
Поскольку
выборка охватывает , как правило,
весьма незначительную часть генеральной
совокупности, то следует предполагать,
что будут иметь место различия между
оценкой и характеристикой генеральной
совокупности, которую эта оценка
отображает. Эти различия получили
название ошибок отображения или ошибок
репрезентативности. Ошибки
репрезентативности подразделяются
на два типа : систематические и случайные.
Систематические
ошибки —
это постоянное завышение или занижение
значения оценки по сравнению с
характеристикой генеральной совокупности
. Причиной появления систематической
ошибки является несоблюдение принципа
равновероятности попадания каждой
единицы генеральной совокупности в
выборку , то есть выборка формируется
из преимущественно «худших» ( или «
лучших») представителей генеральной
совокупности. Соблюдение принципа
равновозможности попадания каждой
единицы в выборку позволяет полностью
исключить этот тип ошибок .
Случайные
ошибки –
это меняющиеся
от выборки к выборке по знаку и величине
различия между оценкой и оцениваемой
характеристикой генеральной совокупности
. Причина возникновения случайных
ошибок- игра случая при формировании
выборки, составляющей лишь часть
генеральной совокупности. Этот тип
ошибок органически присущ выборочному
методу. Исключить их полностью нельзя,
задача состоит в том , чтобы предсказать
их возможную величину и свести их к
минимуму. Порядок связанных в связи
с этим действий вытекает из рассмотрения
трех видов случайных ошибок : конкретной
, средней и предельной.
2.2 Конкретная, средняя и предельная ошибки выборки
2.2.1
Конкретная
ошибка – это ошибка одной проведенной
выборки. Если средняя по этой выборке
(
![]() ) является оценкой для генеральной
) является оценкой для генеральной
средней (![]() 0
0
) и, если
предположить, что эта генеральная
средняя нам известна , то разница
![]() =
=![]()
![]() —
—![]() 0
0
и будет
конкретной ошибкой этой выборки. Если
из этой генеральной совокупности
выборку повторим многократно, то каждый
раз получим новую величину конкретной
ошибки :
![]() …,
…,
и так далее.
Относительно этих конкретных ошибок
можно сказать следующее: некоторые из
них будут совпадать между собой по
величине и знаку, то есть имеет место
распределение ошибок, часть из них
будет равна 0, наблюдается совпадение
оценки и параметра генеральной
совокупности;
2.2.2
Средняя ошибка
– это средняя квадратическая из всех
возможных по воле случая конкретных
ошибок оценки :
 ,
,
где![]() — величина меняющихся конкретных
— величина меняющихся конкретных
ошибок;![]() частота
частота
( вероятность ) встречаемости той или
иной конкретной ошибки. Средняя
ошибка выборки показывает насколько
в среднем можно ошибиться , если на
основе оценки делается суждение о
параметре генеральной совокупности.
Приведенная формула раскрывает
содержание средней ошибки, но она не
может быть использована для практических
расчетов, хотя бы потому, что предполагает
знание параметра генеральной совокупности
, что само по себе исключает необходимость
выборки.
Практические
расчеты средней ошибки оценки
основываются на той предпосылке, что
она ( средняя ошибка ) по сути является
средним квадратическим отклонением
всех возможных значений оценки. Эта
предпосылка позволяет получить алгоритмы
расчета средней ошибки, опирающиеся
на данные одной единственной выборки.
В частности средняя ошибка выборочной
средней может быть установлена на
основе следующих рассуждений. Имеется
выборка (
![]() ,
,![]()
![]() …
…![]() ) состоящая из
) состоящая из![]() единиц. По выборке в качестве оценки
единиц. По выборке в качестве оценки
генеральной средней определена
выборочная средняя . Каждое значение
. Каждое значение![]() (
(![]() ,
,![]()
![]() …
…![]() ) , стоящее под знаком суммы, следует
) , стоящее под знаком суммы, следует
рассматривать как независимую случайную
величину, поскольку при бесконечном
повторении выборки первая, вторая и
т.д. единицы могут принимать любые
значения из присутствующих в генеральной
совокупности. Следовательно Поскольку , как известно, дисперсия
Поскольку , как известно, дисперсия
суммы независимых случайных величин
равна сумме дисперсий , то![]()
 .
.
