
20.8.1. Where to Log
log_destination(string)-
PostgreSQL supports several methods for logging server messages, including stderr, csvlog, jsonlog, and syslog. On Windows, eventlog is also supported. Set this parameter to a list of desired log destinations separated by commas. The default is to log to stderr only. This parameter can only be set in the
postgresql.conffile or on the server command line.If csvlog is included in
log_destination, log entries are output in “comma separated value” (CSV) format, which is convenient for loading logs into programs. See Section 20.8.4 for details. logging_collector must be enabled to generate CSV-format log output.If jsonlog is included in
log_destination, log entries are output in JSON format, which is convenient for loading logs into programs. See Section 20.8.5 for details. logging_collector must be enabled to generate JSON-format log output.When either stderr, csvlog or jsonlog are included, the file
current_logfilesis created to record the location of the log file(s) currently in use by the logging collector and the associated logging destination. This provides a convenient way to find the logs currently in use by the instance. Here is an example of this file’s content:stderr log/postgresql.log csvlog log/postgresql.csv jsonlog log/postgresql.json
current_logfilesis recreated when a new log file is created as an effect of rotation, and whenlog_destinationis reloaded. It is removed when none of stderr, csvlog or jsonlog are included inlog_destination, and when the logging collector is disabled.Note
On most Unix systems, you will need to alter the configuration of your system’s syslog daemon in order to make use of the syslog option for
log_destination. PostgreSQL can log to syslog facilitiesLOCAL0throughLOCAL7(see syslog_facility), but the default syslog configuration on most platforms will discard all such messages. You will need to add something like:local0.* /var/log/postgresql
to the syslog daemon’s configuration file to make it work.
On Windows, when you use the
eventlogoption forlog_destination, you should register an event source and its library with the operating system so that the Windows Event Viewer can display event log messages cleanly. See Section 19.12 for details. logging_collector(boolean)-
This parameter enables the logging collector, which is a background process that captures log messages sent to stderr and redirects them into log files. This approach is often more useful than logging to syslog, since some types of messages might not appear in syslog output. (One common example is dynamic-linker failure messages; another is error messages produced by scripts such as
archive_command.) This parameter can only be set at server start.Note
It is possible to log to stderr without using the logging collector; the log messages will just go to wherever the server’s stderr is directed. However, that method is only suitable for low log volumes, since it provides no convenient way to rotate log files. Also, on some platforms not using the logging collector can result in lost or garbled log output, because multiple processes writing concurrently to the same log file can overwrite each other’s output.
Note
The logging collector is designed to never lose messages. This means that in case of extremely high load, server processes could be blocked while trying to send additional log messages when the collector has fallen behind. In contrast, syslog prefers to drop messages if it cannot write them, which means it may fail to log some messages in such cases but it will not block the rest of the system.
log_directory(string)-
When
logging_collectoris enabled, this parameter determines the directory in which log files will be created. It can be specified as an absolute path, or relative to the cluster data directory. This parameter can only be set in thepostgresql.conffile or on the server command line. The default islog. log_filename(string)-
When
logging_collectoris enabled, this parameter sets the file names of the created log files. The value is treated as astrftimepattern, so%-escapes can be used to specify time-varying file names. (Note that if there are any time-zone-dependent%-escapes, the computation is done in the zone specified by log_timezone.) The supported%-escapes are similar to those listed in the Open Group’s strftime specification. Note that the system’sstrftimeis not used directly, so platform-specific (nonstandard) extensions do not work. The default ispostgresql-%Y-%m-%d_%H%M%S.log.If you specify a file name without escapes, you should plan to use a log rotation utility to avoid eventually filling the entire disk. In releases prior to 8.4, if no
%escapes were present, PostgreSQL would append the epoch of the new log file’s creation time, but this is no longer the case.If CSV-format output is enabled in
log_destination,.csvwill be appended to the timestamped log file name to create the file name for CSV-format output. (Iflog_filenameends in.log, the suffix is replaced instead.)If JSON-format output is enabled in
log_destination,.jsonwill be appended to the timestamped log file name to create the file name for JSON-format output. (Iflog_filenameends in.log, the suffix is replaced instead.)This parameter can only be set in the
postgresql.conffile or on the server command line. log_file_mode(integer)-
On Unix systems this parameter sets the permissions for log files when
logging_collectoris enabled. (On Microsoft Windows this parameter is ignored.) The parameter value is expected to be a numeric mode specified in the format accepted by thechmodandumasksystem calls. (To use the customary octal format the number must start with a0(zero).)The default permissions are
0600, meaning only the server owner can read or write the log files. The other commonly useful setting is0640, allowing members of the owner’s group to read the files. Note however that to make use of such a setting, you’ll need to alter log_directory to store the files somewhere outside the cluster data directory. In any case, it’s unwise to make the log files world-readable, since they might contain sensitive data.This parameter can only be set in the
postgresql.conffile or on the server command line. log_rotation_age(integer)-
When
logging_collectoris enabled, this parameter determines the maximum amount of time to use an individual log file, after which a new log file will be created. If this value is specified without units, it is taken as minutes. The default is 24 hours. Set to zero to disable time-based creation of new log files. This parameter can only be set in thepostgresql.conffile or on the server command line. log_rotation_size(integer)-
When
logging_collectoris enabled, this parameter determines the maximum size of an individual log file. After this amount of data has been emitted into a log file, a new log file will be created. If this value is specified without units, it is taken as kilobytes. The default is 10 megabytes. Set to zero to disable size-based creation of new log files. This parameter can only be set in thepostgresql.conffile or on the server command line. log_truncate_on_rotation(boolean)-
When
logging_collectoris enabled, this parameter will cause PostgreSQL to truncate (overwrite), rather than append to, any existing log file of the same name. However, truncation will occur only when a new file is being opened due to time-based rotation, not during server startup or size-based rotation. When off, pre-existing files will be appended to in all cases. For example, using this setting in combination with alog_filenamelikepostgresql-%H.logwould result in generating twenty-four hourly log files and then cyclically overwriting them. This parameter can only be set in thepostgresql.conffile or on the server command line.Example: To keep 7 days of logs, one log file per day named
server_log.Mon,server_log.Tue, etc., and automatically overwrite last week’s log with this week’s log, setlog_filenametoserver_log.%a,log_truncate_on_rotationtoon, andlog_rotation_ageto1440.Example: To keep 24 hours of logs, one log file per hour, but also rotate sooner if the log file size exceeds 1GB, set
log_filenametoserver_log.%H%M,log_truncate_on_rotationtoon,log_rotation_ageto60, andlog_rotation_sizeto1000000. Including%Minlog_filenameallows any size-driven rotations that might occur to select a file name different from the hour’s initial file name. syslog_facility(enum)-
When logging to syslog is enabled, this parameter determines the syslog “facility” to be used. You can choose from
LOCAL0,LOCAL1,LOCAL2,LOCAL3,LOCAL4,LOCAL5,LOCAL6,LOCAL7; the default isLOCAL0. See also the documentation of your system’s syslog daemon. This parameter can only be set in thepostgresql.conffile or on the server command line. syslog_ident(string)-
When logging to syslog is enabled, this parameter determines the program name used to identify PostgreSQL messages in syslog logs. The default is
postgres. This parameter can only be set in thepostgresql.conffile or on the server command line. syslog_sequence_numbers(boolean)-
When logging to syslog and this is on (the default), then each message will be prefixed by an increasing sequence number (such as
[2]). This circumvents the “— last message repeated N times —” suppression that many syslog implementations perform by default. In more modern syslog implementations, repeated message suppression can be configured (for example,$RepeatedMsgReductionin rsyslog), so this might not be necessary. Also, you could turn this off if you actually want to suppress repeated messages.This parameter can only be set in the
postgresql.conffile or on the server command line. syslog_split_messages(boolean)-
When logging to syslog is enabled, this parameter determines how messages are delivered to syslog. When on (the default), messages are split by lines, and long lines are split so that they will fit into 1024 bytes, which is a typical size limit for traditional syslog implementations. When off, PostgreSQL server log messages are delivered to the syslog service as is, and it is up to the syslog service to cope with the potentially bulky messages.
If syslog is ultimately logging to a text file, then the effect will be the same either way, and it is best to leave the setting on, since most syslog implementations either cannot handle large messages or would need to be specially configured to handle them. But if syslog is ultimately writing into some other medium, it might be necessary or more useful to keep messages logically together.
This parameter can only be set in the
postgresql.conffile or on the server command line. event_source(string)-
When logging to event log is enabled, this parameter determines the program name used to identify PostgreSQL messages in the log. The default is
PostgreSQL. This parameter can only be set in thepostgresql.conffile or on the server command line.
20.8.2. When to Log
log_min_messages(enum)-
Controls which message levels are written to the server log. Valid values are
DEBUG5,DEBUG4,DEBUG3,DEBUG2,DEBUG1,INFO,NOTICE,WARNING,ERROR,LOG,FATAL, andPANIC. Each level includes all the levels that follow it. The later the level, the fewer messages are sent to the log. The default isWARNING. Note thatLOGhas a different rank here than in client_min_messages. Only superusers and users with the appropriateSETprivilege can change this setting. log_min_error_statement(enum)-
Controls which SQL statements that cause an error condition are recorded in the server log. The current SQL statement is included in the log entry for any message of the specified severity or higher. Valid values are
DEBUG5,DEBUG4,DEBUG3,DEBUG2,DEBUG1,INFO,NOTICE,WARNING,ERROR,LOG,FATAL, andPANIC. The default isERROR, which means statements causing errors, log messages, fatal errors, or panics will be logged. To effectively turn off logging of failing statements, set this parameter toPANIC. Only superusers and users with the appropriateSETprivilege can change this setting. log_min_duration_statement(integer)-
Causes the duration of each completed statement to be logged if the statement ran for at least the specified amount of time. For example, if you set it to
250msthen all SQL statements that run 250ms or longer will be logged. Enabling this parameter can be helpful in tracking down unoptimized queries in your applications. If this value is specified without units, it is taken as milliseconds. Setting this to zero prints all statement durations.-1(the default) disables logging statement durations. Only superusers and users with the appropriateSETprivilege can change this setting.This overrides log_min_duration_sample, meaning that queries with duration exceeding this setting are not subject to sampling and are always logged.
For clients using extended query protocol, durations of the Parse, Bind, and Execute steps are logged independently.
Note
When using this option together with log_statement, the text of statements that are logged because of
log_statementwill not be repeated in the duration log message. If you are not using syslog, it is recommended that you log the PID or session ID using log_line_prefix so that you can link the statement message to the later duration message using the process ID or session ID. log_min_duration_sample(integer)-
Allows sampling the duration of completed statements that ran for at least the specified amount of time. This produces the same kind of log entries as log_min_duration_statement, but only for a subset of the executed statements, with sample rate controlled by log_statement_sample_rate. For example, if you set it to
100msthen all SQL statements that run 100ms or longer will be considered for sampling. Enabling this parameter can be helpful when the traffic is too high to log all queries. If this value is specified without units, it is taken as milliseconds. Setting this to zero samples all statement durations.-1(the default) disables sampling statement durations. Only superusers and users with the appropriateSETprivilege can change this setting.This setting has lower priority than
log_min_duration_statement, meaning that statements with durations exceedinglog_min_duration_statementare not subject to sampling and are always logged.Other notes for
log_min_duration_statementapply also to this setting. log_statement_sample_rate(floating point)-
Determines the fraction of statements with duration exceeding log_min_duration_sample that will be logged. Sampling is stochastic, for example
0.5means there is statistically one chance in two that any given statement will be logged. The default is1.0, meaning to log all sampled statements. Setting this to zero disables sampled statement-duration logging, the same as settinglog_min_duration_sampleto-1. Only superusers and users with the appropriateSETprivilege can change this setting. log_transaction_sample_rate(floating point)-
Sets the fraction of transactions whose statements are all logged, in addition to statements logged for other reasons. It applies to each new transaction regardless of its statements’ durations. Sampling is stochastic, for example
0.1means there is statistically one chance in ten that any given transaction will be logged.log_transaction_sample_ratecan be helpful to construct a sample of transactions. The default is0, meaning not to log statements from any additional transactions. Setting this to1logs all statements of all transactions. Only superusers and users with the appropriateSETprivilege can change this setting.Note
Like all statement-logging options, this option can add significant overhead.
log_startup_progress_interval(integer)-
Sets the amount of time after which the startup process will log a message about a long-running operation that is still in progress, as well as the interval between further progress messages for that operation. The default is 10 seconds. A setting of
0disables the feature. If this value is specified without units, it is taken as milliseconds. This setting is applied separately to each operation. This parameter can only be set in thepostgresql.conffile or on the server command line.For example, if syncing the data directory takes 25 seconds and thereafter resetting unlogged relations takes 8 seconds, and if this setting has the default value of 10 seconds, then a messages will be logged for syncing the data directory after it has been in progress for 10 seconds and again after it has been in progress for 20 seconds, but nothing will be logged for resetting unlogged relations.
Table 20.2 explains the message severity levels used by PostgreSQL. If logging output is sent to syslog or Windows’ eventlog, the severity levels are translated as shown in the table.
Table 20.2. Message Severity Levels
| Severity | Usage | syslog | eventlog |
|---|---|---|---|
DEBUG1 .. DEBUG5 |
Provides successively-more-detailed information for use by developers. | DEBUG |
INFORMATION |
INFO |
Provides information implicitly requested by the user, e.g., output from VACUUM VERBOSE. |
INFO |
INFORMATION |
NOTICE |
Provides information that might be helpful to users, e.g., notice of truncation of long identifiers. | NOTICE |
INFORMATION |
WARNING |
Provides warnings of likely problems, e.g., COMMIT outside a transaction block. |
NOTICE |
WARNING |
ERROR |
Reports an error that caused the current command to abort. | WARNING |
ERROR |
LOG |
Reports information of interest to administrators, e.g., checkpoint activity. | INFO |
INFORMATION |
FATAL |
Reports an error that caused the current session to abort. | ERR |
ERROR |
PANIC |
Reports an error that caused all database sessions to abort. | CRIT |
ERROR |
20.8.3. What to Log
Note
What you choose to log can have security implications; see Section 25.3.
application_name(string)-
The
application_namecan be any string of less thanNAMEDATALENcharacters (64 characters in a standard build). It is typically set by an application upon connection to the server. The name will be displayed in thepg_stat_activityview and included in CSV log entries. It can also be included in regular log entries via the log_line_prefix parameter. Only printable ASCII characters may be used in theapplication_namevalue. Other characters will be replaced with question marks (?). debug_print_parse(boolean)
debug_print_rewritten(boolean)
debug_print_plan(boolean)-
These parameters enable various debugging output to be emitted. When set, they print the resulting parse tree, the query rewriter output, or the execution plan for each executed query. These messages are emitted at
LOGmessage level, so by default they will appear in the server log but will not be sent to the client. You can change that by adjusting client_min_messages and/or log_min_messages. These parameters are off by default. debug_pretty_print(boolean)-
When set,
debug_pretty_printindents the messages produced bydebug_print_parse,debug_print_rewritten, ordebug_print_plan. This results in more readable but much longer output than the “compact” format used when it is off. It is on by default. log_autovacuum_min_duration(integer)-
Causes each action executed by autovacuum to be logged if it ran for at least the specified amount of time. Setting this to zero logs all autovacuum actions.
-1disables logging autovacuum actions. If this value is specified without units, it is taken as milliseconds. For example, if you set this to250msthen all automatic vacuums and analyzes that run 250ms or longer will be logged. In addition, when this parameter is set to any value other than-1, a message will be logged if an autovacuum action is skipped due to a conflicting lock or a concurrently dropped relation. The default is10min. Enabling this parameter can be helpful in tracking autovacuum activity. This parameter can only be set in thepostgresql.conffile or on the server command line; but the setting can be overridden for individual tables by changing table storage parameters. log_checkpoints(boolean)-
Causes checkpoints and restartpoints to be logged in the server log. Some statistics are included in the log messages, including the number of buffers written and the time spent writing them. This parameter can only be set in the
postgresql.conffile or on the server command line. The default is on. log_connections(boolean)-
Causes each attempted connection to the server to be logged, as well as successful completion of both client authentication (if necessary) and authorization. Only superusers and users with the appropriate
SETprivilege can change this parameter at session start, and it cannot be changed at all within a session. The default isoff.Note
Some client programs, like psql, attempt to connect twice while determining if a password is required, so duplicate “connection received” messages do not necessarily indicate a problem.
log_disconnections(boolean)-
Causes session terminations to be logged. The log output provides information similar to
log_connections, plus the duration of the session. Only superusers and users with the appropriateSETprivilege can change this parameter at session start, and it cannot be changed at all within a session. The default isoff. log_duration(boolean)-
Causes the duration of every completed statement to be logged. The default is
off. Only superusers and users with the appropriateSETprivilege can change this setting.For clients using extended query protocol, durations of the Parse, Bind, and Execute steps are logged independently.
Note
The difference between enabling
log_durationand setting log_min_duration_statement to zero is that exceedinglog_min_duration_statementforces the text of the query to be logged, but this option doesn’t. Thus, iflog_durationisonandlog_min_duration_statementhas a positive value, all durations are logged but the query text is included only for statements exceeding the threshold. This behavior can be useful for gathering statistics in high-load installations. log_error_verbosity(enum)-
Controls the amount of detail written in the server log for each message that is logged. Valid values are
TERSE,DEFAULT, andVERBOSE, each adding more fields to displayed messages.TERSEexcludes the logging ofDETAIL,HINT,QUERY, andCONTEXTerror information.VERBOSEoutput includes theSQLSTATEerror code (see also Appendix A) and the source code file name, function name, and line number that generated the error. Only superusers and users with the appropriateSETprivilege can change this setting. log_hostname(boolean)-
By default, connection log messages only show the IP address of the connecting host. Turning this parameter on causes logging of the host name as well. Note that depending on your host name resolution setup this might impose a non-negligible performance penalty. This parameter can only be set in the
postgresql.conffile or on the server command line. log_line_prefix(string)-
This is a
printf-style string that is output at the beginning of each log line.%characters begin “escape sequences” that are replaced with status information as outlined below. Unrecognized escapes are ignored. Other characters are copied straight to the log line. Some escapes are only recognized by session processes, and will be treated as empty by background processes such as the main server process. Status information may be aligned either left or right by specifying a numeric literal after the % and before the option. A negative value will cause the status information to be padded on the right with spaces to give it a minimum width, whereas a positive value will pad on the left. Padding can be useful to aid human readability in log files.This parameter can only be set in the
postgresql.conffile or on the server command line. The default is'%m [%p] 'which logs a time stamp and the process ID.Escape Effect Session only %aApplication name yes %uUser name yes %dDatabase name yes %rRemote host name or IP address, and remote port yes %hRemote host name or IP address yes %bBackend type no %pProcess ID no %PProcess ID of the parallel group leader, if this process is a parallel query worker no %tTime stamp without milliseconds no %mTime stamp with milliseconds no %nTime stamp with milliseconds (as a Unix epoch) no %iCommand tag: type of session’s current command yes %eSQLSTATE error code no %cSession ID: see below no %lNumber of the log line for each session or process, starting at 1 no %sProcess start time stamp no %vVirtual transaction ID (backendID/localXID) no %xTransaction ID (0 if none is assigned) no %qProduces no output, but tells non-session processes to stop at this point in the string; ignored by session processes no %QQuery identifier of the current query. Query identifiers are not computed by default, so this field will be zero unless compute_query_id parameter is enabled or a third-party module that computes query identifiers is configured. yes %%Literal %no The backend type corresponds to the column
backend_typein the viewpg_stat_activity, but additional types can appear in the log that don’t show in that view.The
%cescape prints a quasi-unique session identifier, consisting of two 4-byte hexadecimal numbers (without leading zeros) separated by a dot. The numbers are the process start time and the process ID, so%ccan also be used as a space saving way of printing those items. For example, to generate the session identifier frompg_stat_activity, use this query:SELECT to_hex(trunc(EXTRACT(EPOCH FROM backend_start))::integer) || '.' || to_hex(pid) FROM pg_stat_activity;Tip
If you set a nonempty value for
log_line_prefix, you should usually make its last character be a space, to provide visual separation from the rest of the log line. A punctuation character can be used too.Tip
Syslog produces its own time stamp and process ID information, so you probably do not want to include those escapes if you are logging to syslog.
Tip
The
%qescape is useful when including information that is only available in session (backend) context like user or database name. For example:log_line_prefix = '%m [%p] %q%u@%d/%a '
Note
The
%Qescape always reports a zero identifier for lines output by log_statement becauselog_statementgenerates output before an identifier can be calculated, including invalid statements for which an identifier cannot be calculated. log_lock_waits(boolean)-
Controls whether a log message is produced when a session waits longer than deadlock_timeout to acquire a lock. This is useful in determining if lock waits are causing poor performance. The default is
off. Only superusers and users with the appropriateSETprivilege can change this setting. log_recovery_conflict_waits(boolean)-
Controls whether a log message is produced when the startup process waits longer than
deadlock_timeoutfor recovery conflicts. This is useful in determining if recovery conflicts prevent the recovery from applying WAL.The default is
off. This parameter can only be set in thepostgresql.conffile or on the server command line. log_parameter_max_length(integer)-
If greater than zero, each bind parameter value logged with a non-error statement-logging message is trimmed to this many bytes. Zero disables logging of bind parameters for non-error statement logs.
-1(the default) allows bind parameters to be logged in full. If this value is specified without units, it is taken as bytes. Only superusers and users with the appropriateSETprivilege can change this setting.This setting only affects log messages printed as a result of log_statement, log_duration, and related settings. Non-zero values of this setting add some overhead, particularly if parameters are sent in binary form, since then conversion to text is required.
log_parameter_max_length_on_error(integer)-
If greater than zero, each bind parameter value reported in error messages is trimmed to this many bytes. Zero (the default) disables including bind parameters in error messages.
-1allows bind parameters to be printed in full. If this value is specified without units, it is taken as bytes.Non-zero values of this setting add overhead, as PostgreSQL will need to store textual representations of parameter values in memory at the start of each statement, whether or not an error eventually occurs. The overhead is greater when bind parameters are sent in binary form than when they are sent as text, since the former case requires data conversion while the latter only requires copying the string.
log_statement(enum)-
Controls which SQL statements are logged. Valid values are
none(off),ddl,mod, andall(all statements).ddllogs all data definition statements, such asCREATE,ALTER, andDROPstatements.modlogs allddlstatements, plus data-modifying statements such asINSERT,UPDATE,DELETE,TRUNCATE, andCOPY FROM.PREPARE,EXECUTE, andEXPLAIN ANALYZEstatements are also logged if their contained command is of an appropriate type. For clients using extended query protocol, logging occurs when an Execute message is received, and values of the Bind parameters are included (with any embedded single-quote marks doubled).The default is
none. Only superusers and users with the appropriateSETprivilege can change this setting.Note
Statements that contain simple syntax errors are not logged even by the
log_statement=allsetting, because the log message is emitted only after basic parsing has been done to determine the statement type. In the case of extended query protocol, this setting likewise does not log statements that fail before the Execute phase (i.e., during parse analysis or planning). Setlog_min_error_statementtoERROR(or lower) to log such statements.Logged statements might reveal sensitive data and even contain plaintext passwords.
log_replication_commands(boolean)-
Causes each replication command to be logged in the server log. See Section 55.4 for more information about replication command. The default value is
off. Only superusers and users with the appropriateSETprivilege can change this setting. log_temp_files(integer)-
Controls logging of temporary file names and sizes. Temporary files can be created for sorts, hashes, and temporary query results. If enabled by this setting, a log entry is emitted for each temporary file when it is deleted. A value of zero logs all temporary file information, while positive values log only files whose size is greater than or equal to the specified amount of data. If this value is specified without units, it is taken as kilobytes. The default setting is -1, which disables such logging. Only superusers and users with the appropriate
SETprivilege can change this setting. log_timezone(string)-
Sets the time zone used for timestamps written in the server log. Unlike TimeZone, this value is cluster-wide, so that all sessions will report timestamps consistently. The built-in default is
GMT, but that is typically overridden inpostgresql.conf; initdb will install a setting there corresponding to its system environment. See Section 8.5.3 for more information. This parameter can only be set in thepostgresql.conffile or on the server command line.
20.8.4. Using CSV-Format Log Output
Including csvlog in the log_destination list provides a convenient way to import log files into a database table. This option emits log lines in comma-separated-values (CSV) format, with these columns: time stamp with milliseconds, user name, database name, process ID, client host:port number, session ID, per-session line number, command tag, session start time, virtual transaction ID, regular transaction ID, error severity, SQLSTATE code, error message, error message detail, hint, internal query that led to the error (if any), character count of the error position therein, error context, user query that led to the error (if any and enabled by log_min_error_statement), character count of the error position therein, location of the error in the PostgreSQL source code (if log_error_verbosity is set to verbose), application name, backend type, process ID of parallel group leader, and query id. Here is a sample table definition for storing CSV-format log output:
CREATE TABLE postgres_log ( log_time timestamp(3) with time zone, user_name text, database_name text, process_id integer, connection_from text, session_id text, session_line_num bigint, command_tag text, session_start_time timestamp with time zone, virtual_transaction_id text, transaction_id bigint, error_severity text, sql_state_code text, message text, detail text, hint text, internal_query text, internal_query_pos integer, context text, query text, query_pos integer, location text, application_name text, backend_type text, leader_pid integer, query_id bigint, PRIMARY KEY (session_id, session_line_num) );
To import a log file into this table, use the COPY FROM command:
COPY postgres_log FROM '/full/path/to/logfile.csv' WITH csv;
It is also possible to access the file as a foreign table, using the supplied file_fdw module.
There are a few things you need to do to simplify importing CSV log files:
-
Set
log_filenameandlog_rotation_ageto provide a consistent, predictable naming scheme for your log files. This lets you predict what the file name will be and know when an individual log file is complete and therefore ready to be imported. -
Set
log_rotation_sizeto 0 to disable size-based log rotation, as it makes the log file name difficult to predict. -
Set
log_truncate_on_rotationtoonso that old log data isn’t mixed with the new in the same file. -
The table definition above includes a primary key specification. This is useful to protect against accidentally importing the same information twice. The
COPYcommand commits all of the data it imports at one time, so any error will cause the entire import to fail. If you import a partial log file and later import the file again when it is complete, the primary key violation will cause the import to fail. Wait until the log is complete and closed before importing. This procedure will also protect against accidentally importing a partial line that hasn’t been completely written, which would also causeCOPYto fail.
20.8.5. Using JSON-Format Log Output
Including jsonlog in the log_destination list provides a convenient way to import log files into many different programs. This option emits log lines in JSON format.
String fields with null values are excluded from output. Additional fields may be added in the future. User applications that process jsonlog output should ignore unknown fields.
Each log line is serialized as a JSON object with the set of keys and their associated values shown in Table 20.3.
Table 20.3. Keys and Values of JSON Log Entries
| Key name | Type | Description |
|---|---|---|
timestamp |
string | Time stamp with milliseconds |
user |
string | User name |
dbname |
string | Database name |
pid |
number | Process ID |
remote_host |
string | Client host |
remote_port |
number | Client port |
session_id |
string | Session ID |
line_num |
number | Per-session line number |
ps |
string | Current ps display |
session_start |
string | Session start time |
vxid |
string | Virtual transaction ID |
txid |
string | Regular transaction ID |
error_severity |
string | Error severity |
state_code |
string | SQLSTATE code |
message |
string | Error message |
detail |
string | Error message detail |
hint |
string | Error message hint |
internal_query |
string | Internal query that led to the error |
internal_position |
number | Cursor index into internal query |
context |
string | Error context |
statement |
string | Client-supplied query string |
cursor_position |
number | Cursor index into query string |
func_name |
string | Error location function name |
file_name |
string | File name of error location |
file_line_num |
number | File line number of the error location |
application_name |
string | Client application name |
backend_type |
string | Type of backend |
leader_pid |
number | Process ID of leader for active parallel workers |
query_id |
number | Query ID |
20.8.6. Process Title
These settings control how process titles of server processes are modified. Process titles are typically viewed using programs like ps or, on Windows, Process Explorer. See Section 28.1 for details.
cluster_name(string)-
Sets a name that identifies this database cluster (instance) for various purposes. The cluster name appears in the process title for all server processes in this cluster. Moreover, it is the default application name for a standby connection (see synchronous_standby_names.)
The name can be any string of less than
NAMEDATALENcharacters (64 characters in a standard build). Only printable ASCII characters may be used in thecluster_namevalue. Other characters will be replaced with question marks (?). No name is shown if this parameter is set to the empty string''(which is the default). This parameter can only be set at server start. update_process_title(boolean)-
Enables updating of the process title every time a new SQL command is received by the server. This setting defaults to
onon most platforms, but it defaults tooffon Windows due to that platform’s larger overhead for updating the process title. Only superusers and users with the appropriateSETprivilege can change this setting.
Как включить журналы базы данных
Время на прочтение
11 мин
Количество просмотров 10K

PostgreSQL — это система управления реляционными базами данных с открытым исходным кодом, которая используется в непрерывной разработке и продакшне уже 30 лет. Почти все крупные технологические компании используют PostgreSQL, поскольку это одна из самых надежных, проверенных в боях систем реляционных баз данных на сегодняшний день.
PostgreSQL является критически важной точкой в вашей инфраструктуре, поскольку в ней хранятся все данные. Для этого важна наглядность, а значит, вы должны понимать, как работает протоколирование в PostgreSQL. Это достигается с помощью журналов и метрик, которые предоставляет PostgreSQL.
В этой статье я объясню все, что вам нужно знать о журналах (логах) PostgreSQL, начиная с того, как их включить и заканчивая тем, как их легко форматировать и анализировать.
Что такое журналы PostgreSQL?
Журналы PostgreSQL — текстовые файлы, в которых отображается информация о том, что в данный момент происходит в вашей системе баз данных. Это включает в себя сведения о том, кто имеет доступ и к какому компоненту, какие ошибки произошли, что изменилось в настройках, какие запросы находятся в процессе выполнения и какие транзакции выполняются.
Чтобы получить общую картину всех журналов, вы можете разместить их централизованно, а затем организовать возможность поиска среди них. Парсинг позволяет извлекать важную информацию и метрики, которые затем можно нанести на график для лучшей визуализации в виде точек.
В этой статье мы покажем вам, как изменить настройки PostgreSQL с помощью файла конфигурации и интерфейса командной строки. Рекомендуется вносить все эти изменения исключительно с помощью файла конфигурации, иначе ваши изменения могут быть потеряны при перезагрузке сервера.
Местоположение журнала PostgreSQL
Из коробки PostgreSQL будет показывать журналы в stderr, что не очень удобно, так как они будут смешиваться с другими процессами, которые также ведут логирование в stderr. Чтобы PostgreSQL мог создавать собственные логи, необходимо включить параметр logging_collector. Когда вы это сделаете, журналы начнут отправляться в стандартное местоположение, определенное вашей ОС. Ниже приведены директории журналов по умолчанию для нескольких различных операционных систем:
-
Система на базе Debian:
e/var/log/postgresql/postgresql-x.x.main.log. X.x. -
Система на базе Red Hat:
/var/lib/pgsql/data/pg_log -
Windows:
C:Program FilesPostgreSQL9.3datapg_log
Чтобы поменять место хранения файлов журнала при включенном сборщике (коллекторе) логов, вы можете использовать параметр log_directory для указания пользовательского каталога.
Обратите внимание, что иногда ведение журнала может быть затруднительно в PostgreSQL. Коллектор логов не позволит потерять ни одного сообщения журнала, поэтому при высокой нагрузке он может блокировать процессы сервера, что приведет к проблемам. Вместо него можно использовать системный журнал (syslog), так как он позволяет отбрасывать некоторые сообщения и не блокирует систему. Чтобы отключить коллектор логов, вы можете настроить опцию на off:
logging_collector offВ зависимости от условий использования, вам может понадобиться изменить местоположение журналов PostgreSQL. Обычно используются такие варианты, как запись в syslog, CSV, Windows Event и Docker, о которых речь пойдет ниже.
Syslog
Вы можете легко настроить PostgreSQL на ведение журнала в syslog. Вам нужно сделать это на демоне syslog с помощью следующей конфигурации:
local0.* /var/log/postgresqlВы можете использовать такие параметры, как syslog_facility, syslog_indent, syslog_sequence_number в конфигурационном файле PostgreSQL для форматирования логов.
CSV лог
Если вы хотите загрузить журналы в инструмент анализа или программу, можно сохранить их в CSV-файл. CSV хорошо определен, что делает этот процесс простым. Для перевода журналов в CSV необходимо добавить следующую строку в конфигурацию PostgreSQL:
csvlog /log/postgresql.csvВы также можете создать таблицу дополнительно к журналам, а затем использовать SQL для запроса по определенным условиям.
Журнал событий Windows
Для систем PostgreSQL, работающих под Windows, вы можете отправлять логи в журнал событий (event) Windows, используя следующую конфигурацию:
log_destination = 'stderr, eventlog'Обязательно зарегистрируйте систему источника событий в ОС Windows, чтобы она могла получать и показывать вам сообщения журнала событий с помощью программы просмотра событий Windows. Для этого выполните команду:
regsvr32 pgsql_library_directory/pgevent.dllDocker
В настоящее время многие инструменты и базы данных запускаются как Docker-приложения, включая PostgreSQL. Вы также можете легко запустить Docker-версию PostgreSQL на Kubernetes или любой другой платформе оркестрации контейнеров. Однако в таких случаях не стоит вносить изменения непосредственно в поды или контейнеры, поскольку эти изменения могут быть потеряны при перезапуске подов. Вместо этого необходимо передавать конфигурации во время запуска этих контейнеров.
Чтобы включить логирование, необходимо передать конфигурации с помощью ConfigMaps в Kubernetes. Читайте этот блог, чтобы развернуть PostgreSQL на Kubernetes и включить/выключить различные настройки.
Что важно записывать в журнал?
Запись большого количества информации в журнал может привести к пустой трате времени, если вы не сможете определить, какие логи важны, а какие нет. Очень важно уменьшить шум в журналах, чтобы ускорить отладку — это также сэкономит ваше время и ресурсы для их хранения.
Журналы должны показать вам медленные запросы, уровни логов и то, как отловить критическую информацию с минимальным объемом логирования. Этого можно добиться с помощью фильтров, наиболее распространенными из которых являются пороговые значения журнала, его уровни, время выполнения оператора и семплинг. Давайте немного углубимся в каждый из них.
Пороговые значения для медленного запроса
PostgreSQL может регистрировать запросы, которые занимают больше времени, чем определенный порог. Определение медленных запросов в журнале помогает обнаружить проблемы с базой данных и причины задержек в работе вашего приложения.
Чтобы включить эту функцию, необходимо отредактировать файл postgresql.conf. Найдите строку log_min_duration_statement и настройте ее в соответствии с вашими потребностями. Например, приведенный ниже оператор будет регистрировать все запросы, которые выполняются более 1 секунды:
log_min_duration_statement = 1000После этого сохраните файл и перезагрузите PostgreSQL. Ваши настройки будут применены, и вы сможете увидеть логи медленных запросов в файлах журнала PostgreSQL.
Вы также можете задать эти параметры динамически с помощью интерфейса запросов PostgreSQL, выполнив следующую команду:
ALTER DATABASE db SET log_min_duration_statement = ‘1000ms';Время выполнения оператора
Вы можете легко регистрировать продолжительность выполнения каждого оператора в PostgreSQL. Для этого добавьте приведенный ниже оператор в свою конфигурацию, чтобы включить протоколирование каждого оператора:
log_statement allДругим вариантом решения этой задачи является запуск следующего оператора PostgreSQL:
ALTER DATABASE db SET log_statement = ‘all';Обратите внимание, что это включит логирование всех запрошенных операторов, что может оказаться не слишком полезным и попросту будет создавать много шума.
Вместо этого, возможно, вы захотите вести журнал по типу запроса, например, DDL или MOD. DDL состоит из операторов CREATE, ALTER и DROP, а MOD включает в себя DDL плюс другие операторы модификации.
Семплинг
При включенном семплинге вы можете записывать в журнал примеры операторов, которые переходят определенный порог. Если ваш сервер генерирует огромное количество журналов в связи с различными событиями, то вы не захотите регистрировать все, что выходит за порог. Можно делать это выборочно. Это помогает поддерживать меньший объем ввода/вывода при логировании и уменьшить шум в журналах, что облегчает определение того, какие типы операторов вызывают проблему.
Этими порогами и выборкой можно управлять с помощью таких параметров в файле postgresql.conf, как log_min_duration_sample, log_statement_sample_rate и log_transaction_sample_rate. Обратитесь к документации PostgreSQL, чтобы узнать, как правильно их использовать. У вас также есть возможность внести данные изменения через командную строку PostgreSQL.
Обратите внимание, что подобное решение может стать неожиданной ловушкой, так как в результате семплинга можно пропустить единственный оператор, создающий проблему. В таких случаях вы не сможете найти причину ошибки, и отладка займет больше времени, чем обычно.
Уровни журналов PostgreSQL
PostgreSQL предлагает несколько уровней оповещения журнала в зависимости от серьезности события. Вы можете изменить уровень журнала PostgreSQL с помощью параметра log_min_error_statement в конфигурационном файле PostgreSQL, выбрав любой из приведенных ниже:
-
DEBUG1, DEBUG2, DEBUG3… DEBUG5: Предоставляет разработчикам более подробную информацию.
-
INFO: Извлекает конкретные данные, запрошенные пользователем, подобно вербозному выводу
-
NOTICE: Предлагает пользователям полезную информацию, например, об усечении идентификатора.
-
WARNING: Выдает предупреждения о вероятных проблемах
-
ERROR: Регистрирует ошибки, включая те, которые вызывают прерывание любой команды.
-
LOG: Регистрирует данные, например, активность контрольных точек, что может быть полезно для администратора.
-
FATAL: Возникает при ошибках, которые привели к прерыванию текущего сеанса работы.
-
PANIC: Возникает при ошибках, которые приводят к прерыванию всех сеансов базы данных.
Если вы отправляете журналы в Windows eventlog (журнал событий) или syslog (системный журнал), уровень серьезности (log-severity) журнала будет изменен следующим образом:
-
DEBUG1… DEBUG5 будут преобразованы в DEBUG в syslog и INFORMATION в eventlog.
-
INFO будет INFO в syslog и INFORMATION в eventlog.
-
NOTICE будет NOTICE в syslog и INFORMATION в eventlog.
-
WARNING будет NOTICE в syslog и WARNING в eventlog.
-
ERROR будет WARNING в syslog и ERROR в eventlog.
-
LOG будет INFO в syslog и INFORMATION в eventlog.
-
FATAL будет ERR в syslog и ERROR в eventlog.
-
PANIC будет CRIT в syslog и ERROR в eventlog.
Помимо уровней, очень важно понимать, какие типы журналов генерируются PostgreSQL. Это поможет вам понять, какие именно журналы следует просматривать при возникновении определенной проблемы.
Типы журналов
Существует несколько типов журналов PostgreSQL, которые необходимо учитывать при дебаггинге Их можно разделить на два типа: журналы для администратора, и журналы для пользователя приложения.
Журналы, специфичные для администратора, помогают управлять сервером PostgreSQL. Если сервер работает неправильно, они могут указать причину этого и помочь в устранении неполадок.
Существует два типа журналов, специфичных для администратора:
-
Журналы запуска: Здесь отображаются все важные события и любые проблемы (например, связанные с неправильной конфигурацией) в процессе запуска вашего сервера PostgreSQL.
-
Журналы сервера: Они помогут вам определить, что происходит с сервером PostgreSQL во время работы с точки зрения администратора. Они располагаются в стандартном месте вашей инсталляции или в том месте, которое вы указали в конфигурационном файле PostgreSQL.
Когда речь заходит о журналах, специфичных для пользователей приложений, следует обратить внимание на такие важные журналы PostgreSQL:
-
Журналы запросов показывают все запросы, которые были сделаны на сервере; вы можете увидеть зарегистрированные запросы, если у вас включен log_statement.
-
Журналы транзакций — это записи всех событий, происходящих с базой данных; они соответствуют стандарту WAL (write ahead log), который не предназначен для чтения человеком. WAL — это способ хранения записей всех действий, выполняемых с базой данных, и может быть использован для восстановления после аварии. Плагин pg_receivexlog может отображать журналы транзакций, передаваемые вашим сервером PostgreSQL.
-
Журналы соединений полезны для выявления любых нежелательных подключений к серверу. Вы можете включить log_connections в файле postgresql.conf для фиксации каждой попытки подключения к серверу; log_disconnections позволит вам увидеть всех клиентов, которые отключились от сервера.
-
Журналы ошибок помогут вам определить, создают ли какие-либо из ваших запросов нежелательные проблемы на сервере; log_in_error_statement управляет уровнем важности регистрации сообщений об ошибках.
-
Журналы аудита и доступа очень важны с точки зрения администратора. Первые показывают изменения, внесенные в базу данных, а вторые определяют, кто какие запросы делал; их можно включить с помощью конфигурации log_statement или плагина PostgreSQL, например, pgAudit.
Большинство из этих типов журналов находятся в стандартных местах хранения по умолчанию или там, куда вы их определите в файле postgresql.conf. Есть также несколько проектов с открытым исходным кодом, которые я люблю использовать вместе с PostgreSQL для лучшего анализа журналов, например pgBadger.
Просто вести журнал — это еще не все случаи. Вам также нужно подумать о том, как вы будете архивировать или выполнять ротацию журналов. PostgreSQL поддерживает ротацию журналов, о которой пойдет речь в следующем разделе.
Ротация журналов PostgreSQL
PostgreSQL может выполнять ротацию журналов с помощью некоторых базовых параметров конфигурации. Благодаря таким параметрам, как log_rotation_age, log_rotation_size и log_truncate_on_rotation, вы можете легко настроить, в какой момент вы хотите произвести ротацию журналов. Например:
log_rotation_age 60 #default unit is minutes, this will rotate logs every
log_rotation_age 300 #rotate the logs after the time mentioned.Вы также можете использовать CLI для настройки этой конфигурации.
Как уже говорилось, изучение журналов — необходимый шаг в выявлении проблем, а для этого нужно понимать форматирование журналов. В PostgreSQL вы можете легко определить формат журнала в соответствии с вашими потребностями.
Как форматировать журналы
В PostgreSQL есть возможность использовать формат CSV и сгенерировать CSV файл, который можно использовать для добавления логов в таблице, и в дополнение к всему использовать SQL.
Кроме того, параметр log_line_prefix позволяет форматировать начало каждой строки журнала в файле postgresql.conf или через командную строку. Настраиваемые параметры включают имя приложения, имя пользователя, имя базы данных, удаленный хост, тип бэкенда, идентификатор процесса и т.д. Весь список параметров доступен в документации PostgreSQL. Например:
log_line_prefix = '%m [%p] %u@%d/%a 'Приведенный префикс log_line_prefix означает, что журналы будут начинаться со времени в миллисекундах, затем идентификатор процесса, имя пользователя, имя базы данных и имя приложения.
Форматирование журнала, пороговые значения, семплинг, уровни и типы журналов — все это поможет вам в процессе дебаггинга. Но в идеале вам нужен инструмент, который позволяет агрегировать и анализировать все эти журналы и просматривать результаты через одну панель, а не заходить на каждый сервер. Одним из таких инструментов является Sematext. Давайте рассмотрим, как вы можете получить преимущества от ведения журналов PostgreSQL с помощью Sematext.
Ведение журналов PostgreSQL с помощью Sematext

Sematext Logs — это решение для управления журналами и их мониторинга, которое позволяет вам объединять журналы из различных источников данных вашей инфраструктуры в одном месте для просмотра и анализа.
Sematext обладает функцией автоматического обнаружения сервисов, поэтому вам просто нужно установить агент Sematext на свои серверы, выполнить базовую настройку, и ваши журналы PostgreSQL начнут в него стекаться. Они будут представлены на интуитивно понятной, готовой к использованию информационной панели (дашборд). Вы даже можете легко создать собственный дашборд, настроить оповещения и отправлять их по различным каналам передачи уведомлений, таким как Gmail, Slack или PagerDuty.
Sematext также предлагает такие функции, как обнаружение аномалий, что помогает вам заранее выявлять проблемы, а затем принимать меры для их предотвращения. Для более глубокого понимания вы можете сопоставить журналы PostgreSQL с метриками PostgreSQL, чтобы быстрее обнаружить узкие места. Таким образом, вы получаете вид с высоты птичьего полета на ваши установки PostgreSQL, что облегчает поиск и отладку неисправностей.
Sematext Logs (журналы) являются частью Sematext Cloud (облако), полнофункционального решения для ведения журналов и мониторинга, которое позволяет вам получить возможность обзора и интеграции всей вашей ИТ-среды. Помимо баз данных, оно поддерживает интеграцию с широким спектром инструментов, включая HAProxy, Apache Tomcat, JVM и Kubernetes. Кроме того, вы получаете поддержку деплоя Kubernetes, поэтому вам будет проще контролировать свою установку в среде Kubernetes.
Заключение
Следить за журналами PostgreSQL — важная часть работы по устранению неполадок в базе данных. Понимая, как делаются запросы и выполнятся операторы, а также трафик, соединения, ошибки и другие изменения или события на вашем сервере, вы можете легко докопаться до проблематичных процессов и обнаружить первопричину затруднений с производительностью.
Вы можете отслеживать журналы различными способами, например, используя less или tail для файлов журналов, но это будет сложно сделать, если журналы разбросаны по нескольким файлам и машинам. Вам нужны журналы в одном месте, и такое решение, как Sematext Logs, может помочь вам достичь этого.
В преддверии старта курса «Observability — мониторинг, логирование, трейсинг» хотим порекомендовать два абсолютно бесплатных вебинара от OTUS, регистрация на которые доступна по ссылкам ниже.
-
Отказоустойчивый Prometheus. Thanos, VictoriaMetrics
-
Организация мониторинга с помощью Grafana stack
log_destination(string)-
PostgreSQL supports several methods
for logging server messages, including
stderr, csvlog and
syslog. On Windows,
eventlog is also supported. Set this
parameter to a list of desired log destinations separated by
commas. The default is to log to stderr
only.
This parameter can only be set in thepostgresql.conf
file or on the server command line.If csvlog is included in
log_destination,
log entries are output in “comma separated
value” (CSV) format, which is convenient for
loading logs into programs.
See Section 19.8.4 for details.
logging_collector must be enabled to generate
CSV-format log output.When either stderr or
csvlog are included, the file
current_logfilesis created to record the location
of the log file(s) currently in use by the logging collector and the
associated logging destination. This provides a convenient way to
find the logs currently in use by the instance. Here is an example of
this file’s content:stderr log/postgresql.log csvlog log/postgresql.csv
current_logfilesis recreated when a new log file
is created as an effect of rotation, and
whenlog_destinationis reloaded. It is removed when
neither stderr
nor csvlog are included
inlog_destination, and when the logging collector is
disabled.Note
On most Unix systems, you will need to alter the configuration of
your system’s syslog daemon in order
to make use of the syslog option for
log_destination. PostgreSQL
can log to syslog facilities
LOCAL0throughLOCAL7(see syslog_facility), but the default
syslog configuration on most platforms
will discard all such messages. You will need to add something like:local0.* /var/log/postgresql
to the syslog daemon’s configuration file
to make it work.On Windows, when you use the
eventlog
option forlog_destination, you should
register an event source and its library with the operating
system so that the Windows Event Viewer can display event
log messages cleanly.
See Section 18.11 for details. logging_collector(boolean)-
This parameter enables the logging collector, which
is a background process that captures log messages
sent to stderr and redirects them into log files.
This approach is often more useful than
logging to syslog, since some types of messages
might not appear in syslog output. (One common
example is dynamic-linker failure messages; another is error messages
produced by scripts such asarchive_command.)
This parameter can only be set at server start.Note
It is possible to log to stderr without using the
logging collector; the log messages will just go to wherever the
server’s stderr is directed. However, that method is
only suitable for low log volumes, since it provides no convenient
way to rotate log files. Also, on some platforms not using the
logging collector can result in lost or garbled log output, because
multiple processes writing concurrently to the same log file can
overwrite each other’s output.Note
The logging collector is designed to never lose messages. This means
that in case of extremely high load, server processes could be
blocked while trying to send additional log messages when the
collector has fallen behind. In contrast, syslog
prefers to drop messages if it cannot write them, which means it
may fail to log some messages in such cases but it will not block
the rest of the system. log_directory(string)-
When
logging_collectoris enabled,
this parameter determines the directory in which log files will be created.
It can be specified as an absolute path, or relative to the
cluster data directory.
This parameter can only be set in thepostgresql.conf
file or on the server command line.
The default islog. log_filename(string)-
When
logging_collectoris enabled,
this parameter sets the file names of the created log files. The value
is treated as astrftimepattern,
so%-escapes can be used to specify time-varying
file names. (Note that if there are
any time-zone-dependent%-escapes, the computation
is done in the zone specified
by log_timezone.)
The supported%-escapes are similar to those
listed in the Open Group’s strftime
specification.
Note that the system’sstrftimeis not used
directly, so platform-specific (nonstandard) extensions do not work.
The default ispostgresql-%Y-%m-%d_%H%M%S.log.If you specify a file name without escapes, you should plan to
use a log rotation utility to avoid eventually filling the
entire disk. In releases prior to 8.4, if
no%escapes were
present, PostgreSQL would append
the epoch of the new log file’s creation time, but this is no
longer the case.If CSV-format output is enabled in
log_destination,
.csvwill be appended to the timestamped
log file name to create the file name for CSV-format output.
(Iflog_filenameends in.log, the suffix is
replaced instead.)This parameter can only be set in the
postgresql.conf
file or on the server command line. log_file_mode(integer)-
On Unix systems this parameter sets the permissions for log files
whenlogging_collectoris enabled. (On Microsoft
Windows this parameter is ignored.)
The parameter value is expected to be a numeric mode
specified in the format accepted by the
chmodandumask
system calls. (To use the customary octal format the number
must start with a0(zero).)The default permissions are
0600, meaning only the
server owner can read or write the log files. The other commonly
useful setting is0640, allowing members of the owner’s
group to read the files. Note however that to make use of such a
setting, you’ll need to alter log_directory to
store the files somewhere outside the cluster data directory. In
any case, it’s unwise to make the log files world-readable, since
they might contain sensitive data.This parameter can only be set in the
postgresql.conf
file or on the server command line. log_rotation_age(integer)-
When
logging_collectoris enabled,
this parameter determines the maximum lifetime of an individual log file.
After this many minutes have elapsed, a new log file will
be created. Set to zero to disable time-based creation of
new log files.
This parameter can only be set in thepostgresql.conf
file or on the server command line. log_rotation_size(integer)-
When
logging_collectoris enabled,
this parameter determines the maximum size of an individual log file.
After this many kilobytes have been emitted into a log file,
a new log file will be created. Set to zero to disable size-based
creation of new log files.
This parameter can only be set in thepostgresql.conf
file or on the server command line. log_truncate_on_rotation(boolean)-
When
logging_collectoris enabled,
this parameter will cause PostgreSQL to truncate (overwrite),
rather than append to, any existing log file of the same name.
However, truncation will occur only when a new file is being opened
due to time-based rotation, not during server startup or size-based
rotation. When off, pre-existing files will be appended to in
all cases. For example, using this setting in combination with
alog_filenamelikepostgresql-%H.log
would result in generating twenty-four hourly log files and then
cyclically overwriting them.
This parameter can only be set in thepostgresql.conf
file or on the server command line.Example: To keep 7 days of logs, one log file per day named
server_log.Mon,server_log.Tue,
etc, and automatically overwrite last week’s log with this week’s log,
setlog_filenametoserver_log.%a,
log_truncate_on_rotationtoon, and
log_rotation_ageto1440.Example: To keep 24 hours of logs, one log file per hour, but
also rotate sooner if the log file size exceeds 1GB, set
log_filenametoserver_log.%H%M,
log_truncate_on_rotationtoon,
log_rotation_ageto60, and
log_rotation_sizeto1000000.
Including%Minlog_filenameallows
any size-driven rotations that might occur to select a file name
different from the hour’s initial file name. syslog_facility(enum)-
When logging to syslog is enabled, this parameter
determines the syslog
“facility” to be used. You can choose
fromLOCAL0,LOCAL1,
LOCAL2,LOCAL3,LOCAL4,
LOCAL5,LOCAL6,LOCAL7;
the default isLOCAL0. See also the
documentation of your system’s
syslog daemon.
This parameter can only be set in thepostgresql.conf
file or on the server command line. syslog_ident(string)-
When logging to syslog is enabled, this parameter
determines the program name used to identify
PostgreSQL messages in
syslog logs. The default is
postgres.
This parameter can only be set in thepostgresql.conf
file or on the server command line. syslog_sequence_numbers(boolean)-
When logging to syslog and this is on (the
default), then each message will be prefixed by an increasing
sequence number (such as[2]). This circumvents
the “— last message repeated N times —” suppression
that many syslog implementations perform by default. In more modern
syslog implementations, repeated message suppression can be configured
(for example,$RepeatedMsgReduction
in rsyslog), so this might not be
necessary. Also, you could turn this off if you actually want to
suppress repeated messages.This parameter can only be set in the
postgresql.conf
file or on the server command line. syslog_split_messages(boolean)-
When logging to syslog is enabled, this parameter
determines how messages are delivered to syslog. When on (the
default), messages are split by lines, and long lines are split so
that they will fit into 1024 bytes, which is a typical size limit for
traditional syslog implementations. When off, PostgreSQL server log
messages are delivered to the syslog service as is, and it is up to
the syslog service to cope with the potentially bulky messages.If syslog is ultimately logging to a text file, then the effect will
be the same either way, and it is best to leave the setting on, since
most syslog implementations either cannot handle large messages or
would need to be specially configured to handle them. But if syslog
is ultimately writing into some other medium, it might be necessary or
more useful to keep messages logically together.This parameter can only be set in the
postgresql.conf
file or on the server command line. event_source(string)-
When logging to event log is enabled, this parameter
determines the program name used to identify
PostgreSQL messages in
the log. The default isPostgreSQL.
This parameter can only be set in thepostgresql.conf
file or on the server command line.
PostgreSQL is an open-source relational database management system that’s been utilized in continuous development and production for 30 years now. Nearly all the big tech companies use PostgreSQL, as it is one of the most reliable, battle-tested relational database systems today.
PostgreSQL is a critical point in your infrastructure, as it stores all of your data. This makes visibility mandatory, which in turn means you have to understand how logging works in PostgreSQL. With the help of the logs and metrics that PostgreSQL provides, you can achieve visibility.
In this article, I’ll explain everything you need to know about PostgreSQL logs, from how to enable them to how to format and analyze them easily.
What Are PostgreSQL Logs?
PostgreSQL logs are text files showing you information related to what is currently happening in your database system. This includes who has access to what component, what errors have occurred, what settings have changed, what queries are in process, and what transactions are being executed.
To get a bird’s-eye view of these logs, you can ship them to a centralized place and then have a way to search across all of them. Parsing lets you retrieve important information and metrics, which you can then plot to better visualize as data points.
This article will show you how to tweak your settings in PostgreSQL using both a config file and a command line interface. It is recommended to make all these changes using exclusively the config file, otherwise your changes may be lost when you restart your server.
PostgreSQL Log Location
Out of the box, PostgreSQL will show the logs in stderr, which is not very convenient since they’ll get mixed up with other processes logging to stderr as well. To enable PostgreSQL to create its own log files, you have to enable the logging_collector parameter. When you do, logs will start going to the default location defined by your OS. Below are the default log directories for a few different operating systems:
- Debian-based system:e /var/log/postgresql/postgresql-x.x.main.log. X.x.
- Red Hat-based system: /var/lib/pgsql/data/pg_log
- Windows: C:Program FilesPostgreSQL9.3datapg_log
To change the location where the log files are stored when the log collector is enabled, you can use the log_directory parameter to specify a custom directory.
Note that logging can sometimes be a problem in PostgreSQL. The logging collector will not allow any log messages to be lost, so at high load, it can block server processes, resulting in issues. You can use syslog instead, as it can drop some messages and will not block the system. To disable the logging collector, you can configure the option to off:
logging_collector off
Depending on your use case, you might want to change the location of your PostgreSQL logs. Common options here include logging to syslog, CSV, Windows Event, and Docker, all discussed further below.
Syslog
You can easily configure PostgreSQL to log to syslog facilities. You need to do this on the syslog daemon via the following configuration:
local0.* /var/log/postgresql
You can use parameters like syslog_facility, syslog_indent, syslog_sequence_number in the PostgreSQL configuration file to format the logs.
CSV Log
If you want to upload logs to an analysis tool or program, you might want to save logs to a CSV file. CSV is well defined, making this process easy. To switch your logs to CSV, you have to add the following line in the PostgreSQL configuration:
csvlog /log/postgresql.csv
You can also create a table on top of these logs and then use SQL to query for specific conditions.
Windows Event Log
For PostgreSQL systems running on Windows, you can send logs to the Windows Event Log with the following configuration:
log_destination = 'stderr, eventlog'
Make sure to register the event source system in the Windows OS so it can retrieve and show you event log messages using Windows Event Viewer. To do this, use the command:
regsvr32 pgsql_library_directory/pgevent.dll
Docker
Nowadays, many tools and databases are run as Docker applications, PostgreSQL included. You can also run the Docker version of PostgreSQL easily on Kubernetes or any other container orchestration platform. However, in such cases, you don’t want to make changes directly in the pods or containers because those changes can be lost when the pods restart. Instead, you have to pass the configs during the start of these containers.
To enable logging, you have to pass the configurations using the ConfigMaps in Kubernetes. Follow this blog to deploy PostgreSQL on Kubernetes and enable/disable various settings.
What Is Important to Log?
Logging a lot of information can lead to a waste of time if you are not able to point out which logs are important and which are not. It’s very important to reduce the noise in logging to achieve faster debugging—this will also save you time and resources to store those logs.
Logs should show you slow queries, log levels, and how to catch critical information with minimal logging. You can do this by using filters, the most common of which are log thresholds, log levels, statement duration, and sampling. Let’s delve a bit into each of these.
Slow Query Thresholds
PostgreSQL can log queries that are taking more time than a defined threshold. Identifying slow log queries helps discover issues with the database and why there are lags in your application.
To enable this, you need to edit the postgresql.conf file. Find the log_min_duration_statement line, and tune it per your needs. For example, the below statement will log all the queries that are taking more than 1 second:
log_min_duration_statement = 1000
After this, save the file and reload PostgreSQL. Your settings will be applied, and you will be able to see logs for slow queries in your PostgreSQL log files.
You can also set this dynamically using the PostgreSQL query interface via the following command:
ALTER DATABASE db SET log_min_duration_statement = ‘1000ms';
Statement Duration
You can easily log the duration of each statement being executed in PostgreSQL. To do this, add the below statement to your configuration to enable logging of each statement:
log_statement all
Another option to accomplish this is by running the following PostgreSQL statement:
ALTER DATABASE db SET log_statement = ‘all';
Note that this will enable the logging of all statements queried, meaning it may not be that useful and simply create a lot of noise.
Instead, you may want to log per the type of query, like DDL or MOD. DDL consists of CREATE, ALTER, and DROP statements, while MOD includes DDL plus other modifying statements.
Sampling
With sampling enabled, you can log sample statements that cross a particular threshold. If your server generates a huge amount of logs due to different events happening, you don’t want to log everything that crosses just any threshold. Instead, you can log a sample of statements that cross a particular threshold. This helps in maintaining lower I/O in logging and less noise in the logs, making it easier to identify which kinds of statements are causing an issue.
You can control these thresholds and sampling via options in the postgresql.conf file like log_min_duration_sample, log_statement_sample_rate, and log_transaction_sample_rate. Check the PostgreSQL’s documentation to see how to use these parameters. You also have the option of making these changes via the command line of PostgreSQL.
Note that this can also be a pitfall, as sampling can result in missing the one statement causing the issue. In such scenarios, you will not be able to find the problem, and debugging will take more time than usual.
PostgreSQL Log Levels
PostgreSQL offers multiple log alert levels based on the severity of the event. You can change the log level of PostgreSQL using the log_min_error_statement parameter in the PostgreSQL configuration file, selecting any of the following levels:
- DEBUG1, DEBUG2, DEBUG3… DEBUG5: Gives developers more detailed information
- INFO: Retrieves specific data requested by a user like verbose output
- NOTICE: Offers useful information to users like identifier truncation
- WARNING: Delivers warnings of likely problems
- ERROR: Registers errors, including those that cause any command to abort
- LOG: Logs data like checkpoint activity, which can be useful for the administrator
- FATAL: Occurs for errors that caused the current running session to abort
- PANIC: Occurs for errors that cause all database sessions to abort
If you are sending logs to Windows eventlog or syslog, the log-severity level will be changed as follows:
- DEBUG1… DEBUG5 will be translated to DEBUG in syslog and INFORMATION in eventlog.
- INFO will be INFO in syslog and INFORMATION in eventlog.
- NOTICE will be NOTICE in syslog and INFORMATION in eventlog.
- WARNING will be NOTICE in syslog and WARNING in eventlog.
- ERROR will be WARNING in syslog and ERROR in eventlog.
- LOG will be INFO in syslog and INFORMATION in eventlog.
- FATAL will be ERR is syslog and ERROR in eventlog.
- PANIC will be CRIT in syslog and ERROR in eventlog.
Apart from the log levels, it’s really important to understand what type of logs are generated by PostgreSQL. This helps you know what kind of logs you should look at if you see a certain kind of problem.
Log Types
There are multiple types of PostgreSQL logs you need to consider while debugging issues. You can divide them into two types: admin-specific logs and application-user-specific logs.
Admin-specific logs help manage the PostgreSQL server. If the server is not working properly, these can provide the reason for this and aid in troubleshooting.
There are two types of admin-specific logs:
- Startup logs: These show all the important events and any issues (for example, due to any misconfigurations) during the startup process of your PostgreSQL server.
- Server logs: These can help you identify anything going wrong with the PostgreSQL server at runtime from an admin perspective. They are located in the default location of your installation or as prescribed by you in the PostgreSQL configuration file.
When it comes to application-user-specific logs, there are several important PostgreSQL logs to keep an eye on:
- Query logs show you all the queries that have occurred in the server; you can see the logged queries if you have
log_statementenabled. - Transaction logs are the record of all events performed on the database; they follow the WAL (write ahead log) standard, which is not meant to be human readable. WAL is a way to keep a record of all actions performed on the database and can be used to recover from a catastrophic failure. The
pg_receivexlogplugin can show the transaction logs streamed by your PostgreSQL server. - Connection logs are useful to find any unwanted connections to the server. You can enable
log_connectionsin thepostgresql.conffile to log each attempt to connect to your server;log_disconnectionslets you see all the clients that disconnected from the server. - Error logs help you identify if any of your queries create unwanted issues in the server;
log_min_error_statementcontrols the error statement logging severity level. - Audit logs and access logs are critical from the admin’s point of view. The former show changes made to the database, while the latter identify who made what queries; these can be enabled via the
log_statementconfiguration or a PostgreSQL plugin like pgAudit.
You’ll find most of these log types in the default log locations or the location that you define in the postgresql.conf file. There are also multiple open-source projects I like using together with PostgreSQL for better log file analysis like pgBadger.
Just keeping a log won’t cover all cases. You also need to look at how you will archive or rotate your logs. PostgreSQL supports log rotation, as discussed in the next section.
PostgreSQL Log Rotation
PostgreSQL can rotate logs with the help of some basic configuration parameters it offers. With options like log_rotation_age, log_rotation_size, and log_truncate_on_rotation, you can easily configure at what point you want to rotate your logs. For example:
log_rotation_age 60 #default unit is minutes, this will rotate logs every log_rotation_age 300 #rotate the logs after the time mentioned.
You can also use the CLI to set this configuration.
As already mentioned, understanding your logs is a necessary step in identifying issues, and to best do this, you need to understand log formatting. In PostgreSQL, you can easily define the log format per your given needs.
How to Format Logs
PostgreSQL has the option to log in CSV format and generate a CSV file, which you can then use to put the logs in a table and use SQL on top of it.
Apart from this, the log_line_prefix parameter lets you format the beginning of each log line in the postgresql.conf file or via the command line. Configurable parameters include application name, username, database name, remote host, backend type, process ID, etc. The whole list of options is available in PostgreSQL’s documentation. For example:
log_line_prefix = '%m [%p] %u@%d/%a '
The above log_line_prefix means logs will begin with the time in milliseconds, then process ID, username, database name, and application name.
Log formatting, thresholds, sampling, log levels, and log types will all help you in debugging issues. But you ideally need a tool that allows you to aggregate and analyze all of these logs and view the output via one dashboard rather than having to go to each server. One such tool is Sematext. Let’s look at how you can gain from PostgreSQL logging with Sematext.
PostgreSQL Logging with Sematext
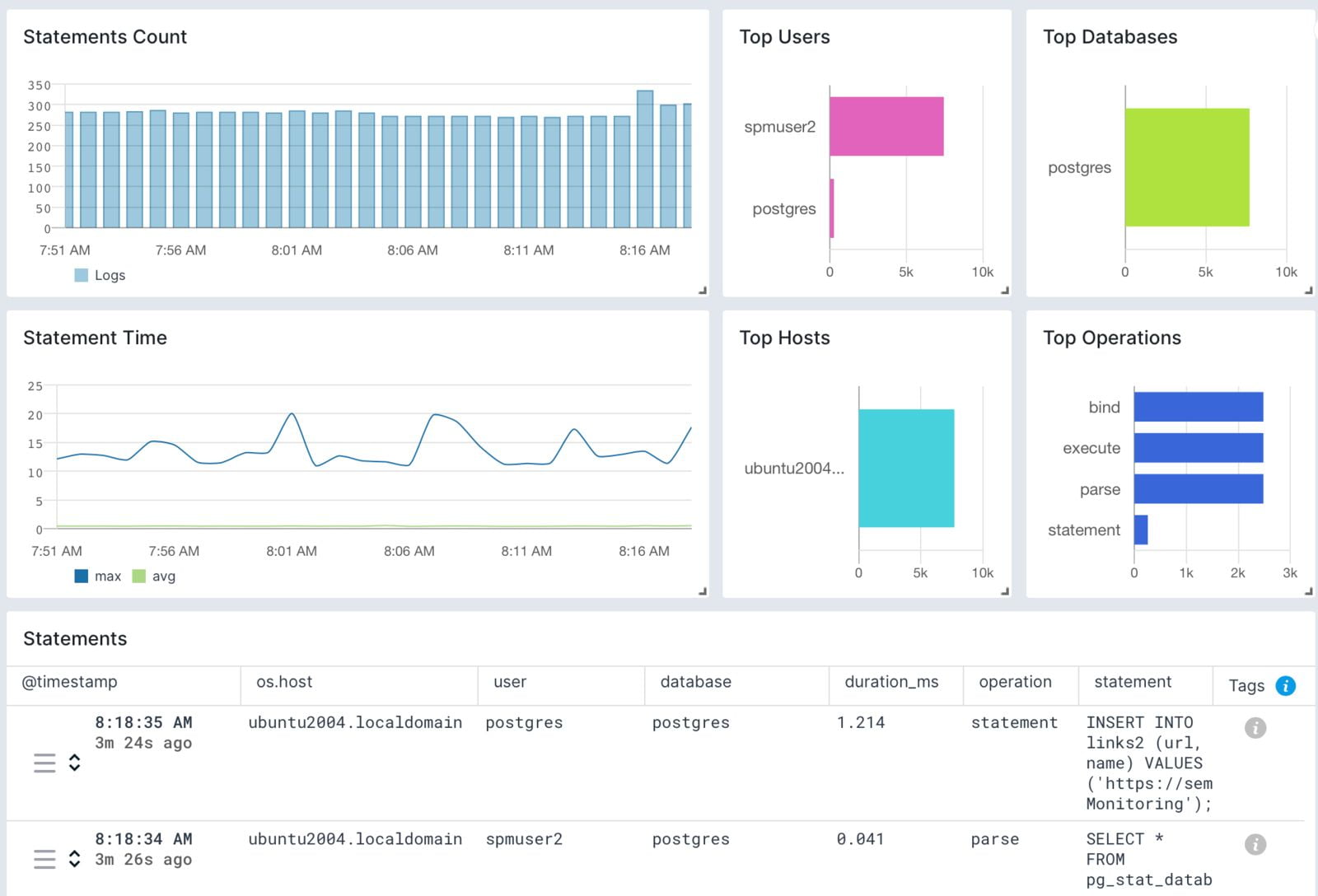
PostgreSQL logging with Sematext
Sematext Logs is a log management and monitoring solution that lets you aggregate logs from various data sources across your infrastructure in one place for viewing and analysis.
Sematext features service auto-discovery so you just have to install the Sematext agent on your servers, perform some basic configuration, and your PostgreSQL logs will start flowing to Sematext and be presented via an intuitive, out-of-the-box dashboard. You can even easily create a custom dashboard, set up alerts, and send the alerts to different notification channels like Gmail, Slack, or PagerDuty.
Sematext also offers features like anomaly detection, which helps you identify issues in advance and then take action to prevent them from happening. For better insight, you can correlate PostgreSQL logs with PostgreSQL metrics to detect bottlenecks faster. That way, you get a bird’s-eye view of your PostgreSQL machines for easier troubleshooting and debugging.
Sematext Logs is part of Sematext Cloud, a full-stack logging and monitoring solution that allows you to gain visibility into and integrate your entire IT environment. Besides databases, it supports integration with a wide variety of tools, including HAProxy, Apache Tomcat, JVM, and Kubernetes. Plus, you get support for Kubernetes deployments, so it will be easier for you to monitor your installation in a Kubernetes environment.
Conclusion
Keeping an eye on PostgreSQL logs is a critical part of database troubleshooting. By understanding how queries made and statements executed, as well as traffic, connections, errors, and other changes or events on your server, you can easily drill down to problematic processes and discover the root cause of your performance issues
You can track logs in various ways, like using less or tail on the log files, but this will become tough to manage when logs are spread across multiple files and machines. You need logs in one place, and a solution like Sematext Logs can help you achieve this.
Try Sematext out for free, and see how it can help your organization with log management and analysis.
Author Bio

Gaurav Yadav
Gaurav has been involved with systems and infrastructure for almost 6 years now. He has expertise in designing underlying infrastructure and observability for large-scale software. He has worked on Docker, Kubernetes, Prometheus, Mesos, Marathon, Redis, Chef, and many more infrastructure tools. He is currently working on Kubernetes operators for running and monitoring stateful services on Kubernetes. He also likes to write about and guide people in DevOps and SRE space through his initiatives Learnsteps and Letusdevops.
Start Free Trial
log_destination(string)-
PostgreSQL supports several methods for logging server messages, including stderr, csvlog and syslog. On Windows, eventlog is also supported. Set this parameter to a list of desired log destinations separated by commas. The default is to log to stderr only. This parameter can only be set in the
postgresql.conffile or on the server command line.If csvlog is included in
log_destination, log entries are output in “comma separated value” (CSV) format, which is convenient for loading logs into programs. See Section 19.8.4 for details. logging_collector must be enabled to generate CSV-format log output.When either stderr or csvlog are included, the file
current_logfilesis created to record the location of the log file(s) currently in use by the logging collector and the associated logging destination. This provides a convenient way to find the logs currently in use by the instance. Here is an example of this file’s content:stderr log/postgresql.log csvlog log/postgresql.csv
current_logfilesis recreated when a new log file is created as an effect of rotation, and whenlog_destinationis reloaded. It is removed when neither stderr nor csvlog are included inlog_destination, and when the logging collector is disabled.Note
On most Unix systems, you will need to alter the configuration of your system’s syslog daemon in order to make use of the syslog option for
log_destination. PostgreSQL can log to syslog facilitiesLOCAL0throughLOCAL7(see syslog_facility), but the default syslog configuration on most platforms will discard all such messages. You will need to add something like:local0.* /var/log/postgresql
to the syslog daemon’s configuration file to make it work.
On Windows, when you use the
eventlogoption forlog_destination, you should register an event source and its library with the operating system so that the Windows Event Viewer can display event log messages cleanly. See Section 18.11 for details. logging_collector(boolean)-
This parameter enables the logging collector, which is a background process that captures log messages sent to stderr and redirects them into log files. This approach is often more useful than logging to syslog, since some types of messages might not appear in syslog output. (One common example is dynamic-linker failure messages; another is error messages produced by scripts such as
archive_command.) This parameter can only be set at server start.Note
It is possible to log to stderr without using the logging collector; the log messages will just go to wherever the server’s stderr is directed. However, that method is only suitable for low log volumes, since it provides no convenient way to rotate log files. Also, on some platforms not using the logging collector can result in lost or garbled log output, because multiple processes writing concurrently to the same log file can overwrite each other’s output.
Note
The logging collector is designed to never lose messages. This means that in case of extremely high load, server processes could be blocked while trying to send additional log messages when the collector has fallen behind. In contrast, syslog prefers to drop messages if it cannot write them, which means it may fail to log some messages in such cases but it will not block the rest of the system.
log_directory(string)-
When
logging_collectoris enabled, this parameter determines the directory in which log files will be created. It can be specified as an absolute path, or relative to the cluster data directory. This parameter can only be set in thepostgresql.conffile or on the server command line. The default islog. log_filename(string)-
When
logging_collectoris enabled, this parameter sets the file names of the created log files. The value is treated as astrftimepattern, so%-escapes can be used to specify time-varying file names. (Note that if there are any time-zone-dependent%-escapes, the computation is done in the zone specified by log_timezone.) The supported%-escapes are similar to those listed in the Open Group’s strftime specification. Note that the system’sstrftimeis not used directly, so platform-specific (nonstandard) extensions do not work. The default ispostgresql-%Y-%m-%d_%H%M%S.log.If you specify a file name without escapes, you should plan to use a log rotation utility to avoid eventually filling the entire disk. In releases prior to 8.4, if no
%escapes were present, PostgreSQL would append the epoch of the new log file’s creation time, but this is no longer the case.If CSV-format output is enabled in
log_destination,.csvwill be appended to the timestamped log file name to create the file name for CSV-format output. (Iflog_filenameends in.log, the suffix is replaced instead.)This parameter can only be set in the
postgresql.conffile or on the server command line. log_file_mode(integer)-
On Unix systems this parameter sets the permissions for log files when
logging_collectoris enabled. (On Microsoft Windows this parameter is ignored.) The parameter value is expected to be a numeric mode specified in the format accepted by thechmodandumasksystem calls. (To use the customary octal format the number must start with a0(zero).)The default permissions are
0600, meaning only the server owner can read or write the log files. The other commonly useful setting is0640, allowing members of the owner’s group to read the files. Note however that to make use of such a setting, you’ll need to alter log_directory to store the files somewhere outside the cluster data directory. In any case, it’s unwise to make the log files world-readable, since they might contain sensitive data.This parameter can only be set in the
postgresql.conffile or on the server command line. log_rotation_age(integer)-
When
logging_collectoris enabled, this parameter determines the maximum lifetime of an individual log file. After this many minutes have elapsed, a new log file will be created. Set to zero to disable time-based creation of new log files. This parameter can only be set in thepostgresql.conffile or on the server command line. log_rotation_size(integer)-
When
logging_collectoris enabled, this parameter determines the maximum size of an individual log file. After this many kilobytes have been emitted into a log file, a new log file will be created. Set to zero to disable size-based creation of new log files. This parameter can only be set in thepostgresql.conffile or on the server command line. log_truncate_on_rotation(boolean)-
When
logging_collectoris enabled, this parameter will cause PostgreSQL to truncate (overwrite), rather than append to, any existing log file of the same name. However, truncation will occur only when a new file is being opened due to time-based rotation, not during server startup or size-based rotation. When off, pre-existing files will be appended to in all cases. For example, using this setting in combination with alog_filenamelikepostgresql-%H.logwould result in generating twenty-four hourly log files and then cyclically overwriting them. This parameter can only be set in thepostgresql.conffile or on the server command line.Example: To keep 7 days of logs, one log file per day named
server_log.Mon,server_log.Tue, etc, and automatically overwrite last week’s log with this week’s log, setlog_filenametoserver_log.%a,log_truncate_on_rotationtoon, andlog_rotation_ageto1440.Example: To keep 24 hours of logs, one log file per hour, but also rotate sooner if the log file size exceeds 1GB, set
log_filenametoserver_log.%H%M,log_truncate_on_rotationtoon,log_rotation_ageto60, andlog_rotation_sizeto1000000. Including%Minlog_filenameallows any size-driven rotations that might occur to select a file name different from the hour’s initial file name. syslog_facility(enum)-
When logging to syslog is enabled, this parameter determines the syslog “facility” to be used. You can choose from
LOCAL0,LOCAL1,LOCAL2,LOCAL3,LOCAL4,LOCAL5,LOCAL6,LOCAL7; the default isLOCAL0. See also the documentation of your system’s syslog daemon. This parameter can only be set in thepostgresql.conffile or on the server command line. syslog_ident(string)-
When logging to syslog is enabled, this parameter determines the program name used to identify PostgreSQL messages in syslog logs. The default is
postgres. This parameter can only be set in thepostgresql.conffile or on the server command line. syslog_sequence_numbers(boolean)-
When logging to syslog and this is on (the default), then each message will be prefixed by an increasing sequence number (such as
[2]). This circumvents the “— last message repeated N times —” suppression that many syslog implementations perform by default. In more modern syslog implementations, repeated message suppression can be configured (for example,$RepeatedMsgReductionin rsyslog), so this might not be necessary. Also, you could turn this off if you actually want to suppress repeated messages.This parameter can only be set in the
postgresql.conffile or on the server command line. syslog_split_messages(boolean)-
When logging to syslog is enabled, this parameter determines how messages are delivered to syslog. When on (the default), messages are split by lines, and long lines are split so that they will fit into 1024 bytes, which is a typical size limit for traditional syslog implementations. When off, PostgreSQL server log messages are delivered to the syslog service as is, and it is up to the syslog service to cope with the potentially bulky messages.
If syslog is ultimately logging to a text file, then the effect will be the same either way, and it is best to leave the setting on, since most syslog implementations either cannot handle large messages or would need to be specially configured to handle them. But if syslog is ultimately writing into some other medium, it might be necessary or more useful to keep messages logically together.
This parameter can only be set in the
postgresql.conffile or on the server command line. event_source(string)-
When logging to event log is enabled, this parameter determines the program name used to identify PostgreSQL messages in the log. The default is
PostgreSQL. This parameter can only be set in thepostgresql.conffile or on the server command line.