
Абсолютная и относительная погрешности (ошибки).
Пусть некоторая
величина x
измерена n
раз. В результате получен ряд значений
этой величины: x1,
x2,
x3,
…, xn
Величиной, наиболее
близкой к действительному значению,
является среднее арифметическое этих
результатов:
![]()
Отсюда следует,
что каждое физическое измерение должно
быть повторено несколько раз.
Разность между
средним значением
![]() измеряемой
измеряемой
величины и значением отдельного измерения
называется абсолютной
погрешностью отдельного измерения:
![]()
(13)
Абсолютная
погрешность может быть как положительной,
так и отрицательной и измеряется в тех
же единицах, что и измеряемая величина.
Средняя абсолютная
ошибка результата — это среднее
арифметическое значений абсолютных
погрешностей отдельных измерений,
взятых по абсолютной величине (модулю):
![]()
(14)
Отношения
![]()
называются относительными погрешностями
(ошибками) отдельных измерений.
Отношение средней
абсолютной погрешности результата
![]()
к среднему арифметическому значению
![]()
измеряемой величины называют относительной
ошибкой результата и выражают в процентах:
![]()
Относительная
ошибка характеризует точность измерения.
Законы распределения случайных величин.
Результат измерения
физической величины зависит от многих
факторов, влияние которых заранее учесть
невозможно. Поэтому значения, полученные
в результате прямых измерений какого
— либо параметра, являются случайными,
обычно не совпадающие между собой.
Следовательно, случайные
величины —
это такие величины, которые в зависимости
от обстоятельств могут принимать те
или иные значения. Если случайная
величина принимает только определенные
числовые значения, то она называется
дискретной.
Например,
количество заболеваний в данном регионе
за год, оценка, полученная студентом на
экзамене, энергия электрона в атоме и
т.д.
Непрерывная
случайная величина принимает любые
значения в данном интервале.
Например: температура
тела человека, мгновенные скорости
теплового движения молекул, содержание
кислорода в воздухе и т.д.
Под событием
понимается всякий результат или исход
испытания. В теории вероятностей
рассматриваются события, которые при
выполнение некоторых условий могут
произойти, а могут не произойти. Такие
события называются
случайными.
Например, событие, состоящее в появлении
цифры 1 при выполнении условия — бросания
игральной кости, может произойти, а
может не произойти.
Если событие
неизбежно происходит в результате
каждого испытания, то оно называется
достоверным.
Событие называется невозможным,
если оно вообще не происходит ни при
каких условиях.
Два события,
одновременное появление которых
невозможно, называются несовместными.
Пусть случайное
событие А в серии из n
независимых испытаний произошло m
раз, тогда отношение:
![]()
называется
относительной частотой события А. Для
каждой относительной частоты выполняется
неравенство:
![]()
При небольшом
числе опытов относительная частота
событий в значительной мере имеет
случайный характер и может заметно
изменяться от одной группы опытов к
другой. Однако при увеличении числа
опытов частота событий все более теряет
свой случайный характер и приближается
к некоторому постоянному положительному
числу, которое является количественной
мерой возможности реализации случайного
события А. Предел, к которому стремится
относительная частота событий при
неограниченном увеличении числа
испытаний, называется статистической
вероятностью события:
![]()
Например, при
многократном бросании монеты частота
выпадения герба будет лишь незначительно
отличаться от ½. Для достоверного события
вероятность Р(А) равна единице. Если
Р=0, то событие невозможно.
Математическим
ожиданием
дискретной случайной величины называется
сумма произведений всех ее возможных
значений хi
на вероятность этих значений рi:
![]()
Статистическим
аналогом математического ожидания
является среднее арифметическое значений
![]() :
:
![]() ,
,
где mi
— число дискретных случайных величин,
имеющих значение хi.
Для непрерывной
случайной величины математическим
ожиданием служит интеграл:
![]() ,
,
где р(х) — плотность
вероятности.
Отдельные значения
случайной величины группируются около
математического ожидания. Отклонение
случайной величины от ее математического
ожидания (среднего значения) характеризуется
дисперсией,
которая для дискретной случайной
величины определяется формулой:
![]()
(15)

(16)
Дисперсия имеет
размерность случайной величины. Для
того, чтобы оценивать рассеяние
(отклонение) случайной величины в
единицах той же размерности, введено
понятие среднего
квадратичного отклонения
σ(Х), которое
равно корню квадратному из дисперсии:
![]()
(17)
Вместо среднего
квадратичного отклонения иногда
используется термин «стандартное
отклонение».
Всякое отношение,
устанавливающее связь между всеми
возможными значениями случайной величины
и соответствующими им вероятностями,
называется законом
распределения случайной величины.
Формы задания закона распределения
могут быть разными:
а) ряд распределения
(для дискретных величин);
б) функция
распределения;
в) кривая распределения
(для непрерывных величин).
Существует
относительно много законов распределения
случайных величин.
Нормальный
закон распределения случайных
величин (закон
Гаусса).
Случайная величина
![]()
распределена по
нормальному закону, если ее плотность
вероятности f(x)
определяется формулой:

(18),
где <x>
— математическое ожидание (среднее
значение) случайной величины <x>
= M
(X);
![]() —
—
среднее квадратичное отклонение;
![]() —
—
основание натурального логарифма
(неперово число);
f
(x)
– плотность вероятности (функция
распределения вероятностей).
Многие случайные
величины (в том числе все случайные
погрешности) подчиняются нормальному
закону распределения (закону Гаусса).
Для этого распределения наиболее
вероятным значением
измеряемой
величины
является
её среднее
арифметическое
значение.
График нормального
закона распределения изображен на
рисунке (колоколообразная кривая).

Кривая симметрична
относительно прямой х=<x>=α,
следовательно, отклонения случайной
величины вправо и влево от <x>=α
равновероятны. При х=<x>±
кривая асимптотически приближается к
оси абсцисс. Если х=<x>,
то функция распределения вероятностей
f(x)
максимальна и принимает вид:
![]()
(19)
Таким образом,
максимальное значение функции fmax(x)
зависит от величины среднего квадратичного
отклонения. На рисунке изображены 3
кривые распределения. Для кривых 1 и 2
<x>
= α = 0 соответствующие значения среднего
квадратичного отклонения различны, при
этом 2>1.
(При увеличении
кривая распределения становится более
пологой, а при уменьшении
– вытягивается вверх). Для кривой 3 <x>
= α ≠ 0 и 3
= 2.
Закон
распределения
молекул в газах по скоростям называется
распределением
Максвелла.
Функция плотности вероятности попадания
скоростей молекул в определенный
интервал
![]()
теоретически была определена в 1860 году
английским физиком Максвеллом

. На рисунке
распределение Максвелла представлено
графически. Распределение движется
вправо или влево в зависимости от
температуры газа (на рисунке Т1
< Т2).
Закон распределения Максвелла определяется
формулой:
![]()
(20),
где mо
– масса молекулы, k
– постоянная Больцмана, Т – абсолютная
температура газа,
![]() —
—
скорость молекулы.
Распределение
концентрации молекул газа в атмосфере
Земли (т.е.
в силовом поле) в зависимости от высоты
было дано австрийским физиком Больцманом
и называется
распределением
Больцмана:

(21)
Где n(h)
– концентрация молекул газа на высоте
h,
n0
– концентрация у поверхности Земли, g
– ускорение свободного падения, m
– масса молекулы.

Распределение
Больцмана.
Совокупность всех
значений случайной величины называется
простым
статистическим рядом.
Так как простой статистический ряд
оказывается большим, то его преобразуют
в вариационный
статистический
ряд или интервальный
статистический ряд. По интервальному
статистическому ряду для оценки вида
функции распределения вероятностей по
экспериментальным данным строят
гистограмму
– столбчатую
диаграмму. (Гистограмма – от греческих
слов “histos”–
столб и “gramma”–
запись).
n

-
h
Гистограмма
распределения Больцмана.
Для построения
гистограммы интервал, содержащий
полученные значения случайной величины
делят на несколько интервалов xi
одинаковой ширины. Для каждого интервала
подсчитывают число mi
значений случайной величины, попавших
в этот интервал. После этого вычисляют
плотность частоты случайной величины
![]()
для каждого интервала xi
и среднее значение случайной величины
<xi
> в каждом интервале.
Затем по оси абсцисс
откладывают интервалы xi,
являющиеся основаниями прямоугольников,
высота которых равна
![]() (или
(или
высотой
![]()
– плотностью относительной частоты
![]() ).
).
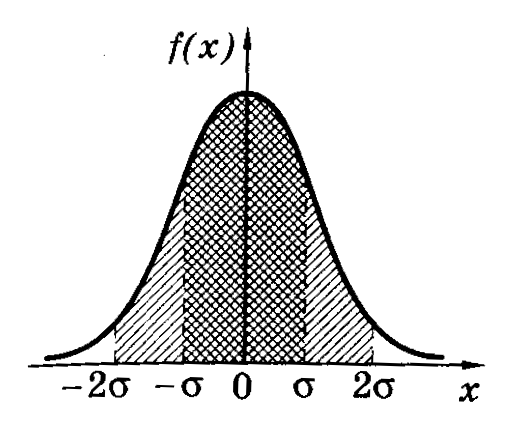
Расчетами показано,
что вероятность попадания нормально
распределенной случайной величины в
интервале значений от <x>–
до <x>+
в среднем равна 68%. В границах вдвое
более широких (<x>–2;
<x>+2)
размещается в среднем 95% всех значений
измерений, а в интервале (<x>–3;<x>+3)
– уже 99,7%. Таким образом, вероятность
того, что отклонение значений нормально
распределенной случайной величины
превысит 3
(
– среднее квадратичное отклонение)
чрезвычайно мала (~0,003). Такое событие
можно считать практически невозможным.
Поэтому границы <x>–3
и <x>+3
принимаются за границы практически
возможных значений нормально распределенной
случайной величины («правило трех
сигм»).
Если число измерений
(объем выборки) невелико (n<30),
дисперсия вычисляется по формуле:
![]()
(22)
Уточненное среднее
квадратичное отклонение отдельного
измерения вычисляется по формуле:

(23)
Напомним, что для
эмпирического распределения по выборке
аналогом математического ожидания
является среднее арифметическое значение
<x>
измеряемой величины.
Чтобы дать
представление о точности и надежности
оценки измеряемой величины, используют
понятия доверительного интервала и
доверительной вероятности.
Доверительным
интервалом
называется интервал (<x>–x,
<x>+x),
в который по определению попадает с
заданной вероятностью действительное
(истинное) значение измеряемой величины.
Доверительный интервал характеризует
точность полученного результата: чем
уже доверительный интервал, тем меньше
погрешность.
Доверительной
вероятностью
(надежностью)
результата серии измерений называется
вероятность того, что истинное значение
измеряемой величины попадает в данный
доверительный интервал (<x>±x).
Чем больше величина доверительного
интервала, т.е. чем больше x,
тем с большей надежностью величина <x>
попадает в этот интервал. Надежность
выбирается самим исследователем
самостоятельно, например, =0,95;
0,98. В медицинских и биологических
исследованиях, как правило, доверительную
вероятность (надежность) принимают
равной 0,95.
Если величина х
подчиняется нормальному закону
распределения Гаусса, а <x>
и <>
оцениваются по выборке (числу измерений)
и если объем выборки невелик (n<30),
то интервал (<x>
– t,n<>,
<x>
+ t,n<>)
будет доверительным интервалом для
известного параметра х с доверительной
вероятностью .
Коэффициент t,n
называется коэффициентом
Стьюдента
(этот коэффициент был предложен в 1908 г.
английским математиком и химиком В.С.
Госсетом, публиковавшим свои работы
под псевдонимом «Стьюдент» – студент).
Значении коэффициента
Стьюдента t,n
зависит от доверительной вероятности
и числа измерений n
(объема выборки). Некоторые значения
коэффициента Стьюдента приведены в
таблице 1.
Таблица 1
|
n |
|
||||||
|
0,6 |
0,7 |
0,8 |
0,9 |
0,95 |
0,98 |
0,99 |
|
|
2 |
1,38 |
2,0 |
3,1 |
6,3 |
12,7 |
31,8 |
63,7 |
|
3 |
1,06 |
1,3 |
1,9 |
2,9 |
4,3 |
7,0 |
9,9 |
|
4 |
0,98 |
1,3 |
1,6 |
2,4 |
3,2 |
4,5 |
5,8 |
|
5 |
0,94 |
1,2 |
1,5 |
2,1 |
2,8 |
3,7 |
4,6 |
|
6 |
0,92 |
1,2 |
1,5 |
2,0 |
2,6 |
3,4 |
4,0 |
|
7 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,1 |
3,7 |
|
8 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,0 |
3,5 |
|
9 |
0,90 |
1,1 |
1,4 |
1,9 |
2,3 |
2,9 |
3,4 |
|
10 |
0,88 |
1,1 |
1,4 |
1,9 |
2,3 |
2,8 |
3,3 |
В таблице 1 в верхней
строке заданы значения доверительной
вероятности
от 0,6 до 0,99, в левом столбце – значение
n.
Коэффициент Стьюдента следует искать
на пересечении соответствующих строки
и столбца.
Окончательный
результат измерений записывается в
виде:
![]()
(25)
Где
![]()
– полуширина доверительного интервала.
Результат серии
измерений оценивается относительной
погрешностью:

(26)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
frac{partial RMSE}{partial widehat{y}_{i}}=frac{1}{2sqrt{MSE}}frac{partial MSE}{partial widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=frac{100}{n}sumlimits_{i=1}^{n}left ( frac{y_{i}-widehat{y}_{i}}{y_{i}} right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=frac{1}{n}sumlimits_{i=1}^{n}left | y_{i}-widehat{y}_{i} right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{left | y_{i} right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{(left | y_{i} right |+left | widehat{y}_{i} right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=frac{1}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y}_{i}right |}{left | y_{i} right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(log(widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}/(n-k)}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
Абсолютная и относительная погрешности (ошибки).
Пусть некоторая
величина x
измерена n
раз. В результате получен ряд значений
этой величины: x1,
x2,
x3,
…, xn
Величиной, наиболее
близкой к действительному значению,
является среднее арифметическое этих
результатов:
![]()
Отсюда следует,
что каждое физическое измерение должно
быть повторено несколько раз.
Разность между
средним значением
![]() измеряемой
измеряемой
величины и значением отдельного измерения
называется абсолютной
погрешностью отдельного измерения:
![]()
(13)
Абсолютная
погрешность может быть как положительной,
так и отрицательной и измеряется в тех
же единицах, что и измеряемая величина.
Средняя абсолютная
ошибка результата — это среднее
арифметическое значений абсолютных
погрешностей отдельных измерений,
взятых по абсолютной величине (модулю):
![]()
(14)
Отношения
![]()
называются относительными погрешностями
(ошибками) отдельных измерений.
Отношение средней
абсолютной погрешности результата
![]()
к среднему арифметическому значению
![]()
измеряемой величины называют относительной
ошибкой результата и выражают в процентах:
![]()
Относительная
ошибка характеризует точность измерения.
Законы распределения случайных величин.
Результат измерения
физической величины зависит от многих
факторов, влияние которых заранее учесть
невозможно. Поэтому значения, полученные
в результате прямых измерений какого
— либо параметра, являются случайными,
обычно не совпадающие между собой.
Следовательно, случайные
величины —
это такие величины, которые в зависимости
от обстоятельств могут принимать те
или иные значения. Если случайная
величина принимает только определенные
числовые значения, то она называется
дискретной.
Например,
количество заболеваний в данном регионе
за год, оценка, полученная студентом на
экзамене, энергия электрона в атоме и
т.д.
Непрерывная
случайная величина принимает любые
значения в данном интервале.
Например: температура
тела человека, мгновенные скорости
теплового движения молекул, содержание
кислорода в воздухе и т.д.
Под событием
понимается всякий результат или исход
испытания. В теории вероятностей
рассматриваются события, которые при
выполнение некоторых условий могут
произойти, а могут не произойти. Такие
события называются
случайными.
Например, событие, состоящее в появлении
цифры 1 при выполнении условия — бросания
игральной кости, может произойти, а
может не произойти.
Если событие
неизбежно происходит в результате
каждого испытания, то оно называется
достоверным.
Событие называется невозможным,
если оно вообще не происходит ни при
каких условиях.
Два события,
одновременное появление которых
невозможно, называются несовместными.
Пусть случайное
событие А в серии из n
независимых испытаний произошло m
раз, тогда отношение:
![]()
называется
относительной частотой события А. Для
каждой относительной частоты выполняется
неравенство:
![]()
При небольшом
числе опытов относительная частота
событий в значительной мере имеет
случайный характер и может заметно
изменяться от одной группы опытов к
другой. Однако при увеличении числа
опытов частота событий все более теряет
свой случайный характер и приближается
к некоторому постоянному положительному
числу, которое является количественной
мерой возможности реализации случайного
события А. Предел, к которому стремится
относительная частота событий при
неограниченном увеличении числа
испытаний, называется статистической
вероятностью события:
![]()
Например, при
многократном бросании монеты частота
выпадения герба будет лишь незначительно
отличаться от ½. Для достоверного события
вероятность Р(А) равна единице. Если
Р=0, то событие невозможно.
Математическим
ожиданием
дискретной случайной величины называется
сумма произведений всех ее возможных
значений хi
на вероятность этих значений рi:
![]()
Статистическим
аналогом математического ожидания
является среднее арифметическое значений
![]() :
:
![]() ,
,
где mi
— число дискретных случайных величин,
имеющих значение хi.
Для непрерывной
случайной величины математическим
ожиданием служит интеграл:
![]() ,
,
где р(х) — плотность
вероятности.
Отдельные значения
случайной величины группируются около
математического ожидания. Отклонение
случайной величины от ее математического
ожидания (среднего значения) характеризуется
дисперсией,
которая для дискретной случайной
величины определяется формулой:
![]()
(15)
(16)
Дисперсия имеет
размерность случайной величины. Для
того, чтобы оценивать рассеяние
(отклонение) случайной величины в
единицах той же размерности, введено
понятие среднего
квадратичного отклонения
σ(Х), которое
равно корню квадратному из дисперсии:
![]()
(17)
Вместо среднего
квадратичного отклонения иногда
используется термин «стандартное
отклонение».
Всякое отношение,
устанавливающее связь между всеми
возможными значениями случайной величины
и соответствующими им вероятностями,
называется законом
распределения случайной величины.
Формы задания закона распределения
могут быть разными:
а) ряд распределения
(для дискретных величин);
б) функция
распределения;
в) кривая распределения
(для непрерывных величин).
Существует
относительно много законов распределения
случайных величин.
Нормальный
закон распределения случайных
величин (закон
Гаусса).
Случайная величина
![]()
распределена по
нормальному закону, если ее плотность
вероятности f(x)
определяется формулой:
(18),
где <x>
— математическое ожидание (среднее
значение) случайной величины <x>
= M
(X);
![]() —
—
среднее квадратичное отклонение;
![]() —
—
основание натурального логарифма
(неперово число);
f
(x)
– плотность вероятности (функция
распределения вероятностей).
Многие случайные
величины (в том числе все случайные
погрешности) подчиняются нормальному
закону распределения (закону Гаусса).
Для этого распределения наиболее
вероятным значением
измеряемой
величины
является
её среднее
арифметическое
значение.
График нормального
закона распределения изображен на
рисунке (колоколообразная кривая).
Кривая симметрична
относительно прямой х=<x>=α,
следовательно, отклонения случайной
величины вправо и влево от <x>=α
равновероятны. При х=<x>±
кривая асимптотически приближается к
оси абсцисс. Если х=<x>,
то функция распределения вероятностей
f(x)
максимальна и принимает вид:
![]()
(19)
Таким образом,
максимальное значение функции fmax(x)
зависит от величины среднего квадратичного
отклонения. На рисунке изображены 3
кривые распределения. Для кривых 1 и 2
<x>
= α = 0 соответствующие значения среднего
квадратичного отклонения различны, при
этом 2>1.
(При увеличении
кривая распределения становится более
пологой, а при уменьшении
– вытягивается вверх). Для кривой 3 <x>
= α ≠ 0 и 3
= 2.
Закон
распределения
молекул в газах по скоростям называется
распределением
Максвелла.
Функция плотности вероятности попадания
скоростей молекул в определенный
интервал
![]()
теоретически была определена в 1860 году
английским физиком Максвеллом
. На рисунке
распределение Максвелла представлено
графически. Распределение движется
вправо или влево в зависимости от
температуры газа (на рисунке Т1
< Т2).
Закон распределения Максвелла определяется
формулой:
![]()
(20),
где mо
– масса молекулы, k
– постоянная Больцмана, Т – абсолютная
температура газа,
![]() —
—
скорость молекулы.
Распределение
концентрации молекул газа в атмосфере
Земли (т.е.
в силовом поле) в зависимости от высоты
было дано австрийским физиком Больцманом
и называется
распределением
Больцмана:
(21)
Где n(h)
– концентрация молекул газа на высоте
h,
n0
– концентрация у поверхности Земли, g
– ускорение свободного падения, m
– масса молекулы.
Распределение
Больцмана.
Совокупность всех
значений случайной величины называется
простым
статистическим рядом.
Так как простой статистический ряд
оказывается большим, то его преобразуют
в вариационный
статистический
ряд или интервальный
статистический ряд. По интервальному
статистическому ряду для оценки вида
функции распределения вероятностей по
экспериментальным данным строят
гистограмму
– столбчатую
диаграмму. (Гистограмма – от греческих
слов “histos”–
столб и “gramma”–
запись).
n
-
h
Гистограмма
распределения Больцмана.
Для построения
гистограммы интервал, содержащий
полученные значения случайной величины
делят на несколько интервалов xi
одинаковой ширины. Для каждого интервала
подсчитывают число mi
значений случайной величины, попавших
в этот интервал. После этого вычисляют
плотность частоты случайной величины
![]()
для каждого интервала xi
и среднее значение случайной величины
<xi
> в каждом интервале.
Затем по оси абсцисс
откладывают интервалы xi,
являющиеся основаниями прямоугольников,
высота которых равна
![]() (или
(или
высотой
![]()
– плотностью относительной частоты
![]() ).
).
Расчетами показано,
что вероятность попадания нормально
распределенной случайной величины в
интервале значений от <x>–
до <x>+
в среднем равна 68%. В границах вдвое
более широких (<x>–2;
<x>+2)
размещается в среднем 95% всех значений
измерений, а в интервале (<x>–3;<x>+3)
– уже 99,7%. Таким образом, вероятность
того, что отклонение значений нормально
распределенной случайной величины
превысит 3
(
– среднее квадратичное отклонение)
чрезвычайно мала (~0,003). Такое событие
можно считать практически невозможным.
Поэтому границы <x>–3
и <x>+3
принимаются за границы практически
возможных значений нормально распределенной
случайной величины («правило трех
сигм»).
Если число измерений
(объем выборки) невелико (n<30),
дисперсия вычисляется по формуле:
![]()
(22)
Уточненное среднее
квадратичное отклонение отдельного
измерения вычисляется по формуле:
(23)
Напомним, что для
эмпирического распределения по выборке
аналогом математического ожидания
является среднее арифметическое значение
<x>
измеряемой величины.
Чтобы дать
представление о точности и надежности
оценки измеряемой величины, используют
понятия доверительного интервала и
доверительной вероятности.
Доверительным
интервалом
называется интервал (<x>–x,
<x>+x),
в который по определению попадает с
заданной вероятностью действительное
(истинное) значение измеряемой величины.
Доверительный интервал характеризует
точность полученного результата: чем
уже доверительный интервал, тем меньше
погрешность.
Доверительной
вероятностью
(надежностью)
результата серии измерений называется
вероятность того, что истинное значение
измеряемой величины попадает в данный
доверительный интервал (<x>±x).
Чем больше величина доверительного
интервала, т.е. чем больше x,
тем с большей надежностью величина <x>
попадает в этот интервал. Надежность
выбирается самим исследователем
самостоятельно, например, =0,95;
0,98. В медицинских и биологических
исследованиях, как правило, доверительную
вероятность (надежность) принимают
равной 0,95.
Если величина х
подчиняется нормальному закону
распределения Гаусса, а <x>
и <>
оцениваются по выборке (числу измерений)
и если объем выборки невелик (n<30),
то интервал (<x>
– t,n<>,
<x>
+ t,n<>)
будет доверительным интервалом для
известного параметра х с доверительной
вероятностью .
Коэффициент t,n
называется коэффициентом
Стьюдента
(этот коэффициент был предложен в 1908 г.
английским математиком и химиком В.С.
Госсетом, публиковавшим свои работы
под псевдонимом «Стьюдент» – студент).
Значении коэффициента
Стьюдента t,n
зависит от доверительной вероятности
и числа измерений n
(объема выборки). Некоторые значения
коэффициента Стьюдента приведены в
таблице 1.
Таблица 1
|
n |
|
||||||
|
0,6 |
0,7 |
0,8 |
0,9 |
0,95 |
0,98 |
0,99 |
|
|
2 |
1,38 |
2,0 |
3,1 |
6,3 |
12,7 |
31,8 |
63,7 |
|
3 |
1,06 |
1,3 |
1,9 |
2,9 |
4,3 |
7,0 |
9,9 |
|
4 |
0,98 |
1,3 |
1,6 |
2,4 |
3,2 |
4,5 |
5,8 |
|
5 |
0,94 |
1,2 |
1,5 |
2,1 |
2,8 |
3,7 |
4,6 |
|
6 |
0,92 |
1,2 |
1,5 |
2,0 |
2,6 |
3,4 |
4,0 |
|
7 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,1 |
3,7 |
|
8 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,0 |
3,5 |
|
9 |
0,90 |
1,1 |
1,4 |
1,9 |
2,3 |
2,9 |
3,4 |
|
10 |
0,88 |
1,1 |
1,4 |
1,9 |
2,3 |
2,8 |
3,3 |
В таблице 1 в верхней
строке заданы значения доверительной
вероятности
от 0,6 до 0,99, в левом столбце – значение
n.
Коэффициент Стьюдента следует искать
на пересечении соответствующих строки
и столбца.
Окончательный
результат измерений записывается в
виде:
![]()
(25)
Где
![]()
– полуширина доверительного интервала.
Результат серии
измерений оценивается относительной
погрешностью:
(26)
Погрешности измерений, представление результатов эксперимента
- Шкала измерительного прибора
- Цена деления
- Виды измерений
- Погрешность измерений, абсолютная и относительная погрешность
- Абсолютная погрешность серии измерений
- Представление результатов эксперимента
- Задачи
п.1. Шкала измерительного прибора
Шкала – это показывающая часть измерительного прибора, состоящая из упорядоченного ряда отметок со связанной с ними нумерацией. Шкала может располагаться по окружности, дуге или прямой линии.
Примеры шкал различных приборов:
п.2. Цена деления
Цена деления измерительного прибора равна числу единиц измеряемой величины между двумя ближайшими делениями шкалы. Как правило, цена деления указана на маркировке прибора.
Алгоритм определения цены деления
Шаг 1. Найти два ближайшие пронумерованные крупные деления шкалы. Пусть первое значение равно a, второе равно b, b > a.
Шаг 2. Посчитать количество мелких делений шкалы между ними. Пусть это количество равно n.
Шаг 3. Разделить разницу значений крупных делений шкалы на количество отрезков, которые образуются мелкими делениями: $$ triangle=frac{b-a}{n+1} $$ Найденное значение (triangle) и есть цена деления данного прибора.
Пример определения цены деления:
 |
Определим цену деления основной шкалы секундомера. Два ближайших пронумерованных деления на основной шкале:a = 5 c b = 10 cМежду ними находится 4 средних деления, а между каждыми средними делениями еще 4 мелких. Итого: 4+4·5=24 деления. Цена деления: begin{gather*} triangle=frac{b-a}{n+1}\ triangle=frac{10-5}{24+1}=frac15=0,2 c end{gather*} |
п.3. Виды измерений
Вид измерений
Определение
Пример
Прямое измерение
Физическую величину измеряют с помощью прибора
Измерение длины бруска линейкой
Косвенное измерение
Физическую величину рассчитывают по формуле, куда подставляют значения величин, полученных с помощью прямых измерений
Определение площади столешницы при измеренной длине и ширине
п.4. Погрешность измерений, абсолютная и относительная погрешность
Погрешность измерений – это отклонение измеренного значения величины от её истинного значения.
Составляющие погрешности измерений
Причины
Инструментальная погрешность
Определяется погрешностью инструментов и приборов, используемых для измерений (принципом действия, точностью шкалы и т.п.)
Погрешность метода
Определяется несовершенством методов и допущениями в методике.
Погрешность теории (модели)
Определяется теоретическими упрощениями, степенью соответствия теоретической модели и реальности.
Погрешность оператора
Определяется субъективным фактором, ошибками экспериментатора.
Инструментальная погрешность измерений принимается равной половине цены деления прибора: $$ d=frac{triangle}{2} $$
Если величина (a_0) — это истинное значение, а (triangle a) — погрешность измерения, результат измерений физической величины записывают в виде (a=a_0pmtriangle a).
Абсолютная погрешность измерения – это модуль разности между измеренным и истинным значением измеряемой величины: $$ triangle a=|a-a_0| $$
Отношение абсолютной погрешности измерения к истинному значению, выраженное в процентах, называют относительной погрешностью измерения: $$ delta=frac{triangle a}{a_0}cdot 100text{%} $$
Относительная погрешность является мерой точности измерения: чем меньше относительная погрешность, тем измерение точнее. По абсолютной погрешности о точности измерения судить нельзя.
На практике абсолютную и относительную погрешности округляют до двух значащих цифр с избытком, т.е. всегда в сторону увеличения.
Значащие цифры – это все верные цифры числа, кроме нулей слева. Результаты измерений записывают только значащими цифрами.
Примеры значащих цифр:
0,403 – три значащих цифры, величина определена с точностью до тысячных.
40,3 – три значащих цифры, величина определена с точностью до десятых.
40,300 – пять значащих цифр, величина определена с точностью до тысячных.
В простейших измерениях инструментальная погрешность прибора является основной.
В таких случаях физическую величину измеряют один раз, полученное значение берут в качестве истинного, а абсолютную погрешность считают равной инструментальной погрешности прибора.
Примеры измерений с абсолютной погрешностью равной инструментальной:
- определение длины с помощью линейки или мерной ленты;
- определение объема с помощью мензурки.
Пример получения результатов прямых измерений с помощью линейки:
 |
Измерим длину бруска линейкой, у которой пронумерованы сантиметры и есть только одно деление между пронумерованными делениями. Цена деления такой линейки: begin{gather*} triangle=frac{b-a}{n+1}= frac{1 text{см}}{1+1}=0,5 text{см} end{gather*} Инструментальная погрешность: begin{gather*} d=frac{triangle}{2}=frac{0,5}{2}=0,25 text{см} end{gather*} Истинное значение: (L_0=4 text{см}) Результат измерений: $$ L=L_0pm d=(4,00pm 0,25) text{см} $$ Относительная погрешность: $$ delta=frac{0,25}{4,00}cdot 100text{%}=6,25text{%}approx 6,3text{%} $$ |
 |
Теперь возьмем линейку с n=9 мелкими делениями между пронумерованными делениями. Цена деления такой линейки: begin{gather*} triangle=frac{b-a}{n+1}= frac{1 text{см}}{9+1}=0,1 text{см} end{gather*} Инструментальная погрешность: begin{gather*} d=frac{triangle}{2}=frac{0,1}{2}=0,05 text{см} end{gather*} Истинное значение: (L_0=4,15 text{см}) Результат измерений: $$ L=L_0pm d=(4,15pm 0,05) text{см} $$ Относительная погрешность: $$ delta=frac{0,05}{4,15}cdot 100text{%}approx 1,2text{%} $$ |
Второе измерение точнее, т.к. его относительная погрешность меньше.
п.5. Абсолютная погрешность серии измерений
Измерение длины с помощью линейки (или объема с помощью мензурки) являются теми редкими случаями, когда для определения истинного значения достаточно одного измерения, а абсолютная погрешность сразу берется равной инструментальной погрешности, т.е. половине цены деления линейки (или мензурки).
Гораздо чаще погрешность метода или погрешность оператора оказываются заметно больше инструментальной погрешности. В таких случаях значение измеренной физической величины каждый раз немного меняется, и для оценки истинного значения и абсолютной погрешности нужна серия измерений и вычисление средних значений.
Алгоритм определения истинного значения и абсолютной погрешности в серии измерений
Шаг 1. Проводим серию из (N) измерений, в каждом из которых получаем значение величины (x_1,x_2,…,x_N)
Шаг 2. Истинное значение величины принимаем равным среднему арифметическому всех измерений: $$ x_0=x_{cp}=frac{x_1+x_2+…+x_N}{N} $$ Шаг 3. Находим абсолютные отклонения от истинного значения для каждого измерения: $$ triangle_1=|x_0-x_1|, triangle_2=|x_0-x_2|, …, triangle_N=|x_0-x_N| $$ Шаг 4. Находим среднее арифметическое всех абсолютных отклонений: $$ triangle_{cp}=frac{triangle_1+triangle_2+…+triangle_N}{N} $$ Шаг 5. Сравниваем полученную величину (triangle_{cp}) c инструментальной погрешностью прибора d (половина цены деления). Большую из этих двух величин принимаем за абсолютную погрешность: $$ triangle x=maxleft{triangle_{cp}; dright} $$ Шаг 6. Записываем результат серии измерений: (x=x_0pmtriangle x).
Пример расчета истинного значения и погрешности для серии прямых измерений:
Пусть при измерении массы шарика с помощью рычажных весов мы получили в трех опытах следующие значения: 99,8 г; 101,2 г; 100,3 г.
Инструментальная погрешность весов d = 0,05 г.
Найдем истинное значение массы и абсолютную погрешность.
Составим расчетную таблицу:
| № опыта | 1 | 2 | 3 | Сумма |
| Масса, г | 99,8 | 101,2 | 100,3 | 301,3 |
| Абсолютное отклонение, г | 0,6 | 0,8 | 0,1 | 1,5 |
Сначала находим среднее значение всех измерений: begin{gather*} m_0=frac{99,8+101,2+100,3}{3}=frac{301,3}{3}approx 100,4 text{г} end{gather*} Это среднее значение принимаем за истинное значение массы.
Затем считаем абсолютное отклонение каждого опыта как модуль разности (m_0) и измерения. begin{gather*} triangle_1=|100,4-99,8|=0,6\ triangle_2=|100,4-101,2|=0,8\ triangle_3=|100,4-100,3|=0,1 end{gather*} Находим среднее абсолютное отклонение: begin{gather*} triangle_{cp}=frac{0,6+0,8+0,1}{3}=frac{1,5}{3}=0,5 text{(г)} end{gather*} Мы видим, что полученное значение (triangle_{cp}) больше инструментальной погрешности d.
Поэтому абсолютная погрешность измерения массы: begin{gather*} triangle m=maxleft{triangle_{cp}; dright}=maxleft{0,5; 0,05right} text{(г)} end{gather*} Записываем результат: begin{gather*} m=m_0pmtriangle m\ m=(100,4pm 0,5) text{(г)} end{gather*} Относительная погрешность (с двумя значащими цифрами): begin{gather*} delta_m=frac{0,5}{100,4}cdot 100text{%}approx 0,050text{%} end{gather*}
п.6. Представление результатов эксперимента
Результат измерения представляется в виде $$ a=a_0pmtriangle a $$ где (a_0) – истинное значение, (triangle a) – абсолютная погрешность измерения.
Как найти результат прямого измерения, мы рассмотрели выше.
Результат косвенного измерения зависит от действий, которые производятся при подстановке в формулу величин, полученных с помощью прямых измерений.
Погрешность суммы и разности
Если (a=a_0+triangle a) и (b=b_0+triangle b) – результаты двух прямых измерений, то
- абсолютная погрешность их суммы равна сумме абсолютных погрешностей
$$ triangle (a+b)=triangle a+triangle b $$
- абсолютная погрешность их разности также равна сумме абсолютных погрешностей
$$ triangle (a-b)=triangle a+triangle b $$
Погрешность произведения и частного
Если (a=a_0+triangle a) и (b=b_0+triangle b) – результаты двух прямых измерений, с относительными погрешностями (delta_a=frac{triangle a}{a_0}cdot 100text{%}) и (delta_b=frac{triangle b}{b_0}cdot 100text{%}) соответственно, то:
- относительная погрешность их произведения равна сумме относительных погрешностей
$$ delta_{acdot b}=delta_a+delta_b $$
- относительная погрешность их частного также равна сумме относительных погрешностей
$$ delta_{a/b}=delta_a+delta_b $$
Погрешность степени
Если (a=a_0+triangle a) результат прямого измерения, с относительной погрешностью (delta_a=frac{triangle a}{a_0}cdot 100text{%}), то:
- относительная погрешность квадрата (a^2) равна удвоенной относительной погрешности
$$ delta_{a^2}=2delta_a $$
- относительная погрешность куба (a^3) равна утроенной относительной погрешности
$$ delta_{a^3}=3delta_a $$
- относительная погрешность произвольной натуральной степени (a^n) равна
$$ delta_{a^n}=ndelta_a $$
Вывод этих формул достаточно сложен, но если интересно, его можно найти в Главе 7 справочника по алгебре для 8 класса.
п.7. Задачи
Задача 1. Определите цену деления и объем налитой жидкости для каждой из мензурок. В каком случае измерение наиболее точно; наименее точно? 
Составим таблицу для расчета цены деления:
| № мензурки | a, мл | b, мл | n | (triangle=frac{b-a}{n+1}), мл |
| 1 | 20 | 40 | 4 | (frac{40-20}{4+1}=4) |
| 2 | 100 | 200 | 4 | (frac{200-100}{4+1}=20) |
| 3 | 15 | 30 | 4 | (frac{30-15}{4+1}=3) |
| 4 | 200 | 400 | 4 | (frac{400-200}{4+1}=40) |
Инструментальная точность мензурки равна половине цены деления.
Принимаем инструментальную точность за абсолютную погрешность и измеренное значение объема за истинное.
Составим таблицу для расчета относительной погрешности (оставляем две значащих цифры и округляем с избытком):
| № мензурки | Объем (V_0), мл | Абсолютная погрешность (triangle V=frac{triangle}{2}), мл |
Относительная погрешность (delta_V=frac{triangle V}{V_0}cdot 100text{%}) |
| 1 | 68 | 2 | 3,0% |
| 2 | 280 | 10 | 3,6% |
| 3 | 27 | 1,5 | 5,6% |
| 4 | 480 | 20 | 4,2% |
Наиболее точное измерение в 1-й мензурке, наименее точное – в 3-й мензурке.
Ответ:
Цена деления 4; 20; 3; 40 мл
Объем 68; 280; 27; 480 мл
Самое точное – 1-я мензурка; самое неточное – 3-я мензурка
Задача 2. В двух научных работах указаны два значения измерений одной и той же величины: $$ x_1=(4,0pm 0,1) text{м}, x_2=(4,0pm 0,03) text{м} $$ Какое из этих измерений точней и почему?
Мерой точности является относительная погрешность измерений. Получаем: begin{gather*} delta_1=frac{0,1}{4,0}cdot 100text{%}=2,5text{%}\ delta_2=frac{0,03}{4,0}cdot 100text{%}=0,75text{%} end{gather*} Относительная погрешность второго измерения меньше. Значит, второе измерение точней.
Ответ: (delta_2lt delta_1), второе измерение точней.
Задача 3. Две машины движутся навстречу друг другу со скоростями 54 км/ч и 72 км/ч.
Цена деления спидометра первой машины 10 км/ч, второй машины – 1 км/ч.
Найдите скорость их сближения, абсолютную и относительную погрешность этой величины.
Абсолютная погрешность скорости каждой машины равна инструментальной, т.е. половине деления спидометра: $$ triangle v_1=frac{10}{2}=5 (text{км/ч}), triangle v_2=frac{1}{2}=0,5 (text{км/ч}) $$ Показания каждого из спидометров: $$ v_1=(54pm 5) text{км/ч}, v_2=(72pm 0,5) text{км/ч} $$ Скорость сближения равна сумме скоростей: $$ v_0=v_{10}+v_{20}, v_0=54+72=125 text{км/ч} $$ Для суммы абсолютная погрешность равна сумме абсолютных погрешностей слагаемых. $$ triangle v=triangle v_1+triangle v_2, triangle v=5+0,5=5,5 text{км/ч} $$ Скорость сближения с учетом погрешности равна: $$ v=(126,0pm 5,5) text{км/ч} $$ Относительная погрешность: $$ delta_v=frac{5,5}{126,0}cdot 100text{%}approx 4,4text{%} $$ Ответ: (v=(126,0pm 5,5) text{км/ч}, delta_vapprox 4,4text{%})
Задача 4. Измеренная длина столешницы равна 90,2 см, ширина 60,1 см. Измерения проводились с помощью линейки с ценой деления 0,1 см. Найдите площадь столешницы, абсолютную и относительную погрешность этой величины.
Инструментальная погрешность линейки (d=frac{0,1}{2}=0,05 text{см})
Результаты прямых измерений длины и ширины: $$ a=(90,20pm 0,05) text{см}, b=(60,10pm 0,05) text{см} $$ Относительные погрешности (не забываем про правила округления): begin{gather*} delta_1=frac{0,05}{90,20}cdot 100text{%}approx 0,0554text{%}approx uparrow 0,056text{%}\ delta_2=frac{0,05}{60,10}cdot 100text{%}approx 0,0832text{%}approx uparrow 0,084text{%} end{gather*} Площадь столешницы: $$ S=ab, S=90,2cdot 60,1 = 5421,01 text{см}^2 $$ Для произведения относительная погрешность равна сумме относительных погрешностей слагаемых: $$ delta_S=delta_a+delta_b=0,056text{%}+0,084text{%}=0,140text{%}=0,14text{%} $$ Абсолютная погрешность: begin{gather*} triangle S=Scdot delta_S=5421,01cdot 0,0014=7,59approx 7,6 text{см}^2\ S=(5421,0pm 7,6) text{см}^2 end{gather*} Ответ: (S=(5421,0pm 7,6) text{см}^2, delta_Sapprox 0,14text{%})
Абсолютная и относительная погрешность

4.2
Средняя оценка: 4.2
Всего получено оценок: 2201.
4.2
Средняя оценка: 4.2
Всего получено оценок: 2201.
Абсолютную и относительную погрешность используют для оценки неточности в производимых расчетах с высокой сложностью. Также они используются в различных измерениях и для округления результатов вычислений. Рассмотрим, как определить абсолютную и относительную погрешность.

Опыт работы учителем математики — более 33 лет.
Абсолютная погрешность
Абсолютной погрешностью числа называют разницу между этим числом и его точным значением.
Рассмотрим пример: в школе учится 374 ученика. Если округлить это число до 400, то абсолютная погрешность измерения равна 400-374=26.
Для подсчета абсолютной погрешности необходимо из большего числа вычитать меньшее.
Существует формула абсолютной погрешности. Обозначим точное число буквой А, а буквой а – приближение к точному числу. Приближенное число – это число, которое незначительно отличается от точного и обычно заменяет его в вычислениях. Тогда формула будет выглядеть следующим образом:
Δа=А-а. Как найти абсолютную погрешность по формуле, мы рассмотрели выше.
На практике абсолютной погрешности недостаточно для точной оценки измерения. Редко когда можно точно знать значение измеряемой величины, чтобы рассчитать абсолютную погрешность. Измеряя книгу в 20 см длиной и допустив погрешность в 1 см, можно считать измерение с большой ошибкой. Но если погрешность в 1 см была допущена при измерении стены в 20 метров, это измерение можно считать максимально точным. Поэтому в практике более важное значение имеет определение относительной погрешности измерения.
Записывают абсолютную погрешность числа, используя знак ±. Например, длина рулона обоев составляет 30 м ± 3 см. Границу абсолютной погрешности называют предельной абсолютной погрешностью.
Относительная погрешность
Относительной погрешностью называют отношение абсолютной погрешности числа к самому этому числу. Чтобы рассчитать относительную погрешность в примере с учениками, разделим 26 на 374.
Получим число 0,0695, переведем в проценты и получим 7 %. Относительную погрешность обозначают процентами, потому что это безразмерная величина. Относительная погрешность – это точная оценка ошибки измерений. Если взять абсолютную погрешность в 1 см при измерении длины отрезков 10 см и 10 м, то относительные погрешности будут соответственно равны 10 % и 0,1 %. Для отрезка длиной в 10 см погрешность в 1 см очень велика, это ошибка в 10 %. А для десятиметрового отрезка 1 см не имеет значения, всего 0,1 %.
Различают систематические и случайные погрешности. Систематической называют ту погрешность, которая остается неизменной при повторных измерениях. Случайная погрешность возникает в результате воздействия на процесс измерения внешних факторов и может изменять свое значение.
Правила подсчета погрешностей
Для номинальной оценки погрешностей существует несколько правил:
- при сложении и вычитании чисел необходимо складывать их абсолютные погрешности;
- при делении и умножении чисел требуется сложить относительные погрешности;
- при возведении в степень относительную погрешность умножают на показатель степени.
Приближенные и точные числа записываются при помощи десятичных дробей. Берется только среднее значение, поскольку точное может быть бесконечно длинным. Чтобы понять, как записывать эти числа, необходимо узнать о верных и сомнительных цифрах.
Верными называются такие цифры, разряд которых превосходит абсолютную погрешность числа. Если же разряд цифры меньше абсолютной погрешности, она называется сомнительной. Например, для дроби 3,6714 с погрешностью 0,002 верными будут цифры 3,6,7, а сомнительными – 1 и 4. В записи приближенного числа оставляют только верные цифры. Дробь в этом случае будет выглядеть таким образом – 3,67.

Что мы узнали?
Абсолютные и относительные погрешности используются для оценки точности измерений. Абсолютной погрешностью называют разницу между точным и приближенным числом. Относительная погрешность – это отношение абсолютной погрешности числа к самому числу. На практике используют относительную погрешность, так как она является более точной.
Тест по теме
Доска почёта
Чтобы попасть сюда — пройдите тест.
-

Светлана Лобанова-Асямолова
10/10
-
Валерий Соломин
10/10
-
Анастасия Юшкова
10/10
-
Ксюша Пономарева
7/10
-
Паша Кривов
10/10
-
Евгений Холопик
9/10
-
Guzel Murtazina
10/10
-
Максим Аполонов
10/10
-
Olga Bimbirene
9/10
-
Света Колодий
10/10
Оценка статьи
4.2
Средняя оценка: 4.2
Всего получено оценок: 2201.
А какая ваша оценка?