
In information theory, a low-density parity-check (LDPC) code is a linear error correcting code, a method of transmitting a message over a noisy transmission channel.[1][2] An LDPC code is constructed using a sparse Tanner graph (subclass of the bipartite graph).[3] LDPC codes are capacity-approaching codes, which means that practical constructions exist that allow the noise threshold to be set very close to the theoretical maximum (the Shannon limit) for a symmetric memoryless channel. The noise threshold defines an upper bound for the channel noise, up to which the probability of lost information can be made as small as desired. Using iterative belief propagation techniques, LDPC codes can be decoded in time linear to their block length.
LDPC codes are finding increasing use in applications requiring reliable and highly efficient information transfer over bandwidth-constrained or return-channel-constrained links in the presence of corrupting noise. Implementation of LDPC codes has lagged behind that of other codes, notably turbo codes. The fundamental patent for turbo codes expired on August 29, 2013.[4][5]
LDPC codes are also known as Gallager codes, in honor of Robert G. Gallager, who developed the LDPC concept in his doctoral dissertation at the Massachusetts Institute of Technology in 1960.[6][7] LDPC codes have also been shown to have ideal combinatorial properties. In his dissertation, Gallager showed that LDPC codes achieve the Gilbert–Varshamov bound for linear codes over binary fields with high probability. In 2020 it was shown that Gallager’s LDPC codes achieve list decoding capacity and also achieve the Gilbert–Varshamov bound for linear codes over general fields. [8]
History[edit]
Impractical to implement when first developed by Gallager in 1963,[9] LDPC codes were forgotten until his work was rediscovered in 1996.[10] Turbo codes, another class of capacity-approaching codes discovered in 1993, became the coding scheme of choice in the late 1990s, used for applications such as the Deep Space Network and satellite communications. However, the advances in low-density parity-check codes have seen them surpass turbo codes in terms of error floor and performance in the higher code rate range, leaving turbo codes better suited for the lower code rates only.[11]
Applications[edit]
In 2003, an irregular repeat accumulate (IRA) style LDPC code beat six turbo codes to become the error-correcting code in the new DVB-S2 standard for digital television.[12] The DVB-S2 selection committee made decoder complexity estimates for the turbo code proposals using a much less efficient serial decoder architecture rather than a parallel decoder architecture. This forced the turbo code proposals to use frame sizes on the order of one half the frame size of the LDPC proposals.[citation needed]
In 2008, LDPC beat convolutional turbo codes as the forward error correction (FEC) system for the ITU-T G.hn standard.[13] G.hn chose LDPC codes over turbo codes because of their lower decoding complexity (especially when operating at data rates close to 1.0 Gbit/s) and because the proposed turbo codes exhibited a significant error floor at the desired range of operation.[14]
LDPC codes are also used for 10GBASE-T Ethernet, which sends data at 10 gigabits per second over twisted-pair cables. As of 2009, LDPC codes are also part of the Wi-Fi 802.11 standard as an optional part of 802.11n and 802.11ac, in the High Throughput (HT) PHY specification.[15] LDPC is a mandatory part of 802.11ax (Wi-Fi 6).[16]
Some OFDM systems add an additional outer error correction that fixes the occasional errors (the «error floor») that get past the LDPC correction inner code even at low bit error rates.
For example:
The Reed-Solomon code with LDPC Coded Modulation (RS-LCM) uses a Reed-Solomon outer code.[17] The DVB-S2, the DVB-T2 and the DVB-C2 standards all use a BCH code outer code to mop up residual errors after LDPC decoding.[18]
5G NR uses polar code for the control channels and LDPC for the data channels.[19][20]
Although LDPC code has had its success in commercial hard disk drives, to fully exploit its error correction capability in SSDs demands unconventional fine-grained flash memory sensing, leading to an increased memory read latency. LDPC-in-SSD[21] is an effective approach to deploy LDPC in SSD with a very small latency increase, which turns LDPC in SSD into a reality. Since then, LDPC has been widely adopted in commercial SSDs in both customer-grades and enterprise-grades by major storage venders. Many TLC (and later) SSDs are using LDPC codes. A fast hard-decode (binary erasure) is first attempted, which can fall back into the slower but more powerful soft decoding.[22]
Operational use[edit]
LDPC codes functionally are defined by a sparse parity-check matrix. This sparse matrix is often randomly generated, subject to the sparsity constraints—LDPC code construction is discussed later. These codes were first designed by Robert Gallager in 1960.[7]
Below is a graph fragment of an example LDPC code using Forney’s factor graph notation. In this graph, n variable nodes in the top of the graph are connected to (n−k) constraint nodes in the bottom of the graph.
This is a popular way of graphically representing an (n, k) LDPC code. The bits of a valid message, when placed on the T’s at the top of the graph, satisfy the graphical constraints. Specifically, all lines connecting to a variable node (box with an ‘=’ sign) have the same value, and all values connecting to a factor node (box with a ‘+’ sign) must sum, modulo two, to zero (in other words, they must sum to an even number; or there must be an even number of odd values).
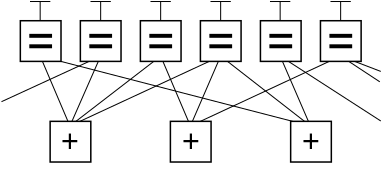
Ignoring any lines going out of the picture, there are eight possible six-bit strings corresponding to valid codewords: (i.e., 000000, 011001, 110010, 101011, 111100, 100101, 001110, 010111). This LDPC code fragment represents a three-bit message encoded as six bits. Redundancy is used, here, to increase the chance of recovering from channel errors. This is a (6, 3) linear code, with n = 6 and k = 3.
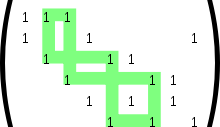
Again ignoring lines going out of the picture, the parity-check matrix representing this graph fragment is

In this matrix, each row represents one of the three parity-check constraints, while each column represents one of the six bits in the received codeword.
In this example, the eight codewords can be obtained by putting the parity-check matrix H into this form  through basic row operations in GF(2):
through basic row operations in GF(2):

Step 1: H.
Step 2: Row 1 is added to row 3.
Step 3: Row 2 and 3 are swapped.
Step 4: Row 1 is added to row 3.
From this, the generator matrix G can be obtained as  (noting that in the special case of this being a binary code
(noting that in the special case of this being a binary code  ), or specifically:
), or specifically:

Finally, by multiplying all eight possible 3-bit strings by G, all eight valid codewords are obtained. For example, the codeword for the bit-string ‘101’ is obtained by:
 ,
,

where  is symbol of mod 2 multiplication.
is symbol of mod 2 multiplication.
As a check, the row space of G is orthogonal to H such that 
The bit-string ‘101’ is found in as the first 3 bits of the codeword ‘101011’.
Example encoder[edit]

During the encoding of a frame, the input data bits (D) are repeated and distributed to a set of constituent encoders. The constituent encoders are typically accumulators and each accumulator is used to generate a parity symbol. A single copy of the original data (S0,K-1) is transmitted with the parity bits (P) to make up the code symbols. The S bits from each constituent encoder are discarded.
The parity bit may be used within another constituent code.
In an example using the DVB-S2 rate 2/3 code the encoded block size is 64800 symbols (N=64800) with 43200 data bits (K=43200) and 21600 parity bits (M=21600). Each constituent code (check node) encodes 16 data bits except for the first parity bit which encodes 8 data bits. The first 4680 data bits are repeated 13 times (used in 13 parity codes), while the remaining data bits are used in 3 parity codes (irregular LDPC code).
For comparison, classic turbo codes typically use two constituent codes configured in parallel, each of which encodes the entire input block (K) of data bits. These constituent encoders are recursive convolutional codes (RSC) of moderate depth (8 or 16 states) that are separated by a code interleaver which interleaves one copy of the frame.
The LDPC code, in contrast, uses many low depth constituent codes (accumulators) in parallel, each of which encode only a small portion of the input frame. The many constituent codes can be viewed as many low depth (2 state) «convolutional codes» that are connected via the repeat and distribute operations. The repeat and distribute operations perform the function of the interleaver in the turbo code.
The ability to more precisely manage the connections of the various constituent codes and the level of redundancy for each input bit give more flexibility in the design of LDPC codes, which can lead to better performance than turbo codes in some instances. Turbo codes still seem to perform better than LDPCs at low code rates, or at least the design of well performing low rate codes is easier for turbo codes.
As a practical matter, the hardware that forms the accumulators is reused during the encoding process. That is, once a first set of parity bits are generated and the parity bits stored, the same accumulator hardware is used to generate a next set of parity bits.
Decoding[edit]
As with other codes, the maximum likelihood decoding of an LDPC code on the binary symmetric channel is an NP-complete problem. Performing optimal decoding for a NP-complete code of any useful size is not practical.
However, sub-optimal techniques based on iterative belief propagation decoding give excellent results and can be practically implemented. The sub-optimal decoding techniques view each parity check that makes up the LDPC as an independent single parity check (SPC) code. Each SPC code is decoded separately using soft-in-soft-out (SISO) techniques such as SOVA, BCJR, MAP, and other derivates thereof. The soft decision information from each SISO decoding is cross-checked and updated with other redundant SPC decodings of the same information bit. Each SPC code is then decoded again using the updated soft decision information. This process is iterated until a valid codeword is achieved or decoding is exhausted. This type of decoding is often referred to as sum-product decoding.
The decoding of the SPC codes is often referred to as the «check node» processing, and the cross-checking of the variables is often referred to as the «variable-node» processing.
In a practical LDPC decoder implementation, sets of SPC codes are decoded in parallel to increase throughput.
In contrast, belief propagation on the binary erasure channel is particularly simple where it consists of iterative constraint satisfaction.
For example, consider that the valid codeword, 101011, from the example above, is transmitted across a binary erasure channel and received with the first and fourth bit erased to yield ?01?11. Since the transmitted message must have satisfied the code constraints, the message can be represented by writing the received message on the top of the factor graph.
In this example, the first bit cannot yet be recovered, because all of the constraints connected to it have more than one unknown bit. In order to proceed with decoding the message, constraints connecting to only one of the erased bits must be identified. In this example, only the second constraint suffices. Examining the second constraint, the fourth bit must have been zero, since only a zero in that position would satisfy the constraint.
This procedure is then iterated. The new value for the fourth bit can now be used in conjunction with the first constraint to recover the first bit as seen below. This means that the first bit must be a one to satisfy the leftmost constraint.

Thus, the message can be decoded iteratively. For other channel models, the messages passed between the variable nodes and check nodes are real numbers, which express probabilities and likelihoods of belief.
This result can be validated by multiplying the corrected codeword r by the parity-check matrix H:

