
Разработка
логической модели БД должна происходить
с учетом необходимости решения задач
минимизации дублирования данных,
упрощения и ускорения процедур их
обработки. При неправильно спроектированной
схеме БД могут возникнуть аномалии
модификации данных. Для решения подобных
проблем проводится нормализация.
Нормализация
– процесс проверки и реорганизации
сущностей и атрибутов с целью удовлетворения
требований к реляционной модели базы
данных. Нормализация позволяет: 1) быть
уверенным, что каждый атрибут определен
для своей сущности, 2) значительно
сократить объем памяти для хранения
информации и 3) устранить аномалии в
организации хранения данных. В результате
проведения нормализации должна быть
создана структура данных, при которой
информация о каждом факте хранится
только в одном месте. Процесс нормализации
сводится к последовательному приведению
структуры
данных к нормальным формам — формализованным
требованиям к организации данных.
Известно 6 нормальных форм:
-
первая нормальная
форма (1NF); -
вторая нормальная
форма (2NF); -
третья нормальная
форма (3NF); -
нормальная форма
Бойса — Кодда (усиленная 3NF); -
четвертая нормальная
форма (4NF); -
пятая нормальная
форма (5NF).
Нормальные
формы основаны на понятии функциональной
зависимости (в дальнейшем будем
использовать термин “зависимость”).
Функциональная
зависимость (FD).
Атрибут В сущности Е функционально
зависит от атрибута А сущности Е тогда
и только тогда, когда каждое значение
А в Е связало с ним точно одно значение
В в Е, т. е. А однозначно определяет В.
Полная функциональная
зависимость.
Атрибут В сущности Е полностью
функционально зависит от ряда атрибутов
А сущности Е тогда и только тогда, когда
В функционально зависит от А и не зависит
ни от какого подряда А.
На рис. 6 в сущности
Сотрудник
значения атрибутов Фамилия,
Имя
и Отчество
однозначно определяются значением
атрибута Табельный
номер, т.
е. атрибуты Фамилия,
Имя
и Отчество
зависят от атрибута Табельный
номер.
Функциональные зависимости определяются
бизнес-правилами предметной области.
Так, если оклад сотрудника определяется
только должностью, то атрибут Оклад
зависит от атрибута Должность;
если оклад зависит еще, например, от
стажа, то такой зависимости нет. В
нижеследующих примерах будем считать
для определенности, что такая зависимость
есть.

Рис.
6. Ненормализованная сущность Сотрудник
Рассмотрим подробнее
первые четыре нормальные формы.
Первая нормальная
форма (1NF).
Сущность находится в первой нормальной
форме тогда и только тогда, когда все
атрибуты содержат атомарные значения.
Среди атрибутов не должно встречаться
повторяющихся групп, т.е. несколько
значений для каждого экземпляра. На
рис. 6 атрибуты Телефон
и Хобби
являются нарушением первой нормальной
формы. Что будет, если у сотрудника
несколько рабочих телефонов? Запись
значения колонки через разделитель,
например “124-56-78, 124-56-79, 124-56-90” или
“Аквалангист, мотоциклист, шахматист”,
приводит к ряду проблем, например,
размера поля может не хватить для
хранения данных (нельзя увеличивать
список телефонов до бесконечности).
Сущность, приведенная на рис. 7, не
является решением проблемы. Что будет,
если у сотрудника появится четвертый
телефон или третье хобби? Эту информацию
будет негде хранить.

Рис.
7. Ненормализованная сущность Сотрудник
Другой ошибкой
нормализации является хранение в одном
атрибуте разных по смыслу значений. На
рис. 6 атрибут Дата
зачисления или увольнения
хранит информацию как о зачислении, так
и об увольнении сотрудника. Если хранится
только одно значение, то невозможно
понять, какая именно дата внесена. Если
внести атрибут-признак типа даты, тип
можно будет определить, но останется
возможность хранения только одной даты
для каждого сотрудника.
Для приведения
сущности к первой нормальной форме
следует:
-
разделить сложные
атрибуты на атомарные; -
создать новую
сущность; -
перенести в нее
все “повторяющиеся” атрибуты; -
выбрать возможный
ключ для нового РК (или создать новый
РК); -
установить
идентифицирующую связь от прежней
сущности к новой, РК прежней сущности
станет внешним ключом (FK) для новой
сущности.
На рис. 8 показана
сущность Сотрудник,
приведенная к первой нормальной форме.
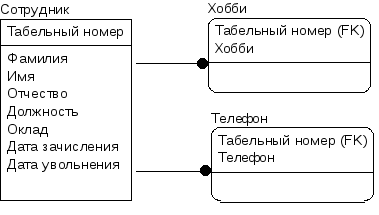
Рис. 8. Сущность
Сотрудник,
приведенная к первой нормальной форме
Вторая
нормальная форма (2NF).
Сущность
находится во второй нормальной форме,
если она находится в первой нормальной
форме и каждый неключевой атрибут
полностью зависит от первичного ключа
(не должно быть зависимости от части
ключа). Вторая нормальная форма имеет
смысл только для сущностей, имеющих
сложный первичный ключ.

Рис. 9. Сущность
Проект
Предположим,
сущность Проект
содержит информацию о проекте, которым
руководит сотрудник, причем информация
содержится как непосредственно о
проекте, так и о руководителе проекта
(рис. 9). Атрибуты Фамилия,
Имя, Отчество
и Должность
зависят только от атрибута Табельный
номер руководителя,
но вовсе не от Наименования
проекта.
Другими словами, имеется зависимость
только от части ключа.
Для приведения
сущности ко второй нормальной форме
следует:
-
выделить атрибуты,
которые зависят только от части
первичного ключа, создать новую сущность; -
поместить атрибуты,
зависящие от части ключа, в их собственную
(новую) сущность; -
установить
идентифицирующую связь от прежней
сущности к новой (рис. 10).
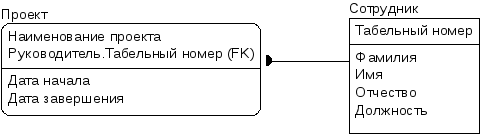
Рис. 10. Сущность
Проект,
приведенная ко второй нормальной форме
Вторая
нормальная форма позволяет избежать
следующих аномалий при выполнении
операций:
-
Обновления
(UPDATE). Имеет
место дублирование данных о сотруднике,
если он руководит несколькими проектами.
Если данные о сотруднике изменяются,
необходимо менять несколько записей
(по числу ведомых проектов). -
Вставки (INSERT).
Невозможно ввести данные о сотруднике,
если он в данный момент не руководит
проектами. -
Удаления (DELETE).
Если сотрудник временно прекращает
руководство проектами, данные о нем
теряются.
На рис. 10 показана
сущность Проект,
приведенная ко второй нормальной форме.
Третья нормальная
форма (3NF).
Сущность
находится в третьей нормальной форме,
если она находится во второй нормальной
форме и никакой неключевой атрибут не
зависит от другого неключевого атрибута
(не должно быть взаимозависимости между
неключевыми атрибутами).
На рис. 8 сущность
Сотрудник
находится во второй нормальной форме
(имеется только один атрибут первичного
ключа, поэтому не может быть зависимости
неключевых атрибутов от части ключа),
но неключевой атрибут Оклад
зависит от другого неключевого атрибута
— Должности.
Для приведения
сущности ко третьей нормальной форме
следует:
-
создать новую
сущность и перенести в нее атрибуты с
одной и той же зависимостью от неключевого
атрибута; -
использовать
атрибут(ы), определяющий эту зависимость,
в качестве первичного ключа новой
сущности; -
установить
неидентифицирующую связь от новой
сущности к старой (рис. 11).
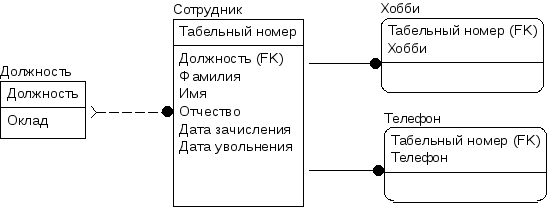
Рис.11. Сущность
Сотрудник,
приведенная к третьей нормальной форме
В
третьей нормальной форме каждый атрибут
сущности зависит от ключа, от всего
ключа целиком и ни от чего другого, кроме
как от ключа.
Третья
нормальная форма также позволяет
избежать ряда аномалий:
-
Обновления
(UPDATE). Имеет
место дублирование данных об окладе,
если должность занимают несколько
сотрудников. Если оклад, соответствующий
должности, меняется, необходимо менять
несколько записей (по числу сотрудников
на одной должности). -
Вставки (INSERT).
Невозможно ввести данные об окладе,
соответствующем должности, если в
данный момент нет сотрудника, занимающего
эту должность. -
Удаления (DELETE).
В случае удаления из таблицы сотрудника,
занимающего уникальную должность,
данные об окладе теряются.
Четвертая
нормальная форма (4NF)
требует отсутствия многозначных
зависимостей между атрибутами.
В примере на рисунке
12 а преподаватель читает лекции по
нескольким предметам и курирует несколько
групп студентов. Одна группа студентов
может изучать несколько предметов,
одному предмету могут обучаться несколько
групп студентов. Имеется многозначная
зависимость между атрибутами Предмет
и Группа.
При этом возможна аномалия: если у
преподавателя появляется новая группа,
приходится добавлять несколько записей,
по числу читаемых предметов.
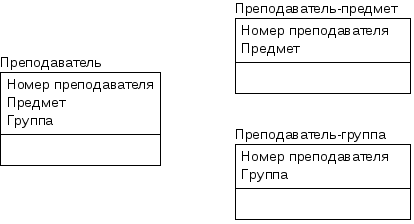
|
а) |
б) |
Рис. 12. Иллюстрация
четвертой нормальной формы.
Для приведения
сущности к четвертой нормальной форме
следует создать новую сущность и
перенести атрибуты с многозначной
зависимостью в разные сущности (рис.
12 б). Связь между новыми сущностями
при этом устанавливать нельзя, поскольку
в результате миграции атрибутов внешних
ключей атрибуты с многозначной
зависимостью вновь окажутся в одной
сущности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
|
|
This article needs attention from an expert in Databases. See the talk page for details. WikiProject Databases may be able to help recruit an expert. (March 2018) |
Database normalization or database normalisation (see spelling differences) is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by British computer scientist Edgar F. Codd as part of his relational model.
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design).
Objectives[edit]
A basic objective of the first normal form defined by Codd in 1970 was to permit data to be queried and manipulated using a «universal data sub-language» grounded in first-order logic.[1] An example of such a language is SQL, though it is one that Codd regarded as seriously flawed.[2]
The objectives of normalisation beyond 1NF (first normal form) were stated by Codd as:
- To free the collection of relations from undesirable insertion, update and deletion dependencies.
- To reduce the need for restructuring the collection of relations, as new types of data are introduced, and thus increase the life span of application programs.
- To make the relational model more informative to users.
- To make the collection of relations neutral to the query statistics, where these statistics are liable to change as time goes by.
— E.F. Codd, «Further Normalisation of the Data Base Relational Model»[3]

An insertion anomaly. Until the new faculty member, Dr. Newsome, is assigned to teach at least one course, their details cannot be recorded.

