
Поскольку
выборка охватывает , как правило,
весьма незначительную часть генеральной
совокупности, то следует предполагать,
что будут иметь место различия между
оценкой и характеристикой генеральной
совокупности, которую эта оценка
отображает. Эти различия получили
название ошибок отображения или ошибок
репрезентативности. Ошибки
репрезентативности подразделяются
на два типа : систематические и случайные.
Систематические
ошибки —
это постоянное завышение или занижение
значения оценки по сравнению с
характеристикой генеральной совокупности
. Причиной появления систематической
ошибки является несоблюдение принципа
равновероятности попадания каждой
единицы генеральной совокупности в
выборку , то есть выборка формируется
из преимущественно «худших» ( или «
лучших») представителей генеральной
совокупности. Соблюдение принципа
равновозможности попадания каждой
единицы в выборку позволяет полностью
исключить этот тип ошибок .
Случайные
ошибки –
это меняющиеся
от выборки к выборке по знаку и величине
различия между оценкой и оцениваемой
характеристикой генеральной совокупности
. Причина возникновения случайных
ошибок- игра случая при формировании
выборки, составляющей лишь часть
генеральной совокупности. Этот тип
ошибок органически присущ выборочному
методу. Исключить их полностью нельзя,
задача состоит в том , чтобы предсказать
их возможную величину и свести их к
минимуму. Порядок связанных в связи
с этим действий вытекает из рассмотрения
трех видов случайных ошибок : конкретной
, средней и предельной.
2.2 Конкретная, средняя и предельная ошибки выборки
2.2.1
Конкретная
ошибка – это ошибка одной проведенной
выборки. Если средняя по этой выборке
(
![]() ) является оценкой для генеральной
) является оценкой для генеральной
средней (![]() 0
0
) и, если
предположить, что эта генеральная
средняя нам известна , то разница
![]() =
=![]()
![]() —
—![]() 0
0
и будет
конкретной ошибкой этой выборки. Если
из этой генеральной совокупности
выборку повторим многократно, то каждый
раз получим новую величину конкретной
ошибки :
![]() …,
…,
и так далее.
Относительно этих конкретных ошибок
можно сказать следующее: некоторые из
них будут совпадать между собой по
величине и знаку, то есть имеет место
распределение ошибок, часть из них
будет равна 0, наблюдается совпадение
оценки и параметра генеральной
совокупности;
2.2.2
Средняя ошибка
– это средняя квадратическая из всех
возможных по воле случая конкретных
ошибок оценки :
 ,
,
где![]() — величина меняющихся конкретных
— величина меняющихся конкретных
ошибок;![]() частота
частота
( вероятность ) встречаемости той или
иной конкретной ошибки. Средняя
ошибка выборки показывает насколько
в среднем можно ошибиться , если на
основе оценки делается суждение о
параметре генеральной совокупности.
Приведенная формула раскрывает
содержание средней ошибки, но она не
может быть использована для практических
расчетов, хотя бы потому, что предполагает
знание параметра генеральной совокупности
, что само по себе исключает необходимость
выборки.
Практические
расчеты средней ошибки оценки
основываются на той предпосылке, что
она ( средняя ошибка ) по сути является
средним квадратическим отклонением
всех возможных значений оценки. Эта
предпосылка позволяет получить алгоритмы
расчета средней ошибки, опирающиеся
на данные одной единственной выборки.
В частности средняя ошибка выборочной
средней может быть установлена на
основе следующих рассуждений. Имеется
выборка (
![]() ,
,![]()
![]() …
…![]() ) состоящая из
) состоящая из![]() единиц. По выборке в качестве оценки
единиц. По выборке в качестве оценки
генеральной средней определена
выборочная средняя . Каждое значение
. Каждое значение![]() (
(![]() ,
,![]()
![]() …
…![]() ) , стоящее под знаком суммы, следует
) , стоящее под знаком суммы, следует
рассматривать как независимую случайную
величину, поскольку при бесконечном
повторении выборки первая, вторая и
т.д. единицы могут принимать любые
значения из присутствующих в генеральной
совокупности. Следовательно Поскольку , как известно, дисперсия
Поскольку , как известно, дисперсия
суммы независимых случайных величин
равна сумме дисперсий , то![]()
 .
.
Отсюда следует, что средняя ошибка для
выборочной средней будет равная![]() и находится она в обратной зависимости
и находится она в обратной зависимости
от численности выборки ( через корень
квадратный из нее ) и в прямой от среднего
квадратического отклонения признака
в генеральной совокупности. Это логично,
поскольку выборочная средняя является
состоятельной оценкой для генеральной
средней и по мере увеличения численности
выборки приближается по своему значению
к оцениваемому параметру генеральной
совокупности. Прямая зависимость
средней ошибки от колеблемости признака
обусловлена тем, что чем больше
изменчивость признака в генеральной
совокупности, тем сложнее на основе
выборки построить адекватную модель
генеральной совокупности. На практике
среднее квадратическое отклонение
признака по генеральной совокупности
заменяется его оценкой по выборке, и
тогда формула для расчета средней
ошибки выборочной средней приобретает
вид:![]() ,
,
при этом учитывая смещенность
выборочной дисперсии ,
,
выборочное среднее квадратическое
отклонение рассчитывается по формуле![]()
 =
= . Так как символомn
. Так как символомn
обозначена численность выборки. ,то
в знаменателе при расчете среднего
квадратического отклонения должна
использоваться не численность выборки
( n
), а так называемое число степеней
свободы (n-1).
Под числом степеней свободы понимается
число единиц в совокупности, которые
могут свободно варьировать ( изменяться
), если по совокупности определена
какая-либо характеристика. В нашем
случае , поскольку по выборке определена
ее средняя, свободно варьировать могут
![]() единицы.
единицы.
В
таблице 2.2 приведены формулы для
расчета средних ошибок различных
выборочных оценок . Как видно из этой
таблицы, величина средней ошибки по
всем оценкам находится в обратной связи
с численностью выборки и в прямой с
колеблемостью. Это можно сказать и
относительно средней ошибки выборочной
доли ( частости ). Под корнем стоит
дисперсия альтернативного признака,
установленная по выборке (
![]() )
)
Приведенные
в таблице 2.2 формулы относятся к так
называемому случайному , повторному
отбору единиц в выборку. При других
способах отбора , о которых речь пойдет
ниже, формулы будут несколько
видоизменяться.
Таблица
2.2
Формулы для
расчета средних ошибок выборочных
оценок
|
Выборочные |
Формулы |
|
Выборочная |
|
|
Выборочная |
|
|
Выборочное |
|
|
Выборочная |
|
2.2.3
Предельная ошибка выборки
Знание оценки и ее средней ошибки в
ряде случаев совершенно недостаточно
. Например , при использовании гормонов
при кормлении животных знать только
средний размер неразложившихся их
вредных остатков и среднюю ошибку,
значит подвергать потребителей продукции
серьезной опасности. Здесь настоятельно
напрашивается необходимость определения
максимальной ( предельной
ошибки ).
При использовании выборочного метода
предельная ошибка устанавливается не
в виде конкретной величины , а виде
равных границ
(
интервалов) в ту и другую сторону от
значения оценки.
Определение
границ предельной ошибки основывается
на особенностях распределения конкретных
ошибок . Для так называемых больших
выборок, численность которых более 30
единиц (
![]() )
)
, конкретные ошибки распределяются в
соответствии с нормальным законом
распределения; при малых выборках (![]() ) конкретные ошибки распределяются
) конкретные ошибки распределяются
в соответствии с законом распределения
Госсета
(
Стьюдента ). Применительно к конкретным
ошибкам выборочной средней функция
нормального распределения имеет
вид:
 ,
,
где![]() — плотность вероятности появления тех
— плотность вероятности появления тех
или иных значений![]() ,
,
при условии, что![]()
 ,
,
где![]() выборочные средние;
выборочные средние;![]() —
—
генеральная средняя,![]()
![]() — средняя ошибка для выборочной
— средняя ошибка для выборочной
средней. Поскольку средняя ошибка
(![]() )
)
является величиной постоянной, то в
соответствии с нормальным законом
распределяются конкретные ошибки ,
,
выраженные в долях средней ошибки, или
так называемых нормированных отклонениях
.
Взяв
интеграл функции нормального
распределения, можно установить
вероятность того , что ошибка будет
заключена в некотором интервале
изменения t
и вероятность того, что ошибка выйдет
за пределы этого интервала ( обратное
событие ). Например , вероятность того,
что ошибка не превысит половину средней
ошибки ( в ту и другую сторону от
генеральной средней ) составляет
0,3829, что ошибка будет заключена в
пределах одной средней ошибки — 0,6827,
2-х средних ошибок -0,9545 и так далее.
Взаимосвязь
между уровнем вероятности и интервалом
изменения t
( а в конечном счете интервалом
изменения ошибки ) позволяет подойти
к определению интервала ( или границ )
предельной ошибки, увязав его величину
с вероятностью осуществления..
Вероятность осуществления -это
вероятность того, что ошибка будет
находится в некотором интервале.
Вероятность осуществления будет
«доверительной» в том случае, если
противоположное событие ( ошибка будет
находится вне интервала ) имеет такую
вероятность появления, которой можно
пренебречь. Поэтому доверительный
уровень вероятности устанавливают,
как правило, не ниже 0,90 (вероятность
противоположного события равна 0,10 ).
Чем больше негативных последствий
имеет появление ошибок вне установленного
интервала, тем выше должен быть
доверительный уровень вероятности (
0,95; 0,99 ; 0,999 и так далее ).
Выбрав
доверительный уровень вероятности
по таблице интеграла вероятности
нормального распределения, следует
найти соответствующее значение t,
а затем используя выражение
 =
=![]()
![]() определить интервал предельной ошибки
определить интервал предельной ошибки![]() .
.
Смысл полученной величины в следующем
– с принятым доверительным уровнем
вероятности предельная ошибка выборочной
средней не превысит величину![]() .
.
Для
установления границ предельной ошибки
на основе больших выборок для других
оценок ( дисперсии, среднего квадратического
отклонения, доли и так далее ) используется
выше рассмотренный подход, с учетом
того, что для определения средней
ошибки для каждой оценки используется
свой алгоритм.
Что
касается малых выборок (![]() ) то, как уже говорилось, распределение
) то, как уже говорилось, распределение
ошибок оценок соответствует в этом
случае распределениюt
— Стьюдента. Особенность этого
распределения состоит в том, что в
качестве параметра в нем , наряду с
ошибкой, присутствует численность
выборки ,вернее не численность выборки,
а число степеней свободы
![]() При увеличении численности выборки
При увеличении численности выборки
распределениеt-Стьюдента
приближается к нормальному, а при
![]() эти распределения практически совпадают.
эти распределения практически совпадают.
Сопоставляя значения величиныt-Стьюдента
и t
— нормального распределения при одной
и той же доверительной вероятности
можно сказать , что величина t-Стьюдента
всегда больше t
— нормального распределения, причем,
различия возрастают с уменьшением
численности выборки и с повышением
доверительного уровня вероятности.
Следовательно, при использовании малых
выборок имеют место по сравнению с
выборками большими , более широкие
границы предельной ошибки, причем , эти
границы расширяются с уменьшением
численности выборки и повышением
доверительного уровня вероятности.
Вопросы для
повторения
6-1.Какова
природа конкретной, средней и предельной
ошибок ?
6-2.Как
соблюсти принцип равновероятности
каждой единицы попасть в выборку при
выборочном устном опросе студентов ?
6-3 Каков источник
систематической ошибки ?
6-4.Какова
вероятность появления ошибки в 2.5 раза
превышающей среднюю?
6-5.Какие
различия в знаках ( + , — ) имеют
систематические и случайные ошибки?
6-6.Каковы основные
пути уменьшения средней и предельной
ошибки ?
6-7.При какой
выборочной доле имеет место ее наибольшая
ошибка ?
6-8.При какой доле
признака имеет место ее наименьшая
ошибка 7
6-9.При
каких выборках ( больших или малых )
при прочих равных условиях имеет место
большая предельная ошибка ?
Резюме по
модульной единице 2
Использование
выборочного метода неизбежно сопряжено
с появлением ошибок. Случайный характер
этих ошибок, нормальный или t
— Стьюдента закон их распределения
позволяет определить их средний и
предельный размер и видеть пути их
снижения
Модульная
единица 3 Типовые задачи решаемые на
основе выборочного метода
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Природа случайных ошибок и распределение выборочных статистик — Никто не любит ошибаться, но некоторые ошибки просто неизбежны! 0 Нажми, если пригодилось =ъ Дембицкий С. Природа случайных ошибок и распределение выборочных средних, — Режим доступа: http://www.soc-research.info/quantitative/3.html Отличия в характеристиках выборочной и генеральной совокупностей называются ошибками репрезентативности.
- Можно выделить два вида таких ошибок – систематические и случайные.
- Систематические ошибки — это определенные постоянные смещения, не уменьшающиеся при увеличении количества опрошенных.
- В свою очередь, случайные ошибки – это те, которые при увеличении выборки изменяются по вероятностным законам.
- Систематическую ошибку можно устранить, изменяя процедуру формирования выборки; случайная же ошибка будет всегда, при любом выборочном опросе.
Тем не менее, систематическая ошибка является значительно опаснее, поскольку: а) ее невозможно оценить; б) она не уменьшается с увеличением выборки. Классическим примером краха исследования по причине систематических ошибок является предвыборный опрос, проведеленный Литерири дайджест в 1936 году.
- По его результатам на выборах президента США должен был победить Альфред Лэндон.
- Показательно то, что для исследования проводимого Литерари Дайджест было отобрано более 2 млн.
- Респондентов.
- На самих же выборах победил Теодор Рузвельт, победу которого предсказывали Гэлап и Роупер на основе опроса всего 4000 человек.
Ошибка Литерари Дайджест заключалась в том, что основой выборки (часть генеральной совокупности из которой отбирались респонденты) выступили телефонные книги. Телефоны же в 1936 году имели преимущественно зажиточные слои населения США, большинство которых собиралось голосовать за Альфреда Лэндона.
- Следовательно полученная выборка отражала не всех избирателей США, а лишь их специфическую группу.
- Очевидно и то, что увеличении выборки получаемой таким способом никак бы не помогло, так как новые респонденты точно так же представляли бы зажиточных американцев.
- Выборка же Гэлапа и Роупера носила случайный характер и отображала все населения США, что позволило им сделать правильный прогноз.
Но если систематические ошибки не уменьшаются с увеличением количества опрошенных и способ устранения таких ошибок следует искать прежде всего в особенностях построения самой выборки, то случайные ошибки подчиняются вероятностным законам и подлежат оценке.
Одно из главных их свойств заключается в том, что они уменьшаются с увеличением выборки. Рассмотрим соответствующий пример (отчасти фантастический). Рассмотрим следующий премер. Представим себе огромный лототрон на 100.000 шаров, в котором 10.000 шаров с №1, 10.000 — с №2, 10.000 — с №3, 10.000 — с №4, 10.000 — с №5, 10.000 — с №6, 10.000 — с №7, 10.000 — с №8, 10.000 — с №9 и 10.000 — с №10.
При условии правильной работы лототрона каждый шар имеет равную вероятность выпадения (по крайней мере в самом начале, а после того как шары начнут выпадать, вероятности будут очень близки).
Что такое случайная ошибка исследования?
СЛУЧАЙНАЯ ОШИБКА отклонение результата отдельного наблюдения в выборке от истинного значения в популяции, обусловленное исключительно случайностью.
Что такое случайная ошибка в физике?
Случайная погрешность — составляющая погрешности результата измерения, изменяющаяся случайным образом (по знаку и значению) в серии повторных измерений одного и того же размера величины с одинаковой тщательностью. В появлении этого вида погрешности не наблюдается какой-либо закономерности.
Почему возникает случайная ошибка?
Случайные ошибки берут свое происхождение из множества одновременно действующих источников помех. Они проявляют- ся лишь при многократных измерениях. Это ошибки, которые поддаются обработке с помощью математической статистики, более точно, теории вероятностей. Их непредсказуемость, таким образом, сводится к минимуму.
Какие ошибки называются систематическими и случайными?
Природа случайных ошибок и распределение выборочных статистик — Никто не любит ошибаться, но некоторые ошибки просто неизбежны! 0 Нажми, если пригодилось =ъ Дембицкий С. Природа случайных ошибок и распределение выборочных средних, — Режим доступа: http://www.soc-research.info/quantitative/3.html Отличия в характеристиках выборочной и генеральной совокупностей называются ошибками репрезентативности.
- Можно выделить два вида таких ошибок – систематические и случайные.
- Систематические ошибки — это определенные постоянные смещения, не уменьшающиеся при увеличении количества опрошенных.
- В свою очередь, случайные ошибки – это те, которые при увеличении выборки изменяются по вероятностным законам.
- Систематическую ошибку можно устранить, изменяя процедуру формирования выборки; случайная же ошибка будет всегда, при любом выборочном опросе.
Тем не менее, систематическая ошибка является значительно опаснее, поскольку: а) ее невозможно оценить; б) она не уменьшается с увеличением выборки. Классическим примером краха исследования по причине систематических ошибок является предвыборный опрос, проведеленный Литерири дайджест в 1936 году.
По его результатам на выборах президента США должен был победить Альфред Лэндон. Показательно то, что для исследования проводимого Литерари Дайджест было отобрано более 2 млн. респондентов. На самих же выборах победил Теодор Рузвельт, победу которого предсказывали Гэлап и Роупер на основе опроса всего 4000 человек.
Ошибка Литерари Дайджест заключалась в том, что основой выборки (часть генеральной совокупности из которой отбирались респонденты) выступили телефонные книги. Телефоны же в 1936 году имели преимущественно зажиточные слои населения США, большинство которых собиралось голосовать за Альфреда Лэндона.
- Следовательно полученная выборка отражала не всех избирателей США, а лишь их специфическую группу.
- Очевидно и то, что увеличении выборки получаемой таким способом никак бы не помогло, так как новые респонденты точно так же представляли бы зажиточных американцев.
- Выборка же Гэлапа и Роупера носила случайный характер и отображала все населения США, что позволило им сделать правильный прогноз.
Но если систематические ошибки не уменьшаются с увеличением количества опрошенных и способ устранения таких ошибок следует искать прежде всего в особенностях построения самой выборки, то случайные ошибки подчиняются вероятностным законам и подлежат оценке.
Одно из главных их свойств заключается в том, что они уменьшаются с увеличением выборки. Рассмотрим соответствующий пример (отчасти фантастический). Рассмотрим следующий премер. Представим себе огромный лототрон на 100.000 шаров, в котором 10.000 шаров с №1, 10.000 — с №2, 10.000 — с №3, 10.000 — с №4, 10.000 — с №5, 10.000 — с №6, 10.000 — с №7, 10.000 — с №8, 10.000 — с №9 и 10.000 — с №10.
При условии правильной работы лототрона каждый шар имеет равную вероятность выпадения (по крайней мере в самом начале, а после того как шары начнут выпадать, вероятности будут очень близки).
Как рассчитать ошибку эксперимента?
Для оценки истинности данных эксперимента следует рассмотреть возможные причины ошибок и степень их влияния на измеряемую величину. Приборные погрешности. Эта погрешность равна той доле шкалы прибора, до которой с уверенностью можно производить отсчет, что определяется конструкцией и ценой деления шкалы прибора.
Как считается случайная погрешность?
Случайная погрешность измерения равна разности погрешности измерения и систематической погрешности измерения.
Как оценить ошибку измерений?
1.1 Результат измерения — Рассмотрим простейший пример: измерение длины стержня с помощью линейки. Линейка проградуирована производителем с помощью некоторого эталона длины — таким образом, сравнивая длину стержня с ценой деления линейки, мы выполняем косвенное сравнение с общепринятым стандартным эталоном.
- Допустим, мы приложили линейку к стержню и увидели на шкале некоторый результат x = x изм,
- Можно ли утверждать, что x изм — это длина стержня? Во-первых, значение x не может быть задано точно, хотя бы потому, что оно обязательно округлено до некоторой значащей цифры: если линейка «обычная», то у неё есть цена деления ; а если линейка, к примеру, «лазерная» — у неё высвечивается конечное число значащих цифр на дисплее.
Во-вторых, мы никак не можем быть уверенны, что длина стержня на самом деле такова хотя бы с точностью до ошибки округления. Действительно, мы могли приложить линейку не вполне ровно; сама линейка могла быть изготовлена не вполне точно; стержень может быть не идеально цилиндрическим и т.п.
- И, наконец, если пытаться хотя бы гипотетически переходить к бесконечной точности измерения, теряет смысл само понятие «длины стержня».
- Ведь на масштабах атомов у стержня нет чётких границ, а значит говорить о его геометрических размерах в таком случае крайне затруднительно! Итак, из нашего примера видно, что никакое физическое измерение не может быть произведено абсолютно точно, то есть у любого измерения есть погрешность,
Замечание. Также используют эквивалентный термин ошибка измерения (от англ. error). Подчеркнём, что смысл этого термина отличается от общеупотребительного бытового: если физик говорит «в измерении есть ошибка», — это не означает, что оно неправильно и его надо переделать.
- Имеется ввиду лишь, что это измерение неточно, то есть имеет погрешность,
- Количественно погрешность можно было бы определить как разность между измеренным и «истинным» значением длины стержня: δ x = x изм — x ист,
- Однако на практике такое определение использовать нельзя: во-первых, из-за неизбежного наличия погрешностей «истинное» значение измерить невозможно, и во-вторых, само «истинное» значение может отличаться в разных измерениях (например, стержень неровный или изогнутый, его торцы дрожат из-за тепловых флуктуаций и т.д.).
Поэтому говорят обычно об оценке погрешности. Об измеренной величине также часто говорят как об оценке, подчеркивая, что эта величина не точна и зависит не только от физических свойств исследуемого объекта, но и от процедуры измерения. Замечание. Термин оценка имеет и более формальное значение.
Что такое абсолютная ошибка?
Смотреть что такое «Ошибка Абсолютная» в других словарях: —
ОШИБКА, АБСОЛЮТНАЯ — абсолютная величина расхождения (разности) между величиной признака (показателя), установленной на основе статистического наблюдения, и действительной его величиной. Понятие А.о. используется, главным образом, при выборочном наблюдении Большой экономический словарь ОШИБКА, АБСОЛЮТНАЯ — Абсолютное значение (то есть безотносительно к знаку) различия между наблюдаемым значением и истинным значением измерения. Например, переоценка чьего то роста на два дюйма приводит к такой абсолютной ошибке, как переоценка на два дюйма Толковый словарь по психологии абсолютная ошибка — абсолютная погрешность — Тематики электросвязь, основные понятия Синонимы абсолютная погрешность EN absolute error Справочник технического переводчика абсолютная ошибка — absoliučioji paklaida statusas T sritis Kūno kultūra ir sportas apibrėžtis Matas, rodantis skirtumą tarp išmatuotos reikšmės ir matuojamojo dydžio tikrosios reikšmės. Absoliučioji paklaida nustatoma pagal vieno arba kelių bandymų rezultatų Sporto terminų žodynas АБСОЛЮТНАЯ ОШИБКА — См. ошибка, абсолютная Толковый словарь по психологии абсолютная погрешность — absoliučioji paklaida statusas T sritis Kūno kultūra ir sportas apibrėžtis Matas, rodantis skirtumą tarp išmatuotos reikšmės ir matuojamojo dydžio tikrosios reikšmės. Absoliučioji paklaida nustatoma pagal vieno arba kelių bandymų rezultatų Sporto terminų žodynas Абсолютная пустота — Doskonała próżnia Жанр: Сборник рассказов Автор: Станислав Лем Язык оригинала: польский Год написания: 1971 год Википедия Абсолютная ошибка (точность) прогноза метеорологической величины — Абсолютная ошибка (точность) прогноза метеорологической величины: разность между прогностическим значением метеорологической величины и фактически наблюдавшимся ее значением. Источник: РД 52.27.724 2009. Руководящий документ. Наставление по Официальная терминология абсолютная ошибка измерений — — Тематики релейная защита EN absolute error of measurement Справочник технического переводчика Ошибка измерения — Погрешность измерения оценка отклонения величины измеренного значения величины от её истинного значения. Погрешность измерения является характеристикой (мерой) точности измерения. Поскольку выяснить с абсолютной точностью истинное значение любой Википедия
Что такое грубая ошибка?
Грубая ошибка — Ошибка типа неверная команда или ‘случайно’ нажатая клавиша, обычно возникающая по вине обслуживающего персонала и приводящая к большой погрешности. [Л.
В чем выражают относительную ошибку?
Физические величины и погрешности их измерений — Задачей физического эксперимента является определение числового значения измеряемых физических величин с заданной точностью. Сразу оговоримся, что при выборе измерительного оборудования часто нужно также знать диапазон измерения и какое именно значение интересует: например, среднеквадратическое значение (СКЗ) измеряемой величины в определённом интервале времени, или требуется измерять среднеквадратическое отклонение (СКО) (для измерения переменной составляющей величины), или требуется измерять мгновенное (пиковое) значение.
При измерении переменных физических величин (например, напряжение переменного тока) требуется знать динамические характеристики измеряемой физической величины: диапазон частот или максимальную скорость изменения физической величины, Эти данные, необходимые при выборе измерительного оборудования, зависят от физического смысла задачи измерения в конкретном физическом эксперименте,
Итак, повторимся: задачей физического эксперимента является определение числового значения измеряемых физических величин с заданной точностью. Эта задача решается с помощью прямых или косвенных измерений, При прямом измерении осуществляется количественное сравнение физической величины с соответствующим эталоном при помощи измерительных приборов.
- Отсчет по шкале прибора указывает непосредственно измеряемое значение.
- Например, термометр дает значения измеряемой температуры, а вольтметр – значение напряжения.
- При косвенных измерениях интересующая нас физическая величина находится при помощи математических операций над непосредственно измеренными физическими величинами (непосредственно измеряя напряжение U на резисторе и ток I через него, вычисляем значение сопротивления R = U / I ).
Точность прямых измерений некоторой величины X оценивается величиной погрешности или ошибки, измерений относительно действительного значения физической величины X Д, Действительное значение величины X Д (согласно РМГ 29-99 ) – это значение физической величины, полученное экспериментальным путем и настолько близкое к истинному значению, что в поставленной измерительной задаче может быть использовано вместо него.
Различают абсолютную (∆ X) и относительную (δ) погрешности измерений. Абсолютная погрешность измерения – это п огрешность средства измерений, выраженная в единицах измеряемой физической величины, характеризующая абсолютное отклонение измеряемой величины от действительного значения физической величины: ∆X = X – X Д,
Относительная погрешность измерения – это п огрешность измерения, выраженная отношением абсолютной погрешности измерения к действительному значению измеряемой величины. Обычно относительную погрешность выражают в процентах: δ = (∆X / Xд) * 100%, При оценке точности косвенных измерений некоторой величины X 1, функционально связанной с физическими величинами X 2, X 3,, X 1 = F (X 2, X 3, ), учитывают погрешности прямых измерений каждой из величин X 2, X 3, и характер функциональной зависимости F (),
Какие виды погрешностей ошибок могут встречаться при работе лаборатории?
Внутрилабораторные ошибки — Надежность результатов исследования при проведении анализов в лаборатории зависит от целого ряда факторов. Погрешность в аналитическом процессе — это внутрилабораторные ошибки, появление и предупреждение которых зависит только от работников лабораторий.
Результаты анализов в большой мере зависят от индивидуальных способностей лабораторного персонала, важным фактором является и качество применяемых измерительных инструментов. Существенным источником ошибок является приготовление стандартных растворов, который может иметь иную концентрацию, чем должна быть по расчету.
Многочисленность применяемых методов, из которых большая часть уже устарела, также является частой причиной многих ненадежных результатов. Помочь этому может последовательное внедрение унифицированных методов. Наиболее распространена следующая классификация ошибок.
Различают три основных вида ошибок: грубые, случайные и систематические. Грубая ошибка — это одиночное значение исследуемого компонента, выходящее за пределы установленного для данного компонента области (за допустимые пределы погрешности). Причиной грубых ошибок является недостаточная тщательность в работе.
Случайная ошибка — одиночное значение, не выходящее за пределы установленной для данного компонента области. Случайными называются неопределенные по величине и знаку ошибки, в появлении каждой из которых не наблюдается какой-либо закономерности. Эти ошибки происходят при любом аналитическом определении.
- Наличие их сказывается в том, что повторные определения того или иного компонента в данном образце, выполненные одним и тем же методом, дают как правило несколько различающиеся между собой результаты.
- Случайные ошибки практически невозможно исключить совсем, они могут возникать из-за негомогенности пробы материала, недостаточно высокого качества оборудования, чаще случайные ошибки вызываются субъективными факторами.
Этот вид ошибок можно значительно ограничить после оценки их размера, величина ошибки (разброс данных) является мерилом воспроизводимости лабораторных результатов. Чем меньше величина случайных ошибок, тем лучше воспроизводимость исследований. Распространенным способом характеристики воспроизводимости результатов является величина среднеквадратического отклонения.
- Для суждения о правильности анализа совпадение или расхождение результатов параллельных проб не имеет значения.
- В этом случае на первый план выступают систематические ошибки.
- Систематическими ошибками называют погрешности, одинаковые по знаку, имеющие определенную причину, влияющие на результат либо в сторону увеличения, либо в сторону уменьшения его.
Систематические ошибки можно обычно предусмотреть или же ввести соответствующие поправки (ошибки методического характера). Систематические ошибки повторяются при каждом измерении, так как они вызываются постоянными причинами, влияют они на всю серию определений.

- Разница между случайной ошибкой и систематической ошибкой
Разница между случайной ошибкой и систематической ошибкой
Ошибка определяется как разница между фактическим или истинным значением и измеренным значением. Измерение количества или стоимости основано на каком-то стандарте. Измерение любого количества осуществляется путем сравнения его с производным стандартом, который не является полностью точным. Чтобы понять ошибки в измерении, следует понимать два термина, которые определяют ошибку, и они являются истинным значением и измеренным значением. Истинное значение невозможно выяснить, оно может быть определено по среднему значению бесконечного числа. Измеренное значение определяется как оценочное значение истинного значения путем взятия нескольких измеренных значений. Ошибка не должна быть перепутана с ошибкой, ошибки можно избежать, но ошибки не избежать, но их можно минимизировать. Так что ошибка не является ошибкой его части измерительной обработки. Измерение — это разница между измеренным значением количества и его истинным значением. мы обсудим случайную ошибку и систематическую ошибку. Погрешности измерения делятся на два обширных класса ошибок.
- Случайная ошибка
- Систематическая ошибка
Случайная ошибка:
Случайная ошибка — это не что иное, как колебания в измерении, которые в основном наблюдаются путем проведения нескольких испытаний данного измерения. Как следует из названия, эта ошибка происходит совершенно случайно. Они непредсказуемы и не могут быть воспроизведены путем повторения эксперимента снова. Так что каждый раз это дает разные результаты. Случайная ошибка варьируется от наблюдения к другому. При случайной ошибке колебание может быть как отрицательным, так и положительным. Не всегда возможно определить источник случайной ошибки. Случайная ошибка происходит из-за фактора, который не может или не будет контролироваться. Случайная ошибка влияет на достоверность результатов. Некоторые из возможных источников или причин случайных ошибок перечислены ниже.
- Наблюдение: ошибка в суждении наблюдателя.
- Небольшие помехи: Небольшие помехи могут привести к ошибкам измерения, например
- Колеблющиеся условия: Некоторое изменение температуры во времени или в окружающей среде может привести к ошибке в измерении.
- Качество: Некоторое время, когда качество объекта, измерение которого должно быть выполнено, не определено должным образом, приводит к ошибке.
Ошибка может быть уменьшена, если взять число чтений, а затем найти среднее или среднее значение чтения.
Систематическая ошибка:
Систематическая ошибка — это когда одна и та же ошибка присутствует во всех показаниях. Систематическая ошибка предсказуема и обычно постоянна или пропорциональна истинному значению. Таким образом, систематическая ошибка повторяется каждый раз, и это приводит к ошибкам согласованности. Если мы повторим эксперимент, мы получим одну и ту же ошибку каждый раз. Систематические ошибки возникают из-за неправильной калибровки прибора. Систематическая ошибка влияет на точность результата. Систематическая ошибка также называется нулевой ошибкой, положительной или отрицательной ошибкой. Некоторые из возможных источников или причин систематической ошибки перечислены ниже.
- Инструментальная ошибка: оборудование, используемое для измерения объекта, может быть не совсем точным.
- Экологическая ошибка: ошибка возникает из-за изменений условий окружающей среды, таких как влажность, давление, температура и т. Д.
- Наблюдательная ошибка: ошибка в записи данных, также называемая человеческими ошибками. После выявления систематической ошибки она может быть в некоторой степени уменьшена. Систематическая ошибка может быть сведена к минимуму путем регулярной калибровки оборудования, использования элементов управления и сравнения значений со стандартным значением.
Сравнение между случайными ошибками и значением систематической ошибки (инфографика)
Ниже приведено 8 основных различий между случайной ошибкой и систематической ошибкой 
Ключевые различия между случайной ошибкой и систематической ошибкой
Давайте обсудим некоторые основные различия между случайной ошибкой и систематической ошибкой
- Случайная ошибка непредсказуема и возникает из-за неизвестных источников, тогда как систематическая ошибка является предсказуемой и возникает из-за дефекта прибора, который используется для измерения.
- Случайная ошибка возникает в обоих направлениях, тогда как систематическая ошибка возникает только в одном направлении.
- Случайная ошибка не может быть устранена, но большинство систематических ошибок может быть уменьшено.
- Случайная ошибка является уникальной и не имеет определенного типа, тогда как систематическая ошибка имеет 3 типа, как указано в таблице выше.
- Систематическую ошибку трудно обнаружить, это происходит из-за одних и тех же результатов каждый раз и не осознает, что проблема вообще существует, тогда как случайную ошибку легко обнаружить из-за разных результатов каждый раз.
Сравнительная таблица случайных ошибок и систематических ошибок
Ниже приведено 8 лучших сравнений между случайной ошибкой и систематической ошибкой.
| Основное сравнение между случайной ошибкой и систематической ошибкой | Случайная ошибка | Систематическая ошибка |
| Определение | Это происходит из-за неопределенных изменений в окружающей среде и колеблется каждый раз при измерении. | Это постоянная ошибка и остается неизменной для всех измерений. |
| Свести к минимуму | Путем многократного взятия показаний и расчета среднего или среднего из повторных показаний. | Сравнивая значение со стандартным значением и улучшая структуру оборудования. |
| Величина ошибки | Каждый раз дают другой результат, который меняется каждый раз. | Результат остается неизменным или постоянным каждый раз. |
| Направление ошибки | Это происходит в обоих направлениях. | Это происходит в том же направлении. |
|
Подтип ошибки |
Нет подтипов | Подтипы Инструмент, Среда и Систематическая Ошибка. |
| воспроизводимый | Невоспроизводимый. | Воспроизводимые. |
| Значение | Цена представляет собой сочетание стоимости. | Затраты снижаются, когда они сравниваются со стоимостью в стоимостном выражении. |
| Пример ошибки | Время реакции, погрешность измерения из-за недостаточной точности, погрешность параллакса (если каждый раз смотреть под случайным углом) | Ошибка шкалы, ошибка нуля, ошибка параллакса (если диск виден под тем же углом) |
Выводы
Таким образом, случайная ошибка в основном возникает из-за каких-либо возмущений в окружающей среде, таких как колебания или различия в давлении, температуре или из-за наблюдателя, который может принять неправильные показания, в то время как систематическая ошибка возникает из-за механической структуры прибора. Случайная ошибка не может быть предотвращена, в то время как систематическая ошибка может быть предотвращена. Полное устранение обеих ошибок невозможно. Основное различие между случайными ошибками и систематическими ошибками заключается в том, что случайная ошибка в основном приводит к колебаниям, тогда как систематические ошибки приводят к предсказуемому и последовательному результату. При работе с промышленными приборами важно, чтобы оператор тщательно следил за экспериментом, чтобы погрешность измерения могла быть уменьшена.
Рекомендуемые статьи
Это было руководство к разнице между случайной ошибкой и систематической ошибкой. Здесь мы также обсудим различия между случайной ошибкой и систематической ошибкой с помощью инфографики и сравнительной таблицы. Вы также можете взглянуть на следующие статьи, чтобы узнать больше.
- Экономический рост против экономического развития
- Бухгалтерский учет и финансовый менеджмент
- Покупка активов против покупки акций
- Ангел Инвестор против Венчурного Капитала
Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





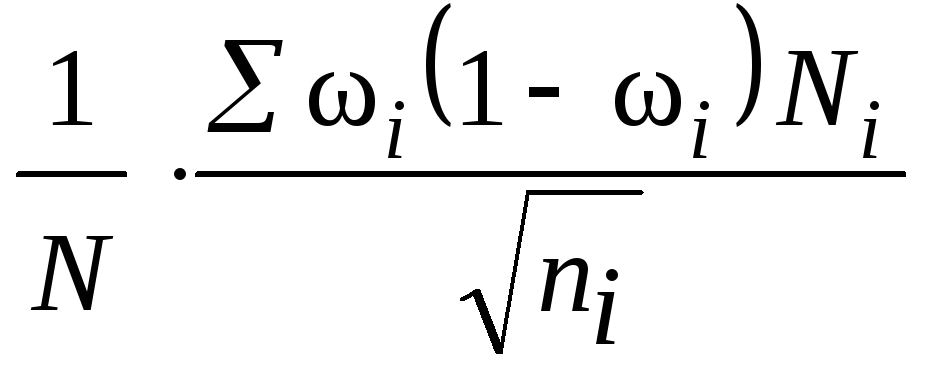


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
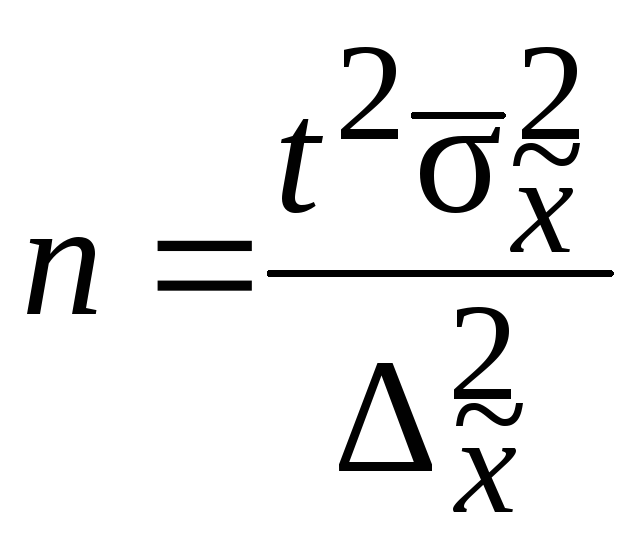

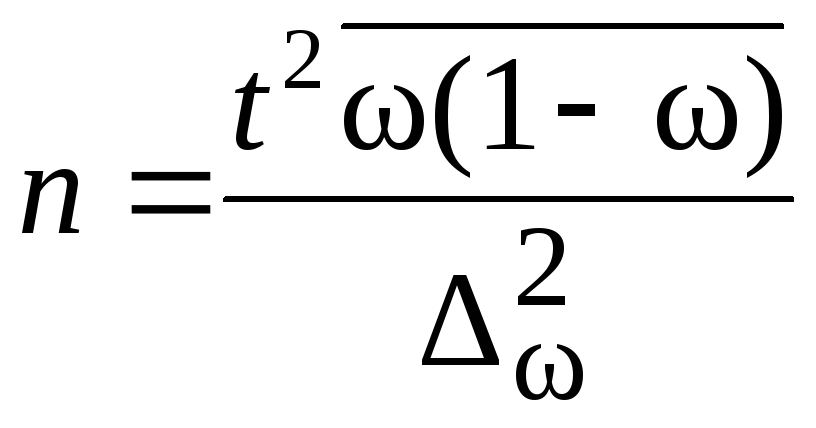

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
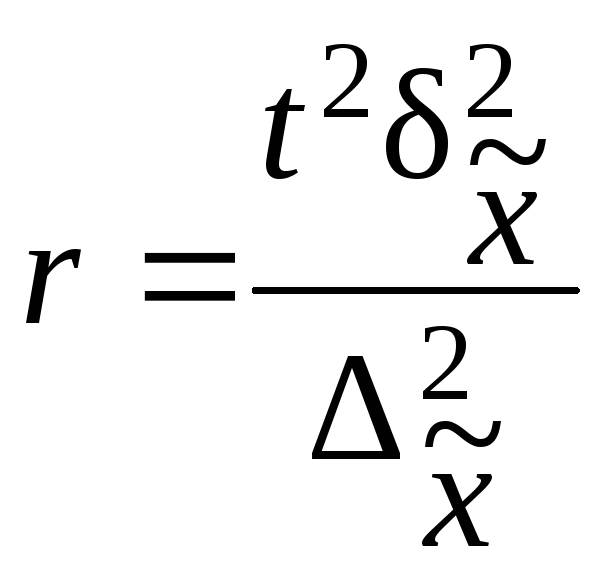


Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Выборка. Типы выборок. Расчет ошибки выборки
Калькуляторы
Калькулятор расчета ошибки и размера выборки
Калькулятор расчета статистической значимости различий
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих
определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и
времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и
т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей
генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на
всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и
нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население
Москвы. - Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать
москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках
соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от
ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой
всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера
выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной
вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об
ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих
результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни.
Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например,
дома). - Проблема респондентов, отказывающихся отвечать на вопросы
анкеты (доля «отказников» в Москве, для разных опросов,
колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот
или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов,
наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата
рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер
генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы
(страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются
случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности,
типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60
лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для
каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны
попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной
совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки
используются в маркетинговых исследованиях достаточно
часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег,
знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за
исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда
необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход,
респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения
и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство
интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром –
активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает
проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Более подробную информацию по выборочным наблюдениям можно получить просмотрев видеокурс по теории статистики:
Выборочное наблюдение Способы формирование выборки
Специальные виды отбора
Калькулятор расчета ошибки и размера выборки (для простой случайной выборки)
Пояснения к полям:
Доверительная вероятность
Вероятность того, что доверительный интервал накроет неизвестное истинное значение параметра, оцениваемого по
выборочным данным. В практике исследований чаще всего используют 95%-ую доверительную вероятность
Ошибка выборки (доверительный интервал)
Интервал, вычисленный по выборочным данным, который с заданной вероятностью (доверительной) накрывает неизвестное
истинное значение оцениваемого параметра распределения.
Доля признака
Ожидаемая доля признака, для которого рассчитывается ошибка. В случае, если данные о доле признака отсутствуют,
необходимо использовать значение равное 50, при котором достигается максимальная ошибка.
Калькулятор расчета статистической значимости различий
Калькулятор позволяет проверить есть ли статистически значимая разница между долями признака, полученными из
независимых выборок.
Например, если до начала рекламной кампании марку знали 55% респондентов, а по окончании – 60% — есть ли между этими
долями статистически значимая разница, или же эта разница укладывается в ошибку выборки?
Примечание. Эта процедура может законно использоваться, только если обе выборки удовлетворяют следующему условию:
произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, должны быть не меньше 5.
Оставить свои комментарии по затронутой теме Вы можете на наших страницах в Facebook и Вконтакте.
При перепечатке материалов ссылка на маркетинговое агентство обязательна
FDF Group © 2023
Разработка сайта — Монохром
В каждой профессии есть свой набор любимых вопросов. Для исследователей рынка этот список возглавляет, безусловно, вопрос о размере выборки. Обычно его формулируют так:
- Мы хотели бы заказать исследование по посетителям московских торговых центров. Какая нам нужна выборка?
- Наша целевая аудитория – примерно 300 000 человек. Сколько людей нам нужно опросить, чтобы было репрезентативно? А если целевая аудитория будет 3 млн?
- Нам нужно оценить потенциал продаж квартир в Санкт-Петербурге жителям северных городов России. Какую сделать выборку?
Размер выборки действительно важен, потому что определяет стоимость будущего исследования, не говоря уже о качестве итоговых результатов и выводов. В этой статье мы расскажем о том, как рассчитать оптимальный размер выборки массового опроса. Наш материал будет полезен всем, кто так или иначе сталкивается с необходимостью проведения маркетинговых исследований своими силами или заказывает их у специализированного агентства.
Главное заблуждение о размере выборки
Многие уверены, что чем больше размер целевой группы, тем больше должен быть размер выборки. Поэтому, якобы, чтобы узнать мнение жителей маленького города, достаточно опросить человек 200-300, ну а для выяснения мнения по России в целом и 5000 будет мало.
Между тем, этот стереотип не имеет ничего общего с реальностью. Размер выборки не зависит от численности целевой группы (на языке статистики она называется «генеральной совокупностью») и определяется двумя совершенно другими факторами. Единственное исключение из этого правила – случаи, когда генеральная совокупность очень маленькая, например, 1-2 тысячи человек, но такие ситуации в реальной практике маркетинговых исследований встречаются редко.
Два фактора, от которых зависит размер выборки
Размер выборки массового опроса зависит от двух факторов:
- Точности данных, которые нужно получить на выходе – это та самая «статистическая погрешность». Для выборки в 100 респондентов она будет в пределах плюс-минус 10%, а для выборки в 1000 респондентов – в пределах плюс-минус 3,1%. Более подробно об этом – ниже.
- Количества и размера подгрупп, на которые нужно разбивать выборку при анализе. Например, если проводится электоральное исследование, то в основном нас будет интересовать ядро активных избирателей. Как правило, доля «ядра» редко превышает 20-25% от всего населения. Поэтому размер выборки нужно рассчитывать так, чтобы одна четверть от ее общего объема позволяла проводить полноценный статистический анализ.
Вопреки расхожему мнению, качество выборки определяется не ее размером, а репрезентативностью. Репрезентативность – это соответствие между выборкой и генеральной совокупности по ключевым параметрам. Чаще всего, в качестве таких «реперных точек» используют легко измеряемые социально-демографические показатели: пол, возраст, образование, род занятий и место жительства.

Две разновидности ошибки выборки
Любое выборочное наблюдение (то есть когда мы опрашиваем не всех подряд, а делаем случайный отбор из генеральной совокупности) сопряжено с погрешностью данных. Эту погрешность обычно называют «ошибкой выборки». Она может быть двух видов:
- Систематическая – связана с ошибками проектирования выборки. Оценить ее размер, направление и степень смещения очень сложно, чаще всего – невозможно. Например, если вопросы респондентам будут задавать представители маргинальных социальных слоев, это повлияет на готовность участвовать в исследовании со стороны представителей более обеспеченных групп населения. В итоге это приведет к крайне трудно оцениваемой систематической ошибке и искажению данных.
- Случайная – связана с действием законов статистики. Ее размер легко рассчитывается по формулам математической статистики и теории вероятности. Они позволяют делать обоснованные выводы о доверительном интервале признака. Например, если статистическая погрешность составляет плюс-минус 10%, а полученное значение показателя оказалось равно 25%, то доверительный интервал равен от 15% до 35%.

Задача исследователя – собрать данные так, чтобы минимизировать систематическую ошибку выборки. Тогда можно будет свести статпогрешность лишь к случайной ошибке, которую можно рассчитать по формулам.
Как рассчитать размер случайной ошибки выборки
Случайная ошибка выборки зависит не только от объема выборки, но и от дисперсии, то есть степени однородности данных. Чем однороднее данные (т.е. чем меньше разброс полученных значений, или дисперсия), тем меньше ошибка выборки.
Существует формула расчета случайной ошибки выборки, однако для удобства рекомендуем пользоваться онлайн-калькуляторами, например, вот этим. Он позволяет легко провести два вида расчета:
- рассчитать величину статистической погрешности на основе размера выборки и предполагаемой дисперсии;
- определить размер выборки, требуемый для получения оценки нужной степени точности.
Вот так выглядит его рабочее окно:

В качестве параметра доверительной надежности (одно из полей в калькуляторе) обычно используется значение в 95%. Это означает, что в 95% случаев распределение признака в генеральной совокупности попадет в рассчитанный доверительный интервал (т.е. само значение признака в выборке плюс-минус размер статистической погрешности). Реже используется значение надежности в 97% или 99% – оно, соответственно, означает, что подобное попадание произойдет в 97% или 99% случаев. В данном случае надежность выборки повышается, но увеличивается размер выборки.
Самое сложное при определении размера выборки – поиск компромисса между требуемой точностью и стоимостью сбора данных. Этот процесс усложняется тем, что увеличение размера выборки в четыре раза приводит к увеличению точности лишь в два раза (соответствует квадратному корню от величины прироста выборки).
Кейс: определение размера выборки для оценки потенциала рынка продаж столичной недвижимости покупателям из регионов
В ноябре-декабре 2016 года мы провели исследование спроса на квартиры в новостройках Москвы и Санкт-Петербурга со стороны жителей разных городов России. Исследование включало в себя три метода сбора данных: массовый репрезентативный опрос населения в возрасте от 20 до 60 лет (проводился с использованием технологии CATI), а также серию экспертных интервью с риэлторами и глубинных интервью с потенциальными покупателями квартир.
Исследование охватывало 33 города, отличающихся повышенным спросом на петербургскую и московскую недвижимость. Плановая выборка исследования, рассчитанная по формулам, составила 21 500 респондентов. Этот объем значительно больше «стандартного» объема выборки, используемого в маркетинговых исследованиях. С чем же связан такой большой размер выборки?
Все дело в том, что клиенту были нужны оценки отдельно по каждому городу, а не просто «в целом по стране». Фактически мы работаем не с 1 выборкой, а с 33 отдельными выборками по каждому городу. Доля людей, заинтересованных в покупке квартиры в Санкт-Петербурге или Москве, была экспертно определена в рамках 5% от числа жителей опрашиваемых городов.
В зависимости от важности города для заказчика, руководитель проекта со стороны Агентства определил допустимую статистическую погрешность, в которую должны укладываться итоговые результаты. Для этого мы использовали специальный макрос в MS Excel, но эти расчеты можно также выполнить с помощью калькулятора выборки. В результате размер выборки варьировал от 500 до 1000 респондентов по каждому из городов исследования, что в сумме и дало заявленные 21 500 человек.
Резюме
Чтобы рассчитать выборку маркетингового исследования, используйте следующий алгоритм:
- Определите структуру целевой группы. Планируете ли вы анализировать отдельные подгруппы или достаточно будет анализа по выборке в целом?
- Определите желаемую точность данных. Например, если нужно оценить динамику рыночной доли за год, подставьте в специальный калькулятор примерное значение доли и «поиграйте» с разными объемами выборки.
- Найдите баланс между стоимостью сбора данных (прямо пропорциональна объему выборки) и требуемой точностью.
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
Таблица
11.2.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
Таблица
11.3.
Формулы для расчета средней ошибки собственно случайной и механической выборки ()
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
Таблица
11.4.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
Таблица
11.5.
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.
Таблица
11.6.
Формулы для расчета средней ошибки выборки ( ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических групп

Здесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
Таблица
11.7.
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия,  |
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
Таблица
11.8.
Формулы для определения численности выборочной совокупности

Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.