

Всем разработчикам известна ситуация, когда приложение заглючило и пользователь не может сделать то, что ему нужно. Причины разные: пользователь ввёл неправильные данные, у него медленный интернет и многое другое. Без системы логирования разобрать эти ошибки сложно, а порой невозможно. С другой стороны, система логирования — хороший индикатор проблемных мест в работе системы. Я расскажу, как построить систему логирования в своём проекте (да, ещё раз). В статье расскажу об Elasticsearch + Logstash + Kibana и Prometheus и как их заинтегрировать со своим приложением.
2ГИС — это веб-карта и справочник организаций. У фирмы может быть дополнительный контент — фотографии, скидки, логотип и прочее. И чтобы владельцам бизнеса было удобно управлять этим добром, был создан Личный кабинет. С помощью Личного кабинета можно:
- Добавлять или изменять контакты организации
- Загружать фотографии, логотип
- Смотреть, что делают пользователи при открытии организации и многое другое.
Личный кабинет состоит из двух проектов: бэкенд и фронтенд. Бэкенд написан на PHP версии 5.6, используется фреймворк Yii 1 (да, да). Активно используем Сomposer для управления зависимостями в проекте, автозагрузку классов в соответствии PSR-4, namespace, trait. В будущем планируем обновлять версию PHP до семёрки. В качестве веб-сервера используем Nginx, данные храним в MongoDB и PostgreSQL. Фронтенд написан на JavaScript, используем фреймворк нашего приготовления Catbee. Бэкенд предоставляет API для фронтенда. Далее в докладе буду говорить исключительно про бэкенд.
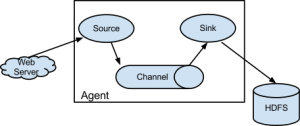
Вот схема наших интеграций. Нам это напоминает звёздное небо. Если приглядеться, можно увидеть Большую медведицу:
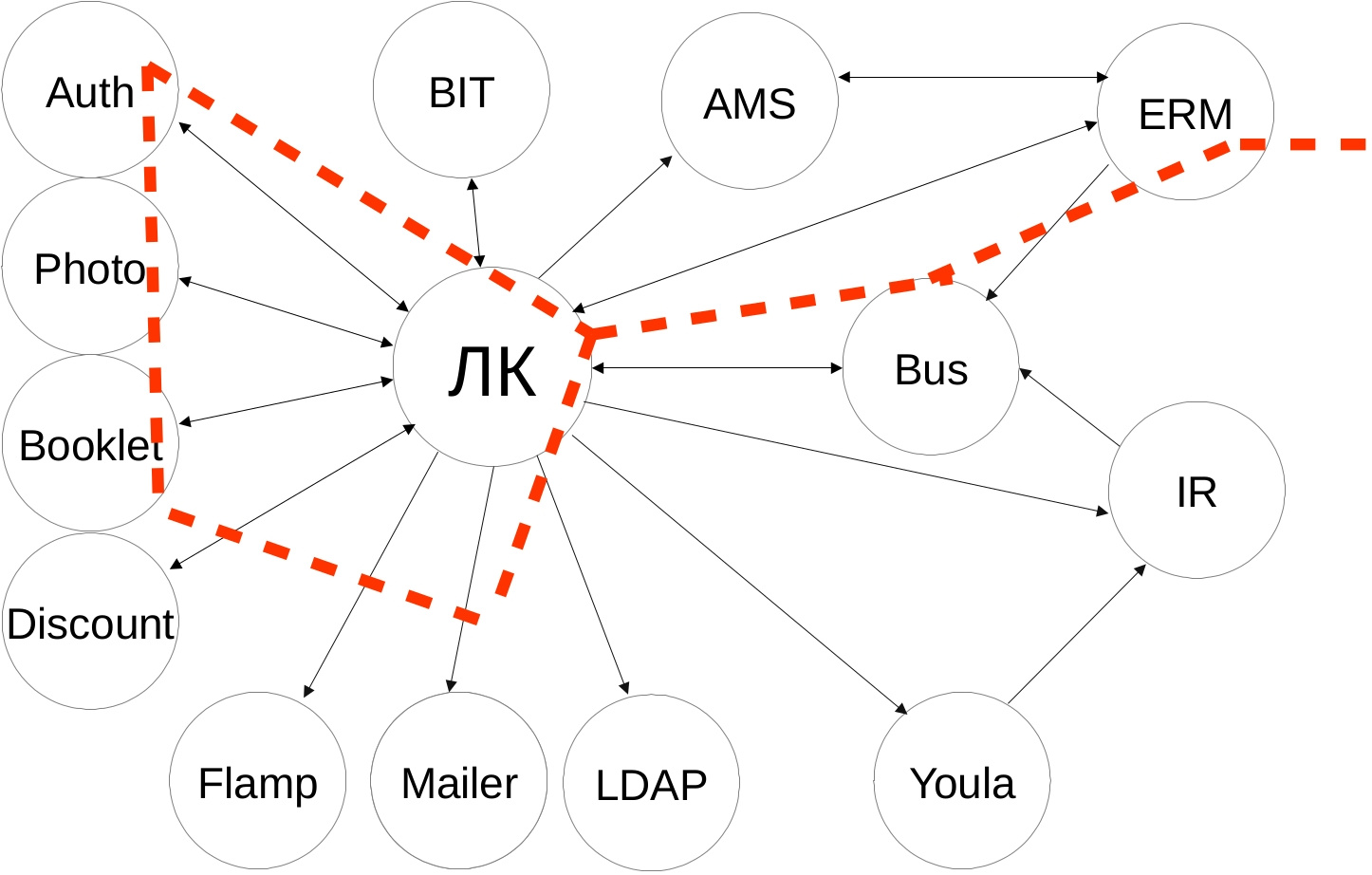
Внешние сервисы разнородные — разрабатываются дюжиной команд, со своим стеком технологий и API. Сценарии интеграции получаются нетривиальными — сначала ходим в один сервис, получаем данные, накладываем свою бизнес-логику, идём ещё в несколько сервисов с новыми данным, объединяем ответы и отдаём результат на фронтенд. И если у пользователя возникает проблема и он не может осуществить желаемое, например, продлить рекламную кампанию, то без системы логирования нам не понять, где была проблема — либо неправильно отправляем данные во внешний сервис, либо неправильно интерпретируем ответ, либо внешний сервис недоступен, либо неправильно накладываем свою бизнес-логику.
У нас было логирование ошибок, но с появлением новых сервисов стало всё труднее отслеживать интеграции и отвечать на запросы техподдержки о возникающей проблеме. Поэтому мы выработали новые требования к нашей системе логирования:
- Нужно больше контекста об ошибках — что произошло и у какого пользователя.
- Собирать входящие запросы в удобном виде.
- Если методы долго отвечают, то нужно уведомить команду об этом.
Логирование ошибок
Исторически сложилось, что в нашей компании для сбора и просмотра логов используется стэк технологий Elasticsearch + Logstash + Kibana, сокращённо ELK. Elasticsearch — NoSQL-хранилище документов, с возможностью полнотекстового поиска. Logstash настроен на приём логов по TCP/UDP-протоколам, читает сообщения из Redis и сохраняет в Elasticsearch. Kibana предоставляет визуальный интерфейс для поиска и отображения собранных данных.
Если у клиента идёт что-то не так, то он обращается в техподдержку из своего аккаунта с описанием проблемы. У нас было логирование ошибок, но не было ни email пользователя, ни вызванного API-метода, ни стэка вызова. В сообщениях была лишь строка из необработанного Exception вида «Запрос вернул некорректный результат». Из-за этого мы искали проблему по времени обращения клиента и ключевым словам, что не всегда было точно — клиент мог обратиться через день, и помочь было очень сложно.
Помучавшись, мы решили, что надо что-то делать и добавили необходимую информацию — email пользователя, API-метод, тело запроса, стэк вызова и наши контроллер и экшен, которые обрабатывали запрос. В итоге мы упростили жизнь техподдержке и себе — ребята нам скидывают email пользователя, а мы по нему находим записи в логах и разбираемся с проблемой. Мы точно знаем, у какого пользователя была проблема, какой метод был вызван и какая часть нашего кода обработала его. Никаких сравнений по времени обращения!
Сообщения об ошибках отправляем во время работы приложения по протоколу UDP в формате Graylog Extended Log Format, или сокращенно GELF. Формат хорош тем, что сообщения могут быть сжаты популярными алгоритмами и разделены на части, тем самым снижая объем передаваемого трафика из нашего приложения в Logstash. Протокол UDP пусть и не гарантирует доставку сообщений, но накладывает минимум накладных расходов на время ответа, поэтому такой вариант нас устраивает. В приложении используем библиотеку gelf-php, которая предоставляет возможности по отправке логов в разных форматах и протоколах. Рекомендую использовать её в своих PHP-приложениях.
Вывод — если ваше приложение работает с внешними пользователями и вам нужно искать ответы на возникающие вопросы техподдержки, смело добавляйте информацию, которая поможет идентифицировать клиента и его действия.
Пример нашего сообщения:
{
"user_email": "test@test.ru",
"api_method": "orgs/124345/edit",
"method_type": "POST",
"payload": "{'name': 'Новое название'}",
"controller": "branches/update",
"message": "Undefined index: 'name'
File: /var/www/protected/controllers/BranchesController.php
Line: 50"
}Логирование запросов
Логирования запросов в структурированном виде и сбор статистики отсутствовали, поэтому было непонятно, какие методы чаще всего вызываются и сколько по времени отвечают. Это привело к тому, что мы не могли:
- оценить допустимое время ответа методов.
- причину возникновения тормозов — на нашей стороне или на стороне внешнего сервиса (помните схему со звёздным небом?)
- как можно оптимизировать наш код, чтобы уменьшить время ответа.
В рамках данной задачи нам предстояло решить вопросы:
- выбор параметров ответа для логирования
- отправка параметров в Logstash
Мы используем веб-сервер Nginx, и он умеет писать access-логи в файл. Для решения первой задачи указали новый формат сохранения логов в конфигурации:
log_format main_logstash
'{'
'"time_local": "$time_local",'
'"request_method": "$request_method",'
'"request_uri": "$request_uri",'
'"request_time": "$request_time",'
'"upstream_response_time": "$upstream_response_time",'
'"status": "$status",'
'"request_id": "$request_id"'
'}';
server {
access_log /var/log/nginx/access.log main_logstash;
}Большинство метрик, думаю, вопросов не вызывает, расскажу подробнее про наиболее интересную — $request_id. Это уникальный идентификатор, UUID версии 4, который генерируется Nginx для каждого запроса. Данный заголовок мы пробрасываем в запросе во внешние сервисы и можем отследить ответ запроса в логах других сервисах. Очень удобно при поиске проблем в других сервисах — никаких сравнений по времени, урлу вызванного метода.
Для отправки логов в Logstash используем утилиту Beaver. Устанавливается на все ноды приложения, с которых планируется отправка логов. В конфигурации указывается файл, который будет парситься для получения новых логов, указываются поля, которые будут отправляться с каждым сообщением. Сообщения отправляются в Redis-кластер, из которого Logstash забирает данные. Вот наша конфигурация Beaver:
[/var/log/nginx/access.log]
type: nginx_accesslog
add_field: team,lk,project,backend
tags: nginx_jsonПо полям type и tags в Logstash по нашим значениям сделана фильтрация и обработка логов, у вас эти значения могут быть свои. Кроме того, добавляем поля team и project, чтобы можно было идентифицировать команду и проект, которым принадлежат логи.
Научившись собирать access-логи, мы перешли к определению SLA методов. SLA, договор на уровень оказания услуг, в нашем случае мы гарантируем, что 95-ый перцентиль по времени ответа методов будет не более 0.4 секунд. Если не укладываемся в допустимое время, то значит, что в приложении либо одна из интеграций тормозит и обращаемся к связанной команде, либо что-то не так в нашем коде и необходима оптимизация.
Вывод по сбору access-логов — мы определили наиболее часто вызываемые методы и их допустимое время ответа.
Вот примеры наших отчётов на одном из измеряемых методов. Первый — чему равны 50, 95 и 99 перцентили времени ответа и среднее время ответа:

Диаграмма статусов ответа:
Среднее время ответа за промежуток времени:

Оповещения команды о падении SLA
После сбора логов нам пришла идея, что нужно оперативно узнавать о падении скорости. Постоянно держать открытым браузер с Kibana, нажимать F5, сравнивать в уме текущее значение 95-ого перцентиля с допустимым оказалось не очень практично — есть много других интересных задач в проекте. Поэтому для формирования оповещений мы добавили интеграцию с системой Prometheus. Prometheus — это система с открытым исходным кодом для сбора, хранения и анализа метрик работающего приложения. Официальный сайт с документацией.
Нам система понравилась тем, что в случае срабатывания триггера можно отправить оповещение на почту. Возможность предоставляется из коробки, без заморочек с доступами к серверам и без написания кастомных скриптов для формирования оповещения. Система написана на языке Go, создатели — компания SoundCloud. Существуют библиотеки для сбора метрик на разными языками — Go, PHP, Python, Lua, C#, Erlang, Haskell и другие.
