
Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





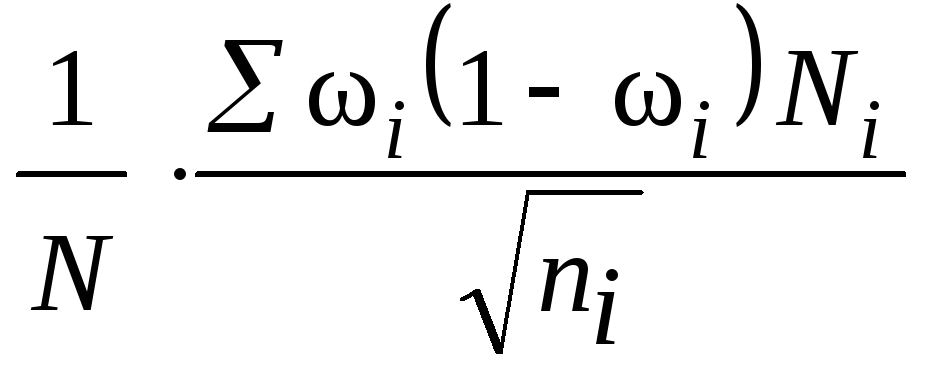


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
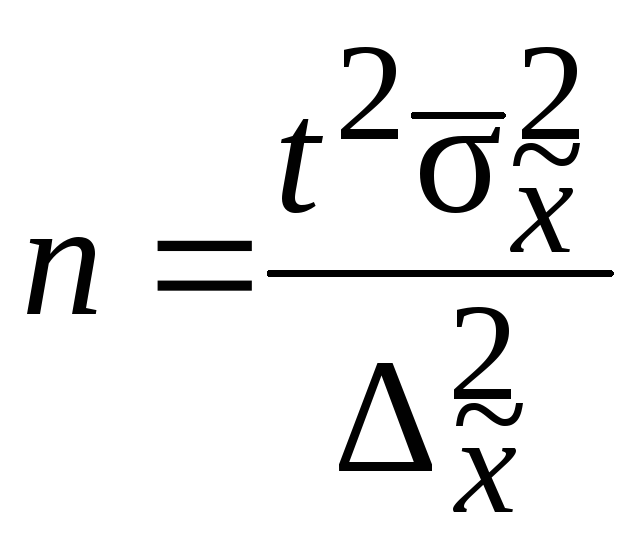

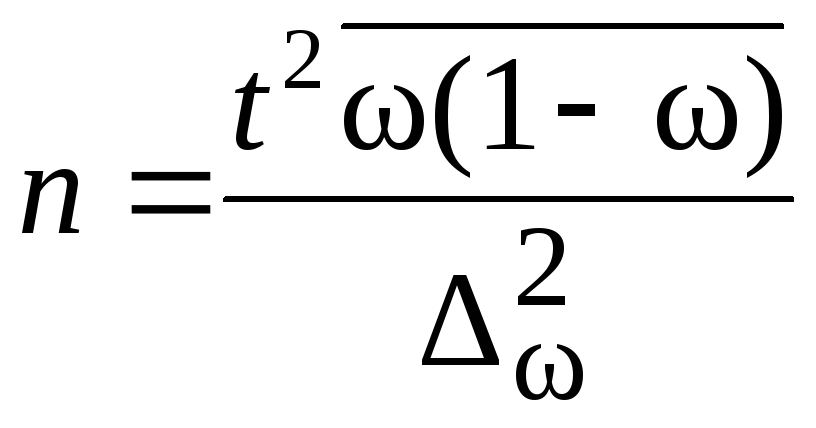

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
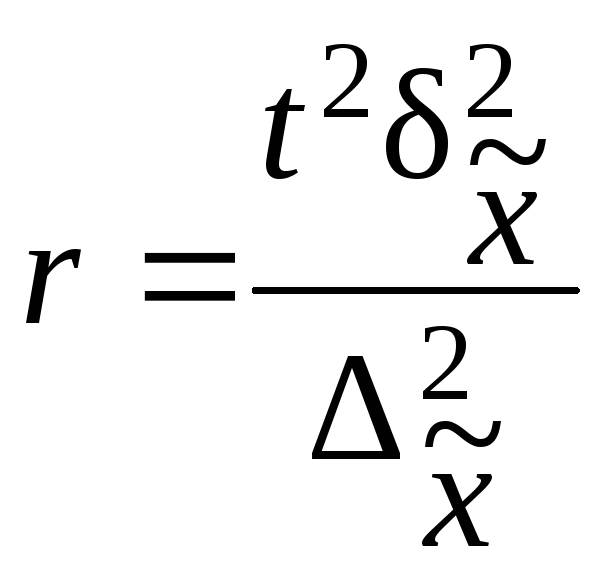

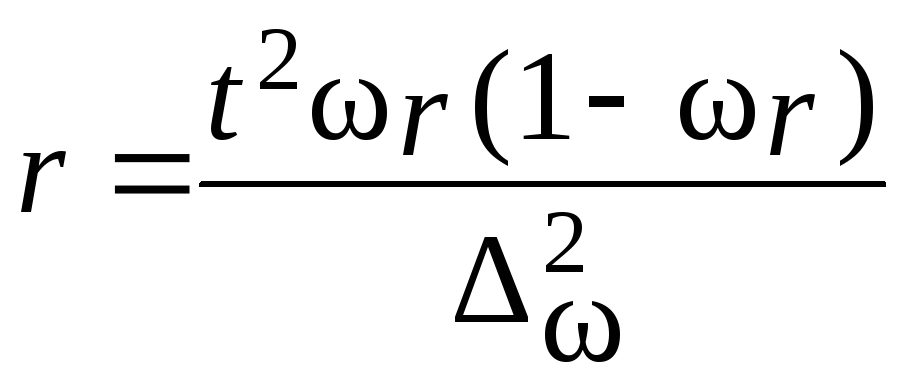

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Аналитика бизнеса
- Методы анализа данных Data Mining
- Выборка. Типы выборок
Оглавление
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы анкеты (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов, наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы (страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности, типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60 лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки используются в маркетинговых исследованиях достаточно часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход, респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром – активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает проблема выбора признака и определения его типичного значения.
Почитать еще



Машинное обучение
Глубокое обучение – это продвинутая форма машинного обучения. Глубокое обучение относится к способности компьютерных систем, известных


Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков


Обзор основных видов сегментации
Загрузить программу ВІ Демонстрации решений Аналитика бизнеса Оглавление Сегментация бренда Сегментация помогает принимать более эффективные


Несколько видео о наших продуктах

Проиграть видео
Презентация аналитической платформы Tibco Spotfire

Проиграть видео
Отличительные особенности Tibco Spotfire 10X

Проиграть видео
Как аналитика данных помогает менеджерам компании