
кандид
>тем|
^математических ЩУКИН Николай Васильевич,
наук
доктор физико-математических наук, профессор
ГРИНЕНКО Владимир Антонович ГРУЗДОВ Федор Владимирович МИЛЮКОВ Федор Владимирович
IV/J
ЫБОР ПОРОГА ЧУВСТВИТЕЛЬНОСТИ СИСТЕМ ДИАГНОСТИКИ1
При работе любой системы, диагностики возникают, ошибки первого и второго рода. Ошибки первого рода и ошибки второго рода в математической статистике — это ключевые понятия, задач, проверки статистических гипотез. Тем. не менее данные понятия, часто используются и в других областях, когда речь идет, о принятии «бинарного» решения, (да/нет) на основе некоего критерия, (теста, проверки, измерения), который с некоторой вероятностью может, давать ложный результат.. В статистических тестах обычно приходится, идти на компромисс между приемлемым уровнем, ошибок первого и второго рода. Зачастую для. принятия, решения, используется, пороговое значение, которое может, варьироваться, с целью сделать тест, более строгим, или, наоборот, более мягким.. Возможны, разные подходы к выбору порога чувствительности. В этой статье будет, описан экономический подход, основанный на выборе порогового значения, таким, образом, чтобы, минимизировать средний ущерб при эксплуатации системы..
Ключевые слова: система диагностики, порог чувствительности, уровень значимости.
In the process of operating any diagnostic system, type I error and type II error may occur. These errors are the key terms of the tasks of the statistical hypotheses examination in mathematical statistics. However, these terms are often used, in other areas when it comes to taking the «binary» decisions (yes / no) based, on a test which may give a false result with certain probability. The statistical tests usually have to compromise on an acceptable level of errors of the first and second kind. Often the decision is taken based, on a threshold. limit value, which, may vary in order to make the test more stringent or alternatively, more lenient. There are different approaches to the threshold, value selection. This article will describe the economic approach, based, on the choice of the threshold, value so as to minimize the average costs during the exploitation, of the diagnostic system..
Keywords: diagnostic system, the threshold, value.
По мере накопления и расширения знаний об окружающем мире все актуальней становятся задачи диагностики в различных областях человеческой деятельности: техника, медицина, экономика и д.р. По своей сути диагностика — это процесс установления диагноза или распознавания проблемы. В процессе диагностики проводится сравнение текущего состояния объекта исследования с его моделью. Если совпадение оказывается неудовлетворительным, выдается предупре-
ждающее сообщение, инициирующее предусмотренные действия. Своевременная диагностика нежелательных событий позволяет минимизировать затраты, связанные с лавинообразным накоплением нарушений в сложных системах. Безусловно, к сложным системам относятся и атомные станции, для которых эффективным признается использование диагностических средств, позволяющих быстро обнаруживать симптомы отказов и ухудшение рабочих характеристик, что
1 — Национальный исследовательский ядерный университет «МИФИ».
непосредственным образом связано с повышением безопасности, надежности и экономической эффективности эксплуатации АЭС и ядерной энергетики в целом.
Для АЭС с реактором РБМК-1000 задача диагностики и мониторинга активных зон была решена к 1999 году в виде программного средства (ПС) ECRAN (Experimental&Calculational Reactor ANalisys), предназначенного для непрерывного контроля измерительных данных, поступающих от системы
01_2012_SPT.indd 35
внутриреакторного контроля и своевременного выявление отказов оборудования и ошибок в исходных данных программ сопровождения эксплуатации ЯЭУ [1, 2, 3].
Однако, как это часто бывает, если программа не является достоянием сообщества людей, которое непрерывно бы поддерживало и совершенствовало ее работоспособность, то программа устаревает и через какое-то время становится неработоспособной. К сожалению, такая судьба постигла и ПС непрерывной диагностики ECRAN.
Тем не менее реализованные в программе алгоритмы не были утеряны, а возможность живого контакта с авторами и разработчиками позволила восстановить заложенный в программу научный потенциал. Использование современных кодов, методов и подходов к разработке программного обеспечения позволило вдохнуть в программу новую жизнь, сделало ее код работоспособным под современными операционными системами на современной компьютерной технике. Проведенные усовершенствования диагностических алгоритмов позволили повысить их точность и скорость работы.
Таким образом, была создана расчетно-измерительная диагностическая система ECRAN 3D [4 — 8], основу которой составляют аттестованные программные средства сопровождения эксплуатации (POLARIS [9], КОНТУР-М [10]), а также апробированные методы обработки экспериментально-расчетной информации о состоянии активной зоны и базы данных РБМК.
Однако при работе любой системы диагностики могут возникать ошибки первого и второго рода. Ошибки первого рода и ошибки второго рода в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее данные понятия часто используются и в других областях, когда речь идет о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Пусть дана выборка X = (Xt,…,Xn)T из неизвестного совместного распределения PX, и поставлена бинарная задача проверки статистических гипотез: H0,
Н1, где Н0 — нулевая гипотеза, а Н1 — альтернативная гипотеза. Предположим, что задан статистический критерий:
Г: К ^ {Но, Н}
сопоставляющий каждой реализации выборки X = х одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации.
Л Распределение Рх выборки X соответствует гипотезе Н0, и она точно определена статистическим критерием, то есть Цх) = Н0.
Распределение Рх выборки X соответствует гипотезе Н0, но она неверно отвергнута статистическим критерием, то есть Цх) = Н
Распределение Рх выборки X соответствует гипотезе Н и она точно определена статистическим критерием, то есть Цх) = Н
^4 Распределение Рх выборки X соответствует гипотезе Н но она неверно отвергнута статистическим критерием, то есть Цх) = Н0.
Во втором и четвертом случае говорят, что произошла статистическая ошибка, и ее называют ошибкой первого и второго рода соответственно. Пропуск отказа при его фактическом наличии назовем ошибкой первого рода. Регистрацию отказа при его отсутствии назовем ошибкой второго рода.
Как видно из вышеприведенного определения, ошибки первого и второго рода являются взаимно симметричными, то есть, если поменять местами гипотезы Н0 и Н то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза Н0 соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что исследуемый объект находится в работоспособном состоянии. Соответственно альтернативная гипотеза Н1 обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции. С учетом этого ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ
положения регулирующего органа показал его обрыв, хотя на самом деле обрыва не произошло. Из-за возможности ложных срабатываний не удается полностью автоматизировать борьбу со многими видами ошибок. Как правило, вероятность ложного срабатывания взаимосвязана с вероятностью пропуска события (ошибки второго рода). То есть, чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система диагностики может выродиться в свою противоположность и привести к тому, что побочный вред от нее будет превышать пользу. Соответственно ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — объект не работоспособен, но анализ состояния этого не показал. Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок [11].
