
У вас куча ошибок и недочётов, и поэтому непонятно, откуда может возникнуть ошибка. Предлагаю просто следить за моей мыслью, и у вас всё будет хорошо для сдачи лабораторной.  (и код понятнее сделаем, и рабочим всё сделаем). При компиляции использовались ключи
(и код понятнее сделаем, и рабочим всё сделаем). При компиляции использовались ключи -ansi , -pedantic , -Wall и -Werror( могут и не использоваться : они всего лишь для самопроверки  ).
).
Сами структуры
-
Посмотрите на
DateOfBirthиHuman. Раз вы делаетеtypedef, то
нужно придумать имя для вашего псевдонима, а у вас оно вообще
отсутствует (не понимаю, как ваш C-компилятор этого не заметил, если
это вообще C-компилятор).Исправляем, назначив то же имя, как и у самой структуры :
typedef struct DateOfBirth {...} DateOfBirth; typedef struct Human {...} Human; -
Когда вы работаете с такими структурами (да и ещё с файлами, которые
с ней потенциально связаны), вам нужно (а по-моему, просто
необходимо) использовать платформонезависимые типы (char-тип, к
счастью, можно оставить). Список полей, в итоге, может быть
следующим (заголовочный файлstdint.h).Для
DateOfBirth:/*дни не могут быть отрицательными + за границы 256 дней по смыслу не выйти*/ uint8_t day; /*аналогично*/ uint8_t month; /*то же самое, только для 2-х байтов*/ uint16_t year;Для
Human(аналогия с полейDateOfBirth):char id[8]; /*3456109 не 'влезет' в ваш 'char id[7]' : '' неуда вмещать*/ char surname[20]; char name[20]; char patronymic[20]; char sex[2]; DateOfBirth dateOfBirth; uint8_t height; uint8_t weight; char city[15]; char interests[30]; char badHabits[20]; char textMyself[30]; uint8_t prefAgeMin; uint8_t prefAgeMax; char prefBadHab[20]; -
Если вы выделяете память для такой структуры в таком положении вещей, то
вы, по факту выделяете больше, чем нужно (у вас такое есть вcheckSize). Посмотрим размер «старого»
Human:printf("%lun", sizeof(Human)); /*216*/А если внимательно посчитаете, то по факту получите 212

Дело всё в
выравнивании,
но не будем заострять на этом внимание. Короче говоря, можете ‘обвернуть’ структуры (на всякий случайDateOfBirthтоже, а то мало ли, как машина ‘захочет’), ипользуя#pragma pack (push,1)и#pragma pack (pop)перед определением и после определения «алиаса» для структуры соответственно, то есть :#pragma pack (push, 1) typedef struct DateOfBirth {...} DateOfBirth; #pragma pack (pop)и
#pragma pack (push, 1) typedef struct Human {...} Human; #pragma pack (pop)Этот пункт не является обязательным, поскольку
pragmaразнится в
зависимости от её реализации, но является желательным, если есть
такая возможность и нельзя по-другому исправить структуру.
В итоге, ваши определения могут быть следующими :
#define ID_SIZE 8
#define SURNAME_SIZE 20
#define NAME_SIZE 20
#define PATRONYMIC_SIZE 20
#define SEX_SIZE 2
#define CITY_SIZE 15
#define INTERESTS_SIZE 30
#define BADHABITS_SIZE 20
#define TEXTMYSELF_SIZE 30
#define PREFBADHAB_SIZE 20
#pragma pack (push, 1)
typedef struct DateOfBirth {
uint8_t day;
uint8_t month;
uint16_t year;
} DateOfBirth;
#pragma pack (pop)
#pragma pack (push, 1)
typedef struct Human {
char id[ID_SIZE];
char surname[SURNAME_SIZE];
char name[NAME_SIZE];
char patronymic[PATRONYMIC_SIZE];
char sex[SEX_SIZE];
DateOfBirth dateOfBirth;
uint8_t height;
uint8_t weight;
char city[CITY_SIZE];
char interests[INTERESTS_SIZE];
char badHabits[BADHABITS_SIZE];
char textMyself[TEXTMYSELF_SIZE];
uint8_t prefAgeMin;
uint8_t prefAgeMax;
char prefBadHab[PREFBADHAB_SIZE];
} Human;
#pragma pack (pop)
checkSize
У вас там мало того, что память выделенная не освобождается, так и слишком запутанный и непереиспользуемый код.
«сложнА-сложнААА» (c)
Предлагаю более подходящий вариант сигнатуры функции и её реализации (здесь уже «опустим» вопрос с кроссплатформенностью, ибо гораздо менее важно):
size_t get_humans_count ( const char* filename )
{
FILE* fp;
size_t lines_count = 0;
char line[ MAX_LINE_SIZE ];
fp = fopen( filename, "r" );
if ( NULL == fp ) return 0;
while ( fgets( line, MAX_LINE_SIZE, fp ) != NULL )
{
if ( 0 == is_empty(line) )
{
fclose(fp);
return 0;
}
lines_count++;
}
fclose(fp);
return lines_count / HUMAN_LINES_COUNT;
}
Реализация is_empty ( была позаимствована и немного переделана отсюда ):
static int is_empty (const char *s)
{
while ( *s != '' )
{
if ( ! isspace( (unsigned char) *s ) ) return -1;
s++;
}
return 0;
}
is_empty нужен для того, чтобы вы не могли засчитать ‘пустую’ строку, как актуальную для записи её в структуру.
Протестируйте сами: оставьте где-нибудь ‘пустые’ строки, т.е. строки, содержащие только пробельный(-е) символ(-ы). В вашей реализации это бы засчиталось, и вы бы записали в какое-нибудь поле структуры ‘пустую’ строку.
В данном случае поля должны идти друг за другом, а иначе функция вернёт 0 ( единственный ‘минус’ тут в неудобочитаемости читаемого файла, потому что описания будут ‘слиты’, но реализация разделения — это просто и дело «десятое», и я не буду на этом останавливаться ).