Because the outcome z (the syndrome) of this operation is the three × one zero vector, the resulting codeword r is successfully validated.
After the decoding is completed, the original message bits ‘101’ can be extracted by looking at the first 3 bits of the codeword.
While illustrative, this erasure example does not show the use of soft-decision decoding or soft-decision message passing, which is used in virtually all commercial LDPC decoders.
Updating node information[edit]
In recent years[when?], there has also been a great deal of work spent studying the effects of alternative schedules for variable-node and constraint-node update. The original technique that was used for decoding LDPC codes was known as flooding. This type of update required that, before updating a variable node, all constraint nodes needed to be updated and vice versa. In later work by Vila Casado et al.,[23] alternative update techniques were studied, in which variable nodes are updated with the newest available check-node information.[citation needed]
The intuition behind these algorithms is that variable nodes whose values vary the most are the ones that need to be updated first. Highly reliable nodes, whose log-likelihood ratio (LLR) magnitude is large and does not change significantly from one update to the next, do not require updates with the same frequency as other nodes, whose sign and magnitude fluctuate more widely.[citation needed]
These scheduling algorithms show greater speed of convergence and lower error floors than those that use flooding. These lower error floors are achieved by the ability of the Informed Dynamic Scheduling (IDS)[23] algorithm to overcome trapping sets of near codewords.[24]
When nonflooding scheduling algorithms are used, an alternative definition of iteration is used. For an (n, k) LDPC code of rate k/n, a full iteration occurs when n variable and n − k constraint nodes have been updated, no matter the order in which they were updated.[citation needed]
Code construction[edit]
For large block sizes, LDPC codes are commonly constructed by first studying the behaviour of decoders. As the block size tends to infinity, LDPC decoders can be shown to have a noise threshold below which decoding is reliably achieved, and above which decoding is not achieved,[25] colloquially referred to as the cliff effect. This threshold can be optimised by finding the best proportion of arcs from check nodes and arcs from variable nodes. An approximate graphical approach to visualising this threshold is an EXIT chart.[citation needed]
The construction of a specific LDPC code after this optimization falls into two main types of techniques:[citation needed]
- Pseudorandom approaches
- Combinatorial approaches
Construction by a pseudo-random approach builds on theoretical results that, for large block size, a random construction gives good decoding performance.[10] In general, pseudorandom codes have complex encoders, but pseudorandom codes with the best decoders can have simple encoders.[26] Various constraints are often applied to help ensure that the desired properties expected at the theoretical limit of infinite block size occur at a finite block size.[citation needed]
Combinatorial approaches can be used to optimize the properties of small block-size LDPC codes or to create codes with simple encoders.[citation needed]
Some LDPC codes are based on Reed–Solomon codes, such as the RS-LDPC code used in the 10 Gigabit Ethernet standard.[27] Compared to randomly generated LDPC codes, structured LDPC codes—such as the LDPC code used in the DVB-S2 standard—can have simpler and therefore lower-cost hardware—in particular, codes constructed such that the H matrix is a circulant matrix.[28]
Yet another way of constructing LDPC codes is to use finite geometries. This method was proposed by Y. Kou et al. in 2001.[29]
LDPC codes vs. turbo codes[edit]
LDPC codes can be compared with other powerful coding schemes, e.g. turbo codes.[30] In one hand, BER performance of turbo codes is influenced by low codes limitations.[31] LDPC codes have no limitations of minimum distance,[32] that indirectly means that LDPC codes may be more efficient on relatively large code rates (e.g. 3/4, 5/6, 7/8) than turbo codes. However, LDPC codes are not the complete replacement: turbo codes are the best solution at the lower code rates (e.g. 1/6, 1/3, 1/2).[33][34]
See also[edit]
People[edit]
- Richard Hamming
- Claude Shannon
- David J. C. MacKay
- Irving S. Reed
- Michael Luby
Theory[edit]
- Graph theory
- Hamming code
- Sparse graph code
- Expander code
Applications[edit]
- G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable)
- 802.3an or 10GBASE-T (10 gigabit/s Ethernet over twisted pair)
- CMMB (China Multimedia Mobile Broadcasting)
- DVB-S2 / DVB-T2 / DVB-C2 (digital video broadcasting, 2nd generation)
- DMB-T/H (digital video broadcasting)[35]
- WiMAX (IEEE 802.16e standard for microwave communications)
- IEEE 802.11n-2009 (Wi-Fi standard)
- DOCSIS 3.1
- ATSC 3.0 (Next generation North America digital terrestrial broadcasting)
- 3GPP (5G-NR data channel)
Other capacity-approaching codes[edit]
- Turbo codes
- Serial concatenated convolutional codes
- Online codes
- Fountain codes
- LT codes
- Raptor codes
- Repeat-accumulate codes (a class of simple turbo codes)
- Tornado codes (LDPC codes designed for erasure decoding)
- Polar codes
References[edit]
- ^ David J.C. MacKay (2003) Information theory, Inference and Learning Algorithms, CUP, ISBN 0-521-64298-1, (also available online)
- ^ Todd K. Moon (2005) Error Correction Coding, Mathematical Methods and Algorithms. Wiley, ISBN 0-471-64800-0 (Includes code)
- ^ Amin Shokrollahi (2003) LDPC Codes: An Introduction
- ^ US 5446747
- ^ NewScientist, Communication speed nears terminal velocity, by Dana Mackenzie, 9 July 2005
- ^ Larry Hardesty (January 21, 2010). «Explained: Gallager codes». MIT News. Retrieved August 7, 2013.
- ^ a b [1] R. G. Gallager, «Low density parity check codes,» IRE Trans. Inf. Theory, vol. IT-8, no. 1, pp. 21- 28, Jan. 1962.
- ^ [2] J. Moshieff, N. Resch, N. Ron-Zewi, S. Silas, M. Wootters, «Low-density parity-check codes achieve list-decoding capacity,» SIAM Journal on Computing, FOCS20-38-FOCS20-73.
- ^ Robert G. Gallager (1963). Low Density Parity Check Codes (PDF). Monograph, M.I.T. Press. Retrieved August 7, 2013.
- ^ a b David J.C. MacKay and Radford M. Neal, «Near Shannon Limit Performance of Low Density Parity Check Codes,» Electronics Letters, July 1996
- ^ Telemetry Data Decoding, Design Handbook
- ^ Presentation by Hughes Systems Archived 2006-10-08 at the Wayback Machine
- ^ HomePNA Blog: G.hn, a PHY For All Seasons
- ^ IEEE Communications Magazine paper on G.hn Archived 2009-12-13 at the Wayback Machine
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009», IEEE, October 29, 2009, accessed March 21, 2011.
- ^ «IEEE SA — IEEE 802.11ax-2021». IEEE Standards Association. Retrieved May 22, 2022.
- ^
Chih-Yuan Yang, Mong-Kai Ku.
http://123seminarsonly.com/Seminar-Reports/029/26540350-Ldpc-Coded-Ofdm-Modulation.pdf
«LDPC coded OFDM modulation for high spectral efficiency transmission» - ^
Nick Wells.
«DVB-T2 in relation to the DVB-x2 Family of Standards» Archived 2013-05-26 at the Wayback Machine - ^ «5G Channel Coding» (PDF). Archived from the original (PDF) on December 6, 2018. Retrieved January 6, 2019.
- ^ Maunder, Robert (September 2016). «A Vision for 5G Channel Coding» (PDF). Archived from the original (PDF) on December 6, 2018. Retrieved January 6, 2019.
- ^ Kai Zhao, Wenzhe Zhao, Hongbin Sun, Tong Zhang, Xiaodong Zhang, and Nanning Zheng (2013). » LDPC-in-SSD: Making Advanced Error Correction Codes Work Effectively in Solid State Drives» (PDF). FAST’ 13. pp. 243–256.
{{cite conference}}: CS1 maint: multiple names: authors list (link) - ^ «Soft-Decoding in LDPC based SSD Controllers». EE Times. 2015.
- ^ a b A.I. Vila Casado, M. Griot, and R.Wesel, «Informed dynamic scheduling for belief propagation decoding of LDPC codes,» Proc. IEEE Int. Conf. on Comm. (ICC), June 2007.
- ^ T. Richardson, «Error floors of LDPC codes,» in Proc. 41st Allerton Conf. Comm., Control, and Comput., Monticello, IL, 2003.
- ^ Thomas J. Richardson and M. Amin Shokrollahi and Rüdiger L. Urbanke, «Design of Capacity-Approaching Irregular Low-Density Parity-Check Codes,» IEEE Transactions on Information Theory, 47(2), February 2001
- ^ Thomas J. Richardson and Rüdiger L. Urbanke, «Efficient Encoding of Low-Density Parity-Check Codes,» IEEE Transactions on Information Theory, 47(2), February 2001
- ^
Ahmad Darabiha, Anthony Chan Carusone, Frank R. Kschischang.
«Power Reduction Techniques for LDPC Decoders» - ^
Zhengya Zhang, Venkat Anantharam, Martin J. Wainwright, and Borivoje Nikolic.
«An Efficient 10GBASE-T Ethernet LDPC Decoder Design With Low Error Floors». - ^ Y. Kou, S. Lin and M. Fossorier, «Low-Density Parity-Check Codes
Based on Finite Geometries: A Rediscovery and New Results,» IEEE
Transactions on Information Theory, vol. 47, no. 7, November 2001, pp. 2711-
2736. - ^ Tahir, B., Schwarz, S., & Rupp, M. (2017, May). BER comparison between Convolutional, Turbo, LDPC, and Polar codes. In 2017 24th International Conference on Telecommunications (ICT) (pp. 1-7). IEEE.
- ^ Moon Todd, K. Error correction coding: mathematical methods and algorithms. 2005 by John Wiley & Sons. ISBN 0-471-64800-0. — p.614
- ^ Moon Todd, K. Error correction coding: mathematical methods and algorithms. 2005 by John Wiley & Sons. ISBN 0-471-64800-0. — p.653
- ^ Andrews, Kenneth S., et al. «The development of turbo and LDPC codes for deep-space applications.» Proceedings of the IEEE 95.11 (2007): 2142-2156.
- ^ Hassan, A.E.S., Dessouky, M., Abou Elazm, A. and Shokair, M., 2012. Evaluation of complexity versus performance for turbo code and LDPC under different code rates. Proc. SPACOMM, pp.93-98.
- ^ «IEEE Spectrum: Does China Have the Best Digital Television Standard on the Planet?». spectrum.ieee.org. Archived from the original on December 12, 2009.
External links[edit]
- Introducing Low-Density Parity-Check Codes (by Sarah J Johnson, 2010)
- LDPC Codes – a brief Tutorial (by Bernhard Leiner, 2005)
- LDPC Codes (TU Wien) Archived February 28, 2019, at the Wayback Machine
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, discusses LDPC codes in Chapter 47.
- Iterative Decoding of Low-Density Parity Check Codes (by Venkatesan Guruswami, 2006)
- LDPC Codes: An Introduction (by Amin Shokrollahi, 2003)
- Belief-Propagation Decoding of LDPC Codes (by Amir Bennatan, Princeton University)
- Turbo and LDPC Codes: Implementation, Simulation, and Standardization (West Virginia University)
- Information theory and coding (Marko Hennhöfer, 2011, TU Ilmenau) — discusses LDPC codes at pages 74–78.
- LDPC codes and performance results
- DVB-S.2 Link, Including LDPC Coding (MatLab)
- Source code for encoding, decoding, and simulating LDPC codes is available from a variety of locations:
- Binary LDPC codes in C
- Binary LDPC codes for Python (core algorithm in C)
- LDPC encoder and LDPC decoder in MATLAB
- A Fast Forward Error Correction Toolbox (AFF3CT) in C++11 for fast LDPC simulations
В теории информации код с низкой плотностью проверки на четность ( LDPC ) — это код с линейной коррекцией ошибок , метод передачи сообщения по каналу передачи с шумом . LDPC строится с использованием разреженного графа Таннера (подкласс двудольного графа ). Коды LDPC — это коды, приближающиеся к емкости , что означает, что существуют практические конструкции, которые позволяют устанавливать порог шума очень близко к теоретическому максимуму ( предел Шеннона ) для симметричного канала без памяти. Порог шума определяет верхнюю границу шума канала, до которого вероятность потери информации может быть минимальной по желанию. Используя методы итеративного распространения уверенности , коды LDPC могут быть декодированы во времени, линейном по отношению к длине их блока.
Коды LDPC находят все более широкое применение в приложениях, требующих надежной и высокоэффективной передачи информации по линиям с ограниченной полосой пропускания или обратным каналом в присутствии искажающего шума. Реализация кодов LDPC отстала от других кодов, особенно турбокодов . Срок действия фундаментального патента на турбокоды истек 29 августа 2013 года.
Коды LDPC также известны как коды Галлагера в честь Роберта Г. Галлагера , который разработал концепцию LDPC в своей докторской диссертации в Массачусетском технологическом институте в 1960 году.
История
Коды LDPC, впервые разработанные Галлагером в 1963 году, были непрактичными для реализации, пока его работа не была заново открыта в 1996 году. Турбокоды , еще один класс кодов , приближающихся к емкости, открытый в 1993 году, стали предпочтительной схемой кодирования в конце 1990-х годов, используемой для такие приложения, как Deep Space Network и спутниковая связь . Однако достижения в области кодов проверки на четность с низкой плотностью показали, что они превосходят турбокоды с точки зрения минимального уровня ошибок и производительности в диапазоне более высоких кодовых скоростей , в результате чего турбокоды лучше подходят только для более низких кодовых скоростей.
Приложения
В 2003 году код LDPC в стиле нерегулярного повторного накопления (IRA) превзошел шесть турбокодов и стал кодом с исправлением ошибок в новом стандарте DVB-S2 для спутниковой передачи цифрового телевидения . Отборочная комиссия DVB-S2 сделала оценки сложности декодера для предложений Turbo Code, используя гораздо менее эффективную архитектуру последовательного декодера, чем архитектуру параллельного декодера. Это вынудило предложения Turbo Code использовать размеры кадра порядка половины размера кадра предложений LDPC.
В 2008 годе LDPC бить сверточные турбокоды как прямая коррекция ошибок системы (ПИО) для МСЭ-Т G.hn стандарта. G.hn предпочел коды LDPC турбокодам из-за их меньшей сложности декодирования (особенно при работе со скоростями передачи данных, близких к 1,0 Гбит / с), а также потому, что предложенные турбокоды демонстрируют значительный минимальный уровень ошибок в желаемом диапазоне работы.
Коды LDPC также используются для 10GBASE-T Ethernet, который передает данные со скоростью 10 гигабит в секунду по кабелям витой пары. С 2009 года коды LDPC также являются частью стандарта Wi-Fi 802.11 в качестве дополнительной части 802.11n и 802.11ac в спецификации PHY с высокой пропускной способностью (HT).
Некоторые системы OFDM добавляют дополнительную внешнюю коррекцию ошибок, которая исправляет случайные ошибки («минимальный уровень ошибок»), которые преодолевают внутренний код коррекции LDPC даже при низкой частоте ошибок по битам . Например: код Рида-Соломона с кодированной модуляцией LDPC (RS-LCM) использует внешний код Рида-Соломона. Стандарты DVB-S2, DVB-T2 и DVB-C2 используют внешний код кода BCH для устранения остаточных ошибок после декодирования LDPC.
Оперативное использование
Коды LDPC функционально определяются разреженной матрицей проверки на четность . Эта разреженная матрица часто генерируется случайным образом с учетом ограничений разреженности — конструкция кода LDPC обсуждается позже . Эти коды были впервые разработаны Робертом Галлагером в 1960 году.
Ниже приведен фрагмент графа примера кода LDPC с использованием обозначения графа факторов Форни . В этом графе n узлов переменных в верхней части графа соединены с ( n — k ) узлами ограничений в нижней части графика.
Это популярный способ графического представления ( n , k ) кода LDPC. Биты действительного сообщения, помещенные в буквы T в верхней части графика, удовлетворяют графическим ограничениям. В частности, все линии, соединяющиеся с узлом переменной (прямоугольник со знаком ‘=’), имеют одинаковое значение, и все значения, соединяющиеся с узлом фактора (прямоугольник со знаком ‘+’), должны суммироваться по модулю два до нуля (в другими словами, они должны быть суммированы до четного числа; или должно быть четное число нечетных значений).
Игнорируя любые строки, выходящие за пределы изображения, существует восемь возможных шестибитных строк, соответствующих допустимым кодовым словам: (т.е. 000000, 011001, 110010, 101011, 111100, 100101, 001110, 010111). Этот фрагмент кода LDPC представляет трехбитовое сообщение, закодированное как шесть битов. Здесь используется избыточность для увеличения шансов восстановления после ошибок канала. Это линейный код (6, 3) с n = 6 и k = 3.
Снова игнорируя строки, выходящие за пределы изображения, матрица проверки на четность, представляющая этот фрагмент графа, имеет вид
В этой матрице каждая строка представляет одно из трех ограничений проверки на четность, а каждый столбец представляет один из шести битов принятого кодового слова.
В этом примере восемь кодовых слов можно получить, поместив матрицу проверки на четность H в эту форму с помощью основных операций со строками в GF (2) :
Шаг 1: H.
Шаг 2: Ряд 1 добавлен к ряду 3.
Шаг 3: строки 2 и 3 меняются местами.
Шаг 4: Ряд 1 добавляем к ряду 3.
Из этого порождающая матрица G может быть получена как (с учетом того, что в частном случае это двоичный код ), или, в частности:
Наконец, умножая все восемь возможных 3-битных строк на G , получают все восемь действительных кодовых слов. Например, кодовое слово для битовой строки «101» получается следующим образом:
-
,
где — символ умножения по модулю 2.
Для проверки, пространство строк G ортогонально H такое, что
Битовая строка «101» находится как первые 3 бита кодового слова «101011».
Пример кодировщика
На рисунке 1 показаны функциональные компоненты большинства кодеров LDPC.
Во время кодирования кадра биты входных данных (D) повторяются и распределяются по набору составляющих кодеров. Составляющие кодеры обычно являются накопителями, и каждый накопитель используется для генерации символа четности. Единственная копия исходных данных (S 0, K-1 ) передается с битами четности (P), чтобы составить кодовые символы. S битов от каждого составляющего кодера отбрасываются.
Бит четности может использоваться в другом составляющем коде.
В примере с использованием кода DVB-S2 со скоростью 2/3 размер кодированного блока составляет 64800 символов (N = 64800) с 43200 битами данных (K = 43200) и 21600 битами четности (M = 21600). Каждый составляющий код (контрольный узел) кодирует 16 бит данных, за исключением первого бита четности, который кодирует 8 битов данных. Первые 4680 битов данных повторяются 13 раз (используются в 13 кодах четности), а остальные биты данных используются в 3 кодах четности (нерегулярный код LDPC).
Для сравнения, в классических турбокодах обычно используются два составляющих кода, сконфигурированных параллельно, каждый из которых кодирует весь входной блок (K) битов данных. Эти составные кодеры представляют собой рекурсивные сверточные коды (RSC) средней глубины (8 или 16 состояний), которые разделены перемежителем кода, который перемежает одну копию кадра.
Код LDPC, напротив, использует параллельно множество составляющих кодов (аккумуляторов) низкой глубины, каждый из которых кодирует только небольшую часть входного кадра. Многие составляющие коды можно рассматривать как множество «сверточных кодов» с низкой глубиной (2 состояния), которые связаны посредством операций повтора и распределения. Операции повтора и распределения выполняют функцию перемежителя в турбо-коде.
Возможность более точного управления соединениями различных составляющих кодов и уровнем избыточности для каждого входного бита дает большую гибкость в разработке кодов LDPC, что в некоторых случаях может привести к лучшей производительности, чем турбокоды. Турбо-коды по-прежнему работают лучше, чем LDPC, при низких скоростях кода, или, по крайней мере, конструкция хорошо работающих кодов с низкой скоростью проще для турбо-кодов.
На практике оборудование, которое формирует аккумуляторы, повторно используется в процессе кодирования. То есть, как только первый набор битов четности сгенерирован и биты четности сохранены, то же самое аппаратное накопительное оборудование используется для генерации следующего набора битов четности.
Расшифровка
Как и в случае с другими кодами, декодирование с максимальной вероятностью кода LDPC в двоичном симметричном канале является NP-полной проблемой. Оптимальное декодирование NP-полного кода любого полезного размера нецелесообразно.
Однако субоптимальные методы, основанные на итеративном декодировании с распространением убеждений, дают отличные результаты и могут быть практически реализованы. Субоптимальные методы декодирования рассматривают каждую проверку четности, которая составляет LDPC, как независимый код одиночной проверки четности (SPC). Каждый код SPC декодируется отдельно с использованием методов программного ввода -вывода (SISO), таких как SOVA , BCJR , MAP и других их производных. Информация мягкого решения от каждого декодирования SISO перекрестно проверяется и обновляется с помощью других избыточных декодирований SPC того же информационного бита. Затем каждый код SPC снова декодируется с использованием обновленной информации мягкого решения. Этот процесс повторяется до тех пор, пока не будет получено допустимое кодовое слово или не будет исчерпано декодирование. Этот тип декодирования часто называют декодированием суммарного произведения.
Декодирование кодов SPC часто упоминается как обработка «узла проверки», а перекрестная проверка переменных часто упоминается как обработка «узла переменной».
В практической реализации декодера LDPC наборы кодов SPC декодируются параллельно для увеличения пропускной способности.
Напротив, распространение убеждений по каналу двоичного стирания особенно просто, если оно состоит из итеративного удовлетворения ограничений.
Например, предположим, что действительное кодовое слово 101011 из приведенного выше примера передается по двоичному каналу стирания и принимается со стертыми первым и четвертым битами, что дает «01» 11. Поскольку переданное сообщение должно удовлетворять кодовым ограничениям, сообщение может быть представлено путем записи полученного сообщения в верхней части графа факторов.
В этом примере первый бит еще не может быть восстановлен, потому что все связанные с ним ограничения имеют более одного неизвестного бита. Чтобы продолжить декодирование сообщения, необходимо определить ограничения, связанные только с одним из стертых битов. В этом примере достаточно только второго ограничения. Рассматривая второе ограничение, четвертый бит должен быть равен нулю, поскольку только ноль в этой позиции будет удовлетворять ограничению.
Затем эта процедура повторяется. Новое значение четвертого бита теперь можно использовать вместе с первым ограничением для восстановления первого бита, как показано ниже. Это означает, что первый бит должен быть единицей, чтобы удовлетворить крайнему левому ограничению.
Таким образом, сообщение можно декодировать итеративно. Для других моделей каналов сообщения, передаваемые между переменными узлами и проверочными узлами, являются действительными числами , которые выражают вероятность и вероятность веры.
Этот результат может быть подтвержден путем умножения исправленного кодового слова r на матрицу проверки на четность H :
Поскольку результатом z ( синдромом ) этой операции является нулевой вектор размером 3 × 1, результирующее кодовое слово r успешно проверяется.
После завершения декодирования исходные биты «101» сообщения могут быть извлечены путем просмотра первых 3 бита кодового слова.
Хотя этот пример стирания является иллюстративным, он не показывает использование декодирования с мягким решением или передачи сообщений с мягким решением, которые используются практически во всех коммерческих декодерах LDPC.
Обновление информации об узле
В последние годы также было проведено много работы по изучению эффектов альтернативных расписаний для обновления переменных-узлов и ограничений-узлов. Первоначальный метод, который использовался для декодирования кодов LDPC, был известен как лавинная рассылка . Этот тип обновления требовал, чтобы перед обновлением узла переменной необходимо было обновить все узлы ограничений, и наоборот. В более поздних работах Вила Касадо и др. были изучены альтернативные методы обновления, при которых переменные узлы обновляются новейшей доступной информацией о проверочных узлах.
Интуиция, лежащая в основе этих алгоритмов, заключается в том, что узлы переменных, значения которых изменяются больше всего, должны быть обновлены в первую очередь. Высоконадежные узлы, величина логарифмического отношения правдоподобия (LLR) которых велика и существенно не меняется от одного обновления к другому, не требуют обновлений с той же частотой, что и другие узлы, знак и величина которых колеблются в более широких пределах. Эти алгоритмы планирования показывают более высокую скорость сходимости и более низкие минимальные уровни ошибок, чем те, которые используют лавинную рассылку. Эти более низкие минимальные уровни ошибок достигаются за счет способности алгоритма информированного динамического планирования (IDS) преодолевать захват наборов близких кодовых слов.
Когда используются алгоритмы планирования без заводнения, используется альтернативное определение итерации. Для ( n , k ) кода LDPC со скоростью k / n полная итерация происходит, когда n переменных и n — k узлов ограничений были обновлены, независимо от порядка, в котором они были обновлены.
Построение кода
Для больших размеров блоков коды LDPC обычно создаются путем предварительного изучения поведения декодеров. Поскольку размер блока стремится к бесконечности, можно показать, что декодеры LDPC имеют порог шума, ниже которого надежно достигается декодирование, а выше которого декодирование не достигается, что в просторечии называется эффектом обрыва . Этот порог можно оптимизировать, найдя наилучшую пропорцию дуг из контрольных узлов и дуг из переменных узлов. Примерный графический подход к визуализации этого порога — диаграмма ВЫХОДА .
Построение конкретного кода LDPC после этой оптимизации делится на два основных типа методов:
- Псевдослучайные подходы
- Комбинаторные подходы
Построение с помощью псевдослучайного подхода основывается на теоретических результатах, которые для большого размера блока случайное построение дает хорошие характеристики декодирования. В общем, псевдослучайные коды имеют сложные кодеры, но псевдослучайные коды с лучшими декодерами могут иметь простые кодеры. Часто применяются различные ограничения, чтобы гарантировать, что желаемые свойства, ожидаемые при теоретическом пределе бесконечного размера блока, возникают при конечном размере блока.
Комбинаторные подходы могут использоваться для оптимизации свойств кодов LDPC небольшого размера или для создания кодов с помощью простых кодировщиков.
Некоторые коды LDPC основаны на кодах Рида – Соломона , например код RS-LDPC, используемый в стандарте 10 Gigabit Ethernet . По сравнению со случайно сгенерированными кодами LDPC, структурированные коды LDPC, такие как код LDPC, используемый в стандарте DVB-S2, могут иметь более простое и, следовательно, более дешевое оборудование — в частности, коды, построенные таким образом, что матрица H является циркулянтной матрицей .
Еще один способ построения LDPC-кодов — использовать конечную геометрию . Этот метод был предложен Y. Kou et al. в 2001.
Коды LDPC против турбокодов
Коды LDPC можно сравнить с другими мощными схемами кодирования, например, с турбокодами. С одной стороны, на производительность турбокодов BER влияют ограничения младших кодов. Коды LDPC не имеют ограничений по минимальному расстоянию, что косвенно означает, что коды LDPC могут быть более эффективными при относительно больших кодовых скоростях (например, 3/4, 5/6, 7/8), чем турбокоды. Однако коды LDPC не являются полной заменой: турбокоды — лучшее решение при более низких скоростях кода (например, 1/6, 1/3, 1/2).
Смотрите также
Люди
- Роберт Г. Галлагер
- Ричард Хэмминг
- Клод Шеннон
- Дэвид Дж. К. Маккей
- Ирвинг С. Рид
- Майкл Луби
Теория
- Распространение веры
- Теория графов
- Код Хэмминга
- Линейный код
- Код разреженного графа
- Код расширителя
Приложения
- G.hn/G.9960 (стандарт ITU-T для сетей по линиям электропередач, телефонным линиям и коаксиальному кабелю)
- 802.3an или 10GBASE-T (10 Гбит / с Ethernet по витой паре)
- CMMB (China Multimedia Mobile Broadcasting)
- DVB-S2 / DVB-T2 / DVB-C2 (цифровое видеовещание, 2-е поколение)
- DMB-T / H (Цифровое видеовещание)
- WiMAX (стандарт IEEE 802.16e для микроволновой связи)
- IEEE 802.11n-2009 ( стандарт Wi-Fi )
- DOCSIS 3.1
Другие коды приближения к мощности
- Турбо коды
- Последовательные каскадные сверточные коды
- Онлайн коды
- Коды фонтанов
- Коды LT
- Коды Raptor
- Коды с повторением-накоплением (класс простых турбокодов)
- Коды торнадо ( коды LDPC, предназначенные для декодирования стирания )
- Полярные коды
Рекомендации
внешняя ссылка
- Представляем коды проверки на четность с низкой плотностью (Сара Дж. Джонсон, 2010 г.)
- Коды LDPC — краткое руководство (Бернхард Лейнер, 2005)
- Коды LDPC (TU Wien)
- Он-лайн учебник: Теория информации, логический вывод и алгоритмы обучения , написанный Дэвидом Дж. К. Маккеем , обсуждает коды LDPC в главе 47.
- Итеративное декодирование кодов контроля четности с низкой плотностью (Венкатесан Гурусвами, 2006)
- Коды LDPC: Введение (Амин Шокроллахи, 2003)
- Декодирование кодов LDPC с распространением убеждений (Амир Беннатан, Принстонский университет)
- Коды Turbo и LDPC: реализация, моделирование и стандартизация (Университет Западной Вирджинии)
- Теория информации и кодирование (Марко Хеннхёфер, 2011, TU Ilmenau) — обсуждает коды LDPC на страницах 74-78.
- Коды LDPC и результаты производительности
- Канал DVB-S.2, включая кодирование LDPC (MatLab)
- Исходный код для кодирования, декодирования и моделирования кодов LDPC доступен в разных местах:
- Двоичные коды LDPC в C
- Двоичные коды LDPC для Python (основной алгоритм на C)
- LDPC — кодер и LDPC — декодер в MATLAB
- Набор инструментов Fast Forward Error Correction Toolbox (AFF3CT) в C ++ 11 для быстрого моделирования LDPC
Код с малой плотностью проверок на чётность (LDPC-код от англ. Low-density parity-check code, LDPC-code, низкоплотностный код) — используемый в передаче информации код, частный случай блокового линейного кода с проверкой чётности. Особенностью является малая плотность значимых элементов проверочной матрицы, за счёт чего достигается относительная простота реализации средств кодирования.
Также называют кодом Галлагера, по имени автора первой работы на тему LDPC-кодов.
Предпосылки
В 1948 году Шеннон опубликовал свою работу по теории передачи информации. Одним из ключевых результатов работы считается теорема о передачи информации для канала с шумами, которая говорит о возможности свести вероятность ошибки передачи по каналу к минимуму при выборе достаточного большой длины ключевого слова — единицы информации передаваемой по каналу[1].

