
From Wikipedia, the free encyclopedia
A debugger or debugging tool is a computer program used to test and debug other programs (the «target» program). The main use of a debugger is to run the target program under controlled conditions that permit the programmer to track its execution and monitor changes in computer resources that may indicate malfunctioning code. Typical debugging facilities include the ability to run or halt the target program at specific points, display the contents of memory, CPU registers or storage devices (such as disk drives), and modify memory or register contents in order to enter selected test data that might be a cause of faulty program execution.
The code to be examined might alternatively be running on an instruction set simulator (ISS), a technique that allows great power in its ability to halt when specific conditions are encountered, but which will typically be somewhat slower than executing the code directly on the appropriate (or the same) processor. Some debuggers offer two modes of operation, full or partial simulation, to limit this impact.
A «trap» occurs when the program cannot normally continue because of a programming bug or invalid data. For example, the program might have tried to use an instruction not available on the current version of the CPU or attempted to access unavailable or protected memory. When the program «traps» or reaches a preset condition, the debugger typically shows the location in the original code if it is a source-level debugger or symbolic debugger, commonly now seen in integrated development environments. If it is a low-level debugger or a machine-language debugger it shows the line in the disassembly (unless it also has online access to the original source code and can display the appropriate section of code from the assembly or compilation).
Features[edit]
Typically, debuggers offer a query processor, a symbol resolver, an expression interpreter, and a debug support interface at its top level.[1] Debuggers also offer more sophisticated functions such as running a program step by step (single-stepping or program animation), stopping (breaking) (pausing the program to examine the current state) at some event or specified instruction by means of a breakpoint, and tracking the values of variables.[2] Some debuggers have the ability to modify program state while it is running. It may also be possible to continue execution at a different location in the program to bypass a crash or logical error.
The same functionality which makes a debugger useful for correcting bugs allows it to be used as a software cracking tool to evade copy protection, digital rights management, and other software protection features. It often also makes it useful as a general verification tool, fault coverage, and performance analyzer, especially if instruction path lengths are shown.[3] Early microcomputers with disk-based storage often benefitted from the ability to diagnose and recover corrupted directory or registry data records, to «undelete» files marked as deleted, or to crack file password protection.
Most mainstream debugging engines, such as gdb and dbx, provide console-based command line interfaces. Debugger front-ends are popular extensions to debugger engines that provide IDE integration, program animation, and visualization features.
Record and replay debugging[edit]
Record and replay debugging,[4] also known as «software flight recording» or «program execution recording», captures application state changes and stores them to disk as each instruction in a program executes. The recording can then be replayed over and over, and interactively debugged to diagnose and resolve defects. Record and replay debugging is very useful for remote debugging and for resolving intermittent, non-deterministic, and other hard-to-reproduce defects.
Reverse debugging[edit]
Some debuggers include a feature called «reverse debugging«, also known as «historical debugging» or «backwards debugging». These debuggers make it possible to step a program’s execution backwards in time. Various debuggers include this feature. Microsoft Visual Studio (2010 Ultimate edition, 2012 Ultimate, 2013 Ultimate, and 2015 Enterprise edition) offers IntelliTrace reverse debugging for C#, Visual Basic .NET, and some other languages, but not C++. Reverse debuggers also exist for C, C++, Java, Python, Perl, and other languages. Some are open source; some are proprietary commercial software. Some reverse debuggers slow down the target by orders of magnitude, but the best reverse debuggers cause a slowdown of 2× or less. Reverse debugging is very useful for certain types of problems, but is still not commonly used yet.[5]
Time Travel debugging[edit]
In addition to the features of reverse debuggers, time-travel debugging also allow users to interact with the program, changing the history if desired, and watch how the program responds.
Language dependency[edit]
Some debuggers operate on a single specific language while others can handle multiple languages transparently. For example, if the main target program is written in COBOL but calls assembly language subroutines and PL/1 subroutines, the debugger may have to dynamically switch modes to accommodate the changes in language as they occur.
Memory protection[edit]
Some debuggers also incorporate memory protection to avoid storage violations such as buffer overflow. This may be extremely important in transaction processing environments where memory is dynamically allocated from memory ‘pools’ on a task by task basis.
Hardware support for debugging[edit]
Most modern microprocessors have at least one of these features in their CPU design to make debugging easier:
- Hardware support for single-stepping a program, such as the trap flag.
- An instruction set that meets the Popek and Goldberg virtualization requirements makes it easier to write debugger software that runs on the same CPU as the software being debugged; such a CPU can execute the inner loops of the program under test at full speed, and still remain under debugger control.
- In-system programming allows an external hardware debugger to reprogram a system under test (for example, adding or removing instruction breakpoints). Many systems with such ISP support also have other hardware debug support.
- Hardware support for code and data breakpoints, such as address comparators and data value comparators or, with considerably more work involved, page fault hardware.[6]
- JTAG access to hardware debug interfaces such as those on ARM architecture processors or using the Nexus command set. Processors used in embedded systems typically have extensive JTAG debug support.
- Micro controllers with as few as six pins need to use low pin-count substitutes for JTAG, such as BDM, Spy-Bi-Wire, or debugWIRE on the Atmel AVR. DebugWIRE, for example, uses bidirectional signaling on the RESET pin.
Debugger front-ends[edit]
Some of the most capable and popular debuggers implement only a simple command line interface (CLI)—often to maximize portability and minimize resource consumption. Developers typically consider debugging via a graphical user interface (GUI) easier and more productive.[citation needed] This is the reason for visual front-ends, that allow users to monitor and control subservient CLI-only debuggers via graphical user interface. Some GUI debugger front-ends are designed to be compatible with a variety of CLI-only debuggers, while others are targeted at one specific debugger.
List of debuggers[edit]
Some widely used debuggers are:
- Arm DTT, formerly known as Allinea DDT
- Eclipse debugger API used in a range of IDEs: Eclipse IDE (Java) Nodeclipse (JavaScript)
- Firefox JavaScript debugger
- GDB — the GNU debugger
- LLDB
- Microsoft Visual Studio Debugger
- Radare2
- Valgrind
- WinDbg
Earlier minicomputer debuggers include:
- Dynamic debugging technique (DDT)
- On-line Debugging Tool (ODT)
Mainframe debuggers include:
- CA/EZTEST
See also[edit]
- Comparison of debuggers
- Core dump
- Kernel debugger
- List of tools for static code analysis
- Memory debugger
- Packet analyzer
- Profiling
- Time travel debugging
References[edit]
Citations[edit]
- ^ Aggarwal and Kumar, p. 302.
- ^ Aggarwal and Kumar 2003, p. 301.
- ^ Aggarwal and Kumar, pp. 307-312.
- ^ O’Callahan, Robert; Jones, Chris; Froyd, Nathan; Huey, Kyle; Noll, Albert; Partush, Nimrod (2017). «Engineering Record And Replay For Deployability Extended Technical Report». arXiv:1705.05937 [cs.PL].
- ^ Philip Claßen; Undo Software. «Why is reverse debugging rarely used?». Programmers Stack Exchange. Stack Exchange, Inc. Retrieved 12 April 2015.
- ^ Aggarwal and Kumar 2003, pp. 299-301.
Sources[edit]
- Sanjeev Kumar Aggarwal; M. Sarath Kumar (2003). «Debuggers for Programming Languages». In Y.N. Srikant; Priti Shankar (eds.). The Compiler Design Handbook: Optimizations and Machine Code Generation. Boca Raton, Florida: CRC Press. pp. 295–327. ISBN 978-0-8493-1240-3.
- Jonathan B. Rosenberg (1996). How Debuggers Work: Algorithms, Data Structures, and Architecture. John Wiley & Sons. ISBN 0-471-14966-7.
External links[edit]
![]()
Look up debugger in Wiktionary, the free dictionary.
- Debugging Tools for Windows
- OpenRCE: Various Debugger Resources and Plug-ins
- IntelliTrace MSDN, Visual Studio 2015
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Виды ошибок
Ошибки компиляции
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки компоновки
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки выполнения (RUNTIME Error)
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Методы отладки программного обеспечения
Метод ручного тестирования
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
Метод индукции
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:
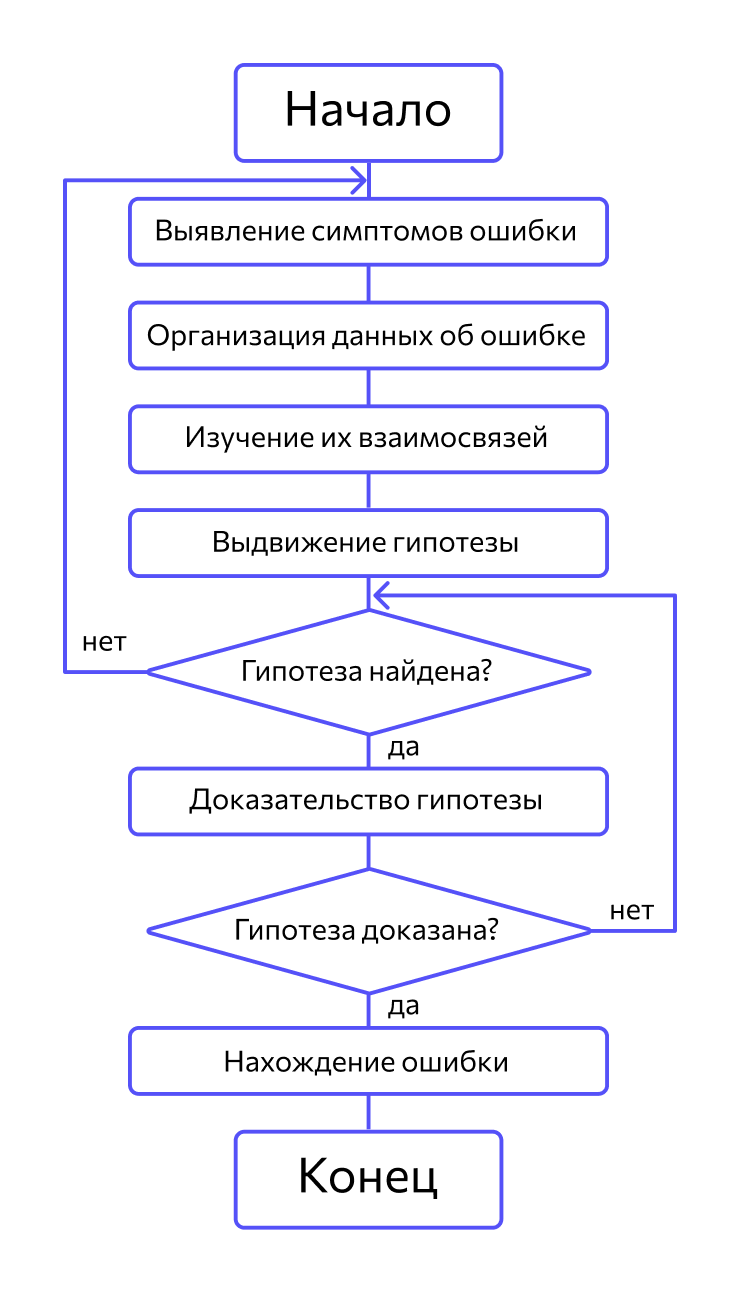
Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Метод дедукции
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.
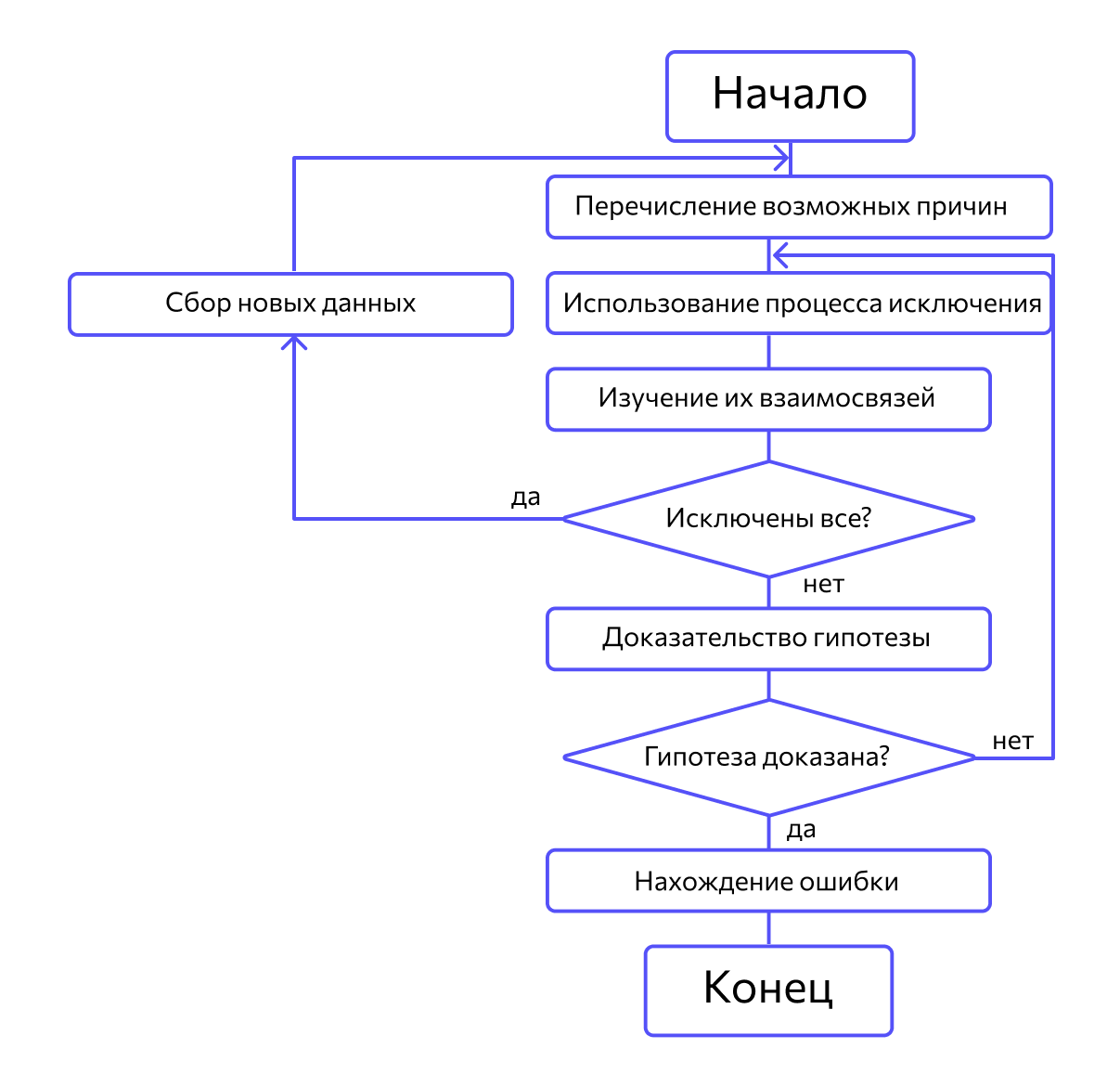
Метод обратного прослеживания
Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Как выполняется отладка в современных IDE
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Шаг с заходом (step into)
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Шаг с обходом (step over)
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
Шаг с выходом (step out)
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Я думаю, вы знаете, что взлом программного обеспечения производится не какими-то мистическими «хакерами» – его осуществляют такие же программисты, как и большинство читающих данную статью. При этом они пользуются тем же инструментарием что и сами разработчики ПО. Конечно, с оговорками, поскольку по большей части инструментарий достаточно специфичен, но, так или иначе, при анализе ПО используется отладчик.
Так как большинство моих статей ориентированы на людей, интересующихся применением защиты в своем ПО, я решил, что подача материала с конкретными кусками кода защиты (наподобие опубликованных ранее) только запутает читателя. Гораздо проще начать от азов и потихоньку давать новый материал на уже готовой базе.
Поэтому в данной статье будет рассмотрен один из базовых инструментов программиста – отладчик.
Цели статьи: рассмотреть основные методы работы с отладчиком, показать его расширенные и редко используемые возможности, дать понимание работы механизмов отладчика на примерах и рассмотреть некоторый набор методов противодействия.
Объем статьи получился неожиданно большим, поэтому я разбил ее на три части:
- В первой части будут рассмотрены возможности интегрированного в IDE Delphi отладчика, даны рекомендации по наиболее оптимальному его использованию и общие советы по конфигурации среды. Материал данного раздела предназначен как начинающим разработчикам, так и более подготовленным специалистам.
- Во второй части статьи будет рассмотрена изнаночная сторона работы отладчика на примере его исходного кода, подробно рассмотрены механизмы, используемые им при отладке приложения, показаны варианты модификаций памяти приложения, производимые отладчиком во время работы.
- В третьей части статьи будет рассмотрено практическое использование отладчика на примере обхода защиты приложения, использующего некоторый набор антиотладочных трюков.
Собственно, приступим.
1.1. Применение точек остановки и модификация локальных переменных
Одним из наиболее часто используемых инструментов встроенного отладчика является точка остановки (BreakPoint – далее BP). После установки BP, программа будет работать до тех пор, пока не достигнет точки остановки, после чего ее работа будет прервана и управление будет передано отладчику.
Самым простым способом установки и снятия BP является горячая клавиша «F5» (или ее аналог в меню «Debug->Toggle breakpoint»). Есть и другие способы, но о них позже.
После того как программа остановлена, мы можем изучить значения локальных переменных процедуры, в которой произошла остановка выполнения приложения, а так же проанализировать стек вызовов, предшествующих вызову данной процедуры. Здесь же мы можем изменить значения этих переменных.
Где ставить ВР – общего ответа конечно же нет. По сути ВР предназначена для облегчения изучения работы кода, в корректности работы которого мы не уверены, либо явно содержащего ошибку, которую мы с ходу не можем обнаружить.
Гораздо проще установить точку остановки и последовательно выполнить каждую строчку кода, чем провести часы за изучением того же самого кода, пытаясь выяснить, в каком месте он начал работать не так, как это было задумано нами.
Давайте рассмотрим следующий пример.
Есть задача: написать код, который 5 раз увеличит значение изначально обниленой переменной на единицу и еще один раз на число 123, после чего выведет результат в виде 10-тичного и 16-тиричного значения. Ожидаемые значения будут следующими: 128 и 00000080.
Допустим, код будет написан с ошибкой:
var
B: Integer = 123;
procedure TForm1.FormCreate(Sender: TObject);
var
A: Integer;
begin
Inc(A);
Inc(A);
Inc(A, B);
Inc(A);
Inc(A);
Inc(A);
ShowMessage(IntToStr(A));
ShowMessage(IntToHex(A, 8));
end;
Данный код будет выводить какие угодно значения, но только не те, какие мы хотели, потому что мы не произвели инициализацию переменной «А» нулем. А так как переменная «А» локальна, значит, она расположена на стеке, и мы никогда не сможем предугадать, какое значение она примет в начале данной процедуры. Но будем считать, что уже конец рабочего дня, мы действительно устали (глаз замылился) и просто забыли написать строчку с инициализацией переменной.
В итоге мы имеем код, который выводит неверные значения, и хотим быстро разобраться в причине подобного поведения. Ставим BP в теле процедуры и запускаем программу на выполнение:
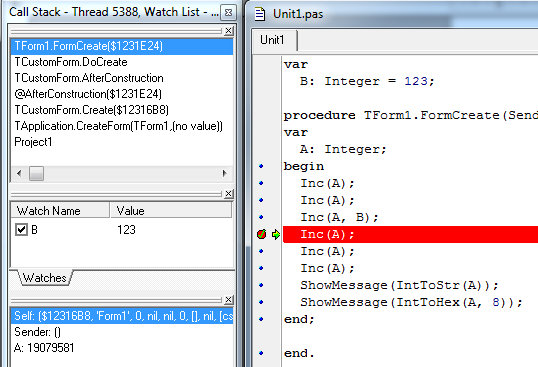
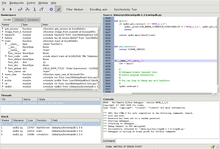
Должно получится примерно так, как на картинке. BP установлен на строчке Inc(A). Слева внизу можно наблюдать значение всех локальных переменных процедуры FormCreate (окно называется «Local Variables»), а именно, переменной Self (она передается неявно и всегда присутствует в методах класса), параметра Sender, и непосредственно локальной переменной «А». Ее значение 19079581. Слева в центре в «WatchList» значение переменной «B».
Даже бегло взглянув на значения обеих переменных и выполненные три строчки кода, мы сможем понять, что значение переменной «А» не соответствует ожидаемому. Так как должно было выполнится два инкремента на единицу и еще одно увеличение на число 123, мы должны были увидеть значением переменной «А» число 125, а раз там другое значение, то это может означать только одно – изначальное значение переменной «А» было не верным.
Для проверки правильности нашего предположения, давайте изменим текущее значение переменной «A» на верное и продолжим выполнение программы, чтобы проверить – те ли результаты вернет процедура, которые ожидались.
Для изменения значений переменных в отладчике предусмотрено два инструмента.
Первый – «Evaluate/Modify», вызывается либо через меню, либо по горячей клавише «Ctrl+F7». Это очень простой инструмент с минимумом функционала, он наиболее часто используется.
Выглядит так:
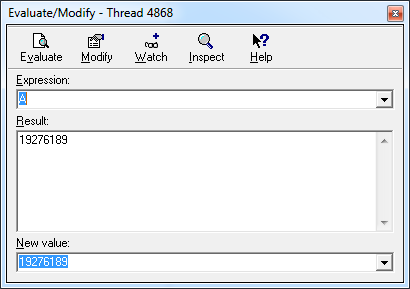
Для изменения в нем значения переменной, достаточно указать новое значение в поле «New value» и нажать клавишу «Enter» или кнопку «Modify».
Второй инструмент – «Inspect», доступен так же либо через меню «Run», либо уже непосредственно из диалога «Evaluate/Modify». Это более продвинутый редактор параметров, о нем чуть позже.
После изменения значения переменной «А», обратите внимание на изменения в списке значений локальных переменных:
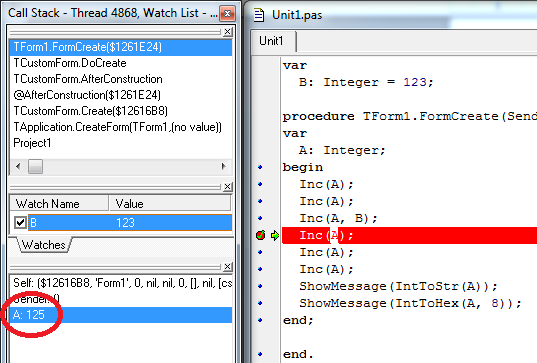
Переменная «А» приняла правильное значение, и теперь мы можем продолжить выполнение нашего приложения нажатием «F9» или через меню, выбрав пункт «Run». В результате такого вмешательства с помощью отладчика, процедура выдаст нам ожидаемые числа 128 и 00000080, и мы уже можем смело исправлять код процедуры, т. к. мы нашли в нём причину ошибки и проверили его исполнение с правильно заданным значением переменной «A».
Теперь вернемся к «Inspect». Помимо двух указанных способов его вызова, он так же вызывается двойным кликом на переменной в окне «Local Variables», либо через контекстное меню при правом клике на ней, либо по горячей клавише «Alt+F5».
Это более «продвинутый» редактор свойств переменных, но его использование оправдано при изменении свойств объектов. Для изменения обычной переменной он несколько не удобен, и вот почему.
При его вызове сначала вы увидите вот такой диалог:
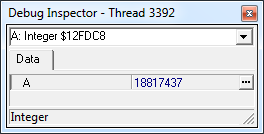
В нем будет указано описание переменной, ее расположение в памяти и ее текущее значение, а для изменения нужно будет еще раз нажать на кнопку с троеточием, после чего появится дополнительное окно:

Лишние телодвижения для такой простой операции, как изменения значения обычной переменной, явно избыточны. Но если его использовать для изменения свойств объектов, то картинка немного поменяется.
Через «Evaluate/Modify» доступ к свойствам объекта несколько затруднен тем, что он не предоставляет информации непосредственно об исследуемом объекте. Например, для получения хэндла канваса формы, нам придется в нем набрать следующий текст: «(Sender as TForm1).Canvas.Handle» – что несколько не удобно, ведь мы можем и опечататься, да и просто банально забыть название того или иного свойства.
В случае с «Inspect» такой проблемы не будет.
К примеру, давайте откроем диалог «Inspect» не для переменной «А», а для переменной Self (которая, как я и говорил ранее, всегда неявно присутствует для всех методов объектов).

Как видите, в данном случае мы имеем доступ практически ко всем полям объекта, которые можем изменять, как нам угодно, и мы не запутаемся в названиях свойств.
1.2. Трассировка (пошаговая отладка)
Суть трассировки заключается в пошаговом выполнении каждой строчки кода.
Допустим, мы остановились на заранее установленной нами ВР, проанализировали код и хотим перейти к следующий строчке. В принципе мы можем на ней так же поставить ВР и запустить программу. И для следующей, и для тех, кто после неё.
Практически, выставляя ВР на каждой строчке кода процедуры, мы вручную имитируем то, что умеет делать сам отладчик (подробнее во втором разделе).
А умеет он следующее:
- Команда «Trace Into» («F7») – отладчик выполнит код текущей строчки кода и остановится на следующей. Если текущая строчка кода вызывает какую либо процедуру, то следующей строчкой будет первая строка вызываемой процедуры.
- Команда «Step Over» («F8») – аналогично первой команде, но вход в тело вызываемой процедуры не происходит.
- Команда «Trace to Next Source Line» («Shift+F7») – так же практически полный аналог первой команды, но используется в окне «CPU-View» (данный режим отладки не рассматривается в статье).
- Команда «Run to Cursor» («F4») – отладчик будет выполнять код программы до той строчки, на которой сейчас находится курсор (с условием, что в процессе выполнения не встретилось других ВР).
- Команда «Run Until Return» («Shift+F8») – отладчик будет выполнять код текущей процедуры до тех пор, пока не произойдет выход из нее. (Часто используется в качестве контрприема на случайно нажатую «F7» и так же с условием, что в процессе выполнения не встретилось других ВР).
- В старших версиях Delphi доступна команда «Set Next Statement», при помощи которой мы можем изменить ход выполнения программы, установив в качестве текущей любую строку кода. Так же эта возможность доступна в редакторе кода там, где можно перетащить стрелочку, указывающую на текущую активную строчку в новую позицию.
Подробного рассмотрения данные команды не требуют. Остановимся только на команда «Trace Into» («F7»).
Для примера возьмем такой код:
procedure TForm1.FormCreate(Sender: TObject);
var
S: TStringList;
begin
S := TStringList.Create;
try
S.Add('My value');
finally
S.Free;
end;
end;
При выполнении трассировки, в тот момент, когда мы находимся на строчке S.Add(), у нас могут быть два варианта реакции отладчика:
- мы войдём внутрь метода TStringList.Add,
- мы туда не войдём.
Обусловлено данное поведение настройками вашего компилятора. Дело в том что в составе Delphi поставляется два набора DCU для системных модулей. Один с отладочной информацией, второй — без. Если у нас подключен второй модуль, то команда «Trace Into» («F7») в данном случае отработает как «Step Over» («F8»). Настраивается переключение между модулями в настройках компилятора:
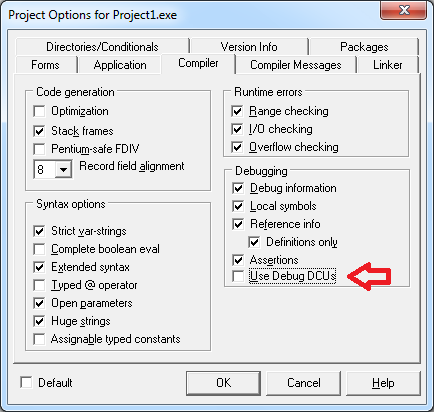
И отвечает за данный функционал параметр «Use Debug DCUs».
1.3. Подробнее о настройках компилятора
Опции в закладке с настройками компилятора влияют непосредственно на то, какой код будет генерироваться при сборке вашего проекта. Очень важно не забывать, что при изменении любого из пунктов данной вкладки, требуется полная пересборка проекта («Project > Build») для того, чтобы изменения вступили в силу. Данные настройки непосредственно влияют на поведение вашего кода в различных ситуациях, а так же на состав информации, доступной вам при отладке проекта.
Рассмотрим их поподробнее:
Группа «Code generation»
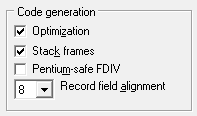
Параметр «Optimization»
Данный параметр влияет непосредственно на оптимизацию кода: при включенном параметре код будет сгенерирован максимально оптимальным способом с учетом как его размера, так и скорости исполнения. Это может привести к потере возможности доступа (даже на чтение) к некоторым локальным переменным, ибо из-за оптимизации кода они уже могут быть удалены из памяти в тот момент, когда мы прервались на BP.
В качестве примера, возьмем код из первой главы и остановимся на той же ВР, но с включенной оптимизацией.
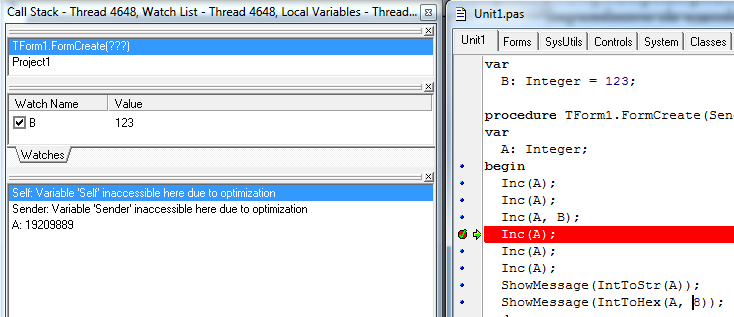
Как видите, значения ранее доступных переменных Self и Sender, более не доступны. Так же из-за отключенного параметра «Use Debug DCUs» произошло кардинальное изменение в окне «Call Stack», ранее заполненного более подробной информацией о списке вызовов.
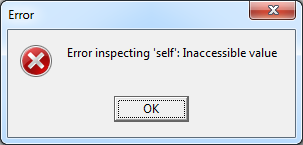
Более того, инструмент «Inspect» так же отказывается работать с объектом Self, выдавая следующую ошибку:
Параметры «Stack Frames» и «Pentiom-safe FDIV»
Описание данных параметров я пропущу – на этапе отладки они не интересны. Вкратце: первый поможет при самостоятельном анализе стека, второй отвечает за нюансы при работе с математическим сопроцессором. Если кого-то интересуют нюансы, то мои координаты для связи в профиле.
Параметр «Record field alignment»
Глобальная настройка выравнивания неупакованных записей, которая может быть изменена локально в пределах модуля директивой «{$Align x}» или «{$A x}»
Для примера рассмотрим следующий код:
type
T = record
a: Int64;
b: Byte;
c: Integer;
d: Byte;
end;
Размер данной записи, который мы можем получить через SizeOf(T), будет для каждой из настроек выравнивания свой:
{$Align 1} = 14
{$Align 2} = 16
{$Align 4} = 20
{$Align 8} = 24
Группа «Syntax options»
Тут лучше вообще ничего не трогать. Ибо, если постараться, то можно сделать даже так, что стандартная VCL откажется собираться.
Единственно остановлюсь на параметре «Complete boolen eval», ибо периодически некоторые его включают. Он грозит ошибкой при выполнении следующего кода:
function IsListDataPresent(Value: TList): Boolean;
begin
Result := (Value <> nil) and (Value.Count > 0);
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
if IsListDataPresent(nil) then
ShowMessage('boo...');
end;
Так как, при включении данной настройки, булево выражение будет проверяться целиком, то произойдет ошибка при обращении к Value.Count, не смотря на то, что первая проверка определила, что параметр Value обнилен. А если вы включите (например) параметр «Extended syntax», то данный код у вас вообще не соберется, пожаловавшись на необъявленную переменную Result.
Группа «Runtime errors»
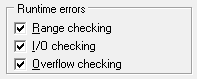
Параметр «Range checking»
Это один из наиболее востребованных параметров при отладке приложения. Он отвечает за проверку границ при доступе к массиву данных.
В самом простом случае вам будет сгенерировано исключение при выполнении вот такого кода:
const
A: array [0..1] of Char = ('A', 'B');
procedure TForm1.FormCreate(Sender: TObject);
var
I: Integer;
begin
for I := 0 to 100 do
Caption := Caption + A[I];
end;
Здесь мы просто пытаемся обратится к элементу массива, и в принципе, при отключенной опции «Range checking», если мы не выйдем за границу выделенной памяти, данный код нам грозит только тем, что в заголовке формы появится некая непонятная строка.

Что неприятно, но некритично для выполнения программы. Гораздо хуже, если вы ошиблись с границами блока при попытке записи в него – в этом случае может произойти разрушение памяти приложения.
Рассмотрим такой пример, оптимизацию отключим:
type
TMyEnum1 = (en1, en2, en3, en4, en5);
TMyEnum2 = en1..en3;
procedure TForm1.FormCreate(Sender: TObject);
var
I: TMyEnum1;
HazardVariable: Integer;
Buff: array [TMyEnum2] of Integer;
begin
HazardVariable := 100;
for I := Low(I) to High(I) do
Buff[I] := Integer(I);
ShowMessage(IntToStr(HazardVariable));
end;
Как вы думаете, чему будет равно значение числа HazardVariable после выполнения данного кода? Нет, не 100. Оно будет равно 4. Так как мы ошиблись при выборе типа итератора и вместо TMyEnum2 написали TMyEnum1, произошел выход за диапазон границ массива и затерлись данные на стеке, изменив значения локальных переменных хранящихся на нём же.
С включенной оптимизацией ситуация будет еще хуже. Мы получим следующую ошибку:

По данному описанию мы даже не сможем предположить, где именно произошло исключение, и почему оно произошло, так как адреса, упомянутые в тексте ошибки, не принадлежат памяти приложения, и если, не дай бог, такая ошибка возникнет у клиента – исправить ее по данному описанию мы не сможем.
Поэтому возьмите себе за правило – отладка приложения всегда должна происходить с включенной настройкой «Range checking»!
Так же данный параметр контролирует выход за границы допустимых значений при изменении значения переменных. Например, будет поднято исключение при попытке присвоения отрицательного значения беззнаковым типам наподобие Cardinal/DWORD, или при попытке присвоить значение большее, чем может содержать переменная данного типа, например, при присвоении 500 переменной типа Byte и т. п…
Параметр «I/O cheking»
Отвечает за проверку результатов ввода/вывода при работе с файлами в стиле Pascal.
Не уверен, что еще остался софт, использующий данный подход, но если вы вдруг все еще работаете с Append/Assign/Rewrite и т. п., то включайте данный параметр при отладке приложения.
Параметр «Overflow cheking»
Контролирует результаты арифметических действий и поднимает исключение в тех случаях, когда результат выходит за диапазон переменной.
Чтобы было проще понять различия между данным параметром и «Range checking», рассмотрим следующий код:
procedure TForm1.FormCreate(Sender: TObject);
var
C: Cardinal;
B: Byte;
I: Integer;
begin
I := -1;
B := I;
C := I;
ShowMessage(IntToStr(C - B));
end;
Данный код не поднимет исключения при включенном параметре «Overflow cheking». Хоть здесь и присваиваются переменным не допустимые значения, но не производится математических операций над ними. Однако исключение будет поднято при включенном параметре «Range checking».
А теперь рассмотрим второй вариант кода:
procedure TForm1.FormCreate(Sender: TObject);
var
C: Cardinal;
B: Byte;
begin
B := 255;
Inc(B);
C := 0;
C := C - 1;
ShowMessage(IntToStr(C - B));
end;
Здесь уже не будет реакции от параметра «Range checking», но произойдет поднятие исключения EIntegerOverflow, за который отвечает «Overflow cheking», на строчках Inc(B) и C := C — 1 из-за того, что результат арифметической операции не может быть сохранен в соответствующей переменной.
Таким образом, при работе с переменными оба параметра взаимодополняют друг друга.
«Overflow cheking» не настолько критичен, как «Range checking», но всё же желательно держать его включенным при отладке приложения.
Небольшой нюанс: если вы вдруг реализуете криптографические алгоритмы, то в них, как правило, операция переполнения является штатной. В таких ситуациях выносите код в отдельный модуль и в начале модуля прописывайте директиву «{$OVERFLOWCHECKS OFF}» для отключения проверки переполнений в текущем модуле.
Группа «Debugging»
С данной вкладкой все очень просто. Все параметры, за исключением параметра «Assertions», никоим образом не влияют на финальный код вашего приложения. В зависимости от активности тех или иных параметров изменяется полнота отладочной информации в DCU файле для каждого модуля. На основе данной информации отладчик производит синхронизацию ассемблерного листинга программы с ее реальным кодом, реализованным программистом, распознает локальные переменные и т. п. При компиляции приложения данная отладочная информация не помещается в теле приложения.
Единственным исключением является параметр «Assertions» – он отвечает за работу процедуры Assert(). Если данный параметр отключен – Assert не выполняется, в противном случае – выполняется, причем его код так же будет помещен в тело приложения на этапе компиляции.
Резюмируя.
На этапе отладки приложения желательно держать все параметры из групп «Runtime errors» и «Debugging» включенными, и отключать их при финальной компиляции релизного приложения. В Delphi 7 и ниже это придется делать руками, но, начиная с Delphi 2005 и выше, появилась нормальная поддержка билдов проекта, в которой можно указывать данные комбинации флагов персонально для каждого типа сборки.
1.4. Окно стека вызовов («Call Stack»)
Если ВР является нашим основным инструментом при отладке приложения, то «Call Stack» второй по значимости.
Выглядит данное окно следующим образом:
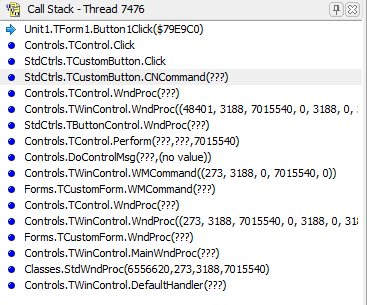
Он содержит полное описание вызовов, которые были выполнены до того, как отладчик прервал выполнение программы на установленном ВР (или остановился из-за возникновения ошибки). Например, на скриншоте изображен стек вызовов, произошедших при нажатии кнопки на форме. Начался он с прихода сообщения WM_COMMAND (273) в процедуру TWinControl.DefaultHandler.
Имея на руках данный список, мы можем быстро переключаться между вызовами двойным кликом (или через меню «View Source»), просматривать список локальных переменных для каждого вызова («View Locals»), устанавливать ВР на любом вызове.
Возможностей у него, конечно, не много, но тем не менее он очень сильно облегчает работу при отладке, так как в большинстве случаев позволяет достаточно быстро локализовать место возникновения ошибки.
Например вот так будет выглядеть стек вызовов при возникновении ошибки EAbstractError:
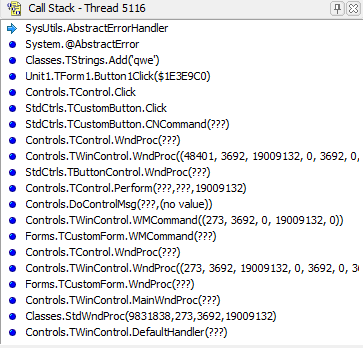
В данном случае достаточно найти самый первый сверху вызов, код которого расположен не в системных модулях Delphi, чтобы с большой долей вероятности сказать, что ошибка именно в нём. Таким вызовом является Unit1.TForm1.Button1Click() — это обработчик кнопки Button1 в котором выполнялся следующий код:
procedure TForm1.Button1Click(Sender: TObject);
begin
TStrings.Create.Add('qwe');
end;
Еще одним из вариантов использования является отслеживание вызовов тех или иных функций. Например, у нас очень большой код приложения, и где-то глубоко внутри него происходит вызов MessageBox, но мы не можем с наскоку найти это место, чтобы локализовать место вызова именно этого MessageBox. Для этого можно воспользоваться следующим методом:
- перейти в модуль, где объявлен вызов интересующей нас функции (в данном случае это windows.pas),
- найти её объявление (строка с синей точкой function MessageBox; external user32…),
- установить на данной строке ВР и запустить программу.
Как только из любого места программы произойдет вызов MessageBox, сработает наш ВР и мы сможем – на основании данных «Call Stack» – выяснить точное место его вызова.
1.5. Работа с расширенными свойствами точек остановки
Допустим, мы точно знаем в каком месте алгоритма у нас происходит ошибка, но ошибка эта происходит не всегда, а при выполнении алгоритмом операций только с определенными данными, в этом случае нет смысла просматривать все сработки ВР в ожидании того момента, когда алгоритм начал работать не верно, гораздо проще указать нашей ВР ожидать необходимые данные, пропуская все лишнее.
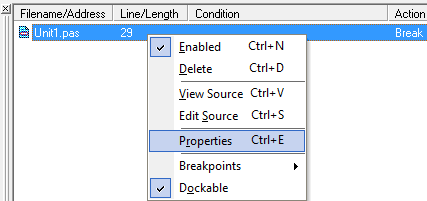
Делается это посредством диалога настроек свойств точки остановки. Вызывается он либо через свойства BP в коде приложения.
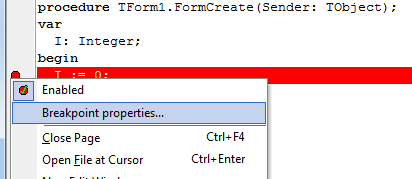
Либо в окне «Breakpoint list» так же через свойства выбранной BP.
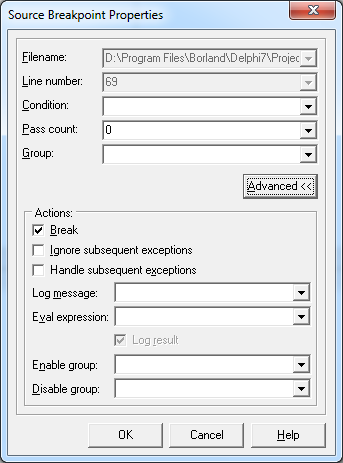
Выглядит диалог настроек следующим образом:

Параметр «Condition» отвечает за условие срабатывания точки остановки.
Параметр «Pass count» указывает, сколько таких условий нужно пропустить, прежде чем ВР будет активирована, причем подсчёт количества срабатываний ведется от самого первого, с учетом значения параметра «Condition».
Рассмотрим абстрактный пример:
procedure TForm1.FormCreate(Sender: TObject);
var
I, RandomValue: Integer;
begin
RandomValue := Random(100);
for I := 1 to 100 do
RandomValue := RandomValue + I;
ShowMessage(IntToStr(RandomValue));
end;
Допустим, ВР установлена на седьмой строчке (RandomValue := …). Если программу просто запустить, то мы получим на руки ровно 100 срабатываний ВР. Для того чтобы данная ВР срабатывала каждый десятый вызов необходимо в свойстве «Pass count» выставить значение 10. В этом случае мы получим ровно десять срабатываний ВР, в тот момент кода итератор «I» будет кратен десяти.
Допустим, теперь мы хотим начать анализ после 75 итерации включительно, для этого выставим следующее условие в параметре «Condition»: I > 75. В этом случае данная ВР сработает всего два раза: в тот момент, когда итератор «I» будет равен 85, и второй раз, при значении 95.
Произошло это по следующим причинам:
В первом случае, когда у нас не было условия, ВР срабатывала на каждой итерации цикла, но т. к. был указан параметр «Pass count», управление не переходило к отладчику, а происходило всего лишь увеличение количество срабатываний ВР до тех пор, пока их количество не становилось равным заданному в «Pass count». Поэтому мы получали управление только каждую десятую итерацию (после чего счетчик обнулялся).
Во втором случае увеличение счетчика сработок начало происходить только после выполнения изначального условия «Condition», т. е., пока итератор «I» был меньше или равен числу 75, отладчик считал, что условие не выполнено и продолжал выполнение программы. Как только первое условие выполнилось, началось увеличение количества срабатываний, которое стало равным значению параметра «Pass count» именно в тот момент, когда итератор «I» достиг значения 85.
Естественно, если мы хотим, чтобы ВР начала срабатывать сразу после превышения итератором «I» числа 75, то параметр «Pass count» необходимо выставить в ноль.
Группируя эти два параметра мы можем более гибко настроить условия срабатывания наших ВР.
Теперь рассмотрим один небольшой нюанс.
Условия передачи управления отладчику, указанные в свойствах ВР, рассчитываются самим отладчиком. Т.е. грубо (взяв за основу вышеописанный пример), не смотря на то, что мы прервались на ВР всего лишь два раза, на самом деле прерывание произошло все 100 раз, просто мы не получали управление в те моменты, которые не соответствовали заданным нами условиям.
Чем это плохо: если подобным образом анализировать достаточно долгий по продолжительности цикл (например, от десяти тысяч итераций и выше), то отладка программы может очень сильно затормозить вашу работу.
Можно проверить на следующем коде:
procedure TForm1.FormCreate(Sender: TObject);
var
I, RandomValue: Integer;
begin
RandomValue := Random(100);
for I := 1 to 10000 do
RandomValue := RandomValue + I;
ShowMessage(IntToStr(RandomValue));
end;
Установим ВР на той же седьмой строчке и укажем в параметре «Condition» значение I=9999. Даже на таком маленьком цикле нам придётся ждать срабатывания условия в районе 3-5 секунд. Конечно же, это не удобно. В таких случаях проще модифицировать код следующим образом:
procedure TForm1.FormCreate(Sender: TObject);
var
I, RandomValue: Integer;
begin
RandomValue := Random(100);
for I := 1 to 10000 do
begin
RandomValue := RandomValue + I;
{$IFDEF DEBUG}
if I = 9999 then
Beep;
{$ENDIF}
end;
ShowMessage(IntToStr(RandomValue));
end;
… и поставить ВР на Beep, чем ждать столь продолжительное время. В этом случае мы получим управление на практически мгновенно.
(В релизной сборке проекта директива DEBUG будет отсутствовать и отладочный код не попадет в неё, но лучше, после отладки, все же не забывать удалять все эти отладочные Beep-ы. )
Подобные «тормоза» обусловлены тем, что всё взаимодействия отладчика с отлаживаемым приложением происходит через механизм структурной обработки исключений (SEH), более известный Delphi программистам через куцую обертку над ним в виде try..finally..except. Работа с SEH является одной из наиболее «тяжелых» операций для приложения. Дабы не быть голословным и показать его влияние на работу программы наглядно, рассмотрим такой код:
function Test1(var Value: Integer): Cardinal;
var
I: Integer;
begin
Result := GetTickCount;
for I := 1 to 100000000 do
Inc(Value);
Result := GetTickCount - Result;
end;
function Test2(var Value: Integer): Cardinal;
var
I: Integer;
begin
Result := GetTickCount;
for I := 1 to 100000000 do
try
Inc(Value);
finally
end;
Result := GetTickCount - Result;
end;
procedure TForm1.FormCreate(Sender: TObject);
var
A: Integer;
begin
A := 0;
ShowMessage(IntToStr(Test1(A)));
A := 0;
ShowMessage(IntToStr(Test2(A)));
end;
В функции Test1 и Test2 происходит инкремент переданного значения 100 миллионов раз.
В первом случае она выполняется в районе 210 миллисекунд, тогда как во втором случае – в четыре с небольшим раза дольше, а изменений между ними по сути нет – всего лишь глухой try..finally.
Это, кстати тоже вам в «копилочку» – по возможности не вставляйте обработку исключений внутрь циклов, лучше выносите её за пределы…
Не рассмотренным у нас остался параметр «Group», он отвечает за включение BP в определенную группу точек остановки. Группа – понятие условное, на самом деле это некий идентификатор, произвольно задаваемый разработчиком, но удобен он тем, что к данным идентификаторам можно применить групповые операции управляя активностью всех BP, входящих в данную группу.
Групповые операции настраиваются в расширенных настройках ВР:
Отвечают за это параметры: «Enable group» – активирующий все ВР группы, и «Disable group» – отключающий все ВР входящие в группу.
Так же при групповых операциях часто применяется параметр «Break», который отвечает за действия отладчика при достижении ВР. Если данный параметр не активен, то прерывания выполнения программы при достижении данной ВР не происходит.
Важно – данный параметр не отключает саму ВР.
В общем случае – использование групповых операций применяется в тех случаях, когда отладка при помощи обычных ВР не удобна.
Давайте рассмотрим применение групп на следующем примере, в нем как раз показано неудобство использования обычных ВР и работа с групповыми операциями.
Перед компиляцией примера обязательно включите в настройках компилятора опцию «Overflow cheking» и отключите оптимизацию.
function Level3(Value: Integer): Integer;
var
I: Integer;
begin
Result := Value;
for I := 0 to 9 do
Inc(Result);
end;
function Level2(Value: Integer): Integer;
var
I: Integer;
begin
Result := Value;
for I := 0 to 9 do
Inc(Result, Level3(Result) shr 1);
end;
function Level1(Value: Integer): Integer;
var
I: Integer;
begin
Result := Value;
for I := 0 to 9 do
Inc(Result, Level2(Result) shr 3);
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
ShowMessage(IntToStr(Level1(0)));
end;
После запуска данного кода, произойдет исключение на шестнадцатой строчке
Inc(Result, Level3(Result) shr 1);.
Обычно, для того чтобы разобраться в причинах ошибки, ставят ВР на строку, в которой произошло поднятие исключения, но в данном конкретном примере нам это не поможет. Причина проста: данная строчка десятки раз подряд будет выполнена успешно, и, если мы поставим ВР на ней, то все эти десятки раз нам придется нажимать «F9» до тех пор, пока мы не достигнем непосредственно самого исключения.
В процессе отладки приложение обычно перезапускается много раз, и, чтобы его было удобно отлаживать, нам необходимо установить ВР на данной строчке таким образом, чтобы она срабатывала непосредственно перед ошибкой.
Сделаем это следующим образом:
- Поставим ВР на шестнадцатой строчке и назначим ей группу «level2BP».
- Отключим данную группу, чтобы установленная ВР не срабатывала раньше времени. Для этого в процедуре FormCreate поставим новую ВР на ShowMessage и в параметре «Disable group» укажем группу «level2BP». Чтобы не прерываться на новой ВР, в его настройках отключим параметр «Break».
- В функции Level1 устанавливаем ВР на строчке №25. Посчитаем, сколько раз выполнится данная ВР перед появлением ошибки.
- Выясняем, что было 9 прерываний (итератор I в этот момент равен восьми). Значит, нам нужно пропустить первые 8 прерываний, в которых ошибок не обнаружено, и на девятом включить ВР из группы «level2BP». Для этого заходим в свойства текущей ВР и выставляем в параметре «Condition» значение I=8, после чего исключаем его из обработки через отключение параметра «Break» и в настройках «Enable group» прописываем «level2BP».
- Перезапустив приложение, мы сразу прервемся в процедуре Level2, но не в момент самой ошибки – ошибка произойдет через несколько итераций. Несколько раз нажмем F9, считая количество итераций, и выясним, что это происходит в тот момент, когда итератор I был равен 5. В параметре «Condition» текущей ВР установим условие I=5, после чего можно смело перезапускать приложение.
- Первое же прерывание в отладчике произойдет непосредственно в месте возникновения ошибки, откуда и можно приступать к разбору причин ее возникновения.
Если из описания примера не все понятно — посмотрите ролик, демонстрирующий всю последовательность действий:
rouse.drkb.ru/blog/bp3.mp4 (17 Мб).
(я извиняюсь, но вставить ссылку так, чтобы ролик отображался прямо в теле статьи, у меня не получилось, поэтому только ссылка)
Таким образом, используя всего три ВР и групповые операции над ними, мы достаточно точно локализовали место ошибки и обеспечили удобство отладки кода.
Почему в примере не использовался параметр «Pass Count», а условия задавались через параметр «Condition»? Дело в том, что «Pass Count» просто отключает прерывание на ВР. Сама же ВР выполняется (т. к. условия её выполнения описаны в параметре «Condition») и раз она выполнилась, то выполняются и её групповые операции.
Осталось рассмотреть еще несколько параметров.
Параметр «Ignore subsequent exceptions» отключает реакцию отладчика на любое исключение, возникшее после выполнения ВР с включенным данным параметром.
Параметр «Handle subsequent exceptions» отменяет действие предыдущего параметра, возвращая отладчик в нормальный режим работы.