readingFromFile
Я «убил» весь день на то, чтобы правильно вывести прочитанные данные в структуру. Немного длиннее, но выглядит это всё более логично, а от такой структурированности маловероятно получить ошибку :
Human* get_humans_from ( const char* filename )
{
FILE* fp;
Human* humans_buffer;
size_t humans_counter = 0;
size_t humans_count = get_humans_count(filename);
fp = fopen( filename, "r" );
if ( NULL == fp || 0 == humans_count ) return NULL;
humans_buffer = ( Human* ) malloc( sizeof(Human) * humans_count );
if ( NULL == humans_buffer ) return NULL;
while ( humans_counter < humans_count)
{
read_and_adjust_string( fp, humans_buffer[humans_counter].id );
read_and_adjust_string( fp, humans_buffer[humans_counter].surname );
read_and_adjust_string( fp, humans_buffer[humans_counter].name );
read_and_adjust_string( fp, humans_buffer[humans_counter].patronymic );
read_and_adjust_string( fp, humans_buffer[humans_counter].sex );
humans_buffer[humans_counter].dateOfBirth.day = (uint8_t) read_and_get_ul ( fp ) ;
humans_buffer[humans_counter].dateOfBirth.month = (uint8_t) read_and_get_ul ( fp );
humans_buffer[humans_counter].dateOfBirth.year = (uint16_t) read_and_get_ul ( fp );
humans_buffer[humans_counter].height = (uint8_t) read_and_get_ul ( fp );
humans_buffer[humans_counter].weight = (uint8_t) read_and_get_ul ( fp );
read_and_adjust_string( fp, humans_buffer[humans_counter].city );
read_and_adjust_string( fp, humans_buffer[humans_counter].interests );
read_and_adjust_string( fp, humans_buffer[humans_counter].badHabits );
read_and_adjust_string( fp, humans_buffer[humans_counter].textMyself );
humans_buffer[humans_counter].prefAgeMin = (uint8_t) read_and_get_ul ( fp );
humans_buffer[humans_counter].prefAgeMax = (uint8_t) read_and_get_ul ( fp );
read_and_adjust_string( fp, humans_buffer[humans_counter].prefBadHab );
print_human_info(humans_buffer[humans_counter]);
humans_counter++;
}
fclose(fp);
return humans_buffer;
}
Участвующие функции read_and_adjust_string и read_and_get_ul имеют следующие реализации :
static void read_and_adjust_string( FILE* opened_fp, char* line )
{
fgets( line, MAX_LINE_SIZE, opened_fp );
line[strcspn(line, "n")] = '';
}
static unsigned long int read_and_get_ul( FILE* opened_fp )
{
char tmp_buf[MAX_LINE_SIZE] = {0};
fgets( tmp_buf, MAX_LINE_SIZE, opened_fp );
return strtoul( tmp_buf, NULL, 10 );
}
loadToFile
Зачем вам в аргументах ‘указатель на указатель’? Этого не нужно : нам всего лишь надо прочитать значения и вывести их в файл.
void load_humans_to ( const char* filename, Human* humans_buffer, size_t humans_count )
{
FILE* fp;
size_t humans_counter = 0;
if ( NULL == humans_buffer || 0 == humans_count ) return;
fp = fopen( filename, "w" );
if ( NULL == fp ) return;
while ( humans_counter < humans_count )
{
fprintf( fp, "%sn", humans_buffer[humans_counter].id );
fprintf( fp, "%sn", humans_buffer[humans_counter].surname );
fprintf( fp, "%sn", humans_buffer[humans_counter].name );
fprintf( fp, "%sn", humans_buffer[humans_counter].patronymic );
fprintf( fp, "%sn", humans_buffer[humans_counter].sex );
fprintf( fp, "%un", humans_buffer[humans_counter].dateOfBirth.day );
fprintf( fp, "%un", humans_buffer[humans_counter].dateOfBirth.month );
fprintf( fp, "%un", humans_buffer[humans_counter].dateOfBirth.year );
fprintf( fp, "%un", humans_buffer[humans_counter].height );
fprintf( fp, "%un", humans_buffer[humans_counter].weight );
fprintf( fp, "%sn", humans_buffer[humans_counter].city );
fprintf( fp, "%sn", humans_buffer[humans_counter].interests );
fprintf( fp, "%sn", humans_buffer[humans_counter].badHabits );
fprintf( fp, "%sn", humans_buffer[humans_counter].textMyself );
fprintf( fp, "%un", humans_buffer[humans_counter].prefAgeMin );
fprintf( fp, "%un", humans_buffer[humans_counter].prefAgeMax );
fprintf( fp, "%sn", humans_buffer[humans_counter].prefBadHab );
humans_counter++;
}
fclose(fp);
}
printOnConsole (опционально)
Реализовал более понятный и приятный ‘вашему соседу’ код для отображения (по крайней мере, мне так удобнее):
void print_humans_info( Human* humans_buffer, size_t size )
{
size_t counter = 0;
while ( counter < size )
{
printf("Human #%lu : n",counter);
print_human_info( humans_buffer[counter] );
puts("");
counter++;
}
}
Реализация print_human_info следующая :
void print_human_info( Human hum )
{
printf("tID : %sn", hum.id);
printf("tSurname : %sn", hum.surname);
printf("tName : %sn", hum.name);
printf("tPatronymic : %sn", hum.patronymic);
printf("tSex : %sn", hum.sex);
printf("tBirth day : %un", hum.dateOfBirth.day);
printf("tBirth month : %un", hum.dateOfBirth.month);
printf("tBirth year : %un", hum.dateOfBirth.year);
printf("tHeight : %un", hum.height);
printf("tWeight : %un", hum.weight);
printf("tCity : %sn", hum.city);
printf("tInterests : %sn", hum.interests);
printf("tBad habits : %sn", hum.badHabits);
printf("tAbout : %sn", hum.textMyself);
printf("tPreferable min-age : %un", hum.prefAgeMin);
printf("tPreferable max-age : %un", hum.prefAgeMax);
printf("tPreferable bad habits : %sn", hum.prefBadHab);
}
Возможный ‘main’ для теста :
int main()
{
char* src_filename = "database.txt";
char* dst_filename = "database2.txt";
size_t humans_count = get_humans_count(src_filename);
Human* human_buffer = get_humans_from(src_filename);
load_humans_to( dst_filename, human_buffer, humans_count );
print_humans_info( human_buffer , humans_count );
free(human_buffer);
return 0;
}
На будущее :
-
Чтобы лучше представлять информацию, нужно создать ещё один
псевдоним :#pragma pack (push, 1) typedef struct People { size_t count; Human* humans; } People; #pragma pack (pop)Таким образом вам не придется постоянно ‘вытягивать’ и то, и то, а
значит меньше аргументов на функции = лучшая удобочитаемость и
чистота (но это уже вам задача, если желаете). -
Задавайте вопрос более конкретно. Вы даже не сказали, в каком
конкретно месте у вас возникают проблемы (у вас в коде не один
fclose). Старайтесь описывать задачу более коротко (пожалуйста).
Использованные заголовочные файлы:
stdio.h
stdint.h
stdlib.h
ctype.h
string.h
Here is a version of the code that works, with embedded comments about why things are different from the posted code.
Note: On linux (and other OSs) the /home directory is not writeable without administrative privileges. so the call to fopen() will always fail.
