Для автоматической и ручной идентификации требуются фото разного качества. Если ручное распознавание осуществляется по фото с высокой детализацией, то нейросети используют стандартные фронтальные проекции с пониженным разрешением.

Решение этих проблем – вовсе не теоретическая задача. Рассмотрим, как они влияют на процесс распознавания лиц.
Проблема?1.?Определение?рисков неточной идентификации
В биометрическом программном обеспечении используется стандарт оценки эталонного качества, разработанный Национальным институтом стандартов и технологий (NIST) при Министерстве торговли США. Он включает в себя несколько тестов, в создании которых задействованы почти все ведущие разработчики ПО в данной отрасли. Алгоритмы этого стандарта тестируются на быстроту и качество обработки на основе нескольких отдельных фотобанков, имеющих разное состояние исходных изображений и широкий диапазон ошибок.
.jpg)
Так, неточности типа FNMR (false non-match rate) одного теста на базе VISA Photos и WILD Photos при неизменном FMR (false match rate) могут показывать разительно отличающиеся результаты. Возникает проблема: какая степень ошибок может считаться допустимой при определении рисков неточной идентификации?
Проблема?2.?Оценка?точности распознавания на своем?датасете
Может быть, эта проблема не столь актуальна, если в распоряжении имеются многомиллионные датасеты. Если же пользователь располагает своей базой данных, то оценить качество работы алгоритма в определенной ситуации становится сложнее. Непросто выявить долю ошибок здесь и сейчас. Также нужно принимать во внимание, что на результат работы алгоритма влияет раса, демографическая группа изображенных людей.
.jpg)
Решить проблему может формирование собственной тестовой базы данных, ее разметка и составление ROC-кривых. Однако выполнение этой задачи может растянуться на несколько месяцев, и нет гарантий, что объем фотобанка даст возможность оперировать оценкой ошибок десять в минус шестой степени.
Рекомендации по использованию систем распознавания лиц
Во избежание ошибок пользователям систем идентификации лиц следует придерживаться нескольких правил.
- Правильное определение точки установки камеры для выполнения задачи. Именно отсюда начинается причина снижения вероятности корректного распознавания. В реальности часто в той точке, откуда было бы идеально решать задачу наблюдения, камеру установить просто невозможно физически, начинается поиск компромисса.
- Используйте быстродействующие и кроссплатформенные сервисы определения качества изображений. Желательно, чтобы они могли сразу оценить возможную долю ошибок при распознавании.
- Отдавайте предпочтение разработчикам, предоставляющим собственный алгоритм тестирования на датасетах клиента, а также готовым предоставить фрагмент датасета для добавления к своему фотобанку.
- Не жалейте средств на оптику. Если используется одно фото человека, то на формирование качественного фотобанка рассчитывать не приходится.

Программы идентификации все еще содержат малоизвестные ошибки систем распознавания лиц. Однако технологии не стоят на месте. Кроме того, долю ошибок вполне можно просчитать и оптимизировать.
Ошибки системы распознавания лиц связаны с ее несовершенством. Но даже развитая технология не обойдется без человека
Председатель правления НАУРР Алиса Конюховская: система распознавания лиц станет совершеннее в ходе работы
В работе системы распознавания лиц в Москве в последние дни заметили ошибки. Мужчину она приняла за приставочного вора, а женщину сочла объявленной в розыске как пропавшую без вести. Технология пока несовершенна, но даже в будущем ей потребуется контроль человека.
Кандидата филологических наук Федора Ермошина 19 октября задержали полицейские. Они решили, что имеют дело с укравшим игровые приставки злоумышленником. Мужчине пришлось провести утро в ОМВД Строгино, рассказал он «360».
Ермошину показали фотографию человека, в котором система распознавания лиц увидела 70% сходство с ним самим. Незнакомец тоже был в очках и толстовке.
«Сходство там усмотреть можно только в том, что оба человека в очках», — заметил мужчина в беседе с «360».
В схожую ситуацию попала москвичка: ее система нашла похожей на без вести пропавшую. Правоохранители проверили у женщины документы и отпустили. Общение с полицейскими она назвала вежливым и милым.
Сырая система
Юрист Анатолий Коровин рассказал «360», что обращений от людей, которых задержали на станциях метрополитена, МЦК или МЦД в последнее время действительно поступает много. Система опознает их в том числе как лиц, находящихся в федеральном розыске.
«Этот недостаток говорит о том, что данная система еще сырая и не доведена до ума», — подчеркнул он.
Коровин добавил, что с правовой точки зрения незаконное задержание подразумевает нарушение прав человека. Он может обжаловать действия сотрудников полиции в соответствии с процессуальными нормами.
«Можно жаловаться, в том числе в суд, предъявлять гражданские иски по этому поводу в счет компенсации определенного морального вреда. Людям неприятно, когда их задерживают, ошибочно принимая за преступников», — заключил юрист.
Технология под контролем человека
Председатель правления Национальной ассоциации участников рынка робототехники (НАУРР) Алиса Конюховская признала, что система распознавания лиц не идеальна.
«Она обучается на базе данных, которая у нее есть. Чем больше она будет использоваться, тем больше у нее вводных, тем лучше она будет работать. В действительности есть люди, которые похожи, что создает сложности для системы. Постепенно будет происходить ее самообучение и повышение точности», — сказала она «360».
Из-за технических ошибок иногда возникают санкции со стороны правоохранительных органов. Конюховская обратила внимание на необходимость в подобных ситуациях сохранять здравый смысл, «не в полной мере доверяться машине и понимать, что она также может ошибаться».
Системы распознавания лиц работают на тех данных, которые у них есть. Изначально в систему загружают фото нарушителей, тех, кого нужно найти. А те, кого не надо находить, добавляются систему в ходе расширения ее применения. Технология может находить что-то общее и идентифицировать похожих людей
Алиса Конюховская
Технологии, напомнила специалист, создаются людьми. Именно человек проектирует и воплощает какую-либо разработку в жизнь, а затем контролирует и поддерживает ее работу.
«Технологии — это результат человеческого труда. Мнение, что технологии могут существовать без человека, — детская иллюзия», — заключила Алиса Конюховская.
Искусственный интеллект
#статьи
- 1 мар 2022
-
0
Мы собрали самые эпичные случаи ошибок в работе умных алгоритмов. И рассказали, почему они часто врут.
