
![]()
Выразим α через
β:
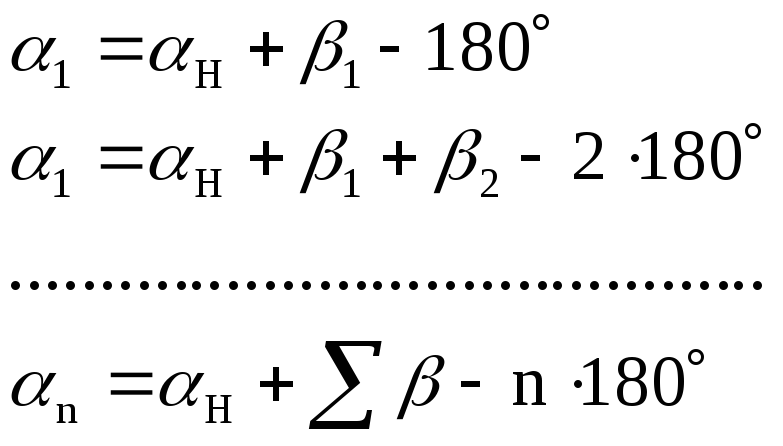
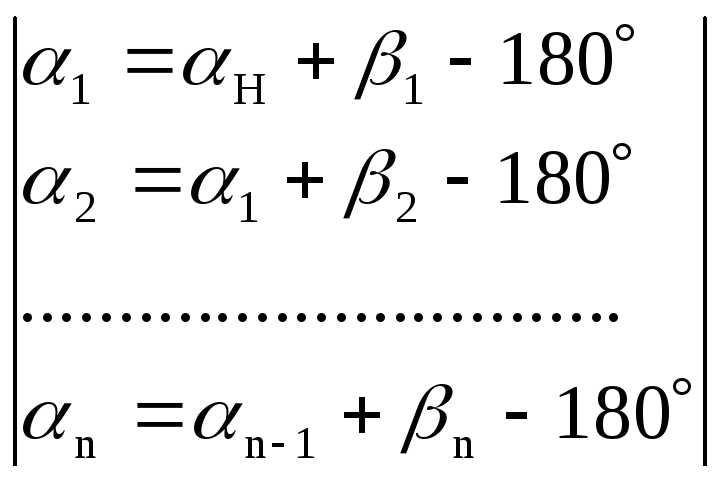
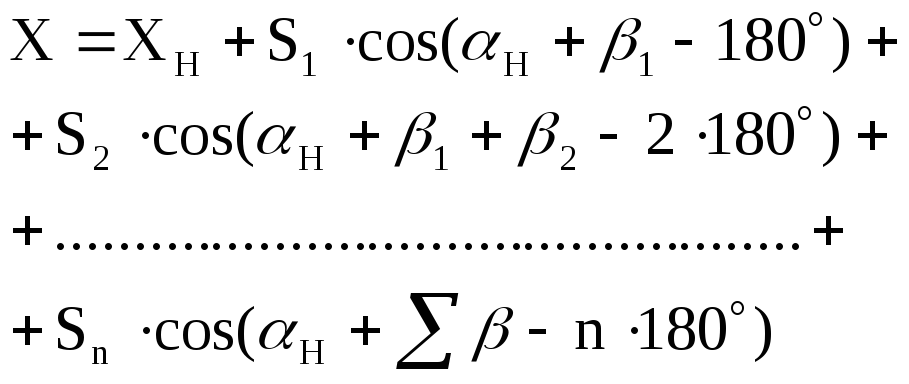
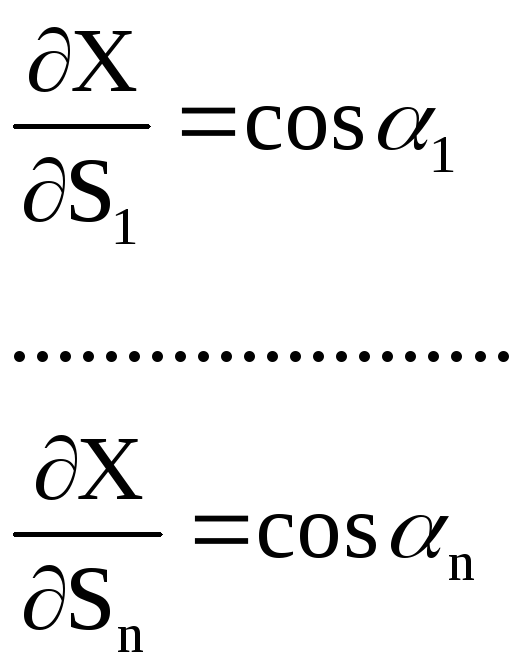
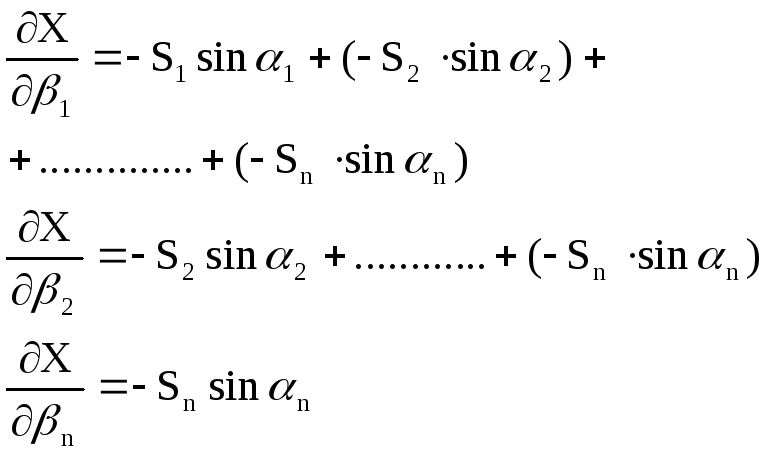
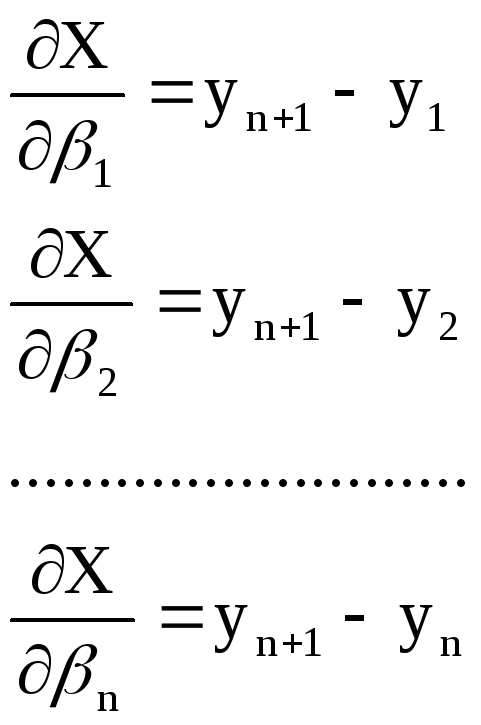
![]()
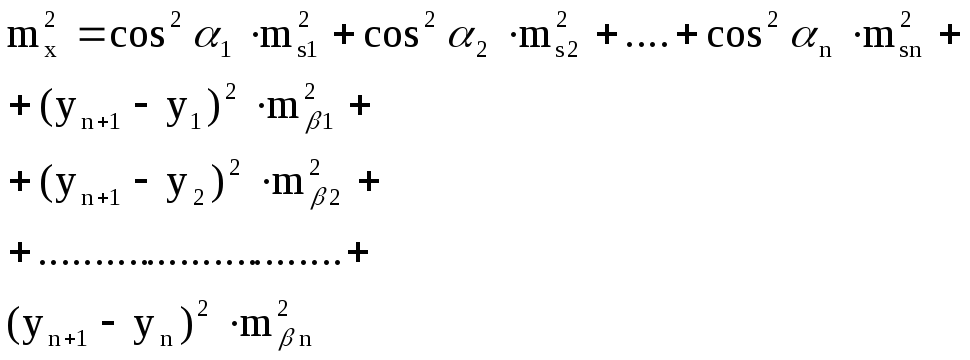
![]()
![]()
![]()
![]() .