//main.c
#include <stdio.h> // fwrite, fopen, fclose, perror
#include <stdlib.h> // exit, EXIT_FAILURE
#include <string.h> // strlen, sprintf, memcpy
// note: no comments at end of #define statement as the comment would be copied into the code
// note no ';' at end of #define statement
#define filename "/home/test.txt"
// to avoid using 'magic' numbers in code
// and this name used throughout the code
#define BUF_SIZE (255)
// prototypes
void sendFile( char *, char *); // so compiler does not make incorrect assumptions
// and no second parameter needed
char fbuf[BUF_SIZE] = {''}; // avoid 'magic' numbers
// avoid placing trash into output file
// however, will place many NUL bytes
// main() function to make executable platform for testing
int main( void )
{
sprintf(fbuf, "%s, %f, %f,%f n", "big", 8.0, 0.0, 0.8);
// changed 3rd parameter type to match actual function parameter type
sendFile(fbuf, filename); // no '&' because in C
// array name degrades to address of array
return 0;
}
void sendFile( char *data, char *pName) // use actual parameter types
{
FILE *pFile = fopen(pName,"a");
if(pFile == NULL) // always check for error immediately after call to system function, not later
{ // then fopen failed
perror( "fopen failed" );
//logger(LOG_INFO, "Error opening filen");
exit( EXIT_FAILURE); // exit, so no other code executed
}
// implied else, fopen successful
char *buf = NULL;
if(NULL == (buf = malloc(BUF_SIZE) ) ) // don't cast returned value
{ // then malloc failed -- always check for error immediately after call to system function
perror( "malloc for output buffer failed");
//logger(LOG_INFO, "malloc for BUF_SIZE failed");
fclose( pFile); // cleanup
exit(EXIT_FAILURE); // exit, so no other code executed
}
// implied else, malloc successful
memcpy(buf, data, BUF_SIZE); // using original 3rd parameter would move 4 times as many bytes,
// I.E. past the end of the source buffer and past the end of the destination buffer
// resulting in undefined behaviour, leading to a seg fault event
// this memcpy() and the destination buffer
// are unneeded as first passed in parameter
// contains ptr to the source buffer
// which can be used in the call to fwrite()
fwrite(buf, BUF_SIZE, 1, pFile); // buf will have NUL byte immediately after 'big' so strlen() would return 3
// and the syntax for fwrite is source buffer, size of one item, number of items, FILE*
// and this parameter order is best
// because, if error checking,
// can just compare returned value to 1
fflush(pFile); // not actually needed as the fclose() performs a flush
fclose(pFile);
free (buf); // original code did this even if malloc had failed
// and even if the fopen had failed
// which would have corrupted the 'heap' leading to a seg fault event
}
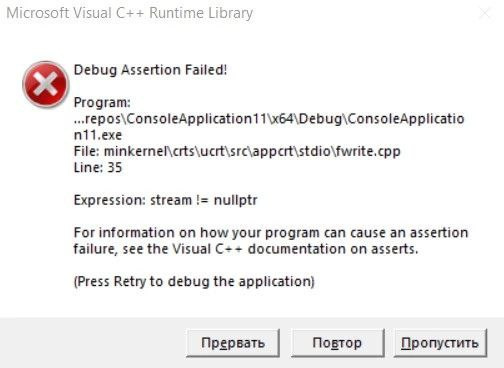
Ребята, кто разбирается в работе с stdio.h в C++?
Скину код для наглядности. Дело в том, что он абсолютно идентичен у меня, и у товарища, однако если у моего знакомого он запускается, то мне, после ввода основных параметров и работы функции добавления данных структуры в бинарный файл, выдаётся такая ошибка.
Сразу говорю, мне советовали проверить версию Visual Studio и компилятор. Они у нас с ним абсолютно идентичны: Visual Studio 2022 и версия компилятора c++ 17. Ошибка возникает в момент использования функции, где записаны стандартные fopen, fwrite и fclose.
Сам код:
#define _CRT_SECURE_NO_WARNINGS
#define _CRT_SECURE_NO_DEPRECATE
#include <iostream>
#include <stdio.h>
#include "windows.h"
using namespace std;
struct TV_channels {
//char label[40];
int short unsigned hours_of_begin;
int short unsigned minutes_of_begin;
unsigned short int channel;
};
void AddChannel(TV_channels channel, const char* path)
{
FILE* f = fopen(path, "ab+");
fwrite(&channel, sizeof(TV_channels), 1, f);
fclose(f);
cout << "Succesfull adding new channel!" << endl;
}
void OutChannelList(const char* path)
{
int unsigned short counter = 1;
FILE* f = fopen(path, "ab+");
TV_channels temp;
while (fread(&temp, sizeof(temp), 1, f)!=0)
{
cout << counter <<". " << //temp.label
" | " << temp.hours_of_begin << ":" << temp.minutes_of_begin << " | " << "Channel: " << temp.channel << " | " << endl;
counter++;
}
fclose(f);
}
void ClearChannelList(const char* path)
{
FILE* f = fopen(path, "wb");
fclose(f);
cout << "Succesful clearing!" << endl;
}
void OneChannel(unsigned short int index,const char* path)
{
FILE* f = fopen(path, "rb");
TV_channels temp;
rewind(f);
for (int i = 1; i < index; i++)
{
fseek(f, sizeof(TV_channels), SEEK_CUR);
}
fread(&temp, sizeof(temp), 1, f);
cout << //temp.label
" | " << temp.hours_of_begin << ":" << temp.minutes_of_begin << " | " << "Channel: " << temp.channel << " | " << endl;
fclose(f);
}
void ChangeByIndex(unsigned short int index, const char* path, int short unsigned hours_of_begin, int short unsigned minutes_of_begin, unsigned short int channel)
{
FILE* f = fopen(path, "rb+");
TV_channels temp = { hours_of_begin , minutes_of_begin, channel };
rewind(f);
for (int i = 1; i < index; i++)
{
fseek(f, sizeof(TV_channels), SEEK_CUR);
}
fwrite(&temp, sizeof(temp), 1, f);
fclose(f);
}
int main()
{
const char* path = "C:\Prorgamms\Utilites\Code_Programms\c++\2lab_bin\file.bin";
unsigned short int choose;
unsigned short int index;
int short unsigned hours_of_begin;
int short unsigned minutes_of_begin;
unsigned short int channel;
//char label[40];
while (true)
{
cout << "1. Add new channel" << endl;
cout << "2. Output channel list" << endl;
cout << "3. Clear channel list" << endl;
cout << "4. Output one channel" << endl;
cout << "5. Change by index" << endl;
cout << ">";
cin >> choose;
system("cls");
switch (choose)
{
case 1:
{
//cout << "Input channel label: ";
//cin >> label;
cout << "Input hours of begin: ";
cin >> hours_of_begin;
cout << "Input minutes of begin: ";
cin >> minutes_of_begin;
cout << "Input channel number: ";
cin >> channel;
TV_channels temp = { //label ,
hours_of_begin ,minutes_of_begin, channel };
AddChannel(temp, path);
break;
}
case 2:
{
OutChannelList(path);
break;
}
case 3:
{
ClearChannelList(path);
break;
}
case 4:
{
cout << "Input channel index: ";
cin >> index;
OneChannel(index, path);
break;
}
case 5:
{
cout << "Input channel index, you want to chage: ";
cin >> index;
cout << "You want to change";
OneChannel(index, path);
cout << "New hours of begin: ";
cin >> hours_of_begin;
cout << "New minutes of begin: ";
cin >> minutes_of_begin;
cout << "New channel number: ";
cin >> channel;
ChangeByIndex(index, path, hours_of_begin, minutes_of_begin, channel);
break;
}
case 6:
{
}
default:
cout << "Unknown command, input correct command!" << endl;
Sleep(2000);
break;
}
Sleep(2000);
system("cls");
}
}|
Максимка_101 0 / 0 / 0 Регистрация: 28.09.2017 Сообщений: 7 |
||||
|
1 |
||||
|
28.09.2017, 17:21. Показов 2967. Ответов 6 Метки нет (Все метки)
Добрый день, господа. Необходимо написать программу, которая посимвольно будет копировать содержимое одного текстового файла в другой файл. Проблема заключается в том, что после копирования текста программа начинает копировать последний знак. Не могу понять в чем дело. Кликните здесь для просмотра всего текста
0 |

|
Programming Эксперт 94731 / 64177 / 26122 Регистрация: 12.04.2006 Сообщений: 116,782 |
28.09.2017, 17:21 |
|
6 |
|
Catstail Модератор
35614 / 19507 / 4079 Регистрация: 12.02.2012 Сообщений: 32,547 Записей в блоге: 13 |
||||
|
28.09.2017, 17:57 |
2 |
|||
|
17-я строка должна быть:
0 |
|
0 / 0 / 0 Регистрация: 28.09.2017 Сообщений: 7 |
|
|
28.09.2017, 18:26 [ТС] |
3 |
|
Вот такая ошибка Миниатюры
0 |
|
737 / 542 / 416 Регистрация: 17.09.2015 Сообщений: 1,601 |
|
|
28.09.2017, 18:41 |
4 |
|
посимвольно будет копировать а почему же тогда вы используете функции для работы со строками?