Иллюстрация: Альберто Блинчиков для Skillbox Media
Старший обозреватель направления «Бизнес» Skillbox Media.
Ретейл, безопасность, банки, общепит, логистика, медицина — это далеко не полный список сфер, куда успели проникнуть и где смогли закрепиться системы распознавания лиц. Технология распространяется так быстро, что пугает общественность. Например, российские правозащитники считают, что работу подобных систем следует ограничить. И страхи людей вполне обоснованны.
Предназначенные для удобства и безопасности алгоритмы иногда работают против пользователей. За последние несколько лет в России и мире прогремело несколько крупных скандалов, связанных с использованием автоматических систем биометрической идентификации. Ранее мы уже писали, как не дать соцсетям распознать своё лицо. А теперь вспомним про тех, кто пострадал от опасных ошибок таких технологий.
- Попасть в полицию на пять часов с перспективой сесть в тюрьму на восемь лет
- Неожиданно превратиться в серийного вора
- Найти повод для иска к Apple на миллиард долларов
- Лишиться работы из-за ошибки системы
- Не опознаваться как женщина из-за цвета кожи
- Почему системы ошибаются?
Россиянин Антон Леушин одним из первых испытал на себе «преимущества» новой системы распознавания лиц в московском «Ашане». В октябре 2020 года мужчина зашёл в гипермаркет за покупками, но так и не смог ничего купить — его остановили охранники. Оказалось, что система распознавания лиц определила в нём преступника, который за три недели до этого украл из «Ашана» элитный алкоголь на 78 тысяч рублей.
«На фото с камер и видео был человек среднего телосложения в чёрной кепке, чёрной кофте, синих джинсах, с обычной белой медицинской маской на лице, из-под которой была видна борода. По этим „особым“ приметам система указала на меня», — пожаловался Леушин на своей странице в Facebook* вскоре после инцидента.
Охранники вызвали полицию, и Леушина доставили в участок. По словам потерпевшего, полицейские несколько часов угрожали ему обыском в квартире. Они также говорили, что Леушину грозит до восьми лет тюрьмы, и ослабили хватку только после того, как приехал адвокат. Тогда они отпустили мужчину без составления протокола — ограничились разговором с адвокатом.
В результате Леушину всё же пришлось оплатить услуги адвоката (15 тысяч рублей). Когда инцидент получил широкий резонанс после поста в Facebook*, представители магазина извинились перед Антоном в соцсети, но причину ошибки так никто и не объяснил.
Спустя примерно год похожая история произошла в подмосковном Одинцово. Там кандидат философских наук Фёдор Ермошин получил не только неприятный опыт общения с полицией, но и побои. Трое неизвестных скрутили его на улице и затолкали в автомобиль.
Оказалось, что нападавшие работали в МВД. Система распознавания лиц в базе данных полиции определила 70-процентное сходство Ермошина с преступником, который тоже носил очки и похожую осеннюю одежду. Настоящий нарушитель закона торговал на рынке украденными ранее игровыми консолями.
«Защёлкнулись наручники, в машине меня положили на заднее сиденье лицом, двое сели сверху. Говорят: „Сейчас ты нам всё расскажешь, как украл приставки в Строгино и сбывал их на Одинцовском рынке“», — вспоминал Ермошин в разговоре с журналистами.
Недоразумение разъяснилось, когда полицейские увидели паспорт Ермошина. Однако его всё равно повезли в местный отдел полиции, где продержали несколько часов.
«„Ну извини“ — это всё, что мне сказали, когда всё выяснилось. Вернули мне паспорт, предварительно сняв отпечатки пальцев и сфотографировав меня, и выпустили», — говорит Ермошин.
После выхода из участка мужчина на всякий случай зафиксировал телесные повреждения в травмпункте. Он также написал заявление в полицию и прокуратуру, чтобы установить личности нападавших.
От ошибок, связанных с биометрической идентификацией, страдают не только россияне. В 2019 году американский студент Усман Бах подал в суд на Apple. В иске он утверждал, что система распознавания лиц в магазинах компании ложно связала его с преступником.
Незадолго до инцидента студент потерял водительское удостоверение. Он предположил, что нашедший документ злоумышленник воспользовался им, чтобы подтвердить личность при покупке в магазине. В этот момент система видеонаблюдения связала имя Баха с лицом другого человека, который позже совершил ещё несколько краж в разных городах и штатах страны. С такой версией согласился даже следователь из Нью-Йорка. Однако в других юрисдикциях Баха до сих пор обвиняют в кражах — даже несмотря на то, что у него есть алиби.
Баха арестовали в его доме в ноябре 2018 года. Однако в ордере полицейских была фотография другого человека. Подозреваемых объединял лишь чёрный цвет кожи, в остальном они были не похожи друг на друга.
В иске Бах потребовал от Apple и её подрядчика по обеспечению безопасности магазинов Security Industry Specialists миллиард долларов. Он написал, что был вынужден ответить на многочисленные ложные обвинения, которые привели к сильному стрессу и лишениям в его жизни, а также к значительному ущербу его положительной репутации, для поддержания которой он приложил много усилий.
Любопытно, что в Apple отказалась комментировать сам иск, но представители компании сказали прессе, что не используют подобных технологий в фирменных магазинах.
В октябре 2021 года ошибка системы идентификации, которую использует компания Uber в Великобритании, оставила темнокожего водителя без средств к существованию. Проработав в компании пять лет, однажды он не смог войти в свой профиль, чтобы начать развозить людей, — система просто перестала распознавать его. Водитель посчитал, что всему виной «расистское» программное обеспечение, которое некорректно работает при идентификации цветных людей.
С помощью приложения Uber пытается исключить из рядов водителей нелегалов и водителей без лицензии. Отстаивать свои права оставшийся без работы мужчина пошёл в комиссию по трудовым спорам, а его позицию поддержал Независимый профсоюз работников Великобритании (IWGB). Там заявили, что с начала пандемии как минимум 35 других водителей попали в похожую ситуацию из-за ошибок в программном обеспечении Uber. Они призвали компанию отказаться от «расистского» алгоритма и восстановить уволенных водителей.
Впрочем, подобные иски в адрес Uber были делом времени — компания использует алгоритмы для распознавания лиц от Microsoft. Ещё в 2019 году Microsoft признала, что программное обеспечение для распознавания лиц цветных людей работает хуже, чем для лиц белых. Исследования нескольких пакетов программного обеспечения для распознавания лиц показали, что частота ошибок при идентификации людей с тёмной кожей выше, чем при идентификации светлокожих.