.
5.Оценка точности угловых измерений по невязкам полигонах
-
по
сумме углов:
![]()
![]()
![]()
![]()
![]() ;
;
![]()
![]()
![]()
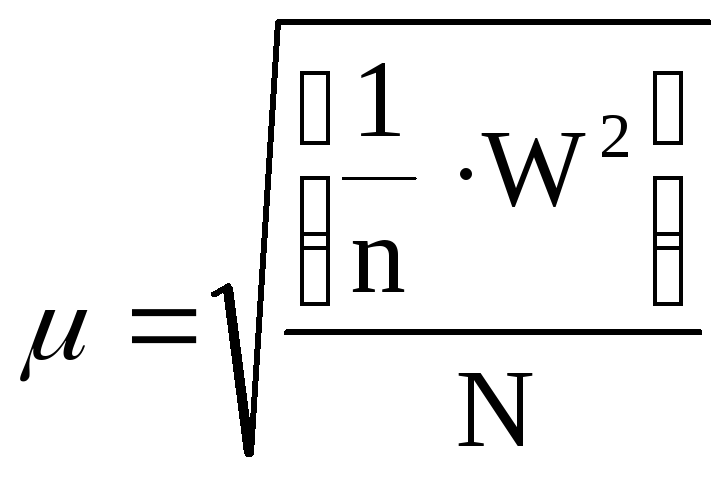 ,
,
где
N–
число невязок.
-
сумме
превышений:
![]()
![]() ,
,
где
L–
длина хода, км.
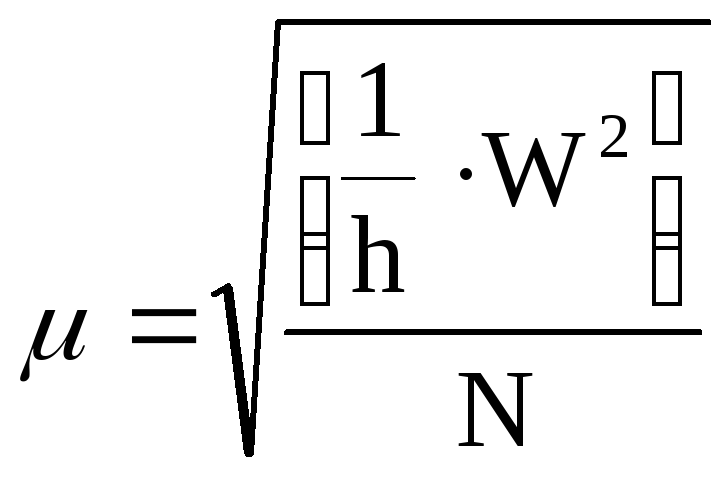
-
по
разностям двойных измерений:
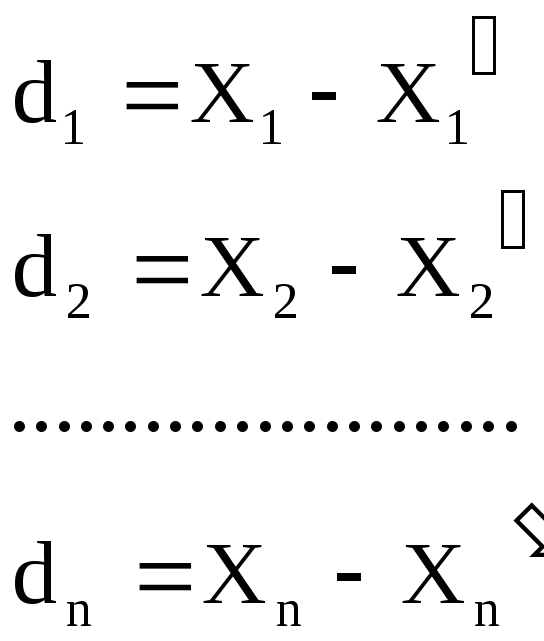
![]()
6. Условные уравнения в полигонометрическом ходе
1)условное уравнение
дирекционных углов:
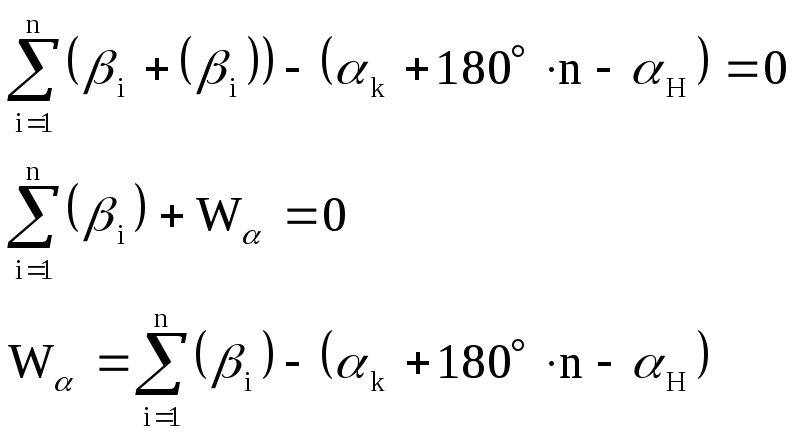
-
условные
уравнения координат:
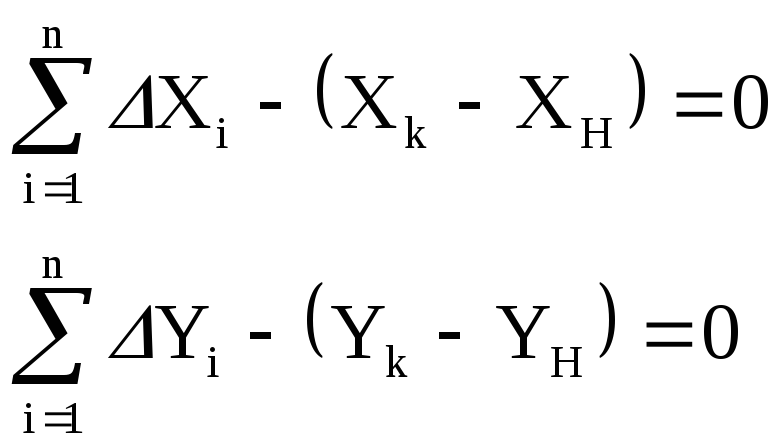
Выразим
эти условные уравнения через поправки.