An update anomaly. Employee 519 is shown as having different addresses on different records.
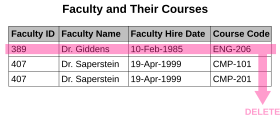
A deletion anomaly. All information about Dr. Giddens is lost if they temporarily cease to be assigned to any courses.
When an attempt is made to modify (update, insert into, or delete from) a relation, the following undesirable side-effects may arise in relations that have not been sufficiently normalized:
- Insertion anomaly. There are circumstances in which certain facts cannot be recorded at all. For example, each record in a «Faculty and Their Courses» relation might contain a Faculty ID, Faculty Name, Faculty Hire Date, and Course Code. Therefore, the details of any faculty member who teaches at least one course can be recorded, but a newly hired faculty member who has not yet been assigned to teach any courses cannot be recorded, except by setting the Course Code to null.
- Update anomaly. The same information can be expressed on multiple rows; therefore updates to the relation may result in logical inconsistencies. For example, each record in an «Employees’ Skills» relation might contain an Employee ID, Employee Address, and Skill; thus a change of address for a particular employee may need to be applied to multiple records (one for each skill). If the update is only partially successful – the employee’s address is updated on some records but not others – then the relation is left in an inconsistent state. Specifically, the relation provides conflicting answers to the question of what this particular employee’s address is.
- Deletion anomaly. Under certain circumstances, deletion of data representing certain facts necessitates deletion of data representing completely different facts. The «Faculty and Their Courses» relation described in the previous example suffers from this type of anomaly, for if a faculty member temporarily ceases to be assigned to any courses, the last of the records on which that faculty member appears must be deleted, effectively also deleting the faculty member, unless the Course Code field is set to null.
Minimize redesign when extending the database structure[edit]
A fully normalized database allows its structure to be extended to accommodate new types of data without changing existing structure too much. As a result, applications interacting with the database are minimally affected.
Normalized relations, and the relationship between one normalized relation and another, mirror real-world concepts and their interrelationships.
Normal forms[edit]
Codd introduced the concept of normalization and what is now known as the first normal form (1NF) in 1970.[4] Codd went on to define the second normal form (2NF) and third normal form (3NF) in 1971,[5] and Codd and Raymond F. Boyce defined the Boyce–Codd normal form (BCNF) in 1974.[6]
Informally, a relational database relation is often described as «normalized» if it meets third normal form.[7] Most 3NF relations are free of insertion, updation, and deletion anomalies.
The normal forms (from least normalized to most normalized) are:
- UNF: Unnormalized form
- 1NF: First normal form
- 2NF: Second normal form
- 3NF: Third normal form
- EKNF: Elementary key normal form
- BCNF: Boyce–Codd normal form
- 4NF: Fourth normal form
- ETNF: Essential tuple normal form
- 5NF: Fifth normal form
- DKNF: Domain-key normal form
- 6NF: Sixth normal form
| Constraint (informal description in parentheses) |
UNF (1970) |
1NF (1970) |
2NF (1971) |
3NF (1971) |
EKNF (1982) |
BCNF (1974) |
4NF (1977) |
ETNF (2012) |
5NF (1979) |
DKNF (1981) |
6NF (2003) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Unique rows (no duplicate records)[4] | |||||||||||
| Scalar columns (columns cannot contain relations or composite values)[5] | |||||||||||
| Every non-prime attribute has a full functional dependency on a candidate key (attributes depend on the complete primary key)[5] | |||||||||||
| Every non-trivial functional dependency either begins with a superkey or ends with a prime attribute (attributes depend only on the primary key)[5] | |||||||||||
| Every non-trivial functional dependency either begins with a superkey or ends with an elementary prime attribute (a stricter form of 3NF) | — | ||||||||||
| Every non-trivial functional dependency begins with a superkey (a stricter form of 3NF) | — | ||||||||||
| Every non-trivial multivalued dependency begins with a superkey | — | ||||||||||
| Every join dependency has a superkey component[8] | — | ||||||||||
| Every join dependency has only superkey components | — | ||||||||||
| Every constraint is a consequence of domain constraints and key constraints | |||||||||||
| Every join dependency is trivial |
Example of a step by step normalization[edit]
Normalization is a database design technique, which is used to design a relational database table up to higher normal form.[9] The process is progressive, and a higher level of database normalization cannot be achieved unless the previous levels have been satisfied.[10]
That means that, having data in unnormalized form (the least normalized) and aiming to achieve the highest level of normalization, the first step would be to ensure compliance to first normal form, the second step would be to ensure second normal form is satisfied, and so forth in order mentioned above, until the data conform to sixth normal form.
However, it is worth noting that normal forms beyond 4NF are mainly of academic interest, as the problems they exist to solve rarely appear in practice.[11]
The data in the following example were intentionally designed to contradict most of the normal forms. In real life, it is quite possible to be able to skip some of the normalization steps because the table doesn’t contain anything contradicting the given normal form. It also commonly occurs that fixing a violation of one normal form also fixes a violation of a higher normal form in the process. Also one table has been chosen for normalization at each step, meaning that at the end of this example process, there might still be some tables not satisfying the highest normal form.
Initial data[edit]
Let a database table exist with the following structure:[10]
| Title | Author | Author Nationality | Format | Price | Subject | Pages | Thickness | Publisher | Publisher Country | Publication Type | Genre ID | Genre Name | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Chad Russell | American | Hardcover | 49.99 |
|
520 | Thick | Apress | USA | E-book | 1 | Tutorial |
For this example, it is assumed that each book has only one author.
As a prerequisite to conform to the relational model, a table must have a primary key, which uniquely identifies a row. Two books could have the same title, but an ISBN uniquely identifies a book, so it can be used as the primary key:
| ISBN | Title | Author | Author Nationality | Format | Price | Subject | Pages | Thickness | Publisher | Publisher Country | Publication Type | Genre ID | Genre Name | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1590593324 | Beginning MySQL Database Design and Optimization | Chad Russell | American | Hardcover | 49.99 |
|
520 | Thick | Apress | USA | E-book | 1 | Tutorial |
Satisfying 1NF[edit]
To satisfy First normal form, each column of a table must have a single value. Columns which contain sets of values or nested records are not allowed.
In the initial table, Subject contains a set of subject values, meaning it does not comply.
To solve the problem, the subjects are extracted into a separate Subject table:[10]
Book
| ISBN | Title | Format | Author | Author Nationality | Price | Pages | Thickness | Publisher | Publisher country | Genre ID | Genre Name |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1590593324 | Beginning MySQL Database Design and Optimization | Hardcover | Chad Russell | American | 49.99 | 520 | Thick | Apress | USA | 1 | Tutorial |
Subject
| ISBN | Subject name |
|---|---|
| 1590593324 | MySQL |
| 1590593324 | Database |
| 1590593324 | Design |
A foreign key column is added to the Subject-table, which refers to the primary key of the row from which the subject was extracted. The same information is therefore represented but without the use of non-simple domains.
Instead of one table in unnormalized form, there are now two tables conforming to the 1NF.
Satisfying 2NF[edit]
If a table has a single column primary key, it automatically satisfies 2NF, but if a table has a multi-column or composite key then it may not satisfy 2NF.
The Book table below has a composite key of {Title, Format} (indicated by the underlining), so it may not satisfy 2NF. At this point in our design the key is not finalised as the primary key, so it is called a candidate key. Consider the following table:
| Title | Format | Author | Author Nationality | Price | Pages | Thickness | Genre ID | Genre Name | Publisher ID |
|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Hardcover | Chad Russell | American | 49.99 | 520 | Thick | 1 | Tutorial | 1 |
| Beginning MySQL Database Design and Optimization | E-book | Chad Russell | American | 22.34 | 520 | Thick | 1 | Tutorial | 1 |
| The Relational Model for Database Management: Version 2 | E-book | E.F.Codd | British | 13.88 | 538 | Thick | 2 | Popular science | 2 |
| The Relational Model for Database Management: Version 2 | Paperback | E.F.Codd | British | 39.99 | 538 | Thick | 2 | Popular science | 2 |
Book
All of the attributes that are not part of the candidate key depend on Title, but only Price also depends on Format. To conform to 2NF and remove duplicities, every non-candidate-key attribute must depend on the whole candidate key, not just part of it.
To normalize this table, make {Title} a (simple) candidate key (the primary key) so that every non-candidate-key attribute depends on the whole candidate key, and remove Price into a separate table so that its dependency on Format can be preserved:
|
Book
|
Format — Price
|
|||||||||||||||||||||||||||||||||||||||
|
Publisher
|
Now, the Book table conforms to 2NF.
Satisfying 3NF[edit]
The Book table still has a transitive functional dependency ({Author Nationality} is dependent on {Author}, which is dependent on {Title}). A similar violation exists for genre ({Genre Name} is dependent on {Genre ID}, which is dependent on {Title}). Hence, the Book table is not in 3NF. To make it in 3NF, let’s use the following table structure, thereby eliminating the transitive functional dependencies by placing {Author Nationality} and {Genre Name} in their own respective tables:
Book
| Title | Author | Pages | Thickness | Genre ID | Publisher ID |
|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Chad Russell | 520 | Thick | 1 | 1 |
| The Relational Model for Database Management: Version 2 | E.F.Codd | 538 | Thick | 2 | 2 |
Price
| Title | Format | Price |
|---|---|---|
| Beginning MySQL Database Design and Optimization | Hardcover | 49.99 |
| Beginning MySQL Database Design and Optimization | E-book | 22.34 |
| The Relational Model for Database Management: Version 2 | E-book | 13.88 |
| The Relational Model for Database Management: Version 2 | Paperback | 39.99 |
| Author | Author Nationality |
|---|---|
| Chad Russell | American |
| E.F.Codd | British |
Author
Genre
| Genre ID | Genre Name |
|---|---|
| 1 | Tutorial |
| 2 | Popular science |
Satisfying EKNF[edit]
The elementary key normal form (EKNF) falls strictly between 3NF and BCNF and is not much discussed in the literature. It is intended «to capture the salient qualities of both 3NF and BCNF» while avoiding the problems of both (namely, that 3NF is «too forgiving» and BCNF is «prone to computational complexity»). Since it is rarely mentioned in literature, it is not included in this example.[12]
Satisfying 4NF[edit]
Assume the database is owned by a book retailer franchise that has several franchisees that own shops in different locations. And therefore the retailer decided to add a table that contains data about availability of the books at different locations:
Franchisee — Book — Location
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Beginning MySQL Database Design and Optimization | Florida |
| 1 | Beginning MySQL Database Design and Optimization | Texas |
| 1 | The Relational Model for Database Management: Version 2 | California |
| 1 | The Relational Model for Database Management: Version 2 | Florida |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 2 | Beginning MySQL Database Design and Optimization | California |
| 2 | Beginning MySQL Database Design and Optimization | Florida |
| 2 | Beginning MySQL Database Design and Optimization | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
| 2 | The Relational Model for Database Management: Version 2 | Florida |
| 2 | The Relational Model for Database Management: Version 2 | Texas |
| 3 | Beginning MySQL Database Design and Optimization | Texas |
As this table structure consists of a compound primary key, it doesn’t contain any non-key attributes and it’s already in BCNF (and therefore also satisfies all the previous normal forms). However, assuming that all available books are offered in each area, the Title is not unambiguously bound to a certain Location and therefore the table doesn’t satisfy 4NF.
That means that, to satisfy the fourth normal form, this table needs to be decomposed as well:
Franchisee — Book
|
Franchisee — Location
|
Now, every record is unambiguously identified by a superkey, therefore 4NF is satisfied.
Satisfying ETNF[edit]
Suppose the franchisees can also order books from different suppliers. Let the relation also be subject to the following constraint:
- If a certain supplier supplies a certain title
- and the title is supplied to the franchisee
- and the franchisee is being supplied by the supplier,
- then the supplier supplies the title to the franchisee.[13]
Supplier — Book — Franchisee
| Supplier ID | Title | Franchisee ID |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | 1 |
| 2 | The Relational Model for Database Management: Version 2 | 2 |
| 3 | Learning SQL | 3 |
This table is in 4NF, but the Supplier ID is equal to the join of its projections: {{Supplier ID, Title}, {Title, Franchisee ID}, {Franchisee ID, Supplier ID}}. No component of that join dependency is a superkey (the sole superkey being the entire heading), so the table does not satisfy the ETNF and can be further decomposed:[13]
|
Supplier — Book
|
Book — Franchisee
|
Franchisee — Supplier
|
The decomposition produces ETNF compliance.
Satisfying 5NF[edit]
To spot a table not satisfying the 5NF, it is usually necessary to examine the data thoroughly. Suppose the table from 4NF example with a little modification in data and let’s examine if it satisfies 5NF:
Franchisee — Book — Location
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Learning SQL | California |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
Decomposing this table lowers redundancies, resulting in the following two tables:
Franchisee — Book
|
Franchisee — Location
|
The query joining these tables would return the following data:
Franchisee — Book — Location JOINed
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Learning SQL | California |
| 1 | The Relational Model for Database Management: Version 2 | California |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 1 | Learning SQL | Texas |
| 1 | Beginning MySQL Database Design and Optimization | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
The JOIN returns three more rows than it should; adding another table to clarify the relation results in three separate tables:
Franchisee — Book
|
Franchisee — Location
|
Location — Book
|
What will the JOIN return now? It actually is not possible to join these three tables. That means it wasn’t possible to decompose the Franchisee — Book — Location without data loss, therefore the table already satisfies 5NF.
C.J. Date has argued that only a database in 5NF is truly «normalized».[14]
Satisfying DKNF[edit]
Let’s have a look at the Book table from previous examples and see if it satisfies the Domain-key normal form:
Book
| Title | Pages | Thickness | Genre ID | Publisher ID |
|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | 520 | Thick | 1 | 1 |
| The Relational Model for Database Management: Version 2 | 538 | Thick | 2 | 2 |
| Learning SQL | 338 | Slim | 1 | 3 |
| SQL Cookbook | 636 | Thick | 1 | 3 |
Logically, Thickness is determined by number of pages. That means it depends on Pages which is not a key. Let’s set an example convention saying a book up to 350 pages is considered «slim» and a book over 350 pages is considered «thick».
This convention is technically a constraint but it is neither a domain constraint nor a key constraint; therefore we cannot rely on domain constraints and key constraints to keep the data integrity.
In other words – nothing prevents us from putting, for example, «Thick» for a book with only 50 pages – and this makes the table violate DKNF.
To solve this, a table holding enumeration that defines the Thickness is created, and that column is removed from the original table:
|
Thickness Enum
|
Book — Pages — Genre — Publisher
|
That way, the domain integrity violation has been eliminated, and the table is in DKNF.
Satisfying 6NF[edit]
A simple and intuitive definition of the sixth normal form is that «a table is in 6NF when the row contains the Primary Key, and at most one other attribute».[15]
That means, for example, the Publisher table designed while creating the 1NF
Publisher
| Publisher ID | Name | Country |
|---|---|---|
| 1 | Apress | USA |
needs to be further decomposed into two tables:
|
Publisher
|
Publisher country
|
The obvious drawback of 6NF is the proliferation of tables required to represent the information on a single entity. If a table in 5NF has one primary key column and N attributes, representing the same information in 6NF will require N tables; multi-field updates to a single conceptual record will require updates to multiple tables; and inserts and deletes will similarly require operations across multiple tables. For this reason, in databases intended to serve Online Transaction Processing needs, 6NF should not be used.
However, in data warehouses, which do not permit interactive updates and which are specialized for fast query on large data volumes, certain DBMSs use an internal 6NF representation – known as a columnar data store. In situations where the number of unique values of a column is far less than the number of rows in the table, column-oriented storage allow significant savings in space through data compression. Columnar storage also allows fast execution of range queries (e.g., show all records where a particular column is between X and Y, or less than X.)
In all these cases, however, the database designer does not have to perform 6NF normalization manually by creating separate tables. Some DBMSs that are specialized for warehousing, such as Sybase IQ, use columnar storage by default, but the designer still sees only a single multi-column table. Other DBMSs, such as Microsoft SQL Server 2012 and later, let you specify a «columnstore index» for a particular table.[16]
See also[edit]
- Denormalization
- Database refactoring
- Lossless join decomposition
Notes and references[edit]
- ^ «The adoption of a relational model of data … permits the development of a universal data sub-language based on an applied predicate calculus. A first-order predicate calculus suffices if the collection of relations is in first normal form. Such a language would provide a yardstick of linguistic power for all other proposed data languages, and would itself be a strong candidate for embedding (with appropriate syntactic modification) in a variety of host languages (programming, command- or problem-oriented).» Codd, «A Relational Model of Data for Large Shared Data Banks» Archived June 12, 2007, at the Wayback Machine, p. 381
- ^ Codd, E.F. Chapter 23, «Serious Flaws in SQL», in The Relational Model for Database Management: Version 2. Addison-Wesley (1990), pp. 371–389
- ^ Codd, E.F. «Further Normalisation of the Data Base Relational Model», p. 34
- ^ a b Codd, E. F. (June 1970). «A Relational Model of Data for Large Shared Data Banks». Communications of the ACM. 13 (6): 377–387. doi:10.1145/362384.362685. S2CID 207549016. Archived from the original on June 12, 2007. Retrieved August 25, 2005.
- ^ a b c d Codd, E. F. «Further Normalization of the Data Base Relational Model». (Presented at Courant Computer Science Symposia Series 6, «Data Base Systems», New York City, May 24–25, 1971.) IBM Research Report RJ909 (August 31, 1971). Republished in Randall J. Rustin (ed.), Data Base Systems: Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- ^ Codd, E. F. «Recent Investigations into Relational Data Base Systems». IBM Research Report RJ1385 (April 23, 1974). Republished in Proc. 1974 Congress (Stockholm, Sweden, 1974), N.Y.: North-Holland (1974).
- ^ Date, C. J. (1999). An Introduction to Database Systems. Addison-Wesley. p. 290.
- ^ Darwen, Hugh; Date, C. J.; Fagin, Ronald (2012). «A Normal Form for Preventing Redundant Tuples in Relational Databases» (PDF). Proceedings of the 15th International Conference on Database Theory. EDBT/ICDT 2012 Joint Conference. ACM International Conference Proceeding Series. Association for Computing Machinery. p. 114. doi:10.1145/2274576.2274589. ISBN 978-1-4503-0791-8. OCLC 802369023. Archived (PDF) from the original on March 6, 2016. Retrieved May 22, 2018.
- ^ Kumar, Kunal; Azad, S. K. (October 2017). Database normalization design pattern. 2017 4th IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics (UPCON). IEEE. doi:10.1109/upcon.2017.8251067. ISBN 9781538630044. S2CID 24491594.
- ^ a b c «Database normalization in MySQL: Four quick and easy steps». ComputerWeekly.com. Archived from the original on August 30, 2017. Retrieved March 23, 2021.
- ^ «Database Normalization: 5th Normal Form and Beyond». MariaDB KnowledgeBase. Retrieved January 23, 2019.
- ^ «Additional Normal Forms — Database Design and Relational Theory — page 151». what-when-how.com. Retrieved January 22, 2019.
- ^ a b Date, C. J. (December 21, 2015). The New Relational Database Dictionary: Terms, Concepts, and Examples. «O’Reilly Media, Inc.». p. 138. ISBN 9781491951699.
- ^ Date, C. J. (December 21, 2015). The New Relational Database Dictionary: Terms, Concepts, and Examples. «O’Reilly Media, Inc.». p. 163. ISBN 9781491951699.
- ^ «normalization — Would like to Understand 6NF with an Example». Stack Overflow. Retrieved January 23, 2019.
- ^ Microsoft Corporation. Columnstore Indexes: Overview. https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview . Accessed March 23, 2020.
Further reading[edit]
- Date, C. J. (1999), An Introduction to Database Systems (8th ed.). Addison-Wesley Longman. ISBN 0-321-19784-4.
- Kent, W. (1983) A Simple Guide to Five Normal Forms in Relational Database Theory, Communications of the ACM, vol. 26, pp. 120–125
- H.-J. Schek, P. Pistor Data Structures for an Integrated Data Base Management and Information Retrieval System
External links[edit]
- Kent, William (February 1983). «A Simple Guide to Five Normal Forms in Relational Database Theory». Communications of the ACM. 26 (2): 120–125. doi:10.1145/358024.358054. S2CID 9195704.
- Database Normalization Basics by Mike Chapple (About.com)
- Database Normalization Intro Archived September 28, 2011, at the Wayback Machine, Part 2 Archived July 8, 2011, at the Wayback Machine
- An Introduction to Database Normalization by Mike Hillyer.
- A tutorial on the first 3 normal forms by Fred Coulson
- Description of the database normalization basics by Microsoft
- Normalization in DBMS by Chaitanya (beginnersbook.com)
- A Step-by-Step Guide to Database Normalization
- ETNF – Essential tuple normal form Archived March 6, 2016, at the Wayback Machine
|
|
This article needs attention from an expert in Databases. See the talk page for details. WikiProject Databases may be able to help recruit an expert. (March 2018) |
Database normalization or database normalisation (see spelling differences) is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by British computer scientist Edgar F. Codd as part of his relational model.
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design).
Objectives[edit]
A basic objective of the first normal form defined by Codd in 1970 was to permit data to be queried and manipulated using a «universal data sub-language» grounded in first-order logic.[1] An example of such a language is SQL, though it is one that Codd regarded as seriously flawed.[2]
The objectives of normalisation beyond 1NF (first normal form) were stated by Codd as:
