
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Тестирование и отладка программ
Тестирование
и отладка написанной программы являются
содержанием четвёртого этапа разработки
ПО.
Тестирование
– выполнение программы с целью
обнаружения наличия ошибок.
Тест
– совокупность специально подобранных
исходных данных и соответствующих им
результатов расчетов (как промежуточных,
так и окончательных).
Отладка
– выполнение программы с целью
локализации, диагностики и исправления
ошибок.
Причины возникновения
ошибок:
-
некорректность
текста (синтаксические ошибки); -
некорректность
компоновки (ошибки редактирования); -
некорректность
данных (семантические ошибки); -
некорректность
алгоритма
(семантические ошибки).
Синтаксические
ошибки
проявляются на этапе компиляции (система
программирования выводит сообщение
об ошибке и указывает место в программе,
содержащее ошибку).
После
компиляции следует компоновка программы,
при которой могут быть ошибки
редактирования
(неправильное использование подключаемых
модулей).
Семантические
ошибки могут
проявляться как на этапе выполнения
программы (до её завершения), так и после
выполнения программы. К первым относятся
такие ошибки, как, например, деление на
ноль, выход за границы диапазона,
нехватка памяти и т.п. О них выводится
сообщение компилятором, что облегчает
исправление. Семантические ошибки
второго типа находить и исправлять
гораздо сложнее, так как компилятор их
не может найти (они связаны с погрешностями
самого алгоритма).
Для
поиска этих ошибок используются
различные специальные приёмы. Они
основаны на получении дополнительной
информации о ходе вычислительного
процесса.
Некоторые
из этих приёмов:
-
Слежение:
-
трассировка
– построчное выполнение программы
(клавиши F7,
F8
в Turbo
Delphi,
Lazarus); -
математическое
слежение
– контроль за изменением значений
определенных переменных в процессе
расчёта (подсказки при наведении
курсора на идентификатор при трассировке).
-
Печать
в узлах
– вывод значений заданных переменных
в узловых точках программы (разветвление
или схождение алгоритма, точки входа
и выхода из подпрограммы и др.).
-
Прокрутка
– вывод значений всех переменных,
используемых в программе после
выполнения каждого оператора в
программе.
Лекция 6. Вычислительные комплексы и сети
Обработка информации
при помощи ЭВМ развивается по двум
направлениям:
-
с
использованием вычислительных
комплексов; -
с
использованием вычислительных
сетей.
Вычислительные
комплексы служат для повышения
производительности и надежности
обработки информации. Они объединяют
несколько ЭВМ, территориально
расположенных в одном месте, и делятся
на два типа:
-
многомашинные
комплексы (несколько самостоятельных
ЭВМ, в том числе и резервных, объединенных
общим управлением); -
многопроцессорные
комплексы (несколько процессоров,
работающих с одной общей памятью с
различными возможными типами доступа
к ней).
Использование
вычислительных комплексов позволяет
разделить поставленную задачу на
несколько подзадач (если это позволяет
сама задача) и решать их параллельно.
Вычислительная
или компьютерная сеть (КС)
– это
совокупность ПО и компьютеров, соединенных
с помощью каналов связи и специального
сетевого оборудования (см. далее) в
единую систему для распределённой
обработки данных.
Компьютерные
сети могут классифицироваться по разным
критериям. Например, по территориальному
признаку, т.е.
по масштабу охвата территории, сети
делят на локальные (LAN – Local Area NetWork),
региональные (MAN – Metropolia Area NetWork) и
глобальные (WAN – Wide Area NetWork):
— локальные
сети, как правило, размещаются в одном
здании или на территории одного
предприятия (примером локальной сети
является локальная сеть в учебном
классе);
— региональные
сети объединяют несколько предприятий
или город (примером сетей такого типа
является сеть кабельного телевидения);
— глобальные
сети охватывают значительную территорию,
часто целую страну или континент, и
представляют собой объединение сетей
меньшего размера (примером глобальной
сети является сеть Интернет).
Информация
в сети передаётся по каналам связи,
которые могут быть:
-
кабельными
каналами (телефонный кабель, витая
пара, коаксиальный кабель, оптоволоконный
кабель); -
радиоканалами.
Для
подключения к сети используется
специальное оборудование — устройства
сопряжения, предназначенные для
согласования сигналов внутреннего
интерфейса ЭВМ с сигналами сети:
-
модемы (при
подключении через телефонную сеть); -
сетевые адаптеры
(при подключении к одному каналу); -
мультиплексоры
(при подключении к нескольким каналам),
Компьютерные
сети используются в следующих целях:
-
совместного
использования ресурсов (данных,
оборудования, программ); -
обеспечения
надёжного хранения данных (в разных
местах); -
для
передачи данных между удалёнными друг
от друга пользователями.
Взаимодействие
в КС происходит по определенным правилам
–
протоколам,
которые обеспечивают подключение к
сети разнотипных ЭВМ с различными ОС.
Основные
характеристики компьютерных сетей:
-
скорость передачи
(бит/с); -
достоверность
передачи информации (количество
ошибок/знак); -
надёжность
(среднее время безотказной работы в
сетях).
Компьютеры
сети могут быть серверами
и клиентами
(рабочими
станциями).
Сервер
– компьютер, обеспечивающий пользователей
сети ресурсами (оборудованием, данными
и программами, выполняющими задания
пользователей). Серверы могут быть
файловыми
(предназначены
для хранения и обработки большого
объема данных для всех пользователей),
выделенными
(на них устанавливается общая сетевая
ОС и общие внешние устройства – принтеры,
модемы, винчестеры т.п.), а также –
одновременно файловыми и выделенными.
Клиент
– компьютер,
через который пользователь получает
доступ к сети.
Компьютеры,
объединенные в локальную сеть, физически
могут располагаться различным образом.
Однако порядок их подсоединения к сети
определяется топологией – усредненной
геометрической схемой соединений узлов
сети.
Наиболее
распространенными топологиями локальных
сетей, в которых передающей средой
является кабель, являются: кольцо, шина,
звезда (рисунки 14, 15 и 16).
Топология
кольцо предусматривает соединение
узлов сети замкнутым контуром и
используется для построения сетей,
занимающих чаще всего сравнительно
небольшое пространство. Выход одного
узла сети соединяется с входом другого.
Информация по кольцу передаются от
узла к узлу в одном направлении. Каждый
промежуточный узел ретранслирует
посланное сообщение. Принимающий узел
распознает и получает только адресованное
ему послание.
Последовательная
организация обслуживания узлов сети
снижает ее быстродействие, а выход из
строя одного из узлов может привести
к нарушению функционирования кольца
(при отсутствии дополнительного
контура).
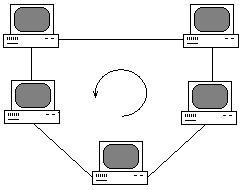
Рисунок
14 — Топология
кольцо
При
топологии шина
узлы подключены к одной передающей
линии — шине. Они передают свои сообщения
по очереди в режиме распределенного
по времени интерфейса. Сообщение от
каждого узла распространяется по шине
в обе стороны. Оно поступает на все
узлы, но принимает его только тот узел,
которому оно адресовано. Узлы не
ретранслируют сообщение, поэтому выход
из строя одного узла не приводит к
нарушению функционирования сети.
Производительность сети зависит от
количества узлов в сети (при увеличении
количества узлов она уменьшается), так
как в каждый момент времени передачу
может вести только один узел.
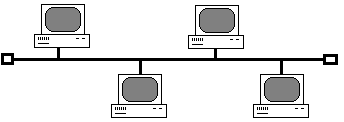
Рисунок
15 — Топология
шина
При
топологии звезда
все устройства сети связаны с центральным
узлом, который ретранслирует, коммутирует
и маршрутизирует (находит путь от
источника к приёмнику) все передаваемые
данные. В качестве центрального узла
может выступать либо концентратор
(hub),
который передаёт сообщение широковещательно
(на все узлы), а воспринимает его только
узел — приёмник, либо — коммутатор
(switch), который передаёт сообщение только
приёмнику (за счет чего повышается
пропускная способность).
Данная
топология значительно упрощает
взаимодействие узлов сети друг с другом,
но в то же время работоспособность
локальной вычислительной сети зависит
от надежности работы центрального
узла.
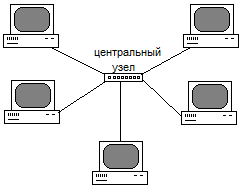
Рисунок
16 — Топология
звезда
При
построении реальных вычислительных
сетей используются эти топологии, а
также их сочетания.
Соседние файлы в предмете Информатика
- #
- #
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.
Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.
Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Дебаг и поиск ошибок

Для опытных разработчиков информация статьи может быть очевидной и если вы себя таковым считаете, то лучше добавьте в комментариях полезных советов.
По опыту работы с начинающими разработчиками, я сталкиваюсь с тем, что поиск ошибок порой занимает слишком много времени. Не из-за того, что они глупее более опытных товарищей или не разбираются в процессах, а из-за отсутствия понимания с чего начать и на чём акцентировать внимание. В статье я собрал общие советы о том где обитают ошибки и как найти причину их возникновения. Примеры в статье даны на JavaScript и .NET, но они актуальны и для других платформ с поправкой на специфику.
Как обнаружить ошибку
Прочитай информацию об исключении
Если выполнение программы прерывается исключением, то это первое место откуда стоит начинать поиск.
В каждом языке есть свои способы уведомления об исключениях. Например в JavaScript для обработки ошибок связанных с Web Api существует DOMException. Для пользовательских сценариев есть базовый тип Error. В обоих случаях в них содержится информация о наименовании и описании ошибки.
Для .NET существует класс Exception и каждое исключение в приложении унаследовано от данного класса, который представляет ошибки происходящие во время выполнения программы. В свойстве Message читаем текст ошибки. Это даёт общее понимание происходящего. В свойстве Source смотрим в каком объекте произошла ошибка. В InnerException смотрим, нет ли внутреннего исключения и если было, то разворачиваем его и смотрим информацию уже в нём. В свойстве StackTrace хранится строковое представление информации о стеке вызова в момент появления ошибки.
Каким бы языком вы не пользовались, не поленитесь изучить каким образом язык предоставляет информацию об исключениях и что эта информация означает.
Всю полученную информацию читаем вдумчиво и внимательно. Любая деталь важна при поиске ошибки. Иногда начинающие разработчики не придают значения этому описанию. Например в .NET при возникновении ошибки NRE с описанием параметра, который разработчик задаёт выше по коду. Из-за этого думает, что параметр не может быть NRE, а значит ошибка в другом месте. На деле оказывается, что ошибки транслируют ту картину, которую видит среда выполнения и первым делом за гипотезу стоит взять утверждение, что этот параметр равен null. Поэтому разберитесь при каких условиях параметр стал null, даже если он определялся выше по коду.
Пример неявного переопределения параметров — использование интерцептора, который изменяет этот параметр в запросе и о котором вы не знаете.
Разверните стек
Когда выбрасывается исключение, помимо самого описания ошибки полезно изучить стек выполнения. Для .NET его можно посмотреть в свойстве исключения StackTrace. Для JavaScript аналогично смотрим в Error.prototype.stack (свойство не входит в стандарт) или можно вывести в консоль выполнив console.trace(). В стеке выводятся названия методов в том порядке в котором они вызывались. Если то место, где падает ошибка зависит от аргументов которые пришли из вызывающего метода, то если развернуть стек, мы проследим где эти аргументы формировались.
Загуглите текст ошибки
Очевидное правило, которым не все пользуются. Применимо к не типовым ошибкам, например связанным с конкретной библиотекой или со специфическим типом исключения. Поиск по тексту ошибки помогает найти аналогичные случаи, которые даже если не дадут конкретного решения, то помогут понять контекст её возникновения.
Прочитайте документацию
Если ошибка связана с использованием внешней библиотеки, убедитесь что понимаете как она работает и как правильно с ней взаимодействовать. Типичные ошибки, когда подключив новую библиотеку после прочтения Getting Started она не работает как ожидалось или выбрасывает исключение. Проблема может быть в том, что базовый шаблон подключения библиотеки не применим к текущему приложению и требуются дополнительные настройки или библиотека не совместима с текущим окружением. Разобраться в этом поможет прочтение документации.
Проведите исследовательское тестирование
Если используете библиотеку которая не работает как ожидалось, а нормальная документация отсутствует, то создайте тесты которые покроют интересующий функционал. В ассертах опишите ожидаемое поведение. Если тесты не проходят, то подбирая различные вариации входных данных выясните рабочую конфигурацию. Цель исследовательских тестов помочь разобраться без документации, какое ожидаемое поведение у изучаемой библиотеки в разных сценариях работы. Получив эти знания будет легче понять как правильно использовать библиотеку в проекте.
Бинарный поиск
В неочевидных случаях, если нет уверенности что проблема в вашем коде, а сообщение об ошибке не даёт понимания где проблема, комментируем блок кода в котором обнаружилась проблема. Убеждаемся что ошибка пропала. Аналогично бинарному алгоритму раскомментировали половину кода, проверили воспроизводимость ошибки. Если воспроизвелась, закомментировали половину выполняемого кода, повторили проверку и так далее пока не будет локализовано место появления ошибки.
Где обитают ошибки
Ошибки в своём коде
Самые распространенные ошибки. Мы писали код, ошиблись в формуле, забыли присвоить значение переменной или что-то не проинициализировали перед вызовом. Такие ошибки легко исправить и легко найти место возникновения если внимательно прочитать описание возникшей ошибки.
