
В выборочном наблюдении используются понятия «ге-нералъная совокупность» – изучаемая совокупность единиц, подлежащая изучению по интересующим исследователя признакам, и «выборочная совокупность» – случайно отобранная из генеральной совокупности некоторая ее часть. К данной выборке предъявляется требование репрезентативности, т. е. при изучении лишь части генеральной совокупности полученные выводы можно применять ко всей совокупности. Характеристиками генеральной и выборочной совокупностей могут служить средние значения изучаемых признаков, их дисперсии и средние квадрати-ческие отклонения, мода и медиана и др.
Исследователя могут интересовать и распределения единиц по изучаемым признакам в генеральной и выборочной совокупностях. В этом случае частоты называются соответственно генеральными и выборочными.
Система правил отбора и способов характеристики единиц изучаемой совокупности составляет содержание выборочного метода, суть которого состоит в получении первичных данных при наблюдении выборки с последующим обобщением, анализом и их распространением на всю генеральную совокупность с целью получения достоверной информации об исследуемом явлении.
Репрезентативность выборки обеспечивается соблюдением принципа случайности отбора объектов совокупности в выборку. Если совокупность является качественно однородной, то принцип случайности реализуется простым случайным отбором объектов выборки. Простым случайным отбором называют такую процедуру образования выборки, которая обеспечивает для каждой единицы совокупности одинаковую вероятность быть выбранной для наблюдения, для любой выборки заданного объема.
Таким образом, цель выборочного метода – сделать вывод о значении признаков генеральной совокупности на основе информации случайной выборки из этой совокупности.
6.2. Ошибки выборочного наблюдения
Между признаками выборочной совокупности и признаками генеральной совокупности, как правило, существует некоторое расхождение, которое называется ошибкой статистического наблюдения. При массовом наблюдении ошибки неизбежны, но возникают они в результате действия различных причин. Величина возможной ошибки выборочного признака происходит из-за ошибок регистрации и ошибок репрезентативности. Ошибки регистрации, или технические ошибки, связаны с недостаточной квалификацией наблюдателей, неточностью подсчетов, несовершенством приборов и т. п.
Под ошибкой репрезентативности (представительства) понимают расхождение между выборочной характеристикой и предполагаемой характеристикой генеральной совокупности. Ошибки репрезентативности бывают случайными и систематическими. Систематические ошибки связаны с нарушением установленных правил отбора. Случайные ошибки объясняются недостаточно равномерным представлением в выборочной совокупности различных категорий единиц генеральной совокупности.
В результате первой причины выборка легко может оказаться смещенной, так как при отборе каждой единицы допускается ошибка, всегда направленная в одну и ту же сторону. Эта ошибка получила название ошибки смещения. Ее размер может превышать величину случайной ошибки. Особенность ошибки смещения состоит в том, что, являясь постоянной частью ошибки репрезентативности, она увеличивается с увеличением объема выборки. Случайная же ошибка с увеличением объема выборки уменьшается. Кроме того, величину случайной ошибки можно определить, тогда как размер ошибки смещения практически определить очень сложно, а иногда и невозможно, поэтому важно знать причины, вызывающие ошибку смещения, и предусмотреть мероприятия по ее устранению.
Ошибки смещения бывают преднамеренные и непреднамеренные. Причиной возникновения преднамеренной ошибки является тенденциозный подход к выбору единиц из генеральной совокупности. Чтобы не допустить появление такой ошибки, необходимо соблюдать принцип случайности отбора единиц.
Непреднамеренные ошибки могут возникать на стадии подготовки выборочного наблюдения, формирования выборочной совокупности и анализа ее данных. Чтобы не допустить появление таких ошибок, необходима хорошая основа выборки, т. е. та генеральная совокупность, из которой предполагается производить отбор, например список единиц отбора. Основа выборки должна быть достоверной, полной и соответствовать цели исследования, а единицы отбора и их характеристики должны соответствовать действительному их состоянию на момент подготовки выборочного наблюдения. Нередки случаи, когда в отношении некоторых единиц, попавших в выборку, трудно собрать сведения из-за их отсутствия на момент наблюдения, нежелания дать сведения и т. п. В таких случаях эти единицы приходится заменять другими. Необходимо следить, чтобы замена осуществлялась равноценными единицами.