Я не буду рассказывать, как установить и запустить Prometheus. Если вам интересно это, предлагаю почитать статью. Я сделаю упор на тех моментах, которые имели практическое значение для нас.
Схема интеграции выглядит так — клиентское приложение по адресу отдаёт набор метрик, Prometheus заходит на данный адрес, забирает и сохраняет метрики в своём хранилище.
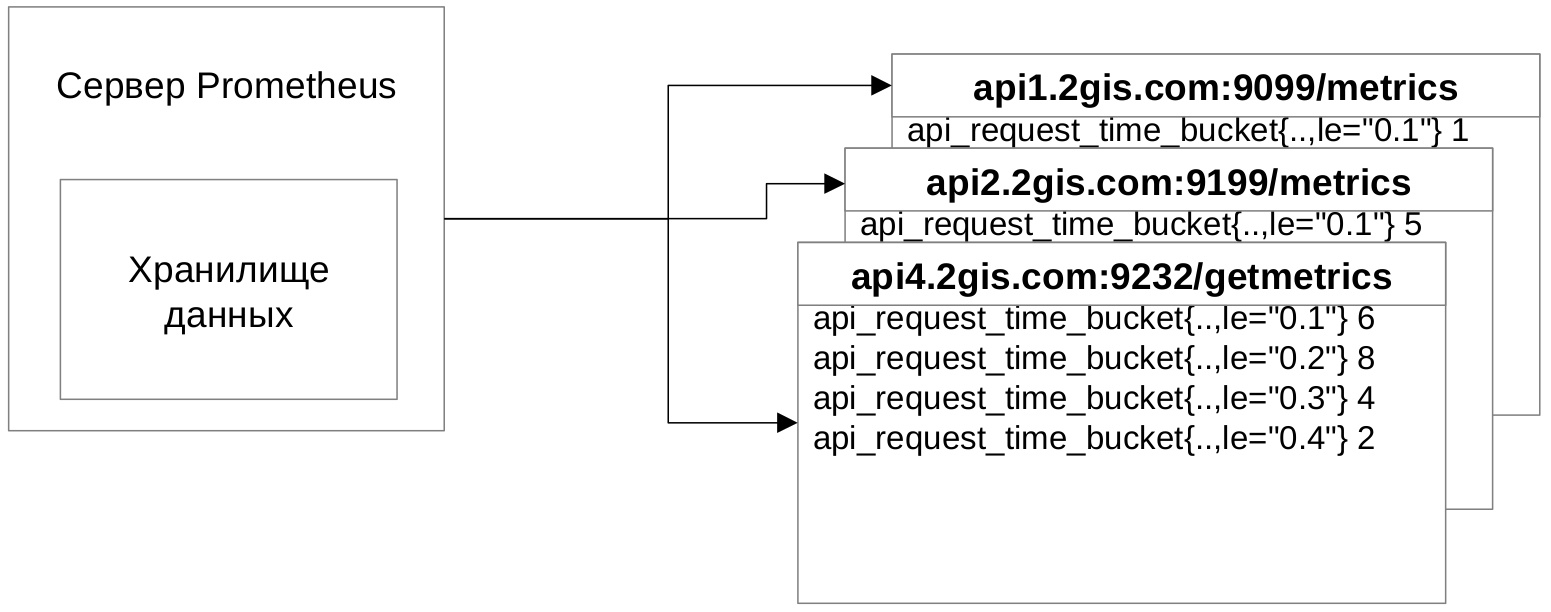
Давайте разберёмся, как выглядят метрики.
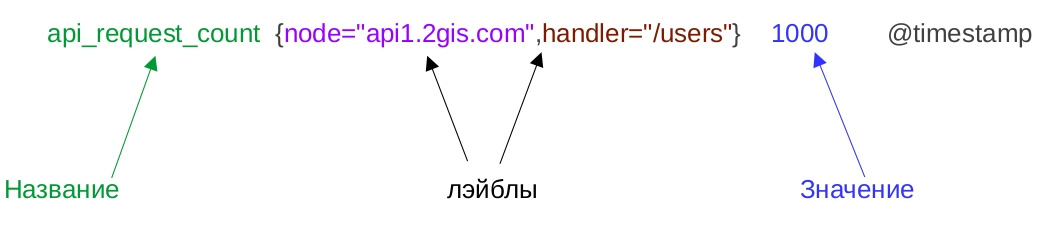
- Название — это идентификатор изучаемой характеристики. Например, количество входящих запросов.
- У метрики в момент времени есть определённое значение. Время проставляет Prometheus при сборе метрик.
- У метрики могут быть лейблы. Они содержат дополнительную информацию о собранном числе. В примере указана нода приложения и API-метод. Основная фишка лейблов в том, что по ним можно осуществлять поиск и делать необходимые выборки данных.
Хранилища данных формата «время — значение» называются Базами данных временных рядов. Это узкоспециализированные NoSQL-хранилище для хранения изменяющихся во времени показателей. Например, количество пользователей на сайте в 10 часов утра, за день, за неделю и так далее. Из-за особенностей решаемых задач и способа хранения такие БД обеспечивают высокую производительность и компактное хранение данных.
Prometheus поддерживает несколько типов метрик. Рассмотрим первый тип, называется Счётчик. Значение Счётчика при новых измерениях всегда растёт вверх. Идеально подходит для измерения общего количества входящих запросов за всю историю — не может быть такого, чтобы сегодня было 100 суммарно запросов, а завтра количество уменьшилось до 80.
Но как быть с измерением времени ответа? Оно не обязательно растёт вверх, более того, может упасть вниз, быть какое-то время на одном уровне, а потом вырасти вверх. Изменение может произойти менее чем за 10 секунд, и нам хочется видеть динамику изменения времени ответа для каждого запроса. К счастью, есть тип Гистограмма. Для формирования необходимо определить интервал измерения времени ответа. В примере возьмём от 0.1 до 0.5 секунды, всё что больше будем считать как Бесконечность.
Вот как выглядит начальное состояние Гистограммы:
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.1"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.2"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.3"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.4"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.5"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="+Inf"} 0
api_request_time_sum{node="api1.2gis.com",handler="/users"} 0
api_request_time_count{node="api1.2gis.com",handler="/users"} 0На каждое значение из интервала мы создаём Счётчик по определённым правилам:
- В названии обязательно должен быть постфикс _bucket
- Должен быть лейбл le, в котором указывается значение из интервала. Плюс должен быть Счётчик со значением +Inf.
- Должны быть Счётчики с постфиксом _sum и _count. В них сохраняется суммарное общее время всех ответов и количество запросов. Нужны для удобного подсчёта 95-ого перцентиля средствами Prometheus.
Давайте разберёмся, как правильно заполнять Гистограмму временем ответа. Для этого нужно найти серии, у которых значение лейбла le больше либо равно времени ответа, и их увеличить на единицу. Предположим, что наш метод ответил за 0.4 секунды. Мы находим те Счётчики, у которых лейбл le больше либо равен 0.4, и к значению добавляем единицу:
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.1"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.2"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.3"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.4"} 1
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.5"} 1
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="+Inf"} 1
api_request_time_sum{node="api1.2gis.com",handler="/users"} 0.4
api_request_time_count{node="api1.2gis.com",handler="/users"} 1
Если метод отвечает за 0.1 секунду, то мы увеличиваем все серии. Если отвечает за 0.6 секунд, то увеличиваем лишь счётчик со значением «+Inf». Не забываем увеличивать счётчики api_request_time_sum и api_request_time_count. С помощью Гистограммы можно измерять время ответа, которое за короткий промежуток может часто меняться.
Prometheus поддерживает ещё два типа метрик — Шкала и Сводка результатов. Шкала описывает характеристику, значение которой может как увеличиваться, так и уменьшаться. В задачах не используем, так как такие показатели у нас не измеряются. Сводка результатов — это расширенная Гистограмма, которая сохраняет вычисляемые на стороне приложения квантили. Теоретически можно было бы рассчитывать 95-процентный перцентиль, или 0.95 квантиль, но это добавило бы кода по подсчёту на клиентской стороне и лишило бы гибкости в отчётах — могли бы использовать только вычисленные нами квантили. Поэтому свой выбор остановили на Гистограмме.
Формирование Гистограммы мы реализовали в Nginx на языке Lua. Нашли готовый проект на GitHub, который подключается в конфигурации Nginx и формирует Гистограмму описанным выше способом. Собирать данные нам необходимо с наиболее часто вызываемых методов, которые, как вы помните, мы определили после отправки access-логов в Logstash. Поэтому потребовалось добавить бизнес-логики по проверке, нужно запрос логировать или нет.
В итоге интеграция заняла неделю, вместе с изучением матчасти Prometheus и основ языка Lua. На наш взгляд, это отличный результат. Ещё очень здорово, что на время ответа добавляется незначительный, порядка 5-10 мс, оверхеад из-за формирования Гистограмм и проверки нашей бизнес-логики, что меньше, чем предполагали.
Но есть и минусы у этого решения — не учитываем время запросов, у которых статус не 200. Причина — директива log_by_lua, в которую мы добавили логирование, в таком случае не вызывается. Вот подтверждение. С другой стороны, нам время ответа таких запросов неинтересно, потому что это ошибка. Ещё один минус — Гистограмма хранится в shared-памяти Nginx. При перезапуске Nginx память очищается, и собранные метрики теряются. С этим тоже можно жить — перезапускать Nginx командой reload, и настроить Prometheus, чтобы он чаще забирал метрики.
Вот конфигурация Nginx для создания Гистограммы:
lua_shared_dict prometheus_metrics 10M;
init_by_lua '
prometheus = require("prometheus").init("prometheus_metrics")
prometheusHelper = require("prometheus_helper")
metric_request_time = prometheus:histogram("nginx_http_request_time", {"api_method_end_point", "request_method"})
'Здесь мы выделяем общую память, подключаем библиотеку и хэлпер с нашей бизнес-логикой и инициализируем Гистограмму — присваиваем имя и лейблы.
За логирование запроса отвечает данная конфигурация:
location / {
log_by_lua '
api_method_end_point = prometheusHelper.convert_request_uri_to_api_method_end_point(ngx.var.request_uri, ngx.var.request_method)
if (api_method_end_point ~= nil) then
metric_request_time:observe(tonumber(ngx.var.request_time),{api_method_end_point, ngx.var.request_method})
'
}Здесь мы в директиве log_by_lua проверяем, нужно ли логировать запрос, и если да, то добавляем его время ответа в Гистограмму.
Метрики отдаются через Nginx по endpoint:
server {
listen 9099;
server_name api1.2gis.com;
location /metrics {
content_by_lua 'prometheus:collect()';
}
}Теперь нужно в конфигурации Prometheus указать ноды нашего приложения для сбора метрик:
- targets:
- api1.2gis.com:9099
- api2.2gis.com:9199
labels:
job: bizaccount
type: nginx
role: monitoring-api-methods
team: lk
project: backendВ разделе targets указываются endpoint наших нод, в разделе labels — лейблы, которые добавляются к собираемым метрикам. По ним определяем назначение метрики и отправителя.
Сбор метрик у нас настроен каждые 15 секунд — Prometheus заходит на указанные ноды и сохраняет себе метрики.
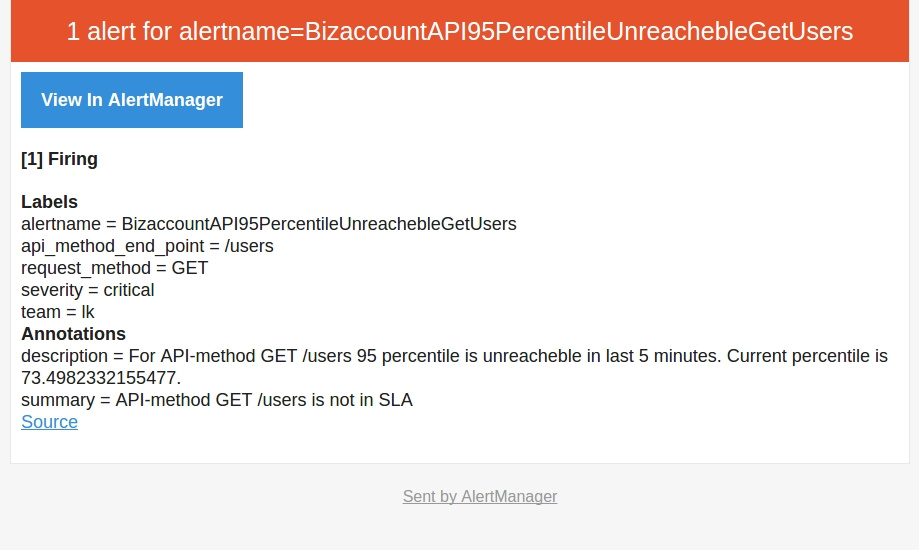
После того, как мы разобрались с метриками, научились их собирать, отдавать в Prometheus, мы перешли к тому, ради чего затевалась интеграция — оповещения на командную почту при падении скорости работы нашего приложения. Вот пример оповещения:
ALERT BizaccountAPI95PercentileUnreachebleGetUsers
IF (sum(rate(nginx_http_request_time_bucket{le="0.4",api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)
/
sum(rate(nginx_http_request_time_count{api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)) * 100 < 95
FOR 5m
LABELS { severity = "critical", team = "lk"}
ANNOTATIONS {
summary = "API-method {{ $labels.request_method}} {{ $labels.api_method_end_point}} is not in SLA",
description = "For API-method {{ $labels.request_method}} {{ $labels.api_method_end_point }} 95 percentile is unreacheble in last 5 minutes. Current percentile is {{ $value }}.",
}У Prometheus лаконичный язык формирования запросов, при помощи которого можно выбирать значения метрик за период и фильтровать по лейблам. В директиве IF с помощью конструкций языка указываем условие срабатывания триггера — если за 0.4 секунды отвечают менее 95 процентов запросов за последние 5 минут. Считается это отношением. В числителе мы высчитываем, сколько запросов укладываются за 0.4 секунды за последние 5 минут:
sum(rate(nginx_http_request_time_bucket{le="0.4",api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)В знаменателе считаем общее количество запросов за последние 5 минут:
sum(rate(nginx_http_request_time_count{api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)Полученную дробь умножаем на 100 и получаем процент запросов, которые отвечают за 0.4 секунды. Функция rate здесь возвращает время ответа за каждый момент в указанный интервале. Функция sum суммирует полученный ряд. Оператор by — это аналог оператора GROUP BY, который выполняет группировку по указанным лейблам.
