
![]()
 – среднее время между ошибками.
– среднее время между ошибками.
![]()

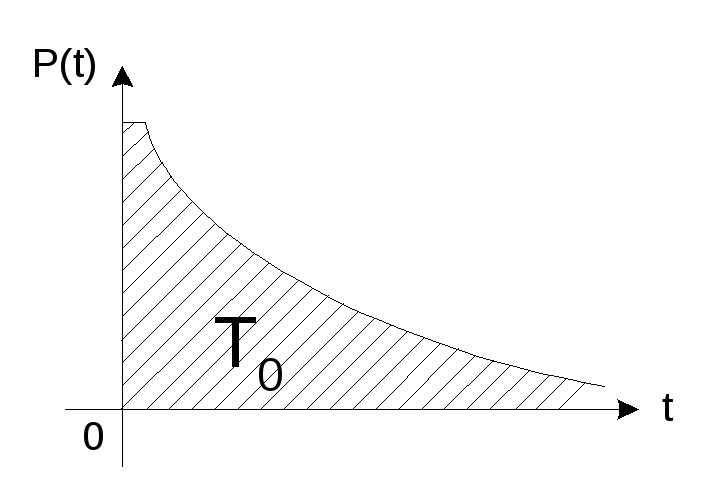 – статистическоеcреднее
– статистическоеcреднее
время между двумя ошибками.
N– общее количество
прогонов.
![]()
P(t)– вероятность безошибочной работы.
![]() –
–
обобщенный закон надежности (λ ≠
const)
9. Основные этапы разработки по
Е динственно
динственно
важная причина ошибок в ПО – это
неправильный перевод из одного
представления в другое.
-
Разработка описания реальной задачи
в виде перечня требований пользователя
(в некоторых случаях пользователь
составляет сам). Ошибка может возникнуть
если пользователь не сумеет адекватно
выразить свои потребности, либо они
будут неверно поняты, либо учтены не
в полном объеме. Ошибки этого уровня
обходятся чрезвычайно дорого. -
Перевод требований пользователя в
цели программы. Ошибки на этом этапе
возникают, когда неверно определяются
требования. -
Преобразование цели программы в ее
внешние спецификации, т.е. поведение
всей системы с точки зрения пользователей.
По объему перевода это самый значительный
этап, он больше всего подвержен ошибкам. -
Этот этап представляет собой несколько
переводов от внешнего описания готового
продукта до получения готового проекта:
-
перевод внешнего описания в структуру
программы (например, модуль); -
перевод каждой из этих компонент в
описание процедурных шагов (например,
блок-схему).
Перевод описания логики программы в
предложения языка программирования.
На этом этапе делается много ошибок,
но они легко обнаруживаются и
корректируются. На этом этапе есть еще
один перевод – перевод текста программы
на языке программирования в объектный
код (выполняется компиляторами и
трансляторами).
В результате работы над программным
проектом возникает документы, описывающие
использование ПО в виде руководств в
бумажном или электронном виде. Если
возникают ошибки при подготовке
документации, то она не будет точно
описывать поведение программы.
Например разработчик операционной
системы опирается на описание процессора
(набор команд, прерывания, средства
защиты и т.д.) и периферийного оборудования.
Неправильное толкование этих данных
может привести к ошибкам в программе.
Прикладные программы взаимодействуют
с базовым ПО (таким, например, как ОС).
Неправильное понимание документации
по базовому ПО – еще один источник
ошибок.
Готовая программа состоит из предложений
хотя бы одного языка программирования.
Непонимание синтаксиса и семантики
языка – также причина ошибок.
Есть две формы связи между пользователем
и готовой программой – это руководство,
описывающее использование и
непосредственно работа с ним. Этот шаг
представляет собой изучение пользователем
руководств и перевод их содержания в
его понимание того, как он желает
применять программу.
10. Модель перевода входной информации в выходную

А – исходная информация.
В – результирующая информация.
ЧМ – читающий механизм (области мозга,
управляющие зрением и слухом).
ПАМ – память.
ПМ – пишущий механизм (области мозга,
управляющие речью и движением рук).
-
Человек получает информацию с помощью
ЧМ. -
Человек запоминает информацию в своей
памяти. -
Выбирает из памяти эту информацию, а
также информацию, описывающую процесс
перевода, выполняет перевод и посылает
результат своему ПМ. -
Информация физически распространяется
с помощью печати на терминале или с
помощью речи.
Ошибки
-
Одна из способностей человека –
понимать входную информацию, сопоставляя
ее с образами, созданными образованием
и жизненным опытом. Человек читает
документ А и видит то, что хочет, а не
то, что написано, пытается восстановить
недостающие факты или не понимает
информацию. Ошибки могут присутствовать
и в самом документе А. -
В большинстве случаев, чтобы правильно
запомнить информацию надо ее понять.
Ошибки появляются в результате
неправильной интерпретации или полного
непонимания входной информации.
Информация может быть слишком сложной
или двусмысленной, образовательный
уровень человека может оказаться
недостаточно высоким. -
Человек может забыть входную информацию
А либо точные правила выполнения
перевода. Слабость других умственных
способностей, таких как четкость
мышления, также способствует появлению
ошибок. -
Многие не умеют ясно писать или выражать
свои мысли, это затуманивает смысл их
сообщений. Если количество выходной
информации велико человека начинает
использовать сокращения либо
предполагает, что факты будут интуитивно
очевидны. Это увеличивает вероятность
того, что следующий участник процесса
разработки при переводе совершит
ошибки.
