

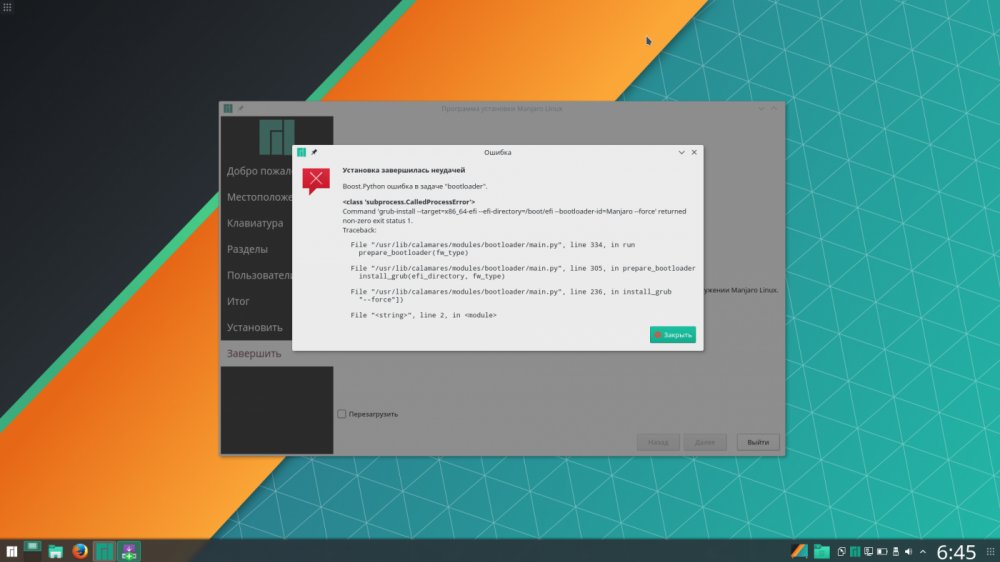
Хотя в современных Linux-системах ядро отличается достаточно высоким уровнем стабильности, вероятность серьезных системных ошибок, тем не менее, имеется всегда. Когда происходит неисправимая ошибка, имеет место состояние, называемое паникой ядра (kernel panic): стандартный обработчик выводит на экран информацию, которая должна помочь в устранении неисправности, и входит в бесконечный цикл.
Для диагностики и анализа причин сбоев ядра разработчиками компании RedHat был разработан специализированный инструмент — kdump. Принцип его работы можно кратко описать следующим образом. Создается два ядра: основное и аварийное (именно оно используется для сбора дампа памяти). При загрузке основного ядра под аварийное ядро выделяется определенный размер памяти. При помощи kexec во время паники основного ядра загружается аварийное и собирает дамп.
В этой статье мы подробно расскажем о том, как конфигурировать kdump и анализировать с его помощью системные ошибки. Мы рассмотрим особенности работы с kdump в OC Ubuntu; в других дистрибутивах процедуры настройки и конфигурирования kdump существенно отличаются.
Установка и настройка kdump
Установим kdump с помощью команды
$ sudo apt-get install linux-crashdump kdump-tools
Настройки kdump хранятся в конфигурационном файле /etc/default/kdump-tools
# kdump-tools configuration # --------------------------------------------------------------------------- # USE_KDUMP - controls kdump will be configured # 0 - kdump kernel will not be loaded # 1 - kdump kernel will be loaded and kdump is configured # KDUMP_SYSCTL - controls when a panic occurs, using the sysctl # interface. The contents of this variable should be the # "variable=value ..." portion of the 'sysctl -w ' command. # If not set, the default value "kernel.panic_on_oops=1" will # be used. Disable this feature by setting KDUMP_SYSCTL=" " # Example - also panic on oom: # KDUMP_SYSCTL="kernel.panic_on_oops=1 vm.panic_on_oom=1" # USE_KDUMP=1 # KDUMP_SYSCTL="kernel.panic_on_oops=1"
Чтобы активировать kdump, отредактируем этот файл и установим значение параметра USE_KDUMP=1.
Также в конфигурационном файле содержатся следующие параметры:
- KDUMP_KERNEL — полный путь к аварийному ядру;
- KDUMP_INITRD — полный путь к initrd аварийного ядра;
- KDUMP_CORE — указывает, где будет сохранен файл дампа ядра. По умолчанию дамп сохраняется в директории /var/crash (KDUMP_CORE=/var/crash);
- KDUMP_FAIL_CMD — указывает, какое действие нужно совершить в случае ошибки при сохранении дампа (по умолчанию будет выполнена команда reboot -f);
- DEBUG_KERNEL — отладочная версия работающего ядра. По умолчанию используются /usr/lib/debug/vmlinux-$. Если значение этого параметра не установлено, утилита makedumpfile создаст только дамп всех страниц памяти;
- MAKEDUMP_ARGS — содержит дополнительные аргументы, передаваемые утилите makedumpfile. По умолчанию этот параметр имеет значение ‘-c -d 31’, указывающую, что необходимо использовать сжатие и включать в дамп только используемые страницы ядра.
Установив все необходимые параметры, выполним команду update-grub и выберем install the package maintainer’s version.
Затем перезагрузим систему и убедимся в том, что kdump готов к работе:
$ cat/proc/cmdline BOOT_IMAGE=/boot/vmlinuz-3.8.0-35-generic root=UUID=bb2ba5e1-48e1-4829-b565-611542b96018 ro crashkernel=384 -:128M quiet splash vt.handoff=7
Обратим особое внимание на параметр crashkernel=384 -:128M. Он означает, что аварийное ядро будет использовать 128 Мб памяти при загрузке. Можно прописать в grub параметр crashkernel = auto: в этом случае память под аварийное ядро будет выделяться автоматически.
Для того, чтобы мы могли анализировать дамп с помощью утилиты crash, нам понадобится также файл vmlinux, содержащий отладочную информацию:
$ sudo tee /etc/apt/sources.list.d/ddebs.list << EOF deb http://ddebs.ubuntu.com/ $(lsb_release -cs) main restricted universe multiverse deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-security main restricted universe multiverse deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-updates main restricted universe multiverse deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-proposed main restricted universe multiverse EOF $ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys ECDCAD72428D7C01 $ sudo apt-get update $ sudo apt-get install linux-image-$(uname -r)-dbgsym
По завершении установки еще раз проверим статус kdump:
$ kdump-config status
Если kdump находится в рабочем состоянии, на консоль будет выведено следующее сообщение:
current state: ready to kdump
Тестируем kdump
Вызовем панику ядра при помощи следующих команд:
echo c | sudo tee /proc/sysrq-trigger
В результате их выполнения система «зависнет».
После этого в течение нескольких минут будет создан дамп, который будет доступен в директории /var/crash после перезагрузки.
Информацию о сбое ядра можно просмотреть с помощью утилиты crash:
$ sudo crash /usr/lib/debug/boot/vmlinux-3.13.0-24-generic /var/crash/201405051934/dump.201405051934
crash 7.0.3
Copyright (C) 2002-2013 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005, 2011 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu"...
KERNEL: /usr/lib/debug/boot/vmlinux-3.13.0-24-generic
DUMPFILE: /var/crash/201405051934/dump.201405051934 [PARTIAL DUMP]
CPUS: 4
DATE: Mon May 5 19:34:38 2014
UPTIME: 00:54:46
LOAD AVERAGE: 0.14, 0.07, 0.05
TASKS: 495
NODENAME: Ubuntu
RELEASE: 3.13.0-24-generic
VERSION: #46-Ubuntu SMP Thu Apr 10 19:11:08 UTC 2014
MACHINE: x86_64 (2675 Mhz)
MEMORY: 8 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)
PID: 7826
COMMAND: "tee"
TASK: ffff8800a2ef8000 [THREAD_INFO: ffff8800a2e68000]
CPU: 2
STATE: TASK_RUNNING (PANIC)
crash>
На основе приведенного вывода мы можем заключить, что системному сбою предшествовало событие «Oops: 0002 [#1] SMP», произошедшее на CPU2 при выполнении команды tee.
Утилита crash обладает также широким спектром возможностей для диагностики причин краха ядра. Рассмотрим их более подробно.
Диагностика причин сбоя с помощью утилиты crash
Crash сохраняет информацию обо всех системных событиях, предшествовавших краху ядра. С ее помощью можно воссоздать состояние системы на момент сбоя: узнать, какие процессы были запущены на момент краха, какие файлы открыты и т.п. Эта информация помогает поставить точный диагноз и предупредить крахи ядра в будущем.
В утилите crash имеется свой набор команд:
$ crash> help * files mach repeat timer alias foreach mod runq tree ascii fuser mount search union bt gdb net set vm btop help p sig vtop dev ipcs ps struct waitq dis irq pte swap whatis eval kmem ptob sym wr exit list ptov sys q extend log rd task crash version: 7.0.3 gdb version: 7.6 For help on any command above, enter "help <command>". For help on input options, enter "help input". For help on output options, enter "help output". crash>
Для каждой этой команды можно вызвать краткий мануал, например:
crash> help set
Все команды мы описывать не будем (с детальной информацией можно ознакомиться в официальном руководстве пользователя от компании RedHat), а расскажем лишь о наиболее важных из них.
В первую очередь следует обратить внимание на команду bt (аббревиатура от backtrace — обратная трассировка). С ее помощью можно посмотреть детальную информацию о содержании памяти ядра (подробности и примеры использования см. здесь). Однако во многих случаях для определения причины системного сбоя бывает вполне достаточно команды log, выводящее на экран содержимое буфера сообщений ядра в хронологическом порядке.
Приведем фрагмент ее вывода:
[ 3288.251955] CPU: 2 PID: 7826 Comm: tee Tainted: PF O 3.13.0-24-generic #46-Ubuntu [ 3288.251957] Hardware name: System manufacturer System Product Name/P7P55D LE, BIOS 2003 12/16/2010 [ 3288.251958] task: ffff8800a2ef8000 ti: ffff8800a2e68000 task.ti: ffff8800a2e68000 [ 3288.251960] RIP: 0010:[<ffffffff8144de76>] [<ffffffff8144de76>] sysrq_handle_crash+0x16/0x20 [ 3288.251963] RSP: 0018:ffff8800a2e69e88 EFLAGS: 00010082 [ 3288.251964] RAX: 000000000000000f RBX: ffffffff81c9f6a0 RCX: 0000000000000000 [ 3288.251965] RDX: ffff88021fc4ffe0 RSI: ffff88021fc4e3c8 RDI: 0000000000000063 [ 3288.251966] RBP: ffff8800a2e69e88 R08: 0000000000000096 R09: 0000000000000387 [ 3288.251968] R10: 0000000000000386 R11: 0000000000000003 R12: 0000000000000063 [ 3288.251969] R13: 0000000000000246 R14: 0000000000000004 R15: 0000000000000000 [ 3288.251971] FS: 00007fb0f665b740(0000) GS:ffff88021fc40000(0000) knlGS:0000000000000000 [ 3288.251972] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b [ 3288.251973] CR2: 0000000000000000 CR3: 00000000368fd000 CR4: 00000000000007e0 [ 3288.251974] Stack: [ 3288.251975] ffff8800a2e69ec0 ffffffff8144e5f2 0000000000000002 00007fff3cea3850 [ 3288.251978] ffff8800a2e69f50 0000000000000002 0000000000000008 ffff8800a2e69ed8 [ 3288.251980] ffffffff8144eaff ffff88021017a900 ffff8800a2e69ef8 ffffffff8121f52d [ 3288.251983] Call Trace: [ 3288.251986] [<ffffffff8144e5f2>] __handle_sysrq+0xa2/0x170 [ 3288.251988] [<ffffffff8144eaff>] write_sysrq_trigger+0x2f/0x40 [ 3288.251992] [<ffffffff8121f52d>] proc_reg_write+0x3d/0x80 [ 3288.251996] [<ffffffff811b9534>] vfs_write+0xb4/0x1f0 [ 3288.251998] [<ffffffff811b9f69>] SyS_write+0x49/0xa0 [ 3288.252001] [<ffffffff8172663f>] tracesys+0xe1/0xe6 [ 3288.252002] Code: 65 34 75 e5 4c 89 ef e8 f9 f7 ff ff eb db 0f 1f 80 00 00 00 00 66 66 66 66 90 55 c7 05 94 68 a6 00 01 00 00 00 48 89 e5 0f ae f8 <c6> 04 25 00 00 00 00 01 5d c3 66 66 66 66 90 55 31 c0 c7 05 be [ 3288.252025] RIP [<ffffffff8144de76>] sysrq_handle_crash+0x16/0x20 [ 3288.252028] RSP <ffff8800a2e69e88> [ 3288.252029] CR2: 0000000000000000
В одной из строк вывода будет указано событие, вызвавшее системную ошибку:
[ 3288.251889] SysRq: Trigger a crash
С помощью команды ps можно вывести на экран список процессов, которые были запущены на момент сбоя:
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
0 0 0 ffffffff81a8d020 RU 0.0 0 0 [swapper]
1 0 0 ffff88013e7db500 IN 0.0 19356 1544 init
2 0 0 ffff88013e7daaa0 IN 0.0 0 0 [kthreadd]
3 2 0 ffff88013e7da040 IN 0.0 0 0 [migration/0]
4 2 0 ffff88013e7e9540 IN 0.0 0 0 [ksoftirqd/0]
7 2 0 ffff88013dc19500 IN 0.0 0 0 [events/0]
Для просмотра информации об использовании виртуальной памяти используется команда vm:
crash> vm
PID: 5210 TASK: ffff8801396f6aa0 CPU: 0 COMMAND: "bash"
MM PGD RSS TOTAL_VM
ffff88013975d880 ffff88013a0c5000 1808k 108340k
VMA START END FLAGS FILE
ffff88013a0c4ed0 400000 4d4000 8001875 /bin/bash
ffff88013cd63210 3804800000 3804820000 8000875 /lib64/ld-2.12.so
ffff880138cf8ed0 3804c00000 3804c02000 8000075 /lib64/libdl-2.12.so
Команда swap выведет на консоль информацию об использовании области подкачки:
crash> swap FILENAME TYPE SIZE USED PCT PRIORITY /dm-1 PARTITION 2064376k 0k 0% -1
Информацию о прерываниях CPU можно просмотреть с помощью команды irq:
crash> irq -s
CPU0
0: 149 IO-APIC-edge timer
1: 453 IO-APIC-edge i8042
7: 0 IO-APIC-edge parport0
8: 0 IO-APIC-edge rtc0
9: 0 IO-APIC-fasteoi acpi
12: 111 IO-APIC-edge i8042
14: 108 IO-APIC-edge ata_piix
Вывести на консоль список файлов, открытых на момент сбоя, можно с помощью команды files:
crash> files PID: 5210 TASK: ffff8801396f6aa0 CPU: 0 COMMAND: "bash" ROOT: / CWD: /root FD FILE DENTRY INODE TYPE PATH 0 ffff88013cf76d40 ffff88013a836480 ffff880139b70d48 CHR /tty1 1 ffff88013c4a5d80 ffff88013c90a440 ffff880135992308 REG /proc/sysrq-trigger 255 ffff88013cf76d40 ffff88013a836480 ffff880139b70d48 CHR /tty1
Наконец, получить в сжатом виде информацию об общем состоянии системы можно с помощью команды sys:
crash> sys
KERNEL: /usr/lib/debug/lib/modules/2.6.32-431.5.1.el6.x86_64/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2014-03-26-12:24:39/vmcore [PARTIAL DUMP]
CPUS: 1
DATE: Wed Mar 26 12:24:36 2014
UPTIME: 00:01:32
LOAD AVERAGE: 0.17, 0.09, 0.03
TASKS: 159
NODENAME: elserver1.abc.com
RELEASE: 2.6.32-431.5.1.el6.x86_64
VERSION: #1 SMP Fri Jan 10 14:46:43 EST 2014
MACHINE: x86_64 (2132 Mhz)
MEMORY: 4 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)
Заключение
Анализ и диагностика причин падения ядра представляет собой очень специфическую и сложную тему, которую невозможно уместить в рамки одной статьи. Мы еще вернемся к ней в следующих публикациях.
Для желающих узнать больше — несколько полезных ссылок:
- Документация kdump на сайте kernel.org
- Книга, целиком посвященная проблемам диагностики сбоев ядра
- Подробная документация для утилиты crash
Читателей, которые не могут оставлять комментарии здесь, приглашаем к нам в блог.
Хотя в современных Linux-системах ядро отличается достаточно высоким уровнем стабильности, вероятность серьезных системных ошибок, тем не менее, имеется всегда. Когда происходит неисправимая ошибка, имеет место состояние, называемое паникой ядра (kernel panic): стандартный обработчик выводит на экран информацию, которая должна помочь в устранении неисправности, и входит в бесконечный цикл.
Для диагностики и анализа причин сбоев ядра разработчиками компании RedHat был разработан специализированный инструмент — kdump. Принцип его работы можно кратко описать следующим образом. Создается два ядра: основное и аварийное (именно оно используется для сбора дампа памяти). При загрузке основного ядра под аварийное ядро выделяется определенный размер памяти. При помощи kexec во время паники основного ядра загружается аварийное и собирает дамп.
В этой статье мы подробно расскажем о том, как конфигурировать kdump и анализировать с его помощью системные ошибки. Мы рассмотрим особенности работы с kdump в OC Ubuntu; в других дистрибутивах процедуры настройки и конфигурирования kdump существенно отличаются.
Установка и настройка kdump
Установим kdump с помощью команды
$ sudo apt-get install linux-crashdump kdump-toolsНастройки kdump хранятся в конфигурационном файле /etc/default/kdump-tools
# kdump-tools configuration
# ---------------------------------------------------------------------------
# USE_KDUMP - controls kdump will be configured
# 0 - kdump kernel will not be loaded
# 1 - kdump kernel will be loaded and kdump is configured
# KDUMP_SYSCTL - controls when a panic occurs, using the sysctl
# interface. The contents of this variable should be the
# "variable=value ..." portion of the 'sysctl -w ' command.
# If not set, the default value "kernel.panic_on_oops=1" will
# be used. Disable this feature by setting KDUMP_SYSCTL=" "
# Example - also panic on oom:
# KDUMP_SYSCTL="kernel.panic_on_oops=1 vm.panic_on_oom=1"
#
USE_KDUMP=1
# KDUMP_SYSCTL="kernel.panic_on_oops=1"Чтобы активировать kdump, отредактируем этот файл и установим значение параметра USE_KDUMP=1.
Также в конфигурационном файле содержатся следующие параметры:
- KDUMP_KERNEL — полный путь к аварийному ядру;
- KDUMP_INITRD — полный путь к initrd аварийного ядра;
- KDUMP_CORE — указывает, где будет сохранен файл дампа ядра. По умолчанию дамп сохраняется в директории /var/crash (KDUMP_CORE=/var/crash);
- KDUMP_FAIL_CMD — указывает, какое действие нужно совершить в случае ошибки при сохранении дампа (по умолчанию будет выполнена команда reboot -f);
- DEBUG_KERNEL — отладочная версия работающего ядра. По умолчанию используются /usr/lib/debug/vmlinux-$. Если значение этого параметра не установлено, утилита makedumpfile создаст только дамп всех страниц памяти;
- MAKEDUMP_ARGS — содержит дополнительные аргументы, передаваемые утилите makedumpfile. По умолчанию этот параметр имеет значение ‘-c -d 31’, указывающую, что необходимо использовать сжатие и включать в дамп только используемые страницы ядра.
Установив все необходимые параметры, выполним команду update-grub и выберем install the package maintainer’s version.
Затем перезагрузим систему и убедимся в том, что kdump готов к работе:
$ cat/proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-3.8.0-35-generic root=UUID=bb2ba5e1-48e1-4829-b565-611542b96018 ro crashkernel=384 -:128M quiet splash vt.handoff=7Обратим особое внимание на параметр crashkernel=384 -:128M. Он означает, что аварийное ядро будет использовать 128 Мб памяти при загрузке. Можно прописать в grub параметр crashkernel = auto: в этом случае память под аварийное ядро будет выделяться автоматически.
Для того, чтобы мы могли анализировать дамп с помощью утилиты crash, нам понадобится также файл vmlinux, содержащий отладочную информацию:
$ sudo tee /etc/apt/sources.list.d/ddebs.list << EOF
deb http://ddebs.ubuntu.com/ $(lsb_release -cs) main restricted universe multiverse
deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-security main restricted universe multiverse
deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-updates main restricted universe multiverse
deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-proposed main restricted universe multiverse
EOF
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys ECDCAD72428D7C01
$ sudo apt-get update
$ sudo apt-get install linux-image-$(uname -r)-dbgsymПо завершении установки еще раз проверим статус kdump:
$ kdump-config statusЕсли kdump находится в рабочем состоянии, на консоль будет выведено следующее сообщение:
current state: ready to kdumpТестируем kdump
Вызовем панику ядра при помощи следующих команд:
echo c | sudo tee /proc/sysrq-triggerВ результате их выполнения система «зависнет».
После этого в течение нескольких минут будет создан дамп, который будет доступен в директории /var/crash после перезагрузки.
Информацию о сбое ядра можно просмотреть с помощью утилиты crash:
$ sudo crash /usr/lib/debug/boot/vmlinux-3.13.0-24-generic /var/crash/201405051934/dump.201405051934
crash 7.0.3
Copyright (C) 2002-2013 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005, 2011 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu"...
KERNEL: /usr/lib/debug/boot/vmlinux-3.13.0-24-generic
DUMPFILE: /var/crash/201405051934/dump.201405051934 [PARTIAL DUMP]
CPUS: 4
DATE: Mon May 5 19:34:38 2014
UPTIME: 00:54:46
LOAD AVERAGE: 0.14, 0.07, 0.05
TASKS: 495
NODENAME: Ubuntu
RELEASE: 3.13.0-24-generic
VERSION: #46-Ubuntu SMP Thu Apr 10 19:11:08 UTC 2014
MACHINE: x86_64 (2675 Mhz)
MEMORY: 8 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)
PID: 7826
COMMAND: "tee"
TASK: ffff8800a2ef8000 [THREAD_INFO: ffff8800a2e68000]
CPU: 2
STATE: TASK_RUNNING (PANIC)
crash>На основе приведенного вывода мы можем заключить, что системному сбою предшествовало событие «Oops: 0002 [#1] SMP», произошедшее на CPU2 при выполнении команды tee.
Утилита crash обладает также широким спектром возможностей для диагностики причин краха ядра. Рассмотрим их более подробно.
Диагностика причин сбоя с помощью утилиты crash
Crash сохраняет информацию обо всех системных событиях, предшествовавших краху ядра. С ее помощью можно воссоздать состояние системы на момент сбоя: узнать, какие процессы были запущены на момент краха, какие файлы открыты и т.п. Эта информация помогает поставить точный диагноз и предупредить крахи ядра в будущем.
В утилите crash имеется свой набор команд:
$ crash> help
* files mach repeat timer
alias foreach mod runq tree
ascii fuser mount search union
bt gdb net set vm
btop help p sig vtop
dev ipcs ps struct waitq
dis irq pte swap whatis
eval kmem ptob sym wr
exit list ptov sys q
extend log rd task
crash version: 7.0.3 gdb version: 7.6
For help on any command above, enter "help ".
For help on input options, enter "help input".
For help on output options, enter "help output".
crash>Для каждой этой команды можно вызвать краткий мануал, например:
crash> help setВсе команды мы описывать не будем (с детальной информацией можно ознакомиться в официальном руководстве пользователя от компании RedHat), а расскажем лишь о наиболее важных из них.
В первую очередь следует обратить внимание на команду bt (аббревиатура от backtrace — обратная трассировка). С ее помощью можно посмотреть детальную информацию о содержании памяти ядра (подробности и примеры использования см. здесь). Однако во многих случаях для определения причины системного сбоя бывает вполне достаточно команды log, выводящее на экран содержимое буфера сообщений ядра в хронологическом порядке.
Приведем фрагмент ее вывода:
[ 3288.251955] CPU: 2 PID: 7826 Comm: tee Tainted: PF O 3.13.0-24-generic #46-Ubuntu
[ 3288.251957] Hardware name: System manufacturer System Product Name/P7P55D LE, BIOS 2003 12/16/2010
[ 3288.251958] task: ffff8800a2ef8000 ti: ffff8800a2e68000 task.ti: ffff8800a2e68000
[ 3288.251960] RIP: 0010:[] [] sysrq_handle_crash+0x16/0x20
[ 3288.251963] RSP: 0018:ffff8800a2e69e88 EFLAGS: 00010082
[ 3288.251964] RAX: 000000000000000f RBX: ffffffff81c9f6a0 RCX: 0000000000000000
[ 3288.251965] RDX: ffff88021fc4ffe0 RSI: ffff88021fc4e3c8 RDI: 0000000000000063
[ 3288.251966] RBP: ffff8800a2e69e88 R08: 0000000000000096 R09: 0000000000000387
[ 3288.251968] R10: 0000000000000386 R11: 0000000000000003 R12: 0000000000000063
[ 3288.251969] R13: 0000000000000246 R14: 0000000000000004 R15: 0000000000000000
[ 3288.251971] FS: 00007fb0f665b740(0000) GS:ffff88021fc40000(0000) knlGS:0000000000000000
[ 3288.251972] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
[ 3288.251973] CR2: 0000000000000000 CR3: 00000000368fd000 CR4: 00000000000007e0
[ 3288.251974] Stack:
[ 3288.251975] ffff8800a2e69ec0 ffffffff8144e5f2 0000000000000002 00007fff3cea3850
[ 3288.251978] ffff8800a2e69f50 0000000000000002 0000000000000008 ffff8800a2e69ed8
[ 3288.251980] ffffffff8144eaff ffff88021017a900 ffff8800a2e69ef8 ffffffff8121f52d
[ 3288.251983] Call Trace:
[ 3288.251986] [] __handle_sysrq+0xa2/0x170
[ 3288.251988] [] write_sysrq_trigger+0x2f/0x40
[ 3288.251992] [] proc_reg_write+0x3d/0x80
[ 3288.251996] [] vfs_write+0xb4/0x1f0
[ 3288.251998] [] SyS_write+0x49/0xa0
[ 3288.252001] [] tracesys+0xe1/0xe6
[ 3288.252002] Code: 65 34 75 e5 4c 89 ef e8 f9 f7 ff ff eb db 0f 1f 80 00 00 00 00 66 66 66 66 90 55 c7 05 94 68 a6 00 01 00 00 00 48 89 e5 0f ae f8 04 25 00 00 00 00 01 5d c3 66 66 66 66 90 55 31 c0 c7 05 be
[ 3288.252025] RIP [] sysrq_handle_crash+0x16/0x20
[ 3288.252028] RSP
[ 3288.252029] CR2: 0000000000000000В одной из строк вывода будет указано событие, вызвавшее системную ошибку:
[ 3288.251889] SysRq: Trigger a crashС помощью команды ps можно вывести на экран список процессов, которые были запущены на момент сбоя:
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
0 0 0 ffffffff81a8d020 RU 0.0 0 0 [swapper]
1 0 0 ffff88013e7db500 IN 0.0 19356 1544 init
2 0 0 ffff88013e7daaa0 IN 0.0 0 0 [kthreadd]
3 2 0 ffff88013e7da040 IN 0.0 0 0 [migration/0]
4 2 0 ffff88013e7e9540 IN 0.0 0 0 [ksoftirqd/0]
7 2 0 ffff88013dc19500 IN 0.0 0 0 [events/0]Для просмотра информации об использовании виртуальной памяти используется команда vm:
crash> vm
PID: 5210 TASK: ffff8801396f6aa0 CPU: 0 COMMAND: "bash"
MM PGD RSS TOTAL_VM
ffff88013975d880 ffff88013a0c5000 1808k 108340k
VMA START END FLAGS FILE
ffff88013a0c4ed0 400000 4d4000 8001875 /bin/bash
ffff88013cd63210 3804800000 3804820000 8000875 /lib64/ld-2.12.so
ffff880138cf8ed0 3804c00000 3804c02000 8000075 /lib64/libdl-2.12.soКоманда swap выведет на консоль информацию об использовании области подкачки:
crash> swap
FILENAME TYPE SIZE USED PCT PRIORITY
/dm-1 PARTITION 2064376k 0k 0% -1Информацию о прерываниях CPU можно просмотреть с помощью команды irq:
crash> irq -s
CPU0
0: 149 IO-APIC-edge timer
1: 453 IO-APIC-edge i8042
7: 0 IO-APIC-edge parport0
8: 0 IO-APIC-edge rtc0
9: 0 IO-APIC-fasteoi acpi
12: 111 IO-APIC-edge i8042
14: 108 IO-APIC-edge ata_piixВывести на консоль список файлов, открытых на момент сбоя, можно с помощью команды files:
crash> files
PID: 5210 TASK: ffff8801396f6aa0 CPU: 0 COMMAND: "bash"
ROOT: / CWD: /root
FD FILE DENTRY INODE TYPE PATH
0 ffff88013cf76d40 ffff88013a836480 ffff880139b70d48 CHR /tty1
1 ffff88013c4a5d80 ffff88013c90a440 ffff880135992308 REG /proc/sysrq-trigger
255 ffff88013cf76d40 ffff88013a836480 ffff880139b70d48 CHR /tty1Наконец, получить в сжатом виде информацию об общем состоянии системы можно с помощью команды sys:
crash> sys
KERNEL: /usr/lib/debug/lib/modules/2.6.32-431.5.1.el6.x86_64/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2014-03-26-12:24:39/vmcore [PARTIAL DUMP]
CPUS: 1
DATE: Wed Mar 26 12:24:36 2014
UPTIME: 00:01:32
LOAD AVERAGE: 0.17, 0.09, 0.03
TASKS: 159
NODENAME: elserver1.abc.com
RELEASE: 2.6.32-431.5.1.el6.x86_64
VERSION: #1 SMP Fri Jan 10 14:46:43 EST 2014
MACHINE: x86_64 (2132 Mhz)
MEMORY: 4 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)Заключение
Анализ и диагностика причин падения ядра представляет собой очень специфическую и сложную тему, которую невозможно уместить в рамки одной статьи. Мы еще вернемся к ней в следующих публикациях.
Для желающих узнать больше — несколько полезных ссылок:
- Документация kdump на сайте kernel.org
- Книга, целиком посвященная проблемам диагностики сбоев ядра
- Подробная документация для утилиты crash
Ошибки в Linux могут возникать из-за различных причин и могут проявляться в разных формах, таких как сообщения об ошибках в системных журналах, неожиданные завершения программ, неисправность оборудования.
Виды ошибок в операционной системе Линукс
Некоторые типичные примеры ошибок в Linux:
1. Ядра: это ошибки, связанные с работой ядра операционной системы Linux. Они могут быть вызваны неправильной работой драйверов оборудования, ошибками в коде ядра или другими проблемами. Такие ошибки могут привести к сбою системы или неожиданному завершению работы.
2. Файловой системы: связаны с работой файловых систем, таких как ext4, Btrfs, NTFS и другие. Они могут проявляться в виде поврежденных файлов, невозможности монтировать диски или других проблем. Ошибки файловой системы могут быть вызваны некорректным отключением диска, ошибками записи или другими причинами.
3. Сети: обозначают проблемы в работе сети, такие как невозможность подключения к сети, медленная скорость передачи данных или другие проблемы. Ошибки сети могут быть вызваны неправильными настройками сетевых параметров, неисправностью оборудования или другими причинами.
4. Приложений: могут проявляться в виде неожиданного завершения работы программы, невозможности открыть файлы или других проблем. Ошибки приложений могут быть вызваны ошибками в коде программы, некорректными настройками или другими причинами.
5. Оборудования: связанные с работой оборудования, такие как жесткие диски, видеокарты, звуковые карты и другие. Они могут проявляться в виде неисправности оборудования, проблем с драйверами или других причин. Ошибки оборудования могут привести к сбою системы или неожиданному завершению работы.
Как проверить Linux на ошибки
Есть несколько способов проверить Linux на ошибки, в зависимости от того, какой тип ошибки вы хотите проверить.
Проверка журналов системы
Команда dmesg покажет журнал сообщений ядра. Вы можете использовать флаг -T для просмотра временных меток в удобном для чтения формате: dmesg -T
Команда journalctl позволяет просмотреть журнал системных сообщений. Вы можете использовать флаг -p для просмотра сообщений только с определенным уровнем приоритета, например: journalctl -p err -b — покажет только ошибки за последнюю загрузку системы.
Проверка жесткого диска
smartctl позволяет проверить состояние жесткого диска и диагностировать возможные проблемы: smartctl -a /dev/sda. Замените /dev/sda на путь к вашему жесткому диску.
fsck запускает проверку и позволяет исправить ошибки файловой системы на жестком диске: sudo fsck /dev/sda1. Замените /dev/sda1 на путь к вашей файловой системе.
Проверка памяти
memtest86 делает возможным проверки памяти на наличие ошибок: загрузите ее с загрузочного диска или флешки и запустите тест.
stress позволяет нагрузить систему, проверяя стабильность работы компьютера: sudo stress -c 4 -i 2 -m 1 -t 60s. Эта команда запустит тест, в котором будет использоваться 4 ядра CPU, 2 входа/выхода и 1 МБ оперативной памяти в течение 60 секунд.
Проверка сетевого соединения
ping делает возможным проверку связи с другими компьютерами и устройствами в сети: ping google.com.
при помощи traceroute можно определить маршрут, который данные проходят на пути к указанному хосту: traceroute google.com.
Эти команды помогут вам начать проверку системы на ошибки в Linux. Однако, для полной диагностики могут потребоваться дополнительные инструменты и методы, в зависимости от типа проблемы, которую вы хотите проверить.
Ядро Linux, как и другие программы может и выводит различные информационные сообщения и сообщения об ошибках. Все они выводятся в буфер сообщения ядра, так называемый kernel ring buffer. Основная причина существования этого буфера — надо сохранить сообщения, которые возникают во время загрузки системы пока сервис Syslog ещё не запущен и не может их собирать.
Для получения сообщений из этого буфера можно просто прочитать файл /var/log/dmesg. Однако, более удобно это можно сделать с помощью команды dmesg. В этой статье мы рассмотрим как пользоваться dmesg. Разберемся с опциями утилиты, а также приведем примеры работы с ней.
Синтаксис команды dmesg очень простой. Надо набрать имя команды и если необходимо, то опции:
$ dmesg опции
Опции позволяют управлять выводом, добавлять или скрывать дополнительную информацию и делать просмотр сообщений более удобным. Вот они:
- -C, —clear — очистить буфер сообщений ядра;
- -c, —read-clear — вывести сообщения из буфера ядра, а затем очистить его;
- -d, —show-delta — выводит время прошедшее между двумя сообщениями;
- -f, —facility — выводить только сообщения от подсистем определенной категории;
- -H, —human — включить вывод, удобный для человека;
- -k, —kernel — отображать только сообщения ядра;
- -L, —color — сделать вывод цветным, автоматически включается при использовании опции -H;
- -l, —level — ограничить вывод указанным уровнем подробности;
- -P, —nopager — выводить информацию обычным текстом, не добавлять постраничную навигацию;
- -r, —raw — печатать сообщения как есть, не убирая служебные префиксы;
- -S, —syslog — использовать Syslog для чтения сообщений от ядра, по умолчанию используется файл /dev/kmsg;
- -T, —ctime — выводить время в удобном для человека формате;
- -t, —notime — не выводить время поступления сообщения;
- -u, —userspace — показывать только сообщения от программ из пространства пользователя;
- -w, —follow — после вывода всех сообщений не завершать программу, а ждать новых;
- -x, —decode — выводить категорию и уровень журналирования в удобном для чтения формате.
Это далеко не все опции, а только самые интересные. Если вы хотите посмотреть другие, воспользуйтесь такой командой:
man dmesg
Поддерживаемые категории журналирования:
- kern — сообщения от ядра;
- user — сообщения от программ пространства пользователя;
- mail — сообщения от сервисов почты;
- daemon — сообщения от системных служб;
- auth — сообщения безопасности и информации об авторизации пользователей;
- syslog — сообщения, отправляемые сервисом Syslogd;
- lpr — сообщения от служб печати.
А вот доступные уровни журналирования:
- emerg — ошибка привела к неработоспособности системы;
- alert — требуется вмешательство пользователя;
- crit — критическая ошибка;
- err — обычная ошибка;
- warn — предупреждение;
- notine — замечание;
- info — информация;
- debug — отладочное сообщение.
Примеры использования dmesg
Как вы уже поняли команда dmesg показывает не только сообщения от ядра, но и другие сообщения от системных служб, например, от системы инициализации systemd. Чтобы вывести вообще все сообщения выполните команду без опций:
dmesg
По умолчанию перед сообщением выводится только временной сдвиг от загрузки системы. Если вы хотите полную временную метку, используйте опцию -T:
dmesg -T
Во время загрузки ядро тестирует оборудование и выводит подробную информацию о нём в буфер сообщений ядра. Таким образом, с помощью dmesg можно посмотреть информацию об оборудовании, просто отфильтруйте нужные данные, например CPU:
dmesg | grep CPU
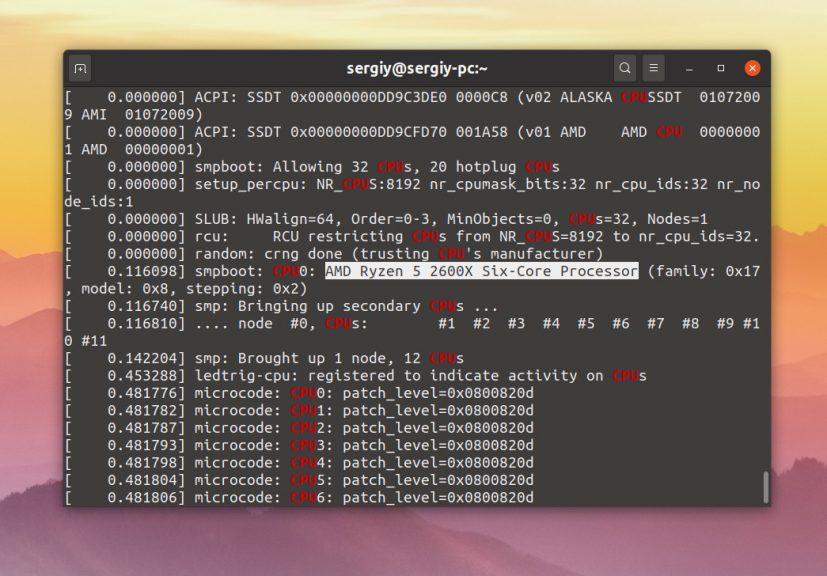
Для того чтобы выводить только сообщения от ядра, а не всё под ряд, используйте опцию -k:
dmesg -k
Теперь в выводе утилиты не будет сообщений от Systemd. Если вы хотите выводить все сообщения ядра в реальном времени, используйте опцию -w:
dmesg -w
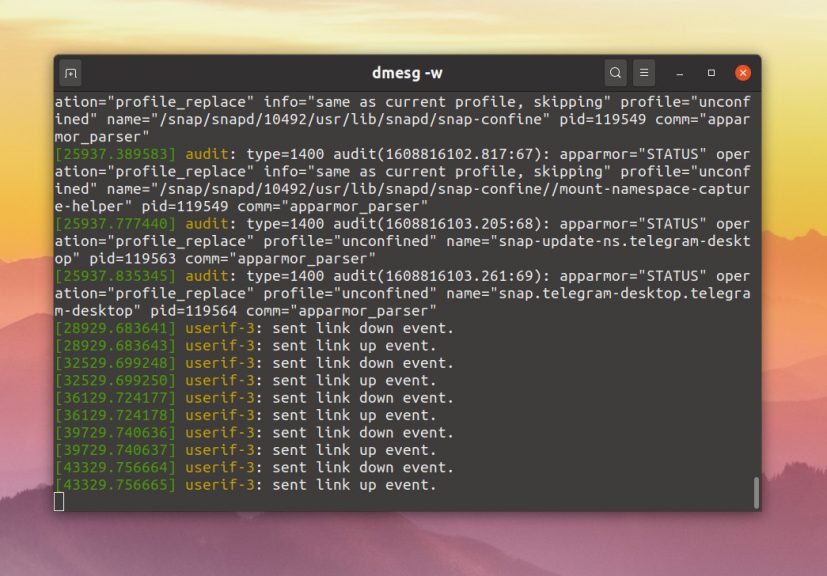
Для того чтобы добавить цвет к выводу и включить постраничную навигацию вместо вывода текста одним большим куском используйте опцию -H:
dmesg -H
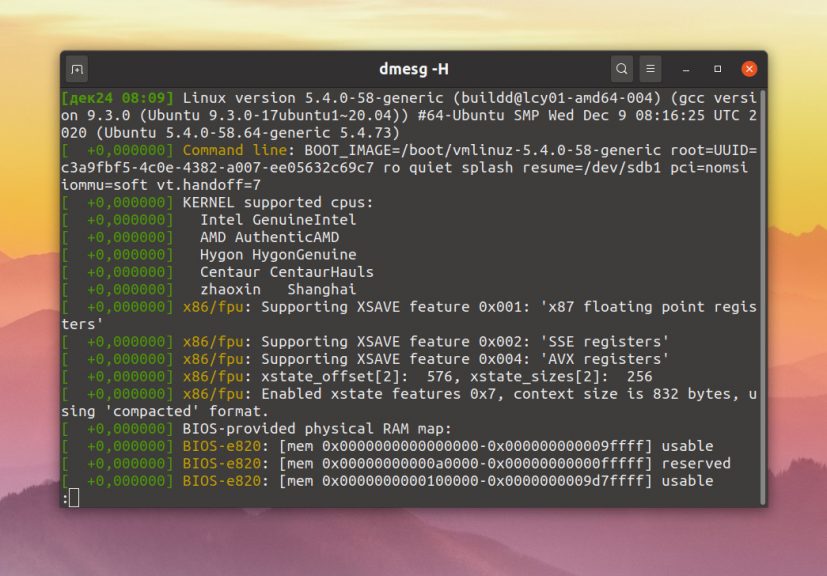
Для того чтобы вывести категорию сообщения и его уровень логирования используйте опцию -x:
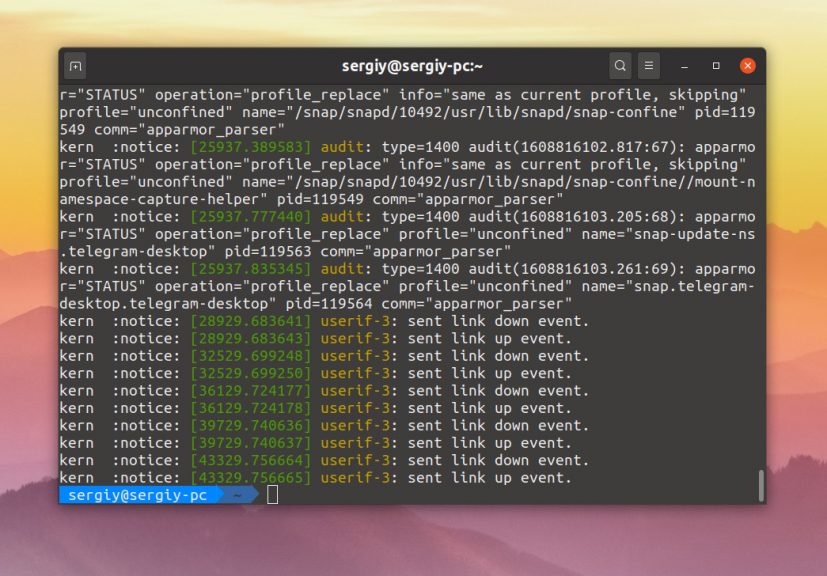
dmesg -x
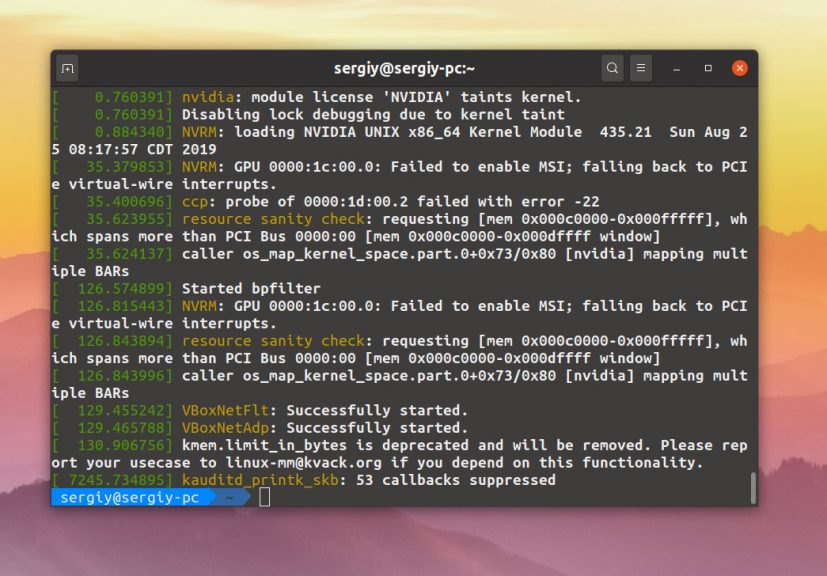
Если вас интересуют только ошибки, можно отсеять их по уровню журналирования:
dmesg -l crit,err
Или только информационные сообщения:
dmesg -l warn
Можно вывести только сообщения, которые попали сюда из пространства пользователя, для этого используйте опцию -u:
dmesg -u
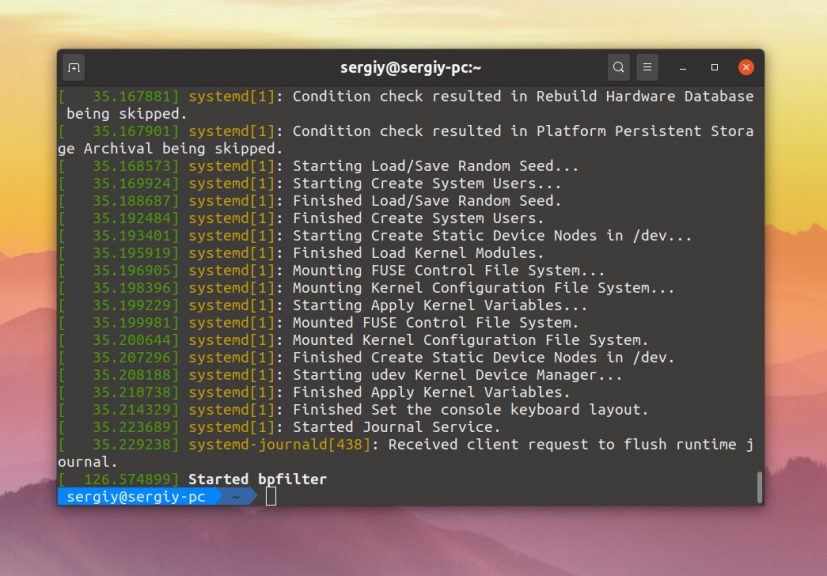
Или же отфильтруйте категории user и daemon с помощью опции -f:
dmesg -f user,daemon
Аналогичным образом вы можете фильтровать и другие категории. Если вы хотите очистить буфер сообщений ядра, используйте опцию -C. При следующем запуске dmesg там будет пусто:
dmesg -C
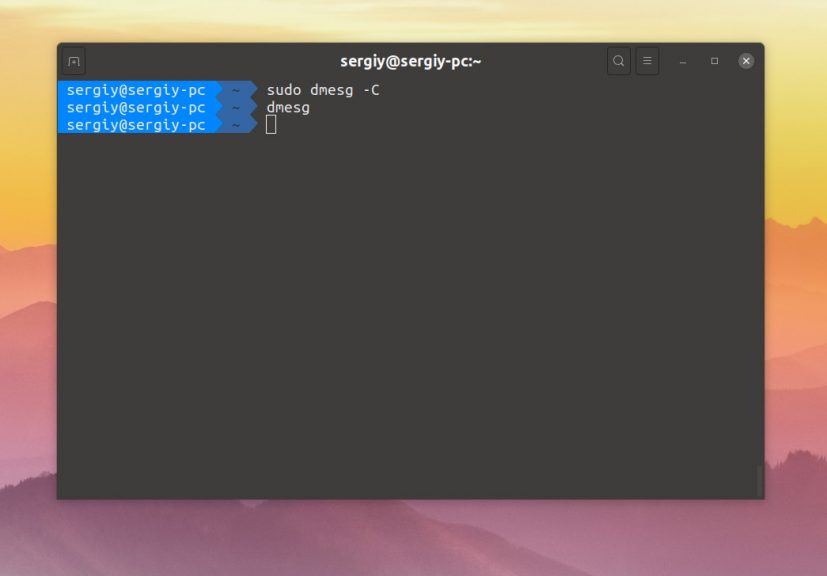
Выводы
В этой небольшой статье мы разобрали как пользоваться dmesg. Теперь вы знаете за что отвечает эта утилита, а также какие опции можно использовать.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Об авторе
![]()
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
Ядро Linux — это ядро операционной системы, которое контролирует доступ к системным ресурсам, таким как процессор, устройства ввода-вывода, физическая память и файловые системы. Ядро записывает различные сообщения в кольцевой буфер ядра в процессе загрузки и во время работы системы. Эти сообщения содержат различную информацию о работе системы.
Кольцевой буфер ядра — это часть физической памяти, которая содержит сообщения журнала ядра. Он имеет фиксированный размер, что означает, что после заполнения буфера старые записи журналов перезаписываются.
dmesg - Утилита командной строки используется для печати и управления кольцевого буфера ядра в Linux и других Unix-подобных операционных систем. Это полезно для изучения загрузочных сообщений ядра и устранения проблем, связанных с оборудованием.
Использование dmesg команды
Синтаксис dmesg команды следующий:
При вызове без каких-либо параметров dmesgзаписывает все сообщения из кольцевого буфера ядра в стандартный вывод:
dmesg
По умолчанию все пользователи могут запускать dmesg команду. Однако в некоторых системах доступ к ним dmesg может быть ограничен для пользователей без полномочий root. В этой ситуации при вызове dmesgвы получите сообщение об ошибке, как показано ниже:
dmesg: read kernel buffer failed: Operation not permitted
Параметр ядра kernel.dmesg_restrict указывает, могут ли непривилегированные пользователи dmesg просматривать сообщения из буфера журнала ядра. Чтобы снять ограничения, установите его на ноль:
sudo sysctl -w kernel.dmesg_restrict=0 Обычно выходные данные содержат много строк информации, так что только последняя часть выходных данных является видимой. Чтобы увидеть одну страницу за раз, перенаправьте вывод в утилиту пейджера, такую как less или more:
dmesg --color=always | less
--color=always Используется для сохранения цветного вывода.
Если вы хотите фильтровать сообщения буфера, используйте grep. Например, чтобы просмотреть только сообщения, связанные с USB, вы должны набрать:
dmesg | grep -i usb
dmesg /proc/kmsg виртуального файла. Этот файл предоставляет интерфейс к кольцевому буферу ядра и может быть открыт только одним процессом. Если syslogв вашей системе запущен процесс, и вы пытаетесь прочитать файл с помощью cat, или less, команда зависнет.
syslog Демон отвалов сообщения ядра /var/log/dmesg, так что вы можете использовать этот файл журнала:
cat /var/log/dmesg
Форматирование dmesg вывода
Команда dmesgпредоставляет ряд опций, которые помогут вам отформатировать и отфильтровать вывод.
Одна из наиболее часто используемых опций dmesg— это -H ( --human), которая обеспечивает удобочитаемый вывод. Эта опция направляет вывод команды в пейджер:
dmesg -H Для печати удобочитаемых временных меток используйте опцию -T ( --ctime):
dmesg -T[Mon Oct 14 14:38:04 2019] IPv6: ADDRCONF(NETDEV_CHANGE): wlp1s0: link becomes ready
Формат --time-format <format> отметок времени также может быть установлен с помощью параметра, который может быть ctime, reltime, delta, notime или iso. Например, чтобы использовать дельта-формат, введите:
dmesg --time-format=deltaВы также можете объединить два или более вариантов:
dmesg -H -T
Чтобы просмотреть вывод dmesg команды в режиме реального времени, используйте параметр -w ( --follow):
dmesg --follow
Фильтрация dmesgвывода
Вы можете ограничить dmesg вывод данными объектами и уровнями.
Средство представляет процесс, который создал сообщение. dmesg поддерживает следующие возможности журнала:
kern— сообщения ядраuser— сообщения уровня пользователяmail— почтовая системаdaemon— системные демоныauth— сообщения безопасности / авторизацииsyslog— внутренние сообщения syslogdlpr— подсистема линейного принтераnews— подсистема сетевых новостей
Опция -f( --facility <list>) позволяет ограничить вывод определенными объектами. Опция принимает одно или несколько разделенных запятыми объектов.
Например, для отображения только сообщений ядра и системных демонов вы должны использовать:
dmesg -f kern,daemon
Каждое сообщение журнала связано с уровнем журнала, который показывает важность сообщения. dmesgподдерживает следующие уровни журнала:
emerg— система неработоспособнаalert— действие должно быть предпринято немедленноcrit— критические условияerr— условия ошибкиwarn— условия предупрежденияnotice— нормальное, но значимое состояниеinfo— информационныйdebug— сообщения уровня отладки
Опция -l( --level <list>) ограничивает вывод определенными уровнями. Опция принимает один или несколько уровней, разделенных запятыми.
Следующая команда отображает только сообщения об ошибках и критические сообщения:
dmesg -l err,crit
Очистка кольцевого буфера
Опция -C( --clear) позволяет очистить кольцевой буфер:
sudo dmesg -C
Только root или пользователи с привилегиями sudo могут очистить буфер.
Чтобы распечатать содержимое буфера перед очисткой, используйте параметр -c( --read-clear):
sudo dmesg -c Если вы хотите сохранить текущие dmesg журналы в файле перед его очисткой, перенаправьте вывод в файл:
dmesg > dmesg_messages
Вывод
Команда dmesgпозволяет вам просматривать и контролировать кольцевой буфер ядра. Это может быть очень полезно при устранении проблем с ядром или оборудованием.
Введите man dmesg в своем терминале информацию о всех доступных dmesg опциях.
Introduction
The dmesg command is a Linux utility that displays kernel-related messages retrieved from the kernel ring buffer. The ring buffer stores information about hardware, device driver initialization, and messages from kernel modules that take place during system startup.
The dmesg command is invaluable when troubleshooting hardware-related errors, warnings, and for diagnosing device failure.
In this tutorial, you will learn how to use the dmesg command in Linux.

Prerequisites
- A computer system running Linux.
- A user account with administrator privileges.
The basic dmesg command syntax is:
dmesg [options]The table below lists the most commonly used dmesg options:
| Option | Description |
|---|---|
-C, --clear |
Clears the ring buffer. |
-c, --read-clear |
Prints the ring buffer contents and then clears. |
-f, --facility [list] |
Restricts output to the specified comma-separated facility [list]. |
-H, --human |
Enables a human-readable output. |
-L, --color[=auto|never|always] |
Adds color to the output. Omitting the [auto|never|always] arguments defaults to auto. |
-l, --level [list] |
Restricts the output to the specified comma-separated level list. |
--noescape |
Disables the feature of automatically escaping unprintable and potentially unsafe characters. |
-S, --syslog |
Instructs dmesg to use the syslog kernel interface to read kernel messages. The default is to use /dev/kmsg instead of syslog. |
-s, --buffer-size [size] |
Uses the specified buffer size to query the kernel ring buffer. The default value is 16392. |
-T, --ctime |
Prints human-readable timestamps. |
-t, --notime |
Instructs dmesg not to print kernel’s timestamps. |
--time-format [format] |
Prints timestamps using the specified [format]. The accepted formats are ctime, reltime, delta, and iso (a dmesg implementation of the ISO-8601 format). |
-w, --follow |
Keeps dmesg running and waiting for new messages. The feature is available only on systems with a readable /dev/kmsg file. |
-x, --decode |
Decodes the facility and level numbers to human-readable prefixes. |
-h, --help |
Displays the help file with all the available options. |
Linux dmesg Command Examples
The examples are common dmesg command use cases.
Display All Messages from Kernel Ring Buffer
Invoking dmesg without any options outputs the entire kernel buffer, without stops, and with no way to navigate the output.
sudo dmesg
The example above is a partial dmesg command output. For easier navigation and better readability, pipe the dmesg output into a terminal pager such as less, more, or use grep.
For example:
sudo dmesg | less
Piping dmesg into less allows you to use the search function to locate and highlight items. Activate search by pressing /. Navigate to the next screen using the Space bar, or reverse using the B key. Exit the output by pressing Q.
Display Colored Messages
By default, dmesg produces a colored output. If the output isn’t colored, use the -L option to colorize it.
sudo dmesg -L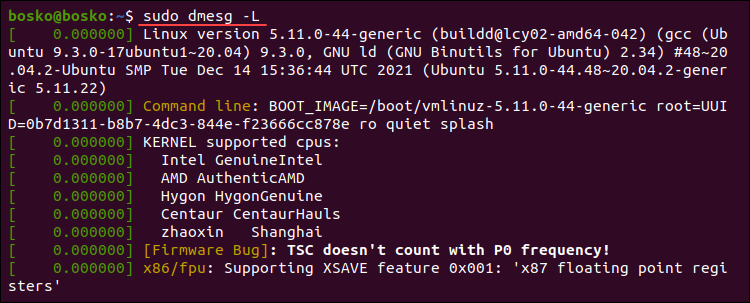
To turn off colored outputs, append the --color=never option to dmesg. Run the following command:
sudo dmesg --color=never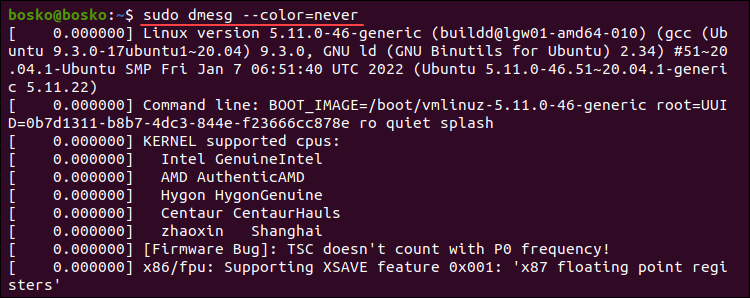
The default dmesg output is now uniform in color.
Display Messages as They Arrive
Monitor the kernel ring buffer in real-time using the --follow option. The option instructs the command to wait for new messages related to hardware or kernel modules after system startup.
Run the following dmesg command to enable real-time kernel ring buffer monitoring:
sudo dmesg --followThe command displays any new messages at the bottom of the terminal window. Stop the process using Ctrl+C.
Search for a Specific Term
When searching for specific issues or hardware messages, pipe the dmesg output into grep to search for a particular string or pattern.
For example, if you are looking for messages about memory, run the following command:
dmesg | grep -i memory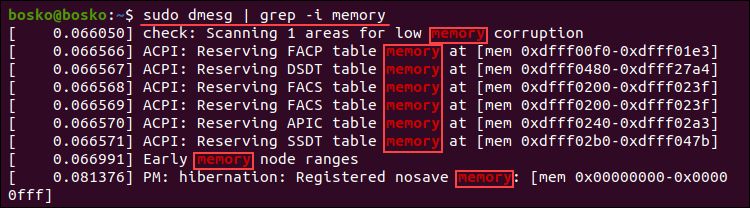
The output shows all the lines from the buffer containing the memory string. The -i (ignore case) switch ignores care sensitivity.
Alternatively, if you are looking for buffer messages about USB, serial ports, network, or hard drives, run the following commands:
USB
dmesg | grep -i usbSerial Ports
dmesg | grep -i ttyNetwork
dmesg | grep -i ethHard Drives
sudo dmesg | grep -i sdaSearch for multiple terms at once by appending the -E option to grep and providing the search terms encased in quotations, separated by pipe delimiters. For example:
sudo dmesg | grep -E "memory|tty"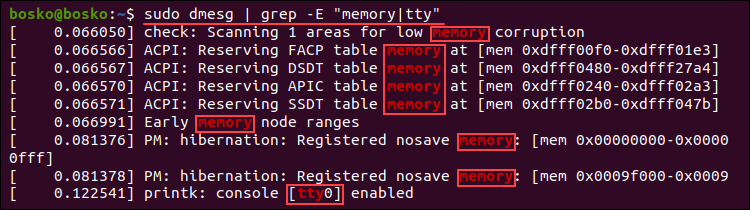
The output prints all the messages containing any of the search terms.
Read and Clear dmesg Logs
The -c (--read-clear) option lets you clear the dmesg log after printing it. Clearing the buffer ensures you have only valid messages from the latest reboot.
Note: To save the entire log in a file before clearing it, redirect the output to a file with sudo dmesg > log_file.
Run the following command:
sudo dmesg -cRerunning dmesg has no output since the log has been cleared.

Enable Timestamps in dmesg Logs
Enable timestamps in dmesg output by appending it with the -H (--human) option, which produces a human-readable output and automatically pipes the output into a pager (less).
Run the following command:
sudo dmesg -H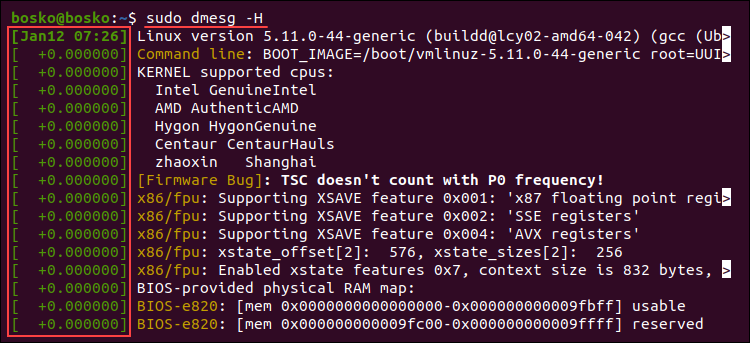
The command adds a timestamp with the date and time resolved in minutes. The events in the same minute are labeled with seconds and nanoseconds.
Quit the pager by pressing Q.
Enable Human-Readable Timestamps
Enable human-readable timestamps using the -T (--ctime) option. The option removes the nanosecond accuracy from the output, but the timestamps are easier to follow.
sudo dmesg -T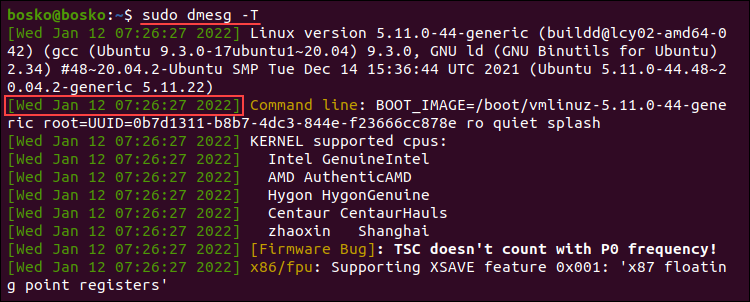
The timestamps in the output are standard dates and time, and the resolution is in minutes. The same timestamp is prepended to each action that occurred in the same minute.
Note: Unlike the -H option, the -T option doesn’t automatically invoke less.
Choose Timestamp Format
Use the --time-format [format] option to choose the timestamp format. The available formats are:
ctimereltimedeltanotimeiso
For example, to use the iso format, run:
sudo dmesg --time-format=iso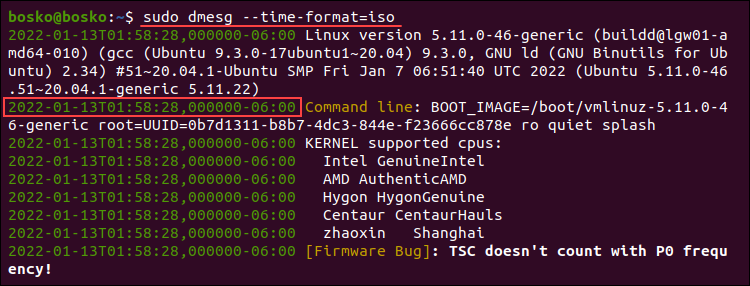
The timestamp format is now YYYY-MM-DD<T>HH:MM:SS,<microseconds>←+><timezone offset from UTC>.
Note: The iso and ctime may show inaccurate time when the system is suspended and resumed.
Limit dmesg Output to a Specific Facility
Filter the dmesg output to a specific category using the -f option. The system groups messages in the kernel ring buffer into the following facilities (categories):
kern. Kernel messages.user. User-level messages.mail. Mail system messages.daemon. Messages about system daemons.auth. Authorization messages.syslog. Internalsyslogdmessages.lpr. Line printer subsystem messages.news. Network news subsystem messages.
For example, the following command limits the output to messages related to the syslog facility:
sudo dmesg -f syslog
To list messages from more than one facility, specify a comma-separated list of facilities. For example:
sudo dmesg -f syslog,daemon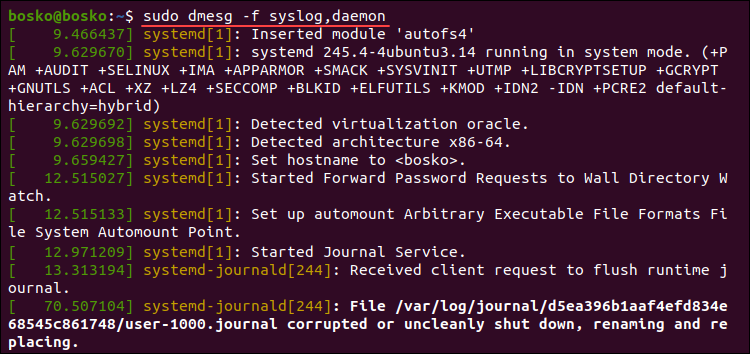
Filter Log Levels
The dmesg command associates each buffer message with a log level characterizing message importance. The available levels are:
emerg. Emergency messages.alert. Alerts requiring immediate action.crit. Critical conditions.err. Error messages.warn. Warning messages.notice. Normal but significant conditions.info. Informational messages.debug. Debugging-level messages.
Instruct dmesg to print only the messages matching a certain level using the -l option, followed by the level name. For example:
sudo dmesg -l info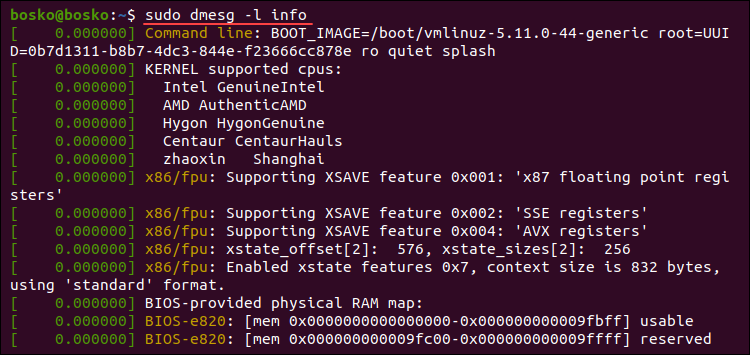
The example above extracts only informational messages from the log.
Combine multiple levels in a comma-separated list to retrieve messages from those levels. For example:
sudo dmesg -l notice,warn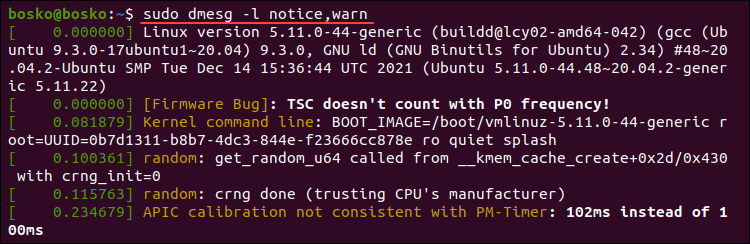
The output combines messages from the specified log levels.
Combining Facility and Level
Explicitly show each buffer message’s facility and log level at the start of each line using the -x (decode) option.
For example:
sudo dmesg -x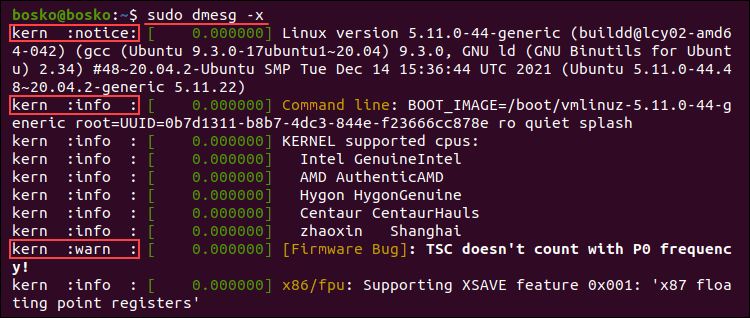
In the example above, each line is prepended with the appropriate facility and log level.
Read dmesg Log File
Each time the system boots up, the messages from the kernel ring buffer are stored in the /var/log/dmesg file. The dmesg command shows the log file contents. If you have issues using the dmesg command, open the log file in a text editor to view the contents.
In the example below, we use the cat command to view the log file and pipe it into grep to search for a particular string occurring in the log:
cat dmesg | grep amd
The command outputs all amd string instances in the log file.
Check for a CD Drive
Check if a remote machine is equipped with a CD drive by inspecting the buffer message log. For example, the following command shows all messages about CD devices initialized on startup:
sudo dmesg | grep -iE 'cdrom|dvd|cd/rw|cd-rom'
The results display information about the available CD-ROM drives, including the virtual CD-ROM drive on this machine.
Remove sudo Requirement
Removing the requirement for superuser privileges allows any user to run dmesg and view kernel ring buffer messages. Run the following command to remove the sudo requirement:
sudo sysctl -w kernel.dmesg_restrict=0
After setting the restrictions to 0, any user on the system can run dmesg.
Conclusion
This guide explained how to use the Linux dmesg command to view and control the kernel ring buffer. The utility is convenient when troubleshooting kernel or hardware issues.
For further reading, we recommend our tutorial on updating the Linux kernel in Ubuntu or checking the Kernel version in Linux.

Хотя в современных Linux-системах ядро отличается достаточно высоким уровнем стабильности, вероятность серьезных системных ошибок, тем не менее, имеется всегда. Когда происходит неисправимая ошибка, имеет место состояние, называемое паникой ядра (kernel panic): стандартный обработчик выводит на экран информацию, которая должна помочь в устранении неисправности, и входит в бесконечный цикл.
Для диагностики и анализа причин сбоев ядра разработчиками компании RedHat был разработан специализированный инструмент — kdump. Принцип его работы можно кратко описать следующим образом. Создается два ядра: основное и аварийное (именно оно используется для сбора дампа памяти). При загрузке основного ядра под аварийное ядро выделяется определенный размер памяти. При помощи kexec во время паники основного ядра загружается аварийное и собирает дамп.
В этой статье мы подробно расскажем о том, как конфигурировать kdump и анализировать с его помощью системные ошибки. Мы рассмотрим особенности работы с kdump в OC Ubuntu; в других дистрибутивах процедуры настройки и конфигурирования kdump существенно отличаются.
Установка и настройка kdump
Установим kdump с помощью команды
$ sudo apt-get install linux-crashdump kdump-tools
Настройки kdump хранятся в конфигурационном файле /etc/default/kdump-tools
# kdump-tools configuration # --------------------------------------------------------------------------- # USE_KDUMP - controls kdump will be configured # 0 - kdump kernel will not be loaded # 1 - kdump kernel will be loaded and kdump is configured # KDUMP_SYSCTL - controls when a panic occurs, using the sysctl # interface. The contents of this variable should be the # "variable=value ..." portion of the 'sysctl -w ' command. # If not set, the default value "kernel.panic_on_oops=1" will # be used. Disable this feature by setting KDUMP_SYSCTL=" " # Example - also panic on oom: # KDUMP_SYSCTL="kernel.panic_on_oops=1 vm.panic_on_oom=1" # USE_KDUMP=1 # KDUMP_SYSCTL="kernel.panic_on_oops=1"
Чтобы активировать kdump, отредактируем этот файл и установим значение параметра USE_KDUMP=1.
Также в конфигурационном файле содержатся следующие параметры:
- KDUMP_KERNEL — полный путь к аварийному ядру;
- KDUMP_INITRD — полный путь к initrd аварийного ядра;
- KDUMP_CORE — указывает, где будет сохранен файл дампа ядра. По умолчанию дамп сохраняется в директории /var/crash (KDUMP_CORE=/var/crash);
- KDUMP_FAIL_CMD — указывает, какое действие нужно совершить в случае ошибки при сохранении дампа (по умолчанию будет выполнена команда reboot -f);
- DEBUG_KERNEL — отладочная версия работающего ядра. По умолчанию используются /usr/lib/debug/vmlinux-$. Если значение этого параметра не установлено, утилита makedumpfile создаст только дамп всех страниц памяти;
- MAKEDUMP_ARGS — содержит дополнительные аргументы, передаваемые утилите makedumpfile. По умолчанию этот параметр имеет значение ‘-c -d 31’, указывающую, что необходимо использовать сжатие и включать в дамп только используемые страницы ядра.
Установив все необходимые параметры, выполним команду update-grub и выберем install the package maintainer’s version.
Затем перезагрузим систему и убедимся в том, что kdump готов к работе:
$ cat/proc/cmdline BOOT_IMAGE=/boot/vmlinuz-3.8.0-35-generic root=UUID=bb2ba5e1-48e1-4829-b565-611542b96018 ro crashkernel=384 -:128M quiet splash vt.handoff=7
Обратим особое внимание на параметр crashkernel=384 -:128M. Он означает, что аварийное ядро будет использовать 128 Мб памяти при загрузке. Можно прописать в grub параметр crashkernel = auto: в этом случае память под аварийное ядро будет выделяться автоматически.
Для того, чтобы мы могли анализировать дамп с помощью утилиты crash, нам понадобится также файл vmlinux, содержащий отладочную информацию:
$ sudo tee /etc/apt/sources.list.d/ddebs.list << EOF deb http://ddebs.ubuntu.com/ $(lsb_release -cs) main restricted universe multiverse deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-security main restricted universe multiverse deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-updates main restricted universe multiverse deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-proposed main restricted universe multiverse EOF $ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys ECDCAD72428D7C01 $ sudo apt-get update $ sudo apt-get install linux-image-$(uname -r)-dbgsym
По завершении установки еще раз проверим статус kdump:
$ kdump-config status
Если kdump находится в рабочем состоянии, на консоль будет выведено следующее сообщение:
current state: ready to kdump
Тестируем kdump
Вызовем панику ядра при помощи следующих команд:
echo c | sudo tee /proc/sysrq-trigger
В результате их выполнения система «зависнет».
После этого в течение нескольких минут будет создан дамп, который будет доступен в директории /var/crash после перезагрузки.
Информацию о сбое ядра можно просмотреть с помощью утилиты crash:
$ sudo crash /usr/lib/debug/boot/vmlinux-3.13.0-24-generic /var/crash/201405051934/dump.201405051934
crash 7.0.3
Copyright (C) 2002-2013 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005, 2011 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu"...
KERNEL: /usr/lib/debug/boot/vmlinux-3.13.0-24-generic
DUMPFILE: /var/crash/201405051934/dump.201405051934 [PARTIAL DUMP]
CPUS: 4
DATE: Mon May 5 19:34:38 2014
UPTIME: 00:54:46
LOAD AVERAGE: 0.14, 0.07, 0.05
TASKS: 495
NODENAME: Ubuntu
RELEASE: 3.13.0-24-generic
VERSION: #46-Ubuntu SMP Thu Apr 10 19:11:08 UTC 2014
MACHINE: x86_64 (2675 Mhz)
MEMORY: 8 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)
PID: 7826
COMMAND: "tee"
TASK: ffff8800a2ef8000 [THREAD_INFO: ffff8800a2e68000]
CPU: 2
STATE: TASK_RUNNING (PANIC)
crash>
На основе приведенного вывода мы можем заключить, что системному сбою предшествовало событие «Oops: 0002 [#1] SMP», произошедшее на CPU2 при выполнении команды tee.
Утилита crash обладает также широким спектром возможностей для диагностики причин краха ядра. Рассмотрим их более подробно.
Диагностика причин сбоя с помощью утилиты crash
Crash сохраняет информацию обо всех системных событиях, предшествовавших краху ядра. С ее помощью можно воссоздать состояние системы на момент сбоя: узнать, какие процессы были запущены на момент краха, какие файлы открыты и т.п. Эта информация помогает поставить точный диагноз и предупредить крахи ядра в будущем.
В утилите crash имеется свой набор команд:
$ crash> help * files mach repeat timer alias foreach mod runq tree ascii fuser mount search union bt gdb net set vm btop help p sig vtop dev ipcs ps struct waitq dis irq pte swap whatis eval kmem ptob sym wr exit list ptov sys q extend log rd task crash version: 7.0.3 gdb version: 7.6 For help on any command above, enter "help <command>". For help on input options, enter "help input". For help on output options, enter "help output". crash>
Для каждой этой команды можно вызвать краткий мануал, например:
crash> help set
Все команды мы описывать не будем (с детальной информацией можно ознакомиться в официальном руководстве пользователя от компании RedHat), а расскажем лишь о наиболее важных из них.
В первую очередь следует обратить внимание на команду bt (аббревиатура от backtrace — обратная трассировка). С ее помощью можно посмотреть детальную информацию о содержании памяти ядра (подробности и примеры использования см. здесь). Однако во многих случаях для определения причины системного сбоя бывает вполне достаточно команды log, выводящее на экран содержимое буфера сообщений ядра в хронологическом порядке.
Приведем фрагмент ее вывода:
[ 3288.251955] CPU: 2 PID: 7826 Comm: tee Tainted: PF O 3.13.0-24-generic #46-Ubuntu [ 3288.251957] Hardware name: System manufacturer System Product Name/P7P55D LE, BIOS 2003 12/16/2010 [ 3288.251958] task: ffff8800a2ef8000 ti: ffff8800a2e68000 task.ti: ffff8800a2e68000 [ 3288.251960] RIP: 0010:[<ffffffff8144de76>] [<ffffffff8144de76>] sysrq_handle_crash+0x16/0x20 [ 3288.251963] RSP: 0018:ffff8800a2e69e88 EFLAGS: 00010082 [ 3288.251964] RAX: 000000000000000f RBX: ffffffff81c9f6a0 RCX: 0000000000000000 [ 3288.251965] RDX: ffff88021fc4ffe0 RSI: ffff88021fc4e3c8 RDI: 0000000000000063 [ 3288.251966] RBP: ffff8800a2e69e88 R08: 0000000000000096 R09: 0000000000000387 [ 3288.251968] R10: 0000000000000386 R11: 0000000000000003 R12: 0000000000000063 [ 3288.251969] R13: 0000000000000246 R14: 0000000000000004 R15: 0000000000000000 [ 3288.251971] FS: 00007fb0f665b740(0000) GS:ffff88021fc40000(0000) knlGS:0000000000000000 [ 3288.251972] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b [ 3288.251973] CR2: 0000000000000000 CR3: 00000000368fd000 CR4: 00000000000007e0 [ 3288.251974] Stack: [ 3288.251975] ffff8800a2e69ec0 ffffffff8144e5f2 0000000000000002 00007fff3cea3850 [ 3288.251978] ffff8800a2e69f50 0000000000000002 0000000000000008 ffff8800a2e69ed8 [ 3288.251980] ffffffff8144eaff ffff88021017a900 ffff8800a2e69ef8 ffffffff8121f52d [ 3288.251983] Call Trace: [ 3288.251986] [<ffffffff8144e5f2>] __handle_sysrq+0xa2/0x170 [ 3288.251988] [<ffffffff8144eaff>] write_sysrq_trigger+0x2f/0x40 [ 3288.251992] [<ffffffff8121f52d>] proc_reg_write+0x3d/0x80 [ 3288.251996] [<ffffffff811b9534>] vfs_write+0xb4/0x1f0 [ 3288.251998] [<ffffffff811b9f69>] SyS_write+0x49/0xa0 [ 3288.252001] [<ffffffff8172663f>] tracesys+0xe1/0xe6 [ 3288.252002] Code: 65 34 75 e5 4c 89 ef e8 f9 f7 ff ff eb db 0f 1f 80 00 00 00 00 66 66 66 66 90 55 c7 05 94 68 a6 00 01 00 00 00 48 89 e5 0f ae f8 <c6> 04 25 00 00 00 00 01 5d c3 66 66 66 66 90 55 31 c0 c7 05 be [ 3288.252025] RIP [<ffffffff8144de76>] sysrq_handle_crash+0x16/0x20 [ 3288.252028] RSP <ffff8800a2e69e88> [ 3288.252029] CR2: 0000000000000000
В одной из строк вывода будет указано событие, вызвавшее системную ошибку:
[ 3288.251889] SysRq: Trigger a crash
С помощью команды ps можно вывести на экран список процессов, которые были запущены на момент сбоя:
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
0 0 0 ffffffff81a8d020 RU 0.0 0 0 [swapper]
1 0 0 ffff88013e7db500 IN 0.0 19356 1544 init
2 0 0 ffff88013e7daaa0 IN 0.0 0 0 [kthreadd]
3 2 0 ffff88013e7da040 IN 0.0 0 0 [migration/0]
4 2 0 ffff88013e7e9540 IN 0.0 0 0 [ksoftirqd/0]
7 2 0 ffff88013dc19500 IN 0.0 0 0 [events/0]
Для просмотра информации об использовании виртуальной памяти используется команда vm:
crash> vm
PID: 5210 TASK: ffff8801396f6aa0 CPU: 0 COMMAND: "bash"
MM PGD RSS TOTAL_VM
ffff88013975d880 ffff88013a0c5000 1808k 108340k
VMA START END FLAGS FILE
ffff88013a0c4ed0 400000 4d4000 8001875 /bin/bash
ffff88013cd63210 3804800000 3804820000 8000875 /lib64/ld-2.12.so
ffff880138cf8ed0 3804c00000 3804c02000 8000075 /lib64/libdl-2.12.so
Команда swap выведет на консоль информацию об использовании области подкачки:
crash> swap FILENAME TYPE SIZE USED PCT PRIORITY /dm-1 PARTITION 2064376k 0k 0% -1
Информацию о прерываниях CPU можно просмотреть с помощью команды irq:
crash> irq -s
CPU0
0: 149 IO-APIC-edge timer
1: 453 IO-APIC-edge i8042
7: 0 IO-APIC-edge parport0
8: 0 IO-APIC-edge rtc0
9: 0 IO-APIC-fasteoi acpi
12: 111 IO-APIC-edge i8042
14: 108 IO-APIC-edge ata_piix
Вывести на консоль список файлов, открытых на момент сбоя, можно с помощью команды files:
crash> files PID: 5210 TASK: ffff8801396f6aa0 CPU: 0 COMMAND: "bash" ROOT: / CWD: /root FD FILE DENTRY INODE TYPE PATH 0 ffff88013cf76d40 ffff88013a836480 ffff880139b70d48 CHR /tty1 1 ffff88013c4a5d80 ffff88013c90a440 ffff880135992308 REG /proc/sysrq-trigger 255 ffff88013cf76d40 ffff88013a836480 ffff880139b70d48 CHR /tty1
Наконец, получить в сжатом виде информацию об общем состоянии системы можно с помощью команды sys:
crash> sys
KERNEL: /usr/lib/debug/lib/modules/2.6.32-431.5.1.el6.x86_64/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2014-03-26-12:24:39/vmcore [PARTIAL DUMP]
CPUS: 1
DATE: Wed Mar 26 12:24:36 2014
UPTIME: 00:01:32
LOAD AVERAGE: 0.17, 0.09, 0.03
TASKS: 159
NODENAME: elserver1.abc.com
RELEASE: 2.6.32-431.5.1.el6.x86_64
VERSION: #1 SMP Fri Jan 10 14:46:43 EST 2014
MACHINE: x86_64 (2132 Mhz)
MEMORY: 4 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)
Заключение
Анализ и диагностика причин падения ядра представляет собой очень специфическую и сложную тему, которую невозможно уместить в рамки одной статьи. Мы еще вернемся к ней в следующих публикациях.
Для желающих узнать больше — несколько полезных ссылок:
- Документация kdump на сайте kernel.org
- Книга, целиком посвященная проблемам диагностики сбоев ядра
- Подробная документация для утилиты crash
Читателей, которые не могут оставлять комментарии здесь, приглашаем к нам в блог.
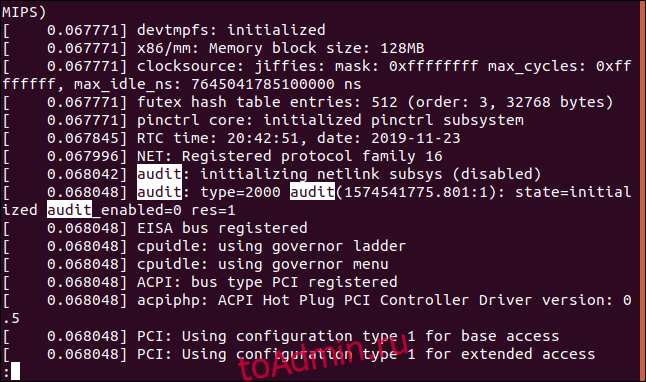
The ‘dmesg‘ command displays the messages from the kernel ring buffer. A system passes multiple runlevel from where we can get lot of information like system architecture, cpu, attached device, RAM etc. When computer boots up, a kernel (core of an operating system) is loaded into memory. During that period number of messages are being displayed where we can see hardware devices detected by kernel.
Read Also: 10 Linux Commands to Collect System and Hardware Information

The messages are very important in terms of diagnosing purpose in case of device failure. When we connect or disconnect hardware device on the system, with the help of dmesg command we come to know detected or disconnected information on the fly. The dmesg command is available on most Linux and Unix based Operating System.
Let’s throw some light on most famous tool called ‘dmesg’ command with their practical examples as discussed below. The exact syntax of dmesg as follows.
# dmseg [options...]
1. List all loaded Drivers in Kernel
We can use text-manipulation tools i.e. ‘more‘, ‘tail‘, ‘less‘ or ‘grep‘ with dmesg command. As output of dmesg log won’t fit on a single page, using dmesg with pipe more or less command will display logs in a single page.
[[email protected] ~]# dmesg | more [[email protected] ~]# dmesg | less
Sample Output
[ 0.000000] Initializing cgroup subsys cpuset [ 0.000000] Initializing cgroup subsys cpu [ 0.000000] Initializing cgroup subsys cpuacct [ 0.000000] Linux version 3.11.0-13-generic ([email protected]) (gcc version 4.8.1 (Ubuntu/Linaro 4.8.1-10ubuntu8) ) #20-Ubuntu SMP Wed Oct 23 17:26:33 UTC 2013 (Ubuntu 3.11.0-13.20-generic 3.11.6) [ 0.000000] KERNEL supported cpus: [ 0.000000] Intel GenuineIntel [ 0.000000] AMD AuthenticAMD [ 0.000000] NSC Geode by NSC [ 0.000000] Cyrix CyrixInstead [ 0.000000] Centaur CentaurHauls [ 0.000000] Transmeta GenuineTMx86 [ 0.000000] Transmeta TransmetaCPU [ 0.000000] UMC UMC UMC UMC [ 0.000000] e820: BIOS-provided physical RAM map: [ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable [ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved [ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x000000007dc08bff] usable [ 0.000000] BIOS-e820: [mem 0x000000007dc08c00-0x000000007dc5cbff] ACPI NVS [ 0.000000] BIOS-e820: [mem 0x000000007dc5cc00-0x000000007dc5ebff] ACPI data [ 0.000000] BIOS-e820: [mem 0x000000007dc5ec00-0x000000007fffffff] reserved [ 0.000000] BIOS-e820: [mem 0x00000000e0000000-0x00000000efffffff] reserved [ 0.000000] BIOS-e820: [mem 0x00000000fec00000-0x00000000fed003ff] reserved [ 0.000000] BIOS-e820: [mem 0x00000000fed20000-0x00000000fed9ffff] reserved [ 0.000000] BIOS-e820: [mem 0x00000000fee00000-0x00000000feefffff] reserved [ 0.000000] BIOS-e820: [mem 0x00000000ffb00000-0x00000000ffffffff] reserved [ 0.000000] NX (Execute Disable) protection: active .....
Read Also: Manage Linux Files Effectively using commands head, tail and cat
2. List all Detected Devices
To discover which hard disks has been detected by kernel, you can search for the keyword “sda” along with “grep” like shown below.
[[email protected] ~]# dmesg | grep sda [ 1.280971] sd 2:0:0:0: [sda] 488281250 512-byte logical blocks: (250 GB/232 GiB) [ 1.281014] sd 2:0:0:0: [sda] Write Protect is off [ 1.281016] sd 2:0:0:0: [sda] Mode Sense: 00 3a 00 00 [ 1.281039] sd 2:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA [ 1.359585] sda: sda1 sda2 < sda5 sda6 sda7 sda8 > [ 1.360052] sd 2:0:0:0: [sda] Attached SCSI disk [ 2.347887] EXT4-fs (sda1): mounted filesystem with ordered data mode. Opts: (null) [ 22.928440] Adding 3905532k swap on /dev/sda6. Priority:-1 extents:1 across:3905532k FS [ 23.950543] EXT4-fs (sda1): re-mounted. Opts: errors=remount-ro [ 24.134016] EXT4-fs (sda5): mounted filesystem with ordered data mode. Opts: (null) [ 24.330762] EXT4-fs (sda7): mounted filesystem with ordered data mode. Opts: (null) [ 24.561015] EXT4-fs (sda8): mounted filesystem with ordered data mode. Opts: (null)
NOTE: The ‘sda’ first SATA hard drive, ‘sdb’ is the second SATA hard drive and so on. Search with ‘hda’ or ‘hdb’ in the case of IDE hard drive.
3. Print Only First 20 Lines of Output
The ‘head’ along with dmesg will show starting lines i.e. ‘dmesg | head -20’ will print only 20 lines from the starting point.
[[email protected] ~]# dmesg | head -20 [ 0.000000] Initializing cgroup subsys cpuset [ 0.000000] Initializing cgroup subsys cpu [ 0.000000] Initializing cgroup subsys cpuacct [ 0.000000] Linux version 3.11.0-13-generic ([email protected]) (gcc version 4.8.1 (Ubuntu/Linaro 4.8.1-10ubuntu8) ) #20-Ubuntu SMP Wed Oct 23 17:26:33 UTC 2013 (Ubuntu 3.11.0-13.20-generic 3.11.6) [ 0.000000] KERNEL supported cpus: [ 0.000000] Intel GenuineIntel [ 0.000000] AMD AuthenticAMD [ 0.000000] NSC Geode by NSC [ 0.000000] Cyrix CyrixInstead [ 0.000000] Centaur CentaurHauls [ 0.000000] Transmeta GenuineTMx86 [ 0.000000] Transmeta TransmetaCPU [ 0.000000] UMC UMC UMC UMC [ 0.000000] e820: BIOS-provided physical RAM map: [ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable [ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved [ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x000000007dc08bff] usable [ 0.000000] BIOS-e820: [mem 0x000000007dc08c00-0x000000007dc5cbff] ACPI NVS [ 0.000000] BIOS-e820: [mem 0x000000007dc5cc00-0x000000007dc5ebff] ACPI data [ 0.000000] BIOS-e820: [mem 0x000000007dc5ec00-0x000000007fffffff] reserved
4. Print Only Last 20 Lines of Output
The ‘tail’ along with dmesg command will print only 20 last lines, this is useful in case we insert removable device.
[[email protected] ~]# dmesg | tail -20 parport0: PC-style at 0x378, irq 7 [PCSPP,TRISTATE] ppdev: user-space parallel port driver EXT4-fs (sda1): mounted filesystem with ordered data mode Adding 2097144k swap on /dev/sda2. Priority:-1 extents:1 across:2097144k readahead-disable-service: delaying service auditd ip_tables: (C) 2000-2006 Netfilter Core Team nf_conntrack version 0.5.0 (16384 buckets, 65536 max) NET: Registered protocol family 10 lo: Disabled Privacy Extensions e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None Slow work thread pool: Starting up Slow work thread pool: Ready FS-Cache: Loaded CacheFiles: Loaded CacheFiles: Security denies permission to nominate security context: error -95 eth0: no IPv6 routers present type=1305 audit(1398268784.593:18630): audit_enabled=0 old=1 auid=4294967295 ses=4294967295 res=1 readahead-collector: starting delayed service auditd readahead-collector: sorting readahead-collector: finished
5. Search Detected Device or Particular String
It’s difficult to search particular string due to length of dmesg output. So, filter the lines with are having string like ‘usb‘ ‘dma‘ ‘tty‘ and ‘memory‘ etc. The ‘-i’ option instruct to grep command to ignore the case (upper or lower case letters).
[[email protected] log]# dmesg | grep -i usb [[email protected] log]# dmesg | grep -i dma [[email protected] log]# dmesg | grep -i tty [[email protected] log]# dmesg | grep -i memory
Sample Output
[ 0.000000] Scanning 1 areas for low memory corruption [ 0.000000] initial memory mapped: [mem 0x00000000-0x01ffffff] [ 0.000000] Base memory trampoline at [c009b000] 9b000 size 16384 [ 0.000000] init_memory_mapping: [mem 0x00000000-0x000fffff] [ 0.000000] init_memory_mapping: [mem 0x37800000-0x379fffff] [ 0.000000] init_memory_mapping: [mem 0x34000000-0x377fffff] [ 0.000000] init_memory_mapping: [mem 0x00100000-0x33ffffff] [ 0.000000] init_memory_mapping: [mem 0x37a00000-0x37bfdfff] [ 0.000000] Early memory node ranges [ 0.000000] PM: Registered nosave memory: [mem 0x0009f000-0x000effff] [ 0.000000] PM: Registered nosave memory: [mem 0x000f0000-0x000fffff] [ 0.000000] please try 'cgroup_disable=memory' option if you don't want memory cgroups [ 0.000000] Memory: 2003288K/2059928K available (6352K kernel code, 607K rwdata, 2640K rodata, 880K init, 908K bss, 56640K reserved, 1146920K highmem) [ 0.000000] virtual kernel memory layout: [ 0.004291] Initializing cgroup subsys memory [ 0.004609] Freeing SMP alternatives memory: 28K (c1a3e000 - c1a45000) [ 0.899622] Freeing initrd memory: 23616K (f51d0000 - f68e0000) [ 0.899813] Scanning for low memory corruption every 60 seconds [ 0.946323] agpgart-intel 0000:00:00.0: detected 32768K stolen memory [ 1.360318] Freeing unused kernel memory: 880K (c1962000 - c1a3e000) [ 1.429066] [drm] Memory usable by graphics device = 2048M
6. Clear dmesg Buffer Logs
Yes, we can clear dmesg logs if required with below command. It will clear dmesg ring buffer message logs till you executed the command below. Still you can view logs stored in ‘/var/log/dmesg‘ files. If you connect any device will generate dmesg output.
[[email protected] log]# dmesg -c
7. Monitoring dmesg in Real Time
Some distro allows command ‘tail -f /var/log/dmesg’ as well for real time dmesg monitoring.
[[email protected] log]# watch "dmesg | tail -20"
Conclusion: The dmesg command is useful as dmesg records all the system changes done or occur in real time. As always you can man dmesg to get more information.
If You Appreciate What We Do Here On TecMint, You Should Consider:
TecMint is the fastest growing and most trusted community site for any kind of Linux Articles, Guides and Books on the web. Millions of people visit TecMint! to search or browse the thousands of published articles available FREELY to all.
If you like what you are reading, please consider buying us a coffee ( or 2 ) as a token of appreciation.

We are thankful for your never ending support.
Команда dmesg позволяет вам заглянуть в скрытый мир процессов запуска Linux. Просматривайте и отслеживайте сообщения аппаратных устройств и драйверов из собственного кольцевого буфера ядра с помощью «друга поисковика ошибок».
В Linux и Unix-подобных компьютерах загрузка и запуск — это две отдельные фазы последовательности событий, которые происходят при включении компьютера.
Процессы загрузки (BIOS или же UEFI, MBR, и GRUB) довести инициализацию системы до момента, когда ядро загружается в память и подключается к начальному ramdisk (initrd или initramfs), и systemd запущен.
Затем процессы запуска принимают эстафету и завершают инициализацию операционной системы. На самых ранних этапах инициализации такие демоны ведения журнала, как syslogd или же rsyslogd еще не запущены. Чтобы избежать потери заметных сообщений об ошибках и предупреждений на этом этапе инициализации, ядро содержит кольцевой буфер что он использует как хранилище сообщений.
Кольцевой буфер — это область памяти, зарезервированная для сообщений. Он прост по конструкции и имеет фиксированный размер. Когда он заполнен, новые сообщения перезаписывают самые старые сообщения. Концептуально это можно рассматривать как «кольцевой буфер. »
В кольцевом буфере ядра хранится такая информация, как сообщения инициализации драйверов устройств, сообщения от оборудования и сообщения от модулей ядра. Поскольку он содержит эти низкоуровневые сообщения запуска, кольцевой буфер является хорошим местом для начала расследования аппаратных ошибок или других проблем при запуске.
Но не уходите с пустыми руками. Возьмите dmesg с собой.
Команда dmesg
Команда dmesg позволяет вам для просмотра сообщений, хранящихся в кольцевом буфере. По умолчанию для использования dmesg необходимо использовать sudo.
sudo dmesg
Все сообщения в кольцевом буфере отображаются в окне терминала.
Это был потоп. Очевидно, что нам нужно сделать это через меньше:
sudo dmesg | less

Теперь мы можем прокручивать сообщения в поисках интересующих элементов.
Вы можете использовать функцию поиска в less, чтобы найти и выделить интересующие вас элементы и термины. Запустите функцию поиска, нажав клавишу с косой чертой «/» в less.
Устранение необходимости в sudo
Если вы не хотите использовать sudo каждый раз при использовании dmesg, вы можете использовать эту команду. Но имейте в виду: он позволяет любому, у кого есть учетная запись пользователя на вашем компьютере, использовать dmesg без необходимости использовать sudo.
sudo sysctl -w kernel.dmesg_restrict=0

Принудительный вывод цвета
По умолчанию dmesg, вероятно, будет настроен на цветной вывод. Если это не так, вы можете указать dmesg раскрасить свой вывод с помощью параметра -L (цвет).
sudo dmesg -L

Чтобы заставить dmesg всегда по умолчанию использовать цветной дисплей, используйте эту команду:
sudo dmesg --color=always

Метки времени человека
По умолчанию dmesg использует обозначение времени в секундах и наносекунды с момента запуска ядра. Чтобы отобразить это в более удобном для человека формате, используйте параметр -H (человек).
sudo dmesg -H

Это вызывает две вещи.
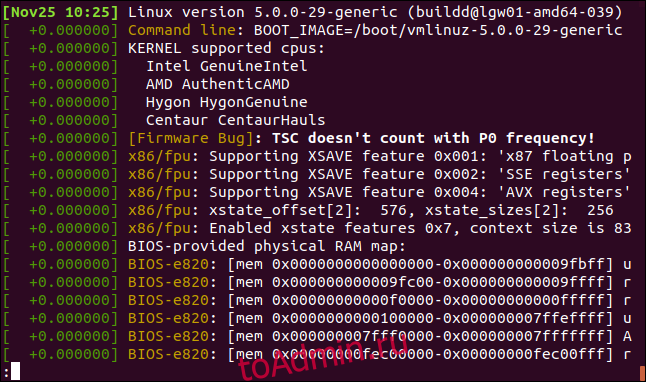
Вывод автоматически отображается меньше.
Метки времени показывают метку времени с датой и временем с точностью до минуты. Сообщения, появляющиеся в каждую минуту, помечаются секундами и наносекундами с начала этой минуты.
Метки времени, удобочитаемые человеком
Если вам не нужна наносекундная точность, но вам нужны метки времени, которые легче читать, чем значения по умолчанию, используйте параметр -T (человекочитаемый). (Это немного сбивает с толку. -H — «человеческий» вариант, -T — «человекочитаемый» вариант.)
sudo dmesg -T

Метки времени отображаются как стандартные даты и время, но разрешение снижено до минуты.
Все, что произошло в течение одной минуты, имеет одинаковую метку времени. Если вас беспокоит только последовательность событий, этого достаточно. Также обратите внимание, что вы вернетесь в командную строку. Эта опция не вызывает автоматически меньше.
Просмотр прямых трансляций
Чтобы увидеть сообщения по мере их поступления в кольцевой буфер ядра, используйте параметр –follow (ждать сообщений). Это предложение может показаться немного странным. Если кольцевой буфер используется для хранения сообщений о событиях, происходящих во время последовательности запуска, как могут живые сообщения поступать в кольцевой буфер после того, как компьютер включен и работает?
Все, что вызывает изменение оборудования, подключенного к вашему компьютеру, вызовет отправку сообщений в кольцевой буфер ядра. Обновите или добавьте модуль ядра, и вы увидите сообщения кольцевого буфера об этих изменениях. Если вы подключите USB-накопитель или подключите или отключите устройство Bluetooth, вы увидите сообщения в выводе dmesg. Даже виртуальное оборудование вызывает появление новых сообщений в кольцевом буфере. Запустите виртуальную машину, и вы увидите новую информацию, поступающую в кольцевой буфер.
sudo dmesg --follow

Обратите внимание, что вы не вернетесь в командную строку. Когда появляются новые сообщения, они отображаются dmesg в нижней части окна терминала.
Даже установка диска CD-ROM воспринимается как изменение, потому что вы перенесли содержимое диска CD-ROM в дерево каталогов.
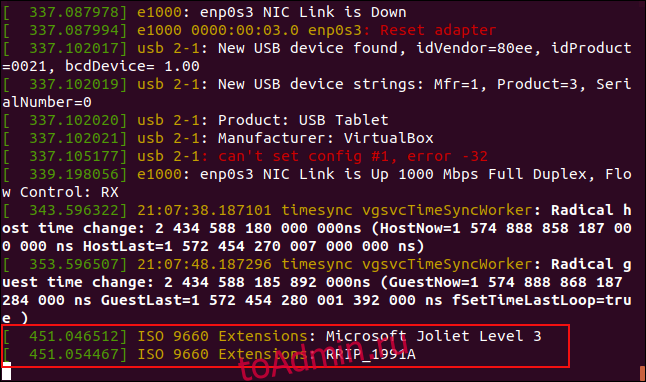
Чтобы выйти из ленты в реальном времени, нажмите Ctrl + C.
Получить последние десять сообщений
Используйте команду tail получить последние десять сообщения кольцевого буфера ядра. Конечно, вы можете получить любое количество сообщений. Десять — это просто наш пример.
sudo dmesg | last -10

Последние десять сообщений извлекаются и отображаются в окне терминала.
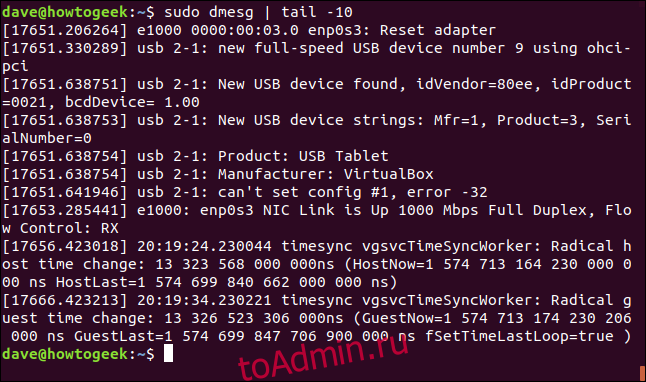
Поиск конкретных терминов
Передайте вывод из dmesg через grep для поиска определенных строк или шаблонов. Здесь мы используем параметр -i (игнорировать регистр), чтобы не учитывать случай совпадения строк. наши результаты будут включать «usb» и «USB», а также любую другую комбинацию строчных и прописных букв.
sudo dmesg | grep -i usb

Выделенные результаты поиска отображаются в верхнем и нижнем регистре.
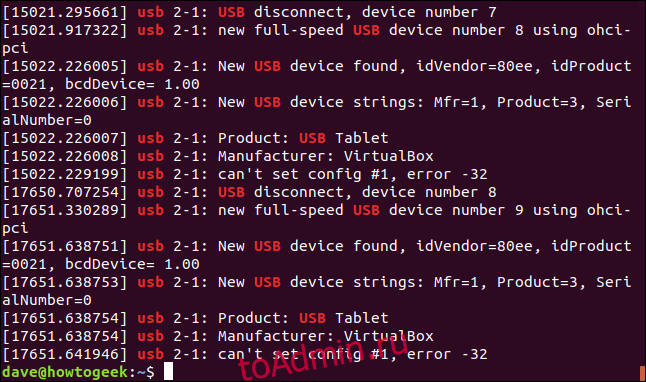
Мы можем выделить сообщения, содержащие ссылки на первые SCSI жесткий диск в системе sda. (На самом деле, sda также используется в настоящее время для первый жесткий диск SATA, и для USB-накопителей.)
sudo dmesg | grep -i sda

Все сообщения, в которых упоминается sda, извлекаются и отображаются в окне терминала.
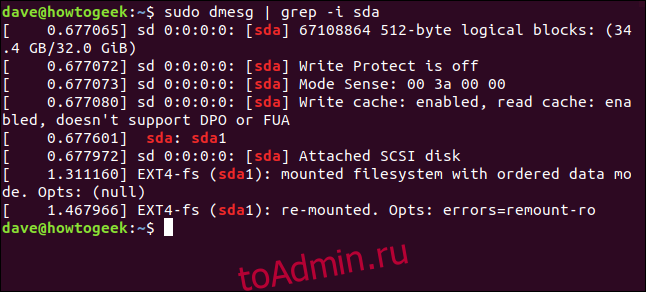
Чтобы grep искать одновременно несколько терминов, используйте параметр -E (расширить регулярное выражение). Вы должны указать условия поиска внутри строки в кавычках с вертикальной чертой «|» разделители между поисковыми запросами:
sudo dmesg | grep -E "memory|tty|dma"

Любое сообщение, в котором упоминается какой-либо из условий поиска, отображается в окне терминала.
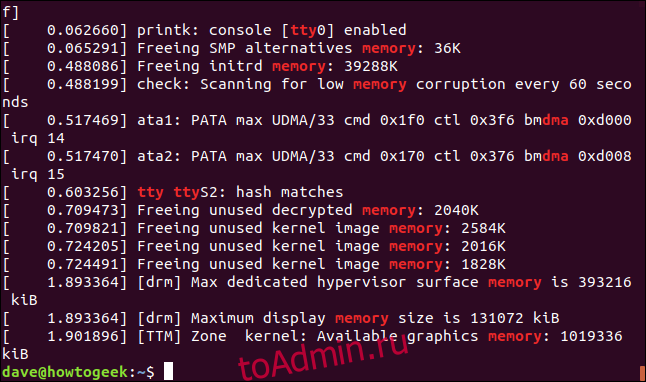
Использование уровней журнала
Каждое сообщение, записываемое в кольцевой буфер ядра, имеет прикрепленный к нему уровень. Уровень представляет важность информации в сообщении. Уровни бывают:
Emerg: Система непригодна для использования.
предупреждение: действие необходимо предпринять немедленно.
крит: Критические условия.
err: условия ошибки.
предупреждение: условия предупреждения.
Примечание: нормальное, но серьезное состояние.
информация: Информационная.
debug: сообщения уровня отладки.
Мы можем заставить dmesg извлекать сообщения, соответствующие определенному уровню, используя параметр -l (level) и передавая имя уровня в качестве параметра командной строки. Чтобы увидеть сообщения только «информационного» уровня, используйте эту команду:
sudo dmesg -l info

Все перечисленные сообщения являются информационными. Они не содержат ошибок или предупреждений, только полезные уведомления.
Объедините два или более уровней журнала в одной команде, чтобы получить сообщения нескольких уровней журнала:
sudo dmesg -l debug,notice

Вывод dmesg представляет собой смесь сообщений каждого уровня журнала:
Категории объектов
Сообщения dmesg сгруппированы по категориям, называемым «удобствами». Перечень объектов:
kern: сообщения ядра.
пользователь: сообщения уровня пользователя.
mail: Почтовая система.
демон: Системные демоны.
auth: сообщения безопасности / авторизации.
syslog: внутренние сообщения syslogd.
lpr: подсистема построчного принтера.
новости: Подсистема сетевых новостей.
Мы можем попросить dmesg отфильтровать свой вывод, чтобы показывать сообщения только в определенном объекте. Для этого мы должны использовать параметр -f (средство):
sudo dmesg -f daemon

dmesg перечисляет все сообщения, относящиеся к демонам в окне терминала.
Как и с уровнями, мы можем попросить dmesg вывести список сообщений от более чем одного объекта одновременно:
sudo dmesg -f syslog, daemon

Вывод представляет собой смесь сообщений системного журнала и журнала демона.

Объединение помещения и уровня
Параметр -x (декодировать) заставляет dmesg отображать средство и уровень в виде удобочитаемых префиксов для каждой строки.
sudo dmesg -x

Объект и уровень можно увидеть в начале каждой строки:
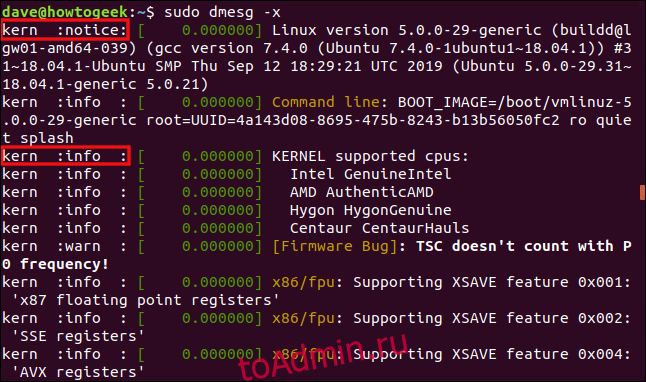
Первый выделенный раздел — это сообщение от средства «ядра» с уровнем «уведомление». Второй выделенный раздел — это сообщение от средства «ядра» с уровнем «информация».
Это здорово, но почему?
Одним словом, поиск неисправностей.
Если у вас возникли проблемы с оборудованием, которое не распознается или работает некорректно, dmesg может пролить свет на проблему.
Используйте dmesg для просмотра сообщений от самого высокого уровня до каждого более низкого уровня, ища любые ошибки или предупреждения, которые упоминают аппаратный элемент или могут иметь отношение к проблеме.
Используйте dmesg для поиска любых упоминаний о соответствующих средствах, чтобы узнать, содержат ли они какую-либо полезную информацию.
Пропустите dmesg через grep и найдите связанные строки или идентификаторы, такие как производитель продукта или номера модели.
Передайте dmesg через grep и найдите общие термины, такие как «gpu» или «хранилище», или такие термины, как «сбой», «сбой» или «невозможно».
Используйте опцию –follow и смотрите сообщения dmesg в режиме реального времени.
Хорошей охоты.
Команда dmesg предназначена для задействования одноименной утилиты, осуществляющей вывод сообщений ядра ОС. В процессе загрузки и функционирования операционной системы ее ядро генерирует множество сообщений, которые позволяют диагностировать различные проблемы с аппаратным и программным обеспечением. Если говорить более предметно, ядро Linux записывает сообщения в кольцевой буфер (область памяти фиксированного размера, в которой осуществляется перезапись устаревших сообщений при добавлении новых), а утилита использует специальный файл /proc/kmesg для доступа к содержимому этого буфера. Данная команда может оказаться крайне полезной в процессе диагностики состояния устройств системы, поэтому ее стоит использовать в первую очередь при возникновении любых аппаратных сбоев.
Базовый синтаксис команды выглядит следующим образом:
$ dmesg [параметры]
Стоит отметить, что в некоторых дистрибутива команда может исполняться лишь от лица пользователя root (что вполне логично, ведь диагностика системы — дело системного администратора). Вообще, утилита может принимать большое количество различных параметров, но чаще всего используется без них. Наиболее полезными ее параметрами являются такие, как параметр -T, позволяющий выводить понятные человеку метки времени, параметры -k и -u, позволяющие выводить лишь сообщения, относящиеся к пространству ядра и пространству пользователя соответственно, параметр -c, позволяющий очистить содержимое кольцевого буфера ядра после вывода, параметр -w, позволяющий вместо завершения работы утилиты ожидать новые сообщения, а также параметры —level и —facility, позволяющие указать приоритет и источник интересующих пользователя сообщений.
В качестве приоритетов сообщений могут использоваться следующие идентификаторы:
| Идентификатор | Значение |
emerg |
Сообщения о событиях, сделавших систему неработоспособной |
alert |
Сообщения о событиях, на которые пользователь должен немедленно отреагировать |
crit |
Сообщения о критических событиях |
err |
Сообщения об ошибках |
warn |
Предупреждения |
notice |
Сообщения о важных событиях |
info |
Информационные сообщения |
debug |
Отладочные сообщения |
В качестве источников сообщений — следующие идентификаторы:
| Идентификатор | Значение |
kern |
Сообщения от ядра ОС |
user |
Сообщения из пространства пользователя |
mail |
Сообщения от подсистемы отправки электронной почты |
daemon |
Сообщения от системных служб (демонов) |
auth |
Сообщения от системы безопасности/авторизации |
syslog |
Сообщения от службы системных журналов (для внутреннего использования) |
lpr |
Сообщения от подсистемы печати |
news |
Сообщения от подсистемы сетевых новостей |
Также нередко для фильтрации вывода dmesg используются такие утилиты, как grep, head, tail, less и more поэтому для продуктивной работы с утилитой dmesg не помешает ознакомиться и с их функциями.
Примеры использования
Вывод всех сообщений ядра ОС
Для вывода всех сообщений ядра ОС может использоваться утилита dmesg без каких-либо параметров:
# dmesg[ 0.000000] microcode: microcode updated early to revision 0xd0, date = 2010-09-30[ 0.000000] Linux version 4.18.0-2-amd64 ([email protected]) (gcc version 7.3.0 (Debian 7.3.0-29)) #1 SMP Debian 4.18.10-2 (2018-10-07)…
Далее будет выведено большое количество системных сообщений, многие из которых могут представлять интерес, особенно в случае неполадок.
Если вам нужно постепенно изучить все сообщения, вы можете воспользоваться утилитами less и more:
# dmesg | more[ 0.000000] microcode: microcode updated early to revision 0xd0, date = 2010-09-30[ 0.000000] Linux version 4.18.0-2-amd64 ([email protected]) (gcc version 7.3.0 (Debian 7.3.0-29)) #1 SMP Debian 4.18.10-2 (2018-10-07)…--More--
# dmesg | less[ 0.000000] microcode: microcode updated early to revision 0xd0, date = 2010-09-30[ 0.000000] Linux version 4.18.0-2-amd64 ([email protected]) (gcc version 7.3.0 (Debian 7.3.0-29)) #1 SMP Debian 4.18.10-2 (2018-10-07)…:
Утилита less позволяет проматывать сообщения как вперед, так и назад, утилита more — только вперед.
Вывод важных сообщений
Для вывода исключительно важных сообщений следует использовать соответствующие приоритеты:
# dmesg --level=emerg,alert,crit,err,warn[ 0.032000] core: PEBS disabled due to CPU errata[ 0.036206] mtrr: your CPUs had inconsistent variable MTRR settings[ 0.053809] pci 0000:00:01.0: ASPM: current common clock configuration is broken, reconfiguring[ 0.088573] pci 0000:03:00.0: [Firmware Bug]: disabling VPD access (can't determine size of non-standard VPD format)…
Очевидно, что теперь в выводе отражены лишь явные проблемы с аппаратным обеспечением, которые в моем случае были решены ядром самостоятельно.
Вывод сообщений, относящихся к определенным устройствам
Для вывода всех сообщений, относящихся к определенным устройствам, достаточно отфильтровать вывод утилиты с помощью утилиты grep:
# dmesg | grep dvb[ 13.019352] dvbdev: DVB: registering new adapter (Mantis DVB adapter)[ 13.143788] dvb-usb: found a 'Mygica T230 DVB-T/T2/C' in warm state.[ 13.384098] dvb-usb: will pass the complete MPEG2 transport stream to the software demuxer.[ 13.384305] dvbdev: DVB: registering new adapter (Mygica T230 DVB-T/T2/C)[ 13.944318] rc rc0: lirc_dev: driver dvb_usb_cxusb registered at minor = 0, scancode receiver, no transmitter[ 13.944319] dvb-usb: schedule remote query interval to 100 msecs.[ 13.944509] dvb-usb: Mygica T230 DVB-T/T2/C successfully initialized and connected.
Это информация обо всех подключенных к компьютеру DVB-картах. Аналогичным образом можно получить все сообщения, относящиеся к устройствам других типов.
Вывод всех сообщений из пространства пользователя
Для вывода всех сообщений из пространства пользователя достаточно воспользоваться параметром -u утилиты dmesg:
# dmesg -u[ 7.483329] systemd[1]: systemd 239 running in system mode. (+PAM +AUDIT +SELINUX +IMA +APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ +LZ4 +SECCOMP +BLKID +ELFUTILS +KMOD -IDN2 +IDN -PCRE2 default-hierarchy=hybrid)[ 7.500111] systemd[1]: Detected architecture x86-64.[ 7.527333] systemd[1]: Set hostname to <debian>.…
Очевидно, что это сообщения от менеджера инициализации systemd.
Оригинал: Linux dmesg Command Tutorial for Beginners (5 Examples)
Автор: Himanshu Arora
Дата публикации: 3 июля 2018 года
Перевод: А. Кривошей
Дата перевода: январь 2019 г.
Знаете ли вы, что ядро Linux загружает несколько драйверов устройств при загрузке системы? На самом деле, когда ваша система запущена и работает, и вы подключаете аппаратное устройство, то также загружается соответствующий драйвер устройства. Конечно, ядро также делает много других вещей. Что если вы хотите узнать информацию, связанную с этими действиями ядра?
Есть команда dmesg, которую вы можете использовать, если хотите получить доступ к сообщениям, выводимым ядром. В этом руководстве мы разберемся, как работает утилита dmesg, используя несколько простых для понимания примеров.
Команда Linux dmesg
Команда dmesg позволяет вам печатать или управлять буфером кольца ядра. Ниже ее синтаксис:
dmesg [options]
И вот как справочная страница утилиты объясняет ее назначение:
dmesg используется для проверки содержимого или управления буфером кольца ядра. Действие по умолчанию — отобразить все сообщения из буфера кольца ядра.
Ниже приведены примеры в стиле вопрос/ответ, которые должны дать вам лучшее представление о том, как работает команда dmesg.
Q1. Как использовать команду dmesg?
Вы можете для начала ввести команду dmesg без опций командной строки.
dmesg
Например, вот небольшая часть вывода команды, созданной в моем случае:
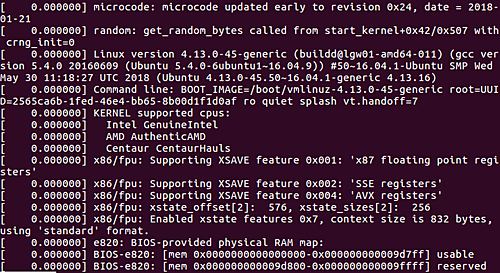
Q2. Как ограничить вывод только ошибками и предупреждениями?
Если вы запустите dmesg в своей системе, вы увидите, что она выводит множество информации. В зависимости от того, что вы ищете, вы можете фильтровать или ограничивать вывод. Со своей стороны, dmesg предлагает вам реализацию этой возможности с помощью «уровней». Ниже приводится полный список уровней (вместе с их объяснением):
emerg — система не работает;
alert — действие должно быть выполнено немедленно;
crit — критические условия;
err — условия ошибок;
warn — условия предупреждениий;
notice — нормальное, но существенное состояние;
info — информационный;
debug — сообщения уровня отладки.
Например, если вы хотите ограничить вывод только ошибками и предупреждениями, вы можете сделать это следующим образом:
dmesg --level=err,warn
В моем случае, вот часть вывода, который выдает указанная выше команда:
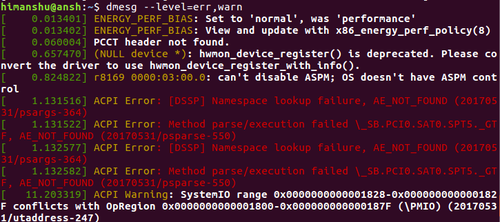
Q3. Как заставить dmesg выводить временные метки?
Иногда вам может понадобиться, чтобы с сообщениями, создаваемыми dmesg, была связана временная метка. Это можно сделать с помощью параметра командной строки -T, который создает удобочитаемые временные метки.
dmesg -T
Пример вывода:
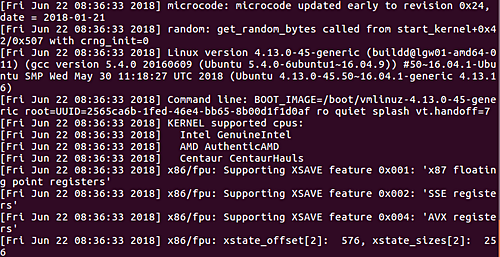
Q4. Как заставить dmesg отображать информацию, специфичную для устройства?
Предположим, вы хотите, чтобы dmesg отображал только информацию, связанную с интерфейсом eth0. Вот как вы можете это сделать:
dmesg | grep -i eth0
Пример вывода:

Q5. Как заставить dmesg отображать только сообщения пользователя?
Если вы хотите ограничить вывод dmesg только сообщениями в пользовательском пространстве, используйте параметр командной строки -u.
dmesg -u
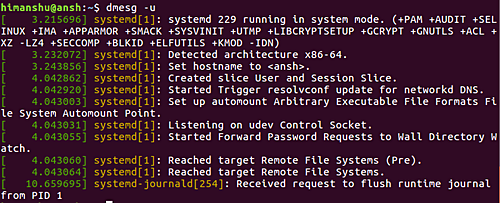
Заключение
Согласен, dmesg — это не та команда, которая будет вам нужна каждый день. Но это инструмент, к которому можно обратиться, когда кто-то (к кому вы обратились за помощью по определенной теме) попросит вас предоставить сообщения ядра. Чаще всего я встречал этот случай на онлайн-форумах, где опытные пользователи запрашивают вывод ядра.
Здесь, в этом уроке, мы обсудили команду dmesg с точки зрения начинающих. Более подробную информацию можно получить, изучив справочную страницу команды.
Если вам понравилась статья, поделитесь ею с друзьями:
Содержание
Отчет о падении ядра
Введение
Отчет о падении ядра является частью содержимого оперативной памяти (RAM), которая копируется на диск всякий раз, когда выполнение ядра прерывается. Следующие события могут стать причиной остановки ядра:
-
Критическая ошибка ядра (Kernel Panic)
-
Незамаскированное прерывание (NMI)
-
Фатальная ошибка проверки машины (MCE)
-
Отказ оборудования
-
Ручное вмешательство
Некоторые из этих событий (паника, NMI) ядро обрабатывает автоматически и запускает механизм сохранения отчета через kexec. В других случаях требуется ручное вмешательство для захвата памяти. Всякий раз как что-то из перечисленного происходит, важно найти основную причину с целью предотвращения такого события снова. Причина может быть определена с помощью инспектирования содержимого памяти.
Механизм отчета о падении ядра
Когда происходит критическая ошибка ядра, ядро полагается на механизм kexec для быстрой перезагрузки новой копии ядра в предварительно зарезервированную секцию памяти, которая выделяется при загрузке системы. Это позволяет существующей памяти остаться нетронутой с целью безопасного копирования ее содержимого в файл.
Установка
Утилита сохранения отчета о падении ядра устанавливается следующей командой:
sudo apt-get install linux-crashdump
После этого потребуется перезагрузка.
Настройка
Никакой дальнейшей настройки не требуется чтобы разрешить механизм отчета о падении ядра.
Проверка
Для подтверждения, что механизм отчета о падении ядра доступен, надо проверить несколько вещей. Во-первых, убедитесь, что указан загрузочный параметр crashkernel. (заметьте, что строка внизу разделена на две для сохранения форматирования документа):
cat /proc/cmdline BOOT_IMAGE=/vmlinuz-3.2.0-17-server root=/dev/mapper/PreciseS-root ro crashkernel=384M-2G:64M,2G-:128M
Параметр crashkernel имеет следующий синтаксис:
crashkernel=<range1>:<size1>[,<range2>:<size2>,...][@offset]
range=start-[end] 'start' is inclusive and 'end' is exclusive.
Таким образом с параметром crashkernel, найденным в файле /proc/cmdline мы имеем:
crashkernel=384M-2G:64M,2G-:128M
Значение выше означает:
-
если оперативная память меньше 384МБ, то ничего не резервировать (это вариант «спасения»)
-
если оперативная память между 384МБ и 2ГБ (привилегированная), то зарезервировать 64МБ
-
если оперативная память больше 2ГБ, то зарезервировать 128МБ
Во-вторых, убедитесь, что ядро зарезервировало требуемую память для kdump ядра, выполнив:
dmesg | grep -i crash ... [ 0.000000] Reserving 64MB of memory at 800MB for crashkernel (System RAM: 1023MB)
Проверка механизма отчета о падении ядра
Проверка механизма отчета о падении ядра вызовет перезагрузку системы. В определенных ситуациях это может привести к потере данных если система будет сильно загружена. Если вы хотите проверить этот механизм, убедитесь, что система простаивает или загружена очень слабо.
Убедитесь, что механизм SysRQ включен, посмотрев значение параметра ядра /proc/sys/kernel/sysrq:
cat /proc/sys/kernel/sysrq
Если возвращается значение 0, свойство отключено. Включите его следующей командой:
sudo sysctl -w kernel.sysrq=1
Как только закончите с этим, вам придется стать суперпользователем (root), поскольку будет недостаточно использовать только sudo.
От имени пользователя root вам нужно выполнить команду echo c > /proc/sysrq-trigger. Если вы используете сетевое соединение, вы потеряете связь с системой. Именно поэтому лучше проводить тест с системной консоли. Это позволит сделать процесс отчета о падении ядра видимым.
Типичный вывод теста будет выглядеть следующим образом:
sudo -s [sudo] password for ubuntu: # echo c > /proc/sysrq-trigger [ 31.659002] SysRq : Trigger a crash [ 31.659749] BUG: unable to handle kernel NULL pointer dereference at (null) [ 31.662668] IP: [<ffffffff8139f166>] sysrq_handle_crash+0x16/0x20 [ 31.662668] PGD 3bfb9067 PUD 368a7067 PMD 0 [ 31.662668] Oops: 0002 [#1] SMP [ 31.662668] CPU 1 ....
Дальнейший вывод отрезан, но вы можете посмотреть перезагрузку системы и где-нибудь в журнале вы сможете найти следующую строчку:
Begin: Saving vmcore from kernel crash ...
После завершения система перезагрузится в нормальный рабочий режим. После чего вы сможете найти файл отчета о падении ядра в каталоге /var/crash:
ls /var/crash linux-image-3.0.0-12-server.0.crash
Ссылки
Отчет о падении ядра — обширная тема, требующая хорошего знания ядра линукс. Вы сможете найти больше информации по следующим ссылкам:
-
Анализ падений ядра линукс (Основано на дистрибутиве Fedora, однако предоставляет хороший критический анализ исследований отчетов падения ядра)

Если у вас в Windows хотя бы раз выпадал синий экран смерти (Blue Screen of Death, ака BSOD), то вы знаете, что после него создаётся так называемый дамп (dump) памяти, в который включается информация об ошибке, о сбойном адресе в памяти и какие процессы были в памяти на момент сбоя. Потом этот дамп можно прочитать утилитой Blue Screen View. В Linux есть похожая технология, созданная инженерами компании Red Hat, под названием KDump, а также утилиту для их чтения под названием Crash. О них пойдёт речь.
Хочу заранее предупредить, что на момент написания статьи, Crash не работал с ядрами выше 4.3. Имейте ввиду. Также хочу обратить внимание на то, что если у вас ядро установлено из Debian Backports — ставьте оттуда же и KDump. Иначе не будет работать.
Итак, есть Debian 8, ядро Linux 4.3, пара рук (желательно прямых), и немного времени на настройку. Устанавливаем:
sudo apt install kdump-tools, crash, linux-image-`uname -r`-dbg
Отладочные символы ядра (debugging symbols) весят много, на диске займут около 3 гигабайт (на корневом разделе). Во премя установки пакета kexec-tools, он спросит активировать или перезагрузку через него. Если вы ответите Да, то ваш компьютер вместо перезагрузки будет просто перезапускать ядро. Таким образом вы, к примеру, не сможете выйти в меню GRUB. Поэтому отвечаем Нет. Как и на вопрос о чтении файла /etc/default/grub. Теперь проводим настройку:
sudo nano /etc/default/kdump-tools
# kdump-tools configuration
# —————————————————————————
# USE_KDUMP — controls kdump will be configured
# 0 — kdump kernel will not be loaded
# 1 — kdump kernel will be loaded and kdump is configured
# KDUMP_SYSCTL — controls when a panic occurs, using the sysctl
# interface. The contents of this variable should be the
# «variable=value …» portion of the ‘sysctl -w ‘ command.
# If not set, the default value «kernel.panic_on_oops=1» will
# be used. Disable this feature by setting KDUMP_SYSCTL=» «
# Example — also panic on oom:
# KDUMP_SYSCTL=»kernel.panic_on_oops=1 vm.panic_on_oom=1″
#
USE_KDUMP=1
#KDUMP_SYSCTL=»kernel.panic_on_oops=1″
# —————————————————————————
# Kdump Kernel:
# KDUMP_KERNEL — A full pathname to a kdump kernel.
# KDUMP_INITRD — A full pathname to the kdump initrd (if used).
# If these are not set, kdump-config will try to use the current kernel
# and initrd if it is relocatable. Otherwise, you will need to specify
# these manually.
KDUMP_KERNEL=/var/lib/kdump/vmlinuz
KDUMP_INITRD=/var/lib/kdump/initrd.img
# —————————————————————————
# vmcore Handling:
# KDUMP_COREDIR — local path to save the vmcore to.
# KDUMP_FAIL_CMD — This variable can be used to cause a reboot or
# start a shell if saving the vmcore fails. If not set, «reboot -f»
# is the default.
# Example — start a shell if the vmcore copy fails:
# KDUMP_FAIL_CMD=»echo ‘makedumpfile FAILED.’; /bin/bash; reboot -f»
# KDUMP_DUMP_DMESG — This variable controls if the dmesg buffer is dumped.
# If unset or set to 1, the dmesg buffer is dumped. If set to 0, the dmesg
# buffer is not dumped.
KDUMP_COREDIR=»/var/crash»
#KDUMP_FAIL_CMD=»reboot -f»
#KDUMP_DUMP_DMESG=
# —————————————————————————
# Makedumpfile options:
# MAKEDUMP_ARGS — extra arguments passed to makedumpfile (8). The default,
# if unset, is to pass ‘-c -d 31’ telling makedumpfile to use compression
# and reduce the corefile to in-use kernel pages only.
#MAKEDUMP_ARGS=»-c -d 31″
# —————————————————————————
# Kexec/Kdump args
# KDUMP_KEXEC_ARGS — Additional arguments to the kexec command used to load
# the kdump kernel
# Example — Use this option on x86 systems with PAE and more than
# 4 gig of memory:
# KDUMP_KEXEC_ARGS=»—elf64-core-headers»
# KDUMP_CMDLINE — The default is to use the contents of /proc/cmdline.
# Set this variable to override /proc/cmdline.
# KDUMP_CMDLINE_APPEND — Additional arguments to append to the command line
# for the kdump kernel. If unset, it defaults to «irqpoll maxcpus=1 nousb»
#KDUMP_KEXEC_ARGS=»»
#KDUMP_CMDLINE=»»
#KDUMP_CMDLINE_APPEND=»irqpoll maxcpus=1 nousb systemd.unit=kdump-tools.service»
# —————————————————————————
# Architecture specific Overrides:
# —————————————————————————
# Remote dump facilities:
# SSH — username and hostname of the remote server that will receive the dump
# and dmesg files.
# SSH_KEY — Full path of the ssh private key to be used to login to the remote
# server. use kdump-config propagate to send the public key to the
# remote server
# HOSTTAG — Select if hostname of IP address will be used as a prefix to the
# timestamped directory when sending files to the remote server.
# ‘ip’ is the default.
# NFS — Hostname and mount point of the NFS server configured to receive
# the crash dump. The syntax must be {HOSTNAME}:{MOUNTPOINT}
# (e.g. remote:/var/crash)
#
# SSH=»»
#
# SSH_KEY=»»
#
# HOSTTAG=»hostname|[ip]»
#
# NFS=»»
#
Раскоментируем строку USE_KDUMP и ставим ей значение 1. Остальные параметры, в принципе, трогать необязательно. В строках KDUMP_KERNEL и KDUMP_INITRD можно указать путь к ядру и начальному рамдиску конкретного ядра, однако по умолчанию будет использоваться текущее загруженное ядро. По ссылке в конце статьи вы можете ознакомиться с прочими опциями. Теперь активируем перезагрузку компьютера после снятия дампа:
sudo nano /etc/sysctl.conf
Добавляем строки:
# Enable reboots on panic to allow kdump make dumps
kernel.hung_task_panic = 1
kernel.panic = 1
kernel.panic_on_io_nmi = 1
kernel.panic_on_oops = 1
kernel.panic_on_unrecovered_nmi = 1
kernel.softlockup_panic = 1
kernel.unknown_nmi_panic = 1
vm.panic_on_oom = 1
kernel.sysrq = 1
Сохраняем и применяем:
sudo sysctl -p
Теперь отредактируем GRUB:
sudo nano /etc/default/grub
В строку GRUB_CMDLINE_LINUX_DEFAULT дописываем crashkernel=128M@32M . Столько будет выделяться памяти для дампа. Теперь:
sudo update-grub
sudo reboot
Настало время проверить работу KDump. Для этого искусственно «повалим» ядро, или иными словами — вызовем Kernel Panic:
echo e | sudo tee /proc/sysrq-trigger
Если всё прошло успешно, система наглухо повиснет, экран возможно покроется разноцветными артефактами, KDump снимет дампа ядра и перезагрузит систему. После перезагрузки, дамп ядра и дамп последнего лога загрузки будут лежать в /var/crash. Давайте прочитаем:
sudo crash /usr/lib/debug/vmlinux-4.3.0-0.bpo.1-amd64 /var/crash/201604301449/dump.201604301449
crash 7.1.4
Copyright (C) 2002-2015 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005, 2011 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter «help copying» to see the conditions.
This program has absolutely no warranty. Enter «help warranty» for details.
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type «show copying»
and «show warranty» for details.
This GDB was configured as «x86_64-unknown-linux-gnu»…
KERNEL: /usr/lib/debug/vmlinux-4.3.0-0.bpo.1-amd64
DUMPFILE: /var/crash/201604301449/dump.201604301449 [PARTIAL DUMP]
CPUS: 4
DATE: Sat Apr 30 14:48:42 2016
UPTIME: 00:11:27
LOAD AVERAGE: 0.41, 0.34, 0.33
TASKS: 402
NODENAME: Debian-PC
RELEASE: 4.3.0-0.bpo.1-amd64
VERSION: #1 SMP Debian 4.3.5-1~bpo8+1 (2016-02-23)
MACHINE: x86_64 (3192 Mhz)
MEMORY: 7.8 GB
PANIC: «sysrq: SysRq : Trigger a crash»
PID: 7930
COMMAND: «tee»
TASK: ffff88022fdd8f00 [THREAD_INFO: ffff88022cdd8000]
CPU: 3
STATE: TASK_RUNNING (SYSRQ)
В строке PANIC мы видим причину — искусственно вызванная паника. Утилита Crash имеет собственный набор команд, список которых можно получить командой help. Если вы введёте команду bt, то получите трассировку ядра:
PID: 7930 TASK: ffff88022fdd8f00 CPU: 3 COMMAND: «tee»
#0 [ffff88022cddbc38] machine_kexec at ffffffff810552d9
#1 [ffff88022cddbc90] crash_kexec at ffffffff810f667d
#2 [ffff88022cddbd58] oops_end at ffffffff81018c94
#3 [ffff88022cddbd78] no_context at ffffffff81060ce0
#4 [ffff88022cddbdd0] page_fault at ffffffff8158cbb8
[exception RIP: sysrq_handle_crash+18]
RIP: ffffffff813ba8f2 RSP: ffff88022cddbe88 RFLAGS: 00010286
RAX: 000000000000000f RBX: ffffffff81abf760 RCX: 0000000000000000
RDX: 0000000000000000 RSI: ffff88023bccdef8 RDI: 0000000000000063
RBP: 0000000000000063 R8: 00000000000000c2 R9: 0000000000000002
R10: ffff8800b4d8bd64 R11: 0000000000000002 R12: 0000000000000007
R13: 0000000000000000 R14: 0000000000000002 R15: 0000000000000008
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#5 [ffff88022cddbe88] __handle_sysrq at ffffffff813bb04f
#6 [ffff88022cddbeb0] write_sysrq_trigger at ffffffff813bb48b
#7 [ffff88022cddbec0] proc_reg_write at ffffffff812355c3
#8 [ffff88022cddbed8] vfs_write at ffffffff811d0114
#9 [ffff88022cddbf10] sys_write at ffffffff811d0e72
#10 [ffff88022cddbf50] system_call_fast_compare_end at ffffffff8158a9f6
RIP: 00007f4c58050e50 RSP: 00007ffc558a4d38 RFLAGS: 00000246
RAX: ffffffffffffffda RBX: 0000000000000002 RCX: 00007f4c58050e50
RDX: 0000000000000002 RSI: 00007ffc558a4df0 RDI: 0000000000000003
RBP: 00007ffc558a4df0 R8: 0000000000000000 R9: 0000000000000001
R10: 00007ffc558a4ba0 R11: 0000000000000246 R12: 00007f4c5831b2a0
R13: 0000000000000002 R14: 0000000000000002 R15: 0000000000000000
ORIG_RAX: 0000000000000001 CS: 0033 SS: 002b
Конечно, не факт что вы сами в этом всё разберётесь, но вы можете показать эти данные более опытным людям, которые помогут вам определить причину сбоя.
Ссылки:
Статья на Habrahabr
Документация к KDump
Документация к Crash
Книга, посвящённая проблемам диагностики сбоев ядра