В разделе FOR указывается интервал между первым срабатываем триггера и моментом, когда нужно отправить оповещения. У нас интервал равен 5 минутам — если за 5 минут ситуация не меняется, то нужно отправить оповещение. В разделе LABELS указываются лейблы с указанием команды и критичности проблемы. В разделе ANNOTATIONS указывается проблемный метод и какой процент запросов отвечает за 0.4 секунды.
В случае возникновения повторяющихся оповещений Prometheus умеет делать дедупликацию, и отправит одно оповещение на командную почту. И это всё из коробки, нам нужно лишь указать правила и интервал срабатывания триггера.
Оповещения в Prometheus получились именно такими, какими мы и хотели — с понятной конфигурацией, без своих велосипедов с дедупликацией оповещений и без реализации логики срабатывания оповещения на каком-либо языке.
Вот как выглядит сообщение:
Заключение
Мы улучшили нашу систему логирования и теперь у нас не возникает проблем с недостатком информации.
- При возникновении ошибки мы обладаем достаточной информацией о проблеме. Теперь на 99 процентов запросов техподдержки мы имеет представление, что произошло у пользователя и точно сориентировать техподдержку о проблеме и возможных сроках исправления.
- С помощью оповещений мы определяем проблемные места в производительности приложения и оптимизируем их, делая приложение быстрее и надёжнее.
- Через Prometheus мы оперативно узнаём о падении скорости, а уже после смотрим в ELK и начинаем детально изучать, что случилось. У связки ELK + Prometheus мы видим большой потенциал, планируем добавить оповещения в случае увеличения ошибок и мониторинг внешних сервисов.

Файлы журнала скажут вам, что пошло не так, когда система внезапно перестает работать. Они также помогут вам отслеживать любые системные изменения и даже могут помочь вам обеспечить безопасность вашей сети. Файлы журналов являются настолько важным элементом источников информации о вашем сетевом администрировании, что существуют инструменты, разработанные специально для того, чтобы помочь вам управлять ими..
Ниже мы подробно рассмотрим каждый из инструментов, которые попали в эту статью, но в случае, если у вас есть время только для быстрого ознакомления, вот наши Список лучших инструментов управления журналами:
- Менеджер событий SolarWinds Security (бесплатная пробная версия) Этот инструмент автоматически генерирует отчеты HIPAA, PCI DSS, SOX, ISO, NCUA, FISMA, FERPA, GLBA, NERC CIP, GPG13, DISA STIG..
- ManageEngine EventLog Analyzer (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Инструмент SIEM, который охотится за угрозами злоумышленников. Устанавливается на Windows, Windows Server или Linux.
- SolarWinds Papertrail (БЕСПЛАТНЫЙ ПЛАН) Облачная служба имеет функции фильтрации содержимого файлов и может извлекать записи по дате, чтобы помочь вам с вашими задачами управления событиями.
- Loggly (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Облачный анализатор логов, который передает данные на удаленные серверы для анализа. Доступен в бесплатной и платной версиях.
- Сетевой монитор Paessler PRTG (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Эта система мониторинга охватывает сети, серверы и приложения; он включает в себя датчик журнала событий Windows и приемник системного журнала.
- Splunk Комплексная система управления журналами для MacOS, Linux и Windows.
- Fluentd Облачный концентратор для информации файла журнала, собранной агентом в вашей системе.
- Logstash Является частью бесплатного Elastic Stack, это инструмент сбора данных журнала.
- Kibana Это приложение для просмотра данных Elastic Stack; Команды, доступные с Kibana, включают базовое управление файлами, которое может разбить любой файл журнала по дате.
- Graylog Бесплатная система с открытым исходным кодом на основе файлов журналов для Ubuntu, Debian, CentOS и SUSE Linux.
- XpoLog Эта утилита может анализировать данные из журналов сервера Apache, журналов событий AWS, Windows и Linux и Microsoft IIS.
- Экспедитор системного журнала ManageEngine Бесплатный менеджер сообщений журнала для Windows, который может отфильтровывать ненужные, обычные или неважные сообщения журнала.
- Managelogs Бесплатная утилита с открытым исходным кодом для управления журналами веб-сервера Apache..
Как только вы найдете инструмент управления журналами, который вам нравится, вы начнете зависеть от него для ряда задач администратора, включая управление информацией о безопасности и событиями (SIEM) и мониторинг вашей сети и ее оборудования в режиме реального времени. Если ваш любимый инструмент выходит из производства, вам нужно будет быстро найти замену, чтобы вы могли продолжать управлять журналами событий и сортировать все данные журналов..
Contents
- 1 Лучшие инструменты управления журналами для Windows, Linux и Mac
- 1.1 1. Менеджер событий SolarWinds Security (бесплатная пробная версия)
- 1.2 2. ManageEngine EventLog Analyzer (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
- 1.3 3. Papertrail (БЕСПЛАТНЫЙ ПЛАН)
- 1.4 4. Loggly (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
- 1.5 5. Paessler PRTG Сетевой монитор (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
- 1.5.1 PRTG Windows Event Log Sensor
- 1.5.2 PRTG Syslog Receiver Sensor
- 1.6 6. Splunk
- 1.7 7. Свободно
- 1.8 8. Logstash
- 1.9 9. Кибана
- 1.10 10. Graylog
- 1.11 11. XpoLog
- 1.12 12. ManageEngine Syslog Forwarder
- 1.13 13. Managelogs
- 2 Архивация журнала
- 3 Заменить Cronolog
Лучшие инструменты управления журналами для Windows, Linux и Mac
К сожалению, Analog был прекращен еще в 2010 году, но вы можете найти наш следующий список инструментов управления и анализа журналов полезным, чтобы помочь вам найти альтернативу. Нашими критериями при выборе следующих инструментов являются в основном их надежность в различных отраслевых применениях, простота использования и установки, обширная документация и поддержка, а также общая производительность и функции..
1. Менеджер событий SolarWinds Security (бесплатная пробная версия)
В отличие от Cronolog, Менеджер событий SolarWinds Security не бесплатно Тем не менее, вы можете получить доступ к нему на 30-дневную бесплатную пробную версию. Это очень комплексная система управления журналами, и она будет особенно полезна для крупных организаций. Это позволит вам в режиме реального времени контролировать и поможет вам быстро найти каждый журнал событий.
Это программное обеспечение работает на Windows Server операционная система, но она не ограничивается управлением зарегистрированными событиями, которые возникают только в Windows. Менеджер — это кроссплатформенная утилита это будет иметь дело со всеми вашими задачами регистрации системы, независимо от того, из какой операционной системы они берутся.
Удивительная особенность этого менеджера журнала заключается в том, что он проверит информацию в ваших файлах журнала, отдельно отслеживая данные в реальном времени. Это отличная функция безопасности в наши дни передовых постоянных угроз, когда хакеры регулярно меняют файлы журналов, чтобы скрыть свои следы. Это пример того, как SolarWinds Security Event Manager выходит за рамки исторической необходимости проверять, что произошло, когда что-то пошло не так.
Сегодня управление файлами журналов стало функцией безопасности системы и процедур целостности данных.. Благодаря новым требованиям ЕС к ВВПР защита данных стала жизненно важным приоритетом системного администрирования.. Необходимость быстро исправлять утечки данных делает файлы журналов основным источником информации. Дополнительные функции этого инструмента включают в себя управление USB-накопителем и функции анализа событий.
Этот менеджер журналов также является хорошим выбором для сайтов, которые требуют соответствия стандартам. Диспетчер журналов и событий автоматически генерирует HIPAA, PCI DSS, SOX, ISO, NCUA, FISMA, FERPA, GLBA, NERC CIP, GPG13, DISA STIG отчеты для демонстрации соответствия или выделения пробелов для корректирующих действий.
Чувствительные к безопасности сайты нуждаются в гораздо большем количестве программного обеспечения для управления журналами, чем Cronolog. Итак, если вы ищете утилиту для замены и вам также нужны функции SIEM, подумайте о том, что нужно вашей компании сейчас из системы управления журналами, не то, что вы могли сойти с рук, когда Cronolog был впервые написан.
Управление событиями журнала SolarWindsСкачать 30-дневную бесплатную пробную версию на SolarWinds.com
2. ManageEngine EventLog Analyzer (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
ManageEngine EventLog Analyzer это больше, чем файл-сервер журнала. Это Система обнаружения вторжений который ищет угрозы в сети.
Почти каждая единица оборудования и программного обеспечения в вашем бизнесе генерирует сообщения журнала периодически и в ответ на исключительные события. EventLog Analyzer ловит эти сообщения при их перемещении по сети и сохраняет их в файл.
Основным источником сообщений является Журнал событий Windows система и Syslog сообщения, поступающие из систем Linux. EventLog Analyzer также получает сообщения журнала от веб-сервера Apache, систем баз данных, брандмауэров, сетевого оборудования и программного обеспечения для обеспечения безопасности..
Как только сообщения журнала сохраняются в файлах, их необходимо периодически архивировать. Файлы должны быть организованы в логической манере, что облегчает доступ к событиям определенных дат. EventLog Analyzer обрабатывает всю эту работу по управлению файлами журналов. В качестве источника раскрытия информации о несанкционированной деятельности хакеры часто используют файлы журналов для удаления следов своего вторжения. EventLog Manager отслеживает изменения в журналах и блокирует несанкционированный доступ.
Данные журнала являются богатым источником информации о состоянии оборудования вашей системы. модуль анализа EventLog Analyzer использует информацию журнала для аудита доступа пользователей к критическим ресурсам. Это особенно важно при охоте на злоумышленников. Вторжение может быть не только несанкционированным доступом посторонних лиц, но и несоответствующим доступом к данным со стороны персонала..
EventLog Analyzer также проверяет действия приложений, проверяя работу веб-серверов, DHCP-серверов, баз данных и других важных служб в вашей системе. Информация, полученная в результате этих действий по мониторингу, важна как для показателей производительности, так и для безопасности..
ManageEngine EventLog Analyzer устанавливается на Windows, Windows Server и RHEL, Mandrake, SUSE, Fedora и CentOS Linux. Это платный продукт, но есть и бесплатная версия, которая собирает журналы из пяти источников. Вы можете получить 30-дневную бесплатную пробную версию Premium Edition. Сетевая версия, называемая Distributed Edition, также доступна для 30-дневной бесплатной пробной версии..
ManageEngine EventLog AnalyzerDownload 30-дневная бесплатная пробная версия
3. Papertrail (БЕСПЛАТНЫЙ ПЛАН)
Papertrail — это система управления бревнами производится SolarWinds, ведущим производителем сетевого программного обеспечения. Основной целью Papertrail является централизация всех данных файла журнала в одном месте, поэтому это журнал агрегатор. Это заметно отличает его от Coronolog, лог-файла синтаксический анализатор. Что сказал, Возможности фильтрации содержимого файлов Papertrail позволяют извлекать записи по дате, чтобы помочь вам в решении задач управления событиями..
Вы можете использовать Papertrail для проверки ряда файлов журнала, включая события Windows, программные сообщения Ruby on Rails, уведомления маршрутизатора и брандмауэра, а также файлы журнала сервера Apache.. Сервис основан на облаке, поэтому вам не нужно беспокоиться о том, будет ли он работать в вашей операционной системе.. Вы получаете доступ к панели инструментов через веб-браузер.
Цена на услугу варьируется в зависимости от объема поиска, который вы через него ставите. Есть бесплатный план это дает вам пропускную способность данных 100 МБ в месяц. Это не очень много, но если вы ограничите покрытие услуг только журналами Apache, вам, возможно, удастся сойти с рук. Самый дешевый платный тариф дает вам надбавку за данные в 1 ГБ в месяц по цене 7 долларов. Платные планы работают по подписке, и вы платите ежемесячную плату.