Для этого первое из них запишем в виде
![]() (1)
(1)
Выводы для второго
уравнения аналогичны, поэтому они не
приводятся.
Разлагая
условное уравнение координат в ряд
Тейлора по поправкам, получим:
![]() ,
,
(2)
где
![]()
![]() (3) Поправки
(3) Поправки
в дирекционные углы выразим через
поправки в измеренные углы. Поскольку
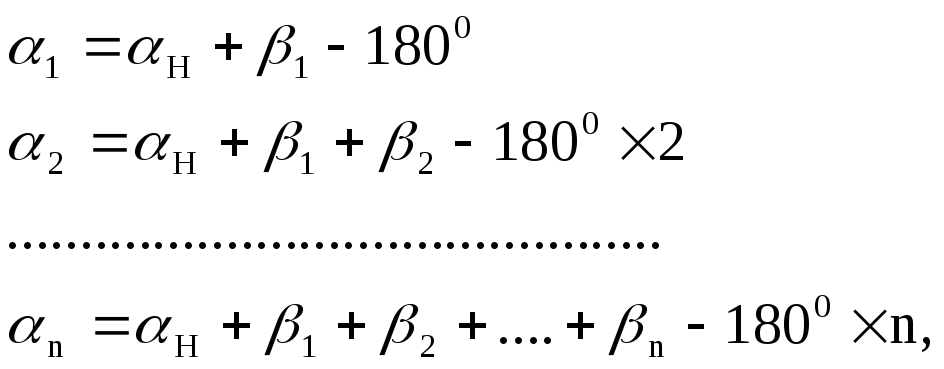
то
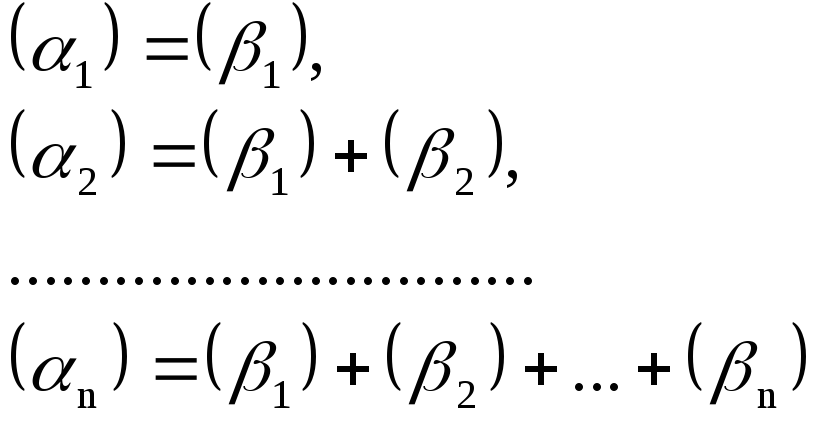
Подставляем эти
значения в условные уравнения (2):
![]()
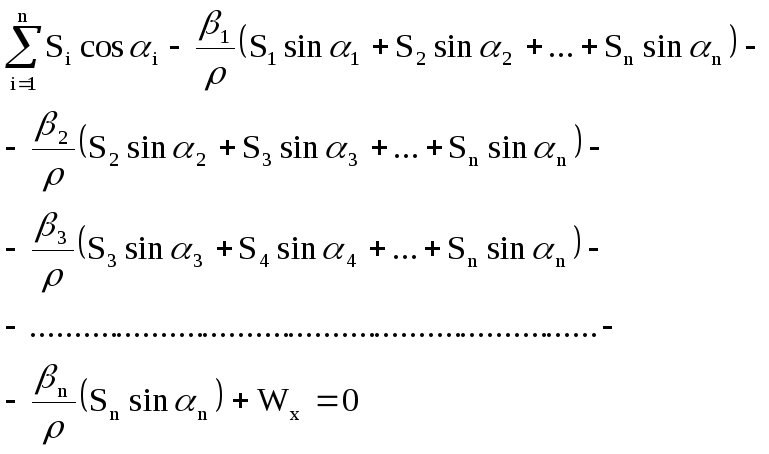
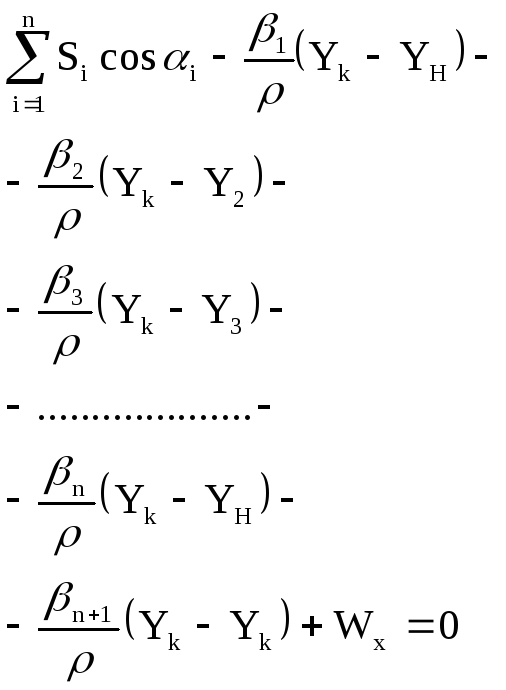
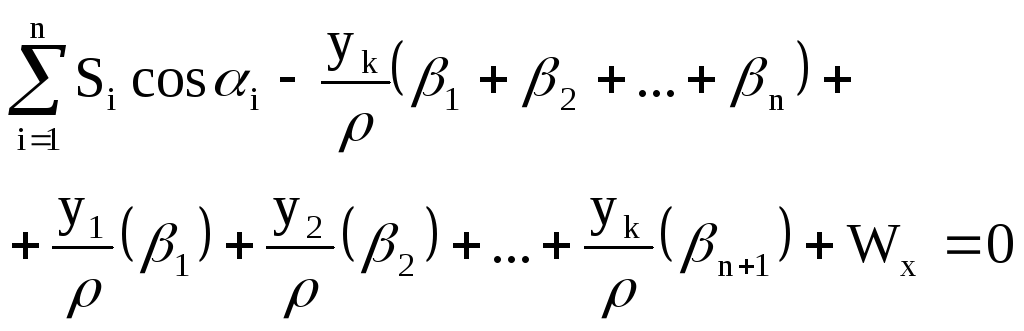
![]()
![]()
![]()
![]() .
.