0 |

|
0 / 0 / 0 Регистрация: 28.09.2017 Сообщений: 7 |
|
|
28.09.2017, 18:47 [ТС] |
5 |
|
Изменил функцию fputs на fputc, ошибка осталась всё та же. Может быть проблема кроется в IDE? Правда, раньше все работало, и таких мыслей не возникало. Правда, я и не встречал подобных ошибок до
0 |
|
LFC 737 / 542 / 416 Регистрация: 17.09.2015 Сообщений: 1,601 |
||||
|
28.09.2017, 20:04 |
6 |
|||
|
Решение Не понимаю,для чего здесь вообще feof. Немного оптимизировал ваш код.
0 |
 Сообщение было отмечено Максимка_101 как решение
Сообщение было отмечено Максимка_101 как решение
|
Максимка_101 0 / 0 / 0 Регистрация: 28.09.2017 Сообщений: 7 |
||||
|
28.09.2017, 20:14 [ТС] |
7 |
|||
|
Не понимаю,для чего здесь вообще feof. Немного оптимизировал ваш код.
Спасибо большое! Ваше решение устранило все проблемы
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
28.09.2017, 20:14 |
|
7 |
Работа с файлами
Стандартная библиотека Си содержит набор функций для работы с файлами. Эти функции описаны в стандарте ANSI. Отметим, что файловый ввод-вывод не является частью языка Си, и ANSI-функции — не единственное средство ввода-вывода. Так, в операционной системе Unix более популярен другой набор функций ввода-вывода, который можно использовать не только для работы с файлами, но и для обмена по сети. В C++ часто используются библиотеки классов для ввода-вывода. Тем не менее, функции ANSI-библиотеки поддерживаются всеми Си-компиляторами, и потому программы, применяющие их, легко переносятся с одной платформы на другую. Прототипы функций ввода-вывода и используемые для этого типы данных описаны в стандартном заголовочном файле «stdio.h.
Открытие файла: функция fopen
Для доступа к файлу применяется тип данных FILE. Это структурный тип, имя которого задано с помощью оператора typedef в стандартном заголовочном файле «stdio.h». Программисту не нужно знать, как устроена структура типа файл: ее устройство может быть системно зависимым, поэтому в целях переносимости программ обращаться явно к полям струтуры FILE запрещено. Тип данных «указатель на структуру FILE используется в программах как черный ящик: функция открытия файла возвращает этот указатель в случае успеха, и в дальнейшем все файловые функции применяют его для доступа к файлу.
Прототип функции открытия файла выглядит следующим образом:
FILE *fopen(const char *path, const char *mode);
Здесь path — путь к файлу (например, имя файла или абсолютный путь к файлу), mode — режим открытия файла. Строка mode может содержать несколько букв. Буква » r » (от слова read) означает, что файл открывается для чтения (файл должен существовать). Буква » w » (от слова write) означает запись в файл, при этом старое содержимое файла теряется, а в случае отсутствия файла он создается. Буква » a » (от слова append) означает запись в конец существующего файла или создание нового файла, если файл не существует.
В некоторых операционных системах имеются различия в работе с текстовыми и бинарными файлами (к таким системам относятся MS DOS и MS Windows; в системе Unix различий между текстовыми и бинарными файлами нет). В таких системах при открытии бинарного файла к строке mode следует добавлять букву » b » (от слова binary), а при открытии текстового файла — букву » t » (от слова text). Кроме того, при открытии можно разрешить выполнять как операции чтения, так и записи; для этого используется символ + (плюс). Порядок букв в строке mode следующий: сначала идет одна из букв » r «, » w «, » a «, затем в произвольном порядке могут идти символы » b «, » t «, » + «. Буквы » b » и » t » можно использовать, даже если в операционной системе нет различий между бинарными и текстовыми файлами, в этом случае они просто игнорируются.
Значения символов в строке mode сведены в следующую таблицу:
| r | Открыть существующий файл на чтение |
| w | Открыть файл на запись. Старое содержимое файла теряется, в случае отсутствия файла он создаётся. |
| a | Открыть файл на запись. Если файл существует, то запись производится в его конец. |
| t | Открыть текстовый файл. |
| b | Открыть бинарный файл. |
| + | Разрешить и чтение, и запись. |
Несколько примеров открытия файлов:
FILE *f, *g, *h;
. . .
// 1. Открыть текстовый файл "abcd.txt" для чтения
f = fopen("abcd.txt", "rt");
// 2. Открыть бинарный файл "c:WindowsTemptmp.dat"
// для чтения и записи
g = fopen("c:/Windows/Temp/tmp.dat", "wb+");
// 3. Открыть текстовый файл "c:WindowsTempabcd.log"
// для дописывания в конец файла
h = fopen("c:\Windows\Temp\abcd.log", "at");
Обратите внимание, что во втором случае мы используем обычную косую черту / для разделения директорий, хотя в системах MS DOS и MS Windows для этого принято использовать обратную косую черту . Дело в том, что в операционной системе Unix и в языке Си, который является для нее родным, символ используется в качестве экранирующего символа, т.е. для защиты следующего за ним символа от интерпретации как специального. Поэтому во всех строковых константах Си обратную косую черту надо повторять дважды, как это и сделано в третьем примере. Впрочем, стандартная библиотека Си позволяет в именах файлов использовать нормальную косую черту вместо обратной; эта возможность была использована во втором примере.
В случае удачи функция fopen открытия файла возвращает ненулевой указатель на структуру типа FILE, описывающую параметры открытого файла. Этот указатель надо затем использовать во всех файловых операциях. В случае неудачи (например, при попытке открыть на чтение несуществующий файл) возвращается нулевой указатель. При этом глобальная системная переменная errno, описанная в стандартном заголовочном файле «errno.h, содержит численный код ошибки. В случае неудачи при открытии файла этот код можно распечатать, чтобы получить дополнительную информацию:
#include <stdio.h>
#include <errno.h>
. . .
FILE *f = fopen("filnam.txt", "rt");
if (f == NULL) {
printf(
"Ошибка открытия файла с кодом %dn",
errno
);
. . .
}
Константа NULL
В приведенном выше примере при открытии файла функция fopen в случае ошибки возвращает нулевой указатель на структуру FILE. Чтобы проверить, произошла ли ошибка, следует сравнить возвращенное значение с нулевым указателем. Для наглядности стандартный заголовочный файл «stdio.h» определяет символическую константу NULL как нулевой указатель на тип void:
#define NULL ((void *) 0)
Сделано это вроде бы с благой целью: чтобы отличить число ноль от нулевого указателя. При этом язык Си, в котором контроль ошибок осуществляется недостаточно строго, позволяет сравнивать указатель общего типа void * с любым другим указателем. Между тем,в Си вместо константы NULL всегда можно использовать просто 0, и вряд ли от этого программа становится менее понятной. Более строгий язык C++ запрещает сравнение разных указателей, поэтому в случае C++ стандартный заголовочный файл определяет константу NULL как обычный ноль:
Автор языка C++ Б. Страуструп советует использовать обычный ноль 0 вместо символического обозначения NULL. Тем не менее, по традиции большинство программистов любят константу NULL.
Константа NULL не является частью языка Си или C++, и без подключения одного из стандартных заголовочных файлов, в котором она определяется, использовать ее нельзя. (По этой причине авторы языка Java добавили в язык ключевое слово null, записываемое строчными буквами.) Так что в случае Си или C++ безопаснее следовать совету Б. Страуструпа и использовать обычный ноль 0 вместо символической константы NULL.
Диагностика ошибок: функция perror
Использовать переменную errno для печати кода ошибки не очень удобно, поскольку необходимо иметь под рукой таблицу возможных кодов ошибок и их значений. В стандартной библиотеке Си существует более удобная функция perror, которая печатает системное сообщение о последней ошибке вместо ее кода. Печать производится на английском языке, но есть возможность добавить к системному сообщению любой текст, который указывается в качестве единственного аргумента функции perror. Например, предыдущий фрагмент переписывается следующим образом:
#include <stdio.h>
. . .
FILE *f = fopen("filnam.txt", "rt");
if (f == 0) {
perror("Не могу открыть файл на чтение");
. . .
}
Функция perror печатает сначала пользовательское сообщение об ошибке, затем после двоеточия системное сообщение. Например, при выполнении приведенного фрагмента в случае ошибки из-за отсутствия файла будет напечатано
Не могу открыть файл на чтение: No such file or directory
Функции бинарного чтения и записи fread и fwrite
После того как файл открыт, можно читать информацию из файла или записывать информацию в файл. Рассмотрим сначала функции бинарного чтения и записи fread и fwrite. Они называются бинарными потому, что не выполняют никакого преобразования информации при вводе или выводе (с одним небольшим исключением при работе с текстовыми файлами, которое будет рассмотрено ниже): информация хранится в файле как последовательность байтов ровно в том виде, в котором она хранится в памяти компьютера.
Функция чтения fread имеет следующий прототип:
size_t fread(
char *buffer, // Массив для чтения данных
size_t elemSize, // Размер одного элемента
size_t numElems, // Число элементов для чтения
FILE *f // Указатель на структуру FILE
);
Здесь size_t определен как беззнаковый целый тип в системных заголовочных файлах. Функция пытается прочесть numElems элементов из файла, который задается указателем f на структуру FILE, размер каждого элемента равен elemSize. Функция возвращает реальное число прочитанных элементов, которое может быть меньше, чем numElems, в случае конца файла или ошибки чтения. Указатель f должен быть возвращен функцией fopen в результате успешного открытия файла. Пример использования функции fread:
FILE *f;
double buff[100];
size_t res;
f = fopen("tmp.dat", "rb"); // Открываем файл
if (f == 0) { // При ошибке открытия файла
// Напечатать сообщение об ошибке
perror("Не могу открыть файл для чтения");
exit(1); // завершить работу с кодом 1
}
// Пытаемся прочесть 100 вещественных чисел из файла
res = fread(buff, sizeof(double), 100, f);
// res равно реальному количеству прочитанных чисел
В этом примере файл » tmp.dat » открывается на чтение как бинарный, из него читается 100 вещественных чисел размером 8 байт каждое. Функция fread возвращает реальное количество прочитанных чисел, которое меньше или равно, чем 100.
Функция fread читает информацию в виде потока байтов и в неизменном виде помещает ее в память. Следует различать текстовое представление чисел и их бинарное представление! В приведенном выше примере числа в файле должны быть записаны в бинарном виде, а не в виде текста. Для текстового ввода чисел надо использовать функции ввода по формату, которые будут рассмотрены ниже.
Внимание! Открытие файла как текстового с помощью функции fopen, например,
FILE *f = fopen("tmp.dat", "rt");
вовсе не означает, что числа при вводе с помощью функции fopen будут преобразовываться из текстовой формы в бинарную! Из этого следует только то, что в операционных системах, в которых строки текстовых файлов разделяются парами символами » rn » (они имеют названия CR и LF — возврат каретки и продергивание бумаги, Carriage Return и Line Feed), при вводе такие пары символов заменяются на один символ » n » (продергивание бумаги). Обратно, при выводе символ » n » заменяется на пару » rn «. Такими операционными системами являются MS DOS и MS Windows. В системе Unix строки разделяются одним символом » n » (отсюда проистекает обозначение » n «, которое расшифровывается как new line). Таким образом, внутреннее представление текста всегда соответствует системе Unix, а внешнее — реально используемой операционной системе. Отметим также, что создатели операционной системы компьютеров Apple Macintosh выбрали, чтобы жизнь не казалась скучной, третий, отличный от двух предыдущих, вариант: текстовые строки разделяются одним символом » r » возврат каретки!
Такое представление текстовых файлов восходит к тем уже далеким временам, когда еще не было компьютерных мониторов и для просмотра текста использовались электрифицированные пишущие машинки или посимвольные принтеры. Текстовый файл фактически представлял собой программу печати на пишущей машинке и, таким образом, содержал команды возврата каретки и продергивания бумаги в конце каждой строки.
Функция бинарной записи в файл fwrite аналогична функции чтения fread. Она имеет следующий прототип:
size_t fwrite(
char *buffer, // Массив записываемых данных
size_t elemSize, // Размер одного элемента
size_t numElems, // Число записываемых элементов
FILE *f // Указатель на структуру FILE
);
Функция возвращает число реально записанных элементов, которое может быть меньше, чем numElems, если при записи произошла ошибка — например, не хватило свободного пространства на диске. Пример использования функции fwrite:
FILE *f;
double buff[100];
size_t num;
. . .
f = fopen("tmp.res", "wb"); // Открываем файл "tmp.res"
if (f == 0) { // При ошибке открытия файла
// Напечатать сообщение об ошибке
perror("Не могу открыть файл для записи");
exit(1); // завершить работу программы с кодом 1
}
// Записываем 100 вещественных чисел в файл
num = fwrite(buff, sizeof(double), 100, f);
// В случае успеха num == 100
Закрытие файла: функция fclose
По окончании работы с файлом его надо обязательно закрыть. Система обычно запрещает полный доступ к файлу до тех пор, пока он не закрыт. (Например, в нормальном режиме система запрещает одновременную запись в файл для двух разных программ.) Кроме того, информация реально записывается полностью в файл лишь в момент его закрытия. До этого она может содержаться в оперативной памяти (в так называемой файловой кеш-памяти), что при выполнении многочисленных операций записи и чтения значительно ускоряет работу программы.