Каждый план позволяет вам просматривать период данных и архивировать данные за различный промежуток времени. Например, бесплатный сервис позволяет вам работать с данными за последние 48 часов, и вы можете архивировать данные в течение семи дней. Этого было бы достаточно, чтобы подражать Cronolog, потому что для этого, вам нужно только смотреть на данные за один день за один раз.
SolarWinds Papertrail Log ManagementЗарегистрируйся для бесплатного плана
4. Loggly (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
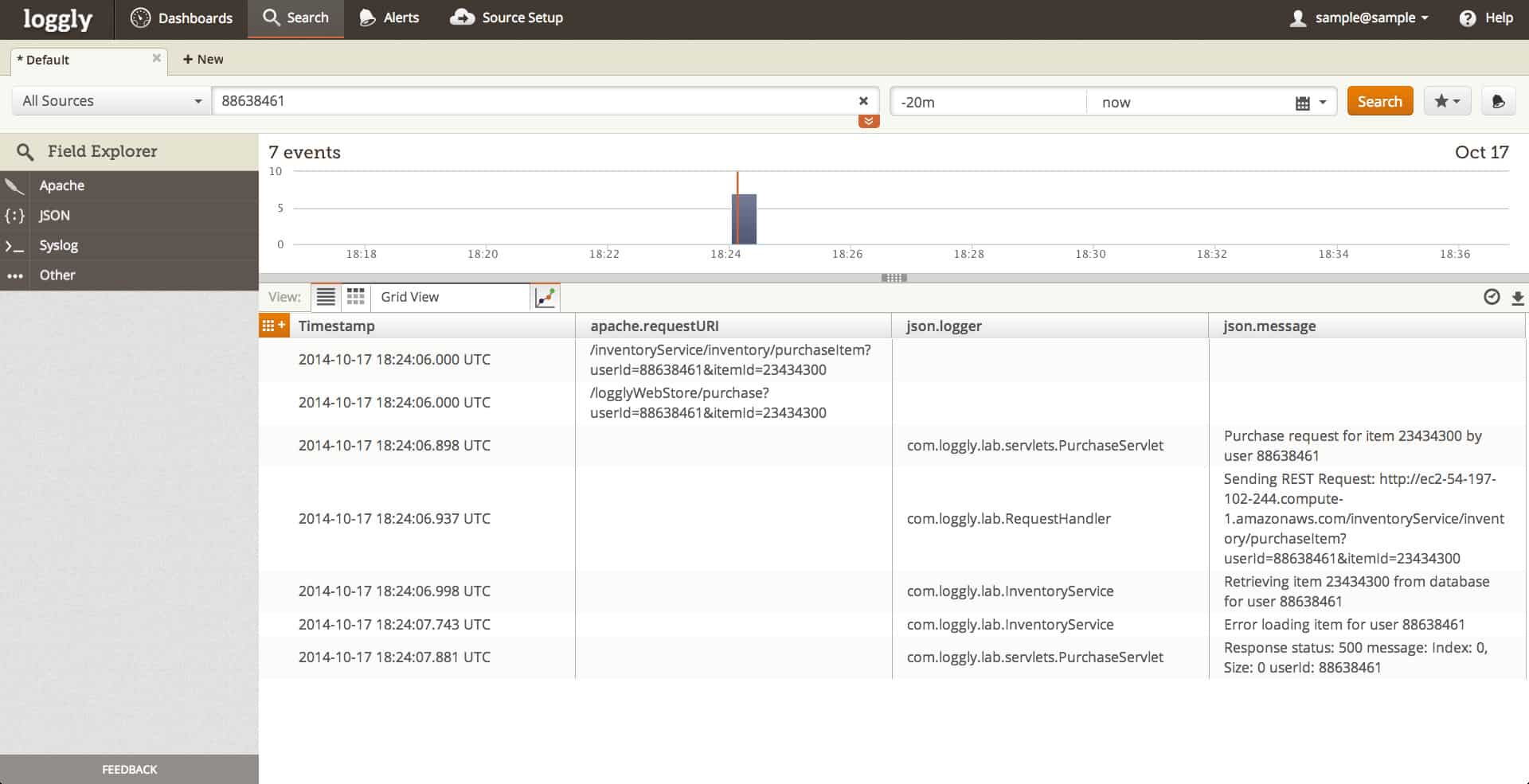
Loggly это консолидатор журналов, который базируется в облаке. Этот онлайн-сервис также предлагает средства анализа журналов. Большим преимуществом этого облачного подхода является то, что вам не нужно поддерживать какое-либо программное обеспечение для использования утилиты. Ваша локальная система должна быть скоординирована со службой Loggly, чтобы она периодически загружала ваши стандартные файлы журнала на онлайн-сервер.
Как консолидатор, Loggly переформатирует загруженные записи файла журнала в стандартный формат. Это позволяет анализатору обрабатывать записи из нескольких разных источников и позволяет отслеживать события в вашей системе независимо от операционной системы или методологии, которая генерировала эти записи событий. Источники сообщений файла журнала не ограничиваются вашими локальными серверами. Он также может обрабатывать записи, созданные онлайн-серверами, такими как AWS, и может включать в себя сообщения, созданные приложениями, такими как Docker и Logstash..
Возможная точка уязвимости в этой операционной модели заключается в передаче данных. Тем не менее, вы, несомненно, уже используете защищенную систему передачи файлов, такую как FTPS. Встроенная в этот стандарт защита TLS защитит ваши данные во время загрузки. TLS также охватывает передачу данных с сервера Loggly на ваш браузер через HTTPS протокол.
Услуга Loggly предлагается в трех тарифных планах. Пакет начального уровня можно использовать бесплатно. Это называется Loggly Lite. Каждый план имеет лимит обработки данных, и вы можете обнаружить, что ограничения на бесплатную услугу не дают вам достаточно места для ваших данных журнала. Вам разрешено загружать 200 МБ данных журнала в день с помощью Loggly Lite, и система будет хранить каждую запись в течение семи дней..
стандарт Пакет Loggly дает вам возможность загрузки 1 ГБ в день и сохраняет каждую запись в течение 30 дней. Вы также получаете доступ к нескольким учетным записям с платными пакетами. В стандартном пакете вы можете иметь три учетных записи. Пакет с более высокой платой не ограничивает количество пользователей, которых вы можете настроить в своей учетной записи. Тот план, который называется Loggly Enterprise, пакет на заказ с ценами в зависимости от объема загрузки и требуемого периода хранения.
Loggly — это сервис подписки, который вы можете оплачивать ежегодно или ежемесячно. Ты можешь получить 14-дневная бесплатная пробная версия Стандартного плана. Если вы решите не использовать этот план в конце пробного периода, ваша учетная запись будет автоматически переключена на бесплатный план Loggly Lite.
logglyСкачать 13-дневную бесплатную пробную версию
5. Paessler PRTG Сетевой монитор (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)

Paessler PRTG Сетевой монитор это комплексный инструмент мониторинга сетей, серверов и приложений. Управление журналами является важной частью системного администрирования, поэтому Paessler позаботился о том, чтобы включить раздел мониторинга журналов в PRTG.
Каждый интерфейс мониторинга в PRTG называется датчиком. Есть два датчика, которые управляют журналами. Эти Журнал событий Windows датчик и Syslog Receiver датчик.
PRTG Windows Event Log Sensor

Журнал событий Windows API-датчик ловит все сообщения журнала, которые генерирует система Windows. Это включает в себя оповещения приложений и уведомления операционной системы. Датчик контролирует скорость сообщений журнала, а не содержание каждого сообщения. Тем не менее, он классифицирует эти тревоги по источнику или типу события. Датчик генерирует сигнал тревоги на приборной панели, если скорость сообщений журнала событий возрастает. Эти уведомления могут быть отправлены вам в виде электронного письма или SMS-сообщения. Вы можете настроить оповещения так, чтобы они отправлялись разным членам команды в зависимости от их серьезности или источника..
PRTG Syslog Receiver Sensor
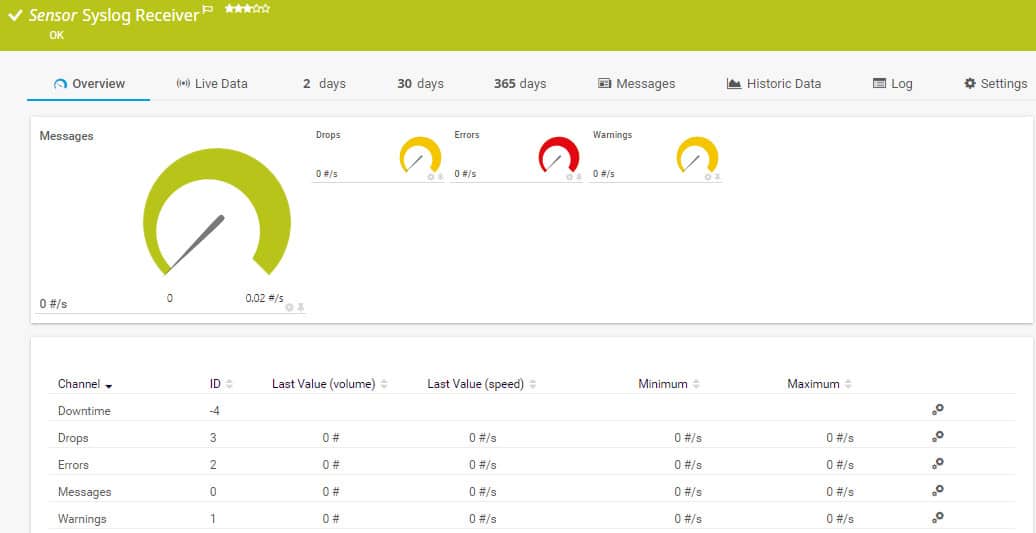
Датчик приемника системного журнала получает, контролирует и сохраняет сообщения системного журнала. Это дает вам инструмент управления файлами системного журнала, но датчик — это не просто пассивная функция создания файлов. Элемент мониторинга обязанностей получателя генерирует сигналы тревоги, если возникают тревожные условия, например, увеличение скорости создания файла. Вы можете установить условия, которые вызывают оповещения, и вы можете решить, кому и как доставляются уведомления..
Paessler PRTG может контролировать до 100 датчиков. Если вы хотите использовать инструмент для мониторинга всей вашей сети, вам понадобится намного больше датчиков, и за этот уровень обслуживания взимается плата. Вы можете получить 30-дневная бесплатная пробная версия с неограниченным количеством датчиков.
Скачать бесплатную пробную версию (42.6MB) Скачать 30-дневную бесплатную пробную версию
6. Splunk
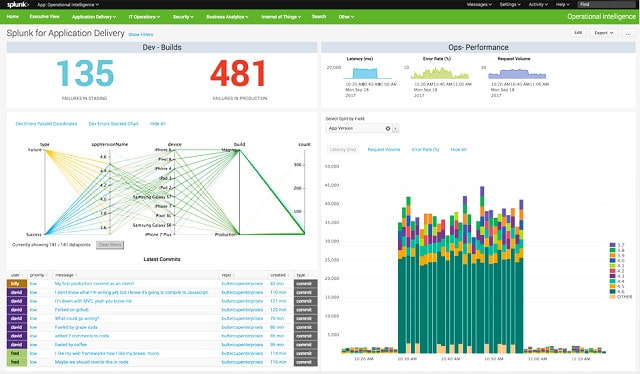
Splunk — это комплексная система управления журналами для macOS, Linux и Windows. Система является широко известной утилитой в сообществе системного администратора. Splunk, Inc выпускает три версии своего программного обеспечения для мониторинга сетевых данных. Самая популярная версия называется Splunk Enterprise, которая стоит 173 доллара в месяц. Это система управления сетью, а не просто органайзер файла журнала. к счастью, Splunk также доступен бесплатно, сделать его в наш список альтернатив Cronolog.
Бесплатный Splunk ограничен анализом входных файлов. Вы можете подавать любые ваши стандартные журналы или направлять текущие данные через файл в анализатор. Бесплатная утилита может иметь только одну учетную запись пользователя, и ее пропускная способность ограничена до 500 МБ в день. Система явно не работает с сетевыми оповещениями, но Вы могли бы форсировать эту функцию, получая оповещения, записанные в файл, а затем перешли в Splunk.
Утилита сортировки и фильтрации данных встроена в Splunk, и вы можете записывать в файлы из анализатора. Эти функции могут эмулировать Cronolog, разделяя записи журнала по дате и записывая каждую группу в новые файлы..
7. Свободно
Как и Cronolog, Fluentd работает в системах Linux — Debian, CentOS и Ubuntu. Он также может быть установлен на Mac OS, Amazon Linux, RHEL и Windows. Эта облачная утилита выступает в роли концентратора для информации из файла журнала, собранной агентом в вашей системе. Инструмент может собирать потоки данных в реальном времени для создания файлов журналов, а также отслеживать и управлять существующими файлами.. Одним из источников данных, которым Fluentd предназначен для управления, является система журналирования Apache..
Результаты анализа записей журнала могут быть использованы для запуска предупреждений, но они должны обрабатываться Nagios или системой мониторинга на основе Nagios. Fluentd — это проект с открытым исходным кодом, поэтому вы можете скачать исходный код. Этот инструмент можно использовать бесплатно.