Случайная ошибка выборки возникает в результате случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности, т. е. она связана со случайным отбором. Теоретическим обоснованием появления случайных ошибок выборки является теория вероятностей и ее предельные теоремы.
Сущность предельных теорем состоит в том, что в массовых явлениях совокупное влияние различных случайных причин на формирование закономерностей и обобщающих характеристик будет сколь угодно малой величиной или практически не зависит от случая. Так как случайная ошибка выборки возникает в результате случайных различий между единицами выборочной и генеральной совокупностей, то при достаточно большом объеме выборки она будет сколь угодно мала.
Предельные теоремы теории вероятностей позволяют определять размер случайных ошибок выборки. Различают среднюю (стандартную) и предельную ошибку выборки. Под средней (стандартной) ошибкой выборки понимают такое расхождение между средней выборочной и генеральной совокупностями (~ —), которое не превышает ±. Предельной ошибкой выборки принято считать максимально возможное расхождение (~ —), т. е. максимум ошибки при заданной вероятности ее появления.
В математической теории выборочного метода сравниваются средние характеристики признаков выборочной и генеральной совокупностей и доказывается, что с увеличением объема выборки вероятность появления больших ошибок и пределы максимально возможной ошибки уменьшаются. Чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик. На основании теоремы, доказанной П.Л. Чебышевым, величину стандартной ошибки простой случайной выборки при достаточно большом объеме выборки (n) можно определить по формуле
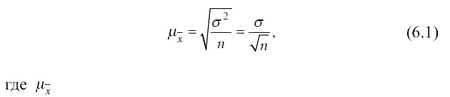
– стандартная ошибка.
Из этой формулы средней (стандартной) ошибки простой случайной выборки видно, что величина зависит от изменчивости признака в генеральной совокупности (чем больше вариация признака, тем больше ошибка выборки) и от объема выборки n (чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик).
Академик A.M. Ляпунов доказал, что вероятность появления случайной ошибки выборки при достаточно большом ее объеме подчиняется закону нормального распределения. Эта вероятность определяется по формуле
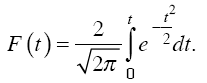
В математической статистике употребляют коэффициент доверия t, значения функции F(t) табулированы при разных его значениях, при этом получают соответствующие уровни доверительной вероятности (табл. 6.1).
Таблица 6.1
Коэффициент доверия t и соответствующие уровни доверительной вероятности
![]()
Коэффициент доверия позволяет вычислить предельную ошибку выборки,
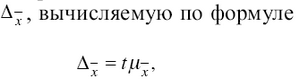
т. е. предельная ошибка выборки равна t-кратному числу средних ошибок выборки.
Между
признаками выборочной совокупности и
генеральной совокупности, как правило,
существует некоторое расхождение,
которое называется ошибкой статистического
наблюдения. При массовом наблюдении
ошибки неизбежны, но возникают они в
результате действия различных причин:
1) ошибки
регистрации или технические
ошибки связаны с недостаточной
квалификацией наблюдателей, неточностью
подсчетов, несовершенством приборов и
т.п;
2) под ошибкой
репрезентативности
(представительства) понимают
расхождение между выборочной
характеристикой и разыскиваемой истинной
характеристикой генеральной совокупности:
а) систематические
ошибки связаны с нарушением
установленных правил отбора;
б) случайные
ошибки объясняются недостаточно
равномерным представлением в выборочной
совокупности различных категорий единиц
генеральной совокупности.
В результате
систематической ошибки выборка легко
может оказаться смещенной, т.к. при
отборе каждой единицы допускается
ошибка, всегда направленная в одну и ту
же сторону. Эта ошибка получила название
ошибки смещения. Ее размер может
превышать величину случайной ошибки.
Особенность ошибки смещения состоит в
том, что, являясь постоянной частью
ошибки репрезентативности, она
увеличивается с увеличением объема
выборки. Размер ошибки смещения
определить очень сложно, иногда
невозможно.
