
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем  ошибок. Это будет характеристикой канала связи.
ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами ( ,
,  ,
,  , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
, …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой ( ), а передачу по каналу связи — волнистой стрелкой (
), а передачу по каналу связи — волнистой стрелкой ( ). Ошибки при передаче будем подчёркивать.
). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения  и
и  . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
. В простейшем случае их можно закодировать нулём и единицей (сюрприз!):

Передача по каналу, в котором возникла ошибка будет записана так:

Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это  и
и  .
.
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:

Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:

Какие выводы мы можем сделать, когда получили  ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.

Проверим в деле:

Получили  . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
. Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали  , а получили
, а получили  . Видно, что эта цепочка больше похожа на исходные , чем на
. Видно, что эта цепочка больше похожа на исходные , чем на  . А так как других кодовых слов у нас нет, то и выбор очевиден.
. А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину  , равную количеству различающихся цифр в соответствующих разрядах цепочек
, равную количеству различающихся цифр в соответствующих разрядах цепочек  и
и  . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
. Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например,  , так как все цифры в соответствующих позициях равны, а вот
, так как все цифры в соответствующих позициях равны, а вот  .
.
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):

- .


 .
.Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:

Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение  , мы получим один из кодов, который принадлежит окрестности радиусом 2.
, мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами  и
и  расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
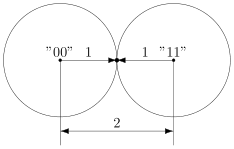
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и  . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
. Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.

Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
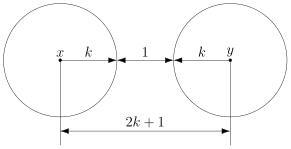
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием  будет успешно работать в канале с ошибками, если выполняется соотношение
будет успешно работать в канале с ошибками, если выполняется соотношение

Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:

Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.

Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние  , а значит
, а значит  , откуда получаем, что такой код может исправить до
, откуда получаем, что такой код может исправить до  ошибок. Обнаруживает же он две ошибки.
ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:

Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.

Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:

Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы  варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):

Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов  с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.

Это свойство прямо следует из определения.

А в этом можно убедиться, прибавив  к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)

Математически равенство всех трёх цифр можно записать как систему:

Или, если воспользоваться свойствами сложения в GF(2), получаем

Или

В матричном виде эта система будет иметь вид

где

Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу  проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:

Соответствующая система имеет вид:

Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если  и
и  — решения системы, то для их суммы верно
— решения системы, то для их суммы верно

что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить  .
.
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:

Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.

Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:

где  равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно
равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно  сочетания.
сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.

Строчки здесь — линейно независимые решения, которые мы получили. Матрица  называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:

Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)

Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?

А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:

Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово  . Тогда вектор ошибки по определению
. Тогда вектор ошибки по определению

Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:

В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то  . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
. Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:

И заметим следующее

Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
 |
|
|---|---|
|
 |
|
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.

Вектор ошибки равен  , а значит ошибка в третьем разряде. Как мы и загадали.
, а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Под корректирующей
способностью кода понимается его
способность обнаруживать или исправлять
ошибки, возникающие в кодовых комбинациях.
Корректирующая способность определяется
только избыточностью кода (степенью
выполнения неравенства (2)). Вид же
комбинаций кода определяет, какие
комбинации ошибок будут обнаруживаться
и (если выполнено разбиение запрещенных
комбинаций на подмножества Mi)
исправляться при одной и той же
корректирующей способности.
Для того, чтобы
код мог обнаруживать любую одиночную
ошибку в любой своей комбинации,
необходимо, чтобы при таких ошибках
разрешенная кодовая комбинация переходила
в запрещенную. Это возможно только
тогда, когда d>1,
или, так как d–целое,
d≥2.
Аналогично, для
того, чтобы код мог обнаруживать любые
ошибки кратности ν0
и менее,
необходимо, чтобы d
кода удовлетворяло условию
![]() . (13)
. (13)
Вопрос о том, может
ли обнаруживать ошибки код с d=1,
решается из рассмотрения неравенства
(2.). Если для кода указанное неравенство
выполняется, то он может обнаруживать
некоторые, хотя и не любые, одиночные и
более высокой кратности ошибки; если
(2) не выполняется, то код не обладает
корректирующей способностью.
Несколько сложнее
обстоит дело с исправлением ошибок.
Обычно исправление ошибок преследует
цель минимизировать вероятность выдачи
неправильной кодовой комбинации
получателю. Естественно, что достижение
этой цели возможно только при учете
статистики появления ошибок. Зная такую
статистику, нетрудно выполнить разбиение
запрещенных комбинаций Bj
на подмножества Mi
так, чтобы вероятность неправильного
исправления ошибок была минимальной.
Статистика ошибок
в комбинациях определяется каналом, по
которому производится передача. В
настоящее время статистика ошибок
получена для большинства реальных
каналов. Это позволило разработать
различные математические модели, с той
или иной степенью точности отражающие
процессы передачи символов по данным
каналам и служащие для их теоретического
исследования. Из широко используемых
моделей каналов рассматривается только
один – двоичный симметричный канал без
памяти, рассмотренный, например, в [2]. В
отношении этой модели корректирующие
коды исследованы наиболее полно.
Ориентация на
двоичный симметричный канал (ДСК) при
исследовании свойств кодов, несмотря
на то, что эта модель лишь весьма
приближенно описывает большинство
реальных каналов связи, объясняется ее
простотой. Действительно, ДСК
характеризуется тем, что искажения
отдельных символов в передаваемых по
нему комбинациях независимы и вероятности
искажений символов 0 и 1 одинаковы
(p01=p10=p).
Поэтому процесс передачи любого двоичного
символа комбинации кода по ДСК может
быть описан при помощи всего двух чисел
– вероятности искажения символа p
и вероятность правильной передачи
q=1–p.
ДСК обычно представляют графом,
изображенным на рис. 3.

Рис. 3. Двоичный симметричный код
Для ДСК при p<q
справедливо утверждение: если на выход
канала пришла некоторая запрещенная
комбинация, то вероятность того, что
она появилась в результате ошибок
меньшей кратности, больше, чем вероятность
того, что она порождена ошибками большей
кратности. Отсюда следует, что для
минимизации вероятности появления
ложной кодовой комбинации на выходе
устройства, осуществляющего передачу
информации по ДСК с исправлением ошибок,
необходимо, чтобы при коде в первую
очередь обеспечивалось исправление
ошибок меньшей кратности. Такой принцип
исправления ошибок определяет следующее
правило разбиения запрещенных комбинаций
на подмножества Mi:
запрещенная комбинация Bj
приписывается такой разрешенной кодовой
комбинации
Vi,
от которой она отличается в наименьшем
числе символов. Исправление ошибок в
соответствии с указанным принципом
получило название «исправление по
методу максимального правдоподобия».
Определим теперь,
каким минимальным d
должен обладать корректирующий код,
который по методу максимального
правдоподобия позволил бы исправлять
ошибки с кратностью от 1 до νu.
В соответствии с этим методом запрещенная
комбинация, получаемая из некоторой
кодовой в результате искажения νu
символов,
должна отличаться от любой другой
кодовой комбинации больше, чем νu
символами, то есть расстояние между
любыми кодовыми комбинациями должно
удовлетворять условию d>2νu,
или
![]() . (14)
. (14)
Из (14) видно,
например, что для того, чтобы код
обеспечивал исправление любой одиночной
ошибки, он должен иметь d≥3.
Теперь найдем,
каково должно быть d
кода, чтобы он мог обнаруживать ошибки
кратности ν0.
и менее и исправлять ошибки кратности
νu
и менее. Во-первых, заметим, что для того,
чтобы код мог исправлять ошибки кратности
от 1 до νu,
он должен их прежде обнаруживать, поэтому
всегде νuν0.
Во-вторых, чтобы
код мог обнаруживать ошибки кратности
ν0
эти ошибки не должны переводить кодовые
комбинации в такие закрещенные, которые
исправляются в другие кодовые комбинации
и, следовательно, отличаются от последних
не более чем в ν0
символах.
Поэтому для такого кода
![]() . (15)
. (15)
Нетрудно убедиться,
что при ν0
=0 (15)
переходит в (13), а при νи
=ν0
– в (14).
Отметим, что
конкретное использование d
кода определяет разработчик устройства
передачи информации.
7.1. Классификация корректирующих кодов
7.2. Принципы помехоустойчивого кодирования
7.3. Систематические коды
7.4. Код с четным числом единиц. Инверсионный код
7.5. Коды Хэмминга
7.6. Циклические коды
7.7. Коды с постоянным весом
7.8. Непрерывные коды
7.1. Классификация корректирующих кодов
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов [12]. На рис. 7.1 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов.
Все известные в настоящее время коды могут быть разделены
на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
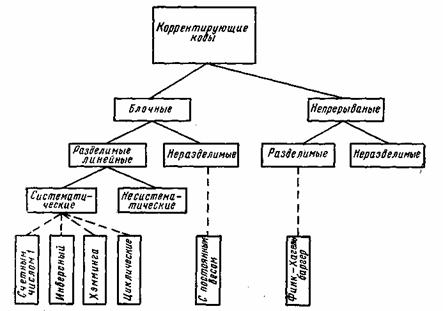
Рис. 7.1. Классификация корректирующих кодов
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат ‘исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.
В свою очередь, линейные коды могут быть |разбиты на два подкласса: систематические и несистематические. Все двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими. Вертикальными прямоугольниками на схеме рис. 7.1 представлены некоторые конкретные коды, описанные в последующих параграфах.
7.2. Принципы помехоустойчивого кодирования
В теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются.
Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d![]() между двумя комбинациями
между двумя комбинациями ![]() и
и ![]() определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
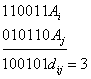
Для любого кода d![]()
![]() . Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
. Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
Расстояние между комбинациями ![]() и
и ![]() условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций
условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций ![]() и
и ![]() , разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация
, разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация ![]() преобразовалась в другую разрешенную комбинацию
преобразовалась в другую разрешенную комбинацию ![]() , должно исказиться d символов.
, должно исказиться d символов.
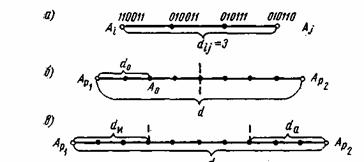
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций
При искажении меньшего числа символов комбинация ![]() перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
![]() (7.1)
(7.1)
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() (7.2)
(7.2)
где ![]() — вероятность искажения одного символа. Так как обычно
— вероятность искажения одного символа. Так как обычно ![]() <<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация
<<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация ![]() (см.рис.7.2б), тогда принимается решение, что была передана комбинация
(см.рис.7.2б), тогда принимается решение, что была передана комбинация ![]() . Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
. Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
![]() (7.3)
(7.3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности ![]() исправляются, а ошибки, кратность которых лежит в пределах
исправляются, а ошибки, кратность которых лежит в пределах ![]() только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах
только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах ![]() , то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А
, то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А![]() вместо A
вместо A![]() или наоборот.
или наоборот.
Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания ![]() . Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов
. Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов ![]() оказалось равным gc, причем
оказалось равным gc, причем
![]() (7.4)
(7.4)
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов ![]() необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок
необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок ![]() , то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
, то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
Если ![]() , то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М![]() увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() (7.5)
(7.5)
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
![]() (7.6)
(7.6)
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
![]()
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
![]() (7.7)
(7.7)
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]()
Здесь суммирование ‘Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() (7.8)
(7.8)
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность Р![]() , избыточность
, избыточность ![]() и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р![]() и
и ![]() . Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
. Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы.
7.3. Систематические коды
Изучение конкретных способов помехоустойчивого кодирования начнем с систематических кодов, которые в соответствии с классификацией (рис. 7.1) относятся к блочным разделимым кодам, т. е. к кодам, где операции кодирования осуществляются независимо в пределах каждой комбинации, состоящей из информационных и контрольных символов.
Остановимся кратко на общих принципах построения систематических кодов. Если обозначить информационные символы буквами с, а контрольные — буквами е, то любую кодовую комбинацию, содержащую k информационных и r контрольных символов, можно представить последовательностью:![]() , где с и е в двоичном коде принимают значения 0 или 1.
, где с и е в двоичном коде принимают значения 0 или 1.
Процесс кодирования на передающем конце сводится к образованию контрольных символов, которые выражаются в виде линейной функции информационных символов:
![]()
![]() (7.9)
(7.9)
Здесь ![]() — коэффициенты, равные 0 или 1, а
— коэффициенты, равные 0 или 1, а ![]() и
и ![]() — знаки суммирования по модулю два. Значения
— знаки суммирования по модулю два. Значения ![]()
![]() выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации
выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации ![]()
![]()
![]() образуется по правилу (7.9) вторая группа контрольных символов
образуется по правилу (7.9) вторая группа контрольных символов ![]()
![]()
Затем производится сравнение обеих групп контрольных символов путем их суммирования по модулю два:
![]()
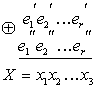 (7.10)
(7.10)
Полученное число X называется контрольным числом или синдромом. С его помощью можно обнаружить или исправить часть ошибок. Если ошибки в принятой комбинации отсутствуют, то все суммы![]()
![]() , а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае
, а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае ![]() , что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
, что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
Для исправления ошибок знание одного факта их возникновения является недостаточным. Необходимо указать номер ошибочно принятых символов. С этой целью каждому сочетанию исправляемых ошибок в комбинации присваивается одно из контрольных чисел, что позволяет по известному контрольному числу определить место положения ошибок и исправить их.
Контрольное число X записывается в двоичной системе, поэтому общее количество различных контрольных чисел, отличающихся от нуля, равно![]()
![]() . Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно
. Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно ![]() . В этом случае должно выполняться условие
. В этом случае должно выполняться условие
![]() (7.11)
(7.11)
Формула (7.11) позволяет при заданном количестве информационных символов k определить необходимое число контрольных символов r, с помощью которых исправляются все одиночные ошибки.
7.4. Код с чётным числом единиц. Инверсионный код
Рассмотрим некоторые простейшие систематические коды, применяемые только для обнаружения ошибок. Одним из кодов подобного типа является код с четным числом единиц. Каждая комбинация этого кода содержит, помимо информационных символов, один контрольный символ, выбираемый равным 0 или 1 так, чтобы сумма единиц в комбинации всегда была четной. Примером могут служить пятизначные комбинации кода Бодо, к которым добавляется шестой контрольный символ: 10101,1 и 01100,0. Правило вычисления контрольного символа можно выразить на
основании (7.9) в следующей форме: ![]() . Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (
. Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (![]() — суммирование по модулю):
— суммирование по модулю):
![]() (7.12)
(7.12)
Это позволяет в декодирующем устройстве сравнительно просто производить обнаружение ошибок путем проверки на четность. Нарушение четности имеет место при появлении однократных, трехкратных и в общем, случае ошибок нечетной кратности, что и дает возможность их обнаружить. Появление четных ошибок не изменяет четности суммы (7.12), поэтому такие ошибки не обнаруживаются. На основании ,(7.8) вероятность необнаруженной ошибки равна:
![]()
![]()
К достоинствам кода следует отнести простоту кодирующих и декодирующих устройств, а также малую .избыточность ![]() , однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
, однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
Значительно лучшими корректирующими способностями обладает инверсный код, который также применяется только для обнаружения ошибок. С принципом построения такого кода удобно ознакомиться на примере двух комбинаций: 11000, 11000 и 01101, 10010. В каждой комбинации символы до запятой являются информационными, а последующие — контрольными. Если количество единиц в информационных символах четное, т. е. сумма этих
символов
![]() (7.13)
(7.13)
равна нулю, то контрольные символы представляют собой простое повторение информационных. В противном случае, когда число единиц нечетное и сумма (7.13) равна 1, контрольные символы получаются из информационных посредством инвертирования, т. е. путем замены всех 0 на 1, а 1 на 0. Математическая форма записи образования контрольных символов имеет вид ![]() . При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е.
. При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е. ![]() , то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘
, то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘![]() =1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность:
=1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность: ![]() . Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
. Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
Анализ показывает, что при ![]() наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения
наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения ![]() равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
![]()
Для g>4 вероятность необнаруженных ошибок еще меньше. Поэтому при достаточно малых вероятностях ошибочных символов ро можно полагать, что полная вероятность необнаруженных ошибок ![]()
Инверсный код обладает высокой обнаруживающей способностью, однако она достигается ценой сравнительно большой избыточности, которая, как нетрудно определить, составляет величину ![]() =0,5.
=0,5.
7.5. Коды Хэмминга
К этому типу кодов обычно относят систематические коды с расстоянием d=3, которые позволяют исправить все одиночные ошибки (7.3).
Рассмотрим построение семизначного кода Хэмминга, каждая комбинация которого содержит четыре информационных и триконтрольных символа. Такой код, условно обозначаемый (7.4), удовлетворяет неравенству (7.11) и имеет избыточность ![]()
Если информационные символы с занимают в комбинация первые четыре места, то последующие три контрольных символа образуются по общему правилу (7.9) как суммы:
![]() (7.14)
(7.14)
Декодирование осуществляется путем трех проверок на четность (7.10):
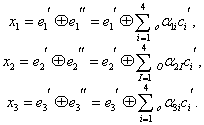 (7.15)
(7.15)
Так как х равно 0 или 1, то всего может быть восемь контрольных чисел Х=х1х2х3: 000, 100, 010, 001, 011, 101, 110 и 111. Первое из них имеет место в случае правильного приема, а остальные семь появляются при наличии искажений и должны использоваться для определения местоположения одиночной ошибки в семизначной комбинации. Выясним, каким образом устанавливается взаимосвязь между контрольными числами я искаженными символами. Если искажен один из контрольных символов: ![]() или
или ![]() , то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
, то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
Таблица 7.1

Порядок присвоения контрольных чисел ошибочным информационным символам может устанавливаться любой, например, как показано в табл. 7.1. Нетрудно показать, что этому распределению контрольных чисел соответствуют коэффициенты ![]() , приведенные в табл. 7.2.
, приведенные в табл. 7.2.
Таблица 7.2
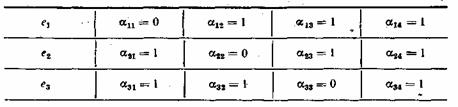
Если подставить коэффициенты ![]() в выражение (7.15), то получим:
в выражение (7.15), то получим:
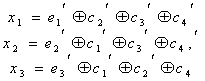 (7.16)
(7.16)
При искажении одного из информационных символов становятся равными единице те суммы х, в которые входит этот символ. Легко проверить, что получающееся в этом случае контрольное число![]() согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов
согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов ![]() . Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются
. Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются ![]() , Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
, Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
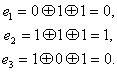
Передаваемая комбинация при этом будет ![]() . Предположим, что принята комбинация — 1001, 010 (искажен символ
. Предположим, что принята комбинация — 1001, 010 (искажен символ ![]() ). Подставляя соответствующие значения в (7.16), получим:
). Подставляя соответствующие значения в (7.16), получим:
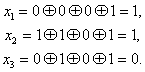
Вычисленное таким образом контрольное число ![]() 110 позволяет согласно табл. 7.1 исправить ошибку в символе.
110 позволяет согласно табл. 7.1 исправить ошибку в символе.
Здесь был рассмотрен простейший способ построения и декодирования кодовых комбинаций, в которых первые места отводились информационным символам, а соответствие между контрольными числами и ошибками определялось таблице. Вместе с тем существует более изящный метод отыскания одиночных ошибок, предложенный впервые самим Хэммингом. При этом методе код строится так, что контрольное число в двоичной системе счисления сразу указывает номер искаженного символа. Правда, в этом случае контрольные символы необходимо располагать среди информационных, что усложняет процесс кодирования. Для кода (7.4) символы в комбинации должны размещаться в следующем порядке: ![]() , а контрольное число вычисляться по формулам:
, а контрольное число вычисляться по формулам:
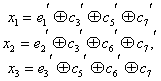 (7.17)
(7.17)
Так, если произошла ошибка в информационном символе с’5 то контрольное число ![]() , что соответствует числу 5 в двоичной системе.
, что соответствует числу 5 в двоичной системе.
В заключение отметим, что в коде (7.4) при появлении многократных ошибок контрольное число также может отличаться от нуля. Однако декодирование в этом случае будет проведено неправильно, так как оно рассчитано на исправление лишь одиночных ошибок.
7.6. Циклические коды
Важное место среди систематических кодов занимают циклические коды. Свойство цикличности состоит в том, что циклическая перестановка всех символов кодовой комбинации ![]() дает другую комбинацию
дает другую комбинацию ![]() также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например,
также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например, ![]()
![]()
![]()
![]() .
.
Комбинации циклического кода, выражаемые двоичными числами, для удобства преобразований обычно определяют в виде полиномов, коэффициенты которых равны 0 или 1. Примером этому может служить следующая запись:
![]()
Помимо цикличности, кодовые комбинации обладают другим важным свойством. Если их представить в виде полиномов, то все они делятся без остатка на так называемый порождающий полином G(z) степени ![]() , где k—значность первичного кода без избыточности, а п-значность циклического кода
, где k—значность первичного кода без избыточности, а п-значность циклического кода
Построение комбинаций циклических кодов возможно путем умножения комбинации первичного кода A*(z) ,на порождающий полином G(z):
A(z)=A*(z)G(z).
Умножение производится по модулю zn и в данном случае сводится к умножению по обычным правилам с приведением подобных членов по модулю два.
В полученной таким способом комбинации A(z) в явном виде не содержатся информационные символы, однако они всегда могут быть выделены в результате обратной операции: деления A(z) на G(z).
Другой способ кодирования, позволяющий представить кодовую комбинацию в виде информационных и контрольных символов, заключается в следующем. К комбинации первичного кода дописывается справа г нулей, что эквивалентно повышению полинома A*(z) на ,г разрядов, т. е. умножению его на гг. Затем произведение zrA*(z) делится на порождающий полином. B общем случае результат деления состоит из целого числа Q(z) и остатка R(z). Отсюда
![]()
Вычисленный остаток К(г) я используется для образования комбинации циклического кода в виде суммы
A(z)=zrA*(z)@R(z).
Так как сложение и вычитание по модулю два дают один и тот же результат, то нетрудно заметить, что A(z) = Q(z)G(z), т. е. полученная комбинация удовлетворяет требованию делимости на порождающий полином. Степень полинома R{z) не превышает r—1, поэтому он замещает нули в комбинации z![]() A*(z).
A*(z).
Для примера рассмотрим циклический код c n = 7, k=4, r=3 и G(z)=z3-z+1=1011. Необходимо закодировать комбинацию A*(z)=z*+1 = 1001. Тогда z![]() A*(z)=z
A*(z)=z![]() +z
+z![]() = 1001000. Для определения остатка делим z3A*(z) на G(z):
= 1001000. Для определения остатка делим z3A*(z) на G(z):
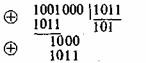
Окончательно получаем
В А(z) высшие четыре разряда занимают информационные символы, а остальные при — контрольные.
Контрольные символы в циклическом коде могут быть вычислены по общим ф-лам (7.9), однако здесь определение коэффициентов ![]() затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
Процедура декодирования принятых комбинаций также основана на использовании полиномов G(z). Если ошибок в процессе передачи не было, то деление принятой комбинации A(z) на G(z) дает целое число. При наличии корректируемых ошибок в результате деления образуется остаток, который и позволяет обнаружить или исправить ошибки.
Кодирующие и декодирующие устройства циклических кодов в большинстве случаев обладают сравнительной простотой, что следует считать одним из основных их преимуществ. Другим важным достоинством этих кодов является их способность корректировать пачки ошибок, возникающие в реальных каналах, где действуют импульсные и сосредоточенные помехи или наблюдаются замирания сигнала.
В теории кодирования весом кодовых комбинаций принято называть .количество единиц, которое они содержат. Если все комбинации кода имеют одинаковый вес, то такой код называется кодом с постоянным весом. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь не представляется возможным выделить информационные и контрольные символы. Из кодов этого типа наибольшее распространение получил обнаруживающий семизначный код 3/4, каждая разрешенная комбинация которого имеет три единицы и четыре нуля. Известен также код 2/5. Примером комбинаций кода 3/4 могут служить следующие семизначные последовательности: 1011000, 0101010, 0001110 и т. д.
Декодирование принятых комбинаций сводится к определению их веса. Если он отличается от заданного, то комбинация принята с ошибкой. Этот код обнаруживает все ошибки нечетной краткости и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Ошибки смещения характеризуются тем, что число искаженных единиц всегда равно числу искаженных нулей. Можно показать, что вероятность необнаруженной ошибки для кода 3/4 равна:
![]() при
при ![]() (7.18)
(7.18)
В этом коде из общего числа комбинаций М = 27=128 разрешенными являются лишь ![]() , поэтому в соответствии с (7.6) коэффициент избыточности
, поэтому в соответствии с (7.6) коэффициент избыточности
![]()
Код 3/4 находит применение при частотной манипуляции в каналах с селективными замираниями, где вероятность ошибок смещения невелика.
7.8. Непрерывные коды
Из непрерывных кодов, исправляющих ошибки, наиболее известны коды Финка—Хагельбаргера, в которых контрольные символы образуются путем линейной операции над двумя или более информационными символами. Принцип построения этих кодов рассмотрим на примере простейшего цепного кода. Контрольные символы в цепном коде формируются путем суммирования двух информационных символов, расположенных один относительно другого на определенном расстоянии:
![]() ;
;![]() (7.19)
(7.19)
Расстояние между информационными символами l=k—i определяет основные свойства кода и называется шагом сложения. Число контрольных символов при таком способе кодирования равно числу информационных символов, поэтому избыточность кода ![]() =0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
=0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
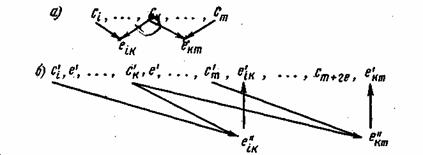
Рис. 7.3. Образование и размещение контрольных символов в цепном коде Финка—Хагельбаргера
При декодировании из принятых информационных символов по тому же правилу (7.19) формируется вспомогательная последовательность контрольных символов е», которая сравнивается с принятой последовательностью контрольных символов е’ (рис. 7.36). Если произошла ошибка в информационном символе, например, c‘k, то это вызовет искажения сразу двух символов e«k и e«km, что и обнаружится в результате их сравнения с ![]() и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’
и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’![]() Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Важное преимущество непрерывных кодов состоит в их способности исправлять не только одиночные ошибки, но я группы (пакеты) ошибок. Если задержка контрольных символов выбрана равной 2l, то можно показать, что максимальная длина исправляемого пакета ошибок также равна 2l при интервале между пакетами не менее 6l+1. Таким образом, возможность исправления длинных пакетов связана с увеличением шага сложения, а следовательно, и с усложнением кодирующих и декодирующих устройств.
Вопросы для повторения
1. Как могут быть классифицированы корректирующие коды?
2. Каким образом исправляются ошибки в кодах, которые только их обнаруживают?
3. В чем состоят основные принципы корректирования ошибок?
4. Дайте определение кодового расстояния.
5. При каких условиях код может обнаруживать или исправлять ошибки?
6. Как используется корректирующий код в системах со стиранием?
7. Какие характеристики определяют корректирующие способности кода?
8. Как осуществляется построение кодовых комбинаций в систематических кодах?
9. На чем основан принцип корректирования ошибок с использованием контрольного числа?
10. Объясните метод построения кода с четным числом единиц.
11. Как осуществляется процедура кодирования в семизначном коде Хэмминга?
12. Почему семизначный код 3/4 не обнаруживает ошибки смещения?
13. Каким образом производится непрерывное кодирование?
14. От чего зависит длина пакета исправляемых ошибок в коде Финка—Хагельбаргера?
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
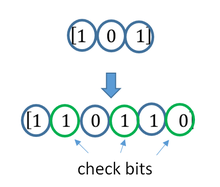
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
Корректирующие коды «на пальцах»
Время на прочтение
11 мин
Количество просмотров 63K
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами (, , , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой (), а передачу по каналу связи — волнистой стрелкой (). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения и . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
Передача по каналу, в котором возникла ошибка будет записана так:
Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это и .
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:
Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:
Какие выводы мы можем сделать, когда получили ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.
Проверим в деле:
Получили . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали , а получили . Видно, что эта цепочка больше похожа на исходные , чем на . А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину , равную количеству различающихся цифр в соответствующих разрядах цепочек и . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например, , так как все цифры в соответствующих позициях равны, а вот .
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):
- .
Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:
Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение , мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами и расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
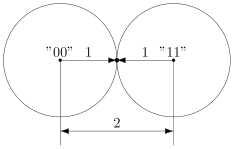
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.
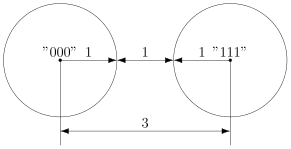
Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.

Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием будет успешно работать в канале с ошибками, если выполняется соотношение
Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:
Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.
Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние , а значит , откуда получаем, что такой код может исправить до ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:
Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.
Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:
Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):
Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.
Это свойство прямо следует из определения.
А в этом можно убедиться, прибавив к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)
Математически равенство всех трёх цифр можно записать как систему:
Или, если воспользоваться свойствами сложения в GF(2), получаем
Или
В матричном виде эта система будет иметь вид
где
Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:
Соответствующая система имеет вид:
Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если и — решения системы, то для их суммы верно
что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить .
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:
Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.
Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:
где равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.
Строчки здесь — линейно независимые решения, которые мы получили. Матрица называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)
Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?
А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:
Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово . Тогда вектор ошибки по определению
Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:
В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:
И заметим следующее
Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.
Вектор ошибки равен , а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Под корректирующей
способностью кода понимается его
способность обнаруживать или исправлять
ошибки, возникающие в кодовых комбинациях.
Корректирующая способность определяется
только избыточностью кода (степенью
выполнения неравенства (2)). Вид же
комбинаций кода определяет, какие
комбинации ошибок будут обнаруживаться
и (если выполнено разбиение запрещенных
комбинаций на подмножества Mi)
исправляться при одной и той же
корректирующей способности.
Для того, чтобы
код мог обнаруживать любую одиночную
ошибку в любой своей комбинации,
необходимо, чтобы при таких ошибках
разрешенная кодовая комбинация переходила
в запрещенную. Это возможно только
тогда, когда d>1,
или, так как d–целое,
d≥2.
Аналогично, для
того, чтобы код мог обнаруживать любые
ошибки кратности ν0
и менее,
необходимо, чтобы d
кода удовлетворяло условию
![]() . (13)
. (13)
Вопрос о том, может
ли обнаруживать ошибки код с d=1,
решается из рассмотрения неравенства
(2.). Если для кода указанное неравенство
выполняется, то он может обнаруживать
некоторые, хотя и не любые, одиночные и
более высокой кратности ошибки; если
(2) не выполняется, то код не обладает
корректирующей способностью.
Несколько сложнее
обстоит дело с исправлением ошибок.
Обычно исправление ошибок преследует
цель минимизировать вероятность выдачи
неправильной кодовой комбинации
получателю. Естественно, что достижение
этой цели возможно только при учете
статистики появления ошибок. Зная такую
статистику, нетрудно выполнить разбиение
запрещенных комбинаций Bj
на подмножества Mi
так, чтобы вероятность неправильного
исправления ошибок была минимальной.
Статистика ошибок
в комбинациях определяется каналом, по
которому производится передача. В
настоящее время статистика ошибок
получена для большинства реальных
каналов. Это позволило разработать
различные математические модели, с той
или иной степенью точности отражающие
процессы передачи символов по данным
каналам и служащие для их теоретического
исследования. Из широко используемых
моделей каналов рассматривается только
один – двоичный симметричный канал без
памяти, рассмотренный, например, в [2]. В
отношении этой модели корректирующие
коды исследованы наиболее полно.
Ориентация на
двоичный симметричный канал (ДСК) при
исследовании свойств кодов, несмотря
на то, что эта модель лишь весьма
приближенно описывает большинство
реальных каналов связи, объясняется ее
простотой. Действительно, ДСК
характеризуется тем, что искажения
отдельных символов в передаваемых по
нему комбинациях независимы и вероятности
искажений символов 0 и 1 одинаковы
(p01=p10=p).
Поэтому процесс передачи любого двоичного
символа комбинации кода по ДСК может
быть описан при помощи всего двух чисел
– вероятности искажения символа p
и вероятность правильной передачи
q=1–p.
ДСК обычно представляют графом,
изображенным на рис. 3.
Рис. 3. Двоичный симметричный код
Для ДСК при p<q
справедливо утверждение: если на выход
канала пришла некоторая запрещенная
комбинация, то вероятность того, что
она появилась в результате ошибок
меньшей кратности, больше, чем вероятность
того, что она порождена ошибками большей
кратности. Отсюда следует, что для
минимизации вероятности появления
ложной кодовой комбинации на выходе
устройства, осуществляющего передачу
информации по ДСК с исправлением ошибок,
необходимо, чтобы при коде в первую
очередь обеспечивалось исправление
ошибок меньшей кратности. Такой принцип
исправления ошибок определяет следующее
правило разбиения запрещенных комбинаций
на подмножества Mi:
запрещенная комбинация Bj
приписывается такой разрешенной кодовой
комбинации
Vi,
от которой она отличается в наименьшем
числе символов. Исправление ошибок в
соответствии с указанным принципом
получило название «исправление по
методу максимального правдоподобия».
Определим теперь,
каким минимальным d
должен обладать корректирующий код,
который по методу максимального
правдоподобия позволил бы исправлять
ошибки с кратностью от 1 до νu.
В соответствии с этим методом запрещенная
комбинация, получаемая из некоторой
кодовой в результате искажения νu
символов,
должна отличаться от любой другой
кодовой комбинации больше, чем νu
символами, то есть расстояние между
любыми кодовыми комбинациями должно
удовлетворять условию d>2νu,
или
![]() . (14)
. (14)
Из (14) видно,
например, что для того, чтобы код
обеспечивал исправление любой одиночной
ошибки, он должен иметь d≥3.
Теперь найдем,
каково должно быть d
кода, чтобы он мог обнаруживать ошибки
кратности ν0.
и менее и исправлять ошибки кратности
νu
и менее. Во-первых, заметим, что для того,
чтобы код мог исправлять ошибки кратности
от 1 до νu,
он должен их прежде обнаруживать, поэтому
всегде νuν0.
Во-вторых, чтобы
код мог обнаруживать ошибки кратности
ν0
эти ошибки не должны переводить кодовые
комбинации в такие закрещенные, которые
исправляются в другие кодовые комбинации
и, следовательно, отличаются от последних
не более чем в ν0
символах.
Поэтому для такого кода
![]() . (15)
. (15)
Нетрудно убедиться,
что при ν0
=0 (15)
переходит в (13), а при νи
=ν0
– в (14).
Отметим, что
конкретное использование d
кода определяет разработчик устройства
передачи информации.
7.1. Классификация корректирующих кодов
7.2. Принципы помехоустойчивого кодирования
7.3. Систематические коды
7.4. Код с четным числом единиц. Инверсионный код
7.5. Коды Хэмминга
7.6. Циклические коды
7.7. Коды с постоянным весом
7.8. Непрерывные коды
7.1. Классификация корректирующих кодов
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов [12]. На рис. 7.1 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов.
Все известные в настоящее время коды могут быть разделены
на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
Рис. 7.1. Классификация корректирующих кодов
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат ‘исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.
В свою очередь, линейные коды могут быть |разбиты на два подкласса: систематические и несистематические. Все двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими. Вертикальными прямоугольниками на схеме рис. 7.1 представлены некоторые конкретные коды, описанные в последующих параграфах.
7.2. Принципы помехоустойчивого кодирования
В теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются.
Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d![]() между двумя комбинациями
между двумя комбинациями ![]() и
и ![]() определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
Для любого кода d![]()
![]() . Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
. Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
Расстояние между комбинациями ![]() и
и ![]() условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций
условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций ![]() и
и ![]() , разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация
, разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация ![]() преобразовалась в другую разрешенную комбинацию
преобразовалась в другую разрешенную комбинацию ![]() , должно исказиться d символов.
, должно исказиться d символов.
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций
При искажении меньшего числа символов комбинация ![]() перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
![]() (7.1)
(7.1)
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() (7.2)
(7.2)
где ![]() — вероятность искажения одного символа. Так как обычно
— вероятность искажения одного символа. Так как обычно ![]() <<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация
<<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация ![]() (см.рис.7.2б), тогда принимается решение, что была передана комбинация
(см.рис.7.2б), тогда принимается решение, что была передана комбинация ![]() . Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
. Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
![]() (7.3)
(7.3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности ![]() исправляются, а ошибки, кратность которых лежит в пределах
исправляются, а ошибки, кратность которых лежит в пределах ![]() только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах
только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах ![]() , то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А
, то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А![]() вместо A
вместо A![]() или наоборот.
или наоборот.
Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания ![]() . Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов
. Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов ![]() оказалось равным gc, причем
оказалось равным gc, причем
![]() (7.4)
(7.4)
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов ![]() необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок
необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок ![]() , то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
, то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
Если ![]() , то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М![]() увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() (7.5)
(7.5)
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
![]() (7.6)
(7.6)
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
![]()
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
![]() (7.7)
(7.7)
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]()
Здесь суммирование ‘Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() (7.8)
(7.8)
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность Р![]() , избыточность
, избыточность ![]() и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р![]() и
и ![]() . Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
. Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы.
7.3. Систематические коды
Изучение конкретных способов помехоустойчивого кодирования начнем с систематических кодов, которые в соответствии с классификацией (рис. 7.1) относятся к блочным разделимым кодам, т. е. к кодам, где операции кодирования осуществляются независимо в пределах каждой комбинации, состоящей из информационных и контрольных символов.
Остановимся кратко на общих принципах построения систематических кодов. Если обозначить информационные символы буквами с, а контрольные — буквами е, то любую кодовую комбинацию, содержащую k информационных и r контрольных символов, можно представить последовательностью:![]() , где с и е в двоичном коде принимают значения 0 или 1.
, где с и е в двоичном коде принимают значения 0 или 1.
Процесс кодирования на передающем конце сводится к образованию контрольных символов, которые выражаются в виде линейной функции информационных символов:
![]()
![]() (7.9)
(7.9)
Здесь ![]() — коэффициенты, равные 0 или 1, а
— коэффициенты, равные 0 или 1, а ![]() и
и ![]() — знаки суммирования по модулю два. Значения
— знаки суммирования по модулю два. Значения ![]()
![]() выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации
выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации ![]()
![]()
![]() образуется по правилу (7.9) вторая группа контрольных символов
образуется по правилу (7.9) вторая группа контрольных символов ![]()
![]()
Затем производится сравнение обеих групп контрольных символов путем их суммирования по модулю два:
![]() (7.10)
(7.10)
Полученное число X называется контрольным числом или синдромом. С его помощью можно обнаружить или исправить часть ошибок. Если ошибки в принятой комбинации отсутствуют, то все суммы![]()
![]() , а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае
, а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае ![]() , что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
, что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
Для исправления ошибок знание одного факта их возникновения является недостаточным. Необходимо указать номер ошибочно принятых символов. С этой целью каждому сочетанию исправляемых ошибок в комбинации присваивается одно из контрольных чисел, что позволяет по известному контрольному числу определить место положения ошибок и исправить их.
Контрольное число X записывается в двоичной системе, поэтому общее количество различных контрольных чисел, отличающихся от нуля, равно![]()
![]() . Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно
. Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно ![]() . В этом случае должно выполняться условие
. В этом случае должно выполняться условие
![]() (7.11)
(7.11)
Формула (7.11) позволяет при заданном количестве информационных символов k определить необходимое число контрольных символов r, с помощью которых исправляются все одиночные ошибки.
7.4. Код с чётным числом единиц. Инверсионный код
Рассмотрим некоторые простейшие систематические коды, применяемые только для обнаружения ошибок. Одним из кодов подобного типа является код с четным числом единиц. Каждая комбинация этого кода содержит, помимо информационных символов, один контрольный символ, выбираемый равным 0 или 1 так, чтобы сумма единиц в комбинации всегда была четной. Примером могут служить пятизначные комбинации кода Бодо, к которым добавляется шестой контрольный символ: 10101,1 и 01100,0. Правило вычисления контрольного символа можно выразить на
основании (7.9) в следующей форме: ![]() . Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (
. Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (![]() — суммирование по модулю):
— суммирование по модулю):
![]() (7.12)
(7.12)
Это позволяет в декодирующем устройстве сравнительно просто производить обнаружение ошибок путем проверки на четность. Нарушение четности имеет место при появлении однократных, трехкратных и в общем, случае ошибок нечетной кратности, что и дает возможность их обнаружить. Появление четных ошибок не изменяет четности суммы (7.12), поэтому такие ошибки не обнаруживаются. На основании ,(7.8) вероятность необнаруженной ошибки равна:
![]()
![]()
К достоинствам кода следует отнести простоту кодирующих и декодирующих устройств, а также малую .избыточность ![]() , однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
, однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
Значительно лучшими корректирующими способностями обладает инверсный код, который также применяется только для обнаружения ошибок. С принципом построения такого кода удобно ознакомиться на примере двух комбинаций: 11000, 11000 и 01101, 10010. В каждой комбинации символы до запятой являются информационными, а последующие — контрольными. Если количество единиц в информационных символах четное, т. е. сумма этих
символов
![]() (7.13)
(7.13)
равна нулю, то контрольные символы представляют собой простое повторение информационных. В противном случае, когда число единиц нечетное и сумма (7.13) равна 1, контрольные символы получаются из информационных посредством инвертирования, т. е. путем замены всех 0 на 1, а 1 на 0. Математическая форма записи образования контрольных символов имеет вид ![]() . При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е.
. При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е. ![]() , то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘
, то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘![]() =1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность:
=1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность: ![]() . Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
. Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
Анализ показывает, что при ![]() наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения
наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения ![]() равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