Сайт Fluentd является источником программы, а также местом нахождения страницы сообщества, где вы можете получить помощь и совет по запуску инструмента от других пользователей. Базовый пакет может быть расширен с помощью плагинов, написанных другими участниками сообщества. Эти плагины, как правило, бесплатно.
Вы можете использовать много других бесплатных интерфейсов в качестве внешнего интерфейса для Fluentd, например, Kibana. Утилита Fluentd также может быть интегрирована с инструментами, которые включают Elasticsearch, MongoDB и InfluxDB для анализа.
8. Logstash

Logstash — это средство для создания бревен, производимое Elastic. Эта голландская организация по разработке программного обеспечения создала ряд продуктов для исследования данных, которые объединены в «Эластичный стек.«Этот пакет программ с открытым исходным кодом, и каждый продукт доступно бесплатно. Основным элементом Elastic Suite является Elasticsearch. Это утилита поиска и сортировки, которая может обрабатывать данные из нескольких файлов в единые результаты. Elasticsearch может быть интегрирован в другие инструменты и доступен для использования со многими другими утилитами в этом списке.
Logstash — это инструмент сбора данных Elastic Stack. Функции Logstash могут быть адаптированы к подражать Cronolog. Средство создает исходные файлы для анализа другими инструментами, такими как Elasticsearch. Сила этого инструмента в том, что он может сопоставлять данные из нескольких разных источников. Однако, если вы хотите реорганизовать файлы журналов Apache, нет никаких причин, по которым вы не можете ограничить поиск данных только одним исходным файлом журнала..
Возможности Logstash включают в себя разбор файлов, поэтому вы можете использовать эту функцию для разделения файлов журнала по дате.. Выходные данные Logstash могут быть отформатированы, чтобы соответствовать длинному списку утилит для анализа или отображения. Его также можно записать в простой текстовый файл на диске, что и делал Cronolog..
9. Кибана
Эластик производит Kibana, который является отличный бесплатный интерфейс для любого инструмента сбора данных. Другие полезные инструменты в этом списке могут передавать данные в Kibana, поэтому вам не нужно полагаться только на другие программы Elastic Stack для получения данных для этого приложения..
Все возможности Kibana выходят далеко за рамки функции разбора файлов в Cronolog.. Однако широкий спектр команд, доступных в Kibana, включает базовое управление файлами, которое может разбить любой файл журнала по дате. Kibana имеет консоль на командном языке, которая позволяет создавать сценарии и программы для обработки файлов. Тем не менее, если у вас нет навыков программирования, предустановленные средства управления данными интерфейса предоставляют вам множество мощных утилит сортировки и фильтрации данных. это поможет вам управлять файлами журналов.
Интерфейс включает инструменты анализа на основе времени, включая фильтры, так что вы можете легко изолировать записи в файле журнала, которые относятся к определенной дате. Необработанные данные, графики и другие визуализации могут быть записаны в файлы или использованы для создания отчетов. Стандартные отчеты можно запускать периодически, поэтому создание фильтра по дате и настройка его ежедневной работы и вывода в простой текстовый файл даст вам те же самые результаты, которые вы использовали в Cronolog..
Преимущество использования Kibana состоит в том, что он может оказать гораздо большую помощь, чем Cronolog.. Вы можете сравнивать данные из разных источников и визуализировать информацию из всех файлов системного журнала. анализировать производительность и прогнозировать требования к мощности. Чтобы получить полное средство управления данными, вам, вероятно, следует использовать Logstash для сопоставления исходных данных, Elasticsearch для сортировки данных и Kibana для отображения результатов. В Kibana имеется множество возможностей для сбора и обработки данных, поэтому его можно использовать как самостоятельный инструмент для анализа данных..
10. Graylog
Graylog является бесплатная система с открытым исходным кодом это может дать вам гораздо больше функциональности, чем просто утилита архивирования журналов. Этот анализатор журналов имеет графический интерфейс пользователя и может работать в Ubuntu, Debian, CentOS и SUSE Linux. Вы также можете запустить его на виртуальной машине в Microsoft Windows и установить систему Graylog в Amazon AWS..
Это средство управления журналами может работать с любыми журналами. Вы можете вводить в него данные из других источников: направлять системные отчеты в файл, создавая собственные журналы. Интерфейс не получает копии журналов, а размещается в оперативных журналах, обновляя информацию, которая поступает в механизм анализа по мере записи новых записей в журнал..
Сценарии действий могут пересылать данные журнала на экран, в другие журналы или в другие приложения.. На панели инструментов отображаются данные в виде гистограмм, круговых диаграмм, линейных графиков и списков с цветовой кодировкой.. Интерфейс включает функцию поиска и запроса, которая позволяет фильтровать записи в журнале, чтобы получать информацию о конкретных типах событий или конкретных источниках..
Graylog обрабатывает агрегированные данные, чтобы упростить отображение на домашней странице панели мониторинга, а также дать возможность указывать условия оповещения для разных источников данных и с течением времени. Эти общие представления данных не единственный вариант, потому что Вы можете развернуть и посмотреть подробные записи это создало резюме. Это делает Graylog инструментом для анализа данных.
Условия оповещения могут быть настроены, и вы можете написать действия, которые будут выполняться в случае возникновения оповещений. Эти действия включают выполнение сценариев или уведомление определенных членов команды по электронной почте или с помощью сообщения Slack..
Это удивительный и очень всеобъемлющий инструмент, который может автоматизировать обработку вашего файла журнала и автоматически выполнять устранение неисправностей..
11. XpoLog
 Два важных элемента Cronolog заключаются в том, что он может разбивать файлы журналов по дате и запускаться автоматически. XpoLog включает в себя обе эти функции. Однако это большое улучшение в Cronolog, поскольку XpoLog включает в себя множество других функций. Это огромное улучшение в этом прекращенном инструменте анализа логов.
Два важных элемента Cronolog заключаются в том, что он может разбивать файлы журналов по дате и запускаться автоматически. XpoLog включает в себя обе эти функции. Однако это большое улучшение в Cronolog, поскольку XpoLog включает в себя множество других функций. Это огромное улучшение в этом прекращенном инструменте анализа логов.
XpoLog может анализировать данные из разных источников, включая журналы сервера Apache, журналы событий AWS, Windows и Linux и Microsoft IIS. Утилита может быть установлена на Mac OS X 10.11, macOS 10.12 и 10.13, Windows Server 2008 R2, Windows Server 2012, Windows Server 2016, Windows 8, 8.1 и 10. Это программное обеспечение также можно установить на Linux Kernel 2.6 и более поздних версиях.. Вы можете выбрать облачную версию, если не хотите устанавливать программное обеспечение. Вы можете получить к нему доступ через Chrome, Firefox, Internet Explorer или Microsoft Edge.
Помимо простого управления файлами журналов, механизм анализа XpoLog обнаруживает несанкционированный доступ к файлам и помогает оптимизировать использование приложений и оборудования.. XpoLog собирает данные из выбранных источников и будет контролировать эти файлы что вы включаете в его сферу. После централизации данных XpoLog объединяет все источники данных и создает собственную базу данных записей. Эти записи можно искать и фильтровать для анализа, а результаты можно записывать в файлы. Эта функциональность предлагает такой же анализ файла как Cronolog. Результаты могут быть записаны в файлы или сохранены в виде архивов для просмотра через панель управления XpoLog.
XpoLog это доступно бесплатно. Если вы просто хотите разделить файлы журнала Apache, то бесплатная версия будет достаточно хорошей. Чтобы работать с большими объемами данных и использовать систему для анализа, вам, возможно, придется перейти на один из платных планов.
Бесплатная версия позволяет обрабатывать до 1 ГБ данных в день, и система будет хранить эти данные в течение пяти дней.. Вы всегда можете записать записи в текстовые файлы, чтобы обойти этот пятидневный лимит. Самый дешевый платный план предлагает тот же лимит пропускной способности и срок хранения данных, что и бесплатный сервис, поэтому трудно понять, почему кто-то заплатил бы 9 долларов в месяц за этот пакет. Более дорогие планы дают вам неограниченный срок хранения данных, с самым дешевым неограниченным вариантом, включая пропускную способность 1 ГБ в день за 39 долларов в месяц. Вы получаете постепенно увеличивающиеся суточные пропускные способности для данных в каждой ценовой категории. Лучший план обеспечивает пропускную способность 8 ГБ в день и стоит 534 доллара в месяц. Вы должны платить за услугу ежегодно заранее, даже если цена указана за месяц. Вы также можете купить бессрочную лицензию.
12. ManageEngine Syslog Forwarder
Пересылка системного журнала работает в операционной системе Windows и совершенно бесплатно использовать. Он перехватывает записи системного журнала и направляет их на разные серверы системного журнала в соответствии с базой правил.. Функции сервера пересылки позволяют отфильтровывать несущественные, обычные или неважные сообщения журнала.. Все заблокированные сообщения отправляются в исходный файл журнала, но не отправляются в конечный файл журнала.
База правил Syslog Forwarder позволяет вам ежедневно записывать новые файлы журналов, тем самым эмулируя функциональность Cronolog. Большая разница между Syslog Forwarder и Cronolog заключается в том, что этот существующий менеджер журналов работает в Windows с графическим интерфейсом, тогда как Cronolog был функцией командной строки для систем Unix и Linux..
13. Managelogs

Вероятно, ближайшая альтернатива Cronolog, Managelogs написана на «С». Утилита не только бесплатная, но исходный код доступен для чтения. Программа специально разработана для управления журналами веб-сервера Apache..
Managelogs имеет различные режимы работы, активируемые переменными, указанными при запуске программы. Вы можете установить утилиту для архивирования файлов журнала по дате, или вы можете указать максимальный размер файла, который будет копировать файл журнала под новым именем, а затем очищать текущий файл журнала, чтобы он мог начинать заново с нуля и создавать новые записи..
Если вы укажете, что журналы должны быть разбиты по дате, Managelogs обеспечит консолидацию файлов между сеансами, поэтому остановка и перезапуск диспетчера сервера не сотрут существующие записи в неполный день..
Архивация журнала
Вы можете написать свою собственную копию Cronolog в виде сценария для Unix или Unix-подобных операционных систем, таких как Linux и Mac OS. Хотя есть много умных вещей, которые вы можете сделать с помощью регулярных выражений и сопоставления с образцом, чтобы выбрать записи на определенную дату, Самый простой способ получить архив журналов в день — написать сценарий копирования, а затем запланировать его запуск в полночь.. Если последние инструкции в сценарии удаляют существующий файл, новые записи будут накапливаться в отдельном файле в течение дня, чтобы снова архивироваться в полночь.
ДАТА = `дата +% Y% m% d`
MV = / USR / бен / мв
LogDir = / Opt / Apache / журналы
LOGARCH = / WWW / журналы
ФАЙЛЫ = «access_log error_log»
CP = / USR / бен / ф
для F в $ ФАЙЛЫ
делать
$ CP $ LOGDIR / $ f $ LOGARCH / $ f. $ DATE.log
$ MV $ LOGDIR / $ f $ LOGDIR / $ f. $ DATE.saved
сделано
cat / dev / null > / Опт / Apache / журналы / access_log
Заменить Cronolog
Не подчеркивайте, что cronolog.org больше не работает или что ни один из сайтов загрузки, которые раньше поставляли Cronolog, больше не перечисляет его. Cronolog был не очень хорош, и вы могли легко написать свою собственную версию всего за пару минут.
Утилиты управления журналами очень полезны, и, несмотря на ограниченные возможности Cronolog, многие системные администраторы стали полагаться на его услуги. Как вы можете видеть из этого обзора, многие другие инструменты управления журналами не только дает вам возможность анализировать файлы журналов по дате, но также дает вам некоторые удивительные возможности визуализации и анализа данных.
Каждая из рекомендаций в нашем списке замен Cronolog можно использовать или попробовать бесплатно. Все эти средства обеспечивают вам лучшее обслуживание, чем самостоятельная репликация Cronolog. Попробуйте любой из этих инструментов и посмотрите, какие из них предоставляют вам дополнительные функции, необходимые для улучшения управления журналами и средствами.

Евгений Холодов
техлид в Dunice
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
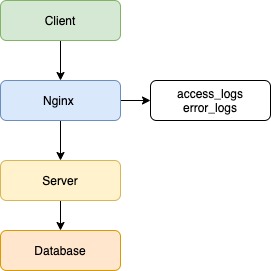
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: "GET /api/v1/users/levels HTTP/2.0", upstream: "http://127.0.0.1:5000/api/v1/users/levels", host: "app.dunice-testing.com"
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.
Точно так же как безопасность, регистрация системных сообщений – другой ключевой компонент веб-приложений (или приложений в целом), который отодвигается на второй план из-за старых привычек и неспособности видеть впереди.
То, что многие считают бесполезными набросками цифровой ленты, – это мощные инструменты, позволяющие заглянуть в ваши приложения, исправить ошибки, улучшить слабые места и порадовать клиентов.
Прежде чем мы перейдем к централизованному ведению журналов, давайте сначала рассмотрим, почему ведение журналов ( логирование ) так важно.
Содержание
- Два типа (уровня) регистрации сообщений журналов
- Логгирование это сила
- Боевой дух и продуктивность команды
- 1 Graylog
- 2 Logstash
- 3 Fluentd
- 4 Flume
- 5 Octopussy
- 6 LOGalyze
- 7 LogPacker
- 8 Logwatch
- 9 Syslog-ng
- 10 Inav
Два типа (уровня) регистрации сообщений журналов
Компьютеры являются детерминированными системами, кроме случаев, когда это не так.
Как безопасник, я сталкивался со многими случаями, когда наблюдаемое поведение приложения ставило всех в тупик целыми днями, но ключ к разгадке всегда был в журналах.
Каждое программное обеспечение, которое мы запускаем, производит (или, по крайней мере, должно генерировать) журналы, которые сообщают нам, через что они проходили, когда возникала проблемная ситуация.
Теперь, как мне кажется, ведение журнала бывает двух типов: автоматически сгенерированные журналы и сгенерированные программистом журналы.
Обращаем ваше внимание, что этих различий и классификации нету в учебниках, и цитирование меня по этой терминологии доставит вам неприятности. ?
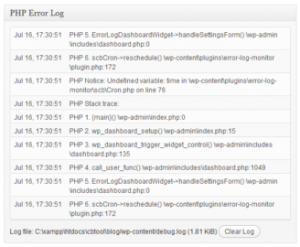
Изображение выше показывает то, что можно назвать автоматически сгенерированным журналом.
В данном конкретном случае это система WordPress, регистрирующая непредвиденное состояние (уведомление) при запуске некоторого кода PHP.
Журналы, подобные этим, создаются постоянно – с помощью инструментов баз данных, таких как MySQL, веб-серверов, таких как Apache, языков программирования и сред, мобильных устройств и даже операционных систем.
Они редко содержат большую ценность, и программисты даже не удосуживаются их изучить, кроме случаев, когда что-то идет не так.
В такие моменты они копаются глубоко в коде, пытаясь понять, что пошло не так.
Но автоматически сгенерированные журналы могут помочь только так сильно.
Если несколько человек имеют доступ администратора к сайту, например, и один из них удаляет важную часть информации, невозможно обнаружить виновника с помощью автоматически сгенерированных журналов.
С точки зрения систем, связанных как приложение, это был просто еще один день в работе – кто-то имел необходимые полномочия для выполнения задачи, и поэтому система выполнила ее.
Здесь нужен дополнительный уровень явной, обширной регистрации, которая создает следы для человеческой стороны вещей.
Это то, что я называю созданными программистом журналами, и они составляют основу чувствительных отраслей, таких как банковское дело.
Вот пример того, как может выглядеть такая схема регистрации:
Логгирование это сила
Итак, с учетом этих двух типов журналов в системе, вот как вы можете использовать их и усилить воздействие.
Боевой дух и продуктивность команды
Как я уже говорил, когда ошибки долго не отслеживаются, разработчики в вашей команде разочаровываются и теряют все больше и больше времени, закрывая свои хвосты.
И вот в чем дело с отладкой – она требует свежего, любопытного ума с самого начала.
И что затрудняет отладку?
По моему опыту, отсутствие ведения журнала или отсутствие знаний о ведении журнала.
Для начала вы можете не осознавать, что ваша любимая база данных – это просто еще одна часть программного обеспечения, которая генерирует журналы, или вы не будете интенсивно регистрировать события в своем приложении (см. Журналы, сгенерированные программистом выше).
Я особенно помню случай, когда приложение перестало отвечать на запросы, и никто не знал, почему.
Несколько дней спустя виновником стало ограничение дискового ввода-вывода из-за чрезмерного трафика.
Потому что никто не удосужился посмотреть журналы,и никто не мог понять, почему система упала.
Если вы регулярно посещаете журнал медленных запросов, вы узнаете, какие операции занимают больше всего времени, и, следовательно, обнаружите небольшие, но важные области, требующие работы.
Часто такие небольшие изменения работают лучше, чем удвоение емкости оборудования.
Невозможно сосчитать, сколько способов решения проблем подарит вам хорошая система журналов.
Возможно, лучшим аргументом является то, что это автоматическое действие, которое когда-то настроено, не нуждается в каком-либо мониторинге и однажды спасет вас от разорения.
В связи с этим давайте рассмотрим некоторые из удивительных сборщиков журналов с открытым исходным кодом (унифицированных инструментов ведения журналов).
1 Graylog
Как мониторить лог файлы с помощью GrayLog Linux
2 Logstash
Если вы являетесь поклонником или пользователем стека Elastic, стоит попробовать Logstash (стек ELK )
Как и другие инструменты ведения журнала в этом списке, у Logstash,полностью открытый исходный код, дает вам свободу развертывания и использования по своему усмотрению.
Но не вводите себя в заблуждение: Logstash – это иснтрумент, возможности которого намного превосходят любые скромные средства ведения журналов.
Он способен собирать огромные объемы данных с разных платформ, позволяет определять и выполнять собственные конвейеры данных, понимать неструктурированные дампы журналов и многое другое.
Конечно, единственным ограничением является то, что он работает только с набором продуктов Elastic, но если вы скоро начнете и хотите масштабироваться, Logstash – это то, что вам нужно!
3 Fluentd
Среди централизованных инструментов ведения журналов, которые выполняют роль промежуточного уровня для приема данных, Flutend является первым среди равных.
Обладая превосходной библиотекой плагинов, Fluentd может собирать данные практически из любой производственной системы, перемешивать их в нужной структуре, создавать собственный конвейер и передавать его на свою любимую аналитическую платформу, будь то MongoDB или Elasticsearch.

Fluentd построен на Ruby, является продуктом с полностью открытым исходным кодом и пользуется большой популярностью благодаря своей гибкости и модульности.
С такими крупными компаниями, как Microsoft, Atlassian и Twilio, использующим эту платформу, Fluentd нечего доказывать. ?
4 Flume
Если на самом деле вам нужны действительно большие наборы данных, и вы в конечном итоге захотите объединить все в нечто вроде Hadoop, Flume – один из лучших вариантов.
Это «чистый» проект с открытым исходным кодом, в том смысле, что он поддерживается нашим любимым Apache Foundation, что означает отсутствие корпоративного плана.
Это может быть то, что вы точно ищете. ?
Написанный на Java (который продолжает удивлять меня, когда дело доходит до революционных технологий), исходный код Flume полностью открыт.
Flume лучше всего подойдет вам, если вы ищете распределенную отказоустойчивую платформу для загрузки данных для работы в тяжелых условиях.
5 Octopussy
Я даю ноль из десяти наименованию продукта, но Octopussy может быть хорошим выбором, если ваши потребности просты, и вы задаетесь вопросом о том, что же такое суета, связанная с конвейерами, приемом, агрегацией и т. д
По моему мнению, Octopussy покрывает потребности большинства продуктов (оценочная статистика бесполезна, но, если бы мне пришлось угадывать, я бы сказал, что в реальном мире она учитывает 80% случаев использования)

У Octopussy нет отличного пользовательского интерфейса:
но он компенсирует скорость и отсутствие раздувания.
Исходный код доступен на GitHub, как и ожидалось, и я думаю, что он заслуживает серьезного изучения.
6 LOGalyze
LOGalyze был коммерческим продуктом, который недавно стал инструментом с открытым исходным кодом.
Хотя я не смог реализовать проект на GitHub, они сделали установщик Windows и весь исходный код загружаемым.
Если вы намерены участвовать в сообществе, вы можете найти подробную информацию о списке рассылки здесь.
LOGalyze – это относительно гибкое и мощное предложение, которое отлично подойдет для развертываний в одной системе, которые стремятся объединить ведение журналов из известных источников, таких как Postfix, Apache и т. д. и выводить их в форматах CSV, PDF, HTML или аналогичных.
Да, он не делает все, но поскольку это был коммерческий продукт в свое время, он делает это довольно хорошо.
7 LogPacker
Когда дело доходит до выбора инструмента для работы, у меня есть два критерия: он должен быть целенаправленным и опираться на активную бизнес-модель.
Проблема программного обеспечения с открытым исходным кодом, как правило, заключается в том, что через несколько месяцев / лет вероятность застоя или выхода из строя высока.
Там нет подсчета того, сколько инструментов ведения журнала было запущено,а только можно найти количество на кладбище GitHub.
По этому критерию LogPacker – мой любимый.
8 Logwatch
Я уверен, что среди нас есть те, кто не хочет, чтобы вся церемония была связана с «единой», «централизованной» системой ведения журналов.
Их бизнес базируется на отдельных серверах, и они ищут что-то быстрое и эффективное для просмотра своих файлов журналов.
Ну тогда, скажи привет Logwatch.
После установки LogWatch может сканировать системные журналы и создавать отчеты нужного вам типа.
Это несколько устаревшее программное обеспечение (читай «надежное»), хотя оно было написано на Perl.
Итак, вам понадобится Perl 5.6+ на вашем сервере для его запуска.
У меня нет скриншотов, которыми можно поделиться, потому что это чисто командная строка, демонизированный процесс.
Если вы наркоман CLI и любите стиль старой школы, вам понравится Logwatch!
9 Syslog-ng
Инструмент Syslog-ng был разработан как способ обработки файлов системного журнала (установленный протокол клиент-сервер для регистрации в системе) в режиме реального времени.
Однако со временем он стал поддерживать другие форматы данных: неструктурированные, SQL и NoSQL.
Как работает протокол системного журнала, довольно четко подытожено на следующем рисунке.
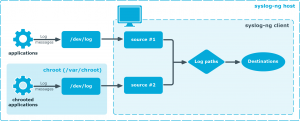
syslog-ng – это надежный инструмент для сбора и классификации журналов промышленного уровня, написанный на языке Си и давно известный в отрасли.
Лучшая часть – это расширяемость, позволяющая вам писать плагины на C, Python, Java, Lua или Perl.
10 Inav
✗ Установите и используйте Log File Navigator – lnav в Ubuntu и CentOS ✗
От глупой командной строки, не требующих настройки инструментов до полномасштабной обработки данных – все это здесь!
Я что-то пропустил? Конечно, я сделал это!
Пожалуйста, дайте мне знать в комментариях, и я буду рад добавить эту сюда
Log management stopped being a very simple operation quite some time ago. Long gone are the “good old days” when you could log into the machine, check the logs, and grep for the interesting parts. Right now things are better. With the observability tools that are now a part of our everyday lives, we can easily troubleshoot without the need to connect to servers at all. With the right tools, we can even predict potential issues and be alerted at the same time an incident happens.
This is where log analysis tools come into play – especially cloud logging services. Cloud logging services aim to provide a service that lets you ship your logs and store them securely, aggregate, and analyze them so that you can take actions based on the current and historical data and correlate it with other information that is part of the whole observability solution – like metrics and traces.
If you’re interested in such a solution, look no further. In this post, we will compare some of the best cloud logging services available to help you get started.
Why Do You Need Cloud Log Management Services
In the modern software era, it is close to impossible to keep an eye on everything, especially in medium and large-scale systems. The number of systems, servers, and IoT devices that are a part of such systems makes it impossible to manually manage, monitor, and analyze their logs. Add to those different business requirements, different compliance requirements and we quickly run into a situation where a well configured and maintained log centralization solution is a necessity.
Keeping the data in-house with one of the available log management tools may seem like an easier and cheaper choice at first, but as the amount of data grows managing the data store used for logs becomes a job on its own. It is not unusual to have a dedicated team managing the clusters responsible for the whole observability pipeline – which logs are a part of.
The cost of housekeeping and managing the logs yourself can be mitigated to one of the commercial vendors that provide SaaS products that allow us to send, store, manage and analyze logs.
With quite a large number of logging services on the market let’s look at the best ones available.
1. Sematext
Sematext Logs is a cloud logging service that allows you to centralize the management of your logs coming from various sources like applications, microservices, operating systems, and various devices. The platform enables you to structure, visualize and analyze all collected data passively and actively. You can create informative dashboards connecting every piece of information and observe how your systems are behaving in real-time or set up alerts to be notified when a critical event happens.
You ship your logs securely with the use of TLS/SSL channel via HTTPS or syslog and use per-user access restrictions to fully control who can access which data. With the possibility to store the data in your own S3-compatible storage you can keep your logs indefinitely without any additional cost.
Sematext Logs is a part of Sematext Cloud, an observability platform that provides a single pane of glass for log management and log monitoring, infrastructure monitoring, real user monitoring, and synthetic monitoring enabling you to combine all the information together for full system visibility.
Features:
- Out-of-the-box integration with popular tools like Syslog, Logstash, Beats, and many more.
- Ease of correlation between various log sources and metrics, frontend and backend.
- Simple slicing and dicing of data allowing quick and easy root cause analysis.
- Powerful alerting including threshold and anomaly detection-based alerts with the possibility of sending the alerts to different destinations, such as Slack, PagerDuty, OpsGenie, and more.
- Log security including TLS/SSL channels via HTTPS, API access control, and per-user access restrictions.
- Saved search with powerful language allowing you to get back exactly the logs that you were looking for.
- Possibility of archiving logs to S3 compatible destinations.
- Flexible pricing allows for overage and overage capping, ensuring that all your data will be accepted and ready for access when needed, with controls that let you limit your costs.
Pricing:
Sematext Logs offers various pricing tiers depending on the features, daily ingestion, and data retention with the option to start with a 14-days free trial that allows you to test all the features.
After the Sematext Logs trial ends, you can start with the Standard plan of as low as $50/month for 1GB worth of data daily and up to 7 days of retention time. The Pro plan with all the platform features starts at only $60/month for 1GB of daily data ingestion with up to 7 days of retention. The platform comes with a free, Basic plan allowing you to store up to 500MB worth of data daily and 7 days of data retention, which is often sufficient for small organizations.
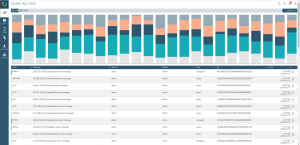
2. SolarWinds Papertrail
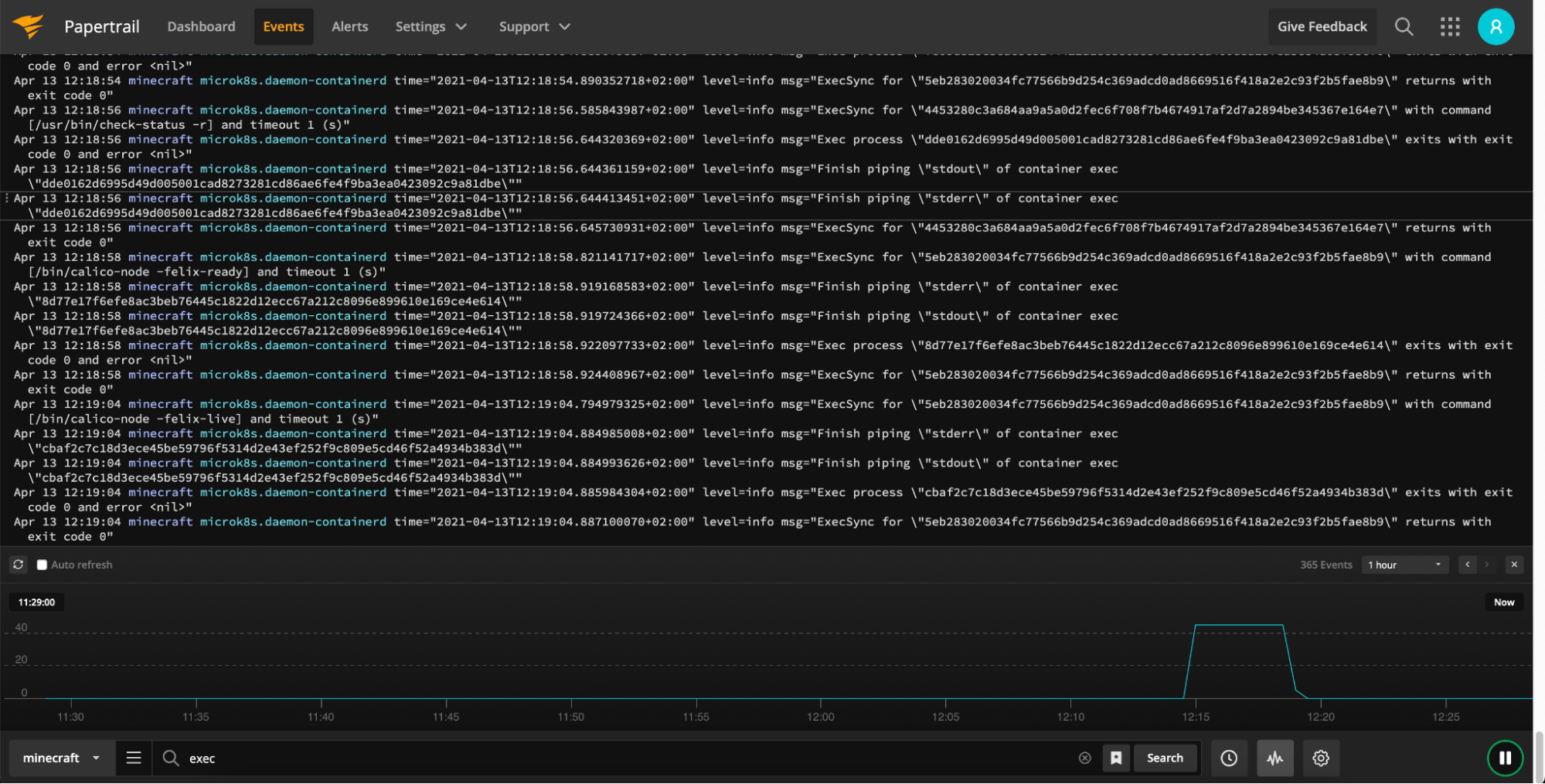
Papertrail is a cloud log management service that allows users to aggregate log data from various sources starting from Syslog sources and ending up with applications like MySQL, Apache, Heroku, and various routers and firewalls. With the simple installation and DevOps-friendly UI, it is very easy to get used to and work regularly. You can get notified about the interesting events with the out-of-the-box alerting that can be integrated with numerous external services such as Slack, PagerDuty, or custom webhook.
Features:
- Easy Syslog integration allowing you to start sending logs in no time.
- Grep-like UI for easy to use and friendly everyday logs searching.
- Log events-based alerting support with external ChatOps services integrations.
Pricing:
Papertrail pricing is a factor of daily ingestion, search period, and data archive retention. It starts with $7 with up to 1GB of data monthly (note: not daily!), search on one week worth of data and 1 year data archive, and goes up to $230 with 25GB of monthly ingestion, search up to two weeks of data and 1 year of data archive. You can also choose to build your own plan with up data ingestion up to 1500GB/month and up to 4 weeks of searchable data that will end up with $5,470 on your invoice.
SolarWinds Papertrail provides a free plan that allows sending up to 50MB of data monthly with 48 hours of searchable data and also gives a bonus of 16GB of data ingestion during the first month.
3. SolarWinds Loggly
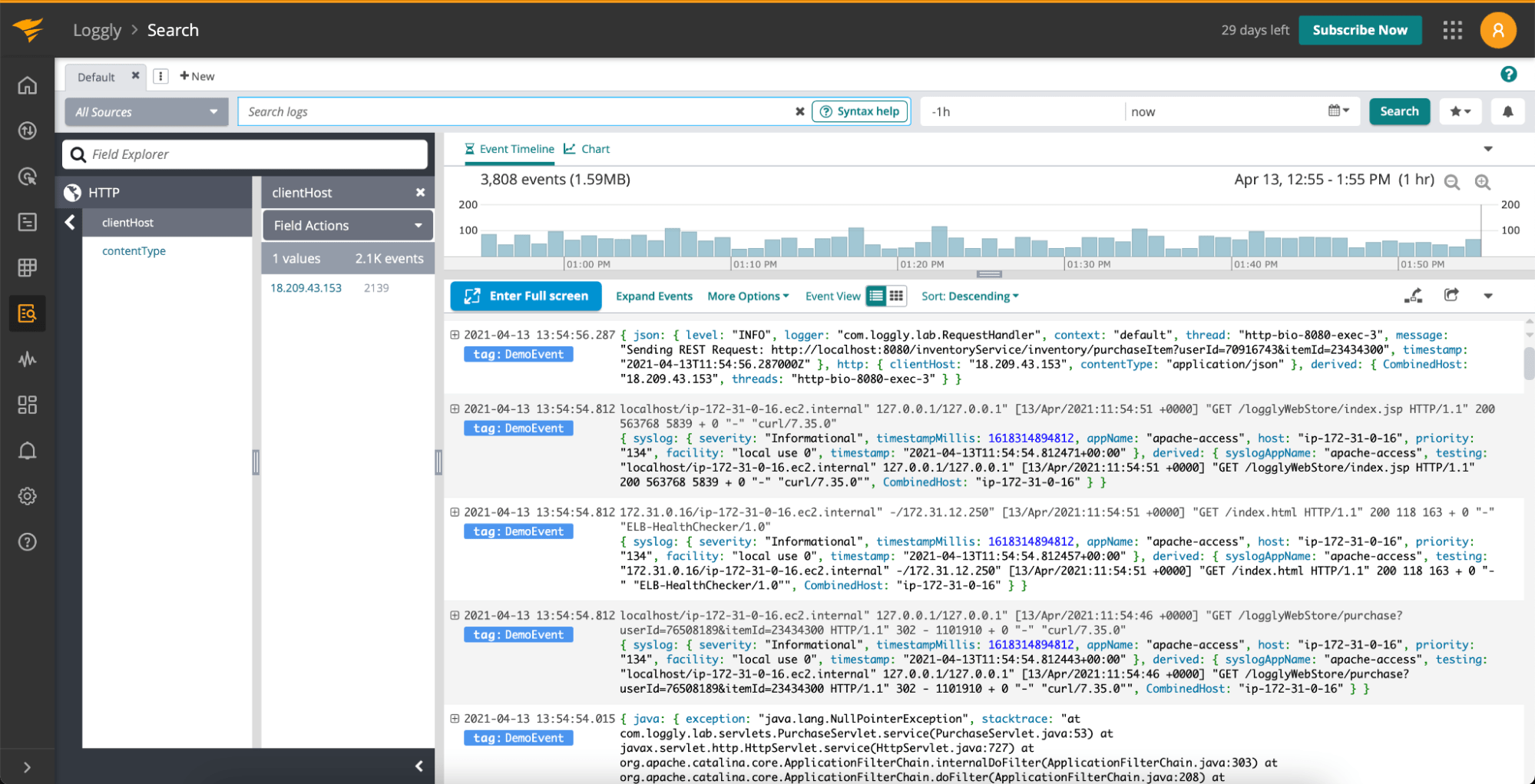
SolarWinds Loggly is another cloud logging service providing log centralization, analysis, and visualizations along with APM integration for full visibility into your environment. The built-in alerting and support for anomaly detection allows you to stay on top of the issues no matter if you were prepared for them or not. Providing the data in the raw text format is not a problem with the Derived Fields functionality enabling you to define how fields should be extracted and used if your data requires it.
Features:
- Automated data indexing and parsing with the promise of supporting any text log format.
- Easy to use query language with the support of the search context for easier troubleshooting.
- Live tail with regex support for efficient, live monitoring of logs coming from different sources.
- Automated logs grouping and linking for faster root cause analysis.
Pricing:
SolarWinds Loggly pricing depends on the features and the amount of data that you need to send and store. The free tier called Light allows for a single user, 200 MB of daily volume and up to 7 days worth of data retention with no support for alerting, customized dashboards, etc.
The first paid plan called Standard starts at $79 per month billed annually and includes up to 3 users, 1GB of daily ingestion volume and up to 15 days worth of data retention with e-mail based alerting. The most expensive Enterprise plan starts at $279 monthly billed annually with all the features, unlimited number of users, custom data volume and up to 90 days of data retention.