Многомерный статистический анализ
-
Среднее
значение и корреляционная матрица
вектора
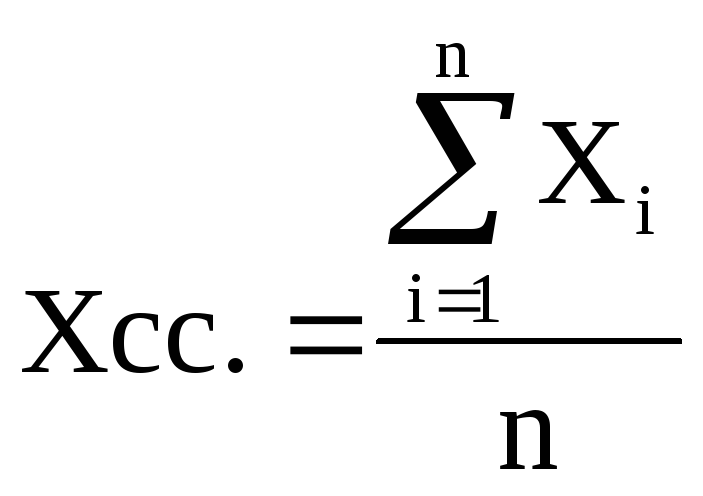
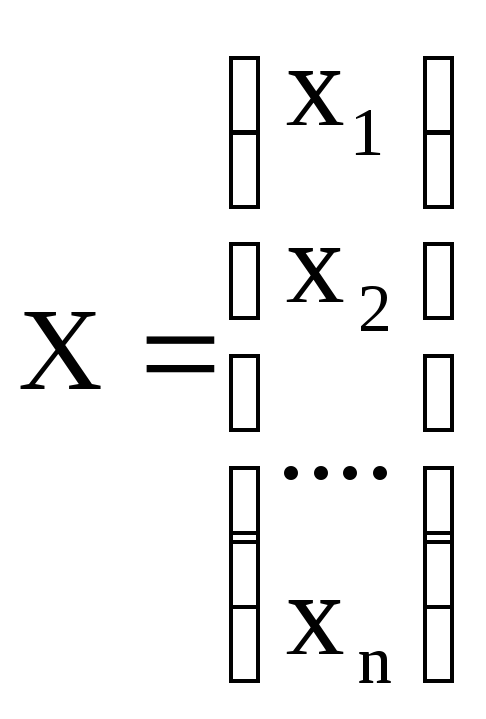
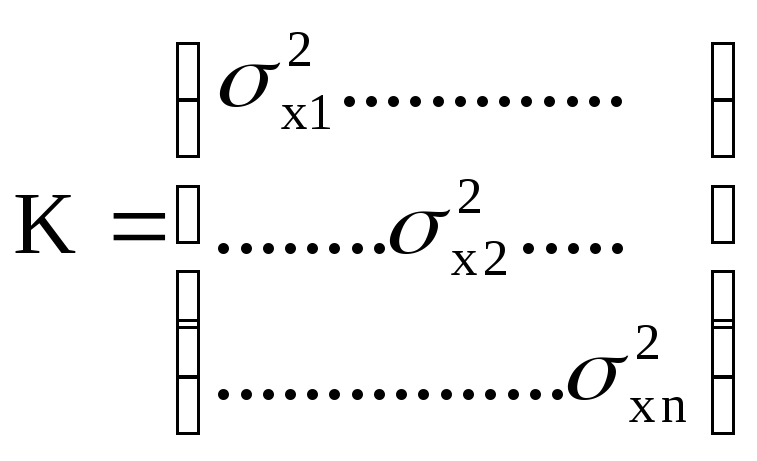
Если задана функция:
![]() ,
,
то
![]()
Нормальное
распределение
-
одномерное
распределение. Математическое ожидание(М)
и дисперсия(D)
Одномерное
распределение – это такое распределение,
где исследуется один признак.
Функция нормального
распределения:
 ,
,
где
![]() –
–
стандарт;![]()
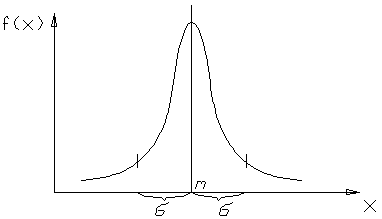
Свойства
функции: 1)всякая кривая достигает точки
максимума в точке X=m;
2)функция
непрерывна и приближается к оси Х;
3)симметрична
относительно прямой, параллельной f(х),
максимальная ордината –
![]() ;
;
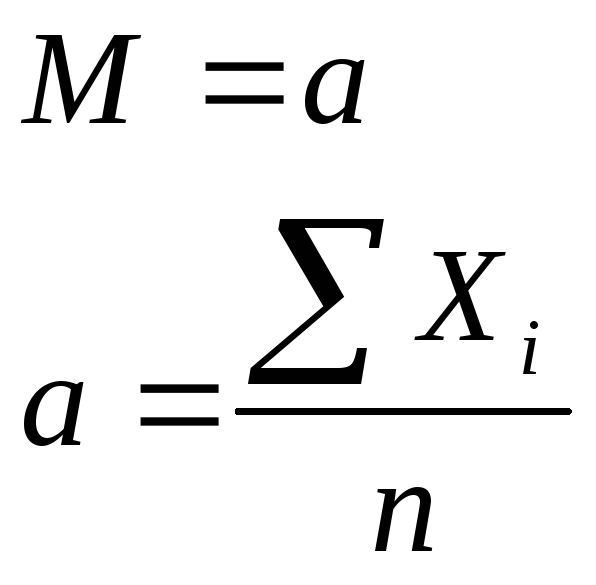
![]()
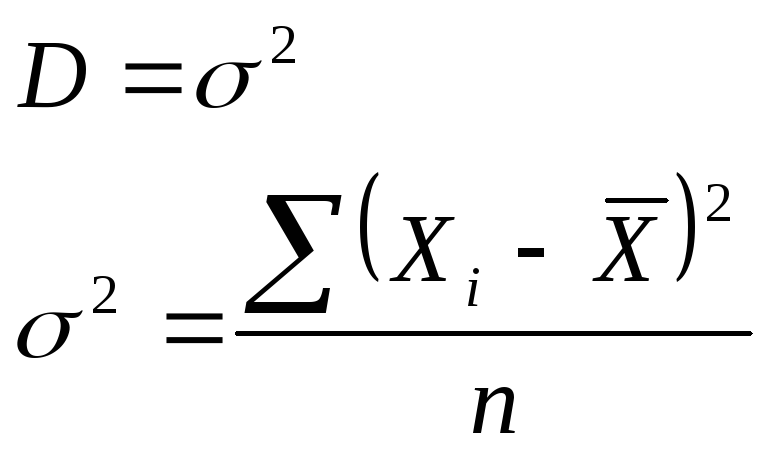
2.Многомерное
нормальное распределение
Многомерное
нормальное распределение – распределение,
характеризующееся вектором случайных
величин, заданным математическим
ожиданием этого вектора и корреляционной
матрицей.
