
Проверка статистической гипотезы позволяет сделать строгий вывод о характеристиках генеральной совокупности на основе выборочных данных. Гипотезы бывают разные. Одна из них – это гипотеза о средней (математическом ожидании). Суть ее в том, чтобы на основе только имеющейся выборки сделать корректное заключение о том, где может или не может находится генеральная средняя (точную правду мы никогда не узнаем, но можем сузить круг поиска).
Распределение Стьюдента
Общий подход в проверке гипотез описан здесь, поэтому сразу к делу. Предположим для начала, что выборка извлечена из нормальной совокупности случайных величин X с генеральной средней μ и дисперсией σ2. Средняя арифметическая из этой выборки, очевидно, сама является случайной величиной. Если извлечь много таких выборок и посчитать по ним средние, то они также будут иметь нормальное распределение с математическим ожиданием μ и дисперсией
![]()
Тогда случайная величина
![]()
имеет стандартное нормальное распределение со всеми вытекающими отсюда последствиями. Например, с вероятностью 95% ее значение не выйдет за пределы ±1,96.
Однако такой подход будет корректным, если известна генеральная дисперсия. В реальности, как правило, она не известна. Вместо нее берут оценку – несмещенную выборочную дисперсию:
![]()
где
![]()
Возникает вопрос: будет ли генеральная средняя c вероятностью 95% находиться в пределах ±1,96sx̅. Другими словами, являются ли распределения случайных величин
![]()
и
![]()
эквивалентными.
Впервые этот вопрос был поставлен (и решен) одним химиком, который трудился на пивной фабрике Гиннесса в г. Дублин (Ирландия). Химика звали Уильям Сили Госсет и он брал пробы пива для проведения химического анализа. В какой-то момент, видимо, Уильяма стали терзать смутные сомнения на счет распределения средних. Оно получалось немного более размазанным, чем должно быть у нормального распределения.
Собрав математическое обоснование и рассчитав значения функции обнаруженного им распределения, химик из Дублина Уильям Госсет написал заметку, которая была опубликована в мартовском выпуске 1908 года журнала «Биометрика» (главред – Карл Пирсон). Гиннесс строго-настрого запретил выдавать секреты пивоварения, и Госсет подписался псевдонимом Стьюдент.
Несмотря на то что, К. Пирсон уже изобрел распределение Хи-квадрат, все-таки всеобщее представление о нормальности еще доминировало. Никто не собирался думать, что распределение выборочных оценок может быть не нормальным. Поэтому статья У. Госсета осталась практически не замеченной и забытой. И только Рональд Фишер по достоинству оценил открытие Госсета. Фишер использовал новое распределение в своих работах и дал ему название t-распределение Стьюдента. Критерий для проверки гипотез, соответственно, стал t-критерием Стьюдента. Так произошла «революция» в статистике, которая шагнула в эру анализа выборочных данных. Это был краткий экскурс в историю.
Посмотрим, что же мог увидеть У. Госсет. Сгенерируем 20 тысяч нормальных выборок из 6-ти наблюдений со средней (X̅) 50 и среднеквадратичным отклонением (σ) 10. Затем нормируем выборочные средние, используя генеральную дисперсию:
![]()
Получившиеся 20 тысяч средних сгруппируем в интервалы длинной 0,1 и подсчитаем частоты. Изобразим на диаграмме фактическое (Norm) и теоретическое (ENorm) распределение частот выборочных средних.

Точки (наблюдаемые частоты) практически совпадают с линией (теоретическими частотами). Оно и понятно, ведь данные взяты из одной и то же генеральной совокупности, а отличия – это лишь ошибки выборки.
Проведем новый эксперимент. Нормируем средние, используя выборочную дисперсию.
![]()
Снова подсчитаем частоты и нанесем их на диаграмму в виде точек, оставив для сравнения линию стандартного нормального распределения. Обозначим эмпирическое частоты средних, скажем, через букву t.

Видно, что распределения на этот раз не очень-то и совпадают. Близки, да, но не одинаковы. Хвосты стали более «тяжелыми».
У Госсета-Стьюдента не было последней версии MS Excel, но именно этот эффект он и заметил. Почему так получается? Объяснение заключается в том, что случайная величина
![]()
зависит не только от ошибки выборки (числителя), но и от стандартной ошибки средней (знаменателя), которая также является случайной величиной.
Давайте немного разберемся, какое распределение должно быть у такой случайной величины. Вначале придется кое-что вспомнить (или узнать) из математической статистики. Есть такая теорема Фишера, которая гласит, что в выборке из нормального распределения:
1. средняя X̅ и выборочная дисперсия s2 являются независимыми величинами;
2. соотношение выборочной и генеральной дисперсии, умноженное на количество степеней свободы, имеет распределение χ2(хи-квадрат) с таким же количеством степеней свободы, т.е.
![]()
где k – количество степеней свободы (на английском degrees of freedom (d.f.))
Вернемся к распределению средней. Разделим числитель и знаменатель выражения
![]()
на σX̅. Получим
![]()
Числитель – это стандартная нормальная случайная величина (обозначим ξ (кси)). Знаменатель выразим из теоремы Фишера.

Тогда исходное выражение примет вид

Это и есть t-критерий Стьюдента в общем виде (стьюдентово отношение). Вывести функцию его распределения можно уже непосредственно, т.к. распределения обеих случайных величин в данном выражении известны. Оставим это удовольствие математикам.
Функция t-распределения Стьюдента имеет довольно сложную для понимания формулу, поэтому не имеет смысла ее разбирать. Вероятности и квантили t-критерия приведены в специальных таблицах распределения Стьюдента и забиты в функции разных ПО вроде Excel.
Итак, вооружившись новыми знаниями, вы сможете понять официальное определение распределения Стьюдента.
Случайной величиной, подчиняющейся распределению Стьюдента с k степенями свободы, называется отношение независимых случайных величин
где ξ распределена по стандартному нормальному закону, а χ2k подчиняется распределению χ2 c k степенями свободы.
Таким образом, формула критерия Стьюдента для средней арифметической
![]()
есть частный случай стьюдентова отношения
Из формулы и определения следует, что распределение т-критерия Стьюдента зависит лишь от количества степеней свободы.

При k > 30 t-критерий практически не отличается от стандартного нормального распределения.
В отличие от хи-квадрат, t-критерий может быть одно- и двусторонним. Обычно пользуются двусторонним, предполагая, что отклонение может происходить в обе стороны от средней. Но если условие задачи допускает отклонение только в одну сторону, то разумно применять односторонний критерий. От этого немного увеличивается мощность критерия.
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.

Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.

Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.
Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.

Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Пример проверки гипотезы о математическом ожидании с помощью t- критерия Стьюдента в MS Excel
В Excel есть несколько функций, связанных с t-распределением. Рассмотрим их.
СТЬЮДЕНТ.РАСП – «классическое» левостороннее t-распределение Стьюдента. На вход подается значение t-критерия, количество степеней свободы и опция (0 или 1), определяющая, что нужно рассчитать: плотность или значение функции. На выходе получаем, соответственно, плотность или вероятность того, что случайная величина окажется меньше указанного в аргументе t-критерия, т.е. левосторонний p-value.
СТЬЮДЕНТ.РАСП.2Х – двухсторонне распределение. В качестве аргумента подается абсолютное значение (по модулю) t-критерия и количество степеней свободы. На выходе получаем вероятность получить такое или еще больше значение t-критерия (по модулю), т.е. фактический уровень значимости (p-value).
СТЬЮДЕНТ.РАСП.ПХ – правостороннее t-распределение. Так, 1-СТЬЮДЕНТ.РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-value.
СТЬЮДЕНТ.ОБР – используется для расчета левостороннего обратного значения t-распределения. В качестве аргумента подается вероятность и количество степеней свободы. На выходе получаем соответствующее этой вероятности значение t-критерия. Отсчет вероятности идет слева. Поэтому для левого хвоста нужен сам уровень значимости α, а для правого 1 — α.
СТЬЮДЕНТ.ОБР.2Х – обратное значение для двухстороннего распределения Стьюдента, т.е. значение t-критерия (по модулю). Также на вход подается уровень значимости α. Только на этот раз отсчет ведется с двух сторон одновременно, поэтому вероятность распределяется на два хвоста. Так, СТЬЮДЕНТ.ОБР(1-0,025;5) = СТЬЮДЕНТ.ОБР.2Х(0,05;5) = 2,57058
СТЬЮДЕНТ.ТЕСТ – функция для проверки гипотезы о равенстве математических ожиданий в двух выборках. Заменяет кучу расчетов, т.к. достаточно указать лишь два диапазона с данными и еще пару параметров. На выходе получим p-value.
ДОВЕРИТ.СТЬЮДЕНТ – расчет доверительного интервала средней с учетом t-распределения.
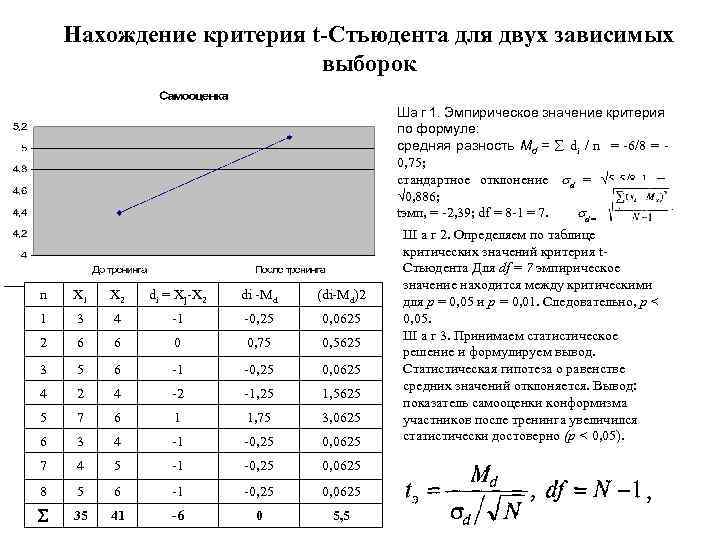
Рассмотрим такой учебный пример. На предприятии фасуют цемент в мешки по 50кг. В силу случайности в отдельно взятом мешке допускается некоторое отклонение от ожидаемой массы, но генеральная средняя должна оставаться 50кг. В отделе контроля качества случайным образом взвесили 9 мешков и получили следующие результаты: средняя масса (X̅) составила 50,3кг, среднеквадратичное отклонение (s) – 0,5кг.
Согласуется ли полученный результат с нулевой гипотезой о том, что генеральная средняя равна 50кг? Другими словами, можно ли получить такой результат по чистой случайности, если оборудование работает исправно и выдает среднее наполнение 50 кг? Если гипотеза не будет отклонена, то полученное различие вписывается в диапазон случайных колебаний, если же гипотеза будет отклонена, то, скорее всего, в настройках аппарата, заполняющего мешки, произошел сбой. Требуется его проверка и настройка.
Краткое условие в обще принятых обозначениях выглядит так.
H0: μ = 50 кг
Ha: μ ≠ 50 кг
Есть основания предположить, что распределение заполняемости мешков подчиняются нормальному распределению (или не сильно от него отличается). Значит, для проверки гипотезы о математическом ожидании можно использовать t-критерий Стьюдента. Случайные отклонения могут происходить в любую сторону, значит нужен двусторонний t-критерий.
Вначале применим допотопные средства: ручной расчет t-критерия и сравнение его с критическим табличным значением. Расчетный t-критерий:
![]()
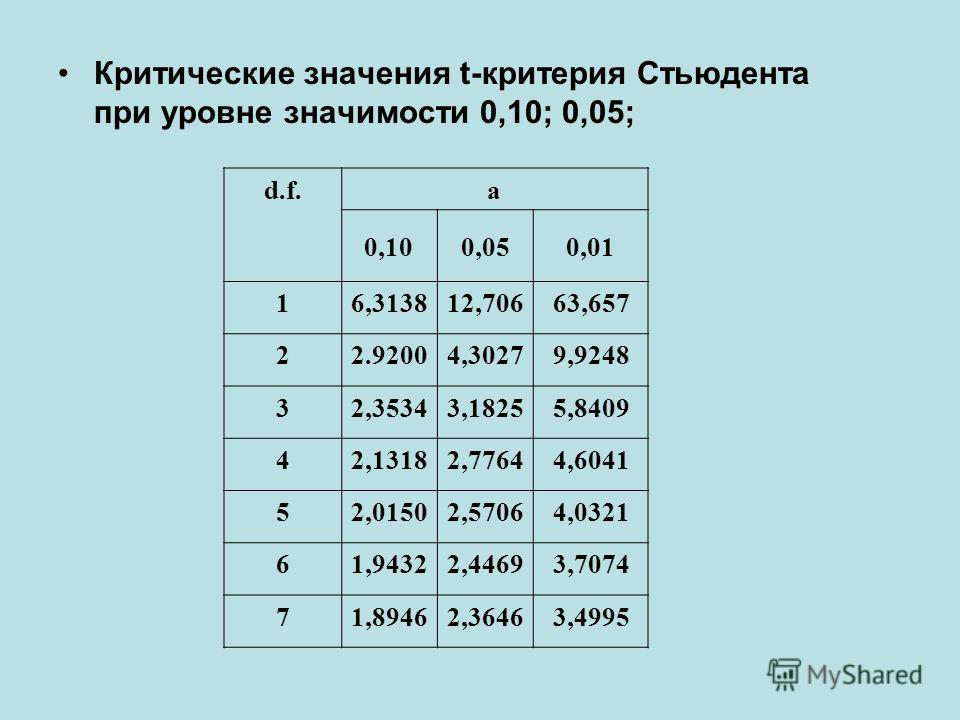
Теперь определим, выходит ли полученное число за критический уровень при уровне значимости α = 0,05. Воспользуемся таблицей для критерия Стьюдента (есть в любом учебнике по статистике).

По столбцам идет вероятность правой части распределения, по строкам – число степеней свободы. Нас интересует двусторонний t-критерий с уровнем значимости 0,05, что равносильно t-значению для половины уровня значимости справа: 1 — 0,05/2 = 0,975. Количество степеней свободы – это объем выборки минус 1, т.е. 9 — 1 = 8. На пересечении находим табличное значение t-критерия – 2,306. Если бы мы использовали стандартное нормальное распределение, то критической точкой было бы значение 1,96, а тут она больше, т.к. t-распределение на небольших выборках имеет более приплюснутый вид.
Сравниваем фактическое (1,8) и табличное значение (2.306). Расчетный критерий оказался меньше табличного. Следовательно, имеющиеся данные не противоречат гипотезе H0 о том, что генеральная средняя равна 50 кг (но и не доказывают ее). Это все, что мы можем узнать, используя таблицы. Можно, конечно, еще p-value попробовать найти, но он будет приближенным. А, как правило, именно p-value используется для проверки гипотез. Поэтому далее переходим в Excel.
Готовой функции для расчета t-критерия в Excel нет. Но это и не страшно, ведь формула t-критерия Стьюдента довольно проста и ее можно легко соорудить прямо в ячейке Excel.

Получили те же 1,8. Найдем вначале критическое значение. Альфа берем 0,05, критерий двусторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.
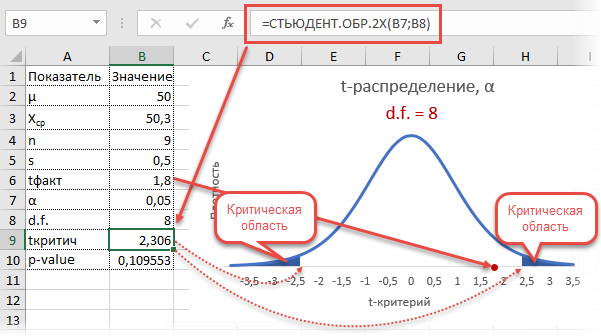
Полученное значение отсекает критическую область. Наблюдаемый t-критерий в нее не попадает, поэтому гипотеза не отклоняется.
Однако это тот же способ проверки гипотезы с помощью табличного значения. Более информативно будет рассчитать p-value, т.е. вероятность получить наблюдаемое или еще большее отклонение от средней 50кг, если эта гипотеза верна. Потребуется функция распределения Стьюдента для двухсторонней гипотезы СТЬЮДЕНТ.РАСП.2Х.

P-value равен 0,1096, что больше допустимого уровня значимости 0,05 – гипотезу не отклоняем. Но теперь можно судить о степени доказательства. P-value оказался довольно близок к тому уровню, когда гипотеза отклоняется, а это наводит на разные мысли. Например, что выборка оказалась слишком мала для обнаружения значимого отклонения.
Пусть через некоторое время отдел контроля снова решил проверить, как выдерживается стандарт заполняемости мешков. На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
Допустим, были получены те же значения средней и стандартного отклонения по выборке, что и в первый раз (50,3 и 0,5 соответственно). Рассчитаем t-критерий.
![]()
Критическое значение для 24-х степеней свободы и α = 0,05 составляет 2,064. На картинке ниже видно, что t-критерий попадает в область отклонения гипотезы.

