
Лекция 16. Репарация ДНК
Причины ошибок при синтезе ДНК
Способность ошибаться заложена в самой структуре фермента.
Скорее всего, ферменты, которые не ошибались, были тупиковыми ветвями эволюции. На первых этапах зарождения жизни разнообразие обеспечивалось только такими ошибками.
In vitro происходит 1 ошибка на 100 тыс. нукл. для средней ДНК-полимеразы.
In vitro можно уменьшить вероятность ошибки до 1 на 1млн. нукл., если добавить SSB, геликазу и лигазу.
Можно и увеличить вероятность ошибки до 1 на 100, если дать неадекватное количество субстрата, а также если добавить ионы серебра, бериллия, меди, кобальта, никеля, свинца. Это происходит из-за конкуренции этих ионов с ионами магния за связывание с ДНК-полимеразой.
Еще один способ повышения количества ошибок — добавление аналогов нуклеотидов. Например бромдезоксиуридина — аналога тимидина.
Это одно из средств борьбы со СПИДом и раком. Аналоги одинаково вредны для всех клеток, однако в пораженных вирусом клетках чаще проходит репликация.
Этапы проверки
Первичный отбор нуклеотидов идет по принципу комплементарности.
Способностью к этому виду отбора обладают все ДНК-полимеразы благодаря полимеризационной 5′3′ активности.
Редактирующий отбор. Его проводят все полимеразы благодаря экзонуклеазной активности 3′5′.
Исправление ошибок в уже синтезированной ДНК. Этим занимаются ферменты репарации.
Вероятность ошибок для ферментов вирусов, про- и эукариот
|
Объект |
Вероятность замены на пару оснований |
|
E.coli |
2х10-10 |
|
Дрозофила |
5х10-11 |
|
Фаг Т4 |
2х10-8 |
Разницу связывают со скоростью работы фермента. Чем медленней, тем точнее!
Основные репарабельные повреждения в ДНК и принципы их устранения
Каждая соматическая клетка теряет за сутки около 10000 пуринов и пиримидинов. В ДНК образуются АП-сайты.
Причины апуринизации: изменение рН, ионизирующее излучение, повышение температуры и т.д.
Разрывается N-гликозидная связь между пуриновым основанием и дезоксирибозой. Если бы апуриновые участки не исправлялись, то была бы катастрофа.
Пиримидины тоже могут отщепляться, но скорость этого процесса на два порядка ниже.
Аденин превращается в гипоксантин, который образует две водород-ные связи с цитозином. Гуанин превращается в ксантин, который образует водородные связи с тимином. При дезаминировании цитозина образуется урацил. Тимин не может быть дезаминирован (единственный в ДНК). Наличие тимина в ДНК (вместо урацила) позволяет отличать дезаминированнный цитозин (т.е. урацил) от законного урацила, если бы он был в ДНК.
N-гликозилаза — фермент, который узнает дезаминированное основание, разрывает N-гликозидную связь и удаляет неправильное основание.
После этого АП-специфическая эндонуклеаза вносит одноцепочечный разрыв, и фосфодиэстераза отщепляет от ДНК ту сахарофосфатную группу, к которой теперь не присоединено основание. Появляется брешь размером в один нуклеотид.
У E. coli она заделывается ДНК-полимеразой I, а лигаза сшивает концы ДНК.
У эукариот брешь заделывает ДНК- полимераза .
ДНК — двуцепочечна в отличие от РНК. Наличие второй цепи обеспечивает исправление ошибок. Дезоксирибоза более устойчива, чем рибоза, к действию щелочи, т.е. при рН > 8, ДНК устойчива, а РНК- нет.
Под действием ультрафио-летого света происходит ковалентное сшивание рядом стоящих пиримидинов. При сшивании тиминов образуется циклобутановое производное, блокирующее репликацию. Фермент фотолиаза — узнает тиминовые димеры и на свету или в темноте образует с ними комплекс. При освещении видимым светом происходит активация фермента, циклобутановое кольцо разрывается, и вновь получаются два тимина. Этот процесс называется фотореактивацией.
И дезаминированные основания, и тиминовые димеры, кроме того, могут удаляться с помощью эксцизионной репарации.
Специфические эндонуклеазы производят одноцепочечные разрезы (инцизия). Затем происходит удаление (эксцизия) нескольких нуклеотидов и заделывание бреши. У E. сoli заделыванием бреши занимается ДНК-полимераза I. Лигаза сшивает цепь. Она же ликвидирует одноцепочечные разрывы, возникающие при действии ионизирующей радиации.
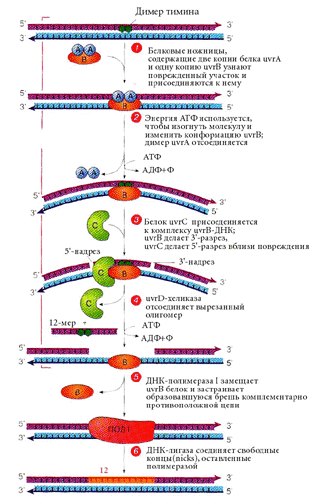
У E.coli эксцизионная репарация осуществляется мультиферментным комплексом, включающим белки uvrA, uvrB, uvrC (ultraviolet repair), которые узнают поврежденный участок и вносят 5′- и 3′- разрывы с разных сторон от него, uvrD — геликазу, которая отсоединяет вырезанный олигомер — 12 нуклеотидов, используя энергию АТФ.
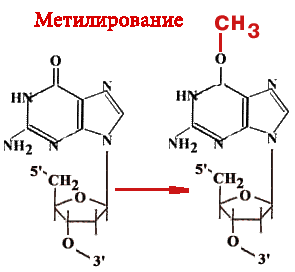
У эукариот существует функциональный (но не структурный) аналог такого мультиферментативного комплекса. О-6-метилгуанинтрансфераза — Фермент-«самоубийца».
Имеется 14 позиций, по которым ДНК метелируется.Гуанин может быть метилирован (по кислороду в 6-ом положении) и в такой форме будет связываться не только с цитозином, но и с тимином. Таким образом, в два шага может произойти замена пары Г-Ц на А-Т. Фермент принимает метильную группу на один из 12 цистеиновых остатков и при этом «гибнет».
Этапы проверки
Первичный отбор
нуклеотидов идет по принципу
комплементарности.
Способностью к
этому виду отбора обладают все
ДНК-полимеразы благодаря полимеризационной
5′![]() 3′
3′
активности.
Редактирующий
отбор.
Его проводят все полимеразы
благодаря экзонуклеазной активности
3′![]() 5′.
5′.
Исправление
ошибок в уже синтезированной ДНК.
Этим занимаются ферменты репарации.
Вероятность ошибок для ферментов вирусов, про- и эукариот
|
Объект |
Вероятность |
|
E.coli |
2х10-10 |
|
Дрозофила |
5х10-11 |
|
Фаг |
2х10-8 |
![]()
Разницу
связывают со скоростью работы фермента.
Чем медленней, тем точнее!
Основные репарабельные повреждения в днк и принципы их устранения
1. Апуринизация.
Каждая соматическая
клетка теряет за сутки около 10000 пуринов
и пиримидинов. В ДНК образуются АП-сайты.
Причины
апуринизации:
изменение рН, ионизирующее
излучение, повышение температуры и т.д.
|
|
Разрывается |
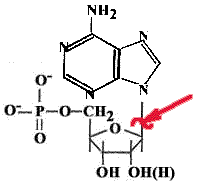
Пиримидины тоже
могут отщепляться, но скорость этого
процесса на два порядка ниже.
2. Дезаминирование.
|
|
Аденин |
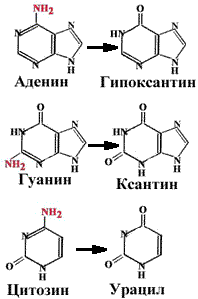
Наличие тимина
в ДНК (вместо урацила) позволяет отличать
дезаминированнный цитозин (т.е. урацил)
от законного урацила, если бы он был в
ДНК.
N-гликозилаза —
фермент, который узнает дезаминированное
основание, разрывает N-гликозидную связь
и удаляет неправильное основание.
После этого
АП-специфическая эндонуклеаза вносит
одноцепочечный разрыв, и фосфодиэстераза
отщепляет от ДНК ту сахарофосфатную
группу, к которой теперь не присоединено
основание. Появляется брешь размером
в один нуклеотид.
У E. coli она
заделывается ДНК-полимеразой I, а лигаза
сшивает концы ДНК.
![]()
У эукариот брешь
заделывает ДНК- полимераза .
![]()
ДНК — двуцепочечна
в отличие от РНК. Наличие второй цепи
обеспечивает исправление ошибок.
Дезоксирибоза более устойчива, чем
рибоза, к действию щелочи, т.е. при рН >
8, ДНК устойчива, а РНК- нет.
3. Тиминовые димеры.
|
|
Под |
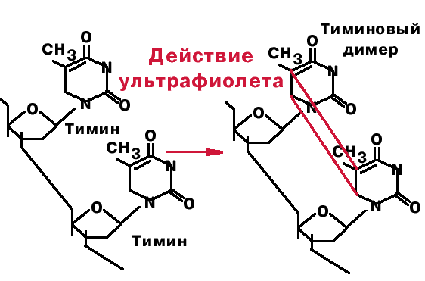
Фермент фотолиаза
— узнает тиминовые димеры и на свету или
в темноте образует с ними комплекс. При
освещении видимым светом происходит
активация фермента, циклобутановое
кольцо разрывается, и вновь получаются
два тимина. Этот процесс называется
фотореактивацией.
![]()
И дезаминированные
основания, и тиминовые димеры, кроме
того, могут удаляться с помощью
эксцизионной репарации.
Специфические
эндонуклеазы производят одноцепочечные
разрезы (инцизия). Затем происходит
удаление (эксцизия) нескольких нуклеотидов
и заделывание бреши. У E. сoli заделыванием
бреши занимается ДНК-полимераза I. Лигаза
сшивает цепь. Она же ликвидирует
одноцепочечные разрывы, возникающие
при действии ионизирующей радиации.
|
|
У E.coli эксцизионная У |
О-6-метилгуанинтрансфераза
— Фермент-«самоубийца».
Имеется 14 позиций,
по которым ДНК метилируется.
|
Гуанин |
|
Определение:
геном
— вся совокупность молекул ДНК клетки
(в случае ряда вирусов говорят о геномной
РНК).
![]()
Существует
ядерный геном, митохондриальный геном
и геном пластид. Мы будем рассматривать
только ядерный геном. Соматические
клетки содержат диплоидный (2n) геном,
половые — гаплоидный (n).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
ПРАКТИКА
Алгоритм ДНК-тестов
Как в Genotek анализируют и интерпретируют данные, записанные в ДНК, и почему результатам генетического анализа можно верить.
Последовательность действий
В Genotek занимаются прикладными генетическими исследованиями, анализируют и интерпретируют данные, записанные в ДНК. Наш научный отдел опубликовал статью о том, как выбрать нужные гены и почему результатам анализа этих генов можно верить. этот пост — краткое изложение публикации.
Иногда в нашей жизни случаются неожиданности (и даже неприятности), но, если относиться к своим поступкам ответственно, то можно признать, что значительная часть происходящего — следствие собственных действий, а не цепь случайных событий. В целом, это вопрос уверенности в себе. Можно вообще не переживать, не сомневаться, не думать об этих вещах и заниматься чем-то прекрасным. С другой стороны, возможность найти собственную инструкцию по эффективной эксплуатации открывает новые возможности. Все очень просто: есть несколько вещей, которые человеку хочется знать наверняка.
Что человек может узнать из ДНК- анализа
К каким болезням он наиболее предрасположен. Возрастные заболевания есть следствие совокупности приобретенного образа жизни и генетической предрасположенности, а не чей-либо умысел.
Здоровье детей. Имея информацию о ДНК обоих родителей, можно рассчитать риски возникновения тех или иных генетических заболеваний у потомства, и в случае высоких рисков предложить предимплантационную диагностику эмбрионов.
Что делать, чтобы жить лучше. Человеческий организм — это механизм. И хотя принципы работы у всех одни, они могут несколько различаться от тела к телу. То, что подходит одному человеку, может быть вредно для другого.
Что «я» такое. С точки зрения функционирования, знание о своем происхождении не поможет жить дольше или лучше. Скорее это позволит ощутить себя героем истории человечества, составить генеалогическое древо, устранить пробелы в семейной истории и передать знание о корнях детям.
Все это можно узнать из ДНК, прочитав определенные участки генов. Ген — это отдельный смысловой фрагмент ДНК, который в самом простом случае кодирует отдельный признак. Под словом «фенотип», кстати, следует понимать совокупность всех признаков наблюдаемого состояния (например, цвет глаз, форму мочки, склонность к диабету, усваиваемость лактозы). И тогда возникает тот же вопрос, что и в школьные годы: что именно нужно читать, можно ли читать не все и как разобраться с прочитанным.
Чтобы сделать из технологии прогностических ДНК-тестов массовую медицинскую услугу, нужно обратить внимание на несколько тонких моментов в анализе данных. Во-первых, это проблема персонализации: отбирать маркеры необходимо тщательно. Большинство исследований, направленных на установление ассоциации «генотип — фенотип», проводятся на больших выборках. Выборки (анализируемые группы людей), как правило, не очень разнородны: они могут быть объемными, но состоять из представителей одной этнической группы. С одной стороны, это упрощает статистический анализ в рамках исследования, с другой — ставит вопрос о релевантности обнаруженной ассоциации по отношению к другим группам людей.
Вторая проблема заключается в количестве маркеров — тот самый случай, когда необходимо найти золотую середину. И тут не обойтись без вечного балансирования между двумя параметрами теста: чувствительностью и специфичностью. Увеличение числа генетических маркеров, несомненно, повышает чувствительность анализа к определенным заболеваниям. И вместе с тем специфичность теста может падать. Так как речь идет о, например, выявлении предрасположенности к серьезным заболеваниям, ложноположительная ошибка при выявлении страшного диагноза будет опаснее, чем уточнение вероятности развития заболевания. Помимо этого, увеличение числа маркеров ведет к повышению себестоимости тест-системы, что также затрудняет выход на масс-маркет.
Универсального решения для этих проблем не существует. На начальном этапе работы исследователь сталкивается с ситуацией, когда «есть много статей, и их все нужно прочитать». По этой причине научный отдел Genotek предложил алгоритм отбора, который значительно упрощает выбор полиморфизмов для анализа признака. Важно, что речь идет именно о полиморфизмах, а не о генах целиком: у двух мужчин на каждой из X хромосом есть один и тот же ген андрогенового рецептора, но у первого мужчины в локусе rs6152находятся аденины (AA), а у второго — гуанины (GG). Вероятность того, что у последнего шевелюра к 40 годам останется такой же пышной, составляет около 30%. В данном случае чтобы понять это, не нужно прочитывать последовательность гена целиком — достаточно найти и прочитать всего одну точку на ДНК, а затем сравнить ее с той, что лежит напротив.
Валерий Ильинский
Генеральный директор Genotek
Научный отдел Genotek предложил алгоритм отбора, который значительно упрощает выбор полиморфизмов для анализа признака.

Что искать?
Характерные черты, которые мы перенимаем у своих предков, генетики называют фенотипическими особенностями. Фундаментальная проблема биологии в целом — это взаимосвязь генотипа и фенотипа, а также то, как одно кодирует другое. В нашем случае есть два взгляда на наследуемость фенотипических особенностей. С одной стороны, различаться может характер наследования. Так, отдельный признак может не наследоваться вовсе, а его проявление никак не будет связано с генетическим вкладом. Такие признаки, возникающие под влиянием образа жизни или внешних условий среды, не представляют интереса для разработчиков ДНК-тестов.
С другой стороны, если признак наследуется, то важно понимать, какое именно генетическое взаимодействие лежит в основе наблюдаемого состояния. В самом простом случае влиять на развитие заболевания может всего один ген — тогда речь идет о моногенном наследовании. Например, фенилкетонурия — метаболическое заболевание, которое развивается в связи с «поломкой» в одном гене. В таком случае нельзя говорить о предрасположенности: если у человека уже есть две копии сломанного гена, у него все равно разовьется заболевание. Однако в такой ситуации генетическая диагностика может уточнить диагноз для выбора более адекватного лечения.
Сложнее, когда вклад в фенотипическую особенность вносят несколько генов. Важно разобраться с тем, как именно происходит формирование признака, полигенный ли он или мультифакторный. Полигенный признак развивается в результате нескольких полиморфизмов — тут также нет вероятностного характера развития признака. При определенном сочетании полиморфизмов можно достоверно получить определенный цвет глаз человека. Сейчас проблема предсказания цвета глаз (и других внешних черт) стоит в криминалистике. Ее решают как с помощью математических моделей, так и путем обучения нейросетей на больших наборах данных. Мультифакторный фенотип, помимо генетической основы, развивается под влиянием определенных условий внешней среды. Именно такие признаки представляют наибольший интерес для медицинского прогностического анализа, поскольку это состояния, которые можно корректировать с помощью определенного образа жизни.

Собственно алгоритм выглядит так
Первый этап — проверка на наличие полногеномного поиска ассоциаций (GWAS — genome wide association study). Это направление генетических исследований стали активно использовать с развитием технологии микрочипирования. Цель исследования — найти отличия между геномами людей с определенным признаком и без него. Для GWAS-исследований характерны большие выборки. Например, в GIANT (Genome Investigation of Antropometric Traits — геномное исследование антропометрических признаков) приняли участие около 300 000 человек. Исследование подтвердило серьезное влияние генетического фактора на развитие ожирения. Вероятность наблюдения ассоциации «генотип — признак» у больных и здоровых испытуемых, при условии, гипотеза об ассоциации неверна, составляет p-value эксперимента. Если это значение GWAS-исследования меньше 0,01 (с поправкой на множественность), полиморфизм попадает в шорт-лист маркеров заболевания. Если оно входит в интервал 0,01–0,05, требуется соответствие одному из критериев функциональной значимости.
Критерий один: известен прямой или опосредованный механизм влияния полиморфизма на признак. Если известен метаболический путь того или иного вещества (то есть цепочка превращений вещества A в вещество X), то знание того, какие ферменты задействованы в этой цепочке, может указывать на релевантность этого полиморфизма. Например, нам известен фермент, который активирует фолиевую кислоту, чтобы та катализировала превращение гомоцистеина в метионин. Метионин — незаменимая аминокислота, а при накоплении гомоцистеина может повреждаться эндотелий кровеносных сосудов. То есть мы можем говорить о замене в локусе, кодирующем активный центр фермента, как о причине снижения метаболизма гомоцистеина. При этом наличие единственного полиморфизма такого рода не гарантирует развития заболевания.
Если по результатам GWAS значение p-value ассоциации больше 0,05, требуется привлечение данных метаанализа. Метаанализ — это исследование, в котором выявление ассоциации проводилось путем обобщения результатов множества исследований. Если в метаанализе показана ассоциация «генотип — фенотип», полиморфизм берут в работу. Если данных по метаанализу нет, полиморфизм снова проходит проверку по критерию функциональной значимости.