В январе 2022 года разгорелся очередной скандал, связанный с проблемами распознавания лиц. Соцсеть Giggle, предназначенную исключительно для женщин, обвинили в дискриминации цветных женщин и в том, что оно ограничивает права транс-женщин.
Чтобы воспользоваться сервисом, нужно не только подтвердить свой номер телефона, но и сфотографироваться. ИИ анализирует лицо пользовательницы: если распознает в мужчину, зайти в приложение не получится. Проблема в том, что умные алгоритмы часто ошибались, распознавая мужчин в темнокожих женщинах и трансгендерных женщинах с мужественными чертами лица. Из-за этого разработчики приложения даже указали в описании, что у трансгендерных людей могут возникнуть проблемы при авторизации. Этими словами они лишь подлили масла в огонь.
Разработчики системы распознавания лиц из компании Kairos заявили, что идентифицируют женщину, только если уверены в результате минимум на 95%. Тем не менее даже такой точности оказалось недостаточно: незначительные ошибки привели к шквалу обвинений в адрес компании и волне негативных откликов о приложении.
Всё большее число исследований показывает, что точность алгоритмов падает, когда им приходится идентифицировать лица людей другой расы. Например, если сеть обучена на распознавание белых, количество ошибок для темнокожих будет выше.
Ещё одним вызовом для разработчиков нейросистем стало повсеместное ношение масок во время пандемии. Первыми с проблемой столкнулись владельцы iPhone, которые привыкли, что телефон разблокируется, распознавая владельца по лицу. В Сети тогда появились многочисленные инструкции, как взломать гаджет, научив его узнавать человека в маске. Это побудило Apple решать проблему масок кардинально — её исправили в анонсированном к марту 2022 года обновлении.
Сравнить человека, ровно стоящего перед камерой, с его фотографией в базе данных сегодня очень просто, поясняет руководитель отдела по машинному обучению NtechLab Андрей Беляев. Но найти человека по фотографии, на которой его плохо видно, в профиль, в маске в базе с более чем миллионом человек, — это уже вызов.
Ещё один аспект, который влияет на точность, — данные, на основе которых обучаются нейросети. Все компании пользуются практически одинаковым набором фреймворков и библиотек, на которых они разрабатывают свои системы и обучают нейросети. Однако различия всё-таки есть — в самих данных. Для обучения нейросети нужно много данных, а данные «локального» производства всегда ищутся лучше.
«Сетки, обученные китайской компанией, скорее всего, будут лучше работать на жителях Китая, чем сетки, обученные в Европе. И наоборот — европейские нейросети будут лучше работать в Европе», — поясняет Беляев в разговоре со Skillbox Media.
Тем не менее тренд по борьбе с дискриминацией укрепляется. Разработчики больше внимания уделяют тому, чтобы алгоритмы одинаково хорошо работали на представителях разных этнических групп и чтобы точность не зависела от страны, в которой находится производитель. Для этого перед выпуском алгоритма видеоаналитики на рынок разработчики проводят набор тестов для каждой отдельной этнической группы и проверяют, чтобы точность во всех случаях была одинаковой.
Затормозить этот процесс могут разве что финансовые возможности компаний, которые внедряют решения на основе Face ID. Операционный директор финтех-платформы «Фаст Ривер» Ксения Артемьева говорит, что высокоточные системы требуют и дорогостоящего оборудования. Например, распознавание 3D‑изображений более точное, чем распознавание 2D, но требует наличия мощного 3D-сканера.
«Сканеры Face ID в телефонах сейчас можно обмануть высокоточным 3D‑отпечатком лица, которое можно напечатать на принтере», — сказала Ксения Артемьева Skillbox Media.
Она также напоминает, что сегодня возможен анализ по структуре кожи и сетчатки глаз, но для этого необходимы высокоточные камеры с высоким разрешением. Существует даже анализ теплового слепка лица. Если комбинировать все доступные инструменты, это потребует больше вычислительных мощностей и сложного оборудования, но позволит снизить количество ошибок для минимума, говорит Артемьева.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook* и Instagram* на территории Российской Федерации по основаниям осуществления экстремистской деятельности».

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать
Научитесь: Философия искусственного интеллекта
Узнать больше
Рассказываем, что произошло, какую правовую оценку дали этому наши юристы и какие действия мы предпринимаем.
В октябре в «Роскомсвободу» обратился наш читатель Сергей Межуев, которого система распознавания лиц в московском метро приняла за другого, объявленного в розыск. И несмотря на то, что полицейские сразу поняли ошибку, они отвели Сергея в отделение, собрали у него все данные, включая биометрические, и сказали, что история с ним не закончится, пока не будет найден разыскиваемый. Представляем подробности от первого лица, а также приводим комментарий наших юристов.
«7 октября я возвращался домой, когда на выходе со станции метро «Братиславская» остановился выбросить мусор в урну. Сзади ко мне подошёл полицейский, представившийся младшим прапорщиком, показал на мобильном телефоне фотографию с камеры на турникетах и спросил, я ли это. На изображении оказался я. Фотография была сделана сбоку. Полицейский сказал, что сработала система распознавания лиц и теперь нужно пройти в полицейский «аквариум» в метро, чтобы разобраться.
В «аквариуме» у меня попросили паспорт. Фотография в паспорте не совпала с изображением человека в розыске. Однако меня досмотрели (на наличие оружия) и посадили в комнате за решёткой. Я спросил: зачем. Мне сказали, что так положено по инструкции. Это было странно и неприятно: выяснилось же, что я другой человек, но мне всё равно ограничили свободу, пусть и ненадолго.
Через некоторое время приехал сотрудник в штатском, препроводил меня в 9 отдел полиции УВД на московском метрополитене и передал полицейским, работающим непосредственно с системой распознавания лиц. Они стали говорить, что я не тот, кого ищут: моя фотография не походила на фоторобот разыскиваемого. Это было видно невооружённым глазом. Фоторобот, кстати, вообще представлял собой какой-то графический рисунок. Тем не менее меня попросили снова показать паспорт, записали данные из него в книгу учёта поступивших, сфотографировали документ, сфотографировали меня на фоне стенда с измерением роста, сняли отпечатки пальцев в электронном виде и записали imei телефона. Далее внесли в какую-то базу, доступ к которой есть только у них, как я понимаю. После этого отпустили. Тем временем в ОВД привели человека, насчёт которого система ошиблась уже в третий раз!
Я спросил: что будет дальше? Мне ответили, что пока человек в розыске, моя история тоже не закончится.
Госсистемы уже не впервые ошибаются в отношении меня. И думаю, не только я один такой, люди просто это принимают как должное. Но это неправильно. Все должны участвовать в работе системы и менять её.
Я обратился в «Роскомсвободу», потому что она борется за благополучие людей. Я тоже хочу и готов всячески помогать. Сегодня, например, в метро человек по громкоговорителю пугал штрафом в 5 тыс. руб. за отсутствие масок. Я вызвал дежурного и спросил, на каком основании это делается. Дежурный не смог дать мне ответ, сказал, что этот человек вообще не с ними. Я подошёл к молодому человеку и попросил нормативные документы. Он показал мне, как я понял, какой-то внутренний документ от начальника. Я попросил официальные документы для общественности. Он сказал, что наверно, можно в интернете поискать. Получается, никаких нормативных актов у них нет. Считаю, всё это запугивание взаимосвязано: система распознавания лиц, данные об удалённых работниках. Всё началось ещё с первой волны».
.
***
.
Почему произошедшее незаконно — рассказывают юристы «Роскомсвободы»
.
Согласно закону «О государственной дактилоскопической регистрации в Российской Федерации» дактилоскопии подлежат:
— граждане Российской Федерации, иностранные граждане и лица без гражданства, подозреваемые в совершении преступления, обвиняемые в совершении преступления, осужденные за совершение преступления, подвергнутые административному аресту;
— совершившие административное правонарушение, если установить их личность иным способом невозможно.
Сергей никаких уголовно-наказуемых и административных деяний не совершал, постановление о привлечении его в качестве
обвиняемого/подозреваемого по уголовному делу ему не предъявляли.
В законе «О персональных данных» говорится, что данные человека, включая биометрические, могут обрабатываться только при наличии согласия в письменной форме их обладателя. Сбор персональных данных Сергея был осуществлен без какой-либо законной цели, предусмотренной законодательством.
.
Руководитель юридической практики «Роскомсвободы» Саркис Дарбинян:
«На нашей памяти это первая такая жалоба на систему распознавания в метро. Но со слов Сергея понятно, что он не первый, в отношении кого она ошиблась. Сергей первый, кто обратил на это внимание.
Также мы узнали следующую тревожащую деталь: получается, систему обкатывают не только на фотографиях граждан, но и на фотороботах. Представьте фотороботы, которые рисуют со слов неких свидетелей.Конечно, такой матчинг будет иметь множество ошибок, что мы и видим.
Однако, если такие ошибки происходят, полицейские перед вами не только не извинятся, но ещё и соберут с вас дополнительные данные, при этом будут обращаться с вами, как с преступниками. Это недопустимо. По указанному факту нами были направлены запрос в 9-ый отдел полиции УВД на Московском метрополитене с требованием разъяснить ситуацию и немедленно уничтожить персональные данные Сергея, полученные в нарушение закона, а также жалоба в прокуратуру Московского метрополитена».
.
18 ноября обращение Сергея в 9 отдел полиции УВД на московском метрополитене зафиксировали в Книге учёта заявлений и сообщений о преступлениях, об административных правонарушениях, о происшествиях.
.
***
Если в отношении вас также ошиблась система распознавания лиц, пишите нам на [email protected].
Напоминаем нашу позицию: пока система видеонаблюдения не станет прозрачной и подотчётной и не будет иметь гарантии защиты от подобных злоупотреблений, использовать технологию распознавания лиц нельзя. Данный кейс — результат пробела в правовой базе.
Сейчас «Роскомсвобода» продолжает активно вести кампанию против распознавания лиц. Вы можете помочь нам, присоединившись к кампании и подписав петицию на сайте Change.org.
Пожалуй нет ни одной другой технологии сегодня, вокруг которой было бы столько мифов, лжи и некомпетентности. Врут журналисты, рассказывающие о технологии, врут политики которые говорят о успешном внедрении, врут большинство продавцов технологий. Каждый месяц я вижу последствия того как люди пробуют внедрить распознавание лиц в системы которые не смогут с ним работать.

Тема этой статьи давным-давно наболела, но было всё как-то лень её писать. Много текста, который я уже раз двадцать повторял разным людям. Но, прочитав очередную пачку треша всё же решил что пора. Буду давать ссылку на эту статью.
Итак. В статье я отвечу на несколько простых вопросов:
- Можно ли распознать вас на улице? И насколько автоматически/достоверно?
- Позавчера писали, что в Московском метро задерживают преступников, а вчера писали что в Лондоне не могут. А ещё в Китае распознают всех-всех на улице. А тут говорят, что 28 конгрессменов США преступники. Или вот, поймали вора.
- Кто сейчас выпускает решения распознавания по лицам в чём разница решений, особенности технологий?
Большая часть ответов будет доказательной, с сылкой на исследования где показаны ключевые параметры алгоритмов + с математикой расчёта. Малая часть будет базироваться на опыте внедрения и эксплуатации различных биометрических систем.
Я не буду вдаваться в подробности того как сейчас реализовано распознавание лиц. На Хабре есть много хороших статей на эту тему: а, б, с (их сильно больше, конечно, это всплывающие в памяти). Но всё же некоторые моменты, которые влияют на разные решения — я буду описывать. Так что прочтение хотя бы одной из статей выше — упростит понимание этой статьи. Начнём!
NB!
Если что, статья 2018 года. Сейчас как минимум 2021. Не то, что что-то принципиально изменилось. Но, точности стали другими (советую смотреть актуальные оригиналы метрик которые я упоминаю в статье). Появилось много новых идей/подходов, которые расширяют области применения распознавания лиц.
А в целом, — советую читать мой канал (vk, telegram) про более новые методы/подходы. Статьи с Хабра свои я там тоже аноншу.
Введение, базис
Биометрия — точная наука. Тут нет места фразам «работает всегда», и «идеальная». Все очень хорошо считается. А чтобы подсчитать нужно знать всего две величины:
- Ошибки первого рода — ситуация когда человека нет в нашей базе, но мы опознаём его как человека присутствующего в базе (в биометрии FAR (false access rate))
- Ошибки второго рода — ситуации когда человек есть в базе, но мы его пропустили. (В биометрии FRR (false reject rate))
Эти ошибки могут иметь ряд особенностей и критериев применения. О них мы поговорим ниже. А пока я расскажу где их достать.
Характеристики
Первый вариант. Давным-давно ошибки производители сами публиковали. Но тут такое дело: доверять производителю нельзя. В каких условиях и как он измерял эти ошибки — никто не знает. И измерял ли вообще, или отдел маркетинга нарисовал.
Второй вариант. Появились открытые базы. Производители стали указывать ошибки по базам. Алгоритм можно заточить под известные базы, чтобы они показывали офигенное качество по ним. Но в реальности такой алгоритм может и не работать.
Третий вариант — открытые конкурсы с закрытым решением. Организатор проверяет решение. По сути kaggle. Самый известный такой конкурс — MegaFace. Первые места в этом конкурсе когда-то давали большую популярность и известность. Например компании N-Tech и Vocord во многом сделали себе имя именно на MegaFace.
Всё бы хорошо, но скажу честно. Подгонять решение можно и тут. Это куда сложнее, дольше. Но можно вычислять людей, можно вручную размечать базу, и.т.д. И главное — это не будет иметь никакого отношения к тому как система будет работать на реальных данных. Можете посмотреть кто сейчас лидер на MegaFace, а потом поискать решения этих ребят в следующем пункте.
Четвёртый вариант. На сегодняшний день самый честный. Мне не известны способы там жульничать. Хотя я их не исключаю.
Крупный и всемирно известный институт соглашается развернуть у себя независимую систему тестирования решений. От производителей поступает SDK которое подвергается закрытому тестированию, в котором производитель не принимает участия. Тестирование имеет множество параметров, которые потом официально публикуются.
Сейчас такое тестирование производит NIST — американский национальный институт стандартов и технологий. Такое тестирование самое честное и интересное.
Нужно сказать, что NIST производит огромную работу. Они выработали пяток кейсов, выпускают новые апдейты раз в пару месяцев, постоянно совершенствуются и включают новых производителей. Вот тут можно ознакомиться с последним выпуском исследования.
Казалось бы, этот вариант идеален для анализа. Но нет! Основной минус такого подхода — мы не знаем, что в базе. Посмотрите вот на этот график:
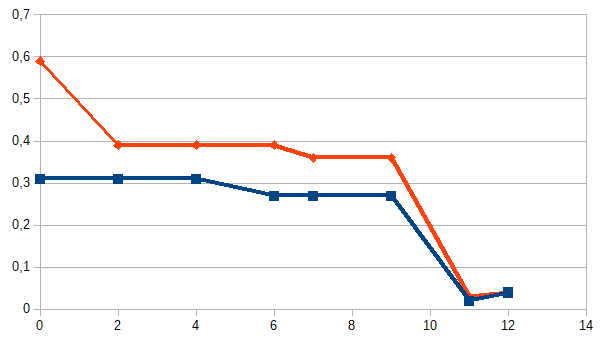
Это данные двух компаний по которым проводилось тестирование. По оси x — месяца, y — процент ошибок. Тест я взял «Wild faces» (чуть ниже описание).
Внезапное повышение точности в 10 раз у двух независимых компаний (вообще там у всех взлетело). Откуда?
В логе NIST стоит пометка «база была слишком сложной, мы её упростили». И нет примеров ни старой базы, ни новой. На мой взгляд это серьёзная ошибка. Именно на старой базу была видна разница алгоритмов вендоров. На новой у всех 4-8% пропусков. А на старой было 29-90%. Моё общение с распознаванием лиц на системах видеонаблюдения говорит, что 30% раньше — это и был реальный результат у гроссмейстерских алгоритмов. Сложно распознать по таким фото:

И конечно, по ним не светит точность 4%. Но не видя базу NIST делать таких утверждений на 100% нельзя. Но именно NIST — это главный независимый источник данных.
В статье я описываю ситуацию актуальную на июль 2018 года. При этом опираюсь на точности, по старой базе лиц для тестов связанных с задачей «Faces in the wild».
Вполне возможно что через пол года всё измениться полностью. А может будет стабильным следующие десять лет.
Итак, нам нужна вот эта таблица:
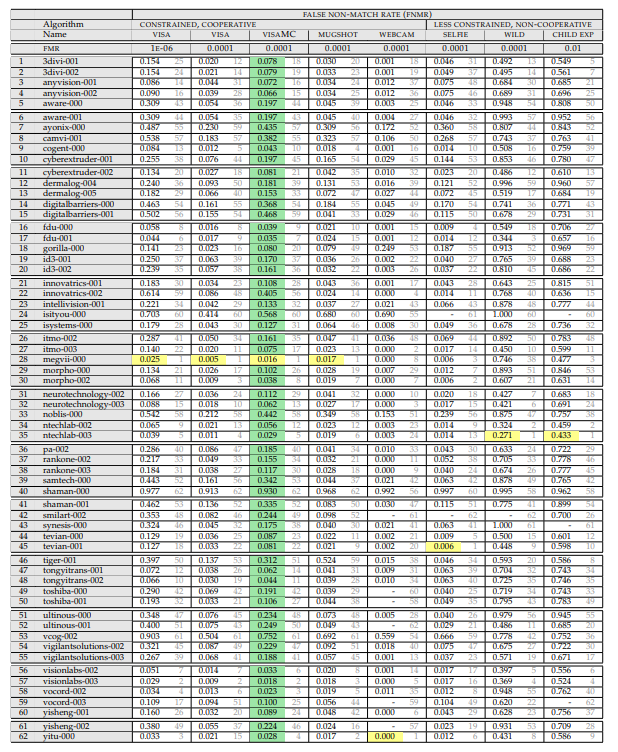
(апрель 2018, т.к. wild тут более адекватный)
Давайте разберём что в ней написано, и как оно измеряется.
Сверху идёт перечисление экспериментов. Эксперимент состоит из:
Того, на каком сете идёт замер. Сеты есть:
Того при каком уровне ошибок первого рода идёт замер (этот параметр рассматривается только для фотогафий на паспорт):
- 10^-4 — FAR (одно ложное срабатывание первого рода) на 10 тысяч сравнений с базой
- 10^-6 — FAR (одно ложное срабатывание первого рода) на миллион сравнений с базой
Результат эксперимента — величина FRR. Вероятность того что мы пропустили человека который есть в базе.