4. Sumo Logic
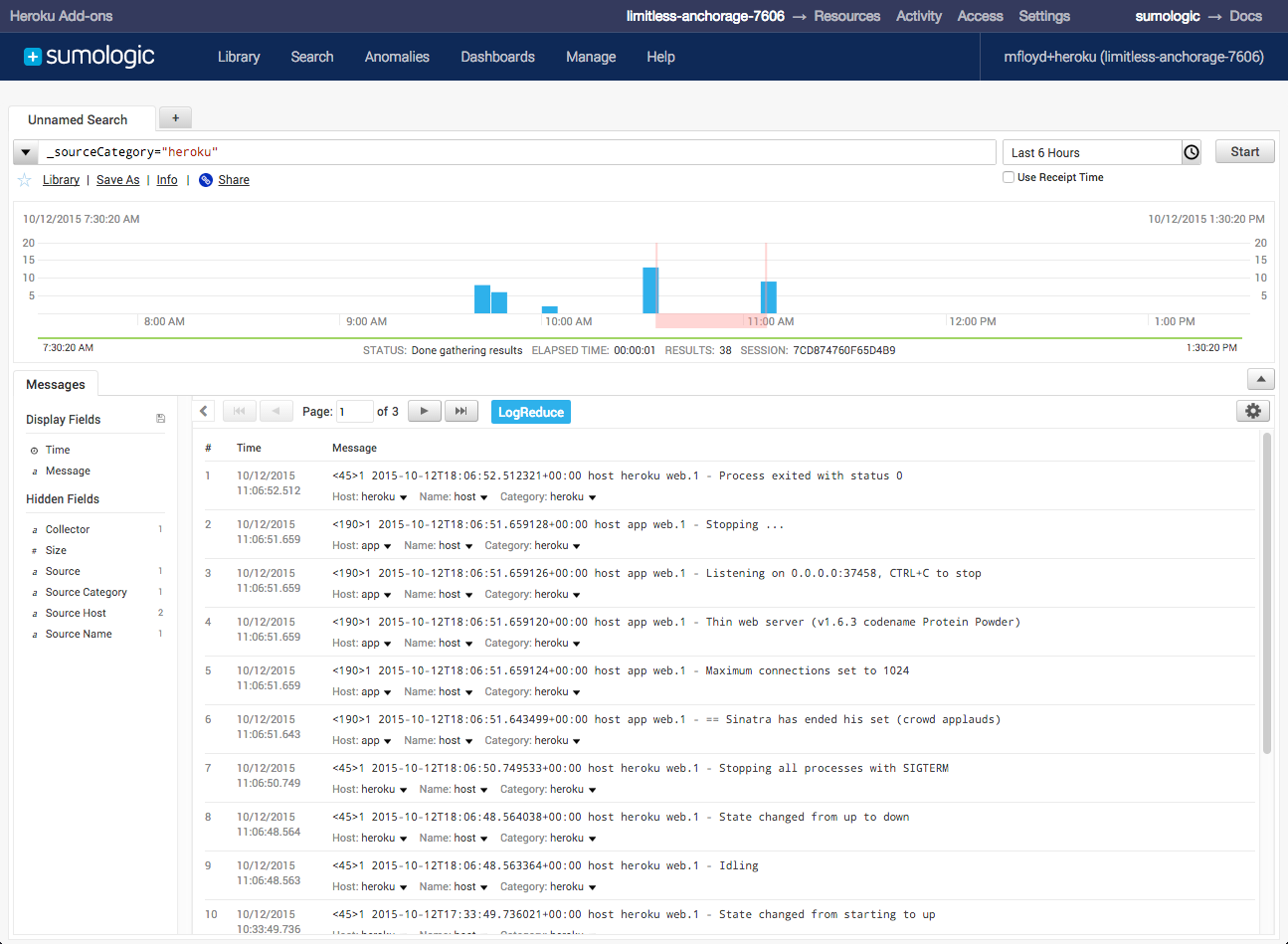
Sumo Logic platform combines logs, metrics, traces, SIEM, and business intelligence in a single product with a focus on logs. It allows powerful log analytics with the LogReduce algorithm reducing the number of similar logs helping with repeating log messages. LogCompare allows comparing different periods of time to find the differences for efficient root cause analysis. Together with its other functionalities, Sumo Logic gives you an observability platform that goes beyond logs.
Features:
- Log analysis with the LogReduce algorithm allows clustering of similar messages.
- LogCompare lets you compare data from two time periods.
- Field extraction enables rule-based data extraction from unstructured data.
- Out-of-the-box support for popular cloud vendors and orchestrated environments.
Pricing:
Sumo Logic pricing is organized around the volume of data that you send and features and is aimed at larger Enterprises. The Essentials plan starts with an estimated cost of $277 monthly billed annually that includes around 3GB of log data a day and 30 days of data retention, metrics, and traces. The Enterprise Suite plan starts with an estimated price of $2,189 monthly billed annually and includes around 15GB of daily ingest and all the features of the platform such as metrics, traces, and SIEM.
The pricing was based on the North America location and will differ in different Sumo Logic locations – for example, at the time of this writing, the Ireland location was more expensive compared to North America. Sumo Logic offers a free tier as well which includes up to 500MB of daily ingest and 7 days of data retention.
5. LogDNA
LogDNA is a scalable, SaaS cloud logging service offering log indexing, aggregation, and analysis. It supports various log event sources from applications, orchestration platforms, and common cloud vendors. The solution provides a rich UI including live tail for real-time log analysis, searching, graphing, and alerting on your log data. When it comes to the log data, LogDNA provides numerous integrations and log format parsing.
Features:
- Easy to use UI for searching and visualizing the log data in the form of graphs.
- Live tail for real-time log analytics.
- Alerting with the support for external services such as Slack, PagerDuty, or custom defined webhooks.
- Numerous sources integrations including common cloud vendors and orchestrated environments.
Pricing:
LogDNA pricing is organized around the amount of data you send and features. It starts with the Birch that includes up to 5 users, 7 days of data retention with the cost of $1.5 per GB of data. The most expensive plan costs $4 per GB of data, 30 days of retention, up to 30 users with a minimum charge of $200/month.
The features of the platform can be tested during a free, 14-days trial with no credit card requirements. It is worth mentioning that LogDNA offers a free plan that offers unlimited live tail functionality for real-time logging without any kind of historical data access.
6. Datadog
Datadog platform combines log management with metrics and traces in a single, cloud-based SaaS solution giving you rich context to analyze and quick root cause analysis. The platform allows you to search, filter and analyze the data with the use of various visualizations and generate metrics derived from logs. Send data from numerous sources with the provided out-of-the-box integrations and enrich the ingested logs to give your data more context for easier troubleshooting.
Features:
- Live-tail for real-time log analysis.
- Easy data exploration with Log Patterns helping you in detecting patterns and trends in your data.
- Processing and data enrichment defined from the platform using the Pipeline Library.
- Log access management for limiting access to only those who should see given data.
Pricing:
DataDog log management pricing starts with $0.10 per GB of ingested or scanned data and includes enrichment of data, parsing on ingestion, log-based metrics, and left-hosted archives. If you wish to retain the data you can do it starting with 3 days retention that will cost you $1.06 per million events when billed annually or $1.59 when billed on demand.
When using Amazon Web Services, Google Cloud Platform, or Microsoft Azure you can rely on the log analysis capabilities offered as part of their platforms or solutions described so far. The cloud provider dedicated solutions may not be as powerful as the solutions that we discussed above and tend to have more basic log monitoring capabilities. If you are using a cloud service solution from Amazon, Microsoft, or Google and you would like to use monitoring provided by those companies have a look at what they offer.
7. Amazon CloudWatch Logs
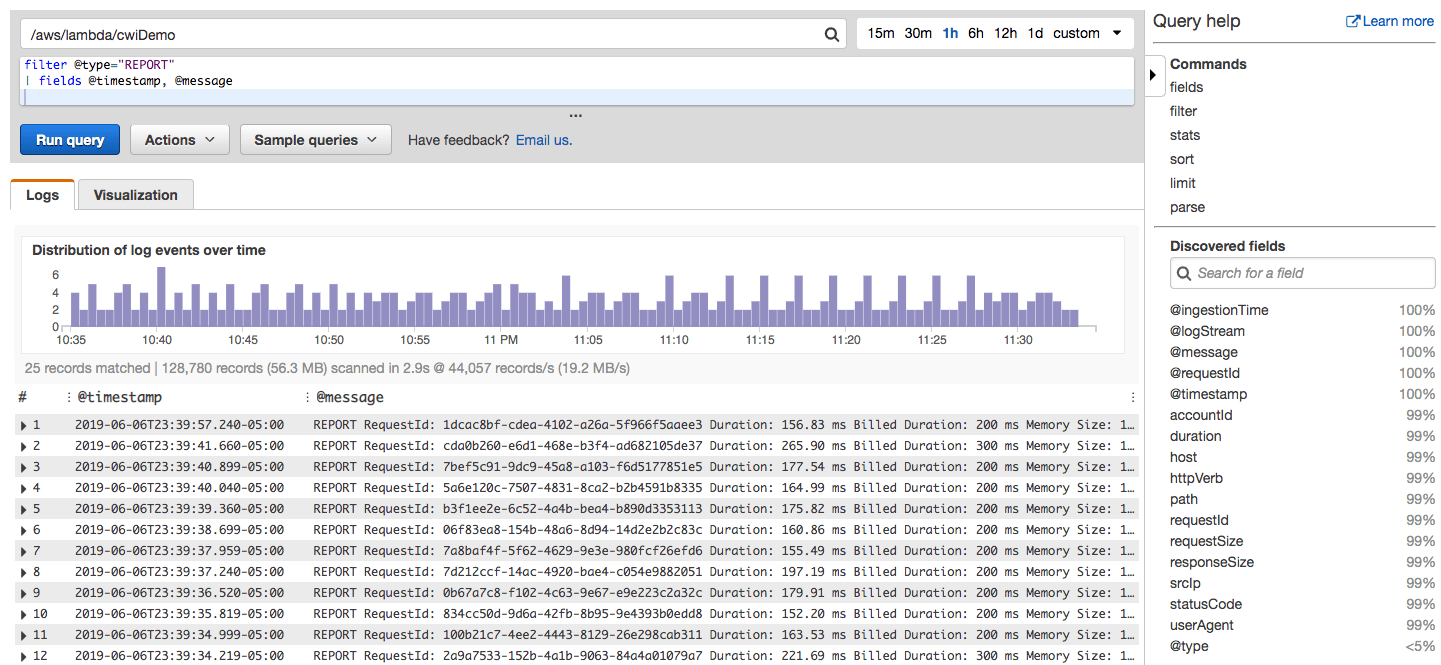
Amazon CloudWatch Logs is a cloud logging service that lets you monitor, store, and access your log files coming from various Amazon services, like Amazon Elastic Compute Cloud instances, AWS CloudTrail, Route 53, and others.
CloudWatch Logs enables you to centralize the log events from all of your systems, applications, and AWS services that you use, in a single, scalable service. You can see all of your logs, regardless of their source, as a single and consistent flow of events ordered by time, order them by the time of the event and visualize them in the form of dashboards. This allows you to easily view them, search and filter them based on specific fields, or archive them for future analysis.
Features:
- Monitor logs from Amazon EC2 instances, Route 53 DNS queries, CloudTrail, and more.
- Easily archive the logs with flexible retention from one day to infinity.
- Use a powerful query language to interactively search and analyze the log data coming from your systems.
Pricing:
Amazon CloudWatch Logs pricing is organized around the volume of data that you generate. The free tier includes up to 5GB logs per month with up to 3 dashboards. After that, the first 10TB of data is charged $0.50/GB, the next 20TB is charged $0.25GB, and so on with up to $0.05/GB over 50TB of data sent.
8. Microsoft Azure Logs
The Azure Monitor Logs is a logging feature of the Azure Monitor that collects and organizes performance and log data coming from different monitored resources, such as Application and Container Insights, Azure network monitor, and certain other Microsoft Azure services. Gathered data can be analyzed, visualized, and alerted on giving a deep insight into the monitored Azure services.
Features:
- Analyze log data gathered from various Microsoft Azure services.
- Present the data in the form of tables or charts generated on the basis of the log data.
- Alert on the data and be notified when an event of interest occurred.
Pricing:
The logs part of the Azure monitor has the option to pay as you go which gives you up to 5GB of logs per billing account per month free and then $2.76 per GB of data. You can also choose to go for the reserved data option – for example, 100GB of data per day will cost you $219.52 daily.
9. Google Operations (formerly Stackdriver)
Formerly Stackdriver, Google Operations suite is designed to monitor Google Cloud Platform infrastructure resources usage and application performance, but it also supports custom metrics and monitoring of other cloud service providers like AWS. The platform provides metrics, logs, and trace support along with the visibility into Google Cloud platform audit logs giving you the full visibility of what is happening inside your GCP account.
Features:
- Rich and powerful query language for navigating through log events.
- Audit logs for visibility info security-related events in your Google Cloud account.
- Support for logs and logs routing with error reporting and alerting.
Pricing:
Similar to Amazon CloudWatch Logs and Microsoft Azure Monitor Logs the Google Operations logs pricing is based on the amount of data your services and applications are generating and sending to the platform. The logs free tier includes up to 50GB of logs per project, and everything above that falls into the paid tier for the price of $0.50 for each additional GB of log data.
What Cloud Logging Service Will You Use?
Choosing the right cloud logging service is not a simple task. You need to look at the features that you need at the moment and that you may potentially need in the future. For example, your use case may require you to have the live-tail with filtering support, so that you can look for certain log events live. You may need to have alerting with anomaly detection so that unusual patterns can be caught and reported to the destination of your choice.
Yes, available ChatOps integrations are also important, because getting the alert to the destination that is close to the on-call person is crucial when issues happen. Those of us that are legally bound to keep data for auditing will require long-term storage, such as S3 compatible storage that can be configured and automatically used. The ability to connect logs with metrics is a crucial enabler for faster troubleshooting, shorter downtimes, and faster MTTR.
Finally, the price may be an important factor – the more logs you store, the higher the invoice will be and different vendors have different prices – for a similar amount of data.
Look for cloud log management solutions that:
- Let you jump between logs and metrics easily and quickly. That’s one of the keys for faster troubleshooting and making your job and life easier.
- Offer powerful log search syntax so you can more quickly and more easily find data you need.
- Offer easy setup, save you time with out-of-the-box dashboards and alert rules.
- Have attractive and flexible pricing. Avoid vendors whose pricing involves per-user and per-usage pricing because that will force you to start thinking about who, and how many people have access to your logs, which is a complication you do not need.
- Can collect logs not only from various backend infrastructure, but also collect mobile application logs, for example.
Remember that migrating to another vendor may not be easy and may end up losing the possibility of searching through your data archive. Such migration will require reconfiguration of your log shipping software or even applications if you have chosen to ship the data directly from them. For large, highly distributed environments such operation can take a vast amount of time and is not negligible.
If you’re looking for a cloud logging service give Sematext Logs a try. Our log management service allows you to stay on top of your application, system, and platform logs. There’s a 14-day free trial for you to test all its functionalities. Give it a try!
Start Free Trial