Можно сделать вывод о том, что с доверительной вероятностью более 95% генеральная средняя отличается от 50кг. Для большей убедительности посмотрим на p-value (последняя строка в таблице). Вероятность получить среднюю с таким или еще большим отклонением от 50, если гипотеза верна, составляет 0,0062, или 0,62%, что при однократном измерении практически невозможно. В общем, гипотезу отклоняем, как маловероятную.
Расчет доверительного интервала для математического ожидания с помощью t-распределения Стьюдента в Excel
С проверкой гипотез тесно связан еще один статистический метод – расчет доверительных интервалов. Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Рассчитаем доверительные интервалы для средней при 9 и 25 наблюдениях. Для этого воспользуемся функцией Excel ДОВЕРИТ.СТЬЮДЕНТ. Здесь, как ни странно, все довольно просто. В аргументах функции нужно указать только уровень значимости α, стандартное отклонение по выборке и размер выборки. На выходе получим полуширину доверительного интервала, то есть значение которое нужно отложить по обе стороны от средней. Проведя расчеты и нарисовав наглядную диаграмму, получим следующее.

Как видно, при выборке в 9 наблюдений значение 50 попадает в доверительный интервал (гипотеза не отклоняется), а при 25-ти наблюдениях не попадает (гипотеза отклоняется). При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
Таким образом, мы решили одну и ту же задачу тремя способами:
1. Древним подходом, сравнивая расчетное и табличное значение t-критерия
2. Более современным, рассчитав p-value, добавив степень уверенности при отклонении гипотезы.
3. Еще более информативным, рассчитав доверительный интервал и получив минимальное значение генеральной средней.
Важно помнить, что t-критерий относится к параметрическим методам, т.к. основан на нормальном распределении (у него два параметра: среднее и дисперсия). Поэтому для его успешного применения важна хотя бы приблизительная нормальность исходных данных и отсутствие выбросов.
Напоследок предлагаю видеоролик о том, как рассчитать критерий Стьюдента и проверить гипотезу о генеральной средней в Excel.
Иногда просят объяснить, как делаются такие наглядные диаграммы с распределением. Ниже можно скачать файл, где проводились расчеты для этой статьи.
Скачать файл с примером.
Всего доброго, будьте здоровы.
Поделиться в социальных сетях:
Цель работы:
научиться
рассчитывать критерий Стьюдента и,
сравнивая его с постоянной величиной,
делать вывод и определять причины
достоверных и не достоверных различий
между двумя выборочными средними
арифметическими
Теоретические
знания
Традиционные
задания по физической культуре, спорту
и реабилитации сложились таким образом,
что в их основе лежат идеи выборочного
метода. Основное сводится к тому, что
исследованию подлежит генеральная
совокупность не в полном составе, а
своей репрезентативной частью –
выборочной совокупностью.
Что
касается объёма выборки, то согласно
основных положений математичской
статистики, выборка тем репрезентативнее,
чем она полнее. В каждом конкретном
случае количество объектов, что отбираются
в выборку, определяется индивидуально.
Основная
задача выборочного метода состоит в
определении двух показателей – среднего
арифметического значения (![]() )
)
и среднего квадратического отклонения
().
В практике
спорта прийнято выбирать надёжность Р
= 0,95 и соответствующий ей уровень
значимости L
= 0,05, отражающий основную группу
исследуемых задач. В отдельных случаях,
при необходимости быстрого увеличения,
надёжность принимается Р = 0,99 и L
= 0,01.
Большинство
задач выборочного метода класифицируются
как сравнительные. Сравниваются две и
более выборочные совокупности. При
сравнении устанавливается принадлежность
этих выборок к одной и той же генеральной
совокупности. Это имеет значение при
определении достоверности различий
между двумя выборочными средними
арифметическими.
Таким
образом, при работе с выборочным методом
в практике физической культуры, спорта
и реабилитации, при изучении небольшого
количества исследованных можно найти
основные среднестатистические показатели
большой группы, а также определить,
существенна ли разница между несколькими
однотипными группами объектов.
С помощью
выборочного метода математической
статистики можно оценить:
-
Эффективность
учебно-воспитательного, учебно-тренировочного,
оздоровительного или реабилитационного
процесса. -
Какая
из двух сравниваемых групп лучше (какой
из двух исследуемых лучший) по:
—
уровню развития физических качеств
(быстроты, силы, выносливости, гибкости,
ловкости);
— уровню
подготовленности (физической, технической,
тактической и …);
— состоянию
здоровья;
—
физическому развитию;
— состоянию
системы организма (сердечно-сосудистой,
дыхательной и…)…
Примечание:
если сравниваются показатели двух
исследуемых, то относительно каждого
проводится несколько измерений (до
10-ти).
-
Преимущество
или идентичность методики:
-обучения
двигательным умениям и навыкам;
-развития
физическим качествам;
-повышения
уровня подготовленности;
-оздоровления;
-реабилитационных
мероприятий и …
Выборочный
метод математической статистики
позволяет сравнивать
показатели:
-
Двух
групп. -
Двух
спортсменов; лиц, не занимающихся
спортом; лиц разных медициских групп
(основная, подготовительная и специальная). -
У одной
группы (одного человека) в начале и по
окончании учебно-тренировочного,
учебно-воспитательного, оздоровительного
или реабилитационного процесса.
Примечание:
продолжительность процесса зависит от
того, через какое время будут иметь
место изменения в исследуемых показателях.
Для
определения достоверности различий
между выборочными средними арифметическими
необходимо обработать числа обеих
сравниваемых выборок способом вариационных
рядов, то есть определить среднее
арифметическое значение (![]()
и
![]() ),
),
среднее квадратическое отклонение (х
и у)
и
ошибку среднего арифметического значения
(mx
и m
y).
Достоверность
и не достоверность различий определяется
при сравнении критерия Стьюдента (t)
и постоянной величины (tгр).
Критерий
Стьюдента определяется по формуле:
-
t
=/

–
 /
/√ mx2
+m
y2
t – критерий
Стьюдента;
![]() ,
,![]()
– среднее
арифметическое значение первой и второй
выборки;
mx,
m
y
– ошибка
среднего арифметического значения
первой и второй выборки.
Примечание:
ошибка среднего арифметического значения
(случайная ошибка) имеет так же название
– ошибка репрезентативности.
Репрезентативность
– выводы,
сделанные
на выборке
можно перенести на всю генеральную
совокупность.
Постоянная
(граничная) величина (tгр)
находится по специальной таблице
критерия Стьюдента (смотри таблицу 1),
для соответствующей надёжности и объёма
выборки.
Чтобы
определить tгр
по
таблице, необходимо знать k-
число степеней свободы, которое
рассчитывается по формуле:
-
k
= Nx
+ Ny
– 2, если Nx
≠ Ny
,
δх
=
δy
или δх
≠
δy -
k
= 2N
– 2, если Nx
= Ny,
δх
≠
δy
При
сравнении t
и tгр
определяется
достоверность различий между двумя
выборочными средними арифметическими:
1. Если
t
≥ tгр
—
различия между сравниваемыми выборочными
средними арифметическими достоверна
(не случайна), существенна и объясняется
влиянием определённых факторов.
Причины
достоверных различий:
а) лучше
одна из групп (один из исследумых);
б) при
сравнении двух методик, одна эффективнее,
чем другая;
в) при
сравнении условий проведения занятий,
проводимых по одной методике, одни
условия лучше, чем другие;
г)
эффективно построенный учебно-тренировочный,
учебно-воспитательный, реабилитационный
или оздоровительный процесс.
Примечание:
для определения лучшей группы, человека
(если сравниваются двое людей по одному
показателю), методики, условий, необходимо
сравнить среднее арифметическое значение
первой и второй выборки (![]() ,
,![]() ).
).
2.Если
t
< tгр
—
различия между сравниваемыми выборочными
средними арифметическими не достоверны
(случайна) и объясняются влиянием
случайных факторов.
Причины
не достоверных различий:
а) не
правильный подбор группы;
б)
недостаточная численность выборки;
в)
одинаковые показатели обеих групп (двух
исследуемых);
г) при
сравнении двух методик – методики
идентичны (одинаковы);
д) при
сравнении условий проведения занятий
по одной методике, условия однаковы;
є) не
эффективно построенный учебно-тренировочный,
учебно-воспитательный, реабилитационный
или оздоровительный процесс.
Примечание:
при сравнении среднего арифметичческого
значения первой и второй выборки (![]() ,
,![]() ),
),
они равны или незначительно отличаются.
Рассмотрим
тему на примере:
Для специальностей
«Физическое воспитание» и «Физическая
реабилитация»
В 2-х
группах спортсменов,
занимающихся плаванием (Xi
и Yi)
измерили
разность ЧСС, уд/мин
(разница ЧСС — измерение ЧСС после
максимально быстрого прохождения
дистанции и в состоянии относительного
покоя). Установить, достоверны ли различия
по показателю ЧСС в исследуемых группах
и в чём их причина
|
Nx
Nx |
||||||||||
|
Ход |
1.
Определяем среднее арифметическое
значение 2-х выборок (![]() ,
,![]() )
)
по формуле взвешенного среднего
арифметического, так как не все варианты
встречаются по одному разу:
![]()
![]() =
=![]() (уд/мин)
(уд/мин)
![]()
![]() (уд/мин)
(уд/мин)
2.Определяем
дисперсию 2-х выборок
(Dх, Dу)
![]()
![]()
![]()
3. Для
дальнейшей работы строим таблицу
а) Для
показателей первой выборки
|
|
ni |
|
( |
( |
|
92 |
3 |
— |
16 |
48 |
|
94 |
4 |
— |
4 |
16 |
|
95 |
7 |
— |
1 |
7 |
|
97 |
2 |
1 |
1 |
2 |
|
99 |
1 |
3 |
9 |
9 |
|
100 |
2 |
4 |
16 |
32 |
|
|
114 |
![]()
![]()
б) Для
показателей второй выборки
-
Yi