Экономический подход к принятию решения
Во время работы системы диагностики обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень наличия отказа, которым задаются при проверке статистических гипотез.
Возможны разные подходы к оценке рисков обоих видов, а соответственно и к выбору уровня наличия отказа. Опишем один из них — экономический. Для этого выберем порог принятия решения так, чтобы минимизировать средний ущерб при эксплуатации системы.
Теперь рассмотрим модель работы диагностической системы. Диагностическая система работает, производя
13.04.2012 13:55:33
периодические проверки с заданным шагом по времени №. Если выходной сигнал для данного типа отказа превышает заданный порог, происходит принятие решения о наличии отказа. Также возможна альтернатива — принятие решения после N превышений порога подряд. После этого происходит проверка наличия отказа дополнительными средствами. При наличии отказа он устраняется мгновенно, с точки зрения системы диагностики.
Примем следующую модель шумов при нормальной эксплуатации системы:
X2
Таблица 1. Ущерб в различных ситуациях
l
e
2і2
Pf(х)
^iai/V 2л
e
(X-X о /
2aL
Величина Отказ есть Отказ зарегистрирован
0 0 0
C v-‘ check 0 l
C + C + ‘-‘fail 1 v-‘check 1 Crepare l 0
f(t) ‘Cfail + Ccheck + Crepare l l
причем отсутствуют корреляции по времени.
Модель отказов такова — отказы случаются с заданной равномерной плотностью по времени Р/. Плотность распределения в условиях наличия отказа тоже нормальна, но с другим законом:
т.е. при появлении отказа возникает смещение и изменяется дисперсия сигнала оценки ошибки. В этих данных также отсутствуют корреляции.
Модель ущерба
В таблице 1:
♦ Сскеск — стоимость проведения проверки на наличие отказа;
♦ Сгераге — стоимость ремонта;
♦ Сш — асимптотическая стоимость ремонта, вызванная несвоевременным обнаружением отказа;
♦ /^) характеризует нарастание последствий при работе без принятия мер по ремонту, она равна нулю при t = 0 и равна 1 при t ^ ~.
В дальнейшем будем пренебрегать Ссьеск + Сгераге по сравнению с членом
С/аЦ.
Работа диагностической системы имеет смысл, если она позволяет обнаружить отказ на начальных этапах нарастания стоимости последствий. Чтобы упростить рассмотрение примем, что темп нарастания последствий невелик по сравнению с временным окном усреднения по времени в алгоритме поиска отказа. Тогда можно заменить: Щ) х С/ац ^ С/ац.
Пропуск отказа
Ложная тревога
Рис. 1. Оценка вероятностей ошибок первого и второго рода
Посчитаем ущерб как функцию порога принятия решения о наличии отказа в предположении, что отказы — редкое явление.
Для дальнейших выкладок нам потребуется соотношение:
erfc І І
вог £. Тогда компонента стоимости С2, связанная с ложными тревогами, с учетом двухсторонних ограничений будет иметь вид:
°ак)
С = с
(1 — Pf )erfc
2yf2
тт. !■
dx.
Для упрощения примем экспоненциальную модель нарастания стоимости последствий отказа:
f(t) = 1 — e -xt.
Пусть вероятность нахождения в состоянии отказа равна Pf, а уровень тре-
72
Обозначим вероятности ошибки первого рода Р1, а вероятность ошибки второго рода Р2:
P1 =
erfc I X7+^ 1 + erfc1 ^ Xo
2^2
P2 = 1 — P1.
01_2012_SPT.indd 37
1
2
Тогда средняя стоимость последствий Таким образом, изменяя £ необходимо минимизировать функционал С1 + С2, что легко осуществляется численными алгоритмами минимизации.
отказа СЇ будет иметь вид:
(-1 + ed£i )К
C = C P
‘-‘1 fail rf
fail f ( da
( — Pi )(1-Pi)
а средняя стоимость С2, связанная с ложными тревогами:
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
C = C P
2 fail f
£ (1 — e-Udt )•/>■
Заключение
В статье был изложен экономический подход, позволяющий выбирать порог чувствительности диагностических систем таким образом, чтобы минимизировать средний экономический
ущерб при эксплуатации системы. Предложенный подход был применен для выбора порога чувствительности в системе ЕСЯЛЫ 3Б, предназначенной для диагностики и мониторинга состояния активных зон и баз данных реакторов РБМК-1000. Проведенная расчетно-экспериментальная верификация созданного программного средства показала, что обеспечен требуемый уровень функционально-технических показателей системы диагностики ■
‘
Литература
Ї. Schukin N.V., Filatov A.V., Chernov E.V., Romanin S.D., Semenov A.A. Development of mathematical models for NPP core analysis during operation./ International conference on the physics of reactors PHYSOR Яв. — Vol. 4. — k-78-k-8в. — September Їв — 2Q, ЇЯЯв
2. Филатов А.В., Щукин Н.В., Семенов А.А., Романин С.Д. Система контроля загрузки активной зоны, методами расчетноэкспериментальной диагностики./ Сборник трудов научной сессии МИФИ-ЇЯЯ8. — Том. 4. — С. ЇЯ — 2Ї.
3. Щукин Н.В., Филатов А.В., Семенов А.А., Романин С.Д. Ecran — система контроля загрузки активной зоны, ядерного реактора./ Сборник трудов «Научные исследования, в области ядерной энергетики в технических вузах России». — МЭИ, 4:3в—38, ЇЯЯЯ.
4. Милюков Ф.В., Щукин Н.В., Семенов А.А., Соловьев Д.А., Черезов А.Л. Программа взаимокорреляционного анализа параметров ядерной безопасности./ Аннотации докладов. — Научная, сессия НИЯУМИФИ-20ЇЇ. — С. в2.