Соседние файлы в папке Сертификация и надежность ПО
- #
- #
10.05.2014198.14 Кб31Рисунки.vsd
- #
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
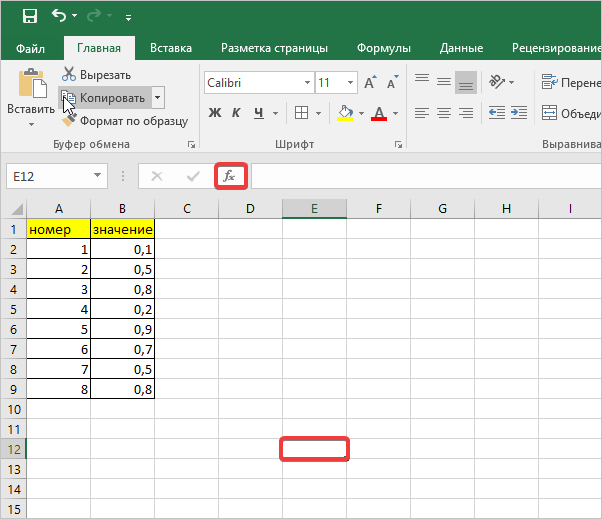
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
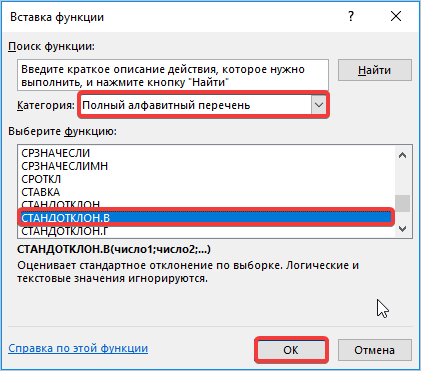
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
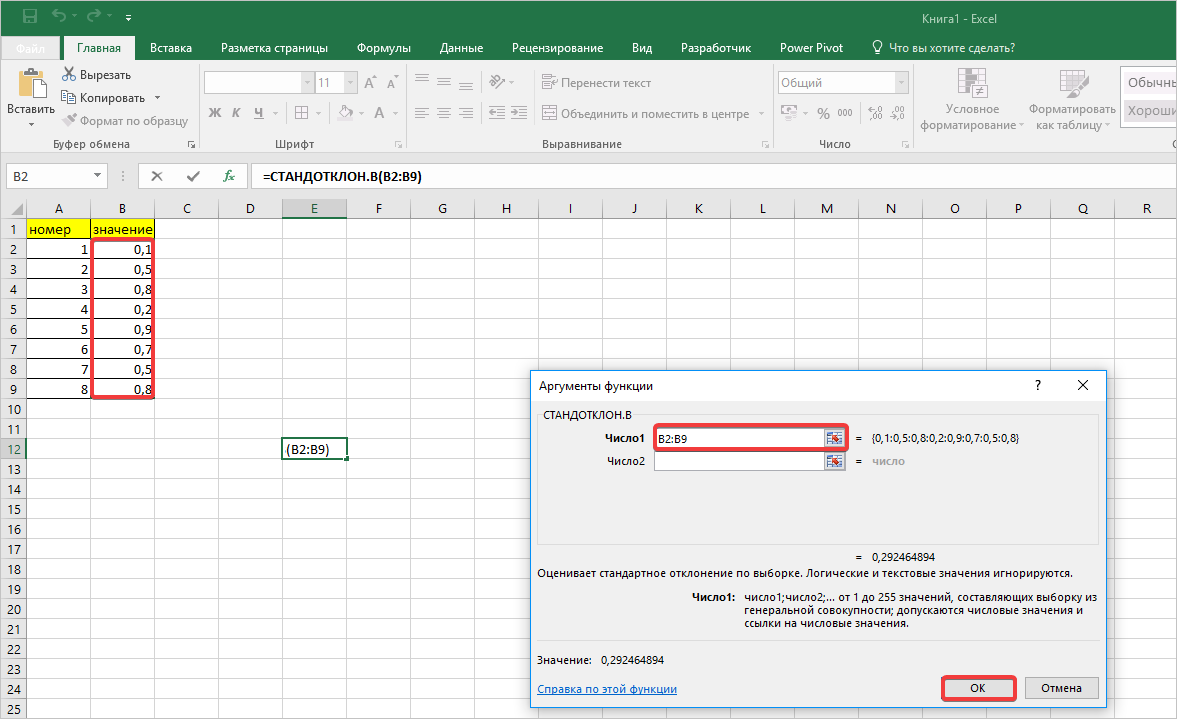
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
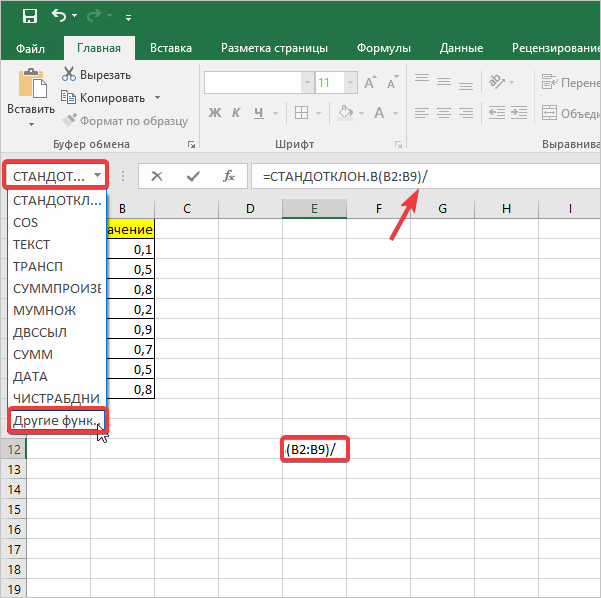
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
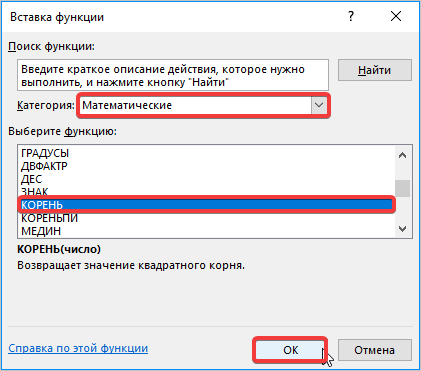
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
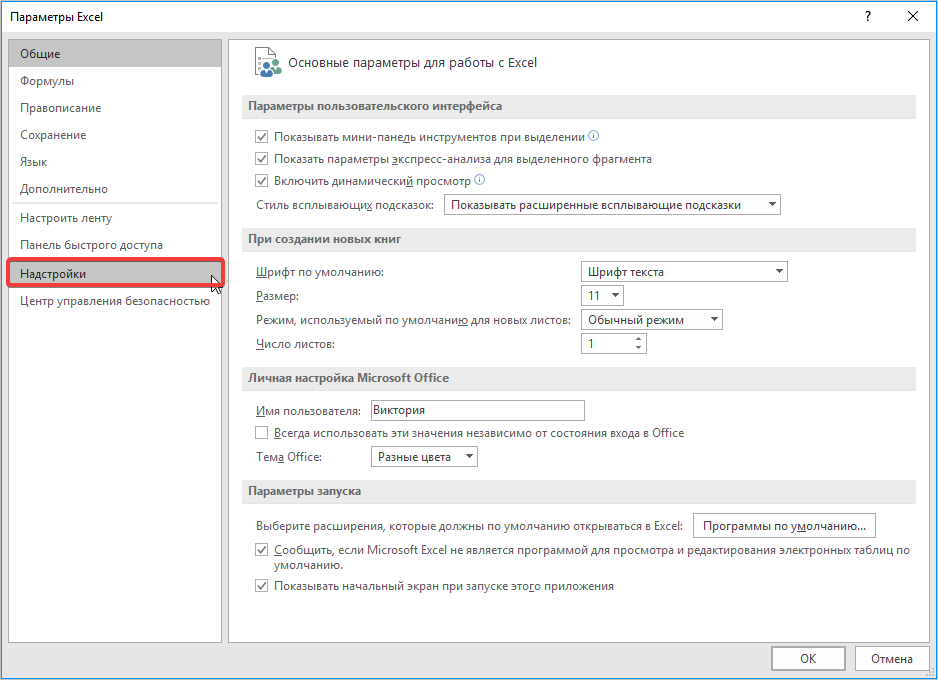
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
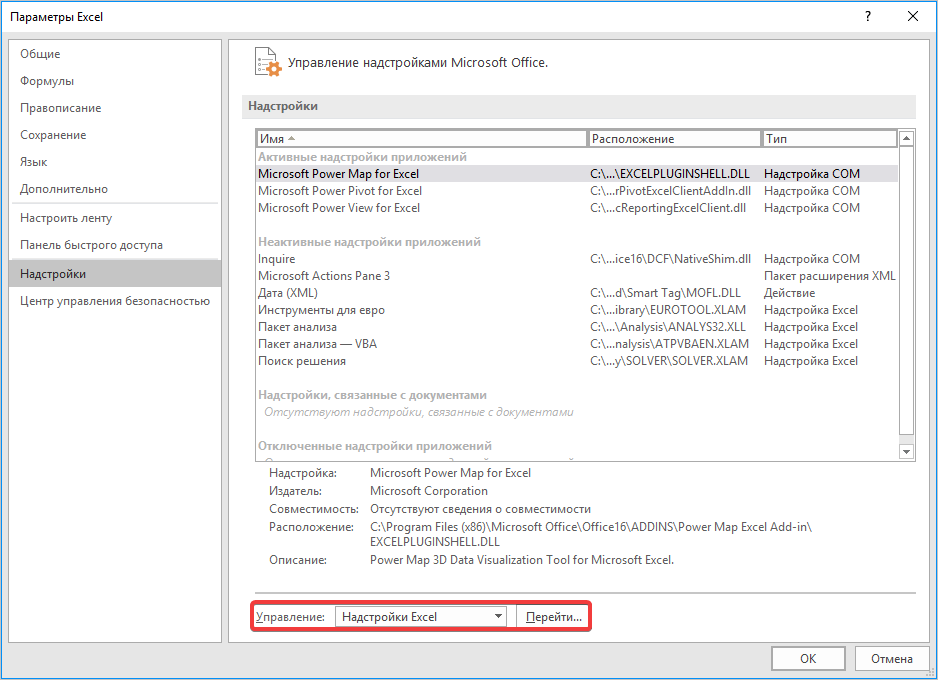
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
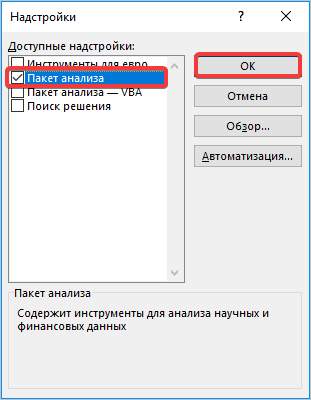
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
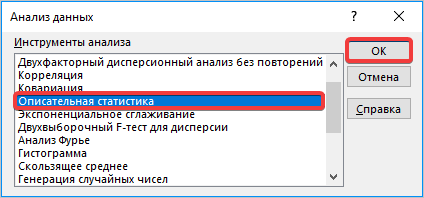
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
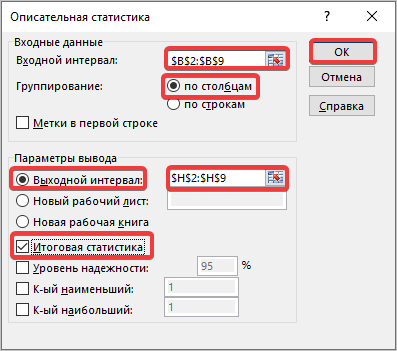
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.
Блог компании Southbridge, DevOps, Системное администрирование, Управление разработкой, IT-инфраструктура
Рекомендация: подборка платных и бесплатных курсов дизайна интерьера — https://katalog-kursov.ru/
Site Reliability Engineering (SRE) — это одна из форм реализации DevOps. SRE-подход возник в Google и стал популярен в среде продуктовых IT-компаний после выхода одноимённой книги в 2016 году.
В статье опишем, как SRE-подход соотносится с DevOps, какие задачи решает инженер по SRE и о каких показателях заботится.

От DevOps к SRE
Во многих IT-компаниях разработкой и эксплуатацией занимаются разные команды с разными целями. Цель команды разработки — выкатывать новые фичи. Цель команды эксплуатации — обеспечить работу старых и новых фич в продакшене. Разработчики стремятся поставить как можно больше кода, системные администраторы — сохранить надёжность системы.
Цели команд противоречат друг другу. Чтобы разрешить эти противоречия, была создана методология DevOps. Она предполагает уменьшение разрозненности, принятие ошибок, опору на автоматизацию и другие принципы.
Проблема в том, что долгое время не было чёткого понимания, как воплощать принципы DevOps на практике. Редкая конференция по этой методологии обходилась без доклада «Что такое DevOps?». Все соглашались с заложенными идеями, но мало кто понимал, как их реализовать.
Ситуация изменилась в 2016 году, когда Google выпустила книгу «Site Reliability Engineering». В этой книге описывалась конкретная реализация DevOps. С неё и началось распространение SRE-подхода, который сейчас применяется во многих международных IT-компаниях.