Отсюда следует, что средняя ошибка для
выборочной средней будет равная![]() и находится она в обратной зависимости
и находится она в обратной зависимости
от численности выборки ( через корень
квадратный из нее ) и в прямой от среднего
квадратического отклонения признака
в генеральной совокупности. Это логично,
поскольку выборочная средняя является
состоятельной оценкой для генеральной
средней и по мере увеличения численности
выборки приближается по своему значению
к оцениваемому параметру генеральной
совокупности. Прямая зависимость
средней ошибки от колеблемости признака
обусловлена тем, что чем больше
изменчивость признака в генеральной
совокупности, тем сложнее на основе
выборки построить адекватную модель
генеральной совокупности. На практике
среднее квадратическое отклонение
признака по генеральной совокупности
заменяется его оценкой по выборке, и
тогда формула для расчета средней
ошибки выборочной средней приобретает
вид:![]() ,
,
при этом учитывая смещенность
выборочной дисперсии ,
,
выборочное среднее квадратическое
отклонение рассчитывается по формуле![]()
 =
= . Так как символомn
. Так как символомn
обозначена численность выборки. ,то
в знаменателе при расчете среднего
квадратического отклонения должна
использоваться не численность выборки
( n
), а так называемое число степеней
свободы (n-1).
Под числом степеней свободы понимается
число единиц в совокупности, которые
могут свободно варьировать ( изменяться
), если по совокупности определена
какая-либо характеристика. В нашем
случае , поскольку по выборке определена
ее средняя, свободно варьировать могут
![]() единицы.
единицы.
В
таблице 2.2 приведены формулы для
расчета средних ошибок различных
выборочных оценок . Как видно из этой
таблицы, величина средней ошибки по
всем оценкам находится в обратной связи
с численностью выборки и в прямой с
колеблемостью. Это можно сказать и
относительно средней ошибки выборочной
доли ( частости ). Под корнем стоит
дисперсия альтернативного признака,
установленная по выборке (
![]() )
)
Приведенные
в таблице 2.2 формулы относятся к так
называемому случайному , повторному
отбору единиц в выборку. При других
способах отбора , о которых речь пойдет
ниже, формулы будут несколько
видоизменяться.
Таблица
2.2
Формулы для
расчета средних ошибок выборочных
оценок
|
Выборочные |
Формулы |
|
Выборочная |
|
|
Выборочная |
|
|
Выборочное |
|
|
Выборочная |
|
2.2.3
Предельная ошибка выборки
Знание оценки и ее средней ошибки в
ряде случаев совершенно недостаточно
. Например , при использовании гормонов
при кормлении животных знать только
средний размер неразложившихся их
вредных остатков и среднюю ошибку,
значит подвергать потребителей продукции
серьезной опасности. Здесь настоятельно
напрашивается необходимость определения
максимальной ( предельной
ошибки ).
При использовании выборочного метода
предельная ошибка устанавливается не
в виде конкретной величины , а виде
равных границ
(
интервалов) в ту и другую сторону от
значения оценки.
Определение
границ предельной ошибки основывается
на особенностях распределения конкретных
ошибок . Для так называемых больших
выборок, численность которых более 30
единиц (
![]() )
)
, конкретные ошибки распределяются в
соответствии с нормальным законом
распределения; при малых выборках (![]() ) конкретные ошибки распределяются
) конкретные ошибки распределяются
в соответствии с законом распределения
Госсета
(
Стьюдента ). Применительно к конкретным
ошибкам выборочной средней функция
нормального распределения имеет
вид:
 ,
,
где![]() — плотность вероятности появления тех
— плотность вероятности появления тех
или иных значений![]() ,
,
при условии, что![]()
 ,
,
где![]() выборочные средние;
выборочные средние;![]() —
—
генеральная средняя,![]()
![]() — средняя ошибка для выборочной
— средняя ошибка для выборочной
средней. Поскольку средняя ошибка
(![]() )
)
является величиной постоянной, то в
соответствии с нормальным законом
распределяются конкретные ошибки ,
,
выраженные в долях средней ошибки, или
так называемых нормированных отклонениях
.
Взяв
интеграл функции нормального
распределения, можно установить
вероятность того , что ошибка будет
заключена в некотором интервале
изменения t
и вероятность того, что ошибка выйдет
за пределы этого интервала ( обратное
событие ). Например , вероятность того,
что ошибка не превысит половину средней
ошибки ( в ту и другую сторону от
генеральной средней ) составляет
0,3829, что ошибка будет заключена в
пределах одной средней ошибки — 0,6827,
2-х средних ошибок -0,9545 и так далее.
Взаимосвязь
между уровнем вероятности и интервалом
изменения t
( а в конечном счете интервалом
изменения ошибки ) позволяет подойти
к определению интервала ( или границ )
предельной ошибки, увязав его величину
с вероятностью осуществления..
Вероятность осуществления -это
вероятность того, что ошибка будет
находится в некотором интервале.
Вероятность осуществления будет
«доверительной» в том случае, если
противоположное событие ( ошибка будет
находится вне интервала ) имеет такую
вероятность появления, которой можно
пренебречь. Поэтому доверительный
уровень вероятности устанавливают,
как правило, не ниже 0,90 (вероятность
противоположного события равна 0,10 ).
Чем больше негативных последствий
имеет появление ошибок вне установленного
интервала, тем выше должен быть
доверительный уровень вероятности (
0,95; 0,99 ; 0,999 и так далее ).
Выбрав
доверительный уровень вероятности
по таблице интеграла вероятности
нормального распределения, следует
найти соответствующее значение t,
а затем используя выражение
 =
=![]()
![]() определить интервал предельной ошибки
определить интервал предельной ошибки![]() .
.
Смысл полученной величины в следующем
– с принятым доверительным уровнем
вероятности предельная ошибка выборочной
средней не превысит величину![]() .
.
Для
установления границ предельной ошибки
на основе больших выборок для других
оценок ( дисперсии, среднего квадратического
отклонения, доли и так далее ) используется
выше рассмотренный подход, с учетом
того, что для определения средней
ошибки для каждой оценки используется
свой алгоритм.
Что
касается малых выборок (![]() ) то, как уже говорилось, распределение
) то, как уже говорилось, распределение
ошибок оценок соответствует в этом
случае распределениюt
— Стьюдента. Особенность этого
распределения состоит в том, что в
качестве параметра в нем , наряду с
ошибкой, присутствует численность
выборки ,вернее не численность выборки,
а число степеней свободы
![]() При увеличении численности выборки
При увеличении численности выборки
распределениеt-Стьюдента
приближается к нормальному, а при
![]() эти распределения практически совпадают.
эти распределения практически совпадают.
Сопоставляя значения величиныt-Стьюдента
и t
— нормального распределения при одной
и той же доверительной вероятности
можно сказать , что величина t-Стьюдента
всегда больше t
— нормального распределения, причем,
различия возрастают с уменьшением
численности выборки и с повышением
доверительного уровня вероятности.
Следовательно, при использовании малых
выборок имеют место по сравнению с
выборками большими , более широкие
границы предельной ошибки, причем , эти
границы расширяются с уменьшением
численности выборки и повышением
доверительного уровня вероятности.
Вопросы для
повторения
6-1.Какова
природа конкретной, средней и предельной
ошибок ?
6-2.Как
соблюсти принцип равновероятности
каждой единицы попасть в выборку при
выборочном устном опросе студентов ?
6-3 Каков источник
систематической ошибки ?
6-4.Какова
вероятность появления ошибки в 2.5 раза
превышающей среднюю?
6-5.Какие
различия в знаках ( + , — ) имеют
систематические и случайные ошибки?
6-6.Каковы основные
пути уменьшения средней и предельной
ошибки ?
6-7.При какой
выборочной доле имеет место ее наибольшая
ошибка ?
6-8.При какой доле
признака имеет место ее наименьшая
ошибка 7
6-9.При
каких выборках ( больших или малых )
при прочих равных условиях имеет место
большая предельная ошибка ?
Резюме по
модульной единице 2
Использование
выборочного метода неизбежно сопряжено
с появлением ошибок. Случайный характер
этих ошибок, нормальный или t
— Стьюдента закон их распределения
позволяет определить их средний и
предельный размер и видеть пути их
снижения
Модульная
единица 3 Типовые задачи решаемые на
основе выборочного метода
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Two Types of Experimental Error
No matter how careful you are, there is always error in a measurement. Error is not a «mistake»—it’s part of the measuring process. In science, measurement error is called experimental error or observational error.
There are two broad classes of observational errors: random error and systematic error. Random error varies unpredictably from one measurement to another, while systematic error has the same value or proportion for every measurement. Random errors are unavoidable, but cluster around the true value. Systematic error can often be avoided by calibrating equipment, but if left uncorrected, can lead to measurements far from the true value.
Key Takeaways
- Random error causes one measurement to differ slightly from the next. It comes from unpredictable changes during an experiment.
- Systematic error always affects measurements the same amount or by the same proportion, provided that a reading is taken the same way each time. It is predictable.
- Random errors cannot be eliminated from an experiment, but most systematic errors can be reduced.
Random Error Example and Causes
If you take multiple measurements, the values cluster around the true value. Thus, random error primarily affects precision. Typically, random error affects the last significant digit of a measurement.
The main reasons for random error are limitations of instruments, environmental factors, and slight variations in procedure. For example:
- When weighing yourself on a scale, you position yourself slightly differently each time.
- When taking a volume reading in a flask, you may read the value from a different angle each time.
- Measuring the mass of a sample on an analytical balance may produce different values as air currents affect the balance or as water enters and leaves the specimen.
- Measuring your height is affected by minor posture changes.
- Measuring wind velocity depends on the height and time at which a measurement is taken. Multiple readings must be taken and averaged because gusts and changes in direction affect the value.
- Readings must be estimated when they fall between marks on a scale or when the thickness of a measurement marking is taken into account.
Because random error always occurs and cannot be predicted, it’s important to take multiple data points and average them to get a sense of the amount of variation and estimate the true value.
Systematic Error Example and Causes
Systematic error is predictable and either constant or else proportional to the measurement. Systematic errors primarily influence a measurement’s accuracy.
Typical causes of systematic error include observational error, imperfect instrument calibration, and environmental interference. For example:
- Forgetting to tare or zero a balance produces mass measurements that are always «off» by the same amount. An error caused by not setting an instrument to zero prior to its use is called an offset error.
- Not reading the meniscus at eye level for a volume measurement will always result in an inaccurate reading. The value will be consistently low or high, depending on whether the reading is taken from above or below the mark.
- Measuring length with a metal ruler will give a different result at a cold temperature than at a hot temperature, due to thermal expansion of the material.
- An improperly calibrated thermometer may give accurate readings within a certain temperature range, but become inaccurate at higher or lower temperatures.
- Measured distance is different using a new cloth measuring tape versus an older, stretched one. Proportional errors of this type are called scale factor errors.
- Drift occurs when successive readings become consistently lower or higher over time. Electronic equipment tends to be susceptible to drift. Many other instruments are affected by (usually positive) drift, as the device warms up.
Once its cause is identified, systematic error may be reduced to an extent. Systematic error can be minimized by routinely calibrating equipment, using controls in experiments, warming up instruments prior to taking readings, and comparing values against standards.
While random errors can be minimized by increasing sample size and averaging data, it’s harder to compensate for systematic error. The best way to avoid systematic error is to be familiar with the limitations of instruments and experienced with their correct use.
Key Takeaways: Random Error vs. Systematic Error
- The two main types of measurement error are random error and systematic error.
- Random error causes one measurement to differ slightly from the next. It comes from unpredictable changes during an experiment.
- Systematic error always affects measurements the same amount or by the same proportion, provided that a reading is taken the same way each time. It is predictable.
- Random errors cannot be eliminated from an experiment, but most systematic errors may be reduced.
Sources
- Bland, J. Martin, and Douglas G. Altman (1996). «Statistics Notes: Measurement Error.» BMJ 313.7059: 744.
- Cochran, W. G. (1968). «Errors of Measurement in Statistics». Technometrics. Taylor & Francis, Ltd. on behalf of American Statistical Association and American Society for Quality. 10: 637–666. doi:10.2307/1267450
- Dodge, Y. (2003). The Oxford Dictionary of Statistical Terms. OUP. ISBN 0-19-920613-9.
- Taylor, J. R. (1999). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. University Science Books. p. 94. ISBN 0-935702-75-X.
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
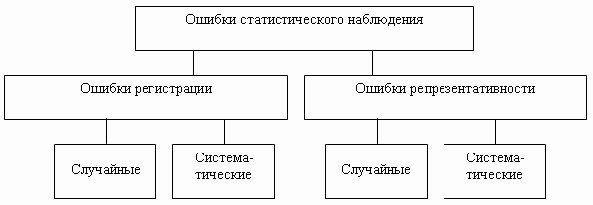
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
Ошибки в статистике
Ошибки в статистике (сплошных и выборочных) могут возникнуть ошибки двух видов: репрезентативности и регистрации.
Ошибки репрезентативности характерны только для выборочного наблюдения и возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Они определяются как расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном сплошном наблюдении с одинаковой степенью точности.
Ошибки регистрации могут иметь случайный, систематический и непреднамеренный характер.
Случайные ошибки часто уравновешивают друг друга, так как они не имеют преимущественного направления в сторону преувеличения (преуменьшении) значения изучаемого показателя. Данные ошибки имеют объективный характер и возникают в следствии случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности. В результате и структуры этих совокупностей чаще всего не совпадают. Научным обоснованием случайных ошибок являются теория вероятностей и ее предельные теоремы.
Систематические ошибки направлены в одну сторону в результате предумышленного нарушения правил отбора. Их можно избежать при правильной организации и проведении наблюдения.
Ошибка выборки в статистике
Ошибка выборки или ошибка репрезентативности определяется как разница между значением показателя, который был получен по выборке, и генеральным параметром. Она характерна только для выборочных наблюдений. Чем больше значение этой ошибки, тем в большей степени выборочные показатели отличаются от соответствующих им генеральных показателей.
Ошибку выборки часто определяют по формулам:
1. Для среднего количественного признака:

где первое — среднее значение признака в генеральной совокупности или генеральная средняя;
второе — выборочная средняя.
2. Для доли (альтернативного признака):

где w — выборочная доля;
р — генеральная доля, или доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности.
Ошибки выборки возникают вследствие двух причин из-за нарушения принципа случайности как основного принципа выборки (систематические ошибки) и в результате случайного отбора (случайные ошибки). Выборки являются случайными величинами и могут принимать разные значения.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.