Для закрытия файла используется функция fclose с прототипом
В случае успеха функция fclose возвращает ноль, при ошибке — отрицательное значение (точнее, константу конец файла EOF, определенную в системных заголовочных файлах как минус единица). При ошибке можно воспользоваться функцией perror, чтобы напечатать причину ошибки. Отметим, что ошибка при закрытии файла — явление очень редкое (чего не скажешь в отношении открытия файла), так что анализировать значение, возвращаемое функцией fclose, в общем-то, не обязательно. Пример использования функции fclose:
FILE *f;
f = fopen("tmp.res", "wb"); // Открываем файл "tmp.res"
if (f == 0) { // При ошибке открытия файла
// Напечатать сообщение об ошибке
perror("Не могу открыть файл для записи");
exit(1); // завершить работу программы с кодом 1
}
. . .
// Закрываем файл
if (fclose(f) < 0) {
// Напечатать сообщение об ошибке
perror("Ошибка при закрытии файла");
}
Пример: подсчет числа символов и строк в текстовом файле
В качестве содержательного примера использования рассмотренных выше функций файлового ввода приведем программу, которая подсчитывает число символов и строк в текстовом файле. Программа сначала вводит имя файла с клавиатуры. Для этого используется функция scanf ввода по формату из входного потока, для ввода строки применяется формат » %s. Затем файл открывается на чтение как бинарный (это означает, что при чтении не будет происходить никакого преобразования разделителей строк). Используя в цикле функцию чтения fread, мы считываем содержимое файла порциями по 512 байтов, каждый раз увеличивая суммарное число прочитанных символов. После чтения очередной порции сканируется массив прочитанных символов и подсчитывается число символов » n » продергивания бумаги, которые записаны в концах строк текстовых файлов как в системе Unix, так и в MS DOS или MS Windows. В конце закрывается файл и печатается результат.
//
// Файл "wc.cpp"
// Подсчет числа символов и строк в текстовом файле
//
#include <stdio.h> // Описания функций ввода-вывода
#include <stdlib.h> // Описание функции exit
int main() {
char fileName[256]; // Путь к файлу
FILE *f; // Структура, описывающая файл
char buff[512]; // Массив для ввода символов
size_t num; // Число прочитанных символов
int numChars = 0; // Суммарное число символов := 0
int numLines = 0; // Суммарное число строк := 0
int i; // Переменная цикла
printf("Введите имя файла: ");
scanf("%s", fileName);
f = fopen(fileName, "rb"); // Открываем файл на чтение
if (f == 0) { // При ошибке открытия файла
// Напечатать сообщение об ошибке
perror("Не могу открыть файл для чтения");
exit(1); // закончить работу программы с кодом 1
// ошибочного завершения
}
while ((num = fread(buff, 1, 512, f)) > 0) { // Читаем
// блок из 512 символов. num -- число реально
// прочитанных символов. Цикл продолжается, пока
// num > 0
numChars += num; // Увеличиваем число символов
// Подсчитываем число символов перевода строки
for (i = 0; i < num; ++i) {
if (buff[i] == 'n') {
++numLines; // Увеличиваем число строк
}
}
}
fclose(f);
// Печатаем результат
printf("Число символов в файле = %dn", numChars);
printf("Число строк в файле = %dn", numLines);
return 0; // Возвращаем код успешного завершения
}
Пример выполнения программы: она применяется к собственному тексту, записанному в файле «wc.cpp.
Введите имя файла: wc.cpp Число символов в файле = 1635 Число строк в файле = 50
Форматный ввод-вывод: функции fscanf и fprintf
В отличие от функции бинарного ввода fread, которая вводит байты из файла без всякого преобразования непосредственно в память компьютера, функция форматного ввода fscanf предназначена для ввода информации с преобразованием ее из текстового представления в бинарное. Пусть информация записана в текстовом файле в привычном для человека виде (т.е. так, что ее можно прочитать или ввести в файл, используя текстовый редактор). Функция fscanf читает информацию из текстового файла и преобразует ее во внутреннее представление данных в памяти компьютера. Информация о количестве читаемых элементов, их типах и особенностях представления задается с помощью формата. В случае функции ввода формат — это строка, содержащая описания одного или нескольких вводимых элементов. Форматы, используемые функцией fscanf, аналогичны применяемым функцией scanf, они уже неоднократно рассматривались (см. раздел 3.5.4). Каждый элемент формата начинается с символа процента » % «. Наиболее часто используемые при вводе форматы приведены в таблице:
| %d | целое десятичное число типа int (d — от decimal) |
| %lf | вещ. число типа double (lf — от long float) |
| %c | один символ типа char |
| %s | ввод строки. Из входного потока выделяется слово, ограниченное пробелами или символами перевода строки ‘n’. Слово помещается в массив символов. Конец слова отмечается нулевым байтом. |
Прототип функции fscanf выглядит следующим образом:
int fscanf(FILE *f, const char *format, ...);
Многоточие здесь означает, что функция имеет переменное число аргументов, большее двух, и что количество и типы аргументов, начиная с третьего, произвольны. На самом деле, фактические аргументы, начиная с третьего, должны быть указателями на вводимые переменные. Несколько примеров использования функции fscanf:
int n, m; double a; char c; char str[256];
FILE *f;
. . .
fscanf(f, "%d", &n); // Ввод целого числа
fscanf(f, "%lf", &a); // Ввод вещественного числа
fscanf(f, "%c", &c); // Ввод одного символа
fscanf(f, "%s", str); // Ввод строки (выделяется очередное
// слово из входного потока)
fscanf(f, "%d%d", &n, &m); // Ввод двух целых чисел
Функция fscanf возвращает число успешно введенных элементов. Таким образом, возвращаемое значение всегда меньше или равно количеству процентов внутри форматной строки (которое равно числу фактических аргументов минус 2).
Функция fprintf используется для форматного вывода в файл. Данные при выводе преобразуются в их текстовое представление в соответствии с форматной строкой. Ее отличие от форматной строки, используемой в функции ввода fscanf, заключается в том, что она может содержать не только форматы для преобразования данных, но и обычные символы, которые записываются без преобразования в файл. Форматы, как и в случае функции fscanf, начинаются с символа процента » % «. Они аналогичны форматам, используемым функцией fscanf. Небольшое отличие заключается в том, что форматы функции fprintf позволяют также управлять представлением данных, например, указывать количество позиций, отводимых под запись числа, или количество цифр после десятичной точки при выводе вещественного числа. Некоторые типичные примеры форматов для вывода приведены в следующей таблице:
| %d | вывод целого десятичного числа |
| %10d | вывод целого десятичного числа, для записи числа отводится 10 позиций, запись при необходимости дополняется пробелами слева |
| %lf | вывод вещественного число типа double в форме с фиксированной десятичной точкой |
| %.3lf | вывод вещественного число типа double с печатью трёх знаков после десятичной точки |
| %12.3lf | вывод вещественного число типа double с тремя знаками после десятичной точки, под число отводится 12 позиций |
| %c | вывод одного символа |
| %s | конец строки, т.е. массива символов. Конец строки задается нулевым байтом |
Прототип функции fprintf выглядит следующим образом:
int fprintf(FILE *f, const char *format, …);
Многоточие, как и в случае функции fscanf, означает, что функция имеет переменное число аргументов. Количество и типы аргументов, начиная с третьего, должны соответствовать форматной строке. В отличие от функции fscanf, фактические аргументы, начиная с третьего, представляют собой выводимые значения, а не указатели на переменные. Для примера рассмотрим небольшую программу, выводящую данные в файл «tmp.dat»:
#include <stdio.h> // Описания функций ввода вывода
#include <math.h> // Описания математических функций
#include <string.h> // Описания функций работы со строками
int main() {
int n = 4, m = 6; double x = 2.;
char str[256] = "Print test";
FILE *f = fopen("tmp.dat", "wt"); // Открыть файл
if (f == 0) { // для записи
perror("Не могу открыть файл для записи");
return 1; // Завершить программу с кодом ошибки
}
fprintf(f, "n=%d, m=%dn", m, n);
fprintf(f, "x=%.4lf, sqrt(x)=%.4lfn", x, sqrt(x));
fprintf(
f, "Строка "%s" содержит %d символов.n",
str, strlen(str)
);
fclose(f); // Закрыть файл
return 0; // Успешное завершение программы
}
В результате выполнения этой программы в файл «tmp.dat» будет записан следующий текст:
n=6, m=4 x=2.0000, sqrt(x)=1.4142 Строка "Print test" содержит 10 символов.
В последнем примере форматная строка содержит внутри себя двойные апострофы. Это специальные символы, выполняющие роль ограничителей строки, поэтому внутри строки их надо экранировать (т.е. защищать от интерпретации как специальных символов) с помощью обратной косой черты , которая, напомним, в системе Unix и в языке Си выполняет роль защитного символа. Отметим также, что мы воспользовались стандартной функцией sqrt, вычисляющей квадратный корень числа, и стандартной функцией strlen, вычисляющей длину строки.
Понятие потока ввода или вывода
В операционной системе Unix и в других системах, использующих идеи системы Unix (например, MS DOS и MS Windows), применяется понятие потока ввода или вывода. Поток представляет собой последовательность байтов. Различают потоки ввода и вывода. Программа может читать данные из потока ввода и выводить данные в поток вывода. Программы можно запускать в конвейере, когда поток вывода первой программы является потоком ввода второй программы и т.д. Для запуска двух программ в конвейере используется символ вертикальной черты | между именами программ в командной строке. Например, командная строка
означает, что поток вывода программы ab направляется на вход программе cd, а поток вывода программы cd — на вход программе ef. По умолчанию, потоком ввода для программы является клавиатура, поток вывода назначен на терминал (или, как говорят программисты, на консоль). Потоки можно перенаправлять в файл или из файла, используя символы больше > и меньше <, которые можно представлять как воронки. Например, командная строка
перенаправляет выходной поток программы abcd в файл «tmp.res», т.е. данные будут выводиться в файл вместо печати на экране терминала. Соответственно, командная строка
заставляет программу abcd читать исходные данные из файла «tmp.dat» вместо ввода с клавиатуры. Командная строка
перенаправляет как входной, так и выходной потоки: входной назначается на файл «tmp.dat», выходной — на файл «tmp.res».
В Си работа с потоком не отличается от работы с файлом. Доступ к потоку осуществляется с помощью переменной типа FILE *. В момент начала работы Си-программы открыты три потока:
- stdin — стандартный входной поток. По умолчанию он назначен на клавиатуру;
- stdout — стандартный выходной поток. По умолчанию он назначен на экран терминала;
- stderr — выходной поток для печати информации об ошибках. Он также назначен по умолчанию на экран терминала.
Переменные stdin, stdout, stderr являются глобальными, они описаны в стандартном заголовочном файле «stdio.h. Операции файлового ввода-вывода могут использовать эти потоки, например, строка
вводит значение целочисленной переменной n из входного потока. Строка
fprintf(stdout, "n = %dn", n);
выводит значение переменой n в выходной поток. Строка
fprintf(stderr, "Ошибка при открытии файлаn");
выводит указанный текст в поток stderr, используемый обычно для печати сообщений об ошибках. Функция perror также выводит сообщения об ошибках в поток stderr.
По умолчанию, стандартный выходной поток и выходной поток для печати ошибок назначены на экран терминала. Однако операция перенаправления вывода в файл > действует только на стандартный выходной поток. Например, в результате выполнения командной строки
обычный вывод программы abcd будет записываться в файл «tmp.res», а сообщения об ошибках по-прежнему будут печататься на экране терминала. Для того чтобы перенаправить в файл «tmp.log» стандартный поток печати ошибок, следует использовать командную строку
(между двойкой и символом > не должно быть пробелов!). Двойка здесь означает номер перенаправляемого потока. Стандартный входной поток имеет номер 0, стандартный выходной поток — номер 1, стандартный поток печати ошибок — номер 2. Данная команда перенаправляет только поток stderr, поток stdout по-прежнему будет выводиться на терминал. Можно перенаправить потоки в разные файлы:
abcd 2> tmp.log > tmp.res
Таким образом, существование двух разных потоков вывода позволяет при необходимости отделить мух от котлет, т.е. направить нормальный вывод и вывод информации об ошибках в разные файлы.
Функции scanf и printf ввода и вывода в стандартные потоки
Поскольку ввод из стандартного входного потока, по умолчанию назначенного на клавиатуру, и вывод в стандартный выходной поток, по умолчанию назначенный на экран терминала, используются особенно часто, библиотека функций ввода-вывода Си предоставляет для работы с этими потоками функции scanf и printf. Они отличаются от функций fscanf и fprintf только тем, что у них отсутствует первый аргумент, означающий поток ввода или вывода. Строка
scanf(format, ...); // Ввод из станд. входного потока
эквивалентна строке
fscanf(stdin, format, ...); // Ввод из потока stdin
Аналогично, строка
printf(format, ...); // Вывод в станд. выходной поток
эквивалентна строке
fprintf(stdout, format, ...); // Вывод в поток stdout
Функции текстового преобразования sscanf и sprintf
Стандартная библиотека ввода-вывода Си предоставляет также две замечательные функции sscanf и sprintf ввода и вывода не в файл или поток, а в строку символов (т.е. массив байтов), расположенную в памяти компьютера. Мнемоника названий функций следующая: в названии функции fscanf первая буква f означает файл (file), т.е. ввод производится из файла; соответственно, в названии функции sscanf первая буква s означает строку (string), т.е. ввод производится из текстовой строки. (Последняя буква f в названиях этих функций означает форматный). Первым аргументом функций sscanf и sprintf является строка (т.е. массив символов, ограниченный нулевым байтом), из которой производится ввод или в которую производится вывод. Эта строка как бы стоит на месте файла в функциях fscanf и fprintf.
Функции sscanf и sprintf удобны для преобразования данных из текстового представления во внутреннее и обратно. Например, в результате выполнения фрагмента
char txt[256] = "-135.76"; double x; sscanf(txt, "%lf", &x);
текстовая запись вещественного числа, содержащаяся в строке txt, преобразуется во внутреннее представление вещественного числа, результат записывается в переменную x. Обратно, при выполнения фрагмента
char txt[256]; int x = 12345; sprintf(txt, "%d", x);
значение целочисленной переменной x будет преобразовано в текстовую форму и записано в строку txt, в результате строка будет содержать текст » 12345 «, ограниченный нулевым байтом.