5. Соловьев Д.А, Семенов А.А., Щукин Н.В. Система пространственно-временной диагностики ECRAN 3D./ Аннотации докладов. — Научная сессия НИЯУ МИФИ-20Ї2. — С. в0
в. Груздов Ф.В., Соловьев Д.А. Построение эмпирической модели определения, расхода теплоносителя, через канал РБМК./ Аннотации докладов. — Научная, сессия НИЯУМИФИ-20Ї2. — С. в5.
7. Глазков О.В., Соловьев Д.А. Выявление отказов в положении ОР СУЗ в РБМК./ Аннотации докладов. — Научная, сессия НИЯУ МИФИ-20Ї2. — С. 7Q.
8. Милюков Ф.В., Соловьев Д.А. Выявление неверных перегрузок в реакторе РБМК./ Аннотации докладов. — Научная, сессия НИЯУ МИФИ-20Ї2. — С. 72.
Я. Лысов Д.А., Погосбекян Л.Р. Программа Polaris, версия. 4.2.Ї: Аттестационный паспорт, программного средства. Регистрационный номер ПС в ЦОЭПпри РНЦ КИ №в32 от. Ї4.0Я.2007. Регистрационный номер паспорта аттестации №23Ї от. Ї8.0Я.2007, ВНИИАЭС, Москва.
Ї0. Апресов А.А. Модернизированная версия, программы. «КОНТУР-М» для. совместного нейтронно-физического и теплогидравлического расчета реакторов типа РБМК. Отчет. ИАЭ, инв. N 33/4Я4484, ЇЯ84.
ЇЇ. http://ru.wikipedia.org/wiki/Oшuбкa_первoгo_рoдa.
20 октября 2021 г.
Многие отрасли нанимают исследователей для проведения исследований, которые приносят пользу компаниям и людям, например клиентам, клиентам или пациентам. Эти исследователи часто используют статистику, чтобы определить, верны или ложны гипотезы, чтобы они могли внести изменения в существующие отрасли или улучшить стандартные методы компании. Как исследователь, вы можете захотеть узнать о потенциальных ошибках, которые могут возникнуть при проверке гипотез с помощью статистических исследований. В этой статье мы определяем ошибку типа II в статистике и ее сравнение с ошибками типа I, а также значение ошибок типа II и советы по их уменьшению при рассмотрении гипотез.
Что такое ошибка второго рода в статистике?
Ошибка типа II в статистике возникает, когда исследователь принимает нулевую гипотезу, которая является ложной. В статистике нулевая гипотеза относится к гипотезе, которая является отправной точкой для исследователей, чтобы проверить и попытаться опровергнуть ее, используя статистически значимые данные. Нулевая гипотеза может быть истинной или ложной в зависимости от статистической значимости ваших данных, что просто означает, полезны ли данные в качестве измерения для опровержения гипотезы. Однако исследователи обычно рассматривают нулевую гипотезу как истинную, пока данные не опровергают ее.
Когда исследователь полагает, что его данные доказывают, что нулевая гипотеза верна, хотя на самом деле она ложна, возникает ошибка типа II. Это распространенная ошибка в статистике, которую исследователи иногда называют ложным отрицанием, потому что гипотеза ложна, но вы не отвергаете ее и не опровергаете.
Ошибки типа II и ошибки типа I
В дополнение к ошибкам типа I существуют также ошибки типа II, которые могут повлиять на исследовательские решения в статистике. Ошибки типа I противоположны и обратно пропорциональны ошибкам типа II, что означает, что если вы исправите ошибку одного типа слишком далеко, вы можете получить ошибку другого типа. Вы можете лучше понять это, изучив следующую таблицу:
Нулевая гипотеза верна**Нулевая гипотеза ложна**Принять/не отклонить нулевую гипотезуПравильное решение (принять истинную гипотезу)Ошибка второго рода (принять ложную гипотезу)Отклонить нулевую гипотезуОшибка первого рода (отклонить верную гипотезу)Правильное решение (отклонить ложную гипотезу) ) Каждая из этих ошибок может нарушить исследование и создать ситуации, когда исследователи упускают из виду важную информацию. Самая большая разница между ошибками типа I и типа II заключается в том, как они создаются. Например, ошибка типа I часто возникает, если вы принимаете случайные или случайные данные как статистически значимые. Часто это означает, что установленный вами уровень значимости, который обычно составляет около 0,05 или 5%, слишком высок. Однако для ошибок типа II ошибка возникает, если вы упускаете важные данные из-за небольшого размера выборки, низкого уровня значимости или ошибки измерения.
Значение ошибок типа II
Ошибки типа II могут существенно повлиять на результаты вашего исследования, потому что они означают, что нулевая гипотеза ложна, но вы верите, что она верна. Когда случаются ошибки такого типа, вы можете упустить возможность создавать инновационные продукты, улучшать свою компанию и приносить пользу людям различными способами. Если вы считаете, что столкнулись с ошибкой типа II в своем исследовании, рассмотрите возможность еще раз просмотреть данные и нулевую гипотезу, чтобы убедиться, что вы включили все важные статистические данные в свое решение принять гипотезу. Примите во внимание следующие причины, по которым вы заметите, что ошибки Типа II могут существенно повлиять на вашу компанию:
-
Производство полезных лекарств, которые сначала казались непригодными
-
Создание эффективных маркетинговых кампаний, которые сначала казались неэффективными
-
Удаление неблагоприятной рекламы, которая сначала показалась благоприятной
-
Предоставление полезных медицинских услуг, которые сначала казались бесполезными
-
Изменение неудачных методов управления, которые сначала казались успешными
Советы по уменьшению ошибок типа II
Вот несколько советов, которые помогут вам уменьшить количество ошибок типа II в вашем исследовании:
-
Тщательно планируйте свое обучение. Тщательное планирование может помочь вам избежать ошибок типа II, обеспечив наличие всех данных для принятия взвешенного решения относительно нулевой гипотезы. Подготовьте свои данные и поймите все переменные в вашей статистике, чтобы убедиться, что внешние факторы не влияют на данные, и вы не упустили ни одной важной информации.
-
Увеличьте размер выборки участников. Часто увеличение размера выборки может помочь вам получить лучшие результаты и избежать принятия ложных нулевых гипотез в вашем исследовании. Это связано с тем, что наличие большего количества данных от разных людей и источников может дать вам более широкий спектр информации для создания более стабильного среднего значения и устранения выбросов, которые могут повлиять на результаты исследования.