![]()
Упрощённая схема передачи информации по каналу с шумами.
При передаче информации её поток разбивается на блоки определённой (чаще всего) длины, которые преобразуются кодером (кодируются) в блоки, называемыми ключевыми словами. Ключевые слова передаются по каналу, возможно с искажениями. На принимающей стороне декодер преобразует ключевые слова в поток информации, исправляя (по возможности) ошибки передачи.
Теорема Шеннона утверждает, что при определённых условиях вероятность ошибки декодирования (то есть невозможность декодером исправить ошибку передачи) можно уменьшить, выбрав большую длину ключевого слова. Однако, данная теорема (и работа вообще) не показывает, как можно выбрать большую длину, а точнее как эффективно организовать процесс кодирования и декодирования информации с большой длиной ключевых слов. Если предположить, что в кодере и декодере есть некие таблицы соответствия между входным блоком информации и соответствующим кодовым словом, то такие таблицы будут занимать очень много места. Для двоичного симметричного канала без памяти (если говорить упрощённо, то на вход кодера поступает поток из нулей и единиц) количество различных блоков составляет 2n, где n — количество бит (нулей или единиц) которые будут преобразовываться в одно кодовое слово. Для 8 бит это 256 блоков информации, каждый из которых будет содержать в себе соответствующее кодовое слово. Причём кодовое слово обычно большей длины, так как содержит в себе дополнительные биты для защиты от ошибок передачи данных. Поэтому одним из способов кодирования является использование проверочной матрицы, которые позволяют за одно математическое действие (умножение строки на матрицу) выполнить декодирование кодового слова. Аналогичным образом каждой проверочной матрице соответствует порождающая матрица, аналогичным способом одной операцией умножения строки на матрицу генерирующей кодовой слово.
Таким образом, для сравнительно коротких кодовых слов кодеры и декодеры могут просто содержать в памяти все возможные варианты, или даже реализовывать их в виде полупроводниковой схемы. Для большего размера кодового слова эффективнее хранить порождающую и проверочную матрицу. Однако, при длинах блоков в несколько тысяч бит хранение матриц размером, соответственно, в мегабиты, уже становится неэффективным. Одним из способов решения данной проблемы становится использования кодов с малой плотностью проверок на чётность, когда в проверяющей матрице количество единиц сравнительно мало, что позволяет эффективнее организовать процесс хранения матрицы или же напрямую реализовать процесс декодирования с помощью полупроводниковой схемы.
Первой работой на эту тему стала работа Роберта Галлагера «Low-Density Parity-Check Codes» 1963 года[2] (основы которой были заложены в его докторской диссертации 1960 года). В работе учёный описал требования к таким кодам, описал возможные способы построения и способы их оценки. Поэтому часто LDPC-коды называют кодами Галлагера. В русской научной литературе коды также называют низкоплотностными кодами или кодами с малой плотностью проверок на чётность.
Однако, из-за сложности в реализации кодеров и декодеров эти коды не использовались[3]. Лишь много позже, с развитием телекоммуникационных технологий, снова возрос интерес к передаче информации с минимальными ошибками. Несмотря на сложность реализации по сравнению с турбо-кодом, отсутствие преград к использованию (незащищённость патентами) сделало LDPC-коды привлекательными для телекоммуникационной отрасли, и фактически стали стандартом де-факто. В 2003 году LDPC-код, вместо турбо-кода, стал частью стандарта DVB-S2 спутниковой передачи данных для цифрового телевидения. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового наземного телевизионного вещания[4].
LDPC-коды
LDPC-коды описываются низкоплотностой проверочной матрицей, содержащей в основном нули и относительно малое количество единиц. По определению, если каждая строка матрицы содержит ровно  и каждый столбец ровно
и каждый столбец ровно  единиц, то код называют регулярным (в противном случае — нерегулярным). В общем случае количество единиц в матрице имеет порядок
единиц, то код называют регулярным (в противном случае — нерегулярным). В общем случае количество единиц в матрице имеет порядок  , то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
, то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
Обычно рассматриваются матрицы больших размеров. Например, в работе Галлагера в разделе экспериментальных результатов используются «малые» количества строк n=124, 252, 504 и 1008 строк (число столбцов проверочной матрицы немного больше). На практике применяются матрицы с большим количеством элементов — от 10 до 100 тысяч строк. Однако количество единиц в строке или в столбце остаётся достаточно малым, обычно меньшим 10. Замечено, что коды с тем же количеством элементов на строку или столбец, но с большим размером, обладают лучшими характеристиками.
![]()
Проверочная матрица LDPC-кода (9, 2, 3) с минимальным циклом длины 8
Важной характеристикой матрицы LDPC-кода является отсутствие циклов определённого размера. Под циклом длины 4 понимают образование в проверочной матрице прямоугольника, в углах которого стоят единицы. Отсутствие цикла длины 4 можно также определить через скалярное произведение столбцов (или строк) матрицы. Если каждое попарное скалярное произведение всех столбцов (или строк) матрицы не более 1, это говорит об отсутствии цикла длины 4. Циклы большей длины (6, 8, 10 и т. д.) можно определить, если в проверочной матрице построить граф, вершинами которого являются единицы, а рёбра — все возможные соединения вершин, параллельные сторонам матрицы (то есть вертикальные или горизонтальные линии). Минимальный цикл в этом графе и будет минимальным циклом в проверочной матрице LDPC-кода. Очевидно, что цикл будет иметь длину как минимум 4, а не 3, так как рёбра графа должны быть параллельны сторонам матрицы. Вообще, любой цикл в этом графе будет иметь чётную длину, минимальный размер 4, а максимальный размер обычно не играет роли (хотя, очевидно, он не более, чем количество узлов в графе, то есть n×k).
Описание LPDC-кода возможно несколькими способами:
- проверочной матрицей
- двудольным графом
- другим графическим способом
- специальные способы
Последний способ является условным обозначением группы представлений кодов, которые построены по заданным правилам-алгоритмам, таким, что для повторного воспроизведения кода достаточно знать лишь инициализирующие параметры алгоритма, и, разумеется, сам алгоритм построения. Однако данный способ не является универсальным и не может описать все возможные LDPC-коды.
Способ задания кода проверочной матрицей является общепринятым для линейных кодов, когда каждая строка матрицы является элементом некоторого множества кодовых слов. Если все строки линейно-независимы, строки матрицы могут рассматриваться как базис множества всех кодовых векторов кода. Однако использование данного способа создаёт сложности для представления матрицы в памяти кодера — необходимо хранить все строки или столбцы матрицы в виде набора двоичных векторов, из-за чего размер матрицы становится равен  бит.
бит.
![]()
Представление LDPC-кода в виде двудольного графа
Распространённым графическим способом является представление кода в виде двудольного графа. Сопоставим все  строк матрицы нижним вершинам графа, а
строк матрицы нижним вершинам графа, а  столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы.
столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы.
К другим графическим способам относят преобразования двудольного графа, происходящие без фактического изменения самого кода. Например, можно все верхние вершины графа представить в виде треугольников, а все нижние — в виде квадратов, после чего расположить рёбра и вершины графа на двухмерной поверхности в порядке, удобном для визуального понимания структуры кода. Например, такое представление используется в качестве иллюстраций в книгах Девида Маккея.
![]()
Представление (9, 2, 3) LDPC-кода в виде графа специального вида. Матрица кода приведена выше.
Вводя дополнительные правила графического отображения и построения LDPC-кода, можно добиться, что в процессе построения код получит определённые свойства. Например, если использовать граф, вершинами которого являются только столбцы проверочной матрицы, а строки изображаются многогранниками, построенными на вершинах графа, то следование правилу «два многогранника не разделяют одно ребро» позволяет избавиться от циклов длины 4.
При использовании специальных процедур построения кода могут использоваться и свои способы представления, хранения и обработки (кодирования и декодирования).
Построение кода
В настоящее время используются два принципа построения проверочной матрицы кода. Первый основан на генерации начальной проверочной матрицы с помощью псевдослучайного генератора. Коды, полученные таким способом называют случайными (англ. random-like codes). Второй — использование специальных методов, основанных, например, на группах и конечных полях. Коды, полученные этими способами называют структурированными. Лучшие результаты по исправлению ошибок показывают именно случайные коды, однако структурированные коды позволяют использовать методы оптимизации процедур хранения, кодирования и декодирования, а также получать коды с более предсказуемыми характеристиками.
В своей работе Галлагер предпочёл с помощью генератора псевдослучайных чисел создать начальную проверочную матрицу небольшого размера с заданными характеристиками, а далее увеличить её размер, дублируя матрицу и используя метод перемешивания строк и столбцов для избавления от циклов определённой длины.
В 2003 году Джеймсом МакГованом и Робертом Вильямсоном был предложен способ удаления циклов из матрицы LDPC-кода, в связи с чем стало возможным в начале сгенерировать матрицу с заданными характеристиками (n, j, k), а затем удалить из неё циклы. Так происходит в схеме Озарова-Вайнера[5].
В 2007 году в журнале «IEEE Transactions on Information Threory» была опубликована статья об использовании конечных полей для построения квази-цикличных LDPC-кодов для каналов с аддитивным белым Гауссовым шумом и двоичных каналов со стиранием.
Декодирование
Как и для любого другого линейного кода, для декодирования используется свойство ортогональности порождающей и транспонированной проверочной матриц:

где  — порождающая матрица, и
— порождающая матрица, и  — проверочная. Тогда для каждого принятого без ошибок кодового слова выполняется отношение
— проверочная. Тогда для каждого принятого без ошибок кодового слова выполняется отношение
- ,
 ,
,а для принятого кодового слова с ошибкой:
- ,
 ,
,где  — принятый вектор,
— принятый вектор,  — синдром. В случае, если после умножения принятого кодового слова на транспонированную проверочную матрицу получается ноль, блок считается принятым без ошибок. В противном случае используются специальные методы для определения местоположения ошибки и её исправления. Для LDPC-кода стандартные способы исправления оказываются слишком трудоёмкими — их относят к классу NP-полных задач, что, учитывая большую длину блока, не может применяться на практике. Вместо них применяют метод вероятностного итеративного декодирования, исправляющую большую долю ошибок за границей половины кодового расстояния[6].
— синдром. В случае, если после умножения принятого кодового слова на транспонированную проверочную матрицу получается ноль, блок считается принятым без ошибок. В противном случае используются специальные методы для определения местоположения ошибки и её исправления. Для LDPC-кода стандартные способы исправления оказываются слишком трудоёмкими — их относят к классу NP-полных задач, что, учитывая большую длину блока, не может применяться на практике. Вместо них применяют метод вероятностного итеративного декодирования, исправляющую большую долю ошибок за границей половины кодового расстояния[6].
Рассмотрим[7] симметричный канал без памяти со входом  и аддитивным гауссовым шумом
и аддитивным гауссовым шумом  . Для принятого кодового слова
. Для принятого кодового слова  нужно найти соответствующий наиболее вероятный вектор
нужно найти соответствующий наиболее вероятный вектор  , такой что
, такой что
- .
- Определим
-
- ;
- ;
- где — принятое значение n-го символа кодового слова (которое для данного канала имеет проивзольное значение, обычно в рамках ).
-
- Будем использовать слово «бит» для обозначения отдельных элементов вектора , и слово «проверка» для обозначения строк проверочной матрицы . Обозначим через набор битов, которые будут участвовать в m-ой проверке. Аналогично, обозначим набор проверок, в которых участвует бит n. (То есть перечислим индексы ненулевых элементов для каждой строки и для каждого столбца проверочной матрицы ).
- Инициализируем матрицы и значениями и соответственно
- (Горизонтальный шаг)
-
- (Вертикальный шаг)
-
- где для каждого и выбраное даёт:
- Теперь также обновляем «псевдопостериорные вероятности» того, что биты вектора принимают значения 0 или 1:
- Также, как и ранее, выбирается таким образом, что
-
 ;
; ;
; — принятое значение n-го символа кодового слова (которое для данного канала имеет проивзольное значение, обычно в рамках
— принятое значение n-го символа кодового слова (которое для данного канала имеет проивзольное значение, обычно в рамках  ).
). набор битов, которые будут участвовать в m-ой проверке. Аналогично, обозначим
набор битов, которые будут участвовать в m-ой проверке. Аналогично, обозначим  набор проверок, в которых участвует бит n. (То есть перечислим индексы ненулевых элементов для каждой строки и для каждого столбца проверочной матрицы
набор проверок, в которых участвует бит n. (То есть перечислим индексы ненулевых элементов для каждой строки и для каждого столбца проверочной матрицы  и
и  значениями
значениями  и
и  соответственно
соответственно