- To free the collection of relations from undesirable insertion, update and deletion dependencies.
- To reduce the need for restructuring the collection of relations, as new types of data are introduced, and thus increase the life span of application programs.
- To make the relational model more informative to users.
- To make the collection of relations neutral to the query statistics, where these statistics are liable to change as time goes by.
— E.F. Codd, «Further Normalisation of the Data Base Relational Model»[3]
An insertion anomaly. Until the new faculty member, Dr. Newsome, is assigned to teach at least one course, their details cannot be recorded.
An update anomaly. Employee 519 is shown as having different addresses on different records.
A deletion anomaly. All information about Dr. Giddens is lost if they temporarily cease to be assigned to any courses.
When an attempt is made to modify (update, insert into, or delete from) a relation, the following undesirable side-effects may arise in relations that have not been sufficiently normalized:
- Insertion anomaly. There are circumstances in which certain facts cannot be recorded at all. For example, each record in a «Faculty and Their Courses» relation might contain a Faculty ID, Faculty Name, Faculty Hire Date, and Course Code. Therefore, the details of any faculty member who teaches at least one course can be recorded, but a newly hired faculty member who has not yet been assigned to teach any courses cannot be recorded, except by setting the Course Code to null.
- Update anomaly. The same information can be expressed on multiple rows; therefore updates to the relation may result in logical inconsistencies. For example, each record in an «Employees’ Skills» relation might contain an Employee ID, Employee Address, and Skill; thus a change of address for a particular employee may need to be applied to multiple records (one for each skill). If the update is only partially successful – the employee’s address is updated on some records but not others – then the relation is left in an inconsistent state. Specifically, the relation provides conflicting answers to the question of what this particular employee’s address is.
- Deletion anomaly. Under certain circumstances, deletion of data representing certain facts necessitates deletion of data representing completely different facts. The «Faculty and Their Courses» relation described in the previous example suffers from this type of anomaly, for if a faculty member temporarily ceases to be assigned to any courses, the last of the records on which that faculty member appears must be deleted, effectively also deleting the faculty member, unless the Course Code field is set to null.
Minimize redesign when extending the database structure[edit]
A fully normalized database allows its structure to be extended to accommodate new types of data without changing existing structure too much. As a result, applications interacting with the database are minimally affected.
Normalized relations, and the relationship between one normalized relation and another, mirror real-world concepts and their interrelationships.
Normal forms[edit]
Codd introduced the concept of normalization and what is now known as the first normal form (1NF) in 1970.[4] Codd went on to define the second normal form (2NF) and third normal form (3NF) in 1971,[5] and Codd and Raymond F. Boyce defined the Boyce–Codd normal form (BCNF) in 1974.[6]
Informally, a relational database relation is often described as «normalized» if it meets third normal form.[7] Most 3NF relations are free of insertion, updation, and deletion anomalies.
The normal forms (from least normalized to most normalized) are:
- UNF: Unnormalized form
- 1NF: First normal form
- 2NF: Second normal form
- 3NF: Third normal form
- EKNF: Elementary key normal form
- BCNF: Boyce–Codd normal form
- 4NF: Fourth normal form
- ETNF: Essential tuple normal form
- 5NF: Fifth normal form
- DKNF: Domain-key normal form
- 6NF: Sixth normal form
| Constraint (informal description in parentheses) |
UNF (1970) |
1NF (1970) |
2NF (1971) |
3NF (1971) |
EKNF (1982) |
BCNF (1974) |
4NF (1977) |
ETNF (2012) |
5NF (1979) |
DKNF (1981) |
6NF (2003) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Unique rows (no duplicate records)[4] | |||||||||||
| Scalar columns (columns cannot contain relations or composite values)[5] | |||||||||||
| Every non-prime attribute has a full functional dependency on a candidate key (attributes depend on the complete primary key)[5] | |||||||||||
| Every non-trivial functional dependency either begins with a superkey or ends with a prime attribute (attributes depend only on the primary key)[5] | |||||||||||
| Every non-trivial functional dependency either begins with a superkey or ends with an elementary prime attribute (a stricter form of 3NF) | — | ||||||||||
| Every non-trivial functional dependency begins with a superkey (a stricter form of 3NF) | — | ||||||||||
| Every non-trivial multivalued dependency begins with a superkey | — | ||||||||||
| Every join dependency has a superkey component[8] | — | ||||||||||
| Every join dependency has only superkey components | — | ||||||||||
| Every constraint is a consequence of domain constraints and key constraints | |||||||||||
| Every join dependency is trivial |
Example of a step by step normalization[edit]
Normalization is a database design technique, which is used to design a relational database table up to higher normal form.[9] The process is progressive, and a higher level of database normalization cannot be achieved unless the previous levels have been satisfied.[10]
That means that, having data in unnormalized form (the least normalized) and aiming to achieve the highest level of normalization, the first step would be to ensure compliance to first normal form, the second step would be to ensure second normal form is satisfied, and so forth in order mentioned above, until the data conform to sixth normal form.
However, it is worth noting that normal forms beyond 4NF are mainly of academic interest, as the problems they exist to solve rarely appear in practice.[11]
The data in the following example were intentionally designed to contradict most of the normal forms. In real life, it is quite possible to be able to skip some of the normalization steps because the table doesn’t contain anything contradicting the given normal form. It also commonly occurs that fixing a violation of one normal form also fixes a violation of a higher normal form in the process. Also one table has been chosen for normalization at each step, meaning that at the end of this example process, there might still be some tables not satisfying the highest normal form.
Initial data[edit]
Let a database table exist with the following structure:[10]
| Title | Author | Author Nationality | Format | Price | Subject | Pages | Thickness | Publisher | Publisher Country | Publication Type | Genre ID | Genre Name | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Chad Russell | American | Hardcover | 49.99 |
|
520 | Thick | Apress | USA | E-book | 1 | Tutorial |
For this example, it is assumed that each book has only one author.
As a prerequisite to conform to the relational model, a table must have a primary key, which uniquely identifies a row. Two books could have the same title, but an ISBN uniquely identifies a book, so it can be used as the primary key:
| ISBN | Title | Author | Author Nationality | Format | Price | Subject | Pages | Thickness | Publisher | Publisher Country | Publication Type | Genre ID | Genre Name | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1590593324 | Beginning MySQL Database Design and Optimization | Chad Russell | American | Hardcover | 49.99 |
|
520 | Thick | Apress | USA | E-book | 1 | Tutorial |
Satisfying 1NF[edit]
To satisfy First normal form, each column of a table must have a single value. Columns which contain sets of values or nested records are not allowed.
In the initial table, Subject contains a set of subject values, meaning it does not comply.
To solve the problem, the subjects are extracted into a separate Subject table:[10]
Book
| ISBN | Title | Format | Author | Author Nationality | Price | Pages | Thickness | Publisher | Publisher country | Genre ID | Genre Name |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1590593324 | Beginning MySQL Database Design and Optimization | Hardcover | Chad Russell | American | 49.99 | 520 | Thick | Apress | USA | 1 | Tutorial |
Subject
| ISBN | Subject name |
|---|---|
| 1590593324 | MySQL |
| 1590593324 | Database |
| 1590593324 | Design |
A foreign key column is added to the Subject-table, which refers to the primary key of the row from which the subject was extracted. The same information is therefore represented but without the use of non-simple domains.
Instead of one table in unnormalized form, there are now two tables conforming to the 1NF.
Satisfying 2NF[edit]
If a table has a single column primary key, it automatically satisfies 2NF, but if a table has a multi-column or composite key then it may not satisfy 2NF.
The Book table below has a composite key of {Title, Format} (indicated by the underlining), so it may not satisfy 2NF. At this point in our design the key is not finalised as the primary key, so it is called a candidate key. Consider the following table:
Book
| Title | Format | Author | Author Nationality | Price | Pages | Thickness | Genre ID | Genre Name | Publisher ID |
|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Hardcover | Chad Russell | American | 49.99 | 520 | Thick | 1 | Tutorial | 1 |
| Beginning MySQL Database Design and Optimization | E-book | Chad Russell | American | 22.34 | 520 | Thick | 1 | Tutorial | 1 |
| The Relational Model for Database Management: Version 2 | E-book | E.F.Codd | British | 13.88 | 538 | Thick | 2 | Popular science | 2 |
| The Relational Model for Database Management: Version 2 | Paperback | E.F.Codd | British | 39.99 | 538 | Thick | 2 | Popular science | 2 |
All of the attributes that are not part of the candidate key depend on Title, but only Price also depends on Format. To conform to 2NF and remove duplicities, every non-candidate-key attribute must depend on the whole candidate key, not just part of it.
To normalize this table, make {Title} a (simple) candidate key (the primary key) so that every non-candidate-key attribute depends on the whole candidate key, and remove Price into a separate table so that its dependency on Format can be preserved:
|
Book
|
Format — Price
|
|||||||||||||||||||||||||||||||||||||||
|
Publisher
|
Now, the Book table conforms to 2NF.
Satisfying 3NF[edit]
The Book table still has a transitive functional dependency ({Author Nationality} is dependent on {Author}, which is dependent on {Title}). A similar violation exists for genre ({Genre Name} is dependent on {Genre ID}, which is dependent on {Title}). Hence, the Book table is not in 3NF. To make it in 3NF, let’s use the following table structure, thereby eliminating the transitive functional dependencies by placing {Author Nationality} and {Genre Name} in their own respective tables:
Book
| Title | Author | Pages | Thickness | Genre ID | Publisher ID |
|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Chad Russell | 520 | Thick | 1 | 1 |
| The Relational Model for Database Management: Version 2 | E.F.Codd | 538 | Thick | 2 | 2 |
Price
| Title | Format | Price |
|---|---|---|
| Beginning MySQL Database Design and Optimization | Hardcover | 49.99 |
| Beginning MySQL Database Design and Optimization | E-book | 22.34 |
| The Relational Model for Database Management: Version 2 | E-book | 13.88 |
| The Relational Model for Database Management: Version 2 | Paperback | 39.99 |
| Author | Author Nationality |
|---|---|
| Chad Russell | American |
| E.F.Codd | British |
Author
Genre
| Genre ID | Genre Name |
|---|---|
| 1 | Tutorial |
| 2 | Popular science |
Satisfying EKNF[edit]
The elementary key normal form (EKNF) falls strictly between 3NF and BCNF and is not much discussed in the literature. It is intended «to capture the salient qualities of both 3NF and BCNF» while avoiding the problems of both (namely, that 3NF is «too forgiving» and BCNF is «prone to computational complexity»). Since it is rarely mentioned in literature, it is not included in this example.[12]
Satisfying 4NF[edit]
Assume the database is owned by a book retailer franchise that has several franchisees that own shops in different locations. And therefore the retailer decided to add a table that contains data about availability of the books at different locations:
Franchisee — Book — Location
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Beginning MySQL Database Design and Optimization | Florida |
| 1 | Beginning MySQL Database Design and Optimization | Texas |
| 1 | The Relational Model for Database Management: Version 2 | California |
| 1 | The Relational Model for Database Management: Version 2 | Florida |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 2 | Beginning MySQL Database Design and Optimization | California |
| 2 | Beginning MySQL Database Design and Optimization | Florida |
| 2 | Beginning MySQL Database Design and Optimization | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
| 2 | The Relational Model for Database Management: Version 2 | Florida |
| 2 | The Relational Model for Database Management: Version 2 | Texas |
| 3 | Beginning MySQL Database Design and Optimization | Texas |
As this table structure consists of a compound primary key, it doesn’t contain any non-key attributes and it’s already in BCNF (and therefore also satisfies all the previous normal forms). However, assuming that all available books are offered in each area, the Title is not unambiguously bound to a certain Location and therefore the table doesn’t satisfy 4NF.
That means that, to satisfy the fourth normal form, this table needs to be decomposed as well:
Franchisee — Book
|
Franchisee — Location
|
Now, every record is unambiguously identified by a superkey, therefore 4NF is satisfied.
Satisfying ETNF[edit]
Suppose the franchisees can also order books from different suppliers. Let the relation also be subject to the following constraint:
- If a certain supplier supplies a certain title
- and the title is supplied to the franchisee
- and the franchisee is being supplied by the supplier,
- then the supplier supplies the title to the franchisee.[13]
Supplier — Book — Franchisee
| Supplier ID | Title | Franchisee ID |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | 1 |
| 2 | The Relational Model for Database Management: Version 2 | 2 |
| 3 | Learning SQL | 3 |
This table is in 4NF, but the Supplier ID is equal to the join of its projections: {{Supplier ID, Title}, {Title, Franchisee ID}, {Franchisee ID, Supplier ID}}. No component of that join dependency is a superkey (the sole superkey being the entire heading), so the table does not satisfy the ETNF and can be further decomposed:[13]
|
Supplier — Book
|
Book — Franchisee
|
Franchisee — Supplier
|
The decomposition produces ETNF compliance.
Satisfying 5NF[edit]
To spot a table not satisfying the 5NF, it is usually necessary to examine the data thoroughly. Suppose the table from 4NF example with a little modification in data and let’s examine if it satisfies 5NF:
Franchisee — Book — Location
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Learning SQL | California |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
Decomposing this table lowers redundancies, resulting in the following two tables:
Franchisee — Book
|
Franchisee — Location
|
The query joining these tables would return the following data:
Franchisee — Book — Location JOINed
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Learning SQL | California |
| 1 | The Relational Model for Database Management: Version 2 | California |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 1 | Learning SQL | Texas |
| 1 | Beginning MySQL Database Design and Optimization | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
The JOIN returns three more rows than it should; adding another table to clarify the relation results in three separate tables:
Franchisee — Book
|
Franchisee — Location
|
Location — Book
|
What will the JOIN return now? It actually is not possible to join these three tables. That means it wasn’t possible to decompose the Franchisee — Book — Location without data loss, therefore the table already satisfies 5NF.
C.J. Date has argued that only a database in 5NF is truly «normalized».[14]
Satisfying DKNF[edit]
Let’s have a look at the Book table from previous examples and see if it satisfies the Domain-key normal form:
Book
| Title | Pages | Thickness | Genre ID | Publisher ID |
|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | 520 | Thick | 1 | 1 |
| The Relational Model for Database Management: Version 2 | 538 | Thick | 2 | 2 |
| Learning SQL | 338 | Slim | 1 | 3 |
| SQL Cookbook | 636 | Thick | 1 | 3 |
Logically, Thickness is determined by number of pages. That means it depends on Pages which is not a key. Let’s set an example convention saying a book up to 350 pages is considered «slim» and a book over 350 pages is considered «thick».
This convention is technically a constraint but it is neither a domain constraint nor a key constraint; therefore we cannot rely on domain constraints and key constraints to keep the data integrity.
In other words – nothing prevents us from putting, for example, «Thick» for a book with only 50 pages – and this makes the table violate DKNF.
To solve this, a table holding enumeration that defines the Thickness is created, and that column is removed from the original table:
|
Thickness Enum
|
Book — Pages — Genre — Publisher
|
That way, the domain integrity violation has been eliminated, and the table is in DKNF.
Satisfying 6NF[edit]
A simple and intuitive definition of the sixth normal form is that «a table is in 6NF when the row contains the Primary Key, and at most one other attribute».[15]
That means, for example, the Publisher table designed while creating the 1NF
Publisher
| Publisher ID | Name | Country |
|---|---|---|
| 1 | Apress | USA |
needs to be further decomposed into two tables:
|
Publisher
|
Publisher country
|
The obvious drawback of 6NF is the proliferation of tables required to represent the information on a single entity. If a table in 5NF has one primary key column and N attributes, representing the same information in 6NF will require N tables; multi-field updates to a single conceptual record will require updates to multiple tables; and inserts and deletes will similarly require operations across multiple tables. For this reason, in databases intended to serve Online Transaction Processing needs, 6NF should not be used.
However, in data warehouses, which do not permit interactive updates and which are specialized for fast query on large data volumes, certain DBMSs use an internal 6NF representation – known as a columnar data store. In situations where the number of unique values of a column is far less than the number of rows in the table, column-oriented storage allow significant savings in space through data compression. Columnar storage also allows fast execution of range queries (e.g., show all records where a particular column is between X and Y, or less than X.)
In all these cases, however, the database designer does not have to perform 6NF normalization manually by creating separate tables. Some DBMSs that are specialized for warehousing, such as Sybase IQ, use columnar storage by default, but the designer still sees only a single multi-column table. Other DBMSs, such as Microsoft SQL Server 2012 and later, let you specify a «columnstore index» for a particular table.[16]
See also[edit]
- Denormalization
- Database refactoring
- Lossless join decomposition
Notes and references[edit]
- ^ «The adoption of a relational model of data … permits the development of a universal data sub-language based on an applied predicate calculus. A first-order predicate calculus suffices if the collection of relations is in first normal form. Such a language would provide a yardstick of linguistic power for all other proposed data languages, and would itself be a strong candidate for embedding (with appropriate syntactic modification) in a variety of host languages (programming, command- or problem-oriented).» Codd, «A Relational Model of Data for Large Shared Data Banks» Archived June 12, 2007, at the Wayback Machine, p. 381
- ^ Codd, E.F. Chapter 23, «Serious Flaws in SQL», in The Relational Model for Database Management: Version 2. Addison-Wesley (1990), pp. 371–389
- ^ Codd, E.F. «Further Normalisation of the Data Base Relational Model», p. 34
- ^ a b Codd, E. F. (June 1970). «A Relational Model of Data for Large Shared Data Banks». Communications of the ACM. 13 (6): 377–387. doi:10.1145/362384.362685. S2CID 207549016. Archived from the original on June 12, 2007. Retrieved August 25, 2005.
- ^ a b c d Codd, E. F. «Further Normalization of the Data Base Relational Model». (Presented at Courant Computer Science Symposia Series 6, «Data Base Systems», New York City, May 24–25, 1971.) IBM Research Report RJ909 (August 31, 1971). Republished in Randall J. Rustin (ed.), Data Base Systems: Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- ^ Codd, E. F. «Recent Investigations into Relational Data Base Systems». IBM Research Report RJ1385 (April 23, 1974). Republished in Proc. 1974 Congress (Stockholm, Sweden, 1974), N.Y.: North-Holland (1974).
- ^ Date, C. J. (1999). An Introduction to Database Systems. Addison-Wesley. p. 290.
- ^ Darwen, Hugh; Date, C. J.; Fagin, Ronald (2012). «A Normal Form for Preventing Redundant Tuples in Relational Databases» (PDF). Proceedings of the 15th International Conference on Database Theory. EDBT/ICDT 2012 Joint Conference. ACM International Conference Proceeding Series. Association for Computing Machinery. p. 114. doi:10.1145/2274576.2274589. ISBN 978-1-4503-0791-8. OCLC 802369023. Archived (PDF) from the original on March 6, 2016. Retrieved May 22, 2018.
- ^ Kumar, Kunal; Azad, S. K. (October 2017). Database normalization design pattern. 2017 4th IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics (UPCON). IEEE. doi:10.1109/upcon.2017.8251067. ISBN 9781538630044. S2CID 24491594.
- ^ a b c «Database normalization in MySQL: Four quick and easy steps». ComputerWeekly.com. Archived from the original on August 30, 2017. Retrieved March 23, 2021.
- ^ «Database Normalization: 5th Normal Form and Beyond». MariaDB KnowledgeBase. Retrieved January 23, 2019.
- ^ «Additional Normal Forms — Database Design and Relational Theory — page 151». what-when-how.com. Retrieved January 22, 2019.
- ^ a b Date, C. J. (December 21, 2015). The New Relational Database Dictionary: Terms, Concepts, and Examples. «O’Reilly Media, Inc.». p. 138. ISBN 9781491951699.
- ^ Date, C. J. (December 21, 2015). The New Relational Database Dictionary: Terms, Concepts, and Examples. «O’Reilly Media, Inc.». p. 163. ISBN 9781491951699.
- ^ «normalization — Would like to Understand 6NF with an Example». Stack Overflow. Retrieved January 23, 2019.
- ^ Microsoft Corporation. Columnstore Indexes: Overview. https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview . Accessed March 23, 2020.
Further reading[edit]
- Date, C. J. (1999), An Introduction to Database Systems (8th ed.). Addison-Wesley Longman. ISBN 0-321-19784-4.
- Kent, W. (1983) A Simple Guide to Five Normal Forms in Relational Database Theory, Communications of the ACM, vol. 26, pp. 120–125
- H.-J. Schek, P. Pistor Data Structures for an Integrated Data Base Management and Information Retrieval System
External links[edit]
- Kent, William (February 1983). «A Simple Guide to Five Normal Forms in Relational Database Theory». Communications of the ACM. 26 (2): 120–125. doi:10.1145/358024.358054. S2CID 9195704.
- Database Normalization Basics by Mike Chapple (About.com)
- Database Normalization Intro Archived September 28, 2011, at the Wayback Machine, Part 2 Archived July 8, 2011, at the Wayback Machine
- An Introduction to Database Normalization by Mike Hillyer.
- A tutorial on the first 3 normal forms by Fred Coulson
- Description of the database normalization basics by Microsoft
- Normalization in DBMS by Chaitanya (beginnersbook.com)
- A Step-by-Step Guide to Database Normalization
- ETNF – Essential tuple normal form Archived March 6, 2016, at the Wayback Machine
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о нормализации базы данных, узнаем, что это такое, какие нормальные формы базы данных существуют и зачем вообще проводить нормализацию базы данных.

Постоянные посетители данного сайта знают, что я здесь публикую достаточно много различных материалов, связанных с языком SQL и системами управления базами данных, однако статей, связанных с теорией баз данных, на текущий момент, к сожалению, нет, поэтому я решил это исправить, и начать цикл статей, посвященных теории баз данных.
Начну я с нормализации баз данных. В этом материале мы поговорим в целом о процессе нормализации, узнаем, зачем проводить нормализацию базы данных, что такое нормальная форма базы данных, а также какие нормальные формы существуют. В следующих материалах я подробно и с примерами расскажу про каждую нормальную форму.
Содержание
- Реляционная база данных
- Нормализация баз данных
- Зачем нормализовать базу данных?
- Нормальные формы базы данных
- Описание нормальных форм базы данных
Реляционная база данных
В целом под базой данных можно понимать любой набор информации, которую можно найти в этой базе данных и воспользоваться ей, однако если говорить в контексте SQL, то речь будет идти, конечно, о реляционных базах данных, а что же это такое?
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями.
Логически такая база данных представлена в виде таблиц, в которых и лежит вся эта информация.
Примечание! Если Вас интересует язык SQL, рекомендую пройти мой онлайн-курс по основам SQL, который ориентирован на изучение SQL как стандарта, таким образом, Вы сможете работать в любой системе управления базами данных. Курс включает много практики: онлайн-тестирование, задания и многое другое.
Нормализация баз данных
В реляционных базах данных есть такое понятия, как «Нормализация».
Нормализация – это процесс удаления избыточных данных.
Также нормализацию можно рассматривать и с позиции проектирования базы данных, в таком случае мы можем сформулировать определение нормализации следующим образом.
Нормализация – это метод проектирования базы данных, который позволяет привести базу данных к минимальной избыточности.
Избыточность устраняется, как правило, за счёт декомпозиции отношений (таблиц), т.е. разбиения одной таблицы на несколько.
Зачем нормализовать базу данных?
У Вас может возникнуть вопрос – а зачем вообще нормализовать базу данных и бороться с этой избыточностью?
Дело в том, что избыточность данных создает предпосылки для появления различных аномалий, снижает производительность, и делает управление данными не гибким и не очень удобным. Отсюда можно сделать вывод, что нормализация нужна для:
- Устранения аномалий
- Повышения производительности
- Повышения удобства управления данными
Теперь давайте поговорим о самой избыточности данных, что же это такое.
Избыточность данных – это когда одни и те же данные хранятся в базе в нескольких местах, именно это и приводит к аномалиям.
Так как в этом случае необходимо добавлять, изменять или удалять одни и те же данные в нескольких местах. Например, если не выполнить операцию в каком-нибудь одном месте, то возникает ситуация, когда одни данные не соответствуют вроде как точно таким же данным в другом месте.
Давайте рассмотрим пример. Допустим, у нас есть следующая таблица, она хранит информацию о предметах мебели, в частности наименование предмета и материал, из которого изготовлен этот предмет.
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Массив дерева |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
А теперь допустим, что у нас возникла необходимость подкорректировать название материала, вместо «Массив дерева» нужно написать «Натуральное дерево», и чтобы это сделать нам необходимо внести изменения сразу в несколько строк, так как предметов, изготовленных из массива дерева, несколько, а именно 2: стол и шкаф.
А теперь представьте, что по каким-то причинам мы внесли изменения только в одну строку, в итоге в нашей таблице будет и «Массив дерева», и «Натуральное дерево».
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Натуральное дерево |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
Какое из этих названий будет правильным? А если представить, что мы можем внести еще какое-то новое значение при добавлении новых записей, например, просто «Дерево».
В этом случае в нашей таблице в скором времени будет и «Массив дерева», и «Натуральное дерево», и просто «Дерево», и вообще, что угодно, ведь это просто текст.
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Натуральное дерево |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
| 6 | Тумба | Дерево |
Однако по своей сути это один и тот же материал, мы просто решили или подкорректировать его название, или ошиблись при добавлении новой записи. Это и есть аномалия, когда одни данные в одном месте не соответствуют вроде как точно таким же данным в другом месте. Это всего лишь один вид аномалии, однако в процессе добавления, изменения и удаления данных может возникать много других противоречивых ситуаций, т.е. аномалий.
При этом, обязательно стоит отметить, что в нашей таблице всего 5 записей, а теперь представьте, что их миллион!
Заметка! Как создать таблицу в PostgreSQL с помощью pgAdmin 4.
Именно поэтому мы должны устранять избыточность данных в базе, т.е. проводить так называемую нормализацию базы данных.
В данном конкретном случае мы должны название материала, из которого изготовлены предметы мебели, вынести в отдельную таблицу, а в таблице с предметами сделать всего лишь ссылку на нужный материал, тем самым, соотнеся эту ссылку с исходной записью, мы будем понимать, из какого материала сделан тот или иной предмет.

Предметы мебели.
| Идентификатор предмета | Наименование предмета | Идентификатор материала |
| 1 | Стул | 2 |
| 2 | Стол | 1 |
| 3 | Кровать | 3 |
| 4 | Шкаф | 1 |
| 5 | Комод | 3 |
Материалы, из которых изготовлены предметы мебели.
| Идентификатор материала | Материал |
| 1 | Массив дерева |
| 2 | Металл |
| 3 | ЛДСП |
В этом случае когда нам потребуется изменить название материала, мы будем вносить изменение только в одном месте, т.е. править только одну строку.
Таким образом, представляя материалы в виде отдельной сущности и создавая для нее отдельную таблицу, мы устраняем описанную выше аномалию.
Другими словами, каждая сущность должна храниться отдельно, а в случае необходимости использования этой сущности в другой таблице на нее делается всего лишь ссылка, т.е. выстраивается связь.
Нормальные формы базы данных
В целом процесс нормализации базы данных выглядит следующим образом: мы, следуя определённым правилам и соблюдая определенные требования, проектируем таблицы в базе данных.
При этом все эти правила и требования можно сгруппировать в несколько наборов, и если спроектировать базу данных с соблюдением всех правил и требований, которые включаются в тот или иной набор, то база данных будет находиться в определённом состоянии, т.е. форме, и такая форма называется нормальная форма базы данных.
Иными словами, следуя определённым правилам и соблюдая определенные требования мы приводим базу данных к определенной нормальной форме.
Нормальная форма базы данных – это набор правил и критериев, которым должна отвечать база данных.
Каждая следующая нормальная форма содержит более строгие правила и критерии, тем самым приводя базу данных к определённой нормальной форме мы устраняем определённый набор аномалий.
Отсюда можно сделать вывод, что чем выше нормальная форма, тем меньше аномалий в базе будет.
Процесс нормализации – это последовательный процесс приведения базы данных к эталонному виду, т.е. переход от одной нормальной формы к следующей.
Иными словами, процесс перехода от одной нормальной формы к следующей – это усовершенствование базы данных. Так как если база данных находится в какой-то определённой нормальной форме – это означает, что в базе данных отсутствует определенный вид аномалий.
Существует 5 основных нормальных форм базы данных:
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
Однако выделяют еще дополнительные нормальные формы:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Нормальная форма Бойса-Кодда (BCNF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Заметка! Установка и настройка PostgreSQL на Windows 10.
Если объединить оба этих списка и упорядочить нормальные формы от менее нормализованной до самой нормализованной, т.е. начиная с формы, при которой база данных по своей сути не является нормализованной, и заканчивая самой строгой нормальной формой, то мы получим следующий перечень:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
База данных считается нормализованной, если она находится как минимум в третьей нормальной форме (3NF).
В реальном мире нормализация до третьей нормальной формы (3NF) является обычной, стандартной практикой, так как 3NF устраняет достаточное количество аномалий, при этом производительность базы данных, а также удобство ее использования не снижается, что нельзя сказать о всех последующих формах.
Ситуации, при которых требуется нормализовать базу данных до четвертой нормальной формы (4NF), в реальном мире встречаются достаточно редко.
Заметка! Если Вас интересует язык SQL, рекомендую почитать мою книгу «SQL код», которая ориентирована на изучение SQL как стандарта, после прочтения книги Вы сможете писать SQL запросы в любой системе управления базами данных.
Если говорить о всех последующих нормальных формах (5NF, DKNF, 6NF), то в реальной жизни трудно даже представить ситуации, при которых потребуется нормализовать базу данных до этих форм.
Иными словами, 5NF, DKNF, 6NF – это в большей степени теоретические нормальные формы, немного отстраненные от реального мира.
Стоит отметить, что приведение базы данных к какой-то конкретной нормальной форме, обязательно требует, чтобы эта база данных уже находилась в предыдущей нормальной форме. Другими словами, если Вы хотите нормализовать базу данных до третьей нормальной формы, то база уже должна находиться во второй нормальной форме, т.е. нельзя нормализовать базу данных до третьей формы, если она еще не нормализована до второй.
Описание нормальных форм базы данных
В следующих статьях представлено подробное описание каждой нормальной формы и приведены примеры.
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Опрос. Какой операционной системой Вы пользуетесь?
На сегодня это все, надеюсь, материал был Вам полезен и интересен, пока!
Разработка
логической модели БД должна происходить
с учетом необходимости решения задач
минимизации дублирования данных,
упрощения и ускорения процедур их
обработки. При неправильно спроектированной
схеме БД могут возникнуть аномалии
модификации данных. Для решения подобных
проблем проводится нормализация.
Нормализация
– процесс проверки и реорганизации
сущностей и атрибутов с целью удовлетворения
требований к реляционной модели базы
данных. Нормализация позволяет: 1) быть
уверенным, что каждый атрибут определен
для своей сущности, 2) значительно
сократить объем памяти для хранения
информации и 3) устранить аномалии в
организации хранения данных. В результате
проведения нормализации должна быть
создана структура данных, при которой
информация о каждом факте хранится
только в одном месте. Процесс нормализации
сводится к последовательному приведению
структуры
данных к нормальным формам — формализованным
требованиям к организации данных.
Известно 6 нормальных форм:
-
первая нормальная
форма (1NF); -
вторая нормальная
форма (2NF); -
третья нормальная
форма (3NF); -
нормальная форма
Бойса — Кодда (усиленная 3NF); -
четвертая нормальная
форма (4NF); -
пятая нормальная
форма (5NF).
Нормальные
формы основаны на понятии функциональной
зависимости (в дальнейшем будем
использовать термин “зависимость”).
Функциональная
зависимость (FD).
Атрибут В сущности Е функционально
зависит от атрибута А сущности Е тогда
и только тогда, когда каждое значение
А в Е связало с ним точно одно значение
В в Е, т. е. А однозначно определяет В.
Полная функциональная
зависимость.
Атрибут В сущности Е полностью
функционально зависит от ряда атрибутов
А сущности Е тогда и только тогда, когда
В функционально зависит от А и не зависит
ни от какого подряда А.
На рис. 6 в сущности
Сотрудник
значения атрибутов Фамилия,
Имя
и Отчество
однозначно определяются значением
атрибута Табельный
номер, т.
е. атрибуты Фамилия,
Имя
и Отчество
зависят от атрибута Табельный
номер.
Функциональные зависимости определяются
бизнес-правилами предметной области.
Так, если оклад сотрудника определяется
только должностью, то атрибут Оклад
зависит от атрибута Должность;
если оклад зависит еще, например, от
стажа, то такой зависимости нет. В
нижеследующих примерах будем считать
для определенности, что такая зависимость
есть.
Рис.
6. Ненормализованная сущность Сотрудник
Рассмотрим подробнее
первые четыре нормальные формы.
Первая нормальная
форма (1NF).
Сущность находится в первой нормальной
форме тогда и только тогда, когда все
атрибуты содержат атомарные значения.
Среди атрибутов не должно встречаться
повторяющихся групп, т.е. несколько
значений для каждого экземпляра. На
рис. 6 атрибуты Телефон
и Хобби
являются нарушением первой нормальной
формы. Что будет, если у сотрудника
несколько рабочих телефонов? Запись
значения колонки через разделитель,
например “124-56-78, 124-56-79, 124-56-90” или
“Аквалангист, мотоциклист, шахматист”,
приводит к ряду проблем, например,
размера поля может не хватить для
хранения данных (нельзя увеличивать
список телефонов до бесконечности).
Сущность, приведенная на рис. 7, не
является решением проблемы. Что будет,
если у сотрудника появится четвертый
телефон или третье хобби? Эту информацию
будет негде хранить.
Рис.
7. Ненормализованная сущность Сотрудник
Другой ошибкой
нормализации является хранение в одном
атрибуте разных по смыслу значений. На
рис. 6 атрибут Дата
зачисления или увольнения
хранит информацию как о зачислении, так
и об увольнении сотрудника. Если хранится
только одно значение, то невозможно
понять, какая именно дата внесена. Если
внести атрибут-признак типа даты, тип
можно будет определить, но останется
возможность хранения только одной даты
для каждого сотрудника.
Для приведения
сущности к первой нормальной форме
следует:
-
разделить сложные
атрибуты на атомарные; -
создать новую
сущность; -
перенести в нее
все “повторяющиеся” атрибуты; -
выбрать возможный
ключ для нового РК (или создать новый
РК); -
установить
идентифицирующую связь от прежней
сущности к новой, РК прежней сущности
станет внешним ключом (FK) для новой
сущности.
На рис. 8 показана
сущность Сотрудник,
приведенная к первой нормальной форме.
Рис. 8. Сущность
Сотрудник,
приведенная к первой нормальной форме
Вторая
нормальная форма (2NF).
Сущность
находится во второй нормальной форме,
если она находится в первой нормальной
форме и каждый неключевой атрибут
полностью зависит от первичного ключа
(не должно быть зависимости от части
ключа). Вторая нормальная форма имеет
смысл только для сущностей, имеющих
сложный первичный ключ.
Рис. 9. Сущность
Проект
Предположим,
сущность Проект
содержит информацию о проекте, которым
руководит сотрудник, причем информация
содержится как непосредственно о
проекте, так и о руководителе проекта
(рис. 9). Атрибуты Фамилия,
Имя, Отчество
и Должность
зависят только от атрибута Табельный
номер руководителя,
но вовсе не от Наименования
проекта.
Другими словами, имеется зависимость
только от части ключа.
Для приведения
сущности ко второй нормальной форме
следует:
-
выделить атрибуты,
которые зависят только от части
первичного ключа, создать новую сущность; -
поместить атрибуты,
зависящие от части ключа, в их собственную
(новую) сущность; -
установить
идентифицирующую связь от прежней
сущности к новой (рис. 10).
Рис. 10. Сущность
Проект,
приведенная ко второй нормальной форме
Вторая
нормальная форма позволяет избежать
следующих аномалий при выполнении
операций:
-
Обновления
(UPDATE). Имеет
место дублирование данных о сотруднике,
если он руководит несколькими проектами.
Если данные о сотруднике изменяются,
необходимо менять несколько записей
(по числу ведомых проектов). -
Вставки (INSERT).
Невозможно ввести данные о сотруднике,
если он в данный момент не руководит
проектами. -
Удаления (DELETE).
Если сотрудник временно прекращает
руководство проектами, данные о нем
теряются.
На рис. 10 показана
сущность Проект,
приведенная ко второй нормальной форме.
Третья нормальная
форма (3NF).
Сущность
находится в третьей нормальной форме,
если она находится во второй нормальной
форме и никакой неключевой атрибут не
зависит от другого неключевого атрибута
(не должно быть взаимозависимости между
неключевыми атрибутами).
На рис. 8 сущность
Сотрудник
находится во второй нормальной форме
(имеется только один атрибут первичного
ключа, поэтому не может быть зависимости
неключевых атрибутов от части ключа),
но неключевой атрибут Оклад
зависит от другого неключевого атрибута
— Должности.
Для приведения
сущности ко третьей нормальной форме
следует:
-
создать новую
сущность и перенести в нее атрибуты с
одной и той же зависимостью от неключевого
атрибута; -
использовать
атрибут(ы), определяющий эту зависимость,
в качестве первичного ключа новой
сущности; -
установить
неидентифицирующую связь от новой
сущности к старой (рис. 11).
Рис.11. Сущность
Сотрудник,
приведенная к третьей нормальной форме
В
третьей нормальной форме каждый атрибут
сущности зависит от ключа, от всего
ключа целиком и ни от чего другого, кроме
как от ключа.
Третья
нормальная форма также позволяет
избежать ряда аномалий:
-
Обновления
(UPDATE). Имеет
место дублирование данных об окладе,
если должность занимают несколько
сотрудников. Если оклад, соответствующий
должности, меняется, необходимо менять
несколько записей (по числу сотрудников
на одной должности). -
Вставки (INSERT).
Невозможно ввести данные об окладе,
соответствующем должности, если в
данный момент нет сотрудника, занимающего
эту должность. -
Удаления (DELETE).
В случае удаления из таблицы сотрудника,
занимающего уникальную должность,
данные об окладе теряются.
Четвертая
нормальная форма (4NF)
требует отсутствия многозначных
зависимостей между атрибутами.
В примере на рисунке
12 а преподаватель читает лекции по
нескольким предметам и курирует несколько
групп студентов. Одна группа студентов
может изучать несколько предметов,
одному предмету могут обучаться несколько
групп студентов. Имеется многозначная
зависимость между атрибутами Предмет
и Группа.
При этом возможна аномалия: если у
преподавателя появляется новая группа,
приходится добавлять несколько записей,
по числу читаемых предметов.
|
а) |
б) |
Рис. 12. Иллюстрация
четвертой нормальной формы.
Для приведения
сущности к четвертой нормальной форме
следует создать новую сущность и
перенести атрибуты с многозначной
зависимостью в разные сущности (рис.
12 б). Связь между новыми сущностями
при этом устанавливать нельзя, поскольку
в результате миграции атрибутов внешних
ключей атрибуты с многозначной
зависимостью вновь окажутся в одной
сущности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Анализ данных
• 08 декабря 2022 • 5 мин чтения
Как привести данные в форму: что такое нормализация и зачем она нужна
Нормализация данных — инструмент, в котором новичку бывает сложно разобраться. Объясняем, как она работает, на примере из жизни — походе в магазин за ингредиентами для салата.
- Что такое нормализация данных
- Зачем нормализовать данные в БД
- Как выполнить нормализацию
- Совет эксперта
Что такое нормализация данных
Данные в базе могут быть в любом виде: числа, проценты, текст. Нормализация — это способ организации данных. В нормализованной базе нет повторяющихся данных, с ней проще работать и можно менять её структуру для разных задач. В процессе нормализации данные преобразуют, чтобы они занимали меньше места, а поиск по элементам был быстрым и результативным. Для этого создают дополнительные таблицы и связывают друг с другом ключами — колонками, в которых нет повторяющихся элементов.
Рассмотрим на примере суть нормирования данных. Александр Сушков каждый день ходит в магазин продуктов рядом с домом. Покупает продукты, например, хлеб и творог, и оплачивает их картой. Данные о покупках, за которые рассчитывались картой, ежедневно сохраняются на сервере магазина в таблицу Google Sheets.

Так покупки Александра Сушкова записаны в таблице данных магазина
К концу дня данные можно проанализировать: посчитать выручку магазина, какие категории товаров продавались лучше и сколько денег принесли. Когда количество записей в таблице превысит миллион — работать с данными станет сложнее. Таблица будет медленно открываться, в ней будет труднее найти ошибки и собрать статистику по определённым товарам или категориям покупателей.
Кроме Александра Сушкова, в магазине ежедневно делают покупки и другие люди, которые тоже живут поблизости — Иван Иванов и Егор Кузнецов. Фамилии и имена покупателей повторяются в каждой записи их покупок. А это в среднем 10–20 символов. Чтобы не дублировать эти данные, можно создать отдельную таблицу.

В отдельной таблице каждому покупателю можно присвоить номер — ключ. Тогда в основной таблице вместо имён будут ключи, которые свяжут обе таблицы. Это сократит количество символов в основной таблице, уберёт повторяющиеся сущности и упростит поиск
Имена и фамилии сотни постоянных покупателей — это в среднем 1 500 символов. Если в год каждый из них посещает магазин 300 раз, то получается 450 000 символов. Только замена имён и фамилий на цифры сократит количество символов в записях в 3–4 раза.
С товарами можно поступить так же: ввести категории, например, хлебобулочные изделия или молочная продукция, и создать для них отдельную таблицу. Так работает нормализация, цель которой — оптимизировать работу с базами данных.
Чтобы работать с нормальными формами БД: добавить, изменить или найти данные в базе из множества взаимосвязанных таблиц, к ней обращаются на языке программирования SQL. Это декларативный язык или язык структурированных запросов. Студенты курса «Аналитик данных» изучают SQL и учатся писать запросы разного уровня сложности.
Повышайте прибыль компании с помощью данных
Научитесь анализировать большие данные, строить гипотезы и соберите 13 проектов в портфолио за 6 месяцев, а не 1,5 года. Сделайте первый шаг к новой профессии в бесплатной вводной части курса «Аналитик данных».

Зачем нормализовать данные в БД
Разберём преимущества нормализации данных на примере. Работа с нормализованными данными отдалённо напоминает поход за продуктами с книгой рецептов. Чтобы купить продукты для салата оливье, нужно открыть первую таблицу — книгу рецептов, перейти в подтаблицу — раздел «Салаты», найти нужный рецепт и положить в корзину продукты из него. Примерно так работают связи между таблицами данных.
Без нормализации данных книга рецептов была бы одной большой таблицей с ингредиентами блюд. Чтобы купить продукты для оливье, пришлось бы сначала собрать в корзину все ингредиенты из книги. Потом найти те, что нужны для салата, а остальные выложить из корзины.
Что даёт нормализация данных и как она упрощает работу с базами:
1. Уменьшает объём базы данных и экономит место.
За счёт отдельных таблиц для категорий и повторяющихся элементов можно уменьшить размер записей в базе данных, а значит, и её вес.
2. Упрощает поиск и делает работу с базой удобнее.
Нормализованную базу данных, которая состоит из связанных таблиц, можно оптимизировать для задач без дополнительных действий. Например, для поиска по заданной категории не придётся искать и перебирать уникальные элементы в базе. Для этого можно обратиться к отдельной таблице с категориями и быстрее найти нужные данные.
3. Уменьшает вероятность ошибок и аномалий.
Нормальные формы данных в таблицах взаимосвязаны. Например, если нужно изменить или удалить данные в одной таблице, то остальные связанные с ней данные автоматически обновятся. Не придётся перебирать все записи в поисках полей, которые нужно изменить или удалить, а значит, не будет ошибок, когда в базу внесут изменения.
Как подготовить данные для машинного обучения
Как выполнить нормализацию
Процесс нормализации данных нужно прописать на этапе проектирования базы, то есть до начала сбора данных. Если этого не сделать, есть риск, что база данных будет спроектирована плохо и её придётся переделывать. Обычно аналитики нормализуют данные вручную или передают задачу специалистам, которые собирают и хранят данные, например, инженерам данных.
Для нормализации данных нет специального программного обеспечения. Данные в базе преобразуют по правилам.
Правила нормализации баз данных
По правилам нормализации есть семь нормальных форм баз данных:
● первая,
● вторая,
● третья,
● нормальная форма Бойса-Кодда,
● четвёртая,
● пятая,
● шестая.
Приводить данные к нормальным формам можно только последовательно. То есть в базе данных второй нормальной формы данные по умолчанию уже должны быть нормализованы по правилам первой нормальной формы и так далее. В итоге база данных в шестой нормальной форме — идеально нормализованная.
В некоторых случаях попытка нормализовать данные до «идеального» состояния может привести к созданию множества таблиц, ключей и связей. Это усложнит работу с базой и снизит производительность СУБД. Поэтому обычно данные нормализуют до третьей нормальной формы. Разберём на примере.
Первая нормальная форма
В базе данных не должно быть дубликатов и составных данных.

Слева данные о фамилии, имени и отчестве покупателей записаны в одно поле. Справа эти данные приведены к первой нормальной форме — каждый элемент записан в отдельное поле
Элементы составных данных лучше разнести по разным полям, иначе в процессе работы с данными могут появиться ошибки и аномалии.
Например, отдел маркетинга решил поздравить всех Александров с именинами и сделать рассылку с промокодом. Если таблица соответствует первой нормальной форме, можно найти нужные данные без дополнительных действий. Когда имя, отчество и фамилия записаны в одно поле, при поиске и сортировке в выборку попадут, например, Александровичи, Александровны и Александровы.
Другой пример — адреса. Их тоже лучше приводить к первой нормальной форме. То есть город, район, улицу, номер дом и номер квартиры записывать в отдельные поля. Если какие-то данные дублируются, как в случае с именами и фамилиями постоянных покупателей, их нужно перенести в другую таблицу.
Вторая нормальная форма
Если упростить: у каждой записи в базе данных должен быть первичный ключ. Первичный ключ — это элемент записи, который не повторяется в других записях.
Допустим, 10 декабря покупатель Егор Кузнецов купил цельнозерновой хлеб за 75 рублей в сетевом магазине продуктов города Москвы. Запись о его покупке появилась в базе данных. Нельзя исключать, что другой Егор Кузнецов в этот день купит такой же товар в другом магазине сети. Запись о покупке тоже появится в базе.

Чтобы записи не перепутались, можно добавить к ним идентификатор покупки, например номер чека. Идентификатор покупки — это первичный ключ
Третья нормальная форма
В записи не должно быть столбцов с неключевыми значениями, которые зависят от других неключевых значений.

Личный номер сотрудника — это первичный ключ. Данные во втором и третьем столбце напрямую зависят от первичного ключа. Но между личным номером сотрудника и руководителем отдела только косвенная или транзитивная связь. Её в базе данных третьей нормальной формы быть не должно
Данные о руководителях отделов нужно вынести в другую таблицу. Тогда в основной таблице не будет транзитивных связей, и она будет соответствовать третьей нормальной форме.
Данные не во всех случаях преобразовывают до третьей формы. Иногда для этого придётся создать много небольших таблиц, что усложнит базу и задачу разработчикам.
Совет эксперта
Александр Сушков
Нормализация — один из методов оптимизации работы с базой данных. Если база данных подходит для магазина, необязательно, что она будет также хорошо работать для документов. Поэтому выбор методов оптимизации всегда индивидуален и зависит от конкретного случая. Кроме того, нормализация — это не лекарство от всех болезней. Стоит обращать внимание не только на то, какие преимущества даст нормализация, но и сколько ресурсов и времени на неё уйдет.
Курлид, автор, преподаватель

Чем занимается аналитик данных, почему он всем так нужен и как освоить эту профессию

Анализ больших данных: зачем он нужен и кто им занимается