DevOps — это философия. SRE — реализация этой философии. Если DevOps — это интерфейс в языке программирования, то SRE — конкретный класс, который реализует DevOps.
Цели и задачи SRE-инженера
Инженеры по SRE нужны, когда в компании пытаются внедрить DevOps и разработчики не справляются с возросшей нагрузкой.
В отличие от классического подхода, согласно которому эксплуатацией занимается обособленный отдел, инженер по SRE входит в команду разработки. Иногда его нанимают отдельно, иногда им становится кто-то из разработчиков. Есть подход, где роль SRE переходит от одного разработчика к другому.
Цель инженера по SRE — обеспечить надёжную работу системы. Он занимается тем же, что раньше входило в задачи системного администратора, — решает инфраструктурные проблемы.
Как правило, инженерами SRE становятся опытные разработчики или, реже, администраторы с сильным бэкграундом в разработке. Кто-то скажет: «программист в роли инженера — не лучшее решение». Возможно и так, если речь идёт о новичке. Но в случае SRE мы говорим об опытном разработчике. Это человек, который хорошо знает, что и когда может сломаться. У него есть опыт и внутри компании, и снаружи.
Предпочтение не просто так отдаётся разработчикам. Имея сильный бэкграунд в программировании и зная систему с точки зрения кода, они более склонны к автоматизации, чем к рутинной администраторской работе. Кроме того, они имеют больший багаж знаний и навыков для внедрения автоматизации.
В задачи инженера по SRE входит ревью кода. Нужно, чтобы на каждый деплой SRE сказал: «OK, это не повлияет на надёжность, а если повлияет, то в допустимых пределах». Он следит, чтобы сложность, которая влияет на надёжность работы системы, была необходимой.
- Необходимая — сложность системы повышается в том объёме, которого требуют новые продуктовые фичи.
- Случайная — сложность системы повышается, но продуктовая фича и требования бизнеса напрямую на это не влияют. Тут либо разработчик ошибся, либо алгоритм не оптимален.
Хороший SRE блокирует любой коммит, деплой или пул-реквест, который повышает сложность системы без необходимости. В крайнем случае SRE может наложить вето на изменение кода (и тут неизбежны конфликты, если действовать неправильно).
Во время ревью SRE взаимодействует с оунерами изменений, от продакт-менеджеров до специалистов по безопасности.
Кроме того, инженер по SRE участвует в выборе архитектурных решений. Оценивает, как они повлияют на стабильность всей системы и как соотносятся с бизнес-потребностями. Отсюда уже делает вывод — допустимы нововведения или нет.
Целевые показатели: SLA, SLI, SLO
Одно из главных противоречий между отделом эксплуатации и разработки происходит из разного отношения к надёжности системы. Если для отдела эксплуатации надёжность — это всё, то для разработчиков её ценность не так очевидна.