Чтобы посмотреть как это выглядит, создадим такой код:
procedure TForm1.Button1Click(Sender: TObject);
begin
ShowMessage('All exceptions ignored');
end;
procedure TForm1.Button2Click(Sender: TObject);
begin
PInteger(0)^ := 123;
end;
procedure TForm1.Button3Click(Sender: TObject);
var
S: TStrings;
begin
S := TStrings.Create;
try
S.Add('abstract')
finally
S.Free;
end;
end;
procedure TForm1.Button4Click(Sender: TObject);
begin
ShowMessage('All exceptions handled');
end;
На первом ShowMessage поставьте ВР, отключите его, сняв галку с параметра «Break», и включите параметр «Ignore subsequent exceptions».
На втором ShowMessage сделайте то же самое, только включите параметр «Handle subsequent exceptions».
Запустите приложение из отладчика и пощелкайте по кнопкам в следующем порядке:
- Button1
- Button2
- Button3
- Button4
- Button2
- Button3
Не смотря на то, что кнопки Button2 и Button3 генерируют исключение, на этапе 2 и 3 отладчик на них никак не прореагирует, мы дождемся от него реакции только на этапах 5 и 6 после того, как активируем нормальную обработку исключений нажатием кнопки Button4.
Осталось 2 параметра:
«Log message» – любая текстовая строчка, которая будет выводится в лог событий при достижении ВР.
«Eval expression» – при достижении ВР, отладчик вычисляет значение данного параметра и (в случае если включен флаг «Log result») выводит его в лог событий. Значение для вычисления может быть любым, хоть тот же «123 * 2».
1.6. Использование «Data breakpoint», «Watch List» и «Call Stack»
Все, что мы рассматривали ранее, относилось к так называемым «Source Breakpoint». Т. е. к точкам остановки, устанавливаемым непосредственно в коде приложения.
Но, помимо кода, мы работаем с данными (переменными, массивами, просто с участками выделенной памяти) и у отладчика есть возможность устанавливать BP на адреса, по которым эти данные расположены в памяти, при помощи «Data breakpoint».
Установка ВР на адрес памяти производится через «Watch List» (не во всех версиях Delphi) или в окне «Breakpoint List» при помощи «Add Breakpoint->Data Breakpoint», где, в появившемся диалоге, указываем требуемый адрес, размер контролируемой области или имя переменной. В случае указания имени переменной, отладчик попробует вычислить ее расположение в памяти и (если это возможно) установит ВР.
Неприятность заключается в том, что получить данное значение достаточно сложно по причине того, что при каждом запуске приложения адрес, по которому расположена переменная, будет каждый раз разный.
Что такое область видимости переменной – вы должны знать. Глобальные переменные доступны нам всегда, и, даже без запуска приложения, отладчик предоставляет нам возможность устанавливать «Data breakpoint» на изменения в таких переменных. Правда, в данном случае он рассчитывает адрес такой переменной на основании предыдущей сборки приложения, и не факт, что он совпадет с ее расположением при следующем запуске. Ситуация гораздо хуже с локальными переменными. Область видимости переменной – это не просто так введенное понятие, локальные переменные расположены на стеке, и, как только они выходят из области видимости, место, занимаемое ими ранее, используется под хранение совершенно других данных. Таким образом установить «Data breakpoint» на локальную переменную можно только в тот момент, пока она не вышла из области видимости.
Те, кто ранее работал с профессиональными отладчиками, вероятно узнают в «Data breakpoint» один из базовых инструментов анализа приложения – «Memory Breakpoint».
К сожалению, отладчик Delphi не позиционируется как профессиональное средство отладки сторонних приложений, поэтому столь полезный инструмент как «Memory Breakpoint» представлен в нем в обрезанном варианте, где от него оставлена только возможность контроля адреса памяти на запись.
Но даже в этаком ограниченном варианте он остается отличным инструментом для контроля изменений в памяти приложения, особенно для отслеживания ошибок при адресной арифметике.
Рассмотрим следующий код:
type
TTest = class
Data: array [0..10] of Char;
Caption: string;
Description: string;
procedure ShowCaption;
procedure ShowDescription;
procedure ShowData;
end;
TForm1 = class(TForm)
procedure FormCreate(Sender: TObject);
private
FT: TTest;
procedure InitData(Value: PChar);
end;
var
Form1: TForm1;
implementation
{$R *.DFM}
{ TTest }
procedure TTest.ShowCaption;
begin
ShowMessage(Caption);
end;
procedure TTest.ShowData;
begin
ShowMessage(PChar(@Data[0]));
end;
procedure TTest.ShowDescription;
begin
ShowMessage(Description);
end;
{ TForm1 }
procedure TForm1.FormCreate(Sender: TObject);
begin
FT := TTest.Create;
try
FT.Caption := 'Test caption';
FT.Description := 'Test Description';
InitData(@FT.Data[0]);
FT.ShowCaption;
FT.ShowDescription;
FT.ShowData;
finally
FT.Free;
end;
end;
procedure TForm1.InitData(Value: PChar);
const
ValueData = 'Test data value';
var
I: Integer;
begin
for I := 1 to Length(ValueData) do
begin
Value^ := ValueData[I];
Inc(Value);
end;
end;
На первый взгляд как будто все правильно, но запустив программу на выполнение мы получим примерно такую ошибку:
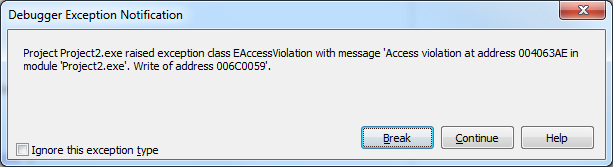
Нажав на «Break», мы окажемся где-то внутри модуля «system»:
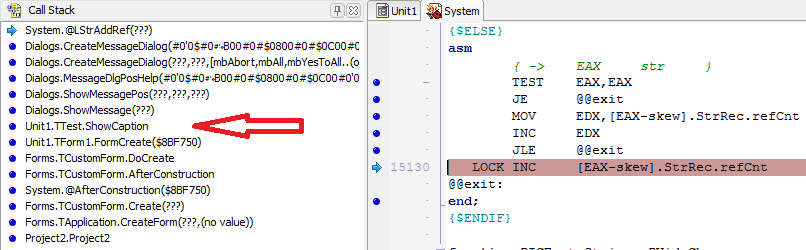
Код, на котором мы прервались, ничего нам не может сказать о причине возникновения ошибки, но у нас есть окно «Call Stack», на основании которого мы можем сделать вывод, что ошибка произошла при вызове процедуры ShowCaption в главном модуле программы.
Если установить BP в данной процедуре и перезапустить программу, а затем, при срабатывании ВР, проверить значение переменной Caption, то окажется что данная переменная не доступна:
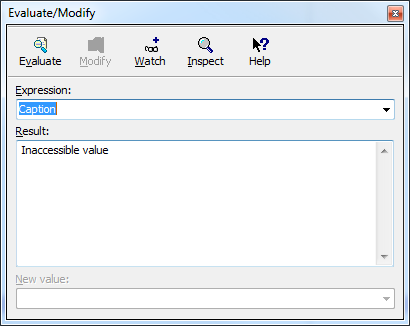
Это означает, что где-то произошло разрушение памяти и затерлись данные по адресу переменной Caption. Определить это место нам поможет «Data breakpoint».
- Дождемся инициализации переменной Caption, для этого установим ВР на строчке FT.Description := ‘Test Description’;.
- При срабатывании ВР, добавим переменную FP.Caption в «Watch List» и в свойствах этой переменной выберем «Break When Changed». Если данного пункта меню у вас нет (например, в Delphi 2010 он отсутствует), то установим «Data breakpoint» немного другим способом. В «Breakpoint List» выбираем «Add->Data Breakpoint», в появившемся диалоге указываем имя переменной FP.Caption и нажимаем ОК.
- Запускаем программу на выполнение.
После выполнения этих действий, программа остановится на строчке №68 – Inc(Value). Особенность «Data breakpoint» в том, что остановка происходит сразу после произошедших изменений, а не при попытке изменения контролируемой памяти, поэтому место, где происходит запись по адресу переменной FP.Caption, находится строчкой выше – это строка Value^ := ValueData[I].
Теперь, найдя проблемное место, мы можем исправить и саму ошибку. Она заключается в том, что длина строки ValueData, которую мы пишем в буфер Data, превышает размер буфера, из-за чего происходит перезапись памяти, в которой расположены переменные Caption и Description.
1.7. В заключение
На этом я заканчиваю краткий обзор возможностей интегрированного отладчика. Осталось несколько нерассмотренных нюансов, как то: настройка игнорируемых исключений, ВР при загрузке модуля и т.п., но они несущественны и крайне редко применяются на практике.
Так же нерассмотренным остался режим отладки в окне «CPU-View» и связанные с ним Address Breakpoint. Его я так же решил пропустить, т.к. читателям не знакомым с ассемблером мое объяснение не даст ничего, а более подкованные специалисты и без меня знают что такое CPU-View и как его правильно применять 
Во второй части статьи, будет рассмотрена программная реализация отладчика. В ней будет показано, что именно происходит при установке BreakPoint, показана обратная сторона Data Breakpoint, не реализованная в отладчике Delphi, показано как в действительности производится трассировка (двумя методами, классический через TF флаг и на основе GUARD страниц), а так же рассмотрен механизм Hardware Breakpoint, тоже отсутствующий в интегрированном отладчике Delphi.
Отдельная благодарность сообществу форума «Мастера Дельфи» за помощь при подготовке статьи, а также персональное спасибо Андрею Васильеву aka Inovet, Тимуру Вильданову aka Palladin и Дмитрию aka Брат Птибурдукова за вычитку материала и ценные советы.
Александр (Rouse_) Багель
Москва, октябрь 2012
Недавно мы рассказали о том, как начать писать программы на JavaScript:
- что такое HTML и JavaScript;
- из чего состоят скрипты;
- как и где их выполнять и куда вставлять;
- где искать готовые решения и что с ними потом делать;
- как работать с разными элементами и обрабатывать нажатия клавиш.
Теперь шагнём дальше — изучим отладку скриптов в браузере и посмотрим, чем она может нам помочь.
Что такое отладка
Отладка — это поиск и исправление ошибок в программе. Например, мы написали скрипт, добавили его на страницу, настроили запуск по нажатию кнопки — а при нажатии ничего не происходит. При этом в консоли нет никаких ошибок — все команды верные, браузер просто что-то делает, а результата нет. Отладка нужна как раз для того, чтобы найти ошибку и исправить её.
Варварская отладка
Самый примитивный вариант отладки — добавить в код на JavaScript метод console.log(), поместив в скобки нужные данные для отладки. Console.log() — это просто способ вывести в консоль какой-нибудь текст.
Например, внутри функции можно сказать: console.log(‘Вызвана такая-то функция’) — и в нужный момент мы увидим, что функция вызвалась (или нет).
Минус этого подхода в том, что в коде появляется много отладочного мусора. А ещё, если мы не предусмотрели логирование для какой-то функции, то мы не поймаем в ней ошибку.
К счастью, помимо console.log() человечество изобрело много удобных инструментов отладки.
Что нужно для отладки
Для несложных проектов на JavaScript проще всего использовать встроенный отладчик в браузере Google Chrome. Единственное ограничение — он работает только с файлами скриптов, а не со встроенным в страницу кодом. Это значит, что если код скрипта находится внутри HTML-файла внутри тега <script>, то отладка не сработает.
Чтобы открыть панель отладки в Chrome, нажимаем ⌘+⌥+I и переходим на вкладку Sources (Источники):

Открываем скрипт
Допустим, мы хотим посмотреть, как работает скрипт из задачи про выпечку и как он перебирает все варианты.
Всё, что у нас есть, — это код. Чтобы мы смогли его отладить, его нужно положить в отдельный файл скрипта, присоединить к HTML-документу и запустить в браузере.
Открываем любой текстовый редактор, например Sublime Text, вставляем код скрипта и сохраняем файл как temp.js. Имя может быть любым, а после точки всегда должно стоять js — так браузер поймёт, что перед нами скрипт.
После этого в новом файле вставляем шаблон пустой HTML-страницы и подключаем наш скрипт — добавляем в раздел <body> такую строку:
<script type="text/javascript" src="temp.js"></script>
Получиться должно что-то вроде такого:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title></title>
</head>
<body>
<script type="text/javascript" src="temp.js"></script>
</body>
</html>Сохраняем этот код как HTML-файл, например index.html, и кладём в ту же папку, что и скрипт. Теперь заходим в папку и дважды щёлкаем по HTML-файлу, чтобы открыть эту страницу в браузере:

На странице ничего нет, но нам нужна не страница, а скрипт, поэтому находим слева наш файл temp.js и нажимаем на него — откроется код скрипта. Теперь можно начинать отладку:

Добавляем точки остановки
Точка остановки — это место, в котором наш скрипт должен остановиться и ждать дальнейших действий программиста. Их ещё называют брейкпоинты, от английского breakpoint — точка, где всё останавливается.
Когда скрипт доходит до этой точки, он ставит скрипт на паузу. При этом все данные и значения переменных скрипта остаются в памяти — в них можно заглянуть.
Брейкпоинт нужен для того, чтобы выполнить скрипт по шагам, начиная с первой команды. Чтобы его установить, нажимаем на номер строки с первой командой — в нашем случае это строка 2:

Обновим страницу и увидим, что скрипт начал работу и остановился. Но он остановился не на второй строке, а на шестой — всё потому, что это первая строка в скрипте, где происходит какое-то действие. Дело в том, что просто объявление новых переменных не влияет на работу скрипта, поэтому он ищет первую команду с действием. В нашем случае — это цикл for:

Пошаговая отладка
Чтобы посмотреть на работу скрипта по шагам, надо нажимать F9 или стрелку вправо с точкой на панели отладки:

Каждый раз, как мы будем нажимать F9 или эту кнопку, скрипт будет переходить к следующей команде, выполнять её и снова становиться на паузу:

Добавляем переменные для отслеживания
Если просто выполнять скрипт по шагам, то мы увидим, какие команды и в каком порядке выполняются, но не будем знать, какие значения лежат в переменных на каждом шагу. Их можно увидеть, просто наведя курсор на любую переменную — над ней появится всплывающая подсказка с текущим значением. Но так работать неудобно — проще сразу видеть значения всех переменных.
Чтобы добавить переменную и видеть её значение во время выполнения, в панели отладки в разделе Watch нажимаем плюсик, вводим имя переменной, выбираем её из списка и нажимаем энтер:

Теперь видно, что на этом шаге значение переменной a равно нулю:

Точно так же добавим остальные переменные: i, b, c. Так мы увидим, что первые два цикла только начались, а внутренний прошёл уже три итерации:

Так, нажимая постоянно F9, мы прогоним весь скрипт до конца и посмотрим, при каких значениях какие условия выполняются и как находится решение:

Но у такого подхода есть минус — если вложенных циклов много или скрипт очень большой, то на пошаговое выполнение уйдёт много времени. Чтобы не перебирать всё вручную, ставят дополнительные брейкпойнты в нужных местах.
Отладка брейкпойнтами
Допустим, нам важно понять, в какой момент скрипт находит и выдаёт решение. Глядя в код, мы понимаем, что как только скрипт дошёл до команды console.log() — он нашёл очередное решение. Это значит, что мы можем поставить брейкпоинт только на эту строчку и не прогонять вручную весь скрипт: он сам остановится, когда дойдёт до неё, а мы сможем посмотреть значения переменных в этот момент.
Для этого:
- Нажимаем снова на строку 2 и убираем предыдущую точку остановки.
- Ставим брейкпоинт на строку 20 — там, где происходит вывод решения в консоль.
- Нажимаем F8.
После этого скрипт продолжит работу сам и снова остановится, как только дойдёт до этой строки. Обратите внимание на значения переменных — они меняются к каждой остановке, а значит, скрипт работает как обычно, но останавливается в нужном нам месте:

Таких точек остановки можно поставить сколько угодно и в любой момент — на каждой из них отладчик остановится и покажет текущее состояние скрипта.
Зачем это всё
Отладка нужна, чтобы найти ошибки в программе. Если мы видим, что на очередном шаге в переменной находится не то, что мы ожидали увидеть, значит, что-то в коде идёт не так. Мы ставим брейкпоинт на начало нужных команд, запускаем отладку и находим команду, которая приводит к ошибке.
В следующей статье мы покажем на примере с реальным кодом, как отладка помогает находить и исправлять такие ошибки. Подпишитесь, чтобы не пропустить это.
Вёрстка:
Кирилл Климентьев