И уже тут внимательный читатель мог заметить первый интересный момент. «Что значит FAR 10^-4?». И это самый интересный момент!
Главная подстава
Что вообще такая ошибка значит на практике? Это значит, что на базу в 10 000 человек будет одно ошибочное совпадение при проверке по ней любого среднестатистического человека. То есть, если у нас есть база из 1000 преступников, а мы сравниваем с ней 10000 человек в день, то у нас будет в среднем 1000 ложных срабатываний. Разве это кому то нужно?
В реальности всё не так плохо.
Если посмотреть построить график зависимости ошибки первого рода от ошибки второго рода, то получится такая классная картинка (тут сразу для десятка разных фирм, для варианта Wild, это то что будет на станции метро, если камеру поставить где-то чтобы её не видели люди):
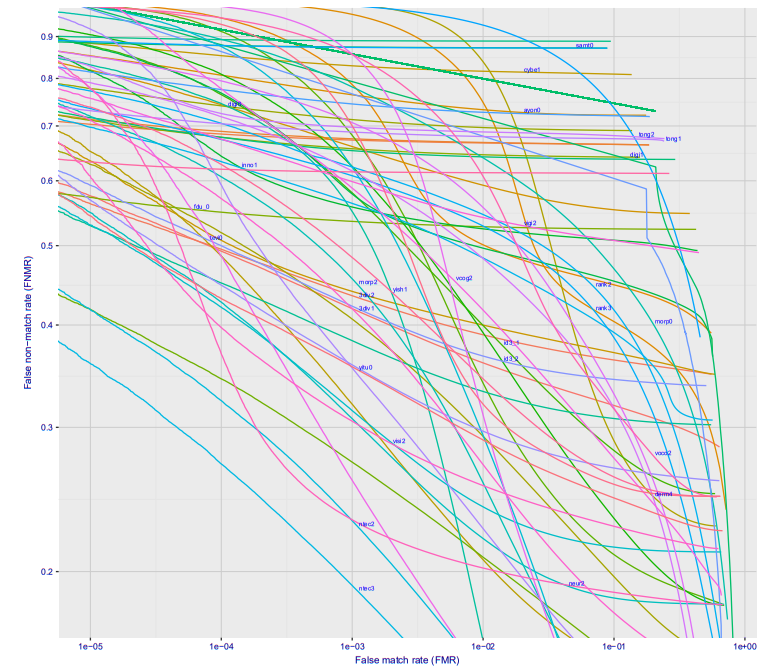
При ошибке 10^-4 27% процентов не распознанных людей. На 10^-5 примерно 40%. Скорее всего на 10^-6 потери составят примерно 50%
Итак, что это значит в реальных цифрах?
Лучше всего идти от парадигмы «сколько ошибок в день можно допустить». У нас на станции идёт поток людей, если каждые 20-30 минут система будет давать ложное срабатывание, то никто не будет её воспринимать всерьёз. Зафиксируем допустимое число ложных срабатываний на станции метро 10 человек в день (по хорошему, чтобы система не была выключена как надоедливая — нужно ещё меньше). Поток одной станции Московского метрополитена 20-120 тысяч пассажиров в сутки. Среднее — 60 тысяч.
Пусть зафиксированное значение FAR — 10^-6 (ниже ставить нельзя, мы и так при оптимистической оценке потеряем 50% преступников). Это значит что допустить 10 ложных тревог мы можем при размере базы в 160 человек.
Много это или мало? Размер базы в федеральном розыске ~ 300 000 человек. Интерпола 35 тысяч. Логично предположить, что где-то 30 тысяч москвичей находятся в розыске.
Это даст уже нереальное число ложных тревог.
Тут стоит отметить, что 160 человек может быть и достаточной базой, если система работает on-line. Если искать тех кто совершил преступление в последние сутки — это уже вполне рабочий объём. При этом, нося чёрные очки/кепки, и.т.д., замаскироваться можно. Но много ли их носит в метро?
Второй важный момент. Несложно сделать в метро систему дающее фото более высокого качества. Например поставить на рамки турникетов камеры. Тут уже будет не 50% потерь на 10^-6, а всего 2-3%. А на 10^-7 5-10%. Тут точности из графика на Visa, всё будет конечно сильно хуже на реальных камерах, но думаю на 10^-6 можно оставить сего 10% потерь:
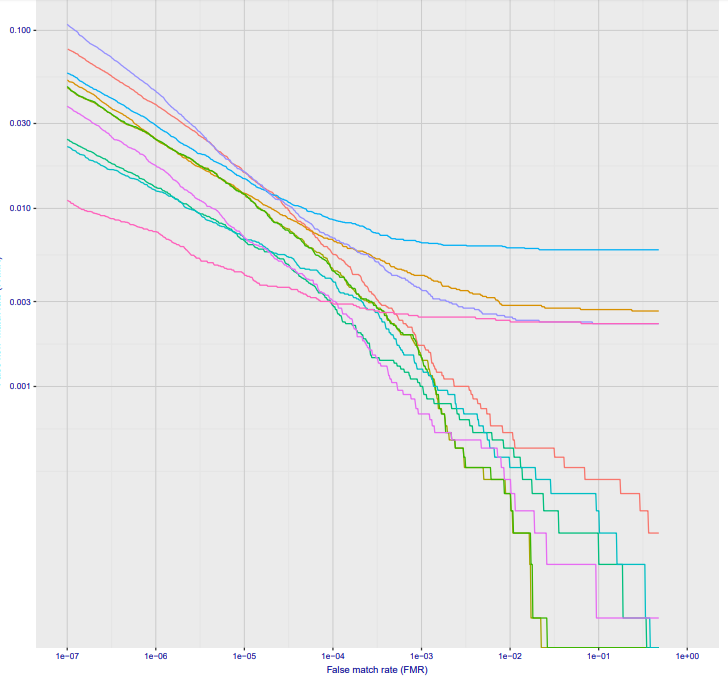
Опять же, базу в 30 тысяч система не потянет, но всё что происходит в реальном времени детектировать позволит.
Первые вопросы
Похоже время ответить на первую часть вопросов:
Ликсутов заявил что выявили 22 находящихся в розыске человека. Правда ли это?
Тут основной вопрос — что эти люди совершили, сколько было проверено не находящихся в розыске, насколько в задержании этих 22 людей помогло распознавание лиц.
Скорее всего, если это люди которых искали планом «перехват» — это действительно задержанные. И это неплохой результат. Но мои скромные предположения позволяют сказать, что для достижения этого результата было проверено минимум 2-3 тысячи людей, а скорее около десятка тысяч.
Это очень хорошо бьётся с цифрами которые называли в Лондоне. Только там эти числа честно публикуют, так как люди протестуют. А у нас замалчивают…
Вчера на Хабре была статья на счёт ложняков по распознаванию лиц. Но это пример манипуляций в обратную сторону. У Амазона никогда не было хорошей системы распознавания лиц. Плюс вопрос того как настроить пороги. Я могу хоть 100% ложняков сделать, подкрутив настройки;)
Про Китайцев, которые распознают всех на улице — очевидный фэйк. Хотя, если они сделали грамотный трекинг, то там можно сделать какой-то более адекватный анализ. Но, если честно, я не верю что пока это достижимо. Скорее набор затычек.
А что с моей безопасностью? На улице, на митинге?
Поехали дальше. Давайте оценим другой момент. Поиск человека с хорошо известной биографией и хорошим профилем в соцсетях.
NIST проверяет распознавание лица к лицу. Берётся два лица одного/разных людей и сравнивается насколько они близки друг к другу. Если близость больше порога, тогда это один человек. Если дальше — разные. Но есть другой подход.
Если вы почитали статьи, которые я советовал в начале — то знаете, что при распознавании лица формируется хэш-код лица, отображающий его положение в N-мерном пространстве. Обычно это 256/512 мерное пространство, хотя у всех систем по разному.
Идеальная система распознавания лиц переводит одно и то же лицо в один и тот же код. Но идеальных систем нет. Одно и то же лицо обычно занимает какую-то область пространства. Ну, например, если бы код был двумерным, то это могло бы быть как-то так:
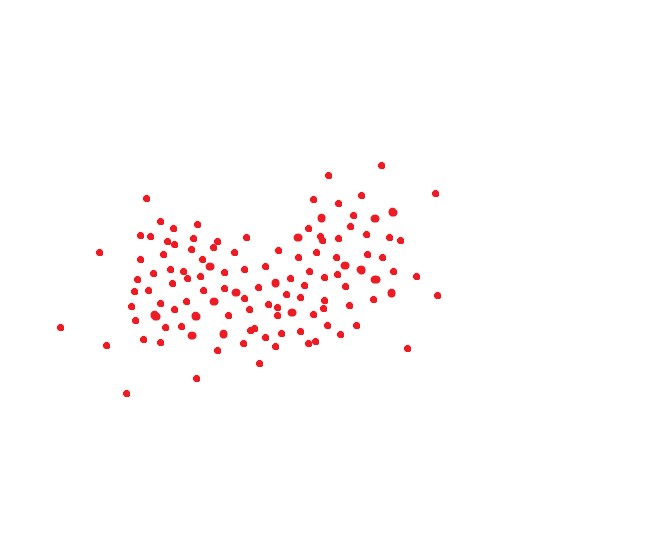
Если мы руководствуемся методом который принимается в NIST, то вот это расстояние было бы целевым порогом, чтобы мы могли распознать человека как одного и того же индивида с вероятностью под 95%:
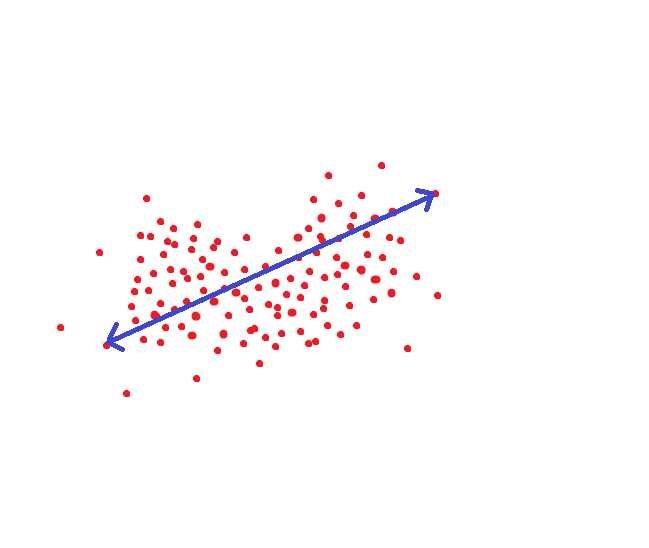
Но ведь можно поступить по другому. Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины:
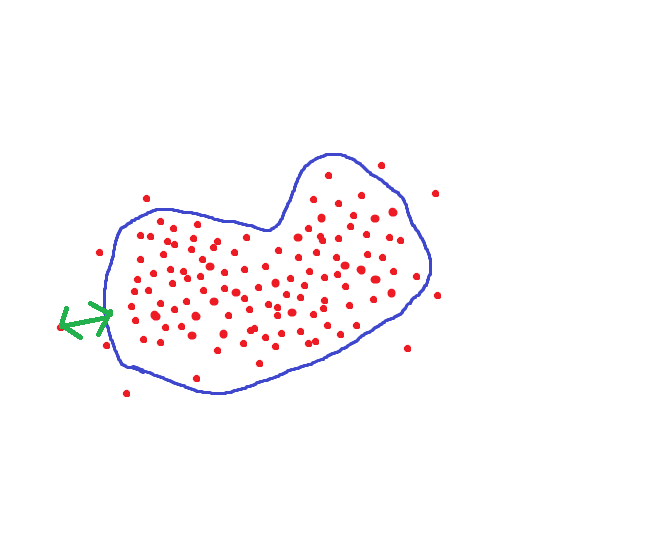
Тогда пороговое расстояние при сохранении точности уменьшится в несколько раз.
Только нам нужно очень много фотографий на каждого человека.
Если у человека есть профиль в социальных сетях / база его снимков разного возраста, то точность распознавания можно повысить очень сильно. Точной оценки того как вырастает FAR|FRR я не знаю. Да и оценивать уже некорректно такие величины. У кого-то в такой базе 2 фото, у кого-то 100. Очень много обёрточной логики. Мне кажется, что максимальная оценка — один/полтора порядка. Что позволяет дострелить до ошибок 10^-7 при вероятности не распознавания 20-30%. Но это умозрительно и оптимистично.
Вообще, конечно, с менеджментом данного пространства проблем не мало (возрастные фишки, фишки редакторов изображений, фишки шумов, фишки резкости), но как я понимаю большая часть уже успешно решена у крупных фирм кому было нужно решение.
К чему это я. К тому, что использование профилей позволяет в несколько раз поднять точность алгоритмов распознавания. Но она далека от абсолютной. С профилями требуется много ручной работы. Похожих людей много. Но если начинать задавать ограничения по возрасту, местонахождению, и.т.д., то этот метод позволяет получить хорошее решение. На пример того как нашли человека по принципу «найти профиль по фото»->«использовать профиль для поиска человека» я давал ссылку в начале.
Но, на мой взгляд, это сложно масштабируемый процесс. И, опять же, людей с большим числом фоток в профиле дай бог 40-50% в нашей стране. Да и многие из них дети, по которым всё плохо работает.
Но, опять же — это оценка.
Так вот. Про вашу безопасность. Чем меньше у вас фото в профиле — тем лучше. Чем более многочисленный митинг куда вы идёте — тем лучше. Никто не будет разбирать 20 тысяч фотографий в ручную. Тем кто заботиться о своей безопасности и приватности — я бы советовал не делать профилей со своими картинками.
На митинге в городе с 100 тысячным населением вас легко найдут, просмотря 1-2 совпадения. В Москве — задолбаются. Где-то пол года назад Vasyutka, с которым мы работаем вместе, давал рассказывал на эту тему:
Кстати, про соцсети
Тут я позволю себе сделать небольшой экскурс в сторону. Качество обучения алгоритма распознавания лиц зависит от трёх факторов:
- Качество выделения лица.
- Используемая метрика близости лиц при обучения Triplet Loss, Center Loss, spherical loss, и.т.д.
- Размер базы
По п.2 вроде как сейчас достигнут предел. В принципе, математика развивается по таким вещам очень быстро. Да и после triplet loss остальные функции потерь не давали драматического прироста, лишь плавное улучшение и понижение размера базы.
Выделение лица — это сложно, если надо найти лица под всеми углами, потеряв доли процента. Но создание такого алгоритма — это достаточно предсказуемый и хорошо управляемый процесс. Чем более всё синее, тем лучше, большие углы корректно обрабатываются:

А полгода назад было так:

Видно, что потихоньку всё больше и больше компаний проходят этот путь, алгоритмы начинают распознавать всё более и более повёрнутые лица.
А вот с размером базы — всё интереснее. Открытые базы — маленькие. Хорошие базы максимум на пару десятков тысяч человек. Те что большие — странно структурированы / плохие (megaface, MS-Celeb-1M).
Как вы думаете, откуда создатели алгоритмов взяли эти базы?
Маленькая подсказка. Первый продукт NTech, который они сейчас сворачивают — Find Face, поиск людей по вконтакту. Думаю пояснения не нужны. Конечно, вконтакт борется с ботами, которые выкачивают все открытые профили. Но, насколько я слышал, народ до сих пор качает. И одноклассников. И инстаграмм.
Вроде как с Facebook — там всё сложнее. Но почти уверен, что что-то тоже придумали.
Так что да, если ваш профиль открыт — то можете гордиться, он использовался для обучения алгоритмов;)
Про решения и про компании
Тут можно гордиться. Из 5 компаний-лидеров в мире сейчас два — Российские. Это N-Tech и VisionLabs. Пол года назад лидерами был NTech и Vocord, первые сильно лучше работали по повёрнутым лицам, вторые по фронтальным.
Сейчас остальные лидеры — 1-2 китайских компании и 1 американская, Vocord что-то сдал в рейтингах.
Еще российские в рейтинге itmo, 3divi, intellivision. Synesis — белорусская компания, хотя часть когда-то была в Москве, года 3 назад у них был блог на Хабре. Ещё про несколько решений знаю, что они принадлежат зарубежным компаниям, но офисы разработки тоже в России. Ещё есть несколько российских компаний которых нет в конкурсе, но у которых вроде неплохие решения. Например есть у ЦРТ. Очевидно, что у Одноклассников и Вконтакте тоже есть свои хорошие, но они для внутреннего пользования.
Короче да, на лицах сдвинуты в основном мы и китайцы.
NTech вообще первым в миру показал хорошие параметры нового уровня. Где-то в конце 2015 года. VisionLabs догнал NTech только только. В 2015 году они были лидерами рынка. Но их решение было прошлого поколения, а пробовать догнать NTech они стали лишь в конце 2016 года.
Если честно, то мне не нравятся обе этих компании. Очень агрессивный маркетинг. Я видел людей которым было впарено явно неподходящее решение, которое не решало их проблем.
С этой стороны Vocord мне нравился сильно больше. Консультировал как-то ребят кому Вокорд очень честно сказал «у вас проект не получится с такими камерами и точками установки». NTech и VisionLabs радостно попробовали продать. Но что-то Вокорд в последнее время пропал.
Выводы
В выводах хочется сказать следующее. Распознавание лиц это очень хороший и сильный инструмент. Он реально позволяет находить преступников сегодня. Но его внедрение требует очень точного анализа всех параметров. Есть применения где достаточно OpenSource решения. Есть применения (распознавание на стадионах в толпе), где надо ставить только VisionLabs|Ntech, а ещё держать команду обслуживания, анализа и принятия решения. И OpenSource вам тут не поможет.
На сегодняшний день нельзя верить всем сказкам о том, что можно ловить всех преступников, или наблюдать всех в городе. Но важно помнить, что такие вещи могут помогать ловить преступников. Например чтобы в метро останавливать не всех подряд, а только тех кого система считает похожими. Ставить камеры так, чтобы лица лучше распознавались и создавать под это соответствующую инфраструктуру. Хотя, например я — против такого. Ибо цена ошибки если вас распознает как кого-то другого может быть слишком велика.
P.S.
В последнее время делаю много мелких статей/видеороликов. Но так как это не формат Хабра — то публикую их в блоге или на ютубе. Трансляция всего есть в телеге и вк.
На Хабре обычно публикую, когда рассказ становится уже более самозамкнутым, иногда собрав 2-3 разных мини-рассказа на соседние темы.