Для преобразования данных из текстового представления во внутреннее в стандартной библиотеке Си имеются также функции atoi и atof с прототипами
int atoi(const char *txt); // текст => int double atof(const char *txt); // текст => double
Функция atoi преобразует текстовое представление целого числа типа int во внутреннее. Соответственно, функция atof преобразует текстовое представление вещественного числа типа double. Мнемоника имен следующая:
- atoi означает «character to integer»;
- atof означает «character to float».
(В последнем случае float следует понимать как плавающее, т.е. вещественное, число, имеющее тип double, а вовсе не float! Тип float является атавизмом и практически не используется.)
Прототипы функций atoi и atof описаны в стандартном заголовочном файле » stdlib.h «, а не «stdio.h», поэтому при их использовании надо подключать этот файл:
(вообще-то, это можно делать всегда, поскольку «stdlib.h» содержит описания многих полезных функций, например, функции завершения программы exit, генератора случайных чисел rand и др.).
Отметим, что аналогов функции sprintf для обратного преобразования из внутреннего в текстовое представление в стандартной библиотеке Си нет. Компилятор Си фирмы Borland предоставляет функции itoa и ftoa, однако, эти функции не входят в стандарт и другими компиляторами не поддерживаются, поэтому пользоваться ими не следует.
Другие полезные функции ввода-вывода
Стандартная библиотека ввода-вывода Си содержит ряд других полезных функций ввода-вывода. Отметим некоторые из них.
| int fgetc(FILE *f); | ввести символ из потока f |
| int fputc(int c, FILE *f); | вывести символ в поток f |
| char *fgets(char *line,int size, FILE *f); | ввести строку из потока f |
| char *fputs(char *line, FILE *f); | вывести строку в поток f |
| int fseek(FILE *f, long offset, int whence); | установить текущую позицию в файле f |
| long ftell(FILE *f); | получить текущую позицию в файле f |
| int feof(FILE *f); | проверить,достигнут ли конец файла f |
Функция fgetc возвращает код введенного символа или константу EOF (определенную как минус единицу) в случае конца файла или ошибки чтения. Функция fputc записывает один символ в файл. При ошибке fputc возвращает константу EOF (т.е. отрицательное значение), в случае удачи — код выведенного символа c (неотрицательное значение).
В качестве примера использования функции fgetc перепишем рассмотренную ранее программу wc, подсчитывающую число символов и строк в текстовом файле:
//
// Файл "wc1.cpp"
// Подсчет числа символов и строк в текстовом файле
// с использованием функции чтения символа fgetc
//
#include <stdio.h> // Описания функций ввода-вывода
int main() {
char fileName[256]; // Путь к файлу
FILE *f; // Структура, описывающая файл
int c; // Код введенного символа
int numChars = 0; // Суммарное число символов := 0
int numLines = 0; // Суммарное число строк := 0
printf("Введите имя файла: ");
scanf("%s", fileName);
f = fopen(fileName, "rb"); // Открываем файл
if (f == 0) { // При ошибке открытия файла
// Напечатать сообщение об ошибке
perror("Не могу открыть файл для чтения");
return 1; // закончить работу программы с кодом 1
}
while ((c = fgetc(f)) != EOF) { // Читаем символ
// Цикл продолжается, пока c != -1 (конец файла)
++numChars; // Увеличиваем число символов
// Подсчитываем число символов перевода строки
if (c == 'n') {
++numLines; // Увеличиваем число строк
}
}
fclose(f);
// Печатаем результат
printf("Число символов в файле = %dn", numChars);
printf("Число строк в файле = %dn", numLines);
return 0; // Возвращаем код успешного завершения
}
Пример выполнения программы wc1 в применении к собственному тексту, записанному в файле «wc1.cpp:
Введите имя файла: wc1.cpp Число символов в файле = 1334 Число строк в файле = 44
Функция fgets с прототипом
char *fgets(char *line, int size, FILE *f);
выделяет из файла или входного потока f очередную строку и записывает ее в массив символов line. Второй аргумент size указывает размер массива для записи строки. Максимальная длина строки на единицу меньше, чем size, поскольку всегда в конец считанной строки добавляется нулевой байт. Функция сканирует входной поток до тех пор, пока не встретит символ перевода строки » n » или пока число введенных символов не станет равным size — 1. Символ перевода строки » n » также записывается в массив непосредственно перед терминирующим нулевым байтом. Функция возвращает указатель line в случае успеха или нулевой указатель при ошибке или конце файла.
Раньше в стандартную библиотеку Си входила также функция gets с прототипом
которая считывала очередную строку из стандартного входного потока и помещала ее в массив, адрес которого являлся ее единственным аргументом. Отличие от функции fgets в том, что не указывается размер массива line. В результате, подав на вход функции gets очень длинную строку, можно добиться переполнения массива и стереть или подменить участок памяти, используемый программой. Если программа имеет привилегии суперпользователя, то применение в ней функции gets открывает путь к взлому системы, который использовался хакерами. Поэтому в настоящее время функция gets считается опасной и применение ее не рекомендовано. Вместо gets следует использовать fgets с третьим аргументом stdin.
При выполнении файловых операций исполняющая система поддерживает указатель текущей позиции в файле. При чтении или записи n байтов указатель текущей позиции увеличивается на n ; таким образом, чтение или запись происходят последовательно. Библиотека ввода-вывода Си предоставляет, однако, возможность нарушать эту последовательность путем позиционирования в произвольную точку файла. Для этого используется стандартная функция fseek с прототипом
int fseek(FILE *f, long offset, int whence);
Первый аргумент f функции определяет файл, для которого производится операция позиционирования. Второй аргумент offset задает смещение в байтах, оно может быть как положительным, так и отрицательным. Третий аргумент whence указывает, откуда отсчитывать смещение. Он может принимать одно из трех значений, заданных как целые константы в стандартном заголовочном файле «stdio.h»:
| SEEK_CUR | смещение отсчитывается от текущей позиции |
| SEEK_SET | смещение отсчитывается от начала файла |
| SEEK_END | смещение отсчитывается от конца файла |
Например, фрагмент
устанавливает текущую позицию в начало файла. Фрагмент
устанавливает текущую позицию в четырех байтах перед концом файла. Наконец, фрагмент
продвигает текущую позицию на 12 байтов вперед.
Отметим, что смещение может быть положительным даже при использовании константы SEEK_END (т.е. при позиционировании относительно конца файла): в этом случае при следующей записи размер файла соответственно увеличивается.
Функция возвращает нулевое значение в случае успеха и отрицательное значение EOF (равное -1) при неудаче — например, если указанное смещение некорректно при заданной операции или если файл или поток не позволяет выполнять прямое позиционирование.
Узнать текущую позицию относительно начала файла можно с помощью функции ftell с прототипом
Функция ftell возвращает текущую позицию (неотрицательное значение) в случае успеха или отрицательное значение -1 при неудаче (например, если файл не разрешает прямое позиционирование).
Наконец, узнать, находится ли текущая позиция в конце файла, можно с помощью функции feof с прототипом
Она возвращает ненулевое значение (т.е. истину), если конец файла достигнут, и нулевое значение (т.е. ложь) в противном случае. Например, в следующем фрагменте в цикле проверяется, достигнут ли конец файла, и, если нет, считывается очередной байт:
FILE *f;
. . .
while (!feof(f)) { // цикл пока не конец файла
int c = fgetc(f); // | прочесть очередной байт
. . . // | . . .
} // конец цикла