-
Запускайте тесты на более длительные периоды. Запуск тестов в течение более длительных периодов — это еще один способ увеличить размер выборки для исследования, гарантируя, что данные непротиворечивы и не связаны с внезапными всплесками или падениями активности. Имея более согласованные данные, вы можете гарантировать, что информация, на которой вы основываете свое решение, будет значимой и более точной, чем при более коротких временных рамках.
-
Поднимите уровень своей значимости. Еще один способ уменьшить количество ошибок типа II — поднять уровень значимости выше 5%, что означает, что вы можете считать большее количество данных значимыми и увеличить размер выборки. Однако слишком большое значение может привести к ошибкам типа I, поэтому рассмотрите возможность проведения нескольких тестов с разными уровнями и сравнения данных с другими исследователями, чтобы быть более точными.
Пример ошибки второго рода
Используйте следующий пример ошибки типа II, чтобы понять, что это за ошибка и как она возникает:
Пример: вы работаете с розничной компанией, которая хочет повысить удовлетворенность клиентов, внедрив функцию живого чата на своем веб-сайте. Ваша нулевая гипотеза состоит в том, что функция живого чата не повысит удовлетворенность клиентов. Чтобы проверить это, вы отправляете опрос об удовлетворенности клиентов в конце каждого живого чата и регулярно просматриваете результаты. Через месяц удовлетворенность клиентов не увеличивается, поэтому вы принимаете свою нулевую гипотезу о том, что функция живого чата не повышает удовлетворенность клиентов.
Однако розничная компания предпочитает проводить опрос в конце каждого живого чата. Вы просматриваете результаты через три месяца и видите, что уровень удовлетворенности клиентов медленно растет с тех пор, как вы в последний раз проверяли результаты. Вы понимаете, что совершили ошибку типа II и приняли ложную гипотезу, не имея достаточно информации для принятия точного решения.
Проверка гипотез является одним из краеугольных камней современных медицинских исследований. Цель многих исследований не ограничивается простым описанием данных, а включает в себя поиск различий между характеристиками тех или иных объектов наблюдений (пациентов, животных, клеточных культур) и оценку их значимости. Любое наблюдение за объектами реального мира с активным вмешательством исследователя или без него может называться экспериментом. В медицинской науке одним из способов проведения экспериментов является выполнение планируемых исследований [1]. Концепция планируемых исследований характеризуется четкими правилами проведения эксперимента с обозначением ряда жестких условий, которые должны быть обозначены и выполнены до его инициации:
- цель исследования сопровождается четко поставленным вопросом исследования;
- ясно сформулированы конкретные задачи, с помощью которых будет достигнута цель;
- обозначены одна или несколько исследовательских гипотез, требующих проверки в рамках вопроса исследования;
- дизайн исследования направлен на максимально эффективное и надежное достижение цели, получение достоверных и воспроизводимых результатов за счет снижения вероятности возникновения ошибок;
- критерии включения и невключения в исследование, а также критерии исключения обозначены однозначно;
- пошагово описаны методы статистического анализа, направленного на получение выводов по каждой задаче и поставленному вопросу исследования.
Таким образом, при планировании эксперимента исследователи моделируют некие идеальные условия, которые позволяют ответить на поставленный вопрос исследования. При этом планируемые исследования достаточно компактны по количеству участников и по времени проведения.
Примером несколько иного подхода являются наблюдательные поисковые исследования, основной задачей которых является не подтверждение заранее сформулированных гипотез о влиянии тех или иных факторов на исход, а поиск любых подобных взаимодействий и генерация гипотез. То есть в обсервационных исследованиях во главу угла ставят поиск любых важных с точки зрения цели исследования взаимодействий факторов внутри исследуемой популяции, при этом узкий основной вопрос исследования, требующий подтверждения, обычно отсутствует. Однако и в поисковых исследованиях должны быть заранее сформулированы: цель, задачи и четко обозначена исследуемая популяция (обычно довольно широкая по сравнению с выборками планируемых исследований).
Целью этого обзора является знакомство читателей с основными аспектами планируемых исследований и облегчение понимания связи между вопросом исследования и ответом на него с точки зрения методологии проведения исследований, ключевым аспектом которого является проверка статистических гипотез.
ИССЛЕДОВАТЕЛЬСКИЕ И СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ
Началом любого исследования (эксперимента) является гипотеза или научное предположение. Исследователи выдвигают такие предположения и пытаются их доказать или опровергнуть. Например, исследователи могут сделать предположение о том, что плохая экология региона оказывает влияние на здоровье жителей, или о том, что курение может быть сопряжено с повышенным риском сердечно-сосудистых заболеваний. Такие предположения получили название «исследовательские гипотезы». От исследовательской гипотезы следует отличать статистическую гипотезу. Последняя, по сути, представляет такую формулировку исследовательской гипотезы, которая может быть проанализирована с помощью статистических методов в рамках концепции дизайна эксперимента.
Статистическая гипотеза представляет собой некое суждение о параметрах, описывающих статистическую популяцию (генеральную совокупность), но не выборку из нее. В свою очередь, статистическая популяция представляет собой группу однородных элементов, например людей в группе риска, представляющих интерес в рамках настоящего исследования (эксперимента). Примером может служить население города или все пациенты стационара за определенный период времени. На начальном этапе исследователи выдвигают две гипотезы о возможной взаимосвязи наблюдаемых явлений (потенциальных факторов риска и исходов): нулевую и альтернативную.
Нулевая гипотеза утверждает, что наблюдаемые эффекты, явления или взаимодействия происходят в силу случайности, то есть связь между ними отсутствует. Нулевую гипотезу традиционно обозначают, как H0. Альтернативная гипотеза, наоборот, утверждает, что наблюдаемые явления неслучайны и между ними есть связь. Альтернативную гипотезу традиционно обозначают как H1 или HA.
Следует иметь в виду, что под связью в данном случае подразумевают любую ассоциацию, не обязательно причинно-следственную. Например, в небольшом исследовании оценивают различия средних значений (μ1 и μ2) вещественного числового признака – уровень общего холестерина плазмы крови – в двух группах: у пациентов с и без инфаркта миокарда в анамнезе. Исследовательская гипотеза может состоять в том, что группы как различаются, так и не различаются. При этом нулевая гипотеза будет утверждать, что уровень общего холестерина никак не связан с риском развития инфаркта миокарда, то есть истинных различий между средними значениями нет (наблюдаемые различия носят случайный характер):
H0 : μ1 = μ2.
Альтернативной гипотезой является утверждение о том, что различия в уровне холестерина между группами существуют, они значимы и неслучайны:
H1 : μ1 ≠ μ2.
Нулевая и альтернативная гипотезы являются взаимоисключающими, то есть если верна H0, то неверна H1, и наоборот. Таким образом, чтобы подтвердить альтернативную гипотезу – наличие истинных различий между группами, – нам нужно отклонить нулевую гипотезу.
СТАТИСТИЧЕСКИЕ ТЕСТЫ
Статистические тесты – это методы статистического доказательства (построения статистического вывода), которые используют для принятия решения о том, можно ли отклонить нулевую гипотезу H0. Следует отметить, что формально статистические тесты не позволяют принять нулевую гипотезу. Они лишь помогают оценить, может ли она быть отклонена в пользу альтернативной или нет.
Каждый статистический тест является математической функцией, вычисляющей так называемую тестовую статистику. Тестовая статистика показывает, насколько близко наблюдаемая величина соответствует ожидаемому распределению величин при условии, что нулевая гипотеза не была отклонена. Чем больше величина тестовой статистики, тем больше несоответствие между наблюдаемым и ожидаемым распределениями.
Совокупность тестовых статистик каждого теста подчиняется определенному закону распределения (подробнее о распределениях см. в [2]). Например, t-тест вычисляет t-статистики, подчиняющиеся t-распределению. Для того чтобы отклонить нулевую гипотезу, нужно обозначить некий порог среди распределения тестовых статистик. Такую величину пороговой тестовой статистики называют критическим значением, а соответствующую ей вероятность в распределении тестовых статистик – уровнем значимости.
Уровень значимости, обозначаемый α, является вероятностью того, что при текущем значении тестовой статистики нулевая гипотеза будет отклонена несмотря на то, что она верна (истинна). Иными словами, величина α отражает вероятность ошибочно отклонить верную нулевую гипотезу. Такая вероятность также получила название ошибка I рода. Величину α и соответствующее ей критическое значение статистического теста исследователи декларируют до проведения статистического теста, чтобы заранее определить вероятность ошибочного отклонения нулевой гипотезы. Чем меньше уровень значимости, тем более низкая вероятность отклонить нулевую гипотезу в случае, если она верна. Однако эта вероятность, пусть в ряде случаев и очень небольшая, существует всегда. Исследователи лишь могут выбрать такое пороговое значение, при котором эта вероятность будет чрезвычайно низкой. В разных областях знаний традиционно используют разные значения α; в частности, в медицинских исследованиях наиболее часто применяют пороговое значение, равное 0,05. Исследователь может использовать и более низкие пороговые значения, например 0,01 или ниже в экспериментах, где критически важно снизить вероятность ошибочного отклонения нулевой гипотезы (обнаружения различий между группами там, где их нет).
После вычисления результата статистического теста в виде тестовой статистики исследователи получают соответствующую ей вероятность получения таких же или более экстремальных по сравнению с наблюдаемыми результатов теста (то есть сильнее отклоняющихся от ожидаемого распределения), в случае если нулевая гипотеза верна. Такая вероятность получила название р-value (p-значение). Малые значения р-value говорят о том, что если нулевая гипотеза верна, то вероятность получения таких же или более экстремальных результатов тестовой статистики крайне мала. Следовательно, имеется высокая вероятность того, что нулевая гипотеза неверна и может быть отклонена. Если p ≤ α, то есть статистика теста равна или превышает критическое значение, результат считается статистически значимым (рис. 1). Именно поэтому в описании статистического анализа в разделе «Материалы и методы» всегда указывают, при каком значении p результаты считают статистически значимыми. Фактически фраза «различия считали значимыми при p < 0,05» означает, что исследователи выбрали для своей работы величину ошибки I рода α = 0,05.

РИС. 1. T-распределение для 50 степеней свободы
FIG. 1. T-distribution for 50 degrees of freedom
Примечания: зелеными пунктирными линиями указаны критические значения -1,96 и 1,96, соответствующие 2,5-му и 97,5-му процентилям – двустороннему уровню значимости α = 0,05. Красной сплошной линией обозначена t-статистика = 2,5, которая превышает критическое значение 1,96 при двустороннем t-тесте (p = 0,0126 при заданном α = 0,05). Таким образом нулевая гипотеза может быть отклонена и принята альтернативная.
Notes: green dotted lines indicate critical values of 1.96 and -1.96 corresponding to the 97.5th percentile and the 2.5th percentile, respectively, i.e. two-sided significance level α = 0,05. B. Red solid line indicates t-statistics = 2.5, which exceeds critical value of 1.96 using two-tailed t-test (p = 0.0126 with specified α = 0.05), thus the null hypothesis can be rejected, and we can accept the alternative one.
Представим себе, что мы проводим параллельное сравнительное исследование с двумя группами: одной группе назначаем антигипертензивный препарат A, другой группе назначаем плацебо. Наша нулевая гипотеза утверждает, что эффективность препарата А в отношении показателей артериального давления (АД) не отличается от плацебо, если мы оцениваем средние цифры АД по завершении исследования в обеих группах:
- μTRT – среднее значение АД среди пациентов, получавших препарат А (treatment, TRT);
- μPLC – среднее значение АД среди пациентов, получавших плацебо (placebo, PLC);
- H0 : μTRT = μPLC или μTRT – μPLC = 0;
- H1 : μTRT ≠ μPLC или μTRT – μPLC ≠ 0.
С помощью t-критерия проверяем, можем ли мы отклонить нулевую гипотезу о том, что μTRT – μPLC = 0. Мы можем построить график распределения t-статистик, соответствующего такой разнице (рис. 1, зеленые линии). После завершения эксперимента мы получили разницу μTRT – μPLC, соответствующую t-статистике 2,5 в случае, если нулевая гипотеза верна (рис. 1, красная линия). Мы видим, что наблюдаемый результат лежит за пределами критических значений, что позволяет отклонить нулевую гипотезу. Соответствующее значение р составляет 0,0126, следовательно, нулевая гипотеза может быть отклонена при выбранном значении α = 0,05, а различие между группами является статистически значимым.