![]() ;
; ![]() ;
;
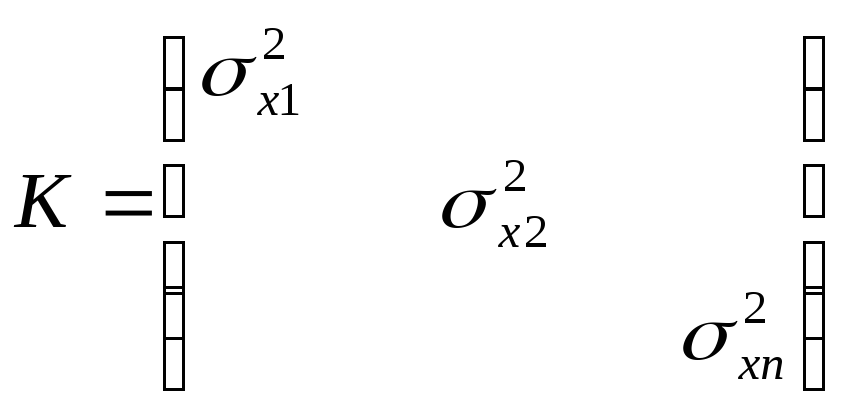 .
.
V–
отклонение вектора, от его математического
ожидания (Хn-Мхn)
![]()
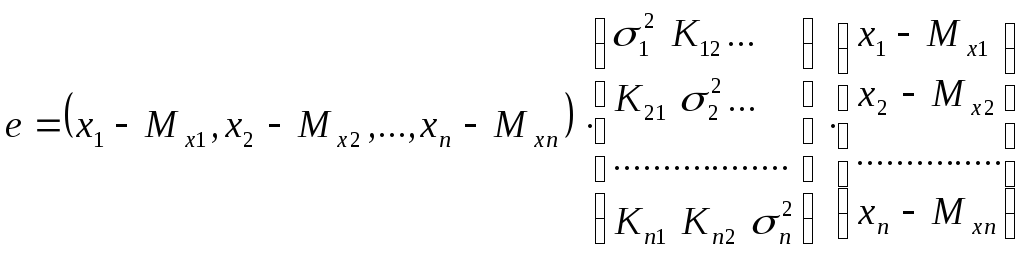
![]()
Метод наименьших
квадратов
1.Параметрический
способ уравнивания
Одну
и ту же функцию можно выразить как через
вектор параметров (Х), так и через вектор
измерений (L)
![]()
Задача
уравнивания сводиться к получению
достаточной, несмещенной и эффективной
оценке функции Z.
А) для получения
несмещенной оценки запишем математическое
ожидание:
![]()
Составляем систему
уравнений поправок:
![]() .
.
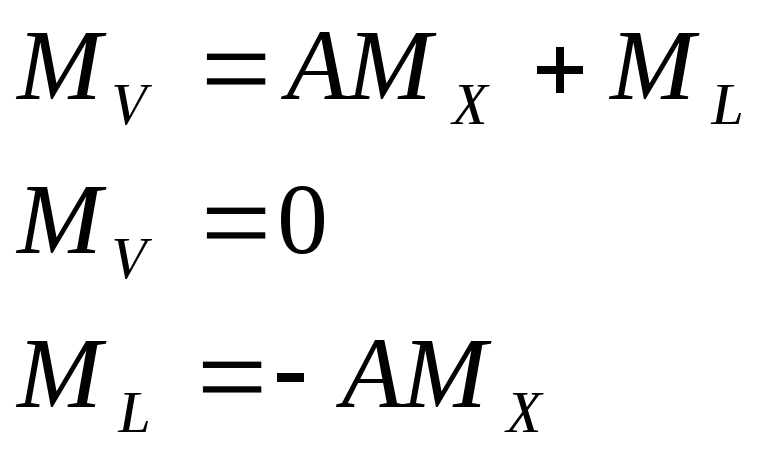
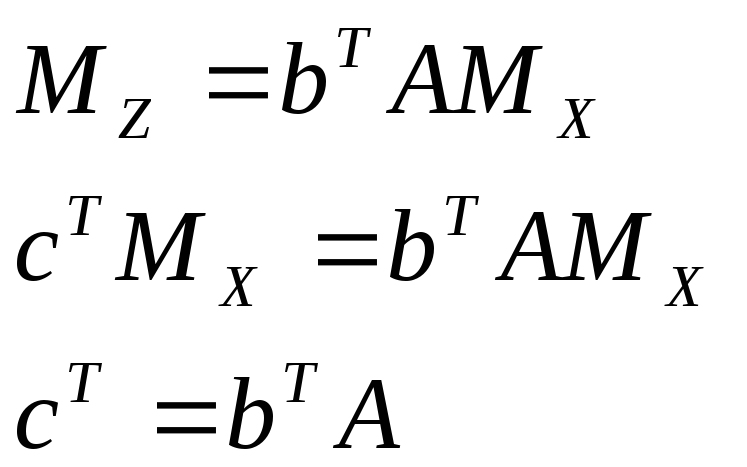
![]()
(1)
Это и есть условие
несмещенности.
В)
чтобы оценка была эффективной, дисперсия
функции Z
должна быть минимальной.
Найдем минимум
функционала Лагранжа:
![]() ,
,
где Λ– вектор
неопределенного множителя Лагранжа.
Найдем производную
по вектору b и приравняем ее к нулю:
![]()
![]()
![]()
![]() (2)
(2)
![]() Вектор
Вектор
множителя Λ – неизвестен.
Подставляем (2) в
(1):
![]()
![]()
![]()
![]()
![]()
![]()
![]() (3)
(3)
Далее, (3) подставляем
в (2):
![]()
![]() .
.
При
таком значении b получается достаточная,
несмещенная и эффективная оценка функции
Z.
Частный
случай:
если
![]() ,
,
где
Е– единичная матрица,то
![]()
-
Коррелатный способ уравнивания
После уравнивания
геодезической сети, любая функция
уравненных величин, должна определяться
однозначно при любом порядке ее
вычисления.
Получаемые
после уравнивания оценки любых функций
уравненных результатов измерений должны
быть достаточными, несмещенными и
эффективными.
Введем обозначения:
F(y)–
функция результатов измерений;
у – вектор
результатов измерений;
у=Y+Δ,
где
Y–
вектор истинных значений измеренных
величин;
Δ – вектор истинных
ошибок.
Линеаризированный
вид функции:
![]()
![]()
-
С
тем, чтобы оценка была достаточной,
необходимо ее выводить с учетом всех
измерений в геодезической сети
![]() ,
,
где
W
– вектор свободных членов;
G
– матрица, которую следует определить.
2)
Для достижения эффективности оценки
следует найти такую матрицу G,
при которой достигается минимальная
дисперсия
F(Y)–
безошибочна, так как Y–
истинное значение
![]() ,
,
где
В – матрица коэффициентов условных
уравнений
Вид
оцениваемой функции:
![]()
![]()
![]() ,
,
а
ее дисперсия
![]() ,
,
где
![]() –
–
корреляционная матрица ошибок.
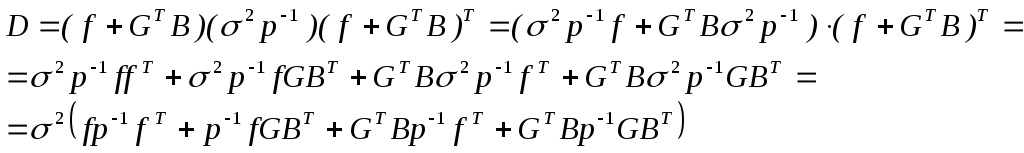
![]()
![]()
![]()
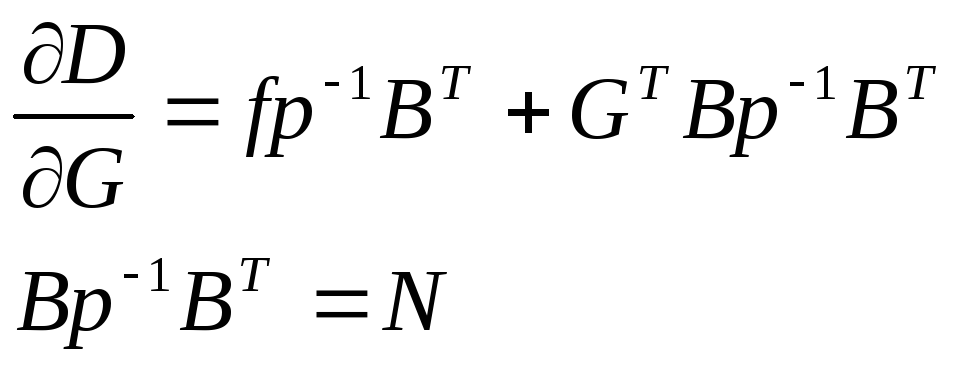
![]()
![]()
![]()
![]()
![]() ,
,
где
![]() –
–
поправка.
3)Полученное
значение будет несмещенным, если ошибки
измерений случайны:
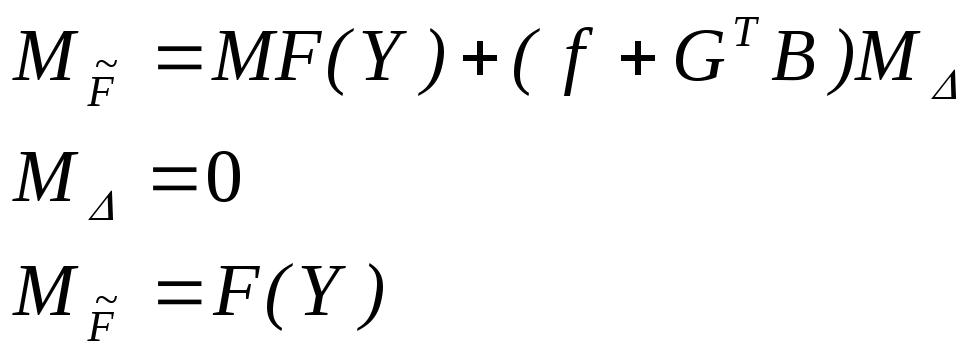
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Беспалый Н.П., Ахонина Л.И.
Геодезия часть 2 Учебное пособие для студентов геодезических специальностей вузов Донецк 1999
7.4 Средняя квадратическая ошибка положения конечной точки полигонометрии
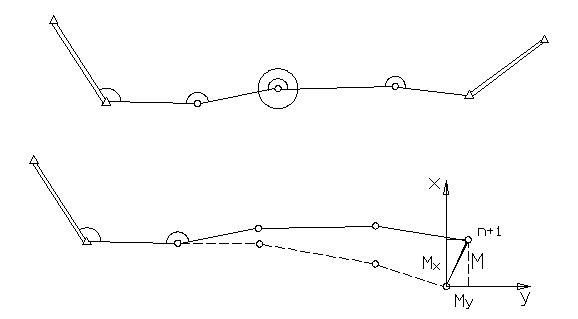
Ход вытянутый (углы не исправлены за невязку).
Ранее были получены формулы для вычисления компонентов ![]() ,
, ![]() (7.20) и (7.28)
(7.20) и (7.28)
![]() ;
; ![]()
По этим величинам можно найти среднюю квадратическую ошибку самого вектора М (рис.7.4) по формуле:
![]() (7.29)
(7.29)
а подставив значение из (7.20) и (7.28) получим:
![]() (7.30)
(7.30)
Эта величина называется средней квадратической ошибкой положения конечной точки хода полигонометрии.
Как видно из (7.30), ошибка последнего угла n+1 не оказывает влияния на величину поперечной невязки, т.е. ход считается как бы висячим. Это и понятно, т. к. углы за угловую невязку не исправлялись.
На практике углы, как правило, исправляются за угловую невязку путем ее распределения поровну на все углы. В этом случае поперечная невязка будет другая, поэтому будет другая формула для вычисления средней квадратической ошибки положения конечной точки хода полигонометрии. Эта формула приводится в конце этого параграфа.
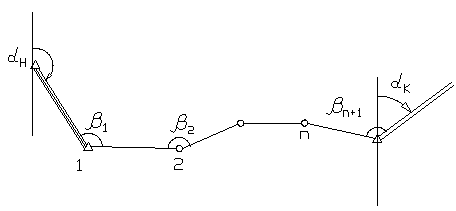
. Ход изогнутый (углы не исправлены за угловую невязку).
В ходе полигонометрии произвольной формы возникают невязки x, y, S, вычисляемые по формулам (7.17), (7.18).
Если в одном и том же ходе измерить все углы и линии «k» раз, то можно найти «k» значений невязок x, y, S, т.е.
![]()

Сложив почленно все равенства и разделив левую и правую части на «k», получим:
![]()
Каждый член этого равенства является соответствующим средним квадратическим значением. Поэтому равенство можно переписать
![]() (7.31)
(7.31)
Для установления зависимости между М и ошибками измерения длин линий mS и углов m возьмем без вывода координатные условные уравнения для одиночного хода полигонометрии. (Вывод этих формул будет рассмотрен при изучении уравнивания полигонометрии).
 (7.32)
(7.32)
i — дирекционный угол линии,
VS, V-поправка в измеренные длины и углы,
![]() ,
, ![]() — разности координат конечной и каждой из точек хода,
— разности координат конечной и каждой из точек хода,
x, y — невязки в приращениях координат, которые являются истинными ошибками в координатах конечного пункта полигонометрии.
Перенеся невязки x, y в правую часть будем иметь
 (7.33)
(7.33)
Так как поправка и ошибка различаются между собой только знаком, то можно записать:
![]() ,
, ![]() , (7.34)
, (7.34)
где dSi и di – ошибки измерения длин линий и углов.
С учетом этого предыдущее выражение (7.33) можно переписать:
 (7.35)
(7.35)
Отсюда по правилам теории ошибок вычисляем средние квадратические ошибки:
 (7.36)
(7.36)
Подставляем эти значения в формулу (7.31), получим среднюю квадратическую ошибку положения конечной точки хода полигонометрии:
![]() ,
,
но так как ![]() , то
, то
![]() (7.37)
(7.37)
Обозначим
![]() (7.38)
(7.38)
Как видно из рисунка 7.6 Dn+1,i есть расстояние между последней и i‑той точкой хода.

Рисунок 7.6 – Схема для определения средней квадратической ошибки положения конечной точки висячего полигонометрического хода
С учетом (7.38) формулу (7.37) перепишем
![]() (7.39)
(7.39)
По этой формуле вычисляется средняя квадратическая ошибка положения конечной точки висячего изогнутого полигонометрического хода. По этой же формуле можно вычислить среднюю квадратическую ошибку положения любой точки висячего полигонометрического хода При этом под n подразумевается число линий от начальной точки до определяемой.
Как видно из формулы (7.39) величина М зависит не только от ошибок измерения длин и углов, но и от степени изогнутости хода и количества углов поворота в нем. Величина ![]() тем меньше, чем больше вытянут ход и чем меньше в нем углов поворота.
тем меньше, чем больше вытянут ход и чем меньше в нем углов поворота.
Полученная формула не учитывает ошибок исходных данных. В этом случае ошибка в положении конечной точки хода будет и невязкой этого хода. В действительности исходные координаты и дирекционные углы сами содержат ошибки, поэтому между невязкой и ошибкой положения точки будет некоторая разница. В этом случае для учета ошибок полевых измерений и ошибок исходных данных пользуются формулой:
![]() (7.40)
(7.40)
МЕТОДЫ ПРЕДРАСЧЕТА СРЕДНЕЙ КВАДРАТИЧЕСКОЙ ПОГРЕШНОСТИ ПОЛОЖЕНИЯ ПУНКТОВ ПРОЕКТИРУЕМОЙ СЕТИ
Алексенко Анастасия Геннадьевна1, Гребенщикова Алена Николаевна2, Грибунина Ксения Антоновна3, Пучнина Алена Ивановна4
1Санкт-Петербургский горный университет, кандидат технических наук, ассистент кафедры маркшейдерского дела
2Санкт-Петербургский горный университет, студент кафедры маркшейдерского дела
3Санкт-Петербургский горный университет, студент кафедры маркшейдерского дела
4Санкт-Петербургский горный университет, студент кафедры маркшейдерского дела
Аннотация
Статья посвящена сравнению двух способов расчета средней квадратической погрешности положения пунктов сети или хода на этапе их проектирования: расчет по формуле, основанной на законе переноса погрешностей и расчет данной величины в программном продукте Credo_DAT.
Ключевые слова: анализ точности, маркшейдерские измерения, маркшейдерское обеспечение, погрешности измерений, точность измерений
Рубрика: 25.00.00 НАУКИ О ЗЕМЛЕ
Библиографическая ссылка на статью:
Алексенко А.Г., Гребенщикова А.Н., Грибунина К.А., Пучнина А.И. Методы предрасчета средней квадратической погрешности положения пунктов проектируемой сети // Современные научные исследования и инновации. 2018. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2018/05/86604 (дата обращения: 02.06.2023).
При оценке точности маркшейдерских съемочных построений на этапе их проектирования, как правило, оценивается погрешность определения какого-либо элемента сети. Например, для открытых горных работ, согласно требованиям инструкции [1], «определение пунктов в съемочных сетях относительно ближайших пунктов маркшейдерской опорной сети осуществляют с погрешностью, не превышающей 0,4 мм на плане в принятом масштабе съемки». Так, на этапе проектирования сети, необходимо рассчитать ожидаемое значение средней квадратической погрешности наиболее слабого пункта и сравнить его с допуском.
Определение предварительного значения погрешности какой-либо величины, являющейся функцией нескольких измеренных параметров, можно выполнить по формулам, полученным с учетом закона накопления погрешностей, выражающегося в следующей формуле:
![]() , (1)
, (1)
где fi – частная производная функции по измеряемому параметру, mi – среднеквадратическая погрешность измерения параметра.
Для висячего хода погрешность положения последнего пункта будет рассчитываться по формуле (в случае измерения расстояний электронным тахеометром) [2, 3]:
![]() , (2)
, (2)
где mβ – СКП угловых измерений; mα – СКП определения дирекционного угла гиростороны; L – замыкающая хода; Ri – длины отрезков, соединяющих последнюю и i-ую точки хода; α – дирекционный угол стороны; a, b – погрешности измерения длины электронным тахеометром.
Первое слагаемое формулы (2) учитывает влияние погрешностей измерения горизонтальных углов хода, второе – погрешность определения исходной стороны, остальные слагаемые – погрешность измерения длин сторон хода. Таким образом, для получения величины СКП положения пункта, которую следует сравнивать с допуском, необходимо снять со схемы хода его геометрические параметры (длины сторон, дирекционные углы сторон, приращения координат и длину замыкающей хода). Заложенная точность измерений учитывается параметрами mβ, mα, a, b.
Величину СКП положения пункта хода можно получить иным способом: провести предрасчет точности в программе Credo_DAT. В данном программном обеспечении реализована функция «уравнивания проектной сети», в ходе выполнения которой предполагаемые значения ошибок для процедуры уравнивания генерируются программой с учетом заданных значений точности измерений. Для получения необходимой величины следует указать в проекте координаты всех пунктов, запроектированные измерения, а также их точность по принятой методике. При этом пункты можно импортировать из другой программы, например, из одной их наиболее распространенных систем автоматизированного проектирования AutoCAD.
Если сравнивать два указанных метода, предрасчет точности в Credo_DAT может оказаться несколько менее трудозатратным, поскольку такой предрасчет не требует ручного снятия графических величин. Тем не менее, определенное время придется потратить на формирование файла проекта сети (указание станций, измерений с каждой из них, указание точности измерений). Поэтому при выборе способа предварительной оценки точности построения следует опираться в первую очередь на точность метода, т.е. на то, насколько достоверны полученные значения погрешностей.
В ходе ряда расчетов для различных съемочных построений было выявлено, что погрешность положения пунктов, полученная при расчете в Credo_DAT, несколько меньше, чем погрешность, полученная при «ручном» расчете по формулам, аналогичным (2).
Схема одного из рассмотренных ходов приведена на рис. 1 (свободный ход, проложенный от исходной стороны 1-2, длина хода 2493 метра). Были приняты следующие значения погрешностей: mβ — 20”, mα — 30”, μ = 0,001м1/2, λ = 0,00005 (случай измерения расстояний стальной рулеткой).
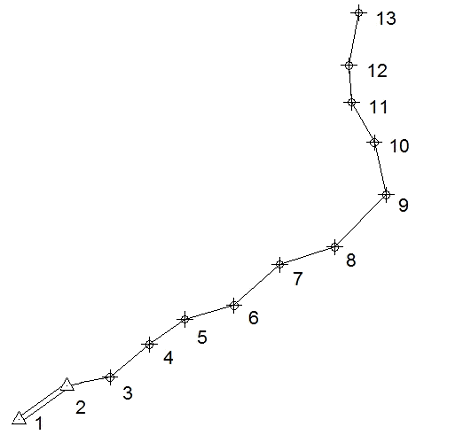
Рис. 1. Схема анализируемого хода
Расчет средней квадратической погрешности положения пункта 13 производился по формуле:
![]()
где μ – коэффициент случайного влияния погрешностей линейных измерений; λ – коэффициент систематического влияния погрешностей линейных измерений.