Ошибки в чужом коде
Если над проектом работает больше одного разработчика, чей код взаимодействует друг с другом, возможна ситуация, когда ошибка происходит в чужом коде. Может сложиться впечатление, что если программа раньше работала, а сломалась только после того, как вы добавили свой код, то проблема в этом коде. На деле может быть, что ваш код обращается к уже существующему чужому коду, но передаёт туда граничные значения данных, работу с которыми забыли протестировать и обработать такие случаи.
В зависимости от соглашений на проекте исправляйте такие ошибки как свои собственные, либо сообщайте о них автору и ждите внесения правок.
Ошибки в библиотеках
Ошибки могут падать во внешних библиотеках к которым нет доступа и в таком случае непонятно что делать. Такие ошибки можно разделить на два типа. Первый- это ошибки в коде библиотеки. Второй- это ошибки связанные с невалидными данными или окружением, которые приводят к внутреннему исключению.
Первый случай хотя и редкий, но не стоит о нём забывать. В этом случае можно откатиться на другую версию библиотеки и создать Issue с описанием проблемы. Если это open-source и нет времени ждать обновления, можно собрать свою версию исправив баг самостоятельно, с последующей заменой на официальную исправленную версию.
Во втором случае определите откуда из вашего кода пришли невалидные данные. Для этого смотрим стек выполнения и по цепочке прослеживаем место в котором библиотека вызывается из нашего кода. Далее с этого места начинаем анализ, как туда попали невалидные данные.
Ошибки не воспроизводимые локально
Ошибка воспроизводится на develop стенде или в production, но не воспроизводится локально. Такие ошибки сложнее отлавливать потому что не всегда есть возможность запустить дебаг на удалённой машине. Поэтому убеждаемся, что ваше окружение соответствует внешнему.
Проверьте версию приложения
На стенде и локально версии приложения должны совпадать. Возможно на стенде приложение развёрнуто из другой ветки.
Проверьте данные
Проблема может быть в невалидных данных, а локальная и тестовая база данных рассинхронизированы. В этом случае поиск ошибки воспроизводим локально подключившись к тестовой БД, либо сняв с неё актуальный дамп.
Проверьте соответствие окружений
Если проект на стенде развёрнут в контейнере, то в некоторых IDE (JB RIder) можно дебажить в контейнере. Если проект развёрнут не в контейнере, то воспроизводимость ошибки может зависеть от окружения. Хотя .Net Core мультиплатформенный фреймворк, не всё что работает под Windows так же работает под Linux. В этом случае либо найти рабочую машину с таким же окружением, либо воспроизвести окружение через контейнеры или виртуальную машину.
Коварные ошибки
Метод из подключенной библиотеки не хочет обрабатывать ваши аргументы или не имеет нужных аргументов. Такие ситуации возникают, когда в проекте подключены две разных библиотеки содержащие методы с одинаковым названием, а разработчик по привычке понадеялся, что IDE автоматически подключит правильный using. Такое часто бывает с библиотеками расширяющими функционал LINQ в .NET. Поэтому при автоматическом добавлении using, если всплывает окно с выбором из нескольких вариантов, будьте внимательны.
Похожая ситуация и с одинаково названными типами. Если сборка включает несколько проектов в которых присутствуют одинаково названные классы, то можно по ошибке обращаться не к тому который требуется. Чтобы избежать обоих случаев, убедитесь, что в месте возникновения ошибки идёт обращение к правильным типам и методам.
Дополнительные материалы
Алгоритм отладки
-
Повтори ошибку.
-
Опиши проблему.
-
Сформулируй гипотезу.
-
Проверь гипотезу — если гипотеза проверку не прошла то п.3.
-
Примени исправления.
-
Убедись что исправлено — если не исправлено, то п.3.
Подробнее ознакомиться с ним можно в докладе Сергея Щегриковича «Отладка как процесс».
Чем искать ошибки, лучше не допускать ошибки. Прочитайте статью «Качество вместо контроля качества», чтобы узнать как это делать.
Итого
-
При появлении ошибки в которой сложно разобраться сперва внимательно и вдумчиво читаем текст ошибки.
-
Смотрим стек выполнения и проверяем, не находится ли причина возникновения выше по стеку.
-
Если по прежнему непонятно, гуглим текст и ищем похожие случаи.
-
Если проблема при взаимодействии с внешней библиотекой, читаем документацию.
-
Если нет документации проводим исследовательское тестирование.
-
Если не удается локализовать причину ошибки, применяем метод Бинарного поиска.
Существует три
основных типа ошибок в программах:
— ошибки этапа
компиляции (или синтаксические ошибки);
— ошибки этапа
выполнения или семантические ошибки);
— логические
ошибки.
Cинтаксические
ошибки происходят из-за нарушений
правил синтаксиса
языка программирования.
Когда компилятор обнаруживает
синтаксическую
ошибку, то отмечает
место (позицию или строку) ошибки и
выводт сообщение
об ошибке.
Наиболее
распространенными синтаксическими
ошибками являются:
— ошибки набора
(опечатки);
— пропущенные
точки с запятой;
— ссылки на
неописанные переменные;
— передача
неверного числа (или типа) параметров
процедуры или
функции;
— присваивание
переменной значений неверного типа.
После исправления
cинтаксической ошибки компиляцию можно
выполнить
заново. После
устранения всех синтаксических ошибок
и успешной компиля-
ции программа готова
к выполнению и поиску ошибок этапа
выполнения и ло-
гических ошибок.
Семантические
ошибки происходят, когда программа
компилируется, но
при выполнении
операторов что-то происходит неверно.
Например, программа
пытается открыть
для ввода несуществующий файл или
выполнить деление на
ноль. При обнаружении
семантических ошибок выполнение
программы заверша-
ется и выводится
сообщение об ошибке. Например, в системе
Turbo Pascal
выводится сообщение
следующего вида:
Run-time error ## at seg:ofs
По номеру
ошибки (##) можно установить причину ее
возникновения.
Логические ошибки
— это ошибки проектирования и реализации
програм-
мы. Логические
ошибки приводят к некорректному или
непредвиденному зна-
чению переменных,
неправильному виду графических
изображений или невы-
полнению кода, когда
это ожидается. Эти ошибки часто трудно
отслежива-
ются, поскольку ни
компилятор, ни исполняющая система не
обнаруживают их
автоматически, как
синтаксические и семантические ошибки.
Обычно системы
программирования
включает в себя средства отладки,
помогающие найти ло-
гические ошибки.
3.4.2. Цели и задачи отладки и тестирования.
Многие программисты
путают отладку программ с тестированием,
пред-
назначенным для
проверки их работоспособности. Отладка
имеет место тог-
да, когда программа
со всей очевидностью работает неправильно.
Поэтому
отладка начинается
всегда в предположении отказа программы.
Если же ока-
зывается, что
программа работает верно, то она
тестируется. Часто случа-
ется так, что после
прогона тестов программа вновь должна
быть подверг-
нута отладке. Таким
образом, тестирование устанавливает
факт наличия
ошибки, а отладка
выявляет ее причину, и эти два этапа
разработки прог-
раммы перекрываются.
3.4.3. Основные возможности интегрированного отладчика системы
программирования
Turbo Pascal.
Основной смысл
использования встроенного отладчика
состоит в управ-
ляемом выполнении
программы. Отслеживая выполнение
каждой инструкции,
можно легко определить,
какая часть программы вызывает проблемы.
В от-
ладчике предусмотрено
шесть основных механизмов управления
выполнением
программы, которые
позволяют:
— выполнять
инструкции по шагам(Run|Step Over или F8);
— трассировать
инструкции (Run|Trace Into или F7);
— выполнять
программы до позиции курсора (Run|Go to
Cursor или F4);
— выполнять
программу до заданной точки (Toggle
Breakpoint или
Ctrl+F8);
— находить
определенную точку (Search|Find Procedure…);
— выполнять сброс
программы (Run¦Reset Program или Ctrl+F2).
Выполнение
программы по шагам (команда Step Over меню
выполнения
Run) и трассировка
программы (команда Trace Into меню выполнения
Run)
дают возможность
построчного выполнения программы.
Единственное отличие
выполнения по шагам
и трассировки состоит в том, как они
работают с вы-
зовами процедур и
функций. Выполнение по шагам вызова
процедуры или
функции интерпретирует
вызов как простой оператор и после
завершения
подпрограммы
возвращает управление на следующую
строку. Трассировка
подпрограммы
загружает код этой подпрограммы и
продолжает ее построчное
выполнение.
Выполнение
программы до заданной точки (команда
Toggle Breakpoint
локального меню
редактора) — более гибкий механизм
отладки, чем исполь-
зование метода
выполнения до позиции курсора (команда
Go to Cursor меню
выполнения Run),
поскольку в программе можно установить
несколько точек
останова.
Интегрированная
среда разработки программы предусматривает
несколь-
ко способов поиска
в программе заданного места. Простейший
способ пре-
доставляет команда
Search|Find Procedure…, которая запрашивает
имя
процедуры или
функции, затем находит соответствующую
строку в файле, где
определяется эта
подпрограмма. Этот подход полезно
использовать при ре-
дактировании, но
его можно комбинировать с возможностью
выполнения прог-
раммы до определенной
точки, чтобы пройти программу до той
части кода,
которую надо отладить.
Чтобы сбрасить
все ранее задействованные отладочные
средства и
прекратитьт отладку
программы необходимо выполнить команду
Run|Program
reset или нажать клавиши
Ctrl+F2.
При выполнении
программы по шагам можно наблюдать ее
вывод несколь-
кими способами:
— переключение
в случае необходимости экранов
(Debug|User screen
или Alt+F5);
— открытие окна
вывода (Debug¦Output);
— использование
второго монитора;
Выполнение
программы по шагам или ее трассировка
могут помочь найти
ошибки в алгоритме
программы, но обычно желательно также
знать, что про-
исходит на каждом
шаге со значениями отдельных переменных.
Например, при
выполнении по шагам
цикла for полезно знать значение переменной
цикла.
Встроенный отладчик
имеет два инструментальных средства
для проверки со-
держимого переменных
программы:
— окно Watches
(Просмотр);
— диалоговое окно
Evaluate and Modify (Вычисление и модификация).
Чтобы открыть
окно Watches, необходимо выполнить
команду
Debug|Watch. Чтобы добавить
в окно Watches переменную, необходимо выпол-
нить
команду
Debug¦Watch¦Add Watch… или
нажать клавиши Ctrl+F7. Если
окно Watches является
активным окном, то можно добавить
выражение
просмотра, нажав
клавишу Ins. Отладчик открывает диалоговое
окно Add
Watch, запрашивающее
тип просматриваемого выражения. По
умолчанию выра-
жением считается
слово в позиции курсора в текущем окне
редактирования.
Просматриваемые
выражения, которые отслеживались ранее,
сохраняются в
списке протокола.
Последнее добавленное или модифицированное
просматри-
ваемое выражение
является текущим просматриваемым
выражением, которое
указывается выводимым
слева от него символом жирной левой
точки. Если
окно Watches активно,
можно удалить текущее выражение, нажав
клавишу Del
или Ctrl+Y. Чтобы
удалить все просматриваемые выражения,
необходимо вы-
полнить команду
Clear All локального меню активного окна
Watches. Чтобы
отредактировать
просматриваемое выражение, нужно
выполнить команду
Modify… или нажать
клавишу Enter локального меню активного
окна
Watches. Отладчик
открывает диалоговое окно Edit Watch,
аналогичное то-
му, которое
используется для добавления просматриваемого
выражения, ко-
торое позволяет
отредактировать текущее выражение.
Чтобы вычислить
выражение, необходимо выполнить
команду
Debug¦Evaluate/Modify…
или
нажать
клавиши
Ctrl+F4. Отладчик
открывает
диалоговое окно
Evaluate and Modify. По умолчанию слово в позиции
курсо-
ра в текущем окне
редактирования выводится подсвеченным
в поле
Expression. Можно
отредактировать это выражение, набрать
другое выраже-
ние или выбрать
вычисленное ранее выражение из списка
протокола.
Даже если не
установлены точки останова, можно выйти
в отладчик при
выполнении программы,
нажав клавиши Ctrl+Break. Отладчик находит
позицию
в исходном коде, где
прервалась программа. Затем, как и в
случае обычной
точки останова,
можно выполнить программу по шагам,
трассировать ее,
отследить или
вычислить выражения.
Иногда в ходе
отладки полезно узнать, как вы попали
в данную часть
кода. Окно Call Stack
показывает последовательность вызовов
процедур или
функций, которые
привели к текущему состоянию (глубиной
до 128 уровней).
Для вывода окна Call
Stack необходимо выполнить команду
Debug¦Call Stack
или нажать клавиши
Ctrl+F3.
13
Соседние файлы в папке 13_3xN
- #
- #
- #
Добавлено 16 апреля 2021 в 20:18
В программном обеспечении распространены ошибки. Их легко сделать, а найти сложно. В этой главе мы рассмотрим темы, связанные с поиском и устранением ошибок в наших программах на C++, включая изучение того, как использовать интегрированный отладчик, который является частью нашей IDE.
Хотя инструменты и методы отладки не входят в стандарт C++, умение находить и устранять ошибки в программах, которые вы пишете, является чрезвычайно важной частью успешной работы программиста. Поэтому мы уделим немного времени рассмотрению этих тем, чтобы по мере усложнения программ, которые вы пишете, ваша способность диагностировать и устранять проблемы развивалась с той же скоростью.