Поскольку основную часть работы составляет изучение публикаций, существуют жесткие критерии отбора научных статей для нахождения ассоциаций. Для исследований GWAS этих критериев 3:
- объем выборки — не менее 750 пациентов в первичном исследовании;
- P-value < 0,01;
- Ассоциации должны быть подтверждены хотя бы в одном исследовании (не обязательно для редких заболеваний), причем импакт-фактор издания должен быть не менее 2.
Для публикаций, направленных на выявление соответствия критерию функциональной значимости, критерии таковы:
Данные должны быть получены при исследовании тканей (прижизненная биопсия, материал аутопсии, послеоперационный материал) или биологических жидкостей участников;
Ассоциации должны быть экспериментально получены в рассматриваемой научной публикации;
Размеры выборок участников должны быть достаточно велики для возможности обнаружения ассоциации генетических маркеров с определенными частотами встречаемости;
Если есть несколько публикаций, в которых исследовали ассоциацию данного генетического маркера с риском развития заболевания, то для анализа выбирают: a) более позднюю (например, из двух статей 2009 и 2015 гг. — статью за 2015 г.); б) публикацию, в которой исследование проводилось на большем количестве образцов.
Результаты метаанализа, если он есть, находятся в приоритете. Требования к метаанализу также очень высокие: в самой публикации должны быть тщательно отобраны источники, среди которых есть как подтверждающие, так и опровергающие ассоциацию полиморфизма с признаком. Должны быть указаны источники информации и ключевые слова, по которым проводился поиск, а также требуется обоснование критериев включения и исключения публикаций (объем выборок, статьи только на английском языке, демографические характеристики участников и прочее). Отдельное внимание уделяется так называемому анализу предвзятости отдельных публикаций методом воронкообразного графика или анализа чувствительности. При включении маркера в анализ мы акцентируем внимание на том, какие популяции принимали участие в исследовании.
Несмотря на то, что сама технология уже давно существует на рынке, это не какая-то «рутинная практика», по которой написаны тонны мануалов. Конвейер ДНК-тестов работает, и это один из его участков. Постепенно будем знакомить вас с каждым его фрагментов.
Секвенирование нуклеиновых кислот — это процесс определения последовательности нуклеотидов в цепочке ДНК.
Основными задачами генетического анализа являются:
- обнаружение неизвестных ранее последовательностей нуклеиновых кислот, например, геномов нового типа;
- распознавание уникальных особенностей конкретного образца среди обобщённой последовательности (ресеквенирование);
- исследование генетического разнообразия, в том числе однонуклеотидных замен (SNP-типирование);
- определение эпигенетических модификаций, например, профиля метилирования;
- изучение профиля экспрессии отдельно взятых клеток секвенированием кДНК, полученной из тотальной мРНК клетки.
Сравнительные таблицы производительности секвенаторов
Капиллярные

Пиросеквенаторы

NGS-секвенаторы:

Генетические анализаторы различаются по ряду характеристик, среди которых:
- Длина прочтений.
- короткие;
- средние;
- длинные.
- Применяемая технология.
- технология по методу Сэнгера;
- пиросеквенирование;
- ионное полупроводниковое секвенирование;
- циклическое лигазное секвенирования;
- секвенирования на молекулярных кластерах с использованием флуоресцентно меченых нуклеотидов;
- одномолекулярное секвенирование.
- Число прочтений за запуск.
- Количество анализируемых одновременно маркеров.
- Время, необходимое для запуска.
- Стоимость самого прибора, одного запуска, анализа одной пробы.
Технологии секвенирования
На сегодняшний день существуют несколько основных методов считывания последовательности ДНК при помощи секвенаторов — классические и нового поколения.
Метод Сэнгера (ферментативный)
Секвенирование по Сэнгеру, также известное как метод «обрыва цепи», было разработано и предложено биохимиком Фредериком Сэнгером в 1977 году. Суть заключается в синтезе новой комплементарной ДНК-цепи на ДНК-матрице с помощью фермента ДНК-полимеразы.
Синтез проводится в 4 разных пробирках с реакционной смесью, состоящей из праймера, стандартных дезоксинуклеотидов (dATP, dGTP, dCTP, dTTP), а также малого количества одного из четырёх радиоактивно меченых дезоксинуклеотидов (дидезоксинуклеотидов). Готовятся четыре раствора с каждым ddNTP по отдельности. У дидезоксирибонуклеотидов (ddATP, ddGTP, ddCTP, or ddTTP) отсутствует 3′-гидроксильная группа, поэтому после их включения в цепь дальнейший синтез обрывается.
Таким образом, в каждой пробирке образуется набор фрагментов ДНК разной длины, которые заканчиваются одним и тем же нуклеотидом (в соответствии с добавленным дидезоксинуклеотидом). После завершения реакции содержимое пробирок разделяют электрофорезом в полиакриламидном геле в денатурирующих условиях и проводят авторадиографию гелей.
На сегодняшний день секвенирование ДНК по Сэнгеру полностью автоматизировано. В настоящее время вместо радиоактивно меченных нуклеотидов используют дидезоксинуклеотиды с флуоресцентными метками с разными длинами волн испускания, благодаря этому реакцию можно проводить в одной пробирке.
Реакционную смесь разделяют капиллярным электрофорезом, фрагменты ДНК, выходящие из капиллярной колонки, регистрируются детектором флуоресценции. Результаты анализируют с помощью компьютера и представляют в виде последовательности разноцветных пиков, соответствующих четырём нуклеотидам. Секвенаторы такого типа могут «прочитывать» за один раз последовательности длиной 500-1000 нуклеотидов.

Циклическое лигазное секвенирование
Технология циклического лигазного секвенирования (Sequencing by Oligonucleotide Ligation and Detection — SOLiD) разработана компанией Life Technologies и является коммерчески доступной с 2006 года. Этот метод можно разделить на следующие этапы: подготовка библиотек, ПЦР в эмульсии, насыщение бусин целевой ДНК, перенос бусин, секвенирование, расшифровка данных.
На первом этапе целевая ДНК разрезается на небольшие фрагменты, а затем к фрагментам пришиваются короткие нуклеотидные последовательности адаптеры А1 и А2. В итоге в библиотеке оказываются одноцепочечные нуклеотидные последовательности A1-(фрагмент ДНК)-A2.
После этого проводят ПЦР ДНК-фрагментов библиотеки в небольших каплях. Каждая капля содержит праймеры P1 и Р2, которые являются комплементарными по отношению к фрагментам А1 и А2. Каждая бусина несёт только один фрагмент праймера. В результате чего на каждой бусине оказывается по одной цепочке ДНК комплементарной исходному образцу.
Секвенирование проходит с помощью лигирования восьми-нуклеотидных зондов, меченных на 5’-конце одним из четырех различных флуорофоров. Последовательность зондов несёт сайт гидролиза, находящийся между пятым и шестым нуклеотидами. Первые два основания (считая с 3’-конца) комплементарны двум нуклеотидам секвенируемой последовательности.
С третьего по пятый основания зонда могут гибридизоваться с любыми тремя нуклеотидами секвенируемой ДНК. 6-8 основания зонда также могут гибридизоваться с любой последовательностью, однако они вместе с флуоресцентным красителем отщепляются от зонда в ходе реакции.
Отщепление флуоресцентной метки вместе с основаниями 6-8 происходит таким образом, что на 5′-конце зонда остается фосфатная группа, способствующая следующему циклу лигирования зонда. Так, два основания каждого зонда точно комплементарны основаниям секвенируемой последовательности в позициях n+1 и n+2, n+6 и n+7 и т.д.
На выходе мы получаем результаты по флуоресценции. Пространство цветов и пространство нуклеотидов содержат по 4 элемента. Каждый цвет кодирует собой 4 из 16 возможных динуклеотидов. Например, «синий» цвет флуоресцентной метки соответствует паре одинаковых нуклеотидов (то есть AA,GG,TT или CC). Дизайн матрицы преобразований цвета способствует коррекции ошибок.
Главным преимуществом этого метода является то, что каждый нуклеодит прочитывается дважды, что сильно повышает точность секвенирования.
Метод пиросеквенирования
Технология была разработана Полом Ниреном и его студентом Мустафой Ронаги в 1996 году. Она основывается на синтезе новой ДНК-цепи на иммобилизированной анализируемой матрице с участием полимеразы. В качестве затравки выступает праймер. Затем происходит поочерёдное добавление каждого типа дезоксинуклеотидтрифосфатов (A, G, C, T).
При встраивании нуклеотида стехиометрически высвобождается побочный продукт — пирофосфат (PPi). Он, в свою очередь, с участием фермента ATP-сульфурилазы в присутствии аденозин-5′-фосфосульфата (dATPαS) превращается в ATP. ATP — источник энергии для фермента люциферазы, превращающей люциферин в оксилюциферин с выделением света. Компьютерная программа осуществляет детекцию и анализ света.
Невовлечённые в синтез нуклеотиды и ATP под воздействием фермента апиразы распадаются, после чего запускается следующий цикл реакции, с новым нуклеотидом.
Ионное полупроводниковое секвенирование
Данная технология является методом определения последовательности ДНК, основанным на обнаружении ионов водорода, которые выделяются во время полимеризации ДНК. Это метод «секвенирования при синтезе», в ходе которого комплементарная цепь строится на основе последовательности матричной цепи.
Микролунки, содержащие предназначенную для секвенирования молекулу матричной ДНК, наполняют дезоксирибонуклеотидтрифосфатом (dNTP) одного вида. Если введенный dNTP является комплементарным к ведущему нуклеотиду матрицы, он включается в растущую комплементарную цепь.
Это вызывает высвобождение ионов водорода, который вызывает срабатывание ионного датчика, который указывает, что реакция произошла. Если в последовательности матричной цепи присутствует повтор одного нуклеотида, несколько молекул dNTP будут присоединены в одном цикле. Это приводит к увеличению количества образовавшихся ионов водорода и пропорционально более высокому электрическому сигналу.
Эта технология отличается от других технологий секвенирования тем, что не использует модифицированные нуклеотиды и оптические датчики. Ion semiconductor sequencing может также упоминаться как Ion torrent sequencing, рН-опосредованное секвенирование, или полупроводниковое секвенирование.
Технология ионного полупроводникового секвенирования позволяет исследовать большие объёмы данных, например: транскриптомы отдельных клеток и тканей, метагеномы микробных сообществ, малые РНК и проводить ChIP-seq.
Одномолекулярное секвенирование
Данный метод разработан компанией Pacific BioScinces. Идея метода состоит в определении последовательности ДНК за счёт наблюдения за работой единичной молекулы ДНК-полимеразы в реальном времени.
При этом ДНК-полимераза достраивает вторую цепь исследуемой молекулы ДНК, используя нуклеотиды, меченные различными флуорофорами; регистрируя данные метки, можно понять, какой нуклеотид ДНК-полимераза встраивает в настоящий момент.
Этот метод секвенирования позволяет получать очень длинные прочтения порядка десятков тысяч нуклеотидов. Кроме того, метод работает без предварительной амплификации образца посредством ПЦР. Одномолекулярное секвенирование работает с минимальным количество исходной ДНК.
Бисульфитный метод
Это название группы методов, в основе которых один принцип: определение паттерна метилирования ДНК посредством её бисульфитной обработки.
Под воздействием бисульфита остатки цитозина превращаются в остатки урацила, но при этом не затрагиваются метилированные остатки 5-метилцитозина. Далее изменённая последовательность сравнивается с исходной, цитозины и тимины разделяются в изученных последовательностях, и можно установить, какие CpG-динуклеотиды были метилированы.