 и
и  даёт:
даёт:



 выбирается таким образом, что
выбирается таким образом, что

Данные значения используются воссоздания вектора x. Если полученный вектор удовлетворяет  , то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжается до некоторого шага (например, 100), то он прерывается и блок объявляется принятым с ошибкой.
, то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжается до некоторого шага (например, 100), то он прерывается и блок объявляется принятым с ошибкой.
Известно, что данный алгоритм даёт точное значение вектора (то есть, совпадающее с классическими способами), если проверочная матрица не содержит циклов[8].
Примечания
- ↑ Shannon C.E. A Mathematical Theory of Communication // Bell System Technical Journal. — 1948. — Т. 27. — С. 379-423, 623–656.
- ↑ Gallager, R. G. Low Density Parity Check Codes. — Cambridge: M.I.T. Press, 1963. — P. 90.
- ↑ David J.C. MacKay Information theory, inference and learning algorithms. — CUP, 2003. — ISBN 0-521-64298-1
- ↑ Dr. Lin-Nan Lee LDPC Codes, Application to Next Generation Communication Systems // IEEE Semiannual Vehicular Technology Conference. — October, 2003.
- ↑ Ю.В. Косолапов. О применении схемы озарова-вайнера для защиты информации в беспроводных многоканальных системах передачи данных // Информационное противодействие угрозам терроризма : Научно-практический журнал. — 2007. — № 10. — С. 111-120.
- ↑ В. Б. Афанасьев, Д. К. Зигангиров «О некоторых конструкциях низкоплотностных кодов с компонентным кодом Рида-Соломона»
- ↑ David J.C. MacKay, Radford M. Neal Near Shannon Limit Performance of Low Density Parity Check Codes
- ↑ J. Pearl. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann, San Mateo, 1988.
См. также
- Турбо-код
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем  ошибок. Это будет характеристикой канала связи.
ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами ( ,
,  ,
,  , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
, …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой ( ), а передачу по каналу связи — волнистой стрелкой (
), а передачу по каналу связи — волнистой стрелкой ( ). Ошибки при передаче будем подчёркивать.
). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения  и
и  . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
. В простейшем случае их можно закодировать нулём и единицей (сюрприз!):

Передача по каналу, в котором возникла ошибка будет записана так:

Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это  и
и  .
.
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:

Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:

Какие выводы мы можем сделать, когда получили  ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.

Проверим в деле:

Получили  . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
. Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали  , а получили
, а получили  . Видно, что эта цепочка больше похожа на исходные , чем на
. Видно, что эта цепочка больше похожа на исходные , чем на  . А так как других кодовых слов у нас нет, то и выбор очевиден.
. А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину  , равную количеству различающихся цифр в соответствующих разрядах цепочек
, равную количеству различающихся цифр в соответствующих разрядах цепочек  и
и  . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
. Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например,  , так как все цифры в соответствующих позициях равны, а вот
, так как все цифры в соответствующих позициях равны, а вот  .
.
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):
- .


 .
.Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:

Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение  , мы получим один из кодов, который принадлежит окрестности радиусом 2.
, мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами  и
и  расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
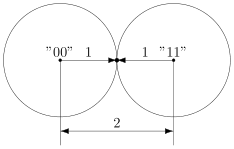
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и  . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
. Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.

Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
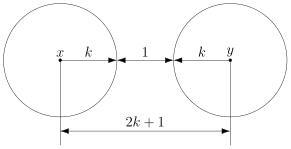
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием  будет успешно работать в канале с ошибками, если выполняется соотношение
будет успешно работать в канале с ошибками, если выполняется соотношение

Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:

Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.

Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние  , а значит
, а значит  , откуда получаем, что такой код может исправить до
, откуда получаем, что такой код может исправить до  ошибок. Обнаруживает же он две ошибки.
ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:

Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.

Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:

Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы  варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):

Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов  с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.

Это свойство прямо следует из определения.

А в этом можно убедиться, прибавив  к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)

Математически равенство всех трёх цифр можно записать как систему:

Или, если воспользоваться свойствами сложения в GF(2), получаем

Или

В матричном виде эта система будет иметь вид

где

Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу  проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:

Соответствующая система имеет вид:

Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если  и
и  — решения системы, то для их суммы верно
— решения системы, то для их суммы верно

что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить  .
.
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:

Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.

Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:

где  равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно
равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно  сочетания.
сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.

Строчки здесь — линейно независимые решения, которые мы получили. Матрица  называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:

Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)

Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?

А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:

Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово  . Тогда вектор ошибки по определению
. Тогда вектор ошибки по определению

Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:

В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то  . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
. Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:

И заметим следующее

Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
 |
|
|---|---|
|
 |
|
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.