ni

(
)2(
)2
ni98
3
84
16
48
102
5
0
0
0
103
6
1
1
6
104
1
2
4
4
105
2
3
9
18

76
![]()
![]()
3.
Определяем среднее квадратическое
отклонение 2-х выборок (х,у)
δх
=
√Дх
δх
= √6,3 = 2,5
δy
= √Дy
δy
=
√ 4,75 = 2,18
4.
Определяем
ошибку среднего арифметического значения
2-х выборок (mx,
my)
|
N |
δ |
|
√ N |
|
mx |
2,5 |
= |
2,5 |
= |
|
√ 19-1 |
√ 18 |
|
my |
2,18 |
= |
2,18 |
= |
2,18 |
= |
|
√ 17-1 |
√ 16 |
4 |
5.
Определяем критерий Стьюдента ( t
).
-
t
=/
–/√ mx2
+m
y2
|
t |
/96-102/ |
= |
/-6/ |
= |
6 |
= |
|
√0,582 |
√0,3364 |
0,8 |
-
Определяем
число степеней свободы (k)
k
= Nx
+ Ny
-2,
т.к. Nx
≠ Ny
(19
≠ 17)
и δх
≠
δy
(2,52 ≠ 2,18)
k
= 19 + 17 – 2 = 36 – 2 = 34
При k
= 34,
tгр
= 2,04 (смотри
таблицу)
при надёжности
Р = 0,95
Р = 0,95 – на 95%
полученным
результатам и сделанным выводам можно
доверять.
7. Сравниваем
t
и
tгр
t
> tгр
(7,5
> 2,04) –
различия
между показателями разницы ЧСС двух
групп спортсменов, занимающихся плаваньем
достоверны (не случайны).
Вывод:
t
> tгр
(7,5
> 2,04) – различия между двумя группами
спортсменов, занимающихся плаваньем,
по показателю разницы ЧСС, достоверны
(не случайны) и объясняются лучшей
подготовленностью и более високим
функциональным состоянием сердечно-сосудистой
системы первой группы, потому что ![]()
<
![]()
(96 <102).
Примечание
Таблиця
1. Граничное
значение
критерия Стьюдента (tгр)
Надёжность
Р = 0,95,
k
– число степеней
свободы
|
k |
tгр |
k |
tгр |
|
1 |
12,71 |
18 |
2,10 |
|
2 |
4,3 |
19 |
2,09 |
|
3 |
3,18 |
20 |
2,09 |
|
4 |
2,78 |
21 |
2,08 |
|
5 |
2,57 |
22 |
2,07 |
|
6 |
2,45 |
23 |
2,07 |
|
7 |
2,36 |
24 |
2,06 |
|
8 |
2,31 |
25 |
2,06 |
|
9 |
2,26 |
26 |
2,06 |
|
10 |
2,71 |
27 |
2,10 |
|
11 |
2,20 |
28 |
2,05 |
|
12 |
2,18 |
29 |
2,05 |
|
13 |
2,16 |
30 |
2,04 |
|
14 |
2,14 |
40 |
2,02 |
|
15 |
2,13 |
60 |
2,00 |
|
16 |
2,12 |
120 |
1,98 |
|
17 |
2,11 |
∞ |
1,96 |
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Наступила осень, а значит, настало время для запуска нового тематического проекта «Статистический анализ с R». В нем мы рассмотрим статистические методы с точки зрения их применения на практике: узнаем какие методы существуют, в каких случаях и каким образом их проводить в . На мой взгляд, Критерий Стьюдента или t-тест (от англ. t-test) идеально подходит в качестве введения в мир статистического анализа. Тест Стьюдента достаточно прост и показателен, а также требует минимум базовых знаний в статистике, с которыми читатель может ознакомиться в ходе прочтения этой статьи.
Примечание_1:
здесь и в других статьях Вы не увидите формул и математических объяснений, т.к. информация рассчитана на студентов естественных и гуманитарных специальностей, которые делают лишь первые шаги в стат. анализе.
Что такое t-тест и в каких случаях его стоит применять
В начале следует сказать, что в статистике зачастую действует принцип бритвы Оккамы , который гласит, что нет смысла проводить сложный статистический анализ, если можно применить более простой (не стоит резать хлеб бензопилой, если есть нож).
Именно поэтому, несмотря на свою простоту, t-тест
является серьезным инструментом, если знать что он из себя представляет и в каких случаях его стоит применять.
Любопытно, что создал этот метод Уильямом Госсет — химик, приглашенный работать на фабрику Guinness. Разработанный им тест служил изначально для оценки качества пива. Однако, химикам фабрики запрещалось независимо публиковать научные работы под своим именем. Поэтому в 1908 году Уильям опубликовал свою статью в журнале «Biometrika» под псевдонимом «Стьюдент». Позже, выдающийся математик и статистик Рональд Фишер доработал метод, который затем получил массовое распространение под названием Student»s t-test.
Критерий Стьюдента (t-тест)
— это статистический метод, который позволяет сравнивать средние значения двух выборок и на основе результатов теста делать заключение о том, различаются ли они друг от друга статистически или нет. Если Вы хотите узнать, отличается ли средний уровень продолжительности жизни в Вашем регионе от среднего уровня по стране; сравнить урожайность картофеля в разных районах; или изменяется ли кровяное давление до и после употребления нового лекарства, то
t-тест
может быть Вам полезен. Почему может быть? Потому что для его проведения, необходимо, чтобы данные выборок имели распределение близкое к нормальному.
Почему может быть? Потому что для его проведения, необходимо, чтобы данные выборок имели распределение близкое к нормальному.
Для этого существуют методы оценки, которые позволяют сказать, допустимо ли в данном случае полагать, что данные распределены нормально или нет. Поговорим об этом подробнее.
Нормальное распределение данных и методы его оценки qqplot и shapiro.test
Нормальное распределение данных характерно для количественных данных, на распределение которых влияет множество факторов, либо оно случайно. Нормальное распределение характеризуется несколькими особенностями:
- Оно всегда симметрично и имеет форму колокола.
- Значения среднего и медианы совпадают.
- В пределах одного стандартного отклонения в обе стороны лежат 68.2% всех данных, в пределах двух — 95,5%, в пределах трех — 99,7%
Давайте создадим случайную выборку с нормальным распределением на , где общее количество измерений = 100, среднее арифметическое = 5, а стандартное отклонение = 1. Затем отобразим его на графике в виде гистограммы:
Затем отобразим его на графике в виде гистограммы:
mydata Ваш график может слегка отличаться от моего, так как числа сгенерированы случайным образом. Как Вы видите, данные не идеально симметричны, но кажется сохраняют форму нормального распределения. Однако, мы воспользуемся более объективными методами определения нормальности данных.
Одним из наиболее простых тестов нормальности является график квантилей (qqplot)
.
Суть теста проста: если данные имеют нормальное распределение, то они не должны сильно отклоняться от линии теоретических квантилей и выходить за пределы доверительных интервалов. Давайте проделаем этот тест в R.
пакета «car» в среду R
qqPlot(mydata) #запустим тест
Как видно из графика, наши данные не имеют серьезных отклонений от теоретического нормального распределения. Но порой при помощи qqplot
невозможно дать однозначный ответ. В этом случае следует использовать тест Шапиро-Уилка
, который основан на нулевой гипотезе, что наши данные распределены нормально.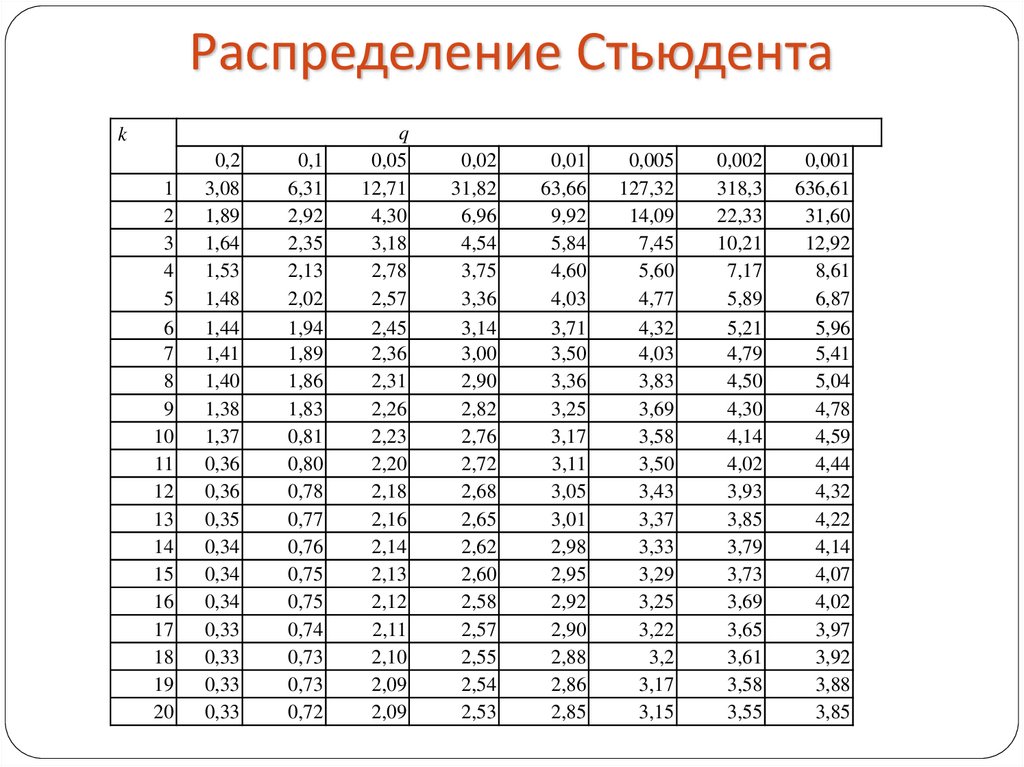 Если же P-значение менее 0.05 (p-value
Если же P-значение менее 0.05 (p-value
Провести тест Шапиро-Уилка в R не составит труда. Для этого нужно всего лишь вызвать функцию shapiro.test, и в скобках вставить имя ваших данных. В нашем случае p-value должен быть значительно больше 0.05, что не позволяет отвергнуть нулевую гипотезу о том, что наши данные распределены нормально.
Запускаем t-тест Стьюдента в среде R
Итак, если данные из выборок имеют нормальное распределение, можно смело приступать к сравнению средних этих выборок. Существует три основных типа t-теста, которые применяются в различных ситуациях. Рассмотрим каждый из них с использованием наглядных примеров.
Одновыборочный критерий Стьюдента (one-sample t-test)
Одновыборочный t-тест следует выбирать, если Вы сравниваете выборку с общеизвестным средним.
Например, отличается ли средний возраст жителей Северо-Кавказского Федерального округа от общего по России. Существует мнение, что климат Кавказа и культурные особенности населяющих его народов способствуют продлению жизни. Для того, чтобы проверить эту гипотезу, мы возьмем данные РосСтата (таблицы среднего ожидаемого продолжительности жизни по регионам России) и применим одновыборочный критерий Стьюдента. Так как критерий Стьюдента основан на проверке статистических гипотез, то за нулевую гипотезу будем принимать то, что различий между средним ожидаемым уровнем продолжительности по России и республикам Северного Кавказа нет. Если различия существуют, то для того, чтобы считать их статистически значимыми
Для того, чтобы проверить эту гипотезу, мы возьмем данные РосСтата (таблицы среднего ожидаемого продолжительности жизни по регионам России) и применим одновыборочный критерий Стьюдента. Так как критерий Стьюдента основан на проверке статистических гипотез, то за нулевую гипотезу будем принимать то, что различий между средним ожидаемым уровнем продолжительности по России и республикам Северного Кавказа нет. Если различия существуют, то для того, чтобы считать их статистически значимыми
p-value
должно быть менее 0.05 (логика та же, что и в вышеописанном тесте Шапиро-Уилка).
Загрузим данные в R. Для этого, создадим вектор со средними значениями по республикам Кавказа (включая Адыгею). Затем, запустим одновыборочный t-тест, указав в параметре mu
среднее значение ожидаемого возраста жизни по России равное 70.93.
rosstat Несмотря на то, что у нас всего 7 точек в выборке, в целом они проходят тесты нормальности и мы можем на них полагаться, так как эти данные уже были усреднены по региону.
Результаты t-теста говорят о том, что средняя ожидаемая продолжительность жизни у жителей Северного Кавказа (74.6 лет) действительно выше, чем в среднем по России (70.93 лет), а результаты теста являются статистически значимыми (p
Двувыборочный для независимых выборок (independent two-sample t-test)
Двувыборочный t-тест используется, когда Вы сравниваете две независимые выборки
. Допустим, мы хотим узнать, отличается ли урожайность картофеля на севере и на юге какого-либо региона. Для этого, мы собрали данные с 40 фермерских хозяйств: 20 из которых располагались на севере и сформировали выборку «North», а остальные 20 — на юге, сформировав выборку «South».
Загрузим данные в среду R. Кроме проверки нормальности данных, будет полезно построить «график с усами», на котором можно видеть медианы и разброс данных для обеих выборок.
North Как видно из графика, медианы выборок не сильно отличаются друг от друга, однако разброс данных гораздо сильнее на севере. Проверим отличаются ли статистически средние значения при помощи функции t.test. Однако в этот раз на место параметра
Проверим отличаются ли статистически средние значения при помощи функции t.test. Однако в этот раз на место параметра
mu
мы ставим имя второй выборки. Результаты теста, которые Вы видите на рисунке снизу, говорят о том, что средняя урожайность картофеля на севере статистически не отличается от урожайности на юге (p
= 0.6339).
Двувыборочный для зависимых выборок (dependent two-sample
t
-test
)
Третий вид t-теста используется в том случае, если элементы выборок зависят друг от друга
. Он идеально подходит для проверки повторяемости результатов
эксперимента: если данные повтора статистически не отличаются от оригинала, то повторяемость данных высокая. Также двувыборочный критерий Стьюдента для зависимых выборок широко применяется в медицинских исследованиях
при изучении эффекта лекарства на организм до и после приема.
Для того, чтобы запустить его в R, следует ввести все ту же функцию t.test
. Однако, в скобках, после таблиц данных, следует ввести дополнительный аргумент paired = TRUE
.
Этот аргумент говорит о том, что Ваши данные зависят друг от друга. Например:
t.test(experiment, povtor.experimenta, paired = TRUE)
t.test(davlenie.do.priema, davlenie.posle.priema, paired = TRUE)
Также в функции t.test
существует два дополнительных аргумента, которые могут улучшить качество результатов теста: var.equal
и alternative
. Если вы знаете, что вариация между выборками равна, вставьте аргумент var.equal = TRUE
. Если же вы хотите проверить гипотезу о том, что разница между средними в выборках значительно меньше или больше 0, то введите аргумент alternative=»less»
или alternative=»greater»
(по умолчанию альтернативная гипотеза говорит о том, что выборки просто отличаются друг от друга: alternative=»two.sided»
).
Заключение
Статья получилась довольно длинной, зато теперь Вы знаете: что такое критерий Стьюдента и нормальное распределение; как при помощи функций qqplot
и shapiro.test
проверять нормальность данных в R; а также разобрали три типа t-тестов и провели их в среде R.
Тема для тех, кто только начинает знакомиться со статистическим анализом — непростая. Поэтому не стесняйтесь, задавайте вопросы, я с удовольствием на них отвечу. Гуру статистики, пожалуйста поправьте меня, если где-нибудь допустил ошибку. В общем, пишите Ваши комментарии, друзья!
Чаще всего в психологическом исследовании наблюдается задачи на выявление различий между двумя или более группами признаков. Выяснение таких различий на уровне средних арифметических рассмотрено в процедуре анализа первичных статистик. Однако возникает вопрос, насколько эти различия достоверны и можно ли их распространить (экстраполировать) на всю популяцию. Для решения этой задачи чаще всего используют (при условии нормального или близкого к нормальному распределению) t — критерий (критерий Стьюдента), который предназначен для выяснения, насколько достоверно отличаются показатели одной выборки испытуемых от другой (например, когда исследуемые получают в результате тестирования одной группы высшие баллы, чем представители другой).
Это параметрический критерий, имеет две основные формы:
1) несвязанный (нечетная) t — критерий, предназначенный для того, чтобы выяснить, есть ли различия между оценками, полученными при использовании одного и того же теста для тестирования двух групп, сформированных из разных людей. Например, это может быть сравнение уровня интеллекта или нервно-психической устойчивости, тревожности успевающих и неуспевающих учеников или сравнение по этим признакам учеников разных классов, возрастов, социальных уровней и тому подобное. Могут быть и разнополые, разнонациональные выборки, а также подвыборки в исследуемых выборках, выделены по определенному признаку. Критерий называют «несвязанный», потому что сравниваемые группы сформированы из разных людей;
2) связан (парный) t — критерий, применяемый для сравнения показателей двух групп, между элементами которых существует специфическая связь. Это означает, что каждому элементу первой группы соответствует элемент второй группы, похожий на него по определенным параметром интересующей исследователя. Чаще всего сравнивают параметры одних и тех же лиц до и после определенного события или действия (например, в процессе проведения лонгитюдного исследования или формирующего эксперимента). Поэтому этот критерий используют для сравнения показателей одних и тех же лиц до и после обследования, эксперимента или истечении определенного времени.
Чаще всего сравнивают параметры одних и тех же лиц до и после определенного события или действия (например, в процессе проведения лонгитюдного исследования или формирующего эксперимента). Поэтому этот критерий используют для сравнения показателей одних и тех же лиц до и после обследования, эксперимента или истечении определенного времени.
Если данные не подлежат нормальному закону распределения, используют непараметрические критерии, эквивалентные t — критерия: критерий Манна — Уитни, эквивалентный нечетном t — критерия, и Двухвыборочный критерий Вилкоксона, эквивалентный парном t — критерия.
С помощью t — критериев и их непараметрических эквивалентов можно только сравнивать результаты двух групп, полученные с использованием одного и того же теста. Однако в некоторых случаях возникает необходимость сравнения нескольких групп или оценок нескольких видов. Это можно сделать поэтапно, разбив задачу на несколько пар сравнений (например, если надо сравнить группы А, Б и Y по результатам тестов X и Y, то можно с помощью t — критерия сначала сравнить группы А и Б по результатам теста X, затем А и Б по результатам теста В, А и В по результатам теста Х и т. д.). Однако это очень трудоемкий метод, поэтому прибегают к более сложному методу дисперсионного анализа.
д.). Однако это очень трудоемкий метод, поэтому прибегают к более сложному методу дисперсионного анализа.
Метод оценки достоверности различий средних арифметических по достаточно эффективным параметрическим критерием Стьюдента предназначен для решения одной из задач, чаще всего наблюдаются при обработке данных — выявление достоверности различий между двумя или более рядами значений. Такая оценка часто необходимо при сравнительном анализе полярных групп. их выделяют на основе различной выраженности определенной целевой признаки (характеристики) изучаемого явления. Как правило, анализ начинают с подсчета первичных статистик выделенных групп «, затем оценивают достоверность различий. Критерий Стьюдента вычисляют по формуле:
Значение критерия Стьюдента для трех уровней доверительной (статистической) значимости (р) приводят в справочниках по матстатистику. Количество степеней свободы определяют по формуле:
С уменьшением объемов выборок (n
Решение о достоверности различий принимают в том случае, если исчисленная величина t превышает табличное значение для определенного количества степеней свободы (d (v)). В публикациях или научных отчетах указывают высокий уровень значимости из трех: р
В публикациях или научных отчетах указывают высокий уровень значимости из трех: р
При любом числового значения критерия достоверности различия между средними этот показатель оценивает не степень выявленной различия (ее оценивают по самой разницей между средними), а только его статистическую достоверность, то есть право распространять полученный на основе сопоставления выборок вывод о наличии разницы на все явление (весь процесс) в целом. Низкий исчисленный критерий отличия не может служить доказательством отсутствия различия между двумя признаками (явлениями), потому что его значимость (степень достоверности) зависит не только от величины средних, но и от количества сравниваемых выборок. Он указывает не на отсутствие различия, а на то, что при такой величины выборок она статистически недостоверная: очень большой шанс, что разница в этих условиях случайная, очень мала вероятность ее достоверности.
Таблица 2.17. Доверительные границы для критерия Стьюдента (t-критерий) для f степеней свободы
ния среднего времени выполнения задания во второй попытке (по сравнению с первой пробой) не является достоверным.
Это выражение не равносильно утверждению о статистической однородности двух выборок, которые сопоставляют. Кроме того, применение критерия Стьюдента в случае таких неодинаковых выборок не вполне корректное математически и, безусловно, сказывается на конечном итоге о недостоверности различий Хср = 9,1 и Хср = 8,5. Пользуясь этим критерием, оценивают не степень близости двух средних, а рассматривают отнесения или невод несения случайной (при заданном уровне значимости). .
Excel для Office 365
Excel для Office 365 для Mac
Excel 2019
Excel 2016
Excel 2019 для Mac
Excel 2013
Excel 2010
Excel 2016 для Mac
Excel для Mac 2011
Excel Online
Excel для iPad
Excel для iPhone
Excel для планшетов с Android
Excel для телефонов с Android
Excel Mobile
Excel Starter 2010
Меньше
Возвращает вероятность, соответствующую t-тесту Стьюдента. Функция СТЬЮДЕНТ.ТЕСТ позволяет определить вероятность того, что две выборки взяты из генеральных совокупностей, которые имеют одно и то же среднее.
Синтаксис
СТЬЮДЕНТ.ТЕСТ(массив1;массив2;хвосты;тип)
Аргументы функции СТЬЮДЕНТ.ТЕСТ описаны ниже.
Массив1
Обязательный. Первый набор данных.
Массив2
Обязательный. Второй набор данных.
Хвосты
Обязательный. Число хвостов распределения. Если значение «хвосты» = 1, функция СТЬЮДЕНТ.ТЕСТ возвращает одностороннее распределение. Если значение «хвосты» = 2, функция СТЬЮДЕНТ.ТЕСТ возвращает двустороннее распределение.
Тип
Обязательный. Вид выполняемого t-теста.
Параметры
Замечания
Если аргументы «массив1» и «массив2» имеют различное число точек данных, а «тип» = 1 (парный), то функция СТЬЮДЕНТ.ТЕСТ возвращает значение ошибки #Н/Д.
Аргументы «хвосты» и «тип» усекаются до целых значений.
Если аргумент «хвосты» или «тип» не является числом, то функция СТЬЮДЕНТ.ТЕСТ возвращает значение ошибки #ЗНАЧ!.
Если аргумент «хвосты» принимает любое значение, отличное от 1 и 2, то функция СТЬЮДЕНТ. ТЕСТ возвращает значение ошибки #ЧИСЛО!.
ТЕСТ возвращает значение ошибки #ЧИСЛО!.
Функция СТЬЮДЕНТ.ТЕСТ использует данные аргументов «массив1» и «массив2» для вычисления неотрицательной t-статистики. Если «хвосты» = 1, СТЬЮДЕНТ.ТЕСТ возвращает вероятность более высокого значения t-статистики, исходя из предположения, что «массив1» и «массив2» являются выборками, принадлежащими к генеральной совокупности с одним и тем же средним. Значение, возвращаемое функцией СТЬЮДЕНТ.ТЕСТ в случае, когда «хвосты» = 2, вдвое больше значения, возвращаемого, когда «хвосты» = 1, и соответствует вероятности более высокого абсолютного значения t-статистики, исходя из предположения, что «массив1» и «массив2» являются выборками, принадлежащими к генеральной совокупности с одним и тем же средним.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
В каких случаях можно использовать t-критерий Стьюдента?
Для применения t-критерия Стьюдента необходимо, чтобы исходные данные имели нормальное распределение
. В случае применения двухвыборочного критерия для независимых выборок также необходимо соблюдение условия равенства (гомоскедастичности) дисперсий
.
При несоблюдении этих условий при сравнении выборочных средних должны использоваться аналогичные методы непараметрической статистики
, среди которых наиболее известными являются U-критерий Манна — Уитни
(в качестве двухвыборочного критерия для независимых выборок), а также критерий знаков
и критерий Вилкоксона
(используются в случаях зависимых выборок).
Для сравнения средних величин t-критерий Стьюдента рассчитывается по следующей формуле:
где М 1
— средняя арифметическая первой сравниваемой совокупности (группы), М 2
— средняя арифметическая второй сравниваемой совокупности (группы), m 1
— средняя ошибка первой средней арифметической, m 2
— средняя ошибка второй средней арифметической.
Как интерпретировать значение t-критерия Стьюдента?
Полученное значение t-критерия Стьюдента необходимо правильно интерпретировать. Для этого нам необходимо знать количество исследуемых в каждой группе (n 1 и n 2). Находим число степеней свободы f
по следующей формуле:
f = (n 1 + n 2) — 2
После этого определяем критическое значение t-критерия Стьюдента для требуемого уровня значимости (например, p=0,05) и при данном числе степеней свободы f
по таблице (см. ниже
).
Сравниваем критическое и рассчитанное значения критерия:
· Если рассчитанное значение t-критерия Стьюдента равно или больше
критического, найденного по таблице, делаем вывод о статистической значимости различий между сравниваемыми величинами.
· Если значение рассчитанного t-критерия Стьюдента меньше
табличного, значит различия сравниваемых величин статистически не значимы.
Пример расчета t-критерия Стьюдента
Для изучения эффективности нового препарата железа были выбраны две группы пациентов с анемией. В первой группе пациенты в течение двух недель получали новый препарат, а во второй группе — получали плацебо. После этого было проведено измерение уровня гемоглобина в периферической крови. В первой группе средний уровень гемоглобина составил 115,4±1,2 г/л, а во второй — 103,7±2,3 г/л (данные представлены в формате M±m
В первой группе пациенты в течение двух недель получали новый препарат, а во второй группе — получали плацебо. После этого было проведено измерение уровня гемоглобина в периферической крови. В первой группе средний уровень гемоглобина составил 115,4±1,2 г/л, а во второй — 103,7±2,3 г/л (данные представлены в формате M±m
), сравниваемые совокупности имеют нормальное распределение. При этом численность первой группы составила 34, а второй — 40 пациентов. Необходимо сделать вывод о статистической значимости полученных различий и эффективности нового препарата железа.
Решение:
Для оценки значимости различий используем t-критерий Стьюдента, рассчитываемый как разность средних значений, поделенная на сумму квадратов ошибок:
После выполнения расчетов, значение t-критерия оказалось равным 4,51. Находим число степеней свободы как (34 + 40) — 2 = 72. Сравниваем полученное значение t-критерия Стьюдента 4,51 с критическим при р=0,05 значением, указанным в таблице: 1,993. Так как рассчитанное значение критерия больше критического, делаем вывод о том, что наблюдаемые различия статистически значимы (уровень значимости р
Так как рассчитанное значение критерия больше критического, делаем вывод о том, что наблюдаемые различия статистически значимы (уровень значимости р
Распределение Фишера – это распределение случайной величины
где случайные величины Х 1
и Х 2
независимы и имеют распределения хи – квадрат с числом степеней свободы k 1
и k 2
соответственно. При этом пара (k 1 , k 2)
– пара «чисел степеней свободы» распределения Фишера, а именно, k 1
– число степеней свободы числителя, а k 2
– число степеней свободы знаменателя. Распределение случайной величины F
названо в честь великого английского статистика Р.Фишера (1890-1962), активно использовавшего его в своих работах.
Распределение Фишера используют при проверке гипотез об адекватности модели в регрессионном анализе, о равенстве дисперсий и в других задачах прикладной статистики.
Таблица критических значений Стьюдента.
Начало формы
| Число степеней свободы, f | Значение t-критерия Стьюдента при p=0. 05 05
|
| 12.706 | |
| 4.303 | |
| 3.182 | |
| 2.776 | |
| 2.571 | |
| 2.447 | |
| 2.365 | |
| 2.306 | |
| 2.262 | |
| 2.228 | |
| 2.201 | |
| 2.179 | |
| 2.160 | |
| 2.145 | |
| 2.131 | |
| 2.120 | |
| 2.110 | |
| 2.101 | |
| 2.093 | |
| 2.086 | |
| 2.080 | |
| 2.074 | |
| 2.069 | |
| 2.064 | |
| 2.060 | |
| 2.056 | |
| 2.052 | |
2. 048 048
|
|
| 2.045 | |
| 2.042 | |
| 2.040 | |
| 2.037 | |
| 2.035 | |
| 2.032 | |
| 2.030 | |
| 2.028 | |
| 2.026 | |
| 2.024 | |
| 40-41 | 2.021 |
| 42-43 | 2.018 |
| 44-45 | 2.015 |
| 46-47 | 2.013 |
| 48-49 | 2.011 |
| 50-51 | 2.009 |
| 52-53 | 2.007 |
| 54-55 | 2.005 |
| 56-57 | 2.003 |
| 58-59 | 2.002 |
| 60-61 | 2.000 |
| 62-63 | 1.999 |
| 64-65 | 1.998 |
| 66-67 | 1.997 |
| 68-69 | 1.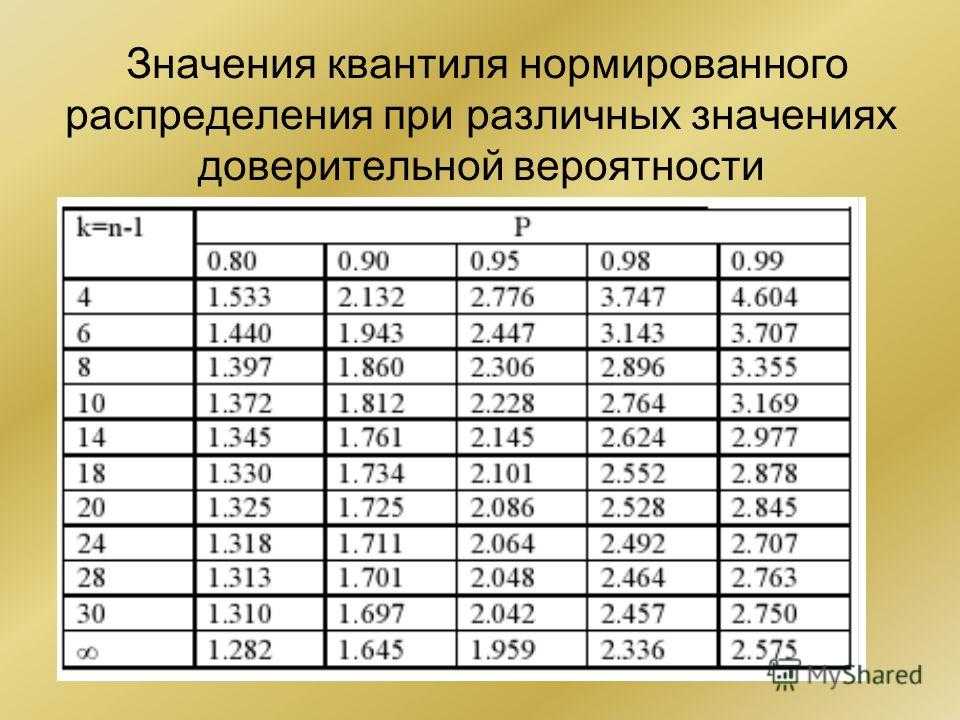 995 995
|
| 70-71 | 1.994 |
| 72-73 | 1.993 |
| 74-75 | 1.993 |
| 76-77 | 1.992 |
| 78-79 | 1.991 |
| 80-89 | 1.990 |
| 90-99 | 1.987 |
| 100-119 | 1.984 |
| 120-139 | 1.980 |
| 140-159 | 1.977 |
| 160-179 | 1.975 |
| 180-199 | 1.973 |
| 1.972 | |
| ∞ | 1.960 |
Эквивалентным подходом к интерпретации результатов теста будет следующий: допустив, что нулевая гипотеза верна, мы можем рассчитать, насколько велика вероятность
получить t
-критерий, равный или превышающий то реальное значение, которое мы рассчитали по имеющимся выборочным данным. Если эта вероятность оказывается меньше, чем заранее принятый уровень значимости (например, Р
Предположим, у нас имеются данные по суточному потреблению энергии, поступающей с пищей (кДж/сутки), для 11 женщин (пример заимствован из книги Altman D. G. (1981) Practical Statistics for Medical Research , Chapman & Hall, London
G. (1981) Practical Statistics for Medical Research , Chapman & Hall, London
):
Среднее значение для этих 11 наблюдений составляет:
Вопрос: отличается ли это выборочное среднее значение от установленной нормы в 7725 кДж/сутки? Разница между нашим выборочным значением и этим нормативом довольно прилична: 7725 — 6753.6 = 971.4. Но насколько велика эта разница статистически? Ответить на этот вопрос поможет одновыборочный t
-тест. Как и другие варианты t
-теста, одновыборочный тест Стьюдента выполняется в R при помощи функции t.test()
:
Вопрос: различаются ли эти средние значения статистически? Проверим гипотезу об отсутствии разницы при помощи t
-теста:
Но как в таких случаях оценить наличие эффекта от воздействия статистически? В общем виде критерий Стьюдента можно представить как
Алгоритм расчета t-критерия Стьюдента для независимых выборок измерений
-
Определить
расчетное значение t-критерия
по формуле
где
f
– степень свободы, которая определяется
как
- Определить
критическое значение t-критерия
с использованием таблицы 1 приложения,
при заданном уровне значимости и
степени свободы.
-
Сравнить
расчетное и критическое значение t
— критерия. Если расчетное значение
больше или равно критическому, то
гипотеза равенства средних значений
в двух выборках изменений отвергается
(Но). Во всех других случаях она
принимается на заданном уровне
значимости.
Пример.
Две
группы студентов обучались по двум
различным методикам. В конце обучения
с ними был проведен тест по всему курсу.
Необходимо оценить, насколько существенны
различия в полученных знаниях. Результаты
тестирования представлены в таблице
4.
Таблица
4
|
25 |
18 |
9 |
13 |
8 |
20 |
25 |
18 |
6 |
12 |
|
19 |
13 |
12 |
12 |
18 |
9 |
7 |
10 |
18 |
20 |
Рассчитаем
выборочное среднее, дисперсию и
стандартное отклонение:
Определим
значение tp
по
формуле tp
= 0,45
По
таблице 1 (см. приложение) находим
приложение) находим
критическое значение tk
для уровня значимости р = 0,01
tk
= 2,88
Вывод:
так как расчетное значение критерия
меньше критического 0,45<2,88 гипотеза
Но подтверждается и существенных
различий в методиках обучения нет на
уровне значимости 0,01.
Алгоритм расчета t-критерия Стьюдента для зависимых выборок измерений
1.
Определить расчетное значение t-критерия
по формуле
,
где
2.
Рассчитать степень свободы f
3.
Определить критическое значение
t-критерия
по таблице 1 приложения.
4.
Сравнить расчетное и критическое
значение t-критерия.
Если расчетное значение больше или
равно критическому, то гипотеза равенства
средних значений в двух выборках
изменений отвергается (Но). Во всех
других случаях она принимается на
заданном уровне значимости.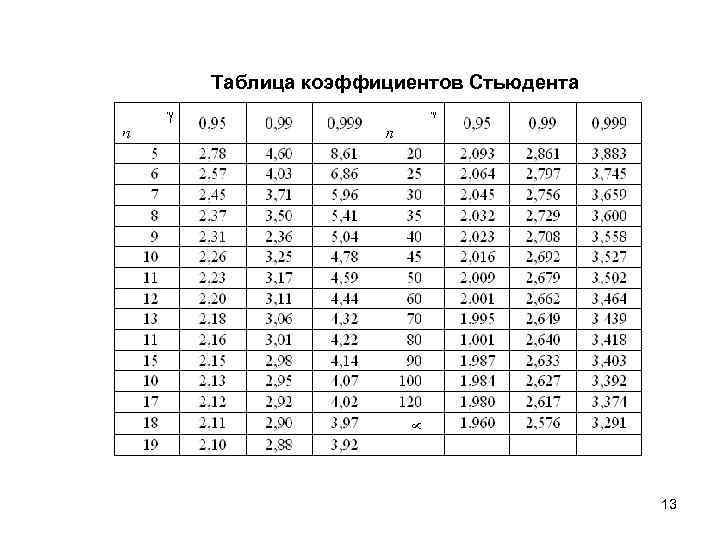
U—критерий
Манна—Уитни
Назначение
критерия
Критерий
предназначен для оценки различий между
двумя
непараметрическими
выборками по уровню
какого-либо
признака, количественно измеренного.
Он позволяет выявлять различия между
малыми
выборками,
когда n
< 30.
Описание критерия
Этот
метод определяет, достаточно ли мала
зона пересекающихся значений между
двумя рядами. Чем меньше эта область,
тем более вероятно, что различия
достоверны. Эмпирическое значение
критерия U
отражает то, насколько велика зона
совпадения между рядами. Поэтому чем
меньше U,
тем
более вероятно,
что различия достоверны.
Гипотезы
НО:
Уровень признака в группе 2 не ниже
уровня признака в
группе
1.
HI:
Уровень признака в группе 2 ниже уровня
признака в группе 1.
Алгоритм расчета критерия Манна-Уитни (u)
-
Перенести
все данные испытуемых на индивидуальные
карточки. -
Пометить
карточки испытуемых выборки 1 одним
цветом, скажем красным, а все карточки
из выборки 2 – другим, например, синим.
-
Разложить
все карточки в единый ряд по степени
нарастания признака, не считаясь с
тем, к какой выборке они относятся, как
если бы мы работали с одной большой
выборкой.
-
Проранжировать
значения на карточках, приписывая
меньшему значению меньший ранг. -
Вновь
разложить карточки на две группы,
ориентируясь на цветные обозначения:
красные карточки в один ряд, синие –
в другой. -
Подсчитать
сумму рангов отдельно на красных
карточках (выборка 1) и на синих карточках
(выборка 2). Проверить, совпадает ли
общая сумма рангов с расчетной. -
Определить
большую из двух ранговых сумм. -
Определить
значение U
по формуле:

где
n1
– количество
испытуемых в выборке 1;
n2
– количество
испытуемых в выборке 2,
Тх
– большая из двух рантовых сумм;
nх
– количество испытуемых в группе с
большей суммой рангов.
9.
Определить критические значения U
по таблице 2 (см. приложение).
Если
Uэмп.>
Uкр0,05,
то гипотеза Но
принимается.
Если Uэмп.≤
Uкр,
то отвергается. Чем меньше значения U,
тем достоверность различий выше.
Пример.
Сравнить
эффективность двух методов обучения
в двух группах. Результаты испытаний
представлены в таблице 5.
Таблица 5
|
18 |
10 |
7 |
15 |
14 |
11 |
13 |
||||
|
15 |
20 |
10 |
8 |
16 |
10 |
19 |
7 |
15 |
14 |
29 |
Перенесем
все данные в другую таблицу, выделив
данные второй группы подчеркиванием
и сделаем ранжирование общей выборки
(см. алгоритм ранжирования в методических
алгоритм ранжирования в методических
указаниях к заданию 3).
|
Значения |
7 |
7 |
8 |
10 |
10 |
10 |
11 |
13 |
14 |
14 |
15 |
15 |
15 |
16 |
18 |
19 |
20 |
29 |
|
Ранги |
1,5 |
1,5 |
3 |
5 |
5 |
5 |
7 |
8 |
9,5 |
9,5 |
12 |
12 |
12 |
14 |
15 |
16 |
17 |
18 |
|
Номер |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
Найдем
сумму рангов двух выборок и выберем
большую из них: Тх
= 113
Рассчитаем
эмпирическое значение критерия по
формуле 2: Up
= 30.
Определим
по таблице 2 приложения критическое
значение критерия при уровне значимости
р = 0.05 : Uk
= 19.
Вывод:
так
как расчетное значение критерия U
больше критического при уровне значимости
р = 0.05 и 30 > 19, то гипотеза о равенстве
средних принимается и различия в
методиках обучения несущественны.
Т-тест Стьюдента: отличный справочник, который вам понравится
Т-тест Стьюдента
В этой статье описывается независимый Т-критерий Стьюдента , который используется для сравнения средних значений двух независимых групп. Этот тест также называется t-критерий Стьюдента , t-критерий Стьюдента и t-критерий равной дисперсии . Например, вы можете сравнить средние веса людей, сгруппированных по полу: мужские и женские группы, которые представляют собой две несвязанные/независимые группы.
Стьюдентный критерий независимых выборок бывает двух разных форм:
- стандартный Стьюдентский критерий , который предполагает, что дисперсии двух групп равны.
- t-критерий Уэлча , который является менее строгим по сравнению с исходным критерием Стьюдента. Этот тест описан в отдельной главе.

Обратите внимание, что t-критерий Уэлча считается более безопасным. Обычно результаты классического t-критерия Стьюдента и t-критерий Велча очень похожи, если только размеры групп и стандартные отклонения не сильно различаются.
В этой статье вы узнаете:
- Формула Стьюдента и предположения
- Как вычислить, интерпретировать и представить t-критерий Стьюдента в R .
- Как проверить предположения t-критерия Стьюдента
Содержимое:
- Предпосылки
- Исследовательские вопросы
- Статистические гипотезы
- Формула
- Предположения и предварительные тесты
- Расчет теста в R
- Демонстрационные данные
- Сводная статистика
- Визуализация
- Вычисление
- d Коэна для t-критерия Стьюдента
- Отчет
- Резюме
Связанная книга
Практическая статистика в R II — Сравнение групп: числовые переменные
Предварительные условия
Убедитесь, что вы установили следующие пакеты R:
-
tidyverseдля обработки данных и визуализации -
ggpubrдля создания готовых к публикации графиков -
rstatix предоставляет удобные функции R для удобного статистического анализа. -
datarium: содержит необходимые наборы данных для этой главы.

Начните с загрузки следующих необходимых пакетов:
библиотека(tidyverse) библиотека (ggpubr) library(rstatix)
Исследовательские вопросы
Типичный исследовательский вопрос: равно ли среднее значение группы A ((m_A)) среднему значению группы B ((m_B))?
Формула
Классический критерий Стьюдента является более строгим. Предполагается, что две группы имеют одинаковую дисперсию населения. Если дисперсия двух групп эквивалентна ( гомоскедастичность ), значение t-теста, сравнивая две выборки (A и B), можно рассчитать следующим образом. 92}}{n_A+n_B-2}
]
со степенями свободы (df): (df = n_A + n_B — 2).
Значение p может быть вычислено для соответствующего абсолютного значения t-статистики (|t|).
Если p-значение меньше или равно уровню значимости 0,05, мы можем отклонить нулевую гипотезу и принять альтернативную гипотезу.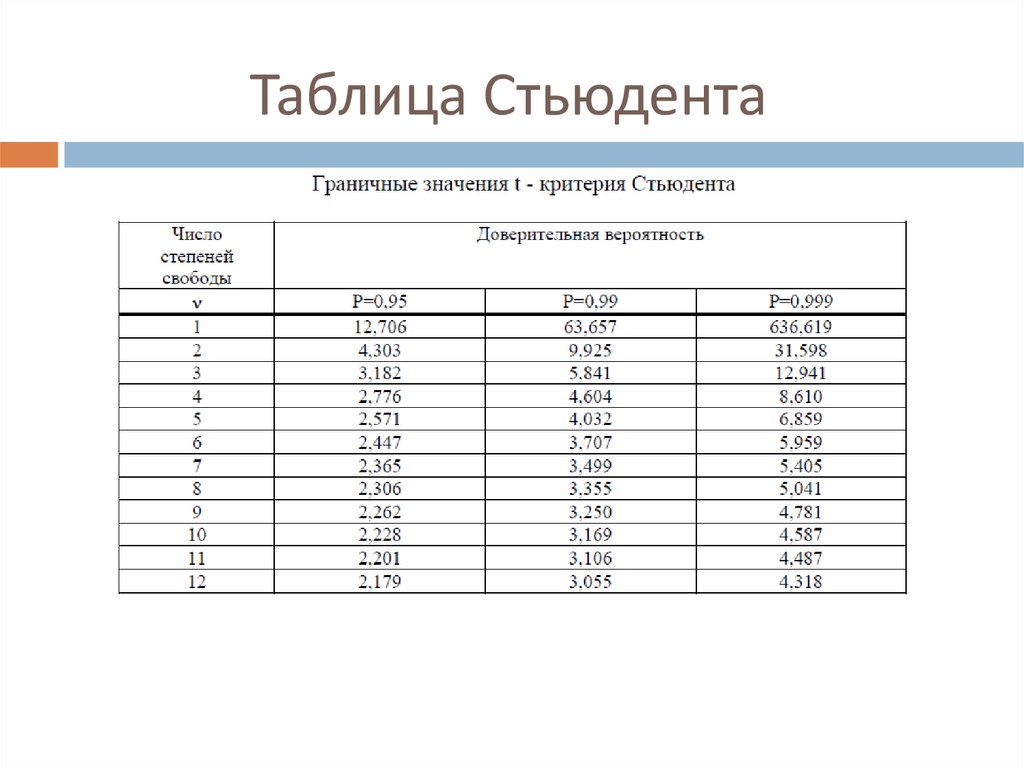 Другими словами, мы можем заключить, что средние значения групп А и В существенно различаются.
Другими словами, мы можем заключить, что средние значения групп А и В существенно различаются.
Предположения и предварительные тесты
Независимый t-тест для двух выборок предполагает следующие характеристики данных:
- Независимость наблюдений . Каждый предмет должен принадлежать только к одной группе.
- Нет значительных выбросов в двух группах
- Нормальность . данные для каждой группы должны быть примерно нормально распределены.
- Однородность отклонений . дисперсия переменной результата должна быть одинаковой в каждой группе.
Нажмите, чтобы проверить предположения t-критерия Стьюдента.
Расчет теста в Р
Демонстрационные данные
Демонстрационный набор данных: гендерный вес [в пакете datarium], содержащий вес 40 человек (20 женщин и 20 мужчин).
Загрузить данные и показать несколько случайных строк по группам:
# Загрузить данные
данные ("половой вес", пакет = "датариум")
# Показать выборку данных по группам
сет. сид(123)
гендерный вес %>% sample_n_by(group, size = 2)
 сид(123)
гендерный вес %>% sample_n_by(group, size = 2)
сид(123)
гендерный вес %>% sample_n_by(group, size = 2) ## # Набор символов: 4 x 3 ## вес группы id ## <фкт> <фкт> ## 1 6 Ж 65,0 ## 2 15 F 65,9## 3 29 М 88,9 ## 4 37 M 77.0
Визуализация
Визуализируйте данные с помощью коробчатых диаграмм. Вес участка по группам.
битхр <- ggboxplot( гендерный вес, x = "группа", y = "вес", ylab = "Вес", xlab = "Группы", add = "дрожание" ) bxp
Вычисление
Мы будем использовать удобную для каналов функцию t_test() [пакет rstatix], оболочку базовой функции R t.test() .
Напомним, что по умолчанию R вычисляет t-критерий Уэлча, который является более безопасным. Это тест, в котором вы не предполагаете, что дисперсия одинакова в двух группах, что приводит к дробным степеням свободы. Если вы хотите предположить равенство дисперсий (критерий Стьюдента), укажите параметр var.equal = TRUE :
stat.test <- гендерный вес %>% t_test(вес ~ группа, var.
 equal = TRUE) %>%
add_significance()
стат.тест
equal = TRUE) %>%
add_significance()
стат.тест ## # Тиббл: 1 x 9 ## .у. группа1 группа2 n1 n2 статистика df p p.signif ## ## 1 масса F M 20 20 -20.8 38 2.33e-22 ****
Приведенные выше результаты показывают следующие компоненты:
-
.y.: переменная y, используемая в тесте. -
group1,group2: сравниваемые группы в попарных тестах. -
статистика: Тестовая статистика, используемая для вычисления p-значения. -
df: степени свободы. -
p: p-значение.
Обратите внимание, что вы можете получить подробный результат, указав опцию details = TRUE .
Коэффициент Коэна для t-критерия Стьюдента
Величина эффекта рассчитывается путем деления средней разницы между группами на объединенное стандартное отклонение.
Формула Коэна d:
d = (mean1 - mean2)/pooled. , где:  sd
sd
-
pooled.sd— общее стандартное отклонение двух групп.pooled.sd = sqrt([var1*(n1-1) + var2*(n2-1)]/[n1 + n2-2]); -
var1иvar2— это дисперсии (квадраты стандартных отклонений) групп 1 и 2 соответственно. -
n1иn2— число выборок для группы 1 и 2 соответственно. -
означает 1иmean2средние значения каждой группы соответственно.
Расчет:
гендерный вес %>% cohens_d(вес ~ группа, var.equal = TRUE)
## # Таблица: 1 x 7 ## .у. группа1 группа2 effsize n1 n2 величина ## * ## 1 вес F M -6,57 20 20 большой
Имеется большой размер эффекта, d = 6,57.
Отчет
Результат можно представить следующим образом:
Средний вес в группе женщин составил 63,5 (SD = 2,03), тогда как средний вес в группе мужчин составил 85,8 (SD = 4,3). Критерий Стьюдента показал, что разница статистически значима, t(38) = -20,8, p < 0,0001, d = 6,57; где t(38) — сокращенное обозначение t-статистики Стьюдента с 38 степенями свободы.
Критерий Стьюдента показал, что разница статистически значима, t(38) = -20,8, p < 0,0001, d = 6,57; где t(38) — сокращенное обозначение t-статистики Стьюдента с 38 степенями свободы.
stat.test <- stat.test %>% add_xy_position(x = "группа") бхп + stat_pvalue_manual (stat.test, tip.length = 0) + labs(subtitle = get_test_label(stat.test, подробный = TRUE))
Резюме
В этой статье описываются формула и основы t-критерия Стьюдента. Приведены примеры R-кодов для расчета теста и размера эффекта, интерпретации и представления результатов.
Версия:
Французский
Непарный Т-тест (предыдущий урок)
(следующий урок) Т-тест Велча
Назад к основам Т-теста: определение, формула и расчет
Учитель
Альбукадель Кассамбара
Роль: Основатель Datanovia
- Веб-сайт: https://www.datanovia.com/en
- Опыт: >10 лет
- Специалист в области биоинформатики и биологии рака
Подробнее
Что такое множественные формулы и когда их использовать
Что такое Т-тест?
Стьюдент-критерий — это выводная статистика, используемая для определения того, существует ли значительная разница между средними значениями двух групп и тем, как они связаны. T-тесты используются, когда наборы данных следуют нормальному распределению и имеют неизвестные отклонения, например, набор данных, записанный при 100-кратном подбрасывании монеты.
T-тесты используются, когда наборы данных следуют нормальному распределению и имеют неизвестные отклонения, например, набор данных, записанный при 100-кратном подбрасывании монеты.
Стьюдентный тест – это тест, используемый для проверки гипотез в статистике. Он использует t-статистику, значения t-распределения и степени свободы для определения статистической значимости.
Ключевые выводы
- Стьюдент-критерий — это статистический вывод, используемый для определения наличия статистически значимой разницы между средними значениями двух переменных.
- Стьюдентный критерий — это критерий, используемый для проверки гипотез в статистике.
- Для расчета t-критерия требуются три основных значения данных, включая разницу между средними значениями из каждого набора данных, стандартное отклонение каждой группы и количество значений данных.
- Т-тесты могут быть зависимыми или независимыми.
Т-тест
Понимание Т-теста
Стьюдентный тест сравнивает средние значения двух наборов данных и определяет, получены ли они из одной и той же совокупности. В приведенных выше примерах выборка учащихся из класса A и выборка учащихся из класса B, скорее всего, не будут иметь одинаковое среднее значение и стандартное отклонение. Точно так же образцы, взятые из контрольной группы, получавшей плацебо, и образцы, взятые из группы, которой прописали лекарство, должны иметь несколько разные среднее значение и стандартное отклонение.
В приведенных выше примерах выборка учащихся из класса A и выборка учащихся из класса B, скорее всего, не будут иметь одинаковое среднее значение и стандартное отклонение. Точно так же образцы, взятые из контрольной группы, получавшей плацебо, и образцы, взятые из группы, которой прописали лекарство, должны иметь несколько разные среднее значение и стандартное отклонение.
Математически t-критерий берет выборку из каждого из двух наборов и устанавливает постановку задачи. Он предполагает нулевую гипотезу о том, что два средних равны.
С помощью формул рассчитываются значения и сравниваются со стандартными значениями. Предполагаемая нулевая гипотеза соответственно принимается или отвергается. Если нулевая гипотеза может быть отвергнута, это указывает на то, что показания данных сильны и, вероятно, не случайны.
Стьюдент-тест — это лишь один из многих тестов, используемых для этой цели. Статистики используют дополнительные тесты, кроме t-критерия, для изучения большего количества переменных и больших размеров выборки. Для выборки большого размера статистики используют z-критерий. Другие варианты тестирования включают тест хи-квадрат и f-тест.
Для выборки большого размера статистики используют z-критерий. Другие варианты тестирования включают тест хи-квадрат и f-тест.
Использование Т-теста
Предположим, что производитель лекарств тестирует новое лекарство. Следуя стандартной процедуре, препарат дается одной группе пациентов, а плацебо — другой группе, называемой контрольной группой. Плацебо — это вещество, не имеющее терапевтической ценности, и служит эталоном для измерения того, как реагирует другая группа, получающая реальное лекарство.
После испытания препарата члены контрольной группы, получавшей плацебо, сообщили об увеличении средней продолжительности жизни на три года, в то время как члены группы, которым прописали новый препарат, сообщили об увеличении средней продолжительности жизни на четыре года.
Начальное наблюдение указывает на то, что препарат работает. Однако также возможно, что наблюдение может быть обусловлено случайностью. Стьюдентный тест можно использовать, чтобы определить, являются ли результаты правильными и применимыми ко всей популяции.
При использовании t-теста делаются четыре предположения. Собранные данные должны соответствовать непрерывной или порядковой шкале, такой как баллы для теста IQ, данные собираются из случайно выбранной части всего населения, данные будут иметь нормальное распределение в виде колоколообразной кривой, и равная или гомогенная дисперсия существует, когда стандартные вариации равны.
Формула Т-теста
Для расчета t-критерия требуются три значения фундаментальных данных. Они включают разницу между средними значениями из каждого набора данных или среднюю разницу, стандартное отклонение каждой группы и количество значений данных в каждой группе.
Это сравнение помогает определить влияние случайности на разницу, а также определить, находится ли разница за пределами этого диапазона вероятности. Стьюдентный тест ставит вопрос о том, представляет ли разница между группами истинную разницу в исследовании или просто случайную разницу.
На выходе t-критерий выдает два значения: t-значение и степени свободы. Значение t или t-оценка представляет собой отношение разницы между средним значением двух наборов выборок и вариацией, которая существует в наборах выборок.
Значение t или t-оценка представляет собой отношение разницы между средним значением двух наборов выборок и вариацией, которая существует в наборах выборок.
Значение числителя представляет собой разницу между средним значением двух наборов выборок. Знаменатель представляет собой вариацию, существующую в наборах выборок, и является мерой дисперсии или изменчивости.
Это рассчитанное t-значение затем сравнивается со значением, полученным из таблицы критических значений, называемой таблицей T-распределения. Более высокие значения t-показателя указывают на большую разницу между двумя наборами выборок. Чем меньше t-значение, тем больше сходства существует между двумя наборами выборок.
T-Score
Большой t-показатель или t-значение указывает на то, что группы различаются, а маленький t-показатель указывает на то, что группы похожи.
Степени свободы относятся к значениям в исследовании, которые могут варьироваться и необходимы для оценки важности и достоверности нулевой гипотезы.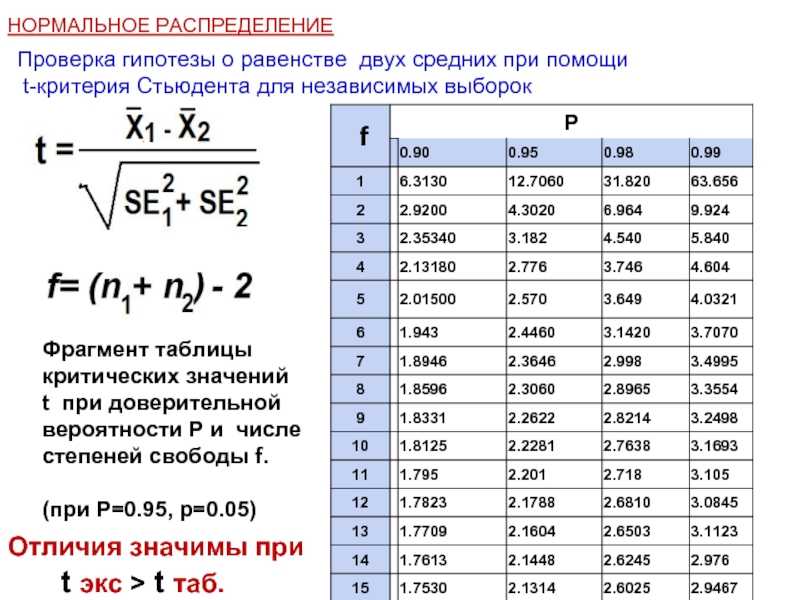 Вычисление этих значений обычно зависит от количества записей данных, доступных в выборке.
Вычисление этих значений обычно зависит от количества записей данных, доступных в выборке.
Парный Т-тест
Коррелированный t-критерий, или парный t-критерий, является зависимым типом теста и выполняется, когда выборки состоят из согласованных пар одинаковых единиц или когда есть случаи повторных измерений. Например, могут быть случаи, когда одни и те же пациенты повторно тестируются до и после получения конкретного лечения. Каждый пациент используется в качестве контрольного образца против себя.
Этот метод также применим к случаям, когда образцы связаны или имеют совпадающие характеристики, например, сравнительный анализ с участием детей, родителей или братьев и сестер.
Формула для вычисления t-значения и степеней свободы для парного t-теста:
Т
знак равно
иметь в виду
1
−
иметь в виду
2
с
(
разница
)
(
н
)
куда:
иметь в виду
1
а также
иметь в виду
2
знак равно
Средние значения каждого из выборочных наборов
с
(
разница
)
знак равно
Стандартное отклонение разностей парных значений данных
н
знак равно
Размер выборки (количество парных различий)
н
−
1
знак равно
Степени свободы
begin{align}&T=frac{textit{mean}1 — textit{mean}2}{frac{s(text{diff})}{sqrt{(n)}}}\& textbf{где:}\&textit{mean}1text{ и }textit{mean}2=text{Средние значения каждого из выборочных наборов}\&s(text{diff}) =text{Стандартное отклонение разностей парных значений данных}\&n=text{Размер выборки (количество парных разностей)}\&n-1=text{Степени свободы}end {выровнено}
T=(n)s(diff)mean1-mean2где:mean1 и mean2=средние значения каждого набора выборокss(diff)=стандартное отклонение разностей парных значений данных n=размер выборки (количество парных различий)n−1=степени свободы
Равная дисперсия или объединенный Т-тест
Стьюдентный критерий равной дисперсии является независимым t-тестом и используется, когда количество выборок в каждой группе одинаково или дисперсия двух наборов данных аналогична.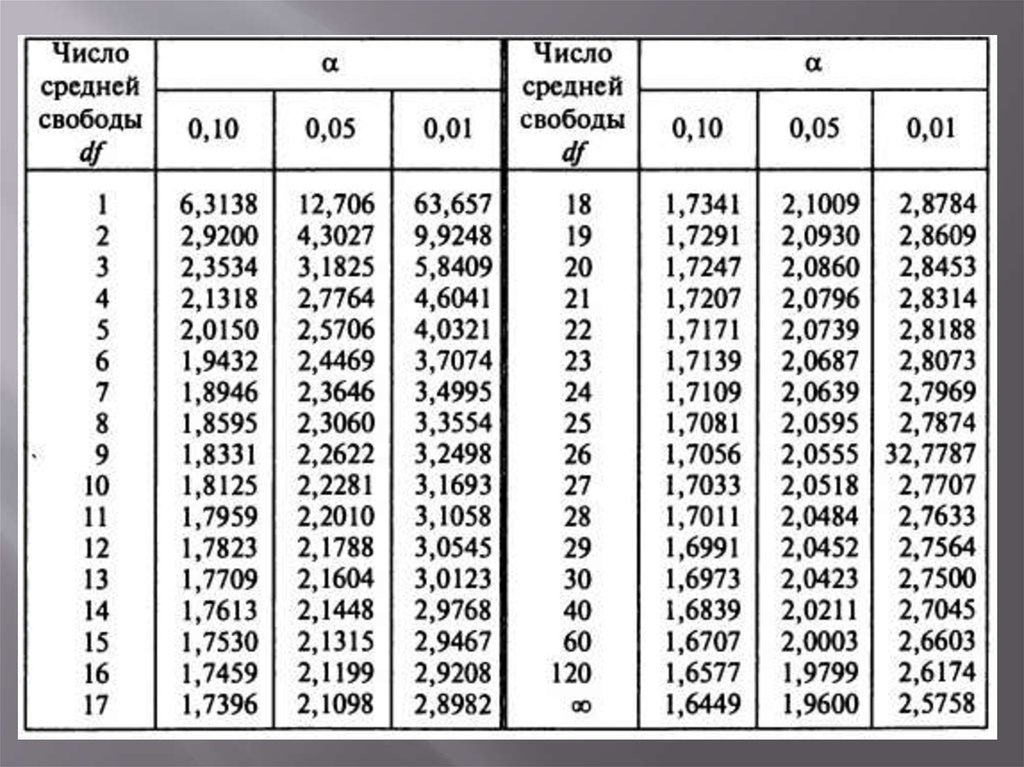 2 }{ n1 + n2 — 2}times sqrt{ frac{1}{n1} + frac{1}{n2}} } \&textbf{где:}\&mean1 text{ и } mean2 = text{ Средние значения каждого} \&text{выборочных наборов}\&var1 text{ и } var2 = text{Дисперсия каждого из выборочных наборов}\&n1 text{ и } n2 = text{ Количество записей в каждом наборе образцов} end{aligned}
2 }{ n1 + n2 — 2}times sqrt{ frac{1}{n1} + frac{1}{n2}} } \&textbf{где:}\&mean1 text{ и } mean2 = text{ Средние значения каждого} \&text{выборочных наборов}\&var1 text{ и } var2 = text{Дисперсия каждого из выборочных наборов}\&n1 text{ и } n2 = text{ Количество записей в каждом наборе образцов} end{aligned}
T-значение=n1+n2−2(n1−1)×var12+(n2−1)×var22×n11+n21среднее1−среднее2, где:среднее1 и среднее2=средние значения каждого из выборочных наборовvar1 и var2 = дисперсия каждого набора образцов n1 и n2 = количество записей в каждом наборе образцов
а также,
Степени свободы
знак равно
н
1
+
н
2
−
2
куда:
н
1
а также
н
2
знак равно
Количество записей в каждом наборе образцов
begin{align} &text{Степени свободы} = n1 + n2 — 2 \ &textbf{где:}\ &n1 text{ и } n2 = text{Количество записей в каждом наборе образцов} конец {выровнено}
Степени свободы=n1+n2−2, где: n1 и n2=количество записей в каждом наборе образцов
Т-тест с неравной дисперсией
Стьюдентный критерий неравной дисперсии является независимым t-тестом и используется, когда количество выборок в каждой группе различно, и дисперсия двух наборов данных также различна. Этот тест также называют t-критерием Уэлча.
Этот тест также называют t-критерием Уэлча.
Формула, используемая для расчета t-значения и степеней свободы для t-критерия неравной дисперсии:
Т-значение
знак равно
м
е
а
н
1
−
м
е
а
н
2
(
в
а
р
1
н
1
+
в
а
р
2
н
2
)
куда:
м
е
а
н
1
а также
м
е
а
н
2
знак равно
Средние значения каждого
наборов образцов
в
а
р
1
а также
в
а
р
2
знак равно
Дисперсия каждого из наборов образцов
н
1
а также
н
2
знак равно
Количество записей в каждом наборе образцов
begin{align}&text{T-value}=frac{mean1-mean2}{sqrt{bigg(frac{var1}{n1}{+frac{var2}{n2}bigg)} }}\&textbf{где:}\&mean1 text{ и } mean2 = text{Средние значения каждого} \&text{набора образцов} \&var1 text{ и } var2 = text{Дисперсия каждого набора образцов} \&n1 text{ и } n2 = text{Количество записей в каждом наборе образцов} end{выравнивание}
T-значение=(n1var1+n2var2)mean1-mean2где:mean1 и mean2=Средние значения каждого из выборочных наборов var1 и var2=дисперсия каждого из выборочных наборов n1 и n2=количество записей в каждом выборочном наборе
92 }{ n2 — 1}} \ &textbf{где:}\ &var1 text{ и } var2 = text{Дисперсия каждого из выборочных наборов} \ &n1 text{ и } n2 = text {Количество записей в каждом наборе образцов} \ end{aligned}
Степени свободы=n1−1(n1var12)2+n2−1(n2var22)2(n1var12+n2var22)2, где: var1 и var2 = дисперсия каждого набора выборки n1 и n2 = число записей в каждом наборе образцов
Какой Т-тест использовать?
Следующая блок-схема может быть использована для определения того, какой t-критерий использовать, исходя из характеристик наборов выборок. Ключевые элементы, которые следует учитывать, включают сходство записей выборки, количество записей данных в каждой выборке и дисперсию каждой выборки.
Ключевые элементы, которые следует учитывать, включают сходство записей выборки, количество записей данных в каждой выборке и дисперсию каждой выборки.
Изображение Джули Банг © Investopedia 2019
Пример T-критерия неравной дисперсии
Предположим, что берется диагональный размер картин, полученных в художественной галерее. В одну группу образцов входит 10 картин, в другую – 20 картин. Наборы данных с соответствующими средними значениями и значениями дисперсии следующие:
| Комплект 1 | Комплект 2 | |
|---|---|---|
| 19,7 | 28,3 | |
| 20,4 | 26,7 | |
| 19,6 | 20,1 | |
| 17,8 | 23,3 | |
| 18,5 | 25,2 | |
| 18,9 | 22,1 | |
| 18,3 | 17,7 | |
| 18,9 | 27,6 | |
| 19,5 | 20,6 | |
| 21,95 | 13,7 | |
| 23,2 | ||
| 17,5 | ||
| 20,6 | ||
| 18 | ||
| 23,9 | ||
| 21,6 | ||
| 24,3 | ||
| 20,4 | ||
| 23,9 | ||
| 13,3 | ||
| Среднее | 19,4 | 21,6 |
| Разница | 1,4 | 17,1 |
Хотя среднее значение набора 2 выше, чем у набора 1, мы не можем заключить, что совокупность, соответствующая набору 2, имеет более высокое среднее значение, чем население, соответствующее набору 1.
Является ли разница между 19,4 и 21,6 исключительно случайной, или существуют различия в общей совокупности всех картин, полученных в художественной галерее? Мы устанавливаем проблему, принимая нулевую гипотезу о том, что среднее значение одинаково для двух наборов выборок, и проводим t-тест, чтобы проверить, правдоподобна ли гипотеза.
Поскольку количество записей данных различно (n1 = 10 и n2 = 20) и дисперсия также различна, значение t и степени свободы вычисляются для вышеуказанного набора данных с использованием формулы, упомянутой в Т-критерии неравной дисперсии. раздел.
Значение t равно -2,24787. Поскольку знак минус можно игнорировать при сравнении двух t-значений, вычисленное значение равно 2,24787.
Значение степени свободы равно 24,38 и уменьшено до 24 из-за определения формулы, требующей округления значения до наименьшего возможного целого числа.
Можно указать уровень вероятности (альфа-уровень, уровень значимости, p ) в качестве критерия приемлемости. В большинстве случаев можно принять значение 5%.
В большинстве случаев можно принять значение 5%.
Используя значение степени свободы, равное 24, и уровень значимости 5%, просмотр таблицы распределения t-значения дает значение 2,064. Сравнение этого значения с вычисленным значением 2,247 показывает, что рассчитанное значение t больше табличного значения при уровне значимости 5%. Следовательно, можно с уверенностью отвергнуть нулевую гипотезу об отсутствии разницы между средними значениями. Набор населения имеет внутренние различия, и они не случайны.
Как используется таблица Т-распределения?
Таблица Т-распределения доступна в одностороннем и двустороннем форматах. Первый используется для оценки случаев, которые имеют фиксированное значение или диапазон с четким направлением, положительным или отрицательным. Например, какова вероятность того, что выходное значение останется ниже -3 или будет больше семи при броске пары игральных костей? Последний используется для анализа с привязкой к диапазону, например, чтобы узнать, находятся ли координаты в диапазоне от -2 до +2.
Обновлено: 05.06.2023
В группу параметрических критериев методов математической статистики входят методы для вычисления описательных статистик, построения графиков на нормальность распределения, проверка гипотез о принадлежности двух выборок одной совокупности. Эти методы основываются на предположении о том, что распределение выборок подчиняется нормальному (гауссовому) закону распределения. Среди параметрических критериев статистики нами будут рассмотрены критерий Стьюдента и Фишера.
Чтобы определить, имеем ли мы дело с нормальным распределением, можно применять следующие методы:
1) в пределах осей можно нарисовать полигон частоты (эмпирическую функцию распределения) и кривую нормального распределения на основе данных исследования. Исследуя формы кривой нормального распределения и графика эмпирической функции распределения, можно выяснить те параметры, которыми последняя кривая отличается от первой;
2) вычисляется среднее, медиана и мода и на основе этого определяется отклонение от нормального распределения. Если мода, медиана и среднее арифметическое друг от друга значительно не отличаются, мы имеем дело с нормальным распределением. Если медиана значительно отличается от среднего, то мы имеем дело с асимметричной выборкой.
3) эксцесс кривой распределения должен быть равен 0. Кривые с положительным эксцессом значительно вертикальнее кривой нормального распределения. Кривые с отрицательным эксцессом являются более покатистыми по сравнению с кривой нормального распределения;
4) после определения среднего значения распределения частоты и стандартного oтклонения находят следующие четыре интервала распределения сравнивают их с действительными данными ряда:
а) — к интервалу должно относиться около 25% частоты совокупности,
б) — к интервалу должно относиться около 50% частоты совокупности,
в) — к интервалу должно относиться около 75% частоты совокупности,
г) — к интервалу должно относиться около 100% частоты совокупности.
При использовании критерия можно выделить два случая. В первом случае его применяют для проверки гипотезы о равенстве генеральных средних двух независимых, несвязанных выборок (так называемый двухвыборочный t-критерий). В этом случае есть контрольная группа и экспериментальная (опытная) группа, количество испытуемых в группах может быть различно.
Во втором случае, когда одна и та же группа объектов порождает числовой материал для проверки гипотез о средних, используется так называемый парный t-критерий. Выборки при этом называют зависимыми, связанными.
Статистика критерия для случая несвязанных, независимых выборок равна:
где , — средние арифметические в экспериментальной и контрольной группах,
— стандартная ошибка разности средних арифметических. Находится из формулы:
где n 1 и n 2 соответственно величины первой и второй выборки.
Если n 1= n 2, то стандартная ошибка разности средних арифметических будет считаться по формуле:
где n величина выборки.
Подсчет числа степеней свободы осуществляется по формуле:
При численном равенстве выборок k = 2 n — 2.
Далее необходимо сравнить полученное значение t эмп с теоретическим значением t—распределения Стьюдента (см. приложение к учебникам статистики). Если t эмп t крит, то гипотеза H 0 принимается, в противном случае нулевая гипотеза отвергается и принимается альтернативная гипотеза.
Рассмотрим пример использования t -критерия Стьюдента для несвязных и неравных по численности выборок.
Пример 1 . В двух группах учащихся — экспериментальной и контрольной — получены следующие результаты по учебному предмету (тестовые баллы; см. табл. 1). [1]
Таблица 1. Результаты эксперимента
Первая группа (экспериментальная) N 1=11 человек
Вторая группа (контрольная)
12 14 13 16 11 9 13 15 15 18 14
13 9 11 10 7 6 8 10 11
Общее количество членов выборки: n 1=11, n 2=9.
Расчет средних арифметических: Хср=13,636; Y ср=9,444
Стандартное отклонение: s x=2,460; s y =2,186
По формуле (2) рассчитываем стандартную ошибку разности арифметических средних:
Считаем статистику критерия:
Сравниваем полученное в эксперименте значение t с табличным значением с учетом степеней свободы, равных по формуле (4) числу испытуемых минус два (18).
Табличное значение tкрит равняется 2,1 при допущении возможности риска сделать ошибочное суждение в пяти случаях из ста (уровень значимости=5 % или 0,05).
Если полученное в эксперименте эмпирическое значение t превышает табличное, то есть основания принять альтернативную гипотезу (H1) о том, что учащиеся экспериментальной группы показывают в среднем более высокий уровень знаний. В эксперименте t=3,981, табличное t=2,10, 3,981>2,10, откуда следует вывод о преимуществе экспериментального обучения.
Здесь могут возникнуть такие вопросы:
1. Что если полученное в опыте значение t окажется меньше табличного? Тогда надо принять нулевую гипотезу.
2. Доказано ли преимущество экспериментального метода? Не столько доказано, сколько показано, потому что с самого начала допускается риск ошибиться в пяти случаях из ста (р=0,05). Наш эксперимент мог быть одним из этих пяти случаев. Но 95% возможных случаев говорит в пользу альтернативной гипотезы, а это достаточно убедительный аргумент в статистическом доказательстве.
3. Что если в контрольной группе результаты окажутся выше, чем в экспериментальной? Поменяем, например, местами, сделав средней арифметической экспериментальной группы, a — контрольной:
Отсюда следует вывод, что новый метод пока не проявил себя с хорошей стороны по разным, возможно, причинам. Поскольку абсолютное значение 3,9811>2,1, принимается вторая альтернативная гипотеза (Н2) о преимуществе традиционного метода.
В случае связанных выборок с равным числом измерений в каждой можно использовать более простую формулу t-критерия Стьюдента.
Вычисление значения t осуществляется по формуле:
где — разности между соответствующими значениями переменной X и переменной У, а d — среднее этих разностей;
Sd вычисляется по следующей формуле:
Число степеней свободы k определяется по формуле k= n -1. Рассмотрим пример использования t -критерия Стьюдента для связных и, очевидно, равных по численности выборок.
Если t эмп t крит, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
Пример 2. Изучался уровень ориентации учащихся на художественно-эстетические ценности. С целью активизации формирования этой ориентации в экспериментальной группе проводились беседы, выставки детских рисунков, были организованы посещения музеев и картинных галерей, проведены встречи с музыкантами, художниками и др. Закономерно встает вопрос: какова эффективность проведенной работы? С целью проверки эффективности этой работы до начала эксперимента и после давался тест. Из методических соображений в таблице 2 приводятся результаты небольшого числа испытуемых. [2]
Таблица 2. Результаты эксперимента
Вспомогательные расчеты
до начала эксперимента (Х)
эксперимента (У)
Вначале произведем расчет по формуле:
Затем применим формулу (6), получим:
И, наконец, следует применить формулу (5). Получим:
Число степеней свободы: k =10-1=9 и по таблице Приложения 1 находим tкрит =2.262, экспериментальное t=6,678, откуда следует возможность принятия альтернативной гипотезы (H1) о достоверных различиях средних арифметических, т. е. делается вывод об эффективности экспериментального воздействия.
В терминах статистических гипотез полученный результат будет звучать так: на 5% уровне гипотеза Н0 отклоняется и принимается гипотеза Н1 .
Критерий Фишера позволяет сравнивать величины выборочных дисперсий двух независимых выборок. Для вычисления Fэмп нужно найти отношение дисперсий двух выборок, причем так, чтобы большая по величине дисперсия находилась бы в числителе, а меньшая – в знаменателе. Формула вычисления критерия Фишера такова:
где — дисперсии первой и второй выборки соответственно.
Так как, согласно условию критерия, величина числителя должна быть больше или равна величине знаменателя, то значение Fэмп всегда будет больше или равно единице.
Число степеней свободы определяется также просто:
k 1=nl — 1 для первой выборки (т.е. для той выборки, величина дисперсии которой больше) и k 2= n 2 — 1 для второй выборки.
В Приложении 1 критические значения критерия Фишера находятся по величинам k 1 (верхняя строчка таблицы) и k 2 (левый столбец таблицы).
Если t эмп> t крит, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
Пример 3. В двух третьих классах проводилось тестирование умственного развития по тесту ТУРМШ десяти учащихся. [3] Полученные значения величин средних достоверно не различались, однако психолога интересует вопрос — есть ли различия в степени однородности показателей умственного развития между классами.
Решение. Для критерия Фишера необходимо сравнить дисперсии тестовых оценок в обоих классах. Результаты тестирования представлены в таблице:
Рассчитав дисперсии для переменных X и Y, получаем:
Тогда по формуле (8) для расчета по F критерию Фишера находим:
По таблице из Приложения 1 для F критерия при степенях свободы в обоих случаях равных k =10 — 1 = 9 находим F крит=3,18 ( c следователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
Сравнивая на глазок (по процентным соотношениям) результаты до и после какого-либо воздействия, исследователь приходит к заключению, что если наблюдаются различия, то имеет место различие в сравниваемых выборках. Подобный подход категорически неприемлем, так как для процентов нельзя определить уровень достоверности в различиях. Проценты, взятые сами по себе, не дают возможности делать статистически достоверные выводы. Чтобы доказать эффективность какого-либо воздействия, необходимо выявить статистически значимую тенденцию в смещении (сдвиге) показателей. Для решения подобных задач исследователь может использовать ряд критериев различия. Ниже будет рассмотрены непараметрические критерии: критерий знаков и критерий хи-квадрат.
Критерий предназначен для сравнения состояния некоторого свойства у членов двух зависимых выборок на основе измерений, сделанных по шкале не ниже ранговой.
Имеется две серии наблюдений над случайными переменными X и У, полученные при рассмотрении двух зависимых выборок. На их основе составлено N пар вида (х i , у i ), где х i , у i — результаты двукратного измерения одного и того же свойства у одного и того же объекта.
В педагогических исследованиях объектами изучения могут служить учащиеся, учителя, администрация школ. При этом х i , у i могут быть, например, балловыми оценками, выставленными учителем за двукратное выполнение одной и той же или различных работ одной и той же группой учащихся до и после применения некоторого педагогическою средства.
Нулевая гипотеза формулируются следующим образом: в состоянии изучаемого свойства нет значимых различий при первичном и вторичном измерениях. Альтернативная гипотеза: законы распределения величин X и У различны, т. е. состояния изучаемого свойства существенно различны в одной и той же совокупности при первичном и вторичном измерениях этого свойства.
Статистика критерия (Т) определяется следующим образом:
Нулевая гипотеза принимается на уровне значимости 0,05, если наблюдаемое значение T n — ta , где значение n — ta определяется из статистических таблиц для критерия знаков Приложения 2.
Пример 4. Учащиеся выполняли контрольную работу, направленную на проверку усвоения некоторого понятия. Пятнадцати учащимся затем предложили электронное пособие, составленное с целью формирования данного понятия у учащихся с низким уровнем обучаемости. После изучения пособия учащиеся снова выполняли ту же контрольного работу, которая оценивалась по пятибалльной системе.
Результаты двукратного выполнения работы представляют измерения по шкале порядка (пятибалльная шкала). В этих условиях возможно применение знакового критерия для выявления тенденции изменения состояния знаний учащихся после изучения пособия, так как выполняются все допущения этого критерия.
Результаты двукратного выполнения работы (в баллах) 15 учащимися запишем в форме таблицы (см. табл. 1). [4]
Сегодня мы говорим о t-критерии. Т-критерий наиболее популярный статистический тест в биомедицинских исследованиях. Также его называют парный Т-критерий Стьюдента, t-test, two-sample unpaired t-test. Однако, при использовании этого статистического инструмента допускается достаточно много ошибок. Сегодня в этой статье мы постараемся разобраться, как избежать ошибок применения t-критерия Стьюдента, как интерпретировать его результаты и как рассчитывать t-критерий самостоятельно. Об этом обо всем читайте далее.
При описании любого статистического критерия, будь то t-критерий Стьюдента, либо какой-либо еще, нужно вспомнить о том, как же вообще используются статистические критерии. Для того, чтобы понять, как используется любой критерий, нужно перейти к нескольким достаточно логичным для понимания этапам:
Этапы статистического вывода (statistic inference)
- Первый из них – это вопрос, который мы хотим изучить с помощью статистических методов. То есть первый этап: что изучаем? И какие у нас есть предположения относительно результата? Этот этап называется этап статистических гипотез.
- Второй этап – нужно определиться с тем, какие у нас есть в реальности данные для того, чтобы ответить на первый вопрос. Этот этап – тип данных.
- Третий этап состоит в том, чтобы выбрать корректный для применения в данной ситуации статистический критерий.
- Четвертый этап это логичный этап применения интерпретации любой формулы, какие результаты мы получили.
- Пятый этап это создание, синтез выводов относительно первого, второго, третьего, четвертого, пятого этапа, то есть что же получили и что же это в реальности значит.
Предлагаю долго не ходить вокруг да около и посмотреть применение t-критерия Стьюдента на реальном примере.
Видео-версия статьи
Пример использования т-критерия Стьюдента
А пример будет достаточно простой: мне интересно, стали ли люди выше за последние 100 лет. Для этого нужно подобрать некоторые данные. Я обнаружил интересную информацию в достаточно известной статье The Guardian (Tall story’s men and women have grown taller over last century, Study Shows (The Guardian, July 2016), которая сравнивает средний возраст человека в разных странах в 1914 году и в аналогичных странах в 2014 году.
Там приведены данные практически по всем государствам. Однако, я взял лишь 5 стран для простоты вычислений: это Россия, Германия, Китай, США и ЮАР, соответственно 1914 год и 2014 год.
Общее количество наблюдений – 5 в 1914 году в группе 1914 года и общее значение также 5 в 2014 году. Будем думать опять же для простоты, что эти данные сопоставимы, и с ними можно работать.
Дальше нужно выбрать критерии – критерии, по которым мы будем давать ответ. Равны ли средние по росту в 1914 году x̅1914 и в 2014 году x̅2014. Я считаю, что нет. Поэтому моя гипотеза это то, что они не равны (x̅1914≠x̅2014). Соответственно альтернативная гипотеза моему предположению, так называемая нулевая гипотеза (нулевая гипотеза консервативна, обратная вашей, часто говорит об отсутствии статистически значимых связей/зависимостей) будет говорить о том, что они между собой на самом деле равны (x̅1914=x̅2014), то есть о том, что все эти находки случайны, и я, по сути, не прав.
Теперь нужно дать какой-то аргументированный ответ. Даем его с помощью статистического критерия. Соответственно теперь наступает самое важное: как выбрать статистический критерий? Я думаю, это будет темой отдельной статьи. Для корректности использования t-критерия Стьюдента лишь скажу, что нужно, чтобы:
Условия применения статистического критерия т-теста (критерия Стьюдента)
— данные распределялись по закону нормального распределения;
— данные были количественными;
— и это две независимые между собой выборки (независимые это значит, что в этих группах разные люди, а никак, например, до и после применения препарата у одной группы, люди должны быть разными, тогда группы являются несвязанными, либо независимыми), этот аспект стоит учитывать для выбора вида т-критерия Стьюдента, так как для парных выборок существует свой парный т-критерий (paired t-test).
В итоге Мы определились с тем, что это будет t-критерий Стьюдента.
Формула t-критерия Стьюдента достаточно простая. Она гласит о том, что в числителе у нас разница средних, в знаменателе у нас корень квадратный суммы ошибок репрезентативности по этим группам:
Ошибки репрезентативности были подробно объяснены мною в статье по доверительным интервалам. Поэтому я рекомендую вам ознакомиться с ней, чтобы лучше разобраться, что такое ошибки репрезентативности, что такое выборка, как она соотносится с генеральной совокупностью.
Для того, чтобы не тратить время, я в принципе все уже рассчитал по каждой из групп: средняя (x̅) ,стандартное отклонение (SD) и ошибка репрезентативности (m r ).
Давайте остановимся на том, что же значат эти значения:
— средняя (x̅) это среднеарифметическое по 5 наблюдениям в каждой группе;
— если совсем упрощать значение стандартного отклонения (SD), то можно сказать, что оно представляет собой обобщенную среднюю отклонения каждого значения от среднего (стандартное отклонение показывает, насколько широко значения рассеяны (разбросаны) относительно средней). И дальше мы находим нечто среднее отклонений каждого варианта в группе от среднего;
— и ошибка репрезентативности она тоже находится достаточно просто: это как раз наше отклонение от средней некоторое стандартизованное, поэтому стандартное отклонение на размер выборки (mr=).
Итак, продолжаем. В ходе подстановки каждого значения в нашу формулу, мы находим, что t-критерий Стьюдента равен 3,78. Однако, я думаю, пока тем, кто не знаком со статистическими критериями, это мало о чем говорит.
Итак, как нам перейти от нашей t к р вероятности? Это сделать достаточно просто, стоит лишь воспользоваться табличными значениями t для определенных степеней свободы. Теперь вопрос: как найти эти степени свободы? Но это сделать достаточно просто. Для того, чтобы обнаружить степени свободы для наших групп, нужно лишь сложить количество наблюдений 5 и 5 в нашем случае и вычесть 2. В нашем случае степень свободы равна 8.
Итак, t=3,78, степень свободы равна 8. Переходим в табличное значение и получаем р вероятность – вероятность равна 0,005. То есть вероятность того, что мы ошибаемся при констатации факта различия роста ранее и сейчас, крайне мала – это 0,005 %, не 5 %, а 0,005 %. То есть мы можем говорить с высокой долей достоверности того, что наш рост сейчас в XXI веке и 100 лет назад отличаются.
Вот то, что касается расчета t-критерия Стьюдента и его интерпретации.
На этом наш разговор о t-критерии Стьюдента закончен. Спасибо, что ознакомились с этой статьей. Я очень надеюсь на вашу обратную связь. Пожалуйста, подписывайтесь на наш сайте, ставьте лайки, предлагайте свои темы для следующих выпусков. Спасибо большое за поддержку. С вами был Кирилл Мильчаков. Пока, до новых встреч!
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Проверка статистической гипотезы позволяет сделать строгий вывод о характеристиках генеральной совокупности на основе выборочных данных. Гипотезы бывают разные. Одна из них – это гипотеза о средней (математическом ожидании). Суть ее в том, чтобы на основе только имеющейся выборки сделать корректное заключение о том, где может или не может находится генеральная средняя (точную правду мы никогда не узнаем, но можем сузить круг поиска).
Распределение Стьюдента
Общий подход в проверке гипотез описан здесь, поэтому сразу к делу. Предположим для начала, что выборка извлечена из нормальной совокупности случайных величин X с генеральной средней μ и дисперсией σ 2 . Средняя арифметическая из этой выборки, очевидно, сама является случайной величиной. Если извлечь много таких выборок и посчитать по ним средние, то они также будут иметь нормальное распределение с математическим ожиданием μ и дисперсией
Тогда случайная величина
имеет стандартное нормальное распределение со всеми вытекающими отсюда последствиями. Например, с вероятностью 95% ее значение не выйдет за пределы ±1,96.
Однако такой подход будет корректным, если известна генеральная дисперсия. В реальности, как правило, она не известна. Вместо нее берут оценку – несмещенную выборочную дисперсию:
Возникает вопрос: будет ли генеральная средняя c вероятностью 95% находиться в пределах ±1,96sx̅. Другими словами, являются ли распределения случайных величин
Впервые этот вопрос был поставлен (и решен) одним химиком, который трудился на пивной фабрике Гиннесса в г. Дублин (Ирландия). Химика звали Уильям Сили Госсет и он брал пробы пива для проведения химического анализа. В какой-то момент, видимо, Уильяма стали терзать смутные сомнения на счет распределения средних. Оно получалось немного более размазанным, чем должно быть у нормального распределения.
Посмотрим, что же мог увидеть У. Госсет. Сгенерируем 20 тысяч нормальных выборок из 6-ти наблюдений со средней (X̅) 50 и среднеквадратичным отклонением (σ) 10. Затем нормируем выборочные средние, используя генеральную дисперсию:
Получившиеся 20 тысяч средних сгруппируем в интервалы длинной 0,1 и подсчитаем частоты. Изобразим на диаграмме фактическое (Norm) и теоретическое (ENorm) распределение частот выборочных средних.

Точки (наблюдаемые частоты) практически совпадают с линией (теоретическими частотами). Оно и понятно, ведь данные взяты из одной и то же генеральной совокупности, а отличия – это лишь ошибки выборки.
Проведем новый эксперимент. Нормируем средние, используя выборочную дисперсию.
Снова подсчитаем частоты и нанесем их на диаграмму в виде точек, оставив для сравнения линию стандартного нормального распределения. Обозначим эмпирическое частоты средних, скажем, через букву t.

У Госсета-Стьюдента не было последней версии MS Excel, но именно этот эффект он и заметил. Почему так получается? Объяснение заключается в том, что случайная величина
зависит не только от ошибки выборки (числителя), но и от стандартной ошибки средней (знаменателя), которая также является случайной величиной.
Давайте немного разберемся, какое распределение должно быть у такой случайной величины. Вначале придется кое-что вспомнить (или узнать) из математической статистики. Есть такая теорема Фишера, которая гласит, что в выборке из нормального распределения:
1. средняя X̅ и выборочная дисперсия s 2 являются независимыми величинами;
2. соотношение выборочной и генеральной дисперсии, умноженное на количество степеней свободы, имеет распределение χ 2 (хи-квадрат) с таким же количеством степеней свободы, т.е.
где k – количество степеней свободы (на английском degrees of freedom (d.f.))
Вернемся к распределению средней. Разделим числитель и знаменатель выражения
Числитель – это стандартная нормальная случайная величина (обозначим ξ (кси)). Знаменатель выразим из теоремы Фишера.
Тогда исходное выражение примет вид
Это и есть t-критерий Стьюдента в общем виде (стьюдентово отношение). Вывести функцию его распределения можно уже непосредственно, т.к. распределения обеих случайных величин в данном выражении известны. Оставим это удовольствие математикам.
Функция t-распределения Стьюдента имеет довольно сложную для понимания формулу, поэтому не имеет смысла ее разбирать. Вероятности и квантили t-критерия приведены в специальных таблицах распределения Стьюдента и забиты в функции разных ПО вроде Excel.
Итак, вооружившись новыми знаниями, вы сможете понять официальное определение распределения Стьюдента.
Случайной величиной, подчиняющейся распределению Стьюдента с k степенями свободы, называется отношение независимых случайных величин
где ξ распределена по стандартному нормальному закону, а χ 2 k подчиняется распределению χ 2 c k степенями свободы.
Таким образом, формула критерия Стьюдента для средней арифметической
есть частный случай стьюдентова отношения
Из формулы и определения следует, что распределение т-критерия Стьюдента зависит лишь от количества степеней свободы.
При k > 30 t-критерий практически не отличается от стандартного нормального распределения.
В отличие от хи-квадрат, t-критерий может быть одно- и двусторонним. Обычно пользуются двусторонним, предполагая, что отклонение может происходить в обе стороны от средней. Но если условие задачи допускает отклонение только в одну сторону, то разумно применять односторонний критерий. От этого немного увеличивается мощность критерия.
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.

Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.
Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.

Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Пример проверки гипотезы о математическом ожидании с помощью t- критерия Стьюдента в MS Excel
В Excel есть несколько функций, связанных с t-распределением. Рассмотрим их.
СТЬЮДЕНТ.РАСП.2Х – двухсторонне распределение. В качестве аргумента подается абсолютное значение (по модулю) t-критерия и количество степеней свободы. На выходе получаем вероятность получить такое или еще больше значение t-критерия (по модулю), т.е. фактический уровень значимости (p-value).
СТЬЮДЕНТ.РАСП.ПХ – правостороннее t-распределение. Так, 1-СТЬЮДЕНТ.РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-value.
СТЬЮДЕНТ.ОБР – используется для расчета левостороннего обратного значения t-распределения. В качестве аргумента подается вероятность и количество степеней свободы. На выходе получаем соответствующее этой вероятности значение t-критерия. Отсчет вероятности идет слева. Поэтому для левого хвоста нужен сам уровень значимости α, а для правого 1 — α.
СТЬЮДЕНТ.ОБР.2Х – обратное значение для двухстороннего распределения Стьюдента, т.е. значение t-критерия (по модулю). Также на вход подается уровень значимости α. Только на этот раз отсчет ведется с двух сторон одновременно, поэтому вероятность распределяется на два хвоста. Так, СТЬЮДЕНТ.ОБР(1-0,025;5) = СТЬЮДЕНТ.ОБР.2Х(0,05;5) = 2,57058
СТЬЮДЕНТ.ТЕСТ – функция для проверки гипотезы о равенстве математических ожиданий в двух выборках. Заменяет кучу расчетов, т.к. достаточно указать лишь два диапазона с данными и еще пару параметров. На выходе получим p-value.
ДОВЕРИТ.СТЬЮДЕНТ – расчет доверительного интервала средней с учетом t-распределения.
Рассмотрим такой учебный пример. На предприятии фасуют цемент в мешки по 50кг. В силу случайности в отдельно взятом мешке допускается некоторое отклонение от ожидаемой массы, но генеральная средняя должна оставаться 50кг. В отделе контроля качества случайным образом взвесили 9 мешков и получили следующие результаты: средняя масса (X̅) составила 50,3кг, среднеквадратичное отклонение (s) – 0,5кг.
Согласуется ли полученный результат с нулевой гипотезой о том, что генеральная средняя равна 50кг? Другими словами, можно ли получить такой результат по чистой случайности, если оборудование работает исправно и выдает среднее наполнение 50 кг? Если гипотеза не будет отклонена, то полученное различие вписывается в диапазон случайных колебаний, если же гипотеза будет отклонена, то, скорее всего, в настройках аппарата, заполняющего мешки, произошел сбой. Требуется его проверка и настройка.
Краткое условие в обще принятых обозначениях выглядит так.
Есть основания предположить, что распределение заполняемости мешков подчиняются нормальному распределению (или не сильно от него отличается). Значит, для проверки гипотезы о математическом ожидании можно использовать t-критерий Стьюдента. Случайные отклонения могут происходить в любую сторону, значит нужен двусторонний t-критерий.
Вначале применим допотопные средства: ручной расчет t-критерия и сравнение его с критическим табличным значением. Расчетный t-критерий:
Теперь определим, выходит ли полученное число за критический уровень при уровне значимости α = 0,05. Воспользуемся таблицей для критерия Стьюдента (есть в любом учебнике по статистике).

По столбцам идет вероятность правой части распределения, по строкам – число степеней свободы. Нас интересует двусторонний t-критерий с уровнем значимости 0,05, что равносильно t-значению для половины уровня значимости справа: 1 — 0,05/2 = 0,975. Количество степеней свободы – это объем выборки минус 1, т.е. 9 — 1 = 8. На пересечении находим табличное значение t-критерия – 2,306. Если бы мы использовали стандартное нормальное распределение, то критической точкой было бы значение 1,96, а тут она больше, т.к. t-распределение на небольших выборках имеет более приплюснутый вид.
Сравниваем фактическое (1,8) и табличное значение (2.306). Расчетный критерий оказался меньше табличного. Следовательно, имеющиеся данные не противоречат гипотезе H0 о том, что генеральная средняя равна 50 кг (но и не доказывают ее). Это все, что мы можем узнать, используя таблицы. Можно, конечно, еще p-value попробовать найти, но он будет приближенным. А, как правило, именно p-value используется для проверки гипотез. Поэтому далее переходим в Excel.
Готовой функции для расчета t-критерия в Excel нет. Но это и не страшно, ведь формула t-критерия Стьюдента довольно проста и ее можно легко соорудить прямо в ячейке Excel.

Получили те же 1,8. Найдем вначале критическое значение. Альфа берем 0,05, критерий двусторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.

Полученное значение отсекает критическую область. Наблюдаемый t-критерий в нее не попадает, поэтому гипотеза не отклоняется.
Однако это тот же способ проверки гипотезы с помощью табличного значения. Более информативно будет рассчитать p-value, т.е. вероятность получить наблюдаемое или еще большее отклонение от средней 50кг, если эта гипотеза верна. Потребуется функция распределения Стьюдента для двухсторонней гипотезы СТЬЮДЕНТ.РАСП.2Х.

P-value равен 0,1096, что больше допустимого уровня значимости 0,05 – гипотезу не отклоняем. Но теперь можно судить о степени доказательства. P-value оказался довольно близок к тому уровню, когда гипотеза отклоняется, а это наводит на разные мысли. Например, что выборка оказалась слишком мала для обнаружения значимого отклонения.
Пусть через некоторое время отдел контроля снова решил проверить, как выдерживается стандарт заполняемости мешков. На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
Допустим, были получены те же значения средней и стандартного отклонения по выборке, что и в первый раз (50,3 и 0,5 соответственно). Рассчитаем t-критерий.
Критическое значение для 24-х степеней свободы и α = 0,05 составляет 2,064. На картинке ниже видно, что t-критерий попадает в область отклонения гипотезы.

Можно сделать вывод о том, что с доверительной вероятностью более 95% генеральная средняя отличается от 50кг. Для большей убедительности посмотрим на p-value (последняя строка в таблице). Вероятность получить среднюю с таким или еще большим отклонением от 50, если гипотеза верна, составляет 0,0062, или 0,62%, что при однократном измерении практически невозможно. В общем, гипотезу отклоняем, как маловероятную.
Расчет доверительного интервала для математического ожидания с помощью t-распределения Стьюдента в Excel
С проверкой гипотез тесно связан еще один статистический метод – расчет доверительных интервалов. Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Рассчитаем доверительные интервалы для средней при 9 и 25 наблюдениях. Для этого воспользуемся функцией Excel ДОВЕРИТ.СТЬЮДЕНТ. Здесь, как ни странно, все довольно просто. В аргументах функции нужно указать только уровень значимости α, стандартное отклонение по выборке и размер выборки. На выходе получим полуширину доверительного интервала, то есть значение которое нужно отложить по обе стороны от средней. Проведя расчеты и нарисовав наглядную диаграмму, получим следующее.

Как видно, при выборке в 9 наблюдений значение 50 попадает в доверительный интервал (гипотеза не отклоняется), а при 25-ти наблюдениях не попадает (гипотеза отклоняется). При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
Таким образом, мы решили одну и ту же задачу тремя способами:
1. Древним подходом, сравнивая расчетное и табличное значение t-критерия
2. Более современным, рассчитав p-value, добавив степень уверенности при отклонении гипотезы.
3. Еще более информативным, рассчитав доверительный интервал и получив минимальное значение генеральной средней.
Важно помнить, что t-критерий относится к параметрическим методам, т.к. основан на нормальном распределении (у него два параметра: среднее и дисперсия). Поэтому для его успешного применения важна хотя бы приблизительная нормальность исходных данных и отсутствие выбросов.
Напоследок предлагаю видеоролик о том, как рассчитать критерий Стьюдента и проверить гипотезу о генеральной средней в Excel.
Иногда просят объяснить, как делаются такие наглядные диаграммы с распределением. Ниже можно скачать файл, где проводились расчеты для этой статьи.

Наступила осень, а значит, настало время для запуска нового тематического проекта «Статистический анализ с R». В нем мы рассмотрим статистические методы с точки зрения их применения на практике: узнаем какие методы существуют, в каких случаях и каким образом их проводить в среде R. На мой взгляд, Критерий Стьюдента или t-тест (от англ. t-test) идеально подходит в качестве введения в мир статистического анализа. Тест Стьюдента достаточно прост и показателен, а также требует минимум базовых знаний в статистике, с которыми читатель может ознакомиться в ходе прочтения этой статьи.
Примечание_1: здесь и в других статьях Вы не увидите формул и математических объяснений, т.к. информация рассчитана на студентов естественных и гуманитарных специальностей, которые делают лишь первые шаги в стат. анализе.
Примечание_2: перед прочтением, я рекомендую ознакомиться с этой статьей, чтобы вспомнить базовые понятия описательной статистики, такие как медиана, стандартное отклонение, квантили и прочее.
Что такое t-тест и в каких случаях его стоит применять
В начале следует сказать, что в статистике зачастую действует принцип бритвы Оккамы, который гласит, что нет смысла проводить сложный статистический анализ, если можно применить более простой (не стоит резать хлеб бензопилой, если есть нож). Именно поэтому, несмотря на свою простоту, t-тест является серьезным инструментом, если знать что он из себя представляет и в каких случаях его стоит применять.

Любопытно, что создал этот метод Уильямом Госсет — химик, приглашенный работать на фабрику Guinness. Разработанный им тест служил изначально для оценки качества пива. Однако, химикам фабрики запрещалось независимо публиковать научные работы под своим именем. Поэтому в 1908 году Уильям опубликовал свою статью в журнале «Biometrika» под псевдонимом «Стьюдент». Позже, выдающийся математик и статистик Рональд Фишер доработал метод, который затем получил массовое распространение под названием Student’s t-test.
Критерий Стьюдента (t-тест) — это статистический метод, который позволяет сравнивать средние значения двух выборок и на основе результатов теста делать заключение о том, различаются ли они друг от друга статистически или нет. Если Вы хотите узнать, отличается ли средний уровень продолжительности жизни в Вашем регионе от среднего уровня по стране; сравнить урожайность картофеля в разных районах; или изменяется ли кровяное давление до и после употребления нового лекарства, то t-тест может быть Вам полезен. Почему может быть? Потому что для его проведения, необходимо, чтобы данные выборок имели распределение близкое к нормальному. Для этого существуют методы оценки, которые позволяют сказать, допустимо ли в данном случае полагать, что данные распределены нормально или нет. Поговорим об этом подробнее.
Нормальное распределение данных и методы его оценки qqplot и shapiro.test
Нормальное распределение данных характерно для количественных данных, на распределение которых влияет множество факторов, либо оно случайно. Нормальное распределение характеризуется несколькими особенностями:
- Оно всегда симметрично и имеет форму колокола.
- Значения среднего и медианы совпадают.
- В пределах одного стандартного отклонения в обе стороны лежат 68.2% всех данных, в пределах двух — 95,5%, в пределах трех — 99,7%

Давайте создадим случайную выборку с нормальным распределением на языке программирования R, где общее количество измерений = 100, среднее арифметическое = 5, а стандартное отклонение = 1. Затем отобразим его на графике в виде гистограммы:
Ваш график может слегка отличаться от моего, так как числа сгенерированы случайным образом. Как Вы видите, данные не идеально симметричны, но кажется сохраняют форму нормального распределения. Однако, мы воспользуемся более объективными методами определения нормальности данных.

Одним из наиболее простых тестов нормальности является график квантилей (qqplot). Суть теста проста: если данные имеют нормальное распределение, то они не должны сильно отклоняться от линии теоретических квантилей и выходить за пределы доверительных интервалов. Давайте проделаем этот тест в R.

Как видно из графика, наши данные не имеют серьезных отклонений от теоретического нормального распределения. Но порой при помощи qqplot невозможно дать однозначный ответ. В этом случае следует использовать тест Шапиро-Уилка, который основан на нулевой гипотезе, что наши данные распределены нормально. Если же P-значение менее 0.05 (p-value
Провести тест Шапиро-Уилка в R не составит труда. Для этого нужно всего лишь вызвать функцию shapiro.test, и в скобках вставить имя ваших данных. В нашем случае p-value должен быть значительно больше 0.05, что не позволяет отвергнуть нулевую гипотезу о том, что наши данные распределены нормально.
Запускаем t-тест Стьюдента в среде R
Итак, если данные из выборок имеют нормальное распределение, можно смело приступать к сравнению средних этих выборок. Существует три основных типа t-теста, которые применяются в различных ситуациях. Рассмотрим каждый из них с использованием наглядных примеров.
Одновыборочный критерий Стьюдента (one-sample t-test)
Одновыборочный t-тест следует выбирать, если Вы сравниваете выборку с общеизвестным средним. Например, отличается ли средний возраст жителей Северо-Кавказского Федерального округа от общего по России. Существует мнение, что климат Кавказа и культурные особенности населяющих его народов способствуют продлению жизни. Для того, чтобы проверить эту гипотезу, мы возьмем данные РосСтата (таблицы среднего ожидаемого продолжительности жизни по регионам России) и применим одновыборочный критерий Стьюдента. Так как критерий Стьюдента основан на проверке статистических гипотез, то за нулевую гипотезу будем принимать то, что различий между средним ожидаемым уровнем продолжительности по России и республикам Северного Кавказа нет. Если различия существуют, то для того, чтобы считать их статистически значимыми p-value должно быть менее 0.05 (логика та же, что и в вышеописанном тесте Шапиро-Уилка).
Загрузим данные в R. Для этого, создадим вектор со средними значениями по республикам Кавказа (включая Адыгею). Затем, запустим одновыборочный t-тест, указав в параметре mu среднее значение ожидаемого возраста жизни по России равное 70.93.
Несмотря на то, что у нас всего 7 точек в выборке, в целом они проходят тесты нормальности и мы можем на них полагаться, так как эти данные уже были усреднены по региону.

Результаты t-теста говорят о том, что средняя ожидаемая продолжительность жизни у жителей Северного Кавказа (74.6 лет) действительно выше, чем в среднем по России (70.93 лет), а результаты теста являются статистически значимыми (p когда Вы сравниваете две независимые выборки . Допустим, мы хотим узнать, отличается ли урожайность картофеля на севере и на юге какого-либо региона. Для этого, мы собрали данные с 40 фермерских хозяйств: 20 из которых располагались на севере и сформировали выборку «North», а остальные 20 — на юге, сформировав выборку «South».
Загрузим данные в среду R. Кроме проверки нормальности данных, будет полезно построить «график с усами», на котором можно видеть медианы и разброс данных для обеих выборок.
Как видно из графика, медианы выборок не сильно отличаются друг от друга, однако разброс данных гораздо сильнее на севере. Проверим отличаются ли статистически средние значения при помощи функции t.test. Однако в этот раз на место параметра mu мы ставим имя второй выборки. Результаты теста, которые Вы видите на рисунке снизу, говорят о том, что средняя урожайность картофеля на севере статистически не отличается от урожайности на юге (p = 0.6339).

Двувыборочный для зависимых выборок ( dependent two-sample t-test )
Третий вид t-теста используется в том случае, если элементы выборок зависят друг от друга . Он идеально подходит для проверки повторяемости результатов эксперимента: если данные повтора статистически не отличаются от оригинала, то повторяемость данных высокая. Также двувыборочный критерий Стьюдента для зависимых выборок широко применяется в медицинских исследованиях при изучении эффекта лекарства на организм до и после приема.
Для того, чтобы запустить его в R, следует ввести все ту же функцию t.test . Однако, в скобках, после таблиц данных, следует ввести дополнительный аргумент paired = TRUE . Этот аргумент говорит о том, что Ваши данные зависят друг от друга. Например:
Также в функции t.test существует два дополнительных аргумента, которые могут улучшить качество результатов теста: var.equal и alternative . Если вы знаете, что вариация между выборками равна, вставьте аргумент var.equal = TRUE . Если же вы хотите проверить гипотезу о том, что разница между средними в выборках значительно меньше или больше 0, то введите аргумент alternative=»less» или alternative=»greater» (по умолчанию альтернативная гипотеза говорит о том, что выборки просто отличаются друг от друга: alternative=»two.sided» ).
Заключение
Статья получилась довольно длинной, зато теперь Вы знаете: что такое критерий Стьюдента и нормальное распределение; как при помощи функций qqplot и shapiro.test проверять нормальность данных в R; а также разобрали три типа t-тестов и провели их в среде R.
Тема для тех, кто только начинает знакомиться со статистическим анализом — непростая. Поэтому не стесняйтесь, задавайте вопросы, я с удовольствием на них отвечу. Гуру статистики, пожалуйста поправьте меня, если где-нибудь допустил ошибку. В общем, пишите Ваши комментарии, друзья!
t-критерий Стьюдента — общее название для класса методов статистической проверки гипотез ( статистических критериев ), основанных на распределении Стьюдента. Наиболее частые случаи применения t-критерия связаны с проверкой равенства средних значений в двух выборках .
Здравствуйте! Благодарю за подробное пояснение по теме t-критерия. Пытаюсь провести сравнительный анализ в своей магистерской диссертации по двум независимым выборкам. Шкал у меня несколько. В результате анализа с помощью программы SPSS какие-то значения по критерию равенства дисперсий Ливиня оказались меньше 0,05. Насколько я понимаю, использование t-критерия в этом случае будет неправомерным. Что посоветуете в этом случае?
Здравствуйте! Спасибо за Ваш комментарий. К сожалению, ни с SPSS, ни с критерием Ливиня мне не доводилось работать, поэтому помочь не в силах.
Добрый день, извините, что не по теме. Пишу дипломную работу и мне нужно оценить 2 уравнения методом максимального правдоподобия в R. Нигде не могу найти про это в интернете.Вы не знаете как это можно сделать?
Читайте также:
- Портретная живопись серова кратко
- Горбачев и его окружение кратко
- Проблема человека в социологии кратко
- Всеобщая история 18 век 8 класс кратко
- Итоги реформ китая во второй половине xx века кратко