РАЗМЕР ЭФФЕКТА
Исследовательские гипотезы наиболее часто связаны с поиском различий или ассоциаций между некими показателями. Однако существенное значение имеет не столько сам факт различий, сколько их клиническая значимость. Например, в одном исследовании сравнивали доли достижения терапевтического эффекта в группах лечения и плацебо, и они составили 10 и 80% соответственно. Мы видим, что доли различаются, и довольно существенно, разница составляет 70%. В другом исследовании аналогичные доли составили 45 и 55%. Мы снова видим, что доли различаются, однако уже не так сильно, разница всего 10%. Еще в одном исследовании эффективность терапии в двух группах составила 75 и 80%. Доли различаются, но разница очень невелика – всего 5%. Другой пример связан с новыми антигипертензивными препаратами. Новый препарат Х снижает систолическое артериальное давление (САД) в среднем на 15 мм рт. ст. Препарат Y также снижает САД, но в среднем на 8 мм рт. ст. Наконец, препарат Z снижает САД, но всего в среднем на 1 мм рт. ст. При использовании традиционной антигипертензивной терапии среднее снижение АД составило 1 мм рт. ст. Во всех примерах мы видим, что некий эффект есть, но он разный, в одних – больший, в других – меньший.
Размер эффекта – довольно широкое статистическое понятие, обозначающее некую статистику или показатель, показывающий величину различий или ассоциации между распределениями исследуемой величины в разных группах. Размер эффекта в медицине крайне важен: именно он привязан не только к статистике, но и к клинической значимости наблюдаемых в исследовании результатов. Например, мы используем среднее снижение САД в качестве размера эффекта. Среднее снижение САД в 1 мм рт. ст., скорее всего, не является клинически значимым – для пациента препарат Z не будет лучше традиционной терапии, таким образом, с практической точки зрения его назначение не дает преимуществ. Слишком большой размер эффекта (препарат X), напротив, может быть ассоциирован с развитием осложнений вследствие гипотензии. Препарат Y, вероятно, является оптимальным выбором среди новых препаратов в клинической практике – он имеет значимый и при этом не чрезмерный антигипертензивный эффект.
Крайне важно понимать, что, проверяя статистические гипотезы, мы пытаемся статистическими методами зафиксировать определенный размер эффекта. Абсолютная разница между средними редко бывает равна нулю, при этом разница может быть небольшой и клинически незначимой и принимать как положительные, так и отрицательные значения. С другой стороны, при проверке статистических гипотез необходимо четко ввести критерий наличия или отсутствия клинического смысла у того или иного эффекта. В примере с антигипертензивными препаратами среднее снижение САД на ≤2 мм рт. ст. можно определить как отсутствие клинического эффекта, на 3–10 мм рт. ст. – как умеренный эффект и на >10 мм рт. ст. – как сильный. В качестве проверяемой исследовательской гипотезы мы хотим выяснить, достигнет ли среднее снижение САД хотя бы умеренного размера эффекта под влиянием препаратов X, Y и Z.
Как оценивается размер эффекта?
Огромный вклад в концепцию размера эффекта внес психолог и статистик Jacob Cohen, который в одной из своих поздних работ писал: «Основным результатом исследования являются одна или несколько оценок размера эффекта, а не p-значения» [3]. Сегодня существует большое количество статистик, позволяющих оценить размер эффекта, фактически при проверке любых гипотез.
Выделяют стандартизованные методы оценки размера эффекта и нестандартизованные. В отличие от последних, стандартизованные методы позволяют оценивать эффект для переменных не только с одинаковой, но и с разной размерностью (например, оценка коэффициента корреляции для переменных, измеряемых в разных единицах), для оценки совокупных результатов разных исследований (метаанализ и метарегрессия), при сравнении результатов исследований с использованием разных метрик переменных (например, при использовании г/л в одном исследовании и ммоль/л в другом) [4].
Выделяют следующие методы оценки размера эффекта (таблицы S1–4 в приложении):
- размер эффекта, оценивающий ассоциацию между распределениями числовых переменных или насколько распределение одной переменной вносит вклад в распределение другой переменной (коэффициент корреляции, коэффициент детерминации и др.);
- размер эффекта, оценивающий разницу между статистиками (Cohen’s d, Glass’ Δ, разница рисков и др.);
- размер эффекта, оценивающий ассоциацию между категориальными переменными (Cohen’s h, отношение шансов и др.).
Исследовательские гипотезы и концепция размера эффекта
Размеру эффекта отдается ключевая роль при формировании исследовательских и статистических гипотез. Первоначально исследователи ставят вопрос о том, случаен ли наблюдаемый ими эффект? Например, различаются ли в действительности уровни общего холестерина в группе лечения новым препаратом и в контрольной группе? Наблюдаемые различия могут быть обусловлены случайностью. Для того чтобы проверить, существует ли эффект в действительности, проводят поисковые и пилотные исследования, основной целью которых является определение наличия эффекта или его отсутствия. Такие исследования получили названия гипотезообразующих (о различных подходах к оптимальному выбору дизайна исследований для различных целей – см. [5]). Безусловно, если удалось зафиксировать эффект, в пилотных исследованиях можно оценить его наблюдаемый или гипотетический размер. Однако пилотные исследования часто довольно компактны и дают возможность лишь ответить на вопрос наличия/отсутствия эффекта, но не позволяют достоверно определить его размер (рис. 2).

РИС. 2. Схема проведения гипотезообразующих исследований
FIG. 2. Flowchart of the hypothesis-generating studies
Следующий этап исследований после пилотных получил название подтверждающих исследований и направлен на то, чтобы зафиксировать эффект определенного размера. Например, в пилотном исследовании было установлено, что курение среди мужчин 35–45 лет, проживающих в городах, увеличивает риск развития сердечно-сосудистых заболеваний за 10 лет, а относительный риск (ОР) равен X. Перед исследователями встает вопрос о влиянии курения на аналогичную группу мужчин, проживающих в сельской местности. Для того, чтобы спланировать такое исследование, мы можем опираться на полученные ранее результаты в городской популяции и исходить из того, что нам нужно зафиксировать размер эффекта (ОР) не менее X (рис. 3). Или, если по нашим исследовательским предположениям эффект будет менее выражен, например в n раз, мы можем спланировать исследование так, чтобы зафиксировать размер эффекта (ОР) не менее X/n.