SRE подход предполагает, что все в компании приходят к общему пониманию. Для этого определяют, что такое надёжность (стабильность, доступность и т. д.) системы, договариваются о показателях и вырабатывают стандарты действий в случае проблем.
Показатели доступности вырабатываются вместе с продакт-оунером и закрепляются в соглашении о целевом уровне обслуживания — Service-Level Objective (SLO). Оно становится гарантом, что в будущем разногласий не возникнет.
Специалисты по SRE рекомендуют указывать настолько низкий показатель доступности, насколько это возможно. «Чем надёжнее система, тем дороже она стоит. Поэтому определите самый низкий уровень надёжности, который может сойти вам с рук, и укажите его в качестве SLO», сказано в рекомендациях Google. Сойти с рук — значит, что пользователи не заметят разницы или заметят, но это не повлияет на их удовлетворенность сервисом.
Чтобы понимание было ясным, соглашение должно содержать конкретные числовые показатели — Service Level Indicator (SLI). Это может быть время ответа, количество ошибок в процентном соотношении, пропускная способность, корректность ответа — что угодно в зависимости от продукта.
SLO и SLI — это внутренние документы, нужные для взаимодействия команды. Обязанности компании перед клиентами закрепляются в в Service Level Agreement (SLA). Это соглашение описывает работоспособность всего сервиса и штрафы за превышение времени простоя или другие нарушения.
Примеры SLA: сервис доступен 99,95% времени в течение года; 99 критических тикетов техподдержки будет закрыто в течение трёх часов за квартал; 85% запросов получат ответы в течение 1,5 секунд каждый месяц.
Почему никто не стремится к 100% доступности
SRE исходит из предположения, что ошибки и сбои неизбежны. Более того, на них рассчитывают.
Оценивая доступность, говорят о «девятках»:
- две девятки — 99%,
- три девятки — 99,9%,
- четыре девятки — 99,99%,
- пять девяток — 99,999%.
Пять девяток — это чуть больше 5 минут даунтайма в год, две девятки — это 3,5 дня даунтайма.
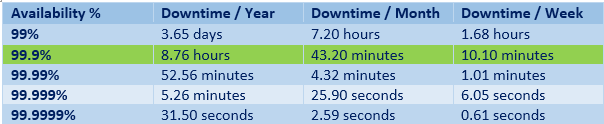
Стремиться к повышению доступности нормально, однако чем ближе она к 100%, тем выше стоимость и техническая сложность сервиса. В какой-то момент происходит уменьшение ROI — отдача инвестиций снижается.
Например, переход от двух девяток к трём уменьшает даунтайм на три с лишним дня в год. Заметный прогресс! А вот переход с четырёх девяток до пяти уменьшает даунтайм всего на 47 минут. Для бизнеса это может быть не критично. При этом затраты на повышение доступности могут превышать рост выручки.
При постановке целей учитывают также надёжность окружающих компонентов. Пользователь не заметит переход стабильности приложения от 99,99% к 99,999%, если стабильность его смартфона 99%. Грубо говоря, из 10 сбоев приложения 8 приходится на ОС. Пользователь к этому привык, поэтому на один лишний раз в год не обратит внимания.
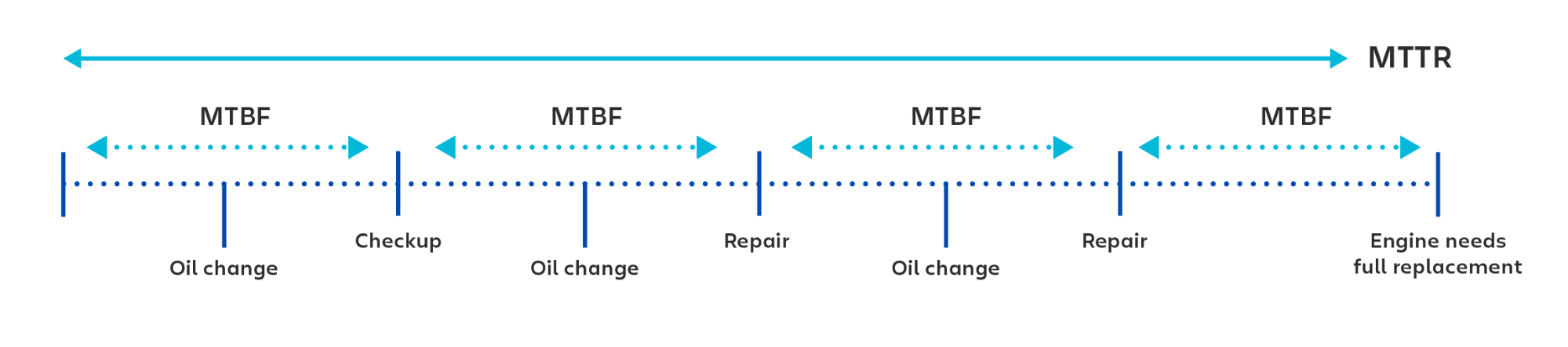
Среднее время между сбоями и среднее время восстановления — MTBF и MTTR
Для работы с надёжностью, ошибками и ожиданиями в SRE применяют ещё два показателя: MTBF и MTTR.
MTBF (Mean Time Between Failures) — среднее время между сбоями.
Показатель MTBF зависит от качества кода. Инженер по SRE влияет на него через ревью и возможность сказать «Нет!». Здесь важно понимание команды, что когда SRE блокирует какой-то коммит, он делает это не из вредности, а потому что иначе страдать будут все.
MTTR (Mean Time To Recovery)— среднее время восстановления (сколько прошло от появления ошибки до отката к нормальной работе).
Показатель MTTR рассчитывается на основе SLO. Инженер по SRE влияет на него за счёт автоматизации. Например, в SLO прописан аптайм 99,99% на квартал, значит, у команды есть 13 минут даунтайма на 3 месяца. В таком случае время восстановления никак не может быть больше 13 минут, иначе за один инцидент весь «бюджет» на квартал будет исчерпан, SLO нарушено.
13 минут на реакцию — это очень мало для человека, поэтому здесь нужна автоматизация. Что человек сделает за 7-8 минут, скрипт — за несколько секунд. При автоматизации процессов MTTR очень часто достигает секунд, иногда миллисекунд.
В идеале инженер по SRE должен полностью автоматизировать свою работу, потому что это напрямую влияет на MTTR, на SLO всего сервиса и, как следствие, на прибыль бизнеса.
Обычно при внедрении автоматизации стараются оценивать время на подготовку скрипта и время, которое этот скрипт экономит. По интернету ходит табличка, которая показывает, как долго можно автоматизировать задачу:
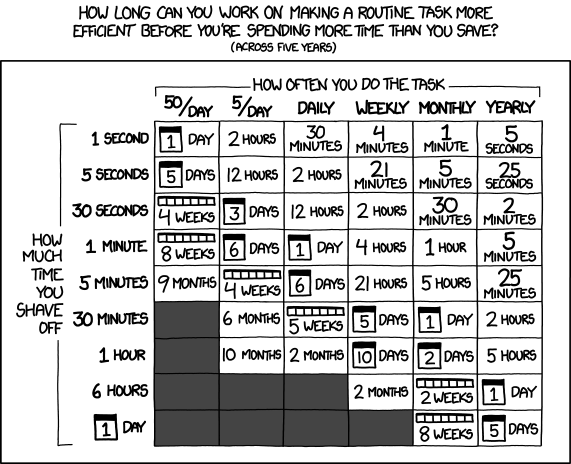
Всё это справедливо, но не относится к работе SRE. По факту, практически любая автоматизация от SRE имеет смысл, потому что экономит не только время, но и деньги, и моральные силы сотрудников, уменьшает рутину. Всё это вместе положительно сказывается на работе и на бизнесе, даже если кажется, что с точки зрения временных затрат автоматизация не имеет смысла.
Бюджет на ошибки
Как мы выяснили, пытаться достичь 100% стабильности не самая лучшая идея, потому что это дорого, технически сложно, а часто и бесполезно — скорее всего, пользователь не оценит старания из-за проблем в «соседних» системах.
Поэтому команды всегда принимают некоторую степень риска и прописывают её в SLO. На основе SLO рассчитывается бюджет на ошибки (Error budget).

Бюджет на ошибки помогает разработчикам договариваться с SRE.
Если бюджет на ошибки содержит 43 минуты даунтайма в месяц, и 40 минут из них сервис уже лежал, то очевидно: чтобы оставаться в рамках SLO, надо сократить риски. Как вариант, остановить выпуск фич и сосредоточиться на баг-фиксах.
Если бюджет на ошибки не исчерпан, то у команды остаётся пространство для экспериментов. В рамках SRE подхода Error budget можно тратить буквально на всё:
- релиз фич, которые могут повлиять на производительность,
- обслуживание,
- плановые даунтаймы,
- тестирование в условиях продакшена.
Чтобы не выйти за рамки, Error budget делят на несколько частей в зависимости от задач. Каждая команда должна оставаться в пределах своего бюджета на ошибки.

В ситуации «профицитного» бюджета на ошибки заинтересованы все: и SRE, и разработчики. Для разработчиков такой бюджет сулит возможность заниматься релизами, тестами, экспериментами. Для SRE является показателем хорошей работы.
Эксперименты в продакшене — это важная часть SRE в больших командах. С подачи команды Netflix её называют Chaos Engineering.
В Netflix выпустили несколько утилит для Chaos Engineering: Chaos Monkey подключается к CI/CD пайплайну и роняет случайный сервер в продакшене; Chaos Gorilla полностью выключает одну из зон доступности в AWS. Звучит дико, но в рамках SRE считается, что упавший сервер — это само по себе не плохо, это ожидаемо. И если это входит в бюджет на ошибки, то не вредит бизнесу.
Chaos Engineering помогает:
- Выявить скрытые зависимости, когда не совсем понятно, что на что влияет и от чего зависит (актуально при работе с микросервисами).
- Выловить ошибки в коде, которые нельзя поймать на стейджинге. Любой стейджинг — это не точная симуляция: другой масштаб и паттерн нагрузок, другое оборудование.
- Отловить ошибки в инфраструктуре, которые стейджинг, автотесты, CI/CD-пайплайн никогда не выловят.
Post mortem вместо поиска виноватых
В SRE придерживаются культуры blameless postmortem, когда при возникновении ошибок не ищут виноватых, а разбирают причины и улучшают процессы.
Предположим, даунтайм в квартал был не 13 минут, а 15. Кто может быть виноват? SRE, потому что допустил плохой коммит или деплой; администратор дата-центра, потому что провел внеплановое обслуживание; технический директор, который подписал договор с ДЦ и не обратил внимания, что его SLA не поддерживает нужный даунтайм. Все понемногу виноваты, значит, нет смысла возлагать вину на кого-то одного. В таком случае организуют постмортемы и правят процессы.
Мониторинг и прозрачность
Без мониторинга нельзя понять, вписывается ли команда в бюджет и соблюдает ли критерии, описанные в SLO. Поэтому задача инженера по SRE — настроить мониторинг. Причём настроить его так, чтобы уведомления приходили только тогда, когда требуются действия.
В стандартном случае есть три уровня событий:
- алерты — требуют немедленного действия («чини прямо сейчас!»);
- тикеты — требуют отложенного действия («нужно что-то делать, делать вручную, но не обязательно в течение следующих нескольких минут»);
- логи — не требуют действия, и при хорошем развитии событий никто их не читает («о, на прошлой неделе у нас микросервис отвалился, пойди посмотри в логах, что случилось»).
SRE определяет, какие события требуют действий, а затем описывает, какими эти действия должны быть, и в идеале приходит к автоматизации. Любая автоматизация начинается с реакции на событие.
С мониторингом связан критерий прозрачности (Observability). Это метрика, которая оценивает, как быстро вы можете определить, что именно пошло не так и каким было состояние системы в этот момент.
С точки зрения кода: в какой функции или сервисе произошла ошибка, каким было состояние внутренних переменных, конфигурации. С точки зрения инфраструктуры: в какой зоне доступности произошел сбой, а если у вас стоит какой-нибудь Kubernetes, то в каком поде, каким было его состояние при этом.
Observability напрямую связана с MTTR. Чем выше Observability сервиса, тем проще определить ошибку, исправить и автоматизировать, и тем ниже MTTR.
SRE для небольших компаний и компаний без разработки
SRE работает везде, где нужно выкатывать апдейты, менять инфраструктуру, расти и масштабироваться. Инженеры по SRE помогают предсказать и определить возможные проблемы, сопутствующие росту. Поэтому они нужны даже в тех компаниях, где основная деятельность не разработка ПО. Например, в энтерпрайзе.
При этом необязательно нанимать на роль SRE отдельного человека, можно сделать роль переходной, а можно вырастить человека внутри команды. Последний вариант подходит для стартапов. Исключение — жёсткие требования по росту (например, со стороны инвесторов). Когда компания планирует расти в десятки раз, тогда нужен человек, ответственный за то, что при заданном росте ничего не сломается.
Внедрять принципы SRE можно с малого: определить SLO, SLI, SLA и настроить мониторинг. Если компания не занимается ПО, то это будут внутренние SLA и внутренние SLO. Обсуждение этих соглашений приводит к интересным открытиям. Нередко выясняется, что компания тратит на инфраструктуру или организацию идеальных процессов гораздо больше времени и сил, чем надо.
Кроме того, для любой компании полезно принять, что ошибки — это нормально, и начать работать с ними. Определить Error budget, стараться тратить его на развитие, а возникающие проблемы разбирать и по результатам разбора внедрять автоматизацию.
Что почитать
В одной статье невозможно рассказать всё об SRE. Вот подборка материалов для тех, кому нужны детали.
Книги об SRE от Google:
Site Reliability Engineering
The Site Reliability Workbook
Building Secure & Reliable Systems
Статьи и списки статей:
SRE как жизненный выбор
SLA, SLI, SLO
Принципы Chaos Engineering от Chaos Community и от Netflix
Список из более чем 200 статей по SRE
Доклады по SRE в разных компаниях (видео):
Keys to SRE
SRE в Дропбоксе
SRE в Гугл
SRE в Нетфликсе
Где поучиться
Одно дело читать о новых практиках, а другое дело — внедрять их. Если вы хотите глубоко погрузиться в тему, приходите на онлайн-интенсив по SRE от Слёрма. Он пройдет 11–13 декабря 2020.
Научим формулировать показатели SLO, SLI, SLA, разрабатывать архитектуру и инфраструктуру, которая их обеспечит, настраивать мониторинг и алёртинг.
На практическом примере рассмотрим внутренние и внешние факторы ухудшения SLO: ошибки разработчиков, отказы инфраструктуры, наплыв посетителей, DoS-атаки. Разберёмся в устойчивости, Error budget, практике тестирования, управлении прерываниями и операционной нагрузкой.
Узнать больше и зарегистрироваться
Понимание некоторых из наиболее распространенных метрик инцидентов
В современном постоянно движущемся мире сбои в работе и технические инциденты становятся как никогда важными. Ошибки и простои ведут к реальным последствиям. Пропущенные сроки. Задержки оплаты. Задержки работы по проектам.
Вот почему для компаний важно количественно оценивать и отслеживать показатели безотказной работы, времени простоя и того, как быстро и эффективно команды решают проблемы.
Некоторые из наиболее часто отслеживаемых в отрасли метрик: MTBF (средняя наработка на отказ), MTTR (среднее время восстановления, исправления, реагирования или устранения), MTTF (средняя наработка до отказа) и MTTA (среднее время подтверждения) — эти метрики предназначены для того, чтобы помочь техническим командам понять, как часто происходят инциденты и как быстро команда справляется с ними.
Многие эксперты спорят о действительной пользе этих метрик, если использовать их в отрыве от остальных показателей, потому что они не дают ответа на сложные вопросы о том, как устраняются инциденты, что работает, а что нет, и как, когда и почему проблемы обостряются или ослабляются.
С другой стороны, MTTR, MTBF и MTTF могут быть хорошей основой или эталоном, с которых стоит начинать обсуждение более глубоких и важных вопросов.

Как профессионалы реагируют на крупные инциденты
Получите наше бесплатное руководство по управлению инцидентами. Изучите все инструменты и методы, которые Atlassian использует для управления крупными инцидентами.
Читать справочник
Оговорка об MTTR
Говоря об MTTR, можно предположить, что это один показатель с одним значением. В действительности за ним скрываются четыре разных показателя. «R» может означать решение (repair), реагирование (respond), устранение (resolve) или восстановление (recovery), и хотя эти четыре показателя перекрываются, каждый имеет собственный смысл и особенности.
Поэтому если вашей команде нужно отслеживать MTTR, рекомендуется уточнить, какой именно MTTR имеется в виду и как его определить. Прежде чем вы начнете отслеживать успехи и неудачи, у вашей команды должно быть общее понимание того, что именно вы отслеживаете.
MTBF: средняя наработка на отказ
Что такое средняя наработка на отказ?
MTBF (средняя наработка на отказ) — это среднее время между исправляемыми сбоями технологического продукта. Эта метрика используется для отслеживания как доступности, так и надежности продукта. Чем больше времени проходит между отказами, тем надежнее система.
Цель для большинства компаний — сохранить наработку на отказ как можно выше, достигнув сотни тысяч (или даже миллионов) часов между инцидентами.
Как рассчитать среднюю наработку на отказ
MTBF рассчитывается с использованием среднего арифметического. По сути, вы должны взять данные за период, на который вы хотите рассчитать MTBF (можно за шесть месяцев, год, за пять лет), и поделить общее время работы за этот период на количество сбоев.
Итак, предположим, что мы оцениваем 24-часовой период и за этот период мы потеряли два часа из-за двух отдельных инцидентов. Наше общее время безотказной работы составляет 22 часа. Разделим на два и получаем 11 часов. Итак, наша наработка на отказ составляет 11 часов.
Поскольку эта метрика используется для отслеживания надежности, наработка на отказ не учитывает ожидаемое время простоя во время планового технического обслуживания. Вместо этого она фокусируется на неожиданных простоях и проблемах.
Происхождение понятия средней наработки на отказ
MTBF берет свое начало в авиационной отрасли, где системные сбои означают особенно серьезные последствия не только с точки зрения стоимости, но и человеческой жизни. С тех пор эта аббревиатура пробралась в различные технические и механические отрасли промышленности и особенно часто используется в производстве.
Как и когда использовать среднюю наработку на отказ
Время наработки на отказ полезно для покупателей, которые хотят быть уверены, что получают самый надежный продукт, полетят на самом надежном самолете или выберут самое безопасное производственное оборудование для своего завода.
Для внутренних команд эта метрика помогает выявлять проблемы и отслеживать успехи и неудачи. Она также может помочь компаниям разработать подробные рекомендации для клиентов, чтобы они знали, когда они должны заменить деталь, обновить систему или принести продукт на техническое обслуживание.
MTBF — это метрика для сбоев в восстанавливаемых системах. Для сбоев, требующих замены системы, обычно используют термин MTTF (средняя наработка до отказа).
Например, представьте двигатель автомобиля. При расчете времени между внеплановыми техническими обслуживаниями двигателя следует использовать MTBF (среднюю наработку на отказ). При расчете времени до полной замены двигателя вы должны использовать MTTF (среднюю наработку до отказа).
MTTR: среднее время исправления
Что такое среднее время исправления?
MTTR (среднее время ремонта) — это среднее время, необходимое для ремонта системы (обычно технического или механического). Оно включает в себя как время ремонта, так и любое время тестирования. В этой метрике учитывается все время до тех пор, пока система не будет снова полностью работоспособна.
Как рассчитать среднее время исправления
Вы можете рассчитать MTTR, суммируя общее время, затраченное на ремонт в течение любого заданного периода, а затем разделив это время на количество ремонтов.
Итак, предположим, мы считаем эту метрику для ремонта в течение недели. За это время было 10 простоев, и системы активно ремонтировались в течение четырех часов. Четыре часа — это 240 минут. 240 делим на 10 и получаем 24. Что означает, что среднее время ремонта в этом случае будет составлять 24 минуты.
Ограничения среднего времени исправления
Среднее время ремонта не всегда совпадает с тем же временем, что и время сбоя работы системы. В некоторых случаях ремонт начинается в течение нескольких минут после сбоя продукта или сбоя системы. В других случаях между собственно инцидентом, обнаружением инцидента и началом ремонта бывает некоторая задержка.
Эта метрика наиболее полезна при отслеживании того, как быстро обслуживающий персонал может устранить проблему. Она не предназначена для выявления проблем с системными оповещениями или задержками перед восстановлением, которые также являются важными факторами при оценке успехов и сбоев программы управления инцидентами.
Как и когда использовать среднее время исправления
MTTR — это метрика, которую используют команды поддержки и технического обслуживания для обеспечения восстановительных работ на нужном уровне. Цель состоит в том, чтобы этот показатель был как можно ниже за счет повышения эффективности процессов восстановления и продуктивности команд.
MTTR: среднее время восстановления
Что такое среднее время восстановления?
MTTR (среднее время восстановления или среднее время стабилизации) — это среднее время восстановления после сбоя работы продукта или системы. Оно включает в себя полное время простоя с момента выхода из строя системы или продукта до момента, когда они снова становятся полностью работоспособными.
Это основной показатель DevOps, который, по мнению программы DevOps Research and Assessment (DORA), можно использовать для оценки стабильности команды DevOps.
Как рассчитать среднее время восстановления
Среднее время восстановления рассчитывается путем суммирования всего времени простоя в работе за определенный период и деления его на количество инцидентов. Итак, предположим, что наши системы были отключены на 30 минут в течение двух отдельных инцидентов за 24-часовой период. 30 делим на два, получаем 15, так что наш MTTR составляет 15 минут.
Ограничения среднего времени восстановления
MTTR используется для измерения скорости полного процесса восстановления. Достаточно ли она высокая? А по сравнению с вашими конкурентами?
Эта общая метрика помогает определить, есть ли у вас проблемы. Однако если вы хотите диагностировать, в какой именно части вашего процесса есть проблема (проблема в вашей системе оповещений? команда слишком много времени работает над исправлением? кто-то слишком долго отвечает на запрос на исправление?), то вам понадобится больше данных. Потому что между сбоем и восстановлением может произойти много чего.
Проблема может быть связана с вашей системой оповещения. Существует ли задержка между сбоем и отправкой оповещения? Достаточно ли быстро оповещения доходят до нужного человека?
Проблема может быть в диагностике. Можете ли вы быстро выяснить, в чем проблема? Существуют ли процессы, которые можно было бы улучшить?
Или проблема может быть с самим процессом исправления. Достаточно ли эффективны ваши команды технического обслуживания? Если они тратят все свое время на исправление, то что именно их тормозит?
Вам нужно будет копнуть глубже, чем MTTR, чтобы ответить на эти вопросы, но среднее время восстановления может стать отправной точкой для диагностики того, существует ли проблема в процессе восстановления и требует ли она более глубокого анализа.
Как и когда использовать среднее время восстановления
MTTR является хорошей метрикой для оценки скорости общего процесса восстановления.
MTTR: среднее время разрешения
Что такое среднее время разрешения?
MTTR (среднее время разрешения) — это среднее время, необходимое для полного устранения сбоя. Оно включает в себя не только время, затраченное на обнаружение сбоя, диагностику проблемы и ее устранение, но и время, затраченное на предотвращение повторения проблемы.
Эта метрика расширяет ответственность команды, обрабатывающей исправление: она задает ожидания в плане повышения ее продуктивности в долгосрочной перспективе. В этом и заключается разница между простым тушением пожара и тушением пожара с последующей установкой противопожарной системы.
Существует сильная связь между этим MTTR и удовлетворенностью клиентов, так что этой метрике нужно уделить особое внимание.
Как рассчитать среднее время разрешения
Чтобы рассчитать этот MTTR, рассчитайте полное время разрешения в течение периода, который вы хотите отслеживать, и разделите на количество инцидентов.
Таким образом, если ваши системы были отключены в общей сложности 2 часа за 24-часовой период из-за одного инцидента и команды потратили еще 2 часа на исправление, чтобы гарантировать, что сбой системы не повторится, в сумме получается 4 часа, потраченных на решение проблемы. Это означает, что ваш MTTR составляет 4 часа.
Заметка об отслеживании среднего времени разрешения
Имейте в виду, что MTTR чаще всего рассчитывается с использованием рабочих часов (поэтому если вы восстановите работу в конце рабочего дня и потратите время на исправление основной проблемы первым делом на следующее утро, ваш MTTR не будет включать 16 часов, в течение которых вы не работали). Если у вас есть команды в разных часовых поясах и вы работаете круглосуточно или если у вас есть дежурные сотрудники, работающие во внеурочное время, важно определить, как вы будете отслеживать время для этой метрики.
Как и когда использовать среднее время разрешения
MTTR обычно используется, когда речь идет о незапланированных инцидентах, а не о запросах на обслуживание (которые обычно планируются).
MTTR: среднее время реагирования
Что такое среднее время реагирования?
MTTR (среднее время реагирования) — это среднее время, необходимое для восстановления после сбоя продукта или системы с момента первого оповещения об этом сбое. Оно не включает время задержки в вашей системе оповещения.
Как рассчитать среднее время реагирования
Чтобы рассчитать этот MTTR, рассчитайте полное время отклика с момента получения оповещения до того, когда продукт или услуга снова полностью функционируют. Затем разделите его на количество инцидентов.
Например: если у вас было 4 инцидента за 40-часовую рабочую неделю и вы потратили на них 1 час (от оповещения до исправления), то MTTR за эту неделю будет составлять 15 минут.
Как и когда использовать среднее время реагирования
MTTR часто используется в кибербезопасности при измерении успеха команды в нейтрализации атак на систему.
MTTA: среднее время подтверждения
Что такое среднее время подтверждения?
MTTA (среднее время подтверждения) — это среднее время, которое проходит с момента отправки оповещения до начала работы над исправлением. Эта метрика полезна для измерения скорости реагирования вашей команды и эффективности вашей системы оповещения.
Как рассчитать среднее время подтверждения
Чтобы рассчитать MTTA, посчитайте время между отправкой оповещения и подтверждением его получения, а затем разделите на количество инцидентов.
Например: если у вас было 10 инцидентов и в общей сложности прошло 40 минут между отправкой оповещения и подтверждением его получения для всех 10, вы поделите 40 на 10 и получите в среднем 4 минуты.
Как и когда использовать среднее время подтверждения
Метрика MTTA полезна для отслеживания отзывчивости. Ваша команда устала от оповещений и слишком долго отвечает на сообщения об инцидентах? Эта метрика поможет вам обнаружить и проанализировать эту проблему.
MTTF: средняя наработка до отказа
Что такое средняя наработка до отказа?
MTTF (средняя наработка до отказа) — среднее время между неремонтируемыми отказами технологического продукта. Например, если автомобильные двигатели марки X исправно работают в среднем 500 000 часов, до того как они полностью выйдут из строя и будут подлежать замене, MTTF двигателей будет составлять 500 000.
Эта метрика помогает понять, как долго система будет исправно работать, и определить, превосходит ли новая версия системы старую. Метрика позволяет предоставить клиентам информацию об ожидаемом сроке исправной работы и о том, когда следует запланировать проверку системы.
Как рассчитать среднюю наработку до отказа
Средняя наработка до отказа — это среднее арифметическое, которое определяется как сумма общего времени работы оцениваемых продуктов, деленная на общее количество устройств.
Например: предположим, вы рассчитываете MTTF лампочек. Как долго лампочки бренда Y в среднем работают, прежде чем они перегорают? Далее предположим, что для расчета у вас есть четыре лампочки (если вам нужны статистически значимые данные, вам понадобится гораздо больше, но, чтобы не перегружать вас расчетами, давайте возьмем всего четыре).
Лампочка А горит 20 часов. Лампочка B — 18. Лампочка C —21. И лампочка D —21 час. Это в общей сложности 80 часов горения лампочки. Делим на четыре и получаем MTTF в 20 часов.

Проблема, связанная со средней наработкой до отказа
Для таких случаев, как лампочки, смысл MTTF совершенно ясен. Мы можем включить лампочки и ждать до тех пор, пока не перегорит последняя, а затем использовать полученную информацию, чтобы сделать выводы о времени работы наших лампочек.
Но что происходит, когда мы измеряем что-то, что не перегорает так быстро? Что-то, что должно бесперебойно работать в течение долгих лет? Хотя MTTF часто используется и для этих случаев, эта метрика — не лучший выбор. Потому что мы не держим продукт включенным до тех пор, пока он не выйдет из строя; в основном мы запускаем продукт на определенный период времени и измеряем количество выходов из строя.
Например: предположим, что мы пытаемся получить статистику MTTF на планшетах бренда Z. Планшеты по-хорошему рассчитаны на долгие годы, но у бренда Z есть всего шесть месяцев для сбора данных. Поэтому тестируют 100 планшетов в течение шести месяцев. Допустим, один планшет ломается ровно на шестимесячной отметке.
Итак, мы умножаем общее время работы (полгода, умноженное на 100 планшетов) и получаем 600 месяцев. Только один планшет вышел из строя, так что мы разделим значение на один, и наш MTTR будет составлять 600 месяцев, то есть 50 лет.
Прослужат ли планшеты Brand Z в среднем 50 лет каждый? Маловероятно. И поэтому эта метрика не подходит в таких случаях.
Как и когда использовать среднюю наработку до отказа
MTTF хорошо работает, когда вы пытаетесь оценить средний срок службы продуктов и систем с коротким сроком службы (например, лампочек). Показатель предназначен только для случаев, когда оценивается полное прекращение работы продукта. При расчете времени между инцидентами, требующими восстановления, предпочтительной аббревиатурой является MTBF (средняя наработка на отказ).
MTBF, MTTR, MTTF и MTTA
Итак, какую метрику лучше использовать, когда дело доходит до отслеживания и улучшения управления инцидентами?
Ответ — все.
Хотя они иногда используются взаимозаменяемо, каждая метрика позволяет рассмотреть ситуацию с разных сторон. При совместном использовании они могут показать более полную картину и дать вам понять, насколько успешна ваша команда в управлении инцидентами и что она может улучшить.
![]()
Среднее время восстановления показывает, как быстро у вас получается возобновить работу ваших систем.
Рассчитайте среднее время реагирования, и вы получите представление о том, сколько времени восстановления тратится на работу вашей команды и сколько — на получение оповещения.
Потом рассчитайте среднее время исправления, и вы поймете, сколько времени команда тратит на исправление, а сколько на диагностику.
Теперь рассчитайте среднее время разрешения, и вы начнете понимать весь процесс исправления и решения проблем, выходящий за рамки самого простоя, который они вызывают.
Посчитайте среднюю наработку на отказ, и картина станет еще шире: вы увидите, насколько успешна ваша команда в предотвращении или сокращении будущих проблем.
А затем добавьте среднюю наработку до отказа, чтобы понять полный жизненный цикл продукта или системы.
Jira Service Management предлагает возможности создания отчетов, чтобы ваша команда могла отслеживать KPI, а также контролировать и оптимизировать управление инцидентами.
Вычислить среднее время ошибки списка
Я пытаюсь вычислить среднее время из списка, используя код из этой темы. Все другие предложения кода не работают для меня, так как они учитывают продолжительность, а не время.
import datetime
import math
import numpy
def datetime_to_radians(x):
# radians are calculated using a 24-hour circle, not 12-hour, starting at north and moving clockwise
time_of_day = x.time()
seconds_from_midnight = 3600 * time_of_day.hour + 60 * time_of_day.minute + time_of_day.second
radians = float(seconds_from_midnight) / float(12 * 60 * 60) * 2.0 * math.pi
return radians
def average_angle(angles):
# angles measured in radians
x_sum = numpy.sum([math.sin(x) for x in angles])
y_sum = numpy.sum([math.cos(x) for x in angles])
x_mean = x_sum / float(len(angles))
y_mean = y_sum / float(len(angles))
return numpy.arctan2(x_mean, y_mean)
def radians_to_time_of_day(x):
# radians are measured clockwise from north and represent time in a 24-hour circle
seconds_from_midnight = int(float(x) / (2.0 * math.pi) * 12.0 * 60.0 * 60.0)
hour = seconds_from_midnight / 3600
minute = (seconds_from_midnight % 3600) / 60
second = seconds_from_midnight % 60
return datetime.time(hour, minute, second)
def average_times_of_day(x):
# input datetime.datetime array and output datetime.time value
angles = [datetime_to_radians(y) for y in x]
avg_angle = average_angle(angles)
return radians_to_time_of_day(avg_angle)
average_times_of_day([datetime.datetime(2017, 6, 9, 0, 10), datetime.datetime(2017, 6, 9, 0, 20)])
# datetime.time(0, 15)
average_times_of_day([datetime.datetime(2017, 6, 9, 23, 50), datetime.datetime(2017, 6, 9, 0, 10)])
# datetime.time(0, 0)
Я получаю следующую ошибку:
TypeError: integer argument expected, got float
Может кто-нибудь помочь?
2017-10-06 13:10
3
ответа
Решение
Вот еще одно решение, которое может обрабатывать список объектов datetime только с учетом часов и минут:
from cmath import phase
from cmath import rect
import datetime
from math import degrees
from math import radians
dfList = ([datetime.datetime(2017, 9, 15, 8, 8),
datetime.datetime(2017, 9, 14, 8, 5),
datetime.datetime(2017, 9, 13, 6, 56),
datetime.datetime(2017, 12, 9, 6, 14),
datetime.datetime(2017, 11, 9, 6, 42)])
dfList = [item.strftime("%H:%M") for item in dfList]
def mean_angle(deg):
return degrees(phase(sum(rect(1, radians(d)) for d in deg) / len(deg)))
def mean_time(times):
t = (time.split(':') for time in times)
seconds = ((int(m) * 60 + int(h) * 3600)
for h, m in t)
day = 24 * 60 * 60
to_angles = [s * 360. / day for s in seconds]
mean_as_angle = mean_angle(to_angles)
mean_seconds = mean_as_angle * day / 360.
if mean_seconds < 0:
mean_seconds += day
h, m = divmod(mean_seconds, 3600)
m, s = divmod(m, 60)
return '%02i:%02i' % (h, m)
print(mean_time(dfList))
2017-10-06 15:02
В Python 3 / выполняет истинное (плавающее) деление, даже если оба операнда являются целыми числами.
использование // вместо
def radians_to_time_of_day(x):
# radians are measured clockwise from north and represent time in a 24-hour circle
seconds_from_midnight = int(float(x) / (2.0 * math.pi) * 12.0 * 60.0 * 60.0)
hour = seconds_from_midnight // 3600
minute = (seconds_from_midnight % 3600) // 60
second = seconds_from_midnight % 60
return datetime.time(hour, minute, second)
2017-10-06 14:13
Ваш код хорошо работает в Python 2.7, но не Python 3.6.
Ошибка выкинула в строку 26, return datetime.time(hour, minute, second),
После произнесения значения hour, minute а также second в int()работает нормально.
def radians_to_time_of_day(x):
# radians are measured clockwise from north and represent time in a 24-hour circle
seconds_from_midnight = int(float(x) / (2.0 * math.pi) * 12.0 * 60.0 * 60.0)
hour = int(seconds_from_midnight / 3600)
minute = int((seconds_from_midnight % 3600) / 60)
second = int(seconds_from_midnight % 60)
return datetime.time(hour, minute, second)
2017-10-06 14:12
Другие вопросы по тегам
python