Ошибки
смещения бывают преднамеренные и
непреднамеренные. Причиной возникновения
преднамеренной ошибки является
тенденциозный подход к выбору единиц
из генеральной совокупности. Чтобы не
допустить появления такой ошибки,
необходимо соблюдать принцип случайности
отбора единиц. Непреднамеренные
ошибки могут возникать на стадии
подготовки выборочного наблюдения,
формирования выборочной совокупности
и анализа ее данных. Чтобы не допустить
появления таких ошибок, необходима
хорошая основа выборки.
Случайная
ошибка выборки возникает в результате
случайных различий между единицами,
попавшими в выборку, и единицами
генеральной совокупности; с увеличением
объёма выборки случайная ошибка
уменьшается. Теоретическим обоснованием
работы со случайными ошибками выборки
является теория вероятностей и ее
предельные теоремы.
Сущность
предельных теорем состоит в том,
что в массовых явлениях совокупное
влияние различных случайных причин на
формирование закономерностей и обобщающих
характеристик будет сколь угодно малой
величиной или практически не зависит
от случая. Поскольку случайная ошибка
выборки возникает в результате случайных
различий между единицами выборочной и
генеральной совокупностей, то при
достаточно большом объеме выборки она
будет сколь угодно мала.
Предельные
теоремы теории вероятностей позволяют
определять размер случайных ошибок
выборки. Различают среднюю (стандартную)
и предельную ошибку выборки. Под средней
(стандартной) ошибкой выборки
понимают такое расхождение между средней
выборочной и генеральной совокупностью
(![]()
),
которое не превышает ±Δ. Предельной
ошибкой выборочного наблюдения
называется разность между величиной
средней в генеральной совокупности и
ее величиной, вычисленной по результатам
выборочного наблюдения (5.1):
![]()
.
(5.1)
В курсах
математической статистики доказано,
что величина предельной ошибки выборки
не должна превышать соотношения (5.2):
![]()
,
(5.2)
где величина μ
называется средней ошибкой выборки
и в общем виде определяется по
формулам (5.3) или (5.4):
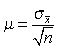
,
(5.3)
μ
=
![]()
.
(5.4)
где
![]()
—
среднее квадратическое отклонение в
генеральной совокупности;
n
— число наблюдений.
В качестве
предельной ошибки обычно рассматривается
произведение средней ошибки выборки и
коэффициента доверия t —
параметра, указывающего на конкретное
значение вероятности того, на какую
величину генеральная средняя будет
отличаться от выборочной средней.
Соотношение
между дисперсиями генеральной и
выборочной совокупности при этом
выражается формулой (5.5):
![]()
.
(5.5)
Случайный
отбор может быть бесповторным и повторным.
При бесповторном
отборе
единица, попавшая в выборочную
совокупность, обратно в генеральную не
возвращается. Следовательно, численность
генеральной совокупности всё время
уменьшается (по такой схеме проходят,
например, тиражи различных лотерей).
При повторном
отборе
отобранная единица наблюдения возвращается
в генеральную совокупность обратно.
Таким образом, численность генеральной
совокупности в процессе проведения
выборочного обследования остается все
время неизменной.
Расчет
средней
ошибки
повторной
случайной выборки:
1) cредняя
ошибка для средней
(5.3) или (5.4);
2) cредняя
ошибка для доли
(5.6):
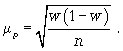
(5.6)
Расчет
средней
ошибки
бесповторной
случайной выборки:
1) средняя
ошибка для средней
(5.7):
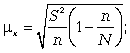
(5.7)
2) средняя
ошибка для доли
(5.8):
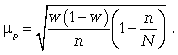
(5.8)
Расчет
предельной
ошибки повторной
случайной выборки:
1) предельная
ошибка для средней
(теорема
Чебышева—Ляпунова—Лапласа)
(5.9):
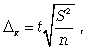
(5.9)
2) предельная
ошибка для доли
(5.10):
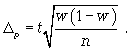
(5.10)
Расчет
предельной
ошибки
бесповторной
случайной выборки:
1) предельная
ошибка для средней
(5.11):
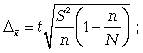
(5.11)
2) предельная
ошибка для доли
(5.12):
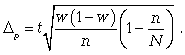
(5.12)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Понятие репрезентативности часто встречается в статистических отчетностях и при подготовке выступлений и докладов. Пожалуй, без нее трудно представить себе какой-либо из видов подачи информации на обозрение.