Расчет показал следующие результаты:
![]()
Ведомость оценки положения погрешностей пунктов по результатам уравнивания, полученная в результате обработки в Credo_DAT, приведена на рис. 2. Как видно из ведомости, расчетное значение СКП 13-ого пункта составило 0,455 м.
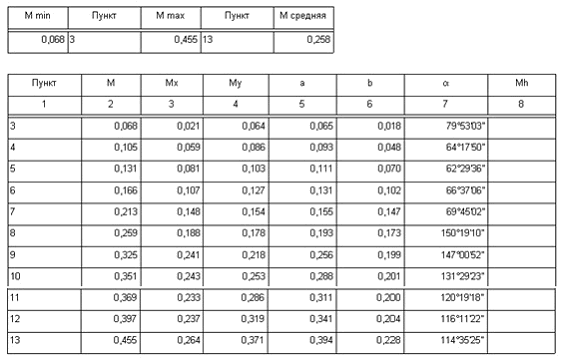
Рис. 2. Ведомость оценки точности положения пунктов
Расхождение в величине погрешности, которую необходимо сравнить с допуском, составило 43 мм. Очевидно, что подобное различие может оказаться критичным в определенных случаях. Например, если для принятой методики измерений и геометрии построения предварительные значения СКП окажутся близкими к допуску. В этом случае при расчете в Credo_DAT мы можем получить меньшее значение СКП, удовлетворяющее допуску, в отличие от погрешности, полученной при расчете по формуле. На практике же значение СКП положения пункта может оказаться равным последнему, что покажет недостаточную точность созданного хода вследствие некорректной проверки точности на этапе проектирования сети.
Остается открытым ряд вопросов:
— какая из методик позволяет получить более достоверные значения погрешностей (более близкие к тем, что будут получены на практике);
— можно ли выявить однозначную закономерность в расхождении величин, полученных указанными способами расчета;
— зависит ли величина расхождения результатов предрасчета от исходных данных (типа построения, его геометрии, точности измерений и т.д.);
— и другие.
Таким образом, вопрос оценки и сравнения двух рассмотренных способов предрасчета точности маркшейдерских съемочных построений требует дополнительных исследований.
Библиографический список
- Инструкция по производству маркшейдерских работ (РД 07 603 03). Серия 07. Вып. 15. / Колл. авт. – М.: Федеральное государственное унитарное предприятие «Научно-технический центр по безопасности в промышленности Госгортехнадзора России», 2004. – 120 с.
- Зверевич В.В., Гусев В.Н., Волохов Е.М. Анализ точности подземных маркшейдерских сетей. Учебное пособие. Санкт-Петербург: РИЦ СПбГГИ(ТУ), 2014,-145 с.
- Маркшейдерское дело [Электронный ресурс]: учебник / В. Н. Гусев [и др.]. – СПб. : Горн. ун-т, 2016. – 448 с. – Библиогр.: с. 444-447 (64 назв.). – ISBN 978-5-94211-774-0 : Б. ц.
Количество просмотров публикации: Please wait
Все статьи автора «Алексенко Анастасия Геннадьевна»
From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of  predictions is generated from a sample of data points on all variables, and
predictions is generated from a sample of data points on all variables, and  is the vector of observed values of the variable being predicted, with
is the vector of observed values of the variable being predicted, with  being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as
being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as

In other words, the MSE is the mean  of the squares of the errors
of the squares of the errors  . This is an easily computable quantity for a particular sample (and hence is sample-dependent).
. This is an easily computable quantity for a particular sample (and hence is sample-dependent).
In matrix notation,

where  is
is  and
and  is the
is the  column vector.
column vector.
The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as statistical learning, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator  with respect to an unknown parameter
with respect to an unknown parameter  is defined as[1]
is defined as[1]
![{displaystyle operatorname {MSE} ({hat {theta }})=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator is derived as a sample statistic and is used to estimate some population parameter, then the expectation is with respect to the sampling distribution of the sample statistic.
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]+operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}+2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+operatorname {E} _{theta }left[2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)right]+operatorname {E} _{theta }left[left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)operatorname {E} _{theta }left[{hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]-theta ={text{const.}}\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)left(operatorname {E} _{theta }[{hat {theta }}]-operatorname {E} _{theta }[{hat {theta }}]right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]={text{const.}}\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}\&=operatorname {Var} _{theta }({hat {theta }})+operatorname {Bias} _{theta }({hat {theta }},theta )^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable  ,
,  . By substituting with,
. By substituting with,  , we have
, we have
![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=mathbb {E} [({hat {theta }}-theta )^{2}]\&=operatorname {Var} ({hat {theta }}-theta )+(mathbb {E} [{hat {theta }}-theta ])^{2}\&=operatorname {Var} ({hat {theta }})+operatorname {Bias} ^{2}({hat {theta }})end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/864646cf4426e2b62a3caf9460382eec1a77fe4e)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size from a population,  . Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the
. Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the  is the sample average
is the sample average

which has an expected value equal to the true mean (so it is unbiased) and a mean squared error of
![{displaystyle operatorname {MSE} left({overline {X}}right)=operatorname {E} left[left({overline {X}}-mu right)^{2}right]=left({frac {sigma }{sqrt {n}}}right)^{2}={frac {sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where  is the population variance.
is the population variance.
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is ), hence also called the unbiased sample variance, and its MSE is[8]

where  is the fourth central moment of the distribution or population, and
is the fourth central moment of the distribution or population, and  is the excess kurtosis.
is the excess kurtosis.
However, one can use other estimators for which are proportional to  , and an appropriate choice can always give a lower mean squared error. If we define
, and an appropriate choice can always give a lower mean squared error. If we define

then we calculate:
![{displaystyle {begin{aligned}operatorname {MSE} (S_{a}^{2})&=operatorname {E} left[left({frac {n-1}{a}}S_{n-1}^{2}-sigma ^{2}right)^{2}right]\&=operatorname {E} left[{frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2left({frac {n-1}{a}}S_{n-1}^{2}right)sigma ^{2}+sigma ^{4}right]\&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)operatorname {E} left[S_{n-1}^{2}right]sigma ^{2}+sigma ^{4}\&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{2}right]=sigma ^{2}\&={frac {(n-1)^{2}}{a^{2}}}left({frac {gamma _{2}}{n}}+{frac {n+1}{n-1}}right)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{4}right]=operatorname {MSE} (S_{n-1}^{2})+sigma ^{4}\&={frac {n-1}{na^{2}}}left((n-1)gamma _{2}+n^{2}+nright)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where  , this means that the MSE is minimized when dividing the sum by
, this means that the MSE is minimized when dividing the sum by  . The minimum excess kurtosis is
. The minimum excess kurtosis is  ,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for
,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for  Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator predicts observations of the parameter with perfect accuracy, is ideal (but typically not possible).
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.