Если у вас есть опыт отладки программ на другом компилируемом языке программирования, многое из этого будет вам знакомо.
Синтаксические и семантические ошибки
Программирование может быть сложной задачей, и C++ – довольно необычный язык. Сложите эти две вещи вместе и получите множество способов сделать ошибку. Ошибки обычно делятся на две категории: синтаксические ошибки и семантические ошибки (логические ошибки).
Синтаксическая ошибка возникает, когда вы пишете инструкцию, недопустимую в соответствии с грамматикой языка C++. Сюда входят такие ошибки, как отсутствие точек с запятой, использование необъявленных переменных, несоответствие круглых или фигурных скобок и т.д. Например, следующая программа содержит довольно много синтаксических ошибок:
#include <iostream>
int main()
{
std::cout < "Hi there"; << x; // недопустимый оператор (<), лишняя точка с запятой, необъявленная переменная (x)
return 0 // отсутствие точки с запятой в конце инструкции
}К счастью, компилятор обычно перехватывает синтаксические ошибки и генерирует предупреждения или ошибки, поэтому вы легко обнаружите и устраните проблему. Затем просто снова попробуйте скомпилировать программу, пока не избавитесь от всех ошибок.
После того, как ваша программа скомпилировалась правильно, может быть непросто добиться от нее желаемого результата. Семантическая ошибка возникает, когда оператор синтаксически правильный, но не выполняет то, что задумал программист.
Иногда это приводит к сбою программы, например, в случае деления на ноль:
#include <iostream>
int main()
{
int a { 10 };
int b { 0 };
std::cout << a << " / " << b << " = " << a / b; // деление на 0 не определено
return 0;
}Чаще всего они просто приводят к неправильному значению или поведению:
#include <iostream>
int main()
{
int x;
std::cout << x; // Использование неинициализированной переменной приводит к неопределенному результату
return 0;
}или же
#include <iostream>
int add(int x, int y)
{
return x - y; // функция должна складывать, но это не так
}
int main()
{
std::cout << add(5, 3); // должен выдать 8, но выдаст 2
return 0;
}или же
#include <iostream>
int main()
{
return 0; // функция завершается здесь
std::cout << "Hello, world!"; // поэтому это никогда не выполняется
}Современные компиляторы стали лучше обнаруживать определенные типы распространенных семантических ошибок (например, использование неинициализированной переменной). Однако в большинстве случаев компилятор не сможет отловить большинство из этих типов проблем, потому что компилятор предназначен для обеспечения соблюдения грамматики, а не намерений.
В приведенных выше примерах ошибки довольно легко обнаружить. Но в большинстве нетривиальных программ, взглянув на код, семантические ошибки найти нелегко. Здесь могут пригодиться методы отладки.
Теги
C++ / CppDebugLearnCppДля начинающихОбучениеОтладкаПрограммирование
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
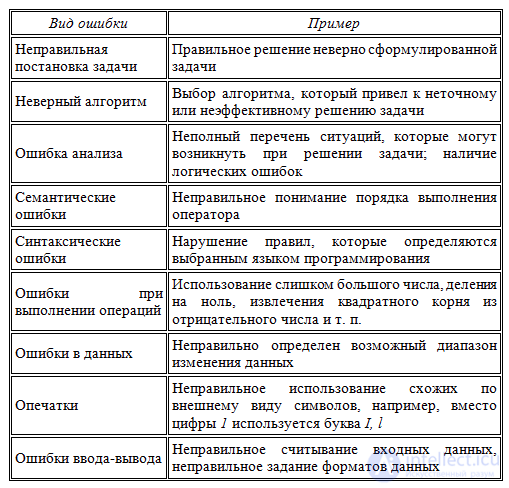
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
Классификация ошибок по этапу обработки программы
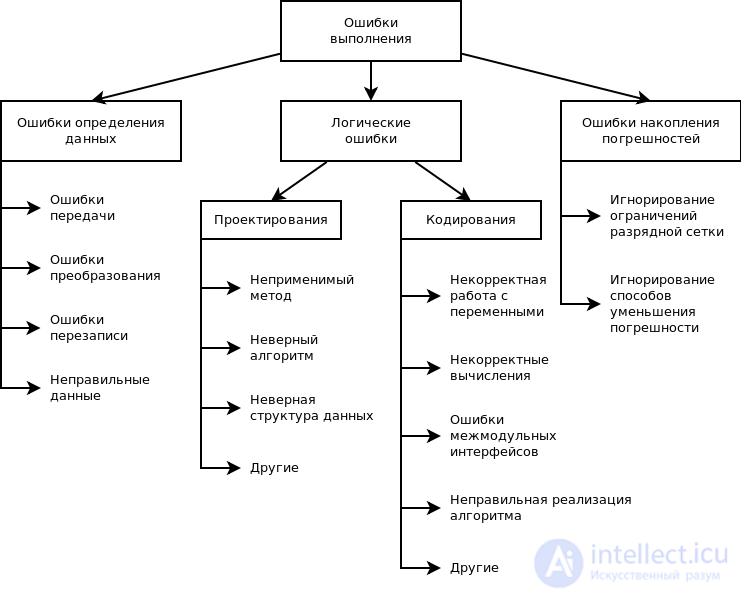
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
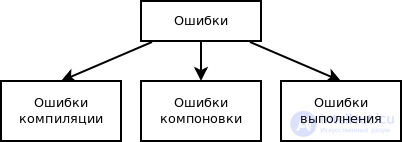
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:

Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.

Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
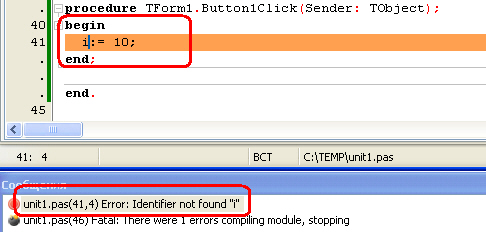
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:

Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Приготовьте отладчик! Пишем приложение с ошибками, затем учимся их находить и дебажить
https://gbcdn.mrgcdn.ru/uploads/post/2735/og_image/ce05da5c8c8f97a3bf7713b7cbaf3802.png

Иногда в приложении встречаются ошибки, которые нельзя увидеть даже после запуска. Например, код компилируется, проект запускается, но результат далёк от желаемого: приложение падает или вдруг появляется какая-то ошибка (баг). В таких случаях приходится «запасаться логами», «брать в руки отладчик» и искать ошибки.
Часто процесс поиска и исправления бага состоит из трёх шагов:
- Воспроизведение ошибки — вы понимаете, какие действия нужно сделать в приложении, чтобы повторить ошибку.
- Поиск места ошибки — определяете класс и метод, в котором ошибка происходит.
- Исправление ошибки.
Если приложение не падает и чтение логов ничего не даёт, то найти точное место ошибки в коде помогает дебаггер (отладчик) — инструмент среды разработки.
Чтобы посмотреть на логи и воспользоваться дебаггером, давайте напишем простое тестовое (и заведомо неправильное) приложение, которое даст нам все возможности для поиска ошибок.
Это будет приложение, которое сравнивает два числа. Если числа равны, то будет выводиться результат «Равно», и наоборот. Начнём с простых шагов:
- Открываем Android Studio.
- Создаём проект с шаблоном Empty Activity.
- Выбираем язык Java, так как его, как правило, знают больше людей, чем Kotlin.
Нам автоматически откроются две вкладки: activity_main.xml и MainActivity.java. Сначала нарисуем макет: просто замените всё, что есть в activity_main.xml, на код ниже:
<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <EditText android:id="@+id/first_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toTopOf="parent" /> <EditText android:id="@+id/second_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/first_number_et" /> <Button android:id="@+id/button" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Равно?" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/second_number_et" /> <TextView android:id="@+id/answer_tv" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="" android:textSize="32sp" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/button" /> </androidx.constraintlayout.widget.ConstraintLayout>
Можете запустить проект и посмотреть, что получилось:
Теперь оживим наше приложение. Скопируйте в MainActivity этот код:
public class MainActivity extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); final Button button = (Button) findViewById(R.id.button); final EditText first = (EditText) findViewById(R.id.first_number_et); final EditText second = (EditText) findViewById(R.id.second_number_et); final TextView answer = (TextView) findViewById(R.id.answer_tv); button.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { Integer firstInt = Integer.parseInt(first.getText().toString()); Integer secondInt = Integer.parseInt(second.getText().toString()); if (firstInt == secondInt) { answer.setText("Равно"); } else { answer.setText("Равно"); } } }); } }
В этом коде всё просто:
- Находим поля ввода, поле с текстом и кнопку.
- Вешаем на кнопку слушатель нажатий.
- По нажатию на кнопку получаем числа из полей ввода и сравниваем их.
- В зависимости от результата выводим «Равно» или «Не равно».
Запустим приложение и введём буквы вместо чисел:
Нажмём на кнопку, и приложение упадёт! Время читать логи. Открываем внизу слева вкладку «6: Logcat» и видим:
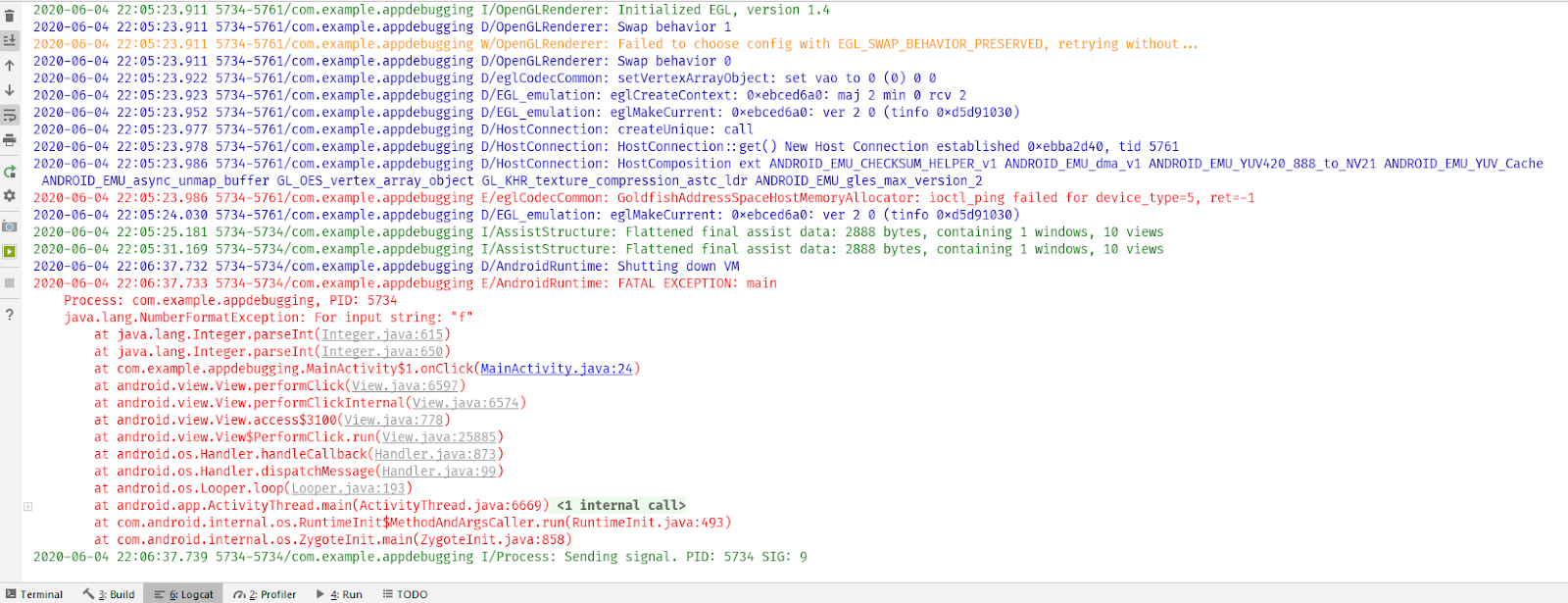
Читать логи просто: нужно найти красный текст и прочитать сообщение системы. В нашем случае это java.lang.NumberFormatException: For input string: «f». Указан тип ошибки NumberFormatException, который говорит, что возникла какая-то проблема с форматированием числа. И дополнение: For input string: «f». Введено “f”. Уже можно догадаться, что программа ждёт число, а мы передаём ей символ. Далее в красном тексте видно и ссылку на проблемную строку: at com.example.appdebugging.MainActivity$1.onClick(MainActivity.java:26). Проблема в методе onClick класса MainActivity, строка 24. Можно просто кликнуть по ссылке и перейти на указанную строку:
int firstInt = Integer.parseInt(first.getText().toString());
Конечно, метод parseInt может принимать только числовые значения, но никак не буквенные! Даже в его описании это сказано — и мы можем увидеть, какой тип ошибки этот метод выбрасывает (NumberFormatException).

Здесь мы привели один из примеров. Типов ошибок может быть огромное количество, все мы рассматривать не будем. Но все ошибки в Logcat’е указываются по похожему принципу:
- красный текст;
- тип ошибки — в нашем случае это NumberFormatException;
- пояснение — у нас это For input string: «f»;
- ссылка на строку, на которой произошла ошибка — здесь видим MainActivity.java:26.
Исправим эту ошибку и обезопасим себя от некорректного ввода. Добавим в наши поля ввода android:inputType=»number», а остальной код оставим без изменений:
... <EditText android:id="@+id/first_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" android:inputType="number" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toTopOf="parent" /> <EditText android:id="@+id/second_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" android:inputType="number" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/first_number_et" /> ...
Теперь можем вводить только числа. Проверим, как работает равенство: введём одинаковые числа в оба поля. Всё в порядке:
На равенство проверили. Введём разные числа:
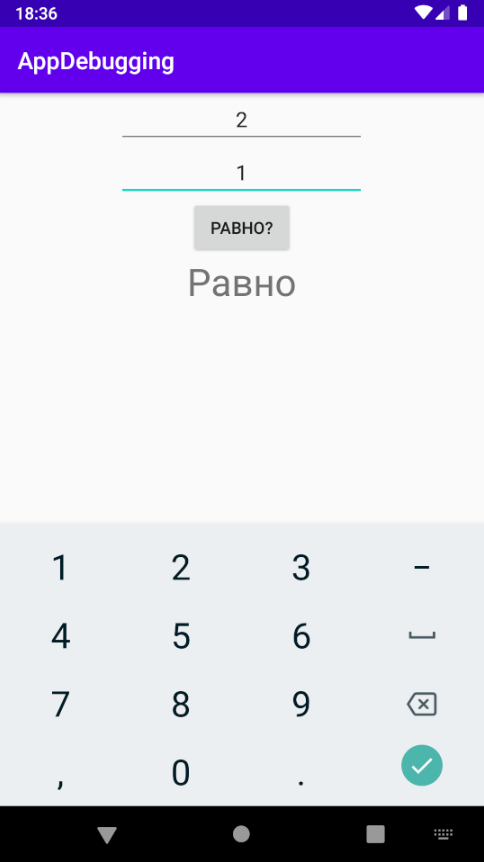
Тоже равно. То есть приложение работает, ничего не падает, но результат не совсем тот, который требуется. Наверняка вы и без дебаггинга догадались, в чём ошибка, потому что приложение очень простое, всего несколько строк кода. Но такие же проблемы возникают в приложениях и на миллион строк. Поэтому пройдём по уже известным нам этапам дебаггинга:
- Воспроизведём ошибку: да, ошибка воспроизводится стабильно с любыми двумя разными числами.
- Подумаем, где может быть ошибка: наверняка там, где сравниваются числа. Туда и будем смотреть.
- Исправим ошибку: сначала найдём её с помощью дебаггера, а когда поймём, в чём проблема, — будем исправлять.
И здесь на помощь приходит отладчик. Для начала поставим точки останова сразу в трёх местах:
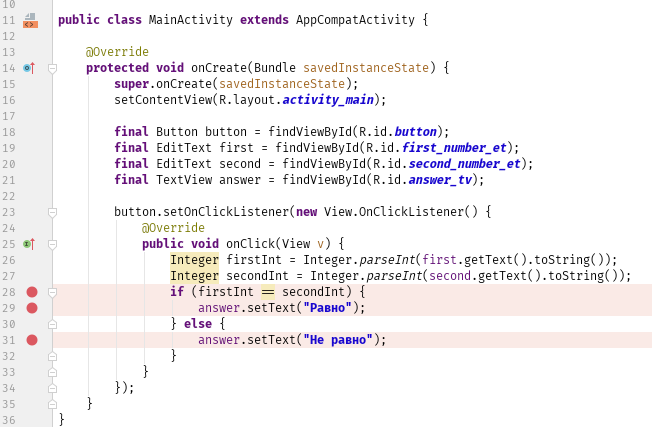
Чтобы поставить или снять точку останова, достаточно кликнуть левой кнопкой мыши справа от номера строки или поставить курсор на нужную строку, а затем нажать CTRL+F8. Почему мы хотим остановить программу именно там? Чтобы посмотреть, правильные ли числа сравниваются, а затем определить, в какую ветку в нашем ветвлении заходит программа дальше. Запускаем программу с помощью сочетания клавиш SHIFT+F9 или нажимаем на кнопку с жучком:
Появится дополнительное окно, в котором нужно выбрать ваш девайс и приложение:
Вы в режиме дебага. Обратите внимание на две вещи:
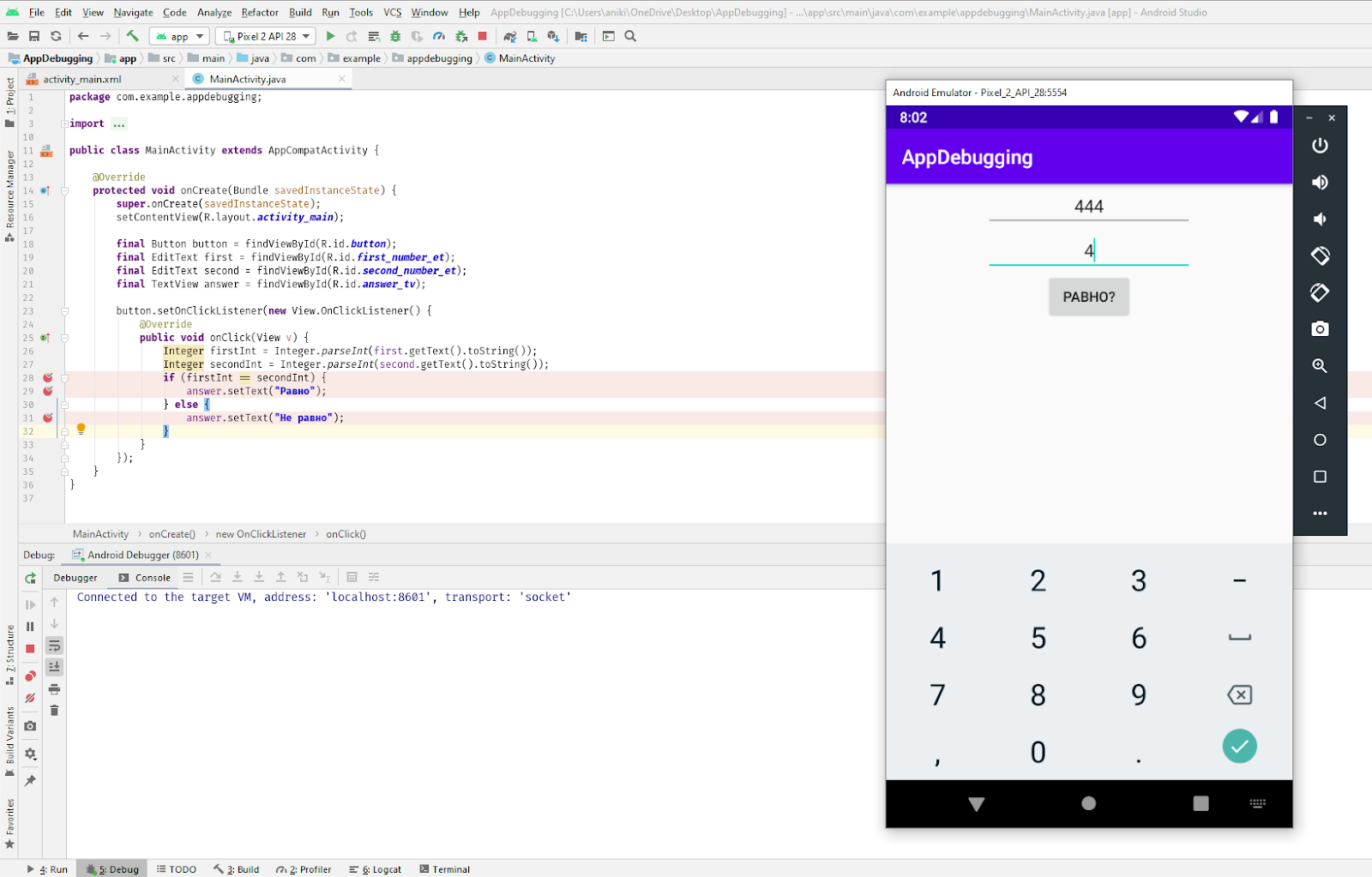
- Точки останова теперь помечены галочками. Это значит, что вы находитесь на экране, где стоят эти точки, и что дебаггер готов к работе.
- Открылось окно дебага внизу: вкладка «5: Debug». В нём будет отображаться необходимая вам информация.
Введём неравные числа и нажмём кнопку «РАВНО?». Программа остановилась на первой точке:
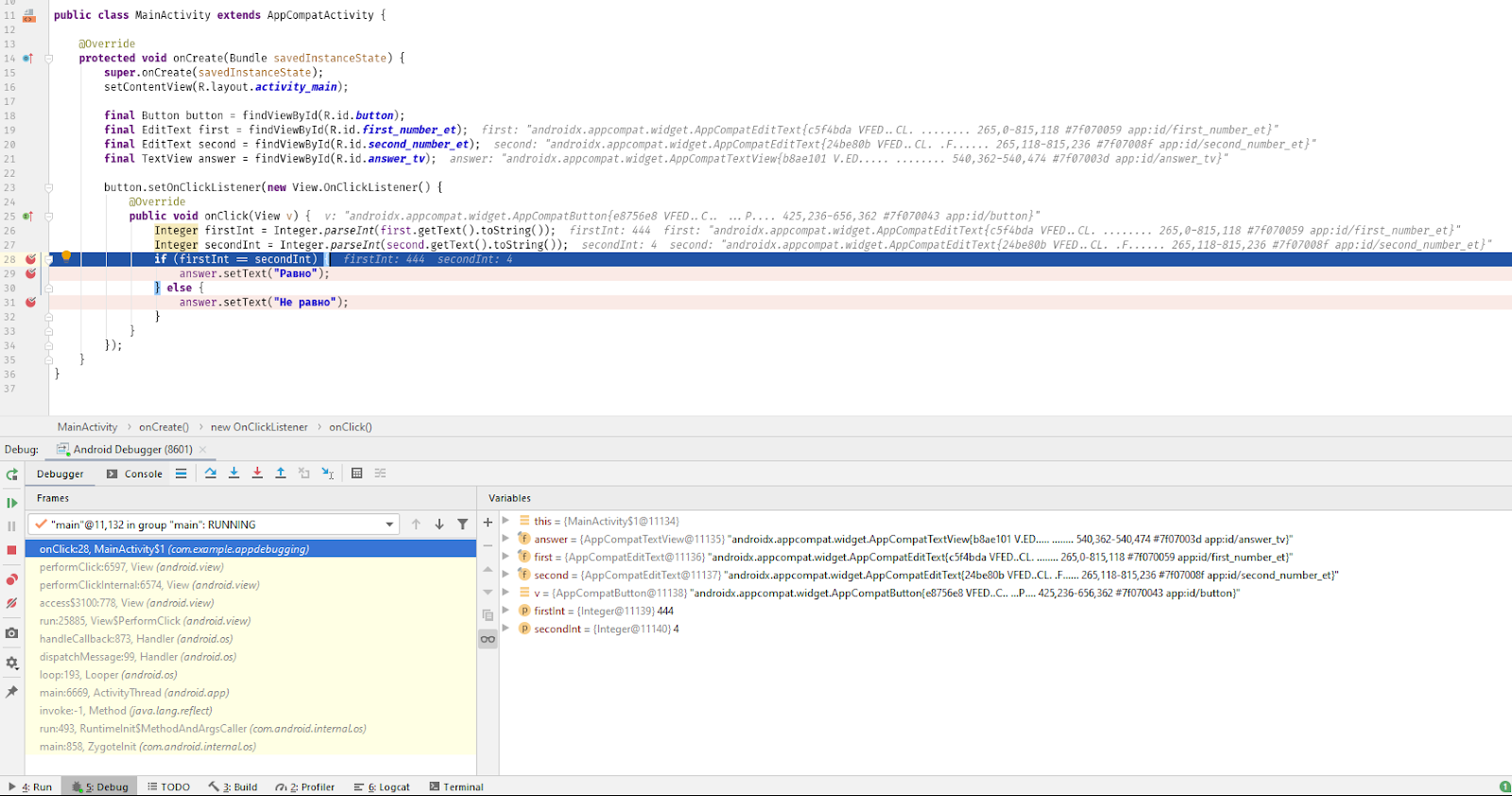
Давайте разбираться:
- Сразу подсвечивается синим строка, где программа остановлена: в окне кода на 28-й строке и в левом окне отладчика (там даже можно увидеть, какой метод вызван, — onClick).
- В правом, основном окне отладчика, всё гораздо интереснее. Здесь можно увидеть инстансы наших вью (answer, first, second), в конце которых серым текстом даже отображаются их id. Но интереснее всего посмотреть на firstInt и secondInt. Там записаны значения, которые мы сейчас будем сравнивать.
Как видим, значения именно такие, какие мы и ввели. Значит, проблема не в получении чисел из полей. Давайте двигаться дальше — нам нужно посмотреть, в правильную ли ветку мы заходим. Для этого можно нажать F8 (перейти на следующую строку выполнения кода). А если следующая точка останова далеко или в другом классе, можно нажать F9 — программа просто возобновит работу и остановится на следующей точке. В интерфейсе эти кнопки находятся здесь:
Остановить дебаггер, если он больше не нужен, можно через CTRL+F2 или кнопку «Стоп»:
В нашем случае неважно, какую кнопку нажимать (F9 или F8). Мы сразу переходим к следующей точке останова программы:
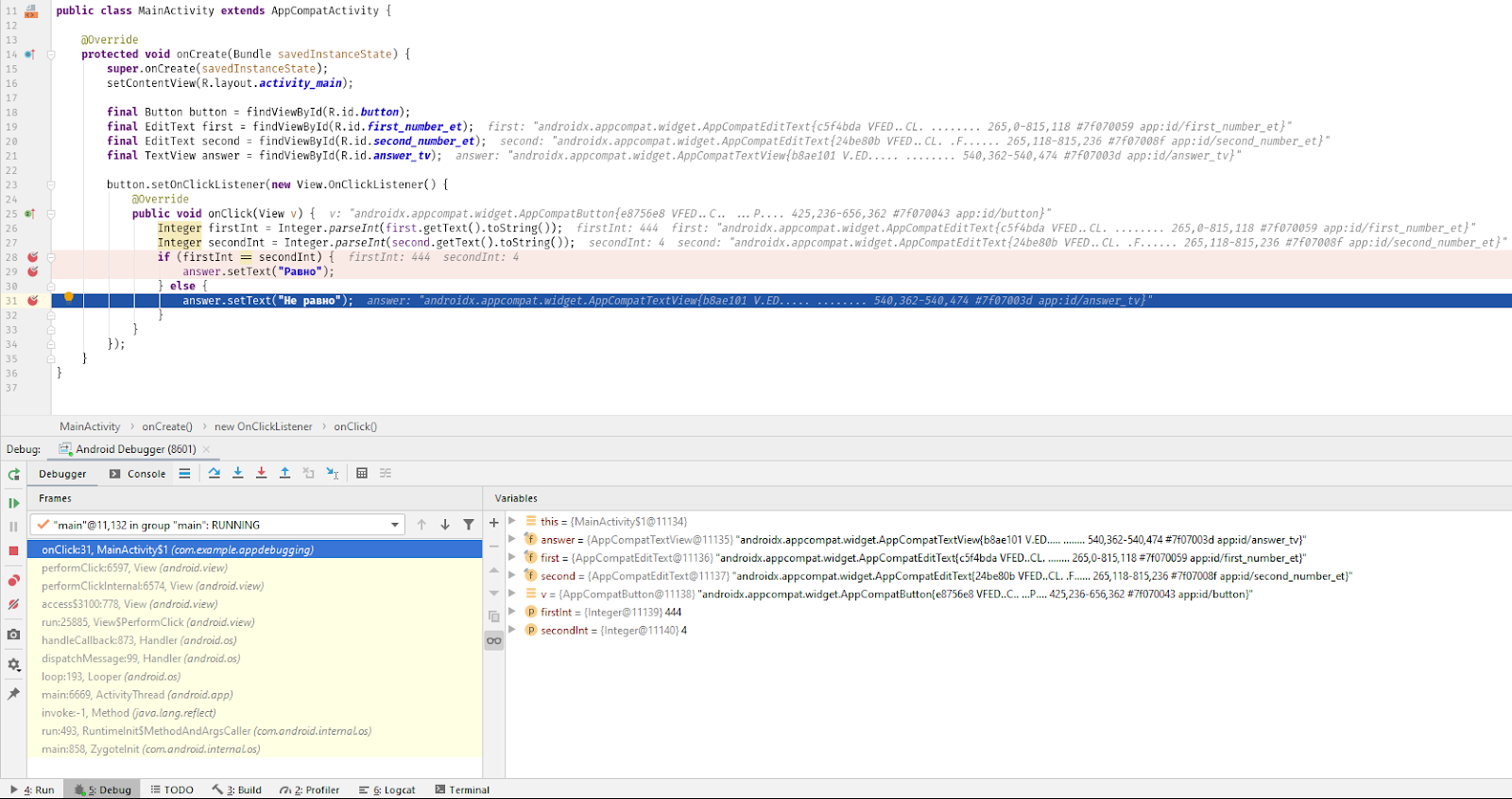
Ветка правильная, то есть логика программы верна, числа firstInt и secondInt не изменились. Зато мы сразу видим, что подпись некорректная! Вот в чём была ошибка. Исправим подпись и проверим программу ещё раз.
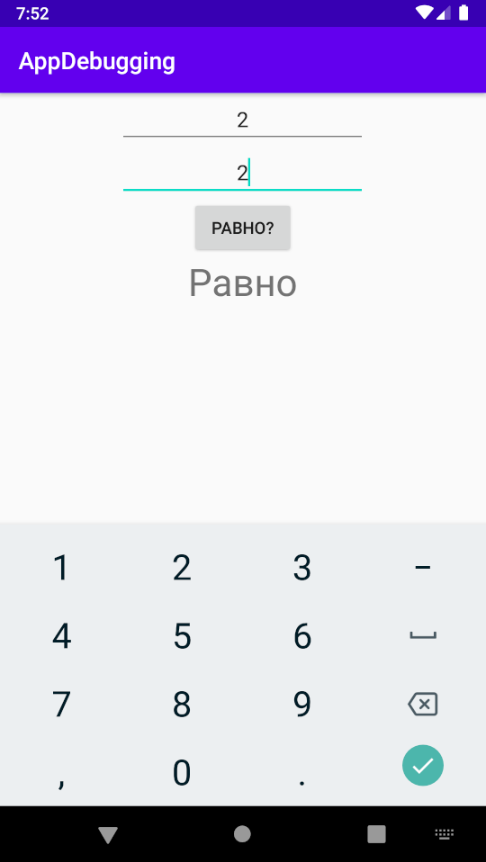
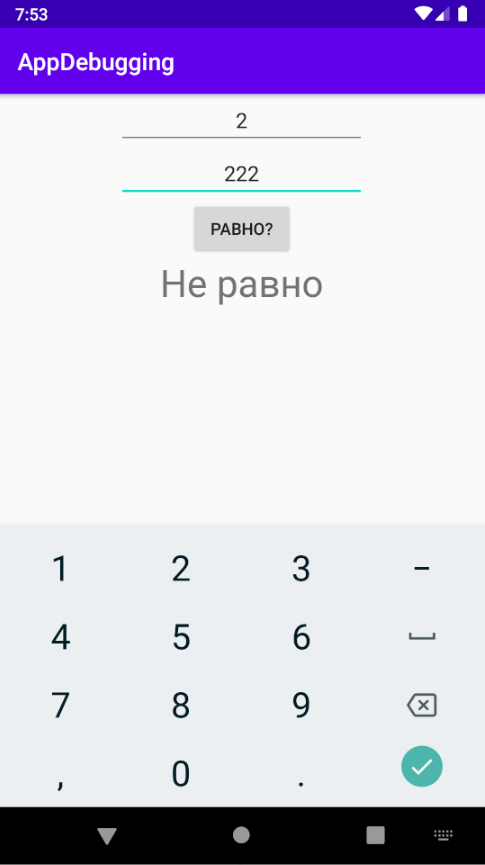
Мы уже починили два бага: падение приложения с помощью логов и некорректную логику (с помощью отладчика). Хеппи пас (happy path) пройден. То есть основная функциональность при корректных данных работает. Но нам надо проверить не только хеппи пас — пользователь может ввести что угодно. И программа может нормально работать в большинстве случаев, но вести себя странно в специфических состояниях. Давайте введём числа побольше и посмотрим, что будет:
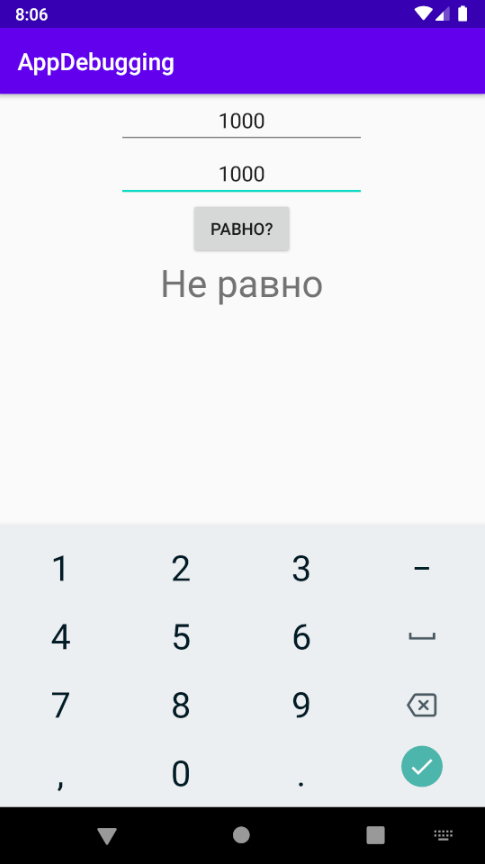
Не сработало — программа хочет сказать, что 1000 не равна 1000, но это абсурд. Запускаем приложение в режиме отладки. Точка останова уже есть. Смотрим в отладчик:
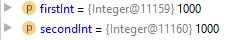
Числа одинаковые, что могло пойти не так? Обращаем внимание на тип переменной — Integer. Так вот в чём проблема! Это не примитивный тип данных, а ссылочный. Ссылочные типы нельзя сравнивать через ==, потому что будут сравниваться ссылки объектов, а не они сами. Но для Integer в Java есть нюанс: Integer может кешироваться до 127, и если мы вводим по единице в оба поля числа до 127, то фактически сравниваем просто int. А если вводим больше, то получаем два разных объекта. Адреса у объектов не совпадают, а именно так Java сравнивает их.
Есть два решения проблемы:
- Изменить тип Integer на примитив int.
- Сравнивать как объекты.
Не рекомендуется менять тип этих полей в реальном приложении: числа могут приходить извне, и тип лучше оставлять прежним. Изменим то, как мы сравниваем числа:
if (firstInt.equals(secondInt)) { answer.setText("Равно"); } else { answer.setText("Не равно"); }
Проверяем:
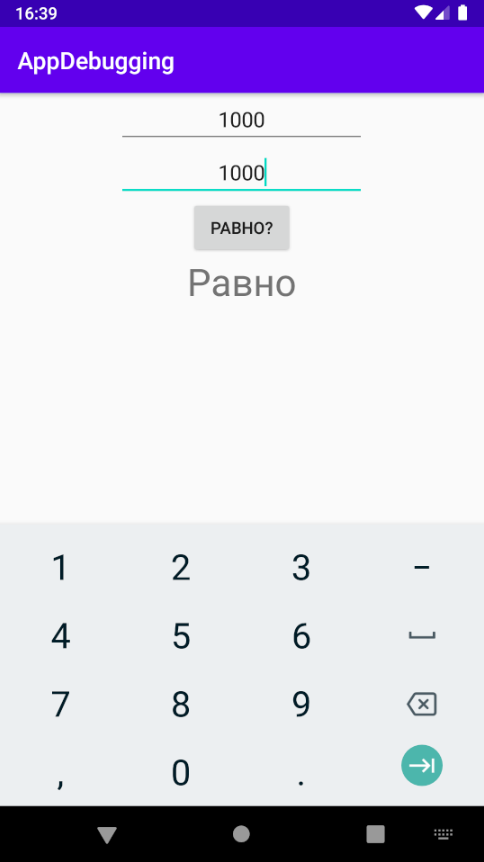
Всё работает. Наконец-то! Хотя… Давайте посмотрим, что будет, если пользователь ничего не введёт, но нажмёт на кнопку? Приложение опять упало… Смотрим в логи:
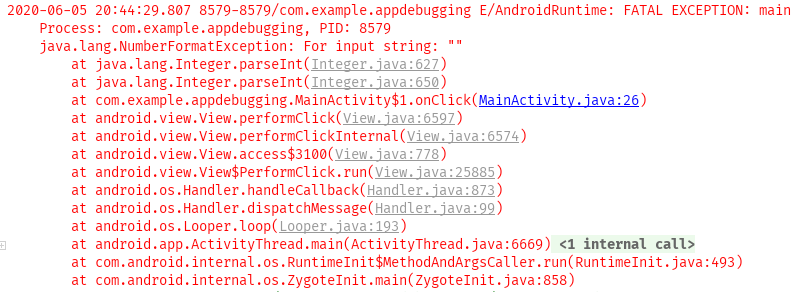
Опять NumberFormatException, при этом строка пустая. Давайте поставим точку останова на 26-й строке и заглянем с помощью отладчика глубже.
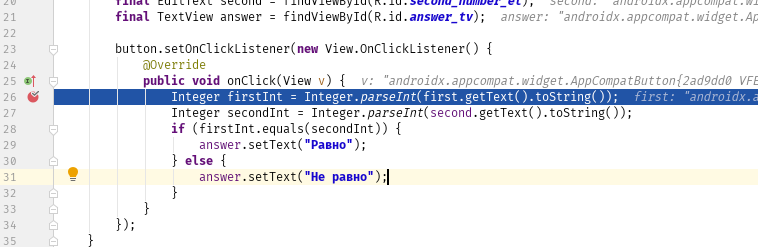
Нажмём F8 — и перейдём в глубины операционной системы:
Интересно! Давайте обернём код в try/catch и посмотрим ошибке в лицо. Если что, поправим приложение. Выделяем код внутри метода onClick() и нажимаем Ctrl+Alt+T:
Выбираем try / catch, среда разработки сама допишет код. Поставим точку останова. Получим:
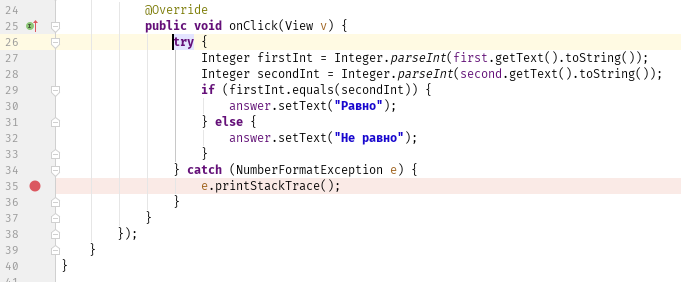
Запускаем приложение и ловим ошибку:
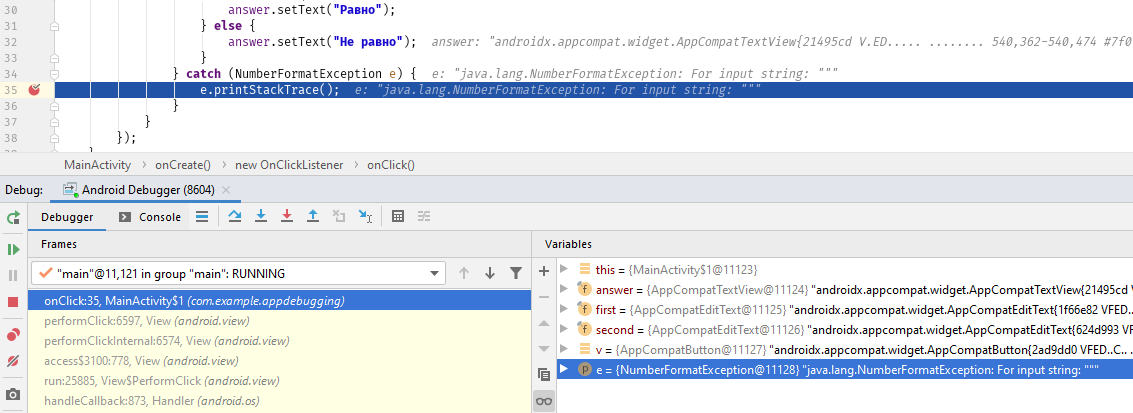
Действительно, как и в логах, — NumberFormatException. Метод parseInt выбрасывает исключение, если в него передать пустую строку. Как обрабатывать такую проблему — решать исключительно вам. Два самых простых способа:
- Проверять получаемые строки first.getText().toString() и second.getText().toString() на пустые значения. И если хоть одно значение пустое — говорить об этом пользователю и не вызывать метод parseInt.
- Или использовать уже готовую конструкцию try / catch:
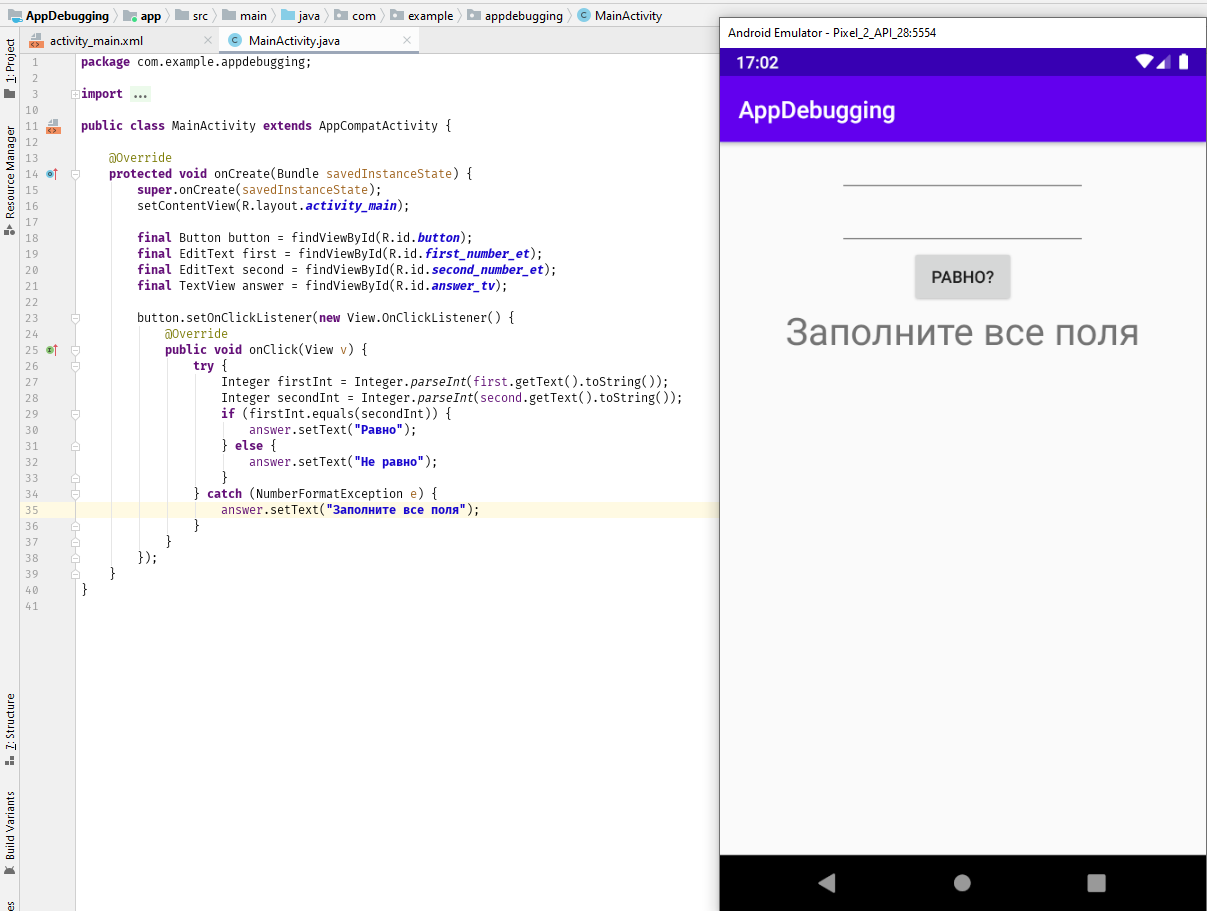
Теперь-то точно всё в порядке! Хотя профессиональным тестировщикам это приложение никто не отдавал: поищете ещё ошибки?
Добавлено 30 мая 2021 в 17:27
В уроке «3.1 – Синтаксические и семантические ошибки» мы рассмотрели синтаксические ошибки, которые возникают, когда вы пишете код, который не соответствует грамматике языка C++. Компилятор уведомит вас об ошибках этого типа, поэтому их легко обнаружить и обычно легко исправить.
Мы также рассмотрели семантические ошибки, которые возникают, когда вы пишете код, который выполняет не то, что вы планировали. Как правило, компилятор не обнаруживает семантических ошибок (хотя в некоторых случаях умные компиляторы могут генерировать предупреждения).
Семантические ошибки могут вызывать большинство из симптомов неопределенного поведения, например, приводить к тому, что программа выдает неправильные результаты, быть причиной неустойчивого поведения, искажать данные программы, вызывать сбой программы – или они могут вообще никак не влиять.
При написании программ семантические ошибки практически неизбежны. Некоторые из них вы, вероятно, заметите, просто используя программу: например, если вы писали игру лабиринт, а ваш персонаж может проходить сквозь стены. Тестирование вашей программы (7.12 – Введение в тестирование кода) также может помочь выявить семантические ошибки.
Но есть еще одна вещь, которая может помочь – это знание того, какой тип семантических ошибок наиболее распространен, чтобы вы могли потратить немного больше времени на то, чтобы убедиться, что в этих случаях всё правильно.
В этом уроке мы рассмотрим ряд наиболее распространенных типов семантических ошибок, возникающих в C++ (большинство из которых так или иначе связаны с управлением порядком выполнения программы).
Условные логические ошибки
Один из наиболее распространенных типов семантических ошибок – это условная логическая ошибка. Условная логическая ошибка возникает, когда программист неправильно пишет логику условного оператора или условия цикла. Вот простой пример:
#include <iostream>
int main()
{
std::cout << "Enter an integer: ";
int x{};
std::cin >> x;
if (x >= 5) // упс, мы использовали operator>= вместо operator>
std::cout << x << " is greater than 5";
return 0;
}А вот результат запуска программы, при котором была обнаружена эта условная логическая ошибка:
Enter an integer: 5
5 is greater than 5Когда пользователь вводит 5, условное выражение x >= 5 принимает значение true, поэтому выполняется соответствующая инструкция.
Вот еще один пример для цикла for:
#include <iostream>
int main()
{
std::cout << "Enter an integer: ";
int x{};
std::cin >> x;
// упс, мы использовали operator> вместо operator<
for (unsigned int count{ 1 }; count > x; ++count)
{
std::cout << count << ' ';
}
return 0;
}Эта программа должна напечатать все числа от 1 до числа, введенного пользователем. Но вот что она на самом деле делает:
Enter an integer: 5Она ничего не напечатала. Это происходит потому, что при входе в цикл for условие count > x равно false, поэтому цикл вообще не повторяется.
Бесконечные циклы
В уроке «7.7 – Введение в циклы и инструкции while» мы рассмотрели бесконечные циклы и показали этот пример:
#include <iostream>
int main()
{
int count{ 1 };
while (count <= 10) // это условие никогда не будет ложным
{
std::cout << count << ' '; // поэтому эта строка выполняется многократно
}
return 0; // эта строка никогда не будет выполнена
}В этом случае мы забыли увеличить count, поэтому условие цикла никогда не будет ложным, и цикл продолжит печатать:
1 1 1 1 1 1 1 1 1 1пока пользователь не закроет программу.
Вот еще один пример, который преподаватели любят задавать в тестах. Что не так со следующим кодом?
#include <iostream>
int main()
{
for (unsigned int count{ 5 }; count >= 0; --count)
{
if (count == 0)
std::cout << "blastoff! ";
else
std::cout << count << ' ';
}
return 0;
}Эта программа должна напечатать «5 4 3 2 1 blastoff!«, что она и делает, но не останавливается на достигнутом. На самом деле она печатает:
5 4 3 2 1 blastoff! 4294967295 4294967294 4294967293 4294967292 4294967291а затем просто продолжает печатать уменьшающиеся числа. Программа никогда не завершится, потому что условие count >= 0 никогда не может быть ложным, если count является целым числом без знака.
Ошибки на единицу
Ошибки «на единицу» возникают, когда цикл повторяется на один раз больше или на один раз меньше, чем это необходимо. Вот пример, который мы рассмотрели в уроке «7.9 – Инструкции for»:
#include <iostream>
int main()
{
for (unsigned int count{ 1 }; count < 5; ++count)
{
std::cout << count << ' ';
}
return 0;
}Этот код должен печатать «1 2 3 4 5«, но он печатает только «1 2 3 4«, потому что был использован неправильный оператор отношения.
Неправильный приоритет операторов
Следующая программа из урока «5.7 – Логические операторы» допускает ошибку приоритета операторов:
#include <iostream>
int main()
{
int x{ 5 };
int y{ 7 };
if (!x > y)
std::cout << x << " is not greater than " << y << 'n';
else
std::cout << x << " is greater than " << y << 'n';
return 0;
}Поскольку логическое НЕ имеет более высокий приоритет, чем operator>, условное выражение вычисляется так, как если бы оно было написано (!x) > y, что не соответствует замыслу программиста.
В результате эта программа печатает:
5 is greater than 7Это также может произойти при смешивании в одном выражении логического ИЛИ и логического И (логическое И имеет больший приоритет, чем логическое ИЛИ). Используйте явные скобки, чтобы избежать подобных ошибок.
Проблемы точности с типами с плавающей запятой
Следующая переменная с плавающей запятой не имеет достаточной точности для хранения всего числа:
#include <iostream>
int main()
{
float f{ 0.123456789f };
std::cout << f;
}Как следствие, эта программа напечатает:
0.123457В уроке «5.6 – Операторы отношения и сравнение чисел с плавающей запятой» мы говорили о том, что использование operator== и operator!= может вызывать проблемы с числами с плавающей запятой из-за небольших ошибок округления (а также о том, что с этим делать). Вот пример:
#include <iostream>
int main()
{
// сумма должна быть равна 1.0
double d{ 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 };
if (d == 1.0)
std::cout << "equal";
else
std::cout << "not equal";
}Эта программа напечатает:
not equalЧем больше вы выполняете арифметических действий с числом с плавающей запятой, тем больше в нем накапливаются небольшие ошибки округления.
Целочисленное деление
В следующем примере мы хотим выполнить деление с плавающей запятой, но поскольку оба операнда принадлежат целочисленному типу, вместо этого мы выполняем целочисленное деление:
#include <iostream>
int main()
{
int x{ 5 };
int y{ 3 };
std::cout << x << " divided by " << y << " is: " << x / y; // целочисленное деление
return 0;
}Этот код напечатает:
5 divided by 3 is: 1В уроке «5.2 – Арифметические операторы» мы показали, что мы можем использовать static_cast для преобразования одного из целочисленных операндов в значение с плавающей запятой, чтобы выполнять деление с плавающей запятой.
Случайные пустые инструкции
В уроке «7.3 – Распространенные проблемы при работе с операторами if» мы рассмотрели пустые инструкции, которые ничего не делают.
В приведенной ниже программе мы хотим взорвать мир, только если у нас есть разрешение пользователя:
#include <iostream>
void blowUpWorld()
{
std::cout << "Kaboom!n";
}
int main()
{
std::cout << "Should we blow up the world again? (y/n): ";
char c{};
std::cin >> c;
if (c=='y'); // здесь случайная пустая инструкция
blowUpWorld(); // поэтому это всегда будет выполняться, так как это не часть оператора if
return 0;
}Однако из-за случайной пустой инструкции вызов функции blowUpWorld() выполняется всегда, поэтому мы взрываем независимо от ввода:
Should we blow up the world again? (y/n): n
Kaboom!Неиспользование составной инструкции, когда она требуется
Еще один вариант приведенной выше программы, которая всегда взрывает мир:
#include <iostream>
void blowUpWorld()
{
std::cout << "Kaboom!n";
}
int main()
{
std::cout << "Should we blow up the world again? (y/n): ";
char c{};
std::cin >> c;
if (c=='y')
std::cout << "Okay, here we go...n";
blowUpWorld(); // упс, всегда будет выполняться. Должно быть внутри составной инструкции.
return 0;
}Эта программа печатает:
Should we blow up the world again? (y/n): n
Kaboom!Висячий else (рассмотренный в уроке «7.3 – Распространенные проблемы при работе с операторами if») также попадает в эту категорию.
Что еще?
Приведенные выше примеры представляют собой хороший образец наиболее распространенных типов семантических ошибок, которые склонны совершать на C++ начинающие программисты, но их гораздо больше. Читатели, если у вас есть дополнительные примеры, которые, по вашему мнению, являются распространенными ошибками, напишите об этом в комментариях.
Теги
C++ / CppLearnCppДля начинающихОбучениеПрограммирование
Отладка программы – это процесс поиска и устранения ошибок. Часть ошибок формального характера, связанных с нарушением правил записи конструкций языка или отсутствием необходимых описаний, обнаруживает транслятор, производя синтаксический анализ текста программы. Транслятор выявляет ошибки и сообщает о них, указывая их тип и место в программе. Такие ошибки называются ошибками времени трансляции или синтаксическими ошибками.
Ошибочные ситуации могут возникнуть и при выполнении программы, например, деление на нуль или извлечение корня квадратного из отрицательного числа. Такие ошибки называются ошибками времени выполнения.
Программа, не имеющая ошибок трансляции и выполнения, может и не дать верных результатов из-за логических ошибок в алгоритме, т. е. алгоритмических или семантических ошибок. Ошибки подобного рода могут возникнуть на любом этапе разработки программы: постановки задачи, разработке математической модели или алгоритма. Необходим действенный контроль над процессом вычислений, позволяющий предотвращать или своевременно обнаруживать ошибки подобного рода. Для этого используются как качественный анализ задачи, основанный на различного рода интуитивных соображениях и правдоподобных рассуждениях, так и контрольный просчет или тестирование программы.
Тестирование программы – это выполнение программы на наборах исходных данных (тестах), для которых известны результаты, полученные другим методом. Система тестов подбирается таким образом, чтобы
а) проверить все возможные режимы работы программы;
б) по возможности, локализовать ошибку.
При тестировании программы простой и действенный метод дополнительного контроля над ходом её выполнения – получение контрольных точек, т. е. контрольный вывод промежуточных результатов.
Для проверки правильности работы программы иногда полезно также выполнить проверку выполнения условий задачи (например, для алгебраического уравнения найденные корни подставляются в исходное уравнение и проверяются расхождения левой и правой частей).
33. ВИДЫ ОШИБОК В ПРОГРАММАХ
Об ошибках в программе сигнализируют некорректная работоспособность программы либо ее полное невыполнение. В наше время для обозначения ошибки в программе используют термин «Баг» (с англ. Bug-жук).
Есть несколько типов ошибок:
1) Логическая ошибка. Это, пожалуй, наиболее серьезная из всех ошибок. Когда написанная программа на любом языке компилирует и работает правильно, но выдает неправильный вывод, недостаток заключается в логике основного программирования. Это ошибка, которая была унаследована от недостатка в базовом алгоритме. Сама логика, на которой базируется вся программа, является ущербной. Чтобы найти решение такой ошибки нужно фундаментальное изменение алгоритма. Вам нужно начать копать в алгоритмическом уровне, чтобы сузить область поиска такой ошибки. (пример: задача программы вывести сумму двух чисел а и b.
varc,a,b:integer;
Begin
readln(a,b);
c:=a-b; {нужнобылонаписатьc:=a+b;}
writeln(c);
readln;
end.
2) Синтаксическая ошибка.Каждый компьютерный язык, такой как C, Java, Perl и Python имеет специфический синтаксис, в котором будет написан код. Когда программист не придерживаться «грамматики» спецификациями компьютерного языка, возникнет ошибка синтаксиса. Такого рода ошибки легко устраняются на этапе компиляции.
begin
writln(‘helloworld!’); {вместоwritElnнаписаноwritln, чтоприведеткошибке}
readln;
end.
3) Ошибка компиляции.Компиляция это процесс, в котором программа, написанная на языке высокого уровня, преобразуется в машиночитаемую форму. Многие виды ошибок могут происходить на этом этапе, в том числе и синтаксические ошибки. Иногда, синтаксис исходного кода может быть безупречным, но ошибка компиляции все же может произойти. Это может быть связано с проблемами в самом компиляторе. Эти ошибки исправляются на стадии разработки.
vara,b:real;
begin
b:=7.5;
с:=b*3; {ошибка компиляции, мы присваиваем значениие несуществующей переменой}
writeln(a);
readln;
end.
4) Ошибки среды выполнения (RunTime).Программный код успешно скомпилирован, и исполняемый файл был создан. Вы можете вздохнуть с облегчением и запустить программу, чтобы проверить ее работу. Ошибки при выполнении программы могут возникнуть в результате аварии или нехватки ресурсов носителя. Разработчик должен был предвидеть реальные условия развертывания программы. Это можно исправить, вернувшись к стадии кодирования.

vara:array[1..5] of integer;
begin
a[0]:=5; {ошибка в том, что мы вышли за предел массива}
writeln(a[0]);
readln;
end;
5) Арифметическая ошибка.Многие программы используют числовые переменные, и алгоритм может включать несколько математических вычислений. Арифметические ошибки возникают, когда компьютер не может справиться с проблемами, такими как «Деление на ноль», или ведущие к бесконечному результату. Это снова логическая ошибка, которая может быть исправлена только путем изменения алгоритма.
vara:real;
begin
a:=10/0; {ошибка, делениена 0}
writeln(a);
readln
end.
6) Ошибки ресурса. Ошибка ресурса возникает, когда значение переменной переполняет максимально допустимое значение. Переполнение буфера, использование неинициализированной переменной, нарушение прав доступа и переполнение стека — примеры некоторых распространенных ошибок.
vara:integer;
begin
a:=32768; {ошибка, максимальное значение переменной типа integer равно 32767}
end.
7) Ошибка взаимодействия. Они могут возникнуть в связи с несоответствием программного обеспечения с аппаратным интерфейсом или интерфейсом прикладного программирования. В случае веб-приложений, ошибка интерфейса может быть результатом неправильного использования веб-протоколов
Синтаксические ошибки – это ошибки в записи конструкций языка программирования (чисел, переменных, функций, выражений, операторов, меток, подпрограмм).
Семантические ошибки – это ошибки, связанные с неправильным содержанием действий и использованием недопустимых значений величин.
Обнаружение большинства синтаксических ошибок автоматизировано в основных системах программирования. Поиск же семантических ошибок гораздо менее формализован; часть их проявляется при исполнении программы в нарушениях процесса автоматических вычислений и индицируется либо выдачей диагностических сообщений рабочей программы, либо отсутствием печати результатов из-за бесконечного повторения одной и той же части программы (зацикливания), либо появлением непредусмотренной формы или содержания печати результатов. Семантически ошибки можно выявить, пользуясь отладчиком, встроенным в компилятор.
Поможем в ✍️ написании учебной работы
Компилятор анализирует и преобразует исходный текст в объектный код (промежуточное состояние программы в относительных адресах и с неразрешенными внешними ссылками) с использованием всей логической структуры программы. Затем программа, представленная в объектном коде, обрабатывается служебной программой – компоновщиком, который осуществляет подключение внешних подпрограмм/разрешение внешних ссылок и выполняет дальнейший перевод программы пользователя в коды машины (в абсолютный/загрузочный код – с абсолютной адресацией машинных команд).
Интерпретатор сразу производит анализ, перевод (в машинный код) и выполнение программы строка за строкой.
Отладка программы– это процесс поиска и устранения ошибок.
Виды ошибок: синтаксические ошибки, ошибки времени выполнения, логических ошибок в алгоритме, т. е. алгоритмических или семантических ошибок.
Тестирование программы– это выполнение программы на наборах исходных данных (тестах), для которых известны результаты, полученные другим методом. Система тестов подбирается таким образом, чтобы проверить все возможные режимы работы программы и локализовать ошибку.
При тестировании программы простой и действенный метод дополнительного контроля над ходом её выполнения – получение контрольных точек, т. е. контрольный вывод промежуточных результатов.
В ходе отладки программа должна быть проверена в двух измерениях: в пространстве и во времени. Первое представляет собой контроль содержимого памяти в конкретные моменты работы программы, отслеживание текущих значений всех или выбранных групп переменных, проверку на соответствие их значений декларированным диапазонам (типам). Второе – это отслеживание хода выполнения алгоритма для проверки правильности заданной последовательности операций и передач управления при различных значениях параметров. Самым распространенным и полезным приемом отладки, позволяющим объединить обе формы контроля, являются отчеты о трассировке. Трассировка программы – это регистрация логического пути выполнения программы – последовательности выполнения ее операторов/блоков с контрольной выдачей информации о результатах каждого шага – обо всех изменениях значений рабочих переменных и параметров связи. Сам принцип трассировки – слишком общий. На практике реализуют трассировку программы в том или ином объеме, используя различные способы и средства отладки.
Самый простой способ отладки – это расстановка в тексте программы отладочных печатей промежуточных результатов вычислений,позволяющих проследить логический и арифметический следы программы, т. е. каким образом она выполнялась и что она вычисляла.Отладочные печати ставятся в узловых/ключевых точках программы, позволяющих контролировать ошибки ввода (эхо-печать введенных данных), результаты вычислительных операций и логику работы программы или отдельных ее частей. Отладочные операторы оформляются в отдельные строки, выделяются особым образом (например, сдвигом влево или вправо) и в зависимости от цели контроля могут содержать вывод значений контролируемых переменных, проверку условий или идентифицирующее сообщение (комментарий) о прохождении заданной точки программы, о начале или завершении работы определенного участка/блока. Средства для отладки могут быть вставлены в программу еще при ее разработке. В ходе отладки количество и место расположения отладочных операторов меняется, но их лучше не удалять, а превращать в комментарии. Такой способ отладки весьма трудоемок и может сам служить источником ошибок.
Процесс отладки значительно облегчается, если использовать для этого системные средства отладки – специальные программы-отладчики, имеющиеся в программном обеспечении компьютера.
Встроенный отладчик среды Delphi или Турбо Паскаля (Debugger) позволяет контролировать ход выполнения программы – выполнять трассировку программы без изменения самой программы с помощью следующих действий:
• выполнения программы построчно/по шагам;
• остановки выполнения программы в заданной точке останова;
• перезапуска программы, не закончив ее выполнение;
• назначения и модификации значений любых переменных и параметров программы, а также получения некоторых дополнительных сведений о программе, например списка активных процедур.
Эти возможности позволяют, отследив выполнение каждого оператора/операции, определить местоположение ошибки и понять ее причину. (Далее рассмотрим все эти управляющие средства.)
Автономный отладчик (TurboDebugger – файл td.exe) предоставляет большие возможности: позволяет осуществить трассировку программы/блока на уровне ассемблерных и машинных инструкций, просмотреть содержимое/дамп памяти и пр., что требует особого режима компиляции исходного текста. Использование дополнительных возможностей автономного отладчика целесообразно при отладке и тестировании больших по объему и сложных программ и при наличии у программиста достаточно высокого уровня квалификации. (В данном пособии автономные средства отладки не рассматриваются.)
28.Виды ошибок в программах
В зависимости от этапа разработки ПО, на котором выявляется ошибка выделяют:
► Ошибка периода компиляции — это синтаксические ошибки
► предупреждения (warnings) компилятора
► ошибки времени исполнения, смысловые ошибки — они могут проявляться только при особых, заранее неизвестн
Отладка программы – это деятельность, направленная на обнаружение и исправление ошибок в программе. Обнаружить ошибки, связанные с нарушением правил записи программы на языке программирования (синтаксические и семантические ошибки), помогает используемая система программирования. Пользователь получает сообщение об ошибке, исправляет ее и снова повторяет попытку исполнить программу.
Тестирование программы – это процесс выполнения программы с целью обнаружения ошибки в программе на некотором наборе данных, для которого заранее известен результат применения или известны правила поведения этих программ. Указанный набор данных называется тестовым, или просто тестом. Прохождение теста – необходимое условие подтверждения правильности программы. На тестах проверяется правильность реализации программой запланированного алгоритма. Таким образом, отладку можно представить в виде многократного повторения трех процессов: тестирования, в результате которого может быть констатировано наличие в ПС ошибки, поиска места ошибки в программах и документации ПС и редактирования программ и документации с целью устранения обнаруженной ошибки.