Вектор ошибки равен  , а значит ошибка в третьем разряде. Как мы и загадали.
, а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
4.3.1. Коды, исправляющие ошибки
Помехоустойчивое
кодирование передаваемой информации
позволяет в приемной части системы
обнаруживать и исправлять ошибки. Коды,
применяемые при помехоустойчивом
кодировании, называются корректирующими
кодамиили кодами, исправляющими
ошибки.
Если применяемый
способ кодирования позволяет обнаружить
ошибочные кодовые комбинации, то в
случае приема изображения можно заменить
принятый с ошибкой элемент изображения
на предыдущий принятый элемент или на
соответствующий элемент предыдущей
строки или предыдущего кадра. При этом
заметность искажений на экране
телевизионного приемника существенно
уменьшается. Такой способ называется
маскировкой ошибки.
Более совершенные
корректирующие коды позволяют не только
обнаруживать, но и исправлять ошибки.
Как правило, корректирующий код может
исправлять меньше ошибок, чем
обнаруживать. Количество ошибок, которые
корректирующий код может исправить
в определенном интервале последовательности
двоичных символов, например, в одной
кодовой комбинации, называется
исправляющей способностью кода.
Основной принцип
построения корректирующих кодов
заключается в том, что в каждую
передаваемую кодовую комбинацию,
содержащую kинформационных двоичных символов,
вводятрдополнительных двоичных
символов. В результате получается новая
кодовая комбинация, содержащая![]() двоичных символов. Такой код будем
двоичных символов. Такой код будем
обозначать![]() .
.
Доля информационных символов в нем
характеризуетсяотносительной
скоростью кода, определяемой
соотношением
 .
.
Количество
возможных кодовых комбинаций кода
![]() равно
равно![]() .
.
Из них передаваться могут![]() кодовых комбинаций, называемых
кодовых комбинаций, называемых
разрешенными. Остальные![]() кодовые комбинации являются запрещенными.
кодовые комбинации являются запрещенными.
Появление одной из этих запрещенных
комбинаций в приемной части означает,
что имеется ошибка.
Для оценки
способности кода обнаруживать и
исправлять ошибки используется
понятие кодового расстояния(расстояния Хемминга). Кодовое расстояние![]() между кодовыми комбинациями
между кодовыми комбинациями![]() и
и![]() определяется как число двоичных
определяется как число двоичных
разрядов, в которых эти комбинации
различаются. Например, кодовое расстояние
между кодовыми комбинациями 0001 и 0011
равно 1, а между комбинациями 0000 и
1111 равно 4.
Если разрешенные
кодовые комбинации выбраны таким
образом, что при изменении любого
двоичного символа разрешенная кодовая
комбинация переходит в запрещенную,
то корректирующий код позволяет
обнаруживать одиночные ошибки в
отдельных кодовых комбинациях.
Одиночная ошибка
переводит исходную кодовую комбинацию
в кодовую комбинацию, отстоящую от нее
на d= 1.
Следовательно, для обнаружения одиночных
ошибок необходимо, чтобы кодовое
расстояние между любыми двумя разрешенными
кодовыми комбинациями корректирующего
кода было не менее 2. Для обнаруженияr1ошибок в
кодовой комбинации необходимо, чтобы
кодовое расстояние между двумя
разрешенными кодовыми комбинациями
удовлетворяло неравенству![]() .
.
Один
из самых простых и известных примеров
помехоустойчивого кодирования –
проверка на четность. В каждую кодовую
комбинацию вводится один дополнительный
двоичный символ хр,
называемый
контрольным или проверочным битом.
Этот бит устанавливается равным 1, если
сумма единиц в исходной кодовой
комбинации равна нечетному числу, и
равным 0 в противоположном случае.
Данное правило выражается соотношением
![]() ,
,
где
![]() – двоичные символы исходной кодовой
– двоичные символы исходной кодовой
комбинации.
Если в приемной
части системы один из двоичных символов
кодовой комбинации принят с ошибкой,
значение контрольного бита не будет
удовлетворять равенству . Это
несоответствие будет обнаружено
специальной схемой и явится признаком
того, что произошла ошибка. Таким
образом, проверка на четность позволяет
обнаруживать одиночные ошибки, но не
позволяет их исправлять (рис. 4.3). Код
с одной проверкой на четность,
обнаруживающий только одиночные ошибки,
применяется в тех случаях, когда
необходимо лишь контролировать качество
передачи, например, в каналах связи с
достаточно малой вероятностью ошибки.
Д
Рис. 4.3.Схема
обнаружения одной ошибки в кодовом
слове
ля исправления одиночных ошибок
необходимо, чтобы кодовое расстояние
между любыми двумя разрешенными кодовыми
комбинациями корректирующего кода
было не менее 3. В этом случае принятая
запрещенная кодовая комбинация
заменяется ближайшей к ней разрешенной
кодовой комбинацией. Так как ошибки
одиночные, то переданная разрешенная
кодовая комбинация отстоит от
принятой запрещенной кодовой комбинации
на 1, а остальные разрешенные кодовые
комбинации – не менее чем на 2. В этом
случае ошибка надежно исправляется.
В общем случае для коррекцииr2ошибок в кодовой комбинации кодовое
расстояниеdмежду
любыми двумя разрешенными кодовыми
комбинациями должно удовлетворять
неравенству![]() .
.
Для увеличения
кодового расстояния между разрешенными
кодовыми комбинациями необходимо
увеличивать число рконтрольных
символов в передаваемых кодовых
комбинациях. Известно соотношение
![]() ,
,
где
![]() – минимальное кодовое расстояние между
– минимальное кодовое расстояние между
двумя разрешенными кодовыми
комбинациями. Чтобы при этом относительная
скорость кода не стала чрезмерно малой,
необходимо в соответствии с увеличивать
и числоkинформационных
символов в кодовой комбинации.
Построение кода
с заданными nиkможет осуществляться разными способами.
Есть хорошо разработанные математические
методы решения этой задачи и обширная
литература. Для цифровых телевизионных
систем большое значение имеет возможность
коррекции пакетных ошибок, искажающих
сразу несколько соседних двоичных
символов. Кроме того, при выборе кода
для системы цифрового телевидения
необходимо обеспечить по возможности
простой метод декодирования, так как
декодер должен быть в каждом телевизионном
приемнике.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
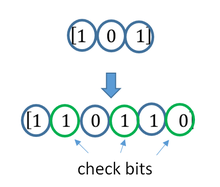
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
7.1. Классификация корректирующих кодов
7.2. Принципы помехоустойчивого кодирования
7.3. Систематические коды
7.4. Код с четным числом единиц. Инверсионный код
7.5. Коды Хэмминга
7.6. Циклические коды
7.7. Коды с постоянным весом
7.8. Непрерывные коды
7.1. Классификация корректирующих кодов
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов [12]. На рис. 7.1 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов.
Все известные в настоящее время коды могут быть разделены
на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
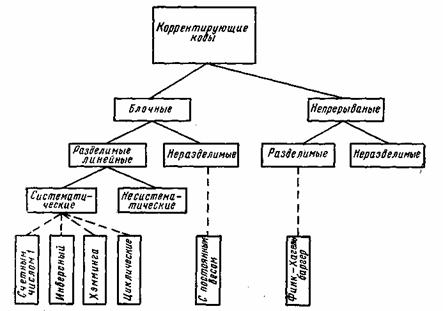
Рис. 7.1. Классификация корректирующих кодов
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат ‘исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.
В свою очередь, линейные коды могут быть |разбиты на два подкласса: систематические и несистематические. Все двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими. Вертикальными прямоугольниками на схеме рис. 7.1 представлены некоторые конкретные коды, описанные в последующих параграфах.
7.2. Принципы помехоустойчивого кодирования
В теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются.
Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d![]() между двумя комбинациями
между двумя комбинациями ![]() и
и ![]() определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
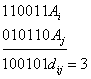
Для любого кода d![]()
![]() . Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
. Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
Расстояние между комбинациями ![]() и
и ![]() условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций
условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций ![]() и
и ![]() , разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация
, разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация ![]() преобразовалась в другую разрешенную комбинацию
преобразовалась в другую разрешенную комбинацию ![]() , должно исказиться d символов.
, должно исказиться d символов.
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций
При искажении меньшего числа символов комбинация ![]() перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
![]() (7.1)
(7.1)
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() (7.2)
(7.2)
где ![]() — вероятность искажения одного символа. Так как обычно
— вероятность искажения одного символа. Так как обычно ![]() <<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация
<<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация ![]() (см.рис.7.2б), тогда принимается решение, что была передана комбинация
(см.рис.7.2б), тогда принимается решение, что была передана комбинация ![]() . Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
. Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
![]() (7.3)
(7.3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности ![]() исправляются, а ошибки, кратность которых лежит в пределах
исправляются, а ошибки, кратность которых лежит в пределах ![]() только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах
только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах ![]() , то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А
, то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А![]() вместо A
вместо A![]() или наоборот.
или наоборот.
Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания ![]() . Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов
. Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов ![]() оказалось равным gc, причем
оказалось равным gc, причем
![]() (7.4)
(7.4)
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов ![]() необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок
необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок ![]() , то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
, то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
Если ![]() , то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М![]() увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() (7.5)
(7.5)
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
![]() (7.6)
(7.6)
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
![]()
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
![]() (7.7)
(7.7)
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]()
Здесь суммирование ‘Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() (7.8)
(7.8)
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность Р![]() , избыточность
, избыточность ![]() и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р![]() и
и ![]() . Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
. Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы.
7.3. Систематические коды
Изучение конкретных способов помехоустойчивого кодирования начнем с систематических кодов, которые в соответствии с классификацией (рис. 7.1) относятся к блочным разделимым кодам, т. е. к кодам, где операции кодирования осуществляются независимо в пределах каждой комбинации, состоящей из информационных и контрольных символов.
Остановимся кратко на общих принципах построения систематических кодов. Если обозначить информационные символы буквами с, а контрольные — буквами е, то любую кодовую комбинацию, содержащую k информационных и r контрольных символов, можно представить последовательностью:![]() , где с и е в двоичном коде принимают значения 0 или 1.
, где с и е в двоичном коде принимают значения 0 или 1.
Процесс кодирования на передающем конце сводится к образованию контрольных символов, которые выражаются в виде линейной функции информационных символов:
![]()
![]() (7.9)
(7.9)
Здесь ![]() — коэффициенты, равные 0 или 1, а
— коэффициенты, равные 0 или 1, а ![]() и
и ![]() — знаки суммирования по модулю два. Значения
— знаки суммирования по модулю два. Значения ![]()
![]() выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации
выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации ![]()
![]()
![]() образуется по правилу (7.9) вторая группа контрольных символов
образуется по правилу (7.9) вторая группа контрольных символов ![]()
![]()
Затем производится сравнение обеих групп контрольных символов путем их суммирования по модулю два:
![]()
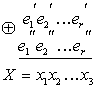 (7.10)
(7.10)
Полученное число X называется контрольным числом или синдромом. С его помощью можно обнаружить или исправить часть ошибок. Если ошибки в принятой комбинации отсутствуют, то все суммы![]()
![]() , а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае
, а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае ![]() , что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
, что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
Для исправления ошибок знание одного факта их возникновения является недостаточным. Необходимо указать номер ошибочно принятых символов. С этой целью каждому сочетанию исправляемых ошибок в комбинации присваивается одно из контрольных чисел, что позволяет по известному контрольному числу определить место положения ошибок и исправить их.
Контрольное число X записывается в двоичной системе, поэтому общее количество различных контрольных чисел, отличающихся от нуля, равно![]()
![]() . Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно
. Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно ![]() . В этом случае должно выполняться условие
. В этом случае должно выполняться условие
![]() (7.11)
(7.11)
Формула (7.11) позволяет при заданном количестве информационных символов k определить необходимое число контрольных символов r, с помощью которых исправляются все одиночные ошибки.
7.4. Код с чётным числом единиц. Инверсионный код
Рассмотрим некоторые простейшие систематические коды, применяемые только для обнаружения ошибок. Одним из кодов подобного типа является код с четным числом единиц. Каждая комбинация этого кода содержит, помимо информационных символов, один контрольный символ, выбираемый равным 0 или 1 так, чтобы сумма единиц в комбинации всегда была четной. Примером могут служить пятизначные комбинации кода Бодо, к которым добавляется шестой контрольный символ: 10101,1 и 01100,0. Правило вычисления контрольного символа можно выразить на
основании (7.9) в следующей форме: ![]() . Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (
. Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (![]() — суммирование по модулю):
— суммирование по модулю):
![]() (7.12)
(7.12)
Это позволяет в декодирующем устройстве сравнительно просто производить обнаружение ошибок путем проверки на четность. Нарушение четности имеет место при появлении однократных, трехкратных и в общем, случае ошибок нечетной кратности, что и дает возможность их обнаружить. Появление четных ошибок не изменяет четности суммы (7.12), поэтому такие ошибки не обнаруживаются. На основании ,(7.8) вероятность необнаруженной ошибки равна:
![]()
![]()
К достоинствам кода следует отнести простоту кодирующих и декодирующих устройств, а также малую .избыточность ![]() , однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
, однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
Значительно лучшими корректирующими способностями обладает инверсный код, который также применяется только для обнаружения ошибок. С принципом построения такого кода удобно ознакомиться на примере двух комбинаций: 11000, 11000 и 01101, 10010. В каждой комбинации символы до запятой являются информационными, а последующие — контрольными. Если количество единиц в информационных символах четное, т. е. сумма этих
символов
![]() (7.13)
(7.13)
равна нулю, то контрольные символы представляют собой простое повторение информационных. В противном случае, когда число единиц нечетное и сумма (7.13) равна 1, контрольные символы получаются из информационных посредством инвертирования, т. е. путем замены всех 0 на 1, а 1 на 0. Математическая форма записи образования контрольных символов имеет вид ![]() . При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е.
. При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е. ![]() , то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘
, то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘![]() =1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность:
=1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность: ![]() . Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
. Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
Анализ показывает, что при ![]() наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения
наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения ![]() равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
![]()
Для g>4 вероятность необнаруженных ошибок еще меньше. Поэтому при достаточно малых вероятностях ошибочных символов ро можно полагать, что полная вероятность необнаруженных ошибок ![]()
Инверсный код обладает высокой обнаруживающей способностью, однако она достигается ценой сравнительно большой избыточности, которая, как нетрудно определить, составляет величину ![]() =0,5.
=0,5.
7.5. Коды Хэмминга
К этому типу кодов обычно относят систематические коды с расстоянием d=3, которые позволяют исправить все одиночные ошибки (7.3).
Рассмотрим построение семизначного кода Хэмминга, каждая комбинация которого содержит четыре информационных и триконтрольных символа. Такой код, условно обозначаемый (7.4), удовлетворяет неравенству (7.11) и имеет избыточность ![]()
Если информационные символы с занимают в комбинация первые четыре места, то последующие три контрольных символа образуются по общему правилу (7.9) как суммы:
![]() (7.14)
(7.14)
Декодирование осуществляется путем трех проверок на четность (7.10):
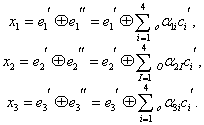 (7.15)
(7.15)
Так как х равно 0 или 1, то всего может быть восемь контрольных чисел Х=х1х2х3: 000, 100, 010, 001, 011, 101, 110 и 111. Первое из них имеет место в случае правильного приема, а остальные семь появляются при наличии искажений и должны использоваться для определения местоположения одиночной ошибки в семизначной комбинации. Выясним, каким образом устанавливается взаимосвязь между контрольными числами я искаженными символами. Если искажен один из контрольных символов: ![]() или
или ![]() , то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
, то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
Таблица 7.1

Порядок присвоения контрольных чисел ошибочным информационным символам может устанавливаться любой, например, как показано в табл. 7.1. Нетрудно показать, что этому распределению контрольных чисел соответствуют коэффициенты ![]() , приведенные в табл. 7.2.
, приведенные в табл. 7.2.
Таблица 7.2
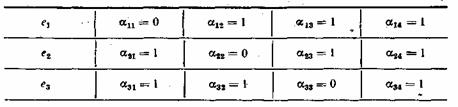
Если подставить коэффициенты ![]() в выражение (7.15), то получим:
в выражение (7.15), то получим:
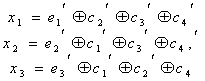 (7.16)
(7.16)
При искажении одного из информационных символов становятся равными единице те суммы х, в которые входит этот символ. Легко проверить, что получающееся в этом случае контрольное число![]() согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов
согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов ![]() . Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются
. Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются ![]() , Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
, Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
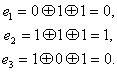
Передаваемая комбинация при этом будет ![]() . Предположим, что принята комбинация — 1001, 010 (искажен символ
. Предположим, что принята комбинация — 1001, 010 (искажен символ ![]() ). Подставляя соответствующие значения в (7.16), получим:
). Подставляя соответствующие значения в (7.16), получим:
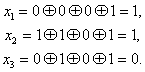
Вычисленное таким образом контрольное число ![]() 110 позволяет согласно табл. 7.1 исправить ошибку в символе.
110 позволяет согласно табл. 7.1 исправить ошибку в символе.
Здесь был рассмотрен простейший способ построения и декодирования кодовых комбинаций, в которых первые места отводились информационным символам, а соответствие между контрольными числами и ошибками определялось таблице. Вместе с тем существует более изящный метод отыскания одиночных ошибок, предложенный впервые самим Хэммингом. При этом методе код строится так, что контрольное число в двоичной системе счисления сразу указывает номер искаженного символа. Правда, в этом случае контрольные символы необходимо располагать среди информационных, что усложняет процесс кодирования. Для кода (7.4) символы в комбинации должны размещаться в следующем порядке: ![]() , а контрольное число вычисляться по формулам:
, а контрольное число вычисляться по формулам:
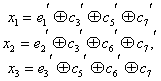 (7.17)
(7.17)
Так, если произошла ошибка в информационном символе с’5 то контрольное число ![]() , что соответствует числу 5 в двоичной системе.
, что соответствует числу 5 в двоичной системе.
В заключение отметим, что в коде (7.4) при появлении многократных ошибок контрольное число также может отличаться от нуля. Однако декодирование в этом случае будет проведено неправильно, так как оно рассчитано на исправление лишь одиночных ошибок.
7.6. Циклические коды
Важное место среди систематических кодов занимают циклические коды. Свойство цикличности состоит в том, что циклическая перестановка всех символов кодовой комбинации ![]() дает другую комбинацию
дает другую комбинацию ![]() также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например,
также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например, ![]()
![]()
![]()
![]() .
.
Комбинации циклического кода, выражаемые двоичными числами, для удобства преобразований обычно определяют в виде полиномов, коэффициенты которых равны 0 или 1. Примером этому может служить следующая запись:
![]()
Помимо цикличности, кодовые комбинации обладают другим важным свойством. Если их представить в виде полиномов, то все они делятся без остатка на так называемый порождающий полином G(z) степени ![]() , где k—значность первичного кода без избыточности, а п-значность циклического кода
, где k—значность первичного кода без избыточности, а п-значность циклического кода
Построение комбинаций циклических кодов возможно путем умножения комбинации первичного кода A*(z) ,на порождающий полином G(z):
A(z)=A*(z)G(z).
Умножение производится по модулю zn и в данном случае сводится к умножению по обычным правилам с приведением подобных членов по модулю два.
В полученной таким способом комбинации A(z) в явном виде не содержатся информационные символы, однако они всегда могут быть выделены в результате обратной операции: деления A(z) на G(z).
Другой способ кодирования, позволяющий представить кодовую комбинацию в виде информационных и контрольных символов, заключается в следующем. К комбинации первичного кода дописывается справа г нулей, что эквивалентно повышению полинома A*(z) на ,г разрядов, т. е. умножению его на гг. Затем произведение zrA*(z) делится на порождающий полином. B общем случае результат деления состоит из целого числа Q(z) и остатка R(z). Отсюда
![]()
Вычисленный остаток К(г) я используется для образования комбинации циклического кода в виде суммы
A(z)=zrA*(z)@R(z).
Так как сложение и вычитание по модулю два дают один и тот же результат, то нетрудно заметить, что A(z) = Q(z)G(z), т. е. полученная комбинация удовлетворяет требованию делимости на порождающий полином. Степень полинома R{z) не превышает r—1, поэтому он замещает нули в комбинации z![]() A*(z).
A*(z).
Для примера рассмотрим циклический код c n = 7, k=4, r=3 и G(z)=z3-z+1=1011. Необходимо закодировать комбинацию A*(z)=z*+1 = 1001. Тогда z![]() A*(z)=z
A*(z)=z![]() +z
+z![]() = 1001000. Для определения остатка делим z3A*(z) на G(z):
= 1001000. Для определения остатка делим z3A*(z) на G(z):
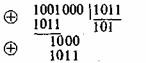
Окончательно получаем
В А(z) высшие четыре разряда занимают информационные символы, а остальные при — контрольные.
Контрольные символы в циклическом коде могут быть вычислены по общим ф-лам (7.9), однако здесь определение коэффициентов ![]() затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
Процедура декодирования принятых комбинаций также основана на использовании полиномов G(z). Если ошибок в процессе передачи не было, то деление принятой комбинации A(z) на G(z) дает целое число. При наличии корректируемых ошибок в результате деления образуется остаток, который и позволяет обнаружить или исправить ошибки.
Кодирующие и декодирующие устройства циклических кодов в большинстве случаев обладают сравнительной простотой, что следует считать одним из основных их преимуществ. Другим важным достоинством этих кодов является их способность корректировать пачки ошибок, возникающие в реальных каналах, где действуют импульсные и сосредоточенные помехи или наблюдаются замирания сигнала.
В теории кодирования весом кодовых комбинаций принято называть .количество единиц, которое они содержат. Если все комбинации кода имеют одинаковый вес, то такой код называется кодом с постоянным весом. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь не представляется возможным выделить информационные и контрольные символы. Из кодов этого типа наибольшее распространение получил обнаруживающий семизначный код 3/4, каждая разрешенная комбинация которого имеет три единицы и четыре нуля. Известен также код 2/5. Примером комбинаций кода 3/4 могут служить следующие семизначные последовательности: 1011000, 0101010, 0001110 и т. д.
Декодирование принятых комбинаций сводится к определению их веса. Если он отличается от заданного, то комбинация принята с ошибкой. Этот код обнаруживает все ошибки нечетной краткости и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Ошибки смещения характеризуются тем, что число искаженных единиц всегда равно числу искаженных нулей. Можно показать, что вероятность необнаруженной ошибки для кода 3/4 равна:
![]() при
при ![]() (7.18)
(7.18)
В этом коде из общего числа комбинаций М = 27=128 разрешенными являются лишь ![]() , поэтому в соответствии с (7.6) коэффициент избыточности
, поэтому в соответствии с (7.6) коэффициент избыточности
![]()
Код 3/4 находит применение при частотной манипуляции в каналах с селективными замираниями, где вероятность ошибок смещения невелика.
7.8. Непрерывные коды
Из непрерывных кодов, исправляющих ошибки, наиболее известны коды Финка—Хагельбаргера, в которых контрольные символы образуются путем линейной операции над двумя или более информационными символами. Принцип построения этих кодов рассмотрим на примере простейшего цепного кода. Контрольные символы в цепном коде формируются путем суммирования двух информационных символов, расположенных один относительно другого на определенном расстоянии:
![]() ;
;![]() (7.19)
(7.19)
Расстояние между информационными символами l=k—i определяет основные свойства кода и называется шагом сложения. Число контрольных символов при таком способе кодирования равно числу информационных символов, поэтому избыточность кода ![]() =0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
=0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
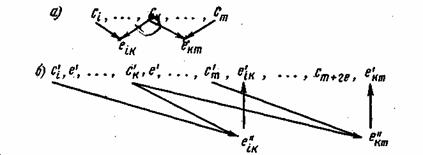
Рис. 7.3. Образование и размещение контрольных символов в цепном коде Финка—Хагельбаргера
При декодировании из принятых информационных символов по тому же правилу (7.19) формируется вспомогательная последовательность контрольных символов е», которая сравнивается с принятой последовательностью контрольных символов е’ (рис. 7.36). Если произошла ошибка в информационном символе, например, c‘k, то это вызовет искажения сразу двух символов e«k и e«km, что и обнаружится в результате их сравнения с ![]() и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’
и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’![]() Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Важное преимущество непрерывных кодов состоит в их способности исправлять не только одиночные ошибки, но я группы (пакеты) ошибок. Если задержка контрольных символов выбрана равной 2l, то можно показать, что максимальная длина исправляемого пакета ошибок также равна 2l при интервале между пакетами не менее 6l+1. Таким образом, возможность исправления длинных пакетов связана с увеличением шага сложения, а следовательно, и с усложнением кодирующих и декодирующих устройств.
Вопросы для повторения
1. Как могут быть классифицированы корректирующие коды?
2. Каким образом исправляются ошибки в кодах, которые только их обнаруживают?
3. В чем состоят основные принципы корректирования ошибок?
4. Дайте определение кодового расстояния.
5. При каких условиях код может обнаруживать или исправлять ошибки?
6. Как используется корректирующий код в системах со стиранием?
7. Какие характеристики определяют корректирующие способности кода?
8. Как осуществляется построение кодовых комбинаций в систематических кодах?
9. На чем основан принцип корректирования ошибок с использованием контрольного числа?
10. Объясните метод построения кода с четным числом единиц.
11. Как осуществляется процедура кодирования в семизначном коде Хэмминга?
12. Почему семизначный код 3/4 не обнаруживает ошибки смещения?
13. Каким образом производится непрерывное кодирование?
14. От чего зависит длина пакета исправляемых ошибок в коде Финка—Хагельбаргера?
Содержание
- 1 Исправление ошибок в помехоустойчивом кодировании
- 2 Параметры помехоустойчивого кодирования
- 3 Контроль чётности
- 4 Классификация помехоустойчивых кодов
- 5 Код Хэмминга
- 5.1 Декодирование кода Хэмминга
- 5.2 Расстояние Хэмминга
- 6 Помехоустойчивые коды
- 6.1 Компромиссы при использовании помехоустойчивых кодов
- 6.2 Необходимость чередования (перемежения)
Назначение помехоустойчивого кодирования – защита информации от помех и ошибок при передаче и хранении информации. Помехоустойчивое кодирование необходимо для устранения ошибок, которые возникают в процессе передачи, хранения информации. При передачи информации по каналу связи возникают помехи, ошибки и небольшая часть информации теряется.

Без использования помехоустойчивого кодирования было бы невозможно передавать большие объемы информации (файлы), т.к. в любой системе передачи и хранении информации неизбежно возникают ошибки.
Рассмотрим пример CD диска. Там информация хранится прямо на поверхности диска, в углублениях, из-за того, что все дорожки на поверхности, часто диск хватаем пальцами, елозим по столу и из-за этого без помехоустойчивого кодирования, информацию извлечь не получится.

Использование кодирования позволяет извлекать информацию без потерь даже с поврежденного CD/DVD диска, когда какая либо область становится недоступной для считывания.
В зависимости от того, используется в системе обнаружение или исправление ошибок с помощью помехоустойчивого кода, различают следующие варианты:
- запрос повторной передачи (Automatic Repeat reQuest, ARQ): с помощью помехоустойчивого кода выполняется только обнаружение ошибок, при их наличии производится запрос на повторную передачу пакета данных;
- прямое исправление ошибок (Forward Error Correction, FEC): производится декодирование помехоустойчивого кода, т. е. исправление ошибок с его помощью.
Возможен также гибридный вариант, чтобы лишний раз не гонять информацию по каналу связи, например получили пакет информации, попробовали его исправить, и если не смогли исправить, тогда отправляется запрос на повторную передачу.
Исправление ошибок в помехоустойчивом кодировании
Любое помехоустойчивое кодирование добавляет избыточность, за счет чего и появляется возможность восстановить информацию при частичной потере данных в канале связи (носителе информации при хранении). В случае эффективного кодирования убирали избыточность, а в помехоустойчивом кодировании добавляется контролируемая избыточность.
Простейший пример – мажоритарный метод, он же многократная передача, в котором один символ передается многократно, а на приемной стороне принимается решение о том символе, количество которых больше.
Допустим есть 4 символа информации, А, B, С,D, и эту информацию повторяем несколько раз. В процессе передачи информации по каналу связи, где-то возникла ошибка. Есть три пакета (A1B1C1D1|A2B2C2D2|A3B3C3D3), которые должны нести одну и ту же информацию.

Но из картинки справа, видно, что второй символ (B1 и C1) они отличаются друг от друга, хотя должны были быть одинаковыми. То что они отличаются, говорит о том, что есть ошибка.
Необходимо найти ошибку с помощью голосования, каких символов больше, символов В или символов С? Явно символов В больше, чем символов С, соответственно принимаем решение, что передавался символ В, а символ С ошибочный.
Для исправления ошибок нужно, как минимум 3 пакета информации, для обнаружения, как минимум 2 пакета информации.
Параметры помехоустойчивого кодирования
Первый параметр, скорость кода R характеризует долю информационных («полезных») данных в сообщении и определяется выражением: R=k/n=k/m+k
- где n – количество символов закодированного сообщения (результата кодирования);
- m – количество проверочных символов, добавляемых при кодировании;
- k – количество информационных символов.
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.д.
Второй параметр, кратность обнаруживаемых ошибок – количество ошибочных символов, которые код может обнаружить.
Третий параметр, кратность исправляемых ошибок – количество ошибочных символов, которые код может исправить (обозначается буквой t).
Контроль чётности
Самый простой метод помехоустойчивого кодирования это добавление одного бита четности. Есть некое информационное сообщение, состоящее из 8 бит, добавим девятый бит.
Если нечетное количество единиц, добавляем 0.
1 0 1 0 0 1 0 0 | 0
Если четное количество единиц, добавляем 1.
1 1 0 1 0 1 0 0 | 1
Если принятый бит чётности не совпадает с рассчитанным битом чётности, то считается, что произошла ошибка.
1 1 0 0 0 1 0 0 | 1
Под кратностью понимается, всевозможные ошибки, которые можно обнаружить. В этом случае, кратность исправляемых ошибок 0, так как мы не можем исправить ошибки, а кратность обнаруживаемых 1.
Есть последовательность 0 и 1, и из этой последовательности составим прямоугольную матрицу размера 4 на 4. Затем для каждой строки и столбца посчитаем бит четности.
Прямоугольный код – код с контролем четности, позволяющий исправить одну ошибку:

И если в процессе передачи информации допустим ошибку (ошибка нолик вместо единицы, желтым цветом), начинаем делать проверку. Нашли ошибку во втором столбце, третьей строке по координатам. Чтобы исправить ошибку, просто инвертируем 1 в 0, тем самым ошибка исправляется.
Этот прямоугольный код исправляет все одно-битные ошибки, но не все двух-битные и трех-битные.
Рассчитаем скорость кода для:
- 1 1 0 0 0 1 0 0 | 1
Здесь R=8/9=0,88
- И для прямоугольного кода:
Здесь R=16/24=0,66 (картинка выше, двадцать пятую единичку (бит четности) не учитываем)
Более эффективный с точки зрения скорости является первый вариант, но зато мы не можем с помощью него исправлять ошибки, а с помощью прямоугольного кода можно. Сейчас на практике прямоугольный код не используется, но логика работы многих помехоустойчивых кодов основана именно на прямоугольном коде.
Классификация помехоустойчивых кодов
- Непрерывные — процесс кодирования и декодирования носит непрерывный характер. Сверточный код является частным случаем непрерывного кода. На вход кодера поступил один символ, соответственно, появилось несколько на выходе, т.е. на каждый входной символ формируется несколько выходных, так как добавляется избыточность.
- Блочные (Блоковые) — процесс кодирования и декодирования осуществляется по блокам. С точки зрения понимания работы, блочный код проще, разбиваем код на блоки и каждый блок кодируется в отдельности.
По используемому алфавиту:
- Двоичные. Оперируют битами.
- Не двоичные (код Рида-Соломона). Оперируют более размерными символами. Если изначально информация двоичная, нужно эти биты превратить в символы. Например, есть последовательность 110 110 010 100 и нужно их преобразовать из двоичных символов в не двоичные, берем группы по 3 бита — это будет один символ, 6, 6, 2, 4 — с этими не двоичными символами работают не двоичные помехоустойчивые коды.
Блочные коды делятся на
- Систематические — отдельно не измененные информационные символы, отдельно проверочные символы. Если на входе кодера присутствует блок из k символов, и в процессе кодирования сформировали еще какое-то количество проверочных символов и проверочные символы ставим рядом к информационным в конец или в начало. Выходной блок на выходе кодера будет состоять из информационных символов и проверочных.
- Несистематические — символы исходного сообщения в явном виде не присутствуют. На вход пришел блок k, на выходе получили блок размером n, блок на выходе кодера не будет содержать в себе исходных данных.
В случае систематических кодов, выходной блок в явном виде содержит в себе, то что пришло на вход, а в случае несистематического кода, глядя на выходной блок нельзя понять что было на входе.

Смотря на картинку выше, код 1 1 0 0 0 1 0 0 | 1 является систематическим, на вход поступило 8 бит, а на выходе кодера 9 бит, которые в явном виде содержат в себе 8 бит информационных и один проверочный.

Код Хэмминга
Код Хэмминга — наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Позволяет устранить одну ошибку и находить двойную.

Код Хэмминга (7,4) — 4 бита на входе кодера и 7 на выходе, следовательно 3 проверочных бита. С 1 по 4 информационные биты, с 6 по 7 проверочные (см. табл. выше). Пятый проверочный бит y5, это сумма по модулю два 1-3 информационных бит. Сумма по модулю 2 это вычисление бита чётности.
Декодирование кода Хэмминга
Декодирование происходит через вычисление синдрома по выражениям:

Синдром это сложение бит по модулю два. Если синдром не нулевой, то исправление ошибки происходит по таблице декодирования:

Расстояние Хэмминга
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух кодовых слов одинаковой длины различны. Если рассматривать два кодовых слова, (пример на картинке ниже, 1 0 1 1 0 0 1 и 1 0 0 1 1 0 1) видно что они отличаются друг от друга на два символа, соответственно расстояние Хэмминга равно 2.

Кратность исправляемых ошибок и обнаруживаемых, связано минимальным расстоянием Хэмминга. Любой помехоустойчивый код добавляет избыточность с целью увеличить минимальное расстояние Хэмминга. Именно минимальное расстояние Хэмминга определяет помехоустойчивость.
Помехоустойчивые коды
Современные коды более эффективны по сравнению с рассматриваемыми примерами. В таблице ниже приведены Коды Боуза-Чоудхури-Хоквингема (БЧХ)

Из таблицы видим, что там один класс кода БЧХ, но разные параметры n и k.
- n — количество символов на входе.
- k — количество символов на выходе.
- t — кратность исправляемых ошибок.
- Отношение k/n — скорость кода.
- G (энергетический выигрыш) — величина, показывающая на сколько можно уменьшить отношение сигнал/шум (Eb/No) для обеспечения заданной вероятности ошибки.
Несмотря на то, что скорость кода близка, количество исправляемых ошибок может быть разное. Количество исправляемых ошибок зависит от той избыточности, которую добавим и от размера блока. Чем больше блок, тем больше ошибок он исправляет, даже при той же самой избыточности.
Пример: помехоустойчивые коды и двоичная фазовая манипуляция (2-ФМн). На графике зависимость отношения сигнал шум (Eb/No) от вероятности ошибки. За счет применения помехоустойчивых кодов улучшается помехоустойчивость.

Из графика видим, код Хэмминга (7,4) на сколько увеличилась помехоустойчивость? Всего на пол Дб это мало, если применить код БЧХ (127, 64) выиграем порядка 4 дБ, это хороший показатель.
Компромиссы при использовании помехоустойчивых кодов
Чем расплачиваемся за помехоустойчивые коды? Добавили избыточность, соответственно эту избыточность тоже нужно передавать. Нужно: увеличивать пропускную способность канала связи, либо увеличивать длительность передачи.

Компромисс:
- Достоверность vs полоса пропускания.
- Мощность vs полоса пропускания.
- Скорость передачи данных vs полоса пропускания
Необходимость чередования (перемежения)
Все помехоустойчивые коды могут исправлять только ограниченное количество ошибок t. Однако в реальных системах связи часто возникают ситуации сгруппированных ошибок, когда в течение непродолжительного времени количество ошибок превышает t.
Например, в канале связи шумов мало, все передается хорошо, ошибки возникают редко, но вдруг возникла импульсная помеха или замирания, которые повредили на некоторое время процесс передачи, и потерялся большой кусок информации. В среднем на блок приходится одна, две ошибки, а в нашем примере потерялся целый блок, включая информационные и проверочные биты. Сможет ли помехоустойчивый код исправить такую ошибку? Эта проблема решаема за счет перемежения.
Пример блочного перемежения:

На картинке, всего 5 блоков (с 1 по 25). Код работает исправляя ошибки в рамках одного блока (если в одном блоке 1 ошибка, код его исправит, а если две то нет). В канал связи отдается информация не последовательно, а в перемешку. На выходе кодера сформировались 5 блоков и эти 5 блоков будем отдавать не по очереди а в перемешку. Записали всё по строкам, но считывать будем, чтобы отправлять в канал связи, по столбцам. Информация в блоках перемешалась. В канале связи возникла ошибка и мы потеряли большой кусок. В процессе приема, мы опять составляем таблицу, записываем по столбцам, но считываем по строкам. За счет того, что мы перемешали большое количество блоков между собой, групповая ошибка равномерно распределится по блокам.
Число обнаруживаемых или исправляемых ошибок.
При применении двоичных кодов учитывают
только дискретные искажения, при которых
единица переходит в нуль (1 → 0) или нуль
переходит в единицу (0 → 1). Переход 1 →
0 или 0 → 1 только в одном элементе кодовой
комбинации называют единичной ошибкой
(единичным искажением). В общем случае
под кратностью ошибки подразумевают
число позиций кодовой комбинации, на
которых под действием помехи одни
символы оказались заменёнными на другие.
Возможны двукратные (t= 2) и многократные (t> 2) искажения элементов в кодовой
комбинации в пределах 0 <t<n.
Минимальное кодовое расстояние является
основным параметром, характеризующим
корректирующие способности данного
кода. Если код используется только для
обнаружения ошибок кратностью t0,
то необходимо и достаточно, чтобы
минимальное кодовое расстояние было
равно
dmin
> t0
+ 1. (13.10)
В этом случае никакая комбинация из t0ошибок не может перевести одну разрешённую
кодовую комбинацию в другую разрешённую.
Таким образом, условие обнаружения всех
ошибок кратностьюt0можно записать в виде:
t0≤ dmin — 1. (13.11)
Чтобы можно было исправить все ошибки
кратностью tии менее, необходимо иметь минимальное
расстояние, удовлетворяющее условию:
![]() . (13.12)
. (13.12)
В этом случае любая кодовая комбинация
с числом ошибок tиотличается от каждой разрешённой
комбинации не менее чем вtи+ 1 позициях. Если условие (13.12) не выполнено,
возможен случай, когда ошибки кратностиtисказят переданную
комбинацию так, что она станет ближе к
одной из разрешённых комбинаций, чем к
переданной или даже перейдёт в другую
разрешённую комбинацию. В соответствии
с этим, условие исправления всех ошибок
кратностью не болееtиможно записать в виде:
tи
≤(dmin
— 1) / 2 . (13.13)
Из (13.10) и (13.12) следует, что если код
исправляет все ошибки кратностью tи,
то число ошибок, которые он может
обнаружить, равноt0= 2∙tи. Следует
отметить, что соотношения (13.10) и (13.12)
устанавливают лишь гарантированное
минимальное число обнаруживаемых или
исправляемых ошибок при заданномdminи не ограничивают возможность обнаружения
ошибок большей кратности. Например,
простейший код с проверкой на чётность
сdmin= 2 позволяет обнаруживать не только
одиночные ошибки, но и любое нечётное
число ошибок в пределахt0<n.
Корректирующие возможности кодов.
Вопрос о минимально необходимой
избыточности, при которой код обладает
нужными корректирующими свойствами,
является одним из важнейших в теории
кодирования. Этот вопрос до сих пор не
получил полного решения. В настоящее
время получен лишь ряд верхних и нижних
оценок (границ), которые устанавливают
связь между максимально возможным
минимальным расстоянием корректирующего
кода и его избыточностью.
Так, граница Плоткинадаёт верхнюю
границу кодового расстоянияdminпри заданном числе разрядовnв
кодовой комбинации и числе информационных
разрядовm, и для
двоичных кодов:
![]() (13.14)
(13.14)
или
![]() при
при![]() . (13.15)
. (13.15)
Верхняя граница Хеммингаустанавливает
максимально возможное число разрешённых
кодовых комбинаций (2m)
любого помехоустойчивого кода при
заданных значенияхnиdmin:
 , (13.16)
, (13.16)
где
![]() —
—
число сочетаний изnэлементов поiэлементам.
Отсюда можно получить выражение для
оценки числа проверочных символов:
 . (13.17)
. (13.17)
Для значений (dmin/n)
≤ 0,3 разница между границей Хемминга и
границей Плоткина сравнительно невелика.
Граница Варшамова-Гильбертадля
больших значенийnопределяет нижнюю
границу для числа проверочных разрядов,
необходимого для обеспечения заданного
кодового расстояния:
 . (13.18)
. (13.18)
Отметим, что для некоторых частных
случаев Хемминг получил простые
соотношения, позволяющие определить
необходимое число проверочных символов:
![]() дляdmin= 3,
дляdmin= 3,
![]() дляdmin= 4.
дляdmin= 4.
Блочные коды с dmin= 3 и 4 в литературе обычно называют кодами
Хемминга.
Все приведенные выше оценки дают
представление о верхней границе числаdminпри фиксированных значенияхnиmили оценку снизу числа проверочных
символовkпри заданныхmиdmin.
Существующие методы построения избыточных
кодов решают в основном задачу нахождения
такого алгоритма кодирования и
декодирования, который позволял бы
наиболее просто построить и реализовать
код с заданным значением dmin.
Поэтому различные корректирующие коды
при одинаковыхdminсравниваются по сложности кодирующего
и декодирующего устройств. Этот критерий
является в ряде случаев определяющим
при выборе того или иного кода.
Соседние файлы в папке ЛБ_3
- #
- #
14.04.2015937 б72KodHemmig.m
- #
14.04.20150 б64ЛБ_3.exe