
Обновлено: 05.06.2023
Для оценки качества прогноза принято использовать такие характеристики как надёжность, точность, достоверность, ошибки прогноза.
Под надёжностью прогнозных расчётов понимается мера неопределённости поведения объекта прогнозирования во времени.
Достоверность прогноза определяется вероятностью осуществления прогноза для заданного варианта или доверительного интервала.
Точность прогноза характеризует интервальный разброс прогнозных траекторий при фиксированном уровне достоверности.
Ошибки прогноза представляют собой меру отклонения прогнозных оценок от реальных значений состояния прогнозируемого объекта.
Рис. 8. Факторы, влияющие на качество прогноза.
Качество исходной информации, в свою очередь, определяется:
— точностью экономических измерений;
— отсутствием ошибок согласования (данные ошибки возникают в тех случаях, когда исходная информация для проведения прогнозных расчётов подготавливается различными специалистами, использующими разные методологические подходы).
Погрешности, связанные с выбором модели прогноза, возникают в результате упрощения, несовершенства теоретических построений или неадекватности моделей прогнозируемым социально-экономическим процессам. Иногда для прогнозирования процессов, протекающих в нашей стране, используются модели разработанные зарубежными специалистами и хорошо себя зарекомендовавшие для прогнозирования аналогичных процессов в других странах. Однако следует помнить о том, что данные модели могут быть неадекватны социально-экономическим процессам, происходящим в нашей стране и их использование может привести к серьезным ошибкам и просчетам.
Наиболее часто на практике для анализа адекватности модели прогноза исследуемым социально-экономическим процессам используются абсолютные показатели, позволяющие количественно определить величину ошибки моделирования в единицах измерения прогнозируемого объекта. К ним относятся:
— абсолютная ошибка, определяемая как разность между фактическим значением показателя и его расчётным значением ;
— средняя абсолютная ошибка ;
Следует отметить, что абсолютные показатели малопригодны для сравнения и анализа точности моделирования разнородных объектов, так как их значения существенно зависят от масштаба измерения исследуемых явлений. В этих случаях используются относительные показатели:
— средняя относительная ошибка .
Прогнозирование численности населения с помощью методов скользящей средней, наименьших квадратов и экспоненциального сглаживания. Построение графика потребления электроэнергии, определения сезонных колебаний и поквартальный прогноз объема потребления.
| Рубрика | Экономико-математическое моделирование |
| Вид | задача |
| Язык | русский |
| Дата добавления | 30.12.2010 |
| Размер файла | 58,3 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Государственное образовательное учреждение
Высшего профессионального образования
Уральский государственный экономический университет
По дисциплине Прогнозирование национальной экономики
Задание 1. Имеются данные размера ввода в действие общей площади жилых домов в городе за 1989-1999 гг., тыс. м 2
2. Постройте график фактического и расчетных показателей.
3. Рассчитайте ошибки полученных прогнозов при использовании каждого метода.
4. Сравните результаты.
Скользящая средняя (n = 3):
Ввод в действие общей площади жилых домов, тыс. м 2 . Уt
Скользящая средняя m
Расчет средней относительной ошибки |Уф — Ур| Уф * 100
Рис. 1 График фактических (чёрная линия) и расчетных (серая линия) показателей. (Составлено по таблице 1)
Прогноз на 2000 г.: У2000=806,7+(652-865)/3=735,7
Прогноз на 2001 г.: У2001=750,9+(735,7-652)/3=778,8 и т.д. (Таблица 1).
Средняя относительная ошибка: ?=42,6/9=4,7
Метод экспоненциального сглаживания:
Значение параметра сглаживания: 2/(n+1)=2/(11+1)=0,2=0,17
Начальное значение Uo двумя способами:
1 способ (средняя арифметическая): Uo = 16262/11 = 1478,4
2 способ (принимаем первое значение базы прогноза): Uo = 2360
Ввод в действие общей площади жилых домов, тыс. м 2 .
Экспоненциально взвешенная средняя Ut
Расчет средней относительной ошибки
Рис. 2 График фактических и расчетных показателей экспоненциально взвешенных средних 1 и 2 способ. (Составлено по таблице 2, 3)
Экспоненциально взвешенная средняя для каждого года:
U1989 = 2360*0,17+(1-0,17) * 1478,4=1628,272 1 способ
U1989 = 2360*0,17+(1-0,17) * 2360=2360 2 способ
(Остальное приведено в таблице до 2009 года с целью прогноза на 2007, 2008 годы)
Средняя относительная ошибка:
? = 442,945295/11 = 40,27% (1 способ)
? = 563,561351/11 = 51,23% (2 способ)
прогнозирование экспоненциальный сглаживание
Задание 2. Имеются данные потребления электроэнергии в городе за 2003-2006 гг., млн. кВт·ч
1. Постройте график исходных данных и определите наличие сезонных колебаний.
2. Постройте прогноз объема потребления электроэнергии в городе на 2007-2008 гг. с разбивкой по кварталам.
3. Рассчитайте ошибки прогноза.
I 1 = 102,5714108
I 2 = 134,6464502
I 3 = 90,91831558
I 4 = 73,11296966
Средняя относительная ошибка: 297,09/16=18,57%
потребления электроэнергии в городе., млн. кВт*ч Уф
потребления электроэнергии в городе., млн. кВт*ч
Подобные документы
Использование принципа дисконтирования информации в методах статистического прогнозирования. Общая формула расчета экспоненциальной средней. Определение значения параметра сглаживания. Ретроспективный прогноз и средняя квадратическая ошибка отклонений.
реферат [9,8 K], добавлен 16.12.2011
Сущность социально-экономического прогнозирования. Роль сахара в жизни человека. Математический аппарат, используемый при прогнозировании потребления. Регрессионный анализ. Методы наименьших квадратов и моментов. Оценка качества моделей прогнозирования.
курсовая работа [1,5 M], добавлен 26.11.2012
Сущность, содержание и цели экономического прогнозирования. Классификация и обзор базовых методов прогнозирования спроса. Основные показатели динамики экономических процессов. Моделирование сезонных колебаний при использовании фиктивных переменных.
дипломная работа [372,5 K], добавлен 29.11.2014
Основные задачи и принципы экстраполяционного прогнозирования, его методы и модели. Экономическое прогнозирование доходов ООО «Уфа-Аттракцион» с помощью экстраполяционных методов. Анализ особенностей применения метода экспоненциального сглаживания Хольта.
курсовая работа [1,7 M], добавлен 21.02.2015
Планирование деятельности предприятия по производству продуктов питания. Прогнозирование объема продаж продукции на заданный период времени, построение графика изменения, используя метод трехчленной скользящей средней; расчет доверительных интервалов.
контрольная работа [668,5 K], добавлен 02.01.2012
Порядок и особенности расчета прогнозных значений урожайности озимой пшеницы в Волгоградский области. Общая характеристика основных методов прогнозирования — аналитического выравнивания, экспоненциального сглаживания, скользящих средних и рядов Фурье.
контрольная работа [2,3 M], добавлен 11.07.2010
Построение поля корреляции, оценка тесноты связи с помощью показателей корреляции и детерминации, адекватности линейной модели. Статистическая надёжность нелинейных моделей по критерию Фишера. Модель сезонных колебаний и расчёт прогнозных значений.
практическая работа [145,7 K], добавлен 13.05.2014


В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Работая с научными публикациями, сталкиваюсь с различными показателями ошибок прогнозирования временных рядов. Среди всех встречающихся оценок ошибки прогнозирования стоит отметить две, которые в настоящее время, являются самыми популярными: MAE и MAPE. Пусть ошибка есть разность:
,
где Z(t) – фактическое значение временного ряда, а – прогнозное.
Тогда формулы для оценок ошибки прогнозирования временных рядов для N отчетов можно записать в следующем виде.
MAPE – средняя абсолютная ошибка в процентах

.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка

.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
Кроме указанных иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
MSE – среднеквадратичная ошибка

.
RMSE – квадратный корень из среднеквадратичной ошибки

.
ME – средняя ошибка

.
SD – стандартное отклонение
Связь точности и ошибки прогнозирования
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE
Величину точности оценивать не принято, говоря о прогнозировании всегда оценивают, то есть определяют значение именно ошибки прогноза, то есть величину MAPE и/или MAE. Однако нужно понимать, что если MAPE = 5%, то точность прогнозирования = 95%. Говоря о высокой точности, мы всегда говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности.
При этом величина MAPE является количественной оценкой именно ошибки, и эта величина нам ясно говорит и о точности прогнозирования, исходя из приведенной выше простой формулы. Таким образом, оценивая ошибку, мы всегда оцениваем точность прогнозирования.
Читайте также:
- Аппаратурные методы вольтамперометрии реферат
- Организация самостоятельной деятельности детей реферат
- Реферат шахматы увлекательная игра
- Реферат на тему праздники
- Реферат женщины и насилие
Статистические методы прогнозирования
Содержание
Введение
Глава 1. Понятие статистических методов прогнозирования
.1 Статистика: понятие, содержание
.2 Виды статистических методов прогнозирования
Глава 2. Применение статистических методов прогнозирования
.1 Процесс прогнозирования, опирающийся на статистические
методы
2.2 Практическое применение статистических методов
прогнозирования (на примере метода наименьших
квадратов)
Заключение
Список литературы
Приложение
Введение
В настоящее время следует отметить непрерывно растущую
потребность в прогнозах. Под прогнозом понимается научно обоснованное суждение
о возможных состояниях объекта в будущем, об альтернативных путях и сроках их
достижения. Каждый прогноз разрабатывается с целью добиться ускоренного
развития объекта прогнозирования в желательном направлении и избежать
нежелательных результатов. Прогноз как новое знание включает, с одной стороны,
знания о свойствах объектов, существующих в действительности, наблюдаемых или
ненаблюдаемых в период прогнозирования, а с другой — знания о свойствах
объектов, которых в период прогнозирования в действительности еще нет. Прогноз
создает идеальный образ, модель, описание вероятных процессов, событий.
Под прогнозированием понимают научное (т.е. основанное на системе фактов
и доказательств, установленных причинно-следственных связей) выявление
вероятностных путей и результатов предстоящего развития явлений и процессов,
оценку показателей, характеризующих эти явления и процессы для более или менее
отдаленного будущего. Прогнозирование — это научная деятельность, направленная
на выявление и изучение возможных альтернатив будущего развития и структуры его
вероятных траекторий. Каждая альтернативная траектория развития связывается с
наличием комплекса внешних относительно исследуемой системы (явлений) условий.
Правильность исходных теоретических предпосылок, методологической основы
прогноза решающим образом влияет на его результаты и возможность их
практического использования. Методами социально-экономического прогнозирования
называется совокупность приемов мышления, позволяющих на основе анализа
ретроспективных внешних и внутренних связей, присущих объекту, а также их
измерений в рамках рассматриваемого явления или процесса вынести суждения
определенной достоверности относительно его будущего развития. Именно методы
прогнозирования позволяют найти меру влияния отдельных закономерностей и причин
развития, представить объект прогноза как динамическую систему измеренных с
определенной степенью достоверности взаимодействий реальных явлений, факторов,
сил общественной деятельности и тем самым дать возможность воспроизвести с
определенной степенью вероятности поведение этой системы в будущем.
Сложность выбора наиболее эффективного метода социально-экономического
прогнозирования заключается в определении относительно классификации методов
прогнозирования характеристик каждого метода, перечня требований к
ретроспективной информации и прогнозному фону.
По оценкам отечественных и зарубежных ученных, в настоящее время
насчитывается свыше 20 методов прогнозирования, однако число базовых
значительно меньше (15-20). Многие из этих методов относятся скорее к отдельным
приемам и процедурам, учитывающим нюансы объекта прогнозирования. Другие
представляют собой набор отдельных приемов, отличающихся от базовых или друг от
друга количеством частных приемов и последовательностью их применения.
В литературе представлены различные классификационные принципы методов
прогнозирования. По признаку «информационное основание метода» методы
прогнозирования делятся на три класса: фактографические, комбинированные и
экспертные (рис. 1, приложение 1). Фактографические базируются на фактической
информации об объекте прогнозирования и его прошлом развитии. Класс
фактографических методов объединяет следующие три подкласса: методы аналогий,
опережающие и статистические методы.
Вопросам статистических методов прогнозирования посвящены работы многих
авторов: Дубровой Т.А., Жихарева В.Н., Орлова А.И., Плошко Б.Г., Светунькова
С.Г., Четыркина Е.М. и др. Однако актуальность темы требует ее дальнейшего
рассмотрения.
Целью настоящей работы является исследование статистических методов
прогнозирования.
Для реализации названной цели необходимо решить следующие задачи работы:
) проанализировать содержание понятия «статистика»;
) охарактеризовать сущность и особенности статистических методов
прогнозирования;
3) изучить
процесс применения статистических методов прогнозирования (на примере одного из
конкретных методов).
Объектом исследования являются статистические методы прогнозирования.
Предметом исследования являются конкретные методы анализа статистических
данных.
Структура работы: введение, две главы основной части (четыре параграфа),
заключение, список использованной литературы.
Глава 1. Понятие статистических методов прогнозирования
.1 Статистика: понятие, содержание
Первая публикация по статистике — это «Книга чисел» в Библии, в
Ветхом Завете, в которой рассказано о переписи военнообязанных, проведённой под
руководством Моисея и Аарона. Впервые термин «статистика» мы находим
в художественной литературе — в «Гамлете» Шекспира (1602 г., акт 5,
сцена 2). Смысл этого слова у Шекспира — знать, придворные. По-видимому, оно
происходит от латинского слова status, что в оригинале означает
«состояние» или «политическое состояние». В течение следующих
400 лет термин «статистика» понимали и понимают по-разному. В
литературе собрано более 200 определений этого термина, некоторые из которых
приводятся ниже.
Вначале под статистикой понимали описание экономического и политического
состояния государства или его части. Например, к 1792 г. относится определение:
«статистика описывает состояние государства в настоящее время или в
некоторый известный момент в прошлом». И в настоящее время деятельность
государственных статистических служб вполне укладывается в это определение.
Однако постепенно термин «статистика» стал использоваться более
широко. По Наполеону Бонапарту, «статистика — это бюджет вещей». Тем
самым статистические методы были признаны полезными не только для
административного управления, но и для применения на уровне отдельного
предприятия. Согласно формулировке 1833 г., «цель статистики заключается в
представлении фактов в наиболее сжатой форме». Приведем ещё два
высказывания. Статистика состоит в наблюдении явлений, которые могут быть
подсчитаны или выражены посредством чисел (1895). Статистика — это численное
представление фактов из любой области исследования в их взаимосвязи (1909).
Сразу после возникновения теории вероятностей (Паскаль, Ферма, XVII век)
вероятностные модели стали использоваться при обработке статистических данных.
Например, изучалась частота рождения мальчиков и девочек, было установлено
отличие вероятности рождения мальчика от 0,5, анализировались причины того, что
в парижских приютах эта вероятность не та, что в самом Париже, и т.д. Имеется
много публикаций по истории теории вероятностей с описанием раннего этапа
развития статистических методов исследований.
В Х1Х веке заметный вклад в развитие практической статистики внёс
бельгиец Кетле, на основе анализа большого числа реальных данных показавший устойчивость
относительных статистических показателей, таких, как доля самоубийств среди
всех смертей. Интересно, что основные идеи статистического приёмочного контроля
и сертификации продукции обсуждались академиком Петербургской АН М.В.
Остроградским (1801-1862) и применялись в российской армии ещё в середине Х1Х
в. Статистические методы управления качеством и сертификации продукции сейчас
весьма актуальны.
Современный этап развития статистических методов можно отсчитывать с 1900
г., когда англичанин К. Пирсон основал журнал «Biometrika». Первая
треть ХХ в. прошла под знаком параметрической статистики. Изучались методы,
основанные на анализе данных из параметрических семейств распределений,
описываемых кривыми семейства Пирсона. Наиболее популярным было нормальное
(гауссово) распределение. Для проверки гипотез использовались критерии Пирсона,
Стьюдента, Фишера. Были предложены метод максимального правдоподобия,
дисперсионный анализ, сформулированы основные идеи планирования эксперимента.
Разработанную в первой трети ХХ в. теорию анализа данных называем
параметрической статистикой, поскольку её основной объект изучения — это
выборки из распределений, описываемых одним или небольшим числом параметров.
Наиболее общим является семейство кривых Пирсона, задаваемых четырьмя
параметрами. Как правило, нельзя указать каких-либо веских причин, по которым
распределение результатов конкретных наблюдений должно входить в то или иное
параметрическое семейство. Исключения хорошо известны: если вероятностная
модель предусматривает суммирование независимых случайных величин, то сумму
естественно описывать нормальным распределением; если же в модели
рассматривается произведение таких величин, то итог, видимо, приближается
логарифмически нормальным распределением, и т. д. Однако подобных моделей нет в
подавляющем большинстве реальных ситуаций, и приближение реального
распределения с помощью кривых из семейства Пирсона или его подсемейств — чисто
формальная операция. Именно из таких соображений критиковал параметрическую
статистику академик АН СССР С. Н. Бернштейн в 1927 г.. Однако эта теория и до
сих пор продолжает использоваться значительной массой прикладников.
В ХХ в. статистику часто рассматривают прежде всего как самостоятельную
научную дисциплину. Статистика есть совокупность методов и принципов, согласно
которым проводится сбор, анализ, сравнение, представление и интерпретация
числовых данных (1920-е гг.). В 1954 г. академик Б.В. Гнеденко дал следующее
определение: «Статистика состоит из трёх разделов:
) сбор статистических сведений, то есть сведений, характеризующих
отдельные единицы каких-либо массовых совокупностей;
) статистическое исследование полученных данных, заключающееся в
выяснении тех закономерностей, которые могут быть установлены на основе данных
массового наблюдения;
) разработка приёмов статистического наблюдения и анализа статистических
данных. Последний раздел, собственно, и составляет содержание математической
статистики».
Термин «статистика» употребляют ещё в двух смыслах.
Во-первых, в обиходе под «статистикой» часто понимают набор
количественных данных о каком-либо явлении или процессе.
Во-вторых, статистикой называют функцию от результатов наблюдений,
используемую для оценивания характеристик и параметров распределений и проверки
гипотез.
Со временем результаты обработки статистических данных стали представлять
в виде таблиц и диаграмм, как это сейчас делает Федеральная служба
государственной статистики России (Росстат) РФ.
Структура современной статистики такова.
Прикладная статистика — методическая дисциплина, являющаяся центром
статистики. При применении методов прикладной статистики к конкретным областям
знаний и отраслям народного хозяйства получаем научно-практические дисциплины
типа «статистика в промышленности», «статистика в медицине»,
«статистика в психологии» и др. С этой точки зрения эконометрика —
это «статистические методы в экономике».
Математическая статистика играет роль математического фундамента для
прикладной статистики.
К настоящему времени очевидно чётко выраженное размежевание этих двух научных
направлений. Математическая статистика исходит из сформулированных в 1930-50
гг. постановок математических задач, происхождение которых связано с анализом
статистических данных. Начиная с 70-х годов ХХ в. исследования по
математической статистике посвящены обобщению и дальнейшему математическому
изучению этих задач. Поток новых математических результатов (теорем) не
ослабевает, но новые практические рекомендации по обработке статистических
данных при этом не появляются. Можно сказать, что математическая статистика как
научное направление замкнулась внутри себя.
Сам термин «прикладная статистика» возник как реакция на
описанную выше тенденцию. Прикладная статистика нацелена на решение реальных
задач. Поэтому в ней возникают новые постановки математических задач анализа
статистических данных, развиваются и обосновываются новые методы. Обоснование
часто проводится математическими методами, то есть путём доказательства теорем.
Большую роль играет методологическая составляющая — как именно ставить задачи, какие
предположения принять с целью дальнейшего математического изучения. Велика роль
современных информационных технологий, в частности, компьютерного эксперимента.
Прикладная статистика включает в себя две внематематические области.
Во-первых, методологию организации статистического исследования: как
планировать исследование, как собирать данные, как подготавливать данные к
обработке, как представлять результаты. Во-вторых, организацию компьютерной
обработки данных, в том числе разработку и использование баз данных и
электронных таблиц, статистических программных продуктов, например, диалоговых
систем анализа данных.
Необходимо отметить, что между математической и прикладной статистикой
имеется и с течением времени углубляется разрыв. Он проявляется, в частности, в
том, что большинство методов, включенных в статистические пакеты программ, даже
не упоминается в учебниках по математической статистике. В результате разрыва
специалист по математической статистике оказывается зачастую беспомощным при
обработке реальных данных, а пакеты программ применяют (что еще хуже — и
разрабатывают) лица, не имеющие необходимой теоретической подготовки.
Естественно, что они допускают разнообразные ошибки. Типовые ошибки при
применении критериев согласия Колмогорова и омега-квадрат давно
проанализированы в литературе.
Выделяется также аналитическая статистика — это процедуры оценки
характеристик совокупности по данным выборок. Аналитическая статистика
включает:
— методы анализа вариации и частотных распределений;
— вопросы теории и практики выборочного наблюдения;
методы и показатели оценки взаимосвязей признаков;
методологию статистического изучения динамики;
основные характеристики, виды и способы исчисления индексов.
Итак, статистика — наука, исследующая с количественной стороны в
неразрывной связи с качественной массовые явления, к какой бы области они ни
относились, но обладающие признаками совокупности. Прикладная статистика и
математическая статистика — это две разные научные дисциплины. Курс
математической статистики состоит в основном из доказательств теорем. В курсах
прикладной статистики основное — методология анализа данных и алгоритмы
расчётов, а теоремы приводятся как обоснования этих алгоритмов, доказательства
же, как правило, опускаются.
1.2 Виды статистических методов прогнозирования
Статисти́ческие ме́тоды — методы анализа статистических
данных. Статистические методы анализа данных применяются практически во всех
областях деятельности человека. Их используют всегда, когда необходимо получить
и обосновать какие-либо суждения о группе (объектов или субъектов) с некоторой
внутренней неоднородностью.
Целесообразно выделить три вида научной и прикладной деятельности в
области статистических методов анализа данных (по степени специфичности
методов, сопряженной с погруженностью в конкретные проблемы):
а) разработка и исследование методов общего назначения, без учета
специфики области применения;
б) разработка и исследование статистических моделей реальных явлений и
процессов в соответствии с потребностями той или иной области деятельности;
в) применение статистических методов и моделей для статистического
анализа конкретных данных.
Кратко рассмотрим три только что выделенных вида научной и прикладной
деятельности. По мере движения от а) к в) сужается широта области применения
конкретного статистического метода, но при этом повышается его значение для
анализа конкретной ситуации. Если работам вида а) соответствуют научные
результаты, значимость которых оценивается по общенаучным критериям, то для
работ вида в) основное — успешное решение конкретных задач той или иной области
применения (техники и технологии, экономики, социологии, медицины и др.).
Работы вида б) занимают промежуточное положение, поскольку, с одной стороны,
теоретическое изучение свойств статистических методов и моделей,
предназначенных для определенной области применения, может быть весьма сложным
и математизированным, с другой — результаты представляют не всеобщий интерес, а
лишь для некоторой группы специалистов. Можно сказать, что работы вида б)
нацелены на решение типовых задач конкретной области применения.
Статистические методы анализа данных, относящиеся к группе а), обычно
называют методами прикладной статистики. Таким образом, прикладная статистика —
это наука о том, как обрабатывать данные произвольной природы, без учета их
специфики.
Математическая основа прикладной статистики и статистических методов
анализа данных в целом — это математическая наука, известная под названием
«теория вероятностей и математическая статистика». Как уже было
отмечено выше, прикладная статистика — другая область знаний, чем
математическая статистика.
Описание вида данных и, при необходимости, механизма их порождения —
начало любого статистического исследования. Отметим, что для описания данных
применяют как детерминированные, так и вероятностные методы. С помощью
детерминированных методов можно проанализировать только те данные, которые
имеются в распоряжении исследователя. Например, с их помощью получены таблицы,
рассчитанные органами официальной государственной статистики на основе
представленных предприятиями и организациями статистических отчетов. Перенести
полученные результаты на более широкую совокупность, использовать их для
предсказания и управления можно лишь на основе вероятностно-статистического
моделирования. Поэтому в математическую статистику часто включают лишь методы,
опирающиеся на теорию вероятностей, оставляя детерминированные методы
экономической учебной дисциплине «Общая теория статистики».
Вряд ли возможно противопоставлять детерминированные и вероятностно-статистические
методы. Мы рассматриваем их как последовательные этапы статистического анализа.
На первом этапе необходимо проанализировать имеющие данные, представить их в
удобном для восприятия виде с помощью таблиц и диаграмм. Затем статистические данные
целесообразно проанализировать на основе тех или иных
вероятностно-статистических моделей. Отметим, что возможность более глубокого
проникновения в суть реального явления или процесса обеспечивается разработкой
адекватной математической модели.
В простейшей ситуации статистические данные — это значения некоторого
признака, свойственного изучаемым объектам. Значения могут быть количественными
или представлять собой указание на категорию, к которой можно отнести объект.
Во втором случае говорят о качественном признаке.
При измерении по нескольким количественным или качественным признакам в
качестве статистических данных об объекте получаем вектор. Его можно
рассматривать как новый вид данных. В таком случае выборка состоит из набора
векторов. Есть часть координат — числа, а часть — качественные
(категоризованные) данные, то говорим о векторе разнотипных данных.
Элементами выборки могут быть и иные математические объекты. Например,
бинарные отношения. Так, при опросах экспертов часто используют упорядочения
(ранжировки) объектов экспертизы — образцов продукции, инвестиционных проектов,
вариантов управленческих решений. В зависимости от регламента экспертного
исследования элементами выборки могут быть различные виды бинарных отношений
(упорядочения, разбиения, толерантности), множества, нечеткие множества и т. д.
Итак, математическая природа элементов выборки в различных задачах
прикладной статистики может быть самой разной. Однако можно выделить два класса
статистических данных — числовые и нечисловые. Соответственно прикладная
статистика разбивается на две части — числовую статистику и нечисловую
статистику.
Числовые статистические данные — это числа, вектора, функции. Их можно
складывать, умножать на коэффициенты. Поэтому в числовой статистике большое
значение имеют разнообразные суммы. Математический аппарат анализа сумм
случайных элементов выборки — это (классические) законы больших чисел и
центральные предельные теоремы.
Нечисловые статистические данные — это категоризованные данные, вектора
разнотипных признаков, бинарные отношения, множества, нечеткие множества и др.
Их нельзя складывать и умножать на коэффициенты. Поэтому не имеет смысла
говорить о суммах нечисловых статистических данных. Они являются элементами
нечисловых математических пространств (множеств). Математический аппарат
анализа нечисловых статистических данных основан на использовании расстояний
между элементами (а также мер близости, показателей различия) в таких
пространствах. С помощью расстояний определяются эмпирические и теоретические
средние, доказываются законы больших чисел, строятся непараметрические оценки
плотности распределения вероятностей, решаются задачи диагностики и кластерного
анализа, и т.д.
В прикладных исследованиях используют статистические данные различных
видов. Это связано, в частности, со способами их получения. Например, если
испытания некоторых технических устройств продолжаются до определенного момента
времени, то получаем т.н. цензурированные данные, состоящие из набора чисел —
продолжительности работы ряда устройств до отказа, и информации о том, что
остальные устройства продолжали работать в момент окончания испытания.
Цензурированные данные часто используются при оценке и контроле надежности
технических устройств.
Выделяют методы прикладной статистики, которые могут применяться во всех
областях научных исследований и любых отраслях национальной экономики, и другие
статистические методы, применимость которых ограничена той или иной сферой.
Имеются в виду такие методы, как статистический приемочный контроль,
статистическое регулирование технологических процессов, надежность и испытания,
планирование экспериментов.
Опыт прогнозирования индекса инфляции и стоимости потребительской корзины
накоплен в Институте высоких статистических технологий и эконометрики. При этом
оказалось полезным преобразование (логарифмирование) переменной — текущего
индекса инфляции. Характерно, что при стабильности условий точность
прогнозирования оказывалась достаточно удовлетворительной — 10-15 %. Однако,
если обратиться к истории, спрогнозированное на осень 1996 г. значительное
повышение уровня цен не осуществилось. Дело в том, что руководство страны
перешло к стратегии сдерживания роста потребительских цен путем массовой
невыплаты зарплаты и пенсий. Условия изменились — и статистический прогноз
оказался непригодным. Влияние решений руководства Москвы проявилось также в
том, что в ноябре 1995 г. (перед парламентскими выборами) цены в Москве упали в
среднем на 9,5%, хотя обычно для ноября характерен более быстрый рост цен, чем
в другие месяцы года, кроме декабря и января.
Оценивание точности прогноза — необходимая часть процедуры
квалифицированного прогнозирования. При этом обычно используют
вероятностно-статистические модели восстановления зависимости, например, строят
наилучший прогноз по методу максимального правдоподобия. Разработаны
параметрические (обычно на основе модели нормальных ошибок) и непараметрические
оценки точности прогноза и доверительные границы для него (на основе
Центральной Предельной Теоремы теории вероятностей). Так, в литературе
предложены и изучены методы доверительного оценивания точки наложения (встречи)
двух временных рядов и их применения для оценки динамики технического уровня
собственной продукции и продукции конкурентов, представленной на мировом рынке.
Применяются также эвристические приемы, не основанные на какой-либо
теории: метод скользящих средних, метод экспоненциального сглаживания.
Адаптивные методы прогнозирования позволяют оперативно корректировать
прогнозы при появлении новых точек. Речь идет об адаптивных методах оценивания
параметров моделей и об адаптивных методах непараметрического оценивания.
Отметим, что с развитием вычислительных мощностей компьютеров проблема сокращения
объемов вычисления теряет свое значение.
Многомерная регрессия, в том числе с использованием непараметрических
оценок плотности распределения — основной на настоящий момент эконометрический
аппарат прогнозирования. Подчеркнем, что нереалистическое предположение о
нормальности погрешностей измерений и отклонений от линии (поверхности)
регрессии использовать не обязательно. Однако для отказа от предположения
нормальности необходимо опереться на иной математический аппарат, основанный на
многомерной центральной предельной теореме теории вероятностей и
эконометрической технологии линеаризации. Он позволяет проводить точечное и
интервальное оценивание параметров, проверять значимость их отличия от 0 в
непараметрической постановке, строить доверительные границы для прогноза.
Весьма важна проблема проверки адекватности модели, а также проблема
отбора факторов. Дело в том, что априорный список факторов, оказывающих влияние
на отклик, обычно весьма обширен, желательно его сократить, и крупное
направление современных эконометрических исследований посвящено методам отбора
«информативного множества признаков». Однако эта проблема пока еще
окончательно не решена. Проявляются необычные эффекты. Так, в литературе
установлено, что обычно используемые оценки степени полинома имеют
геометрическое распределение. Перспективны непараметрические методы оценивания
плотности вероятности и их применения для восстановления регрессионной
зависимости произвольного вида. Наиболее общие постановки в этой области
получены с помощью подходов статистики нечисловых данных.
К современным статистическим методам прогнозирования относятся также
модели авторегрессии, модель Бокса-Дженкинса, системы эконометрических
уравнений, основанные как на параметрических, так и на непараметрических подходах.
Для установления возможности применения асимптотических результатов при
конечных (т.н. «малых») объемах выборок полезны компьютерные
статистические технологии. Они позволяют также строить различные имитационные
модели. Отметим полезность методов размножения данных (бутстреп-методов).
Системы прогнозирования с интенсивным использованием компьютеров объединяют
различные методы прогнозирования в рамках единого автоматизированного рабочего
места прогнозиста.
Прогнозирование на основе данных, имеющих нечисловую природу, в
частности, прогнозирование качественных признаков основано на результатах
статистики нечисловых данных. Весьма перспективными для прогнозирования
представляются регрессионный анализ на основе интервальных данных, включающий,
в частности, определение и расчет нотны и рационального объема выборки, а также
регрессионный анализ нечетких данных. Общая постановка регрессионного анализа в
рамках статистики нечисловых данных и ее частные случаи — дисперсионный анализ
и дискриминантный анализ (распознавание образов с учителем), давая единый
подход к формально различным методам, полезна при программной реализации
современных статистических методов прогнозирования.
Итак, статистические методы представляют собой совокупность методов
обработки количественной информации об объекте прогнозирования, объединенной по
принципу выявления содержащихся в ней математических закономерностей изменения
характеристик данного объекта с целью получения прогнозных моделей.
Глава 2. Применение статистических методов прогнозирования
.1 Процесс прогнозирования, опирающийся на статистические методы
Процессы развития в обществе носят диалектический характер, который, в
частности, проявляется в сочетании черт устойчивости и изменчивости этого
развития. Соотношение этих черт, их удельный вес в характеристике развития за
определенные хронологические интервалы весьма важны для
социально-экономического прогнозирования. Так, если изучаемые и прогнозируемые
процессы имеют достаточно длительную историю и накоплен материал, позволяющий
вскрыть закономерность и тенденции в их развитии и взаимосвязях с другими
явлениями, а сами процессы обладают большой инерционностью, то гипотеза о
будущем развитии этих процессов в значительной мере, хотя и не исключительно,
может базироваться на анализе прошлого. Инерционность в социально-экономических
процессах проявляется двояким образом:
во-первых, как инерционность взаимосвязей, т.е. как сохранение в основных
чертах механизма формирования явления (иначе говоря, сохранение зависимости,
корреляции прогнозируемой переменной от совокупности переменных-аргументов);
во-вторых, как инерционность в развитии отдельных сторон процессов, т.е.
как некоторая степень сохранения их характера — темпов, направления,
колеблемости основных количественных показателей на протяжении сравнительно
длительных хронологических отрезков.
Инерционность развития экономики страны связана с длительно
воздействующими факторами, например, такими, как структура основных фондов, их
возраст и эффективность, размеры инвестиций прошлых лет, степень устойчивости
технологических взаимосвязей отраслей производства, исторически сложившаяся
структура потребления и т.д. Следует также учесть, что научно-технический
прогресс в основном материлизуется путем постепенного накапливания небольших
улучшений, усовершенствований, новшеств, относительно медленным вытеснением
старого. Новые факторы, пришедшие на смену старым, в свою очередь способны
оказывать более или менее длительное инерционное воздействие.
По-видимому, степень инерционности зависит и от такого фактора, как
размер или масштаб изучаемой системы или процесса. Если рассматривать
производственную систему, то чем ниже ее уровень в иерархии «предприятие —
отрасль — экономика», тем менее инерционными оказываются соответствующие
характеристики. Последнее обстоятельство можно объяснить и тем, что влияние
отдельного фактора (например, внедрение новой технологии) на низовом уровне
часто оказывается доминирующим. На макроуровне показатели более устойчивы,
поскольку на их значение оказывает воздействие уже гораздо большее число
факторов. Изменение действия ряда из них (иногда оказывающих противоположное
влияние) приводит к меньшей потере инерционности, чем на микроуровне.
Инерционную тенденцию можно уподобить равнодействующей системе сил в механике.
При большом числе составляющих изменение одной из них не окажет серьезного
влияния на положение и размер равнодействующей в рамках всего хозяйства.
Опыт свидетельствует также и о том, что чем «моложе» изучаемая
система (экономическое явление, процесс, отрасль) и соответственно чем меньше
имелось времени для формирования более или менее устойчивых взаимосвязей и
основных тенденций в ее развитии, тем меньшей инерционностью она обладает.
Таким образом, при значительной инерционности рассматриваемых
экономических процессов и взаимосвязей и сохранении в будущем важных внешних
причин и условий их развития правомерно с достаточной степенью вероятности
ожидать сохранения уже выявившихся черт и характера этого процесса. Причем
наличие инерционности нисколько не означает, что явление в своем развитии будет
жестко следовать уже наметившейся тенденции. Несомненно, различные факторы
будут в большей или меньшей степени воздействовать на явления, приводя к
отклонениям от тенденции. В этих условиях становится целесообразным применять
разнообразные методы обнаружения и экстраполяции преобладающей тенденции
развития анализируемого объекта, использовать для прогнозирования найденные
взаимосвязи экономических показателей и закономерности их изменения. При этом
естественным является применение статистических подходов к прогнозированию.
Процесс прогнозирования, опирающийся на статистические методы,
распадается на два этапа.
Первый, индуктивный, заключается в обобщении данных, наблюдаемых за более
или менее продолжительный период времени, и в представлении соответствующих
статистических закономерностей в виде модели. Статистическую модель получают
или в виде аналитически выраженной тенденции развития, или же в виде уравнения
зависимости от одного или нескольких факторов-аргументов. В ряде случаев — при
изучении сложных комплексов экономических показателей — прибегают к разработке
так называемых взаимозависимых систем уравнений, состоящих в основном
опять-таки из уравнений, характеризующих статистические зависимости. Процесс
построения и применения статистической модели для прогнозирования, какой бы вид
последняя не имела, обязательно включает выбор формы уравнения, описывающего
динамику или взаимосвязь явлений, и оценивание его параметров с помощью того
или иного метода.
Второй этап, собственно прогноз, является дедуктивным. На этом этапе на
основе найденных статистических закономерностей определяют ожидаемое значение
прогнозируемого признака.
Следует подчеркнуть, что полученные результаты не могут рассматриваться
как нечто окончательное. При их оценке и использовании должны приниматься во
внимание факторы, условия или ограничения, которые не были учтены при
разработке статистической модели, должна осуществляться корректировка
обнаруженных статистических характеристик в соответствии с ожидаемым изменением
обстоятельств их формирования. Короче говоря, найденные с помощью
статистических методов прогностические оценки являются важным материалом,
который, однако, должен быть критически осмыслен. При этом главным является
учет возможных изменений в самих тенденциях развития экономических явлений и
объектов.
Известная условность в получаемых выводах связана с тем, что целый ряд
статистических методов базируется на довольно жестких требованиях к качеству
обрабатываемых данных (например, к их однородности) и строгих гипотезах о
характере поведения анализируемых величин (их распределениях). На практике же
прогностик зачастую, особенно если исследуются динамические ряды, имеет дело с
информацией, качество которой в отношении выдвинутых требований оставляет желать
лучшего или просто неизвестно. Обычно неизвестен и тип распределения
переменных.
Таким образом, для практика остаются две альтернативы: или вообще
отказаться от применения большинства методов и довольствоваться достаточно
скудным инструментарием, или применять разнообразные статистические методы
обработки данных, не забывая о соответствующих этим методам требованиях.
Очевидно, что в последнем случае, если существуют сомнения в «чистоте
эксперимента», не следует придавать получаемым статистическим выводам
чрезмерно строгий смысл. В то же время эти выводы, как правило, оказываются
полезными для практической деятельности и прогнозирования. Так, например,
статистическая проверка гипотез основывается на предположении о существовании
нормального распределения соответствующих переменных. На практике же мы в
лучшем случае сталкиваемся с асимптотически нормальными распределениями (т.е. с
распределениями, стремящимися к нормальным с ростом объема выборки). Вместе с
тем проверка гипотез и в этих обстоятельствах дает практически приемлемые
результаты, исключая разве такие ситуации, когда значения, скажем, t-статистики
Стьюдента близки к критическому (ta). В последнем случае вывод, естественно,
нельзя признать надежным.
Далеко не всегда статистические методы прогнозирования применяются
самостоятельно, так сказать, в чистом виде. Часто их включают в виде важных
элементов в комплексные методики, предусматривающие сочетание статистических
методов с другими методами прогнозирования, например с экспертными оценками,
различного рода экономико-математическими моделями и т.д. Такой комплексный
подход к прогнозированию представляется наиболее плодотворным. Из сказанного
выше вытекает, что статистические методы занимают важное место в системе
методов прогнозирования, однако они ни в коей мере не должны рассматриваться
как некий универсальный метод, как «золотой ключик», открывающий
любую дверь.
В ряде случаев собственно статистическая обработка экономической
информации непосредственно не приводит к получению прогноза, однако является
важным звеном в общей системе из разработки. Такая обработка данных наблюдения,
нацеленная на вскрытие различного рода конкретных статистических
закономерностей, представляет собой, по сути дела, первый шаг на пути
осмысливания информации и построения более сложных моделей, отображающих
взаимодействие множества факторов.
Итак, необходимо подчеркнуть важную роль статистической методологии в
рамках построения имитационных моделей, которые все больше привлекают внимание
прогностиков. Потенциальные возможности имитационных моделей в отношении
прогнозирования поведения изучаемых (моделируемых) систем еще далеки от полного
раскрытия. Но уже сейчас очевидно, что успешность прогнозов, получаемых на
основе имитационных моделей, существенно будет зависеть от качества
статистического анализа эмпирического материала, от того, насколько такой
анализ сможет выявить и обобщить закономерности развития изучаемых объектов во
времени.
2.2 Практическое применение статистических методов прогнозирования (на примере метода наименьших квадратов)
прогнозирование фактографический экспертный статистический
Метод наименьших квадратов (МНК) является одним из выдающихся достижений
математики. Данный метод в простейшем случае (линейная функция от одного
фактора) был разработан К. Гауссом более двух столетий назад, в 1794 — 1795 гг.
В 1794 г. (по другим данным — в 1795 г.) Гаусс разработал метод наименьших
квадратов, один из наиболее популярных ныне статистических методов, и применил
его при расчёте орбиты астероида Церера — для борьбы с ошибками астрономических
наблюдений.
Суть МНК состоит в следующем.
Зачастую при исследованиях многих проблем исследователям и менеджерам
приходится работать с уравнениями, содержащими стохастические параметры и
неизвестные. Такие уравнения не решаются обычным путем, так как система из
таких уравнений является несовместной. Поэтому «речь здесь может идти
только о приближенном решении таких уравнений путем обеспечения минимума ошибок
исходных начальных (условных) уравнений. Полученные таким образом значения
искомых неизвестных являются наиболее вероятными».
Соглашение о минимизации суммы модулей ошибок всех условных уравнений
впервые выдвинул Эджворт. Но популярным оно так и не стало. Другое соглашение
было предложено и опубликовано Лежандром. После его публикации Гаусс заявил,
что он много лет пользовался таким соглашением, однако признал, что оно,
бесспорно, принадлежит именно Лежандру.
Этапами решения условных стохастических уравнений по принципу Лежандра
являются: а) составление уравнения суммы ошибок условных уравнений; б)
возведение этой суммы в квадрат; в) взятие частных производных по всем
неизвестным и приравнивание этих производных к нулю; г) приведение подобных
членов и получение системы нормальных уравнений; д) решение системы нормальных
уравнений и нахождение наиболее вероятных значений неизвестных. Главное в этом
решении то, что квадратическая функция ошибок начальных уравнений имеет всегда
минимум, причем только один.
Наилучшее решение рассматриваемых вопросов возможно именно с помощью МНК.
Как и любые другие методы, МНК имеет свои недостатки. Например, может
оказаться (при коллинеарности уравнений), что определитель матрицы нормальных
уравнений равен нулю или весьма незначительно отличается от него. Решение
системы нормальных уравнений в таком случае невозможно и нецелесообразно.
Однако это явление встречается очень редко. Кроме того, существует ряд методов
(например, метод регуляризации), позволяющих перед решением освободиться от
плохой обусловленности матрицы нормальных уравнений, коллинеарности и даже
мультиколлинеарности. Все это ничуть не снижает ценности МНК в технических
приложениях.
Рассмотрим примеры практического использования МНК.
Первый пример — исследование финансового положения потенциальных
заемщиков в банковской практике. Пусть мы имеем систему из n условных
(начальных) уравнений в виде:
kx + Bky + Ckz + Dku + Lk = 0 (k = 1, 2… n),
где x, y, z, u — искомый финансовый вес n различных заемщиков;k, Bk, Ck,
Dk — известные финансовые потери от n
разных заемщиков;k
— случайные значения сумм финансовых потерь от n заемщиков.
Имея несколько начальных уравнений, можно пропустить указанные громоздкие
и очень трудоемкие этапы реализации МНК. При этом необходимо последовательно
умножить все члены первого условного уравнения на свои A, B, C и D. В
результате из одного условного уравнения получим четыре уравнения. Со вторым,
третьим и четвертым условными уравнениями поступаем так же. В итоге имеем 16
новых уравнений. Приведя в них подобные члены, получаем систему четырех
нормальных уравнений. Запишем ее в более удобных обозначениях Гаусса, принятых
в астрономии и геодезии:
[AA]x + [AB]y + [AC]z + [AD]u + [AL] = 0;
[BA]x + [BB]y + [BC]z + [BD]u + [BL] = 0;
[CA]x + [CB]y + [CC]z + [CD]u + [CL] = 0;
[DA]x + [DB]y + [DC]z + [DD]u + [DL] = 0,
где
[BA]=[AB], [CA]=[AC] и т.д., [AA]=SUM Ak2,
[AB]=SUM AkBk, [AL]=SUM AkLk и т.д.
Таким образом, из имеющихся начальных уравнений получилась система
нормальных уравнений, вполне пригодная для решения. Неизвестные x, y, z, u
находим по известным выражениям:
= Dx / D, y = Dy / D, z = Dz / D, u = Du / D,
где D — определитель системы нормальных уравнений;, Dy, Dz, Du —
определители соответствующих неизвестных, образуемые установкой в определитель
D последовательно столбца свободных членов.
Вес неизвестных находится по выражениям:
= D / D11, Py = D / D22, Pz = D / D33, Pu = D / D44,
где D11, D22, D33, D44 — алгебраические дополнения элементов главной
диагонали матрицы нормальных уравнений.
Ошибки вычисления (СКО) неизвестных находятся по выражениям:
Sx = S0 / /Px, Sy = S0 / /Py, Sz = S0 / /Pz, Su = S0/Pu,
где S0 = S / (n — m), S — сумма квадратов ошибок нормальных уравнений;-
число начальных уравнений; m — число неизвестных.
Выходные оценки МНК имеют вид: xb = x +- Sx, yb = y +- Sy, zb = z +- Sz,
ub = u +- Su.
Второй пример. Предприятие столкнулось с проблемой разделения затрат на
текущий ремонт оборудования, которые являются смешанными. Величина этих затрат
и объем производства продукции по месяцам представлены в таблице 1.
Таблица 1 Величина затрат и объем производства
продукции на предприятии
|
Месяц |
Объем производства |
Затраты на текущий ремонт |
|
Январь |
1,2 |
|
|
Февраль |
1,0 |
430 |
|
Март |
1,4 |
580 |
|
Апрель |
1,8 |
690 |
|
Май |
1,6 |
620 |
|
Июнь |
2,0 |
680 |
|
Июль |
2,4 |
730 |
|
Август |
2,2 |
720 |
|
В среднем за месяц |
1,7 |
612,5 |
Алгоритм расчета на основе МНК представлен в таблице 2.
Таблица 2 Алгоритм расчета на основе МНК
|
Месяц |
Объем производства |
Х — Х |
Смешанные затраты всего, З |
З — З |
(Х — Х)2 |
(Х — Х) ´ (З — З) |
|
Январь |
1,2 |
-0,5 |
450 |
-162,5 |
0,25 |
81,25 |
|
Февраль |
1,0 |
-0,7 |
430 |
-182,5 |
0,49 |
127,75 |
|
Март |
1,4 |
-0,3 |
580 |
-32,5 |
0,09 |
9,75 |
|
Апрель |
1,8 |
0,1 |
690 |
77,5 |
0,01 |
7,75 |
|
Май |
1,6 |
-0,1 |
620 |
7,5 |
0,01 |
-0,75 |
|
Июнь |
2,0 |
680 |
67,5 |
0,09 |
20,25 |
|
|
Июль |
2,4 |
0,7 |
730 |
117,5 |
0,49 |
82,25 |
|
Август |
2,2 |
0,5 |
720 |
107,5 |
0,25 |
53,75 |
|
Итого |
4900 |
1,68 |
382,0 |
|||
|
Среднее значение |
1,7 |
612,5 |
Переменные затраты на единицу изделия рассчитываются следующим образом:

В расчете на среднемесячный объем производства продукции переменные
затраты составят: 227,4 ´ 1700 = 386,6 тыс.руб. Постоянные издержки будут равны 225,9 тыс.руб.
(612,5 — 386,6).
В заключение отметим, что метод наименьших квадратов чувствителен к
значительным отклонениям от средних, и иногда более грубые методы могут давать
более точные результаты.
Заключение
Под методами прогнозирования следует понимать совокупность приемов и
способов мышления, позволяющих на основе анализа ретроспективных данных,
экзогенных (внешних) и эндогенных (внутренних) связей объекта прогнозирования,
а также их измерений в рамках рассматриваемого явления или процесса вывести
суждения определенной достоверности относительно его (объекта) будущего
развития.
Значительную группу методов прогнозирования составляют статистические
методы. Статистические методы представляют собой совокупность методов обработки
количественной информации об объекте прогнозирования, объединенной по принципу
выявления содержащихся в ней математических закономерностей изменения
характеристик данного объекта с целью получения прогнозных моделей.
Применение статистических методов и моделей для статистического анализа
конкретных данных тесно привязано к проблемам соответствующей области.
Результаты данной научной и прикладной деятельности находятся на стыке
дисциплин.
Теория статистических методов нацелена на решение реальных задач. Поэтому
в ней постоянно возникают новые постановки математических задач анализа
статистических данных, развиваются и обосновываются новые методы. Обоснование
часто проводится математическими средствами, то есть путем доказательства
теорем. Большую роль играет методологическая составляющая — как именно ставить
задачи, какие предположения принять с целью дальнейшего математического
изучения. Велика роль современных информационных технологий, в частности,
компьютерного эксперимента.
Прикладная статистика — наука о методах обработки статистических данных.
Методы прикладной статистики активно применяются в технических исследованиях,
экономике, теории и практике управления (менеджмента), социологии, медицине,
геологии, истории и т.д. С результатами наблюдений, измерений, испытаний,
опытов, с их анализом имеют дело специалисты во всех отраслях практической деятельности,
почти во всех областях теоретических исследований.
Исследовать явление статистическими методами — значит наблюдать множество
его элементов или наблюдать само явление во множестве его повторений в
пространстве или (и) во времени, охарактеризовать результаты наблюдений в их
совокупности статистическими показателями, анализировать их с учетом формы
проявления закономерностей в массовых явлениях и действующих в них общих
законов.
На каждой из стадий применяются специфические приемы и способы (методы
массовых наблюдений, группировок, обобщающих показателей, табличный метод,
метод графических изображений, способы преобразования динамических рядов, метод
корреляционного анализа и др.), которые в своей совокупности и составляют
содержание статистического метода.
В настоящее время на отечественных предприятиях продолжают развиваться
структуры, нуждающиеся в статистических методах, — подразделения качества,
надежности, управления персоналом, центральные заводские лаборатории и другие.
Толчок к развитию в последние годы получили службы контроллинга, маркетинга и
сбыта, логистики, сертификации, прогнозирования и планирования, инноваций и
инвестиций, управления рисками, которым также полезны различные статистические
методы. Статистические методы необходимы органам государственного и
муниципального управления, организациям силовых ведомств, транспорта и связи,
медицины, образования, агропромышленного комплекса, научным и практическим
работникам всех областей деятельности.
Список литературы
1. Постановление Правительства Российской Федерации от 7
апреля 2004 г. N 188 «Вопросы Федеральной службы государственной
статистики» (с посл. изм. и доп.) // СПС «Консультант-Плюс»,
2009 г.
2. Положение о Федеральной службе государственной
статистики. Утверждено Постановлением Правительства РФ от 30 июля 2004 г. N 399
(с посл. изм. и доп.) // СПС «Консультант-Плюс», 2009 г.
. Распоряжение Правительства РФ от 30 июля 2004 г. N
1024-р о подчинении Федеральной службе государственной статистики
территориальных органов Госкомстата РФ // СПС «Консультант-Плюс»,
2009 г.
. Федеральный план статистических работ на 2008 — 2010
годы, утвержденный распоряжением Правительства Российской Федерации от
06.05.2008 N 671-р // СПС «Консультант-Плюс», 2009 г.
. Арженовский С.В. Методы социально-экономического
прогнозирования. Учебное пособие. — М.: Дашков и К, Наука-Спектр, 2008. — 390
с.
. Басовский Л.Е. Прогнозирование и планирование в
условиях рынка Уч. пос. — М.: Финансы и статистика, 2002. — 345 с.
. Бесфамильная Л.В., Цыганов А.А. Статистика — основа
качества в страховом деле // Стандарты и качество. — 2004. — №7. — С. 22 — 26.
. Большой экономический словарь / Под ред. А.Н.
Азрилияна. — 2-е изд., перераб. и доп. — М.: Ин-т новой экономики, 1997. — 1376
с.
. Большев Л.Н., Смирнов Н.В. Таблицы математической
статистики. 3-е изд. — М.: Наука, 1983.
. Бухонова С.М., Дорошенко Ю.А., Сыров М.В., Тумина
Т.А. Теоретические и методические основы анализа трансакционной составляющей
затрат на инновационную деятельность // Экономический анализ: теория и практика.
— 2008. — №16. — С. 23 — 30.
11. Высшая математика для экономистов / Под ред. Н.Ш.
Кремера. — М.: Республика, 1998. — 456 с.
12. Гнеденко Б.В., Беляев Ю.К., Соловьев А.Д.
Математические методы в теории надежности. — М.: Наука, 1965. — 524 с.
. Гнеденко Б.В., Коваленко И.Н. Введение в теорию
массового обслуживания. — М.: Наука, 1966. — 301 с.
. Дуброва Т.А. Статистические методы прогнозирования в
экономике. — М.: Московский международный институт эконометрики, информатики,
финансов и права, 2003. — 50 с.
. Жихарев В.Н., Орлов А.И. Законы больших чисел и
состоятельность статистических оценок в пространствах произвольной природы. — В
сб.: Статистические методы оценивания и проверки гипотез. Межвузовский сборник
научных трудов. — Пермь: Изд-во Пермского государственного университета, 1998.
— С. 65 — 84.
. Клейн Ф. Лекции о развитии математики в ХIХ
столетии. Часть I. — М.-Л.: Объединенное научно-техническое издательство НКТП
СССР, 1937. — 432 с.
. Крамер Г. Математические методы статистики. 2-е изд.
— М.: Мир, 1975. — 648 с.
. Моисейко В. Управление в структурах малого и
среднего бизнеса: системно-конструктивистский подход // Проблемы теории и
практики управления. — 2003. — №3. — С. 92 — 96.
. Налимов В.В., Мульченко З.М. Наукометрия. Изучение
развития науки как информационного процесса. — М.: Наука, 1969. — 192 с.
. Никитина Е.П., Фрейдлина В.Д., Ярхо А.В. Коллекция
определений термина «статистика». — М.: МГУ, 1972. — 46 с.
. Норман Дрейпер, Гарри Смит. Прикладной регрессионный
анализ. Множественная регрессия = Applied Regression Analysis. 3-е изд. — М.:
«Диалектика», 2007. — 456 с.
. Орлов А.И. Высокие статистические технологии //
Заводская лаборатория. — 2003. — №11. — С. 55 — 60.
. Орлов А.И. О перестройке статистической науки и её
применений // Вестник статистики. — 1990. — №1. — С. 65 — 71.
. Орлов А.И. О современных проблемах внедрения
прикладной статистики и других статистических методов // Заводская лаборатория.
— 1992. — №1. — С. 67 — 74.
. Орлов А.И. Эконометрика. Учебник для вузов. Изд.
3-е, исправленное и дополненное. — М.: Изд-во «Экзамен», 2004. — 576
с.
. Писарева О.М. Методы прогнозирования развития
социально-экономических систем. — М.: Высшая школа, 2007. — 591 с.
. Плошко Б.Г., Елисеева И.И. История статистики: Учеб.
пособие. — М.: Финансы и статистика, 1990. — 295 с.
. Практикум по экономике организации (предприятия):
Учеб. пос. / Под ред. П.В. Тальминой и Е.В. Чернецовой. 2-е изд., доп. — М.:
Финансы и статистика, 2006. — 480 с.
29. Прикладное прогнозирование национальной экономики:
учебное пособие / под ред. В.В. Ивантера, И.А. Буданова, А.Г. Коровкина, В.С.
Сутягина. — М.: Издательство
«ЭкономистЪ», 2007. — 390 с.
. Светуньков С.Г. Основы теории эконометрии
комплексных переменных. — СПб.: Изд-во СПбГУЭФ, 2008. — 108 с.
31. Светуньков С.Г., Светуньков И.С. Производственные
функции комплексных переменных. — СПб.: Издательство СПбГУЭФ, 2006. — 579 с.
33. Тутубалин В.Н. Границы применимости
(вероятностно-статистические методы и их возможности). — М.: Знание, 1977. — 64
с.
. Четыркин Е.М. Статистические методы прогнозирования.
— М.: Статистика, 1977. — 340 с.
. Экономика предприятия: Учеб. пособие / Т.А.
Симунина, Е.Н. Симунин, В.С. Васильцов и др. 3-е изд., перераб. и доп. — М.:
КНОРУС, 2008. — 567 с.
. Экономико-математические методы и прикладные модели
/ Под ред. В.В. Федосеева. — М.: Перспектива, 2001. — 300 с.
Приложение
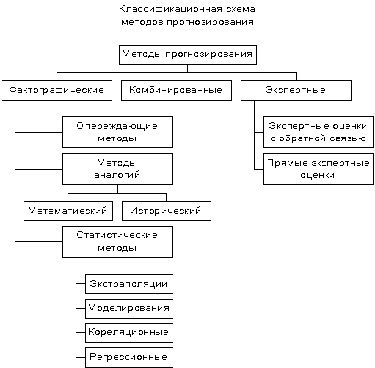
Рис. 1. Конструктивная классификация методов прогнозирования.
Курсовая работа
по дисциплине Статистика
Статистические методы прогнозирования социально-экономических явлений
Содержание
Введение
Глава 1. Прогнозирование
.1 Критерии качества прогнозных моделей
.2 Проработка спецификации
.3 Разработка прогнозной модели
.4 Технология создания систем прогнозирования
Глава 2. Классификация прогнозных моделей
.1 Методы прогнозирования, основанные на сглаживании, экспоненциальном сглаживании и скользящем среднем
.2 Методы Бокса-Дженкинса (ARIMA)
Заключение
Литература
Введение
Чаще всего необходимо знать будущие значения таких показателей, как цена товара на рынке, объем спроса, объемы собственных продаж, объемы производства и продаж конкурентов, рыночная конъюнктура, структура товарного ассортимента конкурентов. Ценность таких знаний существенно возрастает в агрессивной рыночной среде с изменчивым характером спроса, в условиях сезонности и цикличности.
Прогноз может быть экспертным, а может быть рассчитан математически с помощью прогнозных моделей. Математический прогноз является объективным, открытым и научно обоснованным. Только математические прогнозные модели позволяют осуществлять многовариантное моделирование. Математическая прогнозная модель — это математическая модель экономической системы: рынка в целом, отдельного предприятия или группы взаимосвязанных предприятий [20]. Такая модель разрабатывается для расчета прогнозных значений одного или нескольких показателей исследуемой систем.
Применение прогнозных моделей допустимо в условиях стационарности исследуемой системы. Это значит, что должны быть известны правила игры на рынке и эти правила не должны сильно изменяться с течением времени. По своей сути, прогнозная модель — это модель правил игры на рынке. Изменяться могут факторы и стратегии рыночных игроков. Эти изменения учитываются моделью, что и позволяет ей рассчитывать точные прогнозы.
Математическая прогнозная модель представляет собой набор формул с коэффициентами, которые формируются в процессе разработки модели, на стадии численного моделирования. В формулы подставляются факторы, отобранные в процессе разработки модели, на стадии качественного моделирования.
Глава 1. Прогнозирование
1.1 Критерии качества прогнозных моделей
Чем точнее прогноз, тем выше его ценность. Существуют две стадии оценки прогностических способностей моделей: прогнозирование прошедших периодов времени и опытная эксплуатация. В первом случае модель строится не на всей имеющейся статистике, а на так называемой обучающей выборке, из которой исключаются несколько последних точек — так называемая тестовая выборка. Модель как бы «не знает» о существовании этих последних, наиболее свежих данных. Разработчик модели рассчитывает прогнозные значения, соответствующие интервалам времени, на которые приходится тестовая выборка, и оценивает прогностические способности модели на основе разницы между фактическими и прогнозными значениями показателя [1].
Модель, прошедшая первую стадию тестирования, и переданная в опытную эксплуатацию, рассчитывает будущие значения показателя в чистом виде [16]. По мере наступления будущего, прогнозные значения показателя сравниваются с его фактическими значениями.
Прогноз, рассчитываемый с помощью модели, может быть двух типов: точечный и интервальный. Точечный прогноз — это одно число для одного периода времени. Интервальный прогноз — это два числа для одного периода времени: верхняя и нижняя граница прогноза.
Рассчитать прогноз объема продаж с точностью до одной упаковки очень маловероятно. Точечный прогноз будет где-то около фактического значения. В этом случае точностью прогнозной модели будет степень близости расчетного и фактического значений.
В случае с интервальным прогнозом ситуация иная. Расстояние между верхней и нижней границей прогноза называется доверительным интервалом. Чем шире доверительный интервал, тем выше вероятность попадания в этот интервал фактического значения прогнозируемого показателя. Теоретически, можно сделать доверительный интервал настолько широким, что вероятность попадания в него будет равна ста процентам.
Точность модели можно повышать постоянно, для этого есть два способа: экстенсивный и интенсивный. Экстенсивный способ — это пересчет коэффициентов модели на дополнительной статистике. Промышленная реализация прогнозных моделей может включать в себя механизм самонастройки по мере поступления новой информации с течением времени. Интенсивный способ — это дополнительная проработка спецификации модели, одна из самых затратных работ в процессе создания прогнозной модели.
1.2 Проработка спецификации
Спецификацией прогнозной модели называется механизм расчета прогноза. Это набор факторов, вид формул, варианты включения факторов в формулы — простая зависимость, лаговые зависимости, инструментальные переменные на базе факторов и тому подобное.
Процесс проработки спецификации модели — одна из самых затратных работ в процессе создания прогнозной модели [18]. Проработка спецификации начинается с постановки задачи и далее циклически повторяется между стадиями качественного и численного моделирования до тех пор, пока не будет достигнута требуемая точность прогнозирования и степень соответствия модели и исследуемой системы.
Оценить степень проработки спецификации можно, используя две методики: анализ дескриптивных характеристик модели и ее экспертное тестирование. Дескриптивные характеристики — коэффициент множественной регрессии, остаточная вариация, коэффициент детерминации, F-статистика — дают количественную оценку того, насколько успешно модель отражает изменение прогнозируемого показателя в прошлом. Это самая начальная, базовая оценка качества модели. С плохими дескриптивными характеристиками нельзя получить хороший прогноз, ведь прогнозная модель — это модель правил функционирования исследуемой системы [3]. Экспертное тестирование дает оценку модели с точки зрения содержательного смысла.
Сложность проработки спецификации модели заключается, прежде всего, в том, что зависимость между реальными показателями может быть промоделирована несколькими различными способами без существенных изменений дескриптивных характеристик модели. Утрированный пример: из двойки можно получит четверку путем прибавления еще одной двойки, умножения на два или возведения во вторую степень. Понятно, что если сделать еще один шаг тем же методом, результаты будут сильно отличаться друг от друга.
Поэтому проработка спецификации модели требует как непосредственного участия экспертов, так и немалого опыта, аналитических способностей и интуиции разработчиков.
1.3 Разработка прогнозной модели
Разработка прогнозной модели — это циклический процесс, включающий несколько этапов, на каждом из которых происходит тесное взаимодействие специалистов разработчика с экспертами. Разработчик знает толк в методах прогнозирования, но хорошая модель получится лишь после выяснения всех деталей механизма исследуемой системы.
Результаты очередного этапа разработки модели могут потребовать сбор дополнительной статистической информации, выявление скрытых процессов функционирования исследуемой системы на стадии численного моделирования приводит к переработке концепции модели на стадии качественного моделирования и так далее.
1.4 Технология создания систем прогнозирования
Постановка. На первом этапе построения прогнозной модели выявляется и формулируется проблема. На основе этой формулировки ставится задача и определяется набор прогнозируемых показателей [14].
Качественное моделирование. Следующий этап — это качественное моделирование исследуемой системы. Выдвигаются и оцениваются гипотезы касательно механизма функционирования исследуемой системы. Определяется набор факторов, воздействующих на прогнозируемый показатель, выясняется характер зависимости между ними.
Сбор статистической информации. Определившись с набором факторов и показателей, переходим к третьему этапу — сбору статистической информации. Для разработки прогнозной модели требуется достоверная статистическая информация об исследуемой системе. Статистическая информация — пища математических моделей. Чем больше статистики, тем лучше получится модель.
Вся исходная информация в обязательно порядке проходит выверку, так как на основе недостоверных исходных данных ничего, кроме недостоверных результатов, рассчитать не получится. Выверка данных за прошлые периоды времени производится преимущественно на основе косвенных признаков: отсутствующие точки, наличие нулевых и отрицательных значений, проверка минимальных и максимальных значений, содержательное объяснение «всплесков» и «провалов» показателей, наличие цепочек одинаковых значений.
От оперативности сбора и выверки статистической информации за прошлые периоды времени в существенной степени зависит скорость построения модели.
Параллельно с разработкой прогнозной модели необходимо налаживать регламентированный сбор статистической информации в реальном времени, так как для расчета прогноза на будущее необходимо знать всю информацию о прошлом и настоящем [10]. На данном этапе неоценимую роль играют функционирующие учетные системы, из которых можно в реальном времени получать свежую достоверную информацию, необходимую для разработки и эксплуатации прогнозных моделей.
Численное моделирование. Четвертый этап разработки модели посвящен численному моделированию на основе собранной статистической информации. Результатом данного этапа, в конечном счете, становится прототип прогнозной модели, проходящий экспертное тестирование. Прототип модели, как правило, оформляется в виде листа MS Excel, что позволяет самым доступным образом изучить структуру модели: набор вошедших в нее переменных, характер взаимосвязи между ними, коэффициенты переменных.
Экспертному тестированию подлежат два ключевых аспекта: точность прогноза и полученный механизм расчета прогноза. Необходимо определить требования к точности работы модели и таким образом установить один из двух критериев готовности модели. Спецификация подлежит экспертному тестированию для того, чтобы определить, насколько точно в модели отражен механизм функционирования реальной экономической системы — это второй критерий готовности прогнозной модели [7].
Например, в ходе качественного моделирования, было установлено, что цена скоропортящегося товара зависит от температуры воздуха. В результате численного анализа было установлено, что существует сильная зависимость текущей цены от температуры за несколько прошедших недель. В данном случае экспертное тестирование позволяет определить, за какой именно период времени необходимо учитывать температуру воздуха, чтобы это не приводило к рассогласованию со сроком хранения товара.
В результате численного анализа собранной статистической информации нередко удается обнаружить сильные, но неочевидные процессы, присутствующие в исследуемой системе, например внутригодовые циклы [12]. В данном случае процесс экспертного тестирования модели дает двойной результат: способствует уточнению спецификации модели и предоставляет экспертам дополнительную информацию об исследуемой системе.
Рассчитанный прогноз представляется в виде графиков и таблиц с числовыми данными. Все рассчитанные прогнозы записываются в хранилище данных, к ним организован удобный доступ в любое время. Есть механизм сравнения вариантов прогнозов, рассчитанных на разных наборах факторов. В ходе опытной эксплуатации происходит окончательная доработка прогнозного комплекса в соответствии с требованиями, после чего прогнозный комплекс переходит в промышленную эксплуатацию и становится на техническую и методическую поддержку.
После разработки модели можно экстраполировать тенденцию, т.е. получить прогноз. Экстраполяция — метод, который предполагает распространение выводов, полученных при изучении части целого, на другую его часть.
Глава 2. Классификация прогнозных моделей
В зависимости от используемых методик, модель может быть аналитической или алгоритмической. Аналитическая модель рассчитывает прогнозные значения на основе факторов. Алгоритмическая модель работает без факторов как таковых. Факторами алгоритмической модели являются время и прошлые значения прогнозируемого показателя.
Аналитические модели по сравнению с алгоритмическими, как правило, дают более точные прогнозы. Однако они могут давать сильную погрешность, если нет достоверной информации по всем факторам. Для расчета прогнозного значения нужно знать точные значения факторов в прошлом и будущем. Это является основным ограничением длины прогнозного периода в ходе применения аналитических моделей. Горизонт прогнозирования алгоритмических моделей сильно зависит от типа модели: он может не превышать одного периода, а может быть теоретически неограниченным.
Разработка аналитических моделей — это, как правило, более длинный и сложный процесс по сравнению с разработкой алгоритмических моделей. Аналитические модели отражают самую суть функционирования исследуемой системы. Алгоритмические модели отражают основные законы изменения прогнозируемого показателя. Это сезонность, цикличность, годовые и ежемесячные темпы роста, зависимость показателя от его предыдущих значений (автокорреляция).
Процесс получения прогнозов с помощью математических моделей можно начать даже в ситуации, когда нет никакой статистики, но для поддержки принятия решения уже требуются прогнозные значения ряда экономических показателей [8]. Это, конечно, не означает, что полученная в такой ситуации модель будет давать блестящие результаты: все дело в требуемой точности прогнозов.
В такой ситуации необходимо как можно быстрее пройти постановочную часть разработки модели и наладить процесс регистрации текущих значений прогнозируемых показателей. В этом случае сразу открывается дорога к построению простейших алгоритмических моделей. Далее, по мере прохождения стадии качественного моделирования, выясняется круг факторов и налаживается процесс регистрации их текущих значений.
Также необходимо начать работы по поиску статистической информации за прошлые периоды времени. Как показывает практика, часть информации доступна в открытых источниках, а часть можно восстановить даже по разрозненным файловым источникам данных, если предприятие имеет историю. На начальной стадии построения прогнозной модели даже самая незначительная информация играет большую роль, так как позволяет уточнить спецификацию модели на качественном уровне [5].
Общепризнанные методы прогнозирования временных рядов:
1.Эконометрические
2.Регрессионные
.Методы Бокса-Дженкинса (ARIMA, ARMA)
2.1 Методы прогнозирования, основанные на сглаживании, экспоненциальном сглаживании и скользящем среднем
«Наивные» модели прогнозирования
При создании «наивных» моделей предполагается, что некоторый последний период прогнозируемого временного ряда лучше всего описывает будущее этого прогнозируемого ряда, поэтому в этих моделях прогноз, как правило, является очень простой функцией от значений прогнозируемой переменной в недалеком прошлом.
Самой простой моделью является
Y(t+1)=Y(t),
что соответствует предположению, что «завтра будет как сегодня».
Вне всякого сомнения, от такой примитивной модели не стоит ждать большой точности [9]. Она не только не учитывает механизмы, определяющие прогнозируемые данные (этот серьезный недостаток вообще свойственен многим статистическим методам прогнозирования), но и не защищена от случайных флуктуаций, она не учитывает сезонные колебания и тренды. Впрочем, можно строить «наивные» модели несколько по-другому
(t+1)=Y(t)+[Y(t)-Y(t-1)],(t+1)=Y(t)*[Y(t)/Y(t-1)],
такими способами мы пытаемся приспособить модель к возможным трендам
(t+1)=Y(t-s),
это попытка учесть сезонные колебания
Средние и скользящие средние
Самой простой моделью, основанной на простом усреднении является
(t+1)=(1/(t))*[Y(t)+Y(t-1)+…+Y(1)],
и в отличии от самой простой «наивной» модели, которой соответствовал принцип «завтра будет как сегодня», этой модели соответствует принцип «завтра будет как было в среднем за последнее время». Такая модель, конечно более устойчива к флуктуациям, поскольку в ней сглаживаются случайные выбросы относительно среднего. Несмотря на это, этот метод идеологически настолько же примитивен как и «наивные» модели и ему свойственны почти те же самые недостатки [13].
В приведенной выше формуле предполагалось, что ряд усредняется по достаточно длительному интервалу времени. Однако как правило, значения временного ряда из недалекого прошлого лучше описывают прогноз, чем более старые значения этого же ряда. Тогда можно использовать для прогнозирования скользящее среднее
(t+1)=(1/(T+1))*[Y(t)+Y(t-1)+…+Y(t-T)],
Смысл его заключается в том, что модель видит только ближайшее прошлое (на T отсчетов по времени в глубину) и основываясь только на этих данных строит прогноз.
При прогнозировании довольно часто используется метод экспоненциальных средних, который постоянно адаптируется к данным за счет новых значений. Формула, описывающая эту модель записывается как
(t+1)=a*Y(t)+(1-a)*^Y(t),
где Y(t+1) — прогноз на следующий период времени, Y(t) — реальное значение в момент времени t
^Y(t) — прошлый прогноз на момент времени t- постоянная сглаживания (0<=a<=1))
В этом методе есть внутренний параметр a, который определяет зависимость прогноза от более старых данных, причем влияние данных на прогноз экспоненциально убывает с «возрастом» данных. Зависимость влияния данных на прогноз при разных коэффициентах a приведена на графике.
Видно, что при a->1, экспоненциальная модель стремится к самой простой «наивной» модели. При a->0, прогнозируемая величина становится равной предыдущему прогнозу [11].
Если производится прогнозирование с использованием модели экспоненциального сглаживания, обычно на некотором тестовом наборе строятся прогнозы при a=[0.01, 0.02, …, 0.98, 0.99] и отслеживается, при каком a точность прогнозирования выше. Это значение a затем используется при прогнозировании в дальнейшем.
Хотя описанные выше модели («наивные» алгоритмы, методы, основанные на средних, скользящих средних и экспоненциального сглаживания) используются при бизнес-прогнозировании в не очень сложных ситуациях, например, при прогнозировании продаж на спокойных и устоявшихся западных рынках, мы не рекомендуем использовать эти методы в задачах прогнозирования в виду явной примитивности и неадекватности моделей.
Вместе с этим хотелось бы отметить, что описанные алгоритмы вполне успешно можно использовать как сопутствующие и вспомогательные для предобработки данных в задачах прогнозирования. Например, для прогнозирования продаж в большинстве случаев необходимо проводить декомпозицию временных рядов (т.е. выделять отдельно тренд, сезонную и нерегулярную составляющие) [15]. Одним из методов выделения трендовых составляющих является использование экспоненциального сглаживания.
Методы Хольта и Брауна
В середине прошлого века Хольт предложил усовершенствованный метод экспоненциального сглаживания, впоследствии названный его именем. В предложенном алгоритме значения уровня и тренда сглаживаются с помощью экспоненциального сглаживания. Причем параметры сглаживания у них различны.
Здесь первое уравнение описывает сглаженный ряд общего уровня.
Второе уравнение служит для оценки тренда. Третье уравнение определяет прогноз на p отсчетов по времени вперед.
Постоянные сглаживания в методе Хольта идеологически играют ту же роль, что и постоянная в простом экспоненциальном сглаживании. Подбираются они, например, путем перебора по этим параметрам с каким-то шагом. Можно использовать и менее сложные в смысле количества вычислений алгоритмы. Главное, что всегда можно подобрать такую пару параметров, которая дает большую точность модели на тестовом наборе и затем использовать эту пару параметров при реальном прогнозировании.
Частным случаем метода Хольта является метод Брауна, когда a=ß.
Метод Винтерса
Хотя описанный выше метод Хольта (метод двухпараметрического экспоненциального сглаживания) и не является совсем простым (относительно «наивных» моделей и моделей, основанных на усреднении), он не позволяет учитывать сезонные колебания при прогнозировании. Говоря более аккуратно, этот метод не может их «видеть» в предыстории. Существует расширение метода Хольта до трехпараметрического экспоненциального сглаживания. Этот алгоритм называется методом Винтерса [19]. При этом делается попытка учесть сезонные составляющие в данных. Система уравнений, описывающих метод Винтерса выглядит следующим образом:
Дробь в первом уравнении служит для исключения сезонности из Y(t). После исключения сезонности алгоритм работает с «чистыми» данными, в которых нет сезонных колебаний. Появляются они уже в самом финальном прогнозе, когда «чистый» прогноз, посчитанный почти по методу Хольта умножается на сезонный коэффициент.
Регрессионные методы прогнозирования
Наряду с описанными выше методами, основанными на экспоненциальном сглаживании, уже достаточно долгое время для прогнозирования используются регрессионные алгоритмы. Коротко суть алгоритмов такого класса можно описать так.
Существует прогнозируемая переменная Y (зависимая переменная) и отобранный заранее комплект переменных, от которых она зависит — X1, X2, …, XN (независимые переменные). Природа независимых переменных может быть различной. Например, если предположить, что Y — уровень спроса на некоторый продукт в следующем месяце, то независимыми переменными могут быть уровень спроса на этот же продукт в прошлый и позапрошлый месяцы, затраты на рекламу, уровень платежеспособности населения, экономическая обстановка, деятельность конкурентов и многое другое [6]. Главное — уметь формализовать все внешние факторы, от которых может зависеть уровень спроса в числовую форму.
Модель множественной регрессии в общем случае описывается выражением
В более простом варианте линейной регрессионной модели зависимость зависимой переменной от независимых имеет вид:
Здесь — подбираемые коэффициенты регрессии, e- компонента ошибки. Предполагается, что все ошибки независимы и нормально распределены.
Для построения регрессионных моделей необходимо иметь базу данных наблюдений примерно такого вида [17]:
переменные независимыезависимая№X1X2…XNY1x_11x_12…x_1NY_12x_21x_22…x_2NY_2………………mx_M1x_M2…x_MNY_m
С помощью таблицы значений прошлых наблюдений можно подобрать (например, методом наименьших квадратов) коэффициенты регрессии, настроив тем самым модель.
При работе с регрессией надо соблюдать определенную осторожность и обязательно проверить на адекватность найденные модели. Существуют разные способы такой проверки. Обязательным является статистический анализ остатков, тест Дарбина-Уотсона [4]. Полезно, как и в случае с нейронными сетями, иметь независимый набор примеров, на которых можно проверить качество работы модели.
прогнозный спецификация сглаживание arima
2.2 Методы Бокса-Дженкинса (ARIMA)
В середине 90-х годов прошлого века был разработан принципиально новый и достаточно мощный класс алгоритмов для прогнозирования временных рядов. Большую часть работы по исследованию методологии и проверке моделей была проведена двумя статистиками, Г.Е.П. Боксом (G.E.P. Box) и Г.М. Дженкинсом (G.M. Jenkins). С тех пор построение подобных моделей и получение на их основе прогнозов иногда называться методами Бокса-Дженкинса. Более подробно иерархию алгоритмов Бокса-Дженкинса мы рассмотрим чуть ниже, пока же отметим, что в это семейство входит несколько алгоритмов, самым известным и используемым из них является алгоритм ARIMA. Он встроен практически в любой специализированный пакет для прогнозирования. В классическом варианте ARIMA не используются независимые переменные. Модели опираются только на информацию, содержащуюся в предыстории прогнозируемых рядов, что ограничивает возможности алгоритма. В настоящее время в научной литературе часто упоминаются варианты моделей ARIMA, позволяющие учитывать независимые переменные. В данном учебнике мы их рассматривать не будем, ограничившись только общеизвестным классическим вариантом. В отличие от рассмотренных ранее методик прогнозирования временных рядов, в методологии ARIMA не предполагается какой-либо четкой модели для прогнозирования данной временной серии. Задается лишь общий класс моделей, описывающих временной ряд и позволяющих как-то выражать текущее значение переменной через ее предыдущие значения. Затем алгоритм, подстраивая внутренние параметры, сам выбирает наиболее подходящую модель прогнозирования. Как уже отмечалось выше, существует целая иерархия моделей Бокса-Дженкинса. Логически ее можно определить так
(p)+MA(q)->ARMA(p,q)->ARMA(p,q)(P,Q)->ARIMA(p,q,r)(P,Q,R)->…
AR(p) -авторегрессионая модель порядка p.
Модель имеет вид:
(t)=f_0+f_1*Y(t-1)+f_2*Y(t-2)+…+f_p*Y(t-p)+E(t)
Где Y(t)-зависимая переменная в момент времени t. f_0, f_1, f_2, …, f_p — оцениваемые параметры [2]. E(t) — ошибка от влияния переменных, которые не учитываются в данной модели. Задача заключается в том, чтобы определить f_0, f_1, f_2, …, f_p. Их можно оценить различными способами. Правильнее всего искать их через систему уравнений Юла-Уолкера, для составления этой системы потребуется расчет значений автокорреляционной функции. Можно поступить более простым способом — посчитать их методом наименьших квадратов.
MA(q) -модель со скользящим средним порядка q.
Модель имеет вид:
(t)=m+e(t)-w_1*e(t-1)-w_2*e(t-2)-…-w_p*e(t-p)
Где Y(t)-зависимая переменная в момент времени t. w_0, w_1, w_2, …, w_p — оцениваемые параметры.
Заключение
Прогнозирование — это самостоятельная отрасль науки, которая находит широкое применение во всех сферах человеческой деятельности. Существует большое разнообразие видов и способов прогнозирования, разработанных с учетом характера рассматриваемых задач, целей исследования, состояния информации. Этим вопросам посвящено много книг и журнальных статей. Мы здесь не ставим целью рассказать о теории прогнозирования в целом. Наша задача — показать на примере линейной регрессии применение эконометрических моделей в прогнозировании значений экономических показателей. В обыденном понимании прогнозирование — это предсказание будущего состояния интересующего нас объекта или явления на основе ретроспективных данных о прошлом и настоящем состояниях при условии наличия причинно-следственной связи между прошлым и будущим. Можно сказать, что прогноз — это догадка, подкрепленная знанием. Поскольку прогностические оценки по сути своей являются приближенными, может возникнуть сомнение относительно его целесообразности вообще. Поэтому основное требование, предъявляемое к любому прогнозу, заключается в том, чтобы в пределах возможного минимизировать погрешности в соответствующих оценках. По сравнению со случайными и интуитивными прогнозами, научно обоснованные и планомерно разрабатываемые прогнозы без сомнения являются более точными и эффективными. Как раз такими являются прогнозы, основанные на использовании методов статистического анализа. Можно утверждать, что из всех способов прогнозирования именно они внушают наибольшее доверие, во-первых, потому что статистические данные служат надежной основой для принятия решений относительно будущего, во-вторых, такие прогнозы вырабатываются и подвергаются тщательной проверке с помощью фундаментальных методов математической статистики.
Теги:
Статистические методы прогнозирования социально-экономических явлений
Курсовая работа (теория)
Экономическая теория