РИС. 3. Схема проведения подтверждающих исследований
FIG. 3. Flowchart of confirmatory studies
Использование размера эффекта позволяет не проводить пилотные исследования каждый раз, а опираться на опыт предшествующих работ. Концепция размера эффекта требует от врачей понимания концепции порога размера эффекта, который они хотят зафиксировать статистически, если такой порог является целесообразным с точки зрения медицины. И такой порог требует именно медицинского обоснования. Например, при исследовании нового препарата для похудения у пациентов с весом выше 200 кг получено статистически значимое снижение веса в течение одного года, которое составило 1 кг. В результате эффект зафиксирован, он статистически значим, но с точки зрения помощи пациентам такой эффект абсолютно лишен всякого смысла: в течение 1 года диетологи (и сами пациенты) наверняка хотели бы наблюдать более выраженное снижение веса. Вероятно, более оправданным было бы введение порога размера эффекта в 10 или 15 кг.
ОДНОСТОРОННИЕ И ДВУСТОРОННИЕ СТАТИСТИЧЕСКИЕ ТЕСТЫ
Двусторонние тесты
Вернемся к примеру с антигипертензивной терапией. Предположим, что существует новый перспективный препарат, назовем его TRT (treatment), который должен снижать САД исходя из своего механизма действия, но как он себя покажет в клиническом эксперименте с пациентами, мы не знаем. Существует и традиционная антигипертензивная терапия, которая будет использована в контрольной группе (CTRL, control treatment). Измеренное среднее снижение САД в конце исследования в группе TRT будет равно μTRT, а в группе CTRL составит μCTRL.
Если мы формулируем вопрос исследования, как «какая терапия более эффективна?», нулевая гипотеза декларирует, что H0 : μTRT = μCTRL. А альтернативная гипотеза утверждает обратное H1 : μTRT ≠ μCTRL, и, в свою очередь, может состоять из двух более простых утверждений:

То есть мы рассматриваем альтернативные гипотезы и для ситуации, когда новый препарат (TRT) оказался более эффективен, чем традиционное лечение (CTRL), и, наоборот, когда новый препарат (TRT) оказался менее эффективен. Тесты, используемые для такой проверки разнонаправленных по сути предположений, получили название двусторонних. Если рассмотреть диаграмму распределения, например t-статистики, мы увидим 2 зеркальных критических значения с разным знаком: при уровне значимости α = 0,05 для двустороннего теста критические значения будут -1,96 и 1,96 (рис. 1). При двусторонних тестах общий уровень значимости разделяется пополам и критические значения с каждой стороны соответствуют α/2:

При принятом уровне значимости в 5% нулевая гипотеза будет отклонена, если t-статистика наблюдаемого эффекта превысит любое из двух критических значений (зеленые линии) (рис. 1), соответствующие 2,5 и 97,5 процентиля.
Для чего исследователям двусторонние тесты? Так как мы не знаем истинного эффекта препарата TRT, двусторонний тест ответит на все варианты развития событий: TRT приблизительно одинаков по действию с CTRL, лучше или хуже CTRL.
Односторонние тесты
Если главный вопрос исследования «является ли новый препарат (TRT) лучшей альтернативой стандартному лечению (CTRL)?», наши гипотезы изменятся. Теперь нам важно зафиксировать только значимый размер эффекта, когда μTRT > μCTRL.
Таким образом, при формулировании нулевой и альтернативной гипотезы получаем:

Для проверки такой гипотезы используется односторонний тест, позволяющий зафиксировать не только определенный размер эффекта, но и его направление. В данном случае нам важно проверить, превышает ли статистика теста критическое значение, расположенное на распределении справа (рис. 4).

РИС. 4. Иллюстрация одностороннего t-теста
FIG. 4. One-sided t-test illustration
Примечания: зеленая линия обозначает критическое значение 1,65, соответствующее одностороннему уровню значимости α = 0,05. Для статистики t = 2,5 (красная линия) p-value = 0,006: результат статистически значим при выбранном значении ошибки I рода, поскольку p < α.
Notes: the green line indicates critical value of 1.65 which corresponds with one-sided significance level α = 0.05; p-value is 0.006 for t-statistic t = 2.5 (red line): the result is clinically significant, given the chose type I error value as p < α.
ОШИБКИ I И II РОДА
Мы подробно разобрали концепцию ошибки I рода, однако получение и интерпретация результатов исследований связано не с одним, а с двумя типами ошибок (табл.).
Таблица. Ошибки I и II рода
Table. Type I and II errors
|
В статистической популяции / In statistical population |
В ходе исследования / In the study |
Результат проверки H0 / After testing H0 |
Вероятность / Probability |
|
H0 верна / H0 true |
H0 не отклонена / H0 not rejected |
Решение не отклонять верное / Decision not to reject is correct |
P = 1 – α |
|
H0 верна / H0 true |
H0 отклонена / H0 rejected |
Ошибочное отклонение, ошибка I рода / Incorrect (false) rejection, Type I error |
P = α |
|
H0 неверна / H0 false |
H0 не отклонена / H0 not rejected |
Решение не отклонять ошибочное, ошибка II рода / Decision not to reject is incorrect (false), Type II error |
P = β |
|
H0 неверна / H0 false |
H0 отклонена / H0 rejected |
Верное отклонение / Correct rejection |
P = 1 – β |
Ошибка первого рода (α, ложноположительный результат) – ситуация, когда отклонена верная нулевая гипотеза. Принимается альтернативная гипотеза, которая неверна. Например, исследователи считают значимыми различия между группами, а на самом деле различия носят случайный характер.
Ошибка второго рода (β, ложноотрицательный результат) – ситуация, когда не отклонена ошибочная нулевая гипотеза. При этом верная альтернативная гипотеза отклоняется. Например, исследователи расценили как случайные различия между группами, которые на самом деле были значимы и не случайны.
Для планирования эксперимента важно попытаться минимизировать ошибки I и II рода. Ошибка I рода, как мы уже говорили, и является уровнем значимости теста, с которым сопоставляют величину p. Малое значение ошибки I рода позволяет с высокой вероятностью не отклонить нулевую гипотезу при условии, что она верна.
В свою очередь, ошибка II рода отражает возможность отклонить ошибочную нулевую гипотезу с вероятностью 1 – β. Такая вероятность получила название мощность статистического теста: power = 1 – β. В ряде медицинских исследований общепринятая минимальная мощность соответствует не менее 80% (то есть максимально допустимая ошибка II рода не превышает 20%).
ОБЪЕМ ТРЕБУЕМОЙ ВЫБОРКИ В КОНЦЕПЦИИ ПРОВЕРКИ СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Последним элементом, необходимым для проверки статистических гипотез, является минимальный объем требуемой выборки, необходимый для того, чтобы принять или отклонить нулевую гипотезу [6]. Таким образом, мы можем представить концепцию проверки статистических гипотез в виде схемы, представленной на рис. 5.

РИС. 5. Схема проверки статистических гипотез
FIG. 5. Flowchart of the statistical hypothesis testing
Сформулировав вопрос исследования и предположив ожидаемый размер эффекта, исследователь:
- выбирает наиболее подходящий статистический тест, связанный с законом распределения размера эффекта в статистической популяции;
- устанавливает подходящий уровень значимости и мощность исследования;
- после этого рассчитывает требуемый объем выборки.
Только после выполнения этих этапов можно переходить к выполнению статистического теста. Однако каким образом исследователь может связать мощность исследования, уровень значимости, размер эффекта и объем выборки? Представим себе, что мы пытаемся статистически зафиксировать размер эффекта Е с мощностью 1 – β, значимостью α (рис. 6А). Для этого нам потребуется объем выборки n [7]. Заранее отметим, что уровень значимости теста α должен оставаться фиксированным при любом развитии событий. Если исследователь хочет оставить объем выборки неизменным, но при этом повысить мощность, самое простое решение – предположить, что мы будем наблюдать больший размер эффекта, например в 2 раза (или Е × 2). При таких условиях мощность действительно увеличится (рис. 6B). Однако в реальной жизни исследователь не может по собственному желанию наблюдать больший или меньший эффект, более того, предположение о размере эффекта представляет из себя лишь исследовательскую гипотезу. В таком случае размер эффекта также на самом деле не должен увеличиться, однако при увеличении размера выборки увеличивается мощность исследования (рис. 6С). Следовательно, при желании зафиксировать определенный размер эффекта со строгим уровнем значимости единственной возможностью снизить риск ложного принятия ошибочной нулевой гипотезы (β) является увеличение объема требуемой выборки.

РИС. 6. Взаимосвязь между размером эффекта, ошибками I и II рода и размером выборки при проверке статистических гипотез:
А. Взаимосвязь размера эффекта, ошибок I и II рода.
B. Изменение величины ошибки II рода при увеличении размера эффекта.
C. Изменение величины ошибки II рода при увеличении размера выборки.
FIG. 6. The relationship between effect size, type I and II errors, and sample size, when testing statistical hypotheses:
А. Effect size and type I and II errors.
B. Type II error changing after the effect size increasing.
C. Type II error changing after sample size increasing.
Примечание: μ1 – среднее в группе 1, μ2 – среднее в группе 2.
Note: μ1 – mean in group 1, μ2 – mean in group 2.
ЗАКЛЮЧЕНИЕ
Грамотное формулирование исследовательских и статистических гипотез – важнейший навык врача- исследователя, без которого невозможно успешное планирование и проведение исследований в области медицины. Кроме того, концепции размера эффекта, ошибок I и II рода необходимы для интерпретации результатов своих собственных и опубликованных в литературе исследований. Эти идеи универсальны и применимы к любым статистическим тестам, более того, они имеют существенно большее значение для ученого, чем навык применения тех или иных частных методик.
ВКЛАД АВТОРОВ
А.Ю. Суворов, Н.М. Буланов, А.Н. Шведова в равной степени внесли вклад в эту работу и должны считаться первыми соавторами. А.Ю. Суворов, Н.М. Буланов, А.Н. Шведова, Е.А. Тао, А.А. Заикин и М.Ю. Надинская участвовали в написании текста рукописи. А.Ю. Суворов, Н.М. Буланов и А.Н. Шведова выполняли поиск и анализ литературы по теме обзора. А.Ю. Суворов и Д.В. Бутнару разработали общую концепцию статьи и осуществляли руководство ее написанием. Все авторы участвовали в обсуждении и редактировании работы. Все авторы утвердили окончательную версию публикации.
AUTHOR CONTRIBUTIONS
Alexander Yu. Suvorov, Nikolay М. Bulanov, and Anastasia N. Shvedova contributed equally to this work and should be considered as co-first authors. Alexander Yu.vSuvorov, Nikolay М. Bulanov, Anastasia N. Shvedova, Ekaterina A. Tao, Alexey A. Zaikin and Maria Yu. Nadinskaia, participated in writing the text of the manuscript. Alexander Yu. Suvorov, Nikolay M. Bulanov, and Anastasia N. Shvedova searched and analyzed the literature on the review topic. Alexander Yu. Suvorov and Denis V. Butnaru developed the general concept of the article and supervised its writing. All authors participated in the discussion and editing of the work. All authors approved the final version of the publication.
ДОПОЛНИТЕЛЬНЫЕ МАТЕРИАЛЫ
Дополнительные материалы, прилагаемые к этой статье, можно посмотреть в онлайн-версии по адресу: https://doi.org/10.47093/2218-7332.2022.426.08.S
SUPPLEMENTARY MATERIALS
Supplementary materials associated with this article can be found in the online version at doi: https://doi.org/10.47093/2218-7332.2022.426.08.S
Ошибки, встроенные в систему: их роль в статистике
Время на прочтение
6 мин
Количество просмотров 13K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):
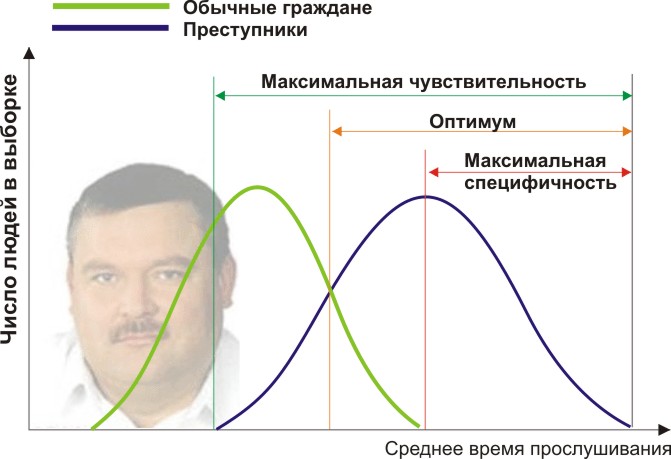
Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:

Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):

А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #