
Предлагаю ознакомиться с расшифровкой доклада начала 2019 года Алексея Лесовского — «Поиск и устранение проблем в Postgres с помощью pgCenter»
Время от времени при эксплуатации Postgres’а возникают проблемы, и чем быстрее найдены и устранены источники проблемы, тем благодарнее пользователи. pgCenter это набор CLI утилит которые является мощным средством для выявления и устранения проблем в режиме «здесь и сейчас». В этом докладе я расскажу как эффективно использовать pgCenter для поиска и устранения проблем, в каких направлениях осуществлять поиск и как реагировать на те или иные проблемы, в частности, как:
- проверить, все ли в порядке с Postgres’ом;
- быстро найти плохих клиентов и устранить их;
- выявлять тяжелые запросы;
- и другие полезные приемы с pgCenter.

Всем привет, меня зовут Алексей Лесовский. Я работаю в компании Data Egret. Это консалтинговая компания. И я вам расскажу, как мы в нашей консалтинговой компании занимаемся поиском и устранением неисправностей в PostgreSQL.
Я расскажу о том, как с помощью консольной утилиты pgCenter можно хорошо, быстро и эффективно находить самые разные проблемы и переходить к их устранению.

Немного о себе. Я долгое время был системным администратором. Занимался Linux, виртуализацией, мониторингом. И в какой-то момент времени стал заниматься больше Postgres’ом. И работа с Postgres стала занимать большую часть времени. И так я стал PostgreSQL DBA. И сейчас уже работая в консалтинговой компании, я работаю с Postgres каждый день. И каждый день наши заказчики предоставляют нам самый разный материал для новых конференций.

Все общение с нашими заказчиками происходит в виде беседы в чатах. Это самые разные чаты: Slack, Telegram. Но наши заказчики часто обнаруживают какую-нибудь проблему у себя и пишут. Мы в свою очередь должны на это отреагировать.

На слайде всем широко известная диаграмма Брендана Грэгга, как находить различные проблемы, связанные с производительностью в Linix. Это довольно познавательная диаграмма. Она показывает, как устроен Linux и какие утилиты есть для нахождения проблем. По сути, можно обложиться всеми этими утилитами и смотреть, что происходит.

Но в любом случае мы увидим то, что у нас все замыкается на Postgres. Процессорное время потребляется Postgres. Дисковый ввод-вывод так же генерируется Postgres’ом. Всю память съел тоже Postgres. Мы будем видеть только один Postgres.

Для Postgres есть аналогичная картинка. Она также разбивает Postgres на несколько подсистем и показывает из чего состоит Postgres. Кроме того, в Postgres есть большое количество статистических представлений (views), с помощью которых можно анализировать работу этих подсистем.
И этих статистических представлений довольно много. Но во всех этих представлениях есть колонки. Эти колонки имеют собственные имена. И держать все это в голове бывает довольно-таки сложно.

И когда ты начинаешь искать какую-то проблему, нужно вспомнить имена нужных представлений, найти свои скрипты, которые ты, возможно, заранее приготовил. И это довольно-таки тяжело. И одновременно возникает масса вопросов: «Что тормозит?», «Где тормозит?» и «Что с этим делать?». На поиск всего этого нужно время, которого как обычно мало.

И разбираясь с проблемой одного из заказчиков, когда я тоже разбирал свои скрипты и пытался диагностировать проблему выполняя рутинные однообразные действия, мне пришла в голову идея, что нужна программа, которая будет это все дело облегчать. Более-менее хороших программ не нашлось и так пришла идея написать pgCenter.
Изначально она была написана на С. Это консольная утилита, которая показывала статистику в TOP-подобном виде.
Через какое-то время я понял, что C мне не очень подходит. т.к. я не профессиональный программист. И я переписал ее на Golang, этот язык показался мне более простым, но при этом напоминал С. И мне на нем легче добавлять новые функции.
Go это компилируемый язык и чтобы использовать pgCenter его нужно скомпилировать. Но в репозитории уже есть пакеты и вам как пользователю не нужно компилировать программу самостоятельно. К репозиторию подключена система сборки, которая после каждого коммита, компилирует бинарник, собирает targz, deb- и rpm-пакеты и выкладывает их в релизы. Т.е. не нужно устанавливать какие-то пакеты, ставить make, GCC или Golang. Достаточно просто зайти в релизы, скопировать нужный пакет по ссылке, распаковать руками или установить через дефолтный пакетный менеджер и можно уже пользоваться.

Изначально весь pgCenter представлял собой именно просмотрщик статистики, который в top-режиме показывает текущие изменения статистики за последнюю секунду (интервал изменений настраивается).

Однако потом я начал добавлять новые функции. И позже уже появились такие штуки, как сохранение статистики в файл и построение отчетов. И буквально совсем недавно я добавил сэмплер wait_events. Это штука позволяет смотреть, на каком месте запросы проводят время в ожидании чего-либо.

По ходу разработки я постарался сохранить синтаксис команды PSQL. Если вы работаете с Postgres, вы знаете что запустив PSQL без аргументов и параметров можно подключиться к Postgres. С pgCenter тоже самое, достаточно запустить «pgcenter top» из под postgres пользователя и она начнет показывать вам какую-то статистику (по-умолчанию, текущая активность в БД).

В более сложных случаях, если вы работаете от другого пользователя или нужно подключиться к какой-то другой базе, или к БД, которая находится на другом хосте, то можно указать те же самые ключи, которые вы используете в PSQL, которые определяют подключения к хосту, к конкретному порту, к конкретной базе и под конкретным именем пользователя.

Но можно даже не указывать хост, можно подключаться через UNIX-сокеты, т. к. go’шный драйвер, который используется под капотом pgCenter позволяет подключиться не только к сетевым сокетам, но и к UNIX.

Кроме того, тот же драйвер поддерживает переменные окружения libpq. Даже если у вас особенный случай, например, pg_stat_statements установлен в отдельной схеме и pgCenter не может его найти, то можно переопределить поведение через переменные окружения. Это тоже поддерживается.

И вот так выглядит внешний вид утилиты (pgcenter top). И в первый раз, когда ее запускаешь, это может немного напрячь. Это похоже, что это какой-то центр управления полетами. Много цифр, много букв, все это быстро меняется. Но это на самом деле не важно. Здесь важно помнить, что интерфейс pgCenter, а именно top-просмотрщика, состоит из трех частей.

Первая часть – системная информация. Эта информация находится в верхнем левом углу.

Вторая часть – верхний правый угол, здесь располагается сводная информация по Postgres. Здесь можно получить уже какую-то детальную информацию о том, как Postgres работает в данный момент.

И третья часть – статистика из самих статистических представлений (views). Здесь информация из stat-представлений, которые есть в Postgres, в этой части отображаются изменения этой статистики.

Кроме того, интерфейс предоставляет дополнительные функции. Нажимая стрелки влево-вправо, вы можете менять сортировку. Вы можете указать сортировать строки по интересующему вас полю. Например, сортировку по именам таблиц, сортировку по текстам запросов, по времени и жизни транзакций, и т. д.
Если информации слишком много, можно использовать фильтры. В качестве фильтров там применяются регулярные выражения (regexp). И вы можете отфильтровать выводимую инфоормацию по интересующим вас критериям. Например, показать запросы конкретного пользователя, базы или конкретно какие-то запросы: селекты или апдейты.

Далее в докладе я расскажу, с какими конкретно кейсами вы можете столкнуться у себя в работе и какие подходы можете применять используя pgCenter. И самый основной кейс – это проверка все ли в порядке с базой и нет ли там каких-то проблем.

И здесь мы все делаем, как по известному USE методу. Нам нужно определить использование ресурсов. Если ресурсы используются более-менее хорошо и прекрасно, то мы смотрим наличие ошибок.

Для этого мы начинаем смотреть системную информацию. У нас есть информация об использовании процессора. Всем, кто знаком с утилитой линуксовой Top, вот этот раздел статистики будет очень хорошо знаком. Он показывает утилизацию процессора: системную, пользовательскую и т.д.

Если нам интересно посмотреть память, то в этой же строке также мы можем посмотреть и память: сколько у нас есть памяти вообще, сколько свободно, сколько занято.

И, соответственно, swap. Если в системе есть swap, а для базы данных он важен, то можно посмотреть еще и статистику по swap. Таким образом в части по системной статистике можно быстро определить – есть ли у нас проблема с утилизацией ресурсов.

Кто-то может спросить: «А как с блочным вводом-выводом и сетью?». Эта статистика тоже есть. Ее я покажу чуть позже, по ней тоже есть цифры.

Когда мы посмотрели нет ли у нас проблем с утилизацией ресурсов, мы можем идти к проверке – нет ли у нас каких-либо ошибок на уровне работы Postgres. Мы можем посмотреть uptime. Вообще, uptime в Postgres – не совсем честный, но тем не менее это лучше, чем совсем ничего. С аптаймом можно быстро определить, как давно у нас работает Postgres и не было ли у него незапланированных рестартов.

Кроме того мы можем посмотреть состояние по подключениям. Не все клиенты, которые работают с Postgres, могут быть хорошими. У нас могут быть ждущие транзакции, которые находятся в ожидании, или транзакции которые ничего не делают. Т. е. это та активность которую важно отслеживать и вовремя принимать меры.

И, конечно, автовакуум. Я думаю, многие из вас знают, что такое автовакуум. С ним связано много интересных историй, поэтому про вакуум тоже можно посмотреть. Например, сколько воркеров запущено и посмотреть их длительность. И после этого можно как-то реагировать на эту информацию.

И долгие транзакции, потому что Postgres MVCC база данных. В ней MVCC движок. И он очень сильно зависит от того, как долго там работают транзакции. Поэтому самые долгие транзакции тоже важно отслеживать и быстро о них узнавать.

На этом слайде было переключение на статистику баз данных с помощью горячей клавиши ‘d’.
Говоря про ошибки, важно отметить pg_stat_database которая предоставляет некоторое количество информации об ошибках, тут нас интересует поле «rollbacks». Это поле не только про команду «ROLLBACK», но еще и про различные ошибки которые привели к отмене запроса/транзакции. Это могут быть ошибки нарушения ограничений (constraints), это могут быть ошибки синтаксиса и т. п. По этой статистике можно уже отследить, что происходит в базе.
И плюс в pg_stat_database есть еще информация по конфликатм репликации (conflicts) и взаимоблокировкам (deadlocks). По сути, это тоже виды ошибок, которые говорят о том, что в базе что-то идет не так.

ОК, мы запустили pgCenter. И за относительно короткое время мы смогли посмотреть много вещей, ради которых нам бы пришлось запустить несколько утилит. Во-первых, это:
-
top
-
vmstat
-
iostat
-
nicstat
-
pg_stat_activity
-
pg_stat_statements
Плюс там еще использовали некоторые функции, которые тоже показывают информацию в более понятном виде.

Допустим, что в процессе проверки мы обнаружили, что у нас какая-то есть нагрузка на процессор.

Вот такой простой пример. Вам не обязательно все это рассматривать, важно отследить те места, которые используются в процессе оценки. Т. е. здесь CPU usage – 85 %. Это говорит о том, что у нас нагрузка на процессоры довольно-таки высокая. И нам нужно найти, кто же так активно использует процессора. Понятно, что это Postgres. Нам нужно заглянуть глубже в Postgres и посмотреть, какие типы запросов у нас больше всего потребляют процессорного времени.

Если мы посмотрим на вторую часть экрана, то мы увидим, что у нас 38 активных клиентов, которые что-то делают. При этом нужно посмотреть на соседние state: на waiting и на idle_xact. Waiting у нас 0, т. е. у нас клиенты не находятся в режиме ожидания и это хорошо. С другой стороны, у нас есть 20 idle транзакций. Соответственно, мы можем включить сортировку по длительности транзакций (xact_age) и посмотреть – сколько времени наши транзакции находятся в простое. И здесь видно, что простаивает всего одна транзакция. И ее время жизни – 15 секунд. Это не страшно, и в большинстве случаев это можно не считать криминалом.

(Примечание: На слайде переключились в pg_stat_statements. Чтобы переключится в pg_stat_statements необходимо нажать «x», там будут нужные столбцы. Второй вариант «shift + x» и в меню выбрать pg_stat_statements_timings. Если будет ошибка «pg_stat_statements not available on this database», то нужно установить расширение pg_stat_statements от юзера postgres в базу postgres: create extension pg_stat_statements;)
Но мы же ищем источник, кто у нас потребляет больше всего (процессорного) времени. Нам нужно оценить, какие запросы используют больше всего времени. Для этого мы используем pg_stat_statements. Это contrib. Он показывает нам статистику по запросам: сколько они выполнялись, сколько ресурсов потребляли. Этот contrib должен быть установлен в базе, чтобы брать с нее статистику. К сожалению, он выключен по-умолчанию. И одна из основных рекомендаций по настройке Postgres – включать pg_stat_statements.
Предположим, что он у нас стоит. Нам нужно посмотреть время, кто у нас тратить больше всего. Мы стрелочками переключаем сортировку. И видим те запросы, которые у нас тратили больше всего CPU с момента сброса статистики pg_stat_statements. Тут отражен примерно суточный разрез – за сутки конкретный тип запроса отработал 2 часа с лишним. Это запрос SELECT COUNT (*) FROM "game_competition_events". Т. е. уже имея на руках запрос, мы можем сходить в логи, взять параметры этого запроса и посмотреть, какой у него план, и попытаться с ним разобраться. Может быть, там нет какого-нибудь индекса, может быть, там запрос написан неоптимальный или еще что-то. Уже у нас есть конкретная информация о том, кто потребляет процессорное время.
Но здесь есть небольшая ловушка. Мы используем сортировку под total_time. А в total_time включается не только процессорное время, но еще и время, потраченное на операции блочного ввода/вывода: на чтение и на запись. Соответственно, нам желательно включить сортировку по полю «t_cpu_t». Оно нам более релевантно. Оно нам позволяет смотреть именно процессороемкие запросы.

Как я уже сказал, эта статистика показывает самые жадные до ресурсов запросы с момента сброса статистики. Если нам нужно смотреть запросы, которые отнимают процессорное время здесь и сейчас, то мы смотрим уже по полю «cpu_t», это, условно говоря, дельта. Мы берем snapshot статистики за прошлую секунду, за текущую секунду, считаем дельту и показываем. Здесь запрос уже совершенно другой. Это SELECT "courses_logs".* FROM course_logs. И здесь видно, что текущую секунду он съел уже 5 секунд процессорного времени. Это либо запрос, который использует параллельные воркеры, либо, возможно, он просто запускается слишком часто.
И если посмотреть на соседнюю колонку «calls», то там будет видно, что запрос выполняется один. Один запрос в секунду. Т. е. это запрос с параллельными воркерами.

Пока мы все это смотрели, мы могли использовать другие утилиты. Это Top и плюс нам нужно было заглянуть в pg_stat_activity и в pg_stat_statements. Но с помощью pgCenter это все в одном месте собрано и можно этим пользоваться.

Другой вариант – это нагрузка на ввод-вывод. Это другая противоположность, когда с процессорами у нас все в порядке, но диски слабые и нужно разобраться, кто утилизирует ввод-вывод.

Ситуация похожа на предыдущий случай. Мы смотрим на утилизацию процессоров и видим, что у нас утилизация процессоров на время ожидания блочного ввода-вывода довольно высокое – 27 %. Нам нужно найти те запросы, которые вызывают этот ввод-вывод.

Плюс мы можем еще обратить внимание на то, что многие клиенты с типом «background worker». Это явный показатель, что у нас параллелизм включен и запрос выполняется параллельно.

Посмотрим по соседним «wait_event». И тут видно, что эти клиенты находятся в ожидание ввода-вывода. Т. е. очень много времени тратится на чтение данных с диска.

И здесь нам уже понадобится статистика по блочному вводу-выводу. С помощью горячей клавиши ‘B’ мы включаем встроенный iostat. И он нам показывает утилизацию дисковых устройств. Здесь видно, что утилизация одного из устройств 99 %. Но здесь самое главное – это не попасть в ловушку, потому что устройство у нас NVME. И нужно уже смотреть не только на утилизацию, но и на latency.

Если посмотреть на latency, то latency для этого устройства будет составлять всего лишь 1 миллисекунду. И это вполне нормально.
Это значит, что у нас нет особых проблем в производительности. Это связано с тем, что современные SSD и NVME-устройства выполняют операции ввода-вывода в несколько потоков, поэтому мы можем видеть большую утилизацию, но при этом низкий latency. Если мы видим большие цифры по latency, то это значит, что у нас действительно уже есть проблемы и нужно что-то делать.

Но тем не менее давайте смотреть, какие запросы выполняют больше операций ввода-вывода. Мы переключаемся на pg_stat_statements и смотрим уже не процессорное время, а время ввода-вывода. Это колонка «t_read_t», т. е. время, потраченное на чтение данных с момента сброса статистики.
Аналогичная колонка есть и для просмотра статистики за последнюю секунду. Это колонка «read_t». Мы можем менять сортировки и смотреть, какие запросы за весь интервал времени сожрали больше всего ввода-вывода, либо за последнюю секунду.
Важно отметить что статистика по ввод/выводу собирается только при включенном track_io_timing.
И уже имея текст запроса мы можем переходить к его поиску в логах, найти его параметры и узнать, что там долго там работает. Но pgCenter еще предоставляет такую штуку как queryid. Это такой идентификатор запроса. Но это не такой идентификатор, который предоставляется в pg_stat_statements. Он немного другой. Его можно использовать для построения отчетов. Т. е. pgCenter предоставляет такую функцию как построение отчетов по конкретной группе запросов. Также через горячие клавиши мы смотрим по queryid. И pgCenter предоставляет отчет.

Отчет состоит из трех частей:
-
Первая часть – это summary, общая картина составленная на основе той статистики, которая накопилась в pg_stat_statements. Это количество запросов, затраченное время в процессорах, затраченное время ввода-вывода.
-
Вторая секция уже связана уже с нашим запросом, эта секция описывает, какой вклад запрос вносит в общую статистику в summary. И мы уже можем видеть статистику связанную с этим запросом относительно всех остальных запросов.
-
И, конечно, сам текст запроса.
Строя такие отчеты, мы можем быстро посмотреть, насколько наш запрос вносит нагрузку в суммарную картину.

И если рассматривать, что мы затронули под капотом, пока это все смотрели, то все это покрывается утилитами top, iostat и представлениями pg_stat_activity, pg_stat_statements. Плюс там есть еще несколько функций, которые приводят все это в понятный вид.

Но запросы клиентские – это не единственная вещь, которая позволяет генерировать ввод-вывод. И в Postgres есть еще всякие фоновые задачи, которые тоже могут создавать нагрузку на диск.
Это:
-
Checkpointer pocess.
-
WAL writer process.
-
Autovacuum workers.
-
Background workers.
На данный момент pgCenter показывает только прогресс по вакууму, по остальным пока информации нет, но тем не менее это уже хорошо.

Предположим, что у нас с ресурсами все в порядке: блочного ввода-вывода никто особо не потребляет, с процессорами тоже полный порядок. И мы переходим к вопросу, что нужно посмотреть, что у нас на уровне ошибок.

И чаще всего это описывается ситуациями, когда клиент пишет в чат, что у него ничего не работает. Всё лежит и нужно что-то делать.

Здесь мы мельком посмотрели утилизацию ресурсов.

И тут нужно уже смотреть на состояние подключенных клиентов. Если посмотреть на клиентов, то будет видно, что у нас 22 активных клиентов и при этом 21 из них находится в режиме ожидания. Это уже показатель того, что что-то работает не так.

Если посмотреть на wait_event этих клиентов, то будет видно, что они все находится в режиме ожидания идентификатора транзакций. Т. е. какой-то клиент что-то делает, а остальные выстроились в некий хвост и пытаются дождаться, когда эта транзакция сделает свою работу.

Нужно посмотреть на соседнее поле, которое показывает транзакции в режиме простоя (idle in transaction). И здесь мы видим, что их 6 штук. И нужно включить сортировку по времени работы транзакции.

Если посмотреть на отсортированное поле, то мы увидим, что у нас есть 10-минутная транзакция, которая ничего не делает в данный момент. Если мы посмотрим ниже, то есть еще куча транзакций, которые 7 минут находятся в ожидании. И они явно выстроились как раз в хвост за 10-минутной транзакцией.

Если посмотреть на wait_etype, wait_event этой транзакции, которая ничего не делает, то мы увидим, что она ждет как раз ожидания ввода со стороны клинского приложения (Client:Client Read). Приложение открыло транзакцию, что-то поделало, а потом ушло делать какую-то другую работу. И, возможно, где-то произошла ошибка, приложаени упало в том участке кода, но транзакция осталась незакрытой. Пришли другие транзакции и попытались обновить другие строки и прочитать данные, которые изменила эта транзакция, но попали в заблокированное состояние и теперь они все ждут завершения транзакции.
Самое просто решение – это отменить эту транзакцию. Есть две функции: pg_cancel_backend и pg_terminate_backend. Они позволяют отменить запрос, либо просто завершить работу этого backend. В pgCenter тоже есть эти функции. Можно с помощью горячих клавиш убивать как отдельный backend и запросы на основе pid, либо убивать их группами на основе маски.

Тем не менее под капотом здесь у нас:
-
Pg_stat_activity.
-
Pg_stat_statements.
-
Pg_cancel_backend ().
-
Pg_terminate_backend ().

Опыт показывает, что ситуации бывают разные. Бывает, не только, что собрался хвост из длинных транзакций.
Бывает долгая транзакция на таблице с очередью. Тот случай когда очередь реализована не отдельным брокером сообщений, а реализованы непосредственно в базе данных. У нас есть какая-то таблица. В нее вставляется много записей, также много строк обновляется и много строк удаляется (добавилось событие, изменился его статус, удалилось событие). Пришла какая-то долгая транзакция, которая поработала с этой таблицей, но также она перешла в состояние idle transaction и ничего не делает. И у нас также собрался длинный хвост из блокировок и все повисло — очередь перестала работать.

Другой кейс – это когда приложение в несколько потоков пытается обновлять одни и те же данные. И эти потоки начинают конфликтовать друг с другом, в результате возникают ситуации блокировок и взаимоблокировок (deadlocks) и все начинает работать совсем плохо.

Миграции. Можно сделать ALTER TABLE, добавление колонки, например, с простановкой дефолтных значений. Это очень тяжелая операция. Ее, к счастью, исправили в 11-ой версии и начиная с нее проставление дефолтов при добавлении поля работает безболезненно. Но тем не менее у многих заказчиков стоят старые версии Postgres, которые работают по старому. И любой такой тяжелый ALTER может также собрать на себе хвост ждущих транзакций и остановить работу приложения.

И классика жанра – это CREATE INDEX без CONCURRENTLY, когда кто-то по незнанию, либо просто забыл, что запустил создание индекса. Создание индекса заблокировало таблицу и появился снова хвост из блокировок.

Сейчас немного про репликацию, т.к. сегодня сложно представить, чтобы в production был сервер Postgres без реплики, поэтому бывает необходимость проверить репликацию и все ли с ней в порядке.

Для этого есть представление pg_stat_replication. Она показывает клиентов, подключенных к Postgres, которые принимают журнал транзакций с этого узла по протоколу репликации.
И pgCenter тоже поддерживает pg_stat_replication. И можно переключиться с помощью горячих клавиш, и посмотреть, что там происходит.
В данном случае у нас здесь 5 клиентов. Они все подключены и принимают журнал транзакций.

Если посмотреть на их имена, то можно будет понять, кто это такие и что они делают. У нас здесь 2 walreceiver, т. е. это конкретно 2 реплики.

И дальше нас интересует, какой лаг репликации у этих клиентов, потому что лаг репликации непосредственно влияет на величину проблемы, которая у нас есть. Если маленький лаг, значит, более-менее все в порядке. Большой лаг, значит, проблемы есть – реплика сильно отстает по каким-то причинам и нам нужно выяснить по каким.
Соответственно, pg_stat_replication предоставляет разную информацию, которая позволяет нам посчитать лаг в байтах и лаг в секундах. И здесь лаг у одной из реплик на уровне 1,5 GB. И replay_lag в секундах – 2 часа. На самом деле это нормальная реплика. Она просто настроена с отложенным восстановлением журнала транзакций. У нее выставлено восстановление на уровне 2-х часов. Она скачивает все журналы к себе и воспроизводит их с задержкой в 2 часа, т. е. это вполне нормальная ситуация.

Если мы посмотрим на других клиентов, то будет видно, что у нас есть 2 pg_basebackup и 1 pg_receivewal. Pg_basebackup – это резервное копирование которое также работает по протоколу репликации. Он также виден в pg_stat_replication. И pg_receivewal – это процесс, который принимает журналы транзакций и сохраняет для задач архивирования. Т. е. здесь, в принципе, никакой проблемы нет. Здесь нет каких-то криминальных реплик, которые нужно было бы расследовать.

Но тем не менее pg_stat_replication позволяет показывать лаг в нескольких единицах измерениях. Это байты. И самое интересное, что этих метрик здесь аж 5 штук. Это: pending, write, flush, replay, total_lag. Т. е. лаг репликации может быть разным.
Pending – это когда журнал транзакций сгенерировался, лежит на Мастере. И Мастер его еще не успел передать реплике.
Write – это когда передача журналов уже идет, но до реплики еще не дошла, т. е. она еще не успела записаться.
Flush – это когда успели записать уже на реплику, но не успели сбросить на надежное хранилище.
Replay – это когда сбросили на надежное хранилище. И осталось только проиграть.
Total_lag – это максимальная величина от момента генерации до момента проигрывания.
Соответственно, наблюдая лаг в этих местах, в этих контрольных точках, мы можем более-менее понять, где у нас проблема. Например, проблема на дисковой подсистеме Мастера; либо ошибки сети, которые снижают скорость передачи; либо это загруженная дисковая подсистема реплики, которая не успевает все это писать, синхронизировать с диском и воспроизводить.

Кроме того, есть лаг репликации во времени. Он более человекопонятный. Когда людям говоришь про минуты, про секунды, они это лучше воспринимают.

И последний момент – это лаг репликации в транзакциях, т. е. можно отследить величину – сколько транзакций нужно проиграть реплике, чтобы она догнала Мастера. Эта штука по умолчанию выключена в Postgres, ее нужно включать отдельно. Но она редко бывает нужна, только в каких-то особых случаях.

Под капотом этой всей диагностики у нас:
-
pg_stat_replication.
-
pg_wal_lsn_diff().
-
pg_current_wal_lsn().
-
pg_last_commited_xact().

Я вам рассказал все эти кейсы, но за кадром есть еще много других вещей.

Например, в top можнос смотреть статистику по таблицам. Табличные статистики – это все Seq Scan, количество update, delete, insert, живые и мертвые строки.

Статистика по индексам. Можно посмотреть утилизацию индексов. Отыскивать неиспользуемые индексы и их заносить в черный список и потом удалять.

Статистика по функциям. Можно смотреть, какие пользовательские функции запускаются больше всего, сколько времени они потребляют. Можно также сортировать, смотреть и выбирать кандидата для оптимизации.

И, конечно, pg_stat_progress_vacuum появился в 9.6. Раньше, в плане статистики, вакуум был черным ящиком, было сложно понять, как долго работает, как скоро он закончится и сколько ему еще работы надо делать. И pg_stat_progress_vacuum – это способ заглянуть в этот черный ящик и понять что там происходит. Можно оценить, сколько ему там осталось доработать. Хотя, конечно, есть недостатки, есть претензии к нему. Но тем не менее лучше, чем ничего.

И есть вспомогательные, админские функции для самого администратора. Это просмотр логов, просмотр и изменение конфигурации, т. е. мы можем через горячие клавиши открыть postgresql.conf, что-то в нем поправить и потом горячей клавишей сделать reload. Это не самая правильная практика, конечно, но тем не менее возможность есть.
Плюс есть функции по просмотру логов. Вам не нужно помнить, где же лежит лог, как он там называется и набирать руками путь до него. Нажимает хоткей и лог открывается в просмотрщике. Можно найти там нужный запрос с нужными параметрами, скопировать и дальше изучать его.
Плюс есть функция вызова psql, т. е. мы также нажимаем горячую клавишу и у нас открывается psql к той базе, к которой у нас подключен pgCenter. Таким образом если есть какие-то вещи, которые нам надо сделать и мы не можем сделать это с помощью pgCenter, мы можем быстро вызвать psql и сделать это там.

top-просмотрщик – это основная утилита, которая развивалась изначально в pgCenter. Но помимо top есть еще другие утилиты, которые тоже являются частью pgCenter. Это record и report.
Суть в том, что мы делаем мгновенные снимки статистики и сохраняем их в файле. Мы можем запускать сбор с нужным интервалом и эти снимки будут сохраняться. А потом с помощью report строить отчеты, аналогичные тому, что показывает Top. В некоторых ситуациях это бывает полезно — например отсутствие полноценого мониторинга.

Я использую это для своих микро-тестов. Когда мне нужно что-то потестировать, я запускаю record. Раз в секунду он там все записывает и мне не нужно ставить никаких мониторинговых агентов. Я могу это все так быстро на коленке посмотреть.

Плюс недавно я добавил сэмплер wait_event’ов, можно брать свои долгие запросы и смотреть, на каких участках запрос тратит свое время на ожидание.

Вот простой пример: SELECT всех строк из таблицы с последующей сортировкой. Если посмотреть, куда тратится время, то видно, что 44 % времени запрос выполняется, делает какую-то полезную работу, а оставшееся время – это ожидание ввода-вывода при чтении файлов, взаимодействие между параллельными воркерами.

Второй пример: это VACUUM FULL. Здесь видно, что большую часть времени VACUUM FULL работает с дисковым IO и читает данные, а работает он всего 12 %. Вот эта штука довольно полезная, когда есть любопытство попрофилировать свои долгие запросы и посмотреть, чем они занимаются и в каких местах проводят время в ожидании.
Вопросы
Спасибо за утилиту! Лично я ею пользуюсь. Она мне нравится. Я часто использую ее с ноутбука. И когда я смотрю, например, pg_stat_statements, у меня колонка query с текстом не влезает. Есть ли какая-то возможность поменять порядок столбцов или какие-то столбцы отключить на время?
К сожалению, такой функции нет. Архитектурно программа так устроена, что эта фичу тяжело запилить, но можно, наверное, что-то придумать там, переписать и такая функция появится. Как минимум, не перестановку колонок, а отключение-включение по желанию. Но отсюда вылезает второй вопрос. Наверняка кто-то захочет сохранить отображение этих колонок и при последующем запуске показать. Т. е. появится необходимость конфига, который нужно поддерживать, хранить где-то. Это такая задачка, которая собирает еще другие задачки, чтобы ее реализовать. Я думаю, что это можно сделать, но пока этого нет.
И второй комментарий из той же оперы. Когда режим базы данных, то у вас количество rollbacks. Иногда хотелось бы отличать rollbacks, которые были по команде от тех rollbacks, которые не по команде.
Это, к сожалению, невозможно, потому что сам интерфейс pg_stat_database не позволяет такого. Он показывает только rollbacks и все.
Там можно из pg_stat_statements считать rollbacks, вычитать.
Можно, если заморочиться. Можно расширить запрос. Мы делаем `SELECT FROM pg_stat_database JNOIN pg_stat_statements` под запрос к pg_stat_statements, где мы считаем rollbacks и плюс арифметика, которая это все высчитывает. Теоретически можно. Но нужно посмотреть, как быстро будет работать этот запрос и не займет ли выполнение больше 10-20 миллисекунд.
Алексей, спасибо за доклад! С какой минимальной версией Postgres ваша утилита работает?
Я ее тестировал с версии 9.0-9.1, когда еще на C писал. Если какие-то запросы, особенно связанные с репликацией, не работают, то она пишет небольшую ошибку и есть возможность переключится на другой скрин, на другую статистику. Go версию тестировал, начиная с 9.4. Потому что в 9.4 появился функционал, когда мы берем SELECT… where filter. Это такой синтаксис интересный. В старых версиях (9.3) его нет. А у меня часть запросов как раз используют этот синтаксис и в старых версиях это работать не будет. Либо это будет работать, но будет показывать нули там, где эта статистика используется. Но я стараюсь на всех версия тестировать, проверять, чтобы, как минимум, ошибок не было.
Алексей, спасибо за утилиту! И спасибо за то, что интерфейс там от TOP. За это двойное спасибо.
Более того, я старался горячие клавиши делать, похожими на другие утилиты. Например, кнопка фильтра – это слеш. Кто знаком с less (пейджер такой), то слеш – это поле ввода, чтобы набрать шаблон для поиска.
У меня вопрос по поводу сортировки. Там так же как в TOP подсветка поля идет сортируемого?
Да. У меня на скриншотах это не видно, я, видимо, упустил этот момент. На некоторых скриншотах видно, на некоторых не видно. Да, поле подсвечивается. Когда вы стрелками перемещаетесь, вы видите, что у вас сортировка меняется и имя в колонке подсвечивается.
Спасибо за утилиту! Сегодня в первый раз о ней узнал. Оказывается, столько много возможностей. Вы размышляете, что вот у меня 85% CPU usage, давайте проанализирую, что сейчас происходит. Для этого пойду и обращусь к временным снимкам pg_stat_statements. Но там же архив находится. А нас интересует, что сейчас происходит.
Не архив. В нагрузке на CPU есть два поля. Первое – t_all_t. Это сколько времени намотал запрос со времени сброса статистики pg_stat_statements. Условно, у нас суточный срез. Если мы раз в сутки сбрасываем статистику, то мы получим статистику за текущий момент от начала суток. Плюс есть разбивка t с подчеркиванием и они уже здесь заканчиваются. Т. е. у нас есть аналогичные поля без префикса «t». Они как раз нам показывают статистику за текущую секунду. Т. е. мы можем смотреть, сколько процессорного времени потрачено запросом прямо сейчас.
Это понятно. Но если сейчас происходит то, что еще нет в pg_stat_statements, то как мы это проанализируем?
Мы каждую секунду выходим к pg_stat_statements и берем снапшот статистики прямо в real time.
Вопрос был в том, что в pg_stat_statements залетит уже после, а цифра 85 CPU usage – она сейчас.
Да, расхождение статистики будет. Но вы все равно можете смотреть текущую статистику, которую вам pg_stat_statements показывает. Если вы видите, что у вас использование процессора упало, то вы уже не увидите тот срез статистики, который был 10 секунд назад, когда использование процессоров было высокое. Тут нет такой интроспекции на 10 секунд назад – запомнить и отмотать, как это сделано, например, в atop. Вы на atop намекаете?
Примерно, да. Тут некое будущее и прошлое pg_stat_statements, а CPU, которая сейчас, нужно потом проанализировать, что залетит в pg_stat_statements.
Для этого придумана система мониторинга. Например, Grafana, там есть отрисовка графиков и вы уже в исторической перспективе все эти графики смотрите и анализируете. Т. е. pgCenter – это инструмент, который нам нужен здесь и сейчас, чтобы быстро продиагностировать, быстро понять, что происходит.
В связи с этим же вопрос. pgCenter умеет как atop сбрасывать статистику в текстовом виде, чтобы потом можно было запихнуть в Grafana?
Есть функции pgCenter report и pgCenter record, т. е. можно снапшоты статистики сбрасывать в текстовые файлы. Единственное, что там нет интерфейса, как по стрелочкам переключаться и смотреть. Т. е., условно говоря, с помощью pgCenter report запросить нужную статистику, например, по pg_stat_database и он прочитаем там все файлы накопленной статистики и как sar покажет. Я вдохновлялся больше им. Нет такого как у atop, когда можно стрелочками работать.
Алексей, большое спасибо! В отличие от всей известной базы Х, в Postgres, к сожалению, нет, кумулятивных статистик ожиданий. Вы сделали профайлер, который показывает разброску по ожиданиям. А с какой частой вы их опрашиваете? Какая там детализация?
Дефолтный интервал в 10 миллисекунд. А через флажок «-f», можно указывать частоту детализаций. Понятно, что высокая частота детализации, например, в 10 миллисекунд тоже создает нагрузку на систему. Но учитывая, что pg_stat_activity в памяти, то запросы там довольно легковесные. Они доли миллисекунд занимают. Но если такая частота напрягает, можно менять. Поставить, например, раз в 50 миллисекунд. Я замерял, как отражается это на конечной статистике, там погрешность есть на уровне 1-2 %. Т. е. если просуммировать все столбики, то мы увидим, что у нас куда-то 0,5-2 % потерялось.
Там в конце суммарная статистика есть. Можно видеть, что что-то потерялось.
Да, там видно будет. Да, даже на нашем примере мы видим, что 0,04 % не учли. Но, я думаю, это не критично. Это не какой-то инструмент для хардкор аналитики.
Но лучше все равно ничего нет.
Интересно просто посмотреть, что там у нас происходит.
Алексей, спасибо за доклад! Вдогонку вопрос по профайлеру. Вот этот wait_event Running – это просто отсутствующий?
Да.
Я его воспринимаю как ожидание на CPU.
Да, именно так. Т. е. когда мы заметили, что wait_events у этого PID нет, то мы считаем, что backend делает какую-то полезную работу, прямо крутится на процессоре, что-то высчитывает. И мы закидываем в Running, типа он работает, т. е. он не находится в ожидании.
Но все же это ближе к CPU?
Да, это ближе к CPU, т. е. запрос делает какую-то работу. Это не ожидание.
Привет! Спасибо за доклад! Насчет пакетирования есть какие-то планы, например, Ubuntu?
Когда она была написана на C, то все майнтейнеры были радостные. Говорили, что круто, сейчас тебе пакетов насобираем. И в официальном репозитории PDGD были пакеты собраны для Ubuntu. Я на Launchpad собирал пакеты, но у них какая-то странная система сборки. Бинарник иногда сегфолтится. И я не мог понять, почему так. А сейчас на Go у меня просто Мастер-ветка, dev-ветка. В Мастере она релизы отсчитывает. И когда я делаю коммит с релизом, то travis-ci не только делает build, он еще делает build бинарника и выкатывает его в раздел релизов. Т. е. если посмотреть в Realeses, то туда релизы будут сваливаться. Вам остается только взять wget, сходить по ссылке, забрать и распаковать tar’ом архив, и можно будет пользоваться.
Есть проект Goreleaser, который позволяет автоматизировать это. И можно собирать пакеты.
Круто, я с GO не очень знаком. Я еще раз повторяю, я не профессиональный программист. Я не знаю, что такое SOLID. И то, что вы говорите, что Goreleaser есть, это интересная штука, я посмотрю, что это такое. Раньше C’шные исходники у меня собирались, и я был счастлив. А сейчас мне приходится всем говорить, что есть ссылка на Realeses. Спасибо за совет!
Updated. Goreleaser успешно добавлен, большое спасибо за идею!
Алексей, вопрос по поводу queryid. Мы там видим queryid. У вас получается, что там поле немножко урезано и мы хвост не видим. Мы можем его полностью увидеть?
Да, конечно. Если мы не будем обрезать названия, то у нас в какой-то момент ширина колонок будет прыгать. И это для глаз не очень хорошо, плохо воспринимается. Поэтому ширина колонок рассчитывается под какую-то величину. Величина рассчитывается по сложному кейсу. Но в итоге ширина колонок ужимается и не прыгает. Если мы хотим ее увеличить, то мы стрелочкой переходим на это поле через сортировку. А потом стрелкой вверх увеличиваем ширину. А стрелкой вниз можем уменьшить ширину. И она сохраняется. Вы потом дальше можете сортировку менять, у вас ширина поля останется той, какой вы задали.
Ясно, это важный момент, потому что queryid – это четкий адрес.
Да, изначально ширина колонок прыгала и это раздражало. Я в dev-ветке это поправил, а в Мастер-ветке этого пока нет. В середине февраля я хочу выпустить Event Profiler. И как раз фиксированная ширина колонок будет.
Замечательно.
Да, через стрелки можно регулировать ширину.
Спасибо, Алексей!
Спасибо большое вам!
Видео:
20.8.1. Where to Log
log_destination(string)-
PostgreSQL supports several methods for logging server messages, including stderr, csvlog, jsonlog, and syslog. On Windows, eventlog is also supported. Set this parameter to a list of desired log destinations separated by commas. The default is to log to stderr only. This parameter can only be set in the
postgresql.conffile or on the server command line.If csvlog is included in
log_destination, log entries are output in “comma separated value” (CSV) format, which is convenient for loading logs into programs. See Section 20.8.4 for details. logging_collector must be enabled to generate CSV-format log output.If jsonlog is included in
log_destination, log entries are output in JSON format, which is convenient for loading logs into programs. See Section 20.8.5 for details. logging_collector must be enabled to generate JSON-format log output.When either stderr, csvlog or jsonlog are included, the file
current_logfilesis created to record the location of the log file(s) currently in use by the logging collector and the associated logging destination. This provides a convenient way to find the logs currently in use by the instance. Here is an example of this file’s content:stderr log/postgresql.log csvlog log/postgresql.csv jsonlog log/postgresql.json
current_logfilesis recreated when a new log file is created as an effect of rotation, and whenlog_destinationis reloaded. It is removed when none of stderr, csvlog or jsonlog are included inlog_destination, and when the logging collector is disabled.Note
On most Unix systems, you will need to alter the configuration of your system’s syslog daemon in order to make use of the syslog option for
log_destination. PostgreSQL can log to syslog facilitiesLOCAL0throughLOCAL7(see syslog_facility), but the default syslog configuration on most platforms will discard all such messages. You will need to add something like:local0.* /var/log/postgresql
to the syslog daemon’s configuration file to make it work.
On Windows, when you use the
eventlogoption forlog_destination, you should register an event source and its library with the operating system so that the Windows Event Viewer can display event log messages cleanly. See Section 19.12 for details. logging_collector(boolean)-
This parameter enables the logging collector, which is a background process that captures log messages sent to stderr and redirects them into log files. This approach is often more useful than logging to syslog, since some types of messages might not appear in syslog output. (One common example is dynamic-linker failure messages; another is error messages produced by scripts such as
archive_command.) This parameter can only be set at server start.Note
It is possible to log to stderr without using the logging collector; the log messages will just go to wherever the server’s stderr is directed. However, that method is only suitable for low log volumes, since it provides no convenient way to rotate log files. Also, on some platforms not using the logging collector can result in lost or garbled log output, because multiple processes writing concurrently to the same log file can overwrite each other’s output.
Note
The logging collector is designed to never lose messages. This means that in case of extremely high load, server processes could be blocked while trying to send additional log messages when the collector has fallen behind. In contrast, syslog prefers to drop messages if it cannot write them, which means it may fail to log some messages in such cases but it will not block the rest of the system.
log_directory(string)-
When
logging_collectoris enabled, this parameter determines the directory in which log files will be created. It can be specified as an absolute path, or relative to the cluster data directory. This parameter can only be set in thepostgresql.conffile or on the server command line. The default islog. log_filename(string)-
When
logging_collectoris enabled, this parameter sets the file names of the created log files. The value is treated as astrftimepattern, so%-escapes can be used to specify time-varying file names. (Note that if there are any time-zone-dependent%-escapes, the computation is done in the zone specified by log_timezone.) The supported%-escapes are similar to those listed in the Open Group’s strftime specification. Note that the system’sstrftimeis not used directly, so platform-specific (nonstandard) extensions do not work. The default ispostgresql-%Y-%m-%d_%H%M%S.log.If you specify a file name without escapes, you should plan to use a log rotation utility to avoid eventually filling the entire disk. In releases prior to 8.4, if no
%escapes were present, PostgreSQL would append the epoch of the new log file’s creation time, but this is no longer the case.If CSV-format output is enabled in
log_destination,.csvwill be appended to the timestamped log file name to create the file name for CSV-format output. (Iflog_filenameends in.log, the suffix is replaced instead.)If JSON-format output is enabled in
log_destination,.jsonwill be appended to the timestamped log file name to create the file name for JSON-format output. (Iflog_filenameends in.log, the suffix is replaced instead.)This parameter can only be set in the
postgresql.conffile or on the server command line. log_file_mode(integer)-
On Unix systems this parameter sets the permissions for log files when
logging_collectoris enabled. (On Microsoft Windows this parameter is ignored.) The parameter value is expected to be a numeric mode specified in the format accepted by thechmodandumasksystem calls. (To use the customary octal format the number must start with a0(zero).)The default permissions are
0600, meaning only the server owner can read or write the log files. The other commonly useful setting is0640, allowing members of the owner’s group to read the files. Note however that to make use of such a setting, you’ll need to alter log_directory to store the files somewhere outside the cluster data directory. In any case, it’s unwise to make the log files world-readable, since they might contain sensitive data.This parameter can only be set in the
postgresql.conffile or on the server command line. log_rotation_age(integer)-
When
logging_collectoris enabled, this parameter determines the maximum amount of time to use an individual log file, after which a new log file will be created. If this value is specified without units, it is taken as minutes. The default is 24 hours. Set to zero to disable time-based creation of new log files. This parameter can only be set in thepostgresql.conffile or on the server command line. log_rotation_size(integer)-
When
logging_collectoris enabled, this parameter determines the maximum size of an individual log file. After this amount of data has been emitted into a log file, a new log file will be created. If this value is specified without units, it is taken as kilobytes. The default is 10 megabytes. Set to zero to disable size-based creation of new log files. This parameter can only be set in thepostgresql.conffile or on the server command line. log_truncate_on_rotation(boolean)-
When
logging_collectoris enabled, this parameter will cause PostgreSQL to truncate (overwrite), rather than append to, any existing log file of the same name. However, truncation will occur only when a new file is being opened due to time-based rotation, not during server startup or size-based rotation. When off, pre-existing files will be appended to in all cases. For example, using this setting in combination with alog_filenamelikepostgresql-%H.logwould result in generating twenty-four hourly log files and then cyclically overwriting them. This parameter can only be set in thepostgresql.conffile or on the server command line.Example: To keep 7 days of logs, one log file per day named
server_log.Mon,server_log.Tue, etc., and automatically overwrite last week’s log with this week’s log, setlog_filenametoserver_log.%a,log_truncate_on_rotationtoon, andlog_rotation_ageto1440.Example: To keep 24 hours of logs, one log file per hour, but also rotate sooner if the log file size exceeds 1GB, set
log_filenametoserver_log.%H%M,log_truncate_on_rotationtoon,log_rotation_ageto60, andlog_rotation_sizeto1000000. Including%Minlog_filenameallows any size-driven rotations that might occur to select a file name different from the hour’s initial file name. syslog_facility(enum)-
When logging to syslog is enabled, this parameter determines the syslog “facility” to be used. You can choose from
LOCAL0,LOCAL1,LOCAL2,LOCAL3,LOCAL4,LOCAL5,LOCAL6,LOCAL7; the default isLOCAL0. See also the documentation of your system’s syslog daemon. This parameter can only be set in thepostgresql.conffile or on the server command line. syslog_ident(string)-
When logging to syslog is enabled, this parameter determines the program name used to identify PostgreSQL messages in syslog logs. The default is
postgres. This parameter can only be set in thepostgresql.conffile or on the server command line. syslog_sequence_numbers(boolean)-
When logging to syslog and this is on (the default), then each message will be prefixed by an increasing sequence number (such as
[2]). This circumvents the “— last message repeated N times —” suppression that many syslog implementations perform by default. In more modern syslog implementations, repeated message suppression can be configured (for example,$RepeatedMsgReductionin rsyslog), so this might not be necessary. Also, you could turn this off if you actually want to suppress repeated messages.This parameter can only be set in the
postgresql.conffile or on the server command line. syslog_split_messages(boolean)-
When logging to syslog is enabled, this parameter determines how messages are delivered to syslog. When on (the default), messages are split by lines, and long lines are split so that they will fit into 1024 bytes, which is a typical size limit for traditional syslog implementations. When off, PostgreSQL server log messages are delivered to the syslog service as is, and it is up to the syslog service to cope with the potentially bulky messages.
If syslog is ultimately logging to a text file, then the effect will be the same either way, and it is best to leave the setting on, since most syslog implementations either cannot handle large messages or would need to be specially configured to handle them. But if syslog is ultimately writing into some other medium, it might be necessary or more useful to keep messages logically together.
This parameter can only be set in the
postgresql.conffile or on the server command line. event_source(string)-
When logging to event log is enabled, this parameter determines the program name used to identify PostgreSQL messages in the log. The default is
PostgreSQL. This parameter can only be set in thepostgresql.conffile or on the server command line.
20.8.2. When to Log
log_min_messages(enum)-
Controls which message levels are written to the server log. Valid values are
DEBUG5,DEBUG4,DEBUG3,DEBUG2,DEBUG1,INFO,NOTICE,WARNING,ERROR,LOG,FATAL, andPANIC. Each level includes all the levels that follow it. The later the level, the fewer messages are sent to the log. The default isWARNING. Note thatLOGhas a different rank here than in client_min_messages. Only superusers and users with the appropriateSETprivilege can change this setting. log_min_error_statement(enum)-
Controls which SQL statements that cause an error condition are recorded in the server log. The current SQL statement is included in the log entry for any message of the specified severity or higher. Valid values are
DEBUG5,DEBUG4,DEBUG3,DEBUG2,DEBUG1,INFO,NOTICE,WARNING,ERROR,LOG,FATAL, andPANIC. The default isERROR, which means statements causing errors, log messages, fatal errors, or panics will be logged. To effectively turn off logging of failing statements, set this parameter toPANIC. Only superusers and users with the appropriateSETprivilege can change this setting. log_min_duration_statement(integer)-
Causes the duration of each completed statement to be logged if the statement ran for at least the specified amount of time. For example, if you set it to
250msthen all SQL statements that run 250ms or longer will be logged. Enabling this parameter can be helpful in tracking down unoptimized queries in your applications. If this value is specified without units, it is taken as milliseconds. Setting this to zero prints all statement durations.-1(the default) disables logging statement durations. Only superusers and users with the appropriateSETprivilege can change this setting.This overrides log_min_duration_sample, meaning that queries with duration exceeding this setting are not subject to sampling and are always logged.
For clients using extended query protocol, durations of the Parse, Bind, and Execute steps are logged independently.
Note
When using this option together with log_statement, the text of statements that are logged because of
log_statementwill not be repeated in the duration log message. If you are not using syslog, it is recommended that you log the PID or session ID using log_line_prefix so that you can link the statement message to the later duration message using the process ID or session ID. log_min_duration_sample(integer)-
Allows sampling the duration of completed statements that ran for at least the specified amount of time. This produces the same kind of log entries as log_min_duration_statement, but only for a subset of the executed statements, with sample rate controlled by log_statement_sample_rate. For example, if you set it to
100msthen all SQL statements that run 100ms or longer will be considered for sampling. Enabling this parameter can be helpful when the traffic is too high to log all queries. If this value is specified without units, it is taken as milliseconds. Setting this to zero samples all statement durations.-1(the default) disables sampling statement durations. Only superusers and users with the appropriateSETprivilege can change this setting.This setting has lower priority than
log_min_duration_statement, meaning that statements with durations exceedinglog_min_duration_statementare not subject to sampling and are always logged.Other notes for
log_min_duration_statementapply also to this setting. log_statement_sample_rate(floating point)-
Determines the fraction of statements with duration exceeding log_min_duration_sample that will be logged. Sampling is stochastic, for example
0.5means there is statistically one chance in two that any given statement will be logged. The default is1.0, meaning to log all sampled statements. Setting this to zero disables sampled statement-duration logging, the same as settinglog_min_duration_sampleto-1. Only superusers and users with the appropriateSETprivilege can change this setting. log_transaction_sample_rate(floating point)-
Sets the fraction of transactions whose statements are all logged, in addition to statements logged for other reasons. It applies to each new transaction regardless of its statements’ durations. Sampling is stochastic, for example
0.1means there is statistically one chance in ten that any given transaction will be logged.log_transaction_sample_ratecan be helpful to construct a sample of transactions. The default is0, meaning not to log statements from any additional transactions. Setting this to1logs all statements of all transactions. Only superusers and users with the appropriateSETprivilege can change this setting.Note
Like all statement-logging options, this option can add significant overhead.
log_startup_progress_interval(integer)-
Sets the amount of time after which the startup process will log a message about a long-running operation that is still in progress, as well as the interval between further progress messages for that operation. The default is 10 seconds. A setting of
0disables the feature. If this value is specified without units, it is taken as milliseconds. This setting is applied separately to each operation. This parameter can only be set in thepostgresql.conffile or on the server command line.For example, if syncing the data directory takes 25 seconds and thereafter resetting unlogged relations takes 8 seconds, and if this setting has the default value of 10 seconds, then a messages will be logged for syncing the data directory after it has been in progress for 10 seconds and again after it has been in progress for 20 seconds, but nothing will be logged for resetting unlogged relations.
Table 20.2 explains the message severity levels used by PostgreSQL. If logging output is sent to syslog or Windows’ eventlog, the severity levels are translated as shown in the table.
Table 20.2. Message Severity Levels
| Severity | Usage | syslog | eventlog |
|---|---|---|---|
DEBUG1 .. DEBUG5 |
Provides successively-more-detailed information for use by developers. | DEBUG |
INFORMATION |
INFO |
Provides information implicitly requested by the user, e.g., output from VACUUM VERBOSE. |
INFO |
INFORMATION |
NOTICE |
Provides information that might be helpful to users, e.g., notice of truncation of long identifiers. | NOTICE |
INFORMATION |
WARNING |
Provides warnings of likely problems, e.g., COMMIT outside a transaction block. |
NOTICE |
WARNING |
ERROR |
Reports an error that caused the current command to abort. | WARNING |
ERROR |
LOG |
Reports information of interest to administrators, e.g., checkpoint activity. | INFO |
INFORMATION |
FATAL |
Reports an error that caused the current session to abort. | ERR |
ERROR |
PANIC |
Reports an error that caused all database sessions to abort. | CRIT |
ERROR |
20.8.3. What to Log
Note
What you choose to log can have security implications; see Section 25.3.
application_name(string)-
The
application_namecan be any string of less thanNAMEDATALENcharacters (64 characters in a standard build). It is typically set by an application upon connection to the server. The name will be displayed in thepg_stat_activityview and included in CSV log entries. It can also be included in regular log entries via the log_line_prefix parameter. Only printable ASCII characters may be used in theapplication_namevalue. Other characters will be replaced with question marks (?). debug_print_parse(boolean)
debug_print_rewritten(boolean)
debug_print_plan(boolean)-
These parameters enable various debugging output to be emitted. When set, they print the resulting parse tree, the query rewriter output, or the execution plan for each executed query. These messages are emitted at
LOGmessage level, so by default they will appear in the server log but will not be sent to the client. You can change that by adjusting client_min_messages and/or log_min_messages. These parameters are off by default. debug_pretty_print(boolean)-
When set,
debug_pretty_printindents the messages produced bydebug_print_parse,debug_print_rewritten, ordebug_print_plan. This results in more readable but much longer output than the “compact” format used when it is off. It is on by default. log_autovacuum_min_duration(integer)-
Causes each action executed by autovacuum to be logged if it ran for at least the specified amount of time. Setting this to zero logs all autovacuum actions.
-1disables logging autovacuum actions. If this value is specified without units, it is taken as milliseconds. For example, if you set this to250msthen all automatic vacuums and analyzes that run 250ms or longer will be logged. In addition, when this parameter is set to any value other than-1, a message will be logged if an autovacuum action is skipped due to a conflicting lock or a concurrently dropped relation. The default is10min. Enabling this parameter can be helpful in tracking autovacuum activity. This parameter can only be set in thepostgresql.conffile or on the server command line; but the setting can be overridden for individual tables by changing table storage parameters. log_checkpoints(boolean)-
Causes checkpoints and restartpoints to be logged in the server log. Some statistics are included in the log messages, including the number of buffers written and the time spent writing them. This parameter can only be set in the
postgresql.conffile or on the server command line. The default is on. log_connections(boolean)-
Causes each attempted connection to the server to be logged, as well as successful completion of both client authentication (if necessary) and authorization. Only superusers and users with the appropriate
SETprivilege can change this parameter at session start, and it cannot be changed at all within a session. The default isoff.Note
Some client programs, like psql, attempt to connect twice while determining if a password is required, so duplicate “connection received” messages do not necessarily indicate a problem.
log_disconnections(boolean)-
Causes session terminations to be logged. The log output provides information similar to
log_connections, plus the duration of the session. Only superusers and users with the appropriateSETprivilege can change this parameter at session start, and it cannot be changed at all within a session. The default isoff. log_duration(boolean)-
Causes the duration of every completed statement to be logged. The default is
off. Only superusers and users with the appropriateSETprivilege can change this setting.For clients using extended query protocol, durations of the Parse, Bind, and Execute steps are logged independently.
Note
The difference between enabling
log_durationand setting log_min_duration_statement to zero is that exceedinglog_min_duration_statementforces the text of the query to be logged, but this option doesn’t. Thus, iflog_durationisonandlog_min_duration_statementhas a positive value, all durations are logged but the query text is included only for statements exceeding the threshold. This behavior can be useful for gathering statistics in high-load installations. log_error_verbosity(enum)-
Controls the amount of detail written in the server log for each message that is logged. Valid values are
TERSE,DEFAULT, andVERBOSE, each adding more fields to displayed messages.TERSEexcludes the logging ofDETAIL,HINT,QUERY, andCONTEXTerror information.VERBOSEoutput includes theSQLSTATEerror code (see also Appendix A) and the source code file name, function name, and line number that generated the error. Only superusers and users with the appropriateSETprivilege can change this setting. log_hostname(boolean)-
By default, connection log messages only show the IP address of the connecting host. Turning this parameter on causes logging of the host name as well. Note that depending on your host name resolution setup this might impose a non-negligible performance penalty. This parameter can only be set in the
postgresql.conffile or on the server command line. log_line_prefix(string)-
This is a
printf-style string that is output at the beginning of each log line.%characters begin “escape sequences” that are replaced with status information as outlined below. Unrecognized escapes are ignored. Other characters are copied straight to the log line. Some escapes are only recognized by session processes, and will be treated as empty by background processes such as the main server process. Status information may be aligned either left or right by specifying a numeric literal after the % and before the option. A negative value will cause the status information to be padded on the right with spaces to give it a minimum width, whereas a positive value will pad on the left. Padding can be useful to aid human readability in log files.This parameter can only be set in the
postgresql.conffile or on the server command line. The default is'%m [%p] 'which logs a time stamp and the process ID.Escape Effect Session only %aApplication name yes %uUser name yes %dDatabase name yes %rRemote host name or IP address, and remote port yes %hRemote host name or IP address yes %bBackend type no %pProcess ID no %PProcess ID of the parallel group leader, if this process is a parallel query worker no %tTime stamp without milliseconds no %mTime stamp with milliseconds no %nTime stamp with milliseconds (as a Unix epoch) no %iCommand tag: type of session’s current command yes %eSQLSTATE error code no %cSession ID: see below no %lNumber of the log line for each session or process, starting at 1 no %sProcess start time stamp no %vVirtual transaction ID (backendID/localXID) no %xTransaction ID (0 if none is assigned) no %qProduces no output, but tells non-session processes to stop at this point in the string; ignored by session processes no %QQuery identifier of the current query. Query identifiers are not computed by default, so this field will be zero unless compute_query_id parameter is enabled or a third-party module that computes query identifiers is configured. yes %%Literal %no The backend type corresponds to the column
backend_typein the viewpg_stat_activity, but additional types can appear in the log that don’t show in that view.The
%cescape prints a quasi-unique session identifier, consisting of two 4-byte hexadecimal numbers (without leading zeros) separated by a dot. The numbers are the process start time and the process ID, so%ccan also be used as a space saving way of printing those items. For example, to generate the session identifier frompg_stat_activity, use this query:SELECT to_hex(trunc(EXTRACT(EPOCH FROM backend_start))::integer) || '.' || to_hex(pid) FROM pg_stat_activity;Tip
If you set a nonempty value for
log_line_prefix, you should usually make its last character be a space, to provide visual separation from the rest of the log line. A punctuation character can be used too.Tip
Syslog produces its own time stamp and process ID information, so you probably do not want to include those escapes if you are logging to syslog.
Tip
The
%qescape is useful when including information that is only available in session (backend) context like user or database name. For example:log_line_prefix = '%m [%p] %q%u@%d/%a '
Note
The
%Qescape always reports a zero identifier for lines output by log_statement becauselog_statementgenerates output before an identifier can be calculated, including invalid statements for which an identifier cannot be calculated. log_lock_waits(boolean)-
Controls whether a log message is produced when a session waits longer than deadlock_timeout to acquire a lock. This is useful in determining if lock waits are causing poor performance. The default is
off. Only superusers and users with the appropriateSETprivilege can change this setting. log_recovery_conflict_waits(boolean)-
Controls whether a log message is produced when the startup process waits longer than
deadlock_timeoutfor recovery conflicts. This is useful in determining if recovery conflicts prevent the recovery from applying WAL.The default is
off. This parameter can only be set in thepostgresql.conffile or on the server command line. log_parameter_max_length(integer)-
If greater than zero, each bind parameter value logged with a non-error statement-logging message is trimmed to this many bytes. Zero disables logging of bind parameters for non-error statement logs.
-1(the default) allows bind parameters to be logged in full. If this value is specified without units, it is taken as bytes. Only superusers and users with the appropriateSETprivilege can change this setting.This setting only affects log messages printed as a result of log_statement, log_duration, and related settings. Non-zero values of this setting add some overhead, particularly if parameters are sent in binary form, since then conversion to text is required.
log_parameter_max_length_on_error(integer)-
If greater than zero, each bind parameter value reported in error messages is trimmed to this many bytes. Zero (the default) disables including bind parameters in error messages.
-1allows bind parameters to be printed in full. If this value is specified without units, it is taken as bytes.Non-zero values of this setting add overhead, as PostgreSQL will need to store textual representations of parameter values in memory at the start of each statement, whether or not an error eventually occurs. The overhead is greater when bind parameters are sent in binary form than when they are sent as text, since the former case requires data conversion while the latter only requires copying the string.
log_statement(enum)-
Controls which SQL statements are logged. Valid values are
none(off),ddl,mod, andall(all statements).ddllogs all data definition statements, such asCREATE,ALTER, andDROPstatements.modlogs allddlstatements, plus data-modifying statements such asINSERT,UPDATE,DELETE,TRUNCATE, andCOPY FROM.PREPARE,EXECUTE, andEXPLAIN ANALYZEstatements are also logged if their contained command is of an appropriate type. For clients using extended query protocol, logging occurs when an Execute message is received, and values of the Bind parameters are included (with any embedded single-quote marks doubled).The default is
none. Only superusers and users with the appropriateSETprivilege can change this setting.Note
Statements that contain simple syntax errors are not logged even by the
log_statement=allsetting, because the log message is emitted only after basic parsing has been done to determine the statement type. In the case of extended query protocol, this setting likewise does not log statements that fail before the Execute phase (i.e., during parse analysis or planning). Setlog_min_error_statementtoERROR(or lower) to log such statements.Logged statements might reveal sensitive data and even contain plaintext passwords.
log_replication_commands(boolean)-
Causes each replication command to be logged in the server log. See Section 55.4 for more information about replication command. The default value is
off. Only superusers and users with the appropriateSETprivilege can change this setting. log_temp_files(integer)-
Controls logging of temporary file names and sizes. Temporary files can be created for sorts, hashes, and temporary query results. If enabled by this setting, a log entry is emitted for each temporary file when it is deleted. A value of zero logs all temporary file information, while positive values log only files whose size is greater than or equal to the specified amount of data. If this value is specified without units, it is taken as kilobytes. The default setting is -1, which disables such logging. Only superusers and users with the appropriate
SETprivilege can change this setting. log_timezone(string)-
Sets the time zone used for timestamps written in the server log. Unlike TimeZone, this value is cluster-wide, so that all sessions will report timestamps consistently. The built-in default is
GMT, but that is typically overridden inpostgresql.conf; initdb will install a setting there corresponding to its system environment. See Section 8.5.3 for more information. This parameter can only be set in thepostgresql.conffile or on the server command line.
20.8.4. Using CSV-Format Log Output
Including csvlog in the log_destination list provides a convenient way to import log files into a database table. This option emits log lines in comma-separated-values (CSV) format, with these columns: time stamp with milliseconds, user name, database name, process ID, client host:port number, session ID, per-session line number, command tag, session start time, virtual transaction ID, regular transaction ID, error severity, SQLSTATE code, error message, error message detail, hint, internal query that led to the error (if any), character count of the error position therein, error context, user query that led to the error (if any and enabled by log_min_error_statement), character count of the error position therein, location of the error in the PostgreSQL source code (if log_error_verbosity is set to verbose), application name, backend type, process ID of parallel group leader, and query id. Here is a sample table definition for storing CSV-format log output:
CREATE TABLE postgres_log ( log_time timestamp(3) with time zone, user_name text, database_name text, process_id integer, connection_from text, session_id text, session_line_num bigint, command_tag text, session_start_time timestamp with time zone, virtual_transaction_id text, transaction_id bigint, error_severity text, sql_state_code text, message text, detail text, hint text, internal_query text, internal_query_pos integer, context text, query text, query_pos integer, location text, application_name text, backend_type text, leader_pid integer, query_id bigint, PRIMARY KEY (session_id, session_line_num) );
To import a log file into this table, use the COPY FROM command:
COPY postgres_log FROM '/full/path/to/logfile.csv' WITH csv;
It is also possible to access the file as a foreign table, using the supplied file_fdw module.
There are a few things you need to do to simplify importing CSV log files:
-
Set
log_filenameandlog_rotation_ageto provide a consistent, predictable naming scheme for your log files. This lets you predict what the file name will be and know when an individual log file is complete and therefore ready to be imported. -
Set
log_rotation_sizeto 0 to disable size-based log rotation, as it makes the log file name difficult to predict. -
Set
log_truncate_on_rotationtoonso that old log data isn’t mixed with the new in the same file. -
The table definition above includes a primary key specification. This is useful to protect against accidentally importing the same information twice. The
COPYcommand commits all of the data it imports at one time, so any error will cause the entire import to fail. If you import a partial log file and later import the file again when it is complete, the primary key violation will cause the import to fail. Wait until the log is complete and closed before importing. This procedure will also protect against accidentally importing a partial line that hasn’t been completely written, which would also causeCOPYto fail.
20.8.5. Using JSON-Format Log Output
Including jsonlog in the log_destination list provides a convenient way to import log files into many different programs. This option emits log lines in JSON format.
String fields with null values are excluded from output. Additional fields may be added in the future. User applications that process jsonlog output should ignore unknown fields.
Each log line is serialized as a JSON object with the set of keys and their associated values shown in Table 20.3.
Table 20.3. Keys and Values of JSON Log Entries
| Key name | Type | Description |
|---|---|---|
timestamp |
string | Time stamp with milliseconds |
user |
string | User name |
dbname |
string | Database name |
pid |
number | Process ID |
remote_host |
string | Client host |
remote_port |
number | Client port |
session_id |
string | Session ID |
line_num |
number | Per-session line number |
ps |
string | Current ps display |
session_start |
string | Session start time |
vxid |
string | Virtual transaction ID |
txid |
string | Regular transaction ID |
error_severity |
string | Error severity |
state_code |
string | SQLSTATE code |
message |
string | Error message |
detail |
string | Error message detail |
hint |
string | Error message hint |
internal_query |
string | Internal query that led to the error |
internal_position |
number | Cursor index into internal query |
context |
string | Error context |
statement |
string | Client-supplied query string |
cursor_position |
number | Cursor index into query string |
func_name |
string | Error location function name |
file_name |
string | File name of error location |
file_line_num |
number | File line number of the error location |
application_name |
string | Client application name |
backend_type |
string | Type of backend |
leader_pid |
number | Process ID of leader for active parallel workers |
query_id |
number | Query ID |
20.8.6. Process Title
These settings control how process titles of server processes are modified. Process titles are typically viewed using programs like ps or, on Windows, Process Explorer. See Section 28.1 for details.
cluster_name(string)-
Sets a name that identifies this database cluster (instance) for various purposes. The cluster name appears in the process title for all server processes in this cluster. Moreover, it is the default application name for a standby connection (see synchronous_standby_names.)
The name can be any string of less than
NAMEDATALENcharacters (64 characters in a standard build). Only printable ASCII characters may be used in thecluster_namevalue. Other characters will be replaced with question marks (?). No name is shown if this parameter is set to the empty string''(which is the default). This parameter can only be set at server start. update_process_title(boolean)-
Enables updating of the process title every time a new SQL command is received by the server. This setting defaults to
onon most platforms, but it defaults tooffon Windows due to that platform’s larger overhead for updating the process title. Only superusers and users with the appropriateSETprivilege can change this setting.
When running a PostgreSQL database system how do I know my database as a whole has 100% integrity? Basically how do I know if my data files and pages are all 100% good with no corruption?
In the Microsoft SQL Server world there’s a command that you can execute DBCC CHECKDB that will tell you if there’re issues. Here’s a link if your intrested in learning more on the command. DBCC CHECKDB (Transact-SQL)
I’m a paranoid database integrity minded person (which anyone who works with the database in a DBA type role should be) and this type of stuff makes it hard for me to sleep well at night. A utility like this is a must! Searches on google have found a few attempts at tools like this and in my opinion unless it’s an official accepted tool by the PostgreSQL project I won’t trust it for something this important.
Here are some links to people asking similar questions with what I consider no real definitive answer. And in my opinion shows that PostgreSQL needs to have some tools in place that Oracle and Microsoft SQL Server seem to have.
The first link is the most interesting I have found on this subject. I think a comment on the article that probably sums it up states: «Postgres is pretty lame when it comes to identifying database corruption and repairing it. The only way to detect it is by dumping the database or select * from every table in the database.»
How PostgreSQL protects against partial page writes and data corruption
Checking data and index file corruption — Dev Shed
Help: my table is corrupt!
PostgreSQL: Corrupt primary key, inconsistent table
I believe there is a chance 9.3 might have some corruption checking features. It appears there may be hope to having page files check summed if one chooses. So things are looking bright if you consider using ZFS and/or a future version of Postgres with page check summing.
https://commitfest.postgresql.org/action/patch_view?id=759
UPDATE: 14-JAN-2012 — Seems like using a file system based on ZFS can detect corruption by check summing each block of data. I will have to look into this further and see if this is a work around to allow one to sleep well at night knowing their database data is not silently going corrupt.
UPDATE: 17-JAN-2012 — How to find what files are corrupt with ZFS. http://docs.oracle.com/cd/E18752_01/html/819-5461/gbbwl.html#gbcuz
UPDATE:14-APR-2014 9.3 did get data checksums. https://wiki.postgresql.org/wiki/What’s_new_in_PostgreSQL_9.3
When running a PostgreSQL database system how do I know my database as a whole has 100% integrity? Basically how do I know if my data files and pages are all 100% good with no corruption?
In the Microsoft SQL Server world there’s a command that you can execute DBCC CHECKDB that will tell you if there’re issues. Here’s a link if your intrested in learning more on the command. DBCC CHECKDB (Transact-SQL)
I’m a paranoid database integrity minded person (which anyone who works with the database in a DBA type role should be) and this type of stuff makes it hard for me to sleep well at night. A utility like this is a must! Searches on google have found a few attempts at tools like this and in my opinion unless it’s an official accepted tool by the PostgreSQL project I won’t trust it for something this important.
Here are some links to people asking similar questions with what I consider no real definitive answer. And in my opinion shows that PostgreSQL needs to have some tools in place that Oracle and Microsoft SQL Server seem to have.
The first link is the most interesting I have found on this subject. I think a comment on the article that probably sums it up states: «Postgres is pretty lame when it comes to identifying database corruption and repairing it. The only way to detect it is by dumping the database or select * from every table in the database.»
How PostgreSQL protects against partial page writes and data corruption
Checking data and index file corruption — Dev Shed
Help: my table is corrupt!
PostgreSQL: Corrupt primary key, inconsistent table
I believe there is a chance 9.3 might have some corruption checking features. It appears there may be hope to having page files check summed if one chooses. So things are looking bright if you consider using ZFS and/or a future version of Postgres with page check summing.
https://commitfest.postgresql.org/action/patch_view?id=759
UPDATE: 14-JAN-2012 — Seems like using a file system based on ZFS can detect corruption by check summing each block of data. I will have to look into this further and see if this is a work around to allow one to sleep well at night knowing their database data is not silently going corrupt.
UPDATE: 17-JAN-2012 — How to find what files are corrupt with ZFS. http://docs.oracle.com/cd/E18752_01/html/819-5461/gbbwl.html#gbcuz
UPDATE:14-APR-2014 9.3 did get data checksums. https://wiki.postgresql.org/wiki/What’s_new_in_PostgreSQL_9.3
Оглавление
- 1 Параметры
- 1.1 Databases
- 1.2 CheckCommands
- 1.3 PhysicalOnly
- 1.4 NoIndex
- 1.5 ExtendedLogicalChecks
- 1.6 TabLock
- 1.7 FileGroups
- 1.8 Objects
- 1.9 MaxDOP
- 1.10 AvailabilityGroups
- 1.11 AvailabilityGroupReplicas
- 1.12 Updateability
- 1.13 LockTimeout
- 1.14 LogToTable
- 1.15 Execute
- 2 Примеры использования вложенной процедуры
-
- 2.0.1 A. Проверка целостности во всех пользовательских базах
- 2.0.2 B. Проверка физической целостности данных во всех пользовательских базах
- 2.0.3 C. Проверка целостности данных во всех пользовательских базах, с использованием опции исключающей проверку не кластеризованных индексов
- 2.0.4 D. Проверка целостности данных во всех пользовательских базах, с использованием опции упрощенной проверки логической структуры
- 2.0.5 E. Проверка целостности данных в файловой группе PRIMARY базы данных AdventureWorks
- 2.0.6 F. Проверка целостности данных во всех файловых группах, за исключением файловой группы PRIMARY базы данных AdventureWorks
- 2.0.7 G. Проверка целостности данных в таблице Production.Product базы данных AdventureWorks
- 2.0.8 H. Проверка целостности данных всех таблиц за исключение таблицы Production.Product базы данных AdventureWorks
- 2.0.9 I. Проверка дискового места во всех пользовательских базах
-
- 3 Выполнение
Процедура от Ola Hallengren — DatabaseIntegrityCheck, позволяет проверить базу, файловую группу или таблицу. Если используется полноценный SQL Server, то можно использовать его в Maintains Paln. Если SQL Express, то можно использовать данную процедуру в планировщике, так как агент-SQL в этой редакции отсутствует. Проверка необходима перед архивацией базы. Нет смысла архивировать разрушенную базу!!! поэтому перед архивацией необходим проверить целостность данных. В качестве параметров можно указать список баз данных, время блокировки, объекты проверки и некоторые другие параметры. Данную процедуру удобно использовать при большом количестве баз данных или при обслуживании баз разработчиков, которые постоянно плодят новые ветки и заливают в новые базы. Полный список параметров и примеры использования ниже
Параметры
В качестве аргументов, отвечающих за выбор объектов проверки можно передать SYSTEM_DATABASES, USER_DATABASES, ALL_DATABASES и AVAILABILITY_GROUP_DATABASES, если поддерживается. Знак (-) используется для исключения базы, а знак процента (%) выполняет роль символа подстановки. Все используемые параметры могут быть разделены занятой (,)
Databases
| Переменная | Описание |
|---|---|
| SYSTEM_DATABASES | Все системные базы (master, msdb, and model) |
| USER_DATABASES | Все пользовательские базы |
| ALL_DATABASES | Все базы |
| AVAILABILITY_GROUP_DATABASES | Все базы и группы доступности |
| USER_DATABASES, -AVAILABILITY_GROUP_DATABASES | Все пользовательские базы, исключая группы доступности |
| Db1 | Ваза Db1 |
| Db1, Db2 | Базы Db1 и Db2 |
| USER_DATABASES, -Db1 | Все пользовательские базы, за исключением Db1 |
| %Db% | Все базы, имеющие в названии Db |
| %Db%, -Db1 | Все базы имеющие в названии Db, за исключением базы Db1 |
| ALL_DATABASES, -%Db% | Все базы, за исключением тех, которые имеют в названии Db |
CheckCommands
Использование данного параметра может ускорить скорость проверки путем исключения не нужных объектов или разделить задание на два этапа.
| Переменная | Описание |
|---|---|
| CHECKDB | Проверяет логическую и физическую целостность всех объектов. По умолчанию |
| CHECKFILEGROUP | Проверяет распределение и структуру целостности всех таблиц и индексированных представлений в файловой группе |
| CHECKTABLE | Проверяет целостность всех страниц и структур, составляющих таблицу или индексированное представление |
| CHECKALLOC | Проверяет согласованность структур выделения места на диске |
| CHECKCATALOG | Проверяет согласованность каталогов в указанной базе данных |
| CHECKALLOC,CHECKCATALOG | Совмещает два параметра — проверку таблиц и представлений |
| CHECKFILEGROUP,CHECKCATALOG | Проверяет представления и таблицы для файловых групп |
| CHECKALLOC,CHECKTABLE,CHECKCATALOG | Проверяет параметры свободного места для таблиц и индексов, а также согласованность каталогов |
При составлении команд использовалось описание для SQL Server: DBCC CHECKDB проверка баз данных, DBCC CHECKFILEGROUP проверка фаловых групп, DBCC CHECKTABLE проверка таблиц и индексных представлений, DBCC CHECKALLOC проверка свободного места в таблицах и DBCC CHECKCATALOG проверка согласованности каталогов.
PhysicalOnly
Ограничиться только физической проверкой структуры базы
| Переменная | Описание |
|---|---|
| Y | Ограничиться только физической проверкой структуры базы |
| N | Не ограничиться только физической проверкой структуры базы. По умолчанию |
Параметр PHYSICAL_ONLY использует опции следующих команд DBCC CHECKDB, DBCC CHECKFILEGROUP и DBCC CHECKTABLE
NoIndex
Не проверять не кластеризированные индексы
| Переменная | Описание |
|---|---|
| Y | Не проверять |
| N | Проверять. По умолчанию |
Параметр NoIndex использует опции следующих команд DBCC CHECKDB, DBCC CHECKFILEGROUP, DBCC CHECKTABLE и DBCC CHECKALLOC
ExtendedLogicalChecks
Упрощенная проверка логической структуры
| Переменная | Описание |
|---|---|
| Y | Провести простую проверку |
| N | Не проводить простую проверку. По умолчанию |
Параметр ExtendedLogicalChecks использует опции следующих команд EXTENDED_LOGICAL_CHECKS и команды SQL Server DBCC CHECKDB
Нельзя комбинировать параметры PhysicalOnly и ExtendedLogicalChecks.
TabLock
Позволяет использовать внешний снапшот
| Переменная | Описание |
|---|---|
| Y | Использовать блокировку, для проверки |
| N | Использовать снапшот. По умолчанию |
Параметр TabLock использует опции следующих команд DBCC CHECKDB, DBCC CHECKFILEGROUP, DBCC CHECKTABLE и DBCC CHECKALLOC
FileGroups
Выбор файловых групп. Данный параметр поддерживает выборку по словам. Знак минус (-) позволяет исключить файловую группу, а знак процента (%) позволяет задать маску. Все операторы могут быть объединены запятой (,)
| Переменная | Описание |
|---|---|
| ALL_FILEGROUPS | Все файловые группы |
| Db1.FileGroup1 | Файловая группа FileGroup1 в базе Db1 |
| Db1.FileGroup1, Db2.FileGroup2 | Файловая группа FileGroup1 в базе Db1 и фаловая группа FileGroup2 в базе Db2 |
| ALL_FILEGROUPS, -Db1.FileGroup1 | Все файловые группы, за исключением FileGroup1 в базе Db1 |
| Db1.%FileGroup% | Все файловые группы в базе Db1 имеющие в своем имени “FileGroup” |
Используются только специфические опции CHECKFILEGROUPS.
Objects
Выбор объектов. Параметр ALL_OBJECTS поддерживает выбор по маске. Знак минус (-) позволяет исключить файловую группу, а знак процента (%) позволяет задать маску. Все операторы могут быть объединены запятой (,)
| Переменная | Описание |
|---|---|
| ALL_OBJECTS | Все объекты |
| Db1.Schema1.Tbl1 | Объект Schema1.Tbl1 в базе Db1 |
| Db1.Schema1.Object1, Db2.Schema2.Object2 | Объект Schema1.Tbl1 в базе Db1 и объект Schema2.Tbl2 б базе данных Db2 |
| ALL_OBJECTS, -Db1.Schema1.Object1 | Все объекты, кроме Schema1.Object1 в базе Db1 |
| Db1.Schema1.% | Все объекты в схеме Schema1 находящейся в базе Db1 |
Данный параметр можно использовать только совместно с параметром CHECKTABLE
MaxDOP
Количество ядер процессора выделенных для проверки базы, файловой группы или таблицы. Если данный параметр не задан, будут использоваться максимальное значение степени параллелизма.
Данный параметр может быть использован совместно с параметрами DBCC CHECKDB, DBCC CHECKFILEGROUP и DBCC CHECKTABLE
AvailabilityGroups
выбор групп доступности. Параметр ALL_AVAILABILITY_GROUPS разрешает использование маски. Знак минус (-) позволяет исключить файловую группу, а знак процента (%) позволяет задать маску. Все операторы могут быть объединены запятой (,)
| Переменная | Описание |
|---|---|
| ALL_AVAILABILITY_GROUPS | Все группы доступности |
| AG1 | Группа доступности AG1 |
| AG1, AG2 | Группа доступности AG1 и AG1 |
| ALL_AVAILABILITY_GROUPS, -AG1 | Все группы доступности, за исключением группы AG1 |
| %AG% | Все группы доступности содержащие в своем имени “AG” |
| %AG%, -AG1 | Все группы доступности содержащие в своем имени “AG” за исключением группы AG1 |
| ALL_AVAILABILITY_GROUPS, -%AG% | Все группы доступности не содержащие в своем имени “AG” |
AvailabilityGroupReplicas
Выбор реплики для необходимости проверки.
| Переменная | Описание |
|---|---|
| ALL | Проверяжтся все реплики. По умолчанию |
| PRIMARY | Проверяется только первичная реплика |
| SECONDARY | Проверяется только вторичная реплика |
Updateability
Задает режим для базы данны READ_ONLY/READ_WRITE
| Переменная | Описание |
|---|---|
| ALL | READ_ONLY и READ_WRITE — база данных. До умолчанию |
| READ_ONLY | READ_ONLY — только чтение |
| READ_WRITE | READ_WRITE — чтение запись |
Переменная READ_ONLY в sys.databases используется если база в режиме READ_ONLY или READ_WRITE (Трудности перевода, пока не разбирался с данной переменной)
LockTimeout
Устанавливает время блокировки, после которого необходимо освободить захваченный объект. По умолчанию лимит отсутствует.
Параметр LockTimeout в хранимой процедуре IndexOptimize использует SET LOCK_TIMEOUT в терминологии SQL Server.
LogToTable
Логирование команд в таблицу dbo.CommandLog
| Переменная | Описание |
|---|---|
| Y | Логировать команды в таблицу |
| N | Не логировать команды. По умолчанию |
Execute
Выполнение команд. По умолчанию команды отправляются на выполнение. Если установлено значение N, то команды будут выведены без выполнения.
| Переменная | Описание |
|---|---|
| Y | Выполнять команды. По умолчанию |
| N | Только вывеси команды |
Примеры использования вложенной процедуры
A. Проверка целостности во всех пользовательских базах
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘USER_DATABASES’,
@CheckCommands = ‘CHECKDB’
B. Проверка физической целостности данных во всех пользовательских базах
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘USER_DATABASES’,
@CheckCommands = ‘CHECKDB’,
@PhysicalOnly = ‘Y’
C. Проверка целостности данных во всех пользовательских базах, с использованием опции исключающей проверку не кластеризованных индексов
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘USER_DATABASES’,
@CheckCommands = ‘CHECKDB’,
@NoIndex = ‘Y’
D. Проверка целостности данных во всех пользовательских базах, с использованием опции упрощенной проверки логической структуры
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘USER_DATABASES’,
@CheckCommands = ‘CHECKDB’,
@ExtendedLogicalChecks = ‘Y’
E. Проверка целостности данных в файловой группе PRIMARY базы данных AdventureWorks
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘AdventureWorks’,
@CheckCommands = ‘CHECKFILEGROUP’,
@FileGroups = ‘AdventureWorks.PRIMARY’
F. Проверка целостности данных во всех файловых группах, за исключением файловой группы PRIMARY базы данных AdventureWorks
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘USER_DATABASES’,
@CheckCommands = ‘CHECKFILEGROUP’,
@FileGroups = ‘ALL_FILEGROUPS, -AdventureWorks.PRIMARY’
G. Проверка целостности данных в таблице Production.Product базы данных AdventureWorks
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘AdventureWorks’,
@CheckCommands = ‘CHECKTABLE’,
@Objects = ‘AdventureWorks.Production.Product’
H. Проверка целостности данных всех таблиц за исключение таблицы Production.Product базы данных AdventureWorks
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘USER_DATABASES’,
@CheckCommands = ‘CHECKTABLE’,
@Objects = ‘ALL_OBJECTS, -AdventureWorks.Production.Product’
I. Проверка дискового места во всех пользовательских базах
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = ‘USER_DATABASES’,
@CheckCommands = ‘CHECKALLOC’
Выполнение
Для выполнения хранимой процедуры, необходимо использовать sqlcmd и опцию -b. Вызов процедуры происходит по имени
|
sqlcmd —E —S $(ESCAPE_SQUOTE(SRVR)) —d master —Q «EXECUTE dbo.DatabaseIntegrityCheck @Databases = ‘USER_DATABASES’» —b |
0
0
голоса
Рейтинг статьи
![]() Загрузка…
Загрузка…
Asked
12 years, 5 months ago
Viewed
28k times
Is there a way to check PostgreSQL database(s) integrity and consistency? I know about SQL Server DBCC CHECKDB and wonder if there is something similar to PostgreSQL.
asked Aug 29, 2010 at 15:46
![]()
2
In 12 version of pgsql, there is pg_checksums.
![]()
answered Nov 26, 2019 at 13:16
![]()
What do you really want to achieve?
The database itself guarantees its integrity. You do not need tools to fiddle with.
answered Aug 29, 2010 at 18:08
![]()
cstamascstamas
6,64724 silver badges42 bronze badges
4
![]()
answered Aug 29, 2010 at 20:26
![]()
alerootaleroot
3,1705 gold badges28 silver badges37 bronze badges
2
Хочу поделиться с вами моим первым успешным опытом восстановления полной работоспособности базы данных Postgres. С СУБД Postgres я познакомился пол года назад, до этого опыта администрирования баз данных у меня не было совсем.

Я работаю полу-DevOps инженером в крупной IT-компании. Наша компания занимается разработкой программного обеспечения для высоконагруженных сервисов, я же отвечаю за работоспособность, сопровождение и деплой. Передо мной поставили стандартную задачу: обновить приложение на одном сервере. Приложение написано на Django, во время обновления выполняются миграции (изменение структуры базы данных), и перед этим процессом мы снимаем полный дамп базы данных через стандартную программу pg_dump на всякий случай.
Во время снятия дампа возникла непредвиденная ошибка (версия Postgres – 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly
Ошибка «invalid page in block» говорит о проблемах на уровне файловой системы, что очень нехорошо. На различных форумах предлагали сделать FULL VACUUM с опцией zero_damaged_pages для решения данной проблемы. Что же, попрробеум…
Подготовка к восстановлению
ВНИМАНИЕ! Обязательно сделайте резервную копию Postgres перед любой попыткой восстановить базу данных. Если у вас виртуальная машина, остановите базу данных и сделайте снепшот. Если нет возможности сделать снепшот, остановите базу и скопируйте содержимое каталога Postgres (включая wal-файлы) в надёжное место. Главное в нашем деле – не сделать хуже. Прочтите это.
Поскольку в целом база у меня работала, я ограничился обычным дампом базы данных, но исключил таблицу с повреждёнными данными (опция -T, —exclude-table=TABLE в pg_dump).
Сервер был физическим, снять снепшот было невозможно. Бекап снят, двигаемся дальше.
Проверка файловой системы
Перед попыткой восстановления базы данных необходимо убедиться, что у нас всё в порядке с самой файловой системой. И в случае ошибок исправить их, поскольку в противном случае можно сделать только хуже.
В моём случае файловая система с базой данных была примонтирована в «/srv» и тип был ext4.
Останавливаем базу данных: systemctl stop postgresql@9.5-main.service и проверяем, что файловая система никем не используется и её можно отмонтировать с помощью команды lsof:
lsof +D /srv
Мне пришлось ещё остановить базу данных redis, так как она тоже исползовала «/srv». Далее я отмонтировал /srv (umount).
Проверка файловой системы была выполнена с помощью утилиты e2fsck с ключиком -f (Force checking even if filesystem is marked clean):
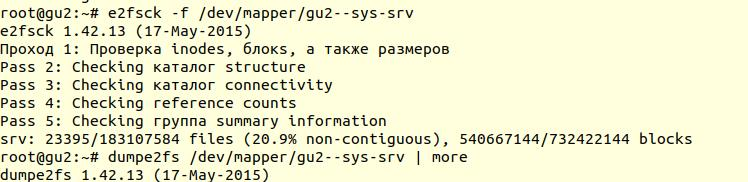
Далее с помощью утилиты dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep checked) можно убедиться, что проверка действительно была произведена:

e2fsck говорит, что проблем на уровне файловой системы ext4 не найдено, а это значит, что можно продолжать попытки восстановить базу данных, а точнее вернуться к vacuum full (само собой, необходимо примонтирвоать файловую систему обратно и запустить базу данных).
Если у вас сервер физический, то обязательно проверьте состояние дисков (через smartctl -a /dev/XXX) либо RAID-контроллера, чтобы убедиться, что проблема не на аппаратном уровне. В моём случае RAID оказался «железный», поэтому я попросил местного админа проверить состояние RAID (сервер был в нескольких сотнях километров от меня). Он сказал, что ошибок нет, а это значит, что мы точно можем начать восстановление.
Попытка 1: zero_damaged_pages
Подключаемся к базе через psql аккаунтом, обладающим правами суперпользователя. Нам нужен именно суперпользователь, т.к. опцию zero_damaged_pages может менять только он. В моём случае это postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
Опция zero_damaged_pages нужна для того, чтобы проигнорировать ошибки чтения (с сайта postgrespro):
При выявлении повреждённого заголовка страницы Postgres Pro обычно сообщает об ошибке и прерывает текущую транзакцию. Если параметр zero_damaged_pages включён, вместо этого система выдаёт предупреждение, обнуляет повреждённую страницу в памяти и продолжает обработку. Это поведение разрушает данные, а именно все строки в повреждённой странице.
Включаем опцию и пробуем делать full vacuum таблицы:
VACUUM FULL VERBOSE
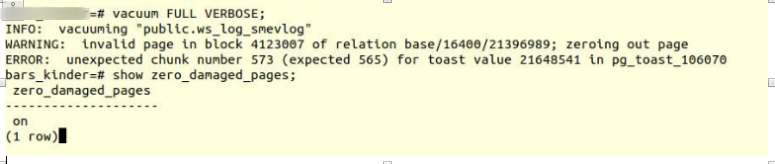
К сожалению, неудача.
Мы столкнулись с аналогичной ошибкой:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast – механизм хранения «длинных данных» в Poetgres, если они не помещаются в одну страницу (по умолчанию 8кб).
Попытка 2: reindex
Первый совет из гугла не помог. После нескольких минут поиска я нашёл второй совет – сделать reindex повреждённой таблицы. Этот совет я встречал во многих местах, но он не внушал доверия. Сделаем reindex:
reindex table ws_log_smevlog

reindex завершился без проблем.
Однако это не помогло, VACUUM FULL аварийно завершался с аналогичной ошибкой. Поскольку я привык к неудачам, я стал искать советов в интернете дальше и наткнулся на довольно интересную статью.
Попытка 3: SELECT, LIMIT, OFFSET
В статье выше предлагали посмотреть таблицу построчно и удалить проблемные данные. Для начала необходимо было просмотреть все строки:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
В моём случае таблица содержала 1 628 991 строк! По-хорошему необходимо было позаботиться о партициирвоании данных, но это тема для отдельного обсуждения. Была суббота, я запустил вот эту команду в tmux и пошёл спать:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
К утру я решил проверить, как обстоят дела. К моему удивлению, я обнаружил, что за 20 часов было просканировано только 2% данных! Ждать 50 дней я не хотел. Очередной полный провал.
Но я не стал сдаваться. Мне стало интересно, почему же сканирование шло так долго. Из документации (опять на postgrespro) я узнал:
OFFSET указывает пропустить указанное число строк, прежде чем начать выдавать строки.
Если указано и OFFSET, и LIMIT, сначала система пропускает OFFSET строк, а затем начинает подсчитывать строки для ограничения LIMIT.Применяя LIMIT, важно использовать также предложение ORDER BY, чтобы строки результата выдавались в определённом порядке. Иначе будут возвращаться непредсказуемые подмножества строк.
Очевидно, что вышенаписанная команда была ошибочной: во-первых, не было order by, результат мог получиться ошибочным. Во-вторых, Postgres сначала должен был просканировать и пропустить OFFSET-строк, и с возрастанием OFFSET производительность снижалась бы ещё сильнее.
Попытка 4: снять дамп в текстовом виде
Далее мне в голову пришла, казалось бы, гениальная идея: снять дамп в текстовом виде и проанализировать последнюю записанную строку.
Но для начала, ознакомимся со структурой таблицы ws_log_smevlog:

В нашем случае у нас есть столбец «id», который содержал уникальный идентификатор (счётчик) строки. План был такой:
1) Начинаем снимать дамп в текстовом виде (в виде sql-команд)
2) В определённый момент времени снятия дампа бы прервалось из-за ошибки, но тектовый файл всё равно сохранился бы на диске
3) Смотрим конец текстового файла, тем самым мы находим идентификатор (id) последней строки, которая снялась успешно
Я начал снимать дамп в текстовом виде:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
Снятия дампа, как и ожидалось, прервался с той же самой ошибкой:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Далее через tail я просмотрел конец дампа (tail -5 ./my_dump.dump) обнаружил, что дамп прервался на строке с id 186 525. «Значит, проблема в строке с id 186 526, она битая, её и надо удалить!» – подумал я. Но, сделав запрос в базу данных:
«select * from ws_log_smevlog where id=186529» обнаружилось, что с этой строкой всё нормально… Строки с индексами 186 530 — 186 540 тоже работали без проблем. Очередная «гениальная идея» провалилась. Позже я понял, почему так произошло: при удаленииизменении данных из таблицы они не удаляются физически, а помечаются как «мёртвые кортежи», далее приходит autuvacuum и помечает эти строки удалёнными и разрешает использовать эти строки повторно. Для понимая, если данные в таблице меняются и включён autovacuum, то они не хранятся последовательно.
Попытка 5: SELECT, FROM, WHERE id=
Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и id идут по порядку, а это значит, что мы можем просто перербрать их по одному:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Если кто не понимает, команда работает следующим образом: просматривает построчно таблицу и отправляет stdout в /dev/null, но если команда SELECT проваливается, то выводится текст ошибки (stderr отправляется в консоль) и выводится строка, содержащая ошибку (благодаря ||, которая означает, что у select возникли проблемы (код возврата команды не 0)).
Мне повезло, у меня были созданы индексы по полю id:

А это значит, что нахождение строки с нужным id не должен занимать много времени. В теории должно сработать. Что же, запускаем команду в tmux и идём спать.
К утру я обнаружил, что просмотрено около 90 000 записей, что составляет чуть более 5%. Отличный результат, если сравнивать с предыдущим способом (2%)! Но ждать 20 дней не хотелось…
Попытка 6: SELECT, FROM, WHERE id >= and id <
У заказчика под БД был выделен отличный сервер: двухпроцессорный Intel Xeon E5-2697 v2, в нашем расположении было целых 48 потоков! Нагрузка на сервере была средняя, мы без особых проблем могли забрать около 20-ти потоков. Оперативной памяти тоже было достаточно: аж 384 гигабайт!
Поэтому команду нужно было распараллелить:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Тут можно было написать красивый и элегантный скрипт, но я выбрал наиболее быстрый способ распараллеливания: разбить диапазон 0-1628991 вручную на интервалы по 100 000 записей и запустить отдельно 16 команд вида:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Но это не всё. По идее, подключение к базе данных тоже отнимает какое-то время и системные ресурсы. Подключать 1 628 991 было не очень разумно, согласитесь. Поэтому давайте при одном подключении извлекать 1000 строк вместо одной. В итоге команда преобразилоась в это:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Открываем 16 окон в сессии tmux и запускаем команды:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
…
15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Через день я получил первые результаты! А именно (значения XXX и ZZZ уже не сохранились):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000
Это значит, что у нас три строки содержат ошибку. id первой и второй проблемной записи находились между 829 000 и 830 000, id третьей – между 146 000 и 147 000. Далее нам предстояло просто найти точное значение id проблемных записей. Для этого просматриваем наш диапазон с проблемными записями с шагом 1 и идентифицируем id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
829417
ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070
829449
for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
829417
ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070
146911
Счастливый финал
Мы нашли проблемные строки. Заходим в базу через psql и пробуем их удалить:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1
К моему удивлению, записи удалились без каких-либо проблем даже без опции zero_damaged_pages.
Затем я подключился к базе, сделал VACUUM FULL (думаю делать было необязательно), и, наконец, успешно снял бекап с помощью pg_dump. Дамп снялся без каких либо ошибок! Проблему удалось решить таким вот тупейшим способом. Радости не было предела, после стольких неудач удалось найти решение!
Благодарности и заключение
Вот такой получился мой первый опыт восстановления реальной базы данных Postgres. Этот опыт я запомню надолго.
Ну и напоследок, хотел бы сказать спасибо компании PostgresPro за переведённую документацию на русский язык и за полностью бесплатные online-курсы, которые очень сильно помогли во время анализа проблемы.
Media failure is one of the crucial things that the database administrator should be aware of. Media failure is nothing but a physical problem reading or writing to files on the storage medium.
A typical example of media failure is a disk head crash, which causes the loss of all files on a disk drive. All files associated with a database are vulnerable to a disk crash, including datafiles, wal files, and control files.
This is the comprehensive post which focuses on disk failure in PostgreSQL and the ways you can retrieve the data from PostgreSQL Database after failure(other than restoring the backup).
In this post, we are going to do archaeology on the below error and will understand how to solve the error.
WARNING: page verification failed, calculated checksum 21135 but expected 3252
ERROR: invalid page in block 0 of relation base/13455/16395
During the process, you are going to learn a whole new bunch of stuff in PostgreSQL.
PostgreSQL Checksum: The definitive guide
- Chapter 1: What is a checksum?
- Chapter 2: PostgreSQL checksum: Practical implementation
- Chapter 3: How to resolve the PostgreSQL corrupted page issue?
With v9.3, PostgreSQL introduced a feature known as data checksums and it has undergone many changes since then. Now we have a well-sophisticated view in PostgreSQL v12 to find the checksums called pg_checksums.
But what is a PostgreSQL checksum?
When the checksum is enabled, a small integer checksum is written to each “page” of data that Postgres stores on your hard drive. Upon reading that block, the checksum value is recomputed and compared to the stored one.
This detects data corruption, which (without checksums) could be silently lurking in your database for a long time.
Good, checksum, when enabled, detects data corruption.
How does PostgreSQL checksum work?
PostgreSQL maintains page validity primarily on the way in and out of its buffer cache.
Also read: A comprehensive guide – PostgreSQL Caching
From here we understood that the PostgreSQL page has to pass through OS Cache before it leaves or enters into shared buffers. So page validity happens before leaving the shared buffers and before entering the shared buffers.
when PostgreSQL tries to copy the page into its buffer cache then it will (if possible) detect that something is wrong, and it will not allow page to enter into shared buffers with this invalid 8k page, and error out any queries that require this page for processing with the ERROR message
ERROR: invalid page in block 0 of relation base/13455/16395
If you already have a block with invalid data at disk-level and its page version at buffer level, during the next checkpoint, while page out, it will update invalid checksum details but which is rarely possible in real-time environments.
confused, bear with me.
And finally,
If the invalid byte is part of the PostgreSQL database buffer cache, then PostgreSQL will quite happily assume nothing is wrong and attempt to process the data on the page. Results are unpredictable; Some times you will get an error and sometimes you may end up with wrong data.
How PostgreSQL Checks Page Validity?
In a typical page, if data checksums are enabled, information is stored in a 2-byte field containing flag bits after the page header.
Also Read: A comprehensive guide on PostgreSQL: page header
This is followed by three 2-byte integer fields (pd_lower, pd_upper, and pd_special). These contain byte offsets from the page start to the start of unallocated space, to the end of unallocated space, and to the start of the special space.
The checksum value typically begins with zero and every time reading that block, the checksum value is recomputed and compared to the stored one. This detects data corruption.
Checksums are not maintained for blocks while they are in the shared buffers – so if you look at a buffer in the PostgreSQL page cache with pageinspect and you see a checksum value, note that when you do page inspect on a page which is already in the buffer, you may not get the actual checksum. The checksum is calculated and stamped onto the page when the page is written out of the buffer cache into the operating system page cache.
Also read: A comprehensive guide – PostgreSQL Caching
Let’s work on the practical understanding of whatever we learned so far.
I have a table check_corruption wherein I am going to do all the garbage work.
- my table size is 8 kB.
- has 5 records.
- the version I am using is PostgreSQL v12.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) postgres=# SELECT * FROM page_header(get_raw_page(‘check_corruption’,0)); lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid ——————+—————+————+————+————+—————+—————+—————+—————— 0/17EFCA0 | 0 | 0 | 44 | 7552 | 8192 | 8192 | 4 | 0 (1 row) postgres=# dt+ check_corruption List of relations Schema | Name | Type | Owner | Size | Description ————+—————————+————+—————+——————+——————— public | check_corruption | table | postgres | 8192 bytes | (1 row) postgres=# select pg_relation_filepath(‘check_corruption’); pg_relation_filepath ——————————— base/13455/16490 (1 row) postgres=# |
First, check whether the checksum is enabled or not?
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 0
[postgres@stagdb ~]$
It is disabled.
Let me enable the page checksum in PostgreSQL v12.
Syntax: pg_checksums -D /u01/pgsql/data –enable –progress –verbose
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —enable —progress —verbose pg_checksums: checksums enabled in file «/u01/pgsql/data/global/2847» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/1260_fsm» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/4175» .. .. 23/23 MB (100%) computed Checksum operation completed Files scanned: 969 Blocks scanned: 3006 pg_checksums: syncing data directory pg_checksums: updating control file Data checksum version: 1 Checksums enabled in cluster |
Again, check the status of checksums in PostgreSQL
[postgres@stagdb ~]$
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 1
[postgres@stagdb ~]$
we can disable the checksums with –disable option
|
[postgres@stagdb ~]$ [postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —disable pg_checksums: syncing data directory pg_checksums: updating control file Checksums disabled in cluster [postgres@stagdb ~]$ |
Let’s first check the current data directory for errors, then play with data.
To check the PostgreSQL page errors, we use the following command.
pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb ~]$ pg_checksums -D /u01/pgsql/data –check
Checksum operation completed
Files scanned: 969
Blocks scanned: 3006
Bad checksums: 0
Data checksum version: 1
[postgres@stagdb ~]$
Warning!! Do not perform the below case study in your production machine.
As the table check_corruption data file is 16490, I am going to corrupt the file with the Operating system’s dd command.
dd bs=8192 count=1 seek=1 of=16490 if=16490
[postgres@stagdb 13455]$ dd bs=8192 count=1 seek=1 of=16490 if=16490
Now, log in and get the result
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
I got the result, but why?
I got the result from shared buffers. Let me restart the cluster and fetch the same.
/usr/local/pgsql/bin/pg_ctl restart -D /u01/pgsql/data
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
But again why?
As we discussed earlier, during restart my PostgreSQL has replaced error checksum with the value of shared buffer.
How can we trigger a checksum warning?
We need to get that row out of shared buffers. The quickest way to do so in this test scenario is to restart the database, then make sure we do not even look at (e.g. SELECT) the table before we make our on-disk modification. Once that is done, the checksum will fail and we will, as expected, receive a checksum error:
i.e., stop the server, corrupt the disk and start it.
- /usr/local/pgsql/bin/pg_ctl stop -D /u01/pgsql/data
- dd bs=8192 count=1 seek=1 of=16490 if=16490
- /usr/local/pgsql/bin/pg_ctl start -D /u01/pgsql/data
During the next fetch, I got below error
postgres=# select * from check_corruption;
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427
WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:06:17.434 IST [25218] ERROR: invalid page in block 1 of relation base/13455/16490
2020-02-06 19:06:17.434 IST [25218] STATEMENT: select * from check_corruption;
ERROR: invalid page in block 1 of relation base/13455/16490
Let us dig deeper into the issue and confirm that the block is corrupted
There are a couple of ways you can find the issue which includes Linux commands like
- dd
- od
- hexdump
Usind dd command : dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -1
[postgres@stagdb 13455]$ dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -2
1+0 records in
1+0 records out
8192 bytes (8.2 kB) copied, 4.5e-05 seconds, 182 MB/s
0000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d >……~…..,…<
here,
00 00 00 00 a0 fc 7e 01 the first 8 bytes indicate pd_lsn and the next two bytes
03 9a indicates checksums.
Using hexdump : hexdump -C 16490 | head -1
[postgres@stagdb 13455]$ hexdump -C 16490 | head -1
00000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d |……~…..,…|
[postgres@stagdb 13455]$
Both hexdump and dd returned same result.
Let’s understand what our PostgreSQL very own pg_checksums has to say?
command: pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb 13455]$ pg_checksums -D /u01/pgsql/data –check
pg_checksums: error: checksum verification failed in file “/u01/pgsql/data/base/13455/16490”, block 1: calculated checksum 9A04 but block contains 9A03
Checksum operation completed
Files scanned: 968
Blocks scanned: 3013
Bad checksums: 1
Data checksum version: 1
[postgres@stagdb 13455]$
here, according to pg_checksums checksum 9A03 is matching with that of hexdump’s checksum 9A03.
Converting Hex 9A03 to decimals, I got 39427
which is matching the error
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427

How to resolve the PostgreSQL corrupted page issue?
use the below function to find the exact location where the page is corrupted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE OR REPLACE FUNCTION find_bad_row(tableName TEXT) RETURNS tid as $find_bad_row$ DECLARE result tid; curs REFCURSOR; row1 RECORD; row2 RECORD; tabName TEXT; count BIGINT := 0; BEGIN SELECT reverse(split_part(reverse($1), ‘.’, 1)) INTO tabName; OPEN curs FOR EXECUTE ‘SELECT ctid FROM ‘ || tableName; count := 1; FETCH curs INTO row1; WHILE row1.ctid IS NOT NULL LOOP result = row1.ctid; count := count + 1; FETCH curs INTO row1; EXECUTE ‘SELECT (each(hstore(‘ || tabName || ‘))).* FROM ‘ || tableName || ‘ WHERE ctid = $1’ INTO row2 USING row1.ctid; IF count % 100000 = 0 THEN RAISE NOTICE ‘rows processed: %’, count; END IF; END LOOP; CLOSE curs; RETURN row1.ctid; EXCEPTION WHEN OTHERS THEN RAISE NOTICE ‘LAST CTID: %’, result; RAISE NOTICE ‘%: %’, SQLSTATE, SQLERRM; RETURN result; END $find_bad_row$ LANGUAGE plpgsql; |
Now, using the function find_bad_row(), you can find the ctid of the corrupted location.
you need hstore extension to use the function
postgres=# CREATE EXTENSION hstore;
CREATE EXTENSION
postgres=#
postgres=# select find_bad_row(‘check_corruption’);
2020-02-06 19:44:24.227 IST [25929] WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:44:24.227 IST [25929] CONTEXT: PL/pgSQL function find_bad_row(text) line 21 at FETCH
WARNING: page verification failed, calculated checksum 39428 but expected 39427
NOTICE: LAST CTID: (0,5)
NOTICE: XX001: invalid page in block 1 of relation base/13455/16490
find_bad_row
————–
(0,5)
(1 row)
Deleting that particular CTID will resolve the issue
postgres=# delete from check_corruption where ctid='(0,6)’;
DELETE 1
postgres=#
If deleting ctid has not worked for you, you have an alternative solution which is setting zero_damaged_pages parameter.
Example.,
postgres=# select * from master;
WARNING: page verification failed, calculated checksum 8770 but expected 8769
ERROR: invalid page in block 1 of relation base/13455/16770
postgres=#
I can’t access the data from table master as block is corrupted.
Solution:
postgres=# SET zero_damaged_pages = on;
SET
postgres=# vacuum full master;
|
postgres=# select * from master; WARNING: page verification failed, calculated checksum 8770 but expected 8769 WARNING: invalid page in block 1 of relation base/13455/16770; zeroing out page id | name | city ——+—————+—————— 1 | Orson | hyderabad 2 | Colin | chennai 3 | Leonard | newyork |
here, it cleared the damaged page and gave the rest of the result.
What your document has to say?
zero_damaged_pages (boolean): Detection of a damaged page header normally causes PostgreSQL to report an error, aborting the current transaction. Setting zero_damaged_pages to on causes the system to instead report a warning, zero out the damaged page in memory, and continue processing. This behavior will destroy data, namely all the rows on the damaged page. However, it does allow you to get past the error and retrieve rows from any undamaged pages that might be present in the table. It is useful for recovering data if corruption has occurred due to a hardware or software error. You should generally not set this on until you have given up hope of recovering data from the damaged pages of a table. Zeroed-out pages are not forced to disk so it is recommended to recreate the table or the index before turning this parameter off again. The default setting is off, and it can only be changed by a superuser.
There are a couple of things to be aware when using this feature though. First, using checksums has a cost in performance as it introduces extra calculations for each data page (8kB by default), so be aware of the tradeoff between data security and performance when using it.
There are many factors that influence how much slower things are when checksums are enabled, including:
- How likely things are to be read from shared_buffers, which depends on how large shared_buffers is set, and how much of your active database fits inside of it
- How fast your server is in general, and how well it (and your compiler) are able to optimize the checksum calculation
- How many data pages you have (which can be influenced by your data types)
- How often you are writing new pages (via COPY, INSERT, or UPDATE)
- How often you are reading values (via SELECT)
The more that shared buffers are used (and using them efficiently is a good general goal), the less checksumming is done, and the less the impact of checksums on database performance will be. On an average if you enable checksum the performance cost would be more than 2% and for inserts, the average difference was 6%. For selects, that jumps to 19%. Complete computation benchmark test can be found here
Bonus
You can dump the content of the file with pg_filedump before and after the test and can use diff command to analyze data corruption
- pg_filedump -if 16770 > before_corrupt.txt
- corrupt the disk block
- pg_filedump -if 16770 > before_corrupt.txt
- diff or beyond compare both the files.
Thank you for giving your valuable time to read the above information. I hope the content served your purpose in reaching out to the blog.
Suggestions for improvement of the blog are highly appreciable. Please contact us for any information/suggestions/feedback.
If you want to be updated with all our articles
please follow us on Facebook | Twitter
Please subscribe to our newsletter.
psql queries to quickly Identify & resolve database performance problems

As a seasoned data store engineer, I often find myself in situations where a production application is down due to some sort of performance issue and I am being asked “What’s wrong with the database?”. In almost all these situations, the database (along with the DBA) is automatically considered guilty until proven innocent. As a DBA, I need the tools and knowledge to help quickly determine the actual problem, if there is one, because maybe there’s nothing wrong with the database or the database server. My favorite approach to start with data driven performance analysis using PostgreSQL systems catalog
In below post, I am sharing bunch of PostgreSQL system catalog queries that can be used to troubleshoot database engine performance
Postgres system catalogs are a place where database management system stores schema metadata, such as information about tables and columns, and internal bookkeeping information. PostgreSQL’s system catalogs are regular tables.
Instance level queries
POSTGRESQL SYSTEM CONFIGURATION
1. Get server IP address, version and port number
-- query server version (standard major.minor.patch format)
SELECT Inet_server_addr() AS "Server IP",
Version() AS "Postgres Version",
setting AS "Port Number",
current_timestamp :: timestamp
FROM pg_settings
WHERE name = 'port';
2. Get server version
SHOW server_version; -- release history | Version | First Release | Final Release | | -------- | ------------------ | ------------------| | 15 | October 13, 2022 | November 11, 2027 | | 14 | September 30, 2021 | November 12, 2026 | | 13 | September 24, 2020 | November 13, 2025 | | 12 | October 3, 2019 | November 14, 2024 | | 11 | October 18, 2018 | November 9, 2023 | | 10 | October 5, 2017 | November 10, 2022 |
3. Get system info
-- Server up time
SELECT Inet_server_addr()
AS
Server_IP --server IP address
,
Inet_server_port()
AS Server_Port --server port
,
Current_database()
AS Current_Database --Current database
,
current_user
AS Current_User --Current user
,
Pg_backend_pid()
AS ProcessID --Current user pid
,
Pg_postmaster_start_time()
AS Server_Start_Time --Last start time
,
current_timestamp :: TIMESTAMP - Pg_postmaster_start_time() :: TIMESTAMP
AS
Running_Since;
4. Get details of postgres configuration parameter
-- Option 1: PG_SETTINGS -- This gives you a lot of useful info about postgres instance SELECT name, unit, setting FROM pg_settings WHERE name ='port' UNION ALL SELECT name, unit, setting FROM pg_settings WHERE name ='shared_buffers' -- shared_buffers determines how much memory is dedicated for caching data UNION ALL SELECT name, unit, setting FROM pg_settings WHERE name ='work_mem' -- work memory required for each incoming connection UNION ALL SELECT name, unit, setting FROM pg_settings WHERE name ='maintenance_work_mem' -- work memory of maintenace type queries "VACUUM, CREATE INDEX etc." UNION ALL SELECT name, unit, setting FROM pg_settings WHERE name ='wal_buffers' -- Sets the number of disk-page buffers in shared memory for WAL UNION ALL SELECT name, unit, setting FROM pg_settings WHERE name ='effective_cache_size' -- used by postgres query planner UNION ALL SELECT name, unit, setting FROM pg_settings WHERE name ='TimeZone' -- server time zone; -- Option 2: SHOW ALL -- The SHOW ALL command displays all current configuration setting of in three columns SHOW all; -- Option 3: PG_FILE_SETTINGS -- To read what is stored in the postgresql.conf file itself, use the view pg_file_settings. SELECT * FROM pg_settings;
5. Get OS information
-- Get OS Version SELECT version(); | OS | Wiki References | | ------ | ----------------------------------------------------- | | RedHat | wikipedia.org/wiki/Red_Hat_Enterprise_Linux | | Windows| wikipedia.org/wiki/List_of_Microsoft_Windows_versions | | Mac OS | wikipedia.org/wiki/MacOS | | Ubuntu | wikipedia.org/wiki/Ubuntu_version_history |
6. Get location of data and log directory (this is where postgres stores the database files)
SELECT NAME,
setting
FROM pg_settings
WHERE NAME IN ( 'data_directory', 'log_directory' );
--OR
SHOW data_directory;
SHOW log_directory;
7. Get data and log (WAL) size for all databases
-- Cumulative size of all databases SELECT Pg_size_pretty(Sum(Pg_database_size(datname))) AS total_database_size FROM pg_database; -- Cumulative size of all Write-Ahead Log (WAL) files SELECT Pg_size_pretty(Sum(size)) AS total_WAL_size FROM Pg_ls_waldir();
8. List all databases along with creation date
SELECT datname AS database_name,
(Pg_stat_file('base/'
||oid
||'/PG_VERSION')).modification as create_timestamp
FROM pg_database
WHERE datistemplate = false;
9. Get an overview of current server activity
SELECT
pid
, datname
, usename
, application_name
, client_addr
, to_char(backend_start, 'YYYY-MM-DD HH24:MI:SS TZ') AS backend_start
, state
, wait_event_type || ': ' || wait_event AS wait_event
, pg_blocking_pids(pid) AS blocking_pids
, query
, to_char(state_change, 'YYYY-MM-DD HH24:MI:SS TZ') AS state_change
, to_char(query_start, 'YYYY-MM-DD HH24:MI:SS TZ') AS query_start
, backend_type
FROM
pg_stat_activity
ORDER BY pid;
CONNECTION DETAILS
10. Get max_connections configuration
SELECT NAME,
setting,
short_desc
FROM pg_settings
WHERE NAME = 'max_connections';
11. Get total count of current user connections
SELECT Count(*) FROM pg_stat_activity;
12. Get active v/s inactive connections
SELECT state,
Count(pid)
FROM pg_stat_activity
GROUP BY state,
datname
HAVING datname = '<your_database_name>'
ORDER BY Count(pid) DESC;
-- One row per server process, showing database OID, database name, process ID, user OID, user name, current query, query's waiting status, time at which the current query began execution
-- Time at which the process was started, and client's address and port number. The columns that report data on the current query are available unless the parameter stats_command_string has been turned off.
-- Furthermore, these columns are only visible if the user examining the view is a superuser or the same as the user owning the process being reported on
Database specific queries
**** Switch to a user database that you are interested in *****
13. Get database size (pretty size)
SELECT Current_database(),
Pg_size_pretty(Pg_database_size(Current_database()));
14. Get top 20 objects in database by size
SELECT nspname AS schemaname,
cl.relname AS objectname,
CASE relkind
WHEN 'r' THEN 'table'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 'v' THEN 'view'
WHEN 'm' THEN 'materialized view'
ELSE 'other'
end AS type,
s.n_live_tup AS total_rows,
Pg_size_pretty(Pg_total_relation_size(cl.oid)) AS size
FROM pg_class cl
LEFT JOIN pg_namespace n
ON ( n.oid = cl.relnamespace )
LEFT JOIN pg_stat_user_tables s
ON ( s.relid = cl.oid )
WHERE nspname NOT IN ( 'pg_catalog', 'information_schema' )
AND cl.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY Pg_total_relation_size(cl.oid) DESC
LIMIT 20;
15. Get size of all tables
SELECT *,
Pg_size_pretty(total_bytes) AS total,
Pg_size_pretty(index_bytes) AS INDEX,
Pg_size_pretty(toast_bytes) AS toast,
Pg_size_pretty(table_bytes) AS TABLE
FROM (SELECT *,
total_bytes - index_bytes - COALESCE(toast_bytes, 0) AS
table_bytes
FROM (SELECT c.oid,
nspname AS table_schema,
relname AS TABLE_NAME,
c.reltuples AS row_estimate,
Pg_total_relation_size(c.oid) AS total_bytes,
Pg_indexes_size(c.oid) AS index_bytes,
Pg_total_relation_size(reltoastrelid) AS toast_bytes
FROM pg_class c
LEFT JOIN pg_namespace n
ON n.oid = c.relnamespace
WHERE relkind = 'r') a) a;
16. Get table metadata
SELECT relname,
relpages,
reltuples,
relallvisible,
relkind,
relnatts,
relhassubclass,
reloptions,
Pg_table_size(oid)
FROM pg_class
WHERE relname = '<table_name_here>';
17. Get table structure (i.e. describe table)
SELECT column_name,
data_type,
character_maximum_length
FROM information_schema.columns
WHERE table_name = '<table_name_here>';
-- Does the table have anything unusual about it?
-- a. contains large objects
-- b. has a large proportion of NULLs in several columns
-- c. receives a large number of UPDATEs or DELETEs regularly
-- d. is growing rapidly
-- e. has many indexes on it
-- f. uses triggers that may be executing database functions, or is calling functions directly
LOCKING
18. Get Lock connection count
SELECT Count(DISTINCT pid) AS count FROM pg_locks WHERE NOT granted;
19. Get locks_relation_count
SELECT relation::regclass AS relname ,
count(DISTINCT pid) AS count
FROM pg_locks
WHERE NOT granted
GROUP BY 1;
20. Get locks_statement_duration
SELECT a.query AS blocking_statement,
Extract('epoch' FROM Now() - a.query_start) AS blocking_duration
FROM pg_locks bl
JOIN pg_stat_activity a
ON a.pid = bl.pid
WHERE NOT bl.granted;
INDEXING
21. Get missing indexes
SELECT relname AS TableName ,seq_scan-idx_scan AS TotalSeqScan ,CASE WHEN seq_scan-idx_scan > 0 THEN 'Missing Index Found' ELSE 'Missing Index Not Found' END AS MissingIndex ,pg_size_pretty(pg_relation_size(relname::regclass)) AS TableSize ,idx_scan AS TotalIndexScan FROM pg_stat_all_tables WHERE schemaname='public' AND pg_relation_size(relname::regclass)>100000 ORDER BY 2 DESC;
22. Get Unused Indexes
SELECT indexrelid::regclass AS INDEX ,
relid::regclass AS TABLE ,
'DROP INDEX '
|| indexrelid::regclass
|| ';' AS drop_statement
FROM pg_stat_user_indexes
JOIN pg_index
using (indexrelid)
WHERE idx_scan = 0
AND indisunique IS false;
23. Get index usage stats
SELECT t.tablename AS
"relation",
indexname,
c.reltuples AS
num_rows,
Pg_size_pretty(Pg_relation_size(Quote_ident(t.tablename) :: text)) AS
table_size,
Pg_size_pretty(Pg_relation_size(Quote_ident(indexrelname) :: text)) AS
index_size,
idx_scan AS
number_of_scans,
idx_tup_read AS
tuples_read,
idx_tup_fetch AS
tuples_fetched
FROM pg_tables t
left outer join pg_class c
ON t.tablename = c.relname
left outer join (SELECT c.relname AS ctablename,
ipg.relname AS indexname,
x.indnatts AS number_of_columns,
idx_scan,
idx_tup_read,
idx_tup_fetch,
indexrelname,
indisunique
FROM pg_index x
join pg_class c
ON c.oid = x.indrelid
join pg_class ipg
ON ipg.oid = x.indexrelid
join pg_stat_all_indexes psai
ON x.indexrelid = psai.indexrelid) AS foo
ON t.tablename = foo.ctablename
WHERE t.schemaname = 'public'
ORDER BY 1, 2;
QUERY PERFORMANCE
24. Get top 10 costly queries
SELECT r.rolname,
Round((100 * total_time / Sum(total_time::numeric) OVER ())::numeric, 2) AS percentage_cpu ,
Round(total_time::numeric, 2) AS total_time,
calls,
Round(mean_time::numeric, 2) AS mean,
Substring(query, 1, 800) AS short_query
FROM pg_stat_statements
JOIN pg_roles r
ON r.oid = userid
ORDER BY total_time DESC limit 10;
CACHING
25. Get TOP cached tables & indexes
-- Measure cache hit ratio for tables
SELECT relname AS "relation",
heap_blks_read AS heap_read,
heap_blks_hit AS heap_hit,
COALESCE((( heap_blks_hit * 100 ) / NULLIF(( heap_blks_hit + heap_blks_read ), 0)),0) AS ratio
FROM pg_statio_user_tables
ORDER BY ratio DESC;
-- Measure cache hit ratio for indexes
SELECT relname AS "relation",
idx_blks_read AS index_read,
idx_blks_hit AS index_hit,
COALESCE((( idx_blks_hit * 100 ) / NULLIF(( idx_blks_hit + idx_blks_read ), 0)),0) AS ratio
FROM pg_statio_user_indexes
ORDER BY ratio DESC;
AUTOVACUUM & Data bloat
26. Last Autovaccum, live & dead tuples
SELECT relname AS "relation",
Extract (epoch FROM CURRENT_TIMESTAMP - last_autovacuum) AS since_last_av,
autovacuum_count AS av_count,
n_tup_ins,
n_tup_upd,
n_tup_del,
n_live_tup,
n_dead_tup
FROM pg_stat_all_tables
WHERE schemaname = 'public'
ORDER BY relname;
PARTITIONING
27. List all table partitions (as parent/child relationship)
SELECT nmsp_parent.nspname AS parent_schema,
parent.relname AS parent,
child.relname AS child,
CASE child.relkind
WHEN 'r' THEN 'table'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 'v' THEN 'view'
WHEN 'm' THEN 'materialized view'
ELSE 'other'
END AS type,
s.n_live_tup AS total_rows
FROM pg_inherits
JOIN pg_class parent
ON pg_inherits.inhparent = parent.oid
JOIN pg_class child
ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent
ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child
ON nmsp_child.oid = child.relnamespace
JOIN pg_stat_user_tables s
ON s.relid = child.oid
WHERE child.relkind = 'r'
ORDER BY parent,
child;
28. List ranges for all partitions (and sub-partitions) for a given table
SELECT pt.relname AS partition_name,
Pg_get_expr(pt.relpartbound, pt.oid, TRUE) AS partition_expression
FROM pg_class base_tb
join pg_inherits i
ON i.inhparent = base_tb.oid
join pg_class pt
ON pt.oid = i.inhrelid
WHERE base_tb.oid = 'public.table_name ' :: regclass;
29. Postgres 12 – pg_partition_tree()
Alternatively, can use new PG12 function pg_partition_tree() to display information about partitions.
SELECT relid,
parentrelid,
isleaf,
level
FROM Pg_partition_tree('<parent_table_name>');
SECURITY Roles and Privileges
30. Checking if user is connected is a “superuser”
SELECT usesuper FROM pg_user WHERE usename = CURRENT_USER;
31. List all users (along with assigned roles) in current database
SELECT usename AS role_name,
CASE
WHEN usesuper
AND usecreatedb THEN Cast('superuser, create database' AS
pg_catalog.TEXT)
WHEN usesuper THEN Cast('superuser' AS pg_catalog.TEXT)
WHEN usecreatedb THEN Cast('create database' AS pg_catalog.TEXT)
ELSE Cast('' AS pg_catalog.TEXT)
END role_attributes
FROM pg_catalog.pg_user
ORDER BY role_name DESC;
EXTENSIONS
32. List extensions installed in a database?
SELECT extname,
extversion
FROM pg_extension;
Like what I write? Join my mailing list, and I’ll let you know whenever I write another post. No spam, I promise! 👨💻
![]()
Hello dear reader,
I’m a Product Manager @Microsoft based in MN, US (beautiful land of 10,000 lakes). I am perpetually curious and always willing to learn and engineer systems that can help solve complex problems using data. When I am not engineering or blogging, you’ll find me cooking and spending time with my family.
Varun.Dhawan@gmail.com
View all posts by Varun Dhawan
JavaScript
является довольно простым языком для тех, кто хочет начать его изучение, но чтобы достичь в нем мастерства, нужно приложить много усилий.
Новички часто допускают несколько распространенных ошибок, которые аукаются им и всплывают в тот момент, когда они меньше всего этого ожидают. Чтобы понять, какие это ошибки, прочитайте эту статью.
1. Пропуск фигурных скобок
Одна из ошибок, которую часто допускают новички JavaScript
— пропуск фигурных скобок после операторов типа if, else,while
и for
. Хотя это не запрещается, вы должны быть очень осторожны, потому что это может стать причиной скрытой проблемы и позже привести к ошибке.
Смотрите пример, приведенный ниже:
JS
// Этот код не делает то, что должен!
if(name === undefined)
console.log(«Please enter a username!»);
fail();
// До этой строки исполнение никогда не дойдет:
success(name);
}
function success(name){
console.log(«Hello, » + name + «!»);
}
function fail(){
throw new Error(«Name is missing. Can»t say hello!»);
}
Хотя вызов fail()
имеет отступ и, кажется, будто он принадлежит оператору if
, это не так. Он вызывается всегда. Так что это полезная практика окружать все блоки кода фигурными скобками, даже если в них присутствует только один оператор.
2. Отсутствие точек с запятой
Во время парсировки JavaScript
осуществляется процесс, известный как автоматическая расстановка точек с запятой. Как следует из названия, анализатор расставляет недостающие знаки вместо вас.
Цель этой функции — сделать JavaScript
более доступным и простым в написании для новичков. Тем не менее, вы должны всегда сами добавлять точку с запятой, потому что существует риск пропустить ее.
Вот пример:
JS
// Результатом обработки этого кода станет вывод сообщения об ошибке. Добавление точки с запятой решило бы проблему.
console.log(«Welcome the fellowship!»)
[«Frodo», «Gandalf», «Legolas», «Gimli»].forEach(function(name){
hello(name)
})
function hello(name){
console.log(«Hello, » + name + «!»)
}
Так как в строке 3 отсутствует точка с запятой, анализатор предполагает, что открывающаяся скобка в строке 5 является попыткой доступа к свойству, используя синтаксис массива аксессора (смотри ошибку № 8), а не отдельным массивом, который является не тем, что предполагалось.
Это приводит к ошибке. Исправить это просто — всегда вставляйте точку с запятой.
Некоторые опытные разработчики JavaScript
предпочитают не расставлять точки с запятой, но они прекрасно знают о возможных ошибках, и то, как их предотвратить.
3. Непонимание приведений типа
JavaScript
поддерживает динамические типы. Это означает, что вам не нужно указывать тип при объявлении новой переменной, вы можете свободно переназначить или конвертировать его значение.
Это делает JavaScript
гораздо более простым, чем, скажем, C#
или Java
. Но это таит в себе потенциальную опасность ошибок, которые в других языках выявляются на этапе компиляции.
Вот пример:
JS
// Ожидание события ввода из текстового поля
var textBox = document.querySelector(«input»);
textBox.addEventListener(«input», function(){
// textBox.value содержит строку. Добавление 10 содержит
// строку «10», но не выполняет ее добавления..
console.log(textBox.value + » + 10 = » + (textBox.value + 10));
});
HTML
Проблема может быть легко исправлена с применением parseInt(textBox.value, 10)
, чтобы перевести строку в число перед добавлением к ней 10.
В зависимости от того, как вы используете переменную, среда выполнения может решить, что она должна быть преобразована в тот или иной тип. Это называется приведение типа
.
Чтобы не допустить преобразования типа при сравнении переменных в операторе if
, вы можете использовать проверку строгого равенства
(===
).
4. Забытые var
Еще одна ошибка, допускаемая новичками — они забывают использовать ключевое слово var
при объявлении переменных. JavaScript
— очень либеральный движок.
В первый раз, когда он увидит, что вы использовали переменную без оператора var
, он автоматически объявит его глобально. Это может привести к некоторым ошибкам.
Вот пример, который кроме того иллюстрирует и другую ошибку — недостающую запятую при объявлении сразу нескольких переменных:
JS
var a = 1, b = 2, c = 3;
function alphabet(str){
var a = «A», b = «B» // Упс, здесь пропущена «,»!
c = «C», d = «D»;
return str + » » + a + b + c + «…»;
}
console.log(alphabet(«Let»s say the alphabet!»));
// О, нет! Что-то не так! У c новое значение!
console.log(a, b, c);
Когда анализатор достигает строки 4, он автоматически добавит точку с запятой, а затем интерпретирует объявления c и d в строке 5, как глобальные.
Это приведет к изменению значения другой переменной c. Больше о подводных камнях JavaScript здесь
.
5. Арифметические операции с плавающей точкой
Эта ошибка характерна практически для любого языка программирования, в том числе и JavaScript
. Из-за способа, которым числа с плавающей точкой представляются в памяти
, арифметические операции выполняются не совсем так, как вы думаете.
Например:
JS
var a = 0.1, b = 0.2;
// Сюрприз! Это неправильно:
console.log(a + b == 0.3);
// Потому что 0.1 + 0.2 не дает в сумме то число, что вы ожидали:
console.log(«0.1 + 0.2 = «, a + b);
Чтобы обойти эту проблему, вы не должны использовать десятичные числа, если вам нужна абсолютная точность — используйте целые числа, или если вам нужно работать с денежными единицами, используйте библиотеку типа bignumber.js
.
6. Использование конструкторов вместо оригинальных обозначений
Когда программисты Java
и C #
начинают писать на JavaScript, они часто предпочитают создавать объекты с использованием конструкторов: new Array(), new Object(), new String()
.
JS
var elem4 = new Array(1,2,3,4);
console.log(«Four element array: » + elem4.length);
// Создание массива из одного элемента. Это не работает так, как вы думаете:
var elem1 = new Array(23);
console.log(«One element array? » + elem1.length);
/* Объекты строки также имеют свои особенности */
var str1 = new String(«JavaScript»),
str2 = «JavaScript»;
// Строгое равенство не соблюдается:
console.log(«Is str1 the same as str2?», str1 === str2);
Решение этой проблемы просто: попробуйте всегда использовать буквальные оригинальные
обозначения. Кроме того, в JS
не обязательно указывать размер массивов заранее.
7. Непонимание того, как разделяются диапазоны
Одна из трудных для понимания новичками вещей в JS
, это правила разграничения и закрытия диапазонов. И это действительно не просто:
JS
for(var i = 0; i
Функции сохраняют связь с переменными в пределах родительских диапазонов. Но поскольку мы откладываем выполнение через setTimeout
, когда наступит время для запуска функций, то цикл будет уже фактически завершен и переменная i
увеличивается до 11.
Самовыполняющаяся функция в комментариях работает, потому что она копирует значение переменной i
и хранит его копию для каждой задержки выполнения функции. Больше о диапазонах вы можете узнать здесь
и здесь
.
8. Использование Eval
Eval есть зло
. Это считается плохой практикой, и в большинстве случаев, когда вы думаете его применить, можно найти лучший и более быстрый способ.
JS
// Это плохая практика. Пожалуйста, не делайте так:
console.log(eval(«obj.name + » is a » + obj.» + access));
// Вместо этого для доступа к свойствам динамически используйте массив примечаний:
console.log(obj.name + » is a » + obj);
/* Использование eval в setTimout */
// Это также неудачная практика. Она медленна и сложна для проверки и отладки:
setTimeout(» if(obj.age == 30) console.log(«This is eval-ed code, » + obj + «!»);», 100);
// Так будет лучше:
setTimeout(function(){
if(obj.age == 30){
console.log(«This code is not eval-ed, » + obj + «!»);
}
}, 100);
Код внутри eval
— это строка. Отладочные сообщения, связанные с Eval-блоками непонятны, и вам придется поломать голову, чтобы правильно расставить одинарные и двойные кавычки.
Не говоря уже о том, что это будет работать медленнее, чем обычный JavaScript
. Не используйте Eval
если вы не знаете точно, что вы делаете.
9. Непонимание асинхронного кода
Что действительно выделяет JavaScript
и делает его уникальным, это то, что почти все элементы работают асинхронно, и вы должны передавать функции обратного вызова для того, чтобы получать уведомления о событиях.
Новичкам еще трудно понимать это интуитивно, и они быстро заходят в тупик, сталкиваясь с ошибками, которые трудно понять.
Вот пример, в котором я использую сервис FreeGeoIP
для определения вашего местоположения по IP-адресу:
JS
// Определение данных местоположения текущего пользователя.
load();
// Вывод местоположения пользователя. Упс, это не работает! Почему?
console.log(«Hello! Your IP address is » + userData.ip + » and your country is » + userData.country_name);
// Загружаемая функция будет определять ip текущего пользователя и его местоположение
// через ajax, используя сервис freegeoip. Когда это сделано она поместит возвращаемые
// данные в переменную userData.
function load(){
$.getJSON(«http://freegeoip.net/json/?callback=?», function(response){
userData = response;
// Выведите из комментариев следующую строку, чтобы увидеть возвращаемый
// результат:
// console.log(response);
});
}
Несмотря на то, что console.log
располагается после вызова функции load()
, на самом деле он выполняется перед определением данных.
10. Злоупотребление отслеживанием событий
Давайте предположим, что вы хотите отслеживать клик кнопки, но только при условии установленного чеккера.
Допустим, я пишу
If(someVal)
alert(«True»);
Затем приходит следующий разработчик и говорит: «О, мне нужно сделать что-то еще», поэтому они пишут
If(someVal)
alert(«True»);
alert(«AlsoTrue»);
Теперь, как вы можете видеть, «AndTrue» всегда будет правдой, потому что первый разработчик не использовал фигурные скобки.
2018-12-04T00:00Z
Абсолютно да
Забудьте о «Это личное предпочтение», «код будет работать отлично», «он отлично работает для меня», «это более читаемо» yada yada BS.
Аргумент: «Это личное предпочтение»
Нет. Если вы не один человек, выходящий на Марс, нет. Большую часть времени будут другие люди, читающие / изменяющие ваш код. В любой серьезной команде кодирования это будет рекомендуемым способом, поэтому это не «личное предпочтение».
Аргумент: «код будет работать просто отлично»
Так же и код спагетти! Означает ли это, что это нормально, чтобы создать его?
Аргумент: «Он отлично работает для меня»
В моей карьере я видел так много ошибок, созданных из-за этой проблемы. Вероятно, вы не помните, сколько раз вы прокомментировали «DoSomething()» и сбиты с толку, почему «SomethingElse()» вызывается:
If (condition)
DoSomething();
SomethingElse();
If (condition)
DoSomething();
SomethingMore();
Вот пример реальной жизни. Кто-то хотел включить все протоколирование, чтобы они запускали find & replace «Console.println» => //»Console.println» :
If (condition)
Console.println(«something»);
SomethingElse();
См. Проблему?
Даже если вы думаете: «Это настолько тривиально, что я никогда этого не сделаю»; помните, что всегда будет член команды с более низкими навыками программирования, чем вы (надеюсь, вы не худшие в команде!)
Аргумент: «это более читаемо»
Если я что-то узнал о программировании, то это очень просто. Очень распространено, что это:
If (condition)
DoSomething();
превращается в следующее после того, как он был протестирован с различными браузерами / средами / примерами использования или добавлены новые функции:
If (a != null)
if (condition)
DoSomething();
else
DoSomethingElse();
DoSomethingMore();
else
if (b == null)
alert(«error b»);
else
alert(«error a»);
И сравните это с этим:
If (a != null) {
if (condition) {
DoSomething();
}
else {
DoSomethingElse();
DoSomethingMore();
}
} else if (b == null) {
alert(«error b»);
} else {
alert(«error a»);
}
PS: Бонусные очки идут к тому, кто заметил ошибку в приведенном выше примере
2018-12-11T00:00Z
В дополнение к причине, упомянутой @Josh K (что также относится к Java, C и т. Д.), Одной из специальных проблем в JavaScript является автоматическая вставка точки с запятой . Из примера в Википедии:
Return
a + b;
// Returns undefined. Treated as:
// return;
// a + b;
Таким образом, это может также дать неожиданные результаты, если они используются следующим образом:
If (x)
return
a + b;
На самом деле не намного лучше писать
If (x) {
return
a + b;
}
но, может быть, здесь ошибка немного легче обнаружить (?)
2018-12-18T00:00Z
Вопрос спрашивает о заявлениях на одной строке. Тем не менее, во многих примерах приводятся причины не оставлять фигурные скобки на основе нескольких строк. Вполне безопасно не использовать скобки на одной линии, если это стиль кодирования, который вы предпочитаете.
Например, вопрос спрашивает, нормально ли это:
If (condition) statement;
Он не спрашивает, все ли в порядке:
If (condition)
statement;
Я думаю, что оставлять скобки предпочтительнее, потому что это делает код более читаемым с менее излишним синтаксисом.
Мой стиль кодирования заключается в том, чтобы никогда не использовать скобки, если код не является блоком. И никогда не использовать несколько операторов в одной строке (разделенных точкой с запятой). Я считаю, что это легко читать и очищать и никогда не иметь проблем, связанных с высказываниями «если». В результате, используя скобки в одном условии if, требуется 3 строки. Как это:
If (condition) {
statement;
}
Использование одной строки, если оператор предпочтительнее, потому что он использует меньше вертикального пространства, а код более компактен.
Я бы не принуждал других использовать этот метод, но он работает для меня, и я не мог больше не соглашаться с примерами, приведенными в том, как исключить скобки из-за ошибок кодирования / определения области видимости.
2018-12-25T00:00Z
нет
Это совершенно верно
If (cond)
alert(«Condition met!»)
else
alert(«Condition not met!»)
Эта же практика следует во всех языках стиля синтаксиса C с привязкой. C, C ++, Java, даже PHP все поддерживают один оператор строки без брекетов. Вы должны понимать, что вы сохраняете только два персонажа,
а с помощью некоторых стилей для некоторых людей вы даже не сохраняете линию. Я предпочитаю полный стиль фигурной скобки (например, следующий), поэтому он имеет тенденцию быть немного дольше. Компромисс встречается очень хорошо с тем, что у вас очень четкая читаемость кода.
If (cond)
{
alert(«Condition met!»)
}
else
{
alert(«Condition not met!»)
}
2019-01-01T00:00Z
Начальный уровень отступа оператора должен быть равен числу открытых фигурных скобок над ним. (исключая цитируемые или комментируемые фигурные скобки или символы в директивах препроцессора)
В противном случае K & R будет хорошим отступом. Чтобы исправить их стиль, я рекомендую размещать короткие простые операторы if на одной строке.
Get Started With PostgreSQL
Duration 00:41:44
Get Started With PostgreSQL — Полный список уроков
Развернуть / Свернуть
- Урок 1. Create a Postgres Table
00:01:45
- Урок 2. Insert Data into Postgres Tables
00:04:24
- Урок 3. Filter Data in a Postgres Table with Query Statements
00:03:35
- Урок 4. Update Data in Postgres
00:01:55
- Урок 5. Delete Postgres Records
00:02:43
- Урок 6. Group and Aggregate Data in Postgres
00:06:45
- Урок 7. Sort Postgres Tables
00:01:20
- Урок 8. Ensure Uniqueness in Postgres
00:03:53
- Урок 9. Use Foreign Keys to Ensure Data Integrity in Postgres
00:02:18
- Урок 10. Create Foreign Keys Across Multiple Fields in Postgres
00:03:08
- Урок 11. Enforce Custom Logic with Check Constraints in Postgres
00:02:07
- Урок 12. Speed Up Postgres Queries with Indexes
00:02:33
- Урок 13. Find Intersecting Data with Postgres_ Inner Join
00:04:26
- Урок 14. Select Distinct Data in Postgres
00:00:52
Курс «Get Started With PostgreSQL» заставить вас сказать что вы «знаете SQL» — создание таблиц, вставки, выборки, обновления, удаления, агрегации, индексы, объединения и ограничения. По пути мы будем моделировать проблемы реального мира, чтобы вы могли увидеть, насколько мощный PostgreSQL!
24-04-2016
30-11—0001
ru
15 уроков
Если Вы начали осваивать SQL, то в процессе изучения Вам предстоит столкнуться со множеством вопросов и непонятных моментов, ответы на которые подготовил данный видеокурс. В процессе обучения будут разобраны такие темы, как: создание базы данных, ее изменение и удаление, оператор вставки INSERT, использование запроса SELECT и конструкций WHERE, операторы UPDATE и DELETE, создание различных связей между таблицами с использованием операторов…
Duration 01:26:19
24-04-2016
30-11—0001
ru
9 уроков
Duration 08:50:57
17-06-2018
30-11—0001
ru
6 уроков
Курс СУБД PostgreSQL состоит из 6 уроков, рассчитан для новичков, которые впервые встречают такое понятием как СУБД. Курс включает в себя как теоретическую, так и практическую часть. На данном курсе учащиеся спроектируют небольшую базу данных сети продуктовых магазинов, определят необходимую структуру. Функционал (индексы, представления, триггеры, функции). После прохождения курса, учащиеся будут понимать принципы проектирования БД,…
Duration 03:05:26
28-11-2018
12-09-2018
en
164 урока
Создайте 9 проектов — освойте две основные и современные технологии в Python и PostgreSQL. Всегда хотели узнать один из самых популярных языков программирования на планете? Почему бы не изучить два из самых популярных одновременно? Python и SQL используются многими технологическими компаниями, малыми и большими. Это потому, что они мощные, но чрезвычайно гибкие.
Duration 21:53:10
27-12-2018
ru
10 уроков
Данный курс предназначен для изучения основ SQL: теоретических основ реляционной модели, операций реляционной алгебры, правил и назначение нормализации, использования ER диаграммы для моделирования предметной области, практического использования всех операторов SQL (операторов определения данных (Data Definition Language, DDL): CREATE, ALTER, DROP; манипуляции данными (Data Manipulation Language, DML):…
Duration 05:23:59
Последнее добавленное
en
13-03-2019
В дополнение к обновлению всех инструментов до последних и самых лучших версий Complete Intro to React v5 реструктурировал семинар, чтобы больше сосредоточиться на обучении основным принципам React, не жертвуя при этом какими-либо инструкциями по инструментарию. В этом двухдневном тренинге Брайан…
en
13-03-2019
Единственный курс, который вам нужен для изучения веб-разработки — HTML, CSS, JS, Node и многое другое! Привет! Добро пожаловать в The Web Developer Bootcamp, единственный курс, который вам нужен для изучения веб-разработки. Существует множество вариантов онлайн-обучения разработчиков…
en
13-03-2019
Знание – сила, и набор материалов по PostgreSQL тому подтверждение. Представляем книги и курсы, с которыми полнофункциональная СУБД станет доступной.
Эта книжка-малышка доступна в электронном и бумажном вариантах. Но важно другое: книга собрала необходимый костяк. Здесь представлена информация о кроссплатформенности, запросах, полнотекстовом поиске и о многом другом. Книгу можно смело назвать «От А до Я». Установкой и настройкой открытой СУБД на разных ОС книга не ограничивается, поэтому будьте готовы к первой практике.
Начинается просто: введение, история, форки и т. д. Дальше – больше: архитектура, включающая в себя разделы о структуре памяти, многоверсионности и расширяемости системы, создание БД из шаблона, табличные пространства, системный каталог, схемы, холодное и горячее резервирование. Это настоящий курс, наполненный слайдами, практическими примерами и видео-уроками.
«Продвинутым» подойдет расширенная версия. Курс дополнен журналированием, репликацией с подключением, видами и вариантами, основами оптимизации, локализацией, обновлением сервера и другой полезной информацией. Кроме слайдов, в архив заключены справочник по Unix-командам, которые используются в курсе, и инструкция по практическим заданиям.
8 лекций и море новых знаний. Здесь есть как общие сведения о подсистемах, так и подробный разбор инструментов разработчика, расширяемости, исходного кода, физического представления данных, разделяемой и локальной памяти, а также устройства экзекутора и планировщика запросов. Лекции сопровождаются обратной связью «вопрос/ответ», примерами и картинками.
Без нее никуда. Наиболее лаконичная и исчерпывающая информация, которая должна быть у каждого, кто работает со свободной объектно-реляционной СУБД. Только актуальные обновляемые версии.
System Administration
Этот пост — краткая инструкция для начинающих, для тех кто впервые установил PostgreSQL. Здесь вся необходимая информация для того, чтобы начать работу с PostgreSQL.
Подключение к СУБД
Первое, что нужно сделать — получить доступ к PostgreSQL, доступ в качестве суперпользователя.
Настройки аутентификации находятся в файле pg_hba.conf.
- local all postgres peer
Эта строка говорит о том, что пользователь postgres может подключаться к любой базе данных локальной СУБД PostgreSQL через сокет. Пароль при этом вводить не надо, операционная система передаст имя пользователя, и оно будет использовано для аутентификации.
Подключаемся:
- $ sudo -u postgres psql postgres postgres
Чтобы иметь возможность подключаться по сети, надо в pg_hdba.conf добавить строку:
- # TYPE DATABASE USER ADDRESS METHOD
- hostssl all all 0.0.0.0/0 md5
Метод аутентификации md5
означает, что для подключения придется ввести пароль. Это не очень удобно, если вы часто пользуетесь консолью psql. Если вы хотите автоматизировать какие-то действия, то плохая новость в том, что psql не принимает пароль в качестве аргумента. Есть два пути решения этих проблем: установка соответствующей переменной окружения и хранение пароля в специальном файле.pgpass .
Установка переменной окружения PGPASSWORD
Сразу скажу, что лучше этот способ не использовать, потому что некоторые операционные системы позволяют просматривать обычным пользователям переменные окружение с помощью ps. Но если хочется, то надо написать в терминале:
- export PGPASSWORD=mypasswd
Переменная будет доступна в текущей сессии. Если нужно задать переменную для всех сессий, то надо добавить строку из примера в файл.bashrc или.bash_profile
Хранение пароля в файле.pgpass
Если мы говорим о Linux, то файл должен находится в $HOME (/home/username). Права на запись и чтение должны быть только у владельца (0600). В файл нужно записывать строки вида:
- hostname:port:database:username:password
В первые четыре поля можно записать «*», что будет означать отсутствие фильтрации (полную выборку).
Получение справочной информации
? — выдаст все доступные команды вместе с их кратким описанием,
h — выдаст список всех доступных запросов,
h CREATE — выдаст справку по конкретному запросу.
Управление пользователями СУБД
Как получить список пользователей PostgreSQL?
Или можно сделать запрос к таблице pg_user.
- SELECT
*
FROM
pg_user
;
Создание нового пользователя PostgreSQL
Из командной оболочки psql это можно сделать с помощью команды CREATE.
- CREATE
USER
username
WITH
password
«password»
;
Или можно воспользоваться терминалом.
- createuser -S -D -R -P username
Ввод пароля будет запрошен.
Изменение пароля пользователя
- ALTER
USER
username
WITH
PASSWORD
«password»
;
Изменение ролей пользователя
Чтобы пользователь имел право создавать базы данных, выполните запрос:
- ALTER
ROLE
username
WITH
CREATEDB
;
Управление базами данных
Вывод списка баз данных в терминале psql:
Тоже самое из терминала Linux:
- psql -l
Создание базы данных из psql (PostgreSQL Terminal)
- CREATE
DATABASE
dbname
OWNER
dbadmin
;
Создание новой базы данных при помощи терминала:
- createdb -O username dbname;
Настройка прав доступа к базе данных
Если пользователь является владельцем (owner) базы данных, то у него есть все права. Но если вы хотите дать доступ другому пользователю, то сделать это можно с помощью команды GRANT. Запрос ниже позволит пользователю подключаться к базе данных. Но не забывайте о конфигурационном файле pg_hba.conf, в нем тоже должны быть соответствующие разрешения на подключение.
- GRANT
CONNECT
ON
DATABASE
dbname
TO
dbadmin
;
PostgreSQL — ýòî ñâîáîäíî ðàñïðîñòðàíÿåìàÿ îáúåêòíî-ðåëÿöèîííàÿ ñèñòåìà
óïðàâëåíèÿ áàçàìè äàííûõ (ORDBMS), íàèáîëåå ðàçâèòàÿ èç îòêðûòûõ ÑÓÁÄ â ìèðå
è ÿâëÿþùàÿñÿ ðåàëüíîé àëüòåðíàòèâîé êîììåð÷åñêèì áàçàì äàííûõ.
PostgreSQL ïðîèçíîñèòñÿ êàê post-gress-Q-L (ìîæíî ñêà÷àòü mp3 ôàéë postgresql.mp3),
â ðàçãîâîðå ÷àñòî óïîòðåáëÿåòñÿ postgres (ïîñò-ãðåññ). Òàêæå, óïîòðåáëÿåòñÿ
ñîêðàùåíèå pgsql (ïý-æý-ýñ-êó-ýëü).
Àäðåñ ýòîé ñòàòüè:
http://www.sai.msu.su/~megera/postgres/talks/what_is_postgresql.html
Èñòîðèÿ ðàçâèòèÿ PostgreSQL
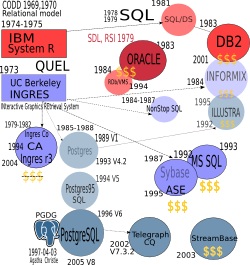
Êðàòêóþ èñòîðèþ PostgreSQL ìîæíî ïðî÷èòàòü â äîêóìåíòàöèè, ðàñïðîñòðàíÿåìîé
ñ äèñòðèáóòèâîì èëè íà ñàéòå.
Òàêæå, åñòü ïåðåâîä íà
ðóññêèé ÿçûê. Èç íåå ñëåäóåò, ÷òî ñîâðåìåííûé ïðîåêò PostgreSQL âåäåò
ïðîèñõîæäåíèå èç ïðîåêòà POSTGRES, êîòîðûé ðàçðàáàòûâàëñÿ ïîä ðóêîâîäñòâîì
Ìàéêëà Ñòîóíáðåéêåðà (Michael Stonebraker), ïðîôåññîðà Êàëèôîðíèéñêîãî
óíèâåðñèòåòà â Áåðêëè (UCB). Ìíå çàõîòåëîñü íåñêîëüêî ïîäðîáíåå ïîêàçàòü
âçàèìîñâÿçè ðîäîñëîâíûõ áàç äàííûõ, ÷òîáû ëó÷øå ïîíÿòü ìåñòî PostgreSQL ñðåäè
îñíîâíûõ èãðîêîâ ñîâðåìåííîãî ðûíêà áàç äàííûõ.
ß ïîïûòàëñÿ ãðàôè÷åñêè
( áîëüøàÿ âåðñèÿ êàðòèíêè
îòêðîåòñÿ â íîâîì îêíå) îòîáðàçèòü âñå
íàèáîëåå çàìåòíûå RDBMS è ñâÿçè ìåæäó íèìè è ïðèáëèçèòåëüíî ïðèâåë äàòû
èõ ñîçäàíèÿ è êîíöà. Ïåðåñå÷åíèå îáúåêòîâ îçíà÷àåò ïîãëîùåíèå, ïðè ýòîì
ïîãëîùàåìûé îáúåêò áîëåå áëåäåí è íå îêàíòîâàí. Çíàê äîëëàðà îçíà÷àåò,
÷òî áàçà äàííûõ ÿâëÿåòñÿ êîììåð÷åñêîé.
Ïðè ýòîì, ÿ îñíîâûâàëñÿ íà èíôîðìàöèè, äîñòóïíîé
â èíòåðíåòå, â ÷àñòíîñòè â Wikipedia,
â íàó÷íûõ ñòàòüÿõ, êîòîðûå ÿ ÷èòàë è êîììåíòàðèÿõ íåïîñðåäñòâåííûõ ïîëüçîâàòåëåé
ÁÄ, êîòîðûå ÿ ïîëó÷èë ïîñëå ïóáëèêàöèè ýòîé êàðòèíêè â èíòåðíåòå.
Íàäî ñêàçàòü, ÷òî íåñìîòðÿ íà òî, ÷òî âñÿ èñòîðèÿ ðåëÿöèîííûõ áàç äàííûõ
íàñ÷èòûâàåò ìåíåå 4 äåñÿòêîâ ëåò, ìíîãèå ôàêòû èç èñòîðèè ñîçäàíèÿ òðàêòóþòñÿ
ïî-ðàçíîìó, äàòû íå ñîãëàñóþòñÿ, à ñàìè ó÷àñòíèêè ñîáûòèé çà÷àñòóþ ïðîñòî
âîëüíî òðàêòóþò ïðîøëîå.Çäåñü íàäî ïðèíèìàòü âî âíèìàíèå òîò ôàêò, ÷òî
áàçû äàííûõ — ýòî áîëüøîé áèçíåñ, â êîòîðîì ðàçâèòèå îäíèõ ÁÄ ÷àñòî ñâÿçàíî ñ
êîíöîì äðóãèõ. Êðîìå òîãî, ÁÄ
â òî âðåìÿ áûëè ïðåäìåòîì íàó÷íûõ èññëåäîâàíèé, ïîýòîìó ïðèîðèòåòíîñòü
ðàáîò ÿâëÿåòñÿ íå ïîñëåäíèì àðãóìåíòîì ïðè íàïèñàíèè âîñïîìèíàíèé è èíòåðâüþ.
Íàâåðíîå, ó÷èòûâàÿ òàêóþ çàïóòàííîñòü, ïðåìèÿ ACM Software System Award #6
áûëà ïðèñóæäåíà
îäíîâðåìåííî äâóì ñîïåðíè÷àþùèì ãðóïïàì èññëåäîâàòåëåé èç IBM çà ðàáîòó íàä
«System R» è Áåðêëè — çà INGRES, õîòÿ Ñòîóíáðåéêåð ïîëó÷èë íàãðàäó îò
ACM SIGMOD (ñåé÷àñ ýòî ïðåìèÿ íàçâàíà â ÷åñòü
Òåäà Êîääà — àâòîðà ðåëÿöèîííîé òåîðèè áàç äàííûõ) #1 â 1992 ã.,
à Ãðåé (Jim Gray, Microsoft) — #2 â 1993 ãîäó.
Èòàê, êàê ñëåäóåò èç ðèñóíêà, âèäíî äâå âåòâè ðàçâèòèÿ áàç äàííûõ —
îäíà ñëåäóåò èç «System R», êîòîðàÿ ðàçðàáàòûâàëàñü â IBM â íà÷àëå 70-õ,
è äðóãàÿ èç ïðîåêòà «INGRES», êîòîðûì ðóêîâîäèë Ñòîóíáðåéêåð ïðèáëèçèòåëüíî
â òîæå âðåìÿ. Ýòè äâà ïðîåêòà íà÷àëèñü êàê íåîáõîäèìîñòü ïðàêòè÷åñêîãî
èñïîëüçîâàíèÿ ðåëÿöèîííîé ìîäåëè áàç äàííûõ, ðàçðàáîòàííîé Òåäîì Êîääîì (Ted Codd)
èç IBM â 1969,1970 ãîäàõ. Íàäî ïîìíèòü, ÷òî â òî âðåìÿ èìåëîñü äâå àëüòåðíàòèâíûå
ìîäåëè áàç äàííûõ — ñåòåâàÿ è èåðàðõè÷åñêàÿ, ïðè÷åì çà íèìè ñòîÿëè ìîùíûå
ñèëû — CODASYL Data Base Task Group (ñåòåâàÿ) è ñàìà IBM ñ åå áàçîé IMS
(Information Management System ñ èåðàðõè÷åñêîé ìîäåëüþ äàííûõ).
Íåìíîãî â ñòîðîíå ñòîèò «Oracle», âçëåò êîòîðîé âî ìíîãîì
ñâÿçàí ñ êîììåð÷åñêèì òàëàíòîì Ýëëèñîíà áûòü â íóæíîì ìåñòå è â íóæíîå âðåìÿ,
êàê ñêàçàë Ñòîóíáðåéêåð â ñâîåì
èíòåðâüþ,
õîòÿ îíà âìåñòå ñ IBM ñûãðàëà áîëüøóþ ðîëü â ñîçäàíèè è ïðîäâèæåíèè SQL.
«System R» ñûãðàëà áîëüøóþ ðîëü â ðàçâèòèè ðåëÿöèîííûõ áàç äàííûõ,
ñîçäàíèè ÿçûêà SQL (èçíà÷àëüíî SEQUEL, íî èç-çà ïðîáëåì ñ óæå
ñóùåñòâóþùåé òîðãîâîé ìàðêîé ïðèøëîñü âûêèíóòü âñå ãëàñíûå áóêâû).
Èç «System R» ðàçâèëàñü SQL/DS è DB2. Íà ñàìîì äåëå, â IBM áûëî åùå íåñêîëüêî
ïðîåêòîâ, íî îíè áûëè ÷èñòî âíóòðåííèìè.
Ïîäðîáíåå îá ýòîé âåòâè ìîæíî ïðî÷èòàòü â âåñüìà ïîó÷èòåëüíîì äîêóìåíòå
«The 1995 SQL Reunion: People, Projects, and Politics»,
òàêæå äîñòóïåí ðóññêèé ïåðåâîä.
INGRES (èëè Ingres89), â îòëè÷èå îò «System R», âïîëíå â äóõå Áåðêëè ðàçâèâàëàñü êàê
îòêðûòàÿ áàçà äàííûõ, êîäû êîòîðîé ðàñïðîñòðàíÿëèñü íà ëåíòàõ ïðàêòè÷åñêè
áåñïëàòíî (îïëà÷èâàëèñü ïî÷òîâûå ðàñõîäû è ñòîèìîñòü ëåíòû). Ê 1980 ãîäó
áûëî ðàñïðîñòðàíåíî ïîðÿäêà 1000 êîïèé.
Íàçâàíèå
ðàñøèôðîâûâàåòñÿ êàê «INteractive Graphics (and) REtrieval System»
è ñîâåðøåííî ñëó÷àéíî ñâÿçàíî
ñ ôðàíöóçñêèì õóäîæíèêîì Jean Auguste Dominique Ingres.
Îòëè÷èòåëüíîé
îñîáåííîñòüþ ýòîé ñèñòåìû ÿâëÿëîñü òî, ÷òî îíà ðàçðàáàòûâàëàñü äëÿ îïåðàöèîííîé
ñèñòåìû UNIX, êîòîðàÿ ðàáîòàëà íà ðàñïðîñòðàíåííûõ òîãäà PDP 11, ÷òî è
ïðåäîïðåäåëèëî åå ïîïóëÿðíîñòü, â òî âðåìÿ êàê «System R» ðàáîòàëà òîëüêî íà
áîëüøèõ è äîðîãèõ mainframe. Áûë ðàçðàáîòàí ÿçûê çàïðîñîâ QUEL, êîòîðûé,
êàê ïèñàë Ñòîóíáðåéêåð, ïîõîæ íà SEQUEL â òîì îòíîøåíèè, ÷òî ïðîãðàììèñò
ñâîáîäåí îò çíàíèÿ î ñòðóêòóðå äàííûõ è àëãîðèòìàõ, ÷òî ñïîñîáñòâóåò
çíà÷èòåëüíîé ñòåïåíè íåçàâèñèìîñòè îò äàííûõ. Äîñòóïíîñòü INGRES è î÷åíü
ëèáåðàëüíàÿ ëèöåíçèÿ BSD, à òàêæå òâîð÷åñêàÿ äåÿòåëüíîñòü, ñïîñîáñòâîâàëè
ïîÿâëåíèþ áîëüøîãî êîëè÷åñòâà ðåëÿöèîííûõ áàç äàííûõ, êàê ïîêàçàíî íà ðèñóíêå.
Ñòîóíáðåéêåð ëè÷íî ñïîñîáñòâîâàë èõ ïîÿâëåíèþ, òàê îí êîíöå 70-õ îí
îðãàíèçîâàë êîìïàíèþ Ingres Corporation (êàê îí ñàì îáúÿñíÿåò, åìó ïðèøëîñü íà
ýòî ïîéòè, òàê êàê Àðèçîíñêèé óíèâåðñèòåò, ïîòðåáîâàë ïîääåðæêè), êîòîðàÿ âûïóñòèëà êîììåð÷åñêóþ
âåðñèþ Ingres, â 1994 ãîäó îíà áûëà êóïëåíà CA (Computer Associates) è êîòîðàÿ
â 2004 ãîäó ñòàëà îòêðûòîé êàê Ingres r3.
«NonStop SQL» êîìïàíèè Tandem Computers ÿâëÿëàñü ìîäèôèöèðîâàííîé âåðñèåé
Ingres, êîòîðàÿ ýôôåêòèâíî ðàáîòàëà íà ïàðàëëåëüíûõ êîìïüþòåðàõ è ñ
ðàñïðåäåëåííûìè äàííûìè. Îíà óìåëà âûïîëíÿòü çàïðîñû ïàðàëëåëüíî è ìàñøòàáèðîâàëàñü
ïî÷òè ëèíåéíî ñ êîëè÷åñòâîì ïðîöåññîðîâ. Åå àâòîðàìè áûëè âûïóñêíèêè èç Áåðêëè. Âïîñëåäñòâèè,
Tandem Computers áûëà êóïëåíà êîìïàíèåé Compaq (2000 ã.), à çàòåì
êîìïàíèåé HP.
Êîìïàíèÿ Sybase òîæå áûëà îðãàíèçîâàíà ÷åëîâåêîì èç Áåðêëè (Ðîáåðò Ýïñòåéí)
è íà îñíîâå Ingres. Èçâåñòíî, ÷òî áàçà äàííûõ êîìïàíèè Ìaéêðîñîôò «SQL Server» —
ýòî íå ÷òî èíîå êàê áàçà äàííûõ Sybase, êîòîðàÿ áûëà ëèöåíçèðîâàíà äëÿ
Windows NT. Ñ 1993 ãîäà ïóòè Sybase è Mirosoft ðàçîøëèñü è óæå â 1995 ãîäó
Sybase ïåðåèìåíîâûâàåò ñâîþ áàçó äàííûõ â ASE (Adaptive Server Enterprise),
à Microsoft ñòàëà ïðîäîëæàòü ðàçâèâàòü MS SQL.
Informix òîæå âîçíèê èç Ingres, íî íà ýòî ðàç ëþäüìè íå èç Áåðêëè, õîòÿ
Ñòîóíáðåéêåð âñå-òàêè ïîðàáîòàë â íåé CEO ïîñëå òîãî, êàê Informix êóïèëà
â 1995 ãîäó êîìïàíèþ Ilustra, ÷òîáû ïðèáàâèòü ñåáå îáúåêòíî-ðåëÿöèîííîñòè
è ðàñøèðÿåìîñòè (DataBlade), êîòîðóþ îðãàíèçîâàë âñå òîò æå Ìàéêë Ñòîóíáðåéêåð êàê ðåçóëüòàò
êîììåðöèàëèçàöèè Postgres â 1992 ãîäó. Â 2001 ãîäó îíà áûëà êóïëåíà IBM,
êîòîðàÿ ïðèîáðåòàëà íåìàëîå êîëè÷åñòâî ïîëüçîâàòåëåé Informix è òåõíîëîãèþ.
Òàêèì îáðàçîì, DB2 òàêæå ïðèîáðåëà íåìíîãî îáúåêòíî-ðåëÿöèîííîñòè.
Ïðîåêò Postgres âîçíèê êàê ðåçóëüòàò îñìûñëåíèÿ îøèáîê Ingres è æåëàíèÿ
ïðåîäîëåòü îãðàíè÷åííîñòü òèïîâ äàííûõ, çà ñ÷åò âîçìîæíîñòè îïðåäåëåíèÿ
íîâûõ òèïîâ äàííûõ. Ðàáîòà íàä ïðîåêòîì íà÷àëàñü â 1985 è â ïåðèîä 1985-1988
áûëî îïóáëèêîâàíî íåñêîëüêî ñòàòåé, îïèñûâàþùèõ ìîäåëü äàííûõ, ÿçûê çàïðîñîâ
POSTQUEL, è õðàíèëèùå Postgres. POSTGRES èíîãäà åùå îòíîñÿò ê òàê íàçûâàåìûì
ïîñòðåëÿöèîííûì ÑÓÁÄ. Îãðàíè÷åííîñòü ðåëÿöèîííîé ìîäåëè
âñåãäà ÿâëÿëàñü ïðåäìåòîì êðèòèêè, õîòÿ âñå ïîíèìàëè, ÷òî ýòî ÿâëÿåòñÿ
ñëåäñòâèåì åå ïðîñòîòû è åå çàñëóãîé. Îäíàêî, ïðîíèêíîâåíèå êîìïüþòåðíûõ
òåõíîëîãèé âî âñå ñôåðû æèçíè òðåáîâàëè íîâûõ ïðèëîæåíèé, à îò áàç äàííûõ —
ïîääåðæêè íîâûõ òèïîâ äàííûõ è âîçìîæíîñòåé, íàïðèìåð, ïîääåðæêà íàñëåäîâàíèÿ,
ñîçäàíèå è óïðàâëåíèå ñëîæíûìè îáúåêòàìè.
Åùå ïðè ïðîåêòèðîâàíèè îðèãèíàëüíîé âåðñèè POSTGRES îñíîâíîå âíèìàíèå
áûëî óäåëåíî ðàñøèðÿåìîñòè è îáúåêòíî-îðèåíòèðîâàííûì âîçìîæíîñòÿì. Óæå
òîãäà áûëî ÿñíà íåîáõîäèìîñòü ðàñøèðåíèÿ ôóíêöèîíàëüíîñòè DMBS îò óïðàâëåíèÿ
äàííûìè (data management) â ñòîðîíó óïðàâëåíèÿ îáúåêòàìè
(object management) è çíàíèÿìè (knowledge management).
Ïðè ýòîì îáúåêòíàÿ ôóíêöèîíàëüíîñòü ïîçâîëèò ýôôåêòèâíî õðàíèòü è
ìàíèïóëèðîâàòü íåòðàäèöèîííûìè òèïàìè äàííûõ, à óïðàâëåíèå çíàíèÿìè ïîçâîëÿåò
õðàíèòü è îáåñïå÷èâàòü âûïîëíåíèÿ êîëëåêöèè ïðàâèë (rules), êîòîðûå
íåñóò ñåìàíòèêó ïðèëîæåíèÿ. Ñòîóíáðåéêåð òàê è îïðåäåëèë îñíîâíóþ çàäà÷ó
POSTGRES êàê «îáåñïå÷èòü ïîääåðæêó ïðèëîæåíèé, êîòîðûå òðåáóþò
ñëóæáû óïðàâëåíèÿ äàííûìè, îáúåêòàìè è çíàíèÿìè«.
Îäíèì èç ôóíäàìåíòàëüíûì ïîíÿòèåì POSTGRES ÿâëÿåòñÿ class. Class åñòü
èìåíîâàííàÿ êîëëåêöèÿ ýêçåìïëÿðîâ (instances) îáúåêòîâ. Êàæäûé ýêçåìïëÿð
èìååò êîëëåêöèþ èìåíîâàííûõ àòðèáóòîâ è êàæäûé àòðèáóò èìååò
îïðåäåëåííûé òèï. Êëàññû ìîãóò áûòü òðåõ òèïîâ — ýòî îñíîâíîé êëàññ,
÷üè ýêçåìïëÿðû õðàíÿòñÿ â áàçå äàííûõ, âèðòóàëüíûé (view), ÷üè ýêçåìïëÿðû
ìàòåðèàëèçóþòñÿ òîëüêî ïðè çàïðîñå (îíè ïîääåðæèâàþòñÿ ñèñòåìîé óïðàâëåíèÿ
ïðàâèëàìè), è ìîæåò áûòü âåðñèåé äðóãîãî (parent) êëàññà.
Ïåðâàÿ âåðñèÿ áûëà âûïóùåíà â 1989 ãîäó,
çàòåì ïîñëåäîâàëî åùå íåñêîëüêî ïåðåïèñûâàíèé ñèñòåìû ïðàâèë (rule system).
Îòìåòèì, ÷òî êîäû Ingres è Postgres íå èìåëè íè÷åãî îáùåãî !
 POSTGRES áûëà ðåàëèçîâàíà ïîääåðæêà òàêèõ òèïîâ êàê ìíîãîìåðíûå ìàññèâû,
÷òî óæå øëî â ïðîòèâîðå÷èå ñ ðåëÿöèîííîé ìîäåëüþ, timetravel — õðàíåíèå
âåðñèîííîñòè îáúåêòîâ (âïîñëåäñòâèè, â âåðñèè 6.3 ýòîò òèï áûë óäàëåí, òàê êàê
åãî ïîääåðæêà òðåáîâàëà áîëüøèõ óñèëèé, à âåðñèîííîñòü ìîãëà áûòü
ðåàëèçîâàíà íà ñòîðîíå ïðèëîæåíèÿ ñ ïîìîùüþ òðèããåðîâ).
 1992 ãîäó áûëà îáðàçîâàíà êîìïàíèÿ Illustra, à ñàì ïðîåêò áûë çàêðûò â
1993 ãîäó âûïócêîì âåðñèè 4.2. Îäíàêî, íåñìîòðÿ íà îôèöèàëüíîå çàêðûòèå ïðîåêòà,
îòêðûòûé êîä è BSD ëèöåíçèÿ ñïîäâèãëè âûïóñêíèêîâ Áåðêëè Andrew Yu è Jolly Chen
â 1994 ãîäó âçÿòüñÿ çà åãî äàëüíåéøåå ðàçâèòèå. Â 1995 ãîäó îíè çàìåíèëè
ÿçûê çàïðîñîâ POSTQUEL íà îáùåïðèíÿòûé SQL, ïðîåêò ïîëó÷èë íàçâàíèå Postgres95,
èçìåíèëàñü íóìåðàöèÿ âåðñèé, áûë ñîçäàí âåá ñàéò ïðîåêòà è ïîÿâèëèñü ìíîãî
íîâûõ ïîëüçîâàòåëåé (ñðåäè êîòîðûõ áûë è àâòîð).
Ê 1996 ãîäó ñòàëî ÿñíî, ÷òî íàçâàíèå «Postgres95» íå âûäåðæèò èñïûòàíèåì
âðåìåíåì è áûëî âûáðàíî íîâîå èìÿ — «PostgreSQL», êîòîðîå îòðàæàåò ñâÿçü
ñ îðèãèíàëüíûì ïðîåêòîì POSTGRES è ïðèîáðåòåíèåì SQL. Òàêæå, âåðíóëè
ñòàðóþ íóìåðàöèþ âåðñèé, òàêèì îáðàçîì íîâàÿ âåðñèÿ ñòàðòîâàëà êàê 6.0.
 1997 áûë ïðåäëîæåí ñëîí â êà÷åñòâå ëîãîòèïà, ñîõðàíèëîñü
ïèñüìî â
àðõèâàõ ðàññûëêè -hackers çà 3 ìàðòà 1997 ãîäà è ïîñëåäóþùàÿ äèñêóññèÿ.
Ñëîí áûë ïðåäëîæåí Äýâèäîì ßíãîì â ÷åñòü ðîìàíà Àãàòû Êðèñòè
«Elephants can remember» (Ñëîíû ìîãóò âñïîìèíàòü). Äî ýòîãî, ëîãîòèïîì
áûë áåãóùèé ëåîïàðä (ÿãóàð). Ïðîåêò ñòàë áîëüøîé è óïðàâëåíèå íà ñåáÿ âçÿëà
íåáîëüøàÿ âíà÷àëå ãðóïïà èíèöèàòèâíûõ ïîëüçîâàòåëåé è ðàçðàáîò÷èêîâ, êîòîðàÿ
è ïîëó÷èëà íàçâàíèå PGDG (PostgreSQL Global Development Group).
Äàëüíåéøåå ðàçâèòèå ïðîåêòà ïîëíîñòüþ
äîêóìåíòèðîâàíî
â äîêóìåíòàöèè è îòðàæåíî â àðõèâàõ ñïèñêà ðàññûëêè -hackers.
×òî åñòü PostgreSQL ñåãîäíÿ ?
Íà ñåãîäíÿøíèé äåíü âûïóùåíà âåðñèÿ PostgreSQL v8 (19 ÿíâàðÿ 2005 ãîäà), êîòîðàÿ ÿâëÿåòñÿ
çíà÷èòåëüíûì ñîáûòèåì â ìèðå áàç äàííûõ, òàê êàê êîëè÷åñòâî íîâûõ âîçìîæíîñòåé
äîáàâëåííûõ â ýòîé âåðñèè, ïîçâîëÿåò ãîâîðèòü î âîçíèêíîâåíèè èíòåðåñà êðóïíîãî
áèçíåñà êàê â èñïîëüçîâàíèè, òàê è åãî ïðîäâèæåíèè. Òàê, êðóïíåéøàÿ êîìïàíèÿ â ìèðå, Fujitsu ïîääåðæàëà ðàáîòû íàä
âåðñèåé 8, âûïóñòèëà êîììåð÷åñêèé ìîäóëü
Extended Storage Management.
Ëèáåðàëüíàÿ BSD-ëèöåíçèÿ
ïîçâîëÿåò êîììåð÷åñêèì êîìïàíèÿì âûïóñêàòü ñâîè âåðñèè PostgreSQL ïîä ñâîèì
èìåíåì è îñóùåñòâëÿòü êîììåð÷åñêóþ ïîääåðæêó. Íàïðèìåð, êîìïàíèÿ
Pervasive îáúÿâèëà î âûïóñêå Pervasive Postgres.
PostgreSQL ïîääåðæèâàåòñÿ íà âñåõ ñîâðåìåííûõ Unix ñèñòåìàõ (34 ïëàòôîðìû),
âêëþ÷àÿ íàèáîëåå ðàñïðîñòðàíåííûå, òàêèå êàê Linux, FreeBSD, NetBSD, OpenBSD, SunOS, Solaris,
DUX, à òàêæå ïîä Mac OS X. Íà÷èíàÿ ñ âåðñèè 8.X PostgreSQL ðàáîòàåò â «native»
ðåæèìå ïîä MS Windows NT, Win2000, WinXP, Win2003.
Èçâåñòíî, ÷òî åñòü óñïåøíûå ïîïûòêè
ðàáîòàòü ñ PostgreSQL ïîä Novell Netware 6 è OS2.
PostgreSQL íåîäíîêðàòíî ïðèçíàâàëàñü áàçîé ãîäà, íàïðèìåð,
Linux New Media AWARD 2004,
2003 Editors’ Choice Awards,
2004 Editors’ Choice Awards.
PostgreSQL èñïîëüçóåòñÿ êàê ïîëèãîí äëÿ èññëåäîâàíèé íîâîãî òèïà
áàç äàííûõ, îðèåíòèðîâàííûõ íà ðàáîòó ñ ïîòîêàìè äàííûõ — ýòî
ïðîåêò TelegraphCQ,
ñòàðòîâàâøèé â 2002 ãîäó â Áåðêëè ïîñëå óñïåøíîãî ïðîåêòà Telegraph
(íàçâàíèå ãëàâíîé óëèöû â Áåðêëè).
Èíòåðåñíî, ÷òî êîìïàíèÿ Streambase,
êîòîðàÿ áûëà îñíîâàíà Ìàéêîì Ñòîóíáðåéêåðîì â 2003 ãîäó (èçíà÷àëüíî «Grassy Brook»)
äëÿ êîììåð÷åñêîãî ïðîäâèæåíèÿ ýòîãî íîâîãî ïîêîëåíèÿ áàç äàííûõ, íèêàêèì îáðàçîì
íå àññîöèèðóåòñÿ ñ ïðîåêòîì Áåðêëè.
Îñíîâíûå âîçìîæíîñòè è ôóíêöèîíàëüíîñòü
Ïîëíûé ñïèñîê âñåõ âîçìîæíîñòåé ïðåäîñòàâëÿåìûõ PostgreSQL è ïîäðîáíîå
îïèñàíèå ìîæíî íàéòè â îáúåìíîé
äîêóìåíòàöèè (1300 ñòðàíèö).
- Íàäåæíîñòü PostgreSQL ÿâëÿåòñÿ ïðîâåðåííûì è äîêàçàííûì ôàêòîì
è îáåñïå÷èâàåòñÿ ñëåäóþùèìè âîçìîæíîñòÿìè:- ïîëíîå ñîîòâåòñòâèå ïðèíöèïàì ACID — àòîìàðíîñòü, íåïðîòèâîðå÷èâîñòü, èçîëèðîâàííîñòü, ñîõðàííîñòü äàííûõ.
- Atomicity — òðàíçàêöèÿ ðàññìàòðèâàåòñÿ êàê åäèíàÿ ëîãè÷åñêàÿ åäèíèöà,
âñå åå èçìåíåíèÿ èëè ñîõðàíÿþòñÿ öåëèêîì, èëè ïîëíîñòüþ îòêàòûâàþòñÿ. - Consistency — òðàíçàêöèÿ ïåðåâîäèò áàçó äàííûõ èç îäíîãî íåïðîòèâîðå÷èâîãî
ñîñòîÿíèÿ (íà ìîìåíò ñòàðòà òðàíçàêöèè) â äðóãîå íåïðîòèâîðå÷èâîå ñîñòîÿíèå
(íà ìîìåíò çàâåðøåíèÿ òðàíçàêöèè).
Íåïðîòèâîðå÷èâûì ñ÷èòàåòñÿ ñîñòîÿíèå áàçû, êîãäà âûïîëíÿþòñÿ âñå îãðàíè÷åíèÿ
ôèçè÷åñêîé è ëîãè÷åñêîé öåëîñòíîñòè áàçû äàííûõ, ïðè ýòîì
äîïóñêàåòñÿ íàðóøåíèå îãðàíè÷åíèé öåëîñòíîñòè â
òå÷åíèå òðàíçàêöèè, íî íà ìîìåíò çàâåðøåíèÿ âñå îãðàíè÷åíèÿ öåëîñòíîñòè,
êàê ôèçè÷åñêèå, òàê è ëîãè÷åñêèå, äîëæíû áûòü ñîáëþäåíû. - Isolation — èçìåíåíèÿ äàííûõ ïðè êîíêóðåíòíûõ òðàíçàêöèÿõ èçîëèðîâàíû
äðóã îò äðóãà íà îñíîâå ñèñòåìû âåðñèîííîñòè - Durability — PostgreSQL çàáîòèòñÿ î òîì, ÷òî ðåçóëüòàòû óñïåøíûõ
òðàíçàêöèé ãàðàíòèðîâàíî ñîõðàíÿþòñÿ íà æåñòêèé äèñê âíå çàâèñèìîñòè
îò ñáîåâ àïïàðàòóðû.
- Atomicity — òðàíçàêöèÿ ðàññìàòðèâàåòñÿ êàê åäèíàÿ ëîãè÷åñêàÿ åäèíèöà,
- ìíîãîâåðñèîííîñòü (Multiversion Concurrency Control,MVCC)
èñïîëüçóåòñÿ äëÿ ïîääåðæàíèÿ ñîãëàñîâàííîñòè äàííûõ â êîíêóðåíòíûõ
óñëîâèÿõ, â òî âðåìÿ êàê â òðàäèöèîííûõ áàçàõ äàííûõ èñïîëüçóþòñÿ
áëîêèðîâêè. MVCC îçíà÷àåò, ÷òî êàæäàÿ òðàíçàêöèÿ âèäèò êîïèþ äàííûõ (âåðñèþ áàçû äàííûõ)
íà âðåìÿ íà÷àëà òðàíçàêöèè, íåñìîòðÿ íà òî, ÷òî ñîñòîÿíèå áàçû ìîãëî óæå èçìåíèòüñÿ.
Ýòî çàùèùàåò òðàíçàêöèþ îò íåñîãëàñîâàííûõ èçìåíåíèé äàííûõ, êîòîðûå ìîãëè
áûòü âûçâàíû (äðóãîé) êîíêóðåíòíîé òðàíçàêöèåé, è îáåñïå÷èâàåò èçîëÿöèþ
òðàíçàêöèé. Îñíîâíîé âûèãðûø îò èñïîëüçîâàíèÿ MVCC ïî ñðàâíåíèþ ñ
áëîêèðîâêîé çàêëþ÷àåòñÿ â òîì, ÷òî áëîêèðîâêà, êîòîðóþ ñòàâèò MVCC äëÿ ÷òåíèÿ íå
êîíôëèêòóåò ñ áëîêèðîâêîé íà çàïèñü, è ïîýòîìó ÷òåíèå íèêîãäà íå áëîêèðóåò
çàïèñü è íàîáîðîò. Êîíêóðåíòíûå îïåðàöèè çàïèñè «ìåøàþò» äðóã äðóãó
òîëüêî ïðè ðàáîòå ñ îäíîé è òîé æå çàïèñüþ. - íàëè÷èå Write Ahead Logging (WAL) — îáùåïðèíÿòûé ìåõàíèçì ïðîòîêîëèðîâàíèÿ
âñåõ òðàíçàêöèé, ÷òî ïîçâîëÿåò âîññòàíîâèòü ñèñòåìó ïîñëå âîçìîæíûõ ñáîåâ.
Îñíîâíàÿ èäåÿ WAL ñîñòîèò â òîì, ÷òî âñå èçìåíåíèÿ äîëæíû çàïèñûâàòüñÿ â
ôàéëû íà äèñê òîëüêî ïîñëå òîãî, êàê ýòè çàïèñè æóðíàëà, îïèñûâàþùèå ýòè
èçìåíåíèÿ áóäóò è ãàðàíòèðîâàíî çàïèñàíû íà äèñê. Ýòî ïîçâîëÿåò
íå ñáðàñûâàòü ñòðàíèöû äàííûõ íà äèñê ïîñëå ôèêñàöèè êàæäîé òðàíçàêöèè, òàê
êàê ìû çíàåì è óâåðåíû, ÷òî ñìîæåì âñåãäà âîññòàíîâèòü áàçó äàííûõ èñïîëüçóÿ
æóðíàë òðàíçàêöèé. - Point in Time Recovery (PITR) — âîçìîæíîñòü âîññòàíîâëåíèÿ
áàçû äàííûõ (èñïîëüçóÿ WAL) íà ëþáîé ìîìåíò â ïðîøëîì, ÷òî ïîçâîëÿåò
îñóùåñòâëÿòü íåïðåðûâíîå ðåçåðâíîå êîïèðîâàíèå êëàñòåðà PostgreSQL. - Ðåïëèêàöèÿ òàêæå ïîâûøàåò íàäåæíîñòü PostgreSQL. Ñóùåñòâóåò
íåñêîëüêî ñèñòåì ðåïëèêàöèè, íàïðèìåð, Slony (òåñòèðóåòñÿ âåðñèÿ 1.1),
êîòîðûé ÿâëÿåòñÿ ñâîáîäíûì è ñàìûì èñïîëüçóåìûì ðåøåíèåì, ïîääåðæèâàåò
master-slaves ðåïëèêàöèþ. Îæèäàåòñÿ, ÷òî Slony-II áóäåò ïîääåðæèâàòü
multi-master ðåæèì. - Öåëîñòíîñòü äàííûõ ÿâëÿåòñÿ ñåðäöåì PostgreSQL. Ïîìèìî MVCC, PostgreSQL
ïîääåðæèâàåò öåëîñòíîñòü äàííûõ íà óðîâíå ñõåìû — ýòî âíåøíèå êëþ÷è (foreign keys),
îãðàíè÷åíèÿ (constraints). - Ìîäåëü ðàçâèòèÿ PostgreSQL, êîòîðàÿ àáñîëþòíî ïðîçðà÷íà
äëÿ ëþáîãî, òàê êàê âñå ïëàíû, ïðîáëåìû è ïðèîðèòåòû îòêðûòî îáñóæäàþòñÿ.
Ïîëüçîâàòåëè è ðàçðàáîò÷èêè íàõîäÿòñÿ â ïîñòîÿííîì äèàëîãå ÷åðåç ìýéëèíã
ëèñòû. Âñå ïðåäëîæåíèÿ, ïàò÷è ïðîõîäÿò òùàòåëüíîå òåñòèðîâàíèå äî ïðèíÿòèÿ
èõ â ïðîãðàììíîå äåðåâî. Áîëüøîå êîëè÷åñòâî áåòà-òåñòåðîâ ñïîñîáñòâóåò
òåñòèðîâàíèþ âåðñèè äî ðåëèçà è âû÷èùåíèþ ìåëêèõ îøèáîê. - Îòêðûòîñòü êîäîâ PostgreSQL îçíà÷àåò èõ àáñîëþòíóþ äîñòóïíîñòü
äëÿ ëþáîãî, à ëèáåðàëüíàÿ BSD ëèöåíçèÿ íå íàêëàäûâàåò íèêàêèõ îãðàíè÷åíèé
íà èñïîëüçîâàíèå êîäà.
- ïîëíîå ñîîòâåòñòâèå ïðèíöèïàì ACID — àòîìàðíîñòü, íåïðîòèâîðå÷èâîñòü, èçîëèðîâàííîñòü, ñîõðàííîñòü äàííûõ.
- Ïðîèçâîäèòåëüíîñòü PostgreSQL îñíîâûâàåòñÿ íà èñïîëüçîâàíèè
èíäåêñîâ, èíòåëëåêòóàëüíîì ïëàíèðîâùèêå çàïðîñîâ, òîíêîé ñèñòåìû áëîêèðîâîê,
ñèñòåìå óïðàâëåíèÿ áóôåðàìè ïàìÿòè è êýøèðîâàíèÿ, ïðåâîñõîäíîé ìàñøòàáèðóåìîñòè
ïðè êîíêóðåíòíîé ðàáîòå.- Ïîääåðæêà èíäåêñîâ
- Ñòàíäàðòíûå èíäåêñû — B-tree, hash, R-tree, GiST (îáîáùåííîå
ïîèñêîâîå äåðåâî) - ×àñòè÷íûå èíäåêñû (partial indices) — ìîæíî ñîçäàâàòü èíäåêñ
ïî îãðàíè÷åííîìó ïîäìíîæåñòâó çíà÷åíèé, íàïðèìåð,
create index idx_partial on foo (x) where x > 0;
- Ôóíêöèîíàëüíûå èíäåêñû (expressional indices) ïîçâîëÿþò ñîçäàâàòü
èíäåêñû èñïîëüçóÿ çíà÷åíèÿ ôóíêöèè îò ïàðàìåòðà, íàïðèìåð,
create index idx_functional on foo ( length(x) );
- Ñòàíäàðòíûå èíäåêñû — B-tree, hash, R-tree, GiST (îáîáùåííîå
- Ïëàíèðîâùèê çàïðîñîâ îñíîâûâàåòñÿ íà ñòîèìîñòè ðàçëè÷íûõ ïëàíîâ,
ó÷èòûâàÿ ìíîæåñòâî ôàêòîðîâ. Îí ïðåäîñòàâëÿåò âîçìîæíîñòü ïîëüçîâàòåëþ
îòëàæèâàòü çàïðîñû è íàñòðàèâàòü ñèñòåìó. - Ñèñòåìà áëîêèðîâîê ïîääåðæèâàåò áëîêèðîâêè íà íèæíåì óðîâíå, ÷òî
ïîçâîëÿåò ñîõðàíÿòü âûñîêèé óðîâåíü êîíêóðåíòíîñòè ïðè çàùèòå öåëîñòíîñòè
äàííûõ. Áëîêèðîâêà ïîääåðæèâàåòñÿ íà óðîâíå òàáëèö è çàïèñåé. Íà íèæíåì
óðîâíå, áëîêèðîâêà äëÿ îáùèõ ðåñóðñîâ îïòèìèçèðîâàíà ïîä êîíêðåòíóþ
ÎÑ è àðõèòåêòóðó. - Óïðàâëåíèå áóôåðàìè è êýøèðîâàíèå èñïîëüçóþò
ñëîæíûå àëãîðèòìû
äëÿ ïîääåðæàíèÿ ýôôåêòèâíîñòè èñïîëüçîâàíèÿ âûäåëåííûõ ðåñóðñîâ ïàìÿòè. - Tablespaces (òàáëè÷íûå ïðîñòðàíñòâà) äëÿ
óïðàâëåíèÿ õðàíåíèÿ äàííûõ íà óðîâíå îáúåêòîâ, òàêèõ êàê
áàçû äàííûõ, ñõåìû, òàáëèöû è èíäåêñû. Ýòî ïîçâîëÿåò ãèáêî èñïîëüçîâàòü
äèñêîâîå ïðîñòðàíñòâî è ïîâûøàåò íàäåæíîñòü, ïðîèçâîäèòåëüíîñòü, à òàêæå
ñïîñîáñòâóåò ìàñøòàáèðóåìîñòè ñèñòåìû. - Ìàñøòàáèðóåìîñòü îñíîâûâàåòñÿ íà îïèñàííûõ âûøå âîçìîæíîñòÿõ.
Íèçêàÿ òðåáîâàòåëüíîñòü PostgreSQL ê ðåñóðñàì è ãèáêàÿ ñèñòåìà áëîêèðîâîê
îáåñïå÷èâàþò åãî øêàëèðîâàíèå, â òî âðåìÿ êàê èíäåêñû è óïðàâëåíèå áóôåðàìè
îáåñïå÷èâàþò õîðîøóþ óïðàâëÿåìîñòü ñèñòåìû äàæå ïðè âûñîêèõ çàãðóçêàõ.
- Ïîääåðæêà èíäåêñîâ
- Ðàñøèðÿåìîñòü PostgreSQL îçíà÷àåò, ÷òî ïîëüçîâàòåëü ìîæåò
íàñòðàèâàòü ñèñòåìó ïóòåì îïðåäåëåíèÿ íîâûõ ôóíêöèé, àãðåãàòîâ, òèïîâ,ÿçûêîâ,
èíäåêñîâ è îïåðàòîðîâ. Îáúåêòíî-îðèåíòèðîâàííîñòü PostgreSQL ïîçâîëÿåò
ïåðåíåñòè ëîãèêó ïðèëîæåíèÿ íà óðîâåíü áàçû äàííûõ, ÷òî ñèëüíî óïðîùàåò
ðàçðàáîòêó êëèåíòîâ, òàê êàê âñÿ áèçíåñ ëîãèêà íàõîäèòñÿ â áàçå äàííûõ.
Ôóíêöèè â PostgreSQL îäíîçíà÷íî îïðåäåëÿþòñÿ íàçâàíèåì, êîëè÷åñòâîì è òèïàìè àðãóìåíòîâ.Íà ðèñóíêå ïðèâåäåíà ER äèàãðàììà ñèñòåìíîãî êàòàëîãà PostgreSQL,
â êîòîðîì çàëîæåíû âñå ñâåäåíèÿ îá îáúåêòàõ ñèñòåìû, îïåðàòîðàõ è ìåòîäàõ äîñòóïà
ê íèì. Ïðè èíèöèàëèçàöèè PostgreSQL êëàñòåðà (êîìàíäà initdb) ñîçäàþòñÿ
äâå áàçû äàííûõ — template0 è template1, êîòîðûå ñîäåðæàò
ïðåäîïðåäåëåííûé ïî óìîë÷àíèþ íàáîð ôóíêöèîíàëüíîñòåé. Ëþáàÿ äðóãàÿ áàçà äàííûõ
íàñëåäóåò template1, òàêèì îáðàçîì, ÷àñòî èñïîëüçóåìûå îáúåêòû è ìåòîäû
ìîæíî äîáàâèòü â ñèñòåìíûé êàòàëîã template1.
PostgreSQL ïðåäîñòàâëÿåò êîìàíäíûé èíòåðôåéñ äëÿ ðàáîòû ñ ñèñòåìíûì êàòàëîãîì,
ñ ïîìîùüþ êîòîðîãî ìîæíî íå òîëüêî ïîëó÷àòü èíôîðìàöèþ îá îáúåêòàõ ñèñòåìû, íî
è ñîçäàâàòü íîâûå. Íàïðèìåð, ñîçäàâàòü áàçû äàííûõ ñ ïîìîùüþ
CREATE DATABASE, íîâûé äîìåí — CREATE DOMAIN, îïåðàòîð —
CREATE OPERATOR, òèï äàííûõ — CREATE TYPE.Äëÿ ñîçäàíèÿ íîâîãî òèïà äàííûõ è èíäåêñíûõ ìåòîäîâ äîñòóïà äîñòàòî÷íî:
- Íàïèñàòü ôóíêöèè ââîäà/âûâîäà è
çàðåãèñòðèðîâàòü èõ â ñèñòåìíîì êàòàëîãå ñ ïîìîùüþ CREATE FUNCTION - Îïðåäåëèòü òèï â ñèñòåìíîì êàòàëîãå ñ ïîìîùüþ CREATE TYPE
- Ñîçäàòü îïåðàòîðû äëÿ ýòîãî òèïà äàííûõ ñ ïîìîùüþ CREATE OPERATOR
- Íàïèñàòü ôóíêöèè ñðàâíåíèÿ è
çàðåãèñòðèðîâàòü èõ â ñèñòåìíîì êàòàëîãå ñ ïîìîùüþ CREATE FUNCTION - Ñîçäàòü îïåðàòîð ïî óìîë÷àíèþ, êîòîðûé áóäåò èñïîëüçîâàòüñÿ äëÿ ñîçäàíèÿ
èíäåêñà ïî primary key — CREATE OPERATOR CLASS
Îïèñàííûé ñöåíàðèé èñïîëüçóåò ñóùåñòâóþùèõ âèä èíäåêñà. Äëÿ ñîçäàíèÿ íîâûõ
èíäåêñîâ íàäî èñïîëüçîâàòü GiST.Îäíîé èç ïðèìå÷àòåëüíûõ îñîáåííîñòüþ PostgreSQL ÿâëÿåòñÿ îáîáùåííîå ïîèñêîâîå
äåðåâî èëè GiST (äîìàøíÿÿ ñòðàíèöà ïðîåêòà),
êîòîðîå äàåò âîçìîæíîñòü ñïåöèàëèñòàì â êîíêðåòíîé îáëàñòè çíàíèé ñîçäàâàòü
ñïåöèàëèçèðîâàííûå òèïû äàííûõ è îáåñïå÷èâàåò èíäåêñíûé äîñòóï ê íèì íå áóäó÷è
ýêñïåðòàìè â îáëàñòè áàç äàííûõ. Àíàëîãîì GiST ÿâëÿåòñÿ òåõíîëîãèÿ DataBlade,
êîòîðîé ñåé÷àñ âëàäååò IBM (ñì. èñòîðè÷åñêóþ ñïðàâêó âûøå).
Èäåÿ GiST áûëà ïðèäóìàíà ïðîôåññîðîì Áåðêëè
Äæîçåôîì Õåëëåðñòåéíîì(Joseph M. Hellerstein)
è îïóáëèêîâàíà
â ñòàòüå Generalized Search Trees for Database Systems.
Îðèãèíàëüíàÿ âåðñèÿ GiST áûëà ðàçðàáîòàíà â Áåðêëè êàê ïàò÷ ê POSTGRES è
ïîçäíåå áûëà èíêîðïîðèðîâàíà â PostgreSQL. Ïîçæå, â 2001 ãîäó êîä áûë ñèëüíî
ìîäèôèöèðîâàí äëÿ ïîääåðæêè êëþ÷åé ïåðåìåííîé äëèíû, ìíîãî-àòðèáóòíûõ èíäåêñîâ
è áåçîïàñíîé ðàáîòû ñ NULL, òàêæå áûëè èñïðàâëåíî íåñêîëüêî îøèáîê. Ê íàñòîÿùåìó âðåìåíè íàïèñàíî
äîâîëüíî ìíîãî èíòåðåñíûõ ðàñøèðåíèé íà îñíîâå GiST, â òîì ÷èñëå:- ìîäóëü ïîëíîòåêñòîâîãî ïîèñêà tsearch2.
Ñ âåðñèè 8.3 ïîëíîòåêñòîâûé ïîèñê áóäåò âñòðîåí â ÿäðî PostgreSQL
(ñì. Ââåäåíèå â ïîëíîòåêñòîâûé ïîèñê). - ìîäóëü äëÿ ðàáîòû ñ èåðàðõè÷åñêèìè äàííûìè (tree-like) ltree
- ìîäóëü äëÿ ðàáîòû ñ ìàññèâàìè öåëûõ ÷èñåë intarray
Äèñòðèáóòèâ PostgreSQL â ïîääèðåêòîðèè contrib/ ñîäåðæèò áîëüøîå
êîëè÷åñòâî (îêîëî 80) òàê íàçûâàåìûõ êîíòðèá-ìîäóëåé, ðåàëèçóþùèõ ðàçíîîáðàçíóþ
äîïîëíèòåëüíóþ ôóíêöèîíàëüíîñòü, òàêóþ êàê, ïîëíîòåêñòîâûé ïîèñê, ðàáîòà ñ xml,
ôóíêöèè ìàòåìàòè÷åñêîé ñòàòèñòèêè, ïîèñê ñ îøèáêàìè, êðèïòîãðàôè÷åñêèå ìîäóëè è ò.ä.
Òàêæå, åñòü óòèëèòû, îáëåã÷àþùèå ìèãðàöèþ ñ mysql, oracle, äëÿ àäìèíèñòðàòèâíûõ
ðàáîò. - Íàïèñàòü ôóíêöèè ââîäà/âûâîäà è
- Ïîääåðæêà SQL, êðîìå îñíîâíûõ âîçìîæíîñòåé, ïðèñóùèõ ëþáîé
SQL áàçå äàííûõ, PostgreSQL ïîääåðæèâàåò:- Î÷åíü âûñîêèé óðîâåíü ñîîòâåòñòâèÿ ANSI SQL 92, ANSI SQL 99 è ANSI SQL 2003.
Ïîäðîáíåå ìîæíî ïðî÷èòàòü â äîêóìåíòàöèè. - Ñõåìû, êîòîðûå îáåñïå÷èâàþò ïðîñòðàíñòâî èìåí íà óðîâíå SQL.
Ñõåìû ñîäåðæàò òàáëèöû, â íèõ ìîæíî îïðåäåëÿòü òèïû äàííûõ, ôóíêöèè è îïåðàòîðû.
Èñïîëüçóÿ ïîëíîå èìÿ îáúåêòà ìîæíî îäíîâðåìåííî ðàáîòàòü ñ íåñêîëüêèìè
ñõåìàìè. Ñõåìû ïîçâîëÿþò îðãàíèçîâàòü áàçû äàííûõ ñîâîêóïíîñòü
íåñêîëüêèõ ëîãè÷åñêèõ ÷àñòåé, êàæäàÿ èõ êîòîðûõ èìååò ñâîþ ïîëèòèêó äîñòóïà,
òèïû äàííûõ. Äëÿ ïðèëîæåíèé, êîòîðûå ñîçäàþò íîâûå îáúåêòû â áàçå äàííûõ óäîáíî
è áåçîïàñíî ñîçäàâàòü îòäåëüíóþ ñõåìó (è âêëþ÷àòü åå â SEARCH_PATH) ñ òåì,
÷òîáû èçáåæàòü âîçìîæíîé êîëëèçèè ñ èìåíàìè îáúåêòîâ è óäîáñòâîì îáíîâëåíèÿ
ïðèëîæåíèÿ. - Subqueries — ïîäçàïðîñû (subselects), ïîëíàÿ ïîääåðæêà SQL92.
Ïîäçàïðîñû äåëàþò ÿçûê SQL áîëåå ãèáêèì è çà÷àñòóþ áîëåå ýôôåêòèâíûì. - Outer Joins — âíåøíèå ñâÿçêè (LEFT,RIGHT, FULL)
- Rules — ïðàâèëà, ñîãëàñíî êîòîðûì ìîäèôèöèðóåòñÿ èñõîäíûé çàïðîñ.
Ãëàâíîå îòëè÷èå îò òðèããåðîâ ñîñòîèò â òîì, ÷òî rule ðàáîòàåò íà óðîâíå
çàïðîñà è ïåðåä èñïîëíåíèåì çàïðîñà, à òðèããåð — ýòî ðåàêöèÿ ñèñòåìû íà
èçìåíåíèå äàííûõ, ò.å. òðèããåð çàïóñêàåòñÿ â ïðîöåññå èñïîëíåíèÿ çàïðîñà
äëÿ êàæäîé èçìåíåííîé çàïèñè (PER ROW). Ïðàâèëà èñïîëüçóþòñÿ äëÿ óêàçàíèÿ ñèñòåìå,
êàêèå äåéñòâèÿ íàäî ïðîèçâåñòè ïðè ïîïûòêå îáíîâëåíèÿ view. - Views — ïðåäñòàâëåíèÿ, âèðòóàëüíûå òàáëèöû. Ðåàëüíûõ ýêçåìïëÿðîâ ýòèõ
òàáëèö íå ñóùåñòâóþò, îíè ìàòåðèàëèçóþòñÿ òîëüêî ïðè çàïðîñå. Îäíèì èç îñíîâíûõ ïðåäíàçíà÷åíèé ‘view’ ÿâëÿåòñÿ
ðàçäåëåíèå ïðàâ äîñòóïà ê ðîäèòåëüñêèì òàáëèöàì è ê ‘view, à òàêæå îáåñïå÷åíèå
ïîñòîÿíñòâà ïîëüçîâàòåëüñêîãî èíòåðôåéñà ïðè èçìåíåíèè ðîäèòåëüñêèõ òàáëèö.
Îáíîâëåíèå ‘view’ (ìàòåðèàëèçàöèÿ) âîçìîæíî â
PostgreSQL ñ ïîìîùüþ pl/pgsql. - Cursors — êóðñîðû, ïîçâîëÿþò óìåíüøèòü òðàôèê ìåæäó êëèåíòîì è
ñåðâåðîì, à òàêæå ïàìÿòü íà êëèåíòå, åñëè òðåáóåòñÿ ïîëó÷èòü íå âåñü ðåçóëüòàò
çàïðîñà, à òîëüêî åãî ÷àñòü. - Table Inheritance — íàñëåäîâàíèå òàáëèö, ïîçâîëÿþùåå ñîçäàâàòü îáúåêòû,
êîòîðûå íàñëåäóþò ñòðóêòóðó ðîäèòåëüñêîãî îáúåêòà è äîáàâëÿòü ñâîè
ñïåöèôè÷åñêèå àòðèáóòû. Ïðè ýòîì íàñëåäóþòñÿ çíà÷åíèÿ àòðèáóòîâ ïî óìîë÷àíèþ
(DEFAULTS) è îãðàíè÷åíèå öåëîñòíîñòè (CONSTRAINTS).
Ïîèñê ïî ðîäèòåëüñêîé òàáëèöå àâòîìàòè÷åñêè âêëþ÷àåò ïîèñê ïî äî÷åðíèì
îáúåêòàì, ïðè ýòîì ñîõðàíÿåòñÿ âîçìîæíîñòü ïîèñêà òîëüêî ïî íåé
(only). Íàñëåäîâàíèå ìîæíî èñïîëüçîâàòü äëÿ ðàáîòû ñ î÷åíü áîëüøèìè òàáëèöàìè äëÿ
ýìóëÿöèè partitioning. - Prepared Statements (ïðåïîäãîòîâëåííûå çàïðîñû) — ýòî îáúåêòû, æèâóùèå
íà ñòîðîíå ñåðâåðà, êîòîðûå ïðåäñòàâëÿþò ñîáîé îðèãèíàëüíûé çàïðîñ
ïîñëå êîìàíäû PREPARE, êîòîðûé óæå ïðîøåë ñòàäèè ðàçáîðà çàïðîñà
(parser), ìîäèôèêàöèè çàïðîñà (rewriting rules) è ñîçäàíèÿ ïëàíà âûïîëíåíèÿ
çàïðîñà (planner), â ðåçóëüòàòå ÷åãî, ìîæíî èñïîëüçîâàòü êîìàíäó EXECUTE,
êîòîðàÿ óæå íå òðåáóåò ïðîõîæäåíèÿ ýòèõ ñòàäèé. Äëÿ ñëîæíûõ çàïðîñîâ ýòî ìîæåò
áûòü áîëüøèì âûèãðûøåì. - Stored Procedures — ñåðâåðíûå (õðàíèìûå) ïðîöåäóðû ïîçâîëÿþò ðåàëèçîâûâàòü
áèçíåñ ëîãèêó ïðèëîæåíèÿ íà ñòîðîíå ñåðâåðà. Êðîìå òîãî, îíè ïîçâîëÿþò ñèëüíî
óìåíüøèòü òðàôèê ìåæäó êëèåíòîì è ñåðâåðîì. - Savepoints(nested transactions) — â îòëè÷èå îò «ïëîñêèõ òðàíçàêöèé», êîòîðûå
íå èìåþò ïðîìåæóòî÷íûõ òî÷åê ôèêñàöèè, èñïîëüçîâàíèå savepoints ïîçâîëÿåò
îòìåíÿòü ðàáîòó ÷àñòè òðàíçàêöèè, íàïðèìåð âñëåäñòâèè îøèáî÷íî ââåäåííîé êîìàíäû,
áåç âëèÿíèÿ íà îñòàâøóþñÿ ÷àñòü òðàíçàêöèè. Ýòî áûâàåò î÷åíü ïîëåçíî äëÿ
òðàíçàêöèé, êîòîðûå ðàáîòàþò ñ áîëüøèìè îáúåìàìè äàííûõ. - Ïðàâà äîñòóïà ê îáúåêòàì ñèñòåìû íà îñíîâå ñèñòåìû ïðèâèëåãèé. Âëàäåëåö
îáúåêòà èëè ñóïåðþçåð ìîæåò êàê ðàçðåøàòü äîñòóï (GRANT), òàê è îòìåíÿòü
(REVOKE). - Ñèñòåìà îáìåíà ñîîáùåíèÿìè ìåæäó ïðîöåññàìè — LISTEN è NOTIFY
ïîçâîëÿþò îðãàíèçîâûâàòü ñîáûòèéíóþ ìîäåëü âçàèìîäåéñòâèÿ ìåæäó êëèåíòîì è
ñåðâåðîì (êëèåíòó ïåðåäàåòñÿ íàçâàíèå ñîáûòèÿ, íàçíà÷åííîå êîìàíäîé
notify è PID ïðîöåññà). - Òðèããåðû ïîçâîëÿþò óïðàâëÿòü ðåàêöèåé ñèñòåìû íà èçìåíåíèå äàííûõ
(INSERT,UPDATE,DELETE), êàê ïåðåä ñàìîé îïåðàöèåé (BEFORE), òàê è ïîñëå (AFTER).
Âî âðåìÿ âûïîëíåíèÿ òðèããåðà äîñòóïíû ñïåöèàëüíûå ïåðåìåííûå NEW (çàïèñü,
êîòîðàÿ áóäåò âñòàâëåíà èëè îáíîâëåíà) è OLD (çàïèñü ïåðåä îáíîâëåíèåì). - Cluster table — óïîðÿäî÷èâàíèå çàïèñåé òàáëèöû íà äèñêå ñîãëàñíî èíäåêñó,
÷òî èíîãäà çà ñ÷åò óìåíüøåíèÿ äîñòóïà ê äèñêó óñêîðÿåò âûïîëíåíèå çàïðîñà.
- Î÷åíü âûñîêèé óðîâåíü ñîîòâåòñòâèÿ ANSI SQL 92, ANSI SQL 99 è ANSI SQL 2003.
- Áîãàòûé íàáîð òèïîâ äàííûõ PostgreSQL âêëþ÷àåò:
- Ñèìâîëüíûå òèïû (character(n)) êàê îïðåäåëåíî â ñòàíäàðòå SQL è òèï text
ñ ïðàêòè÷åñêè íåîãðàíè÷åííîé äëèíîé. - Numeric òèï ïîääåðæèâàåò ïðîèçâîëüíóþ òî÷íîñòü, î÷åíü âîñòðåáîâàííóþ â íàó÷íûõ
è ôèíàíñîâûõ ïðèëîæåíèÿõ. - Ìàññèâû ñîãëàñíî ñòàíäàðòó SQL:2003
- Áîëüøèå îáúåêòû (Large Objects) ïîçâîëÿþò õðàíèòü â áàçå äàííûõ áèíàðíûå äàííûå ðàçìåðîì äî 2Gb
- Ãåîìåòðè÷åñêèå òèïû (point, line, circle,polygon, box,…) ïîçâîëÿþò ðàáîòàòü ñ ïðîñòðàíñòâåííûìè äàííûìè íà ïëîñêîñòè.
- ÃÈÑ (GIS) òèïû â PostgreSQL ÿâëÿþòñÿ äîêàçàòåëüñòâîì ðàñøèðÿåìîñòè PostgreSQL è ïîçâîëÿþò
ýôôåêòèâíî ðàáîòàòü ñ òðåõìåðíûìè äàííûìè. Ïîäðîáíîñòè ìîæíî íàéòè íà ñàéòå
ïðîåêòà PostGis. - Ñåòåâûå òèïû (Network types) ïîääåðæèâàþò òèïû äàííûõ inet äëÿ IPV4, IPV6,
à òàêæå cidr (Classless Internet Domain Routing) áëîêè è macaddr - Êîìïîçèòíûå òèïû (composite types) îáúåäèíÿþò îäèí èëè íåñêîëüêî
ýëåìåíòàðíûõ òèïîâ è ïîçâîëÿþò ïîëüçîâàòåëÿì ìàíèïóëèðîâàòü ñî ñëîæíûìè îáúåêòàìè. - Âðåìåííûå òèïû (timestamp, interval, date, time) ðåàëèçîâàíû ñ î÷åíü áîëüøîé òî÷íîñòüþ
- Ïñåâäîòèïû serial è bigserial ïîçâîëÿþò îðãàíèçîâàòü óïîðÿäî÷åííóþ ïîñëåäîâàòåëüíîñòü
öåëûõ ÷èñåë (AUTO_INCREMENT ó íåêîòîðûõ ÑÓÁÄ).
- Ñèìâîëüíûå òèïû (character(n)) êàê îïðåäåëåíî â ñòàíäàðòå SQL è òèï text
- PostgreSQL èìååò î÷åíü áîãàòûé íàáîð âñòðîåííûõ ôóíêöèé è îïåðàòîðîâ äëÿ ðàáîòû ñ äàííûìè,
ïîëíûé ñïèñîê êîòîðûõ ìîæíî ïîñìîòðåòü â äîêóìåíòàöèè. - Ïîääåðæêà 25 ðàçëè÷íûõ íàáîðîâ ñèìâîëîâ (charsets), âêëþ÷àÿ ASCII, LATIN, WIN, KOI8 è UNICODE,
à òàêæå ïîääåðæêà locale, ÷òî ïîçâîëÿåò êîððåêòíî ðàáîòàòü ñ äàííûìè íà
ðàçíûõ ÿçûêàõ. - Ïîääåðæêà NLS(Native Language Support) — äîêóìåíòàöèÿ, ñîîáùåíèÿ îá îøèáêàõ äîñòóïíû íà ðàçëè÷íûõ
ÿçûêàõ, âêëþ÷àÿ ÿïîíñêèé, íåìåöêèé, èòàëüÿíñêèé, ôðàíöóçñêèé, ðóññêèé, èñïàíñêèé, ïîðòóãàëüñêèé,
ñëîâåíñêèé, ñëîâàöêèé è íåñêîëüêî äèàëåêòîâ êèòàéñêîãî ÿçûêîâ. - Èíòåðôåéñû â PostgreSQL ðåàëèçîâàíû äëÿ äîñòóïà ê áàçå äàííûõ èç ðÿäà
ÿçûêîâ (C,C++,C#,python,perl,ruby,php,Lisp è äðóãèå) è ìåòîäîâ äîñòóïà ê äàííûì (JDBC, ODBC). - Ïðîöåäóðíûå ÿçûêè ïîçâîëÿþò ïîëüçîâàòåëÿì ðàçðàáàòûâàòü ñâîè ôóíêöèè
íà ñòîðîíå ñåðâåðà, òåì ñàìûì ïåðåíîñèòü ëîãèêó ïðèëîæåíèÿ íà ñòîðîíó áàçû äàííûõ,
èñïîëüçóÿ ÿçûêè ïðîãðàììèðîâàíèÿ, îòëè÷íûå îò âñòðîåííûõ
SQL è C. Ê íàñòîÿùåìó âðåìåíè ïîääåðæèâàþòñÿ (âêëþ÷åíû â ñòàíäàðòíûé äèñòðèáóòèâ)
PL/pgSQL, pl/Tcl, Pl/Perl è pl/Python. Êðîìå íèõ, ñóùåñòâóåò ïîääåðæêà
PHP, Java, Ruby, R, shell. - Ïðîñòîòà èñïîëüçîâàíèÿ âñåãäà ÿâëÿëàñü âàæíûì ôàêòîðîì äëÿ
ðàçðàáîò÷èêîâ.Óòèëèòà psql (âõîäèò â äèñòðèáóòèâ) ïðåäîñòàâëÿåò óäîáíûé èíòåðôåéñ äëÿ ðàáîòû
ñ áàçîé äàííûõ, ñîäåðæèò êðàòêèé ñïðàâî÷íèê ïî SQL, îáëåã÷àåò ââîä êîìàíä
(èñïîëüçóÿ ñòðåëêè äëÿ ïîâòîðà è òàáóëÿòîð äëÿ ðàñøèðåíèÿ), ïîääåðæèâàåò
èñòîðèþ è áóôåð çàïðîñîâ, à òàêæå ïîçâîëÿåò ðàáîòàòü êàê â èíòåðàêòèâíîì
ðåæèìå, òàê è ïîòîêîâîì ðåæèìå.phpPgAdmin (ëèöåíçèÿ GPL)
ïðåäñòàâëÿåò âîçìîæíîñòü ñ ïîìîùüþ âåá áðàóçåðà àäìèíèñòðèðîâàòü PostgreSQL êëàñòåð.pgAdmin III (GNU Artistic license) ïðåäîñòàâëÿåò
óäîáíûé èíòåðôåéñ äëÿ ðàáîòû ñ áàçàìè äàííûõ PostgreSQL è ðàáîòàåò ïîä Linux, FreeBSD è
Windows 2000/XP.PgEdit — ïðîãðàììíàÿ ñðåäà äëÿ ðàçðàáîòêè ïðèëîæåíèé è
SQL-ðåäàêòîð, äîñòóïíà äëÿ Windows è Mac. - Áåçîïàñíîñòü äàííûõ òàêæå ÿâëÿåòñÿ âàæíåéøèì àñïåêòîì ëþáîé ÑÓÁÄ. Â PostgreSQL
îíà îáåñïå÷èâàåòñÿ 4-ìÿ óðîâíÿìè áåçîïàñíîñòè:- PostgreSQL íåëüçÿ çàïóñòèòü ïîä ïðèâèëåãèðîâàííûì ïîëüçîâàòåëåì — ñèñòåìíûé êîíòåêñò
- SSL,SSH øèôðîâàíèå òðàôèêà ìåæäó êëèåíòîì è ñåðâåðîì — ñåòåâîé êîíòåêñò
- ñëîæíàÿ ñèñòåìà àóòåíòèôèêàöèè íà óðîâíå õîñòà èëè IP àäðåñà/ïîäñåòè.
Ñèñòåìà àóòåíòèôèêàöèè ïîääåðæèâàåò ïàðîëè, øèôðîâàííûå ïàðîëè, Kerberos, IDENT
è ïðî÷èå ñèñòåìû, êîòîðûå ìîãóò ïîäêëþ÷àòüñÿ èñïîëüçóÿ ìåõàíèçì ïîäêëþ÷àåìûõ
àóòåíòèôèêàöèîííûõ ìîäóëåé. - Äåòàëèçèðîâàííàÿ ñèñòåìà ïðàâ äîñòóïà êî âñåì îáúåêòàì áàçû
äàííûõ, êîòîðàÿ ñîâìåñòíî ñî ñõåìîé, îáåñïå÷èâàþùàÿ èçîëÿöèþ íàçâàíèé îáúåêòîâ
äëÿ êàæäîãî ïîëüçîâàòåëÿ, PostgreSQL ïðåäîñòàâëÿåò áîãàòóþ è ãèáêóþ èíôðàñòðóêòóðó.
Íåêîòîðûå ïðåäåëû PostgreSQL
| Íàçâàíèå | Çíà÷åíèå |
|---|---|
| Ìàêñèìàëüíûé ðàçìåð ÁÄ | Unlimited |
| Ìàêñèìàëüíûé ðàçìåð òàáëèöû | 32 TB |
| Ìàêñèìàëüíàÿ äëèíà çàïèñè | 400Gb |
| Ìàêñèìàëüíûé äëèíà àòðèáóòà | 1 GB |
| Ìàêñèìàëüíîå êîëè÷åñòâî çàïèñåé â òàáëèöå | Unlimited |
| Ìàêñèìàëüíîå êîëè÷åñòâî àòðèáóòîâ â òàáëèöå | 250 — 1600 â çàâèñèìîñòè îò òèïà àòðèáóòà |
| Ìàêñèìàëüíîå êîëè÷åñòâî èíäåêñîâ íà òàáëèöó | Unlimited |
Ñâîäíàÿ òàáëèöà îñíîâíûõ ðåëÿöèîííûõ áàç äàííûõ
Çà îñíîâó âçÿòû äàííûå èç Wikipedia
| Íàçâàíèå | ASE | DB2 | FireBird | InterBase | MS SQL | MySQL | Oracle | PostgreSQL |
|---|---|---|---|---|---|---|---|---|
| Ëèöåíçèÿ | $$$ | $$$ | IPL2 | $$$ | $$$ | GPL/$$$ | $$$ | BSD |
| ACID | Yes | Yes | Yes | Yes | Yes | Depends1 | Yes | Yes |
| Referential integrity | Yes | Yes | Yes | Yes | Yes | Depends1 | Yes | Yes |
| Transaction | Yes | Yes | Yes | Yes | Yes | Depends1 | Yes | Yes |
| Unicode | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Schema | Yes | Yes | Yes | Yes | No5 | No | Yes | Yes |
| Temporary table | No | Yes | No | Yes | Yes | Yes | Yes | Yes |
| View | Yes | Yes | Yes | Yes | Yes | No | Yes | Yes |
| Materialized view | No | Yes | No | No | No | No | Yes | No3 |
| Expression index | No | No | No | No | No | No | Yes | Yes |
| Partial index | No | No | No | No | No | No | Yes | Yes |
| Inverted index | No | No | No | No | No | Yes | Yes | Yes6 |
| Bitmap index | No | Yes | No | No | No | No | Yes | No |
| Domain | No | No | Yes | Yes | No | No | Yes | Yes |
| Cursor | Yes | Yes | Yes | Yes | Yes | No | Yes | Yes |
| User Defined Functions | Yes | Yes | Yes | Yes | Yes | No4 | Yes | Yes |
| Trigger | Yes | Yes | Yes | Yes | Yes | No4 | Yes | Yes |
| Stored procedure | Yes | Yes | Yes | Yes | Yes | No4 | Yes | Yes |
| Tablespace | Yes | Yes | No | ? | No5 | No1 | Yes | Yes |
| Íàçâàíèå | ASE | DB2 | FireBird | InterBase | MS SQL | MySQL | Oracle | PostgreSQL |
Çàìå÷àíèÿ:
- 1 — äëÿ ïîääåðæêè òðàíçàêöèé è ññûëî÷íîé öåëîñòíîñòè òðåáóåòñÿ InnoDB (íå ÿâëÿåòñÿ òèïîì òàáëèöû ïî óìîë÷àíèþ)
- 2 — Interbase Public License
- 3 — Materialized view (îáíîâëÿåìûå ïðåäñòàâëåíèÿ) ìîãóò áûòü ýìóëèðîâàíû íà PL/pgSQL
- 4 — òîëüêî â MySQL 5.0, êîòîðàÿ ÿâëÿåòñÿ ýêñïåðèìåíòàëüíîé âåðñèåé
- 5 — òîëüêî â MS SQL Server 2005 (Yukon)
- 6 — GIN (Generalized Inverted Index) ñ âåðñèè 8.2
×òî îæèäàåòñÿ â áóäóùèõ âåðñèÿõ
Ïîëíûé ñïèñîê íîâûõ âîçìîæíîñòåé ïðèâåäåí â áîëüøîì ñïèñêå
TODO,
êîòîðûé óæå ìíîãî ëåò ïîääåðæèâàåò Áðþñ Ìîìæàí (Bruce Momjian),
îäíàêî ïðèîðèòåòû äëÿ âåðñèè 8.1 åùå íå îïðåäåëåíû, áîëåå òîãî,
ïîêà íå îïðåäåëåíà ïðîäîëæèòåëüíîñòü öèêëà ðàçðàáîòêè.
Ïîêà ìîæíî äîñòàòî÷íî óâåðåííî óòâåðæäàòü, ÷òî â 8.1 âåðñèè, ïîìèìî
èñïðàâëåíèé îøèáîê è óëó÷øåíèÿ ñóùåñòâóþùåé ôóíêöèîíàëüíîñòè èëè
ïðèâåäåíèå ñèíòàêñèñà ê ñòàíäàðòó SQL, áóäóò:
- bitmap èíäåêñû (initial submit CVS)
- èíòåãðèðîâàíèå autovacuum â ñåðâåðíûé ïðîöåññ
- Two phase commit JDBC driver
- ïîääåðæêà IN,OUT,INOUT ïàðàìåòðîâ äëÿ pl/pgsql (CVS)
- óâåëè÷åíèå ïðåäåëà ìàêñèìàëüíîãî êîëè÷åñòâà àðãóìåíòîâ ó ôóíêöèè (100 ïî óìîë÷àíèþ)
(CVS) - Îïòèìèçàöèÿ MIN,MAX çà ñ÷åò èñïîëüçîâàíèÿ èíäåêñîâ (CVS)
- Ïîääåðæêà UTF-16
- GiST Concurrency & Recovery ! (CVS)
Òàêæå, íåäàâíî ïðîõîäèëî îáñóæäåíèå î âîçìîæíûõ ïëàíàõ î ïîääåðæêå
table partitioning, ÷òî ñèëüíî óâåëè÷èâàåò ïðîèçâîäèòåëüíîñòü áàçû
äàííûõ ïðè ðàáîòå ñ áîëüøèìè òàáëèöàìè.
Íîâîñòü:
Âûøëà âåðñèÿ 8.0.2, â êîòîðîé, ïîìèìî èñïðàâëåíèÿ îøèáîê è èçìåíåíèÿ
âåðñèè áèáëèîòåêè libpq (ÂÍÈÌÀÍÈÅ ! Âñå êëèåíòñêèå ïðèëîæåíèÿ,
êîòîðûå èñïîëüçóþò libpq, òðåáóåòñÿ ïåðåñîáðàòü, íàïðèìåð DBD::Pg),
àëãîðèòì êýøèðîâàíèÿ ñòðàíèö «ARC», êîòîðûì âëàäååò IBM, áûë
çàìåíåí íà äðóãîé, «ïàòåíòíî-÷èñòûé» àëãîðèòì «2Q».
Ïîñêîëüêó èñòîðèÿ ñ çàìåíîé àëãîðèòìà «ARC» â PostgreSQL
âûçâàëà áîëüøîé èíòåðåñ è îáñóæäåíèå â ñåòè (à îíà ñâÿçàíà ñ î÷åíü «ãîðÿ÷åé»
òåìîé âûäà÷è è èñïîëüçîâàíèÿ ïàòåíòîâ íà ïðîãðàììíîå îáåñïå÷åíèå),
ÿ îñòàíîâëþñü ïîäðîáíåå íà îïèñàíèè ìåõàíèçìà êýøèðîâàíèÿ (buffer management)
â PostgreSQL. ß èñïîëüçîâàë àðõèâ îáñóæäåíèé,
îðèãèíàëüíûå ðàáîòû è ñòàòüþ Ýëåéí Ìóñòýéí (A. Elein Mustain)
The Saga of the ARC Algorithm and Patent.
Óïðàâëåíèå áóôåðàìè â PostgreSQL
Êýøèðîâàíèå ñòðàíèö, èëè ñîõðàíåíèå ïðî÷èòàííûõ ñ äèñêà
ñòðàíèö â ïàìÿòè, î÷åíü âàæíî äëÿ ýôôåêòèâíîé ðàáîòû ëþáîé ÑÓÁÄ,
òàê êàê âðåìåíà äîñòóïà ê äèñêó è ïàìÿòè îòëè÷àþòñÿ íà ìíîãèå ïîðÿäêè.
 èäåàëå, ìû õîòèì, ÷òîáû âñå ñòðàíèöû, ê êîòîðûì ïðîèñõîäèò îáðàùåíèå,
ïîïàäàëè â ïàìÿòü, ñ òåì, ÷òîáû ïîñëåäóþùåå åå èñïîëüçîâàíèå íå òðåáîâàëî
îáðàùåíèÿ ê äèñêó.
Îäíàêî, òàê êàê êîëè÷åñòâî äîñòóïíîé ïàìÿòè îãðàíè÷åííî, òî âîçíèêàåò
ñèòóàöèÿ, êîãäà òðåáóåòñÿ ïðèíèìàòü ðåøåíèå, êàêóþ ñòðàíèöó íàäî îñâîáîäèòü
(çàìåñòèòü) äëÿ òîãî, ÷òîáû ïîìåñòèòü â êýø íîâóþ ñòðàíèöó.
Ïðàêòè÷åñêè âñå êîììåð÷åñêèå ñèñòåìû èñïîëüçóþò òó èëè èíóþ
âàðèàöèþ LRU (Least Recently Used) àëãîðèòìà,
â êîòîðîì âûñâîáîæäàåòñÿ òà ñòðàíèöà, ê êîòîðîé äîëüøå âñåãî íå îáðàùàëèñü.
 ÷èñòîì âèäå ýòîò àëãîðèòì íå î÷åíü õîðîø äëÿ èñïîëüçîâàíèÿ â ÑÓÁÄ â ñèëó
áîëüøîé ðàçíîîáðàçíîñòè ïîñëåäîâàòåëüíîñòè çàïðîñîâ, íàïðèìåð,
íå ó÷èòûâàåò ÷àñòîòó îáðàùåíèÿ ê ñòðàíèöå, íå çàùèùåí îò
«cache flooding», êîãäà âñåãî
îäíî åäèíè÷íîå ïîñëåäîâàòåëüíîå ÷òåíèå áîëüøîãî êîëè÷åñòâà ñòðàíèö
(sequential scan) ìîæåò çàïîëíèòü êýø ñòðàíèöàìè, ê êîòîðûì ìîæåò íå áûòü
áîëüøå îáðàùåíèÿ, ò.å., ê ïîëíîé ïîòåðå ýôôåêòèâíîñòè êýøèðîâàíèÿ.
Èíîãäà, èñïîëüçóþò òåðìèí «scan-resistant», êîãäà ãîâîðÿò, ÷òî õîðîøèé àëãîðèòì
äîëæåò áûòü óñòîé÷èâ ïî îòíîøåíèþ ê «cache flooding».
PostgreSQL èñïîëüçîâàë ðàçíîâèäíîñòü ýòîãî àëãîðèòìà,
èçâåñòíóþ êàê LRU/K,
ðåàëèçîâàííóþ Òîìîì Ëàéíîì (Tom Lane). Â ýòîì àëãîðèòìå èñïîëüçóåòñÿ
èñòîðèÿ K-ïîñëåäíèõ îáðàùåíèé ê ñòðàíèöå (èìåííî ïîñëåäíèõ, ÷òî ïîçâîëÿåò
ýòîìó àëãîðèòìó àäàïòèðîâàòüñÿ ê èçìåíåíèÿì øàáëîíà çàïðîñîâ, â îòëè÷èå îò
LFU àëãîðèòìà), êîòîðàÿ ïîçâîëÿåò îòëè÷èòü ïîïóëÿðíûå ñòðàíèöû îò
äàâíî íå èñïîëüçóåìûõ. Äëÿ ýòîãî ñòðîèòñÿ óïîðÿäî÷åííàÿ î÷åðåäü (priority queue)
óêàçàòåëåé íà ñòðàíèöû â êýøå íà îñíîâå âðåìåíè îáðàùåíèÿ ê ñòðàíèöå ïî ïðàâèëó:
åñëè ó ñòðàíèöû P1
K-òîå îáðàùåíèå (ïðåäïîñëåäíåå, äëÿ íàèáîëåå âàæíîãî ñëó÷àÿ K=2, LRU/2 ) ÿâëÿåòñÿ áîëåå
ñâåæèì ÷åì ó P2, òî P1 áóäåò çàìåùåíî ïîñëå P2. Êëàññè÷åñêèé LRU àëãîðèòì
ìîæíî ðàññìàòðèâàòü êàê LRU/1,
òàê êàê îí èñïîëüçîâàë èíôîðìàöèþ òîëüêî îá îäíîì (ïîñëåäíåì) îáðàùåíèè
ê ñòðàíèöå. Âàæíûì ÿâëÿåòñÿ íå òî, ÷òî ïðîèçîøëî åäèíè÷íîå îáðàùåíèå
ê ñòðàíèöå, à òî, íàñêîëüêî ýòà ñòðàíèöà áûëà ïîïóëÿðíà â òå÷åíèå íåêîòîðîãî âðåìåíè.
Îäíàêî, ýòîò àëãîðèòì òðåáîâàë íåòðèâèàëüíîé íàñòðîéêè è
âðåìÿ íà ïîñòðîåíèå î÷åðåäè ðàñòåò ëîãàðèôìè÷åñêè â çàâèñèìîñòè îò ðàçìåðà áóôåðà.
ARC
(Adaptive Replacement Cache) àëãîðèòì áûë ïðèâëåêàòåëåí òåì, ÷òî îí ó÷èòûâàë
íå òîëüêî êàê ÷àñòî ñòðàíèöà áûëà èñïîëüçîâàíà, íî è íàñêîëüêî
íåäàâíî ýòî ïðîèñõîäèëî è íå ñèëüíî «íàãðóæàë» ïðîöåññîð,
êàê ýòî ïðîèñõîäèëî ñ LRU/K àëãîðèòìîì. Îí äèíàìè÷åñêè ïîääåðæèâàåò áàëàíñ
ìåæäó ÷àñòî èñïîëüçóåìûìè è íåäàâíî èñïîëüçóåìûìè ñòðàíèöàìè.
Ýòîò àëãîðèòì áûë ðåàëèçîâàí ßíîì Âèêîì
(Jan Wieck) äëÿ âåðñèè 7.5 (âïîñëåäñòâèè 8.0), êîòîðûé âïîñëåäñòâèè áûë
íåñêîëüêî óëó÷øåí ïîñëå ñòàòüè,
îïèñûâàþùåé CAR (Clock with Adaptive Replacement) àëãîðèòì.
Îäíàêî, íåçàäîëãî (çà äâà äíÿ) äî âûõîäà PostgreSQL 8.0 áûëî îáíàðóæåíî
(ñì. ïîñòèíã
Íåéëà Êîíâåÿ (Neil Conway) è ïîñëåäóþùåå îáñóæäåíèå), ÷òî IBM ïîäàëà
çàÿâêó íà àëãîðèòì ARC
åùå â 2002 ãîäó.
Òàê êàê áûëî óæå ïîçäíî ÷òî-ëèáî ìåíÿòü áûëî ðåøåíî âûïóñòèòü 8.0 âåðñèþ
êàê åñòü, à ïîòîì çàíÿòüñÿ ðåøåíèåì ïðîáëåìû. Íåñìîòðÿ íà òî, ÷òî IBM
åùå íå ïîëó÷èëà ïàòåíò íà ARC àëãîðèòì è òî, ÷òî IBM èìååò õîðîøóþ ïðàêòèêó
ïîääåðæêè OSS ïðîåêòîâ,
è ìîæíî áûëî íàäåÿòüñÿ íà ïîëó÷åíèÿ îôèöèàëüíîãî ðàçðåøåíèÿ íà åãî èñïîëüçîâàíèå
â PostgreSQL, êàê ïðåäëàãàëè ìíîãèå, áûëî ðåøåíî èññëåäîâàòü âîïðîñ
î äåéñòâèòåëüíîì íàðóøåíèå ïàòåíòà è âûÿñíèòü âîçìîæíîñòü çàìåíû ARC
àëãîðèòìà íà «ïàòåíòíî-÷èñòûé» àëãîðèòì.
Îñíîâíûì àðãóìåíòîâ â ïîëüçó çàìåíû àëãîðèòìà áûëî æåëàíèå ñîõðàíèòü
PostgreSQL äîñòóïíûì äëÿ «ëþáîãî èñïîëüçîâàíèÿ» ñîãëàñíî
BSD ëèöåíçèè, êîòîðàÿ ïîçâîëÿåò êîììåð÷åñêîå èñïîëüçîâàíèå PostgreSQL
áåç êàêèõ-ëèáî ëèöåíçèîííûõ îò÷èñëåíèé.  íà÷àëå ôåâðàëÿ 2005 ãîäà Òîì Ëýéí
ïðåäëîæèë èçìåíåííóþ âåðñèþ ARC àëãîðèòìà, áëèçêóþ ê
2Q è
îïóáëèêîâàííóþ â 1994 ãîäó çàäîëãî äî ARC, è êîòîðàÿ ðåøàëà
ïðîáëåìó «cache flooding» («scan resistant») è íå òðåáîâàëà áîëüøèõ èçìåíåíèé
â êîäå (â îñíîâíîì óäàëåíèå êîäà), êîòîðàÿ è áûëà ðåàëèçîâàíà â âåðñèè 8.0.2.
2Q àëãîðèòì (Two Queue) ïî÷òè òàêæå ýôôåêòèâåí êàê LRU/K, íî ïðîùå,
íå òðåáóåò íàñòðîéêè è áûñòðåå. Îí äîáèâàåòñÿ ýòîãî òåì, ÷òî õðàíèò â
îñíîâíîì áóôåðå òîëüêî «ãîðÿ÷èå» ñòðàíèöû, à íå çàíèìàåòñÿ
î÷èùåíèåì «õîëîäíûõ» ñòðàíèö â îñíîâíîì áóôåðå êàê LRU/2.
Óïðîùåííî àëãîðèòì âûãëÿäèò òàê: ïðè ïåðâîì
îáðàùåíèè óêàçàòåëü íà ñòðàíèöó ïîìåùàåòñÿ â î÷åðåäü A1 (FIFO), è åñëè âî âðåìÿ âòîðîãî
îáðàùåíèÿ ñòðàíèöà åùå íàõîäèëàñü â A1, òî ñòðàíèöà íàçûâàåòñÿ ãîðÿ÷åé è
ïîìåùàåòñÿ â îñíîâíîé áóôåð, êîòîðûé óæå êîíòðîëèðóåòñÿ êàê LRU î÷åðåäü.
Åñëè ê ñòðàíèöå íå îáðàùàëèñü ïîêà îíà áûëà â A1, òî ñòðàíèöà, âåðîÿòíî,
«õîëîäíàÿ» è 2Q àëãîðèòì óäàëÿåò åå èç áóôåðà.
PGDG — PostgreSQL Global Development Group
PostgreSQL ðàçâèâàåòñÿ ñèëàìè ìåæäóíàðîäíîé ãðóïïû ðàçðàáîò÷èêîâ (PGDG),
â êîòîðóþ âõîäÿò êàê íåïîñðåäñòâåííî ïðîãðàììèñòû, òàê è òå, êòî îòâå÷àþò
çà ïðîäâèæåíèå PostgreSQL (Public Relation), çà ïîääåðæàíèå ñåðâåðîâ
è ñåðâèñîâ, íàïèñàíèå è ïåðåâîä äîêóìåíòàöèè, âñåãî íà 2005 ãîä íàñ÷èòûâàåòñÿ
îêîëî 200 ÷åëîâåê. Äðóãèìè ñëîâàìè, PGDG — ýòî
ñëîæèâøèéñÿ êîëëåêòèâ, êîòîðûé ïîëíîñòüþ ñàìîäîñòàòî÷åí è óñòîé÷èâ.
Ïðîåêò ðàçâèâàåòñÿ ïî îáùåïðèíÿòîé ñðåäè îòêðûòûõ ïðîåêòîâ ñõåìå, êîãäà
ïðèîðèòåòû îïðåäåëÿþòñÿ ðåàëüíûìè íóæäàìè è âîçìîæíîñòÿìè. Ïðè ýòîì,
ïðàêòèêóåòñÿ ïóáëè÷íîå îáñóæäåíèå âñåõ âîïðîñîâ â ñïèñêå ðàññûëêå, ÷òî
ïðàêòè÷åñêè èñêëþ÷àåò âîçìîæíîñòü íåïðàâèëüíûõ è íåñîãëàñîâàííûõ ðåøåíèé.
Ýòî îòíîñèòñÿ è ê òåì ïðåäëîæåíèÿì, êîòîðûå óæå èìåþò èëè ðàññ÷èòûâàþò íà
ôèíàíñîâóþ ïîääåðæêó êîììåð÷åñêèõ êîìïàíèé.
Öèêë ðàçðàáîòêè
Öèêë ðàáîòîé íàä íîâîé âåðñèåé îáû÷íî äëèòñÿ 10-12 ìåñÿöåâ
(ñåé÷àñ âåäåòñÿ äèñêóññèÿ î áîëåå êîðîòêîì öèêëå 2-3 ìåñÿöà) è ñîñòîèò èç
íåñêîëüêèõ ýòàïîâ (óïðîùåííàÿ âåðñèÿ):
- Îáñóæäåíèå ïðåäëîæåíèé â ñïèñêå
-hackers. Íà ñîáñòâåííîì îïûòå ìîãó
çàâåðèòü, ÷òî ýòî î÷åíü íåïðîñòîé ïðîöåññ è ïëîõî ïîäãîòîâëåííûé proposal
íå ïðîéäåò. Ó÷èòûâàþòñÿ ìíîãî ôàêòîðîâ — àëãîðèòìû, ñòðóêòóðû äàííûõ,
ñîâìåñòèìîñòü ñ ñóùåñòâóþùåé àðõèòåêòóðîé, ñîâìåñòèìîñòü ñ SQL è òàê äàëåå. - Ïîñëå ïðèíÿòèÿ ðåøåíèÿ î ðàáîòå íàä íîâîé âåðñèåé â CVS îòêðûâàåòñÿ
íîâàÿ âåòêà è ñ ýòîãî ìîìåíòà âñå èçìåíåíèÿ, êàñàþùèåñÿ íîâûõ âîçìîæíîñòåé,
âíîñÿòñÿ òóäà. Òàêæå, àíàëèçèðóþòñÿ ïàò÷è, êîòîðûå ïðèñûëàþòñÿ â ñïèñîê
-patches.
Âñå èçìåíåíèÿ ïðîòîêîëèðóþòñÿ è äîñòóïíû ëþáîìó äëÿ ðàññìîòðåíèÿ
(anonymous CVS,
-commiters ëèñò ðàññûëêè èëè ÷åðåç
âåá-èíòåðôåéñ ê CVS).
Èíîãäà, â ïðîöåññå ðàáîòû íàä íîâîé âåðñèåé âñêðûâàþòñÿ èëè
èñïðàâëÿþòñÿ ñòàðûå îøèáêè, â ýòîì ñëó÷àå, íàèáîëåå êðèòè÷åñêèå èñïðàâëÿþòñÿ
è â ïðåäûäóùèõ âåðñèÿõ (backporting). Ïî ìåðå íàêîïëåíèÿ òàêèõ èñïðàâëåíèé
ïðèíèìàåòñÿ ðåøåíèå î âûïóñêå íîâîé ñòàáèëüíîé âåðñèè, êîòîðàÿ ñîâìåñòèìà
ñî ñòàðîé è íå òðåáóåò îáíîâëåíèÿ õðàíèëèùà. Íàïðèìåð, 7.4.7 — ÿâëÿåòñÿ
bugfix-îì ñòàáèëüíîé âåðñèè 7.4. - Â íåêîòîðûé ìîìåíò îáúÿâëÿåòñÿ ýòàï code freeze(çàìîðàæèâàíèÿ êîäà),
ïîñëå êîòîðîãî â CVS íå äîïóñêàåòñÿ íîâàÿ ôóíêöèîíàëüíîñòü, à òîëüêî èñïðàâëåíèå
èëè óëó÷øåíèå êîäà. Ãðàíèöà ìåæäó íîâîé ôóíêöèîíàëüíîñòüþ è óëó÷øåíèåì êîäà
íå îïèñàíà è èíîãäà âîçíèêàþò ðàçíîãëàñèÿ íà ýòîò ñ÷åò, ê äîêóìåíòàöèè è
ðàñøèðåíèÿì (contribution modules â ïîääèðåêòîðèè contrib/) îáû÷íî îòíîñÿòñÿ áîëåå ëèáåðàëüíî.
Çàìå÷ó, ÷òî âñå ýòî âðåìÿ âñå CVS âåðñèÿ ïðîõîäèò íåïðåðûâíîå òåñòèðîâàíèå
íà áîëüøîì êîëè÷åñòâå ìàøèí, ïîä ðàçíûìè àðõèòåêòóðàìè, îïåðàöèîííûìè
ñèñòåìàìè è êîìïèëÿòîðàìè. Âñå ýòî ñòàëî âîçìîæíî áëàãîäàðÿ ïðîåêòó
pgbuildfarm, êîòîðûé ÿâëÿåòñÿ
ðàñïðåäåëåííîé ñèñòåìîé òåñòèðîâàíèÿ, îáúåäèíÿþùàÿ äîáðîâîëüöåâ, êîòîðûå
ïðåäîñòàâëÿþò ñâîè ìàøèíû äëÿ òåñòèðîâàíèÿ. Ïðîâåðÿåòñÿ íå òîëüêî êîððåêòíîñòü
ñáîðêè, íî è, áëàãîäàðÿ îáøèðíîìó íàáîðó òåñòîâ (regression test),
è ïðàâèëüíîñòü ðàáîòû. Òåêóùèé ñòàòóñ (âñåõ ïîääåðæèâàåìûõ âåðñèé, íå òîëüêî CVS)
ìîæíî ïîñìîòðåòü íà
ýòîé ñòðàíèöå.
Èñõîäíûå òåêñòû CVS âåðñèè PostgreSQL ïðîõîäÿò òåñòèðîâàíèå
â OSDL
÷òî ïîìîãàåò â
îáíàðóæåíèè ñèñòåìàòè÷åñêèõ èçìåíåíèé ïðîèçâîäèòåëüíîñòè (â îáå ñòîðîíû),
èíîãäà òàêèå îáíàðóæåíèÿ ïðèâîäÿò ê íåîáõîäèìîñòè «ðàçìîðàæèâàíèÿ êîäà».
Íà÷èíàÿ ñ âåðñèè 8 òàêèå òåñòèðîâàíèÿ áóäóò ðåãóëÿðíî ïðîâîäèòüñÿ â
OSDL STP è PLM (STP — Scalable Test Platform è PLM — Patch Lifecycle Manager). - Ïîñëå âíóòðåííåãî òåñòèðîâàíèÿ «ñîáèðàåòñÿ» äèñòðèáóòèâ è îáúÿâëÿåòñÿ
âûõîä áåòà âåðñèè, íà òåñòèðîâàíèå è èñïðàâëåíèå îøèáîê îòâîäèòñÿ
1-3 ìåñÿöà. Áåòà âåðñèÿ íå ðåêîìåíäóåòñÿ äëÿ èñïîëüçîâàíèÿ â ïðîäàêøí ïðîåêòàõ
(production), íî ïðàêòèêà ïîêàçàëà õîðîøåå êà÷åñòâî òàêèõ âåðñèé è
ìíîãèå íà÷èíàþò åå èñïîëüçîâàòü ðàäè àïðîáèðîâàíèÿ íîâîé ôóíêöèîíàëüíîñòè.
Êàê ïðàâèëî, îêîí÷àòåëüíàÿ âåðñèÿ ñîâìåñòèìà ñ áåòà-âåðñèåé è íå òðåáóåò
îáíîâëåíèÿ õðàíèëèùà. Ïî ìåðå èñïðàâëåíèÿ çàìå÷åííûõ îøèáîê âûïóñêàþòñÿ íîâûå
áåòà-âåðñèè. - Ïîñëå èñïðàâëåíèÿ âñåõ çàìå÷åííûõ îøèáîê, âûïóñêàåòñÿ
ðåëèç-êàíäèäàò, êîòîðûé óæå ïðàêòè÷åñêè íè÷åì íå îòëè÷àåòñÿ îò
îêîí÷àòåëüíîé âåðñèè, ðàçâå ÷òî íå õâàòàåò äîêóìåíòàöèè è ñïèñêà èçìåíåíèé. -  òå÷åíèè ìåñÿöà âûõîäèò îêîí÷àòåëüíàÿ âåðñèÿ, êîòîðàÿ àíîíñèðóåòñÿ
íà ãëàâíîì âåá-ñàéòå ïðîåêòà è åãî
çåðêàëàõ, ìýéëèíã ëèñòàõ. Òàêæå,
PR ãðóïïà, êîòîðàÿ ê ýòîìó ìîìåíòó ïîäãîòîâèëà àíîíñû íà ðàçíûõ ÿçûêàõ,
ðàñïðîñòðàíÿåò èõ ïî âñåì âåäóùèì ñàéòàì è ÑÌÈ. Îíè ïðèíèìàþò ó÷àñòèå
â êîíôåðåíöèÿõ, ñåìèíàðàõ è ïðî÷èõ îáùåñòâåííûõ ìåðîïðèÿòèÿõ.
Íà êàðòå îáîçíà÷åíû òî÷êè, ãäå æèâóò è ðàáîòàþò ÷ëåíû PGDG, îðèãèíàëüíàÿ
âåðñèÿ ñ áîëüøåé ôóíêöèîíàëüíîñòüþ íàõîäèòñÿ íà îôèöèàëüíîì
ñàéòå ðàçðàáîò÷èêîâ.
Ñòðóêòóðà
- Óïðàâëÿþùèé êîìèòåò (6 ÷åëîâåê).
Ïðèíèìàåò ðåøåíèå î ïëàíàõ ðàçâèòèÿ è âûïóñêàõ íîâûõ âåðñèé. - Çàñëóæåííûå ðàçðàáîò÷èêè ( 2 ÷åëîâåêà ).
Áûâøèå ÷ëåíû óïðàâëÿþùåãî êîìèòåòà, êîòîðûå îòîøëè îò ó÷àñòèÿ â ïðîåêòå.
- Îñíîâíûå ðàçðàáîò÷èêè (23).
- Ðàçðàáîò÷èêè (22)
Êðîìå PGDG, çíà÷èòåëüíîå ó÷àñòèå â ðàçâèòèè PostgreSQL ïðèíèìàåò íåêîììåð÷åñêàÿ
îðãàíèçàöèÿ «The PostgreSQL Foundation», ñîçäàííàÿ äëÿ ïðîäâèæåíèÿ è
ïîääåðæêè PostgreSQL. Ñàéò ôîíäà íàõîäèòñÿ ïî àäðåñó
www.thepostgresqlfoundation.org.
Ñïîíñîðñêàÿ ïîìîùü íà ðàçâèòèå PostgreSQL ïîñòóïàåò êàê îò ÷àñòíûõ ëèö,
òàê è îò êîììåð÷åñêèõ êîìïàíèé, êîòîðûå:
- ïðèíèìàþò íà ðàáîòó ÷ëåíîâ PGDG
- îïëà÷èâàþò ðàçðàáîòêó êàêèõ-ëèáî íîâûõ âîçìîæíîñòåé
- ïðåäîñòàâëÿþò óñëóãè â âèäå õîñòèíãà èëè îïëàòû òðàôèêà
- ïîääåðæèâàþò ïóáëè÷íûå ìåðîïðèÿòèÿ PGDG
- âûäåëÿþò ñâîèõ ïðîãðàììèñòîâ íà ó÷àñòèå â ðàçðàáîòêå
Êðîìå òîãî, íåêîòîðûå ðàçðàáîòêè ïîääåðæèâàþòñÿ ãîñóäàðñòâåííûìè ôîíäàìè,
íàïðèìåð, Ðîññèéñêèé Ôîíä Ôóíäàìåíòàëüíûõ Èññëåäîâàíèé.
Ãäå èñïîëüçóåòñÿ
Åñëè èçíà÷àëüíî POSTGRES èñïîëüçîâàëñÿ â îñíîâíîì â àêàäåìè÷åñêèõ ïðîåêòàõ
äëÿ èññëåäîâàíèÿ àëãîðèòìîâ áàç äàííûõ, â óíèâåðñèòåòàõ êàê îòëè÷íàÿ áàçà
äëÿ îáó÷åíèÿ, òî ñåé÷àñ PostgreSQL ïðèìåíÿåòñÿ ïðàêòè÷åñêè ïîâñåìåñòíî.
Íàïðèìåð, çîíû .org, .info ïîëíîñòüþ îáñëóæèâàþòñÿ PostgreSQL, èçâåñòíû
ìíîãîòåðàáàéòíûå õðàíèëèùà àñòðîíîìè÷åñêèõ äàííûõ, Lycos, BASF.
Èç ðîññèéñêèõ ïðîåêòîâ,
èñïîëüçóþùèõ PostgreSQL, íàèáîëåå èçâåñòíûìè ÿâëÿåòñÿ ïîðòàë
Ðàìáëåð, â ðàçðàáîòêå êîòîðîãî ÿ ïðèíèìàë
ó÷àñòèå â 2000-2002 ãîäàõ, ôåäåðàëüíûå ïîðòàëû Ìèíîáðàçîâàíèÿ.
Ñîîáùåñòâî
Ñîîáùåñòâî PostgreSQL ñîñòîèò èç áîëüøîãî êîëè÷åñòâà ïîëüçîâàòåëåé, îáúåäèíåííûõ
ðàçíûìè èíòåðåñàìè, òàêèìè êàê ó÷àñòèå â ðàçðàáîòêå, ïîèñê ñîâåòîâ, ðåøåíèé,
âîçìîæíîñòü êîììåð÷åñêîãî èñïîëüçîâàíèÿ.
Ïîääåðæêà
- Îñíîâíîé èñòî÷íèê àêòóàëüíîé èíôîðìàöèè î PostgreSQL ÿâëÿåòñÿ åãî
îôèöèàëüíûé ñàéò www.postgresql.org, êîòîðûé èìååò çåðêàëà ïî âñåìó ìèðó.
Íà íåì ïóáëèêóþòñÿ ñâåäåíèÿ î âñåõ ñîáûòèÿõ (àíîíñû ðåëèçîâ, ñåìèíàðîâ,
êîíôåðåíöèé), ïîääåðæèâàåòñÿ ñïèñîê ðåñóðñîâ, îòíîñÿùèõñÿ ê PostgreSQL. - Îñíîâíàÿ ïîääåðæêà îñóùåñòâëÿåòñÿ ÷åðåç ïî÷òîâóþ ðàññûëêó, àðõèâû êîòîðîé
äîñòóïíû ÷åðåç Web ïî àäðåñàì:- archives.postgresql.org
Àðõèâ pgsql-ru-general —
ðóññêîÿçû÷íîãî ñïèñêà ðàññûëêè,êàê ïîäïèñàòüñÿ. - www.pgsql.ru/db/mw
Êàê ïîêàçàëà ìíîãîëåòíÿÿ ïðàêòèêà, ñïèñêè ðàññûëîê ÿâëÿþòñÿ íàèáîëåå
ýôôåêòèâíûì è î÷åíü ïîëåçíûì èñòî÷íèêîì çíàíèé, îáìåíà ìíåíèÿìè è
ïîìîùè â ñàìûõ ðàçëè÷íûõ ñèòóàöèÿõ. Íà ìàðò 2005 ãîäà çàðåãèñòðèðîâàíî
32812 ïîëüçîâàòåëåé, êîòîðûå êîãäà-ëèáî ïèñàëè â ìýéëèíã ëèñò.Íåáîëüøàÿ ñòàòèñòèêà ñïèñêîâ ðàññûëîê PostgreSQL ïî äàííûì www.pgsql.ru
íà 1 àïðåëÿ 2005 ãîäà.Ïåðâàÿ 20-êà ìýéëèíã ëèñòîâ
ïî êîëè÷åñòâó ïîñòèíãîâÐàñïðåäåëåíèå ïîñòèíãîâ ïî ãîäàì name | count --------------------+-------- HACKERS | 107696 GENERAL | 93272 SQL | 27574 COMMITTERS | 21384 ADMIN | 20397 PATCHES | 17354 NOVICE | 13772 BUGS | 13700 MISC | 13545 INTERFACES | 13029 JDBC | 12705 QUESTIONS | 7865 ADVOCACY | 6676 CYGWIN | 6166 WWW | 5636 PERFORMANCE | 5359 ODBC | 5182 PORTS | 4769 DOCS | 3991 PHP | 3106
# | Year ------------- 19355 | 2005 68403 | 2004 71884 | 2003 61604 | 2002 58072 | 2001 38793 | 2000 25258 | 1999 16779 | 1998 15315 | 1997 612 | 1996 7 | 1995 - archives.postgresql.org
- Ïîèñêîâàÿ ñèñòåìà PGsearch
(ðàçðàáîòàíà ïðè ïîääåðæêå ÐÔÔÈ è
Äåëüòà-Ñîôò)
ïðåäîñòàâëÿåò ïîèñê ïî ñàéòàì ñîîáùåñòâà. Íà ìîìåíò íàïèñàíèÿ ýòîé ñòàòüè
ïðîèíäåêñèðîâàíî 480000 ñòðàíèö èç 67 ñàéòîâ, èíäåêñ îáíîâëÿåòñÿ åæåíåäåëüíî. - Ìíîãî ïîëåçíîé èíôîðìàöèè ïî PostgreSQL ìîæíî íàéòè íà ñàéòàõ
- techdocs.postgresql.org
- Varlena
- Powerpostgresql
- PGnotes
- Äîêóìåíòàöèÿ íà ðóññêîì (ïåðåâîäû è îðèãèíàëüíûå ñòàòüè) äîñòóïíû
íà ñàéòå ðóññêîÿçû÷íîãî ñîîáùåñòâà
http://www.linuxshare.ru/postgresql/. - Îòâåòû íà âàøè âîïðîñû ìîæíî íàéòè â «PostgreSQL FAQ « (÷àñòî çàäàâàåìûå âîïðîñû):
- Îðèãèíàëüíàÿ âåðñèÿ
- íà ðóññêîì ÿçûêå
- Äèñòðèáóòèâû PostgreSQL äîñòóïíû äëÿ ñêà÷èâàíèÿ ñ îñíîâíîãî ftp-ñåðâåðà ïðîåêòà è åãî çåðêàë.
Ïîäðîáíàÿ èíôîðìàöèÿ äîñòóïíà ñî ñòðàíèöû http://www.postgresql.org/download/.
Êðîìå òîãî, ìíîãèå äèñòðèáóòèâû Linux ðàñïðîñòðàíÿþòñÿ ñ áèíàðíîé âåðñèåé
PostgreSQL è îáåñïå÷èâàþò ïîääåðæêó îáíîâëåíèé. Äëÿ îçíàêîìëåíèÿ
ñ PostgreSQL ìîæíî ñêà÷àòü îáðàç çàãðóçî÷íîãî CD (Live CD) —
bittorent ôîðìàò
èëè â ISO ôîðìàòå.
Èíôîðìàöèþ î òîì, êàê èíñòàëëèðîâàòü PostgreSQL ïîä Mac OS X ìîæíî íàéòè
çäåñü.
Èíñòàëëÿòîð äëÿ Win32 ìîæíî ñêà÷àòü ñ ñàéòà ïðîåêòà
Pginstaller. - Êîììåð÷åñêàÿ ïîääåðæêà îñóùåñòâëÿåòñÿ ðÿäîì êîìïàíèé, ñïèñîê êîòîðûõ
äîñòóïåí ïî àäðåñó www.postgresql.org/support/.
Òàêæå íà ðîññèéñêîì ñàéòå âåäåòñÿ ñïèñîê ðîññèéñêèõ êîìïàíèé,
êîòîðûå çàÿâèëè î ïîääåðæêå PostgreSQL.
Ðàçðàáîòêà
Äëÿ ïðîåêòîâ, èìåþùèõ îòíîøåíèå ê PostgreSQL, ïðåäîñòàâëÿåòñÿ âîçìîæíîñòü
ðàçìåùàòü èõ íà ñïåöèàëüíûõ ñàéòàõ, ïîääåðæèâàåìûå PGDG è ïðåäîñòàâëÿþùèå
ïðàêòè÷åñêè âñå, íåîáõîäèìûå äëÿ ðàçðàáîò÷èêîâ, ñåðâèñû:
- gborg.postgresql.org
- pgfoundry.org
Çàêëþ÷åíèå
PostgreSQL ÿâëÿåòñÿ ïîëíîôóíêöèîíàëüíîé îáúåêòíî-ðåëÿöèîííîé ÑÓÁÄ, ãîòîâîé
äëÿ ïðàêòè÷åñêîãî èñïîëüçîâàíèÿ. Åå ôóíêöèîíàëüíîñòü è íàäåæíîñòü
îáóñëîâëåíû áîãàòîé èñòîðèåé ðàçâèòèÿ,ïðîôåññèîíàëèçìîì ðàçðàáîò÷èêîâ è
òåõíîëîãèåé òåñòèðîâàíèÿ, à åå ïåðñïåêòèâû çàëîæåíû â åå ðàñøèðÿåìîñòè è
ñâîáîäíîé ëèöåíçèè.
Áëàãîäàðíîñòè
Àâòîð áëàãîäàðèò ðóññêîÿçû÷íîå ñîîáùåñòâî çà êðèòèêó è äîïîëíåíèÿ, Ðîññèéñêèé Ôîíä Ôóíäàìåíòàëüíûõ Èññëåäîâàíèé
(ÐÔÔÈ) çà ïîääåðæêó ãðàíòà 05-07-90225-â.
Òåêñò íàïèñàí Îëåãîì Áàðòóíîâûì â 2005 ãîäó, ïîïðàâêè è êîììåíòàðèè
ïðèâåòñòâóþòñÿ.
Êðàòêàÿ ñïðàâêà:

Îëåã Áàðòóíîâ (îñíîâíàÿ ñïåöèàëüíîñòü àñòðîíîì, ðàáîòàåò â ÃÀÈØ ÌÃÓ) ÿâëÿåòñÿ ÷ëåíîì PGDG (îñíîâíîé ðàçðàáîò÷èê) ñ 1996 ãîäà, áûë â
÷èñëå îñíîâàòåëåé êîìïàíèè «GreatBridge», ÿâëÿåòñÿ ÷ëåíîì
«The PostgreSQL Foundation». Ïîìèìî èñïîëüçîâàíèÿ PostgreSQL â ïðîåêòàõ
(ñàìûå èçâåñòíûå — ýòo ïîðòàë Ðàìáëåð,
Íàó÷íàÿ Ñåòü, Àñòðîíåò), îí
â 1996 ãîäó äîáàâèë ïîääåðæêó locale â PostgreSQL, çàòåì
ñîâìåñòíî ñ Ôåäîðîì Ñèãàåâûì (êîìïàíèÿ Delta-Soft)
çàíèìàëñÿ ïîääåðæêîé è ðàçðàáîòêîé
GiST â PostgreSQL,
íà îñíîâå êîòîðîãî áûëè ðàçðàáîòàíû òàêèå ïîïóëÿðíûå ìîäóëè êàê
ïîëíîòåêñòîâûé ïîèñê, ðàáîòà ñ ìàññèâàìè, ïîèñê ñ îøèáêàìè, ïîääåðæêà
èåðàðõè÷åñêèõ äàííûõ. Ñîàâòîð ñâîáîäíîãî ïîëíîòåêñòîâîãî ïîèñêà äëÿ
PostgreSQL OpenFTS.
ßâëÿåòñÿ àâòîðîì è ñîçäàòåëåì
(ñîâìåñòíî ñ Ôåäîðîì Ñèãàåâûì) ñàéòà pgsql.ru.
Çàíèìàåòñÿ ïðîäâèæåíèåì PostgreSQL äëÿ èñïîëüçîâàíèÿ â àñòðîíîìèè, â ÷àñòíîñòè,
äëÿ ðàáîòû ñ î÷åíü áîëüøèìè àñòðîíîìè÷åñêèìè êàòàëîãàìè, ïðîåêò
pgSphere — õðàíåíèå äàííûõ ñî ñôåðè÷åñêèìè
êîîðäèíàòàìè è èíäåêñíûå ìåòîäû äîñòóïà ê íèì.
PostgreSQL error reporting follows a style guide aimed at providing the database administrator with the information required to efficiently troubleshoot issues. Error messages normally contain a short description, followed by some detailed information, and a hint, if applicable, suggesting the solution. There are other fine details, explained in the guide, such as the use of past or present tense to indicate if the error is temporary or permanent.
Types of Errors and Severity Levels
When reporting errors, PostgreSQL will also return an SQLSTATE error code, therefore errors are classified into several classes. When reviewing the list of classes, note that success and warning are also logged by PostgreSQL to the error log — that is because logging_collector, the PostgreSQL process responsible for logging, sends all messages to stderr by default.
When the logging collector has not been initialized, errors are logged to the system log. For example, when attempting to start the service following the package installation:
[[email protected] ~]# systemctl start postgresql
Job for postgresql.service failed because the control process exited with error code.
See "systemctl status postgresql.service" and "journalctl -xe" for details.
[[email protected] ~]# systemctl status postgresql
● postgresql.service - PostgreSQL database server
Loaded: loaded (/usr/lib/systemd/system/postgresql.service; disabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Wed 2018-01-24 19:10:04 PST; 8s ago
Process: 1945 ExecStartPre=/usr/libexec/postgresql-check-db-dir postgresql (code=exited, status=1/FAILURE)
Jan 24 19:10:04 omiday.can.local systemd[1]: Starting PostgreSQL database server...
Jan 24 19:10:04 omiday.can.local postgresql-check-db-dir[1945]: Directory "/var/lib/pgsql/data" is missing or empty.
Jan 24 19:10:04 omiday.can.local postgresql-check-db-dir[1945]: Use "/usr/bin/postgresql-setup --initdb"
Jan 24 19:10:04 omiday.can.local postgresql-check-db-dir[1945]: to initialize the database cluster.
Jan 24 19:10:04 omiday.can.local postgresql-check-db-dir[1945]: See /usr/share/doc/postgresql/README.rpm-dist for more information.
Jan 24 19:10:04 omiday.can.local systemd[1]: postgresql.service: Control process exited, code=exited status=1
Jan 24 19:10:04 omiday.can.local systemd[1]: Failed to start PostgreSQL database server.
Jan 24 19:10:04 omiday.can.local systemd[1]: postgresql.service: Unit entered failed state.
Jan 24 19:10:04 omiday.can.local systemd[1]: postgresql.service: Failed with result 'exit-code'.When returning error messages to clients, and therefore logging to error log, messages are logged with a severity level that is controlled using the client_min_messages parameter. Logging to server log files is controlled by the parameter log_min_messages, while log_min_error_statement enables logging of SQL statements that cause an error of a specific severity level.
PostgreSQL can be configured to log at the following severity levels:
- PANIC: All database sessions are aborted. This is a critical situation that affects all clients.
- FATAL: The current session is aborted due to an error. The client may retry. Other databases in the cluster are not affected.
- LOG: Normal operation messages.
- ERROR: Failure to execute a command. This is a permanent error.
- WARNING: An event that, while not preventing the command to complete, may lead to failures if not addressed. Monitoring for warnings is a good practice in early detection of issues on both the server and application side.
- NOTICE: Information that clients can use to improve their code.
- INFO: Logs explicitly requested by clients.
- DEBUG1..DEBUG5: Developer information.
Note: Higher level messages include messages from lower levels i.e. setting the logging level to LOG, will instruct PostgreSQL to also log FATAL and PANIC messages.
Common Errors and How to Fix Them
What follows is a non exhaustive list:
Error Message
psql: could not connect to server: No such file or directoryCause
[[email protected] ~]# psql -U postgres
psql: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/var/run/postgresql/.s.PGSQL.5432"?Resolution
Verify that the PostgreSQL service is running using operating system tools (ps, netstat, ss, systemctl) or check for the presence of postmaster.pid in the data directory.
Error Message
psql: FATAL: Peer authentication failed for user "postgres"Cause
[[email protected] ~]# psql -U postgres
psql: FATAL: Peer authentication failed for user "postgres"Resolution
The log file will contain a more detailed message to that effect:
LOG: provided user name (postgres) and authenticated user name (root) do not match
FATAL: Peer authentication failed for user "postgres"
DETAIL: Connection matched pg_hba.conf line 80: "local all all peer"Follow these steps:
-
Log in as the postgres user:
[[email protected] ~]# su - postgres [postgre[email protected] ~]$ psql psql (9.6.6) Type "help" for help. postgres=# -
Make the following change to pg_hba.conf that will allow the root user to log in without a password:
--- a/var/lib/pgsql/data/pg_hba.conf +++ b/var/lib/pgsql/data/pg_hba.conf @@ -77,6 +77,7 @@ # TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only +local all postgres trust local all all peer # IPv4 local connections: host all all 127.0.0.1/32 ident -
Reload the service and test:
[[email protected] ~]# psql -U postgres psql (9.6.6) Type "help" for help. postgres=#
Error Message
psql: could not connect to server: Connection refused
Is the server running on host "192.168.0.11" and accepting
TCP/IP connections on port 5432?Cause
A client attempted a connection to the public IP address.
Note: This is an error returned to the client, in the example above psql. In case of a web application check the web server error log.
Resolution
Configure the service to listen on the public IP address:
Note: As a best practice use alter system rather than editing postgresql.conf.
postgres=# alter system set listen_addresses TO 'localhost,192.168.0.11';
ALTER SYSTEMThe alter system command has modified the postgresql.auto.conf as shown below:
--- a/var/lib/pgsql/data/postgresql.auto.conf
+++ b/var/lib/pgsql/data/postgresql.auto.conf
@@ -1,2 +1,3 @@
# Do not edit this file manually!
-# It will be overwritten by the ALTER SYSTEM command.
+# It will be overwritten by ALTER SYSTEM command.
+listen_addresses = 'localhost,192.168.0.11'Restart the service and test:
[[email protected] ~]# psql -U webuser -h 192.168.0.11 webapp
psql: FATAL: no pg_hba.conf entry for host "192.168.0.11", user "webuser", database "webapp", SSL offWe’ll address this error in the next topic.
Error Message
psql: FATAL: no pg_hba.conf entry for host "192.168.0.11", user "webuser", database "webapp", SSL offCause
PostgreSQL service running on the IP address 192.168.0.11 is not configured to allow the user webuser to connect to the database webapp.
Resolution
Modify the access file pg_hba.conf to allow the connection:
--- a/var/lib/pgsql/data/pg_hba.conf
+++ b/var/lib/pgsql/data/pg_hba.conf
@@ -81,6 +81,7 @@
local all postgres trust
local all all peer
# IPv4 local connections:
host all webuser 127.0.0.1/32 md5
+host all webuser 192.168.0.11/32 md5
host all all 127.0.0.1/32 ident
# IPv6 local connections:
host all webuser ::1/128 md5Reload the service and test:
[[email protected] ~]# psql -U webuser -h 192.168.0.11 webapp
Password for user webuser:
psql (9.6.6)
Type "help" for help.
webapp=> c
You are now connected to database "webapp" as user "webuser".Error Message
ERROR: syntax error at or near "grant"Cause
Grant is one of the PostgreSQL reserved keywords
Resolution
Reserved keywords must be quoted:
webapp=> create table "grant" (id numeric);
CREATE TABLE
And verify:
webapp=> d "grant"
Table "public.grant"
Column | Type | Modifiers
--------+---------+-----------
id | numeric |
webapp=>Error Message
ERROR: cannot drop table cust because other objects depend on itCause
A client attempted removing the table cust that has child tables.
Resolution
Review HINT in the log file:
ERROR: cannot drop table cust because other objects depend on it
DETAIL: table cust_region_1 depends on table cust
HINT: Use DROP ... CASCADE to drop the dependent objects too.
STATEMENT: drop table cust;Error Message
ERROR: invalid input syntax for type numeric: "b" at character 26Cause
The log file reveals an attempt to insert a value that doesn’t match the column type:
ERROR: invalid input syntax for type numeric: "b" at character 26
STATEMENT: insert into cust values ('b', 2);Resolution
This is an application side error that must be corrected by developers, or if it was initiated by a client such as a DBA running psql. No action is required by the production DBA, since the full error message was also returned to the client.
PostgreSQL Management & Automation with ClusterControl
Learn about what you need to know to deploy, monitor, manage and scale PostgreSQL
Reviewing and Monitoring Logs
The most simple option is configuring PostgreSQL to use syslog via the log_destination parameter so logs can be shipped to your favorite centralized logging system (e.g. rsyslog) and then further processed there for alerting on specific error conditions.
Another tool, that requires a close to none setup is tail_n_mail, which works in combination with the cron daemon.
Yet another tool in this list is pgBadger that comes with a rich set of options for reporting, visualizing and analyzing not only the PostgreSQL log files but also the information logged by the statistics collector.
Moving up on the complexity scale, organization can benefit from investing the time and effort for setting up an ELK stack, which uses the Filebeat PostgreSQL module to generate alerts and reports.
Conclusion
Reviewing the error logs, being notified on critical issues, and having a versatile log management system that aids in troubleshooting is important in maintaining a healthy database environment. Fortunately, PostgreSQL provides a rich error management framework, reflected in the large variety of available products to choose from. The criteria for selecting the ones that best suit a specific environment must include not only the product features but also the technical expertise required.
Subscribe to get our best and freshest content
pg_amcheck-проверяет наличие повреждений в одной или нескольких базах данных PostgreSQL
Description
pg_amcheck поддерживает запуск функций проверки коррупции amcheck для одной или нескольких баз данных, с возможностью выбора, какие схемы, таблицы и индексы проверять, какие виды проверки выполнять, и следует ли выполнять проверки параллельно, и если да, то количество параллельных подключений для установки и использования.
В настоящее время поддерживаются только обычные и тостовые табличные отношения,материализованные представления,последовательности и индексы btree.Другие типы отношений молча пропускаются.
Если указано dbname , это должно быть имя отдельной базы данных для проверки, и никакие другие параметры выбора базы данных присутствовать не должны. В противном случае, если присутствуют какие-либо опции выбора базы данных, будут проверены все соответствующие базы данных. Если таких параметров нет, будет проверена база данных по умолчанию. --database выбора базы данных включают --all , —database и —exclude --exclude-database . Они также включают в себя --relation , --exclude-relation , --table , --exclude-table , --index Задает и --exclude-index , но только тогда , когда такие варианты используются с трехчастным рисунком (например , mydb*.myschema*.myrel* ). Наконец, они включают --schema и —exclude --exclude-schema когда такие параметры используются с двухчастным шаблоном (например, mydb*.myschema* ).
dbname также может быть строкой подключения .
Options
Следующие параметры командной строки управляют тем,что проверяется:
-
-a--all -
Проверить все базы данных, кроме исключенных с помощью
--exclude-database. -
-d pattern--database=pattern -
Проверить базы данных, соответствующие указанному
pattern, за исключением исключенных--exclude-database. Эта опция может быть указана более одного раза. -
-D pattern--exclude-database=pattern -
Исключить базы данных, соответствующие заданному
pattern. Эта опция может быть указана более одного раза. -
-i pattern--index=pattern -
Проверяйте индексы, соответствующие указанному
pattern, если они не исключены иначе. Эта опция может быть указана более одного раза.Это похоже на параметр
--relation, за исключением того, что он применяется только к индексам, а не к другим типам отношений. -
-I pattern--exclude-index=pattern -
Исключить индексы, соответствующие указанному
pattern. Эта опция может быть указана более одного раза.Это похоже на параметр
--exclude-relation, за исключением того, что он применяется только к индексам, а не к другим типам отношений. -
-r pattern--relation=pattern -
Проверить отношения, соответствующие указанному
pattern, если они не исключены иначе. Эта опция может быть указана более одного раза.Шаблоны могут быть неквалифицированными, например
myrel*, или они могут быть квалифицированными схемой, напримерmyschema*.myrel*или квалифицированными базой данных и квалифицированными схемами, напримерmydb*.myscheam*.myrel*. Шаблон с указанием базы данных добавит соответствующие базы данных в список проверяемых баз данных. -
-R pattern--exclude-relation=pattern -
Исключить отношения, соответствующие указанному
pattern. Эта опция может быть указана более одного раза.Как и в случае с
--relation,patternможет быть неквалифицированным, квалифицированным по схеме или с указанием базы данных и схемы. -
-s pattern--schema=pattern -
Проверяйте таблицы и индексы в схемах, соответствующих указанному
pattern, если они не исключены иначе. Эта опция может быть указана более одного раза.Чтобы выбрать только таблицы в схемах, соответствующих определенному шаблону, рассмотрите возможность использования чего-то вроде
--table=SCHEMAPAT.* --no-dependent-indexes. Чтобы выбрать только индексы, рассмотрите возможность использования чего-то вроде--index=SCHEMAPAT.*.Шаблон схемы может быть уточнен базой данных. Например, вы можете написать
--schema=mydb*.myschema*чтобы выбрать схемы, соответствующиеmyschema*в базах данных, соответствующихmydb*. -
-S pattern--exclude-schema=pattern -
Исключить таблицы и индексы из схем, соответствующих указанному
pattern. Эта опция может быть указана более одного раза.Как и в случае с
--schema, шаблон может быть квалифицирован как база данных. -
-t pattern--table=pattern -
Проверьте таблицы, соответствующие указанному
pattern, если они не исключены иначе. Эта опция может быть указана более одного раза.Это похоже на параметр
--relation, за исключением того, что он применяется только к таблицам, материализованным представлениям и последовательностям, а не к индексам. -
-T pattern--exclude-table=pattern -
Исключить таблицы, соответствующие указанному
pattern. Эта опция может быть указана более одного раза.Это похоже на параметр
--exclude-relation, за исключением того, что он применяется только к таблицам, материализованным представлениям и последовательностям, а не к индексам. --no-dependent-indexes-
По умолчанию, если таблица отмечена, любые индексы btree этой таблицы также будут проверены, даже если они не были явно выбраны с помощью такой опции, как
--indexили--relation. Этот параметр подавляет такое поведение. --no-dependent-toast-
По умолчанию, если таблица отмечена, ее всплывающая таблица, если таковая имеется, также будет проверена, даже если она не выбрана явно с помощью такой опции, как
--tableили--relation. Этот параметр подавляет такое поведение. --no-strict-names-
По умолчанию, если аргумент
--database,--table,--indexили--relationне соответствует ни одному объекту , это фатальная ошибка. Эта опция превращает эту ошибку в предупреждение.
Следующие параметры командной строки управляют проверкой таблиц:
--exclude-toast-pointers-
По умолчанию,всякий раз,когда в таблице встречается указатель на тост,выполняется поиск,чтобы убедиться,что он ссылается на очевидно допустимые записи в таблице тостов.Эти проверки могут быть довольно медленными,и эту опцию можно использовать,чтобы пропустить их.
--on-error-stop-
После сообщения обо всех повреждениях на первой странице таблицы,где обнаружены повреждения,прекратите обработку этого отношения таблицы и перейдите к следующей таблице или индексу.
Обратите внимание,что проверка индекса всегда останавливается после первой поврежденной страницы.Этот параметр имеет значение только для табличных отношений.
--skip=option-
Если задано
all-frozen, при проверке повреждения таблиц будут пропускаться страницы во всех таблицах, которые помечены как все замороженные.Если задано значение
all-visible, при проверке повреждений таблицы будут пропускаться страницы во всех таблицах, которые помечены как все видимые.По умолчанию страницы не пропускаются. Это может быть указано как
none, но, поскольку это значение по умолчанию, об этом нет необходимости. --startblock=block-
Начните проверку с указанного номера блока. Ошибка возникнет, если в проверяемой связи таблицы меньше этого количества блоков. Этот параметр не применяется к индексам и, вероятно, полезен только при проверке связи одной таблицы. См.
--endblockдля дальнейших предостережений. --endblock=block-
Завершите проверку на указанном номере блока. Ошибка возникнет, если в проверяемой связи таблицы меньше этого количества блоков. Этот параметр не применяется к индексам и, вероятно, полезен только при проверке связи одной таблицы. Если отмечены как обычная таблица, так и таблица всплывающих окон, этот параметр будет применяться к обоим, но блоки всплывающих уведомлений с более высокими номерами все еще могут быть доступны во время проверки указателей всплывающих окон, если только это не подавлено с помощью
--exclude-toast-pointers.
Следующие параметры командной строки управляют проверкой индексов B-дерева:
--heapallindexed-
Для каждого индекса проверил, проверить наличие всех кучи кортежей в качестве индекса кортежей в индексе использования amcheck «S
heapallindexedвариант. --parent-check-
Для каждого индекса ВТКЕЕ проверил, используйте amcheck «ы
bt_index_parent_checkфункцию, которая выполняет дополнительные проверки отношений родитель / потомок при проверке индекса.По умолчанию используется функция amcheck
bt_index_check, но обратите внимание, что использование параметра--rootdescendнеявно выбираетbt_index_parent_check. --rootdescend-
Для каждого индекса проверяется, повторно находят кортежи на уровне листьев, выполняя новый поиск с корневой страницы для каждого кортежа , используя amcheck «s
rootdescendвариант.Использование этого параметра неявно также выбирает параметр
--parent-check.Эта форма проверки была первоначально написана для помощи в разработке функций индекса btree.Он может быть ограниченно полезен или даже бесполезен для обнаружения тех видов повреждений,которые встречаются на практике.Кроме того,проверка на повреждение может занимать значительно больше времени и потреблять значительно больше ресурсов на сервере.
Warning
Дополнительные проверки, выполняемые для индексов B-tree, когда указан параметр —parent --parent-check или --rootdescend , требуют относительно сильных блокировок на уровне отношений. Эти проверки являются единственными проверками, которые блокируют одновременную модификацию данных командами INSERT , UPDATE и DELETE .
Следующие параметры командной строки управляют подключением к серверу:
-
-h hostname--host=hostname -
Указание имени хоста машины,на которой запущен сервер.Если значение начинается с косой черты,то оно используется в качестве директории для доменного сокета Unix.
-
-p port--port=port -
Указание TCP-порта или расширения файла локального Unix-домена,на котором сервер прослушивает соединения.
-
-U--username=username -
Имя пользователя для подключения как.
-
-w--no-password -
Никогда не запрашивайте пароль. Если сервер требует аутентификации по паролю, а пароль недоступен другими средствами, такими как файл
.pgpass, попытка подключения не удастся. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет пользователя для ввода пароля. -
-W--password -
Заставьте pg_amcheck запрашивать пароль перед подключением к базе данных.
Эта опция никогда не является существенной, поскольку pg_amcheck автоматически запрашивает пароль, если сервер требует аутентификации по паролю. Однако pg_amcheck потратит впустую попытки соединения, обнаружив, что серверу нужен пароль. В некоторых случаях стоит ввести
-W, чтобы избежать лишних попыток подключения. --maintenance-db=dbname-
Указывает базу данных или строку подключения , которая будет использоваться для обнаружения списка баз данных, которые необходимо проверить. Если не используется ни
--all, ни какая-либо опция, включая шаблон базы данных, такое соединение не требуется, и эта опция ничего не делает. В противном случае любые параметры строки подключения, кроме имени базы данных, которые включены в значение этой опции, также будут использоваться при подключении к проверяемым базам данных. Если этот параметр опущен, по умолчанию используетсяpostgresили, если это не удается,template1.
Также доступны и другие опции:
-
-e--echo -
Вывод на stdout всех SQL,отправленных на сервер.
-
-j num--jobs=num -
Используйте
numодновременных соединений с сервером, или один для каждого объекта для проверки, в зависимости от того , что меньше.По умолчанию используется одно соединение.
-
-P--progress -
Показать информацию о ходе выполнения.Информация о ходе выполнения включает количество отношений,проверка которых завершена,и общий размер этих отношений.Она также включает общее количество отношений,которые в конечном итоге будут проверены,и предполагаемый размер этих отношений.
-
-v--verbose -
Печатать больше сообщений.В частности,это позволит печатать сообщение для каждого проверяемого отношения и увеличит уровень детализации,отображаемый для ошибок сервера.
-
-V--version -
Выведите версию pg_amcheck и выйдите.
-
--install-missing--install-missing=schema -
Установите все отсутствующие расширения, необходимые для проверки баз данных. Если еще не установлено, то все объекты расширения будут установлены в данную
schemaили, если они не указаны, в схемуpg_catalog.В настоящее время единственное необходимое расширение — это amcheck .
-
-?--help -
Показать справку об аргументах командной строки pg_amcheck и выйти.
pg_amcheck предназначен для работы с PostgreSQL 14.0 и более поздними версиями.

Зачем вообще нужно логирование в базе данных? Для начала попробуйте ответить себе сами на этот вопрос.
У вас были когда-нибудь ситуации, когда кто-то изменил строку в таблице и на вопрос, почему система стала выдавать странные результаты, разработчики только разводили руками?
А была ли ситуация, когда кто-то случайно удалил таблицу и потом приходилось ее восстанавливать с бэкапа. Вы ведь делаете бэкапы, правда?
А иногда еще хочется посмотреть, кто соединился с базой. Ну и в добавок, когда что-то пойдет не так, логи могут помочь вам разобраться с этой ситуацией.
Надеюсь, каждый понимает насколько важно логирование в системе и почему ему всегда отводится такая большая роль.
Итак, что нужно чтобы включить логирование в postgres?
Да собственно говоря, нужно всего лишь прописать настройку
logging_collector = onи перезапустить сервер.
После этого в папке $PGDATA появится каталог pg_log, где будут находиться ваши логи.
По-умолчанию, формат лога postgresql-%Y-%m-%d_%H%M%S.log.
Файл как правило создается при запуске базы. После этого все логи будут идти в этот файл, если у вас не настроена ротация. О ротации логов читайте дальше. Я при первом знакомстве с базой думал, что такой формат будет производить запись в лог каждую секунду. Это неверно.
Обратите внимание на следующие параметры:
log_rotation_age = 1dговорит, что нужно производить ротацию логов спустя 1 день.
log_rotation_size = 10MBговорит, что нужно производить ротацию логово, как только размер файла превысит 10 Mb.
log_truncate_on_rotation = onговорит, что нужно перезаписывать логи вместо добавления новых.
К примеру, если хотите хранить логи только недельной давности за каждый день, то можно указать
log_filename = postgres-%a.log
log_truncate_on_rotation = on
log_rotation_age = 1dВ общем случаем вам нужно определиться с тремя вещами:
- куда записывать
- когда записывать
- что записывать.
Первые два пункта кажутся более простыми, чем третий.
Что же нужно записывать?
Можно предположить, что разумным будет начать со следующих событий:
- кто соединился с базой/кто отсоединился
- изменения в базе
- ну и хотелось бы иметь кастомизируемое сообщение
Первый пункт – это настройки
log_connections = on
log_disconnections = onПри этом в логе вы увидите что-то похожее на это:
LOG: connection received: host=::1 port=60722
LOG: connection authorized: user=miholeus database=parsers
LOG: connection received: host=::1 port=60724
LOG: connection authorized: user=miholeus database=neuronetworkВторой пункт – это настройка:
log_statement = ‘mod'Вообще имеется несколько различных значений: none (по-умолчанию), ddl, mod, all.
- ddl – логирует изменения схемы базы данных
- mod – тоже, что ddl + операции модификации данных над строками в таблице
- all – тоже, что mod + все select запросы к базе
Третий пункт – это настройка:
log_line_prefix = ‘%t <%d %u %r> %%'t – это timestamp
d – имя базы данных
u – пользователь
r – удаленный хост и порт
% – символ процента
Параметров на самом деле больше, тут я привел лишь часть из них. Все параметры предваряются символом процента.
При этом в логе будет запись вида:
2016-03-23 21:57:16 MSK <test miholeus ::1(61080)> %LOG: statement: ALTER TABLE "public"."t" DROP COLUMN "flag";Итак, еще раз отмечу список настроек для логирования:
log_connections = on
log_disconnections = on
log_statement = ‘mod'
log_line_prefix = ‘%t <%d %u %r> %%'Теперь поговорим о том, когда нужно логировать.
При наступлении какого-либо события Postgres умеет смотреть на уровень возникшей ошибки и принять действие по логированию, основываясь на этой информации.
Настройки, которые помогут в этом:
log_min_messages = warning
client_min_messages = notice
log_min_error_statement = errorПервая настройка (log_min_messages) говорит о том, какие сообщения должны попасть в лог сервера. Уровни ошибок можно устанавливать следующие:
DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, LOG, NOTICE, WARNING, ERROR, FATAL, и PANIC.
Уровень левее включает в себя все ошибки уровня правее, т.е. левый крайний вообще будет все сообщения записывать, крайний справа – только фатальные ошибки.
Вторая настройка (client_min_messages) – говорит о том, какие сообщения могут быть отправлены клиенты. По умолчанию стоит уровень NOTICE.
Третья настройка (log_min_error_statement) – говорит о том, какие ошибочные sql запросы следует записывать в log. По умолчанию стоит уровень ERROR – все ошибочные запросы можно увидеть в логе.
Есть еще одна замечательная опция, которая логирует долговыполняющиеся запросы:
log_min_duration_statement = 2000 # 2 секундыПри такой настройке все запросы, чье время выполнения превышает 2 секунды, окажутся в логе.
Есть еще возможность определить куда вести запись в логе:
- eventlog
- csvlog
- syslog
- stderr
Как выбрать то, что вам нужно?
Если вы хотите потом эти логи загрузить куда-то – то лучше, наверно, будет использовать csvlog.
При этом можно создать такую таблицу
CREATE TABLE postgres_log
(
log_time timestamp(3) with time zone,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text,
session_line_num bigint,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text,
PRIMARY KEY (session_id, session_line_num)И импортировать потом логи таким образом
COPY postgres_log FROM '/full/path/to/logfile.csv' WITH csv;Если вы проповедуете идею централизованного логирования – то для вас подойдет syslog.
В противном же случае остается stderr.
В дальнейшем logging_collector, если он включен, цепляет сообщения из stderr и перенаправляет их в лог файлы.
Еще один важный момент – нужно проверять, что пользователь базы данных имеет права на запись в папку с логами. Иначе получите Permission denied и сервер не сможет запуститься.
Со временем логов может скопиться большое количество и нужно будет следить за тем, чтобы они не занимали слишком много места. Старые логи можно переносить на другие сервера, либо удалять, либо делать и то и то.
Для удаления можно пользоваться простой командой:
find ${logdir} -name «postgres.*» -mtime +10 -exec rm -f {} ;Эта команда удалит все логи, созданные более 10 дней назад.
Каждая из 4х настроек имеет свои плюсы и минусы, и вам решать, что использовать. Я бы не рекомендовал использовать syslog, т.к. будут серьезные проблемы с производительностью.
Я обычно ставлю stderr, настраиваю ротацию и сбор/копирование логов на удаленный сервер.
Есть также еще дополнительные настройки, которые могут помочь вам:
log_checkpoints = onзаписывает чекпоинты в логи, количество записанных буферов и время, которое потребовалось для этого.
log_autovacuum_min_duration = 250Все действия автовакуума, которые заняли боле 250 ms, будут записаны в лог.
log_error_verbosityуказывает насколько детальной будет информация в логе.
Можно устанавливать уровни – TERSE, DEFAULT, VERBOSE.
Посмотреть свои текущие настройки можно командой:
select name, setting, short_desc from pg_settings where category like 'Reporting and Logging%';Теперь, когда у вас есть логи, что делать дальше?
Хотелось бы иметь какую-то отчетность, правда? И желательно, что это происходило в автоматическом режиме.
Тут есть куча разных вариантов: от написания каких-то своих скриптов на основе утилит командной строки до автоматизированных систем.
Из общих систем можно рассмотреть logstash. Из специфичных для postgres – pgfouine (вроде как умер давно), pgbadger.
Их я постараюсь рассмотреть в следующих статьях.
Ну, и не забываем про csvlog настройку. Там практически из коробки получаем готовую систему, останется написать пару скриптов для построения красивых графиков на javascript.