Репрезентативность — что это?
Репрезентативность отражает, насколько выбранные объекты или части соответствуют содержанию и смыслу совокупности данных, из которой они были выбраны.
Другие определения
Понятие репрезентативности можно раскрывать в разных контекстах. Но по своему смыслу репрезентативность – это соответствие черт и свойств выбранных единиц из общей совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.

Также репрезентативность информации определяют как способность выборочных данных представить параметры и свойства совокупности, важные с точки зрения проводимого исследования.
Репрезентативная выборка
Принцип формирования выборки заключается в избрании наиболее важных и точно отображающих свойства общей совокупности данных. Для этого используются различные методы, которые позволяют получать точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качества всех данных.
Таким образом, нет необходимости изучать весь материал, а достаточно рассмотреть выборочную репрезентативность. Что это? Это выборка отдельных данных для того, чтобы иметь понятие об общей массе информации.

Их в зависимости от способа различают как вероятностные и невероятностные. Вероятностная – это выборка, которая производится путем вычисления наиболее важных и интересных данных, являющихся в дальнейшем представителями генеральной совокупности. Это обдуманный выбор или случайная выборка, тем не менее, обоснованная своим содержанием.
Невероятностная – это одна из разновидностей случайной выборки, составляющаяся по принципу обычной лотереи. В таком случае не учитывается мнение того, кто составляет такую выборку. Используется лишь слепой жребий.
Вероятностная выборка
Вероятностные выборки также могут подразделяться на несколько видов:
- Одна из самых простых и понятных принципов – это нерепрезентативная выборка. К примеру, такой способ часто используется при проведении социальных опросов. При этом участники опроса не выбираются из толпы по каким-либо определенным признакам, и получение информации производится у первых 50 людей, принявших участие в нём.
- Преднамеренные выборки отличаются тем, что имеют ряд требований и условий при отборе, однако все же полагаются на случайное совпадение, не преследуя своей целью достижение хорошей статистики.
- Выборка на основании квот – это еще одна из вариаций невероятностной выборки, которая часто используется для исследования больших совокупностей данных. Для нее используется множество условий и норм. Подбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что опрошены будут 100 человек, но только мнение некоторого числа людей, которые будут соответствовать установленным требованиям, будут учтены при составлении статистического отчета.

Вероятностные выборки
Для вероятностных выборок исчисляется ряд параметров, которым объекты в выборке будут соответствовать, и среди них разными способами могут избираться именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Такими способами вычисления нужных данных могут быть:
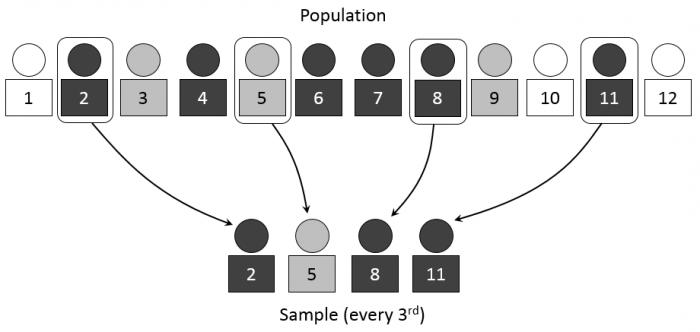
- Простая случайная выборка. Заключается в том, что среди выбранного сегмента совершенно случайным методом лотереи выбирается необходимое количество данных, которые будут являться репрезентативной выборкой.
- Систематическая и случайная выборка дает возможность составить систему вычисления необходимых данных на основе случайно выбранного сегмента. Таким образом, если первое случайное число, которое указывает на порядковый номер данных, выбранных из общей совокупности, будет 5, то последующими данными, которые будут выбраны, могут стать, например, 15, 25, 35 и так далее. Этот пример наглядно объясняет, что даже случайный выбор может основываться на систематических вычислениях необходимых исходных данных.
Выборка потребителей
Осмысленная выборка – это способ, который заключается в рассмотрении каждого отдельного сегмента, и на основании его оценки составляется совокупность, отражающая характеристики и свойства общей базы данных. Таким образом набирается большее количество данных, соответствующих требованиям репрезентативной выборки. Можно легко отобрать некоторое количество вариантов, которые не войдут в общее число, не потеряв при этом качество отобранных данных, представляющих общую совокупность. Таким способом определяется репрезентативность результатов исследования.
Размер выборки
Не последний вопрос, который необходимо решить, – это размер выборки для репрезентативного представления генеральной совокупности. Размер выборки не всегда зависит от количества исходников в генеральной совокупности. Однако репрезентативность выборочной совокупности напрямую зависит от того, на сколько сегментов должен быть в итоге разделён результат. Чем больше таких сегментов, тем больше данных попадает в результативную выборку. Если результаты требуют общего обозначения и не требуют конкретики, тогда, соответственно, выборка становится меньше, поскольку, не вдаваясь в детали, информация излагается более поверхностно, а значит, ее прочтение будет общим.

Понятие ошибки репрезентативности
Ошибка репрезентативности – это конкретные расхождения между характеристиками генеральной совокупности и выборочных данных. При проведении любого выборочного исследования невозможно получить абсолютно точные данные, как при полном исследовании генеральных совокупностей и выборки, представленной лишь частью сведений и параметров, тогда как более детальное изучение возможно только при исследовании всей совокупности. Таким образом, неизбежны некоторые погрешности и ошибки.
Виды ошибок
Различают некоторые ошибки, которые возникают при составлении репрезентативной выборки:
- Систематические.
- Случайные.
- Преднамеренные.
- Непреднамеренные.
- Стандартные.
- Предельные.
Основанием для появления случайных ошибок может быть несплошной характер исследования общей совокупности. Обычно случайная ошибка репрезентативности имеет незначительный размер и характер.
Систематические ошибки между тем возникают при нарушении правил отбора данных из общей совокупности.

Средняя ошибка – это разница между усредненными значениями выборки и основной совокупностью. Она не зависит от количества единиц в выборке. Она обратно пропорциональна объему выборки. Тогда чем больше объем, тем меньше значение средней ошибки.
Предельная ошибка – это наибольшая возможная разница между усредненными значениями сделанной выборки и общей совокупностью. Такая ошибка охарактеризовывается как максимум вероятных ошибок при заданных условиях их появления.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки смещения данных бывают преднамеренными и непреднамеренными.
Тогда причинами появления преднамеренных ошибок является подход к подбору данных по методу определения тенденций. Непреднамеренные ошибки возникают еще на стадии подготовки выборочного наблюдения, формирования репрезентативной выборки. Для недопущения подобных ошибок необходимо создать хорошую основу для выборки, составляющей списки единиц отбора. Она должна полностью соответствовать целям проведения выборки, быть достоверной, охватывающей все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок
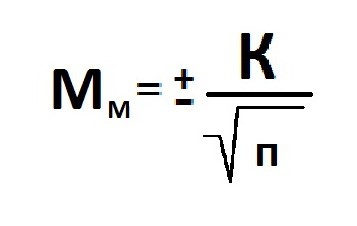
Расчет ошибки репрезентативности (Мм) средней арифметической величины (М).
Среднее квадратическое отклонение: численность выборки (>30).
Ошибка репрезентативности (Мр) и относительная величина (Р): численность выборки (n>30).
В том случае, когда приходится изучать совокупность, где количество выборки мало и составляет меньше 30 единиц, тогда число наблюдений станет меньше на одну единицу.
Величина ошибки прямо порциональна объему выборки. Репрезентативность информации и вычисление степени возможности составления точного прогноза отражает определенная величина предельной ошибки.
Репрезентативные системы
Не только в процессе оценки подачи информации используется репрезентативная выборка, но и сам человек, получающий информацию, использует репрезентативные системы. Таким образом, мозг обрабатывает некоторое количество информации, создавая репрезентативную выборку из всего потока информации, чтобы качественно и быстро оценить подаваемые данные и понять суть вопроса. Ответить на вопрос: «Репрезентативность — что это?» — в масштабах человеческого сознания довольно просто. Для этого мозг использует все подвластные органы чувств, в зависимости от того, какую именно информацию необходимо вычленить из общего потока. Таким образом, различают:
- Визуальную репрезентативную систему, где задействуются органы зрительного восприятия глаза. Люди, часто использующие подобную систему, называются визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Аудиальная репрезентативная система. Главный орган, который используется – это слух. Информация, подаваемая в виде звуковых файлов или речи, обрабатываются именно этой системой. Люди, лучше воспринимающие информацию на слух, называются аудиалами.
- Кинестетическая репрезентативная система представляет собой обработку потока информации, путем восприятия его с помощью обонятельных и осязательных каналов.
- Дигитальная репрезентативная система используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и осмысление полученных данных.

Итак, репрезентативность — что это? Простая выборка из множества или неотъемлемая процедура при обработке информации? Однозначно можно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая вычленить из него наиболее веские и значимые.
Ошибки выборочного наблюдения
- ⇐ Назад
- 1
- 2
- 3
- 4
- 567
- 8
- 9
- 10
- Далее ⇒
Между признаками выборочной совокупности и признаками генеральной совокупности, как правило, существует некоторое расхождение, которое называется ошибкой статистического наблюдения. При массовом наблюдении ошибки неизбежны, но возникают они в результате действия различных причин. Величина возможной ошибки выборочного признака происходит из-за ошибок регистрации и ошибок репрезентативности. Ошибки регистрации, или технические ошибки, связаны с недостаточной квалификацией наблюдателей, неточностью подсчетов, несовершенством приборов и т. п.
Под ошибкой репрезентативности (представительства) понимают расхождение между выборочной характеристикой и предполагаемой характеристикой генеральной совокупности. Ошибки репрезентативности бывают случайными и систематическими. Систематические ошибки связаны с нарушением установленных правил отбора. Случайные ошибки объясняются недостаточно равномерным представлением в выборочной совокупности различных категорий единиц генеральной совокупности.
В результате первой причины выборка легко может оказаться смещенной, так как при отборе каждой единицы допускается ошибка, всегда направленная в одну и ту же сторону. Эта ошибка получила название ошибки смещения. Ее размер может превышать величину случайной ошибки. Особенность ошибки смещения состоит в том, что, являясь постоянной частью ошибки репрезентативности, она увеличивается с увеличением объема выборки. Случайная же ошибка с увеличением объема выборки уменьшается. Кроме того, величину случайной ошибки можно определить, тогда как размер ошибки смещения практически определить очень сложно, а иногда и невозможно, поэтому важно знать причины, вызывающие ошибку смещения, и предусмотреть мероприятия по ее устранению.
Ошибки смещения бывают преднамеренные и непреднамеренные. Причиной возникновения преднамеренной ошибки является тенденциозный подход к выбору единиц из генеральной совокупности. Чтобы не допустить появление такой ошибки, необходимо соблюдать принцип случайности отбора единиц.
Непреднамеренные ошибки могут возникать на стадии подготовки выборочного наблюдения, формирования выборочной совокупности и анализа ее данных. Чтобы не допустить появление таких ошибок, необходима хорошая основа выборки, т. е. та генеральная совокупность, из которой предполагается производить отбор, например список единиц отбора. Основа выборки должна быть достоверной, полной и соответствовать цели исследования, а единицы отбора и их характеристики должны соответствовать действительному их состоянию на момент подготовки выборочного наблюдения. Нередки случаи, когда в отношении некоторых единиц, попавших в выборку, трудно собрать сведения из-за их отсутствия на момент наблюдения, нежелания дать сведения и т. п. В таких случаях эти единицы приходится заменять другими. Необходимо следить, чтобы замена осуществлялась равноценными единицами.
Случайная ошибка выборки возникает в результате случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности, т. е. она связана со случайным отбором. Теоретическим обоснованием появления случайных ошибок выборки является теория вероятностей и ее предельные теоремы.
Сущность предельных теорем состоит в том, что в массовых явлениях совокупное влияние различных случайных причин на формирование закономерностей и обобщающих характеристик будет сколь угодно малой величиной или практически не зависит от случая. Так как случайная ошибка выборки возникает в результате случайных различий между единицами выборочной и генеральной совокупностей, то при достаточно большом объеме выборки она будет сколь угодно мала.
Предельные теоремы теории вероятностей позволяют определять размер случайных ошибок выборки. Различают среднюю (стандартную) и предельную ошибку выборки. Под средней (стандартной) ошибкой выборки понимают такое расхождение между средней выборочной и генеральной совокупностями (~ —), которое не превышает ±.Предельной ошибкой выборки принято считать максимально возможное расхождение (~ —), т. е. максимум ошибки при заданной вероятности ее появления.
В математической теории выборочного метода сравниваются средние характеристики признаков выборочной и генеральной совокупностей и доказывается, что с увеличением объема выборки вероятность появления больших ошибок и пределы максимально возможной ошибки уменьшаются. Чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик. На основании теоремы, доказанной П.Л. Чебышевым, величину стандартной ошибки простой случайной выборки при достаточно большом объеме выборки (n) можно определить по формуле

– стандартная ошибка.
Из этой формулы средней (стандартной) ошибки простой случайной выборки видно, что величина зависит от изменчивости признака в генеральной совокупности (чем больше вариация признака, тем больше ошибка выборки) и от объема выборки n (чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик).
Академик A.M. Ляпунов доказал, что вероятность появления случайной ошибки выборки при достаточно большом ее объеме подчиняется закону нормального распределения. Эта вероятность определяется по формуле

В математической статистике употребляют коэффициент доверия t, значения функции F(t) табулированы при разных его значениях, при этом получают соответствующие уровни доверительной вероятности (табл. 6.1).
17. Малые выборки.
Принято считать, что начало С. м. в. или, как ее часто называют, статистике «малых п»,было положено в первом десятилетии XX века публикацией работы У. Госсета, в к-рой он поместил t-распределение, постулированное получившим чуть позже мировую известность «студентом». В то время Госсет работал статистиком на пивоваренных заводах Гиннесса. Одна из его обязанностей заключалась в том, чтобы анализировать поступающие друг за другом партии бочонков только что сваренного портера. По причине, к-рую он никогда толком не объяснял, Госсет экспериментировал с идеей существенного сокращения числа проб, отбираемых из очень большого количества бочек, находящихся на складах пивоварни, для выборочного контроля качества портера. Это и привело его к постулированию t-распределения. Так как устав пивоваренных заводов Гиннесса запрещал публикацию их работниками результатов исслед., Госсет опубликовал результаты своего эксперимента по сравнению выборочного контроля качества с использованием t-распределения для малых выборок и традиционного z-распределения (нормального распределения) анонимно, под псевдонимом «Студент» (Student — откуда и пошло название t -распределение Стьюдента).
t-распределение.Теория t-распределения, подобно теории z-распределения, используется для проверки нулевой гипотезы о том, что две выборки представляют собой просто случайные выборки из одной генеральной совокупности и, следовательно, вычисленные статистики (напр., среднее и стандартное отклонение) яв-ся несмещенными оценками параметров генеральной совокупности. Однако, в отличие от теории нормального распределения, теория t-распределения для малых выборок не требует априорного знания или точных оценок математического ожидания и дисперсии генеральной совокупности. Более того, хотя проверка различия между средними двух больших выборок на статистическую значимость требует принципиального допущения о нормальном распределении характеристик генеральной совокупности, теория t-распределения не требует допущений относительно параметров.
Общеизвестно, что нормально распределенные характеристики описываются одной единственной кривой — кривой Гаусса, к-рая удовлетворяет следующему уравнению:
 .
.
При t-распределении целое семейство кривых представлено следующей формулой:
 .
.
Вот почему уравнение для t включает гамма-функцию, которая в математике означает, что при изменении п данному уравнению будет удовлетворять другая кривая.
Степени свободы
В уравнении для t буквой п обозначается число степеней свободы (df), сопряженных с оценкой дисперсии генеральной совокупности (S2), к-рая представляет собой второй момент любой производящей функции моментов, такой, напр., как уравнение для t-распределения. В С. число степеней свободы указывает на то, сколько характеристик осталось свободным после их частичного использования в конкретном виде анализа. В t-распределении одно из отклонений от выборочного среднего всегда фиксировано, так как сумма всех таких отклонений должна равняться нулю. Это сказывается на сумме квадратов при вычислении выборочной дисперсии как несмещенной оценки параметра S2 и ведет к тому, что df получается равным числу измерений минус единица для каждой выборки. Отсюда, в формулах и процедурах вычисления t-статистики для проверки нулевой гипотезы df = n — 2.
F-pacnpeделение.Проверяемая с помощью t-критерия нулевая гипотеза состоит в том, что две выборки были случайным образом извлечены из одной генеральной совокупности или же были случайно извлечены из двух разных совокупностей с одинаковой дисперсией. А что делать, если нужно провести анализ большего числа групп? Ответ на этот вопрос искали в течение двадцати лет после того, как Госсет открыл t-распределение. Два самых выдающихся статистика XX столетия непосредственно причастны к его получению. Один — крупнейший английский статистик Р. А. Фишер, предложивший первые теорет. формулировки, развитие к-рых привело к получению F-распределения; его работы по теории малых выборок, развивающие идеи Госсета, были опубликованы в середине 20-х годов (Fisher, 1925). Другой — Джордж Снедекор, один из плеяды первых американских статистиков, разработавший способ сравнения двух независимых выборок любого объема посредством вычисления отношения двух оценок дисперсии. Он назвал это отношение F-отношением, в честь Фишера. Результаты исслед. Снедекора привели к тому, что F-распределение стало задаваться как распределение отношения двух статистик с2, каждой со своими степенями свободы:
 .
.
Из этого вышли классические работы Фишера по дисперсионному анализу — статистическому методу, явно ориентированному на анализ малых выборок.
Выборочное распределение F (где п = df)представлено следующим уравнением:
 .
.
Как и в случае t-распределения, гамма-функция указывает на то, что существует семейство распределений, удовлетворяющих уравнению для F. В этом случае, однако, анализ включает два величины df:число степеней свободы для числителя и для знаменателя F-отношения.
Таблицы для оценивания t- и F-статистик.При проверке нулевой гипотезы с помощью С., основанных на теории больших выборок, обычно требуется только одна справочная таблица — таблица нормальных отклонений (z), позволяющая определить площадь под нормальной кривой между любыми двумя значениями z на оси абсцисс. Однако таблицы для t-и F-распределений по необходимости представлены комплектом таблиц, поскольку эти таблицы основаны на множестве распределений, полученных вследствие варьирования числа степеней свободы. Хотя t- и F-распределения представляют собой распределения плотности вероятности, как и нормальное распределение для больших выборок, они отличаются от последнего в отношении четырех моментов, используемых для их описания. t-распределение, напр., является симметричным (обратите внимание на t2в его уравнении) при всех df, но становится все более островершинным по мере уменьшения объема выборки. Островершинные кривые (с эксцессом больше нормального) имеют тенденцию быть менее асимптотическими (т. е. меньше приближаться к оси абсцисс на концах распределения), чем кривые с нормальным эксцессом, такие как кривая Гаусса. Это различие приводит к заметным расхождениям между точками на оси абсцисс, соответствующими значениям t и z. При df = 5 и двустороннем уровне а, равном 0,05, t = 2,57, тогда как соответствующее z = 1,96. Следовательно, t = 2,57 свидетельствует о статистической значимости на 5% уровне. Однако в случае нормальной кривой z = 2,57 (точнее 2,58) будет уже указывать на 1% уровень статистической значимости. Аналогичные сравнения можно провести и с F-распределением, поскольку t равно F в случае, когда число выборок равно двум.
- ⇐ Назад
- 1
- 2
- 3
- 4
- 567
- 8
- 9
- 10
- Далее ⇒