![]()
Для g>4 вероятность необнаруженных ошибок еще меньше. Поэтому при достаточно малых вероятностях ошибочных символов ро можно полагать, что полная вероятность необнаруженных ошибок ![]()
Инверсный код обладает высокой обнаруживающей способностью, однако она достигается ценой сравнительно большой избыточности, которая, как нетрудно определить, составляет величину ![]() =0,5.
=0,5.
7.5. Коды Хэмминга
К этому типу кодов обычно относят систематические коды с расстоянием d=3, которые позволяют исправить все одиночные ошибки (7.3).
Рассмотрим построение семизначного кода Хэмминга, каждая комбинация которого содержит четыре информационных и триконтрольных символа. Такой код, условно обозначаемый (7.4), удовлетворяет неравенству (7.11) и имеет избыточность ![]()
Если информационные символы с занимают в комбинация первые четыре места, то последующие три контрольных символа образуются по общему правилу (7.9) как суммы:
![]() (7.14)
(7.14)
Декодирование осуществляется путем трех проверок на четность (7.10):
(7.15)
Так как х равно 0 или 1, то всего может быть восемь контрольных чисел Х=х1х2х3: 000, 100, 010, 001, 011, 101, 110 и 111. Первое из них имеет место в случае правильного приема, а остальные семь появляются при наличии искажений и должны использоваться для определения местоположения одиночной ошибки в семизначной комбинации. Выясним, каким образом устанавливается взаимосвязь между контрольными числами я искаженными символами. Если искажен один из контрольных символов: ![]() или
или ![]() , то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
, то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
Таблица 7.1
Порядок присвоения контрольных чисел ошибочным информационным символам может устанавливаться любой, например, как показано в табл. 7.1. Нетрудно показать, что этому распределению контрольных чисел соответствуют коэффициенты ![]() , приведенные в табл. 7.2.
, приведенные в табл. 7.2.
Таблица 7.2
Если подставить коэффициенты ![]() в выражение (7.15), то получим:
в выражение (7.15), то получим:
(7.16)
При искажении одного из информационных символов становятся равными единице те суммы х, в которые входит этот символ. Легко проверить, что получающееся в этом случае контрольное число![]() согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов
согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов ![]() . Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются
. Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются ![]() , Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
, Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
Передаваемая комбинация при этом будет ![]() . Предположим, что принята комбинация — 1001, 010 (искажен символ
. Предположим, что принята комбинация — 1001, 010 (искажен символ ![]() ). Подставляя соответствующие значения в (7.16), получим:
). Подставляя соответствующие значения в (7.16), получим:
Вычисленное таким образом контрольное число ![]() 110 позволяет согласно табл. 7.1 исправить ошибку в символе.
110 позволяет согласно табл. 7.1 исправить ошибку в символе.
Здесь был рассмотрен простейший способ построения и декодирования кодовых комбинаций, в которых первые места отводились информационным символам, а соответствие между контрольными числами и ошибками определялось таблице. Вместе с тем существует более изящный метод отыскания одиночных ошибок, предложенный впервые самим Хэммингом. При этом методе код строится так, что контрольное число в двоичной системе счисления сразу указывает номер искаженного символа. Правда, в этом случае контрольные символы необходимо располагать среди информационных, что усложняет процесс кодирования. Для кода (7.4) символы в комбинации должны размещаться в следующем порядке: ![]() , а контрольное число вычисляться по формулам:
, а контрольное число вычисляться по формулам:
(7.17)
Так, если произошла ошибка в информационном символе с’5 то контрольное число ![]() , что соответствует числу 5 в двоичной системе.
, что соответствует числу 5 в двоичной системе.
В заключение отметим, что в коде (7.4) при появлении многократных ошибок контрольное число также может отличаться от нуля. Однако декодирование в этом случае будет проведено неправильно, так как оно рассчитано на исправление лишь одиночных ошибок.
7.6. Циклические коды
Важное место среди систематических кодов занимают циклические коды. Свойство цикличности состоит в том, что циклическая перестановка всех символов кодовой комбинации ![]() дает другую комбинацию
дает другую комбинацию ![]() также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например,
также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например, ![]()
![]()
![]()
![]() .
.
Комбинации циклического кода, выражаемые двоичными числами, для удобства преобразований обычно определяют в виде полиномов, коэффициенты которых равны 0 или 1. Примером этому может служить следующая запись:
![]()
Помимо цикличности, кодовые комбинации обладают другим важным свойством. Если их представить в виде полиномов, то все они делятся без остатка на так называемый порождающий полином G(z) степени ![]() , где k—значность первичного кода без избыточности, а п-значность циклического кода
, где k—значность первичного кода без избыточности, а п-значность циклического кода
Построение комбинаций циклических кодов возможно путем умножения комбинации первичного кода A*(z) ,на порождающий полином G(z):
A(z)=A*(z)G(z).
Умножение производится по модулю zn и в данном случае сводится к умножению по обычным правилам с приведением подобных членов по модулю два.
В полученной таким способом комбинации A(z) в явном виде не содержатся информационные символы, однако они всегда могут быть выделены в результате обратной операции: деления A(z) на G(z).
Другой способ кодирования, позволяющий представить кодовую комбинацию в виде информационных и контрольных символов, заключается в следующем. К комбинации первичного кода дописывается справа г нулей, что эквивалентно повышению полинома A*(z) на ,г разрядов, т. е. умножению его на гг. Затем произведение zrA*(z) делится на порождающий полином. B общем случае результат деления состоит из целого числа Q(z) и остатка R(z). Отсюда
![]()
Вычисленный остаток К(г) я используется для образования комбинации циклического кода в виде суммы
A(z)=zrA*(z)@R(z).
Так как сложение и вычитание по модулю два дают один и тот же результат, то нетрудно заметить, что A(z) = Q(z)G(z), т. е. полученная комбинация удовлетворяет требованию делимости на порождающий полином. Степень полинома R{z) не превышает r—1, поэтому он замещает нули в комбинации z![]() A*(z).
A*(z).
Для примера рассмотрим циклический код c n = 7, k=4, r=3 и G(z)=z3-z+1=1011. Необходимо закодировать комбинацию A*(z)=z*+1 = 1001. Тогда z![]() A*(z)=z
A*(z)=z![]() +z
+z![]() = 1001000. Для определения остатка делим z3A*(z) на G(z):
= 1001000. Для определения остатка делим z3A*(z) на G(z):
Окончательно получаем
В А(z) высшие четыре разряда занимают информационные символы, а остальные при — контрольные.
Контрольные символы в циклическом коде могут быть вычислены по общим ф-лам (7.9), однако здесь определение коэффициентов ![]() затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
Процедура декодирования принятых комбинаций также основана на использовании полиномов G(z). Если ошибок в процессе передачи не было, то деление принятой комбинации A(z) на G(z) дает целое число. При наличии корректируемых ошибок в результате деления образуется остаток, который и позволяет обнаружить или исправить ошибки.
Кодирующие и декодирующие устройства циклических кодов в большинстве случаев обладают сравнительной простотой, что следует считать одним из основных их преимуществ. Другим важным достоинством этих кодов является их способность корректировать пачки ошибок, возникающие в реальных каналах, где действуют импульсные и сосредоточенные помехи или наблюдаются замирания сигнала.
В теории кодирования весом кодовых комбинаций принято называть .количество единиц, которое они содержат. Если все комбинации кода имеют одинаковый вес, то такой код называется кодом с постоянным весом. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь не представляется возможным выделить информационные и контрольные символы. Из кодов этого типа наибольшее распространение получил обнаруживающий семизначный код 3/4, каждая разрешенная комбинация которого имеет три единицы и четыре нуля. Известен также код 2/5. Примером комбинаций кода 3/4 могут служить следующие семизначные последовательности: 1011000, 0101010, 0001110 и т. д.
Декодирование принятых комбинаций сводится к определению их веса. Если он отличается от заданного, то комбинация принята с ошибкой. Этот код обнаруживает все ошибки нечетной краткости и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Ошибки смещения характеризуются тем, что число искаженных единиц всегда равно числу искаженных нулей. Можно показать, что вероятность необнаруженной ошибки для кода 3/4 равна:
![]() при
при ![]() (7.18)
(7.18)
В этом коде из общего числа комбинаций М = 27=128 разрешенными являются лишь ![]() , поэтому в соответствии с (7.6) коэффициент избыточности
, поэтому в соответствии с (7.6) коэффициент избыточности
![]()
Код 3/4 находит применение при частотной манипуляции в каналах с селективными замираниями, где вероятность ошибок смещения невелика.
7.8. Непрерывные коды
Из непрерывных кодов, исправляющих ошибки, наиболее известны коды Финка—Хагельбаргера, в которых контрольные символы образуются путем линейной операции над двумя или более информационными символами. Принцип построения этих кодов рассмотрим на примере простейшего цепного кода. Контрольные символы в цепном коде формируются путем суммирования двух информационных символов, расположенных один относительно другого на определенном расстоянии:
![]() ;
;![]() (7.19)
(7.19)
Расстояние между информационными символами l=k—i определяет основные свойства кода и называется шагом сложения. Число контрольных символов при таком способе кодирования равно числу информационных символов, поэтому избыточность кода ![]() =0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
=0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
Рис. 7.3. Образование и размещение контрольных символов в цепном коде Финка—Хагельбаргера
При декодировании из принятых информационных символов по тому же правилу (7.19) формируется вспомогательная последовательность контрольных символов е», которая сравнивается с принятой последовательностью контрольных символов е’ (рис. 7.36). Если произошла ошибка в информационном символе, например, c‘k, то это вызовет искажения сразу двух символов e«k и e«km, что и обнаружится в результате их сравнения с ![]() и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’
и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’![]() Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Важное преимущество непрерывных кодов состоит в их способности исправлять не только одиночные ошибки, но я группы (пакеты) ошибок. Если задержка контрольных символов выбрана равной 2l, то можно показать, что максимальная длина исправляемого пакета ошибок также равна 2l при интервале между пакетами не менее 6l+1. Таким образом, возможность исправления длинных пакетов связана с увеличением шага сложения, а следовательно, и с усложнением кодирующих и декодирующих устройств.
Вопросы для повторения
1. Как могут быть классифицированы корректирующие коды?
2. Каким образом исправляются ошибки в кодах, которые только их обнаруживают?
3. В чем состоят основные принципы корректирования ошибок?
4. Дайте определение кодового расстояния.
5. При каких условиях код может обнаруживать или исправлять ошибки?
6. Как используется корректирующий код в системах со стиранием?
7. Какие характеристики определяют корректирующие способности кода?
8. Как осуществляется построение кодовых комбинаций в систематических кодах?
9. На чем основан принцип корректирования ошибок с использованием контрольного числа?
10. Объясните метод построения кода с четным числом единиц.
11. Как осуществляется процедура кодирования в семизначном коде Хэмминга?
12. Почему семизначный код 3/4 не обнаруживает ошибки смещения?
13. Каким образом производится непрерывное кодирование?
14. От чего зависит длина пакета исправляемых ошибок в коде Финка—Хагельбаргера?
| Обноружение ошибок | ||||
| Исправление ошибок | ||||
| Коррекция ошибок | ||||
| Назад | ||||
Методы обнаружения ошибок
В обычном равномерном непомехоустойчивом коде число разрядов n в кодовых
комбинациях определяется числом сообщений и основанием кода.
Коды, у которых все кодовые комбинации разрешены, называются простыми или
равнодоступными и являются полностью безызбыточными. Безызбыточные коды обладают
большой «чувствительностью» к помехам. Внесение избыточности при использовании
помехоустойчивых кодов связано с увеличением n – числа разрядов кодовой комбинации. Таким
образом, все множество
 комбинаций можно разбить на два подмножества:
комбинаций можно разбить на два подмножества:
подмножество разрешенных комбинаций, обладающих определенными признаками, и
подмножество запрещенных комбинаций, этими признаками не обладающих.
Помехоустойчивый код отличается от обычного кода тем, что в канал передаются не все
кодовые комбинации N, которые можно сформировать из имеющегося числа разрядов n, а только
их часть Nk , которая составляет подмножество разрешенных комбинаций. Если при приеме
выясняется, что кодовая комбинация принадлежит к запрещенным, то это свидетельствует о
наличии ошибок в комбинации, т.е. таким образом решается задача обнаружения ошибок. При
этом принятая комбинация не декодируется (не принимается решение о переданном
сообщении). В связи с этим помехоустойчивые коды называют корректирующими кодами.
Корректирующие свойства избыточных кодов зависят от правила их построения, определяющего
структуру кода, и параметров кода (длительности символов, числа разрядов, избыточности и т. п.).
Первые работы по корректирующим кодам принадлежат Хеммингу, который ввел понятие
минимального кодового расстояния dmin и предложил код, позволяющий однозначно указать ту
позицию в кодовой комбинации, где произошла ошибка. К информационным элементам k в коде
Хемминга добавляется m проверочных элементов для автоматического определения
местоположения ошибочного символа. Таким образом, общая длина кодовой комбинации
составляет: n = k + m.
Метричное представление n,k-кодов
В настоящее время наибольшее внимание с точки зрения технических приложений
уделяется двоичным блочным корректирующим кодам. При использовании блочных кодов
цифровая информация передается в виде отдельных кодовых комбинаций (блоков) равной
длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга.
Почти все блочные коды относятся к разделимым кодам, кодовые комбинации которых
состоят из двух частей: информационной и проверочной. При общем числе n символов в блоке
число информационных символов равно k, а число проверочных символов:
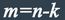
К основным характеристикам корректирующих кодов относятся:
|
— число разрешенных и запрещенных кодовых комбинаций; |
Для блочных двоичных кодов, с числом символов в блоках, равным n, общее число
возможных кодовых комбинаций определяется значением
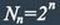
Число разрешенных кодовых комбинаций при наличии k информационных разрядов в
первичном коде:
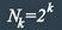
Очевидно, что число запрещенных комбинаций:
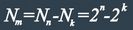
а с учетом ![]() отношение будет
отношение будет
![]()
где m – число избыточных (проверочных) разрядов в блочном коде.
Избыточностью корректирующего кода называют величину
![]()
откуда следует:
![]()
Эта величина показывает, какую часть общего числа символов кодовой комбинации
составляют информационные символы. В теории кодирования величину Bk называют
относительной скоростью кода. Если производительность источника информации равна H
символов в секунду, то скорость передачи после кодирования этой информации будет
![]()
поскольку в закодированной последовательности из каждых n символов только k символов
являются информационными.
Если число ошибок, которые нужно обнаружить или исправить, значительно, то необходимо
иметь код с большим числом проверочных символов. Чтобы при этом скорость передачи
оставалась достаточно высокой, необходимо в каждом кодовом блоке одновременно
увеличивать как общее число символов, так и число информационных символов.
При этом длительность кодовых блоков будет существенно возрастать, что приведет к
задержке информации при передаче и приеме. Чем сложнее кодирование, тем длительнее
временная задержка информации.
Минимальное кодовое расстояние – dmin. Для того чтобы можно было обнаружить и
исправлять ошибки, разрешенная комбинация должна как можно больше отличаться от
запрещенной. Если ошибки в канале связи действуют независимо, то вероятность преобразования
одной кодовой комбинации в другую будет тем меньше, чем большим числом символов они
различаются.
Если интерпретировать кодовые комбинации как точки в пространстве, то отличие
выражается в близости этих точек, т. е. в расстоянии между ними.
Количество разрядов (символов), которыми отличаются две кодовые комбинации, можно
принять за кодовое расстояние между ними. Для определения этого расстояния нужно сложить
две кодовые комбинации «по модулю 2» и подсчитать число единиц в полученной сумме.
Например, две кодовые комбинации xi = 01011 и xj = 10010 имеют расстояние d(xi,xj) , равное 3,
так как:

Здесь под операцией ⊕ понимается сложение «по модулю 2».
Заметим, что кодовое расстояние d(xi,x0) между комбинацией xi и нулевой x0 = 00…0
называют весом W комбинации xi, т.е. вес xi равен числу «1» в ней.
Расстояние между различными комбинациями некоторого конкретного кода могут
существенно отличаться. Так, в частности, в безызбыточном первичном натуральном коде n = k это
расстояние для различных комбинаций может изменяться от единицы до величины n, равной
разрядности кода. Особую важность для характеристики корректирующих свойств кода имеет
минимальное кодовое расстояние dmin, определяемое при попарном сравнении всех кодовых
комбинаций, которое называют расстоянием Хемминга.
В безызбыточном коде все комбинации являются разрешенными и его минимальное
кодовое расстояние равно единице – dmin=1. Поэтому достаточно исказиться одному символу,
чтобы вместо переданной комбинации была принята другая разрешенная комбинация. Чтобы код
обладал корректирующими свойствами, необходимо ввести в него некоторую избыточность,
которая обеспечивала бы минимальное расстояние между любыми двумя разрешенными
комбинациями не менее двух – dmin ≥ 2..
Минимальное кодовое расстояние является важнейшей характеристикой помехоустойчивых
кодов, указывающей на гарантируемое число обнаруживаемых или исправляемых заданным
кодом ошибок.
Число обнаруживаемых или исправляемых ошибок
При применении двоичных кодов учитывают только дискретные искажения, при которых
единица переходит в нуль («1» → «0») или нуль переходит в единицу («0» → «1»). Переход «1» →
«0» или «0» → «1» только в одном элементе кодовой комбинации называют единичной ошибкой
(единичным искажением). В общем случае под кратностью ошибки подразумевают число
позиций кодовой комбинации, на которых под действием помехи одни символы оказались
замененными на другие. Возможны двукратные (g = 2) и многократные (g > 2) искажения
элементов в кодовой комбинации в пределах 0 ≤ g ≤ n.
Минимальное кодовое расстояние является основным параметром, характеризующим
корректирующие способности данного кода. Если код используется только для обнаружения
ошибок кратностью g0, то необходимо и достаточно, чтобы минимальное кодовое расстояние
было равно dmin ≥ g0 + 1.
В этом случае никакая комбинация из go ошибок не может перевести одну разрешенную
кодовую комбинацию в другую разрешенную. Таким образом, условие обнаружения всех ошибок
кратностью g0 можно записать
![]()
Чтобы можно было исправить все ошибки кратностью gu и менее, необходимо иметь
минимальное расстояние, удовлетворяющее условию dmin ≥ 2gu
![]()
В этом случае любая кодовая комбинация с числом ошибок gu отличается от каждой
разрешенной комбинации не менее чем в gu+1 позициях. Если условие ![]() не выполнено,
не выполнено,
возможен случай, когда ошибки кратности g исказят переданную комбинацию так, что она станет
ближе к одной из разрешенных комбинаций, чем к переданной или даже перейдет в другую
разрешенную комбинацию. В соответствии с этим, условие исправления всех ошибок кратностью
не более gи можно записать:
![]()
Из ![]() и
и ![]()
следует, что если код исправляет все ошибки кратностью gu, то число
ошибок, которые он может обнаружить, равно go = 2gu. Следует отметить, что эти соотношения
устанавливают лишь гарантированное минимальное число обнаруживаемых или
исправляемых ошибок при заданном dmin и не ограничивают возможность обнаружения ошибок
большей кратности. Например, простейший код с проверкой на четность с dmin = 2 позволяет
обнаруживать не только одиночные ошибки, но и любое нечетное число ошибок в пределах go < n.
Корректирующие возможности кодов
Вопрос о минимально необходимой избыточности, при которой код обладает нужными
корректирующими свойствами, является одним из важнейших в теории кодирования. Этот вопрос
до сих пор не получил полного решения. В настоящее время получен лишь ряд верхних и нижних
оценок (границ), которые устанавливают связь между максимально возможным минимальным
расстоянием корректирующего кода и его избыточностью.
Коды Хэмминга
Построение кодов Хемминга базируется на принципе проверки на четность веса W (числа
единичных символов «1») в информационной группе кодового блока.
Поясним идею проверки на четность на примере простейшего корректирующего кода,
который так и называется кодом с проверкой на четность или кодом с проверкой по паритету
(равенству).
В таком коде к кодовым комбинациям безызбыточного первичного двоичного k-разрядного
кода добавляется один дополнительный разряд (символ проверки на четность, называемый
проверочным, или контрольным). Если число символов «1» исходной кодовой комбинации
четное, то в дополнительном разряде формируют контрольный символ «0», а если число
символов «1» нечетное, то в дополнительном разряде формируют символ «1». В результате
общее число символов «1» в любой передаваемой кодовой комбинации всегда будет четным.
Таким образом, правило формирования проверочного символа сводится к следующему:
![]()
где i – соответствующий информационный символ («0» или «1»); k – общее их число а, под
операцией ⊕ здесь и далее понимается сложение «по модулю 2». Очевидно, что добавление
дополнительного разряда увеличивает общее число возможных комбинаций вдвое по сравнению
с числом комбинаций исходного первичного кода, а условие четности разделяет все комбинации
на разрешенные и неразрешенные. Код с проверкой на четность позволяет обнаруживать
одиночную ошибку при приеме кодовой комбинации, так как такая ошибка нарушает условие
четности, переводя разрешенную комбинацию в запрещенную.
Критерием правильности принятой комбинации является равенство нулю результата S
суммирования «по модулю 2» всех n символов кода, включая проверочный символ m1. При
наличии одиночной ошибки S принимает значение 1:
![]() — ошибок нет,
— ошибок нет,
![]() — однократная ошибка
— однократная ошибка
Этот код является (k+1,k)-кодом, или (n,n–1)-кодом. Минимальное расстояние кода равно
двум (dmin = 2), и, следовательно, никакие ошибки не могут быть исправлены. Простой код с
проверкой на четность может использоваться только для обнаружения (но не исправления)
однократных ошибок.
Увеличивая число дополнительных проверочных разрядов, и формируя по определенным
правилам проверочные символы m, равные «0» или «1», можно усилить корректирующие
свойства кода так, чтобы он позволял не только обнаруживать, но и исправлять ошибки. На этом и
основано построение кодов Хемминга.
Коды Хемминга позволяют исправлять одиночную ошибку, с помощью непосредственного
описания. Для каждого числа проверочных символов m =3, 4, 5… существует классический код
Хемминга с маркировкой
![]()
т.е. (7,4), (15,11) (31,26) …
При других значениях числа информационных символов k получаются так называемые
усеченные (укороченные) коды Хемминга. Так для кода имеющего 5 информационных символов,
потребуется использование корректирующего кода (9,5), являющегося усеченным от
классического кода Хемминга (15,11), так как число символов в этом коде уменьшается
(укорачивается) на 6.
Для примера рассмотрим классический код Хемминга (7,4), который можно сформировать и
описать с помощью кодера, представленного на рис. 1 В простейшем варианте при заданных
четырех информационных символах: i1, i2, i3, i4 (k = 4), будем полагать, что они сгруппированы в
начале кодового слова, хотя это и не обязательно. Дополним эти информационные символы
тремя проверочными символами (m = 3), задавая их следующими равенствами проверки на
четность, которые определяются соответствующими алгоритмами, где знак ⊕ означает
сложение «по модулю 2»: r1 = i1 ⊕ i2 ⊕ i3, r2 = i2 ⊕ i3 ⊕ i4, r3 = i1 ⊕ i2 ⊕ i4.
В соответствии с этим алгоритмом определения значений проверочных символов mi, в табл.
1 выписаны все возможные 16 кодовых слов (7,4)-кода Хемминга.
Таблица 1 Кодовые слова (7,4)-кода Хэмминга
|
k=4 |
m=4 |
|
i1 i2 i3 i4 |
r1 r2 r3 |
|
0 0 0 0 |
0 0 0 |
|
0 0 0 1 |
0 1 1 |
|
0 0 1 0 |
1 1 0 |
|
0 0 1 1 |
1 0 1 |
|
0 1 0 0 |
1 1 1 |
|
0 1 0 1 |
1 0 0 |
|
0 1 1 0 |
0 0 1 |
|
0 1 1 1 |
0 1 0 |
|
1 0 0 0 |
1 0 1 |
|
1 0 0 1 |
1 0 0 |
|
1 0 1 0 |
0 1 1 |
|
1 0 1 1 |
0 0 0 |
|
1 1 0 0 |
0 1 0 |
|
1 1 0 1 |
0 0 1 |
|
1 1 1 0 |
1 0 0 |
|
1 1 1 1 |
1 1 1 |
На рис.1 приведена блок-схема кодера – устройства автоматически кодирующего
информационные разряды в кодовые комбинации в соответствии с табл.1
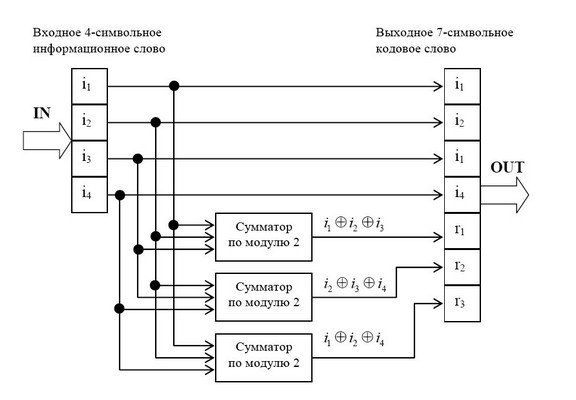
Рис. 1 Кодер для (7,4)-кода Хемминга
На рис. 1.4 приведена схема декодера для (7,4) – кода Хемминга, на вход которого
поступает кодовое слово
![]() . Апостроф означает, что любой символ слова может
. Апостроф означает, что любой символ слова может
быть искажен помехой в телекоммуникационном канале.
В декодере в режиме исправления ошибок строится последовательность:
![]()
![]()
![]()
Трехсимвольная последовательность (s1, s2, s3) называется синдромом. Термин «синдром»
используется и в медицине, где он обозначает сочетание признаков, характерных для
определенного заболевания. В данном случае синдром S = (s1, s2, s3) представляет собой
сочетание результатов проверки на четность соответствующих символов кодовой группы и
характеризует определенную конфигурацию ошибок (шумовой вектор).
Число возможных синдромов определяется выражением:
![]()
При числе проверочных символов m =3 имеется восемь возможных синдромов (23 =  .
.
Нулевой синдром (000) указывает на то, что ошибки при приеме отсутствуют или не обнаружены.
Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и
исправляется. Классические коды Хемминга имеют число синдромов, точно равное их
необходимому числу (что позволяет исправить все однократные ошибки в любом информативном
и проверочном символах) и включают один нулевой синдром. Такие коды называются
плотноупакованными.
Усеченные коды являются неплотноупакованными, так как число синдромов у них
превышает необходимое. Так, в коде (9,5) при четырех проверочных символах число синдромов
будет равно 24 =16, в то время как необходимо всего 10. Лишние 6 синдромов свидетельствуют о
неполной упаковке кода (9,5).
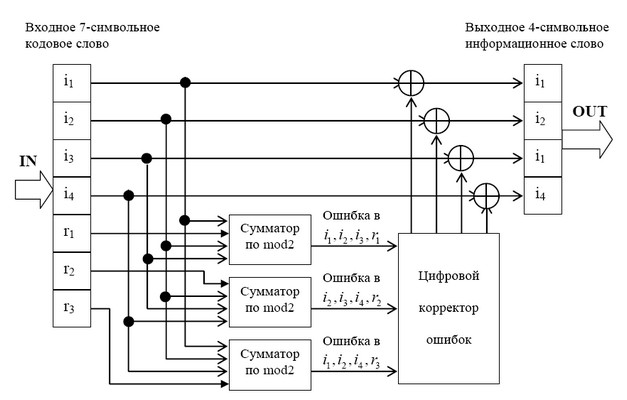
Рис. 2 Декодер для (7, 4)-кода Хемминга
Для рассматриваемого кода (7,4) в табл. 2 представлены ненулевые синдромы и
соответствующие конфигурации ошибок.
Таблица 2 Синдромы (7, 4)-кода Хемминга
|
Синдром |
001 |
010 |
011 |
100 |
101 |
110 |
111 |
|
Конфигурация ошибок |
0000001 |
0000010 |
0000100 |
0001000 |
0010000 |
0100000 |
1000000 |
|
Ошибка в символе |
m1 |
m2 |
i4 |
m1 |
i1 |
i3 |
i2 |
Таким образом, (7,4)-код позволяет исправить все одиночные ошибки. Простая проверка
показывает, что каждая из ошибок имеет свой единственный синдром. При этом возможно
создание такого цифрового корректора ошибок (дешифратора синдрома), который по
соответствующему синдрому исправляет соответствующий символ в принятой кодовой группе.
После внесения исправления проверочные символы ri можно на выход декодера (рис. 2) не
выводить. Две или более ошибок превышают возможности корректирующего кода Хемминга, и
декодер будет ошибаться. Это означает, что он будет вносить неправильные исправления и
выдавать искаженные информационные символы.
Идея построения подобного корректирующего кода, естественно, не меняется при
перестановке позиций символов в кодовых словах. Все такие варианты также называются (7,4)-
кодами Хемминга.
Циклические коды
Своим названием эти коды обязаны такому факту, что для них часть комбинаций, либо все
комбинации могут быть получены путем циклическою сдвига одной или нескольких базовых
комбинаций кода.
Построение такого кода основывается на использовании неприводимых многочленов в поле
двоичных чисел. Такие многочлены не могут быть представлены в виде произведения
многочленов низших степеней подобно тому, как простые числа не могут быть представлены
произведением других чисел. Они делятся без остатка только на себя или на единицу.
Для определения неприводимых многочленов раскладывают на простые множители бином
хn -1. Так, для n = 7 это разложение имеет вид:
(x7)=(x-1)(x3+x2)(x3+x-1)
Каждый из полученных множителей разложения может применяться для построения
корректирующего кода.
Неприводимый полином g(x) называют задающим, образующим или порождающим
для корректирующего кода. Длина n (число разрядов) создаваемого кода произвольна.
Кодовая последовательность (комбинация) корректирующего кода состоит из к информационных
разрядов и n — к контрольных (проверочных) разрядов. Степень порождающего полинома
r = n — к равна количеству неинформационных контрольных разрядов.
Если из сделанного выше разложения (при n = 7) взять полипом (х — 1), для которого
r=1, то k=n-r=7-1=6. Соответствующий этому полиному код используется для контроля
на чет/нечет (обнаружение ошибок). Для него минимальное кодовое расстояние D0 = 2
(одна единица от D0 — для исходного двоичного кода, вторая единица — за счет контрольного разряда).
Если же взять полином (x3+x2+1) из указанного разложения, то степень полинома
r=3, а k=n-r=7-3=4.
Контрольным разрядам в комбинации для некоторого кода могут быть четко определено место (номера разрядов).
Тогда код называют систематическим или разделимым. В противном случае код является неразделимым.
Способы построения циклических кодов по заданному полиному.
1) На основе порождающей (задающей) матрицы G, которая имеет n столбцов, k строк, то есть параметры которой
связаны с параметрами комбинаций кода. Порождающую матрицу строят, взяв в качестве ее строк порождающий
полином g(x) и (k — 1) его циклических сдвигов:
Пример; Определить порождающую матрицу, если известно, что n=7, k=4, задающий полином g(x)=x3+х+1.
Решение: Кодовая комбинация, соответствующая задающему полиному g(x)=x3+х+1, имеет вид 1011.
Тогда порождающая матрица G7,4 для кода при n=7, к=4 с учетом того, что k-1=3, имеет вид:

Порождающая матрица содержит k разрешенных кодовых комбинаций. Остальные комбинации кода,
количество которых (2k — k) можно определить суммированием по модулю 2 всевозможных сочетаний
строк матрицы Gn,k. Для матрицы, полученной в приведенном выше примере, суммирование по модулю 2
четырех строк 1-2, 1-3, 1-4, 2-3, 2-4, 3-4 дает следующие кодовые комбинации циклического кода:
001110101001111010011011101010011101110100
Другие комбинации искомого корректирующего кода могут быть получены сложением трех комбинаций, например,
из сочетания строк 1-3-4, что дает комбинацию 1111111, а также сложением четырех строк 1-2-3-4, что
дает комбинацию 1101001 и т.д.
Ряд комбинаций искомого кода может быть получено путем дальнейшего циклического сдвига комбинаций
порождающей матрицы, например, 0110001, 1100010, 1000101. Всего для образования искомого циклического
кода требуется 2k=24=16 комбинаций.
2) Умножение исходных двоичных кодовых комбинаций на задающий полином.
Исходными комбинациями являются все k-разрядные двоичные комбинации. Так, например, для исходной
комбинации 1111 (при k = 4) умножение ее на задающий полином g(x)=x3+х+1=1011 дает 1101001.
Полученные на основе двух рассмотренных способов циклические коды не являются разделимыми.
3) Деление на задающий полином.
Для получения разделимого (систематического) циклического кода необходимо разделить многочлен
xn-k*h(x), где h(x) — исходная двоичная комбинация, на задающий полином g(x) и прибавить полученный
остаток от деления к многочлену xn-k*h(x).
Заметим, что умножение исходной комбинации h(x) на xn-k эквивалентно сдвигу h(x) на (n-к) разрядов влево.
Пример: Требуется определить комбинации циклического разделимого кода, заданного полиномом g(x)=x3+х+1=1011 и
имеющего общее число разрядов 7, число информационных разрядов 4, число контрольных разрядов (n-k)=3.
Решение: Пусть исходная комбинация h(x)=1100. Умножение ее на xn-k=x3=1000 дает
x3*(x3+x2)=1100000, то есть эквивалентно
сдвигу исходной комбинации на 3 разряда влево. Деление комбинации 1100000 на комбинацию 1011, эквивалентно задающему полиному, дает:

Полученный остаток от деления, содержащий xn-k=3 разряда, прибавляем к полиному, в результате чего получаем искомую комбинацию
разделимого циклического кода: 1100010. В ней 4 старших разряда (слева) соответствуют исходной двоичной комбинации, а три младших
разряда являются контрольными.
Следует сделать ряд указаний относительно процедуры деления:
1) При делении задающий полином совмещается старшим разрядом со старшим «единичными разрядом делимого.
2) Вместо вычитания по модулю 2 выполняется эквивалентная ему процедура сложения по модулю 2.
3) Деление продолжается до тех пор, пока степень очередного остатка не будет меньше степени делителя (задающего полинома). При достижении
этого полученный остаток соответствует искомому содержанию контрольных разрядов для данной искомой двоичной комбинации.
Для проверки правильности выполнения процедуры определения комбинации циклического кода необходимо разделить полученную комб1шацию на задающий полином с
учетом сделанных выше замечаний. Получение нулевого остатка от такого деления свидетельствует о правильности определения комбинации.
Логический код 4В/5В
Логический код 4В/5В заменяет исходные символы длиной в 4 бита на символы длиной в 5 бит. Так как результирующие символы содержат избыточные биты, то
общее количество битовых комбинаций в них больше, чем в исходных. Таким образом, пяти-битовая схема дает 32 (25) двухразрядных буквенно-цифровых символа,
имеющих значение в десятичном коде от 00 до 31. В то время как исходные данные могут содержать только четыре бита или 16 (24) символов.
Поэтому в результирующем коде можно подобрать 16 таких комбинаций, которые не содержат большого количества нулей, а остальные считать запрещенными кодами
(code violation). В этом случае длинные последовательности нулей прерываются, и код становится самосинхронизирующимся для любых передаваемых данных.
Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии,
так как избыточные единицы пользовательской информации не несут, и только «занимают эфирное время». Избыточные коды позволяют приемнику распознавать
искаженные биты. Если приемник принимает запрещенный код, значит, на линии произошло искажение сигнала.
Итак, рассмотрим работу логического кода 4В/5В. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере
приемника пять битов расшифровываются как информационные и служебные сигналы.
Для служебных сигналов отведены девять символов, семь символов — исключены.
Исключены комбинации, имеющие более трех нулей (01 — 00001, 02 — 00010, 03 — 00011, 08 — 01000, 16 — 10000). Такие сигналы интерпретируются символом
V и командой приемника VIOLATION — сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная
комбинация из пяти нулей (00 — 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET — отсутствие сигнала в линии.
Такое кодирование данных решает две задачи — синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения
последовательности более трех нулей, а высокая помехоустойчивость достигается приемником данных на пяти-битовом интервале.
Цена за эти достоинства при таком способе кодирования данных — снижение скорости передачи полезной информации.
К примеру, В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы
частот в протоколах с кодом MLT-3 и кодированием данных 4B/5B уменьшается соответственно на 25%.
Схема кодирования 4В/5В представлена в таблице.
|
Двоичный код 4В |
Результирующий код 5В |
|
0 0 0 0 |
1 1 1 1 0 |
|
0 0 0 1 |
0 1 0 0 1 |
|
0 0 1 0 |
1 0 1 0 0 |
|
0 0 1 1 |
1 0 1 0 1 |
|
0 1 0 0 |
0 1 0 1 0 |
|
0 1 0 1 |
0 1 0 1 1 |
|
0 1 1 0 |
0 1 1 1 0 |
|
0 1 1 1 |
0 1 1 1 1 |
|
1 0 0 0 |
1 0 0 1 0 |
|
1 0 0 1 |
1 0 0 1 1 |
|
1 0 1 0 |
1 0 1 1 0 |
|
1 0 1 1 |
1 0 1 1 1 |
|
1 1 0 0 |
1 1 0 1 0 |
|
1 1 0 1 |
1 1 0 1 1 |
|
1 1 1 0 |
1 1 1 0 0 |
|
1 1 1 1 |
1 1 1 0 1 |
Итак, соответственно этой таблице формируется код 4В/5В, затем передается по линии с помощью физического кодирования по
одному из методов потенциального кодирования, чувствительному только к длинным последовательностям нулей — например, в помощью
цифрового кода NRZI.
Символы кода 4В/5В длиной 5 бит гарантируют, что при любом их сочетании на линии не могут встретиться более трех нулей подряд.
Буква ^ В в названии кода означает, что элементарный сигнал имеет 2 состояния — от английского binary — двоичный. Имеются
также коды и с тремя состояниями сигнала, например, в коде 8В/6Т для кодирования 8 бит исходной информации используется
код из 6 сигналов, каждый из которых имеет три состояния. Избыточность кода 8В/6Т выше, чем кода 4В/5В, так как на 256
исходных кодов приходится 36=729 результирующих символов.
Как мы говорили, логическое кодирование происходит до физического, следовательно, его осуществляют оборудование канального
уровня сети: сетевые адаптеры и интерфейсные блоки коммутаторов и маршрутизаторов. Поскольку, как вы сами убедились,
использование таблицы перекодировки является очень простой операцией, поэтому метод логического кодирования избыточными
кодами не усложняет функциональные требования к этому оборудованию.
Единственное требование — для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код,
должен работать с повышенной тактовой частотой. Так, для передачи кодов 4В/5В со скоростью 100 Мб/с передатчик должен
работать с тактовой частотой 125 МГц. При этом спектр сигнала на линии расширяется по сравнению со случаем, когда по
линии передается чистый, не избыточный код. Тем не менее, спектр избыточного потенциального кода оказывается уже
спектра манчестерского кода, что оправдывает дополнительный этап логического кодирования, а также работу приемника
и передатчика на повышенной тактовой частоте.
В основном для локальных сетей проще, надежней, качественней, быстрей — использовать логическое кодирование данных
с помощью избыточных кодов, которое устранит длительные последовательности нулей и обеспечит синхронизацию
сигнала, потом на физическом уровне использовать для передачи быстрый цифровой код NRZI, нежели без предварительного
логического кодирования использовать для передачи данных медленный, но самосинхронизирующийся манчестерский код.
Например, для передачи данных по линии с пропускной способностью 100М бит/с и полосой пропускания 100 МГц,
кодом NRZI необходимы частоты 25 — 50 МГц, это без кодирования 4В/5В. А если применить для NRZI еще и
кодирование 4В/5В, то теперь полоса частот расширится от 31,25 до 62,5 МГц. Но тем не менее, этот диапазон
еще «влазит» в полосу пропускания линии. А для манчестерского кода без применения всякого дополнительного
кодирования необходимы частоты от 50 до 100 МГц, и это частоты основного сигнала, но они уже не будут пропускаться
линией на 100 МГц.
Скрэмблирование
Другой метод логического кодирования основан на предварительном «перемешивании» исходной информации таким
образом, чтобы вероятность появления единиц и нулей на линии становилась близкой.
Устройства, или блоки, выполняющие такую операцию, называются скрэмблерами (scramble — свалка, беспорядочная сборка) .
При скремблировании данные перемешиваються по определенному алгоритму и приемник, получив двоичные данные, передает
их на дескрэмблер, который восстанавливает исходную последовательность бит.
Избыточные биты при этом по линии не передаются.
Суть скремблирования заключается просто в побитном изменении проходящего через систему потока данных. Практически
единственной операцией, используемой в скремблерах является XOR — «побитное исключающее ИЛИ», или еще говорят —
сложение по модулю 2. При сложении двух единиц исключающим ИЛИ отбрасывается старшая единица и результат записывается — 0.
Метод скрэмблирования очень прост. Сначала придумывают скрэмблер. Другими словами придумывают по какому соотношению
перемешивать биты в исходной последовательности с помощью «исключающего ИЛИ». Затем согласно этому соотношению из текущей
последовательности бит выбираются значения определенных разрядов и складываются по XOR между собой. При этом все разряды
сдвигаются на 1 бит, а только что полученное значение («0» или «1») помещается в освободившийся самый младший разряд.
Значение, находившееся в самом старшем разряде до сдвига, добавляется в кодирующую последовательность, становясь очередным
ее битом. Затем эта последовательность выдается в линию, где с помощью методов физического кодирования передается к
узлу-получателю, на входе которого эта последовательность дескрэмблируется на основе обратного отношения.
Например, скрэмблер может реализовывать следующее соотношение:
![]()
где Bi — двоичная цифра результирующего кода, полученная на i-м такте работы скрэмблера, Ai — двоичная цифра исходного
кода, поступающая на i-м такте на вход скрэмблера, Bi-3 и Bi-5 — двоичные цифры результирующего кода, полученные на
предыдущих тактах работы скрэмблера, соответственно на 3 и на 5 тактов ранее текущего такта, ⊕ — операция исключающего
ИЛИ (сложение по модулю 2).
Теперь давайте, определим закодированную последовательность, например, для такой исходной последовательности 110110000001.
Скрэмблер, определенный выше даст следующий результирующий код:
B1=А1=1 (первые три цифры результирующего кода будут совпадать с исходным, так как еще нет нужных предыдущих цифр)
Таким образом, на выходе скрэмблера появится последовательность 110001101111. В которой нет последовательности из шести нулей, п
рисутствовавшей в исходном коде.
После получения результирующей последовательности приемник передает ее дескрэмблеру, который восстанавливает исходную
последовательность на основании обратного соотношения.
![]()
Существуют другие различные алгоритмы скрэмблирования, они отличаются количеством слагаемых, дающих цифру
результирующего кода, и сдвигом между слагаемыми.
Главная проблема кодирования на основе скремблеров — синхронизация передающего (кодирующего) и принимающего
(декодирующего) устройств. При пропуске или ошибочном вставлении хотя бы одного бита вся передаваемая информация
необратимо теряется. Поэтому, в системах кодирования на основе скремблеров очень большое внимание уделяется методам синхронизации.
На практике для этих целей обычно применяется комбинация двух методов:
а) добавление в поток информации синхронизирующих битов, заранее известных приемной стороне, что позволяет ей при ненахождении
такого бита активно начать поиск синхронизации с отправителем,
б) использование высокоточных генераторов временных импульсов, что позволяет в моменты потери синхронизации производить
декодирование принимаемых битов информации «по памяти» без синхронизации.
Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования.
Для улучшения кода ^ Bipolar AMI используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
Рис. 3 Коды B8ZS и HDB3
На этом рисунке показано использование метода ^ B8ZS (Bipolar with 8-Zeros Substitution) и метода HDB3 (High-Density Bipolar 3-Zeros) для корректировки
кода AMI. Исходный код состоит из двух длинных последовательностей нулей (8- в первом случае и 5 во втором).
Код B8ZS исправляет только последовательности, состоящие из 8 нулей. Для этого он после первых трех нулей вместо оставшихся пяти нулей вставляет пять
цифр: V-1*-0-V-1*. V здесь обозначает сигнал единицы, запрещенной для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей
единицы, 1* — сигнал единицы корректной полярности, а знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль. В
результате на 8 тактах приемник наблюдает 2 искажения — очень маловероятно, что это случилось из-за шума на линии или других сбоев передачи. Поэтому
приемник считает такие нарушения кодировкой 8 последовательных нулей и после приема заменяет их на исходные 8 нулей.
Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр.
Код HDB3 исправляет любые 4 подряд идущих нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS.
Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала
V чередуется при последовательных заменах.
Кроме того, для замены используются два образца четырехтактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, то
используется последовательность 000V, а если число единиц было четным — последовательность 1*00V.
Таким образом, применение логическое кодирование совместно с потенциальным кодированием дает следующие преимущества:
Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей,
которые встречаются в передаваемых данных. В результате коды, полученные из потенциального путем логического кодирования,
обладают более узким спектром, чем манчестерский, даже при повышенной тактовой частоте.
Линейные блочные коды
При передаче информации по каналам связи возможны ошибки вследствие помех и искажений сигналов. Для обнаружения и
исправления возникающих ошибок используются помехоустойчивые коды. Упрощенная схема системы передачи информации
при помехоустойчивом кодировании показана на рис. 4
Кодер служит для преобразования поступающей от источника сообщений последовательности из k информационных
символов в последовательность из n cимволов кодовых комбинаций (или кодовых слов). Совокупность кодовых слов образует код.
Множество символов, из которых составляется кодовое слово, называется алфавитом кода, а число различных символов в
алфавите – основанием кода. В дальнейшем вследствие их простоты и наибольшего распространения рассматриваются главным
образом двоичные коды, алфавит которых содержит два символа: 0 и 1.
Рис. 4 Система передачи дискретных сообщений
Правило, по которому информационной последовательности сопоставляется кодовое слово, называется правилом кодирования.
Если при кодировании каждый раз формируется блок А из k информационных символов, превращаемый затем в n-символьную
кодовую комбинацию S, то код называется блочным. При другом способе кодирования информационная последовательность на
блоки не разбивается, и код называется непрерывным.
С математической точки зрения кодер осуществляет отображение множества из 2k элементов (двоичных информационных
последовательностей) в множество, состоящее из 2n элементов (двоичных последовательностей длины n). Для практики
интересны такие отображения, в результате которых получаются коды, обладающие способностью исправлять часть ошибок
и допускающие простую техническую реализацию кодирующих и декодирующих устройств.
Дискретный канал связи – это совокупность технических средств вместе со средой распространения радиосигналов, включенных
между кодером и декодером для передачи сигналов, принимающих конечное число разных видов. Для описания реальных каналов
предложено много математических моделей, с разной степенью детализации отражающих реальные процессы. Ограничимся рассмотрением
простейшей модели двоичного канала, входные и выходные сигналы которого могут принимать значения 0 и 1.
Наиболее распространено предположение о действии в канале аддитивной помехи. Пусть S=(s1,s2,…,sn)
и Y=(y1,y2,…,yn) соответственно входная и выходная последовательности двоичных символов.
Помехой или вектором ошибки называется последовательность из n символов E=(e1,e2,…,en), которую
надо поразрядно сложить с переданной последовательностью, чтобы получить принятую:
Y=S+E
Таким образом, компонента вектора ошибки ei=0 указывает на то, что 2-й символ принят правильно (yi=si),
а компонента ei=1 указывает на ошибку при приеме (yi≠si).Поэтому важной характеристикой вектора ошибки
является число q ненулевых компонентов, которое называется весом или кратностью ошибки. Кратность ошибки – дискретная случайная величина,
принимающая целочисленные значения от 0 до n.
Классификация двоичных каналов ведется по виду распределения случайного вектора E. Основные результаты теории кодирования получены в
предположении, что вероятность ошибки в одном символе не зависит ни от его номера в последовательности, ни от его значения. Такой
канал называется стационарным и симметричным. В этом канале передаваемые символы искажаются с одинаковой вероятностью
P, т.е. P(ei=1)=P, i=1,2,…,n.
Для симметричного стационарного канала распределение вероятностей векторов ошибки кратности q является биноминальным:
P(Ei)=Pq(1-P)n-q
которая показывает, что при P<0,5 вероятность β2=αj является убывающей функцией q,
т.е. в симметричном стационарном канале более вероятны ошибки меньшей кратности. Этот важный факт используется при построении
помехоустойчивых кодов, т.к. позволяет обосновать тактику обнаружения и исправления в первую очередь ошибок малой кратности.
Конечно, для других моделей канала такая тактика может и не быть оптимальной.
Декодирующее устройство (декодер) предназначено оценить по принятой последовательности Y=(y1,y2,…,yn)
значения информационных символов A‘=(a‘1,a‘2,…,a‘k,).
Из-за действия помех возможны неправильные решения. Процедура декодирования включает решение двух задач: оценивание переданного кодового
слова и формирование оценок информационных символов.
Вторая задача решается относительно просто. При наиболее часто используемых систематических кодах, кодовые слова которых содержат информационные
символы на известных позициях, все сводится к простому их стробированию. Очевидно также, что расположение информационных символов внутри кодового
слова не имеет существенного значения. Удобно считать, что они занимают первые k позиций кодового слова.
Наибольшую трудность представляет первая задача декодирования. При равновероятных информационных последовательностях ее оптимальное решение
дает метод максимального правдоподобия. Функция правдоподобия как вероятность получения данного вектора Y при передаче кодовых слов
Si, i=1,2,…,2k на основании Y=S+E определяется вероятностями появления векторов ошибок:
P(Y/Si)=P(Ei)=Pqi(1-P)n-qi
где qi – вес вектора Ei=Y+Si
Очевидно, вероятность P(Y/Si) максимальна при минимальном qi. На основании принципа максимального правдоподобия оценкой S‘ является кодовое слово,
искажение которого для превращения его в принятое слово Y имеет минимальный вес, т. е. в симметричном канале является наиболее вероятным (НВ):
S‘=Y+EHB
Если несколько векторов ошибок Ei имеют равные минимальные веса, то наивероятнейшая ошибка EHB определяется случайным выбором среди них.
В качестве расстояния между двумя кодовыми комбинациями принимают так называемое расстояние Хэмминга, которое численно равно количеству символов, в которых одна
комбинация отлична от другой, т.е. весу (числу ненулевых компонентов) разностного вектора. Расстояние Хэмминга между принятой последовательностью Y и всеми
возможными кодовыми словами 5, есть функция весов векторов ошибок Ei:
Поэтому декодирование по минимуму расстояния, когда в качестве оценки берется слово, ближайшее к принятой
последовательности, является декодированием по максимуму правдоподобия.
Таким образом, оптимальная процедура декодирования для симметричного канала может быть описана следующей последовательностью операций. По принятому
вектору Y определяется вектор ошибки с минимальным весом EHB, который затем вычитается (в двоичном канале — складывается по модулю 2) из Y:
Y→EHB→S‘=Y+EHB
Наиболее трудоемкой операцией в этой схеме является определение наи-вероятнейшего вектора ошибки, сложность которой
существенно возрастает при увеличении длины кодовых комбинаций. Правила кодирования, которые нацелены на упрощение
процедур декодирования, предполагают придание всем кодовым словам технически легко проверяемых признаков.
Широко распространены линейные коды, называемые так потому, что их кодовые слова образуют линейное
подпространство над конечным полем. Для двоичных кодов естественно использовать поле характеристики p=2.
Принадлежность принятой комбинации Y известному подпространству является тем признаком, по которому
выносится решение об отсутствии ошибок (EHB=0).
Так как по данному коду все пространство последовательностей длины n разбивается на смежные классы,
то для каждого смежного класса можно заранее определить вектор ошибки минимального веса,
называемый лидером смежного класса. Тогда задача декодера состоит в определении номера смежного класса,
которому принадлежит Y, и формировании лидера этого класса.