Успех отладки в значительной степени предопределяет рациональная организация тестирования. При отладке отыскиваются и устраняются в основном те ошибки, наличие которых в программе устанавливается при тестировании. Тестирование не может доказать правильность программы, в лучшем случае оно может продемонстрировать наличие в нем ошибки. Другими словами, нельзя гарантировать, что тестированием программы на соответствующих наборах тестов можно установить наличие каждой имеющейся в программе ошибки. Поэтому возникают две задачи. Первая: подготовить такой набор тестов и применить к ним программу, чтобы обнаружить в нем по возможности большее число ошибок. Однако чем дольше продолжается процесс тестирования (и отладки в целом), тем выше становится стоимость программы. Отсюда вторая задача: определить момент окончания отладки программы (или отдельной ее компоненты). Признаком возможности окончания отладки является полнота охвата тестами, к которым применена программа, множества различных ситуаций, возникающих при выполнении программы, и относительно редкое проявление ошибок в программе на последнем отрезке процесса тестирования. Последнее определяется в соответствии с требуемой степенью надежности программы, указанной в спецификации ее качества.
Для оптимизации набора тестов, т.е. для подготовки такого набора тестов, который позволял бы при заданном их числе (или при заданном интервале времени, отведенном на тестирование) обнаруживать большее число ошибок, необходимо, во-первых, заранее планировать этот набор и, во-вторых, использовать рациональную стратегию планирования тестов.
Таким образом, тестирование и отладка включают в себя синтаксическую отладку; отладку семантики и логической структуры программы; тестовые расчеты и анализ результатов тестирования. Затем идет совершенствование программы.
Документирование программы.При разработке ПС создается большой объем разнообразной документации. Продуманная документация программных разработок облегчает совместную работу над проектом больших групп программистов, позволяет подключать новых людей, избегать дублирования многих действий. В итоге повышается производительность труда программистов и увеличивается надежность кода. Кроме того, документация необходима для управления разработкой ПС и для передачи пользователям информации, необходимой для применения и сопровождения ПС. На создание этой документации приходится большая доля стоимости ПС.
Всю документацию можно разбить на две группы:
– документы управления разработкой ПС;
– документы, входящие в состав ПС.
Документы управления разработкой ПС протоколируют процессы разработки и сопровождения ПС, обеспечивая связи внутри коллектива разработчиков и между коллективом разработчиков и менеджерами – лицами, управляющими разработкой.
Пользовательская документация ПС объясняет пользователям, как они должны действовать, чтобы применить данное ПС.
Она необходима, если ПС предполагает какое-либо взаимодействие с пользователями. К такой документации относятся документы, которыми руководствуется пользователь при инсталляции ПС, при применении ПС для решения своих задач и при управлении ПС (например, когда данное ПС взаимодействует с другими системами). Эти документы частично затрагивают вопросы сопровождения ПС, но не касаются вопросов, связанных с модификацией программ.
Контрольные вопросы
1. Что такое система программирования?
2. Что относится к технологии OLE?
3. Что относится к технологии Microsoft .NET?
4. Что такое модульное программирование?
5. Назовите основные принципы объектно-ориентрованного программирования.
6. Что относится к процедурному программированию?
7. Как происходит отладка и тестирование программ?
8. Какие виды документации используют при разработке программ?
9. Что такое парадигма программирования?
10. Что такое объекты, классы?
…
Читайте также:
©2015-2022 poisk-ru.ru
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2017-04-03
Нарушение авторских прав и Нарушение персональных данных
Поиск по сайту:

Мы поможем в написании ваших работ!
Семантическая
отладка — это процесс нахождения и
исправления ошибок, связанных с
неправильным указанием логических
страниц данных.
Существует
3 способа отладки программы:
Пошаговая
отладка программ с заходом в подпрограммы;
Пошаговая
отладка программ с выполнением
подпрограммы как одного оператора;
Выполнение
программы до точки остановки.
Пошаговая
отладка программ заключается в том,
что выполняется один оператор программы
и, затем контролируются те переменные,
на которые должен был воздействовать
данный оператор.
Если
в программе имеются уже отлаженные
подпрограммы, то подпрограмму можно
рассматривать, как один оператор
программы и воспользоваться вторым
способом отладки программ.
Если
в программе существует достаточно
большой участок программы, уже отлаженный
ранее, то его можно выполнить, не
контролируя переменные, на которые он
воздействует. Использование точек
остановки позволяет пропускать уже
отлаженную часть программы. Точка
остановки устанавливается в местах,
где необходимо проверить содержимое
переменных или просто проконтролировать,
передаётся ли управление данному
оператору.
Тестирование
— это динамический контроль программы,
т.е. проверка правильности программы
при ее выполнении на компьютере.
Каждому
программисту известно, сколько времени
и сил уходит на отладку и тестирование
программ. На этот этап приходится около
50% общей стоимости разработки программного
обеспечения. Но не каждый из разработчиков
программных средств может верно,
определить цель тестирования. Нередко
можно услышать, что тестирование — это
процесс выполнения программы с целью
обнаружения в ней ошибок. Но эта цель
недостижима: ни какое самое тщательное
тестирование не дает гарантии, что
программа не содержит ошибок. Другое
определение: это процесс выполнения
программы с целью обнаружения в ней
ошибок. Отсюда ясно, что “удачным”
тестом является такой, на котором
выполнение программы завершилось с
ошибкой. Напротив, “неудачным” можно
назвать тест, не позволивший выявить
ошибку в программе. Определение также
указывает на объективную трудность
тестирования: это деструктивный ( т.е.
обратный созидательному ) процесс.
Поскольку программирование — процесс
конструктивный, ясно, что большинству
разработчиков программных средств
сложно “переключиться” при тестировании
созданной ими продукции. Основные
принципы организации тестирования:
необходимой
частью каждого теста должно являться
описание ожидаемых результатов работы
программы, чтобы можно было быстро
выяснить наличие или отсутствие ошибки
в ней;
следует
по возможности избегать тестирования
программы ее автором, т.к. кроме уже
указанной объективной сложности
тестирования для программистов здесь
присутствует и тот фактор, что обнаружение
недостатков в своей деятельности
противоречит человеческой психологии
(однако отладка программы эффективнее
всего выполняется именно автором
программы);
по
тем же соображениям организация —
разработчик программного обеспечения
не должна “единолично ” его тестировать
(должны существовать организации,
специализирующиеся на тестировании
программных средств);
должны
являться правилом доскональное изучение
результатов каждого теста, чтобы не
пропустить малозаметную на поверхностный
взгляд ошибку в программе;
необходимо
тщательно подбирать тест не только для
правильных (предусмотренных ) входных
данных, но и для неправильных
(непредусмотренных);
при
анализе результатов каждого теста
необходимо проверять, не делает ли
программа того, что она не должна делать;
следует
сохранять использованные тесты (для
повышения эффективности повторного
тестирования программы после ее
модификации или установки у заказчика);
тестирования
не должно планироваться исходя из
предположения, что в программе не будут
обнаружены ошибки (в частности, следует
выделять для тестирования достаточные
временные и материальные ресурсы);
следует
учитывать так называемый “принцип
скопления ошибок” : вероятность наличия
не обнаруженных ошибок в некоторой
части программы прямо пропорциональна
числу ошибок, уже обнаруженных в этой
части;
следует
всегда помнить, что тестирование —
творческий процесс, а не относиться к
нему как к рутинному занятию.
Существует
два основных вида тестирования:
функциональное и структурное. При
функциональном тестировании программа
рассматривается как “черный ящик”
(то есть ее текст не используется).
Происходит проверка соответствия
поведения программы ее внешней
спецификации. Возможно ли при этом
полное тестирование программы? Очевидно,
что критерием полноты тестирования в
этом случае являлся бы перебор всех
возможных значений входных данных, что
невыполнимо.
Поскольку
исчерпывающее функциональное тестирование
невозможно, речь может идти о разработки
методов, позволяющих подбирать тесты
не “вслепую”, а с большой вероятностью
обнаружения ошибок в программе. При
структурном тестировании программа
рассматривается как “белый ящик”
(т.е. ее текст открыт для пользования).
Происходит проверка логики программы.
Полным тестированием в этом случае
будет такое, которое приведет к перебору
всех возможных путей на графе передач
управления программы (ее управляющем
графе). Даже для средних по сложности
программ числом таких путей может
достигать десятков тысяч.
Таким
образом, ни структурное, ни функциональное
тестирование не может быть исчерпывающим.
Рассмотрим подробнее основные этапы
тестирования программных комплексов.
В тестирование многомодульных программных
комплексов можно выделить четыре этапа:
тестирование
отдельных модулей;
совместное
тестирование модулей;
тестирование
функций программного комплекса (т.е.
поиск различий между разработанной
программой и ее внешней спецификацией
);
тестирование
всего комплекса в целом (т.е. поиск
несоответствия созданного программного
продукта, сформулированным ранее целям
проектирования, отраженным обычно в
техническом задании).
На
первых двух этапах используются, прежде
всего, методы структурного тестирования,
т.к. на последующих этапах тестирования
эти методы использовать сложнее из-за
больших размеров проверяемого
программного обеспечения; последующие
этапы тестирования ориентированы на
обнаружение ошибок различного типа,
которые не обязательно связаны с логикой
программы.
12.
Данные в языке Си: константы и переменные.
Скалярные типы данных. Модификаторы
типов.






13.
Данные числовых типов в языке Си:
объявление, характеристика, допустимые
операции, приведение типов. Пример
использования.
14.
Операции языка Си. Приоритет операций.
Оператор и операция присваивания в
языке операции, приведение типов. Пример
использования.



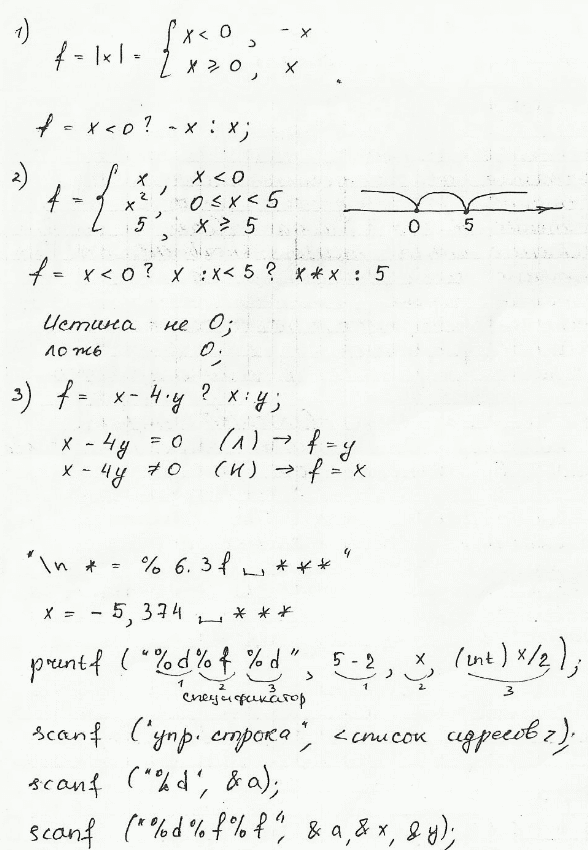
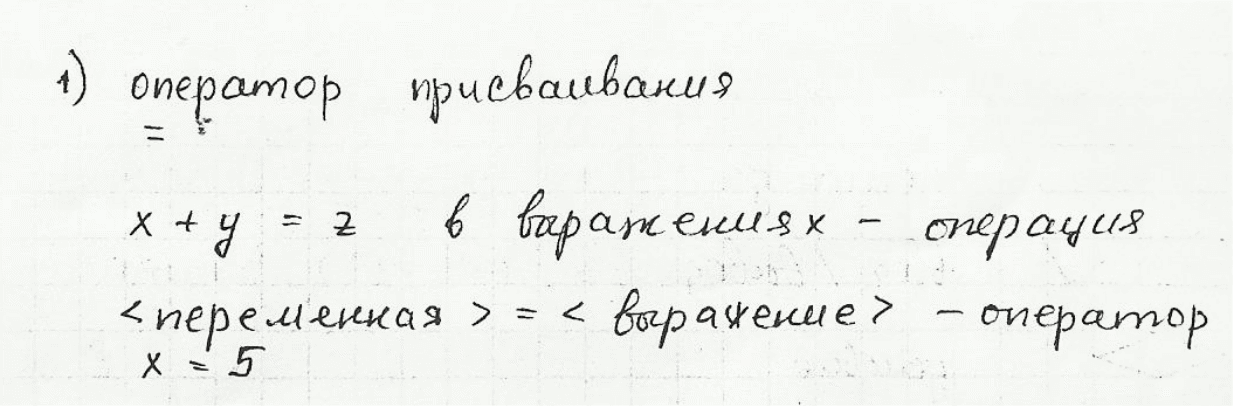
Оператор
присваивания может присутствовать в
любом выражении языка С[1].
Этим С отличается от большинства других
языков программирования (Pascal, BASIC и
FORTRAN), в которых присваивание возможно
только в отдельном операторе. Общая
форма оператора присваивания:
имя_переменной=выражение;
Выражение
может быть просто константой или сколь
угодно сложным выражением. В отличие
от Pascal или Modula-2, в которых для присваивания
используется знак «:=», в языке С
оператором присваивания служит
единственный знак присваивания
«=». Адресатом(получателем),
т.е. левой частью оператора присваивания
должен быть объект, способный получить
значение, например, переменная.
В
книгах по С и в сообщениях компилятора
часто встречаются термины lvalue[2] (left
side value)
и rvalue[3] (right
side value).
Попросту говоря, lvalue —
это объект. Если этот объект может
стоять в левой части присваивания, то
он называется такжемодифицируемым (modifiable) lvalue.
Подытожим сказанное: lvalue —
это объект в левой части оператора
присваивания, получающий значение,
чаще всего этим объектом является
переменная. Термин rvalue означает
значение выражения в правой части
оператора присваивания.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #